Plots2: visualização de tag de todas as tags
Este é um pedido para alguém com acesso à edição de páginas especiais para adicionar esta visualização de tags do início dos tempos até novembro de 2016 no topo de publiclab.org/tags
https://www.dropbox.com/s/s78g3ufhsav5xzo/plots_tag_graph_256_filtered.png?dl=0
CC:
@gretchengehrke
@skilfullycurled
 ebarry
ebarry
Todos 73 comentários
Olá, Liz, estou um pouco relutante em colocar um gráfico estático como este em nossa base de código permanente, mas talvez uma sugestão seja que exibamos um "recurso" (como nossos banners) no topo da página e, em seguida, administradores podem exibir o que quiserem lá. Isso funcionaria?
 jywarren
em 5 jul. 2017
jywarren
em 5 jul. 2017
Iria acima ou abaixo desta linha: https://github.com/publiclab/plots2/blob/master/app/views/tag/index.html.erb#L4
E parecido com:
<% cache('feature_tag-page-header') do %>
<%= feature('tag-page-header') %>
<% end %>
Bem, eu não quero tanto decorar essa página, mas sim adicionar "uma visão rápida".
Um ponto diferente, mas talvez relevante para o motivo de eu sugerir a adição de uma visualização gráfica, é que essa página de tag ainda não tem recursos de classificação para ver "recente" ou "popular", muito menos para ver qualquer um por geografia.
ebarry
em 5 jul. 2017
Na verdade, existem ligações python gephi que podemos usar para gerá-lo dinamicamente. Na verdade, estou trabalhando em uma visualização de rede javascript agora, então deixe-me ver como isso funciona. Se der certo, posso traduzir o que fiz em um script python que pode gerar a estrutura de dados para então ser visualizada em javascript.
 skilfullycurled
em 5 jul. 2017
skilfullycurled
em 5 jul. 2017
Oi, pessoal - acho que um gráfico gerado seria ótimo e é algo que poderíamos colocar no código permanente.
@ebarry, não estou dizendo que isso é decoração e não conteúdo, estou mais dizendo que isso ficaria desatualizado rapidamente, e também nosso objetivo é armazenar / não / conteúdo em nossa infraestrutura apenas de base de código. Portanto, esta é apenas uma maneira de implementá-lo - minha solução proposta parece adequada?
re this tag page still doesn't have any sorting capabilities to see "recent" or "popular" much less to see either of those by geography. Terei prazer em trabalhar com você para apresentar algumas solicitações de recursos para fazer com que os contribuidores que constroem resolvam isso se for uma prioridade para você. Podem ser first-timers-only problemas fáceis se você puder ajudar a colocá-los na fila!
jywarren
em 5 jul. 2017
Vamos voltar ao básico sobre este assunto :)
Qual é o objetivo de visualizar tags?
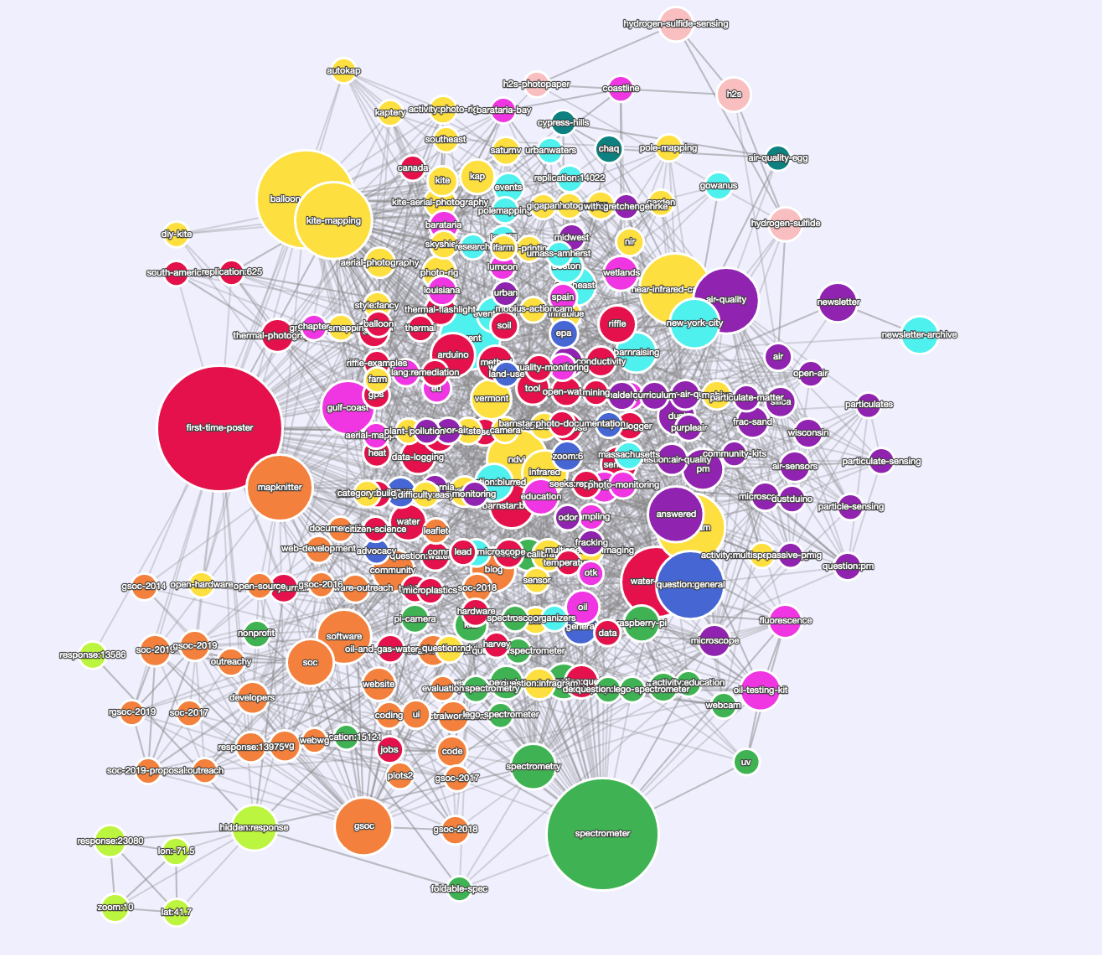
Para mim, visualizar tags é uma maneira de representar visualmente tags associadas, por exemplo, tags que aparecem juntas no mesmo conteúdo. Para um ótimo exemplo, veja os clusters codificados por cores na visualização de @skilfullycurled acima. As tags de agrupamento são importantes porque conectam visualmente a apresentação do site da atividade da comunidade _ mais próxima_ ao que a comunidade do Public Lab culturalmente se refere como "áreas de pesquisa", ou talvez "tópicos" -> este é meu objetivo real com todo este problema.
Aqui estão algumas informações básicas: em nossa página de tags (https://publiclab.org/tags), escrevemos "Usamos tags para agrupar pesquisas por tópico" e encorajamos as pessoas a navegar por tags (atualmente classificadas apenas por atividade recente). Esta é uma forma importante de nomear, criar links e / ou promover as pessoas para encontrar e se envolver com os tópicos. O próprio Dashboard enfatiza as atividades recentes. O Dashboard agora apresenta uma barra de "tags usadas recentemente" - que é uma etapa importante, mas parcial para o objetivo de ver "áreas de pesquisa" ou "tópicos".
Para avançar, não estou interessado em _navegar_ por uma visualização de tag gráfica (tão 2007!), No entanto, os clusters de atividade fornecem uma importante forma adicional de conexão / navegação para tópicos. Para atingir o objetivo, ou seja, a capacidade da página de tags de mostrar quais são as tags mais interconectadas, de comunicar a amplitude dos tópicos conectados em uma área de pesquisa, de navegar / conectar-se a uma área de pesquisa e de se inscrever apropriadamente, nós não precisam necessariamente de setas com código de cores. Vamos pensar em como atingir esses objetivos.
Também podemos considerar o espelhamento de publiclab.org/tags em publiclab.org/topics para tornar a linguagem mais acessível.
ebarry
em 15 nov. 2017
Legal, obrigado Liz!
Para tentar um recurso mais restrito em direção a esse objetivo, o que aconteceria se as páginas de tag (novo nome flutuante: páginas de tópico ...!?!) Tivessem uma lista de "Tópicos relacionados", algo como:
Tópicos relacionados:
waterrunoffwetlandsturbidity
Onde "relacionado" significa que (reconhecendo que existem diferentes maneiras de medir isso e que queremos alguma forma "computacionalmente eficiente") essas são as tags que mais comumente aparecem nas páginas que já possuem a tag principal. Portanto, para o tópico onions , contabilizamos todas as páginas marcadas com onions e pegamos as primeiras, digamos, cinco.
Um pequeno acompanhamento se o acima parecer bom - seria correto fazer isso apenas para as 20-30 páginas mais recentes? Mesmo que seja apenas um ponto de partida, isso tornaria isso mais fácil de implementar sem se preocupar com a lentidão geral do site. Pode haver maneiras mais complexas de contornar isso, mas esta é a maneira mais fácil de começar.
jywarren
em 16 nov. 2017
Eu fiz uma postagem cruzada em https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages - o que você acha sobre mover a discussão para lá até que haja detalhes específicos etapas de codificação (miniprojetos para contribuidores de código) que podemos fazer?
jywarren
em 16 nov. 2017
OK ótimo! vamos voltar a essa discussão e voltar quando tivermos
passos possíveis.
-
+1 336-269-1539 / @lizbarry http://twitter.com/lizbarry / lizbarry.net
Na quarta-feira, 15 de novembro de 2017 às 21h54, Jeffrey Warren [email protected]
escreveu:
Eu fiz uma postagem cruzada em https://publiclab.org/questions/tommystyles/10-20-
2017 / need-your-feedback-on-tag-pages - o que você acha de mudar
discussão lá até que haja etapas de codificação discretas específicas (mini
projetos para contribuidores de código) que podemos fazer?-
Você está recebendo isso porque foi mencionado.
Responda a este e-mail diretamente, visualize-o no GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-344799932 ,
ou silenciar o tópico
https://github.com/notifications/unsubscribe-auth/AAJ2n8PdvpH0GQ_wBU-Utp4xfL7XDmuJks5s26PpgaJpZM4OOvLP
.
ebarry
em 16 nov. 2017
@jywarren , @ebarry , existe alguma API (ou talvez documentação) para saber as 'arestas' do gráfico acima? Quero dizer, como os nós são conectados?
Obrigado 😄!
 sagarpreet-chadha
em 23 jan. 2018
sagarpreet-chadha
em 23 jan. 2018
Ei @ sagarpreet-chadha!
A visualização é apenas uma imagem, então não há API (ainda! Wink), no entanto, posso fornecer a lista de arestas desse gráfico em particular. Os formatos de arquivo mais "brutos" seriam csv e json. Ambos os formatos devem funcionar com um gráfico "programaticamente" ( iGraph , networkx , d3.js ) ou com uma GUI ( Gephi , Cytoscape ).
Aparentemente, você não pode fazer upload de arquivos no github. Tentei enviá-los para a nota de pesquisa do Public Lab, mas não está funcionando. @jywarren existe uma maneira de fazer upload de arquivos para uma nota de pesquisa? Se não, @ sagarpreet-chadha, você pode fazer uma postagem no grupo plots-dev googlegroup (você pode se inscrever aqui se ainda não for)? Vamos esperar para ver o que @jywarren diz porque seria ótimo tê-los diretamente na nota de pesquisa.
Aqui está o que você pode esperar:
plots_tag_communities_edges_w_props_9_16.csv:: lista de arestas únicas com propriedades calculadas, em particular o peso da aresta. O peso se traduz no número de vezes que as tags ocorreram juntas.
plots_tag_communities_nodes_w_props_9_16.csv: lista de nós com propriedades calculadas. Mais relevante para a imagem no site, a "classe de modularidade" que informa a qual comunidade cada nó pertence.
plots_tag_communities_9_16.json: Não acho json tão útil, mas sei que algumas pessoas preferem. Acho que o arquivo json também inclui propriedades para a visualização que está no site (ou seja, cor RGB de cada nó).
skilfullycurled
em 23 jan. 2018
Atualização: removido plots_tag_communities_edgelist_9_16.csv da lista de arquivos acima. Este arquivo é de uso limitado porque as arestas duplicadas já foram mescladas em arestas exclusivas com espessuras. Sem as propriedades, esta lista de arestas só permitirá que você construa um gráfico com pesos de aresta de 1. Procurarei o arquivo original com as duplicatas.
skilfullycurled
em 24 jan. 2018
Obrigado @skilfullycurled pela sua resposta!
Na verdade, eu estava tentando construir o gráfico de visualização usando a biblioteca javascript (d3.js ou vis.js ) para que pudesse ser facilmente adicionado ao site publiclab.org. Essas bibliotecas requerem os dados na forma de:
nodes: [
{
id: 1,
shape: 'circle',
label: 'Infrared } ] para nós .
E para bordas :
edges: [
{from: 1, to: 2},
{from: 1, to: 3}]
Bem, json seria ótimo, caso contrário, eu posso criá-lo, ou talvez criar um objeto Javascript diretamente (desta forma, não há necessidade de analisar o arquivo JSON).
Eu criei um gráfico fictício (podemos brincar com os nós e as arestas aqui 😄):
O que você acha ? @ebarry , @jywarren , @skilfullycurled
sagarpreet-chadha
em 24 jan. 2018
Ah. Isso seria incrível! OK. Para continuar essa conversa, vamos precisar deixar "API-land" e passar para como a visualização em Gephi funciona e a melhor maneira de traduzir esses recursos em javascript.
Posso incomodar você para começar isso como uma pergunta ? Algo como, "Como posso traduzir a visualização da tag criada no Gephi em uma versão javascript?"
Além disso, envie-me um e-mail para benj. [email protected] para que eu possa compartilhar os arquivos. Vou remover meu e-mail assim que você fizer isso.
skilfullycurled
em 24 jan. 2018
Na verdade, acho que não precisamos deixar a API-land - a API existente é bastante robusta atualmente. Estou curioso, @skilfullycurled como você gerou essas bordas -
eles poderiam ser gerados a partir de uma lista de todas as tags e os nós em que foram usados? Essa é uma consulta razoável para gerarmos, se armazenada em cache.
Poderíamos adicioná-lo à API em https://github.com/publiclab/plots2/tree/master/app/api/srch e documentá-lo em https://github.com/publiclab/plots2/blob/master/doc /API.md
Se forem dados suficientes, a consulta pode ser algo como:
r = []
Tag.select(:name, :tid).each do |t|
nids = t.nodes.select(:nid, :status).where(status: 1).collect(&:nid)
r << [t.name, nids] if nids.length > 0
end
r # later, r.to_json
Acabei de executá-lo em produção e demorou cerca de 15 segundos. Se o armazenarmos em cache diariamente, acho que é gerenciável e talvez possamos melhorá-lo ainda mais.
jywarren
em 25 jan. 2018
Além disso, você pode compartilhar arquivos em http://gist.github.com - isso poderia funcionar?
jywarren
em 25 jan. 2018
Então, usando o JSON gerado a partir da minha consulta,
- em JavaScript, poderíamos calcular o número de vezes que as tags ocorreram juntas.
- como você agrupou / calculou "comunidades"?
Aqui está um trecho:
["whitebalance", [12476, 13575]], ["wi", [12143, 13067]], ["wi-fi", [11123]], ["width-of-dvd-grating", [12838, 12875, 12895, 12899, 12902, 12926, 12990, 12991, 12995, 12999, 13006, 13014, 13019, 13037, 13046, 13057, 13062, 13069, 13077, 13088, 13089, 13094, 13103, 13117, 13125, 13131, 13133, 13136, 13152, 13154, 13157, 13159, 13169, 13178, 13181, 13183, 13188, 13226, 13248, 13283, 13302, 13305, 13308, 13315, 13316, 13340, 13349, 13355, 13366, 13401, 13402, 13409, 13414, 13423, 13429, 13432, 13434, 13437, 13439, 13440, 13443]], ["wiki", [9048, 10956]], ["wiki-gardening", [10956]], ["wild", [11707, 11711]], ["wildfires", [14803]], ["wildlife", [670]], ["wilkinson-bay", [220, 265, 280, 281, 282, 283, 284, 677]], ["wilkinsonbay", [606]], ["williamsburg", [10343, 10428, 10444]], ["willow", [9979]], ["wind", [9032, 10660, 12610, 13880, 14487, 14527, 14530, 14531, 14713, 14756]], ["wind-direction", [14527]], ["wind-sensor", [14713]], ["wind-speed-meter", [1962, 5837, 9032, 12103, 13064, 13165, 13231, 13880, 14527]], ["winder", [7717]], ["winders", [1900]], ["window", [147, 1759]], ["windows", [11434, 11677, 13037]], ["windows-7", [13037]], ["windows-7-ultimate", [13037]], ["windows-excel", [13037]], ["windspeed", [745]], ["windvane", [14527]], ["windy", [146]], ["wine", [706, 10955]], ["winter", [5161]], ["wintercamp", [5103]], ["wired", [10315]], ["wireframes", [10623]], ["wireless", [3908, 9940, 11123, 12175]], ["wisconsin", [10504, 10552, 10611, 10619, 11331, 11783, 12142, 12143, 12192, 12221, 12337, 12537, 12539, 12562, 12597, 12610, 12919, 13067, 13216, 13217, 13219, 13222, 13223, 13224, 13406, 13578, 13920, 13921, 13922, 14018, 14044, 14087, 14146, 14648]], ["with", [11772, 13742, 14728]], ["with:abdul", [13407, 13412, 13413, 13428, 13493]], ["with:adam-griffith", [11049]], ["with:amal", [12161]], ["with:amandaf", [11556]], ["with:amberwise", [12338, 13280]], ["with:ann", [12850]], ["with:basurama", [11699, 11705]], ["with:becki", [13571]], ["with:bronwen", [10952, 12480, 13493, 14587]], ["with:bsugar", [13449]], ["with:btbonval", [11789]], ["with:cfastie", [11688, 13493, 13980]], ["with:chrisjob", [10464]], ["with:cindy_excites", [11566, 11567, 14537]], ["with:damarquis", [12338]], ["with:danbeavers", [11417, 11567]],
FWIW pode haver alguma consulta ainda mais eficiente como esta, mas é bastante decente, embora não retorne totalmente o que está acima:
Tag.select('term_data.tid, term_data.name, community_tags.nid, community_tags.tid')
.includes(:node_tag)
.references(:node_tag)
Embora isso não nos diga se o nó foi publicado (vs. spam), a menos que também misturemos node.status lá. Mas isso é possível!
jywarren
em 25 jan. 2018
Olá, tenho apenas algumas perguntas aqui,
1.) Se 2 tags pertencem ao mesmo nó, eles têm uma borda entre eles?
2.) As cores diferentes são para diferentes tipos de nós, como perguntas, notas, notas de pesquisa, etc. ?
Obrigado 😄!
sagarpreet-chadha
em 25 jan. 2018
E também concordo em não sair da API -land :)
sagarpreet-chadha
em 25 jan. 2018
Arg! OK. Não vamos empilhar, por favor. Ninguém quer ficar na terra da API mais do que eu (bem, talvez com exceção de @ebarry ). No meu entendimento, a construção do API-land foi praticamente adiada indefinidamente devido a preocupações com a lentidão do site ( veja a extensão da conversa aqui ). Mas agora @jywarren está dizendo que não é mais um grande negócio, então bons tempos nesse sentido.
Já que usar o Github pode ser uma barreira para informações acessíveis (nem todo mundo tem acesso, sabe como usar), eu acho (er ... pensei) ter conversas que não fossem sobre "fazer as coisas" na base de código seria melhor relegado a o site onde todos podem aprender com eles. Estas não são normas da comunidade que eu defini (veja o comentário do próprio @jywarren acima ), mas eu realmente acho que são boas.
skilfullycurled
em 25 jan. 2018
Ops, desculpe @skilfullycurled, eu não me lembrava do seu último comentário sobre esse tópico - https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages#answer - 556-comment-17709 - onde você sugeriu:
- executando apenas nas 250 marcas principais
- cache semanal
Vou enviar um ping de volta lá, mas acho que com todo o trabalho na API, limpeza de código e alcance, poderíamos fazer uma versão em cache diária ou semanal de tal consulta e estar OK com um cálculo total de 10-15 segundos vez por semana. O resto seria executado localmente no navegador. Repetindo isso ali.
jywarren
em 25 jan. 2018
@jywarren Precisarei responder a você em algumas de suas perguntas. Vou postar meu caderno Jupyter mais tarde. Enquanto isso, veja aqui uma breve explicação de como o gráfico é criado a partir dos pares de tags. Para o código exato, veja aqui .
@ sagarpreet-chadha (e qualquer pessoa interessada) você pode ver como um gráfico d3.js foi criado a partir dos dados da tag verificando o repositório para
Com relação à detecção da comunidade, se você olhar no repositório tagoverflow, verá que o autor implementou seu próprio algoritmo. Desde então, outros foram implementados, como jLouvain , netClustering , uma implementação CNM ( exemplo d3 ). Com um limite de 256 tags, a detecção da comunidade provavelmente funciona bem no navegador.
skilfullycurled
em 25 jan. 2018
Para não sobrecarregar a discussão publiclab.org com muitos dados, aqui está um link para o formato de dados que o TagOverflow usa:
https://api.stackexchange.com/2.1/tags/python/related/?site=stackoverflow&key=of3hmyFapahonChi8EED6g ((& pagesize = 16
Faz cerca de 15 chamadas para buscar quais tags estão relacionadas a uma determinada tag (no exemplo acima, "python")
jywarren
em 25 jan. 2018
Portanto, a diferença entre isso e os dados que gerei acima é que minha consulta lista os ids dos nós, mas não os usou para estabelecer "relação". Mas é claro @skilfullycurled 's notebook Jupyter faz isso! Legal, obrigado por compartilhar!
jywarren
em 25 jan. 2018
@ sagarpreet-chadha, postei uma pergunta que fazia e respondia suas perguntas acima:
https://publiclab.org/questions/bsugar/01-25-2018/how-was-the-tag-graph-visualization-made
Não estou tentando ser "passivo-agressivo" em relação ao meu pedido, mas acho que as pessoas poderiam se beneficiar se esse aspecto da conversa fosse público. Então eu acho que isso o torna "agressivo agressivo". ; )
Brincadeiras à parte, fico feliz em esclarecer qualquer dúvida!
skilfullycurled
em 25 jan. 2018
Ei pessoal!
@ sagarpreet-chadha, coloquei todos os arquivos de que você precisará aqui:
https://spideroak.com/browse/share/skilfullyshared/plots-tag-graph
A pasta vem com um arquivo leia-me que explica o conteúdo.
Por favor, me avise quando você tiver baixado para que eu possa fechar a sala de compartilhamento. Eventualmente, irei publicá-los em minha conta do github para que outras pessoas tenham acesso no wiki.
Fico feliz em responder a quaisquer outras perguntas que você possa ter!
skilfullycurled
em 1 fev. 2018
Obrigado @skilfullycurled !
Eu baixei os arquivos :-)
sagarpreet-chadha
em 2 fev. 2018
Sem problemas @sagarpreet-chadha!
