Openlibrary: Permitir guión `-` para ingresar ISBN-13 al enviar una edición de un libro
Describa el problema que le gustaría resolver
Al ingresar ISBN-13 al enviar una edición de un libro, ¿puede permitir guiones? Actualmente solo se permiten números.
Cuando intento copiar el valor de Amazon que tiene un guión en el valor, la interfaz de usuario arroja un error.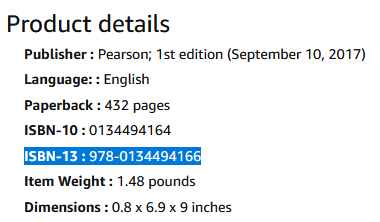
Propuesta y Restricciones
Permitir guiones
Contexto adicional
Parece que https://www.isbn-13.info/ también permite guiones
Partes interesadas
 serv
serv
Todos 17 comentarios
@serv me gustaria trabajar en este tema
 Sabreen-Parveen
en 1 ene. 2021
Sabreen-Parveen
en 1 ene. 2021
eso sería increíble y luego puede convertirlo automáticamente en un número sin el guión
 BrittanyBunk
en 1 ene. 2021
BrittanyBunk
en 1 ene. 2021
@serv en lugar de agregar solo guiones, creo que deberíamos agregar una función de validación adecuada para verificar si cumple la condición de isbn 13 o no, como se muestra en el siguiente fragmento:
def is_isbn13(n):
n = n.replace('-','').replace(' ', '')
if len(n) != 13:
return False
product = (sum(int(ch) for ch in n[::2])
+ sum(int(ch) * 3 for ch in n[1::2]))
return product % 10 == 0
@Sabreen-Parveen que se ve muy bien: agregar la verificación de validación después de que desaparezcan los guiones/espacios. De hecho, recomendaría agregar una coma y un punto a la lista de caracteres para eliminar, ya que a veces, al copiar/pegar, las personas pueden resaltarlos accidentalmente. También podría agregar letras (excepto X) como las que desea eliminar, ya que tal vez alguien también las esté poniendo en copiar/pegar. El resto de los personajes están bien para dar una advertencia (a menos que me perdí una).
BrittanyBunk
en 3 ene. 2021
Es genial probar que es un isbn13 permitido numéricamente, pero no todos esos números corresponden a un libro publicado. Eso solo se puede probar buscando bibliotecas que lo tengan o proveedores con inventario disponible.
 LeadSongDog
en 3 ene. 2021
LeadSongDog
en 3 ene. 2021
@LeadSongDog También diría que sería ridículo que alguien esperara mientras la computadora verifica si su ISBN es válido.
Lo que de verdad es mejor es que si alguien pone un ISBN (10 o 13), que por arte de magia aparezca el que no tiene. La razón es que es muy difícil buscar un libro con un solo ISBN, ya sea el buscador o el motor de búsqueda. Para mí, eso es mucho más importante que preocuparse por si el ISBN es correcto o no, ya que eso se puede corregir. Puede que me equivoque aquí, pero desde el punto de vista del usuario, tener más es mejor que menos, ya que siempre se puede eliminar, pero no tenerlo durante ese tiempo es difícil.
No digo que su problema no sea válido, digo que la primera prioridad es tener 2 ISBN al mismo tiempo y luego la segunda prioridad es hacer que un rastreador verifique dos veces los ISBN. Yo personalmente uso BookFinder para todas mis cosas.
BrittanyBunk
en 4 ene. 2021
@ Sabreen-Parveen Mi sensación es que tenemos dos operaciones.
n = n.replace('-','').replace(' ', '')- la lógica de validación restante del ISBN.
Póngalos en ___dos RP separados___ porque:
- es trivial pero facilitará la vida de los usuarios, por lo que deberíamos aterrizarlo rápidamente.
- es genial, pero podría superponerse con la lógica de validación que importamos de https://pypi.org/project/isbnlib/ , por lo que podría tardar más en revisarse y aterrizar.
 cclauss
en 5 ene. 2021
cclauss
en 5 ene. 2021
@cclauss buena idea, ya que bookfinder no tiene una forma de descargar todos sus isbn.
BrittanyBunk
en 5 ene. 2021
Solo quería decir que estoy muy contento de que la gente esté pensando y trabajando en este tema. Es un problema común que apuesto a que mucha gente enfrenta.
BrittanyBunk
en 7 ene. 2021
He notado que en la página de agregar libros no se verifica si tiene 13 dígitos o no, así que simplemente podemos agregar el isbn y el elemento de entrada acepta el valor. ¿Debo agregar la función de validación en la página Agregar libros también? La función solo verificará si el isbn tiene 13 dígitos o no y también verificará los guiones.
Sabreen-Parveen
en 11 ene. 2021
@Sabreen-Parveen en todas partes es preferible, siempre que los guiones no aparezcan en lo que ve el público, es importante mantener los datos consistentes y concisos para los volcados de datos, todos esos guiones adicionales solo aumentarán los gb allí, lo que lo hará que sea mucho más difícil de usar y almacenar. También cuesta más dinero.
BrittanyBunk
en 12 ene. 2021
No creo que LeadSongDog estuviera sugiriendo que la búsqueda realmente se hiciera, pero antes de llamar a las cosas "ridículas", probablemente valdría la pena sopesar el beneficio frente al costo. Si se pudiera marcar un ISBN no válido en 100 milisegundos, la espera valdría la pena.
Sin embargo, todo esto parece haberse desviado mucho. Los guiones son realmente buenos no solo porque permiten cortar y pegar datos del mundo real, sino porque presentan la información en la forma con la que los usuarios están familiarizados. En mi opinión, deberían conservarse. El único lugar donde deben eliminarse (o normalizarse) es en el campo de búsqueda normalizado, y solo debe haber uno de esos, no necesita formularios de 10 y 13 dígitos ya que son equivalentes.
Entonces, el protocolo debe ser:
- acepte ISBN de 10 o 13 dígitos con o sin guiones y guárdelo tal como se ingresó
- advierta, pero no rechace (ya que a veces se imprimen incorrectamente), ISBN con dígitos de control no válidos
- construir el índice de búsqueda basado en un ISBN 13 normalizado sin guiones
- al buscar convertir el ISBN ingresado por el usuario a la forma normalizada para la búsqueda
Y solo para mayor claridad, 50 millones de ISBN con algunos guiones cada uno es <0,2 GB y fracciones de centavo.
Este trabajo debe ser dirigido por alguien que comprenda los ISBN, su uso en la publicación y la tecnología de búsqueda.
 tfmorris
en 13 ene. 2021
tfmorris
en 13 ene. 2021
Si se pudiera marcar un ISBN no válido en 100 milisegundos, la espera valdría la pena.
Acordado.
Este trabajo debe ser dirigido por alguien que comprenda los ISBN, su uso en la publicación y la tecnología de búsqueda.
¿A quién recomendarías?
cclauss
en 13 ene. 2021
@seabelis entiende los ISBN. No estoy seguro de a quién buscaría, pero el 95 % de lo que necesita está en mi comentario de 2017 https://github.com/internetarchive/openlibrary/issues/609#issuecomment -354509114
Entre la lista de correo de ol-tech , los problemas de Github , etc., hay mucho conocimiento institucional sobre cómo hacer esto correctamente. Simplemente no está presente en este hilo, así que estoy tratando de evitar que las cosas sean secuestradas.
tfmorris
en 13 ene. 2021
@tfmorris Hay varias opciones razonables para la validación externa de los ISBN. Puede valer la pena comparar los tiempos de respuesta. Las posibilidades incluyen Google, Baidu y otros gigantes genéricos de motores de búsqueda, pero también deberíamos considerar opciones más específicas:
https://isbnsearch.org/isbn/9788400047252
https://www.worldcat.org/search?q=bn%3A9788400047252
LeadSongDog
en 13 ene. 2021
@tfmorris Creo que hay cierta confusión, pero me refiero al producto final, que los guiones no aparecen en los conjuntos de datos (sin relación con el sitio web). No mencioné todo (ya que no quiero descarrilar, como podría, pero no lo haré), pero lo que dije puede ser problemático, hacer que todos sean conscientes de cada ángulo mientras trabajamos en esto se supone que nos ayudará. quedarse en el camino.
BrittanyBunk
en 14 ene. 2021
Totalmente de acuerdo con @tfmorris "Advierta, pero no rechace (ya que a veces se imprimen incorrectamente), ISBN con dígitos de control no válidos".
 seabelis
en 14 ene. 2021
seabelis
en 14 ene. 2021
Temas relacionados
 skylerbunny
·
4Comentarios
BrittanyBunk
·
5Comentarios
skylerbunny
·
4Comentarios
BrittanyBunk
·
5Comentarios
 cdrini
·
4Comentarios
cclauss
·
3Comentarios
cdrini
·
4Comentarios
cclauss
·
3Comentarios
 Yashs911
·
5Comentarios
Yashs911
·
5Comentarios
Comentario más útil
@ Sabreen-Parveen Mi sensación es que tenemos dos operaciones.
n = n.replace('-','').replace(' ', '')Póngalos en ___dos RP separados___ porque: