Openlibrary: 書籍のエディションを送信するときにISBN-13を入力するためのダッシュ `-`を許可する
解決したい問題を説明してください
書籍の版を提出するときにISBN-13を入力する場合、ダッシュを許可できますか? 現在、許可されているのは数字のみです。
値にダッシュが含まれているAmazonから値をコピーしようとすると、UIがエラーをスローします。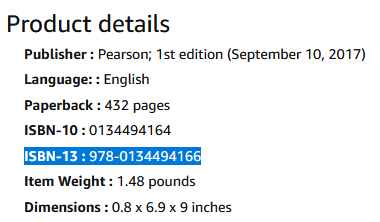
提案と制約
ダッシュを許可する
追加のコンテキスト
ダッシュもhttps://www.isbn-13.info/で許可されているようです
利害関係者
 serv
serv
全てのコメント17件
@servこの問題に取り組みたい
 Sabreen-Parveen
2021年01月01日
Sabreen-Parveen
2021年01月01日
それは素晴らしいでしょうそしてそれからそれはハイフンなしでそれを数字に自動的に変換することができます
 BrittanyBunk
2021年01月01日
BrittanyBunk
2021年01月01日
ダッシュだけを追加するのではなく、 @ servを追加して、次のスニペットに示すように、isbn13の条件を満たすかどうかを確認する適切な検証関数を追加する必要があると思います。
def is_isbn13(n):
n = n.replace('-','').replace(' ', '')
if len(n) != 13:
return False
product = (sum(int(ch) for ch in n[::2])
+ sum(int(ch) * 3 for ch in n[1::2]))
return product % 10 == 0
@ Sabreen-見栄えのするParveen-ハイフン/スペースがなくなった後に検証チェックを追加します。 実際には、削除する文字のリストにコンマとピリオドを追加することをお勧めします。コピー/貼り付けの際に、誤ってそれらを強調表示することがあるためです。 また、削除する文字として(Xを除く)文字を追加することもできます。これは、誰かがそれをコピー/貼り付けに入れている可能性があるためです。 残りの文字は警告を出すのに問題ありません(私が1つを逃した場合を除く)。
BrittanyBunk
2021年01月03日
それが数値的に許可されたisbn13であることをテストするのは素晴らしいことですが、そのような数字のすべてが出版された本に対応しているわけではありません。 それは、それを保持している図書館または利用可能な在庫のあるベンダーを検索することによってのみテストできます。
 LeadSongDog
2021年01月03日
LeadSongDog
2021年01月03日
@LeadSongDogまた、コンピューターがISBNが有効かどうかを確認している間、誰かが待つのはばかげていると思います。
本当に良いのは、誰かがISBN(10または13)を入れると、持っていないものが魔法のように表示されることです。 その理由は、検索者であろうと検索エンジンであろうと、ISBNが1つしかない本を探すのは非常に難しいためです。 私にとって、それはISBNが正しいかどうかを気にするよりもはるかに重要です-それは修正できるからです。 私はここで間違っているかもしれませんが、ユーザー側から見ると、いつでも削除できるので、多い方が少ないよりはましですが、その間にいないことは困難です。
問題が無効であると言っているのではありません。最初の優先順位は2つのISBNを同時に持つことであり、2番目の優先順位はクローラーにISBNを再確認させることです。 私は個人的にBookFinderをすべてのものに使用しています。
BrittanyBunk
2021年01月04日
@ Sabreen-Parveen私の感覚では、2つの操作があります。
n = n.replace('-','').replace(' ', '')- 残りのISBN検証ロジック。
これらを___2つの別々の___PRに入れてください。理由は次のとおりです。
- 些細なことですが、ユーザーの生活が楽になるので、すぐに着陸する必要があります。
- かっこいいですが、 https://pypi.org/project/isbnlib/からインポートする検証ロジックと重複する可能性があるため、レビューと着陸に時間がかかる可能性があります。
 cclauss
2021年01月05日
cclauss
2021年01月05日
@cclaussは良い考えです。bookfinderにはすべてのISBNをダウンロードする方法がないからです。
BrittanyBunk
2021年01月05日
人々がこの問題について考え、取り組んでいることを本当にうれしく思います。 多くの人が直面しているのはよくある問題です。
BrittanyBunk
2021年01月07日
書籍の追加ページで、13桁かどうかのチェックがないことに気付きました。そのため、isbnを追加するだけで、入力要素が値を受け入れます。 書籍の追加ページにも検証機能を追加する必要がありますか? この関数は、isbnが13桁であるかどうかのみをチェックし、ダッシュもチェックします。
