Pytorch: RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached)
CUDA Out of Memory error but CUDA memory is almost empty
I am currently training a lightweight model on very large amount of textual data (about 70GiB of text).
For that I am using a machine on a cluster ('grele' of the grid5000 cluster network).
I am getting after 3h of training this very strange CUDA Out of Memory error message:
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached).
According to the message, I have the required space but it does not allocate the memory.
Any idea what might cause this ?
For information, my preprocessing relies on torch.multiprocessing.Queue and an iterator over the lines of my source data to preprocess the data on the fly.
Full stacktrace
Traceback (most recent call last):
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1228, in <module>
exec_with_profiler(script_filename, prof, args.backend, script_args)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1129, in exec_with_profiler
exec(compile(f.read(), filename, 'exec'), ns, ns)
File "run.py", line 293, in <module>
main(args, save_folder, load_file)
File "run.py", line 272, in main
trainer.all_epochs()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 140, in all_epochs
self.single_epoch()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 147, in single_epoch
tracker.add(*self.single_batch(data, target))
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 190, in single_batch
result = self.model(data)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/papud-bull-nn/model/model.py", line 54, in forward
emb = self.emb(input)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/sparse.py", line 118, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/functional.py", line 1454, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached)
 EMarquer
EMarquer
All 91 comments
I have the same runtime error:
Traceback (most recent call last):
File "carn\train.py", line 52, in <module>
main(cfg)
File "carn\train.py", line 48, in main
solver.fit()
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 95, in fit
psnr = self.evaluate("dataset/Urban100", scale=cfg.scale, num_step=self.step)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 136, in evaluate
sr = self.refiner(lr_patch, scale).data
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 74, in forward
b3 = self.b3(o2)
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 30, in forward
c3 = torch.cat([c2, b3], dim=1)
RuntimeError: CUDA out of memory. Tried to allocate 195.25 MiB (GPU 0; 4.00 GiB total capacity; 2.88 GiB already allocated; 170.14 MiB free; 2.00 MiB cached)
 OmarBazaraa
on 27 Jan 2019
OmarBazaraa
on 27 Jan 2019
@EMarquer @OmarBazaraa Could you give a minimal repro example that we can run?
 yf225
on 28 Jan 2019
yf225
on 28 Jan 2019
I can not reproduce the problem anymore, thus I will close the issue.
The problem disappeared when I stopped storing the preprocessed data in RAM.
@OmarBazaraa, I do not think your problem is the same as mine, as:
- I am trying to allocate 12.50 MiB, with 9.28 GiB free
- you are trying to allocate 195.25 MiB, with 170.14 MiB free
From my previous experience with this problem, either you do not free the CUDA memory or you try to put too much data on CUDA.
By not freeing the CUDA memory, I mean you potentially still have references to tensors in CUDA that you do not use anymore. Those would prevent the allocated memory from being freed by deleting the tensors.
EMarquer
on 28 Jan 2019
Is there any general solution?
CUDA out of memory. Tried to allocate 196.00 MiB (GPU 0; 2.00 GiB total capacity; 359.38 MiB already allocated; 192.29 MiB free; 152.37 MiB cached)
 aniketspurohit
on 31 Jan 2019
aniketspurohit
on 31 Jan 2019
@aniks23 we are working on a patch that I believe will give better experience in this case. Stay tuned
 fmassa
on 31 Jan 2019
fmassa
on 31 Jan 2019
Is there any way to know how big a model or a network my system can handle
without running into this issue?
On Fri, Feb 1, 2019 at 3:55 AM Francisco Massa notifications@github.com
wrote:
@aniks23 https://github.com/aniks23 we are working on a patch that I
believe will give better experience in this case. Stay tuned—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/pytorch/pytorch/issues/16417#issuecomment-459530332,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AUEJD4SYN4gnRkrLgFYEKY6y14P1TMgLks5vI21wgaJpZM4aUowv
.
aniketspurohit
on 1 Feb 2019
I also got this message:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)
It happened when I was trying to run the Fast.ai lesson1 Pets https://course.fast.ai/ (cell 31)
 adrianovieira
on 12 Mar 2019
adrianovieira
on 12 Mar 2019
I too am running into the same errors. My model was working earlier with the exact setup, but now it's giving this error after I modified some seemingly unrelated code.
RuntimeError: CUDA out of memory. Tried to allocate 1.34 GiB (GPU 0; 22.41 GiB total capacity; 11.42 GiB already allocated; 59.19 MiB free; 912.00 KiB cached)
 treble-maker123
on 14 Mar 2019
treble-maker123
on 14 Mar 2019
I don't know if my scenario is relatable to the original issue, but I resolved my problem (the OOM error in the previous message went away) by breaking up the nn.Sequential layers in my model, e.g.
self.input_layer = nn.Sequential(
nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU()
)
output = self.input_layer(x)
to
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0)
self.input_bn = nn.BatchNorm3d(32)
output = F.relu(self.input_bn(self.input_conv(x)))
My model has a lot more of these (5 more to be exact). Am I using nn.Sequential right? Or is this a bug? @yf225 @fmassa
treble-maker123
on 14 Mar 2019
I am getting a similar error as well:
CUDA out of memory. Tried to allocate 196.50 MiB (GPU 0; 15.75 GiB total capacity; 7.09 GiB already allocated; 20.62 MiB free; 72.48 MiB cached)
@treble-maker123 , have you been able to conclusively prove that nn.Sequential is the problem ?
 yasheshgaur
on 17 Mar 2019
yasheshgaur
on 17 Mar 2019
I am having a similar issue. I am using the pytorch dataloader. SaysI should have over 5 Gb free but it gives 0 bytes free.
RuntimeError Traceback (most recent call last)
22
23 data, inputs = states_inputs
---> 24 data, inputs = Variable(data).float().to(device), Variable(inputs).float().to(device)
25 print(data.device)
26 enc_out = encoder(data)
RuntimeError: CUDA out of memory. Tried to allocate 11.00 MiB (GPU 0; 6.00 GiB total capacity; 448.58 MiB already allocated; 0 bytes free; 942.00 KiB cached)
 ahsteven
on 3 Apr 2019
ahsteven
on 3 Apr 2019
Hi, I also got this error.
File "xxx", line 151, in __call__
logits = self.model(x_hat)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 67, in forward
x = up(x, blocks[-i-1])
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 120, in forward
out = self.conv_block(out)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 92, in forward
out = self.block(x)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/container.py", line 92, in forward
input = module(input)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 320, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDA out of memory. Tried to allocate 8.00 MiB (GPU 1; 11.78 GiB total capacity; 10.66 GiB already allocated; 1.62 MiB free; 21.86 MiB cached)
 AlbertZhangHIT
on 17 Apr 2019
AlbertZhangHIT
on 17 Apr 2019
Sadly, I met the same issue too.
RuntimeError: CUDA out of memory. Tried to allocate 1.33 GiB (GPU 1; 31.72 GiB total capacity; 5.68 GiB already allocated; 24.94 GiB free; 5.96 MiB cached)
I have trained my model in a cluster of servers and the error unpredictably happened to one of my servers. Also such wired error only happens in one of my training strategies. And the only difference is that I modify the code during data augmentation, and make the data preprocess more complicated than others. But I am not sure how to solve this problem.
 qingyu-wang
on 25 Apr 2019
qingyu-wang
on 25 Apr 2019
I am also having this issue. How to solve it??? RuntimeError: CUDA out of memory. Tried to allocate 18.00 MiB (GPU 0; 4.00 GiB total capacity; 2.94 GiB already allocated; 10.22 MiB free; 18.77 MiB cached)
 nabil2i
on 10 May 2019
nabil2i
on 10 May 2019
Same issue here RuntimeError: CUDA out of memory. Tried to allocate 54.00 MiB (GPU 0; 11.00 GiB total capacity; 7.89 GiB already allocated; 7.74 MiB free; 478.37 MiB cached)
 williamluke4
on 16 May 2019
williamluke4
on 16 May 2019
@fmassa Do you have any more info on this?
williamluke4
on 18 May 2019
https://github.com/pytorch/pytorch/issues/16417#issuecomment-484264163
The same issue to me
Dear, did you get the solution?
(base) F:\Suresh\st-gcn>python main1.py recognition -c config/st_gcn/ntu-xsub/train.yaml --device 0 --work_dir ./work_dir
C:\Users\cudalab10\Anaconda3lib\site-packages\torch\cuda__init__.py:117: UserWarning:
Found GPU0 TITAN Xp which is of cuda capability 1.1.
PyTorch no longer supports this GPU because it is too old.
warnings.warn(old_gpu_warn % (d, name, major, capability[1]))
[05.22.19|12:02:41] Parameters:
{'base_lr': 0.1, 'ignore_weights': [], 'model': 'net.st_gcn.Model', 'eval_interval': 5, 'weight_decay': 0.0001, 'work_dir': './work_dir', 'save_interval': 10, 'model_args': {'in_channels': 3, 'dropout': 0.5, 'num_class': 60, 'edge_importance_weighting': True, 'graph_args': {'strategy': 'spatial', 'layout': 'ntu-rgb+d'}}, 'debug': False, 'pavi_log': False, 'save_result': False, 'config': 'config/st_gcn/ntu-xsub/train.yaml', 'optimizer': 'SGD', 'weights': None, 'num_epoch': 80, 'batch_size': 64, 'show_topk': [1, 5], 'test_batch_size': 64, 'step': [10, 50], 'use_gpu': True, 'phase': 'train', 'print_log': True, 'log_interval': 100, 'feeder': 'feeder.feeder.Feeder', 'start_epoch': 0, 'nesterov': True, 'device': [0], 'save_log': True, 'test_feeder_args': {'data_path': './data/NTU-RGB-D/xsub/val_data.npy', 'label_path': './data/NTU-RGB-D/xsub/val_label.pkl'}, 'train_feeder_args': {'data_path': './data/NTU-RGB-D/xsub/train_data.npy', 'debug': False, 'label_path': './data/NTU-RGB-D/xsub/train_label.pkl'}, 'num_worker': 4}
[05.22.19|12:02:41] Training epoch: 0
Traceback (most recent call last):
File "main1.py", line 31, in
p.start()
File "F:\Suresh\st-gcn\processor\processor.py", line 113, in start
self.train()
File "F:\Suresh\st-gcn\processor\recognition.py", line 91, in train
output = self.model(data)
File "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(input, *kwargs)
File "F:\Suresh\st-gcn\net\st_gcn.py", line 82, in forward
x, _ = gcn(x, self.A * importance)
File "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(input, *kwargs)
File "F:\Suresh\st-gcn\net\st_gcn.py", line 194, in forward
x, A = self.gcn(x, A)
File "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(input, *kwargs)
File "F:\Suresh\st-gcn\net\utils\tgcn.py", line 60, in forward
x = self.conv(x)
File "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(input, *kwargs)
File "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\conv.py", line 320, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDA out of memory. Tried to allocate 1.37 GiB (GPU 0; 12.00 GiB total capacity; 8.28 GiB already allocated; 652.75 MiB free; 664.38 MiB cached)
 Sureshthommandru
on 22 May 2019
Sureshthommandru
on 22 May 2019
It is because of mini-batch of data does not fit on to GPU memory. Just decrease the batch size. When I set batch size = 256 for cifar10 dataset I got the same error; Then I set the batch size = 128, it is solved.
 balcilar
on 1 Jun 2019
balcilar
on 1 Jun 2019
Yeah @balcilar is right, I reduced the batch size and now it works
 EKELE-NNOROM
on 4 Jun 2019
EKELE-NNOROM
on 4 Jun 2019
I have a similar issue:
RuntimeError: CUDA out of memory. Tried to allocate 11.88 MiB (GPU 4; 15.75 GiB total capacity; 10.50 GiB already allocated; 1.88 MiB free; 3.03 GiB cached)
I am using 8 V100 to train the model. The confusing part is that there is still 3.03GB cached and it cannot be allocated for 11.88MB.
 magic282
on 10 Jun 2019
magic282
on 10 Jun 2019
Did you change the batch size. Reduce the batch size by half. Say the batch
size is 16 to implement, try using a batch size of 8 and see if it works.
Enjoy
On Mon, Jun 10, 2019 at 2:10 AM magic282 notifications@github.com wrote:
I have a similar issue:
RuntimeError: CUDA out of memory. Tried to allocate 11.88 MiB (GPU 4; 15.75 GiB total capacity; 10.50 GiB already allocated; 1.88 MiB free; 3.03 GiB cached)
I am using 8 V100 to train the model. The confusing part is that there is
still 3.03GB cached and it cannot be allocated for 11.88MB.—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AGGVQNIXGPJ3HXGSVRPOYUTPZXV5NA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGODXJAK5Q#issuecomment-500303222,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AGGVQNPVGT5RLM6ZV5KMSULPZXV5NANCNFSM4GSSRQXQ
.
EKELE-NNOROM
on 10 Jun 2019
I tried reducing the batch size and it worked. The confusing part is the error msg that the cached memory is larger than the to be allocated memory.
magic282
on 11 Jun 2019
I get the same problem on a pretrained model, when I use predict. So reducing the batch size will not work.
 pvk444
on 30 Jun 2019
pvk444
on 30 Jun 2019
If you update to the latest version of PyTorch you might have less errors like that
fmassa
on 30 Jun 2019
Can I ask why the numbers in the error don't add up?!
I (like all of you) get:
Tried to allocate 20.00 MiB (GPU 0; 1.95 GiB total capacity; 763.17 MiB already allocated; 6.31 MiB free; 28.83 MiB cached)
To me it means the following should be approximately true:
1.95 (GB total) - 20 (MiB needed) == 763.17 (MiB already used) + 6.31 (MiB free) + 28.83 (MiB cached)
But it is not. What is that I am getting wrong?
 AzimAhmadzadeh
on 3 Jul 2019
AzimAhmadzadeh
on 3 Jul 2019
I have also got the problem when i trained the U-net,the cach is enough ,but it still crash
 tongpinmo
on 10 Jul 2019
tongpinmo
on 10 Jul 2019
I have the same error...
RuntimeError: CUDA out of memory. Tried to allocate 312.00 MiB (GPU 0; 10.91 GiB total capacity; 1.07 GiB already allocated; 109.62 MiB free; 15.21 MiB cached)
 MSKazemi
on 10 Jul 2019
MSKazemi
on 10 Jul 2019
try reducing size (any size that will not change the result) will work.
 giangnguyen2412
on 11 Jul 2019
giangnguyen2412
on 11 Jul 2019
try reducing size (any size that will not change the result) will work.
Hello ,I change the batch_size to 1,but it not work!
 BCWang93
on 14 Jul 2019
BCWang93
on 14 Jul 2019
May you should change another size.
Vào 21:50, CN, 14 Th7, 2019 Bcw93 notifications@github.com đã viết:
try reducing size (any size that will not change the result) will work.
Hello ,I change the batch_size to 1,but it not work!
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AHLNPF7MWQ7U5ULGIT44VRTP7MOKFA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGODZ4EWJI#issuecomment-511200037,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AHLNPF4227GHH32PI4WC4SDP7MOKFANCNFSM4GSSRQXQ
.
giangnguyen2412
on 15 Jul 2019
Getting this error:
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 7.94 GiB total capacity; 7.33 GiB already allocated; 1.12 MiB free; 40.48 MiB cached)
nvidia-smi
Thu Aug 22 21:05:52 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 430.40 Driver Version: 430.40 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Quadro M4000 Off | 00000000:09:00.0 On | N/A |
| 46% 37C P8 12W / 120W | 71MiB / 8126MiB | 10% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX 105... Off | 00000000:41:00.0 On | N/A |
| 29% 33C P8 N/A / 75W | 262MiB / 4032MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1909 G /usr/lib/xorg/Xorg 50MiB |
| 1 1909 G /usr/lib/xorg/Xorg 128MiB |
| 1 5236 G ...quest-channel-token=9884100064965360199 130MiB |
+-----------------------------------------------------------------------------+
OS: Ubuntu 18.04 bionic
Kernel: x86_64 Linux 4.15.0-58-generic
Uptime: 29m
Packages: 2002
Shell: bash 4.4.20
Resolution: 1920x1080 1080x1920
DE: LXDE
WM: OpenBox
GTK Theme: Lubuntu-default [GTK2]
Icon Theme: Lubuntu
Font: Ubuntu 11
CPU: AMD Ryzen Threadripper 2970WX 24-Core @ 48x 3GHz [61.8°C]
GPU: Quadro M4000, GeForce GTX 1050 Ti
RAM: 3194MiB / 64345MiB
 danindiana
on 23 Aug 2019
danindiana
on 23 Aug 2019
Is this fixed? I have decreased size and batch size both to 1. I don't see any other solutions here, but this ticket is closed. I am having the same problem with Cuda 10.1 Windows 10, Pytorch 1.2.0
 hughkf
on 6 Sep 2019
hughkf
on 6 Sep 2019
@hughkf Where in the code do you change batch_size?
 aidoshacks
on 6 Sep 2019
aidoshacks
on 6 Sep 2019
@aidoshacks, It depends on your code. But here is one example. This is one of the notebooks that reliably causes this issue on my machine: https://github.com/fastai/course-v3/blob/master/nbs/dl1/lesson3-camvid-tiramisu.ipynb. I change the following line,
bs,size = 8,src_size//2 to bs,size = 1,1 but still I get this out of memory problem.
hughkf
on 6 Sep 2019
For me changing the batch_size from 128 to 64 worked but that doesn't seem like a disclosed solution for me, or am I missing something?
 shalgi
on 19 Sep 2019
shalgi
on 19 Sep 2019
Has this problem solved? I also got the same problem. I did not change anything of my code, but after running many times, this error occurs:
"RuntimeError: CUDA out of memory. Tried to allocate 40.00 MiB (GPU 0; 15.77 GiB total capacity; 13.97 GiB already allocated; 256.00 KiB free; 824.57 MiB cached)"
 mengxiangming
on 26 Sep 2019
mengxiangming
on 26 Sep 2019
Still having this issue, would be nice if the status would be changed to unresolved.
EDIT:
Had little to do with the batch size seeing as I get it with with batch size 1. Restarting the kernel fixed it for me and it hasn't happened since.
 just-in-kees
on 29 Sep 2019
just-in-kees
on 29 Sep 2019
So what's the resolution on examples like below (i.e. a lot of free memory and trying to allocate very little - which is different from some examples in this thread when there is actually little amount of free mem and nothing is wrong)?
RuntimeError: CUDA out of memory. Tried to allocate 1.33 GiB (GPU 1; 31.72 GiB total capacity; 5.68 GiB already allocated; 24.94 GiB free; 5.96 MiB cached)
I don't see why issue went to 'Closed' status, as it's still happens on latest pytorch ver (1.2) and modern NVIDIA GPU (V-100)
Thanks!
 yuribd
on 3 Oct 2019
yuribd
on 3 Oct 2019
Most of the time you get this particular error message from the fastai package is because you are using an unusually small GPU. I fixed this problem by restarting my kernel and by using a smaller batch size for the path you are giving.
 AurioPinto
on 5 Oct 2019
AurioPinto
on 5 Oct 2019
same problem here. When I use pytorch0.4.1, batch size=4, it's ok. But when I change to pytorch1.3 and even set the batch size to 1, I have the oom problem.
 Sarah20187
on 21 Oct 2019
Sarah20187
on 21 Oct 2019
solved it by updating my pytorch to the latest... conda update pytorch
 kafura0
on 21 Oct 2019
kafura0
on 21 Oct 2019
It is because of mini-batch of data does not fit on to GPU memory. Just decrease the batch size. When I set batch size = 256 for cifar10 dataset I got the same error; Then I set the batch size = 128, it is solved.
thanks, i addressed the error through this way.
 zhangzibao
on 25 Oct 2019
zhangzibao
on 25 Oct 2019
I decreased the batch_size to 8, it works fine. The idea is to have a small batch_size
 Asutosh11
on 30 Oct 2019
Asutosh11
on 30 Oct 2019
I think it depends on the total input size a particular layer is dealing with. For example, if a batch of 256 (32x32) images go through 128 filters in a layer, total input size is 256x32x32x128 = 2^25. This number should be below some threshold, which I guess is machine specific. For AWS p3.2xlarge for example, it is 2^26. So if you're getting CuDA memory errors, try reducing batch size or number of filters or putting more downsampling like stride or pooling layers
 souryadey
on 1 Nov 2019
souryadey
on 1 Nov 2019
Have same issue:
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 7.93 GiB total capacity; 0 bytes already allocated; 3.83 GiB free; 0 bytes cached)
With latest pytorch (1.3) and cuda (10.1) version. Nvidia-smi also shows half-empty GPU, so amount of free memory in error message is correct. Can't reproduce it with simple code yet
 ArgentumWalker
on 3 Nov 2019
ArgentumWalker
on 3 Nov 2019
Resetting the kernel worked for me too! Wasn't working even with batch size= 1 until I did that
 kennethjmyers
on 7 Nov 2019
kennethjmyers
on 7 Nov 2019
Guys, i resolved my problem reducting my batchsize by half.
 faizao
on 19 Nov 2019
faizao
on 19 Nov 2019
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 3.95 GiB total capacity; 0 bytes already allocated; 2.02 GiB free; 0 bytes cached)
Fixed after rebooting
 SomeUserName1
on 22 Nov 2019
SomeUserName1
on 22 Nov 2019
changed batch_size 64(rtx2080 ti) to 32(rtx 2060), problem solved. but i want to know other way to resolve this kind of problem.
 sailfish009
on 3 Dec 2019
sailfish009
on 3 Dec 2019
This is happening to me when I do the prediction!
I changed the batch size from 1024 to 8 and still getting error when 82% of the test set is evaluated.
When I added with torch.no_grad() the problem was RESOLVED.
test_loader = init_data_loader(X_test, y_test, torch.device('cpu'), batch_size, num_workers=0)
print("Starting inference ...")
result = []
model.eval()
valid_loss = 0
with torch.no_grad():
for batch_x, batch_y in tqdm(test_loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
output = model(batch_x)
result.extend(output[:, 0, 0])
loss = torch.sqrt(criterion(output, batch_y))
valid_loss += loss
valid_loss /= len(train_loader)
print("Done!")
 smasoudn
on 17 Dec 2019
smasoudn
on 17 Dec 2019
I solved the problem
loader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4)
to
loader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4)
 zhonghaochen
on 27 Dec 2019
zhonghaochen
on 27 Dec 2019
I had the same issue and I checked the GPU utilization on my machine. There was a lot of it already used and very less amount of memory was left. I killed my jupyter notebook and restarted it. memory became free and things started working. You can use below:
nvidia-smi - To check the memory utilization on GPU
ps -ax | grep jupyter - To get PID of jupyter process
sudo kill PID
 prabhatsharma
on 27 Dec 2019
prabhatsharma
on 27 Dec 2019
I also got this message:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)It happened when I was trying to run the Fast.ai lesson1 Pets https://course.fast.ai/ (cell 31)
Try to reduce the batch size (bs) of your training data.
See what works for you.
 rishi0904
on 27 Dec 2019
rishi0904
on 27 Dec 2019
I found this problem solvable without adjusting your batch size.
Open terminal and a python prompt
import torch
torch.cuda.empty_cache()
Exit the Python interpreter, re-run your original PyTorch command and it should (hopefully) not yield the CUDA memory error.
 cpoptic
on 3 Jan 2020
cpoptic
on 3 Jan 2020
I found out that when my computer use too much CPU RAM, this problem usually comes up. So when we want a bigger batch size, we can try to reduce the usage of CPU RAM.
 dhKwang
on 13 Jan 2020
dhKwang
on 13 Jan 2020
Had a similar issue.
Reducing the batch size and restarting the kernel helped resolve the issue.
 kumarnikhil936
on 19 Jan 2020
kumarnikhil936
on 19 Jan 2020
In my case, replacing Adam optimizer by SGD optimizer solved the same issue.
 tranvanluan2
on 23 Jan 2020
tranvanluan2
on 23 Jan 2020
Well, in my case, used with torch.no_grad(): (train model), output.to("cpu") and torch.cuda.empty_cache() and this problem solved.
 PlanNoa
on 30 Jan 2020
PlanNoa
on 30 Jan 2020
RuntimeError: CUDA out of memory. Tried to allocate 54.00 MiB (GPU 0; 3.95 GiB total capacity; 2.65 GiB already allocated; 39.00 MiB free; 87.29 MiB cached)
i found the solution and i decrease batch_size value.
 sagrawal06
on 30 Jan 2020
sagrawal06
on 30 Jan 2020
I'm training a YOLOv3 with Darknet53 weights on a custom dataset. My GPU is a NVIDIA RTX 2080 anda I was facing the same issue. Changing the batch size solved it.
 wilderrodrigues
on 2 Feb 2020
wilderrodrigues
on 2 Feb 2020
I'm getting this error during inference time....i'm ru
CUDA out of memory. Tried to allocate 102.00 MiB (GPU 0; 15.78 GiB total capacity; 14.54 GiB already allocated; 48.44 MiB free; 14.67 GiB reserved in total by PyTorch)
-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.59 Driver Version: 440.59 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:1E.0 Off | 0 |
| N/A 35C P0 41W / 300W | 16112MiB / 16160MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 13978 C /.conda/envs//bin/python 16101MiB |
+-----------------------------------------------------------------------------+
 tvinith
on 29 Feb 2020
tvinith
on 29 Feb 2020
It is because of mini-batch of data does not fit on to GPU memory. Just decrease the batch size. When I set batch size = 256 for cifar10 dataset I got the same error; Then I set the batch size = 128, it is solved.
thank u,you are right
 Rxma1805
on 2 Mar 2020
Rxma1805
on 2 Mar 2020
For the particular case, where there are enough GPU memory, but an error still is thrown. In my case I SOLVED it by reducing the number of workers in the dataloader.
 Yurasyk
on 14 Mar 2020
Yurasyk
on 14 Mar 2020
Background
py36, pytorch1.4, tf2.0, conda
fine tune the Roberta
Issue
The issue same as @EMarquer : pycharm shows that i still have enough memory, however allocates memory failed, out of memory.
Ways I tried
- "batch_size = 1" failed
- "torch.cuda.empty_cache()" failed
- CUDA_VISIBLE_DEVICES="0" python Run.py failed
- Because i don't use jupyter, no need to restart the kernel
Successful way
- nvidia-smi


- Truth is that what pycharm shows is different with what "nvidia-smi" shows(sorry i didn't save the pic of pycharm) , actually no enough memory.
- The process 6123 and 32644 run on terminal before.
- sudo kill -9 6123
- sudo kill -9 32644
 FernandoZhuang
on 17 Mar 2020
FernandoZhuang
on 17 Mar 2020
What simply worked for me:
import gc
# Your code with pytorch using GPU
gc.collect()
 MastafaF
on 6 Apr 2020
MastafaF
on 6 Apr 2020
I found this problem solvable without adjusting your batch size.
Open terminal and a python prompt
import torch torch.cuda.empty_cache()Exit the Python interpreter, re-run your original PyTorch command and it should (hopefully) not yield the CUDA memory error.
In my case, it solves my problem.
 LiEAEX
on 10 Apr 2020
LiEAEX
on 10 Apr 2020
Make sure your using your GPU at slot 0 with --device_ids 0
I know im butchering the terminology but it worked. I guess it assumes you want to use the CPU instead of GPU if you don't select an id.
 aaron387
on 12 Apr 2020
aaron387
on 12 Apr 2020
I am getting the same error:
RuntimeError: CUDA out of memory. Tried to allocate 4.84 GiB (GPU 0; 7.44 GiB total capacity; 5.22 GiB already allocated; 1.75 GiB free; 18.51 MiB cached)
When I restart the cluster or change the batch size, it works. But I don't like this solution. I even tried torch.cuda.empty_cache() , this doesn't work for me. Is there any other efficient way to solve this?
 Tann10
on 13 Apr 2020
Tann10
on 13 Apr 2020
I don't know if my scenario is relatable to the original issue, but I resolved my problem (the OOM error in the previous message went away) by breaking up the nn.Sequential layers in my model, e.g.
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)to
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0) self.input_bn = nn.BatchNorm3d(32) output = F.relu(self.input_bn(self.input_conv(x)))My model has a lot more of these (5 more to be exact). Am I using nn.Sequential right? Or is this a bug? @yf225 @fmassa
It seems that I also solve the similar error but converserly with you.
I change all
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)to
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)
 xml94
on 14 Apr 2020
xml94
on 14 Apr 2020
For me changing batch_size or any of given solution didn't help. But it turned out that in my .cfg file I had wrong values of classes and filter in one layer. So if nothing helps, double check your .cfg.
 ulaszewskim
on 1 May 2020
ulaszewskim
on 1 May 2020
Open Terminal
First type
nvidia-smi
then select the PID that corresponds to python or anaconda path and write
sudo kill -9 PID
 krypticmouse
on 4 May 2020
krypticmouse
on 4 May 2020
I have been having this bug for some time. For me, it turns out that I keep holding a python variable (i.e. torch tensor) that references the model result, and so it cannot be safely released as the code can still access it.
My code looks something like:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p)
The fix for this was to transfer p to a list. So, the code should look like:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p.tolist())
This ensures that predictions hold values in the main memory, not a tensor in the GPU.
 abdelrahmanhosny
on 8 May 2020
abdelrahmanhosny
on 8 May 2020
I'm having this bug using the fastai.vision module, which relies on pytorch. I'm using CUDA 10.1
 jkomyno
on 16 May 2020
jkomyno
on 16 May 2020
training_args = TrainingArguments(
output_dir="./",
overwrite_output_dir=True,
num_train_epochs=5,
per_gpu_train_batch_size=4, # 4; 8 ;16 out of memory
save_steps=10_000,
save_total_limit=2,
)
reduce the per_gpu_train_batch_size from 16 to 8, it solved my problem.
 autodataming
on 3 Jun 2020
autodataming
on 3 Jun 2020
If you update to the latest version of PyTorch you might have less errors like that
really,why do you say that
 XinyingZheng
on 9 Jun 2020
XinyingZheng
on 9 Jun 2020
The main question of this issue is still an opened problem. I'm getting the same strange CUDA out of memory message. It tried to allocate 2.26 GiB in 4.08 GiB free. Seemingly there is enough memory but it fails to allocate.
Project info: trainning a resnet 10 over activitynet dataset with batch-size 4, it fails in the final of the first epoch.
EDITED: Some perceptions: If I clean my RAM memory and only keep the python code running, the error isn't raised. Maybe there is enough memory in GPU, but the RAM memory isn't able to handle all the other processing steps.
Computer info: Dell G5 - i7 9th - GTX 1660Ti 6GB - 16 GB RAM
EDITED2: I was using "_MultiProcessingDataLoaderIter" with 4 workers and it raises the out of memory message in the forward call. If I reduce the number of workers to 1, it doesn't raise any error. With 1 worker, the ram memory use remain 11/16GB, with 4 it raises to 14.5/16GB. And with just 1 worker, actually, I can raise the batch-size to 32 raising the GPU memory to 3.5GB/6GB.
RuntimeError: CUDA out of memory. Tried to allocate 2.26 GiB (GPU 0; 6.00 GiB total capacity; 209.63 MiB already allocated; 4.08 GiB free; 246.00 MiB reserved in total by PyTorch)
Whole error message
Traceback (most recent call last):
File "main.py", line 450, in
if opt.distributed:
File "main.py", line 409, in main_worker
opt.device, current_lr, train_logger,
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\training.py", line 37, in train_epoch
outputs = model(inputs)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", line 532, in __call__
result = self.forward(input, *kwargs)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nnparallel\data_parallel.py", line 150, in forward
return self.module(inputs[0], *kwargs[0])
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", line 532, in __call__
result = self.forward(input, *kwargs)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\models\resnet.py", line 205, in forward
x = self.layer3(x)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", line 532, in __call__
result = self.forward(input, *kwargs)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\container.py", line 100, in forward
input = module(input)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", line 532, in __call__
result = self.forward(input, *kwargs)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\models\resnet.py", line 51, in forward
out = self.conv2(out)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", line 532, in __call__
result = self.forward(input, *kwargs)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\conv.py", line 480, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDA out of memory. Tried to allocate 2.26 GiB (GPU 0; 6.00 GiB total capacity; 209.63 MiB already allocated; 4.08 GiB free; 246.00 MiB reserved
in total by PyTorch)
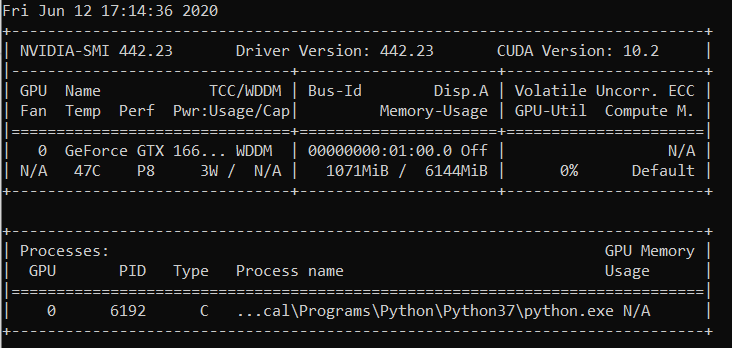
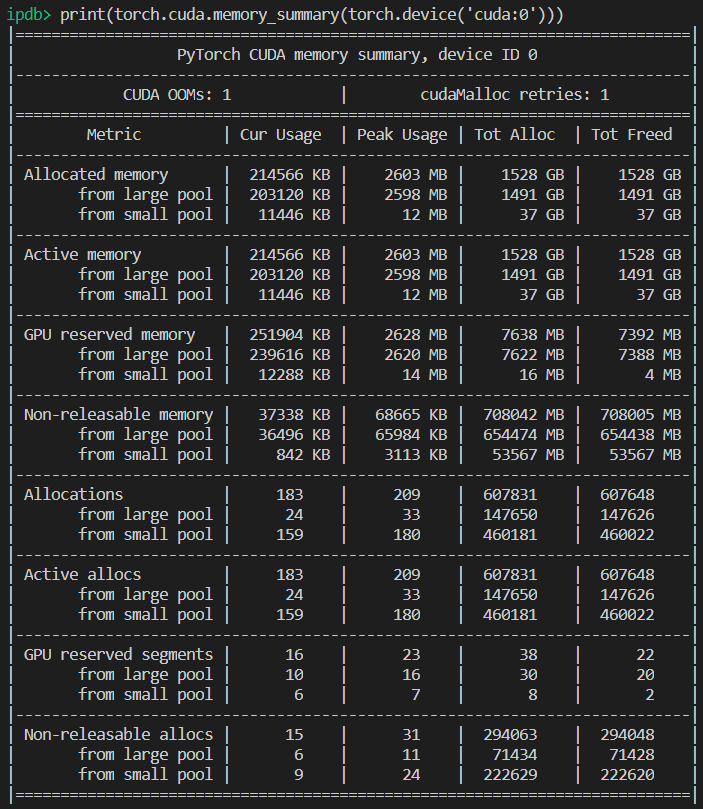
 guilhermesurek
on 12 Jun 2020
guilhermesurek
on 12 Jun 2020
small the batch size, it works
 cuge1995
on 15 Jun 2020
cuge1995
on 15 Jun 2020
I have been having this bug for some time. For me, it turns out that I keep holding a python variable (i.e. torch tensor) that references the model result, and so it cannot be safely released as the code can still access it.
My code looks something like:
predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)The fix for this was to transfer
pto a list. So, the code should look like:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())This ensures that
predictionshold values in the main memory, not a tensor in the GPU.
@abdelrahmanhosny Thanks for pointing this out. I faced the exact same issue in PyTorch 1.5.0, and had no OOM issues during training however during inference I also kept holding a python variable (i.e. torch tensor) that references the model result in memory which resulted in the GPU running out of memory after a certain number of batches.
In my case however transferring the predictions to the list did not work as I am generating images with my network, therefore I had to do the following:
predictions.append(p.detach().cpu().numpy())
This then solved the issue!
 samkellerhals
on 19 Jun 2020
samkellerhals
on 19 Jun 2020
Is there any general solution?
CUDA out of memory. Tried to allocate 196.00 MiB (GPU 0; 2.00 GiB total capacity; 359.38 MiB already allocated; 192.29 MiB free; 152.37 MiB cached)
Is there any general solution?
CUDA out of memory. Tried to allocate 196.00 MiB (GPU 0; 2.00 GiB total capacity; 359.38 MiB already allocated; 192.29 MiB free; 152.37 MiB cached)
 manavkhadka0
on 24 Jun 2020
manavkhadka0
on 24 Jun 2020
I have been having this bug for some time. For me, it turns out that I keep holding a python variable (i.e. torch tensor) that references the model result, and so it cannot be safely released as the code can still access it.
My code looks something like:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)The fix for this was to transfer
pto a list. So, the code should look like:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())This ensures that
predictionshold values in the main memory, not a tensor in the GPU.@abdelrahmanhosny Thanks for pointing this out. I faced the exact same issue in PyTorch 1.5.0, and had no OOM issues during training however during inference I also kept holding a python variable (i.e. torch tensor) that references the model result in memory which resulted in the GPU running out of memory after a certain number of batches.
In my case however transferring the predictions to the list did not work as I am generating images with my network, therefore I had to do the following:
predictions.append(p.detach().cpu().numpy())This then solved the issue!
I have the same issue in ParrallelWaveGAN model and I used the solutions in #16417 but it do not work for me
y = self.model_gan(*x).view(-1).detach().cpu().numpy()
gc.collect()
torch.cuda.empty_cache()
 tuong-olli
on 25 Jun 2020
tuong-olli
on 25 Jun 2020
Had the same problem during training.
Collecting garbage and emptying cuda memory after each epoch solved the issue for me.
gc.collect()
torch.cuda.empty_cache()
 IsakWesterlundBitville
on 5 Aug 2020
IsakWesterlundBitville
on 5 Aug 2020
What simply worked for me:
import gc # Your code with pytorch using GPU gc.collect()
Thank you!! I was having trouble running the Cats and dogs example and this worked for me.
 Michelpayan
on 5 Aug 2020
Michelpayan
on 5 Aug 2020
Had the same problem during training.
Collecting garbage and emptying cuda memory after each epoch solved the issue for me.gc.collect() torch.cuda.empty_cache()
Same for me
 AleksandrTulenkov
on 6 Aug 2020
AleksandrTulenkov
on 6 Aug 2020
decrease the batch size and increase the epochs. that is how i solved it.
 oyekamal
on 18 Sep 2020
oyekamal
on 18 Sep 2020
@areebsyed Check the ram memory, I had this issue when set many workers in parallel.
guilhermesurek
on 29 Sep 2020
I am also getting the same error while finetuning pretrained bert2bert EncoderDecoderModel in pytorch in Colab without even completing a single epoch.
RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 15.90 GiB total capacity; 13.77 GiB already allocated; 59.88 MiB free; 14.98 GiB reserved in total by PyTorch)
 Aakash12980
on 6 Oct 2020
Aakash12980
on 6 Oct 2020
@Aakash12980 did you try and reduce the batch size? Also the input images that you want to train maybe try to resize them
 areebsyed
on 6 Oct 2020
areebsyed
on 6 Oct 2020
@areebsyed Yes i reduced the batch size to 4 and it worked.
Aakash12980
on 6 Oct 2020
same
RuntimeError Traceback (most recent call last)
<ipython-input-116-11ebb3420695> in <module>
28 landmarks = landmarks.view(landmarks.size(0),-1).cuda()
29
---> 30 predictions = network(images)
31
32 # clear all the gradients before calculating them
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
<ipython-input-112-174da452c85d> in forward(self, x)
13 ##out = self.first_conv(x)
14 x = x.float()
---> 15 out = self.model(x)
16 return out
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x)
218
219 def forward(self, x):
--> 220 return self._forward_impl(x)
221
222
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x)
204 x = self.bn1(x)
205 x = self.relu(x)
--> 206 x = self.maxpool(x)
207
208 x = self.layer1(x)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input)
157 return F.max_pool2d(input, self.kernel_size, self.stride,
158 self.padding, self.dilation, self.ceil_mode,
--> 159 self.return_indices)
160
161
~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs)
245 return if_true(*args, **kwargs)
246 else:
--> 247 return if_false(*args, **kwargs)
248
249 if if_true.__doc__ is None and if_false.__doc__ is not None:
~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices)
574 stride = torch.jit.annotate(List[int], [])
575 return torch.max_pool2d(
--> 576 input, kernel_size, stride, padding, dilation, ceil_mode)
577
578 max_pool2d = boolean_dispatch(
RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
 monajalal
on 7 Oct 2020
monajalal
on 7 Oct 2020
same
RuntimeError Traceback (most recent call last) <ipython-input-116-11ebb3420695> in <module> 28 landmarks = landmarks.view(landmarks.size(0),-1).cuda() 29 ---> 30 predictions = network(images) 31 32 # clear all the gradients before calculating them ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), <ipython-input-112-174da452c85d> in forward(self, x) 13 ##out = self.first_conv(x) 14 x = x.float() ---> 15 out = self.model(x) 16 return out ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x) 218 219 def forward(self, x): --> 220 return self._forward_impl(x) 221 222 ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x) 204 x = self.bn1(x) 205 x = self.relu(x) --> 206 x = self.maxpool(x) 207 208 x = self.layer1(x) ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input) 157 return F.max_pool2d(input, self.kernel_size, self.stride, 158 self.padding, self.dilation, self.ceil_mode, --> 159 self.return_indices) 160 161 ~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs) 245 return if_true(*args, **kwargs) 246 else: --> 247 return if_false(*args, **kwargs) 248 249 if if_true.__doc__ is None and if_false.__doc__ is not None: ~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices) 574 stride = torch.jit.annotate(List[int], []) 575 return torch.max_pool2d( --> 576 input, kernel_size, stride, padding, dilation, ceil_mode) 577 578 max_pool2d = boolean_dispatch( RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
@monajalal try reducing the batch size or input dimension size.
Aakash12980
on 7 Oct 2020
So what's the resolution on examples like below (i.e. a lot of _free_ memory and trying to allocate very little - which is different from _some_ examples in this thread when there is actually little amount of free mem and nothing is wrong)?
RuntimeError: CUDA out of memory. Tried to allocate _1.33 GiB_ (GPU 1; 31.72 GiB total capacity; 5.68 GiB already allocated; _24.94 GiB free_; 5.96 MiB cached)
I don't see why issue went to 'Closed' status, as it's still happens on latest pytorch ver (1.2) and modern NVIDIA GPU (V-100)
Thanks!
Yep I feel like most of the people doesn't realize that the problem isn't simply OOM, it is that there is OOM while the error says there is enough free space. I'm facing this problem too on windows, did you find any solution?
 YoadTew
on 6 Nov 2020
YoadTew
on 6 Nov 2020
Related issues
 PhilippPelz
·
128Comments
PhilippPelz
·
128Comments
 colesbury
·
67Comments
colesbury
·
67Comments
 soumith
·
60Comments
soumith
·
60Comments
 dzhulgakov
·
68Comments
dzhulgakov
·
68Comments
 HarshneetBhatia
·
172Comments
HarshneetBhatia
·
172Comments
Most helpful comment
It is because of mini-batch of data does not fit on to GPU memory. Just decrease the batch size. When I set batch size = 256 for cifar10 dataset I got the same error; Then I set the batch size = 128, it is solved.