Lightweight-human-pose-estimation.pytorch: demostración de libtorch c++
Hola, me las arreglé usando la demostración de openvino c ++, se ejecuta alrededor de 15 fps en la CPU. que no es lo suficientemente rápido.
¿Hay algún plan para admitir una demostración de libtorch c ++? Quiero implementar uno si no, hay algunos problemas para mí:
- en términos de preprocesamiento, escaló la imagen según la altura y rellenó los píxeles perdidos con ceros. Creo que es un poco complicado, si cambio el tamaño de la imagen directamente al tamaño objetivo, digamos (256, 456), ¿funcionará?
- Logré rastrear el modelo y cargarlo desde libtorch, pero hay 4 salidas, así que tomé el tensor de las últimas 2 salidas. Vi el método de extracción y grupo de puntos clave en python, es muy difícil de implementar en C ++, ¿hay algún fragmento que pueda ayudar a extraer directamente todos los puntos clave en la instancia del tensor de salida?
Espero que respondas pronto.
 jinfagang
jinfagang
Todos 18 comentarios
Hola, no tengo esos planes. Y no estoy seguro de que la demostración de libtorch c ++ sea más rápida que nuestra demostración de c ++ con OpenVINO. El tamaño de entrada de la red se puede ajustar para un mejor rendimiento, por ejemplo, establezca el lado más corto en 192, se puede hacer aquí , establezca el último parámetro en 192. Puede ser suficiente para un caso específico. Respondiendo a las preguntas:
- La relación de aspecto del video de entrada es importante. Si las formas de las personas están lo suficientemente sesgadas, el modelo no funcionará. Por lo tanto, se debe cambiar el tamaño para preservar la relación de aspecto (misma escala para cada eje). Parece que debería funcionar con un tamaño de imagen impar. La demostración se adapta a dimensiones uniformes para el procesamiento con operaciones vectorizadas (SIMD).
- Tomar los dos últimos tensores está bien, la red tiene 2 etapas, la segunda toma los resultados de la primera (los dos primeros tensores de salida) y los refina. La demostración de c++ está abierta, puede encontrar la implementación de c++ de la agrupación aquí .
Y, por favor, contribuya con la demostración de C++ con PyTorch si decide hacerlo.
 Daniil-Osokin
en 11 jun. 2019
Daniil-Osokin
en 11 jun. 2019
@Daniil-Osokin gracias por su respuesta, ya migré los códigos necesarios de openvino a la demostración de libtorch cpp. Después de tener éxito, enviaré un PR.
El uso de libtorch puede no ser más rápido que openvino, pero no puedo ver una gran ganancia de rendimiento de openvino, pero libtorch puede activar el soporte de GPU opcional.
Ahora hay otro problema a mi alrededor... Esos modelos que usan mapas de calor siempre necesitan mucha memoria para funcionar, incluso usando Mobilenet como columna vertebral. Este modelo funciona a unos 79 fps en mi gtx1080 pero muestra mis recuerdos de 1.7G. Casi un monstruo devorador de memoria. ¿Tiene algún modelo de optimización en términos de reducir el tamaño de la memoria?
jinfagang
en 11 jun. 2019
OK..... Se encontraron algunos problemas......... El programa se ejecuta pero el resultado no es correcto:
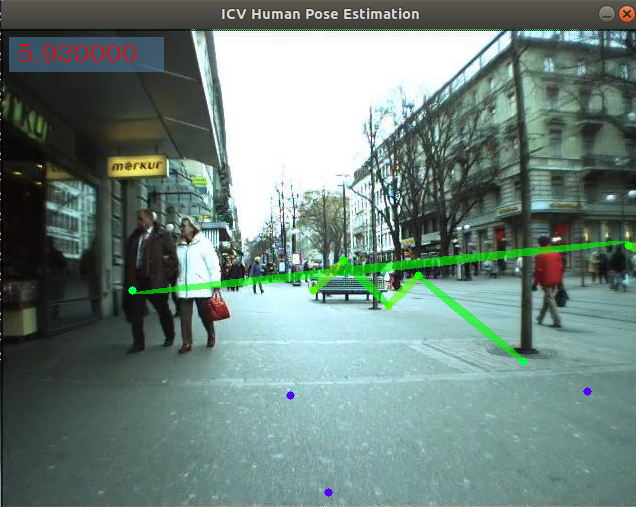
jinfagang
en 12 jun. 2019
Verifiqué el consumo de memoria en PyTorch (ejecutando demo.py ), muestra ~800 MB. Con OpenVINO el consumo es de unos 100 MB.
