Detectron: ERROR: core/context_gpu.cu:343: out of memory Error from operator
Hi!
I tried to train the mask_rcnn with e2e_mask_rcnn_R-101-FPN_2x.yaml and 4 gpu, running the code
python2 tools/train_net.py
--multi-gpu-testing
--cfg configs/12_2017_baselines/e2e_mask_rcnn_R-101-FPN_2x.yaml
OUTPUT_DIR result/m_4gpu
But I encouontered an error as follows.

I already checked the subprocess.py in my files refered to problem "c941633" and the code had already fixed. According to the following picture, which printed just few seconds before the network running error, I used {CUDA_VISIBLE_DEVICES 4,5,6,7}. And seems that truly it about ran out of memory.
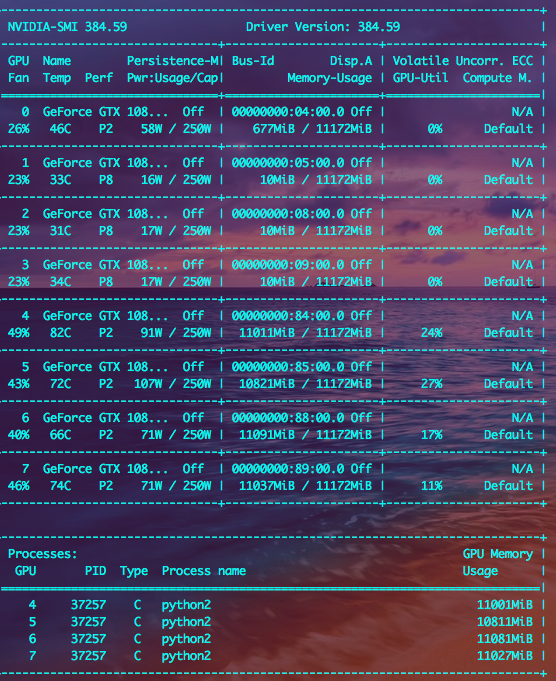
Is there anything wrong with my settings?Or maybe the project truly needs large memory?
My OS:Ubuntu 14.04.5 LTS (GNU/Linux 4.4.0-31-generic x86_64)
My cuda:Cuda compilation tools, release 8.0, V8.0.44
My cudnn:v5.1.5
Hope you can reply me soon.Thanks a lot!
 743341
743341
All 4 comments
This is the wrong message(from 7th line):
json_stats: {"accuracy_cls": 0.893479, "eta": "4 days, 10:07:39", "iter": 740, "loss": 1.423568, "loss_bbox": 0.228167, "loss_cls": 0.507030, "loss_mask": 0.479276, "loss_rpn_bbox_fpn2": 0.027880, "loss_rpn_bbox_fpn3": 0.013740, "loss_rpn_bbox_fpn4": 0.012587, "loss_rpn_bbox_fpn5": 0.007560, "loss_rpn_bbox_fpn6": 0.010346, "loss_rpn_cls_fpn2": 0.041581, "loss_rpn_cls_fpn3": 0.019604, "loss_rpn_cls_fpn4": 0.017486, "loss_rpn_cls_fpn5": 0.009906, "loss_rpn_cls_fpn6": 0.001322, "lr": 0.005000, "mb_qsize": 64, "mem": 10198, "time": 1.063462}
terminate called after throwing an instance of 'caffe2::EnforceNotMet'
what(): [enforce fail at context_gpu.cu:343] error == cudaSuccess. 2 vs 0. Error at: /home/wangzx/caffe2/caffe2/core/context_gpu.cu:343: out of memory Error from operator:
input: "gpu_3/conv5_mask" input: "gpu_3/mask_fcn_logits_w" input: "gpu_3/__m12_shared" output: "gpu_3/mask_fcn_logits_w_grad" output: "gpu_3/mask_fcn_logits_b_grad" output: "gpu_3/__m9_shared" name: "" type: "ConvGradient" arg { name: "kernel" i: 1 } arg { name: "exhaustive_search" i: 0 } arg { name: "pad" i: 0 } arg { name: "order" s: "NCHW" } arg { name: "stride" i: 1 } device_option { device_type: 1 cuda_gpu_id: 3 } engine: "CUDNN" is_gradient_op: true
* Aborted at 1517186530 (unix time) try "date -d @1517186530" if you are using GNU date
PC: @ 0x7f61ae26ac37 (unknown)
SIGABRT (@0x40b00009189) received by PID 37257 (TID 0x7f5fd5ffb700) from PID 37257; stack trace: *
@ 0x7f61aed1a330 (unknown)
@ 0x7f61ae26ac37 (unknown)
@ 0x7f61ae26e028 (unknown)
@ 0x7f61a790045d (unknown)
@ 0x7f61a78fe4c6 (unknown)
@ 0x7f61a78fe511 (unknown)
@ 0x7f61a7928318 (unknown)
@ 0x7f61aed12184 start_thread
@ 0x7f61ae331ffd (unknown)
@ 0x0 (unknown)
Aborted
743341
on 29 Jan 2018
Memory usage for this model is right on the edge of what can fit in a 12GB GPU. When I run it, I observe lower GPU memory usage (10498MiB / 11443MiB on an M40). I'm using a newer version of cuDNN (6.0.21), which maybe has more memory efficient implementations for some ops? You could try upgrading.
Otherwise, you can reduce memory by ~50% by setting TRAIN.IMS_PER_BATCH to 1 instead of the default of 2. If you do this, you need to also drop the learning rate by half and double the length of the training schedule.
 rbgirshick
on 29 Jan 2018
rbgirshick
on 29 Jan 2018
Hi @rbgirshick
When I customize the train and test scale into multiple choices:
python2 tools/train_net.py \
--multi-gpu-testing \
--cfg configs/getting_started/tutorial_4gpu_e2e_faster_rcnn_R-50-FPN.yaml \
OUTPUT_DIR results/detectron-output-hyli-4GPU \
TRAIN.SCALES 600,700,800 \
TEST.SCALES 600,700,800
and tried on 4gpus (each 6G mem); the training is okay without out of mem; however, when it proceeds to testing, OOM occurs. Why such a discrepancy?
 hli2020
on 29 Jan 2018
hli2020
on 29 Jan 2018
Closing as the original was issue addressed.
rbgirshick
on 30 Jan 2018
Related issues
 twmht
·
3Comments
twmht
·
3Comments
 kleingeo
·
3Comments
kleingeo
·
3Comments
 Hwang-dae-won
·
3Comments
Hwang-dae-won
·
3Comments
 elfpattern
·
3Comments
elfpattern
·
3Comments
 netw0rkf10w
·
4Comments
netw0rkf10w
·
4Comments
Most helpful comment
This is the wrong message(from 7th line):
json_stats: {"accuracy_cls": 0.893479, "eta": "4 days, 10:07:39", "iter": 740, "loss": 1.423568, "loss_bbox": 0.228167, "loss_cls": 0.507030, "loss_mask": 0.479276, "loss_rpn_bbox_fpn2": 0.027880, "loss_rpn_bbox_fpn3": 0.013740, "loss_rpn_bbox_fpn4": 0.012587, "loss_rpn_bbox_fpn5": 0.007560, "loss_rpn_bbox_fpn6": 0.010346, "loss_rpn_cls_fpn2": 0.041581, "loss_rpn_cls_fpn3": 0.019604, "loss_rpn_cls_fpn4": 0.017486, "loss_rpn_cls_fpn5": 0.009906, "loss_rpn_cls_fpn6": 0.001322, "lr": 0.005000, "mb_qsize": 64, "mem": 10198, "time": 1.063462}
terminate called after throwing an instance of 'caffe2::EnforceNotMet'
what(): [enforce fail at context_gpu.cu:343] error == cudaSuccess. 2 vs 0. Error at: /home/wangzx/caffe2/caffe2/core/context_gpu.cu:343: out of memory Error from operator:
input: "gpu_3/conv5_mask" input: "gpu_3/mask_fcn_logits_w" input: "gpu_3/__m12_shared" output: "gpu_3/mask_fcn_logits_w_grad" output: "gpu_3/mask_fcn_logits_b_grad" output: "gpu_3/__m9_shared" name: "" type: "ConvGradient" arg { name: "kernel" i: 1 } arg { name: "exhaustive_search" i: 0 } arg { name: "pad" i: 0 } arg { name: "order" s: "NCHW" } arg { name: "stride" i: 1 } device_option { device_type: 1 cuda_gpu_id: 3 } engine: "CUDNN" is_gradient_op: true
* Aborted at 1517186530 (unix time) try "date -d @1517186530" if you are using GNU date
PC: @ 0x7f61ae26ac37 (unknown)
SIGABRT (@0x40b00009189) received by PID 37257 (TID 0x7f5fd5ffb700) from PID 37257; stack trace: *
@ 0x7f61aed1a330 (unknown)
@ 0x7f61ae26ac37 (unknown)
@ 0x7f61ae26e028 (unknown)
@ 0x7f61a790045d (unknown)
@ 0x7f61a78fe4c6 (unknown)
@ 0x7f61a78fe511 (unknown)
@ 0x7f61a7928318 (unknown)
@ 0x7f61aed12184 start_thread
@ 0x7f61ae331ffd (unknown)
@ 0x0 (unknown)
Aborted