Detectron: ERRO: core/context_gpu.cu:343: memória insuficiente Erro do operador
Oi!
Tentei treinar o mask_rcnn com e2e_mask_rcnn_R-101-FPN_2x.yaml e 4 gpu, rodando o código
ferramentas python2/train_net.py
--teste multi-gpu
--cfg configs/12_2017_baselines/e2e_mask_rcnn_R-101-FPN_2x.yaml
OUTPUT_DIR resultado/m_4gpu
Mas eu encontrei um erro da seguinte forma.
Já verifiquei o subprocess.py em meus arquivos referentes ao problema "c941633" e o código já havia corrigido. De acordo com a imagem a seguir, que imprimiu apenas alguns segundos antes do erro de execução da rede, usei {CUDA_VISIBLE_DEVICES 4,5,6,7}. E parece que realmente ficou sem memória.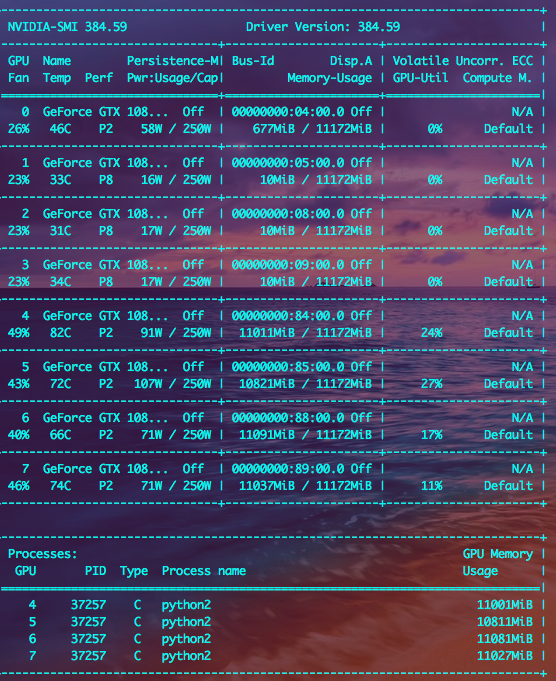
Há algo de errado com minhas configurações? Ou talvez o projeto realmente precise de muita memória?
Meu SO: Ubuntu 14.04.5 LTS (GNU/Linux 4.4.0-31-generic x86_64)
Minhas ferramentas de compilação cuda:Cuda , versão 8.0, V8.0.44
Meu amor: v5.1.5
Espero que você possa me responder em breve. Muito obrigado!
 743341
743341
Todos 4 comentários
Esta é a mensagem errada (da 7ª linha):
json_stats: {"accuracy_cls": 0.893479, "eta": "4 dias, 10:07:39", "iter": 740, "loss": 1.423568, "loss_bbox": 0.228167, "loss_cls": 0.507030, "loss_mask ": 0.479276 " loss_rpn_bbox_fpn2": 0,027880, "loss_rpn_bbox_fpn3": 0,013740, "loss_rpn_bbox_fpn4": 0,012587, "loss_rpn_bbox_fpn5": 0,007560, "loss_rpn_bbox_fpn6": 0,010346, "loss_rpn_cls_fpn2": 0,041581, "loss_rpn_cls_fpn3": 0,019604, "loss_rpn_cls_fpn4": 0,017486, "loss_rpn_cls_fpn5": 0,009906, "loss_rpn_cls_fpn6": 0,001322, "lr": 0,005000, "mb_qsize": 64, "mem": 10198, "tempo": 1,063462}
termina chamado depois de lançar uma instância de 'caffe2::EnforceNotMet'
what(): [impor falha em context_gpu.cu:343] erro == cudaSuccess. 2 vs 0. Erro em: /home/wangzx/caffe2/caffe2/core/context_gpu.cu:343: memória insuficiente Erro do operador:
entrada: "gpu_3/conv5_mask" entrada: "gpu_3/mask_fcn_logits_w" entrada: "gpu_3/__m12_shared" saída: "gpu_3/mask_fcn_logits_w_grad" saída: "gpu_3/mask_fcn_logits_b_grad" saída: "gpu_3/__m9_shared" nome: "" tipo: "ConvGradient " arg { name: "kernel" i: 1 } arg { name: "exhaustive_search" i: 0 } arg { name: "pad" i: 0 } arg { name: "order" s: "NCHW" } arg { name : "stride" i: 1 } device_option { device_type: 1 cuda_gpu_id: 3 } engine: "CUDNN" is_gradient_op: true
* Abortado em 1517186530 (hora do unix) tente "date -d @1517186530" se você estiver usando a data GNU
PC: @ 0x7f61ae26ac37 (desconhecido)
SIGABRT (@0x40b00009189) recebido pelo PID 37257 (TID 0x7f5fd5ffb700) do PID 37257;
@ 0x7f61aed1a330 (desconhecido)
@ 0x7f61ae26ac37 (desconhecido)
@ 0x7f61ae26e028 (desconhecido)
@ 0x7f61a790045d (desconhecido)
@ 0x7f61a78fe4c6 (desconhecido)
@ 0x7f61a78fe511 (desconhecido)
@ 0x7f61a7928318 (desconhecido)
@ 0x7f61aed12184 start_thread
@ 0x7f61ae331ffd (desconhecido)
@ 0x0 (desconhecido)
Abortado
743341
em 29 jan. 2018
O uso de memória para este modelo está no limite do que pode caber em uma GPU de 12 GB. Quando o executo, observo menor uso de memória da GPU (10498MiB / 11443MiB em um M40). Estou usando uma versão mais recente do cuDNN (6.0.21), que talvez tenha implementações mais eficientes de memória para algumas operações? Você pode tentar atualizar.
Caso contrário, você pode reduzir a memória em ~50% definindo TRAIN.IMS_PER_BATCH como 1 em vez do padrão de 2. Se você fizer isso, também precisará diminuir a taxa de aprendizado pela metade e dobrar a duração do cronograma de treinamento .
 rbgirshick
em 29 jan. 2018
rbgirshick
em 29 jan. 2018
Olá @rbgirshick
Quando eu personalizo a escala de treinamento e teste em várias opções:
python2 tools/train_net.py \
--multi-gpu-testing \
--cfg configs/getting_started/tutorial_4gpu_e2e_faster_rcnn_R-50-FPN.yaml \
OUTPUT_DIR results/detectron-output-hyli-4GPU \
TRAIN.SCALES 600,700,800 \
TEST.SCALES 600,700,800
e tentei em 4gpus (cada mem 6G); o treinamento é bom sem mem; no entanto, quando prossegue para o teste, ocorre OOM. Por que tamanha discrepância?
 hli2020
em 29 jan. 2018
hli2020
em 29 jan. 2018
Fechando como o original foi resolvido.
rbgirshick
em 30 jan. 2018
Questões relacionadas
 netw0rkf10w
·
4Comentários
rbgirshick
·
3Comentários
netw0rkf10w
·
4Comentários
rbgirshick
·
3Comentários
 pacelu
·
3Comentários
pacelu
·
3Comentários
 coldgemini
·
3Comentários
coldgemini
·
3Comentários
 gaopeng-eugene
·
4Comentários
gaopeng-eugene
·
4Comentários
Comentários muito úteis
Esta é a mensagem errada (da 7ª linha):
json_stats: {"accuracy_cls": 0.893479, "eta": "4 dias, 10:07:39", "iter": 740, "loss": 1.423568, "loss_bbox": 0.228167, "loss_cls": 0.507030, "loss_mask ": 0.479276 " loss_rpn_bbox_fpn2": 0,027880, "loss_rpn_bbox_fpn3": 0,013740, "loss_rpn_bbox_fpn4": 0,012587, "loss_rpn_bbox_fpn5": 0,007560, "loss_rpn_bbox_fpn6": 0,010346, "loss_rpn_cls_fpn2": 0,041581, "loss_rpn_cls_fpn3": 0,019604, "loss_rpn_cls_fpn4": 0,017486, "loss_rpn_cls_fpn5": 0,009906, "loss_rpn_cls_fpn6": 0,001322, "lr": 0,005000, "mb_qsize": 64, "mem": 10198, "tempo": 1,063462}
termina chamado depois de lançar uma instância de 'caffe2::EnforceNotMet'
what(): [impor falha em context_gpu.cu:343] erro == cudaSuccess. 2 vs 0. Erro em: /home/wangzx/caffe2/caffe2/core/context_gpu.cu:343: memória insuficiente Erro do operador:
entrada: "gpu_3/conv5_mask" entrada: "gpu_3/mask_fcn_logits_w" entrada: "gpu_3/__m12_shared" saída: "gpu_3/mask_fcn_logits_w_grad" saída: "gpu_3/mask_fcn_logits_b_grad" saída: "gpu_3/__m9_shared" nome: "" tipo: "ConvGradient " arg { name: "kernel" i: 1 } arg { name: "exhaustive_search" i: 0 } arg { name: "pad" i: 0 } arg { name: "order" s: "NCHW" } arg { name : "stride" i: 1 } device_option { device_type: 1 cuda_gpu_id: 3 } engine: "CUDNN" is_gradient_op: true
* Abortado em 1517186530 (hora do unix) tente "date -d @1517186530" se você estiver usando a data GNU
PC: @ 0x7f61ae26ac37 (desconhecido)
SIGABRT (@0x40b00009189) recebido pelo PID 37257 (TID 0x7f5fd5ffb700) do PID 37257;
@ 0x7f61aed1a330 (desconhecido)
@ 0x7f61ae26ac37 (desconhecido)
@ 0x7f61ae26e028 (desconhecido)
@ 0x7f61a790045d (desconhecido)
@ 0x7f61a78fe4c6 (desconhecido)
@ 0x7f61a78fe511 (desconhecido)
@ 0x7f61a7928318 (desconhecido)
@ 0x7f61aed12184 start_thread
@ 0x7f61ae331ffd (desconhecido)
@ 0x0 (desconhecido)
Abortado