Tidyr: FR: ordem das colunas resultantes de pivot_wider
Caso eu não esteja apenas perdendo uma solução óbvia pré-existente, seria bom ser capaz de especificar como as colunas resultantes de pivot_wider serão ordenadas. Usando o exemplo us_rent_income ,
us_rent_income %>%
pivot_wider(names_from = variable, values_from = c(estimate, moe))
produz as colunas estimate_income , estimate_rent , moe_income e moe_rent . No meu caso de uso (chegando a uma tabela de cabeçalho duplo), quero que eles estejam na ordem, estimate_income , moe_income , estimate_rent e moe_rent .
 mattantaliss
mattantaliss
Todos 25 comentários
Idem. A "correção" é voltar a espalhar que sempre funcionou "corretamente"? Existem vários problemas fechados, mas não encontrei soluções.
 EarlGlynn
em 15 dez. 2019
EarlGlynn
em 15 dez. 2019
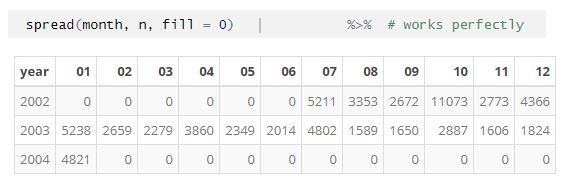
Mais informações. O comentário de Hadley em outro tópico diz para classificar os dados para controlar a ordem das colunas. Mas isso não faz sentido para grandes conjuntos de dados em alguns casos. Tenho dados de julho de 2002 a janeiro de 2004 classificados por ano e mês. Por que eu iria querer classificar primeiro por mês do que por ano para obter a ordem correta dos fatores - esse arquivo eventualmente terá mais de um milhão de registros.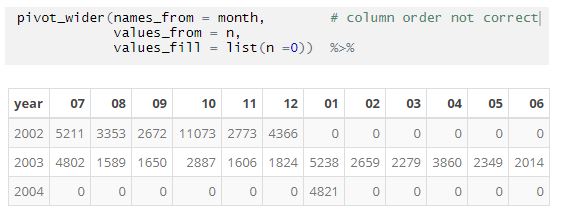
EarlGlynn
em 15 dez. 2019
A ordem da exibição de saída deve ser independente da ordem dos dados de entrada. Em datas de processamento que começam em julho (exemplo acima), isso não deve significar que o primeiro mês do ano é julho para a exibição de saída. Eu quero codificar "pivot_wider" em um novo código, mas a disseminação funciona muito melhor por enquanto.
EarlGlynn
em 29 dez. 2019
Acho que esse problema é realmente dois problemas separados, 1) um para especificar a ordem em que as variáveis de multiplicação são combinadas , de acordo com o comentário original de , e 2) um para como os valores dentro de uma variável são ordenados, como em # 850 (que foi encerrado como uma duplicata deste problema) e os comentários de @ EarlGlynn.
Aqui estão meus comentários e regexp para a segunda parte. As colunas (dentro de uma variável) devem ser ordenadas da mesma forma que em spread() . Por exemplo, para fatores, as colunas devem ser ordenadas
pela ordenação nos níveis de fator . E para variáveis numéricas, elas devem ser ordenadas por números. Aqui está uma regexp, para ambos os fatores, níveis numéricos e de caracteres:
library(tidyr)
library(dplyr)
d = tibble(day_int = c(4,3,5,1,2),
day_fac = factor(day_int, levels=1:5,
labels=c("Mon","Tue", "Wed","Thu","Fri")),
day_char = as.character(day_fac))
d
#> # A tibble: 5 x 3
#> day_int day_fac day_char
#> <dbl> <fct> <chr>
#> 1 4 Thu Thu
#> 2 3 Wed Wed
#> 3 5 Fri Fri
#> 4 1 Mon Mon
#> 5 2 Tue Tue
levels(d$day_fac)
#> [1] "Mon" "Tue" "Wed" "Thu" "Fri"
# spread() respects the ordering of the factor levels ...
d %>%
select(day_fac, day_int) %>%
spread(key = "day_fac", value = "day_int")
#> # A tibble: 1 x 5
#> Mon Tue Wed Thu Fri
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 2 3 4 5
# ... but pivot_wider() does not
d %>%
select(day_fac, day_int) %>%
pivot_wider(names_from = day_fac, values_from = day_int)
#> # A tibble: 1 x 5
#> Thu Wed Fri Mon Tue
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 4 3 5 1 2
# spread() respects the ordering of numeric variables ...
d %>%
select(day_int) %>%
spread(key = "day_int", value = "day_int")
#> # A tibble: 1 x 5
#> `1` `2` `3` `4` `5`
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 2 3 4 5
# ... but pivot_wider() does not
d %>%
select(day_int) %>%
pivot_wider(names_from = day_int, values_from = day_int)
#> # A tibble: 1 x 5
#> `4` `3` `5` `1` `2`
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 4 3 5 1 2
# spread() respects the (alphabetic) ordering of character variables ...
d %>%
select(day_char, day_int) %>%
spread(key = "day_char", value = "day_int")
#> # A tibble: 1 x 5
#> Fri Mon Thu Tue Wed
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 5 1 4 2 3
# ... but pivot_wider() does not
d %>%
select(day_char, day_int) %>%
pivot_wider(names_from = day_char, values_from = day_int)
#> # A tibble: 1 x 5
#> Thu Wed Fri Mon Tue
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 4 3 5 1 2
Basicamente, a solicitação (para o segundo sub-problema) é que pivot_wider() deve usar a mesma ordem de order() :
order(d$day_fac)
#> [1] 4 5 2 1 3
order(d$day_int)
#> [1] 4 5 2 1 3
order(d$day_char)
#> [1] 3 4 1 5 2
 huftis
em 31 mar. 2020
huftis
em 31 mar. 2020
@huftis estão atualmente ordenados por sua primeira aparição no quadro de dados. Infelizmente, não acho que a ordenação para corresponder a order() é um bom padrão porque a ordenação dos vetores de caracteres depende do ambiente atual.
 hadley
em 21 abr. 2020
hadley
em 21 abr. 2020
Para o caso de pedidos, acho que names_sort = TRUE faz sentido.
Não sei como chamar o argumento para o outro caso que é sobre se names_from ou values_from vem primeiro.
hadley
em 22 abr. 2020
Ideia aleatória: talvez names_from possa reconhecer a variável especial .values :
us_rent_income %>%
pivot_wider(names_from = c(variable, .value), values_from = c(estimate, moe))
us_rent_income %>%
pivot_wider(names_from = c(.value, variable), values_from = c(estimate, moe))
Não, eu não acho que posso fazer isso funcionar sem pensar muito mais. Portanto, a única escolha que você tem é se values vem primeiro ou por último. Isso sugere um nome de argumento envolvendo loc ou pos , talvez values_names_loc = "first" ? Ou é names_values_pos = "last" ?
hadley
em 28 abr. 2020
Parece correto alterar a ordem dos nomes das colunas quando você altera a posição do nome da variável?
library(tidyr)
pivot_wider(
us_rent_income,
names_from = variable,
values_from = c(estimate, moe),
names_value_loc = "first"
)
#> # A tibble: 52 x 6
#> GEOID NAME estimate_income estimate_rent moe_income moe_rent
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 01 Alabama 24476 747 136 3
#> 2 02 Alaska 32940 1200 508 13
#> 3 04 Arizona 27517 972 148 4
#> 4 05 Arkansas 23789 709 165 5
#> 5 06 California 29454 1358 109 3
#> 6 08 Colorado 32401 1125 109 5
#> 7 09 Connecticut 35326 1123 195 5
#> 8 10 Delaware 31560 1076 247 10
#> 9 11 District of Columbia 43198 1424 681 17
#> 10 12 Florida 25952 1077 70 3
#> # … with 42 more rows
pivot_wider(
us_rent_income,
names_from = variable,
values_from = c(estimate, moe),
names_value_loc = "last"
)
#> # A tibble: 52 x 6
#> GEOID NAME income_estimate income_moe rent_estimate rent_moe
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 01 Alabama 24476 136 747 3
#> 2 02 Alaska 32940 508 1200 13
#> 3 04 Arizona 27517 148 972 4
#> 4 05 Arkansas 23789 165 709 5
#> 5 06 California 29454 109 1358 3
#> 6 08 Colorado 32401 109 1125 5
#> 7 09 Connecticut 35326 195 1123 5
#> 8 10 Delaware 31560 247 1076 10
#> 9 11 District of Columbia 43198 681 1424 17
#> 10 12 Florida 25952 70 1077 3
#> # … with 42 more rows
Criado em 2020-04-27 pelo pacote reprex (v0.3.0)
hadley
em 28 abr. 2020
Não acho que gostaria de acrescentar mais do que dois argumentos para esses recursos, pois a compensação aumentou a complexidade de pivot_wider() supera o ganho limitado em futuros. (Especialmente porque você também pode gerar a especificação de pivô sozinho para exercer maior controle).
hadley
em 28 abr. 2020
Hmm, eu estaria bem em confiar na geração da especificação de pivô sozinho, se isso produzisse o que você está obtendo com sua ideia para modificar a ordem das colunas. Meu caso de uso original, entretanto, parece um pouco diferente. Parece que sua ideia era lidar com o caso de ter colunas sendo \ Estou pensando em tudo isso como um par de loops aninhados. Eu quero ser capaz de dizer se o loop externo (ou loop interno, o que for mais fácil ou fizer mais sentido especificar) é sobre nomes ou valores, com o comportamento atual / padrão sendo que o loop externo está iterando sobre valores e o loop interno está iterando sobre os nomes.
mattantaliss
em 28 abr. 2020
@mattantaliss sim, parece que você só deseja controlar isso sozinho com uma especificação de pivô. Vou trabalhar em mais documentos para isso.
hadley
em 28 abr. 2020
Não elimine spread . Parei de usar pivot_wider porque spread é o que eu normalmente preciso. Esta "simplificação" está adicionando complexidade.
EarlGlynn
em 29 abr. 2020
@EarlGlynn foi substituído, o que significa que não receberá mais melhorias, mas não temos planos imediatos para removê-lo.
hadley
em 29 abr. 2020
@huftis estão atualmente ordenados por sua primeira aparição no quadro de dados. Infelizmente, não acho que a ordenação para corresponder a
order()é um bom padrão porque a ordenação dos vetores de caracteres depende do ambiente atual.
Isso é verdade, mas o mesmo acontece com a ordem usada em arrange() . E isso é realmente um problema? Pode haver alguns casos raros em que isso causa problemas (para eles, sempre há as_factor() ), mas em geral eu acho que a classificação por local é uma coisa boa . E para outros tipos de variáveis (numéricas, fatores, datas, datas e horas, ...), o order() dá a ordem natural .
Agora usei pivot_wider() algumas vezes (principalmente com fator ou variáveis numéricas), e o 'novo' padrão de organizar as colunas pela linha em que os valores aparecem pela primeira vez no quadro de dados nunca foi o desejado pedido. (A única exceção é quando a ordem das linhas é igual ao fator ou ordem numérica, por exemplo, depois de usar summarise() em uma tabela agrupada.) Na verdade, é tão chato que várias vezes voltei apenas para usando spread() .
huftis
em 29 abr. 2020
Parece correto alterar a ordem dos nomes das colunas quando você altera a posição do nome da variável?
Sim, isso faz sentido. É uma maneira muito fácil e intuitiva de especificar o pedido. (E é como eu esperava que a função funcionasse.)
huftis
em 29 abr. 2020
Parece correto alterar a ordem dos nomes das colunas quando você altera a posição do nome da variável?
Sim, isso faz sentido. É uma maneira muito fácil e intuitiva de especificar o pedido. (E é assim que eu _esperaria_ que a função funcionasse.)
Hm. Acho que entendi mal o exemplo (não dei uma boa olhada no conjunto de dados primeiro). Não tenho mais certeza do que penso disso. Mas parece mais natural sempre usar os valores names_from como o prefixo dos nomes das colunas, não o sufixo.
huftis
em 29 abr. 2020
Não acho que haja acordo sobre o que significa "ordem natural". Meu exemplo original em que "07" ("julho") aparece primeiro nunca será natural para mim quando "01" (janeiro) era minha expectativa. Os resultados foram causados quando um arquivo muito grande começou com dados de julho em vez de dados de janeiro. Quem saberia sobre esse pedido com antecedência em geral?
Acho que a "ordem natural" deve ser uma propriedade do conjunto, não uma propriedade da ordem de processamento. Gostaria que você "não tivesse planos para remover" spread vez de "nenhum plano imediato" - vi o vídeo da sua conferência RStudio falando sobre o ciclo do software. Estou fazendo lobby para que spread sempre esteja disponível para trabalhar com a "ordem natural" que agora oferece, em vez de estar em uma lista para algum dia ser eliminado. Não consigo imaginar o uso de pivot_wider muita frequência na "ordem natural" que você está sugerindo.
EarlGlynn
em 30 abr. 2020
Observe que geralmente não é possível corrigir a ordem das colunas executando arrange() no quadro de dados antes de pivot_wider() . O motivo é que isso pode bagunçar a ordem das linhas, mesmo se você também aplicar uma subclassificação com base nos números das linhas originais. Aqui está um exemplo simples, semelhante em estrutura aos dados com os quais costumo trabalhar:
d = head(mtcars) %>%
group_by(gear, cyl) %>%
summarise(mean_hp = mean(hp)) %>%
ungroup()
Eu quero mostrar a variável mean_hp , com gear como linhas e cyl como colunas, com uma ordem de classificação natural. (Aqui, as variáveis de agrupamento são números, mas normalmente são fatores, às vezes caracteres.)
Um simples pivot_wider() fornece a ordem errada das colunas:
d %>%
pivot_wider(names_from = cyl, values_from = mean_hp)
## A tibble: 2 x 4
# gear `6` `8` `4`
# <dbl> <dbl> <dbl> <dbl>
# 1 3 108. 175 NA
# 2 4 110 NA 93
Classificar o tibble pela variável de coluna fornece a ordem de linha errada:
arrange(d, cyl) %>%
pivot_wider(names_from = cyl, values_from = mean_hp)
# # A tibble: 2 x 4
# gear `4` `6` `8`
# <dbl> <dbl> <dbl> <dbl>
# 1 4 93 110 NA
# 2 3 NA 108. 175
A classificação pela variável de linha original ainda dá a ordem de linha errada.
arrange(d, cyl, gear) %>%
pivot_wider(names_from = cyl, values_from = mean_hp)
# # A tibble: 2 x 4
# gear `4` `6` `8`
# <dbl> <dbl> <dbl> <dbl>
# 1 4 93 110 NA
# 2 3 NA 108. 175
Portanto, parece que ele é realmente impossível obter tanto a linha e a ordem da coluna corretamente. A menos que se use spread() :
spread(d, key = cyl, value = mean_hp)
# # A tibble: 2 x 4
# gear `4` `6` `8`
# <dbl> <dbl> <dbl> <dbl>
# 1 3 NA 108. 175
# 2 4 93 110 NA
Olá.
existe uma maneira de classificar a ordem da coluna conforme necessário usando "contains ()"
pivot_wider(names_from = c(name),values_from = c(value1,value2)) %>%
select(Id_variables,contains(paste(other_table_with_name %>%
distinct(name) %>%
pull(name))))
espero que ajude :)
 alon-sarid
em 30 abr. 2020
alon-sarid
em 30 abr. 2020
@huftis, você pode estar certo ao dizer que names_sort = TRUE é o padrão correto, mas não tenho tempo para analisar totalmente a situação (já que preciso obter uma atualização tidyr antes do dplyr 1.0.0). Portanto, vou adicionar o argumento names_sort mas deixá-lo definido como FALSE para preservar o comportamento existente.
hadley
em 5 mai. 2020
Nota para mim mesmo quando voltar a este assunto: antes de codificar as opções em pivot_wider() , seria melhor documentar completamente como criar sua própria especificação para resolver este problema.
hadley
em 5 mai. 2020
Pelo que vale a pena, a situação que @huftis descreve para valores de fator é exatamente o cenário que me trouxe aqui. Meu pacote, o pesquisador , depende do uso de níveis de fator para organizar as colunas e as linhas.
Eu testei a versão de desenvolvimento do tidyr, e o argumento names_sort = TRUE resolveu meu problema inteiramente. Usarei spread em meu pacote até que a versão de desenvolvimento seja lançada para o CRAN.
Não é minha função dizer se o valor padrão de names_sort deve ou não ser TRUE , mas essa é a única maneira que prevejo usá-lo.
 jdjohn215
em 8 mai. 2020
jdjohn215
em 8 mai. 2020
Ideia aleatória: talvez
names_frompossa reconhecer a variável especial.values:us_rent_income %>% pivot_wider(names_from = c(variable, .value), values_from = c(estimate, moe)) us_rent_income %>% pivot_wider(names_from = c(.value, variable), values_from = c(estimate, moe))
Ele tentou adicionar .value por último em names_from na esperança de iterar nas colunas de valor no loop mais interno - antes de ler seu comentário, por isso é intuitivo! Eu sugeriria que a documentação names_sort diria "As colunas devem ser classificadas?" em vez de "Os nomes das colunas devem ser classificados?". Só percebi que eles são classificados pela forma como as colunas são ordenadas em names_from depois de usar names_glue onde alterei a ordem.
 Superstud
em 21 set. 2020
Superstud
em 21 set. 2020
Estou procurando o mesmo recurso mencionado por @mattantaliss acima:
O que eu estava procurando, no entanto, é ter
<value1>_<name1>, <value2>_<name1>, <value2>_<name2>,etc. em vez de<value1>_<name1>, <value1>_<name2>,etc.
... bem como neste problema de Stack Overflow (em que um usuário forneceu uma solução alternativa bem bacana).
Espero que este recurso seja adicionado algum dia! Se for possível fazer com pivot_wider_spec() , ainda não descobri nem encontrei um explicador online para me ajudar.
 mcleanle
em 29 jan. 2021
mcleanle
em 29 jan. 2021
Questões relacionadas
 thays42
·
3Comentários
thays42
·
3Comentários
 coatless
·
6Comentários
coatless
·
6Comentários
 georgevbsantiago
·
6Comentários
georgevbsantiago
·
6Comentários
 andrewpbray
·
8Comentários
andrewpbray
·
8Comentários
 yuanwxu
·
3Comentários
yuanwxu
·
3Comentários
Comentários muito úteis
Ideia aleatória: talvez
names_frompossa reconhecer a variável especial.values: