性能图,将XXH3与其他 _portable_ 非加密哈希值进行比较:
__大数据带宽 (~100 KB)__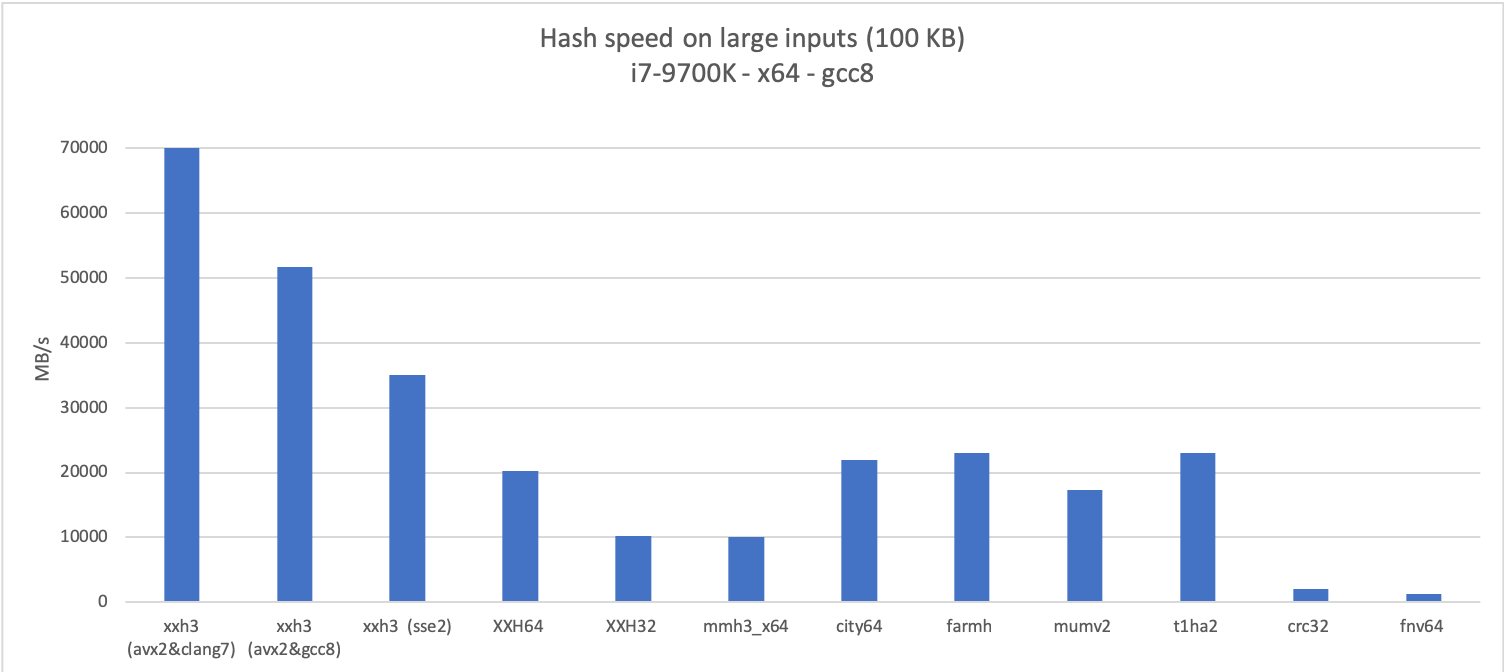
__在 len 2^N__ 的可变大小数据上的 x64 带宽
__在 len 2^N__ 的可变大小数据上的 x86 带宽(32 位友好性)
以下基准集中在小数据上:
__对固定长度N的小数据的吞吐量__
吞吐量测试尝试生成尽可能多的哈希值。 这是基准测量最简单的方法,但主要代表“批处理模式”场景。
__对随机长度[1-N]的小数据的吞吐量__
当输入大小是随机长度时,分支预测器很难在算法中正确选择正确的路径。 对性能的影响可能很大。
__固定长度N的小数据的延迟__
延迟测试要求算法在开始下一个哈希之前完成一个哈希。 这通常更能代表散列被集成到更大算法中的情况。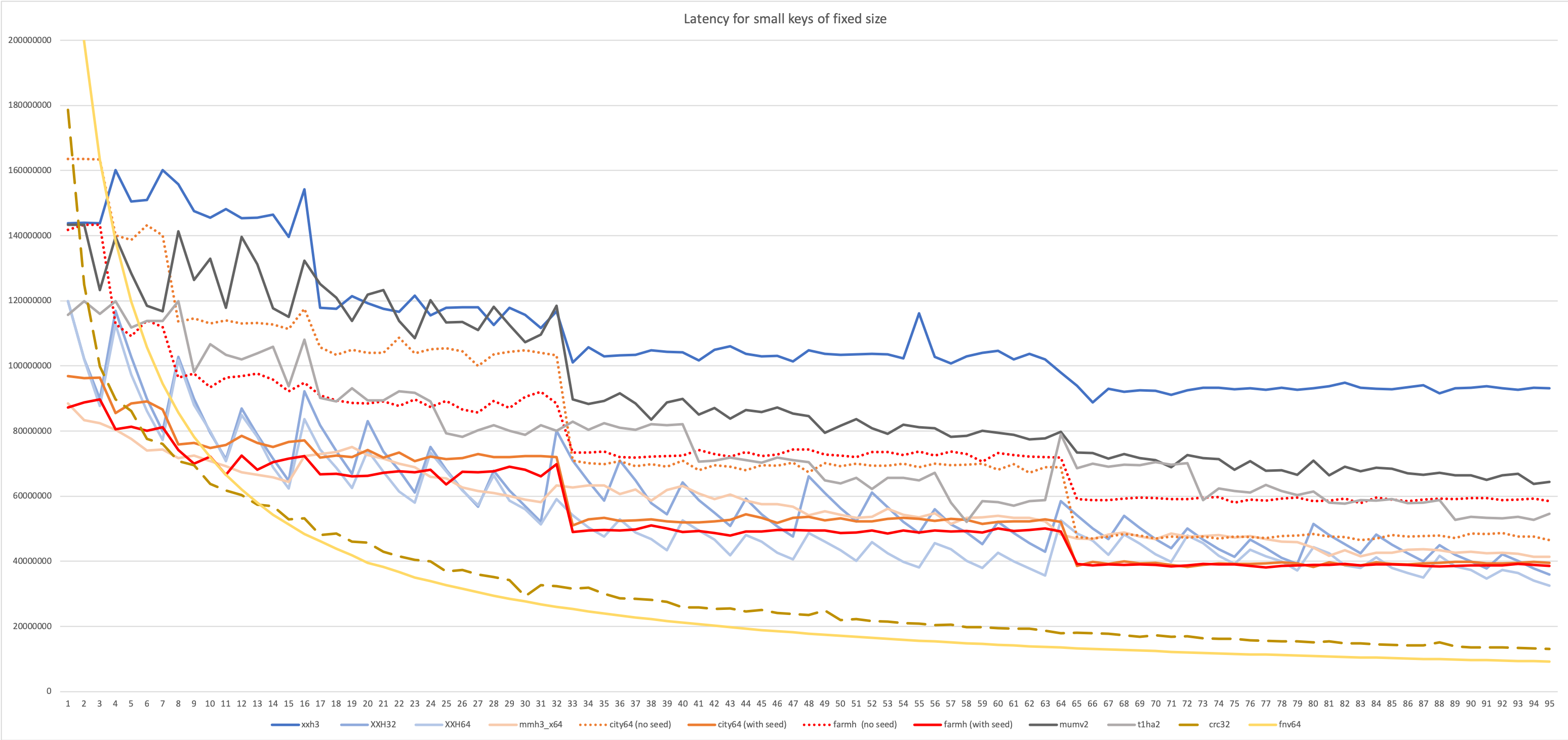
__随机长度[1-N]的小数据的延迟__
 Cyan4973
Cyan4973
所有35条评论
碰撞研究
这是我知道的第一个能够直接探测 64 位哈希的冲突效率的测试(SMHasher 已经很好地涵盖了 32 位冲突效率)。 不幸的是,128 位碰撞分析还有很长的路要走。
该测试生成大量哈希,并计算产生的冲突次数。 它并不便宜,并且需要大量时间和大量 RAM。
生成的输入模式彼此相对接近(低汉明距离),只有几位差异。 对于低质量的哈希,它应该更加困难。
该测试指示哈希数量的预期冲突 nb。 测量的 nb 碰撞不必严格相同,只要在附近就足够了。
在大输入上测试 64 位哈希:
预计 256 字节的输入将始终触发具有多种模式的哈希算法的“长”模式,具体取决于输入长度。
| 算法 | 输入长度 | Nb 哈希 | 预期 | 铌碰撞 | 笔记 |
| --- | --- | --- | --- | --- | --- |
| __XXH3__ | 256 | 100 吉| 312.5 | 326 | |
| __XXH64__ | 256 | 100 吉| 312.5 | 294 | |
| __XXH128__ 低 64 位 | 512 | 100 吉| 312.5 | 321 | |
| __XXH128__ 高 64 位 | 512 | 100 吉| 312.5 | 325 | |
| mmh64a | 256 | 100 吉| 312.5 | 310 | |
| 城市64 | 256 | 100 吉| 312.5 | 303 | |
| t1ha2 | 256 | 100 吉| 312.5 | _761_ | 有点太大了,损失了~1bit的分布|
| 妈妈v2 | 256 | 100 吉| 312.5 | _1229_ | 有点太大了,损失了~2bits的分布|
| 威哈希 | 256 | 100 吉| 312.5 | _1202_ | 有点太大了,损失了~2bits的分布|
| fnv64 | 256 | 100 吉| 312.5 | 303 | _very_ 长测试:23h30,与XXH3的 3h20 相比 |
| blake2b 低 64 位 | 256 | 100 吉| 312.5 | 296 | _非常_长测试:48小时! |
| md5 低 64 位 | 256 | 100 吉| 312.5 | 301 | _非常_长测试:58小时! |
t1ha2和mumv2都具有不理想的碰撞率。 t1ha2的分布更接近 63 位,而mumv2更接近 62 位。 请注意,虽然它不是“可怕的”,但对于大多数实际用途来说,两者都可以被认为是“合理的”。
wyhash是mumv2的非官方变体,毫无疑问它继承了相同的分发问题。
测试 64 位非便携式哈希:
AES哈希基于英特尔的 AES 指令扩展,与 SSE4.2 一起引入。 它们不在不同的平台上运行。
| 算法 | 类型 | 输入长度 | Nb 哈希 | 预期 | 铌碰撞 | 笔记 |
| --- | --- | --- | --- | --- | ---:| --- |
| meowhash 低 64 位 | AES | 256 | 100 吉| 312.5 | _18200_ | 很糟糕|
| aquahash 低 64 位 | AES | 256 | 100 吉| 312.5 | _3488136_ | 无法使用 |
AES暗示加密质量,从逻辑上讲,它对于分散性和随机性也足够好。 这个假设似乎是不正确的:基于AES的哈希具有非常糟糕的碰撞属性。
碰撞率太高,不推荐使用这些算法作为校验和。
在小输入上测试 64 位哈希:
输入 8 字节 => 8 字节输出的测试可以检查在这个长度上是否发生了一些“空间减少”。 如果没有空间缩减,那么变换是完美的双射,这保证了 2 个不同的输入没有冲突。
| 算法 | 输入长度 | Nb 哈希 | 预期 | 铌碰撞 | 笔记 |
| --- | --- | --- | --- | --- | --- |
| __XXH3__ | 8 | 100 吉| 312.5 | __0__ | XXH3对于len==8 $ 是双射的。 它保证没有碰撞。 |
| __XXH64__ | 8 | 100 吉| 312.5 | __0__ | XXH64对于len==8也是双射的 |
| mmh64a | 8 | 100 吉| 312.5 | __0__ | 双射 |
| 城市64 | 8 | 100 吉| 312.5 | 278 | |
| t1ha2 | 8 | 100 吉| 312.5 | _607_ | 有点太大了,损失了~1bit的分布|
| 妈妈v2 | 8 | 100 吉| 312.5 | _544_ | 有点太大了,损失了~1bit的分布|
| 威哈希 | 8 | 100 吉| 312.5 | _583_ | 有点太大了,损失了~1bit的分布|
| fnv64 | 8 | 100 吉| 312.5 | 26 | |
测试 128 位哈希:
这些测试唯一可接受的分数始终是0 。 如果散列算法提供 128 位分散,则出现单次碰撞的概率小于连续两次赢得国家彩票的概率。
与 64 位测试相比,由于资源限制,该测试不提供精确的128-bit碰撞估计。 它只是消除了有效分布小于 80 位的散列。
| 算法 | 输入长度 | Nb 哈希 | 预期 | 铌碰撞 | 笔记 |
| --- | --- | --- | --- | --- | --- |
| __XXH128__ | 256 | 100 吉| 0.0 | 0 | |
| 城市哈希128 | 256 | 100 吉| 0.0 | 0 | |
| t1ha2 128 位 | 256 | 100 吉| 0.0 | _14_ | 相当于约 70 位的分布 |
__小输入长度的测试__
| 算法 | 输入长度 | Nb 哈希 | 预期 | 铌碰撞 | 笔记 |
| --- | --- | --- | --- | --- | --- |
| __XXH128__ | 16 | 25 吉| 0.0 | 0 | 范围 9-16 |
| __XXH128__ | 32 | 25 吉| 0.0 | 0 | 范围 17-128 |
| __XXH128__ | 100 | 13 吉| 0.0 | 0 | 范围 17-128 |
| __XXH128__ | 200 | 13 吉| 0.0 | 0 | 范围 129-240 |
Cyan4973
于 2019-08-16
@Cyan4973如何重现您的基准测试结果? 如果可能的话,您可以将 wyhash 添加到您的图表中吗? 在我的测试中,对于足够大的大小(即大约 256 字节),xxhash 将比 wyhash 更快,但是,让用户知道这一点会非常有帮助。

 hungptit
于 2019-08-16
hungptit
于 2019-08-16
@hungptit ,我还没有开源碰撞分析器。 这个努力还是需要做的。 也许我稍后会在存储库中添加它,通常在/tests目录下。
目前,我只是填充一些测试结果,试图完成一张图片。
如果你觉得这也很有趣,我肯定会添加 aquahash 和 wyhash。
但是,由于每次测量通常需要几个小时,在只能不时访问的特殊服务器上,这需要一些时间。
Cyan4973
于 2019-08-16
@Cyan4973我打算给你发一个 PM 询问碰撞分析器的建议,幸运的是你把我指向了这个线程。 我期待着您的碰撞分析器,并且我假设其他用户也渴望尝试它,因为您一直致力于出色的加密应用程序。 我认为 wyhash 是一个很好的散列,如果你可以将它包含在你的基准测试中,它将对用户有所帮助。 AquaHash(由 Andrew Rogers 创建)是新的,还没有经历过任何严重的战斗,而且它不是便携式的,所以你现在不需要担心它。 一旦你可以开源它,我可以帮助你稍后将它添加到你的碰撞分析器中。
hungptit
于 2019-08-16
我将把图表和表格移到“wiki”部分,我想它更适合作为文档。
暂时,第一页在这里:
https://github.com/Cyan4973/xxHash/wiki/Performance-comparison
我将继续碰撞分析结果。
Cyan4973
于 2019-08-21
顺便说一句@hungptit ,如果您对性能图感兴趣,而不是碰撞分析器,基准工具已经可用,在/tests/bench的存储库中。
它是为(相对)轻松集成其他哈希而设计的。
Cyan4973
于 2019-08-22
我为一些基于 AES 的算法完成了 64 位碰撞测试。
结果是毁灭性的,尤其是对于 Aquahash。 我不建议将此哈希用于任何事情。
Cyan4973
于 2019-08-25
@Cyan4973这对我来说是个坏消息,因为我可能无法将 AquaHash 用于我的本地缓存 :) 但是,这是个好消息,因为您已经确认 AquaHash 对于正常用例可能不够好,我需要弄清楚别的东西。 你对 wyhash 和 clhash 有什么结果吗? 那么其他基于 AES 的算法(例如喵哈希)呢?
我期待在不久的将来使用您的碰撞分析工具,这样我就可以快速评估任何新哈希算法的质量,即性能和质量。 如果您在测试和/或评估分析仪方面需要帮助,请告诉我。
hungptit
于 2019-08-27
你对 wyhash 和 clhash 有什么结果吗?
我已经用更多哈希的结果更新了表格。
clhash仍然需要完成。
Cyan4973
于 2019-08-29
@Cyan4973我认为你的基准+分析足以写一篇优秀的文章。 我很想了解您如何在数学上将哈希函数与一些基准数字进行比较:)
hungptit
于 2019-08-30
轻微错误:AES 是 SSE4.2。
 easyaspi314
于 2019-08-30
easyaspi314
于 2019-08-30
在 Intel Intrinsic Guide 中,它甚至没有被列为 SSE 的一部分:它似乎属于自己的类别:
https://software.intel.com/sites/landingpage/IntrinsicsGuide/#text =aes
这可能就是为什么它有自己的开关-maes 。
话虽如此,它是“同时”发布的,比如 SSE4.2,所以很容易做出等价。
Cyan4973
于 2019-08-30
是 meowhash 0.5 还是以前的版本?
 svpv
于 2019-09-27
svpv
于 2019-09-27
t1ha2 中的 1 位丢失主要是由于作为混合最终结果的最后步骤之一的宽乘法。 问题是, lo, hi = acc * K, lo ^ hi形式的运算是不可逆的。 在这个要点中,我详尽地研究了 32x32 乘法。 lo ^ hi的碰撞率比lo + hi更差,但lo + hi保留了更多位级相关性。 另一方面,宽乘法可以被视为一种安全原语:似乎除了通过蛮力之外,您无法返回数据,这大约是 2^32 或 2^64 步(我尝试了 z3 求解器事实上我不能)。
svpv
于 2019-09-27
你不需要那么大的力量来理解这一点。
只需打印出一张小表格,作为乘法属性规模。
add | xor
0 0 0 0 0 0 0 0 | 0 0 0 0 0 0 0 0
0 1 2 3 4 5 6 7 | 0 1 2 3 4 5 6 7
0 2 4 6 1 3 5 7 | 0 2 4 6 1 3 5 7
0 3 6 2 5 0 4 7 | 0 3 6 0 5 6 0 7
0 4 1 5 2 6 3 7 | 0 4 1 5 2 6 3 7
0 5 3 0 6 4 1 7 | 0 5 3 6 6 2 5 7
0 6 5 4 3 1 0 7 | 0 6 5 0 3 5 0 7
0 7 7 7 7 7 7 7 | 0 7 7 7 7 7 7 7
0: 18 (28.1%) 19 (29.7%)
1: 5 (7.8%) 3 (4.7%)
2: 4 (6.2%) 4 (6.2%)
3: 6 (9.4%) 6 (9.4%)
4: 6 (9.4%) 3 (4.7%)
5: 6 (9.4%) 8 (12.5%)
6: 6 (9.4%) 8 (12.5%)
7: 13 (20.3%) 13 (20.3%)
你可以很清楚地看到 xor 分解了一些模式,但在高位上有更多的偏差,因为它是饱和而不是溢出。 它也不太对称。
这就是经常异或折叠这些高位的主要原因。 这会将东西传播到表现不佳的较低位。
easyaspi314
于 2019-09-27
好消息 :
我终于可以测量 128 位哈希函数的冲突率了。
所以我将开始用这些结果更新表格。
主要目的是检查XXH128()在多个输入长度下是否提供完美的碰撞分数( 0 ),以验证每个内部变体。
冲突生成器不能完全达到 128 位级别,这将需要大量资源。 但它可以接近 80 位,这足以破坏一些宣布 128 位方差的哈希算法。 这是一个有趣的结果,因为到目前为止这种限制是不可见的。
Cyan4973
于 2019-10-04
顺便说一句,我以为我之前说过,但我想我没有。
AES 意味着加密质量,从逻辑上讲,它对于分散性和随机性也足够好。 这个假设似乎不正确:基于 AES 的散列具有令人惊讶的不良碰撞属性。
那是因为 AES 不是散列函数。 它是一种加密算法。
为什么 AES 不适合散列
加密只是一种奇特的排列,它被设计为可逆的。
散列不仅仅是一种花哨的排列,它被设计成不可逆的,并通过基本上改变大多数位来突出一位更改。
AES 没有,它在最后一个属性上惨遭失败。 以下是 AES(来自_mm_aesenc_si128 )对单个位变化的反应:
Key:
f181bfe03e942b6332fb552248a63051
e9254323fdb11aff3b13d720f18bbfe2 189ec62f3f0478a6a65b841445333341
e9354323fdb11aff3b13d720f18bbfe2 189ec62f3f0478a6a65b8414a57a9ae8
^^
7ec24a13eead45e9036831a9988292be c1bfa5fb939a5feb39d9a85616cbe16d
7ec24a13eead45e9236831a9988292be c1bfa5fb939a5feb8384f5b116cbe16d
^^
b6bb76d0bab1e391d1d41c90b6280f79 044ddb11131aebbaab64b775807416b8
b6bb76d0bab1e391d1d41c90b6280779 044ddb11a0d49609ab64b775807416b8
^^
226720675023cf81cc68035f26c815e1 252beff88b231b9b3cb597b86c0a07d9
226720675023cf01cc68035f26c815e1 252beff88b231b9b4cc507586c0a07d9
^^
e59cf0c82dc29d4a52537261cce58333 b4119d68bd4afeda180beec0164733c9
a59cf0c82dc29d4a52537261cce58333 11ce4212bd4afeda180beec0164733c9
^^
eb8329ba04f622075548d06a2a0f4fc6 3ac8338147a19f4b2bdada7f272c021e
eb8329ba04f622075548d06a2a0f4f46 d4261a4647a19f4b2bdada7f272c021e
^^
17f3c1b43d1408b075d495f9089be48b 08dda6414c151a2ab0211e279645dd15
17f3c1b43d1408b055d495f9089be48b 08dda6414c151a2a72407f849645dd15
^^
9e90bbc1971009677a3376c9f976e0ed cf18f1a5f2c13132baf1ec941d21b721
9e90bbc1971089677a3376c9f976e0ed cf18f1a5f2c13132baf1ec94bbd0e087
^^
如您所见,只有 32 位受到影响,因为它被视为单独的通道。
输出源(不是我最好的代码哈哈)
// _mm_aesenc_si128 equivalent
// https://github.com/veorq/aesenc-noNI, modified to not overwrite
#include <stdint.h>
static const uint8_t sbox[256] =
{ 0x63, 0x7c, 0x77, 0x7b, 0xf2, 0x6b, 0x6f, 0xc5, 0x30, 0x01, 0x67, 0x2b, 0xfe,
0xd7, 0xab, 0x76, 0xca, 0x82, 0xc9, 0x7d, 0xfa, 0x59, 0x47, 0xf0, 0xad, 0xd4,
0xa2, 0xaf, 0x9c, 0xa4, 0x72, 0xc0, 0xb7, 0xfd, 0x93, 0x26, 0x36, 0x3f, 0xf7,
0xcc, 0x34, 0xa5, 0xe5, 0xf1, 0x71, 0xd8, 0x31, 0x15, 0x04, 0xc7, 0x23, 0xc3,
0x18, 0x96, 0x05, 0x9a, 0x07, 0x12, 0x80, 0xe2, 0xeb, 0x27, 0xb2, 0x75, 0x09,
0x83, 0x2c, 0x1a, 0x1b, 0x6e, 0x5a, 0xa0, 0x52, 0x3b, 0xd6, 0xb3, 0x29, 0xe3,
0x2f, 0x84, 0x53, 0xd1, 0x00, 0xed, 0x20, 0xfc, 0xb1, 0x5b, 0x6a, 0xcb, 0xbe,
0x39, 0x4a, 0x4c, 0x58, 0xcf, 0xd0, 0xef, 0xaa, 0xfb, 0x43, 0x4d, 0x33, 0x85,
0x45, 0xf9, 0x02, 0x7f, 0x50, 0x3c, 0x9f, 0xa8, 0x51, 0xa3, 0x40, 0x8f, 0x92,
0x9d, 0x38, 0xf5, 0xbc, 0xb6, 0xda, 0x21, 0x10, 0xff, 0xf3, 0xd2, 0xcd, 0x0c,
0x13, 0xec, 0x5f, 0x97, 0x44, 0x17, 0xc4, 0xa7, 0x7e, 0x3d, 0x64, 0x5d, 0x19,
0x73, 0x60, 0x81, 0x4f, 0xdc, 0x22, 0x2a, 0x90, 0x88, 0x46, 0xee, 0xb8, 0x14,
0xde, 0x5e, 0x0b, 0xdb, 0xe0, 0x32, 0x3a, 0x0a, 0x49, 0x06, 0x24, 0x5c, 0xc2,
0xd3, 0xac, 0x62, 0x91, 0x95, 0xe4, 0x79, 0xe7, 0xc8, 0x37, 0x6d, 0x8d, 0xd5,
0x4e, 0xa9, 0x6c, 0x56, 0xf4, 0xea, 0x65, 0x7a, 0xae, 0x08, 0xba, 0x78, 0x25,
0x2e, 0x1c, 0xa6, 0xb4, 0xc6, 0xe8, 0xdd, 0x74, 0x1f, 0x4b, 0xbd, 0x8b, 0x8a,
0x70, 0x3e, 0xb5, 0x66, 0x48, 0x03, 0xf6, 0x0e, 0x61, 0x35, 0x57, 0xb9, 0x86,
0xc1, 0x1d, 0x9e, 0xe1, 0xf8, 0x98, 0x11, 0x69, 0xd9, 0x8e, 0x94, 0x9b, 0x1e,
0x87, 0xe9, 0xce, 0x55, 0x28, 0xdf, 0x8c, 0xa1, 0x89, 0x0d, 0xbf, 0xe6, 0x42,
0x68, 0x41, 0x99, 0x2d, 0x0f, 0xb0, 0x54, 0xbb, 0x16 };
#define XT(x) (((x) << 1) ^ ((((x) >> 7) & 1) * 0x1b))
void aesenc (uint8_t *out, const uint8_t *s, const uint8_t *rk) {
uint8_t i, t, u, v[4][4];
for (i = 0; i < 16; ++i) v[((i / 4) + 4 - (i%4) ) % 4][i % 4] = sbox[s[i]];
for (i = 0; i < 4; ++i) {
t = v[i][0];
u = v[i][0] ^ v[i][1] ^ v[i][2] ^ v[i][3];
v[i][0] ^= u ^ XT(v[i][0] ^ v[i][1]);
v[i][1] ^= u ^ XT(v[i][1] ^ v[i][2]);
v[i][2] ^= u ^ XT( v[i][2] ^ v[i][3]);
v[i][3] ^= u ^ XT(v[i][3] ^ t);
}
for (i = 0; i < 16; ++i) out[i] = v[i / 4][i % 4] ^ rk[i];
}
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
static void print_buf(const uint8_t *buf)
{
for (int i = 0; i < 16; i++) {
printf("%02x", buf[i]);
}
}
int main(void)
{
srand(time(NULL));
uint8_t input[16], output[16], key[16];
for (int i = 0; i < 16; i++) {
key[i] = rand();
}
printf("Key:\n");
print_buf(key);
for (int j = 0; j < 8; j++) {
for (int i = 0; i < 16; i++) {
input[i] = rand();
}
printf("\n");
print_buf(input);
printf(" ");
aesenc(output, input, key);
print_buf(output);
int mask = rand();
input[(mask / 8) % 16] ^= (1 << (mask % 8));
printf("\n");
print_buf(input);
printf(" ");
aesenc(output, input, key);
print_buf(output);
printf("\n%*s\n", ((mask / 8) % 16) * 2 + 2, "^^");
}
}
此外,AES 会自行抵消:
aesenc(x, aesenc(x, y)) == y
虽然这对于加密来说很好,因为您只使用一次input并且key是恒定的,但在散列中,这是一个可怕的属性,因为您可以删除某些东西的存在。
所以如果你有一个看起来像这样的哈希......
uint128_t hash(uint128_t seed, const uint8_t *input, size_t len)
{
uint128_t acc = seed;
for (size_t i = 0; i < len / 16; i++) {
acc ^= aesenc(read128(input + 16 * i), acc);
}
if (len % 16) {
acc ^= aesenc(readpartial128(input + (len & ~(size_t)15), len & 15), acc);
}
return acc;
}
您有 30 秒的时间找到至少 340282366920938463463374607431768211456 长度扩展冲突与此:
最后,如果您没有 AES-NI 或 ARM 加密,AES 会非常慢。 虽然 AES-NI 很常见,所有 Intel >= Nehalem 和 AMD >= Bulldozer (iirc),但 ARM 加密是一个非常新的可选扩展,许多制造商出于成本和简单性而忽略了它(另请参阅:ARMv7 中的整数除法)
而且我们已经证明,您可以编写一个良好、快速的哈希函数,而无需任何不可移植的指令。
只需查看所有 xxHash 变体和基本上任何标量哈希。
easyaspi314
于 2019-11-03
打哈欠,希望从我的中断中回来,我得到了一台新电脑!
AMD 锐龙 5 3600
16 GB 内存
视窗 10
Clang 9.0.0(来自 VS2019)
标量
xxhsum.exe 0.7.2 (64-bits x86_64 little endian), Clang 9.0.0 (tags/RELEASE_900/final), by Yann Collet
Sample of 100 KB...
XXH32 : 102400 -> 18963 it/s ( 1851.9 MB/s)
XXH32 unaligned : 102400 -> 18904 it/s ( 1846.1 MB/s)
XXH64 : 102400 -> 36571 it/s ( 3571.4 MB/s)
XXH64 unaligned : 102400 -> 36572 it/s ( 3571.5 MB/s)
XXH3_64b : 102400 -> 25869 it/s ( 2526.2 MB/s)
XXH3_64b unaligned : 102400 -> 26034 it/s ( 2542.4 MB/s)
XXH3_64b seeded : 102400 -> 25815 it/s ( 2521.0 MB/s)
XXH3_64b seeded unaligne : 102400 -> 26034 it/s ( 2542.4 MB/s)
XXH128 : 102400 -> 26034 it/s ( 2542.4 MB/s)
XXH128 unaligned : 102400 -> 25815 it/s ( 2521.0 MB/s)
XXH128 seeded : 102400 -> 25815 it/s ( 2521.0 MB/s)
XXH128 seeded unaligned : 102400 -> 25815 it/s ( 2521.0 MB/s)
SSE2
xxhsum.exe 0.7.2 (64-bits x86_64 + SSE2 little endian), Clang 9.0.0 (tags/RELEASE_900/final), by Yann Collet
Sample of 100 KB...
XXH32 : 102400 -> 18963 it/s ( 1851.9 MB/s)
XXH32 unaligned : 102400 -> 19081 it/s ( 1863.4 MB/s)
XXH64 : 102400 -> 36830 it/s ( 3596.7 MB/s)
XXH64 unaligned : 102400 -> 37012 it/s ( 3614.5 MB/s)
XXH3_64b : 102400 -> 307200 it/s (30000.0 MB/s)
XXH3_64b unaligned : 102400 -> 307200 it/s (30000.0 MB/s)
XXH3_64b seeded : 102400 -> 302602 it/s (29551.0 MB/s)
XXH3_64b seeded unaligne : 102400 -> 307200 it/s (30000.0 MB/s)
XXH128 : 102400 -> 279273 it/s (27272.7 MB/s)
XXH128 unaligned : 102400 -> 279273 it/s (27272.7 MB/s)
XXH128 seeded : 102400 -> 279273 it/s (27272.7 MB/s)
XXH128 seeded unaligned : 102400 -> 279273 it/s (27272.7 MB/s)
AVX2(该死的!)
```
xxhsum.exe 0.7.2 (64-bits x86_64 + AVX2 little endian), Clang 9.0.0 (tags/RELEASE_900/final), by Yann Collet
100 KB 的样本...
XXH32 : 102400 -> 19081 it/s ( 1863.4 MB/s)
XXH32 未对齐:102400 -> 19021 it/s(1857.5 MB/s)
XXH64 : 102400 -> 37463 it/s ( 3658.5 MB/s)
XXH64 未对齐:102400 -> 37463 it/s(3658.5 MB/s)
XXH3_64b : 102400 -> 768000 it/s (75000.0 MB/s)
XXH3_64b 未对齐:102400 -> 768000 it/s (75000.0 MB/s)
XXH3_64b 种子:102400 -> 768000 it/s (75000.0 MB/s)
XXH3_64b 种子不对齐:102400 -> 614400 it/s (60000.0 MB/s)
XXH128 : 102400 -> 614400 it/s (60000.0 MB/s)
XXH128 未对齐:102400 -> 614400 it/s (60000.0 MB/s)
XXH128 种子:102400 -> 614400 it/s (60000.0 MB/s)
XXH128 种子未对齐:102400 -> 614400 it/s (60000.0 MB/s)
easyaspi314
于 2019-12-07
不错的新配置@easyaspi314 !
并且欢迎使用 AMD 平台,因为它为英特尔平台的测量提供了一个非常好的比较点!
2个突出的细节:
- 标量代码路径似乎很慢,包括旧版 XXH32 和 XXH64。 这真是出乎意料。 我想知道是否有解释。
- 一些制作出来的图形,尤其是矢量端,感觉太“圆”了。 我想知道有限的计时器分辨率是否有某种副作用。 我将在代码中检查它。
同时,我怀疑benchHash会提供一些更可靠的数字,因为它的计时器逻辑更复杂。
Cyan4973
于 2019-12-10
哦,天哪,刚刚意识到 CMake 在 RelWithDbgInfo 上,它执行 /Ob1。
这可以解释它,因为读取功能只是静态的
稍后我会得到一个新的板凳。
easyaspi314
于 2019-12-10
我还更新了内部基准测试功能
从而产生重大舍入误差的风险
由于与定时器的分辨率相比测量周期太小
现在控制得更好了。
Cyan4973
于 2019-12-10
计时器不准确可以解释很多。
我的旧戴尔会在 XXH3 上获得 4800.0 并随机跳转到 9600.0。
由于它绝对没有进入超级赛亚人模式(Core 2 没有 Turbo Boost),因此最好的解释是计时器不准确。
在其他地方我得到了偶数倍数,比如得到 30000.0 的 POWER9。
easyaspi314
于 2019-12-11
这个靠谱多了!
标量
xxhsum.exe 0.7.2 (64-bits x86_64 little endian), Clang 9.0.0 (tags/RELEASE_900/final), by Yann Collet
Sample of 100 KB...
XXH32 : 102400 -> 80603 it/s ( 7871.4 MB/s)
XXH32 unaligned : 102400 -> 80858 it/s ( 7896.3 MB/s)
XXH64 : 102400 -> 161041 it/s (15726.6 MB/s)
XXH64 unaligned : 102400 -> 160885 it/s (15711.4 MB/s)
XXH3_64b : 102400 -> 107670 it/s (10514.6 MB/s)
XXH3_64b unaligned : 102400 -> 106251 it/s (10376.1 MB/s)
XXH3_64b seeded : 102400 -> 108521 it/s (10597.8 MB/s)
XXH3_64b seeded unaligne : 102400 -> 105597 it/s (10312.2 MB/s)
XXH128 : 102400 -> 97262 it/s ( 9498.3 MB/s)
XXH128 unaligned : 102400 -> 97017 it/s ( 9474.3 MB/s)
XXH128 seeded : 102400 -> 97256 it/s ( 9497.7 MB/s)
XXH128 seeded unaligned : 102400 -> 96612 it/s ( 9434.8 MB/s)
SSE2
xxhsum.exe 0.7.2 (64-bits x86_64 + SSE2 little endian), Clang 9.0.0 (tags/RELEASE_900/final), by Yann Collet
Sample of 100 KB...
XXH32 : 102400 -> 81174 it/s ( 7927.1 MB/s)
XXH32 unaligned : 102400 -> 81086 it/s ( 7918.6 MB/s)
XXH64 : 102400 -> 160899 it/s (15712.8 MB/s)
XXH64 unaligned : 102400 -> 161041 it/s (15726.7 MB/s)
XXH3_64b : 102400 -> 310023 it/s (30275.7 MB/s)
XXH3_64b unaligned : 102400 -> 307509 it/s (30030.2 MB/s)
XXH3_64b seeded : 102400 -> 308900 it/s (30166.0 MB/s)
XXH3_64b seeded unaligne : 102400 -> 305375 it/s (29821.8 MB/s)
XXH128 : 102400 -> 275146 it/s (26869.7 MB/s)
XXH128 unaligned : 102400 -> 272461 it/s (26607.6 MB/s)
XXH128 seeded : 102400 -> 274429 it/s (26799.7 MB/s)
XXH128 seeded unaligned : 102400 -> 274066 it/s (26764.3 MB/s)
AVX2
xxhsum.exe 0.7.2 (64-bits x86_64 + AVX2 little endian), Clang 9.0.0 (tags/RELEASE_900/final), by Yann Collet
Sample of 100 KB...
XXH32 : 102400 -> 81895 it/s ( 7997.6 MB/s)
XXH32 unaligned : 102400 -> 81801 it/s ( 7988.4 MB/s)
XXH64 : 102400 -> 162077 it/s (15827.8 MB/s)
XXH64 unaligned : 102400 -> 161465 it/s (15768.1 MB/s)
XXH3_64b : 102400 -> 629577 it/s (61482.1 MB/s)
XXH3_64b unaligned : 102400 -> 628594 it/s (61386.1 MB/s)
XXH3_64b seeded : 102400 -> 628080 it/s (61335.9 MB/s)
XXH3_64b seeded unaligne : 102400 -> 626429 it/s (61174.7 MB/s)
XXH128 : 102400 -> 573136 it/s (55970.3 MB/s)
XXH128 unaligned : 102400 -> 573135 it/s (55970.2 MB/s)
XXH128 seeded : 102400 -> 571006 it/s (55762.3 MB/s)
XXH128 seeded unaligned : 102400 -> 569946 it/s (55658.8 MB/s)
现在一切都正确排列,结果更加准确。
特别是标量,它适合我通常看到的“大约是 XXH32 速度的 1.5 倍”模式。
easyaspi314
于 2019-12-11
这是 x86 标量(使用 XXH3_hashLong_internal_loop 强制内联)
xxhsum.exe 0.7.2 (32-bits i386 little endian), Clang 9.0.0 (tags/RELEASE_900/final), by Yann Collet
Sample of 100 KB...
XXH32 : 102400 -> 81161 it/s ( 7925.9 MB/s)
XXH32 unaligned : 102400 -> 80282 it/s ( 7840.0 MB/s)
XXH64 : 102400 -> 29157 it/s ( 2847.4 MB/s)
XXH64 unaligned : 102400 -> 29171 it/s ( 2848.8 MB/s)
XXH3_64b : 102400 -> 59114 it/s ( 5772.9 MB/s)
XXH3_64b unaligned : 102400 -> 58609 it/s ( 5723.5 MB/s)
XXH3_64b seeded : 102400 -> 58959 it/s ( 5757.7 MB/s)
XXH3_64b seeded unaligne : 102400 -> 58092 it/s ( 5673.1 MB/s)
XXH128 : 102400 -> 62074 it/s ( 6061.9 MB/s)
XXH128 unaligned : 102400 -> 61971 it/s ( 6051.8 MB/s)
XXH128 seeded : 102400 -> 61136 it/s ( 5970.3 MB/s)
XXH128 seeded unaligned : 102400 -> 60714 it/s ( 5929.1 MB/s)
也匹配“32 位 XXH32 的 3/4 速度”模式。 一切似乎都在检查。
我说绝对删除这个黑客:
#if defined(__clang__) && (XXH_VECTOR==0) && !defined(__AVX2__) && !defined(__arm__) && !defined(__thumb__)
static void
#else
XXH_FORCE_INLINE void
#endif
我有点记得XXH3 $ 在 32 位x86 (标量代码路径)上曾经比XXH32稍快(参见 https://github.com/Cyan4973/ xxHash/issues/236#issue-473500687)。
那么,不知何故,这个属性在后来的更新中丢失了?
Cyan4973
于 2019-12-11
我确实看到了一些改变性能的调整,例如将乘法放在块上,但我认为只是 XXH32 相对更快(AMD 似乎有更好的 ROL)或编译器差异(你使用 GCC , 不?)。
我将在 msys2 中尝试使用 GCC。
easyaspi314
于 2019-12-11
我刚刚在配备 i7-8559U 的笔记本电脑上对其进行了测试,
通过 Ubuntu 虚拟机。
在最新的dev分支上,使用gcc v7.4编译器时,在x86 (32 位)模式下, XXH3确实比XXH32慢。
XXH32 : 102400 -> 81824 it/s ( 7990.6 MB/s)
XXH64 : 102400 -> 38282 it/s ( 3738.5 MB/s)
XXH3_64b : 102400 -> 64518 it/s ( 6300.6 MB/s)
XXH128 : 102400 -> 58534 it/s ( 5716.2 MB/s)
但是,如果我改用clang v6.0.0 ,
然后XXH3_64b变得稍微快一些:
XXH32 : 102400 -> 79887 it/s ( 7801.4 MB/s)
XXH64 : 102400 -> 52088 it/s ( 5086.7 MB/s)
XXH3_64b : 102400 -> 88511 it/s ( 8643.6 MB/s)
XXH128 : 102400 -> 68324 it/s ( 6672.2 MB/s)
注意:我必须在编译时强制-DXXH_VECTOR=0 ,否则, clang只是用SSE2自动矢量化代码,这不再具有可比性。
Cyan4973
于 2019-12-11
C:\Users\husse\source\repos\xxHash\xxhsum.exe 0.7.2 (32-bits i386 little endian), GCC 9.2.0, by Yann Collet
Sample of 100 KB...
XXH32 : 102400 -> 82080 it/s ( 8015.6 MB/s)
XXH32 unaligned : 102400 -> 81773 it/s ( 7985.6 MB/s)
XXH64 : 102400 -> 29787 it/s ( 2908.9 MB/s)
XXH64 unaligned : 102400 -> 29940 it/s ( 2923.8 MB/s)
XXH3_64b : 102400 -> 93970 it/s ( 9176.8 MB/s)
XXH3_64b unaligned : 102400 -> 94028 it/s ( 9182.4 MB/s)
XXH3_64b seeded : 102400 -> 95259 it/s ( 9302.7 MB/s)
XXH3_64b seeded unaligne : 102400 -> 94179 it/s ( 9197.2 MB/s)
XXH128 : 102400 -> 75474 it/s ( 7370.5 MB/s)
XXH128 unaligned : 102400 -> 72546 it/s ( 7084.6 MB/s)
XXH128 seeded : 102400 -> 74622 it/s ( 7287.3 MB/s)
XXH128 seeded unaligned : 102400 -> 72019 it/s ( 7033.1 MB/s)

GCC 显然在作弊,它无法生成比 Clang 更好的代码😛
这是交换乘法:
XXH_ALIGN(XXH_ACC_ALIGN) xxh_u64* const xacc = (xxh_u64*) acc; /* presumed aligned on 32-bytes boundaries, little hint for the auto-vectorizer */
const xxh_u8* const xinput = (const xxh_u8*) input; /* no alignment restriction */
const xxh_u8* const xsecret = (const xxh_u8*) secret; /* no alignment restriction */
size_t i;
XXH_ASSERT(((size_t)acc & (XXH_ACC_ALIGN-1)) == 0);
for (i=0; i < ACC_NB; i++) {
xxh_u64 const data_val = XXH_readLE64(xinput + 8*i);
xxh_u64 const data_key = data_val ^ XXH_readLE64(xsecret + i*8);
xacc[i] += XXH_mult32to64(data_key & 0xFFFFFFFF, data_key >> 32);
if (accWidth == XXH3_acc_64bits) {
xacc[i] += data_val;
} else {
xacc[i ^ 1] += data_val; /* swap adjacent lanes */
}
}
有趣的是,我们在各自的平台上得到了gcc / clang速度差异……
Cyan4973
于 2019-12-11
好吧,您使用的是 Clang 6.0,也许有一个回归……
你在使用-mno-sse2吗?
SSE2+XXH_VECTOR=0 的 IIRC,Clang 将对其进行一半矢量化。
easyaspi314
于 2019-12-11
确实。
clang v6.0.0是我的 Ubuntu VM 提供的默认版本。
但是,最多可以安装和测试v8.0.0 。
所以我用clang v8.0.0对xxh进行了基准测试,实际上,性能比v6.0.0差。
XXH32 : 102400 -> 82794 it/s ( 8085.3 MB/s)
XXH64 : 102400 -> 33493 it/s ( 3270.8 MB/s)
XXH3_64b : 102400 -> 55674 it/s ( 5437.0 MB/s)
XXH128 : 102400 -> 45227 it/s ( 4416.7 MB/s)
你在使用-mno-sse2吗?
