Pytorch: RuntimeError : CUDA manque de mémoire. J'ai essayé d'allouer 12,50 Mio (GPU 0 ; 10,92 Gio de capacité totale ; 8,57 Mio déjà alloués ; 9,28 Gio libre ; 4,68 Mio en cache)
Erreur CUDA Out of Memory mais la mémoire CUDA est presque vide
Je forme actuellement un modèle léger sur une très grande quantité de données textuelles (environ 70 Go de texte).
Pour cela j'utilise une machine sur un cluster ( 'grele' du réseau de cluster grid5000 ).
Après 3h d'entraînement, je reçois ce très étrange message d'erreur CUDA Out of Memory :
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached) .
D'après le message, j'ai l'espace requis mais il n'alloue pas la mémoire.
Une idée de ce qui pourrait causer cela ?
Pour information, mon prétraitement s'appuie sur torch.multiprocessing.Queue et un itérateur sur les lignes de mes données sources pour prétraiter les données à la volée.
Trace de pile complète
Traceback (most recent call last):
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1228, in <module>
exec_with_profiler(script_filename, prof, args.backend, script_args)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1129, in exec_with_profiler
exec(compile(f.read(), filename, 'exec'), ns, ns)
File "run.py", line 293, in <module>
main(args, save_folder, load_file)
File "run.py", line 272, in main
trainer.all_epochs()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 140, in all_epochs
self.single_epoch()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 147, in single_epoch
tracker.add(*self.single_batch(data, target))
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 190, in single_batch
result = self.model(data)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/papud-bull-nn/model/model.py", line 54, in forward
emb = self.emb(input)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/sparse.py", line 118, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/functional.py", line 1454, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached)
 EMarquer
EMarquer
Tous les 91 commentaires
J'ai la même erreur d'exécution :
Traceback (most recent call last):
File "carn\train.py", line 52, in <module>
main(cfg)
File "carn\train.py", line 48, in main
solver.fit()
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 95, in fit
psnr = self.evaluate("dataset/Urban100", scale=cfg.scale, num_step=self.step)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 136, in evaluate
sr = self.refiner(lr_patch, scale).data
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 74, in forward
b3 = self.b3(o2)
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 30, in forward
c3 = torch.cat([c2, b3], dim=1)
RuntimeError: CUDA out of memory. Tried to allocate 195.25 MiB (GPU 0; 4.00 GiB total capacity; 2.88 GiB already allocated; 170.14 MiB free; 2.00 MiB cached)
 OmarBazaraa
le 27 janv. 2019
OmarBazaraa
le 27 janv. 2019
@EMarquer @OmarBazaraa Pourriez-vous donner un exemple de repro minimal que nous pouvons exécuter ?
 yf225
le 28 janv. 2019
yf225
le 28 janv. 2019
Je ne peux plus reproduire le problème, je vais donc clore le sujet.
Le problème a disparu lorsque j'ai arrêté de stocker les données prétraitées dans la RAM.
@OmarBazaraa , je ne pense pas que votre problème soit le même que le mien, car :
- J'essaie d'allouer 12,50 Mio, avec 9,28 Gio gratuits
- vous essayez d'allouer 195,25 Mio, avec 170,14 Mio gratuits
D'après mon expérience précédente avec ce problème, soit vous ne libérez pas la mémoire CUDA, soit vous essayez de mettre trop de données sur CUDA.
En ne libérant pas la mémoire CUDA, je veux dire que vous avez potentiellement encore des références à des tenseurs dans CUDA que vous n'utilisez plus. Ceux-ci empêcheraient de libérer la mémoire allouée en supprimant les tenseurs.
EMarquer
le 28 janv. 2019
Existe-t-il une solution générale ?
CUDA à court de mémoire. J'ai essayé d'allouer 196,00 MiB (GPU 0 ; 2,00 Gio de capacité totale ; 359,38 Mio déjà alloués ; 192,29 Mio libres ; 152,37 Mio en cache)
 aniketspurohit
le 31 janv. 2019
aniketspurohit
le 31 janv. 2019
@ aniks23 nous travaillons sur un correctif qui, je pense, donnera une meilleure expérience dans ce cas. Restez à l'écoute
 fmassa
le 31 janv. 2019
fmassa
le 31 janv. 2019
Existe-t-il un moyen de connaître la taille d'un modèle ou d'un réseau que mon système peut gérer
sans rencontrer ce problème ?
Le vendredi 1er février 2019 à 03h55 Francisco Massa [email protected]
a écrit:
@ aniks23 https://github.com/aniks23 nous travaillons sur un patch que je
croire donnera une meilleure expérience dans ce cas. Restez à l'écoute-
Vous recevez ceci parce que vous avez été mentionné.
Répondez directement à cet e-mail, consultez-le sur GitHub
https://github.com/pytorch/pytorch/issues/16417#issuecomment-459530332 ,
ou couper le fil
https://github.com/notifications/unsubscribe-auth/AUEJD4SYN4gnRkrLgFYEKY6y14P1TMgLks5vI21wgaJpZM4aUowv
.
aniketspurohit
le 1 févr. 2019
J'ai aussi ce message :
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)
C'est arrivé lorsque j'essayais d'exécuter la leçon Fast.ai Pets https://course.fast.ai/ (cellule 31)
 adrianovieira
le 12 mars 2019
adrianovieira
le 12 mars 2019
Moi aussi je rencontre les mêmes erreurs. Mon modèle fonctionnait plus tôt avec la configuration exacte, mais maintenant il donne cette erreur après avoir modifié du code apparemment sans rapport.
RuntimeError: CUDA out of memory. Tried to allocate 1.34 GiB (GPU 0; 22.41 GiB total capacity; 11.42 GiB already allocated; 59.19 MiB free; 912.00 KiB cached)
 treble-maker123
le 14 mars 2019
treble-maker123
le 14 mars 2019
Je ne sais pas si mon scénario est lié au problème d'origine, mais j'ai résolu mon problème (l'erreur OOM dans le message précédent a disparu) en brisant les couches nn.Sequential dans mon modèle, par exemple
self.input_layer = nn.Sequential(
nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU()
)
output = self.input_layer(x)
à
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0)
self.input_bn = nn.BatchNorm3d(32)
output = F.relu(self.input_bn(self.input_conv(x)))
Mon modèle en a beaucoup plus (5 de plus pour être exact). Est-ce que j'utilise nn.Sequential, n'est-ce pas ? Ou est-ce un bug ? @yf225 @fmassa
treble-maker123
le 14 mars 2019
J'obtiens également une erreur similaire :
CUDA out of memory. Tried to allocate 196.50 MiB (GPU 0; 15.75 GiB total capacity; 7.09 GiB already allocated; 20.62 MiB free; 72.48 MiB cached)
@treble-maker123 , avez-vous pu prouver de manière concluante que nn.Sequential est le problème ?
 yasheshgaur
le 17 mars 2019
yasheshgaur
le 17 mars 2019
J'ai un problème similaire. J'utilise le chargeur de données pytorch. Dit que je devrais avoir plus de 5 Go d'espace libre, mais cela donne 0 octet d'espace libre.
RuntimeError Traceback (appel le plus récent en dernier)
22
23 données, entrées = états_entrées
---> 24 données, entrées = Variable(data).float().to(device), Variable(inputs).float().to(device)
25 impression (données.périphérique)
26 enc_out = encodeur (données)
RuntimeError : CUDA manque de mémoire. J'ai essayé d'allouer 11,00 Mio (GPU 0 ; capacité totale de 6,00 Gio ; 448,58 Mio déjà alloués ; 0 octet libre ; 942,00 Kio en cache)
 ahsteven
le 3 avr. 2019
ahsteven
le 3 avr. 2019
Salut, j'ai aussi eu cette erreur.
File "xxx", line 151, in __call__
logits = self.model(x_hat)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 67, in forward
x = up(x, blocks[-i-1])
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 120, in forward
out = self.conv_block(out)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 92, in forward
out = self.block(x)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/container.py", line 92, in forward
input = module(input)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 320, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDA out of memory. Tried to allocate 8.00 MiB (GPU 1; 11.78 GiB total capacity; 10.66 GiB already allocated; 1.62 MiB free; 21.86 MiB cached)
 AlbertZhangHIT
le 17 avr. 2019
AlbertZhangHIT
le 17 avr. 2019
Malheureusement, j'ai également rencontré le même problème.
RuntimeError: CUDA out of memory. Tried to allocate 1.33 GiB (GPU 1; 31.72 GiB total capacity; 5.68 GiB already allocated; 24.94 GiB free; 5.96 MiB cached)
J'ai entraîné mon modèle dans un cluster de serveurs et l'erreur s'est produite de manière imprévisible sur l'un de mes serveurs. De plus, une telle erreur câblée ne se produit que dans l'une de mes stratégies d'entraînement. Et la seule différence est que je modifie le code lors de l'augmentation des données et rend le prétraitement des données plus compliqué que d'autres. Mais je ne sais pas comment résoudre ce problème.
 qingyu-wang
le 25 avr. 2019
qingyu-wang
le 25 avr. 2019
J'ai aussi ce problème. Comment le résoudre??? RuntimeError: CUDA out of memory. Tried to allocate 18.00 MiB (GPU 0; 4.00 GiB total capacity; 2.94 GiB already allocated; 10.22 MiB free; 18.77 MiB cached)
 nabil2i
le 10 mai 2019
nabil2i
le 10 mai 2019
Même problème ici RuntimeError: CUDA out of memory. Tried to allocate 54.00 MiB (GPU 0; 11.00 GiB total capacity; 7.89 GiB already allocated; 7.74 MiB free; 478.37 MiB cached)
 williamluke4
le 16 mai 2019
williamluke4
le 16 mai 2019
@fmassa Avez-vous plus d'infos à ce sujet ?
williamluke4
le 18 mai 2019
https://github.com/pytorch/pytorch/issues/16417#issuecomment -484264163
Le même problème pour moi
Cher, avez-vous obtenu la solution?
(base) F:\Suresh\st-gcn>python main1.py reconnaissance -c config/st_gcn/ntu-xsub/train.yaml --device 0 --work_dir ./work_dir
C:\Users\cudalab10\Anaconda3lib\site-packages\torch\cuda__init__.py:117 : Avertissement utilisateur :
Trouvé GPU0 TITAN Xp qui est de capacité cuda 1.1.
PyTorch ne prend plus en charge ce GPU car il est trop ancien.
warnings.warn(old_gpu_warn % (d, nom, majeur, capacité[1]))
[05.22.19|12:02:41] Paramètres :
{'base_lr' : 0,1, 'ignore_weights' : [], 'model' : 'net.st_gcn.Model', 'eval_interval' : 5, 'weight_decay' : 0,0001, 'work_dir' : './work_dir', 'save_interval ' : 10, 'model_args' : {'in_channels' : 3, 'dropout' : 0.5, 'num_class' : 60, 'edge_importance_weighting' : True, 'graph_args' : {'strategy' : 'spatial', 'layout' : 'ntu-rgb+d'}}, 'debug' : False, 'pavi_log' : False, 'save_result' : False, 'config' : 'config/st_gcn/ntu-xsub/train.yaml', 'optimizer' : 'SGD', 'weights' : Aucun, 'num_epoch' : 80, 'batch_size' : 64, 'show_topk' : [1, 5], 'test_batch_size' : 64, 'step' : [10, 50], 'use_gpu ' : True, 'phase' : 'train', 'print_log' : True, 'log_interval' : 100, 'feeder' : 'feeder.feeder.Feeder', 'start_epoch' : 0, 'nesterov' : True, 'device ': [0], 'save_log': True, 'test_feeder_args': {'data_path': './data/NTU-RGB-D/xsub/val_data.npy', 'label_path': './data/NTU- RGB-D/xsub/val_label.pkl'}, 'train_feeder_args' : {'data_path' : './data/NTU-RGB-D/xsub/train_data.npy', 'debug' : False, 'label_path' : ' ./data/NTU-RGB-D/xsub/train_l abel.pkl'}, 'num_worker' : 4}
[05.22.19|12:02:41] Époque d'entraînement : 0
Traceback (appel le plus récent en dernier) :
Fichier "main1.py", ligne 31, dans
p.start()
Fichier "F:\Suresh\st-gcn\processor\processor.py", ligne 113, au début
self.train()
Fichier "F:\Suresh\st-gcn\processor\recognition.py", ligne 91, en train
sortie = self.model(données)
Fichier "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", ligne 489, dans __call__
result = self.forward( input, * kwargs)
Fichier "F:\Suresh\st-gcn\net\st_gcn.py", ligne 82, en avant
x, _ = gcn(x, self.A * importance)
Fichier "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", ligne 489, dans __call__
result = self.forward( input, * kwargs)
Fichier "F:\Suresh\st-gcn\net\st_gcn.py", ligne 194, en avant
x, A = soi.gcn(x, A)
Fichier "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", ligne 489, dans __call__
result = self.forward( input, * kwargs)
Fichier "F:\Suresh\st-gcn\net\utils\tgcn.py", ligne 60, en avant
x = self.conv(x)
Fichier "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", ligne 489, dans __call__
result = self.forward( input, * kwargs)
Fichier "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\conv.py", ligne 320, en avant
self.padding, self.dilatation, self.groups)
RuntimeError : CUDA manque de mémoire. J'ai essayé d'allouer 1,37 Gio (GPU 0 ; 12,00 Gio de capacité totale ; 8,28 Gio déjà alloués ; 652,75 Mio libres ; 664,38 Mio en cache)
 Sureshthommandru
le 22 mai 2019
Sureshthommandru
le 22 mai 2019
C'est parce que le mini-lot de données ne tient pas dans la mémoire du GPU. Diminuez simplement la taille du lot. Lorsque j'ai défini la taille du lot = 256 pour l'ensemble de données cifar10, j'ai eu la même erreur ; Ensuite, j'ai défini la taille du lot = 128, c'est résolu.
 balcilar
le 1 juin 2019
balcilar
le 1 juin 2019
Ouais @balcilar a raison, j'ai réduit la taille du lot et maintenant ça marche
 EKELE-NNOROM
le 4 juin 2019
EKELE-NNOROM
le 4 juin 2019
J'ai un problème similaire:
RuntimeError: CUDA out of memory. Tried to allocate 11.88 MiB (GPU 4; 15.75 GiB total capacity; 10.50 GiB already allocated; 1.88 MiB free; 3.03 GiB cached)
J'utilise 8 V100 pour entraîner le modèle. La partie déroutante est qu'il y a toujours 3,03 Go en cache et qu'il ne peut pas être alloué pour 11,88 Mo.
 magic282
le 10 juin 2019
magic282
le 10 juin 2019
Avez-vous modifié la taille du lot. Réduisez la taille du lot de moitié. Dites le lot
size est de 16 à implémenter, essayez d'utiliser une taille de lot de 8 et voyez si cela fonctionne.
Prendre plaisir
Le lundi 10 juin 2019 à 02h10, magic282 [email protected] a écrit :
J'ai un problème similaire:
RuntimeError : CUDA manque de mémoire. J'ai essayé d'allouer 11,88 Mio (GPU 4 ; 15,75 Gio de capacité totale ; 10,50 Gio déjà alloués ; 1,88 Mio libre ; 3,03 Gio en cache)
J'utilise 8 V100 pour entraîner le modèle. La partie déroutante est qu'il y a
toujours 3,03 Go en cache et il ne peut pas être alloué pour 11,88 Mo.-
Vous recevez ceci parce que vous avez commenté.
Répondez directement à cet e-mail, consultez-le sur GitHub
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AGGVQNIXGPJ3HXGSVRPOYUTPZXV5NA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMV5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMV3WWH2ZLOZP ,
ou couper le fil
https://github.com/notifications/unsubscribe-auth/AGGVQNPVGT5RLM6ZV5KMSULPZXV5NANCNFSM4GSSRQXQ
.
EKELE-NNOROM
le 10 juin 2019
J'ai essayé de réduire la taille du lot et cela a fonctionné. La partie déroutante est le message d'erreur indiquant que la mémoire cache est plus grande que la mémoire à allouer.
magic282
le 11 juin 2019
Je reçois le même problème sur un modèle pré - entraîné, lors de l' utilisation de prédire. Donc, réduire la taille du lot ne fonctionnera pas.
 pvk444
le 30 juin 2019
pvk444
le 30 juin 2019
Si vous mettez à jour vers la dernière version de PyTorch, vous pourriez avoir moins d'erreurs de ce type
fmassa
le 30 juin 2019
Puis-je demander pourquoi les chiffres de l'erreur ne s'additionnent pas ?!
J'obtiens (comme vous tous) :
Tried to allocate 20.00 MiB (GPU 0; 1.95 GiB total capacity; 763.17 MiB already allocated; 6.31 MiB free; 28.83 MiB cached)
Pour moi, cela signifie que ce qui suit devrait être approximativement vrai :
1.95 (GB total) - 20 (MiB needed) == 763.17 (MiB already used) + 6.31 (MiB free) + 28.83 (MiB cached)
Mais ce n'est pas. Qu'est-ce que je me trompe ?
 AzimAhmadzadeh
le 3 juil. 2019
AzimAhmadzadeh
le 3 juil. 2019
J'ai également eu le problème lorsque j'ai entraîné le U-net, le cache est suffisant, mais il plante toujours
 tongpinmo
le 10 juil. 2019
tongpinmo
le 10 juil. 2019
J'ai la même erreur...
RuntimeError : CUDA manque de mémoire. J'ai essayé d'allouer 312,00 MiB (GPU 0 ; 10,91 Gio de capacité totale ; 1,07 Gio déjà alloué ; 109,62 MiB libres ; 15,21 MiB mis en cache)
 MSKazemi
le 10 juil. 2019
MSKazemi
le 10 juil. 2019
essayez de réduire la taille (toute taille qui ne changera pas le résultat) fonctionnera.
 giangnguyen2412
le 11 juil. 2019
giangnguyen2412
le 11 juil. 2019
essayez de réduire la taille (toute taille qui ne changera pas le résultat) fonctionnera.
Bonjour, je change le batch_size en 1, mais ça ne marche pas !
 BCWang93
le 14 juil. 2019
BCWang93
le 14 juil. 2019
Puissiez-vous changer une autre taille.
Vào 21:50, CN, 14 Th7, 2019 Bcw93 [email protected] đã viết:
essayez de réduire la taille (toute taille qui ne changera pas le résultat) fonctionnera.
Bonjour, je change le batch_size en 1, mais ça ne marche pas !
-
Vous recevez ceci parce que vous avez commenté.
Répondez directement à cet e-mail, consultez-le sur GitHub
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AHLNPF7MWQ7U5ULGIT44VRTP7MOKFA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVX5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVX5WWZJLOZGO ,
ou couper le fil
https://github.com/notifications/unsubscribe-auth/AHLNPF4227GHH32PI4WC4SDP7MOKFANCNFSM4GSSRQXQ
.
giangnguyen2412
le 15 juil. 2019
Obtention de cette erreur :
RuntimeError : CUDA manque de mémoire. J'ai essayé d'allouer 2,00 Mio (GPU 0 ; capacité totale de 7,94 Gio ; 7,33 Gio déjà alloués ; 1,12 Mio libre ; 40,48 Mio en cache)
nvidia-smi
jeu. 22 août 21:05:52 2019
+---------------------------------------------------------------- ----------------------------+
| Version du pilote NVIDIA-SMI 430.40 : 430.40 Version CUDA : 10.1 |
|-----------------------------------------------+----------------- -----+----------------------+
| Nom du GPU Persistance-M| Bus-Id Disp.A | Uncorr volatil. CEC |
| Fan Temp Perf Pwr:Usage/Cap | Utilisation de la mémoire | GPU-Util Compute M. |
|===============================+================= =====+======================|
| 0 Quadro M4000 désactivé | 00000000:09:00.0 Activé | S/O |
| 46% 37C P8 12W / 120W | 71 Mio / 8126 Mio | 10 % par défaut |
+--------------------------------+----------------- -----+----------------------+
| 1 GeForce GTX 105... Arrêt | 00000000:41:00.0 Activé | S/O |
| 29% 33C P8 S/O / 75W | 262 Mio / 4032 Mio | 0% par défaut |
+--------------------------------+----------------- -----+----------------------+
+---------------------------------------------------------------- ----------------------------+
| Processus : Mémoire GPU |
| Type de PID GPU Nom du processus Utilisation |
|================================================= ============================|
| 0 1909 G /usr/lib/xorg/Xorg 50MiB |
| 1 1909G /usr/lib/xorg/Xorg 128MiB |
| 1 5236 G ...quest-channel-token=9884100064965360199 130MiB |
+---------------------------------------------------------------- ----------------------------+
Système d'exploitation : Ubuntu 18.04 bionique
Noyau : x86_64 Linux 4.15.0-58-generic
Temps de disponibilité : 29 m
Forfaits : 2002
Coque : bash 4.4.20
Résolution : 1920x1080 1080x1920
DE : LXDE
WM : OpenBox
Thème GTK : Lubuntu par défaut [GTK2]
Thème d'icône : Lubuntu
Police : Ubuntu 11
Processeur : AMD Ryzen Threadripper 2970WX 24 cœurs à 48 x 3 GHz [61,8 °C]
Processeur graphique : Quadro M4000, GeForce GTX 1050 Ti
RAM : 3194 Mio / 64 345 Mio
 danindiana
le 23 août 2019
danindiana
le 23 août 2019
Est-ce que c'est corrigé ? J'ai réduit la taille et la taille du lot à 1. Je ne vois pas d'autres solutions ici, mais ce ticket est fermé. J'ai le même problème avec Cuda 10.1 Windows 10, Pytorch 1.2.0
 hughkf
le 6 sept. 2019
hughkf
le 6 sept. 2019
@hughkf Où dans le code modifiez-vous batch_size ?
 aidoshacks
le 6 sept. 2019
aidoshacks
le 6 sept. 2019
@aidoshacks , Cela dépend de votre code. Mais voici un exemple. C'est l'un des ordinateurs portables qui provoque de manière fiable ce problème sur ma machine : https://github.com/fastai/course-v3/blob/master/nbs/dl1/lesson3-camvid-tiramisu.ipynb. je modifie la ligne suivante,
bs,size = 8,src_size//2 à bs,size = 1,1 mais je reçois toujours ce problème de mémoire.
hughkf
le 6 sept. 2019
Pour moi, changer le batch_size de 128 à 64 a fonctionné mais cela ne semble pas être une solution divulguée pour moi, ou est-ce que j'ai raté quelque chose?
 shalgi
le 19 sept. 2019
shalgi
le 19 sept. 2019
Ce problème est-il résolu ? J'ai aussi eu le même problème. Je n'ai rien changé à mon code, mais après plusieurs exécutions, cette erreur se produit :
"RuntimeError : CUDA manque de mémoire. J'ai essayé d'allouer 40,00 Mio (GPU 0 ; 15,77 Gio de capacité totale ; 13,97 Gio déjà alloués ; 256,00 Kio d'espace libre ; 824,57 Mio en cache)"
 mengxiangming
le 26 sept. 2019
mengxiangming
le 26 sept. 2019
Ayant toujours ce problème, ce serait bien si le statut devenait non résolu.
ÉDITER:
Cela n'a pas grand-chose à voir avec la taille du lot, car je l'obtiens avec la taille du lot 1. Le redémarrage du noyau l'a corrigé pour moi et cela ne s'est pas produit depuis.
 just-in-kees
le 29 sept. 2019
just-in-kees
le 29 sept. 2019
Alors, quelle est la résolution des exemples comme ci-dessous (c'est-à-dire beaucoup de mémoire libre et essayer d'en allouer très peu - ce qui est différent de certains exemples de ce fil quand il y a en fait peu de mémoire libre et que tout va bien) ?
RuntimeError : CUDA manque de mémoire. J'ai essayé d'allouer 1,33 Gio (GPU 1 ; 31,72 Gio de capacité totale ; 5,68 Gio déjà alloués ; 24,94 Gio libres ; 5,96 Mio en cache)
Je ne vois pas pourquoi le problème est passé au statut « Fermé », car cela se produit toujours sur la dernière version de Pytorch (1.2) et le GPU NVIDIA moderne (V-100)
Merci!
 yuribd
le 3 oct. 2019
yuribd
le 3 oct. 2019
La plupart du temps, vous obtenez ce message d'erreur particulier du package fastai parce que vous utilisez un GPU inhabituellement petit. J'ai résolu ce problème en redémarrant mon noyau et en utilisant une taille de lot plus petite pour le chemin que vous donnez.
 AurioPinto
le 5 oct. 2019
AurioPinto
le 5 oct. 2019
Même problème ici. Lorsque j'utilise pytorch0.4.1, taille du lot = 4, ça va. Mais lorsque je passe à pytorch1.3 et que je règle même la taille du lot sur 1, j'ai le problème du oom.
 Sarah20187
le 21 oct. 2019
Sarah20187
le 21 oct. 2019
l'a résolu en mettant à jour mon pytorch avec la dernière... conda update pytorch
 kafura0
le 21 oct. 2019
kafura0
le 21 oct. 2019
C'est parce que le mini-lot de données ne tient pas dans la mémoire du GPU. Diminuez simplement la taille du lot. Lorsque j'ai défini la taille du lot = 256 pour l'ensemble de données cifar10, j'ai eu la même erreur ; Ensuite, j'ai défini la taille du lot = 128, c'est résolu.
merci, j'ai corrigé l'erreur de cette façon.
 zhangzibao
le 25 oct. 2019
zhangzibao
le 25 oct. 2019
J'ai réduit le batch_size à 8, cela fonctionne bien. L'idée est d'avoir un petit batch_size
 Asutosh11
le 30 oct. 2019
Asutosh11
le 30 oct. 2019
Je pense que cela dépend de la taille d'entrée totale à laquelle une couche particulière est confrontée. Par exemple, si un lot de 256 (32x32) images passe par 128 filtres dans un calque, la taille d'entrée totale est de 256x32x32x128 = 2^25. Ce nombre devrait être inférieur à un certain seuil, ce qui, je suppose, est spécifique à la machine. Pour AWS p3.2xlarge par exemple, c'est 2^26. Donc, si vous obtenez des erreurs de mémoire CuDA, essayez de réduire la taille du lot ou le nombre de filtres ou de mettre plus de sous-échantillonnage comme la foulée ou la mise en commun des couches
 souryadey
le 1 nov. 2019
souryadey
le 1 nov. 2019
J'ai le même problème :
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 7.93 GiB total capacity; 0 bytes already allocated; 3.83 GiB free; 0 bytes cached)
Avec les dernières versions pytorch (1.3) et cuda (10.1). Nvidia-smi affiche également un GPU à moitié vide, donc la quantité de mémoire libre dans le message d'erreur est correcte. Je ne peux pas encore le reproduire avec un code simple
 ArgentumWalker
le 3 nov. 2019
ArgentumWalker
le 3 nov. 2019
La réinitialisation du noyau a fonctionné pour moi aussi ! Ne fonctionnait pas même avec la taille du lot = 1 jusqu'à ce que je le fasse
 kennethjmyers
le 7 nov. 2019
kennethjmyers
le 7 nov. 2019
Les gars, j'ai résolu mon problème en réduisant la taille de mes lots de moitié.
 faizao
le 19 nov. 2019
faizao
le 19 nov. 2019
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 3.95 GiB total capacity; 0 bytes already allocated; 2.02 GiB free; 0 bytes cached)
Correction après redémarrage
 SomeUserName1
le 22 nov. 2019
SomeUserName1
le 22 nov. 2019
modifié batch_size 64 (rtx2080 ti) en 32 (rtx 2060), problème résolu. mais je veux savoir une autre façon de résoudre ce genre de problème.
 sailfish009
le 3 déc. 2019
sailfish009
le 3 déc. 2019
Cela m'arrive quand je fais la prédiction !
J'ai changé la taille du lot de 1024 à 8 et j'obtiens toujours une erreur lorsque 82% de l'ensemble de test est évalué.
Lorsque j'ai ajouté with torch.no_grad() le problème était RÉSOLU.
test_loader = init_data_loader(X_test, y_test, torch.device('cpu'), batch_size, num_workers=0)
print("Starting inference ...")
result = []
model.eval()
valid_loss = 0
with torch.no_grad():
for batch_x, batch_y in tqdm(test_loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
output = model(batch_x)
result.extend(output[:, 0, 0])
loss = torch.sqrt(criterion(output, batch_y))
valid_loss += loss
valid_loss /= len(train_loader)
print("Done!")
 smasoudn
le 17 déc. 2019
smasoudn
le 17 déc. 2019
j'ai résolu le problème
loader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4)
à
loader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4)
 zhonghaochen
le 27 déc. 2019
zhonghaochen
le 27 déc. 2019
J'ai eu le même problème et j'ai vérifié l'utilisation du GPU sur ma machine. Il y en avait déjà beaucoup utilisé et il restait très peu de mémoire. J'ai tué mon notebook jupyter et je l'ai redémarré. la mémoire est devenue libre et les choses ont commencé à fonctionner. Vous pouvez utiliser ci-dessous :
nvidia-smi - To check the memory utilization on GPU
ps -ax | grep jupyter - To get PID of jupyter process
sudo kill PID
 prabhatsharma
le 27 déc. 2019
prabhatsharma
le 27 déc. 2019
J'ai aussi ce message :
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)C'est arrivé lorsque j'essayais d'exécuter la leçon Fast.ai Pets https://course.fast.ai/ (cellule 31)
Essayez de réduire la taille du lot (bs) de vos données d'entraînement.
Voyez ce qui fonctionne pour vous.
 rishi0904
le 27 déc. 2019
rishi0904
le 27 déc. 2019
J'ai trouvé ce problème résolu sans ajuster la taille de votre lot.
Terminal ouvert et invite python
import torch
torch.cuda.empty_cache()
Quittez l'interpréteur Python, réexécutez votre commande PyTorch d'origine et elle ne devrait (espérons-le) pas générer l'erreur de mémoire CUDA.
 cpoptic
le 3 janv. 2020
cpoptic
le 3 janv. 2020
J'ai découvert que lorsque mon ordinateur utilise trop de RAM CPU, ce problème survient généralement. Ainsi, lorsque nous voulons une taille de lot plus importante, nous pouvons essayer de réduire l'utilisation de la RAM du processeur.
 dhKwang
le 13 janv. 2020
dhKwang
le 13 janv. 2020
A eu un problème similaire.
La réduction de la taille du lot et le redémarrage du noyau ont permis de résoudre le problème.
 kumarnikhil936
le 19 janv. 2020
kumarnikhil936
le 19 janv. 2020
Dans mon cas, le remplacement de l'optimiseur Adam par l'optimiseur SGD a résolu le même problème.
 tranvanluan2
le 23 janv. 2020
tranvanluan2
le 23 janv. 2020
Eh bien, dans mon cas, j'ai utilisé with torch.no_grad(): (train model) , output.to("cpu") et torch.cuda.empty_cache() et ce problème a été résolu.
 PlanNoa
le 30 janv. 2020
PlanNoa
le 30 janv. 2020
RuntimeError : CUDA manque de mémoire. J'ai essayé d'allouer 54,00 Mio (GPU 0 ; 3,95 Gio de capacité totale ; 2,65 Gio déjà alloués ; 39,00 Mio libres ; 87,29 Mio en cache)
j'ai trouvé la solution et je diminue la valeur batch_size.
 sagrawal06
le 30 janv. 2020
sagrawal06
le 30 janv. 2020
J'entraîne un YOLOv3 avec des poids Darknet53 sur un ensemble de données personnalisé. Mon GPU est un NVIDIA RTX 2080 et j'étais confronté au même problème. La modification de la taille du lot l'a résolu.
 wilderrodrigues
le 2 févr. 2020
wilderrodrigues
le 2 févr. 2020
Je reçois cette erreur pendant le temps d'inférence... je suis ru
CUDA à court de mémoire. J'ai essayé d'allouer 102,00 MiB (GPU 0 ; 15,78 Gio de capacité totale ; 14,54 Gio déjà alloués ; 48,44 Mio gratuits ; 14,67 Gio réservés au total par PyTorch)
-------------------------------------------------- ---------------------------+
| NVIDIA-SMI 440.59 Version du pilote : 440.59 Version CUDA : 10.2 |
|-----------------------------------------------+----------------- -----+----------------------+
| Nom du GPU Persistance-M| Bus-Id Disp.A | Uncorr volatil. CEC |
| Fan Temp Perf Pwr:Usage/Cap | Utilisation de la mémoire | GPU-Util Compute M. |
|===============================+================= =====+======================|
| 0 Tesla V100-SXM2... Activé | 00000000:00:1E.0 Désactivé | 0 |
| S/O 35C P0 41W / 300W | 16112Mio/16160Mio | 0% par défaut |
+--------------------------------+----------------- -----+----------------------+
+---------------------------------------------------------------- ----------------------------+
| Processus : Mémoire GPU |
| Type de PID GPU Nom du processus Utilisation |
|================================================= ============================|
| 0 13978 C /.conda/envs/ /bin/python 16101MiB |
+---------------------------------------------------------------- ----------------------------+
 tvinith
le 29 févr. 2020
tvinith
le 29 févr. 2020
C'est parce que le mini-lot de données ne tient pas dans la mémoire du GPU. Diminuez simplement la taille du lot. Lorsque j'ai défini la taille du lot = 256 pour l'ensemble de données cifar10, j'ai eu la même erreur ; Ensuite, j'ai défini la taille du lot = 128, c'est résolu.
merci tu as raison
 Rxma1805
le 2 mars 2020
Rxma1805
le 2 mars 2020
Pour le cas particulier, où il y a suffisamment de mémoire GPU, mais une erreur est toujours renvoyée. Dans mon cas, je l'ai résolu en réduisant le nombre de travailleurs dans le chargeur de données.
 Yurasyk
le 14 mars 2020
Yurasyk
le 14 mars 2020
Fond
py36, pytorch1.4, tf2.0, conda
affiner la Roberta
Problème
Le problème est le même que @EMarquer : pycharm montre que j'ai encore assez de mémoire, mais l'allocation de mémoire a échoué, à court de mémoire.
Façons que j'ai essayées
- "batch_size = 1" a échoué
- "torch.cuda.empty_cache()" a échoué
- CUDA_VISIBLE_DEVICES="0" python Run.py a échoué
- Parce que je n'utilise pas jupyter, pas besoin de redémarrer le noyau
Façon réussie
- nvidia-smi


- La vérité est que ce que montre pycharm est différent de ce que "nvidia-smi" montre (désolé je n'ai pas enregistré la photo de pycharm), en fait pas assez de mémoire .
- Les processus 6123 et 32644 s'exécutent sur le terminal avant.
- sudo tuer -9 6123
- sudo tuer -9 32644
 FernandoZhuang
le 17 mars 2020
FernandoZhuang
le 17 mars 2020
Ce qui a simplement fonctionné pour moi :
import gc
# Your code with pytorch using GPU
gc.collect()
 MastafaF
le 6 avr. 2020
MastafaF
le 6 avr. 2020
J'ai trouvé ce problème résolu sans ajuster la taille de votre lot.
Terminal ouvert et invite python
import torch torch.cuda.empty_cache()Quittez l'interpréteur Python, réexécutez votre commande PyTorch d'origine et elle ne devrait (espérons-le) pas générer l'erreur de mémoire CUDA.
Dans mon cas, cela résout mon problème.
 LiEAEX
le 10 avr. 2020
LiEAEX
le 10 avr. 2020
Assurez-vous d'utiliser votre GPU à l'emplacement 0 avec --device_ids 0
Je sais que je bousille la terminologie, mais cela a fonctionné. Je suppose que cela suppose que vous souhaitez utiliser le processeur au lieu du processeur graphique si vous ne sélectionnez pas d'identifiant.
 aaron387
le 12 avr. 2020
aaron387
le 12 avr. 2020
Je reçois la même erreur:
RuntimeError : CUDA manque de mémoire. J'ai essayé d'allouer 4,84 Gio (GPU 0 ; 7,44 Gio de capacité totale ; 5,22 Gio déjà alloués ; 1,75 Gio libre ; 18,51 Mio en cache)
Lorsque je redémarre le cluster ou que je modifie la taille du lot, cela fonctionne. Mais je n'aime pas cette solution. J'ai même essayé torch.cuda.empty_cache() , cela ne fonctionne pas pour moi. Existe-t-il un autre moyen efficace de résoudre ce problème ?
 Tann10
le 13 avr. 2020
Tann10
le 13 avr. 2020
Je ne sais pas si mon scénario est lié au problème d'origine, mais j'ai résolu mon problème (l'erreur OOM dans le message précédent a disparu) en brisant les couches nn.Sequential dans mon modèle, par exemple
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)à
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0) self.input_bn = nn.BatchNorm3d(32) output = F.relu(self.input_bn(self.input_conv(x)))Mon modèle en a beaucoup plus (5 de plus pour être exact). Est-ce que j'utilise nn.Sequential, n'est-ce pas ? Ou est-ce un bug ? @yf225 @fmassa
Il semble que je résolve également l'erreur similaire mais à l'inverse avec vous.
je change tout
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)à
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)
 xml94
le 14 avr. 2020
xml94
le 14 avr. 2020
Pour moi, changer batch_size ou l'une des solutions données n'a pas aidé. Mais il s'est avéré que dans mon fichier .cfg, j'avais de mauvaises valeurs de classes et de filtres dans une couche. Donc, si rien ne vous aide, vérifiez votre .cfg.
 ulaszewskim
le 1 mai 2020
ulaszewskim
le 1 mai 2020
Ouvrir le terminal
Premier type
nvidia-smi
puis sélectionnez le PID qui correspond au chemin python ou anaconda et écrivez
sudo kill -9 PID
 krypticmouse
le 4 mai 2020
krypticmouse
le 4 mai 2020
J'ai ce bug depuis quelques temps. Pour moi, il s'avère que je conserve une variable python (c'est-à-dire un tenseur de torche) qui fait référence au résultat du modèle, et qu'elle ne peut donc pas être publiée en toute sécurité car le code peut toujours y accéder.
Mon code ressemble à quelque chose comme :
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p)
Le correctif consistait à transférer p vers une liste. Ainsi, le code devrait ressembler à :
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p.tolist())
Cela garantit que predictions conserve des valeurs dans la mémoire principale, pas un tenseur dans le GPU.
 abdelrahmanhosny
le 8 mai 2020
abdelrahmanhosny
le 8 mai 2020
J'ai ce bug en utilisant le module fastai.vision, qui repose sur pytorch. J'utilise CUDA 10.1
 jkomyno
le 16 mai 2020
jkomyno
le 16 mai 2020
training_args = TrainingArguments(
output_dir="./",
overwrite_output_dir=True,
num_train_epochs=5,
per_gpu_train_batch_size=4, # 4; 8 ;16 out of memory
save_steps=10_000,
save_total_limit=2,
)
réduire le per_gpu_train_batch_size de 16 à 8, cela a résolu mon problème.
 autodataming
le 3 juin 2020
autodataming
le 3 juin 2020
Si vous mettez à jour vers la dernière version de PyTorch, vous pourriez avoir moins d'erreurs de ce type
vraiment, pourquoi tu dis ça
 XinyingZheng
le 9 juin 2020
XinyingZheng
le 9 juin 2020
La question principale de cette question est toujours un problème ouvert. Je reçois le même étrange message de mémoire CUDA. Il a essayé d'allouer 2,26 Gio en 4,08 Gio libres. Apparemment, il y a assez de mémoire mais il ne parvient pas à allouer.
Informations sur le projet : entraîner un ensemble de données resnet 10 sur un ensemble de données d'activité avec une taille de lot 4, il échoue à la fin de la première époque.
ÉDITÉ : Quelques perceptions : Si je nettoie ma mémoire RAM et ne garde que le code python en cours d'exécution, l'erreur n'est pas générée. Peut-être qu'il y a assez de mémoire dans le GPU, mais la mémoire RAM n'est pas capable de gérer toutes les autres étapes de traitement.
Informations sur l'ordinateur : Dell G5 - i7 9th - GTX 1660Ti 6 Go - 16 Go de RAM
EDITED2: j'utilisais "_MultiProcessingDataLoaderIter" avec 4 travailleurs et cela déclenche le message de mémoire insuffisante dans l'appel de transfert. Si je réduis le nombre de travailleurs à 1, cela ne génère aucune erreur. Avec 1 worker, l'utilisation de la mémoire RAM reste de 11/16 Go, avec 4, elle passe à 14,5/16 Go. Et avec seulement 1 travailleur, en fait, je peux augmenter la taille du lot à 32, ce qui porte la mémoire GPU à 3,5 Go/6 Go.
RuntimeError : CUDA manque de mémoire. J'ai essayé d'allouer 2,26 Gio (GPU 0 ; 6,00 Gio de capacité totale ; 209,63 MiB déjà alloués ; 4,08 Gio libres ; 246,00 MiB réservés au total par PyTorch)
Message d'erreur entier
Traceback (appel le plus récent en dernier) :
Fichier "main.py", ligne 450, dans
si opt.distributed :
Fichier "main.py", ligne 409, dans main_worker
opt.device, current_lr, train_logger,
Fichier "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\training.py", ligne 37, dans train_epoch
sorties = modèle (entrées)
Fichier "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", ligne 532, dans __call__
result = self.forward( input, * kwargs)
Fichier "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nnparallel\data_parallel.py", ligne 150, en avant
return self.module( input[0], * kwargs[0])
Fichier "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", ligne 532, dans __call__
result = self.forward( input, * kwargs)
Fichier "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\models\resnet.py", ligne 205, en avant
x = self.layer3(x)
Fichier "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", ligne 532, dans __call__
result = self.forward( input, * kwargs)
Fichier "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\container.py", ligne 100, en avant
entrée = module (entrée)
Fichier "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", ligne 532, dans __call__
result = self.forward( input, * kwargs)
Fichier "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\models\resnet.py", ligne 51, en avant
sortie = self.conv2(sortie)
Fichier "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", ligne 532, dans __call__
result = self.forward( input, * kwargs)
Fichier "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\conv.py", ligne 480, en avant
self.padding, self.dilatation, self.groups)
RuntimeError : CUDA manque de mémoire. J'ai essayé d'allouer 2,26 Gio (GPU 0 ; capacité totale de 6,00 Gio ; 209,63 Mio déjà alloués ; 4,08 Gio libres ; 246,00 Mio réservés
au total par PyTorch)
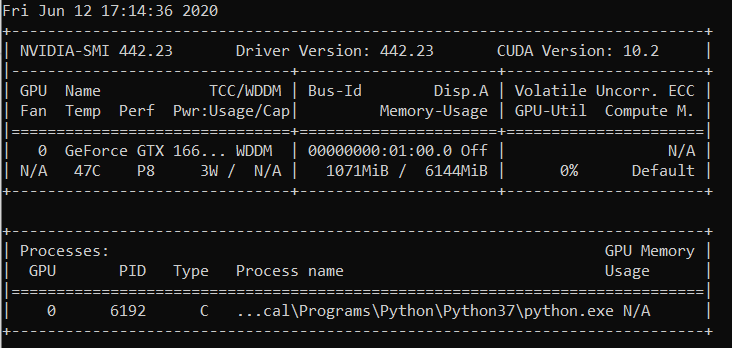
 guilhermesurek
le 12 juin 2020
guilhermesurek
le 12 juin 2020
petit la taille du lot, ça marche
 cuge1995
le 15 juin 2020
cuge1995
le 15 juin 2020
J'ai ce bug depuis quelques temps. Pour moi, il s'avère que je conserve une variable python (c'est-à-dire un tenseur de torche) qui fait référence au résultat du modèle, et qu'elle ne peut donc pas être publiée en toute sécurité car le code peut toujours y accéder.
Mon code ressemble à quelque chose comme :
predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)Le correctif consistait à transférer
pvers une liste. Ainsi, le code devrait ressembler à :predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())Cela garantit que
predictionsconserve des valeurs dans la mémoire principale, pas un tenseur dans le GPU.
@abdelrahmanhosny Merci de l'avoir signalé. J'ai rencontré exactement le même problème dans PyTorch 1.5.0 et je n'ai eu aucun problème de MOO pendant la formation, mais pendant l'inférence, j'ai également conservé une variable python (c'est-à-dire le tenseur de la torche) qui fait référence au résultat du modèle en mémoire, ce qui a entraîné un manque de mémoire du GPU après un certain nombre de lots.
Dans mon cas, cependant, le transfert des prédictions vers la liste n'a pas fonctionné car je génère des images avec mon réseau, j'ai donc dû procéder comme suit :
predictions.append(p.detach().cpu().numpy())
Cela a alors résolu le problème!
 samkellerhals
le 19 juin 2020
samkellerhals
le 19 juin 2020
Existe-t-il une solution générale ?
CUDA à court de mémoire. J'ai essayé d'allouer 196,00 MiB (GPU 0 ; 2,00 Gio de capacité totale ; 359,38 Mio déjà alloués ; 192,29 Mio libres ; 152,37 Mio en cache)
Existe-t-il une solution générale ?
CUDA à court de mémoire. J'ai essayé d'allouer 196,00 MiB (GPU 0 ; 2,00 Gio de capacité totale ; 359,38 Mio déjà alloués ; 192,29 Mio libres ; 152,37 Mio en cache)
 manavkhadka0
le 24 juin 2020
manavkhadka0
le 24 juin 2020
J'ai ce bug depuis quelques temps. Pour moi, il s'avère que je conserve une variable python (c'est-à-dire un tenseur de torche) qui fait référence au résultat du modèle, et qu'elle ne peut donc pas être publiée en toute sécurité car le code peut toujours y accéder.
Mon code ressemble à quelque chose comme :predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)Le correctif consistait à transférer
pvers une liste. Ainsi, le code devrait ressembler à :predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())Cela garantit que
predictionsconserve des valeurs dans la mémoire principale, pas un tenseur dans le GPU.@abdelrahmanhosny Merci de l'avoir signalé. J'ai rencontré exactement le même problème dans PyTorch 1.5.0 et je n'ai eu aucun problème de MOO pendant la formation, mais pendant l'inférence, j'ai également conservé une variable python (c'est-à-dire le tenseur de la torche) qui fait référence au résultat du modèle en mémoire, ce qui a entraîné un manque de mémoire du GPU après un certain nombre de lots.
Dans mon cas, cependant, le transfert des prédictions vers la liste n'a pas fonctionné car je génère des images avec mon réseau, j'ai donc dû procéder comme suit :
predictions.append(p.detach().cpu().numpy())Cela a alors résolu le problème!
J'ai le même problème dans le modèle ParrallelWaveGAN et j'ai utilisé les solutions dans #16417 mais cela ne fonctionne pas pour moi
y = self.model_gan(*x).view(-1).detach().cpu().numpy()
gc.collect()
torch.cuda.empty_cache()
 tuong-olli
le 25 juin 2020
tuong-olli
le 25 juin 2020
J'ai eu le même problème pendant l'entraînement.
La collecte des ordures et le vidage de la mémoire cuda après chaque époque ont résolu le problème pour moi.
gc.collect()
torch.cuda.empty_cache()
 IsakWesterlundBitville
le 5 août 2020
IsakWesterlundBitville
le 5 août 2020
Ce qui a simplement fonctionné pour moi :
import gc # Your code with pytorch using GPU gc.collect()
Merci!! J'avais du mal à exécuter l'exemple des chats et des chiens et cela a fonctionné pour moi.
 Michelpayan
le 5 août 2020
Michelpayan
le 5 août 2020
J'ai eu le même problème pendant l'entraînement.
La collecte des ordures et le vidage de la mémoire cuda après chaque époque ont résolu le problème pour moi.gc.collect() torch.cuda.empty_cache()
Pareil pour moi
 AleksandrTulenkov
le 6 août 2020
AleksandrTulenkov
le 6 août 2020
diminuer la taille du lot et augmenter les époques. c'est comme ça que je l'ai résolu.
 oyekamal
le 18 sept. 2020
oyekamal
le 18 sept. 2020
@areebsyed Vérifiez la mémoire RAM, j'ai eu ce problème lors de la mise en parallèle de nombreux travailleurs.
guilhermesurek
le 29 sept. 2020
J'obtiens également la même erreur lors du réglage fin de bert2bert EncoderDecoderModel préformé dans pytorch dans Colab sans même terminer une seule époque.
RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 15.90 GiB total capacity; 13.77 GiB already allocated; 59.88 MiB free; 14.98 GiB reserved in total by PyTorch)
 Aakash12980
le 6 oct. 2020
Aakash12980
le 6 oct. 2020
@Aakash12980 avez-vous essayé de réduire la taille du lot ? Les images d'entrée que vous souhaitez entraîner peuvent également essayer de les redimensionner
 areebsyed
le 6 oct. 2020
areebsyed
le 6 oct. 2020
@areebsyed Oui, j'ai réduit la taille du lot à 4 et cela a fonctionné.
Aakash12980
le 6 oct. 2020
même
RuntimeError Traceback (most recent call last)
<ipython-input-116-11ebb3420695> in <module>
28 landmarks = landmarks.view(landmarks.size(0),-1).cuda()
29
---> 30 predictions = network(images)
31
32 # clear all the gradients before calculating them
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
<ipython-input-112-174da452c85d> in forward(self, x)
13 ##out = self.first_conv(x)
14 x = x.float()
---> 15 out = self.model(x)
16 return out
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x)
218
219 def forward(self, x):
--> 220 return self._forward_impl(x)
221
222
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x)
204 x = self.bn1(x)
205 x = self.relu(x)
--> 206 x = self.maxpool(x)
207
208 x = self.layer1(x)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input)
157 return F.max_pool2d(input, self.kernel_size, self.stride,
158 self.padding, self.dilation, self.ceil_mode,
--> 159 self.return_indices)
160
161
~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs)
245 return if_true(*args, **kwargs)
246 else:
--> 247 return if_false(*args, **kwargs)
248
249 if if_true.__doc__ is None and if_false.__doc__ is not None:
~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices)
574 stride = torch.jit.annotate(List[int], [])
575 return torch.max_pool2d(
--> 576 input, kernel_size, stride, padding, dilation, ceil_mode)
577
578 max_pool2d = boolean_dispatch(
RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
 monajalal
le 7 oct. 2020
monajalal
le 7 oct. 2020
même
RuntimeError Traceback (most recent call last) <ipython-input-116-11ebb3420695> in <module> 28 landmarks = landmarks.view(landmarks.size(0),-1).cuda() 29 ---> 30 predictions = network(images) 31 32 # clear all the gradients before calculating them ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), <ipython-input-112-174da452c85d> in forward(self, x) 13 ##out = self.first_conv(x) 14 x = x.float() ---> 15 out = self.model(x) 16 return out ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x) 218 219 def forward(self, x): --> 220 return self._forward_impl(x) 221 222 ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x) 204 x = self.bn1(x) 205 x = self.relu(x) --> 206 x = self.maxpool(x) 207 208 x = self.layer1(x) ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input) 157 return F.max_pool2d(input, self.kernel_size, self.stride, 158 self.padding, self.dilation, self.ceil_mode, --> 159 self.return_indices) 160 161 ~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs) 245 return if_true(*args, **kwargs) 246 else: --> 247 return if_false(*args, **kwargs) 248 249 if if_true.__doc__ is None and if_false.__doc__ is not None: ~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices) 574 stride = torch.jit.annotate(List[int], []) 575 return torch.max_pool2d( --> 576 input, kernel_size, stride, padding, dilation, ceil_mode) 577 578 max_pool2d = boolean_dispatch( RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
@monajalal essayez de réduire la taille du lot ou la taille de la dimension d'entrée.
Aakash12980
le 7 oct. 2020
Alors, quelle est la résolution des exemples comme ci-dessous (c'est-à-dire beaucoup de mémoire _libre_ et essayer d'en allouer très peu - ce qui est différent de _quelques_ exemples dans ce fil quand il y a en fait peu de mémoire libre et rien ne va pas) ?
RuntimeError : CUDA manque de mémoire. J'ai essayé d'allouer _ 1,33 Gio _ (GPU 1 ; 31,72 Gio de capacité totale ; 5,68 Gio déjà alloués ; _ 24,94 Gio libres _ ; 5,96 Mio en cache)
Je ne vois pas pourquoi le problème est passé au statut « Fermé », car cela se produit toujours sur la dernière version de Pytorch (1.2) et le GPU NVIDIA moderne (V-100)
Merci!
Oui, j'ai l'impression que la plupart des gens ne réalisent pas que le problème n'est pas simplement OOM, c'est qu'il y a OOM alors que l'erreur indique qu'il y a suffisamment d'espace libre. Je suis également confronté à ce problème sur windows, avez-vous trouvé une solution ?
 YoadTew
le 6 nov. 2020
YoadTew
le 6 nov. 2020
Questions connexes
 cdluminate
·
3Commentaires
cdluminate
·
3Commentaires
 dablyo
·
3Commentaires
dablyo
·
3Commentaires
 keskarnitish
·
3Commentaires
keskarnitish
·
3Commentaires
 soumith
·
3Commentaires
soumith
·
3Commentaires
 ikostrikov
·
3Commentaires
ikostrikov
·
3Commentaires
Commentaire le plus utile
C'est parce que le mini-lot de données ne tient pas dans la mémoire du GPU. Diminuez simplement la taille du lot. Lorsque j'ai défini la taille du lot = 256 pour l'ensemble de données cifar10, j'ai eu la même erreur ; Ensuite, j'ai défini la taille du lot = 128, c'est résolu.