Grafana: Autoriser le mappage personnalisé de la valeur de la variable de modèle -> texte d'affichage
Cas d'utilisation : vous pouvez stocker des métriques basées sur une propriété "ID", mais souhaitez que l'interface utilisateur de sélection des variables de modèle utilise une étiquette plus conviviale. Par exemple, vous suivez les métriques par domaine avec un ID de domaine interne mais souhaitez utiliser l'URL du domaine dans l'interface utilisateur du sélecteur de variable de modèle.
@torkelo Je peux prendre une coupe dans la mise en œuvre de cela, que pensez-vous de la mise en œuvre ? Pour mon cas d'utilisation spécifique, je voudrais être en mesure de fournir une fonction JS arbitraire pour effectuer la conversion valeur -> texte car je dois accéder à un service externe pour la recherche. Je pensais qu'une implémentation initiale pourrait être d'ajouter une valeur de configuration dans le tableau de bord JSON qui définit la fonction de mappage. La prise en charge de l'interface utilisateur pourrait être ajoutée ultérieurement pour gérer des mappages plus triviaux avec des fonctions de mappage prédéfinies (par exemple, des substitutions de regex).
La possibilité de modifier le JSON complet du tableau de bord via l'interface utilisateur serait également liée à cela, bien que l'exportation -> édition -> importation fonctionnerait comme une solution de contournement si cela s'avérait difficile.
 mbell697
mbell697
Tous les 145 commentaires
Vous pouvez le faire avec des tableaux de bord scriptés. Mais vous êtes invités à essayer de l'implémenter dans des tableaux de bord json réguliers/enregistrés.
 torkelo
le 7 nov. 2014
torkelo
le 7 nov. 2014
+1
 dongshengbc
le 11 nov. 2014
dongshengbc
le 11 nov. 2014
Moi aussi, je pourrais utiliser au moins une version plus simple de ceci. Quelque chose comme un mappage configuré de A -> B
Dans mon scénario, je souhaite sélectionner un nom d'entité dans la liste déroulante des variables (CustomerName1, CustomerName2, etc.), mais utiliser un identifiant numérique en interne en ce qui concerne le nom de la métrique.
app.requests.$customer1_ID.count
 Iker-Jimenez
le 7 avr. 2015
Iker-Jimenez
le 7 avr. 2015
+1
 timgriffiths
le 6 juil. 2015
timgriffiths
le 6 juil. 2015
Fusion de #3138
Par exemple, lors de la création d'une variable de modèle personnalisée avec les valeurs
fooBaretbaz_quuxInternal, pour pouvoir faire en sorte que l'interface utilisateur affiche les cases à cocher comme "Foo bar" et "Baz".Cela est particulièrement courant lors de l'utilisation de lignes répétées et d'une variable personnalisée pour réduire la duplication, mais les métriques de niveau supérieur peuvent ne pas être conviviales.
On pourrait potentiellement prendre en charge cela pour les valeurs de modèle interrogées (par exemple, les propriétés du graphite) ainsi qu'en utilisant une expression régulière (si le remplacement est générique). La prise en charge des expressions régulières existe déjà, mais elle s'applique à la fois à la valeur utilisée et à l'étiquette. L'avoir utilisé pour la valeur seulement serait précieux.
Par exemple, si une requête graphite développe
kafka.messagesByTopic.myservice_*pour une utilisation dans des modèles, on peut souhaiter que l'interface utilisateur supprime le préfixe. Mais lorsqu'il est utilisé dans les panneaux réels, le préfixe doit être inclus. Cela peut être contourné (dans Grafana 2.x et versions ultérieures) maintenant que les variables de modèle peuvent être intégrées dans une propriété de métrique, de sorte que l'on peut coder en dur le préfixe dans toutes les métriques de tous les panneaux et lignes, mais il vaut mieux éviter.Une fois que ces valeurs "label" existent, il serait utile de pouvoir y accéder également à l'intérieur des panneaux. Tel lors de l'intégration d'une variable dans un titre de ligne et/ou de panneau. Soit nous pouvons lui faire utiliser l'étiquette par défaut (si elle est intégrée dans un champ de titre), ou peut-être avec une syntaxe alternative (par exemple
$$Variable, ou autre)
 Krinkle
le 4 nov. 2015
Krinkle
le 4 nov. 2015
http://play.grafana.org/dashboard/db/test?editview=templating affiche "Variable Label" en option. Cela peut-il être fermé ?
EDIT : j'ai mal compris le bug, désolé ! :) Continuer.
 bluecmd
le 13 nov. 2015
bluecmd
le 13 nov. 2015
c'est juste une option pour avoir un nom convivial pour la variable, pas les valeurs de la variable
torkelo
le 13 nov. 2015
+1
 malnor
le 27 nov. 2015
malnor
le 27 nov. 2015
+1
 rjromay
le 28 nov. 2015
rjromay
le 28 nov. 2015
+1
 m4dc4p
le 3 déc. 2015
m4dc4p
le 3 déc. 2015
+1
 aalleexxeeii
le 3 mars 2016
aalleexxeeii
le 3 mars 2016
+1
 tboeghk
le 7 mars 2016
tboeghk
le 7 mars 2016
+1
 GautamGupta
le 5 avr. 2016
GautamGupta
le 5 avr. 2016
Quel est le statut de ceci ?
Est-il possible de le faire ?
 sbarale
le 19 avr. 2016
sbarale
le 19 avr. 2016
Est-ce possible pour la finale 3.0 ?
Cela ressemble à une fonctionnalité que beaucoup de gens attendent. Y compris moi :-)
 cosmos78
le 26 avr. 2016
cosmos78
le 26 avr. 2016
+1
J'utilise normalement une partie des expressions régulières qui semble horrible pour les utilisateurs.
 musskopf
le 29 avr. 2016
musskopf
le 29 avr. 2016
+1
 redredgroovy
le 9 mai 2016
redredgroovy
le 9 mai 2016
+1
 srpatatas
le 24 juin 2016
srpatatas
le 24 juin 2016
+1
Sans cela, les expressions régulières sont inutilisables dans les variables de modèle.
 inbilla
le 7 juil. 2016
inbilla
le 7 juil. 2016
+1
 vincenzomos
le 8 août 2016
vincenzomos
le 8 août 2016
+1
 blak3r2
le 11 août 2016
blak3r2
le 11 août 2016
+1
 daaru00
le 4 oct. 2016
daaru00
le 4 oct. 2016
+1
 lucadistefano
le 17 oct. 2016
lucadistefano
le 17 oct. 2016
+1
 rasjoy
le 3 nov. 2016
rasjoy
le 3 nov. 2016
+1
 ihard
le 4 nov. 2016
ihard
le 4 nov. 2016
@mbell697 @torkelo
J'ai implémenté cela pour un service interne qui utilise Grafana. Comme nous utilisons des uuids pour les hôtes (ainsi, un changement de nom d'hôte ne perd pas l'historique des métriques et un certain nombre d'autres choses), il était inacceptable de montrer ces uuids à l'utilisateur. J'ai créé un correctif spécifique pour notre cas d'utilisation dans lequel nous détectons les valeurs uuid et les traduisons à l'aide d'un point de terminaison http de notre application. Cela fonctionne bien pour nous mais je préférerais faire quelque chose de générique et accepté en amont.
Serait-il acceptable d'ajouter une option 'variable_translation_url' qui pointe vers une URL pouvant effectuer le mappage ? (avec un jeton d'autorisation facultatif si nécessaire) ou un variable_translation_script qui pointe vers javascript src qui peut être téléchargé et accroché à templateValuesSrv.js aux points où la traduction est requise (si cette option est définie) ?
 moises-silva
le 6 nov. 2016
moises-silva
le 6 nov. 2016
Pouvez-vous partager votre code templateValuesSrv.js ? Je veux essayer.
 ycodedotme
le 14 nov. 2016
ycodedotme
le 14 nov. 2016
@ZhuWanShan C'est essentiellement ça:
https://github.com/sangoma/grafana/commit/fa109c23bc92c3121173579afbd87a04d7e2f523
Notez que vous y verrez 2 approches. Le premier se voulait plus général, introduisant une nouvelle variable de modèle de type 'http', avec une propriété 'query' qui pointe vers une url HTTP pour effectuer le mappage (voir _getHttpVariableOptions). Plus tard, j'ai implémenté une deuxième méthode qui détecte si un texte d'option (valeur d'affichage) correspond à une expression régulière UUID et force le mappage de n'importe quelle variable en utilisant un appel HTTP codé en dur à /api/v1/nodes/grafana-hosts/ qui renvoie le mappage de toutes les options. Cela a bien fonctionné jusqu'à présent, il suffit d'avoir des instructions sur la façon de convertir cela en une méthode générique.
moises-silva
le 17 nov. 2016
+1
 meverett
le 6 déc. 2016
meverett
le 6 déc. 2016
+1
 linar-jether
le 6 déc. 2016
linar-jether
le 6 déc. 2016
Pour toute personne intéressée, j'ai pu résoudre mon cas d'utilisation particulier en utilisant le plugin Simple JSON Datasource .
Cela dit, le plug-in ne prend actuellement pas en charge les requêtes de variables de modèle, mais ma demande d'extraction qui résout le problème a été fusionnée dans master. Une version Grafana.net mise à jour du plugin devrait suivre à un moment donné.
Avec lui, vous pouvez utiliser des points de terminaison HTTP personnalisés comme sources de données dans Grafana. Il leur suffit d' implémenter 4 méthodes . Lorsqu'il est utilisé avec des variables de modèle basées sur des requêtes, le point de terminaison HTTP recevra une demande d'API /search et le corps sera un objet JSON au format : { "target": "{template query content here}" } . Vous pouvez analyser le contenu de la requête comme vous le souhaitez.
Le renvoi d'un tableau de valeurs à partir de votre point de terminaison créera une liste sous-jacente de valeurs de variables de modèle ["custom value 1", "custom value 2"] sous la forme suivante : [{ "text": "custom value 1", value: 0 }] où la propriété text est la valeur renvoyée par élément du tableau et la propriété value est l'index de la variable dans le tableau de retour.
Vous pouvez également renvoyer un tableau d'objets texte/valeur [{ "text": "label", "value": 123 }] et Grafana utilisera la propriété text comme étiquette de la variable de modèle, et la propriété value comme valeur brute de la variable de modèle.
Il est possible d'injecter dynamiquement d'autres variables de modèle dans la requête sous forme de regex et de les envoyer dynamiquement au point de terminaison pour traitement.
Cela ne résoudra pas tous les scénarios d'aliasing, mais disposer d'une source de données HTTP arbitraire pouvant être utilisée pour les variables de modèle, y compris l'injection dynamique d'autres variables de modèle dans la requête de modèle, est un outil intéressant.
meverett
le 6 déc. 2016
Je suis humain.
+1
 peterfisher
le 14 déc. 2016
peterfisher
le 14 déc. 2016
+1
 daalwr
le 20 janv. 2017
daalwr
le 20 janv. 2017
+1
 mbraeger
le 26 janv. 2017
mbraeger
le 26 janv. 2017
+1
 cattt84
le 27 janv. 2017
cattt84
le 27 janv. 2017
+1
 lghamie
le 27 janv. 2017
lghamie
le 27 janv. 2017
+1
 hzhaop
le 7 févr. 2017
hzhaop
le 7 févr. 2017
+1000
 wokr
le 10 févr. 2017
wokr
le 10 févr. 2017
+1
 Celibat1
le 10 févr. 2017
Celibat1
le 10 févr. 2017
+2
 tereska
le 10 févr. 2017
tereska
le 10 févr. 2017
Ce serait extrêmement utile d'avoir ça. En effet, j'ai un tas d'objets qui ont à la fois un nom et un uuid. Je voudrais afficher le nom, mais stocker l'uuid dans la variable.
Ce serait génial si nous pouvions faire quelque chose comme avoir:
Requête (existante) : AFFICHER LES VALEURS DES ÉTIQUETTES DE "vcd_vm" AVEC CLÉ = "uuid" où "OrgVdc" =~ /^$vDC$/)
Libellé (nouveau) : AFFICHER LES VALEURS DES ÉTIQUETTES DE "vcd_vm" AVEC CLÉ = "nom" où "uuid" =~ /^$tag$/)
 JonathanThorpe
le 21 févr. 2017
JonathanThorpe
le 21 févr. 2017
+1
 0x62ash
le 21 févr. 2017
0x62ash
le 21 févr. 2017
+1
 mahdianpeyman
le 7 mars 2017
mahdianpeyman
le 7 mars 2017
+1
 rkalicinski
le 16 mars 2017
rkalicinski
le 16 mars 2017
+1
 acky6012
le 21 mars 2017
acky6012
le 21 mars 2017
+1
 vaibhavinbayarea
le 22 mars 2017
vaibhavinbayarea
le 22 mars 2017
+1
 sdreep
le 22 mars 2017
sdreep
le 22 mars 2017
+1
Ce serait formidable si la variable de modèle "Personnalisé" prenait en entrée à la fois une liste de "valeurs" et une liste d'"étiquettes" (essentiellement, un hachage/dict personnalisé)
 scharissis
le 26 mars 2017
scharissis
le 26 mars 2017
+1
 gabrielmocan
le 14 avr. 2017
gabrielmocan
le 14 avr. 2017
+1
 satyashanmuka
le 17 avr. 2017
satyashanmuka
le 17 avr. 2017
Cela serait utile pour les données AWS CloudFront, telles qu'exportées par l'exportateur cloudwatch officiel. Les données pour CloudFront sont affichées par ID, qu'aucun humain n'utilise. Beaucoup plus facile pour les humains qui regardent des graphiques de voir "foo.example.com; bar.example.com" au lieu de "EAUUWLGUQEPFWV; EVWWU9PGWIB"...
 vacri
le 28 avr. 2017
vacri
le 28 avr. 2017
+1
 miton18
le 28 avr. 2017
miton18
le 28 avr. 2017
Tout d'abord, merci d'avoir développé un produit génial et de l'avoir partagé avec le monde !
Une indication sur la probabilité que cela soit mis en œuvre dans les mois à venir ? J'essaie simplement de déterminer dans quelle mesure il est logique d'aller de l'avant et de mettre en œuvre la solution de contournement suggérée par @meverett ou d'attendre cela.
L'implémentation via un point de terminaison HTTP est une solution intéressante à une version très généralisée de ce problème, mais semble exagérée pour de nombreux cas d'utilisation décrits ici (y compris le mien) où tout ce qui est nécessaire est un mappage statique de base sur un nombre modeste de "friendly nom d'affichage" -> paires "nom de base de données non convivial".
 svet-b
le 1 mai 2017
svet-b
le 1 mai 2017
@svet-b fwiw, nous avons décidé d'utiliser la suggestion de @meverett et c'était indolore et propre. Quelques heures seulement pour créer le plugin de source de données.
moises-silva
le 1 mai 2017
+1
 prasanth-thangachi
le 27 mai 2017
prasanth-thangachi
le 27 mai 2017
+1
 anitakrueger
le 31 mai 2017
anitakrueger
le 31 mai 2017
+1
 TommiKetola
le 9 juin 2017
TommiKetola
le 9 juin 2017
+1
 wp3xpp
le 16 juin 2017
wp3xpp
le 16 juin 2017
+1
 jaune-rouge
le 27 juin 2017
jaune-rouge
le 27 juin 2017
+1
 feiyuw
le 28 juin 2017
feiyuw
le 28 juin 2017
+1
 iShift
le 12 juil. 2017
iShift
le 12 juil. 2017
+1
 sspetebr
le 7 août 2017
sspetebr
le 7 août 2017
+1
 northtree
le 16 août 2017
northtree
le 16 août 2017
+1
 xokker
le 18 août 2017
xokker
le 18 août 2017
+1
 sevencastles
le 22 août 2017
sevencastles
le 22 août 2017
La solution de contournement de @meverett fonctionne assez bien, mais ne fonctionne pas lorsqu'elle est utilisée avec des variables à plusieurs valeurs car la série ne peut être étiquetée qu'avec des balises de (dans mon cas) influxdb. Des suggestions de solutions de contournement là-bas? :)
 wicol
le 24 août 2017
wicol
le 24 août 2017
+1
 mcortinas
le 31 août 2017
mcortinas
le 31 août 2017
+1
 bluefish6
le 20 sept. 2017
bluefish6
le 20 sept. 2017
+1
 mkue
le 21 sept. 2017
mkue
le 21 sept. 2017
+1
 Ni-k0
le 26 sept. 2017
Ni-k0
le 26 sept. 2017
+1
 langerma
le 3 oct. 2017
langerma
le 3 oct. 2017
Salut à tous, étant donné que ce problème se heurte assez régulièrement, j'ai décidé de créer un exemple d'application Web Node.js qui utilise ma solution ci-dessus .
C'est assez basique, mais il implémente pleinement le modèle que je mentionne dans mon commentaire d'origine. Et si vous pouvez vous contenter de mettre vos données de recherche dans un seul fichier JSON qui ne serait pas mis à jour très souvent, cela pourrait fonctionner pour vous.
Sinon, vous pouvez l'utiliser comme point de départ et l'étendre pour accéder à vos données d'alias à partir de la source de votre choix (programmée par vous bien sûr) et la diffuser via l'application de manière à ce que le plug-in de source de données SimpleJson puisse le consommer. et il peut être utilisé pour piloter l'aliasing/mappage des variables de modèle.
Le référentiel de l'exemple d'application Web se trouve ici .
J'espère que ça aide. J'ai eu des demandes de temps en temps pour plus d'aide/d'explications sur la configuration de la solution.
Acclamations
meverett
le 14 oct. 2017
+1
 inselbuch
le 15 déc. 2017
inselbuch
le 15 déc. 2017
+1
 lotysh
le 20 déc. 2017
lotysh
le 20 déc. 2017
Merci pour votre solution de fortune, @meverett . J'ai créé un référentiel avec Dockerfile pour créer un conteneur Docker pour exécuter votre solution. Il est configuré pour prendre un data.json personnalisé à côté du Dockerfile lors de la construction. J'espère que ça aide les gens :
https://github.com/shirakaba/GrafanaSimpleJsonValueMapper-docker
 shirakaba
le 21 déc. 2017
shirakaba
le 21 déc. 2017
+1
 chalene
le 17 janv. 2018
chalene
le 17 janv. 2018
+1
 chevarria
le 19 janv. 2018
chevarria
le 19 janv. 2018
+1
 oplehto
le 24 janv. 2018
oplehto
le 24 janv. 2018
Lorsque vous souhaitez attribuer +1 à ce problème, n'oubliez pas que vous allez ennuyer les 74 personnes qui sont actuellement abonnées à ce problème et qui espèrent que quelqu'un s'avancera et mettra en œuvre un correctif.
GitHub a ajouté des réactions pour une raison...
 cfstras
le 24 janv. 2018
cfstras
le 24 janv. 2018
+1
 sanchomuzax
le 7 févr. 2018
sanchomuzax
le 7 févr. 2018
+1
 ifelsenayeem
le 19 févr. 2018
ifelsenayeem
le 19 févr. 2018
+1
 seattle
le 21 mars 2018
seattle
le 21 mars 2018
ce serait génial ! a une liste de longues valeurs numériques mais devrait être beaucoup mieux pour montrer une étiquette conviviale pour chacun que la valeur elle-même
variable : myListOfLongs {nom : valeur toyota : 122321312332, nom : valeur renault : 6666666}
 YEMEAC
le 9 mai 2018
YEMEAC
le 9 mai 2018
+1 !
