Nomad: Ability to select private/public IP for specific task/port
Extracted from #209.
We use Nomad with Docker driver to operate cluster of machines. Some of them have both public and private interfaces. These two-NIC machines run internal services that need to listen only on a private interface, as well as public services, which should listen on a public interface.
So we need a way of specifying whether some task should listen on public or private IP.
I think this can be generalized to the ability to specify subnet mask for a specific port:
resources {
network {
mbits = 100
port "http" {
# Listen on all interfaces that match this mask; the task will not be
# started on a machine that has no NICs with IPs in this subnet.
netmask = "10.10.0.1/16"
}
port "internal-bus" {
# The same with static port number
static = 4050
netmask = "127.0.0.1/32"
}
}
}
This would be the most flexible solution that would cover most, if not all, cases. For example, to listen on all interfaces, as requested in #209, you would just pass 0.0.0.0/0 netmask that matches all possible IPs. Maybe it makes sense to make this netmask the default, i.e. bind to all interfaces if no netmask is specified for a port.
I think this is really important feature, because its lack prevents people from running Nomad in VPC (virtual private cloud) environments, like Amazon VPC, Google Cloud Platform with subnetworks, OVH Dedicated Cloud and many others, as well as any other environments where some machines are connected to more than one network.
Another solution is to allow specifying interface name(s), like eth0, but that wouldn't work in our case because:
- different machines may have different order and, thus, different names of network interfaces;
- to make things worse, some machines may have multiple IPs assigned to the same interface, e.g. see DigitalOcean's anchor ip which is enabled by default on each new machine.
Example for point 1: assume that I want to start some task on all machines in the cluster, and that I want this task to listen only on private interface to prevent exposing it to the outer world. Consul agent is a nice example of such service.
Now, some machines in the cluster are connected to both public and private networks, and have two NICs:
eth0corresponds to public network, say,162.243.197.49/24;eth1corresponds to my private network10.10.0.1/24.
But majority of machines are only connected to a private net, and have only one NIC:
eth0corresponds to the private net10.10.0.1/24.
This is fairly typical setup in VPC environments.
You can see that it would be impossible to constrain my service only to private subnet by specifying interface name, because eth0 corresponds to different networks on different machines, and eth1 is even missing on some machines.
 skozin
skozin
All 72 comments
Hey @skozin,
Thanks for the input. I like the idea of a netmask and it is a valid way of constraining your task to the correct network. The one major draw back to this approach is that it forces the end user (not the operator) to know the network configuration. What I would like is to allow operators to set up arbitrary key/value metadata for network interfaces and then end users can use a simpler constraint. For example an operator could tag a network interface as "availability" = "public" and then the user can submit a job with something like this:
port "http" {
constraint {
"availability" = "public"
}
}
Obviously syntax was just something I came up with right now but does this seem reasonable to you? With a more generic constraint system (like that for jobs) we could also support net mask and other constraints.
 dadgar
on 6 Jan 2016
dadgar
on 6 Jan 2016
Hi @dadgar,
Thanks for the prompt response =) Yes, this seems perfectly reasonable to me.
Your proposal is more elegant and flexible than mine, because it yields more readable/maintainable job definitions and, at the same time, allows for greater precision, e.g. it is possible to bind some task to private interface on a set of machines even if those machines have private interfaces pointing into different private networks.
But, in order for this to cover the same cases, the implementation should meet these two requirements:
- If multiple interfaces match constraint for some port, the task should listen on all matching interfaces' addresses;
- if matching interface has multiple addresses, the task should listen on each of these IPs.
So, if some port matches interfaces A and B, where A have addresses a1 and a2, and B have addresses b1 and b2, then the task should listen on a1, a2, b1 and b2.
I'm not sure I understand the new port[name].constraint construct. Do you propose to move static attribute there too? I think it should be done for consistency, because static = xxx is, in fact, a constraint, just like availability = "public":
port "http" {
constraint {
static = 1234
interface {
availability = "public"
}
}
}
Or, maybe, it would be better to not introduce new inner block that would always be required?
port "http" {
static = 1234
interface {
availability = "public"
}
}
Another question is about how to specify metadata for network interfaces. Do I get it right that it would go into client block of Nomad configuration, like this?
client {
network {
interface "eth0" {
availability = "public"
}
interface "eth1" {
availability = "private"
}
interface "docker0" {
is_docker_bridge = true
}
}
}
If that's correct, then client.network_inteface option may now be deprecated, because you can do the same with new port constraints: just mark the desired interface with some metadata, e.g. use_for_nomad_tasks = true, and add this constraint to all ports. However, that would add complexity to job definitions, so maybe some special meta key may be introduced instead:
client {
network {
interface "eth1" {
# Special meta key that prohibits fingerprinting this interface
disable = true
}
interface "eth0" {
availability = "public"
}
}
And the last one: I think it would be useful to support negative meta constraints, e.g.:
# Client config
client {
network {
interface "eth0" {
availability = "public"
}
interface "eth1" {
availability = "private"
}
interface "lo" {
availability = "local"
}
}
}
# Task config
# ...
port "http" {
static = 1234
interface {
# would listen on "eth1" and "lo"
not {
availability = "public"
}
}
}
Or, maybe, regex constraints?
port "http" {
static = 1234
interface {
availability = "/^(?!public)./"
# or:
# availability = "/^(private|local)$/"
}
}
What do you think?
skozin
on 6 Jan 2016
Yeah the constraints should have the follow expressional power of our other constraints: https://www.nomadproject.io/docs/jobspec/index.html#attribute.
As for binding to all interfaces/ips, I think that should be a configurable thing. There are cases in which you only need to bind to a single IP/interface.
dadgar
on 7 Jan 2016
Ah, completely missed the constraints syntax, sorry. So, the port configuration would look like this, right?
port "http" {
static = 1234
constraint {
# "interface." is a prefix for all interface-related attributes
# "availability" is a user-defined attribute; a set of system-defined attributes
# may be added in the future, e.g. "netmask-cidr", "is-default-route", etc.
attribute = "interface.availability"
value = "public"
}
# there may be multiple constraints applied to the same port
}
Regarding binding to all interfaces that match port's constraints: of course there are cases when you need to bind to a single interface; I would even say that these cases are the most common ones. But wouldn't constraints system already enable you to do that? For example, if there are several interfaces marked with availability = "public", and you want to bind to one specific interface, just mark this interface with an additional metadata attribute, and include one more constraint in the port definition. Why wouldn't that work?
As for the case when an interface has several IPs, honestly I have no idea how this can be made configurable without requiring the job author to specify the exact IP or netmask. Of course you can add an option to bind to only one (first/random) IP of an interface, but that would be a fairly useless option, because now you have no idea what address the service will actually listen on, and whether this address would be routable from some network. The only generic and useful options I can think about is port.ipv4 defaulted to true and port.ipv6 defaulted to false, which would include/exclude all IPv4/IPv6 addresses.
skozin
on 7 Jan 2016
Yeah more or less! And I think that is a fairly clean syntax. The constraint system would let you do it but then you are breaking Nomads abstraction a bit by targeting a single IP/interface in particular when you just care about certain attributes. So I think there can be a bind_all_interfaces = true which binds you to all interfaces and similarly for IPs. As for determining your IP, we inject that via environment variables and it is also available via consul.
dadgar
on 7 Jan 2016
@dadgar, I know that IP is being passed to the task and is available via Consul, but, in some cases, you really need to listen on a _specific_ ip. The good example is DigitalOcean's floating IPs. Every instance in DO has two IPs attached to its eth0 interface: the first is regular public IP, and the second is so called anchor IP. In order to make some service accessible via floating IP, you need to listen on anchor IP. If you listen just on regular public IP, the service will be unaccessible via floating IP.
I'm not particularly against bind_all_interfaces option, but I fail to understand how you would usefully choose the IP/interface to listen on when bind_all_interfaces = false and multiple interfaces match the port or when the matching interface has multiple IPs.
I guess that choosing first/random interface/IP would be useless and confusing in such cases, especially if bind_all_interfaces will be false by default. For example, in the DO case you can't be sure that your service will be accessible via regular/floating IP if you constrain your service to eth0, because you can't know whether regular or anchor IP will be chosen by Nomad.
Another reason for listening on all interfaces by default is that it is the behavior that most developers are used to. For example, in Node.js and many other APIs, including Go, the socket will be bound to all interfaces if you don't explicitly pass the interface. It would be intuitive if Nomad exhibited the same behavior: in the absence of constraints, the port would be bound to all interfaces. And when you add constraints, you just narrow the set of chosen interfaces (and thus IPs). This is a really simple mental model.
That said, I understand that listening on multiple, but not all, interfaces in the case when driver doesn't support port mapping makes no sense, because you usually can't tell your program/API to listen on a set of IPs. Usually you have just two choices: either bind to all IPs, or to some particular IP.
So, maybe the following would be a good compromise:
- when no constraints are specified for a port, map that port to all interfaces when driver supports port mapping, and pass
NOMAD_PORT_xxx_IP = 0.0.0.0env. variable otherwise; - when a port has constraints, choose the first matching IP and map the port to that IP or pass
NOMAD_PORT_xxx_IP = a.b.c.denv. variable; - when a port has constraints that match multiple interfaces/IPs, print a message warning that random IP will be chosen.
skozin
on 8 Jan 2016
Yeah I don't think we disagree very much. I think we can randomly select an IP and that will be the desired behavior because the job should have constraints that logically match the desired attributes of the interface or set of IPs. So within that constraint group any IP we choose should be fine. For your DO example, there should be a way for an operator to mark that this CIDR block is of type floating/regular. And if an application cares they can put a constraint.
As for the environment variable I think we made a mistake by injecting only one IP variable. I think moving forward it will be something like NOMAD_IP_port_label="210.123.1.179:4231". So that multiple ports can be on different IPs.
dadgar
on 8 Jan 2016
Yup, passing port and IP together in a single variable would be a good choice too. Do I understand correctly that port_label part of NOMAD_IP_port_label variable name is a single substitution, e.g. http for port "http" { ... }?
But I think that it would be nice to additionally pass IP and port in different variables, to avoid parsing when you need IP and port separately, like in e.g. Node's http.listen API. That way, the task would get three variables for each port:
NOMAD_ADDRESS_portlabel="210.123.1.179:4231"NOMAD_IP_portlabel="210.123.1.179"NOMAD_PORT_portlabel="4231"(this is already present in Nomad).
Regarding random selection, I would suggest printing a warning anyway, because random IP selection, imho, is not what someone usually wants when binding a socket, and with great probability is a result of a mistake.
skozin
on 8 Jan 2016
Hi @dadgar, here are some points by @DanielDent against using interface names: https://github.com/hashicorp/nomad/pull/223#issuecomment-172157245
I don't agree that an interface name is necessarily easily predictable across deployed instances. This is probably even more true for Nomad than it is for Consul where I first raised this issue. Interface names can depend on the order in which interfaces are brought up - on some systems they can depend on some stateful ideas. On a bare metal Debian instance, /etc/udev/rules.d/70-persistent-net.rules is auto-generated during installation.
Interface names often are associated with a network technology. Some machines might be connected to the cluster over a VPN (and have an interface name based on that), while other machines might have the SDN interconnect offloaded to a hypervisor or network-provided routing infrastructure.
Some sites may even be using IP addresses directly for service discovery/bootstrapping purposes. It might involve anycasted IP addresses, IP addresses which are NATted to another IP, an IP address which gets announced to routing infrastructure using a BGP/IGP approach, or a DHCP server cluster which uses MAC addresses/VLAN tags/switch port metadata to assign static IP addresses to some or all nodes.
With heterogenous infrastructure, an IP subnet approach will work in cases where interface based approaches won't.
Furthermore, a single network interface can have multiple IP addresses associated with it. This is especially common in IPv6 configurations, but it can be come up with IPv4 too. A machine having many IPv6 addresses with a variety of scopes is pretty standard. Allowing users to specify an interface name might not actually help disambiguate the appropriate address on which to bind.
I can say that I agree with all of them, and that the cases described in that comment are the real ones and occur fairly frequently in production clusters. In our infrastructure, using interface names will not be a problem because we provision all machines with Ansible, so we can just implement additional logic for configuring Nomad, but not every setup allows this, and anyway it brings additional unneeded complexity.
I understand that CIDR notation is too low-level and infrastructure-specific, but, as you can see, interface names may be even more so.
What if we allowed infra operators to attach metadata to networks instead of interfaces? This way, job authors would still be able to use high-level attributes to specify port constraints. What do you think?
skozin
on 20 Jan 2016
Yeah I think in practice it will be something like that as interfaces can have many IPs
dadgar
on 20 Jan 2016
Hi, is there any update regarding this issue? Will Nomad support this feature fairly soon?
 tugbabodrumlu
on 26 Apr 2016
tugbabodrumlu
on 26 Apr 2016
@tugbabodrumlu Yeah it should be possible to use multiple network interfaces on Nomad fairly soon.
 diptanu
on 27 Apr 2016
diptanu
on 27 Apr 2016
Any updates on this?
 CpuID
on 10 Oct 2016
CpuID
on 10 Oct 2016
Related:
https://github.com/docker/docker/issues/17750
https://github.com/docker/docker/pull/17796#issuecomment-235764596
https://github.com/docker/docker/pull/18906 (available as of 1.10.x)
It seems you can use docker create, then docker network connect, and finally docker start to get multiple networks attached to a single container. But it can't be done in a single docker run call.
CpuID
on 10 Oct 2016
Sorry no update yet, priorities got shuffled a bit
dadgar
on 10 Oct 2016
We are also moving forward docker driver and need to support multiple interfaces per jobs or tasks. Is there any workaround yet? @dadgar do you have any milestone plan for this feature?
 kaskavalci
on 12 Dec 2016
kaskavalci
on 12 Dec 2016
@kaskavalci It will likely be in a 0.6.X release! Timeline on that is early half on next year.
dadgar
on 12 Dec 2016
Would love to see this as well!
 ashald
on 13 Dec 2016
ashald
on 13 Dec 2016
It would be best to abstract iterfaces into client configuration instead. For example put following in job description:
port "public_port" {
static = "80"
}
port "private_port" {
static = "80"
network = "private"
}
port "docker_port" {
static = "80"
network = "docker"
}
and in client configuration
network_interfaces {
public = "eth0"
private = "eth2"
docker = "overlay1"
}
 sheerun
on 3 Jan 2017
sheerun
on 3 Jan 2017
We have a similar case where every Docker container is assigned an ipv6 address (using Docker's fixed-cidr-v6). Our containers usually don't expose ports on the host (since they are reachable directly via IPv6). This however prevents us from letting Nomad register the container in Consul (including health checks), since Nomad only knows about the (host's) IPv4 ip and knows nothing about the ports.
So what we need is either:
a) Nomad to find out what IPv6 address is assigned to the container (after staring it), and use that to register it in Consul; or
b) Nomad to select an IPv6 address before starting a container and assign it while starting (like it does with non-static IPv4 ports).
I thought b) would be easy using Docker's ip and ip6 parameters, but was sadly mistaken...
Is our use case sufficiently covered here, or should we open a separate feature request for this?
 jovandeginste
on 27 Jan 2017
jovandeginste
on 27 Jan 2017
Just to chime in, not being able to have nomad select ipv6 instead of ipv4 address for service registration in consul shall be considered a bug.
 seeder
on 19 Feb 2017
seeder
on 19 Feb 2017
The ability to add additional networks and explicitly specify ip addresses when scheduling Docker containers is something we currently would require for our direct ip / routing of private, public unicast and anycast addressing to containers, not quite ready for ipv6 but would be nice to see that added as requested above.
 robwdux
on 13 Mar 2017
robwdux
on 13 Mar 2017
Hi,
Is there any update on this?
Thanks
 darren-west
on 31 May 2017
darren-west
on 31 May 2017
@darren-west No update yet!
dadgar
on 31 May 2017
My use case is that I need to bind to specific addresses, both IPv4 and IPv6.
Any tasks I could pick up here? If it's cool I could give bind_all_interfaces a try, or the following:
port "ovpn" {
static = 1194
bind = ["198.51.233.0/24", "2620:2:6000::/48"]
}
 ghost
on 14 Jul 2017
ghost
on 14 Jul 2017
For the record, I'm currently working around this with iptables port forwarding:
iptables -t nat -A PREROUTING -p udp -d 198.51.233.233 --dport 1194 -j DNAT --to-destination 10.44.3.1:1194
@dadgar Any update on this?
 dhv
on 27 Feb 2018
dhv
on 27 Feb 2018
Edit: After some more digging I've found this solution, which seems good enough for our case: https://github.com/hashicorp/nomad/issues/209#issuecomment-163144805
Below is my original comment. I hope, together with the link, it will be helpful to someone else.
Hello. In our case all services should only bind to private network - we want to use a load balancer to publish them selectively. Is there a way to achieve that?
Our particular configuration is as follows.
We are using Nomad backed by Consul in HA on DigitalOcean machines. Here is our configuration for Nomad servers:
data_dir = "/var/nomad/data"
bind_addr = "${ self.ipv4_address_private }"
advertise {
serf = "${ self.ipv4_address_private }:4648"
}
server {
enabled = true
bootstrap_expect = 3
}
client {
enabled = true
}
and Consul:
server = true,
data_dir = "/var/consul/data"
ui = true
bind_addr = "${ self.ipv4_address_private }"
bootstrap = ${ count.index == 0 }
We have a test job like that:
job "echo-service" {
datacenters = ["dc1"]
type = "service"
group "echo" {
task "webservice" {
driver = "docker"
resources {
network {
port "http" {}
}
}
config {
image = "hashicorp/http-echo"
args = [
"-text",
"Hello, Nomad!"
]
port_map {
http = 5678
}
}
}
}
}
It always binds to a public network interface. Interestingly, the Web UI shows the address as I would like it to be (probably a bug in its own right):
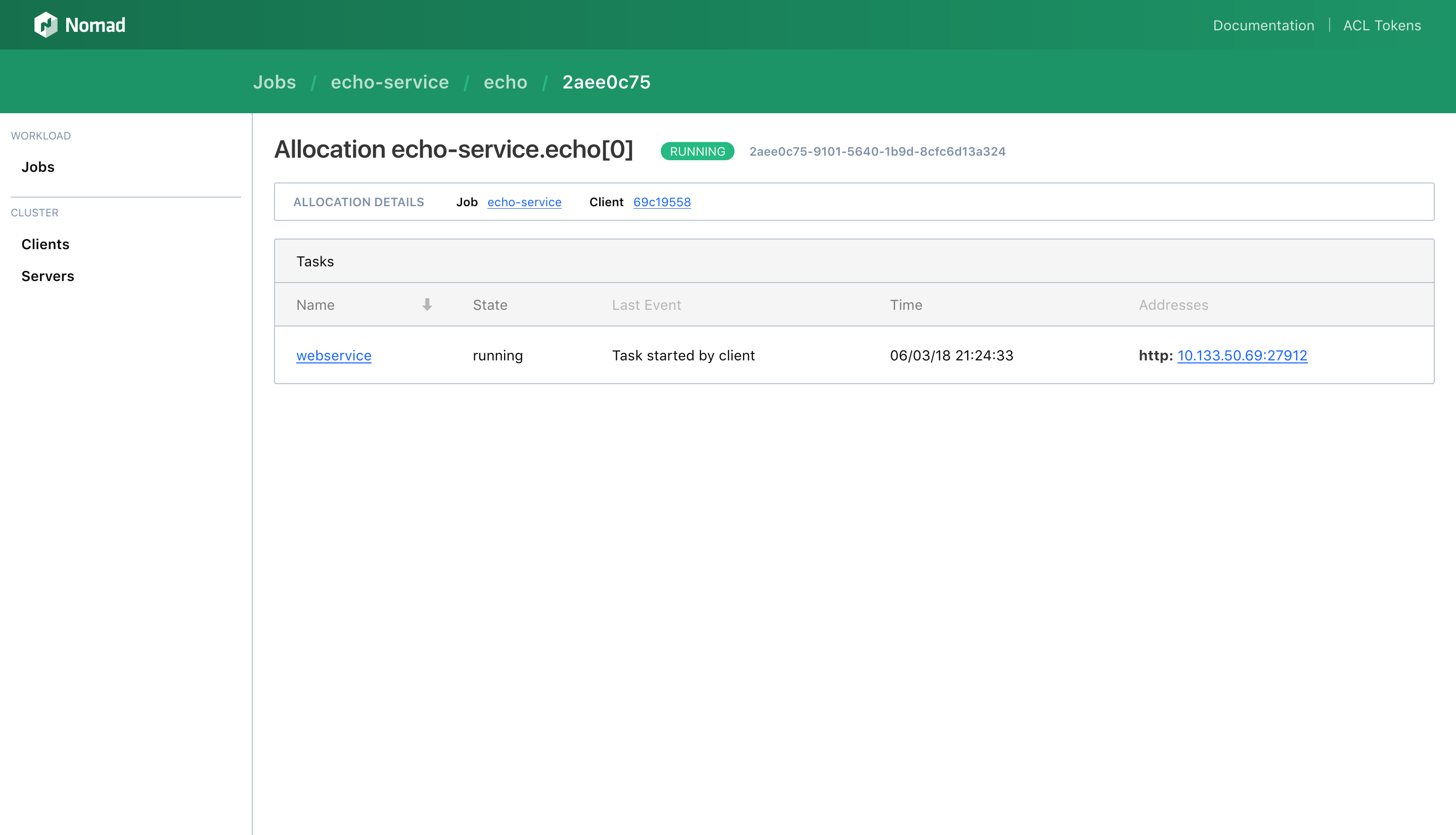
Unfortunately it doesn't seem to reflect reality:
$ http 10.133.50.69:27912
http: error: ConnectionError: HTTPConnectionPool(host='10.133.50.69', port=27912): Max retries exceeded with url: / (Caused by NewConnectionError('<requests.packages.urllib3.connection.HTTPConnection object at 0x7f49dc372810>: Failed to establish a new connection: [Errno 111] Connection refused',))
The CLI shows a real (alas unwanted) binding:
$ nomad alloc status 2aee0c75
ID = 2aee0c75
Eval ID = f7353297
Name = echo-service.echo[0]
Node ID = 69c19558
Job ID = echo-service
Job Version = 0
Client Status = running
Client Description = <none>
Desired Status = run
Desired Description = <none>
Created = 13m20s ago
Modified = 13m7s ago
Task "webservice" is "running"
Task Resources
CPU Memory Disk IOPS Addresses
0/100 MHz 812 KiB/300 MiB 300 MiB 0 http: 206.189.110.181:27912
Task Events:
Started At = 2018-06-03T19:24:33Z
Finished At = N/A
Total Restarts = 0
Last Restart = N/A
Recent Events:
Time Type Description
2018-06-03T19:24:33Z Started Task started by client
2018-06-03T19:24:31Z Driver Downloading image hashicorp/http-echo:latest
2018-06-03T19:24:31Z Task Setup Building Task Directory
2018-06-03T19:24:31Z Received Task received by client
$ http 206.189.110.181:27912
HTTP/1.1 200 OK
Content-Length: 14
Content-Type: text/plain; charset=utf-8
Date: Sun, 03 Jun 2018 19:42:30 GMT
X-App-Name: http-echo
X-App-Version: 0.2.3
Hello, Nomad!
