Grafana: Permitir mapeamento personalizado do valor da variável do modelo -> exibir texto
Caso de uso: você pode armazenar métricas com base em uma propriedade 'ID', mas deseja que a IU de seleção de variável de modelo use um rótulo mais amigável. Por exemplo, você acompanha as métricas por domínio com um ID de domínio interno, mas deseja usar a URL do domínio na interface do seletor de variável de modelo.
@torkelo Posso reduzir a implementação disso, quais são seus pensamentos sobre a implementação? Para o meu caso de uso específico, gostaria de poder fornecer uma função JS arbitrária para executar a conversão de valor -> texto, pois preciso acessar um serviço externo para a pesquisa. Eu estava pensando que uma implementação inicial poderia adicionar um valor de configuração no JSON do painel que define a função de mapeamento. O suporte à interface do usuário pode ser adicionado posteriormente para lidar com mapeamentos mais triviais com funções de mapeamento pré-construídas (por exemplo, substituições de regex).
Também conectado a isso seria a capacidade de editar o JSON do painel completo por meio da interface do usuário, embora exportar -> editar -> importar funcionaria como uma solução alternativa se isso for difícil.
 mbell697
mbell697
Todos 145 comentários
Você pode fazer isso com painéis com script. Mas você é bem-vindo para tentar implementá-lo em painéis json regulares/salvos.
 torkelo
em 7 nov. 2014
torkelo
em 7 nov. 2014
+1
 dongshengbc
em 11 nov. 2014
dongshengbc
em 11 nov. 2014
Eu também poderia usar pelo menos uma versão mais simples disso. Algo como um mapeamento configurado de A -> B
No meu cenário, quero selecionar um nome de entidade na lista suspensa de variáveis (CustomerName1, CustomerName2, etc.), mas usar um id numérico internamente quando se trata do nome da métrica.
app.requests.$customer1_ID.count
 Iker-Jimenez
em 7 abr. 2015
Iker-Jimenez
em 7 abr. 2015
+1
 timgriffiths
em 6 jul. 2015
timgriffiths
em 6 jul. 2015
Mesclando de #3138
Por exemplo, ao criar uma variável de modelo personalizado com os valores
fooBarebaz_quuxInternal, para que a interface do usuário exiba as caixas de seleção como "Foo bar" e "Baz".Isso é especialmente comum ao usar linhas repetidas e uma variável personalizada para reduzir a duplicação, mas as métricas de nível superior podem não ser fáceis de usar.
Pode-se potencialmente suportar isso para valores de modelo consultados (por exemplo, propriedades de grafite) também usando um regex (se a substituição for genérica). O suporte a Regex já existe, mas se aplica ao valor usado e ao rótulo. Tê-lo usado apenas pelo valor seria valioso.
Por exemplo, se uma consulta de grafite expande
kafka.messagesByTopic.myservice_*para uso em modelos, pode-se desejar que a interface do usuário retire o prefixo. Mas quando usado nos painéis reais, o prefixo deve ser incluído. Isso pode ser contornado (no Grafana 2.xe posterior) agora que as variáveis de modelo podem ser incorporadas em uma propriedade de métrica, então é possível codificar o prefixo em todas as métricas em todos os painéis e linhas, mas é melhor evitar isso.Uma vez que esses valores de "rótulo" existam, seria útil poder acessá-los também dentro dos painéis. Tal ao incorporar uma variável em um título de linha e/ou painel. Ou podemos fazê-lo usar o rótulo por padrão (se incorporado em um campo de título), ou talvez com alguma sintaxe alternativa (por exemplo
$$Variable, ou algo assim)
 Krinkle
em 4 nov. 2015
Krinkle
em 4 nov. 2015
http://play.grafana.org/dashboard/db/test?editview=templating mostra "Rótulo variável" como uma opção. Isso pode ser fechado?
EDIT: entendi errado o bug, desculpe! :) Continuar.
 bluecmd
em 13 nov. 2015
bluecmd
em 13 nov. 2015
isso é apenas uma opção para ter um nome amigável para a variável, não os valores da variável
torkelo
em 13 nov. 2015
+1
 malnor
em 27 nov. 2015
malnor
em 27 nov. 2015
+1
 rjromay
em 28 nov. 2015
rjromay
em 28 nov. 2015
+1
 m4dc4p
em 3 dez. 2015
m4dc4p
em 3 dez. 2015
+1
 aalleexxeeii
em 3 mar. 2016
aalleexxeeii
em 3 mar. 2016
+1
 tboeghk
em 7 mar. 2016
tboeghk
em 7 mar. 2016
+1
 GautamGupta
em 5 abr. 2016
GautamGupta
em 5 abr. 2016
Qual é o estado disso?
É possível fazê-lo?
 sbarale
em 19 abr. 2016
sbarale
em 19 abr. 2016
Isso é possível para a final 3.0?
Parece um recurso que muitas pessoas estão esperando. Incluindo eu :-)
 cosmos78
em 26 abr. 2016
cosmos78
em 26 abr. 2016
+1
Eu normalmente uso parte de expressões regulares que parecem horríveis para os usuários.
 musskopf
em 29 abr. 2016
musskopf
em 29 abr. 2016
+1
 redredgroovy
em 9 mai. 2016
redredgroovy
em 9 mai. 2016
+1
 srpatatas
em 24 jun. 2016
srpatatas
em 24 jun. 2016
+1
Sem isso, as expressões regex não podem ser usadas em variáveis de modelo.
 inbilla
em 7 jul. 2016
inbilla
em 7 jul. 2016
+1
 vincenzomos
em 8 ago. 2016
vincenzomos
em 8 ago. 2016
+1
 blak3r2
em 11 ago. 2016
blak3r2
em 11 ago. 2016
+1
 daaru00
em 4 out. 2016
daaru00
em 4 out. 2016
+1
 lucadistefano
em 17 out. 2016
lucadistefano
em 17 out. 2016
+1
 rasjoy
em 3 nov. 2016
rasjoy
em 3 nov. 2016
+1
 ihard
em 4 nov. 2016
ihard
em 4 nov. 2016
@mbell697 @torkelo
Eu implementei isso para um serviço interno que usa o Grafana. Como usamos uuids para hosts (para que uma mudança no hostname não perca o histórico de métricas e várias outras coisas), era inaceitável mostrar esses uuids ao usuário. Eu fiz um patch específico para nosso caso de uso em que detectamos valores uuid e os traduzimos usando um endpoint http do nosso aplicativo. Isso está funcionando bem para nós, mas eu prefiro fazer algo genérico e aceito no upstream.
