Office365-rest-python-client: How to retreive file name (with extension)?
Good Afternoon,
I´ve been working on a recursive loop that allows me to find some items in a library and download them.
So far I´ve been able to get all the elements but I´m unable to download them because in the properties of the element the field "Name" is not appearing.
When I convert the element into a file, the properties are null ({}) so I can´t get the name.
Since the file.dowload() methot requieres a file and I don´t know the current extension of the file, is pretty impossible to dowload the file.
Any sugestions?
The code I´m using is the following:
from office365.runtime.auth.ClientCredential import ClientCredential
from office365.sharepoint.client_context import ClientContext
from office365.sharepoint.file import File
from office365.sharepoint.camlQuery import CamlQuery
ctx = ClientContext.connect_with_credentials(site_url, ClientCredential(client_id, client_secret))
lib = ctx.web.lists.get_by_title("XXX")
caml_query = CamlQuery()
caml_query.ViewXml = """XXX"""
items = lib.get_items(caml_query)
ctx.load(lib)
ctx.execute_query()
for item in items:
file = item.file
with open(download_path, "wb") as local_file:
file.download(local_file)
ctx.execute_query()
print("[Ok] file has been downloaded: {0}".format(download_path))
Thanks in advance!
 pobs93
pobs93
All 4 comments
Good Morning,
I was able to solve my problem.
After iter inside the items list, you need to call the context for each file, it would retrieve the file´s properties which includes the name, then you can download the file.
This is my code below:
client_id = "XXX"
client_secret = "XXX"
site_url = "XXX"
download_folder = r'C:\Users\yourname\sharepoint'
from office365.runtime.auth.ClientCredential import ClientCredential
from office365.sharepoint.client_context import ClientContext
from office365.sharepoint.file import File
from office365.sharepoint.camlQuery import CamlQuery
ctx = ClientContext.connect_with_credentials(site_url, ClientCredential(client_id, client_secret))
lib = ctx.web.lists.get_by_title("REO")
caml_query = CamlQuery()
caml_query.ViewXml = XXX
items = lib.get_items(caml_query)
ctx.load(items)
ctx.execute_query()
for item in items:
file = item.file
ctx.load(file)
ctx.execute_query()
file_name = "{0}".format(file.properties["Name"])
download_path = download_folder + '//' + file_name
with open(download_path, "wb") as local_file:
file.download(local_file)
ctx.execute_query()
print("[Ok] file has been downloaded: {0}".format(download_path))
@pobs93 I am trying o use your source code to download attachments from a Sharepoint list.
I commented this line here as I don't know what parameters to use on it:
caml_query.ViewXml = XXX
But when I run the code I am getting the error below on line ctx.execute_query()
TypeError: Object of type CamlQuery is not JSON serializable
I am new to this type of API so I was wondering if you could clarify.
TKS
 libora6
on 4 Oct 2020
libora6
on 4 Oct 2020
@pobs93 Just to add some explanation about the list I am trying to download attachments from.
Those are the DEFAULT keys from the list that I have and I don't see the attachment's URL here, but they are there (see picture attached).
