Pytorch: Dukungan subclass Tensor yang ditingkatkan, mempertahankan subclass pada panggilan fungsi/metode
Fitur
Terkait: #22402
Fitur ini mengusulkan untuk melewati subkelas Tensor melalui __torch_function__ .
Perilaku yang diinginkan
Contoh perilaku yang diinginkan adalah:
class MyTensor(torch.Tensor):
_additional_attribute = "Kartoffel"
a = MyTensor([0, 1, 2, 3])
# b should be a MyTensor object, with all class attributes passed through.
b = torch_function(a)
Sasaran
Mengutip #22402
Ini adalah _potensial_ tujuan yang telah dikumpulkan dari PR yang dirujuk di atas, masalah PyTorch lainnya (direferensikan di bagian yang relevan), serta dari diskusi dengan sebagian besar Edward Yang, dan juga pengelola PyTorch dan NumPy lainnya:
- Mendukung subkelas
torch.Tensordengan Python- Pertahankan subkelas
Tensorsaat memanggil fungsitorchpada mereka- Pertahankan subkelas
Tensorsaat memanggil fungsinumpypada mereka- Gunakan API NumPy dengan tensor PyTorch (yaitu pengiriman panggilan API NumPy ke fungsi
torch)- Gunakan PyTorch API dengan
torch.Tensor-objek seperti yang _not_Tensorsubclass- Gunakan kembali implementasi ufunc NumPy langsung dari PyTorch
- Izinkan operasi pada tipe array campuran, misalnya
tensor + ndarray
Selain itu, dari https://github.com/pytorch/pytorch/issues/28361#issuecomment -544520934:
- Pertahankan subkelas
Tensorsaat memanggil metodeTensor- Menyebarkan instance subclass dengan benar juga dengan operator, menggunakan tampilan/irisan/dll.
Sketsa Kasar Implementasi
Apa pun dengan tipe seperti tensor bawaan akan mem-bypass __torch_function__ melalui jalur cepatnya (walaupun mereka akan memiliki implementasi default) tetapi apa pun yang ditentukan oleh pustaka eksternal akan memiliki opsi untuk mengizinkannya.
Cuplikan kode berikut menunjukkan seperti apa tampilan default __torch_function__ pada TensorBase .
class Tensor:
def __torch_function__(self, f, t, a, kw):
if not all(issubclass(ti, TensorBase) for ti in t):
return NotImplemented
result = f._wrapped(*a, **kw)
return type(self)(result)
cc @ezyang @gchanan @zou3519 @jerryzh168 @jph00 @rgommers
 hameerabbasi
hameerabbasi
Semua 74 komentar
Bisakah Anda menjelaskan apa sebenarnya delta dari proposal ini dan #22402? Atau apakah ini hanya pola yang dapat digunakan subkelas Tensor untuk mengimplementasikan ekstensi?
 ezyang
pada 21 Okt 2019
ezyang
pada 21 Okt 2019
@ezyang Silakan lihat pembaruan untuk masalah ini, saya telah menambahkan detail lebih lanjut tentang bagaimana ini dapat dibuat otomatis. Saya juga telah menambahkan contoh kasus penggunaan.
Ini pada dasarnya menetapkan bagaimana (jika kita mengizinkan __torch_function__ pada subclass), kita dapat, dengan ekstensi sederhana, membuat default __torch_function__ yang akan membuat melewati subclass otomatis.
hameerabbasi
pada 21 Okt 2019
@hameerabbasi Saya sarankan mengedit deskripsi lagi. Tujuan yang relevan adalah:
- Mendukung subkelas
torch.Tensordengan Python - Pertahankan subkelas
Tensorsaat memanggil fungsi obor pada mereka - Pertahankan subkelas
Tensorsaat memanggil metodeTensor - Menyebarkan instance subclass dengan benar juga dengan operator, menggunakan tampilan/irisan/dll.
Bisakah Anda menjelaskan apa sebenarnya delta dari proposal ini dan #22402?
Tidak ada delta, kami hanya perlu masalah untuk topik ini untuk diskusi (dan pelaporan) yang tidak dicampur dengan multi-topik gh-22402. Masalah itu pada dasarnya dapat diterapkan dalam tiga bagian: __torch_function__ (hampir siap untuk ditinjau), topik subkelas ini (baru saja dimulai), dan dukungan protokol NumPy (prio terendah, belum dimulai).
 rgommers
pada 21 Okt 2019
rgommers
pada 21 Okt 2019
Oke, sgt. @jph00 bagaimana ini terlihat bagi Anda?
ezyang
pada 21 Okt 2019
Terima kasih geng. Saya tidak memiliki komentar tentang implementasi yang diusulkan, tetapi tujuannya tampak hebat. :)
Meskipun sudah tercakup secara implisit oleh tujuan yang dinyatakan, saya harus menyebutkan bahwa kami mengalami kesulitan mendapatkan __getitem__ bekerja dengan benar di subkelas - jadi ini mungkin sesuatu untuk memastikan Anda menguji dengan hati-hati. Misalnya, pastikan untuk menguji tensor yang lewat dari berbagai jenis sebagai indeks, termasuk tensor dan subkelas topeng bool.
 jph00
pada 21 Okt 2019
jph00
pada 21 Okt 2019
Terima kasih @jph00 , itulah jenis input yang kami butuhkan.
rgommers
pada 21 Okt 2019
Sepertinya metode variabel dan tanpa argumen tidak mengurai diri sendiri dalam daftar argumen mereka:
dan
PythonArgParser juga tidak mengambil self : https://github.com/prasunanand/pytorch/blob/torch_function/torch/csrc/utils/python_arg_parser.h#L102
Mungkin baik untuk tujuan masalah ini untuk mengizinkan self sebagai argumen untuk PythonArgParser . Namun, saya tidak yakin apa overhead parsing argumen.
hameerabbasi
pada 15 Nov 2019
Juga, apakah akan lebih baik untuk memiliki metode yang diharapkan pada subkelas untuk default __torch_function__ a.la. __array_wrap__ (alih-alih disebut __torch_wrap__ , untuk mirroring NumPy), atau panggil saja konstruktor default dengan tensor output?
Contoh:
class TensorSubclass(Tensor):
def __init__(self, *a, **kw):
if len(a) == 1 and len(kw) == 0 and isinstance(a[0], torch.Tensor):
# Do conversion here
vs
class TensorSubclass(Tensor):
def __torch_wrap__(self, tensor):
# Do conversion here
@jph00 Pikiran?
hameerabbasi
pada 15 Nov 2019
Sulit untuk membicarakan masalah implementasi yang sangat spesifik tanpa melihat lebih jauh tentang implementasi yang direncanakan. Secara khusus, mengapa PythonArgParser membutuhkan diri sendiri?
ezyang
pada 15 Nov 2019
Inilah alur penalaran saya:
- Kami membutuhkan
__torch_function__default padaTensor(lihat deskripsi masalah), yang juga harus diterapkan padaself. - Kita perlu membuatnya bekerja dengan metode juga, agar ini berhasil.
selfharus ada dalam daftar argumen yang diuraikan, karena sebagian besar logika__torch_function__ada di dalamPythonArgParser.
Opsi lainnya adalah memfaktorkan ulang/menulis ulang logika secara terpisah untuk diri sendiri, yaitu
if type(self) is not Tensor and hasattr(self, '__torch_function__'):
# Process things here, separately.
Ada pendapat tentang jalan mana yang harus diambil?
hameerabbasi
pada 15 Nov 2019
Saya memiliki cabang WIP di https://github.com/Quansight/pytorch/tree/subclassing , saya telah menambahkan tes di: https://github.com/Quansight/pytorch/blob/a68761ef8942041089d5da4815db07f020667260/test/test_subclassing. py
hameerabbasi
pada 16 Nov 2019
Kita perlu membuatnya bekerja dengan metode juga, agar ini berhasil.
Oke, mari kita bicarakan ini sebentar. Dalam PR __torch_function__ saya menyebutkan tentang apakah masuk akal atau tidak untuk memiliki semacam metode ajaib untuk mengesampingkan fungsi dan metode, tetapi kami memutuskan itu di luar cakupan untuk masalah ini. Mari kita singkirkan pertanyaan tentang fungsi tensor default yang melestarikan subkelas sejenak, dan ajukan pertanyaan yang lebih sederhana: bagaimana tepatnya ekstensi ke __torch_function__ untuk mendukung metode bekerja?
ezyang
pada 18 Nov 2019
bagaimana tepatnya ekstensi ke
__tensor_function__untuk mendukung metode bekerja?
Oke, jadi visi saya adalah sebagai berikut: __torch_function__ memiliki tanda tangan (func, args, kwargs) (dari PR sebelumnya). Dalam gaya Python tradisional, jika dipanggil pada Tensor _method_, maka func akan menjadi metode itu sendiri misalnya Tensor.__add__ , dan args / kwargs juga akan berisi self , selain argumen yang diteruskan secara eksplisit lainnya. Dalam contoh ini, args akan berisi self dan other .
hameerabbasi
pada 19 Nov 2019
Oke, ini terdengar masuk akal bagi saya. Namun, sepertinya ini berbeda dari cara Numpy menangani array di __array_function__ . Bisakah Anda membandingkan penyempurnaan ini dengan pendekatan Numpy?
Juga, kita harus berhati-hati dengan perubahan ini karena jika saya mendefinisikan def __add__ dan def __torch_function__ , mana yang "menang"?
ezyang
pada 19 Nov 2019
Bisakah Anda membandingkan penyempurnaan ini dengan pendekatan Numpy?
__array_function__ di NumPy tidak berlaku untuk metode ndarray . NumPy, untuk menangani perilaku subkelas, melakukan ret = ret.view(subclass) di akhir setiap metode, dan kemudian memanggil ret.__array_finalize__(self) (dengan asumsi itu ada).
Juga, kita harus berhati-hati dengan perubahan ini karena jika saya mendefinisikan
def __add__dandef __torch_function__, mana yang "menang"?
__add__ menang, karena __mro__ Python, subclass datang sebelum superclass. NumPy memiliki masalah dan model yang sama.
hameerabbasi
pada 19 Nov 2019
Pada Selasa, 19 November 2019, pukul 08:43, Hameer Abbasi menulis:
Bisakah Anda membandingkan penyempurnaan ini dengan pendekatan Numpy?
__array_function__di NumPy tidak berlaku untuk metodendarray. NumPy, untuk menangani perilaku subkelas, melakukanret = ret.view(subclass)di akhir setiap metode, dan kemudian memanggilret.__array_finalize__(self)(dengan asumsi itu ada).
Ini juga cara kerja fastai v2 BTW - kami memanggil retain_types() di akhir Transform.encodes dan berbagai tempat lainnya (secara otomatis, dalam banyak kasus).
jph00
pada 19 Nov 2019
Opsi untuk menggunakan __array_finalize__ telah dibahas di gh-22402, masalahnya lambat.
NumPy, untuk menangani perilaku subkelas, melakukan
ret = ret.view(subclass)di akhir setiap metode
Ini sebenarnya tidak berfungsi untuk PyTorch karena Tensor.view berperilaku sangat berbeda dari ndarray.view . Kami memiliki pengujian di cabang __torch_function__ yang menggunakannya (diadaptasi dari NumPy) tetapi tidak berhasil sehingga kami mengubah untuk hanya menggunakan cara Python biasa untuk membuat dan membuat instance subkelas.
rgommers
pada 19 Nov 2019
Ini sebenarnya tidak berfungsi untuk PyTorch karena
Tensor.viewberperilaku sangat berbeda darindarray.view. Kami memiliki pengujian di cabang__torch_function__yang menggunakannya (diadaptasi dari NumPy) tetapi tidak berhasil sehingga kami mengubah untuk hanya menggunakan cara Python biasa untuk membuat dan membuat instance subkelas.
Mungkin bisa disebut .cast bukan?
jph00
pada 19 Nov 2019
Mungkin bisa disebut
.castbukan?
Saya menemukan sejumlah diskusi tentang perilaku view , jadi saya pikir itu telah dipertimbangkan sebelumnya dan ditolak. cast menyiratkan perubahan dtype menurut saya daripada perubahan bentuk. view pada dasarnya setara dengan reshape di NumPy. Atau Tensor.reshape , kecuali itu juga berfungsi untuk bentuk yang tidak cocok.
rgommers
pada 20 Nov 2019
Pada Selasa, 19 November 2019, pukul 16.43, Ralf Gommers menulis:
Mungkin bisa disebut
.castbukan?
Saya menemukan sejumlah diskusi tentang perilaku
view, jadi saya pikir itu telah dipertimbangkan sebelumnya dan ditolak.castmenyiratkan perubahan dtype menurut saya daripada perubahan bentuk.viewpada dasarnya setara denganreshapedi NumPy. AtauTensor.reshape, kecuali itu juga berfungsi untuk bentuk yang tidak cocok.
Mungkin salah satu dari kita salah memahami sesuatu (dan bisa jadi itu saya!)
Di numpy, view melakukan hal itu: ini adalah perubahan dtype, bukan perubahan bentuk. Itu sebabnya saya menyarankan cast sebagai nama untuk fungsi yang setara di pytorch.
jph00
pada 20 Nov 2019
Ada sedikit lagi untuk view di NumPy:
>>> import numpy as np
>>> class subarray(np.ndarray):
... newattr = "I'm here!"
...
>>> x = np.arange(4)
>>> x.view(subarray)
subarray([0, 1, 2, 3])
>>> y = x.view(subarray)
>>> isinstance(y, subarray)
True
>>> y.newattr
"I'm here!"
EDIT: Saya akan menggunakan astype untuk perubahan dtype
rgommers
pada 20 Nov 2019
Pada Selasa, 19 November 2019, pukul 16.55, Ralf Gommers menulis:
Ada sedikit lagi untuk
viewdi NumPy:
Ya, benar, tapi itu tidak membatalkan poin dasar saya pikir :)
jph00
pada 20 Nov 2019
Ini sebenarnya tidak berfungsi untuk PyTorch karena
Tensor.viewberperilaku sangat berbeda darindarray.view.
Ya, benar, tapi itu tidak membatalkan poin dasar saya pikir :)
Setuju, intinya adalah untuk menunjukkan perilaku NumPy, dan karena ini adalah pelacak masalah PyTorch, saya seharusnya menyebutkan bahwa yang setara dengan Tensor harus dibuat atau ditemukan. Mungkin @ezyang dapat menentukan apakah ini layak, dan beberapa panduan tentang caranya.
hameerabbasi
pada 20 Nov 2019
@hameerabbasi Anda mungkin ingin menelusuri perbedaan di gh-22235, itu tidak lengkap dan bagian dari serangkaian PR yang sedikit membingungkan, tetapi untuk melestarikan subkelas dalam metode, itu melakukan apa yang view + __array_finalize__ bisa. Jadi setidaknya bagus untuk melihat bagian kode mana yang harus disentuh.