Seria aceitável adicionar uma opção 'variable_translation_url' que aponta para um URL que pode realizar o mapeamento? (com um token de autorização opcional, se necessário) ou um variable_translation_script que aponta para javascript src que pode ser baixado e conectado a templateValuesSrv.js nos pontos em que a tradução é necessária (se essa opção estiver definida) ?
 moises-silva
em 6 nov. 2016
moises-silva
em 6 nov. 2016
Você pode compartilhar seu código templateValuesSrv.js? Eu quero experimentar.
 ycodedotme
em 14 nov. 2016
ycodedotme
em 14 nov. 2016
@ZhuWanShan É basicamente isso:
https://github.com/sangoma/grafana/commit/fa109c23bc92c3121173579afbd87a04d7e2f523
Observe que você verá 2 abordagens lá. A primeira deveria ser mais geral, introduzindo um novo tipo de variável de template 'http', com uma propriedade 'query' que aponta para uma url HTTP para realizar o mapeamento (veja _getHttpVariableOptions). Mais tarde, implementei um segundo método que detecta se um texto de opção (valor de exibição) corresponde a um regex UUID e força o mapeamento de qualquer variável que esteja usando uma chamada HTTP codificada para /api/v1/nodes/grafana-hosts/ que retorna o mapeamento de todas as opções. Isso funcionou bem até agora, só precisa ter orientação de como converter isso em um método genérico.
moises-silva
em 17 nov. 2016
+1
 meverett
em 6 dez. 2016
meverett
em 6 dez. 2016
+1
 linar-jether
em 6 dez. 2016
linar-jether
em 6 dez. 2016
Para quem estiver interessado, consegui resolver meu caso de uso específico usando o plug-in Simple JSON Datasource .
Dito isso, o plug-in atualmente não suporta consultas de variáveis de modelo, mas minha solicitação de pull que corrige o problema foi mesclada no master. Uma versão atualizada do plugin Grafana.net deve seguir em algum momento.
Com ele você pode usar endpoints HTTP personalizados como fontes de dados no Grafana. Eles só precisam implementar 4 métodos . Quando usado com variáveis de modelo baseadas em consulta, o endpoint HTTP receberá uma solicitação de API /search e o corpo será um objeto JSON no formato: { "target": "{template query content here}" } . Você pode analisar o conteúdo da consulta como quiser.
Retornar uma matriz de valores de seu ponto de extremidade criará uma lista subjacente de valores de variável de modelo ["custom value 1", "custom value 2"] na forma de: [{ "text": "custom value 1", value: 0 }] onde a propriedade text é o valor retornado por item de matriz e a propriedade value é o índice da variável no array de retorno.
Alternativamente, você pode retornar uma matriz de objetos de texto/valor [{ "text": "label", "value": 123 }] e o Grafana usará a propriedade text como o rótulo da variável do modelo e a propriedade value como o valor bruto de a variável de modelo.
É possível injetar dinamicamente outras variáveis de modelo na consulta no formato regex e enviá-las dinamicamente para o terminal para processamento.
Isso não resolverá todos os cenários de alias, mas ter uma fonte de dados HTTP arbitrária que possa ser usada para variáveis de modelo, incluindo injetar dinamicamente outras variáveis de modelo na consulta de modelo, é uma boa ferramenta.
meverett
em 6 dez. 2016
Eu sou humano.
+1
 peterfisher
em 14 dez. 2016
peterfisher
em 14 dez. 2016
+1
 daalwr
em 20 jan. 2017
daalwr
em 20 jan. 2017
+1
 mbraeger
em 26 jan. 2017
mbraeger
em 26 jan. 2017
+1
 cattt84
em 27 jan. 2017
cattt84
em 27 jan. 2017
+1
 lghamie
em 27 jan. 2017
lghamie
em 27 jan. 2017
+1
 hzhaop
em 7 fev. 2017
hzhaop
em 7 fev. 2017
+1000
 wokr
em 10 fev. 2017
wokr
em 10 fev. 2017
+1
 Celibat1
em 10 fev. 2017
Celibat1
em 10 fev. 2017
+2
 tereska
em 10 fev. 2017
tereska
em 10 fev. 2017
Seria imensamente útil ter isso. Na verdade, eu tenho um monte de objetos que têm um nome e um uuid. Eu gostaria de exibir o nome, mas armazenar o uuid na variável.
Seria ótimo se pudéssemos fazer algo como ter:
Consulta (existente): SHOW TAG VALUES FROM "vcd_vm" WITH KEY = "uuid" onde "OrgVdc" =~ /^$vDC$/)
Label (novo): SHOW TAG VALUES FROM "vcd_vm" WITH KEY = "name" onde "uuid" =~ /^$tag$/)
 JonathanThorpe
em 21 fev. 2017
JonathanThorpe
em 21 fev. 2017
+1
 0x62ash
em 21 fev. 2017
0x62ash
em 21 fev. 2017
+1
 mahdianpeyman
em 7 mar. 2017
mahdianpeyman
em 7 mar. 2017
+1
 rkalicinski
em 16 mar. 2017
rkalicinski
em 16 mar. 2017
+1
 acky6012
em 21 mar. 2017
acky6012
em 21 mar. 2017
+1
 vaibhavinbayarea
em 22 mar. 2017
vaibhavinbayarea
em 22 mar. 2017
+1
 sdreep
em 22 mar. 2017
sdreep
em 22 mar. 2017
+1
Seria ótimo se a variável de modelo 'Custom' tivesse como entrada uma lista de 'values' e uma lista de 'labels' (essencialmente, um hash/dict personalizado)
 scharissis
em 26 mar. 2017
scharissis
em 26 mar. 2017
+1
 gabrielmocan
em 14 abr. 2017
gabrielmocan
em 14 abr. 2017
+1
 satyashanmuka
em 17 abr. 2017
satyashanmuka
em 17 abr. 2017
Isso seria útil para dados do AWS CloudFront, conforme exportados pelo exportador oficial do cloudwatch. Os dados do CloudFront são exibidos por IDs, que não são usados por humanos. Muito mais fácil para humanos olhando para gráficos para ver "foo.example.com; bar.example.com" em vez de "EAUUWLGUQEPFWV; EVWWU9PGWIB"...
 vacri
em 28 abr. 2017
vacri
em 28 abr. 2017
+1
 miton18
em 28 abr. 2017
miton18
em 28 abr. 2017
Primeiramente, obrigado por desenvolver um produto incrível e compartilhá-lo com o mundo!
Alguma indicação sobre qual é a probabilidade de isso ser implementado nos próximos meses? Estou apenas tentando avaliar até que ponto faz sentido seguir em frente e implementar a solução alternativa sugerida por @meverett ou esperar por isso.
Implementar isso por meio de um endpoint HTTP é uma solução interessante para uma versão altamente generalizada desse problema, mas parece um exagero para muitos dos casos de uso descritos aqui (incluindo o meu), onde tudo o que é necessário é mapeamento estático básico em um número modesto de "amigáveis nome de exibição" -> pares "nome de banco de dados não amigável".
 svet-b
em 1 mai. 2017
svet-b
em 1 mai. 2017
@svet-b fwiw, passamos a usar a sugestão de @meverett e foi indolor e limpo. Apenas algumas horas para construir o plugin de fonte de dados.
moises-silva
em 1 mai. 2017
+1
 prasanth-thangachi
em 27 mai. 2017
prasanth-thangachi
em 27 mai. 2017
+1
 anitakrueger
em 31 mai. 2017
anitakrueger
em 31 mai. 2017
+1
 TommiKetola
em 9 jun. 2017
TommiKetola
em 9 jun. 2017
+1
 wp3xpp
em 16 jun. 2017
wp3xpp
em 16 jun. 2017
+1
 jaune-rouge
em 27 jun. 2017
jaune-rouge
em 27 jun. 2017
+1
 feiyuw
em 28 jun. 2017
feiyuw
em 28 jun. 2017
+1
 iShift
em 12 jul. 2017
iShift
em 12 jul. 2017
+1
 sspetebr
em 7 ago. 2017
sspetebr
em 7 ago. 2017
+1
 northtree
em 16 ago. 2017
northtree
em 16 ago. 2017
+1
 xokker
em 18 ago. 2017
xokker
em 18 ago. 2017
+1
 sevencastles
em 22 ago. 2017
sevencastles
em 22 ago. 2017
A solução alternativa do @meverett funciona muito bem, mas fica aquém quando usada com variáveis de vários valores porque a série só pode ser rotulada com tags de (no meu caso) influxdb. Alguma sugestão para soluções alternativas lá? :)
 wicol
em 24 ago. 2017
wicol
em 24 ago. 2017
+1
 mcortinas
em 31 ago. 2017
mcortinas
em 31 ago. 2017
+1
 bluefish6
em 20 set. 2017
bluefish6
em 20 set. 2017
+1
 mkue
em 21 set. 2017
mkue
em 21 set. 2017
+1
 Ni-k0
em 26 set. 2017
Ni-k0
em 26 set. 2017
+1
 langerma
em 3 out. 2017
langerma
em 3 out. 2017
Olá a todos, já que esse problema é abordado com bastante regularidade, decidi criar um exemplo de aplicativo da Web Node.js que usa minha solução acima .
É bem básico, mas implementa totalmente o padrão que mencionei no meu comentário original. E se você conseguir colocar seus dados de pesquisa em um único arquivo JSON que não seria atualizado com muita frequência, isso pode funcionar imediatamente para você.
Caso contrário, você pode usá-lo como ponto de partida e estendê-lo para acessar seus dados de alias de qualquer fonte que desejar (programado por você, é claro) e servi-lo através do aplicativo de forma que o plug-in de fonte de dados SimpleJson possa consumi-lo e pode ser usado para direcionar o alias/mapeamento de variável de modelo.
O repositório para o aplicativo Web de exemplo está aqui .
Espero que ajude. Eu tive alguns pedidos de tempos em tempos pedindo mais ajuda/explicação para configurar a solução.
Felicidades
meverett
em 14 out. 2017
+1
 inselbuch
em 15 dez. 2017
inselbuch
em 15 dez. 2017
+1
 lotysh
em 20 dez. 2017
lotysh
em 20 dez. 2017
Obrigado por sua solução improvisada, @meverett . Fiz um repositório com Dockerfile para criar um container Docker para executar sua solução. Ele está configurado para receber um data.json personalizado junto com o Dockerfile na compilação. Espero que ajude as pessoas:
https://github.com/shirakaba/GrafanaSimpleJsonValueMapper-docker
 shirakaba
em 21 dez. 2017
shirakaba
em 21 dez. 2017
+1
 chalene
em 17 jan. 2018
chalene
em 17 jan. 2018
+1
 chevarria
em 19 jan. 2018
chevarria
em 19 jan. 2018
+1
 oplehto
em 24 jan. 2018
oplehto
em 24 jan. 2018
Quando você quiser marcar isso com +1, lembre-se de que irritará as 74 pessoas que estão atualmente inscritas neste problema e esperam que alguém dê um passo à frente e implemente uma correção.
O GitHub adicionou reações por um motivo...
 cfstras
em 24 jan. 2018
cfstras
em 24 jan. 2018
+1
 sanchomuzax
em 7 fev. 2018
sanchomuzax
em 7 fev. 2018
+1
 ifelsenayeem
em 19 fev. 2018
ifelsenayeem
em 19 fev. 2018
+1
 seattle
em 21 mar. 2018
seattle
em 21 mar. 2018
isso seria ótimo! a tem uma lista de valores numéricos longos, mas deve ser muito melhor mostrar um rótulo amigável para cada um do que o próprio valor
variável: myListOfLongs {nome: valor toyota: 122321312332, nome: valor renault: 6666666}
 YEMEAC
em 9 mai. 2018
YEMEAC
em 9 mai. 2018
+1!
YEMEAC
em 24 mai. 2018
+1
 darkstar939
em 6 jun. 2018
darkstar939
em 6 jun. 2018
+1
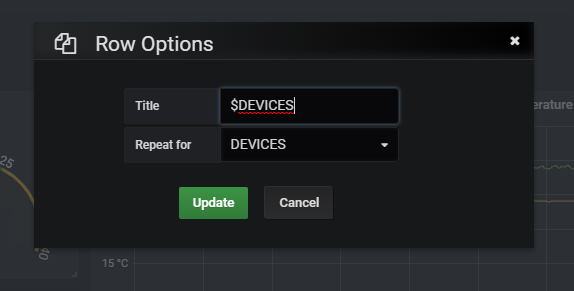
Quaisquer atualizações sobre #11534 (Permitir títulos dinâmicos ao usar painéis/linhas repetidos)
 R-Studio
em 29 jun. 2018
R-Studio
em 29 jun. 2018
+1
 tecmatia-dp
em 3 jul. 2018
tecmatia-dp
em 3 jul. 2018
+111111
 duxiaofeng-github
em 9 jul. 2018
duxiaofeng-github
em 9 jul. 2018
+1
 fjarrett
em 10 jul. 2018
fjarrett
em 10 jul. 2018
+1
 wlay
em 10 jul. 2018
wlay
em 10 jul. 2018
+1, precisa muito desse recurso.
 wolfhong
em 10 jul. 2018
wolfhong
em 10 jul. 2018
+1
 serggp
em 11 jul. 2018
serggp
em 11 jul. 2018
+1
 davidohana
em 16 jul. 2018
davidohana
em 16 jul. 2018
+1
 pargon-the-wise
em 19 jul. 2018
pargon-the-wise
em 19 jul. 2018
+1
 laozhang007
em 27 jul. 2018
laozhang007
em 27 jul. 2018
+1
 gabrielayaelrodriguez
em 27 jul. 2018
gabrielayaelrodriguez
em 27 jul. 2018
Isso funciona para MySQL e PostgreSQL:
Outra opção é uma consulta que pode criar uma variável de chave/valor. A consulta deve retornar duas colunas denominadas __text e __value. O valor da coluna __text deve ser exclusivo (se não for exclusivo, o primeiro valor será usado). As opções na lista suspensa terão um texto e um valor que permitem que você tenha um nome amigável como texto e um id como valor. Um exemplo de consulta com hostname como texto e id como valor:
SELECT hostname AS __text, id AS __value FROM my_host
http://docs.grafana.org/features/datasources/mysql/#query -variable
Eu sugeriria que a variável personalizada fosse:
[{
"__text": "Server 1",
"__value": 1
},
{
"__text": "Server 2",
"__value": 2
}
]
Talvez novo tipo chamado JSON?
 johnymachine
em 31 jul. 2018
johnymachine
em 31 jul. 2018
Obrigado @johnymachine! Isso funcionou lindamente com a fonte de dados PostgreSQL.
Como extensão disso, existe alguma maneira de recuperar a seção __text da variável? Isso seria muito útil para repetir gráficos.
 ryanc-me
em 2 ago. 2018
ryanc-me
em 2 ago. 2018
Ei @MGinshe , isso funciona bem (exibe o texto usa valor) para mim:
johnymachine
em 2 ago. 2018
EDIT: entendeu mal o contexto inicial deste bug, ignore o comentário abaixo, era mais para #9292
@torkelo @nmaniwa
https://github.com/grafana/grafana/pull/12609 parece implementar o que a maioria das pessoas está pedindo aqui, alguma razão pela qual isso é fechado e nunca foi mesclado?
 psarossy
em 20 ago. 2018
psarossy
em 20 ago. 2018
Não, essa questão é sobre algo totalmente diferente, ou você vinculou a questão errada?
torkelo
em 20 ago. 2018
Ainda não há notícias sobre isso? Vamos, estamos em 2018!! Obrigado!
 dmayan
em 21 set. 2018
dmayan
em 21 set. 2018
@dmayan foi respondido por @johnymachine . Você pode usar isso.
Isso funciona para MySQL e PostgreSQL:
Outra opção é uma consulta que pode criar uma variável de chave/valor. A consulta deve retornar duas colunas denominadas __text e __value. O valor da coluna __text deve ser exclusivo (se não for exclusivo, o primeiro valor será usado). As opções na lista suspensa terão um texto e um valor que permitem que você tenha um nome amigável como texto e um id como valor. Um exemplo de consulta com hostname como texto e id como valor:
SELECT hostname AS __text, id AS __value FROM my_hosthttp://docs.grafana.org/features/datasources/mysql/#query -variable
Eu sugeriria que a variável personalizada fosse:
[{ "__text": "Server 1", "__value": 1 }, { "__text": "Server 2", "__value": 2 } ]Talvez novo tipo chamado JSON?
 hiddenrebel
em 27 set. 2018
hiddenrebel
em 27 set. 2018
Eu não uso MySQL nem PostgreSQL. Este deve ser um recurso do Grafana. Não
algum tipo de hack.
Obrigado!
El jue., 27 de set. de 2018 05:52, Muhammad Hendri [email protected]
escreveu:
@dmayan https://github.com/dmayan foi respondido. Você pode usar isso.
Isso funciona para MySQL e PostgreSQL:
Outra opção é uma consulta que pode criar uma variável de chave/valor. A pergunta
deve retornar duas colunas denominadas __text e __value. O texto
valor da coluna deve ser único (se não for único, então o primeiro valor é
usava). As opções na lista suspensa terão um texto e um valor que permitem
que você tenha um nome amigável como texto e um id como valor. Um exemplo
query com hostname como texto e id como valor:SELECT hostname AS __text, id AS __value FROM my_host
http://docs.grafana.org/features/datasources/mysql/#query -variable
Eu sugeriria que a variável personalizada fosse:
[{
"__text": "Servidor 1",
"__valor": 1
},
{
"__text": "Servidor 2",
"__valor": 2
}
]Talvez novo tipo chamado JSON?
—
Você está recebendo isso porque foi mencionado.
Responda a este e-mail diretamente, visualize-o no GitHub
https://github.com/grafana/grafana/issues/1032#issuecomment-425011676 ,
ou silenciar o thread
https://github.com/notifications/unsubscribe-auth/AWcYqEwxjXiXE07uM0ZG-A284TghEIR2ks5ufJG4gaJpZM4C4cjS
.
dmayan
em 27 set. 2018
recurso bastante útil, se esse recurso estiver por aí, pode nos ajudar muito aqui. Porque grafite não pode armazenar caracteres chineses. Então, temos que usar o inglês no Graphite, mas gostaríamos muito de mostrar o chinês no painel do grafana, para que a experiência do usuário fosse muito melhor.
Espero que esse recurso se torne realidade em breve.
 wfhu
em 30 set. 2018
wfhu
em 30 set. 2018
Consegui fazer o mapeamento de ID->nome usando duas variáveis. A primeira variável lista todos os IDs possíveis (valor), enquanto a segunda variável lista o nome (texto de exibição) que corresponde ao ID. Não é o ideal ou bonito, mas faz o truque.
Eu acho que é chamado de variáveis aninhadas . E então você pode ocultar um dos seletores de variáveis.
 FdeFabricio
em 2 out. 2018
FdeFabricio
em 2 out. 2018
+1
R-Studio
em 20 nov. 2018
+1
 mixvin
em 5 dez. 2018
mixvin
em 5 dez. 2018
@FdeFabricio Você usou o InfluxDB? Ele atualiza automaticamente um valor ao alterar o outro? Se sim, como você faz isso?
 bassie1995
em 10 jan. 2019
bassie1995
em 10 jan. 2019
@bassie1995
Você usou o InfluxDB?
sim
Ele atualiza automaticamente um valor ao alterar o outro?
sim
Se sim, como você faz isso?
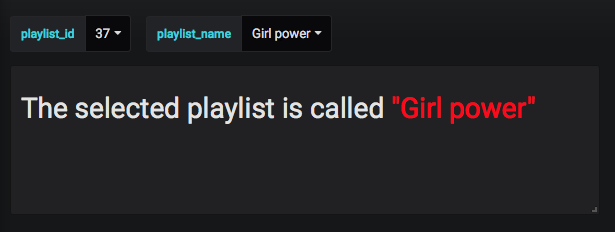
Você cria uma variável do tipo consulta que seleciona o item que corresponde ao valor já selecionado (ex. SELECT "name" FROM playlists WHERE ("id" =~ /^$playlist_id$/) . Então agora você terá duas variáveis: uma com o ID e outra com o nome.
FdeFabricio
em 10 jan. 2019
@bassie1995 @FdeFabricio Você também pode fazer isso ao contrário:
- Uma variável visível, que permite selecionar o nome da lista de reprodução (ou seja, Girl Power)
- Uma variável oculta, que encontra o ID da playlist a partir do nome (algo como
SELECT "id" FROM playlists WHERE ("name" =~ /^$playlist_name$/))
Dessa forma, seus usuários veem uma opção para selecionar a playlist pelo nome, mas o ID da playlist fica oculto. Você ainda pode acessar o ID da lista de reprodução programaticamente, para pesquisar itens da lista de reprodução, etc.
A sintaxe __name e __value da fonte de dados PostgreSQL/MySQL ainda é ideal, pois evita qualquer ambiguidade id->name e reduz o número de consultas de banco de dados necessárias. Deve ser um recurso básico IMO.
ryanc-me
em 10 jan. 2019
Eu encontrei outra solução baseada no comentário de @johnymachine acima. Há suporte para isso em algumas fontes de dados. Se não for suportado em sua fonte de dados, você pode criar um banco de dados MySQL, adicionar os dados lá e escrever uma consulta para retornar __value e __text. Isso funciona se os dados forem estáticos, no meu caso, estado (estado geográfico). Para quem deseja esse recurso para variáveis definidas como personalizadas, acho que essa é uma boa solução alternativa e possivelmente uma solução melhor de qualquer maneira. Ele permite que todas as listas de variáveis sejam armazenadas em 1 local e alteradas com mais facilidade. A única desvantagem é que requer a instalação do MySQL.
SELECT SingleChar AS __value, ShortName AS __text FROM TSDB. State
Devo adicionar que esta solução funciona para gráficos repetidos, linhas repetidas e também se a variável tiver seleção múltipla. O exemplo acima usando 2 variáveis para mostrar "Girl Power" não funciona nessas situações.
 MikeKulls2
em 21 jan. 2019
MikeKulls2
em 21 jan. 2019
Eu estava apenas brincando com esse problema e encontrei uma solução alternativa um pouco hackinsh ...
Eu precisava de um hash, que em notação Perl é escrito como:
Perl
%units = (
'μSv/h' => 1.0,
'mrem/h' => 0.1 );
Eu criei uma variável de painel Type : Custom , Values separated by comma : mrem/h, μSv/h e editei o JSON Model assim:
JSON
{
"allValue": null,
"current": {
"tags": [],
"text": "mrem/h",
"value": "0.1"
},
"hide": 0,
"includeAll": false,
"label": null,
"multi": false,
"name": "units",
"options": [
{
"selected": true,
"text": "mrem/h",
"value": "0.1"
},
{
"selected": false,
"text": "μSv/h",
"value": "1.0"
}
],
"query": "mrem/h, μSv/h",
"skipUrlSync": false,
"type": "custom"
}
Embora isso funcione (por algum tempo), editar o painel por meio da GUI o altera de volta para o estado de não funcionamento :-|
 thinrope
em 24 jan. 2019
thinrope
em 24 jan. 2019
Outra opção para contornar isso se você tiver outro sistema que possa fornecer os dados:
Use um plugin de fonte de dados JSON, estou usando: https://grafana.com/plugins/simpod-json-datasource
Implemente apenas o endpoint de verificação de integridade / e o endpoint /search em algum sistema que tenha os dados necessários. O endpoint /search deve retornar um JSON parecido com: [{ "text": "A Human Name", "value": "123456" }, ...] . A propriedade text será o que aparece no menu suspenso de seleção de variável e o value será o que será usado na consulta de métricas.
Em seguida, configure sua variável de painel para consultar essa nova fonte de dados, é meio hacky, mas você pode usar o campo target para a fonte de dados informar ao back-end o que ela deve retornar se você tiver vários conjuntos de dados com os quais deseja usar.
mbell697
em 12 fev. 2019
+1 nisso. Eu realmente gostaria de uma maneira de fazer isso, mas que não fosse dependente de back-end (usamos grafite).
