Runtime: Предложение API: добавить встроенные аппаратные функции Intel и пространство имен
Это предложение добавляет встроенные функции, которые позволяют программистам использовать управляемый код (C #) для использования Intel® SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, AVX, AVX2, FMA, LZCNT, POPCNT, BMI1 / 2, PCLMULQDQ, и инструкции AES.
Обоснование и предлагаемый API
Векторные типы
В настоящее время .NET предоставляет System.Numerics.Vector<T> и связанные с ним встроенные функции в виде кроссплатформенного интерфейса SIMD, который автоматически соответствует надлежащей аппаратной поддержке во время JIT-компиляции (например, Vector<T> имеет размер 128 бит на машинах SSE2. или 256-битный на машинах AVX2). Однако невозможно одновременно использовать разные размеры Vector<T> , что ограничивает гибкость встроенных функций SIMD. Например, на машинах AVX2 регистры XMM недоступны из Vector<T> , но определенные инструкции должны работать с регистрами XMM (например, SSE4.2). Следовательно, это предложение вводит Vector128<T> и Vector256<T> в новое пространство имен System.Runtime.Intrinsics
namespace System.Runtime.Intrinsics
{
// 128 bit types
[StructLayout(LayoutKind.Sequential, Size = 16)]
public struct Vector128<T> where T : struct {}
// 256 bit types
[StructLayout(LayoutKind.Sequential, Size = 32)]
public struct Vector256<T> where T : struct {}
}
Это пространство имен не зависит от платформы, и другое оборудование может предоставлять встроенные функции, которые работают над ним. Например, Vector128<T> может быть реализовано как абстракция регистров XMM на процессоре с поддержкой SSE или как абстракция регистров Q на процессорах с поддержкой NEON. Между тем, в будущем могут быть добавлены другие типы для поддержки новых архитектур SIMD (например, добавление 512-битных векторных и векторных типов маски для AVX-512).
Внутренние функции
Текущий дизайн System.Numerics.Vector абстрагируется от специфики деталей процессора. Хотя этот подход во многих случаях работает хорошо, разработчики могут не в полной мере использовать преимущества базового оборудования. Внутренние функции позволяют разработчикам получить доступ ко всем возможностям процессоров, на которых работают их программы.
Одна из целей разработки встроенных API-интерфейсов - обеспечить однозначное соответствие встроенным функциям Intel C / C ++ . Таким образом, программисты, уже знакомые с внутренними функциями C / C ++, могут легко использовать свои существующие навыки. Еще одно преимущество этого подхода заключается в том, что мы используем существующий объем документации и примеры кода, написанные для инстринсиков C / C ++.
Внутренние функции, которые манипулируют Vector128/256<T> будут помещены в зависящее от платформы пространство имен System.Runtime.Intrinsics.X86 . Внутренние API-интерфейсы будут разделены на несколько статических классов на основе наборов инструкций, к которым они принадлежат.
// Avx.cs
namespace System.Runtime.Intrinsics.X86
{
public static class Avx
{
public static bool IsSupported {get;}
// __m256 _mm256_add_ps (__m256 a, __m256 b)
[Intrinsic]
public static Vector256<float> Add(Vector256<float> left, Vector256<float> right) { throw new NotImplementedException(); }
// __m256d _mm256_add_pd (__m256d a, __m256d b)
[Intrinsic]
public static Vector256<double> Add(Vector256<double> left, Vector256<double> right) { throw new NotImplementedException(); }
// __m256 _mm256_addsub_ps (__m256 a, __m256 b)
[Intrinsic]
public static Vector256<float> AddSubtract(Vector256<float> left, Vector256<float> right) { throw new NotImplementedException(); }
// __m256d _mm256_addsub_pd (__m256d a, __m256d b)
[Intrinsic]
public static Vector256<double> AddSubtract(Vector256<double> left, Vector256<double> right) { throw new NotImplementedException(); }
......
}
}
Некоторые встроенные функции выигрывают от универсального C # и получают более простые API:
// Sse2.cs
namespace System.Runtime.Intrinsics.X86
{
public static class Sse
{
public static bool IsSupported {get;}
// __m128 _mm_castpd_ps (__m128d a)
// __m128i _mm_castpd_si128 (__m128d a)
// __m128d _mm_castps_pd (__m128 a)
// __m128i _mm_castps_si128 (__m128 a)
// __m128d _mm_castsi128_pd (__m128i a)
// __m128 _mm_castsi128_ps (__m128i a)
[Intrinsic]
public static Vector128<U> StaticCast<T, U>(Vector128<T> value) where T : struct where U : struct { throw new NotImplementedException(); }
......
}
}
Каждый класс набора инструкций содержит свойство IsSupported которое указывает, поддерживает ли базовое оборудование набор инструкций. Программисты используют эти свойства, чтобы гарантировать, что их код может работать на любом оборудовании через кодовый путь, зависящий от платформы. Для JIT-компиляции результатами проверки возможностей являются временные константы JIT, поэтому путь мертвого кода для текущей платформы будет исключен компилятором JIT (условное распространение констант). Для компиляции AOT компилятор / среда выполнения выполняет проверку CPUID для идентификации соответствующих наборов инструкций. Кроме того, встроенные функции не обеспечивают откат программного обеспечения, и вызов встроенных функций на машинах, на которых нет соответствующих наборов инструкций, вызовет PlatformNotSupportedException во время выполнения. Следовательно, мы всегда рекомендуем разработчикам предоставлять резервное программное обеспечение, чтобы программа оставалась переносимой. Ниже показан общий образец пути кода для конкретной платформы и отката программного обеспечения.
if (Avx2.IsSupported)
{
// The AVX/AVX2 optimizing implementation for Haswell or above CPUs
}
else if (Sse41.IsSupported)
{
// The SSE optimizing implementation for older CPUs
}
......
else
{
// Scalar or software-fallback implementation
}
Объем этого предложения API не ограничивается внутренними функциями SIMD (векторными), но также включает скалярные встроенные функции, которые работают над скалярными типами (например, int, short, long или float и т. Д.) Из наборов инструкций, упомянутых выше. В качестве примера, следующий сегмент коды показывает Crc32 собственных функций от Sse42 класса.
// Sse42.cs
namespace System.Runtime.Intrinsics.X86
{
public static class Sse42
{
public static bool IsSupported {get;}
// unsigned int _mm_crc32_u8 (unsigned int crc, unsigned char v)
[Intrinsic]
public static uint Crc32(uint crc, byte data) { throw new NotImplementedException(); }
// unsigned int _mm_crc32_u16 (unsigned int crc, unsigned short v)
[Intrinsic]
public static uint Crc32(uint crc, ushort data) { throw new NotImplementedException(); }
// unsigned int _mm_crc32_u32 (unsigned int crc, unsigned int v)
[Intrinsic]
public static uint Crc32(uint crc, uint data) { throw new NotImplementedException(); }
// unsigned __int64 _mm_crc32_u64 (unsigned __int64 crc, unsigned __int64 v)
[Intrinsic]
public static ulong Crc32(ulong crc, ulong data) { throw new NotImplementedException(); }
......
}
}
Целевая аудитория
Встроенные API-интерфейсы обеспечивают мощность и гибкость доступа к аппаратным инструкциям непосредственно из программ на C #. Однако эта мощность и гибкость означает, что разработчики должны знать, как используются эти API. Помимо обеспечения правильности логики своей программы, разработчики также должны гарантировать, что использование базовых встроенных API-интерфейсов допустимо в контексте их операций.
Например, разработчики, использующие определенные встроенные функции аппаратного обеспечения, должны знать свои требования к выравниванию данных. Обеспечиваются как выровненная, так и невыровненная загрузка памяти и встроенные функции хранилища, и, если требуются выровненные загрузки и сохранения, разработчики должны гарантировать, что данные выровнены соответствующим образом. В следующем фрагменте кода показаны различные варианты встроенных функций загрузки и хранения:
// Avx.cs
namespace System.Runtime.Intrinsics.X86
{
public static class Avx
{
......
// __m256i _mm256_loadu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<sbyte> Load(sbyte* address) { throw new NotImplementedException(); }
// __m256i _mm256_loadu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<byte> Load(byte* address) { throw new NotImplementedException(); }
......
[Intrinsic]
public static Vector256<T> Load<T>(ref T vector) where T : struct { throw new NotImplementedException(); }
// __m256i _mm256_load_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<sbyte> LoadAligned(sbyte* address) { throw new NotImplementedException(); }
// __m256i _mm256_load_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<byte> LoadAligned(byte* address) { throw new NotImplementedException(); }
......
// __m256i _mm256_lddqu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<sbyte> LoadDqu(sbyte* address) { throw new NotImplementedException(); }
// __m256i _mm256_lddqu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<byte> LoadDqu(byte* address) { throw new NotImplementedException(); }
......
// void _mm256_storeu_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void Store(sbyte* address, Vector256<sbyte> source) { throw new NotImplementedException(); }
// void _mm256_storeu_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void Store(byte* address, Vector256<byte> source) { throw new NotImplementedException(); }
......
public static void Store<T>(ref T vector, Vector256<T> source) where T : struct { throw new NotImplementedException(); }
// void _mm256_store_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void StoreAligned(sbyte* address, Vector256<sbyte> source) { throw new NotImplementedException(); }
// void _mm256_store_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void StoreAligned(byte* address, Vector256<byte> source) { throw new NotImplementedException(); }
......
// void _mm256_stream_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void StoreAlignedNonTemporal(sbyte* address, Vector256<sbyte> source) { throw new NotImplementedException(); }
// void _mm256_stream_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void StoreAlignedNonTemporal(byte* address, Vector256<byte> source) { throw new NotImplementedException(); }
......
}
}
IMM-операнды
Большинство встроенных функций можно напрямую перенести на C # из C / C ++, но некоторые инструкции, требующие немедленных параметров (например, imm8) в качестве операндов, заслуживают дополнительного рассмотрения, например pshufd , vcmpps и т. Д. Компиляторы C / C ++ специально обрабатывают эти встроенные функции, которые вызывают ошибки времени компиляции, когда непостоянные значения передаются в непосредственные параметры. Следовательно, CoreCLR также требует немедленной защиты аргументов от компилятора C #. Мы предлагаем добавить в Roslyn новую «функцию компилятора», которая накладывает ограничение const на параметры функции. Затем Roslyn может гарантировать, что эти функции вызываются с «буквальными» значениями формальных параметров const .
// Avx.cs
namespace System.Runtime.Intrinsics.X86
{
public static class Avx
{
......
// __m256 _mm256_blend_ps (__m256 a, __m256 b, const int imm8)
[Intrinsic]
public static Vector256<float> Blend(Vector256<float> left, Vector256<float> right, const byte control) { throw new NotImplementedException(); }
// __m256d _mm256_blend_pd (__m256d a, __m256d b, const int imm8)
[Intrinsic]
public static Vector256<double> Blend(Vector256<double> left, Vector256<double> right, const byte control) { throw new NotImplementedException(); }
// __m128 _mm_cmp_ps (__m128 a, __m128 b, const int imm8)
[Intrinsic]
public static Vector128<float> Compare(Vector128<float> left, Vector128<float> right, const FloatComparisonMode mode) { throw new NotImplementedException(); }
// __m128d _mm_cmp_pd (__m128d a, __m128d b, const int imm8)
[Intrinsic]
public static Vector128<double> Compare(Vector128<double> left, Vector128<double> right, const FloatComparisonMode mode) { throw new NotImplementedException(); }
......
}
}
// Enums.cs
namespace System.Runtime.Intrinsics.X86
{
public enum FloatComparisonMode : byte
{
EqualOrderedNonSignaling,
LessThanOrderedSignaling,
LessThanOrEqualOrderedSignaling,
UnorderedNonSignaling,
NotEqualUnorderedNonSignaling,
NotLessThanUnorderedSignaling,
NotLessThanOrEqualUnorderedSignaling,
OrderedNonSignaling,
......
}
......
}
Семантика и использование
Семантика проста, если пользователи уже знакомы с внутренними функциями Intel C / C ++ . Существующие программы и алгоритмы SIMD, реализованные на C / C ++, могут быть напрямую перенесены на C #. Более того, по сравнению с System.Numerics.Vector<T> , эти встроенные функции используют всю мощь инструкций Intel SIMD и не зависят от других модулей (например, Unsafe ) в высокопроизводительных средах.
Например, SoA (структура массива) является более эффективным шаблоном, чем AoS (массив структуры) в программировании SIMD. Однако для преобразования источника данных (обычно хранящегося в формате AoS) требуются плотные последовательности shuffle , которые не предоставляются Vector<T> . Использование Vector256<T> с инструкциями перемешивания AVX (включая перемешивание, вставку, извлечение и т. Д.) Может привести к более высокой пропускной способности.
public struct Vector256Packet
{
public Vector256<float> xs {get; private set;}
public Vector256<float> ys {get; private set;}
public Vector256<float> zs {get; private set;}
// Convert AoS vectors to SoA packet
public unsafe Vector256Packet(float* vectors)
{
var m03 = Avx.ExtendToVector256<float>(Sse2.Load(&vectors[0])); // load lower halves
var m14 = Avx.ExtendToVector256<float>(Sse2.Load(&vectors[4]));
var m25 = Avx.ExtendToVector256<float>(Sse2.Load(&vectors[8]));
m03 = Avx.Insert(m03, &vectors[12], 1); // load higher halves
m14 = Avx.Insert(m14, &vectors[16], 1);
m25 = Avx.Insert(m25, &vectors[20], 1);
var xy = Avx.Shuffle(m14, m25, 2 << 6 | 1 << 4 | 3 << 2 | 2);
var yz = Avx.Shuffle(m03, m14, 1 << 6 | 0 << 4 | 2 << 2 | 1);
var _xs = Avx.Shuffle(m03, xy, 2 << 6 | 0 << 4 | 3 << 2 | 0);
var _ys = Avx.Shuffle(yz, xy, 3 << 6 | 1 << 4 | 2 << 2 | 0);
var _zs = Avx.Shuffle(yz, m25, 3 << 6 | 0 << 4 | 3 << 2 | 1);
xs = _xs;
ys = _ys;
zs = _zs;
}
......
}
public static class Main
{
static unsafe int Main(string[] args)
{
var data = new float[Length];
fixed (float* dataPtr = data)
{
if (Avx2.IsSupported)
{
var vector = new Vector256Packet(dataPtr);
......
// Using AVX/AVX2 intrinsics to compute eight 3D vectors.
}
else if (Sse41.IsSupported)
{
var vector = new Vector128Packet(dataPtr);
......
// Using SSE intrinsics to compute four 3D vectors.
}
else
{
// scalar algorithm
}
}
}
}
Кроме того, в векторизованных программах включен условный код. Условный путь является повсеместным в скалярных программах ( if-else ), но для него требуются специальные инструкции SIMD в векторизованных программах, такие как сравнение, смешивание, andnot и т. Д.
public static class ColorPacketHelper
{
public static IntRGBPacket ConvertToIntRGB(this Vector256Packet colors)
{
var one = Avx.Set1<float>(1.0f);
var max = Avx.Set1<float>(255.0f);
var rsMask = Avx.Compare(colors.xs, one, FloatComparisonMode.GreaterThanOrderedNonSignaling);
var gsMask = Avx.Compare(colors.ys, one, FloatComparisonMode.GreaterThanOrderedNonSignaling);
var bsMask = Avx.Compare(colors.zs, one, FloatComparisonMode.GreaterThanOrderedNonSignaling);
var rs = Avx.BlendVariable(colors.xs, one, rsMask);
var gs = Avx.BlendVariable(colors.ys, one, gsMask);
var bs = Avx.BlendVariable(colors.zs, one, bsMask);
var rsInt = Avx.ConvertToVector256Int(Avx.Multiply(rs, max));
var gsInt = Avx.ConvertToVector256Int(Avx.Multiply(gs, max));
var bsInt = Avx.ConvertToVector256Int(Avx.Multiply(bs, max));
return new IntRGBPacket(rsInt, gsInt, bsInt);
}
}
public struct IntRGBPacket
{
public Vector256<int> Rs {get; private set;}
public Vector256<int> Gs {get; private set;}
public Vector256<int> Bs {get; private set;}
public IntRGBPacket(Vector256<int> _rs, Vector256<int> _gs, Vector256<int>_bs)
{
Rs = _rs;
Gs = _gs;
Bs = _bs;
}
}
Как указывалось ранее, традиционные скалярные алгоритмы также могут быть ускорены. Например, CRC32 изначально поддерживается процессорами SSE4.2.
public static class Verification
{
public static bool VerifyCrc32(ulong acc, ulong data, ulong res)
{
if (Sse42.IsSupported)
{
return Sse42.Crc32(acc, data) == res;
}
else
{
return SoftwareCrc32(acc, data) == res;
// The software implementation of Crc32 provided by developers or other libraries
}
}
}
Дорожная карта внедрения
Внедрение всех встроенных функций в JIT - это крупномасштабный и долгосрочный проект, поэтому текущий план состоит в том, чтобы изначально реализовать подмножество из них с помощью модульных тестов, тестирования качества кода и тестов.
Первый шаг в реализации будет включать элементы, связанные с инфраструктурой. Этот шаг будет включать в себя подключение основных компонентов, включая, помимо прочего, представления внутренних данных Vector128<T> и Vector256<T> , внутреннее распознавание, проверку поддержки оборудования и внешнюю поддержку со стороны Roslyn / CoreFX. Следующие шаги будут включать реализацию подмножеств встроенных функций в классах, представляющих различные наборы инструкций.
Полный дизайн API
Добавьте встроенные аппаратные API Intel в CoreFX dotnet / corefx # 23489
Добавить реализацию встроенного аппаратного API Intel в mscorlib dotnet / corefx # 13576
Обновлять
17.08.2017
- Измените пространство имен
System.Runtime.CompilerServices.IntrinsicsнаSystem.Runtime.IntrinsicsиSystem.Runtime.CompilerServices.Intrinsics.X86наSystem.Runtime.Intrinsics.X86. - Измените имя класса ISA, чтобы оно соответствовало соглашению об именах CoreFX, например, используя
AvxвместоAVX. - Измените имена некоторых параметров указателя, например, используя
addressвместоmem. - Определите
IsSupportкак свойства. - Добавьте
Span<T>перегрузки к наиболее распространенным встроенным функциям доступа к памяти (Load,Store,Broadcast), но оставьте другие встроенные функции, учитывающие выравнивание или производительность с исходной версией указателя. - Уточните, что эти встроенные функции не обеспечивают отката программного обеспечения.
- Разъясните дизайн класса
Sse2и разделите небольшие ссылки (например,Aes,Lzcntи т. Д.) В отдельные исходные файлы (например,Aes.cs,Lzcnt.csи т. д.). - Измените имя метода
CompareVector*наCompareи удалите префиксCompareсFloatComparisonMode.
22.08.2017
- Замените
Span<T>overloads наref Toverloads.
01.09.2017
- Незначительные изменения по сравнению с обзором кода API.
21.12.2018
- Все предлагаемые API включены в среду выполнения .NET Core.
 fiigii
fiigii
Все 181 Комментарий
Копия: @russellhadley @mellinoe @CarolEidt @terrajobst
fiigii
4 авг. 2017
В целом мне нравится это предложение. У меня есть несколько вопросов / комментариев:
Каждый векторный тип предоставляет метод IsSupported, чтобы проверить, поддерживает ли текущее оборудование
Я думаю, это может быть свойство, как в Vector<T> .
Учитывается ли при этом тип T. Например, вернет ли IsSupported истину для Vector128<float> но ложь для Vector128<CustomStruct> (или в этом случае ожидается выдача)?
А как насчет форматов, которые могут поддерживаться некоторыми процессорами, но не поддерживаются другими? В качестве примера предположим, что существует набор инструкций X, который поддерживает только Vector128<float> а позже идет набор инструкций Y, который поддерживает Vector128<double> . Если ЦП в настоящее время поддерживает только X, будет ли он возвращать истину для Vector128<float> и ложь для Vector128<double> с Vector128<double> возвращающим истину только тогда, когда поддерживается набор инструкций Y?
Кроме того, это пространство имен будет содержать функции преобразования между существующим типом SIMD (Vector
) и новый Vector128 и Vector256 типы.
Меня беспокоит целевое расслоение каждого компонента. Я надеюсь, что System.Runtime.CompilerServices.Intrinsics являются частью самого нижнего уровня и, следовательно, могут использоваться всеми другими API в CoreFX. В то время как Vector<T> , с другой стороны, является частью одного из более высоких уровней и поэтому не является расходным материалом.
Было бы лучше иметь здесь операторы преобразования на Vector<T> или ожидать, что пользователь выполнит явную загрузку / сохранение (как они, вероятно, будут делать с другими настраиваемыми типами)?
SSE2.cs (основная часть встроенной поддержки, которая содержит все встроенные функции SSE и SSE2)
Я понимаю, что с SSE и SSE2, требующимися в RyuJIT, это имеет смысл, но я почти предпочел бы, чтобы явный класс SSE имел последовательное разделение. По сути, я ожидал бы сопоставления класса 1-1 с флагом CPUID.
Other.cs (включает LZCNT, POPCNT, BMI1, BMI2, PCLMULQDQ и AES)
В частности, как вы ожидаете, что пользователь будет проверять, какие подмножества команд поддерживаются? AES и POPCNT - это отдельные флаги CPUID, и не каждый x86-совместимый процессор всегда может предоставлять оба.
Некоторые встроенные функции выигрывают от универсального C # и получают более простые API.
Я не видел примеров скалярных API с плавающей запятой ( _mm_rsqrt_ss ). Как они будут вписываться в API-интерфейсы на основе векторов (с точки зрения именования и т. Д.)?
 tannergooding
4 авг. 2017
tannergooding
4 авг. 2017
Выглядит хорошо и соответствует моим предложениям. Единственное, что, вероятно, не находит отклика у меня (возможно, потому, что мы регулярно работаем с указателями в нашей кодовой базе), это необходимость использовать Load(type*) вместо поддержки возможности вызова функции с помощью void* поскольку семантика операции очень ясна. Вероятно, это я, но за исключением специальных операций, таких как невременное хранилище (где вам нужно будет явно использовать операцию Store / Load), отсутствие поддержки произвольных типов указателей только добавит раздувания к алгоритму без какого-либо фактического улучшения в удобочитаемости / понятности.
 redknightlois
4 авг. 2017
redknightlois
4 авг. 2017
Следовательно, CoreCLR также требует немедленной защиты аргументов от компилятора C #.
Собираюсь явно отметить здесь
Я думаю, что мы можем сделать это без языковой поддержки ( @jaredpar , скажите, если я здесь сумасшедший), если компилятор может распознать что-то вроде System.Runtime.CompilerServices.IsLiteralAttribute и выдает это как modreq isliteral .
Наличие нового распознанного ключевого слова ( const ) здесь, вероятно, более сложно, поскольку требует формального определения языка и т. Д.
tannergooding
4 авг. 2017
Спасибо, что разместили этот @fiigii. Я очень хочу услышать мнение каждого о дизайне.
IMM-операнды
Одна вещь, которая возникла в недавнем обсуждении, заключается в том, что некоторые непосредственные операнды имеют более строгие ограничения, чем просто «должно быть постоянным». В приведенных примерах используется перечисление FloatComparisonMode , а функции, принимающие его, применяют к параметру модификатор const . Но нет никакого способа помешать кому-либо передать значение, отличное от перечисления, которое все еще является константой, методу, принимающему этот параметр.
`AVX.CompareVector256(left, right, (FloatComparisonMode)255);
РЕДАКТИРОВАТЬ: это предупреждение появляется в проекте VC ++, если вы используете приведенный выше код.
Возможно, это не проблема для данного конкретного примера (я не знаком с его точной семантикой), но об этом следует помнить. Были также приведены другие, более эзотерические примеры, такие как непосредственный операнд, который должен быть степенью двойки или который удовлетворяет какому-то другому неясному отношению к другим операндам. Эти ограничения будет гораздо труднее, а скорее всего, невозможно обеспечить на уровне C #. Применение «const» кажется более разумным и достижимым, и, кажется, охватывает большинство случаев проблемы.
SSE2.cs (основная часть встроенной поддержки, которая содержит все встроенные функции SSE и SSE2)
Я повторю то, что сказал
 mellinoe
4 авг. 2017
mellinoe
4 авг. 2017
💭 Большинство моих первоначальных мыслей сводятся к использованию указателей в нескольких местах. Зная, что мы знаем о ссылочных структурах и Span<T> , в каких частях предложения можно использовать новые функции, чтобы избежать небезопасного кода без ущерба для производительности.
❓ Будет ли в следующем коде расширен универсальный метод на каждую из форм, разрешенных процессором, или он будет определен в coed как универсальный?
// __m128i _mm_add_epi8 (__m128i a, __m128i b)
// __m128i _mm_add_epi16 (__m128i a, __m128i b)
// __m128i _mm_add_epi32 (__m128i a, __m128i b)
// __m128i _mm_add_epi64 (__m128i a, __m128i b)
// __m128 _mm_add_ps (__m128 a, __m128 b)
// __m128d _mm_add_pd (__m128d a, __m128d b)
[Intrinsic]
public static Vector128<T> Add<T>(Vector128<T> left, Vector128<T> right) where T : struct { throw new NotImplementedException(); }
 sharwell
4 авг. 2017
sharwell
4 авг. 2017
❓ Если процессор что-то не поддерживает, мы возвращаемся к моделированному поведению или генерируем исключения? Если мы выберем первое, имеет ли смысл переименовать IsSupported в IsHardwareAccelerated ?
sharwell
4 авг. 2017
Зная то, что мы знаем о ссылочных структурах и диапазоне
, какие части предложения могут использовать новые функции, чтобы избежать небезопасного кода без ущерба для производительности.
Лично меня небезопасный код устраивает. Я не верю, что это должна быть функция, которую используют дизайнеры приложений, а вместо этого предназначена для того, чтобы дизайнеры фреймворков использовали дополнительную производительность, а также упростили накладные расходы на JIT.
Люди, использующие встроенные функции, вероятно, уже делают кучу небезопасных вещей, и это просто делает их более явными.
Если процессор что-то не поддерживает, мы возвращаемся к моделированному поведению или генерируем исключения?
Официальный проектный документ (https://github.com/dotnet/designs/blob/master/accepted/platform-intrinsics.md) указывает, что вопрос о том, разрешены ли программные резервные варианты, пока не решен.
Я считаю, что все эти методы должны быть объявлены как extern и никогда не должны иметь программных откатов. Ожидается, что пользователи будут реализовывать резервное программное обеспечение самостоятельно или получить PlatformNotSupportedException брошенное JIT во время выполнения.
Это поможет убедиться, что потребитель осведомлен о базовых платформах, на которые они нацелены, и что они пишут код, который «подходит» для базового оборудования (выполнение векторизованных алгоритмов на оборудовании без поддержки векторизации может привести к снижению производительности).
tannergooding
4 авг. 2017
Если процессор что-то не поддерживает, мы возвращаемся к моделированному поведению или генерируем исключения?
Официальный проектный документ (https://github.com/dotnet/designs/blob/master/accepted/platform-intrinsics.md) указывает, что вопрос о том, разрешены ли программные резервные варианты, пока не решен.
Это необработанные встроенные функции платформы ЦП, например, X86.SSE так что с PNS, вероятно, все в порядке; и поможет вывести их быстрее.
Предполагая, что обнаружение устранено; должно быть легко создать библиотеку поверх, которая затем выполняет резервное копирование программного обеспечения, которое может быть повторено (либо coreclr / corefx, либо сторонняя организация)
 benaadams
4 авг. 2017
benaadams
4 авг. 2017
Лично меня небезопасный код устраивает.
Я не против небезопасного кода. Однако, учитывая выбор между безопасным кодом и небезопасным кодом, которые работают одинаково, я бы выбрал первое.
Я считаю, что все эти методы должны быть объявлены как внешние и никогда не должны иметь программных откатов.
Самым большим преимуществом этого является то, что среда выполнения позволяет избежать доставки резервного программного кода, который никогда не должен выполняться.
Самый большой недостаток этого заключается в том, что нелегко найти тестовые среды для различных возможностей. Запасные варианты обеспечивают функциональную подстраховку на случай, если что-то будет упущено.
sharwell
4 авг. 2017
Самый большой недостаток этого заключается в том, что нелегко найти тестовые среды для различных возможностей.
@sharwell , какие возможности вы видите?
Как они в настоящее время структурированы, предложены, пользователь мог бы написать код:
C#
public static double Cos(double x)
{
if (x86.FMA3.IsSupported)
{
// Do FMA3
}
else if (x86.SSE2.IsSupported)
{
// Do SSE2
}
else if (Arm.Neon.IsSupported)
{
// Do ARM
}
else
{
// Do software fallback
}
}
В соответствии с этим, единственный способ обвинить пользователя - это написать плохой алгоритм или если он забудет предоставить какой-либо резервный программный вариант (и анализатор для обнаружения этого должен быть довольно тривиальным).
tannergooding
4 авг. 2017
выполнение векторизованных алгоритмов на оборудовании без поддержки векторизации может привести к снижению производительности.
Я бы перефразировал мысль @tannergooding следующим образом : «запуск векторизованных алгоритмов на оборудовании без поддержки векторизации с абсолютной уверенностью приведет к снижению производительности».
redknightlois
4 авг. 2017
В частности, как вы ожидаете, что пользователь будет проверять, какие подмножества команд поддерживаются? AES и POPCNT - это отдельные флаги CPUID, и не каждый x86-совместимый процессор всегда может предоставлять оба.
@tannergooding Мы определили отдельный класс для каждого набора инструкций (кроме SSE и SSE2), но поместили определенные небольшие классы в файл Other.cs . Я обновлю предложение, чтобы уточнить.
// Other.cs
namespace System.Runtime.CompilerServices.Intrinsics.X86
{
public static class LZCNT
{
......
}
public static class POPCNT
{
......
}
public static class BMI1
{
.....
}
public static class BMI2
{
......
}
public static class PCLMULQDQ
{
......
}
public static class AES
{
......
}
}
Однако при компиляции AOT компилятор генерирует код проверки CPUID, который будет возвращать разные значения при каждом вызове (на другом оборудовании).
Я не думаю, что это должно быть правдой все время. В некоторых случаях AOT может полностью отказаться от проверки, в зависимости от целевой операционной системы (например, для Win8 и более поздних версий требуется поддержка SSE и SSE2).
В других случаях AOT может / должен отбросить проверку из каждого метода и вместо этого должен объединить их в одну проверку в самой высокой точке входа.
В идеале AOT должен запускать CPUID один раз во время запуска и кэшировать результаты как глобальные (честно говоря, если бы AOT этого не делал, я бы зарегистрировал ошибку). Тогда проверка IsSupported становится, по сути, поиском кэшированного значения (как обычно ведет себя свойство). Это то, что делают реализации CRT, чтобы гарантировать, что такие вещи, как cos(double) остаются работоспособными и что они по-прежнему могут запускать код FMA3, если он поддерживается.
tannergooding
4 авг. 2017
Однако для компиляции AOT компилятор генерирует код проверки CPUID, который будет возвращать разные значения при каждом вызове (на другом оборудовании).
Подразумевается, что с точки зрения использования:
Для Jit мы могли бы быть довольно детализированными в проверках, поскольку они исключаются бесплатно.
Что касается AOT, нам нужно внимательно относиться к проверкам и выполнять их на уровне алгоритмов или библиотек, чтобы компенсировать стоимость CPUID; что может подтолкнуть его намного выше, чем предполагалось, например, вы бы не использовали векторизованный IndexOf; если только ваши строки не были огромными, потому что CPUID будет доминировать.
Вероятно, все еще может кешировать AOT при запуске, поэтому он установит свойство; это не устранит ветвь, но будет довольно дешево?
benaadams
4 авг. 2017
Я понимаю, что с SSE и SSE2, требующимися в RyuJIT, это имеет смысл, но я почти предпочел бы, чтобы явный класс SSE имел последовательное разделение. По сути, я ожидал бы сопоставления класса 1-1 с флагом CPUID.
Я думаю, будет проще иметь отдельный класс для каждого набора инструкций. Я бы хотел, чтобы было очень очевидно, как и где нужно добавлять новые вещи. Если есть что-то вроде типа «мешок для переноски», то он становится немного мрачнее, и нам приходится делать много ненужных суждений.
@tannergooding @mellinoe Текущая цель проекта класса SSE2 состоит в том, чтобы сделать более встроенные функции более удобными для пользователей. Если бы у нас было два класса SSE и SSE2 , некоторые встроенные функции потеряли бы общую сигнатуру. Например, добавление SIMD поддерживает только float в SSE, а SSE2 дополняет другие типы.
public static class SSE
{
// __m128 _mm_add_ps (__m128 a, __m128 b)
public static Vector128<float> Add(Vector128<float> left, Vector128<float> right);
}
public static class SSE2
{
// __m128i _mm_add_epi8 (__m128i a, __m128i b)
public static Vector128<byte> Add(Vector128<byte> left, Vector128<byte> right);
public static Vector128<sbyte> Add(Vector128<sbyte> left, Vector128<sbyte> right);
// __m128i _mm_add_epi16 (__m128i a, __m128i b)
public static Vector128<short> Add(Vector128<short> left, Vector128<short> right);
public static Vector128<ushort> Add(Vector128<ushort> left, Vector128<ushort> right);
// __m128i _mm_add_epi32 (__m128i a, __m128i b)
public static Vector128<int> Add(Vector128<int> left, Vector128<int> right);
public static Vector128<uint> Add(Vector128<uint> left, Vector128<uint> right);
// __m128i _mm_add_epi64 (__m128i a, __m128i b)
public static Vector128<long> Add(Vector128<long> left, Vector128<long> right);
public static Vector128<ulong> Add(Vector128<uint> left, Vector128<ulong> right);
// __m128d _mm_add_pd (__m128d a, __m128d b)
public static Vector128<double> Add(Vector128<double> left, Vector128<double> right);
}
По сравнению с SSE2.Add<T> , вышеуказанный дизайн выглядит сложным, и пользователи должны помнить SSE.Add(float, float) и SSE2.Add(int, int) . Кроме того, SSE2 - это основная часть генерации кода RyuJIT для x86 / x86-64, отделение SSE от SSE2 не имеет преимуществ по функциональности или удобству.
Хотя текущий дизайн (класс SSE2, включая встроенные функции SSE и SSE2) ухудшает согласованность API, существует компромисс между согласованностью дизайна и пользовательским интерфейсом, который стоит обсудить.
fiigii
4 авг. 2017
Вместо X86 может быть, x86x64 поскольку x86 часто используется только для 32-битных пожертвований?
benaadams
4 авг. 2017
Очень рад, что мы наконец видим предложение по этому поводу. Мои первоначальные мысли ниже.
AVX-512 отсутствует, вероятно, потому, что он еще не так широко распространен, но я думаю, было бы хорошо хотя бы подумать об этом и о том, как их структурировать, потому что набор функций AVX-512 очень фрагментирован. В этом случае я бы предположил, что нам нужен класс для каждого набора, т.е. (см. Https://en.wikipedia.org/wiki/AVX-512):
public static class AVX512F {} // Foundation
public static class AVX512CD {} // Conflict Detection
public static class AVX512ER {} // Exponential and Reciprocal
public static class AVX512PF {} // Prefetch Instructions
public static class AVX512BW {} // Byte and Word
public static class AVX512DQ {} // Doubleword and Quadword
public static class AVX512VL {} // Vector Length
public static class AVX512IFMA {} // Integer Fused Multiply Add (Future)
public static class AVX512VBMI {} // Vector Byte Manipulation Instructions (Future)
public static class AVX5124VNNIW {} // Vector Neural Network Instructions Word variable precision (Future)
public static class AVX5124FMAPS {} // Fused Multiply Accumulation Packed Single precision (Future)
и, конечно же, добавить тип struct Vector512<T> . Обратите внимание, что последние два AVX5124VNNIW и AVX5124FMAPS трудно читать из-за номера 4 .
Некоторые из них могут иметь огромное влияние на глубокое обучение, сортировку и т. Д.
Что касается Load меня тоже есть некоторые опасения. Как @redknightlois, я думаю, что также следует учитывать void* , но, что более важно, также загружать из / store в ref . Учитывая это, возможно, они должны быть перемещены в «общее» / платформенно-независимое пространство имен и тип, поскольку предположительно все платформы должны поддерживать загрузку / сохранение для поддерживаемого размера вектора. Так что что-то вроде (не уверен, где мы могли бы это разместить и как должно быть сделано именование, если его можно переместить в тип, не зависящий от платформы.
[Intrinsic]
public static unsafe Vector256<sbyte> Load(sbyte* mem) { throw new NotImplementedException(); }
[Intrinsic]
public static unsafe Vector256<sbyte> LoadSByte(void* mem) { throw new NotImplementedException(); }
[Intrinsic]
public static unsafe Vector256<sbyte> Load(ref sbyte mem) { throw new NotImplementedException(); }
[Intrinsic]
public static unsafe Vector256<byte> Load(byte* mem) { throw new NotImplementedException(); }
[Intrinsic]
public static unsafe Vector256<sbyte> LoadByte(void* mem) { throw new NotImplementedException(); }
[Intrinsic]
public static unsafe Vector256<byte> Load(ref byte mem) { throw new NotImplementedException(); }
// Etc.
Здесь важнее всего будет поддерживаться ref , поскольку это необходимо для поддержки общих алгоритмов. Без сомнения, следует пересмотреть название, но это просто попытка подчеркнуть суть. Если мы хотим поддерживать загрузку из void* имя метода должно включать тип возвращаемого значения или метод должен относиться к статическому классу определенного типа.
 nietras
4 авг. 2017
nietras
4 авг. 2017
Здорово, что мы сейчас обсуждаем конкретное предложение. 😄
Вышеупомянутое связанное предложение языка
const keyword usageбыло создано явно для обеспечения поддержки некоторых инструкций SIMD, требующих немедленных параметров. Я думаю, что это будет просто реализовать, но поскольку это может задержать внедрение встроенных функций, были веские аргументы в пользу того, чтобы сначала перейти кconst method parameters.ИМО, мы должны параллельно обсуждать перспективные проекты, которые включают две разные области:
System.Numerics APIкоторый может бытьpartially implementedс поддержкой обсуждаемых здесь встроенных функций x86Intrinsics APIкоторый должен включать в себя другие архитектуры, а также это повлияет на окончательную форму встроенного API
Внутреннее
Пространство имен и сборка
Я бы предложил переместить встроенные функции в отдельное пространство имен, расположенное относительно высоко в иерархии, и каждый код, специфичный для платформы, в отдельную сборку.
System.Intrinsics общее пространство имен верхнего уровня для всех встроенных функций
System.Intrinsics.X86 x86 ISA-расширения и отдельная сборка
System.Intrinsics.Arm ARM ISA-расширения и отдельная сборка
System.Intrinsics.Power Power ISA-расширения и отдельная сборка
System.Intrinsics.RiscV RiscV ISA-расширения и отдельная сборка
Причина вышеупомянутого разделения - большая область API для каждого набора команд, т.е. AVX-512 будет представлен более чем 2 000 встроенными функциями в компиляторе MsVC. То же самое скоро произойдет и с ARM SVE (см. Ниже). Размер сборки за счет только строкового содержимого будет не малым.
Размеры регистров (в настоящее время XMM, YMM, ZMM - 128, 256, 512 бит в x86)
Текущие реализации поддерживают ограниченный набор размеров регистров:
- 128, 256, 512 бит в x86
- 128 в ARM Neon и IBM Power 8 и Power 9 ISA
Однако недавно ARM опубликовала:
ARM SVE - масштабируемые векторные расширения
см. Расширение Scalable Vector Extension (SVE) для ARMv8-A, опубликованное 31 марта 2017 г. со статусом Неконфиденциальная бета.
Эта спецификация очень важна, поскольку она вводит новые размеры регистров - всего существует 16 размеров регистров, которые кратны 128 битам. Подробности на странице 21 спецификации (таблица ниже).
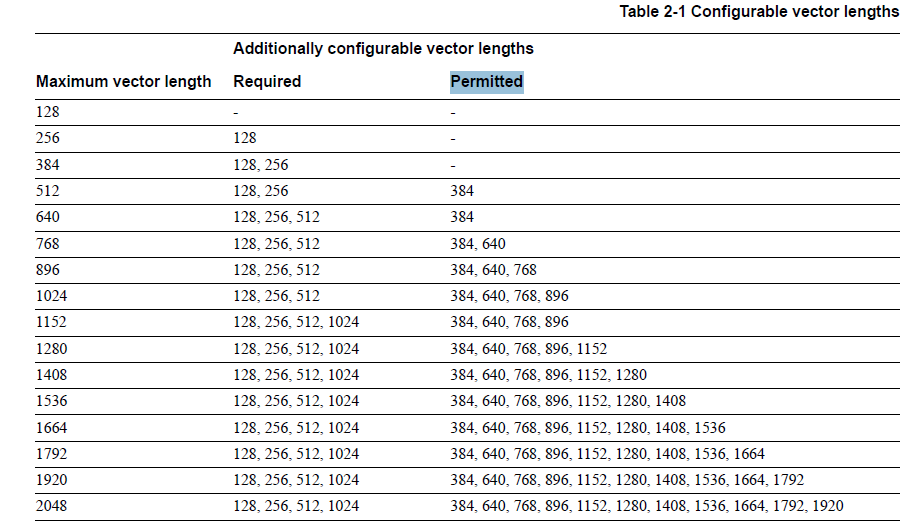
Максимальная длина вектора: 2048 бит
Требуемая длина вектора: 128, 256, 512, 1024 бит
Допустимая длина вектора: 384, 640, 768, 896, 1152, 1280, 1408, 1536, 1664, 1792, 1920.
Было бы необходимо разработать API, способный в ближайшем будущем поддерживать 16 различных размеров регистров и несколько тысяч (или десятков тысяч) кодов операций / функций (считая с перегрузками). Прогнозы отсутствия 2048-битных инструкций SIMD через пару лет, похоже, в этом году, к чьему-либо удивлению, были сфальсифицированы. Если посмотреть на историю ( ARM опубликовала публичную бета-версию ARMv8 ISA 4 сентября 2013 года, и первый процессор, реализующий ее, был доступен пользователям во всем мире в октябре 2014 года - Samsung Galaxy Note 4 ), я ожидаю, что первые микросхемы с расширениями SVE будут доступны в 2018 году. предположим, что это, скорее всего, будет очень близко по времени к общедоступности встроенных функций DotNet SIMD.
Хочу предложить:
Векторы
Реализуйте базовые векторы, поддерживающие все размеры регистров в System.CoreLib.Private.
`` С #
пространство имен System.Numerics
{
[StructLayour (LayoutKind.Explicit)]
публичный небезопасный регистр структуры128
{
[FieldOffset (0)]
публичный фиксированный байт [16];
.....
// аксессоры для других типов
}
// ....
[StructLayour(LayoutKind.Explicit)]
public unsafe struct Register2048
{
[FieldOffset(0)]
public fixed byte [256];
.....
// accessors for other types
}
public struct Vector<T, R> where T, R: struct
{
}
public struct Vector128<T> : Vector<T, Register128>
{
}
// ....
public struct Vector2048<T> : Vector<T, Register2048>
{
}
}
### System.Numerics
All safe APIs would be exposed via Vector<T> and VectorXXX<T> structures and implemented with support of intrinsics.
### System.Intrinsics
All vector APIs will use System.Numerics.VectorXXX<T>.
```C#
public static Vector128<byte> MultiplyHigh<Vector128<byte>>(Vector128<byte> value1, Vector128<byte> value2);
public static Vector128<byte> MultiplyLow<Vector128<byte>>(Vector128<byte> value1, Vector128<byte> value2);
Внутренние API-интерфейсы будут помещены в отдельные классы в соответствии с шаблонами определения функциональности, предоставляемыми процессорами. В случае x86 ISA это будет однозначное соответствие между обнаружением CPUID и поддерживаемыми функциями. Это позволило бы легко понять шаблон программирования, в котором можно было бы использовать функции из данной группы в соответствии с поддержкой платформы.
Основная причина такого разделения - это требование производителей микросхем использовать инструкции только в том случае, если они обнаружены в оборудовании. Это позволяет, например, поставлять процессор с матрицей поддержки, содержащей SSE3, но не SSSE3, или содержащую PCLMULQDQ и SHA, а не AESNI. Это прямое соответствие между классом и поддержкой аппаратного обеспечения является единственным безопасным способом обнаружения IsHardwareSupported и соответствует ограничениям на использование инструкций Intel / AMD. В противном случае ядру придется перехватить #UD исключение 😸
Сопоставление API-интерфейсов с внутренними функциями C / C ++ или кодами операций ISA
Внутренние функции абстрагируются обычно 1 к 1 кодам операций ISA, однако есть некоторые встроенные функции, которые отображаются на несколько инструкций. Я бы предпочел абстрагировать коды операций (используя красивые имена) и реализовать встроенные функции с несколькими кодами операций как функции на VectorXxx
 4creators
4 авг. 2017
4creators
4 авг. 2017
@nietras
Учитывая это, возможно, они должны быть перемещены в «общее» / платформенно-независимое пространство имен и тип, поскольку предположительно все платформы должны поддерживать загрузку / сохранение для поддерживаемого размера вектора.
Лучшим местом будет System.Numerics.VetorXxx <T>
4creators
4 авг. 2017
все платформы должны поддерживать загрузку / сохранение для поддерживаемого размера вектора
Отличается ли независимый от платформы Load/Store от существующего Unsafe.Read/Write ?
 jkotas
4 авг. 2017
jkotas
4 авг. 2017
Отличается ли независимая от платформы Load / Store от существующей Unsafe.Read/Write?
@jkotas У меня была такая же мысль, как они связаны с Unsafe ? Я предполагаю, что тогда они будут невыровненными, и мы можем использовать только выровненные через LoadAligned/StoreAligned ...
Или мы могли бы добавить Unsafe.ReadAligned/WriteAligned и заставить JIT распознавать их для векторных типов?
nietras
4 авг. 2017
IsSupported должно быть свойством (или полем static readonly ), например IntPtr.Size или BitConverter.IsLittleEndian .
Объединение SSE и SSE2 в один класс выглядит как хороший компромисс для более простой функции Add .
Как и @redknightlois и @nietras, меня также беспокоит API загрузки / хранения. Поддержка ref необходима, чтобы избежать ссылок на fixed . Для void* Load/Store дженерики
[Intrinsic]
public static extern unsafe Vector256<T> Load<T>(void* mem) where T : struct;
[Intrinsic]
public static extern unsafe Vector256<sbyte> Load(sbyte* mem);
[Intrinsic]
public static extern Vector256<sbyte> Load(ref sbyte mem);
[Intrinsic]
public static extern unsafe Vector256<byte> Load(byte* mem);
[Intrinsic]
public static extern Vector256<byte> Load(ref byte mem);
// Etc.
С нетерпением жду возможности использовать PDEP/PEXT !
 pentp
4 авг. 2017
pentp
4 авг. 2017
Я бы предложил переместить встроенные функции в отдельное пространство имен, расположенное относительно высоко в иерархии, и каждый код, специфичный для платформы, в отдельную сборку.
Причина вышеупомянутого разделения - большая область API для каждого набора команд, т.е. AVX-512 будет представлен более чем 2 000 встроенными функциями в компиляторе MsVC. То же самое скоро произойдет и с ARM SVE (см. Ниже). Размер сборки за счет только строкового содержимого будет не малым.
@ 4creators , я категорически против переноса этой функции выше в иерархии.
Во-первых, сама среда выполнения должна поддерживать все без исключения встроенные функции (включая строки для их идентификации и т. Д.), Независимо от того, где мы помещаем их в иерархию. Если среда выполнения их не поддерживает, вы не сможете их использовать.
Я также хочу иметь возможность использовать эти встроенные функции со всех уровней стека, включая System.Private.CoreLib . Я хочу иметь возможность писать управляемые реализации System.Math , System.MathF , различных System.String функций и т. Д. Это не только увеличивает ремонтопригодность кода (поскольку большинство из них являются FCALLS или настраиваемая вручную сборка сегодня), но это также увеличивает межплатформенную согласованность (где результирующий FCALL или сборка является частью базовой среды выполнения C).
tannergooding
4 авг. 2017
@pentp
Объединение SSE и SSE2 в один класс выглядит как хороший компромисс для более простой функции Add.
Я не думаю, что встроенные функции должны что-то абстрагироваться - вместо этого на Vector128 - Vector2048 можно создать простое добавление. С другой стороны, это будет открыто против рекомендаций Intel по использованию.
4creators
4 авг. 2017
Я также хочу иметь возможность использовать эти встроенные функции со всех уровней стека, включая System.Private.CoreLib. Я хочу иметь возможность писать управляемые реализации System.Math, System.MathF, различных функций System.String и т. Д.
@tannergooding Согласитесь, что он должен быть доступен из System.Private.CoreLib
Однако это не означает, что он должен находиться на низком уровне иерархии. Никто не будет поставлять среду выполнения (vm, gc, jit), которая будет поддерживать все встроенные функции для всех архитектур. Линия деления проходит через плоскость ISA - x86, Arm, Power. Нет причин поставлять встроенные функции ARM в среду выполнения x86. Имея его в отдельной сборке платформы в coreclr, на которую может ссылаться (циклически) System.Private.CoreLib, может быть решением (я думаю, что это немного лучше, чем если бы все определяло)
4creators
4 авг. 2017
Текущая цель проекта класса SSE2 - сделать более встроенные функции более удобными для пользователей. Если бы у нас было два класса SSE и SSE2, некоторые встроенные функции потеряли бы общую сигнатуру.
@fiigii , почему их разделение означает, что мы теряем общую подпись?
На мой взгляд, у нас есть два варианта:
- Явно перечисляет типы out
Vector128<float> Add(Vector128<float> left, Vector128<float> right)- Это обеспечивает безопасность типов, но увеличивает количество открытых API.
- Используйте дженерики
Vector128<T> Add<T>(Vector128<T> left, Vector128<T> right)- Это уменьшает количество открытых API, но теряет принудительную безопасность типа компилятора.
- Для некоторых функций потребуется несколько универсальных шаблонов (например, для приведения типов требуется
<T, U>, и это потенциально может стать еще более сложным в другом месте)
Я не вижу причин, по которым у нас не может быть SSE и SSE2 и почему мы не можем просто показать оба Vector128<T> Add<T>(Vector128<T> left, Vector128<T> right) .
При этом я лично предпочитаю принудительную форму, которая требует перечисления дополнительных API. Это не только помогает обеспечить, чтобы пользователь передавал нужные данные API, но также уменьшает количество проверок, которые должна выполнить JIT.
Vector128<float> означает, что T уже принудительно / проверено как часть контракта API, Vector128<T> означает, что JIT должен проверить, что T имеет правильный / поддерживаемый тип . Это потенциально может измениться от одной среды выполнения к другой (в зависимости от точного набора встроенных функций, для поддержки которых среда выполнения была построена), что может еще больше запутать.
tannergooding
4 авг. 2017
Однако это не означает, что он должен находиться на низком уровне иерархии. Никто не будет поставлять среду выполнения (vm, gc, jit), которая будет поддерживать все встроенные функции для всех архитектур. Линия деления проходит через плоскость ISA - x86, Arm, Power. Нет причин поставлять встроенные функции ARM в среду выполнения x86. Решением может быть наличие его в отдельной сборке платформы в coreclr, на которую можно ссылаться (циклически) из System.Private.CoreLib.
Я мог бы за этим встать. Предостережения заключаются в следующем:
- В эталонной сборке должны быть перечислены все API независимо от того,
- JIT, вероятно, нуждается в специальной поддержке, чтобы не вызывать исключения, когда он пытается скомпилировать мою функцию (у которой есть пути для x86 и ARM) на одной из архитектур и не находит API для другой архитектуры.
tannergooding
4 авг. 2017
Отличается ли независимая от платформы Load / Store от существующей Unsafe.Read/Write?
@jkotas , я думаю, что основное отличие состоит в том, что Load/Store будет компилироваться до инструкции SIMD и, скорее всего, в большинстве случаев попадет непосредственно в регистр.
tannergooding
4 авг. 2017
Имея его в отдельной сборке платформы в coreclr, на которую может ссылаться (циклически) System.Private.CoreLib, может быть решением
Циркулярные ссылки не являются стартовыми. Существующее решение этой проблемы состоит в том, чтобы иметь подмножество, требуемое CoreLib в CoreLib, как внутреннее, и полную (дублирующую) реализацию в отдельной сборке. Хотя сомнительно, действительно ли это дублирование ради наслоения того стоит.
Еще одна мысль о наименовании. Среда выполнения / генерация кода сегодня имеет множество встроенных функций, например, методы System.Threading.Interlocked или System.Runtime.CompilerServices.RuntimeHelpers реализованы как встроенные функции.
Должно ли имя пространства имен быть более конкретным, чтобы фиксировать, что на самом деле в него входит, скажем, System.Runtime.HardwareIntrinsics ?
jkotas
4 авг. 2017
Раздутие кода из-за конструкции Register128 ... Register2048
При условии, что мы хотели бы иметь прямой доступ к числовым типам, закодированным в структурах RegisterXxx - аналогично текущей реализации System.Numerics.Register, которая является хорошей разработкой IMO, - потребуется создать (скорее сгенерировать) всего 10 064 поля со следующим шаблоном:
`` С #
пространство имен System.Numerics
{
[StructLayout (LayoutKind.Explicit)]
публичный небезопасный регистр структуры128
{
публичный фиксированный байт Reg [16];
// Поля System.Byte
[FieldOffset (0)]
публичный байт byte_0;
[FieldOffset (1)]
публичный байт byte_1;
[FieldOffset (2)]
публичный байт byte_2;
// Поля System.SByte
// так далее.
Specifically due to this problem there exists solution proposal based on extended generics syntax: _Const blittable parameter as a generic type parameter_ (https://github.com/dotnet/csharplang/issues/749)
```C#
namespace System.Numerics
{
public unsafe struct Register<T, const int N>
{
public fixed T Reg[N];
}
public struct Vector128<T> : Vector<T, Register<T, 16>> {}
Позже, специализируясь на обобщениях, можно легко создать необходимое дерево структур.
4creators
4 авг. 2017
Загрузка / сохранение будет компилироваться до инструкции SIMD и, скорее всего, в большинстве случаев попадет непосредственно в регистр.
Unsafe.Load/Store компилируется в инструкцию SIMD для структур нужного размера.
jkotas
4 авг. 2017
Циркулярные ссылки не являются стартовыми. Существующее решение этой проблемы состоит в том, чтобы иметь подмножество, требуемое CoreLib в CoreLib, как внутреннее, и полную (дублирующую) реализацию в отдельной сборке. Хотя сомнительно, действительно ли это дублирование ради наслоения того стоит.
@jkotas @tannergooding Это решает эту проблему, поскольку дублированная реализация для API, содержащего примерно 10 тыс. функций ...
4creators
4 авг. 2017
Unsafe.Load / Store сегодня компилируется в инструкцию SIMD для структур нужного размера.
Это может быть случай implicitly , но это не является явным в API (как в случае Vector128<float> SSE.Load(float* address) ). Также implicit зависит от того, является ли это выровненным чтением / записью или нет.
Одна из моих любимых особенностей этого предложения - очень явные API. Если я скажу LoadAligned , я знаю, что получу инструкцию MOVAPS (без «если», «а» или «но» по этому поводу. Если я скажу LoadUnaligned , я знаю, что получу инструкцию MOVUPS .
tannergooding
4 авг. 2017
Если имя пространства имен будет более конкретным, чтобы фиксировать, что на самом деле в него входит, скажем System.Runtime.HardwareIntrinsics
Простой расчет разницы в размерах сборки для функций, определенных как
C#
public static void System.Runtime.CompilerServices.Intrinsics.AVX2::ShiftLeft
public static void System.Intrinsics.AVX2::ShiftLeft
для 5 000 функций - 250 КБ.
4creators
4 авг. 2017
дублирующая реализация для API, состоящего примерно из 10 тыс. функций ...
То, что продублировано в CoreLib, - это всего лишь 50 функций, которые действительно необходимы в CoreLib.
jkotas
4 авг. 2017
для 5 000 функций - 250 КБ.
Как вы пришли к этому числу? Имя пространства имен сохраняется в управляемом двоичном файле только один раз. Разница между ShortNameSpace и VeryLoooooooooooooooooongNameSpace всегда должна составлять ~ 20 байт, независимо от того, сколько функций содержится в пространстве имен.
jkotas
4 авг. 2017
То, что продублировано в CoreLib, - это всего лишь 50 функций, которые действительно необходимы в CoreLib.
Это решило бы проблему доставки всех архитектур вместе 😄
4creators
4 авг. 2017
Что касается всех утверждений о таких вещах, как раскрытие ref или void* ( @pentp , @nietras , @redknightlois), а также о том, следует ли предоставлять резервное программное обеспечение.
ref может стоить разоблачения
Unsafe.ToPointerчастично решает эту проблему, но требует от пользователей отдельной зависимости. Это также означает, чтоcorlibимеет больше проблем сref
void* , наверное, не стоит выставлять напоказ. Просто приведите к соответствующему типу (float*)((void*)(p)) .
- Мы не можем переопределить на основе возвращаемого типа, поэтому
void*означает, что нам либо нужны уникальные имена методов, либо мы должны использовать<T>и JIT выполнит проверку.
Это может быть уже очевидно из моих существующих утверждений, но я считаю, что эти API должны быть явными, но также простыми:
- Мы должны использовать
Vector128<float>вместоVector128<T>поскольку это принудительно проверяет время компиляции и удаляет накладные расходы JIT. - У нас должны быть API, такие как
LoadиStoreкак часть этого, а не полагаться на что-то еще (System.Runtime.CompilerServices.Unsafe).- Другие API-интерфейсы, где это применимо, следует обновить, чтобы вместо этого вызывать встроенные функции.
- Мы должны обеспечить, чтобы все функции были
extern- Если бы были предоставлены резервные версии программного обеспечения,
CoreFXсам никогда бы не использовал их. - Из-за производительности и по другим причинам потребители никогда не должны полагаться на резервные версии программного обеспечения или использовать их.
- Это заставляет JIT / AOT понять метод, иначе он не сработает.
- Мы всегда можем предоставить API-оболочку на более высоком уровне (читается как
CoreFXExtensionsили стороннее репо), который предоставляет резервные программные средства для каждой инструкции.
- Если бы были предоставлены резервные версии программного обеспечения,
tannergooding
4 авг. 2017
Как вы пришли к этому числу?
@jkotas из спецификации CIL, в которой говорится, что CIL не имеет реализации пространств имен и распознает методы по их полному имени, однако я понимаю, что должен проверить спецификации PE-файла - это плохо.
4creators
4 авг. 2017
Может быть, вместо X86 x86x64, поскольку x86 часто используется только для 32-битной передачи?
@benaadams , В том же духе x86-64 иногда используется для обозначения только 64-bit версии набора инструкций x86 , так что это тоже может сбивать с толку (https: // en.wikipedia.org/wiki/X86-64)
Я думаю, что x86 имеет наибольший смысл и чаще всего используется для обозначения всей платформы.
По крайней мере, для Википедии:
- x86 относится к 16, 32 и 64-битным реализациям (https://en.wikipedia.org/wiki/X86)
- IA-32 или i386 относится к 32-битной реализации (https://en.wikipedia.org/wiki/IA-32)
- Иногда его называют x86.
- x86-64, x64, x86_64, AMD64 и Intel64 используются для обозначения 64-битной реализации (https://en.wikipedia.org/wiki/X86-64)
tannergooding
4 авг. 2017
Кажется, это будет непростой API, и это потребует множества дизайнерских решений - можно ли начать проработку деталей в CoreFXLabs или отдельной ветке в coreclr / corefx?
Отдельное репо будет поддерживать систему отслеживания проблем, которая потребуется ИМО, чтобы сделать это быстро и эффективно.
4creators
4 авг. 2017
Похоже, это будет не простой API, и для этого потребуется несколько дизайнерских решений - можно ли начать проработку деталей в CoreFXLabs или отдельной ветке в coreclr / corefx?
Я собираюсь поддержать это. Я думаю, что было бы целесообразно получить базовую форму API (как предлагается) в CoreFXLabs и «использовать» ее в реальном сценарии.
Я предлагаю взять Vector2 , Vector3 и Vector4 и переопределить их для вызова API согласно https://github.com/Microsoft/DirectXMath и потенциально выполнить то же самое для Cos , Sin и Tan в Math / MathF .
Хотя мы не получим никаких показателей производительности и не сможем запустить код, это позволит нам рассмотреть вариант использования в «реальных» сценариях, чтобы лучше понять, что имеет наибольший смысл и каковы сильные / слабые стороны предложения (и любые предлагаемые изменения предложения).
tannergooding
4 авг. 2017
Хотя мы не получим никаких показателей производительности
Чтобы получить числа производительности, должно быть нормально добавить некоторую поддержку этого в JIT (не раскрывая ее в стабильном профиле доставки) и поэкспериментировать с формой API в corefxlab.
jkotas
4 авг. 2017
Unsafe.ToPointer частично решает эту проблему.
@tannergooding оставляет дыру ref необходим для общих алгоритмов на основе Span<T> , без необходимости закрепления. Unsafe.Read/Write тоже должно работать. Я хочу оба яблока;)
У нас должны быть API, такие как Load и Store, как часть этого, а не полагаться на что-то еще (System.Runtime.CompilerServices.Unsafe).
Согласен, и я этого не говорю. Но Unsafe.Read/Write<Vector128<T>> все равно должно работать. На мой взгляд, это необходимо. В противном случае общий код становится очень сложным, который может обрабатывать различные векторные регистры, базовые типы и т. Д.
nietras
4 авг. 2017
💭 ❓ Могут ли эти новые векторные типы быть кандидатами на звание ref struct а не просто struct ?
sharwell
4 авг. 2017
void *, вероятно, не стоит выставлять напоказ. Просто приведите к соответствующему типу (float ) ((void ) (p)).
@tannergooding вы не можете сделать это в общем коде. Я думаю, что было бы хорошо рассмотреть и общие алгоритмы, здесь можно было бы многое сделать универсальным способом, раскрывая многие числовые операции над изображениями без необходимости в ручном цикле для каждой операции. Есть очень много случаев, когда с этим можно было бы создать общий код.
nietras
4 авг. 2017
Я не вижу проблем с API со статическими методами для void* например.
public class Vector128<T>
{
public static Vector128<T> Load(void* p);
}
JIT, конечно, должен с этим справиться, но это не должно быть достаточно простым делом. Мое предположение заключается в том, что если Vector128<T>.IsSupported тогда вы должны иметь возможность Load и Store поэтому они не должны находиться в определенных местах платформы.
Если они это сделают, то да, нам нужно что-то вроде Vector<128> SSE2.LoadInt(void* p) а в некоторых случаях даже AVX512VL.LoadInt256(void* p) может быть ... без уродливого наименования. В противном случае out может быть запасным вариантом, хотя это делает код громоздким, в меньшей степени с C # 7.
void* p = ...;
AVX512VL.LoadAligned(p, out Vector256<int> v);
Если смотреть отсюда, это не намного более громоздко. И, надеюсь, не имеет проблем с производительностью.
nietras
4 авг. 2017
Не думаете, что void * нужен? Просто версия ref . Можно преобразовать void * в ref с помощью Unsafe.AsRef
например
void* input;
ref Unsafe.AsRef<Vector<short>>(input);
Не думаете, что void * нужен? Просто реф версия.
Да, я мог бы смириться с этим, на самом деле я бы даже сказал, зачем вообще нужны какие-либо версии указателей. Они должны быть основаны исключительно на ref . Указатель можно легко преобразовать в ref и таким образом поддерживаются все сценарии (указатели, диапазон, ref s, Unsafe и т. Д.). И без каких-либо проблем с производительностью, я полагаю.
namespace System.Runtime.CompilerServices.Intrinsics.X86
{
public static class AVX
{
......
// __m256i _mm256_loadu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<sbyte> Load(ref sbyte mem) { throw new NotImplementedException(); }
// __m256i _mm256_loadu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<byte> Load(ref byte mem) { throw new NotImplementedException();
......
}
Использование указателя было бы немного более громоздким, но для меня это не имеет большого значения.
nietras
4 авг. 2017
Что ж, это определение по-прежнему не поддерживает общий сценарий из коробки, хотя нам нужно его для типа, подходящего для этого Vector256<T> для этого, но с Unsafe это можно обойти . Я все же предпочел бы иметь Vector256<T>.Load(ref T mem) поскольку это упрощает общее программирование.
nietras
4 авг. 2017
@nietras Подпись, которая, как мне кажется, нам сойдет с рук, такова:
[Intrinsic]
public static Vector256<sbyte> Load(in Vector256<sbyte> mem);
В этом случае должна работать и общая форма:
[Intrinsic]
public static Vector256<T> Load<T>(in Vector256<T> mem);
JIT, конечно, должен с этим справиться, но это не должно быть достаточно простым делом. Я предполагаю, что если Vector128
.IsSupported, то вы должны иметь возможность загружать и хранить, чтобы они не находились в определенных местах платформы.
Я думаю, что предположение здесь правильное. Однако существует несколько способов «загрузить» значение, и они не всегда могут быть согласованы на разных платформах.
Вы выровнялись и не согласились. Но может существовать платформа, требующая выравнивания, и в этом случае Unaligned неприменимо для использования под Vector128<T> . Итак, теперь у нас есть некоторые методы загрузки для Vector128<T> а некоторые - для SSE и это нарушает согласованность.
У вас также есть различные инструкции загрузки / сохранения, которые явно зависят от платформы, такие как невременные, замаскированные, случайные, широковещательные и т. Д.
Я считаю, что Vector128<T> (и другие типы регистров) должны быть полностью непрозрачными. Пользователи не должны иметь возможность использовать сам регистр для чего-либо, кроме проверки IsSupported и должны быть строго обязаны использовать встроенные функции для загрузки / хранения / управления / и т. Д. Единственным особым случаем здесь является отладчик, который должен иметь специальный тип для отображения соответствующих данных регистра.
Это обеспечивает соблюдение внутренней модели, гарантирует, что нет ничего особенного, помогает предотвратить будущие поломки, если мы будем поддерживать новое оборудование, которое ведет себя иначе, и т. Д.
tannergooding
4 авг. 2017
Вот довольно простой пример универсального преобразования, которое я мог себе представить. И образец, который я показывал здесь много раз 😄
public interface IVectorFunc<T>
{
T Invoke(T a, T b);
Vector128<T> Invoke(Vector128<T> a, Vector128<T> b);
Vector256<T> Invoke(Vector256<T> a, Vector256<T> b);
Vector512<T> Invoke(Vector512<T> a, Vector512<T> b);
}
public static void Transform<T, TFunc>(Span<T> a, Span<T> b, TFunc func, Span<T> result)
where TFunc : IVectorFunc<T>
{
// Check span equal sizes
var length = a.Length;
ref var refA = ref a.DangerousGetPinnableReference();
ref var refB = ref a.DangerousGetPinnableReference();
ref var refRes = ref a.DangerousGetPinnableReference();
int i = 0;
for (; i < length - Vector512<T>.Length; i += Vector512<T>.Length)
{
var va = Vector512<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector512<T>.Load(ref Unsafe.Add(ref refB, i));
Vector512<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
for (; i < length - Vector256<T>.Length; i += Vector256<T>.Length)
{
var va = Vector256<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector256<T>.Load(ref Unsafe.Add(ref refB, i));
Vector256<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
for (; i < length - Vector128<T>.Length; i += Vector128<T>.Length)
{
var va = Vector128<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector128<T>.Load(ref Unsafe.Add(ref refB, i));
Vector128<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
for (; i < length; ++i)
{
var va = Unsafe.Add(ref refA, i);
var vb = Unsafe.Add(ref refB, i);
Unsafe.Add(ref refRes, i) = func.Invoke(va, vb);
}
}
Теперь это, конечно, можно полностью записать с помощью Unsafe.Read/Write/AsRef если это поддерживается, но для оптимальной производительности можно предварительно проверить выравнивание и вместо этого использовать Vector256<T>.LoadAligned и т. Д.
nietras
4 авг. 2017
Теперь это, конечно, можно полностью написать с помощью Unsafe.Read/Write/AsRef
Я думаю, что Unsafe.Read/Write будет рекомендацией для общих алгоритмов. Да, вы можете немного потерять производительность. Это стоимость ведения бизнеса для написания общих алгоритмов.
но для оптимальной производительности можно проверить выравнивание
Для оптимальной производительности вы также можете использовать невременные нагрузки или другие варианты нагрузки, специфичные для платформы ...
jkotas
4 авг. 2017
но для оптимальной производительности можно предварительно проверить выравнивание и использовать Vector256
.LoadAligned и т. Д. Вместо этого.
@nietras @jkotas На текущих процессорах и даже на нескольких поколениях назад нет необходимости проверять выравнивание, поскольку инструкции, используемые для загрузки и сохранения, проверяют выравнивание, а в случае выравнивания данных существует 0 потерь производительности цикла по сравнению с инструкциями, специализированными для выравнивания данные. Код, который будет проверять согласованность, приведет к наказанию в виде нескольких циклов реализации. Это характерно для регистров xmm, ymm, zmm и соответствующих инструкций.
4creators
4 авг. 2017
Вероятно, мой пример void* был неправильно истолкован. Я использовал void* качестве заполнителя, который принимает все, что вы бросаете, используя предполагаемое представление для этого на уровне инструкций.
@benaadams Проблема в том, что вы не можете выполнять арифметические ref Unsafe.AsRef<Vector<short>>(input); каждый раз, когда происходит новый перевод. Вероятно, мне что-то не хватает, но, думая о типах алгоритмов, с которыми я обычно работаю, я могу догадаться, насколько плохим это может стать.
@nietras В коде прототипа вам нужна "исполняемая" версия, чтобы вы могли передать тип функции. Но если вы откажетесь от этого, скажем, просто добавить, код будет намного проще для обычных случаев загрузки / сохранения (здесь я явно избегаю случая невременных видов). Более простой код -> меньше ошибок -> со временем жизнь станет лучше.
redknightlois
4 авг. 2017
Unsafe.Read/Write будет рекомендацией для общих алгоритмов. может немного потерять производительность
Хорошо, но что, если поддерживается только согласованный доступ? Как мы это обнаруживаем? Возможно, у нас может быть три сценария для Unsafe .
| Выравнивание | Только без выравнивания * | Только согласовано | Оба |
| ----- | ---- | ---- | ---- |
| Unsafe.Read/Write | Unaligned | Aligned | Unaligned |
| VectorXXX
| VectorXXX
В случае только выравнивания, как мы определяем, нужно ли сначала выравнивать? Возможно, это теоретически, но если типы VectorXXX<T> будут иметь свойства, говорящие о том, что возможно, тогда это будет минимум для общих методов с ними, самый минимум, например VectorXXX<T>.UnalignedSupported или что-то в этом роде.
Фактически, в качестве более широкого вопроса, как я могу задать простым способом, я могу проверить, на какой архитектуре я работаю, т.е. enum Arch { x86, Arm, etc. }
С помощью всего лишь минимума общих / общих методов открывается множество возможностей, и нам, пользователям, не нужно делать это для этого.
@ 4creators выровнены не только некоторые из векторных инструкций ARM? Не уверен, что особо не занимался ARM. Надеемся, что ForwardCom наберет обороты;)
@tannergooding: да, множество способов загрузки / сохранения / трансляции / перемешивания, но я думаю, что некоторые общие базовые принципы были бы хороши. Отсутствие этого усложняет многие базовые вещи.
nietras
4 авг. 2017
На текущих процессорах и даже на паре поколений назад вам нет необходимости проверять выравнивание, поскольку инструкции, используемые для загрузки и сохранения, проверяют выравнивание, а в случае выравнивания данных снижение производительности составляет 0 циклов по сравнению с инструкциями, специализированными для выровненных данных.
@ 4creators , что может иметь место для современных процессоров Intel / Amd, но может быть не так для всех процессоров (более старые Intel / AMD, возможно ARM, возможно будущее оборудование).
tannergooding
4 авг. 2017
В коде прототипа вам нужна «исполняемая» версия, чтобы вы могли передать тип функции. Но если вы откажетесь от этого, скажем, просто добавить, код будет намного проще для обычных случаев загрузки / хранения.
@redknightlois извини, что ты полностью потерял меня там? 💥 😄 Это будет означать реализацию множества разных VectorFunc например ThresholdVectorFunc , AddVectorFunc и т. Д.
nietras
4 авг. 2017
@nietras Извините, я недостаточно ясно Vector<T> или Vector<float> чтобы его можно было передать функции для работы. Использование void* качестве заполнителя позволит вам выполнить с безопасным для платформы Load операцию прямо из его указателя и избежать множества экземпляров ref Unsafe.Add(ref r, i) есть в функции-прототипе. что с текущим предложением требует генерации экземпляра ref и / или загрузки Vector<T> явным образом вместо простой передачи указателя.
redknightlois
4 авг. 2017
@nietras ForwardCom при всем уважении к
4creators
4 авг. 2017
@tannergooding: да, множество способов загрузки / сохранения / трансляции / перемешивания, но я думаю, что некоторые общие базовые принципы были бы хороши. Отсутствие этого усложняет многие базовые вещи.
@nietras , я думаю, что в обоих случаях (обеспечивая общие встроенные функции загрузки / хранения на VectorXXX<T> и предоставляя встроенные функции для конкретной платформы, такие как SSE.Load ), вы должны иметь какую-то проверку IsSupported (либо на VectorXXX<T> либо на SSE ). Если он не поддерживается, вы должны сами предоставить резервное программное обеспечение (при условии, что внутренние функции не имеют резервного программного обеспечения, как для упрощения, так и для обеспечения его производительности).
Итак, в любом случае вы в конечном итоге напишете какой-то код вроде:
`` С #
если (X.IsSupported)
{
// Копируем Vector512
}
если (Y.IsSupported)
{
// Копируем Vector256
}
если (Z.IsSupported)
{
// Копируем Vector128
}
// Копируем оставшееся (возможно, используя Unsafe )
`` ''
Основное различие заключается в том, являются ли встроенные функции явными (SSE.Load) или неявными (VectorXXX
tannergooding
4 авг. 2017
использование void * в качестве заполнителя
@redknightlois, если я вас правильно понимаю, я явно избегаю указателя и fixed здесь, чтобы поддерживать как управляемую, так и неуправляемую память и не препятствовать сборке мусора . Да, без сомнения, код будет более компактным, используя указатели напрямую ... но проблема здесь не в этом. Меня устраивает, как это выглядит, мне бы хотелось, чтобы это общий вариант.
@tannergooding да, конечно, здесь будут чеки, т.е. ( @redknightlois Unsafe. можно удалить здесь с помощью using static ):
if (Vector512<T>.IsSupported)
{
for (; i < length - Vector512<T>.Length; i += Vector512<T>.Length)
{
var va = Vector512<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector512<T>.Load(ref Unsafe.Add(ref refB, i));
Vector512<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
if (Vector256<T>.IsSupported)
{
for (; i < length - Vector256<T>.Length; i += Vector256<T>.Length)
{
var va = Vector256<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector256<T>.Load(ref Unsafe.Add(ref refB, i));
Vector256<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
if (Vector256<T>.IsSupported)
{
for (; i < length - Vector128<T>.Length; i += Vector128<T>.Length)
{
var va = Vector128<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector128<T>.Load(ref Unsafe.Add(ref refB, i));
Vector128<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
Как минимум. Вероятно, также придется проверить VectorXXX<T>.AlignmentSupport { Aligned, Unaligned } , но с помощью всего лишь нескольких общих методов такой код становится намного проще. Да, он не идеален для высокооптимизированных сценариев, но для 80-90% базовой численной обработки он чертовски хорош по сравнению с обычным одним элементом за цикл.
nietras
4 авг. 2017
Я не уверен, что ясно выражаюсь здесь. Но подумайте о возможностях и комбинаторной силе этого: вместо 1000 пользовательских циклов с кодом в них у меня есть один общий цикл и тысячи небольших функций. Сборка становится намного меньше, мы используем меньше памяти, и только фактические используемые комбинации обрабатываются JIT во время выполнения или даже в AOT.
Можно сделать гораздо меньше кода, гораздо меньше ошибок и много разных комбинаций.
Это комбинаторная мощность, которая исходит от нескольких ключевых алгоритмов Transform / ForEach / InPlaceTransform и т. Д. X размеров (1D, 2D, 3D, тензоры и т. Д.) X 1000s функций. == 10-100.000 комбинаций. Да, многие из них будут менее производительными, чем пользовательские петли, но намного лучше, чем обычные домашние петли.
Тысячи функций, без сомнения, преувеличены. 😉
nietras
4 авг. 2017
это может иметь место для современных процессоров Intel / Amd, но не может быть так для всех процессоров (более старые Intel / AMD, возможно ARM, возможно будущее оборудование).
@tannergooding не совсем - штраф за цикл 0 верен для всех реализаций AVX, AVX2, AVX512 и SSE вплоть до микроархитектуры Nehalem (я прекратил проверку на этом этапе, поскольку Microsoft не полностью поддерживает Windows Vista).
разве не выровнены только некоторые из векторных инструкций ARM?
@nietras Я еще не проверял - но существует так много реализаций ARM ... - ИМО в целом, мы не должны предоставлять LoadAligned / Unaligned, StoreAligned / Unaligned на x86, поскольку штраф за работу с выровненными или невыровненными встроенными функциями, очевидно, отсутствует , это не означает, что невыровненные данные будут перемещаться так же быстро, как и выровненные. Представляя их, мы неявно просим разработчиков проверять выравнивание перед их использованием, и если они увидят в IntelliSense, что есть также инструкция Load / Store, она будет считаться неоптимальной.
Я бы обобщил эту проблему на другой вопрос: как сопоставить встроенные функции с инструкциями x86 ISA? Или мы сопоставляем встроенные функции с встроенными функциями C / C ++?
Проблема перегрузок и дженериков - одна из частей обсуждения, но необходимо принять решение о отображении инструкций как таковых . Сопоставляем ли мы 1 с 1, сопоставляем ли 1 с .... Предоставляем ли мы все инструкции, даже те, которые, как нам известно, являются устаревшими и неэффективными, или мы раскрываем все, кроме тех инструкций, которые были заменены лучшими реализациями. Мы не связаны устаревшим кодом, скомпилированным для x86, как Intel и AMD.
4creators
4 авг. 2017
Мы не связаны устаревшим кодом, скомпилированным для x86, как Intel и AMD.
CoreCLR может и не быть, но CoreCLR также не единственная среда выполнения. Также есть CoreRT, Mono, несколько других реализаций AOT (некоторые даже используются для разработки управляемых операционных систем).
CoreFX не привязан один к одному с CoreCLR, он должен быть применим ко всем этим.
Если я знаю (наверняка), что мои структуры выровнены, я смогу написать свой алгоритм, чтобы явно использовать выровненные инструкции. Если я знаю, что мои структуры могут быть невыровненными, у меня должна быть возможность либо проверить выравнивание и использовать соответствующую инструкцию, либо просто использовать невыровненные инструкции (зная, что на старых / устаревших платформах может быть небольшое нарушение производительности).
Я полностью за выбор пользователя и предоставление пользователям возможности писать алгоритмы так, как они считают оптимальным для их целевых платформ.
tannergooding
4 авг. 2017
@tannergooding @ 4creators Я согласен с вами, что в современных архитектурах на базе Intel стоимость согласованного и невыровненного доступа одинакова; есть определенные случаи, когда что-то пойдет не так (в настоящее время строки кэша разделяются), и по мере того, как векторы становятся шире, даже в лучших случаях расщепления будут происходить из-за гранулярности строки кеша. Таким образом, с точки зрения проектирования, применимого не только к основным архитектурам на базе Intel, но и с поддержкой согласованных и невыровненных форм инструкций. Внутренние компоненты (по крайней мере, изначально) не имеют подстраховки. Разумно спорить о том, нужно ли выставлять все ISA как внутренние, как на нативной стороне. Это вопрос полезности и полноты. :)
 jarodrig
4 авг. 2017
jarodrig
4 авг. 2017
@nietras : Я пытаюсь понять, как это:
`` С #
если (Vector512
{
for (; i <длина - Vector512
{
var va = Vector512
var vb = Vector512
Вектор512
}
}
если (Vector256
{
for (; i <длина - Vector256
{
var va = Vector256
var vb = Vector256
Вектор256
}
}
если (Vector128
{
for (; i <длина - Vector128
{
var va = Vector128
var vb = Vector128
Вектор128
}
}
Is really any better than this:
```C#
if (AVX512.IsSupported)
{
for (; i < length - Vector512<T>.Length; i += Vector512<T>.Length)
{
var va = AVX512.Load(ref Unsafe.Add(ref refA, i));
var vb = AVX512.Load(ref Unsafe.Add(ref refB, i));
AVX512.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
if (AVX.IsSupported)
{
for (; i < length - Vector256<T>.Length; i += Vector256<T>.Length)
{
var va = AVX.Load(ref Unsafe.Add(ref refA, i));
var vb = AVX.Load(ref Unsafe.Add(ref refB, i));
AVX.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
if (SSE.IsSupported)
{
for (; i < length - Vector128<T>.Length; i += Vector128<T>.Length)
{
var va = SSE.Load(ref Unsafe.Add(ref refA, i));
var vb = SSE.Load(ref Unsafe.Add(ref refB, i));
SSE.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
else if (Neon.IsSupported)
{
for (; i < length - Vector128<T>.Length; i += Vector128<T>.Length)
{
var va = Neon.Load(ref Unsafe.Add(ref refA, i));
var vb = Neon.Load(ref Unsafe.Add(ref refB, i));
Neon.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
Хотя реально, для общего использования, я бы, вероятно, объявил оптимальными настраиваемые структуры, которые обертывают load / store:
`` С #
struct Data512
{
public static Data512 Load
публичный статический магазин void
}
struct Data256
{
public static Data256 Load
публичный статический магазин void
}
struct Data128
{
общедоступные статические данные128 Load
публичный статический магазин void
}
`` ''
Или, возможно, даже просто иметь метод CopyBlock который абстрагирует все это и выполняет rep movsb на современном оборудовании (где он может быть быстрее и определенно будет меньше).
tannergooding
4 авг. 2017
Я полностью за выбор пользователя и предоставление пользователям возможности писать алгоритмы так, как они считают оптимальным для их целевых платформ.
Похоже, что если мы решим пойти по этому пути, мы просто должны раскрыть как можно больше технически то, что меня полностью устраивает, и я буду голосовать за это обеими руками.
Но затем, если мы все согласны, мы приняли одно из самых важных дизайнерских решений, которое сужает наше обсуждение до других проблем.
и здесь возникает проблема дженериков и всех возможных реализаций ... 😄
4creators
4 авг. 2017
@tannergooding вы не можете написать (просто пример):
for (; i < length - Vector512<T>.Length; i += Vector512<T>.Length)
{
var va = AVX512.Load(ref Unsafe.Add(ref refA, i));
var vb = AVX512.Load(ref Unsafe.Add(ref refB, i));
AVX512.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
AVX512.Load не является общим, насколько я понял. Так что это не сработает. И тогда вам понадобится еще много проверок, какой набор инструкций позволяет загружать int vs float vs byte vs double и т. Д. Это комбинаторный кошмар ...
rep movsb Я серьезно сомневаюсь, что это будет быстро, у него довольно приличная стоимость установки. По крайней мере, на некоторых платформах ...
nietras
4 авг. 2017
Пара мыслей, основанных на прошлом опыте работы с подобными вещами в нативных компиляторах:
- часто существует «несоответствие импеданса» между использованием встроенных и встроенных типов и соседнего не встроенного кода. Таким образом, получение данных в этих формах и из них требует тщательного рассмотрения, особенно для «тонкого использования», когда вы просто хотите эффективно использовать одну или две внутренние инструкции. Генератор кода также может иметь проблемы в этой области (например, на это намекает обсуждение форм загрузки).
- последствия для библиотек: у нас нет никакого способа описать, как сборка / библиотека теперь может / должна зависеть от наборов функций ISA, поэтому необходимо подумать о том, как nuget и т. д. понимают последствия наличия потенциально множества разных пакетов который может понадобиться или вы захотите использовать в зависимости от минимального поддерживаемого набора функций ISA приложения. Например, вашим приложениям и библиотекам может потребоваться указать «Мне требуется xxx» или «Я могу воспользоваться преимуществами xxx», и тогда система упаковки попытается предоставить вам правильные версии. Пригодность может быть неоднозначной, поэтому процесс выбора «лучшей» версии библиотеки может быть сложным.
- предварительное срабатывание (как мы делаем для SPCorelib) в настоящее время нацелено на самый низкий поддерживаемый набор функций ISA, поэтому такие пути всегда будут нуждаться в резервном коде или пропускать любые такие методы, зависящие от набора функций при предварительном срабатывании, и просто всегда jit такой код (аналогично тому, где мы заканчиваем с векторами сегодня). Для резервных вариантов Full AOT или проективного набора функций / решения по упаковке, как указано выше, потребуется.
- jit принимает независимые решения о том, какие инструкции использовать для генерации кода. Это может вызвать различные проблемы. Например, jit может использовать AVX в методе - если вы через встроенные функции перетащите форму SSE2 в поток AVX, вы понесете штраф за производительность. Это можно рассматривать как проблему «только для экспертов», но это затрудняет написание кода библиотеки, поскольку вы не можете контролировать конечную платформу или логику, которую использует jit. По мере развития наборов функций jit и ISA существующие библиотеки устаревают и становятся потенциально нежизнеспособными. Так что, возможно, должен быть какой-то способ также проверить или ограничить, какой код jit намеревается генерировать вокруг вашего встроенного. Это может быть полезно при частичном решении проблемы с предварительным срабатыванием, поскольку эта проверка всегда будет возвращать наименьший поддерживаемый набор функций ISA при предварительном срабатывании.
 AndyAyersMS
4 авг. 2017
AndyAyersMS
4 авг. 2017
Я пытаюсь понять, как это ... На самом деле лучше, чем это:
@tannergooding @nietras
Если мы предоставляем аппаратные инструкции специфическим для оборудования способом, мы должны обсудить AVX512.IsSupported design и оставить Vector512 <T> на сборке инстринсики только как абстракцию регистра, а не как абстракцию функциональности, доступной в данной группе инструкций.
Однако мы можем довольно эффективно раскрыть эту функциональность в System.Numerics со всеми VectorXxx, имеющими общие статические методы, и аппаратная поддержка проверяет, что будет реализовано с помощью встроенных функций из классов SSE2, AVX, AVX2 ...
4creators
4 авг. 2017
И тогда вам понадобится еще много проверок, какой набор инструкций позволяет загружать int vs float vs byte vs double и т. Д. Это комбинаторный кошмар ...
@nietras , для простого алгоритма копирования (такого как этот) базовый тип не имеет значения. По крайней мере, для загрузки / сохранения вы просто копируете биты ( float и int оба 32-битные, а Vector512<T> всегда 512-битные, независимо от T ). Тип T только при работе с данными ( Sqrt , Convert , Add и т. Д.).
Если по какой-то причине тип имел значение, то для него должны использоваться абстрактные типы оболочек ( Data512 , Data256 , Data128 ). Вы сохраняете "чистоту" встроенных функций, но упрощаете их использование локально, заключая вызовы в другие типы.
tannergooding
4 авг. 2017
предварительное срабатывание (как мы делаем для SPCorelib) в настоящее время нацелено на самый низкий поддерживаемый набор функций ISA, поэтому такие пути всегда будут нуждаться в резервном коде или пропускать любые такие методы, зависящие от набора функций при предварительном срабатывании, и просто всегда jit такой код (аналогично тому, где мы заканчиваем с векторами сегодня)
@AndyAyersMS Можно ли хранить в сборке R2R как собственный код, так и код IL только для встроенных функций, а если платформа поддерживает расширенный ISA, jit его таким образом, чтобы использовать все возможности платформы? (какое-то время назад это было что-то вроде универсальной дурацкой мечты)
4creators
4 авг. 2017
@AndyAyersMS ...
поэтому необходимо подумать о том, как nuget и т. д. понимают последствия наличия потенциально множества разных пакетов
Я не думаю, что в это вообще нужно включать управление пакетами.
Во всех сценариях следует ожидать, что пользователи будут выполнять `If (X.IsSupported) {/ * Do X /} else if (Y.IsSupported) {/ Do Y /} else {/ Do Software * /}
Если пользователь решит прекратить откат программного обеспечения, он выполнит PNSE на неподдерживаемых платформах.
prejitting (как мы делаем для SPCorelib) в настоящее время нацелен на самый низкий поддерживаемый набор функций ISA
Это и AOT попадают в одну категорию. Может произойти однократная проверка при запуске для CPUID и кэшироваться, код для всех применимых путей в архитектуре (все пути для x86 или все пути для Arm, в настоящее время). Затем вы можете либо проверить флаг и перейти к соответствующей реализации (как это делается для реализации cos в MSVCRT), либо вы можете выполнить какую-либо форму динамической отправки (динамически устанавливая точку входа в метод во время запуска приложения).
если вы через встроенные функции перетащите форму SSE2 в поток AVX, вы понесете штраф за производительность.
Я думаю, что это, по большей части, следует рассматривать как экспертную территорию. Есть случай, когда потребитель вызывает метод, который использует AVX, а затем вызывает отдельный метод, который поддерживает только SSE.
Я все еще думаю об этом конкретном сценарии, но я считаю, что мы можем что-то выяснить (однако на самом деле он ничем не отличается от того, с чем сталкивается C / C ++).
tannergooding
4 авг. 2017
@tannergooding - это не алгоритм копирования, явная цель - вызвать функцию, которая принимает общий VectorXXX<T> , как мне тогда перейти от регистра без "типа" к типизированному регистру? Я полностью за то, чтобы иметь неуниверсальный Vector128 с загрузкой / хранением и т. Д., Но нам все еще нужно иметь возможность «преобразовать» его в универсальную версию Vector128<T> . И у Vector128 все еще есть вопрос, есть ли у него элементы для загрузки / сохранения, "независимые" от, скажем, статических методов SSE2 и т. Д.
nietras
4 авг. 2017
@nietras относительно void* и ref , это все хорошо при работе с управляемой памятью, но необходимо иметь возможность запускать это и в _неуправляемой_ памяти.
Очень распространенный вариант использования для уменьшения затрат на память / сборщик мусора - НЕ выделять какую-либо управляемую память для обычных вещей, а полагаться на ручное управление памятью. Я все еще хочу иметь возможность сделать это, и в этом сценарии я хочу иметь возможность делать это с минимальными накладными расходами.
В этом случае было бы очень хорошо не вызывать AsRef (если только JIT просто не сотрет это, чего я не думаю).
 ayende
4 авг. 2017
ayende
4 авг. 2017
отсутствие необходимости вызывать AsRef было бы очень хорошо (если только JIT просто не сотрет это, чего я не думаю).
@ayende JIT полностью их сотрет. Насколько я помню. Это простой состав, не требующий вмешательства / переосмысления. @jkotas может варианта использования в производстве, это будет поддерживать и то, и другое.
nietras
4 авг. 2017
@AndyAyersMS Спасибо, что снова подняли эти вопросы - я думаю, что они очень важны для всей истории.
Это и AOT попадают в одну категорию. Может произойти однократная проверка при запуске для CPUID и кэшироваться, код для всех применимых путей в архитектуре (все пути для x86 или все пути для Arm, в настоящее время). Затем вы можете либо проверить флаг и перейти к соответствующей реализации (как это сделано для реализации cos в MSVCRT), либо вы можете выполнить какую-либо форму динамической отправки (динамически устанавливая точку входа в метод во время запуска приложения).
Однако вы описываете функции, которых еще нет. Последний вариант, который вы описываете, используется во многих нативных библиотеках, насколько я понимаю, но модель программирования сильно отличается от того, что мы здесь описываем. Мне не ясно, можем ли мы сопоставить такое поведение, учитывая, как будут работать встроенные аппаратные средства C #.
Я все еще думаю об этом конкретном сценарии, но я считаю, что мы можем что-то выяснить (однако на самом деле он ничем не отличается от того, с чем сталкивается C / C ++).
Главное было в том, что у вас очень мало информации о том, какой код JIT будет генерировать вокруг вас, и этот код может и будет меняться со временем. Возможно, вы не вызываете явно инструкцию AVX, а затем инструкцию SSE, как в вашем примере, но вы можете просто выполнять некоторую несвязанную работу в середине своего алгоритма, которую JIT решает оптимизировать с помощью инструкций SSE. Эта логика оптимизации непрозрачна и непостоянна - ваша библиотека может стать значительно медленнее после JIT-обновления. Я думаю, это сильно отличается от C / C ++.
Я согласен с тем, что «не смешивать наборы инструкций» - это то, что автору библиотеки просто необходимо понять. Это «экспертная территория»; возможно, лучшее, что мы можем сделать, - это анализатор для выявления очевидных сбоев.
mellinoe
4 авг. 2017
@mellinoe Верно, что JITted-код является движущейся целью, но по сути это то, что мы делаем в производственной среде. Мы микрооптимизируем и исправляем версию среды выполнения, пока не сможем профилировать и проверить, все ли в порядке с новой версией (даже если это служебный выпуск), потому что для кода без SIMD мы все еще плаваем в том же пуле.
redknightlois
4 авг. 2017
@ 4creators, если для метода есть IL, тогда да, он доступен для jit во время выполнения. Если jiting, jit сгенерирует то, что, по его мнению, является наилучшим из возможных кодов для текущей платформы. Вот как Vector
Сборки могут быть частично настроены так, чтобы отложить генерацию кода на методы, и потенциально (NYI, но то, о чем мы думали) среда выполнения может решить не использовать или заменить предварительно настроенный код и вместо этого вызвать jit, чтобы попытаться создать более адаптированный код. Здесь есть компромисс, который потенциально может быть использован для улучшения производительности, но как это сделать сегодня, не очевидно; мы не знаем, сколько пользы можно получить от джиттинга, сколько времени займет jit или как часто будет вызываться этот метод.
Можно было бы представить, что наличие одной из этих проверок IsSupported в методе даст нам довольно сильный намек на то, что джиттинг - хорошая идея, поэтому мы либо пропустили бы предварительное срабатывание таких методов, либо предварительно настроили бы таргетинг на самый низкий поддерживаемый набор функций, а затем решили бы отбросьте этот код и jit, если конечная платформа поддерживает более богатые функции.
AndyAyersMS
4 авг. 2017
мы бы либо пропустили предварительное срабатывание таких методов, либо использовали бы предварительную настройку для наименьшего поддерживаемого набора функций, а затем решили бы отбросить этот код и выполнить jit, если конечная платформа поддерживает более богатые функции.
@AndyAyersMS IMO предвосхищает 2 версии кода с наименьшим общим знаменателем (
Здесь есть компромисс, который потенциально может быть использован для улучшения производительности, но как это сделать сегодня, не очевидно; мы не знаем, сколько пользы можно получить от джиттинга, сколько времени займет jit или как часто будет вызываться этот метод.
Скорее всего, оптимальным решением будет рассмотрение существующей литературы, основанной на трассировке многоуровневого джиттинга.
4creators
4 авг. 2017
Однако вы описываете функции, которых еще нет. Последний вариант, который вы описываете, используется во многих нативных библиотеках, насколько я понимаю, но модель программирования сильно отличается от того, что мы здесь описываем. Мне не ясно, можем ли мы сопоставить такое поведение, учитывая, как будут работать встроенные аппаратные средства C #.
@mellinoe , Мы тоже это обсуждаем для фичи, которой пока нет 😄
Для live JIT значения CPUID известны статически, и все в порядке, и ничего не нужно делать.
Я бы не подумал, что для любого типа AOT (включая prejit, ngen и т. Д.) Было бы слишком сложно получить поддержку этого материала. В основном это требует:
- Запуск CPUID при запуске
- Кэширование результатов проверки CPUID в известном или легкодоступном месте (например, у нас могло бы быть двойное слово
__is_supported_avx) - Вызов
cmp DWORD PTR __is_supported_avx, 0иjne avx_implementation(с дополнительными проверками для других путей).
По большей части эти проверки тривиальны по сравнению с экономией на более совершенном алгоритме. В случаях, когда вы не хотите выполнять предварительные проверки, вы можете делать более сложные вещи, такие как поздняя привязка адреса метода (что также выполняется при запуске, но, вероятно, будет сложнее поддерживать)
tannergooding
4 авг. 2017
Главное было в том, что у вас очень мало информации о том, какой код JIT будет генерировать вокруг вас, и этот код может и будет меняться со временем. Возможно, вы не вызываете явно инструкцию AVX, а затем инструкцию SSE, как в вашем примере, но вы можете просто выполнять некоторую несвязанную работу в середине своего алгоритма, которую JIT решает оптимизировать с помощью инструкций SSE. Эта логика оптимизации непрозрачна и непостоянна - ваша библиотека может стать значительно медленнее после JIT-обновления. Я думаю, это сильно отличается от C / C ++.
У JIT, вероятно, может быть ум, чтобы обнаруживать такие случаи (у него уже есть некоторые умения для таких вещей, как очистка старших битов регистра в некоторых случаях, чтобы помочь с perf), или, может быть, мы можем предоставить атрибут, который сообщает JIT не использовать SIMD в некоторых случаях (возможно, подсказка MethodImpl.IntrinsicWrapper или что-то, что пользователи могут разместить в своих методах, чтобы JIT знала, когда можно оптимизировать для использования SSE, а когда нет).
tannergooding
4 авг. 2017
@mellinoe , Мы тоже это обсуждаем для фичи, которой пока нет 😄
Конечно - плохая формулировка 😄. Я имел в виду, что эти функции AOT, вероятно, сложны сами по себе (особенно идея позднего связывания), и мы еще не включили такое решение в эту функцию. Скорее всего, первая версия просто вызовет отложенную компиляцию а-ля Vector<T> . Но было бы неплохо найти лучшее решение на будущее.
mellinoe
4 авг. 2017
@nietras , ах, я полностью пропустил подпись Invoke .
Это интересный сценарий, и я не особо его обдумывал.
Вы определенно могли бы предоставить это с помощью метода-оболочки, который обрабатывает все различные типы за вас (для JIT они все равно будут постоянными), и я все еще убежден, что это лучше (оставьте самый нижний уровень «простым» и поместите все давление на потребителя, а не на время выполнения).
Что касается rep movsb , на некоторых платформах определенно повышается стоимость, но при публикации Ivy Bridge у нас есть специальный флаг CPUID (конечно, с некоторыми ограничениями и т. Д., Но все это задокументировано в руководстве по оптимизации. ):
tannergooding
4 авг. 2017
@nietras @tannergooding Если вам есть что сказать об инструкциях mov / sto Enhanced REP, я слышу все ... Я более чем несу ответственность за внедрение этой функции в процессоры IA вместе с несколькими друзьями ...
jarodrig
5 авг. 2017
Cosmos - это пример операционной системы, которая также является средой выполнения .Net. Весь код AOT компилируется до создания загрузочного образа, и поэтому мы вынуждены выбирать минимальную ISA, мы решили, что должен поддерживаться хотя бы SSE2 (80887 больше не имеет смысла ...), поэтому возвращаясь к примеру Cos, что мы должны делать:
public static double Cos(double x)
{
if (x86.FMA3.IsSupported)
{
// Do FMA3
}
else if (x86.SSE2.IsSupported)
{
// Do SSE2
}
else if (Arm.Neon.IsSupported)
{
// Do ARM
}
else
{
// Do software fallback
}
}
Мы, несомненно, можем удалить ветвь ARM автоматически во время компиляции AOT для x86, но как наш компилятор может быть настолько умным, чтобы знать, что он должен сохранять версии SSE2 и FMA3, чтобы «переоценить» их во время выполнения (то есть при загрузке системы ОС, как и те, проверяет всякий раз, когда используется Cos, поражает цель этого ИМХО)?
Я имею в виду, как компилятор узнал, что здесь используются встроенные функции и что он должен делать что-то «волшебное»?
 fanoI
5 авг. 2017
fanoI
5 авг. 2017
@fanol , грубо говоря, он мог бы творить магию так же, как он умеет творить любую магию. Компилятору будет сказано, что эти вызовы «особенные» и что они должны обрабатываться иначе, чем другие методы.
Более подробное объяснение
При синтаксическом анализе IL, по сути, вы встретите два типа методов:
- Методы, у которых есть реализация
- Методы, помеченные как
extern
В обоих случаях могут быть дополнительные атрибуты, которые сообщают компилятору, как обрабатывать метод (например, встраивание, внутренний вызов, встроенный и т. Д.).
Методы с реализацией
Подавляющее большинство методов имеют фактические реализации поддержки, и им просто нужно преобразовать их IL в машинный код.
Однако есть некоторые методы с реализациями, которые компилятор должен иметь особое представление.
Один из примеров - это типы System.Runtime.Numerics.Vector . У этих типов есть программная резервная реализация на тот случай, когда компилятор не знает, как обращаться с ними специально (или если вспомогательное оборудование не поддерживает инструкции, необходимые для «оптимальной» реализации).
Другой пример - методы, программная реализация которых не делает ничего, кроме throw PlatformNotSupportedExecption (как предлагается для этих встроенных функций).
Внешние методы
Для внешних методов (например, Math.Cos ) компилятор должен знать, как с ними обращаться, и не должен выдавать, если это не так. Чаще всего это:
- DllImport
- MethodImplOptions.InternalCall
Для DllImport компилятор находит и загружает соответствующий двоичный файл, находит метод с совпадающим символом и вызывает его.
Для MethodImplOptions.InternalCall у компилятора есть внутренняя реализация где-то, о которой он знает, чтобы послать вызов. Например, CoreCLR имеет список сопоставлений между этими внешними методами и внутренней реализацией, которой он заменит вызов. Для Math.Cos это приводит к вызову ComDouble::Cos который сам является оболочкой для реализации CRT.
Некоторые из этих внутренних вызовов далее рассматриваются как «внутренние» и оптимизируются для одной или нескольких оптимизированных машинных инструкций ( Math.Sqrt оптимизирован до sqrtsd на процессорах x86, вместо того, чтобы быть вызовом CRT sqrt функция).
Особое обращение
Я ожидаю, что любой компилятор (AOT или JIT) будет обладать специальными знаниями для всех типов в пространстве имен System.Runtime.CompilerServices.Intrinsics (это одна из причин, по которым я думаю, что они должны быть помечены extern , а не есть программная реализация, которая выкидывает).
Когда они сталкиваются с вызовами методов для этих типов, они не должны вызывать вызов, а должны вместо этого выдавать соответствующую аппаратную инструкцию (т.е. Vector128<float> SSE.Add(Vector128<float>, Vector128<float> следует заменить на addps ).
Для различных свойств IsSupported любой компилятор должен знать, что он компилируется до последовательности аппаратных инструкций, которые проверяют, поддерживает ли базовое оборудование эти вызовы.
Для JIT это «константа», и он может отбрасывать любые пути кода, в которые не попадет. Также не нужно выписывать чеки.
Для AOT самый простой вариант - это два варианта: просто скомпилировать для минимально поддерживаемой архитектуры и отбросить все остальные пути кода и проверки оборудования. Само оборудование выйдет из строя, когда встретит переданные последовательности инструкций, если оно не поддерживает их. В вашем случае это похоже на отбрасывание всего, что не является SSE или SSE2.
Однако вы можете сделать компилятор более умным и поддерживать больше, чем минимальная архитектура, выполнив необходимые проверки. Помня, что эти проверки могут быть дорогостоящими, вы обычно хотите кэшировать эти проверки, чтобы вашим методам не приходилось фактически проверять поддержку в каждой точке входа.
Большинство операционных систем имеют некоторый механизм для запуска некоторого базового кода «инициализации» при загрузке динамической библиотеки. Точно так же у них обычно есть некоторый механизм для запуска некоторого базового кода «инициализации» перед запуском метода точки входа исполняемого файла. Различные библиотеки CRT обычно подключаются к этой точке инициализации, так что они также могут выполнять любой код инициализации.
Один из способов поддержки дополнительных архитектур состоит в том, чтобы в коде «инициализации» компилятор выполнил проверки оборудования и кэшировал результаты по некоторому глобальному / общеизвестному адресу. Затем компилятор может выдать несколько путей кода для метода и получить первые инструкции для метода, проверяющие поддержку кэшированного оборудования и соответствующие переходы ( cmp DWORD PTR _is_supported_fma3, 0 и jne cos_fma3_implementation ).
Другой способ поддержки дополнительных архитектур - выполнить позднее связывание точек входа метода. В основном, это означает , что вы бы cos , а cos_sse2 способ и cos_fma3 метод, каждый с той же подписью ( double method(double) ). Компилятор в коде "инициализации" затем выполняет проверки оборудования и изменяет метод cos чтобы перейти к методу cos_sse2 или cos_fma3 зависимости от того, что лучше всего подходит. для базового оборудования (существует несколько способов позднего связывания точки входа в метод, это был только один пример).
Во всех случаях ожидается, что небольшое увеличение начальных затрат окупится за счет экономии средств на современном оборудовании.
tannergooding
5 авг. 2017
@fanol, вероятно, мне что-то не хватает, потому что я не вижу никаких проблем, которые не решались бы давно, чтобы иметь дело с несколькими путями на основе характеристик процессора. AFAIK (что не так уж много известно) компиляторам AOT в любом случае придется «определять» целевую архитектуру (скажем, x86, x64 и / или ARM).
Теперь обычный способ справиться с этим (есть очень хорошо продуманный пример подпрограмм memcpy от Agnes Fog) - это проверить cpuid в точке входа и настроить таблицу переходов. для подпрограмм, основанных на том, какой путь выдал компилятор AOT (наличие кодов IsSupported подразумевает, что компилятор в любом случае должен делать некоторую магию), поэтому он генерирует все их версии, а в точке входа новую запись для обработки чек cpuid . После этого вы просто выполняете вызов статической области памяти, которая, в свою очередь, выполняет переход к правильной инструкции ввода.
По сути, то, что сказал @tannergooding, при незначительной стоимости запуска; для версии JIT это просто (так работает JIT). Для выполнения позднего связывания не требовалось самомодифицирующегося кода за счет очень предсказуемого перехода, чтобы справиться с этим.
redknightlois
5 авг. 2017
Я ожидаю, что любой компилятор (AOT или JIT) будет обладать специальными знаниями для всех типов в пространстве имен System.Runtime.CompilerServices.Intrinsics (это одна из причин, по которым я думаю, что они должны быть помечены как extern, а не иметь программную реализацию что кидает).
Это внутренняя деталь реализации, которая может отличаться от среды выполнения к среде выполнения или с течением времени. Это не влияет на публичную форму этих API.
В CoreCLR мы использовали фиктивные реализации, которые выбрасывают такие встроенные функции, потому что их было проще реализовать. Вот один пример: https://github.com/dotnet/coreclr/blob/master/src/mscorlib/src/System/ByReference.cs#L21 . Этот метод является внутренним, как и обсуждаемые здесь встроенные функции: JIT должен понимать, что для него делать, и у него нет резервной реализации.
jkotas
6 авг. 2017
Я очень рад видеть это предложение. Было бы здорово иметь доступные строительные блоки самого низкого уровня.
Чтобы пройти через несколько вещей, которые уже обсуждались:
1) Как пользователь, меня полностью устраивает такой API, не имеющий встроенных резервных вариантов. Если я погружаюсь полностью до уровня использования встроенных функций, специфичных для платформы, использование неподдерживаемых встроенных функций будет ошибкой производительности. В этой ситуации я бы предпочел безотказное поведение.
2) Что касается указателя по сравнению с ref на уровне API, почти вся память, с которой я работаю, либо из предварительно выделенной и закрепленной памяти, либо из стека, поэтому указатели не будут большим препятствием для моего использования. Тем не менее, избегание фиксированной / дыры GC действительно полезно в общем случае, и у меня не было бы проблем с API только для ref, пока JIT выводит эффективные результаты для указателя-> ref (в чем я почти уверен это происходит без накладных расходов, последний раз я проверял).
3) Что касается ясности, я бы старался раскрыть аппаратные примитивы, когда это возможно. В случае чего-то вроде выровненных или невыровненных нагрузок было бы немного прискорбно, если бы дизайн API в конечном итоге затруднил нацеливание на платформу, где выровненные нагрузки действительно были значительно быстрее. Это не обязательно означает, что все возможные встроенные функции имеют одинаковый приоритет реализации - некоторые явно менее широко применимы - но для них хорошо оставить место в API.
Мне нравится идея принять чрезвычайно низкоуровневый характер этого API. Если дизайн в конечном итоге скрывает выбор, который предположительно может повлиять на производительность некоторой комбинации инструкций x платформы, в конечном итоге может появиться еще одно предложение, чтобы еще больше отвлечь его. Я бы предпочел сократить эти проблемы и иметь доступ к необработанным строительным материалам, чтобы сделать эти абстракции по мере необходимости.
4) Я не очень хорошо понимаю историю AOT, но создание упаковки с учетом особенностей ISA звучит так, как будто это была бы довольно сложная работа, охватывающая большой кусок инструментов. В интересах ускорения работы этого API кажется, что выполнение минимума, необходимого для его поддержки - например, переход к проверкам кэшированного оборудования - является хорошим выбором. Позже могут быть полезны подходы с меньшими накладными расходами или инструменты для специализированных пакетов функций, генерирующих AOT, но основной API, похоже, не заблокирован им. (Я должен упомянуть, что я предвзято отношусь к iwannaplaywithit, поэтому я буду склоняться к чистой простоте и скорости реализации :))
 RossNordby
6 авг. 2017
RossNordby
6 авг. 2017
В CoreCLR мы использовали фиктивные реализации, которые выбрасывают такие встроенные функции, потому что их было проще реализовать
@jkotas , также есть случай, когда вы выбрасываете на нативной стороне (https://github.com/dotnet/coreclr/search?utf8=%E2%9C%93&q=COMPlusThrowArgumentNull&type=).
Я определенно думаю, что это лучше для каждого конкретного случая, но, в частности, для этой функции я думаю, что выбор времени выполнения ( COMPlusThrowPlatformNotSupported ) был бы выбором "goto".
По крайней мере, исходя из одного только этого предложения, и до сих пор обсуждались несколько сотен API, которые не имеют поддержки программного обеспечения. Кроме того, методы идентифицируются специальным атрибутом, и им (на основе исходной проектной документации) потенциально может быть разрешено иметь программную резервную реализацию.
Итак, я бы подумал, что для кода времени выполнения, который идентифицирует встроенные функции, было бы лучше иметь запасной вариант, который выполняет COMPlusThrowPlatformNotSupported в случае обнаружения метода с пометкой Intrinsic и extern и у него нет какой-либо известной обработки для него.
У этого есть несколько преимуществ:
- Это сэкономит (как минимум) 7 байтов на каждый API (исходя из 7 байтов IL, необходимых для создания исключения). Поскольку это предложение уже включает несколько сотен API (и в будущем появится еще больше для других архитектур), это быстро прибавится.
- У JIT уже должен быть путь кода, в котором он идентифицирует методы, помеченные
Intrinsic, определяет, поддерживает ли текущая архитектура инструкцию, и либо испускает инструкцию, если поддерживается, либо отправляет вызов метода, если это не так. . Изменение этого метода на использование методовexternкажется тривиальным дополнением - Это заставляет компилятор (AOT или JIT) понимать эти методы. Если у нас есть резервное программное обеспечение, которое выдает, компилятор, который не распознает их, с радостью скомпилирует их, и код выйдет из строя во время выполнения. Если вместо этого помечено
extern, компилятор завершится ошибкой во время компиляции (это все еще среда выполнения для JIT, но предварительная среда выполнения для AOT). - Это дает нам возможность сказать, что этот конкретный API не должен иметь запасного программного обеспечения сейчас или в будущем (для них это в первую очередь связано с проблемами производительности, но могут быть и другие причины). Если пользователям требуется резервное программное обеспечение, они могут предоставить свою собственную оболочку (
if (X.IsSupported) { X.API(); } else { /* Software Fallback */ }), которая сама будет должным образом оптимизирована компилятором.
tannergooding
6 авг. 2017
Это сэкономит (как минимум) 7 байтов на каждый API (исходя из 7 байтов IL, необходимых для создания исключения). Поскольку это предложение уже включает несколько сотен API (и в будущем появится еще больше для других архитектур), это быстро прибавится.
Идентичные тела методов IL складываются в один экземпляр (все они используют один и тот же RVA), поэтому не имеет значения, сколько существует таких API. Тем не менее, я также предпочитаю extern .
pentp
6 авг. 2017
Я думаю, что бросок среды выполнения (COMPlusThrowPlatformNotSupported) был бы выбором "goto".
«Код, управляемый вручную», в наши дни никогда не является нашим «выбором». В CoreCLR мы избегаем «кода, управляемого вручную», потому что правильно писать - это космическая наука. В CoreRT нет «кода, управляемого вручную» (например, нет эквивалента COMPlusThrowPlatformNotSupported), и поэтому все, что является «управляемым вручную кодом» в CoreCLR, должно быть повторно реализовано в CoreRT по-другому. Это противоречит нашему желанию разделить как можно больше между CoreCLR и CoreRT.
Это сэкономит (как минимум) 7 байтов на каждый API.
Это ничего не спасет, как указал @pentp .
Изменение этого, чтобы использовать внешние методы, кажется тривиальным дополнением
Это не совсем тривиально. Вы можете взять одну из существующих встроенных функций (например, https://github.com/dotnet/coreclr/blob/master/src/mscorlib/src/System/ByReference.cs#L21) и попытаться повторно подключить ее с помощью extern к лучше понять проблему. Первая проблема, с которой вы, вероятно, столкнетесь, заключается в том, что эти внешние методы должны иметь точку входа, и создать точку входа из ничего нетривиально.
Это дает нам возможность сказать, что у этого конкретного API сейчас не должно быть резервного программного обеспечения.
IMHO, комментарий примерно так же хорош, чтобы сказать, что у этого API не должно быть резервного программного обеспечения.
Кроме того, я ожидаю, что, как только это будет выполнено от начала до конца, мы обнаружим, что встроенные функции должны лучше работать даже как отдельные функции, чтобы такие вещи, как отладчики, расширенные профилировщики или интерпретаторы IL работали хорошо. Мы можем закончить реализацию встроенных функций, рекурсивно вызывая себя, чтобы заставить эту работу работать:
[Intrinsic]
public static Vector256<float> Add(Vector256<float> left, Vector256<float> right) => Add(left, right);
Обратите внимание, что эта реализация имеет точно такое же поведение (например, при выдаче исключения недопустимой инструкции), как если бы встроенная функция была развернута в строке. Этот трюк со встроенным рекурсивным вызовом используется в CoreRT, см., Например, https://github.com/dotnet/corert/blob/master/src/System.Private.CoreLib/src/System/Threading/Interlocked.cs# L236.
jkotas
6 авг. 2017
Спасибо за объяснение @jkotas. Теперь становится понятнее, почему бы не отметить их как extern - лучший вариант.
tannergooding
7 авг. 2017
Я полностью поддерживаю соответствие метода и инструкции один-к-одному. Это здорово, но я все же считаю, что это предложение требует очень ограниченного базового набора платформенных "независимых" методов, таких как.
namespace System.Runtime.CompilerServices.Intrinsics
{
public static class IntrinsicsPlatform // Naming is just an example
{
[Intrinsic]
public static IntrinsicsArchitecture Architecture { get; }
}
public enum IntrinsicsArchitecture // Not bit specific, that can be tested in other ways
{
x86,
Arm,
// etc.
}
[StructLayout(LayoutKind.Sequential, Size = 16)]
public struct Vector128<T> where T : struct
{
[Intrinsic]
public static bool IsSupported() { throw new NotImplementedException(); }
[Intrinsic]
public static Vector128<T> Load(ref T mem) => Load(ref mem);
[Intrinsic]
public static Vector128<T> Store(ref T mem, Vector128<T> value) => Store(ref mem, value);
}
[StructLayout(LayoutKind.Sequential, Size = 32)]
public struct Vector256<T> where T : struct
{
[Intrinsic]
public static bool IsSupported() { throw new NotImplementedException(); }
[Intrinsic]
public static Vector256<T> Load(ref T mem) => Load(ref mem);
[Intrinsic]
public static Vector256<T> Store(ref T mem, Vector256<T> value) => Store(ref mem, value);
}
[StructLayout(LayoutKind.Sequential, Size = 64)]
public struct Vector512<T> where T : struct
{
[Intrinsic]
public static bool IsSupported() { throw new NotImplementedException(); }
[Intrinsic]
public static Vector512<T> Load(ref T mem) => Load(ref mem);
[Intrinsic]
public static Vector512<T> Store(ref T mem, Vector512<T> value) => Store(ref mem, value);
}
}
Это позволило бы писать «общие» алгоритмы без ссылки на x86 , Arm или другие сборки платформы.
Возможно, я не пойму, как все это будет упаковано и т. Д. Но я бы подумал, что было бы хорошо не загружать, скажем, сборку x86 на Arm. Или, говоря иначе, как нам проверить, на какой платформе мы находимся? Мы тестируем через SSE2.IsSupported? Даже при работе на Arm? Как это будет работать и т. Д.?
Я думаю, что некоторые думали о том, как это будет работать в проектах, нацеленных на несколько платформ, и как они могут быть учтены в сборках для разных платформ без фактической загрузки этих сборок и т. Д., Было бы хорошо. Как это будет реализовано на практике?
Я в первую очередь думаю о проектах JIT, но AOT не менее актуален.
nietras
7 авг. 2017
public enum Architecture
{
X86,
X64,
Arm,
Arm64
}
Дох! 😦 Извините, слишком давно .NET Core. Надеюсь, это будет доступно в .NET Framework, когда / если к этому придут встроенные функции.
nietras
7 авг. 2017
Я бы пошел на что-то большее, вроде
[Flags]
public enum Architecture
{
Unknown = 0
32bit = 1 << 0,
64bit = 1 << 1,
IntelAmd = 1 << 8
Arm = 1 << 9
X86 = 1 << 16 | 32bit | IntelAmd,
X64 = 1 << 17 | 64bit | IntelAmd,
Arm = 1 << 24 | 32bit | Arm,
Arm64 = 1 << 25 | 64bit | Arm,
}
@nietras , в соответствии с текущим предложением, я полагаю, вы бы
C#
if (FMA3.IsSupported)
{
}
else if (SSE2.IsSupported)
{
}
else if (Neon.IsSupported)
{
}
else
{
}
Итак, да, вы могли бы кодировать как для x86, так и для ARM без каких-либо дополнительных проверок архитектуры. Ожидается, что JIT рассматривает *.IsSupported как константу, а AOT будет рассматривать его как «некоторую» константу.
С этими ожиданиями компилятор (JIT или AOT) отбрасывает пути кода x86 на ARM и отбрасывает пути кода ARM на x86. Кроме того, ожидается, что JIT удалит пути кода, которые не будут выполнены. Таким образом, если поддерживается FMA3, выдается только первый путь кода. Если SSE2 поддерживается, будет выдан только второй путь кода. Третий путь кода никогда не будет испускаться (на x86), а четвертый путь кода испускается только в том случае, если SSE2 не поддерживается.
tannergooding
7 авг. 2017
Я бы предположил, что, если проверки System.Runtime.InteropServices.RuntimeInformation также рассматриваются как постоянные (может быть, кто-то может прокомментировать это?), Вы могли бы выполнять эти дополнительные проверки без каких-либо штрафов за производительность.
tannergooding
7 авг. 2017
Они не. Это просто обычные методы получения диагностической информации о системе.
mellinoe
7 авг. 2017
[Флаги] public enum Architecture
@benaadams: да, я не пытался спроектировать фактический тип, просто то, как было бы хорошо иметь такую константу. Было бы неплохо иметь информацию о том, возможны ли вообще невыровненная загрузка / сохранение и так далее. У Flags есть проблема, заключающаяся в том, что общий набор ограничен, могли бы мы когда-нибудь иметь более ~ 30 ISA, если бы для перечисления использовалось int 😉
Это просто обычные методы получения диагностической информации о системе.
Да ладно, тогда я бы определенно подумал, что какая-то константа для архитектуры, независимая от сборок x86 / arm, была бы хорошей. Какие минусы это добавление? По сравнению с необходимостью проверять, скажем, SSE2 или Neon , работаем ли мы на ARM или нет? Это кажется довольно недружелюбным к пользователю, учитывая.
nietras
7 авг. 2017
@nietras Почему существующий API недостаточно хорош, если вы просто пытаетесь выяснить, работаете ли вы на ARM или нет?
mellinoe
7 авг. 2017
@mellinoe, возможно, это не имеет большого значения, но для меня просто странно, что я ссылался (возможно, даже загружал) сборку x86 или Arm на другой платформе. И с дополнительными Load/Store в типах VectorXXX базовые алгоритмы тоже могут быть независимыми от них, тогда специфичные для платформы "реализации" могут быть учтены в x86 / Arm специфические сборки, а затем они ссылаются на специфические сборки платформы. В целом, сокращение загруженных сборок и использование памяти. Я полагаю. Если это актуально, я думаю, это будет для платформ с ограниченным объемом памяти.
nietras
7 авг. 2017
Это кажется довольно недружелюбным к пользователю, учитывая.
Не могли бы вы подробнее остановиться на этом вопросе?
Я думаю, что у проверки архитектур есть два недостатка:
- Это может привести к тому, что пользователи будут делать предположения вроде: «Я работаю на ARM, поэтому должен быть доступен NEON».
- Это затрудняет предоставление пути кода для резервного копирования программного обеспечения.
C# if (Architecture == x86) { if (SSE2.IsSupported) { } else { // Sofware } } else if (Architecture == Arm) { if (Neon.IsSupported) { } else { // Software } } // Can't put it here, as it wouldn't be hit
tannergooding
7 авг. 2017
@nietras Вы, безусловно, можете создавать двоичные файлы для конкретной платформы и отправлять их с приложениями для конечных пользователей, ориентированными на платформу, или объединять их в соответствующие места в пакете nuget. Вы можете избежать включения «мертвого кода», который никогда не сработает на этой конкретной платформе. Тем не менее, я готов рискнуть, что выигрыши очень малы и могут иметь значение лишь в небольшом числе случаев.
mellinoe
7 авг. 2017
Использование более безопасного кода с Span будет иметь проблемы с производительностью по отношению к "голым" указателям?
Например вместо:
[Intrinsic]
public static unsafe Vector256<byte> LoadAligned(byte* mem) { throw new NotImplementedException(); }
это:
[Intrinsic]
public static Vector256<byte> LoadAligned(Span<byte> mem) { throw new NotImplementedException(); }
@fanoI Span-нагрузки не будут работать так хорошо во внутреннем цикле, поскольку вам нужно будет создавать диапазон для каждой итерации и нужно будет проверять размеры; затем получить доступ к указателю
public static Vector256<byte> LoadAligned(ReadOnlySpan<byte> mem)
{
mem.Length != sizeof(Vector256<byte>) throw
return LoadAligned(ref mem.GetDangerousPointer())
}
Это должно быть больше ситуации смещения, чтобы Jit мог поднять чеки, например
public static Vector256<byte> LoadAligned(ReadOnlySpan<byte> mem, int index)
Однако, опять же, по-прежнему потребуется распознавать шаблоны, которые (length - index) <= sizeof(Vector256<byte>) ; так что не уверен, что это будет сырой внутренний?
[Intrinsic]
public static Vector256<byte> LoadAligned(ref Vector256<byte>)
Вероятно, сработает; но также, вероятно, сбивает людей с толку относительно того, что он делает; зачем вам загружать тип в себя? (например, загрузка выровненной кучи или небезопасное приведение Vector256 к регистрации Vector256)
Также я не уверен, что вы когда-нибудь сможете сделать LoadAligned безопасным, так как вам нужно знать выравнивание; для чего вам нужно проверить или настроить указатель?
benaadams
8 авг. 2017
Не могли бы вы подробнее остановиться на этом вопросе?
@tannergooding ну, конечно, есть много способов структурировать код;). Однако, чтобы попытаться объяснить, позвольте мне сначала перечислить свои предположения. Они могут быть совершенно неверными.
Я предполагаю, что Intrinsics будет учтено в наборе сборок (хотя я понимаю, что это может зависеть от реализации, любая среда выполнения .NET может делать это так, как они предпочитают, поэтому все пространства имен могут быть в одной сборке, на самом деле это может быть то, что, вероятно, будет делать .NET Core?):
System.Runtime.CompilerServices.Intrinsics.dll // Only the "platform-agnostic" types and primitives here i.e. VectorXXX<T>
System.Runtime.CompilerServices.Intrinsics.X86.dll
System.Runtime.CompilerServices.Intrinsics.Arm.dll
Учитывая, что мы говорим о многих тысячах методов, их можно разделить на несколько:
System.Runtime.CompilerServices.Intrinsics.dll // Only the "platform-agnostic" types and primitives here i.e. VectorXXX<T>
System.Runtime.CompilerServices.Intrinsics.X86.SSE.dll // SSE-SSE4.X
System.Runtime.CompilerServices.Intrinsics.X86.AVX.dll // AVX-AVX2
System.Runtime.CompilerServices.Intrinsics.X86.AVX512.dll // AVX-512
System.Runtime.CompilerServices.Intrinsics.Arm.dll
// Etc.
Учитывая это, можно ограничить ссылочные сборки только теми, которые актуальны для данной архитектуры. Так будет одна или несколько сборок? Если только один, как насчет использования памяти, которое это может вызвать? В этой ветке обсуждается, сколько байтов может использовать тот или иной метод и как это может быть проблемой с учетом множества методов (хотя совместное использование может решить эту проблему), разве это не проблема? Разве сами определения методов не имеют веса?
Для кода, который, как я представляю, строится на основе этого, я бы следовал аналогичному факторингу (разделенному на множество здесь, чтобы прояснить) сборок, например (зависимости, перечисленные ниже -> ):
PerfNumerics.Funcs.dll // Definitions of different func interfaces
-> System.Runtime.CompilerServices.Intrinsics
PerfNumerics.Algorithms.dll // General algorithms i.e. like the Transform I mentioned earlier but for 1D,2D,3D, etc. Tensor etc. etc.
-> PerfNumerics.Funcs.dll
-> System.Runtime.CompilerServices.Intrinsics
-> System.Runtime.CompilerServices.Unsafe
PerfNumerics.Funcs.Software.dll // Software specific implementations of many different funcs (e.g. threshold, multiply, and, xor etc. etc.)
-> PerfNumerics.Funcs.dll
PerfNumerics.Funcs.Arm.dll // ARM specific implementations of many different funcs (e.g. threshold, multiply, and, xor etc. etc.)
-> PerfNumerics.Funcs.dll
PerfNumerics.Funcs.x86.dll
-> PerfNumerics.Funcs.dll
Таким образом, они будут определять алгоритмы и примитивы, которые можно использовать. Их, конечно, нужно где-то составлять, то есть на каком-то уровне функциональности:
PerfNumerics.SomeFunctionality.dll
-> PerfNumerics.Algorithms.dll // General algorithms i.e. like the Transform I mentioned earlier but for 1D,2D,3D, etc. Tensor etc. etc.
-> PerfNumerics.Funcs.dll
-> PerfNumerics.Funcs.Software.dll
-> PerfNumerics.Funcs.Arm.dll // Specific implementations of many different funcs (e.g. threshold, multiply, and, xor etc. etc.)
-> PerfNumerics.Funcs.x86.dll
В этом случае данная функция может быть составлена (чтобы избежать загрузки ненужного кода платформы и т. Д.), Например:
public static class SomeFunctionality
{
public static int SomeFunction(Span<T> src, Span<T> dst)
{
switch (IntrinsicsPlatform.Architecture)
{
case IntrinsicsArchitecture.x86:
return SomeFunction_x86(src, dst);
case IntrinsicsArchitecture.Arm:
return SomeFunction_Arm(src, dst);
default:
return SomeFunction_Software(src, dst);
}
}
}
В SomeFunction_x86 определяется как композиция алгоритма с функцией:
public static int SomeFunction_x86(Span<T> src, Span<T> dst)
{
// Here a given impl is composed of algorithm + func so say
Transform(src, new ThresholdVectorFuncX86(), dst);
// As mentioned before Transform will do switch
}
Сама функция тогда будет иметь переключатель if/else , и в некоторых случаях его необходимо объединить с другой "функцией" и интерфейсом, который может сообщить алгоритму, поддерживается ли, несмотря на то, что Vector512<T> фактических необходимых вмешательств нет, так что это тоже следует пропустить. Фактически, если VectorXXX<T>.Load/Store не добавлены, это можно сделать с помощью другой функции. Однако он быстро становится беспорядочным, это своего рода шаблоны C ++ в C #. Злоупотребление генерацией кода типа значения JIT.
@mellinoe Все это, конечно, может быть реализовано каким-либо образом с существующим API, но не без ссылки на статические классы, специфичные для платформы. При использовании вышесказанного никакая сборка Arm не будет даже загружена в x86 . Может, это совсем не беспокоит?
Я понимаю, что такой способ разложения и структурирования кода определенно не для всех, я даже не уверен, что это обязательно лучший способ для того, что я хочу, так что просто болтайте здесь.
nietras
8 авг. 2017
Вероятно, сработает; но также, вероятно, сбивает людей с толку относительно того, что он делает; зачем вам загружать тип в себя?
@benaadams Не думаю, что это сбивает с толку. Это то же самое, что и все другие встроенные функции - позволяет более эффективно делать то, что вы уже могли бы сделать в противном случае. Во всяком случае, я нахожу это менее запутанным, потому что с подписью ref Vector256 он делает именно то, что можно было бы ожидать на первый взгляд.
sharwell
8 авг. 2017
Но этот "LoadAligned" будет эквивалентом инструкции ASM X86 movdqa? То есть результатом этой интриги должно быть то, что Vector256
Если это так, я не очень понимаю, почему Vector256
fanoI
8 авг. 2017
Если это так, я не очень понимаю, почему возвращается Vector256 ...
Итак, у вас есть ссылка для использования в последующих операциях; так, например, если вы загружали из массива в куче и знали, что индексируете, начиная с выровненного места.
byte[] array = new byte[1000];
// Possible unaligned loads
//Vector256<byte> xmmReg0 = AVX.Load(&array[i]); // GC hole? Invalid C#
//Vector256<byte> xmmReg1 = *(Vector256<byte>*)&array[i]; // implied Load + GC hole? Invalid C#
fixed(byte* ptr = &array[0])
{
Vector256<byte> xmmReg2 = AVX.Load(ptr + i);
Vector256<byte> xmmReg3 = *(Vector256<byte>*)(ptr + i); // implied Load?
}
Vector256<byte> xmmReg4 = ref Unsafe.As<Vector256<byte>>(ref array[i]); // implied Load?
Vector256<byte> xmmReg5 = AVX.Load(ref Unsafe.As<Vector256<byte>>(ref array[i]));
// Possible aligned loads
//Vector256<byte> xmmReg6 = AVX.LoadAligned((byte*)&array[i]); // GC hole? Invalid C#
fixed(byte* ptr = &array[0])
{
Vector256<byte> xmmReg7 = AVX.LoadAligned(ptr + i);
}
Vector256<byte> xmmReg8 = AVX.LoadAligned(ref Unsafe.As<Vector256<byte>>(ref array[i]));
@sharwell , мне не нравится синтаксис ref Vector256 потому что в большинстве случаев у меня не будет Vector256 до тех пор, пока я не вызову инструкцию загрузки. Вместо этого у меня был бы массив из T который равен как минимум sizeof(Vector256) .
Я не хочу, чтобы в моем коде вкраплялись Unsafe.As<float, Vector256<float>>() когда ref T , ref float , void* или float* гораздо понятнее , краткий и соответствует структуре подложки.
tannergooding
8 авг. 2017
Vector256<byte> xmmReg0 = AVX.Load(&array[i]); // GC hole?
Это недопустимый C # ...
вы знали, что индексируете, начиная с выровненного места
Единственный способ узнать это - закрепить массив. ГХ может перемещать его и изменять выравнивание в любое время.
jkotas
8 авг. 2017
Единственный способ узнать это - закрепить массив.
В этот момент у вас есть указатель. Итак, не уверены, что загрузка без выравнивания указателя будет полезна?
benaadams
8 авг. 2017
Я делаю здесь адвоката дьявола, но вся эта небезопасность, дыра в сборке мусора и так далее ... не рискует ли сделать C # слишком похожим на C / C ++? В примере с @benaadams нет безопасности ...
Так плохо проверять перед записью в регистр XMM, что вы записываете не неправильный размер? Лучше быть на 2% медленнее, чем C / C ++, но сохранить хоть немного безопасности, верно?
Cosmos не принимает небезопасный / непроверяемый код за пределами самого нижнего кольца (называемого Core), мы, возможно, можем сделать исключение, если оно является частью среды выполнения C #, но пользовательская библиотека, использующая эти intrisics, не будет принята в Cosmos (то есть не будет компилироваться) .
fanoI
8 авг. 2017
Лучше быть на 2% медленнее, чем C / C ++, но сохранить хоть немного безопасности, верно?
Возможно, нужны перегрузки массива / диапазона?
Vector256<T> AVX.Load(T value)
Vector256<T> AVX.Load(ReadOnlySpan values)
Vector256<T> AVX.Load(T[] values)
Vector256<T> AVX.Load(T[] values, int index)
Однако невыровненная нагрузка не сможет поддерживаться таким образом
benaadams
8 авг. 2017
@fanoI , не предполагается, что это будет использоваться авторами приложений. Вместо этого он предназначен для использования авторами фреймворка, чтобы основные функции могли быть написаны в управляемом коде и могли обеспечить наилучшую возможную производительность.
Скорее всего, это будет использоваться такими вещами, как:
- System.String
- System.Math и MathF
- System.Numerics.Vector
, Вектор2, Вектор3, Вектор4 - так далее
Он также будет использоваться людьми, пишущими такие вещи, как движки мультимедийных приложений или код взаимодействия.
Авторы фреймворка будут использовать эти API при реализации своих собственных API и, скорее всего, обернут все небезопасные биты внутри. Моя точка зрения:
- Разработчик приложения, использующий API, который использует встроенные функции, не должен знать (или уметь определять по самому API), что он использует встроенные функции.
- Разработчику приложения ни в коем случае нельзя прикасаться ни к одному из типов в
System.Runtime.CompilerServices.Intrinsics.
Cosmos не принимает небезопасный / непроверяемый код за пределами нижнего кольца
Это прекрасная позиция, если вы также согласны с тем, что она исключает многие основные API-интерфейсы, которые предоставляет CoreFX. Например, string.IndexOf(char) является «безопасным», но само вызывает небезопасную перегрузку (https://source.dot.net/#System.Private.CoreLib/src/System/String.Searching.cs,eb06d6d166f6a3d9, использованная литература).
Вы также должны быть готовы согласиться с тем, что тот факт, что верификатор считает его непроверяемым, не означает, что это так: https://github.com/dotnet/roslyn/pull/21269. В связанном случае peverify не знает, как обрабатывать некоторые оптимизации, производимые компилятором для ref readonly . Созданный код на самом деле безопасен и поддается проверке, но инструмент проверки не знает, как это распознать.
Возможно, мы сможем сделать исключение, если оно является частью среды выполнения C #.
Ни один из этих API не является и не будет специфичным для C # (на самом деле «C # Runtime» не существует). Они являются частью Core Runtime и Core Framework и поэтому будут доступны практически на любом языке, который компилируется до кода IL (по крайней мере, на любом языке, который поддерживает как минимум ref или pointers ).
Также бывает, что эти функции полностью зависят от среды выполнения, в которой они работают. CoreCLR распознает эти инструкции и выдаст код одним способом, но другая среда выполнения (например, Mono) может сделать это по-другому.
tannergooding
8 авг. 2017
@fanoI @mellinoe
По сути, та же проблема возникает в языке safe system programming таком как Rust. Невозможно выразить все операции низкого уровня, необходимые в нескольких библиотеках, в безопасном синтаксисе Rust, поэтому Rust предоставляет контекст unsafe котором исключены права владения, заимствования и другие функции безопасности. Очень интересное описание проблемы приведено в статье:
Ральф Юнг, Жак-Анри Журдан, Робберт Кребберс, Дерек Дрейер. ICFP'17 / НАДЕЖДА'17
Rust использует сильную систему типов, основанную на владении, но затем расширяет выразительную силу
этой системы основного типа через библиотеки, которые внутренне используют небезопасные функции
По сути, это означает, что иногда невозможно писать безопасные программы, используя только безопасные конструкции. Как было заявлено @mellinoe, можно использовать небезопасные конструкции безопасным способом для создания безопасных фреймворков или библиотек.
4creators
9 авг. 2017
@ 4creators Я думаю, что @tannergooding сказал это, но да. Небезопасный код лежит в основе многих основных библиотек .NET.
mellinoe
9 авг. 2017
Я думаю, что хорошее резюме обсуждений до сих пор:
- Эту функцию, по сути, любят / обожают все.
refvspointersпохоже, требует дальнейшего обдумывания / обсуждения поверхности API- Никакой откат программного обеспечения, похоже, не вызывает положительного отклика
- Определение того, как раскрыть их, не раздувая самый нижний уровень, но при этом делая API-интерфейсы доступными для каждого уровня, кажется, требует более подробного обсуждения.
Некоторые из открытых вопросов, похоже, все еще заключаются в следующем:
- Как будут выглядеть API для скаляров (например,
sqrtssилиmovss) и как они будут совпадать с API векторов? - Имеет ли смысл раскрывать небольшое подмножество вспомогательных функций (таких как общие
load/store)?- Если мы не думаем, что они будут использоваться самим CoreFX, то, вероятно, лучше всего будет использовать стороннюю библиотеку.
- Можем ли мы создать репозиторий (в CoreFX), чтобы люди могли начать над этим работать в свободное время?
tannergooding
9 авг. 2017
@tannergooding Большое спасибо за резюме, давайте обсудим эти темы в обзорах .Net Design на следующей неделе.
Как будут выглядеть API для скаляров (например, sqrtss или movss) и как они будут совпадать с API векторов?
Наш внутренний дизайн API (мы отправим PR после того, как это предложение будет одобрено) включает определенные скалярные инструкции (например, crc32, popcnt и т. Д.), Но те, которые вы упомянули (большинство из SSE / SSE2), еще не включают.
Эти инструкции скалярной точки с плавающей запятой SSE / SSE2 в настоящее время охвачены кодогенератором RyuJIT. Как вы думаете, нужно ли их выставлять как внутренние? Если да, не могли бы вы предоставить более подробную информацию о вариантах использования?
fiigii
9 авг. 2017
popcnt - это то, что мы действительно хотели бы иметь
ayende
9 авг. 2017
Одна, обе или комбинированная форма BSF , TZCNT
Один или оба из BSR , LZCNT
benaadams
9 авг. 2017
@fiigii , (может быть, @mellinoe тоже может
Взаимодействие с другим внутренним кодом
На самом деле нет никакой разницы между Vector128<T> и double кроме:
- Потенциально, как значение передается в стек
- Какая форма инструкции называется (
sdvspd) - Является ли внутреннее свойство явным или неявным
Как автор фреймворка, мне не нужно беспокоиться о преобразовании Vector128<T> в double , просто чтобы вызвать другой метод ( Math.Sqrt ), а затем взять результат и преобразовать его. вернуться к Vector128<T> (вместо этого я просто смогу позвонить SSE2.SqrtScalar ).
Мне также не следует полагаться на предположение, что JIT определенно будет рассматривать мой вызов Math.Sqrt как внутренний и создаст оптимальный код, который соответствует моему алгоритму.
Реализация System.Math и System.MathF в управляемом коде
Сегодня API System.Math и System.MathF в основном реализованы как FCALL s в CRT-реализации соответствующего метода ( System.Math.Cos вызывает cos в libm ).
Между платформами уже есть различия в производительности (https://github.com/dotnet/coreclr/issues/9373), но есть также различия во вводе / выводе для некоторых значений, которые не продиктованы IEEE 754.
Без скалярных встроенных функций единственный способ реализовать их с использованием встроенных функций - это реплицировать вывод во все регистры и вытащить наименьшее значение после завершения (фактически Vector4 v = new Vector4(value); return Vector4.Cos(v).X; ). Это потенциально может усложнить алгоритм и вызвать использование дополнительных регистров, которые в противном случае не потребовались бы.
Последовательность
Я по-прежнему считаю отличной идеей изолировать все встроенные функции времени выполнения (включая те, которые в настоящее время покрывает кодогенератор RyuJIT) и изолировать их до System.Runtime.CompilerServices.Intrinsics .
Я не знаю, что думают по этому поводу люди среды выполнения / фреймворка, но я полагаю, что это значительно упростит перенос этих API-интерфейсов в разные среды выполнения (на такие вещи, как CoreRT, Mono и т. Д.).
В идеале он должен также упростить объем нативного кода, который необходимо поддерживать для этих API (где производительность имеет значение), и должен повысить ремонтопригодность кода и потребляемость исправлений (поскольку для этого требуются изменения структуры, а не изменения времени выполнения. улучшить).
tannergooding
9 авг. 2017
Я по-прежнему считаю отличной идеей изолировать все встроенные функции времени выполнения (включая те, которые в настоящее время покрывает кодогенератор RyuJIT) и изолировать их от System.Runtime.CompilerServices.Intrinsics.
Я не думаю, что это хорошая идея. На самом деле это невозможно даже для некоторых из существующих, например, потому что они являются виртуальными методами.
jkotas
9 авг. 2017
Встроенные аппаратные средства Intel действительно полезны для реализации библиотеки. Однако, насколько мне известно, mscorlib не может полагаться на другие управляемые сборки (например, CoreFX). Если мы хотим, чтобы эти встроенные функции использовались в mscorlib (например, System.Math/MathF ), нужно ли нам изменять организацию встроенных функций или что-то внутри среды выполнения?
fiigii
9 авг. 2017
Встроенные функции должны быть реализованы в System.Private.CoreLib ("mscorlib"). По сути, они в любом случае должны быть реализованы в самой среде выполнения - нет реального способа реализовать их «вне диапазона». Как обсуждалось выше (или, возможно, где-то в другом выпуске), System.Private.CoreLib не может зависеть от каких-либо других сборок, потому что это основная сборка. Мы хотим иметь возможность использовать эти встроенные функции в самом System.Private.CoreLib (для основных типов, таких как String и т. Д.). Следовательно, их необходимо реализовать в System.Private.CoreLib.
mellinoe
9 авг. 2017
@mellinoe Ожидаете ли вы, что все встроенные функции будут реализованы в System.Private.CoreLib ?
Если да, то потребуется несколько тысяч методов - полная поддержка только AVX512 потребует около 2 тысяч методов (включая перегрузки). Если позже встроенные функции ARM SVE будут добавлены для векторов всех размеров (16 различных векторов), мы получим комбинаторный взрыв.
4creators
9 авг. 2017
Есть ли в ARM индивидуальные инструкции для каждого размера вектора или это параметр длины?
benaadams
9 авг. 2017
В настоящее время реализация ARM ISA SIMD поддерживает только размер регистра 128 бит и соотношение вектор-инструкция 1: 1. Я бы предположил, что при доработке дизайна SVE они могут пойти разными путями, например, как Intel, где префикс (VEX, EVEX) используется для различения инструкций и данных регистров, которые закодированы в некоторых частях инструкции. В настоящее время мы этого не знаем.
Однако это не должно иметь никакого влияния на этот анализ, поскольку API должен различать размеры векторов на уровне метода, поэтому можно ожидать наличия 16 методов для добавления byte векторов, 16 методов для добавления word векторы и т. д. и т. д. Это схема, в которой каждая операция для данного базового типа, например byte требует одной перегрузки метода для каждого поддерживаемого размера вектора.
4creators
10 авг. 2017
В зависимости от инструкций, если они все одинаковы, но с параметром в регистре или в качестве аргумента, это может быть Load(* , n) для непрозрачного armRegister type; затем функции, принимающие armRegister
benaadams
10 авг. 2017
@ 4creators Да, "наивный" замысел состоит в том, чтобы просто реализовать их все в System.Private.CoreLib. Но под «всеми» мы на самом деле подразумеваем «все инструкции, которые мы сочли достаточно важными или за которые мы получили помощь». Конечно, есть много инструкций, которые бесполезно или интересно раскрывать напрямую, и в любом случае эта функция требует, чтобы каждая отдельная встроенная функция была распознана специально и конкретно в JIT. Мы определенно начнем с меньшего подмножества, чем «все» - скорее всего, с функций, которые нам нужны для реализации ключевых вещей, таких как Math(F) , String , Vector2/3/4 и т. Д.
Учитывая, что System.Private.CoreLib уже зависит от платформы (например, у нас есть разные двоичные файлы для x86, x64, ARM), я могу представить себе другой дизайн, в котором мы можем опустить неприменимые заглушки встроенных функций для других платформ. Например, System.Private.CoreLib.x64.dll не будет включать заглушки функций ARM. Но это потребует еще более специальной обработки во время выполнения и, в конечном итоге, является оптимизацией реализации, которая явно не нужна на данном этапе.
mellinoe
10 авг. 2017
на самом деле мы имеем в виду "все инструкции, которые мы сочли достаточно важными или за которые мы получили взнос"
@mellinoe
У меня сложилось впечатление, что обсуждаются два набора инструкций:
- Те, которые необходимы для внутреннего использования в
System.Private.CoreLib - Те, которые открываются через внешнюю сборку и которые включают большую часть или все SIMD и другие специальные инструкции
Для разработчиков среды выполнения первый набор наиболее важен для разработчиков, работающих над библиотеками, специфичными для предметной области, это будет важна доступность всех или почти всех встроенных функций. Когда мы рассматриваем несколько алгоритмов, которые можно векторизовать, трудно представить их реализацию с ограниченным набором SIMD или без специальных инструкций.
4creators
10 авг. 2017
@ 4creators Даже во второй категории «настоящая» функциональность должна быть реализована в JIT и во время выполнения - нет возможности сделать это вне репозитория coreclr или каким-либо образом «вне диапазона». Вы можете определять заглушки функций где угодно, но это не имеет значения, если они не понимаются JIT / средой выполнения. Из-за этого я не вижу особого смысла в том, чтобы разрешить их определение в какой-то другой сборке. Это просто усложняет ситуацию, ИМО.
mellinoe
10 авг. 2017
Итак, что нужно, чтобы это стало реальностью? Я думаю, что это БОЛЬШОЕ для C # ... это одно из "оправданий" для использования C ++, и это избавляет от него.
Работа над экспериментальными функциями должна выполняться на CoreFxLabs?
fanoI
12 авг. 2017
@fanoI , я не думаю, что что-либо можно "запустить", пока API не будет рассмотрен и одобрен.
Основываясь на комментарии @fiigii , обзор дизайна будет во вторник (https://www.youtube.com/watch?v=52Fjrhx7pKU)
Я полагаю, что после утверждения API работа действительно может начаться.
Возможно, @jkotas или @mellinoe могли бы прокомментировать, но я предполагаю, что команда CoreFX / CoreCLR должна выполнить начальную работу по крайней мере для 1-2 встроенных функций и должна написать документацию с подробным описанием пошагового процесса того, что делать для других встроенных функций. . Как только это станет доступно, его можно будет открыть для участия всего сообщества. Члены сообщества могли «подписаться» на набор встроенных функций для реализации, а затем начать работу.
tannergooding
12 авг. 2017
Ах, хорошо, официальное обсуждение еще должно начаться ... так что нам нужно подождать :-)
fanoI
12 авг. 2017
Несколько мыслей по поводу этого предложения и обсуждения:
Универсальные и не универсальные (например, Add<T> vs. Add<float> ):
- Меня немного смущает это обсуждение. Поскольку это внутренняя функция и не будет реализована, я не вижу большого преимущества в увеличении количества объявлений. Поскольку это предназначено для разработчиков, которые «знают, что делают», комментарий, указывающий, какие типы поддерживаются для текущей целевой ISA, должен предоставить достаточно информации.
Было бы полезно иметь стандартный API для запроса «наилучшего выравнивания» для данного типа и / или получения выровненной памяти? Я не обязательно предполагаю, что по мере того, как мы идем к большим размерам вектора, всегда будет так, что наилучшее выравнивание (исключение ошибок страницы) обязательно будет размером вектора.
Что касается постоянных аргументов, какого поведения мы ожидаем от компилятора IL (AOT или JIT), когда передается неконстанта? Для AOT ошибка была бы полезна, но для JIT она должна рассматриваться как недопустимый IL, или она должна генерировать код для выдачи исключения, или ...?
Я думаю, что нам нужно очень четко сформулировать стратегию эволюции набора поддерживаемых встроенных функций. Поскольку существует несколько сред выполнения и компиляторов IL, похоже, что есть немаловажная история совместимости, когда предлагаемые свойства или методы IsSupported фактически будут означать разные вещи с течением времени.
Свойство против метода для IsSupported : Я думаю, что настроения уже склоняются в сторону собственности, но я добавлю свой голос за это. Проверка аппаратной поддержки на самом деле не является «действием». Это действительно возвращает свойство цели.
Что касается компиляции AOT и проверки IsSupported : я думаю, что хороший компилятор AOT должен уметь агрегировать и оптимизировать проверку и связанный код. Таким образом, разработчик не должен нести бремя неестественной структурирования своего кода таким образом, чтобы проверки, которые логически относятся к низкоуровневому коду, увеличивались до уровня, на котором их стоимость будет амортизироваться.
Снижение производительности из-за смешанного использования форм SSE2 и AVX: RyuJIT в настоящее время задерживает фактическое кодирование до позднего времени, а инструкции, которые имеют кодировки AVX и SSE, имеют унифицированное представление - определение того, какую кодировку использовать, зависит от того, сообщает ли виртуальная машина JIT что AVX2 есть в наличии.
Обратите внимание, что в настоящее время нам требуется AVX2 для использования кодирования AVX. Это просто для уменьшения матрицы тестирования / поддержки / реализации, поскольку AVX2 обеспечивает более единообразную поддержку 256-битных векторов. Было бы довольно проста в использовании AVX кодировок в любое время либо:
- AVX2 доступен и используется
Vector<T>, или - AVX доступен, и используются встроенные функции AVX
- AVX2 доступен и используется
- Вышесказанное, однако, увеличит нагрузку на тестирование и поддержку - но я думаю, что мы уже на этом пути!
 CarolEidt
15 авг. 2017
CarolEidt
15 авг. 2017
Было бы довольно просто использовать кодировки AVX в любое время:
- AVX2 доступен и Vector
используется, или - AVX доступен, и используются встроенные функции AVX
Итак, я понял, что, очевидно, это не для начала. Мы не можем изменить цель после просмотра характеристической AVX. Итак, я думаю, нам нужно будет изменить стратегию генерации кода, чтобы нацелить на AVX всякий раз, когда он доступен (а не только когда доступен AVX2).
CarolEidt
15 авг. 2017
Мы также должны согласовать с https://github.com/dotnet/roslyn/issues/11475
 tmat
16 авг. 2017
tmat
16 авг. 2017
Не согласен. Это несвязанные предложения.
 jaredpar
16 авг. 2017
jaredpar
16 авг. 2017
Они в чем-то связаны:
- Оба нуждаются в атрибуте для обозначения внутреннего. Мы должны скоординировать именование, чтобы избежать путаницы / столкновения.
- Некоторые встроенные функции компилятора требуют, чтобы аргумент был буквальным, аналогично встроенным функциям оборудования. Мы могли бы рассмотреть возможность использования единой концепции в компиляторе. Для встроенных аппаратных средств это свойство будет закодировано в метаданных, для встроенных компонентов компилятора это будет подразумеваться внутренним именем.
Могут быть и другие сходства.
tmat
16 авг. 2017
Оба нуждаются в атрибуте для обозначения внутреннего.
Не согласен. Встроенная среда выполнения может иногда использовать modreq, но не видит необходимости в дополнительном атрибуте. Конечно, не тот, который компилятор будет обрабатывать.
Некоторые встроенные функции компилятора требуют, чтобы аргумент был буквальным, аналогично встроенным функциям оборудования.
Конечно. Но если мы добавим буквальное требование для встроенных функций времени выполнения, это будет сделано в общем виде.
Могут быть и другие сходства.
Я думаю, они совсем другие. Речь идет о добавлении интрис времени выполнения. Компилятор здесь почти не участвует, кроме запроса функции для буквального принуждения. Интуиция компилятора - это предложение, которое касается способности компилятора генерировать новые инструкции IL.
jaredpar
16 авг. 2017
Не согласен. Встроенная среда выполнения может иногда использовать modreq, но не видит необходимости в дополнительном атрибуте. Конечно, не тот, который компилятор будет обрабатывать.
В приведенном выше предложении используется атрибут [Intrinsic] . Я не предлагаю компилятору понимать этот атрибут. Предложение встроенных функций компилятора также вводит атрибут CompilerIntrinsic - его понимает компилятор. Если бы мы назвали оба атрибута просто Intrinsic и поместили бы их в одно и то же пространство имен, это было бы проблемой. Итак, все, что я говорю, это то, что мы должны координировать именование - я бы предпочел, чтобы внутренняя среда выполнения использовала атрибут RuntimeIntrinsic .
tmat
16 авг. 2017
следовательно, я бы предпочел, чтобы встроенная среда выполнения использовала атрибут RuntimeIntrinsic.
Не имеет значения, какой атрибут будет использоваться средой выполнения. Я ожидаю, что он будет внутренним - он не будет публичным или частью публичной поверхности. Фактически, было бы хорошо вообще не иметь для него атрибутов и использовать какой-либо альтернативный механизм для их распознавания во время выполнения.
jkotas
16 авг. 2017
@jkotas Кстати, видимость не имеет значения. Если бы атрибут был и имя было таким же, как у встроенных функций компилятора, это нарушило бы сборку библиотеки CoreFX, которая использует атрибут внутренне.
tmat
16 авг. 2017
Привет всем, я обновил это предложение API на основе вышеупомянутого обсуждения и встречи по рассмотрению проекта . См. Подробности в разделе « Обновление ». Все изменения применяются и к исходному коду нашего API. Как только это предложение будет одобрено, мы отправим полный дизайн API.
fiigii
18 авг. 2017
@fiigii было ли понятно, почему
Vector128<float> CompareVector128(Vector128<float> left, Vector128<float> right, const FloatComparisonMode mode)
и не
Vector128<float> Compare(Vector128<float> left, Vector128<float> right, const FloatComparisonMode mode)
Гнида была бы в том, что Compar e не нужно повторять в имени перечисления и значении перечисления, чтобы его можно было сократить?
public enum FloatComparisonMode : byte
{
EqualOrderedNonSignaling,
LessThanOrderedSignaling,
LessThanOrEqualOrderedSignaling,
UnorderedNonSignaling,
NotEqualUnorderedNonSignaling,
NotLessThanUnorderedSignaling,
NotLessThanOrEqualUnorderedSignaling,
OrderedNonSignaling,
......
}
В противном случае LGTM
benaadams
18 авг. 2017
@benaadams Извините, это моя ошибка. CompareVector* Compare повсюду заменено на
fiigii
18 авг. 2017
Не будет конфликтовать, например
FloatComparisonMode.CompareEqualOrderedNonSignaling
к
FloatComparisonMode.EqualOrderedNonSignaling
StringComparisonMode.CompareEqualOrderedNonSignaling
к
StringComparisonMode.EqualOrderedNonSignaling
benaadams
18 авг. 2017
Гнида была бы в том, что Compare не нужно повторять в имени перечисления и значении перечисления, чтобы его можно было сократить?
Не будет конфликтовать, например
FloatComparisonMode.CompareEqualOrderedNonSignaling
к
FloatComparisonMode.EqualOrderedNonSignaling
Хорошая точка зрения. Это изменение имеет смысл.
fiigii
18 авг. 2017
Добавить диапазон
перегружает наиболее распространенные встроенные функции доступа к памяти (Load, Store, Broadcast), но оставляет другие встроенные функции с учетом выравнивания или производительности с исходной версией указателя.
👎 Я действительно считаю, что это худший из возможных вариантов. Имея только версии ref T , естественно, можно было бы использовать как для собственной / закрепленной, так и для управляемой памяти, теперь у нас остается что-то, что не идеально для управляемой памяти, если вы уже не используете Span . И две перегрузки вместо одного метода. Кроме того, некоторые перегрузки просто доступны только в версии с указателем, не оставляя другого решения, кроме закрепления памяти, что также нежелательно.
nietras
18 авг. 2017
применяются к нашему исходному коду API
@fiigii это где-нибудь доступно?
nietras
18 авг. 2017
@nietras Я работаю над созданием внутреннего исходного кода API в System.Private.CoreLib , позже отправлю PR.
fiigii
19 авг. 2017
Обновление: замените Span<T> overloads на ref T overloads.
fiigii
23 авг. 2017
Привет всем, исходный код внутреннего API был представлен как PR dotnet / corefx # 23489.
fiigii
23 авг. 2017
Где версии скаляров? Им нужно, например, реализовать тригонометрические операции ...
fanoI
24 авг. 2017
@fanoI Это предложение не включает аппаратные инструкции, которые охватываются текущим кодогенератором RyuJIT.
fiigii
24 авг. 2017
sqrtss и sqrtsd, которые, например, требуются для реализации Math.Sqrt (), генерируются текущим кодогенератором RyuJit? Я понял, что они тоже были частью этого предложения ...
А как иначе: https://dtosoftware.wordpress.com/2013/01/07/fast-sin-and-cos-functions/ ?
fanoI
24 авг. 2017
@fiigii , я думал их кратко обсуждали при обзоре API?
В любом случае, если они не являются частью этого предложения, я хотел бы знать, чтобы я мог представить новое предложение, охватывающее их.
Предоставление скалярных инструкций потребуется для реализации определенных алгоритмов (таких как реализация API System.Math и System.MathF в C #). Это также будет полезно / необходимо в некоторых высокопроизводительных алгоритмах для других сценариев.
tannergooding
24 авг. 2017
Разве RyuJIT уже не генерирует sqrtss для MathF.Sqrt() ?
Также похоже, что sqrtsd поддерживается RyuJIT , но я не могу придумать ничего, что использует его из C #, если только реализация Math.Sqrt() изменилась с тех пор, как я последний раз смотрел
 saucecontrol
24 авг. 2017
saucecontrol
24 авг. 2017
@saucecontrol , RyuJIT рассматривает и Math.Sqrt и MathF.Sqrt как внутренние (через CORINFO_INTRINSIC_Sqrt ).
Однако оставшиеся функции Math и MathF возвращаются к соответствующим вызовам среды выполнения C (все они являются FCALL, технически Math.Sqrt и MathF.Sqrt одинаковы). Это приводит как к производительности, так и к несогласованности результатов между Mac, Linux и Windows, а также между ARM и x86. В идеале это (или новое предложение) добавит скалярные перегрузки, чтобы мы могли легко реализовать эти методы в управляемом коде и обеспечить согласованность всех платформ / архитектур.
tannergooding
24 авг. 2017
@fiigii Если задуматься, действительно имеет смысл избавиться от большей части того, что RyuJIT должен делать сам. Если поверхность покрыта, вам не нужно обрабатывать от случая к случаю всю сложность внутри JIT-кода.
redknightlois
24 авг. 2017
Создал предложение, явно охватывающее скалярные перегрузки: https://github.com/dotnet/corefx/issues/23519
tannergooding
24 авг. 2017
Этот API выглядит действительно здорово. Однако есть одна вещь, которую я хотел бы изменить. Можем ли мы поддержать отказ от программного обеспечения?
Я знаю, что очень опаздываю на это обсуждение, но я хотел бы привести аргументы в пользу этого.
Я вижу, что это обсуждение направлено на то, чтобы не иметь запасного программного обеспечения, но я не вижу какого-либо подробного обсуждения плюсов и минусов этого. Для профессионалов я вижу, что кто-то упоминает, что любой код, который запускает потенциальный резервный режим программного обеспечения, будет ошибкой производительности, и было бы лучше, если бы в сценарии произошел сбой, чтобы упростить отладку. Это, конечно, правда, но я бы сказал, что это не совсем .NET-способ делать что-то. Многие аспекты .NET имеют постепенное снижение производительности вместо выдачи исключений, и я уверен, что где-то написано, что это часть философии .NET. Лучше, чтобы код работал медленнее, чем сразу вылетал из строя, если только программист не укажет, что это именно то, что он хочет. Это то, что мне нравится в старом Vector
Я думаю, что часть аргумента в пользу отказа от программного обеспечения частично основана на том факте, что аудитория этого API - это разработчики довольно низкого уровня, которые привыкли использовать расширения SIMD из C ++, ассемблера и т. реальных наборов инструкций нет - для них более комфортная среда разработки. И хотя я считаю, что это будет верно для 98% разработчиков, использующих этот API, я не думаю, что мы должны забывать о более типичных .NET-разработчиках и предполагать, что они никогда не захотят исследовать этот материал, чтобы увидеть, может ли это принести им пользу. В целом, я считаю ошибкой разрабатывать подобный API и предполагать, что только определенный тип разработчика захочет его использовать. Особенно что-то встроенное в .NET.
Вот некоторые из плюсов, которые я считаю резервным программным обеспечением:
Лучший опыт разработки: я согласен с тем, что сбой при отсутствии используемого расширения имеет некоторые преимущества, но также рассмотрю преимущества резервного программного обеспечения. Резервное программное обеспечение обеспечивает способ надежного изучения использования всех классов набора команд, включая те, которые не поддерживаются на машине разработчика. Это может не волновать многих в этом обсуждении, но дает разработчикам удобный способ протестировать алгоритмы, убедившись, что они логически верны, прежде чем решить, стоит ли их тестировать на реальном оборудовании. Некоторые сценарии отладки проще. Например, если пользователь библиотеки сообщает об ошибке при запуске ее на устройствах ARM из-за ошибки в коде, использующем NEON, разработчик этой библиотеки имеет возможность исправить это на машине x86, поскольку они могут воспроизвести и исправить ошибку с помощью резервного программного обеспечения NEON. Конечно, было бы лучше, если бы у разработчика было оборудование NEON для отладки, но это не всегда практично, и разработчик имеет право улучшить свой код намного легче за меньшее время, чем в противном случае. Резервное программное обеспечение также обеспечит гораздо больший потенциал для модульных тестов, которые могут тестировать путь кода для всех классов набора инструкций, независимо от того, что поддерживает локальная машина разработчика.
Более надежный код: безусловно, любой код, работающий в резервном режиме программного обеспечения, где существуют полезные расширения, которые будут работать быстрее, или написанный от руки программный алгоритм, может считаться ошибкой производительности. Однако в реальном мире у разработчиков неизбежно ограниченное время для написания и отладки кода. Ошибки неизбежны, и разработчики просто предпочтут не утруждать себя написанием кода, который не предполагает наличия определенного набора расширений. .NET выделяется тем, что позволяет разработчикам писать код, который работает быстро и надежно, а затем оптимизировать этот код для более быстрой работы по своему усмотрению. Учитывая кодовую базу, в которой разработчик использует эти расширения, но не имеет времени и ресурсов, чтобы гарантировать, что их код работает надлежащим образом на любой платформе, тогда для потребителя библиотеки или приложения гораздо предпочтительнее, чтобы этот код выполнялся много раз. медленнее, чем полностью вылететь. Я считаю, что это повлияет на разработчиков, использующих библиотеки, написанные с помощью этого API, и на конечных пользователей, которые потенциально могут столкнуться с полным сбоем из-за того, что приложение было написано без тестирования с наборами инструкций, доступными на ЦП пользователя.
В целом, я думаю, что резервное программное обеспечение не принесет почти никаких неудобств разработчикам, которые считают, что они не извлекут из этого выгоду, но в то же время сделает API намного более доступным для обычных разработчиков .NET.
Я не ожидаю, что это изменится, учитывая, как я опоздал с этим, но я подумал, что хотя бы изложу свои мысли здесь.
 battlebottle
2 янв. 2018
battlebottle
2 янв. 2018
Я согласен с тем, что было бы неплохо иметь возможность отката программного обеспечения. Однако, учитывая, что это просто полезная функция, которая также может быть реализована отдельными разработчиками при необходимости или в качестве сторонней библиотеки, я думаю, что ее следует разместить в нижней части список дел. Я бы предпочел, чтобы эта энергия была направлена на полную поддержку AVX-512, которая уже какое-то время доступна на процессорах серверного уровня и на пути к потребительским процессорам.
 skesgin
16 янв. 2018
skesgin
16 янв. 2018
Пинговать новости AVX512?
 oscarbg
12 апр. 2018
oscarbg
12 апр. 2018
У нас еще есть некоторые ISA, которые нужно реализовать до того, как будут завершены уже принятые API - некоторые встроенные функции AVX2 и все AES, BMI1, BMI2, FMA, PCMULQDQ. Я ожидаю, что после завершения этой работы и стабилизации реализации мы начнем работу над AVX512. Однако пока что у нас все еще есть дела с реализациями Arm64.
@fiigii, вероятно, может предоставить больше информации о планах на будущее.
4creators
12 апр. 2018
Я согласен с тем, что было бы неплохо иметь возможность отката программного обеспечения.
Этот API выглядит действительно здорово. Однако есть одна вещь, которую я хотел бы изменить. Можем ли мы поддержать отказ от программного обеспечения?
Текущее представление о реализации встроенных функций аппаратного обеспечения заключается в том, что мы предоставляем встроенные функции низкого уровня, которые позволяют выполнять сборку, такую как программирование, плюс несколько вспомогательных встроенных функций, которые должны облегчить жизнь разработчика.
Реализация, которая обеспечивает большую абстракцию и откат программного обеспечения, частично доступна уже в пространстве имен System.Numerics с Vector<T> . Ожидается, что встроенные функции аппаратного обеспечения позволят расширить функциональность реализации Vector<T> счет добавления новых функций, поддерживаемых резервным программным обеспечением. Реализацию Vector<T> следует рассматривать не как интерфейс программирования более высокого уровня, который может использоваться на всех аппаратных платформах из-за отказа программного обеспечения.
Вышесказанное, однако, является личным мнением члена сообщества.
4creators
12 апр. 2018
Пинговать новости AVX512?
После завершения этих API-интерфейсов (например, AVX2, FMA и т. Д.), Я думаю, нам нужно изучить больше потенциальных проблем с производительностью (например, преобразование вызовов, выравнивание данных), прежде чем мы перейдем к следующему шагу, потому что эти проблемы могут взорваться с более широким SIMD. архитектуры. Между тем, я предпочитаю улучшить / реорганизовать реализацию JIT-бэкэнда (эмиттер, кодген и т. Д.), Прежде чем расширять ее до AVX-512. Да, нам определенно нужно расширить этот план до AVX-512 в будущем, но теперь лучше сосредоточиться на улучшении 128/256-битных встроенных функций.
fiigii
12 апр. 2018
Лично я не считаю, что откат программного обеспечения стоит тратить усилия разработчика, поскольку потребитель может легко реализовать обратную связь с программным обеспечением, если он хочет ее получить, и, кроме того, он работает лучше на уровне алгоритмов, чем откат программного обеспечения на внутреннем уровне.
На самом деле реализация всех десятков встроенных функций, которые существуют для всех целевых платформ, - это не то, что потребитель может сделать сам, и поэтому я лично предпочел бы иметь более высокий приоритет.
Кстати, отличный материал, я очень надеюсь, что все эти встроенные функции будут доступны.
 Jorenkv
13 апр. 2018
Jorenkv
13 апр. 2018
Небольшое предложение по улучшению API с моей стороны:
Добавьте свойство Count ко всем векторным VT, которое будет похоже на System.Numerics.Vector.Count , хотя и даст статическое значение, основанное исключительно на аргументе универсального типа Vector64/128/256/etc<T> .
Реализация может выглядеть как Unsafe.SizeOf<Vector128<T>>() / Unsafe.SizeOf<T>() .
Причина этого предложения - когда аргумент универсального типа известен заранее (например, конкретный тип, такой как ushort , int и т. Д.), Тогда измерение вектора может быть просто жестко закодировано в исходном коде. Но это не относится к коду, который использует подход с обобщениями - измерение должно часто пересчитываться в исходном коде, когда это необходимо (снова).
 voinokin
22 мая 2018
voinokin
22 мая 2018
В. Есть ли шанс, что эта функция когда-либо будет доступна в .NET Standard?
Я поддерживаю библиотеку кода / nuget, которая выиграет от использования этих встроенных аппаратных средств, но в настоящее время она нацелена на .NET Standard для обеспечения хорошей переносимости.
В идеале я хотел бы и дальше предлагать переносимость, но также улучшать производительность, если платформа / среда выполнения предоставляет эти встроенные функции. Прямо сейчас мне кажется, что мой выбор - либо скорость, либо портативность, но не то и другое вместе - вероятно ли, что это изменится в будущем?
 colgreen
25 мая 2018
colgreen
25 мая 2018
@colgreen Это обсуждалось в https://github.com/dotnet/corefx/issues/24346. Рекомендую перенести обсуждение туда.
jkotas
25 мая 2018
Где найти документацию по использованию встроенных функций? Я вижу, что атрибут [Intrinsic] используется в Vector2_Intrinsics.cs , но также и в Vector2.cs , и я не уверен, почему и как это работает.
 aaronfranke
31 мая 2019
aaronfranke
31 мая 2019
@aaronfranke Я не знаю, сколько вы уже знаете, но насколько я понимаю, IntrinsicAttribute применяется к нескольким методам, в которых компилятор должен заменять обычные инструкции специально сгенерированными инструкциями. Это возможно только потому, что вы распространяете код IL для работы на разных платформах, и если платформа имеет инструкцию popcnt, это обрабатывается как особый случай.
Мой пример ненастоящий, но вы, вероятно, сможете найти реальные примеры в CoreCLR, если будете искать использование IntrinsicAttribute.
 Genbox
1 июн. 2019
Genbox
1 июн. 2019
IntrinsicAttribute - это внутренняя деталь реализации. Вам не нужно беспокоиться об этом, чтобы использовать встроенные функции.
https://devblogs.microsoft.com/dotnet/using-net-hardware-intrinsics-api-to-accelerate-machine-learning-scenarios/ описывает хорошие примеры внутреннего использования реального оборудования.
jkotas
1 июн. 2019
Если у вас уже есть опыт программирования SIMD или низкоуровневого программирования на C / C ++, достаточно будет комментария источника API .
Если нет, то эта статья « Аппаратные средства, встроенные в .NET Core 3.0 - Введение», будет хорошим началом.
fiigii
2 июн. 2019
Смежные вопросы
 matty-hall
·
3Комментарии
matty-hall
·
3Комментарии
 Timovzl
·
3Комментарии
Timovzl
·
3Комментарии
 omariom
·
3Комментарии
omariom
·
3Комментарии
 EgorBo
·
3Комментарии
EgorBo
·
3Комментарии
 btecu
·
3Комментарии
btecu
·
3Комментарии
Самый полезный комментарий
Я согласен с тем, что было бы неплохо иметь возможность отката программного обеспечения. Однако, учитывая, что это просто полезная функция, которая также может быть реализована отдельными разработчиками при необходимости или в качестве сторонней библиотеки, я думаю, что ее следует разместить в нижней части список дел. Я бы предпочел, чтобы эта энергия была направлена на полную поддержку AVX-512, которая уже какое-то время доступна на процессорах серверного уровня и на пути к потребительским процессорам.