YEMEAC
le 24 mai 2018
+1
 darkstar939
le 6 juin 2018
darkstar939
le 6 juin 2018
+1
Toute mise à jour concernant #11534 (Autoriser les titres dynamiques lors de l'utilisation de panneaux/lignes répétés)
 R-Studio
le 29 juin 2018
R-Studio
le 29 juin 2018
+1
 tecmatia-dp
le 3 juil. 2018
tecmatia-dp
le 3 juil. 2018
+111111
 duxiaofeng-github
le 9 juil. 2018
duxiaofeng-github
le 9 juil. 2018
+1
 fjarrett
le 10 juil. 2018
fjarrett
le 10 juil. 2018
+1
 wlay
le 10 juil. 2018
wlay
le 10 juil. 2018
+1, J'ai vraiment besoin de cette fonctionnalité.
 wolfhong
le 10 juil. 2018
wolfhong
le 10 juil. 2018
+1
 serggp
le 11 juil. 2018
serggp
le 11 juil. 2018
+1
 davidohana
le 16 juil. 2018
davidohana
le 16 juil. 2018
+1
 pargon-the-wise
le 19 juil. 2018
pargon-the-wise
le 19 juil. 2018
+1
 laozhang007
le 27 juil. 2018
laozhang007
le 27 juil. 2018
+1
 gabrielayaelrodriguez
le 27 juil. 2018
gabrielayaelrodriguez
le 27 juil. 2018
Cela fonctionne pour MySql et PostgreSQL :
Une autre option est une requête qui peut créer une variable clé/valeur. La requête doit renvoyer deux colonnes nommées __text et __value. La valeur de la colonne __text doit être unique (si elle n'est pas unique, la première valeur est utilisée). Les options de la liste déroulante auront un texte et une valeur qui vous permettent d'avoir un nom convivial comme texte et un identifiant comme valeur. Un exemple de requête avec hostname comme texte et id comme valeur :
SELECT hostname AS __text, id AS __value FROM my_host
http://docs.grafana.org/features/datasources/mysql/#query-variable
Je suggérerais que la variable personnalisée soit:
[{
"__text": "Server 1",
"__value": 1
},
{
"__text": "Server 2",
"__value": 2
}
]
Peut-être un nouveau type appelé JSON ?
 johnymachine
le 31 juil. 2018
johnymachine
le 31 juil. 2018
Merci @johnymachine ! Cela a fonctionné à merveille avec la source de données PostgreSQL.
Dans le prolongement de ceci, existe-t-il un moyen de récupérer la section __text de la variable ? Ce serait vraiment utile pour répéter des graphiques.
 ryanc-me
le 2 août 2018
ryanc-me
le 2 août 2018
Hé @MGinshe , cela fonctionne bien (le texte utilise la valeur) pour moi :
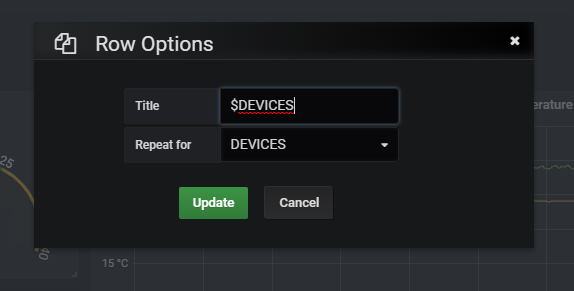
johnymachine
le 2 août 2018
EDIT : mal compris le contexte initial de ce bogue, ignorez le commentaire ci-dessous, il était plutôt destiné à #9292
@torkelo @nmaniwa
https://github.com/grafana/grafana/pull/12609 semble mettre en œuvre ce que la plupart des gens demandent ici, une raison pour laquelle cela est fermé et n'a jamais été fusionné ?
 psarossy
le 20 août 2018
psarossy
le 20 août 2018
Non, ce problème concerne quelque chose de totalement différent, ou avez-vous lié un mauvais problème ?
torkelo
le 20 août 2018
Toujours pas de nouvelles à ce sujet ? Allez, nous sommes en 2018 !! Merci!
 dmayan
le 21 sept. 2018
dmayan
le 21 sept. 2018
@dmayan il a été répondu par @johnymachine . Vous pouvez l'utiliser.
Cela fonctionne pour MySql et PostgreSQL :
Une autre option est une requête qui peut créer une variable clé/valeur. La requête doit renvoyer deux colonnes nommées __text et __value. La valeur de la colonne __text doit être unique (si elle n'est pas unique, la première valeur est utilisée). Les options de la liste déroulante auront un texte et une valeur qui vous permettent d'avoir un nom convivial comme texte et un identifiant comme valeur. Un exemple de requête avec hostname comme texte et id comme valeur :
SELECT hostname AS __text, id AS __value FROM my_hosthttp://docs.grafana.org/features/datasources/mysql/#query-variable
Je suggérerais que la variable personnalisée soit:
[{ "__text": "Server 1", "__value": 1 }, { "__text": "Server 2", "__value": 2 } ]Peut-être un nouveau type appelé JSON ?
 hiddenrebel
le 27 sept. 2018
hiddenrebel
le 27 sept. 2018
Je n'utilise pas MySQL ni PostgreSQL. Cela devrait être une fonctionnalité Grafana. Pas
une sorte de piratage.
Merci!
El jue., 27 sept. de 2018 05:52, Muhammad Hendri [email protected]
écrit :
@dmayan https://github.com/dmayan il a été répondu. Vous pouvez l'utiliser.
Cela fonctionne pour MySql et PostgreSQL :
Une autre option est une requête qui peut créer une variable clé/valeur. La requête
doit renvoyer deux colonnes nommées __text et __value. Le texte
la valeur de la colonne doit être unique (si elle n'est pas unique, la première valeur est
utilisé). Les options de la liste déroulante auront un texte et une valeur qui permettent
vous d'avoir un nom convivial comme texte et un identifiant comme valeur. Un exemple
query avec hostname comme texte et id comme valeur :SELECT hostname AS __text, id AS __value FROM my_host
http://docs.grafana.org/features/datasources/mysql/#query-variable
Je suggérerais que la variable personnalisée soit:
[{
"__text": "Serveur 1",
"__value": 1
},
{
"__text": "Serveur 2",
"__value": 2
}
]Peut-être un nouveau type appelé JSON ?
—
Vous recevez ceci parce que vous avez été mentionné.
Répondez directement à cet e-mail, consultez-le sur GitHub
https://github.com/grafana/grafana/issues/1032#issuecomment-425011676 ,
ou couper le fil
https://github.com/notifications/unsubscribe-auth/AWcYqEwxjXiXE07uM0ZG-A284TghEIR2ks5ufJG4gaJpZM4C4cjS
.
dmayan
le 27 sept. 2018
fonctionnalité assez utile, si cette fonctionnalité existe, cela pourrait nous aider beaucoup ici. Parce que le graphite ne peut pas stocker le caractère chinois. Nous devons donc utiliser l'anglais dans Graphite, mais nous aimerions vraiment montrer le chinois dans le tableau de bord grafana, afin que l'expérience utilisateur soit bien meilleure.
J'espère que cette fonctionnalité se réalisera sous peu.
 wfhu
le 30 sept. 2018
wfhu
le 30 sept. 2018
J'ai réussi à faire le mappage ID-> nom en utilisant deux variables. La première variable répertorie tous les ID possibles (valeur) tandis que la seconde variable répertorie le nom (texte affiché) qui correspond à l'ID. Ce n'est pas l'idéal ni le joli, mais ça fait l'affaire.
Je pense que cela s'appelle des variables imbriquées . Et puis vous pouvez masquer l'un des sélecteurs de variables.
 FdeFabricio
le 2 oct. 2018
FdeFabricio
le 2 oct. 2018
+1
R-Studio
le 20 nov. 2018
+1
 mixvin
le 5 déc. 2018
mixvin
le 5 déc. 2018
@FdeFabricio Vous avez utilisé InfluxDB ? Met-il automatiquement à jour une valeur lors de la modification de l'autre ? Si oui, comment faites-vous cela?
 bassie1995
le 10 janv. 2019
bassie1995
le 10 janv. 2019
@bassie1995
Vous avez utilisé InfluxDB ?
Oui
Met-il automatiquement à jour une valeur lors de la modification de l'autre ?
Oui
Si oui, comment faites-vous cela?
Vous créez une variable de type requête qui sélectionne l'élément qui correspond à la valeur déjà sélectionnée (par exemple SELECT "name" FROM playlists WHERE ("id" =~ /^$playlist_id$/) . Vous aurez donc maintenant deux variables : une avec l'ID et l'autre avec le nom.
FdeFabricio
le 10 janv. 2019
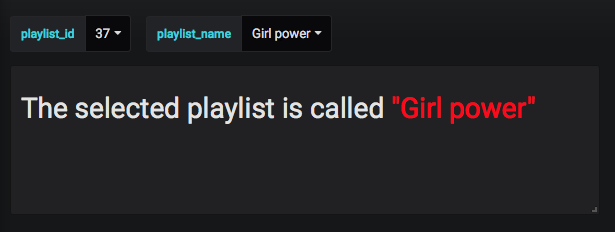
@bassie1995 @FdeFabricio Vous pouvez également le faire à l'envers :
- Une variable visible, qui vous permet de sélectionner le nom de la playlist (c'est-à-dire Girl Power)
- Une variable cachée, qui trouve l'ID de la liste de lecture à partir du nom (quelque chose comme
SELECT "id" FROM playlists WHERE ("name" =~ /^$playlist_name$/))
De cette façon, vos utilisateurs voient une option pour sélectionner la liste de lecture par son nom, mais l'ID de la liste de lecture est masqué. Vous pouvez toujours accéder à l'ID de la liste de lecture par programmation, afin de rechercher des éléments de la liste de lecture, etc.
La syntaxe __name et __value de la source de données PostgreSQL/MySQL reste cependant idéale, car elle évite toute ambiguïté id->name et réduit le nombre de requêtes de base de données requises. Ce devrait être une fonctionnalité de base IMO.
ryanc-me
le 10 janv. 2019
J'ai trouvé une autre solution de contournement basée sur le commentaire de @johnymachine ci-dessus. Cela est pris en charge dans certaines sources de données. Si cela n'est pas pris en charge dans votre source de données, vous pouvez créer une base de données MySQL, y ajouter les données et écrire une requête pour renvoyer __value et __text. Cela fonctionne si les données sont statiques, dans mon état de cas (état géographique). Pour tous ceux qui veulent cette fonctionnalité pour les variables définies comme personnalisées, je pense que c'est une bonne solution de contournement et peut-être une meilleure solution de toute façon. Il permet à toutes les listes de variables d'être stockées dans un seul emplacement et de les modifier plus facilement. Le seul inconvénient est qu'il nécessite l'installation de MySQL.
SÉLECTIONNEZ SingleChar AS __value, ShortName AS __text FROM TSDB. State
Je devrais ajouter que cette solution fonctionne pour les graphiques répétés, les lignes répétées et aussi si la variable a une sélection multiple. L'exemple ci-dessus utilisant 2 variables pour montrer "Girl Power" ne fonctionne pas dans ces situations.
 MikeKulls2
le 21 janv. 2019
MikeKulls2
le 21 janv. 2019
J'étais juste en train de jouer avec ce problème et j'ai trouvé une solution de contournement quelque peu hackinsh ...
J'avais besoin d'un hachage, qui en notation Perl s'écrit :
Perl
%units = (
'μSv/h' => 1.0,
'mrem/h' => 0.1 );
J'ai créé une variable de tableau de bord Type : Custom , Values separated by comma : mrem/h, μSv/h puis j'ai édité le JSON Model comme ça :
JSON
{
"allValue": null,
"current": {
"tags": [],
"text": "mrem/h",
"value": "0.1"
},
"hide": 0,
"includeAll": false,
"label": null,
"multi": false,
"name": "units",
"options": [
{
"selected": true,
"text": "mrem/h",
"value": "0.1"
},
{
"selected": false,
"text": "μSv/h",
"value": "1.0"
}
],
"query": "mrem/h, μSv/h",
"skipUrlSync": false,
"type": "custom"
}
Bien que cela fonctionne (pendant un certain temps), la modification du tableau de bord via l'interface graphique le ramène à l'état non fonctionnel :-|
 thinrope
le 24 janv. 2019
thinrope
le 24 janv. 2019
Une autre option pour contourner ce problème si vous avez un autre système qui peut fournir les données :
Utilisez un plugin de source de données JSON, j'utilise : https://grafana.com/plugins/simpod-json-datasource
Implémentez uniquement le point de terminaison de vérification d'état / et le point de terminaison /search dans un système disposant des données nécessaires. Le point de terminaison /search doit renvoyer un JSON qui ressemble à : [{ "text": "A Human Name", "value": "123456" }, ...] . La propriété text sera celle qui apparaîtra dans la liste déroulante de sélection de variable et la propriété value sera celle qui sera utilisée dans la requête de métrique.
Ensuite, configurez votre variable de tableau de bord pour interroger cette nouvelle source de données, c'est un peu hacky, mais vous pouvez utiliser le champ target pour que la source de données indique au backend ce qu'il doit renvoyer si vous souhaitez l'utiliser avec plusieurs ensembles de données.
mbell697
le 12 févr. 2019
+1 à ce sujet. J'aimerais vraiment un moyen de le faire, mais qui ne dépende pas du backend (nous utilisons du graphite).
 KorkyPlunger
le 5 avr. 2019
KorkyPlunger
le 5 avr. 2019
+1 une solution de travail?
 BlackRider97
le 24 juin 2019
BlackRider97
le 24 juin 2019
@ BlackRider97 Veuillez consulter les commentaires ci-dessus - il existe plusieurs solutions de travail pour PostgreSQL (et probablement MySQL, MSSQL, etc.).
Solution 1 : https://github.com/grafana/grafana/issues/1032#issuecomment -409124505
Solution 2 : https://github.com/grafana/grafana/issues/1032#issuecomment -453242766
ryanc-me
le 25 juin 2019
La mise en œuvre correcte de la solution de contournement de @thinrope serait une solution vraiment élégante à mon humble avis.
Si nous pouvions utiliser JSON dans une variable personnalisée, ou avoir un type de variable "JSON", nous pourrions résoudre ce problème sans hacks et je ne vois aucun inconvénient.
 wildekek
le 27 juin 2019
wildekek
le 27 juin 2019
+1 une mise à jour à ce sujet ?
 jlarmstrong
le 29 oct. 2019
jlarmstrong
le 29 oct. 2019
+1
 siegmund42
le 21 nov. 2019
siegmund42
le 21 nov. 2019
+1
 yvbondarenko
le 23 déc. 2019
yvbondarenko
le 23 déc. 2019
C'est définitivement une fonctionnalité indispensable.
J'utilise des variables pour filtrer certains hôtes en utilisant regex sur le nom d'hôte. Comme mes serveurs contiennent des modèles dans le nom d'hôte, je peux avoir une regex pour obtenir la liste de tous les serveurs d'un groupe donné. Au lieu d'afficher une expression rationnelle laide, je voudrais afficher un joli nom, comme "Serveurs du groupe A" comme étiquette du menu déroulant.
La façon d'entrer ceci dans la valeur personnalisée pourrait être aussi simple que :
label1:value1, value2, label3:value3, label5:value5
L'étiquette serait facultative. Si un : est présent dans la chaîne, alors tout ce qui précède : est l'étiquette et tout ce qui suit est la valeur.
Nous devrions avoir un moyen d'échapper à : si nous en avons besoin dans le nom ou la valeur de l'étiquette, comme nous pouvons le faire pour le caractère , .
 couloum
le 17 févr. 2020
couloum
le 17 févr. 2020
Une autre option pour contourner ce problème si vous avez un autre système qui peut fournir les données :
Utilisez un plugin de source de données JSON, j'utilise : https://grafana.com/plugins/simpod-json-datasource
Implémentez uniquement le point de terminaison de vérification d'état
/et le point de terminaison/searchdans un système disposant des données nécessaires. Le point de terminaison/searchdoit renvoyer un JSON qui ressemble à :[{ "text": "A Human Name", "value": "123456" }, ...]. La propriététextsera celle qui apparaîtra dans la liste déroulante de sélection de variable et la propriétévaluesera celle qui sera utilisée dans la requête de métrique.Ensuite, configurez votre variable de tableau de bord pour interroger cette nouvelle source de données, c'est un peu hacky, mais vous pouvez utiliser le champ
targetpour que la source de données indique au backend ce qu'il doit renvoyer si vous souhaitez l'utiliser avec plusieurs ensembles de données.
J'ai fait cette implémentation et cela fonctionne pour moi, mais je suis coincé à l'étiquetage de la tendance (légende) ... J'obtiens soit id (nombre) ou non défini ou un autre non-sens.
Pouvez vous conseiller?
M
 mato-s
le 25 févr. 2020
mato-s
le 25 févr. 2020
+1
 giorgiofanecco
le 30 mars 2020
giorgiofanecco
le 30 mars 2020
J'utilise également maintenant le hack JSON décrit par @ mbell697 dans le Grafana de mon entreprise. Mais il semble un étrange problème de regex à mon humble avis.
J'ai mis en place une petite application de flacon python qui me fournit les groupes nécessaires pour les requêtes Graphite auxquelles mes données de recherche ressemblent
@app.route('/search', methods=['POST'])
def search():
data = [
{"text": "fs-servers", "value": "{FS-server-1,FS-server-2,FS-server-3}"},
{"text": "db-a-servers", "value": "{db-server-1,}"},
{"text": "db-b-servers", "value": "{db-server-2,db-server-3}"}
]
return jsonify(data)
Donc, dans le tableau de bord, j'ai créé une variable de requête appelée "groupe" en utilisant la source json, puis j'ai essayé de filtrer le groupe "fs-servers" avec le champ regex en utilisant /fs-.*/ - mais cela ne fonctionne pas comme prévu - après avoir bidouillé, j'ai reconnu que la regex est en quelque sorte appliquée à la "valeur" - et non au champ "texte". Quelqu'un a peut-être une solution de contournement ou une idée?
 BBQigniter
le 1 avr. 2020
BBQigniter
le 1 avr. 2020
+1
 alexvaut
le 7 avr. 2020
alexvaut
le 7 avr. 2020
+1
 maplewf
le 22 avr. 2020
maplewf
le 22 avr. 2020
Mon point de vue sur les exigences pour cela:
Dans notre cas, je pense à deux variantes de la même chose. Ce que nous voudrions, ce sont essentiellement des alias. Dans les deux cas, le propriétaire du tableau de bord souhaite fournir à l'utilisateur un modèle de liste de variables facile à comprendre pour l'utilisateur final. Cependant, la valeur utilisée dans la requête est la valeur sous-jacente.
Exemple 1 - simples conversions de nom un à un. Donc, dans ce cas, nous avons des codes de pays numériques publiés sous forme de valeurs métriques. Mais sachez qu'on mémorise les codes numériques. Nous voulons donc afficher "US" ou "Canada"
{ "US" == "01" }
{ "Canada" == "02" }
Si "Canada" est sélectionné, la valeur de la variable de modèle transmise à toute requête est "02"
Exemple 2 - est un mappage un à plusieurs. En interne, nous avons des étapes de déploiement, par exemple s0, s1, s2, s3, s4. Cependant, les utilisateurs finaux peuvent l'utiliser comme "dev, beta, prod"
Ils veulent donc les mapper comme :
{ "dev" == ["s1"] }
{ "bêta" == ["s2", "s3"] }
{ "prod" == ["s4", "s5", "s6"] } ou mieux encore "prod" == s[456]
Donc si "prod" est sélectionné "s4,s5,s6" est passé à la requête
Du point de vue de la requête (en prenant l'exemple 2) où le nom de la variable est stageVar
et le nom de la balise de métrique est stage :
Nous ne voyons pas tellement le besoin d'aliasBy() comme des appels mais plus de choses comme :
étape=~${étapeVar. valeur:regex }
alias($stageVar.label)
Pour filtrer les résultats en fonction des valeurs de variable de modèle sélectionnées. Il est certainement possible que quelqu'un essaie de l'utiliser dans quelque chose comme une fonction aliasBy() mais s'il s'agit d'une erreur de syntaxe, c'est bien. Je ne m'attendrais pas à ce que vous corrigiez comme par magie une conversion d'un tableau passé à une fonction qui attend une valeur unique.
En ce qui concerne les mappages, je pense qu'il suffit que l'utilisateur les définisse statiquement.
Idéalement, vous auriez une requête à MT pour obtenir la liste des valeurs qui doivent être mappées, par exemple "01", "02", "03" et vous auriez ensuite la possibilité d'ajouter facilement les mappages/alias. Les valeurs non mappées iraient dans un compartiment "par défaut".
 shalstea
le 7 mai 2020
shalstea
le 7 mai 2020
+1
 ChrisGute
le 29 mai 2020
ChrisGute
le 29 mai 2020
+1
 xuyixin1996
le 8 juin 2020
xuyixin1996
le 8 juin 2020
Je suis très surpris que cela n'ait pas été inclus - j'ai passé pas mal de temps à essayer de comprendre comment faire cette chose "évidente" et j'ai finalement trouvé mon chemin ici pour découvrir qu'elle n'existe pas.
La possibilité de réécrire dynamiquement comme décrit par certains ci-dessus serait fantastique. Cependant, je serais même satisfait d'un hack à court terme (ou d'un modèle "facile" permanent) qui est une version étendue du champ "Personnalisé", qui mappe statiquement les choix sur des résultats à choix unique ou multiple.
Notre exemple est les codes de pays. Nous souhaitons souvent afficher des groupes de systèmes basés sur des régions géographiques, mais pas par pays. Mais nous stockons uniquement les codes de pays en tant que clés dans notre serveur Prometheus. Donc, pour le moment, si je veux afficher tous les systèmes en Amérique du Nord, je dois sélectionner manuellement US, CA, MX dans une liste d'options basée sur une requête parmi près de 100 pays. Je ne peux même pas vous dire combien de temps je passe à sélectionner chaque pays d'Europe, d'Asie ou d'Afrique pour faire une analyse. Cela vaut presque la peine de mettre en place des tableaux de bord entièrement différents pour chaque région, ce qui est absurde mais c'est le seul moyen de résoudre le problème à court de graphiques codés en dur. Créer une base de données entièrement nouvelle avec des mappages, puis effectuer des requêtes masquées semble également être très, très loin d'être idéal.
Mon rêve de fièvre:
Il semblerait qu'il s'agisse d'une option "Liste personnalisée" comme nouveau type de variable possible. La liste personnalisée commencerait vide si elle était sélectionnée, mais ressemblerait beaucoup au modèle "personnalisé" d'aujourd'hui. Un bouton "Ajouter" apparaît. Cliquer sur "Ajouter" créerait un tableau d'entrée à deux champs avec "Valeur d'affichage :" et "Valeur de recherche :" où chacun pourrait être rempli. La "Valeur d'affichage" serait ce que l'utilisateur voulait afficher dans la liste de sélection - dans notre cas, "Amérique du Nord". Ensuite, la "valeur de recherche" serait ce qui serait présenté dans la requête - encore une fois, dans cet exemple pour l'Amérique du Nord, ce serait "us,ca,mx". A tout moment, une icône "supprimer" (poubelle ?) éloignerait les lignes individuelles. Cliquer à nouveau sur le bouton "Ajouter" créerait un nouveau jumelage, jusqu'à ce que l'utilisateur ait complété sa liste d'options. Les options « Multi-Value » et « Sélectionner tout » resteraient, similaires au modèle personnalisé existant.
 johnhtodd
le 12 juin 2020
johnhtodd
le 12 juin 2020
Je suis très surpris que cela n'ait pas été inclus - j'ai passé pas mal de temps à essayer de comprendre comment faire cette chose "évidente" et j'ai finalement trouvé mon chemin ici pour découvrir qu'elle n'existe pas.
J'ai résolu ce problème en créant une base de données MySQL, je crée une table avec les éléments que je veux dans la liste déroulante, par exemple l'Europe, l'Amérique du Nord, etc. Dans un deuxième champ, j'ai une expression régulière qui correspondra aux entrées que je veux faire correspondre. Ajoutez ensuite MySQL en tant que source de données et utilisez-les pour créer les variables. C'est un hack mais ça marche plutôt bien. Je l'utilise pour à peu près la chose exacte que vous essayez de faire.
MikeKulls2
le 15 juin 2020
J'apprécie le hack astucieux, mais pour nous ce n'est pas vraiment une solution. Configurer une base de données entièrement nouvelle (nous n'utilisons pas du tout MySQL, ce qui signifie que cela est impossible sur le plan opérationnel) pour effectuer une simple substitution clé/valeur qui est assez statique semble être beaucoup d'obstacles à franchir.
J'y pensais un peu plus, et il existe une manière encore plus élégante de fournir cette fonctionnalité que ce que je décris ci-dessus. Je l'appellerais une "macro variable". Cela ressemble à nouveau à une liste personnalisée, sauf qu'elle permet à l'administrateur de spécifier que lorsqu'une (ou plusieurs) de ces macros sont sélectionnées, les variables nommées seront définies et les valeurs données seront ajoutées à l'ensemble de valeurs existant. Ce serait entièrement un modèle basé sur l'interface utilisateur et ne changerait en rien le concept de variable réel - cela créerait simplement une couche de sucre d'auto-complétion au-dessus des variables existantes. Cela le rend rétrocompatible sans variables supplémentaires nécessaires pour la création ou l'intégration dans les requêtes.
Une macro qui définit les variables permettrait à l'utilisateur de voir les valeurs au fur et à mesure qu'elles sont sélectionnées, puis permettrait à l'utilisateur d'ouvrir chaque variable et de voir/manipuler les sélections ou les données au lieu de créer une variable distincte comme mes commentaires précédents impliquer. Ce serait beaucoup plus intuitif.
Exemple:
Ainsi, une macro variable appelée "Amérique du Nord - Cluster principal" définirait mes variables "Pays" sur "us,ca,mx" et définirait ma variable "Cluster :" sur "primaire". Ces paramètres seraient visibles si je devais dérouler chaque variable nommée (ou non, si elles sont masquées) afin que je puisse ajouter ou soustraire des pays à la liste Country: tant que je n'ai pas touché à nouveau le menu déroulant de la variable Macro.
Il existe peut-être un booléen de "effacer les variables nommées avant le réglage" de sorte que si une modification est apportée à la liste de sélection pour cette macro, tous les autres paramètres des variables spécifiées seraient effacés. Cela peut être utile pour les listes où il n'est pas évident que vous puissiez inclure quelque chose qui a déjà été défini. Je suppose que si plus d'une option de macro variable a été choisie, la dernière de la liste à examiner "gagne" s'il existe des paramètres concurrents d'une valeur particulière ; aucun moyen de contourner ce problème. (on peut soutenir que cette action de compensation devrait être spécifiée variable par variable, mais cela semble un peu encombré... mais est-ce le cas ?)
