Pytorch: دعم محسّن لفئات Tensor الفرعية ، مع الاحتفاظ بالفئات الفرعية في استدعاءات الوظيفة / الطريقة
🚀 الميزة
ذات صلة: # 22402
تقترح هذه الميزة المرور عبر الفئات الفرعية Tensor عبر __torch_function__ .
السلوك المرغوب
مثال على السلوك المطلوب سيكون:
class MyTensor(torch.Tensor):
_additional_attribute = "Kartoffel"
a = MyTensor([0, 1, 2, 3])
# b should be a MyTensor object, with all class attributes passed through.
b = torch_function(a)
الأهداف
نقلا عن # 22402
هذه هي الأهداف _ المحتملة_ التي تم جمعها من العلاقات العامة المشار إليها أعلاه ، وقضايا PyTorch الأخرى (المشار إليها في الأقسام ذات الصلة) ، وكذلك من المناقشات مع إدوارد يانج بشكل أساسي ، وأيضًا من المشرفين الآخرين على PyTorch و NumPy:
- دعم التصنيف الفرعي
torch.Tensorفي بايثون- احتفظ بالفئات الفرعية
Tensorعند استدعاء وظائفtorchعليها- احتفظ بالفئات الفرعية
Tensorعند استدعاء وظائفnumpyعليها- استخدم NumPy API مع موتر PyTorch (على سبيل المثال ، إرسال استدعاءات NumPy API إلى وظائف
torch)- استخدم واجهة برمجة تطبيقات PyTorch مع كائنات تشبه
torch.Tensorمثل العناصر _not_Tensor- أعد استخدام تطبيقات NumPy ufunc مباشرة من PyTorch
- السماح بالعمليات على أنواع مصفوفة مختلطة ، على سبيل المثال
tensor + ndarray
بالإضافة إلى ذلك ، من https://github.com/pytorch/pytorch/issues/28361#issuecomment -544520934:
- احتفظ بالفئات الفرعية
Tensorعند استدعاء طرقTensor- نشر مثيلات الفئة الفرعية بشكل صحيح أيضًا مع عوامل التشغيل ، باستخدام طرق العرض / الشرائح / إلخ.
مخطط تقريبي للتنفيذ
سيتجاوز أي شيء بنوع مثل الموتر المدمج __torch_function__ عبر مسارهم السريع (على الرغم من أنه سيكون لديهم تطبيق افتراضي) ولكن أي شيء آخر تحدده مكتبة خارجية سيكون لديه خيار السماح بذلك.
يوضح مقتطف الشفرة التالي الشكل الافتراضي __torch_function__ على TensorBase .
class Tensor:
def __torch_function__(self, f, t, a, kw):
if not all(issubclass(ti, TensorBase) for ti in t):
return NotImplemented
result = f._wrapped(*a, **kw)
return type(self)(result)
سم مكعبezyanggchanan @ zou3519 @ jerryzh168 @ jph00rgommers
 hameerabbasi
hameerabbasi
ال 74 كومينتر
هل يمكنك أن تشرح بالضبط ما هو دلتا من هذا الاقتراح و # 22402؟ أم أن هذا مجرد نمط يمكن للفئات الفرعية من Tensor استخدامه لتنفيذ الامتدادات؟
 ezyang
في ٢١ أكتوبر ٢٠١٩
ezyang
في ٢١ أكتوبر ٢٠١٩
ezyang يرجى الاطلاع على التحديث الخاص بالمشكلة ، لقد أضفت المزيد من التفاصيل حول كيفية جعل ذلك تلقائيًا. لقد أضفت أيضًا مثالًا لحالة الاستخدام.
إنها تحدد بشكل أساسي كيف (إذا سمحنا __torch_function__ على الفئات الفرعية) ، يمكننا ، بامتداد بسيط ، إنشاء __torch_function__ افتراضيًا سيجعل المرور عبر الفئات الفرعية تلقائيًا.
hameerabbasi
في ٢١ أكتوبر ٢٠١٩
hameerabbasi أقترح تعديل الوصف أكثر. الأهداف ذات الصلة هي:
- دعم التصنيف الفرعي
torch.Tensorفي بايثون - احتفظ بالفئات الفرعية
Tensorعند استدعاء وظائف المصباح عليها - احتفظ بالفئات الفرعية
Tensorعند استدعاء طرقTensor - نشر مثيلات الفئة الفرعية بشكل صحيح أيضًا مع عوامل التشغيل ، باستخدام طرق العرض / الشرائح / إلخ.
هل يمكنك أن تشرح بالضبط ما هو دلتا من هذا الاقتراح و # 22402؟
لا توجد دلتا ، نحتاج فقط إلى مشكلة لهذا الموضوع للمناقشة (والإبلاغ) لا تختلط مع gh-22402 متعدد الموضوعات. هذه المشكلة قابلة للتنفيذ بشكل أساسي في ثلاثة أجزاء: __torch_function__ (قريب من جاهز للمراجعة) ، موضوع التصنيف الفرعي هذا (بدأ للتو) ، ودعم بروتوكول NumPy (أقل prio ، لم يبدأ).
 rgommers
في ٢١ أكتوبر ٢٠١٩
rgommers
في ٢١ أكتوبر ٢٠١٩
حسنًا ، sgtm. @ jph00 كيف يبدو هذا لك؟
ezyang
في ٢١ أكتوبر ٢٠١٩
شكرا عصابة. ليس لدي أي تعليق على التنفيذ المقترح ، لكن الأهداف تبدو رائعة. :)
على الرغم من أنها مغطاة ضمنيًا بالأهداف المعلنة ، يجب أن أذكر أننا واجهنا مشكلة في الحصول على __getitem__ يعمل بشكل صحيح في الفئات الفرعية - لذلك قد يكون هذا شيئًا للتأكد من الاختبار بعناية. على سبيل المثال ، تأكد من اختبار الموترات العابرة لأنواع مختلفة كمؤشرات ، بما في ذلك موترات قناع منطقي والفئات الفرعية.
 jph00
في ٢١ أكتوبر ٢٠١٩
jph00
في ٢١ أكتوبر ٢٠١٩
شكرًا @ jph00 ، هذا هو بالضبط نوع الإدخال الذي نحتاجه.
rgommers
في ٢١ أكتوبر ٢٠١٩
يبدو أن الأساليب المتغيرة والغير وسيطة لا تحلل الذات في قائمة الحجج الخاصة بها:
و
PythonArgParser أيضًا لا يأخذ self : https://github.com/prasunanand/pytorch/blob/torch_function/torch/csrc/utils/python_arg_parser.h#L102
قد يكون من الجيد لأغراض هذه المسألة السماح self كوسيطة لـ PythonArgParser . ومع ذلك ، لست متأكدًا من عبء تحليل الحجة.
hameerabbasi
في ١٥ نوفمبر ٢٠١٩
أيضًا ، هل سيكون من الأفضل أن يكون لديك طريقة متوقعة على الفئات الفرعية للافتراضية __torch_function__ a. __array_wrap__ (يُطلق عليه بدلاً من ذلك __torch_wrap__ ، من أجل عكس NumPy) ، أو فقط استدعاء المُنشئ الافتراضي باستخدام موتر الإخراج؟
أمثلة:
class TensorSubclass(Tensor):
def __init__(self, *a, **kw):
if len(a) == 1 and len(kw) == 0 and isinstance(a[0], torch.Tensor):
# Do conversion here
ضد
class TensorSubclass(Tensor):
def __torch_wrap__(self, tensor):
# Do conversion here
@ jph00 خواطر؟
hameerabbasi
في ١٥ نوفمبر ٢٠١٩
من الصعب التحدث عن مشكلة تنفيذ محددة للغاية دون رؤية المزيد حول التنفيذ المخطط له. على وجه الخصوص ، لماذا يحتاج PythonArgParser إلى الذات؟
ezyang
في ١٥ نوفمبر ٢٠١٩
هذا هو خط تفكيري:
- نحتاج إلى
__torch_function__افتراضيًا علىTensor(انظر وصف المشكلة) ، والذي يجب تطبيقه علىselfأيضًا. - نحن بحاجة إلى جعلها تعمل مع الأساليب أيضًا ، حتى ينجح هذا.
- يجب أن يكون
selfفي قائمة الوسيطات المحللة ، لأن معظم المنطق__torch_function__موجود داخلPythonArgParser.
الخيار الآخر هو إعادة بناء / إعادة كتابة المنطق بشكل منفصل للذات ، ie
if type(self) is not Tensor and hasattr(self, '__torch_function__'):
# Process things here, separately.
أي آراء حول أي طريق نسلك؟
hameerabbasi
في ١٥ نوفمبر ٢٠١٩
لدي فرع ويب في https://github.com/Quansight/pytorch/tree/subclassing ، لقد أضفت الاختبارات على: https://github.com/Quansight/pytorch/blob/a68761ef8942041089d5da4815db07f020667260/test/test_subclassing. السنة التحضيرية
hameerabbasi
في ١٦ نوفمبر ٢٠١٩
نحن بحاجة إلى جعلها تعمل مع الأساليب أيضًا ، حتى ينجح هذا.
حسنًا ، لنتحدث عن هذا للحظة. في __torch_function__ PR ، ذكرت ما إذا كان من المنطقي أن يكون لديك نوع من الطريقة السحرية لتجاوز كل من الوظائف والطرق ، لكننا قررنا أنها خارج نطاق هذه المشكلة. دعنا نتجاهل مسألة وظيفة الموتر الافتراضية التي تحافظ على الفئات الفرعية للحظة ، ونطرح سؤالًا أبسط: كيف يعمل الامتداد إلى __torch_function__ لدعم الأساليب بالضبط؟
ezyang
في ١٨ نوفمبر ٢٠١٩
كيف بالضبط يعمل امتداد
__tensor_function__لدعم طرق العمل؟
حسنًا ، لذا فإن رؤيتي هي التالية: __torch_function__ له التوقيع (func, args, kwargs) (من العلاقات العامة السابقة). في نمط Python التقليدي ، إذا تم استدعاؤها وفقًا لطريقة Tensor _method_ ، فستكون func هي الطريقة نفسها ، على سبيل المثال Tensor.__add__ و args / kwargs قد يحتوي self ، بالإضافة إلى الوسائط الأخرى التي تم تمريرها صراحةً. في هذا المثال ، سيتضمن args كلاً من self و other .
hameerabbasi
في ١٩ نوفمبر ٢٠١٩
حسنًا ، هذا يبدو معقولًا بالنسبة لي. ومع ذلك ، يبدو أن هذا يختلف عن الطريقة التي يتعامل بها Numpy مع المصفوفات في __array_function__ . هل يمكنك مقارنة هذا التحسين بنهج Numpy؟
أيضًا ، يجب أن نكون حذرين بشأن هذا التغيير لأنني إذا حددت كلاً من def __add__ و def __torch_function__ ، أيهما "سيفوز"؟
ezyang
في ١٩ نوفمبر ٢٠١٩
هل يمكنك مقارنة هذا التحسين بنهج Numpy؟
لا ينطبق __array_function__ في NumPy على طرق ndarray . NumPy ، من أجل التعامل مع سلوك التصنيف الفرعي ، يقوم بعمل ret = ret.view(subclass) في نهاية كل طريقة ، ثم يستدعي بالإضافة إلى ذلك ret.__array_finalize__(self) (بافتراض وجوده).
أيضًا ، يجب أن نكون حذرين بشأن هذا التغيير لأنني إذا حددت كلاً من
def __add__وdef __torch_function__، أيهما "سيفوز"؟
__add__ يفوز ، بسبب __mro__ من Python ، تأتي الفئات الفرعية قبل الفئات الفائقة. لدى NumPy نفس المشكلة والنموذج.
hameerabbasi
في ١٩ نوفمبر ٢٠١٩
في الثلاثاء 19 نوفمبر 2019 الساعة 8:43 صباحًا كتب حمر عباسي:
هل يمكنك مقارنة هذا التحسين بنهج Numpy؟
لا ينطبق
__array_function__في NumPy على طرقndarray. NumPy ، من أجل التعامل مع سلوك التصنيف الفرعي ، يقوم بعملret = ret.view(subclass)في نهاية كل طريقة ، ثم يستدعي بالإضافة إلى ذلكret.__array_finalize__(self)(بافتراض وجوده).
هذه أيضًا طريقة عمل fastai v2 راجع للشغل - نطلق على retain_types() في نهاية Transform.encodes وأماكن أخرى مختلفة (تلقائيًا ، في معظم الحالات).
jph00
في ١٩ نوفمبر ٢٠١٩
تمت مناقشة خيار استخدام __array_finalize__ في gh-22402 ، المشكلة هي أنه بطيء.
NumPy ، من أجل التعامل مع سلوك التصنيف الفرعي ، يقوم بعمل
ret = ret.view(subclass)في نهاية كل طريقة
هذا في الواقع لا يعمل مع PyTorch لأن Tensor.view يتصرف بشكل مختلف تمامًا عن ndarray.view . لقد أجرينا اختبارات في الفرع __torch_function__ الذي استخدمه (مقتبس من NumPy) لكنها لم تنجح لذا قمنا بتغيير طريقة Python العادية لإنشاء فئة فرعية وإنشاء مثيل لها.
rgommers
في ١٩ نوفمبر ٢٠١٩
هذا في الواقع لا يعمل مع PyTorch لأن
Tensor.viewيتصرف بشكل مختلف تمامًا عنndarray.view. لقد أجرينا اختبارات في الفرع__torch_function__الذي استخدمه (مقتبس من NumPy) لكنها لم تنجح لذا قمنا بتغيير طريقة Python العادية لإنشاء فئة فرعية وإنشاء مثيل لها.
ربما يمكن تسميته .cast بدلاً من ذلك؟
jph00
في ١٩ نوفمبر ٢٠١٩
ربما يمكن تسميته
.castبدلاً من ذلك؟
أجد عددًا من المناقشات حول سلوك view ، لذلك أعتقد أنه تم النظر فيه من قبل ورفضه. يشير cast إلى تغيير dtype الذي أعتقده بدلاً من تغيير الشكل. view يعادل في الأساس reshape في NumPy. أو Tensor.reshape ، باستثناء أنه يعمل أيضًا مع الأشكال غير المتطابقة.
rgommers
في ٢٠ نوفمبر ٢٠١٩
في الثلاثاء ، 19 تشرين الثاني (نوفمبر) 2019 ، الساعة 4:43 مساءً ، كتب رالف غومرز:
ربما يمكن تسميته
.castبدلاً من ذلك؟
أجد عددًا من المناقشات حول سلوك
view، لذلك أعتقد أنه تم النظر فيه من قبل ورفضه. يشيرcastإلى تغيير dtype الذي أعتقده بدلاً من تغيير الشكل.viewيعادل في الأساسreshapeفي NumPy. أوTensor.reshape، باستثناء أنه يعمل أيضًا مع الأشكال غير المتطابقة.
من المحتمل أن يكون أحدنا يسيء فهم شيء ما (ويمكن أن يكون أنا!)
في numpy ، يفعل view ذلك بالضبط: إنه تغيير dtype ، وليس تغيير الشكل. لهذا السبب اقترحت cast كاسم للوظيفة المكافئة في pytorch.
jph00
في ٢٠ نوفمبر ٢٠١٩
هناك ما يزيد قليلاً عن view في NumPy:
>>> import numpy as np
>>> class subarray(np.ndarray):
... newattr = "I'm here!"
...
>>> x = np.arange(4)
>>> x.view(subarray)
subarray([0, 1, 2, 3])
>>> y = x.view(subarray)
>>> isinstance(y, subarray)
True
>>> y.newattr
"I'm here!"
تحرير: سأستخدم astype لتغيير نوع dtype
rgommers
في ٢٠ نوفمبر ٢٠١٩
في الثلاثاء ، 19 تشرين الثاني (نوفمبر) 2019 ، الساعة 4:55 مساءً ، كتب رالف غومرز:
هناك ما يزيد قليلاً عن
viewفي NumPy:
نعم ، صحيح ، لكن هذا لا يبطل النقطة الأساسية على ما أعتقد :)
jph00
في ٢٠ نوفمبر ٢٠١٩
هذا في الواقع لا يعمل مع PyTorch لأن
Tensor.viewيتصرف بشكل مختلف تمامًا عنndarray.view.
