感谢您提出问题! 按下按钮之前,请先回答以下问题。
这是寻求帮助吗? 没有
提交此关键字之前,您在Kubernetes问题中搜索了哪些关键字? (如果发现任何重复项,则应该在该位置答复。):PLEG NotReady kubelet
这是错误报告还是功能请求? 虫子
如果这是错误报告,请:-尽可能填写以下模板。 如果您遗漏了信息,我们也无法为您提供帮助。 如果这是一项功能请求,请:-详细描述*您想要查看的功能/行为/更改。 在这两种情况下,请准备好后续问题,请及时答复。 如果我们无法重现错误或认为功能已经存在,我们可能会解决您的问题。 如果我们错了,请随时重新打开它并解释原因。Kubernetes版本(使用kubectl version ):1.6.2
环境:
- 云提供商或硬件配置:AWS上的CoreOS
- 操作系统(例如/ etc / os-release中的版本):CoreOS 1353.7.0
- 内核(例如
uname -a):4.9.24-coreos - 安装工具:
- 其他:
发生了什么:
我有一个三人群集。 两个节点(有时甚至是三个节点)随着journalctl -u kubelet的以下消息不断进入NotReady journalctl -u kubelet :
May 05 13:59:56 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 13:59:56.872880 2858 kubelet_node_status.go:379] Recording NodeNotReady event message for node ip-10-50-20-208.ec2.internal
May 05 13:59:56 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 13:59:56.872908 2858 kubelet_node_status.go:682] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-05-05 13:59:56.872865742 +0000 UTC LastTransitionTime:2017-05-05 13:59:56.872865742 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.629592089s ago; threshold is 3m0s}
May 05 14:07:57 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:07:57.598132 2858 kubelet_node_status.go:379] Recording NodeNotReady event message for node ip-10-50-20-208.ec2.internal
May 05 14:07:57 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:07:57.598162 2858 kubelet_node_status.go:682] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-05-05 14:07:57.598117026 +0000 UTC LastTransitionTime:2017-05-05 14:07:57.598117026 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.346983738s ago; threshold is 3m0s}
May 05 14:17:58 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:17:58.536101 2858 kubelet_node_status.go:379] Recording NodeNotReady event message for node ip-10-50-20-208.ec2.internal
May 05 14:17:58 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:17:58.536134 2858 kubelet_node_status.go:682] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-05-05 14:17:58.536086605 +0000 UTC LastTransitionTime:2017-05-05 14:17:58.536086605 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.275467289s ago; threshold is 3m0s}
May 05 14:29:59 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:29:59.648922 2858 kubelet_node_status.go:379] Recording NodeNotReady event message for node ip-10-50-20-208.ec2.internal
May 05 14:29:59 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:29:59.648952 2858 kubelet_node_status.go:682] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-05-05 14:29:59.648910669 +0000 UTC LastTransitionTime:2017-05-05 14:29:59.648910669 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.377520804s ago; threshold is 3m0s}
May 05 14:44:00 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:44:00.938266 2858 kubelet_node_status.go:379] Recording NodeNotReady event message for node ip-10-50-20-208.ec2.internal
May 05 14:44:00 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:44:00.938297 2858 kubelet_node_status.go:682] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-05-05 14:44:00.938251338 +0000 UTC LastTransitionTime:2017-05-05 14:44:00.938251338 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.654775919s ago; threshold is 3m0s}
docker daemon很好(本地docker ps , docker images等都可以正常工作并立即响应)。
使用通过kubectl apply -f https://git.io/weave-kube-1.6安装的编织网络
您预期会发生什么:
节点准备就绪。
如何复制它(尽可能少且精确):
希望我知道如何!
我们需要了解的其他信息:
具有专用于Internet的NAT网关的同一专用子网上的所有节点(工作人员和主节点)。 安全组中的工作程序,允许来自主安全组的无限访问(所有端口); 主机允许来自同一子网的所有端口。 代理正在工人上运行; apiserver,控制器管理器,主服务器上的调度程序。
kubectl logs和kubectl exec始终挂起,即使从主服务器本身(或从外部)运行也是如此。
 deitch
deitch
所有225条评论
@deitch ,节点上正在运行多少个容器? 您的节点的总体CPU使用率是多少?
 yujuhong
于 2017-05-05
yujuhong
于 2017-05-05
基本上没有。 kube-dns,weave-net,weave-npc和3个模板样本服务。 实际上只有一个,因为两个没有图像,将被清理。 AWS m4.2xlarge。 不是资源问题。
我最终不得不销毁节点并重新创建。 自从销毁/重新创建以来没有PLEG消息,它们似乎可以50%确定。 他们仍然保留Ready ,尽管他们仍然拒绝允许kubectl exec或kubectl logs 。
我真的很难找到关于PLEG真正是什么的任何文档,但是更重要的是如何检查它自己的日志以及状态和调试它。
deitch
于 2017-05-05
嗯...增加了一个谜,没有容器可以解析任何主机名,而kubedns给出:
E0505 17:30:49.412272 1 reflector.go:199] pkg/dns/config/sync.go:114: Failed to list *api.ConfigMap: Get https://10.200.0.1:443/api/v1/namespaces/kube-system/configmaps?fieldSelector=metadata.name%3Dkube-dns&resourceVersion=0: dial tcp 10.200.0.1:443: getsockopt: no route to host
E0505 17:30:49.412285 1 reflector.go:199] pkg/dns/dns.go:148: Failed to list *api.Service: Get https://10.200.0.1:443/api/v1/services?resourceVersion=0: dial tcp 10.200.0.1:443: getsockopt: no route to host
E0505 17:30:49.412272 1 reflector.go:199] pkg/dns/dns.go:145: Failed to list *api.Endpoints: Get https://10.200.0.1:443/api/v1/endpoints?resourceVersion=0: dial tcp 10.200.0.1:443: getsockopt: no route to host
I0505 17:30:51.855370 1 logs.go:41] skydns: failure to forward request "read udp 10.100.0.3:60364->10.50.0.2:53: i/o timeout"
FWIW, 10.200.0.1是内部的kube api服务, 10.200.0.5是DNS, 10.50.20.0/24和10.50.21.0/24是主节点和工作节点的子网(2个独立的可用区)跑。
联网中真正有用的东西吗?
deitch
于 2017-05-05
联网中真正有用的东西吗?
@bboreham可能与编织而不是kube有关(或至少与配置错误有关)吗? 如在https://github.com/weaveworks/weave/issues/2736上讨论的那样,添加了IPALLOC_RANGE=10.100.0.0/16标准编织
deitch
于 2017-05-05
@deitch pleg用于kubelet定期列出节点中的pod,以检查运行状况并更新缓存。 如果您看到pleg超时日志,它可能与dns无关,但是因为kubelet对docker的调用是超时。
 qiujian16
于 2017-05-11
qiujian16
于 2017-05-11
谢谢@ qiujian16 。 该问题似乎已经消失,但是我不知道如何检查。 Docker本身看起来很健康。 我想知道它是否可能是网络插件,但这不应该影响kubelet本身。
您能在这里给我一些指示来检查大便的健康和状况吗? 然后,我们可以将其关闭,直到我看到问题再次出现为止。
deitch
于 2017-05-11
@deitch pleg是“ pod生命周期事件生成器”的缩写,它是kubelet的内部组件,我认为您无法直接检查其状态,请参阅(https://github.com/kubernetes/community/blob/master /contributors/design-proposals/pod-lifecycle-event-generator.md)
qiujian16
于 2017-05-11
它是kubelet二进制文件中的内部模块吗? 是另一个独立容器(docker,runc,cotnainerd)吗? 它只是一个独立的二进制文件吗?
基本上,如果kubelet报告PLEG错误,找出这些错误是什么,然后检查其状态,尝试并复制非常有帮助。
deitch
于 2017-05-11
它是一个内部模块
qiujian16
于 2017-05-11
@deitch极有可能是
yujuhong
于 2017-05-11
我在所有节点上都遇到了类似的问题,但我刚刚创建了一个集群,
日志:
kube-worker03.foo.bar.com kubelet[3213]: E0511 19:00:59.139374 3213 remote_runtime.go:109] StopPodSandbox "12c6a5c6833a190f531797ee26abe06297678820385b402371e196c69b67a136" from runtime service failed: rpc error: code = 4 desc = context deadline exceeded
May 11 19:00:59 kube-worker03.foo.bar.com kubelet[3213]: E0511 19:00:59.139401 3213 kuberuntime_gc.go:138] Failed to stop sandbox "12c6a5c6833a190f531797ee26abe06297678820385b402371e196c69b67a136" before removing: rpc error: code = 4 desc = context deadline exceeded
May 11 19:01:04 kube-worker03.foo.bar.com kubelet[3213]: E0511 19:01:04.627954 3213 pod_workers.go:182] Error syncing pod 1c43d9b6-3672-11e7-a6da-00163e041106
("kube-dns-4240821577-1wswn_kube-system(1c43d9b6-3672-11e7-a6da-00163e041106)"), skipping: rpc error: code = 4 desc = context deadline exceeded
May 11 19:01:18 kube-worker03.foo.bar.com kubelet[3213]: E0511 19:01:18.627819 3213 pod_workers.go:182] Error syncing pod 1c43d9b6-3672-11e7-a6da-00163e041106
("kube-dns-4240821577-1wswn_kube-system(1c43d9b6-3672-11e7-a6da-00163e041106)"),
skipping: rpc error: code = 4 desc = context deadline exceeded
May 11 19:01:21 kube-worker03.foo.bar.com kubelet[3213]: I0511 19:01:21.627670 3213 kubelet.go:1752] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.339074625s ago; threshold is 3m0s]
我已经将docker降级,并且几乎所有内容都重新启动,但都无济于事,所有节点都通过puppet管理,因此我希望它们完全相同,我不知道哪里出了问题。 Docker在调试模式下的日志显示它正在获取这些请求
 bjhaid
于 2017-05-11
bjhaid
于 2017-05-11
@bjhaid您正在使用什么网络? 当时我看到一些有趣的网络问题。
deitch
于 2017-05-11
@deitch编织,但是我不认为这是与网络相关的问题,因为这似乎是kubelet与docker之间的通信问题。 我可以确认docker通过docker的调试日志记录从kubelet获取这些请求
bjhaid
于 2017-05-11
我的Pleg问题似乎消失了,尽管直到下次我重新建立这些集群(全部通过我构建的terraform模块)时,我才会感到自信。
编织问题似乎存在,或者可能是k8s / docker。
deitch
于 2017-05-11
@deitch您是否采取了任何措施使Pleg问题消失,或者它们发生了魔术?
bjhaid
于 2017-05-11
实际上是主机名解析,控制器无法解析新创建的节点的主机名,对不起。
bjhaid
于 2017-05-11
我很快就报告情况还不错,问题仍然存在,如果发现任何问题,我会继续寻找并报告
bjhaid
于 2017-05-11
我猜这个问题与weave-kube有关,这次我遇到了同样的问题,这次为了解决它而不重新创建群集,我不得不删除编织并重新应用它(重新启动节点才能传播删除订单)...又回来了
所以我不知道为什么或如何确定是由于weave-kube-1.6
 gbergere
于 2017-05-19
gbergere
于 2017-05-19
忘了回到这里,我的问题是由于编织接口未打开,因此容器没有联网,但是这是由于防火墙阻止了编织数据和vxlan端口,一旦打开此端口,一切都很好
bjhaid
于 2017-05-19
我遇到过两套可能相关的问题。
- PLEG。 我相信它们已经消失了,但是我没有重建足够的集群以完全自信。 我不相信我会做出太多(即任何改变)直接实现这一目标。
- 编织一些问题,其中容器无法连接到任何东西。
令人怀疑的是,所有与pleg有关的问题都与编织网络问题完全同时发生。
Bryan @ weaveworks,向我指出了coreos问题。 CoreOS倾向于尝试并管理桥梁,车辆,基本上所有东西。 一旦我禁用了CoreOS,除了在lo以及主机上的实际物理接口上禁用了它,我所有的问题都就剩下了。
人们仍然在运行coreos时遇到问题吗?
deitch
于 2017-05-19
在过去一个月左右的时间里,这些问题困扰着我们(我想说的是,将群集从1.5.x升级到1.6.x之后),而它同样神秘。
我们正在用aws进行编织,debian jessie AMI,并且每隔一段时间,群集就会决定PLEG不健康。
在这种情况下,编织似乎还可以,因为豆荚可以很好地利用一点。
我们注意到的一件事是,如果缩减所有副本的数量,问题似乎就消失了,但是随着我们开始缩减部署和状态集的备份,围绕一定数量的容器,这种情况发生了。 (至少这次)。
码头工人ps; 码头上的码头工人信息似乎很好。
资源利用率是正常的:5%的CPU利用率,使用的1.5 / 8gb的RAM(根据根htop),总节点资源配置约占30%,而所有本应按计划进行的计划都已计划。
我们根本无法解决这个问题。
我真的希望PLEG检查稍微冗长一些,并且我们对蜂鸣声的执行情况有一些实际的详细记录,因为似乎有很多问题需要解决,没人真正知道它是什么,为此关键模块,我希望能够重现它认为失败的检查。
 hollowimage
于 2017-05-26
hollowimage
于 2017-05-26
我赞同关于大腿神秘的想法。 不过,对我而言,在为客户完成大量工作之后,稳定coreos及其与网络的不良行为大有帮助。
deitch
于 2017-05-26
PLEG健康检查功能很少。 在每次迭代中,它调用docker ps来检测容器状态的变化,并调用docker ps和inspect以获取这些容器的详细信息。
完成每次迭代后,它将更新时间戳记。 如果时间戳有一段时间(即3分钟)没有更新,则运行状况检查将失败。
除非您的节点上装有大量的Pod,而PLEG无法在3分钟内完成所有这些操作(这是不应该发生的),否则最可能的原因是docker运行缓慢。 您可能在偶尔的docker ps支票中没有注意到这一点,但这并不意味着它不存在。
如果我们不公开“不健康”状态,它将对用户隐藏许多问题,并可能导致更多问题。 例如,kubelet会默默地不及时对变化做出反应,甚至引起更多的混乱。
欢迎提出有关如何使其更可调试的建议...
yujuhong
于 2017-05-27
遇到PLEG不健康的警告并摆动节点健康状况:编织时k8s 1.6.4。 仅出现在(否则相同)节点的子集上。
 anurag
于 2017-05-27
anurag
于 2017-05-27
请立即注意,在我们的案例中,卡在ContainerCreating中的扑朔迷离的工人和豆荚是EC2实例的安全组的一个问题,不允许主机与工人之间以及工人之间进行通信。 因此,该节点无法正确启动并陷入“未就绪”状态。
kuberrnetes 1.6.4
有了适当的安全组,它现在可以工作。
 agabert
于 2017-06-01
agabert
于 2017-06-01
我在使用此配置时遇到了类似此问题的问题...
Kubernetes版本(使用Kubectl版本):1.6.4
环境:
云提供商或硬件配置:单个System76服务器
操作系统(例如,/ etc / os-release中的版本):Ubuntu 16.04.2 LTS
内核(例如uname -a):Linux系统76服务器4.4.0-78-通用#99-Ubuntu SMP Thu Apr 27 15:29:09 UTC 2017 x86_64 x86_64 x86_64 GNU / Linux
安装工具:kubeadm + weave.works
由于这是一个单节点群集,因此我认为此版本与安全组或防火墙无关。
 wirehead
于 2017-06-01
wirehead
于 2017-06-01
如果您只是启动群集,则安全组的问题将很有意义。 但是,我们看到的这些问题是在已经运行了几个月且具有安全组的群集上。
hollowimage
于 2017-06-02
我在GKE上运行kubelet 1.6.2版时遇到了类似的情况。
我们的一个节点进入了未就绪状态,该节点上的kubelet日志有两个投诉,一个是PLEG状态检查失败,另一个是图像列表操作失败。
某些图像函数调用失败的示例。
image_gc_manager.go:176
kuberuntime_image.go:106
remote_image.go:61
我假设是对docker守护程序的调用。
发生这种情况时,我看到磁盘IO大量增加,尤其是读取操作。 从〜50kb / s标记到8mb / s标记。
在大约30-45分钟后,它会自行纠正,但也许是图像GC扫描导致IO增加?
如前所述,PLEG通过docker守护程序监视pod,如果一次执行大量操作,是否可以将PLEG检查排入队列?
 zoltrain
于 2017-06-02
zoltrain
于 2017-06-02
我在1.6.4和1.6.6(在GKE上)中看到了此问题,结果是扑朔迷离。 因为这是GKE上可用的最新版本,所以我希望将所有修补程序都移植到下一个1.6版本中。
一件有趣的事是,PLEG上次出现的时间不会改变,并且始终是一个_huge_数字(也许在某种存储类型的限制下)。
[container runtime is down PLEG is not healthy: pleg was last seen active 2562047h47m16.854775807s ago; threshold is 3m0s]
 bergman
于 2017-06-26
bergman
于 2017-06-26
[容器运行时已关闭PLEG不健康:上次看到pleg是活动的2562047h47m16.854775807之前; 阈值为3m0s]
@bergman我还没有看到这种情况,但是如果是这种情况,那么您的节点将永远无法准备就绪。 随时通过GKE渠道进行举报,以便GKE团队可以进行更多调查。
在大约30-45分钟后,它会自行纠正,但也许是图像GC扫描导致IO增加?
这当然是可能的。 Image GC有时可能会导致docker守护程序响应非常缓慢。 30-45分钟听起来很长。 @zoltrain ,是在整个持续时间内都删除了图像。
重申一下我之前的声明,PLEG几乎没有做任何事情,并且由于docker守护程序没有响应,因此只能通过运行状况检查。 我们通过PLEG运行状况检查显示此信息,以使控制平面知道节点未正确获取容器统计信息(并对其做出反应)。 盲目删除此检查可能会掩盖更严重的问题。
yujuhong
于 2017-06-26
更新:我们最终发现了与编织和ip-slice设置相关的问题。 由于我们经常在AWS中终止节点,因此编织最初并没有永久性地考虑群集中节点的破坏,而是要遵循新的IP。 结果,网络连接将无法正确设置,因此与内部范围有关的任何事情都将无法正确显示。
https://github.com/weaveworks/weave/issues/2970
对于那些使用编织的人。
hollowimage
于 2017-06-26
[容器运行时已关闭PLEG不健康:上次看到pleg是活动的2562047h47m16.854775807之前; 阈值为3m0s]
@bergman我还没有看到这种情况,但是如果是这种情况,那么您的节点将永远无法准备就绪。 随时通过GKE渠道进行举报,以便GKE团队可以进行更多调查。
该节点大多数时候都处于“就绪”状态。 我相信kubelet要么由于此检查而重新启动,要么其他检查正发出Ready事件信号。 我们每60秒看到大约10秒钟的未就绪状态。 其余时间节点处于就绪状态。
bergman
于 2017-06-27
@yujuhong我认为可以改善PLEG日志记录,对最终用户说PLEG is not healthy超级混乱,它无助于诊断问题,可能包括为什么容器运行时失败或有关容器运行时的一些详细信息回应会更有用
bjhaid
于 2017-06-27
我看不到有1.6.4和印花布的节点出现震荡但始终未就绪的状态,而不是编织。
 chenww
于 2017-07-21
chenww
于 2017-07-21
@yujuhong我认为PLEG日志记录可以改善,因为PLEG不健康会对最终用户造成
当然。 随时发送PR。
yujuhong
于 2017-07-21
我在清理docker映像时遇到了这个问题。 我猜码头工人太忙了。 删除图像后,它又恢复了正常。
 xcompass
于 2017-08-19
xcompass
于 2017-08-19
我遇到了同样的问题。 我怀疑原因是ntpd当前时间正确。
我已经看到v1.6.9中的ntpd正确时间
Sep 12 19:05:08 node-6 systemd: Started logagt.
Sep 12 19:05:08 node-6 systemd: Starting logagt...
Sep 12 19:05:09 node-6 cnrm: "Log":"2017-09-12 19:05:09.197083#011ERROR#011node-6#011knitter.cnrm.mod-init#011TransactionID=1#011InstanceID=1174#011[ObjectType=null,ObjectID=null]#011registerOir: k8s.GetK8sClientSingleton().RegisterOir(oirName: hugepage, qty: 2048) FAIL, error: dial tcp 120.0.0.250:8080: getsockopt: no route to host, retry#011[init.go]#011[68]"
Sep 12 11:04:53 node-6 ntpd[902]: 0.0.0.0 c61c 0c clock_step -28818.771869 s
Sep 12 11:04:53 node-6 ntpd[902]: 0.0.0.0 c614 04 freq_mode
Sep 12 11:04:53 node-6 systemd: Time has been changed
Sep 12 11:04:54 node-6 ntpd[902]: 0.0.0.0 c618 08 no_sys_peer
Sep 12 11:05:04 node-6 systemd: Reloading.
Sep 12 11:05:04 node-6 systemd: Configuration file /usr/lib/systemd/system/auditd.service is marked world-inaccessible. This has no effect as configuration data is accessible via APIs without restrictions. Proceeding anyway.
Sep 12 11:05:04 node-6 systemd: Started opslet.
Sep 12 11:05:04 node-6 systemd: Starting opslet...
Sep 12 11:05:13 node-6 systemd: Reloading.
Sep 12 11:05:22 node-6 kubelet: E0912 11:05:22.425676 2429 event.go:259] Could not construct reference to: '&v1.Node{TypeMeta:v1.TypeMeta{Kind:"", APIVersion:""}, ObjectMeta:v1.ObjectMeta{Name:"120.0.0.251", GenerateName:"", Namespace:"", SelfLink:"", UID:"", ResourceVersion:"", Generation:0, CreationTimestamp:v1.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*v1.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string{"beta.kubernetes.io/os":"linux", "beta.kubernetes.io/arch":"amd64", "kubernetes.io/hostname":"120.0.0.251"}, Annotations:map[string]string{"volumes.kubernetes.io/controller-managed-attach-detach":"true"}, OwnerReferences:[]v1.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:""}, Spec:v1.NodeSpec{PodCIDR:"", ExternalID:"120.0.0.251", ProviderID:"", Unschedulable:false, Taints:[]v1.Taint(nil)}, Status:v1.NodeStatus{Capacity:v1.ResourceList{"cpu":resource.Quantity{i:resource.int64Amount{value:4000, scale:-3}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"DecimalSI"}, "memory":resource.Quantity{i:resource.int64Amount{value:3974811648, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"BinarySI"}, "hugePages":resource.Quantity{i:resource.int64Amount{value:1024, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"DecimalSI"}, "pods":resource.Quantity{i:resource.int64Amount{value:110, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"DecimalSI"}}, Allocatable:v1.ResourceList{"cpu":resource.Quantity{i:resource.int64Amount{value:3500, scale:-3}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"DecimalSI"}, "memory":resource.Quantity{i:resource.int64Amount{value:1345666048, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"BinarySI"}, "hugePages":resource.Quantity{i:resource.int64Amount{value:1024, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"",
Sep 12 11:05:22 node-6 kubelet: Format:"DecimalSI"}, "pods":resource.Quantity{i:resource.int64Amount{value:110, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"DecimalSI"}}, Phase:"", Conditions:[]v1.NodeCondition{v1.NodeCondition{Type:"OutOfDisk", Status:"False", LastHeartbeatTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196025689, loc:(*time.Location)(0x4e8e3a0)}}, LastTransitionTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196025689, loc:(*time.Location)(0x4e8e3a0)}}, Reason:"KubeletHasSufficientDisk", Message:"kubelet has sufficient disk space available"}, v1.NodeCondition{Type:"MemoryPressure", Status:"False", LastHeartbeatTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196099492, loc:(*time.Location)(0x4e8e3a0)}}, LastTransitionTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196099492, loc:(*time.Location)(0x4e8e3a0)}}, Reason:"KubeletHasSufficientMemory", Message:"kubelet has sufficient memory available"}, v1.NodeCondition{Type:"DiskPressure", Status:"False", LastHeartbeatTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196107935, loc:(*time.Location)(0x4e8e3a0)}}, LastTransitionTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196107935, loc:(*time.Location)(0x4e8e3a0)}}, Reason:"KubeletHasNoDiskPressure", Message:"kubelet has no disk pressure"}, v1.NodeCondition{Type:"Ready", Status:"False", LastHeartbeatTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196114314, loc:(*time.Location)(0x4e8e3a0)}}, LastTransitionTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196114314, loc:(*time.Location)(0x4e8e3a0)}}, Reason:"KubeletNotReady", Message:"container runtime is down,PLEG is not healthy: pleg was last seen active 2562047h47m16.854775807s ago; threshold is 3m0s,network state unknown"}}, Addresses:[]v1.NodeAddress{v1.NodeAddress{Type:"LegacyHostIP", Address:"120.0.0.251"}, v1.NodeAddress{Type:"InternalIP", Address:"120.0.0.251"}, v1.NodeAddress{Type:"Hostname", Address:"120.0.0.251"}}, DaemonEndpoints:v1.NodeDaemonEndpoints{KubeletEndpoint:v1.DaemonEndpoint{Port:10250}}, NodeInfo:v1.NodeS
 yanxuean
于 2017-09-14
yanxuean
于 2017-09-14
标记。
 warmchang
于 2017-09-14
warmchang
于 2017-09-14
这里同样的问题。
当吊舱杀死但停留在杀死状态Normal Killing Killing container with docker id 472802bf1dba: Need to kill pod.
和kubelet日志是这样的:
skipping pod synchronization - [PLEG is not healthy: pleg was last seen active
k8s cluste版本:1.6.4
@xcompass是否对kubelet配置使用--image-gc-high-threshold和--image-gc-low-threshold标志? 我怀疑kubelet gc一直忙于docker deamon。
 alirezaDavid
于 2017-09-19
alirezaDavid
于 2017-09-19
@alirezaDavid我遇到了与您一样的问题,pod的启动和终止非常缓慢,并且节点不时变为Ready状态,在节点上重新启动kubelet或重新启动docker看起来可以解决问题,但这不是正确的方法。
 yangyuw
于 2017-09-19
yangyuw
于 2017-09-19
@ yu-yang2是的,我重新启动kubelet
但是在重启kubelet之前,我签出了docker ps和systemctl -u docker ,一切似乎都正常了。
alirezaDavid
于 2017-09-19
我们在使用编织和自动缩放器的kubernetes上遇到了这个问题。 事实证明,编织没有更多的IP地址可以分配。 通过运行检测到。 从此问题编织状态ipam: https :
根本原因在这里: https :
该文档警告有关自动定标器并进行编织: https :
当我们运行weave --local status ipam时,有数百个不可用的节点,并为其分配了大量IP地址。 发生这种情况是因为自动缩放器会在不通知编织的情况下终止实例。 对于实际连接的节点,这只剩下极少数。 我使用编织rmpeer清除了一些不可用的同级项。 然后,这给了我在一组IP地址上运行的节点。 然后,我去了其他正在运行的编织节点,并从中运行了一些rmpeer命令(我不确定是否有必要)。
我终止了一些ec2实例,新的实例由自动缩放器启动,并立即被分配了ip地址。
 mattthelee
于 2017-09-29
mattthelee
于 2017-09-29
嗨伙计。 就我而言,我遇到了删除沙箱的PLEG问题,因为它们没有网络名称空间。 https://github.com/kubernetes/kubernetes/issues/44307中描述的情况
我的问题是:
- 已部署Pod。
- 窗格已删除。 应用程序容器已删除,没有问题。 应用程序的沙箱未删除。
- PLEG尝试提交/删除/完成沙箱,PLEG无法执行此操作并将节点标记为不正常。
如我所见,此bug中的所有人都使用Kubernetes的1.6。*,应该将其修复为1.7。
PS。 在起源3.6(kubernetes 1.6)上看到了这种情况。
 livelace
于 2017-10-02
livelace
于 2017-10-02
你好
我自己遇到了PLEG问题(Azure,k8s 1.7.7):
Oct 5 08:13:27 k8s-agent-27569017-1 docker[1978]: E1005 08:13:27.386295 2209 remote_runtime.go:168] ListPodSandbox with filter "nil" from runtime service failed: rpc error: code = 4 desc = context deadline exceeded
Oct 5 08:13:27 k8s-agent-27569017-1 docker[1978]: E1005 08:13:27.386351 2209 kuberuntime_sandbox.go:197] ListPodSandbox failed: rpc error: code = 4 desc = context deadline exceeded
Oct 5 08:13:27 k8s-agent-27569017-1 docker[1978]: E1005 08:13:27.386360 2209 generic.go:196] GenericPLEG: Unable to retrieve pods: rpc error: code = 4 desc = context deadline exceeded
Oct 5 08:13:30 k8s-agent-27569017-1 docker[1978]: I1005 08:13:30.953599 2209 helpers.go:102] Unable to get network stats from pid 60677: couldn't read network stats: failure opening /proc/60677/net/dev: open /proc/60677/net/dev: no such file or directory
Oct 5 08:13:30 k8s-agent-27569017-1 docker[1978]: I1005 08:13:30.953634 2209 helpers.go:125] Unable to get udp stats from pid 60677: failure opening /proc/60677/net/udp: open /proc/60677/net/udp: no such file or directory
Oct 5 08:13:30 k8s-agent-27569017-1 docker[1978]: I1005 08:13:30.953642 2209 helpers.go:132] Unable to get udp6 stats from pid 60677: failure opening /proc/60677/net/udp6: open /proc/60677/net/udp6: no such file or directory
Oct 5 08:13:31 k8s-agent-27569017-1 docker[1978]: I1005 08:13:31.763914 2209 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 13h42m52.628402637s ago; threshold is 3m0s]
Oct 5 08:13:35 k8s-agent-27569017-1 docker[1978]: I1005 08:13:35.977487 2209 kubelet_node_status.go:467] Using Node Hostname from cloudprovider: "k8s-agent-27569017-1"
Oct 5 08:13:36 k8s-agent-27569017-1 docker[1978]: I1005 08:13:36.764105 2209 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 13h42m57.628610126s ago; threshold is 3m0s]
Oct 5 08:13:39 k8s-agent-27569017-1 docker[1275]: time="2017-10-05T08:13:39.185111999Z" level=warning msg="Health check error: rpc error: code = 4 desc = context deadline exceeded"
Oct 5 08:13:41 k8s-agent-27569017-1 docker[1978]: I1005 08:13:41.764235 2209 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 13h43m2.628732806s ago; threshold is 3m0s]
Oct 5 08:13:41 k8s-agent-27569017-1 docker[1978]: I1005 08:13:41.875074 2209 helpers.go:102] Unable to get network stats from pid 60677: couldn't read network stats: failure opening /proc/60677/net/dev: open /proc/60677/net/dev: no such file or directory
Oct 5 08:13:41 k8s-agent-27569017-1 docker[1978]: I1005 08:13:41.875102 2209 helpers.go:125] Unable to get udp stats from pid 60677: failure opening /proc/60677/net/udp: open /proc/60677/net/udp: no such file or directory
Oct 5 08:13:41 k8s-agent-27569017-1 docker[1978]: I1005 08:13:41.875113 2209 helpers.go:132] Unable to get udp6 stats from pid 60677: failure opening /proc/60677/net/udp6: open /proc/60677/net/udp6: no such file or directory
 sylr
于 2017-10-05
sylr
于 2017-10-05
我们正在稳定的CoreOS上运行v1.7.4+coreos.0 。 我们体验到,由于PLEG,我们的k8s节点每隔8小时就会出现一次故障(直到重新启动docker和/或kubelet服务时才会出现)。 容器继续运行,但在k8中报告为“未知”。 我应该提到我们使用Kubespray进行部署。
与docker通信以列出容器时,我们已将问题归结为GRPC中的退避算法。 此PR https://github.com/moby/moby/pull/33483将退避时间更改为最多2秒,并且在17.06中可用,但是kubernetes在1.8之前不支持17.06,对吗?
PLEG中引起问题的线路是这个。
我们使用普罗米修斯检查了PLEGRelistInterval和PLEGRelistLatency度量,并得到以下结果,这与回退算法理论非常一致。
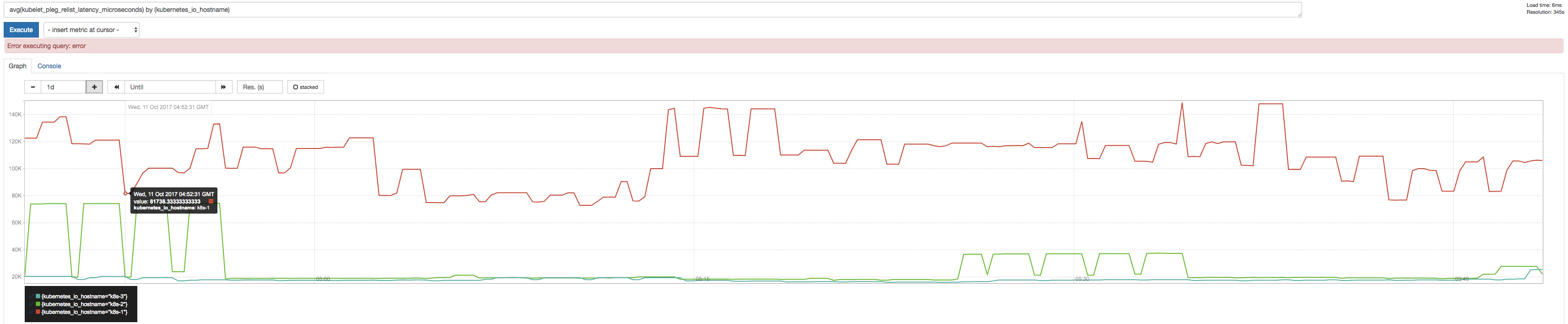


 ssboisen
于 2017-10-11
ssboisen
于 2017-10-11
@ssboisen感谢您使用图表进行报告(它们看起来确实很有趣)!
我们体验到,由于PLEG,我们的k8s节点每隔8小时就会出现一次故障(直到重新启动docker和/或kubelet服务时才会出现)。 容器继续运行,但在k8中报告为“未知”。 我应该提到我们使用Kubespray进行部署。
我有一些问题:
- 重新启动docker和kubelet中的任何一个是否可以解决问题?
- 问题发生时,
docker ps是否正常响应?
与docker通信以列出容器时,我们已将问题归结为GRPC中的退避算法。 此PR Moby / moby#33483最多可将退避时间更改为2秒,并且在17.06中可用,但是kubernetes在1.8之前不支持17.06。
我查看了您提到的Moby问题,但在讨论中,所有docker ps调用仍正常运行(即使dockerd <->容器化连接已断开)。 这似乎与您提到的PLEG问题不同。 另外,kubelet不会使用grpc与dockerd对话。 它确实使用grpc与dockershim进行通信,但是它们本质上是相同的过程,并且不会遇到一个被杀死而另一个仍然存活(导致连接断开)的问题。
grpc http grpc
kubelet <----> dockershim <----> dockerd <----> containerd
您在kubelet日志中看到的错误消息是什么? 上面的大多数评论都有“超出上下文截止日期”错误消息,
yujuhong
于 2017-10-11
- 重新启动docker和kubelet中的任何一个是否可以解决问题?
它改变了,通常足以重启kubelet,但是我们遇到了需要重启docker的情况。
- 问题发生时,
docker ps是否正常响应?
当PLEG运行时,我们在节点上运行docker ps没问题。 我不知道dockershim,我想知道问题是否出在kubelet和dockershim之间的联系,shim不能及时回答导致攀登退缩吗?
日志中的错误消息是以下两行的组合:
generic.go:196] GenericPLEG: Unable to retrieve pods: rpc error: code = 14 desc = grpc: the connection is unavailable
kubelet.go:1820] skipping pod synchronization - [container runtime is down PLEG is not healthy: pleg was last seen active 11h5m56.959313178s ago; threshold is 3m0s]
您对如何获取更多信息有什么建议,以便我们可以更好地调试此问题?
ssboisen
于 2017-10-12
- 重新启动docker和kubelet中的任何一个是否可以解决问题?
是的,只需重启docker就可以修复它,所以这不是k8s的问题 - 问题发生时,docker ps是否正常响应?
不。 它挂了。 Docker在该节点上运行的任何容器都会挂起。
对我来说,最有可能是docker问题,而不是k8s,这是在做正确的事。 但是,找不到为什么docker在这里行为异常。 所有CPU /内存/磁盘资源都很棒。
重新启动docker服务将恢复良好状态。
chenww
于 2017-10-23
您对如何获取更多信息有什么建议,以便我们可以更好地调试此问题?
我认为第一步是确认哪个组件(dockershim或docker / containerd)返回了错误消息。
您可能可以通过交叉引用kubelet和docker日志来解决。
yujuhong
于 2017-10-23
对我来说,最有可能是docker问题,而不是k8s,这是在做正确的事。 但是,找不到为什么docker在这里行为异常。 所有CPU /内存/磁盘资源都很棒。
是的在您的情况下,似乎docker daemon实际挂起。 您可以在调试模式下启动docker守护程序,并在发生时获取stacktrace。
https://docs.docker.com/engine/admin/#force -a-stack-trace-to-be-logged
yujuhong
于 2017-10-23
@yujuhong我在对k8s进行负载测试后再次遇到了这个问题,几乎所有节点都变成not ready并且在清洁了Pod数天后没有恢复,我在每个kubelet中都打开了详细模式并获取了日志下面,希望这些日志有助于解决问题:
Oct 24 21:16:39 docker34-91 kubelet[24165]: I1024 21:16:39.539054 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:39 docker34-91 kubelet[24165]: I1024 21:16:39.639305 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:39 docker34-91 kubelet[24165]: I1024 21:16:39.739585 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:39 docker34-91 kubelet[24165]: I1024 21:16:39.839829 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:39 docker34-91 kubelet[24165]: I1024 21:16:39.940111 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.040374 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.128789 24165 kubelet.go:2064] Container runtime status: Runtime Conditions: RuntimeReady=true reason: message:, NetworkReady=true reason: message:
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.140634 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.240851 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.341125 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.441471 24165 config.go:101] Looking for [api file], have seen map[api:{} file:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.541781 24165 config.go:101] Looking for [api file], have seen map[api:{} file:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.642070 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.742347 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.842562 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.942867 24165 config.go:101] Looking for [api file], have seen map[api:{} file:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.006656 24165 kubelet.go:1752] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 6m20.171705404s ago; threshold is 3m0s]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.043126 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.143372 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.243620 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.343911 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.444156 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.544420 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.644732 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.745002 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.845268 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.945524 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:42 docker34-91 kubelet[24165]: I1024 21:16:42.045814 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
^C
[root@docker34-91 ~]# journalctl -u kubelet -f
-- Logs begin at Wed 2017-10-25 17:19:29 CST. --
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0b 0a 02 76 31 12 05 45 76 65 6e |k8s.....v1..Even|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000010 74 12 d3 03 0a 4f 0a 33 6c 64 74 65 73 74 2d 37 |t....O.3ldtest-7|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000020 33 34 33 39 39 64 67 35 39 2d 33 33 38 32 38 37 |34399dg59-338287|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000030 31 36 38 35 2d 78 32 36 70 30 2e 31 34 66 31 34 |1685-x26p0.14f14|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000040 63 30 39 65 62 64 32 64 66 66 34 12 00 1a 0a 6c |c09ebd2dff4....l|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000050 64 74 65 73 74 2d 30 30 35 22 00 2a 00 32 00 38 |dtest-005".*.2.8|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000060 00 42 00 7a 00 12 6b 0a 03 50 6f 64 12 0a 6c 64 |.B.z..k..Pod..ld|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000070 74 65 73 74 2d 30 30 35 1a 22 6c 64 74 65 73 74 |test-005."ldtest|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000080 2d 37 33 34 33 39 39 64 67 35 39 2d 33 33 38 32 |-734399dg59-3382|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000090 38 37 31 36 38 35 2d 78 32 36 70 30 22 24 61 35 |871685-x26p0"$a5|
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.098922 24165 kubelet.go:2064] Container runtime status: Runtime Conditions: RuntimeReady=true reason: message:, NetworkReady=true reason: message:
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.175027 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.275290 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.375594 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.475872 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.576140 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.676412 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.776613 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.876855 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.977126 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.000354 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "a052cabc-bab9-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.000509 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-276aa6023f-1106740979-hbtcv
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001753 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-276aa6023f-1106740979-hbtcv 404 Not Found in 1 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001768 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001773 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001776 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001780 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001838 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 32 37 36 61 61 36 30 32 33 66 2d 31 31 |st-276aa6023f-11|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 30 36 37 34 30 39 37 39 2d 68 62 74 63 76 22 20 |06740979-hbtcv" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 32 37 |und*.."ldtest-27|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 36 61 61 36 30 32 33 66 2d 31 31 30 36 37 34 30 |6aa6023f-1106740|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 39 37 39 2d 68 62 74 63 76 12 00 1a 04 70 6f 64 |979-hbtcv....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001885 24165 status_manager.go:425] Pod "ldtest-276aa6023f-1106740979-hbtcv" (a052cabc-bab9-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001900 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "a584c63e-bab7-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001946 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-734399dg59-3382871685-x26p0
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002559 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-734399dg59-3382871685-x26p0 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002569 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002573 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002577 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002580 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002627 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 37 33 34 33 39 39 64 67 35 39 2d 33 33 |st-734399dg59-33|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 38 32 38 37 31 36 38 35 2d 78 32 36 70 30 22 20 |82871685-x26p0" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 37 33 |und*.."ldtest-73|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 34 33 39 39 64 67 35 39 2d 33 33 38 32 38 37 31 |4399dg59-3382871|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 36 38 35 2d 78 32 36 70 30 12 00 1a 04 70 6f 64 |685-x26p0....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002659 24165 status_manager.go:425] Pod "ldtest-734399dg59-3382871685-x26p0" (a584c63e-bab7-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002668 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "2727277f-bab3-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002711 24165 round_trippers.go:398] curl -k -v -XGET -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" -H "Accept: application/vnd.kubernetes.protobuf, */*" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-4bc7922c25-2238154508-xt94x
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003318 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-4bc7922c25-2238154508-xt94x 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003328 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003332 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003336 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003339 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003379 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 34 62 63 37 39 32 32 63 32 35 2d 32 32 |st-4bc7922c25-22|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 33 38 31 35 34 35 30 38 2d 78 74 39 34 78 22 20 |38154508-xt94x" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 34 62 |und*.."ldtest-4b|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 63 37 39 32 32 63 32 35 2d 32 32 33 38 31 35 34 |c7922c25-2238154|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 35 30 38 2d 78 74 39 34 78 12 00 1a 04 70 6f 64 |508-xt94x....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003411 24165 status_manager.go:425] Pod "ldtest-4bc7922c25-2238154508-xt94x" (2727277f-bab3-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003423 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "43dd5201-bab4-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003482 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-g02c441308-3753936377-d6q69
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004051 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-g02c441308-3753936377-d6q69 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004059 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004062 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004066 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004069 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004115 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 67 30 32 63 34 34 31 33 30 38 2d 33 37 |st-g02c441308-37|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 35 33 39 33 36 33 37 37 2d 64 36 71 36 39 22 20 |53936377-d6q69" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 67 30 |und*.."ldtest-g0|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 32 63 34 34 31 33 30 38 2d 33 37 35 33 39 33 36 |2c441308-3753936|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 33 37 37 2d 64 36 71 36 39 12 00 1a 04 70 6f 64 |377-d6q69....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004142 24165 status_manager.go:425] Pod "ldtest-g02c441308-3753936377-d6q69" (43dd5201-bab4-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004148 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "8fd9d66f-bab7-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004195 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-cf2eg79b08-3660220702-x0j2j
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004752 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-cf2eg79b08-3660220702-x0j2j 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004761 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004765 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004769 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004773 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004812 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 63 66 32 65 67 37 39 62 30 38 2d 33 36 |st-cf2eg79b08-36|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 36 30 32 32 30 37 30 32 2d 78 30 6a 32 6a 22 20 |60220702-x0j2j" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 63 66 |und*.."ldtest-cf|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 32 65 67 37 39 62 30 38 2d 33 36 36 30 32 32 30 |2eg79b08-3660220|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 37 30 32 2d 78 30 6a 32 6a 12 00 1a 04 70 6f 64 |702-x0j2j....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004841 24165 status_manager.go:425] Pod "ldtest-cf2eg79b08-3660220702-x0j2j" (8fd9d66f-bab7-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004853 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "eb5a5f4a-baba-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004921 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-9b47680d12-2536408624-jhp18
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005436 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-9b47680d12-2536408624-jhp18 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005446 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005450 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005454 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005457 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005499 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 39 62 34 37 36 38 30 64 31 32 2d 32 35 |st-9b47680d12-25|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 33 36 34 30 38 36 32 34 2d 6a 68 70 31 38 22 20 |36408624-jhp18" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 39 62 |und*.."ldtest-9b|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 34 37 36 38 30 64 31 32 2d 32 35 33 36 34 30 38 |47680d12-2536408|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 36 32 34 2d 6a 68 70 31 38 12 00 1a 04 70 6f 64 |624-jhp18....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005526 24165 status_manager.go:425] Pod "ldtest-9b47680d12-2536408624-jhp18" (eb5a5f4a-baba-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005533 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "2db95639-bab5-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005588 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-5f8ba1eag0-2191624653-dm374
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006150 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-5f8ba1eag0-2191624653-dm374 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006176 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006182 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006189 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006195 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006251 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 35 66 38 62 61 31 65 61 67 30 2d 32 31 |st-5f8ba1eag0-21|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 39 31 36 32 34 36 35 33 2d 64 6d 33 37 34 22 20 |91624653-dm374" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 35 66 |und*.."ldtest-5f|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 38 62 61 31 65 61 67 30 2d 32 31 39 31 36 32 34 |8ba1eag0-2191624|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 36 35 33 2d 64 6d 33 37 34 12 00 1a 04 70 6f 64 |653-dm374....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006297 24165 status_manager.go:425] Pod "ldtest-5f8ba1eag0-2191624653-dm374" (2db95639-bab5-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006330 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "ecf58d7f-bab2-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006421 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-0fe4761ce1-763135991-2gv5x
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006983 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-0fe4761ce1-763135991-2gv5x 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006995 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.007001 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.007007 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.007014 24165 round_trippers.go:426] Content-Length: 151
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.007064 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 7f 0a 04 0a 00 12 00 12 07 46 61 69 6c |us..........Fail|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 75 72 65 1a 32 70 6f 64 73 20 22 6c 64 74 65 73 |ure.2pods "ldtes|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 74 2d 30 66 65 34 37 36 31 63 65 31 2d 37 36 33 |t-0fe4761ce1-763|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 31 33 35 39 39 31 2d 32 67 76 35 78 22 20 6e 6f |135991-2gv5x" no|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f 75 6e |t found".NotFoun|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 64 2a 2d 0a 21 6c 64 74 65 73 74 2d 30 66 65 34 |d*-.!ldtest-0fe4|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 37 36 31 63 65 31 2d 37 36 33 31 33 35 39 39 31 |761ce1-763135991|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 2d 32 67 76 35 78 12 00 1a 04 70 6f 64 73 28 00 |-2gv5x....pods(.|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 30 94 03 1a 00 22 00 |0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.007106 24165 status_manager.go:425] Pod "ldtest-0fe4761ce1-763135991-2gv5x" (ecf58d7f-bab2-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.077334 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.177546 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.277737 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.377939 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.478169 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.578369 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.603649 24165 eviction_manager.go:197] eviction manager: synchronize housekeeping
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.678573 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682080 24165 summary.go:389] Missing default interface "eth0" for node:172.23.34.91
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682132 24165 summary.go:389] Missing default interface "eth0" for pod:kube-system_kube-proxy-qcft5
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682176 24165 helpers.go:744] eviction manager: observations: signal=imagefs.available, available: 515801344Ki, capacity: 511750Mi, time: 2017-10-27 10:22:56.499173632 +0800 CST
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682197 24165 helpers.go:744] eviction manager: observations: signal=imagefs.inodesFree, available: 523222251, capacity: 500Mi, time: 2017-10-27 10:22:56.499173632 +0800 CST
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682203 24165 helpers.go:746] eviction manager: observations: signal=allocatableMemory.available, available: 65544340Ki, capacity: 65581868Ki
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682207 24165 helpers.go:744] eviction manager: observations: signal=memory.available, available: 57973412Ki, capacity: 65684268Ki, time: 2017-10-27 10:22:56.499173632 +0800 CST
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682213 24165 helpers.go:744] eviction manager: observations: signal=nodefs.available, available: 99175128Ki, capacity: 102350Mi, time: 2017-10-27 10:22:56.499173632 +0800 CST
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682218 24165 helpers.go:744] eviction manager: observations: signal=nodefs.inodesFree, available: 104818019, capacity: 100Mi, time: 2017-10-27 10:22:56.499173632 +0800 CST
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682233 24165 eviction_manager.go:292] eviction manager: no resources are starved
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.778792 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.879040 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.979304 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.079534 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.179753 24165 config.go:101] Looking for [api file], have seen map[api:{} file:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.280026 24165 config.go:101] Looking for [api file], have seen map[api:{} file:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.380246 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.480450 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.580695 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.680957 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.781224 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.881418 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.981643 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.081882 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.182810 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.283410 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.383626 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.483942 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.584211 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.684460 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.784699 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.884949 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960855 24165 factory.go:115] Factory "docker" was unable to handle container "/system.slice/data-docker-overlay-c0d3c4b3834cfe9f12cd5c35345cab9c8e71bb64c689c8aea7a458c119a5a54e-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960885 24165 factory.go:108] Factory "systemd" can handle container "/system.slice/data-docker-overlay-c0d3c4b3834cfe9f12cd5c35345cab9c8e71bb64c689c8aea7a458c119a5a54e-merged.mount", but ignoring.
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960906 24165 manager.go:867] ignoring container "/system.slice/data-docker-overlay-c0d3c4b3834cfe9f12cd5c35345cab9c8e71bb64c689c8aea7a458c119a5a54e-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960912 24165 factory.go:115] Factory "docker" was unable to handle container "/system.slice/data-docker-overlay-ce9656ff9d3cd03baaf93e42d0874377fa37bfde6c9353b3ba954c90bf4332f3-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960919 24165 factory.go:108] Factory "systemd" can handle container "/system.slice/data-docker-overlay-ce9656ff9d3cd03baaf93e42d0874377fa37bfde6c9353b3ba954c90bf4332f3-merged.mount", but ignoring.
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960926 24165 manager.go:867] ignoring container "/system.slice/data-docker-overlay-ce9656ff9d3cd03baaf93e42d0874377fa37bfde6c9353b3ba954c90bf4332f3-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960931 24165 factory.go:115] Factory "docker" was unable to handle container "/system.slice/data-docker-overlay-b3600c0fe81445773b9241c5d1da8b1f97612d0a235f8b32139478a5717f79e1-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960937 24165 factory.go:108] Factory "systemd" can handle container "/system.slice/data-docker-overlay-b3600c0fe81445773b9241c5d1da8b1f97612d0a235f8b32139478a5717f79e1-merged.mount", but ignoring.
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960944 24165 manager.go:867] ignoring container "/system.slice/data-docker-overlay-b3600c0fe81445773b9241c5d1da8b1f97612d0a235f8b32139478a5717f79e1-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960949 24165 factory.go:115] Factory "docker" was unable to handle container "/system.slice/data-docker-overlay-ed2fe0d57c56cf6b051e1bda1ca0185ceef4756b1a8f9af4c19f4e512bcc60f4-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960955 24165 factory.go:108] Factory "systemd" can handle container "/system.slice/data-docker-overlay-ed2fe0d57c56cf6b051e1bda1ca0185ceef4756b1a8f9af4c19f4e512bcc60f4-merged.mount", but ignoring.
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960979 24165 manager.go:867] ignoring container "/system.slice/data-docker-overlay-ed2fe0d57c56cf6b051e1bda1ca0185ceef4756b1a8f9af4c19f4e512bcc60f4-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960984 24165 factory.go:115] Factory "docker" was unable to handle container "/system.slice/data-docker-overlay-0ba6483a0117c539493cd269be9f87d31d1d61aa813e7e0381c5f5d8b0623275-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960990 24165 factory.go:108] Factory "systemd" can handle container "/system.slice/data-docker-overlay-0ba6483a0117c539493cd269be9f87d31d1d61aa813e7e0381c5f5d8b0623275-merged.mount", but ignoring.
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960997 24165 manager.go:867] ignoring container "/system.slice/data-docker-overlay-0ba6483a0117c539493cd269be9f87d31d1d61aa813e7e0381c5f5d8b0623275-merged.mount"
遇到类似问题:
Oct 28 09:15:38 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:15:38.711430 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:15:51 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:15:51.439135 3299 kuberuntime_manager.go:843] PodSandboxStatus of sandbox "9c1c1f2d4a9d277a41a97593c330f41e00ca12f3ad858c19f61fd155d18d795e" for pod "pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)" error: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:15:51 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:15:51.439188 3299 generic.go:241] PLEG: Ignoring events for pod pickup-566929041-bn8t9/staging: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:15:51 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:15:51.711168 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:16:03 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:16:03.711164 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:16:18 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:16:18.715381 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:16:33 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:16:33.711198 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:16:46 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:16:46.712983 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:16:51 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:16:51.711142 3299 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.31269053s ago; threshold is 3m0s]
Oct 28 09:16:56 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:16:56.711341 3299 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m5.312886434s ago; threshold is 3m0s]
Oct 28 09:17:01 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:17:01.351771 3299 kubelet_node_status.go:734] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-10-28 09:17:01.35173325 +0000 UTC LastTransitionTime:2017-10-28 09:17:01.35173325 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m9.95330596s ago; threshold is 3m0s}
Oct 28 09:17:01 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:17:01.711552 3299 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m10.31309378s ago; threshold is 3m0s]
Oct 28 09:17:06 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:17:06.711871 3299 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m15.313406671s ago; threshold is 3m0s]
Oct 28 09:17:11 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:17:11.712162 3299 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m20.313691126s ago; threshold is 3m0s]
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 transport: http2Server.HandleStreams failed to read frame: read unix /var/run/dockershim.sock->@: use of closed network connection
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 transport: http2Client.notifyError got notified that the client transport was broken EOF.
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 grpc: addrConn.resetTransport failed to create client transport: connection error: desc = "transport: dial unix /var/run/dockershim.sock: connect: no such file or directory"; Reconnecting to {/var/run/dockershim.sock <nil>}
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:17:12.556535 3299 kuberuntime_manager.go:843] PodSandboxStatus of sandbox "9c1c1f2d4a9d277a41a97593c330f41e00ca12f3ad858c19f61fd155d18d795e" for pod "pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)" error: rpc error: code = 13 desc = transport is closing
这些消息之后, kubelet进入重启循环。
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: Main process exited, code=exited, status=1/FAILURE
Oct 28 09:18:42 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: State 'stop-final-sigterm' timed out. Killing.
Oct 28 09:18:42 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: Killing process 1661 (calico) with signal SIGKILL.
Oct 28 09:20:12 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: Processes still around after final SIGKILL. Entering failed mode.
Oct 28 09:20:12 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: Stopped Kubernetes Kubelet.
Oct 28 09:20:12 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: Unit entered failed state.
Oct 28 09:20:12 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: Failed with result 'exit-code'.
在我看来,这是一个docker问题,因为我看到的最后一条消息是:
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 transport: http2Server.HandleStreams failed to read frame: read unix /var/run/dockershim.sock->@: use of closed network connection
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 transport: http2Client.notifyError got notified that the client transport was broken EOF.
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 grpc: addrConn.resetTransport failed to create client transport: connection error: desc = "transport: dial unix /var/run/dockershim.sock: connect: no such file or directory"; Reconnecting to {/var/run/dockershim.sock <nil>}
 zihaoyu
于 2017-10-28
zihaoyu
于 2017-10-28
最后的消息来自dockershim。 这些日志也将非常有用。
 rphillips
于 2017-11-15
rphillips
于 2017-11-15
您好,基于Kops @ AWS的Kubernetes 1.7.10,带有Calico和CoreOS。
我们有同样的PLEG问题
Ready False KubeletNotReady PLEG is not healthy: pleg was last seen active 3m29.396986143s ago; threshold is 3m0s
我们遇到的唯一的额外问题是,我认为这是相关的-特别是在1.7.8+上-当我们重新部署时,例如带来一个新版本的应用程序,以便旧副本集下降,一个新副本集与吊舱,以前部署的吊舱ver /确实永远处于“终止”状态。
然后我必须手动force kill them
 javapapo
于 2017-11-18
javapapo
于 2017-11-18
我们有相同的PLEG问题k8s 1.8.1
 tanhui2333
于 2017-11-21
tanhui2333
于 2017-11-21
+1
1.6.9
使用docker 1.12.6
 zhangxiaoyu-zidif
于 2017-11-29
zhangxiaoyu-zidif
于 2017-11-29
+1
1.8.2
 dElogics
于 2017-11-29
dElogics
于 2017-11-29
+1
1.6.0
 majid021
于 2017-11-29
majid021
于 2017-11-29
- 1.8.4
还有更多问题:
- 是的,CPU和内存接近100%。 但是我的问题是,由于节点长时间未准备就绪,为什么未将Pod分配给另一个节点?
 gogeof
于 2017-12-06
gogeof
于 2017-12-06
+1在升级到Kubernets 1.8.5之后的两天里,使节点进入NotReady状态的情况一直很稳定。 我认为对我来说,问题是我没有升级集群自动缩放器。 将自动定标器升级到1.03(helm 0.3.0)后,我还没有看到任何处于“ NotReady”状态的节点。 看来我又有了一个稳定的群集。
- 磅数:1.8.0
- kubectl:1.8.5
- 掌舵:2.7.2
- cluster-autoscaler:v0.6.0->升级到1.03(helm 0.3.0)
 iamrandys
于 2017-12-11
iamrandys
于 2017-12-11
即使Docker挂起,pleg也不应处于非活动状态
 timchenxiaoyu
于 2017-12-15
timchenxiaoyu
于 2017-12-15
同样在这里1.8.5
不从低版本更新,从空版本创建。
资源足够
记忆
# free -mg
total used free shared buff/cache available
Mem: 15 2 8 0 5 12
Swap: 15 0 15
最佳
top - 04:34:39 up 24 days, 6:23, 2 users, load average: 31.56, 83.38, 66.29
Tasks: 432 total, 5 running, 427 sleeping, 0 stopped, 0 zombie
%Cpu(s): 9.2 us, 1.9 sy, 0.0 ni, 87.5 id, 1.3 wa, 0.0 hi, 0.1 si, 0.0 st
KiB Mem : 16323064 total, 8650144 free, 2417236 used, 5255684 buff/cache
KiB Swap: 16665596 total, 16646344 free, 19252 used. 12595460 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
31905 root 20 0 1622320 194096 51280 S 14.9 1.2 698:10.66 kubelet
19402 root 20 0 12560 9696 1424 R 10.3 0.1 442:05.00 memtester
2626 root 20 0 12560 9660 1392 R 9.6 0.1 446:41.38 memtester
8680 root 20 0 12560 9660 1396 R 9.6 0.1 444:34.38 memtester
15004 root 20 0 12560 9704 1432 R 9.6 0.1 443:04.98 memtester
1663 root 20 0 8424940 424912 20556 S 4.6 2.6 2809:24 dockerd
409 root 20 0 49940 37068 20648 S 2.3 0.2 144:03.37 calico-felix
551 root 20 0 631788 20952 11824 S 1.3 0.1 100:36.78 costor
9527 root 20 0 10.529g 24800 13612 S 1.0 0.2 3:43.55 etcd
2608 root 20 0 421936 6040 3288 S 0.7 0.0 31:29.78 containerd-shim
4136 root 20 0 780344 24580 12316 S 0.7 0.2 45:58.60 costor
4208 root 20 0 755756 22208 12176 S 0.7 0.1 41:49.58 costor
8665 root 20 0 210344 5960 3208 S 0.7 0.0 31:27.75 cont
现在发现以下情况。
由于将Docker Storage Setup配置为占用精简池的80%,因此kubelet硬驱逐为10%。 两者都不在行窃。
Docker在某种程度上内部崩溃了,而kubelet出现了PLEG错误。
将kubelet硬驱逐(imagefs.available)增加到20%会影响docker设置,而kubelet开始删除旧图像。
在1.8中,我们从image-gc-threshold变为硬驱逐,并选择了错误的匹配参数。
我现在将观察我们的集群。
酷比:1.8.5
码头工人:1.12.6
作业系统:RHEL7
 sybnex
于 2017-12-21
sybnex
于 2017-12-21
查看普罗米修斯内部的kubelet_pleg_relist_latency_microseconds指标,这看起来很可疑。
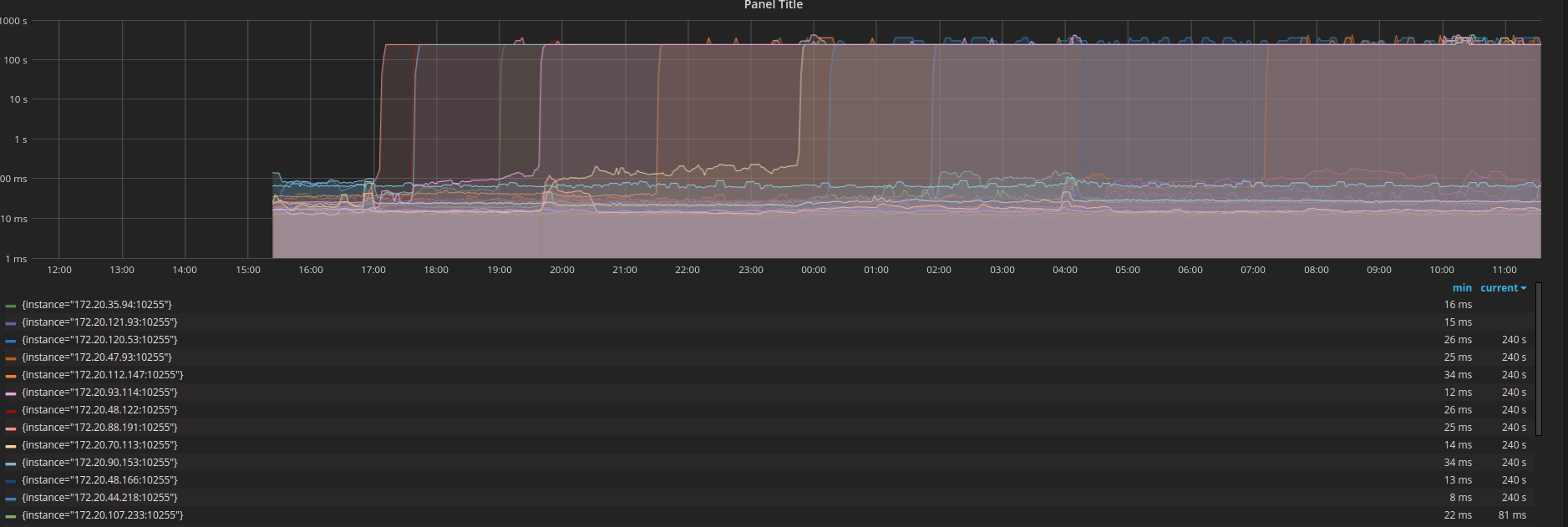
kops使用coreOS安装了kube 1.8.4
docker info
Containers: 246
Running: 222
Paused: 0
Stopped: 24
Images: 30
Server Version: 17.09.0-ce
Storage Driver: overlay
Backing Filesystem: extfs
Supports d_type: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file logentries splunk syslog
Swarm: inactive
Runtimes: runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 06b9cb35161009dcb7123345749fef02f7cea8e0
runc version: 3f2f8b84a77f73d38244dd690525642a72156c64
init version: v0.13.2 (expected: 949e6facb77383876aeff8a6944dde66b3089574)
Security Options:
seccomp
Profile: default
selinux
Kernel Version: 4.13.16-coreos-r2
Operating System: Container Linux by CoreOS 1576.4.0 (Ladybug)
OSType: linux
Architecture: x86_64
CPUs: 8
Total Memory: 14.69GiB
Name: ip-172-20-120-53.eu-west-1.compute.internal
ID: SI53:ECLM:HXFE:LOVY:STTS:C4X2:WRFK:UGBN:7NYP:4N3E:MZGS:EAVM
Docker Root Dir: /var/lib/docker
Debug Mode (client): false
Debug Mode (server): false
Registry: https://index.docker.io/v1/
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
 Deshke
于 2017-12-21
Deshke
于 2017-12-21
+1
原始v3.7.0
kubernetes v1.7.6
泊坞窗v1.12.6
操作系统CentOS 7.4
似乎运行时容器GC对pod创建和终止起作用
让我尝试报告禁用GC后发生的情况。
 esevan
于 2017-12-29
esevan
于 2017-12-29
就我而言,CNI无法处理这种情况。
根据我的分析,代码序列如下
1. kuberuntime_gc.go: client.StopPodSandbox (Timeout Default: 2m)
-> docker_sandbox.go: StopPodSandbox
-> cni.go: TearDownPod
-> CNI deleteFromNetwork (Timeout Default: 3m) <- Nothing gonna happen if CNI doesn't handle this situation.
-> docker_service.go: StopContainer
2. kuberuntime_gc.go: client.RemovePodSandbox
StopPodSandbox引发超时异常,然后返回而不进行处理删除pod沙盒
但是,StopPodSandbox超时后,CNI进程仍在进行中。
就像kubelet线程被CNI进程饿死了一样,因此kubelet无法正确监控PLEG。
我通过修改CNI以使其仅在CNI_NS为空时返回(因为这意味着死容器)而解决了此问题。
(顺便说一句,我正在使用kuryr-kubernetes作为CNI插件)
希望这对你们有所帮助!
esevan
于 2018-01-03
@esevan您可以提出一个补丁吗?
rphillips
于 2018-01-08
@rphillips这个错误实际上与CNI错误很接近,在更多地了解行为之后,我肯定会将补丁上传到openstack / kuryr-kubernetes。
esevan
于 2018-01-09
在我们的情况下,它与https://github.com/moby/moby/issues/33820相关
停止docker容器超时,然后节点开始在带有PLEG消息的ready / notReady之间摆动。
还原Docker版本可解决此问题。 (17.09-ce-> 12.06)
 ghost
于 2018-01-11
ghost
于 2018-01-11
与kubelet v1.9.1相同的错误日志:
...
Jan 15 12:36:52 l23-27-101 kubelet[7335]: I0115 12:36:52.884617 7335 status_manager.go:136] Kubernetes client is nil, not starting status manager.
Jan 15 12:36:52 l23-27-101 kubelet[7335]: I0115 12:36:52.884636 7335 kubelet.go:1767] Starting kubelet main sync loop.
Jan 15 12:36:52 l23-27-101 kubelet[7335]: I0115 12:36:52.884692 7335 kubelet.go:1778] skipping pod synchronization - [container runtime is down PLEG is not healthy: pleg was last seen active 2562047h47m16.854775807s ago; threshold is 3m0s]
Jan 15 12:36:52 l23-27-101 kubelet[7335]: E0115 12:36:52.884788 7335 container_manager_linux.go:583] [ContainerManager]: Fail to get rootfs information unable to find data for container /
Jan 15 12:36:52 l23-27-101 kubelet[7335]: I0115 12:36:52.885001 7335 volume_manager.go:247] Starting Kubelet Volume Manager
...
 shenshouer
于 2018-01-15
shenshouer
于 2018-01-15
有人> docker> 12.6有这个问题吗? (不支持的版本17.09除外)
我只是想知道切换到13.1或17.06是否有用。
sybnex
于 2018-01-15
@sybnex 17.03在我们的群集中也存在此问题,这最像是CNI错误。
yangyuw
于 2018-01-16
对我来说,发生这种情况是因为kubelet在执行家务任务时占用了过多的CPU,因此没有足够的CPU时间用于docker。 减少内务处理间隔对我来说解决了这个问题。
dElogics
于 2018-01-17
@esevan :非常感谢kuryr-kubernetes补丁:-)
 celebdor
于 2018-01-17
celebdor
于 2018-01-17
仅供参考,我们使用Origin 1.5 / Kubernetes 1.5和Kuryr(第一个版本)没有任何问题:)
livelace
于 2018-01-17
@livelace不使用更高版本的任何理由?
celebdor
于 2018-01-17
@celebdor不需要所有工作:)我们使用Origin + Openstack,这些版本可以满足我们的所有需求,我们不需要Kubernetes / Openstack的新功能,Kuryr可以使用。 当另外两个团队加入我们的基础架构时,也许我们会遇到任何问题。
livelace
于 2018-01-18
缺省的pleg-relist-threshold为3分钟。
为什么我们不能使pleg-relist-threshold可配置,然后将其设置为更大的值。
我为此做过公关。
有人可以看看吗?
https://github.com/kubernetes/kubernetes/pull/58279
 linyouchong
于 2018-01-23
linyouchong
于 2018-01-23
我对PLEG和ProbeManager感到困惑。
PLEG应该在节点中保持豆荚和容器的健康。
ProbeManager还会在节点中保持容器的健康状态。
为什么我们让两个模块做同样的事情?
当ProbeManager发现容器停止时,将重新启动容器。
如果PLEG也发现容器已停止,PLEG是否会发出一个事件来通知kubelet这样做
事情?
 liucimin
于 2018-01-31
liucimin
于 2018-01-31
+1
Kubernetes v1.8.4
 erstaples
于 2018-01-31
erstaples
于 2018-01-31
@celebdor将cni更新为守护
esevan
于 2018-02-01
+1
kubernetes v1.9.2
码头工人17.03.2-ce
 huzhengchuan
于 2018-02-27
huzhengchuan
于 2018-02-27
+1
kubernetes v1.9.2
码头工人17.03.2-CE
错误记录在kubelet日志中:
Feb 27 16:19:12 node-2 kubelet: E0227 16:19:12.839866 47544 remote_runtime.go:169] ListPodSandbox with filter nil from runtime service failed: rpc error: code = Unknown desc = Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
Feb 27 16:19:12 node-2 kubelet: E0227 16:19:12.839919 47544 kuberuntime_sandbox.go:192] ListPodSandbox failed: rpc error: code = Unknown desc = Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
Feb 27 16:19:12 node-2 kubelet: E0227 16:19:12.839937 47544 generic.go:197] GenericPLEG: Unable to retrieve pods: rpc error: code = Unknown desc = Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
kubelet使用dockerclient(httpClient)调用ContainerList(所有状态&& io.kubernetes.docker.type ==“ podsandbox”),超时时间为2分钟。
docker ps -a --filter "label=io.kubernetes.docker.type=podsandbox"
当节点进入NotReady时直接运行命令可能有助于调试
以下是在dockerclient中执行请求代码,此错误看起来像是超时:
if err, ok := err.(net.Error); ok {
if err.Timeout() {
return serverResp, ErrorConnectionFailed(cli.host)
}
if !err.Temporary() {
if strings.Contains(err.Error(), "connection refused") || strings.Contains(err.Error(), "dial unix") {
return serverResp, ErrorConnectionFailed(cli.host)
}
}
}
 chestack
于 2018-02-27
chestack
于 2018-02-27
+1
州长1.8.4
码头工人17.09.1-ce
编辑:
kube-aws 0.9.9
 Labbs
于 2018-02-27
Labbs
于 2018-02-27
+1
Kubernetes v1.9.3
码头工人17.12.0-ce(我知道它没有正式支持)
weaveworks /编织-kube:2.2.0
Ubuntu 16.04.3 LTS || 内核:4.4.0-112
通过kubeadm与master + worker一起安装(master不会显示此就绪/未就绪行为,仅显示worker)。
 MarcosCela
于 2018-02-28
MarcosCela
于 2018-02-28
+1
Kubernetes:1.8.8
码头工人:1.12.6-cs13
云提供商:GCE
作业系统:Ubuntu 16.04.3 LTS
内核:4.13.0-1011-gcp
安装工具:kubeadm
我正在使用印花布进行联网
 albertvaka
于 2018-03-13
albertvaka
于 2018-03-13
我的环境中的此提交修复问题
https://github.com/moby/moby/pull/31273/commits/8e425ebc422876ddf2ffb3beaa5a0443a6097e46
这是有关“ docker ps hang”的有用链接:
https://github.com/moby/moby/pull/31273
更新:实际上回滚到docker 1.13.1有所帮助,以上提交不在docker 1.13.1中
chestack
于 2018-03-19
+1
Kubernetes:1.8.9
码头工人:17.09.1-ce
云提供商:AWS
操作系统:CoreOS 1632.3.0
内核:4.14.19-coreos
安装工具:kops
用于网络的Calico 2.6.6
 juris
于 2018-03-19
juris
于 2018-03-19
为了解决此问题,我使用了一个旧的coreos版本(1520.9.0)。 这个版本使用docker 1.12.6。
由于此更改,没有拍打问题。
Labbs
于 2018-03-19
+1
Kubernetes:1.9.3
码头工人:17.09.1-ce
云提供商:AWS
操作系统:CoreOS 1632.3.0
内核:4.14.19-coreos
安装工具:kops
编织
 leeeboo
于 2018-03-22
leeeboo
于 2018-03-22
+1
Kubernetes:1.9.6
码头工人:17.12.0-ce
操作系统:Redhat 7.4
内核:3.10.0-693.el7.x86_64
CNI:法兰绒
 dragon9783
于 2018-03-29
juris
于 2018-03-29
dragon9783
于 2018-03-29
juris
于 2018-03-29
观察到相同的问题:
Kubernetes :1.9.6
码头工人:17.12.0-ce
操作系统:Ubuntu 16.04
CNI :编织
修复了将其降级到Docker 17.03的问题
 briandeheus
于 2018-03-30
briandeheus
于 2018-03-30
我遇到了同样的问题,并且通过升级到Debian Strech似乎可以解决。 集群在使用kops部署的AWS上运行。
Kubernetes:1.8.7
码头工人:1.13.1
操作系统:Debian Stretch
CNI:印花布
内核:4.9.0-5-amd64
默认情况下,我认为Debian Jessie与4.4版内核一起使用,并且运行不正常。
 komljen
于 2018-03-30
komljen
于 2018-03-30
该问题发生在我们的ENV中,我们对此问题进行了一些分析:
k8s version 1.7/1.8
堆栈信息来自k8s 1.7
由于网络插件错误,我们的环境中有很多已退出的容器(超过1k)。
当我们重新启动kubelet时。 过了一会儿, kubelet变成unhealthy 。
我们跟踪日志和堆栈。
当PLEG做重新提交操作。
第一次,它将需要处理许多事件(每个容器都会有一个事件),需要处理https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L228
更新缓存需要花费很多时间(https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L240)
在大多数情况下,当我们打印堆栈时,堆栈就像:
k8s.io/kubernetes/vendor/google.golang.org/grpc/transport.(*Stream).Header(0xc42537aff0, 0x3b53b68, 0xc42204f060, 0x59ceee0)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/transport/transport.go:239 +0x146
k8s.io/kubernetes/vendor/google.golang.org/grpc.recvResponse(0x0, 0x0, 0x59c4c60, 0x5b0c6b0, 0x0, 0x0, 0x0, 0x0, 0x59a8620, 0xc4217f2460, ...)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/call.go:61 +0x9e
k8s.io/kubernetes/vendor/google.golang.org/grpc.invoke(0x7ff04e8b9800, 0xc424be3380, 0x3aa3c5e, 0x28, 0x374bb00, 0xc424ca0590, 0x374bbe0, 0xc421f428b0, 0xc421800240, 0x0, ...)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/call.go:208 +0x862
k8s.io/kubernetes/vendor/google.golang.org/grpc.Invoke(0x7ff04e8b9800, 0xc424be3380, 0x3aa3c5e, 0x28, 0x374bb00, 0xc424ca0590, 0x374bbe0, 0xc421f428b0, 0xc421800240, 0x0, ...)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/call.go:118 +0x19c
k8s.io/kubernetes/pkg/kubelet/apis/cri/v1alpha1/runtime.(*runtimeServiceClient).PodSandboxStatus(0xc4217f6038, 0x7ff04e8b9800, 0xc424be3380, 0xc424ca0590, 0x0, 0x0, 0x0, 0xc424d92870, 0xc42204f3e8, 0x28)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/apis/cri/v1alpha1/runtime/api.pb.go:3409 +0xd2
k8s.io/kubernetes/pkg/kubelet/remote.(*RemoteRuntimeService).PodSandboxStatus(0xc4217ec440, 0xc424c7a740, 0x40, 0x0, 0x0, 0x0)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/remote/remote_runtime.go:143 +0x113
k8s.io/kubernetes/pkg/kubelet/kuberuntime.instrumentedRuntimeService.PodSandboxStatus(0x59d86a0, 0xc4217ec440, 0xc424c7a740, 0x40, 0x0, 0x0, 0x0)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/kuberuntime/instrumented_services.go:192 +0xc4
k8s.io/kubernetes/pkg/kubelet/kuberuntime.(*instrumentedRuntimeService).PodSandboxStatus(0xc4217f41f0, 0xc424c7a740, 0x40, 0xc421f428a8, 0x1, 0x1)
<autogenerated>:1 +0x59
k8s.io/kubernetes/pkg/kubelet/kuberuntime.(*kubeGenericRuntimeManager).GetPodStatus(0xc421802340, 0xc421dfad80, 0x24, 0xc422358e00, 0x1c, 0xc42172aa17, 0x5, 0x50a3ac, 0x5ae88e0, 0xc400000000)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/kuberuntime/kuberuntime_manager.go:841 +0x373
k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).updateCache(0xc421027260, 0xc421f0e840, 0xc421dfad80, 0x24, 0xc423e86ea8, 0x1)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:346 +0xcf
k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).relist(0xc421027260)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:242 +0xbe1
k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).(k8s.io/kubernetes/pkg/kubelet/pleg.relist)-fm()
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:129 +0x2a
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.JitterUntil.func1(0xc4217c81c0)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:97 +0x5e
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.JitterUntil(0xc4217c81c0, 0x3b9aca00, 0x0, 0x1, 0xc420084120)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:98 +0xbd
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.Until(0xc4217c81c0, 0x3b9aca00, 0xc420084120)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:52 +0x4d
created by k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).Start
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:129 +0x8a
我们打印每个事件的时间戳,kubelet处理每个事件大约需要1秒。
因此导致PLEG无法在3分钟内完成重新列出。
然后由于PLEG不健康, syncLoop停止工作(https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/kubelet.go#L1758)。
因此PLEG事件通道不会被syncLoop (https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/kubelet.go#L1862)占用。
但是PLEG继续处理事件并将事件发送到plegChannel(https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L261)
频道满后(频道容量为1000 https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/kubelet.go#L144)
PLEG将卡住。 pleg重新列出的时间戳永远不会更新(https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L201)
堆栈信息:
goroutine 422 [chan send, 3 minutes]:
k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).relist(0xc421027260)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:263 +0x95a
k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).(k8s.io/kubernetes/pkg/kubelet/pleg.relist)-fm()
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:129 +0x2a
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.JitterUntil.func1(0xc4217c81c0)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:97 +0x5e
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.JitterUntil(0xc4217c81c0, 0x3b9aca00, 0x0, 0x1, 0xc420084120)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:98 +0xbd
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.Until(0xc4217c81c0, 0x3b9aca00, 0xc420084120)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:52 +0x4d
created by k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).Start
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:129 +0x8a
删除退出的容器后,重新启动kubelet,它又回来了。
因此,当节点中有超过1k个容器时,有挂起kubelet的风险。
解决方案是我们可以并行更新Pod缓存(https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L236)
否则在处理事件时应设置超时。
@ yingnanzhang666
 wenlxie
于 2018-04-03
wenlxie
于 2018-04-03
由于PLEG问题,当我的节点开始在“就绪” /“未就绪”之间摆动时,它始终是docker inspect挂起的退出的gcr.io/google_containers/pause容器之一。 重新启动docker守护程序可解决此问题。
erstaples
于 2018-04-13
大家好,我可以看到通过CoreOS / Docker / Kubernetes二进制文件的不同组合报告了此问题。 在我们的情况下,我们仍在相同的kubernetes堆栈上(1.7.10 / CoreOS / kops / AWS),我认为问题没有解决,但是当我们最终引入'tini时,我们设法将其影响降低到几乎为零。 (https://github.com/krallin/tini)作为部署在kubernetes上的docker镜像的一部分。 我们大约部署了20个不同的容器(应用程序),并且确实经常部署。 因此,这意味着-大量关闭和拆分新副本等。因此,我们部署的频率越高,对“节点”未就绪和PLEG的打击就越大。 当我们对大多数图像展开Tini时(确保PId被相应地捕获并杀死),我们停止了这种副作用。 我强烈建议您看一下tini或其他任何可以正确处理子进程收获的docker基本映像,因为我认为它与问题高度相关。 希望能有所帮助。 当然,核心问题仍然存在,因此该问题仍然有效。
javapapo
于 2018-04-14
由于此问题仍未解决,并且会半定期地影响我的集群,因此我想成为解决方案的一部分,着手开发一个自定义运算符,该运算符可以自动修复受节点震荡影响的节点, PLEG is not healthy通过某种通用的自动修复运算符发出。 我的灵感来自Node Problem Detector存储库中的这个未解决问题。 我已经使用节点问题检测器配置了一个自定义监视器,该监视器将在PLEG is not healthy开始显示在kubelet日志中时将PLEGNotHealthy节点条件设置为true。 下一步是一个自动补救系统,该系统将检查节点状况,例如PLEGNotHealthy ,该状况指示不健康的节点,然后在该节点上警戒,撤离并重新启动docker守护程序(或适用于给定条件)。 我正在寻找CoreOS更新操作员,作为我要开发的操作
erstaples
于 2018-04-16
在我们的例子中,它有时卡在PodSandboxStatus()持续2分钟,输出kubelet:
rpc error: code = 4 desc = context deadline exceeded
内核输出:
unregister_netdevice: waiting for eth0 to become free. Usage count = 1
但是它只是在特定的Pod删除时发生(网络流量很大)。
首先,PodSpec沙箱停止成功,但是暂停沙箱停止失败(将永远运行)。 然后,当使用相同的沙箱ID提取状态时,它将始终停留在此处。
结果,-> PLEG等待时间长-> PLEG不健康(两次调用,2min * 2 = 4min> 3 min)-> NodeNotReady
docker_sandbox.go相关代码:
func (ds *dockerService) PodSandboxStatus(podSandboxID string) (*runtimeapi.PodSandboxStatus, error) {
// Inspect the container.
// !!! maybe stuck here for 2 min !!!
r, err := ds.client.InspectContainer(podSandboxID)
if err != nil {
return nil, err
}
...
}
func (ds *dockerService) StopPodSandbox(podSandboxID string) error {
var namespace, name string
var checkpointErr, statusErr error
needNetworkTearDown := false
// Try to retrieve sandbox information from docker daemon or sandbox checkpoint
// !!! maybe stuck here !!!
status, statusErr := ds.PodSandboxStatus(podSandboxID)
...
根据Prometheus监视,泊坞窗检查延迟是正常的,但是kubelet运行时检查/停止操作花费的时间太长。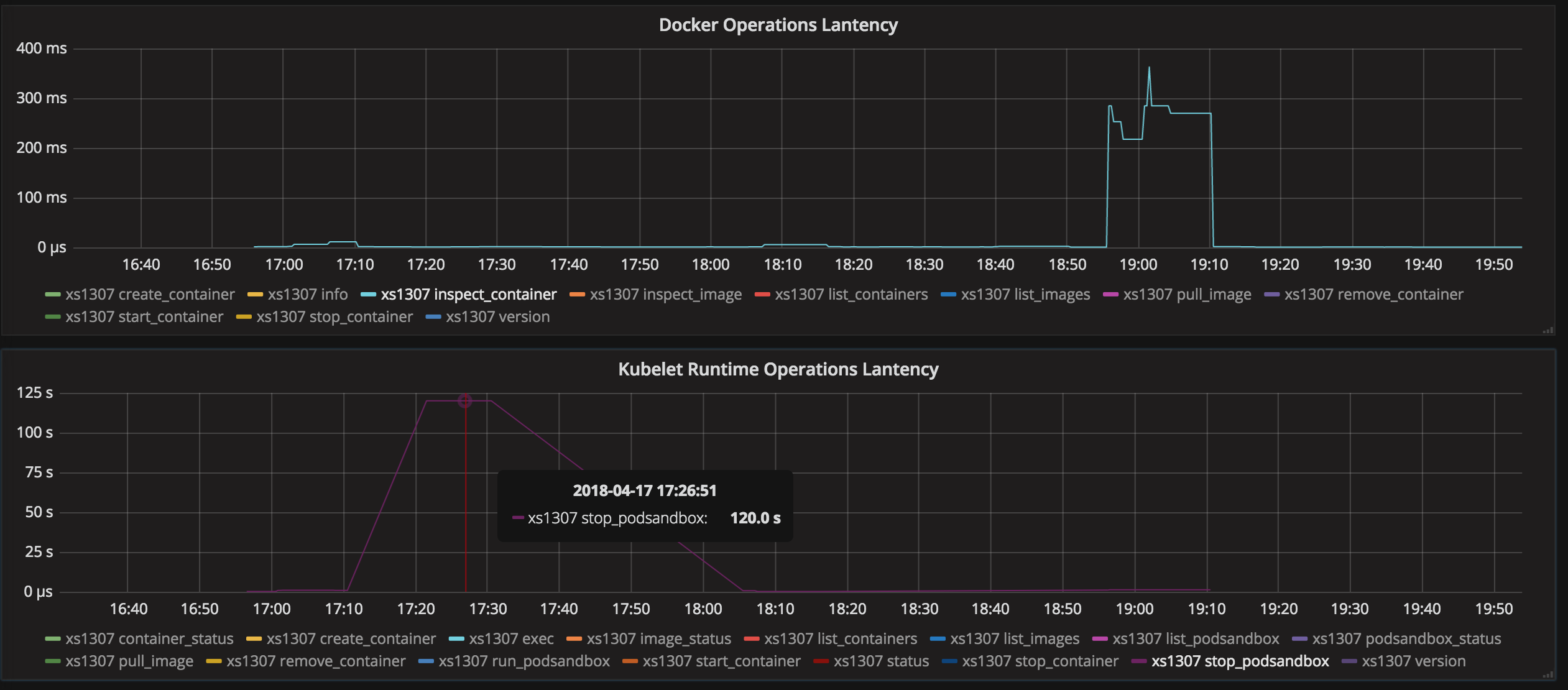
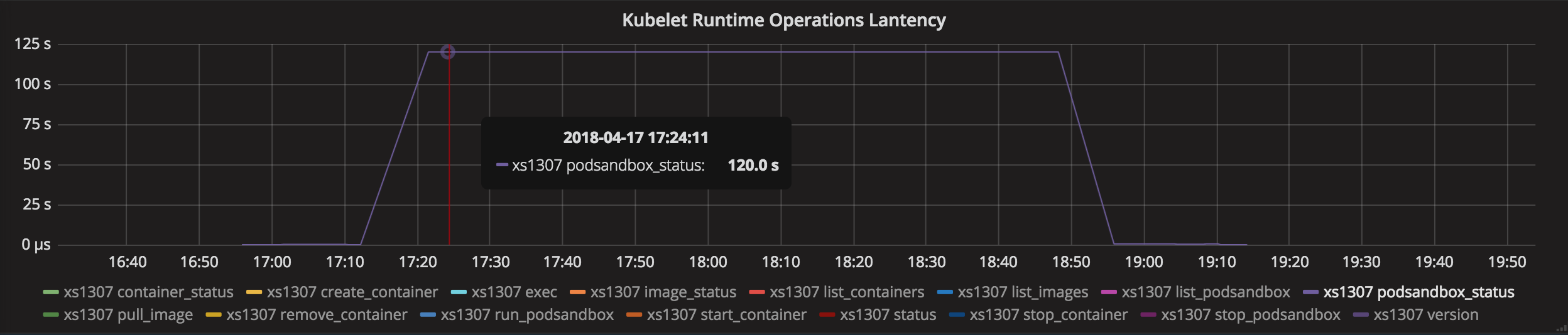
码头工人版本:1.12.6
kubelet版本:1.7.12
linux内核版本:4.4.0-72-generic
CNI:印花布
正如@yujuhong所提到的:
grpc http grpc
kubelet <----> dockershim <----> dockerd <----> containerd
发生这种情况时,我尝试运行docker ps 。 有用。 使用curl到/var/run/docker.sock
获取暂停容器的json也可以。 我想知道kubelet和dockershim之间是否是grpc响应问题?
curl --unix-socket /var/run/docker.sock http:/v1.24/containers/66755504b8dc3a5c17454e04e0b74676a8d45089a7e522230aad8041ab6f3a5a/json
由于PLEG问题,当我的节点开始在“就绪” /“未就绪”之间摆动时,它总是被docker检查挂起的退出的gcr.io/google_containers/pause容器之一。 重新启动docker守护程序可解决此问题。
看来我们的情况类似于@erstaples的描述。 我认为它将仅通过docker stop和docker rm可以暂停的暂停容器来解决,而不是重新启动dockerd。
 whypro
于 2018-04-18
whypro
于 2018-04-18
如果在节点上运行dmesg ,我也可以看到unregister_netdevice: waiting for eth0 to become free. Usage count = 1错误。 由于系统无法释放网络设备,因此Pod永远不会终止。 这将导致PodSandboxStatus of sandbox "XXX" for pod "YYY" error: rpc error: code = DeadlineExceeded desc = context deadline exceeded错误journalctl -u kubelet 。
可能与Kubernetes网络插件有关吗? 此线程中的一些人似乎在使用Calico。 也许那里有东西?
albertvaka
于 2018-04-24
@deitch,您在这里谈论有关CoreOS问题。 您能否提供更多有关如何解决此网络问题的信息?
我在这里面临着同样的问题,但是我正在使用768Gb RAM的裸机节点进行测试。 它加载了超过2k张图像(我正在修剪其中的一些图像)。
我们正在使用k8s 1.7.15和Docker 17.09。 我正在考虑将其还原为Docker 1.13,如此处的一些评论中所述,但是我不确定这是否可以解决我的问题。
我们确实还有一些更具体的问题,例如Bonding失去与其中一台交换机的连接,但是我不知道这与CoreOS网络问题有什么关系。
此外,kubelet和docker花费了大量的CPU时间(几乎比系统中的其他任何时间都多)
谢谢!
 rikatz
于 2018-05-10
rikatz
于 2018-05-10
在Kubernetes v1.8.7和calico v2.8.6上可以看到这一点。 在我们的例子中,某些吊舱卡在Terminating状态,Kubelet引发PLEG错误:
E0515 16:15:34.039735 1904 generic.go:241] PLEG: Ignoring events for pod myapp-5c7f7dbcf7-xvblm/production: rpc error: code = DeadlineExceeded desc = context deadline exceeded
I0515 16:16:34.560821 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.529418824s ago; threshold is 3m0s]
I0515 16:16:39.561010 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m5.529605547s ago; threshold is 3m0s]
I0515 16:16:41.857069 1904 kubelet_node_status.go:791] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2018-05-15 16:16:41.857046605 +0000 UTC LastTransitionTime:2018-05-15 16:16:41.857046605 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.825663114s ago; threshold is 3m0s}
I0515 16:16:44.561281 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m10.52986717s ago; threshold is 3m0s]
I0515 16:16:49.561499 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m15.530093202s ago; threshold is 3m0s]
I0515 16:16:54.561740 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m20.530326452s ago; threshold is 3m0s]
I0515 16:16:59.561943 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m25.530538095s ago; threshold is 3m0s]
I0515 16:17:04.562205 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m30.530802216s ago; threshold is 3m0s]
I0515 16:17:09.562432 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m35.531029395s ago; threshold is 3m0s]
I0515 16:17:14.562644 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m40.531229806s ago; threshold is 3m0s]
I0515 16:17:19.562899 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m45.531492495s ago; threshold is 3m0s]
I0515 16:17:24.563168 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m50.531746392s ago; threshold is 3m0s]
I0515 16:17:29.563422 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m55.532013675s ago; threshold is 3m0s]
I0515 16:17:34.563740 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 4m0.532327398s ago; threshold is 3m0s]
E0515 16:17:34.041174 1904 generic.go:271] PLEG: pod myapp-5c7f7dbcf7-xvblm/production failed reinspection: rpc error: code = DeadlineExceeded desc = context deadline exceeded
当我运行docker ps ,我只看到pause容器Pod myapp-5c7f7dbcf7-xvblm容器。
ip-10-72-160-222 core # docker ps | grep myapp-5c7f7dbcf7-xvblm
c6c34d9b1e86 gcr.io/google_containers/pause-amd64:3.0 "/pause" 9 hours ago Up 9 hours k8s_POD_myapp-5c7f7dbcf7-xvblm_production_baa0e029-5810-11e8-a9e8-0e88e0071844_0
重新启动kubelet ,将删除僵尸pause容器(标识c6c34d9b1e86 )。 kubelet日志:
W0515 16:56:26.439306 79462 docker_sandbox.go:343] failed to read pod IP from plugin/docker: NetworkPlugin cni failed on the status hook for pod "myapp-5c7f7dbcf7-xvblm_production": CNI failed to retrieve network namespace path: Cannot find network namespace for the terminated container "c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b"
W0515 16:56:26.439962 79462 cni.go:265] CNI failed to retrieve network namespace path: Cannot find network namespace for the terminated container "c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b"
2018-05-15 16:56:26.428 [INFO][79799] calico-ipam.go 249: Releasing address using handleID handleID="k8s-pod-network.c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b" workloadID="production.myapp-5c7f7dbcf7-xvblm"
2018-05-15 16:56:26.428 [INFO][79799] ipam.go 738: Releasing all IPs with handle 'k8s-pod-network.c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b'
2018-05-15 16:56:26.739 [INFO][81206] ipam.go 738: Releasing all IPs with handle 'k8s-pod-network.c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b'
2018-05-15 16:56:26.742 [INFO][81206] ipam.go 738: Releasing all IPs with handle 'production.myapp-5c7f7dbcf7-xvblm'
2018-05-15 16:56:26.742 [INFO][81206] calico-ipam.go 261: Releasing address using workloadID handleID="k8s-pod-network.c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b" workloadID="production.myapp-5c7f7dbcf7-xvblm"
2018-05-15 16:56:26.742 [WARNING][81206] calico-ipam.go 255: Asked to release address but it doesn't exist. Ignoring handleID="k8s-pod-network.c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b" workloadID="production.myapp-5c7f7dbcf7-xvblm"
Calico CNI releasing IP address
2018-05-15 16:56:26.745 [INFO][80545] k8s.go 379: Teardown processing complete. Workload="production.myapp-5c7f7dbcf7-xvblm"
从内核日志:
[40473.123736] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[40483.187768] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[40493.235781] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
我认为也有类似的门票开放https://github.com/moby/moby/issues/5618
zihaoyu
于 2018-05-15
这是完全不同的情况。 在这里,您知道节点发生震荡的原因。
dElogics
于 2018-05-18
我们遇到了这个问题,导致生产集群中的节点崩溃。 窗格无法终止或创建。 在Linux内核4.14.32和Docker 17.12.1-ce上具有Kubernetes 1.9.7和CoreOS 1688.5.3(Rhyolite)。 我们的CNI是印花棉布。
containerd的日志显示了有关请求删除的cgroup的一些错误,但不是在错误发生时就直接发生。
May 21 17:35:00 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T17:35:00Z" level=error msg="stat cgroup bf717dbbf392b0ba7ef0452f7b90c4cfb4eca81e7329bfcd07fe020959b737df" error="cgroups: cgroup deleted"
May 21 17:44:32 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T17:44:32Z" level=error msg="stat cgroup a0887b496319a09b1f3870f1c523f65bf9dbfca19b45da73711a823917fdfa18" error="cgroups: cgroup deleted"
May 21 17:50:32 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T17:50:32Z" level=error msg="stat cgroup 2fbb4ba674050e67b2bf402c76137347c3b5f510b8934d6a97bc3b96069db8f8" error="cgroups: cgroup deleted"
May 21 17:56:22 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T17:56:22Z" level=error msg="stat cgroup f9501a4284257522917b6fae7e9f4766e5b8cf7e46989f48379b68876d953ef2" error="cgroups: cgroup deleted"
May 21 18:43:28 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T18:43:28Z" level=error msg="stat cgroup c37e7505019ae279941a7a78db1b7a6e7aab4006dfcdd83d479f1f973d4373d2" error="cgroups: cgroup deleted"
May 21 19:38:28 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T19:38:28Z" level=error msg="stat cgroup a327a775955d2b69cb01921beb747b4bba0df5ea79f637e0c9e59aeb7e670b43" error="cgroups: cgroup deleted"
May 21 19:50:26 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T19:50:26Z" level=error msg="stat cgroup 5d11f13d13b461fe2aa1396d947f1307a6c3a78e87fa23d4a1926a6d46794d58" error="cgroups: cgroup deleted"
May 21 19:52:26 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T19:52:26Z" level=error msg="stat cgroup fb7551cde0f9a640fbbb928d989ca84200909bce2821e03a550d5bfd293e786b" error="cgroups: cgroup deleted"
May 21 20:54:32 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T20:54:32Z" level=error msg="stat cgroup bcd1432a64b35fd644295e2ae75abd0a91cb38a9fa0d03f251c517c438318c53" error="cgroups: cgroup deleted"
May 21 21:56:28 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T21:56:28Z" level=error msg="stat cgroup 2a68f073a7152b4ceaf14d128f9d31fbb2d5c4b150806c87a640354673f11792" error="cgroups: cgroup deleted"
May 21 22:02:30 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T22:02:30Z" level=error msg="stat cgroup aa2224e7cfd0a6f44b52ff058a50a331056b0939d670de461b7ffc7d01bc4d59" error="cgroups: cgroup deleted"
May 21 22:18:32 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T22:18:32Z" level=error msg="stat cgroup 95e0c4f7607234ada85a1ab76b7ec2aa446a35e868ad8459a1cae6344bc85f4f" error="cgroups: cgroup deleted"
May 21 22:21:32 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T22:21:32Z" level=error msg="stat cgroup 76578ede18ba3bc1307d83c4b2ccd7e35659f6ff8c93bcd54860c9413f2f33d6" error="cgroups: cgroup deleted"
Kubelet显示了有关Pod沙箱操作失败的一些有趣的说法。
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.578306 1513 remote_runtime.go:115] StopPodSandbox "922f625ced6d6f6adf33fe67e5dd8378040cd2e5c8cacdde20779fc692574ca5" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.578354 1513 kuberuntime_manager.go:800] Failed to stop sandbox {"docker" "922f625ced6d6f6adf33fe67e5dd8378040cd2e5c8cacdde20779fc692574ca5"}
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: W0523 18:17:25.579095 1513 docker_sandbox.go:196] Both sandbox container and checkpoint for id "a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" could not be found. Proceed without further sandbox information.
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: W0523 18:17:25.579426 1513 cni.go:242] CNI failed to retrieve network namespace path: Error: No such container: a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.723 [INFO][33881] calico.go 338: Extracted identifiers ContainerID="a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" Node="ip-10-5-76-113.ap-southeast-1.compute.internal" Orchestrator="cni" Workload="a89
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.723 [INFO][33881] utils.go 263: Configured environment: [CNI_COMMAND=DEL CNI_CONTAINERID=a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642 CNI_NETNS= CNI_ARGS=IgnoreUnknown=1;IgnoreUnknown=1;K8S_POD_NAMESP
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.723 [INFO][33881] client.go 202: Loading config from environment
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: Calico CNI releasing IP address
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.796 [INFO][33905] utils.go 263: Configured environment: [CNI_COMMAND=DEL CNI_CONTAINERID=a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642 CNI_NETNS= CNI_ARGS=IgnoreUnknown=1;IgnoreUnknown=1;K8S_POD_NAMESP
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.796 [INFO][33905] client.go 202: Loading config from environment
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.796 [INFO][33905] calico-ipam.go 249: Releasing address using handleID handleID="k8s-pod-network.a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" workloadID="a893f57acec1f3779c35aed743f128408e491ff2f53a3
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.796 [INFO][33905] ipam.go 738: Releasing all IPs with handle 'k8s-pod-network.a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642'
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.805 [WARNING][33905] calico-ipam.go 255: Asked to release address but it doesn't exist. Ignoring handleID="k8s-pod-network.a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" workloadID="a893f57acec1f3779c3
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.805 [INFO][33905] calico-ipam.go 261: Releasing address using workloadID handleID="k8s-pod-network.a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" workloadID="a893f57acec1f3779c35aed743f128408e491ff2f53
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.805 [INFO][33905] ipam.go 738: Releasing all IPs with handle 'a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642'
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.822 [INFO][33881] calico.go 373: Endpoint object does not exist, no need to clean up. Workload="a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" endpoint=api.WorkloadEndpointMetadata{ObjectMetadata:unver
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.824925 1513 kubelet.go:1527] error killing pod: failed to "KillPodSandbox" for "9c246b32-4f10-11e8-964a-0a7e4ae265be" with KillPodSandboxError: "rpc error: code = DeadlineExceeded desc = context deadline exceeded"
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.825025 1513 pod_workers.go:186] Error syncing pod 9c246b32-4f10-11e8-964a-0a7e4ae265be ("flntk8-fl01-j7lf4_splunk(9c246b32-4f10-11e8-964a-0a7e4ae265be)"), skipping: error killing pod: failed to "KillPodSandbo
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.969591 1513 kuberuntime_manager.go:860] PodSandboxStatus of sandbox "922f625ced6d6f6adf33fe67e5dd8378040cd2e5c8cacdde20779fc692574ca5" for pod "flntk8-fl01-j7lf4_splunk(9c246b32-4f10-11e8-964a-0a7e4ae265be)"
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.969640 1513 generic.go:241] PLEG: Ignoring events for pod flntk8-fl01-j7lf4/splunk: rpc error: code = DeadlineExceeded desc = context deadline exceeded
May 23 18:20:27 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: I0523 18:20:27.753523 1513 kubelet.go:1790] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.783603773s ago; threshold is 3m0s]
May 23 18:19:27 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:19:27.019252 1513 kuberuntime_manager.go:860] PodSandboxStatus of sandbox "922f625ced6d6f6adf33fe67e5dd8378040cd2e5c8cacdde20779fc692574ca5" for pod "flntk8-fl01-j7lf4_splunk(9c246b32-4f10-11e8-964a-0a7e4ae265be)"
May 23 18:19:27 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:19:27.019295 1513 generic.go:241] PLEG: Ignoring events for pod flntk8-fl01-j7lf4/splunk: rpc error: code = DeadlineExceeded desc = context deadline exceeded
内核显示eth0等待变为免费行,似乎与以下内容有关: https :
[1727395.220036] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[1727405.308152] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[1727415.404335] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[1727425.484491] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[1727435.524626] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[1727445.588785] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
但是,我们的案例没有显示适配器lo并且没有使内核崩溃。 进一步的调查指向https://github.com/projectcalico/calico/issues/1109 ,该结论仍然得出结论,这是一个尚未解决的内核争用条件错误。
重新启动kubelet已解决了足以使Pod终止和创建的问题,但是waiting for eth0 to become free垃圾邮件在dmesg中继续存在。
这是关于这个问题的有趣读物: https ://medium.com/@bcdonadio/when -the-blue-whale-sinks-55c40807c2fc
 integrii
于 2018-05-23
integrii
于 2018-05-23
@integrii
不,它也发生在最新的centOS上。 得到它转载一次。
dElogics
于 2018-06-03
好的,我想更改我之前说的内容–容器运行时突然抱怨
跳过广告连播同步-[PLEG不健康:...
当Docker运行文件时。 同时,重新启动kubelet使PLEG健康,节点再次启动。
docker,kubelet,kube-proxy均设置为RT优先级。
dElogics
于 2018-06-03
还有一件事-在重新启动kubelet时,除非重新启动docker,否则会发生同样的事情。
我尝试在docker的套接字上使用curl,并且工作正常。
dElogics
于 2018-06-03
+1
Kubernetes:1.10.2
码头工人:1.12.6
操作系统:centos 7.4
内核:3.10.0-693.el7.x86_64
CNI:印花布
 lanxenet
于 2018-06-05
lanxenet
于 2018-06-05
+1
总督:1.7.16
码头工人:17.12.1-ce
作业系统:CoreOS 1688.5.3
内核:4.14.32-coreos
CNI:Calico(v2.6.7)
从v1.9.1开始
 phspagiari
于 2018-06-14
phspagiari
于 2018-06-14
您认为增加--runtime-request-timeout会有所帮助吗?
dElogics
于 2018-06-17
我在一个节点上看到CRI-O的问题。 使用Flannel的Kubernetes 1.10.1,CRI-0.0.10.1,Fedora 27,内核4.16.7-200.fc27。
runc list和crictl pods都很快,但是crictl ps需要几分钟才能运行。
 mcronce
于 2018-06-26
mcronce
于 2018-06-26
+1
Kubernetes:v1.8.7 + coreos.0
码头工人:17.05.0-ce
操作系统:Redhat 7x
CNI:印花布
Kubespary 2.4
我们经常看到此问题。 我们重新启动docker和kubelet,它消失了。
 sivarajp
于 2018-07-13
sivarajp
于 2018-07-13
使用最新的稳定CoreOS 1745.7.0我不再看到此问题。
komljen
于 2018-07-13
更新@komljen后您看了多长时间? 对于我们来说,这需要一段时间。
integrii
于 2018-07-13
我每几天在一个大型CI环境中遇到这些问题,我想我尝试了一切都没有成功。 将操作系统更改为高于CoreOS版本是关键,而且我一个月都没有看到任何问题。
komljen
于 2018-07-13
我也已经一个多月没有见到这个问题了。 没有任何变化,所以我不会这么快就宣布患者健康:-)
 oivindoh
于 2018-07-13
oivindoh
于 2018-07-13
@komljen我们运行
sivarajp
于 2018-07-13
我也已经一个多月没有见到这个问题了。 没有任何变化,所以我不会这么快就宣布患者健康:-)
@oivindoh我没有时间检查特定内核版本中的更改,但就我而言,它解决了问题。
komljen
于 2018-07-14
我在我们的集群中找到了此问题的原因。 总而言之,该错误是由永远不会终止的CNI命令(calico)引起的,该命令导致dockershim服务器处理程序永久卡住。 结果,RPC调用PodSandboxStatus()来使坏Pod始终超时,从而使PLEG处于不健康状态。
错误的影响:
- 坏豆荚永远停留在
Terminating状态 - 其他Pod状态可能会在几分钟内失去与kubeapi服务器的同步(导致集群中出现kube2iam错误)
- 内存泄漏,因为该函数被多次调用且永不返回
这是发生这种情况时在节点上可以看到的内容:
- kubelet日志中的以下错误消息:
Jul 13 23:52:15 E0713 23:52:15.461144 1740 kuberuntime_manager.go:860] PodSandboxStatus of sandbox "01d8b790bc9ede72959ddf0669e540dfb1f84bfd252fb364770a31702d9e7eeb" for pod "pod-name" error: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 13 23:52:15 E0713 23:52:15.461215 1740 generic.go:241] PLEG: Ignoring events for pod pod-name: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 13 23:52:16 E0713 23:52:16.682555 1740 pod_workers.go:186] Error syncing pod 7f3fd634-7e57-11e8-9ddb-0acecd2e6e42 ("pod-name"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 13 23:53:15 I0713 23:53:15.682254 1740 kubelet.go:1790] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.267402933s ago; threshold is 3m0s]
- 以下超时指标:
$ curl -s http://localhost:10255/metrics | grep 'quantile="0.5"' | grep "e+08"
kubelet_pleg_relist_interval_microseconds{quantile="0.5"} 2.41047643e+08
kubelet_pleg_relist_latency_microseconds{quantile="0.5"} 2.40047461e+08
kubelet_runtime_operations_latency_microseconds{operation_type="podsandbox_status",quantile="0.5"} 1.2000027e+08
- kubelet的子进程(calico)被卡住:
$ ps -A -o pid,ppid,start_time,comm | grep 1740
1740 1 Jun15 kubelet
5428 1740 Jul04 calico
这是dockershim服务器中的堆栈跟踪:
PodSandboxStatus() :: pkg/kubelet/dockershim/docker_sandbox.go
... -> GetPodNetworkStatus() :: pkg/kubelet/network/plugins.go
^^^^^ this function stuck on pm.podLock(fullPodName).Lock()
要解决此问题,kubelet应该对CNI库函数调用( DelNetwork()等)和其他可能需要永久返回的外部库调用使用超时。
 mechpen
于 2018-07-16
mechpen
于 2018-07-16
@mechpen我很高兴有人在某个地方找到了答案。 我不认为这适用于这里(至少在此群集中,我们使用的是weave,而不是calico;我在其他地方使用了calico,并一直在推动它的多体系结构),而且也没有看到类似的错误消息。
如果确实显示,则您说:
要解决此问题,kubelet应该对CNI库函数调用(DelNetwork()等)或任何可能要永远返回的外部库调用使用超时
可配置的? 还是需要修改kubelet ?
deitch
于 2018-07-16
如果编织CNI命令没有终止(可能由所有系统共享的低级错误引起),则@deitch也会发生该错误。
该修复程序需要更改kubelet代码。
mechpen
于 2018-07-16
@mechpen我们也在绒布中运行的群集中看到此问题吗? 解决方法是一样的吗?
sivarajp
于 2018-07-17
@komljen我刚刚看到了1745.7.0
我目前在k8s 1.9的calico上看到此问题
我确实在停留在终止中的那个确切节点上有一个吊舱。 让我强行杀死它,看看问题是否停止。
 sstarcher
于 2018-07-17
sstarcher
于 2018-07-17
@mechpen您是否为k8s开了个问题供您参考?
sstarcher
于 2018-07-17
@mechpen我们也应该开张印花布票吗?
sstarcher
于 2018-07-17
@sstarcher我尚未提交任何票证。 仍在尝试找出印花棉布永远挂死的原因。
我看到很多内核消息:
[2797545.570844] unregister_netdevice: waiting for eth0 to become free. Usage count = 2
这个错误困扰着Linux /容器很多年了。
mechpen
于 2018-07-18
@mechpen
@sstarcher
@deitch
是的,这个问题我已经在一个月前抓住了。
我已经公开了一个问题。
我尝试在kubelet中修复此问题,但首先应在cni中修复它。
所以我先在cni中修复它,然后在kubelet中修复它。
谢谢
#65743
https://github.com/containernetworking/cni/issues/567
https://github.com/containernetworking/cni/pull/568
liucimin
于 2018-07-19
与这个问题相关的@sstarcher @mechpen印花布票:
https://github.com/projectcalico/calico/issues/1109
 r0bj
于 2018-07-25
r0bj
于 2018-07-25
@mechpen参见https://github.com/moby/moby/issues/5618 。
dElogics
于 2018-07-30
在我们的生产集群上又发生了一次
Kubernetes:1.11.0
coreos:1520.9.0
码头工人:1.12.6
cni:印花布
我在尚未就绪的节点上重新启动了kubelet和dockerd,现在看来还可以。
未就绪节点和就绪节点之间的唯一区别是,很多cronjob pod开始和停止以及在未就绪节点上被杀死。
leeeboo
于 2018-07-31
@mechpen
我不确定是否遇到相同的问题。
Jul 30 17:52:15 cloud-blade-31 kubelet[24734]: I0730 17:52:15.585102 24734 kubelet_node_status.go:431] Recording NodeNotReady event message for node cloud-blade-31
Jul 30 17:52:15 cloud-blade-31 kubelet[24734]: I0730 17:52:15.585137 24734 kubelet_node_status.go:792] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2018-07-30 17:52:15.585076295 -0700 PDT m=+13352844.638760537 LastTransitionTime:2018-07-30 17:52:15.585076295 -0700 PDT m=+13352844.638760537 Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m0.948768335s ago; threshold is 3m0s}
Jul 30 17:52:25 cloud-blade-31 kubelet[24734]: I0730 17:52:25.608101 24734 kubelet_node_status.go:443] Using node IP: "10.11.3.31"
Jul 30 17:52:35 cloud-blade-31 kubelet[24734]: I0730 17:52:35.640422 24734 kubelet_node_status.go:443] Using node IP: "10.11.3.31"
Jul 30 17:52:36 cloud-blade-31 kubelet[24734]: E0730 17:52:36.556409 24734 remote_runtime.go:169] ListPodSandbox with filter nil from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 30 17:52:36 cloud-blade-31 kubelet[24734]: E0730 17:52:36.556474 24734 kuberuntime_sandbox.go:192] ListPodSandbox failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 30 17:52:36 cloud-blade-31 kubelet[24734]: W0730 17:52:36.556492 24734 image_gc_manager.go:173] [imageGCManager] Failed to monitor images: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 30 17:52:45 cloud-blade-31 kubelet[24734]: I0730 17:52:45.667169 24734 kubelet_node_status.go:443] Using node IP: "10.11.3.31"
Jul 30 17:52:55 cloud-blade-31 kubelet[24734]: I0730 17:52:55.692889 24734 kubelet_node_status.go:443] Using node IP: "10.11.3.31"
Jul 30 17:53:05 cloud-blade-31 kubelet[24734]: I0730 17:53:05.729182 24734 kubelet_node_status.go:443] Using node IP: "10.11.3.31"
Jul 30 17:53:15 cloud-blade-31 kubelet[24734]: E0730 17:53:15.265668 24734 remote_runtime.go:169] ListPodSandbox with filter &PodSandboxFilter{Id:,State:&PodSandboxStateValue{State:SANDBOX_READY,},LabelSelector:map[string]string{},} from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
当(貌似)Docker守护程序停止响应运行状况检查时,我的节点进入NotReady 。 在机器本身docker ps挂起,但返回docker version 。 我必须重新启动docker daemon,以使节点再次成为Ready 。 我不确定是否可以说我是否有卡住的豆荚,因为我似乎无法列出任何容器。
Kubernetes:1.9.2
Docker 17.03.1-CE提交C6D412E
操作系统:Ubuntu 16.04
内核:Linux 4.13.0-31-通用#34〜16.04.1-Ubuntu SMP Fri Jan 19 17:11:01 UTC 2018 x86_64 x86_64 x86_64 GNU / Linux
 saurfangg
于 2018-07-31
saurfangg
于 2018-07-31
我有同样的问题。 它是如此频繁地发生,以至于节点无法在5分钟的计划Pod中幸免。
该错误在我的主群集(法兰)和测试群集(calico)上均发生。
我尝试过更改kubernetes版本(1.9.?/1.11.1),发行版(debian,ubuntu),云提供程序(ec2,hetzner cloud),docker版本(17.3.2、17.06.2)。 我只测试一个变量的变体就不会测试完整矩阵。
我的工作非常简单(一个容器的Pod,无卷,默认网络,计划为30个Pod)
集群是使用kubeadm全新设置的,无需自定义(排除了我对法兰绒的初始测试)
错误在几分钟之内发生。 docker ps不返回/卡住,豆荚卡在终端中,等等。
现在我想知道当前是否有任何已知配置(使用debian或ubuntu)不会导致此错误?
是否有没有受此错误影响的人可以共享覆盖网络和产生稳定节点的其他版本的有效组合?
 nielsole
于 2018-08-04
nielsole
于 2018-08-04
它发生在Baremetal节点上的Openshift中。
对于PLEG的这种特殊情况,当在配置了多个vCPU的OpenShift节点上一次(通过失控的cronjob)一次启动大量容器时,就会看到此问题。 节点最多可以达到每个节点250个吊舱,并且变得超负荷。
一种解决方案是通过将vCPU的数量减少到8个(例如)来减少分配给OpenShift节点虚拟机的vCPU,这意味着可以调度的最大Pod数量为80个Pod(每个CPU默认限制为10个Pod) ),而不是250。通常建议使用更大大小的节点,而不是更大的节点。
我有224 cpu的节点。 Kubernetes版本1.7.1-Redhat 7.4
 jcperezamin
于 2018-08-13
jcperezamin
于 2018-08-13
我相信我也有类似的问题。 我的豆荚挂起,等待终止,并且日志中有PLEG不健康的报告。 在我的情况下,直到我手动杀死kubelet过程,它才恢复健康。 一个简单的sudo systemctl restart kubelet已经解决了这个问题,但是每次我们推出时,我都必须在大约1/4的机器上这样做。 它不是很好。
我无法确切知道发生了什么,但是鉴于我看到在kubelet进程下运行的bridge命令,也许与该线程先前提到的CNI有关? 今天,我已经从2个单独的实例中附加了大量日志,并且我很乐意与某人一起调试此问题。
当然,每台出现此问题的机器都在发出经典的unregister_netdevice: waiting for eth0 to become free. Usage count = 2 -我在logs.tar.gz中附加了2个不同的kubelet日志,并发送了SIGABRT以获取正在运行的go例程。 希望这会有所帮助。 我确实看到了几个看起来很相关的电话,所以我在这里给他们打电话。
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: goroutine 2895825 [semacquire, 17 minutes]:
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: sync.runtime_SemacquireMutex(0xc422082d4c)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/runtime/sema.go:62 +0x34
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: sync.(*Mutex).Lock(0xc422082d48)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/sync/mutex.go:87 +0x9d
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: k8s.io/kubernetes/pkg/kubelet/network.(*PluginManager).GetPodNetworkStatus(0xc420ddbbc0, 0xc421e36f76, 0x17, 0xc421e36f69, 0xc, 0x36791df, 0x6, 0xc4223f6180, 0x40, 0x0, ...)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /workspace/anago-v1.8.7-beta.0.34+b30876a5539f09/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/network/plugins.go:376 +0xe6
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: goroutine 2895819 [syscall, 17 minutes]:
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: syscall.Syscall6(0xf7, 0x1, 0x25d7, 0xc422c96d70, 0x1000004, 0x0, 0x0, 0x7f7dc6909e10, 0x0, 0xc4217e9980)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/syscall/asm_linux_amd64.s:44 +0x5
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: os.(*Process).blockUntilWaitable(0xc42216af90, 0xc421328c60, 0xc4217e99e0, 0x1)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/os/wait_waitid.go:28 +0xa5
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: os.(*Process).wait(0xc42216af90, 0x411952, 0xc4222554c0, 0xc422255480)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/os/exec_unix.go:22 +0x4d
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: os.(*Process).Wait(0xc42216af90, 0x0, 0x0, 0x379bbc8)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/os/exec.go:115 +0x2b
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: os/exec.(*Cmd).Wait(0xc421328c60, 0x0, 0x0)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/os/exec/exec.go:435 +0x62
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: os/exec.(*Cmd).Run(0xc421328c60, 0xc422255480, 0x0)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/os/exec/exec.go:280 +0x5c
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: k8s.io/kubernetes/vendor/github.com/containernetworking/cni/pkg/invoke.(*RawExec).ExecPlugin(0x5208390, 0xc4217e98a0, 0x1b, 0xc4212e66e0, 0x156, 0x160, 0xc422b7fd40, 0xf, 0x12, 0x4121a8, ...)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /workspace/anago-v1.8.7-beta.0.34+b30876a5539f09/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/github.com/containernetworking/cni/pkg/invoke/raw_exec.go:42 +0x215
在GCE上使用Kubernetes 1.8.7在Kernel 4.14.33+上使用容器优化的OS。
 theRealWardo
于 2018-08-14
theRealWardo
于 2018-08-14
@jcperezamin ,在3.10和更高版本的OpenShift中,没有默认值(每个核心的
warmchang
于 2018-08-14
我在裸机上得到这个。 使用全新的Ubuntu 18.04安装,配置为kubeadm(单节点主服务器)。
我遇到了Warning ContainerGCFailed 8m (x438 over 8h) ... rpc error: code = ResourceExhausted desc = grpc: trying to send message larger than max (8400302 vs. 8388608)
。 该节点已累积了约11,500个停止的容器。 我手动清理了一些容器,这些容器修复了GC,但是此后由于PLEG,该节点立即进入NotReady。
我使用的是基本的k8s配置,带有法兰绒进行网络连接。 受影响的节点是一台基于旧至强E5-2670的计算机,在硬件RAID6中具有6个10k SAS驱动器。
PLEG问题在一小时内仍未解决,重新启动kubelet立即解决了该问题。
 pnovotnak
于 2018-08-24
pnovotnak
于 2018-08-24
每次我加重机器时似乎都在发生,并且节点永远无法自行恢复。 通过SSH登录时,节点的CPU和其他资源为空。 没有太多的Docker容器,图像,卷等。列出这些资源很快。 只需重新设置kubelet即可立即解决此问题。
我正在使用以下版本:
- Ubuntu的:18.04.1
- Linux:4.15.0-33-通用
- Kubernetes服务器:v1.11.0
- Kubeadm:v1.11.2
- 码头工人:18.06.1-ce
pnovotnak
于 2018-08-27
刚刚在Kubernetes 1.11.1的裸机节点上遇到了这个问题:(
 adampl
于 2018-08-28
adampl
于 2018-08-28
也经常会遇到这种情况,并且节点确实功能强大且未被充分利用。
- Kubernetes:1.10.2
- 内核:3.10.0
- 码头工人:1.12.6
 devlounge
于 2018-08-29
devlounge
于 2018-08-29
同样的问题...
环境:
云提供商或硬件配置:裸机
操作系统(例如/ etc / os-release中的版本):Ubuntu 16.04
内核(例如,uname -a):4.4.0-109-通用
Kubernetes:1.10.5
码头工人:1.12.3-0〜xenial
 x8k
于 2018-09-03
x8k
于 2018-09-03
迁移到kubernetes 1.10.3后会有同样的问题。
客户端版本:version.Info {主要:“ 1”,次要:“ 10”,GitVersion:“ v1.10.5”
服务器版本:version.Info {主要:“ 1”,次要:“ 10”,GitVersion:“ v1.10.3”
 angegar
于 2018-09-04
angegar
于 2018-09-04
在裸机环境中存在相同的问题:
环境:
云提供商或硬件配置:裸机
操作系统(例如,/ etc / os-release中的版本):CoreOS 1688.5.3
内核(例如uname -a):4.14.32
Kubernetes:1.10.4
码头工人:17.12.1
 corest
于 2018-09-12
corest
于 2018-09-12
知道问题到达期间节点上的IOWAIT值很有趣。
livelace
于 2018-09-12
在另一个裸机环境中反复出现相同的问题。 最新热门版本:
- 作业系统: Ubuntu 16.04.5 LTS
- 内核: Linux 4.4.0-134-通用
- Kubernetes:
- 拍打主机: v1.10.3
- 硕士: v1.10.5和v1.10.2
- 拍打主机上的Docker: 18.03.1-ce(与go1.9.5编译)
 calder
于 2018-09-14
calder
于 2018-09-14
原因是已知的。
上游修复发生在这里:
https://github.com/containernetworking/cni/pull/568
下一步是更新kubernetes使用的cni,如果有人想跳进去
准备那个公关您可能需要与@liucimin或我进行协调
避免踩脚趾。
2018年9月14日星期五,上午11:38卡尔德·科森(Calder Coalson) [email protected]
写道:
在另一个裸机环境中反复出现相同的问题。 的版本
最新热门:
- 操作系统: Ubuntu 16.040.5 LTS
- 内核: Linux 4.4.0-134-通用
- Kubernetes:
- 拍打主机: v1.10.3
- 硕士: v1.10.5和v1.10.2
- 拍打主机上的Docker: 18.03.1-ce(与go1.9.5编译)
-
您收到此邮件是因为您发表了评论。
直接回复此电子邮件,在GitHub上查看
https://github.com/kubernetes/kubernetes/issues/45419#issuecomment-421447751 ,
或使线程静音
https://github.com/notifications/unsubscribe-auth/AFctXYnTJjNwtWquPmi5nozVMUYDetRlks5ua_eIgaJpZM4NSBta
。
pnovotnak
于 2018-09-14
@deitch
嗨,我遇到了类似的错误Error syncing pod *********** ("pod-name"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
我通过dockerd请求了容器信息,但发现此请求被阻止并且没有结果返回curl -XGET --unix-socket /var/run/docker.sock http://localhost/containers/******("yourcontainerid")/json
所以我认为这可能是docker错误
 Nebulazhang
于 2018-09-19
Nebulazhang
于 2018-09-19
这是关于将日志持久化到磁盘时docker守护进程的阻塞。
泊坞窗中有工作可解决此问题,但直到18.06才降落(尚未验证k8s使用率的泊坞窗)
https://docs.docker.com/config/containers/logging/configure/#configure -the-delivery-mode-of-log-messages-from-container-to-log-driver
由于docker守护程序默认情况下会阻止日志记录,因此我们无法解决该问题,因此无法解决。
这也与发生问题时的iowait较高有关。
使用exec运行状况检查的容器会产生大量日志。 还有其他模式也会强调日志记录机制。
只是我的2c
 mauilion
于 2018-09-19
mauilion
于 2018-09-19
我们在执行此操作的机器上看不到较高的iowait。 (CoreOS,Kube 1.10,Docker 17.03)
@mauilion您可以指出任何问题或MR来解释日志记录问题吗?
 mariusgrigoriu
于 2018-10-12
mariusgrigoriu
于 2018-10-12
我遇到了同样的问题,两个Kubernetes节点在“就绪”和“未就绪”之间摇摆。 信不信由你,解决方案是删除一个退出的泊坞窗容器和相关的容器。
d4e5d7ef1b5c gcr.io/google_containers/pause-amd64:3.0 Exited (137) 3 days ago
此后,群集再次稳定,无需其他干预。
此外,这是在syslog中找到的日志消息:
E1015 07:48:49.386113 1323 remote_runtime.go:115] StopPodSandbox "d4e5d7ef1b5c3d13a4e537abbc7c4324e735d455969f7563287bcfc3f97b
085f" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
 rchicoli
于 2018-10-16
rchicoli
于 2018-10-16
现在就面对这个问题:
OS: Oracle Linux 7.5
Kernel: 4.17.5-1.el7.elrepo.x86_64
Kubernetes: 1.11.3
Flapping host: v1.11.3
Docker on flapping host: 18.03.1-ce (compiled with go1.9.5)
 emedina
于 2018-10-24
emedina
于 2018-10-24
https://github.com/containernetworking/cni/pull/568合并到CNI中。
IIUC包含上述修复程序的新版本的CNI应该能够在k8s中修复此问题。
需要协调- @ bboreham @liucimin 。 也在sig网络中发布
 nikopen
于 2018-10-24
nikopen
于 2018-10-24
哪个版本的kubernetes-cni将包含此修复程序? 谢谢!
 roywangtj
于 2018-11-16
roywangtj
于 2018-11-16
关于超时的一个更集中的问题是#65743
就像我在那儿所说的那样,下一步是在Kubernetes方面,例如通过编写测试来检查更改是否确实解决了问题。 无需发布即可检查此问题:只需输入最新的libCNI代码即可。
 bboreham
于 2018-11-16
bboreham
于 2018-11-16
/ sig网络
 tossmilestone
于 2018-11-26
tossmilestone
于 2018-11-26
如果发生这种情况并卡住了docker ps有保证的豆荚触发的OOM一起发生的情况,请查看#72294。 由于Pod Infra容器被杀死并重新启动,因此可能会触发cni重新初始化,然后触发上述超时/锁定问题。
 clkao
于 2018-12-22
clkao
于 2018-12-22
我们看到的东西与此类似-在就绪/未就绪之间不断PLEG摆动-重新启动kubelet似乎可以解决此问题。 我注意到从kubelet进行goroutine转储时,我们有很多(目前有15000多个goroutine滞留在以下堆栈中:
goroutine 29624527 [semacquire, 2766 minutes]:
sync.runtime_SemacquireMutex(0xc428facb3c, 0xc4216cca00)
/usr/local/go/src/runtime/sema.go:71 +0x3d
sync.(*Mutex).Lock(0xc428facb38)
/usr/local/go/src/sync/mutex.go:134 +0xee
k8s.io/kubernetes/pkg/kubelet/network.(*PluginManager).GetPodNetworkStatus(0xc420820980, 0xc429076242, 0xc, 0xc429076209, 0x38, 0x4dcdd86, 0x6, 0xc4297fa040, 0x40, 0x0, ...)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/network/plugins.go:395 +0x13d
k8s.io/kubernetes/pkg/kubelet/dockershim.(*dockerService).getIPFromPlugin(0xc4217c4500, 0xc429e21050, 0x40, 0xed3bf0000, 0x1af5b22d, 0xed3bf0bc6)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/dockershim/docker_sandbox.go:304 +0x1c6
k8s.io/kubernetes/pkg/kubelet/dockershim.(*dockerService).getIP(0xc4217c4500, 0xc4240d9dc0, 0x40, 0xc429e21050, 0xe55ef53, 0xed3bf0bc7)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/dockershim/docker_sandbox.go:333 +0xc4
k8s.io/kubernetes/pkg/kubelet/dockershim.(*dockerService).PodSandboxStatus(0xc4217c4500, 0xb38ad20, 0xc429e20ed0, 0xc4216214c0, 0xc4217c4500, 0x1, 0x0)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/dockershim/docker_sandbox.go:398 +0x291
k8s.io/kubernetes/pkg/kubelet/apis/cri/runtime/v1alpha2._RuntimeService_PodSandboxStatus_Handler(0x4d789e0, 0xc4217c4500, 0xb38ad20, 0xc429e20ed0, 0xc425afaf00, 0x0, 0x0, 0x0, 0x0, 0x2)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/apis/cri/runtime/v1alpha2/api.pb.go:4146 +0x276
k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).processUnaryRPC(0xc420294640, 0xb399760, 0xc421940000, 0xc4264d8900, 0xc420d894d0, 0xb335000, 0x0, 0x0, 0x0)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/server.go:843 +0xab4
k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).handleStream(0xc420294640, 0xb399760, 0xc421940000, 0xc4264d8900, 0x0)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/server.go:1040 +0x1528
k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).serveStreams.func1.1(0xc42191c020, 0xc420294640, 0xb399760, 0xc421940000, 0xc4264d8900)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/server.go:589 +0x9f
created by k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).serveStreams.func1
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/server.go:587 +0xa1
我注意到停留在此堆栈中的goroutine的数量随着时间的推移而稳定增长(每2分钟大约增加1个)
遇到这种情况的节点通常将Pod卡在Terminating -当我重新启动kubelet时, Terminating Pod消失了,我不再看到PLEG问题。
@pnovotnak,如果这听起来像是应该通过将超时添加到CNI的更改来解决的相同问题,
 mcginne
于 2019-01-21
mcginne
于 2019-01-21
我有同样的问题: https :
哪个版本的kubernetes-cni将包含此修复程序? 谢谢!
warmchang
于 2019-03-01
@warmchang kubernetes-cni插件包不相关。 所需的更改在libcni中,可从https://github.com/containernetworking/cni出售(复制到此仓库中)
更改已合并; 无需释放(尽管这可能会使人感觉更好)。
bboreham
于 2019-03-01
@bboreham谢谢您的答复。
我的意思是供应商目录中的CNI代码(libcni),而不是CNI插件(例如法兰绒/印花棉布等)。
我发现此PR https://github.com/kubernetes/kubernetes/pull/71653正在等待批准。
warmchang
于 2019-03-01
/里程碑v1.14
nikopen
于 2019-03-01
我遇到了这个问题,我的环境:
码头工人18.06
操作系统:centos7.4
内核:4.19
kubelet:1.12.3
我的节点在“就绪”和“未就绪”之间摇摆。
在此之前,我用--- force --grace-period = 0删除了一些吊舱。 因为我删除的Pod仍处于终止状态。
然后,我在kubelet中发现了一些日志:
kubelet [10937]:I0306 19:23:32.474487 10937 handlers.go:62]执行生命周期挂钩([/home/work/webserver/loadnginx.sh stop]),用于容器“ sas-56bd6d8588-”中的容器“ odp-saas” xlknh(15ebc67d-3bed-11e9-ba81-246e96352590)“失败-错误:命令'/home/work/webserver/loadnginx.sh stop'退出并显示126 :,消息:“无法找到用户工作:passwd中没有匹配的条目文件\ r \ n“ _
因为我在部署中使用了生命周期部分的prestop命令。
#生命周期:
#preStop:
#exec:
##SIGTERM触发快速退出; 优雅地终止
#命令:[“ / home / work / webserver / loadnginx.sh”,“停止”]
其他日志显示:
kubelet [17119]:E0306 19:35:11.223925 17119 remote_runtime.go:282] ContainerStatus“ cbc957993825885269935a343e899b807ea9a49cb9c7f94e68240846af3e701d”
kubelet [17119]:E0306 19:35:11.223970 17119 kuberuntime_container.go:393] cbc957993825885269935a343e899b807ea9a49cb9c7f94e68240846af3e701d e的ContainerStatus
kubelet [17119]:E0306 19:35:11.223978 17119 kuberuntime_manager.go:866] getPodContainerStatus for pod“ gz-saas-56bd6d8588-sk88t_storeic(1303430e-3ffa-11e9-ba8
kubelet [17119]:E0306 19:35:11.223994 17119generic.go:241] PLEG:忽略pod saas-56bd6d8588-sk88t / storeic的事件:rpc错误:代码= DeadlineExceeded d
kubelet [17119]:E0306 19:35:11.224123 17119 pod_workers.go:186]同步pod 1303430e-3ffa-11e9-ba81-246e96352590(“ gz-saas-56bd6d8588-sk88t_storeic(130343
Mkubelet [17119]:E0306 19:35:12.509163 17119 remote_runtime.go:282] ContainerStatus“ 4ff7ff8e1eb18ede5eecbb03b60bdb0fd7f7831d8d7e81f59bc69d166d422fb6”
kubelet [17119]:E0306 19:35:12.509163 17119 remote_runtime.go:282] ContainerStatus“ cbc957993825825269935a343e899b807ea9a49cb9c7f94e68240846af3e701d”
kubelet [17119]:E0306 19:35:12.509220 17119 kubelet_pods.go:1086]杀死Pod“ saas-56bd6d8588-rsfh5”失败:对“ saas” wi的“ KillContainer”失败
kubelet [17119]:E0306 19:35:12.509230 17119 kubelet_pods.go:1086]未能杀死Pod“ saas-56bd6d8588-sk88t”:未能为“ saas” wid“ KillContainer”
kubelet [17119]:I0306 19:35:12.788887 17119 kubelet.go:1821]跳过吊舱同步-[PLEG不健康:最近一次有人在4m1.597223765前看到pleg活跃;
k8s无法停止容器,这些容器处于卡住状态。 这导致PLEG不健康。
最后,我重新启动具有错误容器的docker守护进程,节点恢复就绪。
我不知道为什么容器不能停止! 可能是前奏?
 Damien9527
于 2019-03-06
Damien9527
于 2019-03-06
/里程碑v1.15
nikopen
于 2019-03-11
+1
k8s v1.10.5
码头工人17.09.0-ce
 hello2mao
于 2019-03-22
hello2mao
于 2019-03-22
+1
k8s v1.12.3
码头工人06.18.2-ce
 zhan849
于 2019-04-11
zhan849
于 2019-04-11
+1
k8s v1.13.4
码头工人1.13.1-94.gitb2f74b2.el7.x86_64
 Wade201801
于 2019-04-16
Wade201801
于 2019-04-16
@ kubernetes / sig-network-bugs @thockin @spiffxp :友好的ping。 这似乎又停滞了。
calder
于 2019-04-19
@calder :重申提及以触发通知:
@ kubernetes / sig-network-bugs
针对此:
@ kubernetes / sig-network-bugs @thockin @spiffxp :友好的ping。 这似乎又停滞了。
可在此处获得使用PR注释与我互动的说明。 如果您对我的行为有任何疑问或建议,请针对kubernetes / test-infra存储库提出问题。
 k8s-ci-robot
于 2019-04-19
k8s-ci-robot
于 2019-04-19
你好,
我们还在我们的平台之一上发现了此问题。 我们与其他集群的唯一区别是它只有一个主节点。 确实,我们用3个主服务器重新创建了集群,但到目前为止(至今已有几天)我们还没有注意到这个问题。
所以我想我的问题是:有人在多主机(> = 3)集群上注意到此问题吗?
 Kanshiroron
于 2019-04-29
Kanshiroron
于 2019-04-29
@Kanshiroron是的,我们有3个主群集,昨天在一个工作节点上遇到了此问题。 我们排空了节点并重新启动它,它又干净地回来了。 平台是具有k8s v1.11.8和Docker Enterprise 18.09.2-ee的Docker EE
 mshade
于 2019-05-01
mshade
于 2019-05-01
我们有一个3主机集群(带有3节点的etcd集群)。 有18个工作程序节点,每个节点平均在50-100个Docker容器之间运行(不是Pod,而是总容器)。
我看到较大的Pod Spinup事件与由于PLEG错误而需要重新启动节点之间存在肯定的正相关关系。 有时,我们的某些升级导致在整个基础架构中创建了超过100个容器,当这种情况发生时,我们几乎总是会看到由此产生的PLEG错误。
我们是否在节点或群集级别上了解了造成这种情况的原因?
 standaloneSA
于 2019-05-08
standaloneSA
于 2019-05-08
我对此有点脱节-我们知道发生了什么吗? @bboreham是否有解决
 thockin
于 2019-05-09
thockin
于 2019-05-09
我怀疑这种症状可能是由多种原因引起的,并且对于此处的“我有相同的问题”大多数评论,我们没有太多要做。
其中的一个方式是在详细https://github.com/kubernetes/kubernetes/issues/45419#issuecomment -405168344和类似的https://github.com/kubernetes/kubernetes/issues/45419#issuecomment -456081337 -电话进入CNI可能会永远吊死,从而破坏Kubelet。 问题#65743说我们应该添加超时。
为了解决这个问题,我们决定将Context插入libcni,以便可以由exec.CommandContext()实施取消。 PR#71653在该API的CRI端添加了超时。
(为清楚起见:不涉及对CNI插件的更改;这是对执行插件的代码的更改)
bboreham
于 2019-05-09
好的,有机会在PLEG群上进行一些调试(我们最近称之为),并且我发现K8s报告的PLEG错误与Docker.service日志中的条目之间存在一些关联:
在两台服务器上,我发现了这一点:
从监视错误的脚本中:
Sat May 11 03:27:19 PDT 2019 - SERVER-A
Found: Ready False Sat, 11 May 2019 03:27:10 -0700 Sat, 11 May 2019 03:13:16 -0700 KubeletNotReady PLEG is not healthy: pleg was last seen active 16m53.660513472s ago; threshold is 3m0s
SERVER-A的'journalctl -u docker.service'输出中的匹配条目:
May 11 03:10:20 SERVER-A dockerd[1133]: time="2019-05-11T03:10:20.641064617-07:00" level=error msg="stream copy error: reading from a closed fifo"
May 11 03:10:20 SERVER-A dockerd[1133]: time="2019-05-11T03:10:20.641083454-07:00" level=error msg="stream copy error: reading from a closed fifo"
May 11 03:10:20 SERVER-A dockerd[1133]: time="2019-05-11T03:10:20.740845910-07:00" level=error msg="Error running exec a9fe257c0fca6ff3bb05a7582015406e2f7f6a7db534b76ef1b87d297fb3dcb9 in container: OCI runtime exec failed: exec failed: container_linux.go:344: starting container process caused \"process_linux.go:113: writing config to pipe caused \\\"write init-p: broken pipe\\\"\": unknown"
May 11 03:10:20 SERVER-A dockerd[1133]: time="2019-05-11T03:10:20.767528843-07:00" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
27 lines of this^^ repeated
然后,在另一台服务器上,从我的脚本中:
Sat May 11 03:38:25 PDT 2019 - SERVER-B
Found: Ready False Sat, 11 May 2019 03:38:16 -0700 Sat, 11 May 2019 03:38:16 -0700 KubeletNotReady PLEG is not healthy: pleg was last seen active 3m6.168050703s ago; threshold is 3m0s
并从docker日志中:
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.745124988-07:00" level=error msg="stream copy error: reading from a closed fifo"
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.745139806-07:00" level=error msg="stream copy error: reading from a closed fifo"
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.803182460-07:00" level=error msg="1a5dbb24b27cd516373473d34717edccc095e712238717ef051ce65022e10258 cleanup: failed to delete container from containerd: no such container"
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.803267414-07:00" level=error msg="Handler for POST /v1.38/containers/1a5dbb24b27cd516373473d34717edccc095e712238717ef051ce65022e10258/start returned error: OCI runtime create failed: container_linux.go:344: starting container process caused \"process_linux.go:297: getting the final child's pid from pipe caused \\\"EOF\\\"\": unknown"
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.876522066-07:00" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.964447832-07:00" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
不幸的是,当在我的“健康”节点上对此进行验证时,我也可以找到它们一起出现的实例。
我将努力将其与其他变量相关联,但是搜索这些错误消息将导致一些有趣的讨论:
Docker-ce 18.06.1-ce-rc2:无法运行容器,“流复制错误:从封闭的fifo读取”
Moby:同时从同一检查点启动许多容器会导致错误:“超出上下文截止日期”#29369
最后一个链接的@dElogics有一个特别有趣的评论(引用此票证):
仅添加一些有价值的信息,在每个节点上运行许多Pod就会导致#45419。 作为修复,删除docker目录,然后重新启动docker和kubelet。
standaloneSA
于 2019-05-11
就我而言,我正在使用K8s v1.10.2和docker-ce v18.03.1。 我发现在节点拍打Ready / NotReady上运行的kubelet的一些日志如下:
E0512 09:17:56.721343 4065 pod_workers.go:186] Error syncing pod e5b8f48a-72c2-11e9-b8bf-005056871a33 ("uac-ddfb6d878-f6ph2_default(e5b8f48a-72c2-11e9-b8bf-005056871a33)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
E0512 09:17:17.154676 4065 kuberuntime_manager.go:859] PodSandboxStatus of sandbox "a34943dabe556924a2793f1be2f7181aede3621e2c61daef0838cf3fc61b7d1b" for pod "uac-ddfb6d878-f6ph2_default(e5b8f48a-72c2-11e9-b8bf-005056871a33)" error: rpc error: code = DeadlineExceeded desc = context deadline exceeded
而且我发现此Pod uac-ddfb6d878-f6ph2_default正在终止,因此我的解决方法是强制删除Pod并删除该节点上该Pod的所有容器,然后此节点正常运行:
$ kubectl delete pod uac-ddfb6d878-f6ph2 --force --grace-period=0
$ docker ps -a | grep uac-ddfb6d878-f6ph2_default
 thaonguyenct
于 2019-05-12
thaonguyenct
于 2019-05-12
你好! 我们已经开始以1.15版本的Bug Freeze。 是否仍计划将此问题合并到1.15中?
 soggiest
于 2019-05-29
soggiest
于 2019-05-29
嗨,您好
我们在OKD集群上遇到了同样的问题。
我们调查了正在摆动的节点,经过一些挖掘,我们发现了我们认为的问题。
在研究节点震荡时,我们发现正在震荡的节点的平均负载值非常高,其中一个节点(16个核心,32个线程,96GB内存)的平均负载值在峰值时为850。
我们的三个节点上都运行了Rook Ceph。
我们发现Prometheus正在使用Rook Ceph的块存储,并在块设备中充斥了读/写操作。
同时,ElasticSearch还使用了Rook Ceph的块存储。 我们发现,当Prometheus泛洪块设备时,ElasticSearch进程将尝试执行磁盘I / O操作,并在等待I / O操作完成时进入不间断状态。
然后,另一个ES进程将尝试相同的操作。
然后另一个。
还有一个。
我们将进入一种状态,即节点的整个CPU都为处于不间断状态的ES进程保留了线程,以等待Ceph块设备摆脱Prometheus泛洪。
即使CPU负载不是100%,线程仍被保留。
这导致所有其他进程等待CPU时间,这导致任何Docker操作失败,这导致PLEG超时,并且节点开始震荡。
我们的解决方案是重新启动有问题的Prometheus Pod。
OKD / K8s版本:
$ oc version
oc v3.11.0+0cbc58b
kubernetes v1.11.0+d4cacc0
features: Basic-Auth GSSAPI Kerberos SPNEGO
Server https://okd.example.net:8443
openshift v3.11.0+d0f1080-153
kubernetes v1.11.0+d4cacc0
节点上的Docker版本:
$ docker version
Client:
Version: 1.13.1
API version: 1.26
Package version: docker-1.13.1-88.git07f3374.el7.centos.x86_64
Go version: go1.9.4
Git commit: 07f3374/1.13.1
Built: Fri Dec 7 16:13:51 2018
OS/Arch: linux/amd64
Server:
Version: 1.13.1
API version: 1.26 (minimum version 1.12)
Package version: docker-1.13.1-88.git07f3374.el7.centos.x86_64
Go version: go1.9.4
Git commit: 07f3374/1.13.1
Built: Fri Dec 7 16:13:51 2018
OS/Arch: linux/amd64
Experimental: false
编辑:
总结:我不认为这是K8s / OKD问题,我认为这是“您的节点上的某些资源被某种东西锁定,这导致进程堆积起来等待CPU时间,并且破坏了一切”。
 rblaine95
于 2019-05-29
rblaine95
于 2019-05-29
/里程碑v1.16
soggiest
于 2019-06-07
@bboreham @soggiest您好! 我是1.16发布周期的漏洞分类影子,考虑到此问题已标记为1.16,但很长时间没有更新,所以我想检查一下其状态。 代码冻结将从8月29日开始(从现在开始大约1.5周),这意味着在那之前应该已经准备好PR(并合并)。
我们是否仍将这个问题的目标定为1.16?
 makoscafee
于 2019-08-23
makoscafee
于 2019-08-23
@makoscafee可以确认在1.13.6(及更高版本)和docker 18.06.3-ce中不再发生这种情况
对我们来说,这似乎与调用CNI或某些外部集成时的超时有关。
我们最近遇到了这种情况,但在其他情况下,虽然集群中使用的某些NFS服务器已崩溃(并且节点的整个I / O已冻结),但kubelet开始打印与无法启动新容器有关的PLEG问题,因为I / O超时。
因此,这可能表明使用CNI和CRI可能会解决此问题,因为我们在集群中再也没有看到与网络问题相关的信息。
rikatz
于 2019-08-26
正如我之前评论过的, @ makoscafee ,很多人都在报道这个问题。 我将在此处回答有关CNI请求超时的具体问题。
通过查看代码,我认为kubelet尚未更新为使用可以取消上下文的CNI中的新行为。
例如在此处致电CNI: https :
此PR将添加一个超时:#71653,但是仍然很出色。
我不能说1.13.6中会导致@rikatz体验的更改。
bboreham
于 2019-08-26
确实,自那时以来,我在Calico进行了许多升级,也许那里的某些内容(而不是Kubernetes代码)已更改。 Docker(当时可能也是个问题)也被升级了很多次,因此这里没有正确的路径
我感到遗憾的是,没有在问题发生时记笔记(对此感到抱歉),以便至少告诉您从那里到今天我们的问题发生了什么变化。
rikatz
于 2019-08-26
大家好,
只想与我们分享此错误的经验。
我们在运行docker EE 19.03.1和k8s v1.14.3的新部署集群上遇到了此错误。
对我们来说,该问题似乎是由日志记录驱动程序触发的。 我们的docker引擎设置为使用流利的日志记录驱动程序。 在群集的全新部署之后,尚未部署fluentd。 如果在这一点上,如果我们尝试在工作程序上安排任何Pod,则会遇到与您上述相同的行为(工作程序节点上的kubelet容器上的PLEG错误,并且随机报告工作程序节点不健康)
但是,一旦我们部署了流利的软件,并且docker能够与之建立连接,所有的问题就消失了。 因此,似乎无法与流利的沟通是根本原因。
希望这可以帮助。 干杯
 dariuscernea
于 2019-08-27
dariuscernea
于 2019-08-27
这是一个长期存在的问题(k8s 1.6!),并且困扰了很多使用k8s的人。
除了过载的节点(最大cpu%,io,中断)以外,PLEG问题有时是由kubelet,docker,日志记录,网络等之间的细微问题引起的,对问题的补救有时是残酷的(重新启动所有节点等,具体取决于案子)。
就原始帖子而言, https://github.com/kubernetes/kubernetes/pull/71653最终被合并,kubelet被更新,现在能够使CNI请求超时,在超过截止日期之前取消上下文。
Kubernetes 1.16将包含此修复程序。
我还将打开PR,以将其重新选择为1.14和1.15,因为它们确实具有包含新超时功能(> = 0.7.0)的CNI版本。 1.13具有较旧的CNI v,但没有该功能。
因此,这可以最终关闭。
/关
nikopen
于 2019-08-28
@nikopen :结束此问题。
针对此:
这是一个长期存在的问题(k8s 1.6!),并且困扰了很多使用k8s的人。
导致PLEG问题的原因有很多,并且在kubelet,docker,日志记录,网络连接等之间通常很复杂,有时对问题的补救很残酷(根据情况重新启动所有节点等)。
就原始帖子而言, https://github.com/kubernetes/kubernetes/pull/71653最终被合并,kubelet被更新,现在能够使CNI请求超时,在超过截止日期之前取消上下文。
Kubernetes 1.16将包含此修复程序。
我还将打开PR,以将其重新选择为1.14和1.15,因为它们确实具有包含新超时功能(> = 0.7.0)的CNI版本。 1.13具有较旧的CNI v,但没有该功能。因此,这可以最终关闭。
/关
可在此处获得使用PR注释与我互动的说明。 如果您对我的行为有任何疑问或建议,请针对kubernetes / test-infra存储库提出问题。
k8s-ci-robot
于 2019-08-28
从生产1.6以来的个人经验来看,当节点淹死时,通常会出现PLEG问题。
- CPU负载过高
- 磁盘I / O已最大化(正在记录?)
- 全局过载(CPU +磁盘+网络)=> CPU一直被中断
结果=> Docker守护程序没有响应
 Misteur-Z
于 2019-08-28
Misteur-Z
于 2019-08-28
从生产
1.6以来的个人经验来看,当节点淹死时,通常会出现PLEG问题。
- CPU负载过高
- 磁盘I / O已最大化(正在记录?)
- 全局过载(CPU +磁盘+网络)=> CPU一直被中断
结果=> Docker守护程序没有响应
我同意这一点,我使用的是Kubernetes的1.14.5版本,存在相同的问题。
 Aisuko
于 2019-09-06
Aisuko
于 2019-09-06
与v1.13.10相同的问题在calico网络中运行。
 zx1986
于 2019-09-19
zx1986
于 2019-09-19
/打开
@nikopen :看来PR是1.17? 我没有在1.16.1的变更日志中找到PR号。
 pdhung
于 2019-10-07
pdhung
于 2019-10-07
我没有在1.14的变更日志中看到此问题。 这是否意味着还没有采摘樱桃? 那将会?
 kwaazaar
于 2019-10-24
kwaazaar
于 2019-10-24
从PLEG中恢复不是健康问题
禁用docker和kubelet自动启动,重新启动,然后清理kubelet pod和docker文件:
systemctl禁用docker && systemctl禁用kubelet
重启
rm -rf / var / lib / kubelet / pods /
rm -rf / var / lib / docker
启动并启用docker
systemctl启动docker && systemctl启用docker
systemctl状态泊坞窗
由于/ var / lib / docker已清理,因此如果节点无法连接到k8s图像库,请手动导入必要的图像。
泊坞窗负载-i xxx.tar
启动Kubelet
systemctl启动kubelet && systemctl启用kubelet
systemctl状态小程序
 jackie-qiu
于 2019-11-14
jackie-qiu
于 2019-11-14
@ jackie-qiu最好用手榴弹炸毁您的服务器或将其丢到10楼,以确保问题不再发生...
adampl
于 2019-11-14
在绒布网络中运行的v1.15.6中存在相同的问题。
 leowucn
于 2019-11-27
leowucn
于 2019-11-27
关于导致问题的原因,我没有太多补充,因为似乎所有内容都已经写在这里。 我们正在使用服务器1.10.13的旧版本。 我们已经尝试升级,但这并不是一件容易的事。
对我们来说,它主要发生在生产环境之一中,而在我们的开发环境中则处于最末尾。 在不断复制该生产环境的生产环境中,它仅在滚动更新期间发生,并且仅在两个特定的容器中发生(在滚动更新期间删除其他容器时绝对不会发生)。 在我们的开发环境中,它发生在其他Pod上。
我在日志中看到的唯一一件事是:
成功时:
11月27日11:34:45 ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.453 [INFO] [1946] client.go 202:从环境加载配置
11月27日11:34:45 ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.454 [INFO] [1946] calico-ipam.go 249:使用handleID handleID =释放地址“ k8s-pod-network.e923743c5dc4833e606bf16f388c564c20c4c1373b18881d8ea1c8eb617f6e62” workloadID =“ default.good-pod-name-557644b486-7rxw5”
11月27日11:34:45 ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.454 [INFO] [1946] ipam.go 738:释放所有带有句柄'k8s- pod-network.e923743c5dc4833e606bf16f388c564c20c4c1373b18881d8ea1c8eb617f6e62'
11月27日11:34:45 ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.498 [INFO] [1946] ipam.go 877:减少句柄'k8s-pod-network .e923743c5dc4833e606bf16f388c564c20c4c1373b18881d8ea1c8eb617f6e62'by 1
11月27日11:34:45 ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.498 [INFO] [1946] calico-ipam.go 257:使用handleID handleID =发布的地址“ k8s-pod-network.e923743c5dc4833e606bf16f388c564c20c4c1373b18881d8ea1c8eb617f6e62” workloadID =“ default.good-pod-name-557644b486-7rxw5”
11月27日11:34:45 ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.498 [INFO] [1946] calico-ipam.go 261:使用工作负载ID handleID =释放地址“ k8s-pod-network.e923743c5dc4833e606bf16f388c564c20c4c1373b18881d8ea1c8eb617f6e62” workloadID =“ default.good-pod-name-557644b486-7rxw5”
11月27日11:34:45 ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.498 [INFO] [1946] ipam.go 738:释放所有带有句柄'default'的IP。好豆荚名称557644b486-7rxw5'
11月27日11:34:45 ip-172-31-174-8 kubelet [8024]:netns / proc / 6337 / ns / net中的Calico CNI删除设备
Nov 27 11:34:45 ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.590 [INFO] [1929] k8s.go 379:拆解处理已完成。 Workload =“ default.good-pod-name-557644b486-7rxw5”“
失败时:
11月27日11:46:49 ip-172-31-174-8 kubelet [8024]:2019-11-27 11:46:49.681 [INFO] [5496] client.go 202:从环境加载配置
11月27日11:46:49 ip-172-31-174-8 kubelet [8024]:2019-11-27 11:46:49.681 [INFO] [5496] calico-ipam.go 249:使用handleID handleID =释放地址“ k8s-pod-network.3afc7f2064dc056cca5bb8c8ff20c81aaf6ee8b45a1346386c239b92527b945b” workloadID =“ default.bad-pod-name-5fc88df4b-rkw7m”
11月27日11:46:49 ip-172-31-174-8 kubelet [8024]:2019-11-27 11:46:49.681 [INFO] [5496] ipam.go 738:释放所有带有句柄'k8s- pod-network.3afc7f2064dc056cca5bb8c8ff20c81aaf6ee8b45a1346386c239b92527b945b'
11月27日11:46:49 ip-172-31-174-8 kubelet [8024]:2019-11-27 11:46:49.716 [INFO] [5496] ipam.go 877:减少句柄'k8s-pod-network .3afc7f2064dc056cca5bb8c8ff20c81aaf6ee8b45a1346386c239b92527b945b'by 1
11月27日11:46:49 ip-172-31-174-8 kubelet [8024]:2019-11-27 11:46:49.716 [INFO] [5496] calico-ipam.go 257:使用handleID handleID =发布的地址“ k8s-pod-network.3afc7f2064dc056cca5bb8c8ff20c81aaf6ee8b45a1346386c239b92527b945b” workloadID =“ default.bad-pod-name-5fc88df4b-rkw7m”
11月27日11:46:49 ip-172-31-174-8 kubelet [8024]:2019-11-27 11:46:49.716 [INFO] [5496] calico-ipam.go 261:使用工作负载ID handleID =释放地址“ k8s-pod-network.3afc7f2064dc056cca5bb8c8ff20c81aaf6ee8b45a1346386c239b92527b945b” workloadID =“ default.bad-pod-name-5fc88df4b-rkw7m”
11月27日11:46:49 ip-172-31-174-8 kubelet [8024]:2019-11-27 11:46:49.716 [INFO] [5496] ipam.go 738:释放所有带有默认处理句柄的IP。 Bad-pod-name-5fc88df4b-rkw7m'
11月27日11:46:49 ip-172-31-174-8 kubelet [8024]:netns / proc / 7376 / ns / net中的Calico CNI删除设备
11月27日11:46:51 ip-172-31-174-8 ntpd [8188]:删除接口#1232 cali8e016aaff48,fe80 :: ecee:eeff : Feee:eeee%816#123 ,接口状态:已接收= 0,已发送= 0,掉落= 0,active_time = 242773秒
11月27日11:46:59 ip-172-31-174-8内核:[11155281.312094] unregister_netdevice:等待eth0释放。 使用次数= 1
 gilShin
于 2019-12-02
gilShin
于 2019-12-02
有没有人升级到v1.16? 有人可以确认它是否已解决,并且您不再看到PLEG问题。 我们经常在生产中看到此问题,唯一的选择是重启节点。
 ganeshv02
于 2019-12-05
ganeshv02
于 2019-12-05
我有一个关于修复的问题。
假设我要安装的新版本包括超时修复。 我知道它将释放Kublet,并且我们将允许处于“终止”状态的Pod下降,但它还会释放eth0吗? 新的Pod能够在该节点上运行还是会保持在就绪/未就绪状态?
gilShin
于 2019-12-05
对我而言,Docker 19.03.4修复了两个处于“终止”状态的Pod,以及在PLEG问题引起的Ready / NotReady之间摆动的节点。
Kubernetes版本从1.15.6起没有变化。 集群中唯一的变化是较新的Docker。
 hakman
于 2019-12-05
hakman
于 2019-12-05
将Ubuntu 16.04的内核从4.4升级到4.15。 错误再次发生需要三天。
我将看看是否可以像hakman在Ubuntu 16.04上建议的那样将docker版本从17升级到19。
我不想升级Ubuntu版本。
gilShin
于 2019-12-15
无法使用k8s 1.10将docker升级到19。 我们首先需要升级到1.15,这将需要一些时间,因为无法升级到1.15海峡。 我们需要将1.10-> 1.11-> 1.12等一一升级。
gilShin
于 2019-12-15
PLEG健康检查功能很少。 在每次迭代中,它调用
docker ps来检测容器状态的变化,并调用docker ps和inspect以获取这些容器的详细信息。
完成每次迭代后,它将更新时间戳记。 如果时间戳有一段时间(即3分钟)没有更新,则运行状况检查将失败。除非您的节点上装有大量的Pod,而PLEG无法在3分钟内完成所有这些操作(这是不应该发生的),否则最可能的原因是docker运行缓慢。 您可能在偶尔的
docker ps支票中没有注意到这一点,但这并不意味着它不存在。如果我们不公开“不健康”状态,它将对用户隐藏许多问题,并可能导致更多问题。 例如,kubelet会默默地不及时对变化做出反应,甚至引起更多的混乱。
欢迎提出有关如何使其更可调试的建议...
这是一个长期存在的问题(k8s 1.6!),并且困扰了很多使用k8s的人。
除了过载的节点(最大cpu%,io,中断)以外,PLEG问题有时是由kubelet,docker,日志记录,网络等之间的细微问题引起的,对问题的补救有时是残酷的(重新启动所有节点等,具体取决于案子)。
就原始帖子而言,最终#71653被合并,kubelet被更新,现在能够使CNI请求超时,从而在超出截止日期之前取消上下文。
Kubernetes 1.16将包含此修复程序。
我还将打开PR,以将其重新选择为1.14和1.15,因为它们确实具有包含新超时功能(> = 0.7.0)的CNI版本。 1.13具有较旧的CNI v,但没有该功能。因此,这可以最终关闭。
/关
我很困惑...如果此问题可能是由缓慢的docker守护程序引起的,那么只需在cni调用中添加一个超时就可以解决此问题?
 jmf0526
于 2019-12-30
jmf0526
于 2019-12-30
我正在使用容器+ kubernetes 1.16,当我每个节点有191个容器时,这仍然很容易发生。 增加阈值如何? 还是更好的解决方案? @yujuhong
 haosdent
于 2020-01-31
haosdent
于 2020-01-31
@haosdent检查修复程序是否已合并到您的Kubernetes版本中。 如果完全在1.16上,则它必须是最新版本。 或升级到1.17,您将拥有100%的价格。
adampl
于 2020-02-02
与@haosdent有相同的问题,我去看看#71653是否已被反向移植。
- #71653已反向移植到v1.16(PR:#86825)。 它包含在v1.16.7( changelog )中。
- 它似乎没有被反向移植到v1.15或更早的版本( PR搜索, v1.15 changelog )。
因此,似乎v1.16.7或v1.17.0是获得该修补程序所需的最低k8s版本。
 david-in-perth
于 2020-03-17
david-in-perth
于 2020-03-17
我们使用cilium v1.6.5将kops debian映像将内核升级到4.19,从而在由kops调配的AWS上以最小的负载运行v1.16.7 。
:man_shrugging:所以它仍然在那里:/
但是必须进一步调查。
_sidenote_也发生在kubespray用v1.16.4设置的ubuntu上
目前,节点重新启动可以在短时间内解决该问题。
仅在c5.large ec2节点上发生
两种情况下,Docker均为18.04。 因此,如上所述,我将尝试将docker升级到19.03.4 。
 fentas
于 2020-04-02
fentas
于 2020-04-02
该问题也可能是由于旧版本systemd引起的,请尝试升级systemd。
参考:
https://my.oschina.net/yunqi/blog/3041189 (仅中文)
https://github.com/lnykryn/systemd-rhel/pull/322
 hulucc
于 2020-04-08
hulucc
于 2020-04-08
我们还在1.16.8 + docker 18.06.2中看到了这个问题
# docker info
Containers: 186
Running: 155
Paused: 0
Stopped: 31
Images: 48
Server Version: 18.06.2-ce
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file logentries splunk syslog
Swarm: inactive
Runtimes: nvidia runc
Default Runtime: nvidia
Init Binary: docker-init
containerd version: 468a545b9edcd5932818eb9de8e72413e616e86e
runc version: 6635b4f0c6af3810594d2770f662f34ddc15b40d-dirty (expected: 69663f0bd4b60df09991c08812a60108003fa340)
init version: fec3683
Security Options:
apparmor
seccomp
Profile: default
Kernel Version: 5.0.0-1027-aws
Operating System: Ubuntu 18.04.4 LTS
OSType: linux
Architecture: x86_64
CPUs: 48
Total Memory: 373.8GiB
Name: node-cmp-test-kubecluster-2-0a03fdfa
ID: E74R:BMMI:XOFX:BK4X:53AT:JQLZ:CDF6:M6X7:J56G:2DTZ:OTRK:5OJB
Docker Root Dir: /mnt/docker
Debug Mode (client): false
Debug Mode (server): false
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: true
WARNING: No swap limit support
看到docker在PLEG运行不正常和节点震荡之前,可能会以写入文件套接字的方式遇到超时。 在这种情况下,内核可以杀死阻塞的进程,并且节点可以恢复。 但在许多其他情况下,我们无法看到节点无法恢复,甚至无法将其重置,因此也可能是各种问题的组合。
最大的痛点是,作为平台提供者,docker可能在PLEG被报告为“不健康”之前就走错了路,因此,总是由用户向我们报告错误,而不是我们主动检测问题并为用户清除混乱。 当问题发生时,度量标准中有两个有趣的现象:
- 问题发生之前,CRI指标未显示QPS峰值
- 问题发生后,没有从kubelet生成任何指标(我们的监视后端未收到任何信息,但PLEG不正常的问题通常是节点不可ssh-able的,因此此处缺少调试数据点)
我们正在研究docker指标,看看是否可以对此设置任何警报。
May 8 16:32:25 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:25Z" level=info msg="shim reaped" id=522fbf813ab6c63b17f517a070a5ebc82df7c8f303927653e466b2d12974cf45
--
May 8 16:32:25 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:25.557712045Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:32:26 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:26.204921094Z" level=warning msg="Your kernel does not support swap limit capabilities,or the cgroup is not mounted. Memory limited without swap."
May 8 16:32:26 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:26Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/679b08e796acdd04b40802f2feff8086d7ba7f96182dcf874bb652fa9d9a7aec/shim.sock" debug=false pid=6592
May 8 16:32:26 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:26Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/2ef0c4109b9cd128ae717d5c55bbd59810f88f3d8809424b620793729ab304c3/shim.sock" debug=false pid=6691
May 8 16:32:26 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:26.871411364Z" level=warning msg="Your kernel does not support swap limit capabilities,or the cgroup is not mounted. Memory limited without swap."
May 8 16:32:26 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:26Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/905b3c35be073388e3c037da65fe55bdb4f4b236b86dcf1e1698d6987dfce28c/shim.sock" debug=false pid=6790
May 8 16:32:27 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:27Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/b4e6991f9837bf82533569d83a942fd8f3ae9fa869d5a0e760a967126f567a05/shim.sock" debug=false pid=6884
May 8 16:32:42 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:42.409620423Z" level=warning msg="Your kernel does not support swap limit capabilities,or the cgroup is not mounted. Memory limited without swap."
May 8 16:37:28 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:27Z" level=info msg="shim reaped" id=2ef0c4109b9cd128ae717d5c55bbd59810f88f3d8809424b620793729ab304c3
May 8 16:37:28 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:28.400830650Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:37:30 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:29Z" level=info msg="shim reaped" id=905b3c35be073388e3c037da65fe55bdb4f4b236b86dcf1e1698d6987dfce28c
May 8 16:37:30 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:30.316345816Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:37:30 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:30Z" level=info msg="shim reaped" id=b4e6991f9837bf82533569d83a942fd8f3ae9fa869d5a0e760a967126f567a05
May 8 16:37:30 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:30.931134481Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:37:35 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:35Z" level=info msg="shim reaped" id=679b08e796acdd04b40802f2feff8086d7ba7f96182dcf874bb652fa9d9a7aec
May 8 16:37:36 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:36.747358875Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:39:31 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63281.723692] mybr0: port 2(veth3f150f6c) entered disabled state
May 8 16:39:31 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63281.752694] device veth3f150f6c left promiscuous mode
May 8 16:39:31 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63281.756449] mybr0: port 2(veth3f150f6c) entered disabled state
May 8 16:39:35 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:39:34Z" level=info msg="shim reaped" id=fa731d8d33f9d5a8aef457e5dab43170c1aedb529ce9221fd6d916a4dba07ff1
May 8 16:39:35 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:39:35.106265137Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.505842] INFO: task dockerd:7970 blocked for more than 120 seconds.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.510931] Not tainted 5.0.0-1019-aws #21~18.04.1-Ubuntu
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.515010] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.521419] dockerd D 0 7970 1 0x00000080
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.525333] Call Trace:
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.528060] __schedule+0x2c0/0x870
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.531107] schedule+0x2c/0x70
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.534027] rwsem_down_write_failed+0x157/0x350
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.537630] ? blk_finish_plug+0x2c/0x40
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.540890] ? generic_writepages+0x68/0x90
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.544296] call_rwsem_down_write_failed+0x17/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.547999] ? call_rwsem_down_write_failed+0x17/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.551674] down_write+0x2d/0x40
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.554612] sync_inodes_sb+0xb9/0x2c0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.557762] ? __filemap_fdatawrite_range+0xcd/0x100
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.561468] __sync_filesystem+0x1b/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.564697] sync_filesystem+0x3c/0x50
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.568544] ovl_sync_fs+0x3f/0x60 [overlay]
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.572831] __sync_filesystem+0x33/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.576767] sync_filesystem+0x3c/0x50
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.580565] generic_shutdown_super+0x27/0x120
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.584632] kill_anon_super+0x12/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.587958] deactivate_locked_super+0x48/0x80
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.591696] deactivate_super+0x40/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.594998] cleanup_mnt+0x3f/0x90
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.598081] __cleanup_mnt+0x12/0x20
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.601194] task_work_run+0x9d/0xc0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.604388] exit_to_usermode_loop+0xf2/0x100
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.607843] do_syscall_64+0x107/0x120
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.611173] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.615128] RIP: 0033:0x556561f280e0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.618303] Code: Bad RIP value.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.621256] RSP: 002b:000000c428ec51c0 EFLAGS: 00000206 ORIG_RAX: 00000000000000a6
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.627790] RAX: 0000000000000000 RBX: 0000000000000000 RCX: 0000556561f280e0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.632469] RDX: 0000000000000000 RSI: 0000000000000002 RDI: 000000c4268a0d20
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.637203] RBP: 000000c428ec5220 R08: 0000000000000000 R09: 0000000000000000
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.641900] R10: 0000000000000000 R11: 0000000000000206 R12: ffffffffffffffff
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.646535] R13: 0000000000000024 R14: 0000000000000023 R15: 0000000000000055
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.651404] INFO: task dockerd:33393 blocked for more than 120 seconds.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.655956] Not tainted 5.0.0-1019-aws #21~18.04.1-Ubuntu
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.660155] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.666562] dockerd D 0 33393 1 0x00000080
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.670561] Call Trace:
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.673299] __schedule+0x2c0/0x870
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.676435] schedule+0x2c/0x70
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.679556] rwsem_down_write_failed+0x157/0x350
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.683276] ? blk_finish_plug+0x2c/0x40
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.686744] ? generic_writepages+0x68/0x90
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.690442] call_rwsem_down_write_failed+0x17/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.694243] ? call_rwsem_down_write_failed+0x17/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.698019] down_write+0x2d/0x40
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.700996] sync_inodes_sb+0xb9/0x2c0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.704283] ? __filemap_fdatawrite_range+0xcd/0x100
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.708127] __sync_filesystem+0x1b/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.711511] sync_filesystem+0x3c/0x50
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.714806] ovl_sync_fs+0x3f/0x60 [overlay]
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.718349] __sync_filesystem+0x33/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.721665] sync_filesystem+0x3c/0x50
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.724860] generic_shutdown_super+0x27/0x120
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.728449] kill_anon_super+0x12/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.731817] deactivate_locked_super+0x48/0x80
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.735511] deactivate_super+0x40/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.738899] cleanup_mnt+0x3f/0x90
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.742023] __cleanup_mnt+0x12/0x20
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.745142] task_work_run+0x9d/0xc0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.748337] exit_to_usermode_loop+0xf2/0x100
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.751830] do_syscall_64+0x107/0x120
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.755145] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.759111] RIP: 0033:0x556561f280e0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.762292] Code: Bad RIP value.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.765237] RSP: 002b:000000c4289c51c0 EFLAGS: 00000206 ORIG_RAX: 00000000000000a6
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.771715] RAX: 0000000000000000 RBX: 0000000000000000 RCX: 0000556561f280e0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.776351] RDX: 0000000000000000 RSI: 0000000000000002 RDI: 000000c4252e5e60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.781025] RBP: 000000c4289c5220 R08: 0000000000000000 R09: 0000000000000000
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.785705] R10: 0000000000000000 R11: 0000000000000206 R12: ffffffffffffffff
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.790445] R13: 0000000000000052 R14: 0000000000000051 R15: 0000000000000055
May 8 16:43:40 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:43:40.153619029Z" level=error msg="Handler for GET /containers/679b08e796acdd04b40802f2feff8086d7ba7f96182dcf874bb652fa9d9a7aec/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
May 8 16:43:40 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: http: multiple response.WriteHeader calls
May 8 16:44:15 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:44:15.461023232Z" level=error msg="Handler for GET /containers/fa731d8d33f9d5a8aef457e5dab43170c1aedb529ce9221fd6d916a4dba07ff1/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
May 8 16:44:15 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:44:15.461331976Z" level=error msg="Handler for GET /containers/fa731d8d33f9d5a8aef457e5dab43170c1aedb529ce9221fd6d916a4dba07ff1/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
May 8 16:44:15 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: http: multiple response.WriteHeader calls
May 8 16:44:15 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: http: multiple response.WriteHeader calls
May 8 16:59:55 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:59:55.489826112Z" level=info msg="No non-localhost DNS nameservers are left in resolv.conf. Using default external servers: [nameserver 8.8.8.8 nameserver 8.8.4.4]"
May 8 16:59:55 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:59:55.489858794Z" level=info msg="IPv6 enabled; Adding default IPv6 external servers: [nameserver 2001:4860:4860::8888 nameserver 2001:4860:4860::8844]"
May 8 16:59:55 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:59:55Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/5b85357b1e7b41f230a05d65fc97e6bdcf10537045db2e97ecbe66a346e40644/shim.sock" debug=false pid=5285
May 8 16:59:57 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:59:57Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/89c6e4f2480992f94e3dbefb1cbe0084a8e5637588296a1bb40df0dcca662cf0/shim.sock" debug=false pid=6776
May 8 16:59:58 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:59:58Z" level=info msg="shim reaped" id=89c6e4f2480992f94e3dbefb1cbe0084a8e5637588296a1bb40df0dcca662cf0
只想分享造成我们的原因。
我们运行了一个容器,该容器在大约3天的时间内“产生”了许多过程,并达到了最大值。 这导致系统完全冻结,因为无法产生任何新进程(然后出现PLEG警告)。
对我们来说是无关紧要的问题。 感谢您提供的所有帮助:+1:
fentas
于 2020-05-19
我遇到过两套可能相关的问题。
- PLEG。 我相信它们已经消失了,但是我没有重建足够的集群以完全自信。 我不相信我会做出太多(即任何改变)直接实现这一目标。
- 编织一些问题,其中容器无法连接到任何东西。
令人怀疑的是,所有与pleg有关的问题都与编织网络问题完全同时发生。
Bryan @ weaveworks,向我指出了coreos问题。 CoreOS倾向于尝试并管理桥梁,车辆,基本上所有东西。 一旦我禁用了CoreOS,除了在
lo以及主机上的实际物理接口上禁用了它,我所有的问题都就剩下了。人们仍然在运行coreos时遇到问题吗?
您还记得@deitch进行了哪些更改吗?
 JefClaes
于 2020-05-26
JefClaes
于 2020-05-26
我发现了这个: https :
这可能与@deitch的建议有关。 但是我也想知道是否有一个合适的或更优雅的解决方案,例如创建带有veth *的单元并将其置于不受管理的状态
rikatz
于 2020-05-27
我认为我是在这里看到问题的根本原因:
有时docker可能会在docker ps和docker inspect之间陷入混乱:在容器拆除期间,docker ps可以显示有关容器的缓存信息,包括已经获取垫片的容器:
time="2020-06-01T23:39:03Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/shim.sock" debug=false pid=11377
Jun 02 03:23:06 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T03:23:06Z" level=info msg="shim reaped" id=b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121
Jun 02 03:23:36 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T03:23:36.433087181Z" level=info msg="Container b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121 failed to exit within 30 seconds of signal 15 - using the force"
ps找不到具有容器ID的进程
# ps auxww | grep b7ae92902520
root 21510 0.0 0.0 14852 1000 pts/0 S+ 03:44 0:00 grep --color=auto b7ae92902520
docker ps显示进程仍在
# docker ps -a | grep b7ae92902520
b7ae92902520 450280d6866c "/srv/envoy-discover…" 4 hours ago Up 4 hours k8s_xxxxxx
在这种情况下,拨打docker sock进行docker inspect会卡住并导致客户端超时。 这可能是由于docker inspect将拨打收割的填充程序以获取来自容器的最新信息的事实,而docker ps使用缓存的数据
# strace docker inspect b7ae92902520
......
newfstatat(AT_FDCWD, "/etc/.docker/config.json", {st_mode=S_IFREG|0644, st_size=124, ...}, 0) = 0
openat(AT_FDCWD, "/etc/.docker/config.json", O_RDONLY|O_CLOEXEC) = 3
epoll_ctl(4, EPOLL_CTL_ADD, 3, {EPOLLIN|EPOLLOUT|EPOLLRDHUP|EPOLLET, {u32=2124234496, u64=139889209065216}}) = -1 EPERM (Operation not permitted)
epoll_ctl(4, EPOLL_CTL_DEL, 3, 0xc420689884) = -1 EPERM (Operation not permitted)
read(3, "{\n \"credsStore\": \"ecr-login\","..., 512) = 124
close(3) = 0
futex(0xc420650948, FUTEX_WAKE, 1) = 1
socket(AF_UNIX, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, 0) = 3
setsockopt(3, SOL_SOCKET, SO_BROADCAST, [1], 4) = 0
connect(3, {sa_family=AF_UNIX, sun_path="/var/run/docker.sock"}, 23) = 0
epoll_ctl(4, EPOLL_CTL_ADD, 3, {EPOLLIN|EPOLLOUT|EPOLLRDHUP|EPOLLET, {u32=2124234496, u64=139889209065216}}) = 0
getsockname(3, {sa_family=AF_UNIX}, [112->2]) = 0
getpeername(3, {sa_family=AF_UNIX, sun_path="/var/run/docker.sock"}, [112->23]) = 0
futex(0xc420644548, FUTEX_WAKE, 1) = 1
read(3, 0xc4202c2000, 4096) = -1 EAGAIN (Resource temporarily unavailable)
write(3, "GET /_ping HTTP/1.1\r\nHost: docke"..., 83) = 83
futex(0xc420128548, FUTEX_WAKE, 1) = 1
futex(0x25390a8, FUTEX_WAIT, 0, NULL) = 0
futex(0x25390a8, FUTEX_WAIT, 0, NULL) = 0
futex(0x25390a8, FUTEX_WAIT, 0, NULL) = -1 EAGAIN (Resource temporarily unavailable)
futex(0x25390a8, FUTEX_WAIT, 0, NULL^C) = ? ERESTARTSYS (To be restarted if SA_RESTART is set)
strace: Process 13301 detached
因为pod relist将包括对每个pod的每个容器的docker检查,所以这种超时将导致整个PLEG relist持续很长一段时间
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.523247 28263 generic.go:189] GenericPLEG: Relisting
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541890 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/51f959aa0c4cbcbc318c3fad7f90e5e967537e0acc8c727b813df17c50493af3: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541905 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/6c221cd2fb602fdf4ae5288f2ce80d010cf252a9144d676c8ce11cc61170a4cf: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541909 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/47bb03e0b56d55841e0592f94635eb67d5432edb82424fc23894cdffd755e652: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541913 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/ee861fac313fad5e0c69455a807e13c67c3c211032bc499ca44898cde7368960: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541917 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121: non-existent -> running
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541922 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/dd3f5c03f7309d0a3feb2f9e9f682b4c30ac4105a245f7f40b44afd7096193a0: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541925 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/57960fe13240af78381785cc66c6946f78b8978985bc847a1f77f8af8aef0f54: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541929 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/8ebaeed71f6ce99191a2d839a07d3573119472da221aeb4c7f646f25e6e9dd1b: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541932 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/b04da653f52e0badc54cc839b485dcc7ec5e2f6a8df326d03bcf3e5c8a14a3e3: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541936 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/a23912e38613fd455b26061c4ab002da294f18437b21bc1874e65a82ee1fba05: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541939 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/7f928360f1ba8890194ed795cfa22c5930c0d3ce5f6f2bc6d0592f4a3c1b579f: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541943 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/c3bdab1ed8896399263672ca45365e3d74c4ddc3958f82e3c7549fe12bc6c74b: non-existent -> exited
Jun 2 04:37:05 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:37:05.580912 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:05 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:05.580983 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:18 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:37:18.277091 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:18 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:18.277187 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:29 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:37:29.276942 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:29 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:29.276994 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:44 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:37:44.276919 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:44 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:44.276964 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:56 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:37:56.277039 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:56 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:56.277116 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:08 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:38:08.276838 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:08 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:38:08.276913 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:22 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:38:22.277107 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:22 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:38:22.277151 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:37 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:38:37.277123 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:37 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:38:37.277189 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:51 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:38:51.277059 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:51 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:38:51.277101 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:02 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:02.276836 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:02 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:02.276908 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:03.554207 28263 remote_runtime.go:295] ContainerStatus "b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:03.554252 28263 kuberuntime_container.go:403] ContainerStatus for b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121 error: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:03.554265 28263 kuberuntime_manager.go:1122] getPodContainerStatuses for pod "optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)" failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:03.554272 28263 generic.go:397] PLEG: Write status for optimus-pr-b-6bgc3/jenkins: (*container.PodStatus)(nil) (err: rpc error: code = DeadlineExceeded desc = context deadline exceeded)
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:03.554285 28263 generic.go:252] PLEG: Ignoring events for pod optimus-pr-b-6bgc3/jenkins: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:03.554294 28263 generic.go:284] GenericPLEG: Reinspecting pods that previously failed inspection
Jun 2 04:39:17 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:17.277086 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:17 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:17.277137 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:28 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:28.276905 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:28 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:28.276976 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:40 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:40.276815 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:40 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:40.276858 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:51 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:51.276950 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:51 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:51.277015 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:40:04 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:40:04.276869 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:40:04 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:40:04.276939 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:41:03.566494 28263 remote_runtime.go:295] ContainerStatus "b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:41:03.566543 28263 kuberuntime_container.go:403] ContainerStatus for b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121 error: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:41:03.566554 28263 kuberuntime_manager.go:1122] getPodContainerStatuses for pod "optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)" failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:41:03.566561 28263 generic.go:397] PLEG: Write status for optimus-pr-b-6bgc3/jenkins: (*container.PodStatus)(nil) (err: rpc error: code = DeadlineExceeded desc = context deadline exceeded)
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:41:03.566575 28263 generic.go:288] PLEG: pod optimus-pr-b-6bgc3/jenkins failed reinspection: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:41:03.566604 28263 generic.go:189] GenericPLEG: Relisting
当前的PLEG健康阈值为3分钟,因此,如果PLEG重新列出> 3分钟(在这种情况下相当容易),则PLEG将被报告为不健康。
我没有机会看看是否简单地docker rm会纠正这种状态,例如卡住约40分钟后,码头工人便会自行解除阻止
[root@node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69:/home/hzhang]# journalctl -u docker | grep b7ae92902520
Jun 01 23:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-01T23:39:03Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/shim.sock" debug=false pid=11377
Jun 02 03:23:06 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T03:23:06Z" level=info msg="shim reaped" id=b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121
Jun 02 03:23:36 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T03:23:36.433087181Z" level=info msg="Container b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121 failed to exit within 30 seconds of signal 15 - using the force"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.435460391Z" level=warning msg="Container b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121 is not running"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.435684282Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.435955786Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.436078347Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.436341875Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.436570634Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.436770587Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.436905470Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
......
关于类似现象,已经出现了各种问题:
https://github.com/docker/for-linux/issues/397
https://github.com/docker/for-linux/issues/543
https://github.com/moby/moby/issues/41054
但是据称它仍然可以在docker 19.03看到,即https://github.com/docker/for-linux/issues/397#issuecomment -515425324
可能的补救措施是让一些监视程序比较docker ps和ps ax并清理那些没有填充程序的容器,并强制终止pod解除对这些pod的阻塞或使用docker rm删除容器
zhan849
于 2020-06-02
继续进行以上调查-线程转储显示,在docker挂起期间,docker正在等待容器化,因此可能是容器化问题。 (请参阅下面的线程转储)在这种情况下
- 只有docker ps才能为这些受影响的容器工作
- docker rm / docker stop / docker inspect将挂起
- 当kubelet pod relist尝试检查此类容器时,它将超时,整个relist延迟可能会或可能不会超过3min,因此节点将“扑向”
- 这会导致用户吊舱卡住进度,并且由于整个PLEG速度变慢,kubelet响应缓慢
所以我们在生产中所做的是:
- 检查
ps和docker ps之间的不一致并选择受影响的容器,在我们的例子中,所有卡住了操作的容器已经获得了垫片 - Docker有时会自行解决,但有时无法解决,因此在超时后,我们强制删除受影响的Pod以取消阻止用户
- 如果一定时间后通常存在这种不一致,请重新启动docker
/ cc @ jmf0526 @haosdent @liucimin @yujuhong @thockin
似乎你们也在以后的调查中积极地谈论它
goroutine 1707386 [select, 22 minutes]:
--
github.com/docker/docker/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc420609680, 0x10, 0xc420f60fd8)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/transport/transport.go:222 +0x101
github.com/docker/docker/vendor/google.golang.org/grpc/transport.(*Stream).RecvCompress(0xc420609680, 0x555ab63e0730, 0xc420f61098)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/transport/transport.go:233 +0x2d
github.com/docker/docker/vendor/google.golang.org/grpc.(*csAttempt).recvMsg(0xc4267ef1e0, 0x555ab624f000, 0xc4288fd410, 0x0, 0x0)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/stream.go:515 +0x63b
github.com/docker/docker/vendor/google.golang.org/grpc.(*clientStream).RecvMsg(0xc4204fa800, 0x555ab624f000, 0xc4288fd410, 0x0, 0x0)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/stream.go:395 +0x45
github.com/docker/docker/vendor/google.golang.org/grpc.invoke(0x555ab6415260, 0xc4288fd4a0, 0x555ab581d40c, 0x2a, 0x555ab6249c00, 0xc428c04450, 0x555ab624f000, 0xc4288fd410, 0xc4202d4600, 0xc4202cdc40, ...)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/call.go:83 +0x185
github.com/docker/docker/vendor/github.com/containerd/containerd.namespaceInterceptor.unary(0x555ab57c9d91, 0x4, 0x555ab64151e0, 0xc420128040, 0x555ab581d40c, 0x2a, 0x555ab6249c00, 0xc428c04450, 0x555ab624f000, 0xc4288fd410, ...)
/go/src/github.com/docker/docker/vendor/github.com/containerd/containerd/grpc.go:35 +0xf6
github.com/docker/docker/vendor/github.com/containerd/containerd.(namespaceInterceptor).(github.com/docker/docker/vendor/github.com/containerd/containerd.unary)-fm(0x555ab64151e0, 0xc420128040, 0x555ab581d40c, 0x2a, 0x555ab6249c00, 0xc428c04450, 0x555ab624f000, 0xc4288fd410, 0xc4202d4600, 0x555ab63e07a0, ...)
/go/src/github.com/docker/docker/vendor/github.com/containerd/containerd/grpc.go:51 +0xf6
github.com/docker/docker/vendor/google.golang.org/grpc.(*ClientConn).Invoke(0xc4202d4600, 0x555ab64151e0, 0xc420128040, 0x555ab581d40c, 0x2a, 0x555ab6249c00, 0xc428c04450, 0x555ab624f000, 0xc4288fd410, 0x0, ...)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/call.go:35 +0x10b
github.com/docker/docker/vendor/google.golang.org/grpc.Invoke(0x555ab64151e0, 0xc420128040, 0x555ab581d40c, 0x2a, 0x555ab6249c00, 0xc428c04450, 0x555ab624f000, 0xc4288fd410, 0xc4202d4600, 0x0, ...)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/call.go:60 +0xc3
github.com/docker/docker/vendor/github.com/containerd/containerd/api/services/tasks/v1.(*tasksClient).Delete(0xc422c96128, 0x555ab64151e0, 0xc420128040, 0xc428c04450, 0x0, 0x0, 0x0, 0xed66bcd50, 0x0, 0x0)
/go/src/github.com/docker/docker/vendor/github.com/containerd/containerd/api/services/tasks/v1/tasks.pb.go:430 +0xd4
github.com/docker/docker/vendor/github.com/containerd/containerd.(*task).Delete(0xc42463e8d0, 0x555ab64151e0, 0xc420128040, 0x0, 0x0, 0x0, 0xc42463e8d0, 0x0, 0x0)
/go/src/github.com/docker/docker/vendor/github.com/containerd/containerd/task.go:292 +0x24a
github.com/docker/docker/libcontainerd.(*client).DeleteTask(0xc4203d4e00, 0x555ab64151e0, 0xc420128040, 0xc421763740, 0x40, 0x0, 0x20, 0x20, 0x555ab5fc6920, 0x555ab4269945, ...)
/go/src/github.com/docker/docker/libcontainerd/client_daemon.go:504 +0xe2
github.com/docker/docker/daemon.(*Daemon).ProcessEvent(0xc4202c61c0, 0xc4216469c0, 0x40, 0x555ab57c9b55, 0x4, 0xc4216469c0, 0x40, 0xc421646a80, 0x40, 0x8f0000069c, ...)
/go/src/github.com/docker/docker/daemon/monitor.go:54 +0x23c
github.com/docker/docker/libcontainerd.(*client).processEvent.func1()
/go/src/github.com/docker/docker/libcontainerd/client_daemon.go:694 +0x130
github.com/docker/docker/libcontainerd.(*queue).append.func1(0xc421646900, 0x0, 0xc42a24e380, 0xc420300420, 0xc4203d4e58, 0xc4216469c0, 0x40)
/go/src/github.com/docker/docker/libcontainerd/queue.go:26 +0x3a
created by github.com/docker/docker/libcontainerd.(*queue).append
/go/src/github.com/docker/docker/libcontainerd/queue.go:22 +0x196
我们看到了非常相似的问题(docker ps正常工作,但docker inspect例如卡住了)。 我们正在Fedora CoreOS上使用docker 19.3.8运行kubernetes v1.17.6。
 TeroPihlaja
于 2020-06-18
TeroPihlaja
于 2020-06-18
我们还遇到了这个问题,其中docker ps列出的容器挂在docker inspect上
docker ps -a | tr -s " " | cut -d " " -f1 | xargs -Iarg sh -c 'echo arg; docker inspect arg> /dev/null'
在我们的案例中,我们注意到受影响的容器卡在runc init 。 我们在附加或跟踪runc init的主线程时遇到麻烦。 似乎没有发出信号。 据我们所知,进程停留在内核中,并且没有转换回用户空间。 我并不是真正的Linux内核调试专家,但是据我所知,这似乎是与挂载清理相关的内核问题。 以下是runc init进程在内核领域执行的示例堆栈跟踪。
[<0>] kmem_cache_alloc+0x162/0x1c0
[<0>] kmem_zone_alloc+0x61/0xe0 [xfs]
[<0>] xfs_buf_item_init+0x31/0x160 [xfs]
[<0>] _xfs_trans_bjoin+0x1e/0x50 [xfs]
[<0>] xfs_trans_read_buf_map+0x104/0x340 [xfs]
[<0>] xfs_imap_to_bp+0x67/0xd0 [xfs]
[<0>] xfs_iunlink_remove+0x16b/0x430 [xfs]
[<0>] xfs_ifree+0x42/0x140 [xfs]
[<0>] xfs_inactive_ifree+0x9e/0x1c0 [xfs]
[<0>] xfs_inactive+0x9e/0x140 [xfs]
[<0>] xfs_fs_destroy_inode+0xa8/0x1c0 [xfs]
[<0>] __dentry_kill+0xd5/0x170
[<0>] dentry_kill+0x4d/0x190
[<0>] dput.part.31+0xcb/0x110
[<0>] ovl_destroy_inode+0x15/0x60 [overlay]
[<0>] __dentry_kill+0xd5/0x170
[<0>] shrink_dentry_list+0x94/0x1b0
[<0>] shrink_dcache_parent+0x88/0x90
[<0>] do_one_tree+0xe/0x40
[<0>] shrink_dcache_for_umount+0x28/0x80
[<0>] generic_shutdown_super+0x1a/0x100
[<0>] kill_anon_super+0x14/0x30
[<0>] deactivate_locked_super+0x34/0x70
[<0>] cleanup_mnt+0x3b/0x70
[<0>] task_work_run+0x8a/0xb0
[<0>] exit_to_usermode_loop+0xeb/0xf0
[<0>] do_syscall_64+0x182/0x1b0
[<0>] entry_SYSCALL_64_after_hwframe+0x65/0xca
[<0>] 0xffffffffffffffff
还要注意,重新启动Docker会从Docker移除容器,这足以解决PLEG不健康的问题,但没有移除卡住的runc init 。
编辑:那些感兴趣的版本:
码头工人19.03.8
运行c 1.0.0-rc10
的Linux:4.18.0-147.el8.x86_64
centos:8.1.1911
 debugmiller
于 2020-06-25
debugmiller
于 2020-06-25
这个问题解决了吗?
我的集群中出现PLEG问题,并观察到此未解决的问题。
有什么解决方法吗?
 cshivashankar
于 2020-06-26
cshivashankar
于 2020-06-26
我在集群中也遇到了PLEG问题,该集群已经启动并使用了几天。
设定
带有K8S v1.15.11-eks-af3caf的EKS集群
Docker版本18.09.9-ce
实例类型为m5ad.4xlarge
问题
Jul 08 04:12:36 ip-56-0-1-191.us-west-2.compute.internal kubelet [5354]:I0708 04:12:36.051162 5354 setters.go:533]节点未准备就绪:{类型:就绪状态:False LastHear tbeat时间:2020-07-08 04:12:36.051127368 +0000 UTC m = + 4279967.056220983 LastTransition时间:2020-07-08 04:12:36.051127368 +0000 UTC m = + 4279967.056220983原因:KubeletNotReady消息:PLEG不健康:Pleg最近一次见于3m9.146952991s; 阈值为3m0s}
复苏
Kubelet重新启动恢复了该节点。
有解决方案吗? 升级Docker版本有效吗?
 mak-454
于 2020-07-10
mak-454
于 2020-07-10
也许这是码头集装箱的问题,例如。 容器中的大量僵尸进程导致“ docker ps / inspect”极其缓慢
 jonesmith518
于 2020-07-27
jonesmith518
于 2020-07-27
我所有工人上的systemctl restart docker解决了我的问题。
 jetersen
于 2020-08-04
jetersen
于 2020-08-04
@jetersen您是否在Docker上启用了“实时还原”?
默认是重新启动Docker时重新启动所有容器,这是一个很大的问题。
bboreham
于 2020-08-04
@bboreham不如销毁并重新创建集群big
jetersen
于 2020-08-04
我正在使用Kubernetes 1.15.3、1.16.3和1.17.9来解决此问题。 在Docker版本18.6.3(Container Linux)和19.3.12(Flatcar Linux)上。
每个节点上大约有50个吊舱。
 FrederikNS
于 2020-09-04
FrederikNS
于 2020-09-04
我们还遇到了这个问题,其中docker ps列出的容器挂在docker inspect上
docker ps -a | tr -s " " | cut -d " " -f1 | xargs -Iarg sh -c 'echo arg; docker inspect arg> /dev/null'在我们的案例中,我们注意到受影响的容器卡在
runc init。 我们在附加或跟踪runc init的主线程时遇到麻烦。 似乎没有发出信号。 据我们所知,进程停留在内核中,并且没有转换回用户空间。 我并不是真正的Linux内核调试专家,但是据我所知,这似乎是与挂载清理相关的内核问题。 以下是runc init进程在内核领域执行的示例堆栈跟踪。[<0>] kmem_cache_alloc+0x162/0x1c0 [<0>] kmem_zone_alloc+0x61/0xe0 [xfs] [<0>] xfs_buf_item_init+0x31/0x160 [xfs] [<0>] _xfs_trans_bjoin+0x1e/0x50 [xfs] [<0>] xfs_trans_read_buf_map+0x104/0x340 [xfs] [<0>] xfs_imap_to_bp+0x67/0xd0 [xfs] [<0>] xfs_iunlink_remove+0x16b/0x430 [xfs] [<0>] xfs_ifree+0x42/0x140 [xfs] [<0>] xfs_inactive_ifree+0x9e/0x1c0 [xfs] [<0>] xfs_inactive+0x9e/0x140 [xfs] [<0>] xfs_fs_destroy_inode+0xa8/0x1c0 [xfs] [<0>] __dentry_kill+0xd5/0x170 [<0>] dentry_kill+0x4d/0x190 [<0>] dput.part.31+0xcb/0x110 [<0>] ovl_destroy_inode+0x15/0x60 [overlay] [<0>] __dentry_kill+0xd5/0x170 [<0>] shrink_dentry_list+0x94/0x1b0 [<0>] shrink_dcache_parent+0x88/0x90 [<0>] do_one_tree+0xe/0x40 [<0>] shrink_dcache_for_umount+0x28/0x80 [<0>] generic_shutdown_super+0x1a/0x100 [<0>] kill_anon_super+0x14/0x30 [<0>] deactivate_locked_super+0x34/0x70 [<0>] cleanup_mnt+0x3b/0x70 [<0>] task_work_run+0x8a/0xb0 [<0>] exit_to_usermode_loop+0xeb/0xf0 [<0>] do_syscall_64+0x182/0x1b0 [<0>] entry_SYSCALL_64_after_hwframe+0x65/0xca [<0>] 0xffffffffffffffff还要注意,重新启动Docker会从Docker移除容器,这足以解决PLEG不健康的问题,但没有移除卡住的
runc init。编辑:那些感兴趣的版本:
码头工人19.03.8
运行c 1.0.0-rc10
的Linux:4.18.0-147.el8.x86_64
centos:8.1.1911
这个问题解决了吗? 在哪个版本中?
 liruishan
于 2020-09-05
liruishan
于 2020-09-05
标记
 neighbour-oldhuang
于 2020-10-12
neighbour-oldhuang
于 2020-10-12
在eks上再次kubernetes版本= v1.16.8-eks-e16311和://19.3.6
重新启动docker,kubelet恢复了该节点。
mak-454
于 2020-11-17
@ mak-454今天我在EKS上也遇到了这个问题-您介意与您的节点共享运行区域/ AZ以及问题的持续时间吗? 我很好奇,看是否可能存在一些潜在的基础设施问题。
 JacobHenner
于 2020-11-18
JacobHenner
于 2020-11-18
@JacobHenner我的节点在eu-central-1区域中运行。
mak-454
于 2020-11-18
在Kubernetes版本“ 1.15.12”和docker版本“ 19.03.6-ce”的EKS(ca-central-1)上遇到此问题
重新启动docker / kubelet之后,节点事件中将显示以下行:
Warning SystemOOM 14s (x3 over 14s) kubelet, ip-10-1-2-3.ca-central-1.compute.internal System OOM encountered
 imriss
于 2020-11-18
imriss
于 2020-11-18
相关问题
 alexferl
·
3评论
alexferl
·
3评论
 mml
·
3评论
mml
·
3评论
 ddysher
·
3评论
ddysher
·
3评论
 sjenning
·
3评论
sjenning
·
3评论
 sanjana-bhat
·
3评论
sanjana-bhat
·
3评论
最有用的评论
PLEG健康检查功能很少。 在每次迭代中,它调用
docker ps来检测容器状态的变化,并调用docker ps和inspect以获取这些容器的详细信息。完成每次迭代后,它将更新时间戳记。 如果时间戳有一段时间(即3分钟)没有更新,则运行状况检查将失败。
除非您的节点上装有大量的Pod,而PLEG无法在3分钟内完成所有这些操作(这是不应该发生的),否则最可能的原因是docker运行缓慢。 您可能在偶尔的
docker ps支票中没有注意到这一点,但这并不意味着它不存在。如果我们不公开“不健康”状态,它将对用户隐藏许多问题,并可能导致更多问题。 例如,kubelet会默默地不及时对变化做出反应,甚至引起更多的混乱。
欢迎提出有关如何使其更可调试的建议...