13163将引入期待已久的numpy PRNG基础设施替换。 为了使PR易于管理,我们将在所有决定最终确定之前将其合并到master,例如将$$$ BitGenerator作为默认值。
我们必须在使用新基础结构的第一个版本发布之前做出决定。 一旦发布,我们将在一段时间内坚持选择,因此我们应该确保我们对我们的决定感到满意。
在另一方面,默认的选择并不那么多的后果。 我们不是在讨论numpy.random.*便利功能下的默认BitGenerator 。 根据NEP 19,这些仍然是旧版RandomState别名,旧版BitGenerator仍然是MT19937 。 默认值唯一出现的地方是在没有参数的情况下实例化Generator() 。 例如,当用户请求带有任意状态的Generator时,大概是在上面调用.seed()方法。 这可能很罕见,因为用他们实际想要的种子BitGenerator显式实例化它将很容易。 此处的合理选择实际上可能是不指定任何默认值,并且始终要求用户指定BitGenerator 。
尽管如此,我们会建议哪些人在大多数时间应该使用BitGenerator ,虽然我们可以相当自由地更改建议,但是无论哪个人引以为傲,都可能会在书籍,博客和教程中写到最多的东西。等等。
IMO,有几个主要选项(我的评论是,请随意不同意;我没有尝试移植#13163中的所有相关评论):
没有预设
始终要求Generator(ChosenBitGenerator(maybe_seed)) 。 这有点不友好,但是由于这是使生成器正确初始化以实现可重现性的一种非常便捷的方法,因此即使我们有默认设置,人们仍然可能会这样做。
MT19937
这将是一个很好的保守选择。 这肯定不比现状差。 由于Mersenne Twister仍然被广泛认为是“标准”选择,因此它可能会帮助需要论文的学术用户由可能质疑“非标准”选择的人审阅,而不论PRNG的具体质量如何。 “没有人因为雇用IBM而被解雇。” MT19937的主要缺点主要是,由于状态很大,它比某些可用替代方法要慢,并且它未能通过某些统计质量测试。 在选择另一个PRNG时,这里有一个_opportunity_(但不是_obligation_,IMO),如果愿意,可以尝试移动“标准”。
PCG64
这可能是我个人最常使用的一种。 主要缺点是它使用128位整数算术,如果编译器不提供这种整数类型,则会在C语言中进行仿真。 出现这种情况的两个主要平台是32位CPU和64位MSVC,即使CPU支持,它们也不支持128位整数。 就个人而言,我不建议让性能越来越稀缺的32位CPU来决定我们的选择。 但是,MSVC性能非常重要,因为我们的Windows构建确实需要该编译器,而不需要其他Windows编译器。 可能可以使用一些汇编/编译器内部函数来解决它,但必须有人编写它们。 我们必须这样做的唯一原因是MSVC,这使得它在面对汇编时比其他时候更加可口。
Xoshiro256
小型,快速PRNG的另一种现代选择。 它确实有一些已知的统计怪癖,但对于大多数用途而言,它们不太可能成为主要因素。 这些怪癖使我回避它,但这是我将要编写的代码的个人选择。
 rkern
rkern
所有166条评论
英特尔Windows编译器对128位整数有何作用? 与Windows上的MT1993相比,使用MSVC编译PCG64的速度要慢多少? 我怀疑前跳功能将被广泛使用,因此默认情况下启用它可能会很好。
 charris
于 2019-05-27
charris
于 2019-05-27
英特尔Windows编译器对128位整数有何作用?
不完全确定; 我不知道ICC是否会受到ABI的影响。 如果我们只是想了解可以使用的生成程序集,那么这是一个方便的资源: https :
我怀疑前跳功能将被广泛使用,因此默认情况下启用它可能会很好。
您是说可设置的流吗? 这是一个好点,但是我想知道它是否可能不会反过来。 如果我们对默认值的选择实际上起着很大的作用,那么也许如果我们选择这些功能更全的PRNG之一,人们将在库代码中更广泛地使用这些功能,而无需证明他们需要这些“高级”功能,因为毕竟,它们可用“标准”。 但是,如果另一个用户出于速度或其他原因尝试使用功能较少的BitGenerator来使用该库,则他们将遇到障碍。 在No default或MT19937世界中,图书馆更有可能考虑并记录其所需的高级功能。
另一方面,这种偶然性会使没有可设置流的BitGenerator看起来不太可取,而且我喜欢朝着这个方向推进被认为是最佳实践的想法(纯粹是个人;我不觉得使NumPy-the-project分享这个概念的义务)。 这可能有助于避免我在人们中间看到.seed()的滥用行为。 但是,所有这些再次基于以下观念:违约会极大地改变人们的行为,因此所有这些担忧都可能会大大减弱。
rkern
于 2019-05-27
与Windows上的MT1993相比,使用MSVC编译PCG64的速度要慢多少?
在@bashtage在#13163中发布的基准测试中,PCG64的速度几乎是MT19937的一半,这对于MSVC和朋友而言实在令人失望。 相比之下,Linux的速度要快23%。
英特尔Windows编译器对128位整数有何作用?
其他编译器(例如Clang,GCC和Intel编译器)在64位系统上实现128位整数的方式与在32位系统上实现64位整数的方式相同。 所有相同的技术,不需要任何新的想法。 微软没有为MSVC这么做,因此编译器没有直接支持的128位整数。
结果,对于MSVC,在#13163中,PCG64的现有实现通过调用x86_64中的_umul128之类的Microsoft内部函数来实现128位数学运算(并且它可能还可以使用等效且更便携的Intel内部函数,例如_mulx_u64 ),从而编码GCC,Clang和Intel编译器自己执行的操作。 最大的问题可能是微软的编译器不能很好地优化这些内在函数(希望它们至少内联了?)。 手工编码的汇编程序可能会运行得更快,但是正确的解决方法是使编译器不会出现如此糟糕的状况。
我怀疑前跳功能将被广泛使用,因此默认情况下启用它可能会很好。
我很高兴您喜欢继续前进,但是我很好奇您为什么认为它会被广泛使用。 (个人而言,我真的很喜欢distance ,它告诉您两个PRNG的距离。这是PCG的C ++版本,而不是C的版本。如果有的话,添加它很简单利益。)
 imneme
于 2019-05-27
imneme
于 2019-05-27
我很高兴您喜欢继续前进,但是我很好奇您为什么认为它会被广泛使用。
可能不熟悉当前的术语。 我的意思是容易获得的独立流,可用于并行运行模拟。 我不知道可以并行处理多少个仿真问题,但是我怀疑这是很多问题,而且考虑到如今人们在芯片上获得的内核数量,这很容易弥补速度上的劣势。
微软没有为MSVC这么做,因此编译器没有直接支持的128位整数。
因此,这会伤及我们的方向,OTOH,Windows上的许多人都从Anaconda或Enthought获得了软件包,它们都使用Intel,而真正关心性能的人则可能在Linux,Mac或AIX上。
编辑:也许如果微软担心,他们可以为解决该问题提供悬赏。
charris
于 2019-05-27
FWIW,这是clang将为关键功能生成的程序集,包括将uint128_t拆包/重新包装到uint64_t s的结构中所需的位: https:// godbolt.org/z/Gtp3os
rkern
于 2019-05-27
很酷,@ rkern。 您是否有机会做同样的事情来查看MSVC对手写的128位代码所做的事情?
imneme
于 2019-05-27
很酷,@ rkern。 您是否有机会做同样的事情来查看MSVC对手写的128位代码所做的事情?
恩,不是很漂亮。 〜https ://godbolt.org/z/a5L5Gz~
糟糕,忘记添加-O3 ,但仍然很丑陋: https :
rkern
于 2019-05-27
并没有那么糟糕。 您没有进行优化,因此没有内联任何内容。 我添加了/Ox (也许还有更好的选择?)。 我还修复了使用内置旋转内部函数( _rotr64 )的代码,因为显然MSVC无法发现C旋转惯用法。
不过还是有点火车残骸。 但是我认为可以说,只要稍加注意,就可以对PCG64代码进行调整,以使其在MSVC上编译为完全不让每个人都感到尴尬的东西。
imneme
于 2019-05-27
为了允许其他所有内容合并,为什么现在不选择“ no default”? 这样一来,我们就可以自由地在以后(即使在一个或多个发行版之后)做出默认决定,而不会破坏兼容性。
 eric-wieser
于 2019-05-27
eric-wieser
于 2019-05-27
我们的大多数用户不是随机数专家,我们应该为其提供默认值。
除了平淡无奇的“现在他们需要键入更多代码”之外,当我们更改某些内容时会发生什么? 在对BitGenerator进行硬编码的情况下(因为我们没有提供默认值),每个不老练的用户现在都必须重构其代码,并希望了解他们选择的细微差别(请注意,我们甚至无法就自己达成共识)是最好的)。 但是,如果提供默认值,则由于新的默认值或新版本与位流不兼容,我们可能会吵闹地破坏他们的测试。
在比特流将始终保持恒定的假设与NumPy开发人员知道他们在做什么以及默认值应为最佳品牌的假设之间,我会在第二个假设的一边犯错,即使它打破第一。
编辑:阐明哪些开发人员应该知道他们在做什么
 mattip
于 2019-05-27
mattip
于 2019-05-27
我们的大多数用户不是随机数专家,我们应该为其提供默认值。
好吧,无论我们是否具有默认值或默认值,我们都至少会记录建议。
除了平淡无奇的“现在他们需要键入更多代码”之外,当我们更改某些内容时会发生什么?
您在想什么“东西”? 我听不懂你的说法。
rkern
于 2019-05-27
除了平淡无奇的“现在他们需要键入更多代码”之外,当我们更改某些内容时会发生什么?
您在想什么“东西”? 我听不懂你的说法。
@mattip是指更改默认位生成器。
这会使使用它的用户发疯,并且coudl需要一些代码更改。
例如,如果您使用
g = Generator()
g.bit_generator.seed(1234)
并且更改了底层位生成器,那么这是错误的。
如果您做得更加理智并使用
Generator(BitGenerator(1234))
那么您将看不到它。
IMO,在考虑选择默认值时,我们应该认为它已经修复,直到在底层位生成器中发现致命缺陷或英特尔在其芯片中添加了QUANTUM_NI,这在随机性能方面产生了许多OOM改进。
 bashtage
于 2019-05-27
bashtage
于 2019-05-27
我意识到我在这里有点局外人,但我认为期望哪个PRNG是默认选择永远固定并且永远不会改变是不合理的。 (例如,在C ++中, std::default_random_engine由实现决定,可以在各个发行版之间进行更改。)
而是需要一种机制来重现先前的结果。 因此,一旦存在特定的实现,就很难更改它(例如,MT19937 _is_ MT19937,您无法对其进行调整以提供不同的输出)。 [并且删除已经存在的实现也是不明智的。]
当默认值更改时,想要继续复制旧结果的人将需要按名称要求提供以前的默认值。 (您可以通过提供一种机制来选择与先前发行版相对应的默认值来实现这一点。)
就是说,即使允许您将默认生成器换成其他东西,它实际上也必须严格地做得更好-默认生成器中的任何功能都表示将来会支持该功能。 如果您的默认生成器具有有效的advance ,您以后就无法真正使用它。 (为避免出现此问题,您可能会禁用默认生成器中的高级功能。)
总而言之,有一些方法可以确保使用可以产生可重现的结果,而不必尝试将自己锁定在默认永远不变的合同中。 它还可以减少您做出选择的风险。
(FWIW,这是我在PCG做到了。默认的PCG 32位PRNG是目前XSH-RR变体作为访问pcg_setseq_64_xsh_rr_32_random_r C库和pcg_engines::setseq_xsh_rr_64_32在C类++库],但是原则上,如果您真的想要面向未来的可重复性,则应明确指定XSH-RR,而不要使用别名的pcg32_random_r或pcg32 ,并且原则上可以升级为其他名称)
imneme
于 2019-05-27
它并不是永远永久的(整个项目90%都是由大约14年前做出的真实,真诚和荣幸的永久承诺驱动的),但是正如您所说的,改变需求(a)迫切的改变理由,并且(b)至少需要几年才能给出折旧周期。
今天要努力使它尽可能接近正确是更好的选择。
当然,不被禁止的一件事就是在发布后改进PRNG代码作为登录名,因为它会产生相同的值。 例如,如果我们使用使用uint128的PRNG,则可以让MS添加uint128支持(有机会)或在以后的版本中添加Win64的程序集。
bashtage
于 2019-05-27
例如,如果您使用
g = Generator() g.bit_generator.seed(1234)并且更改了底层位生成器,那么这是错误的。
正确,这似乎是@ eric-wieser争论的“无默认值”选项,我不能将其与最初的陈述“我们的大多数用户不是随机数专家,我们应该为其提供默认值”相提并论。 。”
rkern
于 2019-05-27
在没有默认值和完全假定的默认值之间,我总是选择后者:
现在:
Generator() # OK
Generator(DefaultBitGenerator(seed)) # OK
Generator(seed) # error
_我_首选项:
Generator(1234) == Generator(DefaultBitGenerator(1234)
Generator(*args**kwargs) == Generator(DefaultBitGenerator(*args, **kwargs))
现在,我不认为这会成功,但是我认为延长使用RandomState的一种方法是仅对认为自己足够选择位生成器的用户可用。
bashtage
于 2019-05-27
总而言之,有一些方法可以确保使用可以产生可重现的结果,而不必尝试将自己锁定在默认永远不变的合同中。 它还可以减少您做出选择的风险。
是的,我们有。 用户可以按名称(例如MT19937 , PCG64等)抓取BitGenerator s并用种子实例化它们。 BitGenerator对象使用一组用于绘制制服[0..1) float64 s和整数(以及它们具有的有趣的超前/流功能)的有限方法来实现核心统一PRNG算法。 。 我们正在谈论的Generator类采用一个提供的BitGenerator对象,并对其进行环绕以提供所有非均匀分布,高斯分布,伽玛分布,二项式分布等。对BitGenerator的严格流兼容性保证。 我们不会遗弃任何东西(使其发布),也不会对其进行更改。
关于默认值的中心问题是“没有参数的代码g = Generator()做什么?” 现在,在PR中,它将创建具有任意状态的Xoshiro256 BitGenerator (即从诸如/dev/urandom的良好熵源中提取)。 “无默认值”选项将使该错误; 用户将必须明确命名他们想要的BitGenerator 。 @ eric-wieser的观点是,对于第一个发行版,“无默认值”绝对是_safe_选项。 提供默认值的更高版本不会像更改现有默认值那样引起问题。
rkern
于 2019-05-27
@rkern ,如果您只关心无参数情况,其中种子是根据可用的熵自动生成的,那么底层生成器到底是什么并不重要-它可以每小时更改一次,因为结果永远无法重现(不同的运行将获得不同的种子)。
相比之下, @ bashtage似乎关心种子附带的默认生成器。
imneme
于 2019-05-27
@rkern ,如果您只关心种子是根据可用熵自动生成的_no arguments_情况,那么底层生成器到底是什么并不重要-可能每小时更改一次,因为结果永远无法重现(不同的运行将获得不同的种子)。
您可以在BitGenerator创建后重新设定种子。 因此,如果Generator()工作正常,那么我完全希望发生的事情是,想要种子PRNG的人只会将其种子到下一行,例如@bashtage的示例:
g = Generator()
g.bit_generator.seed(seed)
这有点乏味,这就是为什么我在最上面建议也许大多数人通常还是选择Generator(PCG64(<seed>)) ,因为这和键入一样方便。 但是, @ bashtage面对额外的决定时正确地注意到了一些阻力。
因此,我想我们面前还有一个更广泛的问题:“我们希望用户实例化这些方法之一的所有方式是什么?如果这些方法具有默认设置,那么这些默认值应该是什么?” 我们有一些开放的设计空间,对于Generator(<seed>)或Generator(DefaultBitGenerator(<seed>)) @bashtage的建议仍然可行。
@bashtage您认为文档会有多大帮助? 也就是说,如果我们在顶部说“ PCG64是我们的首选默认值BitGenerator ”,并且在所有示例中始终使用Generator(PCG64(seed)) (当未具体说明其他算法时)?
我可能更相信default_generator(<seed>) _ Generator(<seed>)或g=Generator();g.seed(<seed>) 。 然后,如果我们确实需要更改它并且不想破坏东西,则可以添加一个新功能,并向旧功能添加警告。 我可能建议在第一个版本中将其标记为experimental以便在做出坚定承诺之前给我们一些时间在野外观看此基础结构。
rkern
于 2019-05-27
实际制作一个不公开其内部状态详细信息的DefaultBitGenerator对象呢? 这将是其他位生成器对象之一的代理,但是原则上可以包装它们中的任何一个-当然,除了其特定的生成数字序列。 希望这会阻止用户对使用默认BitGenerator可以做什么进行编程假设,同时允许我们仍然使用改进的算法。
我同意@bashtage ,直接支持整数种子作为Generator (例如np.random.Generator(1234)会更加友好。 当然,这将利用DefaultBitGenerator 。
在Generator文档中,我们可以提供NumPy的每个过去版本中默认位生成器是什么的完整历史记录。 这基本上是@imneme的建议,我认为就可重复性而言就足够了。
 shoyer
于 2019-05-27
imneme
于 2019-05-27
shoyer
于 2019-05-27
imneme
于 2019-05-27
在
Generator文档中,我们可以提供NumPy的每个过去版本中默认位生成器是什么的完整历史记录。 这基本上是@imneme的建议,我认为就可重复性而言就足够了。
实际上,更好的方法是在Generator / DefaultBitGenerator包含一个显式的version参数,例如pickle的protocol参数。 然后,您可以编写类似np.random.Generator(123, version=1)来表示您想要“版本1”随机数(无论是什么)或np.random.Generator(123, version=np.random.HIGHEST_VERSION) (默认行为)来表示您想要最新/最大的位生成器(无论是什么)。
大概version=0将是NumPy到目前为止使用的MT19937 ,而version=1可能是我们选择的任何新默认值。
shoyer
于 2019-05-27
实际制作一个DefaultBitGenerator对象不公开其内部状态的任何细节呢? 这将是其他位生成器对象之一的代理,但是原则上可以包装它们中的任何一个-当然,除了其特定的生成数字序列。 希望这会阻止用户对使用默认BitGenerator可以做什么进行编程假设,同时允许我们仍然使用改进的算法。
嗯很吸引人。 感觉像是使事情变得过于复杂,并在此高迪安结上增加了另一个循环(而且应该向我们提供更多亚历山大式的笔触),但这确实是我唯一要说的坏话。 它确实使剩下的决策变得更容易:我们可以专注于统计质量和绩效。
实际上,更好的做法是在
Generator/DefaultBitGenerator包含一个显式的version参数,例如pickleDefaultBitGenerator。
我不太喜欢这个。 与pickle情况不同,这些东西具有可以使用的有意义的名称,并且我们已经实现了该机制。
rkern
于 2019-05-27
我不太喜欢这个。 与
pickle情况不同,这些东西具有可以使用的有意义的名称,并且我们已经实现了该机制。
从典型的NumPy用户的角度考虑以下内容:
np.random.Generator(seed, version=0)与np.random.Generator(seed, version=1)np.random.Generator(MT19937(seed))与np.random.Generator(PCG64(seed))
我认为可以肯定地说,我们大多数用户对RNG算法的相对优点知之甚少。 但是即使不阅读任何文档,他们也可以放心地猜测version=1 (较新的默认值)在大多数情况下必须比version=0 。 对于大多数用户而言,这实际上是他们需要知道的全部信息。
相反,诸如MT19937和PCG64类的名称实际上仅对专家或已经阅读我们的文档的人有意义:)。
shoyer
于 2019-05-27
在您的用例中,没有人选择他们想要的version 。 他们只选择他们需要的version来复制已知版本的结果。 他们一直在寻找要复制的结果中使用的特定值(隐式,因为我们允许它隐含)。 他们不需要推理多个值之间的关系。
无论如何,这种交叉释放的可再现性水平是我们在NEP 19中所否认的。 反对对发行版进行版本控制的论点在这里同样适用。
rkern
于 2019-05-27
关于默认的一些想法:
- 99.9%的用户不会在乎或不想了解底层算法,他们只想要随机数。 因此,+ 1是为您的默认选择做出的选择,请勿让用户选择。
dSFMT似乎只是比MT19937更快的版本(很高兴在文档中说明如何快速删除“ SSE2”)。 由于我们仍然不能保证比特流的可重复性,因此内部状态差异并不是很有趣,即使这里的优胜论据是“使文章阅读过程中的生活更轻松”,也应优先使用dSFTM而不是MT19937。- 性能对用户群至关重要。 生成器的统计属性仅对一小部分用户重要。 所有包含的生成器都适合正常使用情况。 因此,+ 1是选择最快的默认值的方法。
 rgommers
于 2019-05-27
rgommers
于 2019-05-27
抱歉地说-但Windows上32位仍然很重要-请参见https://github.com/pypa/manylinux/issues/118#issuecomment -481404761
 matthew-brett
于 2019-05-27
matthew-brett
于 2019-05-27
我认为我们应该非常关注统计属性,因为我们正在朝着在数据分析中更多使用重采样方法的方向进行转变。 如果Python因在此问题上有点草率而闻名,即使只是默认情况下,这也可能会成为考虑使用Python进行数据分析的人们的障碍。 如果Python是认真对待置换和模拟的人们的首选软件包,我将感到非常高兴。
我认为可以提供更快的非最新算法,但默认情况下不能这样做,因为我们可以避免这种情况并保持向后兼容。
matthew-brett
于 2019-05-27
有关一些取证和讨论,请参阅: https :
教科书提供的方法隐式或显式地假定PRNG可以代替真正的IIDU [0,1)变量而不会引起实质性错误[20、7、2、16、15]。 我们在这里表明,这种假设对于许多常用统计软件包(包括MATLAB,Python的随机模块,R,SPSS和Stata)中的算法都是错误的。
@kellieotto , @pbstark-你们是否对我们应该在此处选择哪种PRNG有意见,以便为排列和引导提供最佳的基础?
matthew-brett
于 2019-05-27
我认为我们应该非常关注统计属性,因为我们正朝着在数据分析中更多使用重采样方法的方向迈进。
同意只要这些属性与某些实际用例相关,那就非常重要。 通常提出的问题总是非常学术性的。
有关一些取证和讨论,请参阅: https :
非常有趣的文章。 它确实得出结论,与R,Python stdlib&co不同,NumPy是唯一使它正确的库(第9页的顶部)。
获得比本文中更具体的示例将非常有用。 如果我们当前的默认生成器在某个时候也崩溃了,那是什么时候? 例如R的sample函数在绘制约17亿个样本时生成40%的偶数和60%的奇数。 这里的自举/重采样是什么?
rgommers
于 2019-05-27
R(3.6)的最新版本修复了截断与随机位方法
生成随机整数。 Mersenne Twister仍是默认设置
PRNG,但是。
@Kellie Ottoboni [email protected] ,我认为默认的PRNG在
科学语言和统计数据包应使用密码加密
安全(CS-PRNG,例如,计数器模式下的SHA256),并具有掉落选项
回到更快但质量较低的事物(例如,梅森·扭曲者)
如果速度需要的话。
我们一直在为Python设计CS-PRNG:
https://github.com/statlab/cryptorandom
性能还不是很好(尚未)。 瓶颈似乎是类型转换
在Python中将二进制字符串(哈希输出)转换为整数。 我们是
正在致力于将更多工作移交给C的实现。
干杯,
菲利普
于2019年5月27日星期一6:27上午Ralf Gommers [email protected]
写道:
我认为我们应该非常关注统计属性,因为我们
在向更大范围使用重采样方法的重大转变过程中
数据分析同意只要这些属性与某些实际用途相关
情况,这很重要。 通常提出的问题是
总是非常学术。有关一些取证和讨论,请参阅:
https://arxiv.org/pdf/1810.10985.pdf非常有趣的文章。 它的结论是NumPy是唯一的
正确的库(第9页的顶部),与R,Python stdlib&co不同。获得比在示例中更具体的示例将非常有用。
纸。 如果我们当前的默认生成器在某个时候也崩溃了,
那是什么时候像R的样本函数这样的例子甚至产生40%
抽取约17亿个样本时的数字和60%的奇数。 那是什么
自举/重采样在这里吗?-
您收到此邮件是因为有人提到您。
直接回复此电子邮件,在GitHub上查看
https://github.com/numpy/numpy/issues/13635?
或使线程静音
https://github.com/notifications/unsubscribe-auth/AANFDWJW445QDPGZDGXMPA3PXPOUFANCNFSM4HPX3CHA
。
-
Philip B. Stark | 副院长,数学和物理科学|
统计系教授|
加州大学
加利福尼亚州伯克利94720-3860 | 510-394-5077 | statistics.berkeley.edu/~stark |
@philipbstark
 pbstark
于 2019-05-27
pbstark
于 2019-05-27
性能对用户群至关重要。 生成器的统计属性仅对一小部分用户重要。 所有包含的生成器都适合正常使用情况。 因此,+ 1是选择最快的默认值
首先,根本没有办法选择“最快的”。 @bashtage在#13163中的当前代码上运行了一些基准测试,它遍及整个地图,dSFMT在Windows上获胜,在Linux上被PCG-64和Xoroshiro 256击败。 这一切都在具有相同基准的同一台计算机上进行。 不同的硬件体系结构(甚至X86中的修订版)也会产生不同的基准。 (正如该线程中已经讨论的那样,由于MSVC的问题,PCG在Windows基准测试中表现不佳,这也可能是暂时的,因为MSVC可能会有所改善,或者人们可能会解决它的问题。大概类似的MSVC问题可以解释为什么Xoshiro被殴打)
我还想知道关心速度的用户的“显着比例”到底有多大。 Python本身的平均速度比C慢约50倍。 NumPy用户群的哪一部分在PyPy上运行(这将使速度提高4倍)? 当然可以,但是我怀疑这个数字不是很高。
考虑到上面列出的所有可变性,对于那些关心速度的“重要部分”,谁会相信您的话,默认PRNG将为其应用程序最快地运行? 明智的做法(这也很有趣,并且在大多数用户可以承受的范围内)是对不同的可用PRNG进行基准测试,看看哪种对他们最快。
相反,尽管他们可能会在文档中找到线索,但是,正如您所指出的那样,弄清特定PRNG的统计质量并不是大多数用户的关注(甚至对于专家而言也是具有挑战性的)。 大多数人甚至都不知道何时/是否应该在乎。 我认为这是一些家长式作风的地方-大多数用户不关心某事的事实并不意味着维护者不应该关心它。
确实,所有包含的PRNG都适合大多数用例,但这是一个相当低的标准。 Unix系统附带了C语言库PRNG的庞大版本,它们在统计上都非常糟糕,但是它们已经被广泛使用了很多年,而世界还没有脱离它的轴线。
除了统计属性外,用户可能还不知道想要其他一些属性,但我可能想要这些属性。 就个人而言,作为PRNG的提供者,我想避免琐碎的可预测性-我不希望有人查看PRNG的一些输出,然后能够说出未来的所有输出。 在使用NumPy的大多数情况下,可预测性不是问题-没有对手会从容易地预测序列中受益。 但是某个地方的人将使用NumPy的PRNG并不是因为他们需要NumPy来进行统计,而是因为那是他们之前找到PRNG的地方。 该代码可能会面对一个实际的对手,他将从能够预测PRNG的活动中受益。 为应对这种异常情况而付出大量代价(例如,重大的速度损失)是不值得的,但适度的保险可能是值得的。
imneme
于 2019-05-27
有关一些取证和讨论,请参阅: https :
教科书提供的方法隐式或显式地假定PRNG可以代替真正的IIDU [0,1)变量而不会引起实质性错误[20、7、2、16、15]。 我们在这里表明,这种假设对于许多常用统计软件包(包括MATLAB,Python的随机模块,R,SPSS和Stata)中的算法都是错误的。
FWIW, @ lemire发表了一篇不错的论文,内容是有效地生成一个没有偏差的范围内的数字。 在我自己的文章中,我也以此为出发点来探索和运行一些基准测试。 (生成64位时,Lemire的方法的确使用128位乘法来避免缓慢的64位除法,而MSVC用户可能会遇到所有熟悉的问题。)
imneme
于 2019-05-27
@pbstark @kellieotto当它出现在arXiv上时,我很感兴趣地阅读了您的论文。 我拜访了BIDS的一些朋友,他们提到了您的工作。 讨论部分注意到,“对于MT19937,“到目前为止,我们还没有找到一个统计数据,其一致性偏差足以在O(10 ^ 5)复制中检测到”。 你找到一个了吗? 您是否找到了PCG64之类的128位状态PRNG的具体示例? 在我看来,这是一个切合实际的合理门槛,在这种情况下,考虑因素可能开始超过其他考虑因素(IMO),至少出于选择通用默认值的目的。
我们新的PRNG框架#13163的一个不错的功能是,它允许任何人提供自己可以插入的BitGenerator 。它甚至不必为了使人在numpy中使用而变得麻木。码。 我鼓励您考虑将cryptorandom作为C中的BitGenerator ,以便我们可以将其与其他选项进行比较。
rkern
于 2019-05-27
就个人而言,我希望那些真正关心速度的人在必要时会加倍努力(这里并不多)。 我们应该提供安全默认值,而我目前的最佳猜测是,这意味着除密码术外,所有目的的安全默认值(我们可能应该在文档中对此进行警告)。 许多用户都在乎速度,但是坦率地说,这正是我回避优先级的原因。
Numpy表现出色的那篇文章似乎很有趣(对Robert的理解是正确的!),但实际上是采样器而不是位生成器。
@pbstark也许您想将其实现为与numpy / randomgen兼容的BitGenerator? 这可能是加速它并以更有用的形式将其提供给广大受众的最简单方法。 既然您和Kellie Ottoboni似乎在伯克利,我们可以见面一些时间以解决这个问题? (只是一个要约,我应该自己先仔细看看代码)。
 seberg
于 2019-05-27
seberg
于 2019-05-27
关于“随机抽样:实践使不完美”论文,这是一本不错的书,但是值得记住的是,如果我们有1万亿个核,每100纳秒每纳秒产生一个数字,那么我们将产生少于2 ^ 102个数字。
对于微不足道的可预测PRNG(甚至具有较大状态空间的PRNG,例如Mersenne Twister),我们实际上可以知道是否可以生成某些特定的输出序列(并找到会产生该种子的种子(如果存在的话),或者如果不知道就会感到渴望),但对于其他不可预测的PRNG,我们无法(轻松地)知道永远不会生成哪些输出序列,哪些不会出现,但是非常罕见,因此我们几乎不可能在搜索的瞬间找到它们。 (您可能知道,我有一个PRNG ,我知道它会在2 ^ 80的输出中吐出一个_Twelth Night_的zip文件,但是很幸运找到它。
imneme
于 2019-05-27
如果您真的想要cryptoprng,那么现代硬件的唯一选择是
AES,因为它具有专用指令。 @lemire有一个实现
在这里https://github.com/lemire/testingRNG/blob/master/source/aesctr.h
与非加密生成器一样快。 还有ChaCha20可以去
使用SIMD快速。 不过,在旧硬件上,两者都会变得很慢。 ThreeFry和
Philox已包含在内,并且是加密计数器。
IMO加密在成本收益方面被高估了。 我什么都不知道
我认为,由于Mt的PRNG问题,导致重要的撤回
用于订购10e6发表的论文。 我见过的唯一应用
PRNG确实有问题的情况是
小到发电机完成了整个周期。 即使在这里
效果是减少了研究的样本量
结果会在周期较长的系统上重新运行。
在2019年5月27日星期一19:50 Robert Kern [email protected]写道:
@pbstark https://github.com/pbstark @kellieotto
https://github.com/kellieotto我读到你感兴趣的论文时
出现在arXiv上。 我拜访了BIDS的一些朋友,他们
提到你的工作。 讨论部分指出:“到目前为止,我们还没有
发现具有一致偏差的统计量,该偏差足以检测到
MT19937的O(10 ^ 5)复制。您找到了吗?
PCG64这样的128位状态PRNG的具体示例? 在我看来
考虑到实际相关性的合理门槛
至少出于选择的目的,可能会开始超过他人(IMO)
通用默认值。我们的新PRNG框架的不错的功能#13163
https://github.com/numpy/numpy/pull/13163是它允许任何人
提供自己的可以插入的BitGenerator。
甚至必须是numpy,人们才能在numpy代码中使用它。 我会
鼓励您考虑将C语言中的BitGenerator实现为cryptorandom
因此我们可以将其与其他选项进行对比。-
您收到此邮件是因为有人提到您。
直接回复此电子邮件,在GitHub上查看
https://github.com/numpy/numpy/issues/13635?
或使线程静音
https://github.com/notifications/unsubscribe-auth/ABKTSRMRIHC4OYDR52HLTHDPXQUOLANCNFSM4HPX3CHA
。
bashtage
于 2019-05-27
我还想知道关心速度的用户的“显着比例”到底有多大。 Python本身的平均速度比C慢50倍。NumPy用户群中有多少部分在PyPy上运行它(这将使速度提高4倍)? 当然可以,但是我怀疑这个数字不是很高。
我怀疑您不是普通用户:) NumPy在幕后大多是C,并且与在C中完成自己的事情一样快(嗯,通常更快)。 而且,PyPy尚未准备好用于科学应用的生产,并且在任何情况下都变慢(因为它仅限于使用NumPy使用的CPython API,因此无法获得其JIT的好处)。
无论哪种方式,这都是题外话。 宣称速度问题并没有争议。
rgommers
于 2019-05-27
@imneme我们将lemires方法用于有界整数。 由于这个
没有遗留或折旧的全新起点,我们一直努力尝试
好的算法。
在2019年5月27日星期一,19:46 imneme [email protected]写道:
有关一些取证和讨论,请参阅:
https://arxiv.org/pdf/1810.10985.pdf教科书提供的方法隐式或显式地假定PRNG可以
在不引入材料的情况下代替真正的IIDU [0,1)变量
错误[20、7、2、16、15]。 我们在这里表明,该假设对于
许多常用统计软件包(包括MATLAB,
Python的随机模块R,SPSS和Stata。FWIW,@ lemire发表了一篇不错的论文https://arxiv.org/abs/1805.10941
https://github.com/lemire关于有效生成范围内的数字
没有偏见。 我以此为出发点来探索和运行一些
我自己的文章中也有基准
http://www.pcg-random.org/posts/bounded-rands.html 。 (生成时
Lemire的方法使用64位,但确实使用128位乘法来避免缓慢
64位除法,可能会给MSVC带来所有熟悉的问题
用户。)-
您收到此邮件是因为有人提到您。
直接回复此电子邮件,在GitHub上查看
https://github.com/numpy/numpy/issues/13635?
或使线程静音
https://github.com/notifications/unsubscribe-auth/ABKTSRKV3KYKRLNMBKNU4JLPXQUA3ANCNFSM4HPX3CHA
。
bashtage
于 2019-05-27
我们应该提供_safe_默认值,而我目前的最佳猜测是,这意味着除密码术外,所有目的的安全默认值
很难争论。 我的问题是-什么是安全的? 具有各种属性的准随机程度不同。 到目前为止,我还没有看到任何人给出具体的例子,在这里也没有其他问题,PR或线程。 仅仅谈论抽象统计属性并没有帮助。
rgommers
于 2019-05-27
我的感觉是PCG64是一个很好的默认值。 Windows上的速度劣势对于使用Anaconda等人的人来说并不明显。 等,并且可能会在某个时候修复。 随着并行执行成为Python中的新事物,我还认为拥有可设置的流是一个理想的属性。
charris
于 2019-05-27
我非常怀疑Visual Studio中PCG64的速度损失是无法消除的。
是否在某处对此进行了仔细评估?
 lemire
于 2019-05-27
lemire
于 2019-05-27
宣称速度问题并没有争议。
我的问题是-什么是安全的?
始终如一地应用逻辑:“什么是快速的”? 我没有一个好主意,什么numpy程序实际上具有BitGenerator是一个很大的瓶颈。 如果我使用的BitGenerator快一倍,我的完整计算会得到5%的提速吗? 可能甚至没有。 Python不像C那样快不是问题; 即使是实际上有用的PRNG繁重的程序也不会在BitGenerator花费大量时间。 可能任何可用的选择都足够。
rkern
于 2019-05-27
我非常怀疑Visual Studio中PCG64的速度损失是无法消除的。
在线程上,我展示了clang将PCG64编译为可为64位MSVC窃取的程序集,所以我不认为64位Windows上的MSVC是一个无法解决的问题。
可能更棘手的是32位系统上的PCG64,其中只有32位Windows对我们实际上仍然很重要。 在这种情况下,与MSVC相比,与其说是将自己限制在32位ISA上不如说。
rkern
于 2019-05-27
我指出, @ Kellie Ottoboni [email protected]是什么
即使对于中等大小的问题,MT的状态空间也太小而无法近似
均匀排列(n <2100)或均匀随机样本(n = 4e8,k = 1000)。
这会影响从引导程序到排列测试再到MCMC的所有内容。
预期分配与实际分配之间的差异
分布可以任意大(总变化距离接近
2)。 它很大而且很严重。
我们没有做出任何努力打破MT的“统计”功能
许多年。 我很确定有一种系统的方法可以打破它
(由于分布距离很大)。
干杯,
菲利普
在2019年5月27日星期一12:26罗伯特·克恩(Robert Kern) [email protected]
写道:
宣称速度问题并没有争议。
我的问题是-什么是安全的?
始终如一地应用逻辑:“什么是快速的”? 我没有一个好主意
什么numpy程序实际上具有BitGenerator的性能
一个重大的瓶颈。 如果我使用的是两倍快的BitGenerator,
我的完整计算会提高5%吗? 可能甚至没有。
Python不像C那样快不是问题; 就是这样
大量有用的PRNG程序不会花费大量的时间
时间在BitGenerator中。 可能的任何选择是
足够。-
您收到此邮件是因为有人提到您。
直接回复此电子邮件,在GitHub上查看
https://github.com/numpy/numpy/issues/13635?
或使线程静音
https://github.com/notifications/unsubscribe-auth/AANFDWIDCPAJJ6DJ3RO332LPXQYVRANCNFSM4HPX3CHA
。
-
Philip B. Stark | 副院长,数学和物理科学|
统计系教授|
加州大学
加利福尼亚州伯克利94720-3860 | 510-394-5077 | statistics.berkeley.edu/~stark |
@philipbstark
pbstark
于 2019-05-27
@pbstark我想看到的是问题的具体实现(可能是人为的,但不是太想做),在该问题上MT或128位PRNG失败, cryptorandom可以解决。 您能否指出那里的数据集,其中重采样方法使用128位PRNG给出错误的推论,并使用cryptorandom纠正推论?
rkern
于 2019-05-27
转向PCG64会使问题的严重性降低,
因为它的状态空间甚至比MT小。 当然可以
仍然会产生“更好”的随机性,因为它可能会采样
排列组比MT更均匀。 但它必须先分解
500选择10,然后选择21!。
干杯,
菲利普
在2019年5月27日星期一12:30 Robert Robert Kern [email protected]
写道:
我非常怀疑Visual Studio下的PCG64速度损失是
无法抹去的东西。向上线程,我展示了clang如何将PCG64编译成我们可以窃取的程序集
用于64位MSVC,所以不,我不认为64位Windows上的MSVC是
不可克服的问题。可能更棘手的是32位系统上的PCG64,其中只有32位
Windows对我们实际上仍然很重要。 这样的话就少了
关于MSVC,而不是将自己限制为32位ISA。-
您收到此邮件是因为有人提到您。
直接回复此电子邮件,在GitHub上查看
https://github.com/numpy/numpy/issues/13635?email_source=notifications&email_token=AANFDWJFCINQCYGFCI7ULI3PXQZGLA5CNFSM4HPX3CHKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKKTDN5ment
或使线程静音
https://github.com/notifications/unsubscribe-auth/AANFDWK6QTB65Z4TJU76XKTPXQZGLANCNFSM4HPX3CHA
。
-
Philip B. Stark | 副院长,数学和物理科学|
统计系教授|
加州大学
加利福尼亚州伯克利94720-3860 | 510-394-5077 | statistics.berkeley.edu/~stark |
@philipbstark
pbstark
于 2019-05-27
我对PRNG的了解还不够多,在任何情况下都无法真正衡量,我只想首先关注统计属性(如果答案是它们都非常好,很好)。 我现在想知道的一件事是k维均匀分布。 我们目前是否使用说PCG的变体在MT方面比在这里做得好? (来自非线性动力学,这让我有点紧张,但我对PRNG的了解不足,并且在接下来的两天内也不会了解它。
seberg
于 2019-05-27
似乎不太可能有很多Windows 32位用户关心尖端性能。 切换到64位不需要很多工作。
matthew-brett
于 2019-05-27
我也想看看。
根据数学,我们知道必须存在许多大问题,
但是我们还不能举出一个例子。
预防原则会说,既然我们知道
问题,我们知道如何预防(CS-PRNG),我们也可以这样做
默认情况下,并且让用户在选择时更加谨慎。
在2019年5月27日星期一12:39 Robert Robert Kern [email protected]
写道:
@pbstark https://github.com/pbstark我想看到的是具体的
问题的实现(可能是人为的,但不是太人为的)
MT或128位PRNG失败,并且可以使用cryptorandom。 你能
指出那里的数据集重采样方法给出了错误
使用128位PRNG进行推论,并使用cryptorandom进行正确推论?-
您收到此邮件是因为有人提到您。
直接回复此电子邮件,在GitHub上查看
https://github.com/numpy/numpy/issues/13635?
或使线程静音
https://github.com/notifications/unsubscribe-auth/AANFDWITAGQFZDQSIFNEHETPXQ2FPANCNFSM4HPX3CHA
。
-
Philip B. Stark | 副院长,数学和物理科学|
统计系教授|
加州大学
加利福尼亚州伯克利94720-3860 | 510-394-5077 | statistics.berkeley.edu/~stark |
@philipbstark
pbstark
于 2019-05-27
k-equidistribution是PRNG整个输出的整体性质
PRNG的时期。 这是一件好事,但对其他没有说什么
随机性故障的种类,例如输出的串行相关性。
这是一个相对较低的标准。
于2019年5月27日星期一下午12:48塞巴斯蒂安·伯格[email protected]
写道:
我对PRNG的了解不足,在任何情况下都无法真正衡量自己,我只是想
首先将重点放在统计属性上(如果答案是
他们都非常非常好,很好)。 我现在想知道的一件事是
k维平均分布。 我们目前是否使用PCG的变体
与MT相比,在这里做得更好? (来自非线性动力学,
让我有点紧张,但我对PRNG的了解不多,我
在接下来的两天内将无法获得...-
您收到此邮件是因为有人提到您。
直接回复此电子邮件,在GitHub上查看
https://github.com/numpy/numpy/issues/13635?
或使线程静音
https://github.com/notifications/unsubscribe-auth/AANFDWOEB7KR2YJZWHRRAHLPXQ3HZANCNFSM4HPX3CHA
。
-
Philip B. Stark | 副院长,数学和物理科学|
统计系教授|
加州大学
加利福尼亚州伯克利94720-3860 | 510-394-5077 | statistics.berkeley.edu/~stark |
@philipbstark
pbstark
于 2019-05-27
@pbstark MT无法通过PCG(和其他生成器)通过的许多统计测试。
lemire
于 2019-05-27
@rkern
如果要MSVC生成ror指令,我认为需要使用“ _rotr64”内部函数。
同样,人们可能更喜欢使用“ / O2”标志进行优化。
综上所述,如果要使用PCG64,最好以汇编形式编写。
lemire
于 2019-05-27
对于@pbstark ,这是PCG-64的一些输出,使用您不知道的种子初始化(实际上,我什至告诉您流,它是0x559107ab8002ccda3b8daf9dbe4ed480 ):
64bit: 0x21fdab3336e3627d 0x593e5ada8c20b97e 0x4c6dce7b21370ffc
0xe78feafb1a3e4536 0x35a7d7bed633b42f 0x70147a46c2a396a0
Coins: TTTHHTTTHHTHTTTTHTHHTTTTTHTTHHTTHHTHHTHHHHHHHHTTHHTTHHTHHHHHTHTHH
Rolls: 5 3 5 2 5 3 1 6 6 5 4 4 5 5 5 6 2 3 5 3 2 3 2 5 6 2 4 6 2 3 4 6 3
Cards: 5h 3h 3c 8d 9h 7s Kh Ah 5d Kc Tc 6h 7h 8s Ac 5c Ad Td 8c Qd 2h As
8h 2d 3s 5s 4d 6d 2s Jd 3d 4h Ks 6s Qc Js Th 9d 9c Ts Jh 4c 2c 9s
6c 4s 7c 7d Jc Qs Kd Qh
现在,让我们假设您使用随机选择的种子初始化另一个pcg生成器。 为了争辩,我们选择0xb124fedbf31ce435ff0151f8a07496d3 。 发现此已知输出之前,我们必须生成多少输出? 因为我知道我在上面使用的种子,所以可以(通过PCG的距离函数)回答这个问题,大约有2.5×10 ^ 38(或大约2 ^ 127.5)的输出。 作为参考,10 ^ 38纳秒是宇宙年龄的2300亿倍。
因此,PCG-64中确实存在一个序列,但是,实际上,除非我告诉您要看的地方,否则您永远找不到它。 (如果我们改变流,那么将有更多的可能性。)
常规的PCG实际上输出莎士比亚戏剧的机会为零; PCG扩展生成方案实际上可以输出莎士比亚戏剧,但是在无人为案的情况下,这样做的机会非常小,实际上也为零。 在我看来,没有任何实际后果的财产几乎没有价值。
(此外,不能保证密码安全的PRNG都是k维均匀分布的,对于想要PRNG可以生成所有可能序列的人来说,它们也不是魔术宝盒。作为种子并存储其状态,必然会产生一些无法生成的位序列(证明:通过信鸽原理),如果您将自己的输出限制为与种子相同的输出量,如果您的种子输入确实是随机的,而不是PRNG,那么真正要寻找的是哈希函数,或者可能只是身份函数。)
imneme
于 2019-05-27
出于好奇,我使用aesctr.h封装了一个AES计数器位生成器,每个随机值的时间以ns为单位:
+---------------------+--------------+----------+--------------+
| | Xoshiro256 | PCG64 | AESCounter |
|---------------------+--------------+----------+--------------+
| 32-bit Unsigned Int | 3.40804 | 3.59984 | 5.2432 |
| Uniform | 3.71296 | 4.372 | 4.93744 |
| 64-bit Unsigned Int | 3.97516 | 4.55628 | 5.76628 |
| Exponential | 4.60288 | 5.63736 | 6.72288 |
| Normal | 8.10372 | 10.1101 | 12.1082 |
+---------------------+--------------+----------+--------------+
不错,@ bashtage。
需要牢记的几件事是:特定的AES指令可能会因体系结构而异,并且并非在所有活动使用的CPU中都存在,因此需要一条(慢速)回退路径。
另外,这是一个苹果与橘子的比较。 除了使用专门的指令之外,AES代码还通过循环展开获得了很大的速度-实际上,它是在块中生成数字,然后将其读出。 展开可能会加快任何PRNG的速度。 FWIW, @ lemire实际上具有PCG的矢量化版本,该
imneme
于 2019-05-28
让我看看是否可以总结出至少一个共识点:我们都同意numpy应该考虑使用哪种BitGenerator算法,并促进一个BitGenerator优于其他算法。
请允许我再花一点时间草拟与共识一致的“无默认”选项,并避免其他一些选项可能存在的一些问题。 如果没有牵引力,我会闭嘴的。
我真正的意思是“无默认值”选项是“无匿名默认值”。 我们仍然可以通过一些方法来设计API,这样最容易获得种子Generator就是为我们提名的PRNG命名。 例如,假设我们不包含完整的BitGenerator算法。 通常,我们尝试使numpy保持最小,并将完成主义留给scipy和其他第三方库,在这里这样做可能是个好主意。 当前架构的优点在于,它允许我们将$$$ BitGenerator s移至其他库。 假设我们只提供MT19937来支持旧版RandomState和我们希望人们使用的一个BitGenerator 。 为了争辩,我们假设是Xoshiro256 。 让我们使Generator.__init__()构造函数需要BitGenerator 。 而且,让我们定义一个函数np.random.xoshiro256_gen(seed) ,该函数在幕后返回Generator(Xoshiro256(seed)) 。 我们的文件,方便的功能,以获得种子的方式Generator 。
现在快进一些版本。 假设我们将PCG64 , ThreeFry等推迟到random-tng或scipy或其他软件包,其中一个由于额外的功能或新的统计缺陷可在Xoshiro256 。 我们决定要更新numpy关于应该使用哪个BitGenerator人的意见,将其更新为PCG64 。 然后,我们要做的是添加PCG64 BitGenerator类并添加np.random.pcg64_gen(seed)函数。 我们向np.random.xoshiro256_gen(seed)添加了弃用警告,以表明它不再是首选算法:我们建议新代码应使用np.random.pcg64_gen(seed) ,但继续使用Xoshiro256算法而不警告,则应明确使用Generator(Xoshiro256(seed)) 。
我认为这避免了我使用“匿名” API时遇到的一些问题(即Generator(seed) , Generator(DefaultBitGenerator(seed)) , np.random.default_gen(seed) )。 我们可以永久支持不再优先使用的算法。 当我们改变意见时,我们永远不需要让我们自以为是的“首选”构造函数做一些不同的事情。 因为我们使用真实名称来区分事物而不是版本号,所以您始终知道如何更新代码以重现旧结果(如果由于某种原因无法忍受无害警告)。 您甚至可以拿起没有出处或记录的numpy版本号的代码,然后进行更新。 同时,通过将算法的数量限制为绝对最小,并使最佳实践成为使用库的最简单方法,我们就能有效表达numpy的意见。
听上去怎么样? 对于第一个发行版的BitGenerator ,我们仍然应该做出大量努力来做出可靠的选择。 它仍然是后果。
rkern
于 2019-05-28
似乎不太可能有很多Windows 32位用户关心尖端性能。 切换到64位不需要很多工作。
我同意。 由于Win32上PCG64问题仅仅是性能(我们可以通过一些努力来改善它),您是否同意这不是障碍?
rkern
于 2019-05-28
如果要MSVC生成ror指令,我认为需要使用“ _rotr64”内部函数。
同样,人们可能更喜欢使用“ / O2”标志进行优化。
谢谢! @imneme为我指出了所有这些错误。 :-)
rkern
于 2019-05-28
@seberg您是否从您的领域引来了一些警惕? 例如,有一篇论文显示了MT19937的k = 623等分布性质,该问题在非线性动力学仿真中由较小的PRNG引起? 作为参考,我也许可以提供一些更具体的保证。 在_general_中,我对平均分配的观点是,您通常希望PRNG的平均分配接近PRNG的州规模所允许的最大值。 在_practice_中,如果您的PRNG在其他方面足以满足您的目的(通过PractRand,其周期大于您计划抽取的样本数量的平方,等等),我从来没有见过太多的理由担心精确的k 。 其他人可能有不同的意见,也许您所在的领域存在一些我不知道的具体问题。 如果是这样,那么就有特定的解决方案可用!
rkern
于 2019-05-28
出于好奇,我使用
aesctr.h封装了AES计数器位生成器
我可能是错的,但我认为这不会帮助@pbstark解决问题。 AES-CTR是一种CS-RNG,但并非所有CS-RNG都有一个很大的时期(理论上),它需要能够针对较大的k达到所有可能的k!排列。 计数器仍然是一个128位数字,一旦翻转,您就到达了周期的终点。 @pbstark提倡使用非常大的PRNG,其中大多数恰好是CS-RNG。
rkern
于 2019-05-28
通常,我对公平分配的观点是,您通常希望PRNG的公平分配接近PRNG的州规模所允许的最大值。
尽管有些人认为最大均值分布是一种理想的特性,但也可以认为它是一种缺陷(并且有很多论文都在这样说)。 如果我们有一个_k_位PRNG并且每个_k_位序列恰好发生一次,那么最终将违反生日问题,即我们希望看到大约2 ^(k / 2)个输出后重复输出。 (我根据这些想法编写了一个生日问题统计测试。它正确地检测出SplitMix,64位输出64位状态PRNG和Xoroshiro64 +,32位输出64位在统计上令人难以置信地缺少任何重复状态二维分配的PRNG等)。
有趣的是,尽管编写统计测试会由于缺少64位重复(或重复太多-我们期望是泊松分布)而使PRNG失败,这是非常实用的,但是相反,写一个能够如果我们不知道省略哪些值,则检测所有64位值中36.8%的遗漏。
显然,随着_k_变大,测试缺少预期的重复缺陷开始变得不切实际,但是随着状态大小(和周期)变得越来越大,增加的大小意味着表明这既不切实际,一个最大均等分布的PRNG因无法重复而存在缺陷,并且同样不切实际地表明,一个非最大均等分布的PRNG因重复某些_k位序列(以统计学上合理的方式)并完全省略其他_k_bit序列而存在缺陷。 在这两种情况下,PRNG太大,我们无法区分两者。
imneme
于 2019-05-28
我也想看看。 基于数学,我们知道必须存在许多大问题,但是我们还不能指出一个例子。 预防原则是说,由于我们知道有大问题并且知道如何预防(CS-PRNG),因此我们也可以默认情况下这样做,并且让用户在选择时要谨慎一些。
我必须说,我不相信这种论点和证据。 因此,我不会感到麻木的用户站在前面,并告诉他们出于这个原因应该切换。 我没有能力捍卫这一说法,这就是为什么我要这些例子。 这些将很有说服力,并会让我做好捍卫您建议我们采取的这一立场的准备。
有限的PRNG缺乏真正的RNG的许多特性。 从理论上讲,我们要进行很多计算,这取决于真实RNG的那些属性(或者至少我们没有严格地证明我们可以放松多少)。 但是,这些缺点中的许多缺点对我们执行的实际计算结果的影响很小,几乎看不到。 这些违规行为不是决定性的,全有或全无的事情。 它们具有效果大小,我们可以容忍更多或更少的效果。
您确实令人信服地表明,某些大小的PRNG无法均匀地生成某些k所有k!排列。 我所缺少的步骤是无法生成所有这些排列的失败如何影响我感兴趣的具体计算。 我缺少您建议我们添加到PractRand或TestU01中的测试,该测试可以向人们演示此问题。
我从@imneme的PCG论文中发现的很有帮助的分析方法之一是派生每个PRNG的多个较小状态版本,并准确查看它们在哪里导致TestU01失败。 这为我们提供了一种通常比较PRNG架构的方法,而不仅仅是说“有无”,“ X PRNG通过或失败”。 它还可以让我们估计在使用的状态大小(在大量GiB样本上通过TestU01)时我们有多少净空。 您是否可以进行具体的计算来证明8位PRNG存在问题? 16位PRNG? 然后,我们可以查看该新测试是否能够比TestU01 / PractRand当前更早地告诉我们有关PRNG的信息。 那会很有帮助。
另一方面,如果从PRNG提取的更多数据显示的是基于这些排列的故障,而不是PractRand中当前测试套件的小型PRNG的故障点,那么我将得出结论,此问题不切实际关注,我们可以使用“ passs PractRand”作为很好的代理,以了解排列问题是否会对我的计算产生实际影响。
但是,直到我手上有一个程序可以运行并向人们展示问题为止,在此基础上我不愿意推动CS-PRNG。 我将无法令人信服地解释这一选择。
rkern
于 2019-05-28
对于那些在洗牌32项时要求全部32项的人! 随机播放(即全部263130836933693530167218012160160000000)应该是可生成的,而不是仅从这32个中提供随机样本的PRNG! 洗牌,我实际上是说,如果您要要求大量的产品,那么您只是在想不够大。
因此,我会(刻意地)宣称那些混洗的出现顺序也不应该预先确定! 显然,您应该要求它输出全部32个! 以所有可能的顺序洗牌-(32!)! 是您所需要的! 当然,这将需要3.8×10 ^ 18 EB的状态和类似量的熵来初始化,但是知道所有东西都存在确实值得。
imneme
于 2019-05-28
...我们在
np.random.xoshiro256_gen(seed)上添加了弃用警告,以表明它不再是首选算法:我们建议新代码应使用np.random.pcg64_gen(seed),但继续使用Xoshiro256算法而不发出警告,他们应该明确使用Generator(Xoshiro256(seed))
这仍然困扰着用户,因为它们既弃用,也不用他们真正不想知道的听起来奇怪的名字。
NEP表示:第二,谨慎引入允许破坏流兼容性以引入新功能或提高性能。
如果有足够的理由更新我们的默认设置,那么就这样做,并为未明确指定算法的用户打破逐位再现性是更好的选择,恕我直言(您之前一直在争论这种选择)。
我真正的意思是“无默认值”选项是“无匿名默认值”。
那么,您是要让用户知道他们正在使用的PRNG的名称吗?
从用户角度来看。 很难使它们从np.random.rand &co变为np.random.RandomState()然后使用方法。 现在我们将介绍一个更好的系统,他们看到的是np.random.xoshiro256_gen() ? 那将是在可用性方面的主要回归。
rgommers
于 2019-05-28
那么,您是要让用户知道他们正在使用的PRNG的名称吗?
不,这是为了缓解人们正在使用的诸如“ default_generator(seed) ”之类的“指定移动目标” API的问题(例如@shoyer的version参数)。
保持流兼容性(NEP 19否认)是API中断的第二要务。 不同的BitGenerator具有不同的有效API,具体取决于它们的功能集(主要是settable-streams,jumpahead,尽管可能还有其他API,具体取决于PRNG的参数化方式)。 因此,对我们默认的PRNG选择进行一些更改实际上会破坏代码(即不再运行或不再正确运行),而不仅仅是更改输出的值。
例如,假设我们首先选择PCG64 。 它具有128位状态,2 ^ 127个可设置的流,并实现了Jumpahead; 功能齐全。 于是人们开始写default_generator(seed, stream=whatever) 。 现在,让我们说将来的工作会发现其中的一些重大统计缺陷,这使我们希望切换到其他方面。 我们默认升级的下一个PRNG必须具有> = 128位状态(简单;我不建议使用任何较小的通用默认值),超越(硬!),> = 2 ^ 127可设置的流(哇,男孩!),以便不破坏代码中已经存在的default_generator()的使用。 现在也许我们可以忍受那个棘轮了。
@shoyer建议也许我们可以使默认的BitGenerator总是故意拖到最小公分母的特性上。 那行得通! 但这也会错过推广可设置流以解决@charris想要解决的并行流问题的机会。
现在我们将介绍一个更好的系统,他们看到的是
np.random.xoshiro256_gen()? 那将是在可用性方面的主要回归。
如果问题听起来很怪异,那么我很乐意使用一个更友好的通用名称,只要该策略在其他方面相同(我们将添加一个新功能,并就旧功能开始警告)。 我会认为是等效的。 我们不应该经常这样做。
如果我们决定忍住棘轮并避免使用version机制,我也很好。
rkern
于 2019-05-28
我对“默认”的看法是我们可以将其保留为实现细节,以便Generator()始终有效。 我谨此提醒您,始终获得可重复的结果(取决于Generator的更改)的唯一方法是使用语法Generator(BitGenerator(kwarg1=1,kwargs2=b,...))
真正隐藏实现细节是不切实际的,因为需要酸洗才能访问状态。
另一种选择是将其像任何其他功能一样对待-通常是随机生成的-并且如果有迫切需要进行更改,则经过标准的弃用周期。 这将永远不会影响正确执行操作的用户,并且在文档中带有足够的警告时,至少在大型项目中,有可能获得相当不错的命中率。 我在这里建议的是,在考虑新API时,可能会忘记曾经做出过流兼容性保证。
bashtage
于 2019-05-28
@bashtage在#13650我不允许访问Generator().bit_generator中仍然允许,没有直接进入酸洗方式state 。 它以允许在python Thread s中使用的方式传递经过稍微重写的test_pickle
mattip
于 2019-05-28
我的问题是-什么是安全的? 具有各种属性的准随机程度不同。 到目前为止,我还没有看到任何人给出具体的例子,在这里也没有其他问题,PR或线程。
如果您想要明确的亮线合格/不合格标准,则某些_N_( 512,1024)的“在_N_ GiB处通过
如果您希望获得统计质量的更复杂的视图,以便对算法进行排序,那么我确实建议您@imneme的PCG论文的第3节,其中使用了算法的简化状态变式的配置文件来了解如何每个完整算法都有很大的“净空”。 这与密码学家分析不同的密码算法非常相似。 任何可行的方案都必须通过“不被破坏”的基准标准,但这不能帮助您对竞争者进行排名。 取而代之的是,他们构建了竞争者算法的缩减后版本,并查看了在破解之前必须获得的缩减量。 如果在N-1中断了N回合的完整算法,则净空就很少了,密码学家可能会避免。 同样,如果128位BitGenerator通过PractRand但其120位版本失败,则可能存在很大的风险。
rkern
于 2019-05-28
@mattip似乎合理。 虽然某个地方有人
import gc
state = [o for o in gc.get_objects() if 'Xoshiro256' in str(o)][0].state
如果他们想深入研究,那很好。 我只想帮助非专家用户
mattip
于 2019-05-28
它以允许在python
Threads中使用的方式传递经过稍微重写的test_pickle
值得注意的是,这是一个悬而未决的问题(#9650)-理想情况下, Generator()将在子线程中重新放置。 IIRC这仅在Python> = 3.7中才实用
bashtage
于 2019-05-28
我对“默认”的看法是我们可以将其保留为实现细节,以便
Generator()始终有效。 我谨此提醒您,始终获得可重复的结果(取决于Generator的更改)的唯一方法是使用语法Generator(BitGenerator(kwarg1=1,kwargs2=b,...))
我们需要区分两种可重复性。 一种是我使用相同的种子运行程序两次,并获得相同的结果。 那就是我们需要支持的那个。 另一个是至少在最严格的意义上,我们拒绝了numpy版本之间的可重复性。
没有参数的Generator() ,即“给我一个numpy推荐的任意种子PRNG”不是主要的用例。 它不需要太多支持。 “给我numpy建议使用_this_种子的PRNG”是,这就是我们正在讨论的选项。 我们需要numpy对如何获得种子PRNG表示意见,并且这种方式对于用户来说应该是容易和方便的(否则他们将不会使用它)。 我喜欢给算法命名(尽管通过一个更方便的功能),但是@rgommers认为这是太过分了,我对此表示同情。
rkern
于 2019-05-28
无参数的Generator(),即“给我numpy推荐的任意种子PRNG”不是主要的用例。 它不需要太多支持。 “请给我numpy推荐的PRNG使用此种子”,这就是我们正在讨论的选项。 我们需要numpy对如何获得种子PRNG表示意见,并且这种方式对于用户来说应该是容易和方便的(否则他们将不会使用它)。 我喜欢为算法命名(尽管通过更方便的功能),但是@rgommers认为这太过分了,我对此表示同情。
我认为用户实际上没有能力提供好的种子。 例如,有多少用户知道正确的方式播种Mersenne Twister? 这并不像您想的那么
因此,实际上我想说的是,用户获得可重现结果的正确方法是创建PRNG(不提供种子,让其自动很好地播种),然后腌制它。
imneme
于 2019-05-28
如果讨论只是关于正确的方法,那我就是
Generator(BitGenerator(**kwargs))因为这只会由
关心复制的半意识用户。
我确实认为Generator()的默认值很重要,因为这将是
解释为尽可能多的选择,因此将其视为
建议使用种子形式时。
只是抛出一个,类方法Generator.seeded(seed[,
bit_generator]) where bit generator is a string. This would allow the
pattern of switching from one value to None to warn if the default was
going to change, like lstsq. I would also only support a limited pallatte
of but generators initially (i.e. 1). Doesn't make it easy to expose
advanced features I suppose. In a perfect world it would use kwarg only to
allow any keyword argument to be used which avoids most depreciation
problems. Of course, this doesn't really need to be a class function, just
播种了`。
在2019年5月28日,星期二,16:38 Robert Kern [email protected]写道:
我对“默认”的看法是我们可以将其保留为实现
详细信息,以便Generator()始终有效。 我会用一个
请特别注意,始终获得可重复结果的唯一方法
(取决于Generator的更改)是使用语法
生成器(BitGenerator(kwarg1 = 1,kwargs2 = b,...))我们需要区分两种可重复性。 一个是
我用相同的种子运行了两次程序并获得了相同的结果。
那就是我们需要支持的那个。 另一个是
至少在最严格的意义上,我们已经放弃了numpy的版本。无参数的Generator(),即“给我一个任意播种的PRNG,
numpy推荐”不是主要用例。它不需要太多
支持。 “给我numpy推荐给这个种子的PRNG”是,
这就是我们正在讨论的选项。 我们需要一种方法让numpy
表达关于如何获得种子PRNG的意见,这种方式需要
方便用户使用(否则他们将不会使用)。 我喜欢
命名算法(尽管通过更方便的功能),但是
@rgommers https://github.com/rgommers认为这是太过分了,
我对此表示同情。-
您收到此邮件是因为有人提到您。
直接回复此电子邮件,在GitHub上查看
https://github.com/numpy/numpy/issues/13635?
或使线程静音
https://github.com/notifications/unsubscribe-auth/ABKTSROCMLHG6E6BLWI6TWDPXVGW5ANCNFSM4HPX3CHA
。
在2019年5月28日,星期二,16:38 Robert Kern [email protected]写道:
我对“默认”的看法是我们可以将其保留为实现
详细信息,以便Generator()始终有效。 我会用一个
请特别注意,始终获得可重复结果的唯一方法
(取决于Generator的更改)是使用语法
生成器(BitGenerator(kwarg1 = 1,kwargs2 = b,...))我们需要区分两种可重复性。 一个是
我用相同的种子运行了两次程序并获得了相同的结果。
那就是我们需要支持的那个。 另一个是
至少在最严格的意义上,我们已经放弃了numpy的版本。无参数的Generator(),即“给我一个任意播种的PRNG,
numpy推荐”不是主要用例。它不需要太多
支持。 “给我numpy推荐给这个种子的PRNG”是,
这就是我们正在讨论的选项。 我们需要一种方法让numpy
表达关于如何获得种子PRNG的意见,这种方式需要
方便用户使用(否则他们将不会使用)。 我喜欢
命名算法(尽管通过更方便的功能),但是
@rgommers https://github.com/rgommers认为这是太过分了,
我对此表示同情。-
您收到此邮件是因为有人提到您。
直接回复此电子邮件,在GitHub上查看
https://github.com/numpy/numpy/issues/13635?
或使线程静音
https://github.com/notifications/unsubscribe-auth/ABKTSROCMLHG6E6BLWI6TWDPXVGW5ANCNFSM4HPX3CHA
。
bashtage
于 2019-05-28
从可用性角度来看,我认为我们确实需要支持Generator(seed) 。 否则,面对他们不准备做出的选择,用户只会坚持RandomState 。
为了对Generator的默认位生成器进行版本控制,我们可以使用bit_version=1代替version=1 ,尽管我也同意放弃version想法。 我认为用户不需要经常显式设置位生成器。
对于解决需要特定生成器功能的特定用例,我的首选是设计新的通用BitGenerator API,以隐藏实现细节。 可以将它们添加到DefaultBitGenerator或放入新类(如果它们的使用涉及权衡),例如ParallelBitGenerator 。
我绝对希望避免由于更改默认位生成器而对RNG流中的将来更改发出警告。 这些警告只会对绝大多数不依赖于此类细节的用户产生干扰,但他们在Generator中设置了seed只是为了阻止其随机数自发改变。
shoyer
于 2019-05-28
用户只是坚持使用RandomState。
很好,他们不是早期采用者。 我一直在努力(可能太难了?)以争取尽可能少的可行API,因为我们总是可以扩展API,但要缩小它要困难得多。 在Generator(Philox()) , Generator(seed(3))和Generator(bit_version=1)之间的细微差别很难理解,直到最终用户知道。
让我们发布没有Generator(seed)的第一个版本,并获得一些反馈。
mattip
于 2019-05-28
让我们发布没有
Generator(seed)的第一个版本,并获得一些反馈。
好的,我这里没有严重的异议。 在这种情况下,我们可能还需要立即指定完整的BitGenerator。
shoyer
于 2019-05-28
因此,实际上我想说的是,用户获得可重现结果的正确方法是创建PRNG(不提供种子,让其自动很好地播种),然后腌制它。
我说的是同一件事,但是我对此几乎没有吸引力。 正如您所说,“好吧,仅仅因为某事是个坏主意并不意味着人们就不想这样做!”
MT的巨大状态加剧了部分问题,这确实需要将序列化到文件中。 很难使基于文件的舞蹈成为最简单的API,以使用户想要使用它。 使用状态更小的默认PRNG,情况会更好。 UUID的大小为128位,该大小恰好足够以十六进制和复制粘贴的形式打印出来。 因此,一个好的模式可能是编写程序,使其默认为良好的熵种子,然后打印出其状态,以便下次运行该程序时可以将其粘贴粘贴。
❯ python secret_prng.py
Seed: 0x977918d0c7da45e5168f72005586500c
...
Result = 0.7223650399276123
❯ python secret_prng.py
Seed: 0xe8962534e5fb585483b86119fcb852ce
...
Result = 0.10640984721018876
❯ python secret_prng.py --seed 0xe8962534e5fb585483b86119fcb852ce
Seed: 0xe8962534e5fb585483b86119fcb852ce
...
Result = 0.10640984721018876
不知道这样的模式是否会同时提供简单性和将来的可靠性。
NumPy 1.next
class Generator:
def __init__(bitgen_or_seed=None, *, bit_generator='pcg64', inc=0):
NumPy 1.20.x
python
类生成器:
定义__init __(bitgen_or_seed = None,*,bit_generator = None,inc = None):
如果bit_generator不为None或inc不为None:
warn('默认值从PCG64更改为AESCtr。inc关键字'
“不赞成使用参数,并且将来会增加”,FutureWarning)
``
NumPy 1.22
python
类生成器:
def __init __(bitgen_or_seed =无,*,bit_generator ='aesctr',inc =无,计数器= 0):
如果bit_generator =='pcg64'或inc不是None:
引发异常(“不再支持PCG并且已删除inc”)
``
bashtage
于 2019-05-28
不知道这样的模式是否会同时提供简单性和将来的可靠性。
正如我在https://github.com/numpy/numpy/issues/13635#issuecomment -496589421中指出的那样,对于大多数用户来说,这是令人惊讶和沮丧的。 我宁愿要求提供一个明确的BitGenerator对象,而不是计划在用户未设置所有可选参数的情况下开始发出警告。 对于我们发现API意外损坏的情况,这实际上应该是最后的选择。
shoyer
于 2019-05-28
问题是过渡期。 使用默认值的每个人都将突然收到警告,而过渡期间却没有很好的切换方法。 或至少将它们从Generator(seed)的“低能量状态”移动到Generator(seed, bit_generator='aesctr')的不太方便的“高能量状态”。 由于此API的目标是提供一种方便的“低能耗状态”,因此在此过渡过程中我们的目的未能实现。 我们使用直方图功能之一IIRC进行了一次,这是一场噩梦。
这对于所有尝试就地更改参数含义的弃用都是普遍的。 将您从一种功能移到另一种功能的弃用更容易管理,这就是我所提倡的。
rkern
于 2019-05-28
让我们发布没有
Generator(seed)的第一个版本,并获得一些反馈。
“第一个版本”是指完整的numpy版本吗? 还是只是合并了PR(此后已发生)?
如果是完整的numpy版本,那么我们仍然需要确定一些事情,例如我们包含多少BitGenerator 。 如果我们包括当前的全部补充,那么我们已经披露了一些选择。
rkern
于 2019-05-28
将您从一种功能移到另一种功能的弃用更容易管理,这就是我所提倡的。
+1同意
不,这是为了减轻人们正在使用的诸如“ default_generator(seed)”之类的“指定移动目标” API的问题(例如, @ shoyer的version参数)。
保持流兼容性(NEP 19否认)是API中断的第二要务。 不同的BitGenerator具有不同的有效API
好的,现在对我来说更有意义。
如果问题听起来很怪异,那么我很乐意使用一个更友好的通用名称,只要该策略在其他方面相同(我们将添加一个新功能,并就旧功能开始警告)。 我会认为是等效的。 我们不应该经常这样做。
这听起来是迄今为止最好的解决方案。 在这里应该可以选择一个合理的名称。 还有很多其他理智的名称-我们可能永远都不需要。
像np.random.generator或np.random.default_generator 。
rgommers
于 2019-05-28
我们包括多少个BitGenerators
您能否提出一个单独的建议提案,以删除那些您认为应该从当前清单中删除的清单(MT19937,DSFMT,PCG32,PCG64,Philox,ThreeFry,Xoshiro256,Xoshiro512)?
我们仍然没有解决当前的问题:哪个BitGenerator应该是默认值(当前Xoshiro256 )
mattip
于 2019-05-28
好吧,这个问题更多地是关于“哪个应该被numpy推广为杰出的BitGenerator ”,它既可以选择默认值,又可以选择添加或删除默认值。 我们提供默认值的机制(如果提供默认值)会增加一些约束,因此这些都是或多或少需要共同决定的事情。 这是一个很大的毛茸茸的混乱,在完成了该PR的所有工作之后,我确定您已经筋疲力尽,看不到另一个没有任何贡献代码的巨型线程,因此,您会感到同情。 :-)
就算法本身而言,我已经给出了建议:我们必须保留MT19937用于RandomState和比较目的,并且我喜欢PCG64用于建议目的。
rkern
于 2019-05-28
我在Compiler Explorer上搞乱了一点,我想我已经使用内在函数为64位MSVC实现了PCG64,从而迫使编译器生成接近clang的uint128_t数学的程序集: https:// godbolt .org / z / ZnPd7Z
我目前尚未设置Windows开发环境,所以我不知道它是否实际上是_correct _... @bashtage您介意吗?
rkern
于 2019-05-29
没有补丁:
Uniforms per second
************************************************************
PCG64 62.77 million
带补丁:
Uniforms per second
************************************************************
PCG64 154.50 million
该修补程序通过了测试,包括为2个不同的种子生成相同的1000 uint64值集。
bashtage
于 2019-05-29
对于与GCC本机和在同战模式下的同战:
Time to produce 1,000,000 Uniforms
************************************************************
Linux-64, GCC 7.4 PCG64 4.18 ms
Linux-64, GCC 7.4, Forced Emulation PCG64 5.19 ms
Win64 PCG64 6.63 ms
Win32 PCG64 45.55 ms
哇,那真是太糟糕了。 也许我们应该扩展比较页面上的信息,以证明在同一台计算机上的winvc {64,32}与Linux上的gcc7.4 {64,32}的性能(我假设您使用的是msvc2017,您可能应该在某处添加该信息)。
mattip
于 2019-05-29
Win32在这里毫无希望。 我怀疑32位Linux也将非常糟糕,但是没有32位Linux系统可以轻松进行测试。
bashtage
于 2019-05-29
我绝对可以看到为坚持使用32位计算机(最有可能是Windows的企业IT政策)的人们提供建议的理由。 这很清楚:DSFMT为32位(或MT19937也不错)。 基准会很好。
bashtage
于 2019-05-29
对于它的价值,我对经常重复的PCG关于多个独立随机流的主张持怀疑态度。 有没有人做过认真的统计分析来支持独立性的主张? (实际上,我认为奥尼尔的论文仅提及“不同”的流,没有任何独立性的主张。)
我认为有充分的理由对此表示怀疑:对于给定的LCG乘数,所有这些不同的流都仅通过scale [*]进行关联。 因此,给定任何两个具有相同乘数的LCG流,尽管起始点不同,但其中一个将简单地是另一个的恒定倍数( 2**64或2**32取模)。 PCG的置换部分将有助于隐藏这一点,但是如果存在统计上可检测到的相关性,这也就不足为奇了。
如此明确的流当然可以,但是如果没有经过认真的测试,我不会以票面价值来主张独立流的主张。
[*]示例:假设x[0], x[1], x[2], ...是标准的64位LCG流,带有x[i+1] := (m*x[i] + a) % 2**64 。 为所有i设置y[i] := 3*x[i] % 2**64 i 。 然后y[i]是具有y[i+1] := (m*y[i] + 3*a) % 2**64的LCG流,因此,只需缩放原始流,就可以使用相同的乘数但具有不同的加性常数生成这些不同的LCG流之一。 通过使用其他奇数乘法器代替3 ,并假设我们只对全周期LCG感兴趣(因此a是奇数),您将获得所有可能的全-乘数的周期LCG。
编辑:修正了关于共轭类数的错误陈述。
 mdickinson
于 2019-05-29
mdickinson
于 2019-05-29
我认为对PCG流的最彻底的公开分析是在这里: http :
@imneme您能否扩展您的最终建议? “与David Blackman的往来表明,用相关的初始化(例如恒定的种子和1,2,3,4的流)来创建“附近”的流,可能比我想的要容易。如果您要在同时,现在,我建议流ID和种子应该是不同的并且彼此之间没有明显的相关性,这意味着不要同时使它们成为1,2,3,4。”
这是否意味着您认为可以拥有一个单一的好种子(例如,从熵源派生),然后流ID 1,2,3,4吗? 还是应该从良好的熵源中随机选择种子ID和流ID?
rkern
于 2019-05-29
一些Linux-32(Ubuntu 18.04 / GCC 7.4)编号
Time to produce 1,000,000 Uniforms
***************************************************************
Linux-64, GCC 7.4 PCG64 4.18 ms
Linux-64, GCC 7.4, Forced Emulation PCG64 5.19 ms
Win64 PCG64 6.63 ms
Win32 PCG64 45.55 ms
Linux-32, GCC 7.4 PCG64 25.45 ms
因此它的速度是Win-32的两倍,但速度却很慢。 所有4个计时均在同一台机器上进行
Other Linux-32/GCC 7.4 Timing Results
-----------------------------------------------------------------
DSFMT 6.99 ms
MT19937 13.09 ms
Xoshiro256 17.28 ms
numpy 15.89 ms
NumPy是NumPy 1.16.4。 DSFMT是唯一在32位(x86)上具有良好性能的生成器。 对于任何32位用户,都应清楚地记录下来。 对于32位用户,MT19937也是一个相对不错的选择。
bashtage
于 2019-05-29
因此,出于遗留目的,我们需要有MT19937 。 如果我们确实希望尽量减少包含的PRNG(即MT19937加上我们的单一通用建议),那么我不会感到不得不使用32位性能来限制我们的单一通用建议,也不会感觉不得不添加第三个“推荐用于32位” PRNG。 MT19937将始终可用,并且不比其当前的状态差。 第三方软件包将可用于更多细分市场。
当然,如果由于其他原因我们确实希望包括一套更完整的PRNG,那么我们可以在文档中提出各种具体建议。
rkern
于 2019-05-29
我很好奇PCG的“ P”部分减轻了相关流中的潜在问题。
因此,这(可能)是LCG的最坏情况:其中一个LCG流的加性常数恰好是另一个LCG流的加性常数。 然后用种子的适当选择可怕,我们最终与LCG流之一是另一个的确切否定。
但是现在,如果我们同时使用这两个流来生成一系列浮点数,那么PCG的置换部分和对float64的转换都应该对我们有所帮助。
以下图表显示了排列的帮助:

那是一个散布图,其中一个这样的流中有10000个浮点数,而相反的孪生子中有10000个浮点数。 并不可怕,但也不是很好:有明显的人工制品。
不知道从中得出什么结论:这绝对是一个人为的例子,您不太可能(我希望)偶然遇到。 另一方面,它确实表明,如果您确实需要多个不相关的流,则需要进行一些思考和谨慎。
作为记录,以下是来源:
import matplotlib.pyplot as plt
import numpy as np
from pcgrandom import PCG64
gen1, gen2 = PCG64(), PCG64()
multiplier, increment, state = gen1._get_core_state()
new_increment, new_state = -increment % 2**128, -state % 2**128
gen2._set_core_state((multiplier, new_increment, new_state))
xs = np.array([gen1.random() for _ in range(10**4)])
ys = np.array([gen2.random() for _ in range(10**4)])
plt.scatter(xs, ys, s=0.1)
plt.show()
PCG64是O'Neill称为PCG-XSL-RR的生成器(PCG论文的6.3.3节)。 pcgrandom包从这里
mdickinson
于 2019-05-29
我认为获取独立流的标准方法是使用jumpahead()。
重新播种以获得“独立”流通常很危险。
计数器/哈希生成器具有简单的jumpahead()。 PCG吗?
也是用户的恳求:请提供至少一个
加密质量,具有无限的状态空间。
干杯,
菲利普
(seberg编辑:删除了电子邮件报价)
pbstark
于 2019-05-29
@pbstark :这不仅仅是在播种:两个底层的LCG生成器实际上是不同的:x↦mx + a(mod 2 ^ 128)和x↦mx + b(mod 2 ^ 128)不同的增量a和b。 O'Neill的PCG论文提出了一种想法,即可以通过更改LCG增量来创建不同的流(请参见论文的4.3.2节)。
但是LCG的简单性意味着,在原始生成器中将加性常量_does_更改为仅跃升一些未知量,再加上简单的线性变换(乘以一个常量,或者在某些情况下仅添加一个常量)即可。
这不是不使用PCG的理由,我暂时也不认为它不适合NumPy的新主PRNG。 我只是不希望人们被“独立”随机流的承诺所吸引。 充其量,用于PCG的可设置流想法提供了一种便捷的方法来完成等同于快速跳转以及额外的额外乘法或加法变换的操作。
mdickinson
于 2019-05-29
我们在社区电话中讨论了加密技术。 我认为我们对此有些谨慎。 这似乎是个好主意,但是如果我们包含具有加密功能的RNG,我们还必须跟上出现的任何安全问题,因为我们不知道用户是否将其用于实际的加密目的。
关于要包含的数量:共识倾向于使周围有更多位生成器是可以的(当然,一些小的文档会很好)。 维护负担似乎不太大。 最后,我的猜测是我们会接受凯文和罗伯特的建议。
关于名称的注意事项:我个人不介意使用RNG名称并强迫用户使用它们,唯一的缺点是我们可能必须在编码时查找名称。 我们应该尽量减少弃用警告。 我喜欢默认RNG的最小公开API,无需播种。
seberg
于 2019-05-29
@mdickinson ,我尝试自己复制您的图形,但失败了。 我在该程序中使用
#include "pcg_random.hpp"
#include <iostream>
#include <random>
int main() {
std::random_device rdev;
pcg_detail::pcg128_t seed = 0;
pcg_detail::pcg128_t stream = 0;
for (int i = 0; i < 4; ++i) {
seed <<= 32;
seed |= rdev();
stream <<= 32;
stream |= rdev();
}
pcg64 rng1(seed,stream);
pcg64 rng2(-seed,-stream);
std::cerr << "RNG1: " << rng1 << "\n";
std::cerr << "RNG2: " << rng2 << "\n";
std::cout.precision(17);
for (int i = 0; i < 10000; ++i) {
std::cout << rng1()/18446744073709551616.0 << "\t";
std::cout << rng2()/18446744073709551616.0 << "\n";
}
}
当我运行此命令时,它输出(以确保可重复性):
RNG1: 47026247687942121848144207491837523525 203756742601991611962280963671468648533 41579532896305845786243518008404876432
RNG2: 47026247687942121848144207491837523525 136525624318946851501093643760299562925 52472962479578397910044896975270170620
和可以绘制下图的数据点:

如果您能弄清楚我在做些什么,那会有所帮助。
(我并不是说这是为了反驳相关性是可能的想法,因为它们是可行的,我将对该主题写一个单独的评论,但正是在写这篇评论时,我意识到我无法使用来复制您的结果我常用的工具。)
imneme
于 2019-05-29
@mdickinson进入计算状态并直接递增到内部,绕过了通常的初始化例程,该
我编写了一个快速的小驱动程序脚本,该master的numpy。当我直接打入对抗性内部状态/增量时,PractRand很快就会失败。 我不清楚我们是否可以找到合理的方法来找到对抗性_seeds_(实际上通过初始化程序例程)以实现对抗性状态。
rkern
于 2019-05-29
如前所述,我的博客文章中指出,PCG的流与SplitMix的流有很多共同点。
关于@mdickinson的图,对于允许您播送其整个状态的_every_ PRNG,包括基于计数器的加密状态,我们可以设计种子,在其中我们的PRNG的输出以某种方式关联(最简单的方式)是为了使PRNG状态相隔很短的距离,但通常我们可以基于对它们的工作原理的理解来做其他事情。 尽管不允许全状态播种的PRNG可以避免此问题,但这样做只是引入了一个新的问题,仅提供了对可能状态的一小部分的实际访问。
考虑流的正确方法只是需要播种更多随机状态。 对于_any_ PRNG的任何播种目的,使用1,2,3之类的小值通常是个坏主意(因为如果每个人都偏爱这些种子,则它们对应的初始序列将被过多代表)。
我们可以选择根本不将其称为流,而仅将其称为状态。 这就是Marsaglia在XorWow中counter根本不与其余状态交互,并且像LCG一样,初始值的变化实际上只是一个附加常数。
SplitMix,PCG和XorWow的流是我们所谓的“愚蠢”流。 它们构成了生成器的重要重新参数化。 但是,这是有价值的。 假设没有流,我们的PRNG将有一个有趣的接近重复42,其中42快速连续种植几次,并且仅对42进行此操作,而没有其他数字。 对于愚蠢的“只是增量”或“只是异或”流,我们实际上将避免将奇怪的重复硬编码为42; 所有数字都有它们奇怪重复的流。 (由于这个原因,我将用于修复Xoshiro 256中的近重复问题的解决方案是将Weyl序列混合使用。)
imneme
于 2019-05-29
我不是专家,但是在密码学方面,建议的内容在以下方面不可用:
来自Python密码管理局的https://cryptography.io/en/latest/ ?
他们关于随机数生成的页面还提到:
从Python 3.6开始,标准库包括secrets模块,该模块可用于生成加密安全的随机数,并具有基于文本格式的特定帮助器。
我想也许在这一代增加了阵列。 我想知道与低温摄影鲁棒性相关联的潜在维护负担是否真的值得并且在NumPy中合适,而不是说与pyca进行通信,并为此考虑第三方生成器/插件。 我认为纳撒尼尔(Nathaniel)之前也提到过类似的担忧。
的确,在我看来,潜在的dtype重构/增强之类的东西也旨在提供API基础结构,而不必承担维护各种专用新应用程序的负担。
 tylerjereddy
于 2019-05-30
tylerjereddy
于 2019-05-30
顺便说一句,在我对Vigna的PCG批评的答复中,还有更多关于构造相关PRNG状态本节]。 我观察到的一点是,由于PCG具有距离功能,因此您实际上可以使用距离功能进行检查以检测人为种子。 在没有距离功能的PRNG中,人们仍然可以设计出选择不佳的种子对(尤其是如果绕过公共API进行种子种植),但是没有提供可以检测到最明显的贡献的机制。
一方面,考虑是否有可能采用您最喜欢的(或最不喜欢的)PRNG并为其制作种子来使其做有趣或可怕的事情(例如,这种病理状态)很有趣……
但是,从更大的角度来看,我认为在实践中查看用户面临的问题是有意义的。 我们给他们提供了什么建议,等等。大多数用户并没有意识到-对于所有PRNG(过去和将来)_,一个32位种子绝对是一个可怕的主意,无论使用哪种PRNG,它都会导致可察觉的偏差。 当然,我们可以将其清除,而不必花时间担心某人是否可能将Mersenne Twister初始化为一个几乎为零的状态(或LFSR根本无法工作的全零状态!),或者有人是否可能将Xoshiro初始化为在11个输出空间中重复输出7次相同输出的点附近,或者设计两个相似的PCG流,或者其他任何方式,但是如果生成器发生,那么所有这些尝试基本上都会发生的可能性很小(实际上为零)用随机数据播种。 这些转移虽然在智力上令人着迷,而且在学术上也很有趣,但在对它们进行思考的同时,大多数人却忽略了这样一个事实,即用户通常对播种时的工作一无所知,这是在罗马燃烧时摆弄的。
imneme
于 2019-05-30
如果inc=1,2,3,4是个坏主意,那是否不应该建议将其记录得非常清楚,或者我们应该使用稍微不同的API? 甚至new_generator = (Bit)Generator().independent() ,如果(基础)位生成器没有提供实现该目标的好方法,我们也可以发出警告。
另外,取决于32bit种子的糟糕程度。 我们能想到一个好的API来创建和存储种子以冻结它吗? 我不知道。 甚至“如果不存在则创建冻结的种子缓存文件”。
seberg
于 2019-05-30
对于PCG来说,可以只播种-> uint64_t [2]-> splitmix64(seed_by_array)-> uint128,这可以确保散布连续的低种子。
bashtage
于 2019-05-30
对于PCG来说,可以只播种-> uint64_t [2]-> splitmix64(seed_by_array)-> uint128,这可以确保散布连续的低种子。
或者只是使用任何好的整数哈希。 (应该是一个双射。)。 有很多便宜的和短的。 几轮乘-XorShift很好。
imneme
于 2019-05-30
以@mdickinson的观点,我认为他仍然想要说服流媒体依赖仅限于一小部分人为/对抗性设置。 如果是这种情况,那么我们可以通过适当的做法来解决问题,以防止此类情况的发生。 使用我们当前的代码,存在一些不良状态,用户可能会轻易陷入当前的API中。 我可以确认David Blackman的发现,即同时设置seed=1和inc=0,1,2,...会创建关联。 我最新的用于交错PCG32流的PractRand驱动程序可以用来演示这一点。
❯ ./pcg_streams.py --seed 1 --inc 0 |time ./RNG_test stdin32
[
{
"bit_generator": "PCG32",
"state": {
"state": 12728272447693586011,
"inc": 1
}
},
{
"bit_generator": "PCG32",
"state": {
"state": 7009800821677620407,
"inc": 3
}
}
]
RNG_test using PractRand version 0.93
RNG = RNG_stdin32, seed = 0x470537d5
test set = normal, folding = standard (32 bit)
rng=RNG_stdin32, seed=0x470537d5
length= 128 megabytes (2^27 bytes), time= 4.0 seconds
Test Name Raw Processed Evaluation
BCFN(2+0,13-3,T) R= +9.6 p = 2.3e-4 mildly suspicious
...and 116 test result(s) without anomalies
rng=RNG_stdin32, seed=0x470537d5
length= 256 megabytes (2^28 bytes), time= 8.7 seconds
Test Name Raw Processed Evaluation
BCFN(2+0,13-2,T) R= +26.1 p = 6.3e-13 FAIL
...and 123 test result(s) without anomalies
./RNG_test stdin32 8.86s user 0.11s system 93% cpu 9.621 total
我还没有遇到随机种子但以相同的增量递增的失败。 明天我去找你。
我确实注意到,当在构造函数中未指定默认增量时,我们没有使用建议的默认增量。 我们应该解决这个问题。 也许这将是一个很好的基数,从中我们可以从给定的流ID而不是2*inc + 1得出实际的增量。
我们可以尝试构建一些工具来帮助人们使用默认的熵种子并将其保存下来。 我有一个问题是,是否可以简单地生成多个流的增量,或者是否还需要对其进行熵采样并保存它们。 能够将模拟的“初始状态”编码为可以从同事的电子邮件而不是不透明文件中复制粘贴的单个数字,确实非常方便。 使用这些只有128或256位状态的较小的PRNG,我可以轻松地将其以十六进制形式打印到我的日志文件中,然后在想要重现时将其复制粘贴到命令行中。 它大于32位整数,但是可以管理。 如果我也必须对所有流ID进行熵采样,那么就必须放弃这一点,并确保将所有内容都记录在某个状态文件中。 这可能会排除我们已经讨论过的一些要动态生成新流的用例。 如果我可以增加一个计数器以获得一个好的流ID(也许是通过计数器的哈希值派生出来的,或者其他方式),那么我只需要记录初始种子而不是记录流ID。
rkern
于 2019-05-30
IIRC,秘密模块调用操作系统的熵源,这可能非常
在某些系统中不好,并且无论如何都不能复制/再现。
在2019年5月29日星期三下午3:19泰勒·雷迪[email protected]
写道:
我不是专家,但是在加密方面,建议的是
不适用于:
来自Python密码管理局的https://cryptography.io/en/latest/
https://github.com/pyca吗?他们关于随机数生成的页面
https://cryptography.io/en/latest/random-numbers/还提到:从Python 3.6开始,标准库包含了秘密
https://docs.python.org/3/library/secrets.html模块,可以是
用于生成加密安全的随机数,具体
基于文本的格式的帮助器。我想也许在这一代增加了阵列。 我想知道是否
与低温记录相关的潜在维护负担
健壮性确实值得并且在NumPy vs.
与pyca交流,并可能考虑第三方
发电机/插件。 我认为纳撒尼尔提到了类似的担忧
先前。确实,在我看来,像潜在的dtype重构/
增强功能还旨在提供API基础结构,而无需
必须承担维持各种各样
专门的新应用程序。-
您收到此邮件是因为有人提到您。
直接回复此电子邮件,在GitHub上查看
https://github.com/numpy/numpy/issues/13635?
或使线程静音
https://github.com/notifications/unsubscribe-auth/AANFDWKGZMUB67VPCMFZYGTPX36O3ANCNFSM4HPX3CHA
。
-
Philip B. Stark | 副院长,数学和物理科学|
统计系教授|
加州大学
加利福尼亚州伯克利94720-3860 | 510-394-5077 | statistics.berkeley.edu/~stark |
@philipbstark
pbstark
于 2019-05-30
@tylerjereddy那些用于从物理熵源中获取少量随机位,攻击者(和您!)无法预测这些随机位。 它们在密码学中用于初始化向量,随机数,密钥之类的东西,它们都很短。 这些的全部要点是没有办法再现它们,这与np.random的数值模拟目的是矛盾的。 该页面不是在谈论_reproducible_密码安全的PRNG,这也是存在的并且可以从cryptography包中可用的原语构建。 但是,在实践中,我们可以用高效的C代码更好地实现已经可用的算法,至少是为仿真目的而制定和测试的那些算法。 @bashtage为此框架实现了一些。
我还想让Numpy团队清楚
通常用于模拟的大多数基于加密的PRNG都没有@pbstark想要的无界状态。 它们通常基于加密有限计数器。 一旦计数器开始滚动,您就达到了有限期。 从技术上讲,由于固定大小的256位摘要状态和固定大小的64位长度计数器,他的cryptorandom也受限于2**(256+64)唯一的初始条件。 这可能指出了通过使长度计数器为任意大小来实现真正无限制的PRNG的方法,但是我从未见过这种算法的发布或测试。
另一方面,如果您只希望PRNG算法具有任意大小的状态,而只是将其固定在开始时固定在所需大小之上,那么PCG的扩展生成器将可以很好地完成该任务。 这些显然不是CS-PRNG,但是它们实际上可以满足@pbstark的需求,即按需具有巨大的状态空间。 尽管如此,我不建议我们将它们包含在numpy中。
我们可能还希望标准的,有边界的CS-PRNG具有其他属性,但它们不是IMO的默认设置。
rkern
于 2019-05-30
Cryptorandom的状态空间不是256位哈希:它是无界的。 的
种子状态是任意长度的字符串,每次更新都附加一个零
到当前状态。 递增无界整数计数器将
完成同样的事情。 我们最初实现了该功能,但更改为
追加而不是增加,因为它可以更有效地更新
摘要比从头开始对每个状态进行哈希处理(明显的加速)。
在2019年5月29日星期三晚上7:26罗伯特·肯恩(Robert Kern) [email protected]
写道:
@tylerjereddy https://github.com/tylerjereddy这些是为了获得
来自物理熵源的少量随机位
攻击者(和您!)无法预测的。 它们在密码学中用于
初始化向量,随机数,键之类的东西都很短。 的
这些的全部要点是没有办法复制它们,这就是
与np.random的数值模拟目的不符。 该页面是
不是在谈论可复制的加密安全PRNG,
也是存在的东西,可以从原始中构建
在加密软件包中可用。 实际上,我们有
这些算法已经可以更好地实现了
高效的C代码,至少是已经制定和测试过的C代码
用于仿真目的。 @bashtage https://github.com/bashtage已实施
一些https://github.com/numpy/numpy/issues/13635#issuecomment-496287650
对于这个框架。我也想向numpy团队清楚@pbstark是什么
https://github.com/pbstark提出的不仅是任何基于加密的
PRNG。 相反,他想要一个状态不受限制的,它将提供
他正在寻找的数学特性。通常考虑用于仿真的大多数基于加密的PRNG
没有@pbstark的无界状态
https://github.com/pbstark要。 它们通常基于
加密有限计数器。 一旦计数器滚动,您就可以
有限期。 从技术上讲,他的密码随机
https://statlab.github.io/cryptorandom/也限制为2 **(256 + 64)
固定大小的256位摘要状态和
固定大小的64位长度计数器。 这可能会指出
通过使长度计数器实现真正无限制的PRNG
任意大小,但我从未见过这样的算法发布或
经过测试。另一方面,如果您只想拥有一个
任意大小的状态,只是一开始就固定为
超出您所需的东西,然后是PCG的扩展生成器
http://www.pcg-random.org/party-tricks.html可以很好地解决这个问题
任务。 这些显然不是CS-PRNG,但实际上它们可以满足
@pbstark https://github.com/pbstark拥有巨大状态空间的愿望
一经请求。 尽管如此,我不建议我们将它们包含在numpy中。标准的CS-PRNG具有其他属性
我们可能会想要,但它们不是默认值,IMO。-
您收到此邮件是因为有人提到您。
直接回复此电子邮件,在GitHub上查看
https://github.com/numpy/numpy/issues/13635?
或使线程静音
https://github.com/notifications/unsubscribe-auth/AANFDWLIJD3UCVY3NXCLPKDPX43ONANCNFSM4HPX3CHA
。
-
Philip B. Stark | 副院长,数学和物理科学|
统计系教授|
加州大学
加利福尼亚州伯克利94720-3860 | 510-394-5077 | statistics.berkeley.edu/~stark |
@philipbstark
pbstark
于 2019-05-30
恐怕这不是SHA-256在线更新的工作方式。 它维护的状态只是256位摘要和计算更新时附加的固定大小的64位长度计数器。 它不包含整个文本。 哈希压缩。 这就是它能够对每个字节进行有效更新的方式。 从根本上讲,有许多初始化/过去的历史记录映射到相同的内部SHA-256状态,这是有限的。 虽然周期肯定长,甚至可能比2**(256+64) ,但它们确实存在。 在任何情况下,您都只有少于2**(256+64)可能初始条件(对于每个长度为0到2**64-1文本,您最多可以具有2**256内部哈希状态;一旦文字长度超过32个字元,必须有碰撞(la Pigeonhole)。 数据结构中没有更多的位了。
rkern
于 2019-05-30
非常感谢; 了解。 我会用不同的方式表达:状态
空间是无限的,但是(通过信鸽)许多不同的初始状态必须
产生难以区分的输出序列。
在2019年5月29日,星期三,8:21 PM Robert Kern [email protected]
写道:
恐怕这不是SHA-256在线更新的工作方式。 状态
它维护的只是256位摘要和固定大小的64位
计算更新时附加的长度计数器。 它不成立
全文。 哈希压缩。 这样才能做到高效
更新每个字节。 从根本上讲,有很多初始化/过去
映射到相同的内部SHA-256状态的历史记录是有限的。
虽然周期肯定长,可能长于2 (256 + 64),但它们当然存在。
可能的初始条件(对于每个文本长度0到2 64-1,您可以最多具有2 256个内部哈希状态; 一旦文字长度超过32
个字节,则必须有碰撞(la Pigeonhole)。 根本没有
数据结构中的更多位。-
您收到此邮件是因为有人提到您。
直接回复此电子邮件,在GitHub上查看
https://github.com/numpy/numpy/issues/13635?
或使线程静音
https://github.com/notifications/unsubscribe-auth/AANFDWM56HCQRZXDO3BAQHDPX5B3TANCNFSM4HPX3CHA
。
-
Philip B. Stark | 副院长,数学和物理科学|
统计系教授|
加州大学
加利福尼亚州伯克利94720-3860 | 510-394-5077 | statistics.berkeley.edu/~stark |
@philipbstark
pbstark
于 2019-05-30
同样,只有2**(256+64)个状态可以通过。 由于更新每次都采用相同的形式,因此您最终会遇到一个您以前见过的状态,并进入一个未知(对我而言)但周期有限的循环。 不管是初始状态的有限数量还是有限周期, cryptorandom都具有,而且我认为它们甚至比MT19937 。
并不是说我认为这本身就是cryptorandom的问题。 我并没有确信具有无限的初始状态或无限的周期实际上是实际需要的。
rkern
于 2019-05-30
我还没有遇到随机种子但以相同的增量递增的失败。 明天我去找你。
在512GiB上仍然表现强劲:
❯ ./pcg_streams.py -i 0 |time ./RNG_test stdin32
[
{
"bit_generator": "PCG32",
"state": {
"state": 10843219355420032665,
"inc": 1
}
},
{
"bit_generator": "PCG32",
"state": {
"state": 5124747729404067061,
"inc": 3
}
}
]
RNG_test using PractRand version 0.93
RNG = RNG_stdin32, seed = 0xb83f7253
test set = normal, folding = standard (32 bit)
rng=RNG_stdin32, seed=0xb83f7253
length= 128 megabytes (2^27 bytes), time= 4.0 seconds
no anomalies in 117 test result(s)
rng=RNG_stdin32, seed=0xb83f7253
length= 256 megabytes (2^28 bytes), time= 8.6 seconds
no anomalies in 124 test result(s)
rng=RNG_stdin32, seed=0xb83f7253
length= 512 megabytes (2^29 bytes), time= 16.9 seconds
Test Name Raw Processed Evaluation
BCFN(2+2,13-2,T) R= -8.0 p =1-2.1e-4 mildly suspicious
...and 131 test result(s) without anomalies
rng=RNG_stdin32, seed=0xb83f7253
length= 1 gigabyte (2^30 bytes), time= 33.8 seconds
no anomalies in 141 test result(s)
rng=RNG_stdin32, seed=0xb83f7253
length= 2 gigabytes (2^31 bytes), time= 65.7 seconds
Test Name Raw Processed Evaluation
BCFN(2+2,13-1,T) R= -7.8 p =1-3.8e-4 unusual
...and 147 test result(s) without anomalies
rng=RNG_stdin32, seed=0xb83f7253
length= 4 gigabytes (2^32 bytes), time= 136 seconds
no anomalies in 156 test result(s)
rng=RNG_stdin32, seed=0xb83f7253
length= 8 gigabytes (2^33 bytes), time= 270 seconds
no anomalies in 165 test result(s)
rng=RNG_stdin32, seed=0xb83f7253
length= 16 gigabytes (2^34 bytes), time= 516 seconds
no anomalies in 172 test result(s)
rng=RNG_stdin32, seed=0xb83f7253
length= 32 gigabytes (2^35 bytes), time= 1000 seconds
no anomalies in 180 test result(s)
rng=RNG_stdin32, seed=0xb83f7253
length= 64 gigabytes (2^36 bytes), time= 2036 seconds
no anomalies in 189 test result(s)
rng=RNG_stdin32, seed=0xb83f7253
length= 128 gigabytes (2^37 bytes), time= 4064 seconds
no anomalies in 196 test result(s)
rng=RNG_stdin32, seed=0xb83f7253
length= 256 gigabytes (2^38 bytes), time= 8561 seconds
no anomalies in 204 test result(s)
rng=RNG_stdin32, seed=0xb83f7253
length= 512 gigabytes (2^39 bytes), time= 19249 seconds
no anomalies in 213 test result(s)
嗯,如果我们按顺序执行两个以上的流,那么很快就会看到失败。 我们将需要研究使用某种双射从用户输入中推导实际增量以将其扩展到整个空间。
❯ ./pcg_streams.py -n 3 | time ./build/RNG_test stdin32
[
{
"bit_generator": "PCG32",
"state": {
"state": 18394490676042343370,
"inc": 2891336453
}
},
{
"bit_generator": "PCG32",
"state": {
"state": 12676019050026377766,
"inc": 2891336455
}
},
{
"bit_generator": "PCG32",
"state": {
"state": 6957547424010412162,
"inc": 2891336457
}
}
]
RNG_test using PractRand version 0.93
RNG = RNG_stdin32, seed = 0x4a9d21d1
test set = normal, folding = standard (32 bit)
rng=RNG_stdin32, seed=0x4a9d21d1
length= 128 megabytes (2^27 bytes), time= 3.2 seconds
Test Name Raw Processed Evaluation
DC6-9x1Bytes-1 R= +19.4 p = 1.6e-11 FAIL
[Low8/32]DC6-9x1Bytes-1 R= +13.2 p = 4.6e-8 VERY SUSPICIOUS
...and 115 test result(s) without anomalies
@imneme
如果您能弄清楚我在做些什么,那会有所帮助。
我认为您需要将代码中的行pcg64 rng2(-seed,-stream);替换为pcg64 rng2(-seed,-1-stream); ,以允许进行increment = 2 * stream + 1转换。 增量的取反对应于流索引的按位取反。 如果我进行更改并运行您的代码,我会看到与我之前的情节非常相似的东西。 (并且我确认,如果不进行更改,那么一切在外观上都会看起来不错。)
mdickinson
于 2019-05-30
@imneme
考虑流的正确方法只是需要播种更多随机状态。
同意我认为这为LCG提供了一个非常清晰的画面:对于具有固定选择好的乘法器a的64位LCG,我们将得到一个大小2^127的状态空间,包括所有对(x, c)整数mod 2 ^ 64,其中c是奇数增量。 状态更新函数为next : (x, c) ↦ (ax+c, c) ,将状态空间划分2^64每个长度2^63不相交循环。 播种仅涉及在此状态空间中选择起点。
然后,有一个显而易见的组动作使分析变得容易,并使不同流之间的关系变得清晰: Z / 2^64Z上的可逆一维仿射变换组的顺序恰好是2^127 ,并且具有传递性(因此也是忠实地)在状态空间上:仿射变换y ↦ ey + f将对(x, c)映射到(ex + f, ec + (1-a)f) 。 该组动作与next函数转换,因此将状态空间中的一个点(x, c)转换为另一点(x2, c2)的唯一组元素也映射了由(x, c)生成的序列(x2, c2)生成的序列。
tl; dr:对于固定乘数,通过仿射变换将具有相同乘数的任何两个LCG序列(无论是使用相同的增量,还是在超前情况下使用,或使用不同的增量)。 在不幸的情况下,我们想避免仿射变换非常简单,例如加2或乘以-1 。 在一般情况下,我们希望仿射变换足够复杂,以至于标准统计测试无法检测到两个流之间的关系。
mdickinson
于 2019-05-30
@mdickinson很好地介绍了这种情况。 PCG的排列方式与LCG的情况相比会有些变化,但变化不大。 PCG排列的全部要点是我们可以选择要做多少加扰。 因为截断的128位LCG已经通过BigCrush,所以当我为pcg64选择排列时,我为该大小的LCG(XSL RR)选择了适度的加扰。 相比之下,64位LCG很快就无法通过多项统计测试,因此pcg32使用的加扰更多,但它仍然不是PCG论文中最强的排列方式。 正如我在线程请求请求线程中提到的那样,对于pcg32用例,我已经开始倾向于更强大的PCG排列(RXS M)。 它不是默认值,您必须明确要求该版本,但是当我为PCG进行主要版本修改时,很有可能我会切换默认值。 (RXS M是RXS M XS的上半部分,Vigna已经以此尺寸和David Blackman喜欢的排列对它进行了广泛的测试)。
我们可以使用pcg32的两种方案(XSH RR和RCS M [以及原始的底层LCG])将近流测试程序的更新版本的区别可视化:
#include "pcg_random.hpp"
#include <iostream>
#include <random>
// Create a "PCG" variant with a trivial output function, just truncation
template <typename xtype, typename itype>
struct truncate_only_mixin {
static xtype output(itype internal)
{
constexpr size_t bits = sizeof(itype) * 8;
return internal >> (bits/32);
}
};
using lcg32 = pcg_detail::setseq_base<uint32_t, uint64_t, truncate_only_mixin>;
int main() {
std::random_device rdev;
uint64_t seed = 0;
uint64_t stream = 0;
for (int i = 0; i < 2; ++i) {
seed <<= 32;
seed |= rdev();
stream <<= 32;
stream |= rdev();
}
lcg32 rng1(seed,stream);
lcg32 rng2(-seed,-1-stream);
// pcg32 rng1(seed,stream);
// pcg32 rng2(-seed,-1-stream);
// pcg_engines::setseq_rxs_m_64_32 rng1(seed,stream);
// pcg_engines::setseq_rxs_m_64_32 rng2(-seed,-1-stream);
std::cerr << "RNG1: " << rng1 << "\n";
std::cerr << "RNG2: " << rng2 << "\n";
std::cout.precision(17);
for (int i = 0; i < 10000; ++i) {
std::cout << rng1()/4294967296.0 << "\t";
std::cout << rng2()/4294967296.0 << "\n";
}
}
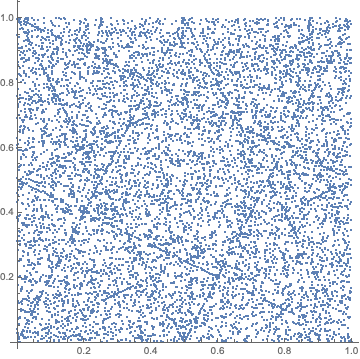
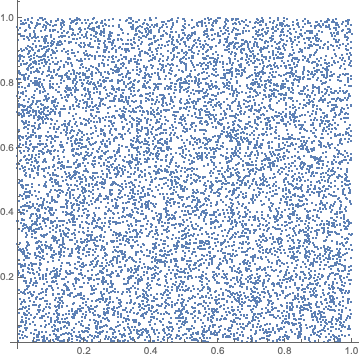
在开始之前,让我们看一下@mdickinson绘制的图,但是对于没有排列的LCG,只是截断:

请注意,这是针对状态相关的病理性LCG。 相反,如果我们只是选择了两个具有随机选择的加性常数(但起始值相同)的LCG,则它看起来像这样:
继续讲到PCG的输出功能,如果我们在病理情况下使用XSH RR,它看起来像这样-在上图中是一个很大的改进,但显然它并未完全掩盖其可怕性:
这是具有相同基础(严重相关)LCG对的RXS M:
但这只是我为pcg32考虑而已。 性能损失很小, pcg32很小,我可以想象一些重度用户担心创建大量随机种子的pcg32生成器,并从中要求大量数字,具有不无限小的相关机会。 坦率地说,我对此有两种看法,因为这个神话般的超级用户会首先使用pcg32 。
我不太想让pcg64的流更独立的原因之一是,我不确定我是否看到用例,可以使所有其他状态保持不变并将流切换到一个不同的值(例如,取一个随机值,更不用说附近的值了)。 对于几乎所有PRNG,进行第二次PRNG的正确方法是使用新的熵对其进行初始化。
总之,对于NumPy,我认为只考虑PCG64需要两个256位状态(从技术上讲,它是255,因为忽略了流的高位)可能是最有意义的,并称之为完成。 这也将避免与API相关的问题,因为它将减少人们在一个BitGenerator中拥有的一项功能,而不是另一项。
(但是您可能希望将32位PCG变体转换为RXSM。对于C源,您需要一个最新版本,因为我以前不愿意在C代码中显式提供RXS M,仅在C ++中可用化身。)
[抱歉,如果您想知道的还不止于此! 好吧,对不起。 ;-)]
imneme
于 2019-05-30
我不太想让
pcg64的流更独立的原因之一是,我不确定我是否看到用例,将所有其他状态保持不变并将流切换到一个不同的值(例如,取一个随机值,更不用说附近的值了)。 对于几乎所有PRNG,进行第二次PRNG的正确方法是使用新的熵对其进行初始化。
我已经在前面描述了用例。 有很强的UX原因需要编写一个随机程序,该程序接受一个简短的“种子”输入(即,大约可以将其从电子邮件复制粘贴到命令行的大小),然后确定程序的输出。 @stevenjkern在一次离线对话中向我指出,这种互动对于与必须验证其软件的监管机构合作至关重要。 如果必须使用程序运行的文件_output_复制结果,则在这种情况下看起来有点可疑。 监管机构将不得不深入研究代码(可能实际上对他们而言不可用),以确保文件中的信息确实符合要求。
现在,我们在Python中拥有
可重现地派生N个流的需求非常强烈,以至于人们会做出奇怪的事情来使用我们当前的MT算法来获取它。 我不得不击落一些高风险的方案,我希望PCG的信息流能够帮助我们达到目标。
您如何在2**63 / 2**127上使用良好的双射哈希从计数器序列0、1、2、3等中导出增量,同时保持状态不变? 您预见到有问题吗? 您如何考虑将散列的增量与后面的跳高相结合以将状态移动到新周期的很远的部分,该怎么办? 也许我们可以将此子讨论移至电子邮件或其他问题并进行报告。
rkern
于 2019-05-30
@rkern ,对于能够为PRNG提供非常短的种子可能会有一些
当每个人都使用相同的PRNG(例如Mersenne Twister)并从相同的小集合(例如,数量小于10000)中选择种子时,问题就变得更加复杂了,因为它不是每个程序的特定偏见,而是每个人都在做这个偏见。 例如,假设您选择一个四位数的种子,然后从Mersenne Twister(例如,少于一百万)中获取一定数量的数字。 在这种情况下,我可以向您保证,不幸的数字13永远不会出现,因为这是100亿个输出中的任何一个(实际上,将不存在约32%整数的10%),而数字123580738的代表数是16.这恰好是我们对100亿个32位整数的随机样本的期望,但是如果每个人都使用相同的sample_,这是一个实际的问题。 如果每个人都选择9位数字的种子并且只绘制10000个数字,我们将遇到一个完全类似的问题。
很多人想要做某事的事实并不意味着这是一个好主意。 (这并不意味着只告诉别人他们做错了或想要做错事情是可以的。您必须弄清楚他们的实际需求(例如,简短的命令行参数可重复的结果-可能是正确的做法是允许从UUID和一个小整数进行播种;有关如何对这些内容进行加扰以生成种子数据的一些想法可以在此博客文章中找到,并进入randutils 。)
(这是要使用的代码,因为它很短...)
// mtbias.cpp -- warning, uses 4GB of RAM, runs for a few minutes
// note: this is *not* showing a problem with the Mersenne Twister per se, it is
// showing a problem with simplistic seeding
#include <vector>
#include <iostream>
#include <random>
#include <cstdint>
int main() {
std::vector<uint8_t> counts(size_t(std::mt19937::max()) + 1);
for (size_t seed=0; seed < 10000; ++seed) {
std::mt19937 rng(seed);
for (uint i = 0; i < 1000000; ++i) {
++counts[rng()];
}
}
size_t shown = 0;
std::cout << "Never occurring: ";
for (size_t i = 0; i <= std::mt19937::max(); ++i) {
if (counts[i] == 0) {
std::cout << i << ", ";
if (++shown >= 20) {
std::cout << "...";
break;
}
}
}
std::cout << "\nMost overrepresented: ";
size_t highrep_count = 0;
size_t highrep_n = 0;
for (size_t i = 0; i <= std::mt19937::max(); ++i) {
if (counts[i] > highrep_count) {
highrep_n = i;
highrep_count = counts[i];
}
}
std::cout << highrep_n << " -- repeated " << highrep_count << " times\n";
}
就像我之前说过的那样,我认为128位种子对于这个目的来说足够短,并且我可以构建工具来帮助人们编写能做正确事情的程序。 即,默认情况下对它们进行熵采样,将它们打印出来或以其他方式记录下来,然后允许其稍后传入。 建议您为每个程序生成一个UUID,并在每次运行中混合一个可能较小的用户提供的种子,这也是一个很好的建议。
让我们假设我可以使人们为PCG64的状态部分使用好的128位种子,一种或另一种方式。 您对从相同状态派生流有任何评论吗? 总的来说,我不希望从单个PCG64流中得出更多的数字。 我只希望能够在不同的过程中绘制这些数字,而无需每次绘制都进行协调。 到目前为止,对于交错的8192个流,使用临时的63位乘-异移位散列似乎还算不错(我现在的速度为32 GiB)。
rkern
于 2019-05-30
@imneme
简短地定义我们的意思可能会有所帮助。
我认为@rkern写道“它们可以从电子邮件复制粘贴到命令行的大小有关”。 我可以用0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff等几个字符表示相当大的数字。
lemire
于 2019-05-30
我只希望能够在不同的过程中绘制这些数字,而无需每次绘制都进行协调。 到目前为止,对于交错的8192个流,使用临时的63位乘-异移位散列似乎还算不错(我现在的速度为32 GiB)。
您是否尝试过通过将状态提前足够大的数量(例如2 ** 64,即PCG64.jumped使用的状态)来使用单个质量种子来交错n流? 这似乎是使用PCG64(seed).jumped(node_id)类在整个集群中松散协调大型n流的最简单方法
其中node_id是0,1,2,...
是否有PRNG真的很擅长使用诸如索引之类的东西来生成简单的独立流? 我相信MLFG可以,但是我不喜欢它,因为它是一个63位的生成器。
bashtage
于 2019-05-30
@bashtage ,那确实不是正确的方法。 正确的方法是获取种子,如果要添加一个小整数,请使用哈希函数对其进行哈希处理。如前所述,我之前(独立于PCG)编写了一个严肃的混合函数[编辑:修复链接[正确的帖子]混合各种大小熵。 您不必使用我的,但我建议您按照这些原则进行操作。
理想情况下,您需要一种不特定于PCG的机制。 PCG可能不是您的默认选择,即使是默认选择,您也希望人们对所有生成器执行类似的操作。 我不认为您应该有一种方案来制作依赖于流或提前跳转的几个独立的PRNG。
imneme
于 2019-05-30
(糟糕,我链接到错误的博客文章;我已经编辑了上一条消息,但是如果您要通过电子邮件阅读,我想链接到此博客文章)
imneme
于 2019-05-31
@imneme现在,我们支持的所有生成器都支持跳转(其中一些实际上是提前类型的调用)。 我毫不怀疑,仔细播种是个好主意,我怀疑许多用户都将倾向于使用PRNG.jumped()调用。 这是应该劝阻的吗?
至于种子,MT生成器全部使用作者的初始化例程,PCG使用您的初始化例程,其余的则类似
seed = np.array(required_size, dtype=np.uint64)
last = 0
for i in range(len(user_seed))
if i < len(user_seed)
last = seed[i] = splitmix64(last ^ user_seed[i])
else:
last = seed[i] = splitmix64(last)
我想这可以改善。
bashtage
于 2019-05-31
这是应该劝阻的吗?
我没有看到jumped 。 对于底层的LCG来说,这非常可怕。
假设我们有一个乘数M, 0x96704a6bb5d2c4fb3aa645df0540268d 。 如果我们计算M ^(2 ^ 64),我们将得到0x6147671fb92252440000000000000001 ,这是一个可怕的LCG乘数。 因此,如果您从128位LCG中取出每2 ^ 64个项目,那将是可怕的(低阶位只是一个计数器)。 PCG的标准排列功能旨在加扰LCG的正常输出,而不加扰计数器。
PCG64目前已在Practrand上进行了高达PB的测试,进一步的分析表明,您可以读取许多PB,而不会出现与2的幂相关的问题。 las,如果您向前跳以跳过2的巨大精确乘方,PCG的通常(略微适度)排列就不能通过跳过下面的LCG巨大距离来充分补偿病理序列。 您可以提高排列强度前的值来解决此问题,实际上,我和Vigna都将PCG的标准排列与可能会这样做的现成整数哈希函数进行了比较(毕竟,它们是SplitMix的基础,_is_只是一个柜台)。 当我在2014年使用Fast Hash对其进行研究时,速度似乎并不理想,但是当Vigna在最近使用murmurhash进行分析时,他声称性能优于标准PCG(!)。
如果您真的想提前2 ^ 64跳,我认为您需要切换到更强大的输出函数排列(如我们所见,可以低成本完成)。 但是,如果您觉得它不再是真正的“标准” PCG,并且希望保持通常的输出排列,则可能需要使用jumped() 。
imneme
于 2019-05-31
(顺便说一句,病理性超前也适用于其他PRNG。众所周知,SplitMix会有一些不良的增量,因此可以合理地假设,尽管通常的增量0xbd24b73a95fb84d9很好,也可以前进2 ^) 32将为您提供0x95fb84d900000000的增量,这并不是很好。对于LFSR,坏的超前跳可能不是2的幂,但是我很确定在基础矩阵以病态结束时会发生跳变疏。)
imneme
于 2019-05-31
我可以确认,至少使用PCG32 ,使用.jumped() 4个交错流很快就会失败。
❯ ./pcg_streams.py --jumped -n 4 | time ./RNG_test stdin32
[
{
"bit_generator": "PCG32",
"state": {
"state": 10149010587776656704,
"inc": 2891336453
}
},
{
"bit_generator": "PCG32",
"state": {
"state": 1158608670957446464,
"inc": 2891336453
}
},
{
"bit_generator": "PCG32",
"state": {
"state": 10614950827847787840,
"inc": 2891336453
}
},
{
"bit_generator": "PCG32",
"state": {
"state": 1624548911028577600,
"inc": 2891336453
}
}
]
RNG_test using PractRand version 0.93
RNG = RNG_stdin32, seed = 0xeedd49a8
test set = normal, folding = standard (32 bit)
rng=RNG_stdin32, seed=0xeedd49a8
length= 128 megabytes (2^27 bytes), time= 2.1 seconds
Test Name Raw Processed Evaluation
BCFN(2+0,13-3,T) R= +58.7 p = 1.3e-27 FAIL !!!
BCFN(2+1,13-3,T) R= +48.0 p = 1.5e-22 FAIL !!
BCFN(2+2,13-3,T) R= +16.0 p = 2.3e-7 very suspicious
DC6-9x1Bytes-1 R= +53.5 p = 1.8e-32 FAIL !!!
[Low8/32]DC6-9x1Bytes-1 R= +27.4 p = 1.1e-17 FAIL !
...and 112 test result(s) without anomalies
理想情况下,您需要一种不特定于PCG的机制。 PCG可能不是您的默认选择,即使是默认选择,您也希望人们对所有生成器执行类似的操作。
好吧,这就是我们要在这里做出的决定。 :-)我们很满意地简单地公开了每个PRNG所提供的任何功能,并假设每种算法公开的属性都得到了很好的研究。 我们也很满意地说“我们推荐的默认PRNG;它具有许多有用的功能;其他功能可能没有”。
对于任何算法,使用哈希从给定状态和流ID派生新状态的想法很有趣。 你知道那是多么好的研究吗? 听起来似乎很难验证所有算法的适用性。 我会毫不犹豫地宣称“这是为我们所有PRNG派生独立流的一般程序”。 我对“这是派生独立流的通用API;每个PRNG以适合该算法的任何方式实现它,并且如果该算法不能很好地支持它,则可能不实现”,将感到更加满意。
另一方面,如果仅仅是分配足够的CPU周期来测试每个BitGenerator到PractRand上的N GiB的交错流的问题,那不是太麻烦。
rkern
于 2019-05-31
对于任何算法,使用哈希从给定状态和流ID派生新状态的想法很有趣。 你知道那是多么好的研究吗? 听起来似乎很难验证所有算法的适用性。 我会毫不犹豫地宣称“这是为我们所有PRNG派生独立流的一般程序”。 我对“这是派生独立流的通用API;每个PRNG以适合该算法的任何方式实现它,并且如果该算法不能很好地支持它,则可能不实现”,将感到更加满意。
我不知道您可以确切地称它为“研究问题”(因此也称“研究充分”),但是C ++ 11(主要是使用久经考验的,久经考验的技术)提供了_SeedSequence_概念(以及一个特定的std::seed_seq实现),其工作是向完全任意的PRNG提供种子数据。
通常,几乎所有PRNG都期望使用随机位进行初始化/播种。 对于从(例如) random.org随机位和从更多算法(CS PRNG,哈希函数等)中产生的随机位,没有什么特别神奇的。
考虑来自相同方案的PRNG的集合是很简单的,所有PRNG都有自己的随机位。 您可以认为我们正在做的是一条线上的选择点(或者实际上是间隔达到某个最大长度,该最大长度对应于我们期望合理地要求的随机数,例如2 ^ 56),例如线与2 ^ 255分)。 我们可以计算如果要求_n_个间隔,则一个将与另一个重叠的概率。 这是相当基本的可能性-我不确定您是否可以发表有关此问题的论文,因为(据我了解),没有人对包含基础数学的论文感到兴奋。 ( @lemire可能会不同意!)
[我认为您通常不应该做的是给PRNG注入种子,并随机产生一些随机位。 对我来说那感觉太乱了。]
imneme
于 2019-05-31
对,对我来说很明显,使用设计良好的_SeedSequence_这样的方法可以获取任意初始种子,并在算法循环中绘制多个不应重叠的起点。 如果那是获得独立流的唯一真正方法,那就去吧。 方便使用将是API设计的问题。
我不太清楚的是,将初始化的PRNG的当前状态,流ID中的哈希混合状态在周期中跳转到新状态是多么安全,这就是我认为您所建议的(后来我想到可能是我错了)。 jumped()的失败表明,周期中的分隔并不是唯一的因素。 jumped()还可以确保您被发送到序列中不会重叠的大部分; 如果选择的跳跃不正确,那么这只是一个可以与初始部分紧密相关的部分。 它可能需要一些关于每种算法的内部知识,才能知道什么是好跳,什么不是好跳。 对于PCG,我们显然不是这样。
从根本上讲,如果我们将PRNG视为转换函数和输出函数,则此new_state = seed_seq(old_state||streamID)只是我们将要使用的另一个转换函数。 我们必须确保seed_seq中涉及的运算与每个PRNG算法(或其逆运算)中的转换函数足够不同,并且可能还必须确定其他事项。 我不想使用从wyhash构建的东西
另一方面,在这方面, new_state = seed_seq(old_state||streamID)可能并不比_SeedSequence_对于多个流的预期用途更糟糕:按顺序拉出两个状态。 如果是这样的话,那么我会很好地依靠C ++的经验,也许还取决于您的实现,并且只需对PractRand进行一些针对我们所有算法的经验测试,即可证明它们的性能并不比单流软件差。
使哈希跳转工作非常好,因为这为以无协调方式生成PRNG创造了一些用例。 使用流ID需要进行一些通信或预分配。 dask过去曾要求这样的事情。
如果有一些好的选择只能依靠好的播种,而我们可以方便地做正确的事情,那么我们应该删除可设置的流作为选择默认值的标准。 我们只需要一个具有足够大状态空间的默认算法。
所有这一切说,它看起来像使用63位散列导出PCG32从顺序流ID增量( range(N) ),似乎工作。 8192个交错流将PractRand传递到2 TiB。 如果我们确实公开了PCG生成器的流ID,则即使我们建议人们使用其他方法可再现地获取独立流,我们也可能希望使用此技术来得出增量。
rkern
于 2019-05-31
我不太清楚的是,将初始化的PRNG的当前状态,流ID中的哈希混合状态在周期中跳转到新状态是多么安全,这就是我认为您所建议的(后来我想到可能是我错了)。
我可能确实表达了自己的含糊,但不,我从来没有打算建议应将PRNG的当前状态用于自我播种。
但是,FWIW,SplitMix做到了,这就是split()操作的作用。 而且,我不喜欢那样做。
这可能是太多信息,但是我将与您分享一些为什么SplitMix的split()函数使我感到恐惧(也许比我应该感到更恐惧)。 作为历史记录,SplitMix和PCG大约在同一时间独立设计(SplitMix于2014年10月20日发布,而pcg-random.org于2014年8月上线并于2014年9月5日链接到PCG论文)。 PCG和SplitMix(以及其他各种PRNG,包括Vigna的xor shift *和xorshift +-也在2014年发布)之间存在一些相似之处。 它们都具有相当简单的,还不够好的状态转换功能,这些功能通过加扰输出功能进行了固定。 当我写PCG论文时,我知道有些人想要的是split()函数,但找不到一种好的方法。 相反,我开发了一个快速的证明,即如果您有一个_k_位PRNG,可以在每个步骤中向左或向右移动,则在_k_个步骤之内您必须能够达到以前所处的状态,从而证明了整个概念是个错误的想法。 这种观察并没有纳入论文。 但是由于我在那次证明之前的深思熟虑的结果,我在论文的最后定稿中的脚注中提出了一些异想天开的建议,因为PCG的输出是其状态的哈希/加扰/排列,如果您是感觉很顽皮,您可以使用自己的输出重新设置生成器并摆脱它。 我将其从最终版本中删除是因为我认为这样的异想天开对于审查者来说是一个危险的信号,因为以自己的状态重新种植PRNG被广泛认为是滥用PRNG的一种,我们从没有经验的人那里看到的东西。
阅读SplitMix论文后,我发现很喜欢,但是当我看到split()时,我非常惊讶。 它做的事情我基本上只是把它当作一个玩笑而已,并使其成为了一个触手可及的功能。 直到几年后,我才开始着手编写更深入的技术文章,以了解发生这种操作时的情况。
总体来说,如果您有足够大的状态空间(而SplitMix的状态空间仅够),则可以通过散列函数进行自我重播而摆脱困境。 我仍然觉得这不是一个好主意。 因为随机映射(这是我们在这种情况下要处理的)具有“非零渐近概率,功能图中最高的树不植根于最长的周期”之类的属性,所以我声称很难完全有信心除非设计人员进行了必要的工作以表明其设计中不存在此类病理。
有趣的是,这是一个很小的SplitMix版本的状态空间的转储,它探索了三种不同的(并且是固定的)组合next()和split() :
Testing: SplitMix16: void advance() { rng = rng.split();}
Finding cycles...
- state 00000000 -> new cycle 1, size 4, at 000043b0 after 516 steps
- state 00000050 -> new cycle 2, size 41, at 00002103 after 2 steps
- state 000000cd -> new cycle 3, size 4, at 0000681a after 6 steps
- state 00000141 -> new cycle 4, size 23, at 00004001 after 11 steps
- state 00000dee -> new cycle 5, size 7, at 00007436 after 4 steps
- state 00008000 -> new cycle 6, size 90278, at 5e5ce38c after 46472 steps
- state 00030000 -> new cycle 7, size 6572, at 12c65374 after 10187 steps
- state 00030016 -> new cycle 8, size 3286, at 65d0fc0c after 402 steps
- state 00058000 -> new cycle 9, size 17097, at 2a2951fb after 31983 steps
- state 08040000 -> new cycle 10, size 36, at 08040000 after 0 steps
- state 08040001 -> new cycle 11, size 218, at 08040740 after 360 steps
- state 08040004 -> new cycle 12, size 10, at 38c01b3d after 107 steps
- state 08040006 -> new cycle 13, size 62, at 38c013a0 after 39 steps
- state 08040009 -> new cycle 14, size 124, at 08045259 after 24 steps
- state 08040019 -> new cycle 15, size 32, at 38c06c63 after 151 steps
- state 08040059 -> new cycle 16, size 34, at 38c00217 after 17 steps
- state 08040243 -> new cycle 17, size 16, at 38c06e36 after 13 steps
- state 123c8000 -> new cycle 18, size 684, at 77d9595f after 194 steps
- state 123c8002 -> new cycle 19, size 336, at 5de8164d after 141 steps
- state 123c9535 -> new cycle 20, size 12, at 123c9535 after 0 steps
- state 139f0000 -> new cycle 21, size 545, at 743e3a31 after 474 steps
- state 139f0b35 -> new cycle 22, size 5, at 139f0b35 after 0 steps
- state 139f1b35 -> new cycle 23, size 5, at 68d3c943 after 8 steps
Cycle Summary:
- Cycle 1, Period 4, Feeders 32095
- Cycle 2, Period 41, Feeders 188
- Cycle 3, Period 4, Feeders 214
- Cycle 4, Period 23, Feeders 180
- Cycle 5, Period 7, Feeders 12
- Cycle 6, Period 90278, Feeders 1479024474
- Cycle 7, Period 6572, Feeders 102385385
- Cycle 8, Period 3286, Feeders 5280405
- Cycle 9, Period 17097, Feeders 560217399
- Cycle 10, Period 36, Feeders 413
- Cycle 11, Period 218, Feeders 51390
- Cycle 12, Period 10, Feeders 1080
- Cycle 13, Period 62, Feeders 4113
- Cycle 14, Period 124, Feeders 4809
- Cycle 15, Period 32, Feeders 2567
- Cycle 16, Period 34, Feeders 545
- Cycle 17, Period 16, Feeders 87
- Cycle 18, Period 684, Feeders 95306
- Cycle 19, Period 336, Feeders 100263
- Cycle 20, Period 12, Feeders 7
- Cycle 21, Period 545, Feeders 163239
- Cycle 22, Period 5, Feeders 12
- Cycle 23, Period 5, Feeders 34
- Histogram of indegrees of all 2147483648 nodes:
0 529334272
1 1089077248
2 528875520
3 131072
4 65536
Testing: SplitMix16: void advance() { rng.next(); rng = rng.split();}
Finding cycles...
- state 00000000 -> new cycle 1, size 36174, at 6b34fe8b after 21045 steps
- state 00000002 -> new cycle 2, size 4300, at 042a7c6b after 51287 steps
- state 0000000f -> new cycle 3, size 11050, at 0b471eb5 after 4832 steps
- state 0000001d -> new cycle 4, size 38804, at 2879c05c after 16280 steps
- state 00000020 -> new cycle 5, size 4606, at 46e0bdf6 after 7379 steps
- state 00046307 -> new cycle 6, size 137, at 0a180f87 after 89 steps
- state 00081c25 -> new cycle 7, size 16, at 177ed4d8 after 27 steps
- state 0044c604 -> new cycle 8, size 140, at 5e1f125b after 44 steps
- state 006e329f -> new cycle 9, size 18, at 006e329f after 0 steps
- state 13ebcefc -> new cycle 10, size 10, at 13ebcefc after 0 steps
Cycle Summary:
- Cycle 1, Period 36174, Feeders 975695553
- Cycle 2, Period 4300, Feeders 766130785
- Cycle 3, Period 11050, Feeders 110698235
- Cycle 4, Period 38804, Feeders 251133911
- Cycle 5, Period 4606, Feeders 43723200
- Cycle 6, Period 137, Feeders 4101
- Cycle 7, Period 16, Feeders 172
- Cycle 8, Period 140, Feeders 2310
- Cycle 9, Period 18, Feeders 124
- Cycle 10, Period 10, Feeders 2
- Histogram of indegrees of all 2147483648 nodes:
0 529334272
1 1089077248
2 528875520
3 131072
4 65536
Testing: SplitMix16: void advance() { rng.next(); rng = rng.split(); rng = rng.split();}
Finding cycles...
- state 00000000 -> new cycle 1, size 40959, at 0069b555 after 49520 steps
- state 00000031 -> new cycle 2, size 1436, at 5f619520 after 2229 steps
- state 000003a4 -> new cycle 3, size 878, at 18d1cb99 after 1620 steps
- state 0000046c -> new cycle 4, size 2596, at 46ba79c0 after 1591 steps
- state 0000c6e2 -> new cycle 5, size 24, at 0212f11b after 179 steps
- state 000af7c9 -> new cycle 6, size 61, at 40684560 after 14 steps
- state 00154c16 -> new cycle 7, size 110, at 29e067ce after 12 steps
- state 0986e055 -> new cycle 8, size 4, at 2b701c82 after 7 steps
- state 09e73c93 -> new cycle 9, size 3, at 352aab83 after 1 steps
- state 19dda2c0 -> new cycle 10, size 1, at 78825f1b after 2 steps
Cycle Summary:
- Cycle 1, Period 40959, Feeders 2129209855
- Cycle 2, Period 1436, Feeders 5125630
- Cycle 3, Period 878, Feeders 7077139
- Cycle 4, Period 2596, Feeders 5997555
- Cycle 5, Period 24, Feeders 24221
- Cycle 6, Period 61, Feeders 1774
- Cycle 7, Period 110, Feeders 1372
- Cycle 8, Period 4, Feeders 23
- Cycle 9, Period 3, Feeders 4
- Cycle 10, Period 1, Feeders 3
- Histogram of indegrees of all 2147483648 nodes:
0 829903716
1 684575196
2 468475086
3 132259769
4 32192209
5 58402
6 17026
7 1982
8 261
9 1
Testing: SplitMix16: void advance() { rng.next(); rng.next(); rng = rng.split();}
Finding cycles...
- state 00000000 -> new cycle 1, size 55038, at 3e57af06 after 30005 steps
- state 00000005 -> new cycle 2, size 376, at 4979e8b5 after 6135 steps
- state 0000001e -> new cycle 3, size 10261, at 0cd55c94 after 1837 steps
- state 0000002d -> new cycle 4, size 3778, at 7f5f6afe after 3781 steps
- state 00000064 -> new cycle 5, size 2596, at 3bc5404b after 5124 steps
- state 0000012b -> new cycle 6, size 4210, at 525cc9f3 after 397 steps
- state 00000277 -> new cycle 7, size 1580, at 410010c8 after 1113 steps
- state 00001394 -> new cycle 8, size 916, at 7b20dfb0 after 193 steps
- state 00063c2d -> new cycle 9, size 51, at 6e92350b after 121 steps
- state 058426a6 -> new cycle 10, size 8, at 058426a6 after 0 steps
- state 0e5d412d -> new cycle 11, size 1, at 0e5d412d after 0 steps
- state 4c2556c2 -> new cycle 12, size 1, at 4c2556c2 after 0 steps
Cycle Summary:
- Cycle 1, Period 55038, Feeders 2027042770
- Cycle 2, Period 376, Feeders 28715945
- Cycle 3, Period 10261, Feeders 49621538
- Cycle 4, Period 3778, Feeders 13709744
- Cycle 5, Period 2596, Feeders 15367156
- Cycle 6, Period 4210, Feeders 10418779
- Cycle 7, Period 1580, Feeders 1782252
- Cycle 8, Period 916, Feeders 744273
- Cycle 9, Period 51, Feeders 2351
- Cycle 10, Period 8, Feeders 24
- Cycle 11, Period 1, Feeders 0
- Cycle 12, Period 1, Feeders 0
- Histogram of indegrees of all 2147483648 nodes:
0 529334272
1 1089077248
2 528875520
3 131072
4 65536
等等
imneme
于 2019-06-01
啊,太好了。 几年前,我本人根据这些建议拒绝了一些建议,所以我担心我们错过了一些好的建议。 :-)
关于散列方法以得出PCG流增量的任何最终想法? 撇开这是否是获取独立流的主要机制。 缺少完全删除对该功能的访问权限,这似乎是我们想要做的事情,以防止易于滥用的顺序流ID。
rkern
于 2019-06-01
出于好奇,是否有任何(简便)方法可以判断PCG64中两个状态的距离?
charris
于 2019-06-01
是的,尽管我们没有公开它: http :
rkern
于 2019-06-01
出于好奇,是否有任何(简便)方法可以判断PCG64中两个状态的距离?
是的,尽管我们没有公开它: http :
在C ++源代码中, distance函数甚至会告诉您流之间的距离,给出它们的最接近点(其中流之间唯一的区别是增加的常数)。
imneme
于 2019-06-01
顺便说一句,对于底层的LCG,我们可以使用距离来计算期望值与期望值之间的相关性。 短距离显然是不好的(并且对任何PRNG都是不利的),但是仅设置一个位的距离也不是很大,这就是为什么要向前跳到2 ^ 64( 0x10000000000000000 ) .jumped是个坏主意。 在我的PCG待办事项列表上,正在编写一个“ independence_score ”函数,该函数查看两个状态之间的距离,并告诉您该距离看起来是如何随机的(通过汉明重量等)-理想情况下,我们希望大约一半位为零和半数,然后将它们自由分散)。
使用PCG64保持jumped一种方法是不跳n * 0x10000000000000000 ,而跳n * 0x9e3779b97f4a7c150000000000000000 (截断为128位)。 这将为您提供所有您想要的常规属性( .jumped(3).jumped(5) == .jumped(8) ),而不会为基础LCG带来麻烦。
(我也知道说“不要提前0x10000000000000000 ”是“好吧,不要以这种方式回应”,我对此并不满意。当然,这是很酷, independence_score可以存在,但是这整个事情(以及类似流的问题)可能会要求使用更强的默认输出函数,因此我即使人们做了(很少)做底层事情完全是病态的事情LCG,不会造成任何危害,此时PCG即将问世5岁了,我正在考虑今年夏天进行版本改进并进行调整,因此这个问题可能会列入清单。就像您放入PCG一样,我对主要版本进行了改进并加以改进。)
imneme
于 2019-06-01
关于散列方法以得出PCG流增量的任何最终想法? 撇开这是否是获取独立流的主要机制。 缺少完全删除对该功能的访问权限,这似乎是我们想要做的事情,以防止易于滥用的顺序流ID。
我建议您将其放入Murmur3混音器中。 没有刻意的努力,没有人可能会意外地产生类似的信息流。 (编辑:我想您需要一个128位版本,但您可以将上半部分和下半部分混合使用。我也要添加一个常数。每个人都喜欢0x9e3779b97f4a7c15f39cc0605cedc835 (ϕ的小数部分),但是0xb7e151628aed2a6abf7158809cf4f3c7 (e的小数部分)也可以,或者是_any_随机数。)
imneme
于 2019-06-01
我推荐wyhash(https://github.com/wangyi-fudan/wyhash),因为它是通过BigCrush和PractRand的最快,最简单的方法。 C代码很简单
inline uint64_t wyrand(uint64_t *seed){
*seed+=0xa0761d6478bd642full;
__uint128_t t=(__uint128_t)(*seed^0xe7037ed1a0b428dbull)*(*seed);
return (t>>64)^t;
}
 wangyi-fudan
于 2019-06-01
wangyi-fudan
于 2019-06-01
@ wangyi-fudan,我不能说服自己这是双射。
imneme
于 2019-06-01
抱歉,我的知识有限:为什么PRNG需要双向射流?
对于某些解释将不胜感激:-) @imneme
wangyi-fudan
于 2019-06-02
@ wangyi-fudan,如果从64位int到64位int的哈希函数不是双射(即1对1函数),则某些结果会生成一次以上,而有些则根本不会生成。 那是一种偏见。
imneme
于 2019-06-02
我明白你的意思。 但是,对于64位随机数生成器R,我们期望在1.2 * 2 ^ 32随机数(http://mathworld.wolfram.com/BirthdayAttack.html)之后发生一次冲突。 具有2 ^ 64个随机数,自然会发生很多冲突。 碰撞是自然的,而双射不是自然随机的。 如果我知道确定赌桌(例如3位PRNG)在8条小径内的值为0,那么在观察到5个非零值后,我将敢于大赌0。
wangyi-fudan
于 2019-06-02
@ wangyi-fudan,在这种情况下,我们正在讨论置换stream-id的方法,以使1,2,3之类的流看起来更随意(又更正常)。 在此过程中,碰撞没有好处。
通常,对于PRNG,您应该阅读基于随机映射的PRNG和基于随机可逆映射(一对一函数)的PRNG之间的区别。 我已经写过,但是其他人也写过。 与基于其他技术的PRNG相比,基于随机映射的PRNG尺寸小,显示出偏差且失效更快。 在大尺寸情况下,可能很难检测到各种缺陷。
imneme
于 2019-06-02
我们可以计算如果要求_n_个间隔,则一个将与另一个重叠的概率。 这是相当基本的可能性-我不确定您是否可以发表有关此问题的论文,因为(据我了解),没有人对包含基础数学的论文感到兴奋。
我认为您只需要成为Pierre L'Ecuyer。 ;-)第15页
rkern
于 2019-06-23
是的,当他解释基本知识时,认为还可以!
imneme
于 2019-06-23
@rkern @imneme Simplicity是软件和数学中的一项功能。 有些人没有被简单的工作所打动,不应被视为矛盾的证据。
lemire
于 2019-06-23
@lemire :我喜欢一个幽默的文章,我认为它有很多道理,叫做“如何批评计算机科学家” 。 该文章背后的基本思想是,理论家偏爱复杂性,而实验家偏爱简单。 因此,如果您的听众是实验主义者之一,那么他们会为简单而感到高兴,但是如果您的听众是理论家之一,那么就不会如此。
imneme
于 2019-06-25
默认BitGenerator是PCG64 。 谢谢大家的周到贡献。 和耐力!
rkern
于 2019-06-26
受到这个主题的启发,我有一些新闻要报道……
背景
从许多方面来看, pcg64都不错。 例如,在通常的统计质量衡量标准下,它将获得干净的健康单。 它已经过各种测试。 最近,我使用PractRand一直将其运行到一半PB。 它在正常使用情况下效果很好。
但是,此线程中出现的病理情况对我不利。 当然,我可以说“好吧,别这样”,但是通用PRNG的全部要点是它应该坚固耐用。 我想做得更好...
因此,大约25天前,我开始考虑设计PCG系列的新成员…
目标
我的目标是设计一个新的PCG家庭成员,该成员可能会取代目前的pcg64变体。 因此:
- 输出功能应比XSL RR加扰更多位(因为这样做可以避免此线程中出现的问题)。
- 性能应该大约与当前
pcg64一样快(或更快)。 - 设计必须是PCG风格的(即,不可预测的,因此不允许轻易撤消输出函数的任何工作)。
一如既往,我们要尽可能快地获得最佳质量,这是一个折衷方案。 如果我们根本不关心速度,那么我们可以在输出函数中采取更多步骤来产生更混乱的输出,但是PCG的要点是底层的LCG“几乎足够好”,因此我们不需要与我们将计数器增加1之类的事情所付出的努力一样大。
扰流板
我很高兴报告成功! 大约25天前,当我第一次想到这个时,我实际上正在休假。 当我大约十天前回来时,我尝试了自己的想法,并很高兴发现它们运作良好。 随后的时间主要花费在各种测试上。 昨天很满意,我将代码
细节
FWIW,新的输出函数是(对于64位输出情况):
uint64_t output(__uint128_t internal)
{
uint64_t hi = internal >> 64;
uint64_t lo = internal;
lo |= 1;
hi ^= hi >> 32;
hi *= 0xda942042e4dd58b5ULL;
hi ^= hi >> 48;
hi *= lo;
return hi;
}
此输出功能受xorshift-multiply启发,已被广泛使用。 乘数的选择是(a)降低魔术常数的数量,(b)防止撤消排列(如果您无法访问低阶位),并且还提供整个“随机化- PCG输出功能通常具有的“自行”质量。
其他变化
同样, 0xda942042e4dd58b5是此PRNG的LCG乘数(以及所有cm_前缀为128位状态PCG生成器)。 与0x2360ed051fc65da44385df649fccf645所使用的pcg64 ,该常数在频谱测试属性方面实际上仍然相当不错,但是乘以起来更便宜,因为128位×64位比128位×128位我已经使用这个LCG常数好几年了。 当使用cheap-multiplier变体时,我在迭代前的状态而不是迭代后的状态上运行输出函数,以实现更高的指令级并行度。
测试中
我已经对其进行了彻底的测试(PractRand和TestU01),对此我感到满意。 测试包括此线程中概述的场景(例如,使用连续生成的或以2 ^ 64推进的帮派生成器,并对其输出进行交织-我测试了四个帮派和一个8192帮派,将其扩展到8 TB,也没有问题)作为溪流及其对岸对应物)。
速度
我可以继续详细讨论速度测试和基准测试。 在给定的基准中,有多种因素会影响一个PRNG是否比另一个PRNG运行得更快,但是总的来说,此变体似乎常常快一些,有时快很多,有时慢一点。 诸如编译器和应用程序之类的因素对基准可变性具有更大的影响。
可用性
C ++标头的用户可以以pcg_engines::cm_setseq_dxsm_128_64身份访问这个新的家庭成员_now_; 在将来的某个时候,我会将pcg64从pcg_engines::setseq_xsl_rr_128_64切换到这个新方案。 我当前的计划是在今年夏天将其作为PCG 2.0版本的一部分。
正式公告
总体而言,我对这个新的家庭成员感到非常满意,并且在夏天的某个晚些时候,将会有更多更详细的博客文章,可能会引用此主题。
您的选择...
当然,您必须弄清楚该怎么做。 不管您是否使用它,我真的很想知道它在您的速度基准测试中是好是坏。
imneme
于 2019-06-27
@imneme是否不需要快速的完整64位乘法器? (在x64上超级快,但在一些较弱的体系结构上慢一点。)
lemire
于 2019-06-27
@lemire :128位×64位乘法,内部将通过x86上的两个乘法指令来完成(低位位为64位×64位→128位结果,而64位×64位在高阶位上。两个乘法可以并行发生,然后需要将两个结果相加。)
它仍可能比128位×128位更好。 尽管好得多取决于此时指令调度的执行情况。
没错,在ARM上,64位×64位→128位的结果实际上是两条指令。
(当然,将两个64位LCG组合在一起是完全有可能的。所有可能存在并且可以正常使用的PRNG的空间都非常大。)
imneme
于 2019-06-27
在我们的框架中进行的快速和肮脏的实现建议至少在64位Linux上性能有所改善:
Time to produce 1,000,000 64-bit unsigned integers
************************************************************
MT19937 5.42 ms
PCG64 2.59 ms
PCG64DXSM 2.41 ms
Philox 4.37 ms
SFC64 2.07 ms
numpy 5.41 ms
dtype: object
64-bit unsigned integers per second
************************************************************
MT19937 184.39 million
PCG64 386.01 million
PCG64DXSM 415.02 million
Philox 228.88 million
SFC64 483.94 million
numpy 184.79 million
dtype: object
我认为,至少在这种情况下,它是从预先声明的状态输出而产生的。 我一开始就忽略了这一点,基本上获得了与PCG64 1.0相同的性能。 我怀疑,真正的胜利将是在128位仿真下,但是我没有写出来,而且我没有很好的方法在重要的平台上对其进行测试。
我想对您来说真正的问题@imneme是,您对使用1.0算法实现的numpy.random.PCG64名称感到恼火吗? 该版本即将发布并且已经延迟,因此我不认为我们现在将要更改算法。 如果在32位平台上的性能特别好,那么我认为我们可能会在后续版本中添加PCG64DXSM ,并且可能会重新考虑默认的一些版本。
rkern
于 2019-06-28
这是您的选择!
我没有运送PCG64 1.0版的问题。 许多其他人都使用了该变体。
我确实认为DXSM变体的优点是避免了此线程中出现的边缘案例使用问题(毕竟,这几乎就是它存在的原因),但是另一方面,它的缺点是迟到了派对。 向用户发布不到一个月的PRNG似乎很鲁ck(即使它基于与经过更多时间测试的PCG变体相同的思想)。
(这就是说,即使是我的选择,尽管可能会鲁re,我还是会寄出新的;我认为在Numpy上启动和运行它的延迟非常小。而且风险非常低-它已经通过BigCrush进行全面测试,并通过PractRand测试达到16 TB(包括cm_mcg_dxsm_64_32 ,这是大小的四分之一[无数据流,32位输出]),并且很可能在不到一周的时间内达到32 TB )
[高兴的是表演确实有所改善。 五年前,使用预先声明的状态是对128位大小和128位乘法器的悲观化。 到那时,在我正在测试的机器上,我正在使用基准测试。]
imneme
于 2019-06-28
当您要使用名称PCG64来引用2.0变体时,我的意思更多是将其用于1.0变体。
rkern
于 2019-06-28
@rkern如果只是命名问题,那么PCG64DXSM和PCG64可以很好地将它们分开,不是吗?
lemire
于 2019-06-29
当然,对于numpy。 我只是想知道@imneme是否更愿意在她将在C ++版本中以该名称推广2.0变体时不将1.0实现命名PCG64 。 我对以下事实感到敏感:名称过于宽松意味着某些人可能会测试numpy的PCG64 ,并将其与将在pcg-random.org上针对2.0版本进行的声明进行比较。 cf关于Bob Jenkin的PRNG的任何对话。
rkern
于 2019-06-29
在PCG论文的6.3节中,它说:
还要注意,尽管根据生成器执行的排列为生成器提供了助记符名称,但PCG库的用户很少应通过这些助记符选择族成员。 该库基于其属性而不是其基础实现提供命名生成器(例如,具有唯一流的通用32位生成器为pcg32_unique)。 这样,当发现并添加表现更好的未来家庭成员时(希望是由于其他人的发现),用户可以无缝切换到他们。
C和C ++库是按这种方式构造的。 这些库提供
- 一个低级接口,使您可以通过排列的名称,其操作的位大小以及底层LCG的特征来选择特定的家庭成员
- 一个高级界面,提供方便的别名,例如
pcg64,用于连接到预先选择的低级家庭成员。
这样,可以更新别名以指向较新的家庭成员,但是想要精确重现较旧结果的用户仍然可以通过使用低级界面来选择以前可以方便地访问的家庭成员。级别名。
如果您要运送名为PCG64的PRNG,我想在您的文档中说出哪个特定PCG变体就足够了,换句话说,就是说它对应的是哪个家庭成员。级别的C或C ++库接口。
imneme
于 2019-06-29
默认生成器的实现在https://github.com/numpy/numpy/pull/13840中实现为np.random.default_gen() 。 ( @rkern供以后参考,最好显式地调用
一个小巧的话:如何称呼这个np.random.default_generator()呢? gen对我来说太短了/不太明显。 我很好奇别人的想法。
shoyer
于 2019-06-30
调用此np.random.default_generator()怎么办?
我也有同样的想法,但是np.random.default_generator()是长发,所以我玩了default_rng 。
charris
于 2019-06-30
👍我也比default_gen更喜欢default_rng 。 尽管我仍然倾向于default_generator ,但我对其中任何一个都感到满意。
shoyer
于 2019-06-30
:+1:为default_rng() 。
rkern
于 2019-06-30
相关问题
 Levstyle
·
3评论
Levstyle
·
3评论
 marcocaccin
·
4评论
marcocaccin
·
4评论
 perezpaya
·
4评论
perezpaya
·
4评论
 thouis
·
4评论
thouis
·
4评论
 MorBilly
·
4评论
MorBilly
·
4评论
最有用的评论
受到这个主题的启发,我有一些新闻要报道……
背景
从许多方面来看,
pcg64都不错。 例如,在通常的统计质量衡量标准下,它将获得干净的健康单。 它已经过各种测试。 最近,我使用PractRand一直将其运行到一半PB。 它在正常使用情况下效果很好。但是,此线程中出现的病理情况对我不利。 当然,我可以说“好吧,别这样”,但是通用PRNG的全部要点是它应该坚固耐用。 我想做得更好...
因此,大约25天前,我开始考虑设计PCG系列的新成员…
目标
我的目标是设计一个新的PCG家庭成员,该成员可能会取代目前的
pcg64变体。 因此:pcg64一样快(或更快)。一如既往,我们要尽可能快地获得最佳质量,这是一个折衷方案。 如果我们根本不关心速度,那么我们可以在输出函数中采取更多步骤来产生更混乱的输出,但是PCG的要点是底层的LCG“几乎足够好”,因此我们不需要与我们将计数器增加1之类的事情所付出的努力一样大。
扰流板
我很高兴报告成功! 大约25天前,当我第一次想到这个时,我实际上正在休假。 当我大约十天前回来时,我尝试了自己的想法,并很高兴发现它们运作良好。 随后的时间主要花费在各种测试上。 昨天很满意,我将代码
细节
FWIW,新的输出函数是(对于64位输出情况):
此输出功能受xorshift-multiply启发,已被广泛使用。 乘数的选择是(a)降低魔术常数的数量,(b)防止撤消排列(如果您无法访问低阶位),并且还提供整个“随机化- PCG输出功能通常具有的“自行”质量。
其他变化
同样,
0xda942042e4dd58b5是此PRNG的LCG乘数(以及所有cm_前缀为128位状态PCG生成器)。 与0x2360ed051fc65da44385df649fccf645所使用的pcg64,该常数在频谱测试属性方面实际上仍然相当不错,但是乘以起来更便宜,因为128位×64位比128位×128位我已经使用这个LCG常数好几年了。 当使用cheap-multiplier变体时,我在迭代前的状态而不是迭代后的状态上运行输出函数,以实现更高的指令级并行度。测试中
我已经对其进行了彻底的测试(PractRand和TestU01),对此我感到满意。 测试包括此线程中概述的场景(例如,使用连续生成的或以2 ^ 64推进的帮派生成器,并对其输出进行交织-我测试了四个帮派和一个8192帮派,将其扩展到8 TB,也没有问题)作为溪流及其对岸对应物)。
速度
我可以继续详细讨论速度测试和基准测试。 在给定的基准中,有多种因素会影响一个PRNG是否比另一个PRNG运行得更快,但是总的来说,此变体似乎常常快一些,有时快很多,有时慢一点。 诸如编译器和应用程序之类的因素对基准可变性具有更大的影响。
可用性
C ++标头的用户可以以
pcg_engines::cm_setseq_dxsm_128_64身份访问这个新的家庭成员_now_; 在将来的某个时候,我会将pcg64从pcg_engines::setseq_xsl_rr_128_64切换到这个新方案。 我当前的计划是在今年夏天将其作为PCG 2.0版本的一部分。正式公告
总体而言,我对这个新的家庭成员感到非常满意,并且在夏天的某个晚些时候,将会有更多更详细的博客文章,可能会引用此主题。
您的选择...
当然,您必须弄清楚该怎么做。 不管您是否使用它,我真的很想知道它在您的速度基准测试中是好是坏。