{'FileSystemObjectType': -,
'Id': -,
'ServerRedirectedEmbedUri': None,
'ServerRedirectedEmbedUrl': '',
'ContentTypeId': -,
'Title': -,
'ComplianceAssetId': None,
'ID': -,
'Modified': -,
'Created': -,
'AuthorId': 12,
'EditorId': 12,
'OData__UIVersionString': '1.0',
'Attachments': True,
'GUID': -}
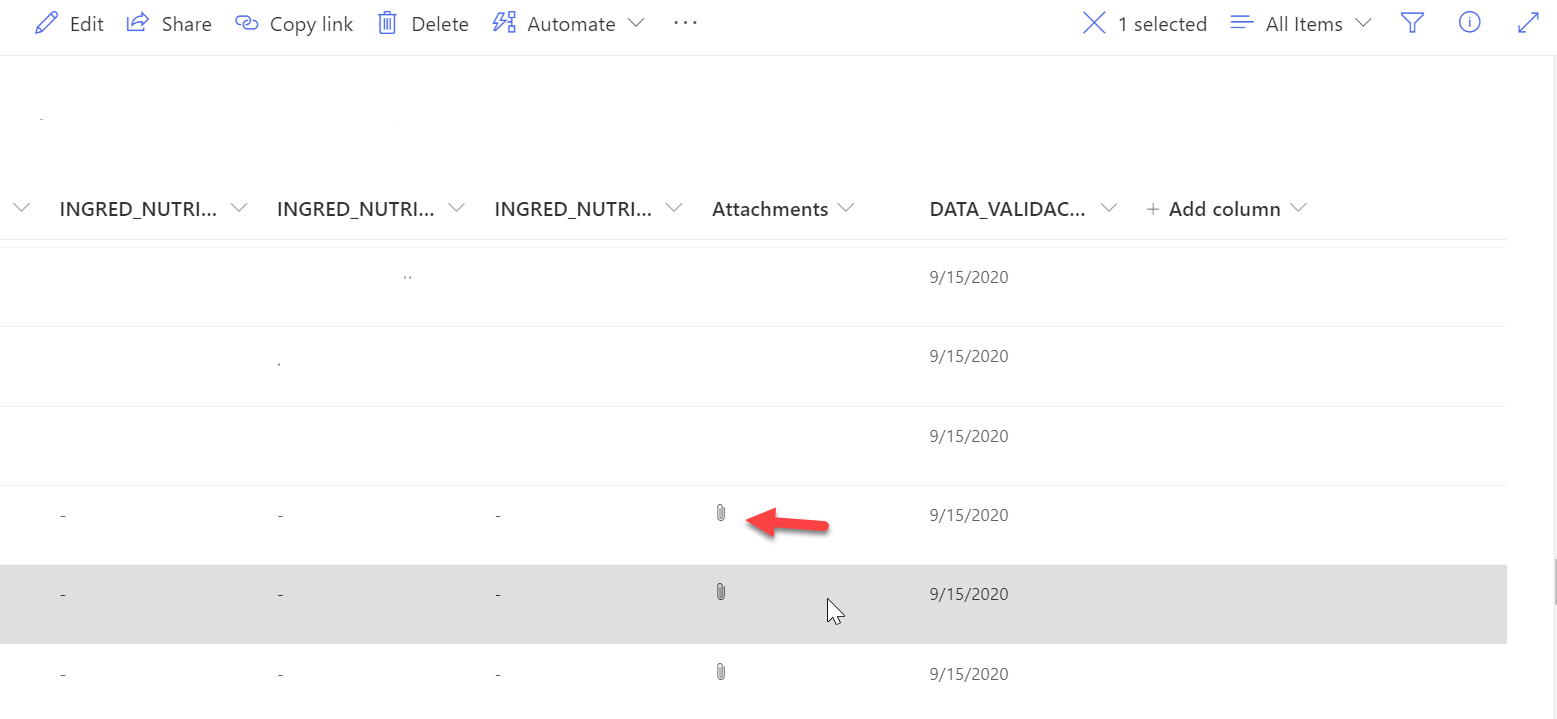
libora6
on 4 Oct 2020
The following example demonstrates how to retrieve _file name_ and _file url_ for list item:
ctx = ClientContext(settings['url']).with_credentials(client_creds)
lib = ctx.web.lists.get_by_title("Documents")
items = lib.items
ctx.load(items, ["ID", "FileLeafRef", "FileRef"])
ctx.execute_query()
for item in items:
print(f"FileRef: {item.properties['FileRef']}")
where
FileLeafRef- Identifies a field that contains information about the server-relative URL for the file node that is associated with ListItemFileRef- Identifies a field that contains information about the server-relative URL for ListItem
 vgrem
on 7 Oct 2020
vgrem
on 7 Oct 2020
Related issues
 bobbydurrett
·
8Comments
bobbydurrett
·
8Comments
 NathanSalez
·
3Comments
NathanSalez
·
3Comments
 Mark531
·
11Comments
Mark531
·
11Comments
 ahulist
·
5Comments
ahulist
·
5Comments
 BradshawI
·
5Comments
BradshawI
·
5Comments
Most helpful comment
Good Morning,
I was able to solve my problem.
After iter inside the items list, you need to call the context for each file, it would retrieve the file´s properties which includes the name, then you can download the file.
This is my code below: