Kubernetes: [Testflocken] Master-Skalierbarkeitssuiten
Fehlgeschlagene Release-Blocking-Suiten:
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-korrektness
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
Alle drei Suiten blättern in letzter Zeit sehr stark ab.
/ sig Skalierbarkeit
/ Priority Failing-Test
/ Art Bug
/ Status für Meilenstein genehmigt
cc @jdumars @jberkus
/ weise @shyamjvs @ wojtek-t zu
 krzyzacy
krzyzacy
Alle 164 Kommentare
- Der Korrektheitsjob schlägt hauptsächlich aufgrund eines Zeitlimits fehl (wir müssen unseren Zeitplan entsprechend anpassen), da kürzlich eine Reihe von e2es zur Suite hinzugefügt wurden (z. B. https://github.com/kubernetes/kubernetes/pull/59391).
- Für die 100-Knoten-Flocken haben wir https://github.com/kubernetes/kubernetes/issues/60500 (und ich glaube, das hängt damit zusammen .. muss überprüft werden).
- Ich glaube, dass es für den Performance-Job eine Regression gibt (es scheint, als ob es sich bei den letzten Läufen um eine Pod-Start-Latenz handelt). Vielleicht auch etwas mehr.
Ich werde versuchen, sie irgendwann in dieser Woche zu erreichen (mit Mangel an freien Zyklen atm).
 shyamjvs
am 28. Feb. 2018
shyamjvs
am 28. Feb. 2018
@shyamjvs Gibt es ein Update für dieses Problem?
krzyzacy
am 2. März 2018
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-korreness
Ich habe einen kurzen Blick darauf geworfen. Und entweder sind einige Tests extrem langsam oder irgendwo hängt etwas. Par der Protokolle vom letzten Lauf:
62571 I0301 23:01:31.360] Mar 1 23:01:31.348: INFO: Running AfterSuite actions on all node
62572 I0301 23:01:31.360]
62573 W0302 07:32:00.441] 2018/03/02 07:32:00 process.go:191: Abort after 9h30m0s timeout during ./hack/ginkgo-e2e.sh --ginkgo.flakeAttempts=2 --ginkgo.skip=\[Serial\]|\[Disruptive \]|\[Flaky\]|\[Feature:.+\]|\[DisabledForLargeClusters\] --allowed-not-ready-nodes=50 --node-schedulable-timeout=90m --minStartupPods=8 --gather-resource-usage=master --gathe r-metrics-at-teardown=master --logexporter-gcs-path=gs://kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-correctness/80/artifacts --report-dir=/workspace/_artifacts --dis able-log-dump=true --cluster-ip-range=10.64.0.0/11. Will terminate in another 15m
62574 W0302 07:32:00.445] SIGABRT: abort
Kein Test innerhalb von 8h30m beendet
 wojtek-t
am 2. März 2018
wojtek-t
am 2. März 2018
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
In der Tat scheint eine Regression. Ich denke, die Regression ist irgendwo zwischen den Läufen passiert:
105 (was noch in Ordnung war)
108 (die sichtbar höhere Startzeit hatte)
Wir können versuchen, in kubemark-5000 nachzuschauen, ob es auch dort sichtbar ist.
wojtek-t
am 2. März 2018
Kubemark-5000 ist ziemlich stabil. 99. Perzentil in dieser Grafik (vielleicht ist die Regression schon vorher passiert, aber ich denke, sie liegt irgendwo zwischen 105 und 108):

wojtek-t
am 2. März 2018
In Bezug auf die Korrektheitstests schlägt auch die gce-large-Korrektheit fehl.
Vielleicht wurde zu dieser Zeit ein extrem langer Test hinzugefügt?
wojtek-t
am 2. März 2018
Vielen Dank, dass Sie sich @ wojtek-t angesehen haben. Wrt Performance Job - Ich habe auch das starke Gefühl, dass es eine Regression gibt (obwohl ich sie nicht richtig untersuchen konnte).
Vielleicht wurde zu dieser Zeit ein extrem langer Test hinzugefügt?
Ich habe mich vor einiger Zeit damit befasst. Und ich habe zwei verdächtige Änderungen gefunden:
- # 59391 - Dies fügte eine Reihe von Tests zum lokalen Speicher hinzu (die Läufe nach dieser Änderung begannen mit dem Timeout)
- StatefulSet mit Pod-Anti-Affinität sollte auf Knoten verteilte Volumes verwenden (dieser Test scheint 3,5 bis 5 Stunden zu laufen) - https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/ci-kubernetes-e2e -gce-scale-Korrektheit / 79
shyamjvs
am 2. März 2018
cc @ kubernetes / sig-storage-bugs
shyamjvs
am 2. März 2018
/zuordnen
Bei einigen lokalen Speichertests wird versucht, jeden Knoten im Cluster zu verwenden, da die Clustergrößen nicht so groß sind. Ich werde einen Fix hinzufügen, um die maximale Anzahl von Knoten zu begrenzen.
 msau42
am 2. März 2018
msau42
am 2. März 2018
Bei einigen lokalen Speichertests wird versucht, jeden Knoten im Cluster zu verwenden, da die Clustergrößen nicht so groß sind. Ich werde einen Fix hinzufügen, um die maximale Anzahl von Knoten zu begrenzen.
Danke @ msau42 - das wäre toll.
wojtek-t
am 2. März 2018
Zurück zu https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance suite
Ich habe mir die Läufe bis 105 und die Läufe 108 und danach genauer angesehen.
Der größte Unterschied zur Startzeit des Pods scheint im Schritt zu erscheinen:
10% worst watch latencies:
[der Name ist irreführend - wird unten erklärt]
Bis zu 105 Runs sah es im Allgemeinen so aus:
I0129 21:17:43.450] Jan 29 21:17:43.356: INFO: perc50: 1.041233793s, perc90: 1.685463015s, perc99: 2.350747103s
Beginnend mit 108 Run sieht es eher so aus:
Feb 12 10:08:57.123: INFO: perc50: 1.122693874s, perc90: 1.934670461s, perc99: 3.195883331s
Das bedeutet im Grunde genommen eine Zunahme von ~ 0,85 Sekunden und ungefähr das, was wir im Endergebnis beobachten.
Nun - was ist das für ein "Watch Lag"?
Es ist im Grunde eine Zeit zwischen "Kubelet hat beobachtet, dass der Pod läuft" und "wenn der Test das Pod-Update beobachtet, das seinen Status auf" Laufen "setzt".
Es gibt ein paar Möglichkeiten, wo wir zurückgegangen sein könnten:
- kubelet wird im Berichtsstatus verlangsamt
- kubelet ist qps-ausgehungert (und daher langsamer im Berichtsstatus)
- Apiserver ist langsamer (z. B. CPU-ausgehungert) und verarbeitet Anfragen daher langsamer (entweder Schreiben, Beobachten oder beides).
- Der Test ist CPU-ausgehungert und verarbeitet eingehende Ereignisse daher langsamer
Da wir keinen Unterschied zwischen "Zeitplan -> Start" eines Pods feststellen, deutet dies darauf hin, dass es höchstwahrscheinlich kein Apiserver ist (da sich auch die Verarbeitung von Anforderungen und die Überwachung auf diesem Pfad befinden) und höchstwahrscheinlich kein langsames Kubelet auch (weil es den Pod startet).
Ich denke also, die wahrscheinlichste Hypothese ist:
- kubelet ist qps-ausgehungert (oder etw, das verhindert, dass es schnell eine Statusaktualisierung sendet)
- Test ist CPU-ausgehungert (oder etw so)
Der Test hat sich zu dieser Zeit überhaupt nicht geändert. Ich denke, es ist höchstwahrscheinlich der erste.
Trotzdem habe ich PRs durchlaufen, die zwischen 105 und 108 Läufen zusammengeführt wurden, und bisher nichts Nützliches gefunden.
wojtek-t
am 2. März 2018
Ich denke, der nächste Schritt ist:
- Schauen Sie sich die langsamsten Pods an (es scheint auch einen Unterschied von O (1s) zwischen den langsamsten zu geben) und prüfen Sie, ob der Unterschied "vor" oder "nach" dem Senden der Aktualisierungsstatusanforderung liegt
wojtek-t
am 2. März 2018
Also habe ich mir Beispielkapseln angesehen. Und das sehe ich schon:
I0209 10:01:19.960823 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.615907ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
...
I0209 10:01:22.464046 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (279.153µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:23.468353 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (218.216µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:24.470944 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.42987ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 09:57:01.559125 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (1.836423ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
...
I0209 09:57:04.452830 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (231.2µs) 429 [[kubelet/v1.10.0 (linu x/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:05.454274 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (213.872µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:06.458831 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (2.13295ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 10:01:53.063575 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (1.410064ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:3391
...
I0209 10:01:55.259949 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (10.4894ms) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:56.266377 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (233.931µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:57.269427 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (182.035µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:58.290456 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (13.44863ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
Es scheint also ziemlich klar zu sein, dass das Problem mit "429" zusammenhängt.
wojtek-t
am 2. März 2018
Sind diese gedrosselten API-Aufrufe auf ein Kontingent auf dem Besitzerkonto zurückzuführen?
 jdumars
am 2. März 2018
jdumars
am 2. März 2018
Sind diese gedrosselten API-Aufrufe auf ein Kontingent auf dem Besitzerkonto zurückzuführen?
Das drosselt nicht, wie ich anfangs dachte. Dies sind 429s auf Apiserver (der Grund kann entweder aus irgendeinem Grund ein langsamerer Apiserver sein oder mehr Anfragen an Apiserver).
wojtek-t
am 2. März 2018
Oh ok. Das sind keine guten Nachrichten.
jdumars
am 2. März 2018
/ Meilenstein klar
krzyzacy
am 2. März 2018
/ Meilenstein v1.10
krzyzacy
am 2. März 2018
/ Meilenstein klar
 cjwagner
am 2. März 2018
cjwagner
am 2. März 2018
@cjwagner : Sie müssen Mitglied des Github- Teams von
Als Antwort darauf :
/ Meilenstein klar
Anweisungen zur Interaktion mit mir mithilfe von PR-Kommentaren finden Sie hier . Wenn Sie Fragen oder Anregungen zu meinem Verhalten haben, reichen Sie bitte ein Problem mit dem Repository
 k8s-ci-robot
am 2. März 2018
k8s-ci-robot
am 2. März 2018
/ Meilenstein v1.9
cjwagner
am 2. März 2018
@cjwagner : Sie müssen Mitglied des Github- Teams von
Als Antwort darauf :
/ Meilenstein v1.9
Anweisungen zur Interaktion mit mir mithilfe von PR-Kommentaren finden Sie hier . Wenn Sie Fragen oder Anregungen zu meinem Verhalten haben, reichen Sie bitte ein Problem mit dem Repository
k8s-ci-robot
am 2. März 2018
Scheint, als hätte PR https://github.com/kubernetes/kubernetes/pull/60740 die Timeout-Probleme behoben - danke @ msau42 für die schnelle Antwort.
Unsere Korrektheitsjobs (sowohl 2k als auch 5k) sind jetzt wieder grün:
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce -large-korrektness
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce -scale-korrektness
Mein Verdacht bezüglich dieser Volumentests war also in der Tat richtig :)
shyamjvs
am 5. März 2018
ACK. In Bearbeitung
ETA: 03.09.2008
Risiken: Mögliche Auswirkungen auf die Leistung von k8s
shyamjvs
am 5. März 2018
Also habe ich mich ein wenig damit befasst und aus dem Diagramm der Pod-Start-Latenz für unseren 5k-Knoten-Test habe ich das Gefühl, dass die Regression auch in den s / w-Läufen 108 und 109 liegen könnte (siehe 99% ile):

shyamjvs
am 5. März 2018
Ich fegte schnell durch den Diff und die folgende Änderung scheint mir verdächtig:
"Zulassen, dass das Anforderungszeitlimit von NewRequest bis zum Ende überschritten wird" # 51042
Dieser PR ermöglicht die Weitergabe des Timeouts des Clients als Abfrageparameter an den API-Aufruf. Und ich sehe tatsächlich folgenden Unterschied bei PATCH node/status -Aufrufen in diesen beiden Läufen (aus den Apiserver-Protokollen):
run-108:
I0207 22:01:06.450385 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-1-2rn2/status: (11.81392ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.227.96.23:47270]
I0207 22:01:03.857892 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-9659/status: (8.570809ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.196.85.108:43532]
I0207 22:01:03.857972 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc4w/status: (8.287643ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.229.110.22:50530]
run-109:
I0209 21:01:08.551289 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-89f2/status?timeout=10s: (71.351634ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.229.77.215:51070]
I0209 21:01:08.551310 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-3ms3/status?timeout=10s: (70.705466ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.227.84.87:49936]
I0209 21:01:08.551394 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc02/status?timeout=10s: (70.847605ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.196.125.143:53662]
Meine Hypothese ist, dass aufgrund des zusätzlichen Zeitlimits von 10 Sekunden für die PATCH-Aufrufe diese Aufrufe nun auf der Serverseite länger dauern (IIUC diesen Kommentar korrekt). Dies bedeutet, dass sie sich jetzt für längere Zeit in der Inflight-Warteschlange befinden. Dies führt zusammen mit der Tatsache, dass diese PATCH-Aufrufe in so großen Clustern in großen Mengen auftreten, dazu, dass PUT pod/status -Anrufe nicht genügend Bandbreite in der Inflight-Warteschlange erhalten und daher mit 429s zurückgegeben werden. Infolgedessen hat sich die kubelet-seitige Verzögerung bei der Aktualisierung des Pod-Status erhöht. Diese Geschichte passt auch gut zu den obigen Beobachtungen von @ wojtek-t.
Ich werde versuchen, weitere Beweise zu sammeln, um diese Hypothese zu überprüfen.
shyamjvs
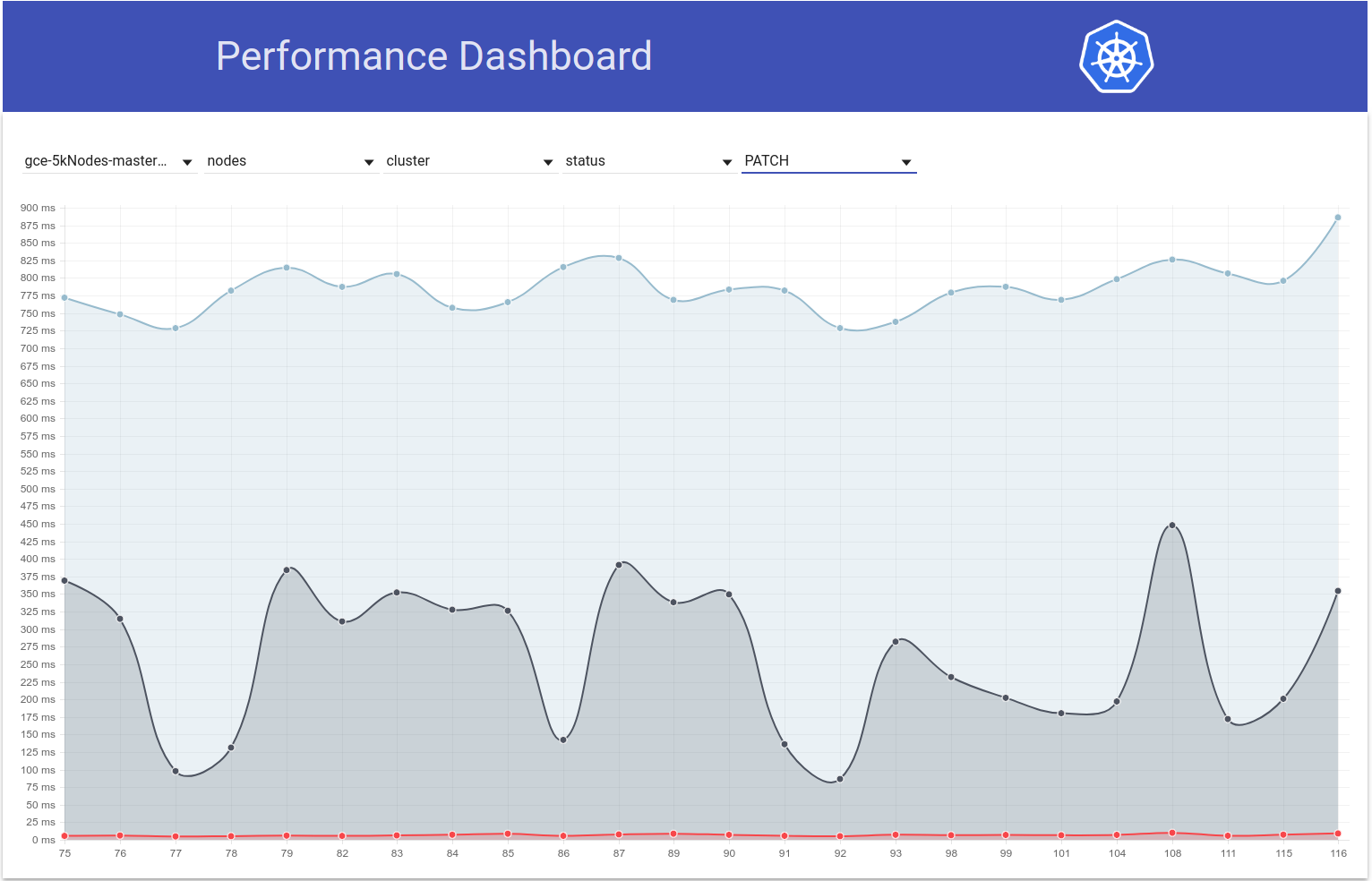
am 5. März 2018
Also habe ich überprüft, wie sich die Latenzen von PATCH node-status während der Testläufe unterscheiden, und es scheint tatsächlich, dass das 99. Perzentil (siehe oberste Zeile) um diese Zeit ansteigt. Es ist jedoch nicht ganz klar, dass es s / w in den Läufen 108 und 109 passiert ist (obwohl ich glaube, dass dies der Fall ist):
shyamjvs
am 5. März 2018
[EDIT: Mein früherer Kommentar erwähnte fälschlicherweise die Anzahl für diese 429er (Client war npd, nicht kubelet)]
Ich habe jetzt mehr Belege:
In Run-108 hatten wir ~ 479.000 PATCH node/status Anrufe mit einem 429:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"479181"
]
},
und in Lauf 109 haben wir ~ 757k davon:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"757318"
]
},
Und ... Schau dir das an:
in run-108:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"28594"
]
},
und in run-109:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"33224"
]
},
Ich habe die Nummer auf einige andere benachbarte Läufe überprüft:
- für run-104 ist es 21187
- für run-105 ist es 22003
- für run-108 ist es 28594
- dass PR fusionierte -
- für run-109 ist es 33224
- für run-110 ist es 30977
- für run-111 ist es 25615
Obwohl es ein bisschen unterschiedlich zu sein scheint, sieht es insgesamt wie das Nein aus. von 429s stieg um etwa 25%.
shyamjvs
am 5. März 2018
Und für PATCH node-status die von Kubelets stammen, die 429 erhalten haben, sehen die Zahlen folgendermaßen aus:
- run-104 = 313348
- run-105 = 309136
- run-108 = 479181
- dass PR fusionierte -
- run-109 = 757318
- run-110 = 752062
- run-111 = 296368
Dies ist ebenfalls unterschiedlich, scheint jedoch im Allgemeinen zuzunehmen.
shyamjvs
am 5. März 2018
Die 99.% ile Anruflatenz von PATCH node-status scheint sich ebenfalls allgemein erhöht zu haben (wie ich unter https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370573938 vorausgesagt habe):
run-104 (798ms), run-105 (783ms), run-108 (826ms)
run-109 (878ms), run-110 (869ms), run-111 (806ms)
Übrigens - Bei allen oben genannten Metriken scheint 108 ein schlechter als normaler Lauf zu sein und 111 scheint ein besser als normaler Lauf zu sein.
shyamjvs
am 5. März 2018
Ich werde versuchen, dies morgen zu überprüfen, indem ich manuell einen großen 5k-Cluster ausführe.
shyamjvs
am 5. März 2018
Danke für die Triage @shyamjvs
krzyzacy
am 5. März 2018
Also habe ich den Dichtetest zweimal gegen 5k-Cluster gegen ~ HEAD ausgeführt, und der Test wurde überraschenderweise beide Male mit einer Startlatenz von 99% ile Pod als 4.510015461s und 4.623276837s . Die "Überwachungslatenzen" zeigten jedoch den Anstieg, auf den @ wojtek-t in https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -369951288 hinwies
Im ersten Lauf war es:
INFO: perc50: 1.123056294s, perc90: 1.932503347s, perc99: 3.061238209s
und der zweite Lauf war es:
INFO: perc50: 1.121218293s, perc90: 1.996638787s, perc99: 3.137325187s
Ich werde jetzt versuchen zu überprüfen, was früher der Fall war.
shyamjvs
am 6. März 2018
https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938 - Ich bin nicht sicher, ob ich dem folge Ja - wir haben eine Zeitüberschreitung hinzugefügt, aber die Standardzeitüberschreitung ist größer als 10s IIRC - daher sollte es nur helfen nicht schlimmer machen.
Ich denke, wir verstehen immer noch nicht, warum wir mehr 429 beobachten (die Tatsache, dass dies irgendwie mit 429 zusammenhängt, die ich bereits in https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370036377 erwähnt habe)
wojtek-t
am 6. März 2018
Und in Bezug auf Ihre Zahlen - ich bin nicht davon überzeugt, dass die Regression in Lauf 109 stattgefunden hat - könnte es zwei Regressionen gegeben haben - eine zwischen 105 und 108 und die andere in 109.
wojtek-t
am 6. März 2018
Hmm ... Ich leugne nicht die Möglichkeiten, die Sie erwähnt haben (das Obige war nur meine Hypothese).
Ich mache gerade eine Halbierung (im Moment gegen 108's Commit), um dies zu überprüfen.
shyamjvs
am 6. März 2018
Mein Gefühl, dass die Regression vor Lauf 108 liegt, ist immer stärker.
Beispielsweise werden die Latenzen von API-Aufrufen bereits in 108 Durchläufen erhöht.
Patch-Knoten-Status:
90%: 198 ms (105) 447 ms (108) 444 ms (109)
Pod-Status setzen:
99%: 83 ms (105) 657 ms (108) 728 ms (109)
wojtek-t
am 6. März 2018
Ich denke, was ich damit sagen will, ist:
- Die Anzahl der 429er ist eine Konsequenz und wir sollten nicht zu viel Zeit damit verbringen
- Die Hauptursache sind entweder langsamere API-Aufrufe oder eine größere Anzahl davon
Wir scheinen deutlich langsamere API-Aufrufe in 108 zu sehen. Die Frage ist, ob wir auch eine größere Anzahl davon sehen.
wojtek-t
am 6. März 2018
Ich denke also, warum die Anfragen sichtbar langsamer sind - es gibt drei Hauptmöglichkeiten
Es gibt deutlich mehr Anfragen (auf den ersten Blick scheint dies nicht der Fall zu sein)
Wir haben dem Verarbeitungspfad etwas hinzugefügt (z. B. zusätzliche Verarbeitung) oder die Objekte selbst sind größer
Etwas anderes auf dem Master-Computer (z. B. Scheduler) verbraucht mehr CPU und hungert somit mehr
wojtek-t
am 6. März 2018
Also haben ich und @ wojtek-t offline diskutiert und wir sind uns jetzt einig, dass es sehr wahrscheinlich eine Regression vor 108 gibt. Einige Punkte hinzufügen:
Es gibt deutlich mehr Anfragen (auf den ersten Blick scheint dies nicht der Fall zu sein)
Scheint mir auch nicht der Fall zu sein
Wir haben dem Verarbeitungspfad etwas hinzugefügt (z. B. zusätzliche Verarbeitung) oder die Objekte selbst sind größer
Mein Gefühl ist, dass es in Kubelet etwas wahrscheinlicher ist als in Apiserver (da wir keine sichtbare Änderung der Patch- / Put-Latenzen auf Kubemark-5000 sehen).
Etwas anderes auf dem Master-Computer (z. B. Scheduler) verbraucht mehr CPU und hungert somit mehr
IMO ist dies nicht der Fall, da unser Master ziemlich viel CPU / Mem-Slack hat. Auch Perf-Dash deutet nicht auf eine erhebliche Zunahme der Verwendung von Hauptkomponenten hin.
Trotzdem habe ich ein bisschen nachgegraben und "zum Glück" scheint es, als würden wir diesen Anstieg der Überwachungslatenzen selbst für Cluster mit 2 k Knoten bemerken:
INFO: perc50: 1.024377533s, perc90: 1.589770858s, perc99: 1.934099611s
INFO: perc50: 1.03503718s, perc90: 1.624451701s, perc99: 2.348645755s
Sollte die Halbierung etwas erleichtern.
shyamjvs
am 6. März 2018
Leider scheint die Variation dieser Uhrenlatenzen einmalig zu sein (ansonsten ist sie ungefähr gleich). Glücklicherweise haben wir eine Latenz von PUT pod-status als zuverlässigen Indikator für die Regression. Ich habe gestern zwei Runden der Halbierung durchgeführt und mich auf diesen Unterschied eingegrenzt (~ 80 Commits). Ich überflog sie und habe starken Verdacht auf:
- # 58990 - Fügt dem Pod-Status ein neues Feld hinzu (obwohl ich nicht sicher bin, ob dies in unseren Tests ausgefüllt wird, in denen keine IIUC-Präemptionen stattfinden - aber überprüft werden müssen)
- # 58645 - Aktualisiert die etcd-Serverversion auf 3.2.14
shyamjvs
am 7. März 2018
Ich bezweifle wirklich, dass die # 58990 hier verwandt ist - NominatedNodeName ist eine Zeichenfolge, die einen einzelnen Knotennamen enthält. Selbst wenn es ständig gefüllt wäre, sollte die Änderung der Objektgröße vernachlässigbar sein.
wojtek-t
am 7. März 2018
@ wojtek-t - Wie Sie offline vorgeschlagen haben, scheinen wir tatsächlich eine andere Version (3.2.16) in kubemark (https://github.com/kubernetes/kubernetes/blob/master/test/kubemark/) zu verwenden. start-kubemark.sh # L62) was der mögliche Grund ist, diese Regression dort nicht zu sehen :)
cc @jpbetz
shyamjvs
am 7. März 2018
Wir verwenden jetzt überall 3.2.16.
wojtek-t
am 7. März 2018
Ups .. Entschuldigung für den Rückblick - ich habe mir eine falsche Kombination von Commits angesehen.
shyamjvs
am 7. März 2018
Übrigens - diese Zunahme der PUT-Pods / Statuslatenz ist auch im Auslastungstest in großen realen Clustern sichtbar.
wojtek-t
am 7. März 2018
Also habe ich ein bisschen mehr ausgegraben und es scheint, als hätten wir zu dieser Zeit angefangen, größere Latenzen für Schreibanforderungen im Allgemeinen zu beobachten (was mich vermuten lässt, dass sich etcd noch mehr ändert):
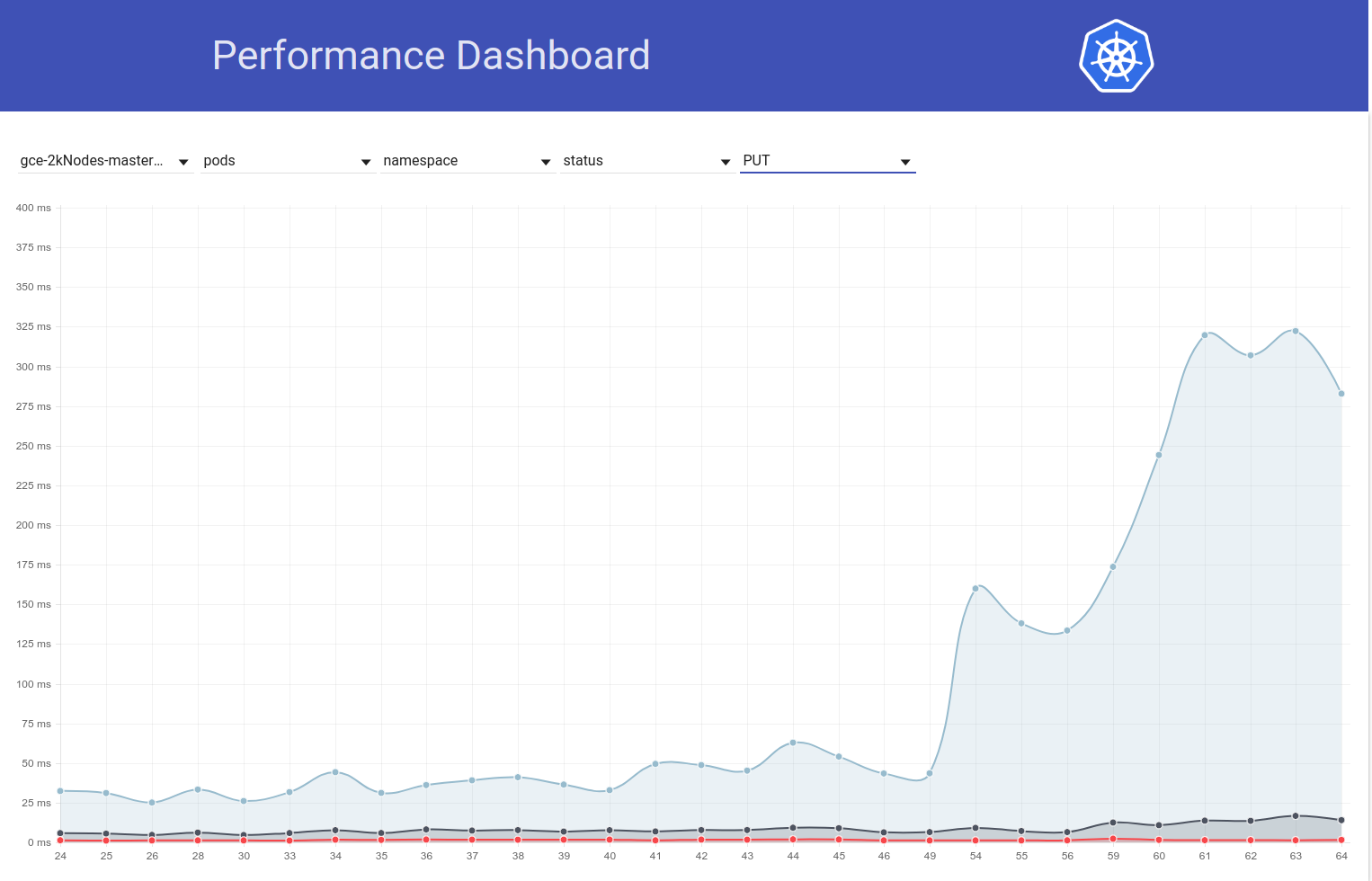
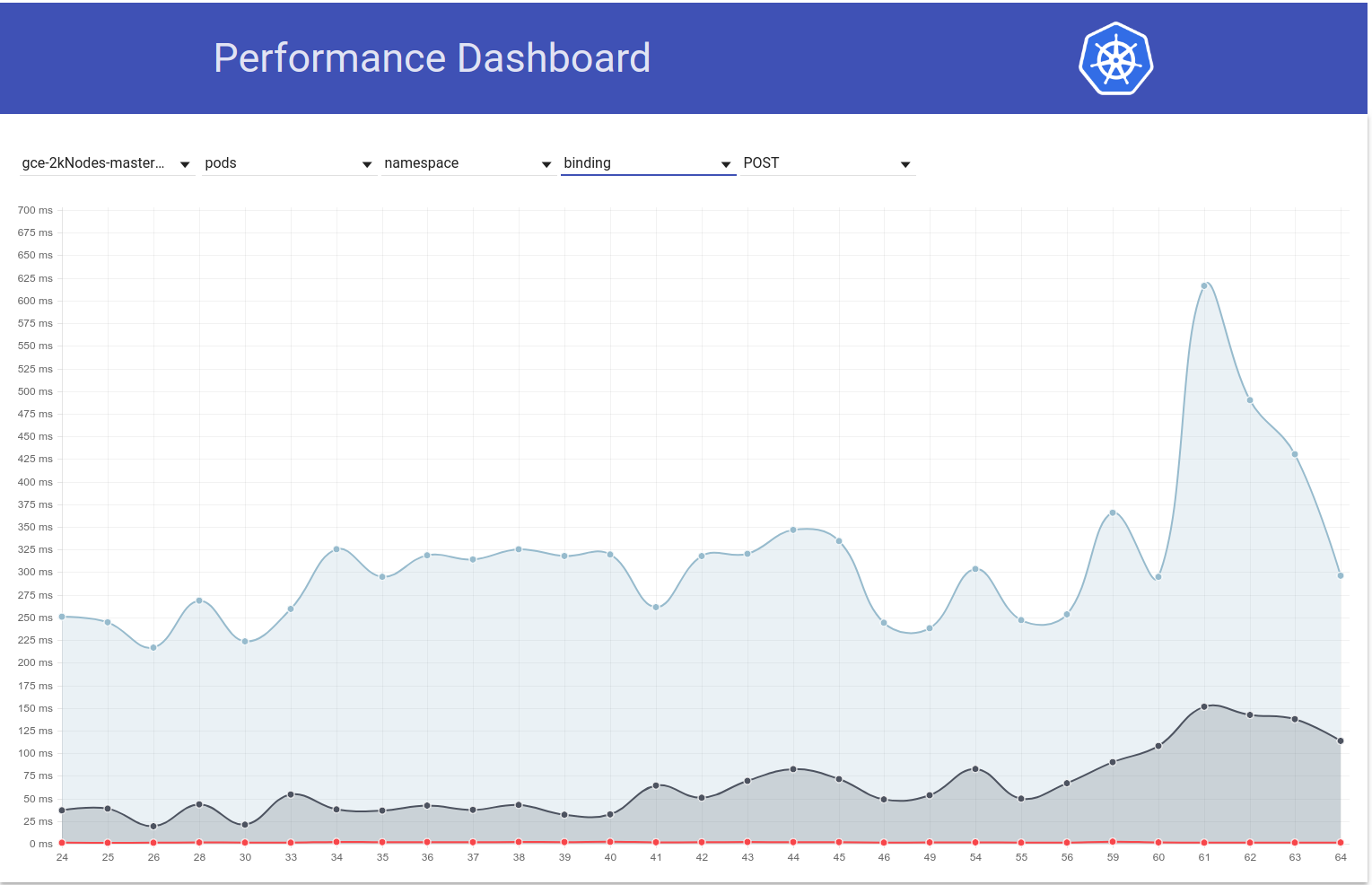

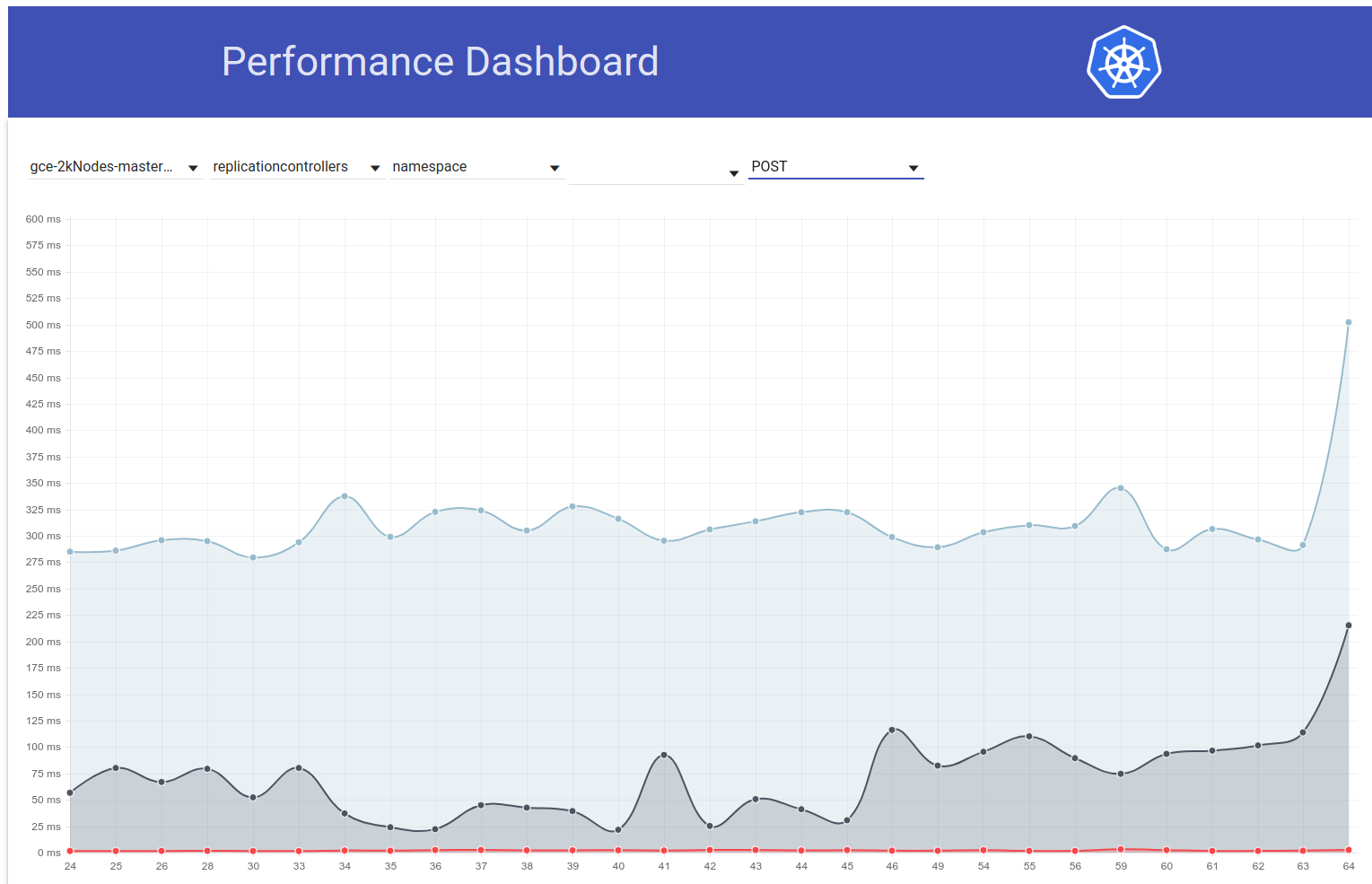
shyamjvs
am 7. März 2018
Eigentlich stimme ich zu, dass zumindest ein Teil des Problems hier liegt:
https://github.com/kubernetes/kubernetes/pull/58990/commits/384a86caa92bdb7cf9ac96b10a6ef333d2d60519#diff -c73f80ad83608f18657d22a06950d929R240
Ich wäre überrascht, wenn es das ganze Problem wäre, aber es könnte dazu beitragen.
Wird eine PR senden, die das in einer Sekunde ändert.
wojtek-t
am 7. März 2018
Zu Ihrer Information - Wenn ich gegen ein Commit vor der Änderung von etcd 3.2.14, aber nach der Änderung der Pod-Status-API lief, scheint die Latenz des Put-Knotenstatus völlig in Ordnung zu sein (dh 99% ile = 39 ms).
shyamjvs
am 7. März 2018
Also habe ich überprüft, dass es tatsächlich durch die etcd-Beule auf 3.2.14 verursacht wird. So sieht die Latenz des Put-Pod-Status aus:
gegen diese PR :
{
"data": {
"Perc50": 1.479,
"Perc90": 10.959,
"Perc99": 163.095
},
"unit": "ms",
"labels": {
"Count": "344494",
"Resource": "pods",
"Scope": "namespace",
"Subresource": "status",
"Verb": "PUT"
}
},
gegen ~ HEAD (ab 5. März) mit dieser PR zurückgesetzt (der Test läuft noch, steht aber kurz vor dem Abschluss):
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.5"} 1669
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.9"} 9597
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.99"} 63392
63ms scheint ziemlich ähnlich zu sein wie vorher .
Wir sollten die Version zurücksetzen und versuchen zu verstehen:
- Warum sehen wir diesen Anstieg in etcd 3.2.14?
- Warum haben wir das nicht in Kubemark gefangen?
cc @jpbetz @ kubernetes / sig-api-machine-bugs
shyamjvs
am 7. März 2018
Eine Hypothese (warum wir das in Kubemark nicht verstanden haben - obwohl es immer noch eine Vermutung ist) ist, dass wir dort möglicherweise etwas in Zertifikate geändert haben.
Wenn ich das etcd-Protokoll von kubemark und real cluster vergleiche, sehe ich nur in letzterem die folgende Zeile:
2018-03-05 08:06:56.389648 I | embed: peerTLS: cert = /etc/srv/kubernetes/etcd-peer.crt, key = /etc/srv/kubernetes/etcd-peer.key, ca = , trusted-ca = /etc/srv/kubernetes/etcd-ca.crt, client-cert-auth = true
Wenn ich mir die PR selbst anschaue, sehe ich keine Änderungen daran, aber ich weiß auch nicht, warum wir diese Linie nur in echten Clustern hätten sehen sollen ...
@jpbetz für Gedanken
wojtek-t
am 7. März 2018
ACK. In Bearbeitung
ETA: 03.09.2008
Risiken: Problem verursacht (meistens)
shyamjvs
am 7. März 2018
Zu PeerTLS - das scheint auch schon vorher der Fall zu sein (mit 3.1.11), also denke ich, dass das ein roter Hering ist
wojtek-t
am 7. März 2018
cc @gyuho @wenjiaswe
 jpbetz
am 7. März 2018
jpbetz
am 7. März 2018
63ms scheint ziemlich ähnlich zu sein
Woher bekommen wir diese Zahlen? Misst apiserver_request_latencies_summary tatsächlich die Latenzen von etcd-Schreibvorgängen? Auch Metriken von etcd würden helfen.
 gyuho
am 7. März 2018
gyuho
am 7. März 2018
einbetten: peerTLS: cert ...
Dies wird gedruckt, wenn Peer-TLS konfiguriert ist (wie in 3.1).
gyuho
am 7. März 2018
Woher bekommen wir diese Zahlen? Misst apiserver_request_latencies_summary tatsächlich die Latenzen von etcd-Schreibvorgängen? Auch Metriken von etcd würden helfen.
Dies misst die Apicalls-Latenz, die (zumindest bei Schreibaufrufen) die Latenz von etcd umfasst.
Wir verstehen immer noch nicht wirklich, was passiert, aber die Rückkehr zur vorherigen etcd-Version (3.1) behebt die Regression. Das Problem liegt also eindeutig irgendwo in etcd.
wojtek-t
am 7. März 2018
@shyamjvs
Welche Kubemark- und Kubernetes-Versionen verwenden Sie? Wir haben Kubemark 1.10 gegen etcd 3.2 gegen 3.3 (Workloads mit 500 Knoten) getestet und dies nicht beobachtet. Wie viele Knoten werden benötigt, um dies zu reproduzieren?
gyuho
am 7. März 2018
Welche Kubemark- und Kubernetes-Versionen verwenden Sie? Wir haben Kubemark 1.10 gegen etcd 3.2 gegen 3.3 (Workloads mit 500 Knoten) getestet und dies nicht beobachtet. Wie viele Knoten werden benötigt, um dies zu reproduzieren?
Wir können es nicht mit Kubemark reproduzieren, auch nicht mit einem 5k-Knoten - siehe unten unter https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -371171837
Dies scheint nur in realen Clustern ein Problem zu sein.
Dies ist eine offene Frage, warum dies der Fall ist.
wojtek-t
am 7. März 2018
Da haben wir auf etcd 3.1 zurückgesetzt. für kubernetes. Wir haben auch etcd 3.1.12 mit dem einzigen ausstehenden kritischen Fix für Kubernetes veröffentlicht: mvcc "unsynced" Watcher Restore Operation . Sobald wir die Hauptursache für die in diesem Problem festgestellte Leistungsregression gefunden und behoben haben, können wir einen Plan für die Aktualisierung des von kubernetes verwendeten etcd-Servers auf 3.2 skizzieren.
jpbetz
am 8. März 2018
Es sieht so aus, als ob https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100 seit heute Morgen durchgehend fehlschlägt
krzyzacy
am 9. März 2018
Die einzige Änderung gegenüber dem Diff ist https://github.com/kubernetes/kubernetes/pull/60421 , wodurch standardmäßig Quoten in unseren Leistungstests aktiviert werden. Der Fehler, den wir sehen, ist:
Container kube-controller-manager-e2e-big-master/kube-controller-manager is using 0.531144723/0.5 CPU
not to have occurred
@gmarek - Das Aktivieren von Quoten scheint unsere Skalierbarkeit zu beeinträchtigen :) Könnten Sie dies
Lassen Sie mich ein weiteres Problem einreichen, um dieses auf dem Laufenden zu halten.
shyamjvs
am 9. März 2018
@ wojtek-t @jpbetz @gyuho @timothysc Ich fand mit der Änderung der etcd-Version etwas wirklich Interessantes, was auf einen signifikanten Effekt des Wechsels von etcd 3.1.11 zu 3.2.16 hindeutet.
Sehen Sie sich das folgende Diagramm der Speichernutzung von etcd in unserem 100-Knoten-Cluster an (es hat sich um das ~ 2-fache erhöht), als der Job von k8s Release 1.9 auf 1.10 verschoben wurde:
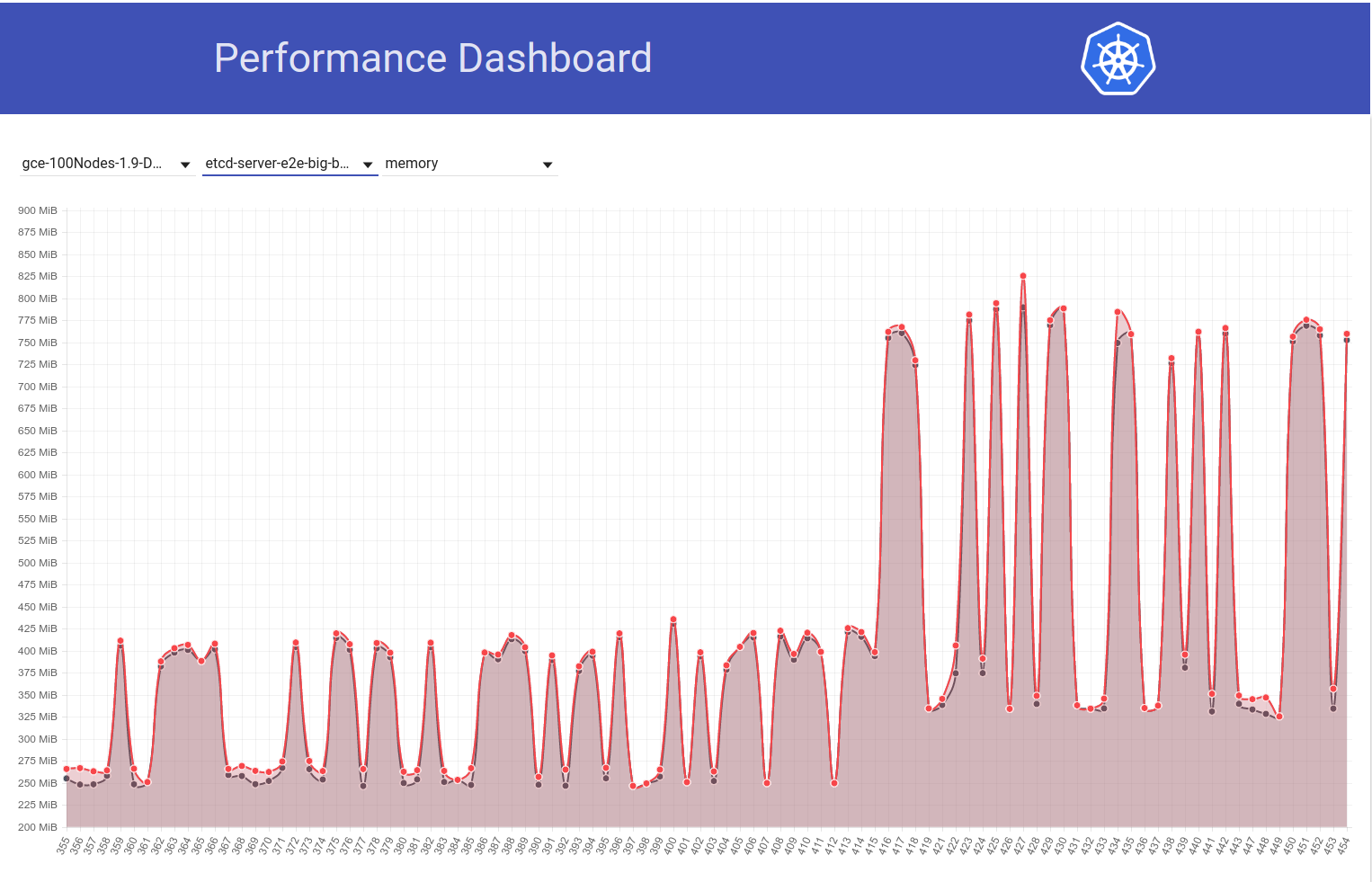
Und als nächstes sehen Sie, wie unser 100-Knoten-Job (der gegen HEAD ausgeführt wird) einen Rückgang der Mem-Nutzung auf die Hälfte direkt nach meiner Rückkehr von etcd 3.2.16 -> 3.1.11 feststellt:
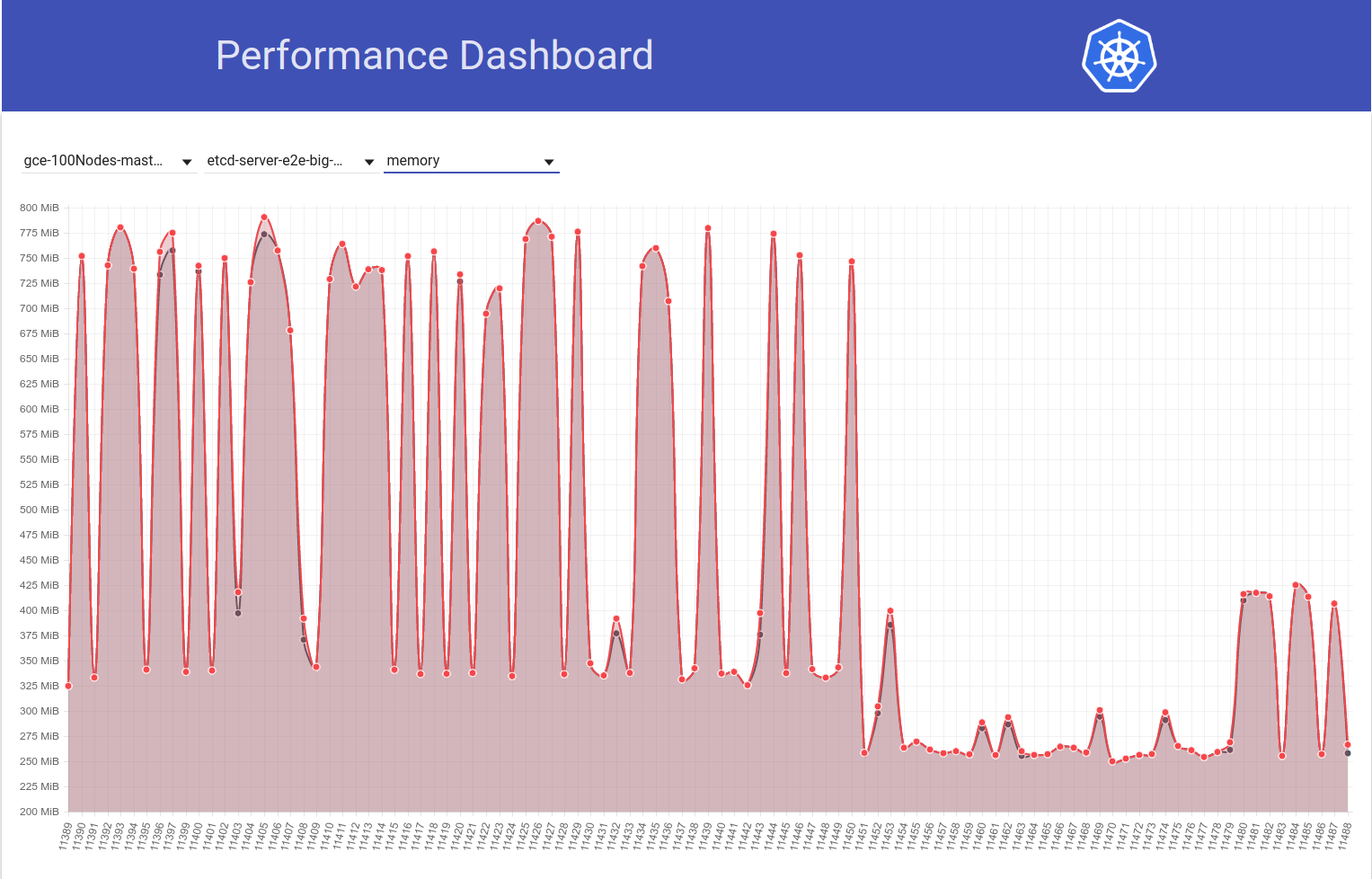
Die Serverversion von etcd 3.2 CLEARLY zeigt also die betroffene Leistung an (wobei alle anderen Variablen gleich bleiben) :)
shyamjvs
am 10. März 2018
meine Rückkehr von etcd 3.2.16 -> 3.2.11:
Meinten wir 3.1.11?
gyuho
am 10. März 2018
Das stimmt ... Entschuldigung. Meinen Kommentar bearbeitet.
shyamjvs
am 10. März 2018
@shyamjvs Wie ist etcd konfiguriert? Wir haben den Standardwert --snapshot-count in Version 3.2 von 10000 auf 100000 erhöht. Wenn also die Anzahl der Snapshots unterschiedlich ist, enthält die mit der größeren Anzahl der Snapshots Raft-Einträge länger und benötigt daher mehr residenten Speicher, bevor alte Protokolle verworfen werden.
gyuho
am 10. März 2018
Aah! Das scheint in der Tat eine verdächtige Veränderung zu sein. Wrt Flags, ich glaube nicht, dass sich an denen von k8s Seite etwas ändert. Denn wie Sie in meinem zweiten Diagramm oben sehen können, ist das Diff s / w, das 11450 und 11451 ausführt, hauptsächlich nur meine usw.-Änderung (die keine Flags zu berühren scheint).
Wir haben den Standardwert --snapshot-count von 10000 auf 100000 erhöht
Können Sie bestätigen, ob dies die Hauptursache für diese erhöhte Mem-Nutzung ist? Wenn ja, möchten wir vielleicht:
- Patch etcd zurück mit Originalwert, oder
- Stellen Sie es in k8s auf 10000 ein
vor dem Zurückschalten auf 3.2
shyamjvs
am 10. März 2018
Aah! Das scheint in der Tat eine verdächtige Veränderung zu sein.
Ja, diese Änderung sollte von der Seite etcd hervorgehoben worden sein (verbessert unsere Änderungsprotokolle und Upgrade-Anleitungen).
Können Sie bestätigen, ob dies die Hauptursache für diese erhöhte Mem-Nutzung ist?
Ich bin mir nicht sicher, ob das die Hauptursache wäre. Eine geringere Anzahl von Schnappschüssen trägt definitiv dazu bei, die spitzen Speichernutzung zu verringern. Wenn beide etcd-Versionen dieselbe Snapshot-Anzahl verwenden, eine etcd jedoch immer noch eine viel höhere Speichernutzung aufweist, sollte es etwas anderes geben.
gyuho
am 10. März 2018
Update: Ich habe überprüft, dass die Zunahme der Verwendung von etcd mem tatsächlich auf einen höheren Standardwert für --snapshot-count zurückzuführen ist. Weitere Details finden Sie hier - https://github.com/kubernetes/kubernetes/pull/61037#issuecomment -372457843
Wir sollten in Betracht ziehen, es auf 10.000 zu setzen, wenn wir auf etcd 3.2.16 stoßen, wenn wir die erhöhte Mem-Nutzung nicht wollen.
cc @gyuho @ xiang90 @jpbetz
shyamjvs
am 12. März 2018
Update: Mit dem etcd-Fix scheint die Pod-Startlatenz von 99% immer noch nahe daran zu sein, das 5s-SLO zu verletzen. Es gibt mindestens eine weitere Regression, und ich habe Beweise dafür gesammelt, dass dies höchstwahrscheinlich in den s / w-Läufen 111 und 112 unseres 5k-Knoten-Leistungsjobs der Fall ist (siehe die Beule s / w dieser Läufe in der Grafik, die ich in https: / eingefügt habe). /github.com/kubernetes/kubernetes/issues/60589#issuecomment-370568929). Momentan halbiere ich den Diff (der ungefähr 50 Commits hat) und der Test dauert ~ 4-5 Stunden pro Iteration.
Die Beweise, auf die ich mich oben bezog, sind die folgenden:
Die Beobachtungslatenzen bei 111 waren:
Feb 14 21:36:05.531: INFO: perc50: 1.070980786s, perc90: 1.743347483s, perc99: 2.629721166s
Die Latenzzeiten für den Pod-Start bei 111 waren insgesamt:
Feb 14 21:36:05.671: INFO: perc50: 2.416307575s, perc90: 3.24553118s, perc99: 4.092430858s
Während die gleichen bei 112 waren:
Feb 16 10:07:43.222: INFO: perc50: 1.131108849s, perc90: 2.18487651s, perc99: 3.570548412s
und
Feb 16 10:07:43.353: INFO: perc50: 2.56160248s, perc90: 3.754024568s, perc99: 4.967573867s
Wenn jemand für das Wettspiel bereit ist, können Sie sich den oben erwähnten Commit-Diff ansehen und den fehlerhaften erraten :)
shyamjvs
am 12. März 2018
ACK. In Bearbeitung
ETA: 13/03/2018
Risiken: Kann das Veröffentlichungsdatum verschieben, wenn es zuvor nicht debuggt wurde
shyamjvs
am 12. März 2018
@shyamjvs toooooooo viele verpflichtet sich, Wetten zu platzieren :)
 dims
am 13. März 2018
dims
am 13. März 2018
@dims Das würde wohl mehr Spaß machen;)
Update: Also habe ich einige Iterationen der Halbierung ausgeführt und hier ist, wie die relevanten Metriken über Commits hinweg (chronologisch geordnet) aussahen. Beachten Sie, dass ich diejenigen, die ich manuell ausgeführt habe, mit der zuvor zurückgesetzten Regression ausgeführt habe (dh 3.2. -> 3.1.11).
| Commit | 99% Latenzzeit | 99% Pod-Start-Latenz | Gut schlecht? |
| ------------- | ------------- | ----- | ------- |
| a042ecde36 (von run-111) | 2.629721166s | 4.092430858s | Gut (erneut manuell bestätigen) |
| 5f7b530d87 (Handbuch) | 3.150616856s | 4.683392706s | Schlecht (wahrscheinlich) |
| a8060ab0a1 (manuell) | 3.11319985s | 4.710277511s | Schlecht (wahrscheinlich) |
| 430c1a68c8 (ab Lauf 112) | 3.570548412s | 4.967573867s | Schlecht |
| 430c1a68c8 (manuell) | 3.63505091s | 4.96697776s | Schlecht |
Aus dem Obigen geht hervor, dass es hier zwei Regressionen geben kann (da es sich nicht um einen direkten Sprung von 2,6 s -> 3,6 s handelt) - eine s / w "a042ecde36 - 5f7b530d87" und eine andere s / w "a8060ab0a1 - 430c1a68c8". Seufzer!
shyamjvs
am 13. März 2018
Ausdrücken als Bereiche, um Vergleichslinks zu erhalten:
a042ecde36 ... 5f7b530
a8060ab0a1 ... 430c1a6
 liggitt
am 13. März 2018
liggitt
am 13. März 2018
Ich habe gerade die Ergebnisse für den manuellen Lauf gegen a042ecde36 erhalten und es macht das Leben nur schwerer:
3.269330734s (watch), 4.939237532s (pod-startup)
da dies wahrscheinlich bedeutet, dass es sich um eine schuppige Regression handeln könnte.
shyamjvs
am 13. März 2018
Ich führe derzeit den Test gegen a042ecde36 noch einmal durch, um die Möglichkeit zu überprüfen, dass die Regression bereits vorher aufgetreten ist.
shyamjvs
am 13. März 2018
Hier ist das Ergebnis eines erneuten Laufs gegen a042ecd:
2.645592996s (watch), 5.026010032s (pod-startup)
Dies bedeutet wahrscheinlich, dass die Regression bereits vor Run-111 eingegeben wurde (eine gute Nachricht, dass wir jetzt ein richtiges Ende für die Halbierung haben).
Ich werde jetzt versuchen, ein linkes Ende anzustreben. Run-108 (Commit 11104d75f) ist ein potenzieller Kandidat, der die folgenden Ergebnisse hatte, als ich ihn zuvor ausgeführt habe (mit etcd 3.1.11):
2.593628224s (watch), 4.321942836s (pod-startup)
Meine Wiederholung gegen Commit 11104d7 scheint zu sagen, dass es eine gute ist:
2.663456162s (watch), 4.288927203s (pod-startup)
Ich werde hier einen Stich bei der Halbierung im Bereich 11104d7 ... a042ecd machen
shyamjvs
am 13. März 2018
Update: Ich musste das Commit 097efb71a315 dreimal testen, um Vertrauen zu gewinnen. Es zeigt einige Abweichungen, scheint aber ein gutes Commit zu sein:
2.578970061s (watch), 4.129003596s (pod-startup)
2.315561531s (watch), 4.70792639s (pod-startup)
2.303510957s (watch), 3.88150234s (pod-startup)
Ich werde weiter halbieren.
Trotzdem scheint es vor ein paar Tagen einen weiteren Anstieg (von ~ 1s) der Pod-Start-Latenz gegeben zu haben. Und dieser drückt die 99% auf fast 6s:
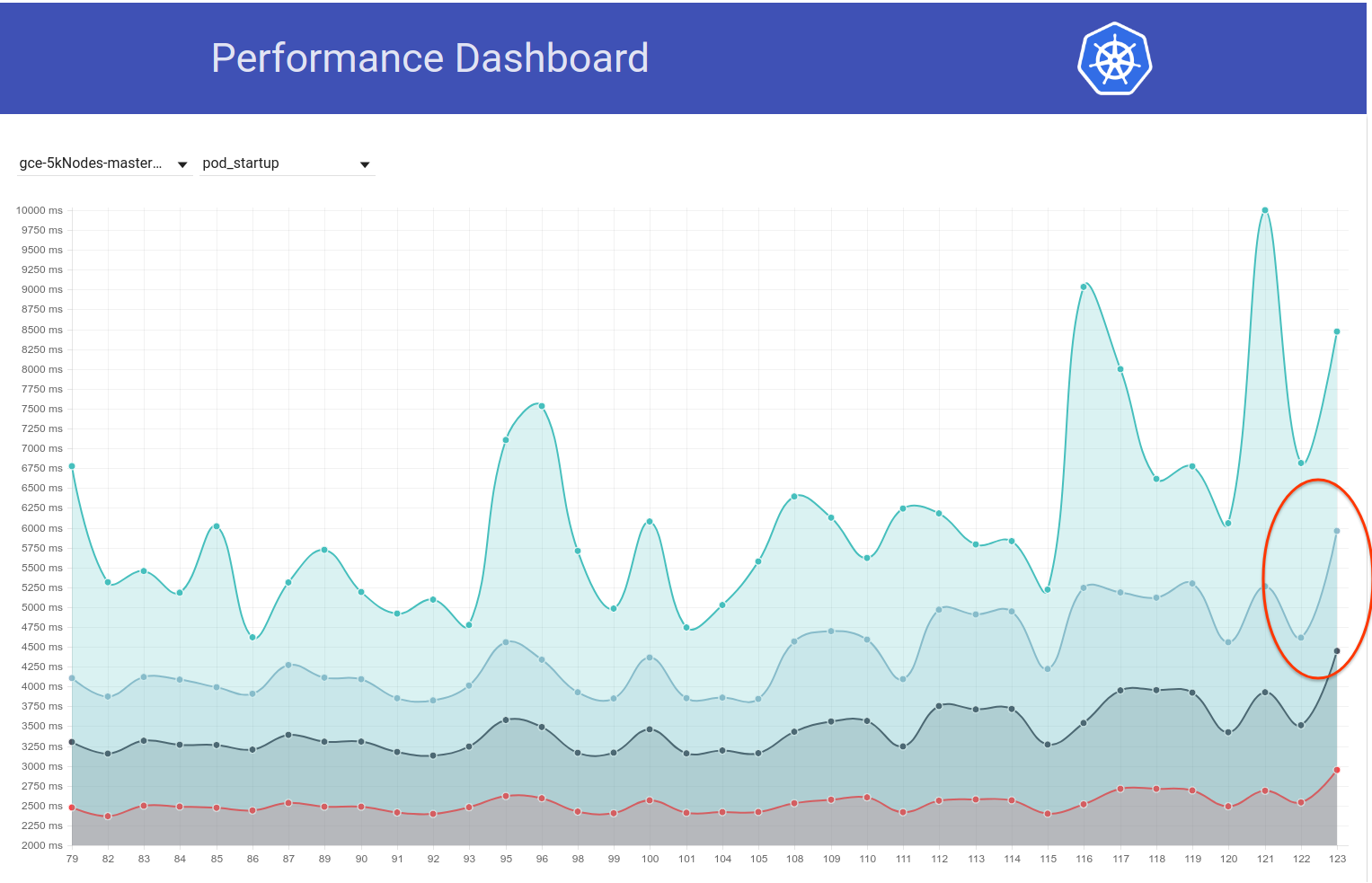
Mein Hauptverdächtiger aus dem Commit-Diff ist die Änderung etcd von 3.1.11 -> 3.1.12 (https://github.com/kubernetes/kubernetes/pull/60998). Ich würde auf den nächsten Lauf warten (derzeit in Bearbeitung), um zu bestätigen, dass es sich nicht um einen einmaligen Lauf handelt - aber wir müssen das wirklich verstehen.
cc @jpbetz @gyuho
shyamjvs
am 14. März 2018
Da ich diese Woche von Donnerstag bis Freitag im Urlaub bin, füge ich Anweisungen ein, um einen Dichtetest für einen 5k-Knoten-Cluster durchzuführen (damit jemand mit Zugriff auf das Projekt die Halbierung fortsetzen kann):
# Start with a clean shell.
# Checkout to the right commit.
make quick-release
# Set the project:
gcloud config set project k8s-scale-testing
# Set some configs for creating/testing 5k-node cluster:
export CLOUDSDK_CORE_PRINT_UNHANDLED_TRACEBACKS=1
export KUBE_GCE_ZONE=us-east1-a
export NUM_NODES=5000
export NODE_SIZE=n1-standard-1
export NODE_DISK_SIZE=50GB
export MASTER_MIN_CPU_ARCHITECTURE=Intel\ Broadwell
export ENABLE_BIG_CLUSTER_SUBNETS=true
export LOGROTATE_MAX_SIZE=5G
export KUBE_ENABLE_CLUSTER_MONITORING=none
export ALLOWED_NOTREADY_NODES=50
export KUBE_GCE_ENABLE_IP_ALIASES=true
export TEST_CLUSTER_LOG_LEVEL=--v=1
export SCHEDULER_TEST_ARGS=--kube-api-qps=100
export CONTROLLER_MANAGER_TEST_ARGS=--kube-api-qps=100\ --kube-api-burst=100
export APISERVER_TEST_ARGS=--max-requests-inflight=3000\ --max-mutating-requests-inflight=1000
export TEST_CLUSTER_RESYNC_PERIOD=--min-resync-period=12h
export TEST_CLUSTER_DELETE_COLLECTION_WORKERS=--delete-collection-workers=16
export PREPULL_E2E_IMAGES=false
export ENABLE_APISERVER_ADVANCED_AUDIT=false
# Bring up the cluster (this brings down pre-existing one if present, so you don't have to explicitly '--down' the previous one) and run density test:
go run hack/e2e.go \
--up \
--test \
--test_args='--ginkgo.focus=\[sig\-scalability\]\sDensity\s\[Feature\:Performance\]\sshould\sallow\sstarting\s30\spods\sper\snode\susing\s\{\sReplicationController\}\swith\s0\ssecrets\,\s0\sconfigmaps\sand\s0\sdaemons$ --allowed-not-ready-nodes=30 --node-schedulable-timeout=30m --minStartupPods=8 --gather-resource-usage=master --gather-metrics-at-teardown=master' \
> somepath/build-log.txt 2>&1
# To re-run the test on same cluster (without re-creating) just omit '--up' in the above.
WICHTIGE NOTIZEN:
- Der derzeitige vermutete Festschreibungsbereich ist ff7918d ... a042ecde3 (halten wir dies auf dem neuesten Stand, während wir halbieren)
- Wir müssen etcd-3.1.11 anstelle von 3.2.14 verwenden (um eine frühere Regression zu vermeiden). Ändern Sie die Version in den folgenden Dateien, um dies minimal zu erreichen:
- cluster / gce / manifestes / etcd.manifest
- cluster / images / etcd / Makefile
- hack / lib / etcd.sh.
shyamjvs
am 14. März 2018
cc: @ wojtek-t
jdumars
am 14. März 2018
etcd v3.1.12 behebt Fehler bei der Wiederherstellung des Überwachungsereignisses. Und dies ist die einzige Änderung, die wir gegenüber Version 3.1.11 vorgenommen haben. Umfasst der Leistungstest irgendetwas mit etcd-Neustart oder Multi-Node, das einen Snapshot vom Leader auslösen kann?
gyuho
am 14. März 2018
Umfasst der Leistungstest irgendetwas mit dem Neustart von etcd?
Aus den etcd-Protokollen geht nicht hervor, dass ein Neustart
Multi-Node
Wir verwenden in unserem Setup nur Einzelknoten usw. (vorausgesetzt, Sie haben danach gefragt).
shyamjvs
am 14. März 2018
Aha. Dann sollten v3.1.11 und v3.1.12 nicht unterschiedlich sein: 0
Wird einen weiteren Blick darauf werfen, wenn der zweite Lauf auch höhere Latenzen zeigt.
gyuho
am 14. März 2018
cc: @jpbetz
jdumars
am 14. März 2018
Stimmen Sie mit
Die einzige andere Änderung ist das Upgrade von etcd von go1.8.5 auf go1.8.7, aber ich bezweifle, dass wir damit eine signifikante Leistungsregression sehen würden.
jpbetz
am 14. März 2018
Wenn Sie also mit der Halbierung fortfahren, scheint ff7918d1f gut zu sein:
2.246719086s (watch), 3.916350274s (pod-startup)
Ich werde den Festschreibungsbereich in https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -373051051 entsprechend aktualisieren.
shyamjvs
am 14. März 2018
Als nächstes scheint Commit aa19a1726 gut zu sein, obwohl ich vorschlagen würde, es noch einmal zu versuchen, um zu bestätigen:
2.715156606s (watch), 4.382527095s (pod-startup)
An diesem Punkt werde ich die Halbierung pausieren und meinen Urlaub beginnen :)
Ich habe meinen Cluster heruntergefahren, um Platz für den nächsten Lauf zu schaffen.
shyamjvs
am 15. März 2018
Danke Shyam. Ich versuche es erneut mit aa19a172693a4ad60d5a08e9b93557267d259c37.
 wasylkowski-a
am 15. März 2018
wasylkowski-a
am 15. März 2018
Für das Festschreiben aa19a172693a4ad60d5a08e9b93557267d259c37 habe ich die folgenden Ergebnisse erhalten:
2.47655243s (watch), 4.174016696s (pod-startup)
Das sieht also gut aus. Fortsetzung der Halbierung.
Derzeitiger Festschreibungsbereich vermutet: aa19a172693a4ad60d5a08e9b93557267d259c37 ... a042ecde362000e51f1e7bdbbda5bf9d81116f84
wasylkowski-a
am 15. März 2018
@ wasylkowski-a Könnten Sie an unserem Release-Meeting um 17.00 Uhr UTC / 13.00 Uhr Ost / 10.00 Uhr Pazifik teilnehmen? Es ist ein Zoom-Meeting: https://zoom.us/j/2018742972
jdumars
am 15. März 2018
Ich werde teilnehmen.
wasylkowski-a
am 15. März 2018
Commit cca7ccbff161255292f72c2d18459cdface62122 sieht mit den folgenden Ergebnissen unklar aus:
2.984185673s (watch), 4.568914929s (pod-startup)
Ich werde dies noch einmal ausführen, um das Vertrauen zu gewinnen, dass ich nicht die falsche Hälfte der Halbierung eingebe.
wasylkowski-a
am 15. März 2018
OK, also bin ich jetzt ziemlich zuversichtlich, dass cca7ccbff161255292f72c2d18459cdface62122 schlecht ist:
3.285168535s (watch), 4.783986141s (pod-startup)
Reduzieren Sie den Bereich auf aa19a172693a4ad60d5a08e9b93557267d259c37 ... cca7ccbff161255292f72c2d18459cdface62122 und probieren Sie 92e4d3da0076f923a45d54d69c84e91ac6a61a55 aus.
wasylkowski-a
am 16. März 2018
Commit 92e4d3da0076f923a45d54d69c84e91ac6a61a55 sieht gut aus:
2.522438984s (watch), 4.21739985s (pod-startup)
Der neue Commit-Bereich für Verdächtige ist 92e4d3da0076f923a45d54d69c84e91ac6a61a55 ... cca7ccbff161255292f72c2d18459cdface62122 und probiert 603ebe466d335a37392315d491782ed18d1bae11 aus
wasylkowski-a
am 16. März 2018
@wasylkowski Bitte beachten Sie, dass eine der Commits nämlich https://github.com/kubernetes/kubernetes/commit/4c289014a05669c376994868d8d91f7565a204b5 in rückgängig gemacht wurde https://github.com/kubernetes/kubernetes/commit/493f33583053bb4ce9f7d348c5bac39975883cb8
dims
am 16. März 2018
Wenn Sie den Kommentar von verfolgen wir hier in der
Können wir das erneute Testen einmal gegen den Zweigkopf von 1,10 priorisieren, anstatt die Halbierung fortzusetzen?
 tpepper
am 16. März 2018
tpepper
am 16. März 2018
@wasylkowski / @ wasylkowski-a ^^^^
tpepper
am 16. März 2018
@ wojtek-t PTAL ASAP
jdumars
am 16. März 2018
Danke @dims und @tpepper. Lassen Sie mich gegen 1.10 Astkopf versuchen und sehen, was passiert.
wasylkowski-a
am 16. März 2018
danke @wasylkowski schlimmstenfalls
dims
am 16. März 2018
1.10 Kopf hat eine Regression:
3.522924087s (watch), 4.946431238s (pod-startup)
Dies ist auf etcd 3.1.12, nicht auf etcd 3.1.11, aber wenn ich es richtig verstehe, sollte dies keinen großen Unterschied machen.
Auch 603ebe466d335a37392315d491782ed18d1bae11 sieht gut aus:
2.744654024s (watch), 4.284582476s (pod-startup)
2.76287483s (watch), 4.326409841s (pod-startup)
2.560703844s (watch), 4.213785531s (pod-startup)
Dies lässt uns den Bereich 603ebe466d335a37392315d491782ed18d1bae11 ... cca7ccbff161255292f72c2d18459cdface62122 und es gibt dort nur 3 Commits. Lassen Sie mich sehen, was ich herausfinde.
Es ist auch möglich, dass tatsächlich 4c289014a05669c376994868d8d91f7565a204b5 der Schuldige hier ist, aber dann bedeutet dies, dass wir eine andere Regression haben, die sich auf dem Kopf manifestiert.
wasylkowski-a
am 16. März 2018
OK, also offensichtlich 6590ea6d5d50700d34255b1e037b2702ad26b7fc festschreiben ist gut:
2.553170576s (watch), 4.22516704s (pod-startup)
während Commit 7b678dc4035c61a1991b5e1442edb13f40deae72 schlecht ist:
3.498855918s (watch), 4.886599251s (pod-startup)
Das schlechte Commit ist die Zusammenführung des von @dims erwähnten
Lassen Sie mich versuchen, den Kopf auf etcd 3.1.11 anstelle von 3.1.12 erneut auszuführen und zu sehen, was passiert.
wasylkowski-a
am 17. März 2018
@ wasylkowski-a ah klassische gute Nachrichten schlechte Nachrichten :) Danke, dass Sie so weitermachen.
@ wojtek-t irgendwelche anderen Vorschläge?
dims
am 17. März 2018
Head on etcd 3.1.11 ist auch schlecht; Mein nächster Versuch wird sein, es direkt nach dem Zurücksetzen zu versuchen (also bei Commit cdecea545553eff09e280d389a3aef69e2f32bf1), aber mit etcd 3.1.11 anstelle von 3.2.14.
wasylkowski-a
am 17. März 2018
Hört sich gut an Andrzej
- verdunkelt
Am 17. März 2018, um 13:19 Uhr, schrieb Andrzej Wasylkowski [email protected] :
Head on etcd 3.1.11 ist auch schlecht; Mein nächster Versuch wird sein, es direkt nach dem Zurücksetzen zu versuchen (also bei commit cdecea5), aber mit etcd 3.1.11 anstelle von 3.2.14.
- -
Sie erhalten dies, weil Sie erwähnt wurden.
Antworten Sie direkt auf diese E-Mail, zeigen Sie sie auf GitHub an oder schalten Sie den Thread stumm.
dims
am 17. März 2018
Commit cdecea545553eff09e280d389a3aef69e2f32bf1 ist gut, daher haben wir eine spätere Regression:
2.66454307s (watch), 4.308091589s (pod-startup)
Commit 2a373ace6eda6a9cf050ce70a6cf99183c5e5b37 ist eindeutig schlecht:
3.656979569s (watch), 6.746987916s (pod-startup)
@ wasylkowski-a Wir betrachten also im Grunde genommen Commits im Bereich https://github.com/kubernetes/kubernetes/compare/cdecea5...2a373ac, um zu sehen, was dann falsch ist? (Halbierung zwischen diesen beiden laufen lassen)?
dims
am 17. März 2018
Ja. Dies ist leider ein riesiger Bereich. Ich untersuche gerade aded0d922592fdff0137c70443caf2a9502c7580.
wasylkowski-a
am 17. März 2018
Danke @wasylkowski was ist der aktuelle Bereich? (damit ich mir die PRs ansehen kann).
dims
am 18. März 2018
Commit aded0d922592fdff0137c70443caf2a9502c7580 ist schlecht:
3.626257043s (watch), 5.00754503s (pod-startup)
Commit f8298702ffe644a4f021e23a616ad6a8790a5537 ist ebenfalls schlecht:
3.747051371s (watch), 6.126914967s (pod-startup)
So ist Commit 20a6749c3f86c7cb9e98442046532380fb5f6e36:
3.641172882s (watch), 5.100922237s (pod-startup)
Und so ist 0e81651e77e0be7e75179e5986ef2c76601f4bd6:
3.687028394s (watch), 5.208157763s (pod-startup)
Der aktuelle Bereich ist cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6. Wir (ich, @ wojtek-t, @shyamjvs) beginnen zu vermuten, dass cdecea545553eff09e280d389a3aef69e2f32bf1 tatsächlich ein schuppiger Pass ist, also brauchen wir ein anderes linkes Ende.
wasylkowski-a
am 19. März 2018
/ me setzt auf https://github.com/kubernetes/kubernetes/commit/b259543985b10875f4a010ed0285ac43e335c8e0 als Schuldigen
cc @ wasylkowski-a
dims
am 19. März 2018
0e81651e77e0be7e75179e5986ef2c76601f4bd6 ist, stellt sich heraus, schlecht, so b259543985b10875f4a010ed0285ac43e335c8e0 (verschmolzen 244549f02afabc5be23fc56e86a60e5b36838828 nach 0e81651e77e0be7e75179e5986ef2c76601f4bd6) nicht die früheste Ursache sein (obwohl es nicht unmöglich ist, dass es noch eine weitere Regression eingeführt hat, die wir, wenn wir dieses man beobachten wird ausschütteln)
wasylkowski-a
am 19. März 2018
Per @ wojtek-t und @shyamjvs führe ich cdecea545553eff09e280d389a3aef69e2f32bf1 erneut aus, da wir vermuten, dass dies ein "schuppiges Gut" gewesen sein könnte
wasylkowski-a
am 19. März 2018
Ich gehe davon aus, dass cdecea545553eff09e280d389a3aef69e2f32bf1 tatsächlich gut ist, basierend auf den folgenden Ergebnissen, die ich beobachtet habe:
2.66454307s (watch), 4.308091589s (pod-startup)
2.695629257s (watch), 4.194027608s (pod-startup)
2.660956347s (watch), 3m36.62259323s (pod-startup) <-- looks like an outlier
2.865445137s (watch), 4.594671099s (pod-startup)
2.412093606s (watch), 4.070130529s (pod-startup)
Derzeit vermuteter Bereich: cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6
Derzeit werden 99c87cf679e9cbd9647786bf7e81f0a2d771084f getestet
wasylkowski-a
am 20. März 2018
Vielen Dank an @wasylkowski für die Fortsetzung dieser Arbeit.
jdumars
am 20. März 2018
pro Diskussion heute: fluentd-scaler hat immer noch Probleme: https://github.com/kubernetes/kubernetes/issues/61190 , die nicht von PRs behoben wurden. Ist es möglich, dass diese Regression durch fließendes verursacht wird?
 jberkus
am 20. März 2018
jberkus
am 20. März 2018
Eine der PRs in Bezug auf fließendes https://github.com/kubernetes/kubernetes/commit/a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2 befindet sich im neuesten Bereich
dims
am 20. März 2018
pro Diskussion heute: fluentd-scaler hat immer noch Probleme: # 61190, die nicht von PRs behoben wurden. Ist es möglich, dass diese Regression durch fließendes verursacht wird?
TBH, ich wäre wirklich überrascht, wenn es an fließenden Problemen liegen würde. Aber ich kann diese Hypothese nicht sicher ausschließen.
Mein persönliches Gefühl wäre eine Veränderung in Kubelet, aber ich habe mich auch mit PRs in diesem Bereich befasst und nichts scheint wirklich verdächtig zu sein ...
Hoffentlich wird die Reichweite morgen 4x kleiner sein, was nur ein paar PRs bedeuten würde.
wojtek-t
am 20. März 2018
OK, also 99c87cf679e9cbd9647786bf7e81f0a2d771084f sieht gut aus, aber ich brauchte drei Läufe, um sicherzustellen, dass dies keine Flocke ist:
2.901624657s (watch), 4.418169754s (pod-startup)
2.938653965s (watch), 4.423465198s (pod-startup)
3.047455619s (watch), 4.455485098s (pod-startup)
Als nächstes ist a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2 schlecht:
3.769747695s (watch), 5.338517616s (pod-startup)
Der aktuelle Bereich ist 99c87cf679e9cbd9647786bf7e81f0a2d771084f ... a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2. Analyse von c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd.
wasylkowski-a
am 20. März 2018
Ich habe mir den oben genannten Bereich angesehen - dort gibt es nur 9 PRs.
https://github.com/kubernetes/kubernetes/pull/59944 - 100% NICHT - ändert nur die Eigentümerdatei
https://github.com/kubernetes/kubernetes/pull/59953 - möglicherweise
https://github.com/kubernetes/kubernetes/pull/59809 - nur kubectl-Code berühren, sollte also in diesem Fall keine Rolle spielen
https://github.com/kubernetes/kubernetes/pull/59955 - 100% NICHT - nur nicht verwandte e2e-Tests berühren
https://github.com/kubernetes/kubernetes/pull/59808 - möglicherweise (dies ändert das Cluster-Setup)
https://github.com/kubernetes/kubernetes/pull/59913 - 100% NICHT - nur nicht verwandte e2e-Tests berühren
https://github.com/kubernetes/kubernetes/pull/59917 - Der Test wird geändert, die Änderungen jedoch nicht aktiviert, was unwahrscheinlich ist
https://github.com/kubernetes/kubernetes/pull/59668 - 100% NICHT - nur AWS-Code berühren
https://github.com/kubernetes/kubernetes/pull/59909 - 100% NICHT - nur Besitzerdateien berühren
Ich denke, wir haben hier zwei Kandidaten: https://github.com/kubernetes/kubernetes/pull/59953 und https://github.com/kubernetes/kubernetes/pull/59808
Ich werde versuchen, tiefer in diese einzudringen, um sie zu verstehen.
wojtek-t
am 21. März 2018
c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd sieht ziemlich schlecht aus:
3.428891786s (watch), 4.909251611s (pod-startup)
Da dies die Zusammenführung von # 59953 ist, einem von Wojteks Verdächtigen, werde ich jetzt ein Commit ausführen, also f60083549a43f152b3142e01756e25611d911770.
Bei diesem Commit handelt es sich jedoch um eine Änderung von OWNERS_ALIASES, und in diesem Bereich ist noch nichts übrig. Daher muss c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd das Problem sein. Ich werde den Test sowieso nur aus Sicherheitsgründen durchführen.
wasylkowski-a
am 21. März 2018
Offline diskutiert - wir werden Tests an der Spitze ausführen, wobei dieses Commit stattdessen lokal zurückgesetzt wird.
wojtek-t
am 21. März 2018
Beeindruckend! Ein Einzeiler, der so viel Ärger macht. danke @wasylkowski @ wojtek-t
dims
am 21. März 2018
@dims Einzeiler können in der Tat Verwüstungen mit Skalierbarkeit verursachen. Ein anderes zB aus der Vergangenheit - https://github.com/kubernetes/kubernetes/pull/53720#issue-145949976
Im Allgemeinen möchten Sie vielleicht https://github.com/kubernetes/community/blob/master/sig-scalability/blogs/scalability-regressions-case-studies.md für eine gute Lektüre sehen :)
shyamjvs
am 21. März 2018
Update re. Test am Kopf: Erster Lauf mit lokal zurückgesetztem Commit bestanden. Dies könnte jedoch eine Flocke sein, also führe ich sie erneut aus.
wasylkowski-a
am 21. März 2018
Sehen Sie sich das Commit unter https: //github.com/kubernetes/kubernetes/pull/59953 an ... wurde nicht ein Fehler behoben? Es scheint einen Fehler behoben zu haben, durch den der Status "Geplant" in das falsche Objekt verschoben wurde. Basierend auf dem in dieser PR genannten Problem sieht es so aus, als könnte das Kubelet die Meldung verpassen, dass ein Pod ohne dieses Update geplant wurde.
liggitt
am 21. März 2018
@ Random-Liu Wer kann uns vielleicht besser erklären, wie sich diese Änderung auswirkt :)
shyamjvs
am 21. März 2018
Schauen Sie sich das Commit in # 59953 an ... hat es nicht einen Fehler behoben? Es scheint einen Fehler behoben zu haben, durch den der Status "Geplant" in das falsche Objekt verschoben wurde. Könnte das Kubelet gemeldet haben, dass ein Pod zu früh vor diesem Fix geplant war?
Ja - ich weiß, dass es eine Fehlerbehebung war. Ich verstehe das einfach nicht ganz.
Es scheint das Problem der Pod-Berichterstellung als "Geplant" zu beheben. Aber wir sehen das Problem erst, wenn die Zeit von Kubelet als "StartedAt" gemeldet wird.
Das Problem ist, dass zwischen der von Kubelet als "StartedAt" gemeldeten Zeit und der Meldung und Aktualisierung des Pod-Status durch den Test ein deutlicher Anstieg zu verzeichnen ist.
Ich denke, das "Geplante" Bit ist hier ein roter Hering.
Meine Vermutung (aber dies ist immer noch nur eine Vermutung) ist, dass wir aufgrund dieser Änderung mehr Pod-Statusaktualisierungen senden, was wiederum zu mehr 429s oder so etwas führt. Und am Ende braucht ein Kubelet mehr Zeit, um den Pod-Status zu melden. Aber das müssen wir noch bestätigen.
wojtek-t
am 21. März 2018
Nach zwei Läufen bin ich ziemlich sicher, dass das Zurücksetzen von # 59953 das Problem behebt:
3.052567319s (watch), 4.489142104s (pod-startup)
2.799364978s (watch), 4.385999497s (pod-startup)
Wir senden mehr Pod-Status-Updates, was wiederum zu mehr 429s oder so etwas führt. Und am Ende braucht ein Kubelet mehr Zeit, um den Pod-Status zu melden.
Dies ist so ziemlich der Effekt, den ich in https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938 vermutet habe (obwohl die Ursache, die ich vermutet habe, falsch war) :)
Auch wir IIRC schienen einen Anstieg der Anzahl von 429s für Put-Anrufe zu sehen (siehe meine https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370582634), aber das war aus einem früheren Bereich, denke ich ( um etcd ändern).
shyamjvs
am 21. März 2018
Nach zwei Läufen bin ich ziemlich sicher, dass das Zurücksetzen von # 59953 das Problem behebt:
Meine Intuition (https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370874602) über das Problem, ziemlich früh im Thread auf der Kubelet-Seite zu sein, war schließlich richtig :)
shyamjvs
am 21. März 2018
/ sig Knoten
@ kubernetes / sig-node-bugs Das Release-Team könnte die Überprüfung von # 59953 Commit versus Revert und das Leistungsproblem hier wirklich gebrauchen
tpepper
am 21. März 2018
Schauen Sie sich das Commit in # 59953 an ... hat es nicht einen Fehler behoben? Es scheint einen Fehler behoben zu haben, durch den der Status "Geplant" in das falsche Objekt verschoben wurde. Basierend auf dem in dieser PR genannten Problem sieht es so aus, als könnte das Kubelet die Meldung verpassen, dass ein Pod ohne dieses Update geplant wurde.
@liggitt Danke, dass du mir das erklärt hast. Ja, diese PR behebt einen Fehler. Bisher hat kubelet nicht immer PodScheduled . Mit # 59953 macht kubelet das richtig.
@shyamjvs Ich bin nicht sicher, ob es weitere Pod-Status-Updates einführen könnte.
Wenn ich das richtig verstehe, wird die Bedingung PodScheduled in der ersten Statusaktualisierung festgelegt und ist dann immer vorhanden und wird nie geändert. Ich verstehe nicht, warum es mehr Statusaktualisierungen generiert.
Wenn es wirklich mehr Statusaktualisierungen einführt, ist es ein Problem, das vor 2 Jahren eingeführt wurde: https://github.com/kubernetes/kubernetes/pull/24459, aber durch einen Fehler abgedeckt, und # 59953 behebt einfach den Fehler ...
@ wasylkowski-a Haben Sie Protokolle für den 2 Testlauf in https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -374982422 und https://github.com/kubernetes/kubernetes/issues/60589## Problemkommentar -374871490? Grundsätzlich eine gute und eine schlechte. Das kubelet.log wird sehr hilfreich sein.
 Random-Liu
am 21. März 2018
Random-Liu
am 21. März 2018
@yujuhong und ich haben festgestellt, dass # 59953 ein Problem aufgedeckt hat, PodScheduled Zustand des statischen Pods ständig aktualisiert wird.
Kubelet generiert eine neue PodScheduled Bedingung für einen Pod, der diese nicht hat. Static Pod hat es nicht und sein Status wird nie aktualisiert (erwartetes Verhalten). Somit generiert kubelet weiterhin eine neue PodScheduled Bedingung für einen statischen Pod.
Das Problem wurde in # 24459 eingeführt, aber durch einen Fehler abgedeckt. # 59953 hat den Fehler behoben und das ursprüngliche Problem aufgedeckt.
Es gibt zwei Möglichkeiten, um dies schnell zu beheben:
- Option 1: Lassen Sie kubelet keine
PodScheduledBedingung hinzufügen, kubelet sollte nur die vom Scheduler festgelegtePodScheduledBedingung beibehalten.- Vorteile: Einfach.
- Nachteile: Statische Pods und Pods, die den Scheduler umgehen (Knotennamen direkt zuweisen), haben keine
PodScheduledBedingung. Eigentlich ohne # 59953, obwohl Kubelet diese Bedingung für diese Pods irgendwann festlegen wird, aber es kann aufgrund eines Fehlers sehr lange dauern.
- Option 2: Generieren Sie eine
PodScheduled-Bedingung für einen statischen Pod, wenn Kubelet sie anfänglich sieht.
Option 2 führt möglicherweise zu weniger Änderungen für den Benutzer.
Aber wir möchten fragen, was PodScheduled für Pods bedeuten, die nicht vom Scheduler geplant werden. Brauchen wir diese Bedingung wirklich für diese Hülsen? / cc @ kubernetes / sig-autoscaling-bugs Weil @yujuhong mir gesagt hat, dass PodScheduled jetzt von der automatischen Skalierung verwendet wird.
/ cc @ kubernetes / sig-node-bugs @ kubernetes / sig-scheduling-bugs
Random-Liu
am 21. März 2018
@ Random-Liu Was bewirkt das very long time for kubelet to eventually set this condition ? Welches Problem wird ein Endbenutzer bemerken (Gesicht außerhalb des Testgeschirrs)? (ab Option 1)
dims
am 21. März 2018
@dims Benutzer wird die Bedingung PodScheduled für eine lange Zeit nicht sehen.
Random-Liu
am 21. März 2018
Ich habe einen Fix # 61504, der Option 2 in https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979 implementiert.
Ich kann es in Option 1 ändern, wenn die Leute denken, dass dies eine bessere Lösung ist. :) :)
Random-Liu
am 21. März 2018
Fragen Sie besser Leute, die das genau wissen! (NICHT das Release-Team 😄!)
ping @dashpole @ dchen1107 @derekwaynecarr
dims
am 21. März 2018
@ Random-Liu IIRC Der einzige statische Pod, der in unseren Tests auf Knoten ausgeführt wird, ist kube-proxy. Können Sie sagen, wie häufig diese "kontinuierlichen Aktualisierungen" von kubelet durchgeführt werden? (Fragen, um die durch den Fehler verursachten zusätzlichen QPS zu schätzen)
shyamjvs
am 21. März 2018
@ Random-Liu IIRC Der einzige statische Pod, der in unseren Tests auf Knoten ausgeführt wird, ist kube-proxy. Können Sie sagen, wie häufig diese "kontinuierlichen Aktualisierungen" von kubelet durchgeführt werden? (Fragen, um die durch den Fehler verursachten zusätzlichen QPS zu schätzen)
@shyamjvs Ja, kube-proxy ist jetzt der einzige auf dem Knoten.
Ich denke , es hängt von pod - Sync - Frequenz https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/kubeletconfig/v1beta1/defaults.go#L47 , die 1 Minute. Daher generiert kubelet alle 1 Minute eine zusätzliche Aktualisierung des Pod-Status.
Random-Liu
am 22. März 2018
Vielen Dank. Das bedeutet also, dass 5000/60 = ~ 83 qps aufgrund der Pod-Status-Anrufe zusätzlich hinzugefügt werden. Scheint die erhöhten 429s zu erklären, die früher im Fehler festgestellt wurden.
shyamjvs
am 22. März 2018
@ Random-Liu, vielen Dank, dass Sie uns dabei geholfen haben, dies zu regeln.
jdumars
am 22. März 2018
@jdumars np ~ @yujuhong hat mir sehr geholfen!
Random-Liu
am 22. März 2018
Aber wir möchten fragen, was PodScheduled für Pods bedeutet, die nicht vom Scheduler geplant werden. Brauchen wir diese Bedingung wirklich für diese Hülsen? / cc @ kubernetes / sig-autoscaling-bugs Weil @yujuhong mir gesagt hat, dass PodScheduled jetzt von der
Ich denke immer noch, dass es etwas seltsam ist, Kubelet die Bedingung PodScheduled zu lassen (wie ich in der ursprünglichen PR bemerkt habe). Selbst wenn kubelet diese Bedingung nicht festlegt, hat dies keine Auswirkungen auf den Cluster-Autoscaler, da der Autoscaler die Pods ohne die spezifische Bedingung ignoriert. Wie auch immer, der Fix, den wir letztendlich gefunden haben, hat nur einen sehr geringen Platzbedarf und würde das aktuelle Verhalten beibehalten (dh immer die PodScheduled-Bedingung festlegen), also werden wir damit weitermachen.
 yujuhong
am 22. März 2018
yujuhong
am 22. März 2018
Außerdem wurde das wirklich alte Problem für das Hinzufügen von Tests für die stationäre Pod-Aktualisierungsrate Nr. 14391 wiederbelebt
yujuhong
am 22. März 2018
Wie auch immer, der Fix, den wir letztendlich gefunden haben, hat nur einen sehr geringen Platzbedarf und würde das aktuelle Verhalten beibehalten (dh immer die PodScheduled-Bedingung festlegen), also werden wir damit weitermachen.
@yujuhong -
@wasylkowski @shyamjvs -
wojtek-t
am 22. März 2018
Ich habe den Test gegen 1.10 HEAD + # 61504 durchgeführt, und die Pod-Start-Latenz scheint in Ordnung zu sein:
INFO: perc50: 2.594635536s, perc90: 3.483550118s, perc99: 4.327417676s
Wird zur Bestätigung erneut ausgeführt.
shyamjvs
am 22. März 2018
@shyamjvs - vielen Dank!
wojtek-t
am 22. März 2018
Der zweite Lauf scheint auch gut zu sein:
INFO: perc50: 2.583489146s, perc90: 3.466873901s, perc99: 4.380595534s
Ziemlich zuversichtlich, dass das Update den Trick getan hat. Lassen Sie es uns so schnell wie möglich in 1.10 bringen.
shyamjvs
am 22. März 2018
Danke @shyamjvs
Während wir offline sprachen - ich denke, wir hatten im letzten Monat oder so eine weitere Regression, aber diese sollte die Veröffentlichung nicht blockieren.
wojtek-t
am 22. März 2018
@yujuhong -
Ja. Der aktuelle Fix in dieser PR ist nicht in den Optionen enthalten, die ursprünglich unter https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979 vorgeschlagen wurden
yujuhong
am 22. März 2018
Wiedereröffnung, bis wir ein gutes Leistungstestergebnis haben.
jberkus
am 25. März 2018
@yujuhong @krzyzacy @shyamjvs @ wojtek-t @ Random-Liu @ wasylkowski-a irgendwelche Updates dazu? Dies blockiert derzeit noch 1.10.
jdumars
am 26. März 2018
Der einzige Teil dieses Fehlers, der die Veröffentlichung blockierte, ist der 5k-Node-Performance-Job. Leider haben wir unseren Lauf von heute aus einem anderen Grund verloren (siehe: https://github.com/kubernetes/kubernetes/issues/61190#issuecomment-376150569).
Wir sind jedoch ziemlich sicher, dass das Update auf der Grundlage meiner manuellen Läufe funktioniert (Ergebnisse in https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-375350217). Meiner Meinung nach müssen wir die Veröffentlichung nicht blockieren (der nächste Lauf wird am Mittwoch stattfinden).
shyamjvs
am 26. März 2018
+1
@jdumars - Ich denke, wir können dies als Nicht-Blocker behandeln.
wojtek-t
am 26. März 2018
Entschuldigung, ich habe meinen Beitrag oben bearbeitet. Ich meinte, wir sollten es als "Nichtblocker" behandeln.
wojtek-t
am 26. März 2018
Ok, vielen Dank. Diese Schlussfolgerung stellt eine enorme Anzahl von Stunden dar, die Sie investiert haben, und ich kann Ihnen unmöglich genug für die geleistete Arbeit danken. Während wir abstrakt über "Community" und "Mitwirkende" sprechen, stellen Sie und die anderen, die dieses Problem bearbeitet haben, es konkret dar. Sie sind das Herz und die Seele dieses Projekts, und ich weiß, dass ich für alle Beteiligten spreche, wenn ich sage, dass es eine Ehre ist, mit dieser Leidenschaft, diesem Engagement und dieser Professionalität zusammenzuarbeiten.
jdumars
am 26. März 2018
[MILESTONENOTIFIER] Meilensteinproblem: Aktuell für den Prozess
@krzyzacy @ msau42 @shyamjvs @ wojtek-t
Etiketten ausstellen
sig/api-machinerysig/autoscalingsig/nodesig/scalabilitysig/schedulingsig/storage: Das Problem wird bei Bedarf an diese SIGs weitergeleitet.priority/critical-urgent: Verschieben Sie das Problem niemals automatisch aus einem Release-Meilenstein heraus. Eskalieren Sie kontinuierlich über alle verfügbaren Kanäle zu Mitwirkenden und SIG.kind/bug: Behebt einen Fehler, der während der aktuellen Version entdeckt wurde.Hilfe
 k8s-github-robot
am 11. Apr. 2018
k8s-github-robot
am 11. Apr. 2018
Dieses Problem wurde mit den entsprechenden Korrekturen in Version 1.10 behoben.
Für 1.11 verfolgen wir die Fehler unter - https://github.com/kubernetes/kubernetes/issues/63030.
/schließen
shyamjvs
am 25. Mai 2018
Verwandte Themen
 alexferl
·
3Kommentare
alexferl
·
3Kommentare
 zetaab
·
3Kommentare
zetaab
·
3Kommentare
 ddysher
·
3Kommentare
ddysher
·
3Kommentare
 chowyu08
·
3Kommentare
chowyu08
·
3Kommentare
 broady
·
3Kommentare
broady
·
3Kommentare
Hilfreichster Kommentar
Ich habe den Test gegen 1.10 HEAD + # 61504 durchgeführt, und die Pod-Start-Latenz scheint in Ordnung zu sein:
Wird zur Bestätigung erneut ausgeführt.