 KorkyPlunger
em 5 abr. 2019
KorkyPlunger
em 5 abr. 2019
+1 qualquer solução de trabalho?
 BlackRider97
em 24 jun. 2019
BlackRider97
em 24 jun. 2019
@BlackRider97 Por favor, dê uma olhada nos comentários acima - existem várias soluções de trabalho para PostgreSQL (e provavelmente MySQL, MSSQL, etc).
Solução 1: https://github.com/grafana/grafana/issues/1032#issuecomment -409124505
Solução 2: https://github.com/grafana/grafana/issues/1032#issuecomment -453242766
ryanc-me
em 25 jun. 2019
Implementar a solução alternativa do @thinrope corretamente seria uma correção muito elegante imho.
Se pudéssemos usar JSON em uma variável personalizada, ou ter uma variável do tipo "JSON", poderíamos resolver isso sem hacks e não vejo desvantagens.
 wildekek
em 27 jun. 2019
wildekek
em 27 jun. 2019
+1 alguma atualização sobre isso?
 jlarmstrong
em 29 out. 2019
jlarmstrong
em 29 out. 2019
+1
 siegmund42
em 21 nov. 2019
siegmund42
em 21 nov. 2019
+1
 yvbondarenko
em 23 dez. 2019
yvbondarenko
em 23 dez. 2019
Este é definitivamente um recurso obrigatório.
Eu uso variáveis para filtrar alguns hosts usando regex no nome do host. Como meus servidores contêm padrões no hostname, posso ter uma regex para obter a lista de todos os servidores de um determinado grupo. Em vez de mostrar um regexp feio, gostaria de exibir um nome bonito, como "Servidores do grupo A" como rótulo do menu suspenso.
A maneira de inserir isso no valor personalizado pode ser tão simples quanto:
label1:value1, value2, label3:value3, label5:value5
O rótulo seria opcional. Se um : estiver presente na string, então tudo antes : é o rótulo e tudo depois é o valor.
Devemos ter uma maneira de escapar : se precisarmos dele no nome ou valor do rótulo, como podemos fazer com o caractere , .
 couloum
em 17 fev. 2020
couloum
em 17 fev. 2020
Outra opção para contornar isso se você tiver outro sistema que possa fornecer os dados:
Use um plugin de fonte de dados JSON, estou usando: https://grafana.com/plugins/simpod-json-datasource
Implemente apenas o endpoint de verificação de integridade
/e o endpoint/searchem algum sistema que tenha os dados necessários. O endpoint/searchdeve retornar um JSON parecido com:[{ "text": "A Human Name", "value": "123456" }, ...]. A propriedadetextserá o que aparece no menu suspenso de seleção de variável e ovalueserá o que será usado na consulta de métricas.Em seguida, configure sua variável de painel para consultar essa nova fonte de dados, é meio hacky, mas você pode usar o campo
targetpara a fonte de dados informar ao back-end o que ela deve retornar se você tiver vários conjuntos de dados com os quais deseja usar.
Eu fiz essa implementação e funcionou para mim, mas estou preso na rotulagem da tendência (legenda)... Recebo ou id (número) ou não definido ou algum outro absurdo.
Você pode aconselhar?
M
 mato-s
em 25 fev. 2020
mato-s
em 25 fev. 2020
+1
 giorgiofanecco
em 30 mar. 2020
giorgiofanecco
em 30 mar. 2020
Também estou usando agora o JSON-hack descrito por @mbell697 no Grafana da minha empresa. Mas parece que um estranho problema de regex IMHO.
Eu configurei um pequeno aplicativo de frasco python que está me fornecendo os grupos necessários para consultas de grafite, meus dados de pesquisa se parecem
@app.route('/search', methods=['POST'])
def search():
data = [
{"text": "fs-servers", "value": "{FS-server-1,FS-server-2,FS-server-3}"},
{"text": "db-a-servers", "value": "{db-server-1,}"},
{"text": "db-b-servers", "value": "{db-server-2,db-server-3}"}
]
return jsonify(data)
Então, no painel, criei uma variável de consulta chamada "group" usando o json-source e tentei filtrar o grupo "fs-servers" com o campo regex usando /fs-.*/ - mas isso não está funcionando como esperado - depois de mexer, reconheci que o regex é de alguma forma aplicado ao "valor" - e não ao campo "texto". Alguém tem talvez alguma solução alternativa ou uma idéia?
 BBQigniter
em 1 abr. 2020
BBQigniter
em 1 abr. 2020
+1
 alexvaut
em 7 abr. 2020
alexvaut
em 7 abr. 2020
+1
 maplewf
em 22 abr. 2020
maplewf
em 22 abr. 2020
Minha opinião sobre os requisitos para isso:
No nosso caso, penso em duas variantes da mesma coisa. O que queremos é essencialmente alias'es. Em ambos os casos, o proprietário do painel deseja fornecer ao usuário uma lista de variáveis de modelo que seja fácil para o usuário final entender. No entanto, o valor usado na consulta é o valor subjacente.
Exemplo 1 - conversões simples de um para um nome. Portanto, neste caso, temos códigos numéricos de país publicados como valores métricos. Mas saiba que se memoriza os códigos numéricos. Então, queremos exibir "EUA" ou "Canadá"
{ "EUA" == "01" }
{ "Canadá" == "02" }
Se "Canadá" for selecionado, o valor da variável de modelo passado para qualquer consulta será "02"
Exemplo 2 - é um mapeamento de um para muitos. Internamente temos estágios para implantação, por exemplo, s0, s1, s2, s3, s4. No entanto, os usuários finais podem usar isso como "dev, beta, prod"
Então eles querem mapeá-los como:
{ "dev" == ["s1"] }
{ "beta" == ["s2", "s3"] }
{ "prod" == ["s4", "s5", "s6"] } ou melhor ainda "prod" == s[456]
Portanto, se "prod" for selecionado, "s4,s5,s6" será passado para a consulta
De uma perspectiva de consulta (tomando o Exemplo 2) em que o nome da variável é stageVar
e o nome da tag de métrica é stage:
Não vemos tanto a necessidade de aliasBy() como chamadas, mas mais coisas como:
estágio=~${estágioVar. valor:regex }
alias($stageVar.label)
Para filtrar os resultados pelos valores da variável de modelo selecionada. Certamente é possível que alguém tente usá-lo em algo como uma função aliasBy(), mas se for um erro de sintaxe, tudo bem. Eu não esperaria que você corrigisse magicamente uma conversão de um array passado para uma função que espera um único valor.
Quanto aos mapeamentos, acho que ter o usuário definindo-os estaticamente é suficiente.
Idealmente você teria uma consulta ao MT para obter a lista de valores que precisam ser mapeados, para você, por exemplo "01", "02", "03" e então teria uma facilidade para adicionar os mapeamentos/aliases. Os valores não mapeados iriam para um bucket "padrão".
 shalstea
em 7 mai. 2020
shalstea
em 7 mai. 2020
+1
 ChrisGute
em 29 mai. 2020
ChrisGute
em 29 mai. 2020
+1
 xuyixin1996
em 8 jun. 2020
xuyixin1996
em 8 jun. 2020
Estou muito surpreso que isso não tenha sido incluído - passei um bom tempo tentando descobrir como fazer essa coisa "óbvia" e, eventualmente, encontrei meu caminho aqui para descobrir que não existe.
A capacidade de reescrever dinamicamente, conforme descrito por alguns acima, seria fantástica. No entanto, eu ficaria feliz com um hack de curto prazo (ou modelo "fácil" permanente) que é uma versão estendida do campo "Personalizado", que mapeava estaticamente as escolhas para resultados de escolha única ou múltipla.
Nosso exemplo são os códigos de país. Frequentemente, desejamos visualizar clusters de sistemas com base em regiões geográficas, mas não por país. Mas só armazenamos códigos de país como chaves em nosso servidor Prometheus. Então, agora, se eu quiser ver todos os sistemas na América do Norte, tenho que selecionar US, CA, MX manualmente em uma lista de opções baseada em consulta de quase 100 países. Não posso nem dizer quanto tempo gasto selecionando cada país da Europa, Ásia ou África para fazer a análise. Quase vale a pena configurar painéis totalmente diferentes para cada região, o que é absurdo, mas é a única maneira de resolver o problema com gráficos de código fixo. Fazer um banco de dados totalmente novo com mapeamentos e depois fazer consultas ocultas também parece muito, muito longe do ideal.
Meu sonho febril:
Parece que esta seria uma opção "Custom List" como um possível novo tipo de variável. A Lista Personalizada começaria vazia se selecionada, mas ficaria muito parecida com a aparência do modelo "Personalizado" hoje. Um botão "Adicionar" aparecerá. Clicar em "Adicionar" criaria uma matriz de entrada de dois campos com "Valor de exibição:" e "Valor de pesquisa:" onde cada um poderia ser preenchido. O "Valor de exibição" seria o que o usuário quisesse mostrar na lista de opções - em nosso caso, "América do Norte". Então o "Valor de pesquisa" seria o que seria apresentado na consulta - novamente, neste exemplo para a América do Norte seria "us,ca,mx". A qualquer momento, um ícone de "excluir" (lixeira?) faria linhas individuais remotas. Clicar no botão "Adicionar" novamente criaria um novo emparelhamento, até que o usuário completasse sua lista de opções. As opções "Multi-Value" e "Select all" permaneceriam, semelhantes ao modelo Personalizado existente.
 johnhtodd
em 12 jun. 2020
johnhtodd
em 12 jun. 2020
Estou muito surpreso que isso não tenha sido incluído - passei um bom tempo tentando descobrir como fazer essa coisa "óbvia" e, eventualmente, encontrei meu caminho aqui para descobrir que não existe.
Resolvi isso criando um banco de dados MySQL, crio uma tabela com os itens que quero no menu suspenso, por exemplo, Europa, América do Norte etc. Em um segundo campo, tenho um regex que corresponderá às entradas que desejo corresponder. Em seguida, adicione o MySQL como fonte de dados e use-os para criar as variáveis. É um hack, mas na verdade funciona muito bem. Eu o uso para praticamente a coisa exata que você está tentando fazer.
MikeKulls2
em 15 jun. 2020
Eu aprecio o truque inteligente, mas para nós não é realmente uma solução. Configurar um banco de dados totalmente novo (nós não usamos MySQL, o que significa que operacionalmente isso é impossível) para realizar uma simples substituição de chave/valor que é bastante estática parece ser um monte de obstáculos para percorrer.
Eu estava pensando um pouco mais sobre isso, e existe uma maneira ainda mais elegante de fornecer essa funcionalidade do que a descrita acima. Eu chamaria de "macro variável". Isso novamente se parece com uma lista personalizada, exceto que permite que o administrador especifique que quando uma (ou mais) dessas macros for selecionada, as variáveis nomeadas serão definidas e os valores fornecidos serão anexados ao conjunto de valores existente. Isso seria inteiramente um modelo orientado à interface do usuário e não alteraria o conceito de variável real - apenas criaria uma camada de açúcar de conclusão automática em cima das variáveis existentes. Isso o torna compatível com versões anteriores sem a necessidade de variáveis adicionais para criação ou integração em consultas.
Uma macro que define as variáveis permitiria ao usuário ver os valores conforme eles estão sendo selecionados e, em seguida, permitiria ao usuário abrir cada variável e ver/manipular as seleções ou dados em vez de criar uma variável separada como meus comentários anteriores implica. Isso seria muito mais intuitivo.
Exemplo:
Portanto, uma macro de variável chamada "América do Norte - Cluster primário" definiria minhas variáveis "País" como "us,ca,mx" e definiria minha variável "Cluster:" como "primária". Essas configurações ficariam visíveis se eu pusesse para baixo cada variável nomeada (ou não, se elas estivessem ocultas) para que eu pudesse adicionar ou subtrair países à lista País: desde que eu não tocasse no menu suspenso da variável Macro novamente.
Possivelmente existe um booleano de "limpar variáveis nomeadas antes de configurar" para que, se uma alteração for feita na lista de opções para esta macro, quaisquer outras configurações das variáveis especificadas sejam apagadas. Isso pode ser útil para listas em que não é óbvio que você pode incluir algo que foi definido anteriormente. Suponho que, se mais de uma opção de Macro Variável for escolhida, a última na lista a ser examinada "ganha" se houver configurações concorrentes de um valor específico; nenhuma maneira de contornar esse problema. (é discutível que essa ação de limpeza deva ser especificada variável por variável, mas isso parece um pouco confuso ... mas é?)
Aqui está meu exemplo hipotético novamente, onde tenho variáveis pré-existentes de "País" e "Cluster".
Nome da Macro Variável: Região
Name1: América do Norte - Cluster primário
Limpar variáveis nomeadas antes de definir: Y
Variável1: País
Valor1: us,ca,mx
Variável2: Agrupamento
Valor2: primário
Name2: Nórdicos - Cluster Secundário
Limpar variáveis nomeadas antes de definir: Y
Variável1: País
Valor1: se,fi,não,dk,é
Variável2: Agrupamento
Valor2: secundário
johnhtodd
em 15 jun. 2020
Eu aprecio o truque inteligente, mas para nós não é realmente uma solução. Configurar um banco de dados totalmente novo (nós não usamos MySQL, o que significa que operacionalmente isso é impossível) para realizar uma simples substituição de chave/valor que é bastante estática parece ser um monte de obstáculos para percorrer.
Eu esperava que você dissesse algo assim. A realidade é que você pediu um hack e esse hack resolve o problema, não é difícil de configurar e não é difícil reverter no futuro. Na verdade, acho bastante útil ter o MySQL lá à medida que continuamos adicionando novos conjuntos de dados a ele, é um local conveniente para rastreá-los e atualizá-los. Se você pensar sobre isso, se você for usar esses conjuntos de dados em vários painéis e quiser mantê-los centralmente, eles precisam ser armazenados em algum lugar. Se o seu banco de dados de séries temporais não puder armazená-los, você precisará de algo configurado para armazená-los. Então, na verdade, faz todo o sentido ter o MySQL. O bônus adicional é que também é muito fácil automatizar a população do MySQL.
MikeKulls2
em 16 jun. 2020
Se você tem o PostgreSQL, não precisa criar uma tabela real para o mapeamento, pode fazer algo como:
SELECT *
FROM
(
VALUES
('London server 1', 'london_srv_1'),
('London server 2', 'london_srv_2'),
('New York server 1', 'ny_srv_1'),
('New York server 2', 'ny_srv_2')
) AS t (__text, __value)
 GlennMatthys
em 1 jul. 2020
GlennMatthys
em 1 jul. 2020
Mas não funciona com valores numéricos:
SELECT * FROM ( VALUES ( 'OK', '0'), ( 'ERROR', '1') ) AS t (__text, __value)
Ao carregar o painel:

E ao selecionar outro parâmetro

Ao selecionar: OK + ERRO

 crodriguez-cl
em 11 ago. 2020
crodriguez-cl
em 11 ago. 2020
Se você quiser valores numéricos você precisa remover as aspas simples, caso contrário é interpretado como texto, ou seja
SELECT * FROM ( VALUES ( 'OK', 0), ( 'ERROR', 1) ) AS t (__text, __value)
GlennMatthys
em 11 ago. 2020
Obrigado @GlennMatthys glenn pela resposta, mas já encontrei onde ocorre o problema.
SELECT * FROM ( VALUES ( 'OK', 0), ( 'Aviso', 1), ('Crítico', 2) ) AS t (__texto, __value)
Configurando vários valores em:
Acontece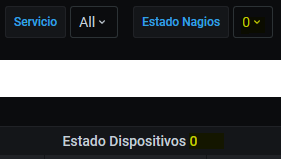
Selecionando 3 estados
E Multi-valor desligado:

crodriguez-cl
em 11 ago. 2020
GlennMatthys - sua solução é perfeita, muito obrigado
 fitovic
em 20 ago. 2020
fitovic
em 20 ago. 2020
Para o MySQL é:
SELECT * FROM ( VALUES row('a', 1), row('b', 2) ) AS t (__text, __value)
 BasvanH
em 24 ago. 2020
BasvanH
em 24 ago. 2020
E o Mariadb? Não está funcionando para mim (versão mariaDB: 10.5.5)
SELECT * FROM ( VALUES row('a', 1), row('b', 2) ) AS t (__text, __value);
ERROR 1064 (42000)..............
Ou o anterior:
SELECT * FROM ( VALUES ( 'OK', 0), ( 'Warning', 1), ('Critical', 2) ) AS t (__text, __value);
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your
MariaDB server version for the right syntax to use near '(__text, __value)' at line 1
Parece que a instrução Values não está mais disponível...
Ou há algo mais que eu faço de errado?
 radoeka
em 12 set. 2020
radoeka
em 12 set. 2020
@radoeka Para MariaDB/MySQL mais antigo
SELECT * FROM
(
SELECT 'London server 1' AS '__text', 'london_srv_1' AS '__value'
UNION ALL SELECT 'London server 2', 'london_srv_2'
UNION ALL SELECT 'New York server 1', 'ny_srv_1'
UNION ALL SELECT 'New York server 2', 'ny_srv_2'
) AS t;
@GlennMatthys uau uau uau, que resposta rápida! E isso funciona.
Eu pensei que estava executando uma versão bastante nova do mariadb, mas não é o caso (usando uma distribuição linux que tem apenas 2 meses).
Obrigado.
radoeka
em 12 set. 2020
Isso parece não ser suportado pelo Prometheus.
 nickdelnano
em 6 out. 2020
nickdelnano
em 6 out. 2020
Reabrir este problema como #27829 só resolve isso para dados estáticos.
 hugohaggmark
em 29 out. 2020
hugohaggmark
em 29 out. 2020
Questões relacionadas
 calind
·
3Comentários
calind
·
3Comentários
 Azef1
·
3Comentários
Azef1
·
3Comentários
 deepujain
·
3Comentários
deepujain
·
3Comentários
 jackmeagher
·
3Comentários
jackmeagher
·
3Comentários
 utkarshcmu
·
3Comentários
utkarshcmu
·
3Comentários
Comentários muito úteis
Implementar a solução alternativa do @thinrope corretamente seria uma correção muito elegante imho.
Se pudéssemos usar JSON em uma variável personalizada, ou ter uma variável do tipo "JSON", poderíamos resolver isso sem hacks e não vejo desvantagens.