نعم ، صحيح ، لكن هذا لا يبطل النقطة الأساسية على ما أعتقد :)
متفق عليه ، كانت النقطة هي إظهار سلوك NumPy ، وبما أن هذا هو أداة تعقب مشكلات PyTorch ، كان يجب أن أذكر أنه يجب إنشاء أو اكتشاف ما يعادل Tensor . ربما يمكن لـ ezyang تحديد ما إذا كان ذلك ممكنًا ، بالإضافة إلى بعض الإرشادات حول كيفية القيام بذلك.
hameerabbasi
في ٢٠ نوفمبر ٢٠١٩
hameerabbasi ، قد ترغب في تصفح الفرق في gh-22235 ، فهو غير مكتمل وجزء من مجموعة العلاقات العامة التي كانت مشوشة بعض الشيء ، ولكن للحفاظ على الفئات الفرعية في الأساليب ، فإنه نوعًا ما يفعل ما view + __array_finalize__ يفعل. لذلك من الجيد على الأقل معرفة أجزاء الكود التي يجب أن تلمسها.
هذا بالطبع اتجاه بديل لفكرة "تحليل self + استخدام __torch_function__ " الأصلية. من الصعب توقع أيهما أنظف / أسرع.
rgommers
في ٢٠ نوفمبر ٢٠١٩
__add__يفوز ، نظرًا لأن Python__mro__، تأتي الفئات الفرعية قبل الفئات الفائقة. لدى NumPy نفس المشكلة والنموذج.
ماذا لو قمت ، في صفي الفرعي ، بتحديد كلا من __add__ و __torch_function__ ؟ ثم MRO لا يعطي التوجيه ، IIUC؟
ezyang
في ٢٠ نوفمبر ٢٠١٩
كنت سأستخدم astype لتغيير نوع dtype
نعم ، هذا الاسم يبدو أفضل
ezyang
في ٢٠ نوفمبر ٢٠١٩
ماذا لو قمت ، في صفي الفرعي ، بتعريف كل من __إضافة__ و __وظيفة __وظيفة __ _ _ _ _ _ _؟ ثم MRO لا يعطي التوجيه ، IIUC؟
تبحث Python دائمًا عن __add__ عند استخدام + ، لذلك تكون الأولوية دائمًا.
hameerabbasi
في ٢٠ نوفمبر ٢٠١٩
تبحث Python دائمًا عن
__add__عند استخدام+، لذلك تكون الأولوية دائمًا.
لا أعتقد أن هذا يحل مشكلتي. أفضل مقارنة هي مقارنة __add__ و __getattr__ ، وكلاهما طريقتان يمكن أن تفرط في تحميل سلوك + . ما أفهمه هو أن قواعد بايثون تعني أنه بمجرد تحديد __add__ في أي فئة عليا ، لن يتم النظر في __getattr__ أبدًا ، حتى لو قمت بإعادة تعريفه في فئة فرعية.
class A:
def __add__(self, other):
return 1
class B(A):
def __getattr__(self, attr):
return lambda other: 2
print(B() + B())
macbook-pro-116:~ ezyang$ python3.7 fof.py
1
لكن السلوك المطلوب المذكور أعلاه هو أنه يمكنني تصنيف فئة فرعية Tensor ، بدون رمز إضافي ، ثم يتم الاحتفاظ بالفئات الفرعية.
class MyTensor(Tensor):
pass
MyTensor() + MyTensor() # results in MyTensor
ولكن MyTensor.__add__ يعرف، وهكذا يمكن القول سوف تتم معالجتها من قبل __torch_function__ . لم أر تفسيراً لكيفية تخطيطك لحل هذا الغموض!
ezyang
في ٢٠ نوفمبر ٢٠١٩
أفترض أن إحدى طرق حل المشكلة هي مطالبة المستخدمين بتعريف __torch_function__ بشكل صريح للاتصال بتطبيق "حفظ الفئات الفرعية". يبدو هذا عمليًا بالنسبة لي ، على الرغم من أنه يتعارض مع كيفية عمل __getattr__ .
ezyang
في ٢٠ نوفمبر ٢٠١٩
أفترض أن إحدى طرق حل المشكلة هي مطالبة المستخدمين بتعريف
__torch_function__بشكل صريح للاتصال بتطبيق "حفظ الفئات الفرعية". يبدو هذا عمليًا بالنسبة لي ، على الرغم من أنه يتعارض مع كيفية عمل__getattr__.
سيكون هناك تطبيق افتراضي __torch_function__ ، والذي سيتم ، في جوهره ، تخطيه لـ torch.Tensor ، والذي سيفعل الشيء الصحيح ، ولكن إذا حدد المستخدمون __add__ ، فسيتم على عاتقهم أن يفعلوا الشيء الصحيح.
hameerabbasi
في ٢٠ نوفمبر ٢٠١٩
hameerabbasi أجرى مكالمة قصيرة. لقد طرحت مشكلتين في تطبيق حمر:
- افترض أنني حددت
__torch_function__وaddفي فئة فرعية. إذا كانaddيستدعىsuper().add()كجزء من تنفيذه ، فسيتم استدعاء__torch_function__لاحقًا! هذا غريب. - لنفترض أنه يتم استدعاء
__torch_function__فقط إذا لم يتم تجاوزadd(وهو ما يصلح (1)). ثم نفقد "تكوين الفئة الفرعية": يمكنك تصنيف فئة Tensor الفرعية في MyTensor والاحتفاظ بالفئات الفرعية ، ولكن إذا كان لديك DiagonalTensor (موسع Tensor) ، ثم صنفه إلى MyDiagonalTensor ، فلن يتم الاحتفاظ بالفئة الفرعية. (هذا لأنه ، حتى لو كان DiagonalTensor.add يستدعي super () ، فلن نتصل بـ__torch_function__لأن الإضافة تم تجاوزها)
ezyang
في ٢٠ نوفمبر ٢٠١٩
أريد أن أشير إلى حالة استخدام أخرى لهذه الوظيفة التي ظهرت في محادثاتنا مع OpenAI. ما تريد OpenAI القيام به هو إدخال خطافات على مستوى كل مشغل ، حتى يتمكنوا من فحص الموترات التي تتدفق خلال كل عملية (في الوقت الحالي ، يتم تثبيتها على مستوى الوحدة النمطية ، ولكن في بعض الأحيان هناك المزيد من العمليات الدقيقة التي يحتاجون إليها ربط في).
__torch_function__ قريب بشكل محير من توفير ما تحتاجه لهذا الغرض ، ولكن:
- نحتاج إلى الحفاظ على فئة فرعية ، لذلك يستمر تشغيل خطافاتنا (هذه المشكلة)
- نحتاج بعيدًا إلى إدخال رمز يعمل على كل من الوظائف والطرق بشكل موحد (حتى نتمكن من كتابة وظيفة واحدة تتجاوز جميع المشغلين)
دعونا نتأكد من أنه يمكننا الوصول إلى هذه الحالة أيضًا!
سم مكعبsuoorionrNarineK الذين كانوا حاضرين لهذه المحادثة.
ezyang
في ٢١ نوفمبر ٢٠١٩
بعض القيود:
- توافق Numpy: يجب أن يعمل الشيء بنفس طريقة عمل numpy ، أو يجب أن يكون لدينا حجة جيدة لماذا كان numpy خاطئًا وقمنا بإصلاح المشكلة (ملاحظة حول Numpy: إذا كان لديك A + B ، فستعود A ، و إذا قمت بإجراء B + A ، فإنها تُرجع B ، إذا لم تكن هناك علاقة فئة فرعية بين A و B)
- يجب أن تعمل طرق التجاوز بمجرد تعريفها في الفئة الفرعية
- والمكالمات الفائقة يجب أن تفعل الشيء الصحيح
غير مقيد:
- لا أمانع إذا كان لدينا
__torch_function__وطريقة سحرية أخرى للقيام بكل من تجاوزات الوظيفة والطريقة (لا أعرف ما إذا كان ذلك ضروريًا)
ezyang
في ٢ ديسمبر ٢٠١٩
قيد آخر: المعلمة هي فئة فرعية من Tensor ، ولا ينبغي أن تحتفظ بالفئات الفرعية (وربما بشكل عام ، قد يحتاج الاحتفاظ بالفئات الفرعية إلى الاشتراك للحفاظ على BC.)
hameerabbasi وأجرينا مكالمة أخرى ، ولدينا مشكلة مثيرة للاهتمام: افترض أن لديك:
class ATensor(Tensor):
def add(self, other):
super().add(other)
class BTensor(ATensor):
def __torch_function__(self):
# pass through
class CTensor(BTensor):
def add(self, other):
super().add(other)
ما هو الترتيب الذي يجب استدعاء الأساليب؟ يجب أن يكون CTensor.add ، BTensor.__torch_function__ ، ATensor.add !! يشير هذا إلى أننا يجب أن نحدد تلقائيًا طريقة BTensor.add (عبر metaclass) لجعل هذا العمل ناجحًا ، إذا أردنا أن نجعل هذا يعمل. (ويجب أن تقوم هذه الطريقة بالإرسال المستند إلى CLASS إلى __torch_function__ .)
بعض ملاحظات الخدش الأخرى:
التفكير الحالي: إذا قمنا بالحفاظ على الفئة الفرعية بشكل منفصل تمامًا عن وظيفة الشعلة ، فلن تستدعي الإضافة سوبر. يجب أن تفعل المكالمات الفائقة الشيء الصحيح ، فهذه مشكلة بشكل عام. لذلك ، يجب أن نحصل على التطبيق المرجعي ، التطبيق الموجود على Tensor نفسه ، بشكل صحيح. هذا صحيح بغض النظر عما إذا كنا نتبع نهج وظيفة الشعلة أم لا. إذا كانت super (). add () يجب أن تفعل الشيء الصحيح ... هل هناك طريقة لاختبار ما إذا كنت قد نجحت في اجتياز كائن فائق ، بدلاً من الأساسي؟ (لا يمكن اختبار Tensor فقط ، لأنه غير قابل للإنشاء).
ماذا لو لم نستخدم سوبر؟ افعل شيئا اخر. (هذا لا يساعد في الواقع: سيتعين عليك استخدام سوبر في كلتا الحالتين).
البديل: بالنسبة إلى __torch_function__ ، نمنع السوبر. هذا هو ما يفعله Numpy بشكل أساسي: فهو يمنع السوبر داخل __array_function__ ، ولكن ما يفعله بدلاً من ذلك ، كانت هناك مقترحات للقيام بذلك ، يجب أن يسمح بالتنفيذ المغلف (التنفيذ غير المرسل) ليكون متاحًا. وهو فقط torch_function مع نقطتين كبيرتين. كانت هذه واحدة من الأفكار من Numpy.
الفكرة: يجب أن يكون __array_function__ أسلوبًا دراسيًا. هناك بعض المشاكل مع هذا. إذا كانت هناك بيانات وصفية في المثيل ، فسيتم فقدها. لا يزال هذا متاحًا في الحجج الوظيفية ، لكنه مفقود.
بحاجة إلى طريقة لمعرفة أين نحن في MRO. آمل أن تدعم بايثون هذا في الأصل.
خذ في حجة أخرى من الفصل. (ليس على طريقة الفصل)
ezyang
في ٢ ديسمبر ٢٠١٩
كنت سأستخدم astype لتغيير نوع dtype
آسف rgommers لم يكن يجب أن أقول "تغيير نوع Dtype". قصدت شيئًا مثل "تغيير إلى self.__class__ ". أرى سبب الارتباك الآن! :)
في الأساس ، هذا ما يفعله Numpy's view() . إذن في هذا العدد ، ما هو الاقتراح الحالي لكيفية فعل الشيء المكافئ بالضبط في pytorch؟
jph00
في ٣ ديسمبر ٢٠١٩
لا يوجد اقتراح حتى الان. hameerabbasi سيقدم اقتراحًا محددًا للنظر فيه.
ezyang
في ٣ ديسمبر ٢٠١٩
اقتراح التصنيف الفرعي Tensor
__torch_function__ والأساليب
نمرر جميع التوابع من خلال __torch_function__ ، حيث تكون الوسيطة الأولى التي تم تمريرها هي self . لذلك ، على سبيل المثال ، بالنسبة إلى MySubTensor.__add__ (إذا لم يتم تجاوزه) ، اتصل بـ MySubTensor.__torch_function__(Torch.__add__, (self, other), {}) . سيتم تغيير __torch_function__ إلى أسلوب فئة لأسباب الإرسال ، والحصول على وسيطة إضافية arrays والتي ستحتوي على المصفوفات التي تم تمريرها.
إضافة Tensor.as_subclass(other_class)
سيحصل Tensor على طريقة جديدة ، Tensor.as_subclass(other_class) والتي ستعرض الكائن Tensor كفئة أخرى مع جميع البيانات سليمة. يجب أن تكون الفئات الفرعية قابلة للاستدعاء بالصيغة MySubTensor(tensor_object) ، والتي ستنسخ السمات من كائن آخر Tensor (أو فئة فرعية). سيحصل Tensor نفسه على دعم لهذا النمط. سيكون هذا _عرض_ للبيانات وليس نسخة.
البدائل
إذا كان هذا غير مدعوم أو غير ممكن لسبب ما ، فيمكن أيضًا اعتبار طريقة الفصل MySubTensor.from(tensor_obj) .
إيفاد طرق محددة
هناك عيب في أن استدعاء super() في MySubTensor.__add__ يمكن أن يعيد الاتصال بـ MySubTensor.__torch_function__ . ومع ذلك ، يعد هذا سلوكًا متوقعًا ، حيث يقوم __torch_function__ بفحص جميع وسيطاته للأنواع بخلاف Tensor ، بما في ذلك MySubTensor . (لدى NumPy نفس المشكلة). الطريقة _correct_ لاستدعاء super من __add__ ستكون عرض جميع الوسائط التي يجب "إزالتها من الإرسال" كـ Tensor ، ثم _ ثم استدعاء super().__add__ .
تطبيق
سيحصل Tensor على تطبيق افتراضي لـ __torch_function__ والذي من شأنه:
- افحص جميع الوسائط لمعرفة ما إذا كان
getattr(t, "__torch_function__", Tensor.__torch_function__) is not Tensor.__torch_function__. في حالة وجود مثل هذه الوسيطة ،return NotImplemented. - قم بإجراء العملية
- قم بعمل
return Minimal_Subclass.from(ret)في النهاية.
ستؤدي أشجار النوع غير ذات الصلة إلى ظهور خطأ.
hameerabbasi
في ٣ ديسمبر ٢٠١٩
شكرا hameerabbasi . سأغير fastai2 لاستخدام as_subclass لهذا أيضًا ، لذا سنكون متوافقين في المستقبل.
jph00
في ٣ ديسمبر ٢٠١٩
@ jph00 فقط
hameerabbasi
في ٤ ديسمبر ٢٠١٩
نعم لا مشكلة - لقد قمت بالفعل بتصحيحها على الرغم من:
<strong i="6">@patch</strong>
def as_subclass(self:Tensor, typ):
"Cast to `typ` (should be in future PyTorch version, so remove this then)"
return torch.Tensor._make_subclass(typ, self)
راجع للشغل الشيء الوحيد الذي لا يعمل مع هذا النهج هو فقدان أي attrs إضافية. سيكون من الجيد أن يتم إصلاح ذلك ، لأننا نعتمد عليه - في الوقت الحالي سنضيف هذا يدويًا إلى الإصدار المصحح. إليك مثال (بناءً على التنفيذ أعلاه):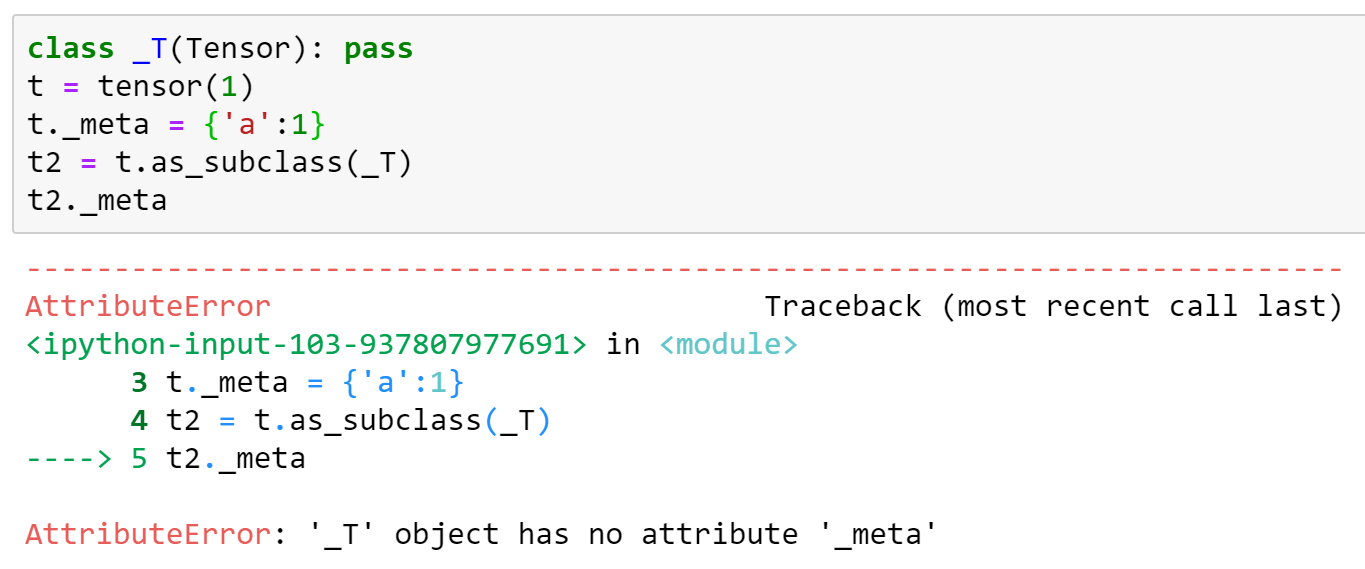
jph00
في ٤ ديسمبر ٢٠١٩
نعم ، سيتعين عليك تحديد __torch_function__ الذي ينسخ هذه الأشياء ، ويجب أن يفعل ذلك لجميع المصفوفات.
hameerabbasi
في ٤ ديسمبر ٢٠١٩
لماذا لا يكون لديك as_subclass يفعل ذلك؟ لا ينبغي أن يؤدي الإرسال إلى حذف السمات ، أليس كذلك؟
jph00
في ٤ ديسمبر ٢٠١٩
يبدو هذا عادلاً ، نعم ، يمكننا نسخ كل شيء في الكائن __dict__ .
hameerabbasi
في ٤ ديسمبر ٢٠١٩
__torch_function__ سيتم تغييرها إلى طريقة فئة لأسباب الإرسال
هل يمكنك أن تقول بوضوح أكثر ماذا يعني هذا؟
الحصول على مصفوفات وسيطة إضافية تحتوي على المصفوفات التي تم تمريرها
هل تقصد موتر؟
هذا الاقتراح يعني الخروج من واجهة برمجة التطبيقات التي أنشأها ngoldbaum . نحن نضيف مؤخرًا __torch_function__ لذلك لا يزال لدينا فرصة لإجراء تغييرات ، لكني أود أن أرى بعض الجدل في الاقتراح حول سبب إجراء هذه التغييرات. على وجه الخصوص ، لماذا يجب أن نفعل ذلك بشكل مختلف عن Numpy؟
انسخ البيانات
حقا نسخة؟ أم أنهم سيتشاركون التخزين؟
Tensor.from (other_class)
هل تقترح تسمية هذا from أو as_subclass ؟
الطريقة الصحيحة لاستدعاء super من
__add__ستكون عرض جميع الوسائط التي يجب "إزالتها من الإرسال" مثل Tensor ، ثم استدعاءsuper().__add__.
هذا مختلف تمامًا عما ناقشناه ، وأريد التراجع عن هذا الاقتراح قليلاً.
افترض أن لديك:
class ATensor(Tensor):
a: SomeAMetaData
class BTensor(ATensor):
b: SomeBMetaData
def __add__(self, other):
...
لقد ذكرت أنه في تعريف __add__ ، نحن ملزمون بـ other.as_subclass(ATensor) لإزالة BTensor من التسلسل الهرمي للإرسال. حسنًا ، يبدو عادلاً بدرجة كافية. ولكن كما رأيتم في المناقشة مع @ jph00 ، هذا يعني أنه يجب علينا نسخ SomeAMetaData إلى عرض A للموتر عندما ننتقل إلى التعريف التالي. يبدو هذا سطحيًا للغاية بالنسبة لي ، لأنك أعدت تطبيق تقطيع كائن C ++ بشكل أساسي في Python (https://stackoverflow.com/questions/274626/what-is-object-slicing). والجميع يكره تقطيع الأشياء.
علاوة على ذلك ، ما زلت لم تحل المشكلة التي تنشأ في هذه الحالة:
class ATensor(Tensor):
def __add__(self, other):
...
class BTensor(ATensor):
def __torch_function__(self, ...):
...
وفقًا لقواعد دقة الطريقة ، سيقوم BTensor.__add__ باستدعاء ATensor.__add__ ، متجاوزًا __torch_function__ تمامًا. سيء!
ezyang
في ٤ ديسمبر ٢٠١٩
عذرًا إذا كان هذا سؤالًا غبيًا - ولكن لماذا نسخ __قرار__ بدلاً من مجرد استخدام مرجع؟ (في fastai2 ، أستخدم مرجعًا فقط في الوقت الحالي ، لأنه عندما قمنا بالإرسال ، لم نتوقع عادةً الحصول على نسخة ، بل عرضًا مختلفًا لنفس البيانات ، بما في ذلك البيانات الوصفية.)
jph00
في ٤ ديسمبر ٢٠١٩
وفقًا لقواعد دقة الطريقة ، سيقوم
BTensor.__add__باستدعاءATensor.__add__، متجاوزًا__torch_function__بالكامل. سيء!
حسنًا ، سأخرج على أحد الأطراف هنا وأدعي أن Tensor.__add__ و Tensor.__torch_function__ يعرفان كيفية التعامل مع أي فئات فرعية من أجلها Subclass.__torch_function__ is Tensor.__torch_function__ . لذلك يمكن لـ ATensor.__add__ استدعاء super دون القلق كثيرًا ، أو "إزالة أي شيء من الإرسال" ، أو القلق بشأن أي نوع من الفئات الفرعية. رائعة!
الآن يأتي الجزء الثاني. بعد أن يقوم ATensor.__add__ بسحره ويدعو super و Tensor.__add__ يلاحظ أنه لا يزال هناك BTensor كائنات هناك و BTensor.__torch_function__ is not Tensor.__torch_function__ ! لذا فهي تعود إلى هناك (مع كل الأشياء كما هي) ، والتعامل معها بشكل صحيح.
يعود التدفق الآن إلى ATensor.__add__ . يلاحظ أن isinstance(super().__add__(self, other), ATensor) ! ينفذ أي معالجة لاحقة أخرى ويعيد القيمة.
هل تقترح تسمية هذا
fromأوas_subclass؟
لقد غيرتها لتكون متسقة.
هل تقصد موتر؟
هذا الاقتراح يعني الخروج من واجهة برمجة التطبيقات التي أنشأها ngoldbaum . نحن نضيف مؤخرًا
__torch_function__لذلك لا يزال لدينا فرصة لإجراء تغييرات ، لكني أود أن أرى بعض الجدل في الاقتراح حول سبب إجراء هذه التغييرات. على وجه الخصوص ، لماذا يجب أن نفعل ذلك بشكل مختلف عن Numpy؟
أفترض أننا لسنا مضطرين لذلك. اعتقدت أنه كان ضروريًا ، لكن التفكير في الأمر مرة أخرى ، بمثالك ، كنت مخطئًا.
حقا نسخة؟ أم أنهم سيتشاركون التخزين؟
تم تغيير هذا ليكون متسقًا أيضًا.
hameerabbasi
في ٥ ديسمبر ٢٠١٩
عذرًا إذا كان هذا سؤالًا غبيًا - ولكن لماذا نسخ
__dict__بدلاً من مجرد استخدام مرجع؟ (في fastai2 ، أستخدم مرجعًا فقط في الوقت الحالي ، لأنه عندما قمنا بالإرسال ، لم نتوقع عادةً الحصول على نسخة ، بل عرضًا مختلفًا لنفس البيانات ، بما في ذلك البيانات الوصفية.)
قصدت نسخة ضحلة ، وليست نسخة عميقة ، ولكن كما يشير ezyang ، فإن هذا يمثل مشكلة ، ويتم التعامل معه بشكل أفضل في __torch_function__ من الفئة الفرعية.
hameerabbasi
في ٥ ديسمبر ٢٠١٩
الآن يأتي الجزء الثاني. بعد ATensor .__ add__ يقوم بالسحر ويستدعي super ، Tensor .__ أضف__ إشعارات بأنه لا يزال هناك كائنات BTensor ، وأن BTensor .__ torch_function__ ليس Tensor .__ torch_function__! لذا فهي تعود إلى هناك (مع كل الأشياء كما هي) ، والتعامل معها بشكل صحيح.
هذا التدفق يبدو عكسيًا تمامًا بالنسبة لي. إذا كانت BTensor فئة فرعية من ATensor ، أتوقع أن تتم معالجة B أولاً قبل الوصول إلى A. OOP 101
ezyang
في ٥ ديسمبر ٢٠١٩
هذا التدفق يبدو عكسيًا تمامًا بالنسبة لي. إذا كان
BTensorفئة فرعية منATensor، أتوقع أن تتم معالجةBأولاً قبل أن أصل إلىA. عفوا 101
على الرغم من أنني أوافق ، فإن الطرق الافتراضية هي ما هي عليه ، للأسف ، والطريقة الوحيدة التي يمكنني التفكير فيها للتغلب على هذا هو نهج metaclass الذي ناقشناه ، وهو الأسلوب الذي يستخدم التصحيح / يستخدم __torch_function__ لكل طريقة واحدة ... والتي يمكن أن يؤدي إلى سلوك أكثر غرابة: يتم تجاهل A.__add__ .
hameerabbasi
في ٥ ديسمبر ٢٠١٩
شيء واحد يمكنني التفكير فيه هنا هو استخدام التصميم التالي: استخدم B.__torch_function__(B.__add__, (self, other), {}) كإعداد افتراضي ، ولكن هذا قد يفسد أي إرسال قائم على القاموس قد يكون موجودًا.
hameerabbasi
في ٥ ديسمبر ٢٠١٩
نقطة تعريف سريعة: إذا لم نتمكن من التفكير في طريقة جيدة (وليس "طريقة للتغلب") للقيام بذلك ، فيجب أن نتوقف عن فعل ذلك ، أو نغير قيودنا الأساسية حتى تكون هناك طريقة جيدة.
ezyang
في ٥ ديسمبر ٢٠١٩
حسنًا ، البديل الآخر هنا هو استخدام __tensor_wrap__ و __tensor_finalize__ . ما يفعله هذان البروتوكولان هو في الأساس المعالجة المسبقة واللاحقة عند "الالتفاف في فئة فرعية".
ومع ذلك ، ملاحظة تحذيرية: هذه لها نفس المشكلة تمامًا مع super التي ناقشناها للتو (على سبيل المثال ، ستتم معالجة الأشياء بترتيب خاطئ في مثالك).
أو تغيير قيودنا الأساسية حتى يكون هناك طريقة جيدة.
ماذا عن هذا: استخدم metaclass الذي يحقن ما يلي في:
شيء واحد يمكنني التفكير فيه هنا هو استخدام التصميم التالي: استخدم
B.__torch_function__(B.__add__, (self, other), {})كإعداد افتراضي ، ولكن هذا قد يفسد أي إرسال قائم على القاموس قد يكون موجودًا.
إذا كان B.__add__ is not Tensor.__add__ ، فإنني أدعي أن الإرسال المستند إلى القاموس يجب أن يفشل ، ويجب على المرء استخدام func.__name__ بدلاً من ذلك.
إذا لم يكن هذا الخيار ممكنًا ، فيجب علينا تغيير القيود.
hameerabbasi
في ٧ ديسمبر ٢٠١٩
ما هو المقصود هنا ب "الإرسال القائم على القاموس"؟ أنا ضائع قليلا الآن.
ezyang
في ٨ ديسمبر ٢٠١٩
الإرسال المستند إلى القاموس هو المكان الذي يستخدم فيه المرء ، داخل __torch_function__ ، قاموسًا للبحث عن func وتحديد تنفيذ الوظيفة. سيفشل هذا كـ B.__add__ is not Tensor.__add__ ، وإذا أرسل فصل دراسي على الأخير ، فلن يتم العثور عليه في dict. لكني أدعي أن هذا هو السلوك الصحيح ، لأن استخدام cls.__add__ سيؤدي إلى السلوك الصحيح. إذا كان الفصل هو B أو أحد فروعه التي لا تتجاوز __add__ ، فإن B.__add__ هي الطريقة الصحيحة للاستخدام ، والبحث عن Tensor.__add__ غير صحيح على أي حال.
hameerabbasi
في ٩ ديسمبر ٢٠١٩
hameerabbasi أود أن أقترح إضافة تفاعل __add__ مع فئات فرعية متعددة إلى حالات الاختبار في فرعك. من الصعب حقًا متابعة المناقشة على هذا النحو ؛ أرغب في أن أكون قادرًا على اكتشاف بسهولة أكبر إذا كانت هذه أداة عرض أم حافظة زاوية.
نقطة تعريف سريعة: إذا لم نتمكن من التفكير في طريقة جيدة (وليس "طريقة للتغلب") للقيام بذلك ، فيجب أن نتوقف عن فعل ذلك ، أو نغير قيودنا الأساسية حتى تكون هناك طريقة جيدة.
يجب أن يكون كل "قيد" حالة اختبار منفصلة.
لتحقيق التقدم بسهولة أكبر ، قد يكون من المفيد إضافة آلية بطيئة مماثلة لـ NumPy's __array_finalize__ والتي تلبي جميع القيود ، ثم تقييم الخطأ الذي يحدث إذا تم استبداله بشيء أسرع (سواء كان metaclass أو __torch_function__ أساس أو غيرها).
أيضًا ، هذه الآلية مستقلة عن تغييرات واجهة برمجة التطبيقات العامة مثل as_subclass ، لذا سيكون من المفيد أن تكون قادرًا على النظر إليها أيضًا - لا ينبغي أن تحتاج إلى تغييرات بعد ذلك.
rgommers
في ١٠ ديسمبر ٢٠١٩
لتحقيق التقدم بسهولة أكبر ، قد يكون من المفيد إضافة آلية بطيئة مماثلة لـ NumPy's
__array_finalize__التي تلبي جميع القيود ، ثم تقييم الخطأ الذي يحدث إذا تم استبداله بشيء أسرع (سواء كان metaclass أو__torch_function__أساس أو غيرها).
هذا سيكون له نفس مشكلة التكوين ، لسوء الحظ. أشرت إلى ذلك هنا :
حسنًا ، البديل الآخر هنا هو استخدام
__tensor_wrap__و__tensor_finalize__. ما يفعله هذان البروتوكولان هو في الأساس المعالجة المسبقة واللاحقة عند "الالتفاف في فئة فرعية".ومع ذلك ، ملاحظة تحذيرية: هذه لها نفس المشكلة تمامًا مع
superالتي ناقشناها للتو (على سبيل المثال ، ستتم معالجة الأشياء بترتيب خاطئ في مثالك).
أيضًا ، هذه الآلية مستقلة عن تغييرات واجهة برمجة التطبيقات العامة مثل
as_subclass، لذا سيكون من المفيد أن تكون قادرًا على النظر إليها أيضًا - لا ينبغي أن تحتاج إلى تغييرات بعد ذلك.
ezyang هل لديك فكرة عما يجب القيام به لمثل هذه الوظيفة ، وما هي البيانات التي تحتاج إلى نسخ وما يحتاج إلى آراء وما إلى ذلك؟
hameerabbasi
في ١٠ ديسمبر ٢٠١٩
hameerabbasi ، لست متأكدًا من دلالات الدلالات الدقيقة لـ as_subclass (نعم أعلم أنه ينظر إلى الموتر كفئة فرعية ، لكن هذا غامض بشكل محبط). بالنسبة للمبتدئين ، هل يستدعي مُنشئ الفئة الفرعية؟
ezyang
في ١٠ ديسمبر ٢٠١٩
كنت آمل أن تكون هناك طريقة للقيام بذلك مع الاحتفاظ بمؤشر البيانات نفسه ، أيًا كان ما يستلزمه ذلك ، وكذلك الاحتفاظ بأي بيانات autograd مرفقة ..
hameerabbasi
في ١٠ ديسمبر ٢٠١٩
أعتقد أن الدلالات يجب أن تكون مماثلة تمامًا لاستبدال __class__ في كائن Python العادي. هذا أيضًا هو سلوك view() في numpy ، على ما أعتقد. وهو القول:
- يتم الاحتفاظ بكل الولايات ، بما في ذلك
__dict__ - لم يتم استدعاء
__init__ - سيعيد
type()النوع الجديد ، وسيستخدم إرسال الأسلوب طرق هذا النوع بطريقة Python المعتادة (بما في ذلك إرسال metaclass ، إذا تم تعريف metaclass)
أعتقد أنه من المفيد أيضًا أن يكون لديك طريقة خاصة يتم استدعاؤها في هذا الوقت إذا كانت موجودة - في fastai2 ، على سبيل المثال ، يطلق عليها __after_cast__ .
jph00
في ١٠ ديسمبر ٢٠١٩
لست متأكدًا من كيفية القيام بذلك. اسمحوا لي أن أقدم بعض المعلومات حول كيفية تنفيذ PyObject في PyTorch وربما يمنحك ذلك بعض المعلومات.
يبدو PyObject الذي يمثل Tensor كما يلي:
// Python object that backs torch.autograd.Variable
// NOLINTNEXTLINE(cppcoreguidelines-pro-type-member-init)
struct THPVariable {
PyObject_HEAD
// Payload
torch::autograd::Variable cdata;
// Hooks to be run on backwards pass (corresponds to Python attr
// '_backwards_hooks', set by 'register_hook')
PyObject* backward_hooks = nullptr;
};
يحتوي كل متغير أيضًا على حقل pyobj يشير إلى الكائن الفريد PyObject يمثل الموتر. هذا يضمن تطابق هوية كائن C ++ وهوية كائن Python.
هل هذا الجواب على سؤالك؟
ezyang
في ١١ ديسمبر ٢٠١٩
هل هذا الجواب على سؤالك؟
قليلا. يبدو لي أنه إذا تم نسخ cdata بأسلوب RAII فعليًا عند إنشاء مهمة / نسخ ، فسنحتاج إلى طريقة لنسخها بشكل ضحل أو تغييرها إلى مؤشر ، لكن هذا تغيير جائر للغاية. بخلاف ذلك ، يمكننا فقط نسخ جميع الحقول ، في الغالب ، بالإضافة إلى النسخ السطحي __dict__ .
hameerabbasi
في ١٩ ديسمبر ٢٠١٩
هذه هي الطريقة التي قمت بها بتحديث تطبيق fastai2 منذ أسبوعين:
def as_subclass(self:Tensor, typ):
res = torch.Tensor._make_subclass(typ, self)
if hasattr(self,'__dict__'): res.__dict__ = self.__dict__
return res
يبدو أنه يعمل بشكل جيد بالنسبة لنا - ولكن إذا فقدنا شيئًا مهمًا ، فأنا أحب أن أعرف الآن حتى نتمكن من محاولة إصلاحه! (وإذا لم نفقد شيئًا مهمًا ، فهل هذا حل يمكن أن تستخدمه pytorch أيضًا؟)
jph00
في ١٩ ديسمبر ٢٠١٩
سأمضي قدمًا وألخص المشكلة بـ __torch_function__ للطرق بالإضافة إلى __torch_finalize__ ، ثم أتحدث عن تفضيلتي وأخذي في
__torch_function__ للطرق (والمشكلة مع super )
ضع في اعتبارك الكود التالي ( __torch_function__ للطرق سيمرر self كمتغير أول).
class SubclassA(torch.Tensor):
def __add__(self, other):
# Do stuff with self, other
temp_result = super().__add__(self_transformed, other_transformed)
# Do stuff with temp_result
return final_result
class SubclassB(SubclassA):
def __torch_function__(self, func, args, kwargs):
# Do stuff with args, kwargs
temp_result = super().__torch_function__(self, func, args_transformed, kwargs_transformed)
# Do stuff with temp_result
return temp_result
الآن ، ضع في اعتبارك ما يحدث عندما نضيف مثيل SubclassB مع مثيل آخر.
نظرًا لأن __add__ موروث من SubclassA ، ينتقل التحكم في التدفق إلى هناك أولاً بدلاً من SubclassB 's __torch_function__ . ما يحدث بشكل ملموس في اقتراحي الحالي هو:
self/otherبواسطةSubclassA.__add__. نأمل ، إذا لم يحدث شيء غريب جدًا ، فإن التحولات تحافظ على الفئة (SubclassBفي هذه الحالة).- نظرًا لأن
self_transformed/other_transformedهو مثيل لـSubclassB، فإن الاستدعاء لـsuperينتقل إلىTensor.__torch_function__، والذي بشكل افتراضي يفعل نفس الشيء تمامًا كـTensor.__add__، وإرجاع النتيجة. - ثم نقوم بتحويل
temp_result، ونعيده إلىSubclassA.__add__. SubclassAبإجراء التحولات النهائية ثم إرجاع النتيجة.
المشكلة في هذا هي: هناك انعكاس في السيطرة. يجب أن يكون SubclassB.__torch_function__ هو الشخص الذي يتحكم في تدفق التنفيذ ، لكنه ليس كذلك.
خلال مكالمة سابقة ، تحدثت أنا و ezyang عن الحل التالي: أضف __add__ افتراضيًا إلى SubclassB (ربما عبر metaclasses) الذي يرسل مباشرةً إلى SubclassB.__torch_function__ .
أود أن أقترح الجانب الآخر من هذا ، والذي له ميزة جعل كل شيء يتصرف تمامًا كما يتصرف Tensor . ربما يمكننا حتى جعل Tensor نفسه يعمل بهذه الطريقة إذا لم يكن الأمر يتعلق بالقيود المفروضة على تراجع الأداء:
اجعل جميع عمليات تنفيذ الطرق في الفئات الفرعية تمر أيضًا عبر __torch_function__ افتراضيًا.
__torch_finalize__ والمشكلة مع super
هنا ، على الرغم من أن المشكلة أقل تفاقمًا ، لا تزال موجودة. يوجد انعكاس عنصر التحكم ، ولكن نظرًا لأن __torch_finalize__ (كما يوحي الاسم) يكمل النتيجة فقط (بناءً على أحد المدخلات من هذا النوع) ، ولكنه لا يؤدي إلى معالجة مسبقة.
as_subclass
أعتقد أن ezyang يمكنه التحدث أكثر عن
def as_subclass(self:Tensor, typ):
res = torch.Tensor._make_subclass(typ, self)
if hasattr(self,'__dict__'): res.__dict__ = self.__dict__.copy() ## I added the copy
return res
وإلا فإن تعديل أي سمة على res سيؤدي أيضًا إلى تعديلها على self (إلا إذا كانت هذه هي النية؟)
hameerabbasi
في ٧ يناير ٢٠٢٠
def as_subclass (self: Tensor، typ):
الدقة = torch.Tensor._make_subclass (النوع ، النفس)
إذا hasattr (self، '__dict__'): res .__dict__ = self .__dict __. copy () ## لقد أضفت النسخة
عودة الدقة
وإلا فإن تعديل أي سمة علىresسيؤدي أيضًا إلى تعديلها علىself(إلا إذا كانت هذه هي النية؟)
هذا هو بالتأكيد النية! :) يجب أن يكون الكائن المصبوب مرجعًا وليس نسخة. لاحظ أن هذا هو السلوك الذي تراه بالفعل في _make_subclass :
a = tensor([1,2,3])
class T(Tensor): pass
res = torch.Tensor._make_subclass(T, a)
res[1] = 5
print(res)
موتر ([1، 5، 3])
سيكون محيرًا للغاية إذا كان الكائن المصبوب يعمل كمرجع عندما يتعلق الأمر ببيانات الموتر الخاصة بهم ، ولكن كنسخة عندما يتعلق الأمر بسماته.
jph00
في ٧ يناير ٢٠٢٠
اجعل جميع عمليات تنفيذ الطرق في الفئات الفرعية تمر أيضًا بـ __torch_function__ افتراضيًا.
إذن هل تقول ، بدلاً من أن يكون super().__add__ طريقة صحيحة للاتصال بتطبيق الوالدين ، يمكنك استدعاء __torch_function__ ؟ أم أن هذا شيء آخر؟ (أعتذر إذا كنت قد وصفت هذا بالفعل أعلاه ولكن المحادثة طويلة جدًا. قد يكون من الجيد تعديل الرسالة الرئيسية بأحدث المقترحات لسهولة الوصول إليها.)
ezyang
في ٨ يناير ٢٠٢٠
أعني أن جميع الطرق التي يستخدمها Tensor بالفعل ستمر عبر __torch_function__ ، _ حتى للفئات الفرعية_. بشكل ملموس ، في المثال أعلاه ، سيتم تزيين SubclassA.__add__ تلقائيًا بـ @torch_function_dispatch _ ، ونوصي بأن تقوم جميع الفئات الفرعية بنفس الشيء. سيكون لهذا التأثير المرغوب في جعل super().__add__ يمر عبر super().__torch_function__ .
hameerabbasi
في ٨ يناير ٢٠٢٠
هذه هي المرة الأولى التي تذكر فيها torch_function_dispatch في هذا العدد. :)
لذا ، إذا فهمت بشكل صحيح ، فإن ما تقترحه هو أنه عند استخدام موتر فئة فرعية ، فأنت ملزم باستخدام مصمم ديكور ، على سبيل المثال ،
class SubclassA(Tensor):
<strong i="8">@torch_function_dispatch</strong>
def __add__(self, other):
...
super().__add__(self)
إذا كانت هذه هي الحالة ، فبأي ترتيب ينتهي بي الأمر باستدعاء هذه الوظائف ، إذا كان لدي فئات فرعية متعددة ، وتم تحديد __torch_function__ و __add__ في كلتا الحالتين؟ ما زلت لا أفهم تماما اقتراحك. سيكون من المفيد إذا كان بإمكانك نشر المزيد من أمثلة التعليمات البرمجية التفصيلية ، وإرشادي إلى ما يحدث في هذه الحالات.
ezyang
في ٩ يناير ٢٠٢٠
لذلك ، بالنسبة للحالة المعيبة ، سنستبدلها بالشفرة التالية:
def _add_dispatcher(self, other):
return self, other
class SubclassA(torch.Tensor):
@torch_function_dispatch(_add_dispatcher)
def __add__(self, other):
# Do stuff with self, other
temp_result = super().__add__(self_transformed, other_transformed)
# Do stuff with temp_result
return final_result
class SubclassB(SubclassA):
def __torch_function__(self, func, args, kwargs):
# Do stuff with args, kwargs
temp_result = super().__torch_function__(self, func, args_transformed, kwargs_transformed)
# Do stuff with temp_result
return temp_result
ما يحدث هو ما يلي:
- سيكون لدينا تطبيق افتراضي لكل فئة مقابل
__torch_function__. - سيتم إرسال الكود إلى تطبيق إذا كان متاحًا بخلاف ذلك الافتراضي.
- افترض أن
x.__add__يسمى حيثtype(x) is SubclassB. سوف تصل إلىSubclassA.__add__. - والذي من شأنه أن يدرك أن هناك فئات أخرى غير الفئات الفائقة
SubclassAوهي نفسها موجودة في قائمة الوسائط ، ستحاولself.__torch_function__ثمother.__torch_function_. - لذلك سوف يمر الرمز من خلال
SubclassB.__torch_function__ - تأخذ التحويلات شكل
t.as_subclass(SubclassA) - عندما يتم استدعاء
super().__torch_function__، سيتم إرساله إلىSubclassA.__add__، حسب الاقتضاء. - تم تمرير التحكم مرة أخرى إلى
SubclassB. - تحدث المعالجة اللاحقة ويتم إرجاع النتيجة.
hameerabbasi
في ١٤ يناير ٢٠٢٠
أشعر أن هناك خطوة مفقودة من قبل
- لذلك سوف يمر الكود من خلال الفئة الفرعية ب .__ وظيفة_وظيفة_الشعلة__
اتصلت بـ x.__add__() حيث x هو SubclassB . وفقًا لقواعد دقة Python العادية ، سأضرب SubclassA.__add__ عندما يحدث هذا. هل تقول أن مصمم الإرسال سيمرر التحكم إلى SubclassB.__torch_function__ ؟ ما زلت غير متأكد من كيفية عمل ذلك.
ezyang
في ١٤ يناير ٢٠٢٠
لذا ، فكر في SubclassA.__add__ ... سيتبع بروتوكول __torch_function__ . عندما يدرك أن هناك فئات أخرى غير الفئات الفائقة SubclassA وهي نفسها موجودة في قائمة الوسائط ، ستحاول self.__torch_function__ ثم other.__torch_function_ . نظرًا لأنك ذكرت أن self هو SubclassB ، فسوف تصل إلى SubclassB.__torch_function__ .
hameerabbasi
في ١٥ يناير ٢٠٢٠
ملاحظة عرضية واحدة ، ربما يجب أن نطلق على الكود الذي يشير إلى أن الرمز torch_function_dispatch شيء مميز عن __torch_function__ ، لأنه ليس نفس الرمز على الإطلاق. سأسمي هذا "مرسل بايثون" في الوقت الحالي.
دعني أرى ما إذا كنت أفهم ما تقوله بشكل صحيح. مقترحك يقول:
- عندما يستدعي المستخدم طريقة على فئة Tensor ، فإننا دائمًا ننقل التحكم إلى مرسل Python أولاً. تحتوي جميع الطرق المضمنة في Tensor على هذه الوظيفة ، وأي طرق تم تجاوزها بشكل صريح في Tensor ترتب لنقل هذا التحكم عبر مصمم إلزامي (ماذا يحدث إذا نسي المستخدم إضافة هذا المصمم؟)
- بمجرد أن نكون في مرسل Python ، نحتاج إلى نقل التحكم إلى الطريقة الصحيحة المحددة من قبل المستخدم أو تطبيق
__torch_function__. على غرار كيفية عمل__torch_function__من العلاقات العامة لـ ngoldbaum ، نتخذ قرارًا بشأن الفئة الأكثر تحديدًا ، ثم نحاول استدعاء الطريقة المقابلة في الفصل (إن وجدت) ، أو__torch_function__on هذا الفصل.
أنت تستخدم super() في مثالك ، لكن مع الخلاصة أعلاه لا أرى كيف يمكن أن يعمل super. ستنقل المكالمة الفائقة التحكم مرة أخرى إلى مرسل بايثون ، لكن مرسل بايثون يحتاج إلى معرفة هذه المرة أننا قد "انتهينا" بالفعل من الفئة الأكثر تحديدًا ، ويجب أن نفعل شيئًا أعلى في التسلسل الهرمي للفصل ، لكنني لا أفعل ذلك. لن ترى كيف يمكنك معرفة ذلك ، في الاقتراح.
ezyang
في ١٦ يناير ٢٠٢٠
أنت تستخدم
super()في مثالك ، لكن مع الخلاصة أعلاه لا أرى كيف يمكن أن يعمل super. ستنقل المكالمة الفائقة التحكم مرة أخرى إلى مرسل بايثون ، لكن مرسل بايثون يحتاج إلى معرفة هذه المرة أننا قد "انتهينا" بالفعل من الفئة الأكثر تحديدًا ، ويجب أن نفعل شيئًا أعلى في التسلسل الهرمي للفصل ، لكنني لا أفعل ذلك. لن ترى كيف يمكنك معرفة ذلك ، في الاقتراح.
الطريقة التي يتعامل بها NumPy مع هذه الوسيطة types في __array_function__ ، تزيل الفئات الفرعية "نفسها" من types قبل استدعاء super()
hameerabbasi
في ٢٣ يناير ٢٠٢٠
أنا أكتب أيضًا RFC على النحو المطلوب.
hameerabbasi
في ٢٣ يناير ٢٠٢٠
ezyang @ jph00 انتهت المسودة الأولى للاقتراح. https://github.com/pytorch/rfcs/pull/3
hameerabbasi
في ٢٤ يناير ٢٠٢٠
القضايا ذات الصلة
 cdluminate
·
3تعليقات
cdluminate
·
3تعليقات
 Coderx7
·
3تعليقات
Coderx7
·
3تعليقات
 bartolsthoorn
·
3تعليقات
bartolsthoorn
·
3تعليقات
 kdexd
·
3تعليقات
kdexd
·
3تعليقات
 dablyo
·
3تعليقات
dablyo
·
3تعليقات
التعليق الأكثر فائدة
أريد أن أشير إلى حالة استخدام أخرى لهذه الوظيفة التي ظهرت في محادثاتنا مع OpenAI. ما تريد OpenAI القيام به هو إدخال خطافات على مستوى كل مشغل ، حتى يتمكنوا من فحص الموترات التي تتدفق خلال كل عملية (في الوقت الحالي ، يتم تثبيتها على مستوى الوحدة النمطية ، ولكن في بعض الأحيان هناك المزيد من العمليات الدقيقة التي يحتاجون إليها ربط في).
__torch_function__قريب بشكل محير من توفير ما تحتاجه لهذا الغرض ، ولكن:دعونا نتأكد من أنه يمكننا الوصول إلى هذه الحالة أيضًا!
سم مكعبsuoorionrNarineK الذين كانوا حاضرين لهذه المحادثة.