Pytorch: خطأ وقت التشغيل: نفاد ذاكرة CUDA. حاولت تخصيص 12.50 MiB (GPU 0 ؛ السعة الإجمالية 10.92 جيجا بايت ؛ 8.57 MiB مخصصة بالفعل ؛ 9.28 جيجا بايت مجانًا ؛ 4.68 ميجا بايت مخزنة مؤقتًا)
خطأ نفاد الذاكرة في CUDA لكن ذاكرة CUDA فارغة تقريبًا
أقوم حاليًا بتدريب نموذج خفيف الوزن على كمية كبيرة جدًا من البيانات النصية (حوالي 70 جيجا بايت من النص).
من أجل ذلك ، أستخدم آلة على مجموعة ( 'grele' لشبكة كتلة Grid5000 ).
أنا أتلقى بعد 3 ساعات من التدريب رسالة خطأ CUDA الغريبة جدًا من الذاكرة:
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached) .
وفقًا للرسالة ، لدي المساحة المطلوبة ولكنها لا تخصص الذاكرة.
أي فكرة عما قد يسبب هذا ؟
للحصول على معلومات ، تعتمد المعالجة المسبقة الخاصة بي على torch.multiprocessing.Queue ومكرر فوق سطور بيانات المصدر الخاصة بي للمعالجة المسبقة للبيانات بسرعة.
تتبع مكدس كامل
Traceback (most recent call last):
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1228, in <module>
exec_with_profiler(script_filename, prof, args.backend, script_args)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1129, in exec_with_profiler
exec(compile(f.read(), filename, 'exec'), ns, ns)
File "run.py", line 293, in <module>
main(args, save_folder, load_file)
File "run.py", line 272, in main
trainer.all_epochs()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 140, in all_epochs
self.single_epoch()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 147, in single_epoch
tracker.add(*self.single_batch(data, target))
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 190, in single_batch
result = self.model(data)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/papud-bull-nn/model/model.py", line 54, in forward
emb = self.emb(input)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/sparse.py", line 118, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/functional.py", line 1454, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached)
 EMarquer
EMarquer
ال 91 كومينتر
لدي نفس خطأ وقت التشغيل:
Traceback (most recent call last):
File "carn\train.py", line 52, in <module>
main(cfg)
File "carn\train.py", line 48, in main
solver.fit()
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 95, in fit
psnr = self.evaluate("dataset/Urban100", scale=cfg.scale, num_step=self.step)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 136, in evaluate
sr = self.refiner(lr_patch, scale).data
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 74, in forward
b3 = self.b3(o2)
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 30, in forward
c3 = torch.cat([c2, b3], dim=1)
RuntimeError: CUDA out of memory. Tried to allocate 195.25 MiB (GPU 0; 4.00 GiB total capacity; 2.88 GiB already allocated; 170.14 MiB free; 2.00 MiB cached)
 OmarBazaraa
في ٢٧ يناير ٢٠١٩
OmarBazaraa
في ٢٧ يناير ٢٠١٩
EMarquerOmarBazaraa هل يمكنك إعطاء مثال بسيط يمكننا تشغيله؟
 yf225
في ٢٨ يناير ٢٠١٩
yf225
في ٢٨ يناير ٢٠١٩
لا يمكنني إعادة إظهار المشكلة بعد الآن ، وبالتالي سأغلق المشكلة.
اختفت المشكلة عندما توقفت عن تخزين البيانات المعالجة مسبقًا في ذاكرة الوصول العشوائي.
OmarBazaraa ، لا أعتقد أن مشكلتك هي نفس مشكلتي ، حيث:
- أحاول تخصيص 12.50 ميجابايت ، مع 9.28 جيجابايت مجانًا
- أنت تحاول تخصيص 195.25 MiB ، مع 170.14 MiB مجانًا
من تجربتي السابقة مع هذه المشكلة ، إما أنك لا تقوم بتحرير ذاكرة CUDA أو تحاول وضع الكثير من البيانات على CUDA.
من خلال عدم تحرير ذاكرة CUDA ، أعني أنه من المحتمل أنه لا يزال لديك مراجع لموترات في CUDA لم تعد تستخدمها. تلك من شأنها منع الذاكرة المخصصة من التحرير عن طريق حذف موترات.
EMarquer
في ٢٨ يناير ٢٠١٩
هل يوجد حل عام؟
CUDA نفاد الذاكرة. حاولت تخصيص 196.00 MiB (GPU 0 ؛ السعة الإجمالية 2.00 جيجا بايت ؛ 359.38 MiB مخصصة بالفعل ؛ 192.29 MiB مجانًا ؛ 152.37 MiB مخزنة مؤقتًا)
 aniketspurohit
في ٣١ يناير ٢٠١٩
aniketspurohit
في ٣١ يناير ٢٠١٩
@ aniks23 ، نحن نعمل على تصحيح أعتقد أنه سيعطي تجربة أفضل في هذه الحالة. ابقوا متابعين
 fmassa
في ٣١ يناير ٢٠١٩
fmassa
في ٣١ يناير ٢٠١٩
هل هناك أي طريقة لمعرفة حجم نموذج أو شبكة يمكن لنظامي التعامل معها
دون الوقوع في هذه المشكلة؟
يوم الجمعة ، 1 شباط (فبراير) 2019 ، الساعة 3:55 صباحًا ، Francisco Massa [email protected]
كتب:
@ aniks23 https://github.com/aniks23 نحن نعمل على التصحيح الذي أنا
يعتقد أنه سيعطي تجربة أفضل في هذه الحالة. ابقوا متابعين-
أنت تتلقى هذا لأنه تم ذكرك.
قم بالرد على هذا البريد الإلكتروني مباشرة ، وقم بعرضه على GitHub
https://github.com/pytorch/pytorch/issues/16417#issuecomment-459530332 ،
أو كتم الخيط
https://github.com/notifications/unsubscribe-auth/AUEJD4SYN4gnRkrLgFYEKY6y14P1TMgLks5vI21wgaJpZM4aUowv
.
aniketspurohit
في ١ فبراير ٢٠١٩
لقد تلقيت هذه الرسالة أيضًا:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)
حدث ذلك عندما كنت أحاول تشغيل درس Fast.ai 1 Pets https://course.fast.ai/ (الخلية 31)
 adrianovieira
في ١٢ مارس ٢٠١٩
adrianovieira
في ١٢ مارس ٢٠١٩
أنا أيضا أواجه نفس الأخطاء. كان نموذجي يعمل في وقت سابق مع الإعداد الدقيق ، ولكنه الآن يعطي هذا الخطأ بعد أن قمت بتعديل بعض التعليمات البرمجية التي تبدو غير مرتبطة.
RuntimeError: CUDA out of memory. Tried to allocate 1.34 GiB (GPU 0; 22.41 GiB total capacity; 11.42 GiB already allocated; 59.19 MiB free; 912.00 KiB cached)
 treble-maker123
في ١٤ مارس ٢٠١٩
treble-maker123
في ١٤ مارس ٢٠١٩
لا أعرف ما إذا كان السيناريو الخاص بي مرتبطًا بالمشكلة الأصلية ، لكنني قمت بحل مشكلتي (اختفى خطأ OOM في الرسالة السابقة) عن طريق تفكيك الطبقات المتسلسلة nn في النموذج الخاص بي ، على سبيل المثال
self.input_layer = nn.Sequential(
nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU()
)
output = self.input_layer(x)
إلى
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0)
self.input_bn = nn.BatchNorm3d(32)
output = F.relu(self.input_bn(self.input_conv(x)))
يحتوي نموذجي على الكثير من هذه (5 على وجه الدقة). هل أستخدم nn.Sequential right؟ أم أن هذا الخلل؟ تضمين التغريدة
treble-maker123
في ١٤ مارس ٢٠١٩
أتلقى خطأ مشابهًا أيضًا:
CUDA out of memory. Tried to allocate 196.50 MiB (GPU 0; 15.75 GiB total capacity; 7.09 GiB already allocated; 20.62 MiB free; 72.48 MiB cached)
@ treble-maker123 ، هل تمكنت من إثبات بشكل قاطع أن المشكلة التتابعية nn.
 yasheshgaur
في ١٧ مارس ٢٠١٩
yasheshgaur
في ١٧ مارس ٢٠١٩
أواجه مشكلة مشابهة. أنا أستخدم أداة تحميل البيانات pytorch. SaysI يجب أن يكون لدي أكثر من 5 غيغابايت مجانًا ولكنه يعطي 0 بايت مجانًا.
RuntimeError Traceback (آخر مكالمة أخيرة)
22
23 بيانات ، المدخلات = States_inputs
---> 24 بيانات ، المدخلات = متغير (بيانات). طفو (). إلى (جهاز) ، متغير (مدخلات). طفو (). إلى (جهاز)
25 طباعة (جهاز البيانات)
26 enc_out = برنامج التشفير (البيانات)
خطأ وقت التشغيل: نفاد ذاكرة CUDA. حاولت تخصيص 11.00 MiB (GPU 0 ؛ السعة الإجمالية 6.00 جيجا بايت ؛ تم تخصيص 448.58 MiB بالفعل ؛ 0 بايت مجانًا ؛ 942.00 كيلوبايت مخزنة مؤقتًا)
 ahsteven
في ٣ أبريل ٢٠١٩
ahsteven
في ٣ أبريل ٢٠١٩
مرحبًا ، لقد تلقيت هذا الخطأ أيضًا.
File "xxx", line 151, in __call__
logits = self.model(x_hat)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 67, in forward
x = up(x, blocks[-i-1])
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 120, in forward
out = self.conv_block(out)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 92, in forward
out = self.block(x)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/container.py", line 92, in forward
input = module(input)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 320, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDA out of memory. Tried to allocate 8.00 MiB (GPU 1; 11.78 GiB total capacity; 10.66 GiB already allocated; 1.62 MiB free; 21.86 MiB cached)
 AlbertZhangHIT
في ١٧ أبريل ٢٠١٩
AlbertZhangHIT
في ١٧ أبريل ٢٠١٩
للأسف ، واجهت نفس المشكلة أيضًا.
RuntimeError: CUDA out of memory. Tried to allocate 1.33 GiB (GPU 1; 31.72 GiB total capacity; 5.68 GiB already allocated; 24.94 GiB free; 5.96 MiB cached)
لقد قمت بتدريب نموذجي في مجموعة من الخوادم وحدث الخطأ بشكل غير متوقع لأحد الخوادم الخاصة بي. أيضًا مثل هذا الخطأ السلكي يحدث فقط في إحدى استراتيجيات التدريب الخاصة بي. والفرق الوحيد هو أنني أقوم بتعديل الكود أثناء زيادة البيانات ، وجعل معالجة البيانات أكثر تعقيدًا من غيرها. لكني لست متأكدًا من كيفية حل هذه المشكلة.
 qingyu-wang
في ٢٥ أبريل ٢٠١٩
qingyu-wang
في ٢٥ أبريل ٢٠١٩
أواجه هذه المسألة أيضا. كيف حلها؟؟؟ RuntimeError: CUDA out of memory. Tried to allocate 18.00 MiB (GPU 0; 4.00 GiB total capacity; 2.94 GiB already allocated; 10.22 MiB free; 18.77 MiB cached)
 nabil2i
في ١٠ مايو ٢٠١٩
nabil2i
في ١٠ مايو ٢٠١٩
نفس المشكلة هنا RuntimeError: CUDA out of memory. Tried to allocate 54.00 MiB (GPU 0; 11.00 GiB total capacity; 7.89 GiB already allocated; 7.74 MiB free; 478.37 MiB cached)
 williamluke4
في ١٦ مايو ٢٠١٩
williamluke4
في ١٦ مايو ٢٠١٩
fmassa هل لديك المزيد من المعلومات حول هذا؟
williamluke4
في ١٨ مايو ٢٠١٩
https://github.com/pytorch/pytorch/issues/16417#issuecomment -484264163
نفس المشكلة بالنسبة لي
عزيزي هل حصلت على الحل؟
(القاعدة) F: \ Suresh \ st-gcn> python main1.py Recognition -c config / st_gcn / ntu-xsub / train.yaml --device 0 --work_dir ./work_dir
C: \ Users \ cudalab10 \ Anaconda3lib \ site -packs \ torch \ cuda__init __. py: 117: UserWarning:
تم العثور على GPU0 TITAN Xp وهو ذو قدرة cuda 1.1.
لم تعد PyTorch تدعم وحدة معالجة الرسومات هذه لأنها قديمة جدًا.
warnings. warn (old_gpu_warn٪ (d، name، major، قدرة [1]))
[05.22.19 | 12: 02: 41] المعلمات:
{'base_lr': 0.1، 'ignore_weights': []، 'model': 'net.st_gcn.Model'، 'Eval_interval': 5، 'weight_decay': 0.0001، 'work_dir': './work_dir'، 'save_interval ': 10،' model_args ': {' in_channels ': 3،' dropout ': 0.5،' num_class ': 60،' edge_importance_weighting ': True،' graph_args ': {' Strategy ':' spatial '،' layout ': 'ntu-rgb + d'}}، 'debug': False، 'pavi_log': False، 'save_result': False، 'config': 'config / st_gcn / ntu-xsub / train.yaml'، 'محسن': 'SGD'، 'weights': None، 'num_epoch': 80، 'batch_size': 64، 'show_topk': [1، 5]، 'test_batch_size': 64، 'step': [10، 50]، 'use_gpu ': True،' stage ':' train '،' print_log ': True،' log_interval ': 100،' feeder ':' feeder.feeder.Feeder '،' start_epoch ': 0،' nesterov ': True،' device ': [0]،' save_log ': صحيح،' test_feeder_args ': {' data_path ':' ./data/NTU-RGB-D/xsub/val_data.npy '،' label_path ':' ./data/NTU- RGB-D / xsub / val_label.pkl '}،' train_feeder_args ': {' data_path ':' ./data/NTU-RGB-D/xsub/train_data.npy '،' debug ': False،' label_path ':' ./data/NTU-RGB-D/xsub/train_l abel.pkl '}،' num_worker ': 4}
[05.22.19 | 12: 02: 41] حقبة التدريب: 0
Traceback (آخر مكالمة أخيرة):
ملف "main1.py" ، السطر 31 ، بتنسيق
p.start ()
ملف "F: \ Suresh \ st-gcn \ processor \ processor.py" ، السطر 113 ، في البداية
تدريب ذاتي ()
ملف "F: \ Suresh \ st-gcn \ processor \ Recognition.py" ، السطر 91 ، في القطار
الإخراج = self.model (البيانات)
ملف "C: \ Users \ cudalab10 \ Anaconda3lib \ site -pack \ torch \ nn \ modules \ module.py" ، السطر 489 ، في __call__
النتيجة = self.forward ( الإدخال ، * kwargs)
ملف "F: \ Suresh \ st-gcn \ net \ st_gcn.py" ، السطر 82 ، للأمام
x، _ = gcn (x، self.A * الأهمية)
ملف "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packs \ torch \ nn \ modules \ module.py" ، السطر 489 ، في __call__
النتيجة = self.forward ( الإدخال ، * kwargs)
ملف "F: \ Suresh \ st-gcn \ net \ st_gcn.py" ، السطر 194 ، في المقدمة
س ، أ = self.gcn (س ، أ)
ملف "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packs \ torch \ nn \ modules \ module.py" ، السطر 489 ، في __call__
النتيجة = self.forward ( الإدخال ، * kwargs)
ملف "F: \ Suresh \ st-gcn \ net \ utils \ tgcn.py" ، السطر 60 ، إلى الأمام
س = self.conv (x)
ملف "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packs \ torch \ nn \ modules \ module.py" ، السطر 489 ، في __call__
النتيجة = self.forward ( الإدخال ، * kwargs)
ملف "C: \ Users \ cudalab10 \ Anaconda3lib \ site -pack \ torch \ nn \ modules \ conv.py" ، السطر 320 ، إلى الأمام
self.padding ، self.dilation ، self.groups)
خطأ وقت التشغيل: نفاد ذاكرة CUDA. حاولت تخصيص 1.37 جيجا بايت (GPU 0 ؛ السعة الإجمالية 12.00 جيجا بايت ؛ تم تخصيص 8.28 جيجا بايت بالفعل ؛ 652.75 ميجا بايت مجانًا ؛ تم تخزين 664.38 ميجا بايت مؤقتًا)
 Sureshthommandru
في ٢٢ مايو ٢٠١٩
Sureshthommandru
في ٢٢ مايو ٢٠١٩
إنه بسبب الدفعة الصغيرة من البيانات التي لا تتناسب مع ذاكرة وحدة معالجة الرسومات. فقط قلل حجم الدفعة. عندما قمت بتعيين حجم الدُفعة = 256 لمجموعة بيانات cifar10 ، حصلت على نفس الخطأ ؛ ثم قمت بتعيين حجم الدفعة = 128 ، يتم حلها.
 balcilar
في ١ يونيو ٢٠١٩
balcilar
في ١ يونيو ٢٠١٩
نعم balcilar صحيح ، لقد قمت بتقليل حجم الدفعة وهو يعمل الآن
 EKELE-NNOROM
في ٤ يونيو ٢٠١٩
EKELE-NNOROM
في ٤ يونيو ٢٠١٩
عندى نفس المشكلة:
RuntimeError: CUDA out of memory. Tried to allocate 11.88 MiB (GPU 4; 15.75 GiB total capacity; 10.50 GiB already allocated; 1.88 MiB free; 3.03 GiB cached)
أنا أستخدم 8 V100 لتدريب النموذج. الجزء المربك هو أنه لا يزال هناك 3.03 جيجابايت مخزنة مؤقتًا ولا يمكن تخصيصها لـ 11.88 ميجابايت.
 magic282
في ١٠ يونيو ٢٠١٩
magic282
في ١٠ يونيو ٢٠١٩
هل قمت بتغيير حجم الدفعة. قلل حجم الدُفعة بمقدار النصف. قل الدفعة
الحجم 16 للتنفيذ ، حاول استخدام حجم دفعة 8 ومعرفة ما إذا كان يعمل.
يتمتع
في يوم الإثنين 10 يونيو 2019 الساعة 2:10 صباحًا ، كتب magic282 [email protected] :
عندى نفس المشكلة:
خطأ وقت التشغيل: نفاد ذاكرة CUDA. حاولت تخصيص 11.88 MiB (GPU 4 ؛ سعة إجمالية قدرها 15.75 جيجا بايت ؛ تم تخصيص 10.50 جيجا بايت بالفعل ؛ 1.88 ميجا بايت مجانًا ؛ 3.03 جيجا بايت مخزنة مؤقتًا)
أنا أستخدم 8 V100 لتدريب النموذج. الجزء المربك هو أن هناك
لا يزال 3.03 جيجا بايت مؤقتًا ولا يمكن تخصيصها لـ 11.88 ميجا بايت.-
أنت تتلقى هذا لأنك علقت.
قم بالرد على هذا البريد الإلكتروني مباشرة ، وقم بعرضه على GitHub
https://github.com/pytorch/pytorch/issues/16417؟email_source=notifications&email_token=AGGVQNIXGPJ3HXGSVRPOYUTPZXV5NA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMM
أو كتم الخيط
https://github.com/notifications/unsubscribe-auth/AGGVQNPVGT5RLM6ZV5KMSULPZXV5NANCNFSM4GSSRQXQ
.
EKELE-NNOROM
في ١٠ يونيو ٢٠١٩
حاولت تقليل حجم الدفعة ونجحت. الجزء المربك هو رسالة الخطأ التي تشير إلى أن الذاكرة المخزنة مؤقتًا أكبر من الذاكرة المخصصة.
magic282
في ١١ يونيو ٢٠١٩
أواجه نفس المشكلة في نموذج تم اختباره مسبقًا ، عندما أستخدم التنبؤ . لذا فإن تقليل حجم الدُفعة لن ينجح.
 pvk444
في ٣٠ يونيو ٢٠١٩
pvk444
في ٣٠ يونيو ٢٠١٩
إذا قمت بالتحديث إلى أحدث إصدار من PyTorch ، فقد يكون لديك أخطاء أقل من هذا القبيل
fmassa
في ٣٠ يونيو ٢٠١٩
هل يمكنني أن أسأل لماذا لا تتراكم الأرقام الموجودة في الخطأ ؟!
أنا (مثلكم جميعًا) أحصل على:
Tried to allocate 20.00 MiB (GPU 0; 1.95 GiB total capacity; 763.17 MiB already allocated; 6.31 MiB free; 28.83 MiB cached)
بالنسبة لي ، هذا يعني أن ما يلي يجب أن يكون تقريبًا صحيحًا:
1.95 (GB total) - 20 (MiB needed) == 763.17 (MiB already used) + 6.31 (MiB free) + 28.83 (MiB cached)
لكنها ليست كذلك. ما الذي أخطأت فيه؟
 AzimAhmadzadeh
في ٣ يوليو ٢٠١٩
AzimAhmadzadeh
في ٣ يوليو ٢٠١٩
لقد واجهت مشكلة أيضًا عندما قمت بتدريب U-net ، ذاكرة التخزين المؤقت كافية ، لكنها لا تزال تتعطل
 tongpinmo
في ١٠ يوليو ٢٠١٩
tongpinmo
في ١٠ يوليو ٢٠١٩
لدي نفس الخطأ...
خطأ وقت التشغيل: نفاد ذاكرة CUDA. حاولت تخصيص 312.00 MiB (GPU 0 ؛ السعة الإجمالية 10.91 جيجا بايت ؛ تم تخصيص 1.07 جيجا بايت بالفعل ؛ 109.62 MiB مجانًا ؛ 15.21 MiB مخزنة مؤقتًا)
 MSKazemi
في ١٠ يوليو ٢٠١٩
MSKazemi
في ١٠ يوليو ٢٠١٩
حاول تقليل الحجم (أي حجم لن يغير النتيجة) سيعمل.
 giangnguyen2412
في ١١ يوليو ٢٠١٩
giangnguyen2412
في ١١ يوليو ٢٠١٩
حاول تقليل الحجم (أي حجم لن يغير النتيجة) سيعمل.
مرحبًا ، لقد غيرت حجم الدفعة إلى 1 ، لكنها لا تعمل!
 BCWang93
في ١٤ يوليو ٢٠١٩
BCWang93
في ١٤ يوليو ٢٠١٩
قد يجب عليك تغيير حجم آخر.
Vào 21:50، CN، 14 Th7، 2019 Bcw93 [email protected] ã viết:
حاول تقليل الحجم (أي حجم لن يغير النتيجة) سيعمل.
مرحبًا ، لقد غيرت حجم الدفعة إلى 1 ، لكنها لا تعمل!
-
أنت تتلقى هذا لأنك علقت.
قم بالرد على هذا البريد الإلكتروني مباشرة ، وقم بعرضه على GitHub
https://github.com/pytorch/pytorch/issues/16417؟email_source=notifications&email_token=AHLNPF7MWQ7U5ULGIT44VRTP7MOKFA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VM37
أو كتم الخيط
https://github.com/notifications/unsubscribe-auth/AHLNPF4227GHH32PI4WC4SDP7MOKFANCNFSM4GSSRQXQ
.
giangnguyen2412
في ١٥ يوليو ٢٠١٩
الحصول على هذا الخطأ:
خطأ وقت التشغيل: نفاد ذاكرة CUDA. حاولت تخصيص 2.00 MiB (GPU 0 ؛ سعة إجمالية 7.94 جيجا بايت ؛ 7.33 جيجا بايت مخصصة بالفعل ؛ 1.12 ميجا بايت مجانية ؛ 40.48 ميجا بايت مخزنة مؤقتًا)
نفيديا سمي
الخميس 22 آب (أغسطس) 21:05:52 2019
+ ------------------------------------------------- ---------------------------- +
| NVIDIA-SMI 430.40 إصدار برنامج التشغيل: 430.40 إصدار CUDA: 10.1 |
| ------------------------------- + ----------------- ----- + ---------------------- +
| استمرار اسم وحدة معالجة الرسومات- M | موزع معرّف الناقل أ | متقلب Uncorr. ECC |
| أداء درجة حرارة المروحة : الاستخدام / الغطاء | استخدام الذاكرة | GPU-Util Compute M. |
| ================================ + ================= ===== + ======================= |
| 0 كوادرو M4000 إيقاف | 00000000: 09: 00.0 تشغيل | غير متاح |
| 46٪ 37C P8 12 واط / 120 واط | 71 ميغا بايت / 8126 ميغا بايت | 10٪ افتراضي |
+ ------------------------------- + ----------------- ----- + ---------------------- +
| 1 GeForce GTX 105 ... إيقاف | 00000000: 41: 00.0 تشغيل | غير متاح |
| 29٪ 33C P8 N / A / 75W | 262 ميغا بايت / 4032 ميغا بايت | 0٪ افتراضي |
+ ------------------------------- + ----------------- ----- + ---------------------- +
+ ------------------------------------------------- ---------------------------- +
| العمليات: ذاكرة وحدة معالجة الرسومات |
| GPU PID اكتب اسم العملية الاستخدام |
| =================================================== ============================== |
| 0 1909 G / usr / lib / xorg / Xorg 50 ميغا بايت |
| 1 1909 G / usr / lib / xorg / Xorg 128 ميجا بايت |
| 1 5236 G ... مهمة قناة الرمز = 9884100064965360199 130MiB |
+ ------------------------------------------------- ---------------------------- +
نظام التشغيل: Ubuntu 18.04 bionic
النواة: x86_64 Linux 4.15.0-58-generic
الجهوزية: 29 م
العبوات: 2002
شل: bash 4.4.20
القرار: 1920x1080 1080x1920
DE: LXDE
WM: OpenBox
موضوع GTK: Lubuntu-default [GTK2]
موضوع الرمز: Lubuntu
الخط: Ubuntu 11
وحدة المعالجة المركزية: AMD Ryzen Threadripper 2970WX 24-Core @ 48x 3GHz [61.8 ° C]
وحدة معالجة الرسومات: Quadro M4000 ، GeForce GTX 1050 Ti
ذاكرة الوصول العشوائي: 3194MiB / 64345 ميغا بايت
 danindiana
في ٢٣ أغسطس ٢٠١٩
danindiana
في ٢٣ أغسطس ٢٠١٩
هل هذا ثابت؟ لقد قمت بتقليل الحجم وحجم الدُفعة إلى 1. لا أرى أي حلول أخرى هنا ، ولكن هذه التذكرة مغلقة. أواجه نفس المشكلة مع Cuda 10.1 Windows 10 و Pytorch 1.2.0
 hughkf
في ٦ سبتمبر ٢٠١٩
hughkf
في ٦ سبتمبر ٢٠١٩
hughkf أين في الكود تغير حجم الدفعة؟
 aidoshacks
في ٦ سبتمبر ٢٠١٩
aidoshacks
في ٦ سبتمبر ٢٠١٩
aidoshacks ، هذا يعتمد على الكود الخاص بك. لكن هنا مثال واحد. هذا أحد أجهزة الكمبيوتر المحمولة التي تسبب هذه المشكلة على جهازي بشكل موثوق: https://github.com/fastai/course-v3/blob/master/nbs/dl1/lesson3-camvid-tiramisu.ipynb. أغير السطر التالي ،
bs,size = 8,src_size//2 إلى bs,size = 1,1 لكن ما زلت أحصل على هذا من مشكلة الذاكرة.
hughkf
في ٦ سبتمبر ٢٠١٩
بالنسبة لي ، فإن تغيير حجم الدفعة من 128 إلى 64 يعمل ولكن هذا لا يبدو كحل تم الكشف عنه بالنسبة لي ، أو هل أفتقد شيئًا ما؟
 shalgi
في ١٩ سبتمبر ٢٠١٩
shalgi
في ١٩ سبتمبر ٢٠١٩
هل حلت هذه المشكلة؟ أنا أيضا لدي نفس المشكلة. لم أغير أي شيء من الكود الخاص بي ، ولكن بعد التشغيل عدة مرات ، يحدث هذا الخطأ:
"RuntimeError: CUDA نفد من الذاكرة. حاولت تخصيص 40.00 MiB (GPU 0 ؛ سعة إجمالية 15.77 جيجا بايت ؛ تم تخصيص 13.97 جيجا بايت بالفعل ؛ 256.00 كيلو بايت مجانًا ؛ تم تخزين 824.57 ميجا بايت مؤقتًا)"
 mengxiangming
في ٢٦ سبتمبر ٢٠١٩
mengxiangming
في ٢٦ سبتمبر ٢٠١٩
لا تزال تواجه هذه المشكلة ، سيكون من الجيد إذا تم تغيير الحالة إلى دون حل.
تعديل:
لم يكن له علاقة بحجم الدُفعة برؤية حجم الدُفعة الذي أحصل عليه مع حجم الدُفعة 1. إعادة تشغيل النواة تم إصلاحها بالنسبة لي ولم يحدث ذلك منذ ذلك الحين.
 just-in-kees
في ٢٩ سبتمبر ٢٠١٩
just-in-kees
في ٢٩ سبتمبر ٢٠١٩
إذن ما هو الحل على أمثلة مثل أدناه (على سبيل المثال ، الكثير من الذاكرة الخالية ومحاولة تخصيص القليل جدًا - وهو يختلف عن بعض الأمثلة في هذا الموضوع عندما يكون هناك بالفعل قدر ضئيل من الميمات المجانية ولا يوجد شيء خاطئ)؟
خطأ وقت التشغيل: نفاد ذاكرة CUDA. حاولت تخصيص 1.33 جيجا بايت (GPU 1 ؛ 31.72 جيجا بايت إجمالي السعة ؛ 5.68 جيجا بايت مخصصة بالفعل ؛ 24.94 جيجا بايت مجانًا ؛ 5.96 ميجا بايت مخزنة مؤقتًا)
لا أفهم سبب انتقال المشكلة إلى حالة "مغلقة" ، حيث لا تزال تحدث في الإصدار الأخير من pytorch (1.2) و NVIDIA GPU (V-100)
شكرا!
 yuribd
في ٣ أكتوبر ٢٠١٩
yuribd
في ٣ أكتوبر ٢٠١٩
في معظم الأوقات ، تتلقى رسالة الخطأ هذه من حزمة fastai لأنك تستخدم وحدة معالجة رسومات صغيرة بشكل غير عادي. لقد أصلحت هذه المشكلة عن طريق إعادة تشغيل kernel الخاص بي وباستخدام حجم دفعة أصغر للمسار الذي تقدمه.
 AurioPinto
في ٥ أكتوبر ٢٠١٩
AurioPinto
في ٥ أكتوبر ٢٠١٩
نفس المشكلة هنا. عندما أستخدم pytorch0.4.1 ، حجم الدُفعة = 4 ، فلا بأس. ولكن عندما أقوم بالتغيير إلى pytorch1.3 وحتى ضبط حجم الدُفعة على 1 ، لدي مشكلة oom.
 Sarah20187
في ٢١ أكتوبر ٢٠١٩
Sarah20187
في ٢١ أكتوبر ٢٠١٩
حلها عن طريق تحديث pytorch الخاص بي إلى أحدث ... pytorch تحديث conda
 kafura0
في ٢١ أكتوبر ٢٠١٩
kafura0
في ٢١ أكتوبر ٢٠١٩
إنه بسبب الدفعة الصغيرة من البيانات التي لا تتناسب مع ذاكرة وحدة معالجة الرسومات. فقط قلل حجم الدفعة. عندما قمت بتعيين حجم الدُفعة = 256 لمجموعة بيانات cifar10 ، حصلت على نفس الخطأ ؛ ثم قمت بتعيين حجم الدفعة = 128 ، يتم حلها.
شكرا لقد عالجت الخطأ بهذه الطريقة.
 zhangzibao
في ٢٥ أكتوبر ٢٠١٩
zhangzibao
في ٢٥ أكتوبر ٢٠١٩
لقد خفضت حجم الدفعة إلى 8 ، وهو يعمل بشكل جيد. الفكرة هي أن يكون لديك حجم_دفعة صغير
 Asutosh11
في ٣٠ أكتوبر ٢٠١٩
Asutosh11
في ٣٠ أكتوبر ٢٠١٩
أعتقد أن ذلك يعتمد على الحجم الإجمالي للمدخلات التي تتعامل معها طبقة معينة. على سبيل المثال ، إذا كانت مجموعة من 256 صورة (32 × 32) تمر عبر 128 مرشحًا في طبقة ، فإن الحجم الإجمالي للإدخال هو 256 × 32 × 32 × 128 = 2 ^ 25. يجب أن يكون هذا الرقم أقل من بعض العتبة ، والتي أعتقد أنها خاصة بالآلة. بالنسبة إلى AWS p3.2xlarge ، على سبيل المثال ، يكون 2 ^ 26. لذلك إذا كنت تحصل على أخطاء في ذاكرة CuDA ، فحاول تقليل حجم الدُفعة أو عدد المرشحات أو وضع المزيد من الاختزال مثل طبقات الخطوة أو التجميع
 souryadey
في ١ نوفمبر ٢٠١٩
souryadey
في ١ نوفمبر ٢٠١٩
لديك نفس المشكلة:
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 7.93 GiB total capacity; 0 bytes already allocated; 3.83 GiB free; 0 bytes cached)
مع أحدث إصدار من pytorch (1.3) و cuda (10.1). يعرض Nvidia-smi أيضًا وحدة معالجة الرسومات نصف فارغة ، لذا فإن مقدار الذاكرة الخالية في رسالة الخطأ صحيح. لا يمكن إعادة إنتاجه برمز بسيط حتى الآن
 ArgentumWalker
في ٣ نوفمبر ٢٠١٩
ArgentumWalker
في ٣ نوفمبر ٢٠١٩
عملت إعادة تعيين النواة بالنسبة لي أيضًا! لم أكن أعمل حتى مع حجم الدفعة = 1 حتى فعلت ذلك
 kennethjmyers
في ٧ نوفمبر ٢٠١٩
kennethjmyers
في ٧ نوفمبر ٢٠١٩
يا رفاق ، لقد قمت بحل مشكلتي في تقليل حجم الدُفعات إلى النصف.
 faizao
في ١٩ نوفمبر ٢٠١٩
faizao
في ١٩ نوفمبر ٢٠١٩
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 3.95 GiB total capacity; 0 bytes already allocated; 2.02 GiB free; 0 bytes cached)
ثابت بعد إعادة التشغيل
 SomeUserName1
في ٢٢ نوفمبر ٢٠١٩
SomeUserName1
في ٢٢ نوفمبر ٢٠١٩
تم تغيير حجم الدفعة 64 (rtx2080 ti) إلى 32 (rtx 2060) ، تم حل المشكلة. لكني أريد أن أعرف طريقة أخرى لحل هذا النوع من المشاكل.
 sailfish009
في ٣ ديسمبر ٢٠١٩
sailfish009
في ٣ ديسمبر ٢٠١٩
هذا يحدث لي عندما أفعل التنبؤ !
