Lorawan-stack: Basic Station Integration: Race condition in re-connection handling causes permanent failure of uplink forwarding
Summary
The Basic Station protocol is based on TCP. Occasionally it may happen, that the client drops this connection without executing a clean TCP connection close sequence. This may occur if link/net layer connectivity suddenly disappears and causes the TCP layer to reset and retry (e.g. a gateway is switching from ethernet backhaul to 3G backhaul because ethernet went away; or gateway is seeing unexpected power cycle and boots up quickly - a common unplug/plugin scenario for TTIG). If Basic Station establishes a new connection within a certain time after the last uplink for the old connection was forwarded, the LNS stops processing uplinks from this gateway permanently. It looks like this timeout is about 60 seconds. Given the symptoms and the fact that this does not happen on the v3 stack, it looks like this issue is related to #1729.
This issue has also been discussed in the TTN forums
Steps to Reproduce
- To simulate unclean TCP connection termination, introduce an iptables rule which blocks TCP FIN packets:
iptables -A OUTPUT -d 52.169.76.203 --protocol tcp --tcp-flags FIN FIN -j DROP - Start Basic on the machine where the iptables rule is active. Make sure you are in an environment of regular uplinks (every 10 seconds or so). Observe
https://console.thethingsnetwork.org/gateways/<GATEWAYID>/trafficfor incoming traffic. - After a few uplinks are forwarded, stop the station process with CTRL+C (the server will see an unclean TCP termination, because of the missing FIN packet). Let us define the time
Tas the time where the last uplink message was forwarded before the station process was killed. - Shortly after, start the station process again (Basic Station will connect and forward uplinks).
- At time
T + 60 s, the error condition kicks in.
What do you see now?
The error condition: The gateway console https://console.thethingsnetwork.org/gateways/<GATEWAYID>/traffic will stop showing uplinks while the connection between Basic Station and the Server as kept alive (TCP keep alive messages are exchanged) and Basic Station continues to receive uplinks. A TCP/IP packet capture shows that the uplinks are actually transferred over the websocket and the TCP packets are acknowledged by the server - i.e. the server definitely receives the uplink messages but does not show them in the gateway console.
What do you want to see instead?
Uplink messages should continue to be processed by the LNS.
Environment
Basic Station (latest version), TTN community network.
(On the v3 stack this does not happen - hence the suspicion that it has something to do with the inactive connection termination heuristic).
How do you propose to implement this?
This is hard to judge without having access to the code. From the symptoms it looks like this issue is tied to the inactive connection termination heuristic as discussed in issue #1729. Probably the server is seeing two connections because a new connection is established before the old one is cleanly closed. Maybe, the connection termination heuristic detects an inactive connection on the 'dead' connection and destroys context related to the gateway without considering that a second connection requires this context to forward uplinks up the stack. Obviously this is a guess, but it could explain the symptoms.
 beitler
beitler
All 16 comments
With the latest update the timeout apparently has been changed from 60 s to 600 s. But the underlying problem remains and can be reliably reproduced with the steps above.
beitler
on 6 Feb 2020
I'll try to simulate this and tweak the Proxy settings to see where the issue is. But it must be noted that this only seems to affect a percentage of the gateways.
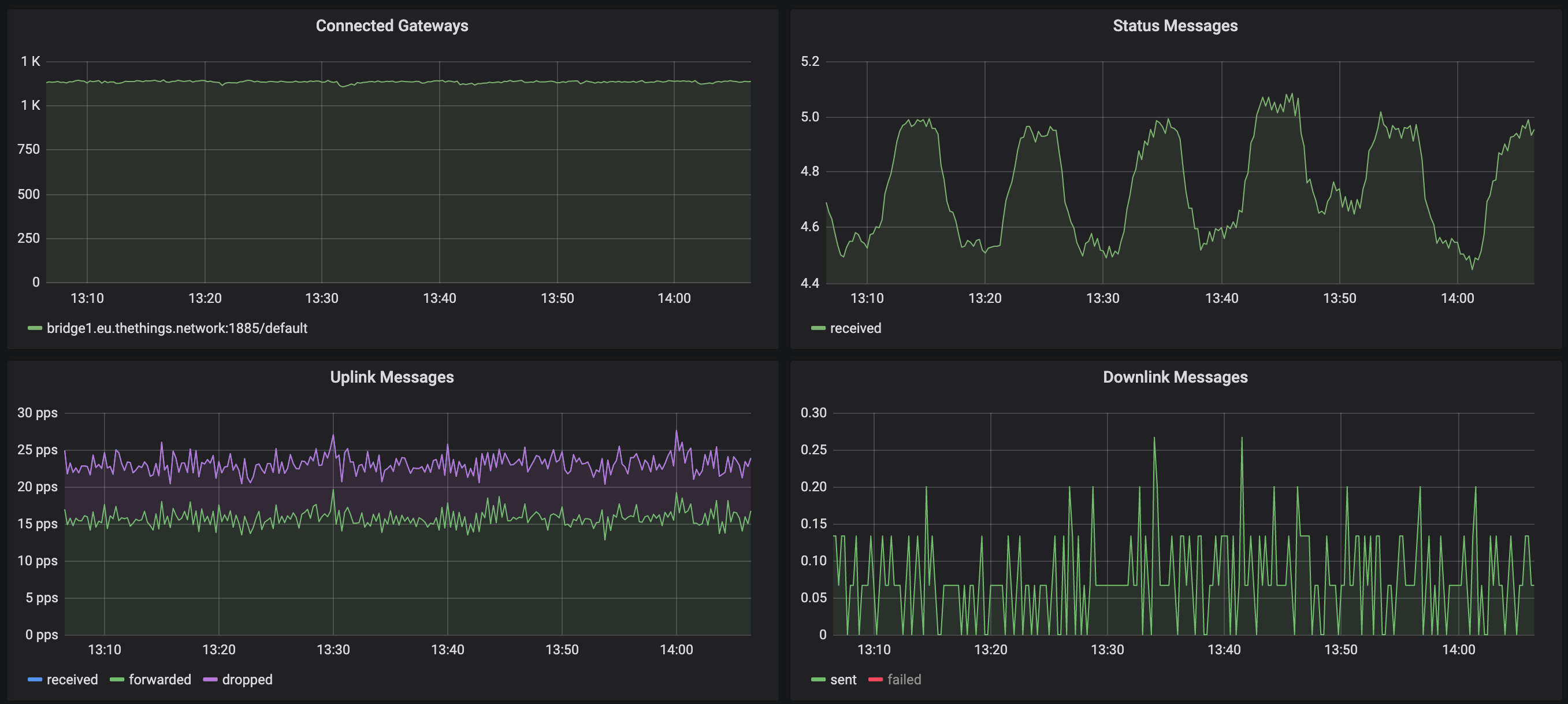
In the following graph, the rising edge of the spike in status messages corresponds to the 600s idle window. Every time the gateway reconnects we log a single status message (which accounts for this spike). But if you see the traffic, the drop is slight but not drastic enough to indicate a problem with all gateways:
 KrishnaIyer
on 8 Feb 2020
KrishnaIyer
on 8 Feb 2020
Hi Krishna, the issue is not related to server-side disconnects but to the way the server handles unclean client side disconnects with immediate reconnects. The issue does affect all Basic Station based gateways and can be reliably reproduced with the instructions above.
The error pattern is like this:
- Device terminates connection uncleanly (power cycle, hard reset, WiFi drop, TTIG unplug/plugin, etc.)
- Device immediately re-connects
- For 600s after disconnect (this number used to be 60s) the forwarded packets are seen in the LNS
- After 600s and beyond after the disconnect the forwarded packets are NOT seen in the LNS
Increasing the timeout from 60s to 600s made the issue more severe: With 60s, the user, who unplugs his TTIG just had to wait for 60s before plugging it back in to avoid running into the issue. This may have happened often enough especially when people do a factory reset. Now with 600s, a larger percentage will run into the issue, which is also what ca be observed.
Would it hurt to deactivate this timeout altogether? Basic Station does TCP keep alive by default (https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637). Doesn't that suffice to check connection aliveness?
beitler
on 8 Feb 2020
For me it looks like the error habbens also, wenn the provider disconect your internet connection and you get a new IP at the reconnect :(
At the moment every day my TTIG Gateway is no longer working, and whenn i show into the logs form my app, the last value i received is short befor the connection was disconected and then reconnected.
To get the gateway running again, I have to unplug it, wait a bit and then plug it in again.
But this behaviour occurs only since 29.01, before this was never a problem.
 JackGruber
on 9 Feb 2020
JackGruber
on 9 Feb 2020
@JackGruber can you confirm that you can also receive uplinks just fine during the first 600 seconds after the internet connection was disconnected? (To be exact: 600 seconds, minus the time it takes for the modem and gateway to be fully reconnected.)
Or if you're not seeing any uplinks in those 600 seconds: how often do your devices transmit? (In other words: would you expect to receive some uplinks during those 600 seconds?)
 avbentem
on 9 Feb 2020
avbentem
on 9 Feb 2020
The device i am monitoring transmits every 5 minutes.
02:42 RX Frame
02:47 RX Frame
02:53 RX Frame
02:56 Reconnect
02:58 RX Frame
no frames
07:30 Unplug/replug TTIG
07:36 RX Frame
JackGruber
on 9 Feb 2020
Considering 600 seconds after the 2:56 reconnect, I guess that after the 2:58 uplink one might also expect a 3:03 uplink (which is still before 2:56 plus 600 seconds = 3:06). But maybe the 600 seconds timeout is reset after the 2:53 uplink (rather than after some later keep-alive/status message), making TTN erroneously wipe the context/state just when the 3:03 uplink should be received. (And of course, uplinks might not be received for other reasons as well.)
Also, all being fine when restarting the TTIG at 7:30, and then not running into problems again 600 seconds after that, seems to confirm the (great) analysis by @beitler, which assumes that TTN erroneously wipes some shared context/state at about 3:03 or 3:06.
avbentem
on 9 Feb 2020
Today I took a closer look at the times
I have also attached a logfile from the TTIG.
Unfortunately not from the time of ISP reconnect.
If desired i create a longterme log, so that also the reconnect is included
TTIG.log
Time schedule (UTC+1)
02:46 RX Messages
02:51 RX Messages
02:56 RX Messages
02:58 RX Messages
02:58 ISP reconnect
03:01 RX Messages
03:03 RX Messages
03:06 RX Messages
no more Messages recived
TTN Console
Status: not connected
Last Seen: 2/11/2020 03:05:04
06:46 Short Un-/Replug TTIG (No power for 10 Sec)
TTN Console
Status: connected
Last Seen: 2/11/2020 06:47:12
06:48 RX Messages
....
I found an error in my firewall rule an the CUPS (rjs.sm.tc) primary connection was not allowed, only the CUPS-BACKUP (mh.sm.tc).
JackGruber
on 11 Feb 2020
Thanks for reporting, we have identified the issue and are fixing it. This issue lives in our proprietary code base but will be closed here.
 johanstokking
on 12 Feb 2020
johanstokking
on 12 Feb 2020
Has something changed on the backend since +/- 18h this afternoon?
It is now next to impossible to run the TTN Indoor Gateway for longer than 10 minutes, while it was working fine as far as I know for months.
Change of IP address via the DHCP server does give 10 minutes of connectivity to the TTN network, but then it is lost again. (replug also works for 10 minutes)
 TD-er
on 13 Feb 2020
TD-er
on 13 Feb 2020
@TD-er, did you leave it unplugged for more than 10 minutes (600 seconds)?
Like explained above, that has been needed since the February 6th change. Before February 7th, one needed to leave it unplugged for 60 seconds. It's unclear to me if today's merged fix has also been deployed.
avbentem
on 13 Feb 2020
Nope, not unplugged for that long.
When unplugged, it was only unplugged for a few seconds.
With the DHCP change of the IP-address, the unit was even never power cycled, it just received a new IP from the DHCP server and thus rebuilt its network connection. This made it work for almost exactly 10 minutes until it was unavailable again.
I will now unplug it for a while and then see what happens after I replug it.
TD-er
on 13 Feb 2020
Had it powered off for roughly 25 minutes and now plugged in for about 15 minutes and it is still working :) Will see if it still runs tomorrow morning.
TD-er
on 14 Feb 2020
We're releasing v3.5.3 today containing the fix, and are likely be able to deploy that to the servers where TTIG connects to. Hopefully that will be resolved very soon.
johanstokking
on 14 Feb 2020
Let's hope it has not yet been deployed, as my indoor gateway is now again offline for about 3 hours already.
TD-er
on 14 Feb 2020
We haven't heard this issue after the deployment of the latest fixes. Please feel free to re-open if observed again.
KrishnaIyer
on 24 Feb 2020
Related issues
 MatteMoveSRL
·
7Comments
johanstokking
·
8Comments
MatteMoveSRL
·
7Comments
johanstokking
·
8Comments
 kschiffer
·
4Comments
kschiffer
·
4Comments
 adriansmares
·
8Comments
adriansmares
·
8Comments
 htdvisser
·
4Comments
htdvisser
·
4Comments
Most helpful comment
Hi Krishna, the issue is not related to server-side disconnects but to the way the server handles unclean client side disconnects with immediate reconnects. The issue does affect all Basic Station based gateways and can be reliably reproduced with the instructions above.
The error pattern is like this:
Increasing the timeout from 60s to 600s made the issue more severe: With 60s, the user, who unplugs his TTIG just had to wait for 60s before plugging it back in to avoid running into the issue. This may have happened often enough especially when people do a factory reset. Now with 600s, a larger percentage will run into the issue, which is also what ca be observed.
Would it hurt to deactivate this timeout altogether? Basic Station does TCP keep alive by default (https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637). Doesn't that suffice to check connection aliveness?