Grafana: Prise en charge des alertes pour les requêtes utilisant des variables de modèle
Il serait très utile que grafana prenne en charge les alertes pour les requêtes utilisant des variables de modèle. La façon dont je le vois fonctionner serait la suivante:
- Générer des requêtes pour chaque combinaison de variables de modèle (en supprimant la variable de modèle pour __all__)
- Lors de la génération de requêtes, tenez compte de la liste figée si la variable de modèle est définie pour ne jamais s'actualiser, sinon mettez à jour la liste des variables de modèle
- Autoriser le filtrage (par regex ou en fournissant une valeur statique) pour chaque variable de modèle
La solution de contournement actuelle consiste à utiliser une métrique générique invisible, mais le problème que je vois avec cette approche est qu'elle perd le contexte.
 calind
calind
Tous les 126 commentaires
+1
 oiooj
le 13 nov. 2016
oiooj
le 13 nov. 2016
- Quelle serait la différence par rapport à tout utiliser ?
 bergquist
le 14 nov. 2016
bergquist
le 14 nov. 2016
+1
Ce serait bien de pouvoir ajouter des alertes sur un serveur avec une faible durée de vie (mise à l'échelle automatique AWS), l'enregistrement automatique du serveur sur grafana est facile avec le modèle mais c'est triste de ne pas pouvoir mettre d'alerte sur eux
 antoiner77
le 14 nov. 2016
antoiner77
le 14 nov. 2016
@bergquist , il n'est pas pratique de tout utiliser, par exemple lorsque vous avez plus d'une douzaine d'hôtes.

Si par exemple seuls quelques-uns d'entre eux échouent, (disons 5), il est très utile de recevoir un email pour chaque alerte défaillante. Cette méthode est également beaucoup plus facile à intégrer avec d'autres outils qui attendent en général une alerte par métrique.
L'approche actuelle (utilisant tout) est plutôt intéressante lorsqu'il y a moins d'instances ou lorsque vous alertez au niveau du service (par exemple, le nombre de travaux en file d'attente).
calind
le 15 nov. 2016
ce que @calind a dit, j'ai plusieurs variables $host qui fonctionnent bien avec influxDB mais pas avec les alertes
 Deshke
le 15 nov. 2016
Deshke
le 15 nov. 2016
+1 aussi.
Juste une pensée, puisque vous pouvez interroger avec une variable de modèle, ne pourriez-vous pas simplement faire la même requête avec les métriques d'alerte et peut-être parcourir les résultats pour voir ceux qui répondent aux critères d'alerte ?
 NotSoCleverLogin
le 18 nov. 2016
NotSoCleverLogin
le 18 nov. 2016
@NotSoCleverLogin Ce serait possible. Mais voudriez-vous modifier le comportement de la règle d'alerte en fonction de la valeur de modèle sélectionnée ?
L'utilisation de l'option all pour le modèle est la seule façon qui a du sens pour moi.
bergquist
le 18 nov. 2016
+1
J'ai une configuration d'environnements X avec les mêmes composants dans chaque environnement. Nous utilisons actuellement prometheus pour alerter, par exemple, sur l'utilisation du processeur / l'utilisation du disque, etc. Là, nous spécifions une alerte pour une requête, et lorsque l'alerte est déclenchée, elle indiquera simplement à partir de quel environnement l'alerte a été déclenchée.
Si nous faisions cela avec la variable All, cela fonctionnerait dans une certaine mesure. Mais, en utilisant l'exemple de @ calind , la capture d'écran serait remplie de la tendance de tous les processeurs de tous mes environnements, et pas seulement de l'environnement où je voudrais être informé dudit problème. Le graphique sera (ou pourra) être obscurci par des informations provenant d'autres environnements. Dans certains scénarios, il peut être intéressant de comparer le processeur dans d'autres environnements, mais il n'y a aucune garantie que ce qui se passe dans un environnement de test se passe dans notre environnement de production, etc.
Nous envisageons également de créer des tableaux de bord utilisables par les opérations, affichant des annotations pour les alertes dans le tableau de bord de synthèse "standard". Étant donné que nous utilisons des variables de modèle 'env' pour ce type de tableaux de bord, il ne nous est pas vraiment possible de le faire avec la façon dont il est implémenté actuellement. Je devrais générer manuellement (au moins dans une certaine mesure) un tableau de bord "fantôme" où les alertes sont déclenchées (ce qui me fait perdre les annotations dans le tableau de bord de vue d'ensemble).
Une autre chose que je pense que les variables de modèle peuvent vous aider à faire est d'acheminer les alertes (si vous choisissez d'implémenter une telle fonctionnalité) vers différentes sources (certaines vers les opérations si en production, vers qa/developers si dans des environnements de test, etc.).
 mstaalesen
le 22 nov. 2016
mstaalesen
le 22 nov. 2016
+1 pour la prise en charge des alertes sur les requêtes basées sur des modèles.
 StianOvrevage
le 23 nov. 2016
StianOvrevage
le 23 nov. 2016
@bergquist , certains tableaux de bord n'ont pas d'option _All_. Par exemple les métriques système par collectd (https://grafana.net/dashboards/24). Avoir une option _All_ ne serait certainement pas pratique pour, disons, 10 serveurs ou plus. C'est pourquoi il est nécessaire de parcourir les variables de modèle.
calind
le 24 nov. 2016
Autoriser l'utilisation de All est un bon début bienvenu.
Dans Prometheus, les requêtes doivent être écrites d'une manière différente pour autoriser All :
some.metric{hostname=~"$Hostname"}
Notez le tilde supplémentaire ici, permettant la recherche d'expressions régulières (et le caractère générique dans All).
Je n'ai pas évalué l'impact possible sur les performances du passage d'une requête directe à une requête de recherche regex, mais au moins pour l'instant, cela résoudrait apparemment nos problèmes.
StianOvrevage
le 25 nov. 2016
+1
 max3163
le 29 nov. 2016
max3163
le 29 nov. 2016
+1
 jordandev
le 29 nov. 2016
jordandev
le 29 nov. 2016
Je ne sais pas comment cela devrait être mis en œuvre, sachez simplement que c'est nécessaire.
 steverweber
le 2 déc. 2016
steverweber
le 2 déc. 2016
+1
Nous utilisons Prometheus comme source de données pour surveiller notre infrastructure Kubernetes pour nos clusters K8S sur site et nos clusters AWS K8S.
Tous nos tableaux de bord utilisent des variables de modèle pour la source de données ($Environment), $Instance/Node, $Namespace et $Pod.
En raison de la structure de la requête Prometheus ; toutes les requêtes ont des variables de modèle ; ce qui empêche les règles d'alerte d'autoriser l'enregistrement.
J'aimerais voir des requêtes variables basées sur un modèle ajoutées à l'alerte.
 Krylon360
le 2 déc. 2016
Krylon360
le 2 déc. 2016
+1
 andrewawagner
le 6 déc. 2016
andrewawagner
le 6 déc. 2016
+1
Nous utilisons des modèles de tableaux de bord pour un environnement multi-serveurs, ce qui est la manière logique (et que beaucoup de gens utilisent), nous ne pouvons donc pas utiliser l'alerte avec grafana pour le moment. Le seul moyen est d'avoir un tableau de bord séparé sans modèle ou de configurer une alerte avec prometheus lui-même, ce qui n'est pas facile.
 shervinkh
le 7 déc. 2016
shervinkh
le 7 déc. 2016
peut-être s'il y avait une option ou un moyen simple de sauvegarder/exporter un tableau de bord avec les variables de modèle sauvegardées/pré-rendues dans tous les champs... ce serait peut-être un bon point à mi-chemin jusqu'à ce qu'une autre solution soit trouvée.
steverweber
le 8 déc. 2016
+1 pour la prise en charge des alertes sur les requêtes basées sur des modèles. Nous utilisons actuellement des modèles sur tous nos tableaux de bord, nous ne pouvons donc pas profiter de cette fonctionnalité vraiment intéressante.
 daraeburn
le 12 déc. 2016
daraeburn
le 12 déc. 2016
+1, nous avons beaucoup de modèles de tableaux de bord, et nous ne pouvons pas utiliser les alertes pour l'instant, nous devons dédupliquer les tableaux de bord pour avoir des alertes, et nous perdons ainsi la puissance des modèles
 tsn77130
le 12 déc. 2016
tsn77130
le 12 déc. 2016
+1, Presque tous nos tableaux de bord utilisent des variables de modèle (et des variables de modèle imbriquées).
Nous aimerions pouvoir définir des alertes sur des panneaux répétés pour obtenir des alertes individuelles par groupe de variables de modèle si nécessaire. De plus, cela signifie que l'alerte est dynamique et non super manuelle comme c'est le cas actuellement.
DANGER : Les variables en théorie seront bonnes à avoir, mais nous devons garder à l'esprit que si quelqu'un va dans votre tableau de bord et change la valeur et enregistre, l'alerte résultante sera affectée. Je ne sais pas si c'est un comportement acceptable ou non, ce sera compliqué.
 drewboswell
le 12 déc. 2016
drewboswell
le 12 déc. 2016
+1
 ebirukov
le 12 déc. 2016
ebirukov
le 12 déc. 2016
Lorsque vous travaillez avec grafana, vous avez l'impression que les modèles sont encouragés partout et qu'il est mal de créer un ensemble supplémentaire de graphiques n'utilisant pas de variables uniquement pour utiliser la fonction d'alerte...
 erSitzt
le 12 déc. 2016
erSitzt
le 12 déc. 2016
+1 pour la prise en charge des alertes sur les requêtes basées sur des modèles.
De plus, nous avons constaté que lorsque nous utilisions le nom de la règle chinoise ou le titre chinois, nous recevions un e-mail anormal avec la règle déclenchée. Par exemple, nous attendions l'alerte "个股分时线接口请求时间(getTimeTrend)" mais avons reçu "ä¸ªè‚¡åˆ†æ—¶çº¿æŽ¥å £è¯·æ±‚æ—¶é—´( getTimeTrend) alert", peut-être que le jeu de caractères n'est pas correct.
 kanwangzjm
le 13 déc. 2016
kanwangzjm
le 13 déc. 2016
+1 pour implémenter des modèles de variables dans les alertes
 AlexMaksimkin
le 14 déc. 2016
AlexMaksimkin
le 14 déc. 2016
+1
 fingul
le 15 déc. 2016
fingul
le 15 déc. 2016
+1 obtiendrait un excellent ajout
 drew-royster
le 17 déc. 2016
drew-royster
le 17 déc. 2016
+1
 tj13
le 20 déc. 2016
tj13
le 20 déc. 2016
+1 pour implémenter des modèles de variables dans les alertes
 felixculpaq
le 20 déc. 2016
felixculpaq
le 20 déc. 2016
+1
 bbae-dev
le 22 déc. 2016
bbae-dev
le 22 déc. 2016
+1 avec impatience
bbae-dev
le 22 déc. 2016
+1
 clhlc
le 23 déc. 2016
clhlc
le 23 déc. 2016
+1
 staslev
le 29 déc. 2016
staslev
le 29 déc. 2016
+1
 actionjax
le 30 déc. 2016
actionjax
le 30 déc. 2016
+1
 jesseorr
le 30 déc. 2016
jesseorr
le 30 déc. 2016
Veuillez arrêter d'écrire +1 !
Tous ceux qui se sont abonnés à ce numéro recevront un e-mail...
Il existe une fonctionnalité github uniquement pour se débarrasser de ces commentaires +1 :
https://github.com/blog/2119-add-reactions-to-pull-requests-issues-and-comments
 thetechnick
le 30 déc. 2016
thetechnick
le 30 déc. 2016
@thetechnick Il y a un lien dans l'e-mail où vous pouvez couper le fil et ne pas recevoir d'e-mails. Mais je comprends que vous souhaitiez peut-être simplement être averti lorsque la fonctionnalité est terminée, mais j'aime aussi que le problème soit résolu afin qu'il soit traité plus tôt, espérons-le :)
StianOvrevage
le 2 janv. 2017
De grands progrès sur l'alerte globale.
Pour les variables de modèle d'alerte, il me manque également. +1 :D
=
En plus de cela, il peut y avoir un bogue dans la manière dont Grafana détecte si la métrique utilisée dans query utilise les variables de modèle.
Lorsque vous avez une série qui utilise indirectement les variables de modèle, Grafana ne vous empêche pas d'ajouter cette série en tant qu'alerte. L'alerte ne fonctionne évidemment pas correctement.
Voir le #K (il utilise #D, qui utilise #A et #A utilise templ. var):
Je pourrais encore le sélectionner :
 tomekit
le 3 janv. 2017
tomekit
le 3 janv. 2017
Des modèles partout, ce qui signifie alerter nulle part.
Vous ne savez pas comment l'alerte a été implémentée, mais pour un graphique simple, la requête est "traduite", les variables de modèle remplacées par des valeurs, avant d'appeler la source de données, n'est-ce pas ? Alors pourquoi pas dans ce cas ? De toute façon, comme dit précédemment, ayant presque toutes les requêtes utilisant des variables de modèle, l'alerte est complètement inutile pour moi. S'il vous plaît, pourriez-vous l'implémenter afin que nous n'ayons pas à déplacer l'alerte en dehors de Grafana ? Merci beaucoup!
 marketadvorackova
le 3 janv. 2017
marketadvorackova
le 3 janv. 2017
Je pense que nous devrions reconnaître que l'alerte avec des modèles n'est pas triviale et je pense que TOUTES les options sont la voie à suivre car nous ne voulons pas que nos alertes changent lorsque quelqu'un utilise le tableau de bord.
Mais grafana devrait toujours créer de nouvelles alertes si la requête de modèle renvoie de nouveaux résultats... ce qui se produit souvent lorsque nous redimensionnons nos applications.
Cela entraîne plus de problèmes si vous utilisez InfluxDB car beaucoup d'entre nous utilisent des balises/valeurs de balises, je suppose, et il n'y a pas de filtre de temps pour eux... donc grafana créerait des alertes pour tous les services qui ont jamais existé sur n'importe quel hôte... .
erSitzt
le 3 janv. 2017
+1
 HyperDevil
le 5 janv. 2017
HyperDevil
le 5 janv. 2017
Le simple fait de permettre de spécifier la source de données dans l'alerte me conviendrait. Cela ne brisera aucune logique, et je peux spécifier au moins les environnements de production et de mise en scène à surveiller.
 yellowmegaman
le 5 janv. 2017
yellowmegaman
le 5 janv. 2017
TOUT est une option, bien sûr. Il serait plus flexible de reconnaître les variables de modèle dans la requête et de laisser l'utilisateur définir les valeurs dans la configuration des conditions d'alerte. Le meilleur, mais compliqué je suppose, serait d'avoir plusieurs alertes (de la même manière qu'il y a plusieurs requêtes) afin qu'une alerte différente puisse être configurée pour des valeurs de variable de modèle différentes dans la requête. Cela permettrait à l'administrateur de configurer différentes conditions d'alerte pour différents hôtes, par exemple.
marketadvorackova
le 5 janv. 2017
Plusieurs profils d'alerte seraient formidables, mais pour une première passe, le simple fait de fournir les mêmes sélecteurs de modèles que ceux disponibles sur le tableau de bord dans le panneau d'alerte résoudrait de nombreux problèmes.
Je pense également qu'il devrait y avoir une bascule pour chaque variable pour agréger les résultats de cette variable dans une seule notification, ceci n'est probablement activé que pour les variables de modèle qui ont la sélection multiple activée. Cela fournit une méthode simple mais efficace pour contrôler la verbosité des notifications - vous pouvez ne vouloir notifier qu'une seule fois pour plusieurs métriques associées, mais notifier pour chaque hôte où une métrique échoue. Ou, vous souhaiterez peut-être ne notifier qu'une seule fois pour une métrique défaillante, quel que soit le nombre d'hôtes concernés.
 pdf
le 14 janv. 2017
pdf
le 14 janv. 2017
avons-nous une étape ciblée pour ce bogue ?
 siteshbehera
le 15 janv. 2017
siteshbehera
le 15 janv. 2017
J'ai eu quelques problèmes avec l'alerte sur des requêtes compliquées et des requêtes de variables de modèle. J'ai trouvé une solution de contournement simple, qui n'est peut-être pas jolie, mais qui fonctionne pour mon cas d'utilisation.
Il s'agit simplement d'extraire la requête après l'avoir créée, il n'y a donc pas de variables de modèle ni de références #ROW. Cela pourrait être évident pour vous, il n'y a pas de science-fusée, mais pour moi, cela a changé ma vie.
Ce que je fais, c'est que je prépare une requête :
puis extrayez-le à l'aide des outils de développement Chrome (copiez la valeur du paramètre cible):
Mettez-le dans une autre ligne (passez d'abord au mode d'édition):
Configurez l'alerte :
Voilà !
tomekit
le 15 janv. 2017
@siteshbehera Ce n'est pas un bug. C'est une demande de fonctionnalité.
Mais non. Nous n'avons pas de jalon pour cela actuellement.
bergquist
le 16 janv. 2017
Le plugin d'intelligence artificielle grafana doit être inclus dans le commit pour cette fonctionnalité.
 lastsky
le 26 janv. 2017
lastsky
le 26 janv. 2017
En attente de modèles dans les alertes aussi +1
 1stdemon
le 1 févr. 2017
1stdemon
le 1 févr. 2017
Je suis également très favorable à ce que calind a fourni comme mise en œuvre possible dans le message d'ouverture. Cela semble correspondre parfaitement au nombre (moi y compris) d'utilisation de tableaux de bord modèles - où vous avez un tableau de bord, mais changez/limitez certaines variables pour examiner manuellement des choses spécifiques. Je pense que l'exemple de la variable "serveur" pourrait être le plus approprié. Là, la variable de modèle (sans _all_-value) deviendrait quelque chose qui ressemble à un "_tab_" dans mon tableau de bord - je peux basculer entre eux pour voir différents ensembles de données. Il est alors facile de supposer que, lors de la configuration d'une alerte, l'alerte existerait pour chaque "_tab_" possible séparément.
 Faradax
le 1 févr. 2017
Faradax
le 1 févr. 2017
En attente de prise en charge des modèles dans Alertes +1
 fahimeh2010
le 7 févr. 2017
fahimeh2010
le 7 févr. 2017
En tant qu'ancien utilisateur de Librato où l'alerte était partiellement capable de cette modélisation, j'aimerais proposer une solution tout aussi partielle. Dans Librato, chaque métrique est accompagnée d'une variable "source", et les alertes sur un graphique seraient automatiquement par source.
Je pense qu'une solution égale satisferait les besoins soulevés ici. Lors de la création d'une alerte, vous devriez pouvoir choisir une seule valeur de modèle comme 'source' et cette source est mentionnée dans l'alerte, toutes les autres étant définies sur 'toutes'. Cette solution évite au moins le problème de combinatoire que vous obtenez si vous autorisez l'utilisation de plusieurs variables de modèle.
Moi-même, je viens de définir un graphique max ou min invisible sur les données qui m'intéressent et de faire l'alerte dessus, pas aussi puissant mais toujours une solution de travail jusqu'à ce que ce problème soit résolu.
 danhallin
le 7 févr. 2017
danhallin
le 7 févr. 2017
Bonjour, je recherche définitivement cette fonctionnalité car, dans la majorité des cas précédents, tous mes tableaux de bord utilisent des requêtes basées sur des modèles pour prendre en charge plusieurs environnements (au moins).
Y a-t-il un endroit où la feuille de route de grafana est suivie ? Ou de toute façon que nous puissions voir si des fonctionnalités (comme celle-ci) seront implémentées dans un futur (proche ou pas si proche) sans pousser les mantainers sur github ? :)
 nadirollo
le 8 févr. 2017
nadirollo
le 8 févr. 2017
Incroyable attend vraiment celui-ci avec impatience
 yannispanousis
le 9 févr. 2017
yannispanousis
le 9 févr. 2017
+1
 artemrootman
le 14 févr. 2017
artemrootman
le 14 févr. 2017
+1
 AlexeyKolychev
le 16 févr. 2017
AlexeyKolychev
le 16 févr. 2017
Nous ne savons toujours pas comment procéder.
Je pense que la réutilisation de la variable de modèle sélectionnée pour l'alerte serait dangereuse, car les utilisateurs peuvent choisir de n'afficher qu'une seule option, puis oublier de revenir à All ou à quelque chose de plus large. Je ne me sentirais pas en sécurité avec un tel comportement. Les règles d'alerte doivent être extrêmement faciles à comprendre et à raisonner. Règles explicites > règles magiques.
Une solution à ce problème serait d'avoir deux valeurs pour chaque variable de modèle. Un pour la visualisation dans le tableau de bord et un pour les alertes. Cela permettrait de toujours avoir l'option la plus large d'alerte et de ne sélectionner que quelques options dans les graphiques. La connexion de ces valeurs devrait être possible mais pas le comportement par défaut.
Cette solution comment chaque serait une fonctionnalité assez importante et complexe.
bergquist
le 20 févr. 2017
J'ai deux propositions de solution.
Une proposition à court terme consiste à ajouter une option d'alerte afin que dans le garph rendu (celui envoyé par e-mail), seules les mesures qui alertent soient affichées. Cela résoudrait l'encombrement lorsque le graphique d'alerte contient des dizaines de métriques.
Une solution à long terme consisterait à parcourir les variables de modèle, de sorte que vous disposiez d'une alerte distincte pour chaque combinaison de valeurs de modèle.
calind
le 20 févr. 2017
Comme je l'ai dit en novembre. Pour les utilisateurs de prometheus, il suffit d'utiliser 'All' comme valeur de variable si les requêtes sont écrites correctement ( some.metric{hostname=~"$Hostname"} ).
Devrait probablement aussi être très facile à mettre en œuvre.
StianOvrevage
le 20 févr. 2017
@bergquist Je pense que l'option 2 va dans la bonne direction (une implémentation partielle de ce que j'ai suggéré dans https://github.com/grafana/grafana/issues/6557#issuecomment-272588490), cela ne semble pas trop complexe, puisque le code pour gérer la sélection de var de modèle existe déjà pour le tableau de bord, et il n'est pas nécessaire de dupliquer la configuration var, juste la sélection. Je ne pense pas que je prendrais la peine de connecter la sélection du tableau de bord à l'alerte lors du premier passage de cette fonctionnalité.
pdf
le 20 févr. 2017
Je l'ai résolu en créant une nouvelle requête de métrique juste pour l'alerte, sans les variables de modèle et en la désactivant (pour l'exclure du graphique) sur Grafana version v4.1.1.
 rahulredde9
le 3 mars 2017
rahulredde9
le 3 mars 2017
+1 pour implémenter des modèles de variables dans les alertes
 arnobroekhof
le 14 mars 2017
arnobroekhof
le 14 mars 2017
+1 pour implémenter des modèles de variables dans les alertes
 seb-margineanu-ft
le 20 mars 2017
seb-margineanu-ft
le 20 mars 2017
Cela affecte-t-il _toutes_ les versions de Grafana ? Ou était-ce une fonctionnalité qui était disponible auparavant ? C'est une sorte de rupture pour moi et cela ne me dérangerait pas d'installer une version précédente.
 alejandroandreu
le 23 mars 2017
alejandroandreu
le 23 mars 2017
L'alerte @alejandroandreu a été ajoutée dans la version 4, elle n'a jamais fonctionné avec les modèles.
 gjgreen
le 23 mars 2017
gjgreen
le 23 mars 2017
+1 pour implémenter des modèles de variables dans les alertes
 iter00
le 23 mars 2017
iter00
le 23 mars 2017
J'aimerais pouvoir sélectionner / entrer les combinaisons que les alertes doivent évaluer, car certains des environnements que j'exécute ne sont pas des environnements de production, Il y a deux façons de mettre cela en œuvre, La première est plus explicite, la seconde est plus facile à configurer.
Saisissez manuellement toutes les combinaisons souhaitées
- Cette configuration doit être affichée dans le panneau de configuration Alert
Par exemple, si j'ai 3 variables de modèles : cloud , region et type , je remplirais un tableau qui ressemble à ceci :
| nuage | région | taper |
|-------|------------|------|
| aws | nous-est-1 | produit |
| aws | nous-ouest-1 | produit |
| azur | Centre des États-Unis | produit |
Le tableau doit avoir une ligne supplémentaire pour insérer de nouvelles lignes et un bouton de suppression pour chaque ligne.
Entrez les valeurs possibles et Grafana calculera le produit cartésien
- Remarque : Cette configuration peut être saisie dans le panneau de configuration des variables de modèle.
| nuage | région | taper |
|-------|------------|------|
| aws | nous-est-1 | produit |
| azur | nous-ouest-1 | |
| | Centre des États-Unis | |
Les combinaisons qui seront créées pour cette entrée sont :
awsus-east-1prodawsus-west-1prodawsCentral USprodazureus-east-1prodazureus-west-1prodazureCentral USprod
Mais Grafana peut gérer cette situation en "saisissant" la première variable ( cloud ), puis en filtrant les valeurs disponibles de la deuxième variable ( region ) jusqu'à ce qu'il trouve toutes les combinaisons possibles (note - il faut le faire de manière itérative pour toutes les variables) . C'est possible lorsque les gens utilisent des requêtes dans les balises comme celle-ci :
SHOW TAG VALUES WITH KEY = "REGION" WHERE "CLOUD" =~ /$CLOUD/
Et dans ce cas, les combinaisons produites iront bien (ce qui est le même que le tableau de la première option) :
awsus-east-1prodawsus-west-1prodazureCentral USprod
J'espère que mes suggestions seront utiles.
 shanielh
le 30 mars 2017
shanielh
le 30 mars 2017
Nous avons ce problème (source de données OpenTSDB) dans un contexte légèrement différent - si vous utilisez un modèle var pour sélectionner un intervalle de sous-échantillonnage dans la métrique, la requête d'alerte échoue avec l'erreur 400. Je comprends les difficultés de mise en œuvre d'une solution générale mais nous sommes va devoir repenser divers tableaux de bord existants pour permettre l'alerte.
 dbcook
le 5 avr. 2017
dbcook
le 5 avr. 2017
@dbcook ressemble à un problème distinct pour lequel vous devriez probablement déposer un problème distinct.
pdf
le 6 avr. 2017
La création de modèles est vraiment une fonctionnalité géniale, tout comme l'alerte. Nous ferions mieux de les faire travailler ensemble en douceur au lieu de toute solution de contournement maladroite.
 skygragon
le 12 avr. 2017
skygragon
le 12 avr. 2017
@tomekit Merci pour la solution de contournement, cela semble prometteur en attendant la véritable implémentation. Cependant, je ne trouve pas où extraire la requête à l'aide des outils de développement Chrome et je ne parviens donc pas à copier la valeur du paramètre cible pour la nouvelle requête. J'ai essayé "Inspecter l'élément" mais j'ai du mal à trouver "Nom" ou "En-têtes" ou "Données de formulaire" que vous avez montré sur la capture d'écran.
Pourriez-vous s'il vous plaît être en mesure d'illustrer les étapes pour le faire? Votre aide sera très appréciée!
Merci
 mathurj
le 26 avr. 2017
mathurj
le 26 avr. 2017
@mathurj C'est l'onglet Réseau -> XHR. Est-ce que ça aide maintenant ?
Cliquez ensuite sur la demande de "rendu".
tomekit
le 26 avr. 2017
Merci @tomekit, je peux voir cette page maintenant, mais je ne vois aucune demande nommée "render". Il existe cependant une autre requête concernant la requête que j'exécute, mais elle n'a aucun paramètre "cible".
Des pistes sur la façon de traiter la demande de "rendu" ?
mathurj
le 26 avr. 2017
@mathurj Je reçois la demande de "rendu", une fois en regardant l'un des graphiques de mon tableau de bord et en cliquant sur Actualiser (coin supérieur droit).
tomekit
le 26 avr. 2017
Je l'ai essayé, toujours pas de demande de "rendu" pour moi :( Et pas de paramètre "cible" aussi. Merci quand même pour votre aide @tomekit . Je suppose que je vais devoir attendre la mise en œuvre réelle, ce qui pourrait prendre un certain temps @bergquist @torkelo ?
mathurj
le 26 avr. 2017
d'accord travailler avec
some.metric{hostname=\~"$Hostname"}
dans la requête elle-même est bien,
mais c'est ma source de données qui est le modèle ici...
environnement=\~"$environnement"
ne semble pas fonctionner ... de toute façon pour que cela fonctionne ai-je raté quelque chose? ou dois-je me débarrasser du modèle :disappointed:
 SvenDhaens
le 18 mai 2017
SvenDhaens
le 18 mai 2017
+2
 matthew-churcher
le 8 juin 2017
matthew-churcher
le 8 juin 2017
cette fonctionnalité est particulièrement utile lorsque vous utilisez le prometheus comme source de données !
 dikang123
le 14 juin 2017
dikang123
le 14 juin 2017
J'en ai également besoin, pour des raisons similaires à celles mentionnées ci-dessus. Je m'attends à ce que cela fonctionne comme une boucle pour chaque boucle sur toute la collection définie par le modèle.
 drekle
le 23 juin 2017
drekle
le 23 juin 2017
Nous en avons besoin!!! :) 👍
 helletheone
le 4 juil. 2017
helletheone
le 4 juil. 2017
Personnellement, je suis également favorable à cette fonctionnalité. Nous testons plus d'un système avec un ensemble de tests de charge qui génèrent des mesures de retard. Au lieu d'avoir un tableau de bord, nous utilisons une variable pour basculer entre les sources de données qui contiennent les données des différents systèmes afin de n'avoir qu'à maintenir un tableau et non à les scripter.
Par conséquent, une prise en charge des modèles dans les alertes serait très appréciée.
 Baiteman
le 4 juil. 2017
Baiteman
le 4 juil. 2017
+1
nous avons besoin de ça aussi
 eloo
le 10 juil. 2017
eloo
le 10 juil. 2017
+1
nous avons besoin de ça aussi
 svenkirsten
le 27 juil. 2017
svenkirsten
le 27 juil. 2017
+1
nous avons besoin de ça aussi
 swift1911
le 28 juil. 2017
swift1911
le 28 juil. 2017
Puis-je demander pourquoi il y a tant de gars "pouce vers le bas" ces réponses +1 ? ?
skygragon
le 28 juil. 2017
@skygragon , c'est essentiellement du spam inutile lorsque l'option de +1 au message d'origine existe. Cliquez simplement sur l'icône du pouce levé dans le premier message.
 austinbutler
le 28 juil. 2017
austinbutler
le 28 juil. 2017
Les variables de modèle et les alertes sont 2 des meilleures fonctionnalités de Grafana.
Triste de voir qu'ils s'excluent mutuellement......
 secure12
le 16 août 2017
secure12
le 16 août 2017
+1
 yzargari
le 20 août 2017
yzargari
le 20 août 2017
@bergquist votre équipe pourrait-elle en discuter à nouveau et, espérons-le, poser un jalon à ce sujet ? C'est la fonctionnalité la plus demandée depuis près de 2 ans maintenant et je parie que de nombreux utilisateurs seraient satisfaits de cette fonctionnalité.
 rogerfar
le 23 août 2017
rogerfar
le 23 août 2017
Aucune bonne solution n'a encore été proposée et nous sommes toujours à peu près sûrs que c'est une mauvaise idée car elle mélange deux fonctionnalités qui servent à des fins différentes. Les variables de modèles sont utilisées pour les tableaux de bord dynamiques et l'exploration. Les règles d'alerte peuvent déjà être rendues dynamiques avec des requêtes regex / wildcard. Mélanger ces deux semble être une idée terrible, du moins d'une manière compréhensible et prévisible.
Il y a cependant de bonnes raisons de le prendre en charge de manière limitée, mais il n'est pas sûr que cela vaille la complexité extrême que cela ajouterait et le coût de développement. Mais nous sommes ouverts aux idées, suggestions et relations publiques.
 torkelo
le 23 août 2017
torkelo
le 23 août 2017
Le problème est que j'ai pas mal de serveurs que je surveille ET qu'ils sont créés dynamiquement via Amazon, donc à un moment donné, je ne sais pas combien de serveurs sont actifs.
J'ai un graphique modélisé qui montre le processeur pour chaque serveur (par exemple), donc j'aimerais aussi alerter là-dessus.
Mais vous dites que je pourrais obtenir la même chose en utilisant des caractères génériques ?
rogerfar
le 23 août 2017
@ yesman85 bien sûr, cela dépend de votre magasin de séries chronologiques. mais la plupart prennent en charge une certaine forme de syntaxe de requête glob/regex pour cibler plusieurs métriques qui suivent un modèle de dénomination.
torkelo
le 23 août 2017
@torkelo Je crois que c'est la première fois que cette position est exprimée publiquement. Je pense qu'il y a peut-être un malentendu ici - je ne pense pas que les utilisateurs souhaitent que les valeurs de modèle sélectionnées pour la sortie du tableau de bord affectent les alertes, mais plutôt que les mêmes sélections de modèles soient disponibles lors de la configuration des alertes.
Suggestions d'implémentation pertinentes de ce fil :
https://github.com/grafana/grafana/issues/6557#issuecomment -272588490
https://github.com/grafana/grafana/issues/6557#issuecomment -281049641 (option 2)
Aussi, problèmes connexes:
https://github.com/grafana/grafana/issues/6041
https://github.com/grafana/grafana/issues/6553
https://github.com/grafana/grafana/issues/6983
https://github.com/grafana/grafana/issues/7252
Ces limitations nous ont empêchés d'utiliser Grafana pour alerter en colère, car les seules façons de faire ce type de travail actuellement sont soit d'ajouter un tas de requêtes cachées distinctes pour l'alerte, soit de créer des tableaux de bord séparés pour alerter vs afficher . Les deux options sont un cauchemar de maintenance et limitent plutôt le grand potentiel de Grafana pour faciliter la configuration et l'interprétation de la surveillance par les utilisateurs.
pdf
le 23 août 2017
Je pense que ma suggestion ci-dessus inspirée par l'alerte basée sur la source de Libratos donne une solution limitée, compréhensible et prévisible qui semble couvrir presque tous les problèmes mentionnés ci-dessus.
Dans grafana, cela se traduirait par la possibilité d'utiliser une et une seule variable de modèle pour l'alerte et chaque valeur de cette variable générerait sa propre alerte. Vous pouvez également ajouter une expression régulière dessus pour filtrer/exclure celles sur lesquelles vous souhaitez créer des alertes.
danhallin
le 23 août 2017
@pdf Je suis d'accord que https://github.com/grafana/grafana/issues/6041 est une grosse limitation, que nous voulons absolument corriger mais qui n'est pas liée à ce problème. C'est dommage que nous n'ayons pas encore réglé le problème. Je suis d'accord, nous avons été un peu en sous-effectif du côté des alertes ces derniers mois, mais cela va bientôt changer !
@danhallin ce n'est pas la même chose, semble-t-il que cela se traduirait par une requête dans Grafana qui cible de nombreuses séries en utilisant des caractères génériques ou des expressions globales dans votre requête ou uniquement des filtres sur un ensemble limité de balises ? Les règles d'alerte Librato sont définies séparément des tableaux de bord, n'est-ce pas, alors comment cela peut-il se traduire par une fonctionnalité de filtrage des données à l'échelle du tableau de bord ?
la façon de faire pour que ce genre de travail fonctionne actuellement est d'ajouter un tas de requêtes cachées distinctes pour l'alerte, ce qui est un cauchemar de maintenance
Comprenez que mélanger des règles d'alerte dans vos graphiques modèles comme celui-ci est un cauchemar. Mais pensez que la prise en charge des variables de modèle dans les alertes pourrait être un cauchemar encore plus grand. Probablement une question stupide, mais ne pouvez-vous pas créer des tableaux de bord et des graphiques axés sur l'alerte ? et laisser les tableaux de bord avec de nombreuses variables de modèle pour l'exploration et le dépannage ? Je sais qu'il y a probablement de nombreux cas où ils seraient similaires, donc cela ressemble à un travail en double :( Le problème avec les règles d'alerte dans le contexte d'un tableau de bord avec quelques variables de modèle est de savoir comment cela devrait fonctionner et être compréhensible, et comment cela peut même être mis en œuvre du tout.