Voici à nouveau mon exemple hypothétique, où j'ai des variables préexistantes de "Pays" et "Cluster".
Nom de la macro variable : Région
Name1 : Amérique du Nord - Cluster principal
Effacer les variables nommées avant de définir : Y
Variable1 : Pays
Valeur 1 : nous,ca,mx
Variable 2 : Grappe
Valeur2 : primaire
Name2 : Pays nordiques - Groupe secondaire
Effacer les variables nommées avant de définir : Y
Variable1 : Pays
Valeur1 : se,fi,no,dk,is
Variable 2 : Grappe
Valeur2 : secondaire
johnhtodd
le 15 juin 2020
J'apprécie le hack astucieux, mais pour nous ce n'est pas vraiment une solution. Configurer une base de données entièrement nouvelle (nous n'utilisons pas du tout MySQL, ce qui signifie que cela est impossible sur le plan opérationnel) pour effectuer une simple substitution clé/valeur qui est assez statique semble être beaucoup d'obstacles à franchir.
Je m'attendais à ce que tu dises quelque chose comme ça. La réalité est que vous avez demandé un hack et ce hack résout le problème, ce n'est pas difficile à configurer et ce n'est pas difficile à inverser à l'avenir. En fait, je trouve assez pratique d'avoir MySQL là-bas car nous continuons à y ajouter de nouveaux ensembles de données, c'est un endroit pratique pour les suivre et les mettre à jour. Si vous y réfléchissez, si vous allez utiliser ces ensembles de données dans plusieurs tableaux de bord et que vous souhaitez les maintenir de manière centralisée, alors ils doivent être stockés quelque part. Si votre base de données de séries chronologiques ne peut pas les stocker, vous avez besoin de quelque chose de configuré pour les stocker. Il est donc parfaitement logique d'avoir MySQL. Le bonus supplémentaire est qu'il est également très facile d'automatiser la population de MySQL.
MikeKulls2
le 16 juin 2020
Si vous avez PostgreSQL, vous n'avez pas besoin de créer une table réelle pour le mappage, vous pouvez faire quelque chose comme :
SELECT *
FROM
(
VALUES
('London server 1', 'london_srv_1'),
('London server 2', 'london_srv_2'),
('New York server 1', 'ny_srv_1'),
('New York server 2', 'ny_srv_2')
) AS t (__text, __value)
 GlennMatthys
le 1 juil. 2020
GlennMatthys
le 1 juil. 2020
Mais cela ne fonctionne pas avec des valeurs numériques :
SELECT * FROM ( VALEURS ( 'OK', '0'), ( 'ERREUR', '1') ) AS t (__texte, __valeur)
Lors du chargement du tableau de bord :

Et lors de la sélection d'un autre paramètre

Lors de la sélection : OK + ERREUR

 crodriguez-cl
le 11 août 2020
crodriguez-cl
le 11 août 2020
Si vous voulez des valeurs numériques, vous devez supprimer les guillemets simples, sinon il est interprété comme du texte, c'est-à-dire
SELECT * FROM ( VALUES ( 'OK', 0), ( 'ERROR', 1) ) AS t (__text, __value)
GlennMatthys
le 11 août 2020
Merci @GlennMatthys glenn pour la réponse, mais j'ai déjà trouvé où le problème se produit.
SELECT * FROM ( VALEURS ( 'OK', 0), ( 'Avertissement', 1), ('Critique', 2) ) AS t (__texte, __valeur)
Configuration de la valeur multiple sur :
Ça arrive
Sélection de 3 états
Et multi-valeur désactivé :

crodriguez-cl
le 11 août 2020
GlennMatthys - votre solution est parfaite, merci beaucoup
 fitovic
le 20 août 2020
fitovic
le 20 août 2020
Pour MySQL, c'est :
SELECT * FROM ( VALUES row('a', 1), row('b', 2) ) AS t (__text, __value)
 BasvanH
le 24 août 2020
BasvanH
le 24 août 2020
Et Mariadb ? Cela ne fonctionne pas pour moi (version mariaDB : 10.5.5)
SELECT * FROM ( VALUES row('a', 1), row('b', 2) ) AS t (__text, __value);
ERROR 1064 (42000)..............
Ou celui d'avant :
SELECT * FROM ( VALUES ( 'OK', 0), ( 'Warning', 1), ('Critical', 2) ) AS t (__text, __value);
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your
MariaDB server version for the right syntax to use near '(__text, __value)' at line 1
Il semble que la déclaration de valeurs ne soit plus disponible...
Ou y a-t-il autre chose que je fais mal?
 radoeka
le 12 sept. 2020
radoeka
le 12 sept. 2020
@radoeka Pour les anciens MariaDB/MySQL
SELECT * FROM
(
SELECT 'London server 1' AS '__text', 'london_srv_1' AS '__value'
UNION ALL SELECT 'London server 2', 'london_srv_2'
UNION ALL SELECT 'New York server 1', 'ny_srv_1'
UNION ALL SELECT 'New York server 2', 'ny_srv_2'
) AS t;
@GlennMatthys wow wow wow, quelle réponse rapide ! Et cela fonctionne.
Je pensais que j'utilisais une version plutôt nouvelle de mariadb, mais ce n'est pas le cas (en utilisant une distribution Linux qui n'a que 2 mois).
Merci.
radoeka
le 12 sept. 2020
Cela ne semble pas être pris en charge pour Prometheus.
 nickdelnano
le 6 oct. 2020
nickdelnano
le 6 oct. 2020
La réouverture de ce problème en tant que # 27829 ne résout ce problème que pour les données statiques.
 hugohaggmark
le 29 oct. 2020
hugohaggmark
le 29 oct. 2020
Questions connexes
 KlavsKlavsen
·
3Commentaires
KlavsKlavsen
·
3Commentaires
 ericuldall
·
3Commentaires
ericuldall
·
3Commentaires
 ADeane6
·
3Commentaires
ADeane6
·
3Commentaires
 yuvaraj951
·
3Commentaires
yuvaraj951
·
3Commentaires
 calind
·
3Commentaires
calind
·
3Commentaires
Commentaire le plus utile
La mise en œuvre correcte de la solution de contournement de @thinrope serait une solution vraiment élégante à mon humble avis.
Si nous pouvions utiliser JSON dans une variable personnalisée, ou avoir un type de variable "JSON", nous pourrions résoudre ce problème sans hacks et je ne vois aucun inconvénient.