Runtime: Proposta de API: Adicionar funções intrínsecas de hardware Intel e namespace
Esta proposta adiciona intrínsecos que permitem aos programadores usar código gerenciado (C #) para aproveitar Intel® SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, AVX, AVX2, FMA, LZCNT, POPCNT, BMI1 / 2, PCLMULQDQ, e instruções AES.
API racional e proposta
Tipos de vetor
Atualmente, o .NET fornece System.Numerics.Vector<T> e funções intrínsecas relacionadas como uma interface SIMD de plataforma cruzada que corresponde automaticamente ao suporte de hardware adequado em tempo de compilação JIT (por exemplo, Vector<T> é o tamanho de 128 bits em máquinas SSE2 ou 256 bits em máquinas AVX2). No entanto, não há como usar simultaneamente tamanhos diferentes Vector<T> , o que limita a flexibilidade dos intrínsecos SIMD. Por exemplo, em máquinas AVX2, os registros XMM não são acessíveis a partir de Vector<T> , mas certas instruções devem funcionar em registros XMM (isto é, SSE4.2). Consequentemente, esta proposta introduz Vector128<T> e Vector256<T> em um novo namespace System.Runtime.Intrinsics
namespace System.Runtime.Intrinsics
{
// 128 bit types
[StructLayout(LayoutKind.Sequential, Size = 16)]
public struct Vector128<T> where T : struct {}
// 256 bit types
[StructLayout(LayoutKind.Sequential, Size = 32)]
public struct Vector256<T> where T : struct {}
}
Este namespace é independente de plataforma e outro hardware pode fornecer intrínsecos que operam sobre eles. Por exemplo, Vector128<T> poderia ser implementado como uma abstração de registros XMM em processadores com capacidade SSE ou como uma abstração de registros Q em processadores com capacidade NEON. Enquanto isso, outros tipos podem ser adicionados no futuro para oferecer suporte a novas arquiteturas SIMD (ou seja, adicionar vetor de 512 bits e tipos de vetor de máscara para AVX-512).
Funções intrínsecas
O design atual de System.Numerics.Vector abstrai as especificações dos detalhes do processador. Embora essa abordagem funcione bem em muitos casos, os desenvolvedores podem não conseguir tirar o máximo proveito do hardware subjacente. As funções intrínsecas permitem que os desenvolvedores acessem a capacidade total dos processadores nos quais seus programas são executados.
Um dos objetivos de design das APIs intrínsecas é fornecer correspondência individual para intrínsecos Intel C / C ++ . Dessa forma, os programadores já familiarizados com os intrínsecos de C / C ++ podem aproveitar facilmente suas habilidades existentes. Outra vantagem dessa abordagem é que aproveitamos o corpo de documentação existente e o código de amostra escrito para instrínsecos C / C ++.
As funções intrínsecas que manipulam Vector128/256<T> serão colocadas em um namespace específico da plataforma System.Runtime.Intrinsics.X86 . APIs intrínsecas serão separadas em várias classes estáticas com base nos conjuntos de instruções aos quais pertencem.
// Avx.cs
namespace System.Runtime.Intrinsics.X86
{
public static class Avx
{
public static bool IsSupported {get;}
// __m256 _mm256_add_ps (__m256 a, __m256 b)
[Intrinsic]
public static Vector256<float> Add(Vector256<float> left, Vector256<float> right) { throw new NotImplementedException(); }
// __m256d _mm256_add_pd (__m256d a, __m256d b)
[Intrinsic]
public static Vector256<double> Add(Vector256<double> left, Vector256<double> right) { throw new NotImplementedException(); }
// __m256 _mm256_addsub_ps (__m256 a, __m256 b)
[Intrinsic]
public static Vector256<float> AddSubtract(Vector256<float> left, Vector256<float> right) { throw new NotImplementedException(); }
// __m256d _mm256_addsub_pd (__m256d a, __m256d b)
[Intrinsic]
public static Vector256<double> AddSubtract(Vector256<double> left, Vector256<double> right) { throw new NotImplementedException(); }
......
}
}
Alguns dos benefícios intrínsecos do C # genérico e obtêm APIs mais simples:
// Sse2.cs
namespace System.Runtime.Intrinsics.X86
{
public static class Sse
{
public static bool IsSupported {get;}
// __m128 _mm_castpd_ps (__m128d a)
// __m128i _mm_castpd_si128 (__m128d a)
// __m128d _mm_castps_pd (__m128 a)
// __m128i _mm_castps_si128 (__m128 a)
// __m128d _mm_castsi128_pd (__m128i a)
// __m128 _mm_castsi128_ps (__m128i a)
[Intrinsic]
public static Vector128<U> StaticCast<T, U>(Vector128<T> value) where T : struct where U : struct { throw new NotImplementedException(); }
......
}
}
Cada classe de conjunto de instruções contém uma propriedade IsSupported que indica se o hardware subjacente suporta o conjunto de instruções. Os programadores usam essas propriedades para garantir que seu código possa ser executado em qualquer hardware por meio do caminho de código específico da plataforma. Para a compilação JIT, os resultados da verificação de capacidade são constantes de tempo JIT, portanto, o caminho do código morto para a plataforma atual será eliminado pelo compilador JIT (propagação de constante condicional). Para a compilação AOT, o compilador / tempo de execução executa a verificação da CPUID para identificar os conjuntos de instruções correspondentes. Além disso, os intrínsecos não fornecem fallback de software e chamar os intrínsecos em máquinas que não têm conjuntos de instruções correspondentes causará PlatformNotSupportedException no tempo de execução. Conseqüentemente, sempre recomendamos que os desenvolvedores forneçam fallback de software para manter a portabilidade do programa. O padrão comum de caminho de código específico da plataforma e fallback de software é parecido com o abaixo.
if (Avx2.IsSupported)
{
// The AVX/AVX2 optimizing implementation for Haswell or above CPUs
}
else if (Sse41.IsSupported)
{
// The SSE optimizing implementation for older CPUs
}
......
else
{
// Scalar or software-fallback implementation
}
O escopo desta proposta de API não está limitado a intrínsecos SIMD (vetor), mas também inclui intrínsecos escalares que operam sobre tipos escalares (por exemplo, int, short, long ou float, etc.) dos conjuntos de instruções mencionados acima. Como exemplo, o seguinte segmento de código mostra Crc32 funções intrínsecas da classe Sse42 .
// Sse42.cs
namespace System.Runtime.Intrinsics.X86
{
public static class Sse42
{
public static bool IsSupported {get;}
// unsigned int _mm_crc32_u8 (unsigned int crc, unsigned char v)
[Intrinsic]
public static uint Crc32(uint crc, byte data) { throw new NotImplementedException(); }
// unsigned int _mm_crc32_u16 (unsigned int crc, unsigned short v)
[Intrinsic]
public static uint Crc32(uint crc, ushort data) { throw new NotImplementedException(); }
// unsigned int _mm_crc32_u32 (unsigned int crc, unsigned int v)
[Intrinsic]
public static uint Crc32(uint crc, uint data) { throw new NotImplementedException(); }
// unsigned __int64 _mm_crc32_u64 (unsigned __int64 crc, unsigned __int64 v)
[Intrinsic]
public static ulong Crc32(ulong crc, ulong data) { throw new NotImplementedException(); }
......
}
}
Audiência pretendida
As APIs intrínsecas trazem o poder e a flexibilidade de acessar instruções de hardware diretamente de programas C #. No entanto, esse poder e flexibilidade significa que os desenvolvedores devem estar cientes de como essas APIs são usadas. Além de garantir que a lógica do programa esteja correta, os desenvolvedores também devem garantir que o uso de APIs intrínsecas subjacentes seja válido no contexto de suas operações.
Por exemplo, os desenvolvedores que usam certos intrínsecos de hardware devem estar cientes de seus requisitos de alinhamento de dados. Os intrínsecos de armazenamento e carga de memória alinhados e não alinhados são fornecidos e, se forem desejados carregamentos e armazenamentos alinhados, os desenvolvedores devem garantir que os dados estejam alinhados de maneira adequada. O seguinte snippet de código mostra os diferentes tipos de intrínsecos de carga e armazenamento propostos:
// Avx.cs
namespace System.Runtime.Intrinsics.X86
{
public static class Avx
{
......
// __m256i _mm256_loadu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<sbyte> Load(sbyte* address) { throw new NotImplementedException(); }
// __m256i _mm256_loadu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<byte> Load(byte* address) { throw new NotImplementedException(); }
......
[Intrinsic]
public static Vector256<T> Load<T>(ref T vector) where T : struct { throw new NotImplementedException(); }
// __m256i _mm256_load_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<sbyte> LoadAligned(sbyte* address) { throw new NotImplementedException(); }
// __m256i _mm256_load_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<byte> LoadAligned(byte* address) { throw new NotImplementedException(); }
......
// __m256i _mm256_lddqu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<sbyte> LoadDqu(sbyte* address) { throw new NotImplementedException(); }
// __m256i _mm256_lddqu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<byte> LoadDqu(byte* address) { throw new NotImplementedException(); }
......
// void _mm256_storeu_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void Store(sbyte* address, Vector256<sbyte> source) { throw new NotImplementedException(); }
// void _mm256_storeu_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void Store(byte* address, Vector256<byte> source) { throw new NotImplementedException(); }
......
public static void Store<T>(ref T vector, Vector256<T> source) where T : struct { throw new NotImplementedException(); }
// void _mm256_store_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void StoreAligned(sbyte* address, Vector256<sbyte> source) { throw new NotImplementedException(); }
// void _mm256_store_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void StoreAligned(byte* address, Vector256<byte> source) { throw new NotImplementedException(); }
......
// void _mm256_stream_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void StoreAlignedNonTemporal(sbyte* address, Vector256<sbyte> source) { throw new NotImplementedException(); }
// void _mm256_stream_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void StoreAlignedNonTemporal(byte* address, Vector256<byte> source) { throw new NotImplementedException(); }
......
}
}
Operandos IMM
A maioria dos intrínsecos pode ser transportada diretamente para C # a partir de C / C ++, mas certas instruções que requerem parâmetros imediatos (ou seja, imm8) como operandos merecem consideração adicional, como pshufd , vcmpps , etc. Os compiladores C / C ++ tratam especialmente esses intrínsecos que lançam erros de tempo de compilação quando valores não constantes são passados para parâmetros imediatos. Portanto, CoreCLR também requer a proteção de argumento imediata do compilador C #. Sugerimos a adição de um novo "recurso de compilador" ao Roslyn, que coloca a restrição const nos parâmetros da função. Roslyn pode então garantir que essas funções sejam chamadas com valores "literais" nos parâmetros formais const .
// Avx.cs
namespace System.Runtime.Intrinsics.X86
{
public static class Avx
{
......
// __m256 _mm256_blend_ps (__m256 a, __m256 b, const int imm8)
[Intrinsic]
public static Vector256<float> Blend(Vector256<float> left, Vector256<float> right, const byte control) { throw new NotImplementedException(); }
// __m256d _mm256_blend_pd (__m256d a, __m256d b, const int imm8)
[Intrinsic]
public static Vector256<double> Blend(Vector256<double> left, Vector256<double> right, const byte control) { throw new NotImplementedException(); }
// __m128 _mm_cmp_ps (__m128 a, __m128 b, const int imm8)
[Intrinsic]
public static Vector128<float> Compare(Vector128<float> left, Vector128<float> right, const FloatComparisonMode mode) { throw new NotImplementedException(); }
// __m128d _mm_cmp_pd (__m128d a, __m128d b, const int imm8)
[Intrinsic]
public static Vector128<double> Compare(Vector128<double> left, Vector128<double> right, const FloatComparisonMode mode) { throw new NotImplementedException(); }
......
}
}
// Enums.cs
namespace System.Runtime.Intrinsics.X86
{
public enum FloatComparisonMode : byte
{
EqualOrderedNonSignaling,
LessThanOrderedSignaling,
LessThanOrEqualOrderedSignaling,
UnorderedNonSignaling,
NotEqualUnorderedNonSignaling,
NotLessThanUnorderedSignaling,
NotLessThanOrEqualUnorderedSignaling,
OrderedNonSignaling,
......
}
......
}
Semântica e uso
A semântica é direta se os usuários já estiverem familiarizados com os intrínsecos Intel C / C ++ . Os programas e algoritmos SIMD existentes que são implementados em C / C ++ podem ser transferidos diretamente para C #. Além disso, em comparação com System.Numerics.Vector<T> , esses intrínsecos aproveitam todo o poder das instruções Intel SIMD e não dependem de outros módulos (por exemplo, Unsafe ) em ambientes de alto desempenho.
Por exemplo, SoA (estrutura da matriz) é um padrão mais eficiente do que AoS (matriz da estrutura) na programação SIMD. No entanto, ele requer sequências shuffle densas para converter a fonte de dados (geralmente armazenada no formato AoS), que não é fornecido por Vector<T> . Usar Vector256<T> com instruções de embaralhamento AVX (incluindo embaralhar, inserir, extrair, etc.) pode levar a um rendimento maior.
public struct Vector256Packet
{
public Vector256<float> xs {get; private set;}
public Vector256<float> ys {get; private set;}
public Vector256<float> zs {get; private set;}
// Convert AoS vectors to SoA packet
public unsafe Vector256Packet(float* vectors)
{
var m03 = Avx.ExtendToVector256<float>(Sse2.Load(&vectors[0])); // load lower halves
var m14 = Avx.ExtendToVector256<float>(Sse2.Load(&vectors[4]));
var m25 = Avx.ExtendToVector256<float>(Sse2.Load(&vectors[8]));
m03 = Avx.Insert(m03, &vectors[12], 1); // load higher halves
m14 = Avx.Insert(m14, &vectors[16], 1);
m25 = Avx.Insert(m25, &vectors[20], 1);
var xy = Avx.Shuffle(m14, m25, 2 << 6 | 1 << 4 | 3 << 2 | 2);
var yz = Avx.Shuffle(m03, m14, 1 << 6 | 0 << 4 | 2 << 2 | 1);
var _xs = Avx.Shuffle(m03, xy, 2 << 6 | 0 << 4 | 3 << 2 | 0);
var _ys = Avx.Shuffle(yz, xy, 3 << 6 | 1 << 4 | 2 << 2 | 0);
var _zs = Avx.Shuffle(yz, m25, 3 << 6 | 0 << 4 | 3 << 2 | 1);
xs = _xs;
ys = _ys;
zs = _zs;
}
......
}
public static class Main
{
static unsafe int Main(string[] args)
{
var data = new float[Length];
fixed (float* dataPtr = data)
{
if (Avx2.IsSupported)
{
var vector = new Vector256Packet(dataPtr);
......
// Using AVX/AVX2 intrinsics to compute eight 3D vectors.
}
else if (Sse41.IsSupported)
{
var vector = new Vector128Packet(dataPtr);
......
// Using SSE intrinsics to compute four 3D vectors.
}
else
{
// scalar algorithm
}
}
}
}
Além disso, o código condicional é habilitado em programas vetorizados. O caminho condicional é onipresente em programas escalares ( if-else ), mas requer instruções SIMD específicas em programas vetorizados, como compare, blend ou andnot, etc.
public static class ColorPacketHelper
{
public static IntRGBPacket ConvertToIntRGB(this Vector256Packet colors)
{
var one = Avx.Set1<float>(1.0f);
var max = Avx.Set1<float>(255.0f);
var rsMask = Avx.Compare(colors.xs, one, FloatComparisonMode.GreaterThanOrderedNonSignaling);
var gsMask = Avx.Compare(colors.ys, one, FloatComparisonMode.GreaterThanOrderedNonSignaling);
var bsMask = Avx.Compare(colors.zs, one, FloatComparisonMode.GreaterThanOrderedNonSignaling);
var rs = Avx.BlendVariable(colors.xs, one, rsMask);
var gs = Avx.BlendVariable(colors.ys, one, gsMask);
var bs = Avx.BlendVariable(colors.zs, one, bsMask);
var rsInt = Avx.ConvertToVector256Int(Avx.Multiply(rs, max));
var gsInt = Avx.ConvertToVector256Int(Avx.Multiply(gs, max));
var bsInt = Avx.ConvertToVector256Int(Avx.Multiply(bs, max));
return new IntRGBPacket(rsInt, gsInt, bsInt);
}
}
public struct IntRGBPacket
{
public Vector256<int> Rs {get; private set;}
public Vector256<int> Gs {get; private set;}
public Vector256<int> Bs {get; private set;}
public IntRGBPacket(Vector256<int> _rs, Vector256<int> _gs, Vector256<int>_bs)
{
Rs = _rs;
Gs = _gs;
Bs = _bs;
}
}
Como afirmado anteriormente, os algoritmos escalares tradicionais também podem ser acelerados. Por exemplo, CRC32 tem suporte nativo em CPUs SSE4.2.
public static class Verification
{
public static bool VerifyCrc32(ulong acc, ulong data, ulong res)
{
if (Sse42.IsSupported)
{
return Sse42.Crc32(acc, data) == res;
}
else
{
return SoftwareCrc32(acc, data) == res;
// The software implementation of Crc32 provided by developers or other libraries
}
}
}
Roteiro de Implementação
A implementação de todos os intrínsecos no JIT é um projeto de larga escala e longo prazo, portanto, o plano atual é implementar inicialmente um subconjunto deles com testes de unidade, teste de qualidade de código e benchmarks.
A primeira etapa da implementação envolveria itens relacionados à infraestrutura. Esta etapa envolveria a fiação dos componentes básicos, incluindo, mas não se limitando a representações de dados internos de Vector128<T> e Vector256<T> , reconhecimento intrínseco, verificação de suporte de hardware e suporte externo de Roslyn / CoreFX. As próximas etapas envolveriam a implementação de subconjuntos de intrínsecos em classes que representam diferentes conjuntos de instruções.
Projeto de API completo
Adicionar APIs intrínsecas de hardware Intel ao CoreFX dotnet / corefx # 23489
Adicionar implementação de API intrínseca de hardware Intel a mscorlib dotnet / corefx # 13576
Atualizar
17/08/2017
- Altere o namespace
System.Runtime.CompilerServices.IntrinsicsparaSystem.Runtime.IntrinsicseSystem.Runtime.CompilerServices.Intrinsics.X86paraSystem.Runtime.Intrinsics.X86. - Altere o nome da classe ISA para corresponder à convenção de nomenclatura CoreFX, por exemplo, usando
Avxvez deAVX. - Altere certos nomes de parâmetro de ponteiro, por exemplo, usando
addressvez demem. - Defina
IsSupportcomo propriedades. - Adicione sobrecargas de
Span<T>aos intrínsecos de acesso à memória mais comuns (Load,Store,Broadcast), mas deixe outros intrínsecos sensíveis ao alinhamento ou sensíveis ao desempenho com a versão original do ponteiro. - Esclareça que esses intrínsecos não fornecerão fallback de software.
- Esclareça o design da classe
Sse2e separe os pequenos calsses (por exemplo,Aes,Lzcnt, etc.) em arquivos de origem individuais (por exemplo,Aes.cs,Lzcnt.cs, etc.). - Mude o nome do método
CompareVector*paraComparee livre-se do prefixoComparedeFloatComparisonMode.
22/08/2017
- Substitua sobrecargas de
Span<T>por sobrecargas deref T.
01/09/2017
- Pequenas alterações na revisão do código API.
21/12/2018
- Todas as APIs propostas são habilitadas no tempo de execução do .NET Core.
 fiigii
fiigii
Todos 181 comentários
cc: @russellhadley @mellinoe @CarolEidt @terrajobst
fiigii
em 4 ago. 2017
No geral, eu amo essa proposta. Eu tenho algumas perguntas / comentários:
Cada tipo de vetor expõe um método IsSupported para verificar se o hardware atual suporta
Acho que isso pode ser uma propriedade, pois está em Vector<T> .
Isso leva o tipo de T em consideração? Por exemplo, IsSupported retornará verdadeiro para Vector128<float> mas falso para Vector128<CustomStruct> (ou espera-se que ele lance neste caso)?
E quanto aos formatos que podem ser suportados em alguns processadores, mas não em outros? Como exemplo, digamos que haja um conjunto de instruções X que suporta apenas Vector128<float> e depois vem o conjunto de instruções Y que oferece suporte a Vector128<double> . Se a CPU atualmente suporta apenas X, ela retornaria verdadeiro para Vector128<float> e falso para Vector128<double> com Vector128<double> retornando apenas verdadeiro quando o conjunto de instruções Y for suportado?
Além disso, este namespace conteria funções de conversão entre o tipo SIMD existente (Vector
) e novo Vector128 e Vector256 tipos.
Minha preocupação aqui é a disposição em camadas de cada componente. Espero que System.Runtime.CompilerServices.Intrinsics façam parte da camada mais baixa e, portanto, sejam consumíveis por todas as outras APIs no CoreFX. Enquanto Vector<T> , por outro lado, faz parte de uma das camadas superiores e, portanto, não é consumível.
Seria melhor ter os operadores de conversão em Vector<T> ou esperar que o usuário execute um carregamento / armazenamento explícito (como provavelmente se espera que eles façam com outros tipos personalizados)?
SSE2.cs (o resultado final do suporte intrínseco que contém todos os elementos intrínsecos de SSE e SSE2)
Eu entendo que, com SSE e SSE2 sendo exigidos no RyuJIT, isso faz sentido, mas eu quase preferiria que uma classe SSE explícita tivesse uma separação consistente. Eu esperaria essencialmente um mapeamento 1-1 de classe para sinalizador CPUID.
Other.cs (inclui LZCNT, POPCNT, BMI1, BMI2, PCLMULQDQ e AES)
Para isso especificamente, como você espera que o usuário verifique quais subconjuntos de instrução são suportados? AES e POPCNT são sinalizadores CPUID separados e nem toda CPU compatível com x86 pode sempre fornecer ambos.
Alguns dos intrínsecos se beneficiam do C # genérico e obtêm APIs mais simples
Não vi nenhum exemplo de APIs de ponto flutuante escalar ( _mm_rsqrt_ss ). Como eles se encaixariam nas APIs baseadas em vetores (nomenclatura, etc)?
 tannergooding
em 4 ago. 2017
tannergooding
em 4 ago. 2017
Parece bom e está de acordo com as sugestões que fiz. A única coisa que provavelmente não ressoa em mim (talvez porque lidamos com ponteiros regularmente em nossa base de código) é ter que usar Load(type*) vez de suportar também a capacidade de chamar a função com um void* porque a semântica da operação é muito clara. Provavelmente sou eu, mas com exceção de operações especiais como um armazenamento atemporal (onde você precisaria usar uma operação Armazenar / Carregar explicitamente), não ter suporte para tipos de ponteiro arbitrários apenas adicionaria inchaço ao algoritmo sem qualquer melhoria real em legibilidade / compreensibilidade.
 redknightlois
em 4 ago. 2017
redknightlois
em 4 ago. 2017
Portanto, CoreCLR também requer a proteção de argumento imediata do compilador C #.
Indo para a tag @jaredpar aqui explicitamente. Devíamos apresentar uma proposta formal.
Acho que podemos fazer isso sem suporte de linguagem ( @jaredpar , diga-me se estou louco aqui) se o compilador puder reconhecer algo como System.Runtime.CompilerServices.IsLiteralAttribute e emitir como modreq isliteral .
Ter uma nova palavra-chave reconhecida ( const ) aqui é provavelmente mais complicado, pois requer especificações formais no idioma, etc.
tannergooding
em 4 ago. 2017
Obrigado por postar este @fiigii. Estou muito ansioso para ouvir a opinião de todos sobre o design.
Operandos IMM
Uma coisa que surgiu em uma discussão recente é que alguns operandos imediatos têm restrições mais rígidas do que apenas "deve ser constante". Os exemplos dados usam um FloatComparisonMode enum e as funções que o aceitam aplicam um modificador const ao parâmetro. Mas não há como evitar que alguém passe um valor diferente de enum, ainda uma constante, para um método que aceita esse parâmetro.
`AVX.CompareVector256(left, right, (FloatComparisonMode)255);
EDIT: Este aviso é emitido em um projeto VC ++ se você usar o código acima.
Agora, isso pode não ser um problema para este exemplo específico (não estou familiarizado com sua semântica exata), mas é algo para se manter em mente. Também foram dados outros exemplos mais esotéricos, como um operando imediato que deve ser uma potência de dois, ou que satisfaz alguma outra relação obscura com os outros operandos. Essas restrições serão muito mais difíceis, provavelmente impossíveis, de serem aplicadas no nível C #. A aplicação "const" parece mais razoável e viável e parece cobrir a maioria dos casos do problema.
SSE2.cs (o resultado final do suporte intrínseco que contém todos os elementos intrínsecos de SSE e SSE2)
Vou repetir o que @tannergooding disse - acho que será mais simples ter apenas uma classe distinta para cada conjunto de instruções. Eu gostaria que fosse muito óbvio como e onde coisas novas devem ser adicionadas. Se houver um tipo de "saco de surpresas", então ele se tornará um pouco mais obscuro e teremos que fazer muitos julgamentos desnecessários.
 mellinoe
em 4 ago. 2017
mellinoe
em 4 ago. 2017
💭 A maior parte dos meus pensamentos iniciais vai para o uso de ponteiros em alguns lugares. Sabendo o que sabemos sobre ref structs e Span<T> , quais partes da proposta podem aproveitar a nova funcionalidade para evitar código inseguro sem comprometer o desempenho.
❓ No código a seguir, o método genérico seria realmente expandido para cada uma das formas permitidas pelo processador ou seria definido em coed como um genérico?
// __m128i _mm_add_epi8 (__m128i a, __m128i b)
// __m128i _mm_add_epi16 (__m128i a, __m128i b)
// __m128i _mm_add_epi32 (__m128i a, __m128i b)
// __m128i _mm_add_epi64 (__m128i a, __m128i b)
// __m128 _mm_add_ps (__m128 a, __m128 b)
// __m128d _mm_add_pd (__m128d a, __m128d b)
[Intrinsic]
public static Vector128<T> Add<T>(Vector128<T> left, Vector128<T> right) where T : struct { throw new NotImplementedException(); }
 sharwell
em 4 ago. 2017
sharwell
em 4 ago. 2017
❓ Se o processador não suportar algo, voltamos ao comportamento simulado ou lançamos exceções? Se escolhermos o primeiro, faria sentido renomear IsSupported para IsHardwareAccelerated ?
sharwell
em 4 ago. 2017
Saber o que sabemos sobre ref structs e Span
, quais partes da proposta podem aproveitar a nova funcionalidade para evitar código inseguro sem comprometer o desempenho.
Pessoalmente, estou bem com o código inseguro. Não acredito que isso seja um recurso usado por designers de aplicativos, mas sim algo que designers de frameworks usam para obter desempenho extra e também para simplificar a sobrecarga no JIT.
Pessoas que usam intrínsecos provavelmente já estão fazendo um monte de coisas inseguras e isso apenas torna mais explícito.
Se o processador não suporta algo, voltamos ao comportamento simulado ou lançamos exceções?
O documento oficial de design (https://github.com/dotnet/designs/blob/master/accepted/platform-intrinsics.md) indica que está no ar se os substitutos de software são permitidos.
Sou de opinião que todos esses métodos devem ser declarados como extern e nunca devem ter fallbacks de software. Espera-se que os próprios usuários implementem um fallback de software ou tenham um PlatformNotSupportedException lançado pelo JIT em tempo de execução.
Isso ajudará a garantir que o consumidor esteja ciente das plataformas subjacentes às quais se destina e que esteja escrevendo um código "adequado" para o hardware subjacente (a execução de algoritmos vetorizados no hardware sem suporte de vetorização pode causar degradação do desempenho).
tannergooding
em 4 ago. 2017
Se o processador não suporta algo, voltamos ao comportamento simulado ou lançamos exceções?
O documento oficial de design (https://github.com/dotnet/designs/blob/master/accepted/platform-intrinsics.md) indica que está no ar se os substitutos de software são permitidos.
Esses são os intrínsecos brutos da plataforma da CPU, por exemplo, X86.SSE então o PNS provavelmente está bem; e ajudará a tirá-los mais rápido.
Supondo que a detecção seja eliminada do branch; deve ser fácil construir uma biblioteca no topo que faça fallbacks de software, que podem ser iterados (coreclr / corefx ou terceiros)
 benaadams
em 4 ago. 2017
benaadams
em 4 ago. 2017
Pessoalmente, estou bem com o código inseguro.
Não sou contra códigos inseguros. No entanto, dada a escolha entre código seguro e código inseguro que executam o mesmo, eu escolheria o primeiro.
Sou de opinião que todos esses métodos devem ser declarados como externos e nunca devem ter fallbacks de software.
A maior vantagem disso é que o tempo de execução pode evitar o envio de código de fallback de software que nunca precisa ser executado.
A maior desvantagem disso são os ambientes de teste, pois as várias possibilidades não são fáceis de encontrar. Fallbacks fornecem uma rede de segurança de funcionalidade caso algo seja perdido.
sharwell
em 4 ago. 2017
A maior desvantagem disso são os ambientes de teste, pois as várias possibilidades não são fáceis de encontrar.
@sharwell , que possibilidades você está imaginando?
A maneira como estão estruturados atualmente, proposta, o usuário codificaria:
C#
public static double Cos(double x)
{
if (x86.FMA3.IsSupported)
{
// Do FMA3
}
else if (x86.SSE2.IsSupported)
{
// Do SSE2
}
else if (Arm.Neon.IsSupported)
{
// Do ARM
}
else
{
// Do software fallback
}
}
Sob isso, a única maneira de um usuário ser defeituoso é se ele escrever um algoritmo incorreto ou se esquecer de fornecer qualquer tipo de fallback de software (e um analisador para detectar isso deve ser bastante trivial).
tannergooding
em 4 ago. 2017
a execução de algoritmos vetorizados no hardware sem suporte de vetorização pode causar degradação do desempenho.
Eu reformularia o pensamento de @tannergooding em: "executar algoritmos vetorizados em hardware sem suporte de vetorização irá com certeza causar degradação de desempenho."
redknightlois
em 4 ago. 2017
Para isso especificamente, como você espera que o usuário verifique quais subconjuntos de instrução são suportados? AES e POPCNT são sinalizadores CPUID separados e nem toda CPU compatível com x86 pode sempre fornecer ambos.
@tannergooding Definimos uma classe individual para cada conjunto de instruções (exceto SSE e SSE2), mas colocamos certas classes pequenas no arquivo Other.cs . Vou atualizar a proposta para esclarecer.
// Other.cs
namespace System.Runtime.CompilerServices.Intrinsics.X86
{
public static class LZCNT
{
......
}
public static class POPCNT
{
......
}
public static class BMI1
{
.....
}
public static class BMI2
{
......
}
public static class PCLMULQDQ
{
......
}
public static class AES
{
......
}
}
Compilação AOT, no entanto, o compilador gera código de verificação CPUID que retornaria valores diferentes cada vez que fosse chamado (em hardware diferente).
Não acho que isso precise ser verdade o tempo todo. Em alguns casos, o AOT pode descartar a verificação por completo, dependendo do sistema operacional de destino (Win8 e superior exigem suporte a SSE e SSE2, por exemplo).
Em outros casos, o AOT pode / deve descartar a verificação de cada método e, em vez disso, agregá-los em uma única verificação no ponto de entrada mais alto.
Idealmente, o AOT executaria CPUID uma vez durante a inicialização e armazenaria em cache os resultados como globais (honestamente, se o AOT não fizesse isso, eu registraria um bug). A verificação IsSupported então se torna essencialmente uma pesquisa do valor em cache (assim como uma propriedade normalmente se comporta). Esse comportamento é o que as implementações CRT fazem para garantir que coisas como cos(double) permaneçam com bom desempenho e que ainda possam executar o código FMA3 onde houver suporte.
tannergooding
em 4 ago. 2017
Para a compilação AOT, no entanto, o compilador gera código de verificação CPUID que retornaria valores diferentes cada vez que fosse chamado (em hardware diferente).
A implicação seria de uma perspectiva de uso:
Para Jit, poderíamos ser bastante granulares nas verificações, uma vez que são eliminadas ramificações sem custo.
Para AOT, precisaríamos ser bastante racionais nas verificações e executá-las no nível do algoritmo ou da biblioteca, para compensar o custo da CPUID; que pode empurrá-lo muito mais alto do que o pretendido, por exemplo, você não usaria um IndexOf vetorizado; a menos que suas strings fossem enormes porque CPUID dominaria.
Provavelmente, ainda poderia armazenar em cache no AOT na inicialização, por isso definiria a propriedade; não eliminaria ramificações, mas teria um custo razoavelmente baixo?
benaadams
em 4 ago. 2017
Eu entendo que, com SSE e SSE2 sendo exigidos no RyuJIT, isso faz sentido, mas eu quase preferiria que uma classe SSE explícita tivesse uma separação consistente. Eu esperaria essencialmente um mapeamento 1-1 de classe para sinalizador CPUID.
Acho que será mais simples ter apenas uma classe distinta para cada conjunto de instruções. Eu gostaria que fosse muito óbvio como e onde coisas novas devem ser adicionadas. Se houver um tipo de "saco de surpresas", então ele se tornará um pouco mais obscuro e teremos que fazer muitos julgamentos desnecessários.
@tannergooding @mellinoe O objetivo do design atual da classe SSE2 é tornar mais fáceis as funções intrínsecas aos usuários. Se tivéssemos duas classes SSE e SSE2 , certos intrínsecos perderiam a assinatura genérica. Por exemplo, a adição de SIMD suporta apenas float em SSE, e SSE2 complementa outros tipos.
public static class SSE
{
// __m128 _mm_add_ps (__m128 a, __m128 b)
public static Vector128<float> Add(Vector128<float> left, Vector128<float> right);
}
public static class SSE2
{
// __m128i _mm_add_epi8 (__m128i a, __m128i b)
public static Vector128<byte> Add(Vector128<byte> left, Vector128<byte> right);
public static Vector128<sbyte> Add(Vector128<sbyte> left, Vector128<sbyte> right);
// __m128i _mm_add_epi16 (__m128i a, __m128i b)
public static Vector128<short> Add(Vector128<short> left, Vector128<short> right);
public static Vector128<ushort> Add(Vector128<ushort> left, Vector128<ushort> right);
// __m128i _mm_add_epi32 (__m128i a, __m128i b)
public static Vector128<int> Add(Vector128<int> left, Vector128<int> right);
public static Vector128<uint> Add(Vector128<uint> left, Vector128<uint> right);
// __m128i _mm_add_epi64 (__m128i a, __m128i b)
public static Vector128<long> Add(Vector128<long> left, Vector128<long> right);
public static Vector128<ulong> Add(Vector128<uint> left, Vector128<ulong> right);
// __m128d _mm_add_pd (__m128d a, __m128d b)
public static Vector128<double> Add(Vector128<double> left, Vector128<double> right);
}
Comparando com SSE2.Add<T> , o design acima parece complexo e os usuários devem se lembrar de SSE.Add(float, float) e SSE2.Add(int, int) . Além disso, SSE2 é o resultado final da geração de código RyuJIT para x86 / x86-64, separando SSE de SSE2 não tem nenhuma vantagem em funcionalidade ou conveniência.
Embora o design atual (classe SSE2 incluindo os intrínsecos SSE e SSE2) prejudique a consistência da API, há uma compensação entre a consistência do design e a experiência do usuário, que vale a pena discutir.
fiigii
em 4 ago. 2017
Em vez de X86 talvez x86x64 já que o x86 costuma ser usado para doar apenas 32 bits?
benaadams
em 4 ago. 2017
Muito entusiasmados, estamos finalmente vendo uma proposta para isso. Meus pensamentos iniciais abaixo.
O AVX-512 está faltando, provavelmente porque ainda não está tão difundido, mas acho que seria bom pelo menos pensar sobre isso e como estruturá-los porque o conjunto de recursos do AVX-512 é muito fragmentado. Nesse caso, eu presumiria que precisamos ter uma classe para cada conjunto, ou seja, (consulte https://en.wikipedia.org/wiki/AVX-512):
public static class AVX512F {} // Foundation
public static class AVX512CD {} // Conflict Detection
public static class AVX512ER {} // Exponential and Reciprocal
public static class AVX512PF {} // Prefetch Instructions
public static class AVX512BW {} // Byte and Word
public static class AVX512DQ {} // Doubleword and Quadword
public static class AVX512VL {} // Vector Length
public static class AVX512IFMA {} // Integer Fused Multiply Add (Future)
public static class AVX512VBMI {} // Vector Byte Manipulation Instructions (Future)
public static class AVX5124VNNIW {} // Vector Neural Network Instructions Word variable precision (Future)
public static class AVX5124FMAPS {} // Fused Multiply Accumulation Packed Single precision (Future)
e adicione um tipo struct Vector512<T> , é claro. Observe que os dois últimos AVX5124VNNIW e AVX5124FMAPS são difíceis de ler devido ao número 4 .
Alguns deles podem ter um grande impacto para o aprendizado profundo, classificação etc.
Com relação a Load também tenho algumas preocupações. Como @redknightlois , acho que void* deve ser considerado, mas o mais importante também é carregar de / store em ref . Diante disso, talvez eles devam ser realocados para o namespace e tipo "genérico" / independente de plataforma, uma vez que, presumivelmente, todas as plataformas devem suportar carregar / armazenar para um tamanho de vetor suportado. Então, algo como (não tenho certeza de onde poderíamos colocar isso e como a nomenclatura deve ser feita, se pode ser movido para o tipo agnóstico de plataforma.
[Intrinsic]
public static unsafe Vector256<sbyte> Load(sbyte* mem) { throw new NotImplementedException(); }
[Intrinsic]
public static unsafe Vector256<sbyte> LoadSByte(void* mem) { throw new NotImplementedException(); }
[Intrinsic]
public static unsafe Vector256<sbyte> Load(ref sbyte mem) { throw new NotImplementedException(); }
[Intrinsic]
public static unsafe Vector256<byte> Load(byte* mem) { throw new NotImplementedException(); }
[Intrinsic]
public static unsafe Vector256<sbyte> LoadByte(void* mem) { throw new NotImplementedException(); }
[Intrinsic]
public static unsafe Vector256<byte> Load(ref byte mem) { throw new NotImplementedException(); }
// Etc.
A coisa mais importante aqui é se ref pode ser suportado, pois seria essencial para suportar algoritmos genéricos. A nomenclatura deve ser revisada, sem dúvida, mas apenas tentando mostrar um ponto. Se quisermos suportar o carregamento de void* , o nome do método precisa incluir o tipo de retorno ou o método precisa estar na classe estática específica do tipo.
 nietras
em 4 ago. 2017
nietras
em 4 ago. 2017
É ótimo estarmos discutindo uma proposta concreta agora. 😄
A proposta de idioma acima vinculada implementação de atributos simples primeiro e depois expandir a sintaxe C # e API incluindo suporte para
const method parameters.IMO, temos que discutir em projetos paralelos voltados para o futuro, que compreendem duas áreas diferentes:
System.Numerics APIque pode serpartially implementedcom suporte dos intrínsecos x86 discutidos aquiIntrinsics APIque deve compreender outras arquiteturas, pois terá um impacto na forma final da API intrínseca
Intrínseco
Namespace e montagem
Eu proporia mover intrínsecos para separar namespace localizado relativamente alto na hierarquia e cada código específico de plataforma em um assembly separado.
System.Intrinsics namespace de nível superior geral para todos os intrínsecos
System.Intrinsics.X86 x86 extensões ISA e montagem separada
System.Intrinsics.Arm ARM extensões ISA e montagem separada
System.Intrinsics.Power Extensões ISA Power e montagem separada
System.Intrinsics.RiscV Extensões RiscV ISA e montagem separada
O motivo da divisão acima é a grande área de API para cada conjunto de instruções, ou seja, AVX-512 será representado por mais de 2.000 intrínsecos no compilador MsVC. O mesmo acontecerá com o ARM SVE muito em breve (veja abaixo). O tamanho da montagem devido ao conteúdo da string não será pequeno.
Tamanhos de registro (atualmente XMM, YMM, ZMM - 128, 256, 512 bits em x86)
As implementações atuais suportam um conjunto limitado de tamanhos de registro:
- 128, 256, 512 bits em x86
- 128 em ARM Neon e IBM Power 8 e Power 9 ISA
No entanto, ARM publicou recentemente:
ARM SVE - Extensões de vetor escaláveis
ver: The Scalable Vector Extension (SVE), para ARMv8-A publicado em 31 de março de 2017 com status Beta não confidencial.
Esta especificação é muito importante, pois introduz novos tamanhos de registro - ao todo, existem 16 tamanhos de registro que são múltiplos de 128 bits. Os detalhes estão na página 21 da especificação (tabela a seguir).
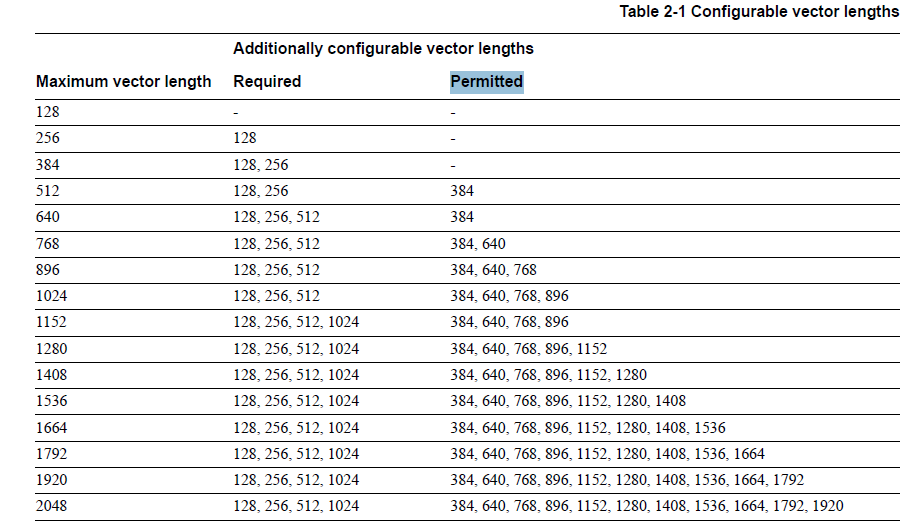
Comprimento máximo do vetor: 2.048 bits
Comprimentos de vetor necessários: 128, 256, 512, 1024 bits
Comprimentos de vetor permitidos: 384, 640, 768, 896, 1152, 1280, 1408, 1536, 1664, 1792, 1920
Seria necessário projetar uma API capaz de suportar em um futuro próximo 16 tamanhos de registradores diferentes e vários milhares (ou dezenas de milhares) de opcodes / funções (contando com sobrecargas). As previsões de não ter instruções SIMD de 2048 bits em alguns anos parecem ter sido falsificadas para a surpresa de alguém pela ARM este ano. Olhando para a história ( ARM publicou a versão beta pública do ARMv8 ISA em 04 de setembro de 2013 e o primeiro processador que o implementou estava disponível para usuários globalmente em outubro de 2014 - Samsung Galaxy Note 4 ) Eu esperaria que o primeiro silício com extensões SVE estivesse disponível em 2018. I suponha que isso seja muito provavelmente próximo à disponibilidade pública dos intrínsecos do DotNet SIMD.
Eu gostaria de propor:
Vetores
Implementar vetores básicos com suporte para todos os tamanhos de registro em System.CoreLib.Private
`` `C #
namespace System.Numerics
{
[StructLayour (LayoutKind.Explicit)]
Registro de struct público inseguro 128
{
[FieldOffset (0)]
byte fixo público [16];
.....
// acessores para outros tipos
}
// ....
[StructLayour(LayoutKind.Explicit)]
public unsafe struct Register2048
{
[FieldOffset(0)]
public fixed byte [256];
.....
// accessors for other types
}
public struct Vector<T, R> where T, R: struct
{
}
public struct Vector128<T> : Vector<T, Register128>
{
}
// ....
public struct Vector2048<T> : Vector<T, Register2048>
{
}
}
### System.Numerics
All safe APIs would be exposed via Vector<T> and VectorXXX<T> structures and implemented with support of intrinsics.