لقد غيرت حجم الدُفعة من 1024 إلى 8 وما زلت أتلقى خطأ عند تقييم 82٪ من مجموعة الاختبار.
عندما أضفت with torch.no_grad() تم حل المشكلة.
test_loader = init_data_loader(X_test, y_test, torch.device('cpu'), batch_size, num_workers=0)
print("Starting inference ...")
result = []
model.eval()
valid_loss = 0
with torch.no_grad():
for batch_x, batch_y in tqdm(test_loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
output = model(batch_x)
result.extend(output[:, 0, 0])
loss = torch.sqrt(criterion(output, batch_y))
valid_loss += loss
valid_loss /= len(train_loader)
print("Done!")
 smasoudn
في ١٧ ديسمبر ٢٠١٩
smasoudn
في ١٧ ديسمبر ٢٠١٩
حللت المشاكل
loader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4)
إلى
loader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4)
 zhonghaochen
في ٢٧ ديسمبر ٢٠١٩
zhonghaochen
في ٢٧ ديسمبر ٢٠١٩
واجهت نفس المشكلة وتحققت من استخدام GPU على جهازي. كان هناك الكثير منها مستخدم بالفعل ولم يتبق سوى قدر أقل من الذاكرة. لقد قتلت دفتر jupyter الخاص بي وأعدت تشغيله. أصبحت الذاكرة خالية وبدأت الأمور تعمل. يمكنك استخدام ما يلي:
nvidia-smi - To check the memory utilization on GPU
ps -ax | grep jupyter - To get PID of jupyter process
sudo kill PID
 prabhatsharma
في ٢٧ ديسمبر ٢٠١٩
prabhatsharma
في ٢٧ ديسمبر ٢٠١٩
لقد تلقيت هذه الرسالة أيضًا:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)حدث ذلك عندما كنت أحاول تشغيل درس Fast.ai 1 Pets https://course.fast.ai/ (الخلية 31)
حاول تقليل حجم الدُفعة (bs) لبيانات التدريب الخاصة بك.
ابحث عن ما يناسبك.
 rishi0904
في ٢٧ ديسمبر ٢٠١٩
rishi0904
في ٢٧ ديسمبر ٢٠١٩
لقد وجدت هذه المشكلة قابلة للحل دون تعديل حجم الدفعة الخاصة بك.
افتح Terminal وموجه python
import torch
torch.cuda.empty_cache()
اخرج من مترجم Python ، وأعد تشغيل أمر PyTorch الأصلي الخاص بك ويجب (نأمل) ألا ينتج عنه خطأ ذاكرة CUDA.
 cpoptic
في ٣ يناير ٢٠٢٠
cpoptic
في ٣ يناير ٢٠٢٠
اكتشفت أنه عندما يستخدم جهاز الكمبيوتر الخاص بي الكثير من ذاكرة الوصول العشوائي ، تظهر هذه المشكلة عادةً. لذلك عندما نريد حجم دفعة أكبر ، يمكننا محاولة تقليل استخدام ذاكرة الوصول العشوائي لوحدة المعالجة المركزية.
 dhKwang
في ١٣ يناير ٢٠٢٠
dhKwang
في ١٣ يناير ٢٠٢٠
كان لديه مشكلة مماثلة.
ساعد تقليل حجم الدُفعة وإعادة تشغيل kernel في حل المشكلة.
 kumarnikhil936
في ١٩ يناير ٢٠٢٠
kumarnikhil936
في ١٩ يناير ٢٠٢٠
في حالتي ، أدى استبدال محسن Adam بواسطة مُحسِّن SGD إلى حل نفس المشكلة.
 tranvanluan2
في ٢٣ يناير ٢٠٢٠
tranvanluan2
في ٢٣ يناير ٢٠٢٠
حسنًا ، في حالتي ، استخدم with torch.no_grad(): (train model) ، output.to("cpu") و torch.cuda.empty_cache() وتم حل هذه المشكلة.
 PlanNoa
في ٣٠ يناير ٢٠٢٠
PlanNoa
في ٣٠ يناير ٢٠٢٠
خطأ وقت التشغيل: نفاد ذاكرة CUDA. حاولت تخصيص 54.00 MiB (GPU 0 ؛ السعة الإجمالية 3.95 جيجا بايت ؛ تم تخصيص 2.65 جيجا بايت بالفعل ؛ 39.00 MiB مجانًا ؛ 87.29 MiB مخبأ)
لقد وجدت الحل وقمت بتقليل قيمة حجم الدُفعة.
 sagrawal06
في ٣٠ يناير ٢٠٢٠
sagrawal06
في ٣٠ يناير ٢٠٢٠
أقوم بتدريب YOLOv3 باستخدام أوزان Darknet53 على مجموعة بيانات مخصصة. إن GPU الخاص بي هو NVIDIA RTX 2080 وكنت أواجه نفس المشكلة. أدى تغيير حجم الدفعة إلى حلها.
 wilderrodrigues
في ٢ فبراير ٢٠٢٠
wilderrodrigues
في ٢ فبراير ٢٠٢٠
أتلقى هذا الخطأ أثناء وقت الاستدلال .... أنا رو
CUDA نفاد الذاكرة. حاولت تخصيص 102.00 MiB (GPU 0 ؛ سعة إجمالية قدرها 15.78 جيجا بايت ؛ تم تخصيص 14.54 جيجا بايت بالفعل ؛ 48.44 ميجا بايت مجانًا ؛ 14.67 جيجا بايت محجوزة في المجموع بواسطة PyTorch)
-------------------------------------------------- --------------------------- +
| NVIDIA-SMI 440.59 إصدار برنامج التشغيل: 440.59 إصدار CUDA: 10.2 |
| ------------------------------- + ----------------- ----- + ---------------------- +
| استمرار اسم وحدة معالجة الرسومات- M | موزع معرّف الناقل أ | متقلب Uncorr. ECC |
| أداء درجة حرارة المروحة : الاستخدام / الغطاء | استخدام الذاكرة | GPU-Util Compute M. |
| ================================ + ================= ===== + ======================= |
| 0 تسلا V100-SXM2 ... تشغيل | 00000000: 00: 1E.0 إيقاف | 0 |
| غير متاح 35C P0 41W / 300W | 16112 ميغا بايت / 16160 ميغا بايت | 0٪ افتراضي |
+ ------------------------------- + ----------------- ----- + ---------------------- +
+ ------------------------------------------------- ---------------------------- +
| العمليات: ذاكرة وحدة معالجة الرسومات |
| GPU PID اكتب اسم العملية الاستخدام |
| =================================================== ============================== |
| 0 13978 C /.conda/envs/ / bin / python 16101MiB |
+ ------------------------------------------------- ---------------------------- +
 tvinith
في ٢٩ فبراير ٢٠٢٠
tvinith
في ٢٩ فبراير ٢٠٢٠
إنه بسبب الدفعة الصغيرة من البيانات التي لا تتناسب مع ذاكرة وحدة معالجة الرسومات. فقط قلل حجم الدفعة. عندما قمت بتعيين حجم الدُفعة = 256 لمجموعة بيانات cifar10 ، حصلت على نفس الخطأ ؛ ثم قمت بتعيين حجم الدفعة = 128 ، يتم حلها.
شكرا لك انت على حق
 Rxma1805
في ٢ مارس ٢٠٢٠
Rxma1805
في ٢ مارس ٢٠٢٠
بالنسبة للحالة المعينة ، حيث توجد ذاكرة GPU كافية ، ولكن لا يزال هناك خطأ. في حالتي ، قمت بحلها عن طريق تقليل عدد العمال في أداة تحميل البيانات.
 Yurasyk
في ١٤ مارس ٢٠٢٠
Yurasyk
في ١٤ مارس ٢٠٢٠
خلفية
py36 و pytorch1.4 و tf2.0 و conda
صقل روبرتا
مشكلة
المشكلة نفسها مثل EMarquer : pycharm يُظهر أنه لا يزال لدي ذاكرة كافية ،
طرق حاولت
- فشل "batch_size = 1"
- فشل "torch.cuda.empty_cache ()"
- CUDA_VISIBLE_DEVICES = فشل تشغيل python Run.py "0"
- لأنني لا أستخدم jupyter ، فلا داعي لإعادة تشغيل kernel
طريقة ناجحة
- نفيديا سمي


- الحقيقة هي أن ما يظهره pycharm يختلف مع ما يظهره "nvidia-smi" (آسف لم أحفظ صورة pycharm) ، في الواقع لا توجد ذاكرة كافية .
- العملية 6123 و 32644 تعمل على المحطة من قبل.
- سودو قتل -9 6123
- سودو قتل -9 32644
 FernandoZhuang
في ١٧ مارس ٢٠٢٠
FernandoZhuang
في ١٧ مارس ٢٠٢٠
ما الذي نجح معي ببساطة:
import gc
# Your code with pytorch using GPU
gc.collect()
 MastafaF
في ٦ أبريل ٢٠٢٠
MastafaF
في ٦ أبريل ٢٠٢٠
لقد وجدت هذه المشكلة قابلة للحل دون تعديل حجم الدفعة الخاصة بك.
افتح Terminal وموجه python
import torch torch.cuda.empty_cache()اخرج من مترجم Python ، وأعد تشغيل أمر PyTorch الأصلي الخاص بك ويجب (نأمل) ألا ينتج عنه خطأ ذاكرة CUDA.
في حالتي ، إنه يحل مشكلتي.
 LiEAEX
في ١٠ أبريل ٢٠٢٠
LiEAEX
في ١٠ أبريل ٢٠٢٠
تأكد من استخدامك لوحدة معالجة الرسومات في الفتحة 0 مع --device_ids 0
أعلم أنني أقطع المصطلحات لكنها نجحت. أعتقد أنه يفترض أنك تريد استخدام وحدة المعالجة المركزية بدلاً من وحدة معالجة الرسومات إذا لم تحدد معرفًا.
 aaron387
في ١٢ أبريل ٢٠٢٠
aaron387
في ١٢ أبريل ٢٠٢٠
أنا على الحصول على نفس الخطأ:
خطأ وقت التشغيل: نفاد ذاكرة CUDA. حاولت تخصيص 4.84 جيجا بايت (GPU 0 ؛ سعة إجمالية 7.44 جيجا بايت ؛ 5.22 جيجا بايت مخصصة بالفعل ؛ 1.75 جيجا بايت مجانًا ؛ 18.51 ميجا بايت مخزنة مؤقتًا)
عندما أقوم بإعادة تشغيل الكتلة أو تغيير حجم الدُفعة ، فإنها تعمل. لكني لا أحب هذا الحل. حتى أنني جربت torch.cuda.empty_cache () ، هذا لا يعمل معي. هل هناك أي طريقة أخرى فعالة لحل هذا؟
 Tann10
في ١٣ أبريل ٢٠٢٠
Tann10
في ١٣ أبريل ٢٠٢٠
لا أعرف ما إذا كان السيناريو الخاص بي مرتبطًا بالمشكلة الأصلية ، لكنني قمت بحل مشكلتي (اختفى خطأ OOM في الرسالة السابقة) عن طريق تفكيك الطبقات المتسلسلة nn في النموذج الخاص بي ، على سبيل المثال
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)إلى
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0) self.input_bn = nn.BatchNorm3d(32) output = F.relu(self.input_bn(self.input_conv(x)))يحتوي نموذجي على الكثير من هذه (5 على وجه الدقة). هل أستخدم nn.Sequential right؟ أم أن هذا الخلل؟ تضمين التغريدة
يبدو أنني أقوم أيضًا بحل الخطأ المماثل ولكن العكس معك.
أغير كل شيء
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)إلى
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)
 xml94
في ١٤ أبريل ٢٠٢٠
xml94
في ١٤ أبريل ٢٠٢٠
بالنسبة لي ، لم يساعد تغيير حجم الدفعة أو أي حل معين. لكن اتضح أنه في ملف .cfg الخاص بي كان لدي قيم خاطئة للفئات وعامل التصفية في طبقة واحدة. لذلك إذا لم يساعدك شيء ، فتحقق مرة أخرى من ملف .cfg.
 ulaszewskim
في ١ مايو ٢٠٢٠
ulaszewskim
في ١ مايو ٢٠٢٠
افتح Terminal
النوع الأول
نفيديا سمي
ثم حدد PID الذي يتوافق مع مسار python أو anaconda والكتابة
سودو قتل -9 PID
 krypticmouse
في ٤ مايو ٢٠٢٠
krypticmouse
في ٤ مايو ٢٠٢٠
لقد كنت أعاني من هذا الخطأ لبعض الوقت. بالنسبة لي ، اتضح أنني احتفظت بمتغير بايثون (أي موتر الشعلة) يشير إلى نتيجة النموذج ، وبالتالي لا يمكن تحريره بأمان حيث لا يزال بإمكان الكود الوصول إليه.
يبدو الرمز الخاص بي مشابهًا لما يلي:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p)
كان الإصلاح لهذا هو نقل p إلى قائمة. لذلك ، يجب أن يبدو الرمز بالشكل التالي:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p.tolist())
هذا يضمن أن predictions يحتفظ بقيم في الذاكرة الرئيسية ، وليس موترًا في وحدة معالجة الرسومات.
 abdelrahmanhosny
في ٨ مايو ٢٠٢٠
abdelrahmanhosny
في ٨ مايو ٢٠٢٠
أواجه هذا الخطأ باستخدام وحدة fastai.vision التي تعتمد على pytorch. أنا أستخدم CUDA 10.1
 jkomyno
في ١٦ مايو ٢٠٢٠
jkomyno
في ١٦ مايو ٢٠٢٠
training_args = TrainingArguments(
output_dir="./",
overwrite_output_dir=True,
num_train_epochs=5,
per_gpu_train_batch_size=4, # 4; 8 ;16 out of memory
save_steps=10_000,
save_total_limit=2,
)
قم بتقليل حجم per_gpu_train_batch_size من 16 إلى 8 ، فقد حل مشكلتي.
 autodataming
في ٣ يونيو ٢٠٢٠
autodataming
في ٣ يونيو ٢٠٢٠
إذا قمت بالتحديث إلى أحدث إصدار من PyTorch ، فقد يكون لديك أخطاء أقل من هذا القبيل
حقا , لماذا تقول ذلك
 XinyingZheng
في ٩ يونيو ٢٠٢٠
XinyingZheng
في ٩ يونيو ٢٠٢٠
السؤال الرئيسي لهذه القضية لا يزال مشكلة مفتوحة. أحصل على نفس CUDA الغريبة من رسالة الذاكرة. حاولت تخصيص 2.26 جيجا بايت في 4.08 جيجا بايت مجانًا. يبدو أن هناك ذاكرة كافية لكنها فشلت في التخصيص.
معلومات المشروع: تدريب Resnet 10 على مجموعة بيانات شبكة النشاط بحجم الدُفعة 4 ، يفشل في نهاية الحقبة الأولى.
تم تحريره: بعض التصورات: إذا قمت بتنظيف ذاكرة RAM الخاصة بي واحتفظت بتشغيل رمز Python فقط ، فلن يظهر الخطأ. ربما توجد ذاكرة كافية في وحدة معالجة الرسومات ، لكن ذاكرة RAM غير قادرة على التعامل مع جميع خطوات المعالجة الأخرى.
معلومات الكمبيوتر: Dell G5 - i7 9th - GTX 1660Ti 6GB - 16GB RAM
EDITED2: كنت أستخدم "_MultiProcessingDataLoaderIter" مع 4 عمال وهو يرفع رسالة نفاد الذاكرة في المكالمة الموجهة. إذا قمت بتقليل عدد العمال إلى 1 ، فلن يثير ذلك أي خطأ. مع عامل واحد ، يظل استخدام ذاكرة الوصول العشوائي 11/16 جيجا بايت ، مع 4 يرتفع إلى 14.5 / 16 جيجا بايت. ومع عامل واحد فقط ، يمكنني في الواقع رفع حجم الدُفعة إلى 32 ورفع ذاكرة وحدة معالجة الرسومات إلى 3.5 جيجابايت / 6 جيجابايت.
