我已经浏览了整个 javadoc 和站点文档,但似乎找不到 SQLLog 的替代机制。 我可以看到 StatementContext 有一些 get*Sql 方法,但没有替代 DBI.setSQLLog。 TimingCollector 接收语句上下文,因此技术上可以在那里完成,但鉴于接口的名称,这感觉像是一种解决方法。
 leaumar
leaumar
所有13条评论
我认为我们已经在 JDBI3 中删除了这个日志抽象。 如果要启用 SQL 日志记录,则需要在 SLF4J 实现的配置中启用。
 arteam
于 2017-12-08
arteam
于 2017-12-08
在SqlStatement
LOG.trace("Execute SQL \"{}\" in {}ms", sql, elapsedTime / 1000000L);
问题是这并没有让我自由决定_如何_我希望我的查询被记录:级别、短语、原始/渲染/解析的 sql、条件......
文档站点说 TimingCollector 还没有完全充实,所以欢迎提出想法,所以我想我在此建议要么制作一个姐妹界面来记录查询而不是传递时间,要么将 TimingCollector 泛化为也用于记录查询。
leaumar
于 2017-12-08
是的,我们现在没有一个很好的界面。 旧的SQLLog有很多不足之处,因此我们在有机会时将其删除,以支持构建更好的东西。
 stevenschlansker
于 2017-12-11
stevenschlansker
于 2017-12-11
现在花了几个小时将我的项目更新到 jdbi3,我发现 TimingCollector 在我的项目中是一个不错的解决方案,只有 3 个小抱怨:它在语义上是错误的,它是在查询之后而不是之前执行的(所以如果查询导致异常,将不会记录它),并且我无法从 statementcontext 的绑定中获取命名/位置参数。
——
与这个问题完全无关,但关于花时间更新到 jdbi3 的话题,我只想说我非常喜欢它。 Jdbi 类充当保存插件的配置存储库的方式非常出色。 直到现在,我的项目都是建立在以一种非常具体的、典型的我的方式使用 jdbi 的基础上的,这种方式有效,但并不是真正的 jdbi 以 jdbi 的方式工作。 由于 jdbi3 通过删除一些自由迫使我按照 jdbi3 的方式做所有事情,因此我学习了一些替代机制,例如 Arguments、基于列而不是行映射以及改进的 fluent api,这只是一个全新的便利世界一旦你设置好了一切。 直到现在我才意识到你的范式在技术和功能上有多大意义。 很棒的工作人员,谢谢你做这个:)
leaumar
于 2017-12-11
感谢您的友好反馈! 您介意将您想要使用 SqlLog / TimingCollector 的方式组合到这张票中作为设计文档的开始吗? 最好概述一些实际用例,这样我们就可以确保解决实际问题。
stevenschlansker
于 2017-12-11
快速伪java代码草图:
public interface Jdbi {
void registerSqlLogger(SqlLogger logger);
void registerSqlLoggerFactory(SqlLoggerFactory factory);
}
public interface SqlLogger {
void logBeforeExecution(StatementContext context);
void logAfterExecution(StatementContext context, long nanos);
void logException(StatementContext context, Exception ex);
}
public interface SqlLoggerFactory {
// the sqlObject, if any
Optional<SqlLogger> build(<strong i="6">@Nullable</strong> SqlObject extension, <strong i="7">@Nullable</strong> Class extensionClass);
}
public interface StatementContext {
// "select * from x where foo = 'bar'"
String getNormalizedSql();
// "select * from x where foo = ?"
// "select * from x where foo = :bar"
String getParamaterizedSql();
List<Object> getPositionalArgs();
Map<String, Object> getNamedArgs();
ParamsType getParamsType();
enum ParamsType {
NONE, POSITIONAL, NAMED
}
}
public class Main {
public static void main(String[] args) {
Jdbi jdbi = Jdbi.create();
jdbi.registerSqlLoggerFactory((sqlObject, sqlObjectClass) -> new SqlLogger() {
private final Logger logger = LoggerFactory.getLogger(sqlObject != null? sqlObjectClass: MyApp.class);
<strong i="10">@Override</strong>
void before(StatementContext context) {
String params;
switch (context.getParamsType()) {
case NONE:
params = "N/A";
case POSITIONAL:
params = context.getPositionalArgs().toString();
case NAMED:
params = toKeyValueString(context.getNamedArgs());
}
logger.debug(Markers.SQL, "query: {}, params: {}", context.getParameterizedSql(), params);
}
<strong i="11">@Override</strong>
void after(StatementContext context, long nanos) {
logger.trace(Markers.SQL, "query {} took {}ns", context.getNormalizedSql, nanos);
}
<strong i="12">@Override</strong>
void exception(StatementContext context, Exception ex) {
logger.error(Markers.SQL, context.getNormalizedSql(), e);
}
});
}
}
对于它的价值,一个简单的 SqlStatementCustomizerFactory 允许您通过注释来实现它,放置在单个方法或整个接口上。 是的,它很容易被遗忘,这是一个问题。 我目前不需要非常精确的查询日志记录,因为它们主要用于调试,并在我需要时打开,但您也可以覆盖 beforeExecution 和 afterExecution 时间。 扩展它以使用一个类来实例化并不太难。
<strong i="6">@NameBinding</strong>
@Retention(AnnotationRetention.RUNTIME)
@Target(AnnotationTarget.CLASS)
@SqlStatementCustomizingAnnotation(WriteQueryToLogFactory::class)
annotation class WriteQueryToLog
class WriteQueryToLogFactory : SqlStatementCustomizerFactory {
val log: Logger = LoggerFactory.getLogger("api.sql-statements")
override fun createForType(annotation: Annotation?, sqlObjectType: Class<*>?): SqlStatementCustomizer {
return SqlStatementCustomizer( { q -> q.addCustomizer(object: StatementCustomizer {
override fun beforeExecution(stmt: PreparedStatement, ctx: StatementContext) {
log.trace("Context: ${ctx.extensionMethod.type}.${ctx.extensionMethod.method.name}")
log.trace("Statement: ${stmt.toString()}")
}
})})
}
}
是的,这意味着您可以访问整个语句并可以将其搞砸,但这真的是一个问题吗?
 pikzen
于 2018-01-12
pikzen
于 2018-01-12
@pikzen这首当其冲,但我的建议是让查询数据更易于访问并添加 onException 方法。 我一开始也尝试了其中一个自定义注释,但发现它对于我想做的事情来说太有限了,这就是我建议所有这些的原因。
leaumar
于 2018-01-12
我只是再看一眼,似乎 ParsedParameters 和 ParsedSql 是我想要看到的一半。 ParsedParameters 只是缺少一种从提供的名称/索引中获取参数值的方法。 我认为这将使图片大致完整。
leaumar
于 2018-01-12
您是否查看过传递给定制器的 StatementContext 对象? 它使您可以访问 SQL 的parsedSql rawSql和renderedSql ,以及包含查询参数的attributes 。
我确实同意在异常上获得一些东西是实用的,但是通过简单地改进当前的 StatementCustomizer 接口和调整核心不是更好吗?
pikzen
于 2018-01-12
以及包含查询参数的
attributes
嗯,不是吗?
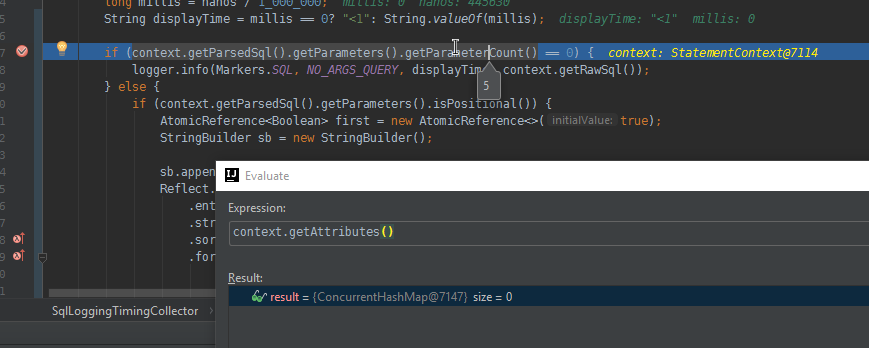
获取查询参数值 AFAIK 的唯一地方是通过对绑定的反射:
Reflect.on(context.getBinding()).<HashMap<Integer, Argument>>get("named")
leaumar
于 2018-01-12
确实,我的错,我的意思是binding ,我只是通过调试器查看它,并没有意识到它无法从外部获得。
有几个地方可以使用它们,是的,binding.positionals/named, statement.parameterValues/parameterTypes(虽然那个不是最实用的),它们确实只能通过反射获得。 一世
pikzen
于 2018-01-12
绑定参数在getBinding() 。 attributes包含通过define()定义的属性——这些属性被内联到 SQL 中的<attr>标记中。
 qualidafial
于 2018-01-12
qualidafial
于 2018-01-12
相关问题
 johanneszink
·
4评论
johanneszink
·
4评论
 keith-miller
·
3评论
keith-miller
·
3评论
 Shujito
·
5评论
Shujito
·
5评论
 nonameplum
·
5评论
nonameplum
·
5评论
 goxr3plus
·
4评论
goxr3plus
·
4评论
最有用的评论
现在花了几个小时将我的项目更新到 jdbi3,我发现 TimingCollector 在我的项目中是一个不错的解决方案,只有 3 个小抱怨:它在语义上是错误的,它是在查询之后而不是之前执行的(所以如果查询导致异常,将不会记录它),并且我无法从 statementcontext 的绑定中获取命名/位置参数。
——
与这个问题完全无关,但关于花时间更新到 jdbi3 的话题,我只想说我非常喜欢它。 Jdbi 类充当保存插件的配置存储库的方式非常出色。 直到现在,我的项目都是建立在以一种非常具体的、典型的我的方式使用 jdbi 的基础上的,这种方式有效,但并不是真正的 jdbi 以 jdbi 的方式工作。 由于 jdbi3 通过删除一些自由迫使我按照 jdbi3 的方式做所有事情,因此我学习了一些替代机制,例如 Arguments、基于列而不是行映射以及改进的 fluent api,这只是一个全新的便利世界一旦你设置好了一切。 直到现在我才意识到你的范式在技术和功能上有多大意义。 很棒的工作人员,谢谢你做这个:)