Go: Proposition : Une fonction de vérification d'erreur Go intégrée, "essayer"
Proposition : une fonction de vérification des erreurs Go intégrée, try
Cette proposition a été fermée .
Avant de commenter, veuillez lire le document de conception détaillé et consulter le résumé de la discussion du 6 juin , le résumé du 10 juin et _surtout les conseils pour rester concentré_ . Votre question ou suggestion a peut-être déjà reçu une réponse ou été formulée. Merci.
Nous proposons une nouvelle fonction intégrée appelée try , conçue spécifiquement pour éliminer les instructions passe-partout if généralement associées à la gestion des erreurs dans Go. Aucun autre changement de langue n'est suggéré. Nous préconisons l'utilisation de l'instruction defer existante et des fonctions de bibliothèque standard pour aider à augmenter ou à envelopper les erreurs. Cette approche minimale répond aux scénarios les plus courants tout en ajoutant très peu de complexité au langage. La fonction intégrée try est facile à expliquer, simple à implémenter, orthogonale aux autres constructions de langage et entièrement rétrocompatible. Cela laisse également la possibilité d'étendre le mécanisme, si nous le souhaitons à l'avenir.
[Le texte ci-dessous a été modifié pour refléter plus précisément la documentation de conception.]
La fonction intégrée try prend une seule expression comme argument. L'expression doit correspondre à n+1 valeurs (où n peut être zéro) où la dernière valeur doit être de type error . Il renvoie les n premières valeurs (le cas échéant) si l'argument d'erreur (final) est nil, sinon il renvoie à partir de la fonction englobante avec cette erreur. Par exemple, un code tel que
f, err := os.Open(filename)
if err != nil {
return …, err // zero values for other results, if any
}
peut être simplifié en
f := try(os.Open(filename))
try ne peut être utilisé que dans une fonction qui renvoie elle-même un résultat error , et ce résultat doit être le dernier paramètre de résultat de la fonction englobante.
Cette proposition réduit à son essence le projet de conception original présenté lors de la GopherCon de l'année dernière. Si l'augmentation ou l'encapsulation des erreurs est souhaitée, il existe deux approches : s'en tenir à l'instruction éprouvée if ou, alternativement, "déclarer" un gestionnaire d'erreurs avec une instruction defer :
defer func() {
if err != nil { // no error may have occurred - check for it
err = … // wrap/augment error
}
}()
Ici, err est le nom du résultat d'erreur de la fonction englobante. En pratique, des fonctions d'assistance appropriées réduiront la déclaration d'un gestionnaire d'erreurs à une seule ligne. Par exemple
defer fmt.HandleErrorf(&err, "copy %s %s", src, dst)
(où fmt.HandleErrorf décore *err ) se lit bien et peut être implémenté sans avoir besoin de nouvelles fonctionnalités de langage.
Le principal inconvénient de cette approche est que le paramètre de résultat d'erreur doit être nommé, ce qui peut conduire à des API moins jolies. En fin de compte, c'est une question de style, et nous pensons que nous nous adapterons à l'attente du nouveau style, tout comme nous nous sommes adaptés à ne pas avoir de points-virgules.
En résumé, try peut sembler inhabituel au premier abord, mais c'est simplement du sucre syntaxique sur mesure pour une tâche spécifique, une gestion des erreurs avec moins de passe-partout et pour gérer cette tâche assez bien. En tant que tel, il s'inscrit parfaitement dans la philosophie de Go. try n'est pas conçu pour résoudre _toutes_ les situations de gestion des erreurs ; il est conçu pour bien gérer le cas _le plus courant_, pour garder une conception simple et claire.
Crédits
Cette proposition est fortement influencée par les commentaires que nous avons reçus jusqu'à présent. Plus précisément, il emprunte des idées à:
- Éléments clés de la gestion des erreurs ,
- numéro 31442
- et, connexe, le numéro #32219 .
Document de conception détaillée
https://github.com/golang/proposal/blob/master/design/32437-try-builtin.md
Outil tryhard pour explorer l'impact de try
 griesemer
griesemer
Tous les 808 commentaires
Je suis d'accord que c'est la meilleure voie à suivre : résoudre le problème le plus courant avec une conception simple.
Je ne veux pas faire de bikeshed (n'hésitez pas à reporter cette conversation), mais Rust y est allé et s'est finalement installé avec l'opérateur postfix ? plutôt qu'une fonction intégrée, pour une lisibilité accrue.
La proposition de gophercon cite ? dans les idées envisagées et donne trois raisons pour lesquelles elle a été rejetée : la première (« les transferts de flux de contrôle sont en règle générale accompagnés de mots-clés ») et la troisième (« les gestionnaires sont plus naturellement définis avec un mot-clé, donc les chèques aussi") ne s'appliquent plus. Le second est stylistique : il dit que, même si l'opérateur postfix fonctionne mieux pour le chaînage, il peut encore lire moins bien dans certains cas comme :
check io.Copy(w, check newReader(foo))
plutôt que:
io.Copy(w, newReader(foo)?)?
mais maintenant on aurait :
try(io.Copy(w, try(newReader(foo))))
ce qui, je pense, est clairement le pire des trois, car il n'est même plus évident de savoir quelle est la fonction principale appelée.
Donc, l'essentiel de mon commentaire est que les trois raisons citées dans la proposition gophercon pour ne pas utiliser ? ne s'appliquent pas à cette proposition try ; ? est concis, très lisible, il n'obscurcit pas la structure de l'instruction (avec sa hiérarchie d'appel de fonction interne) et il est chaîné. Il supprime encore plus l'encombrement de la vue, sans obscurcir le flux de contrôle plus que le try() proposé ne le fait déjà.
 rasky
le 5 juin 2019
rasky
le 5 juin 2019
Clarifier:
Fait
func f() (n int, err error) {
n = 7
try(errors.New("x"))
// ...
}
retourner (0, "x") ou (7, "x") ? Je suppose que ce dernier.
Le retour d'erreur doit-il être nommé dans le cas où il n'y a pas de décoration ou de gestion (comme dans une fonction d'assistance interne) ? Je suppose que non.
 jimmyfrasche
le 5 juin 2019
jimmyfrasche
le 5 juin 2019
Votre exemple renvoie 7, errors.New("x") . Cela devrait être clair dans le document complet qui sera bientôt soumis (https://golang.org/cl/180557).
Le paramètre de résultat d'erreur n'a pas besoin d'être nommé pour utiliser try . Il n'a besoin d'être nommé que si la fonction doit y faire référence dans une fonction différée ou ailleurs.
 ianlancetaylor
le 5 juin 2019
ianlancetaylor
le 5 juin 2019
Je suis vraiment mécontent d'une _fonction_ intégrée affectant le flux de contrôle de l'appelant. J'apprécie l'impossibilité d'ajouter de nouveaux mots-clés dans Go 1, mais contourner ce problème avec des fonctions intégrées magiques me semble tout simplement faux. L'observation d'autres éléments intégrés n'a pas de résultats aussi imprévisibles que le changement de flux de contrôle.
Je n'aime pas l'apparence de postfix ? , mais je pense qu'il bat toujours try() .
Edit : Eh bien, j'ai réussi à oublier complètement que la panique existe et n'est pas un mot-clé.
 dominikh
le 5 juin 2019
dominikh
le 5 juin 2019
La proposition détaillée est maintenant ici (en attendant des améliorations de formatage, à venir sous peu) et, espérons-le, répondra à beaucoup de questions.
griesemer
le 5 juin 2019
@dominikh La proposition détaillée en discute longuement, mais veuillez noter que panic et recover sont deux éléments intégrés qui affectent également le flux de contrôle.
griesemer
le 5 juin 2019
Une précision/suggestion d'amélioration :
if the last argument supplied to try, of type error, is not nil, the enclosing function’s error result variable (...) is set to that non-nil error value before the enclosing function returns
Cela pourrait-il plutôt dire is set to that non-nil error value and the enclosing function returns ? (s/avant/et)
Lors de la première lecture, before the enclosing function returns semblait définir _éventuellement_ la valeur d'erreur à un moment donné dans le futur juste avant le retour de la fonction - éventuellement dans une ligne ultérieure. L'interprétation correcte est que try peut provoquer le retour de la fonction en cours. C'est un comportement surprenant pour le langage actuel, donc un texte plus clair serait le bienvenu.
 nictuku
le 5 juin 2019
nictuku
le 5 juin 2019
Je pense que ce n'est que du sucre, et un petit nombre d'opposants vocaux ont taquiné Golang à propos de l'utilisation répétée de taper if err != nil ... et quelqu'un l'a pris au sérieux. Je ne pense pas que ce soit un problème. Les seules choses manquantes sont ces deux éléments intégrés :
 purpleidea
le 5 juin 2019
purpleidea
le 5 juin 2019
Je ne sais pas pourquoi quelqu'un écrirait jamais une fonction comme celle-ci, mais quelle serait la sortie envisagée pour
try(foobar())
Si foobar renvoyé (error, error)
 webermaster
le 5 juin 2019
webermaster
le 5 juin 2019
Je retire mes préoccupations précédentes concernant le flux de contrôle et je ne suggère plus d'utiliser ? . Je m'excuse pour la réponse instinctive (même si je tiens à souligner que cela ne se serait pas produit si le problème avait été signalé _après_ que la proposition complète était disponible).
Je ne suis pas d'accord avec la nécessité d'une gestion simplifiée des erreurs, mais je suis sûr que c'est une bataille perdue d'avance. try comme indiqué dans la proposition semble être la moins mauvaise façon de le faire.
dominikh
le 5 juin 2019
@webermaster Seul le dernier résultat error est spécial pour l'expression passée à try , comme décrit dans le document de proposition.
ianlancetaylor
le 5 juin 2019
Comme @dominikh , je suis également en désaccord avec la nécessité d'une gestion simplifiée des erreurs.
Il transforme la complexité verticale en complexité horizontale, ce qui est rarement une bonne idée.
Si je devais absolument choisir entre simplifier les propositions de gestion des erreurs, ce serait ma proposition préférée.
 akyoto
le 5 juin 2019
akyoto
le 5 juin 2019
Il serait utile que cela puisse être accompagné (à un certain stade d'acceptation) d'un outil pour transformer le code Go afin d'utiliser try dans un sous-ensemble de fonctions renvoyant des erreurs où une telle transformation peut être facilement effectuée sans changer de sémantique. Trois avantages me viennent à l'esprit :
- Lors de l'évaluation de cette proposition, cela permettrait aux gens d'avoir rapidement une idée de la façon dont
trypourrait être utilisé dans leur base de code. - Si
tryatterrit dans une future version de Go, les gens voudront probablement changer leur code pour l'utiliser. Avoir un outil pour automatiser les cas faciles aidera beaucoup. - Avoir un moyen de transformer rapidement une grande base de code pour utiliser
tryfacilitera l'examen des effets de la mise en œuvre à grande échelle. (Correctivité, performances et taille de code, par exemple.) L'implémentation peut être suffisamment simple pour en faire une considération négligeable, cependant.
 cespare
le 5 juin 2019
cespare
le 5 juin 2019
Je voudrais juste exprimer que je pense qu'un seul try(foo()) renflouant réellement la fonction d'appel nous enlève le signal visuel que le flux de fonction peut changer en fonction du résultat.
Je sens que je peux travailler avec try étant donné qu'il est suffisamment utilisé, mais je pense aussi que nous aurons besoin d'un support IDE supplémentaire (ou d'un autre) pour mettre en évidence try afin de reconnaître efficacement le flux implicite dans les révisions de code /sessions de débogage
 lestrrat
le 5 juin 2019
lestrrat
le 5 juin 2019
La chose qui me préoccupe le plus est la nécessité d'avoir des valeurs de retour nommées juste pour que l'instruction de report soit heureuse.
Je pense que le problème global de gestion des erreurs dont la communauté se plaint est une combinaison du passe-partout de if err != nil ET de l'ajout de contexte aux erreurs. La FAQ indique clairement que ce dernier est intentionnellement laissé de côté en tant que problème distinct, mais j'ai l'impression que cela devient alors une solution incomplète, mais je serai prêt à lui donner une chance après avoir réfléchi à ces 2 choses :
- Déclarez
errau début de la fonction.
Est-ce que ça marche? Je me souviens de problèmes avec des résultats différés et sans nom. Si ce n'est pas le cas, la proposition doit en tenir compte.
func sample() (string, error) {
var err error
defer fmt.HandleErrorf(&err, "whatever")
s := try(f())
return s, nil
}
- Attribuez des valeurs comme nous l'avons fait dans le passé, mais utilisez une fonction d'assistance
wrapfqui a le passe-if err != nil.
func sample() (string, error) {
s, err := f()
try(wrapf(err, "whatever"))
return s, nil
}
func wrapf(err error, format string, ...v interface{}) error {
if err != nil {
// err = wrapped error
}
return err
}
Si l'un ou l'autre fonctionne, je peux m'en occuper.
 Goodwine
le 5 juin 2019
Goodwine
le 5 juin 2019
func sample() (string, error) {
var err error
defer fmt.HandleErrorf(&err, "whatever")
s := try(f())
return s, nil
}
Cela ne fonctionnera pas. Le report mettra à jour la variable locale err , qui n'est pas liée à la valeur de retour.
func sample() (string, error) {
s, err := f()
try(wrapf(err, "whatever"))
return s, nil
}
func wrapf(err error, format string, ...v interface{}) error {
if err != nil {
// err = wrapped error
}
return err
}
Cela devrait fonctionner. Cependant, il appellera wrapf même sur une erreur nulle.
Cela fonctionnera également (continuera à) fonctionner, et est beaucoup plus clair à l'OMI :
func sample() (string, error) {
s, err := f()
if err != nil {
return "", wrap(err)
}
return s, nil
}
Personne ne vous fera utiliser try .
 randall77
le 5 juin 2019
randall77
le 5 juin 2019
Je ne sais pas pourquoi quelqu'un écrirait jamais une fonction comme celle-ci, mais quelle serait la sortie envisagée pour
try(foobar())Si
foobarrenvoyé(error, error)
Pourquoi renverriez-vous plus d'une erreur à partir d'une fonction ? Si vous renvoyez plus d'une erreur de la fonction, peut-être que la fonction devrait être divisée en deux en premier lieu, chacune ne renvoyant qu'une seule erreur.
Pourriez-vous développer avec un exemple?
 singhpradeep
le 5 juin 2019
singhpradeep
le 5 juin 2019
@cespare : Il devrait être possible pour quelqu'un d'écrire un go fix qui réécrit le code existant adapté à try sorte qu'il utilise try . Il peut être utile d'avoir une idée de la façon dont le code existant pourrait être simplifié. Nous ne nous attendons pas à des changements significatifs dans la taille ou les performances du code, car try n'est qu'un sucre syntaxique, remplaçant un modèle commun par un morceau de code source plus court qui produit essentiellement le même code de sortie. Notez également que le code qui utilise try sera obligé d'utiliser une version Go qui est au moins la version à laquelle try a été introduit.
@lestrrat : Convenu qu'il faudra apprendre que try peut changer le flux de contrôle. Nous soupçonnons que les IDE pourraient le mettre en évidence assez facilement.
@Goodwine : Comme @randall77 l' a déjà souligné, votre première suggestion ne fonctionnera pas. Une option à laquelle nous avons pensé (mais non discutée dans la doc) est la possibilité d'avoir une variable prédéclarée qui indique le résultat error (s'il y en a une en premier lieu). Cela éliminerait le besoin de nommer ce résultat juste pour qu'il puisse être utilisé dans un defer . Mais ce serait encore plus magique ; cela ne semble pas justifié. Le problème avec la dénomination du résultat de retour est essentiellement cosmétique, et là où cela compte le plus, c'est dans les API générées automatiquement servies par go doc et ses amis. Il serait facile d'aborder cela dans ces outils (voir aussi la FAQ détaillée de la doc de conception à ce sujet).
griesemer
le 5 juin 2019
@nictuku : Concernant votre suggestion de clarification (s/before/and/) : je pense que le code juste avant le paragraphe auquel vous faites référence indique clairement ce qui se passe exactement, mais je vois votre point, s/before/and/ may rendre la prose plus claire. Je vais faire le changement.
Voir CL 180637 .
griesemer
le 5 juin 2019
J'aime vraiment beaucoup cette proposition. Cependant, j'ai une critique. Le point de sortie des fonctions dans Go a toujours été marqué par un return . Les paniques sont également des points de sortie, mais ce sont des erreurs catastrophiques qui ne sont généralement pas censées être rencontrées.
Faire un point de sortie d'une fonction qui n'est pas un return , et qui est censé être banal, peut conduire à un code beaucoup moins lisible. J'en avais entendu parler lors d'une conférence et il est difficile de ne pas voir la beauté de la structure de ce code :
func CopyFile(src, dst string) error {
r, err := os.Open(src)
if err != nil {
return fmt.Errorf("copy %s %s: %v", src, dst, err)
}
defer r.Close()
w, err := os.Create(dst)
if err != nil {
return fmt.Errorf("copy %s %s: %v", src, dst, err)
}
if _, err := io.Copy(w, r); err != nil {
w.Close()
os.Remove(dst)
return fmt.Errorf("copy %s %s: %v", src, dst, err)
}
if err := w.Close(); err != nil {
os.Remove(dst)
return fmt.Errorf("copy %s %s: %v", src, dst, err)
}
}
Ce code peut ressembler à un gros gâchis, et était _signifié_ par le brouillon de gestion des erreurs, mais comparons-le à la même chose avec try .
func CopyFile(src, dst string) error {
defer func() {
err = fmt.Errorf("copy %s %s: %v", src, dst, err)
}()
r, err := try(os.Open(src))
defer r.Close()
w, err := try(os.Create(dst))
defer w.Close()
defer os.Remove(dst)
try(io.Copy(w, r))
try(w.Close())
return nil
}
Vous pouvez regarder cela à première vue et penser que cela semble mieux, car il y a beaucoup moins de code répété. Cependant, il était très facile de repérer tous les points renvoyés par la fonction dans le premier exemple. Ils étaient tous en retrait et commençaient par return , suivi d'un espace. Cela est dû au fait que tous les retours conditionnels _doivent_ être à l'intérieur de blocs conditionnels, étant ainsi indentés par les normes gofmt . return est aussi, comme indiqué précédemment, le seul moyen de quitter une fonction sans dire qu'une erreur catastrophique s'est produite. Dans le deuxième exemple, il n'y a qu'un seul return , il semble donc que la seule chose que la fonction _ever_ devrait retourner soit nil . Les deux derniers appels try sont faciles à voir, mais les deux premiers sont un peu plus difficiles, et le seraient encore plus s'ils étaient imbriqués quelque part, c'est-à-dire quelque chose comme proc := try(os.FindProcess(try(strconv.Atoi(os.Args[1])))) .
Revenir d'une fonction semble avoir été une chose "sacrée" à faire, c'est pourquoi je pense personnellement que tous les points de sortie d'une fonction devraient être marqués par return .
 deanveloper
le 5 juin 2019
deanveloper
le 5 juin 2019
Quelqu'un l'a déjà mis en place il y a 5 ans. Si vous êtes intéressé, vous pouvez
essayez cette fonctionnalité
https://news.ycombinator.com/item?id=20101417
J'ai implémenté try() dans Go il y a cinq ans avec un préprocesseur AST et je l'ai utilisé dans de vrais projets, c'était plutôt sympa : https://github.com/lunixbochs/og
Voici quelques exemples de mon utilisation dans les fonctions error-check-heavy : https://github.com/lunixbochs/poxd/blob/master/tls.go#L13
 s4n-gt
le 5 juin 2019
s4n-gt
le 5 juin 2019
J'apprécie l'effort qui a été fait. Je pense que c'est la solution la plus efficace que j'ai vue jusqu'à présent. Mais je pense que cela introduit un tas de travail lors du débogage. Déballer essayer et ajouter un bloc if chaque fois que je débogue et le réemballer quand j'ai fini est fastidieux. Et j'ai aussi quelques grincer des dents à propos de la variable d'erreur magique que je dois prendre en compte. Je n'ai jamais été dérangé par la vérification explicite des erreurs, alors je suis peut-être la mauvaise personne à qui demander. Il m'a toujours semblé "prêt à déboguer".
 jasonmoo
le 5 juin 2019
jasonmoo
le 5 juin 2019
@griesemer
Mon problème avec votre utilisation proposée de différer comme moyen de gérer l'emballage d'erreur est que le comportement de l'extrait que j'ai montré (répété ci-dessous) n'est pas très courant AFAICT, et parce que c'est très rare, je peux imaginer que les gens écrivent ceci en pensant que cela fonctionne quand ce n'est pas le cas.
Comme .. un débutant ne le saurait pas, s'il a un bogue à cause de cela, il n'ira pas "bien sûr, j'ai besoin d'un retour nommé", il serait stressé parce que ça devrait marcher et ça ne marche pas.
var err error
defer fmt.HandleErrorf(err);
try est déjà trop magique, vous pouvez donc aller jusqu'au bout et ajouter cette valeur d'erreur implicite. Pensez aux débutants, pas à ceux qui connaissent toutes les nuances du Go. Si ce n'est pas assez clair, je ne pense pas que ce soit la bonne solution.
Ou... Ne suggérez pas d'utiliser un report comme celui-ci, essayez une autre méthode plus sûre mais toujours lisible.
Goodwine
le 5 juin 2019
@deanveloper Il est vrai que cette proposition (et d'ailleurs, toute proposition essayant de tenter la même chose) supprimera les déclarations explicitement visibles return du code source - c'est tout l'intérêt de la proposition après tout, n'est-ce pas? Pour supprimer le passe-partout des déclarations if et returns qui sont toutes identiques. Si vous voulez conserver les return , n'utilisez pas try .
Nous sommes habitués à reconnaître immédiatement les instructions return (et panic ) car c'est ainsi que ce type de flux de contrôle est exprimé en Go (et dans de nombreux autres langages). Il ne semble pas exagéré que nous reconnaissions également try comme un changement de flux de contrôle après s'y être habitué, tout comme nous le faisons pour return . Je ne doute pas qu'un bon support IDE aidera également à cela.
griesemer
le 5 juin 2019
J'ai deux soucis :
- les retours nommés ont été très déroutants, ce qui les encourage avec un nouveau cas d'utilisation important
- cela découragera l'ajout de contexte aux erreurs
D'après mon expérience, ajouter du contexte aux erreurs immédiatement après chaque site d'appel est essentiel pour avoir un code qui peut être facilement débogué. Et les retours nommés ont semé la confusion chez presque tous les développeurs Go que je connais à un moment donné.
Une préoccupation stylistique plus mineure est qu'il est regrettable de voir combien de lignes de code seront désormais enveloppées dans try(actualThing()) . Je peux imaginer voir la plupart des lignes dans une base de code enveloppée dans try() . C'est malheureux.
Je pense que ces préoccupations seraient résolues avec un ajustement:
a, b, err := myFunc()
check(err, "calling myFunc on %v and %v", a, b)
check() se comporterait un peu comme try() , mais abandonnerait le comportement de transmission générique des valeurs de retour de fonction et offrirait à la place la possibilité d'ajouter du contexte. Cela déclencherait quand même un retour.
Cela conserverait de nombreux avantages de try() :
- c'est un intégré
- il suit le flux de contrôle existant WRT pour différer
- il s'aligne sur la pratique existante consistant à bien ajouter du contexte aux erreurs
- il s'aligne sur les propositions et les bibliothèques actuelles pour l'emballage des erreurs, telles que
errors.Wrap(err, "context message") - il en résulte un site d'appel propre : il n'y a pas de passe-partout sur la ligne
a, b, err := myFunc() - décrire les erreurs avec
defer fmt.HandleError(&err, "msg")est toujours possible, mais n'a pas besoin d'être encouragé. - la signature de
checkest légèrement plus simple, car elle n'a pas besoin de renvoyer un nombre arbitraire d'arguments de la fonction qu'elle enveloppe.
 buchanae
le 5 juin 2019
buchanae
le 5 juin 2019
@s4n-gt Merci pour ce lien. Je n'en étais pas conscient.
griesemer
le 5 juin 2019
@Goodwine Point pris. La raison de ne pas fournir une prise en charge plus directe de la gestion des erreurs est expliquée en détail dans la documentation de conception. C'est aussi un fait qu'au cours d'un an environ (depuis les projets de conception publiés au Gophercon de l'année dernière), aucune solution satisfaisante pour la gestion explicite des erreurs n'a été proposée. C'est pourquoi cette proposition laisse cela exprès (et suggère à la place d'utiliser un defer ). Cette proposition laisse encore la porte ouverte à de futures améliorations à cet égard.
griesemer
le 5 juin 2019
La proposition mentionne la modification des tests de package pour permettre aux tests et aux benchmarks de renvoyer une erreur. Bien que ce ne soit pas "un changement de bibliothèque modeste", nous pourrions également envisager d'accepter func main() error . Cela rendrait l'écriture de petits scripts beaucoup plus agréable. La sémantique serait équivalente à :
func main() {
if err := newmain(); err != nil {
println(err.Error())
os.Exit(1)
}
}
 josharian
le 5 juin 2019
josharian
le 5 juin 2019
Une dernière critique. Pas vraiment une critique de la proposition elle-même, mais plutôt une critique d'une réponse commune au contre-argument de la "fonction contrôlant le flux".
La réponse à "Je n'aime pas qu'une fonction contrôle le flux" est que " panic contrôle également le flux du programme!". Cependant, il y a quelques raisons pour lesquelles il est plus acceptable que panic fasse cela qui ne s'applique pas à try .
panicest convivial pour les programmeurs débutants car ce qu'il fait est intuitif, il continue à déballer la pile. On ne devrait même pas avoir à chercher comment fonctionnepanicpour comprendre ce qu'il fait. Les programmeurs débutants n'ont même pas besoin de s'inquiéter derecover, puisque les débutants ne construisent généralement pas de mécanismes de récupération de panique, d'autant plus qu'ils sont presque toujours moins favorables que d'éviter simplement la panique en premier lieu.panicest un nom facile à voir. Cela apporte de l'inquiétude, et il le faut. Si quelqu'un voitpanicdans une base de code, il devrait immédiatement penser à comment _éviter_ la panique, même si c'est trivial.En s'appuyant sur le dernier point,
panicne peut pas être imbriqué dans un appel, ce qui le rend encore plus facile à voir.
Il n'y a rien de mal à paniquer pour contrôler le déroulement du programme car il est extrêmement facile à repérer et il est intuitif quant à ce qu'il fait.
La fonction try ne satisfait aucun de ces points.
On ne peut pas deviner ce que fait
trysans consulter la documentation correspondante. De nombreuses langues utilisent le mot-clé de différentes manières, ce qui rend difficile de comprendre ce que cela signifierait en Go.tryn'attire pas mon attention, surtout lorsqu'il s'agit d'une fonction. _Surtout_ lorsque la coloration syntaxique le mettra en évidence en tant que fonction. _SPECIALLY_ après avoir développé dans un langage comme Java, oùtryest considéré comme un passe-partout inutile (à cause des exceptions vérifiées).trypeut être utilisé dans un argument d'un appel de fonction, comme dans mon exemple dans mon commentaire précédentproc := try(os.FindProcess(try(strconv.Atoi(os.Args[1])))). Cela le rend encore plus difficile à repérer.
Mes yeux ignorent les fonctions try , même lorsque je les recherche spécifiquement. Mes yeux les verront, mais passeront immédiatement aux appels os.FindProcess ou strconv.Atoi . try est un retour conditionnel. Le flux de contrôle ET les retours sont tous deux maintenus sur des socles en Go. Tout le flux de contrôle dans une fonction est en retrait et tous les retours commencent par return . Mélanger ces deux concepts ensemble dans un appel de fonction facile à manquer semble juste un peu décalé.
Ce commentaire et mon dernier sont cependant mes seules véritables critiques à l'idée. Je pense que je n'aime peut-être pas cette proposition, mais je pense toujours que c'est une victoire globale pour Go. Cette solution ressemble toujours plus à Go que les autres solutions. Si cela était ajouté, je serais heureux, mais je pense que cela peut encore être amélioré, je ne sais pas comment.
deanveloper
le 5 juin 2019
@buchanae intéressant. Tel qu'il est écrit, cependant, il déplace le formatage de style fmt d'un paquet vers le langage lui-même, ce qui ouvre une boîte de Pandore.
josharian
le 5 juin 2019
Tel qu'il est écrit, cependant, il déplace le formatage de style fmt d'un paquet vers le langage lui-même, ce qui ouvre une boîte de Pandore.
Bon point. Un exemple plus simple :
a, b, err := myFunc()
check(err, "calling myFunc")
@buchanae Nous avons envisagé de rendre la gestion des erreurs explicite plus directement liée à try - veuillez consulter la documentation de conception détaillée, en particulier la section sur les itérations de conception. Votre suggestion spécifique de check ne permettrait d'augmenter les erreurs qu'à travers quelque chose comme une API de type fmt.Errorf (dans le cadre du check ), si je comprends bien. En général, les gens peuvent vouloir faire toutes sortes de choses avec des erreurs, pas seulement en créer une nouvelle qui fait référence à l'original via sa chaîne d'erreur.
Encore une fois, cette proposition ne tente pas de résoudre toutes les situations de gestion d'erreurs. Je suppose que dans la plupart des cas, try a du sens pour un code qui ressemble maintenant à ceci :
a, b, c, ... err := try(someFunctionCall())
if err != nil {
return ..., err
}
Il y a énormément de code qui ressemble à ça. Et chaque morceau de code ressemblant à celui-ci n'a pas besoin de plus de gestion des erreurs. Et là où defer n'est pas correct, on peut toujours utiliser une instruction if .
griesemer
le 5 juin 2019
Je ne suis pas cette ligne :
defer fmt.HandleErrorf(&err, “foobar”)
Il laisse tomber l'erreur entrante sur le sol, ce qui est inhabituel. Est-il destiné à être utilisé quelque chose de plus comme ça?
defer fmt.HandleErrorf(&err, “foobar: %v”, err)
La duplication de err est un peu bégaiement. Ce n'est pas vraiment directement à propos de la proposition, juste un commentaire secondaire sur la doc.
josharian
le 5 juin 2019
Je partage les deux préoccupations soulevées par @buchanae , concernant les retours nommés et les erreurs contextuelles.
Je trouve les retours nommés un peu gênants ; Je pense qu'ils ne sont vraiment utiles que comme documentation. S'appuyer plus lourdement sur eux est un souci. Désolé d'être aussi vague, cependant. Je vais y réfléchir davantage et fournir des réflexions plus concrètes.
Je pense qu'il y a un réel souci que les gens s'efforcent de structurer leur code de sorte que try puisse être utilisé, et évitent donc d'ajouter du contexte aux erreurs. C'est un moment particulièrement étrange pour introduire cela, étant donné que nous venons tout juste de fournir de meilleurs moyens d'ajouter du contexte aux erreurs grâce aux fonctionnalités officielles d'encapsulation des erreurs.
Je pense que try tel que proposé rend un code beaucoup plus agréable. Voici une fonction que j'ai choisie plus ou moins au hasard dans la base de code de mon projet actuel, avec certains noms modifiés. Je suis particulièrement impressionné par le fonctionnement try lors de l'attribution de champs struct. (Cela suppose que ma lecture de la proposition est correcte et que cela fonctionne ?)
Le code existant :
func NewThing(thingy *foo.Thingy, db *sql.DB, client pb.Client) (*Thing, error) {
err := dbfile.RunMigrations(db, dbMigrations)
if err != nil {
return nil, err
}
t := &Thing{
thingy: thingy,
}
t.scanner, err = newScanner(thingy, db, client)
if err != nil {
return nil, err
}
t.initOtherThing()
return t, nil
}
Avec try :
func NewThing(thingy *foo.Thingy, db *sql.DB, client pb.Client) (*Thing, error) {
try(dbfile.RunMigrations(db, dbMigrations))
t := &Thing{
thingy: thingy,
scanner: try(newScanner(thingy, db, client)),
}
t.initOtherThing()
return t, nil
}
Aucune perte de lisibilité, sauf peut-être qu'il est moins évident que newScanner puisse échouer. Mais alors, dans un monde avec try Go, les programmeurs seraient plus sensibles à sa présence.
 adg
le 5 juin 2019
adg
le 5 juin 2019
@josharian Concernant main renvoyant un error : Il me semble que votre petite fonction d'assistance est tout ce qui est nécessaire pour obtenir le même effet. Je ne suis pas sûr que la modification de la signature de main soit justifiée.
Concernant l'exemple "foobar": C'est juste un mauvais exemple. Je devrais probablement le changer. Merci de l'avoir soulevé.
griesemer
le 5 juin 2019
defer fmt.HandleErrorf(&err, “foobar: %v”, err)
En fait, cela ne peut pas être vrai, car err sera évalué trop tôt. Il y a plusieurs façons de contourner cela, mais aucune d'entre elles n'est aussi propre que l'original (je pense défectueux) HandleErrorf. Je pense qu'il serait bon d'avoir un ou deux exemples travaillés plus réalistes d'une fonction d'assistance.
EDIT : ce bogue d'évaluation précoce est présent dans un exemple
vers la fin de la doc :
defer fmt.HandleErrorf(&err, "copy %s %s: %v", src, dst, err)
josharian
le 5 juin 2019
@adg Oui, try peut être utilisé comme vous l'utilisez dans votre exemple. Je laisse vos commentaires sur les retours nommés tels quels.
griesemer
le 5 juin 2019
les gens peuvent vouloir faire toutes sortes de choses avec des erreurs, pas seulement en créer une nouvelle qui fait référence à l'original via sa chaîne d'erreur.
try n'essaie pas de gérer toutes les sortes de choses que les gens veulent faire avec des erreurs, seulement celles que nous pouvons trouver un moyen pratique de rendre beaucoup plus simples. Je crois que mon exemple check va dans le même sens.
D'après mon expérience, la forme la plus courante de code de gestion des erreurs est le code qui ajoute essentiellement une trace de pile, parfois avec un contexte supplémentaire. J'ai trouvé que cette trace de pile était très importante pour le débogage, où je suis un message d'erreur à travers le code.
Mais peut-être que d'autres propositions ajouteront des traces de pile à toutes les erreurs ? J'ai perdu la trace.
Dans l'exemple donné par @adg , il y a deux échecs potentiels mais pas de contexte. Si newScanner et RunMigrations ne fournissent pas eux-mêmes des messages qui vous indiquent lequel s'est mal passé, alors vous n'avez plus qu'à deviner.
buchanae
le 5 juin 2019
Dans l'exemple donné par @adg , il y a deux échecs potentiels mais pas de contexte. Si newScanner et RunMigrations ne fournissent pas eux-mêmes des messages qui vous indiquent lequel s'est mal passé, alors vous n'avez plus qu'à deviner.
C'est vrai, et c'est le choix de conception que nous avons fait dans ce morceau de code particulier. Nous encapsulons beaucoup d'erreurs dans d'autres parties du code.
adg
le 5 juin 2019
Je partage l'inquiétude de @deanveloper et d'autres que cela pourrait rendre le débogage plus difficile. Il est vrai que nous pouvons choisir de ne pas l'utiliser, mais les styles des dépendances tierces ne sont pas sous notre contrôle.
Si moins répétitif if err := ... { return err } est le point principal, je me demande si un "retour conditionnel" suffirait, comme https://github.com/golang/go/issues/27794 proposé.
return nil, err if f, err := os.Open(...)
return nil, err if _, err := os.Write(...)
 typeless
le 5 juin 2019
typeless
le 5 juin 2019
Je pense que le ? serait un meilleur ajustement que try , et avoir toujours à chasser le defer pour erreur serait également délicat.
Cela ferme également les portes pour avoir des exceptions en utilisant try/catch pour toujours.
 twisted1919
le 5 juin 2019
twisted1919
le 5 juin 2019
Cela ferme également les portes pour avoir des exceptions en utilisant try/catch pour toujours.
Je suis _plus_ que d'accord avec ça.
deanveloper
le 5 juin 2019
Je suis d'accord avec certaines des préoccupations soulevées ci-dessus concernant l'ajout de contexte à une erreur. J'essaie lentement de passer du simple renvoi d'une erreur à toujours la décorer avec un contexte, puis à la renvoyer. Avec cette proposition, je devrai complètement changer ma fonction pour utiliser des paramètres de retour nommés (ce qui me semble étrange car j'utilise à peine des retours nus).
Comme le dit @griesemer :
Encore une fois, cette proposition ne tente pas de résoudre toutes les situations de gestion d'erreurs. Je soupçonne que dans la plupart des cas, try a du sens pour un code qui ressemble maintenant essentiellement à ceci :
a, b, c, ... err := try(someFunctionCall())
si err != néant {
retour ..., euh
}
Il y a énormément de code qui ressemble à ça. Et chaque morceau de code ressemblant à celui-ci n'a pas besoin de plus de gestion des erreurs. Et là où différer n'est pas correct, on peut toujours utiliser une instruction if.
Oui, mais un bon code idiomatique ne devrait-il pas toujours envelopper/décorer ses erreurs ? Je pense que c'est pourquoi nous introduisons des mécanismes de gestion des erreurs raffinés pour ajouter des erreurs de contexte/d'encapsulation dans stdlib. Comme je le vois, cette proposition ne semble considérer que le cas d'utilisation le plus élémentaire.
De plus, cette proposition n'aborde que le cas de l'emballage/décoration de plusieurs sites de retour d'erreur possibles à un _seul endroit_, en utilisant des paramètres nommés avec un appel différé.
Mais cela ne fait rien dans le cas où l'on doit ajouter différents contextes à différentes erreurs dans une seule fonction. Par exemple, il est très essentiel de décorer les erreurs de base de données pour obtenir plus d'informations sur leur origine (en supposant qu'il n'y a pas de traces de pile)
Ceci est un exemple d'un vrai code que j'ai -
func (p *pgStore) DoWork() error {
tx, err := p.handle.Begin()
if err != nil {
return err
}
var res int64
err = tx.QueryRow(`INSERT INTO table (...) RETURNING c1`, ...).Scan(&res)
if err != nil {
tx.Rollback()
return fmt.Errorf("insert table: %w", err)
}
_, err = tx.Exec(`INSERT INTO table2 (...) VALUES ($1)`, res)
if err != nil {
tx.Rollback()
return fmt.Errorf("insert table2: %w", err)
}
return tx.Commit()
}
Selon la proposition :
Si l'augmentation ou l'encapsulation des erreurs est souhaitée, il existe deux approches : s'en tenir à l'instruction if éprouvée ou, alternativement, "déclarer" un gestionnaire d'erreurs avec une instruction defer :
Je pense que cela tombera dans la catégorie "s'en tenir à l'instruction if éprouvée". J'espère que la proposition pourra être améliorée pour résoudre ce problème également.
 agnivade
le 5 juin 2019
agnivade
le 5 juin 2019
Je suggère fortement à l'équipe Go de donner la priorité aux génériques , car c'est là que Go entend le plus de critiques, et d'attendre la gestion des erreurs. La technique d'aujourd'hui n'est pas si douloureuse (bien que go fmt devrait la laisser reposer sur une seule ligne).
Le concept try() a tous les problèmes de check de check/handle :
Il ne se lit pas comme Go. Les gens veulent une syntaxe d'affectation, sans le test nul ultérieur, car cela ressemble à Go. Treize réponses distinctes à vérifier / gérer l'ont suggéré; voir _Thèmes récurrents_ ici :
https://github.com/golang/go/wiki/Go2ErrorHandlingFeedback#recurring -themesf, # := os.Open(...) // return on error f, #panic := os.Open(...) // panic on error f, #hname := os.Open(...) // invoke named handler on error // # is any available symbol or unambiguous pairL'imbrication des appels de fonction qui renvoient des erreurs obscurcit l'ordre des opérations et entrave le débogage. L'état des choses lorsqu'une erreur se produit, et donc la séquence d'appel, devrait être clair, mais ici ce n'est pas le cas :
try(step4(try(step1()), try(step3(try(step2())))))
Rappelons maintenant que la langue interdit :
f(t ? a : b)etf(a++)Il serait trivial de renvoyer des erreurs sans contexte. L'une des principales raisons d'être de check/handle était d'encourager la contextualisation.
Il est lié au type
erroret à la dernière valeur de retour. Si nous devons inspecter d'autres valeurs/types de retour pour un état exceptionnel, nous revenons à :if errno := f(); errno != 0 { ... }Il n'offre pas plusieurs voies. Le code qui appelle les API de stockage ou de mise en réseau gère ces erreurs différemment de celles dues à une entrée incorrecte ou à un état interne inattendu. Mon code en fait une beaucoup plus souvent que
return err:- log.Fatal()
- panique() pour les erreurs qui ne devraient jamais survenir
- enregistrer un message et réessayer
@gopherbot ajouter Go2, LanguageChange
 networkimprov
le 5 juin 2019
networkimprov
le 5 juin 2019
Que diriez-vous d'utiliser seulement ? pour déballer le résultat comme rust
 leaxoy
le 5 juin 2019
leaxoy
le 5 juin 2019
La raison pour laquelle nous sommes sceptiques quant à l'appel de try() peut être due à deux liaisons implicites. Nous ne pouvons pas voir la liaison pour l'erreur de valeur de retour et les arguments pour try(). Pour environ try (), nous pouvons établir une règle selon laquelle nous devons utiliser try () avec une fonction d'argument qui a une erreur dans les valeurs de retour. Mais la liaison aux valeurs de retour ne le sont pas. Je pense donc que plus d'expression est nécessaire pour que les utilisateurs comprennent ce que fait ce code.
func doSomething() (int, %error) {
f := try(foo())
...
}
- Nous ne pouvons pas utiliser try() si doSomething n'a pas
%errordans les valeurs de retour. - Nous ne pouvons pas utiliser try() si foo() n'a pas d'erreur dans la dernière des valeurs de retour.
Il est difficile d'ajouter de nouvelles exigences/fonctionnalités à la syntaxe existante.
Pour être honnête, je pense que foo() devrait également avoir %error.
Ajouter 1 règle supplémentaire
- %error ne peut être qu'un dans la liste des valeurs de retour d'une fonction.
 mattn
le 5 juin 2019
mattn
le 5 juin 2019
Dans le document de conception détaillée, j'ai remarqué que dans une itération précédente, il avait été suggéré de transmettre un gestionnaire d'erreurs à la fonction intégrée try. Comme ça:
handler := func(err error) error {
return fmt.Errorf("foo failed: %v", err) // wrap error
}
f := try(os.Open(filename), handler)
ou encore mieux, comme ceci :
f := try(os.Open(filename), func(err error) error {
return fmt.Errorf("foo failed: %v", err) // wrap error
})
Bien que, comme l'indique le document, cela soulève plusieurs questions, je pense que cette proposition serait beaucoup plus souhaitable et utile si elle avait conservé cette possibilité de spécifier éventuellement une telle fonction de gestionnaire d'erreurs ou de fermeture.
Deuxièmement, cela ne me dérange pas qu'une fonction intégrée puisse provoquer le retour de la fonction, mais, pour faire un peu de vélo, le nom 'try' est trop court pour suggérer qu'il peut provoquer un retour. Donc un nom plus long, comme attempt me semble mieux.
EDIT: Troisièmement, idéalement, le langage go devrait d'abord gagner des génériques, où un cas d'utilisation important serait la possibilité d'implémenter cette fonction d'essai en tant que générique, afin que le bikeshedding puisse se terminer et que chacun puisse obtenir la gestion des erreurs qu'il préfère lui-même.
 beoran
le 5 juin 2019
beoran
le 5 juin 2019
Les nouvelles des hackers ont un certain intérêt : try ne se comporte pas comme une fonction normale (elle peut revenir), il n'est donc pas bon de lui donner une syntaxe semblable à une fonction. Une syntaxe return ou defer serait plus appropriée :
func CopyFile(src, dst string) (err error) {
r := try os.Open(src)
defer r.Close()
w := try os.Create(dst)
defer func() {
w.Close()
if err != nil {
os.Remove(dst) // only if a “try” fails
}
}()
try io.Copy(w, r)
try w.Close()
return nil
}
 sheerun
le 5 juin 2019
sheerun
le 5 juin 2019
@sheerun le contre-argument commun à cela est que panic est également une fonction intégrée de modification du flux de contrôle. Personnellement, je ne suis pas d'accord avec cela, mais c'est correct.
deanveloper
le 5 juin 2019
- En écho à @deanveloper ci- dessus , ainsi qu'aux commentaires similaires d'autres personnes, j'ai très peur que nous sous-estimions les coûts d'ajout d'un nouveau mot-clé quelque peu subtil et, en particulier lorsqu'il est intégré dans d'autres appels de fonction, facilement négligé qui gère le contrôle de la pile d'appels couler.
panic(...)est une exception relativement claire (jeu de mots non voulu) à la règle selon laquellereturnest le seul moyen de sortir d'une fonction. Je ne pense pas que nous devrions utiliser son existence comme justification pour en ajouter un troisième. - Cette proposition canoniserait le renvoi d'une erreur non encapsulée comme comportement par défaut, et reléguerait les erreurs d'encapsulation comme quelque chose auquel vous devez vous inscrire, avec une cérémonie supplémentaire. Mais, d'après mon expérience, c'est précisément l'inverse des bonnes pratiques. J'espère qu'une proposition dans cet espace faciliterait, ou du moins pas plus difficile, l'ajout d'informations contextuelles aux erreurs sur le site d'erreur.
 peterbourgon
le 5 juin 2019
peterbourgon
le 5 juin 2019
peut-être pouvons-nous ajouter une variante avec une fonction d'augmentation optionnelle quelque chose comme tryf avec cette sémantique :
func tryf(t1 T1, t1 T2, … tn Tn, te error, fn func(error) error) (T1, T2, … Tn)
traduit ceci
x1, x2, … xn = tryf(f(), func(err error) { return fmt.Errorf("foobar: %q", err) })
dans ce
t1, … tn, te := f()
if te != nil {
if fn != nil {
te = fn(te)
}
err = te
return
}
puisqu'il s'agit d'un choix explicite (au lieu d'utiliser try ), nous pouvons trouver des réponses raisonnables aux questions de la version précédente de cette conception. par exemple, si la fonction d'augmentation est nulle, ne faites rien et renvoyez simplement l'erreur d'origine.
 unexge
le 5 juin 2019
unexge
le 5 juin 2019
Je crains que try supplante la gestion traditionnelle des erreurs et que cela rende l'annotation des chemins d'erreur plus difficile en conséquence.
Le code qui gère les erreurs en enregistrant les messages et en mettant à jour les compteurs de télémétrie sera considéré comme défectueux ou inapproprié à la fois par les linters et les développeurs qui s'attendent à tout try .
a, b, err := doWork()
if err != nil {
updateCounters()
writeLogs()
return err
}
Go est un langage extrêmement social avec des idiomes communs renforcés par des outils (fmt, lint, etc.). Veuillez garder à l'esprit les ramifications sociales de cette idée - il y aura une tendance à vouloir l'utiliser partout.
 dzrw
le 5 juin 2019
dzrw
le 5 juin 2019
@politician , désolé, mais le mot que vous cherchez n'est pas _social_ mais _opinionated_. Go est un langage de programmation opiniâtre. Pour le reste, je suis plutôt d'accord avec ce que tu veux dire.
beoran
le 5 juin 2019
@beoran Les outils communautaires comme Godep et les différents linters démontrent que Go est à la fois opiniâtre et social, et de nombreux drames avec le langage découlent de cette combinaison. Espérons que nous puissions tous les deux convenir que try ne devrait pas être le prochain drame.
dzrw
le 5 juin 2019
@politicien Merci d'avoir précisé, je ne l'avais pas compris de cette façon. Je peux certainement convenir que nous devrions essayer d'éviter le drame.
beoran
le 5 juin 2019
Je suis confus à ce sujet.
Extrait du blog : Les erreurs sont des valeurs , de mon point de vue, elles sont conçues pour être valorisées pour ne pas être ignorées.
Et je crois ce que Rop Pike a dit, "Les valeurs peuvent être programmées, et puisque les erreurs sont des valeurs, les erreurs peuvent être programmées.".
Nous ne devrions pas considérer error comme exception , c'est comme importer de la complexité non seulement pour la réflexion mais aussi pour le codage si nous le faisons.
"Utilisez le langage pour simplifier votre gestion des erreurs." --Rob Pike
Et plus, nous pouvons revoir cette diapositive

 DavexPro
le 5 juin 2019
DavexPro
le 5 juin 2019
Une situation où je trouve la vérification des erreurs via if particulièrement gênante est lors de la fermeture de fichiers (par exemple sur NFS). Je suppose que, actuellement, nous sommes censés écrire ce qui suit, si des retours d'erreur de .Close() sont possibles ?
r, err := os.Open(src)
if err != nil {
return err
}
defer func() {
// maybe check whether a previous error occured?
return r.Close()
}()
defer try(r.Close()) pourrait-il être un bon moyen d'avoir une syntaxe gérable pour traiter de telles erreurs ? Au moins, il serait logique d'ajuster l'exemple CopyFile() dans la proposition d'une certaine manière, pour ne pas ignorer les erreurs de r.Close() et w.Close() .
 seehuhn
le 5 juin 2019
seehuhn
le 5 juin 2019
@seehuhn Votre exemple ne sera pas compilé car la fonction différée n'a pas de type de retour.
func doWork() (err error) {
r, err := os.Open(src)
if err != nil {
return err
}
defer func() {
err = r.Close() // overwrite the return value
}()
}
Fonctionnera comme prévu. La clé est la valeur de retour nommée.
dzrw
le 5 juin 2019
J'aime la proposition mais je pense que l'exemple de @seehuhn devrait également être abordé :
defer try(w.Close())
renverrait l'erreur de Close() uniquement si l'erreur n'était pas déjà définie.
Ce modèle est si souvent utilisé...
 pierrec
le 5 juin 2019
pierrec
le 5 juin 2019
Je suis d'accord avec les préoccupations concernant l'ajout de contexte aux erreurs. Je le vois comme l'une des meilleures pratiques qui garde les messages d'erreur très conviviaux (et clairs) et facilite le processus de débogage.
La première chose à laquelle j'ai pensé était de remplacer le fmt.HandleErrorf par une fonction tryf , qui préfixe l'erreur avec un contexte supplémentaire.
func tryf(t1 T1, t1 T2, … tn Tn, te error, ts string) (T1, T2, … Tn)
Par exemple (à partir d'un vrai code que j'ai):
func (c *Config) Build() error {
pkgPath, err := c.load()
if err != nil {
return nil, errors.WithMessage(err, "load config dir")
}
b := bytes.NewBuffer(nil)
if err = templates.ExecuteTemplate(b, "main", c); err != nil {
return nil, errors.WithMessage(err, "execute main template")
}
buf, err := format.Source(b.Bytes())
if err != nil {
return nil, errors.WithMessage(err, "format main template")
}
target := fmt.Sprintf("%s.go", filename(pkgPath))
if err := ioutil.WriteFile(target, buf, 0644); err != nil {
return nil, errors.WithMessagef(err, "write file %s", target)
}
// ...
}
Peut être changé en quelque chose comme :
func (c *Config) Build() error {
pkgPath := tryf(c.load(), "load config dir")
b := bytes.NewBuffer(nil)
tryf(emplates.ExecuteTemplate(b, "main", c), "execute main template")
buf := tryf(format.Source(b.Bytes()), "format main template")
target := fmt.Sprintf("%s.go", filename(pkgPath))
tryf(ioutil.WriteFile(target, buf, 0644), fmt.Sprintf("write file %s", target))
// ...
}
Ou, si je prends l'exemple de @agnivade :
func (p *pgStore) DoWork() (err error) {
tx := tryf(p.handle.Begin(), "begin transaction")
defer func() {
if err != nil {
tx.Rollback()
}
}()
var res int64
tryf(tx.QueryRow(`INSERT INTO table (...) RETURNING c1`, ...).Scan(&res), "insert table")
_, = tryf(tx.Exec(`INSERT INTO table2 (...) VALUES ($1)`, res), "insert table2")
return tryf(tx.Commit(), "commit transaction")
}
Cependant, @josharian a soulevé un bon point qui me fait hésiter sur cette solution :
Tel qu'il est écrit, cependant, il déplace le formatage de style fmt d'un paquet vers le langage lui-même, ce qui ouvre une boîte de Pandore.
 a8m
le 5 juin 2019
a8m
le 5 juin 2019
Je suis totalement d'accord avec cette proposition et je peux voir ses avantages à travers un certain nombre d'exemples.
Ma seule préoccupation avec la proposition est la dénomination de try , je pense que ses connotations avec d'autres langues peuvent fausser les perceptions des développeurs sur son objectif lorsqu'il vient d'autres langues. Java vient trouver ici.
Pour moi, je préférerais que la fonction intégrée s'appelle pass . Je pense que cela donne une meilleure représentation de ce qui se passe. Après tout, vous ne gérez pas l'erreur - vous la renvoyez plutôt pour qu'elle soit gérée par l'appelant. try donne l'impression que l'erreur a été traitée.
 jacobcartledge
le 5 juin 2019
jacobcartledge
le 5 juin 2019
C'est un pouce vers le bas de moi, principalement parce que le problème qu'il vise à résoudre ("le passe-partout si les instructions sont généralement associées à la gestion des erreurs") n'est tout simplement pas un problème pour moi. Si toutes les vérifications d'erreur étaient simplement if err != nil { return err } , alors je pourrais voir une certaine valeur dans l'ajout de sucre syntaxique pour cela (bien que Go soit un langage relativement sans sucre par inclination).
En fait, ce que je veux faire en cas d'erreur non nulle varie assez considérablement d'une situation à l'autre. Peut-être que je veux t.Fatal(err) . Peut-être que je veux ajouter un message de décoration return fmt.Sprintf("oh no: %v", err) . Peut-être que je viens de consigner l'erreur et de continuer. Peut-être que j'ai défini un indicateur d'erreur sur mon objet SafeWriter et que je continue, en vérifiant l'indicateur à la fin d'une séquence d'opérations. Peut-être que je dois prendre d'autres mesures. Aucun de ceux-ci ne peut être automatisé avec try . Donc, si l'argument pour try est qu'il éliminera tous les blocs if err != nil , cet argument ne tient pas.
Cela éliminera-t-il _certains_ d'entre eux ? Sûr. Est-ce une proposition intéressante pour moi ? Meh. Je ne suis vraiment pas concerné. Pour moi, if err != nil fait partie du Go, comme les accolades, ou defer . Je comprends que cela semble verbeux et répétitif pour les personnes qui découvrent Go, mais les personnes qui découvrent Go ne sont pas les mieux placées pour apporter des changements radicaux à la langue, pour tout un tas de raisons.
La barre pour des changements significatifs à Go a traditionnellement été que le changement proposé doit résoudre un problème qui est (A) significatif, (B) affecte beaucoup de gens, et (C) est bien résolu par la proposition. Je ne suis convaincu sur aucun de ces trois critères. Je suis assez satisfait de la gestion des erreurs de Go telle qu'elle est.
 bitfield
le 5 juin 2019
bitfield
le 5 juin 2019
Pour faire écho à @peterbourgon et @deanveloper , l'une de mes choses préférées à propos de Go est que le flux de code est clair et que panic() n'est pas traité comme un mécanisme de contrôle de flux standard comme c'est le cas en Python.
Concernant le débat sur la panique, panic() apparaît presque toujours seul sur une ligne car il n'a aucune valeur. Vous ne pouvez pas fmt.Println(panic("oops")) . Cela augmente considérablement sa visibilité et le rend beaucoup moins comparable à try() que les gens ne le prétendent.
S'il doit y avoir une autre construction de contrôle de flux pour les fonctions, je préférerais _de loin_ qu'il s'agisse d'une instruction garantie d'être l'élément le plus à gauche sur une ligne.
 Redundancy
le 5 juin 2019
Redundancy
le 5 juin 2019
L'un des exemples de la proposition me pose problème :
func printSum(a, b string) error {
fmt.Println(
"result:",
try(strconv.Atoi(a)) + try(strconv.Atoi(b)),
)
return nil
}
Le flux de contrôle devient vraiment moins évident et très obscur.
Cela va également à l'encontre de l'intention initiale de Rob Pike selon laquelle toutes les erreurs doivent être traitées explicitement.
Bien qu'une réaction à cela puisse être "alors ne l'utilisez pas", le problème est que d'autres bibliothèques l'utiliseront, et les déboguer, les lire et les utiliser devient plus problématique. Cela motivera mon entreprise à ne jamais adopter go 2 et à commencer à n'utiliser que des bibliothèques qui n'utilisent pas try . Si je ne suis pas seul avec cela, cela pourrait conduire à une division à la python 2/3.
De plus, le nommage de try impliquera automatiquement que catch finira par apparaître dans la syntaxe, et nous redeviendrons Java.
Donc, à cause de tout cela, je suis _fortement_ contre cette proposition.
 hmage
le 5 juin 2019
hmage
le 5 juin 2019
Je n'aime pas le nom try . Cela implique une _tentative_ de faire quelque chose avec un risque élevé d'échec (j'ai peut-être un préjugé culturel contre _try_ car je ne suis pas de langue maternelle anglaise), alors qu'à la place try serait utilisé au cas où nous nous attendrions à des échecs rares (motivation à vouloir réduire la verbosité de la gestion des erreurs) et sont optimistes. De plus, try dans cette proposition _attrape_ une erreur pour la renvoyer plus tôt. J'aime la suggestion pass de @HiImJC.
Outre le nom, je trouve gênant d'avoir une instruction de type return maintenant cachée au milieu des expressions. Cela rompt le style de flux Go. Cela rendra les revues de code plus difficiles.
En général, je trouve que cette proposition ne profitera qu'au programmeur paresseux qui a maintenant une arme pour un code plus court et encore moins de raison de faire l'effort d'envelopper les erreurs. Comme cela va aussi rendre les révisions plus difficiles (retour en milieu d'expression), je pense que cette proposition va à l'encontre de l'objectif "programmation à l'échelle" du Go.
 dolmen
le 5 juin 2019
dolmen
le 5 juin 2019
L'une de mes choses préférées à propos de Go que je dis généralement lorsque je décris le langage est qu'il n'y a qu'une seule façon de faire les choses, pour la plupart des choses. Cette proposition va un peu à l'encontre de ce principe en offrant plusieurs façons de faire la même chose. Je pense personnellement que ce n'est pas nécessaire et que cela enlèverait plutôt que d'ajouter à la simplicité et à la lisibilité du langage.
 gbbr
le 5 juin 2019
gbbr
le 5 juin 2019
J'aime cette proposition dans l'ensemble. L'interaction avec defer semble suffisante pour fournir un moyen ergonomique de renvoyer une erreur tout en ajoutant un contexte supplémentaire. Bien qu'il serait bien de résoudre le problème que @josharian a souligné sur la façon d'inclure l'erreur d'origine dans le message d'erreur encapsulé.
Ce qui manque, c'est une manière ergonomique d'interagir avec la ou les propositions d'inspection des erreurs sur la table. Je pense que les API devraient être très délibérées quant aux types d'erreurs qu'elles renvoient, et la valeur par défaut devrait probablement être "les erreurs renvoyées ne sont en aucun cas inspectables". Il devrait alors être facile de passer à un état où les erreurs sont inspectables de manière précise, comme documenté par la signature de la fonction ("Il signale une erreur de type X dans la circonstance A et une erreur de type Y dans la circonstance B").
Malheureusement, à partir de maintenant, cette proposition rend l'option la plus ergonomique la plus indésirable (pour moi); passant aveuglément par des types d'erreurs arbitraires. Je pense que ce n'est pas souhaitable car cela encourage à ne pas penser aux types d'erreurs que vous renvoyez et à la façon dont les utilisateurs de votre API les consommeront. La commodité supplémentaire de cette proposition est certainement agréable, mais je crains qu'elle n'encourage un mauvais comportement car la commodité perçue l'emportera sur la valeur perçue de réfléchir attentivement aux informations d'erreur que vous fournissez (ou divulguez).
Un pansement serait si les erreurs renvoyées par try étaient converties en erreurs qui ne sont pas "déballables". Malheureusement, cela a également des inconvénients assez graves, car cela fait en sorte que tout defer ne peut pas inspecter les erreurs lui-même. De plus, cela empêche l'utilisation où try renverra une erreur d'un type souhaitable (c'est-à-dire les cas d'utilisation où try est utilisé avec précaution plutôt qu'avec insouciance).
Une autre solution consisterait à réutiliser l'idée (rejetée) d'avoir un deuxième argument facultatif à try pour définir/ajouter à la liste blanche le ou les types d'erreur pouvant être renvoyés par ce site. C'est un peu gênant car nous avons deux manières différentes de définir un "type d'erreur", soit par valeur ( io.EOF etc) soit par type ( *os.PathError , *exec.ExitError ). Il est facile de spécifier des types d'erreurs qui sont des valeurs en tant qu'arguments d'une fonction, mais plus difficile de spécifier des types. Je ne sais pas comment gérer cela, mais je lance l'idée là-bas.
 eandre
le 5 juin 2019
eandre
le 5 juin 2019
Le problème signalé par @josharian peut être évité en retardant l'évaluation de err :
defer func() { fmt.HandleErrorf(&err, "oops: %v", err) }()
Ça n'a pas l'air génial, mais ça devrait marcher. Je préférerais cependant si cela peut être résolu en ajoutant un nouveau verbe/indicateur de formatage pour les pointeurs d'erreur, ou peut-être pour les pointeurs en général, qui imprime la valeur déréférencée comme avec plain %v . Pour les besoins de l'exemple, appelons-le %*v :
defer fmt.HandleErrorf(&err, "oops: %*v", &err)
Le hic mis à part, je pense que cette proposition semble prometteuse, mais il semble crucial de garder l'ergonomie de l'ajout de contexte aux erreurs sous contrôle.
Éditer:
Une autre approche consiste à envelopper le pointeur d'erreur dans une structure qui implémente Stringer :
type wraperr struct{ err *error }
func (w wraperr) String() string { return (*w.err).Error() }
...
defer handleErrorf(&err, "oops: %v", wraperr{&err})
 boomlinde
le 5 juin 2019
boomlinde
le 5 juin 2019
Quelques choses de mon point de vue. Pourquoi sommes-nous si soucieux d'économiser quelques lignes de code ? Je considère cela dans le même sens que les petites fonctions considérées comme nuisibles .
De plus, je trouve qu'une telle proposition enlèverait la responsabilité de gérer correctement l'erreur à une "magie" dont je crains qu'elle ne soit simplement abusée et encourage la paresse entraînant un code de mauvaise qualité et des bogues.
La proposition, telle qu'elle est indiquée, comporte également un certain nombre de comportements peu clairs, ce qui est déjà problématique par rapport à _explicit_ supplémentaires ~ 3 lignes plus claires.
 prologic
le 5 juin 2019
prologic
le 5 juin 2019
Nous utilisons actuellement le modèle de report avec parcimonie en interne. Il y a un article ici qui a eu un accueil mitigé lorsque nous l'avons écrit - https://bet365techblog.com/better-error-handling-in-go
Cependant, nous l'avons utilisé en prévision de la progression de la proposition check / handle .
Check/handle était une approche beaucoup plus complète pour rendre la gestion des erreurs plus concise. Son bloc handle a conservé la même portée de fonction que celle dans laquelle il a été défini, alors que toutes les instructions defer sont de nouveaux contextes avec une quantité, quelle qu'en soit la hauteur, de surcharge. Cela semblait être plus conforme aux idiomes de go, en ce sens que si vous vouliez le comportement de "retourner simplement l'erreur quand elle se produit", vous pouviez le déclarer explicitement comme handle { return err } .
Defer repose évidemment sur le maintien de la référence err également, mais nous avons vu des problèmes survenir en masquant la référence de l'erreur avec des vars à portée de bloc. Il n'est donc pas suffisamment infaillible pour être considéré comme le moyen standard de gérer les erreurs au go.
try , dans ce cas, ne semble pas trop résoudre et je partage la même crainte que d'autres que cela conduirait simplement à des implémentations paresseuses, ou à des implémentations qui sur-utilisent le modèle de report.
 kungfusheep
le 5 juin 2019
kungfusheep
le 5 juin 2019
Si la gestion des erreurs basée sur le report va être une chose, alors quelque chose comme ceci devrait probablement être ajouté au package d'erreurs :
f := try(os.Create(filename))
defer errors.Deferred(&err, f.Close)
Ignorer les erreurs des instructions Close différées est un problème assez courant. Il devrait y avoir un outil standard pour l'aider.
 carlmjohnson
le 5 juin 2019
carlmjohnson
le 5 juin 2019
Une fonction intégrée qui renvoie est plus difficile à vendre qu'un mot-clé qui fait la même chose.
Je l'aimerais plus s'il s'agissait d'un mot-clé comme c'est le cas dans Zig[1].
 komuw
le 5 juin 2019
komuw
le 5 juin 2019
Les fonctions intégrées, dont la signature de type ne peut pas être exprimée à l'aide du système de type du langage, et dont le comportement confond ce qu'est normalement une fonction, ressemblent à une trappe de sortie qui peut être utilisée à plusieurs reprises pour éviter l'évolution réelle du langage.
 frou
le 5 juin 2019
frou
le 5 juin 2019
Nous sommes habitués à reconnaître immédiatement les instructions de retour (et les paniques) car c'est ainsi que ce type de flux de contrôle est exprimé en Go (et dans de nombreux autres langages). Il ne semble pas exagéré que nous reconnaissions également l'essai comme un changement de flux de contrôle après s'y être habitué, tout comme nous le faisons pour le retour. Je ne doute pas qu'un bon support IDE aidera également à cela.
Je pense que c'est assez tiré par les cheveux. Dans le code gofmt, un retour correspond toujours à /^\t*return / - c'est un modèle très trivial à repérer à l'œil nu, sans aucune aide. try , d'autre part, peut apparaître n'importe où dans le code, imbriqué arbitrairement profondément dans les appels de fonction. Aucune formation ne nous permettra de repérer immédiatement tous les flux de contrôle dans une fonction sans l'aide d'outils.
De plus, une fonctionnalité qui dépend d'un "bon support IDE" sera désavantagée dans tous les environnements où il n'y a pas de bon support IDE. Les outils de revue de code me viennent immédiatement à l'esprit – Gerrit mettra-t-il en évidence tous les essais pour moi ? Qu'en est-il des personnes qui choisissent de ne pas utiliser les IDE ou la mise en évidence de code fantaisiste, pour diverses raisons ? Acme commencera-t-il à mettre en évidence try ?
Une fonctionnalité de langage doit être facile à comprendre en elle-même et ne pas dépendre de la prise en charge de l'éditeur.
dominikh
le 5 juin 2019
@kungfusheep J'aime cet article. Prendre soin d'envelopper dans un report seul augmente déjà un peu la lisibilité sans try .
Je suis dans le camp qui ne pense pas que les erreurs de Go soient vraiment un problème. Même ainsi, if err != nil { return err } peut être tout à fait le bégaiement sur certaines fonctions. J'ai écrit des fonctions qui nécessitaient une vérification des erreurs après presque chaque instruction et aucune n'avait besoin d'une gestion spéciale autre que wrap et return. Parfois, il n'y a tout simplement pas de structure Buffer intelligente qui rendra les choses plus agréables. Parfois, il s'agit simplement d'une étape critique différente après l'autre et vous devez simplement court-circuiter si quelque chose ne va pas.
Bien que try rendrait certainement ce code beaucoup plus facile à lire tout en étant entièrement rétrocompatible, je conviens que try n'est pas une fonctionnalité indispensable, donc si les gens ont trop peur de il vaut peut-être mieux ne pas l'avoir.
La sémantique est assez claire cependant. Chaque fois que vous voyez try , soit il suit le bon chemin, soit il revient. Je ne peux vraiment pas faire plus simple que ça.
 qrpnxz
le 5 juin 2019
qrpnxz
le 5 juin 2019
Cela ressemble à une macro spéciale en boîtier.
 docmerlin
le 5 juin 2019
docmerlin
le 5 juin 2019
@dominikh try correspond toujours à /try\(/ donc je ne sais pas vraiment ce que vous voulez dire. Il est tout aussi consultable et chaque éditeur dont j'ai entendu parler dispose d'une fonction de recherche.
qrpnxz
le 5 juin 2019
@qrpnxz Je pense que le point qu'il essayait de faire valoir n'est pas que vous ne pouvez pas le rechercher par programme, mais qu'il est plus difficile de le rechercher avec vos yeux. L'expression rationnelle n'était qu'une analogie, mettant l'accent sur le /^\t* , ce qui signifie que tous les retours se distinguent clairement en étant au début d'une ligne (en ignorant les espaces en tête).
eandre
le 5 juin 2019
En y réfléchissant davantage, il devrait y avoir quelques fonctions d'assistance communes. Peut-être devraient-ils être dans un package appelé "différé".
Abordant la proposition d'un check avec un format pour éviter de nommer le retour, vous pouvez simplement le faire avec une fonction qui vérifie nil, comme ceci
func Format(err error, message string, args ...interface{}) error {
if err == nil {
return nil
}
return fmt.Errorf(...)
}
Ceci peut être utilisé sans retour nommé comme ceci :
func foo(s string) (int, error) {
n, err := strconv.Atoi(s)
try(deferred.Format(err, "bad string %q", s))
return n, nil
}
Le fmt.HandleError proposé pourrait être placé dans le package différé à la place et ma fonction d'assistance errors.Defer pourrait être appelée deferred.Exec et il pourrait y avoir un exec conditionnel pour que les procédures s'exécutent uniquement si l'erreur est non nulle.
En le mettant ensemble, vous obtenez quelque chose comme
func CopyFile(src, dst string) (err error) {
defer deferred.Annotate(&err, "copy %s %s", src, dst)
r := try(os.Open(src))
defer deferred.Exec(&err, r.Close)
w := try(os.Create(dst))
defer deferred.Exec(&err, r.Close)
defer deferred.Cond(&err, func(){ os.Remove(dst) })
try(io.Copy(w, r))
return nil
}
Un autre exemple:
func (p *pgStore) DoWork() (err error) {
tx := try(p.handle.Begin())
defer deferred.Cond(&err, func(){ tx.Rollback() })
var res int64
err = tx.QueryRow(`INSERT INTO table (...) RETURNING c1`, ...).Scan(&res)
try(deferred.Format(err, "insert table")
_, err = tx.Exec(`INSERT INTO table2 (...) VALUES ($1)`, res)
try(deferred.Format(err, "insert table2"))
return tx.Commit()
}
Cette proposition nous fait passer de if err != nil partout à try partout. Il déplace le problème proposé et ne le résout pas.
Cependant, je dirais que le mécanisme actuel de gestion des erreurs n'est pas un problème pour commencer. Nous avons juste besoin d'améliorer l' outillage et de contrôler tout cela.
De plus, je dirais que if err != nil est en fait plus lisible que try car il n'encombre pas la ligne du langage de logique métier, mais se trouve plutôt juste en dessous :
file := try(os.OpenFile("thing")) // less readable than,
file, err := os.OpenFile("thing")
if err != nil {
}
Et si Go devait être plus magique dans sa gestion des erreurs, pourquoi ne pas le posséder totalement. Par exemple, Go peut appeler implicitement la fonction intégrée try si un utilisateur n'attribue pas d'erreur. Par exemple:
func getString() (string, error) { ... }
func caller() {
defer func() {
if err != nil { ... } // whether `err` must be defined or not is not shown in this example.
}
// would call try internally, because a user is not
// assigning an error value. Also, it can add a compile error
// for "defined and not used err value" if the user does not
// handle the error.
str := getString()
}
Pour moi, cela résoudrait en fait le problème de la redondance au prix de la magie et de la lisibilité potentielle.
Par conséquent, je propose que nous résolvions vraiment le "problème" comme dans l'exemple ci-dessus ou que nous conservions la gestion des erreurs actuelle, mais au lieu de changer le langage pour résoudre la redondance et l'emballage, nous ne changeons pas le langage mais nous améliorons l' outillage et la vérification de code pour améliorer l'expérience.
Par exemple, dans VSCode, il y a un extrait appelé iferr si vous le tapez et appuyez sur Entrée, il se transforme en une déclaration complète de gestion des erreurs... par conséquent, l'écrire ne me semble jamais fastidieux, et lire plus tard est mieux .
 marwan-at-work
le 5 juin 2019
marwan-at-work
le 5 juin 2019
@josharian
Bien que ce ne soit pas "un changement de bibliothèque modeste", nous pourrions également envisager d'accepter l'erreur func main().
Le problème avec cela est que toutes les plates-formes n'ont pas une sémantique claire sur ce que cela signifie. Votre réécriture fonctionne bien dans les programmes Go "traditionnels" exécutés sur un système d'exploitation complet - mais dès que vous écrivez un micrologiciel de microcontrôleur ou même simplement WebAssembly, la signification os.Exit(1) n'est pas très claire. Actuellement, os.Exit est un appel de bibliothèque, donc les implémentations Go sont libres de ne pas le fournir. La forme de main est cependant un problème de langage.
Une question sur la proposition à laquelle il est probablement préférable de répondre par "non": comment try interagit-il avec les arguments variadiques ? C'est le premier cas d'une fonction variadique (ish) qui n'a pas ses variadic-nes dans le dernier argument. Est-ce autorisé :
var e []error
try(e...)
Laissant de côté pourquoi vous feriez cela. Je soupçonne que la réponse est "non" (sinon le suivi est "et si la longueur de la tranche étendue est de 0). Il suffit d'en parler pour que cela puisse être gardé à l'esprit lors de la formulation de la spécification.
 Merovius
le 5 juin 2019
Merovius
le 5 juin 2019
- Plusieurs des plus grandes fonctionnalités de go sont que les fonctions intégrées actuelles garantissent un flux de contrôle clair, la gestion des erreurs est explicite et encouragée, et les développeurs sont fortement dissuadés d'écrire du code "magique". La proposition
tryn'est pas cohérente avec ces principes de base, car elle favorisera la sténographie au détriment de la lisibilité du flux de contrôle. - Si cette proposition est adoptée, envisagez peut-être de faire de la fonction intégrée
tryune déclaration au lieu d'une fonction . Ensuite, il est plus cohérent avec d'autres instructions de flux de contrôle commeif. De plus, la suppression des parenthèses imbriquées améliore légèrement la lisibilité. - Encore une fois, si la proposition est adoptée, mettez-la peut-être en œuvre sans utiliser
deferou similaire. Il ne peut déjà pas être implémenté en pur go (comme l'ont souligné d'autres), il peut donc tout aussi bien utiliser une implémentation plus efficace sous le capot.
 RobertGrantEllis
le 5 juin 2019
RobertGrantEllis
le 5 juin 2019
J'y vois deux problèmes :
- Il met BEAUCOUP de code imbriqué dans les fonctions. Cela ajoute beaucoup de charge cognitive supplémentaire, en essayant d'analyser le code dans votre tête.
- Cela nous donne des endroits où le code peut sortir du milieu d'une instruction.
Je pense que le numéro 2 est bien pire. Tous les exemples ici sont des appels simples qui renvoient une erreur, mais ce qui est beaucoup plus insidieux, c'est ceci :
func doit(abc string) error {
a := fmt.Sprintf("value of something: %s\n", try(getValue(abc)))
log.Println(a)
return nil
}
Ce code peut sortir au milieu de ce sprintf, et il sera SUPER facile de rater ce fait.
Mon vote est non. Cela n'améliorera pas le code go. Cela ne facilitera pas la lecture. Cela ne le rendra pas plus robuste.
Je l'ai déjà dit, et cette proposition en est un exemple - j'ai l'impression que 90% des plaintes concernant Go sont "Je ne veux pas écrire d'instruction if ou de boucle". Cela supprime certaines instructions if très simples, mais ajoute une charge cognitive et permet de manquer facilement des points de sortie pour une fonction.
 natefinch
le 5 juin 2019
natefinch
le 5 juin 2019
Je veux juste souligner que vous ne pouvez pas l'utiliser dans la main et que cela peut être déroutant pour les nouveaux utilisateurs ou lors de l'enseignement. Évidemment, cela s'applique à toute fonction qui ne renvoie pas d'erreur, mais je pense que main est spécial car il apparaît dans de nombreux exemples.
func main() {
f := try(os.Open("foo.txt"))
defer f.Close()
}
Je ne suis pas sûr que faire essayer de paniquer dans le main soit acceptable non plus.
De plus, cela ne serait pas particulièrement utile dans les tests ( func TestFoo(t* testing.T) ) ce qui est regrettable :(
 predmond
le 5 juin 2019
predmond
le 5 juin 2019
Le problème que j'ai avec cela est qu'il suppose que vous voulez toujours simplement renvoyer l'erreur lorsqu'elle se produit. Lorsque vous souhaitez peut-être ajouter du contexte à l'erreur et la renvoyer ou peut-être souhaitez-vous simplement vous comporter différemment lorsqu'une erreur se produit. Cela dépend peut-être du type d'erreur renvoyé.
Je préférerais quelque chose qui s'apparente à un try/catch qui pourrait ressembler à
En supposant foo() défini comme
func foo() (int, error) {}
Vous pourriez alors faire
n := try(foo()) {
case FirstError:
// do something based on FirstError
case OtherError:
// do something based on OtherError
default:
// default behavior for any other error
}
Ce qui se traduit par
n, err := foo()
if errors.Is(err, FirstError) {
// do something based on FirstError
if errors.Is(err, OtherError) {
// do something based on OtherError
} else {
// default behavior for any other error
}
 MrTravisB
le 5 juin 2019
MrTravisB
le 5 juin 2019
Pour moi, la gestion des erreurs est l'une des parties les plus importantes d'une base de code.
Déjà trop de code go est if err != nil { return err } , renvoyant une erreur du plus profond de la pile sans ajouter de contexte supplémentaire, ou même (peut-être) pire en ajoutant du contexte en masquant l'erreur sous-jacente avec fmt.Errorf wraping.
Fournir un nouveau mot-clé qui est une sorte de magie qui ne fait que remplacer if err != nil { return err } semble être une route dangereuse à suivre.
Maintenant, tout le code sera simplement enveloppé dans un appel pour essayer. C'est assez correct (bien que la lisibilité soit nulle) pour le code qui ne traite que des erreurs dans le package telles que :
func foo() error {
/// stuff
try(bar())
// more stuff
}
Mais je dirais que l'exemple donné est vraiment horrible et laisse essentiellement l'appelant essayer de comprendre une erreur qui est vraiment profonde dans la pile, un peu comme la gestion des exceptions.
Bien sûr, c'est au développeur de faire ce qu'il faut ici, mais cela donne au développeur un excellent moyen de ne pas se soucier de ses erreurs avec peut-être un "nous corrigerons cela plus tard" (et nous savons tous comment cela se passe ).
J'aimerais que nous examinions le problème d'un point de vue différent de *"comment pouvons-nous réduire la répétition" et plus sur "comment pouvons-nous rendre la gestion des erreurs (correcte) plus simple et les développeurs plus productifs".
Nous devrions réfléchir à la manière dont cela affectera l'exécution du code de production.
*Remarque : Cela ne réduit pas réellement la répétition, change simplement ce qui est répété, tout en rendant le code moins lisible car tout est enfermé dans un try() .
Un dernier point : lire la proposition au début ça semble sympa, puis on commence à rentrer dans tous les pièges (du moins ceux listés) et c'est comme "ok ouais c'est trop".
Je me rends compte qu'une grande partie de cela est subjectif, mais c'est quelque chose qui m'importe. Cette sémantique est extrêmement importante.
Ce que je veux voir, c'est un moyen de simplifier l'écriture et la maintenance du code de niveau de production, de sorte que vous puissiez tout aussi bien faire des erreurs "correctes", même pour le code de niveau POC/démo.
 cpuguy83
le 5 juin 2019
cpuguy83
le 5 juin 2019
Puisque le contexte d'erreur semble être un thème récurrent...
Hypothèse : la plupart des fonctions Go renvoient (T, error) au lieu de (T1, T2, T3, error)
Et si, au lieu de définir try comme try(T1, T2, T3, error) (T1, T2, T3) nous le définissions comme
try(func (args) (T1, T2, T3, error))(T1, T2, T3) ? (c'est une approximation)
c'est-à-dire que la structure syntaxique d'un appel try est toujours un premier argument qui est une expression renvoyant plusieurs valeurs, dont la dernière est une erreur.
Ensuite, tout comme make , cela ouvre la porte à une forme d'appel à 2 arguments, où le deuxième argument est le contexte de l'essai (par exemple, une chaîne fixe, une chaîne avec un %v , une fonction qui prend un argument d'erreur et renvoie une autre erreur, etc.)
Cela permet toujours l'enchaînement pour le cas (T, error) mais vous ne pouvez plus enchaîner plusieurs retours qui ne sont généralement pas requis par l'OMI.
 gotwarlost
le 5 juin 2019
gotwarlost
le 5 juin 2019
@ cpuguy83 Si vous lisez la proposition, vous verrez que rien ne vous empêche d'envelopper l'erreur. En fait, il existe plusieurs façons de le faire tout en utilisant try . Beaucoup de gens semblent supposer que pour une raison quelconque.
if err != nil { return err } équivaut à "nous corrigerons cela plus tard" à try , sauf que c'est plus ennuyeux lors du prototypage.
Je ne sais pas comment les choses étant à l'intérieur d'une paire de parenthèses sont moins lisibles que les étapes de fonction étant toutes les quatre lignes de passe-partout non plus.
Ce serait bien si vous souligniez certains de ces "pièges" particuliers qui vous dérangent puisque c'est le sujet.
qrpnxz
le 5 juin 2019
La lisibilité semble être un problème, mais qu'en est-il de go fmt présentant try() pour qu'il se démarque, quelque chose comme :
f := try(
os.Open("file.txt")
)
@MrTravisB
Le problème que j'ai avec cela est qu'il suppose que vous voulez toujours simplement renvoyer l'erreur lorsqu'elle se produit.
Je ne suis pas d'accord. Cela suppose que vous vouliez le faire assez souvent pour justifier un raccourci pour cela. Si vous ne le faites pas, cela ne vous empêchera pas de gérer clairement les erreurs.
Lorsque vous souhaitez peut-être ajouter du contexte à l'erreur et la renvoyer ou peut-être souhaitez-vous simplement vous comporter différemment lorsqu'une erreur se produit.
La proposition décrit un modèle pour ajouter un contexte à l'échelle du bloc aux erreurs. @josharian a cependant souligné qu'il y avait une erreur dans les exemples et que la meilleure façon de l'éviter n'était pas claire. J'ai écrit quelques exemples de façons de le gérer.
Pour un contexte d'erreur plus spécifique, encore une fois, try fait une chose, et si vous ne voulez pas cette chose, n'utilisez pas try .
boomlinde
le 5 juin 2019
@boomlinde Exactement ce que je veux dire. Cette proposition tente de résoudre un cas d'utilisation singulier plutôt que de fournir un outil pour résoudre le problème plus large de la gestion des erreurs. Je pense que la question fondamentale est exactement ce que vous avez souligné.
Cela suppose que vous vouliez le faire assez souvent pour justifier un raccourci pour cela.
À mon avis et par expérience, ce cas d'utilisation est une petite minorité et ne justifie pas une syntaxe abrégée.
De plus, l'approche consistant à utiliser defer pour gérer les erreurs pose des problèmes dans la mesure où elle suppose que vous souhaitez gérer toutes les erreurs possibles de la même manière. Les relevés defer ne peuvent pas être annulés.
defer fmt.HandleErrorf(&err, “foobar”)
n := try(foo())
x : try(foo2())
Que se passe-t-il si je veux une gestion des erreurs différente pour les erreurs qui pourraient être renvoyées de foo() vs foo2() ?
MrTravisB
le 5 juin 2019
@MrTravisB
Que se passe-t-il si je veux une gestion des erreurs différente pour les erreurs qui pourraient être renvoyées par foo() vs foo2() ?
Ensuite, vous utilisez autre chose. C'est le point que @boomlinde faisait valoir.
Peut-être que vous ne voyez pas souvent ce cas d'utilisation personnellement, mais beaucoup de gens le font, et l'ajout try ne vous affecte pas vraiment. En fait, plus le cas d'utilisation est rare pour vous, moins cela vous affecte que try soit ajouté.
qrpnxz
le 5 juin 2019
@qrpnxz
f := try(os.Open("/foo"))
data := try(ioutil.ReadAll(f))
try(send(data))
(oui, je comprends qu'il y a ReadFile et que cet exemple particulier n'est pas la meilleure façon de copier des données quelque part, pas le point)
Cela demande plus d'efforts à lire car vous devez analyser le try en ligne. La logique d'application est enveloppée dans un autre appel.
Je dirais également qu'un gestionnaire d'erreurs defer ici ne serait pas bon, sauf pour simplement envelopper l'erreur avec un nouveau message ... ce qui est bien mais il y a plus à traiter les erreurs que de le rendre facile pour le humain de lire ce qui s'est passé.
Dans Rust, au moins l'opérateur est un suffixe ( ? ajouté à la fin d'un appel) qui n'impose pas de charge supplémentaire pour déterrer la logique réelle.
cpuguy83
le 5 juin 2019
Contrôle de flux basé sur l'expression
panic peut être une autre fonction de contrôle de flux, mais elle ne renvoie pas de valeur, ce qui en fait une instruction. Comparez cela à try , qui est une expression et peut apparaître n'importe où.
recover a une valeur et affecte le contrôle de flux, mais doit apparaître dans une instruction defer . Ces defer s sont généralement des littéraux de fonction, recover n'est appelé qu'une seule fois, et donc recover apparaît également comme une instruction. Encore une fois, comparez cela à try qui peut se produire n'importe où.
Je pense que ces points signifient que try rend beaucoup plus difficile de suivre le flux de contrôle d'une manière que nous n'avons pas eue auparavant, comme cela a été souligné précédemment, mais je n'ai pas vu la distinction entre les déclarations et les expressions souligné.
Une autre proposition
Autoriser les déclarations telles que
if err != nil {
return nil, 0, err
}
être formaté sur une ligne par gofmt lorsque le bloc ne contient qu'une instruction return et que cette instruction ne contient pas de nouvelles lignes. Par exemple:
if err != nil { return nil, 0, err }
Raisonnement
- Il ne nécessite aucun changement de langue
- La règle de formatage est simple et claire
- La règle peut être conçue pour être opt-in où
gofmtconserve les retours à la ligne s'ils existent déjà (comme les littéraux de structure). L'activation permet également à l'auteur de mettre l'accent sur la gestion des erreurs - Si ce n'est pas le cas, le code peut être automatiquement transféré vers le nouveau style avec un appel à
gofmt - C'est seulement pour les instructions
return, donc il ne sera pas inutilement abusé pour coder le golf - Interagit bien avec les commentaires décrivant pourquoi certaines erreurs peuvent se produire et pourquoi elles sont renvoyées. L'utilisation de nombreuses expressions imbriquées
trygère cela mal - Il réduit l'espace vertical de gestion des erreurs de 66 %
- Aucun flux de contrôle basé sur l'expression
- Le code est lu beaucoup plus souvent qu'il n'est écrit, il doit donc être optimisé pour le lecteur. Le code répétitif prenant moins de place est utile au lecteur, où
tryse penche davantage vers l'auteur - Les gens ont déjà proposé
tryexistant sur plusieurs lignes. Par exemple ce commentaire ou ce commentaire qui introduit un style comme
f, err := os.Open(file)
try(maybeWrap(err))
- Le style "essayer sur sa propre ligne" supprime toute ambiguïté sur la
errrenvoyée. Par conséquent, je soupçonne que ce formulaire sera couramment utilisé. Autoriser une ligne si les blocs est presque la même chose, sauf qu'il est également explicite sur les valeurs de retour - Il ne favorise pas l'utilisation de retours nommés ou d'emballages basés
deferpeu clairs. Les deux lèvent la barrière aux erreurs d'emballage et le premier peut nécessiter des modifications degodoc - Il n'est pas nécessaire de discuter du moment où utiliser
trypar rapport à l'utilisation traditionnelle de la gestion des erreurs - N'empêche pas de faire
tryou autre chose dans le futur. Le changement peut être positif même sitryest accepté - Aucune interaction négative avec la bibliothèque
testingou les fonctionsmain. En fait, si la proposition autorise n'importe quelle instruction sur une seule ligne au lieu de simplement retourner, cela peut réduire l'utilisation des bibliothèques basées sur des assertions. Considérer
value, err := something()
if err != nil { t.Fatal(err) }
- Aucune interaction négative avec la vérification d'erreurs spécifiques. Considérer
n, err := src.Read(buf)
if err == io.EOF { return nil }
else if err != nil { return err }
En résumé, cette proposition a un petit coût, peut être conçue pour être opt-in, n'empêche pas d'autres modifications puisqu'elle est uniquement stylistique et réduit la difficulté de lire le code de gestion des erreurs verbeux tout en gardant tout explicite. Je pense que cela devrait au moins être considéré comme une première étape avant de faire tapis sur try .
Quelques exemples portés
De https://github.com/golang/go/issues/32437#issuecomment -498941435
Avec essai
func NewThing(thingy *foo.Thingy, db *sql.DB, client pb.Client) (*Thing, error) {
try(dbfile.RunMigrations(db, dbMigrations))
t := &Thing{
thingy: thingy,
scanner: try(newScanner(thingy, db, client)),
}
t.initOtherThing()
return t, nil
}
Avec ça
func NewThing(thingy *foo.Thingy, db *sql.DB, client pb.Client) (*Thing, error) {
err := dbfile.RunMigrations(db, dbMigrations))
if err != nil { return nil, fmt.Errorf("running migrations: %v", err) }
t := &Thing{thingy: thingy}
t.scanner, err = newScanner(thingy, db, client)
if err != nil { return nil, fmt.Errorf("creating scanner: %v", err) }
t.initOtherThing()
return t, nil
}
Il est compétitif en termes d'utilisation de l'espace tout en permettant d'ajouter du contexte aux erreurs.
De https://github.com/golang/go/issues/32437#issuecomment -499007288
Avec essai
func (c *Config) Build() error {
pkgPath := try(c.load())
b := bytes.NewBuffer(nil)
try(emplates.ExecuteTemplate(b, "main", c))
buf := try(format.Source(b.Bytes()))
target := fmt.Sprintf("%s.go", filename(pkgPath))
try(ioutil.WriteFile(target, buf, 0644))
// ...
}
Avec ça
func (c *Config) Build() error {
pkgPath, err := c.load()
if err != nil { return nil, errors.WithMessage(err, "load config dir") }
b := bytes.NewBuffer(nil)
err = templates.ExecuteTemplate(b, "main", c)
if err != nil { return nil, errors.WithMessage(err, "execute main template") }
buf, err := format.Source(b.Bytes())
if err != nil { return nil, errors.WithMessage(err, "format main template") }
target := fmt.Sprintf("%s.go", filename(pkgPath))
err = ioutil.WriteFile(target, buf, 0644)
if err != nil { return nil, errors.WithMessagef(err, "write file %s", target) }
// ...
}
Le commentaire d'origine utilisait un hypothétique tryf pour joindre la mise en forme, qui a été supprimée. La meilleure façon d'ajouter tous les contextes distincts n'est pas claire, et peut-être try ne serait même pas applicable.
 zeebo
le 5 juin 2019
zeebo
le 5 juin 2019
@ cpuguy83
Pour moi, c'est plus lisible avec try . Dans cet exemple, je lis "ouvrir un fichier, lire tous les octets, envoyer des données". Avec la gestion des erreurs régulière, je lisais "ouvrez un fichier, vérifiez s'il y a eu une erreur, la gestion des erreurs le fait, puis lisez tous les octets, vérifiez maintenant si quelque chose s'est passé ..." Je sais que vous pouvez parcourir le err != nil s, mais pour moi try c'est juste plus facile parce que quand je le vois je connais tout de suite le comportement : renvoie if err != nil. Si vous avez une succursale, je dois voir ce qu'elle fait. Cela pourrait faire n'importe quoi.
Je dirais également qu'un gestionnaire d'erreur différé ici ne serait pas bon, sauf pour simplement envelopper l'erreur avec un nouveau message
Je suis sûr qu'il y a d'autres choses que vous pouvez faire dans le report, mais quoi qu'il en soit, try est de toute façon pour le cas général simple. Chaque fois que vous voulez faire quelque chose de plus, il y a toujours une bonne gestion des erreurs Go. Cela ne va pas disparaître.
qrpnxz
le 5 juin 2019
@zeebo Oui, je suis dedans.
L'article de @kungfusheep utilisait une vérification d'erreur sur une ligne comme celle-ci et j'ai été excité de l'essayer. Puis dès que j'ai sauvegardé, gofmt l'a étendu en trois lignes, ce qui était triste. De nombreuses fonctions de la stdlib sont définies sur une ligne comme celle-ci, donc cela m'a surpris que gofmt élargisse cela.
qrpnxz
le 5 juin 2019
@qrpnxz
Il se trouve que je lis beaucoup de code go. L'une des meilleures choses à propos du langage est la facilité avec laquelle la plupart des codes suivent un style particulier (merci gofmt).
Je ne veux pas lire un tas de code enveloppé dans try(f()) .
Cela signifie qu'il y aura soit une divergence dans le style/la pratique du code, soit des linters comme "oh, vous auriez dû utiliser try() ici" (ce que je n'aime même pas, ce qui est le but de moi et d'autres commentant sur cette proposition).
Ce n'est pas objectivement mieux que if err != nil { return err } , juste moins à taper.
Une dernière chose:
Si vous lisiez la proposition, vous verriez que rien ne vous empêche de
Pouvons-nous s'il vous plaît nous abstenir d'un tel langage? Bien sûr, j'ai lu la proposition. Il se trouve que je l'ai lu hier soir, puis que j'ai commenté ce matin après y avoir réfléchi et que je n'ai pas expliqué la minutie de ce que j'avais l'intention.
C'est un ton incroyablement contradictoire.
cpuguy83
le 5 juin 2019
@ cpuguy83
Mon méchant processeur. Je ne voulais pas dire ça comme ça.
Et je suppose que vous devez souligner que le code qui utilise try sera assez différent du code qui ne le fait pas, donc je peux imaginer que cela affecterait l'expérience d'analyse de ce code, mais je ne peux pas être totalement d'accord que différent signifie pire dans ce cas, même si je comprends que vous ne l'aimez pas personnellement, tout comme je l'aime personnellement. Beaucoup de choses en Go sont ainsi. Quant à ce que les linters vous disent de faire, c'est une tout autre affaire, je pense.
Bien sûr, ce n'est pas objectivement mieux. J'exprimais que c'était plus lisible de cette façon pour moi . J'ai soigneusement formulé cela.
Encore une fois, désolé de sonner ainsi. Bien que ce soit un argument, je ne voulais pas vous contrarier.
qrpnxz
le 5 juin 2019
https://github.com/golang/go/issues/32437#issuecomment -498908380
Personne ne va vous faire essayer.
Ignorant le désinvolture, je pense que c'est une façon assez simple de rejeter une critique de conception.
Bien sûr, je n'ai pas à l'utiliser. Mais n'importe qui avec qui j'écris du code pourrait l'utiliser et me forcer à essayer de déchiffrer try(try(try(to()).parse().this)).easily()) . C'est comme dire
Personne ne va vous faire utiliser l'interface vide{}.
Quoi qu'il en soit, Go est assez strict en matière de simplicité : gofmt donne à tout le code le même aspect. Le chemin heureux reste à gauche et tout ce qui pourrait être coûteux ou surprenant est explicite . try tel qu'il est proposé est un virage à 180 degrés par rapport à cela. Simplicité != concis.
À tout le moins try devrait être un mot-clé avec des lvalues.
 elagergren-spideroak
le 5 juin 2019
elagergren-spideroak
le 5 juin 2019
Ce n'est pas _objectivement_ meilleur que
if err != nil { return err }, juste moins à taper.
Il y a une différence objective entre les deux : try(Foo()) est une expression. Pour certains, cette différence est un inconvénient (la critique try(strconv.Atoi(x))+try(strconv.Atoi(y)) ). Pour d'autres, cette différence est un avantage pour la même raison. Toujours pas objectivement meilleur ou pire - mais je ne pense pas non plus que la différence devrait être balayée sous le tapis et prétendre que c'est "juste moins à taper" ne rend pas justice à la proposition.
Merovius
le 5 juin 2019
@elagergren-spideroak difficile de dire que try est ennuyeux à voir d'un seul souffle, puis de dire que ce n'est pas explicite dans le suivant. Tu dois en choisir un.
il est courant de voir d'abord les arguments de fonction placés dans des variables temporaires. Je suis sûr qu'il serait plus courant de voir
this := try(to()).parse().this
that := try(this.easily())
que votre exemple.
try ne rien faire est le chemin le plus heureux, donc cela ressemble à ce que nous attendions. Dans le chemin malheureux, il ne fait que revenir. Voir qu'il y a un try est suffisant pour recueillir cette information. Il n'y a rien de cher à revenir d'une fonction non plus, donc d'après cette description, je ne pense pas que try fasse un 180
qrpnxz
le 5 juin 2019
@josharian Concernant votre commentaire dans https://github.com/golang/go/issues/32437#issuecomment -498941854 , je ne pense pas qu'il y ait une erreur d'évaluation précoce ici.
différer fmt.HandleErrorf(&err, "foobar : %v", err)
La valeur non modifiée de err est passée à HandleErrorf , et un pointeur vers err est passé. Nous vérifions si err est nil (en utilisant le pointeur). Sinon, nous formatons la chaîne en utilisant la valeur non modifiée de err . Ensuite, nous définissons err sur la valeur d'erreur formatée, à l'aide du pointeur.
ianlancetaylor
le 5 juin 2019
@Merovius La proposition n'est en réalité qu'une macro de sucre de syntaxe, donc cela finira par concerner ce que les gens pensent être plus beau ou causer le moins de problèmes. Si vous pensez que non, veuillez m'expliquer. C'est pourquoi je suis pour, personnellement. C'est un bel ajout sans ajouter de mots-clés de mon point de vue.
qrpnxz
le 5 juin 2019
@ianlancetaylor , je pense que @josharian a raison : la valeur "non modifiée" de err est la valeur au moment où le defer est poussé sur la pile, pas la valeur (vraisemblablement prévue) de err défini par try avant de revenir.
 bcmills
le 5 juin 2019
bcmills
le 5 juin 2019
L'autre problème que j'ai avec try est qu'il est tellement plus facile pour les gens de vider plus de logique dans une seule ligne. C'est mon problème majeur avec la plupart des autres langages, c'est qu'ils permettent de mettre très facilement 5 expressions sur une seule ligne, et je ne veux pas que ça marche.
this := try(to()).parse().this
that := try(this.easily())
^^ même c'est carrément horrible. La première ligne, je dois sauter d'avant en arrière en faisant correspondre les parenthèses dans ma tête. Même la deuxième ligne qui est en fait assez simple... est vraiment difficile à lire.
Les fonctions imbriquées sont difficiles à lire.
parser, err := to()
if err != nil {
return err
}
this := parser.parse().this
that, err := this.easily()
if err != nil {
return err
}
^^ C'est tellement plus facile et meilleur IMO. C'est hyper simple et clair. oui, c'est beaucoup plus de lignes de code, je m'en fous. C'est très évident.
natefinch
le 5 juin 2019
@bcmills @josharian Ah, bien sûr, merci. Il faudrait donc
defer func() { fmt.HandleErrorf(&err, “foobar: %v”, err) }()
Pas si cool. Peut-être que fmt.HandleErrorf devrait implicitement passer la valeur d'erreur comme dernier argument après tout.
ianlancetaylor
le 5 juin 2019
Cette question a suscité beaucoup de commentaires très rapidement, et bon nombre d'entre eux me semblent répéter des commentaires qui ont déjà été faits. Bien sûr, n'hésitez pas à commenter, mais je voudrais gentiment suggérer que si vous voulez reformuler un point qui a déjà été fait, que vous le fassiez en utilisant les emojis de GitHub, plutôt qu'en répétant le point. Merci.
ianlancetaylor
le 5 juin 2019
@ianlancetaylor si fmt.HandleErrorf envoie err comme premier argument après le format, l'implémentation sera plus agréable et l'utilisateur pourra toujours le référencer par %[1]v .
qrpnxz
le 5 juin 2019
@natefinch Absolument d'accord.
Je me demande si une approche de style rouille serait plus acceptable?
Notez que ce n'est pas une proposition juste en y réfléchissant...
this := to()?.parse().this
that := this.easily()?
En fin de compte, je pense que c'est plus agréable, mais (pourrait utiliser un ! ou autre chose aussi...), mais ne résout toujours pas bien le problème de la gestion des erreurs.
bien sûr, la rouille a aussi try() peu près comme ça, mais... l'autre style de rouille.
cpuguy83
le 5 juin 2019
Ce n'est pas _objectivement_ meilleur que
if err != nil { return err }, juste moins à taper.Il y a une différence objective entre les deux :
try(Foo())est une expression. Pour certains, cette différence est un inconvénient (la critiquetry(strconv.Atoi(x))+try(strconv.Atoi(y))). Pour d'autres, cette différence est un avantage pour la même raison. Toujours pas objectivement meilleur ou pire - mais je ne pense pas non plus que la différence devrait être balayée sous le tapis et prétendre que c'est "juste moins à taper" ne rend pas justice à la proposition.
C'est l'une des principales raisons pour lesquelles j'aime cette syntaxe ; cela me permet d'utiliser une fonction de retour d'erreur dans le cadre d'une expression plus large sans avoir à nommer tous les résultats intermédiaires. Dans certaines situations, les nommer est facile, mais dans d'autres, il n'y a pas de nom particulièrement significatif ou non redondant à leur donner, auquel cas je préfère ne pas leur donner de nom du tout.
 dpinela
le 5 juin 2019
dpinela
le 5 juin 2019
@MrTravisB
Exactement mon propos. Cette proposition tente de résoudre un cas d'utilisation singulier plutôt que de fournir un outil pour résoudre le problème plus large de la gestion des erreurs. Je pense que la question fondamentale est exactement ce que vous avez souligné.
Qu'est-ce que j'ai dit précisément qui correspond exactement à votre point de vue ? Il me semble plutôt que vous avez fondamentalement mal compris mon propos si vous pensez que nous sommes d'accord.
À mon avis et par expérience, ce cas d'utilisation est une petite minorité et ne justifie pas une syntaxe abrégée.
Dans la source Go, il y a des milliers de cas qui pourraient être traités par try prêts à l'emploi même s'il n'y avait aucun moyen d'ajouter du contexte aux erreurs. Si mineur, c'est toujours une cause fréquente de plainte.
En outre, l'approche consistant à utiliser le report pour gérer les erreurs présente des problèmes dans la mesure où elle suppose que vous souhaitez gérer toutes les erreurs possibles de la même manière. les instructions différées ne peuvent pas être annulées.
De même, l'approche consistant à utiliser + pour gérer l'arithmétique suppose que vous ne voulez pas soustraire, donc vous ne le faites pas si vous ne le faites pas. La question intéressante est de savoir si le contexte d'erreur à l'échelle du bloc représente au moins un modèle commun.
Que se passe-t-il si je veux une gestion des erreurs différente pour les erreurs qui pourraient être renvoyées par foo() vs foo2()
Encore une fois, vous n'utilisez pas try . Ensuite, vous ne gagnez rien de try , mais vous ne perdez rien non plus.
boomlinde
le 5 juin 2019
@ cpuguy83
Je me demande si une approche de style rouille serait plus acceptable?
La proposition présente un argument contre cela.
boomlinde
le 5 juin 2019
À ce stade, je pense qu'avoir try{}catch{} est plus lisible :upside_down_face:
- L'utilisation d'importations nommées pour contourner les cas d'angle
defern'est pas seulement horrible pour des choses comme godoc, mais surtout c'est très sujet aux erreurs. Je m'en fous, je peux envelopper le tout avec un autrefunc()pour contourner le problème, c'est juste plus de choses que je dois garder à l'esprit, je pense que cela encourage une "mauvaise pratique". Personne ne va vous faire essayer.
Cela ne veut pas dire que c'est une bonne solution, je souligne que l'idée actuelle a un défaut dans la conception et je demande qu'elle soit traitée d'une manière moins sujette aux erreurs.
- Je pense que des exemples comme
try(try(try(to()).parse().this)).easily())sont irréalistes, cela pourrait déjà être fait avec d'autres fonctions et je pense qu'il serait juste que ceux qui examinent le code demandent qu'il soit divisé. Que se passe-t-il si j'ai 3 emplacements qui peuvent générer des erreurs et que je souhaite envelopper chaque emplacement séparément ?
try()rend cela très difficile, en faittry()décourage déjà les erreurs d'emballage compte tenu de sa difficulté, mais voici un exemple de ce que je veux dire :func before() error { x, err := foo() if err != nil { wrap(err, "error on foo") } y, err := bar(x) if err != nil { wrapf(err, "error on bar with x=%v", x) } fmt.Println(y) return nil } func after() (err error) { defer fmt.HandleErrorf(&err, "something failed but I don't know where: %v", err) x := try(foo()) y := try(bar(x)) fmt.Println(y) return nil }Encore une fois, vous n'utilisez pas
try. Ensuite, vous ne gagnez rien detry, mais vous ne perdez rien non plus.Disons que c'est une bonne pratique d'envelopper les erreurs avec un contexte utile,
try()serait considéré comme une mauvaise pratique car cela n'ajoute aucun contexte. Cela signifie quetry()est une fonctionnalité que personne ne veut utiliser et qui devient une fonctionnalité si rarement utilisée qu'elle n'a peut-être pas existé.Au lieu de simplement dire "eh bien, si vous ne l'aimez pas, ne l'utilisez pas et taisez-vous" (c'est ainsi qu'il se lit), je pense qu'il serait préférable d'essayer de résoudre ce que beaucoup d'utilisateurs considèrent comme un défaut Dans le design. Pouvons-nous discuter à la place de ce qui pourrait être modifié par rapport à la conception proposée afin que notre préoccupation soit mieux gérée ?
Goodwine
le 5 juin 2019
@boomlinde Le point sur lequel nous sommes d'accord est que cette proposition tente de résoudre un cas d'utilisation mineur et le fait que "si vous n'en avez pas besoin, ne l'utilisez pas" est l'argument principal pour cela. Comme @elagergren-spideroak l'a déclaré, cet argument ne fonctionne pas car même si je ne veux pas l'utiliser, d'autres le feront, ce qui m'oblige à l'utiliser. Selon la logique de votre argument, Go devrait également avoir une déclaration ternaire. Et si vous n'aimez pas les déclarations ternaires, ne les utilisez pas.
Avis de non-responsabilité - Je pense que Go devrait avoir une déclaration ternaire, mais étant donné que l'approche de Go en matière de fonctionnalités linguistiques consiste à ne pas introduire de fonctionnalités susceptibles de rendre le code plus difficile à lire, il ne devrait pas en être ainsi.
MrTravisB
le 5 juin 2019
Une autre chose me vient à l'esprit : je vois beaucoup de critiques basées sur l'idée qu'avoir try pourrait encourager les développeurs à gérer les erreurs avec négligence. Mais à mon avis, c'est plutôt vrai du langage actuel ; le passe-partout de gestion des erreurs est suffisamment ennuyeux pour inciter à avaler ou à ignorer certaines erreurs pour les éviter. Par exemple, j'ai écrit plusieurs fois des choses comme ça :
func exists(filename string) bool {
_, err := os.Stat(filename)
return err == nil
}
afin de pouvoir écrire if exists(...) { ... } , même si ce code ignore silencieusement certaines erreurs possibles. Si j'avais try , je ne prendrais probablement pas la peine de le faire et je retournerais simplement (bool, error) .
dpinela
le 5 juin 2019
Étant chaotique ici, je vais lancer l'idée d'ajouter une deuxième fonction intégrée appelée catch qui recevra une fonction qui prend une erreur et renvoie une erreur écrasée, puis si un catch est appelé, il écraserait le gestionnaire. par exemple:
func catch(handler func(err error) error) {
// .. impl ..
}
Désormais, cette fonction intégrée sera également une fonction de type macro qui gérera la prochaine erreur renvoyée par try comme ceci :
func wrapf(format string, ...values interface{}) func(err error) error {
// user defined
return func(err error) error {
return fmt.Errorf(format + ": %v", ...append(values, err))
}
}
func sample() {
catch(wrapf("something failed in foo"))
try(foo()) // "something failed in foo: <error>"
x := try(foo2()) // "something failed in foo: <error>"
// Subsequent calls for catch overwrite the handler
catch(wrapf("something failed in bar with x=%v", x))
try(bar(x)) // "something failed in bar with x=-1: <error>"
}
C'est bien parce que je peux envelopper les erreurs sans defer qui peuvent être sujettes aux erreurs à moins que nous n'utilisions des valeurs de retour nommées ou envelopper avec une autre fonction, c'est aussi bien parce que defer ajouterait le même gestionnaire d'erreurs pour toutes les erreurs même si je veux en gérer 2 différemment. Vous pouvez également l'utiliser comme bon vous semble, par exemple :
func foo(a, b string) (int64, error) {
return try(strconv.Atoi(a)) + try(strconv.Atoi(b))
}
func withContext(a, b string) (int64, error) {
catch(func (err error) error {
return fmt.Errorf("can't parse a: %s, b: %s, err: %v", a, b, err)
})
return try(strconv.Atoi(a)) + try(strconv.Atoi(b))
}
func moreExplicitContext(a, b string) (int64, error) {
catch(func (err error) error {
return fmt.Errorf("can't parse a: %s, err: %v", a, err)
})
x := try(strconv.Atoi(a))
catch(func (err error) error {
return fmt.Errorf("can't parse b: %s, err: %v", b, err)
})
y := try(strconv.Atoi(b))
return x + y
}
func withHelperWrapf(a, b string) (int64, error) {
catch(wrapf("can't parse a: %s", a))
x := try(strconv.Atoi(a))
catch(wrapf("can't parse b: %s", b))
y := try(strconv.Atoi(b))
return x + y
}
func before(a, b string) (int64, error) {
x, err := strconv.Atoi(a)
if err != nil {
return 0, fmt.Errorf("can't parse a: %s, err: %v", a, err)
}
y, err := strconv.Atoi(b)
if err != nil {
return 0, fmt.Errorf("can't parse b: %s, err: %v", b, err)
}
return x + y
}
Et toujours d'humeur chaotique (pour vous aider à comprendre) Si vous n'aimez pas catch , vous n'êtes pas obligé de l'utiliser.
Maintenant... Je ne parle pas vraiment de la dernière phrase, mais j'ai l'impression que ce n'est pas utile pour la discussion, très agressif IMO.
Pourtant, si nous suivions cette voie, je pense que nous pourrions aussi bien avoir try{}catch(error err){} la place :stuck_out_tongue:
Goodwine
le 5 juin 2019
Voir aussi #27519 - le modèle d'erreur #id/catch
networkimprov
le 5 juin 2019
Personne ne va vous faire essayer.
Ignorant le désinvolture, je pense que c'est une façon assez simple de rejeter une critique de conception.
Désolé, le glib n'était pas mon intention.
Ce que j'essaie de dire, c'est que try n'est pas censé être une solution à 100 %. Il existe divers paradigmes de gestion des erreurs qui ne sont pas bien gérés par try . Par exemple, si vous devez ajouter un contexte dépendant du site d'appel à l'erreur. Vous pouvez toujours recourir à if err != nil { pour gérer ces cas plus compliqués.
C'est certainement un argument valable que try ne peut pas gérer X, pour diverses instances de X. Mais souvent, gérer le cas X signifie rendre le mécanisme plus compliqué. Il y a un compromis ici, manipulant X d'une part mais compliquant le mécanisme pour tout le reste. Ce que nous faisons dépend de la fréquence de X et de la complexité nécessaire pour gérer X.
Donc par "personne ne va te faire utiliser try", je veux dire que je pense que l'exemple en question est dans les 10%, pas dans les 90%. Cette affirmation est certainement sujette à débat, et je suis heureux d'entendre des contre-arguments. Mais finalement, nous devrons tracer une ligne quelque part et dire "ouais, try ne gérera pas ce cas. Vous devrez utiliser la gestion des erreurs à l'ancienne. Désolé.".
randall77
le 5 juin 2019
Ce n'est pas "essayer ne peut pas gérer ce cas spécifique de gestion des erreurs" qui est le problème, c'est "essayer vous encourage à ne pas envelopper vos erreurs". L'idée check-handle vous obligeait à écrire une instruction de retour, donc écrire un emballage d'erreur était assez trivial.
Dans cette proposition, vous devez utiliser un retour nommé avec un defer , ce qui n'est pas intuitif et semble très hacky.
deanveloper
le 5 juin 2019
L'idée
check-handlevous obligeait à écrire une instruction de retour, donc écrire un emballage d'erreur était assez trivial.
Ce n'est pas vrai - dans le brouillon de conception, chaque fonction qui renvoie une erreur a un gestionnaire par défaut qui renvoie simplement l'erreur.
dpinela
le 5 juin 2019
S'appuyant sur le point espiègle de @Goodwine , vous n'avez pas vraiment besoin de fonctions séparées comme HandleErrorf si vous avez une seule fonction de pont comme
func handler(err *error, handle func(error) error) {
// nil handle is treated as the identity
if *err != nil && handle != nil {
*err = handle(*err)
}
}
que vous utiliseriez comme
defer handler(&err, func(err error) error {
if errors.Is(err, io.EOF) {
return nil
}
return fmt.Errorf("oops: %w", err)
})
Vous pourriez faire handler lui-même un semi-magique intégré comme try .
Si c'est magique, il pourrait prendre implicitement son premier argument, lui permettant d'être utilisé même dans des fonctions qui ne nomment pas leur retour error , éliminant l'un des aspects les moins chanceux de la proposition actuelle tout en la rendant moins pointilleux et sujet aux erreurs pour décorer les erreurs. Bien sûr, cela ne réduit pas beaucoup l'exemple précédent :
defer handler(func(err error) error {
if errors.Is(err, io.EOF) {
return nil
}
return fmt.Errorf("oops: %w", err)
})
Si c'était magique de cette manière, il faudrait que ce soit une erreur de compilation s'il était utilisé n'importe où sauf comme argument de defer . Vous pourriez aller plus loin et le faire différer implicitement, mais defer handler se lit assez bien.
Puisqu'il utilise defer , il pourrait appeler sa fonction handle chaque fois qu'une erreur non nulle est renvoyée, ce qui le rend utile même sans try puisque vous pouvez ajouter un
defer handler(wrapErrWithPackageName)
en haut à fmt.Errorf("mypkg: %w", err) tout.
Cela vous donne une grande partie de l'ancienne proposition check / handle mais cela fonctionne avec le report naturellement (et explicitement) tout en vous débarrassant de la nécessité, dans la plupart des cas, de nommer explicitement un err retour. Comme try , c'est une macro relativement simple qui (j'imagine) pourrait être entièrement implémentée dans le front-end.
jimmyfrasche
le 5 juin 2019
Ce n'est pas vrai - dans le brouillon de conception, chaque fonction qui renvoie une erreur a un gestionnaire par défaut qui renvoie simplement l'erreur.
Mon mauvais, vous avez raison.
deanveloper
le 5 juin 2019
Je veux dire que je pense que l'exemple en question est dans les 10%, pas dans les 90%. Cette affirmation est certainement sujette à débat, et je suis heureux d'entendre des contre-arguments. Mais finalement, nous devrons tracer une ligne quelque part et dire "oui, essayer ne traitera pas ce cas. Vous devrez utiliser la gestion des erreurs à l'ancienne. Désolé.".
D'accord, mon opinion est que cette ligne doit être tracée lors de la vérification d'EOF ou similaire, pas lors de l'emballage. Mais peut-être que si les erreurs avaient plus de contexte, cela ne serait plus un problème.
Est-ce try() peut envelopper automatiquement les erreurs avec un contexte utile pour le débogage ? Par exemple, si xerrors devient errors , les erreurs devraient avoir quelque chose qui ressemble à une trace de pile que try() pourrait ajouter, non ? Si oui, cela suffirait peut-être 🤔
Goodwine
le 5 juin 2019
Si les objectifs sont (lire https://github.com/golang/proposal/blob/master/design/32437-try-builtin.md) :
- éliminer le passe-partout
- changements de langue minimes
- couvrant "les scénarios les plus courants"
- ajoutant très peu de complexité au langage
Je prendrais la suggestion, donnez-lui un angle et autorisez la migration de code "par petites étapes" pour tous les milliards de lignes de code qui existent.
au lieu de la suggestion :
func printSum(a, b string) error {
defer fmt.HandleErrorf(&err, "sum %s %s: %v", a,b, err)
x := try(strconv.Atoi(a))
y := try(strconv.Atoi(b))
fmt.Println("result:", x + y)
return nil
}
Nous pouvons:
func printSum(a, b string) error {
var err ErrHandler{HandleFunc : twoStringsErr("printSum",a,b)}
x, err.Error := strconv.Atoi(a)
y,err.Error := strconv.Atoi(b)
fmt.Println("result:", x + y)
return nil
}
Que gagnerions-nous ?
twoStringsErr peut être intégré à printSum, ou un gestionnaire général qui sait comment capturer les erreurs (dans ce cas avec 2 paramètres de chaîne) - donc si j'ai les mêmes signatures func répétitives utilisées dans plusieurs de mes fonctions, je n'ai pas besoin de réécrire le gestionnaire chaque temps
de la même manière, je peux avoir le type ErrHandler étendu de la manière suivante :
type ioErrHandler ErrHandler
func (i ErrHandler) Handle() ...{
}
ou
type parseErrHandler ErrHandler
func (p parseErrHandler) Handle() ...{
}
ou
type str2IntErrHandler ErrHandler
func (s str2IntErrHandler) Handle() ...{
}
et utilisez ceci tout autour de mon mon code:
func printSum(a, b string) error {
var pErr str2IntErrHandler
x, err.Error := strconv.Atoi(a)
y,err.Error := strconv.Atoi(b)
fmt.Println("result:", x + y)
return nil
}
Ainsi, le besoin réel serait de développer un déclencheur lorsque err.Error est défini sur not nil
En utilisant cette méthode, nous pouvons également :
func (s str2IntErrHandler) Handle() bool{
**return false**
}
Ce qui dirait à la fonction appelante de continuer au lieu de revenir
Et utilisez différents gestionnaires d'erreurs dans la même fonction :
func printSum(a, b string) error {
var pErr str2IntErrHandler
var oErr overflowError
x, err.Error := strconv.Atoi(a)
y,err.Error := strconv.Atoi(b)
fmt.Println("result:", x + y)
totalAsByte,oErr := sumBytes(x,y)
sunAsByte,oErr := subtractBytes(x,y)
return nil
}
etc.
Revoir les objectifs
- éliminer le passe-partout - c'est fait
- changements de langage minimaux - terminé
- couvrant les "scénarios les plus courants" - plus que l'OMI suggérée
- ajoutant très peu de complexité à la langue - sone
Plus - migration de code plus facile à partir de
x, err := strconv.Atoi(a)
pour
x, err.Error := strconv.Atoi(a)
et en fait - une meilleure lisibilité (IMO, encore une fois)
 guybrand
le 5 juin 2019
guybrand
le 5 juin 2019
@guybrand vous êtes le dernier adhérent à ce thème récurrent (que j'aime).
Voir https://github.com/golang/go/wiki/Go2ErrorHandlingFeedback#recurring -themes
networkimprov
le 5 juin 2019
@guybrand Cela semble être une proposition entièrement différente; Je pense que vous devriez le classer comme son propre problème afin que celui-ci puisse se concentrer sur la discussion de la proposition de @griesemer .
dpinela
le 5 juin 2019
@natefinch est d'accord. Je pense que cela vise davantage à améliorer l'expérience lors de l'écriture de Go au lieu d'optimiser la lecture. Je me demande si des macros ou des extraits IDE pourraient résoudre le problème sans que cela devienne une caractéristique du langage.
 owais
le 5 juin 2019
owais
le 5 juin 2019
@Bon vin
Disons que c'est une bonne pratique d'envelopper les erreurs avec un contexte utile,
try()serait considéré comme une mauvaise pratique car cela n'ajoute aucun contexte. Cela signifie quetry()est une fonctionnalité que personne ne veut utiliser et qui devient une fonctionnalité si rarement utilisée qu'elle n'a peut-être pas existé.
Comme indiqué dans la proposition (et illustré par un exemple), try ne vous empêche pas fondamentalement d'ajouter du contexte. Je dirais que la façon dont c'est proposé, ajouter du contexte aux erreurs est tout à fait orthogonale. Ceci est spécifiquement abordé dans la FAQ de la proposition.
Je reconnais que try ne sera pas utile si dans une seule fonction s'il existe une multitude de contextes différents que vous souhaitez ajouter à différentes erreurs d'appels de fonction. Cependant, je pense également que quelque chose dans la veine générale de HandleErrorf couvre un large domaine d'utilisation, car il n'est pas inhabituel d'ajouter uniquement un contexte à l'échelle de la fonction aux erreurs.
Au lieu de simplement dire "eh bien, si vous ne l'aimez pas, ne l'utilisez pas et taisez-vous" (c'est ainsi qu'il se lit), je pense qu'il serait préférable d'essayer de résoudre ce que beaucoup d'utilisateurs considèrent comme un défaut Dans le design.
Si c'est ainsi qu'il se lit, je m'en excuse. Mon propos n'est pas que vous devriez prétendre qu'il n'existe pas si vous ne l'aimez pas. C'est qu'il est évident qu'il y a des cas dans lesquels try seraient inutiles et que vous ne devriez pas l'utiliser dans de tels cas, ce qui, pour cette proposition, je crois, établit un bon équilibre entre KISS et l'utilité générale. Je ne pensais pas avoir été flou sur ce point.
boomlinde
le 5 juin 2019
Merci à tous pour les commentaires prolifiques jusqu'à présent ; c'est très instructif.
Voici ma tentative de résumé initial, pour avoir une meilleure idée des commentaires. Toutes mes excuses à l'avance pour tous ceux que j'ai manqués ou mal représentés ; J'espère que j'ai bien compris l'essentiel.
0) Du côté positif, @rasky , @adg , @eandre , @dpinela et d'autres ont explicitement exprimé leur bonheur face à la simplification du code fournie par try .
1) La préoccupation la plus importante semble être que try n'encourage pas un bon style de gestion des erreurs, mais favorise plutôt la "sortie rapide". ( @agnivade , @peterbourgon , @politician , @a8m , @eandre , @prologic , @kungfusheep , @cpuguy , et d'autres ont exprimé leur inquiétude à ce sujet.)
2) Beaucoup de gens n'aiment pas l'idée d'une fonction intégrée ou la syntaxe de fonction qui l'accompagne car elle cache un return . Il serait préférable d'utiliser un mot-clé. ( @sheerun , @Redundancy , @dolmen , @komuw , @RobertGrantEllis , @elagergren-spideroak). try peut également être facilement ignoré (@peterbourgon), notamment parce qu'il peut apparaître dans des expressions arbitrairement imbriquées. @natefinch craint que try ne rende "trop facile d'en vider trop sur une seule ligne", ce que nous essayons généralement d'éviter dans Go. De plus, le support IDE pour mettre l'accent sur try peut ne pas être suffisant (@dominikh); try doit "être autonome".
3) Pour certains, le statu quo des déclarations explicites if n'est pas un problème, ils en sont satisfaits ( @bitfield , @marwan-at-work, @natefinch). Il vaut mieux n'avoir qu'une seule façon de faire les choses (@gbbr); et les instructions if explicites sont meilleures que return implicites ( @DavexPro , @hmage , @prologic , @natefinch).
Dans le même ordre d'idées, @mattn est préoccupé par la "liaison implicite" du résultat d'erreur à try - la connexion n'est pas explicitement visible dans le code.
4) L'utilisation try rendra plus difficile le débogage du code ; par exemple, il peut être nécessaire de réécrire une expression try dans une instruction if juste pour que les instructions de débogage puissent être insérées ( @deanveloper , @typeless , @networkimprov , autres).
5) L'utilisation de retours nommés ( @buchanae , @adg) suscite des inquiétudes.
Plusieurs personnes ont fourni des suggestions pour améliorer ou modifier la proposition :
6) Certains ont repris l'idée d'un gestionnaire d'erreurs facultatif (@beoran) ou d'une chaîne de format fournie à try ( @unexge , @a8m , @eandre , @gotwarlost) pour encourager une bonne gestion des erreurs.
7) @pierrec a suggéré que gofmt pourrait formater les expressions try manière appropriée pour les rendre plus visibles.
Alternativement, on pourrait rendre le code existant plus compact en permettant gofmt de formater les instructions if vérifiant les erreurs sur une ligne (@zeebo).
8) @marwan-at-work soutient que try déplace simplement la gestion des erreurs des instructions $#$ if $#$ vers les expressions try . Au lieu de cela, si nous voulons réellement résoudre le problème, Go devrait "posséder" la gestion des erreurs en la rendant vraiment implicite. L'objectif devrait être de rendre la gestion des erreurs (correcte) plus simple et les développeurs plus productifs (@cpuguy).
9) Enfin, certaines personnes n'aiment pas le nom try ( @beoran , @HiImJC , @dolmen) ou préféreraient un symbole tel que ? ( @twisted1919 , @leaxoy , autres) .
Quelques commentaires sur ces commentaires (numérotés en conséquence) :
0) Merci pour les commentaires positifs ! :-)
1) Il serait bon d'en savoir plus sur ce souci. Le style de codage actuel utilisant les instructions if pour tester les erreurs est à peu près aussi explicite que possible. Il est très facile d'ajouter des informations supplémentaires à une erreur, sur une base individuelle (pour chaque if ). Souvent, il est logique de gérer toutes les erreurs détectées dans une fonction de manière uniforme, ce qui peut être fait avec un defer - c'est déjà possible maintenant. C'est le fait que nous avons déjà tous les outils pour une bonne gestion des erreurs dans le langage, et le problème d'une construction de gestionnaire non orthogonale à defer , qui nous a conduit à laisser de côté un nouveau mécanisme uniquement pour augmenter les erreurs .
2) Il y a bien sûr la possibilité d'utiliser un mot-clé ou une syntaxe spéciale au lieu d'un intégré. Un nouveau mot clé ne sera pas rétrocompatible. Un nouvel opérateur pourrait, mais semble encore moins visible. La proposition détaillée discute longuement des différents avantages et inconvénients. Mais peut-être méconnaît-on cela.
3) La raison de cette proposition est que la gestion des erreurs (en particulier le code passe-partout associé) a été mentionnée comme un problème important dans Go (à côté du manque de génériques) par la communauté Go. Cette proposition répond directement à la préoccupation passe-partout. Il ne fait pas plus que résoudre le cas le plus élémentaire car tout cas plus complexe est mieux traité avec ce que nous avons déjà. Ainsi, alors qu'un bon nombre de personnes sont satisfaites du statu quo, il existe un contingent (probablement) tout aussi important de personnes qui aimeraient une approche plus rationalisée telle que try , sachant bien que c'est "juste" sucre syntaxique.
4) Le point de débogage est une préoccupation valable. S'il est nécessaire d'ajouter du code entre la détection d'une erreur et un return , devoir réécrire une expression try dans une instruction if peut être ennuyeux.
5) Valeurs de retour nommées : Le document détaillé en parle longuement. Si c'est la principale préoccupation de cette proposition, alors nous sommes dans une bonne position, je pense.
6) Argument optionnel du gestionnaire à try : Le document détaillé en parle également. Voir la section sur les itérations de conception.
7) Utiliser gofmt pour formater les expressions try manière à ce qu'elles soient plus visibles serait certainement une option. Mais cela enlèverait certains des avantages de try lorsqu'il est utilisé dans une expression.
8) Nous avons envisagé d'examiner le problème du point de vue de la gestion des erreurs ( handle ) plutôt que du point de vue du test des erreurs ( try ). Plus précisément, nous avons brièvement envisagé d'introduire uniquement la notion de gestionnaire d'erreurs (similaire au projet de conception original présenté à la Gophercon de l'année dernière). L'idée était que si (et seulement si) un gestionnaire est déclaré, dans les affectations à plusieurs valeurs où la dernière valeur est de type error , cette valeur peut simplement être laissée de côté dans une affectation. Le compilateur vérifierait implicitement s'il est non-nil, et si c'est le cas, branchez-le au gestionnaire. Cela ferait disparaître complètement la gestion explicite des erreurs et encouragerait tout le monde à écrire un gestionnaire à la place. Cela semblait une approche extrême car elle serait complètement implicite - le fait qu'une vérification se produise serait invisible.
9) Puis-je suggérer que nous ne perdons pas le nom à vélo à ce stade. Une fois que toutes les autres préoccupations sont réglées, il est préférable d'affiner le nom.
Cela ne veut pas dire que les préoccupations ne sont pas fondées - les réponses ci-dessus indiquent simplement notre pensée actuelle. À l'avenir, il serait bon de commenter les nouvelles préoccupations (ou de nouvelles preuves à l'appui de ces préoccupations) - le simple fait de répéter ce qui a déjà été dit ne nous fournit pas plus d'informations.
Et enfin, il semble que tous ceux qui commentent le problème n'ont pas lu la doc détaillée. Veuillez le faire avant de commenter pour éviter de répéter ce qui a déjà été dit. Merci.
griesemer
le 5 juin 2019
Ceci n'est pas un commentaire sur la proposition, mais un rapport de faute de frappe. Il n'a pas été corrigé depuis la publication de la proposition complète, alors j'ai pensé le mentionner :
func try(t1 T1, t1 T2, … tn Tn, te error) (T1, T2, … Tn)
devrait être:
func try(t1 T1, t2 T2, … tn Tn, te error) (T1, T2, … Tn)
 mirtchovski
le 5 juin 2019
mirtchovski
le 5 juin 2019
Cela vaudrait-il la peine d'analyser le code Go librement disponible pour les instructions de vérification des erreurs afin d'essayer de déterminer si la plupart des vérifications d'erreurs sont vraiment répétitives ou si, dans la plupart des cas, plusieurs vérifications au sein de la même fonction ajoutent des informations contextuelles différentes ? La proposition aurait beaucoup de sens pour le premier cas, mais n'aiderait pas le second. Dans ce dernier cas, les utilisateurs continueront d'utiliser if err != nil ou renonceront à ajouter un contexte supplémentaire, utiliseront try() et auront recours à l'ajout d'un contexte d'erreur commun par fonction, ce qui, selon l'OMI, serait nuisible. Avec les fonctionnalités de valeurs d'erreur à venir, je pense que nous nous attendons à ce que les gens enveloppent plus souvent les erreurs avec plus d'informations. J'ai probablement mal compris la proposition, mais AFAIU, cela aide à réduire le passe-partout uniquement lorsque toutes les erreurs d'une seule fonction doivent être enveloppées exactement d'une manière et n'aide pas si une fonction traite cinq erreurs qui pourraient devoir être enveloppées différemment. Je ne sais pas à quel point de tels cas sont courants dans la nature (assez courants dans la plupart de mes projets), mais je crains que try() n'encourage les gens à utiliser des wrappers communs par fonction même s'il serait logique d'envelopper différentes erreurs différemment.
owais
le 5 juin 2019
Juste un commentaire rapide soutenu par les données d'un petit jeu d'échantillons :
Nous proposons une nouvelle fonction intégrée appelée try, conçue spécifiquement pour éliminer le passe-partout si les instructions généralement associées à la gestion des erreurs dans Go
Si c'est le problème principal résolu par cette proposition, je trouve que ce "type standard" ne représente qu'environ 1,4 % de mon code sur des dizaines de projets open source accessibles au public totalisant environ 60 000 SLOC.
Curieux de savoir si quelqu'un d'autre a des statistiques similaires ?
Sur une base de code beaucoup plus grande comme Go elle-même totalisant environ ~ 1,6 million de SLOC, cela équivaut à environ 0,5 % de la base de code ayant des lignes comme if err != nil .
Est-ce vraiment le problème le plus impactant à résoudre avec Go 2 ?
prologic
le 5 juin 2019
Merci beaucoup @griesemer d'avoir pris le temps de passer en revue les idées de chacun et d'avoir explicitement fourni des réflexions. Je pense que cela aide vraiment à donner l'impression que la communauté est entendue dans le processus.
- @pierrec a suggéré que gofmt pourrait formater les expressions try de manière appropriée pour les rendre plus visibles.
Alternativement, on pourrait rendre le code existant plus compact en permettant à gofmt de formater les instructions if vérifiant les erreurs sur une ligne (@zeebo).
- Utiliser
gofmtpour formater les expressionstrymanière à ce qu'elles soient plus visibles serait certainement une option. Mais cela enlèverait certains des avantages detrylorsqu'il est utilisé dans une expression.
Ce sont des réflexions précieuses sur l'exigence gofmt pour formater try , mais je suis intéressé s'il y a des réflexions en particulier sur gofmt permettant la vérification de l'instruction if l'erreur d'être une ligne. La proposition a été regroupée avec un formatage de try , mais je pense que c'est une chose complètement orthogonale. Merci.
zeebo
le 6 juin 2019
@griesemer merci pour le travail incroyable qui a parcouru tous les commentaires et répondu à la plupart sinon à tous les commentaires 🎉
Une chose qui n'a pas été abordée dans vos commentaires était l'idée d'utiliser la partie outils/vérification du langage Go pour améliorer l'expérience de gestion des erreurs, plutôt que de mettre à jour la syntaxe Go.
Par exemple, avec l'arrivée du nouveau LSP ( gopls ), cela semble être un endroit parfait pour analyser la signature d'une fonction et prendre en charge le passe-partout de gestion des erreurs pour le développeur, avec un emballage et une vérification appropriés également.
marwan-at-work
le 6 juin 2019
@griesemer Je suis sûr que ce n'est pas bien pensé, mais j'ai essayé de modifier votre suggestion plus près de quelque chose avec laquelle je serais à l'aise ici : https://www.reddit.com/r/golang/comments/bwvyhe /proposal_a_builtin_go_error_check_function_try/eq22bqa?utm_source=share&utm_medium=web2x
Redundancy
le 6 juin 2019
@zeebo Il serait facile de faire le format $ gofmt if err != nil { return ...., err } sur une seule ligne. Vraisemblablement, ce ne serait que pour ce type spécifique de modèle if , pas toutes les instructions "courtes" if ?
Dans le même ordre d'idées, on craignait que try ne soit invisible car il se trouve sur la même ligne que la logique métier. Nous avons toutes ces options :
Style actuel :
a, b, c, ... err := BusinessLogic(...)
if err != nil {
return ..., err
}
Une ligne if :
a, b, c, ... err := BusinessLogic(...)
if err != nil { return ..., err }
try sur une ligne distincte (!) :
a, b, c, ... err := BusinessLogic(...)
try(err)
try tel que proposé :
a, b, c := try(BusinessLogic(...))
La première et la dernière ligne me semblent les plus claires, surtout une fois que l'on est habitué à reconnaître try comme ce qu'il est. Avec la dernière ligne, une erreur est explicitement vérifiée, mais comme ce n'est (généralement) pas l'action principale, elle est un peu plus en arrière-plan.
griesemer
le 6 juin 2019
@marwan-at-work Je ne suis pas sûr de ce que vous proposez que les outils fassent pour vous. Suggérez-vous qu'ils cachent la gestion des erreurs d'une manière ou d'une autre ?
griesemer
le 6 juin 2019
@dpinela
@guybrand Cela semble être une proposition entièrement différente; Je pense que vous devriez le classer comme son propre problème afin que celui-ci puisse se concentrer sur la discussion de la proposition de @griesemer .
IMO ma proposition ne diffère que par la syntaxe, ce qui signifie :
- Les objectifs sont similaires dans leur contenu et leur priorité.
- L'idée de capturer chaque erreur dans sa propre ligne et en conséquence (sinon nil) de quitter la fonction tout en passant par une fonction de gestionnaire est similaire (pseudo asm - c'est un "jnz" et un "appel").
- Cela signifie même que le nombre de lignes dans un corps de fonction (sans le report) et le flux se ressembleraient exactement (et par conséquent, AST se révélerait probablement le même également)
donc le diff principal est de savoir si nous enveloppons l'appel de fonction d'origine avec try(func()) qui analyserait toujours la dernière var pour jnz l'appel ou utiliserait la valeur de retour réelle pour le faire.
Je sais que ça a l'air différent, mais en fait très similaire dans son concept.
D'un autre côté - si vous prenez l'essai habituel .... catch dans de nombreux langages de type c - ce serait une implémentation très différente, une lisibilité différente, etc.
Je pense cependant sérieusement à écrire une proposition, merci pour l'idée.
guybrand
le 6 juin 2019
@griesemer
Je ne suis pas sûr de ce que vous proposez que les outils font pour vous. Suggérez-vous qu'ils cachent la gestion des erreurs d'une manière ou d'une autre ?
Bien au contraire : je suggère que gopls puisse éventuellement écrire le passe-partout de gestion des erreurs pour vous.
Comme vous l'avez mentionné dans votre dernier commentaire :
La raison de cette proposition est que la gestion des erreurs (en particulier le code passe-partout associé) a été mentionnée comme un problème important dans Go (à côté du manque de génériques) par la communauté Go
Ainsi, le cœur du problème est que le programmeur finit par écrire beaucoup de code passe-partout. Il s'agit donc d'écrire, pas de lire. Par conséquent, ma suggestion est la suivante : laissez l'ordinateur (tooling/gopls) écrire pour le programmeur en analysant la signature de la fonction et en plaçant les clauses de gestion des erreurs appropriées.
Par exemple:
// user begins to write this function:
func openFile(path string) ([]byte, error) {
file, err := os.Open(path)
defer file.Close()
bts, err := ioutil.ReadAll(file)
return bts, nil
}
Ensuite, l'utilisateur déclenche l'outil, peut-être en enregistrant simplement le fichier (similaire au fonctionnement typique de gofmt/goimports) et gopls regarderait cette fonction, analyserait sa signature de retour et augmenterait le code pour qu'il soit celui-ci :
// user has triggered the tool (by saving the file, or code action)
func openFile(path string) ([]byte, error) {
file, err := os.Open(path)
if err != nil {
return nil, fmt.Errorf("openFile: %w", err)
}
defer file.Close()
bts, err := ioutil.ReadAll(file)
if err != nil {
return nil, fmt.Errorf("openFile: %w", err)
}
return bts, nil
}
De cette façon, nous obtenons le meilleur des deux mondes : nous obtenons la lisibilité/l'explicitation du système de gestion des erreurs actuel, et le programmeur n'a écrit aucun passe-partout de gestion des erreurs. Mieux encore, l'utilisateur peut continuer et modifier les blocs de gestion des erreurs plus tard pour adopter un comportement différent : gopls peut comprendre que le bloc existe, et il ne le modifiera pas.
marwan-at-work
le 6 juin 2019
Comment l'outil saurait-il que j'ai l'intention de gérer le err plus tard dans la fonction au lieu de revenir plus tôt ? Bien que rare, mais le code que j'ai écrit néanmoins.
prologic
le 6 juin 2019
Je m'excuse si cela a déjà été soulevé, mais je n'ai trouvé aucune mention à ce sujet.
try(DoSomething()) se lit bien pour moi et a du sens : le code essaie de faire quelque chose. try(err) , OTOH, se sent un peu décalé, sémantiquement parlant : comment tenter une erreur ? Dans mon esprit, on pourrait _tester_ ou _vérifier_ une erreur, mais _essayer_ une ne semble pas correcte.
Je me rends compte qu'il est important d'autoriser try(err) pour des raisons de cohérence : je suppose que ce serait étrange si try(DoSomething()) fonctionnait, mais pas err := DoSomething(); try(err) . Pourtant, on a l'impression que try(err) semble un peu gênant sur la page. Je ne peux pas penser à d'autres fonctions intégrées qui peuvent être rendues aussi étranges si facilement.
Je n'ai pas de suggestions concrètes à ce sujet, mais je voulais quand même faire ce constat.
 acln0
le 6 juin 2019
acln0
le 6 juin 2019
@griesemer Merci. En effet, la proposition ne devait être que pour return , mais je soupçonne que permettre à une seule déclaration d'être une seule ligne serait bien. Par exemple, dans un test, on pourrait, sans modification de la bibliothèque de test, avoir
if err != nil { t.Fatal(err) }
La première et la dernière ligne me semblent les plus claires, surtout une fois qu'on a l'habitude de reconnaître l'essai pour ce qu'il est. Avec la dernière ligne, une erreur est explicitement vérifiée, mais comme ce n'est (généralement) pas l'action principale, elle est un peu plus en arrière-plan.
Avec la dernière ligne, une partie du coût est masquée. Si vous voulez annoter l'erreur, ce qui, je crois, est la meilleure pratique souhaitée par la communauté et devrait être encouragée, il faudrait changer la signature de la fonction pour nommer les arguments et espérer qu'un seul defer s'applique à chaque sortie dans le corps de la fonction, sinon try n'a pas de valeur ; peut-être même négatif en raison de sa facilité.
Je n'ai rien de plus à ajouter qui je crois n'ait déjà été dit.
Je n'ai pas vu comment répondre à cette question dans la doc de conception. Que fait ce code:
func foo() (err error) {
src := try(getReader())
if src != nil {
n, err := src.Read(nil)
if err == io.EOF {
return nil
}
try(err)
println(n)
}
return nil
}
D'après ce que j'ai compris, cela désucrerait
func foo() (err error) {
tsrc, te := getReader()
if err != nil {
err = te
return
}
src := tsrc
if src != nil {
n, err := src.Read(nil)
if err == io.EOF {
return nil
}
terr := err
if terr != nil {
err = terr
return
}
println(n)
}
return nil
}
qui ne parvient pas à compiler car err est masqué lors d'un retour nu. Cela ne compilerait-il pas ? Si tel est le cas, il s'agit d'un échec très subtil et il ne semble pas trop improbable qu'il se produise. Sinon, alors il se passe plus que du sucre.
zeebo
le 6 juin 2019
@marwan-au-travail
Comme vous l'avez mentionné dans votre dernier commentaire :
La raison de cette proposition est que la gestion des erreurs (en particulier le code passe-partout associé) a été mentionnée comme un problème important dans Go (à côté du manque de génériques) par la communauté Go
Ainsi, le cœur du problème est que le programmeur finit par écrire beaucoup de code passe-partout. Il s'agit donc d'écrire, pas de lire.
Je pense que c'est en fait l'inverse - pour moi, le plus gros ennui avec le passe-partout actuel de gestion des erreurs n'est pas tant d'avoir à le taper, mais plutôt comment il disperse le chemin heureux de la fonction verticalement sur l'écran, ce qui le rend plus difficile à comprendre à un coup d'oeil. L'effet est particulièrement prononcé dans le code lourd en E/S, où il y a généralement un bloc de passe-partout entre deux opérations. Même une version simpliste de CopyFile prend environ 20 lignes même si elle n'effectue en réalité que cinq étapes : ouvrir la source, différer la fermeture de la source, ouvrir la destination, copier la source -> destination, fermer la destination.
Un autre problème avec la syntaxe actuelle est que, comme je l'ai noté plus tôt, si vous avez une chaîne d'opérations dont chacune peut renvoyer une erreur, la syntaxe actuelle vous oblige à donner des noms à tous les résultats intermédiaires, même si vous préférez laisser quelques anonymes. Lorsque cela se produit, cela nuit également à la lisibilité car vous devez passer des cycles cérébraux à analyser ces noms, même s'ils ne sont pas très informatifs.
dpinela
le 6 juin 2019
J'aime try sur une ligne séparée.
Et j'espère qu'il pourra spécifier indépendamment la fonction handler .
func try(error, optional func(error)error)
func (p *pgStore) DoWork() error {
tx, err := p.handle.Begin()
try(err)
handle := func(err error) error {
tx.Rollback()
return err
}
var res int64
_, err = tx.QueryRow(`INSERT INTO table (...) RETURNING c1`, ...).Scan(&res)
try(err, handle)
_, err = tx.Exec(`INSERT INTO table2 (...) VALUES ($1)`, res)
try(err, handle)
return tx.Commit()
}
 eihigh
le 6 juin 2019
eihigh
le 6 juin 2019
@zeebo : Les exemples que j'ai donnés sont des traductions 1:1. Le premier (traditionnel if ) n'a pas géré l'erreur, pas plus que les autres. Si le premier a géré l'erreur, et si c'était le seul endroit où une erreur est vérifiée dans une fonction, le premier exemple (utilisant un if ) pourrait être le choix approprié pour écrire le code. S'il y a plusieurs vérifications d'erreurs, qui utilisent toutes la même gestion des erreurs (wrapping), disons parce qu'elles ajoutent toutes des informations sur la fonction actuelle, on peut utiliser une instruction defer pour gérer les erreurs en un seul endroit. En option, on pourrait réécrire les if en try (ou les laisser seuls). S'il y a plusieurs erreurs à vérifier et qu'elles gèrent toutes les erreurs différemment (ce qui peut être un signe que le problème de la fonction est trop large et qu'il peut être nécessaire de le scinder), l'utilisation if est la marche à suivre. Oui, il y a plus d'une façon de faire la même chose, et le bon choix dépend du code ainsi que des goûts personnels. Bien que nous nous efforcions en Go d'avoir "une façon de faire une chose", ce n'est bien sûr déjà pas le cas, en particulier pour les constructions courantes. Par exemple, lorsqu'une séquence if - else - if devient trop longue, parfois un switch peut être plus approprié. Parfois, une déclaration de variable var x int exprime mieux l'intention que x := 0 , et ainsi de suite (bien que cela ne plaise pas à tout le monde).
Concernant votre question sur la "réécriture": Non, il n'y aurait pas d'erreur de compilation. Notez que la réécriture se produit en interne (et peut être plus efficace que ne le suggère le modèle de code), et il n'est pas nécessaire que le compilateur se plaigne d'un retour caché. Dans votre exemple, vous avez déclaré une variable locale err dans une portée imbriquée. try aurait toujours un accès direct à la variable de résultat err , bien sûr. La réécriture pourrait ressembler davantage à ceci sous les couvertures.
[modifié] PS : Une meilleure réponse serait : try n'est pas un retour nu (même si la réécriture y ressemble). Après tout, on donne explicitement à try un argument qui contient (ou est) l'erreur renvoyée si ce n'est pas nil . L'erreur fantôme pour les retours nus est une erreur sur la source (et non la traduction sous-jacente de la source. Le compilateur n'a pas besoin de l'erreur.
griesemer
le 6 juin 2019
Si le type de retour final de la fonction globale n'est pas de type erreur, pouvons-nous paniquer ?
Cela rendra l'intégration plus polyvalente (comme satisfaire ma préoccupation dans # 32219)
 pjebs
le 6 juin 2019
pjebs
le 6 juin 2019
@pjebs Cela a été considéré et rejeté. Veuillez lire la documentation de conception détaillée (qui fait explicitement référence à votre problème à ce sujet).
griesemer
le 6 juin 2019
Je tiens également à souligner que try() est traité comme une expression même s'il fonctionne comme une instruction de retour. Oui, je sais que try est une macro intégrée, mais la plupart des utilisateurs l'utiliseront comme une programmation fonctionnelle, je suppose.
func doSomething() (error, error, error, error, error) {
...
}
try(try(try(try(try(doSomething)))))
La conception indique que vous avez exploré en utilisant panic au lieu de revenir avec l'erreur.
Je mets en évidence une subtile différence :
Faites exactement ce que votre proposition actuelle indique, à l'exception de la suppression de la restriction selon laquelle la fonction globale doit avoir un type de retour final de type error .
S'il n'a pas de type de retour final de error => panique
Si vous utilisez try pour les déclarations de variables au niveau du package => panique (supprime le besoin de convention MustXXX( ) )
Pour les tests unitaires, un changement de langage modeste.
pjebs
le 6 juin 2019
@mattn , je doute fortement qu'un nombre significatif de personnes écrira du code comme ça.
@pjebs , cette sémantique - paniquez s'il n'y a pas de résultat d'erreur dans la fonction actuelle - est exactement ce dont parle le document de conception dans https://github.com/golang/proposal/blob/master/design/32437-try-builtin. md#discussion.
De plus, dans une tentative de rendre try utile non seulement à l'intérieur des fonctions avec un résultat d'erreur, la sémantique de try dépendait du contexte : si try était utilisé au niveau du package, ou s'il était appelé à l'intérieur d'une fonction sans résultat d'erreur, try paniquerait en rencontrant une erreur. (Soit dit en passant, à cause de cette propriété, la fonction intégrée a été appelée must plutôt que try dans cette proposition.) Avoir try (ou must) se comporter de cette manière sensible au contexte semblait naturel et aussi très utile : cela permettrait l'élimination de de nombreuses fonctions d'assistance must définies par l'utilisateur actuellement utilisées dans les expressions d'initialisation de variables au niveau du package. Cela ouvrirait également la possibilité d'utiliser try dans les tests unitaires via le package de test.
Pourtant, la sensibilité au contexte de try était considérée comme lourde : par exemple, le comportement d'une fonction contenant des appels try pouvait changer silencieusement (de paniquer éventuellement à ne pas paniquer, et vice versa) si un résultat d'erreur était ajouté ou supprimé de la signature. Cela semblait une propriété trop dangereuse. La solution évidente aurait été de diviser la fonctionnalité de try en deux fonctions distinctes, must et try (très similaire à ce qui est suggéré par le problème #31442). Mais cela aurait nécessité deux nouvelles fonctions intégrées, avec seulement un essai directement lié au besoin immédiat d'une meilleure prise en charge de la gestion des erreurs.
 rsc
le 6 juin 2019
rsc
le 6 juin 2019
@pjebs C'est _exactement_ ce que nous avons considéré dans une proposition précédente (voir doc détaillé, section sur les itérations de conception, 4e paragraphe):
De plus, dans une tentative de rendre try utile non seulement à l'intérieur des fonctions avec un résultat d'erreur, la sémantique de try dépendait du contexte : si try était utilisé au niveau du package, ou s'il était appelé à l'intérieur d'une fonction sans résultat d'erreur, try paniquerait en rencontrant une erreur. (Soit dit en passant, à cause de cette propriété, la fonction intégrée a été appelée must plutôt que try dans cette proposition.)
Le consensus (interne de l'équipe Go) était qu'il serait déroutant pour try de dépendre du contexte et d'agir si différemment. Par exemple, ajouter un résultat d'erreur à une fonction (ou le supprimer) pourrait changer silencieusement le comportement de la fonction de paniquer à ne pas paniquer (ou vice versa).
griesemer
le 6 juin 2019
@griesemer Merci pour la clarification sur la réécriture. Je suis content qu'il compile.
Je comprends que les exemples étaient des traductions qui n'annotaient pas les erreurs. J'ai tenté de faire valoir que try rend plus difficile la bonne annotation des erreurs dans des situations courantes, et que l'annotation des erreurs est très importante pour la communauté. Jusqu'à présent, une grande partie des commentaires ont exploré des moyens d'ajouter une meilleure prise en charge des annotations à try .
À propos de devoir gérer les erreurs différemment, je ne suis pas d'accord que c'est un signe que la préoccupation de la fonction est trop large. J'ai traduit quelques exemples de code réel revendiqué à partir des commentaires et les ai placés dans une liste déroulante au bas de mon commentaire d'origine , et l'exemple dans https://github.com/golang/go/issues/32437#issuecomment - 499007288, je pense, illustre bien un cas courant:
func (c *Config) Build() error {
pkgPath, err := c.load()
if err != nil { return nil, errors.WithMessage(err, "load config dir") }
b := bytes.NewBuffer(nil)
err = templates.ExecuteTemplate(b, "main", c)
if err != nil { return nil, errors.WithMessage(err, "execute main template") }
buf, err := format.Source(b.Bytes())
if err != nil { return nil, errors.WithMessage(err, "format main template") }
target := fmt.Sprintf("%s.go", filename(pkgPath))
err = ioutil.WriteFile(target, buf, 0644)
if err != nil { return nil, errors.WithMessagef(err, "write file %s", target) }
// ...
}
Le but de cette fonction est d'exécuter un modèle sur certaines données dans un fichier. Je ne pense pas qu'il soit nécessaire de le diviser, et il serait regrettable que toutes ces erreurs gagnent la ligne sur laquelle elles ont été créées à partir d'un report. C'est peut-être bien pour les développeurs, mais c'est beaucoup moins utile pour les utilisateurs.
Je pense que c'est aussi un peu un signal à quel point les bogues defer wrap(&err, "message: %v", err) étaient subtils et comment ils ont fait trébucher même les programmeurs Go expérimentés.
Pour résumer mon argument : je pense que l'annotation d'erreur est plus importante que la vérification d'erreur basée sur l'expression, et nous pouvons obtenir une bonne réduction du bruit en permettant à la vérification d'erreur basée sur les instructions d'être sur une ligne au lieu de trois. Merci.
zeebo
le 6 juin 2019
@griesemer désolé, j'ai lu une section différente qui parlait de panique et n'a pas vu la discussion sur les dangers.
pjebs
le 6 juin 2019
@zeebo Merci pour cet exemple. Il semble que l'utilisation d'une instruction if soit exactement le bon choix dans ce cas. Mais point pris, le formatage des si en une seule ligne peut rationaliser un peu cela.
griesemer
le 6 juin 2019
Je voudrais évoquer une fois de plus l'idée d'un gestionnaire comme deuxième argument de try , mais avec l'ajout que l'argument du gestionnaire soit _requis_, mais nil-able. Cela fait de la gestion de l'erreur la valeur par défaut, au lieu de l'exception. Dans les cas où vous voulez vraiment transmettre l'erreur inchangée, fournissez simplement une valeur nulle au gestionnaire et try se comportera comme dans la proposition d'origine, mais l'argument nul agira comme un indice visuel que le l'erreur n'est pas traitée. Il sera plus facile de s'en apercevoir lors de la révision du code.
file := try(os.Open("my_file.txt"), nil)
Que doit-il se passer si le gestionnaire est fourni mais n'est pas ? Devriez-vous essayer de paniquer ou le traiter comme un gestionnaire d'erreurs absent ?
Comme mentionné ci-dessus, try se comportera conformément à la proposition initiale. Il n'y aurait pas de gestionnaire d'erreur absent, seulement un nul.
Que se passe-t-il si le gestionnaire est invoqué avec une erreur non nulle et renvoie ensuite un résultat nul ? Cela signifie-t-il que l'erreur est "annulée" ? Ou la fonction englobante doit-elle renvoyer une erreur nulle ?
Je crois que la fonction englobante reviendrait avec une erreur nulle. Ce serait potentiellement très déroutant si try pouvait parfois continuer l'exécution même après avoir reçu une valeur d'erreur non nulle. Cela permettrait aux gestionnaires de "prendre soin" de l'erreur dans certaines circonstances. Ce comportement peut être utile dans une fonction de style "obtenir ou créer", par exemple.
func getOrCreateObject(obj *object) error {
defaultObjectHandler := func(err error) error {
if err == ObjectDoesNotExistErr {
*obj = object{}
return nil
}
return fmt.Errorf("getting or creating object: %v", err)
}
*obj = try(db.getObject(), defaultObjectHandler)
}
Il n'était pas non plus clair si l'autorisation d'un gestionnaire d'erreurs facultatif conduirait les programmeurs à ignorer complètement la gestion appropriée des erreurs. Il serait également facile de gérer correctement les erreurs partout, mais de manquer une seule occurrence d'un essai. Et ainsi de suite.
Je crois que ces deux préoccupations sont atténuées en faisant du gestionnaire un argument obligatoire et nul. Cela nécessite que les programmeurs prennent une décision consciente et explicite qu'ils ne géreront pas leur erreur.
En prime, je pense que le fait d'exiger le gestionnaire d'erreurs décourage également les try profondément imbriqués car ils sont moins brefs. Certains pourraient voir cela comme un inconvénient, mais je pense que c'est un avantage.
 velovix
le 6 juin 2019
velovix
le 6 juin 2019
@velovix J'adore l'idée, mais pourquoi le gestionnaire d'erreurs doit-il être requis ? Ne peut-il pas être nil par défaut ? Pourquoi avons-nous besoin d'un "indice visuel" ?
@griesemer Et si l'idée @velovix était adoptée mais avec builtin contenant une fonction prédéfinie qui convertit l'erreur en panique ET Nous supprimons l'exigence que la fonction globale ait une valeur de retour d'erreur?
L'idée est que si la fonction globale ne renvoie pas d'erreur, l'utilisation try sans gestionnaire d'erreur est une erreur de compilation.
Le gestionnaire d'erreurs peut également être utilisé pour envelopper l'erreur qui sera bientôt renvoyée en utilisant diverses bibliothèques, etc. à l'emplacement de l'erreur, au lieu d'un defer en haut qui modifie une erreur renvoyée nommée.
pjebs
le 6 juin 2019
@pjebs
pourquoi le gestionnaire d'erreurs doit-il être requis ? Ne peut-il pas être nul par défaut ? Pourquoi avons-nous besoin d'un "indice visuel" ?
Il s'agit de répondre aux préoccupations que
- La proposition
trytelle qu'elle est actuellement pourrait décourager les gens de fournir un contexte à leurs erreurs, car cela n'est pas si simple.
Le fait d'avoir un gestionnaire en premier lieu facilite la fourniture de contexte, et le fait que le gestionnaire soit un argument obligatoire envoie un message : le cas courant et recommandé consiste à gérer ou à contextualiser l'erreur d'une manière ou d'une autre, et non simplement à la transmettre dans la pile. C'est conforme à la recommandation générale de la communauté Go.
- Une préoccupation du document de proposition d'origine. Je l'ai cité dans mon premier commentaire :
Il n'était pas non plus clair si l'autorisation d'un gestionnaire d'erreurs facultatif conduirait les programmeurs à ignorer complètement la gestion appropriée des erreurs. Il serait également facile de gérer correctement les erreurs partout, mais de manquer une seule occurrence d'un essai. Et ainsi de suite.
Le fait de devoir passer un nil explicite rend plus difficile d'oublier de gérer correctement une erreur. Vous devez explicitement décider de ne pas gérer l'erreur au lieu de le faire implicitement en omettant un argument.
velovix
le 6 juin 2019
Penser davantage au retour conditionnel brièvement mentionné sur https://github.com/golang/go/issues/32437#issuecomment -498947603.
Il semble
return if f, err := os.Open("/my/file/path"); err != nil
serait plus conforme à l'apparence if existante de Go.
Si nous ajoutons une règle pour l'instruction return if qui
lorsque la dernière expression de condition (comme err != nil ) n'est pas présente,et la dernière variable de la déclaration dans l'instruction return if est du type error ,alors la valeur de la dernière variable sera automatiquement comparée à nil comme condition implicite.
Ensuite, l'instruction return if peut être abrégée en :
return if f, err := os.Open("my/file/path")
Ce qui est très proche du rapport signal/bruit fourni par le try .
Si nous changeons le return if en try , il devient
try f, err := os.Open("my/file/path")
Cela redevient similaire aux autres variantes proposées du try dans ce fil, du moins syntaxiquement.
Personnellement, je préfère toujours return if à try dans ce cas car cela rend les points de sortie d'une fonction très explicites. Par exemple, lors du débogage, je mets souvent en surbrillance le mot-clé return dans l'éditeur pour identifier tous les points de sortie d'une grande fonction.
Malheureusement, cela ne semble pas non plus aider suffisamment avec l'inconvénient d'insérer la journalisation de débogage.
À moins que nous n'autorisions également un bloc body pour return if , comme
Original:
return if f, err := os.Open("my/path")
Lors du débogage :
- return if f, err := os.Open("my/path")
+ return if f, err := os.Open("my/path") {
+ fmt.Printf("DEBUG: os.Open: %s\n", err)
+ }
La signification du bloc de corps de return if est évidente, je suppose. Il sera exécuté avant defer et retour.
Cela dit, je n'ai rien à redire sur l'approche de gestion des erreurs existante dans Go.
Je suis plus préoccupé par l'impact de l'ajout de la nouvelle gestion des erreurs sur la qualité actuelle de Go.
typeless
le 6 juin 2019
@velovix Nous avons bien aimé l'idée d'un try avec une fonction de gestionnaire explicite comme 2ème argument. Mais il y avait trop de questions qui n'avaient pas de réponses évidentes, comme l'indique le document de conception. Vous avez répondu à certaines d'entre elles d'une manière qui vous semble raisonnable. Il est fort probable (et c'était notre expérience au sein de l'équipe Go) que quelqu'un d'autre pense que la bonne réponse est tout à fait différente. Par exemple, vous indiquez que l'argument du gestionnaire doit toujours être fourni, mais qu'il peut être nil , pour le rendre explicite, nous ne nous soucions pas de gérer l'erreur. Maintenant, que se passe-t-il si l'on fournit une valeur de fonction (et non un littéral nil ) et que cette valeur de fonction (stockée dans une variable) est nulle ? Par analogie avec la valeur explicite nil , aucune manipulation n'est nécessaire. Mais d'autres pourraient dire qu'il s'agit d'un bogue dans le code. Ou, alternativement, on pourrait autoriser des arguments de gestionnaire de valeur nulle, mais une fonction pourrait alors gérer des erreurs de manière incohérente dans certains cas et pas dans d'autres, et ce n'est pas nécessairement évident d'après le code, car il semble qu'un gestionnaire est toujours présent . Un autre argument était qu'il est préférable d'avoir une déclaration de niveau supérieur d'un gestionnaire d'erreurs car cela indique très clairement que la fonction gère les erreurs. D'où le defer . Il y en a probablement plus.
griesemer
le 6 juin 2019
Il serait bon d'en savoir plus sur cette préoccupation. Le style de codage actuel utilisant des instructions if pour tester les erreurs est à peu près aussi explicite que possible. Il est très facile d'ajouter des informations supplémentaires à une erreur, sur une base individuelle (pour chaque si). Souvent, il est logique de gérer toutes les erreurs détectées dans une fonction de manière uniforme, ce qui peut être fait avec un report - c'est déjà possible maintenant. C'est le fait que nous disposions déjà de tous les outils pour une bonne gestion des erreurs dans le langage, et le problème d'une construction de gestionnaire non orthogonale à différer, qui nous a conduit à laisser de côté un nouveau mécanisme uniquement pour augmenter les erreurs.
@griesemer - IIUC, vous dites que pour les contextes d'erreur dépendant du site d'appel, l'instruction if actuelle est correcte. Alors que cette nouvelle fonction try est utile dans les cas où la gestion de plusieurs erreurs à un seul endroit est utile.
Je pense que le problème était que, bien que le simple fait de faire un if err != nil { return err} puisse convenir dans certains cas, il est généralement recommandé de décorer l'erreur avant de revenir. Et cette proposition semble répondre à la précédente et ne fait pas grand-chose pour la seconde. Ce qui signifie essentiellement que les gens seront encouragés à utiliser un modèle de retour facile.
agnivade
le 6 juin 2019
@agnivade Vous avez raison, cette proposition ne fait exactement rien pour aider à la décoration des erreurs (mais pour recommander l'utilisation de defer ). L'une des raisons est que des mécanismes linguistiques pour cela existent déjà. Dès qu'une décoration d'erreur est requise, en particulier sur une base d'erreur individuelle, la quantité supplémentaire de texte source pour le code de décoration rend le if moins onéreux en comparaison. Ce sont les cas où aucune décoration n'est requise, ou où la décoration est toujours la même, où le passe-partout devient une nuisance visible et nuit alors au code important.
Les gens sont déjà encouragés à utiliser un modèle de retour facile, try ou pas try , il y a juste moins à écrire. À bien y penser, _la seule façon d'encourager la décoration des erreurs est de la rendre obligatoire_, car quelle que soit la langue disponible, la décoration des erreurs nécessitera plus de travail.
Une façon d'adoucir l'affaire serait de n'autoriser quelque chose comme try (ou toute notation de raccourci analogue) _si_ un gestionnaire explicite (éventuellement vide) est fourni quelque part (notez que le brouillon original n'avait pas un tel exigence non plus).
Je ne suis pas sûr qu'on veuille aller aussi loin. Permettez-moi de réaffirmer que beaucoup de code parfaitement fin, disons les composants internes d'une bibliothèque, n'ont pas besoin de décorer les erreurs partout. C'est bien de simplement propager les erreurs et de les décorer juste avant qu'elles ne quittent les points d'entrée de l'API, par exemple. (En fait, les décorer partout ne conduira qu'à des erreurs sur-décorées qui, avec les vrais coupables cachés, rendront plus difficile la localisation des erreurs importantes ; tout comme une journalisation trop détaillée peut rendre difficile de voir ce qui se passe réellement).
griesemer
le 6 juin 2019
Je pense que nous pouvons également ajouter une fonction catch , ce qui serait une belle paire, donc :
func a() int {
x := randInt()
// let's assume that this is what recruiters should "fix" for us
// or this happens in 3rd-party package.
if x % 1337 != 0 {
panic("not l33t enough")
}
return x
}
func b() error {
// if a() panics, then x = 0, err = error{"not l33t enough"}
x, err := catch(a())
if err != nil {
return err
}
sendSomewhereElse(x)
return nil
}
// which could be simplified even further
func c() error {
x := try(catch(a()))
sendSomewhereElse(x)
return nil
}
dans cet exemple, catch() serait recover() une panique et return ..., panicValue .
bien sûr, nous avons un cas évident dans lequel nous avons une fonction, qui renvoie également une erreur. dans ce cas, je pense qu'il serait pratique de simplement transmettre la valeur d'erreur.
donc, en gros, vous pouvez ensuite utiliser catch() pour récupérer les paniques() et les transformer en erreurs.
cela me semble assez drôle, car Go n'a pas réellement d'exceptions, mais dans ce cas, nous avons un modèle try()-catch() assez soigné, qui ne devrait pas non plus faire exploser toute votre base de code avec quelque chose comme Java ( catch(Throwable) dans Main + throws LiterallyAnything ). vous pouvez facilement traiter les paniques de quelqu'un comme si c'était des erreurs habituelles. J'ai actuellement environ 6 millions de LoC en Go dans mon projet actuel, et je pense que cela simplifierait les choses au moins pour moi.
 kirillDanshin
le 6 juin 2019
kirillDanshin
le 6 juin 2019
@griesemer Merci pour votre récapitulatif de la discussion.
Je remarque qu'il manque un point là-dedans : certaines personnes ont fait valoir que nous devrions attendre avec cette fonctionnalité jusqu'à ce que nous ayons des génériques, ce qui, espérons-le, nous permettra de résoudre ce problème de manière plus élégante.
De plus, j'aime aussi la suggestion de @velovix , et bien que j'apprécie que cela soulève quelques questions comme décrit dans la spécification, je pense qu'il est facile d'y répondre de manière raisonnable, comme @velovix l' a déjà fait.
Par exemple:
Que se passe-t-il si l'on fournit une valeur de fonction (pas un littéral nul) et que cette valeur de fonction (stockée dans une variable) se trouve être nulle ? => Ne pas gérer l'erreur, point final. Ceci est utile dans le cas où la gestion des erreurs dépend du contexte et la variable du gestionnaire est définie selon que la gestion des erreurs est requise ou non. Ce n'est pas un bug, c'est plutôt une fonctionnalité. :)
Un autre argument était qu'il est préférable d'avoir une déclaration de niveau supérieur d'un gestionnaire d'erreurs car cela indique très clairement que la fonction gère les erreurs. => Définissez donc le gestionnaire d'erreurs en haut de la fonction en tant que fonction de fermeture nommée et utilisez-la, il est donc également très clair que l'erreur doit être gérée. Ce n'est pas un problème sérieux, plus une exigence de style.
Quelles autres préoccupations y avait-il? Je suis presque sûr qu'on peut tous y répondre de la même manière d'une manière raisonnable.
Enfin, comme vous le dites, "une façon d'adoucir l'affaire serait de n'autoriser quelque chose comme try (ou toute notation de raccourci analogue) que si un gestionnaire explicite (éventuellement vide) est fourni quelque part". Je pense que si nous voulons aller de l'avant avec cette proposition, nous devrions en fait aller "jusqu'ici", pour encourager une gestion des erreurs appropriée, "explicite vaut mieux qu'implicite".
beoran
le 6 juin 2019
@griesemer
Maintenant, que se passe-t-il si l'on fournit une valeur de fonction (pas un littéral nil) et que cette valeur de fonction (stockée dans une variable) se trouve être nil ? Par analogie avec la valeur nulle explicite, aucune manipulation n'est nécessaire. Mais d'autres pourraient dire qu'il s'agit d'un bogue dans le code.
En théorie, cela semble être un piège potentiel, même si j'ai du mal à conceptualiser une situation raisonnable où un gestionnaire finirait par être nul par accident. J'imagine que les gestionnaires proviendraient le plus souvent soit d'une fonction d'utilité définie ailleurs, soit d'une fermeture définie dans la fonction elle-même. Ni l'un ni l'autre ne sont susceptibles de devenir nuls de manière inattendue. Vous pourriez théoriquement avoir un scénario où les fonctions de gestionnaire sont transmises en tant qu'arguments à d'autres fonctions, mais à mes yeux, cela semble plutôt tiré par les cheveux. Peut-être y a-t-il un modèle comme celui-ci dont je ne suis pas au courant.
Un autre argument était qu'il est préférable d'avoir une déclaration de niveau supérieur d'un gestionnaire d'erreurs car cela indique très clairement que la fonction gère les erreurs. D'où le
defer.
Comme @beoran l'a mentionné, définir le gestionnaire comme une fermeture près du haut de la fonction aurait un style très similaire, et c'est ainsi que je m'attends personnellement à ce que les gens utilisent le plus souvent les gestionnaires. Bien que j'apprécie la clarté gagnée par le fait que toutes les fonctions qui gèrent les erreurs utiliseront defer , cela peut devenir moins clair lorsqu'une fonction doit pivoter dans sa stratégie de gestion des erreurs à mi-chemin de la fonction. Ensuite, il y aura deux defer à regarder et le lecteur devra raisonner sur la façon dont ils interagiront l'un avec l'autre. C'est une situation où je pense qu'un argument de gestionnaire serait à la fois plus clair et ergonomique, et je pense que ce sera un scénario _relativement_ courant.
velovix
le 6 juin 2019
Est-il possible de le faire fonctionner sans crochets ?
C'est à dire quelque chose comme :
a := try func(some)
 Cyberax
le 6 juin 2019
Cyberax
le 6 juin 2019
@Cyberax - Comme déjà mentionné ci-dessus, il est essentiel que vous lisiez attentivement le document de conception avant de publier. Puisqu'il s'agit d'un problème à fort trafic, avec beaucoup de personnes abonnées.
La doc discute en détail des opérateurs et des fonctions.
agnivade
le 6 juin 2019
J'aime beaucoup plus cette version que j'ai aimé la version d'août.
Je pense qu'une grande partie des commentaires négatifs, qui ne sont pas carrément opposés aux retours sans le mot-clé return , peuvent être résumés en deux points :
- les gens n'aiment pas les paramètres de résultat nommés, qui deviendraient obligatoires dans la plupart des cas
- cela décourage l'ajout d'un contexte détaillé aux erreurs
Voir par exemple :
- https://github.com/golang/go/issues/32437#issuecomment -498937169
- https://github.com/golang/go/issues/32437#issuecomment -498967099
- https://github.com/golang/go/issues/32437#issuecomment -499194787
- https://github.com/golang/go/issues/32437#issuecomment -499309304
La réfutation de ces deux objections est respectivement :
- "nous avons décidé que [paramètres de résultat nommés] étaient corrects"
- "Personne ne va vous faire utiliser
try" / ça ne va pas convenir à 100% des cas
Je n'ai vraiment rien à dire sur 1 (je n'y tiens pas vraiment). Mais concernant 2, je noterais que la proposition auguste n'avait pas ce problème, la plupart des contre-propositions n'ont pas non plus ce problème.
En particulier, ni la contre-proposition tryf (qui a été publiée deux fois indépendamment dans ce fil) ni la contre-proposition try(X, handlefn) (qui faisait partie des itérations de conception) n'avaient ce problème.
Je pense qu'il est difficile d'affirmer que try , tel qu'il est, éloignera les gens de la décoration des erreurs avec un contexte pertinent et vers une seule décoration d'erreur générique par fonction.
Pour ces raisons, je pense qu'il vaut la peine d'essayer de résoudre ce problème et je souhaite proposer une solution possible :
- Actuellement, le paramètre de
deferne peut être qu'un appel de fonction ou de méthode. Autoriserdeferà avoir également un nom de fonction ou un littéral de fonction, c'est-à-dire
defer func(...) {...}
defer packageName.functionName
Lorsque panique ou deferreturn rencontrent ce type de report, ils appellent la fonction en passant la valeur zéro pour tous leurs paramètres
Autoriser
tryà avoir plus d'un paramètreLorsque
tryrencontre le nouveau type de report, il appelle la fonction en passant un pointeur vers la valeur d'erreur comme premier paramètre suivi de tous les paramètres proprestry, sauf le premier.
Par exemple, étant donné :
func errorfn() error {
return errors.New("an error")
}
func f(fail bool) {
defer func(err *error, a, b, c int) {
fmt.Printf("a=%d b=%d c=%d\n", a, b, c)
}
if fail {
try(errorfn, 1, 2, 3)
}
}
ce qui suit se produira :
f(false) // prints "a=0 b=0 c=0"
f(true) // prints "a=1 b=2 c=3"
Le code dans https://github.com/golang/go/issues/32437#issuecomment -499309304 par @zeebo pourrait alors être réécrit comme suit :
func (c *Config) Build() error {
defer func(err *error, msg string, args ...interface{}) {
if *err == nil || msg == "" {
return
}
*err = errors.WithMessagef(err, msg, args...)
}
pkgPath := try(c.load(), "load config dir")
b := bytes.NewBuffer(nil)
try(templates.ExecuteTemplate(b, "main", c), "execute main template")
buf := try(format.Source(b.Bytes()), "format main template")
target := fmt.Sprintf("%s.go", filename(pkgPath))
try(ioutil.WriteFile(target, buf, 0644), "write file %s", target)
// ...
}
Et définir ErrorHandlef comme :
func HandleErrorf(err *error, format string, args ...interface{}) {
if *err != nil && format != "" {
*err = fmt.Errorf(format + ": %v", append(args, *err)...)
}
}
donnerait à tout le monde le très recherché tryf gratuitement, sans extraire les chaînes de format de style fmt dans le langage de base.
Cette fonctionnalité est rétrocompatible car defer n'autorise pas les expressions de fonction comme argument. Il n'introduit pas de nouveaux mots-clés.
Les modifications qui doivent être apportées pour l'implémenter, en plus de celles décrites dans https://github.com/golang/proposal/blob/master/design/32437-try-builtin.md , sont :
- enseigner à l'analyseur le nouveau type de report
- changer le vérificateur de type pour vérifier qu'à l'intérieur d'une fonction tous les reports qui ont une fonction en paramètre (au lieu d'un appel) ont aussi la même signature
- changer le vérificateur de type pour vérifier que les paramètres passés à
trycorrespondent à la signature des fonctions passées àdefer - changer le backend (?) pour générer l'appel deferproc approprié
- modifier l'implémentation de
trypour copier ses arguments dans les arguments de l'appel différé lorsqu'il rencontre un appel différé par le nouveau type de report.
 aarzilli
le 6 juin 2019
aarzilli
le 6 juin 2019
Après les complexités de la conception du brouillon de check/handle , j'ai été agréablement surpris de voir cette proposition beaucoup plus simple et pragmatique, bien que je sois déçu qu'il y ait eu tant de refoulement contre elle.
Certes, une grande partie de la réticence vient de personnes qui sont assez satisfaites de la verbosité actuelle (une position parfaitement raisonnable à prendre) et qui n'accueilleraient vraisemblablement pas vraiment toute proposition pour l'atténuer. Pour le reste d'entre nous, je pense que cette proposition a le mérite d'être simple et de ressembler à Go, de ne pas essayer d'en faire trop et de bien s'accorder avec les techniques de gestion des erreurs existantes sur lesquelles vous pouvez toujours vous rabattre si try n'a pas fait exactement ce que vous vouliez.
Concernant certains points particuliers :
La seule chose que je n'aime pas dans la proposition est la nécessité d'avoir un paramètre de retour d'erreur nommé lorsque
deferest utilisé mais, cela dit, je ne peux penser à aucune autre solution qui ne serait pas en contradiction avec la façon dont le reste de la langue fonctionne. Je pense donc que nous devrons simplement l'accepter si la proposition est adoptée.Il est dommage que
tryne fonctionne pas bien avec le package de test pour les fonctions qui ne renvoient pas de valeur d'erreur. Ma propre solution préférée à cela serait d'avoir une deuxième fonction intégrée (peut-êtreptryoumust) qui paniquait toujours plutôt que de revenir en rencontrant une erreur non nulle et qui pourrait donc être utilisé avec les fonctions susmentionnées (y comprismain). Bien que cette idée ait été rejetée dans la présente itération de la proposition, j'ai eu l'impression qu'il s'agissait d'un « appel de proximité » et qu'elle pourrait donc être réexaminée.Je pense qu'il serait difficile pour les gens de comprendre ce que
go try(f)oudefer try(f)faisaient et qu'il est donc préférable de les interdire complètement.Je suis d'accord avec ceux qui pensent que les techniques de gestion des erreurs existantes auraient l'air moins détaillées si
go fmtne réécrivait pas les déclarationsifseule ligne. Personnellement, je préférerais une règle simple selon laquelle cela serait autorisé pour _toute_ déclaration uniqueif, qu'elle concerne ou non la gestion des erreurs. En fait, je n'ai jamais été en mesure de comprendre pourquoi cela n'est pas actuellement autorisé lors de l'écriture de fonctions à une seule ligne où le corps est placé sur la même ligne que la déclaration est autorisée.
 alanfo
le 6 juin 2019
alanfo
le 6 juin 2019
En cas d'erreurs de décoration
func myfunc()( err error){
try(thing())
defer func(){
err = errors.Wrap(err,"more context")
}()
}
Cela semble considérablement plus verbeux et douloureux que les paradigmes existants, et pas aussi concis que check/handle. La variante try() sans encapsulation est plus concise, mais on a l'impression que les gens finiront par utiliser un mélange d'essais et de retours d'erreur simples. Je ne suis pas sûr d'aimer l'idée de mélanger les retours d'essais et d'erreurs simples, mais je suis totalement convaincu des erreurs de décoration (et j'attends avec impatience Is/As). Faites-moi penser que même si c'est syntaxiquement soigné, je ne suis pas sûr de vouloir l'utiliser réellement. check/handle senti quelque chose que j'embrasserais plus complètement.
 tcolgate
le 6 juin 2019
tcolgate
le 6 juin 2019
J'aime vraiment la simplicité de cela et l'approche "faire bien une chose". Dans mon interpréteur GoAWK , ce serait très utile - j'ai environ 100 constructions if err != nil { return nil } qui simplifieraient et rangeraient, et c'est dans une base de code assez petite.
J'ai lu la justification de la proposition pour en faire une fonction intégrée plutôt qu'un mot-clé, et cela revient à ne pas avoir à ajuster l'analyseur. Mais n'est-ce pas une douleur relativement faible pour les compilateurs et les rédacteurs d'outils, alors que le fait d'avoir les parenthèses supplémentaires et les problèmes de lisibilité de ceci-ressemble-à-une-fonction-mais-n'est-ce pas sera quelque chose que tous les codeurs et code Go- les lecteurs doivent endurer. À mon avis, l'argument (excuse ? :-) selon lequel "mais panic() contrôle le flux" ne suffit pas, car la panique et la récupération sont, par leur nature même, exceptionnelles , alors que try() le fera être la gestion normale des erreurs et le flux de contrôle.
Je l'apprécierais certainement même si cela se passait tel quel, mais ma forte préférence serait que le flux de contrôle normal soit clair, c'est-à-dire effectué via un mot-clé.
 benhoyt
le 6 juin 2019
benhoyt
le 6 juin 2019
Je suis favorable à cette proposition. Cela évite ma plus grande réserve à propos de la proposition précédente : la non-orthogonalité de handle par rapport à defer .
Je voudrais mentionner deux aspects qui, je pense, n'ont pas été mis en évidence ci-dessus.
Tout d'abord, bien que cette proposition ne facilite pas l'ajout d'un texte d'erreur spécifique au contexte à une erreur, elle facilite l'ajout d'informations de traçage d'erreur de cadre de pile à une erreur : https://play.golang.org/p /YL1MoqR08E6
Deuxièmement, try est sans doute une solution équitable à la plupart des problèmes sous-jacents https://github.com/golang/go/issues/19642. Pour prendre un exemple de ce problème, vous pouvez utiliser try pour éviter d'écrire toutes les valeurs de retour à chaque fois. Ceci est également potentiellement utile lors du retour de types de structure par valeur avec des noms longs.
func (f *Font) viewGlyphData(b *Buffer, x GlyphIndex) (buf []byte, offset, length uint32, err error) {
xx := int(x)
if f.NumGlyphs() <= xx {
try(ErrNotFound)
}
i := f.cached.locations[xx+0]
j := f.cached.locations[xx+1]
if j < i {
try(errInvalidGlyphDataLength)
}
if j-i > maxGlyphDataLength {
try(errUnsupportedGlyphDataLength)
}
buf, err = b.view(&f.src, int(i), int(j-i))
return buf, i, j - i, err
}
 rogpeppe
le 6 juin 2019
rogpeppe
le 6 juin 2019
J'aime aussi cette proposition.
Et j'ai une demande.
Comme make , pouvons-nous autoriser try à prendre un nombre variable de paramètres
- essayer(f):
comme ci-dessus.
une valeur d'erreur de retour est obligatoire (comme dernier paramètre de retour).
MODÈLE D'UTILISATION LE PLUS COURANT - try(f, doPanic bool):
comme ci-dessus, mais si doPanic, alors panique (erreur) au lieu de revenir.
Dans ce mode, une valeur d'erreur de retour n'est pas nécessaire. - essayer(f, fn):
comme ci-dessus, mais appelez fn(err) avant de revenir.
Dans ce mode, une valeur d'erreur de retour n'est pas nécessaire.
De cette façon, c'est un intégré qui peut gérer tous les cas d'utilisation, tout en étant explicite. Ses avantages :
- toujours explicite - pas besoin de déduire s'il faut paniquer ou définir une erreur et revenir
- prend en charge le gestionnaire spécifique au contexte (mais pas de chaîne de gestionnaire)
- prend en charge les cas d'utilisation où il n'y a pas de variable de retour d'erreur
- prend en charge la sémantique must(...)
 ugorji
le 6 juin 2019
ugorji
le 6 juin 2019
Bien que if err !=nil { return ... err } répétitif soit certainement un vilain bégaiement, je suis avec ceux
qui pensent que la proposition try() est très peu lisible et quelque peu inexplicite.
L'utilisation de retours nommés est également problématique.
Si ce type de rangement est nécessaire, pourquoi ne pas try(err) comme sucre syntaxique pour
if err !=nil { return err } :
file, err := os.Open("file.go")
try(err)
pour
file, err := os.Open("file.go")
if err != nil {
return err
}
Et s'il y a plus d'une valeur de retour, try(err) pourrait return t1, ... tn, err
où t1, ... tn sont les valeurs nulles des autres valeurs de retour.
Cette suggestion peut éviter le besoin de valeurs de retour nommées et être,
à mon avis, plus facile à comprendre et plus lisible.
Encore mieux, je pense que ce serait :
file, try(err) := os.Open("file.go")
Ou même
file, err? := os.Open("file.go")
Ce dernier est rétrocompatible (? n'est actuellement pas autorisé dans les identifiants).
(Cette suggestion est liée à https://github.com/golang/go/wiki/Go2ErrorHandlingFeedback#recurring-themes. Mais les exemples de thèmes récurrents semblent différents car c'était à un stade où une poignée explicite était encore en cours de discussion au lieu de partir cela à un report.)
Merci à l'équipe go pour cette proposition soignée et intéressante.
 patrick-nyt
le 6 juin 2019
patrick-nyt
le 6 juin 2019
@rogpeppe commente si try ajoute automatiquement le cadre de la pile, pas moi, je suis d'accord pour décourager l'ajout de contexte.
Goodwine
le 6 juin 2019
@aarzilli - Donc, selon votre proposition, une clause de report est-elle obligatoire à chaque fois que nous donnons des paramètres supplémentaires à tryf ?
Que se passe-t-il si je fais
try(ioutil.WriteFile(target, buf, 0644), "write file %s", target)
et ne pas écrire de fonction différée ?
agnivade
le 6 juin 2019
@agnivade
Que se passe-t-il si je fais (...) et que je n'écris pas de fonction différée ?
erreur de vérification de type.
aarzilli
le 6 juin 2019
À mon avis, utiliser try pour éviter d'écrire toutes les valeurs de retour n'est en fait qu'une autre attaque contre elle.
func (f *Font) viewGlyphData(b *Buffer, x GlyphIndex) (buf []byte, offset, length uint32, err error) {
xx := int(x)
if f.NumGlyphs() <= xx {
try(ErrNotFound)
}
//...
Je comprends parfaitement le désir d'éviter d'avoir à écrire return nil, 0, 0, ErrNotFound , mais je préférerais de loin résoudre cela d'une autre manière.
Le mot try ne signifie pas "retour". Et c'est ainsi qu'il est utilisé ici. Je préférerais en fait que la proposition change pour que try ne puisse pas prendre une error directement, car je ne veux jamais que quelqu'un écrive du code comme ça ^^ . Il se lit mal . Si vous montriez ce code à un débutant, il n'aurait aucune idée de ce que faisait cet essai.
Si nous voulons un moyen de renvoyer facilement les valeurs par défaut et une valeur d'erreur, résolvons cela séparément. Peut-être un autre intégré comme
return default(ErrNotFound)
Au moins, cela se lit avec une sorte de logique.
Mais n'abusons pas de try pour résoudre un autre problème.
natefinch
le 6 juin 2019
@natefinch si le try intégré est nommé check comme dans la proposition originale, ce serait check(err) qui se lit beaucoup mieux, imo.
Cela mis à part, je ne sais pas si c'est vraiment un abus d'écrire try(err) . Cela tombe clairement hors de la définition. Mais, d'un autre côté, cela signifie aussi que c'est légal :
a, b := try(1, f(), err)
Je suppose que mon principal problème avec try est que c'est vraiment juste un panic qui ne monte que d'un niveau... sauf que contrairement à la panique, c'est une expression, pas une déclaration, donc vous pouvez cacher au milieu d'une déclaration quelque part. C'est presque pire que la panique.
natefinch
le 6 juin 2019
@natefinch Si vous le conceptualisez comme une panique qui monte d'un niveau et fait ensuite d'autres choses, cela semble assez désordonné. Cependant, je le conceptualise différemment. Les fonctions qui renvoient des erreurs dans Go renvoient effectivement un résultattry est un utilitaire qui décompresse le résultat et soit renvoie un "résultat d'erreur" si error != nil , soit décompresse la partie T du résultat si error == nil .
Bien sûr, dans Go, nous n'avons pas réellement d'objets de résultat, mais c'est effectivement le même modèle et try semble être une codification naturelle de ce modèle. Je pense que toute solution à ce problème devra codifier certains aspects de la gestion des erreurs, et try s'en chargent me semblent raisonnables. Moi-même et d'autres suggérons d'étendre un peu la capacité de try pour mieux s'adapter aux modèles de gestion des erreurs Go existants, mais le concept sous-jacent reste le même.
velovix
le 6 juin 2019
@ugorji La variante try(f, bool) que vous proposez ressemble au must de #32219.
dpinela
le 6 juin 2019
@ugorji La variante
try(f, bool)que vous proposez ressemble aumustde #32219.
Oui c'est le cas. J'avais juste l'impression que les 3 cas pouvaient être traités avec une fonction intégrée unique et satisfaire tous les cas d'utilisation avec élégance.
ugorji
le 6 juin 2019
Étant donné que try() est déjà magique et conscient de la valeur de retour d'erreur, pourrait-il être augmenté pour renvoyer également un pointeur vers cette valeur lorsqu'il est appelé sous la forme nullaire (argument zéro) ? Cela éliminerait le besoin de retours nommés et, je pense, aiderait à corréler visuellement d'où l'erreur devrait provenir dans les instructions différées. Par exemple:
func foo() error {
defer fmt.HandleErrorf(try(), "important foo context info")
try(bar())
try(baz())
try(etc())
}
 jargv
le 6 juin 2019
jargv
le 6 juin 2019
@ugorji
Je pense que le booléen sur try(f, bool) le rendrait difficile à lire et facile à manquer. J'aime votre proposition, mais pour le cas de panique, je pense que cela pourrait être laissé de côté pour que les utilisateurs l'écrivent à l'intérieur du gestionnaire à partir de votre troisième puce, par exemple try(f(), func(err error) { panic('at the disco'); }) , cela le rend plus explicite pour les utilisateurs qu'un try(f(), true) caché
Goodwine
le 6 juin 2019
@ugorji
Je pense que le booléen surtry(f, bool)le rendrait difficile à lire et facile à manquer. J'aime votre proposition, mais pour le cas de panique, je pense que cela pourrait être laissé de côté pour que les utilisateurs l'écrivent à l'intérieur du gestionnaire à partir de votre troisième puce, par exempletry(f(), func(err error) { panic('at the disco'); }), cela le rend plus explicite pour les utilisateurs qu'untry(f(), true)caché
Après réflexion, j'ai tendance à être d'accord avec votre position et votre raisonnement, et cela a toujours l'air élégant en tant que one-liner.
ugorji
le 6 juin 2019
@patrick-nyt est encore un autre partisan de la _syntaxe d'affectation_ pour déclencher un test nul, dans https://github.com/golang/go/issues/32437#issuecomment -499533464
Ce concept apparaît dans 13 réponses distinctes à la proposition check/handle
https://github.com/golang/go/wiki/Go2ErrorHandlingFeedback#recurring -themes
f, ?return := os.Open(...)
f, ?panic := os.Open(...)
Pourquoi? Parce qu'il se lit comme Go 1, alors que try() et check ne le font pas.
networkimprov
le 6 juin 2019
 NARKOZ
le 6 juin 2019
NARKOZ
le 6 juin 2019
Une objection à try semble être qu'il s'agit d'une expression. Supposons à la place qu'il existe une instruction postfixée unaire ? qui signifie retour si non nul. Voici l'exemple de code standard (en supposant que mon package différé proposé est ajouté):
func CopyFile(src, dst string) error {
var err error // Don't need a named return because err is explicitly named
defer deferred.Annotate(&err, "copy %s %s", src, dst)
r, err := os.Open(src)
err?
defer deferred.AnnotatedExec(&err, r.Close)
w, err := os.Create(dst)
err?
defer deferred.AnnotatedExec(&err, r.Close)
defer deferred.Cond(&err, func(){ os.Remove(dst) })
_, err = io.Copy(w, r)
return err
}
L'exemple pgStore :
func (p *pgStore) DoWork() error {
tx, err := p.handle.Begin()
err?
defer deferred.Cond(&err, func(){ tx.Rollback() })
var res int64
err = tx.QueryRow(`INSERT INTO table (...) RETURNING c1`, ...).Scan(&res)
// tricky bit: this would not change the value of err
// but the deferred.Cond would still be triggered by err being set before
deferred.Format(err, "insert table")?
_, err = tx.Exec(`INSERT INTO table2 (...) VALUES ($1)`, res)
deferred.Format(err, "insert table2")?
return tx.Commit()
}
J'aime ça de @jargv :
Étant donné que try() est déjà magique et conscient de la valeur de retour d'erreur, pourrait-il être augmenté pour renvoyer également un pointeur vers cette valeur lorsqu'il est appelé sous la forme nullaire (argument zéro) ? Cela éliminerait le besoin de retours nommés
Mais au lieu de surcharger le nom try en fonction du nombre d'arguments, je pense qu'il pourrait y avoir une autre magie intégrée, disons reterr ou quelque chose du genre.
carlmjohnson
le 6 juin 2019
J'ai passé en revue certains packages très souvent utilisés, à la recherche de code go qui "souffre" de la gestion des erreurs mais qui doit avoir été bien pensé avant d'être écrit, en essayant de comprendre quelle "magie" le try() proposé ferait.
Actuellement, à moins que j'aie mal compris la proposition, beaucoup d'entre eux (par exemple, pas une gestion des erreurs super basique) ne gagneraient pas grand-chose, ou devraient rester avec le "vieux" style de gestion des erreurs.
Exemple tiré de net/http/request.go :
func (r *Request) write(w io.Writer, usingProxy bool, extraHeaders Header, waitForContinue func() bool) (err error) {
`
trace := httptrace.ContextClientTrace(r.Context())
if trace != nil && trace.WroteRequest != nil {
defer func() {
trace.WroteRequest(httptrace.WroteRequestInfo{
Err: err,
})
}()
}
// Find the target host. Prefer the Host: header, but if that
// is not given, use the host from the request URL.
//
// Clean the host, in case it arrives with unexpected stuff in it.
host := cleanHost(r.Host)
if host == "" {
if r.URL == nil {
return errMissingHost
}
host = cleanHost(r.URL.Host)
}
// According to RFC 6874, an HTTP client, proxy, or other
// intermediary must remove any IPv6 zone identifier attached
// to an outgoing URI.
host = removeZone(host)
ruri := r.URL.RequestURI()
if usingProxy && r.URL.Scheme != "" && r.URL.Opaque == "" {
ruri = r.URL.Scheme + "://" + host + ruri
} else if r.Method == "CONNECT" && r.URL.Path == "" {
// CONNECT requests normally give just the host and port, not a full URL.
ruri = host
if r.URL.Opaque != "" {
ruri = r.URL.Opaque
}
}
if stringContainsCTLByte(ruri) {
return errors.New("net/http: can't write control character in Request.URL")
}
// TODO: validate r.Method too? At least it's less likely to
// come from an attacker (more likely to be a constant in
// code).
// Wrap the writer in a bufio Writer if it's not already buffered.
// Don't always call NewWriter, as that forces a bytes.Buffer
// and other small bufio Writers to have a minimum 4k buffer
// size.
var bw *bufio.Writer
if _, ok := w.(io.ByteWriter); !ok {
bw = bufio.NewWriter(w)
w = bw
}
_, err = fmt.Fprintf(w, "%s %s HTTP/1.1\r\n", valueOrDefault(r.Method, "GET"), ruri)
if err != nil {
return err
}
// Header lines
_, err = fmt.Fprintf(w, "Host: %s\r\n", host)
if err != nil {
return err
}
if trace != nil && trace.WroteHeaderField != nil {
trace.WroteHeaderField("Host", []string{host})
}
// Use the defaultUserAgent unless the Header contains one, which
// may be blank to not send the header.
userAgent := defaultUserAgent
if r.Header.has("User-Agent") {
userAgent = r.Header.Get("User-Agent")
}
if userAgent != "" {
_, err = fmt.Fprintf(w, "User-Agent: %s\r\n", userAgent)
if err != nil {
return err
}
if trace != nil && trace.WroteHeaderField != nil {
trace.WroteHeaderField("User-Agent", []string{userAgent})
}
}
// Process Body,ContentLength,Close,Trailer
tw, err := newTransferWriter(r)
if err != nil {
return err
}
err = tw.writeHeader(w, trace)
if err != nil {
return err
}
err = r.Header.writeSubset(w, reqWriteExcludeHeader, trace)
if err != nil {
return err
}
if extraHeaders != nil {
err = extraHeaders.write(w, trace)
if err != nil {
return err
}
}
_, err = io.WriteString(w, "\r\n")
if err != nil {
return err
}
if trace != nil && trace.WroteHeaders != nil {
trace.WroteHeaders()
}
// Flush and wait for 100-continue if expected.
if waitForContinue != nil {
if bw, ok := w.(*bufio.Writer); ok {
err = bw.Flush()
if err != nil {
return err
}
}
if trace != nil && trace.Wait100Continue != nil {
trace.Wait100Continue()
}
if !waitForContinue() {
r.closeBody()
return nil
}
}
if bw, ok := w.(*bufio.Writer); ok && tw.FlushHeaders {
if err := bw.Flush(); err != nil {
return err
}
}
// Write body and trailer
err = tw.writeBody(w)
if err != nil {
if tw.bodyReadError == err {
err = requestBodyReadError{err}
}
return err
}
if bw != nil {
return bw.Flush()
}
return nil
}
`
ou tel qu'utilisé dans un test approfondi tel que pprof/profile/profile_test.go :
`
func checkAggregation(prof *Profile, a *aggTest) erreur {
// Vérifie que le nombre total d'échantillons pour les lignes a été conservé.
totale := int64(0)
samples := make(map[string]bool)
for _, sample := range prof.Sample {
tb := locationHash(sample)
samples[tb] = true
total += sample.Value[0]
}
if total != totalSamples {
return fmt.Errorf("sample total %d, want %d", total, totalSamples)
}
// Check the number of unique sample locations
if a.rows != len(samples) {
return fmt.Errorf("number of samples %d, want %d", len(samples), a.rows)
}
// Check that all mappings have the right detail flags.
for _, m := range prof.Mapping {
if m.HasFunctions != a.function {
return fmt.Errorf("unexpected mapping.HasFunctions %v, want %v", m.HasFunctions, a.function)
}
if m.HasFilenames != a.fileline {
return fmt.Errorf("unexpected mapping.HasFilenames %v, want %v", m.HasFilenames, a.fileline)
}
if m.HasLineNumbers != a.fileline {
return fmt.Errorf("unexpected mapping.HasLineNumbers %v, want %v", m.HasLineNumbers, a.fileline)
}
if m.HasInlineFrames != a.inlineFrame {
return fmt.Errorf("unexpected mapping.HasInlineFrames %v, want %v", m.HasInlineFrames, a.inlineFrame)
}
}
// Check that aggregation has removed finer resolution data.
for _, l := range prof.Location {
if !a.inlineFrame && len(l.Line) > 1 {
return fmt.Errorf("found %d lines on location %d, want 1", len(l.Line), l.ID)
}
for _, ln := range l.Line {
if !a.fileline && (ln.Function.Filename != "" || ln.Line != 0) {
return fmt.Errorf("found line %s:%d on location %d, want :0",
ln.Function.Filename, ln.Line, l.ID)
}
if !a.function && (ln.Function.Name != "") {
return fmt.Errorf(`found file %s location %d, want ""`,
ln.Function.Name, l.ID)
}
}
}
return nil
}
`
Ce sont deux exemples auxquels je peux penser dans lesquels on dirait : "Je voudrais une meilleure option de gestion des erreurs"
Quelqu'un peut-il démontrer comment ceux-ci s'amélioreraient en utilisant try() ?
guybrand
le 6 juin 2019
Je suis majoritairement favorable à cette proposition.
Ma principale préoccupation, partagée avec de nombreux commentateurs, concerne les paramètres de résultat nommés. La proposition actuelle encourage certainement beaucoup plus l'utilisation de paramètres de résultat nommés et je pense que ce serait une erreur. Je ne crois pas que ce soit simplement une question de style comme l'indique la proposition : les résultats nommés sont une caractéristique subtile du langage qui, dans de nombreux cas, rend le code plus sujet aux bogues ou moins clair. Après environ 8 ans de lecture et d'écriture de code Go, je n'utilise vraiment que des paramètres de résultat nommés à deux fins :
- Documentation des paramètres de résultat
- Manipulation d'une valeur de résultat (généralement un
error) dans un délai
Pour attaquer ce problème dans une nouvelle direction, voici une idée qui, à mon avis, ne correspond pas étroitement à tout ce qui a été discuté dans le document de conception ou dans ce fil de commentaires sur le problème. Appelons-le "report d'erreur":
Autoriser l'utilisation du report pour appeler des fonctions avec un paramètre d'erreur implicite.
Donc, si vous avez une fonction
func f(err error, t1 T1, t2 T2, ..., tn Tn) error
Ensuite, dans une fonction g où le dernier paramètre de résultat a le type error (c'est-à-dire, toute fonction où try peut être utilisé), un appel à f peut être reporté comme suit :
func g() (R0, R0, ..., error) {
defer f(t0, t1, ..., tn) // err is implicit
}
La sémantique de error-defer est :
- L'appel différé à
fest appelé avec le dernier paramètre de résultat degcomme premier paramètre d'entrée def fn'est appelé que si cette erreur n'est pas nulle- Le résultat de
fest affecté au dernier paramètre de résultat deg
Donc, pour utiliser un exemple de l'ancien document de conception de gestion des erreurs, en utilisant error-defer et try, nous pourrions faire
func printSum(a, b string) error {
defer func(err error) error {
return fmt.Errorf("printSum(%q + %q): %v", a, b, err)
}()
x := try(strconv.Atoi(a))
y := try(strconv.Atoi(b))
fmt.Println("result:", x+y)
return nil
}
Voici comment HandleErrorf fonctionnerait :
func printSum(a, b string) error {
defer handleErrorf("printSum(%q + %q)", a, b)
x := try(strconv.Atoi(a))
y := try(strconv.Atoi(b))
fmt.Println("result:", x+y)
return nil
}
func handleErrorf(err error, format string, args ...interface{}) error {
return fmt.Errorf(format+": %v", append(args, err)...)
}
Un cas particulier qui devrait être résolu est de savoir comment gérer les cas où la forme de report que nous utilisons est ambiguë. Je pense que cela ne se produit qu'avec des fonctions (très inhabituelles) avec des signatures comme celle-ci :
func(error, ...error) error
Il semble raisonnable de dire que ce cas est traité de manière non différée (et cela préserve la compatibilité descendante).
En pensant à cette idée depuis quelques jours, c'est un peu magique, mais le fait d'éviter les paramètres de résultat nommés est un grand avantage en sa faveur. Étant donné que try encourage une utilisation accrue de defer pour la manipulation des erreurs, il est logique que defer puisse être étendu pour mieux l'adapter à cette fin. De plus, il existe une certaine symétrie entre try et le report d'erreur.
Enfin, les reports d'erreurs sont utiles aujourd'hui même sans essai, car ils remplacent l'utilisation de paramètres de résultat nommés pour manipuler les retours d'erreur. Par exemple, voici une version modifiée d'un code réel :
// GetMulti retrieves multiple files through the cache at once and returns its
// results as a slice parallel to the input.
func (c *FileCache) GetMulti(keys []string) (_ []*File, err error) {
files := make([]*file, len(keys))
defer func() {
if err != nil {
// Return any successfully retrieved files.
for _, f := range files {
if f != nil {
c.put(f)
}
}
}
}()
// ...
}
Avec le report d'erreur, cela devient :
// GetMulti retrieves multiple files through the cache at once and returns its
// results as a slice parallel to the input.
func (c *FileCache) GetMulti(keys []string) ([]*File, error) {
files := make([]*file, len(keys))
defer func(err error) error {
// Return any successfully retrieved files.
for _, f := range files {
if f != nil {
c.put(f)
}
}
return err
}()
// ...
}
@beoran Concernant votre commentaire selon lequel nous devrions attendre les génériques. Les génériques ne vous aideront pas ici - veuillez lire la FAQ .
En ce qui concerne vos suggestions sur le comportement par défaut du try 2 arguments de @velovix : comme je l'ai déjà dit, votre idée de ce qui est le choix évidemment raisonnable est le cauchemar de quelqu'un d'autre.
Puis-je suggérer que nous poursuivions cette discussion une fois qu'un large consensus aura émergé sur le fait que try avec un gestionnaire d'erreurs explicite est une meilleure idée que le try minimal actuel. À ce stade, il est logique de discuter des subtilités d'une telle conception.
(J'aime bien avoir un gestionnaire, d'ailleurs. C'est l'une de nos propositions précédentes. Et si nous adoptons try tel quel, nous pouvons toujours passer à un try avec un gestionnaire dans un avant -compatibilité - du moins si le gestionnaire est facultatif. Mais procédons une étape à la fois.)
griesemer
le 6 juin 2019
@aarzilli Merci pour votre suggestion .
Tant que les erreurs de décoration sont facultatives, les gens auront tendance à ne pas le faire (c'est du travail supplémentaire après tout). Voir aussi mon commentaire ici .
Donc, je ne pense pas que le try proposé _décourage_ les gens à faire des erreurs de décoration (ils sont déjà découragés même avec le if pour la raison ci-dessus) ; c'est que try ne l'encourage pas.
(Une façon de l'encourager est de le lier à try : on ne peut utiliser try que si l'on décore également l'erreur ou si l'on se désengage explicitement.)
Mais revenons à vos suggestions : je pense que vous introduisez beaucoup plus de machines ici. Changer la sémantique de defer juste pour qu'elle fonctionne mieux pour try n'est pas quelque chose que nous voudrions considérer à moins que ces changements defer soient bénéfiques d'une manière plus générale. De plus, votre suggestion lie defer à try et rend ainsi ces deux mécanismes moins orthogonaux ; quelque chose que nous voudrions éviter.
Mais plus important encore, je doute que vous vouliez forcer tout le monde à écrire un defer juste pour pouvoir utiliser try . Mais sans faire cela, nous revenons à la case départ : les gens pencheront pour ne pas décorer les erreurs.
griesemer
le 6 juin 2019
(J'aime bien avoir un gestionnaire, d'ailleurs. C'est l'une de nos propositions précédentes. Et si nous adoptons try tel quel, nous pouvons toujours passer à un essai avec un gestionnaire d'une manière compatible vers l'avant - du moins si le gestionnaire est facultatif. Mais procédons une étape à la fois.)
Bien sûr, une approche en plusieurs étapes est peut-être la voie à suivre. Si nous ajoutons un argument de gestionnaire facultatif à l'avenir, un outil pourrait être créé pour avertir l'auteur d'un try non géré dans le même esprit que l'outil errcheck . Quoi qu'il en soit, j'apprécie vos commentaires!
velovix
le 6 juin 2019
@alanfo Merci pour vos commentaires positifs.
Concernant les points que vous avez soulevés :
1) Si le seul problème avec try est le fait qu'il faudra nommer un retour d'erreur afin que nous puissions décorer une erreur via defer , je pense que nous sommes bons. Si nommer le résultat s'avère être un vrai problème, nous pourrions y remédier. Un mécanisme simple auquel je peux penser serait une variable prédéclarée qui est un alias vers un résultat d'erreur (pensez-y comme contenant l'erreur qui a déclenché le plus récent try ). Il peut y avoir de meilleures idées. Nous ne l'avons pas proposé car il existe déjà un mécanisme dans le langage, qui consiste à nommer le résultat.
2) try et tests : cela peut être résolu et mis en œuvre. Voir la doc détaillée.
3) Ceci est explicitement abordé dans la doc détaillée.
4) Reconnu.
griesemer
le 6 juin 2019
@benhoyt Merci pour vos commentaires positifs.
Si le principal argument contre cette proposition est le fait que try est intégré, nous sommes bien placés. L'utilisation d'un intégré est simplement une solution pragmatique au problème de rétrocompatibilité (il arrive qu'il n'y ait pas de travail supplémentaire pour l'analyseur, les outils, etc. - mais c'est juste un avantage secondaire intéressant, pas la raison principale). Il y a aussi quelques avantages à devoir écrire des parenthèses, ceci est discuté en détail dans le document de conception (section sur les propriétés de la conception proposée).
Cela dit, si l'utilisation d'un élément intégré est le clou du spectacle, nous devrions envisager le mot-clé try . Il ne sera cependant pas rétrocompatible avec le code existant car le mot-clé peut entrer en conflit avec les identifiants existants.
(Pour être complet, il y a aussi l'option d'un opérateur tel que ? , qui serait rétrocompatible. Cela ne me semble pas être le meilleur choix pour un langage tel que Go, cependant. Mais encore une fois, si c'est tout ce qu'il faut pour rendre try agréable au goût, nous devrions peut-être l'envisager.)
griesemer
le 7 juin 2019
@ugorji Merci pour vos commentaires positifs.
try pourrait être étendu pour prendre un argument supplémentaire. Notre préférence serait de ne prendre qu'une fonction avec la signature func (error) error . Si vous voulez paniquer, il est facile de fournir une fonction d'assistance en une ligne :
func doPanic(err error) error { panic(err) }
Mieux vaut garder la conception de try simple.
griesemer
le 7 juin 2019
@patrick-nyt Ce que vous proposez :
file, err := os.Open("file.go")
try(err)
sera possible avec la proposition actuelle.
griesemer
le 7 juin 2019
@dpinela , @ugorji Veuillez également lire la doc de conception au sujet de must vs try . Il est préférable de garder try aussi simple que possible. must est un "modèle" courant dans les expressions d'initialisation, mais il n'est pas urgent de "réparer" cela.
griesemer
le 7 juin 2019
@jargv Merci pour votre suggestion . C'est une idée intéressante (voir aussi mon commentaire ici à ce sujet). Résumer:
try(x)fonctionne comme proposétry()renvoie un*errorpointant vers le résultat de l'erreur
Ce serait en effet une autre façon d'arriver au résultat sans avoir à le nommer.
griesemer
le 7 juin 2019
@cespare La suggestion de @jargv me semble beaucoup plus simple que ce que vous proposez . Il résout le même problème d'accès à l'erreur de résultat. Qu'est-ce que tu penses?
griesemer
le 7 juin 2019
Selon https://github.com/golang/go/issues/32437#issuecomment -499320588 :
func doPanic(err error) error { panique(err) }
Je prévois que cette fonction serait assez courante. Cela pourrait-il être prédéfini dans "builtin" (ou ailleurs dans un package standard, par exemple errors ) ?
pjebs
le 7 juin 2019
Dommage que vous ne prévoyiez pas des génériques assez puissants à mettre en place
essayer, j'aurais en fait espéré qu'il serait possible de le faire.
Oui, cette proposition pourrait être une première étape, même si je n'y vois pas beaucoup d'utilité
moi-même tel qu'il est maintenant.
Certes, ce numéro met peut-être trop l'accent sur des alternatives détaillées,
mais cela montre que de nombreux participants ne sont pas entièrement satisfaits
ce. Ce qui semble faire défaut, c'est un large consensus autour de cette proposition...
Op vr 7 juin. 2019 01:04 schreef pj [email protected] :
Asper #32437 (commentaire)
https://github.com/golang/go/issues/32437#issuecomment-499320588 :func doPanic(err error) error { panique(err) }
Je prévois que cette fonction serait assez courante. Cela pourrait-il être prédéfini
dans "intégré" ?—
Vous recevez ceci parce que vous avez été mentionné.
Répondez directement à cet e-mail, consultez-le sur GitHub
https://github.com/golang/go/issues/32437?email_source=notifications&email_token=AAARM6OOOLLYO5ZCE6VVL2TPZGJWRA5CNFSM4HTGCZ72YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGODXEMYZY#issuecomment-49196,9
ou couper le fil
https://github.com/notifications/unsubscribe-auth/AAARM6K5AOR2DES4QDTNLSTPZGJWRANCNFSM4HTGCZ7Q
.
beoran
le 7 juin 2019
@pjebs , j'ai écrit la fonction équivalente des dizaines de fois. Je l'appelle généralement "orDie" ou "check". C'est si simple qu'il n'est pas vraiment nécessaire de l'intégrer à la bibliothèque standard. De plus, différentes personnes peuvent vouloir se connecter ou quoi que ce soit avant la résiliation.
carlmjohnson
le 7 juin 2019
@beoran Vous pourriez peut-être développer le lien entre les génériques et la gestion des erreurs. Quand je pense à eux, ils semblent être deux choses différentes. Les génériques ne sont pas un fourre-tout qui peut résoudre tous les problèmes avec la langue. C'est la capacité d'écrire une seule fonction qui peut fonctionner sur plusieurs types.
Cette proposition spécifique de gestion des erreurs tente de réduire le passe-partout en introduisant une fonction prédéclarée try qui modifie le contrôle de flux dans certaines circonstances. Les génériques ne changeront jamais le flux de contrôle. Donc je ne vois vraiment pas le rapport.
ianlancetaylor
le 7 juin 2019
Ma première réaction à cela a été un 👎 car j'imaginais que la gestion de plusieurs appels sujets aux erreurs dans une fonction rendrait le gestionnaire d'erreur defer déroutant. Après avoir lu toute la proposition, j'ai inversé ma réaction à un ❤️ et 👍 car j'ai appris que cela peut encore être réalisé avec une complexité relativement faible.
 dndungu
le 7 juin 2019
dndungu
le 7 juin 2019
@carlmjohnson Oui c'est simple mais...
J'ai écrit la fonction équivalente des dizaines de fois.
Les avantages d'une fonction prédéclarée sont :
- Nous pouvons le mettre en ligne
- Nous n'avons pas besoin de redéclarer la fonction err => panic dans chaque paquet que nous utilisons, ou de conserver un emplacement commun pour celle-ci. Puisqu'il est probablement commun à tout le monde dans la communauté Go, le "paquet standard" est _ l' _ emplacement commun pour celui-ci.
@griesemer Avec la variante de gestionnaire d'erreurs de la proposition try originale, l'exigence de la fonction globale pour renvoyer une erreur n'est plus nécessaire.
Lorsque je me suis renseigné pour la première fois à ce sujet, l'err => panique, on m'a fait remarquer que la proposition l'envisageait mais la considérait comme trop dangereuse (pour une bonne raison). Mais si nous utilisons try() sans gestionnaire d'erreurs dans un scénario où la fonction globale ne renvoie pas d'erreur, en faire une erreur de compilation atténue le problème évoqué dans la proposition
pjebs
le 7 juin 2019
@pjebs L'exigence de la fonction globale pour renvoyer une erreur n'était pas requise dans la conception d'origine _if_ un gestionnaire d'erreurs était fourni. Mais c'est juste une autre complication de try . C'est _beaucoup_ mieux de rester simple. Au lieu de cela, il serait plus clair d'avoir une fonction must séparée, qui panique toujours en cas d'erreur (mais sinon, c'est comme try ). Ensuite, ce qui se passe dans le code est évident et il n'est pas nécessaire de regarder le contexte.
Le principal attrait d'avoir un tel must serait qu'il pourrait être utilisé avec des tests unitaires ; surtout si le package testing a été correctement ajusté pour se remettre des paniques causées par must et les signaler comme des échecs de test d'une manière agréable. Mais pourquoi ajouter encore un autre nouveau mécanisme de langage alors que nous pouvons simplement ajuster le package de test pour accepter également la fonction de test de la forme TestXxx(t *testing.T) error ? S'ils renvoient une erreur, ce qui semble assez naturel après tout (nous aurions peut-être dû le faire dès le début), alors try fonctionnera très bien. Les tests locaux nécessiteront un peu plus de travail, mais c'est probablement faisable.
L'autre utilisation relativement courante de must est dans les expressions d'initialisation globale ( must(regexp.Compile... , etc.). Ce serait un "bien d'avoir" mais cela ne l'élève pas nécessairement au niveau requis pour une nouvelle fonctionnalité linguistique.
griesemer
le 7 juin 2019
@griesemer Étant donné que must est vaguement lié à try , et étant donné que l'élan est vers la mise en œuvre try , ne pensez-vous pas qu'il est bon d'envisager must en même temps - même si ce n'est qu'un "bon à avoir".
Il y a de fortes chances que si ce n'est pas discuté dans ce cycle, il ne sera tout simplement pas mis en œuvre/sérieusement envisagé, au moins pendant 3 ans et plus (ou peut-être jamais). Le chevauchement des discussions serait également une bonne chose plutôt que de partir de zéro et de recycler les discussions.
Beaucoup de gens ont déclaré que must complimente très bien try .
pjebs
le 7 juin 2019
@pjebs Il ne semble certainement pas qu'il y ait un "momentum vers la mise en œuvre try " en ce moment ... - Et nous venons également de publier cela il y a deux jours. Rien non plus n'a été décidé. Donnons-nous un peu de temps.
Il ne nous a pas échappé que must s'harmonise bien avec try , mais ce n'est pas la même chose que de l'intégrer au langage. Nous avons seulement commencé à explorer cet espace avec un groupe plus large de personnes. Nous ne savons pas encore vraiment ce qui pourrait venir en faveur ou contre. Merci.
griesemer
le 7 juin 2019
Après avoir passé des heures à lire tous les commentaires et la documentation de conception détaillée, je voulais ajouter mon point de vue à cette proposition.
Je ferai de mon mieux pour respecter la demande de @ianlancetaylor de ne pas simplement reformuler les points précédents, mais d'ajouter à la place de nouveaux commentaires à la discussion. Cependant, je ne pense pas pouvoir faire de nouveaux commentaires sans faire référence à des commentaires antérieurs.
Préoccupations
Malheureuse surcharge de report
La préférence pour surcharger la nature évidente et simple de defer comme alarmante. Si j'écris defer closeFile(f) c'est simple et évident pour moi ce qui se passe et pourquoi ; à la fin de la fonction qui sera appelée. Et bien que l'utilisation defer pour panic() et recover() soit moins évidente, je l'utilise rarement, voire jamais, et je ne le vois presque jamais en lisant le code des autres.
Spoo pour surcharger defer pour gérer également les erreurs n'est pas évident et déroutant. Pourquoi le mot-clé defer ? Est-ce que defer ne signifie pas _"Faire plus tard"_ au lieu de _"Peut-être à plus tard ?"_
Il y a aussi la préoccupation mentionnée par l'équipe Go concernant les performances de defer . Compte tenu de cela, il semble doublement regrettable que defer soit envisagé pour le flux de code _"hot path"_.
Aucune statistique vérifiant un cas d'utilisation significatif
Comme @prologic l'a mentionné, cette proposition try() est-elle basée sur un grand pourcentage de code qui utiliserait ce cas d'utilisation, ou est-elle plutôt basée sur une tentative d'apaiser ceux qui se sont plaints de la gestion des erreurs Go ?
J'aimerais savoir comment vous donner des statistiques à partir de ma base de code sans examiner de manière exhaustive chaque fichier et prendre des notes ; Je ne sais pas comment @prologic a pu être content de l'avoir fait.
Mais pour l'anecdote, je serais surpris si try() traitait 5 % de mes cas d'utilisation et je soupçonnerais qu'il en traiterait moins de 1 %. Savez-vous avec certitude que d'autres ont des résultats très différents ? Avez-vous pris un sous-ensemble de la bibliothèque standard et essayé de voir comment il serait appliqué ?
Parce que sans statistiques connues que cela convient à un gros morceau de code dans la nature, je dois demander si ce nouveau changement compliqué du langage qui obligera tout le monde à apprendre les nouveaux concepts concerne vraiment un nombre convaincant de cas d'utilisation ?
Permet aux développeurs d'ignorer plus facilement les erreurs
C'est une répétition totale de ce que d'autres ont commenté, mais ce qui fournit fondamentalement try() est analogue à bien des égards à simplement embrasser ce qui suit comme code idomatique, et c'est un code qui ne trouvera jamais sa place dans aucun code -respecter les navires développeurs :
f, _ := os.Open(filename)
Je sais que je peux être meilleur dans mon propre code, mais je sais aussi que beaucoup d'entre nous dépendent des largesses des autres développeurs Go qui publient des packages extrêmement utiles, mais d'après ce que j'ai vu dans _"Other People's Code(tm)"_ les meilleures pratiques en matière de gestion des erreurs sont souvent ignorées.
Alors sérieusement, voulons-nous vraiment permettre aux développeurs d'ignorer plus facilement les erreurs et leur permettre de polluer GitHub avec des packages non robustes ?
Peut (principalement) déjà implémenter try() dans userland
Sauf si j'ai mal compris la proposition - ce que je fais probablement - voici try() dans le Go Playground implémenté dans userland , mais avec une seule (1) valeur de retour et renvoyant une interface au lieu du type attendu :
package main
import (
"errors"
"fmt"
"strings"
)
func main() {
defer func() {
r := recover()
if r != nil && strings.HasPrefix(r.(string),"TRY:") {
fmt.Printf("Ouch! %s",strings.TrimPrefix(r.(string),"TRY: "))
}
}()
n := try(badjuju()).(int)
fmt.Printf("Just chillin %dx!",n)
}
func badjuju() (int,error) {
return 10, errors.New("this is a really bad error")
}
func try(args ...interface{}) interface{} {
err,ok := args[1].(error)
if ok && err != nil {
panic(fmt.Sprintf("TRY: %s",err.Error()))
}
return args[0]
}
Ainsi, l'utilisateur peut ajouter un try2() , try3() et ainsi de suite en fonction du nombre de valeurs de retour qu'il doit renvoyer.
Mais Go n'aurait besoin que d'une (1) fonctionnalité de langage simple _ mais universelle _ pour permettre aux utilisateurs qui veulent try() de déployer leur propre support, bien que celui-ci nécessite toujours une assertion de type explicite. Ajoutez une fonctionnalité _(entièrement rétrocompatible)_ pour un Go func afin de renvoyer un nombre variable de valeurs de retour, par exemple :
func try(args ...interface{}) ...interface{} {
err,ok := args[1].(error)
if ok && err != nil {
panic(fmt.Sprintf("TRY: %s",err.Error()))
}
return args[0:len(args)-2]
}
Et si vous vous adressez d'abord aux génériques, les assertions de type ne seraient même pas nécessaires _ (bien que je pense que les cas d'utilisation des génériques devraient être réduits en ajoutant des fonctions intégrées pour traiter les cas d'utilisation des génériques plutôt que d'ajouter la sémantique confuse et la salade de syntaxe des génériques de Java et al.)_
Manque d'évidence
Lors de l'étude du code de la proposition, je trouve que le comportement n'est pas évident et quelque peu difficile à raisonner.
Lorsque je vois try() envelopper une expression, que se passe-t-il si une erreur est renvoyée ?
L'erreur sera-t-elle simplement ignorée ? Ou sautera-t-il au premier ou au plus récent defer , et si c'est le cas, définira-t-il automatiquement une variable nommée err à l'intérieur de la fermeture, ou le passera-t-il en tant que paramètre _(I ne voyez pas un paramètre ?)_. Et si ce n'est pas un nom d'erreur automatique, comment puis-je le nommer ? Et cela signifie-t-il que je ne peux pas déclarer ma propre variable err dans ma fonction, pour éviter les conflits ?
Et appellera-t-il tous les defer s ? En ordre inverse ou en ordre normal ?
Ou reviendra-t-il à la fois de la fermeture et du func où l'erreur a été renvoyée ? _(Quelque chose que je n'aurais jamais envisagé si je n'avais pas lu ici des mots qui impliquent cela.)_
Après avoir lu la proposition et tous les commentaires jusqu'à présent, honnêtement, je ne connais toujours pas les réponses aux questions ci-dessus. Est-ce le genre de fonctionnalité que nous voulons ajouter à un langage dont les défenseurs sont _"Captain Obvious?"_
Manque de contrôle
En utilisant defer , il semble que le seul contrôle que les développeurs auraient les moyens est de se brancher sur _(le plus récent ?)_ defer . Mais d'après mon expérience avec toutes les méthodes au-delà d'un trivial func , c'est généralement plus compliqué que cela.
Souvent, j'ai trouvé utile de partager l'aspect de la gestion des erreurs dans un func - ou même sur un package - mais aussi d'avoir une gestion plus spécifique partagée entre un ou plusieurs autres packages.
Par exemple, je peux appeler cinq (5) appels func qui renvoient un error() depuis un autre func ; étiquetons-les A() , B() , C() , D() et E() . J'ai peut-être besoin C() pour avoir sa propre gestion des erreurs, A() , B() , D() et E() pour partager une gestion des erreurs, et B() et E() pour avoir un traitement spécifique.
Mais je ne crois pas qu'il serait possible de le faire avec cette proposition. Du moins pas facilement.
Ironiquement, cependant, Go possède déjà des fonctionnalités de langage qui permettent un haut niveau de flexibilité qui n'a pas besoin d'être limité à un petit ensemble de cas d'utilisation ; func s et fermetures. Donc ma question rhétorique est :
_ "Pourquoi ne pouvons-nous pas simplement ajouter de légères améliorations au langage existant pour répondre à ces cas d'utilisation et ne pas avoir besoin d'ajouter de nouvelles fonctions intégrées ou d'accepter une sémantique confuse ?" _
C'est une question rhétorique car j'ai l'intention de soumettre une proposition alternative, celle que j'ai conçue lors de l'étude de cette proposition et en considérant tous ses inconvénients.
Mais je m'égare, cela viendra plus tard et ce commentaire explique pourquoi la proposition actuelle doit être réexaminée.
Absence de soutien déclaré pour break
Cela peut sembler sortir du champ gauche car la plupart des gens utilisent les premiers retours pour la gestion des erreurs, mais j'ai trouvé qu'il est préférable d'utiliser break pour la gestion des erreurs en enveloppant la plupart ou la totalité d'une fonction avant return .
J'utilise cette approche depuis un certain temps et ses avantages pour faciliter la refactorisation la rendent préférable à return précoce, mais elle présente plusieurs autres avantages, notamment un point de sortie unique et la possibilité de terminer une section d'une fonction plus tôt mais toujours être capable d'exécuter le nettoyage _ (ce qui est probablement la raison pour laquelle j'utilise si rarement defer , ce sur quoi je trouve plus difficile de raisonner en termes de déroulement du programme.)_
Pour utiliser break au lieu d'un retour anticipé, utilisez une boucle for range "1" {...} pour créer un bloc permettant à la pause de sortir de _ (je crée en fait un package appelé only qui ne contient qu'une constante appelé Once avec une valeur de "1" ):_
func (me *Config) WriteFile() (err error) {
for range only.Once {
var j []byte
j, err = json.MarshalIndent(me, "", " ")
if err != nil {
err = fmt.Errorf("unable to marshal config; %s",
err.Error(),
)
break
}
err = me.MaybeMakeDir(me.GetDir(), os.ModePerm)
if err != nil {
err = fmt.Errorf("unable to make directory'%s'; %s",
me.GetDir(),
err.Error(),
)
break
}
err = ioutil.WriteFile(string(me.GetFilepath()), j, os.ModePerm)
if err != nil {
err = fmt.Errorf("unable to write to config file '%s'; %s",
me.GetFilepath(),
err.Error(),
)
break
}
}
return err
}
Je prévois de bloguer longuement sur le modèle dans un avenir proche et de discuter des nombreuses raisons pour lesquelles j'ai trouvé qu'il fonctionnait mieux que les premiers retours.
Mais je m'égare. Ma raison de l'évoquer ici est que je devrais pour Go mettre en œuvre une gestion des erreurs qui suppose au début return s et ignore l'utilisation break pour la gestion des erreurs
Mon avis err == nil est problématique
Comme digression supplémentaire, je veux évoquer le souci que j'ai ressenti à propos de la gestion des erreurs idiomatiques dans Go. Bien que je sois un fervent partisan de la philosophie de Go pour gérer les erreurs lorsqu'elles se produisent par rapport à l'utilisation de la gestion des exceptions, je pense que l'utilisation de nil pour indiquer qu'aucune erreur n'est problématique car je trouve souvent que je voudrais renvoyer un message de réussite de une routine - à utiliser dans les réponses de l'API - et ne renvoie pas seulement une valeur non nulle juste en cas d'erreur.
Donc, pour Go 2, j'aimerais vraiment voir Go envisager d'ajouter un nouveau type intégré de status et trois fonctions intégrées iserror() , iswarning() , issuccess() . status pourrait implémenter error — permettant une grande rétrocompatibilité et une nil passée à issuccess() renverrait true — mais status aurait un état interne supplémentaire pour le niveau d'erreur afin que le test du niveau d'erreur soit toujours effectué avec l'une des fonctions intégrées et idéalement jamais avec une vérification nil . Cela permettrait plutôt quelque chose comme l'approche suivante :
func (me *Config) WriteFile() (sts status) {
for range only.Once {
var j []byte
j, sts = json.MarshalIndent(me, "", " ")
if iserror(sts) {
sts.AddMessage("unable to marshal config")
break
}
sts = me.MaybeMakeDir(me.GetDir(), os.ModePerm)
if iserror(sts) {
sts.AddMessage("unable to make directory'%s'", me.GetDir())
break
}
sts = ioutil.WriteFile(string(me.GetFilepath()), j, os.ModePerm)
if iserror(sts) {
sts.AddMessage("unable to write to config file '%s'",
me.GetFilepath(),
)
break
}
sts = fmt.Status("config file written")
}
return sts
}
J'utilise déjà une approche utilisateur dans un package à usage interne de niveau pré-bêta qui est similaire à ce qui précède pour la gestion des erreurs. Franchement , je passe beaucoup moins de temps à réfléchir à la façon de structurer le code lorsque j'utilise cette approche que lorsque j'essayais de suivre la gestion idiomatique des erreurs Go.
Si vous pensez qu'il est possible de faire évoluer le code Go idiomatique vers cette approche, veuillez en tenir compte lors de la mise en œuvre de la gestion des erreurs, y compris lors de l'examen de cette proposition try() .
_"Pas pour tout le monde"_ justification
L'une des principales réponses de l'équipe Go a été _"Encore une fois, cette proposition ne tente pas de résoudre toutes les situations de gestion des erreurs."_
Et c'est probablement la préoccupation la plus troublante, du point de vue de la gouvernance.
Cette nouvelle modification complexe du langage qui obligera tout le monde à apprendre les nouveaux concepts concerne-t-elle vraiment un nombre convaincant de cas d'utilisation ?
Et n'est-ce pas la même justification que les membres de l'équipe principale ont refusé de nombreuses demandes de fonctionnalités de la part de la communauté ? Ce qui suit est une citation directe d'un commentaire fait par un membre de l'équipe Go dans une réponse archétypique à une demande de fonctionnalité soumise il y a environ 2 ans _ (je ne nomme pas la personne ou la demande de fonctionnalité spécifique car cette discussion ne devrait pas pouvoir les gens mais plutôt sur la langue):_
_"Une nouvelle fonctionnalité de langage a besoin de cas d'utilisation convaincants. Toutes les fonctionnalités de langage sont utiles, sinon personne ne les proposerait ; la question est : sont-elles suffisamment utiles pour justifier de compliquer le langage et d'obliger tout le monde à apprendre les nouveaux concepts ? ici ? Comment les gens les utiliseront-ils ? Par exemple, les gens s'attendraient-ils à pouvoir... et si oui, comment feraient-ils cela ? Cette proposition fait-elle plus que vous permettre...?"_
— Un membre principal de l'équipe Go
Franchement, quand j'ai vu ces réponses, j'ai ressenti l'un des deux sentiments suivants :
- Indignation s'il s'agit d'une caractéristique avec laquelle je suis d'accord, ou
- Exaltation si c'est une caractéristique avec laquelle je ne suis pas d'accord.
Mais dans les deux cas, mes sentiments étaient/sont hors de propos ; Je comprends et je suis d'accord qu'une partie de la raison pour laquelle Go est la langue dans laquelle tant d'entre nous choisissent de se développer est à cause de cette garde jalouse de la pureté de la langue.
Et c'est pourquoi cette proposition me trouble tellement, parce que l'équipe principale de Go semble approfondir cette proposition au même niveau que quelqu'un qui veut dogmatiquement une fonctionnalité ésotérique qu'il n'y a aucun moyen que la communauté Go tolère jamais.
_(Et j'espère vraiment que l'équipe ne tirera pas sur le messager et ne prendra pas cela comme une critique constructive de la part de quelqu'un qui veut voir Go continuer à être le meilleur possible pour nous tous car je devrais être considéré comme "Persona non grata" par l'équipe de base.)_
Si l'exigence d'un ensemble convaincant de cas d'utilisation réels est la barre pour toutes les propositions de fonctionnalités générées par la communauté, ne devrait-elle pas également être la même pour _ toutes _ les propositions de fonctionnalités ?
Imbrication de try()
Cela aussi a été couvert par quelques-uns, mais je veux établir une comparaison entre try() et la demande continue d'opérateurs ternaires. Citant les commentaires d'un autre membre de l'équipe Go il y a environ 18 mois :
_"lors de la "programmation à grande échelle" (grandes bases de code avec de grandes équipes sur de longues périodes), le code est lu BEAUCOUP plus souvent qu'il n'est écrit, nous optimisons donc la lisibilité, pas l'écriture."_
L'une des _principales_ raisons invoquées pour ne pas ajouter d'opérateurs ternaires est qu'ils sont difficiles à lire et/ou faciles à mal lire lorsqu'ils sont imbriqués. Pourtant, la même chose peut être vraie pour les instructions try() imbriquées comme try(try(try(to()).parse().this)).easily()) .
Des raisons supplémentaires pour argumenter contre les opérateurs ternaires ont été qu'ils sont des _"expressions"_ avec cet argument que les expressions imbriquées peuvent ajouter de la complexité. Mais try() ne crée-t-il pas aussi une expression emboîtable ?
Maintenant, quelqu'un ici a dit _"Je pense que des exemples comme [ try() s imbriqués] sont irréalistes"_ et cette affirmation n'a pas été contestée.
Mais si les gens acceptent comme postulat que les développeurs n'imbriqueront pas try() alors pourquoi la même déférence n'est-elle pas accordée aux opérateurs ternaires quand les gens disent _"Je pense que les opérateurs ternaires profondément imbriqués sont irréalistes?"_
En bout de ligne pour ce point, je pense que si l'argument contre les opérateurs ternaires est vraiment valable, alors ils devraient également être considérés comme des arguments valables contre cette proposition try() .
En résumé
Au moment d'écrire ces lignes, les votes contre $ 58% contre 42% votent pour. Je pense que cela seul devrait suffire à indiquer qu'il s'agit d'une proposition suffisamment controversée pour qu'il soit temps de revenir à la planche à dessin sur cette question.
fwiw
PS Pour le dire plus ironiquement, je pense que nous devrions suivre la sagesse paraphrasée de Yoda :
_"Il n'y a pas
try(). Seulementdo()."_
 mikeschinkel
le 7 juin 2019
mikeschinkel
le 7 juin 2019
@ianlancetaylor
@beoran Vous pourriez peut-être développer le lien entre les génériques et la gestion des erreurs.
Je ne parle pas pour @beoran mais dans mon commentaire d'il y a quelques minutes, vous verrez que si nous avions des génériques _(plus des paramètres de retour variadic)_ alors nous pourrions construire notre propre try() .
Cependant — et je vais répéter ce que j'ai dit plus haut à propos des génériques ici où il sera plus facile de voir :
_"Je pense que les cas d'utilisation des génériques devraient être réduits en ajoutant des éléments intégrés pour traiter les cas d'utilisation des génériques plutôt que d'ajouter la sémantique confuse et la salade de syntaxe des génériques de Java et al.)"_
mikeschinkel
le 7 juin 2019
@ianlancetaylor
En essayant de formuler une réponse à votre question, j'ai essayé d'implémenter la fonction try dans Go telle quelle, et à mon grand plaisir, il est en fait déjà possible d'émuler quelque chose d'assez similaire :
func try(v interface{}, err error) interface{} {
if err != nil {
panic(err)
}
return v
}
Voyez ici comment il peut être utilisé : https://play.golang.org/p/Kq9Q0hZHlXL
Les inconvénients de cette approche sont :
- Un sauvetage différé est nécessaire, mais avec
trycomme dans cette proposition, un gestionnaire différé est également nécessaire si nous voulons gérer correctement les erreurs. Donc, je pense que ce n'est pas un inconvénient grave. Cela pourrait même être mieux si Go avait une sorte desuper(arg1, ..., argn)intégré qui fait que l'appelant de l'appelant, un niveau supérieur dans la pile des appels, retourne avec les arguments donnés arg1,...argn, une sorte de super retour si vous voulez. - Ce
tryque j'ai implémenté ne peut fonctionner qu'avec une fonction qui renvoie un seul résultat et une erreur. - Vous devez taper assert les résultats de l'interface vide renvoyés.
Des génériques suffisamment puissants pourraient résoudre les problèmes 2 et 3, en laissant seulement 1, qui pourrait être résolu en ajoutant un super() . Avec ces deux fonctionnalités en place, nous pourrions obtenir quelque chose comme :
func (T ... interface{})try(T, err error) super {
if err != nil {
super(err)
}
super(T...)
}
Et alors le sauvetage différé ne serait plus nécessaire. Cet avantage serait disponible même si aucun générique n'est ajouté à Go.
En fait, cette idée d'un super() intégré est si puissante et intéressante que je pourrais poster une proposition séparément.
beoran
le 7 juin 2019
@beoran C'est bien de voir que nous sommes arrivés à exactement les mêmes contraintes indépendamment concernant l'implémentation try() dans userland, à l'exception de la super partie que je n'ai pas incluse parce que je voulais parler de quelque chose de similaire dans une proposition alternative. :-)
mikeschinkel
le 7 juin 2019
J'aime la proposition, mais le fait que vous deviez spécifier explicitement que defer try(...) et go try(...) ne sont pas autorisés m'a fait penser que quelque chose n'allait pas... L'orthogonalité est un bon guide de conception. En lisant plus loin et en voyant des choses comme
x = try(foo(...))
y = try(bar(...))
Je me demande si try doit être un contexte ! Considérer:
try (
x = foo(...)
y = bar(...)
)
Ici, foo() et bar() renvoient deux valeurs, dont la seconde est error . La sémantique d'essai n'a d'importance que pour les appels dans le bloc try où la valeur d'erreur renvoyée est élidée (pas de récepteur) et non ignorée (le récepteur est _ ). Vous pouvez même gérer certaines erreurs entre les appels foo et bar .
Sommaire:
a) le problème d'interdiction de try pour go et defer disparaît grâce à la syntaxe.
b) la gestion des erreurs de plusieurs fonctions peut être factorisée.
c) sa nature magique est mieux exprimée par une syntaxe spéciale que par un appel de fonction.
 bakul
le 7 juin 2019
bakul
le 7 juin 2019
Si try est un contexte, nous venons de créer des blocs try/catch que nous essayons spécifiquement d'éviter (et pour une bonne raison)
deanveloper
le 7 juin 2019
Il n'y a pas de piège. Exactement le même code serait généré que lorsque la proposition actuelle a
x = try(foo(...))
y = try(bar(...))
C'est juste une syntaxe différente, pas une sémantique.
````
bakul
le 7 juin 2019
Je suppose que j'avais fait quelques hypothèses à ce sujet que je n'aurais pas dû faire, bien qu'il y ait encore quelques inconvénients.
Que se passe-t-il si foo ou bar ne renvoient pas d'erreur, peuvent-ils également être placés dans le contexte try ? Sinon, cela semble être un peu moche de basculer entre les fonctions d'erreur et de non-erreur, et si elles le peuvent, alors nous retombons sur les problèmes de blocs try dans les langages plus anciens.
La deuxième chose est que, typiquement, la syntaxe keyword ( ... ) signifie que vous préfixez le mot-clé sur chaque ligne. Donc pour import, var, const, etc : chaque ligne commence par le mot clé. Faire une exception à cette règle ne semble pas être une bonne décision
deanveloper
le 7 juin 2019
Au lieu d'utiliser une fonction, serait-il simplement plus idiomatique d'utiliser un identifiant spécial ?
Nous avons déjà l'identifiant vide _ qui ignore les valeurs.
Nous pourrions avoir quelque chose comme # qui ne peut être utilisé que dans les fonctions qui ont la dernière valeur renvoyée de type error.
func foo() (error) {
f, # := os.Open()
defer f.Close()
_, # = f.WriteString("foo")
return nil
}
lorsqu'une erreur est affectée à # la fonction retourne immédiatement avec l'erreur reçue. Quant aux autres variables, leurs valeurs seraient :
- s'ils ne sont pas nommés valeur zéro
- la valeur attribuée aux variables nommées sinon
 klaidliadon
le 7 juin 2019
klaidliadon
le 7 juin 2019
@deanveloper , la sémantique du bloc try n'a d'importance que pour les fonctions qui renvoient une valeur d'erreur et où la valeur d'erreur n'est pas affectée. Ainsi, le dernier exemple de la proposition actuelle pourrait également être écrit comme
try(x = foo(...))
try(y = bar(...))
mettre les deux instructions dans le même bloc est similaire à ce que nous faisons pour les instructions répétées import , const et var .
Maintenant, si vous avez, par exemple
try(
x = foo(...))
go zee(...)
defer fum()
y = bar(...)
)
Cela équivaut à écrire
try(x = foo(...))
go zee(...)
defer fum()
try(y = bar(...))
La factorisation de tout cela dans un bloc d'essai le rend moins occupé.
Considérer
try(x = foo())
Si foo() ne renvoie pas de valeur d'erreur, cela équivaut à
x = foo()
Considérer
try(f, _ := os.open(filename))
Étant donné que la valeur d'erreur renvoyée est ignorée, cela équivaut à juste
f, _ := os.open(filename)
Considérer
try(f, err := os.open(filename))
Étant donné que la valeur d'erreur renvoyée n'est pas ignorée, cela équivaut à
f, err := os.open(filename)
if err != nil {
return ..., err
}
Tel qu'il est actuellement spécifié dans la proposition.
Et cela désencombre également les essais imbriqués !
bakul
le 7 juin 2019
Voici un lien vers la proposition alternative que j'ai mentionnée ci-dessus :
Il appelle à l'ajout de deux (2) fonctionnalités de langage petites mais à usage général pour traiter les mêmes cas d'utilisation que try()
- Possibilité d'appeler un
func/closing dans une instruction d'affectation. - Possibilité de
break,continueoureturnplus d'un niveau.
Avec ces deux fonctionnalités, ce ne serait pas _"magique"_ et je pense que leur utilisation produirait un code Go plus facile à comprendre et plus conforme au code Go idiomatique que nous connaissons tous.
mikeschinkel
le 7 juin 2019
J'ai lu la proposition et j'aime vraiment où essayer va.
Étant donné la prévalence de l'essai, je me demande si en faire un comportement par défaut le rendrait plus facile à gérer.
Pensez aux cartes. C'est valable :
v := m[key]
tel quel:
v, ok := m[key]
Et si nous gérons les erreurs exactement comme try le suggère, mais supprimons le fichier intégré. Donc si on commençait par :
v, err := fn()
Au lieu d'écrire :
v := try(fn())
On pourrait plutôt écrire :
v := fn()
Lorsque la valeur err n'est pas capturée, elle est gérée exactement comme try. Il faudrait un peu de temps pour s'y habituer, mais cela ressemble beaucoup à v, ok := m[key] et v, ok := x.(string) . Fondamentalement, toute erreur non gérée entraîne le retour de la fonction et la définition de la valeur err.
Pour revenir aux conclusions des documents de conception et aux exigences de mise en œuvre :
• La syntaxe du langage est conservée et aucun nouveau mot-clé n'est introduit
• Cela continue d'être du sucre syntaxique comme try et, espérons-le, c'est facile à expliquer.
• Ne nécessite pas de nouvelle syntaxe
• Il doit être entièrement compatible avec les versions antérieures.
J'imagine que cela aurait à peu près les mêmes exigences de mise en œuvre que try car la principale différence est plutôt que le déclenchement intégré du sucre syntaxique, maintenant c'est l'absence du champ err.
Donc, en utilisant l'exemple CopyFile de la proposition avec defer fmt.HandleErrorf(&err, "copy %s %s", src, dst) , nous obtenons :
func CopyFile(src, dst string) (err error) {
defer fmt.HandleErrorf(&err, "copy %s %s", src, dst)
r := os.Open(src)
defer r.Close()
w := os.Create(dst)
defer func() {
err := w.Close()
if err != nil {
os.Remove(dst) // only if a “try” fails
}
}()
io.Copy(w, r)
w.Close()
return nil
}
 savaki
le 7 juin 2019
savaki
le 7 juin 2019
@savaki J'aime ça et je pensais à ce qu'il faudrait pour que Go retourne la gestion des erreurs en gérant toujours les erreurs par défaut et en laissant le programmeur spécifier quand ne pas le faire (en capturant l'erreur dans une variable) mais absence totale de tout l'identifiant rendrait le code difficile à suivre car on ne pourrait pas voir tous les points de retour. Peut-être qu'une convention pour nommer les fonctions qui pourraient renvoyer une erreur différemment pourrait fonctionner (comme la capitalisation des identifiants publics). Peut-être que si une fonction renvoie une erreur, elle doit toujours se terminer par, disons ? . Ensuite, Go pourrait toujours gérer implicitement l'erreur et la renvoyer automatiquement à la fonction appelante, tout comme try. Cela le rend très similaire à certaines propositions suggérant d'utiliser un identifiant ? au lieu d'essayer, mais une différence importante est qu'ici ? ferait partie du nom de la fonction et non un identifiant supplémentaire. En fait, une fonction qui renvoyait error comme dernière valeur de retour ne serait même pas compilée si elle n'était pas suffixée ? . Bien sûr, ? est arbitraire et pourrait être remplacé par n'importe quoi d'autre qui rendrait l'intention plus explicite. operation?() équivaudrait à envelopper try(someFunc()) mais ? ferait partie du nom de la fonction et son seul but serait d'indiquer que la fonction peut renvoyer une erreur tout comme la mise en majuscule la première lettre d'une variable.
Cela finit par être très similaire à d'autres propositions demandant de remplacer try par ? mais une différence critique est que la gestion des erreurs est implicite (automatique) et rend à la place explicite les erreurs d'ignorance (ou d'emballage) qui une sorte de meilleure pratique de toute façon. Le problème le plus évident avec cela est bien sûr qu'il n'est pas rétrocompatible et je suis sûr qu'il y en a beaucoup d'autres.
Cela dit, je serais très intéressé de voir comment Go peut gérer les erreurs de cas par défaut/implicite en l'automatisant et laisser le programmeur écrire un peu de code supplémentaire pour ignorer/remplacer la gestion. Je pense que le défi est de savoir comment rendre tous les points de retour évidents dans ce cas, car sans cela, les erreurs deviendront plus comme des exceptions dans le sens où elles pourraient provenir de n'importe où car le déroulement du programme ne le rendrait pas évident. On pourrait dire que faire des erreurs implicites avec un indicateur visuel revient à implémenter try et à faire errcheck un échec du compilateur.
owais
le 7 juin 2019
pourrions-nous faire quelque chose comme des exceptions c++ avec des décorateurs pour les anciennes fonctions ?
func some_old_test() (int, error){
return 0, errors.New("err1")
}
func some_new_test() (int){
if true {
return 1
}
throw errors.New("err2")
}
func throw_res(int, e error) int {
if e != nil {
throw e
}
return int
}
func main() {
fmt.Println("Hello, playground")
try{
i := throw_res(some_old_test())
fmt.Println("i=", i + some_new_test())
} catch(err io.Error) {
return err
} catch(err error) {
fmt.Println("unknown err", err)
}
}
 TheZeroSlave
le 7 juin 2019
TheZeroSlave
le 7 juin 2019
@owais Je pensais que la sémantique serait exactement la même que try donc au moins vous auriez besoin de déclarer le type err. Donc si on commençait par :
func foo() error {
_, err := fn()
if err != nil {
return err
}
return nil
}
Si je comprends la proposition d'essai, faites simplement ceci:
func foo() error {
_ := fn()
return nil
}
ne compilerait pas. Un avantage intéressant est que cela donne à la compilation l'opportunité de dire à l'utilisateur ce qui manque. Quelque chose à l'effet que l'utilisation de la gestion implicite des erreurs nécessite que le type de retour d'erreur soit nommé, err.
Cela fonctionnerait alors:
func foo() (err error) {
_ := fn()
return nil
}
pourquoi ne pas simplement gérer le cas d'une erreur qui n'est pas affectée à une variable.
- supprimez le besoin de retours nommés, le compilateur peut le faire tout seul.
- permet d'ajouter du contexte.
- gère le cas d'utilisation courant.
- rétrocompatible
- n'interagit pas bizarrement avec le report, les boucles ou les commutateurs.
retour implicite pour le cas if err != nil, le compilateur peut générer un nom de variable locale pour les retours si nécessaire inaccessible au programmeur.
personnellement, je n'aime pas ce cas particulier du point de vue de la lisibilité du code
f := os.Open("foo.txt")
préfère un retour explicite, suit le code est lu plus qu'un mantra écrit
f := os.Open("foo.txt") else return
fait intéressant, nous pourrions accepter les deux formes et demander à gofmt d'ajouter automatiquement le retour else.
ajout de contexte, également nommage local de la variable. return devient explicite car nous voulons ajouter du contexte.
f := os.Open("foo.txt") else err {
return errors.Wrap(err, "some context")
}
ajouter du contexte avec plusieurs valeurs de retour
f := os.Open("foo.txt") else err {
return i, j, errors.Wrap(err, "some context")
}
les fonctions imbriquées nécessitent que les fonctions externes traitent tous les résultats dans le même ordre
moins l'erreur finale.
bits := ioutil.ReadAll(os.Open("foo")) else err {
// either error ends up here.
return i, j, errors.Wrap(err, "some context")
}
le compilateur refuse la compilation en raison d'une valeur de retour d'erreur manquante dans la fonction
func foo(s string) int {
i := strconv.Atoi(s) // cannot implicitly return error due to missing error return value for foo.
return i * 2
}
se compile avec bonheur car l'erreur est explicitement ignorée.
func foo(s string) int {
i, _ := strconv.Atoi(s)
return i * 2
}
le compilateur est content. il ignore l'erreur comme il le fait actuellement car aucune affectation ou autre suffixe ne se produit.
func foo() error {
return errors.New("whoops")
}
func bar() {
foo()
}
dans une boucle, vous pouvez utiliser continue.
for _, s := range []string{"1","2","3","4","5","6"} {
i := strconv.Atoi(s) else continue
}
edit : remplacé ; par else
 james-lawrence
le 7 juin 2019
james-lawrence
le 7 juin 2019
@savaki Je pense avoir compris votre commentaire d'origine et j'aime l'idée que Go gère les erreurs par défaut, mais je ne pense pas que ce soit viable sans ajouter quelques modifications de syntaxe supplémentaires et une fois que nous l'avons fait, cela devient étonnamment similaire à la proposition actuelle.
Le plus gros inconvénient de ce que vous proposez est qu'il n'expose pas tous les points à partir desquels une fonction peut revenir contrairement à l'actuel if err != nil {return err} ou à la fonction try introduite dans cette proposition. Même s'il fonctionnerait exactement de la même manière sous le capot, visuellement, le code serait très différent. Lors de la lecture du code, il n'y aurait aucun moyen de savoir quels appels de fonction pourraient renvoyer une erreur. Cela finirait par être une expérience pire que les exceptions IMO.
Peut-être que la gestion des erreurs pourrait être rendue implicite si le compilateur imposait une convention sémantique sur les fonctions susceptibles de renvoyer des erreurs. Comme s'ils devaient commencer ou se terminer par une certaine phrase ou un certain caractère. Cela rendrait tous les points de retour très évidents et je pense que ce serait mieux que la gestion manuelle des erreurs, mais je ne sais pas à quel point c'est mieux étant donné qu'il existe déjà des contrôles de charpie qui crient lorsqu'ils repèrent une erreur ignorée. Il serait très intéressant de voir si le compilateur peut forcer les fonctions à être nommées d'une certaine manière selon qu'elles peuvent renvoyer d'éventuelles erreurs.
owais
le 7 juin 2019
Le principal inconvénient de cette approche est que le paramètre de résultat d'erreur doit être nommé, ce qui peut conduire à des API moins jolies (mais voir la FAQ à ce sujet). Nous pensons que nous nous y habituerons une fois que ce style se sera imposé.
Je ne sais pas si quelque chose comme ça a déjà été suggéré, je ne le trouve pas ici ou dans la proposition. Avez-vous envisagé une autre fonction intégrée qui renvoie un pointeur vers la valeur de retour d'erreur de la fonction actuelle ?
par exemple:
func example() error {
var err *error = funcerror() // always return a non-nil pointer
fmt.Print(*err) // always nil if the return parameters are not named and not in a defer
defer func() {
err := funcerror()
fmt.Print(*err) // "x"
}
return errors.New("x")
}
func exampleNamed() (err error) {
funcErr := funcerror()
fmt.Print(*funcErr) // "nil"
err = errors.New("x")
fmt.Print(*funcErr) // "x", named return parameter is reflected even before return is called
*funcErr = errors.New("y")
fmt.Print(err) // "y", unfortunate side effect?
defer func() {
funcErr := funcerror()
fmt.Print(*funcErr) // "z"
fmt.Print(err) // "z"
}
return errors.New("z")
}
utilisation avec try:
func CopyFile(src, dst string) (error) {
defer func() {
err := funcerror()
if *err != nil {
*err = fmt.Errorf("copy %s %s: %v", src, dst, err)
}
}()
// one liner alternative
// defer fmt.HandleErrorf(funcerror(), "copy %s %s", src, dst)
r := try(os.Open(src))
defer r.Close()
w := try(os.Create(dst))
defer func() {
w.Close()
err := funcerror()
if *err != nil {
os.Remove(dst) // only if a “try” fails
}
}()
try(io.Copy(w, r))
try(w.Close())
return nil
}
Alternativement funcerror (le nom est un travail en cours :D ) pourrait retourner nil s'il n'est pas appelé à l'intérieur de defer.
Une autre alternative est que funcerror renvoie une interface "Errorer" pour la rendre en lecture seule :
type interface Errorer() {
Error() error
}
 masterada
le 7 juin 2019
masterada
le 7 juin 2019
@savaki En fait, j'aime bien votre proposition d'omettre try() et de lui permettre de ressembler davantage à un test de carte ou à une assertion de type. Cela ressemble beaucoup plus à _"Go-like."_
Cependant, il y a toujours un problème flagrant que je vois, et c'est que votre proposition suppose que toutes les erreurs utilisant cette approche déclencheront un return et quitteront la fonction. Ce qu'il n'envisage pas, c'est d'émettre un break sur les for actuels ou un continue pour les for actuels.
Les premiers return s sont un marteau de forgeron alors qu'un scalpel est souvent le meilleur choix.
Donc, j'affirme que break et continue devraient être autorisés à être des stratégies de gestion des erreurs valides et actuellement votre proposition ne suppose que return alors que try() suppose que ou appelle une erreur gestionnaire qui lui-même ne peut que return , pas break ou continue .
mikeschinkel
le 7 juin 2019
On dirait que savaki et moi avons eu des idées similaires, j'ai juste ajouté la sémantique de bloc pour traiter l'erreur si vous le souhaitez. Par exemple, ajouter du texte, des boucles où vous voulez court-circuiter, etc.
james-lawrence
le 7 juin 2019
@mikeschinkel voir mon extension, lui et moi avions des idées similaires, je viens de l'étendre avec une instruction de bloc facultative
james-lawrence
le 7 juin 2019
@james-lawrence
@mikesckinkel voir mon extension, lui et moi avions des idées similaires, je viens de l'étendre avec une instruction de bloc facultative
Prenant ton exemple :
f := os.Open("foo.txt"); err {
return errors.Wrap(err, "some context")
}
Ce qui se compare à ce que nous faisons aujourd'hui :
f,err := os.Open("foo.txt");
if err != nil {
return errors.Wrap(err, "some context")
}
M'est définitivement préférable. Sauf qu'il a quelques problèmes :
errsemble être _"magiquement"_ déclaré. La magie devrait être minimisée, non ? Alors déclarons-le :
f, err := os.Open("foo.txt"); err {
return errors.Wrap(err, "some context")
}
- Mais cela ne fonctionne toujours pas car Go n'interprète pas les valeurs
nilcommefalseni les valeurs de pointeur commetrue, il faudrait donc:
f, err := os.Open("foo.txt"); err != nil {
return errors.Wrap(err, "some context")
}
Et ce que cela fonctionne, cela commence à ressembler à autant de travail et à beaucoup de syntaxe sur une seule ligne, donc et je pourrais continuer à faire à l'ancienne pour plus de clarté.
Mais que se passerait-il si Go ajoutait deux (2) commandes intégrées ; iserror() et error() ? Ensuite, nous pourrions faire ceci, ce qui ne me semble pas si mal :
f := os.Open("foo.txt"); iserror() {
return errors.Wrap(error(), "some context")
}
Ou mieux _(quelque chose comme):_
f := os.Open("foo.txt"); iserror() {
return error().Extend("some context")
}
Qu'en pensez-vous, et les autres ?
En aparté, vérifiez l'orthographe de mon nom d'utilisateur. Je n'aurais pas été informé de votre mention si je n'avais pas fait attention de toute façon...
mikeschinkel
le 7 juin 2019
@mikeschinkel désolé pour le nom que j'avais sur mon téléphone et github ne suggérait pas automatiquement.
err semble être "magiquement" déclaré. La magie devrait être minimisée, non ? Alors déclarons-le :
meh, toute l'idée d'insérer automatiquement un retour est magique. ce n'est pas la chose la plus magique qui se passe dans toute cette proposition. De plus, je dirais que l'erreur a été déclarée ; juste à la fin dans le contexte d'un bloc de portée, l'empêchant de polluer la portée parent tout en conservant toutes les bonnes choses que nous obtenons normalement avec l'utilisation des instructions if.
Je suis généralement assez satisfait de la gestion des erreurs de go avec les ajouts à venir au package d'erreurs. Je ne vois rien dans cette proposition comme super utile. J'essaie juste d'offrir l'ajustement le plus naturel pour le golang si nous sommes déterminés à le faire.
james-lawrence
le 7 juin 2019
_"l'idée même d'insérer automatiquement un retour est magique."_
Vous n'obtiendrez aucun argument de ma part là-bas.
_"Ce n'est pas la chose la plus magique qui se passe dans toute cette proposition."_
Je suppose que j'essayais de dire que _"toute magie est problématique."_
_"De plus, je dirais que l'erreur a été déclarée ; juste à la fin dans le contexte d'un bloc de portée..."_
Donc, si je voulais l'appeler err2 , cela fonctionnerait aussi ?
f := os.Open("foo.txt"); err2 {
return errors.Wrap(err, "some context")
}
Je suppose donc que vous proposez également une gestion spéciale des cas de err / err2 après le point-virgule, c'est-à-dire qu'il serait supposé être nil ou non nil au lieu de bool comme lors de la vérification d'une carte ?
if _,ok := m[a]; !ok {
print("there is no 'a' in 'm'")
}
Je suis généralement assez satisfait de la gestion des erreurs de go avec les ajouts à venir au package d'erreurs.
Moi aussi, je suis satisfait de la gestion des erreurs, lorsqu'elle est combinée avec break et continue _ (mais pas return .)_
Dans l'état actuel des choses, je considère cette proposition de try() comme plus nuisible qu'utile, et je préférerais ne rien voir que cette mise en œuvre telle que proposée. #jmtcw.
mikeschinkel
le 7 juin 2019
@beoran @mikeschinkel Plus tôt, j'ai suggéré que nous ne pouvions pas implémenter cette version de try en utilisant des génériques, car cela modifie le flux de contrôle. Si je lis correctement, vous suggérez tous les deux que nous pourrions utiliser des génériques pour implémenter try en le faisant appeler panic . Mais cette version de try très explicitement ne fait pas panic . Nous ne pouvons donc pas utiliser de génériques pour implémenter cette version de try .
Oui, nous pourrions utiliser des génériques (une version des génériques nettement plus puissante que celle du brouillon de conception sur https://go.googlesource.com/proposal/+/master/design/go2draft-contracts.md) pour écrire une fonction qui panique en cas d'erreur. Mais paniquer en cas d'erreur n'est pas le genre de gestion d'erreurs que les programmeurs Go écrivent aujourd'hui, et cela ne me semble pas être une bonne idée.
ianlancetaylor
le 7 juin 2019
@mikeschinkel une gestion spéciale serait que le bloc ne s'exécute qu'en cas d'erreur.
```
f := os.Open('foo'); err { return err } // err serait toujours non nul ici.
james-lawrence
le 7 juin 2019
@ianlancetaylor
_"Oui, nous pourrions utiliser des génériques... Mais paniquer en cas d'erreur n'est pas le genre de gestion d'erreurs que les programmeurs Go écrivent aujourd'hui, et cela ne me semble pas être une bonne idée."_
En fait, je suis fortement d'accord avec vous sur ce point, il semble donc que vous ayez mal interprété l'intention de mon commentaire. Je ne suggérais pas du tout que l'équipe Go mettrait en œuvre une gestion des erreurs utilisant panic() - bien sûr que non.
Au lieu de cela, j'essayais de suivre votre exemple à partir de bon nombre de vos commentaires passés sur d'autres problèmes et j'ai suggéré que nous évitions d'apporter à Go des modifications qui ne sont pas absolument nécessaires, car elles sont plutôt possibles dans userland . Donc _si_ les génériques étaient adressés _alors_ les personnes qui voudraient try() pourraient en fait l'implémenter elles-mêmes, mais en tirant parti panic() . Et ce serait une fonctionnalité de moins que l'équipe aurait besoin d'ajouter et de documenter pour Go.
Ce que je ne faisais pas - et peut-être que ce n'était pas clair - préconisait que les gens utilisent réellement panic() pour implémenter try() , juste qu'ils le pouvaient s'ils le voulaient vraiment, et ils avaient les fonctionnalités de génériques.
Est-ce que cela clarifie?
mikeschinkel
le 7 juin 2019
Pour moi, appeler panic , quelle que soit la façon dont cela est fait, est assez différent de cette proposition pour try . Donc, bien que je pense comprendre ce que vous dites, je ne suis pas d'accord pour dire qu'ils sont équivalents. Même si nous avions des génériques suffisamment puissants pour implémenter une version de try qui panique, je pense qu'il y aurait toujours un désir raisonnable pour la version de try présentée dans cette proposition.
ianlancetaylor
le 7 juin 2019
@ianlancetaylor Reconnu. Encore une fois, je cherchais une raison pour laquelle try() n'aurait pas besoin d'être ajouté plutôt que de trouver un moyen de l'ajouter. Comme je l'ai dit plus haut, je préférerais de loin ne rien avoir de nouveau pour la gestion des erreurs que d'avoir try() comme proposé ici.
mikeschinkel
le 7 juin 2019
Personnellement, j'aimais plus la proposition précédente check , basée sur des aspects purement visuels ; check avait la même puissance que ce try() mais bar(check foo()) est plus lisible pour moi que bar(try(foo())) (j'ai juste eu besoin d'une seconde pour compter les parenthèses !).
Plus important encore, mon principal reproche à propos handle / check était qu'il ne permettait pas d'envelopper des chèques individuels de différentes manières - et maintenant cette proposition try() a le même défaut, tout en invoquant des fonctionnalités délicates, rarement utilisées et déroutantes pour les débutants, des reports et des retours nommés. Et avec handle au moins, nous avions la possibilité d'utiliser des portées pour définir des blocs de poignée, avec defer même cela n'est pas possible.
En ce qui me concerne, cette proposition perd à la proposition précédente handle / check à tous égards.
 tv42
le 7 juin 2019
tv42
le 7 juin 2019
Voici un autre problème lié à l'utilisation de reports pour la gestion des erreurs.
try est une sortie contrôlée/intentionnelle d'une fonction. reporte toujours l'exécution, y compris les sorties incontrôlées/involontaires des fonctions. Cette incompatibilité pourrait prêter à confusion. Voici un scénario imaginaire :
func someHTTPHandlerGuts() (err error) {
defer func() {
recordMetric("db call failed")
return fmt.HandleErrorf("db unavailable: %v", err)
}()
data := try(makeDBCall)
// some code that panics due to a bug
return nil
}
Rappelez-vous que net/http récupère des paniques et imaginez le débogage d'un problème de production autour de la panique. Vous regarderiez votre instrumentation et verriez un pic d'échecs d'appels db, à partir des appels recordMetric . Cela pourrait masquer le vrai problème, qui est la panique dans la ligne suivante.
Je ne sais pas à quel point cela est grave dans la pratique, mais c'est (malheureusement) peut-être une autre raison de penser que le report n'est pas un mécanisme idéal pour la gestion des erreurs.
josharian
le 7 juin 2019
Voici une modification qui peut aider à résoudre certains des problèmes soulevés : traitez try comme un goto au lieu de comme un return . Écoutez-moi. :)
try serait plutôt du sucre syntaxique pour :
t1, … tn, te := f() // t1, … tn, te are local (invisible) temporaries
if te != nil {
err = te // assign te to the error result parameter
goto error // goto "error" label
}
x1, … xn = t1, … tn // assignment only if there was no error
Avantages:
defern'est pas nécessaire pour décorer les erreurs. (Les retours nommés sont toujours requis, cependant.)- L'existence de l'étiquette
error:est un indice visuel qu'il y a untryquelque part dans la fonction.
Cela fournit également un mécanisme pour ajouter des gestionnaires qui contourne les problèmes de gestionnaire en tant que fonction : Utilisez des étiquettes comme gestionnaires. try(fn(), wrap) donnerait goto wrap au lieu de goto error . Le compilateur peut confirmer que wrap: est présent dans la fonction. Notez que le fait d'avoir des gestionnaires aide également au débogage : vous pouvez ajouter/modifier le gestionnaire pour fournir un chemin de débogage.
Exemple de code :
func CopyFile(src, dst string) (err error) {
r := try(os.Open(src))
defer r.Close()
w := try(os.Create(dst))
defer func() {
w.Close()
if err != nil {
os.Remove(dst) // only if a “try” fails
}
}()
try(io.Copy(w, r), copyfail)
try(w.Close())
return nil
error:
return fmt.Errorf("copy %s %s: %v", src, dst, err)
copyfail:
recordMetric("copy failure") // count incidents of this failure
return fmt.Errorf("copy %s %s: %v", src, dst, err)
}
Autres commentaires:
- Nous pourrions exiger que toute étiquette utilisée comme cible d'un
trysoit précédée d'une instruction de fin. En pratique, cela les forcerait à la fin de la fonction et pourrait empêcher certains codes spaghetti. D'un autre côté, cela pourrait empêcher certaines utilisations raisonnables et utiles. trypourrait être utilisé pour créer une boucle. Je pense que cela relève de la bannière "si ça fait mal, ne le fais pas", mais je n'en suis pas sûr.- Cela nécessiterait de corriger https://github.com/golang/go/issues/26058.
Crédit : Je crois qu'une variante de cette idée a été suggérée pour la première fois par @griesemer en personne à GopherCon l'année dernière.
josharian
le 7 juin 2019
@josharian Penser à l'interaction avec panic est important ici, et je suis content que vous en ayez parlé, mais votre exemple me semble étrange. Dans le code suivant, cela n'a pas de sens pour moi que le report enregistre toujours une métrique "db call failed" . Ce serait une fausse métrique si someHTTPHandlerGuts réussit et renvoie nil . Le defer s'exécute dans tous les cas de sortie, pas seulement dans les cas d'erreur ou de panique, de sorte que le code semble erroné même s'il n'y a pas de panique.
func someHTTPHandlerGuts() (err error) {
defer func() {
recordMetric("db call failed")
return fmt.HandleErrorf("db unavailable: %v", err)
}()
data := try(makeDBCall)
// some code that panics due to a bug
return nil
}
 ChrisHines
le 7 juin 2019
ChrisHines
le 7 juin 2019
@josharian Oui, c'est plus ou moins exactement la version dont nous avons discuté l'année dernière (sauf que nous avons utilisé check au lieu de try ). Je pense qu'il serait crucial que l'on ne puisse pas "revenir" dans le reste du corps de la fonction, une fois que nous sommes à l'étiquette error . Cela garantirait que le goto est quelque peu "structuré" (pas de code spaghetti possible). Une préoccupation qui a été soulevée était que l'étiquette du gestionnaire d'erreurs (l'étiquette error: ) se retrouverait toujours à la fin de la fonction (sinon il faudrait la contourner d'une manière ou d'une autre). Personnellement, j'aime le code de gestion des erreurs à l'écart (à la fin), mais d'autres ont estimé qu'il devrait être visible dès le début.
griesemer
le 7 juin 2019
@mikeshenkel Je vois le retour d'une boucle comme un plus plutôt que comme un négatif. Je suppose que cela encouragerait les développeurs à utiliser une fonction distincte pour gérer le contenu d'une boucle ou à utiliser explicitement err comme nous le faisons actuellement. Ces deux éléments me semblent être de bons résultats.
D'après mon point de vue, je n'ai pas l'impression que cette syntaxe d'essai doive gérer tous les cas d'utilisation, tout comme je ne pense pas avoir besoin d'utiliser le
V, ok := m[touche]
Formulaire de lecture d'une carte
savaki
le 7 juin 2019
Vous pouvez éviter que les étiquettes goto ne forcent les gestionnaires à la fin de la fonction en ressuscitant la proposition handle / check sous une forme simplifiée. Et si nous utilisions la syntaxe handle err { ... } mais ne laissions pas les gestionnaires s'enchaîner, à la place, seul le dernier est utilisé. Cela simplifie beaucoup cette proposition et est très similaire à l'idée de goto, sauf qu'elle rapproche la manipulation du point d'utilisation.
func CopyFile(src, dst string) (err error) {
handle err {
return fmt.Errorf("copy %s %s: %v", src, dst, err)
}
r := check os.Open(src)
defer r.Close()
w := check os.Create(dst)
defer func() {
w.Close()
if err != nil {
os.Remove(dst) // only if a “check” fails
}
}()
{
// handlers are scoped, after this scope the original handle is used again.
// as an alternative, we could have repeated the first handle after the io.Copy,
// or come up with a syntax to name the handlers, though that's often not useful.
handle err {
recordMetric("copy failure") // count incidents of this failure
return fmt.Errorf("copy %s %s: %v", src, dst, err)
}
check io.Copy(w, r)
}
check w.Close()
return nil
}
En prime, cela a une voie future pour laisser les gestionnaires s'enchaîner, car toutes les utilisations existantes auraient un retour.
tv42
le 7 juin 2019
@josharian @griesemer si vous introduisez des gestionnaires nommés (dont de nombreuses réponses à vérifier/traiter sont demandées, voir les thèmes récurrents ), il existe des options de syntaxe préférables à try(f(), err) :
try.err f()
try?err f()
try#err f()
?err f() // because 'try' is redundant
?return f() // no handler
?panic f() // no handler
(?err f()).method()
f?err() // lead with function name, instead of error handling
f?err().method()
file, ?err := os.Open(...) // many check/handle responses also requested this style
L'une des choses que j'aime le plus à propos de Go est que sa syntaxe est relativement exempte de ponctuation et peut être lue à haute voix sans problèmes majeurs. Je détesterais vraiment que Go finisse comme un $#@!perl .
tv42
le 7 juin 2019
Pour moi, faire "essayer" une fonction intégrée et activer les chaînes pose 2 problèmes :
- Il est incohérent avec le reste du flux de contrôle dans go (par exemple, les mots-clés for/if/return/etc).
- Cela rend le code moins lisible.
Je préférerais en faire une déclaration sans parenthèse. Les exemples de la proposition nécessiteraient plusieurs lignes mais deviendraient plus lisibles (c'est-à-dire qu'il serait plus difficile de rater des instances « essayer » individuelles). Oui, cela casserait les analyseurs externes mais je préfère préserver la cohérence.
L'opérateur ternaire est un autre endroit où aller n'a rien et nécessite plus de frappes mais en même temps améliore la lisibilité/maintenabilité. L'ajout de "essayer" dans cette forme plus restreinte permettra de mieux équilibrer l'expressivité et la lisibilité, IMO.
 carloslenz
le 7 juin 2019
carloslenz
le 7 juin 2019
FWIW, panic affecte le flux de contrôle et a des parenthèses, mais go et defer affectent également le flux et non. J'ai tendance à penser que try ressemble plus à defer en ce sens qu'il s'agit d'une opération de flux inhabituelle et qu'il est plus difficile de faire try (try os.Open(file)).Read(buf) parce que nous voulons décourager les one-liners de toute façon, mais peu importe. N'importe quel.
Suggestion que tout le monde détestera pour un nom implicite pour une variable de retour d'erreur finale : $err . C'est mieux que try() IMO. :-)
carlmjohnson
le 8 juin 2019
@griesemer
_"Personnellement, j'aime le code de gestion des erreurs à l'écart (à la fin)"_
+1 à ça !
Je trouve que la gestion des erreurs implémentée _avant_ que l'erreur se produise est beaucoup plus difficile à raisonner que la gestion des erreurs implémentée _après_ que l'erreur se produit. Devoir mentalement revenir en arrière et forcer à suivre le flux logique me donne l'impression d'être de retour en 1980 en écrivant Basic avec GOTOs.
Permettez-moi de proposer encore une autre façon potentielle de gérer les erreurs en utilisant à nouveau CopyFile() comme exemple :
func CopyFile(src, dst string) (err error) {
r := os.Open(src)
defer r.Close()
w := os.Create(dst)
defer w.Close()
io.Copy(w, r)
w.Close()
for err := error {
switch err.Source() {
case w.Close:
os.Remove(dst) // only if a “try” fails
fallthrough
case os.Open, os.Create, io.Copy:
err = fmt.Errorf("copy %s %s: %v", src, dst, err)
default:
err = fmt.Errorf("an unexpected error occurred")
}
}
return err
}
Les changements de langue requis seraient :
Autoriser une construction
for error{}, similaire àfor range{}mais uniquement saisie en cas d'erreur et exécutée une seule fois.Autoriser l' omission de la capture des valeurs de retour qui implémentent
<object>.Error() stringmais uniquement lorsqu'une constructionfor error{}existe dans le mêmefunc.Faire sauter le flux de contrôle du programme à la première ligne de la construction
for error{}lorsqu'unfuncrenvoie une _"erreur"_ dans sa dernière valeur de retour.Lors du retour d'une _"erreur"_ Go ajouterait une référence à la fonction qui a renvoyé l'erreur qui devrait être récupérable par
<error>.Source()
Qu'est-ce qu'une _"erreur"_ ?
Actuellement, une _"erreur"_ est définie comme tout objet qui implémente Error() string et bien sûr n'est pas nil .
Cependant, il est souvent nécessaire d'étendre l'erreur _même en cas de succès_ pour permettre le retour des valeurs nécessaires aux résultats de réussite d'une API RESTful. Je demanderais donc à l'équipe Go de ne pas supposer automatiquement que err!=nil signifie _"erreur"_ mais plutôt de vérifier si un objet d'erreur implémente un IsError() et si IsError() renvoie true avant de supposer que toute valeur autre que nil est une _"erreur"._
_(Je ne parle pas nécessairement du code dans la bibliothèque standard mais principalement si vous choisissez votre flux de contrôle pour créer une branche sur une _"erreur"_. Si vous ne regardez que err!=nil , nous serons très limités dans ce que nous peut faire en termes de valeurs de retour dans nos fonctions.)_
BTW, permettre à tout le monde de tester une _"erreur"_ de la même manière pourrait probablement être fait plus facilement en ajoutant une nouvelle fonction intégrée iserror() :
type ErrorIser interface {
IsError() bool
}
func iserror(err error) bool {
if err == nil {
return false
}
if _,ok := err.(ErrorIser); !ok {
return true
}
return err.IsError()
}
Un côté avantages de permettre la non-capture des _"erreurs"_
Notez qu'autoriser la non-capture de la dernière _"erreur"_ à partir des appels func permettrait une refactorisation ultérieure pour renvoyer des erreurs à partir de func s qui n'avaient initialement pas besoin de renvoyer des erreurs. Et cela permettrait cette refactorisation sans casser le code existant qui utilise cette forme de récupération d'erreur et appelle ces func s.
Pour moi, cette décision de _"Devrais-je renvoyer une erreur ou renoncer à la gestion des erreurs pour appeler la simplicité?"_ est l'un de mes plus grands dilemmes lors de l'écriture de code Go. Autoriser la non-capture des _"erreurs"_ ci-dessus éliminerait pratiquement ce dilemme.
mikeschinkel
le 8 juin 2019
J'ai en fait essayé de mettre en œuvre cette idée en tant que traducteur Go il y a environ six mois. Je n'ai pas d'opinion précise quant à savoir si cette fonctionnalité doit être ajoutée en tant que Go intégré, mais permettez-moi de partager l'expérience (bien que je ne sois pas sûr que ce soit utile).
https://github.com/rhysd/trygo
J'ai appelé le langage étendu TryGo et implémenté le traducteur TryGo to Go.
Avec le traducteur, le code
func CreateFileInSubdir(subdir, filename string, content []byte) error {
cwd := try(os.Getwd())
try(os.Mkdir(filepath.Join(cwd, subdir)))
p := filepath.Join(cwd, subdir, filename)
f := try(os.Create(p))
defer f.Close()
try(f.Write(content))
fmt.Println("Created:", p)
return nil
}
peut être traduit en
func CreateFileInSubdir(subdir, filename string, content []byte) error {
cwd, _err0 := os.Getwd()
if _err0 != nil {
return _err0
}
if _err1 := os.Mkdir(filepath.Join(cwd, subdir)); _err1 != nil {
return _err1
}
p := filepath.Join(cwd, subdir, filename)
f, _err2 := os.Create(p)
if _err2 != nil {
return _err2
}
defer f.Close()
if _, _err3 := f.Write(content); _err3 != nil {
return _err3
}
fmt.Println("Created:", p)
return nil
}
Pour la restriction de la langue, je ne pouvais pas implémenter l'appel générique try() . Il est restreint à
- RHS de l'énoncé de définition
- RHS de la déclaration d'affectation
- Relevé d'appel
mais je pourrais essayer cela avec mon petit projet. Mon expérience a été
- cela fonctionne très bien et économise plusieurs lignes
- La valeur de retour nommée est en fait inutilisable pour
errpuisque la valeur de retour de sa fonction est déterminée à la fois par l'affectation et la fonction spécialetry(). Très perturbant - cette fonction
try()manquait de la fonction "erreur d'emballage" comme indiqué ci-dessus.
 rhysd
le 8 juin 2019
rhysd
le 8 juin 2019
_"Les deux me semblent être de bons résultats."_
Nous devrons accepter d'être en désaccord ici.
_"cette syntaxe d'essai (n'a pas à) gérer tous les cas d'utilisation"_
Ce mème est probablement le plus troublant. Au moins compte tenu de la résistance de l'équipe / de la communauté Go à tout changement dans le passé qui n'est pas largement applicable.
Si nous acceptons cette justification ici, pourquoi ne pouvons-nous pas revenir sur des propositions antérieures qui ont été rejetées parce qu'elles n'étaient pas largement applicables?
Et sommes-nous maintenant prêts à plaider en faveur de changements dans Go qui ne sont utiles que pour certains cas extrêmes ?
À mon avis, créer ce précédent ne produira pas de bons résultats à long terme...
_"@mikeshenkel"_
PS Je n'ai pas vu votre message au début à cause d'une faute d'orthographe. _(cela ne m'offense pas, c'est juste que je ne reçois pas de notification lorsque mon nom d'utilisateur est mal orthographié...)_
mikeschinkel
le 8 juin 2019
J'apprécie l'engagement envers la rétrocompatibilité qui vous motive à faire try un élément intégré plutôt qu'un mot-clé, mais après avoir lutté avec l'étrangeté totale d'avoir une fonction fréquemment utilisée qui peut changer le flux de contrôle ( panic et recover sont extrêmement rares), je me suis demandé : quelqu'un a-t-il fait une analyse à grande échelle de la fréquence de try comme identifiant dans les bases de code open source ? J'étais curieux et sceptique, alors j'ai fait une recherche préliminaire parmi les éléments suivants :
- https://github.com/google/go-github
- https://github.com/cockroachdb/cockroach
- https://github.com/golang/net
- https://github.com/exercism/xgo
- https://github.com/GoogleCloudPlatform/kubernetes
- https://github.com/syncthing/syncthing
- https://github.com/mitchellh/packer
- https://github.com/drone/drone
- https://github.com/coreos/etcd
- https://github.com/docker/docker
- https://github.com/sjwhitworth/golearn
- https://github.com/bitly/nsq
- https://github.com/smartystreets/goconvey
- https://github.com/golang/tools
- https://github.com/coreos/fleet
- https://github.com/limetext/lime
- https://github.com/flynn/flynn
- https://github.com/dropbox/godropbox
- https://github.com/hashicorp/consul
- https://github.com/hashicorp/terraform
Sur les 11 108 770 lignes importantes de Go vivant dans ces dépôts, il n'y avait que 63 instances de try utilisées comme identifiant. Bien sûr, je me rends compte que ces bases de code (bien que vastes, largement utilisées et importantes en elles-mêmes) ne représentent qu'une fraction du code Go disponible, et en plus, que nous n'avons aucun moyen d'analyser directement les bases de code privées, mais c'est certainement un résultat intéressant.
De plus, comme try , comme tout mot-clé, est en minuscules, vous ne le trouverez jamais dans l'API publique d'un package. Les ajouts de mots clés n'affecteront que les éléments internes du package.
Tout cela est une préface à quelques idées que je voulais ajouter au mélange et qui bénéficieraient de try comme mot-clé.
Je proposerais les constructions suivantes.
1) Pas de gestionnaire
// The existing proposal, but as a keyword rather than builtin. When an error is
// "caught", the function returns all zero values plus the error. Nothing
// particularly new here.
func doSomething() (int, error) {
try SomeFunc()
a, b := try AnotherFunc()
// ...
return 123, nil
}
2) Gestionnaire
Notez que les gestionnaires d'erreurs sont de simples blocs de code, destinés à être intégrés, plutôt que des fonctions. Plus à ce sujet ci-dessous.
func doSomething() (int, error) {
// Inline error handler
a, b := try SomeFunc() else err {
return 0, errors.Wrap(err, "error in doSomething:")
}
// Named error handlers
handler logAndContinue err {
log.Errorf("non-critical error: %v", err)
}
handler annotateAndReturn err {
return 0, errors.Wrap(err, "error in doSomething:")
}
c, d := try SomeFunc() else logAndContinue
e, f := try OtherFunc() else annotateAndReturn
// ...
return 123, nil
}
Restrictions proposées :
- Vous ne pouvez que
tryappeler une fonction. Nontry err. - Si vous ne spécifiez pas de gestionnaire, vous ne pouvez que
trydepuis une fonction qui renvoie une erreur comme valeur de retour la plus à droite. Il n'y a aucun changement dans le comportementtryen fonction de son contexte. Il ne panique jamais (comme discuté beaucoup plus tôt dans le fil). - Il n'y a aucune "chaîne de gestionnaires" d'aucune sorte. Les gestionnaires ne sont que des blocs de code inlineables.
Avantages:
- La syntaxe
try/elsepourrait être simplifiée de manière triviale dans le "composé si":
go a, b := try SomeFunc() else err { return 0, errors.Wrap(err, "error in doSomething:") }
devient
go if a, b, err := SomeFunc(); err != nil { return 0, errors.Wrap(err, "error in doSomething:") }
À mes yeux, les si composés ont toujours semblé plus déroutants qu'utiles pour une raison très simple : les conditions surviennent généralement _après_ une opération et ont quelque chose à voir avec le traitement de ses résultats. Si l'opération est coincée à l'intérieur de l'instruction conditionnelle, il est tout simplement moins évident qu'elle se produise. L'œil est distrait. De plus, la portée des variables définies n'est pas aussi immédiatement évidente que lorsqu'elles sont les plus à gauche sur une ligne. - Les gestionnaires d'erreurs ne sont intentionnellement pas définis comme des fonctions (ni avec quoi que ce soit qui ressemble à une sémantique de type fonction). Cela nous fait plusieurs choses :
- Le compilateur peut simplement intégrer un gestionnaire nommé partout où il est référencé. Cela ressemble beaucoup plus à un simple modèle de macro/codegen qu'à un appel de fonction. Le runtime n'a même pas besoin de savoir que les gestionnaires existent.
- Nous ne sommes pas limités quant à ce que nous pouvons faire à l'intérieur d'un gestionnaire. Nous contournons la critique de
check/handleselon laquelle "ce cadre de gestion des erreurs n'est bon que pour les renflouements". Nous contournons également la critique de la "chaîne de traitement". Tout code arbitraire peut être placé dans l'un de ces gestionnaires, et aucun autre flux de contrôle n'est impliqué. - Nous n'avons pas besoin de détourner
returnà l'intérieur du gestionnaire pour signifiersuper return. Le détournement d'un mot-clé est extrêmement déroutant.returnsignifie simplementreturn, et il n'y a pas vraiment besoin desuper return. defern'a pas besoin de clair de lune comme mécanisme de gestion des erreurs. On peut continuer à y penser principalement comme un moyen de nettoyer les ressources, etc.
- Concernant l'ajout de contexte aux erreurs :
- L'ajout de contexte avec les gestionnaires est extrêmement simple et ressemble beaucoup aux blocs
if err != nilexistants - Même si la construction "essayer sans gestionnaire" n'encourage pas directement l'ajout de contexte, il est très simple de refactoriser dans la forme du gestionnaire. Son utilisation prévue serait principalement pendant le développement, et il serait extrêmement simple d'écrire une vérification
go vetpour mettre en évidence les erreurs non gérées.
- L'ajout de contexte avec les gestionnaires est extrêmement simple et ressemble beaucoup aux blocs
Toutes mes excuses si ces idées sont très similaires à d'autres propositions - j'ai essayé de toutes les suivre, mais j'ai peut-être raté beaucoup.
 brynbellomy
le 8 juin 2019
brynbellomy
le 8 juin 2019
@brynbellomy Merci pour l'analyse des mots clés - c'est une information très utile. Il semble que try comme mot-clé puisse convenir. (Vous dites que les API ne sont pas affectées - c'est vrai, mais try peut toujours apparaître comme nom de paramètre ou similaire - donc la documentation peut devoir changer. Mais je suis d'accord que cela n'affecterait pas les clients de ces packages.)
Concernant votre proposition : elle irait très bien même sans gestionnaires nommés, n'est-ce pas ? (Cela simplifierait la proposition sans perte de puissance. On pourrait simplement appeler une fonction locale à partir du gestionnaire en ligne.)
griesemer
le 8 juin 2019
Concernant votre proposition : elle irait très bien même sans gestionnaires nommés, n'est-ce pas ? (Cela simplifierait la proposition sans perte de puissance. On pourrait simplement appeler une fonction locale à partir du gestionnaire en ligne.)
@griesemer En effet - je me sentais plutôt tiède à l'idée de les inclure. Certainement plus Go-ish sans.
D'un autre côté, il semble que les gens veuillent pouvoir gérer les erreurs d'une seule ligne, y compris les lignes simples qui return . Un cas typique serait log, puis return . Si nous déboursons pour une fonction locale dans la clause else , nous perdons probablement cela :
a, b := try SomeFunc() else err {
someLocalFunc(err)
return 0, err
}
(Je préfère toujours cela aux ifs composés, cependant)
Cependant, vous pouvez toujours obtenir des retours d'une ligne qui ajoutent un contexte d'erreur en implémentant un simple ajustement gofmt discuté plus tôt dans le fil :
a, b := try SomeFunc() else err { return 0, errors.Wrap(err, "bad stuff!") }
Le nouveau mot clé est-il nécessaire dans la proposition ci-dessus ? Pourquoi pas:
SomeFunc() else return
a, b := SomeOtherFunc() else err { return 0, errors.Wrap(err, "bad stuff!") }
 smonkewitz
le 8 juin 2019
smonkewitz
le 8 juin 2019
@griesemer si les gestionnaires sont de retour sur la table, je vous suggère de créer un nouveau problème pour discuter de try/handle ou try/_label_. Cette proposition a spécifiquement omis les gestionnaires, et il existe d'innombrables façons de les définir et de les invoquer.
Toute personne suggérant des gestionnaires devrait d'abord lire le wiki de vérification/gestion des commentaires. Il y a de fortes chances que tout ce dont vous rêvez y soit déjà décrit :-)
https://github.com/golang/go/wiki/Go2ErrorHandlingFeedback
networkimprov
le 8 juin 2019
@smonkewitz non, un nouveau mot-clé n'est pas nécessaire dans cette version car il est lié aux instructions d'affectation, qui a été mentionné plusieurs fois jusqu'à présent dans divers sucres de syntaxe.
https://github.com/golang/go/issues/32437#issuecomment -499808741
https://github.com/golang/go/issues/32437#issuecomment -499852124
https://github.com/golang/go/issues/32437#issuecomment -500095505
@ianlancetaylor cette saveur particulière de gestion des erreurs a-t-elle déjà été envisagée par l'équipe go ? Ce n'est pas aussi facile à mettre en œuvre que l'essai intégré proposé, mais cela semble plus idiomatique. ~déclaration inutile, désolé.~
james-lawrence
le 8 juin 2019
Je voudrais répéter quelque chose que @deanveloper et quelques autres ont dit, mais avec ma propre emphase. Dans https://github.com/golang/go/issues/32437#issuecomment -498939499 @deanveloper a dit :
tryest un retour conditionnel. Le flux de contrôle ET les retours sont tous deux maintenus sur des socles en Go. Tout le flux de contrôle dans une fonction est en retrait et tous les retours commencent parreturn. Mélanger ces deux concepts ensemble dans un appel de fonction facile à manquer semble juste un peu décalé.
De plus, dans cette proposition, try est une fonction qui renvoie des valeurs, elle peut donc être utilisée dans le cadre d'une expression plus grande.
Certains ont fait valoir que panic a déjà créé un précédent pour une fonction intégrée qui modifie le flux de contrôle, mais je pense que panic est fondamentalement différent pour deux raisons :
- La panique n'est pas conditionnelle ; il abandonne toujours la fonction appelante.
- Panic ne renvoie aucune valeur et ne peut donc apparaître que comme une instruction autonome, ce qui augmente sa visibilité.
Essayez d'autre part :
- Est conditionnel ; il peut ou non revenir de la fonction appelante.
- Renvoie des valeurs et peut apparaître dans une expression composée, éventuellement plusieurs fois, sur une seule ligne, potentiellement au-delà de la marge droite de la fenêtre de mon éditeur.
Pour ces raisons, je pense que try semble plus qu'un "peu décalé", je pense que cela nuit fondamentalement à la lisibilité du code.
Aujourd'hui, lorsque nous rencontrons du code Go pour la première fois, nous pouvons rapidement le parcourir pour trouver les points de sortie possibles et contrôler les points de flux. Je crois que c'est une propriété très précieuse du code Go. En utilisant try , il devient trop facile d'écrire du code dépourvu de cette propriété.
J'admets qu'il est probable que les développeurs Go qui apprécient la lisibilité du code convergent vers des idiomes d'utilisation pour try qui évitent ces pièges de lisibilité. J'espère que cela se produira puisque la lisibilité du code semble être une valeur fondamentale pour de nombreux développeurs Go. Mais il n'est pas évident pour moi que try ajoute suffisamment de valeur par rapport aux idiomes de code existants pour supporter le poids de l'ajout d'un nouveau concept au langage que tout le monde peut apprendre et qui peut si facilement nuire à la lisibilité.
ChrisHines
le 8 juin 2019
````
si c'est != "cassé" {
ne le répare pas
}
 eggsbenjamin
le 8 juin 2019
eggsbenjamin
le 8 juin 2019
@ChrisHines À votre point (qui est repris ailleurs dans ce fil), ajoutons une autre restriction :
- toute instruction
try(même celles sans gestionnaire) doit apparaître sur sa propre ligne.
Vous bénéficieriez toujours d'une grande réduction du bruit visuel. Ensuite, vous avez des retours garantis annotés par return et des retours conditionnels annotés par try , et ces mots-clés se trouvent toujours au début d'une ligne (ou au pire, directement après une affectation de variable).
Donc, rien de ce genre de bêtises:
try EmitEvent(try (try DecodeMsg(m)).SaveToDB())
mais plutôt ceci :
dm := try DecodeMsg(m)
um := try dm.SaveToDB()
try EmitEvent(um)
qui se sent encore plus clair que cela:
dm, err := DecodeMsg(m)
if err != nil {
return nil, err
}
um, err := dm.SaveToDB()
if err != nil {
return nil, err
}
err = EmitEvent(um)
if err != nil {
return nil, err
}
Une chose que j'aime à propos de cette conception est qu'il est impossible d'ignorer silencieusement les erreurs sans toujours annoter qu'une erreur pourrait se produire . Alors qu'en ce moment, vous voyez parfois x, _ := SomeFunc() (quelle est la valeur de retour ignorée ? une erreur ? quelque chose d'autre ?), maintenant vous devez annoter clairement :
x := try SomeFunc() else err {}
Depuis mon précédent message à l'appui de la proposition, j'ai vu deux idées publiées par @jagv (sans paramètre try renvoie *error ) et par @josharian (gestionnaires d'erreurs étiquetés) que je crois en un une forme légèrement modifiée améliorerait considérablement la proposition.
En rassemblant ces idées avec une autre que j'ai moi-même eue, nous aurions quatre versions de try :
- essayer()
- essayez (paramètres)
- essayer (paramètres, étiquette)
- essayez (paramètres, panique)
1 renverrait simplement un pointeur vers le paramètre de retour d'erreur (ERP) ou nil s'il n'y en avait pas (#4 uniquement). Cela fournirait une alternative à un ERP nommé sans qu'il soit nécessaire d'ajouter un autre intégré.
2 fonctionnerait exactement comme actuellement envisagé. Une erreur non nulle serait renvoyée immédiatement mais pourrait être décorée par une instruction defer .
3 fonctionnerait comme suggéré par @josharian , c'est-à-dire que sur une erreur non nulle, le code se brancherait sur l'étiquette. Cependant, il n'y aurait pas d'étiquette de gestionnaire d'erreurs par défaut car ce cas dégénérerait maintenant en #2.
Il me semble que ce sera généralement une meilleure façon de décorer les erreurs (ou de les gérer localement puis de retourner nil) que defer car c'est plus simple et plus rapide. Quiconque n'aimait pas cela pouvait toujours utiliser #2.
Il serait préférable de placer l'étiquette/le code de gestion des erreurs vers la fin de la fonction et de ne pas revenir dans le reste du corps de la fonction. Cependant, je ne pense pas que le compilateur devrait appliquer non plus car il pourrait y avoir des occasions étranges où ils sont utiles et l'application pourrait être difficile dans tous les cas.
Donc, l'étiquette normale et le comportement goto s'appliqueraient sous réserve (comme l'a dit @josharian ) que # 26058 soit corrigé en premier, mais je pense qu'il devrait être corrigé de toute façon.
Le nom de l'étiquette ne peut pas être panic car cela entrerait en conflit avec #4.
4 serait panic immédiatement plutôt que de retourner ou de se ramifier. Par conséquent, s'il s'agissait de la seule version de try utilisée dans une fonction particulière, aucun ERP ne serait nécessaire.
J'ai ajouté ceci afin que le package de test puisse fonctionner comme il le fait maintenant sans avoir besoin d'autres modifications intégrées ou autres. Cependant, cela pourrait également être utile dans d'autres scénarios _fatal_.
Cela doit être une version distincte de try au lieu de se brancher sur un gestionnaire d'erreurs, puis de paniquer à partir de ce qui nécessiterait toujours un ERP.
alanfo
le 9 juin 2019
L'un des types de réactions les plus fortes à la proposition initiale était l'inquiétude concernant la perte de visibilité facile du flux normal de l'endroit où une fonction revient.
Par exemple, @deanveloper a très bien exprimé cette préoccupation dans https://github.com/golang/go/issues/32437#issuecomment -498932961, qui, je pense, est le commentaire le plus voté ici.
@dominikh a écrit dans https://github.com/golang/go/issues/32437#issuecomment -499067357 :
Dans le code gofmt'ed, un retour correspond toujours à /^\t*return / - c'est un modèle très trivial à repérer à l'œil nu, sans aucune aide. try, d'autre part, peut se produire n'importe où dans le code, imbriqué arbitrairement profondément dans les appels de fonction. Aucune formation ne nous permettra de repérer immédiatement tous les flux de contrôle dans une fonction sans l'aide d'outils.
Pour vous aider, @brynbellomy a suggéré hier :
toute instruction try (même celles sans gestionnaire) doit apparaître sur sa propre ligne.
En allant plus loin, le try pourrait être requis pour être le début de la ligne, même pour une affectation.
Donc ça pourrait être :
try dm := DecodeMsg(m)
try um := dm.SaveToDB()
try EmitEvent(um)
plutôt que ce qui suit (de l'exemple de @brynbellomy ):
dm, err := DecodeMsg(m)
if err != nil {
return nil, err
}
um, err := dm.SaveToDB()
if err != nil {
return nil, err
}
err = EmitEvent(um)
if err != nil {
return nil, err
}
Cela semble préserver une bonne quantité de visibilité, même sans aucune assistance d'éditeur ou d'IDE, tout en réduisant le passe-partout.
Cela pourrait fonctionner avec l'approche basée sur le report actuellement proposée qui repose sur des paramètres de résultat nommés, ou cela pourrait fonctionner avec la spécification de fonctions de gestionnaire normales. (Spécifier des fonctions de gestionnaire sans exiger de valeurs de retour nommées me semble mieux que d'exiger des valeurs de retour nommées, mais c'est un point distinct).
La proposition comprend cet exemple :
info := try(try(os.Open(file)).Stat()) // proposed try built-in
Cela pourrait plutôt être :
try f := os.Open(file)
try info := f.Stat()
C'est encore une réduction du passe-partout par rapport à ce que quelqu'un pourrait écrire aujourd'hui, même s'il n'est pas aussi court que la syntaxe proposée. Ce serait peut-être suffisamment court ?
@elagergren-spideroak a fourni cet exemple :
try(try(try(to()).parse().this)).easily())
Je pense que cela a des parenthèses incompatibles, ce qui est peut-être un point délibéré ou un peu d'humour subtil, donc je ne sais pas si cet exemple a l'intention d'avoir 2 try ou 3 try . Dans tous les cas, il serait peut-être préférable d'exiger une répartition sur 2-3 lignes commençant par try .
 thepudds
le 9 juin 2019
thepudds
le 9 juin 2019
@thepudds , c'est ce que je voulais dire dans mon commentaire précédent. Sauf que donné
try f := os.Open(file)
try info := f.Stat()
Une chose évidente à faire est de considérer try comme un bloc try où plusieurs phrases peuvent être mises entre parenthèses . Ainsi, ce qui précède peut devenir
try (
f := os.Open(file)
into := f.Stat()
)
Si le compilateur sait comment gérer cela, la même chose fonctionne également pour l'imbrication. Alors maintenant, ce qui précède peut devenir
try info := os.Open(file).Stat()
À partir des signatures de fonction, le compilateur sait que Open peut renvoyer une valeur d'erreur et, comme il se trouve dans un bloc try, il doit générer une gestion des erreurs, puis appeler Stat() sur la valeur renvoyée primaire, etc.
La prochaine chose est d'autoriser les déclarations où aucune valeur d'erreur n'est générée ou est gérée localement. Donc, vous pouvez maintenant dire
try (
f := os.Open(file)
debug("f: %v\n", f) // debug returns nothing
into := f.Stat()
)
Cela permet de faire évoluer le code sans avoir à réorganiser les blocs try. Mais pour une raison étrange, les gens semblent penser que la gestion des erreurs doit être explicitement expliquée ! Ils veulent
try(try(try(to()).parse()).this)).easily())
Alors que je suis parfaitement bien avec
try to().parse().this().easily()
Même si dans les deux cas, exactement le même code de vérification d'erreur peut être généré. Mon point de vue est que vous pouvez toujours écrire un code spécial pour la gestion des erreurs si vous en avez besoin. try (ou quel que soit le nom que vous préférez lui donner) désencombre simplement la gestion des erreurs par défaut (qui consiste à la transmettre à l'appelant).
Un autre avantage est que si le compilateur génère la gestion des erreurs par défaut, il peut ajouter des informations d'identification supplémentaires afin que vous sachiez laquelle des quatre fonctions ci-dessus a échoué.
bakul
le 9 juin 2019
J'étais quelque peu préoccupé par la lisibilité des programmes où try apparaît à l'intérieur d'autres expressions. J'ai donc exécuté grep "return .*err$" sur la bibliothèque standard et j'ai commencé à lire des blocs au hasard. Il y a 7214 résultats, je n'en ai lu que quelques centaines.
La première chose à noter est que là où try s'applique, cela rend presque tous ces blocs un peu plus lisibles.
La deuxième chose est que très peu d'entre eux, moins de 1 sur 10, mettraient try dans une autre expression. Le cas typique est celui des déclarations de la forme x := try(...) ou ^try(...)$ .
Voici quelques exemples où try apparaîtrait dans une autre expression :
texte/modèle
func gt(arg1, arg2 reflect.Value) (bool, error) {
// > is the inverse of <=.
lessOrEqual, err := le(arg1, arg2)
if err != nil {
return false, err
}
return !lessOrEqual, nil
}
devient:
func gt(arg1, arg2 reflect.Value) (bool, error) {
// > is the inverse of <=.
return !try(le(arg1, arg2)), nil
}
texte/modèle
func index(item reflect.Value, indices ...reflect.Value) (reflect.Value, error) {
...
switch v.Kind() {
case reflect.Map:
index, err := prepareArg(index, v.Type().Key())
if err != nil {
return reflect.Value{}, err
}
if x := v.MapIndex(index); x.IsValid() {
v = x
} else {
v = reflect.Zero(v.Type().Elem())
}
...
}
}
devient
func index(item reflect.Value, indices ...reflect.Value) (reflect.Value, error) {
...
switch v.Kind() {
case reflect.Map:
if x := v.MapIndex(try(prepareArg(index, v.Type().Key()))); x.IsValid() {
v = x
} else {
v = reflect.Zero(v.Type().Elem())
}
...
}
}
(c'est l'exemple le plus discutable que j'ai vu)
regexp/syntaxe :
regexp/syntax/parse.go
func Parse(s string, flags Flags) (*Regexp, error) {
...
if c, t, err = nextRune(t); err != nil {
return nil, err
}
p.literal(c)
...
}
devient
func Parse(s string, flags Flags) (*Regexp, error) {
...
c, t = try(nextRune(t))
p.literal(c)
...
}
Ce n'est pas un exemple d'essayer dans une autre expression mais je veux l'appeler car cela améliore la lisibilité. Il est beaucoup plus facile de voir ici que les valeurs de c et t vivent au-delà de la portée de l'instruction if.
réseau/http
net/http/request.go:readRequest
mimeHeader, err := tp.ReadMIMEHeader()
if err != nil {
return nil, err
}
req.Header = Header(mimeHeader)
devient:
req.Header = Header(try(tp.ReadMIMEHeader())
base de données/sql
if driverCtx, ok := driveri.(driver.DriverContext); ok {
connector, err := driverCtx.OpenConnector(dataSourceName)
if err != nil {
return nil, err
}
return OpenDB(connector), nil
}
devient
if driverCtx, ok := driveri.(driver.DriverContext); ok {
return OpenDB(try(driverCtx.OpenConnector(dataSourceName))), nil
}
base de données/sql
si, err := ctxDriverPrepare(ctx, dc.ci, query)
if err != nil {
return nil, err
}
ds := &driverStmt{Locker: dc, si: si}
devient
ds := &driverStmt{
Locker: dc,
si: try(ctxDriverPrepare(ctx, dc.ci, query)),
}
réseau/http
if http2isconnectioncloserequest(req) && dialonmiss {
// it gets its own connection.
http2tracegetconn(req, addr)
const singleuse = true
cc, err := p.t.dialclientconn(addr, singleuse)
if err != nil {
return nil, err
}
return cc, nil
}
devient
if http2isconnectioncloserequest(req) && dialonmiss {
// it gets its own connection.
http2tracegetconn(req, addr)
const singleuse = true
return try(p.t.dialclientconn(addr, singleuse))
}
réseau/http
func (f *http2Framer) endWrite() error {
...
n, err := f.w.Write(f.wbuf)
if err == nil && n != len(f.wbuf) {
err = io.ErrShortWrite
}
return err
}
devient
func (f *http2Framer) endWrite() error {
...
if try(f.w.Write(f.wbuf) != len(f.wbuf) {
return io.ErrShortWrite
}
return nil
}
(Celui-ci, j'aime beaucoup.)
réseau/http
if f, err := fr.ReadFrame(); err != nil {
return nil, err
} else {
hc = f.(*http2ContinuationFrame) // guaranteed by checkFrameOrder
}
devient
hc = try(fr.ReadFrame()).(*http2ContinuationFrame)// guaranteed by checkFrameOrder
}
(Aussi sympa.)
net :
if ctrlFn != nil {
c, err := newRawConn(fd)
if err != nil {
return err
}
if err := ctrlFn(fd.ctrlNetwork(), laddr.String(), c); err != nil {
return err
}
}
devient
if ctrlFn != nil {
try(ctrlFn(fd.ctrlNetwork(), laddr.String(), try(newRawConn(fd))))
}
c'est peut-être trop, et à la place ça devrait être:
if ctrlFn != nil {
c := try(newRawConn(fd))
try(ctrlFn(fd.ctrlNetwork(), laddr.String(), c))
}
Dans l'ensemble, j'apprécie assez l'effet de try sur le code de bibliothèque standard que j'ai lu.
Un dernier point : voir try appliqué pour lire du code au-delà des quelques exemples de la proposition était instructif. Je pense qu'il vaut la peine d'envisager d'écrire un outil pour convertir automatiquement le code pour utiliser try (où cela ne change pas la sémantique du programme). Il serait intéressant de lire un échantillon des différences produites par rapport aux packages populaires sur github pour voir si ce que j'ai trouvé dans la bibliothèque standard tient la route. Les résultats d'un tel programme pourraient fournir un aperçu supplémentaire de l'effet de la proposition.
 crawshaw
le 9 juin 2019
crawshaw
le 9 juin 2019
@crawshaw merci d'avoir fait ça, c'était super de le voir en action. Mais le voir en action m'a fait prendre plus au sérieux les arguments contre la gestion des erreurs en ligne que j'avais jusqu'à présent rejetés.
Comme c'était si proche de la suggestion intéressante de @thepudds de faire try une déclaration, j'ai réécrit tous les exemples en utilisant cette syntaxe et je l'ai trouvé beaucoup plus clair que l'expression- try ou le statu quo, sans nécessiter trop de lignes supplémentaires :
func gt(arg1, arg2 reflect.Value) (bool, error) {
// > is the inverse of <=.
try lessOrEqual := le(arg1, arg2)
return !lessOrEqual, nil
}
func index(item reflect.Value, indices ...reflect.Value) (reflect.Value, error) {
...
switch v.Kind() {
case reflect.Map:
try index := prepareArg(index, v.Type().Key())
if x := v.MapIndex(index); x.IsValid() {
v = x
} else {
v = reflect.Zero(v.Type().Elem())
}
...
}
}
func Parse(s string, flags Flags) (*Regexp, error) {
...
try c, t = nextRune(t)
p.literal(c)
...
}
try mimeHeader := tp.ReadMIMEHeader()
req.Header = Header(mimeHeader)
if driverCtx, ok := driveri.(driver.DriverContext); ok {
try connector := driverCtx.OpenConnector(dataSourceName)
return OpenDB(connector), nil
}
Celui-ci serait sans doute meilleur avec une expression- try s'il y avait plusieurs champs qui devaient être try -ed, mais je préfère toujours l'équilibre de ce compromis
try si := ctxDriverPrepare(ctx, dc.ci, query)
ds := &driverStmt{Locker: dc, si: si}
C'est fondamentalement le pire des cas pour cela et ça a l'air bien:
if http2isconnectioncloserequest(req) && dialonmiss {
// it gets its own connection.
http2tracegetconn(req, addr)
const singleuse = true
try cc := p.t.dialclientconn(addr, singleuse)
return cc, nil
}
J'ai débattu avec moi-même si if try serait ou devrait être légal, mais je n'ai pas pu trouver d'explication raisonnable pour laquelle cela ne devrait pas l'être et cela fonctionne assez bien ici:
func (f *http2Framer) endWrite() error {
...
if try n := f.w.Write(f.wbuf); n != len(f.wbuf) {
return io.ErrShortWrite
}
return nil
}
try f := fr.ReadFrame()
hc = f.(*http2ContinuationFrame) // guaranteed by checkFrameOrder
if ctrlFn != nil {
try c := newRawConn(fd)
try ctrlFn(fd.ctrlNetwork(), laddr.String(), c)
}
Parcourir les exemples de @crawshaw ne fait que me rendre plus sûr que le flux de contrôle sera souvent suffisamment crypté pour être encore plus prudent sur la conception. Relatant même une petite quantité de complexité devient difficile à lire et facile à bâcler. Je suis heureux de voir les options envisagées, mais compliquer le flux de contrôle dans un langage aussi réservé semble exceptionnellement hors de propos.
func (f *http2Framer) endWrite() error {
...
if try(f.w.Write(f.wbuf) != len(f.wbuf) {
return io.ErrShortWrite
}
return nil
}
De plus, try n'est pas "essayer" quoi que ce soit. C'est un "relais de protection". Si la sémantique de base de la proposition est désactivée, je ne suis pas surpris que le code résultant soit également problématique.
func (f *http2Framer) endWrite() error {
...
relay n := f.w.Write(f.wbuf)
return checkShortWrite(n, len(f.wbuf))
}
 daved
le 9 juin 2019
daved
le 9 juin 2019
Si vous faites une instruction try, vous pouvez utiliser un indicateur pour indiquer quelle valeur de retour et quelle action :
try c, @ := newRawConn(fd) // return
try c, <strong i="6">@panic</strong> := newRawConn(fd) // panic
try c, <strong i="7">@hname</strong> := newRawConn(fd) // invoke named handler
try c, <strong i="8">@_</strong> := newRawConn(fd) // ignore, or invoke "ignored" handler if defined
Vous avez toujours besoin d'une syntaxe de sous-expression (Russ a déclaré que c'est une exigence), au moins pour les actions de panique et d'ignorance.
networkimprov
le 9 juin 2019
Tout d'abord, j'applaudis @crawshaw d'avoir pris le temps d'examiner environ 200 exemples réels et d'avoir pris le temps de son article réfléchi ci-dessus.
Deuxièmement, @jimmyfrasche , concernant votre réponse ici à propos de l'exemple http2Framer :
J'ai débattu avec moi-même si
if tryserait ou devrait être légal, mais je n'ai pas pu trouver d'explication raisonnable pour laquelle cela ne devrait pas l'être et cela fonctionne assez bien ici :```
func (f *http2Framer) erreur endWrite() {
...
if try n := fwWrite(f.wbuf); n != len(f.wbuf) {
retourner io.ErrShortWrite
}
retour nul
}
At least under what I was suggesting above in https://github.com/golang/go/issues/32437#issuecomment-500213884, under that proposal variation I would suggest `if try` is not allowed.
That `http2Framer` example could instead be:
func (f *http2Framer) erreur endWrite() {
...
essayez n := fwEcrit(f.wbuf)
si n != len(f.wbuf) {
retourner io.ErrShortWrite
}
retour nul
}
``
That is one line longer, but hopefully still "light on the page". Personally, I think that (arguably) reads more cleanly, but more importantly it is easier to see the essayer`.
@deanveloper a écrit ci-dessus dans https://github.com/golang/go/issues/32437#issuecomment -498932961 :
Revenir d'une fonction a semblé avoir été une chose "sacrée" à faire
Cet exemple spécifique http2Framer finit par ne pas être aussi court qu'il pourrait l'être. Cependant, il retient le retour d'une fonction plus "sacrée" si le try doit être la première chose sur une ligne.
@crawshaw a mentionné :
La deuxième chose est que très peu d'entre eux, moins de 1 sur 10, mettraient try dans une autre expression. Le cas typique est celui des instructions de la forme x := try(...) ou ^try(...)$.
Peut-être est-il acceptable de n'aider que partiellement ces 1 exemples sur 10 avec une forme plus restreinte de try , surtout si le cas typique de ces exemples se termine avec le même nombre de lignes même si try est nécessaire d'être la première chose sur une ligne?
thepudds
le 9 juin 2019
@jimmyfrasche
@crawshaw merci d'avoir fait ça, c'était super de le voir en action. Mais le voir en action m'a fait prendre plus au sérieux les arguments contre la gestion des erreurs en ligne que j'avais jusqu'à présent rejetés.
Comme c'était si proche de la suggestion intéressante de @thepudds de faire
tryune déclaration, j'ai réécrit tous les exemples en utilisant cette syntaxe et je l'ai trouvé beaucoup plus clair que l'expression-tryou le statu quo, sans nécessiter trop de lignes supplémentaires :func gt(arg1, arg2 reflect.Value) (bool, error) { // > is the inverse of <=. try lessOrEqual := le(arg1, arg2) return !lessOrEqual, nil }
Votre premier exemple illustre bien pourquoi je préfère fortement l'expression- try . Dans votre version, je dois mettre le résultat de l'appel à le dans une variable, mais cette variable n'a pas de signification sémantique que le terme le n'implique pas déjà. Donc, je ne peux pas lui donner de nom qui ne soit ni dénué de sens (comme x ) ni redondant (comme lessOrEqual ). Avec expression- try , aucune variable intermédiaire n'est nécessaire, donc ce problème ne se pose même pas.
Je préférerais ne pas avoir à faire d'efforts mentaux pour inventer des noms pour des choses qu'il vaut mieux laisser anonymes.
dpinela
le 9 juin 2019
Je suis heureux d'apporter mon soutien derrière les derniers messages où try (le mot-clé) a été déplacé au début de la ligne. Il devrait vraiment partager le même espace visuel que return .
Re : la suggestion de @jimmyfrasche d'autoriser try dans les instructions composées if , c'est exactement le genre de chose que je pense que beaucoup ici essaient d'éviter, pour plusieurs raisons :
- il regroupe deux mécanismes de flux de contrôle très différents en une seule ligne
- l'expression
tryest en fait évaluée en premier et peut provoquer le retour de la fonction, mais elle apparaît après leif - ils reviennent avec des erreurs totalement différentes, dont une que nous ne voyons pas réellement dans le code, et une que nous faisons
- cela rend moins évident que le
tryn'est en fait pas géré, car le bloc ressemble beaucoup à un bloc de gestionnaire (même s'il gère un problème totalement différent)
On pourrait aborder cette situation sous un angle légèrement différent qui favorise le fait de pousser les gens à manipuler les try s. Que diriez-vous de permettre à la syntaxe try / else de contenir des conditions suivantes (ce qui est un modèle courant avec de nombreuses fonctions d'E/S qui renvoient à la fois un err et un n , l'un ou l'autre pouvant indiquer un problème) :
func (f *http2Framer) endWrite() error {
// ...
try n := f.w.Write(f.wbuf) else err {
return errors.Wrap(err, "error writing:")
} else if n != len(f.wbuf) {
return io.ErrShortWrite
}
return nil
}
Dans le cas où vous ne gérez pas l'erreur renvoyée par .Write , vous auriez toujours une annotation claire indiquant que .Write pourrait être une erreur (comme l'a souligné @thepudds):
func (f *http2Framer) endWrite() error {
// ...
try n := f.w.Write(f.wbuf)
if n != len(f.wbuf) {
return io.ErrShortWrite
}
return nil
}
Je seconde la réponse de @daved . À mon avis, chaque exemple mis en évidence par @crawshaw est devenu moins clair et plus sujet aux erreurs à la suite de try .
 davecheney
le 9 juin 2019
davecheney
le 9 juin 2019
Je suis heureux d'apporter mon soutien derrière les derniers messages où
try(le mot-clé) a été déplacé au début de la ligne. Il devrait vraiment partager le même espace visuel quereturn.
Compte tenu des deux options pour ce point et en supposant qu'une a été choisie et crée ainsi un précédent pour les futures fonctionnalités potentielles :
UNE.)
try f := os.Open(filepath) else err {
return errors.Wrap(err, "can't open")
}
B.)
f := try os.Open(filepath) else err {
return errors.Wrap(err, "can't open")
}
Lequel des deux offre plus de flexibilité pour l'utilisation future de nouveaux mots clés ? _(Je ne connais pas la réponse à cette question car je ne maîtrise pas l'art sombre d'écrire des compilateurs.)_ Une approche serait-elle plus limitative qu'une autre ?
mikeschinkel
le 10 juin 2019
@davecheney @daved @crawshaw
J'aurais tendance à être d'accord avec les Daves sur celui-ci : dans les exemples de @crawshaw , il y a beaucoup d'instructions try intégrées profondément dans les lignes qui contiennent beaucoup d'autres choses. Vraiment difficile de repérer les points de sortie. De plus, les try semblent encombrer assez mal les choses dans certains des exemples.
Voir un tas de code stdlib transformé comme celui-ci est très utile, j'ai donc pris les mêmes exemples mais les ai réécrits selon la proposition alternative, qui est plus restrictive :
trycomme mot-clé- un seul
trypar ligne trydoit être au début d'une ligne
J'espère que cela nous aidera à comparer. Personnellement, je trouve que ces exemples semblent beaucoup plus concis que leurs originaux, mais sans obscurcir le flux de contrôle. try reste très visible partout où il est utilisé.
texte/modèle
func gt(arg1, arg2 reflect.Value) (bool, error) {
// > is the inverse of <=.
lessOrEqual, err := le(arg1, arg2)
if err != nil {
return false, err
}
return !lessOrEqual, nil
}
devient:
func gt(arg1, arg2 reflect.Value) (bool, error) {
// > is the inverse of <=.
try lessOrEqual := le(arg1, arg2)
return !lessOrEqual, nil
}
texte/modèle
func index(item reflect.Value, indices ...reflect.Value) (reflect.Value, error) {
...
switch v.Kind() {
case reflect.Map:
index, err := prepareArg(index, v.Type().Key())
if err != nil {
return reflect.Value{}, err
}
if x := v.MapIndex(index); x.IsValid() {
v = x
} else {
v = reflect.Zero(v.Type().Elem())
}
...
}
}
devient
func index(item reflect.Value, indices ...reflect.Value) (reflect.Value, error) {
...
switch v.Kind() {
case reflect.Map:
try index := prepareArg(index, v.Type().Key())
if x := v.MapIndex(index); x.IsValid() {
v = x
} else {
v = reflect.Zero(v.Type().Elem())
}
...
}
}
regexp/syntaxe :
regexp/syntax/parse.go
func Parse(s string, flags Flags) (*Regexp, error) {
...
if c, t, err = nextRune(t); err != nil {
return nil, err
}
p.literal(c)
...
}
devient
func Parse(s string, flags Flags) (*Regexp, error) {
...
try c, t = nextRune(t)
p.literal(c)
...
}
réseau/http
net/http/request.go:readRequest
mimeHeader, err := tp.ReadMIMEHeader()
if err != nil {
return nil, err
}
req.Header = Header(mimeHeader)
devient:
try mimeHeader := tp.ReadMIMEHeader()
req.Header = Header(mimeHeader)
base de données/sql
if driverCtx, ok := driveri.(driver.DriverContext); ok {
connector, err := driverCtx.OpenConnector(dataSourceName)
if err != nil {
return nil, err
}
return OpenDB(connector), nil
}
devient
if driverCtx, ok := driveri.(driver.DriverContext); ok {
try connector := driverCtx.OpenConnector(dataSourceName)
return OpenDB(connector), nil
}
base de données/sql
si, err := ctxDriverPrepare(ctx, dc.ci, query)
if err != nil {
return nil, err
}
ds := &driverStmt{Locker: dc, si: si}
devient
try si := ctxDriverPrepare(ctx, dc.ci, query)
ds := &driverStmt{Locker: dc, si: si}
réseau/http
if http2isconnectioncloserequest(req) && dialonmiss {
// it gets its own connection.
http2tracegetconn(req, addr)
const singleuse = true
cc, err := p.t.dialclientconn(addr, singleuse)
if err != nil {
return nil, err
}
return cc, nil
}
devient
if http2isconnectioncloserequest(req) && dialonmiss {
// it gets its own connection.
http2tracegetconn(req, addr)
const singleuse = true
try cc := p.t.dialclientconn(addr, singleuse)
return cc, nil
}
réseau/http
Celui-ci ne nous fait pas économiser de lignes, mais je le trouve beaucoup plus clair car if err == nil est une construction relativement rare.
func (f *http2Framer) endWrite() error {
...
n, err := f.w.Write(f.wbuf)
if err == nil && n != len(f.wbuf) {
err = io.ErrShortWrite
}
return err
}
devient
func (f *http2Framer) endWrite() error {
...
try n := f.w.Write(f.wbuf)
if n != len(f.wbuf) {
return io.ErrShortWrite
}
return nil
}
réseau/http
if f, err := fr.ReadFrame(); err != nil {
return nil, err
} else {
hc = f.(*http2ContinuationFrame) // guaranteed by checkFrameOrder
}
devient
try f := fr.ReadFrame()
hc = f.(*http2ContinuationFrame) // guaranteed by checkFrameOrder
}
rapporter:
if ctrlFn != nil {
c, err := newRawConn(fd)
if err != nil {
return err
}
if err := ctrlFn(fd.ctrlNetwork(), laddr.String(), c); err != nil {
return err
}
}
devient
if ctrlFn != nil {
try c := newRawConn(fd)
try ctrlFn(fd.ctrlNetwork(), laddr.String(), c)
}
@james-lawrence En réponse à https://github.com/golang/go/issues/32437#issuecomment -500116099 : Je ne me souviens pas que des idées comme un , err facultatif aient été sérieusement envisagées, non. Personnellement, je pense que c'est une mauvaise idée, car cela signifie que si une fonction change pour ajouter un paramètre de fin error , le code existant continuera à compiler, mais agira très différemment.
ianlancetaylor
le 10 juin 2019
L'utilisation de defer pour gérer les erreurs a beaucoup de sens, mais cela conduit à devoir nommer l'erreur et un nouveau type de passe- if err != nil .
Les gestionnaires externes doivent faire ceci :
func handler(err *error) {
if *err != nil {
*err = handle(*err)
}
}
qui s'habitue comme
defer handler(&err)
Les gestionnaires externes n'ont besoin d'être écrits qu'une seule fois, mais il faudrait deux versions de nombreuses fonctions de gestion des erreurs : celle destinée à être différée et celle à utiliser de manière régulière.
Les gestionnaires internes doivent faire ceci :
defer func() {
if err != nil {
err = handle(err)
}
}()
Dans les deux cas, l'erreur de la fonction externe doit être nommée pour être accessible.
Comme je l'ai mentionné plus tôt dans le fil, cela peut être résumé en une seule fonction :
func catch(err *error, handle func(error) error) {
if *err != nil && handle != nil {
*err = handle(*err)
}
}
Cela va à l'encontre de l'inquiétude de @griesemer concernant l'ambiguïté des fonctions de gestionnaire de nil et a son propre passe-partout defer et func(err error) error , en plus de devoir nommer err dans la fonction externe.
Si try finit comme mot-clé, alors il pourrait être judicieux d'avoir un mot-clé catch , qui sera également décrit ci-dessous.
Syntaxiquement, ce serait un peu comme handle :
catch err {
return handleThe(err)
}
Sémantiquement, ce serait du sucre pour le code du gestionnaire interne ci-dessus :
defer func() {
if err != nil {
err = handleThe(err)
}
}()
Comme c'est quelque peu magique, il pourrait saisir l'erreur de la fonction externe, même si elle n'était pas nommée. (Le err après catch ressemble plus à un nom de paramètre pour le bloc catch ).
catch aurait la même restriction que try qu'il doit être dans une fonction qui a un retour d'erreur final, car ils sont tous les deux du sucre qui en dépend.
C'est loin d'être aussi puissant que la proposition originale handle , mais cela éviterait l'obligation de nommer une erreur afin de la gérer et cela supprimerait le nouveau passe-partout décrit ci-dessus pour les gestionnaires internes tout en le rendant assez facile à ne pas nécessitent des versions distinctes des fonctions pour les gestionnaires externes.
La gestion des erreurs compliquées peut nécessiter de ne pas utiliser catch la même manière qu'elle peut nécessiter de ne pas utiliser try .
Comme ce sont tous les deux du sucre, il n'est pas nécessaire d'utiliser catch avec try . Les gestionnaires catch sont exécutés chaque fois que la fonction renvoie une erreur autre que nil , permettant, par exemple, de conserver une journalisation rapide :
catch err {
log.Print(err)
return err
}
ou simplement envelopper toutes les erreurs renvoyées :
catch err {
return fmt.Errorf("foo: %w", err)
}
@ianlancetaylor
_" Je pense que c'est une mauvaise idée, car cela signifie que si une fonction change pour ajouter un paramètre de fin
error, le code existant continuera à compiler, mais agira très différemment."_
C'est probablement la bonne façon de voir les choses, si vous êtes en mesure de contrôler à la fois le code en amont et en aval, de sorte que si vous devez modifier une signature de fonction afin de renvoyer également une erreur, vous pouvez le faire.
Mais je vous demanderais de considérer ce qui se passe lorsque quelqu'un ne contrôle ni en amont ni en aval de ses propres packages ? Et aussi pour considérer les cas d'utilisation où des erreurs peuvent être ajoutées, et que se passe-t-il si des erreurs doivent être ajoutées mais que vous ne pouvez pas forcer le code en aval à changer ?
Pouvez-vous penser à un exemple où quelqu'un changerait de signature pour ajouter une valeur de retour ? Pour moi, ils sont généralement tombés dans la catégorie _"Je ne savais pas qu'une erreur se produirait"_ ou _"Je me sens paresseux et je ne veux pas faire d'effort car l'erreur ne se produira probablement pas." _
Dans ces deux cas, je pourrais ajouter un retour d'erreur car il devient évident qu'une erreur doit être traitée. Lorsque cela se produit, si je ne peux pas modifier la signature parce que je ne veux pas rompre la compatibilité pour les autres développeurs utilisant mes packages, que faire ? Je suppose que la grande majorité du temps, l'erreur se produira et que le code qui a appelé la fonction qui ne renvoie pas l'erreur agira très différemment, _de toute façon._
En fait, je fais rarement ce dernier mais trop souvent le premier. Mais j'ai remarqué que les packages tiers ignorent fréquemment les erreurs de capture là où elles devraient se trouver, et je le sais parce que lorsque j'affiche leur code dans les drapeaux GoLand en orange vif à chaque fois. J'aimerais pouvoir soumettre des demandes d'extraction pour ajouter la gestion des erreurs aux packages que j'utilise beaucoup, mais si je le fais, la plupart ne les accepteront pas car je briserais leurs signatures de code.
En n'offrant pas de moyen rétrocompatible d'ajouter des erreurs à renvoyer par les fonctions, les développeurs qui distribuent du code et se soucient de ne pas casser les choses pour leurs utilisateurs ne pourront pas faire évoluer leurs packages pour inclure la gestion des erreurs comme ils le devraient.
Peut-être plutôt que de considérer le problème étant que le code agira différemment, considérez plutôt le problème comme un défi d'ingénierie concernant la façon de minimiser les inconvénients d'une méthode qui ne capture pas activement une erreur ? Cela aurait une valeur plus large et à plus long terme.
Par exemple, envisagez d'ajouter un gestionnaire d'erreurs de package que l'on doit définir avant de pouvoir ignorer les erreurs ?
Pour être franc, l'idiome de Go consistant à renvoyer des erreurs en plus des valeurs de retour régulières était l'une de ses meilleures innovations. Mais comme cela arrive souvent lorsque vous améliorez les choses, vous exposez souvent d'autres faiblesses et je soutiendrai que la gestion des erreurs de Go n'a pas suffisamment innové.
Nous, Gophers, sommes devenus habitués à renvoyer une erreur plutôt qu'à lancer une exception, donc la question que je me pose est _ "Pourquoi ne devrions-nous pas renvoyer des erreurs de chaque fonction?" _ Nous ne le faisons pas toujours car écrire du code sans gestion des erreurs est plus pratique que de coder avec. Nous omettons donc la gestion des erreurs lorsque nous pensons pouvoir nous en éloigner. Mais souvent nous devinons mal.
Donc vraiment, s'il était possible de comprendre comment rendre le code élégant et lisible, je dirais que les valeurs de retour et les erreurs devraient vraiment être traitées séparément, et que _chaque_ fonction devrait avoir la capacité de renvoyer des erreurs indépendamment de ses signatures de fonction passées. Et faire en sorte que le code existant gère avec élégance le code qui génère maintenant des erreurs serait une entreprise louable.
Je n'ai rien proposé parce que je n'ai pas pu imaginer une syntaxe viable, mais si nous voulons être honnêtes avec nous-mêmes, tout ce qui se passe dans ce fil et lié à la gestion des erreurs de Go en général n'a-t-il pas été lié au fait que la gestion des erreurs et la logique du programme sont des compagnons de lit étranges, donc idéalement, les erreurs seraient mieux gérées hors bande d'une manière ou d'une autre?
mikeschinkel
le 10 juin 2019
try en tant que mot-clé aide certainement à la lisibilité (par rapport à un appel de fonction) et semble moins complexe. @brynbellomy @crawshaw merci d'avoir pris le temps d'écrire les exemples.
Je suppose que ma pensée générale est que try en fait trop. Il résout : appeler la fonction, affecter des variables, vérifier l'erreur et renvoyer l'erreur si elle existe. Je propose plutôt de réduire la portée et de résoudre uniquement pour le retour conditionnel : "return if last arg not nil".
Ce n'est probablement pas une idée nouvelle... Mais après avoir parcouru les propositions dans le wiki error feedback , je ne l'ai pas trouvé (cela ne veut pas dire qu'il n'y est pas)
Mini proposition sur retour conditionnel
extrait:
err, thing := newThing(name)
refuse nil, err
Je l'ai également ajouté au wiki sous "idées alternatives"
Ne rien faire semble également être une option très raisonnable.
 alexhornbake
le 10 juin 2019
alexhornbake
le 10 juin 2019
@alexhornbake ça me donne une idée un peu différente qui serait plus utile
assert(nil, err)
assert(len(a), len(b))
assert(true, condition)
assert(expected, given)
de cette façon, cela ne s'appliquerait pas seulement à la vérification des erreurs, mais à de nombreux types d'erreurs logiques.
Le donné serait enveloppé dans une erreur et renvoyé.
qrpnxz
le 10 juin 2019
@alexhornbake
Tout comme try n'essaie pas réellement, refuse ne "refuse" pas réellement. L'intention commune ici a été de définir un "relais de protection" ( relay est court, précis et allitératif à return ) qui "se déclenche" lorsque l'une des valeurs câblées répond à une condition (ie est une erreur non nulle). C'est une sorte de disjoncteur et, je crois, peut ajouter de la valeur si sa conception était limitée à des cas inintéressants pour simplement réduire certains des passe-partout les plus bas. Tout ce qui est complexe à distance devrait s'appuyer sur du code Go simple.
daved
le 10 juin 2019
Je félicite également Cranshaw pour son travail de recherche dans la bibliothèque standard, mais je suis arrivé à une conclusion très différente... Je pense que cela rend presque tous ces extraits de code plus difficiles à lire et plus sujets aux malentendus.
req.Header = Header(try(tp.ReadMIMEHeader())
Je vais très souvent rater cette erreur. Une lecture rapide me donne "ok, définissez l'en-tête sur l'en-tête de ReadMimeHeader de la chose".
if driverCtx, ok := driveri.(driver.DriverContext); ok {
return OpenDB(try(driverCtx.OpenConnector(dataSourceName))), nil
}
Celui-ci, mes yeux se croisent en essayant d'analyser cette ligne OpenDB. Il y a tellement de densité là-bas ... Cela montre le problème majeur de tous les appels de fonction imbriqués, en ce sens que vous devez lire de l'intérieur vers l'extérieur et que vous devez l'analyser dans votre tête afin de déterminer où se trouve la partie la plus interne .
Notez également que cela peut revenir de deux endroits différents dans la même ligne.. .vous allez déboguer, et cela va dire qu'il y a eu une erreur renvoyée par cette ligne, et la première chose que tout le monde va faire est d'essayer de comprendre pourquoi OpenDB échoue avec cette erreur étrange, alors qu'il s'agit en fait d'un échec d'OpenConnector (ou vice versa).
ds := &driverStmt{
Locker: dc,
si: try(ctxDriverPrepare(ctx, dc.ci, query)),
}
C'est un endroit où le code peut échouer là où auparavant cela aurait été impossible. Sans try , la construction du littéral struct ne peut pas échouer . Mes yeux vont le parcourir comme "ok, construire un driverStmt ... continuer .." et il sera si facile de le manquer qu'en fait, cela peut entraîner une erreur de votre fonction. La seule façon qui aurait été possible auparavant est si ctxDriverPrepare a paniqué... et nous savons tous que c'est un cas qui 1.) ne devrait fondamentalement jamais arriver et 2.) si c'est le cas, cela signifie que quelque chose ne va pas du tout.
Faire essayer un mot clé et une déclaration résout beaucoup de mes problèmes avec cela. Je sais que ce n'est pas rétrocompatible, mais je ne pense pas que l'utilisation d'une version pire soit la solution au problème de rétrocompatibilité.
natefinch
le 10 juin 2019
@daved Je ne suis pas sûr de suivre. N'aimez-vous pas le nom, ou n'aimez-vous pas l'idée ?
Quoi qu'il en soit, j'ai posté ceci ici comme alternative... S'il y a un intérêt légitime, je peux ouvrir un nouveau sujet de discussion, je ne veux pas polluer ce fil (peut-être trop tard ?) nous un sens... Bien sûr ouvert aux noms alternatifs. La partie importante est "le retour conditionnel sans essayer de gérer l'affectation".
alexhornbake
le 10 juin 2019
Bien que j'aime la proposition de catch de @jimmyfrasche , je voudrais proposer une alternative :
go
handler fmt.HandleErrorf("copy %s %s", src, dst)
serait équivalent à :
go
defer func(){
if(err != nil){
fmt.HandleErrorf(&err,"copy %s %s", src, dst)
}
}()
où err est la dernière valeur de retour nommée, avec le type error. Cependant, les gestionnaires peuvent également être utilisés lorsque les valeurs de retour ne sont pas nommées. Le cas plus général serait également autorisé :
go
handler func(err *error){ *err = fmt.Errorf("foo: %w", *err) }() `
Le principal problème que j'ai avec l'utilisation de valeurs de retour nommées (que catch ne résout pas) est que err est superflu. Lors du report d'un appel à un gestionnaire comme fmt.HandleErrorf , il n'y a pas de premier argument raisonnable sauf un pointeur vers la valeur de retour d'erreur, pourquoi donner à l'utilisateur la possibilité de faire une erreur ?
Par rapport à catch, la principale différence est que handler facilite un peu l'appel de gestionnaires prédéfinis au détriment de rendre plus verbeux pour les définir en place. Je ne suis pas sûr que ce soit l'idéal, mais je pense que c'est plus conforme à la proposition initiale.
 yiyus
le 10 juin 2019
yiyus
le 10 juin 2019
@yiyus catch , comme je l'ai défini, il n'est pas nécessaire que err soit nommé sur la fonction contenant le catch .
Dans catch err { , le err correspond au nom de l'erreur dans le bloc catch . C'est comme un nom de paramètre de fonction.
Avec cela, il n'y a pas besoin de quelque chose comme fmt.HandleErrorf car vous pouvez simplement utiliser le fmt.Errorf normal :
func f() error {
catch err {
return fmt.Errorf("foo: %w", err)
}
return errors.New("bar")
}
qui renvoie une erreur qui s'imprime sous la forme foo: bar .
jimmyfrasche
le 10 juin 2019
Je n'aime pas cette approche, à cause de:
- L'appel de la fonction
try()interrompt l'exécution du code dans la fonction parent. - il n'y a pas de mot-clé
return, mais le code renvoie en fait.
 ubombi
le 10 juin 2019
ubombi
le 10 juin 2019
De nombreuses façons de faire des gestionnaires sont proposées, mais je pense qu'elles manquent souvent deux exigences clés :
Il doit être significativement différent et meilleur que
if x, err := thingie(); err != nil { handle(err) }. Je pense que les suggestions du typetry x := thingie else err { handle(err) }ne répondent pas à cette barre. Pourquoi ne pas simplement direif?Il doit être orthogonal à la fonctionnalité existante de
defer. C'est-à-dire qu'il devrait être suffisamment différent pour qu'il soit clair que le mécanisme de gestion proposé est nécessaire en soi sans créer de cas bizarres lorsque handle et defer interagissent.
Veuillez garder ces desiderata à l'esprit lorsque nous discutons de mécanismes alternatifs pour try /handle.
carlmjohnson
le 10 juin 2019
@carlmjohnson J'aime l' idée catch @jimmyfrasche concernant votre point 2 - c'est juste du sucre de syntaxe pour un defer qui économise 2 lignes et vous permet d'éviter d'avoir à nommer la valeur de retour d'erreur (qui dans tourner exigerait également que vous nommiez tous les autres si vous ne l'aviez pas déjà fait). Cela ne pose pas de problème d'orthogonalité avec defer , car c'est defer .
dpinela
le 10 juin 2019
faisant écho à ce que @ubombi a dit :
L'appel de la fonction try() interrompt l'exécution du code dans la fonction parent.; il n'y a pas de mot-clé de retour, mais le code renvoie en fait.
Dans Ruby, les procs et les lambdas sont un exemple de ce que fait try ... Un proc est un bloc de code que son instruction return ne renvoie pas du bloc lui-même, mais de l'appelant.
C'est exactement ce que fait try ... c'est juste un proc Ruby prédéfini.
Je pense que si nous devions emprunter cette voie, nous pourrions peut-être laisser l'utilisateur définir sa propre fonction try en introduisant proc functions
Je préfère toujours if err != nil , parce que c'est plus lisible mais je pense que try serait plus avantageux si l'utilisateur définissait son propre proc :
proc try(err *error, msg string) {
if *err != nil {
*err = fmt.Errorf("%v: %w", msg, *err)
return
}
}
Et puis vous pouvez l'appeler:
func someFunc() (string, error) {
err := doSomething()
try(&err, "someFunc failed")
}
L'avantage ici est que vous pouvez définir la gestion des erreurs dans vos propres termes. Et vous pouvez également créer un proc exposé, privé ou interne.
C'est aussi mieux que la clause handle {} dans la proposition Go2 d'origine car vous ne pouvez la définir qu'une seule fois pour l'ensemble de la base de code et non dans chaque fonction.
Une considération pour la lisibilité est qu'un func () et un proc () peuvent être appelés différemment, comme func() et proc!() afin qu'un programmeur sache qu'un appel proc peut en fait revenir hors du fonction d'appel.
marwan-at-work
le 10 juin 2019
@marwan-at-work, try(err, "someFunc failed") ne devrait-il pas être try(&err, "someFunc failed") dans votre exemple ?
dpinela
le 10 juin 2019
@dpinela merci pour la correction, mise à jour du code :)
marwan-at-work
le 10 juin 2019
La pratique courante que nous essayons de remplacer ici est ce que le déroulement standard de la pile dans de nombreuses langues suggère dans une exception (et donc le mot "essayer" a été sélectionné...).
Mais si nous ne pouvions autoriser qu'une fonction (... try () ou autre) qui remonterait de deux niveaux dans la trace, alors
try := handler(err error) { //which corelates with - try := func(err error)
if err !=nil{
//do what ever you want to do when there's an error... log/print etc
return2 //2 levels
}
}
puis un code comme
f := try(os.Open(filename))
pourrait faire exactement comme le conseille la proposition, mais comme il s'agit d'une fonction (ou en fait d'une "fonction de gestionnaire"), le développeur aura beaucoup plus de contrôle sur ce que fait la fonction, comment elle formate l'erreur dans différents cas, utilisez un gestionnaire similaire tout autour le code pour gérer (disons) os.Open, au lieu d'écrire fmt.Errorf("erreur lors de l'ouverture du fichier %s ....") à chaque fois.
Cela forcerait également la gestion des erreurs comme si "try" n'était pas défini - c'est une erreur de compilation.
guybrand
le 10 juin 2019
@guybrand Avoir un tel retour à deux niveaux return2 (ou "retour non local" comme le concept général est appelé dans Smalltalk) serait un bon mécanisme à usage général (également suggéré par @mikeschinkel dans # 32473) . Mais il semble que try soit toujours nécessaire dans votre suggestion, donc je ne vois pas de raison pour le return2 - le try peut simplement faire le return . Ce serait plus intéressant si on pouvait aussi écrire try localement, mais ce n'est pas possible pour les signatures arbitraires.
griesemer
le 10 juin 2019
@griesemer
_"donc je ne vois pas de raison pour le
return2- letrypeut juste faire lereturn."_
Une raison — comme je l'ai souligné dans #32473 _(merci pour la référence)_ — serait d'autoriser plusieurs niveaux de break et continue , en plus de return .
mikeschinkel
le 10 juin 2019
Merci encore à tous pour tous les nouveaux commentaires ; c'est un investissement de temps important pour suivre la discussion et rédiger des commentaires détaillés. Et mieux encore, malgré les arguments parfois passionnés, cela a été un fil plutôt civil jusqu'à présent. Merci!
Voici un autre résumé rapide, cette fois un peu plus condensé ; excuses à ceux que je n'ai pas mentionnés, oubliés ou déformés. À ce stade, je pense que des thèmes plus larges émergent :
1) En général, l'utilisation d'une fonctionnalité intégrée pour la fonctionnalité try est ressentie comme un mauvais choix : étant donné qu'elle affecte le flux de contrôle, elle devrait être _au moins_ un mot-clé ( @carloslenz "préfère en faire une déclaration sans parenthèse"); try comme expression ne semble pas une bonne idée, cela nuit à la lisibilité ( @ChrisHines , @jimmyfrasche), ce sont des "retours sans return ". @brynbellomy a fait une analyse réelle de try utilisés comme identifiants ; il semble y en avoir très peu en pourcentage, il pourrait donc être possible d'emprunter la route des mots clés sans affecter trop de code.
2) @crawshaw a pris un certain temps pour analyser quelques centaines de cas d'utilisation de la bibliothèque std et est arrivé à la conclusion que try tel que proposé améliorait presque toujours la lisibilité. @jimmyfrasche est arrivé à la conclusion opposée .
3) Un autre thème est que l'utilisation defer pour la décoration des erreurs n'est pas idéale. @josharian souligne que les defer sont toujours exécutés au retour de la fonction, mais s'ils sont là pour la décoration d'erreur, nous ne nous soucions de leur corps que s'il y a une erreur, ce qui pourrait être une source de confusion.
4) Beaucoup ont écrit des suggestions pour améliorer la proposition. @zeebo , @patrick-nyt sont en charge de gofmt formatant des instructions simples if sur une seule ligne (et soyez satisfait du statu quo). @jargv a suggéré que try() (sans arguments) pourrait renvoyer un pointeur vers l'erreur actuellement "en attente", ce qui supprimerait le besoin de nommer le résultat de l'erreur juste pour y avoir accès dans un defer ; @masterada a suggéré d'utiliser errorfunc() la place. @velovix a relancé l'idée d'un argument à 2 try où le 2ème argument serait un gestionnaire d'erreurs.
@klaidliadon , @networkimprov sont en faveur des "opérateurs d'affectation" spéciaux comme dans f, # := os.Open() au lieu de try . @networkimprov a déposé une proposition alternative plus complète enquêtant sur ces approches (voir numéro 32500). @mikeschinkel a également déposé une proposition alternative suggérant d'introduire deux nouvelles fonctionnalités de langage à usage général qui pourraient également être utilisées pour la gestion des erreurs, plutôt qu'un try spécifique à l'erreur (voir le problème #32473). @josharian a relancé une possibilité dont nous avons discuté à GopherCon l'année dernière où try ne revient pas sur une erreur mais saute à la place (avec un goto ) vers une étiquette nommée error (alternativement , try peut prendre le nom d'un libellé cible).
5) Au sujet de try comme mot-clé, deux lignes de pensée sont apparues. @brynbellomy a suggéré une version qui pourrait alternativement spécifier un gestionnaire :
a, b := try f()
a, b := try f() else err { /* handle error */ }
@thepudds va un peu plus loin et suggère try au début de la ligne, donnant try la même visibilité qu'un return :
try a, b := f()
Les deux pourraient fonctionner avec defer .
griesemer
le 11 juin 2019
@griesemer
Merci pour la référence à @mikeschinkel # 32473, il a beaucoup en commun.
En ce qui concerne
Mais il semble que try soit toujours nécessaire dans votre suggestion
Bien que ma suggestion puisse être implémentée avec "n'importe quel" gestionnaire et non un "build in/keyword/expression" réservé, je ne pense pas que "try()" soit une mauvaise idée (et donc je ne l'ai pas voté contre), j'essaie pour "l'élargir" - afin qu'il montre plus d'avantages, beaucoup s'attendaient "une fois que le go 2.0 est introduit"
Je pense que cela peut également être la source des "ambiances mixtes" que vous avez signalées dans votre dernier résumé - ce n'est pas "try () n'améliore pas la gestion des erreurs" - bien sûr, c'est "en attente de Go 3.0 pour résoudre une autre erreur majeure douleurs de manipulation" les personnes indiquées ci-dessus, semble trop longue :)
Je mène une enquête sur les "douleurs de la gestion des erreurs" (et sonne que certaines des douleurs sont simplement "je n'utilise pas de bonnes pratiques", alors que certaines que je n'imaginais même pas que les gens (venant pour la plupart d'autres langues) voudraient faire - de cool à WTF).
J'espère que je pourrai bientôt partager des résultats intéressants.
enfin -Merci pour le travail incroyable et la patience !
guybrand
le 11 juin 2019
En regardant simplement la longueur de la syntaxe proposée actuelle par rapport à ce qui est disponible maintenant, le cas où l'erreur doit simplement être renvoyée sans la manipuler ou la décorer est le cas où le plus de commodité est gagnée. Un exemple avec ma syntaxe préférée jusqu'à présent :
try a, b := f() else err { return fmt.Errorf("Decorated: %s", err); }
if a,b, err :=f; err != nil { return fmt.Errorf("Decorated: %s", err); }
try a, b := f()
if a,b, err :=f; err != nil { return err; }
Donc, différent de ce que je pensais auparavant, il suffit peut-être simplement de modifier go fmt, au moins pour le cas d'erreur décorée/traitée. Alors que pour le cas d'erreur, quelque chose comme try peut toujours être souhaitable en tant que sucre syntaxique pour ce cas d'utilisation très courant.
beoran
le 11 juin 2019
En ce qui concerne try else , je pense que les fonctions d'erreur conditionnelle comme fmt.HandleErrorf (édition : je suppose qu'elle renvoie nil lorsque l'entrée est nulle) dans le commentaire initial fonctionnent bien, donc en ajoutant else est inutile.
a, b, err := doSomething()
try fmt.HandleErrorf(&err, "Decorated "...)
Comme beaucoup d'autres ici, je préfère que try soit une déclaration plutôt qu'une expression, principalement parce qu'une expression modifiant le flux de contrôle est complètement étrangère à Go. Aussi parce que ce n'est pas une expression, il devrait être au début de la ligne.
Je suis également d'accord avec @daved que le nom n'est pas approprié. Après tout, ce que nous essayons de réaliser ici est une affectation protégée, alors pourquoi ne pas utiliser guard comme dans Swift et rendre la clause else facultative ? Quelque chose comme
GuardStmt = "guard" ( Assignment | ShortVarDecl | Expression ) [ "else" Identifier Block ] .
où Identifier est le nom de la variable d'erreur lié dans le Block . Sans clause else , revenez simplement de la fonction actuelle (et utilisez un gestionnaire de report pour décorer les erreurs si nécessaire).
Au départ, je n'aimais pas une clause else parce que c'est juste du sucre syntaxique autour de l'affectation habituelle suivie de if err != nil , mais après avoir vu certains des exemples, cela a du sens : utiliser guard rend l'intention plus claire.
EDIT : certains ont suggéré d'utiliser des choses comme catch pour spécifier d'une manière ou d'une autre différents gestionnaires d'erreurs. Je trouve else tout aussi viable sémantiquement parlant et c'est déjà dans la langue.
 db47h
le 11 juin 2019
db47h
le 11 juin 2019
Bien que j'aime l'instruction try-else, qu'en est-il de cette syntaxe ?
a, b, (err) := func() else { return err }
 kybin
le 11 juin 2019
kybin
le 11 juin 2019
L'expression try - else est un opérateur ternaire.
a, b := try f() else err { ... }
fmt.Println(try g() else err { ... })`
L'instruction try - else est une instruction if .
try a, b := f() else err { ... }
// (modulo scope of err) same as
a, b, err := f()
if err != nil { ... }
try intégré avec un gestionnaire optionnel peut être réalisé avec une fonction d'assistance (ci-dessous) ou sans utiliser try (non illustré, nous savons tous à quoi cela ressemble).
a, b := try(f(), decorate)
// same as
a, b := try(g())
// where g is
func g() (whatever, error) {
x, err := f()
if err != nil {
try(decorate(err))
}
return x, nil
}
Tous les trois réduisent le passe-partout et aident à contenir la portée des erreurs.
Il offre le plus d'économies pour les try intégrés, mais cela présente les problèmes mentionnés dans le document de conception.
Pour l'instruction try - else , cela offre un avantage par rapport à l'utilisation if au lieu de try . Mais l'avantage est tellement marginal que j'ai du mal à le voir se justifier, même si j'aime bien ça.
Tous les trois supposent qu'il est courant d'avoir besoin d'un traitement d'erreur spécial pour des erreurs individuelles.
La gestion de toutes les erreurs peut également être effectuée dans defer . Si la même gestion des erreurs est effectuée dans chaque bloc else , c'est un peu répétitif :
func printSum(a, b string) error {
try x := strconv.Atoi(a) else err {
return fmt.Errorf("printSum: %w", err)
}
try y := strconv.Atoi(b) else err {
return fmt.Errorf("printSum: %w", err)
}
fmt.Println("result:", x + y)
return nil
}
Je sais certainement qu'il y a des moments où une certaine erreur nécessite un traitement spécial. Ce sont les exemples qui ressortent dans ma mémoire. Mais, si cela ne se produit, disons, que 1 fois sur 100, ne serait-il pas préférable de garder try simple et de ne pas utiliser try dans ces situations ? D'un autre côté, si c'est plutôt 1 fois sur 10, ajouter else /handler semble plus raisonnable.
Il serait intéressant de voir une distribution réelle de la fréquence à laquelle try sans else /handler vs try avec un else /handler serait utile, cependant ce ne sont pas des données faciles à recueillir.
jimmyfrasche
le 11 juin 2019
Je veux développer le récent commentaire de @jimmyfrasche .
L'objectif de cette proposition est de réduire le passe-partout
a, b, err := f()
if err != nil {
return nil, err
}
Ce code est facile à lire. Cela ne vaut la peine d'étendre le langage que si nous pouvons parvenir à une réduction considérable du passe-partout. Quand je vois quelque chose comme
try a, b := f() else err { return nil, err }
Je ne peux pas m'empêcher de penser que nous n'économisons pas tant que ça. Nous économisons trois lignes, ce qui est bien, mais d'après mes calculs, nous réduisons de 56 à 46 caractères. Ce n'est pas beaucoup. Comparer aux
a, b := try(f())
qui passe de 56 à 18 caractères, une réduction beaucoup plus importante. Et bien que l'instruction try rende le changement potentiel de flux de contrôle plus clair, dans l'ensemble, je ne trouve pas l'instruction plus lisible. Bien que du côté positif, l'instruction try facilite l'annotation de l'erreur.
Quoi qu'il en soit, mon point est le suivant : si nous allons changer quelque chose, cela devrait réduire considérablement le passe-partout ou devrait être beaucoup plus lisible. Ce dernier est assez difficile, donc tout changement doit vraiment travailler sur le premier. Si nous n'obtenons qu'une réduction mineure du passe-partout, alors, à mon avis, cela ne vaut pas la peine d'être fait.
ianlancetaylor
le 11 juin 2019
Comme d'autres, je voudrais remercier @crawshaw pour les exemples.
En lisant ces exemples, j'encourage les gens à essayer d'adopter un état d'esprit dans lequel vous ne vous inquiétez pas du flux de contrôle dû à la fonction try . Je crois, peut-être à tort, que ce flux de contrôle deviendra rapidement une seconde nature pour les personnes qui connaissent la langue. Dans le cas normal, je crois que les gens cesseront simplement de s'inquiéter de ce qui se passe en cas d'erreur. Essayez de lire ces exemples tout en glaciant sur try tout comme vous glaciez déjà sur if err != nil { return err } .
ianlancetaylor
le 11 juin 2019
Après avoir tout lu ici, et après réflexion, je ne suis pas sûr de voir essayer même comme une déclaration quelque chose qui mérite d'être ajouté.
la raison semble être de réduire les erreurs de traitement du code de la plaque chauffante. À mon humble avis, cela "désencombre" le code mais cela ne supprime pas vraiment la complexité ; ça l' obscurcit juste. Cela ne semble pas une raison assez forte. Le feu vert
" syntaxe magnifiquement capturée à partir d'un thread concurrent. Je ne ressens pas ce genre de sentiment "aha!" Ici. Cela ne me semble pas correct. Le rapport coût/bénéfice n'est pas assez important. son nom ne reflète pas sa fonction. Dans sa forme la plus simple, ce qu'il fait est ceci : "si une fonction renvoie une erreur, le retour de l'appelant avec une erreur" mais c'est trop long :-) À tout le moins, un nom différent est nécessaire.
avec le retour implicite sur erreur de try, on a l'impression que Go recule à contrecœur dans la gestion des exceptions. C'est-à-dire que si A appelle être dans une garde try et B appelle C dans une garde try, et C appelle D dans une garde try, si D renvoie une erreur en effet vous avez causé un goto non local. C'est trop "magique".
et pourtant je crois qu'une meilleure façon peut être possible. Choisir essayer maintenant fermera cette option.
bakul
le 11 juin 2019
@ianlancetaylor
Si je comprends bien la proposition "essayez autrement", il semble que le bloc else soit facultatif et réservé à la gestion fournie par l'utilisateur. Dans votre exemple try a, b := f() else err { return nil, err } la clause else est en fait redondante, et l'expression entière peut être écrite simplement comme try a, b := f()
 DmitriyMV
le 11 juin 2019
DmitriyMV
le 11 juin 2019
Je suis d'accord avec @ianlancetaylor ,
La lisibilité et le passe-partout sont deux préoccupations principales et peut-être la volonté de
la gestion des erreurs go 2.0 (bien que je puisse ajouter d'autres préoccupations importantes)
Aussi, que le courant
a, b, err := f()
if err != nil {
return nil, err
}
Est très lisible.
Et puisque je crois
if a, b, err := f(); err != nil {
return nil, err
}
Est presque aussi lisible, mais avait des "problèmes" de portée, peut-être un
ifErr a, b, err := f() {
return nil, err
}
Cela ne ferait que le ; err != partie nulle, et ne créerait pas de portée, ou
De même
essayez a, b, euh := f() {
retour nul, erreur
}
Conserve les deux lignes supplémentaires, mais reste lisible.
Le mar. 11 juin 2019, 20:19 Dmitriy Matrenichev, [email protected]
a écrit:
@ianlancetaylor https://github.com/ianlancetaylor
Si je comprends bien la proposition "essayez autre chose", il semble que le bloc d'autre
est facultatif et réservé à la gestion fournie par l'utilisateur. Dans votre exemple
try a, b := f() else err { return nil, err } la clause else est en fait
redondant, et l'expression entière peut être écrite simplement comme try a, b :=
F()—
Vous recevez ceci parce que vous avez été mentionné.
Répondez directement à cet e-mail, consultez-le sur GitHub
https://github.com/golang/go/issues/32437?email_source=notifications&email_token=ABNEY4XPURMASWKZKOBPBVDPZ7NALA5CNFSM4HTGCZ72YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGODXN3VDA#issuecomment-500 ,
ou couper le fil
https://github.com/notifications/unsubscribe-auth/ABNEY4SAFK4M5NLABF3NZO3PZ7NALANCNFSM4HTGCZ7Q
.
guybrand
le 11 juin 2019
@ianlancetaylor
Quoi qu'il en soit, mon point est le suivant : si nous allons changer quelque chose, cela devrait réduire considérablement le passe-partout ou devrait être beaucoup plus lisible. Ce dernier est assez difficile, donc tout changement doit vraiment travailler sur le premier. Si nous n'obtenons qu'une réduction mineure du passe-partout, alors, à mon avis, cela ne vaut pas la peine d'être fait.
D'accord, et considérant qu'un else ne serait que du sucre syntaxique (avec une syntaxe bizarre !), très probablement utilisé rarement, je m'en fiche un peu. Je préférerais toujours que try soit une déclaration.
db47h
le 11 juin 2019
@ianlancetaylor Faisant écho à @DmitriyMV , le bloc else serait facultatif. Permettez-moi de donner un exemple qui illustre les deux (et qui ne semble pas trop éloigné de la vérité en termes de proportion relative de blocs try gérés par rapport aux blocs non gérés dans le code réel):
func createMergeCommit(r *repo.Repo, index *git.Index, remote *git.Remote, remoteBranch *git.Branch) error {
headRef, err := r.Head()
if err != nil {
return err
}
parentObjOne, err := headRef.Peel(git.ObjectCommit)
if err != nil {
return err
}
parentObjTwo, err := remoteBranch.Reference.Peel(git.ObjectCommit)
if err != nil {
return err
}
parentCommitOne, err := parentObjOne.AsCommit()
if err != nil {
return err
}
parentCommitTwo, err := parentObjTwo.AsCommit()
if err != nil {
return err
}
treeOid, err := index.WriteTree()
if err != nil {
return err
}
tree, err := r.LookupTree(treeOid)
if err != nil {
return err
}
remoteBranchName, err := remoteBranch.Name()
if err != nil {
return err
}
userName, userEmail, err := r.UserIdentityFromConfig()
if err != nil {
userName = ""
userEmail = ""
}
var (
now = time.Now()
author = &git.Signature{Name: userName, Email: userEmail, When: now}
committer = &git.Signature{Name: userName, Email: userEmail, When: now}
message = fmt.Sprintf(`Merge branch '%v' of %v`, remoteBranchName, remote.Url())
parents = []*git.Commit{
parentCommitOne,
parentCommitTwo,
}
)
_, err = r.CreateCommit(headRef.Name(), author, committer, message, tree, parents...)
if err != nil {
return err
}
return nil
}
func createMergeCommit(r *repo.Repo, index *git.Index, remote *git.Remote, remoteBranch *git.Branch) error {
try headRef := r.Head()
try parentObjOne := headRef.Peel(git.ObjectCommit)
try parentObjTwo := remoteBranch.Reference.Peel(git.ObjectCommit)
try parentCommitOne := parentObjOne.AsCommit()
try parentCommitTwo := parentObjTwo.AsCommit()
try treeOid := index.WriteTree()
try tree := r.LookupTree(treeOid)
try remoteBranchName := remoteBranch.Name()
try userName, userEmail := r.UserIdentityFromConfig() else err {
userName = ""
userEmail = ""
}
var (
now = time.Now()
author = &git.Signature{Name: userName, Email: userEmail, When: now}
committer = &git.Signature{Name: userName, Email: userEmail, When: now}
message = fmt.Sprintf(`Merge branch '%v' of %v`, remoteBranchName, remote.Url())
parents = []*git.Commit{
parentCommitOne,
parentCommitTwo,
}
)
try r.CreateCommit(headRef.Name(), author, committer, message, tree, parents...)
return nil
}
Bien que le modèle try / else n'enregistre pas beaucoup de caractères sur le composé if , il le fait :
- unifier la syntaxe de gestion des erreurs avec le
trynon géré - indiquer clairement en un coup d'œil qu'un bloc conditionnel gère une condition d'erreur
- donnez-nous une chance de réduire l'étrangeté de la portée dont souffrent les
ifcomposés
Les try non gérés seront probablement les plus courants, cependant.
brynbellomy
le 11 juin 2019
@ianlancetaylor
Essayez de lire ces exemples tout en survolant, essayez comme vous l'avez déjà fait sur if err != nil { return err }.
Je ne pense pas que ce soit possible/équivalent. Manquant qu'un essai existe dans une ligne encombrée, ou ce qu'il enveloppe exactement, ou qu'il y ait plusieurs instances dans une ligne... Ce n'est pas la même chose que de marquer facilement/rapidement un point de retour et de ne pas se soucier des détails qui s'y trouvent.
daved
le 11 juin 2019
@ianlancetaylor
Quand je vois un panneau d'arrêt, je le reconnais par sa forme et sa couleur plus qu'en lisant le mot imprimé dessus et en réfléchissant à ses implications plus profondes.
Mes yeux peuvent vitrer sur if err != nil { return err } mais en même temps, cela enregistre toujours clairement et instantanément.
Ce que j'aime dans la variante try -statement, c'est qu'elle réduit le passe-partout, mais d'une manière à la fois facile à masquer mais difficile à manquer.
Cela peut signifier une ligne supplémentaire ici ou là, mais c'est toujours moins de lignes que le statu quo.
jimmyfrasche
le 11 juin 2019
@brynbellomy
- Comment proposez-vous de gérer les fonctions qui renvoient plusieurs valeurs, comme :
func createMergeCommit(r *repo.Repo, index *git.Index, remote *git.Remote, remoteBranch *git.Branch) (hachage, erreur) { - Comment garderiez-vous une trace de la ligne correcte qui a renvoyé l'erreur
- rejetant le problème de portée (qui peut être résolu d'autres manières), je ne suis pas sûr
func createMergeCommit(r *repo.Repo, index *git.Index, remote *git.Remote, remoteBranch *git.Branch) error {
if headRef, err := r.Head(); err != nil {
return err
} else if parentObjOne, err := headRef.Peel(git.ObjectCommit); err != nil {
return err
} else parentObjTwo, err := remoteBranch.Reference.Peel(git.ObjectCommit); err != nil {
return err
} ...
n'est pas si différent en termes de lisibilité, mais (ou fmt.Errorf("error with getting head : %s", err.Error() ) vous permet de modifier et de donner facilement des données supplémentaires.
Ce qui est encore un bourrin, c'est le
- avoir à revérifier ; erreur != néant
- renvoyer l'erreur telle quelle si nous ne voulons pas donner les informations supplémentaires - ce qui, dans certains cas, n'est pas une bonne pratique, car vous dépendez de la fonction que vous appelez pour refléter une "bonne" erreur qui indiquera "ce qui s'est mal passé ", dans le cas des fonctions file.Open , close , Remove , Db, etc., de nombreux appels de fonction peuvent renvoyer la même erreur (nous pouvons discuter si cela signifie que le développeur qui a écrit l'erreur a fait du bon travail ou non... mais il arrive) - et ensuite - vous avez une erreur, enregistrez-la probablement à partir de la fonction qui a appelé
" createMergeCommit", mais je ne peux pas le retracer jusqu'à la ligne exacte sur laquelle il s'est produit.
guybrand
le 11 juin 2019
Désolé si quelqu'un a déjà posté quelque chose comme ça (il y a beaucoup de bonnes idées :P ) Que diriez-vous de cette syntaxe alternative :
fail := func(err error) error {
log.Print("unexpected error", err)
return err
}
a, b, err := f1() // normal
c, d := f2() -> throw // calls throw(err)
e, f := f3() -> panic // calls panic(err)
g, h := f4() -> t.Error // calls t.Error(err)
i, j := f5() -> fail // calls fail(err)
c'est-à-dire que vous avez un -> handler à droite d'un appel de fonction qui est appelé si l'erreur renvoyée != nil. Le gestionnaire est une fonction qui accepte une erreur en tant qu'argument unique et renvoie éventuellement une erreur (par exemple, func(error) ou func(error) error ). Si le gestionnaire renvoie une erreur nulle, la fonction continue, sinon l'erreur est renvoyée.
donc a := b() -> handler équivaut à :
a, err := b()
if err != nil {
if herr := handler(err); herr != nil {
return herr
}
}
Maintenant, en tant que raccourci, vous pouvez prendre en charge un try intégré (ou un mot-clé ou un opérateur ?= ou autre) qui est l'abréviation de a := b() -> throw afin que vous puissiez écrire quelque chose comme :
func() error {
a, b := try(f1())
c, d := try(f2())
e, f := try(f3())
...
return nil
}() -> panic // or throw/fail/whatever
Personnellement, je trouve un opérateur ?= plus facile à lire qu'un mot-clé try/intégré :
func() error {
a, b ?= f1()
c, d ?= f2()
e, f ?= f3()
...
return nil
}() -> panic
note : ici, j'utilise throw comme espace réservé pour une fonction intégrée qui renverrait l'erreur à l'appelant.
predmond
le 11 juin 2019
Je n'ai pas commenté les propositions de gestion des erreurs jusqu'à présent parce que je suis généralement en faveur et j'aime la façon dont elles se dirigent. La fonction try définie dans la proposition et l'instruction try proposée par @thepudds semblent être des ajouts raisonnables au langage. Je suis convaincu que tout ce que l'équipe de Go proposera sera une bonne chose.
Je veux soulever ce que je considère comme un problème mineur avec la façon dont try est défini dans la proposition et comment cela pourrait avoir un impact sur les extensions futures.
Try est défini comme une fonction prenant un nombre variable d'arguments.
func try(t1 T1, t2 T2, … tn Tn, te error) (T1, T2, … Tn)
Passer le résultat d'un appel de fonction à try comme dans try(f()) fonctionne implicitement en raison de la façon dont plusieurs valeurs de retour fonctionnent dans Go.
D'après ma lecture de la proposition, les extraits suivants sont à la fois valides et sémantiquement équivalents.
a, b = try(f())
//
u, v, err := f()
a, b = try(u, v, err)
La proposition soulève également la possibilité d'étendre try avec des arguments supplémentaires.
Si nous déterminons en cours de route que le fait d'avoir une forme de fonction de gestionnaire d'erreurs fournie explicitement, ou tout autre paramètre supplémentaire d'ailleurs, est une bonne idée, il est trivialement possible de transmettre cet argument supplémentaire à un appel try.
Supposons que nous voulions ajouter un argument de gestionnaire. Il peut soit aller au début soit à la fin de la liste des arguments.
var h handler
a, b = try(h, f())
// or
a, b = try(f(), h)
Le mettre au début ne fonctionne pas, car (compte tenu de la sémantique ci-dessus) try ne serait pas en mesure de faire la distinction entre un argument de gestionnaire explicite et une fonction qui renvoie un gestionnaire.
func f() (handler, error) { ... }
func g() (error) { ... }
try(f())
try(h, g())
Le mettre à la fin fonctionnerait probablement, mais alors try serait unique dans le langage comme étant la seule fonction avec un paramètre varargs au début de la liste d'arguments.
Aucun de ces problèmes n'est un obstacle, mais ils font que try semble incompatible avec le reste de la langue, et donc je ne suis pas sûr que try soit facile à étendre à l'avenir comme le états de la proposition.
 magical
le 11 juin 2019
magical
le 11 juin 2019
@magique
Avoir un gestionnaire est puissant, peut-être :
Je t'ai déjà déclaré h,
tu peux
var h handler
a, b, h = f()
ou
a, b, h.err = f()
si c'est une fonction comme:
h:= handler(err error){
log(...)
return ....
}
Ensuite, il y a eu une suggestion de
a, b, h(err) = f()
Tous peuvent invoquer le gestionnaire
Et vous pouvez également "sélectionner" le gestionnaire qui renvoie ou ne capture que l'erreur (conitnue/break/return) comme certains l'ont suggéré.
Et donc le problème des varargs a disparu.
guybrand
le 11 juin 2019
Une alternative à la suggestion else de @brynbellomy :
a, b := try f() else err { /* handle error */ }
pourrait être de prendre en charge une fonction de décoration immédiatement après le else :
decorate := func(err error) error { return fmt.Errorf("foo failed: %v", err) }
try a, b := f() else decorate
try c, d := g() else decorate
Et peut-être aussi des fonctions utilitaires du genre :
decorate := fmt.DecorateErrorf("foo failed")
La fonction de décoration peut avoir la signature func(error) error et être appelée par try en présence d'une erreur, juste avant que try ne revienne de la fonction associée en cours d'essai.
Ce serait similaire dans l'esprit à l'une des "itérations de conception" précédentes du document de proposition :
f := try(os.Open(filename), handler) // handler will be called in error case
Si quelqu'un veut quelque chose de plus complexe ou un bloc d'instructions, il peut utiliser à la place if (comme il le peut aujourd'hui).
Cela dit, il y a quelque chose de bien dans l'alignement visuel de try montré dans l'exemple de @brynbellomy dans https://github.com/golang/go/issues/32437#issuecomment -500949780.
Tout cela pourrait toujours fonctionner avec defer si cette approche est choisie pour une décoration d'erreur uniforme (ou même en théorie, il pourrait y avoir une autre forme d'enregistrement d'une fonction de décoration, mais c'est un point distinct).
Quoi qu'il en soit, je ne sais pas ce qui est le mieux ici, mais je voulais rendre explicite une autre option.
thepudds
le 11 juin 2019
Voici l'exemple de @brynbellomy réécrit avec la fonction try , en utilisant un bloc var pour conserver le bel alignement que @thepudds a souligné dans https://github.com/golang/go/issues /32437#issuecomment -500998690.
package main
import (
"fmt"
"time"
)
func createMergeCommit(r *repo.Repo, index *git.Index, remote *git.Remote, remoteBranch *git.Branch) error {
var (
headRef = try(r.Head())
parentObjOne = try(headRef.Peel(git.ObjectCommit))
parentObjTwo = try(remoteBranch.Reference.Peel(git.ObjectCommit))
parentCommitOne = try(parentObjOne.AsCommit())
parentCommitTwo = try(parentObjTwo.AsCommit())
treeOid = try(index.WriteTree())
tree = try(r.LookupTree(treeOid))
remoteBranchName = try(remoteBranch.Name())
)
userName, userEmail, err := r.UserIdentityFromConfig()
if err != nil {
userName = ""
userEmail = ""
}
var (
now = time.Now()
author = &git.Signature{Name: userName, Email: userEmail, When: now}
committer = &git.Signature{Name: userName, Email: userEmail, When: now}
message = fmt.Sprintf(`Merge branch '%v' of %v`, remoteBranchName, remote.Url())
parents = []*git.Commit{
parentCommitOne,
parentCommitTwo,
}
)
_, err = r.CreateCommit(headRef.Name(), author, committer, message, tree, parents...)
return err
}
C'est aussi succinct que la version try -statement, et je dirais tout aussi lisible. Étant donné que try est une expression, quelques-unes de ces variables intermédiaires pourraient être éliminées, au prix d'une certaine lisibilité, mais cela ressemble plus à une question de style qu'autre chose.
Cependant, cela soulève la question de savoir comment try fonctionne dans un bloc var . Je suppose que chaque ligne du var compte comme une déclaration distincte, plutôt que le bloc entier étant une seule déclaration, en ce qui concerne l'ordre de ce qui est attribué quand.
magical
le 11 juin 2019
Ce serait bien si la proposition "essayer" indiquait explicitement les conséquences pour des outils tels que cmd/cover qui se rapprochent des statistiques de couverture de test en utilisant un comptage naïf des déclarations. Je crains que le flux de contrôle d'erreur invisible n'entraîne un sous-dénombrement.
 masiulaniec
le 11 juin 2019
masiulaniec
le 11 juin 2019
@thepudds
essayez a, b := f() sinon décorer
C'est peut-être une brûlure trop profonde dans mes cellules cérébrales, mais cela me frappe trop en tant que
try a, b := f() ;catch(decorate)
et une pente glissante vers un
a, b := f()
catch(decorate)
Je pense que vous pouvez voir où cela mène, et pour moi, comparer
try headRef := r.Head()
try parentObjOne := headRef.Peel(git.ObjectCommit)
try parentObjTwo := remoteBranch.Reference.Peel(git.ObjectCommit)
try parentCommitOne := parentObjOne.AsCommit()
try parentCommitTwo := parentObjTwo.AsCommit()
try treeOid := index.WriteTree()
try tree := r.LookupTree(treeOid)
try remoteBranchName := remoteBranch.Name()
avec
try (
headRef := r.Head()
parentObjOne := headRef.Peel(git.ObjectCommit)
parentObjTwo := remoteBranch.Reference.Peel(git.ObjectCommit)
parentCommitOne := parentObjOne.AsCommit()
parentCommitTwo := parentObjTwo.AsCommit()
treeOid := index.WriteTree()
tree := r.LookupTree(treeOid)
remoteBranchName := remoteBranch.Name()
)
(ou même un hic à la fin)
La seconde est plus lisible, mais met l'accent sur le fait que les fonctions ci-dessous renvoient 2 vars, et nous en supprimons une comme par magie, en la collectant dans un "magic return err" .
try(err) (
headRef := r.Head()
parentObjOne := headRef.Peel(git.ObjectCommit)
parentObjTwo := remoteBranch.Reference.Peel(git.ObjectCommit)
parentCommitOne := parentObjOne.AsCommit()
parentCommitTwo := parentObjTwo.AsCommit()
treeOid := index.WriteTree()
tree := r.LookupTree(treeOid)
remoteBranchName := remoteBranch.Name()
); err!=nil {
//handle the err
}
définit au moins explicitement la variable à renvoyer et me laisse la gérer dans la fonction, quand je le souhaite.
guybrand
le 11 juin 2019
J'ajoute juste un commentaire spécifique car je n'ai vu personne d'autre le mentionner explicitement, en particulier à propos de la modification gofmt pour prendre en charge le formatage sur une seule ligne suivant, ou toute variante :
if f() { return nil, err }
Je t'en prie, non. Si nous voulons une seule ligne if alors veuillez créer une seule ligne if , par exemple :
if f() then return nil, err
Mais s'il vous plaît, s'il vous plaît, s'il vous plaît, n'acceptez pas la salade de syntaxe en supprimant les sauts de ligne qui facilitent la lecture du code qui utilise des accolades.
mikeschinkel
le 12 juin 2019
J'aime souligner quelques points qui ont peut-être été oubliés dans le feu de la discussion :
1) L'intérêt de cette proposition est de faire en sorte que la gestion des erreurs courantes passe à l'arrière-plan - la gestion des erreurs ne doit pas dominer le code. Mais doit encore être explicite. Toutes les suggestions alternatives qui font ressortir encore plus la gestion des erreurs manquent le point. Comme @ianlancetaylor l' a déjà dit, si ces suggestions alternatives ne réduisent pas de manière significative la quantité de passe-partout, nous pouvons simplement rester avec les déclarations if . (Et la demande de réduction passe-partout vient de vous, la communauté Go.)
2) L'une des plaintes concernant la proposition actuelle est la nécessité de nommer le résultat d'erreur afin d'y avoir accès. Toute proposition alternative aura le même problème à moins que l'alternative n'introduise une syntaxe supplémentaire, c'est-à-dire plus de passe-partout (comme ... else err { ... } et autres) pour nommer explicitement cette variable. Mais ce qui est intéressant : si nous ne nous soucions pas de décorer une erreur et que nous ne nommons pas les paramètres de résultat, mais que nous avons toujours besoin d'un return explicite parce qu'il existe une sorte de gestionnaire explicite, cette instruction return devra énumérer toutes les valeurs de résultat (généralement zéro) car un retour nu n'est pas autorisé dans ce cas. Surtout si une fonction fait beaucoup de retours d'erreur sans décorer l'erreur, ces retours explicites ( return nil, err , etc.) s'ajoutent au passe-partout. La proposition actuelle, et toute alternative qui ne nécessite pas de return explicite, supprime cela. D'autre part, si l'on veut décorer l'erreur, la proposition actuelle _requiert_ que l'on nomme le résultat de l'erreur (et avec cela tous les autres résultats) pour avoir accès à la valeur de l'erreur. Cela a l'effet secondaire agréable que dans un gestionnaire explicite, on peut utiliser un retour nu et n'a pas à répéter toutes les autres valeurs de résultat. (Je sais qu'il y a des sentiments forts à propos des retours nus, mais la réalité est que lorsque tout ce qui nous intéresse est le résultat d'erreur, c'est une véritable nuisance d'avoir à énumérer toutes les autres valeurs de résultat (généralement zéro) - cela n'ajoute rien au compréhension du code). En d'autres termes, le fait de devoir nommer le résultat d'erreur afin qu'il puisse être décoré permet une réduction supplémentaire du passe-partout.
griesemer
le 12 juin 2019
@magical Merci de l' avoir signalé. J'ai remarqué la même chose peu de temps après avoir publié la proposition (mais je ne l'ai pas évoquée pour ne pas semer la confusion). Vous avez raison de dire que tel quel, try ne peut pas être étendu. Heureusement, la solution est assez simple. (Il se trouve que nos propositions internes précédentes n'avaient pas ce problème - il a été introduit lorsque j'ai réécrit notre version finale pour publication et essayé de simplifier try pour qu'il corresponde plus étroitement aux règles de passage de paramètres existantes. - mais il s'avère qu'il est imparfait et surtout inutile - avantage de pouvoir écrire try(a, b, c, handle) .)
Une version antérieure de try définissait à peu près comme suit : try(expr, handler) prend une (ou peut-être deux) expressions comme arguments, où la première expression peut être à valeurs multiples (ne peut se produire que si l'expression est un appel de fonction). La dernière valeur de cette expression (éventuellement à valeurs multiples) doit être de type error , et cette valeur est testée par rapport à nil. (etc. - le reste vous pouvez imaginer).
Quoi qu'il en soit, le fait est que try n'accepte syntaxiquement qu'une ou peut-être deux expressions. (Mais il est un peu plus difficile de décrire la sémantique de try .) La conséquence serait ce code tel que :
a, b := try(u, v, err)
ne serait plus autorisé. Mais il y a peu de raisons pour que cela fonctionne en premier lieu : dans la plupart des cas (à moins que a et b ne soient des résultats nommés), ce code - s'il est important pour une raison quelconque - pourrait être réécrit facilement dans
a, b := u, v // we don't care if the assignment happens in case of an error
try(err)
(ou utilisez une instruction if si nécessaire). Mais encore une fois, cela semble sans importance.
griesemer
le 12 juin 2019
cette instruction de retour devra énumérer toutes les valeurs de résultat (généralement zéro) car un retour nu n'est pas autorisé dans ce cas
Un retour nu n'est pas autorisé, mais essayer le serait. Une chose que j'aime à propos de try (que ce soit en tant que fonction ou instruction) est que je n'aurai plus besoin de réfléchir à la façon de définir des valeurs sans erreur lors du renvoi d'une erreur, j'utiliserai simplement try.
yiyus
le 12 juin 2019
@griesemer Merci pour l'explication. C'est aussi la conclusion à laquelle je suis arrivé.
magical
le 12 juin 2019
Un bref commentaire sur try comme déclaration : comme je pense que l'on peut le voir dans l'exemple de https://github.com/golang/go/issues/32437#issuecomment -501035322, le try enterre le lede. Le code devient une série d'instructions try , ce qui masque ce que le code fait réellement.
ianlancetaylor
le 12 juin 2019
Le code existant peut réutiliser une variable d'erreur nouvellement déclarée après le bloc if err != nil . Masquer la variable casserait cela, et ajouter une variable de retour nommée à la signature de la fonction ne le résoudra pas toujours.
Il est peut-être préférable de laisser la déclaration/affectation d'erreur telle quelle et de trouver un stmt de gestion des erreurs sur une ligne.
err := f() // followed by one of
on err, return err // any type can be tested for non-zero
on err, return fmt.Errorf(...)
on err, fmt.Println(err) // doesn't stop the function
on err, hname err // handler invocation without parens
on err, ignore err // optional ignore handler logs error if defined
if err, return err // alternatively, use if
handle hname(err error, clr caller) { // type caller has results of runtime.Caller()
if err == io.Bad { return err }
fmt.Println(clr.name, err)
}
Une sous-expression try pourrait paniquer, ce qui signifie qu'une erreur n'est jamais attendue. Une variante de cela pourrait ignorer toute erreur.
f(try g()) // panic on error
f(try_ g()) // ignore any error
L'intérêt de cette proposition est de faire en sorte que la gestion des erreurs courantes passe à l'arrière-plan - la gestion des erreurs ne doit pas dominer le code. Mais doit encore être explicite.
J'aime l'idée des commentaires listant try comme une déclaration. C'est explicite, toujours facile à passer sous silence (puisqu'il est de longueur fixe), mais pas si facile à passer sous silence (puisque c'est toujours au même endroit) qu'ils peuvent être cachés dans une ligne bondée. Il peut également être combiné avec le defer fmt.HandleErrorf(...) comme indiqué précédemment, mais il a le piège d'abuser des paramètres nommés afin d'envelopper les erreurs (ce qui me semble toujours être un hack intelligent. les hacks intelligents sont mauvais.)
L'une des raisons pour lesquelles je n'ai pas aimé try en tant qu'expression est qu'il est soit trop facile à passer sous silence, soit pas assez facile à passer sous silence. Prenons les deux exemples suivants :
Essayer comme expression
// Too hidden, it's in a crowded function with many symbols that complicate the function.
f, err := os.OpenFile(try(FileName()), os.O_APPEND|os.O_WRONLY, 0600)
// Not easy enough, the word "try" already increases horizontal complexity, and it
// being an expression only encourages more horizontal complexity.
// If this code weren't collapsed to multiple lines, it would be extremely
// hard to read and unclear as to what's executing when.
fullContents := try(io.CopyN(
os.Stdout,
try(net.Dial("tcp", "localhost:"+try(buf.ReadString("\n"))),
try(strconv.Atoi(try(buf.ReadString("\n")))),
))
Essayez comme déclaration
// easy to see while still not being too verbose
try name := FileName()
os.OpenFile(name, os.O_APPEND|os.O_WRONLY, 0600)
// does not allow for clever one-liners, code remains much more readable.
// also, the code reads in sequence from top-to-bottom.
try port := r.ReadString("\n")
try lengthStr := r.ReadString("\n")
try length := strconv.Atoi(lengthStr)
try con := net.Dial("tcp", "localhost:"+port)
try io.CopyN(os.Stdout, con, length)
Plats à emporter
Ce code est définitivement artificiel, je l'admets. Mais ce que je veux dire, c'est que, en général, try en tant qu'expression ne fonctionne pas bien dans :
- Au milieu d'expressions encombrées qui ne nécessitent pas beaucoup de vérification d'erreurs
- Instructions multilignes relativement simples nécessitant de nombreuses vérifications d'erreurs
Je suis cependant d'accord avec @ianlancetaylor sur le fait que commencer chaque ligne par try semble gêner la partie importante de chaque instruction (la variable en cours de définition ou la fonction en cours d'exécution). Cependant, je pense que parce qu'il se trouve au même endroit et qu'il a une largeur fixe, il est beaucoup plus facile de passer sous silence, tout en le remarquant. Cependant, les yeux de chacun sont différents.
Je pense aussi qu'encourager les one-liners intelligents dans le code est juste une mauvaise idée en général. Je suis surpris de pouvoir créer un one-liner aussi puissant que dans mon premier exemple, c'est un extrait qui mérite toute sa fonction car il en fait tellement - mais il tient sur une ligne si je ne l'avais pas effondré à plusieurs pour des raisons de lisibilité. Tout en une ligne :
fullContents := try(io.CopyN(os.Stdout, try(net.Dial("tcp", "localhost:"+try(r.ReadString("\n"))), try(strconv.Atoi(try(r.ReadString("\n"))))))
Il lit un port à partir d'un *bufio.Reader , démarre une connexion TCP et copie un nombre d'octets spécifié par le même *bufio.Reader vers stdout . Le tout avec gestion des erreurs. Pour un langage avec des conventions de codage aussi strictes, je ne pense pas que cela devrait vraiment être autorisé. Je suppose que gofmt pourrait aider avec ça, cependant.
deanveloper
le 12 juin 2019
Pour un langage avec des conventions de codage aussi strictes, je ne pense pas que cela devrait vraiment être autorisé.
Il est possible d'écrire du code abominable en Go. Il est même possible de le formater terriblement ; il n'y a que des normes et des outils solides contre cela. Go a même goto .
Lors des révisions de code, je demande parfois aux gens de décomposer des expressions compliquées en plusieurs instructions, avec des noms intermédiaires utiles. Je ferais quelque chose de similaire pour les try profondément imbriqués, pour la même raison.
Ce qui revient à dire : n'essayons pas trop d'interdire le mauvais code, au prix de déformer le langage. Nous avons d'autres mécanismes pour garder le code propre qui conviennent mieux à quelque chose qui implique fondamentalement un jugement humain au cas par cas.
josharian
le 12 juin 2019
Il est possible d'écrire du code abominable en Go. Il est même possible de le formater terriblement ; il n'y a que des normes et des outils solides contre cela. Allez même a goto.
Lors des révisions de code, je demande parfois aux gens de décomposer des expressions compliquées en plusieurs instructions, avec des noms intermédiaires utiles. Je ferais quelque chose de similaire pour les trys profondément imbriqués, pour la même raison.
Ce qui revient à dire : n'essayons pas trop d'interdire le mauvais code, au prix de déformer le langage. Nous avons d'autres mécanismes pour garder le code propre qui conviennent mieux à quelque chose qui implique fondamentalement un jugement humain au cas par cas.
C'est un bon point. Nous ne devrions pas interdire une bonne idée simplement parce qu'elle peut être utilisée pour créer du mauvais code. Cependant, je pense que si nous avons une alternative qui favorise un meilleur code, cela peut être une bonne idée. Je n'ai vraiment pas vu beaucoup parler _contre_ l'idée brute derrière try en tant que déclaration (sans tous les déchets else { ... } ) jusqu'au commentaire de @ianlancetaylor , mais je l'ai peut-être manqué.
De plus, tout le monde n'a pas de réviseurs de code, certaines personnes (surtout dans un avenir lointain) devront maintenir un code Go non révisé. Go en tant que langage fait normalement un très bon travail en s'assurant que presque tout le code écrit est bien maintenable (au moins après un go fmt ), ce qui n'est pas un exploit à négliger.
Cela étant dit, je critique terriblement cette idée alors qu'elle n'est vraiment pas horrible.
deanveloper
le 12 juin 2019
Try en tant qu'instruction réduit considérablement le passe-partout, et plus que try en tant qu'expression, si nous lui permettons de fonctionner sur un bloc d'expressions comme cela a été proposé auparavant, même sans autoriser un bloc else ou un gestionnaire d'erreurs. En utilisant ceci, l'exemple de deandeveloper devient :
try (
name := FileName()
file := os.OpenFile(name, os.O_APPEND|os.O_WRONLY, 0600)
port := r.ReadString("\n")
lengthStr := r.ReadString("\n")
length := strconv.Atoi(lengthStr)
con := net.Dial("tcp", "localhost:"+port)
io.CopyN(os.Stdout, con, length)
)
Si l'objectif est de réduire le passe-partout if err!= nil {return err} , alors je pense que l'énoncé try qui permet de prendre un bloc de code a le plus de potentiel pour le faire, sans devenir flou.
beoran
le 12 juin 2019
@beoran À ce stade, pourquoi avoir essayé du tout ? Autorisez simplement une affectation où la dernière valeur d'erreur est manquante et faites-la se comporter comme s'il s'agissait d'une instruction try (ou d'un appel de fonction). Non pas que je le propose, mais cela réduirait encore plus le passe-partout.
Je pense que le passe-partout serait efficacement réduit par ces blocs var, mais je crains que cela ne conduise à une énorme quantité de code en retrait d'un niveau supplémentaire, ce qui serait malheureux.
yiyus
le 12 juin 2019
@deanveloper
fullContents := try(io.CopyN(os.Stdout, try(net.Dial("tcp", "localhost:"+try(r.ReadString("\n"))), try(strconv.Atoi(try(r.ReadString("\n"))))))
Je dois admettre que ce n'est pas lisible pour moi, j'aurais probablement l'impression que je dois :
fullContents := try(io.CopyN(os.Stdout,
try(net.Dial("tcp", "localhost:"+try(r.ReadString("\n"))),
try(strconv.Atoi(try(r.ReadString("\n"))))))
ou similaire, pour la lisibilité, puis nous revenons avec un "essayer" au début de chaque ligne, avec une indentation.
guybrand
le 12 juin 2019
Eh bien, je pense que nous aurions toujours besoin de l'essai pour la rétrocompatibilité, et aussi pour être explicite sur un retour qui peut se produire dans le bloc. Mais notez que je ne fais que suivre la logique de réduire la plaque de chaudière et de voir ensuite où cela nous mène. Il y a toujours une tension entre la réduction du passe-partout et la clarté. Je pense que le principal problème qui se pose dans ce dossier est que nous semblons tous ne pas être d'accord sur l'équilibre à trouver.
En ce qui concerne les retraits, c'est à cela que sert go fmt, donc personnellement, je ne pense pas que ce soit vraiment un problème.
beoran
le 12 juin 2019
J'aimerais me joindre à la mêlée pour mentionner deux autres possibilités, chacune étant indépendante, je les garderai donc dans des articles séparés.
Je pensais que la suggestion selon laquelle try() (sans arguments) pouvait être définie pour renvoyer un pointeur vers la variable de retour d'erreur était intéressante, mais je n'étais pas enthousiaste à l'idée de ce genre de jeu de mots - cela sent la surcharge de fonction , quelque chose que Go évite.
Cependant, j'ai aimé l'idée générale d'un identifiant prédéfini qui fait référence à la valeur d'erreur locale.
Alors, que diriez-vous de prédéfinir l'identifiant err lui-même comme un alias pour la variable de retour d'erreur ? Donc ce serait valable :
func foo() error {
defer handleError(&err, etc)
try(something())
}
Il serait fonctionnellement identique à :
func foo() (err error) {
defer handleError(&err, etc)
try(something())
}
L'identificateur err serait défini au niveau de l'univers, même s'il agit comme un alias de fonction locale, de sorte que toute définition au niveau du package ou de fonction locale de err le remplacerait. Cela peut sembler dangereux mais j'ai scanné les lignes de Go de 22m dans le corpus Go et c'est très rare. Il n'y a que 4 instances distinctes err utilisées comme global (toutes comme une variable, pas un type ou une constante) - c'est quelque chose dont vet pourrait avertir.
Il est possible qu'il y ait deux variables de retour d'erreur de fonction dans la portée ; dans ce cas, je pense qu'il est préférable que le compilateur se plaigne de l'ambiguïté et demande à l'utilisateur de nommer explicitement la variable de retour correcte. Ce serait donc invalide :
func foo() error {
f := func() error {
defer handleError(&err, etc)
try(something())
return nil
}
return f()
}
mais vous pouvez toujours écrire ceci à la place :
func foo() error {
f := func() (err error) {
defer handleError(&err, etc)
try(something())
return nil
}
return f()
}
Au sujet de try comme identifiant prédéfini plutôt que comme opérateur,
Je me suis retrouvé à avoir tendance à préférer ce dernier après s'être trompé à plusieurs reprises dans les crochets lors de l'écriture :
try(try(os.Create(filename)).Write(data))
Sous "Pourquoi ne pouvons-nous pas utiliser ? comme Rust", la FAQ indique :
Jusqu'à présent, nous avons évité les abréviations ou symboles cryptés dans le langage, y compris les opérateurs inhabituels tels que ?, qui ont des significations ambiguës ou non évidentes.
Je ne suis pas tout à fait sûr que ce soit vrai. L'opérateur .() est inhabituel jusqu'à ce que vous connaissiez Go, tout comme les opérateurs de canal. Si nous ajoutions un opérateur ? , je pense qu'il deviendrait bientôt suffisamment omniprésent pour ne pas constituer un obstacle important.
L'opérateur Rust ? est cependant ajouté après la parenthèse fermante d'un appel de fonction, ce qui signifie qu'il est facile de le rater lorsque la liste d'arguments est longue.
Que diriez-vous d'ajouter ?() en tant qu'opérateur d'appel :
Donc au lieu de :
x := try(foo(a, b))
tu ferais :
x := foo?(a, b)
La sémantique de ?() serait très similaire à celle de l'intégré try proposé. Il agirait comme un appel de fonction sauf que la fonction ou la méthode appelée doit renvoyer une erreur comme dernier argument. Comme avec try , si l'erreur est non nulle, l'instruction ?() la renverra.
rogpeppe
le 12 juin 2019
Il semble que la discussion soit suffisamment focalisée pour que nous tournions maintenant autour d'une série de compromis bien définis et discutés. C'est encourageant, du moins pour moi, car le compromis est tout à fait dans l'esprit de ce langage.
@ianlancetaylor Je concéderai absolument que nous nous retrouverons avec des dizaines de lignes préfixées par try . Cependant, je ne vois pas en quoi c'est pire que des dizaines de lignes postfixées par une expression conditionnelle de deux à quatre lignes indiquant explicitement la même expression return . En fait, try (avec des clauses else ) permet de repérer un peu plus facilement quand un gestionnaire d'erreurs fait quelque chose de spécial/non par défaut. De plus, tangentiellement, re: expressions conditionnelles if , je pense qu'elles enterrent le lede plus que le try proposé -as-a-statement: l'appel de fonction vit sur la même ligne que le conditionnel , la condition elle-même se termine à la toute fin d'une ligne déjà encombrée et les affectations de variables sont limitées au bloc (ce qui nécessite une syntaxe différente si vous avez besoin de ces variables après le bloc).
@josharian J'ai eu cette pensée assez récemment. Go aspire au pragmatisme, pas à la perfection, et son développement semble souvent être axé sur les données plutôt que sur les principes. Vous pouvez écrire un Go terrible, mais c'est généralement plus difficile que d'écrire un Go décent (ce qui est assez bon pour la plupart des gens). Il convient également de souligner que nous disposons de nombreux outils pour lutter contre le mauvais code : pas seulement gofmt et go vet , mais aussi nos collègues et la culture que cette communauté a (très soigneusement) conçue pour se guider. Je détesterais éviter les améliorations qui aident le cas général simplement parce que quelqu'un quelque part pourrait s'en prendre à lui-même.
@beoran C'est élégant, et quand on y pense, c'est en fait sémantiquement différent des blocs try des autres langages, car il n'a qu'un seul résultat possible : revenir de la fonction avec une erreur non gérée. Cependant : 1) cela est probablement déroutant pour les nouveaux codeurs Go qui ont travaillé avec ces autres langages (honnêtement, ce n'est pas ma plus grande préoccupation ; je fais confiance à l'intelligence des programmeurs), et 2) cela entraînera l'indentation d'énormes quantités de code dans de nombreux bases de code. En ce qui concerne mon code, j'ai même tendance à éviter les blocs type / const / var existants pour cette raison. De plus, les seuls mots-clés qui autorisent actuellement des blocs comme celui-ci sont les définitions, pas les instructions de contrôle.
@yiyus Je ne suis pas d'accord avec la suppression du mot-clé, car l'explicitation est (à mon avis) l'une des vertus de Go. Mais je conviens que l'indentation d' énormes quantités de code pour tirer parti des expressions try est une mauvaise idée. Alors peut-être pas de blocs try du tout ?
brynbellomy
le 12 juin 2019
@rogpeppe Je pense que ce type d'opérateur subtil n'est raisonnable que pour les appels qui ne devraient jamais renvoyer d'erreur, et donc paniquez s'ils le font. Ou des appels où vous ignorez toujours l'erreur. Mais les deux semblent rares. Si vous êtes ouvert à un nouvel opérateur, voir #32500.
J'ai suggéré que f(try g()) devrait paniquer dans https://github.com/golang/go/issues/32437#issuecomment -501074836, avec un stmt de gestion d'une ligne :
on err, return ...
networkimprov
le 12 juin 2019
Je pense que l'option else dans try ... else { ... } poussera trop le code vers la droite, l'obscurcissant peut-être. Je m'attends à ce que le bloc d'erreur prenne au moins 25 caractères la plupart du temps. De plus, jusqu'à présent, les blocs ne sont pas conservés sur la même ligne par go fmt et je m'attends à ce que ce comportement soit conservé pendant try else . Nous devrions donc discuter et comparer des échantillons où le bloc else se trouve sur une ligne distincte. Mais même alors, je ne suis pas sûr de la lisibilité de else { à la fin de la ligne.
carloslenz
le 12 juin 2019
@yiyus https://github.com/golang/go/issues/32437#issuecomment -501139662
@beoran À ce stade, pourquoi avoir essayé du tout ? Autorisez simplement une affectation où la dernière valeur d'erreur est manquante et faites-la se comporter comme s'il s'agissait d'une instruction try (ou d'un appel de fonction). Non pas que je le propose, mais cela réduirait encore plus le passe-partout.
Cela ne peut pas être fait car Go1 permet déjà d'appeler un func foo() error comme juste foo() . L'ajout , error aux valeurs de retour de l'appelant modifierait le comportement du code existant à l'intérieur de cette fonction. Voir https://github.com/golang/go/issues/32437#issuecomment -500289410
tv42
le 13 juin 2019
@rogpeppe Dans votre commentaire sur la bonne mise en place des parenthèses avec les try imbriqués : Avez-vous des opinions sur la priorité de try ? Voir aussi la doc de conception détaillée à ce sujet .
griesemer
le 13 juin 2019
@griesemer Je ne suis en effet pas très intéressé par try en tant qu'opérateur de préfixe unaire pour les raisons qui y sont indiquées. Il m'est venu à l'esprit qu'une approche alternative serait d'autoriser try comme pseudo-méthode sur un tuple de retour de fonction :
f := os.Open(path).try()
Cela résout le problème de priorité, je pense, mais ce n'est pas vraiment très Go-like.
rogpeppe
le 13 juin 2019
@rogpeppe
Très intéressant! . Vous pouvez vraiment être sur quelque chose ici.
Et si on étendait cette idée comme ça ?
for _,fp := range filepaths {
f := os.Open(path).try(func(err error)bool{
fmt.Printf( "Cannot open file %s\n", fp );
continue;
});
}
BTW, je préférerais peut-être un nom différent try() comme peut-être guard() mais je ne devrais pas changer le nom avant que l'architecture ne soit discutée par d'autres.
mikeschinkel
le 13 juin 2019
vs :
for _,fp := range filepaths {
if f,err := os.Open(path);err!=nil{
fmt.Printf( "Cannot open file %s\n", fp )
}
}
?
guybrand
le 13 juin 2019
J'aime le try a,b := foo() au lieu de if err!=nil {return err} car il remplace un passe-partout pour un cas vraiment simple. Mais pour tout ce qui ajoute du contexte, faut-il vraiment autre chose que if err!=nil {...} (ce sera très difficile de trouver mieux) ?
 flibustenet
le 13 juin 2019
flibustenet
le 13 juin 2019
Si une ligne supplémentaire est généralement requise pour la décoration/l'emballage, "attribuons-lui" simplement une ligne.
f, err := os.Open(path) // normal Go \o/
on err, return fmt.Errorf("Cannot open %s, due to %v", path, err)
@networkimprov Je pense que je pourrais aussi aimer ça. Poussant un terme plus allitératif et descriptif que j'ai déjà évoqué...
f, err := os.Open(path)
relay err { nil, fmt.Errorf("Cannot open %s, due to %v", path, err) }
// marginally shorter, doesn't trigger vertical formatting unless excessively wide
// enclosed expression restricted to a list of values that match the return args
ou
f, err := os.Open(path)
relay(err) nil, fmt.Errorf("Cannot open %s, due to %v", path, err)
// somewhere between statement and func, prob more pleasing to type w/out completion
// trailing expression restricted to a list of values that match the return args
// maybe excessive width triggers linting noise - with a reformatter available
// providing a reformatter would make swapping old (narrow enough) code easy
@daved content que ça te plaise ! on err, ... autoriserait n'importe quel gestionnaire stmt :
err := f() // followed by one of
on err, return err // any type can be tested for non-zero
on err, return fmt.Errorf(...)
on err, fmt.Println(err) // doesn't stop the function
on err, continue // retry in a loop
on err, hname err // named handler invocation without parens
on err, ignore err // logs error if handle ignore() defined
handle hname(err error, clr caller) { // type caller has results of runtime.Caller()
if err == io.Bad { return err } // non-local return
fmt.Println(clr, err)
}
EDIT : on emprunte à Javascript. Je ne voulais pas surcharger if .
Une virgule n'est pas essentielle, mais je n'aime pas le point-virgule ici. Peut-être du côlon ?
Je ne suis pas tout à fait relay ; cela signifie retour sur erreur?
networkimprov
le 13 juin 2019
Un relais de protection est déclenché lorsqu'une condition est remplie. Dans ce cas, lorsqu'une valeur d'erreur n'est pas nulle, le relais modifie le flux de contrôle pour revenir en utilisant les valeurs suivantes.
* Je ne voudrais pas surcharger , pour ce cas, et je ne suis pas fan du terme on , mais j'aime la prémisse et l'aspect général de la structure du code.
daved
le 13 juin 2019
Pour le point de @josharian plus tôt, j'ai l'impression qu'une grande partie de la discussion sur la correspondance des parenthèses est principalement hypothétique et utilise des exemples artificiels. Je ne sais pas pour vous, mais je n'ai pas de difficulté à écrire des appels de fonction dans ma programmation quotidienne. Si j'arrive à un point où une expression devient difficile à lire ou à comprendre, je la divise en plusieurs expressions à l'aide de variables intermédiaires. Je ne vois pas pourquoi try() avec la syntaxe d'appel de fonction serait différent à cet égard dans la pratique.
eandre
le 13 juin 2019
@eandre Normalement, les fonctions n'ont pas une telle définition dynamique. De nombreuses formes de cette proposition diminuent la sécurité entourant la communication du flux de contrôle, et c'est gênant.
daved
le 13 juin 2019
@networkimprov @daved Je n'aime pas ces deux idées, mais elles ne semblent pas être une amélioration suffisante par rapport à l'autorisation d'instructions if err != nil { ... } sur une seule ligne pour justifier un changement de langue. En outre, fait-il quelque chose pour réduire le passe-partout répétitif dans le cas où vous renvoyez simplement l'erreur? Ou est-ce l'idée que vous devez toujours écrire le return ?
brynbellomy
le 13 juin 2019
@brynbellomy Dans mon exemple, il n'y a pas return . relay est un relais de protection défini comme "si cette erreur n'est pas nulle, ce qui suit sera renvoyé".
En utilisant mon deuxième exemple de plus tôt:
f, err := os.Open(path)
relay(err) nil, fmt.Errorf("Cannot open %s, due to %v", path, err)
Peut aussi être quelque chose comme :
f, err := os.Open(path)
relay(err)
L'erreur qui déclenche le relais étant renvoyée avec des valeurs nulles pour les autres valeurs de retour (ou toutes les valeurs définies pour les valeurs renvoyées nommées). Autre formulaire qui pourrait être utile :
wrap := func(err error, msg string) error {
if err != nil {
fmt.Errorf("%s: %s", msg, err)
}
return nil
}
// ...
f, err := os.Open(path)
relay(err, wrap(err, fmt.Sprintf("Cannot open %s", path)))
Où le deuxième relais arg n'est pas appelé à moins que le relais ne soit déclenché par le premier relais arg. Le deuxième argument optionnel d'erreur de relais serait la valeur renvoyée.
daved
le 13 juin 2019
_go fmt_ devrait-il autoriser une seule ligne if mais pas case, for, else, var () ? Je les veux tous s'il vous plait ;-)
L'équipe Go a rejeté de nombreuses demandes de vérification d'erreurs sur une seule ligne.
Les instructions on err, return err peuvent être répétitives, mais elles sont explicites, concises et claires.
networkimprov
le 13 juin 2019
@magical Vos commentaires ont été pris en compte dans la version mise à jour de la proposition détaillée .
griesemer
le 13 juin 2019
Une petite chose, mais si try est un mot-clé, il pourrait être reconnu comme une instruction de fin donc au lieu de
func f() error {
try(g())
return nil
}
tu peux juste faire
func f() error {
try g()
}
( try -statement obtient cela gratuitement, try -operator aurait besoin d'un traitement spécial, je me rends compte que ce qui précède n'est pas un bon exemple: mais c'est minime)
jimmyfrasche
le 13 juin 2019
@jimmyfrasche try pourrait être reconnu comme une instruction de fin même s'il ne s'agit pas d'un mot-clé - nous le faisons déjà avec panic , il n'y a pas de traitement spécial supplémentaire nécessaire en plus de ce que nous faisons déjà. Mais à part cela, try n'est pas une instruction de fin, et essayer d'en faire une artificiellement semble étrange.
griesemer
le 13 juin 2019
Tous les points valides. Je suppose que cela ne peut être considéré de manière fiable comme une instruction de fin que si c'est la toute dernière ligne d'une fonction qui ne renvoie qu'une erreur, comme CopyFile dans la proposition détaillée, ou si elle est utilisée comme try(err) dans un if où il est connu que err != nil . Cela ne semble pas en valoir la peine.
jimmyfrasche
le 13 juin 2019
Étant donné que ce fil devient long et difficile à suivre (et commence à se répéter dans une certaine mesure), je pense que nous serions tous d'accord pour dire que nous aurions besoin de faire des compromis sur "certains des avantages de toute proposition".
Comme nous continuons à aimer ou à ne pas aimer les permutations de code proposées ci-dessus, nous ne nous aidons pas à comprendre "est-ce un compromis plus sensé qu'un autre/ce qui a déjà été proposé" ?
Je pense que nous avons besoin de critères objectifs pour évaluer nos variantes "à essayer" et nos propositions alternatives.
- Est-ce que ça diminue le passe-partout ?
- Lisibilité
- Complexité ajoutée au langage
- Normalisation des erreurs
- Go-ish
...
... - effort de mise en œuvre et risques
...
Nous pouvons bien sûr également définir des règles de base pour les interdictions (aucune rétrocompatibilité n'en serait une), et laisser une zone grise pour "est-ce que ça a l'air attrayant/sentiment instinctif, etc. (les critères "durs" ci-dessus peuvent également être discutables.. .).
Si nous testons une proposition par rapport à cette liste et évaluons chaque point (type 5 points, lisibilité 4 points, etc.), je pense plutôt que nous pouvons nous aligner sur :
Nos options sont probablement A, B et C, de plus, quelqu'un souhaitant ajouter une nouvelle proposition, pourrait tester (dans une certaine mesure) si sa proposition répond aux critères.
Si cela a du sens, pouce vers le haut , nous pouvons essayer de revoir la proposition originale
https://github.com/golang/proposal/blob/master/design/32437-try-builtin.md
Et peut-être que certaines des autres propositions sont alignées sur les commentaires ou liées, peut-être que nous apprendrions quelque chose, ou même trouverions un mélange qui aurait une note plus élevée.
guybrand
le 13 juin 2019
Critères += réutilisation du code de gestion des erreurs, à travers le package et au sein de la fonction
networkimprov
le 13 juin 2019
Merci à tous pour vos commentaires continus sur cette proposition.
La discussion s'est un peu éloignée de la question centrale. Il est également devenu dominé par une douzaine de contributeurs (vous savez qui vous êtes) qui élaborent ce qui équivaut à des propositions alternatives.
Permettez-moi donc de vous rappeler amicalement que ce problème concerne une proposition _spécifique_ . Ceci n'est _pas_ une sollicitation de nouvelles idées syntaxiques pour la gestion des erreurs (ce qui est une bonne chose à faire, mais ce n'est pas _ce_ problème).
Concentrons à nouveau la discussion et remettons-nous sur les rails.
Les commentaires sont plus productifs s'ils aident à identifier les _faits_ techniques que nous avons manqués, tels que "cette proposition ne fonctionne pas correctement dans ce cas" ou "elle aura cette implication que nous n'avions pas réalisée".
Par exemple, @magical a souligné que la proposition telle qu'écrite n'était pas aussi extensible que prétendu (le texte original aurait rendu impossible l'ajout d'un futur 2e argument). Heureusement, il s'agissait d'un problème mineur qui a été facilement résolu avec un petit ajustement à la proposition. Sa contribution a directement contribué à améliorer la proposition.
@crawshaw a pris le temps d'analyser quelques centaines de cas d'utilisation de la bibliothèque std et a montré que try se retrouve rarement dans une autre expression, réfutant ainsi directement la crainte que try puisse devenir enterré et invisible. Il s'agit d'un retour factuel très utile, qui dans ce cas valide la conception.
En revanche, les jugements _esthétiques_ personnels ne sont pas très utiles. Nous pouvons enregistrer ces commentaires, mais nous ne pouvons pas agir en conséquence (en plus de proposer une autre proposition).
En ce qui concerne l'élaboration de propositions alternatives : La proposition actuelle est le fruit d'un long travail, à commencer par le projet de conception de l'année dernière . Nous avons réitéré cette conception plusieurs fois et sollicité les commentaires de nombreuses personnes avant de nous sentir suffisamment à l'aise pour la publier et recommander de la faire passer à la phase d'expérimentation réelle, mais nous n'avons pas encore fait l'expérience. Il est logique de revenir à la planche à dessin si l'expérience échoue, ou si les commentaires nous disent à l'avance qu'elle échouera clairement. Si nous reconcevons à la volée, sur la base des premières impressions, nous perdons simplement le temps de tout le monde, et pire, nous n'apprenons rien dans le processus.
Cela dit, la préoccupation la plus importante exprimée par beaucoup avec cette proposition est qu'elle n'encourage pas explicitement la décoration des erreurs en plus de ce que nous pouvons déjà faire dans le langage. Merci, nous avons enregistré ce commentaire. Nous avons reçu les mêmes commentaires en interne, avant de publier cette proposition. Mais aucune des alternatives que nous avons envisagées n'est meilleure que celle que nous avons maintenant (et nous en avons examiné plusieurs en profondeur). Au lieu de cela, nous avons décidé de proposer une idée minimale qui traite bien une partie de la gestion des erreurs, et qui peut être étendue si nécessaire, exactement pour répondre à cette préoccupation (la proposition en parle longuement).
Merci.
(Je note que quelques personnes plaidant pour des propositions alternatives ont lancé leurs propres problèmes séparés. C'est une bonne chose à faire et aide à garder les problèmes respectifs concentrés. Merci.)
griesemer
le 13 juin 2019
@griesemer
Je suis tout à fait d'accord que nous devrions nous concentrer et c'est exactement ce qui m'a amené à écrire :
Si cela a du sens, pouce vers le haut , nous pouvons essayer de revoir la proposition originale
https://github.com/golang/proposal/blob/master/design/32437-try-builtin.md
Deux questions:
- Êtes-vous d'accord si nous marquons les avantages (réduction passe-partout, lisibilité, etc.) par rapport aux inconvénients (pas de décoration d'erreur explicite/traçabilité inférieure de la source de la ligne d'erreur), nous pouvons en fait dire : cette proposition vise fortement à résoudre a,b , quelque peu aide c, ne vise pas à résoudre d,e
Et par là, perdez tout l'encombrement de "mais ce n'est pas d", "comment peut-il e" et orientez-vous davantage vers des problèmes techniques tels que @magical l' a souligné
Et aussi décourager les commentaires de "mais la solution XXX résout mieux d,e. - de nombreux messages en ligne sont des "suggestions de changements mineurs dans la proposition" - je sais que c'est une ligne fine, mais je pense qu'il est logique de les conserver.
LMKWYT.
guybrand
le 13 juin 2019
Utilise try() avec zéro argument (ou un autre élément intégré) toujours à prendre en considération ou cela a-t-il été exclu.
Après les modifications apportées à la proposition, je suis toujours préoccupé par la façon dont cela rend l'utilisation de valeurs de retour nommées plus "commune". Cependant, je n'ai pas de données pour étayer cela :upside_down_face :.
Si try() avec zéro argument (ou une autre fonction intégrée) est ajouté à la proposition, les exemples de la proposition pourraient-ils être mis à jour pour utiliser try() (ou une autre fonction intégrée) afin d'éviter les retours nommés ?
Goodwine
le 13 juin 2019
@guybrand Le vote positif et négatif est une bonne chose pour exprimer le _sentiment_ - mais c'est à peu près tout. Il n'y a pas plus d'informations là-dedans. Nous n'allons pas prendre une décision basée sur le décompte des voix, c'est-à-dire uniquement sur le sentiment. Bien sûr, si tout le monde - disons 90% + - déteste une proposition, c'est probablement un mauvais signe et nous devrions réfléchir à deux fois avant d'aller de l'avant. Mais cela ne semble pas être le cas ici. Un bon nombre de personnes semblent être satisfaites d'essayer des choses et sont passées à d'autres choses (et ne vous embêtez pas à commenter ce fil).
Comme j'ai essayé de l'exprimer ci- dessus , le sentiment à ce stade de la proposition n'est pas basé sur une expérience réelle avec la fonctionnalité ; c'est un sentiment. Les sentiments ont tendance à changer avec le temps, surtout quand on a eu l'occasion de faire l'expérience du sujet sur lequel portent les sentiments... :-)
griesemer
le 14 juin 2019
@Goodwine Personne n'a exclu try() pour atteindre la valeur d'erreur ; bien que _if_ quelque chose comme ça soit nécessaire, il peut être préférable d'avoir une variable prédéclarée err comme @rogpeppe l' a suggéré (je pense).
Encore une fois, cette proposition n'exclut rien de tout cela. Allons-y si nous découvrons que c'est nécessaire.
griesemer
le 14 juin 2019
@griesemer
Je pense que tu m'as totalement mal compris.
Je n'envisage pas de voter pour/contre cette proposition ou toute autre proposition, je cherchais juste un moyen d'avoir une bonne idée de "Pensons-nous qu'il est logique de prendre une décision basée sur des critères stricts plutôt que" j'aime x ' ou 'y n'a pas l'air bien' "
D'après ce que vous avez écrit - c'est EXACTEMENT ce que vous pensez ... alors s'il vous plaît, votez pour mon commentaire en disant:
"Je pense que nous devrions établir une liste de ce que cette proposition vise à améliorer, et sur cette base, nous pouvons
A. décider si c'est assez significatif
B. décider s'il semble que la proposition résolve vraiment ce qu'elle vise à résoudre
C. (comme vous l'avez ajouté) faites l'effort supplémentaire d'essayer de voir si c'est faisable...
guybrand
le 14 juin 2019
@guybrand, ils sont évidemment convaincus qu'il vaut la peine de prototyper dans la pré-version 1.14 (?) Et de recueillir les commentaires des utilisateurs pratiques. IOW une décision a été prise.
Aussi, déposé #32611 pour discussion de on err, <statement>
networkimprov
le 14 juin 2019
@guybrand Mes excuses. Oui, je suis d'accord que nous devons examiner les diverses propriétés d'une proposition, telles que la réduction passe-partout, résout-elle le problème à résoudre, etc. Mais une proposition est plus que la somme de ses parties - en fin de compte, nous besoin de regarder l'image globale. C'est de l'ingénierie, et l'ingénierie est désordonnée : il y a de nombreux facteurs qui jouent dans une conception, et même si objectivement (sur la base de critères stricts) une partie d'une conception n'est pas satisfaisante, il peut toujours s'agir de la "bonne" conception dans son ensemble. J'hésite donc un peu à soutenir une décision basée sur une sorte d'évaluation _indépendante_ des aspects individuels d'une proposition.
(J'espère que cela répond mieux à ce que vous vouliez dire.)
Mais en ce qui concerne les critères pertinents, je pense que cette proposition indique clairement ce qu'elle essaie d'aborder. Autrement dit, la liste à laquelle vous faites référence existe déjà :
..., notre objectif est de rendre la gestion des erreurs plus légère en réduisant la quantité de code source dédiée uniquement à la vérification des erreurs. Nous voulons également rendre plus pratique l'écriture de code de gestion des erreurs, pour augmenter la probabilité que les programmeurs prennent le temps de le faire. En même temps, nous voulons garder le code de gestion des erreurs explicitement visible dans le texte du programme.
Il se trouve que pour la décoration d'erreur, nous suggérons d'utiliser un defer et des paramètres de résultat nommés (ou votre ancienne instruction if ) car cela ne nécessite pas de changement de langue - ce qui est une chose fantastique parce que les changements linguistiques ont d'énormes coûts cachés. Nous comprenons que de nombreux commentateurs pensent que cette partie de la conception "est totalement nul". Pourtant, à ce stade, dans l'image globale, avec tout ce que nous savons, nous pensons que cela peut être assez bon. D'un autre côté, nous avons besoin d'un changement de langue - plutôt d'un support de langue - pour nous débarrasser du passe-partout, et try est à peu près le changement le plus minime que nous puissions proposer. Et clairement, tout est encore explicite dans le code.
griesemer
le 14 juin 2019
Je dirais que la raison pour laquelle il y a tant de réactions et tant de mini-propositions est qu'il s'agit d'un problème où presque tout le monde convient que le langage Go doit faire quelque chose pour réduire le passe-partout de la gestion des erreurs, mais nous ne le faisons pas vraiment s'entendre sur la façon de le faire.
Cette proposition se résume essentiellement à une "macro" intégrée pour un cas très courant, mais spécifique, de passe-partout, un peu comme la fonction intégrée append() . Ainsi, bien qu'il soit utile pour le cas d'utilisation particulier id err!=nil { return err } , c'est aussi tout ce qu'il fait. Comme ce n'est pas très utile dans d'autres cas, ni vraiment applicable de manière générale, je dirais que c'est décevant. J'ai le sentiment que la plupart des programmeurs Go attendaient un peu plus, et donc la discussion dans ce fil continue.
beoran
le 14 juin 2019
C'est contre-intuitif en tant que fonction. Parce qu'il n'est pas possible en Go d'avoir une fonction avec cet ordre d'arguments func(... interface{}, error) .
Tapé en premier, puis un nombre variable de motifs quelconques est partout dans les modules Go.
 mishak87
le 14 juin 2019
mishak87
le 14 juin 2019
Plus je pense, plus j'aime la proposition actuelle, telle quelle.
Si nous avons besoin d'une gestion des erreurs, nous avons toujours l'instruction if.
kybin
le 14 juin 2019
Salut à tous. Merci pour la discussion calme, respectueuse et constructive jusqu'à présent. J'ai passé du temps à prendre des notes et j'ai finalement été assez frustré pour créer un programme pour m'aider à conserver une vue différente de ce fil de commentaires qui devrait être plus navigable et plus complet que ce que montre GitHub. (Il se charge également plus rapidement !) Voir https://swtch.com/try.html. Je le tiendrai à jour mais par lots, pas minute par minute. (Il s'agit d'une discussion qui nécessite une réflexion approfondie et qui n'est pas aidée par le "temps Internet".)
J'ai quelques réflexions à ajouter, mais cela devra probablement attendre jusqu'à lundi. Merci encore.
rsc
le 14 juin 2019
@mishak87 Nous abordons cela dans la proposition détaillée . Notez que nous avons d'autres éléments intégrés ( try , make , unsafe.Offsetof , etc.) qui sont "irréguliers" - c'est à cela que servent les éléments intégrés.
griesemer
le 14 juin 2019
@rsc , super utile ! Si vous êtes toujours en train de le réviser, peut-être lier les références du problème #id ? Et le style de police sans empattement ?
networkimprov
le 14 juin 2019
Cela a probablement été couvert auparavant, donc je m'excuse d'avoir ajouté encore plus de bruit, mais je voulais juste faire un point sur l'idée d'essai intégré vs l'idée d'essai.
Je pense que la fonction d'essai intégrée peut être un peu frustrante pendant le développement. Nous pouvons parfois souhaiter ajouter des symboles de débogage ou ajouter un contexte plus spécifique à l'erreur avant de revenir. Il faudrait réécrire une ligne comme
user := try(getUser(userID))
pour
user, err := getUser(userID)
if err != nil {
// inspect error here
return err
}
L'ajout d'une instruction différée peut aider, mais ce n'est toujours pas la meilleure expérience lorsqu'une fonction génère plusieurs erreurs, car elle se déclencherait à chaque appel try().
Réécrire plusieurs appels try() imbriqués dans la même fonction serait encore plus ennuyeux.
D'autre part, l'ajout de contexte ou de code d'inspection à
user := try getUser(userID)
serait aussi simple que d'ajouter une instruction catch à la fin suivie du code
user := try getUser(userID) catch {
// inspect error here
}
Supprimer ou désactiver temporairement un gestionnaire serait aussi simple que de casser la ligne avant la capture et de la commenter.
Basculer entre try() et if err != nil semble beaucoup plus ennuyeux à mon avis.
Cela s'applique également à l'ajout ou à la suppression d'un contexte d'erreur. On peut écrire try func() tout en prototypant quelque chose très rapidement, puis ajouter du contexte à des erreurs spécifiques selon les besoins à mesure que le programme mûrit, par opposition à try() en tant que module intégré où il faudrait réécrire le lignes pour ajouter du contexte ou ajouter du code d'inspection supplémentaire pendant le débogage.
Je suis sûr que try() serait utile, mais comme j'imagine l'utiliser dans mon travail quotidien, je ne peux pas m'empêcher d'imaginer comment try ... catch serait tellement plus utile et beaucoup moins ennuyeux quand je ' d besoin d'ajouter/supprimer du code supplémentaire spécifique à certaines erreurs.
De plus, je pense que l'ajout try() puis la recommandation d'utiliser if err != nil pour ajouter du contexte est très similaire à avoir make() vs new() vs := contre var . Ces fonctionnalités sont utiles dans différents scénarios, mais ne serait-il pas agréable d'avoir moins de moyens ou même un seul moyen d'initialiser les variables ? Bien sûr, personne n'oblige personne à utiliser try et les gens peuvent continuer à utiliser if err != nil mais je pense que cela divisera la gestion des erreurs dans Go, tout comme les multiples façons d'affecter de nouvelles variables. Je pense que toute méthode ajoutée au langage devrait également fournir un moyen d'ajouter/supprimer facilement des gestionnaires d'erreurs au lieu de forcer les gens à réécrire des lignes entières pour ajouter/supprimer des gestionnaires. Cela ne me semble pas être un bon résultat.
Désolé encore pour le bruit, mais je voulais le signaler au cas où quelqu'un voudrait écrire une proposition détaillée séparée pour l'idée try ... else .
//cc @brynbellomy
owais
le 14 juin 2019
Merci, @owais , d'avoir soulevé ce point à nouveau - c'est un point juste (et le problème de débogage a en effet déjà été mentionné). try laisse la porte ouverte aux extensions, comme un deuxième argument, qui pourrait être une fonction de gestionnaire. Mais il est vrai qu'une fonction try ne facilite pas le débogage - on peut avoir à réécrire le code un peu plus qu'un try - catch ou try - else .
griesemer
le 14 juin 2019
@owais
L'ajout d'une instruction différée peut aider, mais ce n'est toujours pas la meilleure expérience lorsqu'une fonction génère plusieurs erreurs, car elle se déclencherait à chaque appel try().
Vous pouvez toujours inclure un commutateur de type dans la fonction différée qui gérerait (ou non) différents types d'erreurs de manière appropriée avant de revenir.
alanfo
le 15 juin 2019
Compte tenu de la discussion jusqu'à présent - en particulier les réponses de l'équipe Go - j'ai la forte impression que l'équipe prévoit d'aller de l'avant avec la proposition qui est sur la table. Si oui, alors un commentaire et une demande :
La proposition telle quelle de l'OMI entraînera une réduction non négligeable de la qualité du code dans les référentiels accessibles au public. Je m'attends à ce que de nombreux développeurs empruntent le chemin de la moindre résistance, utilisent efficacement des techniques de gestion des exceptions et choisissent d'utiliser
try()au lieu de gérer les erreurs au moment où elles se produisent. Mais étant donné le sentiment qui prévaut sur ce fil, je me rends compte que toute démagogie maintenant ne ferait que mener une bataille perdue d'avance, alors j'enregistre simplement mon objection pour la postérité.En supposant que l'équipe aille de l'avant avec la proposition telle qu'elle est actuellement écrite, pouvez-vous s'il vous plaît ajouter un commutateur de compilateur qui désactivera
try()pour ceux qui ne veulent pas de code qui ignore les erreurs de cette manière et pour interdire les programmeurs qu'ils embauchent de l'utiliser ? _(via CI, bien sûr.)_ Merci d'avance pour cette considération.
mikeschinkel
le 15 juin 2019
pouvez-vous s'il vous plaît ajouter un commutateur de compilateur qui désactivera try ()
Cela devrait être sur un outil de peluche, pas sur le compilateur IMO, mais je suis d'accord
Goodwine
le 15 juin 2019
Cela devrait être sur un outil de peluche, pas sur le compilateur IMO, mais je suis d'accord
Je demande explicitement une option de compilateur et non un outil de linting car pour interdire la compilation telle que l'option. Sinon il sera trop facile d'_"oublier"_ de pelucher lors du développement local.
mikeschinkel
le 15 juin 2019
@mikeschinkel Ne serait-il pas tout aussi facile d'oublier d'activer l'option du compilateur dans cette situation ?
dpinela
le 15 juin 2019
Les drapeaux du compilateur ne doivent pas modifier les spécifications du langage. C'est beaucoup plus adapté pour le vétérinaire/les peluches
deanveloper
le 15 juin 2019
Ne serait-il pas tout aussi facile d'oublier d'activer l'option du compilateur dans cette situation ?
Pas lors de l'utilisation d'outils comme GoLand où il n'y a aucun moyen de forcer l'exécution d'un lint avant une compilation.
mikeschinkel
le 15 juin 2019
Les drapeaux du compilateur ne doivent pas modifier les spécifications du langage.
-nolocalimports modifie la spécification et -s avertit.
mikeschinkel
le 15 juin 2019
Les drapeaux du compilateur ne doivent pas modifier les spécifications du langage.
-nolocalimportsmodifie la spécification et-savertit.
Non, cela ne change rien à la spécification. Non seulement la grammaire de la langue reste la même, mais la spécification indique spécifiquement :
L'interprétation de ImportPath dépend de l'implémentation, mais il s'agit généralement d'une sous-chaîne du nom de fichier complet du package compilé et peut être relatif à un référentiel de packages installés.
deanveloper
le 15 juin 2019
Pas lors de l'utilisation d'outils comme GoLand où il n'y a aucun moyen de forcer l'exécution d'un lint avant une compilation.
https://github.com/vmware/dispatch/wiki/Configure-GoLand-with-golint
deanveloper
le 15 juin 2019
@deanveloper
https://github.com/vmware/dispatch/wiki/Configure-GoLand-with-golint
Cela existe certainement, mais vous comparez la pomme à l'organge. Ce que vous montrez est un observateur de fichiers qui s'exécute sur les fichiers qui changent et puisque GoLand enregistre automatiquement les fichiers, cela signifie qu'il fonctionne constamment, ce qui génère beaucoup plus de bruit que de signal.
La peluche n'est pas toujours et ne peut pas (AFAIK) être configurée comme condition préalable à l'exécution du compilateur :
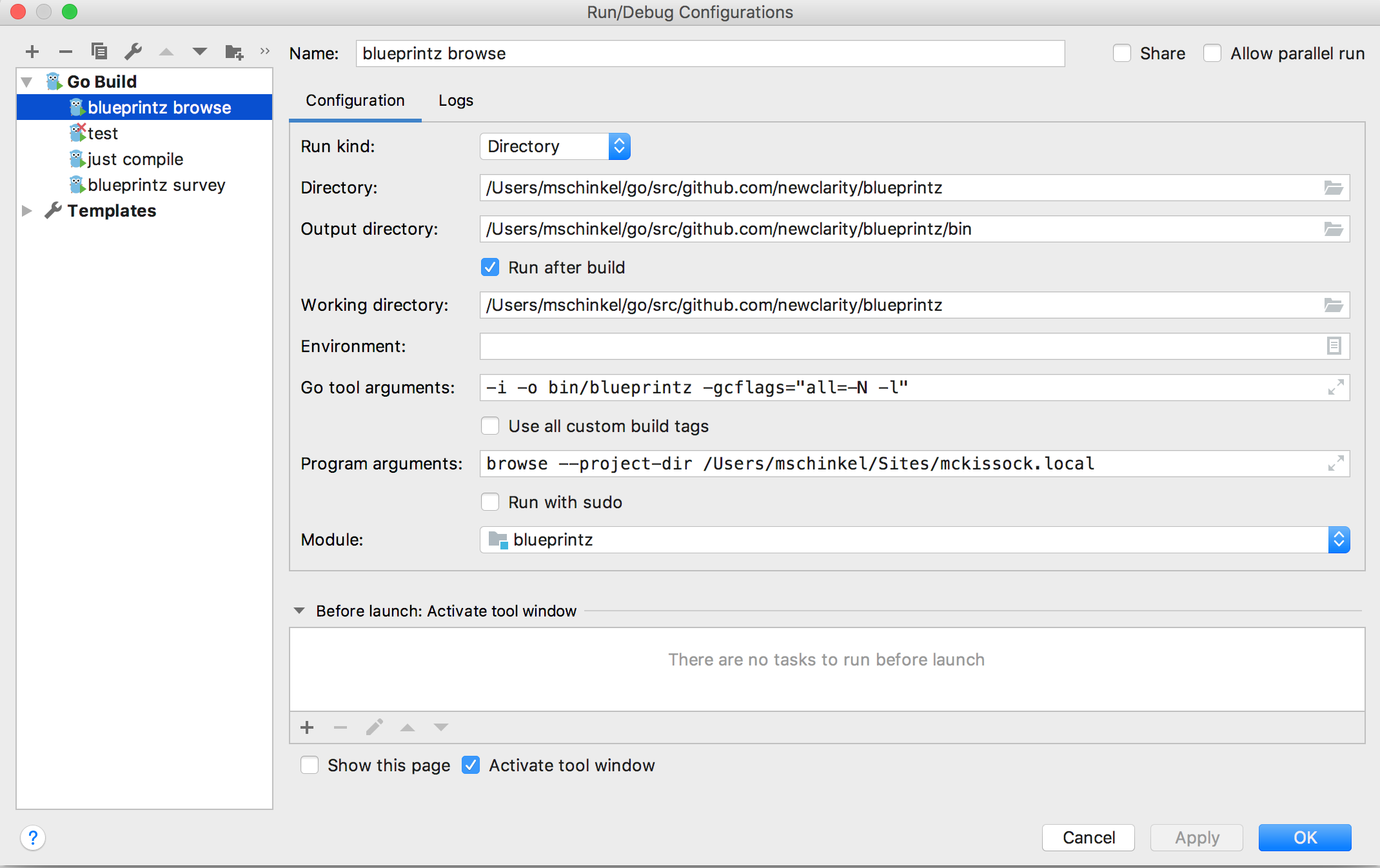
Non, cela ne change rien à la spécification. Non seulement la grammaire de la langue reste la même, mais la spécification indique spécifiquement :
Vous jouez ici avec la sémantique au lieu de vous concentrer sur le résultat. Je vais donc faire de même.
Je demande qu'une option de compilateur soit ajoutée qui interdira la compilation de code avec try() . Ce n'est pas une demande de changement de spécification de langage, c'est juste une demande pour que le compilateur s'arrête dans ce cas particulier.
Et si cela vous aide, la spécification de langue peut être mise à jour pour dire quelque chose comme :
L'interprétation de
try()dépend de l'implémentation, mais c'est généralement celle qui déclenche un retour lorsque le dernier paramètre est une erreur, mais elle peut être implémentée pour ne pas être autorisée.
mikeschinkel
le 15 juin 2019
Le temps de demander un changement de compilateur ou une vérification vétérinaire est après que le prototype try() atterrit dans l'astuce 1.14(?). À ce stade, vous déposeriez un nouveau problème (et oui, je pense que c'est une bonne idée). On nous a demandé de limiter les commentaires ici à des informations factuelles sur le document de conception actuel.
networkimprov
le 15 juin 2019
Salut donc juste pour ajouter à tout le problème avec l'ajout d'instructions de débogage et autres pendant le développement.
Je pense que la deuxième idée de paramètre est bonne pour la fonction try() , mais une autre idée juste pour la lancer est d'ajouter une clause emit pour être une deuxième partie pour try() .
Par exemple, je pense que lors du développement et autres, il pourrait y avoir un cas où je veux appeler fmt pour cet instant pour imprimer l'erreur. Donc je pourrais partir de ça :
func writeStuff(filename string) (io.ReadCloser, error) {
f := try(os.Open(filename))
try(fmt.Fprintf(f, "stuff\n"))
return f, nil
}
Peut être réécrit dans quelque chose comme ça pour les instructions de débogage ou la gestion générale ou l'erreur avant de revenir.
func writeStuff(filename string) (io.ReadCloser, error) {
emit err {
fmt.Printf("something happened [%v]\n", err.Error())
return nil, err
}
f := try(os.Open(filename))
try(fmt.Fprintf(f, "stuff\n"))
return f, nil
}
Donc, ici, j'ai fini par proposer un nouveau mot-clé emit qui pourrait être une déclaration ou une ligne pour un retour immédiat comme la fonctionnalité initiale try() :
emit return nil, err
Ce que serait l'émission serait essentiellement une clause dans laquelle vous pouvez mettre n'importe quelle logique si le try() est déclenché par une erreur non égale à zéro. Une autre capacité avec le mot-clé emit est que vous pouvez accéder à l'erreur ici si vous ajoutez juste après le mot-clé un nom de variable comme je l'ai fait dans le premier exemple en l'utilisant.
Cette proposition crée un peu de verbosité dans la fonction try() , mais je pense que c'est au moins un peu plus clair sur ce qui se passe avec l'erreur. De cette façon, vous pouvez également décorer les erreurs sans les bloquer sur une seule ligne et vous pouvez voir comment les erreurs sont gérées immédiatement lorsque vous lisez la fonction.
 damienfamed75
le 15 juin 2019
damienfamed75
le 15 juin 2019
Ceci est une réponse à @mikeschinkel , je mets ma réponse dans un bloc détail pour ne pas trop encombrer la discussion. Quoi qu'il en soit, @networkimprov a raison de dire que cette discussion devrait être déposée jusqu'à ce que cette proposition soit mise en œuvre (si c'est le cas).
détails sur un drapeau pour désactiver essayer
@mikeschinkel
La peluche n'est pas toujours et ne peut pas (AFAIK) être configurée comme condition préalable à l'exécution du compilateur :
GoLand réinstallé juste pour tester cela. Cela semble fonctionner très bien, la seule différence étant que si le lint trouve quelque chose qu'il n'aime pas, il n'échoue pas la compilation. Cela pourrait facilement être corrigé avec un script personnalisé, qui exécute golint et échoue avec un code de sortie différent de zéro s'il y a une sortie.
(Edit: j'ai corrigé l'erreur qu'il essayait de me dire en bas. Il fonctionnait bien même lorsque l'erreur était présente, mais changer "Run Kind" en répertoire a supprimé l'erreur et cela a bien fonctionné)
Aussi une autre raison pour laquelle il ne devrait PAS être un indicateur de compilateur - tout le code Go est compilé à partir de la source. Cela inclut les bibliothèques. Cela signifie que si vous souhaitez désactiver try via le compilateur, vous désactiverez également try pour chacune des bibliothèques que vous utilisez. C'est juste une mauvaise idée de l'avoir comme indicateur de compilateur.
Vous jouez ici avec la sémantique au lieu de vous concentrer sur le résultat.
Non, je ne suis pas. Les drapeaux du compilateur ne doivent pas modifier les spécifications du langage. La spécification est très bien présentée et pour que quelque chose soit "Go", il doit suivre la spécification. Les drapeaux du compilateur que vous avez mentionnés modifient le comportement du langage, mais quoi qu'il en soit, ils garantissent que le langage suit toujours la spécification. C'est un aspect important du Go. Tant que vous suivez la spécification Go, votre code doit être compilé sur n'importe quel compilateur Go.
Je demande qu'une option de compilateur soit ajoutée qui interdira la compilation de code avec try(). Ce n'est pas une demande de changement de spécification de langage, c'est juste une demande pour que le compilateur s'arrête dans ce cas particulier.
Il s'agit d'une demande de changement de spécification. Cette proposition en elle-même est une demande de modification de la spécification. Les fonctions intégrées sont très spécifiquement incluses dans la spécification. . Demander d'avoir un indicateur de compilateur qui supprime la commande intégrée try serait donc un indicateur de compilateur qui modifierait la spécification du langage compilé.
Cela étant dit, je pense que ImportPath devrait être standardisé dans la spécification. Je peux faire une proposition pour cela.
Et si cela aide, la spécification de langue peut être mise à jour pour dire quelque chose comme [...]
Bien que cela soit vrai, vous ne voudriez pas que l'implémentation de try dépende de l'implémentation. Il est conçu pour être une partie importante de la gestion des erreurs du langage, ce qui devrait être le même pour tous les compilateurs Go.
deanveloper
le 15 juin 2019
@deanveloper
_"De toute façon, @networkimprov a raison de dire que cette discussion devrait être déposée jusqu'à ce que cette proposition soit mise en œuvre (si c'est le cas)."_
Alors pourquoi avez-vous décidé d'ignorer cette suggestion et de poster dans ce fil de toute façon au lieu d'attendre plus tard ? Vous avez fait valoir vos points ici tout en affirmant que je ne devrais pas contester vos points. Pratiquez ce que vous prêchez...
Si vous avez le choix, je choisirai de répondre également, également dans un bloc de détailsici:
_"Cela pourrait facilement être corrigé avec un script personnalisé, qui exécute golint et échoue avec un code de sortie différent de zéro s'il y a une sortie."_
Oui, avec suffisamment de codage, tout problème peut être résolu. Mais nous savons tous les deux par expérience que plus une solution est complexe, moins les personnes qui souhaitent l'utiliser finiront par l'utiliser.
Je demandais donc explicitement une solution simple ici, pas une solution sur mesure.
_"vous désactiverez également l'essai pour chacune des bibliothèques que vous utilisez."_
Et c'est _explicitement_ la raison pour laquelle je l'ai demandé. Parce que je veux m'assurer que tout le code qui utilise cette _"fonctionnalité"_ gênante ne se retrouvera pas dans les exécutables que nous distribuons.
_"Il s'agit d'une demande de modification de la spécification. Cette proposition en elle-même est une demande de modification de la spécification._"
Ce n'est ABSOLUMENT pas un changement de spécification. Il s'agit d'une demande de commutateur pour modifier le _comportement_ de la commande build , et non d'un changement de spécification de langue.
Si quelqu'un demande la commande go pour avoir un commutateur pour afficher sa sortie de terminal en mandarin, cela ne change pas la spécification de la langue.
De même, si go build devait voir ce commutateur, il émettrait simplement un message d'erreur et s'arrêterait lorsqu'il rencontrerait un try() . Aucune modification des spécifications linguistiques n'est nécessaire.
_"Il est conçu pour être une partie importante de la gestion des erreurs du langage, ce qui devrait être le même pour tous les compilateurs Go."_
Ce sera une partie problématique de la gestion des erreurs du langage et le rendre facultatif permettra à ceux qui veulent éviter ses problèmes de pouvoir le faire.
Sans le commutateur, il est probable que la plupart des gens verront simplement comme une nouvelle fonctionnalité et l'adopteront et ne se demanderont jamais si elle doit en fait être utilisée.
_Avec le switch_ — et des articles expliquant la nouvelle fonctionnalité qui mentionnent le switch — beaucoup de gens comprendront qu'il a un potentiel problématique et permettront ainsi à l'équipe Go d'étudier s'il s'agissait d'une bonne inclusion ou non en voyant combien de code public évite de l'utiliser vs comment le code public l'utilise. Cela pourrait informer la conception de Go 3.
_"Non, je ne le suis pas. Les drapeaux du compilateur ne doivent pas modifier les spécifications du langage."_
Dire que vous ne jouez pas à la sémantique ne signifie pas que vous ne jouez pas à la sémantique.
Amende. Ensuite, je demande à la place une nouvelle commande de niveau supérieur appelée _(quelque chose comme)_ build-guard utilisée pour interdire les fonctionnalités problématiques lors de la compilation, en commençant par interdire try() .
Bien sûr, le meilleur résultat est si la fonctionnalité try() est déposée avec un plan pour reconsidérer la résolution du problème d'une manière différente à l'avenir, une manière avec laquelle la grande majorité est d'accord. Mais je crains que le navire n'ait déjà navigué avec try() donc j'espère minimiser ses inconvénients.
Alors maintenant, si vous êtes vraiment d'accord avec @networkimprov , retenez votre réponse pour plus tard, comme ils l'ont suggéré.
mikeschinkel
le 16 juin 2019
Désolé de vous interrompre, mais j'ai des faits à signaler :-)
Je suis sûr que l'équipe Go a déjà comparé le report, mais je n'ai vu aucun chiffre...
$ go test -bench=.
goos: linux
goarch: amd64
BenchmarkAlways2-2 20000000 72.3 ns/op
BenchmarkAlways4-2 20000000 68.1 ns/op
BenchmarkAlways6-2 20000000 68.0 ns/op
BenchmarkNever2-2 100000000 16.5 ns/op
BenchmarkNever4-2 100000000 13.1 ns/op
BenchmarkNever6-2 100000000 13.5 ns/op
La source
package deferbench
import (
"fmt"
"errors"
"testing"
)
func Always(iM, iN int) (err error) {
defer func() {
if err != nil {
err = fmt.Errorf("d: %v", err)
}
}()
if iN % iM == 0 {
return errors.New("e")
}
return nil
}
func Never(iM, iN int) (err error) {
if iN % iM == 0 {
return fmt.Errorf("r: %v", errors.New("e"))
}
return nil
}
func BenchmarkAlways2(iB *testing.B) { for a := 0; a < iB.N; a++ { Always(1e2, a) }}
func BenchmarkAlways4(iB *testing.B) { for a := 0; a < iB.N; a++ { Always(1e4, a) }}
func BenchmarkAlways6(iB *testing.B) { for a := 0; a < iB.N; a++ { Always(1e6, a) }}
func BenchmarkNever2(iB *testing.B) { for a := 0; a < iB.N; a++ { Never(1e2, a) }}
func BenchmarkNever4(iB *testing.B) { for a := 0; a < iB.N; a++ { Never(1e4, a) }}
func BenchmarkNever6(iB *testing.B) { for a := 0; a < iB.N; a++ { Never(1e6, a) }}
@networkimprov
De https://github.com/golang/proposal/blob/master/design/32437-try-builtin.md#efficiency -of-defer (mon emphase en gras)
Indépendamment, l'équipe d'exécution et de compilateur Go a discuté d'options d'implémentation alternatives et nous pensons que nous pouvons faire des utilisations différées typiques pour la gestion des erreurs à peu près aussi efficaces que le code "manuel" existant. Nous espérons rendre cette implémentation de report plus rapide disponible dans Go 1.14 (voir aussi * CL 171758 * qui est un premier pas dans cette direction).
c'est-à-dire que le report est maintenant une amélioration de 30% des performances pour go1.13 pour une utilisation courante, et devrait être plus rapide et tout aussi efficace que le mode non différé dans go 1.14
ugorji
le 16 juin 2019
Peut-être que quelqu'un peut poster des chiffres pour 1.13 et le 1.14 CL ?
Les optimisations ne survivent pas toujours au contact avec l'ennemi... euh, l'écosystème.
networkimprov
le 16 juin 2019
Les reports de la 1.13 seront environ 30 % plus rapides :
name old time/op new time/op delta
Defer-4 52.2ns ± 5% 36.2ns ± 3% -30.70% (p=0.000 n=10+10)
Voici ce que j'obtiens sur les tests de @networkimprov ci-dessus (1.12.5 au pourboire):
name old time/op new time/op delta
Always2-4 59.8ns ± 1% 47.5ns ± 1% -20.57% (p=0.008 n=5+5)
Always4-4 57.9ns ± 2% 43.5ns ± 1% -24.96% (p=0.008 n=5+5)
Always6-4 57.6ns ± 2% 44.1ns ± 1% -23.43% (p=0.008 n=5+5)
Never2-4 13.7ns ± 8% 3.8ns ± 4% -72.27% (p=0.008 n=5+5)
Never4-4 10.5ns ± 6% 1.3ns ± 2% -87.76% (p=0.008 n=5+5)
Never6-4 10.8ns ± 6% 1.2ns ± 1% -88.46% (p=0.008 n=5+5)
(Je ne sais pas pourquoi ceux de Never sont tellement plus rapides. Peut-être que des changements d'inline?)
Les optimisations pour les reports pour 1.14 ne sont pas encore implémentées, nous ne savons donc pas quelles seront les performances. Mais nous pensons que nous devrions nous rapprocher des performances d'un appel de fonction normal.
randall77
le 16 juin 2019
Alors pourquoi avez-vous décidé d'ignorer cette suggestion et de poster dans ce fil de toute façon au lieu d'attendre plus tard ?
Le bloc de détails a été modifié plus tard, après avoir lu le commentaire de @networkimprov . Je suis désolé d'avoir donné l'impression d'avoir compris ce qu'il a dit et de l'avoir ignoré. Je mets fin à la discussion après cette déclaration, je tenais à m'expliquer puisque vous m'aviez demandé pourquoi j'avais posté le commentaire.
Concernant les optimisations à reporter, j'en suis ravi. Ils aident un peu cette proposition, rendant defer HandleErrorf(...) un peu moins lourd. Cependant, je n'aime toujours pas l'idée d'abuser des paramètres nommés pour que cette astuce fonctionne. De combien devrait-il accélérer pour 1.14 ? Doivent-ils rouler à des vitesses similaires ?
deanveloper
le 16 juin 2019
@griesemer Un domaine qui mériterait peut-être d'être développé un peu plus est le fonctionnement des transitions dans un monde avec try , y compris peut-être :
- Le coût de la transition entre les styles de décoration d'erreur.
- Les classes d'erreurs possibles qui pourraient survenir lors de la transition entre les styles.
- Quelles classes d'erreurs seraient (a) interceptées immédiatement par une erreur du compilateur, vs. (b) interceptées par
vetoustaticcheckou similaire, vs. (c) pourrait conduire à un bogue qui pourraient ne pas être remarqués ou devraient être détectés via des tests. - La mesure dans laquelle l'outillage peut atténuer le coût et le risque d'erreur lors de la transition entre les styles, et en particulier, si
gopls(ou un autre utilitaire) pourrait ou devrait avoir un rôle dans l'automatisation des transitions de style de décoration courantes.
Étapes de la décoration d'erreur
Ce n'est pas exhaustif, mais un ensemble représentatif d'étapes pourrait ressembler à :
0. Aucune décoration d'erreur (par exemple, en utilisant try sans aucune décoration).
1. Décoration d'erreur uniforme (par exemple, en utilisant try + defer pour une décoration uniforme).
2. N-1 points de sortie ont une décoration d'erreur uniforme , mais 1 point de sortie a une décoration différente (par exemple, peut-être une décoration d'erreur détaillée permanente à un seul emplacement, ou peut-être un journal de débogage temporaire, etc.).
3. Tous les points de sortie ont chacun une décoration d'erreur unique , ou quelque chose qui s'approche de l'unique.
Toute fonction donnée n'aura pas une progression stricte à travers ces étapes, donc peut-être que "étapes" n'est pas le bon mot, mais certaines fonctions passeront d'un style de décoration à un autre, et il pourrait être utile d'être plus explicite sur ce que ces transitions sont comme quand ou si elles se produisent.
L'étape 0 et l'étape 1 semblent être des zones idéales pour la proposition actuelle, et se trouvent également être des cas d'utilisation assez courants. Une transition étape 0->1 semble simple. Si vous utilisiez try sans aucune décoration à l'étape 0, vous pouvez ajouter quelque chose comme defer fmt.HandleErrorf(&err, "foo failed with %s", arg1) . À ce moment-là, vous devrez peut-être également introduire des paramètres de retour nommés dans la proposition telle qu'elle a été rédigée initialement. Cependant, si la proposition adopte l'une des suggestions dans le sens d'une variable intégrée prédéfinie qui est un alias pour le paramètre de résultat d'erreur final, alors le coût et le risque d'erreur ici pourraient être faibles ?
D'un autre côté, une transition d'étape 1-> 2 semble gênante (ou "ennuyeuse" comme certains l'ont dit) si l'étape 1 était une décoration d'erreur uniforme avec un defer . Pour ajouter un élément de décoration spécifique à un point de sortie, vous devez d'abord supprimer le defer (pour éviter la double décoration), puis il semble qu'il faudrait visiter tous les points de retour pour désucrer le try utilise dans les instructions if , N-1 des erreurs étant décorées de la même manière et 1 étant décorée différemment.
Une transition d'étape 1 -> 3 semble également gênante si elle est effectuée manuellement.
Erreurs lors de la transition entre les styles de décoration
Certaines erreurs pouvant survenir dans le cadre d'un processus de désucrage manuel incluent l'occultation accidentelle d'une variable ou la modification de la manière dont un paramètre de retour nommé est affecté, etc. Par exemple, si vous regardez le premier et le plus grand exemple dans la section "Exemples" du essayez la proposition, la fonction CopyFile a 4 utilisations try , y compris dans cette section :
w := try(os.Create(dst))
defer func() {
w.Close()
if err != nil {
os.Remove(dst) // only if a “try” fails
}
}()
Si quelqu'un a fait un désucrage manuel "évident" de w := try(os.Create(dst)) , cette ligne pourrait être étendue à :
w, err := os.Create(dst)
if err != nil {
// do something here
return err
}
Cela semble bon à première vue, mais selon le bloc dans lequel se trouve ce changement, cela pourrait également masquer accidentellement le paramètre de retour nommé err et interrompre la gestion des erreurs dans le defer .
Automatisation de la transition entre les styles de décoration
Pour réduire le coût en temps et le risque d'erreurs, peut-être gopls (ou un autre utilitaire) pourrait avoir un type de commande pour désucrer un try spécifique, ou une commande pour désucrer toutes les utilisations de try dans une fonction donnée qui pourrait être sans erreur 100 % du temps. Une approche pourrait être que toutes les commandes gopls se concentrent uniquement sur la suppression et le remplacement try , mais peut-être qu'une commande différente pourrait désucrer toutes les utilisations de try tout en transformant au moins les cas courants de choses comme defer fmt.HandleErrorf(&err, "copy %s %s", src, dst) en haut de la fonction dans le code équivalent à chacun des anciens emplacements try (ce qui aiderait lors de la transition de l'étape 1-> 2 ou de l'étape 1-> 3). Ce n'est pas une idée entièrement cuite, mais cela vaut peut-être la peine de réfléchir davantage à ce qui est possible ou souhaitable ou de mettre à jour la proposition avec la réflexion actuelle.
Des résultats idiomatiques ?
Un commentaire connexe est qu'il n'est pas immédiatement évident de savoir à quelle fréquence une transformation sans erreur programmatique d'un try finirait par ressembler à un code Go idiomatique normal. Adaptation d'un des exemples de la proposition, si par exemple vous vouliez désucrer :
x1, x2, x3 = try(f())
Dans certains cas, une transformation programmatique qui préserve le comportement peut aboutir à quelque chose comme :
t1, t2, t3, te := f() // visible temporaries
if te != nil {
return x1, x2, x3, te
}
x1, x2, x3 = t1, t2, t3
Cette forme exacte est peut-être rare, et il semble que les résultats d'un éditeur ou d'un IDE faisant du desugaring programmatique pourraient souvent finir par sembler plus idiomatiques, mais il serait intéressant d'entendre à quel point c'est vrai, y compris face à des paramètres de retour nommés pouvant devenir plus courant, et en tenant compte du shadowing, := vs = , d'autres utilisations de err dans la même fonction, etc.
La proposition parle de différences de comportement possibles entre if et try en raison de paramètres de résultat nommés, mais dans cette section particulière, il semble parler principalement de la transition de if à try (dans la section qui conclut _"Bien qu'il s'agisse d'une différence subtile, nous pensons que de tels cas sont rares. Si le comportement actuel est attendu, conservez l'instruction if."_). En revanche, il peut y avoir différentes erreurs possibles qui méritent d'être élaborées lors de la transition de try vers if tout en conservant un comportement identique.
Quoi qu'il en soit, désolé pour le long commentaire, mais il semble que la crainte de coûts de transition élevés entre les styles sous-tende certaines des préoccupations exprimées dans certains des autres commentaires publiés ici, et donc la suggestion d'être plus explicite sur ces coûts de transition et atténuations potentielles.
thepudds
le 17 juin 2019
@thepudds Je t'aime met en évidence les coûts et les bogues potentiels associés à la façon dont les fonctionnalités du langage peuvent affecter positivement ou négativement la refactorisation. Ce n'est pas un sujet dont je vois souvent parler, mais qui peut avoir un effet important en aval.
une transition étape 1->2 semble gênante si l'étape 1 était une décoration d'erreur uniforme avec un report. Pour ajouter un peu de décoration spécifique à un point de sortie, vous devez d'abord supprimer le report (pour éviter la double décoration), puis il semble qu'il faudrait visiter tous les points de retour pour désucrer le try utilise dans les déclarations if, avec N -1 des erreurs est décorée de la même manière et 1 est décorée différemment.
C'est là que l'utilisation break au lieu de return brille avec 1.12. Utilisez-le dans un bloc for range once { ... } où once = "1" délimite la séquence de code dont vous voudrez peut-être sortir, puis si vous avez besoin de décorer une seule erreur, vous le faites au point de break . Et si vous avez besoin de décorer toutes les erreurs, vous le faites juste avant le seul return à la fin de la méthode.
La raison pour laquelle c'est un si bon modèle est qu'il est résilient aux exigences changeantes; vous devez rarement casser le code de travail pour implémenter de nouvelles exigences. Et c'est une approche plus propre et plus évidente à l'OMI que de revenir au début de la méthode avant d'en sortir.
fwiw
mikeschinkel
le 17 juin 2019
Les résultats de @ randall77 pour mon benchmark montrent une surcharge de 40 + ns par appel pour 1,12 et pourboire. Cela implique que le report peut inhiber les optimisations, rendant les améliorations pour reporter sans objet dans certains cas.
networkimprov
le 17 juin 2019
@networkimprov Defer inhibe actuellement les optimisations, et cela fait partie de ce que nous aimerions corriger. Par exemple, il serait bien d'intégrer le corps de la fonction différée comme nous incorporons les appels normaux.
Je ne vois pas en quoi les améliorations que nous apporterions seraient inutiles. D'où vient cette affirmation ?
randall77
le 17 juin 2019
D'où vient cette affirmation ?
La surcharge de 40 + ns par appel pour une fonction avec un report pour envelopper l'erreur n'a pas changé.
networkimprov
le 17 juin 2019
Les modifications apportées à la version 1.13 font partie de l'optimisation du report. D'autres améliorations sont prévues. Ceci est couvert dans le document de conception et dans la partie du document de conception citée à un moment donné ci-dessus.
josharian
le 17 juin 2019
Concernant swtch.com/try.html et https://github.com/golang/go/issues/32437#issuecomment -502192315 :
@rsc , super utile ! Si vous êtes toujours en train de le réviser, peut-être lier les références du problème #id ? Et le style de police sans empattement ?
Cette page concerne le contenu. Ne vous focalisez pas sur les détails du rendu. J'utilise la sortie de blackfriday sur le démarquage d'entrée inchangé (donc pas de liens #id spécifiques à GitHub), et je suis satisfait de la police serif.
rsc
le 17 juin 2019
Essai de désactivation/vérification :
Je suis désolé, mais il n'y aura pas d'options de compilation pour désactiver des fonctionnalités Go spécifiques, et il n'y aura pas non plus de vérifications vétérinaires indiquant de ne pas utiliser ces fonctionnalités. Si la fonctionnalité est suffisamment mauvaise pour être désactivée ou vérifiée, nous ne l'intégrerons pas. Inversement, si la fonctionnalité est présente, elle peut être utilisée. Il existe un langage Go, pas un langage différent pour chaque développeur en fonction de son choix d'indicateurs de compilateur.
rsc
le 17 juin 2019
@mikeschinkel , deux fois maintenant sur ce problème, vous avez décrit l'utilisation de try comme des erreurs _ignorantes_.
Le 7 juin , vous avez écrit, sous le titre "Permet aux développeurs d'ignorer plus facilement les erreurs":
C'est une répétition totale de ce que d'autres ont commenté, mais ce qui fournit fondamentalement
try()est analogue à bien des égards à simplement embrasser ce qui suit comme code idomatique, et c'est un code qui ne trouvera jamais sa place dans aucun code -respecter les navires développeurs :f, _ := os.Open(filename)Je sais que je peux être meilleur dans mon propre code, mais je sais aussi que beaucoup d'entre nous dépendent des largesses des autres développeurs Go qui publient des packages extrêmement utiles, mais d'après ce que j'ai vu dans _"Other People's Code(tm)"_ les meilleures pratiques en matière de gestion des erreurs sont souvent ignorées.
Alors sérieusement, voulons-nous vraiment permettre aux développeurs d'ignorer plus facilement les erreurs et leur permettre de polluer GitHub avec des packages non robustes ?
Et puis, le 14 juin , vous avez de nouveau fait référence à l'utilisation de try comme "code qui ignore les erreurs de cette manière".
Sinon pour l'extrait de code f, _ := os.Open(filename) , je penserais que vous exagériez simplement en caractérisant "vérifier une erreur et la renvoyer" comme "ignorer" une erreur. Mais l'extrait de code, ainsi que les nombreuses questions déjà répondues dans le document de proposition ou dans la spécification du langage, me font me demander si nous parlons de la même sémantique après tout. Alors juste pour être clair et répondre à tes questions :
Lors de l'étude du code de la proposition, je trouve que le comportement n'est pas évident et quelque peu difficile à raisonner.
Lorsque je vois
try()envelopper une expression, que se passe-t-il si une erreur est renvoyée ?
Lorsque vous voyez try(f()) , si f() renvoie une erreur, le try arrêtera l'exécution du code et renverra cette erreur à partir de la fonction dans le corps de laquelle le try apparaît.
L'erreur sera-t-elle simplement ignorée ?
Non. L'erreur n'est jamais ignorée. Elle est renvoyée, comme si vous utilisiez une instruction return. Comme:
{ err := f(); if err != nil { return err } }
Ou sautera-t-il au premier ou au plus récent
defer,
La sémantique est la même que l'utilisation d'une instruction return.
Les fonctions différées s'exécutent dans " dans l'ordre inverse où elles ont été différées ".
et si c'est le cas, définira-t-il automatiquement une variable nommée
errà l'intérieur de la fermeture, ou la passera-t-il en tant que paramètre _(je ne vois pas de paramètre ?)_.
La sémantique est la même que l'utilisation d'une instruction return.
Si vous avez besoin de faire référence à un paramètre de résultat dans le corps d'une fonction différée, vous pouvez lui donner un nom. Voir l'exemple result dans https://golang.org/ref/spec#Defer_statements.
Et si ce n'est pas un nom d'erreur automatique, comment puis-je le nommer ? Et cela signifie-t-il que je ne peux pas déclarer ma propre variable
errdans ma fonction, pour éviter les conflits ?
La sémantique est la même que l'utilisation d'une instruction return.
Une instruction de retour affecte toujours les résultats réels de la fonction, même si le résultat n'a pas de nom, et même si le résultat est nommé mais masqué.
Et appellera-t-il tous les
defers ? En ordre inverse ou en ordre normal ?
La sémantique est la même que l'utilisation d'une instruction return.
Les fonctions différées s'exécutent dans " dans l'ordre inverse où elles ont été différées ". (L'ordre inverse est l'ordre normal.)
Ou reviendra-t-il à la fois de la fermeture et du
funcoù l'erreur a été renvoyée ? _(Quelque chose que je n'aurais jamais envisagé si je n'avais pas lu ici des mots qui impliquent cela.)_
Je ne sais pas ce que cela signifie, mais la réponse est probablement non. J'encouragerais à se concentrer sur le texte de la proposition et la spécification et non sur d'autres commentaires ici sur ce que ce texte pourrait ou ne pourrait pas signifier.
Après avoir lu la proposition et tous les commentaires jusqu'à présent, honnêtement, je ne connais toujours pas les réponses aux questions ci-dessus. Est-ce le genre de fonctionnalité que nous voulons ajouter à un langage dont les défenseurs sont _"Captain Obvious?"_
En général, nous visons un langage simple et facile à comprendre. Je suis désolé que vous ayez tant de questions. Mais cette proposition réutilise vraiment autant que possible le langage existant (en particulier, reporte), il devrait donc y avoir très peu de détails supplémentaires à apprendre. Une fois que vous savez que
x, y := try(f())
moyens
tmp1, tmp2, tmpE := f()
if tmpE != nil {
return ..., tmpE
}
x, y := tmp1, tmp2
presque tout le reste devrait découler des implications de cette définition.
Ce n'est pas "ignorer" les erreurs. Ignorer une erreur, c'est quand vous écrivez:
c, _ := net.Dial("tcp", "127.0.0.1:1234")
io.Copy(os.Stdout, c)
et le code panique car net.Dial a échoué et l'erreur a été ignorée, c est nul et l'appel de io.Copy à c.Read échoue. En revanche, ce code vérifie et renvoie l'erreur :
c := try(net.Dial("tcp", "127.0.0.1:1234"))
io.Copy(os.Stdout, c)
Pour répondre à votre question de savoir si nous voulons encourager les seconds plutôt que les premiers : oui.
rsc
le 17 juin 2019
@damienfamed75 Votre proposition de déclaration emit ressemble essentiellement à la déclaration handle du projet de conception . La principale raison de l'abandon de la déclaration handle était son chevauchement avec defer . Je ne comprends pas pourquoi on ne pourrait pas simplement utiliser un defer pour obtenir le même effet que emit .
griesemer
le 17 juin 2019
@dominikh a demandé :
Acme commencera-t-il à mettre en évidence l'essai ?
Tant de choses sur la proposition d'essai sont indécises, en l'air, inconnues.
Mais à cette question je peux répondre définitivement : non.
rsc
le 17 juin 2019
@rsc
Merci pour votre réponse.
_"à deux reprises sur ce problème, vous avez décrit l'utilisation de try comme ignorant les erreurs."_
Oui, je commentais en utilisant mon point de vue et n'étant pas techniquement correct.
Ce que je voulais dire, c'était _"Permettre aux erreurs d'être transmises sans être décorées."_ Pour moi, c'est _"ignorer"_ - un peu comme la façon dont les personnes utilisant la gestion des exceptions _"ignorent"_ les erreurs - mais je peux certainement voir comment les autres le feraient considérer ma formulation comme n'étant pas techniquement correcte.
_"Lorsque vous voyez
try(f()), sif()renvoie une erreur, le try arrêtera l'exécution du code et renverra cette erreur à partir de la fonction dans le corps de laquelle le try apparaît."_
C'était une réponse à une question de mon commentaire il y a quelque temps, mais maintenant j'ai compris cela.
Et ça finit par faire deux choses qui me rendent triste. Les raisons:
Cela ouvrira la voie de la moindre résistance pour éviter les erreurs de décoration - encourageant de nombreux développeurs à faire exactement cela - et beaucoup publieront ce code pour que d'autres l'utilisent, ce qui se traduira par un code accessible au public de qualité inférieure avec une gestion des erreurs/rapports d'erreurs moins robustes .
Pour ceux qui, comme moi, utilisent
breaketcontinuepour la gestion des erreurs au lieu dereturn- un modèle plus résistant aux changements d'exigences - nous ne pourrons même pas utilisertry(), même s'il n'y a vraiment aucune raison d'annoter l'erreur.
_"Ou reviendra-t-il à la fois de la fermeture et de la fonction où l'erreur a été renvoyée ? (Quelque chose que je n'aurais jamais envisagé si je n'avais pas lu ici des mots qui impliquent cela.)"_
_"Je ne sais pas ce que cela signifie, mais la réponse est probablement non. Je vous encourage à vous concentrer sur le texte de la proposition et la spécification et non sur d'autres commentaires ici sur ce que ce texte pourrait signifier ou non."_
Encore une fois, cette question a été posée il y a plus d'une semaine, donc je comprends mieux maintenant.
Pour clarifier, pour la postérité, le defer a une fermeture, non ? Si vous revenez de cette fermeture, alors - à moins que je ne comprenne mal - il reviendra non seulement de la fermeture mais aussi du func où l'erreur s'est produite, n'est-ce pas ? _(Pas besoin de répondre si oui.)_
func example() {
defer func(err) {
return err // returns from both defer and example()
}
try(SomethingThatReturnsAnError)
}
BTW, si j'ai bien compris, la raison pour laquelle try() est parce que les développeurs se sont plaints du passe-partout. Je trouve également cela triste car je pense que l'obligation d'accepter les erreurs renvoyées qui se traduit par ce passe-partout est ce qui contribue à rendre les applications Go plus robustes que dans de nombreux autres langages.
Personnellement, je préférerais que vous rendiez plus difficile de ne pas décorer les erreurs que de rendre plus facile de les ignorer. Mais je reconnais que je semble être en minorité sur ce point.
BTW, certaines personnes ont proposé une syntaxe comme l'une des suivantes _ (j'ai ajouté un hypothétique .Extend() pour garder mes exemples concis):_
f := try os.Open(filename) else err {
err.Extend("Cannot open file %s",filename)
//break, continue or return err
}
Ou
try f := os.Open(filename) else err {
err.Extend("Cannot open file %s",filename)
//break, continue or return err
}
Et puis d'autres prétendent que cela ne sauve pas vraiment de caractères par-dessus:
f,err := os.Open(filename)
if err != nil {
err.Extend("Cannot open file %s",filename)
//break, continue or return err
}
Mais une chose qui manque à la critique est qu'elle passe de 5 lignes à 4 lignes, une réduction de l'espace vertical et qui semble significative, surtout lorsque vous avez besoin de nombreuses constructions de ce type dans un func .
Encore mieux serait quelque chose comme ça qui éliminerait 40% de l'espace vertical _ (bien que compte tenu des commentaires sur les mots-clés, je doute que cela soit pris en compte):_
try f := os.Open(filename)
else err().Extend("Cannot open file %s",filename)
end //break, continue or return err
#fwiw
Quoi qu'il en soit, comme je l'ai dit plus tôt, je suppose que le navire a navigué, donc je vais juste apprendre à l'accepter.
mikeschinkel
le 17 juin 2019
Buts
Quelques commentaires ici ont remis en question ce que nous essayons de faire avec la proposition. Pour rappel, l' Error Handling Problem Statement que nous avons publié en août dernier indique dans la section "Objectifs" :
"Pour Go 2, nous aimerions rendre les vérifications d'erreurs plus légères, en réduisant la quantité de texte du programme Go dédiée à la vérification des erreurs. Nous voulons également rendre plus pratique l'écriture de la gestion des erreurs, augmentant ainsi la probabilité que les programmeurs prennent le temps de le faire.
Les vérifications et la gestion des erreurs doivent rester explicites, c'est-à-dire visibles dans le texte du programme. Nous ne voulons pas répéter les pièges de la gestion des exceptions.
Le code existant doit continuer à fonctionner et rester aussi valide qu'il l'est aujourd'hui. Toute modification doit interagir avec le code existant. »
Pour en savoir plus sur « les pièges de la gestion des exceptions », consultez la discussion dans la section « Problème » plus longue. En particulier, les vérifications d'erreurs doivent être clairement liées à ce qui est vérifié.
rsc
le 17 juin 2019
@mikeschinkel ,
Pour clarifier, pour la postérité, le
defera une fermeture, non ? Si vous revenez de cette fermeture, alors - à moins que je ne comprenne mal - il reviendra non seulement de la fermeture mais aussi dufuncoù l'erreur s'est produite, n'est-ce pas ? _(Pas besoin de répondre si oui.)_
Non. Il ne s'agit pas de la gestion des erreurs mais des fonctions différées. Ce ne sont pas toujours des fermetures. Par exemple, un modèle courant est :
func (d *Data) Op() int {
d.mu.Lock()
defer d.mu.Unlock()
... code to implement Op ...
}
Tout retour de d.Op exécute l'appel de déverrouillage différé après l'instruction de retour mais avant que le code ne soit transféré à l'appelant de d.Op. Rien de ce qui est fait à l'intérieur de d.mu.Unlock n'affecte la valeur de retour de d.Op. Une instruction de retour dans d.mu.Unlock revient de Unlock. Il ne revient pas par lui-même de d.Op. Bien sûr, une fois que d.mu.Unlock revient, d.Op aussi, mais pas directement à cause de d.mu.Unlock. C'est un point subtil mais important.
Venons-en à votre exemple :
func example() { defer func(err) { return err // returns from both defer and example() } try(SomethingThatReturnsAnError) }
Au moins tel qu'il est écrit, il s'agit d'un programme invalide. Je n'essaie pas d'être pédant ici - les détails comptent. Voici un programme valide :
func example() (err error) {
defer func() {
if err != nil {
println("FAILED:", err.Error())
}
}()
try(funcReturningError())
return nil
}
Tout résultat d'un appel de fonction différé est ignoré lorsque l'appel est exécuté, donc dans le cas où ce qui est différé est un appel à une fermeture, cela n'a aucun sens d'écrire la fermeture pour renvoyer une valeur. Donc, si vous deviez écrire return err à l'intérieur du corps de fermeture, le compilateur vous dira "trop d'arguments à retourner" .
Donc, non, écrire return err ne revient pas à la fois de la fonction différée et de la fonction externe dans un sens réel, et dans l'utilisation conventionnelle, il n'est même pas possible d'écrire du code qui semble faire cela.
rsc
le 17 juin 2019
De nombreuses contre-propositions publiées sur ce problème suggérant d'autres constructions de gestion des erreurs plus performantes dupliquent les constructions de langage existantes, comme l'instruction if. (Ou ils entrent en conflit avec l' objectif de "rendre les vérifications d'erreurs plus légères, en réduisant la quantité de texte du programme Go à la vérification des erreurs". Ou les deux.)
En général, Go a déjà une construction parfaitement capable de gérer les erreurs : le langage entier, en particulier les instructions if. @DavexPro a eu raison de se référer à l'entrée de blog Go Les erreurs sont des valeurs . Nous n'avons pas besoin de concevoir un sous-langage entièrement séparé concernant les erreurs, et nous ne le devrions pas non plus. Je pense que la principale idée au cours des six derniers mois a été de supprimer "handle" de la proposition "check/handle" en faveur de la réutilisation du langage que nous avons déjà, y compris en revenant aux déclarations if, le cas échéant. Cette observation sur le fait d'en faire le moins possible élimine de la considération la plupart des idées autour d'un paramétrage plus poussé d'une nouvelle construction.
Avec mes remerciements à @brynbellomy pour ses nombreux bons commentaires, j'utiliserai son essai comme exemple illustratif. Oui, on pourrait écrire :
func doSomething() (int, error) {
// Inline error handler
a, b := try SomeFunc() else err {
return 0, errors.Wrap(err, "error in doSomething:")
}
// Named error handlers
handler logAndContinue err {
log.Errorf("non-critical error: %v", err)
}
handler annotateAndReturn err {
return 0, errors.Wrap(err, "error in doSomething:")
}
c, d := try SomeFunc() else logAndContinue
e, f := try OtherFunc() else annotateAndReturn
// ...
return 123, nil
}
mais tout bien considéré, ce n'est probablement pas une amélioration significative par rapport à l'utilisation de constructions de langage existantes :
func doSomething() (int, error) {
a, b, err := SomeFunc()
if err != nil {
return 0, errors.Wrap(err, "error in doSomething:")
}
// Named error handlers
logAndContinue := func(err error) {
log.Errorf("non-critical error: %v", err)
}
annotate:= func(err error) (int, error) {
return 0, errors.Wrap(err, "error in doSomething:")
}
c, d, err := SomeFunc()
if err != nil {
logAndContinue(err)
}
e, f, err := SomeFunc()
if err != nil {
return annotate(err)
}
// ...
return 123, nil
}
Autrement dit, continuer à s'appuyer sur le langage existant pour écrire la logique de gestion des erreurs semble préférable à la création d'une nouvelle instruction, que ce soit try-else, try-goto, try-arrow ou toute autre chose.
C'est pourquoi try est limité à la sémantique simple if err != nil { return ..., err } et rien de plus : raccourcissez le modèle commun mais n'essayez pas de réinventer tous les flux de contrôle possibles. Lorsqu'une instruction if ou une fonction d'assistance est appropriée, nous nous attendons à ce que les gens continuent à les utiliser.
rsc
le 17 juin 2019
@rsc Merci pour la clarification.
Exact, je n'ai pas bien saisi les détails. Je suppose que je n'utilise pas defer assez souvent pour me souvenir de sa syntaxe.
_(FWIW Je trouve que l'utilisation defer pour quelque chose de plus complexe que la fermeture d'un descripteur de fichier est moins évidente à cause du saut en arrière dans le func avant de revenir. Donc, mettez toujours ce code à la fin du func après le for range once{...} mon code de gestion d'erreur break s out of.)_
mikeschinkel
le 17 juin 2019
La suggestion de gofmt chaque appel d'essai sur plusieurs lignes est directement en conflit avec l' objectif de "rendre les vérifications d'erreurs plus légères, en réduisant la quantité de texte du programme Go à la vérification des erreurs".
La suggestion de gofmt une instruction if de test d'erreur sur une seule ligne est également en conflit direct avec cet objectif. Les contrôles d'erreur ne deviennent pas sensiblement plus légers ni réduits en quantité en supprimant les caractères de nouvelle ligne intérieurs. Au contraire, ils deviennent plus difficiles à parcourir.
Le principal avantage de try est d'avoir une abréviation claire pour le cas le plus courant, ce qui fait que les cas inhabituels se démarquent davantage comme méritant d'être lus attentivement.
En passant de gofmt aux outils généraux, la suggestion de se concentrer sur l'outillage pour écrire des vérifications d'erreurs au lieu d'un changement de langue est tout aussi problématique. Comme le disent Abelson et Sussman, "les programmes doivent être écrits pour que les gens les lisent, et seulement accessoirement pour que les machines les exécutent". Si la machine-outil est _nécessaire_ pour faire face au langage, alors le langage ne fait pas son travail. La lisibilité ne doit pas être limitée aux personnes utilisant des outils spécifiques.
Quelques personnes ont suivi la logique dans la direction opposée : les gens peuvent écrire des expressions complexes, donc ils le feront inévitablement, donc vous auriez besoin d'IDE ou d'un autre support d'outil pour trouver les expressions try, donc try est une mauvaise idée. Il y a cependant quelques sauts non pris en charge ici. La principale est l'affirmation selon laquelle parce qu'il est _possible_ d'écrire du code complexe et illisible, ce code deviendra omniprésent. Comme l'a noté @josharian , il est déjà « possible d'écrire du code abominable en Go ». Ce n'est pas courant car les développeurs ont des normes pour essayer de trouver la manière la plus lisible d'écrire un morceau de code particulier. Donc, ce n'est certainement pas le cas où le support IDE sera requis pour lire les programmes impliquant try. Et dans les rares cas où les gens écrivent un code vraiment terrible en abusant, il est peu probable que le support IDE soit très utile. Cette objection - les gens peuvent écrire du très mauvais code en utilisant la nouvelle fonctionnalité - est soulevée dans presque toutes les discussions sur chaque nouvelle fonctionnalité de langage dans chaque langue. Ce n'est pas très utile. Une objection plus utile serait de la forme "les gens écriront du code qui semble bon au début mais qui s'avère moins bon pour cette raison inattendue", comme dans la discussion sur le débogage des empreintes .
Encore une fois : la lisibilité ne doit pas être limitée aux personnes utilisant des outils spécifiques.
(J'imprime et lis toujours des programmes sur papier, bien que les gens me donnent souvent des regards bizarres pour le faire.)
rsc
le 17 juin 2019
Merci @rsc d'avoir fait part de vos réflexions sur l'autorisation d'afficher les déclarations if sur une seule ligne.
La suggestion de gofmt une instruction if de test d'erreur sur une seule ligne est également en conflit direct avec cet objectif. Les contrôles d'erreur ne deviennent pas sensiblement plus légers ni réduits en quantité en supprimant les caractères de nouvelle ligne intérieurs. Au contraire, ils deviennent plus difficiles à parcourir.
J'estime ces affirmations différemment.
Je trouve que réduire le nombre de lignes de 3 à 1 est beaucoup plus léger. Est-ce que gofmt n'exigerait pas qu'une instruction if contienne, par exemple, 9 (ou même 5) nouvelles lignes au lieu de 3 serait beaucoup plus lourd? C'est le même facteur (quantité) de réduction/expansion. Je dirais que les littéraux de structure ont ce compromis exact, et avec l'ajout de try , permettront le flux de contrôle autant qu'une instruction if .
Deuxièmement, je trouve que l'argument selon lequel ils deviennent plus difficiles à parcourir s'applique aussi bien à try , sinon plus. Au moins une instruction if devrait être sur sa propre ligne. Mais peut-être ai-je mal compris ce que l'on entend par "écrémé" dans ce contexte. Je l'utilise pour signifier "surtout sauter mais être conscient de".
Cela dit, la suggestion du gofmt reposait sur une mesure encore plus conservatrice que try et n'a aucun impact sur try moins que cela ne soit suffisant. On dirait que ce n'est pas le cas, et donc si je veux en discuter davantage, j'ouvrirai un nouveau problème/proposition. :+1:
zeebo
le 17 juin 2019
Je trouve que réduire le nombre de lignes de 3 à 1 est beaucoup plus léger.
Je pense que tout le monde convient qu'il est possible que le code soit trop dense. Par exemple, si votre package entier est d'une ligne, je pense que nous sommes tous d'accord pour dire que c'est un problème. Nous sommes probablement tous en désaccord sur la ligne précise. Pour moi, nous avons établi
n, err := src.Read(buf)
if err == io.EOF {
return nil
} else if err != nil {
return err
}
comme moyen de formater ce code, et je pense qu'il serait assez choquant d'essayer de passer à votre exemple
n, err := src.Read(buf)
if err == io.EOF { return nil }
else if err != nil { return err }
au lieu. Si nous avions commencé de cette façon, je suis sûr que ce serait bien. Mais nous ne l'avons pas fait, et ce n'est pas là où nous en sommes maintenant.
Personnellement, je trouve l'ancien poids plus léger sur la page dans le sens où il est plus facile à parcourir. Vous pouvez voir le if-else en un coup d'œil sans lire de lettres réelles. En revanche, la version plus dense est difficile à distinguer d'un coup d'œil à partir d'une séquence de trois déclarations, ce qui signifie que vous devez regarder plus attentivement avant que sa signification ne devienne claire.
En fin de compte, c'est OK si nous traçons la ligne densité vs lisibilité à différents endroits en ce qui concerne le nombre de retours à la ligne. La proposition try se concentre non seulement sur la suppression des retours à la ligne, mais également sur la suppression complète des constructions, ce qui produit une présence de page plus légère, distincte de la question gofmt.
rsc
le 17 juin 2019
Quelques personnes ont suivi la logique dans la direction opposée : les gens peuvent écrire des expressions complexes, donc ils le feront inévitablement, donc vous auriez besoin d'IDE ou d'un autre support d'outil pour trouver les expressions try, donc try est une mauvaise idée. Il y a cependant quelques sauts non pris en charge ici. La principale est l'affirmation selon laquelle parce qu'il est _possible_ d'écrire du code complexe et illisible, ce code deviendra omniprésent. Comme l'a noté @josharian , il est déjà « possible d'écrire du code abominable en Go ». Ce n'est pas courant car les développeurs ont des normes pour essayer de trouver la manière la plus lisible d'écrire un morceau de code particulier. Donc, ce n'est certainement pas le cas où le support IDE sera requis pour lire les programmes impliquant try. Et dans les rares cas où les gens écrivent un code vraiment terrible en abusant, il est peu probable que le support IDE soit très utile. Cette objection - les gens peuvent écrire du très mauvais code en utilisant la nouvelle fonctionnalité - est soulevée dans presque toutes les discussions sur chaque nouvelle fonctionnalité de langage dans chaque langue. Ce n'est pas très utile.
N'est-ce pas la raison pour laquelle Go n'a pas d'opérateur ternaire ?
MrTravisB
le 17 juin 2019
N'est-ce pas la raison pour laquelle Go n'a pas d'opérateur ternaire ?
Non. Nous pouvons et devons faire la distinction entre "cette fonctionnalité peut être utilisée pour écrire du code très lisible, mais peut également être utilisée abusivement pour écrire du code illisible" et "l'utilisation dominante de cette fonctionnalité sera d'écrire du code illisible".
L'expérience avec C suggère que ? : tombe carrément dans la deuxième catégorie. (À l'exception possible de min et max, je ne suis pas sûr d'avoir déjà vu du code utilisant ? : cela n'a pas été amélioré en le réécrivant pour utiliser une instruction if à la place. Mais ce paragraphe sort du sujet.)
rsc
le 17 juin 2019
Syntaxe
Cette discussion a identifié six syntaxes différentes pour écrire la même sémantique à partir de la proposition :
f := try(os.Open(file)), à partir de la proposition (fonction intégrée)f := try os.Open(file), en utilisant un mot-clé (mot-clé préfixé)f := os.Open(file)?, comme dans Rust (opérateur suffixe d'appel)f := os.Open?(file), suggéré par @rogpeppe (opérateur call-infix)try f := os.Open(file), suggéré par @thepudds (instruction try)try ( f := os.Open(file); f.Close() ), suggéré par @bakul (essayer de bloquer)
(Excuses si je me suis trompé dans les histoires d'origine !)
Tous ont des avantages et des inconvénients, et la bonne chose est que, comme ils ont tous la même sémantique, il n'est pas trop important de choisir entre les différentes syntaxes afin d'expérimenter davantage.
J'ai trouvé cet exemple de @brynbellomy qui donne à réfléchir :
headRef := try(r.Head())
parentObjOne := try(headRef.Peel(git.ObjectCommit))
parentObjTwo := try(remoteBranch.Reference.Peel(git.ObjectCommit))
parentCommitOne := try(parentObjOne.AsCommit())
parentCommitTwo := try(parentObjTwo.AsCommit())
treeOid := try(index.WriteTree())
tree := try(r.LookupTree(treeOid))
// vs
try headRef := r.Head()
try parentObjOne := headRef.Peel(git.ObjectCommit)
try parentObjTwo := remoteBranch.Reference.Peel(git.ObjectCommit)
try parentCommitOne := parentObjOne.AsCommit()
try parentCommitTwo := parentObjTwo.AsCommit()
try treeOid := index.WriteTree()
try tree := r.LookupTree(treeOid)
// vs
try (
headRef := r.Head()
parentObjOne := headRef.Peel(git.ObjectCommit)
parentObjTwo := remoteBranch.Reference.Peel(git.ObjectCommit)
parentCommitOne := parentObjOne.AsCommit()
parentCommitTwo := parentObjTwo.AsCommit()
treeOid := index.WriteTree()
tree := r.LookupTree(treeOid)
)
Il n'y a pas beaucoup de différence entre ces exemples spécifiques, bien sûr. Et si l'essai est présent dans toutes les lignes, pourquoi ne pas les aligner ou les factoriser ? N'est-ce pas plus propre ? Je me suis aussi posé la question.
Mais comme l'a observé @ianlancetaylor , "l'essai enterre le lede. Le code devient une série d'instructions try, qui obscurcissent ce que le code fait réellement.
Je pense que c'est un point critique: aligner l'essai de cette façon, ou le factoriser comme dans le bloc, implique un faux parallélisme. Cela implique que ce qui est important dans ces déclarations, c'est qu'elles essaient toutes. Ce n'est généralement pas la chose la plus importante à propos du code et ce sur quoi nous devrions nous concentrer lors de sa lecture.
Supposons, pour les besoins de l'argumentation, qu'AsCommit n'échoue jamais et par conséquent ne renvoie pas d'erreur. Maintenant nous avons:
headRef := try(r.Head())
parentObjOne := try(headRef.Peel(git.ObjectCommit))
parentObjTwo := try(remoteBranch.Reference.Peel(git.ObjectCommit))
parentCommitOne := parentObjOne.AsCommit()
parentCommitTwo := parentObjTwo.AsCommit()
treeOid := try(index.WriteTree())
tree := try(r.LookupTree(treeOid))
// vs
try headRef := r.Head()
try parentObjOne := headRef.Peel(git.ObjectCommit)
try parentObjTwo := remoteBranch.Reference.Peel(git.ObjectCommit)
parentCommitOne := parentObjOne.AsCommit()
parentCommitTwo := parentObjTwo.AsCommit()
try treeOid := index.WriteTree()
try tree := r.LookupTree(treeOid)
// vs
try (
headRef := r.Head()
parentObjOne := headRef.Peel(git.ObjectCommit)
parentObjTwo := remoteBranch.Reference.Peel(git.ObjectCommit)
)
parentCommitOne := parentObjOne.AsCommit()
parentCommitTwo := parentObjTwo.AsCommit()
try (
treeOid := index.WriteTree()
tree := r.LookupTree(treeOid)
)
Ce que vous voyez à première vue, c'est que les deux lignes du milieu sont clairement différentes des autres. Pourquoi? Cela s'avère à cause de la gestion des erreurs. Est-ce le détail le plus important de ce code, la chose que vous devriez remarquer au premier coup d'œil ? Ma réponse est non. Je pense que vous devriez remarquer la logique de base de ce que le programme fait en premier, et la gestion des erreurs plus tard. Dans cet exemple, l'instruction try et le bloc try entravent cette vue de la logique de base. Pour moi, cela suggère qu'ils ne sont pas la bonne syntaxe pour ces sémantiques.
Cela laisse les quatre premières syntaxes, qui sont encore plus similaires les unes aux autres :
headRef := try(r.Head())
parentObjOne := try(headRef.Peel(git.ObjectCommit))
parentObjTwo := try(remoteBranch.Reference.Peel(git.ObjectCommit))
parentCommitOne := parentObjOne.AsCommit()
parentCommitTwo := parentObjTwo.AsCommit()
treeOid := try(index.WriteTree())
tree := try(r.LookupTree(treeOid))
// vs
headRef := try r.Head()
parentObjOne := try headRef.Peel(git.ObjectCommit)
parentObjTwo := try remoteBranch.Reference.Peel(git.ObjectCommit)
parentCommitOne := parentObjOne.AsCommit()
parentCommitTwo := parentObjTwo.AsCommit()
treeOid := try index.WriteTree()
tree := try r.LookupTree(treeOid)
// vs
headRef := r.Head()?
parentObjOne := headRef.Peel(git.ObjectCommit)?
parentObjTwo := remoteBranch.Reference.Peel(git.ObjectCommit)?
parentCommitOne := parentObjOne.AsCommit()
parentCommitTwo := parentObjTwo.AsCommit()
treeOid := index.WriteTree()?
tree := r.LookupTree(treeOid)?
// vs
headRef := r.Head?()
parentObjOne := headRef.Peel?(git.ObjectCommit)
parentObjTwo := remoteBranch.Reference.Peel?(git.ObjectCommit)
parentCommitOne := parentObjOne.AsCommit()
parentCommitTwo := parentObjTwo.AsCommit()
treeOid := index.WriteTree?()
tree := r.LookupTree?(treeOid)
Il est difficile de trop s'énerver pour en choisir un plutôt que les autres. Ils ont tous leurs bons et leurs mauvais points. Les avantages les plus importants du formulaire intégré sont les suivants :
(1) l'opérande exact est très clair, surtout par rapport à l'opérateur de préfixe try x.y().z() .
(2) les outils qui n'ont pas besoin de connaître try peuvent le traiter comme un simple appel de fonction, donc par exemple goimports fonctionnera bien sans aucun ajustement, et
(3) il y a de la place pour une expansion future et un ajustement si nécessaire.
Il est tout à fait possible qu'après avoir vu du code réel utilisant ces constructions, nous développions une meilleure idée pour savoir si les avantages de l'une des trois autres syntaxes l'emportent sur ces avantages de la syntaxe d'appel de fonction. Seules les expériences et l'expérience peuvent nous le dire.
rsc
le 17 juin 2019
Merci pour toutes les précisions. Plus j'y pense, plus j'aime la proposition et je vois comment elle correspond aux objectifs.
Pourquoi ne pas utiliser une fonction comme recover() au lieu de err dont on ne sait pas d'où elle vient ? Ce serait plus cohérent et peut-être plus facile à mettre en œuvre.
func f() error {
defer func() {
if err:=error();err!=nil {
...
}
}()
}
edit: je n'utilise jamais de retour nommé, alors ce sera étrange pour moi d'ajouter un retour nommé juste pour ça
flibustenet
le 17 juin 2019
@flibustenet , voir aussi https://swtch.com/try.html#named pour quelques suggestions similaires.
(Répondre à tous : nous pourrions le faire, mais ce n'est pas strictement nécessaire étant donné les résultats nommés, nous pourrions donc aussi bien essayer d'utiliser le concept existant avant de décider que nous devons fournir une deuxième méthode.)
rsc
le 17 juin 2019
Une conséquence involontaire de try() peut être que les projets abandonnent _go fmt_ afin d'obtenir des contrôles d'erreur sur une seule ligne. C'est presque tous les avantages de try() sans les coûts. J'ai fait ça pendant quelques années; Ça marche bien.
Mais je préférerais pouvoir définir un gestionnaire d'erreurs de dernier recours pour le package et éliminer toutes les vérifications d'erreurs qui en ont besoin. Ce que je définirais n'est pas try() .
networkimprov
le 17 juin 2019
@networkimprov , vous semblez venir d'une position différente de celle des utilisateurs Go que nous ciblons, et votre message contribuerait davantage à la conversation s'il contenait des détails ou des liens supplémentaires afin que nous puissions mieux comprendre votre point de vue.
On ne sait pas quels "coûts" vous pensez que l'essai a. Et tandis que vous dites que l'abandon de gofmt n'a "aucun des coûts" d'essayer (quels qu'ils soient), vous semblez ignorer que le formatage de gofmt est celui utilisé par tous les programmes qui aident à réécrire le code source de Go, comme goimports, par exemple, gorename , etc. Vous abandonnez go fmt au prix de l'abandon de ces assistants, ou du moins en acceptant d'importantes modifications accidentelles de votre code lorsque vous les invoquez. Même ainsi, si cela fonctionne bien pour vous, c'est très bien : continuez à le faire par tous les moyens.
On ne sait pas non plus ce que signifie "définir un gestionnaire d'erreurs de dernier recours pour le package" ou pourquoi il serait approprié d'appliquer une politique de gestion des erreurs à un package entier plutôt qu'à une seule fonction à la fois. Si la principale chose que vous voudriez faire dans un gestionnaire d'erreurs est d'ajouter un contexte, le même contexte ne serait pas approprié pour l'ensemble du package.
rsc
le 17 juin 2019
@rsc , Comme vous l'avez peut-être vu, alors que j'ai suggéré la syntaxe du bloc try, je suis ensuite revenu du côté "non" pour cette fonctionnalité - en partie parce que je me sens mal à l'aise de cacher un ou plusieurs retours d'erreur conditionnels dans une instruction ou une application de fonction. Mais permettez-moi de clarifier un point. Dans la proposition de bloc try, j'ai explicitement autorisé les instructions qui n'ont pas besoin try . Ainsi, votre dernier exemple de bloc d'essai serait :
try (
headRef := r.Head()
parentObjOne := headRef.Peel(git.ObjectCommit)
parentObjTwo := remoteBranch.Reference.Peel(git.ObjectCommit)
parentCommitOne := parentObjOne.AsCommit()
parentCommitTwo := parentObjTwo.AsCommit()
treeOid := index.WriteTree()
tree := r.LookupTree(treeOid)
)
Cela indique simplement que toutes les erreurs renvoyées dans le bloc try sont renvoyées à l'appelant. Si le contrôle dépasse le bloc try, il n'y a pas eu d'erreurs dans le bloc.
Tu as dit
Je pense que vous devriez remarquer la logique de base de ce que le programme fait en premier, et la gestion des erreurs plus tard.
C'est exactement la raison pour laquelle j'ai pensé à un bloc try! Ce qui est pris en compte n'est pas seulement le mot-clé, mais la gestion des erreurs. Je ne veux pas avoir à penser à N endroits différents qui peuvent générer des erreurs (sauf lorsque j'essaie explicitement de gérer des erreurs spécifiques).
Quelques autres points qui méritent d'être mentionnés :
- L'appelant ne sait pas exactement d'où vient l'erreur au sein de l'appelé. Cela est également vrai de la proposition simple que vous envisagez en général. J'ai supposé que le compilateur pouvait être amené à ajouter sa propre annotation concernant le point de retour d'erreur. Mais je n'y ai pas beaucoup réfléchi.
- Je ne sais pas si des expressions telles que
try(try(foo(try(bar)).fum())sont autorisées. Une telle utilisation peut être mal vue mais leur sémantique doit être précisée. Dans le cas du bloc try, le compilateur doit travailler plus dur pour détecter de telles utilisations et extraire toute la gestion des erreurs au niveau du bloc try. - Je suis plus enclin à aimer
return-on-errorau lieu detry. C'est plus facile à avaler au niveau du bloc ! - D'un autre côté, tous les mots-clés longs rendent les choses moins lisibles.
FWIW, je ne pense toujours pas que cela en vaille la peine.
bakul
le 17 juin 2019
@rsc
[...]
La principale est l'affirmation selon laquelle, parce qu'il est possible d'écrire du code complexe et illisible, ce code deviendra omniprésent. Comme @josharian l'a noté, il est déjà "possible d'écrire du code abominable en Go".
[...]headRef := try(r.Head()) parentObjOne := try(headRef.Peel(git.ObjectCommit)) parentObjTwo := try(remoteBranch.Reference.Peel(git.ObjectCommit)) parentCommitOne := try(parentObjOne.AsCommit()) parentCommitTwo := try(parentObjTwo.AsCommit())Je comprends votre position sur le "mauvais code", c'est que nous pouvons écrire du code affreux aujourd'hui comme le bloc suivant.
parentCommitOne := try(try(try(r.Head()).Peel(git.ObjectCommit)).AsCommit())
parentCommitTwo := try(try(remoteBranch.Reference.Peel(git.ObjectCommit)).AsCommit())
Que pensez-vous de l'interdiction des appels try imbriqués afin que nous ne puissions pas écrire accidentellement du mauvais code ?
Si vous n'autorisez pas les try imbriqués sur la première version, vous pourrez supprimer cette limitation plus tard si nécessaire, l'inverse ne serait pas possible.
Goodwine
le 18 juin 2019
J'ai déjà discuté de ce point, mais il semble pertinent - la complexité du code doit être mise à l'échelle verticalement et non horizontalement.
try en tant qu'expression encourage la complexité du code à évoluer horizontalement en encourageant les appels imbriqués. try en tant qu'instruction encourage la complexité du code à évoluer verticalement.
deanveloper
le 18 juin 2019
@rsc , à vos questions,
Mon gestionnaire de dernier recours au niveau du package - lorsqu'une erreur n'est pas attendue :
func quit(err error) {
fmt.Fprintf(os.Stderr, "quit after %s\n", err)
debug.PrintStack() // because panic(err) produces a pile of noise
os.Exit(3)
}
Contexte : J'utilise beaucoup os.File (où j'ai trouvé deux bugs : #26650 & #32088)
Un décorateur au niveau du package ajoutant un contexte de base aurait besoin d'un argument caller -- une structure générée qui fournit les résultats de runtime.Caller().
Je souhaite que le réécrivain _go fmt_ utilise le formatage existant ou vous permette de spécifier le formatage par transformation. Je me débrouille avec d'autres outils.
Les coûts (c'est-à-dire les inconvénients) de try() sont bien documentés ci-dessus.
Honnêtement, je suis étonné que l'équipe de Go nous ait proposé d'abord check/handle (charitablement, une idée novatrice), puis le ternaire try() . Je ne vois pas pourquoi vous n'avez pas publié d'appel d'offres concernant la gestion des erreurs , puis collecté les commentaires de la communauté sur certaines des propositions résultantes (voir # 29860). Il y a beaucoup de sagesse ici que vous pourriez exploiter !
networkimprov
le 18 juin 2019
@rsc
Syntaxe
Cette discussion a identifié six syntaxes différentes pour écrire la même sémantique à partir de la proposition :
f := try(os.Open(file)), à partir de la proposition (fonction intégrée)f := try os.Open(file), en utilisant un mot-clé (mot-clé préfixé)f := os.Open(file)?, comme dans Rust (opérateur suffixe d'appel)f := os.Open?(file), suggéré par @rogpeppe (opérateur call-infix)try f := os.Open(file), suggéré par @thepudds (instruction try)try ( f := os.Open(file); f.Close() ), suggéré par @bakul (essayer de bloquer)
try {error} {optional wrap func} {optional return args in brackets}
f, err := os.Open(file)
try err wrap { a, b }
... et, IMO, améliorant la lisibilité (grâce à l'allitération) ainsi que la précision sémantique :
f, err := os.Open(file)
relay err
ou
f, err := os.Open(file)
relay err wrap
ou
f, err := os.Open(file)
relay err wrap { a, b }
ou
f, err := os.Open(file)
relay err { a, b }
Je sais qu'il est facile de rejeter le fait de plaider pour le relais contre l'essai comme étant hors sujet, mais je peux simplement imaginer essayer d'expliquer comment l'essai n'essaie rien et ne jette rien. Ce n'est pas clair ET a des bagages. relay étant un nouveau terme permettrait une explication claire, et la description a une base dans les circuits (c'est de toute façon de quoi il s'agit).
Modifier pour clarifier:
Essayer peut signifier - 1. faire l'expérience de quelque chose puis le juger subjectivement 2. vérifier quelque chose objectivement 3. tenter de faire quelque chose 4. déclencher plusieurs flux de contrôle qui peuvent être interrompus et lancer une notification interceptable si c'est le cas
Dans cette proposition, try ne fait rien de tout cela. Nous exécutons en fait une fonction. Il recâble ensuite le flux de contrôle sur la base d'une valeur d'erreur. C'est littéralement la définition d'un relais de protection. Nous repositionnons directement les circuits (c'est-à-dire court-circuitons la portée de la fonction actuelle) en fonction de la valeur d'une erreur testée.
daved
le 18 juin 2019
Dans la proposition de bloc try, j'ai explicitement autorisé les déclarations qui n'ont pas besoin d'essayer
Le principal avantage de la gestion des erreurs de Go que je vois par rapport au système try-catch de langages comme Java et Python est qu'il est toujours clair quels appels de fonction peuvent entraîner une erreur et lesquels ne le peuvent pas. La beauté de try telle que documentée dans la proposition originale est qu'elle peut réduire le passe-partout de gestion des erreurs simples tout en conservant cette fonctionnalité importante.
Pour emprunter aux exemples de @Goodwine , malgré sa laideur, du point de vue de la gestion des erreurs, même ceci :
parentCommitOne := try(try(try(r.Head()).Peel(git.ObjectCommit)).AsCommit())
parentCommitTwo := try(try(remoteBranch.Reference.Peel(git.ObjectCommit)).AsCommit())
... est mieux que ce que vous voyez souvent dans les langages try-catch
parentCommitOne := r.Head().Peel(git.ObjectCommit).AsCommit()
parentCommitTwo := remoteBranch.Reference.Peel(git.ObjectCommit).AsCommit()
... parce que vous pouvez toujours dire quelles parties du code peuvent détourner le flux de contrôle en raison d'une erreur et lesquelles ne le peuvent pas.
Je sais que @bakul ne préconise pas cette proposition de syntaxe de bloc de toute façon, mais je pense que cela soulève un point intéressant sur la gestion des erreurs de Go par rapport aux autres. Je pense qu'il est important que toute proposition de gestion des erreurs adoptée par Go ne masque pas les parties du code qui peuvent et ne peuvent pas générer d'erreur.
velovix
le 18 juin 2019
J'ai écrit un petit outil : tryhard (qui n'essaie pas très fort pour le moment) fonctionne fichier par fichier et utilise une simple correspondance de modèle AST pour reconnaître les candidats potentiels pour try et de les signaler (et de les réécrire). L'outil est primitif (pas de vérification de type) et il y a une chance décente de faux positifs, selon le style de codage répandu. Lisez la documentation pour plus de détails.
L'appliquer à $GOROOT/src au pourboire rapporte > 5000 (!) opportunités pour try . Il peut y avoir beaucoup de faux positifs, mais vérifier un échantillon décent à la main suggère que la plupart des opportunités sont réelles.
L'utilisation de la fonction de réécriture montre à quoi ressemblera le code en utilisant try . Encore une fois, un coup d'œil rapide à la sortie montre une amélioration significative dans mon esprit.
( Attention : la fonction de réécriture détruira les fichiers ! À utiliser à vos risques et périls. )
Espérons que cela fournira un aperçu concret de ce à quoi le code pourrait ressembler en utilisant try et nous permettra de dépasser les spéculations inactives et improductives.
Merci et profitez-en.
griesemer
le 18 juin 2019
Je comprends votre position sur le "mauvais code", c'est que nous pouvons écrire du code affreux aujourd'hui comme le bloc suivant.
parentCommitOne := try(try(try(r.Head()).Peel(git.ObjectCommit)).AsCommit()) parentCommitTwo := try(try(remoteBranch.Reference.Peel(git.ObjectCommit)).AsCommit())
Ma position est que les développeurs Go font un travail décent en écrivant du code clair et que le compilateur n'est presque certainement pas la seule chose qui vous empêche, vous ou vos collègues, d'écrire du code qui ressemble à ça.
Que pensez-vous de l'interdiction des appels
tryimbriqués afin que nous ne puissions pas écrire accidentellement du mauvais code ?
Une grande partie de la simplicité de Go provient de la sélection de caractéristiques orthogonales qui se composent indépendamment. L'ajout de restrictions rompt l'orthogonalité, la composabilité, l'indépendance et, ce faisant, rompt la simplicité.
Aujourd'hui, c'est une règle que si vous avez:
x := expression
y := f(x)
sans autre utilisation de x nulle part, alors c'est une transformation de programme valide pour simplifier cela à
y := f(expression)
Si nous devions adopter une restriction sur les expressions try, cela casserait tout outil qui supposait qu'il s'agissait toujours d'une transformation valide. Ou si vous aviez un générateur de code qui fonctionnait avec des expressions et pouvait traiter des expressions try, il devrait faire tout son possible pour introduire des temporaires pour satisfaire les restrictions. Ainsi de suite.
En bref, les restrictions ajoutent une complexité importante. Ils ont besoin d'une justification significative, pas "voyons si quelqu'un se heurte à ce mur et nous demande de l'abattre".
J'ai écrit une explication plus longue il y a deux ans sur https://github.com/golang/go/issues/18130#issuecomment -264195616 (dans le contexte des alias de type) qui s'applique également ici.
rsc
le 18 juin 2019
@bakul ,
Mais permettez-moi de clarifier un point. Dans la proposition de bloc try, j'ai explicitement autorisé les déclarations qui _n'ont pas besoin_
try.
Faire cela serait en deçà du deuxième objectif : "Les contrôles d'erreurs et la gestion des erreurs doivent rester explicites, c'est-à-dire visibles dans le texte du programme. Nous ne voulons pas répéter les pièges de la gestion des exceptions."
Le principal écueil de la gestion traditionnelle des exceptions est de ne pas savoir où se trouvent les vérifications. Considérer:
try {
s = canThrowErrors()
t = cannotThrowErrors()
u = canThrowErrors() // a second call
} catch {
// how many ways can you get here?
}
Si les fonctions n'ont pas été nommées de manière aussi utile, il peut être très difficile de dire quelles fonctions peuvent échouer et lesquelles sont garanties de réussir, ce qui signifie que vous ne pouvez pas facilement déterminer quels fragments de code peuvent être interrompus par une exception et lesquels ne le peuvent pas.
Comparez cela avec l'approche de Swift , où ils adoptent une partie de la syntaxe traditionnelle de gestion des exceptions mais font en fait une gestion des erreurs, avec un marqueur explicite sur chaque fonction cochée et aucun moyen de se dérouler au-delà du cadre de pile actuel :
do {
let s = try canThrowErrors()
let t = cannotThrowErrors()
let u = try canThrowErrors() // a second call
} catch {
handle error from try above
}
Qu'il s'agisse de Rust ou Swift ou de cette proposition, l'amélioration clé et critique par rapport à la gestion des exceptions consiste à marquer explicitement dans le texte - même avec un marqueur très léger - chaque endroit où se trouve une vérification.
Pour en savoir plus sur le problème des vérifications implicites, voir la section Problème de l'aperçu du problème d'août dernier, en particulier les liens vers les deux articles de Raymond Chen.
Edit : voir aussi le commentaire trois up de @velovix , qui est arrivé pendant que je travaillais sur celui-ci.
rsc
le 18 juin 2019
@daved , je suis content que l'analogie du "relais de protection" fonctionne pour vous. Cela ne fonctionne pas pour moi. Les programmes ne sont pas des circuits.
N'importe quel mot peut être mal compris :
"break" ne casse pas votre programme.
"continue" ne continue pas l'exécution à l'instruction suivante comme d'habitude.
"goto" ... eh bien goto est impossible à mal comprendre en fait. :-)
https://www.google.com/search?q=define+try indique "faire une tentative ou un effort pour faire quelque chose" et "sujet à un procès". Les deux s'appliquent à "f := try(os.Open(file))". Il tente de faire os.Open (ou, il soumet le résultat de l'erreur à un essai), et si la tentative (ou le résultat de l'erreur) échoue, il revient de la fonction.
Nous avons utilisé le chèque en août dernier. C'était un bon mot aussi. Nous sommes passés à try, malgré le bagage historique de C++/Java/Python, car la signification actuelle de try dans cette proposition correspond à la signification de try de Swift (sans le do-catch environnant) et de try original de Rust ! . Ce ne sera pas terrible si nous décidons plus tard que vérifier est le bon mot après tout, mais pour l'instant, nous devrions nous concentrer sur d'autres choses que le nom.
rsc
le 18 juin 2019
Voici un intéressant faux négatif tryhard , de github.com/josharian/pct . Je le mentionne ici parce que :
- cela montre comment la détection automatisée
tryest délicate - cela montre que le coût visuel de
if err != nila un impact sur la façon dont les gens (moi du moins) structurent leur code, et quetrypeut aider à cela
Avant de:
var err error
switch {
case *flagCumulative:
_, err = fmt.Fprintf(w, "% 6.2f%% % 6.2f%%% 6d %s\n", p, f*float64(runtot), line.n, line.s)
case *flagQuiet:
_, err = fmt.Fprintln(w, line.s)
default:
_, err = fmt.Fprintf(w, "% 6.2f%%% 6d %s\n", p, line.n, line.s)
}
if err != nil {
return err
}
Après (réécriture manuelle) :
switch {
case *flagCumulative:
try(fmt.Fprintf(w, "% 6.2f%% % 6.2f%%% 6d %s\n", p, f*float64(runtot), line.n, line.s))
case *flagQuiet:
try(fmt.Fprintln(w, line.s))
default:
try(fmt.Fprintf(w, "% 6.2f%%% 6d %s\n", p, line.n, line.s))
}
Le changement https://golang.org/cl/182717 mentionne ce problème : src: apply tryhard -r $GOROOT/src
 gopherbot
le 18 juin 2019
gopherbot
le 18 juin 2019
Pour une idée visuelle de try dans la bibliothèque std, rendez-vous sur CL 182717 .
griesemer
le 18 juin 2019
Merci, @josharian , pour cela . Oui, il peut même être impossible pour un bon outil de détecter tous les candidats d'utilisation possibles pour try . Mais heureusement, ce n'est pas l'objectif principal (de cette proposition). Avoir un outil est utile, mais je vois le principal avantage de try dans le code qui n'est pas encore écrit (car il y aura beaucoup plus que le code que nous avons déjà).
griesemer
le 18 juin 2019
"break" ne casse pas votre programme.
"continue" ne continue pas l'exécution à l'instruction suivante comme d'habitude.
"goto" ... eh bien goto est impossible à mal comprendre en fait. :-)
break casse la boucle. continue continue la boucle, et goto va à la destination indiquée. En fin de compte, je vous entends, mais veuillez considérer ce qui se passe lorsqu'une fonction se termine et renvoie une erreur, mais ne revient pas en arrière. Ce n'était pas un essai. Je pense que check est de loin supérieur à cet égard (pour "arrêter la progression de" à travers "l'examen" est certainement approprié).
Plus pertinent, je suis curieux de la forme de try/check que j'ai proposée par opposition aux autres syntaxes.
try {error} {optional wrap func} {optional return args in brackets}
f, err := os.Open(file)
try err wrap { a, b }
La bibliothèque standard finit par ne pas être représentative du "vrai" code Go dans la mesure où elle ne passe pas beaucoup de temps à coordonner ou à connecter d'autres packages. Nous avons remarqué cela dans le passé comme la raison pour laquelle il y a si peu d'utilisation de canal dans la bibliothèque standard par rapport aux packages plus haut dans la chaîne alimentaire de dépendance. Je soupçonne que la gestion et la propagation des erreurs finissent par être similaires aux canaux à cet égard: vous en trouverez plus au fur et à mesure que vous montez.
Pour cette raison, il serait intéressant pour quelqu'un d'exécuter tryhard sur des bases de code d'application plus larges et de voir quelles choses amusantes peuvent être découvertes dans ce contexte. (La bibliothèque standard est également intéressante, mais plus comme un microcosme qu'un échantillon précis du monde.)
rsc
le 18 juin 2019
Je suis curieux de connaître la forme de try/check que j'ai proposée par opposition aux autres syntaxes.
Je pense que cette forme finit par recréer des structures de contrôle existantes .
rsc
le 18 juin 2019
@networkimprov , concernant https://github.com/golang/go/issues/32437#issuecomment -502879351
Je suis honnêtement étonné que l'équipe Go nous ait proposé d'abord check/handle (charitablement, une idée nouvelle), puis le ternaire try(). Je ne vois pas pourquoi vous n'avez pas publié d'appel d'offres concernant la gestion des erreurs, puis collecté les commentaires de la communauté sur certaines des propositions résultantes (voir # 29860). Il y a beaucoup de sagesse ici que vous pourriez exploiter !
Comme nous en avons discuté au # 29860, je ne vois honnêtement pas beaucoup de différence entre ce que vous suggérez que nous aurions dû faire en ce qui concerne la sollicitation des commentaires de la communauté et ce que nous avons réellement fait. La page des projets de conception indique explicitement qu'il s'agit de "points de départ pour la discussion, dans le but éventuel de produire des conceptions suffisamment bonnes pour être transformées en propositions réelles". Et les gens ont écrit beaucoup de choses allant de courts commentaires à des propositions alternatives complètes. Et la plupart ont été utiles et j'apprécie votre aide en particulier dans l'organisation et la synthèse. Vous semblez déterminé à lui donner un nom différent ou à introduire des couches supplémentaires de bureaucratie, ce dont nous n'avons pas vraiment besoin, comme nous en avons discuté à ce sujet.
Mais s'il vous plaît, ne prétendez pas que nous n'avons pas sollicité l'avis de la communauté ou que nous l'avons ignoré. Ce n'est tout simplement pas vrai.
Je ne vois pas non plus en quoi try est en quelque sorte "ternaire", quoi que cela signifie.
rsc
le 18 juin 2019
D'accord, je pense que c'était mon objectif; Je ne pense pas que des mécanismes plus complexes valent la peine. Si j'étais à votre place, tout ce que j'offrirais, c'est un peu de sucre syntaxique pour faire taire la majorité des plaintes et rien de plus.
daved
le 18 juin 2019
@rsc , toutes mes excuses pour le hors-sujet !
J'ai soulevé des gestionnaires au niveau du package dans https://github.com/golang/go/issues/32437#issuecomment -502840914
et répondu à votre demande de clarification dans https://github.com/golang/go/issues/32437#issuecomment -502879351
Je vois les gestionnaires au niveau des packages comme une fonctionnalité que pratiquement tout le monde pourrait suivre.
networkimprov
le 18 juin 2019
veuillez utiliser la syntaxe try {} catch{}, ne construisez pas plus de roues
 jimwei
le 18 juin 2019
jimwei
le 18 juin 2019
veuillez utiliser la syntaxe try {} catch{}, ne construisez pas plus de roues
je pense qu'il est approprié de construire de meilleures roues lorsque les roues que les autres utilisent ont la forme de carrés
deanveloper
le 18 juin 2019
@jimwei
La gestion des erreurs basée sur les exceptions peut être une roue préexistante, mais elle présente également de nombreux problèmes connus. L' énoncé du problème dans le projet de conception original fait un excellent travail pour décrire ces problèmes.
Pour ajouter mon propre commentaire moins bien pensé, je pense qu'il est intéressant que de nombreux nouveaux langages très réussis (à savoir Swift, Rust et Go) n'aient pas adopté d'exceptions. Cela me dit que la communauté logicielle au sens large repense les exceptions après les nombreuses années que nous avons dû travailler avec elles.
velovix
le 18 juin 2019
En réponse à https://github.com/golang/go/issues/32437#issuecomment -502837008 (commentaire de @rsc sur try comme déclaration)
Vous soulevez un bon point. Je suis désolé d'avoir manqué ce commentaire avant de faire celui-ci : https://github.com/golang/go/issues/32437#issuecomment -502871889
Vos exemples avec try comme expression sont bien meilleurs que ceux avec try comme instruction. Le fait que l'instruction commence par try la rend en fait beaucoup plus difficile à lire. Cependant, je crains toujours que les gens essaient d'emboîter les appels ensemble pour créer un mauvais code, car try en tant qu'expression _encourage vraiment_ ce comportement à mes yeux.
Je pense que j'apprécierais un peu plus cette proposition si golint interdisait les appels try imbriqués. Je pense qu'interdire tous les appels try à l'intérieur d'autres expressions est un peu trop strict, avoir try comme expression a ses mérites.
En empruntant votre exemple, même le simple fait d'imbriquer 2 appels try ensemble semble assez hideux, et je peux voir les programmeurs Go le faire, surtout s'ils travaillent sans réviseurs de code.
parentCommitOne := try(remoteBranch.Reference.Peel(git.ObjectCommit)).AsCommit()
parentCommitTwo := try(try(r.Head()).Peel(git.ObjectCommit)).AsCommit()
tree := try(r.LookupTree(try(index.WriteTree())))
L'exemple original avait en fait l'air plutôt sympa, mais celui-ci montre que l'imbrication des expressions try (même seulement 2 en profondeur) nuit vraiment considérablement à la lisibilité du code. Refuser les appels try imbriqués aiderait également à résoudre le problème de "débogage", car il est beaucoup plus facile de développer un try en un if s'il se trouve à l'extérieur d'une expression.
Encore une fois, j'aimerais presque dire qu'un try à l'intérieur d'une sous-expression devrait être marqué par golint , mais je pense que c'est peut-être un peu trop strict. Cela signalerait également un code comme celui-ci, ce qui à mes yeux est bien:
x := 5 + try(strconv.Atoi(input))
De cette façon, nous obtenons à la fois les avantages d'avoir try comme expression, mais nous ne favorisons pas l'ajout de trop de complexité à l'axe horizontal.
Peut-être qu'une autre solution serait que golint ne devrait autoriser qu'un maximum de 1 try par instruction, mais il est tard, je commence à être fatigué et j'ai besoin d'y réfléchir plus rationnellement. Quoi qu'il en soit, j'ai été assez négatif envers cette proposition à certains moments, mais je pense que je peux vraiment l'aimer tant qu'il y a des normes golint qui y sont liées.
deanveloper
le 18 juin 2019
@rsc
Nous pouvons et devons faire la distinction entre _"cette fonctionnalité peut être utilisée pour écrire du code très lisible, mais peut également être utilisée abusivement pour écrire du code illisible"_ et "l'utilisation dominante de cette fonctionnalité sera d'écrire du code illisible".
L'expérience avec C suggère que ? : tombe carrément dans la deuxième catégorie. (À l'exception possible du min et du max,
Ce qui m'a d'abord frappé à propos try() - contre try en tant qu'énoncé - était à quel point il était similaire dans l'imbrication à l'opérateur ternaire et pourtant à quel point les arguments pour try() et contre ternaire étaient opposés étaient _(paraphrasé):_
- ternaire : _"Si nous le permettons, les gens l'imbriqueront et le résultat sera beaucoup de mauvais code"_ en ignorant que certaines personnes écrivent un meilleur code avec eux, vs.
try():_"Vous pouvez l'imbriquer, mais nous doutons que beaucoup le fassent car la plupart des gens veulent écrire du bon code"_,
Respectueusement, ce rationnel pour la différence entre les deux semble si subjectif que je demanderais une introspection et au moins considérer si vous pourriez rationaliser une différence pour une fonctionnalité que vous préférez par rapport à une fonctionnalité que vous n'aimez pas ? #Please_dont_shoot_the_messenger
_"Je ne suis pas sûr d'avoir déjà vu du code utilisant ? : cela n'a pas été amélioré en le réécrivant pour utiliser une instruction if à la place. Mais ce paragraphe sort du sujet.)"_
Dans d'autres langages, j'améliore fréquemment les instructions en les réécrivant d'un if à un opérateur ternaire, par exemple à partir du code que j'ai écrit aujourd'hui en PHP :
return isset( $_COOKIE[ CookieNames::CART_ID ] )
? intval( $_COOKIE[ CookieNames::CART_ID ] )
: null;
Comparer aux:
if ( isset( $_COOKIE[ CookieNames::CART_ID ] ) ) {
return intval( $_COOKIE[ CookieNames::CART_ID ] );
} else {
return null;
}
En ce qui me concerne, le premier est bien meilleur que le second.
fwiw
mikeschinkel
le 18 juin 2019
Je pense que les critiques à l'encontre de cette proposition sont en grande partie dues aux attentes élevées suscitées par la proposition précédente, qui aurait été beaucoup plus complète. Cependant, je pense que des attentes aussi élevées étaient justifiées pour des raisons de cohérence. Je pense que ce que beaucoup de gens auraient aimé voir, c'est une construction unique et complète pour la gestion des erreurs qui est utile dans tous les cas d'utilisation.
Comparez cette fonctionnalité, par exemple, avec la fonction intégrée append() . Append a été créé parce que l'ajout à slice était un cas d'utilisation très courant, et s'il était possible de le faire manuellement, il était également facile de le faire mal. Désormais, append() permet d'ajouter non pas un seul, mais de nombreux éléments, voire une tranche entière, et il permet même d'ajouter une chaîne à une tranche de []octets. Il est suffisamment puissant pour couvrir tous les cas d'utilisation d'ajout à une tranche. Et par conséquent, plus personne n'ajoute de tranches manuellement.
Cependant, try() est différent. Il n'est pas assez puissant pour qu'on puisse l'utiliser dans tous les cas de gestion d'erreur. Et je pense que c'est le défaut le plus grave de cette proposition. La fonction intégrée try() n'est vraiment utile que dans le sens où elle réduit le passe-partout, dans les cas les plus simples, à savoir simplement transmettre une erreur à l'appelant, et avec une instruction différée, si toutes les erreurs du fonction doit être gérée de la même manière.
Pour une gestion des erreurs plus complexe, nous devrons toujours utiliser if err != nil {} . Cela conduit alors à deux styles distincts pour la gestion des erreurs, là où auparavant il n'y en avait qu'un. Si cette proposition est tout ce que nous obtenons pour aider à la gestion des erreurs dans Go, alors, je pense qu'il serait préférable de ne rien faire et de continuer à gérer la gestion des erreurs avec if comme nous l'avons toujours fait, car au moins, c'est cohérent et avait l'avantage de "il n'y a qu'une seule façon de le faire".
beoran
le 18 juin 2019
@rsc , toutes mes excuses pour le hors-sujet !
J'ai augmenté les gestionnaires de niveau package dans # 32437 (commentaire)
et répondu à votre demande de clarification dans #32437 (commentaire)Je vois les gestionnaires au niveau des packages comme une fonctionnalité que pratiquement tout le monde pourrait suivre.
Je ne vois pas ce qui relie le concept de package à une gestion d'erreur spécifique. Il est difficile d'imaginer que le concept d'un gestionnaire au niveau du package soit utile pour, disons, net/http . Dans le même ordre d'idées, malgré l'écriture de packages plus petits que net/http en général, je ne peux pas penser à un seul cas d'utilisation où j'aurais préféré une construction au niveau du package pour gérer les erreurs. En général, j'ai trouvé que l'hypothèse selon laquelle tout le monde partage ses expériences, ses cas d'utilisation et ses opinions est dangereuse :)
eandre
le 18 juin 2019
@beoran je crois que cette proposition rend possible d'autres améliorations. Comme un décorateur au dernier argument de try(..., func(err) error) , ou un tryf(..., "context of my error: %w") ?
flibustenet
le 18 juin 2019
@flibustenet Bien que de telles extensions ultérieures puissent être possibles, la proposition telle qu'elle est maintenant semble décourager de telles extensions, principalement parce que l'ajout d'un gestionnaire d'erreurs serait redondant avec le report.
Je suppose que le problème difficile est de savoir comment avoir une gestion complète des erreurs sans dupliquer la fonctionnalité de defe. Peut-être que l'instruction de report elle-même pourrait être améliorée d'une manière ou d'une autre pour permettre une gestion plus facile des erreurs dans des cas plus complexes... Mais c'est un autre problème.
beoran
le 18 juin 2019
https://github.com/golang/go/issues/32437#issuecomment -502975437
Cela conduit alors à deux styles distincts pour la gestion des erreurs, là où auparavant il n'y en avait qu'un. Si cette proposition est tout ce que nous obtenons pour aider à la gestion des erreurs dans Go, alors, je pense qu'il serait préférable de ne rien faire et de continuer à gérer la gestion des erreurs avec
ifcomme nous l'avons toujours fait, car au moins, c'est cohérent et avait l'avantage de "il n'y a qu'une seule façon de le faire".
@beoran D'accord. C'est pourquoi j'ai suggéré d'unifier la grande majorité des cas d'erreur sous le mot-clé try ( try et try / else ). Même si la syntaxe try / else ne nous donne aucune réduction significative de la longueur du code par rapport au style if err != nil existant, elle nous donne une cohérence avec le try (pas else ). Ces deux cas (try et try-else) sont susceptibles de couvrir la grande majorité des cas de gestion des erreurs. Je mets cela en opposition à la version no-else intégrée de try qui ne s'applique que dans les cas où le programmeur ne fait rien pour gérer l'erreur en plus de revenir (ce qui, comme d'autres l'ont mentionné dans ce fil, n'est pas nécessairement quelque chose que nous voulons vraiment encourager en premier lieu).
La cohérence est importante pour la lisibilité.
append est le moyen définitif d'ajouter des éléments à une tranche. make est le moyen définitif de construire un nouveau canal, une nouvelle carte ou une nouvelle tranche (à l'exception des littéraux, dont je ne suis pas ravi). Mais try() (en tant que fonction intégrée, et sans else ) serait dispersé dans les bases de code, selon la façon dont le programmeur doit gérer une erreur donnée, d'une manière qui est probablement un peu chaotique et déroutante pour le lecteur. Cela ne semble pas être dans l'esprit des autres éléments intégrés (à savoir, gérer un cas qui est soit assez difficile, soit carrément impossible à faire autrement). Si c'est la version de try qui réussit, la cohérence et la lisibilité m'obligeront à ne pas l'utiliser, tout comme j'essaie d'éviter les littéraux de carte/tranche (et d'éviter new comme la peste).
Si l'idée est de changer la façon dont les erreurs sont gérées, il semble sage d'essayer d'unifier l'approche dans autant de cas que possible, plutôt que d'ajouter quelque chose qui, au mieux, sera "à prendre ou à laisser". Je crains que ce dernier n'ajoute du bruit plutôt que de le réduire.
brynbellomy
le 18 juin 2019
@deanveloper a écrit :
Je pense que j'apprécierais un peu plus cette proposition si Golint interdisait les appels d'essai imbriqués.
Je suis d'accord que try profondément imbriqué pourrait être difficile à lire. Mais cela est également vrai pour les appels de fonction standard, pas seulement pour la fonction intégrée try . Donc je ne vois pas pourquoi golint devrait interdire cela.
 ngrilly
le 18 juin 2019
ngrilly
le 18 juin 2019
@brynbellomy a écrit :
Même si la syntaxe try/else ne nous donne aucune réduction significative de la longueur du code par rapport au style if err != nil existant, elle nous donne une cohérence avec le cas try (no else).
L'objectif unique de la fonction intégrée try est de réduire le passe-partout, il est donc difficile de voir pourquoi nous devrions adopter la syntaxe try/else que vous proposez lorsque vous reconnaissez qu'elle "ne nous donne aucune réduction significative en longueur de code".
Vous mentionnez également que la syntaxe que vous proposez rend le cas try cohérent avec le cas try/else. Mais cela crée également une manière incohérente de créer des branches, alors que nous avons déjà if/else. Vous gagnez un peu de cohérence sur un cas d'utilisation spécifique mais perdez beaucoup d'incohérence sur le reste.
ngrilly
le 18 juin 2019
Je ressens le besoin d'exprimer mes opinions pour ce qu'elles valent. Bien que tout cela ne soit pas de nature académique et technique, je pense qu'il faut le dire.
Je crois que ce changement est l'un de ces cas où l'ingénierie est faite pour l'ingénierie et le "progrès" est utilisé pour la justification. La gestion des erreurs dans Go n'est pas rompue et cette proposition viole une grande partie de la philosophie de conception que j'aime chez Go.
Rendre les choses faciles à comprendre, pas faciles à faire
Cette proposition choisit l'optimisation pour la paresse plutôt que pour l'exactitude. L'accent est mis sur la simplification de la gestion des erreurs et, en retour, une énorme quantité de lisibilité est perdue. La nature fastidieuse occasionnelle de la gestion des erreurs est acceptable en raison des gains de lisibilité et de débogabilité.
Évitez de nommer les arguments de retour
Il existe quelques cas extrêmes avec des instructions defer où nommer l'argument de retour est valide. En dehors de ceux-ci, il faut l'éviter. Cette proposition promeut l'utilisation d'arguments de retour de nommage. Cela ne va pas aider à rendre le code Go plus lisible.
L'encapsulation devrait créer une nouvelle sémantique où l'on est absolument précis
Il n'y a aucune précision dans cette nouvelle syntaxe. Cacher la variable d'erreur et le retour n'aide pas à rendre les choses plus faciles à comprendre. En fait, la syntaxe semble très étrangère à tout ce que nous faisons en Go aujourd'hui. Si quelqu'un écrivait une fonction similaire, je pense que la communauté serait d'accord que l'abstraction cache le coût et ne vaut pas la simplicité qu'elle essaie de fournir.
Qui essayons-nous d'aider ?
Je crains que ce changement ne soit mis en place dans le but d'inciter les développeurs d'entreprise à abandonner leurs langages actuels et à adopter Go. La mise en œuvre de changements de langage, juste pour augmenter les chiffres, crée un mauvais précédent. Je pense qu'il est juste de poser cette question et d'obtenir une réponse au problème commercial qui tente d'être résolu et au gain attendu qui tente d'être atteint ?
J'ai déjà vu cela plusieurs fois maintenant. Il semble assez clair, avec toute l'activité récente de l'équipe linguistique, cette proposition est fondamentalement gravée dans le marbre. Il y a plus de défense de la mise en œuvre que de débat réel sur la mise en œuvre elle-même. Tout cela a commencé il y a 13 jours. Nous verrons l'impact de ce changement sur la langue, la communauté et l'avenir de Go.
 ardan-bkennedy
le 18 juin 2019
ardan-bkennedy
le 18 juin 2019
La gestion des erreurs dans Go n'est pas rompue et cette proposition viole une grande partie de la philosophie de conception que j'aime chez Go.
Bill exprime parfaitement mes pensées.
Je ne peux pas empêcher l'introduction try , mais si c'est le cas, je ne l'utiliserai pas moi-même ; Je ne l'enseignerai pas et je ne l'accepterai pas dans les relations publiques que je passe en revue. Il sera simplement ajouté à la liste des autres "choses dans Go que je n'utilise jamais" (voir la discussion amusante de Mat Ryer sur YouTube pour en savoir plus).
bitfield
le 18 juin 2019
@ardan-bkennedy, merci pour vos commentaires.
Vous avez posé une question sur le "problème commercial qui tente d'être résolu". Je ne crois pas que nous ciblons les problèmes d'une entreprise en particulier, à l'exception peut-être de la "programmation Go". Mais plus généralement, nous avons articulé le problème que nous essayons de résoudre en août dernier dans le coup d'envoi de la discussion sur le projet de conception de Gophercon (voir l' aperçu du problème , en particulier la section Objectifs). Le fait que cette conversation se poursuive depuis août dernier contredit également catégoriquement votre affirmation selon laquelle "tout cela a commencé il y a 13 jours".
Vous n'êtes pas la seule personne à avoir suggéré que ce n'est pas un problème ou qu'il ne vaut pas la peine d'être résolu. Voir https://swtch.com/try.html#nonissue pour d'autres commentaires de ce type. Nous les avons notés et voulons nous assurer que nous résolvons un problème réel. Une partie du moyen de le savoir consiste à évaluer la proposition sur des bases de code réelles. Des outils comme Robert's tryhard nous aident à le faire. J'ai demandé plus tôt aux gens de nous faire savoir ce qu'ils trouvent dans leurs propres bases de code. Ces informations seront d'une importance cruciale pour évaluer si le changement en vaut la peine ou non. Vous avez une supposition et j'en ai une autre, et c'est très bien. La réponse est de substituer des données à ces suppositions.
Nous ferons le nécessaire pour nous assurer que nous résolvons un problème réel.
Encore une fois, la voie à suivre est constituée de données expérimentales, pas de réactions viscérales. Malheureusement, la collecte de données demande plus d'efforts. À ce stade, j'encourage les personnes qui souhaitent aider à sortir et à collecter des données.
rsc
le 18 juin 2019
@ardan-bkennedy, désolé pour le deuxième suivi mais concernant :
Je crains que ce changement ne soit mis en place dans le but d'inciter les développeurs d'entreprise à abandonner leurs langages actuels et à adopter Go. La mise en œuvre de changements de langage, juste pour augmenter les chiffres, crée un mauvais précédent.
Il y a deux problèmes sérieux avec cette ligne que je ne peux pas contourner.
Tout d'abord, je rejette l'affirmation implicite selon laquelle il existe des classes de développeurs - dans ce cas, les "développeurs d'entreprise" - qui ne sont en quelque sorte pas dignes d'utiliser Go ou de voir leurs problèmes pris en compte. Dans le cas spécifique de "l'entreprise", nous voyons de nombreux exemples de petites et grandes entreprises utilisant Go très efficacement.
Deuxièmement, depuis le début du projet Go, nous - Robert, Rob, Ken, Ian et moi - avons évalué les changements de langage et les fonctionnalités sur la base de notre expérience collective dans la construction de nombreux systèmes. Nous demandons "est-ce que cela fonctionnerait bien dans les programmes que nous écrivons?" Cela a été une recette réussie avec une large applicabilité et c'est celle que nous avons l'intention de continuer à utiliser, encore une fois complétée par les données que j'ai demandées dans le commentaire précédent et les rapports d'expérience plus généralement. Nous ne suggérerions ni ne soutiendrions un changement de langage que nous ne nous voyions pas utiliser dans nos propres programmes ou qui, selon nous, ne s'intègre pas bien dans Go. Et nous ne suggérerions ou ne soutiendrions certainement pas un mauvais changement juste pour avoir plus de programmeurs Go. Nous utilisons aussi Go après tout.
rsc
le 18 juin 2019
@rsc
Il ne manquera pas d'endroits où cette commodité peut être placée. Quelle métrique est recherchée qui prouvera la substance du mécanisme en dehors de cela? Existe-t-il une liste de cas classés de gestion des erreurs ? Comment la valeur sera-t-elle dérivée des données alors qu'une grande partie du processus public est motivée par le sentiment ?
daved
le 18 juin 2019
Les outils tryhard sont très instructifs !
J'ai pu voir que j'utilise souvent return ...,err , mais seulement quand je sais que j'appelle une fonction qui enveloppe déjà l'erreur (avec pkg/errors ), principalement dans les gestionnaires http. Je gagne en lisibilité avec moins de ligne de code.
Ensuite, dans ces gestionnaires http, j'ajouterais un defer fmt.HandleErrorf(&err, "handler xyz") et j'ajouterais enfin plus de contexte qu'auparavant.
Je vois aussi beaucoup de cas où je ne me soucie pas du tout de l'erreur fmt.Printf et je le ferai avec try .
Sera-t-il possible par exemple de faire defer try(f.Close()) ?
Donc, peut-être try aidera enfin à ajouter du contexte et à promouvoir les meilleures pratiques plutôt que le contraire.
Je suis très impatient de tester en vrai !
flibustenet
le 18 juin 2019
@flibustenet La proposition telle quelle n'autorisera pas defer try(f()) (voir la justification ). Il y a toutes sortes de problèmes avec ça.
griesemer
le 18 juin 2019
Lors de l'utilisation de cet outil tryhard pour voir les changements dans une base de code, pourrions-nous également comparer le rapport de if err != nil avant et après pour voir s'il est plus courant d'ajouter du contexte ou de simplement renvoyer l'erreur ?
Je pense que peut-être qu'un énorme projet hypothétique peut voir 1000 endroits où try() ont été ajoutés, mais il y a 10000 if err != nil qui ajoutent du contexte, donc même si 1000 semblent énormes, ce n'est que 10% du tout .
Goodwine
le 18 juin 2019
@ Goodwine Oui. Je ne pourrai probablement pas faire ce changement cette semaine, mais le code est assez simple et autonome. N'hésitez pas à essayer (sans jeu de mots), à cloner et à ajuster au besoin.
griesemer
le 18 juin 2019
defer try(f()) ne serait-il pas équivalent à
defer func() error {
if err:= f(); err != nil { return err }
return nil
}()
Ceci (la version if) n'est actuellement pas interdit, n'est-ce pas ? Il me semble que vous ne devriez pas faire d'exception ici - peut-être générer un avertissement ? Et il n'est pas clair si le code de report ci-dessus est nécessairement faux. Que se passe-t-il si close(file) échoue dans une instruction defer ? Devrions-nous signaler cette erreur ou non ?
J'ai lu la justification qui semble parler de defer try(f) non defer try(f()) . Peut être une faute de frappe ?
Un argument similaire peut être avancé pour go try(f()) , ce qui se traduit par
go func() error {
if err:= f(); err != nil { return err }
return nil
}()
Ici, try ne fait rien d'utile mais est inoffensif.
bakul
le 18 juin 2019
@ardan-bkennedy Merci pour vos pensées. Avec tout le respect que je vous dois, je pense que vous avez déformé l'intention de cette proposition et fait plusieurs allégations non fondées .
Concernant certains des points que @rsc n'a pas abordés plus tôt :
Nous n'avons jamais dit que la gestion des erreurs était cassée. La conception est basée sur l'observation (par la communauté Go !) Que la gestion actuelle est correcte, mais verbeuse dans de nombreux cas - cela est incontesté. Il s'agit d'une prémisse majeure de la proposition.
Rendre les choses plus faciles à faire peut également les rendre plus faciles à comprendre - ces deux éléments ne s'excluent pas mutuellement, ni même ne s'impliquent l'un l'autre. Je vous invite à regarder ce code pour un exemple. L'utilisation
trysupprime une quantité importante de passe-partout, et ce passe-partout n'ajoute pratiquement rien à la compréhensibilité du code. La factorisation du code répétitif est une pratique de codage standard et largement acceptée pour améliorer la qualité du code.En ce qui concerne "cette proposition viole une grande partie de la philosophie de conception": ce qui est important, c'est que nous ne devenions pas dogmatiques à propos de la "philosophie de conception" - c'est souvent la chute des bonnes idées (en plus, je pense que nous savons une chose ou deux sur la philosophie de conception de Go). Il y a beaucoup de "ferveur religieuse" (faute d'un meilleur terme) autour des paramètres de résultat nommés et non nommés. Les mantras tels que "vous ne devez jamais utiliser de paramètres de résultat nommés" hors contexte n'ont aucun sens. Elles peuvent servir de lignes directrices générales, mais pas de vérités absolues. Les paramètres de résultat nommés ne sont pas intrinsèquement "mauvais". Des paramètres de résultat bien nommés peuvent s'ajouter à la documentation d'une API de manière significative. En bref, n'utilisons pas de slogans pour prendre des décisions de conception de langage.
C'est un point de cette proposition de ne pas introduire de nouvelle syntaxe. Il propose juste une nouvelle fonction. Nous ne pouvons pas écrire cette fonction dans le langage, donc une fonction intégrée est son emplacement naturel dans Go. Non seulement c'est une fonction simple, mais elle est également définie très précisément. Nous avons choisi cette approche minimale plutôt que des solutions plus complètes, précisément parce qu'elle fait très bien une chose et ne laisse presque rien aux décisions de conception arbitraires. Nous ne sommes pas non plus hors des sentiers battus puisque d'autres langages (par exemple Rust) ont des constructions très similaires. Suggérer que "la communauté serait d'accord que l'abstraction cache le coût et ne vaut pas la simplicité qu'elle essaie de fournir", c'est mettre des mots dans la bouche des autres. Alors que nous pouvons clairement entendre les opposants virulents à cette proposition, il y a un pourcentage significatif (environ 40%) de personnes qui ont exprimé leur approbation pour aller de l'avant avec l'expérience. Ne les privons pas de leurs droits avec des hyperboles.
Merci.
griesemer
le 18 juin 2019
return isset( $_COOKIE[ CookieNames::CART_ID ] )
? intval( $_COOKIE[ CookieNames::CART_ID ] )
: null;
À peu près sûr que cela devrait être return intval( $_COOKIE[ CookieNames::CART_ID ] ) ?? null; FWIW. 😁
carlmjohnson
le 18 juin 2019
@bakul parce que les arguments sont évalués immédiatement, cela équivaut en fait à peu près à :
<result list> := f()
defer try(<result list>)
Cela peut être un comportement inattendu pour certains car le f() n'est pas reporté à plus tard, il est exécuté immédiatement. La même chose s'applique à go try(f()) .
deanveloper
le 18 juin 2019
@bakul La doc mentionne defer try(f) (plutôt que defer try(f()) car try s'applique en général à n'importe quelle expression, pas seulement à un appel de fonction (vous pouvez dire try(err) pour exemple, si err est de type error ). Ce n'est donc pas une faute de frappe, mais peut-être déroutant au début. f représente simplement une expression, qui se trouve généralement être une fonction appel.
griesemer
le 18 juin 2019
@deanveloper , @griesemer Peu importe :-) Merci.
bakul
le 18 juin 2019
@carl-mastrangelo
_"Je suis presque sûr que cela devrait être
return intval( $_COOKIE[ CookieNames::CART_ID ] ) ?? null;_
Vous supposez PHP 7.x. Je n'étais pas. Mais là encore, étant donné votre visage sarcastique, vous savez que ce n'était pas le but. :clin d'œil:
mikeschinkel
le 18 juin 2019
Je prépare une courte démonstration pour afficher cette discussion lors d'un go meetup qui aura lieu demain, et entendre de nouvelles réflexions, car je crois que la plupart des participants sur ce fil (contributeurs ou observateurs), sont ceux qui sont plus profondément impliqués dans la langue, et très probablement "pas le développeur go moyen" (juste une intuition).
En faisant cela, je me suis souvenu que nous avions en fait eu une rencontre sur les erreurs et une discussion sur deux modèles :
- Étendre la structure d'erreur tout en prenant en charge l'interface d'erreur mystruct.Error()
- Incorporer l'erreur en tant que champ ou champ anonyme de la structure
type ExtErr struct{
error
someOtherField string
}
Ceux-ci sont utilisés dans quelques piles que mes équipes ont réellement construites.
La proposition de questions et réponses indique
Q : Le dernier argument passé à try doit être de type error. Pourquoi n'est-il pas suffisant que l'argument entrant soit assignable à erreur ?
R : "... Nous pouvons revenir sur cette décision à l'avenir si nécessaire"
Quelqu'un peut-il commenter des cas d'utilisation similaires afin que nous puissions comprendre si ce besoin est commun aux deux options d'extension d'erreur ci-dessus?
guybrand
le 18 juin 2019
@mikeschinkel Je ne suis pas le Carl que vous recherchez.
 carl-mastrangelo
le 18 juin 2019
carl-mastrangelo
le 18 juin 2019
@daved , re :
Il ne manquera pas d'endroits où cette commodité peut être placée. Quelle métrique est recherchée qui prouvera la substance du mécanisme en dehors de cela? Existe-t-il une liste de cas classés de gestion des erreurs ? Comment la valeur sera-t-elle dérivée des données alors qu'une grande partie du processus public est motivée par le sentiment ?
La décision est basée sur la façon dont cela fonctionne dans de vrais programmes. Si les gens nous montrent que try est inefficace dans la majeure partie de leur code, ce sont des données importantes. Le processus est piloté par ce type de données. Il n'est _pas_ motivé par le sentiment.
rsc
le 18 juin 2019
Contexte d'erreur
La préoccupation sémantique la plus importante qui a été soulevée dans ce problème est de savoir si try encouragera une annotation meilleure ou pire des erreurs avec le contexte.
L' aperçu du problème d'août dernier donne une séquence d'exemples d'implémentations de CopyFile dans les sections Problème et Objectifs. C'est un objectif explicite, à la fois à l'époque et aujourd'hui, que toute solution rende _plus probable_ que les utilisateurs ajoutent un contexte approprié aux erreurs. Et nous pensons que try peut le faire, sinon nous ne l'aurions pas proposé.
Mais avant d'essayer, il vaut la peine de s'assurer que nous sommes tous sur la même longueur d'onde concernant le contexte d'erreur approprié. L'exemple canonique est os.Open. Citant le billet du blog Go " Gestion des erreurs et Go " :
Il est de la responsabilité de l'implémentation d'erreur de résumer le contexte.
L'erreur renvoyée par os.Open se présente sous la forme "ouvrir /etc/passwd : autorisation refusée", et pas seulement "autorisation refusée".
Voir aussi la section de Effective Go sur les erreurs .
Notez que cette convention peut différer des autres langages que vous connaissez et qu'elle n'est également suivie que de manière incohérente dans le code Go. Un objectif explicite d'essayer de rationaliser la gestion des erreurs est de permettre aux gens de suivre plus facilement cette convention et d'ajouter un contexte approprié, et ainsi de la rendre plus cohérente.
Il y a beaucoup de code qui suit la convention Go aujourd'hui, mais il y a aussi beaucoup de code qui suppose la convention opposée. Il est trop courant de voir du code comme :
f, err := os.Open(file)
if err != nil {
log.Fatalf("opening %s: %v", file, err)
}
qui imprime bien sûr la même chose deux fois (de nombreux exemples dans cette discussion ressemblent à ceci). Une partie de cet effort devra consister à s'assurer que tout le monde connaît et suit la convention.
Dans le code suivant la convention de contexte d'erreur Go, nous nous attendons à ce que la plupart des fonctions ajoutent correctement le même contexte à chaque retour d'erreur, de sorte qu'une décoration s'applique en général. Par exemple, dans l'exemple CopyFile, ce qui doit être ajouté dans chaque cas, ce sont des détails sur ce qui a été copié. D'autres retours spécifiques peuvent ajouter plus de contexte, mais généralement en complément plutôt qu'en remplacement. Si nous nous trompons sur cette attente, ce serait bon à savoir. Des preuves claires à partir de bases de code réelles aideraient.
La conception du brouillon de vérification/manipulation de Gophercon aurait utilisé un code tel que :
func CopyFile(src, dst string) error {
handle err {
return fmt.Errorf("copy %s %s: %v", src, dst, err)
}
r := check os.Open(src)
defer r.Close()
w := check os.Create(dst)
...
}
Cette proposition a révisé cela, mais l'idée est la même :
func CopyFile(src, dst string) (err error) {
defer func() {
if err != nil {
err = fmt.Errorf("copy %s %s: %v", src, dst, err)
}
}()
r := try(os.Open(src))
defer r.Close()
w := try(os.Create(dst))
...
}
et nous voulons ajouter un assistant qui n'a pas encore de nom pour ce modèle commun :
func CopyFile(src, dst string) (err error) {
defer HelperToBeNamedLater(&err, "copy %s %s", src, dst)
r := try(os.Open(src))
defer r.Close()
w := try(os.Create(dst))
...
}
En bref, le caractère raisonnable et le succès de cette approche dépendent de ces hypothèses et étapes logiques :
- Les gens doivent suivre la convention Go déclarée "l'appelé ajoute un contexte pertinent qu'il connaît".
- Par conséquent, la plupart des fonctions n'ont besoin que d'ajouter un contexte au niveau de la fonction décrivant l'ensemble
opération, et non le sous-élément spécifique qui a échoué (ce sous-élément a déjà été signalé). - Beaucoup de code Go aujourd'hui n'ajoute pas le contexte au niveau de la fonction car il est trop répétitif.
- Fournir un moyen d'écrire le contexte au niveau de la fonction une fois rendra plus probable que
les développeurs font ça. - Le résultat final sera plus de code Go suivant la convention et ajoutant le contexte approprié.
S'il y a une hypothèse ou une étape logique que vous pensez être fausse, nous voulons le savoir. Et la meilleure façon de nous le dire est de pointer vers des preuves dans les bases de code réelles. Montrez-nous des modèles communs que vous avez où essayer est inapproprié ou aggrave les choses. Montrez-nous des exemples de choses où essayer a été plus efficace que prévu. Essayez de quantifier la part de votre base de code qui tombe d'un côté ou de l'autre. Etc. Les données comptent.
Merci.
rsc
le 18 juin 2019
Merci @rsc pour les informations supplémentaires sur les meilleures pratiques en matière de contexte d'erreur. Ce point sur les meilleures pratiques en particulier m'a fait allusion, mais améliore considérablement la relation de try avec le contexte d'erreur.
Par conséquent, la plupart des fonctions n'ont besoin que d'ajouter un contexte au niveau de la fonction décrivant l'ensemble
opération, et non le sous-élément spécifique qui a échoué (ce sous-élément a déjà été signalé).
Alors, l'endroit où try n'aide pas, c'est quand nous devons réagir aux erreurs, pas seulement les contextualiser.
Pour adapter un exemple de Cleaner, more elegant, and false , voici leur exemple d'une fonction qui se trompe subtilement dans sa gestion des erreurs. Je l'ai adapté à Go en utilisant l'emballage d'erreur de style try et defer :
func AddNewGuy(name string) (guy Guy, err error) {
defer func() {
if err != nil {
err = fmt.Errorf("adding guy %v: %v", name, err)
}
}()
guy = Guy{name: name}
guy.Team = ChooseRandomTeam()
try(guy.Team.Add(guy))
try(AddToLeague(guy))
return guy, nil
}
Cette fonction est incorrecte car si guy.Team.Add(guy) réussit mais AddToLeague(guy) échoue, l'équipe aura un objet Guy invalide qui n'est pas dans une ligue. Le code correct ressemblerait à ceci, où nous annulons guy.Team.Add(guy) et ne pouvons plus utiliser try :
func AddNewGuy(name string) (guy Guy, err error) {
defer func() {
if err != nil {
err = fmt.Errorf("adding guy %v: %v", name, err)
}
}()
guy = Guy{name: name}
guy.Team = ChooseRandomTeam()
try(guy.Team.Add(guy))
if err := AddToLeague(guy); err != nil {
guy.Team.Remove(guy)
return Guy{}, err
}
return guy, nil
}
Ou, si nous voulons éviter d'avoir à fournir des valeurs nulles pour les valeurs de retour sans erreur, nous pouvons remplacer return Guy{}, err par try(err) . Quoi qu'il en soit, la fonction defer -ed est toujours exécutée et le contexte est ajouté, ce qui est agréable.
Encore une fois, cela signifie que try s'efforce de réagir aux erreurs, mais pas de leur ajouter du contexte. C'est une distinction à laquelle j'ai fait allusion, à moi et peut-être à d'autres. Cela a du sens car la façon dont une fonction ajoute du contexte à une erreur n'est pas d'un intérêt particulier pour un lecteur, mais la façon dont une fonction réagit aux erreurs est importante. Nous devrions rendre les parties les moins intéressantes de notre code moins détaillées, et c'est ce que fait try .
velovix
le 18 juin 2019
Vous n'êtes pas la seule personne à avoir suggéré que ce n'est pas un problème ou qu'il ne vaut pas la peine d'être résolu. Voir https://swtch.com/try.html#nonissue pour d'autres commentaires de ce type. Nous les avons notés et voulons nous assurer que nous résolvons un problème réel.
@rsc Je pense aussi qu'il n'y a pas de problème avec le code d'erreur actuel. Alors, s'il vous plaît, comptez sur moi.
Des outils comme Robert's tryhard nous aident à le faire. J'ai demandé plus tôt aux gens de nous faire savoir ce qu'ils trouvent dans leurs propres bases de code. Ces informations seront d'une importance cruciale pour évaluer si le changement en vaut la peine ou non. Vous avez une supposition et j'en ai une autre, et c'est très bien. La réponse est de substituer des données à ces suppositions.
J'ai regardé https://go-review.googlesource.com/c/go/+/182717/1/src/cmd/link/internal/ld/macho_combine_dwarf.go et j'aime mieux l'ancien code. Il est surprenant pour moi que l'appel de la fonction try puisse interrompre l'exécution en cours. Ce n'est pas ainsi que fonctionne le Go actuel.
Je suppose que vous trouverez des opinions varient. Je pense que c'est très subjectif.
Et, je soupçonne, la majorité des utilisateurs ne participent pas à ce débat. Ils ne savent même pas que ce changement est à venir. Je suis moi-même assez impliqué dans le Go, mais je ne participe pas à ce changement, car je n'ai pas de temps libre.
Je pense que nous aurions besoin de rééduquer tous les utilisateurs de Go existants pour qu'ils pensent différemment maintenant.
Nous aurions également besoin de décider quoi faire avec certains utilisateurs / entreprises qui refuseront d'utiliser try dans leur code. Il y en aura certainement.
Peut-être devrions-nous changer gofmt pour réécrire automatiquement le code actuel. Pour forcer ces utilisateurs "voyous" à utiliser la nouvelle fonction try. Est-il possible de faire faire ça à gofmt ?
Comment traiterions-nous les erreurs de compilation lorsque les gens utilisent go1.13 et avant pour construire du code avec try ?
J'ai probablement manqué de nombreux autres problèmes que nous devions surmonter pour mettre en œuvre ce changement. Est-ce que ça vaut la peine ? Je ne le crois pas.
Alexandre
 alexbrainman
le 18 juin 2019
alexbrainman
le 18 juin 2019
@griesemer
En essayant tryhard sur un fichier avec 97 err's none catched, j'ai trouvé que les 2 modèles n'étaient pas traduits
1 :
if err := updateItem(tx, fields, entityView.DataBinding, entityInstance); err != nil {
tx.Rollback()
return nil, err
}
N'est pas remplacé, probablement parce que le tx.Rollback() entre err := et la ligne de retour,
Ce qui, je suppose, ne peut être géré que par report - et si tous les chemins d'erreur doivent être tx.Rollback()
Est-ce correct ?
- Il ne suggère pas non plus :
if err := db.Error; err != nil {
return nil, err
} else if itemDb, err := GetItem(c, entity, entityView, ItemRequest{recNo}); err != nil {
return nil, err
} else {
return itemDb, nil
}
ou
if err := db.Error; err != nil {
return nil, err
} else {
if itemDb, err := GetItem(c, entity, entityView, ItemRequest{recNo}); err != nil {
return nil, err
} else {
return itemDb, nil
}
return result, nil
}
Est-ce à cause de l'ombrage ou de l'essai d'imbrication qui se traduirait par ? sens - cette utilisation devrait-elle essayer ou être suggérée comme err := ... return err ?
guybrand
le 18 juin 2019
@guybrand Re : les deux modèles que vous avez trouvés :
1) oui, tryhard n'essaie pas très fort. la vérification de type est nécessaire pour les cas plus complexes. Si tx.Rollback() doit être fait dans tous les chemins, defer pourrait être la bonne approche. Sinon, conserver les if pourrait être la bonne approche. Cela dépend du code spécifique.
2) Pareil ici : tryhard ne recherche pas ce modèle plus complexe. Peut-être que ça pourrait.
Encore une fois, il s'agit d'un outil expérimental pour obtenir des réponses rapides. Bien faire les choses demande un peu plus de travail.
griesemer
le 18 juin 2019
@alexbrainman
Comment traiterions-nous les erreurs de compilation lorsque les gens utilisent go1.13 et avant pour construire du code avec try ?
Ma compréhension est que la version du langage lui-même sera contrôlée par la directive de version de langage go dans le fichier go.mod pour chaque morceau de code compilé.
La documentation en vol go.mod décrit la directive de version de langue go comme suit :
La version de langue attendue, définie par la directive
go, détermine
quelles fonctionnalités de langage sont disponibles lors de la compilation du module.
Les fonctionnalités linguistiques disponibles dans cette version pourront être utilisées.
Fonctionnalités linguistiques supprimées dans les versions antérieures ou ajoutées dans les versions ultérieures,
ne sera pas disponible. Notez que la version linguistique n'affecte pas
balises de construction, qui sont déterminées par la version Go utilisée.
Si hypothétiquement quelque chose comme un nouveau try intégré atterrit dans quelque chose comme Go 1.15, alors quelqu'un dont le fichier go.mod lit go 1.12 n'aurait pas accès à ce nouveau try intégrés même s'ils compilent avec la chaîne d'outils Go 1.15. Ma compréhension du plan actuel est qu'ils devraient changer la version de la langue Go déclarée dans leur go.mod de go 1.12 pour lire à la place go 1.15 s'ils veulent utiliser le nouveau Go 1.15 fonction de langue de try .
D'un autre côté, si vous avez du code qui utilise try et que ce code réside dans un module dont le fichier go.mod déclare sa version en langage Go comme go 1.15 , mais que quelqu'un essaie de construisez cela avec la chaîne d'outils Go 1.12, à ce stade, la chaîne d'outils Go 1.12 échouera avec une erreur de compilation. La chaîne d'outils Go 1.12 ne sait rien de try , mais elle en sait assez pour imprimer un message supplémentaire indiquant que le code qui n'a pas réussi à compiler prétendait nécessiter Go 1.15 en fonction de ce qui se trouve dans le fichier go.mod . Vous pouvez en fait tenter cette expérience dès maintenant en utilisant la chaîne d'outils Go 1.12 d'aujourd'hui et voir le message d'erreur qui en résulte :
.\hello.go:3:16: undefined: try
note: module requires Go 1.15
Il y a une discussion beaucoup plus longue dans le document de proposition de transitions Go2 .
Cela dit, les détails exacts de cela pourraient être mieux discutés ailleurs (par exemple, peut-être dans # 30791, ou ce récent fil golang-nuts ).
thepudds
le 19 juin 2019
@griesemer , désolé si j'ai raté une demande plus spécifique pour un format, mais j'aimerais partager quelques résultats et avoir accès (une éventuelle autorisation) au code source de certaines entreprises.
Vous trouverez ci-dessous un exemple réel pour un petit projet, je pense que les résultats ci-joints donnent un bon échantillon, si c'est le cas, nous pouvons probablement partager un tableau avec des résultats similaires :
Total = Nombre de lignes de code
$find /path/to/repo -name '*.go' -exec cat {} \; | wc -l
Errs = nombre de lignes avec err := (cela manque probablement err = , et myerr := , mais je pense que dans la plupart des cas, cela couvre)
$find /path/to/repo -name '*.go' -exec cat {} \; | grep "err :=" | wc -l
tryhard = nombre de lignes tryhard trouvées
le premier cas que j'ai testé pour étudier a renvoyé:
totale = 5106
Erreur = 111
essai dur = 16
plus grande base de code
Somme = 131777
Erreur = 3289
essai dur = 265
Si ce format est acceptable, faites-nous savoir comment vous voulez obtenir les résultats, je suppose que le simple fait de le jeter ici ne serait pas le bon format
De plus, ce serait probablement un quickie d'avoir tryhard compter les lignes, les occasions de err := (et probablement err = , seulement 4 sur la base de code sur laquelle j'ai essayé d'apprendre)
Merci.
guybrand
le 19 juin 2019
De @griesemer dans https://github.com/golang/go/issues/32437#issuecomment -503276339
Je vous invite à regarder ce code pour un exemple.
En ce qui concerne ce code, j'ai remarqué que le fichier out créé ici ne semble jamais être fermé. De plus, il est important de vérifier les erreurs de fermeture des fichiers sur lesquels vous avez écrit, car c'est peut-être la seule fois où vous êtes informé qu'il y a eu un problème avec une écriture.
J'aborde cela non pas comme un rapport de bogue (bien que cela devrait peut-être l'être ?), mais comme une chance de voir si try a un effet sur la façon dont on pourrait le réparer. Je vais énumérer toutes les façons auxquelles je peux penser pour résoudre ce problème et déterminer si l'ajout de try aiderait ou blesserait. Voici quelques façons :
- Ajoutez des appels explicites à
outf.Close()juste avant tout retour d'erreur. - Nommez la valeur de retour et ajoutez un délai pour fermer le fichier, en enregistrant l'erreur si elle n'est pas déjà présente. par exemple
func foo() (err error) {
outf := try(os.Create())
defer func() {
cerr := outf.Close()
if err == nil {
err = cerr
}
}()
...
}
- Le modèle "double fermeture" où l'on fait
defer outf.Close()pour assurer le nettoyage des ressources, ettry(outf.Close())avant de revenir pour s'assurer qu'il n'y a pas d'erreurs. - Refactoriser pour qu'une fonction d'assistance prenne le fichier ouvert plutôt qu'un chemin afin que l'appelant puisse s'assurer que le fichier est fermé de manière appropriée. par exemple
func foo() error {
outf := try(os.Create())
if err := helper(outf); err != nil {
outf.Close()
return err
}
try(outf.Close())
return nil
}
Je pense que dans tous les cas, sauf le cas numéro 1, try est au pire neutre et généralement positif. Et je considérerais que le numéro 1 est l'option la moins acceptable compte tenu de la taille et du nombre de possibilités d'erreur dans cette fonction, donc l'ajout try réduirait l'attrait d'un choix négatif.
J'espère que cette analyse a été utile.
zeebo
le 19 juin 2019
Si hypothétiquement quelque chose comme un nouveau
tryintégré atterrit dans quelque chose comme Go 1.15, alors à ce moment-là quelqu'un dont le fichiergo.modlitgo 1.12n'aurait pas accès
@thepudds merci pour l'explication. Mais je n'utilise pas de modules. Votre explication me dépasse donc.
Alexandre
alexbrainman
le 19 juin 2019
@alexbrainman
Comment traiterions-nous les erreurs de compilation lorsque les gens utilisent go1.13 et avant pour construire du code avec try ?
Si try devait atterrir hypothétiquement dans quelque chose comme Go 1.15, alors la réponse très courte à votre question est que quelqu'un utilisant Go 1.13 pour construire du code avec try verrait une erreur de compilation comme celle-ci :
.\hello.go:3:16: undefined: try
note: module requires Go 1.15
(Du moins pour autant que je comprenne ce qui a été dit à propos de la proposition de transition).
thepudds
le 19 juin 2019
@alexbrainman Merci pour vos commentaires.
Un grand nombre de commentaires sur ce fil sont de la forme "cela ne ressemble pas à Go", ou "Go ne fonctionne pas comme ça", ou "je ne m'attends pas à ce que cela se produise ici". C'est tout à fait correct, _existing_ Go ne fonctionne pas comme ça.
C'est peut-être le premier changement de langue suggéré qui affecte la sensation de la langue de manière plus substantielle. Nous en sommes conscients, c'est pourquoi nous l'avons gardé si minime. (J'ai du mal à imaginer le tollé qu'une proposition concrète de génériques pourrait provoquer - en parlant d'un changement de langage).
Mais revenons à votre point : les programmeurs s'habituent au fonctionnement et à la sensation d'un langage de programmation. S'il y a une chose que j'ai apprise au cours de ces quelque 35 années de programmation, c'est qu'on s'habitue à presque tous les langages, et cela se fait très rapidement. Après avoir appris le Pascal original comme premier langage de haut niveau, il était _inconcevable_ qu'un langage de programmation ne capitalise pas tous ses mots clés. Mais il n'a fallu qu'une semaine environ pour s'habituer à la "mer de mots" qu'était le C où "on ne pouvait pas voir la structure du code car tout était en minuscules". Après ces premiers jours avec C, le code Pascal avait l'air terriblement bruyant, et tout le code réel semblait enfoui dans un gâchis de mots-clés criants. Avance rapide vers Go, lorsque nous avons introduit la capitalisation pour marquer les identifiants exportés, c'était un changement choquant par rapport à l'approche précédente, si je me souviens bien, basée sur des mots clés (c'était avant que Go ne soit public). Maintenant, nous pensons que c'est l'une des meilleures décisions de conception (l'idée concrète venant en fait de l'extérieur de l'équipe Go). Ou, considérez l'expérience de pensée suivante : Imagine Go n'avait pas d'instruction defer et maintenant quelqu'un fait un cas solide pour defer . defer n'a pas de sémantique comme quoi que ce soit d'autre dans le langage, le nouveau langage ne ressemble plus à ça avant defer Go. Pourtant, après avoir vécu avec pendant une décennie, il semble totalement "Go-like".
Le fait est que la réaction initiale à un changement de langage est presque dénuée de sens sans réellement essayer le mécanisme dans du code réel et recueillir des commentaires concrets. Bien sûr, le code de gestion des erreurs existant est correct et semble plus clair que le remplacement utilisant try - nous avons été entraînés à penser ces déclarations if depuis une décennie maintenant. Et bien sûr, le code try semble étrange et a une sémantique "étrange", nous ne l'avons jamais utilisé auparavant, et nous ne le reconnaissons pas immédiatement comme faisant partie du langage.
C'est pourquoi nous demandons aux gens de s'engager réellement dans le changement en l'expérimentant dans votre propre code ; c'est-à-dire, l'écrire réellement, ou faire exécuter tryhard sur du code existant, et considérer le résultat. Je recommanderais de le laisser reposer pendant un certain temps, peut-être une semaine environ. Regardez-le à nouveau et faites un rapport.
Enfin, je suis d'accord avec votre évaluation selon laquelle une majorité de personnes ne connaissent pas cette proposition ou ne s'y sont pas engagées. Il est tout à fait clair que cette discussion est dominée par peut-être une douzaine de personnes. Mais il est encore tôt, cette proposition n'est sortie que depuis deux semaines, et aucune décision n'a été prise. Il y a beaucoup de temps pour que plus de personnes différentes s'y engagent.
griesemer
le 19 juin 2019
https://github.com/golang/go/issues/32437#issuecomment -503297387 indique à peu près si vous encapsulez des erreurs de plusieurs manières dans une seule fonction, vous le faites apparemment mal. En attendant, j'ai beaucoup de code qui ressemble à ceci:
if err := gen.Execute(tmp, s); err != nil {
return fmt.Errorf("template error: %v", err)
}
if err := tmp.Close(); err != nil {
return fmt.Errorf("cannot write temp file: %v", err)
}
closed = true
if err := os.Rename(tmp.Name(), *genOutput); err != nil {
return fmt.Errorf("cannot finalize file: %v", err)
}
removed = true
( closed et removed sont utilisés par les reports pour nettoyer, le cas échéant)
Je ne pense vraiment pas que tout cela doive être donné dans le même contexte décrivant la mission de haut niveau de cette fonction. Je ne pense vraiment pas que l'utilisateur devrait simplement voir
processing path/to/dir: template: gen:42:17: executing "gen" at <.Broken>: can't evaluate field Broken in type main.state
lorsque le modèle est foiré, je pense que c'est la responsabilité de mon gestionnaire d'erreurs pour l'appel d'exécution du modèle pour ajouter "modèle d'exécution" ou un petit extra. (Ce n'est pas le meilleur contexte, mais je voulais copier-coller du vrai code au lieu d'un exemple inventé.)
Je ne pense pas que l'utilisateur devrait voir
processing path/to/dir: rename /tmp/blahDs3x42aD commands.gen.go: No such file or directory
sans aucune idée de _pourquoi_ mon programme essaie de faire en sorte que ce changement de nom se produise, quelle est la sémantique, quelle est l'intention. Je pense que l'ajout de ce petit "impossible de finaliser le fichier :" aide vraiment.
Si ces exemples ne vous convainquent pas suffisamment, imaginez cette sortie d'erreur d'une application en ligne de commande :
processing path/to/dir: open /some/path/here: No such file or directory
Qu'est-ce que ça veut dire? Je veux ajouter une raison pour laquelle l'application a essayé de créer un fichier ici (vous ne saviez même pas que c'était une création, pas seulement os.Open ! C'est ENOENT car il n'existe pas de chemin intermédiaire.). Ce n'est pas quelque chose qui doit être ajouté à _chaque_ erreur renvoyée par cette fonction.
Alors, qu'est-ce que je rate. Est-ce que je "tiens mal" ? Suis-je censé pousser chacune de ces choses dans une petite fonction distincte qui utilise toutes un report pour envelopper toutes leurs erreurs?
tv42
le 19 juin 2019
@guybrand Merci pour ces chiffres . Il serait bon de savoir pourquoi les chiffres tryhard sont ce qu'ils sont. Peut-être y a-t-il beaucoup de décorations d'erreur spécifiques en cours? Si c'est le cas, c'est très bien et les instructions if sont le bon choix.
J'améliorerai l'outil quand j'y arriverai.
griesemer
le 19 juin 2019
Merci, @zeebo pour votre analyse . Je ne connais pas spécifiquement ce code , mais il semble que outf fasse partie d'un loadCmdReader (ligne 173) qui est ensuite transmis à la ligne 204. C'est peut-être la raison outf n'est pas fermé. (Désolé, je n'ai pas écrit ce code).
griesemer
le 19 juin 2019
@ tv42 D'après les exemples de votre https://github.com/golang/go/issues/32437#issuecomment -503340426, en supposant que vous ne le faites pas "mal", il semble que vous utilisiez une instruction if est le moyen de traiter ces cas s'ils nécessitent tous des réponses différentes. try n'aidera pas, et defer ne fera que le rendre plus difficile (toute autre proposition de changement de langage dans ce fil qui tente de rendre ce code plus simple à écrire est si proche du if déclaration indiquant qu'il ne vaut pas la peine d'introduire un nouveau mécanisme). Voir aussi la FAQ de la proposition détaillée.
griesemer
le 19 juin 2019
@griesemer Alors tout ce à quoi je peux penser, c'est que vous et @rsc n'êtes pas d'accord. Ou que je suis, en effet, "en train de le faire mal", et que j'aimerais avoir une conversation à ce sujet.
C'est un objectif explicite, à la fois à l'époque et aujourd'hui, que toute solution rende plus probable que les utilisateurs ajoutent un contexte approprié aux erreurs. Et nous pensons que try peut le faire, sinon nous ne l'aurions pas proposé.
tv42
le 19 juin 2019
@ tv42 @rsc post concerne la structure globale de gestion des erreurs d'un bon code, avec laquelle je suis d'accord. Si vous avez un morceau de code existant qui ne correspond pas exactement à ce modèle et que vous êtes satisfait du code, laissez-le tranquille.
griesemer
le 19 juin 2019
Diffère
Le principal changement entre le projet de vérification/gestion de Gophercon et cette proposition consistait à supprimer handle au profit de la réutilisation de defer . Maintenant, le contexte d'erreur serait ajouté par code comme cet appel différé (voir mon commentaire précédent sur le contexte d'erreur):
func CopyFile(src, dst string) (err error) {
defer HelperToBeNamedLater(&err, "copy %s %s", src, dst)
r := check os.Open(src)
defer r.Close()
w := check os.Create(dst)
...
}
La viabilité de différer en tant que mécanisme d'annotation d'erreur dans cet exemple dépend de quelques éléments.
_Résultats d'erreur nommés._ L'ajout de résultats d'erreur nommés a suscité de nombreuses inquiétudes. Il est vrai que nous avons découragé cela dans le passé lorsqu'il n'était pas nécessaire à des fins de documentation, mais c'est une convention que nous avons choisie en l'absence de tout facteur décisif plus fort. Et même dans le passé, un facteur décisif plus fort, comme la référence à des résultats spécifiques dans la documentation, l'emportait sur la convention générale pour les résultats sans nom. Maintenant, il y a un deuxième facteur décisif plus fort, à savoir vouloir se référer à l'erreur dans un report. Cela semble ne pas être plus répréhensible que de nommer les résultats à utiliser dans la documentation. Un certain nombre de personnes ont réagi assez négativement à cela, et honnêtement, je ne comprends pas pourquoi. Il semble presque que les gens confondent les retours sans listes d'expressions (appelés "retours nus") avec des résultats nommés. Il est vrai que les retours sans listes d'expressions peuvent prêter à confusion dans les grandes fonctions. Éviter cette confusion en évitant ces retours dans les fonctions longues est souvent logique. Peindre des résultats nommés avec le même pinceau ne le fait pas.
_Expressions d'adresse._ Quelques personnes ont fait part de leurs inquiétudes quant au fait que l'utilisation de ce modèle obligera les développeurs Go à comprendre les expressions d'adresse de. Stocker n'importe quelle valeur avec des méthodes de pointeur dans une interface l'exige déjà, donc cela ne semble pas être un inconvénient majeur.
_Différer lui-même._ Quelques personnes ont exprimé des inquiétudes quant à l'utilisation du report comme concept de langage, encore une fois parce que les nouveaux utilisateurs pourraient ne pas le connaître. Comme pour les expressions d'adresse, différer est un concept de langage de base qui doit être appris par la suite. Les idiomes standard autour de choses comme
defer f.Close()etdefer l.mu.Unlock()sont si courants qu'il est difficile de justifier d'éviter de différer en tant que coin obscur du langage._Performance._ Nous avons discuté pendant des années de travail sur la création de modèles de report courants comme un report en haut d'une fonction sans surcharge par rapport à l'insertion manuelle de cet appel à chaque retour. Nous pensons savoir comment faire cela et nous l'explorerons pour la prochaine version de Go. Même si ce n'est pas le cas, la surcharge actuelle d'environ 50 ns ne devrait pas être prohibitive pour la plupart des appels qui doivent ajouter un contexte d'erreur. Et les quelques appels sensibles aux performances peuvent continuer à utiliser les instructions if jusqu'à ce que le report soit plus rapide.
Les trois premières préoccupations reviennent toutes à des objections à la réutilisation de fonctionnalités linguistiques existantes. Mais la réutilisation des fonctionnalités de langage existantes est exactement l'avancée de cette proposition par rapport à check/handle : il y a moins à ajouter au langage de base, moins de nouvelles pièces à apprendre et moins d'interactions surprenantes.
Néanmoins, nous apprécions que l'utilisation du report de cette manière soit nouvelle et que nous devons donner aux gens le temps d'évaluer si le report fonctionne suffisamment bien dans la pratique pour les idiomes de gestion des erreurs dont ils ont besoin.
Depuis que nous avons lancé cette discussion en août dernier, j'ai fait l'exercice mental de "à quoi ressemblerait ce code avec check/handle ?" et plus récemment "avec try/defer?" chaque fois que j'écris un nouveau code. Habituellement, la réponse signifie que j'écris un code différent et meilleur, avec le contexte ajouté à un endroit (le report) au lieu d'être à chaque retour ou complètement omis.
Étant donné l'idée d'utiliser un gestionnaire différé pour agir sur les erreurs, il existe une variété de modèles que nous pourrions activer avec un simple package de bibliothèque. J'ai déposé #32676 pour y réfléchir davantage, mais en utilisant l'API de package dans ce numéro, notre code ressemblerait à :
func CopyFile(src, dst string) (err error) {
defer errd.Add(&err, "copy %s %s", src, dst)
r := check os.Open(src)
defer r.Close()
w := check os.Create(dst)
...
}
Si nous étions en train de déboguer CopyFile et que nous voulions voir toute erreur renvoyée et trace de pile (similaire à vouloir insérer une impression de débogage), nous pourrions utiliser :
func CopyFile(src, dst string) (err error) {
defer errd.Trace(&err)
defer errd.Add(&err, "copy %s %s", src, dst)
r := check os.Open(src)
defer r.Close()
w := check os.Create(dst)
...
}
etc.
Utiliser defer de cette manière finit par être assez puissant, et il conserve l'avantage de check/handle que vous pouvez écrire "faire ceci sur n'importe quelle erreur" une fois en haut de la fonction et ne pas vous en soucier pour le reste de le corps. Cela améliore la lisibilité de la même manière que les premières sorties rapides .
Cela fonctionnera-t-il dans la pratique ? Nous voulons savoir.
Après avoir fait l'expérience mentale de ce à quoi ressemblerait le report dans mon propre code pendant quelques mois, je pense que cela fonctionnera probablement. Mais bien sûr, l'utiliser dans du code réel n'est pas toujours le même. Nous devrons expérimenter pour le savoir.
Les gens peuvent expérimenter cette approche aujourd'hui en continuant à écrire des instructions if err != nil mais en copiant les assistants de report et en les utilisant de manière appropriée. Si vous êtes enclin à le faire, veuillez nous faire savoir ce que vous apprenez.
rsc
le 19 juin 2019
@tv42 , je suis d'accord avec @griesemer. Si vous trouvez qu'un contexte supplémentaire est nécessaire pour lisser une connexion comme le changement de nom étant une étape de "finalisation", il n'y a rien de mal à utiliser des instructions if pour ajouter un contexte supplémentaire. Dans de nombreuses fonctions, cependant, il n'y a guère besoin d'un tel contexte supplémentaire.
rsc
le 19 juin 2019
@guybrand , les nombres tryhard sont excellents, mais ce serait encore mieux de décrire pourquoi des exemples spécifiques n'ont pas été convertis et, en outre, il aurait été inapproprié de les réécrire pour pouvoir les convertir. L'exemple et l'explication de @ tv42 en sont un exemple.
rsc
le 19 juin 2019
@griesemer à propos de votre préoccupation concernant le report . J'allais pour ce emit ou dans la proposition initiale handle . Le emit/handle serait appelé si le err n'est pas nul. Et s'initiera à ce moment-là plutôt qu'à la fin de la fonction. Le report est appelé à la fin. emit/handle mettrait fin à la fonction si err est nul ou non. C'est pourquoi le report ne fonctionnerait pas.
damienfamed75
le 19 juin 2019
quelques données:
sur un projet LOC d'environ 70k que j'ai colporté pour éliminer les "retours d'erreur nus" religieusement, nous avons toujours 612 retours d'erreur nus. traitant principalement d'un cas où une erreur est consignée, mais le message n'est important qu'en interne (le message à l'utilisateur est prédéfini). try() aura une plus grande économie que seulement deux lignes par chaque retour nu, car avec des erreurs prédéfinies, nous pouvons différer un gestionnaire et utiliser try à plus d'endroits.
plus intéressant, dans le répertoire du fournisseur, sur ~ 620k + LOC, nous n'avons que 1600 retours d'erreurs nues. les bibliothèques que nous choisissons ont tendance à décorer les erreurs encore plus religieusement que nous.
mirtchovski
le 19 juin 2019
@rsc si, plus tard, des gestionnaires sont ajoutés à try , y aura-t-il un paquet errors/errc avec des fonctions comme func Wrap(msg string) func(error) error pour que vous puissiez faire try(f(), errc.Wrap("f failed")) ?
jimmyfrasche
le 19 juin 2019
@damienfamed75 Merci pour vos explications . Ainsi, le emit sera appelé lorsque try trouvera une erreur, et il sera appelé avec cette erreur. Cela semble assez clair.
Vous dites également que le emit mettrait fin à la fonction s'il y avait une erreur, et non si l'erreur était gérée d'une manière ou d'une autre. Si vous ne terminez pas la fonction, où continue le code ? Vraisemblablement avec le retour de try (sinon je ne comprends pas le emit qui ne termine pas la fonction). Ne serait-il pas plus simple et plus clair dans ce cas d'utiliser simplement un if au lieu de try ? L'utilisation d'un emit ou d' handle obscurcirait énormément le flux de contrôle dans ces cas, en particulier parce que la clause emit peut se trouver dans une partie complètement différente (probablement plus tôt) de la fonction. (Sur cette note, peut-on avoir plus d'un emit ? Sinon, pourquoi pas ? Que se passe-t-il s'il n'y a pas emit check / handle ébauche de conception.)
Ce n'est que si l'on veut revenir d'une fonction sans beaucoup de travail supplémentaire en plus de la décoration d'erreur, ou avec toujours le même travail, qu'il est logique d'utiliser try et une sorte de gestionnaire. Et ce mécanisme de gestionnaire, qui s'exécute avant le retour d'une fonction, existe déjà dans defer .
griesemer
le 19 juin 2019
@guybrand (et @griesemer) concernant votre deuxième modèle non reconnu, voir https://github.com/griesemer/tryhard/issues/2
josharian
le 19 juin 2019
@daved
Comment la valeur sera-t-elle dérivée des données alors qu'une grande partie du processus public est motivée par le sentiment ?
Peut-être que d'autres peuvent avoir une expérience comme la mienne rapportée ici . Je m'attendais à parcourir quelques instances de try insérées par tryhard , à trouver qu'elles ressemblaient plus ou moins à ce qui existait déjà dans ce fil, et à passer à autre chose. Au lieu de cela, j'ai été surpris de trouver un cas dans lequel try a conduit à un code clairement meilleur, d'une manière qui n'avait pas été discutée auparavant.
Donc il y a au moins de l'espoir. :)
josharian
le 19 juin 2019
Pour les personnes qui essaient tryhard , si vous ne l'avez pas déjà fait, je vous encourage non seulement à regarder les modifications apportées par l'outil, mais aussi à grep pour les instances restantes de err != nil et à regarder ce qu'il a laissé seul, et pourquoi.
(Et notez également qu'il y a quelques problèmes et relations publiques sur https://github.com/griesemer/tryhard/.)
josharian
le 19 juin 2019
@rsc voici ma perspicacité quant à la raison pour laquelle je n'aime personnellement pas le modèle defer HandleFunc(&err, ...) . Ce n'est pas parce que je l'associe à des retours nus ou quoi que ce soit, c'est juste trop "intelligent".
Il y a quelques mois (peut-être un an ?) il y a eu une proposition de gestion des erreurs, mais j'en ai perdu la trace maintenant. J'ai oublié ce qu'il demandait, mais quelqu'un avait répondu avec quelque chose du genre :
func myFunction() (i int, err error) {
defer func() {
if err != nil {
err = fmt.Errorf("wrapping the error: %s", err)
}
}()
// ...
return 0, err
// ...
return someInt, nil
}
C'était intéressant à voir, c'est le moins qu'on puisse dire. C'était la première fois que je voyais defer utilisé pour la gestion des erreurs, et maintenant il est affiché ici. Je le vois comme "intelligent" et "hacky", et, au moins dans l'exemple que j'évoque, ça ne ressemble pas à Go. Cependant, l'envelopper dans un appel de fonction approprié avec quelque chose comme fmt.HandleErrorf l'aide à se sentir beaucoup plus agréable. Je me sens toujours négativement à son égard, cependant.
deanveloper
le 19 juin 2019
Une autre raison pour laquelle je peux voir que les gens ne l'aiment pas est que lorsque l'on écrit return ..., err , il semble que err devrait être renvoyé. Mais elle n'est pas renvoyée, mais la valeur est modifiée avant l'envoi. J'ai déjà dit que return a toujours semblé être une opération « sacrée » dans Go, et encourager le code qui modifie une valeur renvoyée avant de revenir est tout simplement faux.
deanveloper
le 19 juin 2019
OK, les chiffres et les données, c'est alors. :)
J'ai exécuté tryhard sur les sources de plusieurs services de notre plate-forme de microservices et les ai comparés avec les résultats de loccount et grep 'if err'. J'ai obtenu les résultats suivants dans l'ordre loccount/grep 'if err' | wc / essai :
1382 / 64 / 14
108554 / 66 / 5
58401 / 22 / 5
2052/247/39
12024 / 1655 / 1
Certains de nos microservices gèrent beaucoup d'erreurs et d'autres très peu, mais malheureusement, tryhard n'a pu améliorer automatiquement le code que dans au mieux 22 % des cas, au pire moins de 1 %. Maintenant, nous n'allons pas réécrire manuellement notre gestion des erreurs donc un outil comme tryhard sera essentiel pour introduire try() dans notre base de code. J'apprécie qu'il s'agisse d'un outil préliminaire simple, mais j'ai été surpris de voir à quel point il était rarement en mesure d'aider.
Mais je pense que maintenant, avec le nombre en main, je peux dire que pour notre utilisation, try() ne résout vraiment aucun problème, ou, du moins pas jusqu'à ce que tryhard devienne bien meilleur.
J'ai également trouvé dans nos bases de code que le cas d'utilisation if err != nil { return err } de try() est en fait très rare, contrairement au compilateur go, où il est courant. Avec tout le respect que je vous dois, mais je pense que les concepteurs de Go, qui examinent le code source du compilateur Go beaucoup plus souvent que d'autres bases de code, surestiment l'utilité de try() cause de cela.
beoran
le 19 juin 2019
@beoran tryhard est très rudimentaire pour le moment. Avez-vous une idée des raisons les plus courantes pour lesquelles try serait rare dans votre base de code ? Par exemple, parce que vous décorez les erreurs? Parce que vous faites d'autres travaux supplémentaires avant de revenir ? Autre chose?
josharian
le 19 juin 2019
@rsc , @griesemer
En ce qui concerne les exemples , j'ai donné ici deux exemples répétitifs que tryHard a manqués, l'un restera probablement comme "if Err :=", l'autre peut être résolu
en ce qui concerne la décoration d'erreur , deux modèles récurrents que je vois dans le code sont (j'ai mis les deux en un seul extrait de code):
if v, err := someFunction(vars...) ; err != nil {
return fmt.Errorf("extra data to help with where did error occur and params are %s , %d , err : %v",
strParam, intParam, err)
} else if v2, err := passToAnotherFunc(v,vars ...);err != nil {
extraData := DoSomethingAccordingTo(v2,err)
return formatError(err,extraData)
} else {
}
Et la plupart du temps, le formatError est une norme pour l'application ou les dépôts croisés, la plupart des répétitions sont le formatage DbError (une fonction dans toutes les applications/applications, utilisée dans des dizaines d'emplacements), dans certains cas (sans entrer dans "est-ce un modèle correct") en enregistrant certaines données dans le journal (échec de la requête sql que vous ne voudriez pas laisser passer la pile) et un autre texte à l'erreur.
En d'autres termes, si je veux "faire quelque chose d'intelligent avec des données supplémentaires telles que la journalisation de l'erreur A et la génération de l'erreur B, en plus de ma mention de ces deux options pour étendre la gestion des erreurs
C'est une autre option pour "plus que simplement renvoyer l'erreur et laisser 'quelqu'un d'autre' ou 'une autre fonction' s'en occuper"
Ce qui signifie qu'il y a probablement plus d'utilisation de try() dans les "bibliothèques" que dans les "programmes exécutables", peut-être que j'essaierai d'exécuter la comparaison Total/Errs/tryHard en différenciant les bibliothèques des exécutables ("applications").
guybrand
le 19 juin 2019
Je me suis retrouvé exactement dans la situation décrite dans https://github.com/golang/go/issues/32437#issuecomment -503297387
Dans certains niveaux, j'enveloppe les erreurs individuellement, je ne changerai pas cela avec try , ça va avec if err!=nil .
À un autre niveau, j'ai juste return err c'est pénible d'ajouter le même contexte pour tous les retours, alors j'utiliserai try et defer .
Je le fais même déjà avec un enregistreur spécifique que j'utilise en début de fonction juste en cas d'erreur. Pour moi try et la décoration par fonction c'est déjà goish.
flibustenet
le 19 juin 2019
@thepudds
Si
trydevait atterrir hypothétiquement dans quelque chose comme Go 1.15, alors la réponse très courte à votre question est que quelqu'un utilisant Go 1.13
Go 1.13 n'est même pas encore sorti, donc je ne peux pas l'utiliser. Et, étant donné que mon projet n'utilise pas de modules Go, je ne pourrai pas passer à Go 1.13. (Je crois que Go 1.13 obligera tout le monde à utiliser les modules Go)
construire du code avec
tryverrait une erreur de compilation comme celle-ci :.\hello.go:3:16: undefined: try note: module requires Go 1.15(Du moins pour autant que je comprenne ce qui a été dit à propos de la proposition de transition).
Tout cela est hypothétique. Il m'est difficile de commenter des choses fictives. Et, peut-être que vous aimez cette erreur, mais je la trouve déroutante et inutile.
Si try n'est pas défini, je le ferais grep. Et je ne trouverai rien. Que dois-je faire alors ?
Et le note: module requires Go 1.15 est la pire aide dans cette situation. Pourquoi module ? Pourquoi Go 1.15 ?
@griesemer
C'est peut-être le premier changement de langue suggéré qui affecte la sensation de la langue de manière plus substantielle. Nous en sommes conscients, c'est pourquoi nous l'avons gardé si minime. (J'ai du mal à imaginer le tollé qu'une proposition concrète de génériques pourrait provoquer - en parlant d'un changement de langage).
Je préférerais que vous passiez du temps sur les génériques, plutôt que d'essayer. Il y a peut-être un avantage à avoir des génériques dans Go.
Mais revenons à votre point : les programmeurs s'habituent au fonctionnement et à la sensation d'un langage de programmation. ...
Je suis d'accord avec tous vos points. Mais nous parlons de remplacer une forme particulière d'instruction if par un appel de fonction try. C'est dans la langue qui se targue de simplicité et d'orthogonalité. Je peux m'habituer à tout, mais à quoi bon ? Pour enregistrer quelques lignes de code ?
Ou, considérez l'expérience de pensée suivante : Imagine Go n'avait pas d'instruction
deferet maintenant quelqu'un fait un cas solide pourdefer.defern'a pas de sémantique comme quoi que ce soit d'autre dans le langage, le nouveau langage ne ressemble plus à ça avantdeferGo. Pourtant, après avoir vécu avec pendant une décennie, il semble totalement "Go-like".
Après de nombreuses années, je suis toujours trompé par defer body et fermé sur des variables. Mais defer paie son prix en pique quand il s'agit de la gestion des ressources. Je ne peux pas imaginer Go sans defer . Mais je ne suis pas prêt à payer un prix similaire pour try , car je ne vois aucun avantage ici.
C'est pourquoi nous demandons aux gens de s'engager réellement dans le changement en l'expérimentant dans votre propre code ; c'est-à-dire, l'écrire réellement, ou faire exécuter
tryhardsur du code existant, et considérer le résultat. Je recommanderais de le laisser reposer pendant un certain temps, peut-être une semaine environ. Regardez-le à nouveau et faites un rapport.
J'ai essayé de changer mon petit projet (environ 1200 lignes de code). Et cela ressemble à votre changement sur https://go-review.googlesource.com/c/go/+/182717/1/src/cmd/link/internal/ld/macho_combine_dwarf.go Je ne vois pas mon opinion changer à ce sujet après une semaine. Mon esprit est toujours occupé par quelque chose, et j'oublierai.
... Mais il est encore tôt, cette proposition n'est sortie que depuis deux semaines, ...
Et je peux voir qu'il y a déjà 504 messages à propos de cette proposition sur ce fil. Si cela m'intéresse de pousser ce changement, il me faudra des jours, voire des semaines, pour lire et comprendre tout cela. Je n'envie pas votre travail.
Merci d'avoir pris le temps de répondre à mon message. Désolé, si je ne répondrai pas à ce fil - il est tout simplement trop volumineux pour que je puisse le surveiller, si le message m'est adressé ou non.
Alexandre
alexbrainman
le 19 juin 2019
@griesemer Merci pour la merveilleuse proposition et tryhard semble être plus utile que ce à quoi je m'attendais. Je veux aussi apprécier.
@rsc merci pour la réponse et l'outil bien articulés.
Je suis ce fil depuis un moment et les commentaires suivants de @beoran me donnent des frissons
Cacher la variable d'erreur et le retour n'aide pas à rendre les choses plus faciles à comprendre
J'ai déjà géré plusieurs bad written code et je peux témoigner que c'est le pire cauchemar pour tout développeur.
Le fait que la documentation indique d'utiliser A aime ne signifie pas qu'il serait suivi, le fait demeure s'il est possible d'utiliser AA , AB alors il n'y a pas de limite à la façon dont ça peut être utilisé.
To my surprise, people already think the code below is cool ... Je pense it's an abomination avec tout le respect que je dois à toute personne offensée.
parentCommitOne := try(try(try(r.Head()).Peel(git.ObjectCommit)).AsCommit())
parentCommitTwo := try(try(remoteBranch.Reference.Peel(git.ObjectCommit)).AsCommit())
Attendez de cocher AsCommit et vous voyez
func AsCommit() error(){
return try(try(try(tail()).find()).auth())
}
La folie continue et honnêtement je ne veux pas croire que c'est la définition de @robpike simplicity is complicated (Humour)
Basé sur l'exemple @rsc
// Example 1
headRef := try(r.Head())
parentObjOne := try(headRef.Peel(git.ObjectCommit))
parentObjTwo := try(remoteBranch.Reference.Peel(git.ObjectCommit))
parentCommitOne := parentObjOne.AsCommit()
parentCommitTwo := parentObjTwo.AsCommit()
treeOid := try(index.WriteTree())
tree := try(r.LookupTree(treeOid))
// Example 2
try headRef := r.Head()
try parentObjOne := headRef.Peel(git.ObjectCommit)
try parentObjTwo := remoteBranch.Reference.Peel(git.ObjectCommit)
parentCommitOne := parentObjOne.AsCommit()
parentCommitTwo := parentObjTwo.AsCommit()
try treeOid := index.WriteTree()
try tree := r.LookupTree(treeOid)
// Example 3
try (
headRef := r.Head()
parentObjOne := headRef.Peel(git.ObjectCommit)
parentObjTwo := remoteBranch.Reference.Peel(git.ObjectCommit)
)
parentCommitOne := parentObjOne.AsCommit()
parentCommitTwo := parentObjTwo.AsCommit()
try (
treeOid := index.WriteTree()
tree := r.LookupTree(treeOid)
)
Suis en faveur de Example 2 avec un peu else , veuillez noter que ce n'est peut-être pas la meilleure approche cependant
- Il est facile de voir clairement l'erreur
- Le moins possible de muter en
abominationque les autres peuvent donner naissance tryne se comporte pas comme une fonction normale. lui donner une syntaxe de type fonction est peu de chose.goutiliseifet si je peux juste le changer entry tree := r.LookupTree(treeOid) else {ça semble plus naturel- Les erreurs peuvent être très très coûteuses, elles ont besoin d'autant de visibilité que possible et je pense que c'est la raison pour laquelle go n'a pas pris en charge les traditionnels
try&catch
try headRef := r.Head()
try parentObjOne := headRef.Peel(git.ObjectCommit)
try parentObjTwo := remoteBranch.Reference.Peel(git.ObjectCommit)
parentCommitOne := parentObjOne.AsCommit()
parentCommitTwo := parentObjTwo.AsCommit()
try treeOid := index.WriteTree()
try tree := r.LookupTree(treeOid) else {
// Heal the world
// I may return with return keyword
// I may not return but set some values to 0
// I may remember I need to log only this
// I may send a mail to let the cute monkeys know the server is on fire
}
Encore une fois, je tiens à m'excuser d'avoir été un peu égoïste.
 olekukonko
le 19 juin 2019
olekukonko
le 19 juin 2019
@josharian Je ne peux pas trop en divulguer ici, cependant, les raisons sont assez diverses. Comme vous le dites, nous décorons les erreurs, et ou effectuons également un traitement différent, et aussi, un cas d'utilisation important est que nous les enregistrons, où le message de journal diffère pour chaque erreur qu'une fonction peut renvoyer, ou parce que nous utilisons le if err := foo() ; err != nil { /* various handling*/ ; return err } formulaire, ou d'autres raisons.
Ce que je veux souligner, c'est ceci : le cas d'utilisation simple pour lequel try() est conçu ne se produit que très rarement dans notre base de code. Donc, pour nous, il n'y a pas grand-chose à gagner à ajouter 'try()' au langage.
EDIT : Si try() doit être implémenté, je pense que la prochaine étape devrait être de rendre tryhard bien meilleur, afin qu'il puisse être largement utilisé pour mettre à niveau les bases de code existantes.
beoran
le 19 juin 2019
@griesemer Je vais essayer de répondre à toutes vos préoccupations une par une à partir de votre dernière réponse .
Vous avez d'abord demandé si le gestionnaire ne retournait pas ou ne quittait pas la fonction d'une manière ou d'une autre, puis ce qui se passerait. Oui, il peut y avoir des cas où la clause emit / handle ne retournera pas ou ne quittera pas une fonction, mais reprendra plutôt là où elle s'était arrêtée. Par exemple, dans le cas où nous essayons de trouver un délimiteur ou quelque chose de simple à l'aide d'un lecteur et que nous atteignons le EOF , nous ne voudrons peut-être pas renvoyer d'erreur lorsque nous le frapperons. J'ai donc construit cet exemple rapide de ce à quoi cela pourrait ressembler:
func findDelimiter(r io.Reader) ([]byte, error) {
emit err {
// if this doesn't return then continue from where we left off
// at the try function that was called last.
if err != io.EOF {
return nil, err
}
}
bufReader := bufio.NewReader(r)
token := try(bufReader.ReadSlice('|'))
return token, nil
}
Ou même pourrait être encore simplifié à ceci:
func findDelimiter(r io.Reader) ([]byte, error) {
emit err != io.EOF {
return nil, err
}
bufReader := bufio.NewReader(r)
token := try(bufReader.ReadSlice('|'))
return token, nil
}
La deuxième préoccupation concernait la perturbation du flux de contrôle. Et oui, cela perturberait le flux, mais pour être juste, la plupart des propositions perturbent quelque peu le flux pour avoir une fonction centrale de gestion des erreurs, etc. Ce n'est pas différent je crois.
Ensuite, vous avez demandé si nous avions utilisé emit / handle plus d'une fois dans laquelle je dis que c'est redéfini.
Si vous utilisez emit plus d'une fois, il écrasera le dernier et ainsi de suite. Si vous n'en avez pas, le try aura un gestionnaire par défaut qui ne renvoie que des valeurs nulles et l'erreur. Cela signifie que cet exemple ici :
func writeStuff(filename string) (io.ReadCloser, error) {
emit err {
return nil, err
}
f := try(os.Open(filename))
try(fmt.Fprintf(f, "stuff\n"))
return f, nil
}
Ferait la même chose que cet exemple:
func writeStuff(filename string) (io.ReadCloser, error) {
// when not defining a handler then try's default handler kicks in to
// return nil valued then error as usual.
f := try(os.Open(filename))
try(fmt.Fprintf(f, "stuff\n"))
return f, nil
}
Votre dernière question concernait la déclaration d'une fonction de gestionnaire appelée dans un defer avec, je suppose, une référence à un error . Cette conception ne fonctionne pas de la même manière que cette proposition fonctionne dans la mesure où un defer ne peut pas arrêter immédiatement une fonction étant donné une condition elle-même.
Je crois avoir tout abordé dans votre réponse et j'espère que cela clarifie un peu plus ma proposition. S'il y a encore des préoccupations, faites-le moi savoir parce que je pense que toute cette discussion avec tout le monde est assez amusante pour réfléchir à de nouvelles idées. Continuez votre excellent travail à tous!
damienfamed75
le 19 juin 2019
@velovix , concernant https://github.com/golang/go/issues/32437#issuecomment -503314834 :
Encore une fois, cela signifie que
trys'efforce de réagir aux erreurs, mais pas de leur ajouter du contexte. C'est une distinction à laquelle j'ai fait allusion, à moi et peut-être à d'autres. Cela a du sens car la façon dont une fonction ajoute du contexte à une erreur n'est pas d'un intérêt particulier pour un lecteur, mais la façon dont une fonction réagit aux erreurs est importante. Nous devrions rendre les parties les moins intéressantes de notre code moins détaillées, et c'est ce que faittry.
C'est une très belle façon de le dire. Merci.
rsc
le 19 juin 2019
@olekukonko , concernant https://github.com/golang/go/issues/32437#issuecomment -503508478 :
To my surprise, people already think the code below is cool... Je penseit's an abominationavec tout le respect que je dois à toute personne offensée.parentCommitOne := try(try(try(r.Head()).Peel(git.ObjectCommit)).AsCommit()) parentCommitTwo := try(try(remoteBranch.Reference.Peel(git.ObjectCommit)).AsCommit())
Grepping https://swtch.com/try.html , cette expression s'est produite trois fois dans ce fil.
@goodwine l'a présenté comme un mauvais code, j'ai accepté, et @velovix a dit "malgré sa laideur ... c'est mieux que ce que vous voyez souvent dans les langages try-catch ... parce que vous pouvez toujours dire quelles parties du code peuvent détourner flux de contrôle en raison d'une erreur et qui ne peut pas."
Personne n'a dit que c'était "cool" ou quelque chose à présenter comme un excellent code. Encore une fois, il est toujours possible d'écrire du mauvais code .
Je dirais aussi juste re
Les erreurs peuvent coûter très très cher, elles nécessitent le plus de visibilité possible
Les erreurs en Go sont censées ne pas coûter cher. Ce sont des événements quotidiens, ordinaires et censés être légers. (Cela contraste avec certaines implémentations d'exceptions en particulier. Nous avions autrefois un serveur qui passait beaucoup trop de temps CPU à préparer et à supprimer des objets d'exception contenant des traces de pile pour les appels d'"ouverture de fichier" ayant échoué dans une boucle vérifiant une liste d'objets connus. emplacements pour un fichier donné.)
rsc
le 19 juin 2019
@alexbrainman , je suis désolé pour la confusion sur ce qui se passe si les anciennes versions de code de construction Go contenant try. La réponse courte est que c'est comme à chaque fois que nous changeons de langage : l'ancien compilateur rejettera le nouveau code avec un message généralement inutile (dans ce cas "undefined : try"). Le message n'est pas utile car l'ancien compilateur ne connaît pas la nouvelle syntaxe et ne peut pas vraiment être plus utile. À ce moment-là, les gens feraient probablement une recherche sur le Web pour "go indefined try" et se renseigneraient sur la nouvelle fonctionnalité.
Dans l'exemple de @thepudds , le code utilisant try a un go.mod qui contient la ligne 'go 1.15', ce qui signifie que l'auteur du module dit que le code est écrit par rapport à la version du langage Go. Cela sert de signal aux anciennes commandes go pour suggérer après une erreur de compilation que le message inutile est peut-être dû à une version trop ancienne de Go. Il s'agit explicitement d'une tentative de rendre le message un peu plus utile sans obliger les utilisateurs à recourir à des recherches sur le Web. Si cela aide, tant mieux ; sinon, les recherches sur le Web semblent de toute façon assez efficaces.
rsc
le 19 juin 2019
@guybrand , concernant https://github.com/golang/go/issues/32437#issuecomment -503287670 et avec mes excuses pour être probablement trop tard pour votre rencontre :
Un problème en général avec les fonctions qui renvoient des types d'erreur pas tout à fait est que pour les non-interfaces, la conversion en erreur ne préserve pas le néant. Ainsi, par exemple, si vous avez votre propre type concret personnalisé * MyError (par exemple, un pointeur vers une structure) et que vous utilisez err == nil comme signal de réussite, c'est très bien jusqu'à ce que vous ayez
func f() (int, *MyError)
func g() (int, error) { x, err := f(); return x, err }
Si f renvoie un nil *MyError, g renvoie la même valeur qu'une erreur non nulle, ce qui n'est probablement pas ce qui était prévu. Si *MyError est une interface au lieu d'un pointeur de struct, alors la conversion préserve le néant, mais c'est quand même une subtilité.
Pour try, vous pourriez penser que puisque try ne se déclencherait que pour des valeurs non nulles, pas de problème. Par exemple, c'est en fait OK pour ce qui est de renvoyer une erreur non nulle lorsque f échoue, et c'est également OK pour renvoyer une erreur nulle lorsque f réussit :
func g() (int, error) {
return try(f()), nil
}
C'est donc très bien, mais vous pourriez alors voir ceci et penser à le réécrire pour
func g() (int, error) {
return f()
}
ce qui semble être le même, mais ce n'est pas le cas.
Il y a suffisamment d'autres détails de la proposition d'essai qui nécessitent un examen minutieux et une évaluation dans une expérience réelle pour qu'il semble préférable de reporter la décision sur cette subtilité particulière.
rsc
le 19 juin 2019
Merci à tous pour tous les commentaires jusqu'à présent . À ce stade, il semble que nous ayons identifié les principaux avantages, les préoccupations et les éventuelles implications positives et négatives de try . Pour progresser, ceux-ci doivent être évalués plus avant en examinant ce que try signifierait pour les bases de code réelles. La discussion à ce stade tourne autour et répète ces mêmes points.
L'expérience est maintenant plus précieuse que la discussion continue. Nous voulons encourager les gens à prendre le temps d'expérimenter ce à quoi try ressemblerait dans leurs propres bases de code et à écrire et lier des rapports d'expérience sur la page de commentaires .
Pour donner à chacun le temps de respirer et d'expérimenter, nous allons mettre cette conversation en pause et verrouiller le problème pour la semaine et demie prochaine.
Le verrouillage commencera vers 13h00 PDT/16h00 EDT (dans environ 3h à partir de maintenant) pour donner aux gens une chance de soumettre un message en attente. Nous rouvrirons le sujet pour plus de discussion le 1er juillet.
Soyez assuré que nous n'avons pas l'intention de précipiter les nouvelles fonctionnalités du langage sans prendre le temps de bien les comprendre et de nous assurer qu'elles résolvent de vrais problèmes dans du code réel. Nous prendrons le temps nécessaire pour bien faire les choses, comme nous l'avons fait par le passé.
griesemer
le 19 juin 2019
Cette page wiki est remplie de réponses à vérifier/traiter. Je vous propose de commencer une nouvelle page.
De toute façon, je n'aurai pas le temps de continuer à jardiner dans le wiki.
networkimprov
le 19 juin 2019
@networkimprov , merci pour votre aide au jardinage. J'ai créé une nouvelle section supérieure dans https://github.com/golang/go/wiki/Go2ErrorHandlingFeedback. Je pense que cela devrait être mieux qu'une toute nouvelle page.
J'ai aussi raté la note 1p PDT / 4p EDT de Robert pour la serrure, donc je l'ai brièvement verrouillée un peu trop tôt. Il est à nouveau ouvert, pour un peu plus longtemps.
rsc
le 19 juin 2019
J'avais l'intention d'écrire ceci et je voulais juste le terminer avant qu'il ne soit verrouillé.
J'espère que l'équipe de go ne voit pas la critique et estime qu'elle est révélatrice du sentiment de la majorité. La minorité vocale a toujours tendance à submerger la conversation, et j'ai l'impression que cela aurait pu arriver ici. Quand tout le monde prend la tangente, cela décourage les autres qui veulent juste parler de la proposition TELLE QUELLE.
Donc - j'aimerais exprimer ma position positive pour ce qu'elle vaut.
J'ai du code qui utilise déjà le report pour décorer/annoter les erreurs, même pour cracher des traces de pile, exactement pour cette raison.
Voir:
https://github.com/ugorji/go-ndb/blob/master/ndb/ndb.go#L331
https://github.com/ugorji/go-serverapp/blob/master/app/baseapp.go#L129
https://github.com/ugorji/go-serverapp/blob/master/app/webrouter.go#L180
qui appellent tous errorutil.OnError(*error)
https://github.com/ugorji/go-common/blob/master/errorutil/errors.go#L193
Cela va dans le sens des aides différées que Russ/Robert mentionnent plus tôt.
C'est un modèle que j'utilise déjà, FWIW. Ce n'est pas de la magie. C'est complètement à mon humble avis.
Je l'utilise aussi avec des paramètres nommés, et cela fonctionne parfaitement.
Je dis cela pour contester l'idée que tout ce qui est recommandé ici est magique.
Deuxièmement, je voulais ajouter quelques commentaires sur try(...) en tant que fonction.
Il a un net avantage par rapport à un mot-clé, en ce sens qu'il peut être étendu pour prendre des paramètres.
Il existe 2 modes d'extension qui ont été discutés ici :
- étendre essayer de prendre une étiquette pour sauter à
- extend essaie de prendre un gestionnaire de la forme func(error) error
Pour chacune d'entre elles, il faut que la fonction try prenne un seul paramètre, et elle peut être étendue ultérieurement pour prendre un deuxième paramètre si nécessaire.
La décision n'a pas été prise sur la nécessité de prolonger l'essai et, le cas échéant, sur la direction à prendre. Par conséquent, la première direction est d'essayer d'éliminer la plupart du bégaiement "if err != nil { return err }" que j'ai toujours détesté mais que j'ai pris comme le coût de faire des affaires en cours.
Personnellement, je suis content que try soit une fonction, que je puisse appeler en ligne, par exemple, je peux écrire
var u User = db.loadUser(try(strconv.Atoi(stringId)))
AS opposé à :
var id int // i have to define this on its own if err is already defined in an enclosing block
id, err = strconv.Atoi(stringId)
if err != nil {
return
}
var u User = db.loadUser(id)
Comme vous pouvez le voir, je viens de réduire 6 lignes à 1. Et 5 de ces lignes sont vraiment passe-partout.
C'est quelque chose que j'ai traité plusieurs fois, et j'ai écrit beaucoup de code go et de packages - vous pouvez consulter mon github pour voir certains de ceux que j'ai publiés en ligne, ou ma bibliothèque go-codec.
Enfin, beaucoup de commentaires ici n'ont pas vraiment montré de problèmes avec la proposition, dans la mesure où ils ont proposé leur propre manière préférée de résoudre le problème.
Personnellement, je suis ravi que try(...) arrive. Et j'apprécie les raisons pour lesquelles try as a function est la solution préférée. J'aime clairement que le report soit utilisé ici, car cela n'a que du sens.
Rappelons-nous l'un des principes fondamentaux du go - des concepts orthogonaux qui peuvent être bien combinés. Cette proposition exploite un tas de concepts orthogonaux de go (différer, paramètres de retour nommés, fonctions intégrées pour faire ce qui n'est pas possible via le code utilisateur, etc.) pour fournir l'avantage clé que
go les utilisateurs ont universellement demandé pendant des années, c'est-à-dire réduire/éliminer le passe-partout if err != nil { return err }. Les enquêtes auprès des utilisateurs de Go montrent qu'il s'agit d'un véritable problème. L'équipe de go est consciente que c'est un vrai problème. Je suis heureux que les voix fortes de quelques-uns ne faussent pas trop la position de l'équipe de go.
J'avais une question à propos de try en tant que goto implicite if err != nil.
Si nous décidons que c'est la direction, sera-t-il difficile de transformer "essayer fait un retour" en "essayer fait un aller-retour",
étant donné que goto a une sémantique définie, vous ne pouvez pas dépasser les variables non allouées ?
ugorji
le 19 juin 2019
Merci pour votre note, @ugorji.
J'avais une question à propos de try en tant que goto implicite if err != nil.
Si nous décidons que c'est la direction, sera-t-il difficile de transformer "essayer fait un retour" en "essayer fait un aller-retour",
étant donné que goto a une sémantique définie, vous ne pouvez pas dépasser les variables non allouées ?
Oui, exactement. Il y a une discussion sur #26058.
Je pense que "try-goto" a au moins trois frappes contre lui :
(1) vous devez répondre à des variables non affectées,
(2) vous perdez des informations sur la pile concernant l'échec de la tentative, que vous pouvez toujours capturer dans le cas retour + report, et
(3) tout le monde aime détester goto.
rsc
le 19 juin 2019
Oui, try est la voie à suivre.
J'ai essayé d'ajouter try une fois, et j'ai aimé ça.
Correctif - https://github.com/ascheglov/go/pull/1
Sujet sur Reddit - https://www.reddit.com/r/golang/comments/6vt3el/the_try_keyword_proofofconcept/
 ascheglov
le 19 juin 2019
ascheglov
le 19 juin 2019
@griesemer
Suite de https://github.com/golang/go/issues/32825#issuecomment -507120860 ...
En partant du principe que l'abus de try sera atténué par la révision du code, la vérification et/ou les normes communautaires, je peux voir la sagesse d'éviter de changer le langage afin de restreindre la flexibilité de try . Je ne vois pas la sagesse de fournir des installations supplémentaires qui encouragent fortement les manifestations les plus difficiles/désagréables à consommer.
En décomposant cela, il semble y avoir deux formes de flux de contrôle de chemin d'erreur exprimés : manuel et automatique. En ce qui concerne l'emballage d'erreur, il semble y avoir trois formes exprimées : Direct, Indirect et Pass-through. Il en résulte un total de six "modes" de gestion des erreurs.
Les modes Manual Direct et Automatic Direct semblent agréables :
wrap := func(err error) error {
return fmt.Errorf("failed to process %s: %v", filename, err)
}
f, err := os.Open(filename)
if err != nil {
return nil, wrap(err)
}
defer f.Close()
info, err := f.Stat()
if err != nil {
return nil, wrap(err)
}
// in errors, named better, and optimized
WrapfFunc := func(format string, args ...interface{}) func(error) error {
return func(err error) error {
if err == nil {
return nil
}
s := fmt.Sprintf(format, args...)
return errors.Errorf(s+": %w", err)
}
}
``` allez
wrap := errors.WrapfFunc("échec du traitement de %s", nom du fichier)
f, err := os.Open(filename)
essayer (envelopper (erreur))
différer f.Fermer()
info, err := f.Stat()
essayer (envelopper (erreur))
Manual Pass-through, and Automatic Pass-through modes are also simple enough to be agreeable (despite often being a code smell):
```go
f, err := os.Open(filename)
if err != nil {
return nil, err
}
defer f.Close()
info, err := f.Stat()
if err != nil {
return nil, err
}
f := try(os.Open(filename))
defer f.Close()
info := try(f.Stat())
Cependant, les modes manuel indirect et automatique indirect sont tous deux assez désagréables en raison de la forte probabilité d'erreurs subtiles :
defer errd.Wrap(&err, "failed to do X for %s", filename)
var f *os.File
f, err = os.Open(filename)
if err != nil {
return
}
defer f.Close()
var info os.FileInfo
info, err = f.Stat()
if err != nil {
return
}
defer errd.Wrap(&err, "failed to do X for %s", filename)
f := try(os.Open(filename))
defer f.Close()
info := try(f.Stat())
Encore une fois, je peux comprendre de ne pas les interdire, mais faciliter / bénir les modes indirects est là où cela soulève toujours des drapeaux rouges clairs pour moi. Assez pour le moment, pour que je reste catégoriquement sceptique quant à l'ensemble de la prémisse.
daved
le 1 juil. 2019
Essayer ne doit pas être une fonction pour éviter ça maudit
info := try(try(os.Open(filename)).Stat())
fuite de fichier.
Je veux dire que l'instruction try ne permettra pas le chaînage. Et c'est mieux vu en bonus. Il y a cependant des problèmes de compatibilité.
 sirkon
le 1 juil. 2019
sirkon
le 1 juil. 2019
@sirkon Étant donné que try est spécial, le langage peut interdire les try imbriqués si c'est important - même si try ressemble à une fonction. Encore une fois, s'il s'agit du seul barrage routier pour try , cela pourrait être facilement résolu de différentes manières ( go vet , ou restriction de langue). Passons à autre chose - nous l'avons entendu plusieurs fois maintenant. Merci.
griesemer
le 1 juil. 2019
Passons à autre chose - nous l'avons entendu plusieurs fois auparavant
"C'est tellement ennuyeux, passons à autre chose"
Il y a un autre bon analogue:
- Votre théorie contredit les faits !
- Tant pis pour les faits !
Par Hegel
Je veux dire que vous résolvez un problème qui n'existe pas en fait. Et la manière laide à cela.
Voyons où ce problème apparaît réellement : gérer les effets secondaires du monde extérieur, c'est tout. Et c'est en fait l'une des parties les plus faciles logiquement en génie logiciel. Et le plus important à cela. Je ne comprends pas pourquoi avons-nous besoin d'une simplification pour la chose la plus simple qui nous coûtera moins de fiabilité.
Pour l'OMI, le problème le plus difficile de ce type est la préservation de la cohérence des données dans les systèmes distribués (et pas si distribués en fait). Et la gestion des erreurs n'était pas un problème avec lequel je me battais dans Go lors de la résolution de ces problèmes. Le manque de compréhension des tranches et des cartes, le manque de somme/algébrique/variance/quel que soit les types était BEAUCOUP plus ennuyeux.
sirkon
le 1 juil. 2019
Étant donné que le débat ici semble se poursuivre sans relâche, permettez-moi de répéter à nouveau :
L'expérience est maintenant plus précieuse que la discussion continue. Nous voulons encourager les gens à prendre le temps d'expérimenter à quoi ressemblerait
trydans leurs propres bases de code et à écrire et lier des rapports d'expérience sur la page de commentaires.
Si l'expérience concrète fournit des preuves significatives pour ou contre cette proposition, nous aimerions l'entendre ici. Les bêtes noires personnelles, les scénarios hypothétiques, les conceptions alternatives, etc., nous pouvons le reconnaître, mais ils sont moins exploitables.
Merci.
griesemer
le 1 juil. 2019
Je ne veux pas être grossier ici, et j'apprécie toute votre modération, mais la communauté s'est prononcée très fortement sur la modification de la gestion des erreurs. Changer des choses ou ajouter du nouveau code bouleversera _tous_ ceux qui préfèrent le système actuel. Vous ne pouvez pas rendre tout le monde heureux, alors concentrons-nous sur les 88 % que nous pouvons rendre heureux (nombre dérivé du taux de vote ci-dessous).
Au moment d'écrire ces lignes, le fil "laissez-le tranquille" est à 1322 votes en hausse et 158 en baisse. Ce fil est à 158 en haut et 255 en bas. Si ce n'est pas la fin directe de ce fil sur la gestion des erreurs, alors nous devrions avoir une très bonne raison de continuer à pousser le problème.
Il est possible de toujours faire ce que votre communauté réclame et de détruire votre produit exactement au même moment.
Au minimum, je pense que cette proposition spécifique devrait être considérée comme un échec.
 integrii
le 1 juil. 2019
integrii
le 1 juil. 2019
Heureusement, go n'est pas conçu par un comité. Nous devons avoir confiance que les gardiens de la langue que nous aimons tous continueront à prendre la meilleure décision compte tenu de toutes les données dont ils disposent, et ne prendront pas une décision basée sur l'opinion populaire des masses. Rappelez-vous - ils utilisent aussi le go, tout comme nous. Ils ressentent les points douloureux, tout comme nous.
Si vous avez une position, prenez le temps de la défendre comme l'équipe Go défend ses propositions. Sinon, vous ne faites que noyer la conversation avec des sentiments imprévisibles qui ne sont pas exploitables et ne font pas avancer les conversations. Et cela rend la tâche plus difficile pour les personnes qui souhaitent s'engager, car ces personnes voudront peut-être simplement attendre que le bruit se calme.
Lorsque le processus de proposition a commencé, Russ a mis l'accent sur l'évangélisation du besoin de rapports d'expérience comme moyen d'influencer une proposition ou de faire entendre votre demande. Essayons au moins d'honorer cela.
L'équipe Go a pris en considération tous les commentaires exploitables. Ils ne nous ont pas encore déçus. Voir les documents détaillés produits pour les alias, pour les modules, etc. Accordons-leur au moins le même respect et prenons le temps de réfléchir à nos objections, de répondre à leur position sur vos objections et de rendre plus difficile l'ignorance de votre objection.
L'avantage de Go a toujours été qu'il s'agit d'un petit langage simple avec des constructions orthogonales conçues par un petit groupe de personnes qui réfléchiraient de manière critique à l'espace avant de s'engager dans un poste. Aidons-les là où nous le pouvons, au lieu de simplement dire "voyez, le vote populaire dit non" - là où de nombreuses personnes qui votent n'ont peut-être même pas beaucoup d'expérience dans le go ou ne comprennent pas complètement le go. J'ai lu des affiches en série qui ont admis ne pas connaître certains concepts fondamentaux de ce langage certes petit et simple. Il est donc difficile de prendre vos commentaires au sérieux.
Quoi qu'il en soit, ça craint que je fasse ça ici - n'hésitez pas à supprimer ce commentaire. Je ne serai pas offensé. Mais quelqu'un doit le dire sans ambages !
ugorji
le 1 juil. 2019
Toute cette deuxième proposition ressemble beaucoup aux influenceurs numériques qui organisent un rassemblement pour moi. Les concours de popularité n'évaluent pas les mérites techniques.
Les gens peuvent être silencieux mais ils attendent toujours Go 2. Personnellement, j'attends cela avec impatience et le reste de Go 2. Go 1 est un excellent langage et bien adapté à différents types de programmes. J'espère que Go 2 élargira cela.
Enfin, j'inverserai également ma préférence pour avoir try comme déclaration. Maintenant, je soutiens la proposition telle qu'elle est. Après tant d'années sous la promesse de compatibilité "Go 1", les gens pensent que Go a été gravé dans la pierre. En raison de cette hypothèse problématique, ne pas modifier la syntaxe du langage dans ce cas semble être un bien meilleur compromis à mes yeux maintenant. Edit : J'ai également hâte de voir les rapports d'expérience pour la vérification des faits.
PS : Je me demande quel genre d'opposition se produira lorsque des génériques seront proposés.
carloslenz
le 1 juil. 2019
Nous avons une douzaine d'outils écrits d'un coup dans notre entreprise. J'ai exécuté l'outil tryhard sur notre base de code et j'ai trouvé 933 candidats try() potentiels. Personnellement, je pense que la fonction try () est une idée brillante car elle résout plus qu'un simple problème de code passe-partout.
Il force à la fois l'appelant et la fonction/méthode appelée à renvoyer l'erreur comme dernier paramètre. Cela ne sera pas autorisé :
var file= try(parse())
func parse()(err, result) {
}
Il applique une façon de traiter les erreurs au lieu de déclarer la variable d'erreur et d'autoriser vaguement le modèle err!=nil err==nil, qui entrave la lisibilité, augmente le risque de code sujet aux erreurs dans IMO :
func Foo() (err error) {
var file, ferr = os.Open("file1.txt")
if ferr == nil {
defer file.Close()
var parsed, perr = parseFile(file)
if perr != nil {
return
}
fmt.Printf("%s", parsed)
}
return nil
}
Avec try(), le code est plus lisible, cohérent et plus sûr à mon avis :
func Foo() (err error) {
var file = try(os.Open("file.txt"))
defer file.Close()
var parsed = try(parseFile(file))
fmt.Printf(parsed)
return
}
 ubikenobi
le 2 juil. 2019
ubikenobi
le 2 juil. 2019
J'ai effectué des expériences similaires à ce que @lpar a fait sur tous les référentiels Go non archivés de Heroku (publics et privés).
Les résultats sont dans cet essentiel : https://gist.github.com/freeformz/55abbe5da61a28ab94dbb662bfc7f763
cc @davecheney
 freeformz
le 2 juil. 2019
freeformz
le 2 juil. 2019
@ubikenobi Votre fonction plus sûre ~is~ fuyait.
De plus, je n'ai jamais vu une valeur renvoyée après une erreur. Cependant, je peux imaginer que cela a du sens lorsqu'une fonction concerne uniquement l'erreur et que les autres valeurs renvoyées ne dépendent pas de l'erreur elle-même (conduisant peut-être à deux retours d'erreur avec le second "gardant" les valeurs précédentes).
Enfin, bien qu'il ne soit pas courant, err == nil fournit un test légitime pour certains retours précoces.
daved
le 2 juil. 2019
@David
Merci d'avoir signalé la fuite, j'ai oublié d'ajouter defer.Close() sur les deux exemples. (actuellement mis à jour).
Je vois rarement des erreurs revenir dans cet ordre aussi, mais il est toujours bon de pouvoir les attraper au moment de la compilation s'il s'agit d'erreurs que par conception.
Je vois le cas err==nil comme une exception plutôt qu'une norme dans la plupart des cas. Cela peut être utile dans certains cas, comme vous l'avez mentionné, mais ce que je n'aime pas, ce sont les développeurs qui choisissent de manière incohérente sans raison valable. Heureusement, dans notre base de code, la grande majorité des instructions sont err!=nil, ce qui peut facilement bénéficier de la fonction try().
ubikenobi
le 2 juil. 2019
- J'ai couru
tryhardcontre une grande API Go que je maintiens avec une équipe de quatre autres ingénieurs à plein temps. Dans 45580 lignes de code Go,tryharda identifié 301 erreurs à réécrire (ce serait donc un changement de +301/-903), ou réécrirait environ 2 % du code en supposant que chaque erreur prend environ 3 lignes. En tenant compte des commentaires, des espaces blancs, des importations, etc., cela me semble important. - J'ai utilisé l'outil de ligne de tryhard pour explorer comment
trychangerait mon travail, et subjectivement, ça me va très bien ! Le verbe try me semble plus clair que quelque chose pourrait mal tourner dans la fonction d'appel, et l'accomplit de manière compacte. Je suis très habitué à écrireif err != nil, et cela ne me dérange pas vraiment, mais cela ne me dérangerait pas non plus de changer. Écrire et refactoriser la variable vide précédant l'erreur (c'est-à-dire rendre la tranche/carte/variable vide à renvoyer) de manière répétitive est probablement plus fastidieux que leerrlui-même. - Il est un peu difficile de suivre tous les fils de discussion, mais je suis curieux de savoir ce que cela signifie pour les erreurs d'emballage. Ce serait bien si
tryétait variadique si vous vouliez éventuellement ajouter un contexte commetry(json.Unmarshal(b, &accountBalance), "failed to decode bank account info for user %s", user). Edit : ce point est probablement hors sujet ; en regardant les réécritures sans tentative, c'est là que cela se produit, cependant. - J'apprécie vraiment la réflexion et le soin apportés à cela ! La rétrocompatibilité et la stabilité sont vraiment importantes pour nous et l'effort de Go 2 à ce jour a été vraiment fluide pour la maintenance des projets. Merci!
 kingishb
le 2 juil. 2019
kingishb
le 2 juil. 2019
Cela ne devrait-il pas être fait sur une source qui a été vérifiée par des Gopher expérimentés pour s'assurer que les remplacements sont rationnels ? Quelle part de cette réécriture "2 %" aurait dû être réécrite avec un traitement explicite ? Si nous ne le savons pas, alors le LOC reste une métrique relativement inutile.
* C'est exactement pourquoi mon message plus tôt ce matin s'est concentré sur les "modes" de gestion des erreurs. Il est plus facile et plus substantiel de discuter des modes de gestion des erreurs facilités par try , puis de lutter contre les dangers potentiels du code que nous sommes susceptibles d'écrire que d'exécuter un compteur de lignes plutôt arbitraire.
daved
le 2 juil. 2019
@kingishb Combien de spots _try_ trouvés se trouvent dans des fonctions publiques à partir de packages non principaux ? En règle générale, les fonctions publiques doivent renvoyer des erreurs natives du package (c'est-à-dire encapsulées ou décorées) ....
networkimprov
le 2 juil. 2019
@networkimprov C'est une formule trop simpliste pour ma sensibilité. Là où cela sonne vrai, c'est en termes de surfaces API renvoyant des erreurs inspectables. Il est normalement approprié d'ajouter un contexte à un message d'erreur en fonction de la pertinence du contexte, et non de sa position dans la pile des appels.
De nombreux faux positifs sont probablement en train de passer dans les mesures actuelles. Et qu'en est-il des ratés qui se produisent en raison des pratiques suggérées suivantes (https://blog.golang.org/errors-are-values) ? try réduirait probablement l'utilisation de ces pratiques et, en ce sens, ce sont des cibles de choix pour le remplacement (probablement l'un des seuls cas d'utilisation qui m'intrigue vraiment). Donc, encore une fois, cela semble inutile de gratter la source existante sans beaucoup plus de diligence raisonnable.
daved
le 2 juil. 2019
Merci @ubikenobi , @freeformz et @kingishb pour la collecte de vos données, très apprécié ! Soit dit en passant, si vous exécutez tryhard avec l'option -err="" si vous essayez également de travailler avec du code où la variable d'erreur est appelée autre chose que err (comme e ). Cela peut produire quelques cas supplémentaires, en fonction de la base de code (mais peut également augmenter le risque de faux positifs).
griesemer
le 2 juil. 2019
@griesemer au cas où vous recherchez plus de points de données. J'ai exécuté tryhard contre deux de nos micro-services, avec ces résultats :
cloc v 1.82 / tryhard
13280 lignes de code Go / 148 identifiées pour try (1%)
Une autre prestation :
9768 lignes de code Go / 50 identifiées pour essai (0,5%)
Par la suite, tryhard a inspecté un ensemble plus large de divers micro-services :
314343 lignes de code Go / 1563 identifiées pour essai (0,5%)
Faire une inspection rapide. Les types de packages que try pourraient optimiser sont généralement des adaptateurs/encapsuleurs de service qui renvoient de manière transparente l'erreur (GRPC) renvoyée par le service encapsulé.
J'espère que cela t'aides.
 mibes
le 2 juil. 2019
mibes
le 2 juil. 2019
C'est une très mauvaise idée.
- Quand
errvar apparaît-il pourdefer? Qu'en est-il de "mieux explicite qu'implicite" ? - Nous utilisons une règle simple : vous devez rapidement trouver exactement un endroit où vous avez renvoyé une erreur. Chaque erreur est entourée d'un contexte pour comprendre ce qui ne va pas et où.
defercréera beaucoup de code laid et difficile à comprendre. - @davecheney a écrit un excellent article sur les erreurs et la proposition est totalement contre tout dans cet article.
- Enfin, si vous utilisez
os.Exit, vos erreurs seront décochées.
 makhov
le 2 juil. 2019
makhov
le 2 juil. 2019
Je viens d'exécuter tryhard sur un package (avec le fournisseur) et il a rapporté 2478 avec le nombre de codes passant de 873934 à 851178 mais je ne suis pas sûr comment interpréter cela parce que je ne sais pas dans quelle mesure cela est dû au suremballage (la stdlib ne prenant pas en charge l'emballage des erreurs de trace de pile) ou dans quelle mesure ce code concerne même la gestion des erreurs.
Ce que je sais, cependant, c'est que rien que cette semaine, j'ai perdu un temps embarrassant à cause de copier-coller comme if err != nil { return nil } et d'erreurs qui ressemblent à error: cannot process ....file: cannot parse ...file: cannot open ...file .
\
Je ne prendrais pas non plus trop au sérieux les tentatives d'appel à l'autorité, car ces mêmes autorités sont connues pour rejeter de nouvelles idées et propositions même après que leur propre ignorance et/ou incompréhension ait été signalée.
\
 DisposaBoy
le 2 juil. 2019
DisposaBoy
le 2 juil. 2019
Nous avons exécuté tryhard -err="" sur notre service le plus important (±163 000 lignes de code, y compris les tests) : il a trouvé 566 occurrences. Je soupçonne que ce serait encore plus pratique, car une partie du code a été écrit avec if err != nil à l'esprit, donc il a été conçu autour de lui (l'article "les erreurs sont des valeurs" de Rob Pike sur le fait d'éviter de répéter vient à l'esprit).
DmitriyMV
le 2 juil. 2019
@griesemer J'ai ajouté un nouveau fichier à l'essentiel. Il a été généré avec -err="". J'ai vérifié sur place et il y a quelques changements. J'ai également mis à jour tryhard ce matin, donc la nouvelle version a également été utilisée.
freeformz
le 2 juil. 2019
@griesemer Je pense que tryhard serait plus utile s'il pouvait correspondre:
a) le nombre de sites d'appel produisant une erreur
b) le nombre de gestionnaires à déclaration unique if err != nil [&& ...] (candidats pour on err #32611)
c) le nombre de ceux qui retournent n'importe quoi (candidats pour defer #32676)
d) le nombre de ceux qui retournent err (candidats pour try() )
e) le nombre de ceux qui sont dans les fonctions exportées des packages non principaux (probablement des faux positifs)
Comparer la LoC totale à des instances de return err manque en quelque sorte de contexte, IMO.
networkimprov
le 2 juil. 2019
@networkimprov D'accord - des suggestions similaires ont déjà été faites. Je vais essayer de trouver du temps dans les prochains jours pour améliorer cela.
griesemer
le 2 juil. 2019
Voici les statistiques de l'exécution de tryhard sur notre base de code interne (uniquement notre code, pas les dépendances) :
Avant de:
- 882 fichiers .go
- 352434 lieu
- 329909 loc non vide
Après essai :
- 2701 remplacements (moyenne 3.1 remplacements/fichier)
- 345364 lieu (-2.0%)
- 322838 loc non vide (-2,1%)
Edit : Maintenant que @griesemer a mis à jour tryhard pour inclure des statistiques récapitulatives, en voici quelques autres :
- 39,2 % des relevés
ifsontif <err> != nil - 69,6 % d'entre eux sont des candidats
try
En examinant les remplacements trouvés par tryhard, il existe certainement des types de code où l'utilisation de try serait très répandue, et d'autres types où il serait rarement utilisé.
J'ai également remarqué certains endroits que tryhard ne pouvait pas transformer, mais qui bénéficieraient grandement de try. Par exemple, voici un code que nous avons pour décoder les messages selon un protocole filaire simple (édité pour plus de simplicité/clarté) :
func (req *Request) Decode(r Reader) error {
typ, err := readByte(r)
if err != nil {
return err
}
req.Type = typ
req.Body, err = readString(r)
if err != nil {
return unexpected(err)
}
req.ID, err = readID(r)
if err != nil {
return unexpected(err)
}
n, err := binary.ReadUvarint(r)
if err != nil {
return unexpected(err)
}
req.SubIDs = make([]ID, n)
for i := range req.SubIDs {
req.SubIDs[i], err = readID(r)
if err != nil {
return unexpected(err)
}
}
return nil
}
// unexpected turns any io.EOF into an io.ErrUnexpectedEOF.
func unexpected(err error) error {
if err == io.EOF {
return io.ErrUnexpectedEOF
}
return err
}
Sans try , nous avons juste écrit unexpected aux points de retour où c'est nécessaire car il n'y a pas de grande amélioration en le manipulant en un seul endroit. Cependant, avec try , nous pouvons appliquer la transformation d'erreur unexpected avec un délai, puis raccourcir considérablement le code, le rendant plus clair et plus facile à parcourir :
func (req *Request) Decode(r Reader) (err error) {
defer func() { err = unexpected(err) }()
req.Type = try(readByte(r))
req.Body = try(readString(r))
req.ID = try(readID(r))
n := try(binary.ReadUvarint(r))
req.SubIDs = make([]ID, n)
for i := range req.SubIDs {
req.SubIDs[i] = try(readID(r))
}
return nil
}
@cespare Rapport fantastique !
L'extrait de code entièrement réduit est généralement meilleur, mais les parenthèses sont encore pires que ce à quoi je m'attendais, et le try dans la boucle est aussi mauvais que prévu.
Un mot-clé est beaucoup plus lisible et c'est un peu surréaliste que ce soit un point sur lequel beaucoup d'autres ne sont pas d'accord. Ce qui suit est lisible et ne me préoccupe pas des subtilités dues au retour d'une seule valeur (bien qu'elle puisse toujours apparaître dans des fonctions plus longues et/ou celles avec beaucoup d'imbrication):
func (req *Request) Decode(r Reader) (err error) {
defer func() { err = wrapEOF(err) }()
req.Type = try readByte(r)
req.Body = try readString(r)
req.ID = try readID(r)
n := try binary.ReadUvarint(r)
req.SubIDs = make([]ID, n)
for i := range req.SubIDs {
req.SubIDs[i], err = readID(r)
try err
}
return nil
}
* Pour être juste, la mise en évidence du code aiderait beaucoup, mais cela ressemble à du rouge à lèvres bon marché.
daved
le 2 juil. 2019
Comprenez-vous que le plus d'avantages que vous obtenez en cas de code vraiment mauvais ?
Si vous utilisez unexpected() ou renvoyez une erreur telle quelle, vous ne savez rien de votre code et de votre application.
try ne peut pas vous aider à écrire un meilleur code, mais peut produire plus de mauvais code.
makhov
le 2 juil. 2019
@cespare Un décodeur peut également être une structure contenant un type d'erreur, les méthodes vérifiant err == nil avant chaque opération et renvoyant un booléen ok.
Parce que c'est le processus que nous utilisons pour les codecs, try est absolument inutile car on peut facilement créer un idiome non magique, plus court et plus succinct pour gérer les erreurs dans ce cas spécifique.
 as
le 2 juil. 2019
as
le 2 juil. 2019
@makhov Par "vraiment mauvais code", je suppose que vous voulez dire un code qui n'enveloppe pas les erreurs.
Si c'est le cas, vous pouvez prendre un code qui ressemble à ceci :
a, b, c, err := someFn()
if err != nil {
return ..., errors.Wrap(err, ...)
}
Et transformez-le en un code sémantiquement identique[1] qui ressemble à ceci :
a, b, c, err := someFn()
try(errors.Wrap(err, ...))
La proposition ne dit pas que vous devez utiliser le report pour l'encapsulation des erreurs, expliquant seulement pourquoi le mot-clé handle de l'itération précédente de la proposition n'est pas nécessaire, car il peut être implémenté en termes de report sans aucun changement de langue.
(Votre autre commentaire semble également être basé sur des exemples ou un pseudo-code dans la proposition, par opposition au cœur de ce qui est proposé)
 balasanjay
le 2 juil. 2019
balasanjay
le 2 juil. 2019
J'ai exécuté tryhard sur ma base de code avec 54K LOC, 1116 instances ont été trouvées.
J'ai vu le diff, et je dois dire que j'ai très peu de construction qui bénéficierait grandement d'essayer, car presque toute mon utilisation du type de construction if err != nil est un simple bloc à un seul niveau qui renvoie simplement le erreur avec contexte ajouté. Je pense que je n'ai trouvé que quelques cas où try changerait réellement la construction du code.
En d'autres termes, mon point de vue est que try dans sa forme actuelle me donne :
- moins de frappe (une réduction de ~ 30 caractères par occurrence, indiqués par les "**" ci-dessous)
- **if err := **json.NewEncoder(&buf).Encode(in)**; err != nil {**
- **return err**
- **}**
+ try(json.NewEncoder(&buf).Encode(in))
alors qu'il introduit ces problèmes pour moi:
- Encore une autre façon de gérer les erreurs
- repère visuel manquant pour la division du chemin d'exécution
Comme je l'ai écrit plus tôt dans ce fil, je peux vivre avec try , mais après l'avoir essayé sur mon code, je pense que je préférerais personnellement ne pas l'introduire dans le langage. mon $.02
lestrrat
le 3 juil. 2019
fonctionnalité inutile, cela évite de taper, mais ce n'est pas grave.
Je choisis plutôt l'ancienne méthode.
écrire plus de gestionnaire d'erreurs pour programmer facilement le dépannage.
 fastfading
le 3 juil. 2019
fastfading
le 3 juil. 2019
Juste quelques réflexions...
Cet idiome est utile au go mais ce n'est que cela : un idiome que vous devez
enseigner aux nouveaux arrivants. Un nouveau programmeur de go doit apprendre cela, sinon il
peut même être tenté de refactoriser la gestion des erreurs "cachées". Également
le code n'est pas plus court en utilisant cet idiome (bien au contraire) sauf si vous oubliez
compter les méthodes.
Imaginons maintenant que try soit implémenté, à quel point cet idiome sera-t-il utile pour
ce cas d'utilisation? Considérant:
- Essayez de garder la mise en œuvre plus proche plutôt que de la répartir entre les méthodes.
- Les programmeurs liront et écriront du code avec try beaucoup plus souvent que cela
idiome spécifique (qui est rarement utilisé sauf pour toutes les tâches spécifiques). UNE
l'idiome plus utilisé devient plus naturel et lisible à moins qu'il y ait un clair
inconvénient, ce qui n'est clairement pas le cas ici si l'on compare les deux avec un
esprit ouvert.
Alors peut -être que cet idiome sera considéré comme remplacé par try.
Em ter, 2 juillet 2019 18:06, comme [email protected] escreveu :
@cespare https://github.com/cespare Un décodeur peut aussi être une structure avec
un type d'erreur à l'intérieur, avec les méthodes vérifiant err == nil avant
chaque opération et retour d'un booléen ok.Parce que c'est le processus que nous utilisons pour les codecs, essayer est absolument inutile
parce qu'on peut facilement faire un idiome non magique, plus court et plus succinct
pour gérer les erreurs pour ce cas précis.—
Vous recevez ceci parce que vous avez été mentionné.
Répondez directement à cet e-mail, consultez-le sur GitHub
https://github.com/golang/go/issues/32437?email_source=notifications&email_token=AAT5WM3YDDRZXVXOLDQXKH3P5O7L5A5CNFSM4HTGCZ72YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGODZCRHXA#issuecom
ou couper le fil
https://github.com/notifications/unsubscribe-auth/AAT5WMYXLLO74CIM6H4Y2RLP5O7L5ANCNFSM4HTGCZ7Q
.
carloslenz
le 3 juil. 2019
La verbosité dans la gestion des erreurs est une bonne chose à mon avis. En d'autres termes, je ne vois pas de cas d'utilisation solide pour try.
 trende-jp
le 3 juil. 2019
trende-jp
le 3 juil. 2019
Je suis ouvert à cette idée, mais je pense qu'elle devrait inclure un mécanisme pour déterminer où la division d'exécution s'est produite. Xerror/Is conviendrait dans certains cas (par exemple, si l'erreur est un ErrNotExists, vous pouvez en déduire qu'elle s'est produite sur un Open), mais pour d'autres - y compris les erreurs héritées dans les bibliothèques - il n'y a pas de substitut.
Une fonction intégrée similaire à recovery pourrait-elle être incluse pour fournir des informations contextuelles sur l'endroit où le flux de contrôle a changé ? Peut-être, pour le garder bon marché, une fonction distincte utilisée à la place de try().
Ou peut-être un debug.Try avec la même syntaxe que try() mais avec les informations de débogage ajoutées ? De cette façon, try() pourrait être tout aussi utile avec du code utilisant d'anciennes erreurs, sans vous obliger à recourir à l'ancienne gestion des erreurs.
L'alternative serait que try() enveloppe et ajoute du contexte, mais dans la plupart des cas, cela réduirait inutilement les performances, d'où la suggestion de fonctions supplémentaires.
Edit: après avoir écrit ceci, il m'est venu à l'esprit que le compilateur pourrait déterminer quelle variante de try() utiliser en fonction du fait que des instructions de report utilisent ou non cette fonction de fourniture de contexte similaire à "récupérer". Pas certain de la complexité de cela cependant
 fbnz156
le 3 juil. 2019
fbnz156
le 3 juil. 2019
@lestrrat Je ne dirais pas mon opinion dans ce commentaire mais s'il y a une chance de vous expliquer comment "essayer" peut affecter le bien pour nous, ce serait que deux jetons ou plus peuvent être écrits dans l'instruction if. Donc, si vous écrivez 200 conditions dans une instruction if, vous pourrez réduire de nombreuses lignes.
if try(foo()) == 1 && try(bar()) == 2 {
// err
}
n1, err := foo()
if err != nil {
// err
}
n2, err := bar()
if err != nil {
// err
}
if n1 == 1 && n2 == 2 {
// err
}
@mattn c'est la chose cependant, _théoriquement_ vous avez absolument raison. Je suis sûr que nous pouvons trouver des cas où try conviendrait parfaitement.
Je viens de fournir des données qui, dans la vraie vie, au moins _I_ n'ont trouvé presque aucune occurrence de telles constructions qui bénéficieraient de la traduction à essayer dans _mon code_.
Il est possible que j'écrive du code différemment du reste du monde, mais j'ai juste pensé que cela valait la peine que quelqu'un dise que, sur la base de la traduction PoC, que certains d'entre nous ne gagnent pas vraiment beaucoup de l'introduction de try dans la langue.
En aparté, je n'utiliserais toujours pas votre style dans mon code. je l'écrirais comme
n1 := try(foo())
n2 := try(bar())
if n1 == 1 && n2 == 2 {
return errors.New(`boo`)
}
donc j'économiserais toujours environ la même quantité de frappe par instance de ces n1/n2/....n(n)s
lestrrat
le 3 juil. 2019
Pourquoi avoir un mot-clé (ou une fonction) ?
Si le contexte appelant attend n+1 valeurs, alors tout est comme avant.
Si le contexte appelant attend n valeurs, le comportement try s'enclenche.
(Ceci est particulièrement utile dans le cas n = 1, d'où vient tout l'affreux fouillis.)
Mon ide met déjà en évidence les valeurs de retour ignorées ; il serait trivial d'offrir des repères visuels pour cela si nécessaire.
 jan-g
le 3 juil. 2019
jan-g
le 3 juil. 2019
@balasanjay Oui, les erreurs d'emballage sont le cas. Mais nous avons aussi la journalisation, différentes réactions sur différentes erreurs (ce que nous devrions faire avec les variables d'erreur, par exemple sql.NoRows ?), du code lisible, etc. Nous écrivons defer f.Close() immédiatement après l'ouverture d'un fichier pour le rendre clair pour les lecteurs. Nous vérifions immédiatement les erreurs pour la même raison.
Plus important encore, cette proposition viole la règle " les erreurs sont des valeurs ". C'est ainsi que Go est conçu. Et cette proposition va directement à l'encontre de la règle.
try(errors.Wrap(err, ...)) est un autre morceau de code terrible car il contredit à la fois cette proposition et la conception actuelle de Go.
makhov
le 3 juil. 2019
J'ai tendance à être d'accord avec @lestrat
Comme d'habitude foo() et bar() sont en fait :
UneFonctionAvecBonNom(Parm1, Parms2)
alors la syntaxe @mattn suggérée serait en fait :
if try(SomeFunctionWithGoodName(Parm1, Parms2)) == 1 && try(package.SomeOtherFunction(Parm1, Parms2,Parm3))) == 2 {
}
La lisibilité sera généralement un gâchis.
considérer une valeur de retour :
someRetVal, err := SomeFunctionWithGoodName(Parm1, Parms2)
est utilisé plus souvent qu'une simple comparaison avec un const tel que 1 ou 2 et cela ne s'aggrave pas mais nécessite une fonction de double affectation :
if a := try(SomeFunctionWithGoodName(Parm1, Parms2)) && b:= try(package.SomeOtherFunction(Parm1, Parms2,Parm3))) {
}
En ce qui concerne tous les cas d'utilisation ("comment tryhard m'a-t-il aidé") :
- Je pense que vous verriez un grand diff entre les bibliothèques et l'exécutable, il serait intéressant de voir d'autres s'ils obtiennent également ce diff
- ma suggestion est de ne pas comparer le % de sauvegarde en lignes dans le code mais plutôt le nombre d'erreurs dans le code par rapport au nombre refactorisé.
(mon point de vue à ce sujet était
$find /path/to/repo -name '*.go' -exec cat {} \; | grep "err :=" | wc -l
)
guybrand
le 3 juil. 2019
@makhov
cette proposition enfreint la règle "les erreurs sont des valeurs"
Pas vraiment. Les erreurs sont toujours des valeurs dans cette proposition. try() simplifie simplement le flux de contrôle en étant un raccourci pour if err != nil { return ...,err } . Le type error est déjà en quelque sorte "spécial" en étant un type d'interface intégré. Cette proposition ajoute simplement une fonction intégrée qui complète le type error . Il n'y a rien d'extraordinaire ici.
ngrilly
le 3 juil. 2019
@ngrilly Simplifier? Comment?
func (req *Request) Decode(r Reader) error {
defer func() { err = unexpected(err) }()
req.Type = try(readByte(r))
req.Body = try(readString(r))
req.ID = try(readID(r))
n := try(binary.ReadUvarint(r))
req.SubIDs = make([]ID, n)
for i := range req.SubIDs {
req.SubIDs[i] = try(readID(r))
}
return nil
}
Comment dois-je comprendre que l'erreur a été renvoyée à l'intérieur de la boucle? Pourquoi est-il assigné à err var, pas à foo ?
Est-il plus simple de le garder à l'esprit et de ne pas le garder dans le code ?
makhov
le 3 juil. 2019
@daved
les parenthèses sont encore pires que ce à quoi je m'attendais [...] Un mot-clé est beaucoup plus lisible et c'est un peu surréaliste que ce soit un point sur lequel beaucoup d'autres ne s'entendent pas.
Le choix entre un mot-clé et une fonction intégrée est principalement une question esthétique et syntaxique. Honnêtement, je ne comprends pas pourquoi c'est si important pour vos yeux.
PS : La fonction intégrée a l'avantage d'être rétrocompatible, d'être extensible avec d'autres paramètres à l'avenir et d'éviter les problèmes liés à la priorité des opérateurs. Le mot-clé a l'avantage de... être un mot-clé, et signaler try est "spécial".
ngrilly
le 3 juil. 2019
@makhov
Simplifier ?
D'accord. Le mot juste est "raccourcir".
try() raccourcit notre code en remplaçant le motif if err != nil { return ..., err } par un appel à la fonction intégrée try() .
C'est exactement comme lorsque vous identifiez un motif récurrent dans votre code et que vous l'extrayez dans une nouvelle fonction.
Nous avons déjà des fonctions intégrées comme append(), que nous pourrions remplacer en écrivant le code "in extenso" nous-mêmes chaque fois que nous avons besoin d'ajouter quelque chose à une tranche. Mais parce que nous le faisons tout le temps, c'était intégré dans le langage. try() n'est pas différent.
Comment dois-je comprendre que l'erreur a été renvoyée à l'intérieur de la boucle?
Le try() dans la boucle agit exactement comme le try() dans le reste de la fonction, en dehors de la boucle. Si readID() renvoie une erreur, alors la fonction renvoie l'erreur (après avoir décoré le if).
Pourquoi est-il assigné à err var, pas à foo ?
Je ne vois aucune variable foo dans votre exemple de code...
ngrilly
le 3 juil. 2019
@makhov Je pense que l'extrait est incomplet car l'erreur renvoyée n'est pas nommée (j'ai relu rapidement la proposition mais je n'ai pas pu voir si le nom de la variable err est le nom par défaut si aucun n'est défini).
Devoir renommer les paramètres renvoyés est l'un des points que les personnes qui rejettent cette proposition n'aiment pas.
func (req *Request) Decode(r Reader) (err error) {
defer func() { err = unexpected(err) }()
req.Type = try(readByte(r))
req.Body = try(readString(r))
req.ID = try(readID(r))
n := try(binary.ReadUvarint(r))
req.SubIDs = make([]ID, n)
for i := range req.SubIDs {
req.SubIDs[i] = try(readID(r))
}
return nil
}
@pierrec peut-être pourrions-nous avoir une fonction comme recover() pour récupérer l'erreur si elle n'est pas dans le paramètre nommé ?
defer func() {err = unexpected(tryError())}
flibustenet
le 3 juil. 2019
@makhov Vous pouvez le rendre plus explicite :
func (req *Request) Decode(r Reader) error {
req.Type, err := readByte(r)
try(err) // or add annotation like try(annotate(err, ...))
req.Body, err := readString(r)
try(err)
req.ID, err := readID(r)
try(err)
n, err := binary.ReadUvarint(r)
try(err)
req.SubIDs = make([]ID, n)
for i := range req.SubIDs {
req.SubIDs[i], err := readID(r)
try(err)
}
return nil
}
 reusee
le 3 juil. 2019
reusee
le 3 juil. 2019
@pierrec Ok, changeons ça :
func (req *Request) Decode(r Reader) error {
var errOne, errTwo error
defer func() { err = unexpected(???) }()
req.Type = try(readByte(r))
…
}
@reusee Et pourquoi est-ce mieux que ça ?
func (req *Request) Decode(r Reader) error {
req.Type, err := readByte(r)
if err != nil { return err }
…
}
À quel moment avons-nous tous décidé que la brièveté était meilleure que la lisibilité ?
makhov
le 3 juil. 2019
@flibustenet Merci d'avoir compris le problème. Cela semble beaucoup mieux mais je ne suis toujours pas sûr que nous ayons besoin d'une rétrocompatibilité cassée pour cette petite "amélioration". C'est très ennuyeux si j'ai une application qui arrête de construire sur la nouvelle version de Go :
package main
func main() {
// ...
try("a", "b")
// ...
}
func try(a, b string) {
// ...
}
@makhov Je suis d'accord que cela doit être clarifié: le compilateur se trompe-t-il lorsqu'il ne peut pas comprendre la variable? Je pensais que ce serait le cas.
Peut-être que la proposition doit clarifier ce point ? Ou est-ce que je l'ai raté dans le document ?
@flibustenet oui c'est une façon d'utiliser try() mais il me semble que ce n'est pas une façon idiomatique d'utiliser try.
pierrec
le 3 juil. 2019
@cespare D'après ce que vous avez écrit, il semble que la modification des valeurs de retour dans le report soit une fonctionnalité de try mais vous pouvez déjà le faire.
https://play.golang.com/p/ZMauFmt9ezJ
(Désolé si j'ai mal interprété ce que vous avez dit)
 nerg4l
le 3 juil. 2019
nerg4l
le 3 juil. 2019
@jan-g Concernant https://github.com/golang/go/issues/32437#issuecomment -507961463 : L'idée de gérer les erreurs de manière invisible a été évoquée à plusieurs reprises. Le problème avec une telle approche implicite est que l'ajout d'un retour d'erreur à une fonction appelée peut amener la fonction appelante à se comporter différemment de manière silencieuse et invisible. Nous voulons absolument être explicites lors de la vérification des erreurs. Une approche implicite va également à l'encontre du principe général de Go selon lequel tout est explicite.
griesemer
le 3 juil. 2019
@griesemer
J'ai essayé tryhand sur l'un de mes projets (https://github.com/komuw/meli) et cela n'a apporté aucun changement.
gobin github.com/griesemer/tryhard
Installed github.com/griesemer/[email protected] to ~/go/bin/tryhard
```bash
~/go/bin/tryhard -err "" -r
0
most of my err handling looks like;
```Go
import "github.com/pkg/errors"
func CreateDockerVolume(volName string) (string, error) {
volume, err := VolumeCreate(volName)
if err != nil {
return "", errors.Wrapf(err, "unable to create docker volume %v", volName)
}
return volume.Name, nil
}
@komuw Tout d'abord, assurez-vous de fournir un argument de nom de fichier ou de répertoire à tryhard , comme dans
tryhard -err="" -r . // <<< note the dot
tryhard -err="" -r filename
De plus, le code comme celui que vous avez dans votre commentaire ne sera pas réécrit car il gère des erreurs spécifiques dans le bloc if . Veuillez lire la documentation de tryhard pour savoir quand cela s'applique. Merci.
griesemer
le 3 juil. 2019
func CreateDockerVolume(volName string) (string, error) {
volume, err := VolumeCreate(volName)
if err != nil {
return "", errors.Wrapf(err, "unable to create docker volume %v", volName)
}
return volume.Name, nil
}
C'est un exemple quelque peu intéressant. Ma première réaction en le regardant a été de demander si cela produirait des chaînes d'erreur de bégaiement comme :
unable to create docker volume: VolumeName: could not create volume VolumeName: actual problem
La réponse est que ce n'est pas le cas, car la fonction VolumeCreate (d'un dépôt différent) est :
func (cli *Client) VolumeCreate(ctx context.Context, options volumetypes.VolumeCreateBody) (types.Volume, error) {
var volume types.Volume
resp, err := cli.post(ctx, "/volumes/create", nil, options, nil)
defer ensureReaderClosed(resp)
if err != nil {
return volume, err
}
err = json.NewDecoder(resp.body).Decode(&volume)
return volume, err
}
En d'autres termes, la décoration supplémentaire sur l'erreur est utile car la fonction sous-jacente n'a pas décoré son erreur. Cette fonction sous-jacente peut être légèrement simplifiée avec try .
Peut-être que la fonction VolumeCreate devrait vraiment décorer ses erreurs. Dans ce cas, cependant, il n'est pas clair pour moi que la fonction CreateDockerVolume doive ajouter une décoration supplémentaire, car elle n'a aucune nouvelle information à fournir.
 neild
le 3 juil. 2019
neild
le 3 juil. 2019
@neild
Même si VolumeCreate décorait les erreurs, nous aurions toujours besoin CreateDockerVolume pour ajouter sa décoration, car VolumeCreate peut être appelé depuis diverses autres fonctions, et si quelque chose échoue (et espérons-le connecté) vous aimeriez savoir ce qui a échoué - qui dans ce cas est CreateDockerVolume ,
Néanmoins, Considérant VolumeCreate fait partie de l'interface APIclient.
Il en va de même pour les autres bibliothèques - os.Open peut bien décorer le nom du fichier, la raison de l'erreur, etc., mais
func ReadConfigFile(...
func WriteDataFile(...
etc - appeler os.Open sont les pièces défaillantes que vous aimeriez voir afin de consigner, tracer et gérer vos erreurs - en particulier, mais pas seulement dans l'environnement de production.
guybrand
le 3 juil. 2019
@neild merci.
Je ne veux pas faire dérailler ce fil, mais...
Peut-être que la fonction VolumeCreate devrait vraiment décorer ses erreurs.
Dans ce cas, cependant, il n'est pas clair pour moi que le
Fonction CreateDockerVolume
devrait ajouter une décoration supplémentaire,
Le problème est que, en tant qu'auteur de la fonction CreateDockerVolume , je ne peux pas
savoir si l'auteur de VolumeCreate avait décoré ses erreurs alors je
pas besoin de décorer le mien.
Et même si je savais qu'ils l'avaient fait, ils pourraient décider de ne pas décorer leur
fonctionner dans une version ultérieure. Et puisque ce changement n'est pas un changement d'API, ils
le publierait sous forme de correctif / version mineure et maintenant ma fonction qui était
dépendant de leur fonction ayant des erreurs décorées n'a pas tous les
infos dont j'ai besoin.
Donc généralement je me retrouve à décorer/emballer même si la bibliothèque que je suis
l'appel est déjà terminé.
komuw
le 3 juil. 2019
J'ai eu une pensée en parlant de try avec un collègue. Peut-être que try ne devrait être activé que pour la bibliothèque standard en 1.14. @crawshaw et @jimmyfrasche ont tous deux fait un rapide tour d'horizon de certains cas et ont donné une certaine perspective, mais en fait, réécrire le code de bibliothèque standard en utilisant autant que possible try serait précieux.
Cela donne à l'équipe Go le temps de réécrire un projet non trivial en l'utilisant, et la communauté peut avoir un rapport d'expérience sur la façon dont cela fonctionne. Nous saurions à quelle fréquence il est utilisé, à quelle fréquence il doit être associé à un defer , s'il modifie la lisibilité du code, à quel point tryhard est utile, etc.
C'est un peu contre l'esprit de la bibliothèque standard, lui permettant d'utiliser quelque chose que le code Go normal ne peut pas, mais cela nous donne un terrain de jeu pour voir comment try affecte une base de code existante.
Toutes mes excuses si quelqu'un d'autre y a déjà pensé ; J'ai parcouru les différentes discussions et je n'ai pas vu de proposition similaire.
 jonbodner
le 3 juil. 2019
jonbodner
le 3 juil. 2019
@jonbodner https://go-review.googlesource.com/c/go/+/182717 vous donne une assez bonne idée de ce à quoi cela pourrait ressembler.
griesemer
le 3 juil. 2019
Et j'ai oublié de dire : j'ai participé à votre sondage et j'ai voté pour une meilleure gestion des erreurs, pas pour ça.
Je voulais dire que j'aimerais voir plus strict impossible d'oublier le traitement des erreurs.
sirkon
le 3 juil. 2019
@jonbodner https://go-review.googlesource.com/c/go/+/182717 vous donne une assez bonne idée de ce à quoi cela pourrait ressembler.
Pour résumer:
- 1 ligne remplace universellement 4 lignes (2 lignes pour ceux qui utilisent
if ... { return err }) - L'évaluation des résultats renvoyés peut être optimisée - uniquement sur le chemin de l'échec, cependant.
Environ 6 000 remplacements au total de ce qui semble n'être qu'un changement cosmétique : n'exposera pas les erreurs existantes, n'en introduira peut-être pas de nouvelles (corrigez-moi si je me trompe sur l'un ou l'autre.)
Aurais-je, en tant que mainteneur, la peine de faire quelque chose comme ça avec mon propre code ? Pas à moins que j'écrive l'outil de remplacement moi-même. Ce qui convient pour le référentiel golang/go .
PS Une clause de non-responsabilité intéressante dans CL :
... Some transformations may be incorrect due to the limitations of the
tool (see https://github.com/griesemer/tryhard)...
 av86743
le 4 juil. 2019
av86743
le 4 juil. 2019
Comme xerrors , que diriez-vous de faire le premier pas pour l'utiliser comme package tiers ?
Par exemple, essayez d'utiliser le package ci-dessous.
https://github.com/junpayment/gotry
- Il peut être court pour votre cas d'utilisation parce que je l'ai fait.
Cependant, je pense que l'essai lui-même est une excellente idée, donc je pense qu'il existe également une approche qui l'utilise en fait avec moins d'influence.
===
Soit dit en passant, il y a deux choses qui m'inquiètent.
1.Il existe une opinion selon laquelle la ligne peut être omise, mais il semble que la clause de report (ou de gestionnaire) ne soit pas prise en compte.
Par exemple, lorsque la gestion des erreurs est détaillée.
foo, err: = Foo ()
if err! = nil {
if err.Error () = "AAA" {
some action for AAA
} else if err.Error () = "BBB" {
some action for BBB
} else if err.Error () = "CCC" {
some action for CCC
} else {
return err
}
}
Si vous remplacez simplement ceci par try, ce sera comme suit.
handler: = func (err error) {
if err.Error () = "AAA" {
some action for AAA
} else if err.Error () = "BBB" {
some action for BBB
} else if err.Error () = "CCC" {
some action for CCC
} else {
return err
}
}
foo: = try (Foo (), handler)
- Je vois ce modèle https://github.com/golang/proposal/blob/master/design/32437-try-builtin.md#design -iterations
2. Il peut y avoir d'autres paquets défectueux qui ont accidentellement implémenté l'interface d'erreur.
type Bad struct {}
func (bad * Bad) Error () {
return "i really do not intend to be an error"
}
 junpayment
le 4 juil. 2019
junpayment
le 4 juil. 2019
@junpayment Merci pour votre package gotry - je suppose que c'est une façon d'avoir une idée de try mais ce sera un peu ennuyeux d'avoir à taper tous les Try résulte d'un interface{} en cours d'utilisation.
Concernant tes deux questions :
1) Je ne sais pas où vous voulez en venir. Suggérez-vous que try devrait accepter un gestionnaire comme dans votre exemple ? (et comme nous l'avions fait dans une version interne antérieure de try ?)
2) Je ne m'inquiète pas trop des fonctions implémentant accidentellement l'interface d'erreur. Ce problème n'est pas nouveau et ne semble pas avoir causé de problèmes sérieux à notre connaissance.
griesemer
le 4 juil. 2019
@jonbodner https://go-review.googlesource.com/c/go/+/182717 vous donne une assez bonne idée de ce à quoi cela pourrait ressembler.
Merci d'avoir fait cet exercice. Cependant, cela me confirme ce que je soupçonnais, le code source go lui-même a beaucoup d'endroits où try() serait utile car l'erreur est simplement transmise. Cependant, comme je peux le voir dans les expériences avec tryhard que d'autres et moi-même avons soumises ci-dessus, pour de nombreuses autres bases de code, try() ne serait pas très utile car dans le code d'application, les erreurs ont tendance à être réellement gérées, pas vient de transmettre.
Je pense que c'est quelque chose que les concepteurs de Go devraient garder à l'esprit, le compilateur go et le temps d'exécution sont un code Go quelque peu "unique", différent du code d'application Go. Par conséquent, je pense que try() devrait être amélioré pour être également utile dans d'autres cas où l'erreur doit réellement être gérée et où la gestion des erreurs avec une instruction différée n'est pas vraiment souhaitable.
beoran
le 4 juil. 2019
@griesemer
il sera un peu ennuyeux d'avoir à taper tous les résultats Try d'une interface{} en cours d'utilisation.
Tu as raison. Cette méthode nécessite que l'appelant transtype le type.
Je ne sais pas où vous voulez en venir. Suggérez-vous que try devrait accepter un gestionnaire comme dans votre exemple? (et comme nous l'avions fait dans une version interne antérieure de try ?)
J'ai fait une erreur. Aurait dû être expliqué en utilisant defer plutôt que handler. Je suis désolé.
Ce que je voulais dire, c'est qu'il y a un cas où cela ne contribue pas à la quantité de code car le processus de traitement des erreurs qui est omis doit de toute façon être décrit dans le report.
L'impact devrait être plus prononcé lorsque vous souhaitez traiter les erreurs en détail.
Ainsi, plutôt que de réduire le nombre de lignes de code, on peut comprendre la proposition, qui organise les emplacements de gestion des erreurs.
Je ne m'inquiète pas trop des fonctions implémentant accidentellement l'interface d'erreur. Ce problème n'est pas nouveau et ne semble pas avoir causé de problèmes sérieux à notre connaissance.
Exactement c'est cas rare.
junpayment
le 4 juil. 2019
@beoran J'ai fait une analyse initiale du Go Corpus (https://github.com/rsc/corpus). Je pense que tryhard dans son état actuel pourrait éliminer 41,7 % de tous les err != nil chèques du corpus. Si j'exclus le modèle "_test.go", ce nombre monte à 51,1 % ( tryhard ne fonctionne que sur les fonctions qui renvoient des erreurs, et il a tendance à ne pas en trouver beaucoup dans les tests). Attention, prenez ces chiffres avec un grain de sel, j'ai obtenu le dénominateur (c'est-à-dire le nombre d'endroits dans le code où nous effectuons des vérifications err != nil ) en utilisant une version piratée de tryhard , et idéalement nous attendrions que tryhard rapporte lui-même ces statistiques.
De plus, si tryhard devenait sensible au type, il pourrait théoriquement effectuer des transformations comme celle-ci :
// Before.
a, err := foo()
if err != nil {
return 0, nil, errors.Wrapf(err, "some message %v", b)
}
// After.
a, err := foo()
try(errors.Wrapf(err, "some message %v", b))
Cela tire parti du comportement de errors.Wrap qui renvoie nil lorsque l'argument d'erreur transmis est nil . (github.com/pkg/errors n'est pas non plus unique à cet égard, la bibliothèque interne que j'utilise pour faire l'encapsulation des erreurs préserve également les erreurs nil et fonctionnerait également avec ce modèle, comme le feraient la plupart des bibliothèques de gestion des erreurs après- try , j'imagine). La nouvelle génération de bibliothèques de support nommerait probablement aussi ces aides à la propagation légèrement différemment.
Étant donné que cela s'appliquerait à 50% des vérifications err != nil non testées, avant toute évolution de la bibliothèque pour prendre en charge le modèle, il ne semble pas que le compilateur Go et le runtime soient uniques, comme vous le suggérez .
balasanjay
le 4 juil. 2019
À propos de l'exemple avec CreateDockerVolume https://github.com/golang/go/issues/32437#issuecomment -508199875
J'ai retrouvé exactement le même genre d'utilisation. Dans lib, j'enveloppe l'erreur avec le contexte à chaque erreur, lors de l'utilisation de la lib, j'aimerais utiliser try et ajouter du contexte dans defer pour l'ensemble de la fonction.
J'ai essayé d'imiter cela en ajoutant une fonction de gestionnaire d'erreurs au début, ça marche bien :
func MyLib() error {
return errors.New("Error from my lib")
}
func MyOtherLib() error {
return errors.New("Error from my otherLib")
}
func Caller(a, b int) error {
eh := func(err error) error {
return fmt.Errorf("From Caller with %d and %d i found this error: %v", a, b, err)
}
err := MyLib()
if err != nil {
return eh(err)
}
err = MyOtherLib()
if err != nil {
return eh(err)
}
return nil
}
Cela aura l'air bien et idiomatique avec try+defer
func Caller(a, b int) (err error) {
defer fmt.Errorf("From Caller with %d and %d i found this error: %v", a, b, &err)
try(MyLib())
try(MyOtherLib())
return nil
}
@griesemer
Le document de conception contient actuellement les déclarations suivantes :
Si la fonction englobante déclare d'autres paramètres de résultat nommés, ces paramètres de résultat conservent la valeur qu'ils ont. Si la fonction déclare d'autres paramètres de résultat sans nom, ils assument leurs valeurs nulles correspondantes (ce qui revient à conserver la valeur qu'ils ont déjà).
Cela implique que ce programme imprimerait 1, au lieu de 0 : https://play.golang.org/p/KenN56iNVg7.
Comme cela m'a été signalé sur Twitter, cela fait try se comporte comme un retour nu, où les valeurs renvoyées sont implicites ; pour déterminer quelles valeurs réelles sont renvoyées, il peut être nécessaire de regarder le code à une distance significative de l'appel à try lui-même.
Étant donné que cette propriété des retours nus (non-localité) est généralement détestée, que pensez-vous du fait que try renvoie toujours les valeurs nulles des arguments sans erreur (s'il revient du tout) ?
Quelques considérations :
Cela peut rendre certains modèles impliquant l'utilisation de valeurs de retour nommées incapables d'utiliser try . Par exemple, pour les implémentations de io.Writer , qui doivent renvoyer un nombre d'octets écrits, même dans la situation d'écriture partielle. Cela dit, il semble que try soit de toute façon sujet aux erreurs dans ce cas (par exemple, n += try(wrappedWriter.Write(...)) ne définit pas n sur le bon nombre en cas de retour d'erreur). Il me semble bien que try sera rendu inutilisable pour ce genre de cas d'utilisation, car les scénarios où nous avons besoin à la fois de valeurs et d'une erreur sont plutôt rares, d'après mon expérience.
S'il existe une fonction avec de nombreuses utilisations de try , cela peut entraîner un gonflement du code, où de nombreux endroits dans une fonction doivent mettre à zéro les variables de sortie. Premièrement, le compilateur est assez bon pour optimiser les écritures inutiles de nos jours. Et deuxièmement, si cela s'avère nécessaire, cela semble être une optimisation simple d'avoir tous les blocs générés par try goto sur une étiquette commune partagée à l'échelle de la fonction, qui met à zéro les valeurs de sortie sans erreur.
De plus, comme je suis sûr que vous le savez, tryhard est déjà implémenté de cette façon, donc comme avantage secondaire, cela rendra rétroactivement tryhard plus correct.
balasanjay
le 4 juil. 2019
@jonbodner https://go-review.googlesource.com/c/go/+/182717 vous donne une assez bonne idée de ce à quoi cela pourrait ressembler.
Merci d'avoir fait cet exercice. Cependant, cela me confirme ce que je soupçonnais, le code source go lui-même a beaucoup d'endroits où
try()serait utile car l'erreur est simplement transmise. Cependant, comme je peux le voir dans les expériences avectryhardque d'autres et moi-même avons soumises ci-dessus, pour de nombreuses autres bases de code,try()ne serait pas très utile car dans le code d'application, les erreurs ont tendance à être réellement gérées, pas vient de transmettre.
J'interpréterais cela différemment.
Nous n'avons pas eu de génériques, il sera donc difficile de trouver du code dans la nature qui bénéficierait directement de génériques basés sur du code écrit. Cela ne veut pas dire que les génériques ne seraient pas utiles.
Pour moi, il y a 2 modèles que j'ai utilisés dans le code pour la gestion des erreurs
- utiliser des paniques dans le package, et récupérer la panique et renvoyer un résultat d'erreur dans les quelques méthodes exportées
- utiliser de manière sélective un gestionnaire différé dans certaines méthodes afin que je puisse décorer les erreurs avec des informations riches sur le fichier de pile/numéro de ligne PC et plus de contexte
Ces modèles ne sont pas répandus mais ils fonctionnent. 1) est utilisé dans la bibliothèque standard dans ses fonctions non exportées et 2) est largement utilisé dans ma base de code ces dernières années car je pensais que c'était une bonne façon d'utiliser les fonctionnalités orthogonales pour faire une décoration d'erreur simplifiée, et la proposition recommande et a béni l'approche. Le fait qu'ils ne soient pas répandus ne signifie pas qu'ils ne sont pas bons. Mais comme pour tout, les directives de l'équipe Go le recommandant conduiront à les utiliser davantage dans la pratique, à l'avenir .
Un dernier point à noter est que la décoration des erreurs dans chaque ligne de votre code peut être un peu trop. Il y aura des endroits où il est logique de décorer les erreurs, et d'autres où ce n'est pas le cas. Parce que nous n'avions pas de bonnes directives auparavant, les gens ont décidé qu'il était logique de toujours décorer les erreurs. Mais cela n'ajoutera peut-être pas beaucoup de valeur à toujours décorer chaque fois qu'un fichier ne s'ouvre pas, car il peut être suffisant dans le package d'avoir simplement une erreur comme "unable to open file: conf.json", par opposition à : "unable pour obtenir le nom d'utilisateur : impossible d'obtenir la connexion à la base de données : impossible de charger le fichier système : impossible d'ouvrir le fichier : conf.json".
Avec la combinaison des valeurs d'erreur et la gestion concise des erreurs, nous obtenons maintenant de meilleures directives sur la façon de gérer les erreurs. La préférence semble être :
- une erreur sera simple par exemple "impossible d'ouvrir le fichier : conf.json"
- une trame d'erreur peut être attachée qui inclut le contexte : GetUserName --> GetConnection --> LoadSystemFile.
- Si cela ajoute au contexte, vous pouvez envelopper quelque peu cette erreur, par exemple MyAppError{error}
J'ai tendance à avoir l'impression que nous continuons à négliger les objectifs de la proposition d'essai et les problèmes de haut niveau qu'elle tente de résoudre :
- réduire le passe-partout de if err != nil { return err } pour les endroits où il est logique de propager l'erreur vers le haut pour qu'elle soit gérée plus haut dans la pile
- Autoriser l'utilisation simplifiée des valeurs de retour où err == nil
- permettre à la solution d'être étendue ultérieurement pour permettre, par exemple, plus de décoration d'erreur sur le site, passer au gestionnaire d'erreurs, utiliser goto au lieu de la sémantique de retour, etc.
- Autoriser la gestion des erreurs pour ne pas encombrer la logique de la base de code, c'est-à-dire la mettre quelque peu de côté avec une sorte de gestionnaire d'erreurs.
Beaucoup de gens ont encore 1). Beaucoup de gens ont travaillé autour de 1) parce que de meilleures directives n'existaient pas auparavant. Mais cela ne signifie pas qu'après avoir commencé à l'utiliser, leur réaction négative ne changera pas pour devenir plus positive.
Beaucoup de gens peuvent utiliser 2). Il peut y avoir un désaccord sur la quantité, mais j'ai donné un exemple où cela rend mon code beaucoup plus facile.
var u user = try(db.LoadUser(try(strconv.ParseInt(stringId)))
En java où les exceptions sont la norme, nous aurions :
User u = db.LoadUser(Integer.parseInt(stringId)))
Personne ne regarderait ce code et dirait que nous devons le faire en 2 lignes, c'est-à-dire.
int id = Integer.parseInt(stringId)
User u = db.LoadUser(id))
Nous ne devrions pas avoir à le faire ici, sous la directive que try NE DOIT PAS être appelé inline et DOIT toujours être sur sa propre ligne .
De plus, aujourd'hui, la plupart des codes feront des choses comme :
var u user
var err error
var id int
id, err = strconv.ParseInt(stringId)
if err != nil {
return u, errors.Wrap("cannot load userid from string: %s: %v", stringId, err)
}
u, err = db.LoadUser(id)
if err != nil {
return u, errors.Wrap("cannot load user given user id: %d: %v", id, err)
}
// now work with u
Maintenant, quelqu'un qui lit ceci doit analyser ces 10 lignes, qui en Java auraient été 1 ligne, et qui pourraient être 1 ligne avec la proposition ici. Je dois visuellement essayer mentalement de voir quelles lignes ici sont vraiment pertinentes lorsque je lis ce code. Le passe-partout rend ce code plus difficile à lire et à comprendre.
Je me souviens dans ma vie passée de travailler sur/avec la programmation orientée aspect en Java. Là, le but était de
Cela permet d'ajouter à un programme des comportements qui ne sont pas au cœur de la logique métier (comme la journalisation) sans encombrer le code, au cœur de la fonctionnalité. (citation de wikipedia https://en.wikipedia.org/wiki/Aspect-oriented_programming ).
La gestion des erreurs n'est pas au cœur de la logique métier, mais au cœur de l'exactitude. L'idée est la même - nous ne devrions pas encombrer notre code avec des choses qui ne sont pas centrales à la logique métier car " mais la gestion des erreurs est très importante ". Oui, et oui, nous pouvons le mettre de côté.
Concernant 4), de nombreuses propositions ont suggéré des gestionnaires d'erreurs, qui sont du code du côté qui gère les erreurs mais n'encombre pas la logique métier. La proposition initiale a le mot-clé handle pour cela, et les gens ont suggéré d'autres choses. Cette proposition dit que nous pouvons tirer parti du mécanisme de report pour cela, et simplement accélérer ce qui était son talon d'Achille auparavant. Je sais - j'ai fait du bruit à plusieurs reprises sur les performances du mécanisme de report à l'équipe de go.
Notez que tryhard ne marquera pas ce code comme quelque chose qui peut être simplifié. Mais avec try et de nouvelles directives, les gens voudront peut-être simplifier ce code en une ligne et laisser le cadre d'erreur capturer le contexte requis.
Le contexte, qui a été très bien utilisé dans les langages basés sur les exceptions, capturera que l'on a essayé de faire une erreur lors du chargement d'un utilisateur parce que l'identifiant de l'utilisateur n'existait pas, ou parce que le stringId n'était pas dans un format qu'un identifiant entier pourrait être analysé à partir de celui-ci.
Combinez cela avec Error Formatter, et nous pouvons maintenant inspecter richement le cadre d'erreur et l'erreur elle-même et formater le message correctement pour les utilisateurs, sans le style a: b: c: d: e: underlying error difficile à lire que beaucoup de gens ont fait et que nous n'avons pas avait d'excellentes lignes directrices pour.
N'oubliez pas que toutes ces propositions nous donnent ensemble la solution que nous voulons : une gestion concise des erreurs sans passe-partout inutile, tout en offrant de meilleurs diagnostics et un meilleur formatage des erreurs pour les utilisateurs. Ce sont des concepts orthogonaux mais qui ensemble deviennent extrêmement puissants.
Enfin, étant donné 3) ci-dessus, il est difficile d'utiliser un mot-clé pour résoudre ce problème. Par définition, un mot-clé ne permet pas à l'extension de passer à l'avenir un gestionnaire par son nom, ou d'autoriser la décoration d'erreur sur place, ou de prendre en charge la sémantique goto (au lieu de la sémantique de retour). Avec un mot-clé, nous devons d'abord avoir la solution complète à l'esprit. Et un mot clé n'est pas rétrocompatible. L'équipe de go a déclaré au début de Go 2 qu'elle voulait essayer de maintenir autant que possible la rétrocompatibilité. La fonction try maintient cela, et si nous voyons plus tard qu'aucune extension n'est nécessaire, un simple gofix peut facilement modifier le code pour changer la fonction try en un mot-clé.
Encore mes 2 centimes !
ugorji
le 4 juil. 2019
Le 04/07/19, Sanjay Menakuru [email protected] a écrit :
@griesemer
[ ... ]
Comme on me l'a fait remarquer sur Twitter, cela faittryse comporte comme un nu
return, où les valeurs renvoyées sont implicites ; pour comprendre ce que
les valeurs réelles sont renvoyées, il peut être nécessaire de regarder le code à un
distance significative entre l'appel ettrylui-même.Étant donné que cette propriété des rendements nus (non-localité) est généralement
n'a pas aimé, que pensez-vous du fait quetryrenvoie toujours le zéro
valeurs des arguments sans erreur (s'il revient du tout) ?Les retours nus ne sont autorisés que lorsque les arguments de retour sont nommés. Ce
semble que try suit une règle différente?
 lootch
le 4 juil. 2019
lootch
le 4 juil. 2019
J'aime l'idée générale de réutiliser defer pour résoudre le problème. Cependant, je me demande si le mot-clé try est la bonne façon de le faire. Et si nous pouvions réutiliser un modèle déjà existant. Quelque chose que tout le monde sait déjà des importations :
Traitement explicite
res, err := doSomething()
if err != nil {
return err
}
Ignorer explicitement
res, _ := doSomething()
Traitement différé
Comportement similaire à ce que try va faire.
res, . := doSomething()
 piotrkowalczuk
le 4 juil. 2019
piotrkowalczuk
le 4 juil. 2019
@piotrkowalczuk
C'est peut-être une syntaxe plus agréable, mais je ne sais pas à quel point il serait facile d'adapter Go pour rendre cela légal, à la fois dans Go et dans les surligneurs de syntaxe.
fbnz156
le 4 juil. 2019
@balasanjay (et @lootch): Selon votre commentaire ici , oui, le programme https://play.golang.org/p/KenN56iNVg7 imprimera 1.
Étant donné que try ne s'intéresse qu'au résultat de l'erreur, il laisse tout le reste seul. Cela pourrait définir d'autres valeurs de retour sur leurs valeurs nulles, mais on ne sait pas pourquoi ce serait mieux. D'une part, cela peut entraîner plus de travail lorsque les valeurs de résultat sont nommées car elles doivent peut-être être définies sur zéro ; pourtant, l'appelant va (probablement) les ignorer s'il y a eu une erreur. Mais c'est une décision de conception qui pourrait être modifiée s'il y a de bonnes raisons à cela.
[edit : notez que cette question (de savoir s'il faut effacer les résultats sans erreur en cas d'erreur) n'est pas spécifique à la proposition try . Toutes les alternatives proposées qui ne nécessitent pas un return explicite devront répondre à la même question.]
Concernant votre exemple d'un écrivain n += try(wrappedWriter.Write(...)) : Oui, dans une situation où vous devez incrémenter n même en cas d'erreur, on ne peut pas utiliser try - même si try ne met pas à zéro les valeurs de résultat sans erreur. En effet, try ne renvoie rien que s'il n'y a pas d'erreur : try se comporte proprement comme une fonction (mais une fonction qui peut ne pas renvoyer à l'appelant, mais à l'appelant de l'appelant). Voir l'utilisation des temporaires dans l' implémentation de try .
Mais dans des cas comme votre exemple, il faudrait également être prudent avec une instruction if et s'assurer d'incorporer le nombre d'octets renvoyés dans n .
Mais peut-être ai-je mal compris votre préoccupation.
griesemer
le 4 juil. 2019
@griesemer : Je suggère qu'il est préférable de définir les autres valeurs de retour sur leurs valeurs nulles, car il est alors clair ce que try fera en inspectant simplement le site d'appel. Il va soit a) ne rien faire, soit b) revenir de la fonction avec des valeurs nulles et l'argument à essayer.
Comme spécifié, try conservera les valeurs des valeurs de retour nommées sans erreur, et il faudrait donc inspecter toute la fonction pour savoir clairement quelles valeurs try renvoient.
C'est le même problème avec un retour nu (avoir à analyser toute la fonction pour voir quelle valeur est renvoyée), et était probablement la raison du dépôt https://github.com/golang/go/issues/21291. Cela, pour moi, implique que try dans une grande fonction avec des valeurs de retour nommées, devrait être découragé sous la même base que les retours nus (https://github.com/golang/go/wiki/CodeReviewComments #paramètres-de-résultat-nommés). Au lieu de cela, je suggère que try soit spécifié pour toujours renvoyer les valeurs zéro de l'argument sans erreur.
balasanjay
le 4 juil. 2019
déconcerté et se sentir mal pour l'équipe de go ces derniers temps. try est une solution propre et compréhensible au problème spécifique qu'il tente de résoudre : la verbosité dans la gestion des erreurs.
la proposition se lit comme suit : après une longue discussion d'un an, nous ajoutons cette fonctionnalité intégrée. utilisez-le si vous voulez un code moins verbeux, sinon continuez à faire ce que vous faites. la réaction est une résistance non entièrement justifiée pour une fonctionnalité opt-in pour laquelle les membres de l'équipe ont montré des avantages évidents !
J'encourage encore plus l'équipe de go à créer try un variadique intégré si c'est facile à faire
try(outf.Seek(linkstart, 0))
try(io.Copy(outf, exef))
devient
try(outf.Seek(linkstart, 0)), io.Copy(outf, exef)))
la prochaine chose détaillée pourrait être ces appels successifs à try .
 nvictor
le 5 juil. 2019
nvictor
le 5 juil. 2019
Je suis d'accord avec nvictor pour la plupart, à l'exception des paramètres variadiques pour try . Je crois toujours qu'il devrait y avoir une place pour un gestionnaire et la proposition variadic peut repousser la limite de lisibilité pour moi.
damienfamed75
le 5 juil. 2019
@nvictor Go est un langage qui n'aime pas les fonctionnalités non orthogonales. Cela signifie que si nous, à l'avenir, nous trouvons une meilleure solution de gestion des erreurs qui n'est pas try , il sera beaucoup plus compliqué de changer (si elle n'est pas catégoriquement rejetée parce que notre actuel la solution est "assez bonne").
Je pense qu'il existe une meilleure solution que try , et je préfère prendre mon temps et trouver cette solution plutôt que de me contenter de celle-ci.
Cependant, je ne serais pas en colère si cela était ajouté. Ce n'est pas une mauvaise solution, je pense juste que nous pourrons peut-être en trouver une meilleure.
deanveloper
le 5 juil. 2019
À mon avis, je veux essayer un code de bloc, maintenant try comme un handle err func
 shaodahong
le 5 juil. 2019
shaodahong
le 5 juil. 2019
En lisant cette discussion (et les discussions sur Reddit), je n'ai pas toujours eu l'impression que tout le monde était sur la même longueur d'onde.
Ainsi, j'ai écrit un petit article de blog qui montre comment try peut être utilisé : https://faiface.github.io/post/how-to-use-try/.
J'ai essayé de montrer plusieurs aspects de cette proposition afin que tout le monde puisse voir ce qu'elle peut faire et se forger une opinion plus éclairée (même si négative).
Si j'ai raté quelque chose d'important, n'hésitez pas à me le faire savoir !
 faiface
le 5 juil. 2019
faiface
le 5 juil. 2019
@faiface je suis à peu près sûr que vous pouvez remplacer
if err != nil {
return resps, err
}
avec try(err) .
A part ça - super article!
DmitriyMV
le 5 juil. 2019
@DmitriyMV Vrai ! Mais je suppose que je vais le garder tel quel, afin qu'il y ait au moins un exemple du classique if err != nil , bien que pas très bon.
faiface
le 5 juil. 2019
J'ai deux soucis :
- les retours nommés ont été très déroutants, ce qui les encourage avec un nouveau cas d'utilisation important
- cela découragera l'ajout de contexte aux erreurs
D'après mon expérience, ajouter du contexte aux erreurs immédiatement après chaque site d'appel est essentiel pour avoir un code qui peut être facilement débogué. Et les retours nommés ont semé la confusion chez presque tous les développeurs Go que je connais à un moment donné.
Une préoccupation stylistique plus mineure est qu'il est regrettable de voir combien de lignes de code seront désormais enveloppées dans
try(actualThing()). Je peux imaginer voir la plupart des lignes dans une base de code enveloppée danstry(). C'est malheureux.Je pense que ces préoccupations seraient résolues avec un ajustement:
a, b, err := myFunc() check(err, "calling myFunc on %v and %v", a, b)
check()se comporterait un peu commetry(), mais abandonnerait le comportement de transmission générique des valeurs de retour de fonction et offrirait à la place la possibilité d'ajouter du contexte. Cela déclencherait quand même un retour.Cela conserverait de nombreux avantages de
try():
- c'est un intégré
- il suit le flux de contrôle existant WRT pour différer
- il s'aligne sur la pratique existante consistant à bien ajouter du contexte aux erreurs
- il s'aligne sur les propositions et les bibliothèques actuelles pour l'emballage des erreurs, telles que
errors.Wrap(err, "context message")- il en résulte un site d'appel propre : il n'y a pas de passe-partout sur la ligne
a, b, err := myFunc()- décrire les erreurs avec
defer fmt.HandleError(&err, "msg")est toujours possible, mais n'a pas besoin d'être encouragé.- la signature de
checkest légèrement plus simple, car elle n'a pas besoin de renvoyer un nombre arbitraire d'arguments de la fonction qu'elle enveloppe.
C'est bien, je pense que l'équipe de go devrait vraiment prendre celui-ci. C'est mieux que d'essayer, plus clairement !!!
 99yun
le 5 juil. 2019
99yun
le 5 juil. 2019
@buchanae Je serais intéressé par ce que vous pensez de mon article de blog parce que vous avez soutenu que try découragera l'ajout de contexte aux erreurs, alors que je dirais qu'au moins dans mon article, c'est encore plus facile que d'habitude.
faiface
le 5 juil. 2019
Je vais juste jeter ça là-bas au stade actuel. Je vais y réfléchir un peu plus, mais je pensais poster ici pour voir ce que vous en pensez. Peut-être devrais-je ouvrir un nouveau sujet pour ça ? J'ai aussi posté ceci sur #32811
Alors, qu'en est-il de faire une sorte de macro C générique à la place pour s'ouvrir à plus de flexibilité?
Comme ça:
define returnIf(err error, desc string, args ...interface{}) {
if (err != nil) {
return fmt.Errorf("%s: %s: %+v", desc, err, args)
}
}
func CopyFile(src, dst string) error {
r, err := os.Open(src)
:returnIf(err, "Error opening src", src)
defer r.Close()
w, err := os.Create(dst)
:returnIf(err, "Error Creating dst", dst)
defer w.Close()
...
}
Essentiellement, returnIf sera remplacé/incorporé par celui défini ci-dessus. La flexibilité est que c'est à vous de décider ce qu'il fait. Le débogage peut être un peu étrange, à moins que l'éditeur ne le remplace dans l'éditeur d'une manière agréable. Cela le rend également moins magique, car vous pouvez clairement lire la définition. Et aussi, cela vous permet d'avoir une ligne qui pourrait potentiellement revenir en cas d'erreur. Et capable d'avoir différents messages d'erreur selon l'endroit où cela s'est produit (contexte).
Edit : Deux points également ajoutés devant la macro pour suggérer que cela peut être fait pour clarifier qu'il s'agit d'une macro et non d'un appel de fonction.
 Chillance
le 5 juil. 2019
Chillance
le 5 juil. 2019
@nvictor
J'encourage encore plus l'équipe go à créer
tryun variadique intégré
Que retournerait try(foo(), bar()) si foo et bar ne retournaient pas la même chose ?
ngrilly
le 5 juil. 2019
Je vais juste jeter ça là-bas au stade actuel. Je vais y réfléchir un peu plus, mais je pensais poster ici pour voir ce que vous en pensez. Peut-être devrais-je ouvrir un nouveau sujet pour ça ? J'ai aussi posté ceci sur #32811
Alors, qu'en est-il de faire une sorte de macro C générique à la place pour s'ouvrir à plus de flexibilité?
@Chillance , à mon humble avis, je pense qu'un système de macros hygiénique comme Rust (et de nombreux autres langages) donnerait aux gens une chance de jouer avec des idées comme try ou des génériques, puis une fois l'expérience acquise, les meilleures idées peuvent devenir partie du langage et des bibliothèques. Mais je pense aussi qu'il y a très peu de chance qu'une telle chose soit ajoutée au Go.
jonbodner
le 5 juil. 2019
@jonbodner il y a actuellement une proposition pour ajouter des macros hygiéniques dans Go. Aucune syntaxe proposée ou quoi que ce soit pour le moment, mais il n'y a pas eu beaucoup de _contre_ l'idée d'ajouter des macros hygiéniques. #32620
deanveloper
le 5 juil. 2019
@Allenyn , concernant la suggestion précédente de @buchanae que vous venez de citer :
a, b, err := myFunc()
check(err, "calling myFunc on %v and %v", a, b)
D'après ce que j'ai vu de la discussion, je suppose qu'il serait peu probable que la sémantique de fmt soit tirée dans une fonction intégrée. (Voir par exemple la réponse de @josharian ).
Cela dit, ce n'est pas vraiment nécessaire, notamment parce que l'autorisation d'une fonction de gestionnaire peut éviter d'extraire la sémantique fmt directement dans une fonction intégrée. Une telle approche a été proposée par @eihigh le premier jour de la discussion ici, qui est similaire à l'esprit de la suggestion de @buchanae , et qui suggérait de peaufiner le try intégré pour avoir à la place la signature suivante :
func try(error, optional func(error) error)
Comme cette alternative try ne renvoie rien, cette signature implique :
- il ne peut pas être imbriqué dans un autre appel de fonction
- ça doit être en début de ligne
Je ne veux pas déclencher le bikeshedding du nom, mais cette forme de try pourrait mieux se lire avec un nom alternatif tel que check . On pourrait imaginer des assistants de bibliothèque standard qui pourraient rendre pratique l'annotation facultative sur place, tandis que defer pourrait rester une option pour une annotation uniforme si nécessaire.
Certaines propositions connexes ont été créées plus tard dans # 32811 ( catch en tant que fonction intégrée) et # 32611 ( mot-clé on pour autoriser on err, <statement> ). Ce pourraient être de bons endroits pour discuter davantage, ou pour ajouter un pouce vers le haut ou vers le bas, ou pour suggérer des ajustements possibles à ces propositions.
thepudds
le 5 juil. 2019
@jonbodner il y a actuellement une proposition pour ajouter des macros hygiéniques dans Go. Aucune syntaxe proposée ou quoi que ce soit pour le moment, mais il n'y a pas eu beaucoup de _contre_ l'idée d'ajouter des macros hygiéniques. #32620
C'est bien qu'il y ait une proposition, mais je soupçonne que l'équipe principale de Go n'a pas l'intention d'ajouter des macros. Cependant, je serais heureux de me tromper à ce sujet car cela mettrait fin à tous les arguments concernant les changements qui nécessitent actuellement des modifications du noyau du langage. Pour citer une marionnette célèbre, "Faites. Ou ne faites pas. Il n'y a pas d'essai."
jonbodner
le 5 juil. 2019
@jonbodner Je ne pense pas que l'ajout de macros hygiéniques mettrait fin à l'argument. Plutôt l'inverse. Une critique courante est que try "cache" le retour. Les macros seraient strictement pires de ce point de vue, car tout serait possible dans une macro. Et même si Go autoriserait les macros hygiéniques définies par l'utilisateur, nous aurions encore à débattre si try devrait être une macro intégrée prédéclarée dans le bloc d'univers, ou non. Il serait logique que les opposants aux try soient encore plus opposés aux macros hygiéniques ;-)
ngrilly
le 5 juil. 2019
@ngrilly , il existe plusieurs façons de s'assurer que les macros ressortent et sont faciles à voir. La façon dont Rust le fait est que les macros sont toujours précédées de ! (c'est-à-dire try!(...) et println!(...) ).
Je dirais que si des macros hygiéniques étaient adoptées et faciles à voir, et ne ressemblaient pas à des appels de fonction normaux, elles s'adapteraient beaucoup mieux. Nous devrions opter pour des solutions plus générales plutôt que de résoudre des problèmes individuels.
deanveloper
le 5 juil. 2019
@thepudds Je suis d'accord que l'ajout d'un paramètre optionnel de type func(error) error pourrait être utile (cette possibilité est discutée dans la proposition, avec quelques problèmes qui devraient être résolus), mais je ne vois pas l'intérêt de try ne renvoie rien. Le try proposé par l'équipe Go est un outil plus généraliste.
ngrilly
le 5 juil. 2019
@deanveloper Oui, le ! à la fin des macros dans Rust est intelligent. Cela rappelle les identifiants exportés commençant par une lettre majuscule en Go :-)
Je serais d'accord pour avoir des macros hygiéniques dans Go si et seulement si nous pouvons préserver la vitesse de compilation et résoudre des problèmes complexes concernant l'outillage (les outils de refactoring auraient besoin d'étendre les macros pour comprendre la sémantique du code, mais doivent générer du code avec les macros non développées) . C'est dur. En attendant, peut-être try pourrait être renommé try! ? ;-)
ngrilly
le 5 juil. 2019
Une idée légère : si le corps d'une construction if/for contient une seule instruction, pas besoin d'accolades à condition que cette instruction soit sur la même ligne que if ou for . Exemple:
fd, err := os.Open("foo")
if err != nil return err
Notez qu'à l'heure actuelle, un type error n'est qu'un type d'interface ordinaire. Le compilateur ne le traite pas comme quelque chose de spécial. try change cela. Si le compilateur est autorisé à traiter error comme spécial, je préférerais un /bin/sh inspiré || :
fd, err := os.Open("foo") || return err
La signification d'un tel code serait assez évidente pour la plupart des programmeurs, il n'y a pas de flux de contrôle caché et, comme à l'heure actuelle ce code est illégal, aucun code de travail n'est endommagé.
Bien que je puisse imaginer que certains d'entre vous reculent d'horreur.
bakul
le 5 juil. 2019
@bakul Dans if err != nil return err , comment savez-vous où se termine l'expression err != nil et où commence l'instruction return err ? Votre idée serait un changement majeur de la grammaire de la langue, beaucoup plus important que ce qui est proposé avec try .
Votre deuxième idée ressemble à catch |err| return err en Zig . Personnellement, je ne « recule pas d'horreur » et je dirais pourquoi pas ? Mais il faut noter que Zig a aussi un mot-clé try , qui est un raccourci pour catch |err| return err , et presque équivalent à ce que l'équipe Go propose ici comme fonction intégrée. Alors peut-être que le try est suffisant et que nous n'avons pas besoin du mot-clé catch ? ;-)
ngrilly
le 5 juil. 2019
@ngrilly , Actuellement <expr> <statement> n'est pas valide donc je ne pense pas que ce changement rendrait la grammaire plus ambiguë mais pourrait être un peu plus fragile.
Cela générerait exactement le même code que la proposition try mais a) le retour est explicite ici b) il n'y a pas d'imbrication possible comme avec try et c) ce serait une syntaxe familière aux utilisateurs du shell (qui sont de loin plus nombreux que les utilisateurs zig). Il n'y a pas catch ici.
J'ai évoqué cela comme une alternative, mais pour être franc, je suis parfaitement d'accord avec tout ce que les concepteurs de langage de base décident.
bakul
le 5 juil. 2019
J'ai téléchargé une version légèrement améliorée de tryhard . Il rapporte maintenant des informations plus détaillées sur les fichiers d'entrée. Par exemple, en cours d'exécution contre la pointe du référentiel Go, il signale maintenant :
$ tryhard $HOME/go/src
...
--- stats ---
55620 (100.0% of 55620) function declarations
14936 ( 26.9% of 55620) functions returning an error
116539 (100.0% of 116539) statements
27327 ( 23.4% of 116539) if statements
7636 ( 27.9% of 27327) if <err> != nil statements
119 ( 1.6% of 7636) <err> name is different from "err" (use -l flag to list file positions)
6037 ( 79.1% of 7636) return ..., <err> blocks in if <err> != nil statements
1599 ( 20.9% of 7636) more complex error handler in if <err> != nil statements; prevent use of try (use -l flag to list file positions)
17 ( 0.2% of 7636) non-empty else blocks in if <err> != nil statements; prevent use of try (use -l flag to list file positions)
5907 ( 77.4% of 7636) try candidates (use -l flag to list file positions)
Il y a plus à faire, mais cela donne une image plus claire. Plus précisément, 28 % de toutes les instructions if semblent être destinées à la vérification des erreurs ; cela confirme qu'il y a une quantité importante de code répétitif. Parmi ces vérifications d'erreurs, 77 % se prêtent à try .
griesemer
le 6 juil. 2019
$ essayer dur .
--- Statistiques ---
2930 (100,0 % de 2930) déclarations de fonction
1408 ( 48,1% de 2930) fonctions retournant une erreur
10497 (100,0 % de 10497) déclarations
2265 (21,6% de 10497) si déclarations
1383 ( 61,1% de 2265) si
0 ( 0,0 % de 1383)
pour lister les positions des fichiers)
645 ( 46,6% de 1383) retour ...,
déclarations
738 (53,4 % de 1383) gestionnaire d'erreurs plus complexe dans if
déclarations ; empêcher l'utilisation de try (utiliser l'indicateur -l pour lister les positions des fichiers)
1 (0,1 % de 1 383) blocs d'autre non vides dans si
déclarations ; empêcher l'utilisation de try (utiliser l'indicateur -l pour lister les positions des fichiers)
638 (46,1% de 1383) essaient des candidats (utilisez l'indicateur -l pour lister les fichiers
postes)
$ go vendeur de mods
$ vendeur acharné
--- Statistiques ---
37757 (100,0 % de 37757) déclarations de fonction
12557 ( 33,3% de 37757) fonctions renvoyant une erreur
88919 (100,0 % de 88919) déclarations
20143 ( 22,7% de 88919) si déclarations
6555 ( 32,5% de 20143) si
109 ( 1,7% de 6555)
pour lister les positions des fichiers)
5545 ( 84,6% de 6555) retour ...,
déclarations
1010 (15,4 % de 6555) gestionnaire d'erreurs plus complexe dans if
déclarations ; empêcher l'utilisation de try (utiliser l'indicateur -l pour lister les positions des fichiers)
12 (0,2 % de 6 555) blocs non vides sinon dans si
déclarations ; empêcher l'utilisation de try (utiliser l'indicateur -l pour lister les positions des fichiers)
5427 (82,8% de 6555) essaient des candidats (utilisez l'indicateur -l pour lister le fichier
postes)
mirtchovski
le 6 juil. 2019
C'est pourquoi j'ai ajouté deux-points dans l'exemple de macro, afin qu'il ressorte et ne ressemble pas à un appel de fonction. N'a pas besoin d'être deux-points bien sûr. C'est juste un exemple. De plus, une macro ne cache rien. Il suffit de regarder ce que fait la macro, et voilà. Comme si c'était une fonction, mais elle sera en ligne. C'est comme si vous faisiez une recherche et un remplacement avec le morceau de code de la macro dans vos fonctions où l'utilisation de la macro a été effectuée. Naturellement, si les gens font des macros de macros et commencent à compliquer les choses, eh bien, blâmez-vous d'avoir rendu le code plus compliqué. :)
Chillance
le 6 juil. 2019
@mirtchovski
$ tryhard .
--- stats ---
2930 (100.0% of 2930) function declarations
1408 ( 48.1% of 2930) functions returning an error
10497 (100.0% of 10497) statements
2265 ( 21.6% of 10497) if statements
1383 ( 61.1% of 2265) if <err> != nil statements
0 ( 0.0% of 1383) <err> name is different from "err" (use -l flag to list file positions)
645 ( 46.6% of 1383) return ..., <err> blocks in if <err> != nil statements
738 ( 53.4% of 1383) more complex error handler in if <err> != nil statements; prevent use of try (use -l flag to list file positions)
1 ( 0.1% of 1383) non-empty else blocks in if <err> != nil statements; prevent use of try (use -l flag to list file positions)
638 ( 46.1% of 1383) try candidates (use -l flag to list file
positions)
$ go mod vendor
$ tryhard vendor
--- stats ---
37757 (100.0% of 37757) function declarations
12557 ( 33.3% of 37757) functions returning an error
88919 (100.0% of 88919) statements
20143 ( 22.7% of 88919) if statements
6555 ( 32.5% of 20143) if <err> != nil statements
109 ( 1.7% of 6555) <err> name is different from "err" (use -l flag to list file positions)
5545 ( 84.6% of 6555) return ..., <err> blocks in if <err> != nil statements
1010 ( 15.4% of 6555) more complex error handler in if <err> != nil statements; prevent use of try (use -l flag to list file positions)
12 ( 0.2% of 6555) non-empty else blocks in if <err> != nil statements; prevent use of try (use -l flag to list file positions)
5427 ( 82.8% of 6555) try candidates (use -l flag to list file
positions)
$
@av86743 ,
désolé, je n'ai pas considéré que "les réponses par e-mail ne prennent pas en charge Markdown"
mirtchovski
le 6 juil. 2019
Certaines personnes ont fait remarquer qu'il n'est pas juste de compter le code fourni dans les résultats tryhard . Par exemple, dans la bibliothèque std, le code fourni inclut les packages syscall générés qui contiennent de nombreuses vérifications d'erreurs et qui peuvent déformer l'image globale. La dernière version de tryhard exclut désormais les chemins de fichiers contenant "vendor" par défaut (cela peut également être contrôlé avec le nouveau drapeau -ignore ). Appliqué à la bibliothèque std à tip :
tryhard $HOME/go/src
/Users/gri/go/src/cmd/go/testdata/src/badpkg/x.go:1:1: expected 'package', found pkg
/Users/gri/go/src/cmd/go/testdata/src/notest/hello.go:6:1: expected declaration, found Hello
/Users/gri/go/src/cmd/go/testdata/src/syntaxerror/x_test.go:3:11: expected identifier
--- stats ---
45424 (100.0% of 45424) func declarations
8346 ( 18.4% of 45424) func declarations returning an error
71401 (100.0% of 71401) statements
16666 ( 23.3% of 71401) if statements
4812 ( 28.9% of 16666) if <err> != nil statements
86 ( 1.8% of 4812) <err> name is different from "err" (-l flag lists details)
3463 ( 72.0% of 4812) return ..., <err> blocks in if <err> != nil statements
1349 ( 28.0% of 4812) complex error handler in if <err> != nil statements; cannot use try (-l flag lists details)
17 ( 0.4% of 4812) non-empty else blocks in if <err> != nil statements; cannot use try (-l flag lists details)
3345 ( 69.5% of 4812) try candidates (-l flag lists details)
Maintenant, 29 % (28,9 %) de toutes les déclarations if semblent être destinées à la vérification des erreurs (donc un peu plus qu'avant), et parmi celles-ci, environ 70 % semblent être des candidats pour try (un peu moins qu'avant).
griesemer
le 6 juil. 2019
Le changement https://golang.org/cl/185177 mentionne ce problème : src: apply tryhard -err="" -ignore="vendor" -r $GOROOT/src
gopherbot
le 6 juil. 2019
@griesemer vous avez compté les "gestionnaires d'erreurs complexes" mais pas les "gestionnaires d'erreurs à instruction unique".
Si la plupart des gestionnaires "complexes" sont une seule instruction, alors on err #32611 produirait à peu près autant d'économies passe-partout que try() -- 2 lignes contre 3 lignes x 70 %. Et on err ajoute l'avantage d'un modèle cohérent pour la grande majorité des erreurs.
networkimprov
le 6 juil. 2019
@nvictor
tryest une solution propre et compréhensible au problème spécifique qu'il tente de résoudre :
verbosité dans la gestion des erreurs.
La verbosité dans la gestion des erreurs n'est pas _un problème_, c'est la force de Go.
la proposition se lit comme suit : après une longue discussion d'un an, nous ajoutons cette fonctionnalité intégrée. utilisez-le si vous voulez un code moins verbeux, sinon continuez à faire ce que vous faites. la réaction est une résistance non entièrement justifiée pour une fonctionnalité opt-in pour laquelle les membres de l'équipe ont montré des avantages évidents !
Votre _opt-in_ au moment de la rédaction est un _must_ pour tous les lecteurs, y compris les futurs-vous.
avantages clairs
Si le flux de contrôle confus peut être qualifié d '«avantage», alors oui.
try , pour le bien des habitudes des expatriés Java et C++, introduit une magie qui doit être comprise par tous les Gophers. En attendant, épargnant quelques lignes à une minorité pour écrire à quelques endroits (comme tryhard runs l'ont montré).
Je dirais que ma macro onErr plus simple épargnerait plus d'écriture de lignes, et pour la majorité:
x, err = fa()
onErr break
r, err := fb(x)
onErr return 0, nil, err
if r, err := fc(x); onErr && triesleft > 0 {
triesleft--
continue retry
}
_(notez que je suis dans le camp "laisser if err!= nil seul" et la contre-proposition ci-dessus a été publiée pour montrer une solution plus simple qui peut rendre plus de pleurnicheurs heureux.)_
Éditer:
J'encouragerais en outre l'équipe de go à créer
tryun variadique intégré si c'est facile à faire
try(outf.Seek(linkstart, 0)), io.Copy(outf, exef)))
~Court à écrire, long à lire, sujet aux dérapages ou aux malentendus, feuilleté et dangereux au stade de la maintenance.~
J'avais tort. En fait, le variadique try serait bien meilleur que les nids, car nous pourrions l'écrire par lignes :
try( outf.Seek(linkstart, 0),
io.Copy(outf, exef),
)
et ont try(…) retour après la première erreur.
 ohir
le 6 juil. 2019
ohir
le 6 juil. 2019
Je ne pense pas que ce handle d'erreur implicite (sucre de syntaxe) comme try soit bon, car vous ne pouvez pas gérer plusieurs erreurs de manière intuitive, en particulier lorsque vous devez exécuter plusieurs fonctions de manière séquentielle.
Je suggérerais quelque chose comme Elixir avec déclaration : https://www.openmymind.net/Elixirs-With-Statement/
Quelque chose comme ça ci-dessous dans golang:
switch a, b, err1 := go_func_01(),
apple, banana, err2 := go_func_02(),
fans, dissman, err3 := go_func_03()
{
normal_func()
else
err1 -> handle_err1()
err2 -> handle_err2()
_ -> handle_other_errs()
}
 YongHaoWu
le 6 juil. 2019
YongHaoWu
le 6 juil. 2019
Est-ce que ce genre de violation du "Go préfère moins de fonctionnalités" et "ajouter des fonctionnalités à Go ne le rendrait pas meilleur mais plus grand" ? Je ne suis pas sûr...
Je veux juste dire, personnellement, je suis parfaitement satisfait de l'ancienne méthode
if err != nil {
return …, err
}
Et certainement je ne veux pas lire le code écrit par d'autres en utilisant le try ... La raison peut être double :
- il est parfois difficile de deviner ce qu'il y a à l'intérieur au premier coup d'œil
trys peuvent être imbriqués, c'est-à-diretry( ... try( ... try ( ... ) ... ) ... ), difficiles à lire
Si vous pensez qu'écrire du code à l'ancienne pour passer des erreurs est fastidieux, pourquoi ne pas simplement copier et coller puisqu'ils font toujours le même travail ?
Eh bien, vous pourriez penser que nous ne voulons pas toujours faire le même travail, mais ensuite vous devrez écrire votre fonction "handler". Alors peut-être que vous ne perdez rien si vous écrivez toujours à l'ancienne.
 yukai-yang
le 6 juil. 2019
yukai-yang
le 6 juil. 2019
La performance du report n'est-elle pas un problème avec cette solution proposée ? J'ai comparé les fonctions avec et sans report et il y a eu un impact significatif sur les performances. Je viens de chercher sur Google quelqu'un d'autre qui a fait une telle référence et a trouvé un coût 16x. Je ne me souviens pas que le mien était si mauvais, mais 4x plus lent me dit quelque chose. Comment quelque chose qui pourrait doubler ou aggraver le temps d'exécution de nombreuses fonctions peut-il être considéré comme une solution générale viable ?
 eric-hawthorne
le 7 juil. 2019
eric-hawthorne
le 7 juil. 2019
@eric-hawthorne Différer les performances est un problème distinct. Try ne nécessite pas de manière inhérente un report et ne supprime pas la possibilité de gérer les erreurs sans lui.
fbnz156
le 7 juil. 2019
@fabian-f Mais cette proposition pourrait encourager le remplacement du code dans lequel quelqu'un décore les erreurs séparément pour chaque erreur en ligne dans le cadre du bloc if err != nil. Ce serait une différence de performances significative.
eric-hawthorne
le 7 juil. 2019
@eric-hawthorne Citant le document de conception :
Q : L'utilisation du report pour les erreurs d'encapsulation ne va-t-elle pas être lente ?
R : Actuellement, une instruction différée est relativement coûteuse par rapport au flux de contrôle ordinaire. Cependant, nous pensons qu'il est possible de rendre les cas d'utilisation courants de report pour la gestion des erreurs comparables en termes de performances avec l'approche "manuelle" actuelle. Voir également CL 171758 qui devrait améliorer les performances du report d'environ 30 %.
ianlancetaylor
le 7 juil. 2019
Voici une conversation intéressante de Rust liée sur Reddit. La partie la plus pertinente commence à 47:55
deanveloper
le 7 juil. 2019
J'ai essayé tryhard sur mon plus grand référentiel public, https://github.com/dpinela/mflg , et j'ai obtenu ce qui suit :
--- stats ---
309 (100.0% of 309) func declarations
36 ( 11.7% of 309) func declarations returning an error
305 (100.0% of 305) statements
73 ( 23.9% of 305) if statements
29 ( 39.7% of 73) if <err> != nil statements
0 ( 0.0% of 29) <err> name is different from "err"
19 ( 65.5% of 29) return ..., <err> blocks in if <err> != nil statements
10 ( 34.5% of 29) complex error handler in if <err> != nil statements; cannot use try
0 ( 0.0% of 29) non-empty else blocks in if <err> != nil statements; cannot use try
15 ( 51.7% of 29) try candidates
La plupart du code de ce dépôt gère l'état de l'éditeur interne et n'effectue aucune E/S, et a donc peu de contrôles d'erreurs - ainsi, les endroits où try peut être utilisé sont relativement limités. Je suis allé de l'avant et j'ai réécrit manuellement le code pour utiliser try si possible; git diff --stat renvoie ce qui suit :
application.go | 42 +++++++++++-------------------------------
internal/atomicwrite/write.go | 35 ++++++++++++++---------------------
internal/clipboard/clipboard.go | 17 +++--------------
internal/config/config.go | 15 +++++++--------
internal/termesc/term.go | 5 +----
render.go | 8 ++------
6 files changed, 38 insertions(+), 84 deletions(-)
(Diffusion complète ici .)
Sur les 10 gestionnaires signalés par tryhard comme "complexes", 5 sont des faux négatifs dans internal/atomicwrite/write.go ; ils utilisaient pkg/errors.WithMessage pour envelopper l'erreur. L'emballage était exactement le même pour tous, j'ai donc réécrit cette fonction pour utiliser les gestionnaires try et différé. Je me suis retrouvé avec ce diff (+14, -21 lignes):
@@ -20,21 +20,20 @@ const (
// The file is created with mode 0644 if it doesn't already exist; if it does, its permissions will be
// preserved if possible.
// If some of the directories on the path don't already exist, they are created with mode 0755.
-func Write(filename string, contentWriter func(io.Writer) error) error {
+func Write(filename string, contentWriter func(io.Writer) error) (err error) {
+ defer func() { err = errors.WithMessage(err, errString(filename)) }()
+
dir := filepath.Dir(filename)
- if err := os.MkdirAll(dir, defaultDirPerms); err != nil {
- return errors.WithMessage(err, errString(filename))
- }
- tf, err := ioutil.TempFile(dir, "mflg-atomic-write")
- if err != nil {
- return errors.WithMessage(err, errString(filename))
- }
+ try(os.MkdirAll(dir, defaultDirPerms))
+ tf := try(ioutil.TempFile(dir, "mflg-atomic-write"))
name := tf.Name()
- if err = contentWriter(tf); err != nil {
- os.Remove(name)
- tf.Close()
- return errors.WithMessage(err, errString(filename))
- }
+ defer func() {
+ if err != nil {
+ tf.Close()
+ os.Remove(name)
+ }
+ }()
+ try(contentWriter(tf))
// Keep existing file's permissions, when possible. This may race with a chmod() on the file.
perms := defaultPerms
if info, err := os.Stat(filename); err == nil {
@@ -42,14 +41,8 @@ func Write(filename string, contentWriter func(io.Writer) error) error {
}
// It's better to save a file with the default TempFile permissions than not save at all, so if this fails we just carry on.
tf.Chmod(perms)
- if err = tf.Close(); err != nil {
- os.Remove(name)
- return errors.WithMessage(err, errString(filename))
- }
- if err = os.Rename(name, filename); err != nil {
- os.Remove(name)
- return errors.WithMessage(err, errString(filename))
- }
+ try(tf.Close())
+ try(os.Rename(name, filename))
return nil
}
Remarquez le premier report, qui annote l'erreur - j'ai pu l'insérer confortablement dans une seule ligne grâce à WithMessage renvoyant nil pour une erreur nulle. Il semble que ce type d'emballage fonctionne aussi bien avec cette approche que ceux suggérés dans la proposition.
Deux des autres gestionnaires "complexes" étaient dans des implémentations de ReadFrom et WriteTo :
var line string
line, err = br.ReadString('\n')
b.lines = append(b.lines, line)
if err != nil {
if err == io.EOF {
err = nil
}
return
}
func (b *Buffer) WriteTo(w io.Writer) (int64, error) {
var n int64
for _, line := range b.lines {
nw, err := w.Write([]byte(line))
n += int64(nw)
if err != nil {
return n, err
}
}
return n, nil
}
Ceux-ci n'étaient vraiment pas susceptibles d'essayer, alors je les ai laissés seuls.
Deux autres étaient du code comme celui-ci, où je renvoie une erreur entièrement différente de celle que j'ai vérifiée (pas seulement en l'enveloppant). Je les ai laissé inchangés également :
n, err := strconv.ParseInt(s[1:], 16, 32)
if err != nil {
return Color{}, errors.WithMessage(err, fmt.Sprintf("color: parse %q", s))
}
Le dernier était dans une fonction pour charger un fichier de configuration, qui renvoie toujours une configuration (non nulle) même s'il y a une erreur. Il n'y avait qu'une seule vérification d'erreur, donc il n'a pas beaucoup profité, voire pas du tout, de try:
-func Load() (*Config, error) {
- c := Config{
+func Load() (c *Config, err error) {
+ defer func() { err = errors.WithMessage(err, "error loading config file") }()
+
+ c = &Config{
TabWidth: 4,
ScrollSpeed: 1,
Lang: make(map[string]LangConfig),
}
- f, err := basedir.Config.Open(filepath.Join("mflg", "config.toml"))
- if err != nil {
- return &c, errors.WithMessage(err, "error loading config file")
- }
+ f := try(basedir.Config.Open(filepath.Join("mflg", "config.toml")))
defer f.Close()
- _, err = toml.DecodeReader(f, &c)
+ _, err = toml.DecodeReader(f, c)
if c.TextStyle.Comment == (Style{}) {
c.TextStyle.Comment = Style{Foreground: &color.Color{R: 0, G: 200, B: 0}}
}
if c.TextStyle.String == (Style{}) {
c.TextStyle.String = Style{Foreground: &color.Color{R: 0, G: 0, B: 200}}
}
- return &c, errors.WithMessage(err, "error loading config file")
+ return c, err
}
En fait, s'appuyer sur le comportement de try consistant à conserver les valeurs des paramètres de retour - comme un retour nu - semble, à mon avis, un peu plus difficile à suivre ; à moins que j'ajoute plus de contrôles d'erreur, je m'en tiendrai à if err != nil dans ce cas particulier.
TL; DR : try n'est utile que dans un pourcentage assez faible (par nombre de lignes) de ce code, mais là où ça aide, ça aide vraiment.
dpinela
le 7 juil. 2019
(Noob ici). Une autre idée pour plusieurs arguments. Que diriez-vous:
package trytest
import "fmt"
func errorInner() (string, error) {
return "", fmt.Errorf("inner error")
}
func errorOuter() (string, error) {
tryreturn errorInner()
return "", nil
}
func errorOuterWithArg() (string, error) {
var toProcess string
tryreturn toProcess, _ = errorOuter()
return toProcess + "", nil
}
func errorOuterWithArgStretch() (bool, string, error) {
var toProcess string
tryreturn false, ( toProcess,_ = errorOuterWithArg() )
return true, toProcess + "", nil
}
c'est-à-dire tryreturn déclenche le retour de toutes les valeurs si une erreur dans le dernier
valeur, sinon l'exécution continue.
 guilt
le 7 juil. 2019
guilt
le 7 juil. 2019
Les principes avec lesquels je suis d'accord :
-
- Une erreur de gestion d'un appel de fonction mérite sa propre ligne. Go est délibérément explicite dans le flux de contrôle, et je pense que le fait de le résumer dans une expression est en contradiction avec son caractère explicite.
- Il serait avantageux d'avoir une méthode de gestion des erreurs qui tient sur une seule ligne. (Et idéalement ne nécessite qu'un seul mot ou quelques caractères de passe-partout avant la gestion réelle des erreurs). 3 lignes de gestion des erreurs pour chaque appel de fonction est un point de friction dans le langage qui mérite un peu d'amour et d'attention.
- Toute commande intégrée qui retourne (comme le
tryproposé) devrait au moins être une déclaration, et idéalement contenir le mot return. Encore une fois, je pense que le flux de contrôle dans Go devrait être explicite. - Les erreurs de Go sont plus utiles lorsqu'elles incluent un contexte supplémentaire (j'ajoute presque toujours du contexte à mes erreurs). Une solution à ce problème doit également prendre en charge le code de gestion des erreurs d'ajout de contexte.
Syntaxe que je supporte :
-
- une instruction
reterr _x_(sucre syntaxique pourif err != nil { return _x_ }, nommé explicitement pour indiquer qu'il reviendra)
Ainsi, les cas courants pourraient être une belle ligne courte et explicite :
func foo() error {
a, err := bar()
reterr err
b, err := baz(a)
reterr fmt.Errorf("getting the baz of %v: %v", a, err)
return nil
}
Au lieu des 3 lignes, ils sont maintenant :
func foo() error {
a, err := bar()
if err != nil {
return err
}
b, err := baz()
if err != nil {
return fmt.Errorf("getting the baz of %v: %v", a, err)
}
return nil
}
Choses avec lesquelles je ne suis pas d'accord :
- "C'est un changement trop petit pour valoir la peine de changer de langue"
Je ne suis pas d'accord, c'est un changement de qualité de vie qui supprime la plus grande source de friction que j'ai lors de l'écriture de code Go. Lorsque l'appel d'une fonction nécessite 4 lignes
- "C'est un changement trop petit pour valoir la peine de changer de langue"
- "Il vaudrait mieux attendre une solution plus générale"
Je ne suis pas d'accord, je pense que ce problème mérite sa propre solution dédiée. La version généralisée de ce problème réduit le code passe-partout, et la réponse généralisée est les macros - ce qui va à l'encontre de l'éthique Go du code explicite. Si Go ne fournit pas de fonctionnalité de macro générale, il devrait plutôt fournir des macros spécifiques très largement utilisées telles quereterr(toute personne qui écrit Go bénéficierait de reterr).
 Qhesz
le 7 juil. 2019
Qhesz
le 7 juil. 2019
@Qhesz Ce n'est pas très différent avec try:
func foo() error {
a, err := bar()
try(err)
b, err := baz(a)
try(wrap(err, "getting the baz of %v", a))
return nil
}
@reusee J'apprécie cette suggestion, je ne savais pas qu'elle pouvait être utilisée comme ça. Cela me semble un peu agaçant, j'essaie de comprendre pourquoi.
Je pense que "essayer" est un mot étrange à utiliser de cette façon. "try(action())" a du sens en anglais, alors que "try(value)" n'en a pas vraiment. Je serais plus d'accord avec ça si c'était un mot différent.
De plus, try(wrap(...)) évalue wrap(...) en premier, n'est-ce pas ? Selon vous, quelle part de cela est optimisée par le compilateur ? (Par rapport à l'exécution if err != nil ?)
De plus, # 32611 est une proposition vaguement similaire, et les commentaires ont des opinions éclairantes de la part de l'équipe principale de Go et des membres de la communauté, en particulier sur les différences entre les mots-clés et les fonctions intégrées.
Qhesz
le 7 juil. 2019
@Qhesz Je suis d'accord avec vous sur la dénomination. Peut-être que check est plus approprié puisque "check(action())" ou "check(err)" se lit bien.
reusee
le 7 juil. 2019
@reusee Ce qui est un peu ironique, puisque le projet de conception original utilisait check .
Qhesz
le 7 juil. 2019
Le 06/07/19, mirtchovski [email protected] a écrit :
$ essayer dur .
--- Statistiques ---
2930 (100,0 % de 2930) déclarations de fonction
1408 ( 48,1% de 2930) fonctions retournant une erreur
[ ... ]
Je ne peux pas m'empêcher d'être malicieux ici : est-ce que "les fonctions renvoyant un
erreur comme dernier argument" ?
Lucio.
lootch
le 7 juil. 2019
Réflexion finale sur ma question ci-dessus, je préférerais toujours la syntaxe try(err, wrap("getting the baz of %v: %v", a, err)) , avec wrap() exécuté uniquement si err n'est pas nil. Au lieu de try(wrap(err, "getting the baz of %v", a)) .
Qhesz
le 7 juil. 2019
@Qhesz Une implémentation possible de wrap pourrait être :
func wrap(err error, format string, args ...interface{}) error {
if err == nil {
return nil
}
return fmt.Errorf("%s: %w", fmt.Sprintf(format, args...), err)
}
Si le compilateur peut inline wrap , alors il n'y a pas de différence de performances entre les clauses wrap et if err != nil .
reusee
le 7 juil. 2019
@reusee je pense que tu voulais dire if err == nil ;)
deanveloper
le 7 juil. 2019
@Qhesz Une implémentation possible de
wrappourrait être :func wrap(err error, format string, args ...interface{}) error { if err == nil { return nil } return fmt.Errorf("%s: %w", fmt.Sprintf(format, args...), err) }Si le compilateur peut inline
wrap, alors il n'y a pas de différence de performances entre les clauseswrapetif err != nil.
%w n'est pas valide go verbe
olekukonko
le 7 juil. 2019
(Je suppose qu'il voulait dire %v...)
Ainsi, bien qu'il soit préférable d'écrire un mot-clé, je comprends qu'une fonction intégrée est le moyen préféré de l'implémenter.
Je pense que je serais d'accord avec cette proposition si
- c'était
checkau lieu detry - une partie de l'outillage Go a imposé qu'il ne pouvait être utilisé que comme une déclaration (c'est-à-dire le traiter comme une "déclaration" intégrée, pas comme une "fonction" intégrée. Ce n'est qu'une fonction intégrée pour des raisons pratiques, il essaie d'être une déclaration sans être implémenté par le langage.) Par exemple, s'il ne renvoyait rien, il n'était donc jamais valide dans une expression, comme
panic(). - ~ peut-être un indicateur qu'il s'agit d'une macro et influence le flux de contrôle, quelque chose qui le différencie d'un appel de fonction. (par exemple
check!(...)comme Rust le fait, mais je n'ai pas d'opinion bien arrêtée sur la syntaxe spécifique) ~ J'ai changé d'avis
Alors ce serait génial, je l'utiliserais à chaque appel de fonction que je fais.
Et mes excuses mineures pour le fil, je viens seulement de trouver les commentaires ci-dessus qui décrivent à peu près ce que je viens de dire.
Qhesz
le 7 juil. 2019
@deanveloper corrigé, merci.
@olekukonko @Qhesz %w vient d'être ajouté dans l'astuce : https://tip.golang.org/pkg/fmt/#Errorf
reusee
le 7 juil. 2019
Je m'excuse de ne pas avoir tout lu dans ce sujet, mais je voudrais mentionner quelque chose que je n'ai pas vu.
Je vois deux cas distincts où la gestion des erreurs de Go1 peut être gênante : "bon" code correct mais un peu répétitif ; et "mauvais" code qui est faux, mais qui fonctionne la plupart du temps.
Dans le premier cas, il devrait vraiment y avoir une certaine logique dans le bloc if-err, et le passage à une construction de style try décourage cette bonne pratique en rendant plus difficile l'ajout de logique supplémentaire.
Dans le second cas, le mauvais code est souvent de la forme :
..., _ := might_error()
ou juste
might_error()
Lorsque cela se produit, c'est normalement parce que l'auteur ne pense pas que ce soit assez important pour passer du temps sur la gestion des erreurs, et espère simplement que tout fonctionne. Ce cas pourrait être amélioré par quelque chose de très proche du zéro effort, comme :
..., XXX := might_error()
où XXX est un symbole qui signifie "quelque chose ici devrait arrêter l'exécution d'une manière ou d'une autre". Cela indiquerait clairement qu'il ne s'agit pas d'un code prêt pour la production - l'auteur est conscient d'un cas d'erreur, mais n'a pas investi le temps de décider quoi faire.
Bien sûr, cela n'exclut pas une solution de type returnif handle(err) .
 undeconstructed
le 7 juil. 2019
undeconstructed
le 7 juil. 2019
Je suis contre l'essai, dans l'ensemble, avec des compliments aux contributeurs sur le design joliment minimal. Je ne suis pas un gros expert en Go, mais j'ai été l'un des premiers à adopter et j'ai du code en production ici et là. Je travaille dans le groupe Serverless d'AWS et il semble que nous publierons un service basé sur Go plus tard cette année, dont le premier enregistrement a été essentiellement écrit par moi. Je suis un très vieux gars, mon chemin a traversé C, Perl, Java et Ruby. Mes problèmes sont déjà apparus dans le très utile résumé du débat, mais je pense toujours qu'ils méritent d'être réitérés.
- Go est un petit langage simple et a donc atteint une lisibilité inégalée. Je suis par réflexe contre l'ajout de quoi que ce soit à moins que l'avantage ne soit vraiment substantiel sur le plan qualitatif. On ne remarque généralement pas une pente glissante tant qu'on n'y est pas, alors ne faisons pas le premier pas.
- J'ai été assez fortement affecté par l'argument ci-dessus sur la facilitation du débogage. J'aime le rythme visuel, dans le code d'infrastructure de bas niveau, de petites strophes de code du type « Do A. Check if it works. Faites B. Vérifiez si cela a fonctionné… etc" Parce que les lignes "Vérifier" sont l'endroit où vous placez le printf ou le point d'arrêt. Peut-être que tout le monde est plus intelligent, mais je finis par utiliser régulièrement cet idiome de point d'arrêt.
- En supposant que les valeurs de retour nommées, "try" est à peu près équivalente à
if err != nil { return }(je pense ?) J'aime personnellement les valeurs de retour nommées et, étant donné les avantages des décorateurs d'erreur, je soupçonne que la proportion de valeurs de retour err nommées va augmenter de façon monotone ; ce qui affaiblit les avantages de l'essai. - J'ai d'abord aimé la proposition d'avoir gofmt bénir le one-liner dans la ligne ci-dessus, mais dans l'ensemble, les IDE adopteront sans aucun doute cet idiome d'affichage de toute façon, et le one-liner sacrifierait l'avantage du débogage ici.
- Il semble assez probable que certaines formes d'imbrication d'expressions contenant "essayer" ouvriront la porte aux complicateurs de notre profession pour causer le même genre de ravages qu'ils ont avec les flux Java et les séparateurs, etc. Go a mieux réussi que la plupart des autres langages à priver les plus intelligents d'entre nous de la possibilité de démontrer leurs compétences.
Encore une fois, félicitations à la communauté pour la belle proposition propre et la discussion constructive.
 timbray
le 7 juil. 2019
timbray
le 7 juil. 2019
J'ai passé beaucoup de temps à explorer et à lire des bibliothèques ou des morceaux de code inconnus au cours des dernières années. Malgré l'ennui, if err != nil fournit un idiome très facile à lire, bien que verbeux verticalement. L'esprit de ce que try() essaie d'accomplir est noble, et je pense qu'il y a quelque chose à faire, mais cette fonctionnalité semble mal priorisée et que la proposition voit le jour trop tôt (c'est-à-dire qu'elle devrait venir après xerr et les génériques ont eu la chance de mariner dans une version stable pendant 6 à 12 mois).
L'introduction try() semble être une proposition noble et valable (par exemple , 29 % - ~40 % des déclarations de if sont destinées à la vérification de if err != nil ). À première vue, il semble que le passe-partout réducteur associé à la gestion des erreurs améliorera l'expérience des développeurs. Le compromis de l'introduction de try() se présente sous la forme d'une charge cognitive des cas spéciaux semi-subtils. L'une des plus grandes vertus de Go est qu'il est simple et qu'il y a très peu de charge cognitive requise pour faire quelque chose (par rapport à C++ où la spécification du langage est large et nuancée). Réduire une métrique quantitative (LoC de if err != nil ) en échange de l'augmentation de la métrique quantitative de la complexité mentale est une pilule difficile à avaler (c'est-à-dire la taxe mentale sur la ressource la plus précieuse dont nous disposons, le cerveau).
En particulier, les nouveaux cas spéciaux pour la façon dont try() est géré avec go , defer et les variables de retour nommées rendent try() assez magique pour rendre le code moins explicite de sorte que tous les auteurs ou lecteurs de code Go devront connaître ces nouveaux cas particuliers afin de lire ou d'écrire correctement Go et un tel fardeau n'existait pas auparavant. J'aime le fait qu'il existe des cas particuliers explicites pour ces situations - en particulier par rapport à l'introduction d'une forme de comportement indéfini, mais le fait qu'ils doivent exister en premier lieu indique que cela est incomplet pour le moment. Si les cas spéciaux concernaient autre chose que la gestion des erreurs, cela pourrait être acceptable, mais si nous parlons déjà de quelque chose qui pourrait avoir un impact jusqu'à 40 % de tous les LoC, ces cas spéciaux devront être formés dans l'ensemble de la communauté et cela augmente le coût de la charge cognitive de cette proposition à un niveau suffisamment élevé pour justifier des inquiétudes.
Il existe un autre exemple dans Go où les règles de cas particuliers sont déjà une pente cognitive glissante, à savoir les variables épinglées et non épinglées. Le besoin d'épingler des variables n'est pas difficile à comprendre dans la pratique, mais il est manqué car il y a un comportement implicite ici et cela provoque une incompatibilité entre l'auteur, le lecteur et ce qui se passe avec l'exécutable compilé au moment de l'exécution. Même avec des linters tels que scopelint , de nombreux développeurs ne semblent toujours pas saisir ce piège (ou pire, ils le savent mais le manquent parce que ce piège leur échappe). Certains des bogues d'exécution les plus inattendus et les plus difficiles à diagnostiquer des programmes fonctionnels proviennent de ce problème particulier (par exemple, N objets sont tous remplis avec la même valeur au lieu d'itérer sur une tranche et d'obtenir les valeurs distinctes attendues). Le domaine d'échec de try() est différent des variables épinglées, mais il y aura un impact sur la façon dont les gens écrivent le code en conséquence.
IMNSHO, les propositions xerr et génériques ont besoin de temps pour cuire en production pendant 6 à 12 mois avant de tenter de conquérir le passe-partout à partir de if err != nil . Les génériques ouvriront probablement la voie à une gestion des erreurs plus riche et à une nouvelle méthode idiomatique de gestion des erreurs. Une fois que la gestion des erreurs idiomatiques avec les génériques commence à émerger, alors et seulement alors, est-il logique de revoir une discussion autour try() ou autre.
Je ne prétends pas savoir comment les génériques auront un impact sur la gestion des erreurs, mais il me semble certain que les génériques seront utilisés pour créer des types riches qui seront presque certainement utilisés dans la gestion des erreurs. Une fois que les génériques ont imprégné les bibliothèques et ont été ajoutés à la gestion des erreurs, il peut y avoir un moyen évident de réutiliser les try() pour améliorer l'expérience des développeurs en ce qui concerne la gestion des erreurs.
Les points qui m'inquiètent sont :
try()n'est pas compliqué isolément, mais c'est une surcharge cognitive là où il n'y en avait pas auparavant.- En intégrant
err != nildans le comportement supposé detry(), le langage empêche l'utilisation deerrcomme moyen de communiquer l'état vers le haut de la pile. - Esthétiquement
try()ressemble à de l'intelligence forcée mais pas assez intelligente pour satisfaire le test explicite et évident que la plupart des langues Go apprécient. Comme la plupart des choses impliquant des critères subjectifs, c'est une question de goût et d'expérience personnelle et difficile à quantifier. - La gestion des erreurs avec les instructions
switch/caseet l'encapsulation des erreurs ne semblent pas affectées par cette proposition, et une occasion manquée, ce qui me porte à croire que cette proposition est une brique timide pour faire d'un inconnu inconnu un connu -connu (ou au pire, un connu-inconnu).
Enfin, la proposition try() ressemble à une nouvelle rupture dans le barrage qui retenait un flot de nuances spécifiques au langage comme ce à quoi nous avons échappé en laissant C++ derrière nous.
TL; DR : n'est pas une réponse #nevertry , c'est plutôt "pas maintenant, pas encore, et réfléchissons à cela à l'avenir après xerr et que les génériques arrivent à maturité dans l'écosystème. "
 sean-
le 7 juil. 2019
sean-
le 7 juil. 2019
Le # 32968 lié ci-dessus n'est pas exactement une contre-proposition complète, mais il s'appuie sur mon désaccord avec la dangereuse capacité d'imbrication que possède la macro try . Contrairement au # 32946, celui-ci est une proposition sérieuse, qui, je l'espère, manque de sérieux défauts (c'est à vous de voir, d'évaluer et de commenter, bien sûr). Extrait:
- _La macro
checkn'est pas une ligne : elle aide le plus là où de nombreux éléments répétitifs
les contrôles utilisant la même expression doivent être effectués à proximité._ - _Sa version implicite se compile déjà chez playground._
Contraintes de conception (respectées)
C'est un intégré, il ne s'imbrique pas dans une seule ligne, il permet bien plus de flux que try et n'a aucune attente quant à la forme d'un code à l'intérieur. Il n'encourage pas les retours nus.
exemple d'utilisation
// built-in 'check' macro signature:
func check(Condition bool) {}
check(err != nil) // explicit catch: label.
{
ucred, err := getUserCredentials(user)
remote, err := connectToApi(remoteUri)
err, session, usertoken := remote.Auth(user, ucred)
udata, err := session.getCalendar(usertoken)
catch: // sad path
ucred.Clear() // cleanup passwords
remote.Close() // do not leak sockets
return nil, 0, err // dress before leaving
}
// happy path
// implicit catch: label is above last statement
check(x < 4)
{
x, y = transformA(x, z)
y, z = transformB(x, y)
x, y = transformC(y, z)
break // if x was < 4 after any of above
}
J'espère que cela vous aidera, profitez-en !
ohir
le 7 juil. 2019
J'ai lu autant que je peux pour comprendre ce fil. Je suis en faveur de laisser les choses exactement telles qu'elles sont.
Mes raisons :
- Moi, et personne à qui j'ai enseigné Go n'a _jamais_ compris la gestion des erreurs
- Je me retrouve à ne jamais sauter un piège d'erreur parce qu'il est si facile de le faire sur-le-champ
De plus, je comprends peut-être mal la proposition, mais généralement, la construction try dans d'autres langages entraîne plusieurs lignes de code qui peuvent toutes potentiellement générer une erreur, et elles nécessitent donc des types d'erreur. Ajoutant de la complexité et souvent une sorte d'architecture d'erreur initiale et d'effort de conception.
Dans ces cas (et je l'ai fait moi-même), plusieurs blocs try sont ajoutés. qui allonge le code et éclipse l'implémentation.
Si l'implémentation Go de try diffère de celle des autres langages, alors encore plus de confusion surviendra.
Ma suggestion est de laisser la gestion des erreurs telle quelle
 camstuart
le 8 juil. 2019
camstuart
le 8 juil. 2019
Je sais que beaucoup de gens ont pesé, mais je voudrais ajouter ma critique de la spécification telle quelle.
La partie de la spécification qui me dérange le plus sont ces deux demandes :
Par conséquent, nous suggérons d'interdire try comme fonction appelée dans une instruction go.
...
Par conséquent, nous suggérons également d'interdire try en tant que fonction appelée dans une instruction différée.
Ce serait la première fonction intégrée dont cela est vrai (vous pouvez même modifier defer et go a panic ) car le résultat n'a pas besoin d'être ignoré. Créer une nouvelle fonction intégrée qui oblige le compilateur à accorder une attention particulière au flux de contrôle semble être une grande demande et rompt la cohérence sémantique de go. Tout autre jeton de flux de contrôle dans go n'est pas une fonction.
Un contre-argument à ma plainte est que pouvoir defer et go un panic est probablement un accident et pas très utile. Cependant, ce que je veux dire, c'est que la cohérence sémantique des fonctions dans go est rompue par cette proposition, non pas qu'il soit important que defer et go toujours un sens à utiliser. Il y a probablement beaucoup de fonctions non intégrées qui n'auraient jamais de sens d'utiliser defer ou go avec, mais il n'y a aucune raison explicite, sémantiquement, pour laquelle elles ne peuvent pas l'être. Pourquoi ce builtin arrive-t-il à s'exempter du contrat sémantique des fonctions en go ?
Je sais que @griesemer ne veut pas que des opinions esthétiques sur cette proposition soient injectées dans la discussion, mais je pense que l'une des raisons pour lesquelles les gens trouvent cette proposition esthétiquement révoltante est qu'ils peuvent sentir qu'elle ne correspond pas tout à fait à une fonction.
La proposition dit :
Nous proposons d'ajouter une nouvelle fonction intégrée appelée try with signature (pseudo-code)
func try(expr) (T1, T2, … Tn)
Sauf que ce n'est pas une fonction (ce que la proposition admet essentiellement). Il s'agit en fait d'une macro unique intégrée à la spécification du langage (si elle devait être acceptée). Il y a quelques problèmes avec cette signature.
Qu'est-ce que cela signifie pour une fonction d'accepter une expression générique comme argument, sans parler d'une expression appelée. Chaque fois que le mot "expression" est utilisé dans la spécification, cela signifie quelque chose comme une fonction non appelée. Comment se fait-il qu'une fonction "appelée" puisse être considérée comme une expression, alors que dans tous les autres contextes, ses valeurs de retour sont ce qui est sémantiquement actif. IE nous pensons à une fonction appelée comme étant ses valeurs de retour. Les exceptions, révélatrices, sont
goetdefer, qui sont tous deux des jetons bruts et non des fonctions intégrées.De plus, cette proposition obtient sa propre signature de fonction incorrecte, ou du moins cela n'a pas de sens, la signature réelle est :
func try(R1, R2, ... Rn) ((R|T)1, (R|T)2, ... (R|T)(n-1), ?Rn)
// where T is the return params of the function that try is being called from
// where `R` is a return value from a function, `Rn` must be an error
// try will return the R values if Rn is nil and not return Tn at all
// if Rn is not nil then the T values will be returned as well as Rn at the end
- La proposition n'inclut pas ce qui se passe dans les situations où try est appelé avec des arguments. Que se passe-t-il si
tryest appelé avec des arguments :
try(arg1, arg2,..., err)
Je pense que la raison pour laquelle cela n'est pas résolu est que try essaie d'accepter un argument expr qui représente en fait n nombre d'arguments de retour d'une fonction plus quelque chose d'autre, ce qui illustre davantage le fait que cette proposition rompt la cohérence sémantique de ce qu'est une fonction.
Ma dernière plainte contre cette proposition est qu'elle brise davantage la signification sémantique des fonctions intégrées. Je ne suis pas indifférent à l'idée que les fonctions intégrées doivent parfois être exemptées des règles sémantiques des fonctions "normales" (comme ne pas pouvoir les affecter à des variables, etc.), mais cette proposition crée un grand nombre d'exemptions du " règles "normales" qui semblent régir les fonctions à l'intérieur de golang.
Cette proposition fait effectivement try une nouvelle chose que go n'a pas eue, ce n'est pas tout à fait un jeton et ce n'est pas tout à fait une fonction, c'est les deux, ce qui semble être un mauvais précédent à créer en termes de création de cohérence sémantique tout au long la langue.
Si nous allons ajouter une nouvelle chose de contrôle de flux, je soutiens qu'il est plus logique d'en faire un jeton brut comme goto , et al. Je sais que nous ne sommes pas censés faire des propositions dans cette discussion, mais à titre d'exemple, je pense que quelque chose comme ça a beaucoup plus de sens :
f, err := os.Open("/dev/stdout")
throw err
Bien que cela ajoute une ligne de code supplémentaire, je pense que cela résout tous les problèmes que j'ai soulevés et élimine également toute la déficience des signatures de fonction "alternatives" avec try .
edit1 : note sur les exceptions aux cas defer et go où la fonction intégrée ne peut pas être utilisée, car les résultats seront ignorés, alors qu'avec try cela ne peut même pas vraiment l'être dit que la fonction a des résultats.
 nathanjsweet
le 8 juil. 2019
nathanjsweet
le 8 juil. 2019
@nathanjsweet la proposition que vous cherchez est #32611 :-)
networkimprov
le 8 juil. 2019
@nathanjsweet Une partie de ce que vous dites s'avère ne pas être le cas. Le langage ne permet pas d'utiliser defer ou go avec les fonctions pré-déclarées append cap complex imag len make new real . Il n'autorise pas non plus defer ou go avec les fonctions définies par les spécifications unsafe.Alignof unsafe.Offsetof unsafe.Sizeof .
ianlancetaylor
le 8 juil. 2019
Merci @nathanjsweet pour votre commentaire détaillé - @ianlancetaylor a déjà souligné que vos arguments sont techniquement incorrects. Permettez-moi de développer un peu:
1) Vous mentionnez que la partie de la spécification qui interdit try avec go et defer vous dérange le plus parce que try serait le premier intégré où cela est vrai. Ce n'est pas correct. Le compilateur n'autorise déjà pas, par exemple, defer append(a, 1) . Il en va de même pour les autres éléments intégrés qui produisent un résultat qui est ensuite déposé sur le sol. Cette restriction s'appliquerait également à try d'ailleurs (sauf lorsque try ne renvoie pas de résultat). (La raison pour laquelle nous avons même mentionné ces restrictions dans le document de conception est d'être aussi minutieux que possible - elles ne sont vraiment pas pertinentes dans la pratique. De plus, si vous lisez précisément le document de conception, il ne dit pas que nous ne pouvons pas gagner try fonctionne avec go ou defer - cela suggère simplement que nous l'interdisons ; principalement comme mesure pratique. C'est une "grande demande" - pour reprendre vos mots - pour faire try fonctionne avec go et defer même si c'est pratiquement inutile.)
2) Vous suggérez que certaines personnes trouvent try "esthétiquement révoltant" parce qu'il ne s'agit pas techniquement d'une fonction, puis vous vous concentrez sur les règles spéciales de la signature. Considérez new , make , append , unsafe.Offsetof : ils ont tous des règles spécialisées que nous ne pouvons pas exprimer avec une fonction Go ordinaire. Regardez unsafe.Offsetof qui a exactement le type d'exigence syntaxique pour son argument (il doit s'agir d'un champ struct !) que nous exigeons de l'argument pour try (il doit s'agir d'une valeur unique de type error ou un appel de fonction renvoyant un error comme dernier résultat). Nous n'exprimons pas ces signatures formellement dans la spécification, car aucun de ces éléments intégrés ne s'intègre dans le formalisme existant - s'ils le faisaient, ils n'auraient pas besoin d'être intégrés. Au lieu de cela, nous exprimons leurs règles en prose. C'est _ pourquoi _ ce sont des éléments intégrés qui _ sont _ la trappe d'évacuation de Go, par conception, dès le premier jour. Notez également que la doc de conception est très explicite à ce sujet.
3) La proposition traite également de ce qui se passe lorsque try est appelé avec des arguments (plus d'un) : ce n'est pas autorisé. La documentation de conception indique explicitement que try accepte une (une) expression d'argument entrante.
4) Vous déclarez que "cette proposition brise la signification sémantique des fonctions intégrées". Nulle part Go ne limite ce qu'un intégré peut faire et ce qu'il ne peut pas faire. Nous avons ici une totale liberté.
Merci.
griesemer
le 8 juil. 2019
@griesemer
Notez également que la doc de conception est très explicite à ce sujet.
Pouvez-vous le signaler. J'ai été surpris de lire cela.
Vous déclarez que "cette proposition brise la signification sémantique des fonctions intégrées". Nulle part Go ne limite ce qu'un intégré peut faire et ce qu'il ne peut pas faire. Nous avons ici une totale liberté.
Je pense que c'est un point juste. Cependant, je pense qu'il y a ce qui est énoncé dans les documents de conception et ce qui ressemble à "go" (ce dont Rob Pike parle beaucoup). Je pense qu'il est juste pour moi de dire que la proposition try élargit les façons dont les fonctions intégrées enfreignent les règles selon lesquelles nous nous attendons à ce que les fonctions se comportent, et j'ai reconnu que je comprends pourquoi cela est nécessaire pour d'autres fonctions intégrées , mais je pense que dans ce cas, l'expansion de la violation des règles est :
- Contre-intuitif à certains égards. Il s'agit de la première fonction qui modifie la logique de flux de contrôle d'une manière qui ne déroule pas la pile (comme
panicetos.Exitdo) - Une nouvelle exception au fonctionnement des conventions d'appel d'une fonction. Vous avez donné l'exemple de
unsafe.Offsetofcomme cas où il y a une exigence syntaxique pour un appel de fonction (il est surprenant pour moi en fait que cela provoque une erreur de compilation, mais c'est un autre problème), mais l'exigence syntaxique , dans ce cas, est une exigence syntaxique différente de celle que vous avez indiquée.unsafe.Offsetofnécessite un argument, alors quetrynécessite une expression qui ressemblerait, dans tous les autres contextes, à une valeur renvoyée par une fonction (c'est-à-diretry(os.Open("/dev/stdout"))) et pourrait être supposée en toute sécurité dans tous les autres contextes pour ne renvoyer qu'une seule valeur (sauf si l'expression ressemblait àtry(os.Open("/dev/stdout")...)).
nathanjsweet
le 8 juil. 2019
@nathanjsweet a écrit :
Notez également que la doc de conception est très explicite à ce sujet.
Pouvez-vous le signaler. J'ai été surpris de lire cela.
C'est dans la section "Conclusions" de la proposition :
Dans Go, les éléments intégrés sont le mécanisme d'échappement du langage de choix pour les opérations qui sont irrégulières d'une certaine manière mais qui ne justifient pas une syntaxe spéciale.
Je suis surpris que vous l'ayez raté ;-)
ngrilly
le 8 juil. 2019
@ngrilly Je ne veux pas dire dans cette proposition, je veux dire dans la spécification du langage go. J'ai eu l'impression que @griesemer disait que la spécification de langage go appelle les fonctions intégrées comme étant le mécanisme particulièrement utile pour briser la convention syntaxique.
nathanjsweet
le 8 juil. 2019
@nathanjsweet
Contre-intuitif à certains égards. Il s'agit de la première fonction qui modifie la logique de flux de contrôle d'une manière qui ne déroule pas la pile (comme panique et os.Exit do)
Je ne pense pas que os.Exit déroule la pile de manière utile. Il termine le programme immédiatement sans exécuter de fonctions différées. Il me semble que os.Exit est l'étrange ici, car panic et try exécutent des fonctions différées et remontent la pile.
velovix
le 8 juil. 2019
Je suis d'accord que os.Exit est l'intrus, mais il doit en être ainsi. os.Exit arrête toutes les goroutines ; cela n'aurait aucun sens d'exécuter uniquement les fonctions différées de la goroutine qui appelle os.Exit . Il doit soit exécuter toutes les fonctions différées, soit aucune. Et c'est beaucoup plus facile d'en exécuter aucun.
ianlancetaylor
le 8 juil. 2019
Exécuté tryhard sur notre base de code et voici ce que nous avons :
--- stats ---
15298 (100.0% of 15298) func declarations
3026 ( 19.8% of 15298) func declarations returning an error
33941 (100.0% of 33941) statements
7765 ( 22.9% of 33941) if statements
3747 ( 48.3% of 7765) if <err> != nil statements
131 ( 3.5% of 3747) <err> name is different from "err"
1847 ( 49.3% of 3747) return ..., <err> blocks in if <err> != nil statements
1900 ( 50.7% of 3747) complex error handler in if <err> != nil statements; cannot use try
19 ( 0.5% of 3747) non-empty else blocks in if <err> != nil statements; cannot use try
1789 ( 47.7% of 3747) try candidates
Tout d'abord, je tiens à préciser que parce que Go (avant 1.13) manque de contexte dans les erreurs, nous avons implémenté notre propre type d'erreur qui implémente l'interface error , certaines fonctions sont déclarées comme renvoyant foo.Error au lieu de error , et il semble que cet analyseur n'ait pas compris cela, donc ces résultats ne sont pas "équitables".
J'étais dans le camp du "oui ! faisons-le", et je pense que ce sera une expérience intéressante pour les bêtas 1.13 ou 1.14, mais je suis préoccupé par les _" 47,7% ... essayez les candidats"_. Cela signifie maintenant qu'il y a 2 façons de faire les choses, ce que je n'aime pas. Cependant, il existe également 2 façons de créer un pointeur ( new(Foo) vs &Foo{} ) ainsi que 2 façons de créer une tranche ou une carte avec make([]Foo) et []Foo{} .
Maintenant, je suis sur le camp de "let's _try_ this" :^) et je vois ce que la communauté en pense. Peut-être allons-nous changer nos modèles de codage pour qu'ils soient paresseux et cesser d'ajouter du contexte, mais peut-être que ce n'est pas grave si les erreurs obtiennent un meilleur contexte à partir de l' xerrors qui arrive de toute façon.
Goodwine
le 8 juil. 2019
Merci, @Goodwine pour avoir fourni des données plus concrètes !
(En passant, j'ai apporté une petite modification à tryhard hier soir afin qu'il divise le nombre de "gestionnaires d'erreurs complexes" en deux comptes : les gestionnaires complexes et les retours de la forme return ..., expr où le dernier la valeur du résultat n'est pas <err> . Cela devrait fournir des informations supplémentaires.)
griesemer
le 8 juil. 2019
Qu'en est-il de modifier la proposition pour qu'elle soit variadique au lieu de cet argument d'expression étrange ?
Cela résoudrait beaucoup de problèmes. Dans le cas où les gens voudraient simplement renvoyer l'erreur, la seule chose qui changerait serait le variadique explicite ... . PAR EXEMPLE:
try(os.Open("/dev/stdout")...)
cependant, les personnes qui souhaitent une situation plus flexible peuvent faire quelque chose comme :
f, err := os.Open("/dev/stdout")
try(WrapErrorf(err, "whatever wrap does: %v"))
Une chose que cette idée fait est de rendre le mot try moins approprié, mais il maintient la rétrocompatibilité.
nathanjsweet
le 8 juil. 2019
@nathanjsweet a écrit :
Je ne veux pas dire dans cette proposition, je veux dire dans la spécification du langage go.
Voici les extraits que vous recherchiez dans la spécification de langue :
Dans la section "Instructions d'expression":
Les fonctions intégrées suivantes ne sont pas autorisées dans le contexte de l'instruction :
append cap complex imag len make new real unsafe.Alignof unsafe.Offsetof unsafe.Sizeof
Dans les sections "Instructions Go" et "Instructions différées" :
Les appels de fonctions intégrées sont limités comme pour les instructions d'expression.
Dans la section "Fonctions intégrées":
Les fonctions intégrées n'ont pas de types Go standard, elles ne peuvent donc apparaître que dans les expressions d'appel ; elles ne peuvent pas être utilisées comme valeurs de fonction.
@nathanjsweet a écrit :
J'ai eu l'impression que @griesemer disait que la spécification de langage go appelle les fonctions intégrées comme étant le mécanisme particulièrement utile pour briser la convention syntaxique .
Les fonctions intégrées ne cassent pas les conventions syntaxiques de Go (parenthèses, virgules entre les arguments, etc.). Ils utilisent la même syntaxe que les fonctions définies par l'utilisateur, mais ils permettent des choses qui ne peuvent pas être faites dans les fonctions définies par l'utilisateur.
ngrilly
le 8 juil. 2019
@nathanjsweet Cela a déjà été envisagé (en fait c'était un oubli) mais cela rend try non extensible. Voir https://go-review.googlesource.com/c/proposal/+/181878 .
Plus généralement, je pense que vous concentrez votre critique sur la mauvaise chose : les règles spéciales pour l'argument try ne sont vraiment pas un problème - pratiquement chaque intégré a des règles spéciales.
griesemer
le 8 juil. 2019
@griesemer merci d'avoir travaillé dessus et d'avoir pris le temps de répondre aux préoccupations de la communauté. Je suis sûr que vous avez répondu à beaucoup des mêmes questions à ce stade. Je me rends compte qu'il est vraiment difficile de résoudre ces problèmes et de maintenir la rétrocompatibilité en même temps. Merci!
nathanjsweet
le 8 juil. 2019
@nathanjsweet Concernant votre commentaire ici :
Voir la section Conclusion qui parle en évidence du rôle des éléments intégrés dans Go.
En ce qui concerne vos commentaires sur try étendant les éléments intégrés de différentes manières : oui, l'exigence que unsafe.Offsetof met sur son argument est différente de celle de try . Mais les deux attendent syntaxiquement une expression. Les deux ont des restrictions supplémentaires sur cette expression. L'exigence de try s'intègre si facilement dans la syntaxe de Go qu'aucun des outils d'analyse frontale n'a besoin d'être ajusté. Je comprends que cela me semble inhabituel pour vous, mais ce n'est pas la même chose qu'une raison technique contre cela.
griesemer
le 8 juil. 2019
@griesemer le dernier _tryhard_ compte les "gestionnaires d'erreurs complexes" mais pas les "gestionnaires d'erreurs à instruction unique". Cela pourrait-il être ajouté?
networkimprov
le 8 juil. 2019
@networkimprov Qu'est-ce qu'un gestionnaire d'erreurs à instruction unique ? Un bloc if contenant une seule instruction de non-retour ?
griesemer
le 8 juil. 2019
@griesemer , un gestionnaire d'erreurs à instruction unique est un bloc if err != nil qui contient _toute_ instruction unique, y compris un retour.
networkimprov
le 8 juil. 2019
@networkimprov Terminé. Les "gestionnaires complexes" sont désormais divisés en "instruction unique puis branche" et "complexe puis branche".
Cela dit, notez que ces nombres peuvent être trompeurs : par exemple, ces nombres incluent toute instruction if qui vérifie n'importe quelle variable par rapport à zéro (si -err="" qui est maintenant la valeur par défaut pour tryhard ). Je devrais régler ça. En bref, tel quel tryhard surestime de beaucoup le nombre d'opportunités de traitement complexes ou à instruction unique. Pour un exemple, voir archive/tar/common.go , ligne 701.
griesemer
le 8 juil. 2019
@networkimprov tryhard fournit désormais des comptes plus précis sur les raisons pour lesquelles une vérification d'erreur n'est pas un candidat try . Le nombre total de décomptes de try est inchangé, mais le nombre d'opportunités pour des gestionnaires plus simples et complexes est désormais plus précis (et environ 50 % plus petit qu'auparavant, car avant tout then complexe branche d'une instruction if était considérée tant que le if contenait une vérification <varname> != nil , qu'elle impliquait ou non une vérification d'erreur).
griesemer
le 9 juil. 2019
Si quelqu'un veut essayer try d'une manière un peu plus pratique, j'ai créé ici un terrain de jeu WASM avec une implémentation prototype :
https://ccbrown.github.io/wasm-go-playground/experimental/try-builtin/
Et si quelqu'un est réellement intéressé par la compilation de code localement avec try, j'ai un fork Go avec ce que je pense être une implémentation entièrement fonctionnelle / à jour ici: https://github.com/ccbrown/go/pull/1
 ccbrown
le 9 juil. 2019
ccbrown
le 9 juil. 2019
j'aime "essayer". Je trouve que la gestion de l'état local d'err et l'utilisation de := vs = avec err, avec les importations associées, sont une distraction régulière. aussi, je ne vois pas cela comme créant deux façons de faire la même chose, plus comme deux cas, l'un où vous voulez transmettre une erreur sans agir dessus, l'autre où vous voulez explicitement le gérer dans la fonction appelante par exemple. enregistrement.
 ronpastore
le 9 juil. 2019
ronpastore
le 9 juil. 2019
J'ai couru tryhard contre un petit projet interne sur lequel j'ai travaillé il y a plus d'un an. Le répertoire en question contient le code de 3 serveurs ("microservices", je suppose), un crawler qui s'exécute périodiquement en tant que tâche cron et quelques outils de ligne de commande. Il dispose également de tests unitaires assez complets. (FWIW, les différentes pièces fonctionnent sans problème depuis plus d'un an, et il s'est avéré simple de déboguer et de résoudre tous les problèmes qui surviennent)
Voici les statistiques :
--- stats ---
370 (100.0% of 370) func declarations
115 ( 31.1% of 370) func declarations returning an error
1159 (100.0% of 1159) statements
258 ( 22.3% of 1159) if statements
123 ( 47.7% of 258) if <err> != nil statements
64 ( 52.0% of 123) try candidates
0 ( 0.0% of 123) <err> name is different from "err"
--- non-try candidates (-l flag lists file positions) ---
54 ( 43.9% of 123) { return ... zero values ..., expr }
2 ( 1.6% of 123) single statement then branch
3 ( 2.4% of 123) complex then branch; cannot use try
1 ( 0.8% of 123) non-empty else branch; cannot use try
Quelques commentaires :
1) 50 % de toutes les instructions if de cette base de code effectuaient une vérification des erreurs, et try pourraient en remplacer la moitié. Cela signifie qu'un quart de toutes les déclarations if dans cette (petite) base de code sont une version tapée de try .
2) Je dois noter que c'est étonnamment élevé pour moi, car quelques semaines avant de commencer ce projet, il m'est arrivé de lire une famille de fonctions d'assistance internes ( status.Annotate ) qui annotent un message d'erreur mais préservent le Code d'état gRPC. Par exemple, si vous appelez un RPC et qu'il renvoie une erreur avec un code d'état associé de PERMISSION_DENIED, l'erreur renvoyée par cette fonction d'assistance aura toujours un code d'état associé de PERMISSION_DENIED (et théoriquement, si ce code d'état associé a été propagé à tous les chemin jusqu'à un gestionnaire RPC, alors le RPC échouerait avec ce code d'état associé). J'avais résolu d'utiliser ces fonctions pour tout sur ce nouveau projet. Mais apparemment, pour 50% de toutes les erreurs, j'ai simplement propagé une erreur non annotée. (Avant de courir tryhard , j'avais prédit 10%).
3) status.Annotate conserve les erreurs nil (c'est-à-dire status.Annotatef(err, "some message: %v", x) renverra nil ssi err == nil ). J'ai parcouru tous les candidats non essayés de la première catégorie, et il semble que tous se prêteraient à la réécriture suivante :
```
// Before
enc, err := keymaster.NewEncrypter(encKeyring)
if err != nil {
return status.Annotate(err, "failed to create encrypter")
}
// After
enc, err := keymaster.NewEncrypter(encKeyring)
try(status.Annotate(err, "failed to create encrypter"))
```
To be clear, I'm not saying this transformation is always necessarily a good idea, but it seemed worth mentioning since it boosts the count significantly to a bit under half of all `if` statements.
4) L'annotation d'erreur basée sur defer semble quelque peu orthogonale à try , pour être honnête, car elle fonctionnera avec et sans try . Mais en parcourant le code de ce projet, puisque j'examinais de près la gestion des erreurs, j'ai remarqué plusieurs cas où les erreurs générées par l'appelé auraient plus de sens. Par exemple, j'ai remarqué plusieurs instances de code appelant des clients gRPC comme ceci :
```
resp, err := s.someClient.SomeMethod(ctx, req)
if err != nil {
return ..., status.Annotate(err, "failed to call SomeMethod")
}
```
This is actually a bit redundant in retrospect, since gRPC already prefixes its errors with something like "/Service.Method to [ip]:port : ".
There was also code that called standard library functions using the same pattern:
```
hreq, err := http.NewRequest("GET", targetURL, nil)
if err != nil {
return status.Annotate(err, "http.NewRequest failed")
}
```
In retrospect, this code demonstrates two issues: first, `http.NewRequest` isn't calling a gRPC API, so using `status.Annotate` was unnecessary, and second, assuming the standard library also return errors with callee context, this particular use of error annotation was unnecessary (although I am fairly certain the standard library does not consistently follow this pattern).
En tout cas, j'ai pensé que c'était un exercice intéressant de revenir sur ce projet et de regarder attentivement comment il gérait les erreurs.
Une chose, @griesemer : est-ce que tryhard a le bon dénominateur pour les "candidats sans essai" ?
Edit: répondu ci-dessous, j'ai mal lu les statistiques.
balasanjay
le 9 juil. 2019
EDIT : Ce qui était censé être un retour d'information a été transformé en une proposition, ce qu'on nous a explicitement demandé de ne pas faire ici. J'ai déplacé mon commentaire vers un point essentiel .
 subfuzion
le 9 juil. 2019
subfuzion
le 9 juil. 2019
@balasanjay Merci pour votre commentaire factuel ; c'est très utile.
Concernant votre question sur tryhard : les "candidats non essayés" (meilleure suggestion de titre bienvenue) sont simplement le nombre de cas où l'instruction if a satisfait à tous les critères d'une "vérification d'erreur" (c'est-à-dire , nous avions ce qui ressemblait à une affectation à une variable d'erreur <err> , suivie d'une vérification if <err> != nil dans la source), mais où nous ne pouvons pas facilement utiliser try cause de le code dans les blocs if . Plus précisément, dans l'ordre d'apparition dans la sortie "candidats non essayés", il s'agit d'instructions if qui ont une instruction return qui renvoie autre chose que <err> à la fin, des instructions if avec une seule instruction return (ou autre) plus complexe, des instructions if avec plusieurs instructions dans la branche "alors" et des instructions if avec branche else non vide. Certaines de ces instructions if peuvent avoir plusieurs de ces conditions satisfaites simultanément, de sorte que ces chiffres ne s'additionnent pas. Ils sont destinés à donner une idée de ce qui n'a pas fonctionné pour que try soit utilisable.
J'ai fait les ajustements les plus récents à cela aujourd'hui (vous avez exécuté la dernière version). Avant le dernier changement, certaines de ces conditions étaient comptées même s'il n'y avait pas de vérification d'erreur impliquée, ce qui semblait moins logique car il semblait que try ne pouvait pas être utilisé dans de nombreux autres cas alors qu'en fait try n'avait pas de sens dans ces cas en premier lieu.
Mais surtout, pour une base de code donnée, le nombre total de candidats try n'a pas changé avec ces raffinements, puisque les conditions pertinentes pour try sont restées les mêmes.
Si vous avez une meilleure suggestion comment et/ou quoi mesurer, je serais heureux de l'entendre. J'ai fait plusieurs ajustements en fonction des commentaires de la communauté. Merci.
griesemer
le 9 juil. 2019
@subfuzion Merci pour votre commentaire, mais nous ne recherchons pas de propositions alternatives. Veuillez consulter https://github.com/golang/go/issues/32437#issuecomment -501878888 . Merci.
griesemer
le 9 juil. 2019
Dans l'intérêt d'être compté, quel que soit le résultat :
Je suis d'avis, avec mon équipe, que si le framework try tel que proposé par Rob est une idée raisonnable et intéressante, il n'atteint pas le niveau où il serait approprié en tant que fonction intégrée. Un package de bibliothèque standard serait une approche beaucoup plus appropriée jusqu'à ce que les modèles d'utilisation soient établis dans la pratique. Si try arrivait dans le langage de cette façon, nous l'utiliserions dans un certain nombre d'endroits différents.
Sur une note plus générale, la combinaison de Go d'un langage de base très stable et d'une bibliothèque standard très riche mérite d'être préservée. Plus l'équipe linguistique évolue lentement sur les changements de langage de base, mieux c'est. Le pipeline x -> stdlib reste une approche solide pour ce genre de choses.
 mattparlmer
le 9 juil. 2019
mattparlmer
le 9 juil. 2019
@griesemer Ah, désolé. J'ai mal interprété les statistiques, il utilise le compteur "if err != nil states" (123) comme dénominateur, et non le compteur "try candidates" (64) comme dénominateur. Je vais supprimer cette question.
Merci!
balasanjay
le 9 juil. 2019
@mattpalmer Les modèles d'utilisation se sont établis depuis environ une décennie. Ce sont ces modèles d'utilisation exacts qui ont directement influencé la conception de try . À quels modèles d'utilisation faites-vous référence ?
griesemer
le 9 juil. 2019
@griesemer Désolé, c'est de ma faute - ce qui a commencé dans mon esprit comme expliquant ce qui me dérangeait à propos try s'est transformé en sa propre proposition pour faire valoir mon point de ne pas l'ajouter. Cela allait clairement à l'encontre des règles de base énoncées (sans oublier que contrairement à cette proposition de nouvelle fonction intégrée, elle introduit un nouvel opérateur). Serait-il utile de supprimer le commentaire pour rationaliser la conversation (ou est-ce considéré comme une mauvaise forme) ?
subfuzion
le 9 juil. 2019
@subfuzion Je ne m'en soucierais pas. C'est une suggestion controversée et il y a beaucoup de propositions. Beaucoup sont bizarres
fbnz156
le 9 juil. 2019
Nous avons réitéré cette conception plusieurs fois et sollicité les commentaires de nombreuses personnes avant de nous sentir suffisamment à l'aise pour la publier et recommander de la faire passer à la phase d'expérimentation réelle, mais nous n'avons pas encore fait l'expérience. Il est logique de revenir à la planche à dessin si l'expérience échoue, ou si les commentaires nous disent à l'avance qu'elle échouera clairement.
@griesemer pouvez-vous élaborer sur les mesures spécifiques que l'équipe utilisera pour établir le succès ou l'échec de l'expérience ?
 iand
le 9 juil. 2019
iand
le 9 juil. 2019
@moi et
J'ai posé cette question à @rsc il y a quelque temps (https://github.com/golang/go/issues/32437#issuecomment-503245958):
@rsc
Il ne manquera pas d'endroits où cette commodité peut être placée. Quelle métrique est recherchée qui prouvera la substance du mécanisme en dehors de cela? Existe-t-il une liste de cas classés de gestion des erreurs ? Comment la valeur sera-t-elle dérivée des données alors qu'une grande partie du processus public est motivée par le sentiment ?
La réponse était volontaire, mais sans intérêt et manquant de substance (https://github.com/golang/go/issues/32437#issuecomment-503295558) :
La décision est basée sur la façon dont cela fonctionne dans de vrais programmes. Si les gens nous montrent que try est inefficace dans la majeure partie de leur code, ce sont des données importantes. Le processus est piloté par ce type de données. Il n'est pas motivé par le sentiment.
Un sentiment supplémentaire a été proposé (https://github.com/golang/go/issues/32437#issuecomment-503408184) :
J'ai été surpris de trouver un cas dans lequel
trya conduit à un code clairement meilleur, d'une manière qui n'avait pas été discutée auparavant.
Finalement, j'ai répondu à ma propre question "Existe-t-il une liste de cas de gestion d'erreurs classés ?". Il y aura effectivement 6 modes de gestion des erreurs - manuel direct, manuel direct, manuel indirect, automatique direct, automatique direct, automatique indirect. Actuellement, il n'est courant d'utiliser que 2 de ces modes. Les modes indirects, qui consacrent beaucoup d'efforts à leur facilitation, semblent fortement prohibitifs pour la plupart des Gophers vétérans et cette préoccupation est apparemment ignorée. (https://github.com/golang/go/issues/32437#issuecomment-507332843).
De plus, j'ai suggéré que les transformations automatisées soient vérifiées avant la transformation pour essayer de garantir la valeur des résultats (https://github.com/golang/go/issues/32437#issuecomment-507497656). Au fil du temps, heureusement, un plus grand nombre des résultats proposés semblent avoir de meilleures rétrospectives, mais cela n'aborde toujours pas l'impact des méthodes indirectes de manière sobre et concertée. Après tout (à mon avis), tout comme les utilisateurs doivent être traités comme hostiles, les développeurs doivent être traités comme des paresseux.
L'échec de l'approche actuelle pour manquer des candidats précieux a également été souligné (https://github.com/golang/go/issues/32437#issuecomment-507505243).
Je pense qu'il vaut la peine d'être bruyant sur le fait que ce processus fait généralement défaut et notamment sourd.
daved
le 9 juil. 2019
@iand La réponse donnée par @rsc est toujours valable. Je ne sais pas quelle partie de cette réponse "manque de substance" ou ce qu'il faut pour être "inspirant". Mais laissez-moi essayer d'ajouter plus de "substance":
Le but du processus d'évaluation de la proposition est d'identifier en fin de compte "si un changement a produit les avantages attendus ou créé des coûts inattendus" (étape 5 du processus).
Nous avons passé l'étape 1 : L'équipe Go a sélectionné des propositions spécifiques qui semblent valoir la peine d'être acceptées ; cette proposition en est une. Nous ne l'aurions pas choisi si nous n'y avions pas beaucoup réfléchi et jugé que cela en valait la peine. Plus précisément, nous pensons qu'il existe une quantité importante de passe-partout dans le code Go uniquement lié à la gestion des erreurs. La proposition ne sort pas non plus de nulle part - nous en discutons depuis plus d'un an sous diverses formes.
Nous sommes actuellement à l'étape 2, donc encore assez loin d'une décision finale. L'étape 2 consiste à recueillir les commentaires et les préoccupations - qui semblent être nombreux. Mais pour être clair ici : jusqu'à présent, il n'y avait qu'un seul commentaire signalant une lacune _technique_ de conception, que nous avons corrigée . Il y avait aussi pas mal de commentaires avec des données concrètes basées sur du code réel qui indiquaient que try réduirait en effet le passe-partout et simplifierait le code ; et il y avait quelques commentaires - également basés sur des données sur du code réel - qui montraient que try n'aiderait pas beaucoup. Ces commentaires concrets, basés sur des données réelles ou soulignant des lacunes techniques, sont exploitables et très utiles. Nous en tiendrons absolument compte.
Et puis il y a eu la grande quantité de commentaires qui sont essentiellement des sentiments personnels. C'est moins exploitable. Cela ne veut pas dire que nous l'ignorons. Mais ce n'est pas parce que nous nous en tenons au processus que nous sommes "sourds".
Concernant ces commentaires : Il y a peut-être deux, peut-être trois douzaines d'opposants virulents à cette proposition - vous savez qui vous êtes. Ils dominent cette discussion avec des messages fréquents, parfois plusieurs par jour. Il y a peu de nouvelles informations à en tirer. L'augmentation du nombre de publications ne reflète pas non plus un sentiment "plus fort" de la part de la communauté ; cela signifie simplement que ces personnes sont plus vocales que d'autres.
griesemer
le 9 juil. 2019
@iand La réponse donnée par @rsc est toujours valable. Je ne sais pas quelle partie de cette réponse "manque de substance" ou ce qu'il faut pour être "inspirant". Mais laissez-moi essayer d'ajouter plus de "substance":
@griesemer Je suis sûr que ce n'était pas intentionnel, mais je voudrais noter qu'aucun des mots que vous avez cités n'était de moi mais d'un commentateur ultérieur.
Cela mis à part, j'espère qu'en plus de réduire le passe-partout et de simplifier le succès de try sera jugé sur la question de savoir s'il nous permet d'écrire un code meilleur et plus clair.
iand
le 9 juil. 2019
@iand Indeed - c'était juste un oubli de ma part. Mes excuses.
Nous croyons que try nous permet d'écrire du code plus lisible - et la plupart des preuves que nous avons reçues du code réel et nos propres expériences avec tryhard montrent des nettoyages importants. Mais la lisibilité est plus subjective et plus difficile à quantifier.
griesemer
le 9 juil. 2019
@griesemer
À quels modèles d'utilisation faites-vous référence ?
Je fais référence aux modèles d'utilisation qui se développeront autour try au fil du temps, et non au modèle de contrôle nul existant pour la gestion des erreurs. Le potentiel d'utilisation abusive et d'abus est une grande inconnue, en particulier avec l'afflux continu de programmeurs qui ont utilisé des versions sémantiquement différentes de try-catch dans d'autres langues.
Tout cela et les considérations sur la stabilité à long terme du langage de base m'amènent à penser que l'introduction de cette fonctionnalité au niveau des packages x ou de la bibliothèque standard (soit en tant que package errors/try soit en tant que errors.Try() ) serait préférable de l'introduire en tant que fonction intégrée.
mattparlmer
le 9 juil. 2019
@mattparlmer Corrigez-moi si je me trompe, mais je pense que cette proposition devrait être dans le runtime Go afin d'utiliser les g, m (nécessaires pour remplacer le flux d'exécution).
fbnz156
le 9 juil. 2019
@fabian-f
@mattparlmer Corrigez-moi si je me trompe, mais je pense que cette proposition devrait être dans le runtime Go afin d'utiliser les g, m (nécessaires pour remplacer le flux d'exécution).
Ce n'est pas le cas; comme le note la documentation de conception , il est implémentable en tant que transformation d'arbre de syntaxe au moment de la compilation.
Cela est possible car la sémantique de try peut être entièrement exprimée en termes de if et return ; il ne "remplace pas vraiment le flux d'exécution" pas plus que if et return ne le font.
dpinela
le 9 juil. 2019
Voici un rapport tryhard de la base de code Go de 300 000 lignes de mon entreprise :
Exécution initiale :
--- stats ---
13879 (100.0% of 13879) func declarations
4381 ( 31.6% of 13879) func declarations returning an error
38435 (100.0% of 38435) statements
8028 ( 20.9% of 38435) if statements
4496 ( 56.0% of 8028) if <err> != nil statements
453 ( 10.1% of 4496) try candidates
4 ( 0.1% of 4496) <err> name is different from "err"
--- non-try candidates (-l flag lists file positions) ---
3066 ( 68.2% of 4496) { return ... zero values ..., expr }
356 ( 7.9% of 4496) single statement then branch
345 ( 7.7% of 4496) complex then branch; cannot use try
63 ( 1.4% of 4496) non-empty else branch; cannot use try
Nous avons une convention d'utilisation du package errgo de juju (https://godoc.org/github.com/juju/errgo) pour masquer les erreurs et leur ajouter des informations de trace de pile, ce qui empêcherait la plupart des réécritures de se produire. Cela signifie qu'il est peu probable que nous adoptions try , pour la même raison que nous évitons généralement les retours d'erreur nus.
Puisqu'il semble que cela pourrait être une mesure utile, j'ai supprimé les appels errgo.Mask() (qui renvoient l'erreur sans annotation) et j'ai réexécuté tryhard . Il s'agit d'une estimation du nombre de vérifications d'erreurs qui pourraient être réécrites si nous n'utilisions pas errgo :
--- stats ---
13879 (100.0% of 13879) func declarations
4381 ( 31.6% of 13879) func declarations returning an error
38435 (100.0% of 38435) statements
8028 ( 20.9% of 38435) if statements
4496 ( 56.0% of 8028) if <err> != nil statements
3114 ( 69.3% of 4496) try candidates
7 ( 0.2% of 4496) <err> name is different from "err"
--- non-try candidates (-l flag lists file positions) ---
381 ( 8.5% of 4496) { return ... zero values ..., expr }
358 ( 8.0% of 4496) single statement then branch
345 ( 7.7% of 4496) complex then branch; cannot use try
63 ( 1.4% of 4496) non-empty else branch; cannot use try
Donc, je suppose que ~ 70% des retours d'erreur seraient autrement compatibles avec try .
Enfin, ma principale préoccupation concernant la proposition ne semble être reflétée dans aucun des commentaires que j'ai lus ni dans les résumés de discussion :
Cette proposition augmente considérablement le coût relatif des erreurs d'annotation.
Actuellement, le coût marginal de l'ajout d'un contexte à une erreur est très faible ; c'est à peine plus que de taper la chaîne de format. Si cette proposition était adoptée, je crains que les ingénieurs ne préfèrent de plus en plus l'esthétique offerte par try , à la fois parce que cela rend leur code "plus élégant" (ce que je suis triste de dire est une considération pour certaines personnes, d'après mon expérience), et nécessite maintenant un bloc supplémentaire pour ajouter du contexte. Ils pourraient le justifier en se basant sur un argument de "lisibilité", comment l'ajout de contexte étend la méthode de 3 lignes supplémentaires et détourne le lecteur du point principal. Je pense que les bases de code d'entreprise sont différentes de la bibliothèque standard Go dans le sens où le fait de faciliter la bonne action a probablement un impact mesurable sur la qualité du code résultant, les revues de code sont de qualité variable et les pratiques d'équipe varient indépendamment les unes des autres . Quoi qu'il en soit, comme vous l'avez déjà dit, nous ne pourrions toujours pas adopter try pour notre base de code.
Merci pour la considération
 robfig
le 9 juil. 2019
robfig
le 9 juil. 2019
@mattparlmer
Tout cela et les considérations sur la stabilité à long terme du langage de base m'amènent à penser que l'introduction de cette fonctionnalité au niveau des packages x ou de la bibliothèque standard (soit en tant que package
errors/trysoit en tant queerrors.Try()) serait préférable de l'introduire en tant que fonction intégrée.
try ne peut pas être implémenté en tant que fonction de bibliothèque ; il n'y a aucun moyen pour une fonction de revenir de son appelant (activation qui a été proposée comme #32473) et, comme la plupart des autres fonctions intégrées, il n'y a également aucun moyen d'exprimer la signature de try en Go. Même avec des génériques, il est peu probable que cela devienne possible ; voir la FAQ de la documentation de conception , vers la fin.
De plus, l'implémentation try en tant que fonction de bibliothèque nécessiterait qu'elle ait un nom plus détaillé, ce qui annule en partie l'intérêt de l'utiliser.
Cependant, il peut être - et a été deux fois - implémenté en tant que préprocesseur de code source : voir https://github.com/rhysd/trygo et https://github.com/lunixbochs/og.
dpinela
le 9 juil. 2019
Il semble qu'environ 60 % de la base de code de tegola serait en mesure d'utiliser cette fonctionnalité.
Voici la sortie de tryhard pour le projet tegola : (http://github.com/go-spatial/tegola)
--- try candidates ---
1 tegola/atlas/atlas.go:84
2 tegola/atlas/map.go:232
3 tegola/atlas/map.go:238
4 tegola/atlas/map.go:248
5 tegola/atlas/map.go:253
6 tegola/basic/geometry_math.go:248
7 tegola/basic/geometry_math.go:251
8 tegola/basic/geometry_math.go:268
9 tegola/basic/geometry_math.go:276
10 tegola/basic/json_marshal.go:33
11 tegola/basic/json_marshal.go:153
12 tegola/basic/json_marshal.go:276
13 tegola/cache/azblob/azblob.go:54
14 tegola/cache/azblob/azblob.go:61
15 tegola/cache/azblob/azblob.go:67
16 tegola/cache/azblob/azblob.go:74
17 tegola/cache/azblob/azblob.go:80
18 tegola/cache/azblob/azblob.go:105
19 tegola/cache/azblob/azblob.go:109
20 tegola/cache/azblob/azblob.go:204
21 tegola/cache/azblob/azblob.go:259
22 tegola/cache/file/file.go:42
23 tegola/cache/file/file.go:56
24 tegola/cache/file/file.go:110
25 tegola/cache/file/file.go:116
26 tegola/cache/file/file.go:129
27 tegola/cache/redis/redis.go:41
28 tegola/cache/redis/redis.go:46
29 tegola/cache/redis/redis.go:51
30 tegola/cache/redis/redis.go:56
31 tegola/cache/redis/redis.go:70
32 tegola/cache/redis/redis.go:79
33 tegola/cache/redis/redis.go:84
34 tegola/cache/s3/s3.go:85
35 tegola/cache/s3/s3.go:102
36 tegola/cache/s3/s3.go:112
37 tegola/cache/s3/s3.go:118
38 tegola/cache/s3/s3.go:123
39 tegola/cache/s3/s3.go:138
40 tegola/cache/s3/s3.go:164
41 tegola/cache/s3/s3.go:172
42 tegola/cache/s3/s3.go:179
43 tegola/cache/s3/s3.go:284
44 tegola/cache/s3/s3.go:340
45 tegola/cmd/tegola/cmd/cache/format.go:97
46 tegola/cmd/tegola/cmd/cache/seed_purge.go:94
47 tegola/cmd/tegola/cmd/cache/seed_purge.go:103
48 tegola/cmd/tegola/cmd/cache/seed_purge.go:170
49 tegola/cmd/tegola/cmd/cache/tile_list.go:51
50 tegola/cmd/tegola/cmd/cache/tile_list.go:64
51 tegola/cmd/tegola/cmd/cache/tile_name.go:35
52 tegola/cmd/tegola/cmd/cache/tile_name.go:43
53 tegola/cmd/tegola/cmd/root.go:58
54 tegola/cmd/tegola/cmd/root.go:61
55 tegola/cmd/xyz2svg/cmd/draw.go:62
56 tegola/cmd/xyz2svg/cmd/draw.go:70
57 tegola/cmd/xyz2svg/cmd/draw.go:214
58 tegola/config/config.go:96
59 tegola/internal/env/parse.go:30
60 tegola/internal/env/parse.go:69
61 tegola/internal/env/parse.go:116
62 tegola/internal/env/parse.go:174
63 tegola/internal/env/parse.go:221
64 tegola/internal/env/types.go:67
65 tegola/internal/env/types.go:86
66 tegola/internal/env/types.go:105
67 tegola/internal/env/types.go:124
68 tegola/internal/env/types.go:143
69 tegola/maths/makevalid/main.go:189
70 tegola/maths/makevalid/main.go:207
71 tegola/maths/makevalid/main.go:221
72 tegola/maths/makevalid/main.go:295
73 tegola/maths/makevalid/main.go:504
74 tegola/maths/makevalid/makevalid.go:77
75 tegola/maths/makevalid/makevalid.go:89
76 tegola/maths/makevalid/makevalid.go:118
77 tegola/maths/makevalid/makevalid_test.go:93
78 tegola/maths/makevalid/makevalid_test.go:163
79 tegola/maths/makevalid/plyg/ring.go:518
80 tegola/maths/triangle.go:1023
81 tegola/mvt/layer.go:73
82 tegola/mvt/layer.go:79
83 tegola/mvt/vector_tile/vector_tile.pb.go:64
84 tegola/provider/gpkg/gpkg.go:138
85 tegola/provider/gpkg/gpkg.go:223
86 tegola/provider/gpkg/gpkg_register.go:46
87 tegola/provider/gpkg/gpkg_register.go:51
88 tegola/provider/gpkg/gpkg_register.go:186
89 tegola/provider/gpkg/gpkg_register.go:227
90 tegola/provider/gpkg/gpkg_register.go:240
91 tegola/provider/gpkg/gpkg_register.go:245
92 tegola/provider/gpkg/gpkg_register.go:256
93 tegola/provider/gpkg/gpkg_register.go:377
94 tegola/provider/postgis/postgis.go:112
95 tegola/provider/postgis/postgis.go:117
96 tegola/provider/postgis/postgis.go:122
97 tegola/provider/postgis/postgis.go:127
98 tegola/provider/postgis/postgis.go:136
99 tegola/provider/postgis/postgis.go:142
100 tegola/provider/postgis/postgis.go:148
101 tegola/provider/postgis/postgis.go:153
102 tegola/provider/postgis/postgis.go:158
103 tegola/provider/postgis/postgis.go:163
104 tegola/provider/postgis/postgis.go:181
105 tegola/provider/postgis/postgis.go:198
106 tegola/provider/postgis/postgis.go:264
107 tegola/provider/postgis/postgis.go:441
108 tegola/provider/postgis/postgis.go:446
109 tegola/provider/postgis/postgis.go:529
110 tegola/provider/postgis/postgis.go:559
111 tegola/provider/postgis/postgis.go:603
112 tegola/provider/postgis/util.go:31
113 tegola/provider/postgis/util.go:36
114 tegola/provider/postgis/util.go:200
115 tegola/server/bindata/bindata.go:89
116 tegola/server/bindata/bindata.go:109
117 tegola/server/bindata/bindata.go:129
118 tegola/server/bindata/bindata.go:149
119 tegola/server/bindata/bindata.go:169
120 tegola/server/bindata/bindata.go:189
121 tegola/server/bindata/bindata.go:209
122 tegola/server/bindata/bindata.go:229
123 tegola/server/bindata/bindata.go:370
124 tegola/server/bindata/bindata.go:374
125 tegola/server/bindata/bindata.go:378
126 tegola/server/bindata/bindata.go:382
127 tegola/server/bindata/bindata.go:386
128 tegola/server/bindata/bindata.go:402
129 tegola/server/middleware_gzip.go:71
130 tegola/server/middleware_gzip.go:78
131 tegola/server/server_test.go:85
--- <err> name is different from "err" ---
1 tegola/basic/json_marshal.go:276
--- { return ... zero values ..., expr } ---
1 tegola/basic/geometry_math.go:214
2 tegola/basic/geometry_math.go:222
3 tegola/basic/geometry_math.go:230
4 tegola/cache/azblob/azblob.go:131
5 tegola/cache/azblob/azblob.go:140
6 tegola/cache/azblob/azblob.go:149
7 tegola/cache/azblob/azblob.go:171
8 tegola/cache/file/file.go:47
9 tegola/cache/s3/s3.go:92
10 tegola/cmd/internal/register/maps.go:108
11 tegola/cmd/tegola/cmd/cache/flags.go:20
12 tegola/cmd/tegola/cmd/cache/tile_name.go:51
13 tegola/cmd/tegola/cmd/cache/worker.go:112
14 tegola/cmd/tegola/cmd/cache/worker.go:123
15 tegola/cmd/tegola/cmd/root.go:73
16 tegola/cmd/tegola/cmd/root.go:78
17 tegola/cmd/xyz2svg/cmd/root.go:60
18 tegola/provider/gpkg/gpkg.go:90
19 tegola/provider/gpkg/gpkg.go:95
20 tegola/provider/gpkg/gpkg_register.go:264
21 tegola/provider/gpkg/gpkg_register.go:297
22 tegola/provider/gpkg/gpkg_register.go:302
23 tegola/provider/gpkg/gpkg_register.go:313
24 tegola/provider/gpkg/gpkg_register.go:328
25 tegola/provider/postgis/postgis.go:193
26 tegola/provider/postgis/postgis.go:208
27 tegola/provider/postgis/postgis.go:222
28 tegola/provider/postgis/postgis.go:228
29 tegola/provider/postgis/postgis.go:234
30 tegola/provider/postgis/postgis.go:243
31 tegola/provider/postgis/postgis.go:249
32 tegola/provider/postgis/postgis.go:255
33 tegola/provider/postgis/postgis.go:304
34 tegola/provider/postgis/postgis.go:315
35 tegola/provider/postgis/postgis.go:319
36 tegola/provider/postgis/postgis.go:364
37 tegola/provider/postgis/postgis.go:456
38 tegola/provider/postgis/postgis.go:520
39 tegola/provider/postgis/postgis.go:534
40 tegola/provider/postgis/postgis.go:565
41 tegola/provider/postgis/util.go:108
42 tegola/provider/postgis/util.go:113
43 tegola/server/bindata/bindata.go:29
44 tegola/server/bindata/bindata.go:245
45 tegola/server/bindata/bindata.go:271
46 tegola/server/bindata/bindata.go:396
--- single statement then branch ---
1 tegola/cache/azblob/azblob.go:241
2 tegola/cache/file/file.go:87
3 tegola/cache/s3/s3.go:321
4 tegola/cmd/internal/register/caches.go:18
5 tegola/cmd/internal/register/providers.go:43
6 tegola/cmd/internal/register/providers.go:62
7 tegola/cmd/internal/register/providers.go:75
8 tegola/config/config.go:192
9 tegola/config/config.go:207
10 tegola/config/config.go:217
11 tegola/internal/env/dict.go:43
12 tegola/internal/env/dict.go:121
13 tegola/internal/env/dict.go:197
14 tegola/internal/env/dict.go:273
15 tegola/internal/env/dict.go:348
16 tegola/internal/env/parse.go:79
17 tegola/internal/env/parse.go:126
18 tegola/internal/env/parse.go:184
19 tegola/internal/env/parse.go:231
20 tegola/maths/makevalid/plyg/ring.go:541
21 tegola/maths/maths.go:239
22 tegola/maths/validate/validate.go:49
23 tegola/maths/validate/validate.go:53
24 tegola/maths/validate/validate.go:59
25 tegola/maths/validate/validate.go:69
26 tegola/mvt/feature.go:94
27 tegola/mvt/feature.go:99
28 tegola/mvt/feature.go:592
29 tegola/mvt/feature.go:603
30 tegola/mvt/layer.go:90
31 tegola/mvt/tile.go:48
32 tegola/provider/postgis/postgis.go:570
33 tegola/provider/postgis/postgis.go:586
34 tegola/tile.go:172
--- complex then branch; cannot use try ---
1 tegola/cache/azblob/azblob.go:226
2 tegola/cache/file/file.go:78
3 tegola/cache/file/file.go:122
4 tegola/cache/s3/s3.go:195
5 tegola/cache/s3/s3.go:206
6 tegola/cache/s3/s3.go:219
7 tegola/cache/s3/s3.go:307
8 tegola/provider/gpkg/gpkg.go:39
9 tegola/provider/gpkg/gpkg.go:45
10 tegola/provider/gpkg/gpkg.go:131
11 tegola/provider/gpkg/gpkg.go:154
12 tegola/provider/gpkg/gpkg_register.go:171
13 tegola/provider/gpkg/gpkg_register.go:195
--- stats ---
1294 (100.0% of 1294) func declarations
246 ( 19.0% of 1294) func declarations returning an error
2693 (100.0% of 2693) statements
551 ( 20.5% of 2693) if statements
238 ( 43.2% of 551) if <err> != nil statements
131 ( 55.0% of 238) try candidates
1 ( 0.4% of 238) <err> name is different from "err"
--- non-try candidates ---
46 ( 19.3% of 238) { return ... zero values ..., expr }
34 ( 14.3% of 238) single statement then branch
13 ( 5.5% of 238) complex then branch; cannot use try
0 ( 0.0% of 238) non-empty else branch; cannot use try
Et le projet compagnon : (http://github.com/go-spatial/geom)
--- try candidates ---
1 geom/bbox.go:202
2 geom/encoding/geojson/geojson.go:152
3 geom/encoding/geojson/geojson.go:157
4 geom/encoding/wkb/internal/tcase/symbol/symbol.go:73
5 geom/encoding/wkb/internal/tcase/tcase.go:161
6 geom/encoding/wkb/internal/tcase/tcase.go:172
7 geom/encoding/wkb/wkb.go:50
8 geom/encoding/wkb/wkb.go:110
9 geom/encoding/wkt/internal/token/token.go:176
10 geom/encoding/wkt/internal/token/token.go:252
11 geom/internal/parsing/parsing.go:44
12 geom/internal/parsing/parsing.go:85
13 geom/internal/rtreego/rtree_test.go:110
14 geom/multi_line_string.go:34
15 geom/multi_polygon.go:35
16 geom/planar/clip/linestring.go:82
17 geom/planar/clip/linestring.go:181
18 geom/planar/clip/point.go:23
19 geom/planar/intersect/xsweep.go:106
20 geom/planar/makevalid/makevalid.go:92
21 geom/planar/makevalid/makevalid.go:191
22 geom/planar/makevalid/setdiff/polygoncleaner.go:283
23 geom/planar/makevalid/setdiff/polygoncleaner.go:345
24 geom/planar/makevalid/setdiff/polygoncleaner.go:543
25 geom/planar/makevalid/setdiff/polygoncleaner.go:554
26 geom/planar/makevalid/setdiff/polygoncleaner.go:572
27 geom/planar/makevalid/setdiff/polygoncleaner.go:578
28 geom/planar/simplify/douglaspeucker.go:84
29 geom/planar/simplify/douglaspeucker.go:88
30 geom/planar/simplify.go:13
31 geom/planar/triangulate/constraineddelaunay/triangle.go:186
32 geom/planar/triangulate/constraineddelaunay/triangulator.go:134
33 geom/planar/triangulate/constraineddelaunay/triangulator.go:138
34 geom/planar/triangulate/constraineddelaunay/triangulator.go:142
35 geom/planar/triangulate/constraineddelaunay/triangulator.go:173
36 geom/planar/triangulate/constraineddelaunay/triangulator.go:176
37 geom/planar/triangulate/constraineddelaunay/triangulator.go:203
38 geom/planar/triangulate/constraineddelaunay/triangulator.go:248
39 geom/planar/triangulate/constraineddelaunay/triangulator.go:396
40 geom/planar/triangulate/constraineddelaunay/triangulator.go:466
41 geom/planar/triangulate/constraineddelaunay/triangulator.go:553
42 geom/planar/triangulate/constraineddelaunay/triangulator.go:583
43 geom/planar/triangulate/constraineddelaunay/triangulator.go:667
44 geom/planar/triangulate/constraineddelaunay/triangulator.go:672
45 geom/planar/triangulate/constraineddelaunay/triangulator.go:677
46 geom/planar/triangulate/constraineddelaunay/triangulator.go:814
47 geom/planar/triangulate/constraineddelaunay/triangulator.go:818
48 geom/planar/triangulate/constraineddelaunay/triangulator.go:823
49 geom/planar/triangulate/constraineddelaunay/triangulator.go:865
50 geom/planar/triangulate/constraineddelaunay/triangulator.go:870
51 geom/planar/triangulate/constraineddelaunay/triangulator.go:875
52 geom/planar/triangulate/constraineddelaunay/triangulator.go:897
53 geom/planar/triangulate/constraineddelaunay/triangulator.go:901
54 geom/planar/triangulate/constraineddelaunay/triangulator.go:907
55 geom/planar/triangulate/constraineddelaunay/triangulator.go:1107
56 geom/planar/triangulate/constraineddelaunay/triangulator.go:1146
57 geom/planar/triangulate/constraineddelaunay/triangulator.go:1157
58 geom/planar/triangulate/constraineddelaunay/triangulator.go:1202
59 geom/planar/triangulate/constraineddelaunay/triangulator.go:1206
60 geom/planar/triangulate/constraineddelaunay/triangulator.go:1216
61 geom/planar/triangulate/delaunaytriangulationbuilder.go:66
62 geom/planar/triangulate/incrementaldelaunaytriangulator.go:46
63 geom/planar/triangulate/incrementaldelaunaytriangulator.go:78
64 geom/planar/triangulate/quadedge/lastfoundquadedgelocator.go:65
65 geom/planar/triangulate/quadedge/quadedgesubdivision.go:976
66 geom/slippy/tile.go:133
--- { return ... zero values ..., expr } ---
1 geom/internal/parsing/parsing.go:125
2 geom/planar/triangulate/constraineddelaunay/triangulator.go:428
3 geom/planar/triangulate/constraineddelaunay/triangulator.go:447
4 geom/planar/triangulate/constraineddelaunay/triangulator.go:460
--- single statement then branch ---
1 geom/bbox.go:259
2 geom/encoding/wkb/internal/decode/decode.go:29
3 geom/encoding/wkb/internal/decode/decode.go:55
4 geom/encoding/wkb/internal/decode/decode.go:63
5 geom/encoding/wkb/internal/decode/decode.go:70
6 geom/encoding/wkb/internal/decode/decode.go:79
7 geom/encoding/wkb/internal/decode/decode.go:84
8 geom/encoding/wkb/internal/decode/decode.go:93
9 geom/encoding/wkb/internal/decode/decode.go:99
10 geom/encoding/wkb/internal/decode/decode.go:105
11 geom/encoding/wkb/internal/decode/decode.go:114
12 geom/encoding/wkb/internal/decode/decode.go:119
13 geom/encoding/wkb/internal/decode/decode.go:135
14 geom/encoding/wkb/internal/decode/decode.go:140
15 geom/encoding/wkb/internal/decode/decode.go:149
16 geom/encoding/wkb/internal/decode/decode.go:155
17 geom/encoding/wkb/internal/decode/decode.go:161
18 geom/encoding/wkb/internal/decode/decode.go:170
19 geom/encoding/wkb/internal/decode/decode.go:176
20 geom/encoding/wkb/internal/tcase/token/token.go:162
21 geom/encoding/wkt/internal/token/token.go:136
--- complex then branch; cannot use try ---
1 geom/encoding/wkb/internal/tcase/tcase.go:74
2 geom/encoding/wkt/internal/symbol/symbol.go:125
3 geom/planar/intersect/xsweep.go:165
4 geom/planar/makevalid/makevalid.go:85
5 geom/planar/makevalid/makevalid.go:172
6 geom/planar/makevalid/triangulate.go:19
7 geom/planar/makevalid/triangulate.go:28
8 geom/planar/makevalid/triangulate.go:36
9 geom/planar/makevalid/triangulate.go:58
10 geom/planar/triangulate/constraineddelaunay/triangulator.go:358
11 geom/planar/triangulate/constraineddelaunay/triangulator.go:373
12 geom/planar/triangulate/constraineddelaunay/triangulator.go:453
13 geom/planar/triangulate/constraineddelaunay/triangulator.go:1237
14 geom/planar/triangulate/constraineddelaunay/triangulator.go:1243
15 geom/planar/triangulate/constraineddelaunay/triangulator.go:1249
--- stats ---
820 (100.0% of 820) func declarations
146 ( 17.8% of 820) func declarations returning an error
1715 (100.0% of 1715) statements
391 ( 22.8% of 1715) if statements
111 ( 28.4% of 391) if <err> != nil statements
66 ( 59.5% of 111) try candidates
0 ( 0.0% of 111) <err> name is different from "err"
--- non-try candidates ---
4 ( 3.6% of 111) { return ... zero values ..., expr }
21 ( 18.9% of 111) single statement then branch
15 ( 13.5% of 111) complex then branch; cannot use try
0 ( 0.0% of 111) non-empty else branch; cannot use try
 gdey
le 9 juil. 2019
gdey
le 9 juil. 2019
Au sujet des frais imprévus, je reposte ceci du #32611...
Je vois trois classes de coût :
- le coût à la spécification, qui est élaboré dans le document de conception.
- le coût de l'outillage (c'est-à-dire la révision du logiciel), également exploré dans le document de conception.
- le coût pour l'écosystème, que la communauté a longuement détaillé ci-dessus et dans #32825.
Re nos. 1 & 2, les coûts de try() sont modestes.
Pour simplifier non. 3, la plupart des commentateurs pensent que try() endommagerait notre code et/ou l'écosystème de code dont nous dépendons, et réduirait ainsi notre productivité et la qualité de nos produits. Cette perception répandue et raisonnée ne doit pas être décriée comme "non factuelle" ou "esthétique".
Le coût pour l'écosystème est bien plus important que le coût pour les spécifications ou l'outillage.
@griesemer , il est manifestement injuste de prétendre que "trois douzaines d'opposants vocaux" constituent le gros de l'opposition. Des centaines de personnes ont commenté ici et dans #32825. Vous m'avez dit le 12 juin : "Je reconnais qu'environ 2/3 des répondants ne sont pas satisfaits de la proposition." Depuis lors, plus de 2 000 personnes ont voté pour "laisser err != nil tranquilles" avec 90 % de pouce vers le haut.
networkimprov
le 10 juil. 2019
@gdey pourriez-vous modifier votre message pour n'inclure que les candidats _stats & non-try_ ?
networkimprov
le 10 juil. 2019
@robfig , @gdey Merci d'avoir fourni ces données, en particulier la comparaison avant/après.
griesemer
le 10 juil. 2019
@griesemer
Vous avez certainement ajouté de la substance en précisant que mes préoccupations (et celles des autres) pourraient être traitées directement. Ma question est donc de savoir si l'équipe Go considère l'abus probable des modes indirects (c'est-à-dire les retours nus et/ou la mutation d'erreur de portée post-fonction via le report) comme un coût qui mérite d'être discuté lors de l'étape 5, et que cela vaut potentiellement la peine prendre des mesures en vue de son atténuation. L'ambiance actuelle est que cet aspect le plus déconcertant de la proposition est considéré comme une fonctionnalité intelligente/nouvelle par l'équipe Go (Cette préoccupation n'est pas abordée par l'évaluation des transformations automatisées et semble être activement encouragée/soutenue. - errd , en conversation, etc.).
modifier pour ajouter... Le souci avec l'équipe de Go d'encourager ce que les vétérans Gopher considèrent comme prohibitif est ce que je voulais dire en ce qui concerne la surdité.
... L'indirection est un coût dont beaucoup d'entre nous sont profondément préoccupés par la douleur expérientielle. Ce n'est peut-être pas quelque chose qui peut être comparé facilement (voire pas du tout raisonnablement), mais il est malhonnête de considérer cette préoccupation comme sentimentale en soi. Au contraire, ignorer la sagesse d'une expérience partagée en faveur de chiffres simples sans jugement contextuel solide est le genre de sentiment contre lequel j'essaie/nous essayons de lutter.
daved
le 10 juil. 2019
@networkimprov Toutes mes excuses pour ne pas être assez claires. Ce que j'ai dit c'est :
Il y a peut-être deux, peut-être trois douzaines d'opposants virulents à cette proposition - vous savez qui vous êtes. Ils dominent cette discussion avec des messages fréquents, parfois plusieurs par jour.
Je parlais de commentaires réels (comme dans "messages fréquents"), pas d'emojis. Il n'y a qu'un nombre relativement restreint de personnes postant ici _à plusieurs reprises_, ce qui, je pense, est toujours correct. Je ne parlais pas non plus du #32825 ; Je parlais de cette proposition.
Du côté des émojis, la situation est quasiment inchangée depuis un mois : 1/3 des émojis indiquent un avis favorable, et 2/3 indiquent un avis négatif.
griesemer
le 10 juil. 2019
@griesemer
Je me suis souvenu de quelque chose en écrivant mon commentaire ci-dessus : bien que le document de conception indique que try peut être implémenté comme une simple transformation d'arbre de syntaxe, et dans de nombreux cas, c'est évidemment le cas, il y a des cas où je ne le fais pas voir une façon simple de le faire. Par exemple, supposons que nous ayons les éléments suivants :
switch x {
case rand.Int():
a()
case 5, try(strconv.Atoi(y)):
b()
}
Étant donné l' ordre d'évaluation de switch , je ne vois pas comment retirer trivialement le strconv.Atoi(y) de la clause case tout en préservant la sémantique voulue ; le mieux que je puisse trouver est de réécrire les switch comme la chaîne équivalente d'instructions if / else , comme ceci :
if x == rand.Int() {
a()
} else if x == 5 {
b()
} else if _v, _err := strconv.Atoi(y); _err != nil {
return _err
} else if x == _v {
b()
}
(Il existe d'autres situations où cela peut se produire, mais c'est l'un des exemples les plus simples et le premier qui me vient à l'esprit.)
En fait, avant que vous ne publiiez cette proposition, je travaillais sur un traducteur AST pour implémenter l'opérateur check à partir du projet de conception et j'ai rencontré ce problème. Cependant, j'utilisais une version piratée des packages go/* stdlib ; peut-être que le frontal du compilateur est structuré de manière à faciliter cela? Ou ai-je raté quelque chose et il existe vraiment un moyen simple de le faire?
Voir aussi https://github.com/rhysd/trygo ; selon le README, il n'implémente pas les expressions try et note essentiellement la même préoccupation que je soulève ici; Je soupçonne que c'est peut-être la raison pour laquelle l'auteur n'a pas implémenté cette fonctionnalité.
dpinela
le 10 juil. 2019
Le code @daved Professional n'est pas développé dans le vide - il existe des conventions locales, des recommandations de style, des révisions de code, etc. (je l'ai déjà dit). Ainsi, je ne vois pas pourquoi l'abus serait "probable" (c'est possible, mais c'est vrai pour toute construction de langage).
Notez que l'utilisation defer pour décorer les erreurs est possible avec ou sans try . Il y a certainement de bonnes raisons pour qu'une fonction qui contient de nombreuses vérifications d'erreurs, qui décorent toutes les erreurs de la même manière, fasse cette décoration une fois, par exemple en utilisant un defer . Ou peut-être utiliser une fonction wrapper qui fait la décoration. Ou tout autre mécanisme qui correspond à la facture et aux recommandations de codage locales. Après tout, "les erreurs ne sont que des valeurs" et il est tout à fait logique d'écrire et de factoriser du code qui traite des erreurs.
Les retours nus peuvent être problématiques lorsqu'ils sont utilisés de manière indisciplinée. Cela ne signifie pas qu'ils sont généralement mauvais. Par exemple, si les résultats d'une fonction ne sont valides que s'il n'y a pas eu d'erreur, il semble parfaitement correct d'utiliser un retour nu dans le cas d'une erreur - tant que nous sommes disciplinés avec la définition de l'erreur (car les autres valeurs de retour ne ' peu importe dans ce cas). try garantit exactement cela. Je ne vois aucun "abus" ici.
griesemer
le 10 juil. 2019
@dpinela Le compilateur traduit déjà une instruction switch telle que la vôtre en une séquence de if-else-if , donc je ne vois pas de problème ici. De plus, "l'arbre de syntaxe" utilisé par le compilateur n'est pas l'arbre de syntaxe "go/ast". La représentation interne du compilateur permet un code beaucoup plus flexible qui ne peut pas nécessairement être traduit en Go.
griesemer
le 10 juil. 2019
@griesemer
Oui, bien sûr, tout ce que vous dites est fondé. La zone grise, cependant, n'est pas aussi simpliste que vous l'imaginez. Les retours nus sont normalement traités avec beaucoup de prudence par ceux d'entre nous qui enseignent aux autres (nous, qui nous efforçons de développer/promouvoir la communauté). J'apprécie que le stdlib l'ait jonché partout. Mais, lorsque l'on enseigne aux autres, les retours explicites sont toujours mis en avant. Laisser l'individu atteindre sa propre maturité pour se tourner vers l'approche la plus "fantaisiste", mais l'encourager dès le départ reviendrait sûrement à favoriser un code difficile à lire (c'est-à-dire de mauvaises habitudes). Ceci, encore une fois, est la surdité que j'essaie de mettre en lumière.
Personnellement, je ne souhaite pas interdire les retours nus ou la manipulation de valeur différée. Lorsqu'ils sont vraiment adaptés, je suis heureux que ces fonctionnalités soient disponibles (cependant, d'autres utilisateurs expérimentés peuvent adopter une position plus rigide). Néanmoins, encourager l'application de ces fonctionnalités moins courantes et généralement fragiles d'une manière aussi omniprésente est tout à fait la direction opposée que j'aurais jamais imaginé prendre. Le changement prononcé de caractère consistant à éviter la magie et les formes précaires d'indirection est-il un changement délibéré ? Devrions-nous également commencer à mettre l'accent sur l'utilisation de DIC et d'autres mécanismes difficiles à déboguer ?
ps Votre temps est grandement apprécié. Votre équipe et la langue ont mon respect et mon attention. Je ne souhaite de chagrin à personne en s'exprimant; J'espère que vous entendrez la nature de mes/notres préoccupations et que vous essaierez de voir les choses de notre point de vue "de première ligne".
daved
le 10 juil. 2019
Ajout de quelques commentaires à mon vote négatif.
Pour la proposition spécifique à portée de main :
1) Je préférerais grandement que ce soit un mot-clé plutôt qu'une fonction intégrée pour des raisons précédemment articulées de flux de contrôle et de lisibilité du code.
2) Sémantiquement, "essayer" est un paratonnerre. Et, à moins qu'une exception ne soit levée, "try" serait mieux renommé en quelque chose comme guard ou ensure .
3) Outre ces deux points, je pense que c'est la meilleure proposition que j'ai vue pour ce genre de chose.
Quelques commentaires supplémentaires exprimant mon objection à tout ajout d'un concept try/guard/ensure plutôt que de laisser if err != nil seul :
1) Cela va à l'encontre de l'un des mandats originaux de golang (du moins tel que je le percevais) d'être explicite, facile à lire/comprendre, avec très peu de "magie".
2) Cela favorisera la paresse au moment précis où la réflexion s'impose : "quelle est la meilleure chose à faire pour mon code dans le cas de cette erreur ?". De nombreuses erreurs peuvent survenir lors de l'exécution de tâches "standard" telles que l'ouverture de fichiers, le transfert de données sur un réseau, etc. Bien que vous puissiez commencer avec un tas d'"essais" qui ignorent les scénarios d'échec non courants, un grand nombre de ces " trys" disparaîtra car vous devrez peut-être implémenter vos propres tâches d'interruption/de nouvelle tentative, de journalisation/de traçage et/ou de nettoyage. Les "événements à faible probabilité" sont garantis à grande échelle.
 nathangoulding
le 10 juil. 2019
nathangoulding
le 10 juil. 2019
Voici quelques statistiques plus brutes tryhard . Ceci n'est que légèrement validé, alors n'hésitez pas à signaler les erreurs. ;-)
Les 20 premiers "forfaits populaires" sur godoc.org
Ce sont les référentiels qui correspondent aux 20 premiers packages populaires sur https://godoc.org , triés par pourcentage d'essais candidats. Cela utilise les paramètres par défaut tryhard , qui en théorie devraient exclure les répertoires vendor .
La valeur médiane des candidats à l'essai sur ces 20 pensions est de 58 %.
| projet | loc | si stmts | si != néant (% de si) | essayer les candidats (% de si != néant) |
|---------|-----|---------------|---------------- -----|---------------
| github.com/google/uuid | 1714 | 12 | 16,7 % | 0,0 % |
| github.com/pkg/errors | 1886 | 10 | 0,0 % | 0,0 % |
| github.com/aws/aws-sdk-go | 1911309 | 32015 | 9,4 % | 8,9 % |
| github.com/jinzhu/gorm | 15246 | 44 | 11,4 % | 20,0 % |
| github.com/robfig/cron | 1911 | 20 | 35,0 % | 28,6 % |
| github.com/gorille/websocket | 6959 | 212 | 32,5 % | 39,1 % |
| github.com/dgrijalva/jwt-go | 3270 | 118 | 29,7 % | 40,0 % |
| github.com/gomodule/redigo | 7119 | 187 | 34,8 % | 41,5 % |
| github.com/unixpickle/kahoot-hack | 1743 | 52 | 75,0 % | 43,6 % |
| github.com/lib/pq | 13396 | 239 | 30,1 % | 55,6 % |
| github.com/sirupsen/logrus | 5063 | 29 | 17,2 % | 60,0 % |
| github.com/prometheus/client_golang | 17791 | 194 | 49,0 % | 62,1 % |
| github.com/go-redis/redis | 21182 | 326 | 42,6 % | 73,4 % |
| github.com/mongodb/mongo-go-driver | 86605 | 2097 | 37,8 % | 73,9 % |
| github.com/uber-go/zap | 15363 | 84 | 36,9 % | 74,2 % |
| github.com/golang/protobuf | 42959 | 685 | 22,9 % | 77,1 % |
| github.com/gin-gonic/gin | 14574 | 96 | 53,1 % | 86,3 % |
| github.com/go-pg/pg | 26369 | 831 | 37,7 % | 86,9 % |
| github.com/Shopify/sarama | 36427 | 1369 | 68,2 % | 91,0 % |
| github.com/stretchr/témoigner | 13496 | 32 | 43,8 % | 92,9 % |
La colonne " if stmts " ne compte que les instructions if dans les fonctions renvoyant une erreur, c'est ainsi que tryhard la signale, et qui, espérons-le, explique pourquoi elle est si faible pour quelque chose comme gorm .
10 divers. "grands" projets Go
Étant donné que les packages populaires sur godoc.org ont tendance à être des packages de bibliothèque, je voulais également vérifier les statistiques de certains projets plus importants.
Ce sont divers. de grands projets qui se sont avérés être une priorité pour moi (c'est-à-dire qu'il n'y a pas de véritable logique derrière ces 10). Ceci est à nouveau trié par pourcentage d'essais candidats.
La valeur médiane des candidats à l'essai sur ces 10 pensions est de 59 %.
| projet | loc | si stmts | si != néant (% de si) | essayer les candidats (% de si != néant) |
|---------|-----|---------------|---------------- -----|---------------------------------|
| github.com/juju/juju | 1026473 | 26904 | 51,9 % | 17,5 % |
| github.com/go-kit/kit | 38949 | 467 | 57,0 % | 51,9 % |
| github.com/boltdb/bolt | 12426 | 228 | 46,1 % | 53,3 % |
| github.com/hashicorp/consul | 249369 | 5477 | 47,6 % | 54,5 % |
| github.com/docker/docker | 251152 | 8690 | 48,7 % | 56,8 % |
| github.com/istio/istio | 429636 | 7564 | 40,4 % | 61,9 % |
| github.com/gohugoio/hugo | 94875 | 1853 | 42,4 % | 64,8 % |
| github.com/etcd-io/etcd | 209603 | 4657 | 38,3 % | 65,5 % |
| github.com/kubernetes/kubernetes | 1789172 | 40289 | 43,3 % | 66,5 % |
| github.com/cockroachdb/cafard | 1038529 | 22018 | 39,9 % | 74,0 % |
Ces deux tableaux ne représentent bien sûr qu'un échantillon de projets open source, et seulement ceux raisonnablement connus. J'ai vu des gens théoriser que les bases de code privé montreraient une plus grande diversité, et il y a au moins quelques preuves de cela sur la base de certains des chiffres que diverses personnes ont publiés.
thepudds
le 10 juil. 2019
@thepudds , cela ne ressemble pas au dernier _tryhard_, qui donne des "candidats sans essai".
networkimprov
le 10 juil. 2019
@networkimprov Je peux confirmer qu'au moins pour gorm ce sont les résultats du dernier tryhard . Les "candidats sans essai" ne sont tout simplement pas signalés dans les tableaux ci-dessus.
griesemer
le 10 juil. 2019
@daved Tout d'abord, permettez-moi de vous assurer que je/nous vous entendons haut et fort. Bien que nous soyons encore au début du processus et que beaucoup de choses puissent changer. Ne sautons pas le pistolet.
Je comprends (et j'apprécie) que l'on puisse choisir une approche plus conservatrice lors de l'enseignement du Go. Merci.
griesemer
le 10 juil. 2019
@griesemer FYI voici les résultats de l'exécution de cette dernière version de tryhard sur 233 000 lignes de code dans lesquelles j'ai été impliqué, dont une grande partie n'est pas open source:
--- stats ---
8760 (100.0% of 8760) functions (function literals are ignored)
2942 ( 33.6% of 8760) functions returning an error
22991 (100.0% of 22991) statements in functions returning an error
5548 ( 24.1% of 22991) if statements
2929 ( 52.8% of 5548) if <err> != nil statements
163 ( 5.6% of 2929) try candidates
0 ( 0.0% of 2929) <err> name is different from "err"
--- non-try candidates (-l flag lists file positions) ---
2213 ( 75.6% of 2929) { return ... zero values ..., expr }
167 ( 5.7% of 2929) single statement then branch
253 ( 8.6% of 2929) complex then branch; cannot use try
14 ( 0.5% of 2929) non-empty else branch; cannot use try
Une grande partie du code utilise un idiome similaire à :
if err != nil {
return ... zero values ..., errors.Wrap(err)
}
Il pourrait être intéressant si tryhard pouvait identifier quand toutes ces expressions dans une fonction utilisent une expression identique - c'est-à-dire quand il serait possible de réécrire la fonction avec un seul gestionnaire defer commun.
rogpeppe
le 10 juil. 2019
Voici les statistiques d'un petit outil d'assistance GCP pour automatiser la création d'utilisateurs et de projets :
$ tryhard -r .
--- stats ---
129 (100.0% of 129) functions (function literals are ignored)
75 ( 58.1% of 129) functions returning an error
725 (100.0% of 725) statements in functions returning an error
164 ( 22.6% of 725) if statements
93 ( 56.7% of 164) if <err> != nil statements
64 ( 68.8% of 93) try candidates
0 ( 0.0% of 93) <err> name is different from "err"
--- non-try candidates (-l flag lists file positions) ---
17 ( 18.3% of 93) { return ... zero values ..., expr }
7 ( 7.5% of 93) single statement then branch
1 ( 1.1% of 93) complex then branch; cannot use try
0 ( 0.0% of 93) non-empty else branch; cannot use try
Après cela, je suis allé de l'avant et j'ai vérifié tous les endroits du code qui traitent toujours d'une variable err pour voir si je pouvais trouver des modèles significatifs.
Collecte err s
À quelques endroits, nous ne voulons pas arrêter l'exécution à la première erreur et être en mesure de voir toutes les erreurs qui se sont produites une fois à la fin de l'exécution. Peut-être existe-t-il une manière différente de procéder qui s'intègre bien avec try ou une forme de prise en charge des erreurs multiples est ajoutée à Go lui-même.
var errs []error
for _, p := range toDelete {
fmt.Println("delete:", p.ProjectID)
if err := s.DeleteProject(ctx, p.ProjectID); err != nil {
errs = append(errs, err)
}
}
Responsabilité de décoration d'erreur
Après avoir relu ce commentaire , il y avait soudainement beaucoup de cas potentiels de try qui ont attiré mon attention. Ils sont tous similaires en ce sens que la fonction appelante décore l'erreur d'une fonction appelée avec des informations que la fonction appelée aurait déjà pu ajouter à l'erreur :
func run() error {
key := "MY_ENV_VAR"
client, err := ClientFromEnvironment(key)
if err != nil {
// "github.com/pkg/errors"
return errors.Wrap(err, key)
}
// do something with `client`
}
func ClientFromEnvironment(key string) (*http.Client, error) {
filename, ok := os.LookupEnv(key)
if !ok {
return nil, errors.New("environment variable not set")
}
return ClientFromFile(filename)
}
Citant la partie importante du blog Go ici encore ici pour plus de clarté :
Il est de la responsabilité de l'implémentation d'erreur de résumer le contexte. L'erreur renvoyée par os.Open se présente sous la forme "ouvrir /etc/passwd : autorisation refusée", et pas seulement "autorisation refusée". L'erreur renvoyée par notre Sqrt manque d'informations sur l'argument non valide.
Dans cet esprit, le code ci-dessus devient maintenant :
func run() error {
key := "MY_ENV_VAR"
client := try(ClientFromEnvironment(key))
// do something with `client`
}
func ClientFromEnvironment(key string) (*http.Client, error) {
filename, ok := os.LookupEnv(key)
if !ok {
return nil, fmt.Errorf("environment variable not set: %s", key)
}
return ClientFromFile(filename)
}
À première vue, cela semble être un changement mineur, mais à mon avis, cela pourrait signifier que try incite en fait à pousser une gestion des erreurs meilleure et plus cohérente vers le haut de la chaîne de fonctions et plus près de la source ou du package.
Remarques finales
Dans l'ensemble, je pense que la valeur que try apporte à long terme est supérieure aux problèmes potentiels que je vois actuellement avec elle, qui sont :
- Un mot clé peut "se sentir" mieux car
trymodifie le flux de contrôle. - L'utilisation
trysignifie que vous ne pouvez plus mettre d'arrêt de débogage dans le casreturn err.
Étant donné que ces préoccupations sont déjà connues de l'équipe Go, je suis curieux de voir comment elles se dérouleront dans "le monde réel". Merci d'avoir pris le temps de lire et de répondre à tous nos messages.
Mettre à jour
Correction d'une signature de fonction qui ne renvoyait pas error auparavant. Merci @magical d'avoir remarqué ça !
 mrkanister
le 10 juil. 2019
mrkanister
le 10 juil. 2019
func main() { key := "MY_ENV_VAR" client := try(ClientFromEnvironment(key)) // do something with `client` }
@mrkanister Nitpicking, mais vous ne pouvez pas réellement utiliser try dans cet exemple car main ne renvoie pas un error .
magical
le 10 juil. 2019
Ceci est un commentaire d'appréciation;
merci @griesemer pour le jardinage et tout ce que vous avez fait sur cette question ainsi qu'ailleurs.
komuw
le 10 juil. 2019
Au cas où vous auriez plusieurs lignes comme celles-ci (de https://github.com/golang/go/issues/32437#issuecomment-509974901) :
if !ok {
return nil, fmt.Errorf("environment variable not set: %s", key)
}
Vous pouvez utiliser une fonction d'assistance qui ne renvoie une erreur non nulle que si une condition est vraie :
try(condErrorf(!ok, "environment variable not set: %s", key))
Une fois les modèles communs identifiés, je pense qu'il sera possible de gérer beaucoup d'entre eux avec seulement quelques assistants, d'abord au niveau du package, et peut-être éventuellement d'atteindre la bibliothèque standard. Tryhard est génial, il fait un travail formidable et donne beaucoup d'informations intéressantes, mais il y a bien plus.
yiyus
le 10 juil. 2019
Monofilaire compact si
En plus de la proposition if sur une seule ligne de @zeebo et d'autres, l'instruction if pourrait avoir une forme compacte qui supprime le != nil et les accolades :
if err return err
if err return errors.Wrap(err, "foo: failed to boo")
if err return fmt.Errorf("foo: failed to boo: %v", err)
Je pense que c'est simple, léger et lisible. Il y a deux parties :
- Avoir si les instructions vérifient implicitement les valeurs d'erreur pour nil (ou peut-être les interfaces plus généralement). À mon humble avis, cela améliore la lisibilité en réduisant la densité et le comportement est assez évident.
- Ajout de la prise en charge de
if variable return .... Étant donné que lereturnest si proche du côté gauche, il semble encore assez facile de parcourir le code - la difficulté supplémentaire de le faire étant l'un des principaux arguments contre les ifs sur une seule ligne (?) Go a également déjà un précédent pour simplifier la syntaxe en supprimant par exemple les parenthèses de son instruction if.
Style actuel :
a, err := BusinessLogic(state)
if err != nil {
return nil, err
}
Une ligne si :
a, err := BusinessLogic(state)
if err != nil { return nil, err }
Compact unifilaire si :
a, err := BusinessLogic(state)
if err return nil, err
a, err := BusinessLogic(state)
if err return nil, errors.Wrap(err, "some context")
func (c *Config) Build() error {
pkgPath, err := c.load()
if err return nil, errors.WithMessage(err, "load config dir")
b := bytes.NewBuffer(nil)
err = templates.ExecuteTemplate(b, "main", c)
if err return nil, errors.WithMessage(err, "execute main template")
buf, err := format.Source(b.Bytes())
if err return nil, errors.WithMessage(err, "format main template")
target := fmt.Sprintf("%s.go", filename(pkgPath))
err = ioutil.WriteFile(target, buf, 0644)
if err return nil, errors.WithMessagef(err, "write file %s", target)
// ...
}
 eug48
le 10 juil. 2019
eug48
le 10 juil. 2019
@eug48 voir #32611
networkimprov
le 10 juil. 2019
Voici les statistiques d'essai pour un monorepo (lignes de code go, à l'exclusion du code du fournisseur : 2 282 731) :
--- stats ---
117551 (100.0% of 117551) functions (function literals are ignored)
35726 ( 30.4% of 117551) functions returning an error
263725 (100.0% of 263725) statements in functions returning an error
50690 ( 19.2% of 263725) if statements
25042 ( 49.4% of 50690) if <err> != nil statements
12091 ( 48.3% of 25042) try candidates
36 ( 0.1% of 25042) <err> name is different from "err"
--- non-try candidates (-l flag lists file positions) ---
3561 ( 14.2% of 25042) { return ... zero values ..., expr }
3304 ( 13.2% of 25042) single statement then branch
4966 ( 19.8% of 25042) complex then branch; cannot use try
296 ( 1.2% of 25042) non-empty else branch; cannot use try
Étant donné que les gens proposent toujours des alternatives, j'aimerais savoir plus en détail quelle fonctionnalité la communauté Go au sens large attend réellement de toute nouvelle fonctionnalité de gestion des erreurs proposée.
J'ai mis en place une enquête répertoriant un tas de fonctionnalités différentes, des éléments de fonctionnalité de gestion des erreurs que j'ai vu des gens proposer. J'ai soigneusement _omis toute proposition de dénomination ou de syntaxe_, et bien sûr essayé de rendre l'enquête neutre plutôt que de favoriser mes propres opinions.
Si des personnes souhaitent participer, voici le lien, raccourci pour le partage :
https://forms.gle/gaCBgxKRE4RMCz7c7
Tous les participants doivent pouvoir voir les résultats récapitulatifs. Peut-être que cela pourrait aider à orienter la discussion ?
 lpar
le 10 juil. 2019
lpar
le 10 juil. 2019
if err := os.Setenv("GO111MODULE", "on"); err != nil {
return err
}
Le gestionnaire de report ajoutant du contexte ne fonctionne pas dans ce cas ou le fait-il ? Sinon, ce serait bien de le rendre plus visible, si possible car cela se produit assez rapidement, d'autant plus que c'est la norme jusqu'à présent.
Oh, et s'il vous plaît introduisez try , trouvé beaucoup de cas d'utilisation ici aussi.
--- stats ---
929 (100.0% of 929) functions (function literals are ignored)
230 ( 24.8% of 929) functions returning an error
1480 (100.0% of 1480) statements in functions returning an error
320 ( 21.6% of 1480) if statements
206 ( 64.4% of 320) if <err> != nil statements
109 ( 52.9% of 206) try candidates
2 ( 1.0% of 206) <err> name is different from "err"
--- non-try candidates (-l flag lists file positions) ---
53 ( 25.7% of 206) { return ... zero values ..., expr }
18 ( 8.7% of 206) single statement then branch
17 ( 8.3% of 206) complex then branch; cannot use try
2 ( 1.0% of 206) non-empty else branch; cannot use try
 fabstu
le 10 juil. 2019
fabstu
le 10 juil. 2019
@lpar Vous pouvez discuter d' alternatives , mais veuillez ne pas le faire dans ce numéro. Il s'agit de la proposition try . Le meilleur endroit serait en fait l'une des listes de diffusion, par exemple go-nuts. Le suivi des problèmes est vraiment le meilleur pour suivre et discuter d'un problème spécifique plutôt qu'une discussion générale. Merci.
griesemer
le 10 juil. 2019
@fabstu Le gestionnaire defer fonctionnera très bien dans votre exemple, avec et sans try . Développez votre code avec la fonction englobante :
func f() (err error) {
defer func() {
if err != nil {
err = decorate(err, "msg") // here you can modify the result error as you please
}
}()
...
if err := os.Setenv("GO111MODULE", "on"); err != nil {
return err
}
...
}
(notez que le résultat err sera défini par le return err ; et le err utilisé par le return est celui déclaré localement avec le if - ce ne sont que les règles de portée normales en action).
Ou, en utilisant un try , ce qui éliminera le besoin de la variable locale err :
func f() (err error) {
defer func() {
if err != nil {
err = decorate(err, "msg") // here you can modify the result error as you please
}
}()
...
try(os.Setenv("GO111MODULE", "on"))
...
}
Et très probablement, vous voudriez utiliser l'une des fonctions errors/errd proposées :
func f() (err error) {
defer errd.Wrap(&err, ... )
...
try(os.Setenv("GO111MODULE", "on"))
...
}
Et si vous n'avez pas besoin d'emballage, ce sera simplement :
func f() error {
...
try(os.Setenv("GO111MODULE", "on"))
...
}
@fastu Et enfin, vous pouvez utiliser errors/errd également sans try et vous obtenez alors :
func f() (err error) {
defer errd.Wrap(&err, ... )
...
if err := os.Setenv("GO111MODULE", "on"); err != nil {
return err
}
...
}
Plus j'y pense, plus j'aime cette proposition.
Les seules choses qui me dérangent sont d'utiliser le retour nommé partout. Est-ce finalement une bonne pratique et je devrais l'utiliser (jamais essayé) ?
Quoi qu'il en soit, avant de changer tout mon code, est-ce que ça marchera comme ça ?
func f() error {
var err error
defer errd.Wrap(&err,...)
try(...)
}
@flibustenet Les paramètres de résultat nommés en eux-mêmes ne sont pas du tout une mauvaise pratique; le problème habituel avec les résultats nommés est qu'ils activent naked returns ; c'est-à-dire qu'on peut simplement écrire return sans avoir besoin de spécifier les résultats réels _avec les return _. En général (mais pas toujours !), une telle pratique rend plus difficile la lecture et le raisonnement sur le code car on ne peut pas simplement regarder l'instruction return et conclure quel est le résultat. Il faut scanner le code pour les paramètres de résultat. On peut manquer de définir une valeur de résultat, et ainsi de suite. Ainsi, dans certaines bases de code, les retours nus sont tout simplement déconseillés.
Mais, comme je l'ai mentionné précédemment , si les résultats ne sont pas valides en cas d'erreur, il est parfaitement possible de définir l'erreur et d'ignorer le reste. Un retour nu dans de tels cas est parfaitement acceptable tant que le résultat d'erreur est défini de manière cohérente. try assurera exactement cela.
Enfin, les paramètres de résultat nommés ne sont nécessaires que si vous souhaitez augmenter le retour d'erreur avec defer . La documentation de conception discute également brièvement de la possibilité de fournir une autre fonction intégrée pour accéder au résultat d'erreur. Cela éliminerait complètement le besoin de déclarations nommées.
Concernant votre exemple de code : cela ne fonctionnera pas comme prévu car try définit _toujours_ l'_erreur de résultat_ (qui est sans nom dans ce cas). Mais vous déclarez une variable locale différente err et le errd.Wrap fonctionne sur celle-là. Il ne sera pas défini par try .
griesemer
le 10 juil. 2019
Rapport d'expérience rapide : j'écris un gestionnaire de requêtes HTTP qui ressemble à ceci :
func Handler(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
id := chi.URLParam(r, "id")
var err error
// starts as bad request, then it's an internal server error after we parse inputs
var statusCode = http.StatusBadRequest
defer func() {
if err != nil {
wrap := xerrors.Errorf("handler fail: %w", err)
logger.With(zap.Error(wrap)).Error("error")
http.Error(w, wrap.Error(), statusCode)
}
}()
var c Thingie
err = unmarshalBody(r, &c)
if err != nil {
return
}
statusCode = http.StatusInternalServerError
s, err := DoThing(ctx, c)
if err != nil {
return
}
d, err := DoThingWithResult(ctx, id, s)
if err != nil {
return
}
data, err := json.Marshal(detail)
if err != nil {
return
}
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusCreated)
_, err = w.Write(data)
if err != nil {
return
}
}
À première vue, il semble que ce soit un candidat idéal pour try car il y a beaucoup de gestion d'erreurs où il n'y a rien à faire sauf renvoyer un message, ce qui peut être différé. Mais vous ne pouvez pas utiliser try car un gestionnaire de requêtes ne renvoie pas error . Pour l'utiliser, je devrais envelopper le corps dans une fermeture avec la signature func() error . Cela semble ... inélégant et je soupçonne que le code qui ressemble à ceci est un modèle assez courant.
jonbodner
le 10 juil. 2019
@jonbodner
Cela fonctionne (https://play.golang.org/p/NaBZe-QShpu):
package main
import (
"errors"
"fmt"
"golang.org/x/xerrors"
)
func main() {
var err error
defer func() {
filterCheck(recover())
if err != nil {
wrap := xerrors.Errorf("app fail (at count %d): %w", ct, err)
fmt.Println(wrap)
}
}()
check(retNoErr())
n, err := intNoErr()
check(err)
n, err = intErr()
check(err)
check(retNoErr())
check(retErr())
fmt.Println(n)
}
func check(err error) {
if err != nil {
panic(struct{}{})
}
}
func filterCheck(r interface{}) {
if r != nil {
if _, ok := r.(struct{}); !ok {
panic(r)
}
}
}
var ct int
func intNoErr() (int, error) {
ct++
return 0, nil
}
func retNoErr() error {
ct++
return nil
}
func intErr() (int, error) {
ct++
return 0, errors.New("oops")
}
func retErr() error {
ct++
return errors.New("oops")
}
Ah, le premier vote négatif ! Bien. Laissez le pragmatisme couler à travers vous.
daved
le 10 juil. 2019
Ran tryhard sur certaines de mes bases de code. Malheureusement, certains de mes packages ont 0 try candidats bien qu'ils soient assez volumineux car les méthodes qu'ils contiennent utilisent une implémentation d'erreur personnalisée. Par exemple, lors de la construction de serveurs, j'aime que mes méthodes de couche de logique métier n'émettent que SanitizedError s plutôt que error s pour garantir au moment de la compilation que des choses comme les chemins du système de fichiers ou les informations système ne le font pas fuite aux utilisateurs dans les messages d'erreur.
Par exemple, une méthode qui utilise ce modèle pourrait ressembler à ceci :
func (a *App) GetFriendsOfUser(userId model.Id) ([]*model.User, SanitizedError) {
if user, err := a.GetUserById(userId); err != nil {
// (*App).GetUserById returns (*model.User, SanitizedError)
// This could be a try() candidate.
return err
} else if user == nil {
return NewUserError("The specified user doesn't exist.")
}
friends, err := a.Store.GetFriendsOfUser(userId)
// (*Store).GetFriendsOfUser returns ([]*model.User, error)
// This could be a SQL error or a network error or who knows what.
return friends, NewInternalError(err)
}
Y a-t-il une raison pour laquelle nous ne pouvons pas assouplir la proposition actuelle pour qu'elle fonctionne tant que la dernière valeur de retour de la fonction englobante et de l'expression de la fonction try implémente l'erreur et est du même type ? Cela éviterait toujours toute confusion concrète nil -> interface, mais cela permettrait d'essayer dans des situations comme celles ci-dessus.
ccbrown
le 11 juil. 2019
Merci, @jonbodner , pour votre exemple . J'écrirais ce code comme suit (malgré les erreurs de traduction):
func Handler(w http.ResponseWriter, r *http.Request) {
statusCode, err := internalHandler(w, r)
if err != nil {
wrap := xerrors.Errorf("handler fail: %w", err)
logger.With(zap.Error(wrap)).Error("error")
http.Error(w, wrap.Error(), statusCode)
}
}
func internalHandler(w http.ResponseWriter, r *http.Request) (statusCode int, err error) {
ctx := r.Context()
id := chi.URLParam(r, "id")
// starts as bad request, then it's an internal server error after we parse inputs
statusCode = http.StatusBadRequest
var c Thingie
try(unmarshalBody(r, &c))
statusCode = http.StatusInternalServerError
s := try(DoThing(ctx, c))
d := try(DoThingWithResult(ctx, id, s))
data := try(json.Marshal(detail))
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusCreated)
try(w.Write(data))
return
}
Il utilise deux fonctions mais il est beaucoup plus court (29 lignes contre 40 lignes) - et j'ai utilisé un espacement agréable - et ce code n'a pas besoin d'un defer . Le defer en particulier, ainsi que le statusCode modifié en cours de route et utilisé dans le defer , rendent le code d'origine plus difficile à suivre que nécessaire. Le nouveau code, bien qu'il utilise des résultats nommés et un retour nu (vous pouvez facilement le remplacer par return statusCode, nil si vous le souhaitez) est plus simple car il sépare proprement la gestion des erreurs de la "logique métier".
griesemer
le 11 juil. 2019
Republiez simplement mon commentaire dans un autre numéro https://github.com/golang/go/issues/32853#issuecomment -510340544
Je pense que si nous pouvons fournir un autre paramètre funcname , ce sera formidable, sinon nous ne savons toujours pas que l'erreur est renvoyée par quelle fonction.
func foo() error {
handler := func(err error, funcname string) error {
return fmt.Errorf("%s: %v", funcname, err) // wrap something
//return nil // or dismiss
}
a, b := try(bar1(), handler)
c, d := try(bar2(), handler)
}
 lunny
le 11 juil. 2019
lunny
le 11 juil. 2019
@ccbrown Je me demande si votre exemple se prêterait au même traitement que ci- dessus ; c'est-à-dire s'il serait logique de factoriser le code de telle sorte que les erreurs internes soient enveloppées une fois (par une fonction englobante) avant de disparaître (plutôt que de les envelopper partout). Il me semblerait (sans en savoir beaucoup sur votre système) que ce serait préférable car cela centraliserait l'enveloppement des erreurs en un seul endroit plutôt que partout.
Mais en ce qui concerne votre question : je devrais penser à faire en sorte que try accepte un type d'erreur plus général (et en renvoie un également). Je n'y vois pas de problème pour le moment (sauf que c'est plus compliqué à expliquer) - mais il peut y avoir un problème après tout.
Dans ce sens, nous nous sommes demandé très tôt si try pouvait être généralisé afin qu'il ne fonctionne pas seulement pour les types error , mais pour n'importe quel type, et le test err != nil serait alors devient x != zero où x est l'équivalent de err (le dernier résultat), et zero la valeur zéro respective pour le type de x . Malheureusement, cela ne fonctionne pas pour le cas courant des booléens (et à peu près n'importe quel autre type de base), car la valeur zéro de bool est false et ok != false est exactement l'inverse de ce que l'on voudrait tester.
griesemer
le 11 juil. 2019
@lunny La version proposée de try n'accepte pas de fonction de gestionnaire.
griesemer
le 11 juil. 2019
@griesemer Oh. Quel dommage ! Sinon, je peux supprimer github.com/pkg/errors et tous les errors.Wrap .
lunny
le 11 juil. 2019
@ccbrown Je me demande si votre exemple se prêterait au même traitement que ci-dessus; c'est-à-dire s'il serait logique de factoriser le code de telle sorte que les erreurs internes soient enveloppées une fois (par une fonction englobante) avant de disparaître (plutôt que de les envelopper partout). Il me semblerait (sans en savoir beaucoup sur votre système) que ce serait préférable car cela centraliserait l'enveloppement des erreurs en un seul endroit plutôt que partout.
@griesemer Retourner error à la place d'une fonction englobante permettrait d'oublier de catégoriser chaque erreur comme une erreur interne, une erreur utilisateur, une erreur d'autorisation, etc. Tel quel, le compilateur l'attrape et utilise try ne vaudrait pas la peine d'échanger ces vérifications à la compilation contre des vérifications à l'exécution.
ccbrown
le 11 juil. 2019
Je voudrais dire que j'aime la conception de try , mais il y a toujours l'instruction if dans le gestionnaire defer pendant que vous utilisez try . Je ne pense pas que ce serait plus simple que les instructions if sans les gestionnaires try et defer . Peut-être qu'utiliser uniquement try serait bien mieux.
 Fallensouls
le 11 juil. 2019
Fallensouls
le 11 juil. 2019
@ccbrown Compris . Rétrospectivement, je pense que votre assouplissement suggéré ne devrait pas poser de problème. Je pense que nous pourrions assouplir try pour travailler avec n'importe quel type d'interface (et type de résultat correspondant), d'ailleurs, pas seulement error , tant que le test pertinent reste x != nil . Quelque chose à quoi penser. Cela pourrait être fait tôt, ou rétroactivement car ce serait un changement rétrocompatible, je crois.
griesemer
le 11 juil. 2019
@jonbodner example , et la façon dont @griesemer l' a réécrit , est exactement le genre de code que j'ai où j'aimerais vraiment utiliser try .
ngrilly
le 11 juil. 2019
Personne n'est gêné par ce type d'utilisation de try:
data := try(json.Marshal(détail))
Indépendamment du fait que l'erreur de marshaling peut entraîner la recherche de la ligne correcte dans le code écrit, je me sens mal à l'aise de savoir qu'il s'agit d'une erreur nue renvoyée sans qu'aucune information sur le numéro de ligne / l'appelant ne soit incluse. Connaître le fichier source, le nom de la fonction et le numéro de ligne est généralement ce que j'inclus lors de la gestion des erreurs. Peut-être que je comprends mal quelque chose cependant.
trende-jp
le 12 juil. 2019
@griesemer Je n'avais pas l'intention de discuter d'alternatives ici. Le fait que tout le monde continue de suggérer des alternatives est exactement la raison pour laquelle je pense qu'un sondage pour savoir ce que les gens veulent réellement serait une bonne idée. Je viens d'en parler ici pour essayer d'attirer autant de personnes que possible intéressées par la possibilité d'améliorer la gestion des erreurs Go.
lpar
le 12 juil. 2019
@ trende-jp Je dépend vraiment du contexte de cette ligne de code - à elle seule, elle ne peut être jugée de manière significative. S'il s'agit du seul appel à json.Marshal et que vous souhaitez augmenter l'erreur, une instruction if peut être préférable. S'il y a beaucoup d'appels json.Marshal , ajouter du contexte à l'erreur pourrait être bien fait avec un defer ; ou peut-être en enveloppant tous ces appels dans une fermeture locale qui renvoie l'erreur. Il existe une multitude de façons de factoriser cela si nécessaire (c'est-à-dire s'il existe de nombreux appels de ce type dans la même fonction). "Les erreurs sont des valeurs" est également vrai ici : utilisez du code pour rendre la gestion des erreurs gérable.
try ne va pas résoudre tous vos problèmes de gestion des erreurs - ce n'est pas l'intention. C'est simplement un autre outil dans la boîte à outils. Et ce n'est pas vraiment une nouvelle machinerie non plus, c'est une forme de sucre syntaxique pour un modèle que nous avons fréquemment observé au cours de près d'une décennie. Nous avons des preuves que cela fonctionnerait très bien dans certains codes, et que cela ne serait pas non plus d'une grande aide dans d'autres codes.
griesemer
le 12 juil. 2019
@tendance-jp
Cela ne peut-il pas être résolu avec defer ?
defer fmt.HandleErrorf(&err, "decoding %q", path)
Les numéros de ligne dans les messages d'erreur peuvent également être résolus comme je l'ai montré dans mon blog : Comment utiliser 'try' .
faiface
le 12 juil. 2019
@trende-jp @faiface En plus du numéro de ligne, vous pouvez stocker la chaîne de décorateur dans une variable. Cela vous permettrait d'isoler l'appel de fonction spécifique qui échoue.
fbnz156
le 12 juil. 2019
Je pense vraiment que cela ne devrait absolument pas être une fonction intégrée .
Il a été mentionné à plusieurs reprises que panic() et recover() modifient également le flux de contrôle. Très bien, n'en rajoutons pas.
@networkimprov a écrit https://github.com/golang/go/issues/32437#issuecomment -498960081 :
Il ne se lit pas comme Go.
Je ne pourrais pas être plus d'accord.
Si quoi que ce soit, je crois que tout mécanisme pour résoudre le problème racine (et je ne suis pas sûr qu'il y en ait un), il devrait être déclenché par un mot-clé (ou un symbole de clé ?).
Comment vous sentiriez-vous si go func() devenait go(func()) ?
 sylr
le 12 juil. 2019
sylr
le 12 juil. 2019
Que diriez-vous d'utiliser bang(!) au lieu de la fonction try . Cela pourrait rendre la chaîne de fonctions possible :
func foo() {
f := os.Open!("")
defer f.Close()
// etc
}
func bar() {
count := mustErr!().Read!()
}
 nonblockio
le 12 juil. 2019
nonblockio
le 12 juil. 2019
@sylr
Comment vous sentiriez-vous si go func() devait être go(func()) ?
Allez, ce serait plutôt acceptable.
faiface
le 12 juil. 2019
@sylr Merci, mais nous ne sollicitons pas de propositions alternatives sur ce fil. Voir aussi ceci sur rester concentré.
Concernant votre commentaire : Go est un langage pragmatique - utiliser un intégré ici est un choix pragmatique. Il présente plusieurs avantages par rapport à l'utilisation d'un mot-clé, comme expliqué en détail dans le document de conception . Notez que try est simplement du sucre syntaxique pour un modèle commun (contrairement à go qui implémente une fonctionnalité majeure de Go et ne peut pas être implémenté avec d'autres mécanismes Go), comme append , copy , etc. L'utilisation d'une fonction intégrée est un bon choix.
(Mais comme je l'ai déjà dit, si _that_ est la seule chose qui empêche try d'être acceptable, nous pouvons envisager d'en faire un mot-clé.)
griesemer
le 12 juil. 2019
Je réfléchissais juste à un morceau de mon propre code, et à quoi cela ressemblerait avec try :
slurp, err := ioutil.ReadFile(path)
if err != nil {
return err
}
return ioutil.WriteFile(path, append(copyrightText, slurp...), 0666)
Pourrait devenir:
return ioutil.WriteFile(path, append(copyrightText, try(ioutil.ReadFile(path))...), 0666)
Je ne sais pas si c'est mieux. Cela semble rendre le code beaucoup plus difficile à lire. Mais ce n'est peut-être qu'une question d'habitude.
gbbr
le 12 juil. 2019
@gbbr Vous avez le choix ici. Vous pourriez l'écrire ainsi :
slurp := try(ioutil.ReadFile(path))
return ioutil.WriteFile(path, append(copyrightText, slurp...), 0666)
ce qui vous évite encore beaucoup de passe-partout tout en le rendant beaucoup plus clair. Ce n'est pas inhérent à try . Ce n'est pas parce que vous pouvez tout regrouper dans une seule expression que vous devriez le faire. Cela s'applique généralement.
griesemer
le 12 juil. 2019
@griesemer Cet exemple _est_ inhérent à essayer, vous ne pouvez pas imbriquer du code qui peut échouer aujourd'hui - vous êtes obligé de gérer les erreurs avec le flux de contrôle. Je voudrais clarifier quelque chose de https://github.com/golang/go/issues/32825#issuecomment -507099786 / https://github.com/golang/go/issues/32825#issuecomment -507136111 auquel vous a répondu https://github.com/golang/go/issues/32825#issuecomment -507358397. Plus tard, le même problème a été discuté à nouveau dans https://github.com/golang/go/issues/32825#issuecomment -508813236 et https://github.com/golang/go/issues/32825#issuecomment -508937177 - le dernier dont je précise :
Heureux que vous ayez lu mon argument central contre try : l'implémentation n'est pas assez restrictive. Je pense que soit la mise en œuvre doit correspondre à toutes les propositions d'exemples d'utilisation qui soient concis et faciles à lire.
_Ou_ la proposition doit contenir des exemples qui correspondent à l'implémentation afin que toutes les personnes qui l'envisagent puissent être exposées à ce qui apparaîtra inévitablement dans le code Go. Avec tous les cas particuliers auxquels nous pouvons être confrontés lors du dépannage de logiciels moins qu'idéalement écrits, qui se produisent dans n'importe quelle langue / environnement. Il devrait répondre à des questions comme à quoi ressembleront les traces de pile avec plusieurs niveaux d'imbrication, les emplacements des erreurs sont-ils facilement reconnaissables ? Qu'en est-il des valeurs de méthode, des littéraux de fonction anonymes ? Quel type de trace de pile les éléments ci-dessous produisent-ils si la ligne contenant les appels à fn() échoue ?
fn := func(n int) (int, error) { ... } return try(func() (int, error) { mu.Lock() defer mu.Unlock() return try(try(fn(111111)) + try(fn(101010)) + try(func() (int, error) { // yea... })(2)) }(try(fn(1)))Je suis bien conscient qu'il y aura beaucoup de code raisonnable écrit, mais nous fournissons maintenant un outil qui n'a jamais existé auparavant : la possibilité d'écrire potentiellement du code sans flux de contrôle clair. Je veux donc justifier pourquoi nous l'autorisons même en premier lieu, je ne veux jamais perdre mon temps à déboguer ce type de code. Parce que je sais que je le ferai, l'expérience m'a appris que quelqu'un le fera si vous le lui permettez. Ce quelqu'un est souvent un moi non informé.
Go fournit le moins de moyens possibles aux autres développeurs et à moi-même pour nous faire perdre du temps en nous limitant à utiliser les mêmes constructions banales. Je ne veux pas perdre cela sans un avantage écrasant. Je ne pense pas que "parce que try est implémenté en tant que fonction" soit un avantage écrasant. Pouvez-vous fournir une raison pour laquelle il est?
Avoir une trace de pile qui montre où ce qui précède échoue serait utile, peut-être ajouter un littéral composite avec des champs qui appellent cette fonction dans le mélange ? Je demande cela parce que je sais à quoi ressemblent les traces de pile aujourd'hui pour ce type de problème, Go ne fournit pas d'informations de colonne facilement digestibles dans les informations de pile uniquement l'adresse d'entrée de la fonction hexadécimale. Plusieurs choses m'inquiètent à ce sujet, telles que la cohérence de la trace de la pile entre les architectures, par exemple, considérez ce code :
package main
import "fmt"
func dopanic(b bool) int { if b { panic("panic") }; return 1 }
type bar struct { a, b, d int; b *bar }
func main() {
fmt.Println(&bar{
a: 1,
c: 1,
d: 1,
b: &bar{
a: 1,
c: 1,
d: dopanic(true) + dopanic(false),
},
})
}
Remarquez comment le premier terrain de jeu échoue au dopanique de gauche, le second à droite, mais les deux impriment une trace de pile identique :
https://play.golang.org/p/SYs1r4hBS7O
https://play.golang.org/p/YMKkflcQuav
panic: panic
goroutine 1 [running]:
main.dopanic(...)
/tmp/sandbox709874298/prog.go:7
main.main()
/tmp/sandbox709874298/prog.go:27 +0x40
Je me serais attendu à ce que le second soit + 0x41 ou un décalage après 0x40, qui pourrait être utilisé pour déterminer l'appel réel qui a échoué dans la panique. Même si nous obtenons les décalages hexadécimaux corrects, je ne pourrai pas déterminer où l'échec s'est produit sans débogage supplémentaire. Aujourd'hui, il s'agit d'un cas marginal, auquel les gens seront rarement confrontés. Si vous publiez une version emboîtable de try, cela deviendra la norme, car même la proposition inclut un try() + try() strconv montrant qu'il est à la fois possible et acceptable d'utiliser try de cette façon.
1) Compte tenu des informations ci-dessus, quelles modifications des traces de pile prévoyez-vous d'apporter (le cas échéant) afin que je puisse toujours dire où mon code a échoué ?
2) L'imbrication d'essais est-elle autorisée parce que vous pensez qu'elle devrait l'être ? Si oui, quels sont selon vous les avantages d'essayer l'imbrication et comment éviterez-vous les abus ? Je pense que tryhard devrait être ajusté pour effectuer des essais imbriqués là où vous le considérez comme acceptable afin que les gens puissent prendre une décision plus éclairée sur la façon dont cela affecte leur code, car actuellement nous n'obtenons que les exemples d'utilisation les meilleurs/les plus stricts. Cela nous donnera une idée du type de limitations vet qui seront imposées, à partir de maintenant, vous avez dit que le vétérinaire sera la défense contre les essais déraisonnables, mais comment cela se matérialisera-t-il ?
3) Essayez-vous d'imbriquer parce qu'il se trouve que c'est une conséquence de la mise en œuvre ? Si tel est le cas, cela ne semble-t-il pas être un argument très faible pour le changement de langage le plus notable depuis la sortie de Go ?
Je pense que ce changement nécessite plus de réflexion autour de l'imbrication d'essais. Chaque fois que j'y pense, un nouveau point douloureux émerge quelque part, je suis très inquiet que tous les négatifs potentiels n'émergent pas tant qu'ils ne seront pas révélés dans la nature. L'imbrication fournit également un moyen simple de fuir des ressources, comme mentionné dans https://github.com/golang/go/issues/32825#issuecomment -506882164, ce qui n'est pas possible aujourd'hui. Je pense que l'histoire "vétérinaire" a besoin d'un plan beaucoup plus concret avec des exemples de la façon dont il fournira des commentaires s'il sera utilisé comme défense contre les exemples try() nuisibles que j'ai donnés ici, ou l'implémentation devrait fournir des erreurs de temps de compilation pour une utilisation en dehors de vos meilleures pratiques idéales.
edit : j'ai demandé à gophers l'architecture de play.golang.org et quelqu'un a mentionné qu'il se compile via NaCl, donc probablement juste une conséquence / un bogue de cela. Mais je pouvais voir que cela était un problème sur d'autres arcs, je pense que beaucoup de problèmes qui pourraient survenir de l'introduction de plusieurs retours par ligne n'ont tout simplement pas été pleinement explorés puisque la plupart des utilisations sont centrées sur une utilisation saine et propre d'une seule ligne.
 cstockton
le 14 juil. 2019
cstockton
le 14 juil. 2019
Oh non, s'il vous plaît, n'ajoutez pas cette "magie" dans le langage.
Ceux-ci ne ressemblent pas au reste du langage.
Je vois déjà un code comme celui-ci apparaître partout.
a, b := try( f() )
if a != 0 && b != "" {
...
}
...
au lieu de
a,b,err := f()
if err != nil {
...
}
...
ou
a,b,_:= f()
Le call if err.... n'était pas naturel au début pour moi, mais maintenant je suis habitué à
Je me sens plus facile à gérer les erreurs car elles peuvent arriver dans le flux d'exécution au lieu d'écrire des wrappers/gestionnaires qui devront suivre une sorte d'état pour agir une fois déclenchés.
Et si je décide d'ignorer les erreurs pour sauver la vie de mon clavier, je suis conscient que je paniquerai un jour.
j'ai même changé mes habitudes en vbscript pour :
on error resume next
a = f()
if er.number <> 0 then
...
end if
...
 Ju-B
le 16 juil. 2019
Ju-B
le 16 juil. 2019
j'aime cette proposition
Toutes les préoccupations que j'avais (par exemple, idéalement, il devrait s'agir d'un mot-clé et non d'un élément intégré) sont traitées par le document détaillé
Ce n'est pas parfait à 100%, mais c'est une solution assez bonne qui a) résout un problème réel et b) le fait en tenant compte de beaucoup de problèmes de rétrocompatibilité et d'autres problèmes
Bien sûr, il fait un peu de "magie", mais il en va de même pour defer . La seule différence est le mot-clé par rapport à l'intégration, et le choix d'éviter un mot-clé ici est logique.
 DavidR91
le 16 juil. 2019
DavidR91
le 16 juil. 2019
J'ai l'impression que tous les commentaires importants contre la proposition try() ont déjà été exprimés. Mais je vais essayer de résumer :
1) try () déplace la complexité du code vertical vers l'horizontal
2) Les appels try() imbriqués sont aussi difficiles à lire que les opérateurs ternaires
3) Introduit un flux de contrôle de «retour» invisible qui n'est pas visuellement distinctif (par rapport aux blocs en retrait commençant par le mot-clé return )
4) Aggrave la pratique de l'emballage des erreurs (contexte de la fonction au lieu d'une action spécifique)
5) Divise la communauté #golang et le style de code (anti-gofmt)
6) Les développeurs réécriront try() en if-err-nil et vice versa souvent (tryhard vs. ajouter une logique de nettoyage / des journaux supplémentaires / un meilleur contexte d'erreur)
 VojtechVitek
le 16 juil. 2019
VojtechVitek
le 16 juil. 2019
@VojtechVitek Je pense que les remarques que vous faites sont subjectives et ne peuvent être évaluées qu'une fois que les gens commencent à l'utiliser sérieusement.
Cependant, je crois qu'il y a un point technique qui n'a pas été beaucoup discuté. Le modèle d'utilisation de defer pour l'habillage/décoration des erreurs a des implications sur les performances au-delà du simple coût de defer lui-même puisque les fonctions qui utilisent defer ne peuvent pas être intégrées.
Cela signifie que l'adoption try avec emballage d'erreur impose deux coûts potentiels par rapport au renvoi d'une erreur encapsulée directement après une vérification err != nil :
- un report pour tous les parcours dans la fonction, même ceux réussis
- perte d'inlining
Même s'il y a des améliorations de performances impressionnantes à venir pour defer , le coût est toujours non nul.
try a beaucoup de potentiel, il serait donc bon que l'équipe Go puisse revoir la conception pour permettre une sorte d'emballage au point de défaillance au lieu de préemption via defer .
iand
le 16 juil. 2019
l'histoire du vétérinaire a besoin d'un plan beaucoup plus concret
l'histoire du vétérinaire est un conte de fées. Cela ne fonctionnera que pour les types connus et sera inutile pour les types personnalisés.
sirkon
le 16 juil. 2019
Salut tout le monde,
Notre objectif avec des propositions comme celle-ci est d'avoir une discussion à l'échelle de la communauté sur les implications, les compromis et la manière de procéder, puis d'utiliser cette discussion pour aider à décider de la voie à suivre.
Sur la base de la réponse écrasante de la communauté et des discussions approfondies ici, nous marquons que cette proposition a été refusée plus tôt que prévu .
En ce qui concerne les commentaires techniques, cette discussion a utilement identifié certaines considérations importantes que nous avons manquées, notamment les implications pour l'ajout d'impressions de débogage et l'analyse de la couverture du code.
Plus important encore, nous avons clairement entendu les nombreuses personnes qui ont fait valoir que cette proposition ne ciblait pas un problème valable. Nous pensons toujours que la gestion des erreurs dans Go n'est pas parfaite et peut être améliorée de manière significative, mais il est clair qu'en tant que communauté, nous devons parler davantage des aspects spécifiques de la gestion des erreurs qui sont des problèmes que nous devons résoudre.
En ce qui concerne la discussion du problème à résoudre, nous avons essayé d'exposer notre vision du problème en août dernier dans le « Go 2 error handling problem overview », mais rétrospectivement, nous n'avons pas suffisamment attiré l'attention sur cette partie et n'avons pas suffisamment encouragé discussion pour savoir si le problème spécifique était le bon. La proposition try peut être une bonne solution au problème décrit ici, mais pour beaucoup d'entre vous, ce n'est tout simplement pas un problème à résoudre. À l'avenir, nous devons faire un meilleur travail en attirant l'attention sur ces premiers énoncés de problèmes et en nous assurant qu'il existe un large consensus sur le problème à résoudre.
(Il est également possible que l'énoncé du problème de gestion des erreurs ait été entièrement éclipsé par la publication d'un brouillon de conception générique le même jour.)
Sur le sujet plus large de ce qu'il faut améliorer dans la gestion des erreurs Go, nous serions très heureux de voir des rapports d'expérience sur les aspects de la gestion des erreurs dans Go qui vous posent le plus de problèmes dans vos propres bases de code et environnements de travail et l'impact d'une bonne solution. avez dans votre propre développement. Si vous rédigez un tel rapport, veuillez publier un lien sur la page Go2ErrorHandlingFeedback .
Merci à tous ceux qui ont participé à cette discussion, ici et ailleurs. Comme Russ Cox l'a déjà souligné, les discussions à l'échelle de la communauté comme celle-ci sont open source à leur meilleur . Nous apprécions vraiment l'aide de chacun pour examiner cette proposition spécifique et plus généralement pour discuter des meilleurs moyens d'améliorer l'état de la gestion des erreurs dans Go.
Robert Griesemer, pour le comité d'examen des propositions.
griesemer
le 17 juil. 2019
Merci, Go Team, pour le travail effectué dans la proposition d'essai. Et merci aux commentateurs qui ont lutté avec cela et ont proposé des alternatives. Parfois, ces choses prennent une vie propre. Merci Go Team pour votre écoute et votre réponse appropriée.
 rmorriso
le 17 juil. 2019
rmorriso
le 17 juil. 2019
Yay!
 bobbytables
le 17 juil. 2019
bobbytables
le 17 juil. 2019
Merci à tous d'avoir préparé cela afin que nous puissions avoir le meilleur résultat possible !
L'appel concerne une liste de problèmes et d'expériences négatives avec la gestion des erreurs de Go. Cependant,
Les équipes et moi-même sommes très satisfaits de xerrors.As, xerrors.Is et xerrors.Errorf en production. Ces nouveaux ajouts changent complètement la gestion des erreurs d'une manière merveilleuse pour nous maintenant que nous avons pleinement adopté les changements. Pour le moment, nous n'avons rencontré aucun problème ou besoin non résolu.
 tebruno99
le 17 juil. 2019
tebruno99
le 17 juil. 2019
@griesemer Je voulais juste vous remercier (et probablement beaucoup d'autres qui ont travaillé avec vous) pour votre patience et vos efforts.
lestrrat
le 17 juil. 2019
bien!
 aimuz
le 17 juil. 2019
aimuz
le 17 juil. 2019
@griesemer Merci à vous et à tous les autres membres de l'équipe Go d'avoir écouté sans relâche tous les commentaires et d'avoir accepté toutes nos opinions variées.
Alors peut-être que le moment est venu de clore ce fil et de passer à des choses futures ?
mikeschinkel
le 17 juil. 2019
@griesemer @rsc et @all , cool, merci à tous. pour moi, c'est une excellente discussion/identifier/clarifier. l'amélioration de certaines parties comme le problème "d'erreur" dans go, nécessite une discussion plus ouverte (dans la proposition et les commentaires ...) pour identifier / clarifier les problèmes fondamentaux en premier.
ps, le x/xerrors est bon pour l'instant.
 tsingson
le 17 juil. 2019
tsingson
le 17 juil. 2019
(il serait peut-être judicieux de verrouiller ce fil également...)
 justaugustus
le 17 juil. 2019
justaugustus
le 17 juil. 2019
Merci à l'équipe et à la communauté pour leur participation. J'aime le nombre de personnes qui se soucient de Go.
J'espère vraiment que la communauté verra d'abord les efforts et les compétences qui ont été nécessaires à la proposition d'essai en premier lieu, puis l'esprit de l'engagement qui a suivi et qui nous a aidés à prendre cette décision. L'avenir du Go est très prometteur si nous pouvons continuer ainsi, surtout si nous pouvons tous maintenir des attitudes positives.
 matryer
le 17 juil. 2019
matryer
le 17 juil. 2019
func M() (Données, erreur){
un, err1 := A()
b, err2 := B()
retour b, nul
} => (if err1 != nil){ return a, err1}.
(if err2 != nil){ return b, err2}
 cuteLittleDevil
le 17 juil. 2019
cuteLittleDevil
le 17 juil. 2019
D'accord... J'ai aimé cette proposition mais j'aime la façon dont la communauté et l'équipe de Go ont réagi et engagé une discussion constructive, même si c'était parfois un peu difficile.
J'ai cependant 2 questions concernant ce résultat :
1/ La "gestion des erreurs" est-elle encore un domaine de recherche ?
2/ Les améliorations différées sont-elles repriorisées ?
pierrec
le 17 juil. 2019
Cela prouve une fois de plus que la communauté Go est entendue et capable de discuter de propositions controversées de changement de langue. Comme les changements qui le font dans la langue, les changements qui ne sont pas une amélioration. Merci, l'équipe Go et la communauté, pour le travail acharné et la discussion civilisée autour de cette proposition !
 danrl
le 17 juil. 2019
danrl
le 17 juil. 2019
Excellent!
 miguel550
le 17 juil. 2019
miguel550
le 17 juil. 2019
génial, très utile
 FelixSeptem
le 17 juil. 2019
FelixSeptem
le 17 juil. 2019
Je suis peut-être trop attaché au Go, mais je pense qu'un point a été montré ici, car
Russ a décrit : il y a un point où la communauté n'est pas seulement un
poulet sans tête, c'est une force avec laquelle il faut compter et
exploité pour son propre bien.
Grâce à la coordination assurée par la Go Team, nous pouvons
soyez tous fiers que nous soyons arrivés à une conclusion, une conclusion avec laquelle nous pouvons vivre et
reviendrons, sans aucun doute, lorsque les conditions seront plus mûres.
Espérons que la douleur ressentie ici nous servira bien à l'avenir
(ne serait-ce pas triste, sinon ?).
Lucio.
lootch
le 17 juil. 2019
Je ne suis pas d'accord sur la décision. Cependant, j'approuve absolument l'approche que l'équipe de go a entreprise. Avoir une discussion à l'échelle de la communauté et tenir compte des commentaires des développeurs est ce que l'open source voulait dire.
 egopher
le 17 juil. 2019
egopher
le 17 juil. 2019
Je me demande si les optimisations différées viendront aussi. J'aime beaucoup annoter les erreurs avec et xerrors ensemble et c'est trop coûteux en ce moment.
fabstu
le 17 juil. 2019
@pierrec Je pense que nous avons besoin de mieux comprendre quels changements dans la gestion des erreurs seraient utiles. Certains des changements de valeurs d'erreur seront dans la prochaine version 1.13 (https://tip.golang.org/doc/go1.13#errors), et nous acquerrons de l'expérience avec eux. Au cours de cette discussion, nous avons vu de nombreuses propositions de gestion des erreurs syntaxiques, et il serait utile que les gens puissent voter et commenter celles qui semblent particulièrement utiles. Plus généralement, comme l'a dit @griesemer , des rapports d'expérience seraient utiles.
Il serait également utile de mieux comprendre dans quelle mesure la syntaxe de gestion des erreurs est problématique pour les personnes novices dans le langage, bien que cela soit difficile à déterminer.
Il y a un travail actif sur l'amélioration des performances de defer dans https://golang.org/cl/183677 , et à moins qu'un obstacle majeur ne soit rencontré, je m'attendrais à ce que cela soit intégré à la version 1.14.
ianlancetaylor
le 17 juil. 2019
@griesemer @ianlancetaylor @rsc Prévoyez -vous toujours de traiter la verbosité de la gestion des erreurs, avec une autre proposition résolvant tout ou partie des problèmes soulevés ici ?
ngrilly
le 17 juil. 2019
Donc, en retard à la fête, puisque cela a déjà été refusé, mais pour une discussion future sur le sujet, qu'en est-il d'une syntaxe de retour conditionnel de type ternaire ? (Je n'ai rien vu de similaire dans mon analyse du sujet ou en regardant la vue que Russ Cox a publiée sur Twitter.) Exemple :
f, err := Foo()
return err != nil ? nil, err
Renvoie nil, err si err est non nul, continue l'exécution si err est nul. Le formulaire de déclaration serait
return <boolean expression> ? <return values>
et ce serait du sucre syntaxique pour:
if <boolean expression> {
return <return values>
}
Le principal avantage est qu'il est plus flexible qu'un mot-clé check ou qu'une fonction intégrée try , car il peut déclencher plus d'erreurs (ex. return err != nil || f == nil ? nil, fmt.Errorf("failed to get Foo") , sur plus que juste l'erreur non nulle (ex. return err != nil && err != io.EOF ? nil, err ), etc., tout en restant assez intuitif à comprendre lors de la lecture (en particulier pour ceux qui sont habitués à lire des opérateurs ternaires dans d'autres langages).
Cela garantit également que la gestion des erreurs _a toujours lieu à l'emplacement de l'appel_, plutôt que de se produire automatiquement en fonction d'une instruction différée. L'un des plus gros reproches que j'ai eu avec la proposition originale est qu'elle tente, d'une certaine manière, de faire de la gestion réelle des erreurs un processus implicite qui se produit automatiquement lorsque l'erreur est non nulle, sans indication claire que le flux de contrôle reviendra si l'appel de la fonction renvoie une erreur non nulle. L'ensemble du _point_ de Go utilisant des retours d'erreur explicites au lieu d'un système de type exception est d'encourager les développeurs à vérifier et à gérer explicitement et intentionnellement leurs erreurs, plutôt que de simplement les laisser se propager dans la pile pour être, en théorie, traitées à un point supérieur en haut. Au moins une déclaration de retour explicite, si conditionnelle, annote clairement ce qui se passe.
 kaedys
le 17 juil. 2019
kaedys
le 17 juil. 2019
@ngrilly Comme @griesemer l' a dit, je pense que nous devons mieux comprendre quels aspects de la gestion des erreurs les programmeurs Go trouvent les plus problématiques.
Personnellement, je ne pense pas qu'une proposition qui supprime une petite quantité de verbosité en vaille la peine. Après tout, la langue fonctionne assez bien aujourd'hui. Chaque changement a un coût. Si nous voulons apporter un changement, nous avons besoin d'un avantage significatif. Je pense que cette proposition a fourni un avantage significatif en termes de verbosité réduite, mais il y a clairement un segment important de programmeurs Go qui estiment que les coûts supplémentaires qu'elle a imposés étaient trop élevés. Je ne sais pas s'il y a un juste milieu ici. Et je ne sais pas si le problème mérite d'être traité.
ianlancetaylor
le 17 juil. 2019
@kaedys Ce problème fermé et extrêmement verbeux n'est certainement pas le bon endroit pour discuter de syntaxes alternatives spécifiques pour la gestion des erreurs.
ianlancetaylor
le 17 juil. 2019
@ianlancetaylor
Je pense que cette proposition a fourni un avantage significatif en termes de verbosité réduite, mais il y a clairement un segment important de programmeurs Go qui estiment que les coûts supplémentaires qu'elle a imposés étaient trop élevés.
J'ai peur qu'il y ait un biais d'auto-sélection. Go est connu pour sa gestion détaillée des erreurs et son manque de génériques. Cela attire naturellement les développeurs qui ne se soucient pas de ces deux problèmes. En attendant, d'autres développeurs continuent d'utiliser leurs langages actuels (Java, C++, C#, Python, Ruby, etc.) et/ou passent à des langages plus modernes (Rust, TypeScript, Kotlin, Swift, Elixir, etc.) à cause de cela . Je connais de nombreux développeurs qui évitent Go principalement pour cette raison.
Je pense aussi qu'il y a un biais de confirmation en jeu. Les gophers ont été utilisés pour défendre la gestion détaillée des erreurs et l'absence de gestion des erreurs lorsque les gens critiquent Go. Cela rend plus difficile l'évaluation objective d'une proposition comme try.
Steve Klabnik a publié il y a quelques jours un commentaire intéressant sur Reddit . Il était contre l'introduction ? dans Rust, car c'était « deux façons d'écrire la même chose » et c'était « trop implicite ». Mais maintenant, après avoir écrit plus de quelques lignes de code avec, ? est l'une de ses fonctionnalités préférées.
ngrilly
le 17 juil. 2019
@ngrilly Je suis d'accord avec vos commentaires. Ces biais sont très difficiles à éviter. Ce qui serait très utile, c'est une meilleure compréhension du nombre de personnes qui évitent Go en raison de la gestion détaillée des erreurs. Je suis sûr que le nombre n'est pas nul, mais il est difficile à mesurer.
Cela dit, il est également vrai que try a introduit un nouveau changement dans le flux de contrôle qui était difficile à voir, et que bien que try était destiné à aider à gérer les erreurs, il n'a pas aidé à annoter les erreurs .
Merci pour la citation de Steve Klabnik. Bien que j'apprécie et que je sois d'accord avec le sentiment, il convient de considérer qu'en tant que langage, Rust semble un peu plus disposé à s'appuyer sur des détails syntaxiques que Go ne l'a été.
ianlancetaylor
le 17 juil. 2019
En tant que partisan de cette proposition, je suis naturellement déçu qu'elle soit maintenant retirée, même si je pense que l'équipe Go a fait ce qu'il fallait dans les circonstances.
Une chose qui semble maintenant assez claire est que la majorité des utilisateurs de Go ne considèrent pas la verbosité de la gestion des erreurs comme un problème et je pense que c'est quelque chose que le reste d'entre nous devra vivre avec même si cela rebute les nouveaux utilisateurs potentiels .
J'ai perdu le compte du nombre de propositions alternatives que j'ai lues et, bien que certaines soient assez bonnes, je n'en ai vu aucune qui, à mon avis, valait la peine d'être adoptée si try devait mordre la poussière. Donc, la chance qu'une proposition de terrain d'entente émerge maintenant me semble lointaine.
Sur une note plus positive, la discussion actuelle a souligné les moyens par lesquels toutes les erreurs potentielles dans une fonction peuvent être décorées de la même manière et au même endroit (en utilisant defer ou même goto ) ce que je n'avais pas envisagé auparavant et j'espère que l'équipe Go envisagera au moins de changer go fmt pour permettre à une seule instruction if d'être écrite sur une seule ligne, ce qui permettra au moins de gérer les erreurs _look_ plus compact même s'il ne supprime en fait aucun passe-partout.
alanfo
le 17 juil. 2019
@pierrec
1/ La "gestion des erreurs" est-elle encore un domaine de recherche ?
C'est le cas depuis plus de 50 ans ! Il ne semble pas y avoir de théorie globale ni même de guide pratique pour une gestion cohérente et systématique des erreurs. Dans le pays de Go (comme pour les autres langues), il y a même confusion sur ce qu'est une erreur. Par exemple, un EOF peut être une condition exceptionnelle lorsque vous essayez de lire un fichier, mais pourquoi est-ce une erreur ? Qu'il s'agisse d'une erreur réelle ou non dépend vraiment du contexte. Et il y a d'autres problèmes de ce genre.
Peut-être qu'une discussion de niveau supérieur est nécessaire (pas ici, cependant).
bakul
le 18 juil. 2019
Merci @griesemer @rsc et tous ceux qui ont participé à la proposition. Beaucoup d'autres l'ont dit ci-dessus, et il convient de répéter que vos efforts pour réfléchir au problème, rédiger la proposition et en discuter de bonne foi sont appréciés. Merci.
 arschles
le 18 juil. 2019
arschles
le 18 juil. 2019
@ianlancetaylor
Merci pour la citation de Steve Klabnik. Bien que j'apprécie et que je sois d'accord avec le sentiment, il convient de considérer qu'en tant que langage, Rust semble un peu plus disposé à s'appuyer sur des détails syntaxiques que Go ne l'a été.
Je suis d'accord en général sur le fait que Rust s'appuie plus que Go sur des détails syntaxiques, mais je ne pense pas que cela s'applique à cette discussion spécifique sur la verbosité de la gestion des erreurs.
Les erreurs sont des valeurs dans Rust comme elles le sont dans Go. Vous pouvez les gérer à l'aide d'un flux de contrôle standard, comme dans Go. Dans les premières versions de Rust, c'était le seul moyen de gérer les erreurs, comme en Go. Ensuite, ils ont introduit la macro try! , qui est étonnamment similaire à la proposition de fonction intégrée try . Ils ont finalement ajouté l'opérateur ? , qui est une variation syntaxique et une généralisation de la macro try! , mais ce n'est pas nécessaire pour démontrer l'utilité de try , et le fait que la communauté Rust ne regrette pas de l'avoir ajouté.
Je suis bien conscient des énormes différences entre Go et Rust, mais en ce qui concerne la verbosité de la gestion des erreurs, je pense que leur expérience est transposable à Go. Les RFC et les discussions liées à try! et ? valent vraiment la peine d'être lues. J'ai été vraiment surpris de voir à quel point les problèmes et les arguments pour et contre les changements de langage sont similaires.
ngrilly
le 18 juil. 2019
@griesemer , vous avez annoncé la décision de refuser la proposition try , dans sa forme actuelle, mais vous n'avez pas dit ce que l'équipe Go prévoit de faire ensuite.
Prévoyez-vous toujours de traiter la verbosité de la gestion des erreurs, avec une autre proposition qui résoudrait les problèmes soulevés dans cette discussion (impressions de débogage, couverture du code, meilleure décoration des erreurs, etc.) ?
ngrilly
le 18 juil. 2019
Je suis d'accord en général sur le fait que Rust s'appuie plus que Go sur des détails syntaxiques, mais je ne pense pas que cela s'applique à cette discussion spécifique sur la verbosité de la gestion des erreurs.
Étant donné que d'autres ajoutent encore leur grain de sel, je suppose qu'il y a encore de la place pour que je fasse de même.
Bien que je programme depuis 1987, je ne travaille avec Go que depuis environ un an. Il y a environ 18 mois, lorsque je cherchais un nouveau langage pour répondre à certains besoins, j'ai regardé à la fois Go et Rust. J'ai choisi Go parce que je pensais que le code Go était beaucoup plus facile à apprendre et à utiliser, et que le code Go était beaucoup plus lisible car Go semble préférer les mots pour transmettre le sens plutôt que les symboles laconiques.
Donc, pour ma part, je serais très mécontent de voir Go devenir plus Rust-like , y compris l'utilisation de points d'exclamation ( ! ) et de points d'interrogation ( ? ) pour impliquer le sens.
Dans le même ordre d'idées, je pense que l'introduction de macros changerait la nature de Go et entraînerait des milliers de dialectes de Go, comme c'est effectivement le cas avec Ruby. J'espère donc que les macros ne seront jamais ajoutées Go non plus, même si je suppose qu'il y a peu de chances que cela se produise, heureusement IMO.
jmtcw
mikeschinkel
le 18 juil. 2019
@ianlancetaylor
Ce qui serait très utile, c'est une meilleure compréhension du nombre de personnes qui évitent Go en raison de la gestion détaillée des erreurs. Je suis sûr que le nombre n'est pas nul, mais il est difficile à mesurer.
Ce n'est pas une "mesure" en soi, mais cette discussion Hacker News fournit des dizaines de commentaires de développeurs mécontents de la gestion des erreurs Go en raison de sa verbosité (et certains commentaires expliquent leur raisonnement et donnent des exemples de code) : https://news.ycombinator. com/item?id=20454966.
ngrilly
le 18 juil. 2019
Tout d'abord, merci à tous pour les commentaires positifs sur la décision finale, même si cette décision n'a pas été satisfaisante pour beaucoup. C'était vraiment un effort d'équipe, et je suis vraiment heureux que nous ayons tous réussi à traverser les discussions intenses d'une manière globalement civile et respectueuse.
@ngrilly Parlant juste pour moi, je pense toujours qu'il serait bien d'aborder la verbosité de la gestion des erreurs à un moment donné. Cela dit, nous venons de consacrer pas mal de temps et d'énergie à cela au cours du dernier semestre et surtout des 3 derniers mois, et nous étions assez satisfaits de la proposition, mais nous avons évidemment sous-estimé la réaction possible à son égard. Maintenant, il est très logique de prendre du recul, de digérer et de distiller les commentaires, puis de décider des meilleures prochaines étapes.
De plus, de manière réaliste, puisque nous n'avons pas de ressources illimitées, je vois que la réflexion sur le support linguistique pour la gestion des erreurs est mise en veilleuse un peu en faveur de plus de progrès sur d'autres fronts, notamment le travail sur les génériques, au moins pour le les prochains mois. if err != nil peut être ennuyeux, mais ce n'est pas une raison pour une action urgente.
Si vous souhaitez poursuivre la discussion, je voudrais suggérer gentiment à tout le monde de partir d'ici et de poursuivre la discussion ailleurs, dans un numéro séparé (s'il y a une proposition claire), ou dans d'autres forums mieux adaptés à une discussion ouverte. Ce sujet est clos, après tout. Merci.
griesemer
le 18 juil. 2019
J'ai peur qu'il y ait un biais d'auto-sélection.
J'aimerais inventer un nouveau terme ici et maintenant : "parti pris du créateur". Si quelqu'un est prêt à mettre le travail, ils devraient avoir le bénéfice du doute.
Il est très facile pour la galerie de cacahuètes de crier haut et fort sur des forums indépendants qu'elle n'aime pas une solution proposée à un problème. Il est également très facile pour tout le monde d'écrire une tentative incomplète de 3 paragraphes pour une solution différente (sans véritable travail présenté en marge). Si on est d'accord avec le statu quo, ok. Point juste. Présenter quoi que ce soit d'autre comme une solution sans proposition complète vous donne -10 000 points.
mirtchovski
le 19 juil. 2019
Je ne soutiens pas ou ne suis pas contre l'essai, mais je fais confiance au jugement des équipes Go sur la question, jusqu'à présent, leur jugement a fourni un excellent langage, donc je pense que tout ce qu'ils décideront fonctionnera pour moi, essayer ou non, je considère nous devons comprendre, en tant qu'étrangers, que les mainteneurs ont une plus grande visibilité sur le sujet. syntaxe dont nous pouvons discuter toute la journée. J'aimerais remercier tous ceux qui ont travaillé ou essaient d'améliorer Go en ce moment pour leurs efforts, nous sommes reconnaissants et attendons avec impatience de nouvelles améliorations (non révolutionnaires) dans les bibliothèques de langage et Runtime, le cas échéant. utile par vous les gars.
 dataf3l
le 19 juil. 2019
dataf3l
le 19 juil. 2019
Il est également très facile pour tout le monde d'écrire une tentative incomplète de 3 paragraphes pour une solution différente (sans véritable travail présenté en marge).
La seule chose que je (et un certain nombre d'autres) voulais rendre try utile était un argument facultatif pour lui permettre de renvoyer une version encapsulée de l'erreur au lieu de l'erreur inchangée. Je ne pense pas que cela ait nécessité une énorme quantité de travail de conception.
lpar
le 19 juil. 2019
Oh non.
 ab-pivot
le 19 juil. 2019
ab-pivot
le 19 juil. 2019
Je vois. Allez vouloir faire quelque chose de différent des autres langues.
 mrdulin
le 21 juil. 2019
mrdulin
le 21 juil. 2019
Peut-être que quelqu'un devrait verrouiller ce problème ? La discussion est probablement mieux adaptée ailleurs.
 simskij
le 21 juil. 2019
simskij
le 21 juil. 2019
Ce problème est déjà si long que le verrouiller semble inutile.
Tout le monde, sachez que ce problème est clos et que les commentaires que vous faites ici seront presque certainement ignorés pour toujours. Si cela vous convient, commentez.
ianlancetaylor
le 21 juil. 2019
Au cas où quelqu'un détesterait le mot try qui lui ferait penser au langage Java, C*, je conseille de ne pas utiliser 'try' mais d'autres mots comme 'help' ou 'must' ou 'checkError'.. (ignorez-moi)
 OuSatoru
le 22 juil. 2019
OuSatoru
le 22 juil. 2019
Au cas où quelqu'un détesterait le mot try qui lui ferait penser au langage Java, C*, je conseille de ne pas utiliser 'try' mais d'autres mots comme 'help' ou 'must' ou 'checkError'.. (ignorez-moi)
Il y aura toujours des mots-clés et des concepts qui se chevauchent et qui ont de petites ou de grandes différences sémantiques dans des langues raisonnablement proches les unes des autres (comme les langues de la famille C). Une fonctionnalité de langue ne doit pas causer de confusion à l'intérieur de la langue elle-même, des différences entre les langues se produiront toujours.
 thomasf
le 22 juil. 2019
thomasf
le 22 juil. 2019
mal. c'est un modèle anti, manque de respect à l'auteur de cette proposition
 alersenkevich
le 25 juil. 2019
alersenkevich
le 25 juil. 2019
@alersenkevich S'il vous plaît soyez poli. Veuillez consulter https://golang.org/conduct.
ianlancetaylor
le 26 juil. 2019
Je pense que je suis content de la décision de ne pas aller plus loin. Pour moi, cela ressemblait à un hack rapide pour résoudre un petit problème concernant if err != nil étant sur plusieurs lignes. Nous ne voulons pas gonfler Go avec des mots clés mineurs pour résoudre des problèmes mineurs comme celui-ci, n'est-ce pas ? C'est pourquoi la proposition avec des macros hygiéniques https://github.com/golang/go/issues/32620 se sent mieux. Il essaie d'être une solution plus générique pour ouvrir plus de flexibilité avec plus de choses. Discussion sur la syntaxe et l'utilisation en cours là-bas, alors ne pensez pas seulement s'il s'agit de macros C/C++. Le point ici est de discuter d'une meilleure façon de faire des macros. Avec lui, vous pouvez implémenter votre propre essai.
Chillance
le 27 juil. 2019
J'aimerais avoir des commentaires sur une proposition similaire qui résout un problème avec la gestion des erreurs actuelle https://github.com/golang/go/issues/33161.
 mvndaai
le 29 juil. 2019
mvndaai
le 29 juil. 2019
Honnêtement, cela devrait être rouvert, de toutes les propositions de gestion des erreurs, c'est la plus sensée.
 OneOfOne
le 31 juil. 2019
OneOfOne
le 31 juil. 2019
@OneOfOne respectueusement, je ne suis pas d'accord pour que cela soit rouvert. Ce fil a établi qu'il existe de réelles limitations avec la syntaxe. Peut-être avez-vous raison de dire que c'est la proposition la plus "saine": mais je crois que le statu quo est encore plus sain.
Je suis d'accord que if err != nil est écrit beaucoup trop souvent en Go- mais avoir une façon singulière de revenir d'une fonction améliore énormément la lisibilité. Bien que je puisse généralement accepter les propositions qui réduisent le code passe-partout, le coût ne devrait jamais être la lisibilité à mon humble avis.
Je sais que beaucoup de développeurs déplorent l'erreur "longue" lors de la vérification de go, mais honnêtement, le laconisme est souvent en contradiction avec la lisibilité. Go a de nombreux modèles établis ici et ailleurs qui encouragent une façon particulière de faire les choses, et, d'après mon expérience, le résultat est un code fiable qui vieillit bien. Ceci est essentiel : le code du monde réel doit être lu et compris plusieurs fois tout au long de sa vie, mais il n'est écrit qu'une seule fois. Les frais généraux cognitifs représentent un coût réel, même pour les développeurs expérimentés.
RobertGrantEllis
le 31 juil. 2019
Au lieu de:
f := try(os.Open(filename))
Je m'attendrais à :
f := try os.Open(filename)
 florisvdg
le 13 sept. 2019
florisvdg
le 13 sept. 2019
Tout le monde, sachez que ce problème est clos et que les commentaires que vous faites ici seront presque certainement ignorés pour toujours. Si cela vous convient, commentez.
—@ianlancetaylor
bitfield
le 13 sept. 2019
Ce serait bien si nous pouvions utiliser try pour un bloc de codes parallèlement à la manière actuelle de gérer les erreurs.
Quelque chose comme ça:
// Generic Error Handler
handler := func(err error) error {
return fmt.Errorf("We encounter an error: %v", err)
}
a := "not Integer"
b := "not Integer"
try(handler){
f := os.Open(filename)
x := strconv.Atoi(a)
y, err := strconv.Atoi(b) // <------ If you want a specific error handler
if err != nil {
panic("We cannot covert b to int")
}
}
Le code ci-dessus semble plus propre que le commentaire initial. J'aimerais pouvoir proposer cela.
J'ai fait une nouvelle proposition #35179
 aminsol
le 26 oct. 2019
aminsol
le 26 oct. 2019
val := essayer f() (erreur){
panique (erreur)
}
 NareshDen
le 3 nov. 2019
NareshDen
le 3 nov. 2019
Je l'espère:
i, err := strconv.Atoi("1")
if err {
println("ERROR")
} else {
println(i)
}
ou
i, err := strconv.Atoi("1")
if err {
io.EOF:
println("EOF")
io.ErrShortWrite:
println("ErrShortWrite")
} else {
println(i)
}
 myroid
le 8 nov. 2019
myroid
le 8 nov. 2019
@myroid Cela ne me dérangerait pas que votre deuxième exemple soit un peu plus générique sous la forme d'une instruction switch-else :
``` allez
je, err := strconv.Atoi("1")
commutateur err != néant ; erreur {
cas io.EOF :
println("EOF")
cas io.ErrShortWrite :
println("ErrShortWrite")
} autre {
println(i)
}
piotrkowalczuk
le 8 nov. 2019
@piotrkowalczuk Votre code est bien meilleur que le mien. Je pense que le code peut être plus concis.
i, err := strconv.Atoi("1")
switch err {
case io.EOF:
println("EOF")
case io.ErrShortWrite:
println("ErrShortWrite")
} else {
println(i)
}
Cela ne considère pas l'option qu'il y aura un œil de type différent
Il doit y avoir
Erreur de cas !=néant
Pour les erreurs que le développeur n'a pas capturées explicitement
Le ven. 8 novembre 2019, 12:06 Yang Fan, [email protected] a écrit :
@piotrkowalczuk https://github.com/piotrkowalczuk Votre code ressemble beaucoup
mieux que le mien. Je pense que le code peut être plus concis.je, err := strconv.Atoi("1")switch err {case io.EOF :
println("EOF")case io.ErrShortWrite :
println("ErrShortWrite")
} autre {
println(i)
}—
Vous recevez ceci parce que vous avez été mentionné.
Répondez directement à cet e-mail, consultez-le sur GitHub
https://github.com/golang/go/issues/32437?email_source=notifications&email_token=ABNEY4VH4KS2OX4M5BVH673QSU24DA5CNFSM4HTGCZ72YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEDPTTY5#50comment-50,20comment-50 ,
ou désabonnez-vous
https://github.com/notifications/unsubscribe-auth/ABNEY4W4XIIHGUGIW2KXRPTQSU24DANCNFSM4HTGCZ7Q
.
guybrand
le 8 nov. 2019
switch n'a pas besoin d'un else , il a default .
tv42
le 8 nov. 2019
J'ai ouvert https://github.com/golang/go/issues/39890 qui propose quelque chose de similaire au guard de Swift devrait répondre à certaines des préoccupations concernant cette proposition :
- flux de contrôle
- localité de la gestion des erreurs
- lisibilité
Il n'a pas gagné beaucoup de terrain mais pourrait intéresser ceux qui ont commenté ici.
 andig
le 7 juil. 2020
andig
le 7 juil. 2020
Questions connexes
gopherbot
·
3Commentaires
 rakyll
·
3Commentaires
rakyll
·
3Commentaires
 mingrammer
·
3Commentaires
rsc
·
3Commentaires
mingrammer
·
3Commentaires
rsc
·
3Commentaires
 go101
·
3Commentaires
go101
·
3Commentaires
Commentaire le plus utile
Salut tout le monde,
Notre objectif avec des propositions comme celle-ci est d'avoir une discussion à l'échelle de la communauté sur les implications, les compromis et la manière de procéder, puis d'utiliser cette discussion pour aider à décider de la voie à suivre.
Sur la base de la réponse écrasante de la communauté et des discussions approfondies ici, nous marquons que cette proposition a été refusée plus tôt que prévu .
En ce qui concerne les commentaires techniques, cette discussion a utilement identifié certaines considérations importantes que nous avons manquées, notamment les implications pour l'ajout d'impressions de débogage et l'analyse de la couverture du code.
Plus important encore, nous avons clairement entendu les nombreuses personnes qui ont fait valoir que cette proposition ne ciblait pas un problème valable. Nous pensons toujours que la gestion des erreurs dans Go n'est pas parfaite et peut être améliorée de manière significative, mais il est clair qu'en tant que communauté, nous devons parler davantage des aspects spécifiques de la gestion des erreurs qui sont des problèmes que nous devons résoudre.
En ce qui concerne la discussion du problème à résoudre, nous avons essayé d'exposer notre vision du problème en août dernier dans le « Go 2 error handling problem overview », mais rétrospectivement, nous n'avons pas suffisamment attiré l'attention sur cette partie et n'avons pas suffisamment encouragé discussion pour savoir si le problème spécifique était le bon. La proposition
trypeut être une bonne solution au problème décrit ici, mais pour beaucoup d'entre vous, ce n'est tout simplement pas un problème à résoudre. À l'avenir, nous devons faire un meilleur travail en attirant l'attention sur ces premiers énoncés de problèmes et en nous assurant qu'il existe un large consensus sur le problème à résoudre.(Il est également possible que l'énoncé du problème de gestion des erreurs ait été entièrement éclipsé par la publication d'un brouillon de conception générique le même jour.)
Sur le sujet plus large de ce qu'il faut améliorer dans la gestion des erreurs Go, nous serions très heureux de voir des rapports d'expérience sur les aspects de la gestion des erreurs dans Go qui vous posent le plus de problèmes dans vos propres bases de code et environnements de travail et l'impact d'une bonne solution. avez dans votre propre développement. Si vous rédigez un tel rapport, veuillez publier un lien sur la page Go2ErrorHandlingFeedback .
Merci à tous ceux qui ont participé à cette discussion, ici et ailleurs. Comme Russ Cox l'a déjà souligné, les discussions à l'échelle de la communauté comme celle-ci sont open source à leur meilleur . Nous apprécions vraiment l'aide de chacun pour examiner cette proposition spécifique et plus généralement pour discuter des meilleurs moyens d'améliorer l'état de la gestion des erreurs dans Go.
Robert Griesemer, pour le comité d'examen des propositions.