Any soultion, even a hackish workaround, will be welcome.
 tad-lispy
on 3 Jun 2018
tad-lispy
on 3 Jun 2018
@lzrski Hm the UI does look like a bug, we will look into that. Nomad currently does not manage load balancers for you. A common approach is to set up an external load balancer that points to an internal load balancer such as Fabio register services in your internal load balancer
dadgar
on 4 Jun 2018
Mentioned in related issue #209 was binding to all interfaces by binding to 0.0.0.0. It was also mentioned in this original question. Is there any progress for that? I can't figure out how to go about configuring my service to be available on all network interfaces.
 radiomime
on 28 Jun 2018
radiomime
on 28 Jun 2018
@dadgar
We have a use case where we have to start public facing loadbalancers in AWS VPC (Fabio/Gobetween).
This is a blocker for us using Nomad + Docker and have temporarily reverted to using "raw_exec" to launch the loadbalancer.
Wouldn't it be possible to be able to easily allow the docker port forwarding on 0.0.0.0 rather the private IP ?
Maybe a config parameter ?
 shantanugadgil
on 6 Sep 2018
shantanugadgil
on 6 Sep 2018
Any luck we will have this feature in 2018?
Right now it is required to mess with NAT and/or routing for specific services and do all advertising in our own code instead of consul+nomad stack.
 yukron
on 26 Sep 2018
yukron
on 26 Sep 2018
+1. Having the ability to specify public/private in my jobspec is critical to us. I would really love to see this implemented at some point if it has not been done already.
 cofonseca
on 22 Oct 2018
cofonseca
on 22 Oct 2018
Another use case for allowing to bind to 0.0.0.0 instead of just the interface ip that faces the default route. We use anycast load balancing where a separate loopback is configured on the host per service. Because Nomad tells docker to only bind to a single IP, all requests to this loopback IP fail.
It is also quite mind boggling why Nomad would tell docker to bind to a specific IP rather than 0.0.0.0 which docker itself does and fully supports ?
 mayuresh82
on 24 Oct 2018
mayuresh82
on 24 Oct 2018
Or the capacity to bind on loopback only.
As of now this even ignore the ip option of docker (to set the default ip binding daemon wide). This also mean that without "iptables": false in your daemon config, the services you are running via docker will ignore any of your firewall configuration and may end-up available to the whole world.
The sane & secure default should anyway be loopback binding only, and any other IP or interface via an option.
 Mayeu
on 24 Oct 2018
Mayeu
on 24 Oct 2018
Just echoing what a few others have said here. This feature would be very helpful for me. In my case, I would love to be able to bind to 0.0.0.0 in bridged networking mode with docker driver.
 khimaros
on 27 Apr 2019
khimaros
on 27 Apr 2019
This is quite a critical feature. Currently, nomad only binds to 127.0.0.1, what if the request is coming on another network interface ?
 beenishkh
on 7 May 2019
beenishkh
on 7 May 2019
Any plan to add support to specify IP for the tasks in multihomed nomad-client machines in 2019?
 ping2balaji
on 15 May 2019
ping2balaji
on 15 May 2019
Any update?
 koalalorenzo
on 19 May 2019
koalalorenzo
on 19 May 2019
I'm just starting out with Nomad/Consul. Both agents are running on the same server. It seems like this limitation is also affecting me?
I'm running Python WSGI servers via Raw Fork/Exec (Can't use docker because of a Windows host/domain permission thing). I'm using Connect to authorize requests to the WSGI server.
I can't get Nomad to set $NOMAD_IP_http to 127.0.0.1. It's always set to the host IP. If I ignore that variable and always listen on 127.0.0.1 then Nomad still registers its host IP for the service health check. The check stanza doesn't seem to allow a manual override of ip value either.
The service must listen on localhost, otherwise someone could make requests without going through Connect.
Are there any workarounds for this?
UPDATE
The workaround I came up with was to ignore $NOMAD_IP_http and always listen on 127.0.0.1 then use a script health check like this:
check {
name = "HTTP Check"
type = "script"
command = "curl.exe"
args = ["-I", "127.0.0.1:${NOMAD_PORT_http}"]
interval = "10s"
timeout = "2s"
}
I'd still like to get this fixed though because Consul/Nomad are showing the host IP instead of 127.0.0.1 in the UI. I'd like what's displayed there to be accurate.
 Vye
on 6 Jun 2019
Vye
on 6 Jun 2019
+1 The ability to select address to bind for docker is really wanted. For some tasks, I want it to bind to private address; for the others, public, so network_interface is not an option to me. From what I read, current solutions are
- set network
mode="host"to export host interface - set
network_interfaceto instruct nomad to use ip on that interface. - mess with network routing
- do not use docker driver
Or even a way to allow docker to bind on 0.0.0.0 and then user setup firewall is better than current situation. mode=host is exclusive.
 jackhftang
on 11 Sep 2019
jackhftang
on 11 Sep 2019
I fail to understand how would Nomad be useful for docker container management at all when it does not even allow to select on which network interface a service is listening.
This is blocker for considering nomad for cluster management.
 vkukk
on 8 Oct 2019
vkukk
on 8 Oct 2019
Same issue here.
@dadgar @schmichael help, please
 ifokeev
on 10 Oct 2019
ifokeev
on 10 Oct 2019
@dadgar @schmichael we also facing the limitation, which we didn't expected.
We need to be able to use 0.0.0.0 as bind address for some docker tasks as we use virtual ip addresses to create ha in our on premise world!
 rkno82
on 28 Oct 2019
rkno82
on 28 Oct 2019
Yes. This is pretty important feature.
 suppix
on 13 Nov 2019
suppix
on 13 Nov 2019
Bump, I just setup a cluster with nomad and consul, and the inability to do this just made all that work of learning and configuration for naught.
 dariusj18
on 14 Nov 2019
dariusj18
on 14 Nov 2019
Discussing this internally now. :)
 yishan-lin
on 20 Nov 2019
yishan-lin
on 20 Nov 2019
And to add to the idea train, need to make sure that if you can have multiple interfaces per task that the service stanza also has some way to declare some way to map tags to interfaces. ex.
service {
network_interfaces {
"public" = [ "web" ]
}
}
The idea that if the task is bound to the public and private network interface, then consul would be updated so both ips are returned for the SRV records for the service, but you can also query for the tag web to get only the public ip addresses.
I guess the alternative would be to just have a new service stanza per ip binding with a setting to limit it to a network interface. ex.
service {
name = "private-admin"
network_interface = "private"
}
service {
name = "public-web"
network_interface = "public"
}
Wow, going all the way to 2016 with a lot of "i need" replies and nothing done. I can't believe even their contract customers wouldn't want this. Hashicorp :(
 daledude
on 31 Dec 2019
daledude
on 31 Dec 2019
Hi, also interested in being able to select specific IP addresses for specific services. Thanks!
 jjzazuet
on 14 Jan 2020
jjzazuet
on 14 Jan 2020
@yishan-lin Any results of the discuss?
 luckyraul
on 15 Jan 2020
luckyraul
on 15 Jan 2020
@luckyraul On the roadmap! Coming soon.
yishan-lin
on 9 Mar 2020
Another use case: I am just starting out with the Hashicorp stack, and I'm running Nomad (+Consul) on an untrusted network. I have a WireGuard peer-to-peer VPN setup, and I want jobs to map ports only to the VPN network interface. Then I can expose them properly through something like Traefik to manage access control.
 sbrl
on 18 Apr 2020
sbrl
on 18 Apr 2020
Thanks all for the input and appreciate deeply the patience from the community.
Please feel free to writeup any of your targeted use-cases in thread. We’re currently in design phase and are targeting this for our next major release in Nomad 0.12.
While we’re confident in our understanding of the core problem from earlier feedback, all voices are still welcome. Helps us cover and consider all potential angles and edge cases. 🙂
yishan-lin
on 4 May 2020
suggest having an option to allow binding on 0.0.0.0, and let users to configure firewall. This is an easy and flexible way and should satisfy most of the use cases.
jackhftang
on 4 May 2020
My current workaround for this is specifying a macvlan Docker network as a network_mode and passing through an IP address using ipv4_address. My only strong wish is that this capability isn't disturbed, but I definitely look forward to a better solution.
 nferch
on 4 May 2020
nferch
on 4 May 2020
My use case is that each server has localhost, a public use IP and a internal use IP. The localhost IP is IPv6 whereas the other IPs are IPv4. At a bare minimum I would like to restrict some services to only bind to the local IP, others that are only for server to server communications I would bind to the internal use IPs and services such as proxy servers I would bind to the external IPs.
In this case it would be easiest to allow configuration on each server to create a named group of IPs and/or network interfaces to be used.
dariusj18
on 4 May 2020
Hi Nomad friends! I'm currently working on the design for this feature and wanted to solicit some feedback since there has been alot of participants on this issue. You can either reply to this thread or feel free to reach out to me directly at [email protected] Thanks!
The TL;DR is to support fingerprinting multiple interfaces and addresses on Nomad clients, then expose a couple ways to select which of those interfaces a port should be allocated for.
From the perspective of the jobspec the idea is to support a new field in the port block host_network. Example:
network {
mode = "bridge"
port "admin" {
host_network = "10.0.0.0/8"
to = "8080"
}
port "http" {
host_network = "1.2.3.0/24"
to = "443"
}
}
This example says to allocate 2 dynamic ports. The admin port must be allocated to a client with an address in the 10.0.0.0/8 range then forward it from that host address/port to port 8080 inside the allocation network namespace. Port http follows the same pattern but must be allocated to an address in our example public range 1.2.3.0/24. The scheduler will then only select nodes which have addresses in both of these ranges.
This work without bridge networking and port forwarding as well. Nomad just expects the application to honor the NOMAD_IP_label|NOMAD_ADDR_label environment variables so the application binds to the correct ip and port.
To further enhance the UX of this I want to introduce a new client configuration to alias a node’s network to a string name. Example:
client {
host_network_aliases {
public = "1.1.1.0/24"
internal = "10.10.0.0/16"
}
}
With this configuration, the host node networks would get fingerprinted with the corresponding aliases. Then the job author could use the alias–in the above example, "public" or "internal"– instead of a cidr notation range for the host_network field.
If no host_network is given Nomad will default to use to the first routable private IP (current default strategy).
With this approach there are no changes to how a service advertises the address to consul. It will use the address associated with the given port.
 nickethier
on 15 May 2020
nickethier
on 15 May 2020
Looks good, my main focus is docker, would this work as I imagine, binding a docker container to a specific IP?
dariusj18
on 15 May 2020
@dariusj18 yeah the associated IP will get passed in with the port spec.
nickethier
on 15 May 2020
For our on premise network we are using nomad to deploy our applications.
Behind the firewall we are using keepalived to masquerade public to a
floating internal ip.
To use nomad to deploy HAProxy as „ingress controller“ we would need the
option to bind haproxy to the host and the keepalive virtual ip.
For that to work we need the support to bind haproxy to 0.0.0.0:80/443.
Thanks,
Robert
Nick Ethier notifications@github.com schrieb am Fr. 15. Mai 2020 um 20:09:
@dariusj18 https://github.com/dariusj18 yeah the associated IP will get
passed in with the port spec.—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
https://github.com/hashicorp/nomad/issues/646#issuecomment-629403671,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/ABCZH2IDMBAWCGFW744ULWLRRWANBANCNFSM4BX4EILA
.
rkno82
on 15 May 2020
I like how your handling the IP selection using CIDR.
How about the reverse where the driver tells nomad the ip's it's using? Currently the driver can only expose a single IP. We only use the host network for prometheus exporters. All our containers have their IP's assigned by the container program.
We use podman with CNI where all of our containers have a private IP and for services needing to be accessed from the internet are also assigned an additional public IP. I can imagine docker being similar when using a docker network plugin such as weave. We use raw_exec with a wrapper around podman that registers services/checks with consul because multiple service stanza's per task cannot specify which IP the service is for.
daledude
on 15 May 2020
I like your suggestion. Please remember to support IPv6 😉
jovandeginste
on 16 May 2020
@rkno82 Yeah this is an edge case I thought about initially but forgot to write down so thankyou! I'll be sure to cover it as well.
@daledude Yeah I explored this a bit in my initial discovery. Unfortunately it is not something I'm working to include in this initial design but is something we'll think about in iterative improvements. I tried to narrow the scope to portmapping/multiple host networks and address multiple interfaces/networks inside the netns later.
After some discussions with @schmichael I think I'm going to drop the support for using a cidr in the port block and instead require any host network to be defined in the client config (other than the current default one). This lines up a bit more with host volumes. You can't just mount any filesystem path on the host and I think we need the same safe guards around binding to an address. I've changes the proposed client configuration to be:
client {
host_network "public" {
cidr = "1.1.1.0/24"
interface = "{{ GetPublicInterfaces | limit 1 | attr \"name\" }}"
reserved_ports = "22,80"
}
}
In the host_network block cidr or interface is required to select which address or addresses can be used to allocate ports from for the host network. This also simplifies some ideas around configuring reserved ports by dropping them right into the block.
nickethier
on 19 May 2020
@nickethier , in case I wasn't clear. I'm talking about possibly changing drivers.DriverNetwork.IP from string to []string the driver (i.e. docker) fills in within it's StartTask(). No need to deal with netns's.
daledude
on 19 May 2020
Will this issue be solved with "Multi-Interface Networking" mentioned in https://www.hashicorp.com/blog/announcing-hashicorp-nomad-0-12-beta/ ?
rkno82
on 23 Jun 2020
@rkno82 correct!
yishan-lin
on 27 Jun 2020
@yishan-lin , @nickethier can you help me?
Is there any documentation how to configure my use-case?
I've watched https://digital.hashiconf.com/post-live/nomad-networking-demystified and tried to reproduce with "nomad -dev" mode, but cannot get the "redis-task" of the example.job to bind to 0.0.0.0.
config
client config
client {
host_network "public" {
# preferred way: cidr = "0.0.0.0/0"
cidr = "172.29.10.19/27"
}
network_interface = "eth0"
}
bind_addr = "0.0.0.0"
advertise {
http = "172.29.10.6:14646"
rpc = "172.29.10.6:14647"
serf = "172.29.10.6:14648"
}
ports {
http = 14646
rpc = 14647
serf = 14648
}
example.job with adjustment
network {
mode = "bridge"
mbits = 10
port "db" {
static = "1234"
host_network = "public"
}
}
logs
[root@rkno-dev rkno_temp]# ./nomad agent -dev -config nomad_client.hcl [141/1860]
==> Loaded configuration from nomad_client.hcl
==> Starting Nomad agent...
==> Nomad agent configuration:
Advertise Addrs: HTTP: 172.29.10.6:14646; RPC: 172.29.10.6:14647; Serf: 172.29.10.6:14648
Bind Addrs: HTTP: 0.0.0.0:14646; RPC: 0.0.0.0:14647; Serf: 0.0.0.0:14648
Client: true
Log Level: DEBUG
Region: global (DC: dc1)
Server: true
Version: 0.12.0-beta1
==> Nomad agent started! Log data will stream in below:
2020-06-29T11:26:08.584+0200 [DEBUG] agent.plugin_loader.docker: using client connection initialized from environment: plugin_dir=
2020-06-29T11:26:08.584+0200 [DEBUG] agent.plugin_loader.docker: using client connection initialized from environment: plugin_dir=
2020-06-29T11:26:08.584+0200 [INFO] agent: detected plugin: name=raw_exec type=driver plugin_version=0.1.0
2020-06-29T11:26:08.584+0200 [INFO] agent: detected plugin: name=exec type=driver plugin_version=0.1.0
2020-06-29T11:26:08.584+0200 [INFO] agent: detected plugin: name=qemu type=driver plugin_version=0.1.0
2020-06-29T11:26:08.584+0200 [INFO] agent: detected plugin: name=java type=driver plugin_version=0.1.0
2020-06-29T11:26:08.584+0200 [INFO] agent: detected plugin: name=docker type=driver plugin_version=0.1.0
2020-06-29T11:26:08.584+0200 [INFO] agent: detected plugin: name=nvidia-gpu type=device plugin_version=0.1.0
2020-06-29T11:26:08.586+0200 [INFO] nomad.raft: initial configuration: index=1 servers="[{Suffrage:Voter ID:172.29.10.6:14647 Address:172.29.10.6:14647}]"
2020-06-29T11:26:08.586+0200 [INFO] nomad.raft: entering follower state: follower="Node at 172.29.10.6:14647 [Follower]" leader=
2020-06-29T11:26:08.587+0200 [INFO] nomad: serf: EventMemberJoin: rkno-dev.global 172.29.10.6
2020-06-29T11:26:08.587+0200 [INFO] nomad: starting scheduling worker(s): num_workers=2 schedulers=[service, batch, system, _core]
2020-06-29T11:26:08.587+0200 [INFO] nomad: adding server: server="rkno-dev.global (Addr: 172.29.10.6:14647) (DC: dc1)"
2020-06-29T11:26:08.588+0200 [INFO] client: using state directory: state_dir=/tmp/NomadClient077148051
2020-06-29T11:26:08.589+0200 [INFO] client: using alloc directory: alloc_dir=/tmp/NomadClient646311894
2020-06-29T11:26:08.593+0200 [DEBUG] client.fingerprint_mgr: built-in fingerprints: fingerprinters=[arch, bridge, cgroup, cni, consul, cpu, host, memory, network, nomad, signal, storage, vault, env_aws, env_gce]
2020-06-29T11:26:08.593+0200 [INFO] client.fingerprint_mgr.cgroup: cgroups are available
2020-06-29T11:26:08.593+0200 [DEBUG] client.fingerprint_mgr: CNI config dir is not set or does not exist, skipping: cni_config_dir=/opt/cni/config
2020-06-29T11:26:08.594+0200 [DEBUG] client.fingerprint_mgr: fingerprinting periodically: fingerprinter=cgroup period=15s
2020-06-29T11:26:08.596+0200 [INFO] client.fingerprint_mgr.consul: consul agent is available
2020-06-29T11:26:08.596+0200 [DEBUG] client.fingerprint_mgr.cpu: detected cpu frequency: MHz=2793
2020-06-29T11:26:08.596+0200 [DEBUG] client.fingerprint_mgr.cpu: detected core count: cores=2
2020-06-29T11:26:08.600+0200 [DEBUG] client.fingerprint_mgr: fingerprinting periodically: fingerprinter=consul period=15s
2020-06-29T11:26:08.600+0200 [DEBUG] client.fingerprint_mgr.network: link speed detected: interface=eth0 mbits=10000
2020-06-29T11:26:08.600+0200 [DEBUG] client.fingerprint_mgr.network: detected interface IP: interface=eth0 IP=172.29.10.6
2020-06-29T11:26:08.600+0200 [DEBUG] client.fingerprint_mgr.network: detected interface IP: interface=eth0 IP=172.29.10.19
2020-06-29T11:26:08.601+0200 [WARN] client.fingerprint_mgr.network: unable to parse speed: path=/usr/sbin/ethtool device=lo
2020-06-29T11:26:08.601+0200 [DEBUG] client.fingerprint_mgr.network: unable to read link speed: path=/sys/class/net/lo/speed
2020-06-29T11:26:08.601+0200 [DEBUG] client.fingerprint_mgr.network: link speed could not be detected, falling back to default speed: mbits=1000
2020-06-29T11:26:08.607+0200 [WARN] client.fingerprint_mgr.network: unable to parse speed: path=/usr/sbin/ethtool device=docker0
2020-06-29T11:26:08.608+0200 [DEBUG] client.fingerprint_mgr.network: unable to read link speed: path=/sys/class/net/docker0/speed
2020-06-29T11:26:08.608+0200 [DEBUG] client.fingerprint_mgr.network: link speed could not be detected, falling back to default speed: mbits=1000
2020-06-29T11:26:08.611+0200 [DEBUG] client.fingerprint_mgr: fingerprinting periodically: fingerprinter=vault period=15s
2020-06-29T11:26:08.648+0200 [DEBUG] consul.sync: sync complete: registered_services=3 deregistered_services=0 registered_checks=3 deregistered_checks=0
2020-06-29T11:26:10.215+0200 [WARN] nomad.raft: heartbeat timeout reached, starting election: last-leader=
2020-06-29T11:26:10.216+0200 [INFO] nomad.raft: entering candidate state: node="Node at 172.29.10.6:14647 [Candidate]" term=2
2020-06-29T11:26:10.216+0200 [DEBUG] nomad.raft: votes: needed=1
2020-06-29T11:26:10.216+0200 [DEBUG] nomad.raft: vote granted: from=172.29.10.6:14647 term=2 tally=1
2020-06-29T11:26:10.216+0200 [INFO] nomad.raft: election won: tally=1
2020-06-29T11:26:10.216+0200 [INFO] nomad.raft: entering leader state: leader="Node at 172.29.10.6:14647 [Leader]"
2020-06-29T11:26:10.216+0200 [INFO] nomad: cluster leadership acquired
2020-06-29T11:26:10.217+0200 [INFO] nomad.core: established cluster id: cluster_id=126510a3-e438-2bcb-9457-9d97065c8dc7 create_time=1593422770217319790
2020-06-29T11:26:11.356+0200 [DEBUG] nomad: memberlist: Stream connection from=127.0.0.1:36770
2020-06-29T11:26:13.617+0200 [DEBUG] client.fingerprint_mgr.env_gce: could not read value for attribute: attribute=machine-type error="Get "http://169.254.169.254/computeMetadata/v1/instance/machine-type": context deadline exceeded (
Client.Timeout exceeded while awaiting headers)"
2020-06-29T11:26:13.617+0200 [DEBUG] client.fingerprint_mgr.env_gce: error querying GCE Metadata URL, skipping [81/1860]
2020-06-29T11:26:13.617+0200 [DEBUG] client.fingerprint_mgr: detected fingerprints: node_attrs=[arch, bridge, cgroup, consul, cpu, host, network, nomad, signal, storage]
2020-06-29T11:26:13.617+0200 [INFO] client.plugin: starting plugin manager: plugin-type=csi
2020-06-29T11:26:13.617+0200 [INFO] client.plugin: starting plugin manager: plugin-type=driver
2020-06-29T11:26:13.617+0200 [INFO] client.plugin: starting plugin manager: plugin-type=device
2020-06-29T11:26:13.618+0200 [DEBUG] client.driver_mgr: initial driver fingerprint: driver=java health=undetected description=
2020-06-29T11:26:13.618+0200 [DEBUG] client.driver_mgr: initial driver fingerprint: driver=raw_exec health=healthy description=Healthy
2020-06-29T11:26:13.618+0200 [DEBUG] client.driver_mgr: initial driver fingerprint: driver=exec health=healthy description=Healthy
2020-06-29T11:26:13.619+0200 [DEBUG] client.driver_mgr: initial driver fingerprint: driver=qemu health=undetected description=
2020-06-29T11:26:13.619+0200 [DEBUG] client.plugin: waiting on plugin manager initial fingerprint: plugin-type=driver
2020-06-29T11:26:13.620+0200 [DEBUG] client.plugin: waiting on plugin manager initial fingerprint: plugin-type=device
2020-06-29T11:26:13.620+0200 [DEBUG] client.plugin: finished plugin manager initial fingerprint: plugin-type=device
2020-06-29T11:26:13.620+0200 [DEBUG] client.server_mgr: new server list: new_servers=[0.0.0.0:14647, 172.29.10.6:14647] old_servers=[]
2020-06-29T11:26:13.647+0200 [DEBUG] client.driver_mgr: initial driver fingerprint: driver=docker health=healthy description=Healthy
2020-06-29T11:26:13.647+0200 [DEBUG] client.driver_mgr: detected drivers: drivers="map[healthy:[raw_exec exec docker] undetected:[qemu java]]"
2020-06-29T11:26:13.648+0200 [DEBUG] client.plugin: finished plugin manager initial fingerprint: plugin-type=driver
2020-06-29T11:26:13.648+0200 [INFO] client: started client: node_id=9e515b0f-c7c5-d866-5336-7d486e66671c
2020-06-29T11:26:13.652+0200 [INFO] client: node registration complete
2020-06-29T11:26:13.652+0200 [DEBUG] client: updated allocations: index=1 total=0 pulled=0 filtered=0
2020-06-29T11:26:13.652+0200 [DEBUG] client: allocation updates: added=0 removed=0 updated=0 ignored=0
2020-06-29T11:26:13.652+0200 [DEBUG] client: allocation updates applied: added=0 removed=0 updated=0 ignored=0 errors=0
2020-06-29T11:26:13.652+0200 [DEBUG] client: state updated: node_status=ready
2020-06-29T11:26:13.652+0200 [DEBUG] client.server_mgr: new server list: new_servers=[172.29.10.6:14647] old_servers=[0.0.0.0:14647, 172.29.10.6:14647]
2020-06-29T11:26:13.671+0200 [DEBUG] consul.sync: sync complete: registered_services=1 deregistered_services=0 registered_checks=1 deregistered_checks=0
2020-06-29T11:26:14.652+0200 [DEBUG] client: state changed, updating node and re-registering
2020-06-29T11:26:14.653+0200 [INFO] client: node registration complete
2020-06-29T11:26:16.139+0200 [DEBUG] worker: dequeued evaluation: eval_id=6d8f6a0b-9309-bb31-2f72-8e5c938ab36e
2020-06-29T11:26:16.139+0200 [DEBUG] http: request complete: method=PUT path=/v1/jobs duration=3.093456ms
2020-06-29T11:26:16.140+0200 [DEBUG] worker.service_sched: reconciled current state with desired state: eval_id=6d8f6a0b-9309-bb31-2f72-8e5c938ab36e job_id=example namespace=default results="Total changes: (place 1) (destructive 0) (
inplace 0) (stop 0)
Created Deployment: "f9cd2be0-3dcf-3611-9d00-17ec75b42adf"
Desired Changes for "cache": (place 1) (inplace 0) (destructive 0) (stop 0) (migrate 0) (ignore 0) (canary 0)"
2020-06-29T11:26:16.144+0200 [DEBUG] worker: submitted plan for evaluation: eval_id=6d8f6a0b-9309-bb31-2f72-8e5c938ab36e
2020-06-29T11:26:16.144+0200 [DEBUG] worker.service_sched: setting eval status: eval_id=6d8f6a0b-9309-bb31-2f72-8e5c938ab36e job_id=example namespace=default status=complete
2020-06-29T11:26:16.144+0200 [DEBUG] worker: updated evaluation: eval="<Eval "6d8f6a0b-9309-bb31-2f72-8e5c938ab36e" JobID: "example" Namespace: "default">"
2020-06-29T11:26:16.145+0200 [DEBUG] worker: ack evaluation: eval_id=6d8f6a0b-9309-bb31-2f72-8e5c938ab36e
2020-06-29T11:26:16.144+0200 [DEBUG] http: request complete: method=GET path=/v1/evaluation/6d8f6a0b-9309-bb31-2f72-8e5c938ab36e duration=227.133µs
2020-06-29T11:26:16.146+0200 [DEBUG] client: updated allocations: index=12 total=1 pulled=1 filtered=0
2020-06-29T11:26:16.146+0200 [DEBUG] client: allocation updates: added=1 removed=0 updated=0 ignored=0
2020-06-29T11:26:16.148+0200 [DEBUG] client: allocation updates applied: added=1 removed=0 updated=0 ignored=0 errors=0
2020-06-29T11:26:16.148+0200 [DEBUG] http: request complete: method=GET path=/v1/evaluation/6d8f6a0b-9309-bb31-2f72-8e5c938ab36e/allocations duration=207.628µs
2020-06-29T11:26:16.151+0200 [DEBUG] client.alloc_runner.task_runner.task_hook.logmon: starting plugin: alloc_id=b9af8ce1-58b9-4274-7cc3-8911aef475da task=redis path=/root/rkno_temp/nomad args=[/root/rkno_temp/nomad, logmon]
2020-06-29T11:26:16.156+0200 [DEBUG] client.alloc_runner.task_runner.task_hook.logmon: plugin started: alloc_id=b9af8ce1-58b9-4274-7cc3-8911aef475da task=redis path=/root/rkno_temp/nomad pid=5763
2020-06-29T11:26:16.156+0200 [DEBUG] client.alloc_runner.task_runner.task_hook.logmon: waiting for RPC address: alloc_id=b9af8ce1-58b9-4274-7cc3-8911aef475da task=redis path=/root/rkno_temp/nomad
2020-06-29T11:26:16.159+0200 [DEBUG] client.alloc_runner.task_runner.task_hook.logmon.nomad: plugin address: alloc_id=b9af8ce1-58b9-4274-7cc3-8911aef475da task=redis @module=logmon address=/tmp/plugin052518290 network=unix timestamp=
2020-06-29T11:26:16.159+0200
2020-06-29T11:26:16.159+0200 [DEBUG] client.alloc_runner.task_runner.task_hook.logmon: using plugin: alloc_id=b9af8ce1-58b9-4274-7cc3-8911aef475da task=redis version=2
2020-06-29T11:26:16.161+0200 [INFO] client.alloc_runner.task_runner.task_hook.logmon.nomad: opening fifo: alloc_id=b9af8ce1-58b9-4274-7cc3-8911aef475da task=redis @module=logmon path=/tmp/NomadClient646311894/b9af8ce1-58b9-4274-7cc3
-8911aef475da/alloc/logs/.redis.stdout.fifo timestamp=2020-06-29T11:26:16.161+0200
2020-06-29T11:26:16.162+0200 [INFO] client.alloc_runner.task_runner.task_hook.logmon.nomad: opening fifo: alloc_id=b9af8ce1-58b9-4274-7cc3-8911aef475da task=redis @module=logmon path=/tmp/NomadClient646311894/b9af8ce1-58b9-4274-7cc3
-8911aef475da/alloc/logs/.redis.stderr.fifo timestamp=2020-06-29T11:26:16.162+0200
2020-06-29T11:26:16.166+0200 [DEBUG] client.driver_mgr.docker: image reference count incremented: driver=docker image_name=redis:3.2 image_id=sha256:87856cc39862cec77541d68382e4867d7ccb29a85a17221446c857ddaebca916 references=1
2020-06-29T11:26:16.166+0200 [DEBUG] client.driver_mgr.docker: configured resources: driver=docker task_name=redis memory=268435456 memory_reservation=0 cpu_shares=500 cpu_quota=0 cpu_period=0
2020-06-29T11:26:16.166+0200 [DEBUG] client.driver_mgr.docker: binding directories: driver=docker task_name=redis binds="[]string{"/tmp/NomadClient646311894/b9af8ce1-58b9-4274-7cc3-8911aef475da/alloc:/alloc", "/tmp/NomadClient6463118
94/b9af8ce1-58b9-4274-7cc3-8911aef475da/redis/local:/local", "/tmp/NomadClient646311894/b9af8ce1-58b9-4274-7cc3-8911aef475da/redis/secrets:/secrets"}"
2020-06-29T11:26:16.166+0200 [DEBUG] client.driver_mgr.docker: networking mode not specified; using default: driver=docker task_name=redis
2020-06-29T11:26:16.166+0200 [DEBUG] client.driver_mgr.docker: allocated static port: driver=docker task_name=redis ip=172.29.10.6 port=1234
2020-06-29T11:26:16.166+0200 [DEBUG] client.driver_mgr.docker: exposed port: driver=docker task_name=redis port=1234
2020-06-29T11:26:16.166+0200 [DEBUG] client.driver_mgr.docker: applied labels on the container: driver=docker task_name=redis labels=map[com.hashicorp.nomad.alloc_id:b9af8ce1-58b9-4274-7cc3-8911aef475da]
2020-06-29T11:26:16.166+0200 [DEBUG] client.driver_mgr.docker: setting container name: driver=docker task_name=redis container_name=redis-b9af8ce1-58b9-4274-7cc3-8911aef475da
2020-06-29T11:26:16.189+0200 [INFO] client.driver_mgr.docker: created container: driver=docker container_id=2e879f49e317f52f607b15be281504a4f728c7f15ac2deb518198eb820a063fb
Is it possible that this is currently not working at all for localhost address? It seems to ignore all my attempts to bind a job to the localhost (127.0.0.1)?
 iBoMbY
on 29 Jun 2020
iBoMbY
on 29 Jun 2020
Hey @rkno82 @iBoMbY you are correct the logic is that the mapped ports now have a destination address rule to match the host_network IP. I added a PR to augment this logic when not using host_networks. See #8321
If this doesn't solve your usecase would you mind explaining a bit what you expect to happen and I'll dive in. Thanks!
nickethier
on 30 Jun 2020
Well, the idea would be to have services running behind a reverse proxy on the machine. So there would be no need for them to be accessible directly from the outside, plus the connection between the proxy and the services should be faster when using the loopback device.
iBoMbY
on 30 Jun 2020
Folks with 0.12 GA with support for multiple host network interfaces I'm going to close this one out. There was a lot of discussion on this _*checks notes*_ 4 year old issue so please don't hesitate to open a new issue if this feature doesn't cover your use case. Thank you to everyone for contributing to the discussion and design of this feature.
If you have any questions head on over to our discuss forum and please open an issue if you run into any bugs.
Cheers!
nickethier
on 10 Jul 2020
Related issues
 hynek
·
3Comments
hynek
·
3Comments
 dvusboy
·
3Comments
dvusboy
·
3Comments
 leowmjw
·
3Comments
leowmjw
·
3Comments
 jippi
·
3Comments
jippi
·
3Comments
 Gerrrr
·
3Comments
Gerrrr
·
3Comments
Most helpful comment
Folks with 0.12 GA with support for multiple host network interfaces I'm going to close this one out. There was a lot of discussion on this _*checks notes*_ 4 year old issue so please don't hesitate to open a new issue if this feature doesn't cover your use case. Thank you to everyone for contributing to the discussion and design of this feature.
If you have any questions head on over to our discuss forum and please open an issue if you run into any bugs.
Cheers!