Sabreen-Parveen
2021年01月11日
@ Sabreen-どこにでもあるParveenが望ましい-ダッシュが一般の人に表示されない場合-データの一貫性を保ち、データダンプを簡潔にすることが重要です-これらの余分なダッシュはすべて、そこにあるGBを増やすだけです。使用と保管がはるかに困難になります。 それはまたより多くのお金がかかります。
BrittanyBunk
2021年01月12日
LeadSongDogがルックアップが実際に行われることを示唆していたとは思いませんが、物事を「ばかげている」と呼ぶ前に、利益とコストを比較検討する価値があるでしょう。 無効なISBNが100ミリ秒でフラグ付けされる可能性がある場合、それは完全に待つ価値があります。
しかし、このすべてが非常に間違っているようです。 ダッシュは、実際のデータのカットアンドペーストを可能にするだけでなく、ユーザーが使い慣れた形式で情報を表示するため、実際に優れています。 私の意見では、それらは保存されるべきです。 それらを削除(または正規化)する必要があるのは、正規化された検索フィールドだけです。そのうちの1つだけが必要です。同等であるため、10桁と13桁の両方の形式は必要ありません。
したがって、プロトコルは次のようになります。
- ダッシュ付きまたはダッシュなしの10桁または13桁のISBNを受け入れ、入力したとおりに保存します
- 警告しますが、(間違って印刷されることがあるため)禁止しないでください。チェックディジットが無効なISBN
- ダッシュなしで正規化されたISBN13に基づいて検索インデックスを作成します
- 検索時に、ユーザーが入力したISBNを検索用の正規化された形式に変換します
わかりやすくするために、それぞれ数個のダッシュが付いた5,000万のISBNは、0.2 GB未満であり、1ペニーの何分の1かです。
この作業は、ISBN、発行での使用法、および検索テクノロジを理解している人が指示する必要があります。
 tfmorris
2021年01月13日
tfmorris
2021年01月13日
無効なISBNが100ミリ秒でフラグ付けされる可能性がある場合、それは完全に待つ価値があります。
同意しました。
この作業は、ISBN、発行での使用法、および検索テクノロジを理解している人が指示する必要があります。
誰をお勧めしますか?
cclauss
2021年01月13日
@seabelisはISBNを理解しています。 誰を検索するかはわかりませんが、必要なものの95%は2017年のコメントhttps://github.com/internetarchive/openlibrary/issues/609#issuecomment-354509114にあります。
ol-techメーリングリスト、 Githubの問題などの間には、これを正しく行う方法についての制度的な知識がたくさんあります。 このスレッドには存在しないため、ハイジャックされないようにしています。
tfmorris
2021年01月13日
@tfmorrisISBNの外部検証にはいくつかの合理的なオプションがあります。 応答時間を比較する価値があるかもしれません。 可能性には、Google、Baidu、およびその他の一般的な検索エンジンの巨人が含まれますが、より具体的なオプションも検討する必要があります。
https://isbnsearch.org/isbn/9788400047252
https://www.worldcat.org/search?q=bn%3A9788400047252
LeadSongDog
2021年01月13日
@tfmorris多少の混乱があると思いますが、ダッシュがデータセットに表示されないという最終製品について言及しています(Webサイトとは関係ありません)。 私はすべてを取り上げたわけではありませんが(できる限り脱線したくないのですが、そうはしません)、私が言ったことは、これに取り組んでいる間、すべての人にあらゆる角度を認識させるのに問題がある可能性があります軌道に乗る。
BrittanyBunk
2021年01月14日
@tfmorrisに強く同意します。「警告しますが、チェックディジットが無効なISBNは(間違って印刷されることがあるため)許可しないでください」。
 seabelis
2021年01月14日
seabelis
2021年01月14日
関連する問題
 cdrini
·
4コメント
cdrini
·
4コメント
cdrini
·
4コメント
cdrini
·
4コメント
 jdlrobson
·
5コメント
BrittanyBunk
·
5コメント
jdlrobson
·
5コメント
BrittanyBunk
·
5コメント
 nonom
·
3コメント
nonom
·
3コメント
最も参考になるコメント
@ Sabreen-Parveen私の感覚では、2つの操作があります。
n = n.replace('-','').replace(' ', '')これらを___2つの別々の___PRに入れてください。理由は次のとおりです。