Supposons qu'une requête utilise 2 variables de modèle, $A et $B, elles ont chacune 50 valeurs. Cela entraînerait-il l'évaluation de la règle d'alerte 2 500 fois ? Je veux dire que si les variables sont à "valeur unique", c'est-à-dire que les requêtes sont conçues pour ne fonctionner que si $A et $B ont une valeur unique, nous devrons le faire. Pas un bouchon de spectacle peut-être, nous devrions expliquer que seules les variables à valeurs multiples sont prises en charge. Il y a probablement beaucoup plus de limitations et de détails problématiques qui rendront cette fonctionnalité très difficile à mettre en œuvre, à utiliser et à comprendre
Mais je ne suis pas contre à 100 %, je pense qu'il pourrait y avoir un moyen de le faire de manière limitée (comme ne soutenir qu'un seul
variable à valeurs multiples). Il existe également le cas d'utilisation d'avoir plusieurs sources de données et de pouvoir cibler une variable de source de données dans votre règle d'alerte afin de réutiliser ces règles d'alerte dans de nombreux centres de données/environnements (qui ont des TSDB distincts) ce cas d'utilisation devrait être résolu l'utilisation d'une variable de modèle de source de données comme requête de métrique avec des caractères génériques ne peut pas le résoudre.
torkelo
le 23 août 2017
mais ne pouvez-vous pas créer des tableaux de bord et des graphiques axés sur l'alerte ? et laisser les tableaux de bord avec de nombreuses variables de modèle pour l'exploration et le dépannage ? Je sais qu'il y a probablement de nombreux cas où ils seraient similaires, donc cela ressemble à du travail en double :(
J'ai en fait modifié mon commentaire pour faire référence à cette option (et ajouter quelques autres problèmes liés aux alertes). Comme vous l'avez identifié, cela signifie multiplier la création de tableaux de bord/panneaux (et la maintenance, si toutes ces requêtes nécessitent une mise à jour) par le nombre de variantes de modèle sur lesquelles vous souhaitez alerter, et sépare également les annotations d'alerte de l'emplacement où elles peuvent être le plus utile dans - un tableau de bord basé sur un modèle avec des annotations d'alerte peut être très utile pour établir des corrélations, mais pas tellement si vous devez essayer d'explorer plusieurs onglets de navigateur et essayer d'aligner les choses.
Supposons qu'une requête utilise 2 variables de modèle, $A et $B, elles ont chacune 50 valeurs. Cela entraînerait-il l'évaluation de la règle d'alerte 2 500 fois ? Je veux dire que si les variables sont à "valeur unique", c'est-à-dire que les requêtes sont conçues pour ne fonctionner que si $A et $B ont une valeur unique, nous devrons le faire. Pas un bouchon de spectacle peut-être, nous devrions expliquer que seules les variables à valeurs multiples sont prises en charge. Il y a probablement beaucoup plus de limitations et de détails problématiques qui rendront cette fonctionnalité très difficile à mettre en œuvre, à utiliser et à comprendre
Il y a deux problèmes distincts ici, je pense. L'un _est_ (je crois) étroitement lié à # 6041, en ce sens qu'il peut y avoir un désir d'évaluer les conditions d'alerte individuellement par valeurs de série/modèle (la bascule agrégée que j'ai mentionnée dans un commentaire précédent). Si nous mettons cela de côté pour l'instant, je pense que le moyen idéal de résoudre l'essentiel de ce problème est d'autoriser plusieurs configurations d'alerte par panneau, et de faire simplement une interpolation variable exactement de la même manière que pour la sortie du tableau de bord : permettre aux utilisateurs de sélectionner un seul ou des valeurs de modèle à valeurs multiples lors de la configuration des requêtes d'alerte ; les requêtes seront exécutées une fois par configuration d'alerte, avec les valeurs sélectionnées renseignées ; et les résultats seront interprétés exactement de la même manière qu'ils le sont actuellement. À moins que je ne comprenne grossièrement quelque chose, je ne vois pas cela comme une augmentation significative de la complexité et devrait être assez convivial.
La possibilité de sélectionner des valeurs de modèle pour limiter simplement la portée des alertes serait toujours utile sans plusieurs configurations d'alerte (si cela aide à développer cette fonctionnalité dans cet ordre), mais serait exponentiellement plus précieuse avec plusieurs configurations.
Il existe également le cas d'utilisation d'avoir plusieurs sources de données et de pouvoir cibler une variable de source de données dans votre règle d'alerte afin de réutiliser ces règles d'alerte dans de nombreux centres de données/environnements (qui ont des TSDB distincts) ce cas d'utilisation devrait être résolu l'utilisation d'une variable de modèle de source de données comme requête de métrique avec des caractères génériques ne peut pas le résoudre.
Plusieurs configurations/requêtes d'alerte par panneau fourniraient une méthode pour traiter plusieurs TSDB, et une option pourrait être d'autoriser le regroupement des requêtes d'alerte, de sorte que les transitions d'état se produisent en fonction du résultat de toutes les requêtes du groupe (similaire à la façon dont les choses fonctionnent actuellement pour les séries). Cela ne semble pas trop compliqué.
pdf
le 23 août 2017
C'est certainement un besoin populaire. Maintenant, pour atteindre Alerting, nous avons dû déménager
loin de Grafana et créez notre solution personnalisée à l'aide de Graphite's Render
Données brutes des API .. Je ne pense pas que les alertes soient prises en charge de manière dynamique / basée sur des modèles
les données sont complexes au moins en utilisant Graphite ..
Une autre pensée est,. Pourquoi Grafana a la section Alertes fait partie du tableau de bord
config si cela est considéré comme complexe. Vous pouvez l'éloigner pour séparer
Vue d'alerte où les utilisateurs peuvent simplement saisir/configurer leur requête dynamique,
intervalle, condition d'évaluation là-bas .. Peut-être que cela pourrait signifier que nous
n'avez pas de tableaux de bord en double. Est-ce logique ?
BR,
Viswa..
Le 23 août 2017 à 8 h 01, "Peter Fern" [email protected] a écrit :
mais ne pouvez-vous pas créer des tableaux de bord et des graphiques axés sur l'alerte ?
et laissez les tableaux de bord avec de nombreuses variables de modèle pour l'exploration et
dépannage? Je sais qu'il y a probablement de nombreux cas où ils seraient
similaire ressemble donc à un travail en double :(J'ai en fait modifié mon commentaire pour faire référence à cette option (et ajouter quelques
des autres problèmes douloureux liés aux alertes). Comme vous l'avez identifié,
cela revient à multiplier la création (et la maintenance, le cas échéant) de tableaux de bord/panneaux
ces requêtes ont besoin d'une mise à jour) par le nombre de variantes de modèle que vous souhaitez
pour alerter, et sépare également les annotations d'alerte de l'emplacement
ils peuvent être plus utiles dans - un tableau de bord basé sur un modèle avec des annotations d'alerte
peut être très utile pour faire des corrélations, mais pas tellement si vous devez
essayez d'explorer plusieurs onglets de navigateur et essayez d'aligner les choses.Supposons qu'une requête utilise 2 variables de modèle, $A et $B, elles en ont chacune 50
valeurs. Cela entraînerait-il l'évaluation de la règle d'alerte 2 500 fois ? je veux dire
si les variables sont "à valeur unique", c'est-à-dire que les requêtes sont construites pour fonctionner uniquement
si $A et $B ont une valeur unique, nous devrons le faire. Pas un spectacle
bouchon peut-être, nous aurions à expliquer que seules les variables à valeurs multiples sont
prise en charge. Il y a probablement beaucoup plus de limitations et de détails problématiques
cela rendra cette fonctionnalité très difficile à mettre en œuvre, à utiliser et à comprendreIl y a deux problèmes distincts ici, je pense. On est (je crois) de près
lié à #6041 https://github.com/grafana/grafana/issues/6041 , dans
qu'il peut y avoir un désir d'évaluer les conditions d'alerte individuellement par
valeurs de série / modèle (la bascule agrégée que j'ai mentionnée dans un précédent
commenter). Si nous mettons cela de côté pour l'instant, je pense que le moyen idéal de résoudre
l'essentiel de ce problème consiste à autoriser plusieurs configurations d'alerte par panneau, et
faites simplement une interpolation variable exactement de la même manière que pour le tableau de bord
sortie - permet aux utilisateurs de sélectionner des valeurs de modèle à valeur unique ou multiple lorsque
configuration des requêtes d'alerte ; les requêtes seront exécutées une fois par alerte
config, avec les valeurs sélectionnées renseignées ; et les résultats seront
interprétés exactement de la même manière qu'ils le sont actuellement. Sauf si je suis grossièrement
malentendu quelque chose, je ne vois pas cela comme une augmentation significative de
complexité et devrait être assez convivial.La possibilité de sélectionner des valeurs de modèle pour simplement limiter la portée des alertes
être toujours utile sans plusieurs configurations d'alerte (si cela aide à développer
cette fonctionnalité dans cet ordre), mais serait exponentiellement plus précieux
avec plusieurs configurations.—
Vous recevez ceci parce que vous êtes abonné à ce fil.
Répondez directement à cet e-mail, consultez-le sur GitHub
https://github.com/grafana/grafana/issues/6557#issuecomment-324363795 ,
ou couper le fil
https://github.com/notifications/unsubscribe-auth/AAz1sbIwOT7Xb1MwoDYgZCPz182h2ENxks5sbD62gaJpZM4Kwf5K
.
 vishwanathh
le 23 août 2017
vishwanathh
le 23 août 2017
@danhallin ce n'est pas la même chose, semble-t-il que cela se traduirait par une requête dans Grafana qui cible de nombreuses séries en utilisant des caractères génériques ou des expressions globales dans votre requête ou uniquement des filtres sur un ensemble limité de balises ? Les règles d'alerte Librato sont définies séparément des tableaux de bord, n'est-ce pas, alors comment cela peut-il se traduire par une fonctionnalité de filtrage des données à l'échelle du tableau de bord ?
Je vois maintenant que ce dont je parle est essentiellement une copie de : https://github.com/grafana/grafana/issues/6041
Je soutiens cette demande de fonctionnalité plutôt que celle-ci.
danhallin
le 24 août 2017
Nous faisons régulièrement tourner les serveurs et nous avons des modèles de tableaux de bord qui mesurent les éléments communs à tous les hôtes (mem, hd, cpu, etc.). Faire un tableau de bord « alerte » ayant des graphiques pour chaque combinaison possible est trop fastidieux, bon nombre des alertes souhaitées peuvent être généralisées sur tous les hôtes. AFAIKT, ce problème demande un moyen de rendre ce cas d'utilisation possible et ne serait pas résolu dans # 6041. A moins qu'il me manque quelque chose.
 wavded
le 24 août 2017
wavded
le 24 août 2017
Faire un graphique et une alerte pour chaque combinaison n'est pas ce que nous proposons, juste que votre requête d'alerte utilise des caractères génériques ou des regex afin qu'elle couvre tous les hôtes, etc. Ensuite, vous avez une alerte et un graphique qui peuvent être réglés pour alerter et ne pas être en concurrence avec exigences pour le dépannage et le filtrage dynamique.
torkelo
le 24 août 2017
Pour notre cas d'utilisation, nous avons un certain nombre d'instances (potentiellement) éphémères fournissant un traitement en temps réel des événements - nous aurions besoin d'être alertés si certaines métriques générées par l'application tombent à 0. Cependant, si des instances sont supprimées ou arrêtées, elles auront toujours une métrique nommée qui leur sont associés et qui apparaissent dans une recherche générique directe menant à des alertes générées par erreur.
J'ai contourné ce problème en utilisant une variable à plusieurs valeurs basée sur un modèle (définie sur Tout) générée à partir d'une "source de données JSON simple" qui contient une source de vérité pour les instances qui doivent être exécutées - tout fonctionne parfaitement. Hélas, dès que j'ai tenté d'activer l'alerte, j'ai été amené à cette demande de fonctionnalité :)
Je ne sais pas à quel point notre cas d'utilisation particulier est unique, mais je ne suis pas sûr d'un autre moyen d'alerter à ce sujet sans utiliser de modèles - pour l'instant, nous devrons continuer à alerter pour ces problèmes en dehors de Grafana (ce qui est dommage - nous sommes de très gros utilisateurs de Grafana !)
 pdolan
le 14 sept. 2017
pdolan
le 14 sept. 2017
+1
 olsib
le 24 nov. 2017
olsib
le 24 nov. 2017
Donc, un cas où nous n'avons aucun de ces problèmes est celui où la variable de modèle est un type constant. Par exemple, nous avons plusieurs tableaux de bord reposant sur une variable constante pour limiter les données de ce tableau de bord à une ressource particulière (la raison pour laquelle nous n'avons pas utilisé de variable à valeurs multiples est que chaque tableau de bord est suffisamment différent pour justifier des configurations différentes mais assez proche pour justifier un tableau de bord "modèle"). Au moins dans ce cas (variables constantes), rien dans le comportement d'alerte actuel ne doit changer.
 JonathanTroyer
le 20 déc. 2017
JonathanTroyer
le 20 déc. 2017
Des news sur ce sujet ?
 crazy-canux
le 24 janv. 2018
crazy-canux
le 24 janv. 2018
Salut,
Y a-t-il des espoirs d'obtenir cette fonctionnalité? Je me demande simplement comment d'autres systèmes disposent de ces fonctionnalités, car ils doivent également utiliser une sorte de modèle, car lorsque nous installons l'agent, il apparaît automatiquement sur le portail et des alertes peuvent également être définies pour cela. (Ceci est mon expérience avec New Relic).
@vishwanathh j'ai aimé l'approche d'avoir une section séparée pour l'alerte (s'il est compliqué de l'avoir dans le panneau graphique) où nous pouvons mettre nos requêtes juste pour l'alerte. car de cette façon, nos utilisateurs ne verront pas le panneau d'espace réservé (utilisé pour les alertes).
Désolé pour le bruit supplémentaire, mais ce serait une très bonne fonctionnalité à avoir à Grafana.
 ashuw018
le 28 janv. 2018
ashuw018
le 28 janv. 2018
+1, fonctionnalité très très importante !
 tangyong
le 30 janv. 2018
tangyong
le 30 janv. 2018
De plus, si je me laisse modifier l'expression de requête de métrique prometheus pour supprimer la variable de modèle, ce n'est pas du tout faisable. Donc, je pense que cette fonctionnalité est la plus importante pour que le prometheus+grafana débarque en production !
Quoi qu'il en soit, s'il vous plaît, l'équipe peut considérer la priorité, merci !
tangyong
le 30 janv. 2018
Avec la sortie prochaine de la version 5.0, j'aimerais voir une attention particulière donnée à l'alerte lors de la prochaine série de versions. En regardant les réactions de Github, les lacunes liées aux alertes semblent avoir de loin le plus d'intérêt de la part des utilisateurs.
Je sais qu'il y a eu une certaine réticence à s'attaquer à ces problèmes en raison de problèmes de complexité UI/UX, mais je ne suis pas convaincu que ces préoccupations soient nécessairement justifiées. En tant qu'utilisateurs, y a-t-il quelque chose que nous puissions faire qui pourrait aider à planifier/concevoir ou faire avancer ces problèmes, à moins de demandes d'extraction avec du code réel ?
pdf
le 2 févr. 2018
@torkelo Cela m'a aidé à configurer l'alerte pour tous mes hôtes à l'aide de balises et maintenant, chaque graphique d'alerte contient plusieurs séries formées par la combinaison de balises. Tout semblait bien fonctionner. Mais en parcourant la documentation et d'autres problèmes, j'ai réalisé que si l'une des séries du graphique avait déjà pris un état d'alerte, les alertes des autres séries ne se déclencheraient pas si elles franchissaient également la limite.
C'est encore une limitation.
Merci.
ashuw018
le 2 févr. 2018
Des nouvelles de cette fonctionnalité ?
 deiv061
le 9 févr. 2018
deiv061
le 9 févr. 2018
Quel est l'effort pour un nouveau contributeur d'ajouter cette fonctionnalité ?
 spiffytech
le 9 févr. 2018
spiffytech
le 9 févr. 2018
+1
 sjayaraman
le 14 févr. 2018
sjayaraman
le 14 févr. 2018
Veuillez autoriser l'utilisation de variables de modèle pour les notifications d'alerte.
+1
 nookalavikas
le 19 mars 2018
nookalavikas
le 19 mars 2018
+1
 amihura
le 22 mars 2018
amihura
le 22 mars 2018
Nous espérons être résolus.
 Moon-Tae-Kwon
le 2 avr. 2018
Moon-Tae-Kwon
le 2 avr. 2018
+1
 rpelau
le 2 avr. 2018
rpelau
le 2 avr. 2018
Je ne veux pas battre un cheval mort ici, mais nous avons le même problème, et je veux fournir un contexte expliquant pourquoi les propositions existantes ne fonctionnent pas dans toutes les circonstances. J'ai également quelques idées de solutions de contournement, mais pourquoi nous avons besoin de _certaines fonctionnalités_ pour aider à rendre les solutions de contournement suffisantes.
Pour tous les scénarios ci-dessous, nous utilisons une seule variable basée sur un modèle : $env
"Pourquoi ne pas simplement créer des tableaux de bord d'alerte ?"
Nous voulons alerter sur quelques environnements différents, pas seulement sur la production. Nous aurions donc besoin d'avoir la même métrique à _au moins_ 3 endroits différents (le tableau de bord de dépannage avec toutes les métriques, pas seulement la métrique pour laquelle nous alertons ; le tableau de bord des alertes prod ; le tableau de bord des alertes d'intégration). Cela peut devenir incontrôlable assez rapidement et est sujet aux erreurs de l'utilisateur.
Tout aussi important, cela annule une grande partie du gain des annotations automatisées des alertes. Si je dois aller et venir de mon tableau de bord exploratoire à mon tableau de bord des alertes pour voir les annotations indiquant quand un événement a commencé et quand il s'est terminé, cela va être assez fastidieux.
Tentative de solution
Ce que nous avons fait pour essayer de contourner ce problème, c'est que nous avons ajouté des métriques en double _spécifiquement pour les alertes_ à nos tableaux de bord. Donc, s'il y a une métrique sur laquelle nous voulons alerter, nous allons dans le panneau et ajoutons des métriques explicites pour ces alertes (et les masquons).
Notre liste de séries pour un panneau donné qui doit alerter ressemblera à :
Avec les séries sans modèle marquées comme masquées. Ensuite, dans l'onglet d'alerte, nous définissons des seuils pour _ces_ séries, pas pour la série de variables.
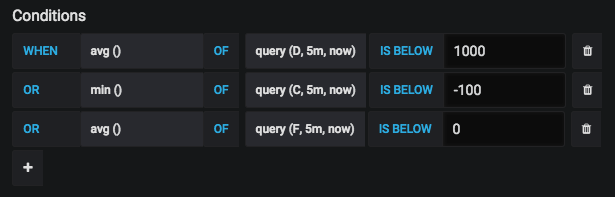
Problèmes avec cette solution
Cela ne fonctionne pas très bien cependant. Par exemple:
Comme vous pouvez le voir, le panneau Alertes ne nous permet pas de spécifier _quel environnement_ est en alerte - nous devons donc explorer l'alerte pour déterminer quel environnement est bloqué en ce moment. Cependant, une solution simple à ce problème pourrait simplement permettre à la description d'être aussi détaillée que le panneau Historique des alertes qui affiche les transitions d'état :
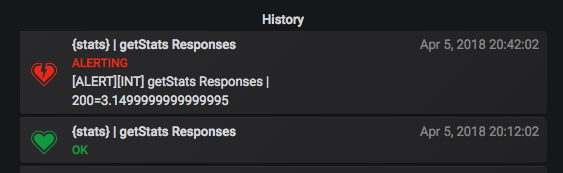
C'est au moins quelque peu utile, mais même dans ce panneau, rien n'indique quelle alerte est revenue à Healthy (la description de la capture d'écran ci-dessus est dérivée de l'alias que nous avons défini sur la série si quelqu'un se demande comment pour au moins obtenir autant à montrer).
Choses qui pourraient aider jusqu'à ce que ce ticket spécifique soit résolu
- Autoriser l'option d'affichage de l'alias de la série au lieu d'une description typée pour l'alerte (de cette façon, l'alias peut au moins spécifier la variable $ pour laquelle il alerte)
- Autoriser la transition d'état vers sain pour afficher également l'alias de la série (dans la capture d'écran de l'historique ci-dessus)
- Autoriser une valeur de légende pour les alertes actives (en utilisant l'alias de série que je suppose) pour un panneau donné
Choses que je ne sais pas comment résoudre
Annotations sur les graphiques comportant des alertes configurées pour plusieurs environnements/variables :
Avec cela, nous ne pouvons pas vraiment dire quelle alerte se déclenche sans entrer dans le panneau. La suggestion de légende pourrait aider à clarifier cela, mais ne fait pas grand-chose pour l'annotation si le bon $env n'est pas sélectionné (dans l'image ci-dessus, int alerte, mais prod est la variable sélectionnée sur le tableau de bord, nous affichons donc les annotations de l'alerte int au-dessus du graphique en utilisant prod .
 calebtote
le 5 avr. 2018
calebtote
le 5 avr. 2018
+1
 unixway
le 9 avr. 2018
unixway
le 9 avr. 2018
un de plus :)
 PheonixS
le 9 avr. 2018
PheonixS
le 9 avr. 2018
Veuillez arrêter d'attribuer +1 à ce problème. Il génère des spams inutiles. La possibilité d'ajouter une réaction à un commentaire sur un problème github existe depuis un certain temps maintenant, et plus de 429 personnes ont compris comment aimer le commentaire initial au lieu de spammer tous ceux qui sont abonnés.
 adamcstephens
le 9 avr. 2018
adamcstephens
le 9 avr. 2018
S'il vous plaît, nous avons vraiment besoin de cette fonctionnalité, nous aimerions utiliser des modèles, mais dans notre cas, il est très important d'avoir un système d'alerte clair. Donc, pour contourner ce problème, nous évitons les modèles dans notre tableau de bord... c'est un gâchis.
 manueligno78
le 23 mai 2018
manueligno78
le 23 mai 2018
Je suis d'accord et cette fonctionnalité nous aidera beaucoup !!!!
 thiagocorredor
le 30 mai 2018
thiagocorredor
le 30 mai 2018
+1 s'il vous plait
 kamzhuyuqing
le 28 juin 2018
kamzhuyuqing
le 28 juin 2018
nous en avons besoin
 cmuzyunda
le 28 juin 2018
cmuzyunda
le 28 juin 2018
+1 s'il vous plaît. C'est vraiment nécessaire.
 ChahatB
le 29 juin 2018
ChahatB
le 29 juin 2018
@bergquist @torkelo pouvons-nous verrouiller ce problème pour arrêter le spam +1 ?
pdf
le 29 juin 2018
Questions connexes
 Azef1
·
3Commentaires
Azef1
·
3Commentaires
 deepujain
·
3Commentaires
deepujain
·
3Commentaires
 kcajf
·
3Commentaires
kcajf
·
3Commentaires
 yuvaraj951
·
3Commentaires
yuvaraj951
·
3Commentaires
 ericuldall
·
3Commentaires
ericuldall
·
3Commentaires
Commentaire le plus utile
Veuillez arrêter d'attribuer +1 à ce problème. Il génère des spams inutiles. La possibilité d'ajouter une réaction à un commentaire sur un problème github existe depuis un certain temps maintenant, et plus de 429 personnes ont compris comment aimer le commentaire initial au lieu de spammer tous ceux qui sont abonnés.