Office365-rest-python-client: 如何检索文件名(带扩展名)?
下午好,
我一直在研究一个递归循环,它允许我在库中找到一些项目并下载它们。
到目前为止,我已经能够获得所有元素,但我无法下载它们,因为在元素的属性中没有出现“名称”字段。
当我将元素转换为文件时,属性为空 ({}),因此我无法获取名称。
由于 file.dowload() 方法需要一个文件,而我不知道该文件的当前扩展名,因此下载该文件几乎是不可能的。
有什么建议吗?
我正在使用的代码如下:
from office365.runtime.auth.ClientCredential import ClientCredential
from office365.sharepoint.client_context import ClientContext
from office365.sharepoint.file import File
from office365.sharepoint.camlQuery import CamlQuery
ctx = ClientContext.connect_with_credentials(site_url, ClientCredential(client_id, client_secret))
lib = ctx.web.lists.get_by_title("XXX")
caml_query = CamlQuery()
caml_query.ViewXml = """XXX"""
items = lib.get_items(caml_query)
ctx.load(lib)
ctx.execute_query()
for item in items:
file = item.file
with open(download_path, "wb") as local_file:
file.download(local_file)
ctx.execute_query()
print("[Ok] file has been downloaded: {0}".format(download_path))
提前致谢!
 pobs93
pobs93
所有4条评论
早上好,
我能够解决我的问题。
在项目列表中迭代后,您需要调用每个文件的上下文,它将检索包含名称的文件属性,然后您可以下载文件。
这是我的代码如下:
client_id = "XXX"
client_secret = "XXX"
site_url = "XXX"
download_folder = r'C:\Users\yourname\sharepoint'
from office365.runtime.auth.ClientCredential import ClientCredential
from office365.sharepoint.client_context import ClientContext
from office365.sharepoint.file import File
from office365.sharepoint.camlQuery import CamlQuery
ctx = ClientContext.connect_with_credentials(site_url, ClientCredential(client_id, client_secret))
lib = ctx.web.lists.get_by_title("REO")
caml_query = CamlQuery()
caml_query.ViewXml = XXX
items = lib.get_items(caml_query)
ctx.load(items)
ctx.execute_query()
for item in items:
file = item.file
ctx.load(file)
ctx.execute_query()
file_name = "{0}".format(file.properties["Name"])
download_path = download_folder + '//' + file_name
with open(download_path, "wb") as local_file:
file.download(local_file)
ctx.execute_query()
print("[Ok] file has been downloaded: {0}".format(download_path))
@ pobs93我正在尝试使用您的源代码从 Sharepoint 列表下载附件。
我在这里评论了这一行,因为我不知道在它上面使用什么参数:
caml_query.ViewXml = XXX
但是当我运行代码时,我在ctx.execute_query()行收到以下错误
类型错误:CamlQuery 类型的对象不是 JSON 可序列化的
我是这种类型的 API 的新手,所以我想知道您是否可以澄清一下。
TKS
 libora6
于 2020-10-04
libora6
于 2020-10-04
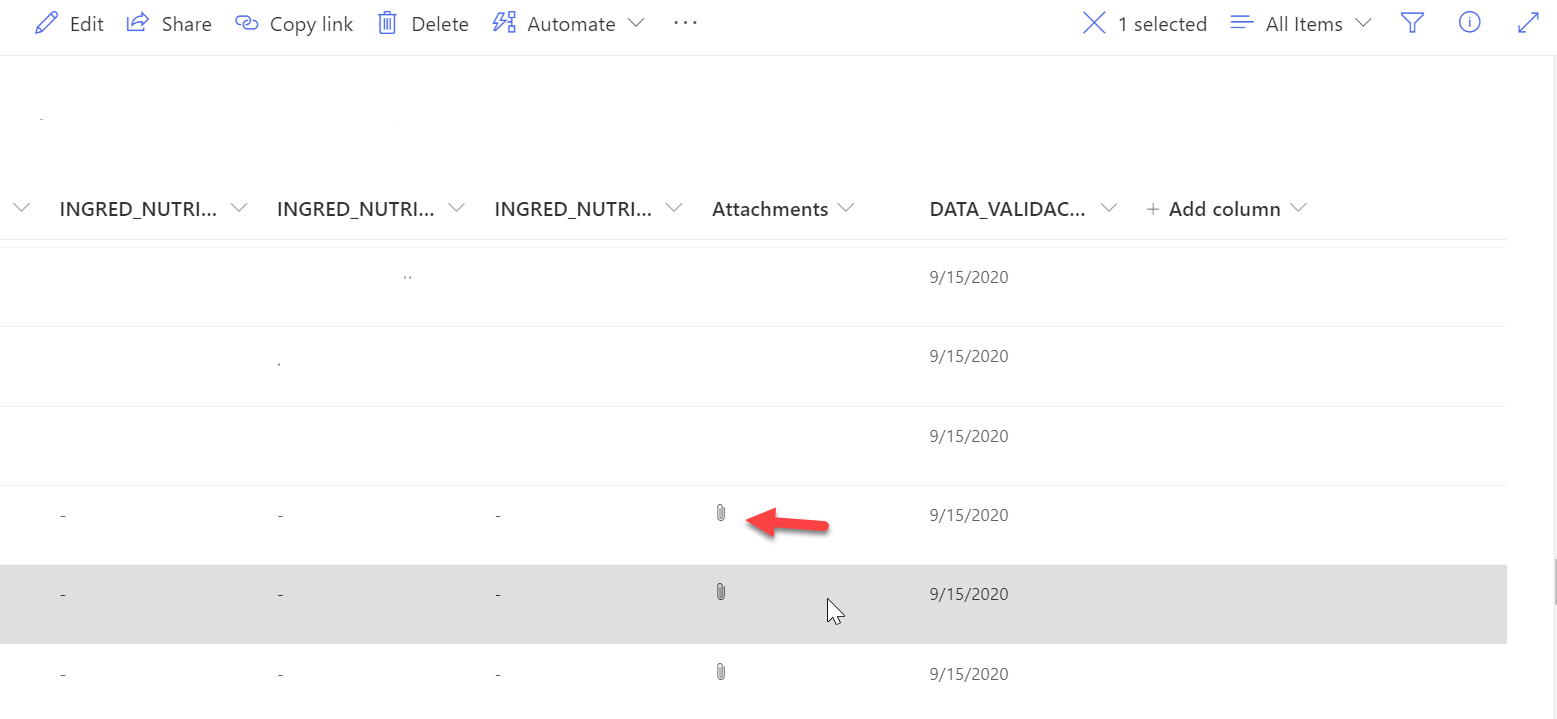
@ pobs93只是为了添加一些关于我试图从中下载附件的列表的解释。
这些是我拥有的列表中的默认键,我在这里没有看到附件的 URL,但它们在那里(见附图)。
{'文件系统对象类型':-,
'ID': -,
'ServerRedirectedEmbedUri':无,
'ServerRedirectedEmbedUrl': '',
'ContentTypeId':-,
'标题': -,
'ComplianceAssetId':无,
'ID': -,
'修改的': -,
'创建':-,
'作者ID':12,
'EditorId': 12,
'OData__UIVersionString': '1.0',
'附件':是的,
'GUID':-}
libora6
于 2020-10-04
以下示例演示如何检索列表项的 _file name_ 和 _file url_:
ctx = ClientContext(settings['url']).with_credentials(client_creds)
lib = ctx.web.lists.get_by_title("Documents")
items = lib.items
ctx.load(items, ["ID", "FileLeafRef", "FileRef"])
ctx.execute_query()
for item in items:
print(f"FileRef: {item.properties['FileRef']}")
在哪里
FileLeafRef- 标识一个字段,该字段包含有关与 ListItem 关联的文件节点的服务器相对 URL 的信息FileRef- 标识包含有关 ListItem 的服务器相对 URL 信息的字段
 vgrem
于 2020-10-07
vgrem
于 2020-10-07
相关问题
 ahulist
·
5评论
ahulist
·
5评论
 etiennecelery
·
4评论
etiennecelery
·
4评论
 erfannariman
·
6评论
erfannariman
·
6评论
 haimat
·
5评论
haimat
·
5评论
 domdinicola
·
4评论
domdinicola
·
4评论
最有用的评论
早上好,
我能够解决我的问题。
在项目列表中迭代后,您需要调用每个文件的上下文,它将检索包含名称的文件属性,然后您可以下载文件。
这是我的代码如下: