Hello
is there an easy way build in MVE to transform the point cloud of scene2pset to the scene coordinate system.
I'm developing a depth map reconstruction algorithm and feed these maps to MVE to create point cloud, I used dino dataset for testing the reconstruction is fine but it's not in scene coordinate. If I use bounding Box arg with scene2pset I get an empty ply file. otherwise, i get my points which mean my cloud is not in scene coordinate how do I fix this
note: even if I used dmrecon the same thing happen
thank you
 HelliceSaouli
HelliceSaouli
All 12 comments
The scene2pset app exports the point cloud in the scene coordinate system. No transformations are applied. You can check by loading the point cloud and the scene in UMVE in the "Scene Inspect" tab.
 simonfuhrmann
on 27 Oct 2017
simonfuhrmann
on 27 Oct 2017
No, i don't think so. I don't have UMVE build in right now I will check later. but this is scene2pset output.
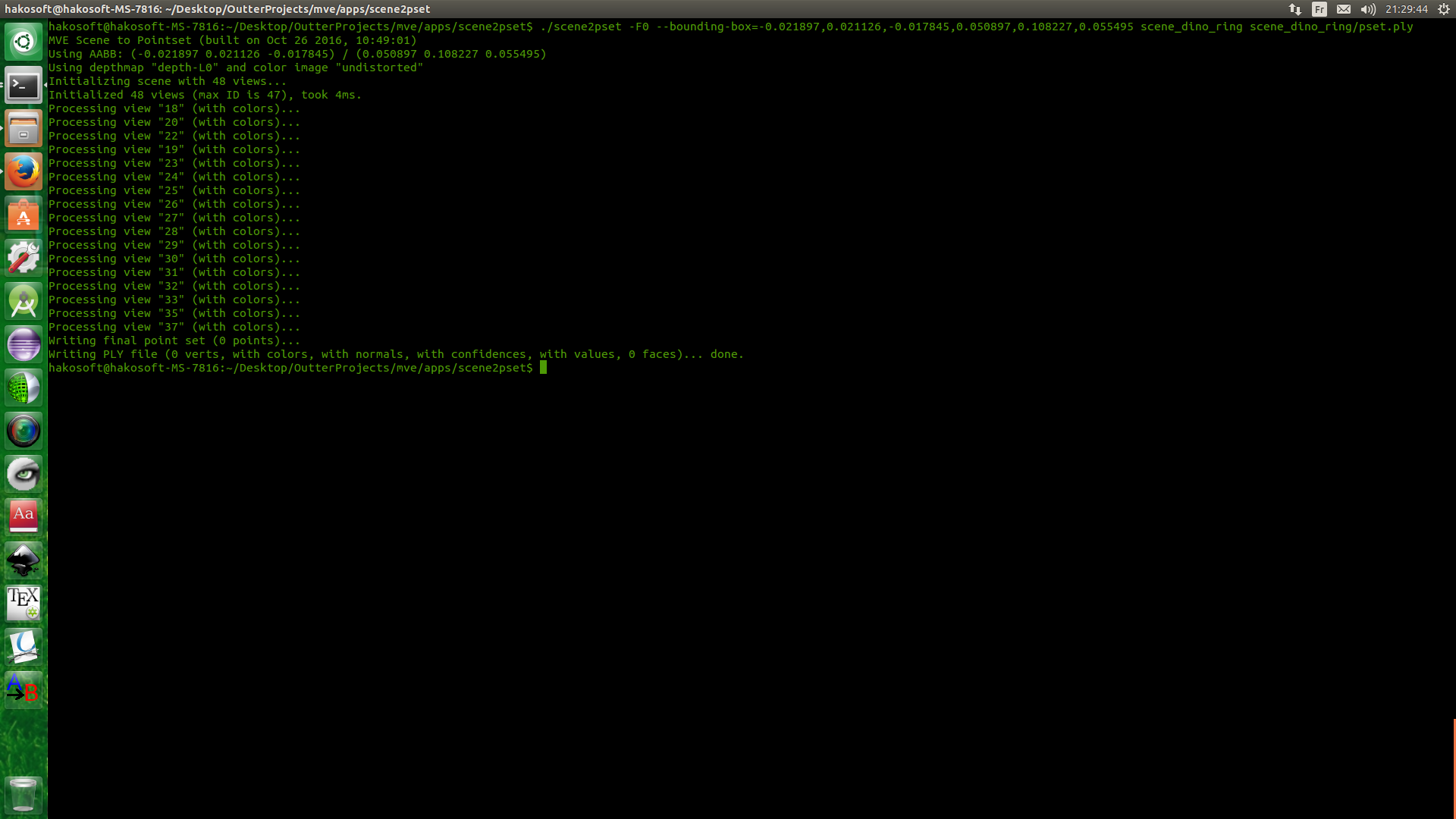
this mean all point are not in BB thus they are not in scene coordinate
HelliceSaouli
on 27 Oct 2017
Your bounding box, or how you specify the bounding box, must be wrong. scene2pset outputs in the scene coordinate system, that's a fact. UMVE also has a bounding box creator that can help you find the right parameters.
simonfuhrmann
on 27 Oct 2017
The bounding box is not mine. it is actually from vision.Middelburry, and the reason i bring this up is that i sent my result for evaluation to Middlebury and they said my points are not in the correct coordinate and they asked me to run sanity check using their bounding box and the image above is the result.
Also according to your answer for issue 358 : " All results are in the coordinate system dictated by SfM. If you want a specific scene coordinate system, you have to transform it yourself". the points are not in scene coordinate system
HelliceSaouli
on 27 Oct 2017
Are you running SfM on the Middleburry datasets? This will basically create an arbitrary scene coordinate system that has nothing to do with the one Middleburry expects. If you want to do this properly, this is what you have to do:
1) Use the camera intrinsics and extrinsics as specified in the Middleburry dataset, and use that for the views, i.e., insert the parameters into the meta.ini files.
2) Create SfM features without actually running SfM. That's the tricky part, because you want to detect, match, triangulate features, and then run an optimization that doesn't change the camera parameters. I don't think we have code for this exact scenario right now.
3) Run your code on the resulting scene, which is in the Middleburry corrdinate system.
simonfuhrmann
on 27 Oct 2017
oh ok, it weird and I don't see the logic behind this XD. I will do what you said, but step 2 is going to be hard -__-
HelliceSaouli
on 27 Oct 2017
last question and i will go to sleep x') : if I run sfmrecon with this 2 arg = true
- args.add_option('0', "fixed-intrinsics", false, "Do not optimize camera intrinsics");
- args.add_option('0', "shared-intrinsics", false, "Share intrinsics between all cameras");
will it work?
HelliceSaouli
on 27 Oct 2017
No. Because you'll also have to fix the extrinsics. And fixing the extrinsics is not supported by nature of the incremental SfM approach.
What's weird about these steps? Step 1 should be fairly self-explanatory, you have to use the Middleburry provided parameters as these "ground truth" camera parameters are better than what any SfM can produce. Step 2 is required because our MVS requires SfM points to work. If you have a MVS algorithm that doesn't require SfM points, you can probably omit this step.
simonfuhrmann
on 28 Oct 2017
Thank you for all the answers you provided. it is really helpful.
It is not the steps that are weird. but why sfm parameters are way off from the ground truth. and no I can't omit the 2end step since my work is based on your work a specially _dmrecon_ , I also use features as seed to estimate depth and normals. This is why I'm posting a lot of issues and asking so many question ^__^
HelliceSaouli
on 28 Oct 2017
The SfM reconstruction has a 7 dimensional ambiguity, that is position, orientation and scale with respect to the original real world object. This ambiguity is resolved in the first SfM steps by making some arbitrary decisions.
So the reconstruction is not "way off", just different with respect to this ambiguity.
simonfuhrmann
on 28 Oct 2017
I added a simple tool that does what you want. Please read this page.
https://github.com/simonfuhrmann/mve/wiki/Middlebury-Datasets
simonfuhrmann
on 30 Oct 2017
Thank you so much ,
HelliceSaouli
on 31 Oct 2017
Related issues
 MaxDidIt
·
30Comments
MaxDidIt
·
30Comments
 Jus80687
·
11Comments
HelliceSaouli
·
14Comments
Jus80687
·
11Comments
HelliceSaouli
·
14Comments
 daleydeng
·
8Comments
daleydeng
·
8Comments
 GustavoCamargoRL
·
13Comments
GustavoCamargoRL
·
13Comments
Most helpful comment
The SfM reconstruction has a 7 dimensional ambiguity, that is position, orientation and scale with respect to the original real world object. This ambiguity is resolved in the first SfM steps by making some arbitrary decisions.
So the reconstruction is not "way off", just different with respect to this ambiguity.