就是这样。 我只是设置-DXXH_VECTOR=0 。
添加-mno-sse2标志, clang v6.0.0的性能现在与v8.0.0一致:
./xxhsum32 0.7.2 (32-bits i386 little endian), Clang 6.0.0 (tags/RELEASE_600/final), by Yann Collet
XXH32 : 102400 -> 79827 it/s ( 7795.6 MB/s)
XXH64 : 102400 -> 37508 it/s ( 3662.9 MB/s)
XXH3_64b : 102400 -> 55968 it/s ( 5465.6 MB/s)
XXH128 : 102400 -> 45588 it/s ( 4452.0 MB/s)
我现在真的很好奇。
我的意思是标量 x86 并不那么重要,因为可以安全地假设 SSE2,但 GCC 生成速度明显更快的代码这一事实激起了我的兴趣。
easyaspi314
于 2019-12-11
@easyaspi314 gcc 在某些优化方面比 clang 更好。 如果您在编译器资源管理器中尝试 double y = 1.0 * x,那么您会发现 gcc 比 clang 和 msvc 更智能。
hungptit
于 2019-12-11
easyaspi314
于 2019-12-11
我们知道编译器的优化方式不同,我们有很多丑陋的技巧来纠正错误优化/愚蠢的扩展:
- 防止 Clang 在 SSE4.1 中对 XXH32 进行矢量化的内联汇编黑客
- 防止 MSVC x86 在XXH3中发出错误的
__lmul调用的内在函数 - 防止 GCC x86 向量化长乘法例程的属性。
- 防止 Clang将 rotl->multiply 变为两个乘法的内置函数
我主要是在开玩笑,因为 Clang 通常更适合这些东西,而且它是我最喜欢的编译器。
easyaspi314
于 2019-12-11
相关问题
easyaspi314
·
7评论
easyaspi314
·
6评论
 xinglin
·
6评论
xinglin
·
6评论
 hiqbn
·
7评论
hiqbn
·
7评论
 boazsegev
·
6评论
boazsegev
·
6评论
最有用的评论
碰撞研究
这是我知道的第一个能够直接探测 64 位哈希的冲突效率的测试(SMHasher 已经很好地涵盖了 32 位冲突效率)。 不幸的是,128 位碰撞分析还有很长的路要走。
该测试生成大量哈希,并计算产生的冲突次数。 它并不便宜,并且需要大量时间和大量 RAM。
生成的输入模式彼此相对接近(低汉明距离),只有几位差异。 对于低质量的哈希,它应该更加困难。
该测试指示哈希数量的预期冲突 nb。 测量的 nb 碰撞不必严格相同,只要在附近就足够了。
在大输入上测试 64 位哈希:
预计 256 字节的输入将始终触发具有多种模式的哈希算法的“长”模式,具体取决于输入长度。
| 算法 | 输入长度 | Nb 哈希 | 预期 | 铌碰撞 | 笔记 |
| --- | --- | --- | --- | --- | --- |
| __XXH3__ | 256 | 100 吉| 312.5 | 326 | |
| __XXH64__ | 256 | 100 吉| 312.5 | 294 | |
| __XXH128__ 低 64 位 | 512 | 100 吉| 312.5 | 321 | |
| __XXH128__ 高 64 位 | 512 | 100 吉| 312.5 | 325 | |
| mmh64a | 256 | 100 吉| 312.5 | 310 | |
| 城市64 | 256 | 100 吉| 312.5 | 303 | |
| t1ha2 | 256 | 100 吉| 312.5 | _761_ | 有点太大了,损失了~1bit的分布|
| 妈妈v2 | 256 | 100 吉| 312.5 | _1229_ | 有点太大了,损失了~2bits的分布|
| 威哈希 | 256 | 100 吉| 312.5 | _1202_ | 有点太大了,损失了~2bits的分布|
| fnv64 | 256 | 100 吉| 312.5 | 303 | _very_ 长测试:23h30,与
XXH3的 3h20 相比 || blake2b 低 64 位 | 256 | 100 吉| 312.5 | 296 | _非常_长测试:48小时! |
| md5 低 64 位 | 256 | 100 吉| 312.5 | 301 | _非常_长测试:58小时! |
t1ha2和mumv2都具有不理想的碰撞率。t1ha2的分布更接近 63 位,而mumv2更接近 62 位。 请注意,虽然它不是“可怕的”,但对于大多数实际用途来说,两者都可以被认为是“合理的”。wyhash是mumv2的非官方变体,毫无疑问它继承了相同的分发问题。测试 64 位非便携式哈希:
AES哈希基于英特尔的 AES 指令扩展,与 SSE4.2 一起引入。 它们不在不同的平台上运行。| 算法 | 类型 | 输入长度 | Nb 哈希 | 预期 | 铌碰撞 | 笔记 |
| --- | --- | --- | --- | --- | ---:| --- |
| meowhash 低 64 位 | AES | 256 | 100 吉| 312.5 | _18200_ | 很糟糕|
| aquahash 低 64 位 | AES | 256 | 100 吉| 312.5 | _3488136_ | 无法使用 |
AES暗示加密质量,从逻辑上讲,它对于分散性和随机性也足够好。 这个假设似乎是不正确的:基于AES的哈希具有非常糟糕的碰撞属性。碰撞率太高,不推荐使用这些算法作为校验和。
在小输入上测试 64 位哈希:
输入 8 字节 => 8 字节输出的测试可以检查在这个长度上是否发生了一些“空间减少”。 如果没有空间缩减,那么变换是完美的双射,这保证了 2 个不同的输入没有冲突。
| 算法 | 输入长度 | Nb 哈希 | 预期 | 铌碰撞 | 笔记 |
| --- | --- | --- | --- | --- | --- |
| __XXH3__ | 8 | 100 吉| 312.5 | __0__ |
XXH3对于len==8$ 是双射的。 它保证没有碰撞。 || __XXH64__ | 8 | 100 吉| 312.5 | __0__ |
XXH64对于len==8也是双射的 || mmh64a | 8 | 100 吉| 312.5 | __0__ | 双射 |
| 城市64 | 8 | 100 吉| 312.5 | 278 | |
| t1ha2 | 8 | 100 吉| 312.5 | _607_ | 有点太大了,损失了~1bit的分布|
| 妈妈v2 | 8 | 100 吉| 312.5 | _544_ | 有点太大了,损失了~1bit的分布|
| 威哈希 | 8 | 100 吉| 312.5 | _583_ | 有点太大了,损失了~1bit的分布|
| fnv64 | 8 | 100 吉| 312.5 | 26 | |
测试 128 位哈希:
这些测试唯一可接受的分数始终是
0。 如果散列算法提供 128 位分散,则出现单次碰撞的概率小于连续两次赢得国家彩票的概率。与 64 位测试相比,由于资源限制,该测试不提供精确的
128-bit碰撞估计。 它只是消除了有效分布小于 80 位的散列。| 算法 | 输入长度 | Nb 哈希 | 预期 | 铌碰撞 | 笔记 |
| --- | --- | --- | --- | --- | --- |
| __XXH128__ | 256 | 100 吉| 0.0 | 0 | |
| 城市哈希128 | 256 | 100 吉| 0.0 | 0 | |
| t1ha2 128 位 | 256 | 100 吉| 0.0 | _14_ | 相当于约 70 位的分布 |
__小输入长度的测试__
| 算法 | 输入长度 | Nb 哈希 | 预期 | 铌碰撞 | 笔记 |
| --- | --- | --- | --- | --- | --- |
| __XXH128__ | 16 | 25 吉| 0.0 | 0 | 范围 9-16 |
| __XXH128__ | 32 | 25 吉| 0.0 | 0 | 范围 17-128 |
| __XXH128__ | 100 | 13 吉| 0.0 | 0 | 范围 17-128 |
| __XXH128__ | 200 | 13 吉| 0.0 | 0 | 范围 129-240 |