Itu tentu saja merupakan arah alternatif dari ide asli "parse self + use __torch_function__ " Anda. Sulit untuk memprediksi mana yang lebih bersih/lebih cepat.
rgommers
pada 20 Nov 2019
__add__menang, karena__mro__Python, subclass datang sebelum superclass. NumPy memiliki masalah dan model yang sama.
Bagaimana jika saya, di subkelas saya, mendefinisikan __add__ dan __torch_function__ ? Lalu MRO tidak memberikan bimbingan, IIUC?
ezyang
pada 20 Nov 2019
Saya akan menggunakan astype untuk perubahan dtype
Ya, nama ini sepertinya lebih baik
ezyang
pada 20 Nov 2019
Bagaimana jika saya, di subkelas saya, mendefinisikan __add__ dan __torch_function__? Lalu MRO tidak memberikan bimbingan, IIUC?
Python selalu mencari __add__ ketika + digunakan, sehingga selalu diutamakan.
hameerabbasi
pada 20 Nov 2019
Python selalu mencari
__add__ketika+digunakan, sehingga selalu diutamakan.
Saya tidak berpikir ini menyelesaikan masalah saya. Perbandingan yang lebih baik adalah membandingkan __add__ dan __getattr__ , keduanya merupakan cara Anda dapat membebani perilaku + . Pemahaman saya adalah bahwa aturan Python berarti bahwa setelah saya mendefinisikan __add__ di superclass APAPUN, __getattr__ tidak akan pernah dipertimbangkan, bahkan jika saya mendefinisikannya kembali di subclass.
class A:
def __add__(self, other):
return 1
class B(A):
def __getattr__(self, attr):
return lambda other: 2
print(B() + B())
macbook-pro-116:~ ezyang$ python3.7 fof.py
1
Tetapi perilaku yang diinginkan yang dinyatakan di atas adalah bahwa saya dapat mensubklasifikasikan Tensor, tanpa kode tambahan, dan subkelas kemudian dipertahankan.
class MyTensor(Tensor):
pass
MyTensor() + MyTensor() # results in MyTensor
tapi MyTensor.__add__ didefinisikan, sehingga bisa dibilang itu akan diproses sebelum __torch_function__ . Saya belum melihat penjelasan tentang bagaimana Anda berencana untuk menyelesaikan ambiguitas ini!
ezyang
pada 20 Nov 2019
Saya kira salah satu cara untuk memecahkan masalah adalah dengan meminta pengguna untuk secara eksplisit mendefinisikan __torch_function__ untuk memanggil implementasi "melestarikan subkelas" Anda. Ini tampaknya bisa diterapkan bagi saya, meskipun tidak konsisten dengan cara kerja __getattr__ .
ezyang
pada 20 Nov 2019
Saya kira salah satu cara untuk memecahkan masalah adalah dengan meminta pengguna untuk secara eksplisit mendefinisikan
__torch_function__untuk memanggil implementasi "melestarikan subkelas" Anda. Ini tampaknya bisa diterapkan bagi saya, meskipun tidak konsisten dengan cara kerja__getattr__.
Akan ada implementasi default __torch_function__ , yang pada dasarnya akan dilewati torch.Tensor , yang akan melakukan hal yang benar, tetapi jika pengguna mendefinisikan __add__ , itu akan terserah mereka untuk melakukan hal yang benar.
hameerabbasi
pada 20 Nov 2019
@hameerabbasi melakukan panggilan singkat. Saya menyajikan dua masalah dengan implementasi Hameer:
- Misalkan saya mendefinisikan
__torch_function__danaddpada subclass. Jikaaddmemanggilsuper().add()sebagai bagian dari implementasinya,__torch_function__akan dipanggil nanti! Itu aneh. - Misalkan
__torch_function__hanya dipanggil jikaaddtidak ditimpa (yang diperbaiki (1)). Kemudian kita kehilangan "komposisi subkelas": Anda dapat mensubklasifikasikan Tensor ke MyTensor dan mempertahankan subkelas, tetapi jika Anda memiliki DiagonalTensor (memperluas Tensor), dan kemudian mensubkelaskannya ke MyDiagonalTensor, subkelas tidak dipertahankan. (Ini karena, meskipun DiagonalTensor.add memanggil super(), kita tidak akan memanggil__torch_function__karena add ditimpa)
ezyang
pada 20 Nov 2019
Saya ingin menunjukkan kasus penggunaan lain dari fungsi ini yang muncul dalam percakapan kami dengan OpenAI. Apa yang ingin dilakukan OpenAI adalah memasukkan kait pada tingkat per operator, sehingga mereka dapat memeriksa tensor yang mengalir melalui setiap operasi (saat ini, mereka terhubung pada tingkat modul, tetapi terkadang ada operasi berbutir halus yang mereka butuhkan untuk melakukannya kaitkan ke dalam).
__torch_function__ sangat menggoda untuk menyediakan apa yang Anda butuhkan untuk ini, tetapi:
- Kami membutuhkan pelestarian subkelas, sehingga kait kami terus berjalan (masalah ini)
- Kita perlu menyisipkan kode yang beroperasi pada kedua fungsi dan metode secara seragam (sehingga kita dapat menulis satu fungsi yang menimpa semua operator)
Mari kita pastikan kita bisa mencapai kasus ini juga!
cc @suo @orionr @NarineK yang hadir untuk percakapan ini.
ezyang
pada 21 Nov 2019
Beberapa kendala:
- Kompatibilitas numpy: hal kami harus bekerja dengan cara yang sama seperti numpy, atau kami harus memiliki argumen yang baik mengapa numpy salah dan kami telah memperbaiki masalahnya (catatan tentang Numpy: jika Anda memiliki A + B, itu akan mengembalikan A, dan jika Anda melakukan B + A, ia mengembalikan B, jika tidak ada hubungan subclass antara A dan B)
- Mengganti metode dengan hanya mendefinisikannya di subkelas seharusnya berhasil
- Dan panggilan super harus melakukan hal yang benar
Non-kendala:
- Saya tidak keberatan jika kami memiliki
__torch_function__dan metode ajaib LAINNYA untuk melakukan penggantian fungsi dan metode (saya tidak tahu apakah itu perlu)
ezyang
pada 2 Des 2019
Satu kendala lagi: Parameter adalah subclass dari Tensor, dan seharusnya tidak mempertahankan subclass (dan mungkin secara umum, melestarikan subclass mungkin perlu ikut serta untuk mempertahankan BC.)
@hameerabbasi dan saya mendapat panggilan lain, dan kami memiliki masalah yang menarik: misalkan Anda memiliki:
class ATensor(Tensor):
def add(self, other):
super().add(other)
class BTensor(ATensor):
def __torch_function__(self):
# pass through
class CTensor(BTensor):
def add(self, other):
super().add(other)
Urutan apa yang harus dipanggil metode? Seharusnya CTensor.add , BTensor.__torch_function__ , ATensor.add !! Ini menunjukkan bahwa kita harus secara otomatis mendefinisikan metode BTensor.add (melalui metaclass) untuk membuat ini berfungsi, jika kita ingin membuatnya berfungsi. (Dan metode ini harus melakukan pengiriman berbasis CLASS ke __torch_function__ .)
Beberapa catatan awal lainnya:
Pemikiran saat ini: jika kami melakukan pelestarian subkelas sepenuhnya terpisah dari fungsi obor, maka add tidak akan memanggil super. Panggilan super harus melakukan hal yang benar, itu secara umum merupakan masalah. Untuk itu, kita harus mendapatkan implementasi referensi, yang ada di Tensor itu sendiri, kan. Itu benar terlepas dari apakah kita menggunakan pendekatan fungsi obor atau tidak. Jika super().add() harus melakukan hal yang benar... apakah ada cara untuk menguji apakah Anda melewati objek super, daripada yang dasar? (Tidak bisa hanya menguji Tensor, karena tidak dapat dikomposisi).
Bagaimana jika kita tidak menggunakan super? Lakukan sesuatu yang lain. (Ini sebenarnya tidak membantu: Anda harus menggunakan super dengan cara apa pun).
Alternatif: Untuk __torch_function__ , kami melarang super. Ini pada dasarnya apa yang dilakukan Numpy: melarang super di dalam __array_function__ , tetapi apa yang dilakukan, ada proposal untuk melakukannya, itu harus memungkinkan implementasi yang dibungkus (implementasi non-pengiriman) tersedia. Yang hanya torch_function dengan titik dua super. Ini adalah salah satu ide dari numpy.
Ide: __array_function__ harus menjadi metode kelas. Ada beberapa masalah dengan ini. Jika ada metadata pada instance, itu akan hilang. Itu masih tersedia dalam argumen fungsi, tetapi hilang pada diri sendiri.
Perlu cara untuk mengetahui di mana kita berada di MRO. Semoga Python secara asli mendukung ini.
Ambil argumen lain dari kelas. (bukan pada metode kelas)
ezyang
pada 2 Des 2019
Saya akan menggunakan astype untuk perubahan dtype
Maaf @rgommers, saya seharusnya tidak mengatakan "perubahan tipe". Maksud saya sesuatu seperti "perubahan ke self.__class__ ". Saya melihat penyebab kebingungan sekarang! :)
Pada dasarnya, inilah yang dilakukan numpy's view() . Jadi dalam masalah ini, apa proposal saat ini tentang bagaimana tepatnya melakukan hal yang setara di pytorch?
jph00
pada 3 Des 2019
Belum ada usulan. @hameerabbasi akan mengajukan proposal khusus untuk dipertimbangkan.
ezyang
pada 3 Des 2019
Tensor proposal subkelas
__torch_function__ dan metode
Kami melewati semua metode melalui __torch_function__ , di mana argumen yang diteruskan pertama adalah self . Jadi, misalnya, untuk MySubTensor.__add__ akan (jika tidak diganti), panggil MySubTensor.__torch_function__(Torch.__add__, (self, other), {}) . __torch_function__ akan diubah menjadi metode kelas untuk alasan pengiriman, dan mendapatkan argumen tambahan arrays yang akan berisi array yang diteruskan.
Menambahkan Tensor.as_subclass(other_class)
Tensor akan mendapatkan metode baru, Tensor.as_subclass(other_class) yang akan melihat objek Tensor sebagai kelas lain dengan semua data utuh. Subclass harus dapat dipanggil dalam bentuk MySubTensor(tensor_object) , yang akan menyalin atribut dari objek Tensor (atau subclass) lainnya. Tensor sendiri akan mendapatkan dukungan untuk pola ini. Ini akan menjadi _view_ data daripada salinan.
Alternatif
Jika ini tidak didukung atau tidak dapat dilakukan karena alasan tertentu, metode kelas MySubTensor.from(tensor_obj) juga dapat dipertimbangkan.
Pengiriman metode tertentu
Ada kelemahan bahwa memanggil super() di MySubTensor.__add__ dapat memanggil kembali ke MySubTensor.__torch_function__ . Namun, ini adalah perilaku yang diharapkan, karena __torch_function__ memeriksa semua argumennya untuk tipe non- Tensor , termasuk MySubTensor . (NumPy memiliki masalah yang sama). Cara _correct_ untuk memanggil super dari __add__ adalah dengan melihat semua argumen yang harus "dihapus dari pengiriman" sebagai Tensor , dan _then_ call super().__add__ .
Penerapan
Tensor akan mendapatkan implementasi default untuk __torch_function__ yang akan:
- Periksa semua argumen untuk melihat apakah
getattr(t, "__torch_function__", Tensor.__torch_function__) is not Tensor.__torch_function__. Jika argumen seperti itu ada,return NotImplemented. - Lakukan operasi
- Lakukan
return Minimal_Subclass.from(ret)di akhir.
Pohon tipe yang tidak terkait akan memunculkan kesalahan.
hameerabbasi
pada 3 Des 2019
Terima kasih @hameerabbasi . Saya akan mengubah fastai2 untuk menggunakan as_subclass untuk ini juga, jadi kami akan kompatibel di masa mendatang.
jph00
pada 3 Des 2019
@jph00 Untuk memperjelas, metode itu belum ada. Kita harus menambahkannya.
hameerabbasi
pada 4 Des 2019
Ya tidak masalah - saya sudah menambalnya:
<strong i="6">@patch</strong>
def as_subclass(self:Tensor, typ):
"Cast to `typ` (should be in future PyTorch version, so remove this then)"
return torch.Tensor._make_subclass(typ, self)
BTW satu hal yang tidak bekerja dengan pendekatan ini adalah bahwa setiap attrs tambahan hilang. Akan lebih baik jika ini diperbaiki, karena kami mengandalkannya - untuk saat ini kami akan menambahkan ini secara manual ke versi yang ditambal. Berikut ini contohnya (berdasarkan implementasi di atas):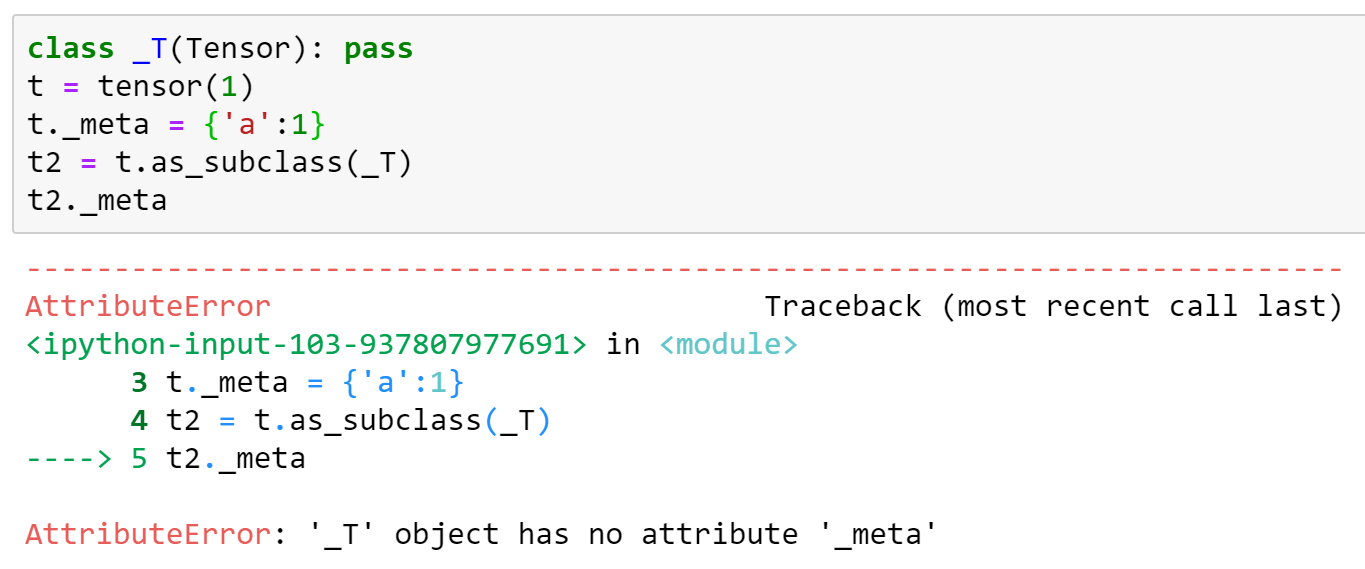
jph00
pada 4 Des 2019
Ya, Anda harus mendefinisikan __torch_function__ yang menyalin semua itu, dan itu harus dilakukan untuk semua array.
hameerabbasi
pada 4 Des 2019
Mengapa tidak as_subclass melakukannya? Casting seharusnya tidak menghapus atribut, bukan?
jph00
pada 4 Des 2019
Tampaknya adil, ya, kita dapat menyalin semua yang ada di objek __dict__ .
hameerabbasi
pada 4 Des 2019
__torch_function__ akan diubah menjadi metode kelas untuk alasan pengiriman
Bisakah Anda mengatakan lebih jelas apa artinya ini?
dapatkan array argumen tambahan yang akan berisi array yang diteruskan
Apakah yang Anda maksud: tensor
Proposal ini berarti melanggar dari API yang dibuat oleh __torch_function__ sehingga kami masih memiliki kesempatan untuk membuat perubahan, tetapi saya ingin melihat beberapa argumen dalam proposal tentang mengapa kami harus melakukan perubahan ini. Secara khusus, mengapa kita harus melakukannya secara berbeda dari Numpy?
salin datanya
Benar-benar salinan? Atau akankah mereka berbagi penyimpanan?
Tensor.from(kelas_lain)
Apakah Anda mengusulkan untuk menamai ini from atau as_subclass ?
Cara yang benar untuk memanggil super dari
__add__adalah dengan melihat semua argumen yang harus "dihapus dari pengiriman" sebagai Tensor, dan kemudian memanggilsuper().__add__.
Ini sangat berbeda dari apa yang telah kita diskusikan, dan saya ingin mendorong kembali proposal ini sedikit.
Misalkan Anda memiliki:
class ATensor(Tensor):
a: SomeAMetaData
class BTensor(ATensor):
b: SomeBMetaData
def __add__(self, other):
...
Anda telah menyatakan bahwa dalam definisi __add__ , kami berkewajiban untuk other.as_subclass(ATensor) untuk menghapus BTensor dari hierarki pengiriman. Oke, sepertinya cukup adil. Tetapi seperti yang telah Anda lihat dalam diskusi dengan @jph00 , ini berarti kita harus MENYALIN SomeAMetaData ke dalam tampilan-A tensor saat kita beralih ke definisi berikutnya. Ini tampak sangat samar bagi saya, karena pada dasarnya Anda telah mengimplementasikan kembali pemotongan objek C++ dengan Python ( https://stackoverflow.com/questions/274626/what-is-object-slicing ). Dan semua orang membenci pemotongan objek.
Selanjutnya, Anda masih belum menyelesaikan masalah yang muncul dalam kasus ini:
class ATensor(Tensor):
def __add__(self, other):
...
class BTensor(ATensor):
def __torch_function__(self, ...):
...
Dengan aturan resolusi metode, BTensor.__add__ akan langsung memanggil ATensor.__add__ , melewati __torch_function__ seluruhnya. Buruk!
ezyang
pada 4 Des 2019
Maaf jika ini pertanyaan bodoh - tetapi mengapa menyalin __dict__ alih-alih hanya menggunakan referensi? (Dalam fastai2 saya hanya menggunakan referensi saat ini, karena ketika kami mentransmisikan, kami biasanya tidak berharap untuk mendapatkan salinan, melainkan tampilan yang berbeda dari data yang sama, termasuk metadata.)
jph00
pada 4 Des 2019
Dengan aturan resolusi metode,
BTensor.__add__akan langsung memanggilATensor.__add__, melewati__torch_function__seluruhnya. Buruk!
Oke, saya akan mengambil risiko di sini dan mengklaim bahwa Tensor.__add__ dan Tensor.__torch_function__ tahu cara menangani subkelas yang Subclass.__torch_function__ is Tensor.__torch_function__ . Jadi ATensor.__add__ dapat memanggil super tanpa terlalu khawatir, atau "menghapus apa pun dari pengiriman", atau mengkhawatirkan segala jenis subkelas. Besar!
Sekarang datang bagian kedua. Setelah ATensor.__add__ melakukan keajaibannya dan memanggil super , Tensor.__add__ memperhatikan bahwa masih ada objek BTensor di sana, dan BTensor.__torch_function__ is not Tensor.__torch_function__ ! Jadi itu jatuh kembali ke sana (dengan semua objek apa adanya), menanganinya dengan benar.
Sekarang aliran kembali ke ATensor.__add__ . Ia memperhatikan bahwa isinstance(super().__add__(self, other), ATensor) ! Ia melakukan pasca-pemrosesan lebih lanjut dan mengembalikan nilainya.
Apakah Anda mengusulkan untuk menamai ini
fromatauas_subclass?
Saya telah mengubahnya menjadi konsisten.
Apakah yang Anda maksud: tensor
Proposal ini berarti melanggar dari API yang dibuat oleh
__torch_function__jadi kami masih memiliki kesempatan untuk membuat perubahan, tetapi saya ingin melihat beberapa argumen dalam proposal tentang mengapa kami harus melakukan perubahan ini. Secara khusus, mengapa kita harus melakukannya secara berbeda dari Numpy?
Saya kira kita tidak perlu. Saya pikir itu perlu, tetapi memikirkannya sekali lagi, dengan contoh Anda, saya salah.
Benar-benar salinan? Atau akankah mereka berbagi penyimpanan?
Mengubah ini menjadi konsisten juga.
hameerabbasi
pada 5 Des 2019
Maaf jika ini pertanyaan bodoh - tetapi mengapa menyalin
__dict__alih-alih hanya menggunakan referensi? (Dalam fastai2 saya hanya menggunakan referensi saat ini, karena ketika kami mentransmisikan, kami biasanya tidak berharap untuk mendapatkan salinan, melainkan tampilan yang berbeda dari data yang sama, termasuk metadata.)
Maksud saya salinan yang dangkal, bukan salinan yang dalam, tetapi seperti yang ditunjukkan oleh @ezyang , ini bermasalah, dan lebih baik ditangani di __torch_function__ dari subkelas.
hameerabbasi
pada 5 Des 2019
Sekarang datang bagian kedua. Setelah ATensor.__add__ melakukan sihirnya dan memanggil super, Tensor.__add__ memperhatikan bahwa masih ada objek BTensor di sana, dan BTensor.__torch_function__ bukan Tensor.__torch_function__! Jadi itu jatuh kembali ke sana (dengan semua objek apa adanya), menanganinya dengan benar.
Aliran ini tampaknya benar-benar mundur bagi saya. Jika BTensor adalah subclass dari ATensor, saya berharap B diproses terlebih dahulu sebelum saya masuk ke A. OOP 101
ezyang
pada 5 Des 2019
Aliran ini tampaknya benar-benar mundur bagi saya. Jika
BTensoradalah subkelas dariATensor, saya berharapBdiproses terlebih dahulu sebelum saya mencapaiA. OOP 101
Meskipun saya setuju, metode virtual adalah apa adanya, sayangnya, dan satu-satunya cara untuk mengatasi ini yang dapat saya pikirkan adalah pendekatan metaclass yang kita diskusikan, yang menambal/menggunakan __torch_function__ untuk setiap metode... Yang dapat menyebabkan perilaku yang lebih aneh: A.__add__ diabaikan.
hameerabbasi
pada 5 Des 2019
Satu hal yang dapat saya pikirkan di sini adalah menggunakan desain berikut: gunakan B.__torch_function__(B.__add__, (self, other), {}) sebagai default, tetapi itu mungkin mengacaukan pengiriman berbasis kamus yang mungkin ada.
hameerabbasi
pada 5 Des 2019
Sebuah titik meta cepat: jika kita tidak bisa memikirkan cara yang baik (bukan "jalan di sekitar") untuk melakukan ini, kita harus berhenti melakukan ini, atau mengubah batasan mendasar kita sampai ada cara yang baik.
ezyang
pada 5 Des 2019
Oke, alternatif lain di sini adalah menggunakan __tensor_wrap__ dan __tensor_finalize__ . Apa yang dilakukan kedua protokol ini pada dasarnya adalah pra-dan pasca-pemrosesan ketika "membungkus menjadi subkelas".
Namun, catatan peringatan: Ini memiliki masalah yang persis sama dengan super yang baru saja kita diskusikan (yaitu hal-hal akan diproses dalam urutan yang salah dalam contoh Anda).
atau ubah batasan mendasar kami sampai ada cara yang baik.
Bagaimana dengan ini: gunakan metaclass yang menyuntikkan yang berikut ini di:
Satu hal yang dapat saya pikirkan di sini adalah menggunakan desain berikut: gunakan
B.__torch_function__(B.__add__, (self, other), {})sebagai default, tetapi itu mungkin mengacaukan pengiriman berbasis kamus yang mungkin ada.
Jika B.__add__ is not Tensor.__add__ , saya mengklaim bahwa pengiriman berbasis kamus harus gagal, dan seseorang harus menggunakan func.__name__ sebagai gantinya.
Jika opsi ini tidak layak, maka kita harus mengubah batasannya.
hameerabbasi
pada 7 Des 2019
Apa yang dimaksud di sini dengan "pengiriman berbasis kamus"? Saya agak tersesat sekarang.
ezyang
pada 8 Des 2019
Pengiriman berbasis kamus adalah tempat, di dalam __torch_function__ , seseorang menggunakan kamus untuk mencari func dan memutuskan implementasi fungsi. Ini akan gagal sebagai B.__add__ is not Tensor.__add__ , dan jika sebuah kelas mengirimkan yang terakhir, itu tidak akan ditemukan di dict. Tapi saya mengklaim ini adalah perilaku yang benar, karena menggunakan cls.__add__ akan menghasilkan perilaku yang benar. Jika sebuah kelas adalah B atau salah satu turunannya yang tidak menimpa __add__ , maka B.__add__ adalah metode yang benar untuk digunakan, dan mencari Tensor.__add__ bagaimanapun juga tidak benar.
hameerabbasi
pada 9 Des 2019
@hameerabbasi Saya akan menyarankan untuk menambahkan interaksi __add__ dengan beberapa subkelas ke kasus uji di cabang Anda. Diskusi ini sangat sulit untuk diikuti seperti ini; Saya ingin dapat mengetahui dengan lebih mudah apakah ini showstopper atau kasus sudut.
Sebuah titik meta cepat: jika kita tidak bisa memikirkan cara yang baik (bukan "jalan di sekitar") untuk melakukan ini, kita harus berhenti melakukan ini, atau mengubah batasan mendasar kita sampai ada cara yang baik.
Setiap "kendala" harus menjadi kasus uji yang terpisah.
Untuk membuat kemajuan lebih mudah, mungkin berguna untuk menambahkan mekanisme lambat yang analog dengan __array_finalize__ NumPy yang memenuhi semua batasan, dan kemudian menilai apa yang salah jika diganti dengan sesuatu yang lebih cepat (apakah metaclass atau __torch_function__ berbasis atau lainnya).
Juga, mekanisme ini tidak tergantung pada perubahan API publik seperti as_subclass , jadi akan berguna untuk dapat melihatnya juga - mereka tidak perlu perubahan setelahnya.
rgommers
pada 10 Des 2019
Untuk membuat kemajuan lebih mudah, mungkin berguna untuk menambahkan mekanisme lambat yang analog dengan
__array_finalize__NumPy yang memenuhi semua batasan, dan kemudian menilai apa yang salah jika diganti dengan sesuatu yang lebih cepat (apakah metaclass atau__torch_function__berbasis atau lainnya).
Sayangnya, ini akan memiliki masalah komposisi yang sama. Saya menunjukkan itu di sini :
Oke, alternatif lain di sini adalah menggunakan
__tensor_wrap__dan__tensor_finalize__. Apa yang dilakukan kedua protokol ini pada dasarnya adalah pra-dan pasca-pemrosesan ketika "membungkus menjadi subkelas".Namun, catatan peringatan: Ini memiliki masalah yang persis sama dengan
superyang baru saja kita diskusikan (yaitu hal-hal akan diproses dalam urutan yang salah dalam contoh Anda).
Juga, mekanisme ini tidak tergantung pada perubahan API publik seperti
as_subclass, jadi akan berguna untuk dapat melihatnya juga - mereka tidak perlu perubahan setelahnya.
@ezyang Apakah Anda memiliki gagasan tentang apa yang perlu dilakukan untuk fungsi seperti itu, data apa yang perlu disalin dan apa yang perlu dilihat, dan sebagainya?
hameerabbasi
pada 10 Des 2019
@hameerabbasi Saya sebenarnya tidak yakin apa semantik yang tepat dari as_subclass itu (ya saya tahu itu memandang tensor sebagai subkelas, tetapi ini sangat tidak jelas). Sebagai permulaan, apakah itu memanggil konstruktor subclass?
ezyang
pada 10 Des 2019
Saya berharap akan ada cara untuk melakukannya sambil menjaga pointer data yang sama, apa pun yang diperlukan, dan juga menyimpan data autograd apa pun yang terlampir..
hameerabbasi
pada 10 Des 2019
Saya percaya semantik harus persis sama dengan mengganti __class__ dalam objek python biasa. Itu juga perilaku view() di numpy, saya percaya. Artinya:
- Semua status, termasuk dalam
__dict__, dipertahankan __init__tidak dipanggiltype()akan mengembalikan tipe baru, dan metode pengiriman akan menggunakan metode tipe itu dengan cara python biasa (termasuk pengiriman metaclass, jika metaclass didefinisikan)
Saya pikir itu juga membantu untuk memiliki beberapa metode khusus yang dipanggil saat ini jika ada - di fastai2, misalnya, itu disebut __after_cast__ .
jph00
pada 10 Des 2019
Saya tidak yakin bagaimana melakukannya. Izinkan saya memberikan beberapa informasi tentang bagaimana PyObject diimplementasikan di PyTorch dan mungkin itu memberi Anda beberapa informasi.
PyObject yang mewakili Tensor terlihat seperti ini:
// Python object that backs torch.autograd.Variable
// NOLINTNEXTLINE(cppcoreguidelines-pro-type-member-init)
struct THPVariable {
PyObject_HEAD
// Payload
torch::autograd::Variable cdata;
// Hooks to be run on backwards pass (corresponds to Python attr
// '_backwards_hooks', set by 'register_hook')
PyObject* backward_hooks = nullptr;
};
Setiap Variabel juga berisi bidang pyobj yang menunjuk ke objek unik PyObject mewakili tensor. Ini memastikan bahwa identitas objek C++ dan identitas objek Python bertepatan.
Apakah itu menjawab pertanyaan Anda?
ezyang
pada 11 Des 2019
Apakah itu menjawab pertanyaan Anda?
Agak. Tampaknya bagi saya bahwa jika dalam mode RAII yang sebenarnya, cdata benar-benar disalin pada pembuatan tugas/salin, kita akan memerlukan cara untuk menyalinnya secara dangkal atau mengubahnya menjadi sebuah pointer, tetapi itu adalah perubahan yang cukup invasif. Selain itu, kami hanya dapat menyalin semua bidang, sebagian besar, serta menyalin dangkal __dict__ .
hameerabbasi
pada 19 Des 2019
Beginilah cara saya memperbarui implementasi fastai2 beberapa minggu yang lalu:
def as_subclass(self:Tensor, typ):
res = torch.Tensor._make_subclass(typ, self)
if hasattr(self,'__dict__'): res.__dict__ = self.__dict__
return res
Tampaknya berfungsi dengan baik untuk kami - tetapi jika kami kehilangan sesuatu yang penting, saya ingin tahu sekarang sehingga kami dapat mencoba memperbaikinya! (Dan jika kita tidak melewatkan sesuatu yang penting, apakah ini solusi yang dapat digunakan pytorch juga?)
jph00
pada 19 Des 2019
Saya hanya akan melanjutkan dan meringkas masalah dengan __torch_function__ untuk metode serta __torch_finalize__ , dan kemudian berbicara tentang preferensi saya dan pendapat saya tentang masalah komposisi @ezyang .
__torch_function__ untuk metode (dan masalah dengan super )
Pertimbangkan kode berikut ( __torch_function__ untuk metode hanya akan melewati self sebagai argumen pertama).
class SubclassA(torch.Tensor):
def __add__(self, other):
# Do stuff with self, other
temp_result = super().__add__(self_transformed, other_transformed)
# Do stuff with temp_result
return final_result
class SubclassB(SubclassA):
def __torch_function__(self, func, args, kwargs):
# Do stuff with args, kwargs
temp_result = super().__torch_function__(self, func, args_transformed, kwargs_transformed)
# Do stuff with temp_result
return temp_result
Sekarang, pertimbangkan apa yang terjadi ketika kita menambahkan instance SubclassB dengan instance lain seperti itu.
Karena __add__ diwarisi dari SubclassA , kontrol aliran berjalan ke sana terlebih dahulu alih-alih SubclassB 's __torch_function__ . Apa yang terjadi, secara konkret, dalam proposal saya saat ini, adalah:
self/otherditransformasikan olehSubclassA.__add__. Mudah-mudahan, jika tidak ada yang terlalu aneh terjadi, transformasi mempertahankan kelas (SubclassBdalam kasus ini).- Karena
self_transformed/other_transformedadalah turunan dariSubclassB, panggilan kesuperpergi keTensor.__torch_function__, yang secara default melakukan hal yang sama sebagaiTensor.__add__, dan mengembalikan hasilnya. - Kami kemudian mengubah
temp_result, dan meneruskannya kembali keSubclassA.__add__. SubclassAmelakukan transformasi akhir dan kemudian mengembalikan hasilnya.
Masalah dengan ini adalah sebagai berikut: Ada inversi kontrol. SubclassB.__torch_function__ seharusnya yang mengontrol aliran eksekusi, tetapi tidak.
Selama panggilan sebelumnya, saya dan @ezyang berbicara tentang solusi berikut: Tambahkan default __add__ ke SubclassB (mungkin melalui metaclasses) yang dikirim langsung ke SubclassB.__torch_function__ .
Saya ingin mengusulkan sisi lain dari ini, yang memiliki manfaat membuat semuanya berperilaku persis seperti Tensor berperilaku. Mungkin kita bahkan dapat membuat Tensor sendiri bekerja dengan cara ini jika bukan karena batasan pada regresi kinerja:
Jadikan semua implementasi metode pada subkelas juga melalui __torch_function__ secara default.
__torch_finalize__ dan masalah dengan super
Di sini, meskipun tidak terlalu parah, masalahnya masih ada. Pembalikan kontrol ada, tetapi karena __torch_finalize__ (sesuai namanya) hanya menyelesaikan hasil (berdasarkan salah satu input dari jenis itu), tetapi tidak melakukan pra-pemrosesan.
as_subclass
Saya percaya @ezyang dapat berbicara lebih banyak tentang bagaimana ini baik-baik saja atau tidak, tetapi saya melihat setidaknya satu masalah dengannya:
def as_subclass(self:Tensor, typ):
res = torch.Tensor._make_subclass(typ, self)
if hasattr(self,'__dict__'): res.__dict__ = self.__dict__.copy() ## I added the copy
return res
Jika tidak, mengubah atribut apa pun pada res juga akan mengubahnya pada self (kecuali itu tujuannya?)
hameerabbasi
pada 7 Jan 2020
def as_subclass(self:Tensor, ketik):
res = torch.Tensor._make_subclass(ketik, mandiri)
if hasattr(self,'__dict__'): res.__dict__ = self.__dict__.copy() ## Saya menambahkan salinan
kembalikan res
Jika tidak, mengubah atribut apa pun padaresjuga akan mengubahnya padaself(kecuali itu tujuannya?)
Itu benar-benar niatnya! :) Sebuah objek cor harus menjadi referensi, bukan salinan. Perhatikan bahwa ini sudah merupakan perilaku yang Anda lihat di _make_subclass :
a = tensor([1,2,3])
class T(Tensor): pass
res = torch.Tensor._make_subclass(T, a)
res[1] = 5
print(res)
tensor([1, 5, 3])
Akan sangat membingungkan jika objek cor bertindak sebagai referensi ketika datang ke data tensor mereka, tetapi sebagai salinan ketika datang ke atributnya.
jph00
pada 7 Jan 2020
Jadikan semua implementasi metode pada subclass juga melalui __torch_function__ secara default.
Jadi maksud Anda, alih-alih super().__add__ menjadi cara yang valid untuk memanggil implementasi induk, Anda memanggil __torch_function__ ? Atau ini sesuatu yang lain? (Saya minta maaf jika Anda sudah menjelaskan hal ini di atas tetapi percakapannya cukup panjang. Mungkin ada baiknya untuk mengedit pesan teratas dengan proposal terbaru untuk akses yang mudah.)
ezyang
pada 8 Jan 2020
Maksud saya, semua metode yang sudah dimiliki Tensor akan melalui __torch_function__ , _bahkan untuk subkelas_. Secara konkret, pada contoh di atas, SubclassA.__add__ akan _secara otomatis didekorasi dengan @torch_function_dispatch _, dan kami akan merekomendasikan semua subclass melakukan hal yang sama. Ini akan memiliki efek yang diinginkan untuk membuat super().__add__ melalui super().__torch_function__ .
hameerabbasi
pada 8 Jan 2020
Ini adalah pertama kalinya Anda menyebutkan torch_function_dispatch dalam edisi ini. :)
Jadi, jika saya mengerti dengan benar, apa yang Anda usulkan adalah ketika Anda mensubklasifikasikan tensor, Anda wajib menggunakan dekorator, misalnya,
class SubclassA(Tensor):
<strong i="8">@torch_function_dispatch</strong>
def __add__(self, other):
...
super().__add__(self)
Jika ini masalahnya, dalam urutan apa saya akhirnya memanggil fungsi-fungsi ini, jika saya memiliki beberapa subkelas, dan __torch_function__ dan __add__ didefinisikan dalam kedua kasus? Saya masih belum sepenuhnya memahami proposal Anda. Akan sangat membantu jika Anda dapat memposting kode contoh yang lebih lengkap, dan memandu saya melalui apa yang terjadi dalam kasus ini.
ezyang
pada 9 Jan 2020
Jadi, untuk kasus yang salah, kami akan menggantinya dengan kode berikut:
def _add_dispatcher(self, other):
return self, other
class SubclassA(torch.Tensor):
@torch_function_dispatch(_add_dispatcher)
def __add__(self, other):
# Do stuff with self, other
temp_result = super().__add__(self_transformed, other_transformed)
# Do stuff with temp_result
return final_result
class SubclassB(SubclassA):
def __torch_function__(self, func, args, kwargs):
# Do stuff with args, kwargs
temp_result = super().__torch_function__(self, func, args_transformed, kwargs_transformed)
# Do stuff with temp_result
return temp_result
Apa yang terjadi adalah sebagai berikut:
- Kami akan memiliki implementasi default untuk setiap kelas untuk
__torch_function__. - Kode akan dikirim ke implementasi jika tersedia jika tidak, default.
- Misalkan
x.__add__dipanggil di manatype(x) is SubclassB. Itu akan mencapaiSubclassA.__add__. - Yang akan menyadari bahwa ada kelas selain superclass dari
SubclassAdan itu sendiri hadir dalam daftar argumen, itu akan mencobaself.__torch_function__dan kemudianother.__torch_function_. - Jadi kode akan melalui
SubclassB.__torch_function__ - Transformasi akan berbentuk
t.as_subclass(SubclassA) - Ketika
super().__torch_function__dipanggil, itu akan dikirim keSubclassA.__add__, sebagaimana mestinya. - Kontrol diteruskan kembali ke
SubclassB. - Pasca-pemrosesan terjadi dan hasilnya dikembalikan.
hameerabbasi
pada 14 Jan 2020
Saya merasa ada langkah yang hilang sebelumnya
- Jadi kode akan melalui SubclassB.__torch_function__
Saya menelepon x.__add__() mana x adalah SubclassB . Dengan aturan resolusi Python normal, saya akan menekan SubclassA.__add__ ketika ini terjadi. Apakah Anda mengatakan dekorator pengiriman akan memberikan kontrol ke SubclassB.__torch_function__ ? Saya masih tidak yakin bagaimana ini akan berhasil.
ezyang
pada 14 Jan 2020
Jadi, pikirkan SubclassA.__add__ ... Ini akan mengikuti protokol __torch_function__ . Ketika menyadari bahwa ada kelas selain superclass dari SubclassA dan itu sendiri hadir dalam daftar argumen, ia akan mencoba self.__torch_function__ dan kemudian other.__torch_function_ . Karena Anda menyebutkan self adalah SubclassB , itu akan mencapai SubclassB.__torch_function__ .
hameerabbasi
pada 15 Jan 2020
Satu catatan presentasi, kita mungkin harus memanggil kode itu torch_function_dispatch sesuatu yang berbeda dari __torch_function__ , karena itu bukan kode yang sama sama sekali. Saya akan menyebutnya "petugas operator Python" untuk saat ini.
Biarkan saya melihat apakah saya mengerti apa yang Anda katakan dengan benar. Proposal Anda mengatakan:
- Setiap kali pengguna memanggil metode pada kelas Tensor, kami selalu mentransfer kontrol ke operator Python terlebih dahulu. Semua metode bawaan di Tensor memiliki fungsi ini, dan metode apa pun yang diganti secara eksplisit di Tensor mengatur transfer kontrol ini melalui dekorator wajib (apa yang terjadi jika pengguna lupa menambahkan dekorator ini?)
- Setelah kita berada di operator Python, kita perlu mentransfer kontrol ke metode yang ditentukan pengguna yang benar atau implementasi
__torch_function__. Mirip dengan bagaimana__torch_function__beroperasi dari PR ngoldbaum, kami membuat keputusan tentang kelas yang paling spesifik, dan kemudian mencoba untuk memanggil metode yang sesuai di kelas (jika ada), atau__torch_function__pada kelas itu.
Anda menggunakan super() dalam contoh Anda, tetapi dengan rekap saya di atas, saya tidak melihat bagaimana super bisa bekerja. Panggilan super akan mentransfer kontrol kembali ke operator Python, tetapi operator Python perlu tahu kali ini bahwa kita telah "selesai" dengan kelas yang paling spesifik, dan kita harus melakukan sesuatu yang lebih tinggi dalam hierarki kelas, tapi saya tidak' t melihat bagaimana Anda bisa tahu itu, dalam proposal.
ezyang
pada 16 Jan 2020
Anda menggunakan
super()dalam contoh Anda, tetapi dengan rekap saya di atas, saya tidak melihat bagaimana super bisa bekerja. Panggilan super akan mentransfer kontrol kembali ke operator Python, tetapi operator Python perlu tahu kali ini bahwa kita telah "selesai" dengan kelas yang paling spesifik, dan kita harus melakukan sesuatu yang lebih tinggi dalam hierarki kelas, tapi saya tidak' t melihat bagaimana Anda bisa tahu itu, dalam proposal.
Cara NumPy menangani ini adalah argumen types di __array_function__ , subkelas menghapus "diri mereka sendiri" dari types sebelum memanggil super()
hameerabbasi
pada 23 Jan 2020
Saya juga menulis RFC seperti yang diminta.
hameerabbasi
pada 23 Jan 2020
@ezyang @jph00 Draf pertama proposal sudah siap. https://github.com/pytorch/rfcs/pull/3
hameerabbasi
pada 24 Jan 2020
Masalah terkait
 a1363901216
·
3Komentar
a1363901216
·
3Komentar
 kdexd
·
3Komentar
kdexd
·
3Komentar
 bartolsthoorn
·
3Komentar
bartolsthoorn
·
3Komentar
 szagoruyko
·
3Komentar
szagoruyko
·
3Komentar
 soumith
·
3Komentar
soumith
·
3Komentar
Komentar yang paling membantu
Saya ingin menunjukkan kasus penggunaan lain dari fungsi ini yang muncul dalam percakapan kami dengan OpenAI. Apa yang ingin dilakukan OpenAI adalah memasukkan kait pada tingkat per operator, sehingga mereka dapat memeriksa tensor yang mengalir melalui setiap operasi (saat ini, mereka terhubung pada tingkat modul, tetapi terkadang ada operasi berbutir halus yang mereka butuhkan untuk melakukannya kaitkan ke dalam).
__torch_function__sangat menggoda untuk menyediakan apa yang Anda butuhkan untuk ini, tetapi:Mari kita pastikan kita bisa mencapai kasus ini juga!
cc @suo @orionr @NarineK yang hadir untuk percakapan ini.