Daniil-Osokin
en 12 jun. 2019
Python toma 800M? ¿Menos el uso de su escritorio? El mío casi token 1.2G al menos
jinfagang
en 12 jun. 2019
@Daniil-Osokin Hola, Danill, ¿viste algún lugar en el que openvino c ++ hiciera una normalización en la imagen de entrada? (que es menos 128 y divide 256) No encontré ningún código haciendo esto. Después de la depuración, creo que me perdí algunos pasos de preprocesamiento en la demostración de libtorch_cpp...
jinfagang
en 12 jun. 2019
Buena pregunta. De forma predeterminada, todos los modelos tienen procesamiento previo (si es necesario) dentro de sus archivos .xml como una capa separada justo después de la capa de datos, por ejemplo:
<layer id="0" name="data" precision="FP32" type="Input">
<output>
<port id="0">
<dim>1</dim>
<dim>3</dim>
<dim>256</dim>
<dim>456</dim>
</port>
</output>
</layer>
<layer id="1" name="Mul_/Fused_Mul_/FusedScaleShift_" precision="FP32" type="ScaleShift">
<input>
<port id="0">
<dim>1</dim>
<dim>3</dim>
<dim>256</dim>
<dim>456</dim>
</port>
</input>
<output>
<port id="3">
<dim>1</dim>
<dim>3</dim>
<dim>256</dim>
<dim>456</dim>
</port>
</output>
<blobs>
<weights offset="0" size="12"/>
<biases offset="12" size="12"/>
</blobs>
</layer>
Así que creo que la normalización desde arriba debería ayudar (menos 128 y divide 256).
Y para el consumo de memoria, sí, es solo la memoria, que tomó Python.
Daniil-Osokin
en 12 jun. 2019
@Daniil-Osokin gracias Danill. Agregué un preproceso a la demostración de libtorch pero no obtuve ningún resultado, el resultado aún no es correcto.
¿Me ayudaría a revisar algunos pasos de preprocesamiento en C++? Ahora estoy fuera de dirección para averiguar qué paso se ha perdido. Deseando su ayuda..
Tomé los códigos necesarios de openvino y los integré con libtorch. Lo muevo a un repositorio separado aquí Solo necesita editar una ruta de libtorch y luego se puede construir, el modelo pt c ++ rastreado ya está allí (concateno la última salida a un solo tensor cuando rastrea el modelo ya que libtorch tiene algún problema con tupla ).
Puede compilar y ejecutarse, pero no puedo averiguar dónde falla la lógica...
Si puedes ayudar puedes echarle un vistazo cuando tengas tiempo.
jinfagang
en 12 jun. 2019
Creo que el problema es que OpenCV lee la imagen en formato intercalado (HxWxC), y el tensor espera una entrada planar (orden CxHxW), hizo un problema en su repositorio.
Daniil-Osokin
en 13 jun. 2019
@jinfagang ¿Esto ayudó?
Daniil-Osokin
en 17 jun. 2019
@Daniil-Osokin gracias Danill, ¡funciona después de editar el orden de los canales! Cerraré este problema y enviaré un PR después de limpiar algunos códigos.
jinfagang
en 17 jun. 2019
@jinfagang hola, tu repositorio (https://github.com/jinfagang/light_human_pose_libtorch) ya no puede visitarse.
y ¿puede decirme cómo obtener el modelo pt c++ rastreado?
 chenxian9999
en 21 jun. 2019
chenxian9999
en 21 jun. 2019
Lo siento, actualmente estoy desarrollando algunas otras funcionalidades y las mantengo privadas por un tiempo.
Puede rastrearlo directamente como dice el tutorial de pytorch. Puede rastrear fácilmente
jinfagang
en 21 jun. 2019
@jinfagang Gracias.
chenxian9999
en 22 jun. 2019
Hola @jinfagang ,
¿Has terminado con tu libtorch? ¿Podrías compartirlo para todos?
¡Cordial saludo!
 tucachmo2202
en 11 may. 2021
tucachmo2202
en 11 may. 2021
Hola @jinfagang ,
¿Has terminado con tu libtorch? ¿Podrías compartirlo para todos?
¡Cordial saludo!
Soy capaz de crear una versión en c++ con libtorch y opencv, es un proyecto comercial, aunque los códigos me pertenecen, pero los clientes no querrían que lo publique. La buena noticia es que la mayoría de las operaciones numéricas son compatibles con libtorch, puede implementarlas gradualmente, verificar la salida de los scripts de python y c ++ coinciden entre sí o no. Tomó horas hacerlo, pero no fue difícil.
 stereomatchingkiss
en 2 sept. 2021
stereomatchingkiss
en 2 sept. 2021
@stereomatchingkiss gracias por responder. También creé con éxito la versión C ++ que sigue la estimación de pose humana de la muestra openvino también.
tucachmo2202
en 2 sept. 2021
@tucachmo2202 ¿Puedes compartirlo por favor?)
Daniil-Osokin
en 3 sept. 2021
Temas relacionados
 anerisheth19
·
10Comentarios
anerisheth19
·
10Comentarios
 mohamdev
·
4Comentarios
mohamdev
·
4Comentarios
 RCpengnan
·
6Comentarios
RCpengnan
·
6Comentarios
 zhenzhongle
·
5Comentarios
zhenzhongle
·
5Comentarios
 hxm1150310617
·
4Comentarios
hxm1150310617
·
4Comentarios
Comentario más útil
@stereomatchingkiss gracias por responder. También creé con éxito la versión C ++ que sigue la estimación de pose humana de la muestra openvino también.