Caffe: GPU 0 is also used when running on other GPUs (#440 reocurred?)
I just built caffe-rc2 with CUDA 7.0 and Driver 346.47. When running the test on my first GPU (with id 0), everything works fine. However, when running the test on 2nd GPU (with id 1, or build/test/test_all.testbin 1), the command nvidia-smi shows that both GPUs are being used. This is not the case when I'm running the test on GPU0, nor when I'm running the test using caffe-rc1 (built with CUDA 6.5 a while ago). I tried building caffe-rc2 using CUDA 6.5, and the problem persists.
By setting export CUDA_VISIBLE_DEVICES=1, and running build/test/test_all.testbin 0, the problem disappeared. So this seems like a problem like that in https://github.com/BVLC/caffe/issues/440?
Update: when I ran build/test/test_all.testbin 1 --gtest_filter=DataLayerTest*, with my GPU0's memory filled up using some other software (cuda_memtest in my case), the program failed:
build/test/test_all.testbin 1 --gtest_filter=DataLayerTest/3*
Cuda number of devices: 2
Setting to use device 1
Current device id: 1
Note: Google Test filter = DataLayerTest/3*
[==========] Running 12 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 12 tests from DataLayerTest/3, where TypeParam = caffe::DoubleGPU
[ RUN ] DataLayerTest/3.TestReadLevelDB
F0324 20:34:20.499236 20499 benchmark.cpp:111] Check failed: error == cudaSuccess (2 vs. 0) out of memory
*** Check failure stack trace: ***
@ 0x7f16777cfdaa (unknown)
@ 0x7f16777cfce4 (unknown)
@ 0x7f16777cf6e6 (unknown)
@ 0x7f16777d2687 (unknown)
@ 0x7f1675f133b8 caffe::Timer::Init()
@ 0x7f1675f13569 caffe::CPUTimer::CPUTimer()
@ 0x7f1675ebacec caffe::DataLayer<>::InternalThreadEntry()
@ 0x7f166de8da4a (unknown)
@ 0x7f16755f5182 start_thread
@ 0x7f167532247d (unknown)
@ (nil) (unknown)
Aborted (core dumped)
With other test categories (at least NeuronLayerTest and FlattenLayerTest), the program works fine.
 zym1010
zym1010
All 9 comments
Thanks for the report. We've seen this as well; a fix is forthcoming.
 longjon
on 8 May 2015
longjon
on 8 May 2015
Closing as fixed.
 shelhamer
on 13 Apr 2017
shelhamer
on 13 Apr 2017
@shelhamer thanks. so is the fix PR merged?
zym1010
on 13 Apr 2017
It should be fixed, yes. Sorry, but I can't find the PR number at the moment.
shelhamer
on 14 Apr 2017
@shelhamer thanks. I just checked the RC5 version and it seems to be working!
zym1010
on 14 Apr 2017
Still has the problem using 1.0.
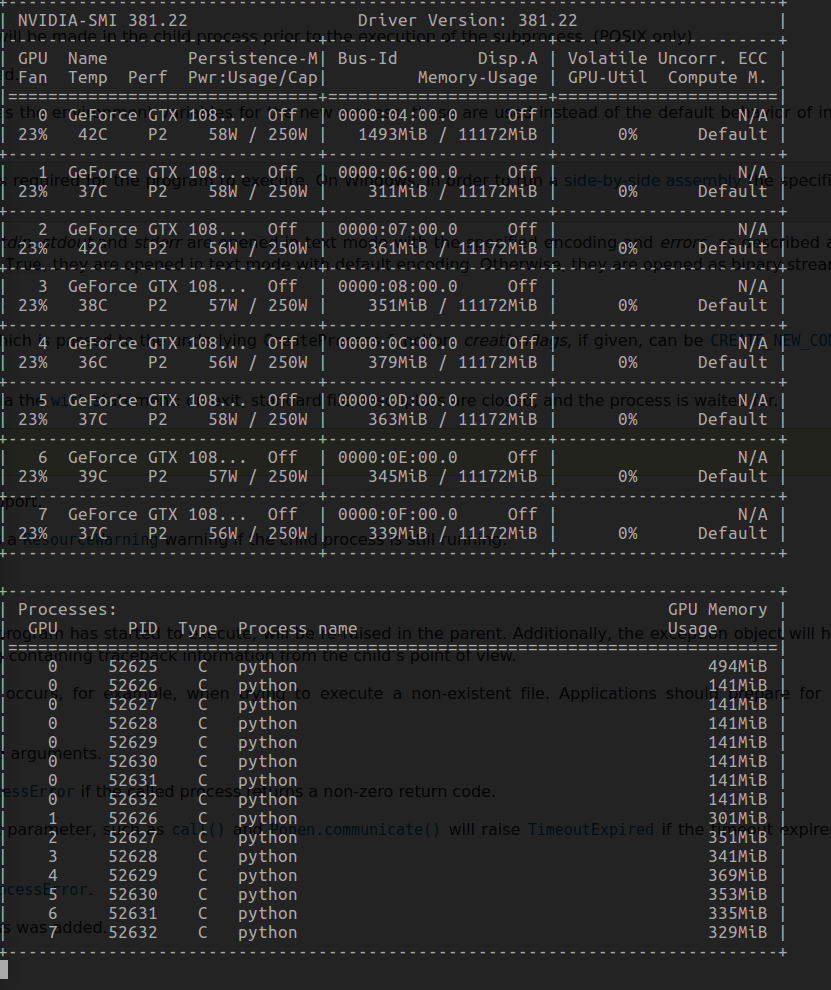
8 x 1080Ti. python2
One process set_device_id(1):
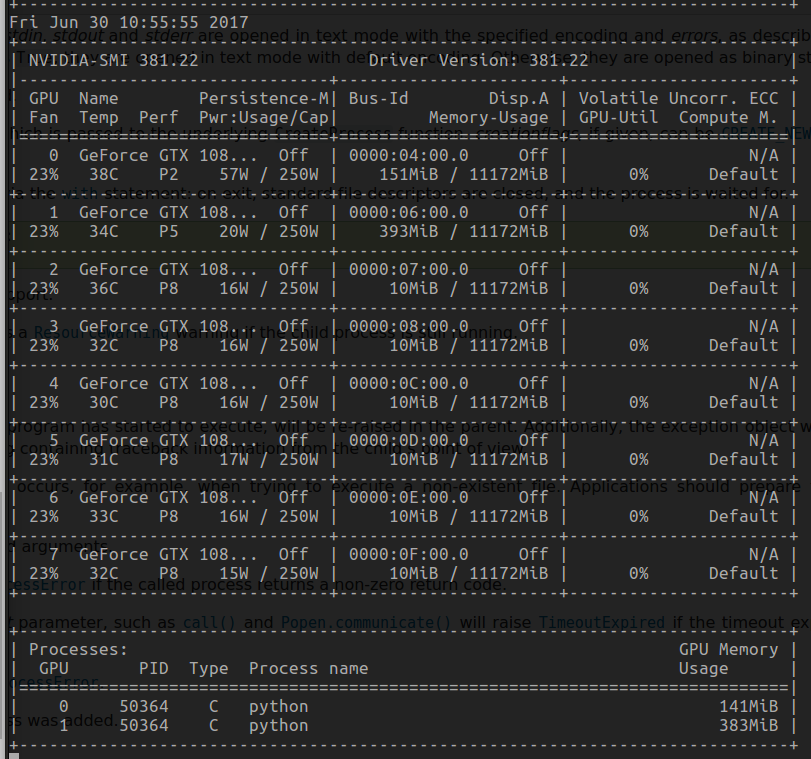
10 processes set_device_id($i), i from [0,9]:
 sczhengyabin
on 30 Jun 2017
sczhengyabin
on 30 Jun 2017
@sczhengyabin Have you fixed it ? I meet the same problem as you. Is the pythonlayer relative to the issue?
 646677064
on 16 Oct 2017
646677064
on 16 Oct 2017
@646677064
Not yet.
However, I set the ENV variable "CUDA_VISIBLE_DEVICES=#gpu_id" to prevent the caffe program from seeing other GPUs.
Examples:
CUDA_VISIBLE_DEVICES=0 python caffe_test.py
sczhengyabin
on 16 Oct 2017
@646677064 @sczhengyabin
Do you call caffe.set_gpu_mode beforecaffe.set_device? If your answer is 'yes', you only need call caffe.set_device beforecaffe.set_gpu:
caffe.set_device(devide_id)
caffe.set_mode_gpu()
 aaronshan
on 8 Nov 2017
aaronshan
on 8 Nov 2017
Related issues
 amit-dat
·
3Comments
amit-dat
·
3Comments
 hawklucky
·
3Comments
hawklucky
·
3Comments
 OpenHero
·
3Comments
OpenHero
·
3Comments
 vladislavdonchev
·
3Comments
vladislavdonchev
·
3Comments
 iamhankai
·
3Comments
iamhankai
·
3Comments
Most helpful comment
@646677064 @sczhengyabin
Do you call
caffe.set_gpu_modebeforecaffe.set_device? If your answer is 'yes', you only need callcaffe.set_devicebeforecaffe.set_gpu: