Marlin: [BUG] JUNCTION_DEVIATION membuat perlambatan / akselerasi yang tidak terduga pada belokan yang mulus
Deskripsi Bug
Dengan penyimpangan Persimpangan diaktifkan, printer melambat dan mempercepat secara tidak terduga pada kurva yang mulus. JUNCTION_DEVIATION_MM disetel ke 0,017. Tidak ada perbedaan jika saya tingkatkan menjadi 0,2.
Dalam gambar ini saya telah menandai lokasi di mana perlambatan terjadi dengan panah. Ini terjadi di lokasi lain juga, tetapi ini yang paling jelas.

Dengan CLASSIC_JERK , cetakannya mulus dan tanpa perlambatan / akselerasi yang tidak terduga.
Contoh video (lihat visualisator ekstruder saat ini terjadi):
Dengan Simpangan Persimpangan = 0,017
Dengan Classic Jerk
#define DEFAULT_XJERK 10.0
#define DEFAULT_YJERK 10.0
#define DEFAULT_ZJERK 0.3
Konfigurasi Saya
LIN_ADVANCE diaktifkan dan LIN_ADVANCE_K disetel ke 0.1. Pengaturan ini ke 0 tidak berpengaruh.
S_CURVE_ACCELERATION diaktifkan.
Langkah-langkah untuk Mereproduksi
Cetak objek lengkung besar seperti yang ada di foto.
Perilaku yang diharapkan:
Lekukannya dicetak halus, sama seperti brengsek klasik.
Perilaku sebenarnya:
Kurva dicetak dengan gerakan yang setidaknya diperlambat / dipercepat.
Saya menggunakan Marlin bugfix-2.0.x commit e7a9f17 mulai tanggal 22 Maret.
 ktand
ktand
Semua 265 komentar
17146
Memiliki masalah yang sama.
SKR Mini E3 v1.2, Cura / PrusaSlicer / Fusion 360
 qwewer0
pada 30 Mar 2020
qwewer0
pada 30 Mar 2020
Iya. Saya punya masalah yang sama (sebenarnya juga mencetak pelindung wajah: D).
Perbedaan dalam penyiapan, menghasilkan masalah yang sama:
- Anda menggunakan Slic3r dan saya menggunakan Cura.
- Papan Anda 32 bit (ARMED STM32) dan papan saya 8 bit (ZUM Mega 3D).
- Model STL berbeda (saya mencetak yang ini ).
Kesamaan:
- Modelnya memiliki busur yang panjang dan tipis.
- S_CURVE: diaktifkan (diuji ON dan OFF, masalah yang sama).
- Deviasi persimpangan: diaktifkan.
- LIN_ADVANCE: diaktifkan (diuji ON dan OFF, masalah yang sama).
Lebih banyak parameter:
- Saya mengaktifkan ADAPTIVE_STEP_SMOOTHING (menguji ON dan OFF, masalah yang sama).
Saya sedang mempertimbangkan untuk beralih kembali secara permanen ke brengsek klasik karena tidak ada masalah ini. Bantuan Anda akan sangat dihargai!
Mungkin terkait: # 15473
 CarlosGS
pada 31 Mar 2020
CarlosGS
pada 31 Mar 2020
Karena masalah ini, saya menghabiskan banyak waktu untuk menguji pengaturan JD dan LA. Intinya saya adalah mengatur JD lebih tinggi, tentu saja berdasarkan pengaturan saya yang lain. Mencetak kurva seperti @ktand di posting pertama dengan default 0.013 JD membuat komputer saya tersendat-sendat. Meningkatkan JD ke nilai yang jauh lebih tinggi membuatnya berfungsi seperti yang diharapkan. Dalam kasus saya, pengaturan JD ke 0,07 gagap jarang terjadi. Meningkatkan ke 0,09 membuat gagap hampir hilang, kecuali tikungan dan sudut kecil di mana ia melakukan tugasnya seperti yang diharapkan.
Ini file config saya, mungkin untuk membandingkan setting seperti akselerasi, E-brengsek, ...
Configuration.zip
Configuration_adv.zip
 rado79
pada 31 Mar 2020
rado79
pada 31 Mar 2020
Saya meningkatkan JUNCTION_DEVIATION_MM menjadi 0,2, hampir 11 kali lebih tinggi, tetapi
masalah masih terjadi.
Den tis 31 mars 2020 kl 19:43 skrev rado79 [email protected] :
Karena masalah ini, saya menghabiskan banyak waktu untuk menguji pengaturan JD dan LA.
Intinya saya adalah menetapkan JD jauh lebih tinggi, tentu saja berdasarkan yang lain
pengaturan. Mencetak kurva seperti @ktand https://github.com/ktand di
posting pertama dengan default 0.013 JD membuat banyak komputer saya tersendat-sendat.
Meningkatkan JD ke nilai yang jauh lebih tinggi membuatnya berfungsi seperti yang diharapkan. Dalam saya
pengaturan kasus JD ke 0,07 gagap jarang terjadi. Meningkatkan menjadi 0,09 membuat
gagap hampir hilang, kecuali tikungan dan sudut kecil yang dilakukannya
pekerjaan seperti yang diharapkan.Ini file konfigurasi saya, mungkin untuk membandingkan pengaturan seperti akselerasi,
Brengsek, ...
Configuration.zip
https://github.com/MarlinFirmware/Marlin/files/4410644/Configuration.zip
Configuration_adv.zip
https://github.com/MarlinFirmware/Marlin/files/4410645/Configuration_adv.zip-
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/MarlinFirmware/Marlin/issues/17342#issuecomment-606773983 ,
atau berhenti berlangganan
https://github.com/notifications/unsubscribe-auth/AEHQ2JDBQG34PUYSMZVYDKTRKITSLANCNFSM4LW33CGA
.
ktand
pada 31 Mar 2020
Saya meningkatkannya menjadi 0,3mm dan masalah masih terjadi.
El mar., 31 mar. 2020 19:56, Karl Andersson [email protected]
escribió:
Saya meningkatkan JUNCTION_DEVIATION_MM menjadi 0,2, hampir 11 kali lebih tinggi, tetapi
masalah masih terjadi.Den tis 31 mars 2020 kl 19:43 skrev rado79 [email protected] :
Karena masalah ini, saya menghabiskan banyak waktu untuk menguji JD dan LA
pengaturan.
Intinya saya adalah menetapkan JD jauh lebih tinggi, tentu saja berdasarkan yang lain
pengaturan. Mencetak kurva seperti @ktand https://github.com/ktand di
posting pertama dengan default 0.013 JD membuat saya banyak gagap
mesin.
Meningkatkan JD ke nilai yang jauh lebih tinggi membuatnya berfungsi seperti yang diharapkan. Dalam saya
pengaturan kasus JD ke 0,07 gagap jarang terjadi. Meningkatkan menjadi 0,09 membuat
gagap hampir hilang, kecuali tikungan dan sudut kecil yang dilakukannya
pekerjaan seperti yang diharapkan.Ini file konfigurasi saya, mungkin untuk membandingkan pengaturan seperti akselerasi,
Brengsek, ...
Configuration.zip
<
https://github.com/MarlinFirmware/Marlin/files/4410644/Configuration.zip>
Configuration_adv.zip
<
https://github.com/MarlinFirmware/Marlin/files/4410645/Configuration_adv.zip-
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
<
https://github.com/MarlinFirmware/Marlin/issues/17342#issuecomment -606773983
,
atau berhenti berlangganan
<
https://github.com/notifications/unsubscribe-auth/AEHQ2JDBQG34PUYSMZVYDKTRKITSLANCNFSM4LW33CGA.
-
Anda menerima ini karena Anda berkomentar.
Balas email ini secara langsung, lihat di GitHub
https://github.com/MarlinFirmware/Marlin/issues/17342#issuecomment-606780696 ,
atau berhenti berlangganan
https://github.com/notifications/unsubscribe-auth/AAMPPKS64M6XGUXUT6YIQNLRKIVEDANCNFSM4LW33CGA
.
CarlosGS
pada 31 Mar 2020
Pertama, pastikan untuk mematikan semua akselerasi dan penyetelan kecepatan di alat pengiris Anda. Prusa Slicer dan Cura sama-sama cenderung memasukkan banyak perubahan parameter, dan ini terkadang dapat mengganggu perencana.
Sayangnya, men-debug masalah dinamis semacam ini bukanlah hal yang mudah tanpa banyak pengumpulan data dan isolasi efek. Jadi kita perlu mengumpulkan penebangan sebanyak mungkin untuk menentukan akar penyebabnya.
Satu hal yang ingin saya catat adalah bahwa ketika melakukan kurva, Anda cenderung mendapatkan variasi yang lebih besar dalam kecepatan linier dan batasan pada kecepatan tersebut. Jika kecepatan gerakan Anda disetel sangat tinggi di alat pengiris sehingga Anda bisa mendapatkan kurva yang cepat, Anda juga akan mendapatkan banyak tempat di mana batasan maksimum printer Anda berperan untuk mengubah kecepatan. Jadi, Anda dapat mencoba menyetel nilai akselerasi maks dan kecepatan maks yang sangat tinggi pada pencetak untuk menghilangkan batasan tersebut.
Kurva dengan banyak segmen juga sedikit lebih menuntut, jadi Anda mungkin juga mencapai batas komputasi dalam beberapa kasus, dan memperlambat perencana untuk menjaga buffer tetap penuh. Jika papan Anda memiliki banyak SRAM, Anda dapat meningkatkan ukuran buffer dan mengatur batas perlambatan ke proporsi yang lebih kecil.
Kami baru saja memperbaiki masalah dengan busur G2 / G3, tetapi pemotong Anda mungkin tidak memproduksinya….
 thinkyhead
pada 31 Mar 2020
thinkyhead
pada 31 Mar 2020
Salah satu pengaturan yang saya lihat CH3D tunjukkan baru-baru ini adalah pengaturan "panjang segmen minimum" di alat pengiris. Ini memastikan untuk tidak membanjiri mesin dengan terlalu banyak segmen kecil, ketika panjang minimum 0,6 mm sudah cukup untuk sebagian besar aplikasi.
Saya tidak bermaksud menyarankan bahwa menyetel alat pengiris dan mengurangi beban pada mesin adalah solusi akhir untuk masalah JD (dan LA), tetapi ini akan membantu dalam pengujian isolasi.
thinkyhead
pada 31 Mar 2020
Ini adalah parameter percepatan yang saat ini disetel di pemotong. Saya akan mengaturnya ke 0 agar default printer digunakan (saya juga akan mengatur ulang konfigurasi printer untuk memastikan tidak ada parameter yang berubah) dan mencoba pencetakan lain.

Mengenai perlambatan saya telah mencoba yang berikut:
- Mengaktifkan
SLOWDOWNdenganSLOWDOWN_DIVISOR2. Tidak ada perbedaan. - Tingkatkan
BLOCK_BUFFER_SIZEmenjadi 64, tidak ada perbedaan.
Saya mencetak dari SD.
Apakah ada perbedaan cara perencana memperlakukan segmen dengan JD vs classic brengsek diaktifkan, kecuali dari membuat segmen dengan percepatan / perlambatan yang berbeda? Dengan klasik brengsek hasil cetaknya sangat halus.
Mencoba menemukan pengaturan mengenai panjang segmen minimum tetapi satu-satunya pengaturan yang dapat saya temukan adalah ini:

ktand
pada 31 Mar 2020
Ingatlah untuk meningkatkan SLOWDOWN_DIVISOR jika Anda menambah jumlah baris buffer, jika tidak maka akan melambat terlalu cepat. Dengan 64, pembagi 16 seharusnya bagus.
thinkyhead
pada 31 Mar 2020
Saya mencoba tanpa SLOWDOWN tetapi dengan BLOCK_BUFFER_SIZE 64, tidak ada perbedaan.
ktand
pada 31 Mar 2020
Apakah ada perbedaan cara perencana memperlakukan segmen dengan JD vs classic brengsek yang diaktifkan…?
Ada perbedaan dalam berapa banyak akselerasi dan deselerasi yang diterapkan di persimpangan segmen. Dan ada lebih banyak perhitungan (mahal) yang dilakukan di setiap persimpangan segmen.
Idealnya, kita perlu menyusun tabel / grafik kecepatan yang diterapkan pada persimpangan, membandingkan sentakan klasik dengan deviasi persimpangan, dan keduanya dengan kecepatan terbaik yang diinginkan.
thinkyhead
pada 31 Mar 2020
Hai! Terima kasih telah melihat ini! Apakah JD diterapkan pada setiap gerakan baru berapa pun panjangnya?
CarlosGS
pada 31 Mar 2020
🌊 Apakah JD diterapkan pada setiap gerakan baru berapa pun panjangnya? 🦁
Iya.
thinkyhead
pada 31 Mar 2020
Ok terima kasih. (Saya tidak meletakkan ikon itu .. laporan bug baru?: P)
CarlosGS
pada 31 Mar 2020
Mencoba menemukan pengaturan mengenai panjang segmen minimum tetapi satu-satunya pengaturan yang dapat saya temukan adalah ini:
@ktand Di mana Anda menemukannya? Apakah PrusaSlicer? Tidak dapat menemukannya di 2.2
qwewer0
pada 31 Mar 2020
Karena ini telah menjadi duplikat dari 17146, saya menutup masalah itu untuk mengurangi kebisingan.
thinkyhead
pada 31 Mar 2020
@thinkyhead lihat komentar saya tentang masalah duplikat: https://github.com/MarlinFirmware/Marlin/issues/17146#issuecomment -606901454. Pengirisan yang ceroboh / beresolusi rendah bukanlah solusi; itu merusak hal-hal lain.
 richfelker
pada 1 Apr 2020
richfelker
pada 1 Apr 2020
Mencoba menemukan pengaturan mengenai panjang segmen minimum tetapi satu-satunya pengaturan yang dapat saya temukan adalah ini:
@ktand Di mana Anda menemukannya? Apakah PrusaSlicer? Tidak dapat menemukannya di 2.2
@ qwewer0 Saya menggunakan Slic3r ++ 2.2.48
ktand
pada 1 Apr 2020
Saya sedang menulis balasan di laporan lain ketika @thinkyhead menutupnya jadi saya hanya menyalin apa yang mulai saya ketik di sana. Ada baiknya untuk mengkonsolidasikannya ke satu utas.
@swilkens menulis
Jika ini adalah masalah khusus dengan SKR Mini E3 v1.2 dan mungkin dengan papan SKR lainnya juga, lalu bagaimana kita bisa memastikannya, lalu mengatasinya?
Saya terbuka untuk ide.Bangun kembali papan asli Anda, gunakan opsi firmware yang sama dan verifikasi di papan asli dengan gcode yang sama?
Board saya adalah DIP SKR E3 tetapi pada dasarnya itu "sama" dengan mini yang saya kira. Saya masih memiliki papan kreativitas asli saya tetapi itu adalah driver stepper yang berbeda (A4988). Akhir pekan ini saya dapat mencoba menukarnya kembali hanya untuk menguji tetapi saya tidak yakin apakah saya dapat mengaktifkan semuanya tanpa kehabisan memori. Mungkin tidak, tapi saya bisa mencobanya.
@CarlosGS @ qwewer0 @ktand @ rado79 dan lainnya yang mungkin saya lewatkan. Karena penasaran apa driver stepper dan papan utama yang tepat yang digunakan semua orang.
SKR E3 DIP v1.1 dan semua driver 4 stepper adalah TMC2209 di printer saya.
Seperti yang dikatakan @thinkyhead , kita perlu mulai mengumpulkan data dan mencatat. Untuk mencoba dan membuatnya konsisten di seluruh papan, kita semua harus memutuskan atau membuat model pengujian pencetakan yang cukup cepat yang dapat kita gunakan semua dan daftar data apa yang harus kita kumpulkan. Saya mungkin bukan yang terbaik untuk membuat keputusan itu, tetapi jika seseorang menulis hampir selangkah demi selangkah dan data apa yang perlu dicatat, saya pasti akan melakukannya.
Sepertinya M928 dapat menghasilkan log "konsol dan masukan host" dan mengirimkannya ke kartu SD untuk diambil dengan mudah. Apakah itu jenis penebangan yang Anda bicarakan di @thinkyhead? Juga level M111 apa yang akan membantu untuk ini?
 DaMadOne
pada 1 Apr 2020
DaMadOne
pada 1 Apr 2020
Hai! Saya tidak tahu apakah ini membantu, tetapi saya mengalami masalah yang sama. CJ lebih baik tetapi saya mendapat perilaku yang tidak terduga di beberapa bagian. Dua video:
Simpangan Persimpangan 0.013
Klasik Brengsek
#define DEFAULT_XJERK 10.0
#define DEFAULT_YJERK 10.0
#define DEFAULT_ZJERK 0.3
GT2560 Motherboard dengan mega1280. Semua driver stepper adalah TMC2208 sebagai standalone.
S_CURVE_ACCELERATION diaktifkan.
#define BLOCK_BUFFER_SIZE 32
TIDAK ADA Muka Linear
 skarcha
pada 1 Apr 2020
skarcha
pada 1 Apr 2020
BQ Zum Mega 3D dengan driver DRV8825 terintegrasi
CarlosGS
pada 1 Apr 2020
@CarlosGS @ qwewer0 @ktand @ rado79 dan lainnya yang mungkin saya lewatkan. Karena penasaran apa driver stepper dan papan utama yang tepat yang digunakan semua orang.
BTT SKR1.3 dan TMC2208 / 2209, 24V
rado79
pada 1 Apr 2020
@bayu_joo
Sekarang saya telah mengonfigurasi alat pengiris untuk menggunakan default yang sama dengan printer. Sayangnya ini tidak membantu.
#define DEFAULT_MAX_FEEDRATE { 200, 200, 30, 120 }
#define DEFAULT_MAX_ACCELERATION { 2000, 2000, 200, 10000 }
#define DEFAULT_ACCELERATION 2000 // X, Y, Z and E acceleration for printing moves
#define DEFAULT_RETRACT_ACCELERATION 2000 // E acceleration for retracts
#define DEFAULT_TRAVEL_ACCELERATION 2000 // X, Y, Z acceleration for travel (non printing) moves
Awal dari skrip G-code:
M201 X2000 Y2000 Z200 E10000 ; sets maximum accelerations, mm/sec^2
M203 X200 Y200 Z30 E120 ; sets maximum feedrates, mm/sec
M204 P2000 R2000 T2000 ; sets acceleration (P, T) and retract acceleration (R), mm/sec^2
M205 X10.00 Y10.00 Z0.40 E4.50 ; sets the jerk limits, mm/sec
M205 S0 T0 ; sets the minimum extruding and travel feed rate, mm/sec
Memeriksa file G-code di S3D menunjukkan tidak ada perubahan kecepatan di area kritis. (Tidak yakin saya akan bisa melihat mereka jika ada).

Mengenai saran Anda:
Jadi, Anda dapat mencoba menyetel nilai akselerasi maks dan kecepatan maks yang sangat tinggi pada pencetak untuk menghilangkan batasan tersebut.
apa nilai yang cocok untuk max-accel? Dan bagi saya untuk memastikan bahwa saya membuat modifikasi yang benar, apakah itu DEFAULT_MAX_ACCELERATION atau DEFAULT_ACCELERATION sedang kita bicarakan? Saya selalu bertanya-tanya bagaimana hubungan DEFAULT_MAX_ACCELERATION dengan DEFAULT_ACCELERATION . Apakah itu hanya batas atau apakah DEFAULT_MAX_ACCELERATION digunakan oleh perencana?
ktand
pada 1 Apr 2020
@CarlosGS @ qwewer0 @ktand @ rado79 dan lainnya yang mungkin saya lewatkan. Karena penasaran apa driver stepper dan papan utama yang tepat yang digunakan semua orang.
SKR Mini E3 v1.2, TMC2209
qwewer0
pada 1 Apr 2020
Board saya adalah driver SKR E3 DIP dan TMC2208 UART. Tapi hasilnya sama saja.
 Viking117
pada 1 Apr 2020
Viking117
pada 1 Apr 2020
Apakah itu pemegang Masker Wajah untuk rumah sakit? Kami mencetak sesuatu yang sangat mirip dengan apa yang ditunjukkan gambar Anda di Houston. Kecuali yang kami katakan "Houston Strong" pada mereka!

 Roxy-3D
pada 2 Apr 2020
Roxy-3D
pada 2 Apr 2020
@ Roxy-3D Ya itu. Link . Saya telah mengirimkan dua batch ke rumah sakit setempat.
ktand
pada 2 Apr 2020
Saya benar-benar bingung. Saya mencoba berbagai kombinasi (dihidupkan dan dimatikan) parameter:
LIN_ADVANCE
S_CURVE_ACCELERATION
CLASSIC_JERK
Tapi saya selalu mendapat jerawat pada model saya, terkadang bahkan di garis lurus. Saya coba tingkatkan resolusi maksimalnya menjadi 0.8, hasilnya lebih bagus tapi belum sempurna. Foto di posting saya di reddit https://www.reddit.com/r/ender3/comments/ft3fse/pimples_when_printing_a_3d_printer/
Apakah benar-benar perlu untuk kembali ke papan saham dan marlin 1,1,9? (
Viking117
pada 2 Apr 2020
Dengan PrusaSlicer , dalam kasus saya, gerakan jittering terjadi pada layer "gap fill" (jejak putih)

Mungkin penyebabnya adalah ini terlihat seperti busur bagi kami, tetapi gcode-nya berbeda.
Ini adalah busur di PrusaSlicer:
G1 X42.099 Y31.207 E0.10230
G1 X43.391 Y29.547 E0.17992
G1 X44.569 Y28.161 E0.15551
G1 X45.807 Y26.811 E0.15659
G1 X47.091 Y25.514 E0.15609
G1 X48.420 Y24.268 E0.15574
G1 X49.788 Y23.074 E0.15526
G1 X51.682 Y21.563 E0.20715
G1 X52.647 Y20.832 E0.10354
G1 X54.132 Y19.786 E0.15529
G1 X55.144 Y19.120 E0.10360
G1 X57.732 Y17.530 E0.25974
Dan ini adalah segmen busur paralel untuk "pengisian celah" di PrusaSlicer:
G1 F7056.755
G1 X56.875 Y18.516 E0.00036
G1 F6344.481
G1 X55.363 Y19.465 E0.10529
G1 X54.418 Y20.079 E0.06647
G1 F6581.463
G1 X54.412 Y20.084 E0.00043
G1 F6541.549
G1 X54.359 Y20.120 E0.00367
G1 F6525.710
G1 X52.886 Y21.159 E0.10338
G1 X52.566 Y21.393 E0.02269
G1 F6783.652
G1 X52.560 Y21.398 E0.00046
G1 F6517.417
G1 X51.930 Y21.883 E0.04563
G1 X50.318 Y23.158 E0.11800
G1 F6861.681
G1 X50.312 Y23.162 E0.00039
G1 F6617.866
G1 X50.046 Y23.383 E0.01958
G1 X49.192 Y24.121 E0.06381
G1 F6822.325
G1 X49.186 Y24.126 E0.00041
G1 F6353.068
G1 X48.694 Y24.571 E0.03908
G1 F6333.234
G1 X47.377 Y25.807 E0.10673
G1 X46.932 Y26.241 E0.03670
G1 F6762.339
G1 X46.927 Y26.246 E0.00043
G1 F6512.778
G1 X46.100 Y27.090 E0.06787
G1 X45.896 Y27.307 E0.01709
G1 F6670.677
G1 X45.891 Y27.312 E0.00041
G1 F6227.178
G1 X44.879 Y28.434 E0.09080
G1 X44.120 Y29.307 E0.06950
G1 F6689.505
G1 X44.114 Y29.315 E0.00052
G1 F6283.570
G1 X43.710 Y29.806 E0.03789
G1 X42.420 Y31.449 E0.12439
Video dari kedua gcode:

CarlosGS
pada 2 Apr 2020
Tes yang sama tetapi dengan Cura:

Jadi busur gelisah di Cura juga memiliki segmen dengan panjang yang tidak rata. Dugaan saya adalah bahwa ini dilunakkan oleh Classic Jerk dan sekarang diperhatikan.
CarlosGS
pada 3 Apr 2020
Saya juga telah merekam contoh PrusaSlicer (memperbarui posting sebelumnya), dan itu menunjukkan segmen busur dengan panjang yang tidak rata juga. Maaf atas spam, tapi sepertinya menjanjikan !!
CarlosGS
pada 3 Apr 2020
Tidak yakin apakah ini akan membantu siapa pun di sini. Meskipun gagap masih terjadi pada mesin saya, ekstrusi tampaknya jauh lebih dapat diandalkan:
Dengan seri SKR E3 (Mini 1.2, DIP), saya menemukan langkah Z stepper hilang (diverifikasi oleh M48, dan mendengar probe secara acak mengenai tempat tidur pada penerapan kedua). Pengekstrusi juga menunjukkan ketidakkonsistenan yang sangat kecil, yang terlihat saat saya menjalankan nozel 0,8.
Saya mencoba menghidupkan dan mematikan Stealthchop, memperlambat proses probing, dll, dan masih mengalami masalah. Rata-rata, probingnya keluar 0,08 hingga 0,1.
Saya baru-baru ini mengonversi printer ke 24V untuk melihat apakah itu masalah voltase, tetapi masalahnya tetap ada. Akhirnya, saya mengubah pengaturan waktu motor di Configuration_Adv.h ke nilai DRV8825:
tentukan MINIMUM_STEPPER_POST_DIR_DELAY 650
tentukan MINIMUM_STEPPER_PRE_DIR_DELAY 650
tentukan MINIMUM_STEPPER_PULSE 2
tentukan MAXIMUM_STEPPER_RATE 250000
Segera, M48 saya turun menjadi 0,001. Gagap-gagap masih ada, tetapi ekstrusi tampak jauh lebih bersih.
 XBrav
pada 5 Apr 2020
XBrav
pada 5 Apr 2020
Saya selalu bertanya-tanya bagaimana
DEFAULT_MAX_ACCELERATIONberhubungan denganDEFAULT_ACCELERATION. Apakah itu hanya batas atau apakahDEFAULT_MAX_ACCELERATIONdigunakan oleh perencana?
Ini hanya default yang Anda setel di konfigurasi. Perencana menggunakan nilai saat ini. Nilai saat ini mungkin telah dimuat dari EEPROM atau mungkin telah diubah oleh M201 / M204 .
- Akselerasi Maks: Semua akselerasi dijepit ke nilai ini.
- Akselerasi: Akselerasi yang akan digunakan untuk langkah selanjutnya.
Prediksi sentakan, deviasi persimpangan, dan pergerakan bergantung pada nilai akselerasi dan laju gerak makan saat ini, sehingga tampaknya mengubah laju gerak makan atau percepatan terus-menerus selama pemindahan dapat merusak perencana. Sebaiknya bandingkan kode-G yang sangat bersih yang tidak mengubah laju gerak kecuali saat beralih di antara jenis fitur (pengisi vs. dinding) ke kode-G yang lebih sering mengubah parameter gerakan.
Saya tidak yakin mengapa G-kode di atas terpisah G1 F perintah ketika F parameter dapat berada di akhir baris berikut ini sebagai gantinya. Itu akan membuatnya sedikit lebih ramping.
thinkyhead
pada 5 Apr 2020
Ini layak dibaca oleh siapa pun yang menggunakan 2208 dan 2209… https://github.com/MarlinFirmware/Marlin/issues/11825#issuecomment -421809385
thinkyhead
pada 6 Apr 2020
@thinkyhead Tidak berhasil untuk saya. https://github.com/MarlinFirmware/Marlin/issues/17146#issuecomment -609656052
qwewer0
pada 6 Apr 2020
Ini layak dibaca untuk siapa pun yang menggunakan 2208 dan 2209… # 11825 (komentar)
Halo semua! jadi saya membacanya dan apa yang saya ambil darinya mungkin stealthchop adalah masalahnya? atau apakah saya salah membaca?
Saya menerima kit drive langsung mikro-swiss untuk digunakan dengan hot end mereka yang sudah saya miliki untuk ender 3 pro saya dan menginstalnya. Saya tidak menggunakan perbaikan bug 2.0.x (seperti kemarin) hanya untuk mendapatkan yang terbaru dan mengaturnya. E-langkah, aliran, dan nilai k yang dikalibrasi. Perlu lebih banyak penyetelan, tetapi inilah yang menurut saya penting untuk mendorong saya dan menguji "bug" ini
Sebagian dari diri saya berharap dengan beralih ke pengaturan ini dan dapat benar-benar menurunkan pencabutan saya yang belum benar-benar saya kalibrasi tetapi saya berjalan pada 1mm @ 25mm / s dan saya mendapatkan hasil yang layak. Tambahkan itu ke nilai k yang jauh lebih rendah yaitu 0,08 dan saya berharap masalah ini akan hilang. * petunjuk ... tidak beruntung! :(
Saya mengeluarkan model tux terpercaya dan mengiris sedikit bagian tengah dan setelah lapisan pertama yang lebih lambat dicetak saya dapat segera mendengar suara yang familiar dari alat pengekstrusi yang berputar, tetapi sekarang jauh lebih halus. Pada akhirnya, "tampilan" model tux akhirnya tampak hampir sama dengan JD / LA yang diaktifkan sebelum penggerak langsung seperti yang diuraikan dalam # 17146 OP.
Jadi saya pikir mari kita uji teori stealthchop ini dan mencetak gcode yang sama lagi tetapi di tengahnya saya mengirim 'M569 S0 E' yang saya tahu memasukkan stepper ekstruder ke mode spreadcycle karena saya bisa mendengarnya tetapi saya juga memverifikasinya LCD Ender 3 dalam pengaturan lanjutan / TMC Drivers dan juga dengan M569 setelah pencetakan selesai yang menunjukkan "mode driver E: spreadCycle"
Saya mencetak separuh model dengan stealthchop dan separuh dengan speadcycle dan tidak dapat membedakannya. Pengekstrusi gagap tetap sama dengan siklus menyebar.
@bayu_joo Karena saya menggunakan papan dengan soket driver, saya bersedia memesan satu atau dua driver stepper lagi dan mengujinya untuk mencoba dan melihat apakah ini adalah masalah TMC2208 / 9 tetapi saya ingin masukan dari seseorang yang tahu tentang apa untuk memesan. Driver TMC yang berbeda (mungkin 5160)? A4988 standar rawa? DRV8825? Saya bahkan akan bertanya apakah ada yang memiliki beberapa pengemudi berbeda yang mungkin tidak punya waktu atau ingin mengujinya untuk mengirimkannya kepada saya dan saya akan mengirimkannya kembali. Saya hanya akan meminta pengirim BENAR-BENAR membersihkannya dengan beberapa IPA dan saya akan melakukan hal yang sama sebelum mengirimnya kembali.
DaMadOne
pada 7 Apr 2020
Jadi saya pikir mari kita uji teori stealthchop ini dan mencetak gcode yang sama lagi tetapi di tengahnya saya mengirim 'M569 S0 E' yang saya tahu menempatkan stepper ekstruder ke mode sebaran
@DaMadOne Bukankah sumbu X dan Y yang menjadi masalah di sini?
qwewer0
pada 7 Apr 2020
Diuji dengan driver A4988. Masalah yang sama.
skarcha
pada 7 Apr 2020
Saya dapat mengonfirmasi bahwa saya memiliki masalah yang sama pada kurva di bagian ini dari koleksi TeachingTech Thingiverse . Ini hanya muncul di sekitar lapisan 100 hingga 125 pada 0,2 mm LH.
Perangkat keras:
Stok Ender 3 Pro
Papan Creality 1.1.4
ATMega 1284
Driver A4988
Firmware:
Marlin 1.1.9 (1.1.x rilis cabang dari 05.04.20, BUKAN cabang perbaikan bug)
Konfigurasi saat ini
-> Juga diuji dengan pengaturan yang berbeda: Linear Advance en- / disabled, S-Curve en- / disabled, Adaptive Step Smoothing en- / nonaktif. Mereka _tidak berpengaruh_ pada masalah ini.
Alat pengiris:
Cura 4.5, kontrol akselerasi & brengsek dinonaktifkan
GCode
-> Saya juga dapat mengonfirmasi panjang segmen _inconsistent / quick alternating_ yang telah disebutkan pada lapisan yang terpengaruh di wilayah bagian yang terpengaruh. Ini terlihat di pratinjau Cura. Sementara pada lapisan yang tidak terpengaruh, segmen dalam kurva memiliki panjang yang sama, segmen pada lapisan yang terpengaruh bergantian pendek / panjang / pendek / panjang sebagai perbandingan. Namun, ini tidak memengaruhi cetakan dengan Jerk klasik sama sekali. Hanya cetakan dengan Simpangan Persimpangan yang rusak.
 XDA-Bam
pada 10 Apr 2020
XDA-Bam
pada 10 Apr 2020
Masalah yang sama dengan Sidewinder-X1 - Mengurangi resolusi tidak membantu. Mengiris dengan Cura menghasilkan hasil yang lebih buruk daripada Slic3r, namun keduanya kembali bagus setelah saya menonaktifkan JD
 thierryzoller
pada 11 Apr 2020
thierryzoller
pada 11 Apr 2020
Saya telah menemukan solusi untuk masalah ini, yang menghilangkan masalah untuk cetakan percobaan saya: Dengan meningkatkan MIN_STEPS_PER_SEGMENT dari default 6 menjadi 16 (yang merupakan 1/2 diameter nosel untuk saya), kurva menjadi sangat mulus saat menggunakan JD. Saya tidak menguji nilai yang lebih rendah, jadi 10 atau 12 langkah per segmen mungkin sudah cukup. Ini tentunya bukan perbaikan, karena sedikit mengurangi presisi.
XDA-Bam
pada 12 Apr 2020
Sangat menarik bahwa meningkatkan MIN_STEPS_PER_SEGMENT memiliki efek positif. Tentunya kita tidak menginginkan jutaan blok dengan hanya satu langkah di dalamnya, karena ini membuat akselerasi / deselerasi apa pun berubah menjadi kelompok akar kuadrat floating point, dan pasti ada potensi jebakan lainnya dengan banyak segmen kecil.
Setelah saya memiliki lebih banyak waktu luang, saya harus menyelami analisis lebih dalam untuk melihat apa yang diringankan oleh perubahan MIN_STEPS_PER_SEGMENT , dan kemudian mencari tahu poin sebelumnya untuk menerapkan mitigasi.
Sementara itu, saya akan senang mendengar dari orang lain apa pengalaman mereka bermain dengan MIN_STEPS_PER_SEGMENT , dan jika ada ambang batas "ajaib" yang berbeda tergantung pada perangkat keras.
thinkyhead
pada 12 Apr 2020
Bagi saya, saya harus menetapkan JD ke nilai serendah mungkin 0,010
Apa pun yang lebih tinggi menciptakan artefak
 Grogyan
pada 12 Apr 2020
Grogyan
pada 12 Apr 2020
Saya tidak melihat perlambatan pada SKR PRO selama pencetakan gcode dengan banyak segmen kecil. Namun perbedaan kualitas permukaan antara JD dan Jerk masih ada. MIN_STEPS_PER_SEGMENT tidak banyak berubah.
Saya hampir tidak melihat perbedaan kualitas permukaan untuk MIN_STEPS 6 dan 16. MIN_STEPS 16 memiliki "noise" yang sedikit lebih sedikit di permukaan, tetapi masih sangat jauh dari kualitas JERK.
Kualitas permukaan brengsek lebih baik dengan semua nilai MIN_STEPS (16, 6, 1).

 BarsMonster
pada 12 Apr 2020
BarsMonster
pada 12 Apr 2020
@BarsMonster Anda menggunakan perangkat keras yang berbeda dari saya. Apakah 16 langkah juga setara dengan 0,2 mm dalam casing Anda? Itulah yang harus Anda tuju. Saya Memiliki 80 langkah / mm pada X dan Y, oleh karena itu MIN_STEPS_PER_SEGMENT = 16 menyaring semua segmen kecil <0,2 mm dari GCode.
XDA-Bam
pada 12 Apr 2020
Berapa ukuran lingkar yang Anda gunakan untuk melihat gagap? Saya telah menyusun tes stl / gcode hanya untuk melihat apakah saya dapat melihat artefak. Ini file-nya. Anda mungkin ingin meregangkannya secara vertikal jika Anda menginginkan lebih banyak lapisan perbandingan, tetapi saya menyertakan file gcode dari S3D pada ketinggian lapisan 0,2 mm pada 0,4 mm:
https://drive.google.com/open?id=1zZSb3GSWtmA65jmILRCykF0DZYADhaPb
Setiap cincin memiliki jumlah tepi yang berbeda. Lapisan bawah adalah lingkaran standar di Fusion 360. Lapisan berikutnya memiliki 1000 tepi, diikuti oleh 500, 100, dan 50.
Satu perubahan yang telah saya mainkan adalah meningkatkan ukuran buffer. Saya perhatikan 16 tampaknya agak kasar dengan banyak gerakan kecil. Dengan papan 32 bit saya yang memiliki banyak RAM, saya meningkatkannya menjadi 128:
#if ENABLED(SDSUPPORT)
#define BLOCK_BUFFER_SIZE 128 // SD,LCD,Buttons take more memory, block buffer needs to be smaller
Hasil saya tampaknya cukup mulus, bahkan dengan MIN_STEPS_PER_SEGMENT = 1. Ini ada di Ender 5 dengan E3 DIP STM32F103RC dengan semua stepper sebagai TMC2208 dan LA diaktifkan. Saya juga menjalankan pencetakan dengan kecepatan 300% hanya untuk melihat apakah saya memenuhi 128 buffer. Stealthchop dimatikan untuk ekstruder karena saya berhasil menghentikannya dengan mengaktifkannya.
EDIT Menambahkan versi 'tinggi' yang membentang 500% di Z. Akan diperbarui dengan foto.
EDIT 2 Hasil tinggi dengan kecepatan 300%:

XBrav
pada 12 Apr 2020
@ XDA-Bam @XBrav Saya menguji fitur R = 8mm, yang mungkin terlalu ketat. Mungkin kerucut dalam mode vas akan lebih efisien dan menutupi semua lengkungan. Kurva saya diekspor dengan resolusi maksimum di Fusion, dan diiris dalam Cura dengan resolusi maksimum jadi itu pasti mendorong batas.
Langkah per mm adalah 160 dalam kasus saya, jadi ya, sepertinya MIN_STEPS yang lebih tinggi akan dibutuhkan dalam kasus saya sesuai dengan rumus Anda. Saya akan menguji langkah min = 32.
BLOCK_BUFFER_SIZE adalah 64 dalam kasus saya.
BarsMonster
pada 13 Apr 2020
@ XDA-Bam Diuji dengan MIN_STEPS_PER_SEGMENT = 32. "Noise" masih sama dalam amplitudo, tetapi frekuensinya lebih rendah. Mungkin pada lingkaran yang lebih besar itu akan kurang terlihat, tetapi pada R = 8mm itu masih sangat signifikan dan menurunkan kualitas permukaan secara signifikan.
BarsMonster
pada 13 Apr 2020
Bisakah saya mendapatkan sedikit informasi tentang BLOCK_BUFFER_SIZE, BUFSIZE, TX_BUFFER_SIZE, untuk apa yang mereka lakukan dalam kasus kami?
qwewer0
pada 13 Apr 2020
Saya tidak melihat perlambatan pada SKR PRO selama pencetakan gcode dengan banyak segmen kecil. Namun perbedaan kualitas permukaan antara JD dan Jerk masih ada. MIN_STEPS_PER_SEGMENT tidak banyak berubah.
Saya hampir tidak melihat perbedaan kualitas permukaan untuk MIN_STEPS 6 dan 16. MIN_STEPS 16 memiliki "noise" yang sedikit lebih sedikit di permukaan, tetapi masih sangat jauh dari kualitas JERK.
Kualitas permukaan brengsek lebih baik dengan semua nilai MIN_STEPS (16, 6, 1).
Saya tidak bisa meniru ini di SKR Mini V1.2 saya yang menjalankan 2.0.5.3, juga dicetak dengan JD dan Classic Jerk. Diiris dengan PrusaSlicer 2.2.0 dengan resolusi maksimal. S_CURVE_ACCELERATION diaktifkan sementara LINEAR_ADVANCE dinonaktifkan.
Saya juga tidak yakin ini adalah masalah yang sama dengan OP, yang tampaknya telah menunjukkan hal ini terjadi dengan segmen pengisi - yang tidak dimiliki model ini.

 swilkens
pada 13 Apr 2020
swilkens
pada 13 Apr 2020
@ Syahrul Linear?
qwewer0
pada 13 Apr 2020
@ Syahrul Linear?
Tidak, saya tidak menggunakan Linear Advance. Ini diaktifkan di firmware, tetapi nilai K diatur ke 0 - sama seperti di posting pertama topik ini.
Saya juga tidak berpikir LA akan berpengaruh kuat pada geometri ini, karena garis terluar adalah garis singgung konstan. Tapi saya sedang memeriksa sekarang.
swilkens
pada 13 Apr 2020
Tidak dapat mereproduksi masalah dengan file uji @BarsMonster dengan JD. (SKR Mini E3 v1.2)
Punyaku mulus seperti @swilkens
Akan mencoba dengan peningkatan MIN_STEPS_PER_SEGMENT, dengan model yang berbeda .
qwewer0
pada 13 Apr 2020
@ Syahrul Linear?
Tidak, saya tidak menggunakan Linear Advance. Ini diaktifkan di firmware, tetapi nilai K diatur ke 0 - sama seperti di posting pertama topik ini.
Saya juga tidak berpikir LA akan berpengaruh kuat pada geometri ini, karena garis terluar adalah garis singgung konstan. Tapi saya sedang memeriksa sekarang.
A kepala, LA dengan K = 0 tidak sama dengan menyusun tanpa itu dari apa yang saya dengar. Jika Anda tidak membutuhkan LA, komentari definisikan dan kompilasi ulang.
Bukan berarti ini solusi untuk Anda, hanya sebuah catatan.
 randellhodges
pada 13 Apr 2020
randellhodges
pada 13 Apr 2020
A kepala, LA dengan K = 0 tidak sama dengan menyusun tanpa itu dari apa yang saya dengar. Jika Anda tidak membutuhkan LA, komentari definisikan dan kompilasi ulang.
Bukan berarti ini solusi untuk Anda, hanya sebuah catatan.
Saya tidak yakin itu benar.
jika Anda hanya perlu mencetak sebagian dengan cepat tanpa kebutuhan khusus dalam hal kualitas, tidak ada alasan untuk mengaktifkan LIN_ADVANCE sama sekali. Untuk cetakan itu, Anda cukup menyetel K ke 0. "
https://marlinfw.org/docs/features/lin_advance.html
 patriot1889
pada 13 Apr 2020
patriot1889
pada 13 Apr 2020
Jangan ragu untuk melihat kode dan memverifikasi eksekusi kode / antrian perencana tidak sama. Jika itu sama, maka mereka akan mengaktifkannya secara default dengan K = 0.
Saya menyadari situs web mengatakan itu, tetapi saya tidak berbicara tentang hasil, saya berbicara tentang kode spesifik yang dijalankan dengan K = 0 vs tidak diaktifkan. Hasil kompilasi berbeda. X / 10 kali mungkin menghasilkan hasil yang terlihat.
Anda mungkin menganggapnya sebagai Semua jalan menuju Roma, tetapi setiap jalan berbeda dan Anda mungkin tersesat di jalur yang jarang dilalui.
randellhodges
pada 13 Apr 2020
Persis. Misalnya, juga berbeda untuk mengkompilasi dengan Simpangan Persimpangan dan mengaturnya ke nol daripada mengkompilasi dengan Jerk Klasik dan mengaturnya ke nol. Tujuannya adalah agar tidak ada perbedaan _apparent_ ... tetapi kode internal adalah yang membawa kita ke sini;)
Uptate: Dalam kasus saya, saya telah mengamati printer dengan Classic Jerk dan juga sedikit "goyah" di bagian pengisi celah . Saya juga perlu menguji mengubah ukuran buffer dan min_steps_per_segment tetapi tidak punya waktu untuk melakukan ini dengan benar :(
Berharap untuk mempelajari penyebab & solusinya, tetaplah aman!
CarlosGS
pada 13 Apr 2020
Persis. Misalnya, juga berbeda untuk mengkompilasi dengan Simpangan Persimpangan dan mengaturnya ke nol daripada mengkompilasi dengan Jerk Klasik dan mengaturnya ke nol. Tujuannya adalah agar tidak ada perbedaan _apparent_ ... tetapi kode internal adalah yang membawa kita ke sini;)
Uptate: Dalam kasus saya, saya telah mengamati printer dengan Classic Jerk dan juga sedikit "goyah" di bagian pengisi celah . Saya juga perlu menguji mengubah ukuran buffer dan min_steps_per_segment tetapi tidak punya waktu untuk melakukan ini dengan benar :(
Berharap untuk mempelajari penyebab & solusinya, tetaplah aman!
Nah, itu berbeda. JD hanya diaktifkan dengan menonaktifkan brengsek klasik secara khusus. Oleh karena itu JD 0 tidak akan menjadi JD dan tidak ada Jerk, benar?
Dan @randellhodges yang cukup adil. Saya setuju dalam hal pengujian ini bahwa LA K0! = JD OFF.
Saya mengomentari lebih banyak tentang fakta bahwa itu memiliki perbedaan yang terlihat ... tetapi sebenarnya itu tidak relevan dengan masalah ini jadi ... saya buruk.
patriot1889
pada 13 Apr 2020
Saya memverifikasi g-code yang dihasilkan oleh Cura, yang menunjukkan masalah tersebut.
Segmen cetak berukuran 0,4-0,6 mm, pengganda ekstrusi (berapa banyak filamen yang diekstrusi vs panjang gerakan) sama untuk semua gerakan (dalam 0,1%). Jadi sepertinya gcode sudah benar. Dengan itu saya tidak yakin bagaimana MIN_STEPS_PER_SEGMENT dapat mempengaruhi cetakan karena semua segmen lebih besar dari 32 langkah. (160 langkah per mm dalam kasus saya)
@swilkens @ qwewer0 Bisakah Anda mencoba mencetak dalam mode vas atau menggunakan gcode saya? Mungkin perubahan Z secara bertahap membuatnya terlihat.
Saya ingin tahu apa itu Z-brengsek saat menggunakan JD? Jika Z sering berubah, dan Z-jerk adalah 0 dengan JD, gerakan kecil pada gerakan Z ini bisa sangat lambat dan menyebabkan kerusakan permukaan.
BarsMonster
pada 14 Apr 2020
Dengan atau tanpa mode vas, tidak dapat mereproduksi masalah di Xtest-HR.stl
qwewer0
pada 14 Apr 2020
@BarsMonster @ qwewer0 bagi saya masalahnya muncul di "mengisi celah" yang tidak dihasilkan dalam pengaturan pemotongan Anda, lihat komentar ini di atas
CarlosGS
pada 14 Apr 2020
Namun, kode Anda memiliki langkah Z yang tidak rata:
G1 X143.954 Y66.913 E1745.41495
G1 X144.322 Y66.652 Z13.002 E1745.43261
G1 X144.7 Y66.403 E1745.45033
G1 X144.895 Y66.282 E1745.45931
G1 X145.282 Y66.057 E1745.47684
G1 X145.483 Y65.948 E1745.48579
G1 X145.878 Y65.747 Z13.003 E1745.50314
G1 X146.294 Y65.555 E1745.52108
G1 X146.71 Y65.38 E1745.53874
G1 X147.126 Y65.224 E1745.55614
G1 X147.337 Y65.151 E1745.56488
G1 X147.774 Y65.014 Z13.004 E1745.58281
G1 X148.201 Y64.897 E1745.60014
G1 X148.64 Y64.793 E1745.6178
G1 X149.09 Y64.704 E1745.63576
G1 X149.535 Y64.633 Z13.005 E1745.6534
G1 X149.976 Y64.579 E1745.67079
G1 X150.206 Y64.558 E1745.67983
G1 X150.535 Y64.533 E1745.69275
G1 X150.993 Y64.515 E1745.71069
G1 X151.438 Y64.513 Z13.006 E1745.72811
G1 X151.79 Y64.523 E1745.7419
Jika Anda memiliki percepatan berbeda untuk Z, ini mungkin menyebabkan guncangan.
CarlosGS
pada 14 Apr 2020
Langkah @CarlosGS Z bersifat monotonik, dengan langkah 1um. Memiliki koordinat Z pada setiap baris akan membutuhkan resolusi 50nm (0.05um) pada sumbu Z yang hampir tidak membantu. Saya setuju bahwa langkah Z dapat menyebabkan masalah, tetapi sulit untuk membuatnya lebih kecil dari 1um.
BarsMonster
pada 14 Apr 2020
Menguji model penguin bagian bawah dengan default MIN_STEPS_PER_SEGMENT 6 dan 16 seperti @ XDA-Bam menulis, tetapi hasilnya sama. (penguin tidak memiliki celah mengisi, tetapi masih memiliki kegelisahan) (Kiri 6, Kanan 16)
Model penguin memiliki lebih sedikit segitiga dan lebih besar daripada di Xtest-HR.stl, tetapi Xtest-HR.stl tetap mulus dan penguin gelisah.
qwewer0
pada 14 Apr 2020
@BarsMonster Saya tidak bisa memicu masalah ini pada model Anda, terlepas dari mode vas, lin_adv, brengsek klasik dari pengaturan deviasi juction.
@CarlosGS Saya tidak bisa memaksa sepotong di mana isinya panjangnya tidak rata seperti yang Anda tunjukkan dalam analisis gcode dari pelindung wajah. Saya mengambil model yang sama dan mengiris, semua dengan panjang busur yang sama. Tampaknya ini hanya terjadi untuk irisan tertentu dengan konfigurasi ketebalan cangkang / lebar nosel tertentu di pemotong. Saya membayangkan juga kualitas STL mempengaruhi ini. Berapa diameter nosel yang Anda konfigurasikan di prusa? versi pengiris prusa mana yang Anda gunakan?
Untuk mereplikasi ini di sini, kita membutuhkan model sederhana kecil yang memicu ini dengan andal.
swilkens
pada 14 Apr 2020
@Barsonster Ah! Apakah Anda mencoba dengan dan tanpa mode vas? (Hanya mencetak 1 perimeter juga)
@swilkens 0.4mm untuk Cura dan Prusaslicer, meskipun itu juga bergantung pada infill overlap .. terlalu banyak parameter x)
CarlosGS
pada 14 Apr 2020
@CarlosGS Saya membuat kerucut sederhana yang mulai dari ketebalan 2.0 mm di bagian bawah menjadi ketebalan 0.6 mm di bagian atas, ini akan menjamin garis isi yang terjadi di sebagian dari ketinggian total terlepas dari pengaturan nosel.
Saya masih tidak bisa mengiris sedemikian rupa sehingga pengisian panjang segmen variabel ini terjadi. Dapatkah Anda mencoba memotong STL yang sama dan memeriksa panjang segmen isian? Saya menggunakan PrusaSlicer 2.2.0
Bahkan lebih baik - dapatkah Anda memberikan GCODE yang memicu ini?
swilkens
pada 14 Apr 2020
@swilkens OK Saya sudah mencoba dengan pengaturan standar PrusaSlicer, ini hasilnya:
Model hebat BTW, tes sempurna untuk mengisi celah "lengkung"!
CarlosGS
pada 14 Apr 2020
Saya masih tidak bisa mendapatkan ini untuk berperilaku buruk, apakah Anda mencetak dari kartu SD atau melalui antarmuka serial (misalnya melalui octoprint atau sesuatu)?
Mungkin terkait: https://github.com/MarlinFirmware/Marlin/issues/17117
swilkens
pada 14 Apr 2020
Dengan kerucut, saya mendapat hasil yang agak ok, kecuali untuk dua lapisan di mana ada celah kecil tersegmentasi. Di bagian atas dan bawah masalahnya ada, tetapi tidak begitu mencolok seperti di garis tengah. Jadi, mungkin jika saya mendapatkan lebih banyak celah yang terisi maka hasilnya akan sangat buruk.

qwewer0
pada 14 Apr 2020
Tuan-tuan tolong lampirkan penghematan proyek slicer 3mf, ini memungkinkan kami untuk secara otomatis memiliki semua pengaturan Anda dan karenanya mengiris dengan cara yang persis sama. Saya mulai bertanya-tanya apakah ini tidak perlahan berubah menjadi laporan bug slicer daripada marlin.
thierryzoller
pada 14 Apr 2020
Saya percaya bahwa alasan mengapa hasil CURA tampaknya lebih buruk daripada hasil Slic3r dapat dikaitkan dengan (dalam kasus saya) contoh berikut. Perhatikan bahwa hasil Slic3r dengan JD di mana juga buruk bahkan tanpa dinding bagian dalam yang bergoyang.
Slic3r
Cura

thierryzoller
pada 14 Apr 2020
Ini adalah potongan dari Slic3r dengan pengaturan yang sedikit berbeda. Kami tidak akan dapat menemukan akar masalah dengan mudah karena menurut saya ini adalah overlay dari pengaturan firmware, pengaturan slicer dan model 3d yang menghasilkan hasil akhir yang tidak konsisten ini. Bandingkan dengan yang di atas:

thierryzoller
pada 14 Apr 2020
Itu bukan gapfill di slic3r (itu adalah garis abu-abu-putih) - yang Anda miliki adalah Infill yang dicampur dengan garis tegak lurus Gapfill.
Oke.
qwewer0
pada 14 Apr 2020
Tuan-tuan tolong lampirkan penghematan proyek slicer 3mf, ini memungkinkan kami untuk secara otomatis memiliki semua pengaturan Anda dan karenanya mengiris dengan cara yang persis sama.
Ini kerucut saya: Body1.zip
Saya mulai bertanya-tanya apakah ini tidak perlahan berubah menjadi laporan bug slicer daripada marlin.
Model penguin tidak memiliki celah pengisian, namun dapat melihat bagian luar yang kasar dengan JD, tetapi pemotong yang berbeda (Cura, PrusaSlicer, Fusion 360) masih berpengaruh padanya.
Pengaturan pengiris seperti isian aneh antara dua garis luar akan menghasilkan permukaan yang kasar.
Tapi, gcode yang sama yang jelek dengan JD mulus dengan CJ.
qwewer0
pada 14 Apr 2020
@ qwewer0 : dapatkah Anda mencoba dan mencetak ini:
Body1_tzo.zip
thierryzoller
pada 14 Apr 2020
@ qwewer0 : dapatkah Anda mencoba dan mencetak ini:
Body1_tzo.zip
Ya, perlu waktu lebih dari 30 menit untuk mencetaknya.
Hanya dengan JD?
qwewer0
pada 14 Apr 2020
@thierryzoller Ini adalah hasilnya. Itu sama seperti sebelumnya, hanya lapisan jeleknya yang naik, karena lebar garis adalah 0,3 dari 0,36.

qwewer0
pada 14 Apr 2020
"Isi celah di dinding" dapat menyebabkan masalah dengan ekstrusi kecil dan / atau celah di antara dinding pada benda melengkung. Saya sudah mengalaminya dua minggu lalu dengan desain yang sama sekali berbeda. Di Cura, itu bug yang dikenal . Itu bukan masalah dengan JD, tapi pasti ada masalah dengan JD juga. Mungkin kita harus mengambil celah mengisi persamaan untuk saat ini dan hanya fokus pada permukaan melengkung dan artefak? Gunakan benda berdinding tipis dan hindari celah?
Ini cetakan saya, ketebalan dinding 2, tidak ada pengisi atau celah (juga tidak perlu):
Brengsek kiri, JD kanan. Kurva R = 15, dicetak @ 100 mm / s dengan akselerasi 750 mm / s².
XDA-Bam
pada 14 Apr 2020
Bisakah kita memiliki ini sebagai file 3MF?
thierryzoller
pada 14 Apr 2020
Terima kasih untuk tes mendetailnya, sekarang sudah jelas:
Perhatikan masih ada segmen dengan panjang berbeda dan cocok dengan area yang terdistorsi dengan JD !!
G1 X139.056 Y114.37 E1229.2764
G1 X139.179 Y114.987 E1229.29733
G1 X139.276 Y115.613 E1229.3184
G1 X139.286 Y115.715 E1229.32181
G1 X139.345 Y116.248 E1229.33964
G1 X139.35 Y116.339 E1229.34267
G1 X139.386 Y116.874 E1229.36051
G1 X139.387 Y116.965 E1229.36354
G1 X139.399 Y117.592 E1229.38439
G1 X139.38 Y118.241 E1229.40599
Saya menggunakan https://ncviewer.com/ untuk melihat jalur & menemukannya.
Setelah melihat ini, itu cocok dengan sebelumnya1 & sebelumnya2 . Ya, itu dengan Isi Celah dan bukan di perimeter, tetapi hasilnya sama: segmen pendek acak disisipkan dengan yang berjarak sama.
CarlosGS
pada 14 Apr 2020
Sedikit keluar dari topik, tapi saya ingin tahu apakah plugin eksperimental ini akan banyak membantu:
https://community.octoprint.org/t/new-plugin-anti-stutter-need-testers/18077
Idenya adalah bahwa itu akan mengubah semua segmen kecil itu menjadi gerakan busur. Segmen kecil yang membentuk kurva tampaknya menjadi masalah, atau setidaknya menjadi penyumbang besar.
Sepertinya kode itu juga bisa masuk ke plugin cura.
randellhodges
pada 14 Apr 2020
Ini adalah hasil saya di Teaching_Tech_speed_test.stl, dan file 3mf: Teaching_Tech_speed_test.zip
Tidak dapat melihat atau merasakan perbedaan apa pun di antara mereka.
JD Kiri, CJ Kanan
Sunting: Saya ingin melihat dukungan busur di pemotong ...
qwewer0
pada 14 Apr 2020
@ XDA-Bam Bisakah Anda menguji G-code ini yang hanya mengulangi busur bermasalah?
JD_single_arc_test.zip
Harap dicatat bahwa saya telah menghapus semua bagian terkait ekstrusi / suhu. Jika Anda dapat melihat kenakalan yang sama, itu berarti masalahnya tidak terkait dengan ekstrusi tetapi gerakan XYZ. Saya telah mengujinya pada printer saya dengan Classic Jerk dan tidak ada gagap yang terlihat.
CarlosGS
pada 14 Apr 2020
@ qwewer0 Sebaiknya gunakan GCode saya jika Anda ingin membandingkan, karena ada segmen garis kecil di sekitar lapisan 120. Di sinilah artefak muncul untuk saya. Selain itu, Anda tidak akan melihatnya di lapisan bawah. Jadi hanya mencetak bagian bawah akan selalu terlihat oke. Anda mungkin lolos hanya dengan mencetak sepertiga teratas - belum mengujinya.
@CarlosGS Saya akan memeriksanya.
XDA-Bam
pada 14 Apr 2020
@ XDA-Bam Anda mungkin benar, tetapi saya tidak hanya mencetak bagian bawahnya, tetapi menekannya di Z.
qwewer0
pada 14 Apr 2020
@ XDA-Bam Bisakah Anda menguji G-code ini yang hanya mengulangi busur bermasalah?
JD_single_arc_test.zipHarap dicatat bahwa saya telah menghapus semua bagian terkait ekstrusi / suhu. Jika Anda dapat melihat kenakalan yang sama, itu berarti masalahnya tidak terkait dengan ekstrusi tetapi gerakan XYZ. Saya telah mengujinya pada printer saya dengan Classic Jerk dan tidak ada gagap yang terlihat.
Ini adalah cara cerdas untuk melakukan ini, terima kasih.
Tidak ada gagap pada Classic Jerk, tampaknya terhenti di puncak kurva dengan Simpangan Persimpangan. Perbedaan besar bagi saya, tampaknya melambat secara dramatis di tengah kurva dengan JUNCTION_DEVIATION
swilkens
pada 14 Apr 2020
@CarlosGS JD_single_arc_test.gcode dengan CJ rasanya oke, tapi dengan JD itu terasa lebih gelisah.
qwewer0
pada 14 Apr 2020
Ah ya !! :)
Jika lebih banyak orang dapat mengonfirmasi ini, maka kita dapat mulai melakukan debug!
CarlosGS
pada 14 Apr 2020
Hasil sejauh ini, semua dilakukan pada rilis Marlin 2.0.5.3 dengan file The JD_single_arc_test.gcode dari @CarlosGS pada SKR Mini V1.2 dengan TMC 2209.
Mencetak mulai dari SD Card maupun melalui antarmuka Serial, tidak ada perbedaan.
LINEAR_ADVANCE sepertinya tidak mempengaruhinya, begitu pula mode stepper. Tetapi meningkatkan MINIMUM_STEPS_PER_SEGMENT menjadi 16 (naik dari 6) tentu saja memperbaiki situasi secara dramatis. Saya berasumsi ini mengikat beberapa segmen yang lebih kecil menjadi satu.
S_CURVE_ACCELERATION juga tidak berpengaruh.
Di samping catatan - alangkah baiknya jika fitur-fitur ini dapat dihidupkan / dimatikan dengan pengaturan konfigurasi jika perangkat memiliki RAM yang cukup untuk mengkompilasinya.
Gagap | CJ | JD | LA | Mode | MIN_STEPS_PER_SEG. | S_CURVE_ACC.
------------ | ------------ | ------------- | ------------- | ------------- | ------------- | -------------
TIDAK | Y | - | Y | Stealth | 6 | Y
YA | - | Y | Y | Stealth | 6 | Y
YA | - | Y | - | Stealth | 6 | Y
YA | - | Y | - | SpreadCycle | 6 | Y
MENINGKATKAN | - | Y | - | Stealth | 16 | Y
YA | - | Y | - | Stealth | 6 | -
swilkens
pada 14 Apr 2020
Dengan JD dan MIN_STEPS_PER_SEGMENT 16 , JD_single_arc_test.gcode dekat dengan hasil CJ, dan pasti gagapnya berkurang, tetapi masih tidak semulus CJ. Jadi secara keseluruhan itu membantu, tetapi tidak menyelesaikannya.
qwewer0
pada 14 Apr 2020
Untuk mereplikasi tabel @swilkens dan meringkas pengujian saya (ASS adalah pemulusan langkah adaptif):
| Tipe brengsek | LA | Kurva-S | ASS | Langkah Min | Gagap |
| --- | --- | --- | --- | --- | --- |
| JD | - | AKTIF | AKTIF | 6 | YA |
| JD | AKTIF | - | AKTIF | 6 | YA |
| JD | AKTIF | - | - | 6 | YA |
| JD | AKTIF | - | - | 16 | JAUH KURANG * |
| CJ | AKTIF | - | - | 6 | TIDAK |
(*: Karena sekarang saya tahu apa yang harus dicari, saya masih bisa melihat 3 gagap kecil di permukaan bahkan dengan MIN_STEPS_PER_SEGMENT = 16 . Tapi itu sekitar 90% lebih sedikit dibandingkan dengan 6 langkah.)
XDA-Bam
pada 14 Apr 2020
@CarlosGS Saya baru saja menguji JD_single_arc_test.gcode dan dapat mengonfirmasi:
- Dengan JD , ada gangguan yang terlihat. Sumbu Y terputus-putus sekitar setengah jalan di sekitar busur untuk beberapa langkah pendek. Sumbu X terdengar sangat kasar tetapi tidak terasa terlalu buruk.
- Dengan CJ , kedua sumbu jauh lebih mulus, tidak ada gagap keras pada Y dan X terdengar normal & halus.
XDA-Bam
pada 14 Apr 2020
Melihat ke arah yang benar! Bisakah Anda mencoba mengkompilasi dengan JD dan mengaturnya ke nol? Saya ingin tahu apakah masih menghasilkan gagap. [HAPUS INI]
CarlosGS
pada 15 Apr 2020
Saya tidak terlalu paham dengan kodenya, tetapi baris ini mungkin masalahnya. Tampaknya mengurangi kecepatan untuk segmen kecil:
https://github.com/MarlinFirmware/Marlin/blob/fc11e7217460056473f91dfb7dd574884319f567/Marlin/src/module/planner.cpp#L2354
Dalam contoh arc gcode, segmen reguler adalah ~ 0.6mm dan yang kecil ~ 0.1mm, yang akan diterjemahkan dengan tiba-tiba menyetel ulang variabel limit_sqr ke 17% dari nilai normalnya selama arc.
CarlosGS
pada 15 Apr 2020
@CarlosGS Saya telah membandingkan kode JD dengan implementasi GRBL.
GRBL tidak memiliki keseluruhan bagian ini "if (block-> milimeter <1) {", dan tidak mencoba membatasi kecepatan untuk segmen kecil. Saya tidak yakin apa tujuan dari perlakuan khusus pada segmen kecil. Saya akan mencoba menemukan komit yang memperkenalkan perlakuan khusus pada segmen kecil ini.
Matematika JD lainnya hampir identik.
BarsMonster
pada 15 Apr 2020
Jadi ini adalah komit yang memperkenalkan kode untuk menangani segmen cetakan kecil dengan JD: https://github.com/MarlinFirmware/Marlin/commit/a11eb50a3eab6d58d595a67e526fb51190018db3#diff -e4800bd68f101b55ac4ff95513184458
Komentarnya adalah "Enkapsulasi yang lebih baik dan sangat mengurangi gangguan stepper"
Itu ditulis oleh @ejtagle dan dilakukan oleh @thinkyhead
Mungkin mereka tahu lebih banyak.
Di sisi saya - Saya mencoba untuk (tidak tepat) mengganti perkiraan matematika dengan panggilan FPU perangkat keras ke acos () - yang membuat seluruh pencetakan jauh lebih lambat (yaitu kondisi selalu diambil). Jadi mungkin bagian ini tidak memicu semua segmen kecil melainkan hanya untuk beberapa segmen saja, yang mungkin menjadi penyebab kebisingan di permukaan ini.
BarsMonster
pada 15 Apr 2020
Oke, kita menuju ke suatu tempat.
Jadi di planner.cpp dengan (tentunya ini hanya bisa dilakukan sebagai tes pada platform dengan HW FPU)
const float junction_theta = acos(junction_cos_theta);
dari pada
const float junction_theta = (RADIANS(-40) * sq(junction_cos_theta) - RADIANS(50)) * junction_cos_theta + RADIANS(90) - 0.18f;
kebisingan di permukaan hilang. Jika saya benar memahami maksud kode, kita dapat membandingkan junction_cos_theta dengan -0.7071 (cos dari RADIANS (135)), karena kami tidak terlalu tertarik dengan nilai sebenarnya dari acos.
Kebisingan juga hilang jika saya menghapus seluruh bagian dengan "if (block-> milimeter <1) {". Jadi kita perlu mencari tahu apa maksud asli dari blok kode ini agar tidak merusak yang lain.

BarsMonster
pada 15 Apr 2020
Bagi saya operasi acos mungkin terlalu mahal pada perangkat keras lain, dan dengan demikian diperkirakan oleh baris saat ini, yang mungkin (harus memeriksa ini) mengevaluasi ke deviasi yang lebih tinggi untuk segmen yang lebih kecil dalam kurva.
https://github.com/MarlinFirmware/Marlin/issues/10341#issuecomment -388191754
* hoffbaked: on May 10 2018 tuned and improved the GRBL algorithm for Marlin:
Okay! It seems to be working good. I somewhat arbitrarily cut it off at 1mm
on then on anything with less sides than an octagon. With this, and the
reverse pass actually recalculating things, a corner acceleration value
of 1000 junction deviation of .05 are pretty reasonable. If the cycles
can be spared, a better acos could be used. For all I know, it may be
already calculated in a different place. */
Bagus!!!
Bagi siapa pun yang penasaran, ini adalah perbedaan antara acos dan aproksimasi:

Anda memutuskan baris mana yang acos () dan yang mana perkiraannya;)
Saya pikir -0.18 seharusnya tidak ada di sana ... jika tidak maka akan terlihat oke: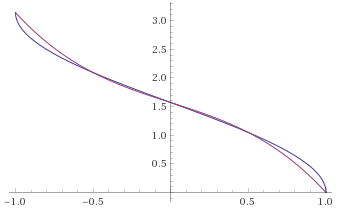
Namun memang seperti yang ditunjukkan @BarsMonster, bagian ini dapat disederhanakan.
PS: Saya suka bagaimana ini perlahan berubah menjadi "_bagaimana ini berhasil! _" Bug: rofl:
CarlosGS
pada 15 Apr 2020
0.18f tampaknya merupakan koreksi bilah kesalahan pada perkiraan, atau setidaknya dimaksudkan seperti itu. Mungkin ada kesalahan yang dibuat di sini, melihat plot Anda dari kedua fungsi tersebut.
https://github.com/MarlinFirmware/Marlin/commit/a11eb50a3eab6d58d595a67e526fb51190018db3#diff -e4800bd68f101b55ac4ff95513184458R2139
// Fast acos approximation, minus the error bar to be safe
float junction_theta = (RADIANS(-40) * sq(junction_cos_theta) - RADIANS(50)) * junction_cos_theta + RADIANS(90) - 0.18;
Saya juga melihat ini di planner.cpp
// TODO: Technically, the acceleration used in calculation needs to be limited by the minimum of the
// two junctions. However, this shouldn't be a significant problem except in extreme circumstances.
@ejtagle ?
swilkens
pada 15 Apr 2020
Fungsinya adalah perkiraan yang sempurna ... di wilayah ini :)
: rofl:
EDIT: Tampaknya ini sebenarnya perilaku yang diinginkan! : exploding_head:
CarlosGS
pada 15 Apr 2020
Grafik sangat ... grafis.
Tapi saya yakin perbedaan antara grafik tidak bisa menjelaskan hasilnya.
Sejauh yang saya pahami - Tujuannya adalah memiliki gerakan yang lebih lambat untuk perubahan arah yang besar, sekitar 45 °. Jika bukan 45, melainkan 35 atau 55 - itu mungkin toleransi yang dapat diterima.
Tetapi di bagian pengujian saya - perbedaan sudut antara segmen yang berurutan hanya beberapa derajat, seharusnya tidak pernah setinggi untuk memicu kondisi ini bahkan dengan perkiraan yang tidak sempurna. Harus ada hal lain yang terjadi dengan segmen kecil. Mungkin kita kehilangan resolusi pada langkah-langkah sebelumnya karena segmen yang sangat pendek.
Juga, saya tidak yakin mengapa segmen pendek harus mendapat perlakuan khusus. Belokan tajam sama kerasnya untuk segmen panjang dan pendek.
BarsMonster
pada 15 Apr 2020
Saya sedang memikirkan pengujian di mana Anda mengganti perkiraan secara langsung dengan acos () dan hal-hal yang diperbaiki.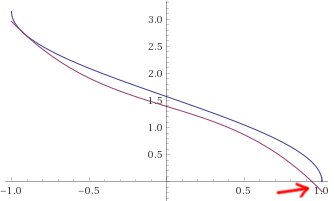
Masalahnya bukan hanya toleransi tetapi offset umum yang tidak mengulang sudut dengan benar.
Bisakah Anda menguji lagi menghapus 0.18f dan membiarkan sisanya seperti itu?
CarlosGS
pada 15 Apr 2020
Masalah dari pendekatan acos () - adalah, bahwa kesalahannya terbesar di wilayah yang diinginkan (> 135 °). Jika Anda menjatuhkan -0.18f , kesalahan theta menjadi sekitar + 10,2 °. Artinya, untuk 2,75 RAD atau theta =157,6° , perkiraan yang tidak dikoreksi akan memberi Anda theta =167.8° . Ini, dalam istilah, mengurangi (RADIANS(180) - junction_theta) di baris ini dan dengan demikian menyebabkan peningkatan kecepatan yang tidak diinginkan. Peningkatan kecepatan inilah yang dihindari oleh faktor koreksi.
Koreksi -0.18f juga berarti, bahwa batas koreksi kami bukanlah 135 ° dalam kondisi jika , tetapi sebenarnya 129,2 °. Saya tidak berpikir bahwa ini adalah masalah.
Keuntungan dari perkiraan dan koreksi saat ini adalah, bahwa (RADIANS(180) - junction_theta) tidak akan pernah lebih kecil dari 0,18. Saat kami membagi dengan istilah ini, ini memastikan hasil kami tidak pernah "meledak".
Yang sedang berkata, saya tidak melihat ada masalah dengan acos-aproksimasi selain itu tidak terlalu tepat. Akos-perkiraan yang lebih baik akan menyenangkan dan menghindari -0.18f -faktor yang kikuk ini, tetapi saya tidak melihat bagaimana hal ini akan menyebabkan gagap.
XDA-Bam
pada 15 Apr 2020
Saya telah melihat JD_single_arc_test.gcode dan menghitung panjang segmen. Panjang segmen MEAN adalah 0,60 mm, MAX adalah 0,73 dan MIN adalah 0,09. Berikut adalah plotnya:
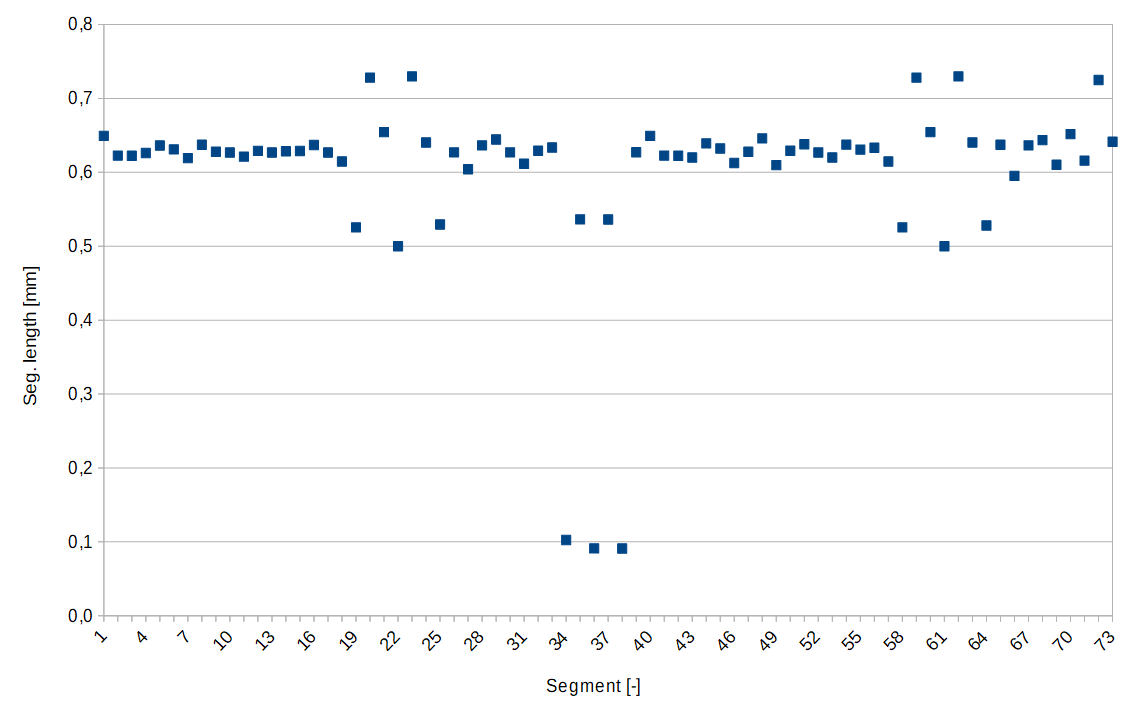
Anda dapat dengan jelas melihat tiga segmen kecil busur tengah, yang juga secara kasar dapat Anda rasakan gagap saat mencetak.
Saya kemudian melanjutkan untuk memperkirakan batas kecepatan persimpangan, yaitu SQRT(limit_sqr) (cmp. Limit_sqr ). Saya berasumsi, bahwa sudut kita mendekati 180 °, yang berarti (RADIANS(180) - junction_theta) kita kira-kira 0,18. Ini kasus terbaik untuk kecepatan, karena perbedaan (180-theta) tidak pernah lebih kecil dari ini. Apa pun di atas 175 ° akan mendekati identik. junction_acceleration ditentukan di planner.h menggunakan minimum semua akselerasi sumbu yang sedang bergerak. Karena Z dan E tidak bergerak dalam JD_single_arc_test.gcode , ini seharusnya - menurut pemahaman saya - memberikan minimum akselerasi X dan Y. Untuk printer saya, ukurannya 750 mm / s². Ini menghasilkan kecepatan berikut:
| Panjang segmen [mm] | Kecepatan [mm / s] |
| --- | --- |
| 0.73 | 55.1 |
| 0.60 | 50.1 |
| 0,09 | 19.5 |
Seperti yang Anda lihat, kami lebih dari separuh batas kecepatan kami untuk segmen kecil di busur. Lebih buruk lagi, batas kami melonjak naik turun beberapa kali secara berurutan. Ada gagap sialan kita!
XDA-Bam
pada 15 Apr 2020
Bagus!!! apakah itu hasil penskalaan dengan blok-> milimeter? https://github.com/MarlinFirmware/Marlin/issues/17342#issuecomment -613716956
Saya benar-benar bertanya-tanya mengapa @BarsMonster dapat menyelesaikan gagap dengan mengganti perkiraan secara langsung fungsi acos (): berpikir:
CarlosGS
pada 15 Apr 2020
Bagus!!! apakah itu hasil penskalaan dengan blok-> milimeter? # 17342 (komentar)
Saya benar-benar bertanya-tanya mengapa @BarsMonster dapat mengatasi gagap dengan mengganti perkiraan secara langsung fungsi acos () 🤔
Baik, keduanya: Menggunakan true acos() berarti junction_theta bisa menjadi lebih besar dari 2,96, dengan demikian (RADIANS(180) - junction_theta) bisa menjadi lebih kecil dari 0,18 dan kecepatan "meledak", mengurangi masalah sudut pandang mendekati 180 °. Ini adalah perlombaan 1 / (perbedaan sudut) vs. panjang balok. Namun, untuk sudut yang mendekati 135 °, panjang balok masih akan menjadi masalah dari pemahaman saya.
Mungkin kita harus mencari pendekatan acos () - yang lebih baik DAN berpikir untuk menangani masalah dengan segmen bergantian dengan panjang yang sangat berbeda.
XDA-Bam
pada 15 Apr 2020
Ah!! Terima kasih banyak telah merinci penyebab pastinya, tidak heran ini membuat kami gila: exploding_head:
CarlosGS
pada 15 Apr 2020
Mencari implementasi yang lebih baik mungkin membutuhkan waktu beberapa saat - banyak perkiraan trigonometri.
Sebagai solusi perantara; Kita mungkin mengubah MIN_STEPS_PER_SEGMENT menjadi fungsi dari STEPS_PER_MM dan batas bawah pada panjang segmen yang kita putuskan di sini. Mungkin ini berarti meningkatkan nilai standar MIN_STEPS_PER_SEGMENT untuk sebagian besar pengguna. Ini seharusnya hanya diterapkan saat menggunakan JUNCTION_DEVIATION jelas.
Pro : Kurangi gagap saat menggunakan JD, balut masalah hingga kami menemukan perbaikan yang baik.
Kontra : Kehilangan beberapa akurasi model
Atau kita kembali ke CLASSIC_JERK untuk default sementara kita mengevaluasi ini lebih lanjut.
swilkens
pada 15 Apr 2020
Pembaruan cepat: Dan saya juga menemukan alasan di balik penanganan segmen kecil . Lihat komentar ini .
Singkatnya: Jika Anda membagi kurva "nyata" menjadi segmen diskrit, sudut antara setiap segmen akan ditentukan oleh jumlah segmen. Karena JD biasanya hanya menentukan batas kecepatan persimpangan berdasarkan sudut ini, JD akan bergerak lebih cepat di sekitar kurva yang identik, jika memiliki lebih banyak segmen. Pada akhirnya, itu tidak akan melambat sama sekali untuk kurva dengan jumlah segmen yang tak terbatas. Itu tidak masuk akal, tentu saja. Oleh karena itu, diskriminasi if (block->millimeters < 1) telah diterapkan sejauh yang saya mengerti.
Saya pikir solusi if < 1 ini adalah peretasan yang baik untuk sebagian besar situasi, tetapi jelas, kami menemukan beberapa masalah dengannya. Berpikir tentang pendekatan yang berbeda.
XDA-Bam
pada 15 Apr 2020
@swilkens : MIN_STEPS_PER_SEGMENT harus 1 untuk mendapatkan cetakan detail halus yang benar. Defaul 6 saat ini sudah menghasilkan masalah; meningkatkannya bukanlah perbaikan yang cocok.
Seharusnya mungkin untuk memperbaiki fungsionalitas MIN_STEPS_PER_SEGMENT agar tidak rusak. Daripada menggabungkan segmen berdasarkan sejumlah kecil langkah-langkah terkuantisasi, itu harus menggabungkan mereka berdasarkan kecilnya relatif terhadap ukuran langkah (mikro) dan perubahan sudut absolut yang sangat rendah antara segmen sebelum kuantisasi (kedua kondisi terpenuhi), di mana Kasus segmen kecil hampir pasti hanyalah artefak dari diskritisasi kurva dan tidak mungkin fitur skala mikro.
richfelker
pada 15 Apr 2020
Bisakah Anda menguji lagi menghapus 0.18f dan membiarkan sisanya seperti itu?
_Saya melakukan itu dan tidak mendapat suara._ Tapi saya juga melihat beberapa gagap yang terlihat selama pencetakan penuh pada lapisan pertama. Saya mencoba untuk menyelidiki apa itu dan apakah itu relevan dengan perubahan ini.
Masalahnya di sini adalah jika kita membuat kesalahan negatif palsu dalam perbandingan acos ini atau menghitung kecepatan terlalu tinggi - juga tidak akan ada suara. Jadi itu tidak berarti bahwa itu memperbaiki masalah. Ini berarti tidak ada gagap di belokan, tetapi mungkin berarti kecepatan yang lebih cepat dari yang diinginkan.
Pada perkiraan acos - meskipun dimungkinkan untuk membandingkan junction_cos_theta ke -0.7071 untuk menghindari kesalahan apa pun di sini, tetapi itu hanya akan membuat perbandingan lebih tepat, kecepatan sebenarnya masih akan dihitung dengan kesalahan.
Ini juga bisa menjelaskan masalah yang saya alami dengan LA, JD dan kontrol akselerasi # 15473 - kontrol akselerasi di Cura memecah gerakan cetak menjadi segmen kecil dengan percepatan berbeda, bahkan jika itu adalah garis lurus.
BarsMonster
pada 15 Apr 2020
Sepertinya terlepas dari apakah pendekatannya baik atau tidak, seharusnya tidak ada perilaku terputus-putus seperti hard cutoff di sini. Jika pembatasan diterapkan dengan fungsi jendela kontinu daripada aktif / nonaktif diskrit, gagap semacam ini seharusnya tidak mungkin dilakukan.
richfelker
pada 15 Apr 2020
Pemotong @richfelker biasanya memecah gerakan menjadi segmen berdasarkan logika ini - berdasarkan penyimpangan dan panjang. akan sulit untuk memikirkan kembali kuantisasi di belakang alat pengiris dan menghindari artefak apa pun.
BarsMonster
pada 15 Apr 2020
@ BarMonster : Saya sadar dan tahu cara mengkonfigurasi pemotong agar tidak mengacaukannya. Slicer tidak melakukan kuantisasi langkah, hanya penggabungan segmennya sendiri berdasarkan deviasi maksimum yang diizinkan dan batas panjang segmen gabungan, sehingga nilai floating point asli masih tersedia dengan cukup presisi untuk membedakan antara sudut 90 derajat dengan lebar 1 microstep dan perkiraan presisi yang berlebihan dari sebuah kurva.
richfelker
pada 15 Apr 2020
Saya mencoba untuk mencari tahu perkiraan acos. Terlihat sangat dekat, tetapi menggunakan sqrt, apakah layak?
 daleckystepan
pada 15 Apr 2020
daleckystepan
pada 15 Apr 2020
Saya mencoba untuk mencari tahu perkiraan acos. Terlihat sangat dekat, tetapi menggunakan sqrt, apakah layak?
Ada dua yang mendekati menggunakan sqrt() :
acos = sqrt(2-2*costheta)*pi/sqrt(8) dengan kemungkinan hanya precalc pi/sqrt(8)=1.11072073
Faktor koreksi pi/sqrt(8)=pi/2/sqrt(2) memastikan bahwa kita mencapai nilai yang sama pada pi / 2, dimana tanda flip terjadi. Kalau tidak, itu identik dengan solusi Anda, saya pikir. Sign flip harus ditangani, karena ini hanya bagus untuk [0, 1]. Kesalahan maksimum + -0.066 rad ( Plot kesalahan ).
Lalu ada kebalikan dari pendekatan Bhaskara :
pi*sqrt((1-costheta)/(4+costheta))
Sama halnya dengan rentang valid [0, 1] dan tanda flip. Kesalahan maksimum adalah + -0.023 rad ( Plot kesalahan ). Yang ini akan menjadi favorit saya, jika satu sqrt() dan satu pembagian dapat diterima.
EDIT: ganti nama theta menjadi costheta
XDA-Bam
pada 15 Apr 2020
@ XDA-Bam Akar dan pembagian kuadrat adalah 14 jam masing-masing di M4F. Perkalian adalah 1. Jadi relatif lambat. Pada CPU 32-bit tanpa FPU, kita dapat mengharapkan clock 10 kali lebih banyak. Pada kecepatan pencetakan 100mm / s dan segmen 0.05mm yang berarti 560000 jam per detik pada perkiraan matematika yang diperbarui, yang bisa jadi sekitar 1% dari STM32 kelas bawah. Tapi AVR akan menderita.
Tetapi jika kita membandingkan dengan -0.7071 dan menghitung acos hanya saat kondisi diambil - ini akan menghemat penggunaan CPU secara rata-rata, karena sudut dianggap jarang memicu.
BarsMonster
pada 15 Apr 2020
Sekadar ide: jika kita menggunakannya hanya di sudut, di mana kecepatan cetak lebih rendah, itu bisa berfungsi.
daleckystepan
pada 15 Apr 2020
@ XDA-Bam Saya percaya jika kita menggunakan tabel pencarian dengan beberapa rentang 4-8, kita dapat lolos hanya dengan perkalian cepat dan presisi yang relatif tinggi. Saya yakin kami memiliki lebih banyak memori flash daripada siklus CPU gratis. Satu catatan lagi: mungkin kita tidak membutuhkan presisi tinggi di semua tempat, melainkan mendekati -1? Pembaruan2: Kami hanya perlu mencakup rentang -1 ..- 0,7071 dengan perkiraan, yang secara signifikan dapat menyederhanakan tugas.
BarsMonster
pada 15 Apr 2020
@BarsMonster OK, saya tidak terbiasa dengan pemrograman C ++ dan tentunya tidak pada AVR. Jika Anda memiliki beberapa kode yang bagus untuk tabel pencarian, mungkin memasukkannya ke sini? 😄
XDA-Bam
pada 15 Apr 2020
@ XDA-Bam: Memanggil variabel independen theta benar-benar menyesatkan / membingungkan ...
richfelker
pada 15 Apr 2020
Saya telah melihat lebih dalam pada JD_single_arc_test.gcode . Saya telah menghitung jari-jari yang setara dan menghasilkan kecepatan persimpangan untuk a = 750 mm / s². Untuk wilayah kritis dengan gagap, hasilnya adalah sebagai berikut (EDIT: kecepatan sekitar dua kali lebih tinggi dari di Marlin, karena spreadsheet saya menggunakan tepat arccos() ):
Seg. panjang | Junc. sudut (ke _prev._) | Equiv. radius | Persimpangan V_max
- | - | - | -
0.6291 | 177.47 | 14.2 | 103.278
0.6335 | 177.53 | 14.7 | 105.066
0.1025 | 176,79 | 1,8 ⏬ | 37.050
0,5363 | 179.28 | 42,8 ⏫ | 179.243
0.0911 | 176,83 | 1,6 ⏬ | 35.142
0,5362 | 179.30 | 43,6 ⏫ | 180.831
0,0910 | 176,78 | 1,6 ⏬ | 34.852
0,6271 | 179,53 | 77,0 ⏫ | 240.261
Jari-jari sebenarnya adalah 14,375 mm, jadi sebagian besar perkiraan mendekati. Namun, yang aneh adalah bahwa pada segmen yang sangat pendek, _both_ panjang segmen _dan_ sudut persimpangan turun. Sudut persimpangan berikut kemudian lebih panjang. Perbedaan + -1,5 ° ini sangat penting di sini. Sudut dalam spreadsheet saya dihitung mundur, seperti pada kode .
Jika saya sekarang beralih ke maju menghitung sudut persimpangan, sudut persimpangan yang sedikit meningkat selalu sejalan dengan segmen pendek:
Seg. panjang | Junc. sudut (ke _next_) | Equiv. radius | Persimpangan V_max
- | - | - | -
0.6291 | 177.53 | 14.6 | 104.706
0.6335 | 176,79 | 11,3 🔽 | 92.112
0.1025 | 179.28 | 8.2 🔽 | 78.360
0,5363 | 176,83 | 9,7 🔽 | 85.244
0.0911 | 179.30 | 7,4 🔽 | 74.551
0,5362 | 176,78 | 9,5 🔽 | 84.598
0,0910 | 179,53 | 11.2 🔽 | 91.526
0,6271 | 177.23 | 13.0 | 98.579
Dan apakah Anda akan melihat itu: Penurunan kecepatan dan radius hampir habis! Dan mereka semua dalam satu arah sekarang, tidak ada lagi pasang surut yang keras. Masih ada penurunan kecepatan maksimum sekitar 25%, tetapi tidak lagi + 71 / -66%, seperti sebelumnya.
Oleh karena itu, pertanyaannya, bagi siapa pun yang mengetahui kodenya dengan baik: Mengapa kita menghitung sudut persimpangan ke belakang dan bukan ke depan?
EDIT: Salah ketik penting di header tabel kedua diperbaiki.
XDA-Bam
pada 15 Apr 2020
@ XDA-Bam: Memanggil variabel independen
thetabenar-benar menyesatkan / membingungkan ...
Benar. Berubah.
XDA-Bam
pada 15 Apr 2020
Saya telah menemukan polinomial MinMax di sini , yang mencapai kesalahan maksimum + -0.033 rad ( plot kesalahan ) hanya dengan menggunakan perkalian.
acos(x) = π * 0.5f
- (0.032843707f
+ x * (-1.451838349f
+ x * (29.66153956f
+ x * (-131.1123477f
+ x * (262.8130562f
+ x * (-242.7199627f
+ x * (84.31466202f
)))))))
Sekali lagi dengan kisaran yang valid [0, 1] dan membutuhkan penanganan flip tanda.
@BarsMonster Apakah ini lebih cepat dari sqrt + divide?
XDA-Bam
pada 15 Apr 2020
Saya belum melihat jauh ke dalam kode JD sejak perombakan terakhir, tetapi saya sepertinya ingat sesuatu tentang tikungan sempit dengan segmen yang sangat kecil, yang sebenarnya merupakan belokan sangat cepat, tetapi yang brengsek klasik atau JD hanya akan melihat sedikit belokan dan jadi tidak akan melambat dengan benar. Saya mungkin salah mengingat, atau itu mungkin telah dibahas dan diabaikan.
Bagaimanapun, saya senang melihat perkiraan acos lebih baik sedang dieksplorasi sebagai solusi. Apa pun yang lebih cepat dari SQRT bisa diterima. Kode perencana semuanya dijalankan dalam konteks pengguna jadi jika matematika dilakukan sebagai double pada ARM yang memiliki akselerasi FP, kecepatannya harus sangat cepat.
thinkyhead
pada 16 Apr 2020
@ Thinkyhead Ya, masalah dari kode JD utama adalah, bahwa sudut persimpangan menyusut, jika jumlah segmen pada suatu kurva meningkat. Lihat komentar ini tentang masalah asli dan mitigasi yang dihasilkan.
Namun, mengganti perkiraan acos() ini hanya akan _mengurangi masalah gagap untuk sudut di atas 169.69 ° (itu pi-0.18f rad). Ini akan menjadi langkah pertama yang bagus. Tetapi seperti yang dijelaskan dalam komentar saya sudut persimpangan saat ini dihitung: Kami menghitungnya "mundur" ke elemen terakhir, yang tampaknya memperkenalkan osilasi yang kuat di limit_sqr . Inilah, menurut saya, penyebab utama gagap. Jika kita beralih untuk menghitung sudut persimpangan ke depan, ini sepertinya menyelesaikan masalah. Apa pendapat Anda tentang perubahan seperti itu?
XDA-Bam
pada 16 Apr 2020
Maaf saya tidak mengerti Apa maju? Apa itu terbelakang?
Kecepatan persimpangan yang ingin kita hitung bergantung pada sudut antara segmen a (datang dari) dan segmen b (menuju). Itu tidak tergantung pada apakah kita mengambil sudut antara (a dan b) atau antara (b dan a).
Jika ada segmen lain yang terlibat - itu adalah kesalahan.
sudut persimpangan yang sedikit meningkat selalu sejalan dengan segmen pendek:
Itu tidak mungkin. Sudutnya selalu di antara dua segmen. Hanya dalam spreadsheet, nilai dapat muncul di satu atau di baris lain.
Semua kode perencana dijalankan dalam konteks pengguna jadi jika matematika dilakukan sebagai ganda pada ARM yang memiliki akselerasi FP, kecepatannya harus sangat cepat.
F3 (dan DUE) tidak memiliki Floating Point Unit (FPU) - hanya F4 yang memilikinya, dan itu hanya dapat menangani _floats_ secara langsung, bukan _doubles_. Namun - pada ARM, kodenya, bagaimanapun tampilannya, kemungkinan akan cukup cepat. Tidak demikian halnya di AVR. (Untuk alasan yang baik, kita harus selalu menggunakan 1. Notasi- F agar tidak secara tidak sengaja menggunakan konstanta ganda. Kecuali kita benar-benar ingin ganda untuk ketepatannya. Biasanya kita tidak membutuhkannya. (F4 biasanya dikompilasi dengan opsi kompilator seperti USE_FLOAT_CONSTANTS - tetapi untuk F3 itu penting. AVR selalu menghitung hanya dalam float. Saya tidak tahu bagaimana ESP mungkin menangani ini.))
Sejauh yang saya ingat acos() diimplementasikan sebagai tabel pencarian dengan interpolasi untuk yang paling prosesor floating point perpustakaan bahkan untuk itu dengan FPUs - setidaknya itu bukan instruksi hardware. Tolok ukur terhadap pustaka adalah wajib untuk pendekatan apa pun yang lebih cepat (untuk semua platform yang relevan dan arsitektur prosesor (AVR, ARM32 dengan dan tanpa FPU))
 AnHardt
pada 16 Apr 2020
AnHardt
pada 16 Apr 2020
Maaf saya tidak mengerti Apa maju? Apa itu terbelakang?
Maaf, itu mungkin tidak jelas.
- Mundur: Menghitung sudut persimpangan sebagai sudut ke segmen sebelumnya.
- Maju: Menghitung sudut persimpangan sebagai sudut ke segmen berikut.
Kecepatan persimpangan yang ingin kita hitung bergantung pada sudut antara segmen a (datang dari) dan segmen b (menuju). Itu tidak tergantung pada apakah kita mengambil sudut antara (a dan b) atau antara (b dan a).
Jika ada segmen lain yang terlibat - itu adalah kesalahan.
Menurut saya, perencana Marlin selalu beroperasi segmen demi segmen. Per segmen, hanya ada satu sudut persimpangan yang dihitung. Oleh karena itu, saya akan menganggap setiap sudut kurang lebih "melekat" pada segmen tertentu. Seperti sekarang, sejauh yang saya pahami kodenya, sudut persimpangan didefinisikan sebagai sudut antara segmen yang sedang direncanakan dan segmen sebelumnya. Saya harap ini menjelaskan alur pemikiran saya.
Hanya karena penasaran, saya telah menguji apa yang terjadi jika kita mendefinisikan sudut persimpangan sebagai sudut dari segmen saat ini ke segmen berikutnya. Itulah yang ditunjukkan tabel kedua saya. Ini pasti menghilangkan gagap. Saya tidak yakin, apakah perubahan dalam definisi sudut persimpangan masuk akal dalam konteks kode Marlin. Itu sebabnya saya bertanya.
sudut persimpangan yang sedikit meningkat selalu sejalan dengan segmen pendek:
Itu tidak mungkin. Sudutnya selalu di antara dua segmen. Hanya dalam spreadsheet, nilai dapat muncul di satu atau di baris lain.
Rambut ini agak membelah sekarang. Tapi ya. Meskipun demikian, setiap segmen memiliki tepat satu sudut persimpangan yang sesuai di Marlin: Satu ke segmen sebelumnya. Itulah yang saya maksud dengan "sejalan dengan segmen pendek". Dalam kode saat ini, sudut persimpangan yang sedikit lebih kecil dihitung saat kode melihat segmen pendek yang tidak biasa. Ini memperkuat masalah gagap.
Semua kode perencana dijalankan dalam konteks pengguna jadi jika matematika dilakukan sebagai ganda pada ARM yang memiliki akselerasi FP, kecepatannya harus sangat cepat.
F3 (dan DUE) tidak memiliki Floating Point Unit (FPU) - hanya F4 yang memilikinya, dan itu hanya dapat menangani _floats_ secara langsung, bukan _doubles_. Namun - pada ARM, kodenya, bagaimanapun tampilannya, kemungkinan akan cukup cepat. Tidak demikian halnya di AVR. (Untuk alasan yang baik, kita harus selalu menggunakan 1. Notasi- F agar tidak secara tidak sengaja menggunakan konstanta ganda. Kecuali kita benar-benar ingin ganda untuk ketepatannya. Biasanya kita tidak membutuhkannya. (F4 biasanya dikompilasi dengan opsi kompilator seperti USE_FLOAT_CONSTANTS - tetapi untuk F3 itu penting. AVR selalu menghitung hanya dalam float. Saya tidak tahu bagaimana ESP mungkin menangani ini.))
Sejauh yang saya ingat
acos()diimplementasikan sebagai tabel pencarian dengan interpolasi untuk yang paling prosesor floating point perpustakaan bahkan untuk itu dengan FPUs - setidaknya itu bukan instruksi hardware. Tolok ukur terhadap pustaka adalah wajib untuk pendekatan apa pun yang lebih cepat (untuk semua platform yang relevan dan arsitektur prosesor (AVR, ARM32 dengan dan tanpa FPU))
Saya mengharapkan implementasi perpustakaan default menjadi cepat. Meskipun demikian, konsensus dalam utas ini hingga saat ini tampaknya, bahwa / library asli acos() mungkin terlalu lambat untuk digunakan untuk JD pada beberapa arsitektur. Saya tidak tahu seberapa cepat atau lambat itu sebenarnya dan saya tidak punya cara untuk mengujinya sendiri. Saya berharap seseorang dapat memberikan beberapa angka pasti, atau melakukan tes cepat.
Saya telah membuat PR dengan polinomial MinMax yang disebutkan sebelumnya. Ini berjalan dengan baik di ATMega1284 saya, sejauh yang saya coba. Jika pustaka default acos() bahkan lebih cepat: Sempurna. Ayo gunakan itu. Jika tidak, MinMax akan melakukannya, saya pikir. Harus mudah diuji menggunakan PR itu. Bagaimanapun, saya yakin bahwa kita membutuhkan peningkatan presisi mendekati cos(180°) untuk mengurangi gagap.
XDA-Bam
pada 16 Apr 2020
Saya mengharapkan implementasi perpustakaan default menjadi cepat.
Ini adalah harapan yang salah. Perpustakaan matematika standar ada untuk memberikan hasil yang benar, bukan perkiraan cepat. Ada banyak cara berbeda untuk melakukan aproksimasi cepat, kebanyakan sederhana, dan semuanya disesuaikan dengan penggunaan tertentu, jadi tidak masuk akal bagi mereka untuk menjadi bagian dari pustaka standar; Anda cukup menuliskan hal yang masuk akal untuk apa yang perlu Anda lakukan. Tugas berat yang tidak dapat diharapkan oleh pemrogram per program adalah membuat versi yang akurat di seluruh domain.
richfelker
pada 16 Apr 2020
Rencana Marlin selalu tepat satu planer-buffer-line, the new line, the last line. Segmen ini selalu berhenti pada kecepatan nol. Tidak ada pengetahuan tentang langkah apa yang akan terjadi selanjutnya atau apakah akan ada langkah selanjutnya. Jadi satu-satunya persimpangan yang bisa dihitung adalah satu ke ruas garis sebelumnya. Jadi kecepatan persimpangan adalah kecepatan masuk tertinggi yang diizinkan untuk segmen yang saat ini direncanakan.
Pada tahap kedua dari proses planing maju / mundur / recalculate-path (pengoptimal) kami mencoba menaikkan kecepatan keluar dari segmen sebelumnya (yang masih nol) ke kecepatan masuk segmen baru, jika memungkinkan (segmen terakhir harus bisa melambat ke nol).
Planer menghitung maks. kecepatan target, maks. de / akselerasi und max. kecepatan masuk untuk setiap segmen tergantung pada sumbu yang terlibat dan pengaturan ditambah jumlah langkah untuk setiap sumbu dan menentukan sumbu utama (dengan langkah terbanyak). Pengoptimal menentukan pada nomor langkah apa (dari sumbu utama) fase akselerasi berakhir dan fase perlambatan dimulai - mencoba mencapai kecepatan maksimum yang ditentukan oleh proses perencanaan. Itu meninjau kembali semua kecuali baris yang saat ini dilangkah dan sudah dimaksimalkan di buffer perencana.
AnHardt
pada 16 Apr 2020
Terima kasih telah menjelaskan hal ini secara detail, @AnHardt
Saya juga menyadari bahwa menghitung sudut persimpangan ke segmen berikut - meskipun tidak mungkin, dengan kode saat ini - juga hanya akan menutupi masalah gagap untuk file uji khusus kami JD_single_arc_test.gcode . Jika, di GCode lain, pemotong memutuskan untuk mendistribusikan sudut yang sedikit lebih kecil dari rata-rata secara berbeda ke segmen kecil, kita akan memiliki masalah yang sama lagi. Ini melekat pada diskritisasi dan tidak ada "kesalahan" dalam kode dalam pengertian itu.
Itu masih mengganggu saya, bahwa kami melihat gigi gergaji / gagap ini di limit_sqr . Apakah layak untuk mengganti block->millimeters di segmen kecil hack dengan _ rata-rata panjang dari blok saat ini dan sebelumnya_? Itu akan menjadi bulls geometris * , tetapi itu akan bertindak sebagai jalan rendah berbiaya rendah dan menghaluskan gagap. Apakah itu bisa diterima?
XDA-Bam
pada 16 Apr 2020
Berpikir tentang masalah kecepatan persimpangan secara naif…
Di satu sisi, ketika Anda memiliki alas-Y dan kereta-X yang masing-masing berada pada motor dan rel linier yang berbeda, torsi sebenarnya akan dipisahkan antara kedua sumbu. Jadi menyesuaikan kecepatan berdasarkan perubahan sudut tidak beralasan. Untuk alasan ini, pada mesin Mendel yang khas, pilihan yang lebih baik adalah Classic Jerk. (CAMB.)
Lagi pula, ketika Anda ingin mempertimbangkan perubahan sudut dalam situasi dengan segmen kecil, Anda perlu trik untuk dapat meneliti lebih dari segmen (selain memiliki buffer perencana besar) dan untuk dapat menentukan bahwa perubahan tumpul dalam sudut terjadi. Artinya, cara untuk "mengakumulasi perlambatan" di mana Anda membobotkan perubahan sudut dalam proporsi terbalik dengan jumlah waktu yang berlalu sejak perubahan sudut terakhir.
Salah satu cara untuk mendekati ini adalah dengan mempertahankan akumulator "perubahan sudut dari waktu ke waktu" yang dimulai dari nol, dan Anda dapat menganggapnya sebagai arah yang ditunjukkan ke arah pergerakan massa inersia. Dalam keadaan di mana tidak diperlukan perlambatan, nilai ini akan tetap mendekati nol - atau setidaknya di bawah ambang perlambatan.
Ketika ada perubahan sudut antar segmen, jumlah perubahan sudut (torsi off-axis) dibobotkan dengan panjang invers (durasi invers) segmen. Jika cukup banyak perubahan sudut terakumulasi maka sejumlah perlambatan diterapkan.
Sementara itu, seiring waktu Anda juga mengurangi jumlah tertentu dari akumulator ini, sehingga dibutuhkan banyak perubahan sudut selama periode waktu yang singkat sebelum melebihi ambang batasnya. Putaran sempurna 90 derajat yang ditempatkan pada sepuluh segmen yang sangat pendek mungkin merupakan kasus yang paling jelas di mana Anda perlu memperlambat hingga nol tetapi perencana saat ini mungkin melewatkannya sepenuhnya dan hanya memperlambat setengahnya….
Diperlukan beberapa eksperimen untuk melihat apakah pendekatan akumulator-plus-ambang dapat berfungsi.
thinkyhead
pada 19 Apr 2020
Pemikiran lain adalah, jika perkiraan asos awal tidak bagus, dan yang baru juga tidak bagus, mungkin rata-rata keduanya akan lebih buruk.
junction_theta = RADIANS(90)
+ ((t * (sq(t) * RADIANS(-40) - RADIANS(50)) - 0.18f) - (neg * asinx)) / 2;
… Mengoptimalkan operasi ekstra…
const float
neg = junction_cos_theta < 0 ? -1 : 1,
t = neg * junction_cos_theta,
asinx = (0.032843707f / 2)
+ t * (-(1.451838349f / 2)
+ t * ( (29.66153956f / 2)
+ t * (-(131.1123477f / 2)
+ t * ( (262.8130562f / 2)
+ t * (-(242.7199627f / 2) + t * (84.31466202f / 2) ) )))),
junction_theta = RADIANS(90) - (neg * asinx)
+ (t * (sq(t) * (RADIANS(-40) / 2) - (RADIANS(50) / 2)) - (0.18f / 2));
Dari patokan saya di # 17575, saya akan mengatakan.
1/3 + 2/3 = 3/3. Berarti - jika Anda tidak dapat mempercepat penghitungan rata-rata kedua perkiraan - gunakan fungsi fp-libraries acos () - itu, setidaknya, tepat.
AnHardt
pada 19 Apr 2020
acos() cukup bagus, tetapi tidak super cepat. Rata-rata dengan yang lama akan secara drastis mengurangi precison di wilayah kritis mendekati 180 °, di mana perkiraan lama buruk. Ditambah lagi, ini lebih lambat seperti yang ditunjukkan @AnHardt . Jadi, rata-rata kedua korelasi ini memiliki banyak kelemahan. Ini mungkin bisa diterapkan dengan persamaan yang sama sekali berbeda, tetapi kita harus menemukannya terlebih dahulu. Saya suka ide @BarsMonster untuk hanya "membagi dan menaklukkan" beberapa rentang secara terpisah. Mungkin ini juga bisa menawarkan keuntungan dalam perhitungan waktu.
Karena itu, acos() sudah lebih baik, yang menghilangkan masalah untuk sebagian besar cetakan. Dan itu mungkin akan ditingkatkan lebih jauh. Masalah utama dengan segmen pendek dan sudut 'sial' masih ada. Saya suka ide pendekatan akumulator untuk perubahan sudut. Saya akan menjelajahinya lebih banyak.
XDA-Bam
pada 19 Apr 2020
Saya suka ide pendekatan akumulator untuk perubahan sudut. Saya akan menjelajahinya lebih banyak.
Ya saya juga. Saya hanya memiliki gambaran yang tidak jelas bagaimana cara kerjanya, tetapi perlu banyak penyetelan untuk menemukan keseimbangan yang tepat dari "pemanasan dan pendinginan" akumulator pada perubahan sudut tersebut.
ambil fungsi fp-libraries acos () asli - itu, setidaknya, tepat.
Kalau saja kita bisa menemukan "apa-apaan ini?" untuk acos seperti yang ada untuk sqrt inv cepat.
float Q_rsqrt(float number) {
long i;
float x2, y;
const float threehalfs = 1.5F;
x2 = number * 0.5F;
y = number;
i = * ( long * ) &y; // evil floating point bit level hacking
i = 0x5f3759df - ( i >> 1 ); // what the fuck?
y = * ( float * ) &i;
y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration
//y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration, this can be removed
return y;
}
Saya telah bermain-main sedikit dengan ide-ide berbeda mengenai akumulator dan telah mengumpulkan skrip tes kecil di MATLAB / Oktaf. Saya akan menyajikan beberapa hasil.
Kondisi saat ini
Pertama-tama mari kita lihat JD_single_arc_test.gcode kesayangan kita, yang merupakan dinding luar setengah lingkaran di bagian ini (titik awal ditandai dengan panah merah):
Pada kurva ini, profil kecepatan batas saat ini di Marlin akan terlihat seperti ini (skala LOG pada sumbu Y!):
Apa itu:
- Kurva merah adalah deviasi persimpangan "default"
v_max_junctiondan tidak pernah bisa dilampaui. - Kurva kuning adalah tambahan
limituntuk segmen <1 mm dengan sudut persimpangan di atas> 135 °. - Area abu-abu terang di latar belakang (yang tidak menutupi keseluruhan grafik!) Adalah area, di mana jalur kode
< 1 mm & >135°digunakan.
Perlu diingat, perencana dapat memilih kecepatan yang lebih rendah untuk segmen tersebut, misalnya karena percepatannya terlalu rendah untuk mencapai batas kecepatan yang diberikan dalam plot. Selain itu, print head / perencana mempercepat dan memperlambat, yang juga tidak diperlihatkan dalam plot. Plotnya hanya menunjukkan batas kecepatan.
Solusi yang memungkinkan
Idenya adalah, entah bagaimana menghindari penurunan tersebut pada tanda 20 mm. @thinkyhead menyarankan beberapa bentuk "akumulator", yang memperhitungkan tingkat perubahan junction_theta . Setelah banyak mengutak-atik, saya telah membangun delta_angle_indicator yang membusuk secara eksponensial, yang secara kasar memberi tahu kita, berapa banyak sudut persimpangan kita berubah per mm panjang perjalanan. Kode utama terlihat seperti ini:
[MATLAB pseudocode]
delta_angle_indicator = delta_angle_indicator * max(0, 1 - delta_angle_decay ...
* block_millimeters) + abs(delta_theta)) * inverse_millimeters;
Indikator dimulai pada 0 dan bertambah, jika sudut persimpangan berubah. Itu terus menyusut / membusuk, tergantung seberapa jauh kita bepergian. Istilah (1 - delta_angle_decay * block_millimeters) menghasilkan delta_angle_indicator agak tidak tergantung pada panjang blok, tanpa membutuhkan penggunaan kekuatan atau logaritma. Untuk memahami indikatornya, kita juga perlu mengetahui variabel-variabel berikut:
delta_theta = rad2deg(junction_theta - previous_junction_theta);
=> delta_theta [°] menjelaskan perubahan sudut persimpangan ke blok sebelumnya.
delta_angle_threshold = 2.5e-1;
=> delta_angle_threshold [° / mm] adalah "ambang batas tindakan sekarang" kami. Jika delta_angle_indicator> delta_angle_threshold, kita berada dalam semacam kurva dan mungkin harus mengurangi kecepatan.
delta_angle_decay = 1.0;
=> delta_angle_decay [1 / mm] menentukan pengurangan pecahan dari delta_angle_indicator per mm perjalanan. Nilai 1 berarti, indikator kita harus kembali ke nol setelah 1 mm jika tidak ada kurva lagi yang muncul.
Sekarang kita memiliki ukuran gradien sudut per mm, kita dapat memikirkan tentang bagaimana bereaksi terhadapnya. Saya telah mencoba berbagai cara untuk membuatnya berskala bagus antara limit_sqr dan vmax_junction_sqr dan gagasan lainnya. Tetapi pada akhirnya, peluruhan eksponensial membuatnya sangat sulit, karena indikator menjangkau beberapa lipatnya. Apa yang terbukti lebih bermanfaat adalah pendekatan berikut:
[MATLAB pseudocode]
if delta_angle_indicator > delta_angle_threshold
% The angle is changing fast and we should update limit_sqr to make sure our limit is low enough.
limit_sqr = block_millimeters ./ (deg2rad(180) - junction_theta) .* junction_acceleration;
else
% Not much going on with the angle. We can keep going fast.
limit_sqr = max( block_millimeters ./ (deg2rad(180) - junction_theta(i)) .* junction_acceleration, ...
previous_limit_sqr );
end
Pada dasarnya, limit_sqr berlaku seperti sebelumnya jika sudut persimpangan berubah terlalu cepat. Jika itu berubah perlahan atau tidak sama sekali, kita hanya "meluncur" dan menjaga kecepatan tetap konstan. Dan itu saja. Grafik kecepatan yang dihasilkan terlihat seperti ini (penskalaan LOG lagi):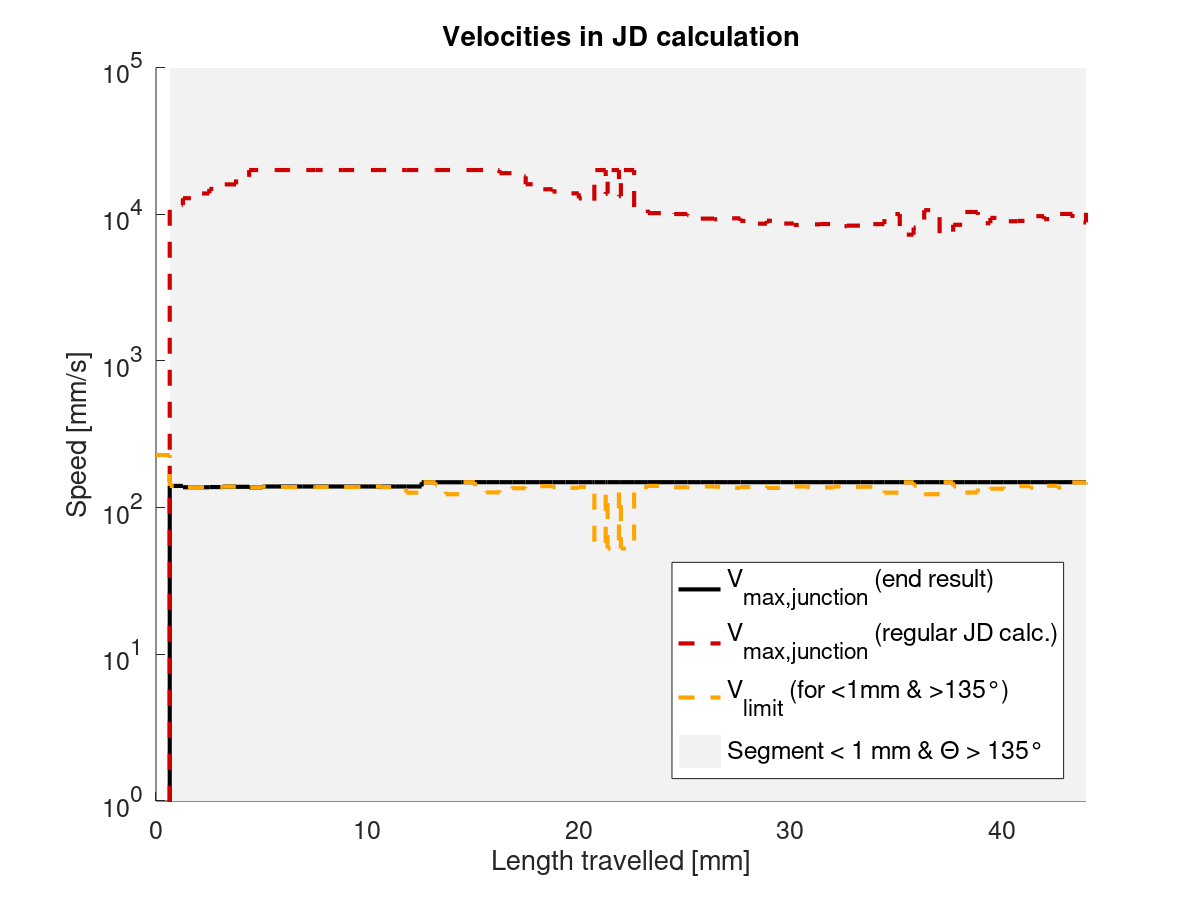
Anda dapat melihat bahwa - dengan nilai untuk delta_angle_threshold dan delta_angle_decay dipilih di sini - kami cukup menjaga kecepatan tetap konstan, kecuali untuk tonjolan kecil setelah sekitar 12 mm atau lebih.
Kesimpulan
Ini adalah kondisi perkembangan saat ini. Belum ada kode C ++, dan ini tidak dapat dijalankan di printer mana pun. Juga, delta_angle_threshold dan delta_angle_decay mungkin sulit untuk disetel dalam praktiknya. Tapi saya meletakkan ini untuk diskusi di sini. Komentar diterima.
CATATAN: Saya akan segera menulis posting kedua dengan grafik untuk file contoh yang berbeda.
XDA-Bam
pada 22 Apr 2020
Oke, inilah GCode kedua yang saya uji. Bagiannya terlihat seperti ini (sekali lagi, titik awal dan arah cetak ditandai dengan panah merah):
Kondisi saat ini
Profil batas kecepatan dengan Marlin hulu untuk satu dinding luar di bagian ini akan terlihat seperti ini: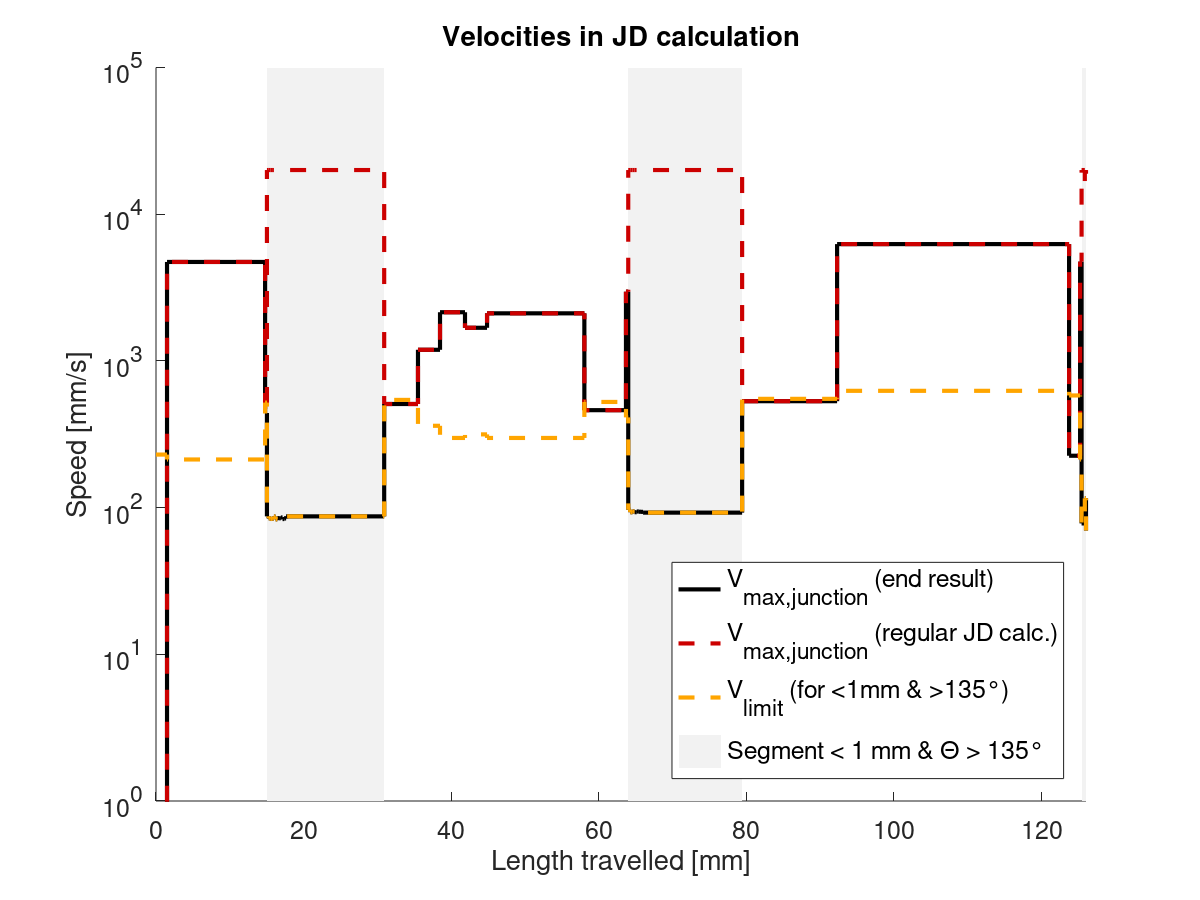
Perhatikan bahwa area abu-abu, di mana jalur kode < 1 mm & > 135° kita aktif jauh lebih kecil di sini. Ini juga satu-satunya wilayah di mana solusi yang diusulkan akan diintervensi.
Solusi yang diusulkan
Menggunakan delta_angle_indicator dengan pengaturan yang sama seperti pada posting terakhir saya, profil batas kecepatan terlihat seperti ini:
Perhatikan bahwa tidak banyak perbedaan. Faktanya, dengan pengecualian wilayah sekitar 70 mm, profilnya identik. Dan mungkin memang begitu, karena ada banyak sudut tajam dan perubahan besar pada sudut persimpangan di bagian ini, jadi untungnya kita tidak melaju melewatinya.
Dan hanya untuk bersenang-senang, berikut adalah plot dari indikator sebenarnya, sesuai dengan grafik batas kecepatan di atas: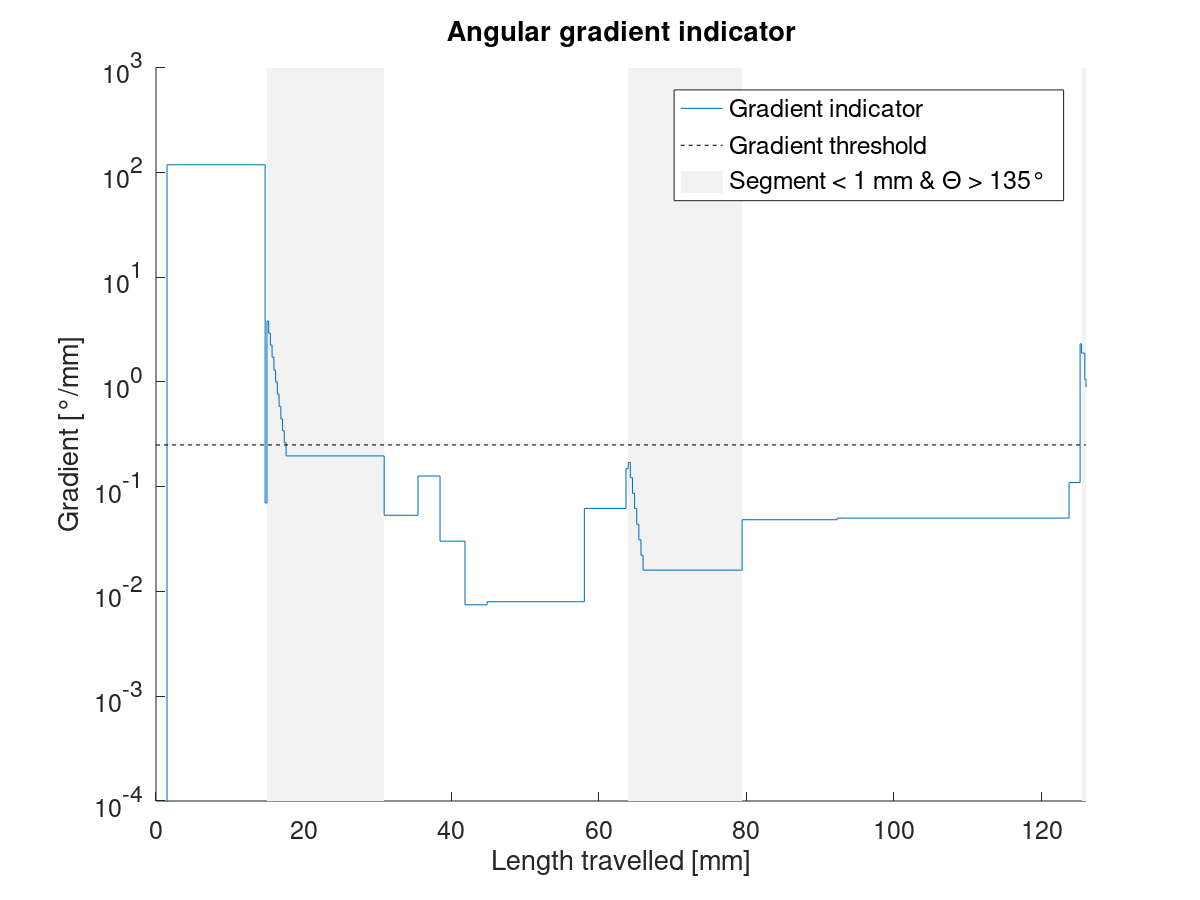
Saya belum yakin apa yang harus saya lakukan dengan semua ini. Hasil pertama terlihat menjanjikan, tetapi mungkin masih gagal dalam praktiknya. Indikatornya sangat dinamis dan bahkan perubahan kecil pada pengaturan bagian atau slicer dapat berdampak besar pada profil kecepatan yang dihasilkan. Kita lihat.
XDA-Bam
pada 22 Apr 2020
Itu memang terlihat menjanjikan! Dan itu membuat saya merenungkan dasar-dasarnya…
Saya tertarik untuk melihat perbandingan antara kotak persegi yang sejajar dengan tempat tidur versus kotak persegi yang berukuran 45 ° ke tempat tidur. Di Mendel, Anda harus bisa menggambar zigzag dari kiri ke kanan tanpa banyak memperlambat. Tapi garis "gelombang persegi" di Mendel harus berhenti di setiap sudut. Dari perspektif JD, apakah ini terlihat sama? Keduanya melakukan putaran 90 °.
Hal lain terpikir oleh saya sekarang…
Segmen kecil (terakhir) mungkin keluar dari segmenter perencana untuk delta dan leveling, dan segmen kecil itu dapat menyebabkan masalah, jadi saya ingin melakukan sapuan cepat untuk memastikan dua segmen terakhir dari setiap garis tersegmentasi adalah (segment_size + last_len) / 2.
thinkyhead
pada 24 Apr 2020
Memikirkannya lebih lanjut, saya melihat masalah brengsek lebih sederhana, sebagai salah satu perubahan arah dari satu kecepatan maju ke kecepatan mundur, di mana lebih banyak sudut datar kurang tersentak dalam semua kasus, dan lebih banyak sudut runcing lebih tersentak dalam semua kasus.
Tampaknya akan bermanfaat untuk melihat metode akumulator di semua perubahan sudut dan di semua panjang segmen, dengan akumulasi dan perlambatan pada semua perubahan sudut. Jadi, Anda menambahkan "jumlah momentum yang ditransfer oleh perubahan sudut ke bingkai", kurangi jumlah yang dapat diserap bingkai, dan perlambat dengan persentase yang dibutuhkan untuk mengambil selisihnya.
Saya bisa saja salah tetapi saya pikir jika Anda memperlambat dengan (hingga) dua kali lipat jumlah yang Anda pikir Anda belokkan pada gilirannya, itu sebenarnya akan membatalkan semua dering.
thinkyhead
pada 24 Apr 2020
Karena akselerasi fisik / batasan brengsek sangat bergantung pada mekanisme mesin (kartesian lurus vs corexy vs delta ...) menurut saya model penyimpangan persimpangan dalam melakukan batas dalam ruang cetak kartesian salah; model brengsek klasik benar. Classic brengsek memang memiliki banyak bug mendasar, seperti bagaimana ia dapat terakumulasi di banyak segmen kecil dan memungkinkan gerakan yang melebihi kemampuan fisik mesin, tetapi hal itu dapat dan harus diselesaikan dengan pendekatan "akumulasi seiring waktu dengan pembusukan" diusulkan di atas untuk JD, hanya akumulasinya yang jauh lebih sederhana ketika berada dalam ruang sumbu motor (tidak ada sudut yang terlibat).
richfelker
pada 24 Apr 2020
Sepakat. Tetapi masih meninggalkan kesalahan dalam kedua pendekatan ketika Anda memiliki banyak segmen yang sangat kecil dalam putaran 90 ° dan perencana hanya melihat kurva 18 ° pada satu waktu.
thinkyhead
pada 24 Apr 2020
… Saya kira penskalaan perubahan sudut ke waktu segmen mungkin mencapai beberapa sisi. Perubahan 18 ° dalam 1 md mungkin tidak diskalakan secara linier ke perubahan 18 ° dalam 10 md atau 100 md….
thinkyhead
pada 24 Apr 2020
Dari beberapa sudut pandang, sudut tersebut tidak relevan. Satu-satunya perubahan nyata adalah perubahan kecepatan yang diinginkan secara individual di sepanjang sumbu motor. Namun saya mungkin melangkah terlalu jauh dengan mengatakan bahwa JD benar-benar salah, karena massa kepala cetak memang bergerak dalam ruang kartesius, dan perlambatan di sepanjang satu sumbu motor dapat memberikan energi untuk membantu percepatan di sepanjang sumbu yang berbeda.
Bagaimanapun, apakah Anda memiliki belokan 90 ° sebagai satu sudut atau tersebar di beberapa segmen super-kecil, Anda masih melihat perubahan kecepatan yang terakumulasi dan membusuk yang sama di sepanjang setiap sumbu selama jendela waktu yang dibatasi dari nol.
richfelker
pada 24 Apr 2020
Ya, dalam tinjauan mental saya hari ini, saya menyadari bahwa bekerja di ruang vektor akan menghasilkan hasil yang konsisten dari bekerja di ruang Cartesian. Tetapi, Anda benar bahwa Jerk memiliki kemampuan untuk mempertimbangkan massa / kelembaman / momentum kereta dan alas secara individual dan untuk mempertimbangkan (secara tidak langsung) berapa banyak momentum yang diberikan oleh setiap sumbu.
Saya membayangkan sintesis dari dua pendekatan, sehingga komponen massa X (pembawa) dapat diberi bobot lebih atau kurang dari komponen massa Y (alas). Idealnya, akan baik untuk memodelkan segala sesuatu dalam kaitannya dengan sifat fisik dan kemudian menyederhanakannya, tetapi banyak dari apa yang kita miliki saat ini hanya berasal dari proses itu. Membongkar kembali semua kode yang dioptimalkan akan menjadi latihan yang baik untuk menemukan tempat di mana hal-hal dapat dioptimalkan.
thinkyhead
pada 24 Apr 2020
Ngomong-ngomong… Karena kita hanya menggunakan hasil junction_theta ketika berada dalam kisaran tertentu, saya bertanya-tanya apakah perkiraan asinx hanya dapat dievaluasi sebagian dan sisanya hanya dapat dievaluasi ketika itu bisa menghasilkan theta> 135. Saya harus memasukkannya ke dalam kalkulator grafik….
const float neg = junction_cos_theta < 0 ? -1 : 1,
t = neg * junction_cos_theta,
asinx = 0.032843707f
+ t * (-1.451838349f
+ t * ( 29.66153956f
+ t * (-131.1123477f
+ t * ( 262.8130562f
+ t * (-242.7199627f
+ t * ( 84.31466202f )))))),
junction_theta = RADIANS(90) - neg * asinx;
if (junction_theta > RADIANS(135)) { ... }
Satu optimasi kecil: Turunkan acos(-t) alih-alih acos(t) untuk menghilangkan satu operasi pengurangan. # 17684
thinkyhead
pada 24 Apr 2020
Saat memiliki "kecepatan brengsek" yang berbeda untuk sumbu, "lingkaran JD" berubah menjadi "elips". Matematika menantang ke depan.
AnHardt
pada 24 Apr 2020
Saya setuju bahwa model dasar yang berada di ruang kartesius adalah suatu masalah. Saya belum melihat kode brengseknya, tetapi untuk JD, itu hanya benar untuk mesin kartesius. Saya pikir jika Anda memecah mekanik dan meninggalkan ekstruder untuk saat ini (yang menurut saya harus ditangani dalam lingkaran / lingkungan terpisah), ada tujuh elemen yang bergerak:
- Tiga motor stepper SA, SB dan SC
- Tiga bagian bingkai FA, FB dan FC
- Kepala cetak P
Masing-masing bagian tersebut memiliki batas percepatan dan sentakan (dalam arti fisik -> da / dt), di atasnya mereka - dalam hal motor - kehilangan langkah, atau gaya menjadi terlalu tinggi sehingga menyebabkan masalah pada cetakan. Saat ini, kami tidak memiliki empat belas batas terpisah itu - tujuh untuk akselerasi, tujuh untuk brengsek - tetapi saya pikir kami memang membutuhkannya.
Data cetak kami dan semua penghitungan terjadi dalam ruang kartesius di sepanjang sumbu X, Y, dan Z. Jika sekarang Anda melihat batas percepatan atau sentakan dari bagian-bagian tersebut, bagian-bagian tersebut saling berhubungan dengan cara yang berbeda bergantung pada geometri mesin:
- Untuk mesin kartesius, motor SA dan bagian rangka FA saling berhubungan ("sumbu X"), begitu pula motor SB dan bagian rangka FB ("sumbu Y") dan seterusnya. Kepala cetak biasanya terhubung dengan FA dan FC (sumbu X dan Z), SA dan SC (steppers X dan Z). Setiap batas percepatan yang diterapkan pada motor SA (stepper sumbu X), misalnya, juga berlaku untuk bagian rangka FA (rangka sumbu X) dan sebaliknya. Jadi untuk pergerakan ke arah X dari sistem koordinat Marlin, yang terendah dari tiga batas akselerasi untuk SA, FA dan P harus diperhatikan. Logika yang sama berlaku untuk batasan brengsek.
- Untuk mesin delta, pergerakan frame atau stepper tidak sejajar dengan sistem koordinat Marlin kartesius. Jadi untuk gerakan di bidang X, kita harus menghormati yang terendah dari semua tujuh percepatan dan tujuh batas sentakan untuk setiap gerakan: Yang dari setiap bagian kerangka bergerak FA-FC, yang dari tiga steppers SA-SC dan batas kepala. P.
- Untuk mesin CoreXY, beda lagi. Steppers SA dan SB keduanya bertanggung jawab atas pergerakan ke arah X dari sistem kordinat Marlin. Lebih lanjut, batas percepatan dan sentakan dari bagian bingkai FA dan kepala cetak P juga berlaku pada arah X. Dan seterusnya, dan lain sebagainya.
Jadi, jika Anda ingin berpikir tentang mendesain ulang brengsek dan / atau JD dari awal, saya pikir pertama-tama kita perlu memisahkan semua batas percepatan dan sentakan dari sumbu X, Y, dan Z dan mendefinisikannya kembali untuk tujuh bagian utama yang bergerak. Kami mungkin dapat mengabaikan print head P, karena secara efektif dibatasi oleh setidaknya satu bagian bingkai pada printer apa pun yang dapat saya bayangkan. Tapi selain itu, menurut saya tiga batasan di X / Y / Z tidak cukup untuk membuat model printer dengan benar.
XDA-Bam
pada 24 Apr 2020
Juga: Saya memiliki barang delta_angle_indicator yang berjalan di printer saya. Itu belum berakhir (belum). Anda ingin saya memasukkan ini ke dalam bugfix-2.0.x untuk pengujian? Atau apakah ini sesuatu untuk dev-2.1.x?
XDA-Bam
pada 24 Apr 2020
@ XDA-Bam - Ya, silakan. Kita membutuhkan semua bagian pengujian yang baik yang bisa kita dapatkan di bidang analisis gerak dan perencana. Saya telah bermain-main dengan perhitungan di https://www.desmos.com/calculator/pg3q7fh1ja
thinkyhead
pada 24 Apr 2020
Saya perhatikan bahwa (menurut grafik) setiap kali nilai input ke pendekatan arcsine lebih besar dari 0,7071067812, nilai junction_theta keluar dari kisaran dalam tes junction_theta < RADIANS(45) . Jadi tidak perlu melakukan rumus untuk nilai masukan di atas 0.7071067812.
Harap perbaiki saya jika saya salah menafsirkan sesuatu dalam hasil.
thinkyhead
pada 24 Apr 2020
Mungkin saya melewatkan sesuatu (saya belum membaca kodenya) tetapi jika Anda ingin membandingkan sudut terhadap nilai tetap, mengapa Anda menghitung acos untuk mendapatkan sudut daripada hanya membandingkan x terhadap cos dari referensi (135 atau Masa bodo)? Mungkin ada beberapa masalah domain tetapi yang terburuk harus ada beberapa tes interval ...
richfelker
pada 24 Apr 2020
Anda dapat membandingkan cos_junction_theta dengan cos(135) diketahui untuk kondisi if, tetapi Anda masih memerlukan junction_theta untuk menghitung limit_sqr . Atau apakah Anda berbicara tentang jalur yang berbeda?
EDIT: Dan ya, itu berarti Anda dapat menghitung persimpangan theta SETELAH if (junction_theta > RADIANS(135)) { , jika Anda memeriksa junction_cos_theta sebagai gantinya.
XDA-Bam
pada 24 Apr 2020
@thinkyhead "Ya, mohon" perbaikan bug-2.0.x atau "Ya, mohon" dev-2.1.x? : D
XDA-Bam
pada 25 Apr 2020
Silakan kirim ke bugfix-2.0.x Itu akan menjadi cara termudah untuk tetap sinkron selama pengujian.
thinkyhead
pada 25 Apr 2020
Grafik mengatakan ini mungkin benar…
const float neg = junction_cos_theta < 0 ? -1 : 1,
t = neg * junction_cos_theta;
// Only under sin(-45°) [== cos(135)] can the final result be under 45°
if (t < -0.7071067812f) {
const float asinx = 0.032843707f
+ t * (-1.451838349f
+ t * ( 29.66153956f
+ t * (-131.1123477f
+ t * ( 262.8130562f
+ t * (-242.7199627f
+ t * ( 84.31466202f ) ))))),
junction_theta = RADIANS(90) + neg * asinx; // acos(-t)
// If angle is under 45 degrees (octagon), find speed for approximate arc
if (junction_theta < RADIANS(45)) {
// NOTE: MinMax acos(-x) approximation (junction_theta) bottoms out at 0.033 which avoids divide by 0.
const float limit_sqr = (block->millimeters * junction_acceleration) / junction_theta;
NOMORE(vmax_junction_sqr, limit_sqr);
}
}
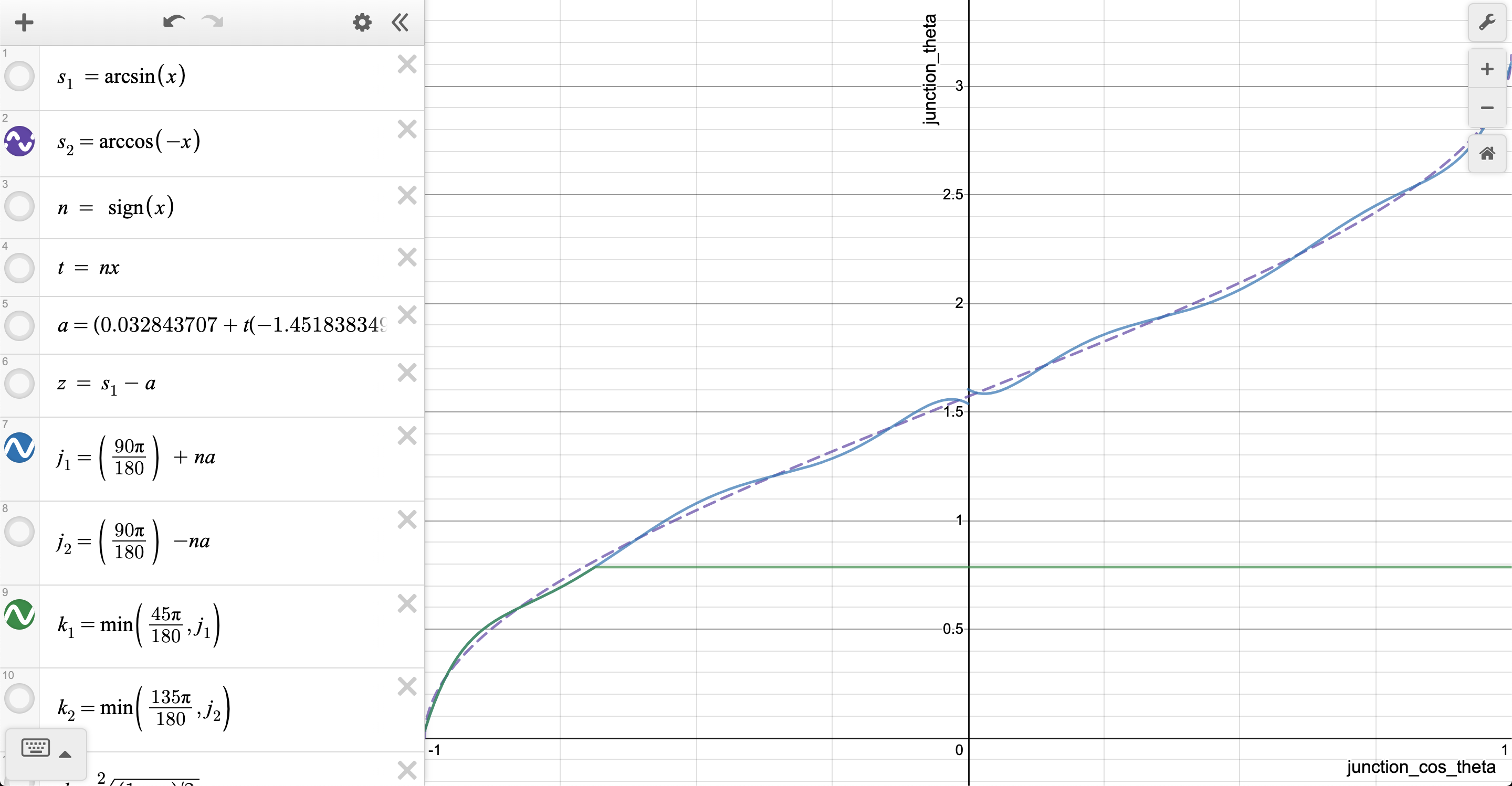
thinkyhead
pada 25 Apr 2020
Soal PR: OK, oke.
Mengenai cuplikan kode Anda: Mengapa harus membandingkan t dan junction_theta ? Kecuali untuk kesalahan numerik kecil, ini akan memberikan hasil yang sama. Kenapa tidak pergi
if (junction_cos_theta < -0.7071067812f) { // -1/sqrt(2) equiv. to 135°
const float t = -junction_cos_theta,
junction_theta = RADIANS(90)
+ 0.032843707f
+ t * (-1.451838349f
+ t * ( 29.66153956f
+ t * (-131.1123477f
+ t * ( 262.8130562f
+ t * (-242.7199627f
+ t * ( 84.31466202f ) )))));
const float limit_sqr = (block->millimeters * junction_acceleration) / (RADIANS(180) - junction_theta);
NOMORE(vmax_junction_sqr, limit_sqr);
}
Dengan memeriksa junction_cos_theta , tidak ada ambiguitas. Ini lebih kecil dari -1/sqrt(2) untuk sudut di atas 135 °.
XDA-Bam
pada 25 Apr 2020
Domain tempat kami menghitung perlambatan cukup kecil sehingga dapat direduksi menjadi beberapa pencocokan kurva sederhana, dan kemudian 6 perkalian atau lebih juga tidak diperlukan. Cukup satu pengurangan dan satu kali mengalikan…
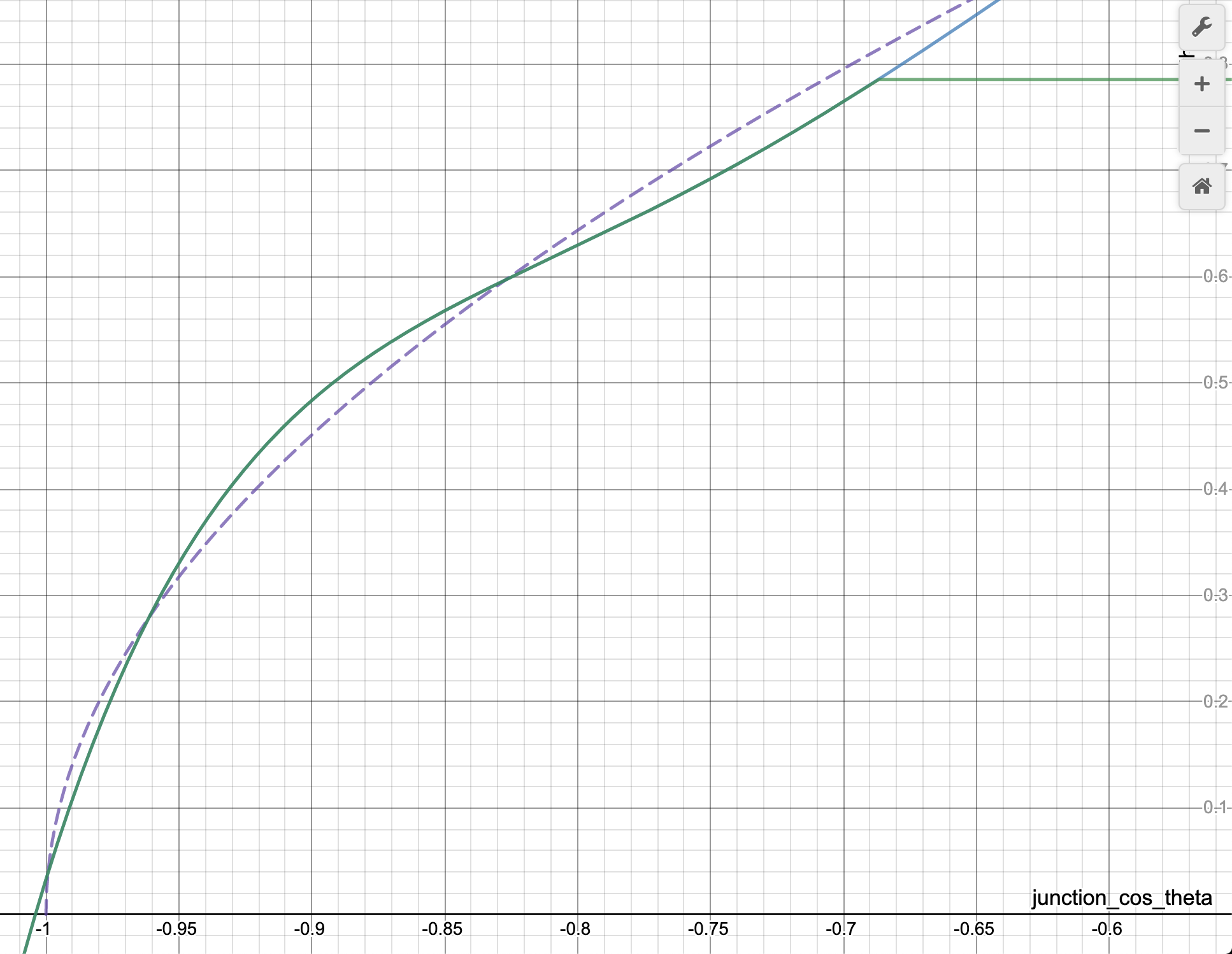
thinkyhead
pada 25 Apr 2020
Antara nilai -1 / sqrt (2) dan -0.85 rumus ini cukup dekat dengan hasil arccos yang sebenarnya sehingga berguna:
acos_minus_t = 0.785f + 1.6f * (q + 0.7071067812f);
Berikut perkiraan yang cukup bagus dengan tidak terlalu banyak kesalahan…
const float neg = junction_cos_theta < 0 ? -1 : 1,
t = neg * junction_cos_theta;
// Only under sin(-45°) can the final result be under 45°
if (t < -0.7071067812f) {
junction_theta =
(t >= -0.85f) ? 0.7850f + (t + 0.7071067812f)
: (t >= -0.89f) ? 0.5550f + (t + 0.85f) * 2
: (t >= -0.93f) ? 0.4750f + (t + 0.89f) * 2.46f
: (t >= -0.97f) ? 0.3766f + (t + 0.93f) * 3.275f
: (t >= -0.98f) ? 0.2456f + (t + 0.97f) * 4.527f
: (t >= -0.99f) ? 0.20033f + (t + 0.98f) * 5.879f
: 0.14154f + (t + 0.99f) * 14.154f;
const float limit_sqr = (block->millimeters * junction_acceleration) / junction_theta;
NOMORE(vmax_junction_sqr, limit_sqr);
}
Saya berasumsi bahwa kompilator cukup pintar untuk membagi dua rentang pengujian sehingga dapat melakukan 4 perbandingan, bukan 6, tetapi dapat dibuat eksplisit, seperti ini ...
junction_theta =
(t >= -0.93f) ?
( (t >= -0.85f) ? 0.7850f + (t + 0.7071067812f)
: (t >= -0.89f) ? 0.5550f + (t + 0.85f) * 2
: 0.4750f + (t + 0.89f) * 2.46f )
: (t >= -0.98f) ?
( (t >= -0.97f) ? 0.3766f + (t + 0.93f) * 3.275f
: 0.2456f + (t + 0.97f) * 4.527f )
: ( (t >= -0.99f) ? 0.20033f + (t + 0.98f) * 5.879f
: 0.14154f + (t + 0.99f) * 14.154f );
Anda bahkan mungkin dapat mematikan cabang dan mengubahnya menjadi pencarian tabel (di mana konstanta aditif dan perkalian akan digunakan) berdasarkan beberapa bit representasi float, jika itu membantu.
richfelker
pada 25 Apr 2020
Perwujudan dalam kode cenderung lebih cepat dalam prosesor ini, tetapi LUT layak untuk diuji. Pertanyaan lainnya adalah apakah perbandingan mengambang selalu menghasilkan pengurangan, atau apakah menggunakan trik perbandingan biner.
thinkyhead
pada 25 Apr 2020
Keterampilan C ++ saya tidak terlalu bagus, tetapi t = neg * junction_cos_theta; harus selalu positif, bukan? Melihat bahwa semua perbandingan diatur untuk nilai negatif t , dan semua persamaan juga hanya berfungsi untuk t<0 , tampaknya tidak benar. Baris pertama harus const float neg = junction_cos_theta > 0 ? -1 : 1, , atau apakah saya salah membaca?
Juga, kesalahan dari pendekatan ini meroket untuk nilai di antara titik kisi. Ini sangat bermasalah dan kemungkinan besar akan memunculkan kembali masalah gagap yang baru saja kita atasi . Melihat hanya pada wilayah terakhir, terlihat seperti ini:
| cos | 180 - acos () [°] | lin tersegmentasi. kira-kira. [°] | penyimpangan [%] |
| --- | --- | --- | --- |
| -0,99 | 8.110 | 8.110 | 0.0 |
| -0,999 | 2.563 | 0.811 | -68,4 |
| -0,9999 | 0.810 | 0.081 | -90,0 |
| -0,99999 | 0.256 | 0,008 | -96,8 |
| -0.999999 | 0.081 | 0,001 | -99,0 |
Apa yang mungkin berhasil adalah, jika Anda memperhalus kisi titik mendekati -1. Jadi menggunakan sesuatu seperti [-0,99, -0,993, -0,996, -0.999, -0.9993, -0.9996, -0.9999, ...] bisa bekerja dengan cukup baik. Tetapi Anda harus memeriksa kesalahan relatif antara titik-titik kisi.
EDIT: Mungkin lebih masuk akal untuk bekerja secara terbalik. Tentukan sudut di mana kita ingin titik grid, kemudian hitung cos () dan gunakan sebagai grid.
XDA-Bam
pada 25 Apr 2020
Karena C ++ saya bukan yang terbaik, saya menulis kode untuk rangkaian daya LUT yang telah dihitung sebelumnya di MATLAB / Oktaf. Ini hanya memiliki 16 elemen tetapi masih terbatas pada + -0.75% dari acos() hingga 0.45 ° ( cos=0.999962 ). 16 elemen tersebut juga berarti bahwa terdapat paling banyak 4 langkah untuk menentukan daerah interpolasi. Untuk ketepatan hingga batas cos=0.999999 seperti yang ditemukan dalam kode, pendekatan ini membutuhkan 21 elemen yang menghasilkan paling banyak 5 langkah untuk menentukan wilayah.
Hasil untuk 16 elemen terlihat seperti ini:
"Marlin v1" adalah pendekatan asli, "v2" adalah yang saat ini aktif di bugfix-2.0.x. Presisi mendekati 180 ° sama dengan mendekati 0 ° ( cos() -simetri).
Detail sekitar 1 °:
Ini adalah kode MATLAB untuk mempersiapkan LUT:
%% Prepare LUT at startup
% Generate power series
entries = 16; % Switch to 21 for precision up to 0.999999
dX = 0.5;
for i=1:entries-2
dX(i+1) = 0.5*dX(i);
end
% Calculate acos()
dXInv = 1./dX;
X = [0, cumsum(dX)];
Y = acos(X);
Y(2:end) = Y(2:end)*1.0074696392; % Correction factor centers the error around 0. Avoid correcting first entry to keep approximation below pi/2.
Selama runtime, evaluasi rutin dapat terlihat seperti ini:
%% Evaluate LUT during runtime
x = cos(rand(1,1)*pi); % Random angle in range [0, 180]° for testing purposes
% Binary search
lowInd = 1;
highInd = entries;
currInd = round(0.5*highInd);
while true
if x > X(currInd)
lowInd = currInd;
currInd = ceil( 0.5*(currInd + highInd));
elseif x < X(currInd)
highInd = currInd;
currInd = floor(0.5* (currInd + lowInd) );
else
lowInd = currInd;
highInd = currInd;
end
if (highInd-lowInd <= 1)
% Alternatively use 'if (highInd-lowInd < 2)', if it's faster
break;
end
end
% Linear interpolation
if highInd ~= lowInd % This if-condition is not necessary, just more elegant. It may be faster to drop it, as the 'else' is only run in the rare case where we query a value directly listed in our LUT.
acosApprox(i) = Y(lowInd) + (Y(highInd) - Y(lowInd)) * (x - X(lowInd)) * dXInv(lowInd);
else
acosApprox(i) = Y(lowInd);
end
Kode sengaja dibuat aneh dari sudut pandang MATLAB dengan tujuan agar lebih cepat menerjemahkan ke C ++. Sebenarnya, saya tidak bisa membandingkannya dengan kode yang ada di cabang perbaikan bug atau acosf() . Itu memang membutuhkan lima atau enam if / else evals, beberapa additons dan substractions dan enam sampai tujuh perkalian. Ini adalah masalah dalam hal kecepatan. Sebagian besar mults berada dalam pencarian biner, sehingga mereka dapat dihilangkan dengan menerima lebih banyak evaluasi if / else atau beberapa tipu daya pemrograman yang saat ini tidak saya lihat.
Meskipun demikian saya pikir ini adalah titik awal yang baik, karena cukup tepat sekitar 0 ° & 180 ° dibandingkan dengan pendekatan kami sebelumnya. Saya pikir itu bisa dipercepat ke tingkat di mana itu adalah kompromi yang baik.
XDA-Bam
pada 29 Apr 2020
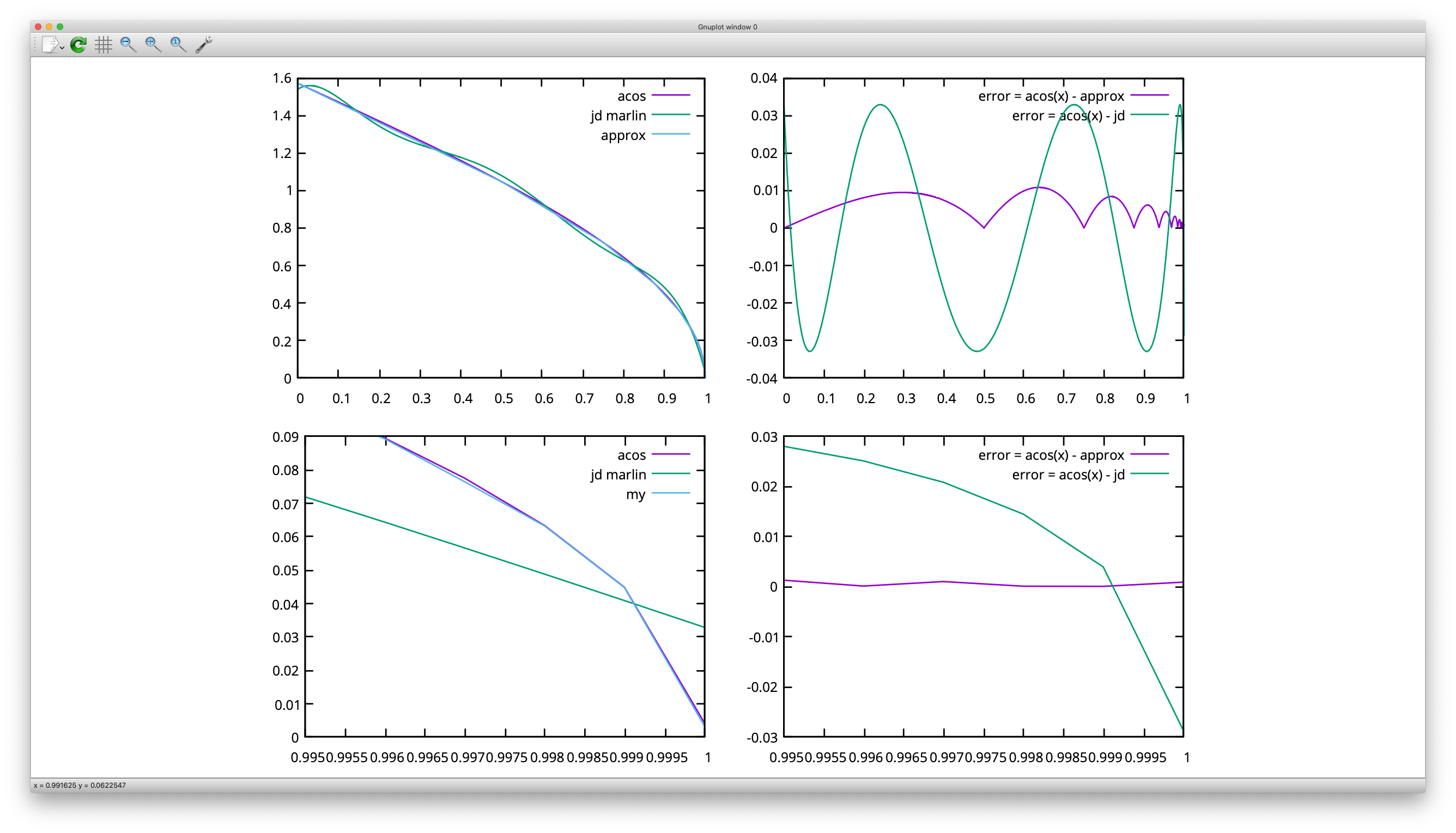
#include <iostream>
#include <math.h>
const int N = 16;
float array[N][2] = {};
float fce(float theta)
{
// linear non uniform
//float ret = fx0*(theta-x1)/(x0-x1)-fx1*(theta-x0)/(x0-x1);
// quadratic non uniform
//float ret = fx0*(theta-x1)*(theta-x2)/(x0-x1)/(x0-x2)+fx1*(theta-x0)*(theta-x2)/(x1-x0)/(x1-x2)+fx2*(theta-x0)*(theta-x1)/(x2-x0)/(x2-x1);
int lowIdx = 0;
int highIdx = N;
int idx;
float val;
while(highIdx - lowIdx > 1)
{
idx = (highIdx + lowIdx) >> 1;
val = array[idx][0];
if(theta < val)
highIdx = idx;
else if (theta > val)
lowIdx = idx;
else
{
lowIdx = idx;
highIdx = idx+1;
break;
}
}
float x0 = array[lowIdx][0];
float x1 = array[highIdx][0];
float fx0 = array[lowIdx][1];
float fx1 = array[highIdx][1];
//int dx = 2 << lowIdx; // dx is 2 x dx of next item
float ret = fx1*(theta-x0) - fx0*(theta-x1)*2;
std::cerr << "Theta: " << theta << " Low:" << lowIdx << " High: " << highIdx << " Idx: " << idx << " Ret: " << ret << " acos: " << acos(theta) << std::endl;
return ret;
}
int main()
{
std::cerr << "Fill Table" << std::endl;
for(int i = 0; i < N-1; ++i)
{
float theta = (pow(2,i) - 1)/pow(2,i);
array[i][0] = theta;
array[i][1] = acos(theta)*pow(2,i);
std::cerr << i << "\t" << array[i][0] << "\t" << array[i][1] << "\t" << std::endl;
}
array[N-1][0] = 1;
array[N-1][1] = 0;
std::cerr << "Canary test" << std::endl;
float theta = 0.94;
//theta = 0.5;
if( abs(acos(theta) - fce(theta)) > 0.1 )
{
std::cerr << "Canary failed" << std::endl;
return 1;
}
//return 1;
std::cerr << "Data plot" << std::endl;
for(float t = 0; t <= 1; t += 0.001)
{
float asinx = 0.032843707f
+ t * (-1.451838349f
+ t * ( 29.66153956f
+ t * (-131.1123477f
+ t * ( 262.8130562f
+ t * (-242.7199627f + t * 84.31466202f) ))));
std::cout << t << " " << acos(t) << " " << fce(t) << " " << acos(t) - fce(t) << " " << M_PI_2 - asinx << " " << acos(t) - M_PI_2 + asinx << std::endl;
}
return 0;
}
Saya telah menerapkan solusi dengan beberapa penyesuaian dan pengoptimalan kecil. Ini hanya membutuhkan 16 * 2 float LUT dalam memori.
daleckystepan
pada 29 Apr 2020
Bagus. Dua perbaikan kecil: Anda dapat menggunakan faktor koreksi untuk memusatkan kesalahan di sekitar 0, yang juga mengurangi setengah dari kesalahan maksimum. Dan yang Anda sebut theta dalam kode sebenarnya adalah cos(theta) , yang agak menyesatkan.
Bisakah Anda membandingkan ini di papan printer?
XDA-Bam
pada 30 Apr 2020
Berubah menjadi meja dengan 2 * 21 tempat.
Hasilnya bagus - tetapi bertahan sekitar 8,1 kali lebih lama dari acos () asli pada AVR 8bit 16MHz (UNO).
sketch_apr30a.txt
Times:
cos/acos: 0.90, fce/acos: 8.16, acosx/acos: 0.84
cos/acos: 0.90, fce/acos: 8.13, acosx/acos: 0.83
cos/acos: 0.89, fce/acos: 8.11, acosx/acos: 0.83
cos/acos: 0.90, fce/acos: 8.18, acosx/acos: 0.84
Dengan N = 16 tampilannya hampir sama
Times:
cos/acos: 0.90, fce/acos: 8.13, acosx/acos: 0.83
cos/acos: 0.89, fce/acos: 8.11, acosx/acos: 0.83
cos/acos: 0.90, fce/acos: 8.16, acosx/acos: 0.84
cos/acos: 0.90, fce/acos: 8.11, acosx/acos: 0.83
Versi saya menggunakan int __builtin_clzl(unsigned long x) (CountLeadingZerosLong ())
ACOS __- aproximation.txt
berlangsung saat ini hampir sama.
Speedratio lookup_acos()/acos(): 4767/567 = 8.41
Diganti
float array[N][2] = {};
dengan
float array0[N] = {};
float array1[N] = {};
fce / acos: 7.74
Perhitungan alamat lambat pada AVR.
AnHardt
pada 30 Apr 2020
Wow, itu tidak menggembirakan 😐
Saya melihat Anda menggunakan divide selama pencarian:
float acos_table_lookup(float x) {
// uint8_t i = acos_table_interval_index(x);
int8_t i = __builtin_clzl( long((1.0f-x) * _TLL_)) - _TLL0_;
i = constrain(i, 0, ACOS_TABLESIZE - 1);
// like map() in float.
return (x - acos_table_x[i]) * (acos_table_y[i+1] - acos_table_y[i]) / (acos_table_x[i+1] - acos_table_x[i]) + acos_table_y[i];
}
@daleckystepan menggunakan solusi dengan hanya mengalikan dan yang asli saya juga menghitung penyebut sebelumnya. Jadi pasti ada kecepatan yang bisa didapat di sini. Tapi faktor 10? Bagaimana dengan perhitungan alamat yang membuat ini sangat lambat?
XDA-Bam
pada 30 Apr 2020
Saya punya ide lain bagaimana saya bisa lebih mengoptimalkan kode. Saya akan mencobanya dan kita akan lihat. Saya akan terus mengabari Anda (semoga dalam beberapa jam).
daleckystepan
pada 30 Apr 2020
1000 evaluasi pada atmega 2560 16MHz
acos: 180 ms
asinx: 127 ms
kira-kira: 103 ms (fungsi saya tanpa penyetelan apa pun)
kira-kira: 99 ms (menggunakan dua larik berbeda, bukan satu larik besar dengan aritmatika penunjuk)
daleckystepan
pada 30 Apr 2020
Alamat AVR adalah 16 bit -> dihitung dalam register 8 bit -> jauh lebih dari satu siklus.
AnHardt
pada 30 Apr 2020
const int N = 16;
const unsigned long _TLL_ = 1L << N;
const int _TLL0_ = __builtin_clzl( _TLL_ ) + 1;
float array0[N] = {};
float array1[N] = {};
inline float approx(float t)
{
int lowIdx = __builtin_clzl( long((1.0f-t) * _TLL_)) - _TLL0_;
float *a0 = array0+lowIdx;
float *a1 = array1+lowIdx;
return *(a1+1)*(t-*a0) - *a1*(t-*(a0+1))*2;
}
for(int i = 0; i < N-1; ++i)
{
float theta = (pow(2,i) - 1)/pow(2,i);
array0[i] = t;
array1[i] = acos(t)*pow(2,i);
}
array0[N-1] = 1;
array1[N-1] = 0;
Kami mungkin tidak akan menemukan solusi yang lebih cepat :) Tidak cantik tapi cukup cepat.
Faktor koreksi juga bisa kita terapkan dan semoga begitu saja.
Untuk 10 ribu sampel:
acos: 1820 ms
asinx: 1301 md
perkiraan: 1008 ms
daleckystepan
pada 30 Apr 2020
Dengan
...
while(highIdx - lowIdx > 1)
{
idx = (highIdx + lowIdx) >> 1;
val = array0[idx];
// Precalculating sign(theta - val) is not faster. Adds two integer compares to the two float compares.
if(theta < val) highIdx = idx; // this is at least 2 times more likely than the other case(s).
/* Removed because this case is handled by the while loop.
* Speeding up the N case where it bites is in average not worth the infinit cases where we have the extra compare
* else if (theta == val) { // seems to evaluate a bit faster than '>'.
* lowIdx = idx; highIdx = idx+1; break;
* }
*/
else lowIdx = idx;
}
return array1[highIdx]*(theta-array0[lowIdx]) - array1[lowIdx]*(theta-array0[highIdx])*2.0f;
// Next idea is to calculate a[i]*theta + b[i]; what needs a further array.
}
saya sekarang di fce/acos: 7.60
AnHardt
pada 30 Apr 2020
Wow! Versi pointer dengan __builtin_clzl() sudah cukup mengesankan.
Jika array lebih kecil maka 16 elemen ada juga __builtin_clz() untuk 16 bit integer.
Dengan pencarian ini kita tidak membutuhkan array0 lama [].
Jadi kita tidak membutuhkan array ketiga saat menghitung return a[i]*theta + b[i];
AnHardt
pada 30 Apr 2020
10 ribu sampel
acos: 1819 ms
asinx: 1301 md
sekitar: 653 ms
const int N = 15;
const unsigned int _TLL_ = 1 << N;
const int _TLL0_ = __builtin_clz( _TLL_ ) + 1;
float lutK[N] = {};
float lutB[N] = {};
inline float approx(float t)
{
int idx = __builtin_clz( int((1.0f-t) * _TLL_)) - _TLL0_;
return lutK[idx]*t + lutB[idx];
}
for(int i = 0; i < N-1; ++i)
{
float t = (pow(2,i) - 1)/pow(2,i);
float c = (i==0)?1.0:1.0074696392;
float x0 = t;
float y0 = acos(x0)*c;
float x1 = 0.5*x0 + 0.5;
float y1 = acos(x1)*c;
float dx = x0-x1;
lutK[i] = (y0-y1)/dx;
lutB[i] = (y1*x0 - y0*x1)/dx;
}
lutK[N-1] = 0;
lutB[N-1] = 0;
Perlombaan sedang berlangsung 😅 Jika saya tidak salah, itu lebih cepat dari yang ada dan pendekatan lama _ dan_ lebih tepat. Satu-satunya kelemahan menggunakan 15 elemen adalah, kita sudah menyimpang sekitar 0,6 °, bukan 0,45 °. Tetapi kesalahannya adalah 7,5% yang dapat diterima pada 0,5 °. Jadi, kerugian marjinal untuk fungsi 35% lebih cepat.
PR?
XDA-Bam
pada 30 Apr 2020
Ya, kesalahan masih dapat diterima dan kami dapat memperbaikinya dengan mudah dengan menambahkan lebih banyak elemen (dan memperbarui ke __builtin_clzl). Saya telah membuat PR tetapi saya tidak yakin tentang kodenya sama sekali: D
daleckystepan
pada 1 Mei 2020
Silakan uji perbaikan bug saat ini untuk melihat apakah kami dapat menutup masalah ini.
thinkyhead
pada 3 Mei 2020
Apakah perbaikan yang diusulkan masih memiliki efek samping seperti meningkatkan persyaratan waktu CPU? Itu bisa merusak papan kelas bawah jika demikian.
richfelker
pada 3 Mei 2020
Usulan perbaikan kira-kira 2x lebih cepat dan sekitar 3x lebih akurat.
daleckystepan
pada 3 Mei 2020
Apakah https://github.com/MarlinFirmware/Marlin/issues/15473 diyakini telah diperbaiki juga? Saya telah menghindari JD karena ketidakpastian tentang itu juga.
richfelker
pada 3 Mei 2020
Saat ini saya menggunakan versi 2.0.5.2, dan saya sah tidak dapat menyebabkan masalah ini muncul. Saya mencoba menggunakan model tux yang sama seperti yang digunakan pada edisi # 17146, dan saya tidak bisa mendapatkan perbedaan untuk muncul dengan JD yang diaktifkan dan dinonaktifkan.
Pada gambar, JD diaktifkan (kiri), klasik Jerk (kanan). Saya menggunakan SKR1.4 Turbo dengan driver TMC2209.
Apakah saya melewatkan sesuatu ...?
 Thorinair
pada 15 Mei 2020
Thorinair
pada 15 Mei 2020
@Thorinair Bisakah Anda menguji JD_single_arc_test.zip kami?
qwewer0
pada 15 Mei 2020
Benar-benar, akan melakukan dan melaporkan hasilnya.
EDIT: Gores itu, tidak bisa mengujinya karena dalam format gcode. Mengapa tidak STL?
EDIT2: Begitu, itu hanya cetakan "kering", itu seharusnya baik-baik saja ... Saya akan mencoba dan melihat
Thorinair
pada 15 Mei 2020
@Thorinair Ini pada dasarnya adalah masalah diskritisasi, yang berarti (juga) tergantung pada alat pengiris Anda. Jika Anda mengunduh pinguin dan mengirisnya sendiri, pemotong dan pengaturannya kemungkinan besar akan berbeda dari pengguna lain, yang melihat masalahnya. Jika Anda menjalankan JD_single_arc_test GCode, pemotong keluar dari persamaan dan lebih mudah untuk membandingkan hasil.
Selain itu, beri tahu kami pemotong dan setelan mana yang Anda gunakan untuk memotong Tux Anda!
XDA-Bam
pada 15 Mei 2020
Inilah mengapa saya benci menjalankan gcode yang tidak dikenal. Membuat sumbu Z melaju terlalu cepat, menghentikan motor. Sekarang saya perlu menyesuaikan lagi offset antara motor kiri dan kanan.
Tapi, untuk menjawab pertanyaan itu, motor bergerak dengan mulus tanpa ada satupun suara gagap.
Thorinair
pada 15 Mei 2020
Selain itu, beri tahu kami pemotong dan setelan mana yang Anda gunakan untuk memotong Tux Anda!
Saya menggunakan Cura, namun, saya menggunakan resolusi maks 0,4, jika tidak, Octoprint adalah salah satu rantai saya yang tidak dapat mengikutinya.
Thorinair
pada 15 Mei 2020
Inilah mengapa saya benci menjalankan gcode yang tidak dikenal. Membuat sumbu Z melaju terlalu cepat, menghentikan motor. Sekarang saya perlu menyesuaikan lagi offset antara motor kiri dan kanan.
Anda dapat memeriksa gcode sendiri. Ini bukan gcode yang diiris penuh dari stl, tetapi hanya cuplikan dari yang asli, diulang 15 kali.
Dan hanya memiliki satu perintah gerakan Z yang kemungkinan besar dibatasi oleh pengaturan DEFAULT_MAX_FEEDRATE di firmware.
Anda dapat mengubah gcode yang sesuai:
Dari:
G1 F3000 ; Set the motion velocity
G1 Z10.0 ; Raise Z Axis 10mm
Untuk:
G1 Z10.0 F180; Raise Z Axis 10mm
G1 F3000 ; Set the motion velocity
Tapi, untuk menjawab pertanyaan itu, motor bergerak dengan mulus tanpa ada satupun suara gagap.
Apakah Anda meletakkan tangan Anda pada motor sumbu X dan Y atau kepala tempat tidur / cetak untuk merasakan gagap?
qwewer0
pada 15 Mei 2020
Apakah Anda meletakkan tangan Anda pada motor sumbu X dan Y atau kepala tempat tidur / cetak untuk merasakan gagap?
Saya tidak dapat mengatakan bahwa saya pernah, tetapi gagap, ketika terjadi, biasanya cukup keras pada printer saya. Saya pernah mengalaminya sebelumnya pada papan 8-bit ketika itu kelaparan untuk perintah dari Octoprint. Apapun. Saya akan mencobanya lagi setelah tes tux berikutnya selesai (menghapus batas resolusi maksimal).
Thorinair
pada 15 Mei 2020
Sudah mencobanya, sejujurnya saya tidak yakin apakah saya merasakan sesuatu yang luar biasa baik dengan JD diaktifkan dan dinonaktifkan ...
Thorinair
pada 15 Mei 2020
@Thorinair Terima kasih untuk pengujian. Apakah Anda mencetak Tux lagi tanpa batas resolusi, seperti yang Anda tulis sebelumnya? Jika ya, apakah ada perbedaan yang terlihat?
XDA-Bam
pada 16 Mei 2020
@Thorinair Terima kasih untuk pengujian. Apakah Anda mencetak Tux lagi tanpa batas resolusi, seperti yang Anda tulis sebelumnya? Jika ya, apakah ada perbedaan yang terlihat?
Aku melakukannya, dan tuksedo itu benar-benar keluar lebih baik, karena tidak ada lagi ketidaktepatan yang diperkenalkan oleh Cura. Memang dicetak lagi dengan JD dihidupkan.
Thorinair
pada 16 Mei 2020
Satu hal yang saya perhatikan adalah bahwa orang yang memiliki masalah tersebut mengaktifkan akselerasi kurva-s, sedangkan saya tidak. Saya mencoba menggunakannya beberapa saat yang lalu pada kubus kalibrasi sederhana, dan menghasilkan getaran dalam jumlah besar (jauh lebih dari akselerasi normal), dan bahkan menghasilkan celah di bagian atas cetakan, jadi saya menyerah saat saya melakukannya. tidak melihat manfaat tambahan. Mungkinkah interaksi antara kurva-s dan JD secara khusus yang menyebabkan hal ini?
Thorinair
pada 16 Mei 2020
Kurva-S telah dibahas dan diuji. Tidak ada bedanya bagi yang mencobanya (termasuk saya). Jika Anda mengaktifkan LA + S-Curve, itu mungkin juga memberi Anda masalah - dengan penyebab yang berbeda. Jadi, sayangnya, tidak mudah untuk mendiagnosis semua ini.
XDA-Bam
pada 16 Mei 2020
Tunggu, jadi apa yang direkomendasikan untuk sesuatu seperti Ender 3 dengan papan 32bit aftermarket (tanpa FPU)?
Karena tampaknya menggabungkan salah satu fitur ini tampaknya menjadi masalah, haruskah Anda menggabungkannya?
Maksud saya: Akselerasi Kurva S, Deviasi Persimpangan, Maju Linear
Karena saya mengalami sedikit goyangan di kurva saat hanya menggunakan SCA & LA yang diperbesar saat menggunakan JD, bukan Classic Jerk.
Apakah mengaktifkan Akselerasi Kurva S bahkan direkomendasikan untuk penyetelan bowden? Saya agak bingung di sini karena semua fitur entah bagaimana mempengaruhi satu sama lain secara negatif :(
 Seref
pada 16 Mei 2020
Seref
pada 16 Mei 2020
Tunggu, jadi apa yang direkomendasikan untuk sesuatu seperti Ender 3 dengan papan 32bit aftermarket (tanpa FPU)?
Ini semacam pertanyaan di luar topik, tetapi untuk membuatnya singkat:
- Jangan gabungkan LA dengan S-Curve, ini mungkin berhasil tetapi juga bisa gagal, tergantung pada cetakannya.
- JD saat ini tampaknya disadap di semua cabang, dengan masalah yang berbeda di setiap cabang. Lebih aman menggunakan Jerk untuk saat ini.
XDA-Bam
pada 17 Mei 2020
JD saat ini tampaknya disadap di semua cabang
Tampaknya tidak terlalu buruk di sebagian besar rilis Marlin 1.1.x dan 2.0.x. Menarik untuk melihat bagaimana versi paling awal diuji sebagai perbandingan.
thinkyhead
pada 19 Mei 2020
JD saat ini tampaknya disadap di semua cabang
Tampaknya tidak terlalu buruk di sebagian besar rilis Marlin 1.1.x dan 2.0.x. Menarik untuk melihat bagaimana versi paling awal diuji sebagai perbandingan.
Saya masih menjalankan 1.1.9 untuk tugas-tugas produktif di Ender 3. Saya memiliki masalah yang sama dengan jerawat / ketidaksempurnaan permukaan karena gagap pada kurva saat menggunakan JD. Begitulah awalnya saya menemukan utas ini dan menjadi terlibat (lihat kiriman waaaay di utas ini).
XDA-Bam
pada 20 Mei 2020
Ini memiliki masalah yang sama dengan jerawat / ketidaksempurnaan permukaan karena gagap pada kurva saat menggunakan JD
Apakah Anda masih melihat bahwa jika Anda mengikuti "saran YouTuber" baru-baru ini untuk menyetel pemotong agar menggunakan segmen dengan panjang minimum? Ini dimaksudkan untuk menghilangkan kelaparan perencana yang menyebabkan terjadinya jeda saat mencetak banyak segmen kecil berturut-turut.
Ada juga kemungkinan masalah terkait dengan pembatasan layar di beberapa versi sebelumnya. Jika Anda mencetak dengan layar dinonaktifkan sepenuhnya, apakah Anda melihat adanya peningkatan pada kualitas permukaan?
thinkyhead
pada 20 Mei 2020
Ini memiliki masalah yang sama dengan jerawat / ketidaksempurnaan permukaan karena gagap pada kurva saat menggunakan JD
Apakah Anda masih melihat bahwa jika Anda mengikuti "saran YouTuber" baru-baru ini untuk menyetel pemotong agar menggunakan segmen dengan panjang minimum? Ini dimaksudkan untuk menghilangkan kelaparan perencana yang menyebabkan terjadinya jeda saat mencetak banyak segmen kecil berturut-turut.
Belum diperiksa. JD_single_arc_test.gcode gagap pada tiga segmen, yang panjangnya hanya ~ 0,1 mm. Itu hilang ketika saya meningkatkan #define MIN_STEPS_PER_SEGMENT menjadi 16, yang menghilangkan semua segmen yang lebih kecil dari ~ 0,2 mm dari cetakan dengan menggabungkannya ke yang berikutnya. Namun, meningkatkan ukuran buffer tidak berpengaruh.
EDIT: Beralih ke //#define SLOWDOWN juga tidak berpengaruh pada gagap. Ini akan menunjukkan, bahwa kelaparan perencana tidak terjadi di sini, bukan?
Ada juga kemungkinan masalah terkait dengan pembatasan layar di beberapa versi sebelumnya. Jika Anda mencetak dengan layar dinonaktifkan sepenuhnya, apakah Anda melihat adanya peningkatan pada kualitas permukaan?
Saat ini tidak ada setup untuk mencetak tanpa layar, maaf.
XDA-Bam
pada 20 Mei 2020
Saya melakukan beberapa tes tadi malam sebelum melompat ke Discord, tetapi tampaknya itu tidak menjadi hambatan komputasi dengan LCD. Saya mengubah interval penyegaran dari 100 menjadi 250, dan pencetakan mulai berhenti di lokasi yang sama. Saya juga mengubah tingkat pembaruan menjadi 50ms tanpa kehilangan kinerja. Ini dengan 2.0.x dengan perubahan di atas pada perencana.
Seperti disebutkan, gagap terjadi mulai dari lokasi file gcode yang sama persis di komputer saya, apa pun pengaturannya. Masalah terjadi di tempat yang sama terlepas dari kecepatannya.
Saya dapat memposting file gcode, tetapi ketahuilah bahwa ini didasarkan pada nozzle 0.8. Masalahnya sepenuhnya hilang dengan brengsek klasik.
XBrav
pada 21 Mei 2020
Seperti yang disarankan oleh @swilkens di # 18031, saya baru saja memeriksa perbaikan bug terbaru (929b3f6) dan menghapus semua kode yang terkait dengan limit_sqr dari planner.cpp (itu baris 2308 hingga 2389 ). Seperti yang diharapkan, ini menghilangkan semua gagap dari busur di JD_single_arc_test.gcode . "Jeda" singkat pada langkah terakhir sebelum homing tetap ada.
XDA-Bam
pada 25 Mei 2020
Saya telah menggunakan brengsek klasik karena masalah dengan JD, tetapi hari ini saya mengalami masalah serupa, dan masalah pergeseran lapisan terkait, dengan brengsek klasik, dijelaskan dalam komentar di sini: https://github.com/MarlinFirmware/Marlin/issues / 12403 # penerbitan -633659126
Apakah ada batasan panjang segmen yang mirip dengan brengsek klasik yang bisa menjadi penyebabnya?
richfelker
pada 25 Mei 2020
Inilah tes yang menyenangkan untuk kalian coba. Saya menggunakannya untuk menemukan kemacetan di sistem saya saat ini:
Tes ini menjalankan beberapa gerakan menggunakan y = sin (x / 360 × 2 × 3.14159) * 90, dengan siklus gerakan terakhir menggerakkan Z pada Z = Y
Ada total 5 tes:
1) Kemajuan 90 poin dari X: 0 Y: 0 ke X: 90 Y: 90 dengan kelipatan 1mm pada X.
2) 900 poin kemajuan dari X: 0 Y: 0 ke X: 90 Y: 90 dengan peningkatan 0.1mm pada X.
3) Progresi 9000 poin dari X: 0 Y: 0 ke X: 90 Y: 90 dengan peningkatan 0,01 mm pada X, dibulatkan ke presisi 0,0001.
4) Kemajuan 9000 titik dari X: 0 Y: 0 ke X: 90 Y: 90 dengan peningkatan 0,01 mm pada X, dengan presisi penuh.
5) Progresi 9000 poin dari X: 0 Y: 0 Z: 0 ke X: 90 Y: 90 Z: 90 dengan peningkatan 0,01mm pada X, dengan presisi penuh.
Berdasarkan menjalankan tes ini pada Classic Jerk, saya menemukan yang paling gagap pada tes terakhir, bahkan dengan vmax tinggi pada Z. Setelah bermain sebentar, saya menemukan ada semacam kemacetan dalam langkah Z, yaitu 400 / mm di mesin saya. Setelah mengurangi microstepping menjadi 4, dan menurunkan langkah / mm menjadi 100, ada peningkatan kecepatan yang terlihat pada pengujian 5.
Mengingat hal ini tidak secara langsung mengatasi kemacetan komputasi yang terlihat pada tiket ini, ini dapat memberikan diagnostik yang sedikit lebih baik dalam menemukan sumber kemacetan. Dengan tes ini, Anda dapat menjalankannya dengan atau tanpa perataan tempat tidur. Pastikan Anda memiliki 90mm perjalanan yang tersedia sejak awal, dan jalankan G28 terlebih dahulu (saya tidak menyertakan panggilan homing).
Sebagai catatan, pengalaman saya menggunakan BTT E3 DIP STM32F103RET6, dengan 2209 di UART untuk X, Y dan E0, dan 5160 SPI untuk Z.
XBrav
pada 25 Mei 2020
Masalah di https://github.com/MarlinFirmware/Marlin/issues/17342#issuecomment -633670626 di atas tampaknya dipicu oleh segmen yang sangat pendek. Model ini diproduksi di OpenSCAD dengan $fn=200 dan diiris dengan Cura dengan pengaturan resolusi / deviasi presisi tinggi biasa. Mereplikasi dengan default Cura menghasilkan gerakan melingkar yang mulus dan sejauh ini belum mengenai pergeseran lapisan apa pun.
richfelker
pada 27 Mei 2020
Cross-post: Saya baru saja mendapatkan kabel yang tepat dan melakukan beberapa serial debugging yang menjalankan 2.0.x-bugfix. Membandingkan hasil LUT untuk junction_theta dengan Minimax poly ( #define JD_USE_LOOKUP_TABLE vs. //#define JD_USE_LOOKUP_TABLE ). Hasil di posting ini .
EDIT: Perbarui mulai hari ini di
XDA-Bam
pada 29 Mei 2020
Saya ingin Anda semua untuk bergabung dan bertukar ide untuk mendapatkan solusi. Masalah utama kami adalah - sejauh pengetahuan saya - dijelaskan dalam posting ini . Ide diterima.
XDA-Bam
pada 10 Jun 2020
>>> Untuk semua orang yang terpengaruh oleh masalah ini <<<
Saat menggunakan bugfix-2.0.x terbaru, Anda sekarang dapat mengubah parameter config
#define JD_HANDLE_SMALL_SEGMENTS
di Configuration.h sampai
//#define JD_HANDLE_SMALL_SEGMENTS
dan dengan demikian menonaktifkan kode yang menyebabkan sebagian besar (semua?) gagap dan gumpalan permukaan. Ini adalah solusi sampai perbaikan yang sebenarnya dapat diterapkan, yang - saya kira - setidaknya beberapa bulan lagi.
XDA-Bam
pada 17 Jun 2020
Dapatkah Anda menjelaskan efek samping apa yang mungkin kita lihat dari mengaktifkan solusi ini? Tentunya ada beberapa kontra (yang tampaknya tidak disebutkan oleh PR) atau ini akan memenuhi syarat sebagai perbaikan bukan solusi.
richfelker
pada 17 Jun 2020
Ini mengembalikan perilaku Penyimpangan Persimpangan asli, seperti yang diterapkan di GRBL. Itu berarti panjang segmen tidak mempengaruhi kecepatan persimpangan. Dengan demikian, kecepatan persimpangan jalan di sepanjang jalur melengkung lebih tinggi, jalur yang diiris lebih halus (lebih banyak segmen untuk kurva yang sama ➡️ sudut lebih kecil per persimpangan ➡️ kecepatan lebih tinggi).
Dari contoh yang saya lihat, ini mencetak banyak kurva lebih cepat secara keseluruhan. Anda dapat mengatasi efek samping ini dengan meningkatkan segmen terkecil yang digunakan pemotong Anda ke nilai yang masuk akal (katakanlah, 0,5 mm).
XDA-Bam
pada 17 Jun 2020
@ XDA-Bam Saya telah menonaktifkan panggilan NOMORE(vmax_junction_sqr, limit_sqr); di planner.cpp pada setiap pembaruan.
Apakah JD_HANDLE_SMALL_SEGMENTS menonaktifkan panggilan di atas?
 Lord-Quake
pada 17 Jun 2020
Lord-Quake
pada 17 Jun 2020
@ Lord-Quake Ya. Ditambah kode yang diperlukan untuk menghitung limit_sqr , karena tidak digunakan di tempat lain.
XDA-Bam
pada 17 Jun 2020
Saya dapat mengonfirmasi dengan mengatur
//#define JD_HANDLE_SMALL_SEGMENTS
cetakan keluar seperti yang diharapkan tanpa masalah.
Lord-Quake
pada 18 Jun 2020
@ XDA-Bam: Jika saya membaca balasan Anda dengan benar, itu berarti bahwa penggunaan segmen yang cukup kecil memungkinkan bypass batas brengsek JD untuk melebihi kemampuan akselerasi fisik mesin dengan margin tak terbatas. Apakah ini benar? Dalam hal ini, menonaktifkan JD_HANDLE_SMALL_SEGMENTS hanya akan aman dengan asumsi batasan yang sesuai pada ukuran segmen diterapkan di pemotong.
richfelker
pada 21 Jun 2020
@richfelker Tidak, ini bukanlah masalahnya. Setidaknya dalam teori. Batas percepatan untuk ketiga sumbu tetap diterapkan untuk setiap persimpangan. Jika ada lebih banyak persimpangan dalam kurva tertentu, setiap persimpangan akan memiliki sudut yang lebih kecil. Itu berarti percepatan efektif per sumbu dan persimpangan juga lebih kecil, sedangkan percepatan yang diizinkan tetap sama. Ini menghasilkan kecepatan persimpangan yang lebih tinggi dan secara fisik benar.
Namun, JD dasar dengan desain tidak memperhitungkan inersia dan efek peredam dan mengasumsikan bahwa kepala cetak memasuki setiap persimpangan "tidak terganggu", yang sama sekali tidak terjadi jika setiap segmen hanya berukuran 0,1 mm. Dengan demikian, dalam praktiknya, akan ada terlalu banyak gangguan yang tersisa dari perubahan arah terakhir saat memasuki persimpangan berikutnya dalam sepersekian milimeter. Panjang yang tepat setelah Anda dapat mempertimbangkan pemindahan tanpa gangguan bervariasi per printer dan pengaturan cetak. Pada akhirnya, Anda harus menetapkan pengaturan alat pengiris yang masuk akal untuk panjang segmen terkecil dan menyetel ulang JD Anda sesuai dengan itu (-> lebih rendah).
XDA-Bam
pada 21 Jun 2020
Sama seperti pembaruan, dengan JD_HANDLE_SMALL_SEGMENTS baru, CR10s5 saya dengan SKR 1.4 Turbo menghasilkan beberapa hasil yang sangat baik. Tampaknya tidak ada perencana yang gagap saat mencetak helm Mandalorian, dan ghosting sepertinya tidak ada.
XBrav
pada 6 Jul 2020
@ XDA-Bam: Saya tidak memikirkan slicings yang semakin halus dari kurva yang sama, tetapi model di mana seluruh GCODE diproduksi oleh "penyerang" yang mencoba membuat mesin berperilaku tidak semestinya. Bahkan di bawah model itu, tidak mungkinkah menghasilkan akselerasi tak terbatas dengan segmen kecil dan JD tidak menanganinya?
richfelker
pada 7 Jul 2020
@richfelker Itu tercakup dalam jawaban terakhir saya: Secara teori, semua batas percepatan dihormati. Dalam praktiknya, kelembaman, getaran, dan efek peredam tidak tercakup dan tidak dapat diprediksi. Saya tidak dapat mengecualikan bahwa serangan semacam itu akan mendorong printer Anda di atas batasnya - terutama jika Anda mengonfigurasi akselerasi maksimum atau laju gerak makan maksimum ke nilai batas yang secara fisik aman.
Bagaimanapun, ini adalah skenario super eksotis dan mencetak GCode yang tidak dikenal selalu merupakan risiko keamanan dan tidak disarankan untuk alasan yang tepat ini. Plus, ada banyak vektor serangan tambahan yang lebih andal untuk merusak mesin (lihat contoh di sini ). Jika Anda merasa tidak nyaman menyetel #define JD_HANDLE_SMALL_SEGMENTS , jangan lakukan itu.
XDA-Bam
pada 7 Jul 2020
Memang saya sebenarnya tidak menggunakan gcode yang tidak tepercaya; itu hanya model terbaik untuk alasan dalam hal. Saya lebih memikirkan file STL dengan detail halus yang konyol, yang cukup umum di situs berbagi model yang penuh dengan hal-hal yang diproduksi oleh orang-orang grafis 3D yang tidak memahami desain untuk kemampuan cetak.
Untuk konteks tentang mengapa saya bertanya, untuk saat ini saya masih menggunakan brengsek klasik, karena saya mengalami banyak masalah dengan JD, tetapi saya mencoba melacak peningkatan dan mengukur kapan / apakah saya mungkin ingin mencobanya lagi . Mendapatkan pergeseran lapisan selama cetakan panjang benar-benar membuat frustrasi dan itulah mengapa saya sangat berhati-hati tentang apa pun yang mungkin memperkenalkan kembali gerakan melebihi batas akselerasi / jerk yang dimaksudkan.
richfelker
pada 7 Jul 2020
Oke, itu pasti skenario yang lebih mungkin. Singkatnya: Saya menggunakan Classic Jerk lagi dan saya tidak melihat diri saya beralih kembali ke JD hingga algoritme baru diterapkan, yang dapat melihat ke depan saat menghitung kecepatan persimpangan. Jika Anda konservatif dan hanya menginginkan cetakan yang andal, saya akan merekomendasikan CJ 😉
XDA-Bam
pada 7 Jul 2020
di baris planner.cpp 2335 Variabel persimpangan deviasi junction_cos_theta tampaknya dihitung dengan kecepatan ekstruder.
1 - mengapa?
2- ketika Anda menambahkan elemen ke-4 ke vektor 3D maka perkalian titik tidak sama dengan fungsi trigonometri 3D apa pun yang kita ketahui, dan oleh karena itu menurut saya inilah mengapa mengaktifkan Penyimpangan Persimpangan dan Kemajuan Linier akan menghasilkan perilaku jalur ekstruder yang tidak diketahui. bahkan jika Anda akan menggunakan koreksi kecepatan ekstruder dari kemajuan linier dalam fungsi deviasi persimpangan saya rasa Anda perlu menambahkan kecepatan itu ke kecepatan masuk dan keluar dan kemudian melakukan perhitungan untuk vektor 3D.
tolong beritahu saya mengapa saya salah.
salam
 ShadowOfTheDamn
pada 9 Jul 2020
ShadowOfTheDamn
pada 9 Jul 2020
tolong beritahu saya mengapa saya salah.
Saya tidak dapat memberi tahu Anda mengapa Anda salah - tetapi Anda salah.
Hanya karena manusia tidak dapat membayangkan sudut dalam ruangan 4 dimensi bukan berarti tidak ada.
Mungkin itu akan membantu Anda membuat lembar excel sederhana. Masukkan 2 vektor dengan 4 dimensi. Hitung panjangnya dan hasil kali titik umumnya. Akhirnya hitung sudut dari itu.
Mulailah dengan satu dimensi. Misalnya, masukkan bilangan positif ke dalam komponen x vektor pertama dan nilai positif lainnya ke dalam komponen x vektor kedua. Hasilnya akan menjadi 0 °.
Sekarang buat bilangan positif di salah satu vektor menjadi negatif. Hasilnya akan menjadi 180 °.
Tidak ada hasil yang lebih mungkin hanya dalam satu dimensi. Entah itu searah atau yang lain.
Sekarang coba hal yang sama dengan komponen y, z dan e. Jika komponen lainnya nol, Anda akan mendapatkan hasil yang persis sama.
Selanjutnya coba dalam dua dimensi (x, y) dan rasakan bagaimana sudut berubah ketika Anda mengubah nilainya.
Setelah itu coba dua dimensi tetapi (x, z), (x, e), (y, z) dan seterusnya. Itu semua berperilaku baik dan Anda harus bisa membayangkan sudutnya.
Setelah itu cobalah untuk mengisi 3 dimensi - jadi biarkan satu komponen selalu nol. Terlepas dari komponen apa yang Anda tinggalkan nol, Anda harus dapat memvisualisasikan 3 yang tersisa sebagai sistem 3 dimensi normal hanya dengan mengabaikan dimensi keempat.
Apa yang harus Anda atur untuk mendapatkan 0 °, 180 ° atau 90 °. (coba angka sederhana seperti 0 dan + -1)
Terakhir tambahkan komponen dimensi keempat. Coba lagi untuk menghasilkan sudut 0 °, 90 °, 180 °.
Apakah itu mengikuti aturan yang sama seperti di 3-dimensi?
Apakah itu terlihat dapat dipercaya bagi Anda? Bagi saya itu bisa.
AnHardt
pada 9 Jul 2020
1 - mengapa?
Karena untuk sumbu-e sebagai (im) memungkinkan untuk membuat perubahan kecepatan secara tiba-tiba seperti yang lainnya. (Tidak - kami tidak melanggar fisika dengan percepatan tak terbatas )
'persimpangan simpangan' sebenarnya hanya satu, secara matematis relatif murah, cara menghitung kecepatan untuk sudut itu - jalur tidak akan mengikuti segmen lingkaran yang dibayangkan.
AnHardt
pada 9 Jul 2020
Terima kasih atas balasannya tetapi Anda salah.
sekarang izinkan saya memberi tahu Anda beberapa fisika,
inersia ekstrusi tidak berhubungan dengan gerakan kepala secara logis. Extruder inersia atau lag dikendalikan oleh gerak maju linier dan akselerasi Kurva S jadi jangan beri tahu saya bahwa kita mendapatkan akselerasi tak terbatas.
penggunaan deviasi persimpangan pada ekstruder harus dipisahkan dari gerakan kepala XYZ. yang bening seperti kaca. jenis inersia di head berasal dari massa yang bergerak dari head sedangkan inersia ekstruder terutama disebabkan oleh gaya ekstrusi plastik dan terkait dengan viskositas cairan non-Newtonian dari plastik cair.
ShadowOfTheDamn
pada 9 Jul 2020
deviasi persimpangan untuk ekstruder harus dihitung untuk vektor 1D, yang saya yakin Linear advance akan melakukannya dengan benar.
sementara itu dihitung untuk vektor gerakan 3D untuk gerakan XYZ. Hubungan antara kecepatan minimum ekstruder dan perubahan kecepatan gerakan maksimum adalah karena tinggi lapisan dan diameter nosel dan ketika perubahan kecepatan maksimum ekstruder lebih rendah, ini akan menghubungkan sistem dengan gerakan dan sebaliknya.
ShadowOfTheDamn
pada 9 Jul 2020
Dalam mesin seperti Pusa-i3 tidak ada sumbu yang bergantung. Kelambanan umum atau 'Gaya sentrifugal' dalam lingkaran sama sekali tidak relevan / ada. Dalam sistem CORE- atau DELTA- jauh lebih rumit. Dalam semua kasus massa yang bergerak berbeda untuk sumbu yang berbeda.
Untuk itu saya katakan hanya satu model untuk menghitung beberapa kecepatan di tikungan. Ini menghitung kecepatan yang lebih rendah untuk sudut yang lebih tajam dan lebih tinggi untuk sudut yang tidak terlalu tajam dalam ruangan multidimensi. Itu benar. Setidaknya, ketika disarankan, tampaknya lebih baik daripada 'kecepatan brengsek' tetap dari 'brengsek klasik'.
Perhitungan 'ketajaman' sudut pada ruangan yang lebih dari 3 dimensi sepertinya benar - itulah poin utama saya .
The "harapan" 'persimpangan deviasi' bisa menjadi model "benar" dari fisika yang terlibat salah - itu tidak pernah dimaksudkan. Untuk itu - itu jauh lebih sederhana.
'Linear advance' dan 'S-Curve-Acceleration' bukan tentang kecepatan di persimpangan.
Jika Anda telah mengikuti tautan saya, Anda akan melihat mengapa akselerasi 'brengsek klasik' yang tampaknya tak terbatas adalah mungkin. (Karena pada saat itu hanya medan magnet yang melompat - yang mempercepat massa)
AnHardt
pada 9 Jul 2020
sebenarnya definisi penyimpangan persimpangan itu sendiri mendefinisikan percepatan tak terbatas, seperti brengsek (tolong ganti nama variabel karena salah dipahami, sesuatu seperti perubahan kecepatan seketika maksimum akan baik)), deviasi persimpangan hanya menggunakan sudut sudut untuk menentukan kecepatan persimpangan alih-alih menggunakan kecepatan tetap dalam definisi brengsek. Jadi kita menggerakkan bingkai printer dengan pulsa langkah, menggunakan sentakan berbeda atau deviasi persimpangan akan menghasilkan energi kinetik yang berbeda dan sehubungan dengan redaman sistem bergerak akan menghasilkan riak di sudut. ini dapat dengan mudah diverifikasi dengan mengukur jarak riak dan tinggi tonjolannya untuk berbagai percepatan dan kecepatan cetak. Anda akan menemukan frekuensi getaran yang sama. Jadi percepatan tak hingga (dibutuhkan gaya tak hingga pada momen itu yang akan menghasilkan gerak langkah dan getaran sistem gerak). seperti yang Anda katakan penyimpangan persimpangan adalah metode yang sangat sederhana. Metode canggih diperlukan untuk sistem di setiap sumbu atau bahkan gerakan multi sumbu untuk gerakan sempurna yang mengkompensasi getaran online.
dengan mengurangi simpangan simpangan atau sentakan anda mengurangi kecepatan dan energi aktuasi yang akan menghasilkan frekuensi dan jarak riak yang sama pada permukaan benda tetapi dengan ketinggian benturan yang lebih rendah.
jadi untuk menghapus artefak itu, Anda memiliki tiga pilihan (setidaknya ketiganya hanya ada dalam pikiran saya):
1- membuat kerangka printer yang sangat sangat kaku (maksud saya bahkan bagian yang bergerak harus memiliki kekakuan yang baik) jadi frekuensi alami pertama yang selalu menyerap sebagian besar energi menjadi sangat tinggi terkait kecepatan printer sehingga getarannya lembab begitu cepat agar permukaan tidak terpengaruh dalam gerakan kepala yang panjang.
2- Turunkan kecepatan dan percepatan pencetakan yang sekali lagi akan menghasilkan jarak getaran yang lebih rendah di sepanjang jalur pergerakan head
3- Membuat kontrol yang canggih yang memperkirakan dan mengimbangi jalur pergerakan head terkait dengan arah dan frekuensi sistem (hampir tidak mungkin selama setidaknya satu abad karena kebutuhan daya komputasi untuk perhitungan semacam itu)
jadi untuk menyimpulkan deviasi persimpangan hanya membantu printer / perencana untuk memilih kecepatan sentakan yang lebih sesuai sehubungan dengan sudut dan kelengkungan persimpangan.
Percepatan kurva s hanya akan membantu kontinyu dan sentakan yang dapat dibedakan (turunan percepatan) serta percepatan dan kecepatan serta posisi gerakan linier.
gerak maju linier akan mengimbangi lead dan lag dari tekanan ekstruder. (buat tekanan ekstruder berlanjut dan mungkin dapat dibedakan)
setiap pengontrol ini harus terpisah dan independen satu sama lain atau mereka membuat ketidakstabilan dalam algoritme pengontrolnya.
siapa pun yang ingin menghapus ghosting atau artefak serupa jangan gunakan opsi ini. opsi ini dapat mengurangi ghosting tetapi tidak akan menghapusnya.
untuk printer gaya prusa atau i3 yang telah Anda sebutkan, seperti yang telah Anda katakan sebelumnya penyimpangan persimpangan adalah algoritma yang sangat sederhana dan murah dan jika Anda ingin mengontrol printer gaya i3 Anda harus mengontrol semua sumbu secara terpisah.
sekarang beberapa jenius mengatakan itu mudah untuk gerakan 1 sumbu tetapi apa yang akan Anda lakukan untuk gerakan multi sumbu yaitu bergerak di garis x = y.
jawabannya sangat sederhana, bahkan lebih sederhana dari algoritma penyimpangan persimpangan.
kecepatan yang dihasilkan di sini x = y adalah sesuatu seperti vektor (V_x, V_y) di mana V_x = V_y
kami menggunakan kecepatan yang diproyeksikan pada setiap sumbu karena percepatan maksimum yang dapat ditoleransi dengan setiap sumbu berbeda dalam hal massanya. (Anda dapat memahami saya dengan membayangkan gerakan 2d seperti lingkaran) sekarang jika Anda menghilangkan sumbu X Anda melihat bahwa sumbu Y hanya bergerak maju mundur dengan kecepatan yang diproyeksikan V pada sumbu Y yaitu V_y sehingga Anda dapat mengontrol getarannya dengan mengendalikan V_y
hanya agar singkatnya hal yang sama diterapkan untuk sumbu X.
untuk Core-XY getaran pada sumbu Y akan mengakibatkan pergeseran sumbu X (tegangan sabuk) yang kemudian dapat ditambahkan ke kecepatan sumbu x yang diproyeksikan
tetapi untuk delta matematika lebih rumit.
jadi setiap mesin membutuhkan akselerasi dan kontrol JD / Jerk yang berbeda dan keduanya tidak universal.
bila perubahan kecepatan maksimum di sumbu mana pun mencapai nilai kritis, semua kecepatan sistem akan diperkecil secara aman ke kecepatan yang benar dengan rasio tunggal tersebut.
Begitulah cara saya melihat mekanisme pergerakan yang lebih sederhana dan lebih baik.
ShadowOfTheDamn
pada 9 Jul 2020
Jika Anda tertarik dengan 'dering', ada beberapa strategi yang sangat berbeda yang dibahas dalam "[FR] (Algoritme praktis disediakan) Kompensasi getaran" # 16531.
1 - buat kerangka printer yang sangat sangat kaku
Itu saja tidak akan banyak membantu. Ini juga akan membutuhkan arus yang sangat sangat tinggi di kumparan stepper untuk menghasilkan momen yang sangat sangat tinggi. Jika tidak, rotor steppers akan berosilasi di bidang dengan frekuensi paling rendah.
Untuk penurunan amplitudo yang lebih cepat, beberapa resistansi lebih banyak akan membantu - semacam putus - dan daripada lebih banyak daya.
AnHardt
pada 10 Jul 2020
1 - mengapa?
2- ketika Anda menambahkan elemen ke-4 ke vektor 3D maka perkalian titik tidak sama dengan fungsi trigonometri 3D apa pun yang kita ketahui, dan oleh karena itu menurut saya inilah mengapa mengaktifkan Penyimpangan Persimpangan dan Kemajuan Linier akan menghasilkan perilaku jalur ekstruder yang tidak diketahui. bahkan jika Anda akan menggunakan koreksi kecepatan ekstruder dari kemajuan linier dalam fungsi deviasi persimpangan saya rasa Anda perlu menambahkan kecepatan itu ke kecepatan masuk dan keluar dan kemudian melakukan perhitungan untuk vektor 3D.
Saya pikir @ShadowOfTheDamn mungkin benar, ada yang mau mencobanya?
thierryzoller
pada 10 Jul 2020
Saya telah mencoba dan menghapus kecepatan ekstruder dari perhitungan sudut deviasi persimpangan Anda perlu mengubah cpp perencana:
float junction_cos_theta = (-prev_unit_vec.x * unit_vec.x) + (-prev_unit_vec.y * unit_vec.y)
+ (-prev_unit_vec.z * unit_vec.z) + (-prev_unit_vec.e * unit_vec.e);
UNTUK
float junction_cos_theta = (-prev_unit_vec.x * unit_vec.x) + (-prev_unit_vec.y * unit_vec.y)
+ (-prev_unit_vec.z * unit_vec.z);
dan perencana.h:
FORCE_INLINE static void normalize_junction_vector(xyze_float_t &vector) {
float magnitude_sq = 0;
LOOP_XYZE(idx) if (vector[idx]) magnitude_sq += sq(vector[idx]);
vector *= RSQRT(magnitude_sq);
}
FORCE_INLINE static float limit_value_by_axis_maximum(const float &max_value, xyze_float_t &unit_vec) {
float limit_value = max_value;
LOOP_XYZE(idx) {
if (unit_vec[idx]) {
if (limit_value * ABS(unit_vec[idx]) > settings.max_acceleration_mm_per_s2[idx])
limit_value = ABS(settings.max_acceleration_mm_per_s2[idx] / unit_vec[idx]);
}
}
return limit_value;
}
UNTUK
FORCE_INLINE static void normalize_junction_vector(xyze_float_t &vector) {
float magnitude_sq = 0;
LOOP_XYZ(idx) if (vector[idx]) magnitude_sq += sq(vector[idx]);
vector *= RSQRT(magnitude_sq);
}
FORCE_INLINE static float limit_value_by_axis_maximum(const float &max_value, xyze_float_t &unit_vec) {
float limit_value = max_value;
LOOP_XYZ(idx) {
if (unit_vec[idx]) {
if (limit_value * ABS(unit_vec[idx]) > settings.max_acceleration_mm_per_s2[idx])
limit_value = ABS(settings.max_acceleration_mm_per_s2[idx] / unit_vec[idx]);
}
}
return limit_value;
}
dan juga menggunakan steps_dist_mm.a dan steps_dist_mm.b sebagai ganti steps_dist_mm.x dan steps_dist_mm.y di baris planner.cpp 2315 saat mendeklarasikan variabel unit_vec untuk pengaturan inti-XY saya. lol hasilnya sekarang lebih baik tanpa akselerasi dan perlambatan yang aneh terjadi dan juga menurunkan dering di sudut tajam.
Hanya perlu menambahkan beberapa kontrol untuk deviasi persimpangan maksimum ekstruder. (tapi aku tahu itu tidak berguna)
Itu sebabnya: akselerasi ekstruder default marlin adalah 10000 dan perubahan kecepatan ekstruder maksimum adalah 5mm / s dalam pengaturan brengsek.
5 mm / s untuk nosel 0,4 mm dengan tinggi lapisan 0,2 berarti perubahan kecepatan nosel 150 mm / dtk yang jelas tidak terjadi saat mencetak.
Saya menggunakan M204 P1250 R1250 T1250
dan M205 J0.03 untuk pengaturan saya.
ShadowOfTheDamn
pada 10 Jul 2020
Gambar dengan sebelum dan sesudah atau tidak terjadi 😉
Lord-Quake
pada 10 Jul 2020
lol ini dia:
Gambar dengan sebelum dan sesudah atau tidak terjadi 😉
pergi setelah, tepat sebelumnya.
tolong bersikap sopan dan jangan meragukan orang lain.
Jadi sekarang itu terjadi. Sekarang saatnya kalian mengatakan bahwa saya salah.
ShadowOfTheDamn
pada 10 Jul 2020
Oke, sekarang kita punya sesuatu untuk dilakukan :-)
Saya ingin Anda memposting pengaturan yang tepat, tinggi lapisan, jenis isian, persentase, kecepatan cetak dinding luar ... berfungsi .....
LA ON / OFF pada pengaturan apa? Nilai JD apa yang Anda gunakan dan hanya untuk referensi printer apa.
Juga posting link stl dari benda uji.
Saya penasaran secara alami :-)
Lord-Quake
pada 10 Jul 2020
BAIK,
S3D
tinggi lapisan 0.2
mengisi 20%, bujursangkar,
dinding luar 37.5mm / s, cangkang 75mm / s, isi 60mm / s
LA aktif, K = 0,14
JD = 0,0309
Printer adalah buatan rumah.
tautan stl: https://www.thingiverse.com/thing : 277394
ShadowOfTheDamn
pada 10 Jul 2020
@ShadowOfTheDamn dapatkah Anda memberikan tambalan sehingga - individu yang kurang paham seperti saya - juga dapat memposting hasil mereka? Saya juga menggunakan CORExy dan hasil saya terlihat seperti milik Anda di sebelah kanan.
thierryzoller
pada 10 Jul 2020
gunakan perbaikan bug terbaru dengan file-file berikut alih-alih yang ada di
.. \ Marlin \ Marlin \ src \ modul:
Saya menggunakan M204 P1250 R1250 T1250
dan M205 J0.0309 untuk pengaturan saya.
Sederhanakan 3D
tinggi lapisan 0.2
mengisi 20%, bujursangkar,
dinding luar 37.5mm / s, cangkang 75mm / s, isi 60mm / s
LA aktif, K = 0,14
JD = 0,0309
Printer adalah buatan rumah.
tautan stl: https://www.thingiverse.com/thing : 277394
ShadowOfTheDamn
pada 10 Jul 2020
Seperti yang saya sebutkan, saya penasaran jadi saya berteriak pada Ender 3 saya dan memotong pengaturan yang Anda berikan. Sayangnya Anda melewatkan ".... karya ..." jadi pengaturan yang hilang adalah asumsi di pihak saya. Misal nozzle 0.4mm, 2 perimeter, bottom / top infill 4 layer, ....
Dan saya meningkatkan bibi dengan menggunakan kecepatan cetak dinding luar 40mm / s.
Gambar close up selalu menampilkan lebih banyak detail daripada mata telanjang jadi di sini hasil saya tanpa melakukan mengutak-atik seperti penempatan jahitan dan sejenisnya (gambar kubus yang sama).

Dicetak dengan Marlin STRING_DISTRIBUTION_DATE "2020-06-29"
Dicetak sebagai referensi untuk perbandingan di masa mendatang dan untuk diskusi.
Saya akan menahan diri dari komentar apa pun sesuai persyaratan kesopanan :-)
Lord-Quake
pada 10 Jul 2020
@ Lord-Quake: Saya tidak yakin yang mana sebelum dan sesudah, mengapa menunjukkan sisi yang berbeda? Apakah Anda mencoba untuk menunjukkan bahwa Anda tidak memiliki riak atau sebelum dan sesudah tambalan. Jika yang pertama, saya tidak yakin apa yang memberikan kontribusi :)
thierryzoller
pada 10 Jul 2020
Ya, saya harus menambahkan itu kubus yang sama. (Saya mengedit posting saya)
Secara pribadi saya tidak melihat masalah dalam kode ini jika dibandingkan dengan contoh yang diposting oleh ShadowOfTheDamn. Tapi sejauh itu yang akan saya lakukan karena alasan kesopanan :-)
Namun saya punya referensi jika ternyata kesimpulannya adalah kode yang ada sekarang ini kurang optimal.
Lord-Quake
pada 10 Jul 2020
Seperti yang saya sebutkan, saya penasaran jadi saya berteriak pada Ender 3 saya dan memotong pengaturan yang Anda berikan. Sayangnya Anda melewatkan ".... karya ..." jadi pengaturan yang hilang adalah asumsi di pihak saya. Misal nozzle 0.4mm, 2 perimeter, bottom / top infill 4 layer, ....
Dan saya meningkatkan bibi dengan menggunakan kecepatan cetak dinding luar 40mm / s.Gambar close up selalu menampilkan lebih banyak detail daripada mata telanjang jadi di sini hasil saya tanpa melakukan mengutak-atik seperti penempatan jahitan dan sejenisnya (gambar kubus yang sama).
Dicetak dengan Marlin STRING_DISTRIBUTION_DATE "2020-06-29"
Dicetak sebagai referensi untuk perbandingan di masa mendatang dan untuk diskusi.
Terima kasih balasannya
Pengaturannya tepat nozzle 0,4 mm dan 2 dinding 4 bot dan lapisan atas.
Pertama-tama saya berbicara tentang konfigurasi inti xy saya. Jadi ender 3?
Kedua, bagian saya tidak menunjukkan dering apa pun pada sumbu Y (memiliki tanda dering yang sangat samar)
Ketiga, karena Anda telah meminta saya, beri tahu kami konfigurasi Anda, misalnya, penyimpangan persimpangan percepatan dan ....
Keempat slicer apa yang Anda gunakan, jangan biarkan slicer mengurangi kecepatan cetak sehubungan dengan waktu layer. Saya menggunakan waktu lapisan minimum 5 detik.
Saya di sini untuk membantu diri saya sendiri meningkatkan kualitas cetak saya dan dengan caranya mungkin, hanya mungkin membantu orang lain juga.
ShadowOfTheDamn
pada 10 Jul 2020
Ya, saya harus menambahkan itu kubus yang sama. (Saya mengedit posting saya)
Secara pribadi saya tidak melihat masalah dalam kode ini jika dibandingkan dengan contoh yang diposting oleh ShadowOfTheDamn. Tapi sejauh itu yang akan saya lakukan karena alasan kesopanan :-)
Namun saya punya referensi jika ternyata kesimpulannya adalah kode yang ada sekarang ini kurang optimal.
Jadi apa yang Anda tunjukkan adalah bahwa Anda tidak memiliki masalah yang jelas, ok, bagi mereka yang memilikinya, tambalannya mungkin berfungsi membuktikan maksudnya tentang arsitektur yang selaras JD
thierryzoller
pada 10 Jul 2020
Ini adalah subjek yang menarik dan saya memiliki pengaturan referensi untuk perubahan kode akhirnya.
Lord-Quake
pada 10 Jul 2020
Maaf, untuk mundur sedikit ke masa lalu, tetapi diskusi ini berkembang sangat cepat. Saya memiliki beberapa komentar tentang aspek yang disebutkan @ShadowOfTheDamn :
jadi untuk menghapus artefak itu, Anda memiliki tiga pilihan (setidaknya ketiganya hanya ada dalam pikiran saya):
1- membuat kerangka printer yang sangat sangat kaku (maksud saya bahkan bagian yang bergerak harus memiliki kekakuan yang baik) jadi frekuensi alami pertama yang selalu menyerap sebagian besar energi menjadi sangat tinggi terkait kecepatan printer sehingga getarannya lembab begitu cepat agar permukaan tidak terpengaruh dalam gerakan kepala yang panjang.
2- Turunkan kecepatan dan percepatan pencetakan yang sekali lagi akan menghasilkan jarak getaran yang lebih rendah di sepanjang jalur pergerakan head
3- Membuat kontrol yang canggih yang memperkirakan dan mengimbangi jalur pergerakan head terkait dengan arah dan frekuensi sistem (hampir tidak mungkin selama setidaknya satu abad karena kebutuhan daya komputasi untuk perhitungan semacam itu)
Sangat kaku, atau sangat basah - jadi mungkin empat pilihan.
jadi untuk menyimpulkan deviasi persimpangan hanya membantu printer / perencana untuk memilih kecepatan sentakan yang lebih sesuai sehubungan dengan sudut dan kelengkungan persimpangan.
Percepatan kurva s hanya akan membantu kontinyu dan sentakan yang dapat dibedakan (turunan percepatan) serta percepatan dan kecepatan serta posisi gerakan linier.
gerak maju linier akan mengimbangi lead dan lag dari tekanan ekstruder. (buat tekanan ekstruder berlanjut dan mungkin dapat dibedakan)
setiap pengontrol ini harus terpisah dan independen satu sama lain atau mereka membuat ketidakstabilan dalam algoritme pengontrolnya.
Algoritme ini tidak bisa semuanya independen, karena beberapa bekerja pada bagian dan motor yang sama. Anda dapat membuatnya berjalan independen dalam perangkat lunak, tetapi hasil pada perangkat keras akan ditumpangkan sebagian. Mungkin yang terbaik adalah sudah meramalkan interaksi ini di perangkat lunak kontrol.
siapa pun yang ingin menghapus ghosting atau artefak serupa jangan gunakan opsi ini. opsi ini dapat mengurangi ghosting tetapi tidak akan menghapusnya.
Nah ... tidak ada tongkat ajaib untuk menghapus artefak ini, dan konfigurasi yang benar & pengaturan cetak dapat membuatnya tidak terlihat. Jadi saya tidak akan terlalu kasar untuk tidak merekomendasikan penggunaannya.
untuk printer gaya prusa atau i3 yang telah Anda sebutkan, seperti yang telah Anda katakan sebelumnya penyimpangan persimpangan adalah algoritma yang sangat sederhana dan murah dan jika Anda ingin mengontrol printer gaya i3 Anda harus mengontrol semua sumbu secara terpisah.
sekarang beberapa jenius mengatakan itu mudah untuk gerakan 1 sumbu tetapi apa yang akan Anda lakukan untuk gerakan multi sumbu yaitu bergerak di garis x = y.
jawabannya sangat sederhana, bahkan lebih sederhana dari algoritma penyimpangan persimpangan.
kecepatan yang dihasilkan di sini x = y adalah sesuatu seperti vektor (V_x, V_y) di mana V_x = V_y
kami menggunakan kecepatan yang diproyeksikan pada setiap sumbu karena percepatan maksimum yang dapat ditoleransi dengan setiap sumbu berbeda dalam hal massanya. (Anda dapat memahami saya dengan membayangkan gerakan 2d seperti lingkaran) sekarang jika Anda menghilangkan sumbu X Anda melihat bahwa sumbu Y hanya bergerak maju mundur dengan kecepatan yang diproyeksikan V pada sumbu Y yaitu V_y sehingga Anda dapat mengontrol getarannya dengan mengendalikan V_y
hanya agar singkatnya hal yang sama diterapkan untuk sumbu X.
untuk Core-XY getaran pada sumbu Y akan mengakibatkan pergeseran sumbu X (tegangan sabuk) yang kemudian dapat ditambahkan ke kecepatan sumbu x yang diproyeksikan
tetapi untuk delta matematika lebih rumit.jadi setiap mesin membutuhkan akselerasi dan kontrol JD / Jerk yang berbeda dan keduanya tidak universal.
bila perubahan kecepatan maksimum di sumbu mana pun mencapai nilai kritis, semua kecepatan sistem akan diperkecil secara aman ke kecepatan yang benar dengan rasio tunggal tersebut.
...
Saya agak setuju. Saya telah mengatakan sebelumnya bahwa pada dasarnya kita perlu melihat batas bagian bergerak dasar dari setiap printer:
- Grup 1: Satu percepatan dan satu batas sentakan "nyata" (da / dt) per sumbu gerakan (sebut saja A, B, C)
(pada Delta, Anda mungkin memerlukan enam, bukan tiga batas per sumbu, untuk menutupi gerakan horizontal dan vertikal kolom secara terpisah) - Grup 2: Satu percepatan dan satu batas sentakan "nyata" per motor (A, B, C + ekstruder E, opsional A2, B2, dll.)
- Grup 3: Satu percepatan dan satu sentakan "nyata" untuk print head
Bergantung pada penyiapan printer apa yang Anda gunakan, Anda akan dapat menggabungkan beberapa batasan. Pada kartesius, sumbu A, B dan C dan motor A, B dan C dapat berbagi satu set batas masing-masing dan kepala cetak biasanya terikat ke batas sumbu A & B. Pada CoreXY, ini berbeda dan batas gerakan A dan B ditentukan dalam sistem koordinat yang diputar. Di Delta, berbeda lagi.
Jika Anda ingin mengerjakan ulang sistem kontrol gerak, saya akan mulai dengan pendekatan yang lebih kompleks seperti ini. Jika nanti kita melihat, bahwa kita tidak memerlukan beberapa parameter pada printer yang sebenarnya, kita masih bisa "membodohi" hanya di file konfigurasi.
XDA-Bam
pada 10 Jul 2020
@ShadowOfTheDamn membuat poin yang menarik. Melihat apa yang sebenarnya dilakukan Persimpangan Deviasi, sangat mengejutkan melihat vektor ekstruder dalam perhitungan.
Kepala bergerak terutama di ruang X, Y, Z juga - tetapi gerakannya sangat terbatas, kami mungkin mencoba mengabaikannya untuk lebih menyederhanakannya.
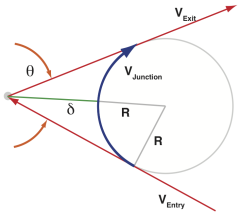
Mengingat bahwa @ XDA-Bam melihat ini secara ekstensif selama periode terakhir, apakah Anda melihat alasan mengapa vektor ekstruder menjadi bagian dari perhitungan ini?
Sumber relevan:
[1] https://onehossshay.wordpress.com/2011/09/24/improving_grbl_cornering_algorithm/
[2] https://reprap.org/forum/read.php?1 , 739819
[3] http://blog.kyneticcnc.com/2018/10/computing-junction-deviation-for-marlin.html
swilkens
pada 12 Jul 2020
Tidak, saya setuju. Saya juga bertanya-tanya tentang ini. Saya juga menyarankan di suatu tempat, bahwa ekstruder harus ditangani secara terpisah, tetapi tidak ingat di masalah mana. Saya tidak ingin mengubahnya, karena saya tidak 100% yakin mengapa (nilai-E) awalnya disertakan dan saya curiga itu mungkin merusak beberapa fitur / konfigurasi printer yang tidak jelas saat dihapus. Pada titik ini, akan sangat membantu jika penulis asli baris-baris tersebut dapat menjelaskan hal ini.
XDA-Bam
pada 12 Jul 2020
Sepertinya kami awalnya tidak menyertakan E, bahkan memiliki opsi untuk mengecualikannya yang diaktifkan secara default. Tapi itu diaktifkan secara default di sini oleh @ Sebastianv650
https://github.com/MarlinFirmware/Marlin/pull/10906
Banyak sekali pembahasan sebelumnya tentang ini di sini, kebanyakan tentang menghubungkan kecepatan persimpangan di lokasi lompatan kecepatan sumbu:
https://github.com/MarlinFirmware/Marlin/issues/9917
Membaca sejarah sekarang, masih aneh bagiku.
swilkens
pada 12 Jul 2020
Bisakah kita memasukkan mod @ShadowOfTheDamn ke dalam agenda COREXY? Apakah kita membutuhkan lebih banyak tes?
thierryzoller
pada 31 Jul 2020
@thierryzoller : Saya telah melewatkan dua utas yang disarankan @swilkens . Ini tidak semudah menghilangkan gerakan ekstruder dari perhitungan. Dari apa yang saya pahami, masalahnya adalah Marlin menggunakan kecepatan persimpangan yang salah (terlalu tinggi / terlalu rendah) di JD ketika gerakan ekstruder tidak diperhitungkan. Ini memengaruhi beberapa sakelar tertentu dari retract / un-retract ke print atau travel move.
Pada dasarnya, next_entry_speed salah dalam kasus tersebut, karena ini juga berlaku untuk gerakan khusus ekstruder. Setidaknya sejauh yang saya mengerti tentang diskusi di utas tersebut. Ini adalah masalah dari struktur kode saat ini dan harus diperbaiki _sebelum_ kita mengambil gerakan ekstruder dari perhitungan JD. Jadi, pada akhirnya, kami harus menangani batas kecepatan ekstruder secara mandiri seperti yang disarankan sebelumnya oleh orang lain dan saya sendiri. Sayangnya, saat ini saya tidak punya waktu untuk membahas ini lebih jauh.
XDA-Bam
pada 3 Agu 2020
Masalah ini basi karena telah dibuka selama 30 hari tanpa aktivitas. Hapus label / komentar basi atau ini akan ditutup dalam 5 hari.
![github-actions[bot] picture](https://avatars2.githubusercontent.com/in/15368?v=4&s=40) github-actions[bot]
pada 3 Sep 2020
github-actions[bot]
pada 3 Sep 2020
ada berita?
ShadowOfTheDamn
pada 4 Sep 2020
@ Boelle : Apa kesimpulan dari masalah ini? Apakah ini benar-benar terselesaikan (rilis yang mana?) Atau hanya sesuatu yang tidak dapat diselesaikan saat ini?
Apakah Anda menyarankan tetap menggunakan CLASSIC_JERK atau menggunakan JUNCTION_DEVIATION untuk Marlin 2.0.6?
 SidShetye
pada 15 Sep 2020
SidShetye
pada 15 Sep 2020
saya tidak tahu, saya baru saja menambahkan label basi karena "ada berita?" tidak masuk akal untuk menghapus label
pribadi saya tidak menggunakan JD atau barang baru yang mewah, brengsek classick dll berfungsi dengan baik
 boelle
pada 16 Sep 2020
boelle
pada 16 Sep 2020
Mengapa Anda melakukan ini @boelle? Basi berarti orang benar-benar mengabaikan hal-hal, yang jelas tidak terjadi di sini.
 sjasonsmith
pada 16 Sep 2020
sjasonsmith
pada 16 Sep 2020
Masalah ini tidak ada aktivitas dalam 30 hari terakhir. Harap tambahkan balasan jika Anda ingin masalah ini tetap aktif, jika tidak maka akan ditutup secara otomatis dalam 7 hari.
github-actions[bot]
pada 17 Okt 2020
Jangan tutup. Bot buruk 😉
XDA-Bam
pada 24 Okt 2020
Masalah saya ditutup meskipun hanya terkait dengan yang satu ini.
Gagap saat bergerak Diagonal dengan JD aktif dan driver TMC2209
https://github.com/MarlinFirmware/Marlin/issues/20029
Video 1: https://youtu.be/kngqQIPUP1c
_JD Diaktifkan (Lihat Gerakan Diagonal)
Video 2: https://youtu.be/yOadfORpKuw
Classic Jerk Enabled (Lihat - TMC 2209 Hybrid Threshold gerakan lurus tapi berisik)
Deskripsi Bug
Mengaktifkan Deviasi Persimpangan menyebabkan gerakan XY Diagonal yang tersendat. Lihat Video di bawah.
Menonaktifkan JD menyelesaikan masalah.
File Konfigurasi
Marlin.zip
Mode UART TMC2209
Hybrid Threshold (tidak mengubah efeknya)
informasi tambahan
Video 1: https://youtu.be/kngqQIPUP1c
_JD Diaktifkan (Lihat Gerakan Diagonal)
Video 2: https://youtu.be/yOadfORpKuw
Classic Jerk Enabled (Lihat - TMC 2209 Hybrid Threshold gerakan lurus tapi berisik)
thierryzoller
pada 6 Nov 2020
hapus ekstruder dari kalkulasi JD. Itu cara termudah yang bisa saya pikirkan. gerakan extruder hanya bolak-balik tidak perlu JD.
ShadowOfTheDamn
pada 6 Nov 2020
@ShadowOfTheDamn : Saya tidak yakin ini dapat diterapkan, bagaimana gerakan ekstruder akan memengaruhi gerakan Diagonal XY yang tersendat di video saya?
thierryzoller
pada 7 Nov 2020
Menghapus E dari kalkulasi JD bukanlah solusi terbaik untuk ini. (lihat di sini https://github.com/MarlinFirmware/Marlin/issues/17342#issuecomment-657256980)
Kami dulu tidak memiliki E di JD tetapi ini menyebabkan terputusnya akselerasi lokal, menyebabkan lompatan tiba-tiba.
Sayangnya, ini masih bukan masalah langsung.
swilkens
pada 7 Nov 2020
Hanya menambahkan, saya memiliki pengaturan yang sama (TMC2209) pada COREXY saya dan saya tidak memiliki gerakan diagonal yang tersendat-sendat.
Jika ada yang membutuhkan pengujian bug saat mencoba meningkatkan perencana - saya tersedia.
thierryzoller
pada 11 Nov 2020
sunting: analisis gcode ternyata ada yang aneh di gcode yang akan saya selidiki dulu ...
Jangan berpikir ini adalah tempat terbaik, tetapi juga tidak tahu apakah itu layak untuk edisi baru ...?!
Ini terkait dengan Junction_deviation, karena saya mengujinya dan tidak menyelesaikan gagap ...:)
Saya mencoba mengoptimalkan kecepatan printer fdm besar (600x1000x600) mm dengan menyetel marlin, tetapi beberapa hal tidak begitu jelas bagi saya dan tidak dapat menemukannya di lebih baik / masalah github lainnya ...
Dengan garis resolusi tinggi gerakannya mulus (bagus ... !!!) tapi dengan garis resolusi rendah gerakannya tersendat-sendat.
Saya perhatikan karena permukaannya sangat halus saat classic brengsek diaktifkan dan banyak mendorong kecepatan dan permukaannya masih mulus. Gerakan 'sambungkan garis pengisi' terputus-putus, dan garis tersebut memiliki resolusi yang lebih rendah.
Apa yang terjadi, apakah brengsek bekerja pada jalur resolusi tinggi dan bukan pada jalur resolusi rendah ?! atau sebaliknya ?!
Bisakah ini secara teoritis diselesaikan dengan mengubah pengaturan brengsek dan akselerasi ...?!
Dengan JUNCTION_DEVIATION, dalam kasus saya, kualitas saya kurang dibandingkan dengan brengsek 'klasik' yang diaktifkan.
(Penafian kecil, saya masih harus menguji pengaturan dengan firmware 2.0.7.2, hasil ini dengan 2.0.5.3, saya mencoba memperbarui ke 2.0.7.2 untuk melihat apakah saya mendapatkan hasil yang lebih baik dengan 'gerakan busur)
 rooiejoris
pada 19 Nov 2020
rooiejoris
pada 19 Nov 2020
Masalah terkait
 W8KDB
·
4Komentar
W8KDB
·
4Komentar
 Matts-Hub
·
3Komentar
Matts-Hub
·
3Komentar
 manianac
·
4Komentar
manianac
·
4Komentar
 Tamonir
·
3Komentar
Tamonir
·
3Komentar
 jerryerry
·
4Komentar
jerryerry
·
4Komentar
Komentar yang paling membantu
Baik, keduanya: Menggunakan true
acos()berartijunction_thetabisa menjadi lebih besar dari 2,96, dengan demikian(RADIANS(180) - junction_theta)bisa menjadi lebih kecil dari 0,18 dan kecepatan "meledak", mengurangi masalah sudut pandang mendekati 180 °. Ini adalah perlombaan 1 / (perbedaan sudut) vs. panjang balok. Namun, untuk sudut yang mendekati 135 °, panjang balok masih akan menjadi masalah dari pemahaman saya.Mungkin kita harus mencari pendekatan acos () - yang lebih baik DAN berpikir untuk menangani masalah dengan segmen bergantian dengan panjang yang sangat berbeda.