خطأ وقت التشغيل: نفاد ذاكرة CUDA. حاولت تخصيص 2.26 جيجا بايت (GPU 0 ؛ السعة الإجمالية 6.00 جيجا بايت ؛ 209.63 MiB مخصصة بالفعل ؛ 4.08 جيجا بايت مجانًا ؛ 246.00 ميجا بايت محجوزة في المجموع بواسطة PyTorch)
رسالة خطأ كاملة
Traceback (آخر مكالمة أخيرة):
ملف "main.py" ، السطر 450 ، في
إذا اخترت التوزيع:
ملف "main.py" ، السطر 409 ، في main_worker
opt.device ، current_lr ، train_logger ،
ملف "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ training.py" ، السطر 37 ، في train_epoch
المخرجات = النموذج (المدخلات)
ملف "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site -pack \ torch \ nn \ modules \ module.py" ، السطر 532 ، في __call__
النتيجة = self.forward ( الإدخال ، * kwargs)
ملف "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site -pack \ torch \ nnparallel \ data_parallel.py" ، السطر 150 ، في المقدمة
إرجاع الوحدة الذاتية ( المدخلات [0] ، * kwargs [0])
ملف "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site -pack \ torch \ nn \ modules \ module.py" ، السطر 532 ، في __call__
النتيجة = self.forward ( الإدخال ، * kwargs)
الملف "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ Models \ resnet.py" ، السطر 205 ، في المقدمة
س = self.layer3 (س)
ملف "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site -pack \ torch \ nn \ modules \ module.py" ، السطر 532 ، في __call__
النتيجة = self.forward ( الإدخال ، * kwargs)
ملف "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site -pack \ torch \ nn \ modules \ container.py" ، السطر 100 ، في المقدمة
المدخلات = الوحدة (المدخلات)
ملف "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site -pack \ torch \ nn \ modules \ module.py" ، السطر 532 ، في __call__
النتيجة = self.forward ( الإدخال ، * kwargs)
ملف "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ Models \ resnet.py" ، السطر 51 ، في المقدمة
خارج = self.conv2 (خارج)
ملف "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site -pack \ torch \ nn \ modules \ module.py" ، السطر 532 ، في __call__
النتيجة = self.forward ( الإدخال ، * kwargs)
ملف "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site -pack \ torch \ nn \ modules \ conv.py" ، السطر 480 ، إلى الأمام
self.padding ، self.dilation ، self.groups)
خطأ وقت التشغيل: نفاد ذاكرة CUDA. حاولت تخصيص 2.26 جيجا بايت (GPU 0 ؛ السعة الإجمالية 6.00 جيجا بايت ؛ 209.63 MiB مخصصة بالفعل ؛ 4.08 جيجا بايت مجانًا ؛ 246.00 ميجا بايت محجوز
في المجموع بواسطة PyTorch)
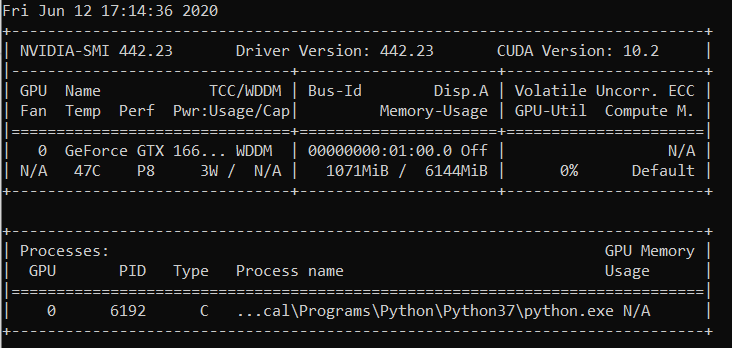
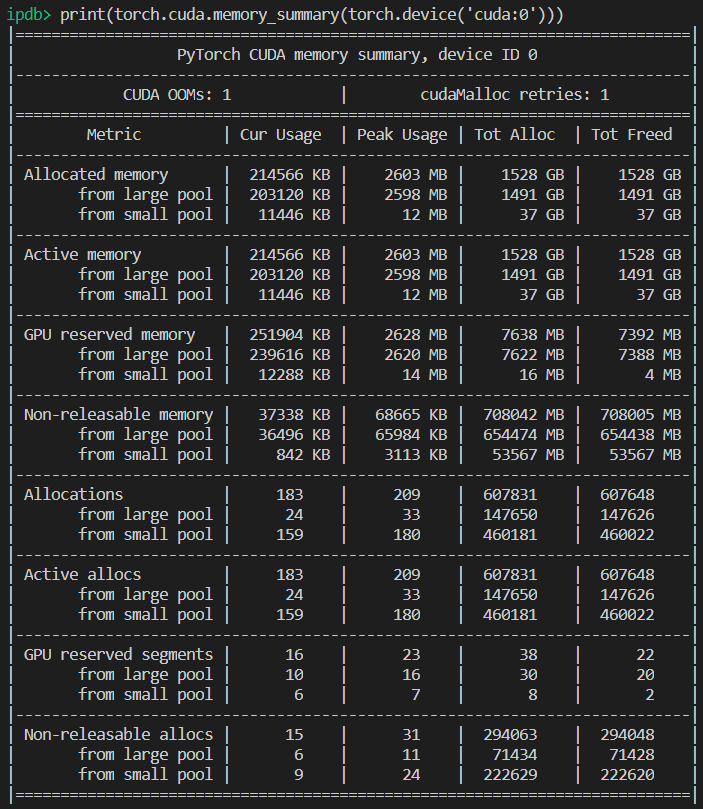
 guilhermesurek
في ١٢ يونيو ٢٠٢٠
guilhermesurek
في ١٢ يونيو ٢٠٢٠
صغير حجم الدفعة ، وهو يعمل
 cuge1995
في ١٥ يونيو ٢٠٢٠
cuge1995
في ١٥ يونيو ٢٠٢٠
لقد كنت أعاني من هذا الخطأ لبعض الوقت. بالنسبة لي ، اتضح أنني احتفظت بمتغير بايثون (أي موتر الشعلة) يشير إلى نتيجة النموذج ، وبالتالي لا يمكن تحريره بأمان حيث لا يزال بإمكان الكود الوصول إليه.
يبدو الرمز الخاص بي مشابهًا لما يلي:
predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)كان الإصلاح لهذا هو نقل
pإلى قائمة. لذلك ، يجب أن يبدو الرمز بالشكل التالي:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())هذا يضمن أن
predictionsيحتفظ بقيم في الذاكرة الرئيسية ، وليس موترًا في وحدة معالجة الرسومات.
abdelrahmanhosny شكرًا على الإشارة إلى هذا. لقد واجهت نفس المشكلة بالضبط في PyTorch 1.5.0 ، ولم يكن لدي أي مشاكل في OOM أثناء التدريب ، ولكن أثناء الاستدلال ظللت أيضًا أمسك متغير python (أي موتر الشعلة) يشير إلى نتيجة النموذج في الذاكرة مما أدى إلى نفاد ذاكرة GPU بعد عدد معين من الدفعات.
في حالتي ، لم ينجح نقل التنبؤات إلى القائمة لأنني أقوم بتوليد الصور باستخدام شبكتي ، لذلك كان علي القيام بما يلي:
predictions.append(p.detach().cpu().numpy())
هذا ثم حل المشكلة!
 samkellerhals
في ١٩ يونيو ٢٠٢٠
samkellerhals
في ١٩ يونيو ٢٠٢٠
هل يوجد حل عام؟
CUDA نفاد الذاكرة. حاولت تخصيص 196.00 MiB (GPU 0 ؛ السعة الإجمالية 2.00 جيجا بايت ؛ 359.38 MiB مخصصة بالفعل ؛ 192.29 MiB مجانًا ؛ 152.37 MiB مخزنة مؤقتًا)
هل يوجد حل عام؟
CUDA نفاد الذاكرة. حاولت تخصيص 196.00 MiB (GPU 0 ؛ السعة الإجمالية 2.00 جيجا بايت ؛ 359.38 MiB مخصصة بالفعل ؛ 192.29 MiB مجانًا ؛ 152.37 MiB مخزنة مؤقتًا)
 manavkhadka0
في ٢٤ يونيو ٢٠٢٠
manavkhadka0
في ٢٤ يونيو ٢٠٢٠
لقد كنت أعاني من هذا الخطأ لبعض الوقت. بالنسبة لي ، اتضح أنني احتفظت بمتغير بايثون (أي موتر الشعلة) يشير إلى نتيجة النموذج ، وبالتالي لا يمكن تحريره بأمان حيث لا يزال بإمكان الكود الوصول إليه.
يبدو الرمز الخاص بي مشابهًا لما يلي:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)كان الإصلاح لهذا هو نقل
pإلى قائمة. لذلك ، يجب أن يبدو الرمز بالشكل التالي:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())هذا يضمن أن
predictionsيحتفظ بقيم في الذاكرة الرئيسية ، وليس موترًا في وحدة معالجة الرسومات.abdelrahmanhosny شكرًا على الإشارة إلى هذا. لقد واجهت نفس المشكلة بالضبط في PyTorch 1.5.0 ، ولم يكن لدي أي مشاكل في OOM أثناء التدريب ، ولكن أثناء الاستدلال ظللت أيضًا أمسك متغير python (أي موتر الشعلة) يشير إلى نتيجة النموذج في الذاكرة مما أدى إلى نفاد ذاكرة GPU بعد عدد معين من الدفعات.