### System.Intrinsics
All vector APIs will use System.Numerics.VectorXXX<T>.
```C#
public static Vector128<byte> MultiplyHigh<Vector128<byte>>(Vector128<byte> value1, Vector128<byte> value2);
public static Vector128<byte> MultiplyLow<Vector128<byte>>(Vector128<byte> value1, Vector128<byte> value2);
As APIs intrínsecas serão colocadas em classes separadas de acordo com os padrões de detecção de funcionalidade fornecidos pelos processadores. No caso do ISA x86, essa correspondência seria um para um entre a detecção de CPUID e as funções suportadas. Isso permitiria um padrão de programação fácil de entender, onde se usaria funções de determinado grupo de maneira consistente com o suporte da plataforma.
O principal motivo para esse tipo de divisão é um requisito estabelecido pelos fabricantes de silício de usar as instruções apenas se forem detectadas no hardware. Isso permite, por exemplo, enviar processador com matriz de suporte compreendendo SSE3, mas não SSSE3, ou compreendendo PCLMULQDQ e SHA e não AESNI. Esta correspondência direta de detecção de suporte de classe - hardware é a única maneira segura de ter a detecção de IsHardwareSupported e estar em conformidade com as restrições de uso das instruções da Intel / AMD. Caso contrário, o kernel terá que capturar para nós # exceção de UUD 😸
Mapeamento de APIs para intrínsecos C / C ++ ou para opcodes ISA
Os intrínsecos abstraem normalmente em opcodes ISA de 1 a 1 via, no entanto, existem alguns intrínsecos que mapeiam para várias instruções. Eu preferiria abstrair opcodes (usando nomes legais) e implementar vários opcodes intrínsecos como funções no VectorXxx
 4creators
em 4 ago. 2017
4creators
em 4 ago. 2017
@nietras
Diante disso, talvez eles devam ser realocados para o namespace e tipo "genérico" / independente de plataforma, uma vez que, presumivelmente, todas as plataformas devem suportar carregar / armazenar para um tamanho de vetor suportado.
O melhor lugar seria System.Numerics.VetorXxx <T>
4creators
em 4 ago. 2017
todas as plataformas devem suportar carregar / armazenar para um tamanho de vetor compatível
A plataforma agnóstica Load/Store diferente da Unsafe.Read/Write ?
 jkotas
em 4 ago. 2017
jkotas
em 4 ago. 2017
A plataforma de carga / armazenamento agnóstica é diferente da existente Unsafe.Read/Write?
@jkotas Eu pensei o mesmo, como isso se relaciona com Unsafe ? Presumo que eles não estejam alinhados, e só podemos usar alinhados por meio de LoadAligned/StoreAligned ...
Ou poderíamos adicionar Unsafe.ReadAligned/WriteAligned e fazer com que o JIT os reconheça para os tipos de vetor?
nietras
em 4 ago. 2017
IsSupported deve ser uma propriedade (ou um campo static readonly ) como IntPtr.Size ou BitConverter.IsLittleEndian .
Combinar SSE e SSE2 em uma única classe parece uma boa troca por uma função Add simples.
Assim como @redknightlois e @nietras , também estou preocupado com a API Carregar / Armazenar. ref suporte é necessário para evitar fixed referências. Por void* Load/Store genéricos podem ajudar:
[Intrinsic]
public static extern unsafe Vector256<T> Load<T>(void* mem) where T : struct;
[Intrinsic]
public static extern unsafe Vector256<sbyte> Load(sbyte* mem);
[Intrinsic]
public static extern Vector256<sbyte> Load(ref sbyte mem);
[Intrinsic]
public static extern unsafe Vector256<byte> Load(byte* mem);
[Intrinsic]
public static extern Vector256<byte> Load(ref byte mem);
// Etc.
Estou ansioso para usar PDEP/PEXT !
 pentp
em 4 ago. 2017
pentp
em 4 ago. 2017
Eu proporia mover intrínsecos para separar namespace localizado relativamente alto na hierarquia e cada código específico de plataforma em um assembly separado.
O motivo da divisão acima é a grande área de API para cada conjunto de instruções, ou seja, AVX-512 será representado por mais de 2.000 intrínsecos no compilador MsVC. O mesmo acontecerá com o ARM SVE muito em breve (veja abaixo). O tamanho da montagem devido ao conteúdo da string não será pequeno.
@ 4creatores , sou veementemente contra mover esse recurso para um nível mais alto na hierarquia.
Para começar, o próprio tempo de execução deve oferecer suporte a todo e qualquer intrínseco (incluindo as strings para identificá-los etc.), independentemente de onde os colocamos na hierarquia. Se o tempo de execução não os suportar, você não poderá usá-los.
Também quero consumir esses intrínsecos de todas as camadas da pilha, incluindo System.Private.CoreLib . Eu quero ser capaz de escrever implementações gerenciadas de System.Math , System.MathF , várias funções System.String , etc. Isso não apenas aumenta a sustentabilidade do código (já que a maioria delas são FCALLS ou assembly ajustado manualmente hoje), mas também aumenta a consistência entre plataformas (onde o FCALL ou assembly resultante é parte do tempo de execução C subjacente).
tannergooding
em 4 ago. 2017
@pentp
Combinar SSE e SSE2 em uma única classe parece uma boa troca por uma função Add mais simples.
Não acho que os intrínsecos devam abstrair qualquer coisa - em vez disso, uma adição simples pode ser criada no Vector128 - Vector2048. Por outro lado, seria abertamente contra as recomendações de uso da Intel.
4creators
em 4 ago. 2017
Também quero consumir esses intrínsecos de todas as camadas da pilha, incluindo System.Private.CoreLib. Eu quero ser capaz de escrever implementações gerenciadas de System.Math, System.MathF, várias funções System.String, etc.
@tannergooding Concorda que deve estar disponível em System.Private.CoreLib
No entanto, isso não significa que deva ser hierarquicamente inferior. Ninguém enviará o tempo de execução (vm, gc, jit) que oferecerá suporte a todos os intrínsecos para todas as arquiteturas. A linha de divisão passa pelo plano ISA - x86, Arm, Power. Não há razão para distribuir intrínsecos ARM no tempo de execução x86. Tê-lo em um conjunto de plataforma separado em coreclr que poderia ser referenciado (circularmente) por System.Private.CoreLib poderia ser uma solução (acho que é um pouco melhor do que definir tudo)
4creators
em 4 ago. 2017
A intenção do projeto atual da classe SSE2 é tornar as funções intrínsecas mais amigáveis para os usuários. Se tivéssemos duas classes SSE e SSE2, certos intrínsecos perderiam a assinatura genérica.
@fiigii , por que separar isso significa que perdemos a assinatura genérica?
A meu ver, temos duas opções:
- Lista explicitamente os tipos
Vector128<float> Add(Vector128<float> left, Vector128<float> right)- Isso impõe segurança de tipo, mas aumenta o número de APIs expostas
- Use genéricos
Vector128<T> Add<T>(Vector128<T> left, Vector128<T> right)- Isso diminui o número de APIs expostas, mas perde a segurança forçada do tipo de compilador
- Algumas funções exigirão vários genéricos (casts, por exemplo, exigem
<T, U>, e isso pode se tornar potencialmente ainda mais complexo em outro lugar)
Não vejo razão para não termos SSE e SSE2 e porque não podemos simplesmente expor Vector128<T> Add<T>(Vector128<T> left, Vector128<T> right) .
Dito isso, eu pessoalmente prefiro a forma imposta que exige que APIs adicionais sejam listadas. Isso não apenas ajuda a garantir que o usuário está passando as coisas certas para a API, mas também diminui o número de verificações que o JIT deve fazer.
Vector128<float> significa que T já foi aplicado / validado como parte do contrato de API, Vector128<T> significa que o JIT deve validar T é de um tipo correto / suportado . Isso pode mudar potencialmente de um tempo de execução para o próximo (dependendo do conjunto exato de intrínsecos para o qual o tempo de execução foi criado), o que pode tornar isso ainda mais confuso.
tannergooding
em 4 ago. 2017
No entanto, isso não significa que deva ser hierarquicamente inferior. Ninguém enviará o tempo de execução (vm, gc, jit) que oferecerá suporte a todos os intrínsecos para todas as arquiteturas. A linha de divisão passa pelo plano ISA - x86, Arm, Power. Não há razão para distribuir intrínsecos ARM no tempo de execução x86. Tê-lo em uma montagem de plataforma separada em coreclr que poderia ser referenciada (circularmente) por System.Private.CoreLib poderia ser uma solução.
Eu poderia ficar por trás disso. As advertências são que:
- O assembly de referência deve listar todas as APIs, independentemente
- O JIT provavelmente precisa de suporte especial para não lançar uma exceção ao tentar compilar minha função (que tem caminhos para x86 e ARM) em uma das arquiteturas e não encontrar as APIs para a outra arquitetura.
tannergooding
em 4 ago. 2017
A plataforma de carga / armazenamento agnóstica é diferente da existente Unsafe.Read/Write?
@jkotas , acho que a principal diferença é que Load/Store compilará em uma instrução SIMD e provavelmente irá diretamente para um registrador na maioria dos casos.
tannergooding
em 4 ago. 2017
Tê-lo em um conjunto de plataforma separado em coreclr que poderia ser referenciado (circularmente) por System.Private.CoreLib poderia ser uma solução
As referências circulares não são iniciais. A solução existente para esse problema é ter um subconjunto exigido pelo CoreLib no CoreLib como interno e a implementação completa (duplicada) em um assembly separado. Porém, é questionável se essa duplicação por uma questão de camadas realmente vale a pena.
Outra ideia sobre nomear. O runtime / codegen tem muitos intrínsecos hoje em todo o lugar, por exemplo, métodos em System.Threading.Interlocked ou System.Runtime.CompilerServices.RuntimeHelpers são implementados como intrínsecos.
O nome do namespace deve ser mais específico para capturar o que realmente está nele, digamos System.Runtime.HardwareIntrinsics ?
jkotas
em 4 ago. 2017
Aumento do código devido ao projeto de Register128 ... Register2048
Desde que desejemos ter acesso direto aos tipos numéricos codificados em estruturas RegisterXxx - semelhante à implementação atual de System.Numerics.Register, que é um bom design IMO - seria necessário criar (em vez de gerar) um total de 10 064 campos com o seguinte padrão:
`` `C #
namespace System.Numerics
{
[StructLayout (LayoutKind.Explicit)]
Registro de struct público inseguro 128
{
public fixed byte Reg [16];
// System.Byte Fields
[FieldOffset (0)]
public byte byte_0;
[FieldOffset (1)]
byte público byte_1;
[FieldOffset (2)]
byte público byte_2;
// System.SByte Fields
// etc.
Specifically due to this problem there exists solution proposal based on extended generics syntax: _Const blittable parameter as a generic type parameter_ (https://github.com/dotnet/csharplang/issues/749)
```C#
namespace System.Numerics
{
public unsafe struct Register<T, const int N>
{
public fixed T Reg[N];
}
public struct Vector128<T> : Vector<T, Register<T, 16>> {}
Posteriormente, ao se especializar em genéricos, pode-se criar facilmente a árvore de estrutura necessária.
4creators
em 4 ago. 2017
Load / Store compilará em uma instrução SIMD e provavelmente irá diretamente para um registrador na maioria dos casos.
Unsafe.Load/Store compila em uma instrução SIMD para as estruturas de tamanho certo hoje.
jkotas
em 4 ago. 2017
As referências circulares não são iniciais. A solução existente para esse problema é ter um subconjunto exigido pelo CoreLib no CoreLib como interno e a implementação completa (duplicada) em um assembly separado. Porém, é questionável se essa duplicação por uma questão de camadas realmente vale a pena.
@jkotas @tannergooding Isso resolve o problema, uma vez que a implementação duplicada da API compreende cerca de 10k funções ...
4creators
em 4 ago. 2017
Unsafe.Load / Store compila em uma instrução SIMD para as estruturas de tamanho certo hoje.
Pode ser o caso implicitly , mas não está explícito na API (que é o caso de Vector128<float> SSE.Load(float* address) ). Também é implicit se esta é uma leitura / gravação alinhada ou se não está alinhada.
Um dos meus recursos favoritos desta proposta é que as APIs são muito explícitas. Se eu disser LoadAligned , sei que vou obter a instrução MOVAPS (sem "ifs" "ands" ou "buts" sobre isso). Se eu disser LoadUnaligned , sei que vou obter a instrução MOVUPS .
tannergooding
em 4 ago. 2017
Se o nome do namespace for mais específico para capturar o que realmente está nele, diga System.Runtime.HardwareIntrinsics
Cálculo simples para diferença de tamanho de montagem para funções definidas como
C#
public static void System.Runtime.CompilerServices.Intrinsics.AVX2::ShiftLeft
public static void System.Intrinsics.AVX2::ShiftLeft
para 5 000 funções é 250 KB.
4creators
em 4 ago. 2017
implementação duplicada para API compreendendo cerca de 10k funções ...
O material duplicado no CoreLib seria apenas, digamos, as 50 funções que são realmente necessárias no CoreLib.
jkotas
em 4 ago. 2017
para 5 000 funções é 250 KB.
Como você chegou a esse número? O nome do namespace é armazenado no binário gerenciado apenas uma vez. A diferença entre ShortNameSpace e VeryLoooooooooooooooooongNameSpace deve ser sempre ~ 20 bytes, independente de quantas funções estão contidas no namespace.
jkotas
em 4 ago. 2017
O material duplicado no CoreLib seria apenas, digamos, as 50 funções que são realmente necessárias no CoreLib.
Isso resolveria o problema de enviar todas as arquiteturas juntas 😄
4creators
em 4 ago. 2017
Quanto a todas as declarações sobre coisas como expor ref ou void* ( @pentp , @nietras , @redknightlois) e também se um substituto de software deve ou não ser fornecido.
ref pode valer a pena expor
Unsafe.ToPointerresolve parte disso, mas requer que os usuários façam uma dependência separada. Isso também significa quecorlibtem mais problemas para lidar comref
void* provavelmente não vale a pena expor. Basta lançar no tipo apropriado (float*)((void*)(p)) .
- Não podemos substituir com base no tipo de retorno, então
void*significa que precisamos de nomes de métodos exclusivos ou temos que usar<T>e fazer com que o JIT execute a validação
Já pode ser óbvio por minhas declarações existentes, mas acredito que essas APIs devem ser explícitas, mas também simples:
- Devemos usar
Vector128<float>vez deVector128<T>pois isso impõe verificações de tempo de compilação e remove a sobrecarga JIT - Devemos ter APIs como
LoadeStorecomo parte disso e não depender de outras coisas (System.Runtime.CompilerServices.Unsafe).- As outras APIs, quando aplicável, devem ser atualizadas para chamar as funções intrínsecas ao invés
- Devemos impor que todas as funções sejam
extern- Se substitutos de software fossem fornecidos,
CoreFXsi os usaria / nunca deveria usá-los - Devido ao desempenho e outras razões, os consumidores nunca devem confiar ou usar os substitutos de software de qualquer maneira
- Isso força o JIT / AOT para entender o método ou fazê-lo falhar
- Sempre podemos expor uma API de wrapper em um nível superior (leia como
CoreFXExtensionsou repo de terceiros) que fornece substitutos de software para cada instrução
- Se substitutos de software fossem fornecidos,
tannergooding
em 4 ago. 2017
Como você chegou a esse número?
@jkotas da especificação CIL que afirma que CIL não tem implementação de namespaces e reconhece métodos por seus nomes completos, no entanto, entendo que devo verificar as especificações do arquivo PE - meu mal.
4creators
em 4 ago. 2017
Em vez de X86, talvez x86x64, já que o x86 costuma ser usado para doar apenas 32 bits?
@benaadams , da mesma forma x86-64 às vezes é usado para denotar a versão 64-bit only do conjunto de instruções x86 , então isso também seria confuso (https: // en.wikipedia.org/wiki/X86-64)
Acho que x86 faz mais sentido e é usado com mais frequência para se referir a toda a plataforma.
Pelo menos para a Wikipedia:
- x86 refere-se às implementações de 16, 32 e 64 bits (https://en.wikipedia.org/wiki/X86)
- IA-32 ou i386 refere-se à implementação de 32 bits (https://en.wikipedia.org/wiki/IA-32)
- Às vezes é chamado de x86
- x86-64, x64, x86_64, AMD64 e Intel64 são usados para se referir à implementação de 64 bits (https://en.wikipedia.org/wiki/X86-64)
tannergooding
em 4 ago. 2017
Parece que não será uma API simples e exigiria várias decisões de design - é possível começar a trabalhar nos detalhes dela no CoreFXLabs ou ramificação separada no coreclr / corefx?
O repo separado apoiaria o sistema de rastreamento de problemas que a IMO seria necessário para fazê-lo de forma rápida e eficiente.
4creators
em 4 ago. 2017
Parece que não será uma API simples e exigiria várias decisões de design - é possível começar a trabalhar nos detalhes dela em CoreFXLabs ou ramificação separada em coreclr / corefx?
Eu vou apoiar isso. Acho que valeria a pena obter o formato básico da API (conforme proposto) no CoreFXLabs e "usá-lo" em um cenário real.
Eu proporia que pegássemos Vector2 , Vector3 e Vector4 e os reimplementássemos para chamar as APIs de acordo com https://github.com/Microsoft/DirectXMath e potencialmente fazer o o mesmo para Cos , Sin e Tan em Math / MathF .
Embora não obtenhamos nenhum número de desempenho com isso e não possamos executar o código, isso nos permitirá visualizar o caso de uso em cenários do "mundo real" para ter uma ideia melhor do que faz mais sentido e quais são os pontos fortes / deficiências da proposta (e quaisquer modificações sugeridas à proposta).
tannergooding
em 4 ago. 2017
Embora não recebamos nenhum número de desempenho
Para obter números de desempenho, deve ser adequado adicionar algum suporte para isso no JIT (sem expô-lo no perfil de envio estável) e experimentar a forma de API no corefxlab.
jkotas
em 4 ago. 2017
Unsafe.ToPointer resolve parte disso
@tannergooding deixando um buraco de GC ou exigindo fixação, que é especificamente o que queremos evitar;) ref é essencial para algoritmos genéricos baseados em Span<T> , sem a necessidade de fixação. Unsafe.Read/Write deve funcionar. Eu quero as duas maçãs;)
Devemos ter APIs como Carregar e Armazenar como parte disso e não depender de coisas em outro lugar (System.Runtime.CompilerServices.Unsafe).
Concordo, e não estou dizendo isso. Mas Unsafe.Read/Write<Vector128<T>> ainda deve funcionar. Isso é uma obrigação, na minha opinião. Caso contrário, o código genérico se torna muito difícil, que pode lidar com diferentes registros de vetores, tipos básicos, etc.
nietras
em 4 ago. 2017
💭 ❓ Esses novos tipos de vetor seriam candidatos a ref struct vez de apenas struct ?
sharwell
em 4 ago. 2017
void * provavelmente não vale a pena expor. Basta converter para o tipo apropriado (float ) ((void ) (p)).
@tannergooding você não pode fazer isso em código genérico. Acho que seria bom considerar algoritmos que também são genéricos, muitas coisas poderiam ser feitas aqui de uma maneira genérica, expondo muitas operações numéricas em imagens, digamos, sem a necessidade de um loop personalizado para cada operação. Existem muitos casos em que código genérico pode ser feito com isso.
nietras
em 4 ago. 2017
Não vejo nenhum problema com uma API com métodos estáticos para void* eg
public class Vector128<T>
{
public static Vector128<T> Load(void* p);
}
O JIT, é claro, tem que lidar com isso, mas isso não deveria ser bastante direto. Minha suposição aqui é que se Vector128<T>.IsSupported então você deve ser capaz de Load e Store para que eles não precisem estar em locais específicos da plataforma.
Se o fizerem, então sim, precisamos de algo como Vector<128> SSE2.LoadInt(void* p) e, em alguns casos, até AVX512VL.LoadInt256(void* p) talvez ... nomenclatura feia à parte. Caso contrário, out poderia ser um substituto, embora torne o código complicado, menos ainda com C # 7.
void* p = ...;
AVX512VL.LoadAligned(p, out Vector256<int> v);
Não é muito mais complicado quando visto disso. E espero que não tenha problemas de desempenho.
nietras
em 4 ago. 2017
Não acha que void * é necessário? Apenas uma versão ref . Pode converter void * em ref com Unsafe.AsRef
por exemplo
void* input;
ref Unsafe.AsRef<Vector<short>>(input);
Não acha que void * é necessário? Apenas uma versão ref.
Sim, eu poderia viver com isso, na verdade, eu iria mais longe e diria por que existem versões de qualquer ponteiro. Eles devem ser baseados exclusivamente em ref . Um ponteiro pode ser facilmente convertido em ref e desta forma todos os cenários são suportados (ponteiros, intervalo, ref s, Unsafe etc.). E sem problemas de desempenho, imagino.
namespace System.Runtime.CompilerServices.Intrinsics.X86
{
public static class AVX
{
......
// __m256i _mm256_loadu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<sbyte> Load(ref sbyte mem) { throw new NotImplementedException(); }
// __m256i _mm256_loadu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<byte> Load(ref byte mem) { throw new NotImplementedException();
......
}
O uso com o ponteiro seria um pouco mais complicado, mas não seria um grande problema para mim.
nietras
em 4 ago. 2017
Bem, esta definição ainda não suportaria cenário genérico pronto para uso, porém, precisamos dela no tipo apropriado para Vector256<T> para isso, mas com Unsafe isso pode ser contornado . Eu ainda preferiria ter Vector256<T>.Load(ref T mem) pois isso torna a programação genérica mais fácil.
nietras
em 4 ago. 2017
@nietras A assinatura que eu acho que podemos usar é esta:
[Intrinsic]
public static Vector256<sbyte> Load(in Vector256<sbyte> mem);
Nesse caso, o formulário genérico também deve funcionar:
[Intrinsic]
public static Vector256<T> Load<T>(in Vector256<T> mem);
O JIT, é claro, tem que lidar com isso, mas isso não deveria ser bastante direto. Minha suposição aqui é que se Vector128
.IsSupported então você deve ser capaz de carregar e armazenar para que eles não precisem estar em locais específicos da plataforma.
Acho que a suposição aqui está correta. No entanto, existem várias maneiras de "carregar" um valor e nem sempre elas podem ser consistentes entre as plataformas.
Você está alinhado e desalinhado. Mas pode haver uma plataforma que requer alinhamento; nesse caso, Unaligned não pode ser usado em Vector128<T> . Portanto, agora temos alguns métodos de carregamento em Vector128<T> e alguns em SSE e isso quebra a consistência.
Você também tem várias instruções para carregar / armazenar que são claramente específicas da plataforma, como atemporal, mascarada, aleatória, transmissão, etc.
Minha opinião é que Vector128<T> (e os outros tipos de registro) devem ser completamente opacos. Os usuários não devem ser capazes de usar o próprio registro para outra coisa senão a verificação IsSupported e devem ser estritamente obrigados a usar intrínsecos para carregar / armazenar / manipular / etc. O único caso especial aqui é o depurador, que deve ter um tipo especial para exibir dados de registro relevantes.
Isso reforça o modelo intrínseco, garante que nada seja especial, ajuda a evitar interrupções futuras se oferecermos suporte a novos hardwares que se comportam de maneira diferente, etc.
tannergooding
em 4 ago. 2017
Aqui está um exemplo bastante simples da transformação genérica que eu poderia imaginar. E um padrão que mostrei muitas vezes aqui 😄
public interface IVectorFunc<T>
{
T Invoke(T a, T b);
Vector128<T> Invoke(Vector128<T> a, Vector128<T> b);
Vector256<T> Invoke(Vector256<T> a, Vector256<T> b);
Vector512<T> Invoke(Vector512<T> a, Vector512<T> b);
}
public static void Transform<T, TFunc>(Span<T> a, Span<T> b, TFunc func, Span<T> result)
where TFunc : IVectorFunc<T>
{
// Check span equal sizes
var length = a.Length;
ref var refA = ref a.DangerousGetPinnableReference();
ref var refB = ref a.DangerousGetPinnableReference();
ref var refRes = ref a.DangerousGetPinnableReference();
int i = 0;
for (; i < length - Vector512<T>.Length; i += Vector512<T>.Length)
{
var va = Vector512<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector512<T>.Load(ref Unsafe.Add(ref refB, i));
Vector512<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
for (; i < length - Vector256<T>.Length; i += Vector256<T>.Length)
{
var va = Vector256<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector256<T>.Load(ref Unsafe.Add(ref refB, i));
Vector256<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
for (; i < length - Vector128<T>.Length; i += Vector128<T>.Length)
{
var va = Vector128<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector128<T>.Load(ref Unsafe.Add(ref refB, i));
Vector128<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
for (; i < length; ++i)
{
var va = Unsafe.Add(ref refA, i);
var vb = Unsafe.Add(ref refB, i);
Unsafe.Add(ref refRes, i) = func.Invoke(va, vb);
}
}
Agora, isso pode, é claro, ser escrito inteiramente com Unsafe.Read/Write/AsRef se for suportado, mas para um desempenho ideal, pode-se verificar o alinhamento antes e usar Vector256<T>.LoadAligned etc. em vez disso.
nietras
em 4 ago. 2017
Agora, isso pode, é claro, ser escrito inteiramente com Unsafe.Read/Write/AsRef
Eu acho que Unsafe.Read/Write vai ser a recomendação para algoritmos genéricos. Sim, você pode perder um pouco de desempenho. É o custo de fazer negócios para escrever algoritmos genéricos.
mas para um desempenho ideal, pode-se verificar o alinhamento
Para obter o desempenho ideal, você também pode usar carregamentos não temporais ou outras variantes de carregamento específicas da plataforma ...
jkotas
em 4 ago. 2017
mas para um desempenho ideal, pode-se verificar o alinhamento antes e usar o Vector256
.LoadAligned etc. em vez disso.
@nietras @jkotas Nos processadores atuais e até mesmo algumas gerações atrás, não há necessidade de verificar o alinhamento, pois as instruções usadas para carregar e armazenar verificar o alinhamento e, no caso de os dados estarem alinhados, há 0 penalidade de desempenho de ciclo em comparação com as instruções especializadas para alinhamento dados. O código que verificará o alinhamento penalizaria com a implementação de vários ciclos. Isso é específico para registros xmm, ymm, zmm e instruções correspondentes.
4creators
em 4 ago. 2017
Provavelmente meu void* exemplo foi mal interpretado. Eu estava usando void* como espaço reservado, aquele que aceita tudo o que você joga usando a representação pretendida para isso no nível de instrução.
@benaadams O problema é que você não pode fazer aritmética de ponteiro sobre referências. Isso significa que o código que faz aritmética de ponteiro ficará inchado com chamadas para ref Unsafe.AsRef<Vector<short>>(input); toda vez que uma nova tradução acontecer. Provavelmente estou perdendo alguma coisa, mas pensando no tipo de algoritmo com que costumo trabalhar, posso imaginar o quão ruim isso pode se tornar.
@nietras No código do protótipo, você precisa da versão "runtime" para que possa passar o tipo para a função. Mas se você deixar isso para fazer, digamos apenas adicionar, o código seria muito mais simples para os casos comuns de Carregar / Armazenar (estou evitando explicitamente o caso de tipos não temporais aqui). Código mais simples -> menos bugs -> vida melhor ao longo do tempo.
redknightlois
em 4 ago. 2017
Unsafe.Read/Write será a recomendação para algoritmos genéricos. pode perder um pouco de desempenho
Ok, mas e se apenas o acesso alinhado for compatível? Como podemos detectar isso? Podemos ter três cenários para Unsafe talvez.
| Alinhamento | Unaligned Only * | Alinhado apenas | Ambos |
| ----- | ---- | ---- | ---- |
| Unsafe.Read/Write | Desalinhado | Alinhado | Desalinhado |
| VectorXXX
| VectorXXX
No caso de alinhamento apenas, como determinamos se temos que alinhar primeiro? Talvez isso seja teórico, mas se os tipos VectorXXX<T> tivessem propriedades dizendo o que é possível, então isso seria um mínimo para métodos gerais com eles, mínimo absoluto, por exemplo, VectorXXX<T>.UnalignedSupported ou algo assim.
Na verdade, como uma questão mais ampla, como posso perguntar de maneira simples, posso verificar qual arquitetura estou executando, ou seja, enum Arch { x86, Arm, etc. }
Com apenas um mínimo de métodos gerais / globais, muitas oportunidades são abertas sem que nós, usuários, tenhamos que fazer isso.
@ 4creatores não são algumas das instruções vetoriais ARM alinhadas apenas? Não tenho certeza se não fiz muitas coisas ARM. Esperando que o ForwardCom obtenha alguma tração;)
@tannergooding sim, muitas maneiras de carregar / armazenar / transmitir / embaralhar, mas acho que alguns pontos básicos comuns seriam bons. Não ter isso dificulta muitas coisas básicas.
nietras
em 4 ago. 2017
Nos processadores atuais e até mesmo algumas gerações anteriores, não há necessidade de verificar o alinhamento, pois as instruções usadas para carregar e armazenar verifique o alinhamento e, no caso de os dados estarem alinhados, há 0 penalidade de desempenho de ciclo em comparação com instruções especializadas para dados alinhados.
@ 4creatores , pode ser o caso dos processadores Intel / Amd modernos, mas pode não ser o caso de todos os processadores (Intel / AMD mais antigo, possivelmente ARM, possivelmente hardware futuro).
tannergooding
em 4 ago. 2017
No código do protótipo, você precisa da versão "runtime" para que possa passar o tipo para a função. Mas se você deixar isso para fazer, digamos, apenas adicionar, o código seria muito mais simples para os casos comuns de Carregar / Armazenar
@redknightlois pena que você me perdeu completamente lá? 💥 😄 Isso significaria implementar muitas diferenças VectorFunc s, por exemplo, ThresholdVectorFunc , AddVectorFunc etc.
nietras
em 4 ago. 2017
@nietras Desculpe, não fui claro o suficiente. O que eu quis dizer é que, com esse código, o objetivo exige explicitamente um Vector<T> ou Vector<float> para que possa ser passado para uma função para operação. O uso de void* como espaço reservado permitiria a você executar com a plataforma segura Load uma operação direto de seu ponteiro e evitar as muitas instâncias de ref Unsafe.Add(ref r, i) que existem na função de protótipo que com a proposta atual requer a geração de uma instância ref e / ou o carregamento de um Vector<T> explicitamente em vez de apenas passar o ponteiro.
redknightlois
em 4 ago. 2017
@nietras ForwardCom com todo o respeito por Agner Fog por seu trabalho é um caso perdido, já que RiscV conseguiu tração suficiente para essencialmente eliminar toda a concorrência (outros unis com arquiteturas concorrentes ficaram realmente chateados com isso). Se RiscV for implementado em silício por alguns jogadores maiores, podemos começar a pensar como portar nosso código de arquitetura de 64 bits para 128 bits 😄
4creators
em 4 ago. 2017
@tannergooding sim, muitas maneiras de carregar / armazenar / transmitir / embaralhar, mas acho que alguns pontos básicos comuns seriam bons. Não ter isso dificulta muitas coisas básicas.
@nietras , acho que em ambos os casos (fornecendo intrínsecos gerais de carga / armazenamento em VectorXXX<T> e fornecendo intrínsecos específicos de plataforma, como SSE.Load ), você deve ter algum tipo de cheque IsSupported (em VectorXXX<T> ou em SSE ). Se não for compatível, você mesmo terá que fornecer um fallback de software (assumindo que as funções intrínsecas não tenham um fallback de software, tanto para mantê-lo simples quanto para manter seu desempenho).
Então, em qualquer caso, você acaba escrevendo algum código como:
`` `C #
if (X.IsSupported)
{
// Copiar Vector512
}
if (Y.IsSupported)
{
// Copiar Vector256
}
if (Z.IsSupported)
{
// Copiar vetor128
}
// Copiar restante (provavelmente usando Unsafe )
`` `
A principal diferença é se os intrínsecos são explícitos (SSE.Load) ou implícitos (VectorXXX
tannergooding
em 4 ago. 2017
uso de void * como espaço reservado
@redknightlois se entendi corretamente, estou evitando explicitamente o ponteiro e fixed aqui para oferecer suporte a memória gerenciada e não gerenciada e evitar obstruir o GC. Sim, sem dúvida, o código seria mais enxuto usando ponteiros diretamente ... mas esse não é realmente o problema aqui. Estou bem com a aparência, é uma opção genérica que eu gostaria.
@tannergooding sim, claro que haveria verificações aqui, isto é ( @redknightlois Unsafe. pode ser removido aqui com using static ):
if (Vector512<T>.IsSupported)
{
for (; i < length - Vector512<T>.Length; i += Vector512<T>.Length)
{
var va = Vector512<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector512<T>.Load(ref Unsafe.Add(ref refB, i));
Vector512<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
if (Vector256<T>.IsSupported)
{
for (; i < length - Vector256<T>.Length; i += Vector256<T>.Length)
{
var va = Vector256<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector256<T>.Load(ref Unsafe.Add(ref refB, i));
Vector256<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
if (Vector256<T>.IsSupported)
{
for (; i < length - Vector128<T>.Length; i += Vector128<T>.Length)
{
var va = Vector128<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector128<T>.Load(ref Unsafe.Add(ref refB, i));
Vector128<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
No mínimo. Provavelmente também terá que verificar VectorXXX<T>.AlignmentSupport { Aligned, Unaligned } , mas com apenas esses poucos métodos gerais, esse tipo de código se torna imensamente mais simples de fazer. Sim, não é ideal para cenários altamente otimizados, mas para 80-90% do processamento numérico básico é muito bom, comparado a um elemento normal em um loop de tempo.
nietras
em 4 ago. 2017
Não tenho certeza se estou sendo claro aqui. Mas pense nas possibilidades aqui e no poder combinatório disso, em vez de 1000 loops personalizados com código neles, eu tenho um loop genérico e 1000s de pequenas funções. O assembly fica muito menor, usamos menos memória e apenas as combinações reais usadas são JIT'ed em tempo de execução ou mesmo em AOT.
Muito menos código, muito menos bugs e muitas combinações podem ser feitas.
É o poder combinatório que vem de alguns algoritmos-chave Transform / ForEach / InPlaceTransform etc. x dimensões (1D, 2D, 3D, tensores etc.) x funções 1000s == 10-100.000 combinações. Sim, muitos terão menos desempenho do que um loop personalizado, mas muito melhores do que os loops caseiros comuns.
Milhares de funções são sem dúvida exagerados. 😉
nietras
em 4 ago. 2017
esse pode ser o caso para os processadores Intel / Amd modernos, mas pode não ser o caso para todos os processadores (Intel / AMD mais antigo, possivelmente ARM, possivelmente hardware futuro).
@tannergooding not really - 0 penalidade de ciclo é verdadeira para todas as implementações AVX, AVX2, AVX512 e SSE para a microarquitetura Nehalem (parei de verificar neste ponto, pois a Microsoft não oferece suporte completo ao Windows Vista).
algumas das instruções vetoriais ARM não estão alinhadas apenas?
@nietras ainda não verifiquei - mas existem tantas implementações ARM ... - IMO em geral, não devemos fornecer LoadAligned / Unaligned, StoreAligned / Unaligned em x86, pois a penalidade de trabalhar em intrínsecos alinhados ou desalinhados não existe, obviamente , isso não significa que os dados não alinhados serão movidos tão rápido quanto os alinhados. Ao apresentá-los, pedimos aos desenvolvedores implicitamente que verifiquem o alinhamento antes de usá-los e, se virem no IntelliSense que também há instrução Carregar / Armazenar, ela será tratada como não sendo a ideal.
Eu generalizaria esse problema para outra pergunta: Como mapeamos intrínsecos para instruções x86 do ISA? Ou mapeamos intrínsecos para instrínsecos C / C ++?
O problema de sobrecargas e genéricos é uma parte da discussão, mas a decisão deve ser tomada sobre o mapeamento das instruções em si . Mapeamos 1 para 1, mapeamos 1 para .... Expomos todas as instruções, mesmo aquelas que sabemos que são legadas e não têm desempenho, ou expomos tudo, exceto aquelas instruções que foram substituídas por implementações melhores. Não somos limitados por código legado compilado para x86 como a Intel e a AMD.
4creators
em 4 ago. 2017
Não somos limitados por código legado compilado para x86 como a Intel e a AMD.
CoreCLR pode não ser, mas CoreCLR também não é o único tempo de execução. Há também CoreRT, Mono e várias outras implementações AOT (algumas até usadas para desenvolver sistemas operacionais gerenciados).
O CoreFX não está vinculado 1 a 1 com o CoreCLR, ele deve ser utilizável em todos eles.
Se eu souber (com certeza) que minhas estruturas estão alinhadas, devo ser capaz de escrever meu algoritmo para usar explicitamente as instruções alinhadas. Se eu souber que minhas estruturas podem estar desalinhadas, devo ter a opção de verificar o alinhamento e usar a instrução apropriada ou apenas usar as instruções não alinhadas (sabendo que em plataformas antigas / legadas pode haver um ligeiro acerto de desempenho).
Eu sou totalmente a favor da escolha do usuário aqui e deixo aberto para os usuários escreverem os algoritmos da maneira que eles acham que é a melhor para suas plataformas de destino.
tannergooding
em 4 ago. 2017
@tannergooding @ 4creators Concordo com você que nas arquiteturas modernas baseadas em Intel, os custos de acessos alinhados versus não alinhados são os mesmos; há casos definitivos em que as coisas vão despencar (atualmente, as divisões da linha de cache) e, à medida que os vetores se tornam mais amplos, mesmo nos melhores casos, as divisões acontecem devido à granularidade da linha de cache. Portanto, de uma perspectiva de ponto de design, aplicando-se a mais do que apenas as arquiteturas convencionais baseadas em Intel, suportando formas alinhadas e não alinhadas de instruções. Os intrínsecos (pelo menos nativamente) não têm rede de segurança. É saudável debater se todos os ISA precisam ser expostos como intrínsecos, assim como no lado nativo. É uma questão de utilidade versus integridade. :)
 jarodrig
em 4 ago. 2017
jarodrig
em 4 ago. 2017
@nietras : Estou tentando entender como isso:
`` `C #
if (Vector512
{
para (; i <comprimento - Vector512
{
var va = Vector512
var vb = Vector512
Vector512
}
}
if (Vector256
{
para (; i <comprimento - Vector256
{
var va = Vector256
var vb = Vector256
Vector256
}
}
if (Vector128
{
para (; i <comprimento - Vector128
{
var va = Vector128
var vb = Vector128
Vector128
}
}
Is really any better than this:
```C#
if (AVX512.IsSupported)
{
for (; i < length - Vector512<T>.Length; i += Vector512<T>.Length)
{
var va = AVX512.Load(ref Unsafe.Add(ref refA, i));
var vb = AVX512.Load(ref Unsafe.Add(ref refB, i));
AVX512.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
if (AVX.IsSupported)
{
for (; i < length - Vector256<T>.Length; i += Vector256<T>.Length)
{
var va = AVX.Load(ref Unsafe.Add(ref refA, i));
var vb = AVX.Load(ref Unsafe.Add(ref refB, i));
AVX.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
if (SSE.IsSupported)
{
for (; i < length - Vector128<T>.Length; i += Vector128<T>.Length)
{
var va = SSE.Load(ref Unsafe.Add(ref refA, i));
var vb = SSE.Load(ref Unsafe.Add(ref refB, i));
SSE.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
else if (Neon.IsSupported)
{
for (; i < length - Vector128<T>.Length; i += Vector128<T>.Length)
{
var va = Neon.Load(ref Unsafe.Add(ref refA, i));
var vb = Neon.Load(ref Unsafe.Add(ref refB, i));
Neon.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
Embora seja realista, para um uso genérico, eu provavelmente declararia as estruturas personalizadas que envolvem a carga / armazenamento como ideais:
`` `C #
struct Data512
{
public static Data512 Load
public static void Store
}
struct Data256
{
public static Data256 Load
public static void Store
}
struct Data128
{
public static Data128 Load
public static void Store
}
`` `
Ou possivelmente apenas ter um método CopyBlock que abstrai tudo isso e faz rep movsb em hardware moderno (onde pode ser mais rápido e definitivamente será menor).
tannergooding
em 4 ago. 2017
Eu sou totalmente a favor da escolha do usuário aqui e deixo aberto para os usuários escreverem os algoritmos da maneira que eles acham que é a melhor para suas plataformas de destino.
Parece que, se decidirmos seguir esse caminho, simplesmente temos que expor tanto quanto tecnicamente possível o que está perfeitamente bem para mim e eu votarei a favor com minhas duas mãos.
Mas então, se todos concordarmos, tomamos uma das decisões de design mais importantes, que restringe nossa discussão a outros problemas.
e aí vem o problema dos genéricos e de todas as implementações possíveis ... 😄
4creators
em 4 ago. 2017
@tannergooding você não consegue escrever (apenas um exemplo):
for (; i < length - Vector512<T>.Length; i += Vector512<T>.Length)
{
var va = AVX512.Load(ref Unsafe.Add(ref refA, i));
var vb = AVX512.Load(ref Unsafe.Add(ref refB, i));
AVX512.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
AVX512.Load não é genérico, pelo que entendi. Então isso não funcionará. E, então, você precisa de muito mais verificações, que conjunto de instruções permite carregar int vs float vs byte vs double etc. É um pesadelo combinatório ...
rep movsb Duvido seriamente que seja rápido, tem um custo de configuração bastante elevado. Em algumas plataformas, pelo menos ...
nietras
em 4 ago. 2017
Algumas reflexões baseadas em experiências anteriores com esse tipo de coisa em compiladores nativos:
- frequentemente há uma "incompatibilidade de impedância" entre o uso de tipos intrínsecos e intrínsecos e o código não intrínseco vizinho. Portanto, inserir e retirar dados desses formulários exige uma consideração cuidadosa, especialmente para "usos limitados", em que você deseja apenas usar com eficiência uma ou duas instruções intrínsecas. O gerador de código também pode ter problemas nesta área (a discussão sobre os formulários de carregamento sugere isso, por exemplo).
- implicações para as bibliotecas: não temos nenhuma maneira de descrever como uma montagem / biblioteca agora pode / deve depender dos conjuntos de recursos do ISA, portanto, é necessário pensar em como o nuget, etc. compreende as implicações de haver potencialmente muitos pacotes diferentes que alguém pode precisar ou querer usar, dependendo do conjunto mínimo de recursos ISA com suporte de um aplicativo. Por exemplo, seus aplicativos e bibliotecas podem precisar indicar "Eu preciso de xxx" ou "Eu posso tirar proveito de xxx" e o sistema de empacotamento tentaria obter as versões corretas. A adequação pode não ser preto e branco, portanto, o processo de escolha da "melhor" versão da biblioteca pode ser complicado.
- Prejuízo (como fazemos para SPCorelib) atualmente tem como alvo o conjunto de recursos ISA com suporte mais baixo e, portanto, tais caminhos sempre precisariam de um código substituto ou então pulariam quaisquer métodos dependentes de conjunto de recursos ao fazer o pré-julgamento e apenas sempre jit tal código (semelhante a onde acabamos com vetores hoje). Para Full AOT fallbacks ou um conjunto de recursos projetivos / solução de empacotamento como acima seria necessário.
- o jit está tomando decisões independentes sobre quais instruções usar para o codegen. Isso pode causar vários problemas. Por exemplo, o jit pode estar usando AVX em um método - se você, via intrínseca, soltar um formulário SSE2 em um fluxo AVX, você sofrerá penalidades de desempenho. Isso pode ser visto como um problema "somente para especialistas", mas torna a escrita de código de biblioteca um desafio, pois você não pode controlar a plataforma final ou a lógica que o jit usa. À medida que os conjuntos de recursos jit e ISA evoluem, as bibliotecas existentes tornam-se obsoletas e potencialmente inviáveis. Portanto, talvez deva haver alguma maneira de também verificar ou restringir o código que o jit pretende gerar em torno de seu intrínseco. Isso pode ser útil para abordar parcialmente o problema do pré-julgamento, pois essa verificação sempre retornaria o conjunto de recursos ISA com suporte mais baixo durante o pré-julgamento.
 AndyAyersMS
em 4 ago. 2017
AndyAyersMS
em 4 ago. 2017
Estou tentando entender como isso ... é realmente melhor do que isso:
@tannergooding @nietras
Se expormos as instruções de hardware de uma maneira específica de hardware, devemos discutir AVX512.IsSupported design e deixar Vector512 <T> na montagem instrinsics como uma abstração do registro apenas e não uma abstração da funcionalidade disponível em um determinado grupo de instruções.
No entanto, podemos então expor essa funcionalidade de forma bastante eficaz em System.Numerics com todos os VectorXxx tendo métodos estáticos gerais e verificações de suporte de hardware o que seria implementado com a ajuda de intrínsecos das classes SSE2, AVX, AVX2 ....
4creators
em 4 ago. 2017
E, então, você precisa de muito mais verificações, que conjunto de instruções permite carregar int vs float vs byte vs double etc. É um pesadelo combinatório ...
@nietras , para um algoritmo de cópia simples (como aquele), o tipo subjacente realmente não importa. Pelo menos para carregar / armazenar, você está apenas copiando bits ( float e int são ambos de 32 bits e Vector512<T> são sempre 512 bits, independentemente de T ). O tipo de T só entra em jogo ao operar nos dados ( Sqrt , Convert , Add , etc).
Se, por alguma razão, o tipo importa, é para isso que os tipos de invólucro abstratos ( Data512 , Data256 , Data128 ) devem ser feitos. Você mantém o intrínseco "puro", mas facilita o uso localmente, envolvendo as chamadas em outros tipos.
tannergooding
em 4 ago. 2017
Prejuízo (como fazemos para SPCorelib) atualmente visa o conjunto de recursos ISA com suporte mais baixo e, portanto, tais caminhos sempre precisariam de um código substituto ou então pulariam quaisquer métodos dependentes do conjunto de recursos ao fazer o pré-julgamento e apenas sempre jit tal código (semelhante a onde acabamos com vetores hoje)
@AndyAyersMS Seria possível armazenar no assembly R2R código nativo e IL apenas para intrínsecos e então se a plataforma oferecer suporte a ISA expandido de forma a explorar todos os recursos da plataforma? (isso era uma espécie de sonho jit universal algum tempo atrás)
4creators
em 4 ago. 2017
@AndyAyersMS ...
portanto, é necessário pensar em como o nuget, etc. compreende as implicações de haver potencialmente muitos pacotes diferentes
Eu não acho que o gerenciamento de pacotes precise ser incluído nisso.
Em todos os cenários, espera-se que os usuários façam `If (X.IsSupported) {/ * Do X /} else if (Y.IsSupported) {/ Do Y /} else {/ Do Software * /}
Se o usuário decidir deixar o fallback de software, ele executará o PNSE em plataformas não suportadas.
Prejuízo (como fazemos para SPCorelib) atualmente tem como alvo o conjunto de recursos ISA com suporte mais baixo
Este e o AOT se enquadram na mesma categoria. Uma única verificação de inicialização para CPUID pode ocorrer e ser armazenada em cache, o código para todos os caminhos aplicáveis na arquitetura (todos os caminhos para x86 ou todos os caminhos para Arm, atualmente). Você pode então verificar o sinalizador e pular para a implementação apropriada (como é feito para a implementação cos no MSVCRT) ou pode fazer alguma forma de envio dinâmico (configurando dinamicamente o ponto de entrada do método durante a inicialização do aplicativo).
se você, via intrínseca, soltar um formulário SSE2 em um fluxo AVX, sofrerá penalidades de desempenho.
Acho que isso, na maior parte, deve ser considerado território de especialista. É o caso em que um consumidor chama um método que usa AVX e, em seguida, chama um método separado que só oferece suporte a SSE.
Ainda estou pensando sobre esse cenário específico, mas acredito que podemos descobrir algo (no entanto, não é diferente do que C / C ++ encontrou).
tannergooding
em 4 ago. 2017
@tannergooding não é um algoritmo de cópia, o propósito explícito é invocar uma função que recebe VectorXXX<T> genérico, como eu iria então de um registrador sem "tipo" para um registrador digitado? Sou totalmente a favor de um Vector128 não genérico com carga / armazenamento etc., mas ainda precisamos ser capazes de "converter" isso em uma versão genérica Vector128<T> . E Vector128 ainda tem a questão de saber se tem membros para carregar / armazenar "independentes" de, digamos, métodos estáticos SSE2 etc.
nietras
em 4 ago. 2017
@nietras em relação a void* e ref , isso é muito bom quando se trabalha em memória gerenciada, mas há uma necessidade de ser capaz de executar isso também em memória _não gerenciada_.
Um caso de uso muito comum para reduzir os custos de memória / GC é NÃO alocar nenhuma memória gerenciada para as coisas comuns, mas confiar no gerenciamento manual de memória. Ainda quero ser capaz de fazer isso e, nesse cenário, quero ser capaz de fazer isso com o mínimo de sobrecarga possível.
Nesse caso, não ter que chamar AsRef seria uma coisa muito boa (a menos que o JIT apenas apague isso, o que eu acho que não faz).
 ayende
em 4 ago. 2017
ayende
em 4 ago. 2017
não ter que chamar AsRef seria uma coisa muito boa (a menos que o JIT apenas apague isso, o que eu acho que não faz).
@ayende o JIT os apagará completamente. Tanto quanto me lembro. É um elenco simples sem operação / reinterpretação. @jkotas pode
nietras
em 4 ago. 2017
@AndyAyersMS Obrigado por trazer esses pontos à tona novamente - acho que eles são muito importantes para a história geral.
Este e o AOT se enquadram na mesma categoria. Uma única verificação de inicialização para CPUID pode ocorrer e ser armazenada em cache, o código para todos os caminhos aplicáveis na arquitetura (todos os caminhos para x86 ou todos os caminhos para Arm, atualmente). Você pode então verificar o sinalizador e pular para a implementação apropriada (como é feito para a implementação cos no MSVCRT) ou pode fazer alguma forma de envio dinâmico (definir dinamicamente o ponto de entrada do método durante a inicialização do aplicativo).
No entanto, você está descrevendo recursos que ainda não existem. A última opção que você está descrevendo é usada em muitas bibliotecas nativas, como eu a entendo, mas o modelo de programação é muito diferente do que estamos descrevendo aqui. Não está claro para mim se podemos corresponder a esse tipo de comportamento, considerando como os intrínsecos de hardware do C # funcionarão.
Ainda estou pensando sobre esse cenário específico, mas acredito que podemos descobrir algo (no entanto, não é diferente do que C / C ++ encontrou).
O ponto principal é que você tem muito pouca visibilidade do código que o JIT estará gerando ao seu redor, e esse código pode e vai mudar com o tempo. Você pode não estar chamando explicitamente uma instrução AVX e, em seguida, uma instrução SSE como em seu exemplo, mas pode apenas estar fazendo algum trabalho não relacionado no meio de seu algoritmo que o JIT decide otimizar com instruções SSE. Essa lógica de otimização é opaca e não constante - sua biblioteca pode se tornar significativamente mais lenta após uma atualização JIT. Acho que isso é muito diferente de C / C ++.
Eu concordo que "não misturar conjuntos de instruções" é algo que o autor da biblioteca precisa apenas entender. É um "território especialista"; talvez o melhor que possamos fazer seja um analisador para detectar falhas óbvias.
mellinoe
em 4 ago. 2017
@mellinoe Verdadeiro sobre o código JITted ser um alvo móvel, mas isso é essencialmente o que estamos fazendo em ambientes de produção. Nós microotimizamos e corrigimos a versão de tempo de execução até que possamos criar um perfil e verificar se está tudo OK com a nova versão (mesmo que seja uma versão de serviço) porque para código não SIMD ainda estamos nadando na mesma piscina.
redknightlois
em 4 ago. 2017
@ 4creators se houver IL para um método, então sim, ele estará disponível para o jit em tempo de execução. Se jitting, o jit irá gerar o que pensa ser o melhor código possível para a plataforma atual. É assim que Vector
Os assemblies podem ser parcialmente pré-definidos para adiar o codegen nos métodos e, potencialmente (JNI, mas algo em que pensamos), o tempo de execução pode decidir não usar ou substituir o código pré-definido e invocar o jit, para tentar gerar um código mais personalizado. Há uma troca aqui que pode ser potencialmente aproveitada para melhorar o desempenho, mas como fazer isso hoje não é óbvio; não sabemos quanto benefício pode ser obtido com o jit, quanto tempo o jit levará ou com que frequência esse método será chamado.
Pode-se imaginar que a presença de uma dessas verificações de IsSupported em um método nos daria uma dica bastante forte de que o jitting é uma boa ideia, então iríamos pular o preconceito de tais métodos ou o preconceito visando o conjunto de recursos mais baixo suportado e, então, decidiríamos jogue esse código e jit se a plataforma final oferecer suporte a recursos mais ricos.
AndyAyersMS
em 4 ago. 2017
pularíamos o pré-julgamento de tais métodos ou o pré-julgamento do conjunto de recursos com suporte mais baixo e, em seguida, decidiríamos jogar esse código e jit se a plataforma final oferecer suporte a recursos mais ricos.
@AndyAyersMS IMO prejudicando as versões de código 2 de menor denominador comum (fallback + SSE2 para escolher na inicialização permitiria uma inicialização rápida) e jitting em camadas posteriores poderiam fazer uma compilação mais otimizada e substituir a versão do código antigo assim que ficar quente. Seria o melhor de dois mundos, primeiro a inicialização rápida e, posteriormente, o desempenho ideal. Pode ser um dos cenários perfeitos para mostrar o poder real do jit. O mesmo pode ser verdadeiro para ativar otimizações de vetorização mais caras.
Há uma troca aqui que pode ser potencialmente aproveitada para melhorar o desempenho, mas como fazer isso hoje não é óbvio; não sabemos quanto benefício pode ser obtido com o jit, quanto tempo o jit levará ou com que frequência esse método será chamado.
Muito provavelmente, olhar a literatura atual baseada em rastreamento de jitting em camadas seria a solução ideal.
4creators
em 4 ago. 2017
No entanto, você está descrevendo recursos que ainda não existem. A última opção que você está descrevendo é usada em muitas bibliotecas nativas, como eu a entendo, mas o modelo de programação é muito diferente do que estamos descrevendo aqui. Não está claro para mim se podemos corresponder a esse tipo de comportamento, considerando como os intrínsecos de hardware do C # funcionarão.
@mellinoe , Também estamos discutindo isso para um recurso que ainda não existe 😄
Para o Live JIT, os valores do CPUID são estaticamente conhecidos e está tudo bem e nada precisa ser feito.
Para qualquer tipo de AOT (incluindo preconceito, ngen, etc), eu não imagino que seja muito difícil obter suporte para essas coisas. Basicamente, requer:
- Executando CPUID na inicialização
- Armazenando em cache os resultados da verificação da CPUID em algum local conhecido ou facilmente acessível (por exemplo, poderíamos ter um dword
__is_supported_avx) - Chamando
cmp DWORD PTR __is_supported_avx, 0ejne avx_implementation(com verificações adicionais para outros caminhos).
Na maioria das vezes, essas verificações são triviais em comparação com a economia de custos do melhor algoritmo. Para casos em que você não deseja fazer as verificações prévias, você pode fazer coisas mais complicadas como a vinculação tardia do endereço do método (que também é feito na inicialização, mas provavelmente seria mais complicado de suportar)
tannergooding
em 4 ago. 2017
O ponto principal é que você tem muito pouca visibilidade do código que o JIT estará gerando ao seu redor, e esse código pode e vai mudar com o tempo. Você pode não estar chamando explicitamente uma instrução AVX e, em seguida, uma instrução SSE como em seu exemplo, mas pode apenas estar fazendo algum trabalho não relacionado no meio de seu algoritmo que o JIT decide otimizar com instruções SSE. Essa lógica de otimização é opaca e não constante - sua biblioteca pode se tornar significativamente mais lenta após uma atualização JIT. Acho que isso é muito diferente de C / C ++.
O JIT provavelmente poderia ter inteligência para detectar casos como este (ele já tem alguma inteligência para coisas como limpar partes superiores do registro em alguns casos para ajudar com o perf), ou talvez possamos fornecer um atributo que diga ao JIT para não usar SIMD em alguns casos (possivelmente uma dica MethodImpl.IntrinsicWrapper ou algo que os usuários podem colocar em seus métodos para que o JIT saiba quando pode otimizar para usar SSE e quando não deve).
tannergooding
em 4 ago. 2017
@mellinoe , Também estamos discutindo isso para um recurso que ainda não existe 😄
Claro - má formulação 😄. O que eu quis dizer é que esses recursos AOT provavelmente são complicados por si próprios (especialmente a ideia de ligação tardia), e ainda não tínhamos definido o escopo dessa solução para esse recurso. É provável que a primeira versão apenas force a compilação adiada a la Vector<T> . Mas é bom pensar em uma solução melhor para o futuro.
mellinoe
em 4 ago. 2017
@nietras , ah, perdi a assinatura Invoke completamente.
Esse é um cenário interessante, e não um que eu realmente tenha considerado.
Você poderia definitivamente fornecer isso com um método wrapper que lida com todos os vários tipos para você (para JIT, eles ainda seriam constantes) e ainda estou convencido de que fazer isso é melhor (manter a camada mais baixa "simples" e colocar todos os pressão sobre o consumidor, não sobre o tempo de execução).
Quanto a rep movsb , há definitivamente um aumento no custo em algumas plataformas, mas após Ivy Bridge , temos um sinalizador CPUID especial (é claro, com algumas limitações, etc, mas está tudo documentado no manual de otimização ):
tannergooding
em 4 ago. 2017
@nietras @tannergooding Se você tem algo a dizer sobre as instruções mov / sto do Enhanced REP, sou todo ouvidos ... Sou mais do que responsável por conduzir o recurso aos processadores IA junto com alguns amigos ...
jarodrig
em 5 ago. 2017
Cosmos é um exemplo de sistema operacional que também é um .Net Runtime. Todo o código é compilado AOT antes da imagem inicializável ser criada e, portanto, somos forçados a escolher um ISA mínimo, decidimos que pelo menos SSE2 deve ser suportado (80887 não faz mais sentido ...), portanto, voltando ao exemplo Cos o que deveríamos Faz:
public static double Cos(double x)
{
if (x86.FMA3.IsSupported)
{
// Do FMA3
}
else if (x86.SSE2.IsSupported)
{
// Do SSE2
}
else if (Arm.Neon.IsSupported)
{
// Do ARM
}
else
{
// Do software fallback
}
}
Certamente podemos excluir o branch ARM automaticamente durante a compilação AOT para x86, mas como nosso compilador poderia ser tão inteligente para saber que deveria reter as versões SSE2 e FMA3 para "revalorá-las" em tempo de execução (ou seja, na inicialização do sistema operacional como fazendo aquelas verifica sempre que Cos é usado anula o objetivo deste IMHO)?
Quero dizer, como o compilador sabe que há intrínsecos usados aqui e que é suposto fazer algo "mágico"?
 fanoI
em 5 ago. 2017
fanoI
em 5 ago. 2017
@fanol , grosso modo, saberia fazer mágica da mesma forma que sabe fazer qualquer mágica. O compilador seria informado de que essas chamadas são "especiais" e que deveriam ser tratadas de maneira diferente de outros métodos.
Uma explicação mais aprofundada
Ao analisar IL, existem, essencialmente, dois tipos de métodos que você encontrará:
- Métodos que têm uma implementação
- Métodos marcados
extern
Para ambos os casos, pode haver atributos adicionais que informam ao compilador como tratar o método (como inlining, chamada interna, intrínseco, etc.).
Métodos com uma implementação
A grande maioria dos métodos tem implementações de apoio reais e só precisam ter seu IL convertido em código de máquina.
No entanto, existem alguns métodos com implementações sobre os quais se espera que o compilador tenha uma compreensão especial.
Um exemplo disso são os tipos System.Runtime.Numerics.Vector . Esses tipos têm uma implementação de fallback de software para quando o compilador não sabe como tratá-los de maneira especial (ou se o hardware de apoio não oferece suporte às instruções necessárias para uma implementação "ideal").
O outro exemplo são métodos que possuem uma implementação de software que não faz nada além de throw PlatformNotSupportedExecption (como é proposto para esses intrínsecos).
Métodos Externos
Para métodos externos ( Math.Cos , por exemplo) o compilador deve saber como lidar com isso e deve falhar em emitir se não o fizer. Mais comumente, é:
- DllImport
- MethodImplOptions.InternalCall
Para DllImport, o compilador localiza e carrega o binário apropriado, encontra o método com o símbolo correspondente e o invoca.
Para MethodImplOptions.InternalCall, o compilador tem uma implementação interna em algum lugar para o qual ele sabe emitir uma chamada. Por exemplo, CoreCLR tem uma lista de mapeamentos entre esses métodos externos e a implementação interna pela qual ele substituirá a chamada. Para Math.Cos , isso resulta em uma chamada para ComDouble::Cos que envolve a implementação do CRT.
Algumas dessas chamadas internas são tratadas como "intrínsecas" e otimizadas para uma ou mais instruções de máquina otimizadas ( Math.Sqrt é otimizado para sqrtsd em CPUs x86, em vez de ser uma chamada para o CRT Função sqrt ).
Manuseio Especial
Eu esperaria que qualquer compilador (AOT ou JIT) tivesse conhecimento especial para todos os tipos no namespace System.Runtime.CompilerServices.Intrinsics (esta é uma das razões pelas quais eu acho que eles deveriam ser marcados com extern , em vez de tem uma implementação de software que joga).
Quando eles encontram chamadas de método nesses tipos, eles não devem emitir uma chamada e, em vez disso, devem emitir a instrução de hardware apropriada (ou seja, Vector128<float> SSE.Add(Vector128<float>, Vector128<float> deve ser substituído por addps ).
Para as várias propriedades IsSupported , qualquer compilador deve saber que ele compila em uma sequência de instruções de hardware que verificam se o hardware subjacente suporta essas chamadas.
Para um JIT, isso é "constante" e pode descartar qualquer caminho de código que não acertar. Ele também não precisa emitir os cheques.
Para um AOT, a opção mais básica é dois, apenas compilar para uma arquitetura mínima suportada e descartar todos os outros caminhos de código e as verificações de hardware. O próprio hardware irá falhar ao encontrar as sequências de instruções emitidas se não as suportar. No seu caso, isso soa como abandonar tudo que não seja SSE ou SSE2.
Você pode, no entanto, fazer com que o compilador seja mais inteligente e suporte mais do que a arquitetura mínima, emitindo as verificações necessárias. Tendo em mente que essas verificações podem ser caras, geralmente você deseja armazená-las em cache para que seus métodos não precisem realmente verificar o suporte em cada ponto de entrada.
A maioria dos sistemas operacionais tem algum mecanismo para executar algum código de "inicialização" básico quando uma biblioteca dinâmica é carregada. Da mesma forma, eles geralmente têm algum mecanismo para executar algum código de "inicialização" básico antes que o método de ponto de entrada de um executável seja executado. As várias bibliotecas CRT geralmente se conectam a esse ponto de inicialização para que também possam fazer qualquer código de inicialização.
Uma maneira de oferecer suporte a arquiteturas adicionais é, no código de "inicialização", fazer com que o compilador emita as verificações de hardware e armazene em cache os resultados em algum endereço global / conhecido. O compilador pode então emitir vários caminhos de código para um método e fazer com que as primeiras instruções do método verifiquem o suporte de hardware em cache e ramifiquem apropriadamente ( cmp DWORD PTR _is_supported_fma3, 0 e jne cos_fma3_implementation ).
Outra maneira de oferecer suporte a arquiteturas adicionais é fazer a ligação tardia dos pontos de entrada do método. Basicamente, isso significa que você teria um método cos , um método cos_sse2 e um método cos_fma3 , cada um com a mesma assinatura ( double method(double) ). O compilador, no código de "inicialização", emite verificações de hardware e modifica o método cos para saltar para o método cos_sse2 ou cos_fma3 , dependendo do que for mais adequado para o hardware subjacente (há várias maneiras de fazer a ligação tardia do ponto de entrada do método, este foi apenas um exemplo).
Em todos os casos, espera-se que o ligeiro aumento no custo de inicialização valha a pena devido às economias posteriores no hardware moderno.
tannergooding
em 5 ago. 2017
@fanol provavelmente estou faltando alguma coisa, porque não vejo nenhum problema que não tenha sido resolvido há muito tempo para lidar com caminhos múltiplos com base nas características da CPU. Compiladores AOT AFAIK (que não é muito conhecido) terão que "decidir" a arquitetura alvo (digamos x86, x64 e / ou ARM) de qualquer maneira.
Agora, a maneira usual de lidar com isso (há um exemplo muito bem delineado nas rotinas memcpy de Agnes Fog) é fazer uma verificação cpuid no ponto de entrada e configurar a mesa de salto para as rotinas com base em qual caminho o compilador AOT emitiu (tendo IsSupported códigos implicam que o compilador tem que fazer alguma mágica lá de qualquer maneira) para que ele emita todas as versões daqueles e no ponto de entrada uma nova entrada para lidar com o cheque cpuid . Depois disso, você está apenas fazendo uma chamada para um local de memória estática que, por sua vez, executa um salto para a instrução de entrada de rotina apropriada.
Essencialmente o que @tannergooding disse com um custo inicial insignificante; para a versão JIT é simples (é assim que funciona um JIT). Nenhum código de auto-modificação foi necessário para fazer a ligação tardia ao custo de um salto muito previsível para lidar com isso.
redknightlois
em 5 ago. 2017
Eu esperaria que qualquer compilador (AOT ou JIT) tivesse conhecimento especial para todos os tipos no namespace System.Runtime.CompilerServices.Intrinsics (esta é uma das razões pelas quais eu acho que eles deveriam ser marcados com extern, em vez de ter uma implementação de software que joga).
Este é um detalhe de implementação interno que pode diferir de tempo de execução para tempo de execução ou ao longo do tempo. Isso não afeta a forma pública dessas APIs.
No CoreCLR, temos usado implementações fictícias que geram intrínsecos como esse por serem mais fáceis de implementar. Aqui está um exemplo: https://github.com/dotnet/coreclr/blob/master/src/mscorlib/src/System/ByReference.cs#L21 . Esse método é intrínseco, assim como os intrínsecos discutidos aqui: O JIT precisa entender o que fazer por ele e não tem nenhuma implementação de fallback.
jkotas
em 6 ago. 2017
Estou muito feliz em ver esta proposta. Seria ótimo ter os blocos de construção de nível mais baixo disponíveis.
Para examinar algumas das coisas já discutidas:
1) Como usuário, estou totalmente bem com esse tipo de API sem fallbacks embutidos. Se eu estou mergulhando até o nível de uso de intrínsecos específicos de plataforma, o uso de um fallback intrínseco sem suporte seria um bug de desempenho. Nessa situação, eu realmente prefiro um comportamento rápido à falha.
2) Com relação ao ponteiro versus ref no nível da API, praticamente toda a memória com a qual trabalho é da memória pré-alocada e fixada ou da pilha, portanto, os ponteiros não seriam um grande bloqueador para meus usos. Dito isso, evitar o furo fixo / GC é realmente útil no caso geral, e eu não teria nenhum problema com uma API ref-only, desde que o JIT produza resultados eficientes para ponteiro-> ref (do qual tenho certeza faz sem sobrecarga, pela última vez que verifiquei).
3) Com relação à explicitação, eu tenderia a expor os primitivos de hardware sempre que razoável. No caso de algo como cargas alinhadas vs. cargas não alinhadas, seria um pouco infeliz se o design da API acabasse dificultando o direcionamento de uma plataforma onde as cargas alinhadas fossem, na verdade, notavelmente mais rápidas. Isso não significa necessariamente que todos os intrínsecos possíveis tenham a mesma prioridade de implementação - alguns são claramente menos aplicáveis - mas é bom manter espaço na API para eles.
Gosto da ideia de abraçar a natureza de nível extremamente baixo dessa API. Se o projeto acabar escondendo uma escolha que poderia afetar o desempenho em alguma combinação de instrução x plataforma, poderia acabar havendo outra proposta no caminho para distratá-la ainda mais. Prefiro curto-circuitar essas questões e ter acesso aos materiais de construção brutos para fazer essas abstrações conforme necessário.
4) Eu não tenho um grande entendimento da história AOT, mas fazer o empacotamento com reconhecimento de recursos do ISA parece que seria um trabalho muito complicado abrangendo uma grande quantidade de ferramentas. No interesse de fazer essa API rodar mais rapidamente, parece que fazer o mínimo necessário para suportá-la - como pular nas verificações de hardware em cache - é uma boa escolha. Posteriormente, abordagens ou ferramentas de menor sobrecarga para pacotes especializados de recursos geradores de AOT podem ser úteis, mas a API principal não parece bloqueada por ela. (Devo mencionar que sou meio tendencioso por iwannaplaywithit, então vou me inclinar para a simplicidade crua e velocidade de implementação :))
 RossNordby
em 6 ago. 2017
RossNordby
em 6 ago. 2017
No CoreCLR, temos usado implementações fictícias que geram intrínsecos como este, porque eram mais fáceis de implementar
@jkotas , também há o caso em que você joga no lado nativo (https://github.com/dotnet/coreclr/search?utf8=%E2%9C%93&q=COMPlusThrowArgumentNull&type=).
Eu definitivamente acho que é uma base caso a caso sobre qual é o melhor, mas para este recurso em particular, acho que ter o tempo de execução lançado ( COMPlusThrowPlatformNotSupported ) seria a escolha "ir para".
Haverá, pelo menos com base nesta proposta e nas discussões até agora, várias centenas de APIs que não têm uma implementação de software de apoio. Além disso, os métodos são identificados por um atributo especial e podem (com base no documento de design original) potencialmente ter uma implementação de fallback de software.
Então, eu acho que seria melhor para o código de tempo de execução que identifica intrínsecos ter um substituto que faça COMPlusThrowPlatformNotSupported no caso de encontrar um método marcado Intrinsic e extern e não tendo nenhum manuseio conhecido para isso.
Existem alguns benefícios em fazer isso:
- Isso economizará (pelo menos) 7 bytes por API (provenientes dos 7 bytes de IL necessários para lançar uma exceção). Com esta proposta já sendo várias centenas de APIs (e mais vindo no futuro para outras arquiteturas), isso vai somar rapidamente.
- O JIT já terá que ter um caminho de código onde identifica os métodos marcados com
Intrinsic, determinar se a arquitetura atual suporta a instrução e emitir a instrução se for suportada ou emitir uma chamada para o método se não . Modificar isso para lançar métodos deexternparece uma adição trivial - Isso força o compilador (AOT ou JIT) a entender esses métodos. Se tivermos um fallback de software que lança, um compilador que não os reconhece irá compilá-los e o código falhará em tempo de execução. Se, em vez disso, for marcado
extern, o compilador falhará no tempo de compilação (ainda é o tempo de execução para JIT, mas pré-execução para AOT). - Ele reforça a capacidade de dizermos que essa API em particular não deve ter um fallback de software agora ou no futuro (para isso, é principalmente devido a preocupações com o desempenho, mas também pode haver outros motivos). Se os usuários desejam um fallback de software, eles podem fornecer seu próprio wrapper (
if (X.IsSupported) { X.API(); } else { /* Software Fallback */ }), que será otimizado adequadamente pelo compilador.
tannergooding
em 6 ago. 2017
Isso economizará (pelo menos) 7 bytes por API (provenientes dos 7 bytes de IL necessários para lançar uma exceção). Com esta proposta já sendo várias centenas de APIs (e mais vindo no futuro para outras arquiteturas), isso vai somar rapidamente.
Corpos de método IL idênticos são dobrados em uma única instância (todos eles compartilham o mesmo RVA), portanto, não importa quantas dessas APIs existem. Dito isso, eu também prefiro extern .
pentp
em 6 ago. 2017
Eu acho que ter o lançamento de tempo de execução (COMPlusThrowPlatformNotSupported) seria a escolha "goto".
O "código gerenciado manualmente" nunca é nossa escolha "ir para" atualmente. No CoreCLR, evitamos "código gerenciado manualmente" porque escrever corretamente é uma ciência do foguete. No CoreRT, não há "código gerenciado manualmente" por design (por exemplo, não há equivalente a COMPlusThrowPlatformNotSupported) e, portanto, tudo que é "código gerenciado manualmente" no CoreCLR deve ser reimplementado de forma diferente no CoreRT. Isso vai contra nosso desejo de compartilhar o máximo possível entre CoreCLR e CoreRT.
Isso economizará (pelo menos) 7 bytes por API
Ele não salvará nada como @pentp apontou.
Modificar isso para lançar métodos externos parece uma adição trivial
Não é exatamente trivial. Você pode pegar um dos intrínsecos existentes (por exemplo, https://github.com/dotnet/coreclr/blob/master/src/mscorlib/src/System/ByReference.cs#L21) e tentar reenviá-lo usando extern para entender melhor o problema. O primeiro problema que você provavelmente encontrará é que esses métodos externos precisam ter um ponto de entrada e não é trivial fazer um ponto de entrada do nada.
Ele reforça a capacidade de dizermos, esta API em particular não deveria ter um substituto de software agora
IMHO, o comentário é quase tão bom para dizer que esta API não deve ter um fallback de software.
Além disso, espero que, uma vez que isso seja testado de ponta a ponta, vamos descobrir que o intrínseco deve funcionar melhor, mesmo como funções individuais, para fazer coisas como depuradores, profilers avançados ou intérpretes de IL funcionarem bem. Podemos terminar a implementação dos intrínsecos chamando-se recursivamente para fazer esse trabalho:
[Intrinsic]
public static Vector256<float> Add(Vector256<float> left, Vector256<float> right) => Add(left, right);
Observe que essa implementação tem exatamente o mesmo comportamento (por exemplo, em torno de lançar uma exceção de instrução inválida) como se o intrínseco fosse expandido em linha. Este truque com intrínseco implementado chamando-se recursivamente é usado no CoreRT, consulte, por exemplo, https://github.com/dotnet/corert/blob/master/src/System.Private.CoreLib/src/System/Threading/Interlocked.cs# L236.
jkotas
em 6 ago. 2017
Obrigado pela explicação @jkotas. Agora faz mais sentido porque não marcá-los extern é a melhor opção.
tannergooding
em 7 ago. 2017
Sou totalmente a favor do mapeamento 1 para 1 entre método e instrução. Isso é ótimo, mas ainda sinto que essa proposta precisa de um conjunto básico muito limitado de métodos "agnósticos" de plataforma como.
namespace System.Runtime.CompilerServices.Intrinsics
{
public static class IntrinsicsPlatform // Naming is just an example
{
[Intrinsic]
public static IntrinsicsArchitecture Architecture { get; }
}
public enum IntrinsicsArchitecture // Not bit specific, that can be tested in other ways
{
x86,
Arm,
// etc.
}
[StructLayout(LayoutKind.Sequential, Size = 16)]
public struct Vector128<T> where T : struct
{
[Intrinsic]
public static bool IsSupported() { throw new NotImplementedException(); }
[Intrinsic]
public static Vector128<T> Load(ref T mem) => Load(ref mem);
[Intrinsic]
public static Vector128<T> Store(ref T mem, Vector128<T> value) => Store(ref mem, value);
}
[StructLayout(LayoutKind.Sequential, Size = 32)]
public struct Vector256<T> where T : struct
{
[Intrinsic]
public static bool IsSupported() { throw new NotImplementedException(); }
[Intrinsic]
public static Vector256<T> Load(ref T mem) => Load(ref mem);
[Intrinsic]
public static Vector256<T> Store(ref T mem, Vector256<T> value) => Store(ref mem, value);
}
[StructLayout(LayoutKind.Sequential, Size = 64)]
public struct Vector512<T> where T : struct
{
[Intrinsic]
public static bool IsSupported() { throw new NotImplementedException(); }
[Intrinsic]
public static Vector512<T> Load(ref T mem) => Load(ref mem);
[Intrinsic]
public static Vector512<T> Store(ref T mem, Vector512<T> value) => Store(ref mem, value);
}
}
Isso permitiria escrever algoritmos "genéricos" sem fazer referência a x86 , Arm ou outros assemblies de plataforma.
Talvez eu não entenda como tudo isso será empacotado etc. Mas acho que seria bom evitar carregar, digamos, um assembly x86 no Arm. Ou, para dizer de outra forma, como testamos em qual plataforma estamos? Testamos via SSE2.IsSupported? Mesmo quando executado no Arm? Como isso funcionaria, etc.?
Acho que alguma reflexão sobre como isso funcionará em projetos que visam várias plataformas e como eles podem ser fatorados em diferentes assemblies específicos de plataforma sem realmente carregar esses assemblies e assim por diante seria bom. Como isso será feito na prática?
Estou pensando principalmente em projetos JIT, mas AOT é igualmente relevante.
nietras
em 7 ago. 2017
public enum Architecture
{
X86,
X64,
Arm,
Arm64
}
Doh! 😦 Desculpe, muito tempo desde o .NET Core. Esperançosamente, isso estará disponível no .NET Framework quando / se os intrínsecos chegarem a esse ponto.
nietras
em 7 ago. 2017
Eu teria optado por algo mais parecido com
[Flags]
public enum Architecture
{
Unknown = 0
32bit = 1 << 0,
64bit = 1 << 1,
IntelAmd = 1 << 8
Arm = 1 << 9
X86 = 1 << 16 | 32bit | IntelAmd,
X64 = 1 << 17 | 64bit | IntelAmd,
Arm = 1 << 24 | 32bit | Arm,
Arm64 = 1 << 25 | 64bit | Arm,
}
@nietras , de acordo com a proposta atual, acredito que você codificaria:
C#
if (FMA3.IsSupported)
{
}
else if (SSE2.IsSupported)
{
}
else if (Neon.IsSupported)
{
}
else
{
}
Portanto, sim, você codificaria para x86 e ARM sem nenhuma verificação adicional de arquitetura. Espera-se que o JIT trate *.IsSupported como uma constante e AOT o trate como "um pouco" constante.
Com essas expectativas, o compilador (JIT ou AOT) eliminaria os caminhos do código x86 no ARM e eliminaria os caminhos do código ARM no x86. Além disso, espera-se que um JIT elimine caminhos de código que não seriam executados. Portanto, se FMA3 for suportado, apenas o primeiro caminho de código é emitido. Se SSE2 for suportado, apenas o segundo caminho de código será emitido. O terceiro caminho de código nunca seria emitido (em x86) e o quarto caminho de código só é emitido se SSE2 não for compatível.
tannergooding
em 7 ago. 2017
Eu presumiria que, se as verificações de System.Runtime.InteropServices.RuntimeInformation também fossem tratadas como constantes (talvez alguém pudesse comentar sobre isso?), Você poderia fazer essas verificações adicionais sem incorrer em nenhuma penalidade de desempenho.
tannergooding
em 7 ago. 2017
Eles não são. Eles são apenas métodos regulares para obter informações de diagnóstico sobre o sistema.
mellinoe
em 7 ago. 2017
[Sinalizadores] public enum Architecture
@benaadams sim, não estava tentando projetar o tipo real, apenas como seria bom ter essa constante. Pode ser bom ter informações sobre se cargas / armazenamentos desalinhados também são possíveis e assim por diante. Flags tem o problema de que o conjunto total é limitado, poderíamos ter mais de ~ 30 ISAs algum dia se int fosse usado para enum 😉
Eles são apenas métodos regulares para obter informações de diagnóstico sobre o sistema.
Sim, ok, então eu definitivamente acho que algum tipo de constante para arquitetura, independente de conjuntos x86 / arm, seria bom. Quais seriam as desvantagens de adicionar isso? Comparado a ter que verificar, digamos SSE2 ou Neon se estamos executando no ARM ou não? Parece bastante hostil ao usuário, considerando.
nietras
em 7 ago. 2017
@nietras Por que a API existente não é boa o suficiente se você está apenas tentando descobrir se está executando no ARM ou não?
mellinoe
em 7 ago. 2017
@mellinoe talvez não seja grande coisa, mas para mim é apenas estranho que eu me refira (talvez até carregue) a montagem x86 ou Arm em uma plataforma diferente. E com os Load/Store extras nos algoritmos básicos de VectorXXX types também podem ser independentes deles, então as "implementações" específicas da plataforma podem ser fatoradas em x86 / Arm assemblies específicos e estes então referenciam os assemblies específicos da plataforma. No geral, reduzindo assemblies carregados e uso de memória. Eu assumo. Se isso for relevante, acho que seria para plataformas de memória restrita.
nietras
em 7 ago. 2017
Parece bastante hostil ao usuário, considerando.
Você poderia expandir este ponto?
Acho que verificar as arquiteturas tem duas falhas:
- Isso pode levar os usuários a fazer suposições como: "Estou executando no ARM, então NEON deve estar disponível"
- Isso torna difícil fornecer um caminho de código para um fallback de software
C# if (Architecture == x86) { if (SSE2.IsSupported) { } else { // Sofware } } else if (Architecture == Arm) { if (Neon.IsSupported) { } else { // Software } } // Can't put it here, as it wouldn't be hit
tannergooding
em 7 ago. 2017
@nietras Você certamente é livre para construir binários específicos de plataforma e enviá-los com seus aplicativos de usuário final específicos de plataforma ou agrupá-los nos locais apropriados em um pacote nuget. Você pode evitar a inclusão de "código morto" que nunca será acionado nessa plataforma específica. No entanto, eu estaria disposto a arriscar que os ganhos são muito pequenos e provavelmente só importarão em um pequeno número de casos.
mellinoe
em 7 ago. 2017
Usar código mais seguro com Span terá problemas de desempenho em relação a ponteiros "nus"?
Por exemplo, em vez de:
[Intrinsic]
public static unsafe Vector256<byte> LoadAligned(byte* mem) { throw new NotImplementedException(); }
isto:
[Intrinsic]
public static Vector256<byte> LoadAligned(Span<byte> mem) { throw new NotImplementedException(); }
@fanoI Carregamentos de span não funcionariam tão bem em um loop interno, pois seria necessário criar o span por iteração e verificar os tamanhos; então acesse o ponteiro
public static Vector256<byte> LoadAligned(ReadOnlySpan<byte> mem)
{
mem.Length != sizeof(Vector256<byte>) throw
return LoadAligned(ref mem.GetDangerousPointer())
}
Precisaria ser mais uma situação de compensação para que o Jit pudesse içar os cheques, por exemplo
public static Vector256<byte> LoadAligned(ReadOnlySpan<byte> mem, int index)
Porém, novamente, ele ainda precisaria reconhecer os padrões que (length - index) <= sizeof(Vector256<byte>) ; então não tenho certeza se seria um intrínseco bruto?
[Intrinsic]
public static Vector256<byte> LoadAligned(ref Vector256<byte>)
Provavelmente funcionaria; mas também provavelmente confundiria as pessoas quanto ao que está fazendo; por que você carregaria um tipo para si mesmo? (por exemplo, carregar heap alinhado ou vetor256 lançado inseguro para registrar Vector256)
Além disso, não tenho certeza se você poderia usar o LoadAligned com segurança, pois você precisaria saber o alinhamento; para qual você precisa verificar ou ajustar o ponteiro?
benaadams
em 8 ago. 2017
Você poderia expandir este ponto?
@tannergooding well são, claro, muitas maneiras de estruturar o código;). No entanto, para tentar explicar, primeiro vou listar minhas suposições. Isso pode estar totalmente incorreto.
Presumo que Intrinsics será fatorado em um conjunto de assemblies (embora eu entenda que isso pode ser dependente da implementação, qualquer runtime .NET pode fazer isso da maneira que preferir, então todos os namespaces podem estar em um assembly, na verdade isso pode ser o que o .NET Core provavelmente fará?):
System.Runtime.CompilerServices.Intrinsics.dll // Only the "platform-agnostic" types and primitives here i.e. VectorXXX<T>
System.Runtime.CompilerServices.Intrinsics.X86.dll
System.Runtime.CompilerServices.Intrinsics.Arm.dll
Visto que estamos falando de muitos milhares de métodos, isso pode até ser dividido em mais:
System.Runtime.CompilerServices.Intrinsics.dll // Only the "platform-agnostic" types and primitives here i.e. VectorXXX<T>
System.Runtime.CompilerServices.Intrinsics.X86.SSE.dll // SSE-SSE4.X
System.Runtime.CompilerServices.Intrinsics.X86.AVX.dll // AVX-AVX2
System.Runtime.CompilerServices.Intrinsics.X86.AVX512.dll // AVX-512
System.Runtime.CompilerServices.Intrinsics.Arm.dll
// Etc.
Diante disso, pode-se limitar os assemblies referenciados apenas àqueles que são relevantes para uma determinada arquitetura. Então, haverá uma ou mais assembleias? Se for apenas um, e quanto ao uso de memória que isso pode causar? Neste tópico, há discussões sobre quantos bytes qualquer método pode usar e como isso pode ser um problema, dados os vários métodos (embora o compartilhamento possa resolvê-lo), isso não é um problema? As próprias definições de método não têm algum peso?
Para o código que imagino construir com base nisso, eu seguiria uma fatoração semelhante (dividida em muitas aqui para deixar claro) de assemblies, por exemplo (dependências listadas abaixo -> ):
PerfNumerics.Funcs.dll // Definitions of different func interfaces
-> System.Runtime.CompilerServices.Intrinsics
PerfNumerics.Algorithms.dll // General algorithms i.e. like the Transform I mentioned earlier but for 1D,2D,3D, etc. Tensor etc. etc.
-> PerfNumerics.Funcs.dll
-> System.Runtime.CompilerServices.Intrinsics
-> System.Runtime.CompilerServices.Unsafe
PerfNumerics.Funcs.Software.dll // Software specific implementations of many different funcs (e.g. threshold, multiply, and, xor etc. etc.)
-> PerfNumerics.Funcs.dll
PerfNumerics.Funcs.Arm.dll // ARM specific implementations of many different funcs (e.g. threshold, multiply, and, xor etc. etc.)
-> PerfNumerics.Funcs.dll
PerfNumerics.Funcs.x86.dll
-> PerfNumerics.Funcs.dll
Isso definiria, portanto, os algoritmos e primitivos que podem ser usados. É claro que eles precisam ser compostos em algum lugar, ou seja, em alguma camada de funcionalidade:
PerfNumerics.SomeFunctionality.dll
-> PerfNumerics.Algorithms.dll // General algorithms i.e. like the Transform I mentioned earlier but for 1D,2D,3D, etc. Tensor etc. etc.
-> PerfNumerics.Funcs.dll
-> PerfNumerics.Funcs.Software.dll
-> PerfNumerics.Funcs.Arm.dll // Specific implementations of many different funcs (e.g. threshold, multiply, and, xor etc. etc.)
-> PerfNumerics.Funcs.x86.dll
Nesse caso, uma determinada função pode ser composta (para evitar o carregamento de código de plataforma desnecessário, etc.) como:
public static class SomeFunctionality
{
public static int SomeFunction(Span<T> src, Span<T> dst)
{
switch (IntrinsicsPlatform.Architecture)
{
case IntrinsicsArchitecture.x86:
return SomeFunction_x86(src, dst);
case IntrinsicsArchitecture.Arm:
return SomeFunction_Arm(src, dst);
default:
return SomeFunction_Software(src, dst);
}
}
}
Dentro de SomeFunction_x86 então definido como a composição do algoritmo com func:
public static int SomeFunction_x86(Span<T> src, Span<T> dst)
{
// Here a given impl is composed of algorithm + func so say
Transform(src, new ThresholdVectorFuncX86(), dst);
// As mentioned before Transform will do switch
}
A própria função teria então a opção if/else e, em alguns casos, ela precisa ser combinada com outra "função" e interface que pode dizer ao algoritmo se, apesar de dizer que Vector512<T> é suportado, o as intruções reais necessárias não estão presentes, portanto, também devem ser ignoradas. Na verdade, se VectorXXX<T>.Load/Store não forem adicionados, isso pode ser tratado por meio de outra função. Porém, fica confuso rapidamente, é uma espécie de modelos C ++ em C #. Abuso de geração de código de tipo de valor do JIT.
@mellinoe Tudo isso pode, é claro, ser implementado de alguma forma com a API existente, mas não sem fazer referência a classes estáticas específicas da plataforma. Com o conjunto acima, nenhum Arm seria carregado em x86 . Talvez isso não seja uma preocupação?
Eu entendo que fatorar e estruturar código dessa forma definitivamente não é para todos, eu nem tenho certeza se é necessariamente a melhor maneira para o que eu quero, então apenas cuspindo aqui.
nietras
em 8 ago. 2017
Provavelmente funcionaria; mas também provavelmente confundiria as pessoas quanto ao que está fazendo; por que você carregaria um tipo para si mesmo?
@benaadams Não acho que seria confuso. É igual a todos os outros intrínsecos - permite que você faça algo que você já faria de outra forma com mais eficiência. Acho que é menos confuso porque com a assinatura ref Vector256 está fazendo exatamente o que seria de se esperar à primeira vista.
sharwell
em 8 ago. 2017
Mas este "LoadAligned" seria o equivalente da instrução ASM X86 movdqa? Esse é o resultado desta intrisic deve ser que Vector256
Se é isso eu não entendo bem porque um Vector256
fanoI
em 8 ago. 2017
Se for assim, não entendo bem porque é devolvido um Vector256 ...
Portanto, você tem uma referência para usar nas operações subsequentes; então, por exemplo, se você estiver carregando de uma matriz na pilha e souber que está indexando começando em um local alinhado.
byte[] array = new byte[1000];
// Possible unaligned loads
//Vector256<byte> xmmReg0 = AVX.Load(&array[i]); // GC hole? Invalid C#
//Vector256<byte> xmmReg1 = *(Vector256<byte>*)&array[i]; // implied Load + GC hole? Invalid C#
fixed(byte* ptr = &array[0])
{
Vector256<byte> xmmReg2 = AVX.Load(ptr + i);
Vector256<byte> xmmReg3 = *(Vector256<byte>*)(ptr + i); // implied Load?
}
Vector256<byte> xmmReg4 = ref Unsafe.As<Vector256<byte>>(ref array[i]); // implied Load?
Vector256<byte> xmmReg5 = AVX.Load(ref Unsafe.As<Vector256<byte>>(ref array[i]));
// Possible aligned loads
//Vector256<byte> xmmReg6 = AVX.LoadAligned((byte*)&array[i]); // GC hole? Invalid C#
fixed(byte* ptr = &array[0])
{
Vector256<byte> xmmReg7 = AVX.LoadAligned(ptr + i);
}
Vector256<byte> xmmReg8 = AVX.LoadAligned(ref Unsafe.As<Vector256<byte>>(ref array[i]));
@sharwell , não gosto da sintaxe ref Vector256 porque na maioria das vezes, eu não teria um Vector256 até depois de chamar a instrução load. Em vez disso, eu teria um array de T que é pelo menos sizeof(Vector256) .
Não quero ter Unsafe.As<float, Vector256<float>>() intercalados em todo o meu código quando ref T , ref float , void* ou float* é muito mais claro , conciso e corresponde à estrutura de apoio.
tannergooding
em 8 ago. 2017
Vector256<byte> xmmReg0 = AVX.Load(&array[i]); // GC hole?
Este não é um C # válido ...
você sabia que estava indexando começando em um local alinhado
A única maneira de saber isso é fixando a matriz. O GC pode movê-lo e alterar o alinhamento a qualquer momento.
jkotas
em 8 ago. 2017
A única maneira de saber isso é fixando a matriz.
Em que ponto você tem um ponteiro. Então, não tem certeza se o carregamento alinhado sem ponteiro seria útil?
benaadams
em 8 ago. 2017
Estou fazendo o advogado do diabo aqui, mas todo esse buraco GC inseguro e assim por diante ... não corre o risco de tornar o C # muito semelhante ao C / C ++? Não há segurança no exemplo de @benaadams ...
É tão ruim verificar antes de gravar em um registro XMM se você não está gravando no tamanho errado? Melhor ser 2% mais lento do que C / C ++, mas manter pelo menos um pouco de segurança, certo?
O Cosmos não aceita código inseguro / não verificável fora do anel inferior (chamado Core); talvez possamos fazer uma exceção se for parte do tempo de execução C #, mas uma biblioteca de usuário usando esses intrísicos não será aceita no Cosmos (ou seja, não compilará) .
fanoI
em 8 ago. 2017
Melhor ser 2% mais lento do que C / C ++, mas manter pelo menos um pouco de segurança, certo?
Provavelmente precisa de algumas sobrecargas de array / span?
Vector256<T> AVX.Load(T value)
Vector256<T> AVX.Load(ReadOnlySpan values)
Vector256<T> AVX.Load(T[] values)
Vector256<T> AVX.Load(T[] values, int index)
No entanto, a carga desalinhada não poderia ser suportada desta forma
benaadams
em 8 ago. 2017
@fanoI , não se espera que seja usado pelos autores do aplicativo. Em vez disso, ele deve ser usado por autores de framework para que a funcionalidade central possa ser escrita em código gerenciado e possa atingir o melhor desempenho possível.
Provavelmente será usado por coisas como:
- System.String
- System.Math e MathF
- System.Numerics.Vector
, Vector2, Vector3, Vector4 - etc
Também seria usado por pessoas que escrevem coisas como motores de aplicativos multimídia ou código de interoperabilidade
Os autores do framework usariam essas APIs ao implementar suas próprias APIs e provavelmente envolveriam todos os bits inseguros internamente. Minha opinião é:
- Um desenvolvedor de aplicativo que consome uma API que usa intrínsecos não precisa saber (ou ser capaz de saber pela própria API) que está usando intrínsecos.
- Um desenvolvedor de aplicativos nunca deve ter que tocar em nenhum dos tipos em
System.Runtime.CompilerServices.Intrinsics.
Cosmos não aceita código inseguro / não verificável fora do anel inferior
Esta é uma postura perfeitamente adequada para se ter, contanto que você também aceite que ela corta muitas APIs principais que o CoreFX expõe. Por exemplo, string.IndexOf(char) é "seguro", mas ele próprio chama a sobrecarga insegura (https://source.dot.net/#System.Private.CoreLib/src/System/String.Searching.cs,eb06d6d166f6a3d9, referências).
Você também deve estar disposto a aceitar que, só porque o verificador acha que não é verificável, não significa que seja: https://github.com/dotnet/roslyn/pull/21269. No caso vinculado, peverify não sabe como lidar com algumas das otimizações que o compilador emite para ref readonly . O código emitido é realmente seguro e verificável, mas a ferramenta de verificação não sabe como reconhecer isso.
Podemos fazer uma exceção se for parte do tempo de execução do C #
Nenhuma dessas APIs é ou será específica do C # (não há realmente um "tempo de execução C #"). Eles fazem parte do Core Runtime e do Core Framework e, portanto, serão acessíveis por quase qualquer linguagem que compile em código IL (pelo menos qualquer linguagem que suporte ref ou pointers pelo menos).
Também é o caso de que esses recursos dependem inteiramente do tempo de execução em que estão sendo executados. CoreCLR reconhecerá essas instruções e emitirá código de uma maneira, mas outro runtime (Mono, por exemplo) pode fazer isso de forma diferente.
tannergooding
em 8 ago. 2017
@fanoI @mellinoe
Essencialmente, o mesmo problema surge em linguagem safe system programming como o Rust. Não se pode expressar todas as operações de baixo nível necessárias em várias bibliotecas na sintaxe Rust safe, portanto, Rust fornece unsafe contexto
Ralf Jung, Jacques-Henri Jourdan, Robbert Krebbers, Derek Dreyer. ICFP'17 / HOPE'17
Rust emprega um sistema de tipo forte e baseado na propriedade, mas, em seguida, estende o poder expressivo
deste tipo de sistema central por meio de bibliotecas que usam recursos inseguros internamente
Essencialmente, isso significa que às vezes é impossível escrever programas seguros usando apenas construções seguras. A maneira de proceder conforme foi declarada por @mellinoe é usar construções não seguras de uma maneira segura para criar frameworks ou bibliotecas seguras.
4creators
em 9 ago. 2017
@ 4creators , acho que @tannergooding disse isso, mas sim 😄. O código inseguro é fundamental para muitas das principais bibliotecas do .NET.
mellinoe
em 9 ago. 2017
Acho que um bom resumo das discussões até agora é:
- O recurso é, essencialmente, universalmente amado / adorado
refvspointersparece precisar de mais reflexão / discussões para a superfície da API- Nenhum substituto de software parece ressoar positivamente
- Determinar como expô-los sem inchar a camada inferior, mas ainda tornar as APIs utilizáveis de todas as camadas, parece exigir mais discussão
Algumas das questões em aberto ainda parecem ser:
- Qual será a aparência das APIs para escalares (ou seja,
sqrtssoumovss) e como elas coincidem com as APIs de vetor? - Vale a pena expor um pequeno subconjunto de funções auxiliares (como
load/storegenérico)?- Se não acharmos que eles serão usados pelo próprio CoreFX, então expor em uma biblioteca de terceiros é provavelmente o melhor.
- Podemos fazer um repo (no CoreFX) para que as pessoas possam começar a trabalhar nisso em seu tempo livre?
tannergooding
em 9 ago. 2017
@tannergooding Muito obrigado pelo resumo e vamos discutir esses tópicos em .Net Design Reviews na próxima semana.
Qual será a aparência das APIs para escalares (ou seja, sqrtss ou movss) e como elas coincidem com as APIs de vetor?
Nosso design de API intrínseco (enviaremos o PR depois que esta proposta for aprovada) incluiu certas instruções escalares (por exemplo, crc32, popcnt, etc.), mas essas que você mencionou (a maioria de SSE / SSE2) ainda não.
Essas instruções de ponto flutuante escalar SSE / SSE2 foram cobertas pelo codegen RyuJIT atualmente. Você acha que é necessário expô-los como intrínsecos? Em caso afirmativo, você poderia fornecer mais detalhes sobre os casos de uso?
fiigii
em 9 ago. 2017
popcnt em particular é algo que realmente gostaríamos de ter
ayende
em 9 ago. 2017
Um, ambos ou uma forma combinada de BSF , TZCNT
Um ou ambos BSR , LZCNT
benaadams
em 9 ago. 2017
@fiigii , (talvez @mellinoe possa se
Interop com outro código intrínseco
Realisticamente, não há diferença entre Vector128<T> e double além de:
- Potencialmente, como o valor é passado na pilha
- Qual forma da instrução é chamada (
sdvspd) - Se o intrínseco é explícito ou implícito
Como autor do framework, não devo me preocupar em converter Vector128<T> em double , apenas para chamar outro método ( Math.Sqrt ) e, em seguida, pegar o resultado e convertê-lo de volta a Vector128<T> (ao invés disso, devo apenas ser capaz de chamar SSE2.SqrtScalar ).
Eu também não deveria ter que presumir que o JIT definitivamente tratará minha chamada Math.Sqrt como intrínseca e produzirá um código ideal que se encaixa em meu algoritmo.
Implementando System.Math e System.MathF em código gerenciado
Hoje, as APIs System.Math e System.MathF são implementadas principalmente como FCALL s na implementação CRT do método correspondente ( System.Math.Cos chama cos em libm ).
Já existem diferenças de desempenho entre as plataformas (https://github.com/dotnet/coreclr/issues/9373), mas também existem diferenças nas entradas / saídas para alguns dos valores que não são ditados pelo IEEE 754.
Sem os intrínsecos escalares, a única maneira de implementá-los usando os intrínsecos é replicar a saída para todos os registradores e extrair o valor mais baixo depois de concluído (efetivamente Vector4 v = new Vector4(value); return Vector4.Cos(v).X; ). Isso pode tornar o algoritmo mais complexo e causar o uso de registros adicionais que, de outra forma, não seriam necessários.
Consistência
Eu ainda acho que é uma ótima ideia isolar todos os intrínsecos de tempo de execução (incluindo aqueles que o codegen RyuJIT cobre atualmente) e isolá-los em System.Runtime.CompilerServices.Intrinsics .
Não sei qual é a opinião do pessoal de runtime / framework sobre isso, mas acredito que isso simplificaria significativamente a portabilidade dessas APIs em tempos de execução (para coisas como CoreRT, Mono, etc).
Deve, idealmente, também simplificar a quantidade de código nativo que deve ser mantido para essas APIs (onde o desempenho é importante) e deve aumentar a capacidade de manutenção do código e consumibilidade das correções (pois requer alterações de estrutura, em vez de alterações de tempo de execução melhorar).
tannergooding
em 9 ago. 2017
Ainda acho uma ótima ideia isolar todos os intrínsecos de tempo de execução (incluindo aqueles que o codegen RyuJIT cobre atualmente) e isolá-los em System.Runtime.CompilerServices.Intrinsics.
Não acho que seja uma boa ideia. Na verdade, nem mesmo é possível para alguns dos existentes, por exemplo, porque são métodos virtuais.
jkotas
em 9 ago. 2017
Os intrínsecos do hardware Intel são realmente úteis para a implementação da biblioteca. Como eu sei, no entanto, mscorlib não pode depender de outros assemblies gerenciados (ou seja, CoreFX). Se quisermos que esses intrínsecos sejam usados em mscorlib (ou seja, System.Math/MathF ), temos que mudar a organização dos intrínsecos ou algo do tempo de execução interno?
fiigii
em 9 ago. 2017
Os intrínsecos precisam ser implementados em System.Private.CoreLib ("mscorlib"). Fundamentalmente, eles precisam ser implementados no próprio tempo de execução de qualquer maneira - não há uma maneira viável de implementá-los "fora da banda". Conforme discutido acima (ou talvez em outro problema em algum lugar), System.Private.CoreLib não pode depender de quaisquer outros assemblies, porque é o assembly principal. Queremos ser capazes de usar esses intrínsecos dentro do próprio System.Private.CoreLib (em tipos fundamentais como String , etc.). Portanto, eles precisam ser implementados em System.Private.CoreLib.
mellinoe
em 9 ago. 2017
@mellinoe Você espera que todos os intrínsecos sejam implementados em System.Private.CoreLib ?
Se sim, isso exigiria vários milhares de métodos - o suporte completo para AVX512 levaria apenas cerca de 2k métodos (incluindo sobrecargas). Se mais tarde ARM SVE intrínsecos fossem adicionados para todos os tamanhos de vetor (16 vetores diferentes), entraríamos em explosão combinatória.
4creators
em 9 ago. 2017
O ARM tem instruções individuais para cada tamanho de vetor ou é um parâmetro de comprimento?
benaadams
em 9 ago. 2017
Atualmente a implementação do ARM ISA SIMD suporta apenas 128 bits de tamanho de registro e relação de 1 para 1 vetor - instrução. Suponho que, ao finalizar o design do SVE, eles poderiam seguir caminhos diferentes, ou seja, como a Intel, onde prefixo (VEX, EVEX) são usados para diferenciar instruções mais dados de registro que são codificados em algumas partes da instrução. Atualmente não sabemos disso.
No entanto, isso não deve ter nenhum impacto nesta análise, pois a API deve diferenciar entre os tamanhos de vetor no nível do método, portanto, seria de se esperar ter 16 métodos para adicionar byte vetores, 16 métodos para adicionar word vetores etc. etc. É um esquema no qual cada operação para determinado tipo subjacente, ou seja, byte precisa de uma sobrecarga de método para cada tamanho de vetor suportado.
4creators
em 10 ago. 2017
Depende de quais são as instruções, se elas são todas iguais, mas com param no registro ou como argumento, poderia ser Load(* , n) para opaco armRegister type; em seguida, funções levando armRegister
benaadams
em 10 ago. 2017
@ 4creators Sim, o design "ingênuo" é simplesmente implementá-los todos em System.Private.CoreLib. Mas por "todas", realmente queremos dizer "todas as instruções que consideramos importantes o suficiente ou para as quais recebemos uma contribuição". Certamente há muitas instruções que não são úteis ou interessantes para expor diretamente e, em qualquer caso, esse recurso requer que cada indivíduo intrínseco seja reconhecido especial e especificamente no JIT. Certamente começaremos com um subconjunto menor do que "tudo" - provavelmente as funções de que precisamos para implementar coisas-chave como Math(F) , String , Vector2/3/4 , etc.
Dado que System.Private.CoreLib já é específico da plataforma (por exemplo, temos diferentes binários para x86, x64, ARM), posso imaginar um design diferente onde podemos omitir stubs de função intrínseca inaplicáveis para outras plataformas. Por exemplo, System.Private.CoreLib.x64.dll não incluiria os stubs de função ARM. Mas isso exigiria tratamento ainda mais especial no tempo de execução e, em última análise, é uma otimização de implementação - que não é claramente necessária neste estágio.
mellinoe
em 10 ago. 2017
realmente queremos dizer "todas as instruções que consideramos importantes o suficiente ou pelas quais recebemos uma contribuição"
@mellinoe
Minha impressão foi que há dois conjuntos de instruções sendo discutidos:
- Aqueles necessários para uso interno em
System.Private.CoreLib - Aqueles que são expostos por meio de montagem externa e que compreendem a maioria ou a totalidade do SIMD e outras instruções especiais
Para desenvolvedores de tempo de execução, o primeiro conjunto é mais importante para desenvolvedores que trabalham em bibliotecas específicas de domínio; o que é importante é a disponibilidade de todos ou quase todos os intrínsecos. Quando passamos por vários algoritmos que poderiam ser vetorizados, é difícil imaginar sua implementação com um conjunto limitado de SIMD ou sem instruções especializadas.
4creators
em 10 ago. 2017
@ 4creators Mesmo nessa segunda categoria, a funcionalidade "real" em si precisará ser implementada no JIT e no tempo de execução - não há como fazer isso fora do repositório coreclr, ou "fora da banda" de qualquer forma. Você pode definir stubs de função onde quiser, mas não importa, a menos que sejam compreendidos pelo JIT / runtime. Por causa disso, não vejo muito valor em permitir que eles sejam definidos em alguma outra montagem. Isso só torna as coisas mais complicadas, IMO.
mellinoe
em 10 ago. 2017
Então, o que é necessário para tornar isso realidade? Eu acho que isso é GRANDE para C # ... é uma das "desculpas" para usar C ++ e isso faz com que ele desapareça.
O trabalho em recursos experimentais deve ser feito no CoreFxLabs?
fanoI
em 12 ago. 2017
@fanoI , não acho que nada possa ser "iniciado" até que a API seja revisada e aprovada.
Com base no comentário de @fiigii , a análise do design será na próxima terça-feira (https://www.youtube.com/watch?v=52Fjrhx7pKU)
Assim que a API for aprovada, imagino que o trabalho possa realmente começar.
Talvez @jkotas ou @mellinoe possam comentar, mas imagino que a equipe CoreFX / CoreCLR deva fazer o trabalho inicial para pelo menos 1-2 intrínsecos e escrever documentação detalhando o processo passo a passo do que fazer para outros intrínsecos . Assim que estiver disponível, pode ser aberto para a comunidade em geral intervir. Os membros da comunidade podem "inscrever-se" em um conjunto de intrínsecos para implementar e, em seguida, começar a trabalhar.
tannergooding
em 12 ago. 2017
Ok, a discussão oficial ainda deve começar ... então precisamos esperar :-)
fanoI
em 12 ago. 2017
Algumas reflexões sobre esta proposta e discussão:
Genérico vs. não genérico (por exemplo, Add<T> vs. Add<float> ):
- Estou um pouco confuso com esta discussão. Como isso é um intrínseco interno e não terá uma implementação, vejo pouca vantagem em explodir o número de declarações. Como se destina a desenvolvedores que "sabem o que estão fazendo", um comentário indicando quais tipos são compatíveis com o ISA de destino atual deve fornecer informações suficientes.
Seria útil ter uma API padrão para consultar o "melhor alinhamento" para um determinado tipo e / ou obter memória alinhada? Eu não presumiria necessariamente que, à medida que avançamos em direção a tamanhos de vetor maiores, sempre será o caso de que o melhor alinhamento (excluindo falhas de página) seja necessariamente o tamanho do vetor.
Para os argumentos constantes, que comportamento esperamos do compilador IL (AOT ou JIT) quando uma não constante é passada? Para o AOT, um erro seria útil, mas para o JIT ele deve ser tratado como IL ilegal ou deve gerar um código para lançar uma exceção ou ...?
Acho que precisamos ser muito claros sobre a estratégia de evolução do conjunto de intrínsecos suportados. Como existem vários tempos de execução e compiladores IL, parece que há uma história de compatibilidade não insignificante em que as propriedades ou métodos IsSupported propostos implicarão em coisas diferentes ao longo do tempo.
Propriedade vs. método para IsSupported : Acho que o sentimento já está se inclinando na direção da propriedade, mas acrescentarei meu voto a isso. Verificar o suporte de hardware não é realmente uma "ação". Na verdade, isso está retornando uma propriedade do destino.
Com relação à compilação AOT e à verificação de IsSupported : Acho que um bom compilador AOT deve ser capaz de agregar e otimizar a verificação e o código associado. Ou seja, o encargo não deve recair sobre o desenvolvedor em estruturar seu código de maneira não natural, de modo que as verificações que logicamente pertencem ao código de baixo nível sejam borbulhadas até um nível em que seu custo seja amortizado.
Penalidades de desempenho devido ao uso misto de formulários SSE2 e AVX: atualmente, o RyuJIT atrasa a codificação real até o final, e as instruções que têm codificações AVX e SSE têm uma representação unificada - a determinação de qual codificação usar é baseada no fato de a VM informar o JIT que AVX2 está disponível.
Observe que atualmente exigimos AVX2 para usar a codificação AVX. Isso é simplesmente para reduzir a matriz de teste / suporte / implementação, uma vez que AVX2 fornece suporte mais uniforme para vetores de 256 bits. Seria bastante simples de usar AVX codificações qualquer momento qualquer um:
- AVX2 está disponível e
Vector<T>é usado, ou - AVX está disponível e intrínsecos de AVX são usados
- AVX2 está disponível e
- O que foi dito acima, no entanto, aumentará a carga de teste e suporte - mas acho que já estamos trilhando esse caminho!
 CarolEidt
em 15 ago. 2017
CarolEidt
em 15 ago. 2017
Seria bastante simples usar codificações AVX a qualquer momento:
- AVX2 está disponível e Vector
é usado, ou - AVX está disponível e intrínsecos de AVX são usados
Então, percebi que obviamente isso não é um bom começo. Não podemos mudar o alvo depois de ver um AVX intrínseco. Portanto, acho que precisaremos mudar a estratégia de geração de código para direcionar o AVX sempre que estiver disponível (não apenas quando o AVX2 estiver disponível).
CarolEidt
em 15 ago. 2017
Também devemos coordenar com https://github.com/dotnet/roslyn/issues/11475
 tmat
em 16 ago. 2017
tmat
em 16 ago. 2017
Discordo. Estas são propostas não relacionadas.
 jaredpar
em 16 ago. 2017
jaredpar
em 16 ago. 2017
Eles estão um tanto relacionados:
- Ambos precisam de um atributo para marcar o intrínseco. Devemos coordenar a nomenclatura para evitar confusão / colisão.
- Alguns dos intrínsecos do compilador requerem que o argumento seja literal, de forma semelhante aos intrínsecos do hardware. Podemos considerar ter um único conceito no compilador. Para os intrínsecos de hardware, esta propriedade seria codificada em metadados, para os intrínsecos do compilador seria implícita pelo nome intrínseco.
Pode haver outras semelhanças.
tmat
em 16 ago. 2017
Ambos precisam de um atributo para marcar o intrínseco.
Discordo. O tempo de execução intrínseco pode usar um modreq em alguns lugares, mas não vê a necessidade de um atributo adicional. Certamente não aquele que o compilador irá processar.
Alguns dos intrínsecos do compilador requerem que o argumento seja literal, de forma semelhante aos intrínsecos do hardware.
Certo. Mas se adicionarmos o requisito literal para intrínsecos de tempo de execução, isso seria feito de uma maneira geral.
Pode haver outras semelhanças.
Acho que são bem diferentes. Trata-se de adicionar intrisicts de tempo de execução. O compilador tem quase 0 participação aqui, exceto uma solicitação de recurso para aplicação literal. A intrisics do compilador é uma proposta que trata da habilidade do compilador de emitir novas instruções IL.
jaredpar
em 16 ago. 2017
Discordo. O tempo de execução intrínseco pode usar um modreq em alguns lugares, mas não vê a necessidade de um atributo adicional. Certamente não aquele que o compilador irá processar.
A proposta acima usa o atributo [Intrinsic] . Não estou sugerindo que o compilador precise entender esse atributo. A proposta intrínseca do compilador também introduz um atributo CompilerIntrinsic - este o compilador entende. Se nomearmos ambos os atributos apenas Intrinsic e colocá-los no mesmo namespace, isso seria um problema. Portanto, tudo o que estou dizendo é que devemos coordenar a nomenclatura - eu preferiria que o tempo de execução intrínseco usasse o atributo RuntimeIntrinsic .
tmat
em 16 ago. 2017
portanto, eu preferiria que o tempo de execução intrínseco usasse o atributo RuntimeIntrinsic.
Não deve importar qual será o atributo usado pelo tempo de execução. Espero que seja interno - não será público ou parte da superfície pública. Na verdade, seria bom não ter nenhum atributo para ele e usar algum mecanismo alternativo para reconhecê-los no tempo de execução.
jkotas
em 16 ago. 2017
@jkotas BTW, visibilidade não importaria. Se houvesse um atributo e o nome fosse igual ao dos intrínsecos do compilador, ele interromperia a compilação da biblioteca CoreFX que usa o atributo internamente.
tmat
em 16 ago. 2017
Olá a todos, atualizei esta proposta de API com base na discussão acima e na reunião de revisão de design . Por favor, veja a seção de atualização para detials. Todas as alterações são aplicadas ao nosso código-fonte da API também. Assim que esta proposta for aprovada, enviaremos o design completo da API.
fiigii
em 18 ago. 2017
@fiigii houve alguma clareza sobre o porquê
Vector128<float> CompareVector128(Vector128<float> left, Vector128<float> right, const FloatComparisonMode mode)
e não
Vector128<float> Compare(Vector128<float> left, Vector128<float> right, const FloatComparisonMode mode)
Um nit seria que Compar e não precisa ser repetido no nome e valor do enum para que possa ser encurtado?
public enum FloatComparisonMode : byte
{
EqualOrderedNonSignaling,
LessThanOrderedSignaling,
LessThanOrEqualOrderedSignaling,
UnorderedNonSignaling,
NotEqualUnorderedNonSignaling,
NotLessThanUnorderedSignaling,
NotLessThanOrEqualUnorderedSignaling,
OrderedNonSignaling,
......
}
Caso contrário, LGTM
benaadams
em 18 ago. 2017
@benaadams Desculpe, esse é meu erro. CompareVector* foi alterado para Compare .
fiigii
em 18 ago. 2017
Não entraria em conflito, por exemplo
FloatComparisonMode.CompareEqualOrderedNonSignaling
para
FloatComparisonMode.EqualOrderedNonSignaling
StringComparisonMode.CompareEqualOrderedNonSignaling
para
StringComparisonMode.EqualOrderedNonSignaling
benaadams
em 18 ago. 2017
Um nit seria que Compare não precisa ser repetido no nome e valor do enum para que possa ser encurtado?
Não entraria em conflito, por exemplo
FloatComparisonMode.CompareEqualOrderedNonSignaling
para
FloatComparisonMode.EqualOrderedNonSignaling
Bom ponto. Essa mudança faz sentido.
fiigii
em 18 ago. 2017
Adicionar Span
sobrecarrega os intrínsecos de acesso à memória mais comuns (Carregar, Armazenar, Transmitir), mas deixa outros intrínsecos sensíveis ao alinhamento ou desempenho com a versão original do ponteiro.
👎 Eu realmente acho que essa é a pior das opções para isso. Ter apenas ref T versões seria naturalmente utilizável para memória nativa / fixada e gerenciada, agora ficamos com algo que é menos do que ideal para memória gerenciada, a menos que você já use Span . E duas sobrecargas, em vez de apenas um único método. Além disso, algumas sobrecargas estão simplesmente disponíveis apenas na versão de ponteiro, não deixando outra solução a não ser ter que fixar a memória, o que também é indesejável.
nietras
em 18 ago. 2017
são aplicados ao nosso código-fonte da API
@fiigii isso está disponível em algum lugar?
nietras
em 18 ago. 2017
@nietras , estou trabalhando na construção do código-fonte intrínseco da API em System.Private.CoreLib . Vou enviar o PR mais tarde.
fiigii
em 19 ago. 2017
Atualização: substitua Span<T> sobrecargas por ref T sobrecargas.
fiigii
em 23 ago. 2017
Olá a todos, o código-fonte intrínseco da API foi enviado como PR dotnet / corefx # 23489.
fiigii
em 23 ago. 2017
Onde estão as versões escalares? Eles são necessários para implementar operações trigonométricas, por exemplo ...
fanoI
em 24 ago. 2017
@fanoI Esta proposta não inclui as instruções de hardware que foram cobertas pelo codegen RyuJIT atual.
fiigii
em 24 ago. 2017
sqrtss e sqrtsd que são, por exemplo, necessários para implementar Math.Sqrt () são gerados pelo codegen RyuJit atual? Eu tinha entendido que eles faziam parte dessa proposta também ...
Caso contrário, como você faria isso: https://dtosoftware.wordpress.com/2013/01/07/fast-sin-and-cos-functions/ ?
fanoI
em 24 ago. 2017
@fiigii , achei que eles foram discutidos brevemente durante a análise da API.
Em qualquer dos casos, caso não façam parte desta proposta, gostaria de saber para que possa apresentar uma nova proposta abrangendo-os.
O fornecimento de instruções escalares será necessário para a implementação de certos algoritmos (como a implementação de APIs System.Math e System.MathF em C #). Também será útil / necessário em certos algoritmos de alto desempenho para outros cenários.
tannergooding
em 24 ago. 2017
O RyuJIT já não gera sqrtss para MathF.Sqrt() ?
Também parece que sqrtsd é compatível com RyuJIT , mas não consigo pensar em nada que o use em C #, a menos que a implementação de Math.Sqrt() mudado desde a última vez que olhei
 saucecontrol
em 24 ago. 2017
saucecontrol
em 24 ago. 2017
@saucecontrol , RyuJIT trata Math.Sqrt e MathF.Sqrt como intrínsecos (via CORINFO_INTRINSIC_Sqrt ).
No entanto, as funções restantes Math e MathF retornam para as chamadas de tempo de execução C correspondentes (todas são FCALLs, tecnicamente Math.Sqrt e MathF.Sqrt são iguais). Isso leva a inconsistências de desempenho e resultado entre Mac, Linux e Windows e entre ARM e x86. Idealmente, isso (ou uma nova proposta) irá adicionar as sobrecargas escalares para que possamos implementar prontamente esses métodos em código gerenciado e garantir que todas as plataformas / arquiteturas sejam consistentes.
tannergooding
em 24 ago. 2017
@fiigii Se você pensar sobre isso, faria sentido eventualmente se livrar da maior parte do que o RyuJIT tem que fazer sozinho. Se a superfície for coberta, você não precisará lidar com cada caso com toda a complexidade dentro do código JIT.
redknightlois
em 24 ago. 2017
Criou uma proposta cobrindo explicitamente as sobrecargas escalares: https://github.com/dotnet/corefx/issues/23519
tannergooding
em 24 ago. 2017
Esta API parece realmente ótima. No entanto, há uma coisa que eu gostaria de ver mudada. Podemos oferecer suporte a um substituto de software?
Sei que estou muito atrasado para essa discussão, mas gostaria de apresentar o caso.
Posso ver que o ímpeto dessa discussão é por não haver nenhum substituto de software, mas não vejo nenhuma discussão aprofundada sobre os prós e os contras disso. Para os profissionais, vejo alguém mencionar que qualquer código que execute um suposto modo de fallback de software seria um bug de desempenho e seria melhor travar no cenário para facilitar a depuração. Isso certamente é verdade, mas eu diria que essa não é uma maneira muito .NET de fazer as coisas. Muitos aspectos do .NET têm degradação de desempenho normal em vez de lançar exceções e tenho certeza que está escrito em algum lugar que isso faz parte da filosofia .NET. Melhor para o código rodar mais devagar do que travar completamente, a menos que o programador especifique que isso é o que eles querem que aconteça. Isso é algo que eu gosto no antigo Vector
Acho que parte do argumento para nenhum fallback de software é parcialmente baseado no fato de que o público para esta API é para desenvolvedores de baixo nível que estão acostumados a usar extensões SIMD de C ++ e assembler e outros enfeites, e tendo o código travado imediatamente quando o conjuntos de instruções reais não estão disponíveis é um ambiente de desenvolvimento mais confortável para eles. E embora eu acredite que isso seja verdade para 98% dos desenvolvedores que usam essa API, não acho que devemos esquecer o desenvolvedor .NET mais típico e assumir que eles nunca vão querer explorar essas coisas para ver se isso pode beneficiá-los. Em geral, acho que é um erro projetar uma API como essa e presumir que apenas um determinado tipo de desenvolvedor desejará usá-la. Especialmente algo embutido no .NET.
Aqui estão alguns dos profissionais que considero que um substituto de software forneceria:
Melhor experiência de desenvolvimento: vou aceitar o ponto de que travar quando uma extensão usada não está presente tem algumas vantagens, mas considere os benefícios de um fallback de software também. Um fallback de software fornece uma maneira confiável de explorar o uso de todas as classes de conjunto de instruções, incluindo aquelas não suportadas na máquina do desenvolvedor. Isso pode não entusiasmar muitos nesta discussão, mas fornece uma boa maneira para os desenvolvedores testarem algoritmos, garantindo que sejam logicamente sólidos antes de decidir se vale a pena testá-los em hardware real. Alguns cenários de depuração são mais fáceis. Por exemplo, se um usuário de uma biblioteca relatar um bug ao executá-la em dispositivos ARM por causa de um bug no código que usa NEON, um desenvolvedor dessa biblioteca tem a possibilidade de consertar isso de uma máquina x86, pois eles podem reproduzir e conserte o bug usando o fallback de software NEON. Claro que seria melhor se o desenvolvedor tivesse hardware NEON para depurar, mas isso nem sempre é prático e o desenvolvedor tem autonomia para melhorar seu código muito mais facilmente em menos tempo do que faria de outra forma. Um fallback de software também forneceria um potencial muito melhor para testes de unidade que podem testar o caminho do código para todas as classes de conjunto de instruções, não importando o que a máquina de desenvolvimento local suporte.
Código mais confiável: Certamente, qualquer código executado no modo de fallback de software onde existem extensões utilizáveis que seriam executadas mais rapidamente ou um algoritmo de software escrito à mão pode ser considerado um bug de desempenho. No entanto, no mundo real, é inevitável que os desenvolvedores tenham tempo limitado para escrever e depurar o código. É inevitável que erros sejam cometidos e que os desenvolvedores simplesmente optem por não se incomodar em escrever um código que não espere que um determinado conjunto de extensões esteja presente. O .NET se destaca por permitir que os desenvolvedores escrevam códigos que funcionem de maneira confiável e rápida e, em seguida, otimizem esse código para ser executado mais rapidamente de acordo com sua preferência. Dada uma base de código onde o desenvolvedor faz uso dessas extensões, mas não tem tempo e recursos para garantir que seu código seja executado adequadamente em qualquer plataforma, então, para o consumidor da biblioteca ou aplicativo, é muito mais preferível que esse código seja executado muito mais lento do que travar completamente. Eu acredito que isso é algo que afetará os desenvolvedores que consomem bibliotecas escritas com esta API e os usuários finais que podem enfrentar travamentos completos porque um aplicativo foi escrito sem ser testado com conjuntos de instruções disponíveis na CPU do usuário.
Em geral, acho que um fallback de software forneceria pouca ou nenhuma desvantagem para os desenvolvedores que sentem que não se beneficiariam com isso, mas ao mesmo tempo tornaria a API muito mais acessível para os desenvolvedores .NET regulares.
Não espero que isso mude dado o quão atrasado estou para isso, mas pensei em pelo menos colocar minhas idéias no registro aqui.
 battlebottle
em 2 jan. 2018
battlebottle
em 2 jan. 2018
Eu concordo que ter o recurso de fallback de software seria bom. No entanto, visto que é apenas um recurso interessante e também pode ser implementado por desenvolvedores individuais conforme a necessidade ou como uma biblioteca de terceiros, acho que deve ser colocado na parte inferior do lista de afazeres. Eu preferiria ver essa energia sendo direcionada para ter suporte completo ao AVX-512, que já está disponível em CPUs de nível de servidor por um tempo e em seu caminho para CPUs de consumo.
 skesgin
em 16 jan. 2018
skesgin
em 16 jan. 2018
Ping em notícias AVX512?
 oscarbg
em 12 abr. 2018
oscarbg
em 12 abr. 2018
Ainda temos alguns ISAs para implementar antes que APIs já aceitos sejam finalizados - alguns intrínsecos de AVX2 e todo AES, BMI1, BMI2, FMA, PCMULQDQ. Minha expectativa é que após o término desse trabalho e a estabilização da implementação, comecemos a trabalhar no AVX512. No entanto, enquanto isso, ainda temos muito a fazer com as implementações do Arm64.
@fiigii provavelmente poderia fornecer mais informações sobre planos futuros.
4creators
em 12 abr. 2018
Eu concordo que ter o recurso de fallback de software seria bom.
Esta API parece realmente ótima. No entanto, há uma coisa que eu gostaria de ver mudada. Podemos oferecer suporte a um substituto de software?
O pensamento atual em torno da implementação de intrínsecos de hardware é que fornecemos intrínsecos de baixo nível que permitem montagem como a programação, além de vários intrínsecos auxiliares que devem tornar a vida do desenvolvedor mais fácil.
A implementação que fornece mais abstração e fallback de software já está parcialmente disponível no namespace System.Numerics com Vector<T> . A expectativa é que os intrínsecos de hardware permitam expandir a funcionalidade da implementação de Vector<T> adicionando novas funcionalidades apoiadas por fallback de software. Vector<T> implementação de
A descrição acima, no entanto, é uma visão pessoal do membro da comunidade.
4creators
em 12 abr. 2018
Ping em notícias AVX512?
Depois de terminar essas APIs (por exemplo, AVX2, FMA, etc.), acho que temos que investigar mais problemas de desempenho em potencial (por exemplo, conversão de chamada, alinhamento de dados) antes de passar para a próxima etapa, porque esses problemas podem explodir com SIMD mais amplo arquiteturas. Enquanto isso, prefiro melhorar / refatorar a implementação do backend JIT (emissor, codgen, etc.) antes de estendê-lo para AVX-512. Sim, definitivamente precisamos estender esse plano para o AVX-512 no futuro, mas agora é melhor nos concentrarmos no aprimoramento dos intrínsecos de 128/256 bits.
fiigii
em 12 abr. 2018
Pessoalmente, não acho que valha a pena gastar o esforço do desenvolvedor no fallback de software, já que o consumidor pode facilmente implementar o feedback de software por conta própria se quiser e, além disso, funciona melhor no nível de algoritmo do que ter um fallback de software no nível intrínseco.
Na verdade, implementar todas as dezenas de intrínsecos que existem por aí para todas as plataformas direcionadas não é algo que o consumidor possa fazer sozinho e, portanto, pessoalmente, preferiria ter uma prioridade mais alta.
A propósito, ótimas coisas, estou muito ansioso para ter todos esses intrínsecos disponíveis.
 Jorenkv
em 13 abr. 2018
Jorenkv
em 13 abr. 2018
Sugestão secundária de aprimoramento de API de minha parte:
Adicione a propriedade Count a todos os VTs vetoriais que seriam semelhantes a System.Numerics.Vector.Count , embora fornecesse o valor estático baseado unicamente no argumento de tipo genérico de Vector64/128/256/etc<T> .
A implementação pode ser algo parecido com Unsafe.SizeOf<Vector128<T>>() / Unsafe.SizeOf<T>() .
A razão para esta proposta é - quando o argumento do tipo genérico é conhecido antecipadamente (por exemplo, tipo concreto como ushort , int , etc), então a dimensão do vetor poderia ser apenas codificada no código-fonte. Mas este não é o caso para o código que usa abordagem com genéricos - a dimensão deve ser recalculada no código-fonte frequentemente quando necessário (novamente).
 voinokin
em 22 mai. 2018
voinokin
em 22 mai. 2018
P. Existe alguma chance dessa funcionalidade estar disponível no .NET Standard?
Eu mantenho uma biblioteca / nuget de código que se beneficiaria com o uso desses intrínsecos de hardware, mas atualmente tem como objetivo o .NET Standard para fornecer boa portabilidade.
Idealmente, gostaria de continuar a oferecer portabilidade, mas também melhorar o desempenho se a plataforma / ambiente de tempo de execução fornecer esses intrínsecos. No momento, parece que minha escolha é velocidade ou portabilidade, mas não ambas - é provável que isso mude no futuro?
 colgreen
em 25 mai. 2018
colgreen
em 25 mai. 2018
@colgreen Isso foi discutido em https://github.com/dotnet/corefx/issues/24346. Eu recomendo mover a discussão para lá.
jkotas
em 25 mai. 2018
Onde podemos encontrar documentação sobre como usar o intrínseco? Posso ver que o atributo [Intrinsic] é usado em Vector2_Intrinsics.cs , mas também em Vector2.cs , e não tenho certeza por que / como funciona.
 aaronfranke
em 31 mai. 2019
aaronfranke
em 31 mai. 2019
@aaronfranke Eu não sei o quanto você já sabe, mas é meu entendimento que o IntrinsicAttribute é aplicado a alguns métodos onde o compilador deve substituir as instruções usuais por instruções especialmente geradas. Isso só é possível porque você distribui o código IL para execução em plataformas diferentes e, se uma plataforma tiver a instrução popcnt, ela será tratada como um caso especial.
Meu exemplo não é real, mas você provavelmente pode encontrar exemplos reais no CoreCLR se pesquisar os usos de IntrinsicAttribute.
 Genbox
em 1 jun. 2019
Genbox
em 1 jun. 2019
IntrinsicAttribute é um detalhe de implementação interno. Você não precisa se preocupar com isso para usar os intrínsecos.
https://devblogs.microsoft.com/dotnet/using-net-hardware-intrinsics-api-to-accelerate-machine-learning-scenarios/ descreve bons exemplos de usos intrínsecos de hardware real.
jkotas
em 1 jun. 2019
Se você já tem SIMD ou experiência em programação de baixo nível em C / C ++, o comentário da fonte da API seria suficiente.
Do contrário, este artigo Hardware intrínseco ao .NET Core 3.0 - Introdução seria um bom começo.
fiigii
em 2 jun. 2019
Questões relacionadas
 jamesqo
·
3Comentários
jamesqo
·
3Comentários
 iCodeWebApps
·
3Comentários
iCodeWebApps
·
3Comentários
 btecu
·
3Comentários
btecu
·
3Comentários
 GitAntoinee
·
3Comentários
GitAntoinee
·
3Comentários
 bencz
·
3Comentários
bencz
·
3Comentários
Comentários muito úteis
Eu concordo que ter o recurso de fallback de software seria bom. No entanto, visto que é apenas um recurso interessante e também pode ser implementado por desenvolvedores individuais conforme a necessidade ou como uma biblioteca de terceiros, acho que deve ser colocado na parte inferior do lista de afazeres. Eu preferiria ver essa energia sendo direcionada para ter suporte completo ao AVX-512, que já está disponível em CPUs de nível de servidor por um tempo e em seu caminho para CPUs de consumo.