PS: Eu deixei um pensamento de acompanhamento na pergunta sobre o wiki .
skilfullycurled
em 2 fev. 2018
Grande atualização sobre cálculos de relação de tag baseados em ruby aqui: https://publiclab.org/questions/bsugar/01-25-2018/how-was-the-tag-graph-visualization-made
mais cedo!
jywarren
em 17 jan. 2019
Algum progresso em https://github.com/publiclab/plots2/pull/4657 , onde implementei uma instância extremamente básica, mas ao vivo, do Cytoscape.js (http://js.cytoscape.org/), executando a partir de um coleção em cache semanal de
Demorou mais de 50 segundos para executar TODAS as tags no site (que podiam ser armazenadas em cache semanalmente), mas também gerou mais de 8200 tags e 31k bordas ... o que é muito para representar graficamente. Aqui está o conjunto completo; Acho que inclui muitas tags de spam: https://gist.github.com/jywarren/4b1f9a032092a8187dd802a375fcb700
Você pode especificar o número de tags que deseja consultar assim: https://stable.publiclab.org/tag/graph.json?limit=10 (uma vez totalmente publicado, https://publiclab.org/tag/graph. json? limit = 10)
Atualmente está limitado a 5 "bordas" por tagname, representando as 5 tags que ocorrem com mais frequência ao lado da tag original.
Isso agora está ativo no servidor de teste estável (embora este branch seja reconstruído com bastante frequência, então a URL nem sempre está online ... ironicamente) aqui:
https://stable.publiclab.org/stats/graph?limit=75
As contagens maiores, como limite = 100 ou 250, parecem estar mostrando algum tipo de erro e tenho que perseguir isso um pouco. Mas este é um bom começo.
Existem MUITAS configurações que podem ser adicionadas para refinar isso - tamanho do nó, força do link, muito mais - verifique a galeria em http://js.cytoscape.org para algumas possibilidades. E fazer "famílias" também pode ser possível, embora eu precise de mais informações para isso.
jywarren
em 18 jan. 2019

jywarren
em 18 jan. 2019
Ooh, https://stable.publiclab.org/stats/graph?limit=300 parece funcionar também
jywarren
em 18 jan. 2019
Detecção de comunidade aqui! https://github.com/upphiminn/jLouvain/blob/master/README.md
jywarren
em 19 jan. 2019
@jywarren , Super legal !!!
sagarpreet-chadha
em 19 jan. 2019
Além disso, há uma variedade de algoritmos de agrupamento - eles podem ser testados no console JavaScript:
http://js.cytoscape.org/#collection/clustering
- eles.markovClustering ()
- nodes.kMeans ()
- nodes.kMedoids ()
- nodes.fuzzyCMeans ()
- nodes.hierarchicalClustering ()
- nodes.affinityPropagation ()
Não estou familiarizado com eles, mas todos parecem usar atributos dos nós ou arestas para criar grupos de elementos semelhantes. Então, o que devemos dar como atributos sobre os quais basear a similaridade?
Você pode tentar isso no console usando os exemplos nos documentos, coisas como:
var clusters = cy.elements().hca({
mode: 'threshold',
threshold: 5,
attributes: [
function( node ){ return node.data('count'); }
]
});
clusters; // <= then inspect what this returns to see the clusters
OK, usando jlouvain consegui adicionar detecção de comunidade: https://github.com/upphiminn/jLouvain
Não tenho dados de teste suficientes para ver como isso funcionará, mas se # 4679 for aprovado, irei mesclá-lo e poderemos vê-lo em execução com detecção de comunidade em:
https://stable.publiclab.org/stats/graph?limit=101
(uma vez que constrói)
jywarren
em 21 jan. 2019
Ei pessoal! Parece incrível. Lamento não ter respondido, estou atualizando algumas coisas e retornarei a este assunto mais tarde hoje.
Nesse ínterim, outro ingrediente que acho que não mencionei em nenhum dos meus outros posts é o layout. O mais próximo do que usei é provavelmente o layout da
O layout de força é uma espécie de recozimento de atração / repulsão que atinge um estado estacionário com base nos parâmetros que você definiu (ou seja, o número de iterações, força de atração / repulsão). Aqui está uma demonstração do d3 .
Quanto à detecção de comunidade e os pesos de borda, você tem algumas opções, mas se quiser recriar aquele gráfico de tag a que se refere, então você precisa da coocorrência, cujo citoscape, como a fortuna teria, tem uma função para ajudar a fazer mais fácil.
oe_ratio = (all_questions_count * tag_count_AB) / (tag_count_A * tag_count_B)
Onde tag_count_AB = edge.parallelEdges ()
Como estava, primeiro reduzi o conjunto de tags a um número razoável (digamos, 512 principais), mas depois reduzi as tags que usei para a visualização, incluindo apenas as n tags principais (talvez 64?) Com um observado para relação esperada acima de 1.
Você pode ler mais em Tag Overflow . Este método é uma maneira de cuidar do problema em que um nó de borda ou nó pode ser importante, mas de pouco uso. Por exemplo, em uma loja, 100 pessoas _podem_ ter 85% de probabilidade de comprar café e creme, mas cinco dessas pessoas _sempre_ compram café, creme e ovos. Portanto, definitivamente quero manter 5 caixas de ovos em estoque.
Uma alternativa fácil é apenas tornar o peso da aresta entre dois nós o tag_count_AB e apenas levar arestas / nós acima de um determinado limite. Pessoalmente, raramente consigo bons resultados com isso devido ao motivo acima.
Com relação aos outros métodos, você pode estar interessado na pág 3. (2.2) a - pág. 7 (3.1) deste artigo (sem matemática para essas partes), que tenta classificar os diferentes tipos de métodos de detecção de comunidade. Isso me ajudou a escolher aqueles que fornecem os resultados mais evidentes, dada a forma como estruturei o gráfico e o que desejo saber dele. Por exemplo, comunidades de conexões sociais comuns vs. comunidades com base na frequência com que as mensagens são enviadas entre duas pessoas.
skilfullycurled
em 21 jan. 2019
Trabalhando agora em um servidor estável!
jywarren
em 25 jan. 2019

Aqui estão as 99 principais tags!
jywarren
em 25 jan. 2019
Ele deve estar rodando no site ao vivo hoje à noite, mas eu queria observar que o "uso excessivo" de tags por alguns usuários distorceu o gráfico de uma forma que reconhecemos antes. Eu acredito que um dos usuários foi moderado do site, e eu me pergunto se as pessoas acham apropriado excluir essas tags do site ou pelo menos omiti-las do gráfico. Excluí-los seria mais fácil, mas também podemos criar algo apenas para ocultá-los. Preferência, @ebarry @skilfullycurled ?
Ainda assim, parece bom, embora as configurações na elasticidade da borda ainda precisem de alguns ajustes, e talvez um tipo de layout diferente funcione melhor ...

jywarren
em 25 jan. 2019
Sim! Definitivamente encontramos esse problema. Infelizmente, a única coisa a fazer era remover esse usuário específico como um outlier. Alguém que usa tantas tags pode não ser um outlier em si, mas se estiver criando tags que são tão específicas para si mesmo e usando-as continuamente, então não está realmente capturando os dados.
skilfullycurled
em 25 jan. 2019
Acho que até registrei um problema no github com uma solicitação de recurso que exibia um aviso que, em essência, diria: "Uau, calma cara! Parece que você tem várias tags aí, hein?".
skilfullycurled
em 25 jan. 2019
Oh, PS. A propósito, está incrível !!
skilfullycurled
em 25 jan. 2019
AAAAAAHHHHHHHHHMAYZINGGGGGGGGGG !!!!!!!!!!!!
Sim para manualmente "remover aquele usuário específico como um outlier"
ebarry
em 26 jan. 2019
Eu continuo voltando a este tópico por causa de como ele é incrível e pensando nas coisas (espero que minúsculo). Outra coisa que você pode considerar em filtrar são as tags de energia (aquelas com dois-pontos, certo?). Acho que assim que o problema de uso excessivo de tag for corrigido, saberemos mais sobre o layout.
Nota para mim mesmo: aqui está um link para um commit com as páginas que são importantes para a implementação.
skilfullycurled
em 26 jan. 2019
Olá a todos, fico feliz pelo entusiasmo! Fiquei doente, mas estou me recuperando agora e irei trabalhar um pouco nisso no vôo para casa na terça-feira.
Eu queria perguntar - minha pergunta específica é se devemos:
- realmente exclua as tags deste usuário moderado, ou
- se devemos tentar preservá-los, mas filtrá-los.
A filtragem seria consideravelmente mais trabalhosa tanto para o código quanto para as chamadas do banco de dados, mas é possível.
jywarren
em 27 jan. 2019
Em casos como este em que uma conta foi tornada "inativa" devido à moderação, então acho que não há problema em excluir as tags do banco de dados de uma vez. Especialmente se você tiver um backup. Não porque você queira restaurá-lo, apenas porque estou ansioso para perder dados para sempre. Não é saudável, mas o espaço barato é um facilitador infeliz. Meus sentimentos seriam mais complicados se esta fosse uma conta que foi tornada "inativa" por escolha, mas podemos discutir isso em outra ocasião (ou agora).
skilfullycurled
em 27 jan. 2019
Sim, este é um grande tópico a ser considerado. Depois de verificar se existem tags que _apenas_ este usuário usou (exemplo: aries city-point ), descobri que na verdade existem muito poucas tags completamente isoladas para este usuário (mesmo purelab foi originalmente usado por Shan He sobre a filtragem de água DIY, e research-notes foi originalmente usado em postagens que discutem o design de notas de pesquisa no site).
Visto que este usuário é moderado, nossa visualização de tag pode excluir todo o conteúdo dos usuários moderados - e por extensão as tags usadas no conteúdo dessa pessoa - sem excluir essa tag em geral, pois pode ser usada no conteúdo de outras pessoas?
ebarry
em 28 jan. 2019
@ebarry , devo esclarecer (caso não tenha sido).
Quando eu disse:
exclua as tags do banco de dados imediatamente
Eu quis dizer o que você fechou:
... [que] nossa visualização de tag [irá] excluir todo o conteúdo de usuários moderados - e por extensão as tags usadas no conteúdo dessa pessoa - sem excluir essa tag em geral [uma vez que] pode ser usada no conteúdo de outras pessoas. ..
Se o usuário moderado e Shan He usassem a tag "purelab", "purelab" não seria excluído, apenas qualquer instância da tag do usuário moderado ou ITMU's, se preferir.
A questão restante (se estou entendendo @jywarren) é se devemos ou não excluir esses ITMU's do banco de dados inteiramente, ou devemos mantê-los no banco de dados, mas filtrar os ITMU's quando todas as tags forem solicitadas para a visualização. Excluí-los torna a vida muito mais fácil para aqueles que implementam a visualização, mas pode haver argumentos para preservá-los.
Pessoalmente, acho que o primeiro é aceitável quando o usuário é moderado, pois não há chance de o conteúdo retornar ao site. No entanto, isso pode ser diferente se um usuário decidir excluir sua conta com base na existência ou não de alguma funcionalidade na qual ele possa reativá-la. Acho que podemos deixar essa situação para outro momento, mas para que fique registrado, eu só queria dizer que minha opinião judicial tem alcance limitado.
skilfullycurled
em 28 jan. 2019
Sim, não se preocupe. NodeTags não exclui a tag, apenas o link que associa
tags com nós e autores. Eu já fiz isso, mas preciso dar descarga
o cache semanal (isso é o que tornou tudo isso possível) e há
mais alguns bugs urgentes para resolver primeiro que surgiram hoje, desculpe!
Na segunda-feira, 28 de janeiro de 2019, 15h24 habilmente curvo < notificaçõ[email protected]
escreveu:
@ebarry https://github.com/ebarry , devo esclarecer (caso não fosse).
Quando eu disse:
exclua as tags do banco de dados imediatamente
Eu quis dizer o que você fechou:
... [que] nossa visualização de tag [irá] excluir todo o conteúdo do moderado
usuários - e, por extensão, as tags usadas no conteúdo dessa pessoa - sem
excluindo essa tag em geral [uma vez que] pode ser usada em outras pessoas
contente...Se o usuário moderado e Shan He usaram a tag "purelab", "purelab"
não seria excluído, apenas qualquer instância da tag do usuário moderado
ou ITMU's, se preferir.A questão restante (se estou entendendo @jywarren
https://github.com/jywarren ) é se deve ou não excluir esses ITMUs
do banco de dados inteiramente, ou os mantemos no banco de dados, mas filtramos
o ITMU sai quando todas as tags são solicitadas para a visualização.Excluí-los torna a vida muito mais fácil para aqueles que implementam o
visualização, mas pode haver argumentos para preservá-los.-
Você está recebendo isso porque foi mencionado.
Responda a este e-mail diretamente, visualize-o no GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-458244753 ,
ou silenciar o tópico
https://github.com/notifications/unsubscribe-auth/AABfJzTXlk18FzlER4PQyoomFE5VTFcrks5vH0AqgaJpZM4OOvLP
.
jywarren
em 28 jan. 2019
OK, consegui apagar todas as tags criadas pelo usuário moderado. Eles são armazenados em backups. Isso foi muito fácil e não afetará o código no futuro, ao contrário da outra solução.
Agora, quero sugerir que pode haver um layout diferente que queremos usar - estamos usando um layout cose e há variações ( bilkent e outros), mas também há um Layout de cola . Eu realmente não sei o apropriado para usar aqui, mas alguns parecem complicar menos os links. Embora muitas das demos em http://js.cytoscape.org/ tenham menos interlinks do que nosso conjunto de dados. Qualquer entrada é apreciada!
Documentos sobre layouts integrados em http://js.cytoscape.org/#layouts
Outra questão que podemos pedir a alguém para testar e resolver é a questão da detecção da comunidade. Não consegui descobrir como funciona ou por que não está reconhecendo grupos aqui. As cores são boas, mas são um nó por comunidade. Bah.
jywarren
em 28 jan. 2019
Portanto, este problema agora precisa ser dividido em:
- iteração de layout (entrada de boas-vindas da multidão atual)
- detecção de comunidade
- filtragem de tag adicional (talvez filtrar tags sem nós não aprovados para nos livrar do spam?)
também quero revisitar que agora estamos vendo um número especificado de tags (por favor, não teste isso até seus limites, a menos que esteja em https://stable.publiclab.org - eu tentei até 1000 tags e ele carrega bem, mas não mais do que isso, por favor, no servidor de produção, mesmo uma vez)
E estamos limitados a links entre eles, com cada tag relatando um máximo de 10 tags que ocorreram ao lado. Isso não é abrangente, mas parecia um equilíbrio viável de otimização x meticulosidade.
jywarren
em 28 jan. 2019
jywarren
em 28 jan. 2019
@jywarren , este ainda é o commit mais recente? Eu porque queria ver o json vindo do endpoint /tag/graph.json e ele me enviou todas as tags. Com base no código naquele commit, eu esperava que 250 fosse o limite rígido (minha nota de legibilidade Ruby suportando).
skilfullycurled
em 31 jan. 2019
@jywarren deixa
skilfullycurled
em 31 jan. 2019
OK. Acabei de passar um bom tempo explorando isso e estou tendo uma ideia melhor de como o gráfico está funcionando.
Agora, quero sugerir que pode haver um layout diferente que desejamos usar - estamos usando um modelo
Vou dar uma olhada e pensar sobre isso. Acho que a pergunta que precisa ser respondida aqui é o que queremos ver no gráfico? Por exemplo, se estivermos principalmente interessados em que um visitante seja capaz de ver quais tags estão associadas a quais, então o layout do círculo concêntrico pode ser o melhor, mas enfadonho.
Se eu tivesse que dar um palpite (informado, mas ainda assim um palpite) de por que o CoSE não está produzindo um resultado tão bom, seria porque, ao olhar para os dados, conforme você alcança uma certa contagem de nós, a contagem começa para todos serem semelhantes. Portanto, se CoSE está repelindo os nós com base apenas no peso do nó, então é possível que haja uma quantidade igual de repulsão entre eles. Quando eu uso repulsão aqui, quero dizer todas as coisas que entram em repulsão, por exemplo, é a configuração da gravidade também. Nesse caso, pode ser que não haja iterações suficientes do algoritmo ou os fatores de repulsão não causam / permitem propagação suficiente.
Outra questão que podemos pedir a alguém para testar e resolver é a questão da detecção da comunidade.
Quando tiver um momento, você pode me apontar para o commit com o JavaScript mais recente sobre isso? Posso obtê-lo através do navegador, mas apenas naquela forma em que não tem nenhuma estrutura e é apenas uma única linha. Assim que eu fizer, posso ver mais. Eu olhei para o exemplo do jLouvain, e ele não parece ter uma configuração para quantas comunidades você deseja, o que pode ser uma parte do problema. Normalmente, Louvain oferece um "melhor número", mas às vezes não é o melhor. A implementação python na qual jLouvain se baseia tem esse parâmetro, mas pode não ter sido substituído.
skilfullycurled
em 31 jan. 2019
Aqui estamos:
jywarren
em 1 fev. 2019

jywarren
em 1 fev. 2019
Oh, pensei ter deixado outro comentário ... para onde foi? espere...
jywarren
em 1 fev. 2019
De qualquer forma, eu ia dizer que acho que descobri alguns dos problemas de layout, mas julgue por si mesmos:
https://publiclab.org/stats/graph?limit=50
https://publiclab.org/stats/graph?limit=100
jywarren
em 1 fev. 2019
Este é o JS para a detecção da comunidade: https://github.com/publiclab/plots2/blob/master/app/views/tag/graph.html.erb#L263
E aqui está a configuração do layout, que poderíamos ajustar muito para experimentar:
jywarren
em 1 fev. 2019
Em primeiro lugar, gostaria de me desculpar por não poder ajudar com o trabalho pesado no final da codificação. É fácil para alguém apenas sugerir coisas, mas eu percebo que elas também devem ser implementadas por pessoas e não esqueci que não estou ajudando nesse sentido.
Existem várias possibilidades de por que o jLouvain não está tendo um bom desempenho. @jywarren , acho que você já está resolvendo um deles que é que não havia cores suficientes. Ainda assim, verifiquei no console as comunidades e cada nó é uma comunidade diferente, o que para mim implica que o algoritmo não está encontrando um bom lugar para parar. Normalmente, há um parâmetro para quantas comunidades / sensibilidade / resolução você gostaria de ter e então você brinca com ele até obter algo que pareça certo.
Veja este problema no repositório jLouvain. Alguém escreveu uma correção muito simples que pode ser implementada. Não tenho certeza de como funciona em termos do que retorna: o ideal é que ele retorne um resultado de detecção de comunidade inteira para cada elemento na matriz? Isso seria incrível e provavelmente resolveria o problema de cada nó ser sua própria comunidade.
Mais tarde…
skilfullycurled
em 1 fev. 2019
Retransmitindo uma pergunta de @shapironick, que estava se perguntando em outro canal se em uma edição futura poderia haver espessura e espessura variáveis nas linhas de conexão para mostrar o quão intimamente relacionadas estão duas tags em particular? Obrigado!
ebarry
em 6 fev. 2019
essa é uma ótima ideia. Acho que, neste ponto, precisamos fechar isso e abrir um
novo problema com uma lista de verificação de possíveis refinamentos para a tela, e
será muito mais fácil para os novatos (menos contexto e histórico necessários para
participar) para entrar e começar a implementá-los. Estou quase tentado a
gire-o para um novo repositório que é / apenas este gráfico /, uma vez que
não se interconecta de outra forma com a base de código PL, mas por causa de
coesão da comunidade vamos mantê-lo em parcelas2.
Liz, você poderia começar a nova edição e começar com uma lista de verificação?
Na quarta-feira, 6 de fevereiro de 2019 às 11h17, Liz Barry [email protected] escreveu:
Retransmitindo uma pergunta de @shapironick https://github.com/shapironick
que estava se perguntando em outro canal se em uma edição futura poderia haver
variação de finura e espessura nas linhas de conexão para mostrar o quão próximo
relacionadas a quaisquer duas tags em particular? Obrigado!-
Você está recebendo isso porque foi mencionado.
Responda a este e-mail diretamente, visualize-o no GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-461083862 ,
ou silenciar o tópico
https://github.com/notifications/unsubscribe-auth/AABfJ9nxysbBtCAYHEW2tA8UwNH9zelFks5vKv_hgaJpZM4OOvLP
.
jywarren
em 6 fev. 2019
Yay! @shapironick! No momento, a consulta do banco de dados envia apenas as tags top-n e a contagem dessas tags para todo o site. No futuro, para ter pesos de borda, precisaríamos fazer uma alteração no back-end para enviar todas as tags para o front end para que as contagens de interconexão pudessem ser agregadas, ou eles precisam ser agregados no Processo interno. Alternativamente, no front end calculamos alguma propriedade da borda da rede (por exemplo, alguma centralidade: grau, proximidade, intermediação, etc.).
skilfullycurled
em 6 fev. 2019
Muito legal! Sem pressa nessa ideia +1 para começar uma nova edição, este é épico e incrível!
 shapironick
em 6 fev. 2019
shapironick
em 6 fev. 2019
Agora, nos dados que estamos passando para o código do gráfico, acho que vemos quando uma tag (digamos, a tag A) está vinculada à tag B, e vemos uma segunda conexão se a tag B vincula de volta à tag A. Mas isso realmente não nos diz muito. Refatorar para fornecer "peso" é interessante ... eu poderia imaginar algumas maneiras de fazer isso também. Concordo, poderíamos passar todos os node.ids que cada tag possui e calcular isso localmente, ou podemos tentar pré-calcular isso no momento em que coletarmos as 5 principais tags mais relacionadas de cada tag. (acho que mudei para 10 recentemente, mas mesmo assim).
Grande refinamento de acompanhamento. Assim que tivermos a lista de verificação, podemos priorizar um pouco e melhorar gradualmente. Obrigado!
jywarren
em 6 fev. 2019
Veja, isso entrou no registro histórico;): https://publiclab.org/wiki/community-development#2019
ebarry
em 8 fev. 2019
Enquanto procurava por um possível projeto Summer of Code neste próximo verão, encontrei o bug de detecção da comunidade, que era sutil - os dados estavam em um objeto aninhado como {data: { DATA }} vez de apenas { DATA } . Corrigido em https://github.com/publiclab/plots2/pull/9169 !
jywarren
em 9 fev. 2021

jywarren
em 9 fev. 2021
Isso é apenas com nossos dados de teste; a correção completa ficará visível no servidor estável assim que fundirmos e recompilarmos; provavelmente 30m ou mais.
jywarren
em 9 fev. 2021
Bom, vamos lá:
https://stable.publiclab.org/tags (lembre-se de que isso diminuirá por 10 minutos cada vez que mesclarmos uma nova alteração)
jywarren
em 9 fev. 2021
Questões relacionadas
ebarry
·
3Comentários
 bronwen9
·
3Comentários
bronwen9
·
3Comentários
![first-timers[bot] picture](https://avatars.githubusercontent.com/in/4832?v=4&s=40) first-timers[bot]
·
3Comentários
first-timers[bot]
·
3Comentários
 milaaraujo
·
3Comentários
milaaraujo
·
3Comentários
 noi5e
·
3Comentários
noi5e
·
3Comentários
Comentários muito úteis
Ele deve estar rodando no site ao vivo hoje à noite, mas eu queria observar que o "uso excessivo" de tags por alguns usuários distorceu o gráfico de uma forma que reconhecemos antes. Eu acredito que um dos usuários foi moderado do site, e eu me pergunto se as pessoas acham apropriado excluir essas tags do site ou pelo menos omiti-las do gráfico. Excluí-los seria mais fácil, mas também podemos criar algo apenas para ocultá-los. Preferência, @ebarry @skilfullycurled ?
Ainda assim, parece bom, embora as configurações na elasticidade da borda ainda precisem de alguns ajustes, e talvez um tipo de layout diferente funcione melhor ...