في حالتي ، لم ينجح نقل التنبؤات إلى القائمة لأنني أقوم بتوليد الصور باستخدام شبكتي ، لذلك كان علي القيام بما يلي:
predictions.append(p.detach().cpu().numpy())هذا ثم حل المشكلة!
لدي نفس المشكلة في نموذج ParrallelWaveGAN واستخدمت الحلول في # 16417 لكنها لا تعمل بالنسبة لي
y = self.model_gan (* x) .view (-1) .detach (). cpu (). numpy ()
gc.collect ()
torch.cuda.empty_cache ()
 tuong-olli
في ٢٥ يونيو ٢٠٢٠
tuong-olli
في ٢٥ يونيو ٢٠٢٠
واجهت نفس المشكلة أثناء التدريب.
جمع القمامة وتفريغ ذاكرة cuda بعد كل حقبة حل المشكلة بالنسبة لي.
gc.collect()
torch.cuda.empty_cache()
 IsakWesterlundBitville
في ٥ أغسطس ٢٠٢٠
IsakWesterlundBitville
في ٥ أغسطس ٢٠٢٠
ما الذي نجح معي ببساطة:
import gc # Your code with pytorch using GPU gc.collect()
شكرا لك!! كنت أواجه مشكلة في إدارة مثال القطط والكلاب وقد نجح ذلك بالنسبة لي.
 Michelpayan
في ٥ أغسطس ٢٠٢٠
Michelpayan
في ٥ أغسطس ٢٠٢٠
واجهت نفس المشكلة أثناء التدريب.
جمع القمامة وتفريغ ذاكرة cuda بعد كل حقبة حل المشكلة بالنسبة لي.gc.collect() torch.cuda.empty_cache()
نفس الشيء بالنسبة لي
 AleksandrTulenkov
في ٦ أغسطس ٢٠٢٠
AleksandrTulenkov
في ٦ أغسطس ٢٠٢٠
تقليل حجم الدُفعة وزيادة العهود. هذه هي الطريقة التي قمت بحلها.
 oyekamal
في ١٨ سبتمبر ٢٠٢٠
oyekamal
في ١٨ سبتمبر ٢٠٢٠
areebsyed تحقق من ذاكرة الوصول العشوائي ، لقد واجهت هذه المشكلة عند تعيين العديد من العمال على التوازي.
guilhermesurek
في ٢٩ سبتمبر ٢٠٢٠
كما أنني أتلقى نفس الخطأ أثناء ضبط نموذج bert2bert EncoderDecoder المدروس مسبقًا في pytorch في Colab دون حتى إكمال حقبة واحدة.
RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 15.90 GiB total capacity; 13.77 GiB already allocated; 59.88 MiB free; 14.98 GiB reserved in total by PyTorch)
 Aakash12980
في ٦ أكتوبر ٢٠٢٠
Aakash12980
في ٦ أكتوبر ٢٠٢٠
@ Aakash12980 هل حاولت تقليل حجم الدفعة؟ أيضًا ربما تحاول الصور المدخلة التي تريد تدريبها تغيير حجمها
 areebsyed
في ٦ أكتوبر ٢٠٢٠
areebsyed
في ٦ أكتوبر ٢٠٢٠
areebsyed نعم لقد خفضت حجم الدُفعة إلى 4
Aakash12980
في ٦ أكتوبر ٢٠٢٠
نفس
RuntimeError Traceback (most recent call last)
<ipython-input-116-11ebb3420695> in <module>
28 landmarks = landmarks.view(landmarks.size(0),-1).cuda()
29
---> 30 predictions = network(images)
31
32 # clear all the gradients before calculating them
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
<ipython-input-112-174da452c85d> in forward(self, x)
13 ##out = self.first_conv(x)
14 x = x.float()
---> 15 out = self.model(x)
16 return out
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x)
218
219 def forward(self, x):
--> 220 return self._forward_impl(x)
221
222
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x)
204 x = self.bn1(x)
205 x = self.relu(x)
--> 206 x = self.maxpool(x)
207
208 x = self.layer1(x)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input)
157 return F.max_pool2d(input, self.kernel_size, self.stride,
158 self.padding, self.dilation, self.ceil_mode,
--> 159 self.return_indices)
160
161
~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs)
245 return if_true(*args, **kwargs)
246 else:
--> 247 return if_false(*args, **kwargs)
248
249 if if_true.__doc__ is None and if_false.__doc__ is not None:
~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices)
574 stride = torch.jit.annotate(List[int], [])
575 return torch.max_pool2d(
--> 576 input, kernel_size, stride, padding, dilation, ceil_mode)
577
578 max_pool2d = boolean_dispatch(
RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
 monajalal
في ٧ أكتوبر ٢٠٢٠
monajalal
في ٧ أكتوبر ٢٠٢٠
نفس
RuntimeError Traceback (most recent call last) <ipython-input-116-11ebb3420695> in <module> 28 landmarks = landmarks.view(landmarks.size(0),-1).cuda() 29 ---> 30 predictions = network(images) 31 32 # clear all the gradients before calculating them ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), <ipython-input-112-174da452c85d> in forward(self, x) 13 ##out = self.first_conv(x) 14 x = x.float() ---> 15 out = self.model(x) 16 return out ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x) 218 219 def forward(self, x): --> 220 return self._forward_impl(x) 221 222 ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x) 204 x = self.bn1(x) 205 x = self.relu(x) --> 206 x = self.maxpool(x) 207 208 x = self.layer1(x) ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input) 157 return F.max_pool2d(input, self.kernel_size, self.stride, 158 self.padding, self.dilation, self.ceil_mode, --> 159 self.return_indices) 160 161 ~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs) 245 return if_true(*args, **kwargs) 246 else: --> 247 return if_false(*args, **kwargs) 248 249 if if_true.__doc__ is None and if_false.__doc__ is not None: ~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices) 574 stride = torch.jit.annotate(List[int], []) 575 return torch.max_pool2d( --> 576 input, kernel_size, stride, padding, dilation, ceil_mode) 577 578 max_pool2d = boolean_dispatch( RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
monajalal حاول تقليل حجم الدُفعة أو حجم بُعد الإدخال.
Aakash12980
في ٧ أكتوبر ٢٠٢٠
إذن ما هو الحل على أمثلة مثل أدناه (على سبيل المثال ، الكثير من الذاكرة _free_ ومحاولة تخصيص القليل جدًا - والذي يختلف عن _بعض _ الأمثلة في هذا الموضوع عندما يكون هناك بالفعل قدر ضئيل من الميمات المجانية ولا يوجد شيء خاطئ)؟
خطأ وقت التشغيل: نفاد ذاكرة CUDA. حاولت تخصيص _ 1.33 جيجا بايت _ (GPU 1 ؛ سعة إجمالية 31.72 جيجا بايت ؛ تم تخصيص 5.68 جيجا بايت بالفعل ؛ _ 24.94 جيجا بايت مجانًا _ ؛ 5.96 ميجا بايت مخزنة مؤقتًا)
لا أفهم سبب انتقال المشكلة إلى حالة "مغلقة" ، حيث لا تزال تحدث في الإصدار الأخير من pytorch (1.2) و NVIDIA GPU (V-100)
شكرا!
نعم أشعر أن معظم الناس لا يدركون أن المشكلة ليست مجرد OOM ، إنها أن هناك OOM بينما الخطأ يقول أن هناك مساحة خالية كافية. أواجه هذه المشكلة أيضًا على النوافذ ، هل وجدت أي حل؟
 YoadTew
في ٦ نوفمبر ٢٠٢٠
YoadTew
في ٦ نوفمبر ٢٠٢٠
القضايا ذات الصلة
 kdexd
·
3تعليقات
kdexd
·
3تعليقات
 keskarnitish
·
3تعليقات
keskarnitish
·
3تعليقات
 szagoruyko
·
3تعليقات
szagoruyko
·
3تعليقات
 negrinho
·
3تعليقات
negrinho
·
3تعليقات
 cdluminate
·
3تعليقات
cdluminate
·
3تعليقات
التعليق الأكثر فائدة
إنه بسبب الدفعة الصغيرة من البيانات التي لا تتناسب مع ذاكرة وحدة معالجة الرسومات. فقط قلل حجم الدفعة. عندما قمت بتعيين حجم الدُفعة = 256 لمجموعة بيانات cifar10 ، حصلت على نفس الخطأ ؛ ثم قمت بتعيين حجم الدفعة = 128 ، يتم حلها.