Kubernetes: Nœud flottant entre Ready / NotReady avec des problèmes PLEG
Merci d'avoir signalé un problème! Avant d'appuyer sur le bouton, veuillez répondre à ces questions.
Est-ce une demande d'aide? Non
Quels mots clés avez-vous recherchés dans les problèmes Kubernetes avant de déposer celui-ci? (Si vous avez trouvé des doublons, vous devriez plutôt y répondre.): PLEG NotReady kubelet
S'agit-il d'un rapport de bogue ou d'une demande de fonctionnalité? Punaise
S'il s'agit d'un RAPPORT DE BOGUE, veuillez: - Remplir autant que possible le modèle ci-dessous. Si vous omettez des informations, nous ne pouvons pas non plus vous aider. S'il s'agit d'une DEMANDE DE FONCTIONNALITÉ, veuillez: - Décrivez * en détail * la fonctionnalité / le comportement / le changement que vous aimeriez voir. Dans les deux cas, soyez prêt pour les questions de suivi et répondez en temps opportun. Si nous ne pouvons pas reproduire un bogue ou si nous pensons qu'une fonctionnalité existe déjà, nous pouvons fermer votre problème. Si nous nous trompons, n'hésitez pas à le rouvrir et à expliquer pourquoi.Version Kubernetes (utilisez kubectl version ): 1.6.2
Environnement :
- Fournisseur de cloud ou configuration matérielle : CoreOS sur AWS
- OS (par exemple à partir de / etc / os-release): CoreOS 1353.7.0
- Noyau (par exemple
uname -a): 4.9.24-coreos - Installer les outils :
- Autres :
Qu'est-il arrivé :
J'ai un cluster de 3 travailleurs. Deux et parfois les trois nœuds continuent de tomber dans NotReady avec les messages suivants dans journalctl -u kubelet :
May 05 13:59:56 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 13:59:56.872880 2858 kubelet_node_status.go:379] Recording NodeNotReady event message for node ip-10-50-20-208.ec2.internal
May 05 13:59:56 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 13:59:56.872908 2858 kubelet_node_status.go:682] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-05-05 13:59:56.872865742 +0000 UTC LastTransitionTime:2017-05-05 13:59:56.872865742 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.629592089s ago; threshold is 3m0s}
May 05 14:07:57 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:07:57.598132 2858 kubelet_node_status.go:379] Recording NodeNotReady event message for node ip-10-50-20-208.ec2.internal
May 05 14:07:57 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:07:57.598162 2858 kubelet_node_status.go:682] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-05-05 14:07:57.598117026 +0000 UTC LastTransitionTime:2017-05-05 14:07:57.598117026 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.346983738s ago; threshold is 3m0s}
May 05 14:17:58 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:17:58.536101 2858 kubelet_node_status.go:379] Recording NodeNotReady event message for node ip-10-50-20-208.ec2.internal
May 05 14:17:58 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:17:58.536134 2858 kubelet_node_status.go:682] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-05-05 14:17:58.536086605 +0000 UTC LastTransitionTime:2017-05-05 14:17:58.536086605 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.275467289s ago; threshold is 3m0s}
May 05 14:29:59 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:29:59.648922 2858 kubelet_node_status.go:379] Recording NodeNotReady event message for node ip-10-50-20-208.ec2.internal
May 05 14:29:59 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:29:59.648952 2858 kubelet_node_status.go:682] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-05-05 14:29:59.648910669 +0000 UTC LastTransitionTime:2017-05-05 14:29:59.648910669 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.377520804s ago; threshold is 3m0s}
May 05 14:44:00 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:44:00.938266 2858 kubelet_node_status.go:379] Recording NodeNotReady event message for node ip-10-50-20-208.ec2.internal
May 05 14:44:00 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:44:00.938297 2858 kubelet_node_status.go:682] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-05-05 14:44:00.938251338 +0000 UTC LastTransitionTime:2017-05-05 14:44:00.938251338 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.654775919s ago; threshold is 3m0s}
Le démon docker est très bien (local docker ps , docker images , etc. tous fonctionnent et répondent immédiatement).
en utilisant un réseau tissé installé via kubectl apply -f https://git.io/weave-kube-1.6
Ce à quoi vous vous attendiez :
Les nœuds doivent être prêts.
Comment le reproduire (de la manière la plus minimale et la plus précise possible):
J'aimerais savoir comment!
Tout ce que nous devons savoir :
Tous les nœuds (travailleurs et maîtres) sur le même sous-réseau privé avec une passerelle NAT vers Internet. Travailleurs dans le groupe de sécurité qui permet un accès illimité (tous les ports) à partir du groupe de sécurité maître; les maîtres autorisent tous les ports du même sous-réseau. le proxy s'exécute sur les travailleurs; apiserver, contrôleur-gestionnaire, ordonnanceur sur masters.
kubectl logs et kubectl exec bloquent toujours, même lorsqu'ils sont exécutés depuis le maître lui-même (ou depuis l'extérieur).
 deitch
deitch
Tous les 225 commentaires
@deitch , combien de conteneurs fonctionnaient sur le nœud? Quelle est l'utilisation globale du processeur par vos nœuds?
 yujuhong
le 5 mai 2017
yujuhong
le 5 mai 2017
Fondamentalement aucun. kube-dns, weave-net, weave-npc et 3 exemples de services. En fait, un seul, car deux n'avaient pas d'image et allaient être nettoyés. AWS m4.2xlarge. Pas un problème de ressources.
J'ai fini par devoir détruire les nœuds et recréer. Aucun message PLEG depuis détruire / recréer, et ils semblent corrects à 50%. Ils restent Ready , bien qu'ils refusent toujours de permettre kubectl exec ou kubectl logs .
J'ai vraiment eu du mal à trouver de la documentation sur ce qu'est vraiment PLEG, mais surtout sur la façon de vérifier ses propres journaux et son état et de le déboguer.
deitch
le 5 mai 2017
Hmm ... pour ajouter au mystère, aucun conteneur ne peut résoudre aucun nom d'hôte, et kubedns donne:
E0505 17:30:49.412272 1 reflector.go:199] pkg/dns/config/sync.go:114: Failed to list *api.ConfigMap: Get https://10.200.0.1:443/api/v1/namespaces/kube-system/configmaps?fieldSelector=metadata.name%3Dkube-dns&resourceVersion=0: dial tcp 10.200.0.1:443: getsockopt: no route to host
E0505 17:30:49.412285 1 reflector.go:199] pkg/dns/dns.go:148: Failed to list *api.Service: Get https://10.200.0.1:443/api/v1/services?resourceVersion=0: dial tcp 10.200.0.1:443: getsockopt: no route to host
E0505 17:30:49.412272 1 reflector.go:199] pkg/dns/dns.go:145: Failed to list *api.Endpoints: Get https://10.200.0.1:443/api/v1/endpoints?resourceVersion=0: dial tcp 10.200.0.1:443: getsockopt: no route to host
I0505 17:30:51.855370 1 logs.go:41] skydns: failure to forward request "read udp 10.100.0.3:60364->10.50.0.2:53: i/o timeout"
FWIW, 10.200.0.1 est le service api Kube en interne, 10.200.0.5 est DNS, 10.50.20.0/24 et 10.50.21.0/24 sont les sous-réseaux (2 AZ séparés) sur lesquels les maîtres et les workers courir.
Quelque chose de vraiment fubar dans le réseautage?
deitch
le 5 mai 2017
Quelque chose de vraiment fubar dans le réseautage?
@bboreham cela pourrait-il être lié au tissage et non au kube (ou au moins au tissage mal configuré)? Tissage standard avec le IPALLOC_RANGE=10.100.0.0/16 ajouté comme indiqué sur https://github.com/weaveworks/weave/issues/2736
deitch
le 5 mai 2017
@deitch pleg permet à kubelet de répertorier périodiquement les pods dans le nœud pour vérifier l'intégrité et mettre à jour le cache. Si vous voyez le journal de timeout pleg, cela peut ne pas être lié à DNS, mais parce que l'appel de kubelet à docker est timeout.
 qiujian16
le 11 mai 2017
qiujian16
le 11 mai 2017
Merci @ qiujian16 . Le problème semble avoir disparu, mais je ne sais pas comment le vérifier. Docker lui-même semblait sain. Je me demandais si cela pouvait être un plugin de réseau, mais cela ne devrait pas affecter le kubelet lui-même.
Pouvez-vous me donner quelques conseils ici pour vérifier la salubrité et l'état de la pleg? Ensuite, nous pouvons fermer cela jusqu'à ce que je vois le problème se reproduire.
deitch
le 11 mai 2017
@deitch pleg est l'abréviation de "pod lifecycle event generator", c'est un composant interne de kubelet et je ne pense pas que vous puissiez vérifier directement son statut, voir (https://github.com/kubernetes/community/blob/master /contributors/design-proposals/pod-lifecycle-event-generator.md)
qiujian16
le 11 mai 2017
S'agit-il d'un module interne dans le binaire kubelet? S'agit-il d'un autre conteneur autonome (docker, runc, cotnainerd)? C'est juste un binaire autonome?
Fondamentalement, si kubelet signale des erreurs PLEG, il est très utile de savoir quelles sont ces erreurs, puis de vérifier son état, d'essayer de répliquer.
deitch
le 11 mai 2017
c'est un module interne
qiujian16
le 11 mai 2017
Le docker
yujuhong
le 11 mai 2017
J'ai un problème similaire sur tous les nœuds sauf un cluster que je viens de créer,
journaux:
kube-worker03.foo.bar.com kubelet[3213]: E0511 19:00:59.139374 3213 remote_runtime.go:109] StopPodSandbox "12c6a5c6833a190f531797ee26abe06297678820385b402371e196c69b67a136" from runtime service failed: rpc error: code = 4 desc = context deadline exceeded
May 11 19:00:59 kube-worker03.foo.bar.com kubelet[3213]: E0511 19:00:59.139401 3213 kuberuntime_gc.go:138] Failed to stop sandbox "12c6a5c6833a190f531797ee26abe06297678820385b402371e196c69b67a136" before removing: rpc error: code = 4 desc = context deadline exceeded
May 11 19:01:04 kube-worker03.foo.bar.com kubelet[3213]: E0511 19:01:04.627954 3213 pod_workers.go:182] Error syncing pod 1c43d9b6-3672-11e7-a6da-00163e041106
("kube-dns-4240821577-1wswn_kube-system(1c43d9b6-3672-11e7-a6da-00163e041106)"), skipping: rpc error: code = 4 desc = context deadline exceeded
May 11 19:01:18 kube-worker03.foo.bar.com kubelet[3213]: E0511 19:01:18.627819 3213 pod_workers.go:182] Error syncing pod 1c43d9b6-3672-11e7-a6da-00163e041106
("kube-dns-4240821577-1wswn_kube-system(1c43d9b6-3672-11e7-a6da-00163e041106)"),
skipping: rpc error: code = 4 desc = context deadline exceeded
May 11 19:01:21 kube-worker03.foo.bar.com kubelet[3213]: I0511 19:01:21.627670 3213 kubelet.go:1752] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.339074625s ago; threshold is 3m0s]
J'ai rétrogradé docker et redémarré pratiquement tout en vain, les nœuds sont tous gérés via marionnette, donc je m'attends à ce qu'ils soient complètement identiques, je n'ai aucune idée de ce qui ne va pas. Les journaux Docker en mode débogage montrent qu'il reçoit ces demandes
 bjhaid
le 11 mai 2017
bjhaid
le 11 mai 2017
@bjhaid qu'utilisez -vous pour le réseautage? Je voyais à l'époque des problèmes de réseautage intéressants.
deitch
le 11 mai 2017
@deitch weave, mais je ne pense pas que ce soit un problème lié au réseau, car cela semble être un problème de communication entre kubelet et docker. Je peux confirmer que docker reçoit ces demandes de kubelet via la journalisation de débogage de docker
bjhaid
le 11 mai 2017
Mes problèmes avec Pleg semblent avoir disparu, même si je ne me sentirai pas en confiance jusqu'à la prochaine fois que je réinstalle ces clusters (le tout via les modules terraform que j'ai construits).
Des problèmes de tissage semblent exister, ou peut-être k8s / docker.
deitch
le 11 mai 2017
@deitch avez-vous fait quelque chose pour faire disparaître les problèmes de Pleg ou la magie s'est-elle produite?
bjhaid
le 11 mai 2017
En fait, c'est la résolution du nom d'hôte, les contrôleurs n'ont pas pu résoudre le nom d'hôte des nœuds nouvellement créés, désolé pour le bruit
bjhaid
le 11 mai 2017
J'ai rapidement signalé que tout allait bien, le problème existe toujours, je continuerai à chercher et je ferai un rapport si je trouve quelque chose
bjhaid
le 11 mai 2017
Je suppose que ce problème est lié à weave-kube J'ai eu le même problème et cette fois pour le résoudre sans recréer le cluster, j'ai dû supprimer le tissage et le réappliquer (avec un redémarrage du nœud afin de propager l'ordre de suppression) ... Et c'est de retour
Donc je ne sais pas pourquoi ni comment je suis presque sûr que c'est dû à weave-kube-1.6
 gbergere
le 19 mai 2017
gbergere
le 19 mai 2017
J'ai oublié de revenir ici, mon problème était dû au fait que l'interface de tissage ne montait pas, donc les conteneurs n'avaient pas de réseau, mais cela était dû au blocage des données de tissage et des ports vxlan par notre pare-feu, une fois que j'ai ouvert ces ports, tout allait bien
bjhaid
le 19 mai 2017
J'ai eu deux séries de problèmes, peut-être liés.
- PLEG. Je pense qu'ils sont partis, mais je n'ai pas recréé suffisamment de grappes pour être complètement confiant. Je ne crois pas avoir beaucoup changé (c'est-à-dire quoi que ce soit) _directement_ pour que cela se produise.
- Problèmes de tissage dans lesquels les conteneurs ne pouvaient pas se connecter à quoi que ce soit.
De manière suspecte, tous les problèmes avec pleg se sont produits exactement au même moment que les problèmes de réseau de tissage.
Bryan @ weaveworks, m'a indiqué les problèmes de coreos. CoreOS a une tendance plutôt agressive à essayer de gérer les ponts, les veths, en gros tout. Une fois que j'ai désactivé CoreOS de le faire, sauf sur lo et en fait les interfaces physiques sur l'hôte, tous mes problèmes sont restés.
Les gens ont-ils encore des problèmes pour exécuter des coreos?
deitch
le 19 mai 2017
Nous sommes en proie à ces problèmes depuis environ un mois (je veux dire après la mise à niveau des clusters vers 1.6.x à partir de 1.5.x) et c'est tout aussi mystérieux.
nous exécutons des AMI de debian jessie dans aws, et de temps en temps un cluster décidera que PLEG n'est pas sain.
Le tissage semble correct dans ce cas, car les pods remontent bien d'un point à l'autre.
Une chose que nous avons notée est que si nous réduisons TOUS nos réplicas, le problème semble disparaître, mais lorsque nous commençons à redimensionner les déploiements et les ensembles avec état, cela se produit autour d'un certain nombre de conteneurs. (au moins cette fois).
docker ps; les informations du docker semblent correctes sur le nœud.
l'utilisation des ressources est nominale: 5% d'utilitaire CPU, 1,5 / 8 Go de RAM utilisée (selon root htop), l'approvisionnement total des ressources du nœud se situe autour de 30% avec tout ce qui est supposé être planifié dessus, planifié.
Nous ne pouvons pas du tout comprendre cela.
J'aurais vraiment aimé que le contrôle PLEG soit un peu plus détaillé, et nous avions un document détaillé sur ce que fait le bip , car il semble y avoir un nombre ÉNORME de problèmes ouverts à ce sujet, personne ne sait vraiment ce que c'est, et pour un tel un module critique, je serais ravi de ne pas pouvoir reproduire les vérifications qu'il considère comme défaillantes.
 hollowimage
le 26 mai 2017
hollowimage
le 26 mai 2017
Je seconde les pensées sur le mystérieux pleg. De mon côté cependant, après beaucoup de travail pour mon client, la stabilisation des coreos et son mauvais comportement avec les réseaux ont beaucoup aidé.
deitch
le 26 mai 2017
Le bilan de santé PLEG fait très peu. À chaque itération, il appelle docker ps pour détecter les changements d'états des conteneurs, et appelle docker ps et inspect pour obtenir les détails de ces conteneurs.
Après avoir terminé chaque itération, il met à jour un horodatage. Si l'horodatage n'a pas été mis à jour pendant un certain temps (c'est-à-dire 3 minutes), la vérification de l'état échoue.
À moins que votre nœud ne soit chargé avec un grand nombre de pods que PLEG ne peut pas finir de faire tout cela en 3 minutes (ce qui ne devrait pas arriver), la cause la plus probable serait que le docker soit lent. Vous ne pouvez pas observer cela dans votre docker ps occasionnel
Si nous n'exposons pas le statut "malsain", cela cacherait de nombreux problèmes aux utilisateurs et causerait potentiellement plus de problèmes. Par exemple, kubelet ne réagissait pas silencieusement aux changements en temps opportun et causait encore plus de confusion.
Les suggestions sur la façon de rendre cela plus débuggable sont les bienvenues ...
yujuhong
le 27 mai 2017
Exécution d'avertissements malsains PLEG et état de santé du nœud flottant: k8s 1.6.4 avec tissage. Apparaît uniquement sur un sous-ensemble de nœuds (sinon identiques).
 anurag
le 27 mai 2017
anurag
le 27 mai 2017
Juste un petit avertissement, dans notre cas, le battement des travailleurs et des pods coincés dans ContainerCreating était un problème avec les groupes de sécurité de nos instances EC2 ne permettant pas le trafic tissé entre le maître et les travailleurs et entre les travailleurs. Par conséquent, le nœud n'a pas pu monter correctement et est resté bloqué dans NotReady.
kuberrnetes 1.6.4
avec un groupe de sécurité approprié, cela fonctionne maintenant.
 agabert
le 1 juin 2017
agabert
le 1 juin 2017
Je rencontre quelque chose comme ce problème avec cette configuration ...
Version Kubernetes (utilisez la version kubectl): 1.6.4
Environnement:
Fournisseur de cloud ou configuration matérielle: serveur System76 unique
OS (par exemple à partir de / etc / os-release): Ubuntu 16.04.2 LTS
Noyau (par exemple uname -a): Linux system76-server 4.4.0-78-generic # 99-Ubuntu SMP Thu Apr 27 15:29:09 UTC 2017 x86_64 x86_64 x86_64 GNU / Linux
Installer les outils: kubeadm + weave.works
Puisqu'il s'agit d'un cluster à nœud unique, je ne pense pas que ma version de ce problème soit liée aux groupes de sécurité ou aux pare-feu.
 wirehead
le 1 juin 2017
wirehead
le 1 juin 2017
Le problème avec les groupes de sécurité aurait du sens si vous venez de démarrer le cluster. Mais ces problèmes que nous constatons concernent des clusters qui fonctionnent depuis des mois, avec des groupes de sécurité en place.
hollowimage
le 2 juin 2017
Il m'est arrivé quelque chose de similaire en exécutant la version 1.6.2 de kubelet sur GKE.
L'un de nos nœuds a été déplacé dans un état non prêt, les journaux de kubelet sur ce nœud ont eu deux plaintes, l'une selon laquelle la vérification de l'état PLEG a échoué et deux, fait intéressant, que les opérations de liste d'images ont échoué.
Quelques exemples d'appels de fonction d'image qui ont échoué.
image_gc_manager.go: 176
kuberuntime_image.go: 106
remote_image.go: 61
Je suppose que ce sont des appels au démon docker.
Au fur et à mesure que cela se produisait, j'ai vu beaucoup de pics d'E / S disque, en particulier les opérations de lecture. De ~ 50 kb / s à 8 mb / s.
Il s'est corrigé après environ 30 à 45 minutes, mais peut-être était-ce un balayage GC d'image provoquant une augmentation des IO?
Comme cela a été dit, PLEG surveille les pods via le démon docker, si cela fait beaucoup d'opérations une fois, les contrôles PLEG pourraient-ils être mis en file d'attente?
 zoltrain
le 2 juin 2017
zoltrain
le 2 juin 2017
Je vois ce problème dans 1.6.4 et 1.6.6 (sur GKE) avec le battement de NotReady comme résultat. Comme il s'agit de la dernière version disponible sur GKE, j'aimerais que les correctifs soient rétroportés vers la prochaine version 1.6.
Une chose intéressante est que l'heure à laquelle PLEG a été vu pour la dernière fois actif ne change pas et est toujours un nombre énorme (peut-être qu'il est à une certaine limite de quelque type qu'il soit stocké).
[container runtime is down PLEG is not healthy: pleg was last seen active 2562047h47m16.854775807s ago; threshold is 3m0s]
 bergman
le 26 juin 2017
bergman
le 26 juin 2017
[l'exécution du conteneur est en panne. PLEG n'est pas sain: pleg a été vu pour la dernière fois actif il y a 2562047h47m16.854775807s; le seuil est de 3m0s]
@bergman Je n'ai pas vu cela mais si tel est le cas, votre nœud n'aurait jamais été prêt. N'hésitez pas à le signaler via le canal GKE afin que l'équipe GKE puisse enquêter davantage.
Il s'est corrigé après environ 30 à 45 minutes, mais peut-être était-ce un balayage GC d'image provoquant une augmentation des IO?
C'est certainement possible. Image GC pouvait parfois provoquer une réponse extrêmement lente du démon docker. 30 à 45 minutes semblent assez longues. @zoltrain , les images ont été supprimées pendant toute la durée.
Pour réitérer ma déclaration précédente, PLEG fait très peu et échoue uniquement à la vérification de l'état parce que le démon docker ne répond pas. Nous présentons ces informations via la vérification de l'état de PLEG pour informer le plan de contrôle que le nœud ne reçoit pas les statistiques du conteneur (et y réagit) correctement. La suppression aveugle de cette vérification peut masquer des problèmes plus graves.
yujuhong
le 26 juin 2017
Pour mettre à jour: nous avons trouvé le problème de notre côté en ce qui concerne le provisionnement de tissage et d'ip-slice. comme nous terminons souvent les nœuds dans AWS, le tissage ne tenait pas compte à l'origine de la destruction permanente des nœuds dans un cluster, avec de nouvelles adresses IP qui suivront. par conséquent, la mise en réseau ne serait pas correctement configurée, de sorte que tout ce qui concernait les plages internes ne se présenterait pas correctement.
https://github.com/weaveworks/weave/issues/2970
pour ceux qui utilisent le tissage.
hollowimage
le 26 juin 2017
[l'exécution du conteneur est en panne. PLEG n'est pas sain: pleg a été vu pour la dernière fois actif il y a 2562047h47m16.854775807s; le seuil est de 3m0s]
@bergman Je n'ai pas vu cela mais si tel est le cas, votre nœud n'aurait jamais été prêt. N'hésitez pas à le signaler via le canal GKE afin que l'équipe GKE puisse enquêter davantage.
Le nœud est prêt la plupart du temps. Je crois que kubelet est soit redémarré en raison de cette vérification, soit une autre vérification signale l'événement Ready. Nous voyons environ 10 secondes de NotReady toutes les 60 secondes. Le reste du temps, le nœud est prêt.
bergman
le 27 juin 2017
@yujuhong Je pense que la journalisation PLEG peut être améliorée, en disant que PLEG is not healthy est très déroutant pour l'utilisateur final et qu'il n'aide pas à diagnostiquer les problèmes, y compris peut-être pourquoi l'exécution du conteneur a échoué, ou certains détails sur l'exécution du conteneur non répondre sera plus utile
bjhaid
le 27 juin 2017
Je ne vois pas de battement mais toujours pas prêt pour le nœud avec 1.6.4 et calico, pas de tissage.
 chenww
le 21 juil. 2017
chenww
le 21 juil. 2017
@yujuhong Je pense que la journalisation PLEG peut être améliorée, dire que PLEG n'est pas sain est très déroutant pour l'utilisateur final et qu'il n'aide pas à diagnostiquer les problèmes, y compris peut-être pourquoi le runtime du conteneur a échoué, ou que certains détails sur le runtime du conteneur ne répondent pas. être plus utile
Sûr. N'hésitez pas à envoyer un PR.
yujuhong
le 21 juil. 2017
J'avais ce problème lors du nettoyage de l'image du docker. Je suppose que docker était trop occupé. Une fois les images supprimées, le retour à la normale.
 xcompass
le 19 août 2017
xcompass
le 19 août 2017
J'ai rencontré le même problème. Je soupçonne que la raison est que ntpd est l'heure actuelle correcte.
J'ai vu que l'heure correcte de ntpd dans la v1.6.9
Sep 12 19:05:08 node-6 systemd: Started logagt.
Sep 12 19:05:08 node-6 systemd: Starting logagt...
Sep 12 19:05:09 node-6 cnrm: "Log":"2017-09-12 19:05:09.197083#011ERROR#011node-6#011knitter.cnrm.mod-init#011TransactionID=1#011InstanceID=1174#011[ObjectType=null,ObjectID=null]#011registerOir: k8s.GetK8sClientSingleton().RegisterOir(oirName: hugepage, qty: 2048) FAIL, error: dial tcp 120.0.0.250:8080: getsockopt: no route to host, retry#011[init.go]#011[68]"
Sep 12 11:04:53 node-6 ntpd[902]: 0.0.0.0 c61c 0c clock_step -28818.771869 s
Sep 12 11:04:53 node-6 ntpd[902]: 0.0.0.0 c614 04 freq_mode
Sep 12 11:04:53 node-6 systemd: Time has been changed
Sep 12 11:04:54 node-6 ntpd[902]: 0.0.0.0 c618 08 no_sys_peer
Sep 12 11:05:04 node-6 systemd: Reloading.
Sep 12 11:05:04 node-6 systemd: Configuration file /usr/lib/systemd/system/auditd.service is marked world-inaccessible. This has no effect as configuration data is accessible via APIs without restrictions. Proceeding anyway.
Sep 12 11:05:04 node-6 systemd: Started opslet.
Sep 12 11:05:04 node-6 systemd: Starting opslet...
Sep 12 11:05:13 node-6 systemd: Reloading.
Sep 12 11:05:22 node-6 kubelet: E0912 11:05:22.425676 2429 event.go:259] Could not construct reference to: '&v1.Node{TypeMeta:v1.TypeMeta{Kind:"", APIVersion:""}, ObjectMeta:v1.ObjectMeta{Name:"120.0.0.251", GenerateName:"", Namespace:"", SelfLink:"", UID:"", ResourceVersion:"", Generation:0, CreationTimestamp:v1.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*v1.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string{"beta.kubernetes.io/os":"linux", "beta.kubernetes.io/arch":"amd64", "kubernetes.io/hostname":"120.0.0.251"}, Annotations:map[string]string{"volumes.kubernetes.io/controller-managed-attach-detach":"true"}, OwnerReferences:[]v1.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:""}, Spec:v1.NodeSpec{PodCIDR:"", ExternalID:"120.0.0.251", ProviderID:"", Unschedulable:false, Taints:[]v1.Taint(nil)}, Status:v1.NodeStatus{Capacity:v1.ResourceList{"cpu":resource.Quantity{i:resource.int64Amount{value:4000, scale:-3}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"DecimalSI"}, "memory":resource.Quantity{i:resource.int64Amount{value:3974811648, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"BinarySI"}, "hugePages":resource.Quantity{i:resource.int64Amount{value:1024, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"DecimalSI"}, "pods":resource.Quantity{i:resource.int64Amount{value:110, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"DecimalSI"}}, Allocatable:v1.ResourceList{"cpu":resource.Quantity{i:resource.int64Amount{value:3500, scale:-3}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"DecimalSI"}, "memory":resource.Quantity{i:resource.int64Amount{value:1345666048, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"BinarySI"}, "hugePages":resource.Quantity{i:resource.int64Amount{value:1024, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"",
Sep 12 11:05:22 node-6 kubelet: Format:"DecimalSI"}, "pods":resource.Quantity{i:resource.int64Amount{value:110, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"DecimalSI"}}, Phase:"", Conditions:[]v1.NodeCondition{v1.NodeCondition{Type:"OutOfDisk", Status:"False", LastHeartbeatTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196025689, loc:(*time.Location)(0x4e8e3a0)}}, LastTransitionTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196025689, loc:(*time.Location)(0x4e8e3a0)}}, Reason:"KubeletHasSufficientDisk", Message:"kubelet has sufficient disk space available"}, v1.NodeCondition{Type:"MemoryPressure", Status:"False", LastHeartbeatTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196099492, loc:(*time.Location)(0x4e8e3a0)}}, LastTransitionTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196099492, loc:(*time.Location)(0x4e8e3a0)}}, Reason:"KubeletHasSufficientMemory", Message:"kubelet has sufficient memory available"}, v1.NodeCondition{Type:"DiskPressure", Status:"False", LastHeartbeatTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196107935, loc:(*time.Location)(0x4e8e3a0)}}, LastTransitionTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196107935, loc:(*time.Location)(0x4e8e3a0)}}, Reason:"KubeletHasNoDiskPressure", Message:"kubelet has no disk pressure"}, v1.NodeCondition{Type:"Ready", Status:"False", LastHeartbeatTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196114314, loc:(*time.Location)(0x4e8e3a0)}}, LastTransitionTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196114314, loc:(*time.Location)(0x4e8e3a0)}}, Reason:"KubeletNotReady", Message:"container runtime is down,PLEG is not healthy: pleg was last seen active 2562047h47m16.854775807s ago; threshold is 3m0s,network state unknown"}}, Addresses:[]v1.NodeAddress{v1.NodeAddress{Type:"LegacyHostIP", Address:"120.0.0.251"}, v1.NodeAddress{Type:"InternalIP", Address:"120.0.0.251"}, v1.NodeAddress{Type:"Hostname", Address:"120.0.0.251"}}, DaemonEndpoints:v1.NodeDaemonEndpoints{KubeletEndpoint:v1.DaemonEndpoint{Port:10250}}, NodeInfo:v1.NodeS
 yanxuean
le 14 sept. 2017
yanxuean
le 14 sept. 2017
marque.
 warmchang
le 14 sept. 2017
warmchang
le 14 sept. 2017
Même problème ici.
Il apparaît lorsque le pod tue mais reste dans l'état Normal Killing Killing container with docker id 472802bf1dba: Need to kill pod. à mort
et les journaux de kubelet comme ceci:
skipping pod synchronization - [PLEG is not healthy: pleg was last seen active
version cluste de k8s: 1.6.4
@xcompass Utilisez-vous les --image-gc-high-threshold et --image-gc-low-threshold pour la configuration de kubelet? Je soupçonne que kubelet gc occupe le docker deamon.
 alirezaDavid
le 19 sept. 2017
alirezaDavid
le 19 sept. 2017
@alirezaDavid J'ai rencontré le même problème, tout comme le vôtre, le démarrage et la fin du pod sont très lents, et le nœud n'est pas prêt de temps en temps, redémarrez kubelet sur le nœud ou redémarrez le docker semble résoudre le problème, mais ce n'est pas la bonne façon.
 yangyuw
le 19 sept. 2017
yangyuw
le 19 sept. 2017
@ yu-yang2 Yap exactement, je redémarre kubelet
Mais avant de redémarrer kubelet, j'ai vérifié docker ps et systemctl -u docker et tout semble fonctionner.
alirezaDavid
le 19 sept. 2017
Nous avons eu ce problème sur kubernetes avec tissage et autoscalers. Il s'est avéré que Weave n'avait plus d'adresse IP à attribuer. Cela a été détecté en exécutant. Weave status ipam de ce numéro: https://github.com/weaveworks/weave/issues/2970
La cause première est ici: https://github.com/weaveworks/weave/issues/2797
La documentation met en garde contre les autoscalers et le tissage: https://www.weave.works/docs/net/latest/operational-guide/tasks/
Lorsque nous avons exécuté weave --local status ipam, il y avait des centaines de nœuds indisponibles avec un grand nombre d'adresses IP qui leur étaient attribuées. Cela se produit car l'autoscaler met fin aux instances sans en informer Weave. Cela ne laissait qu'une poignée pour les nœuds réellement connectés. J'ai utilisé le motif de tissage pour éliminer certains des pairs indisponibles. Cela a ensuite donné au nœud que je courais sur un groupe d'adresses IP. Je suis ensuite allé sur d'autres nœuds de tissage en cours d'exécution et j'ai également exécuté quelques commandes rmpeer (je ne suis pas sûr que cela soit nécessaire).
J'ai mis fin à certaines des instances ec2 et de nouvelles ont été mises en place par l'autoscaler et se sont immédiatement vu attribuer des adresses IP.
 mattthelee
le 29 sept. 2017
mattthelee
le 29 sept. 2017
Salut les gens. Dans mon cas, j'ai eu le problème PLEG avec une suppression de sandbox, car ils n'avaient pas d'espace de noms réseau. Cette situation décrite dans https://github.com/kubernetes/kubernetes/issues/44307
Mon problème était:
- Pod déployé.
- Pod supprimé. Conteneur d'application supprimé sans problèmes. Le bac à sable de l'application n'a pas été supprimé.
- PLEG essaie de valider / supprimer / terminer le bac à sable, PLEG ne peut pas le faire et marque le nœud comme défectueux.
Comme je peux le voir, toutes les personnes dans ce bogue utilisent 1.6. * De Kubernetes, il devrait être corrigé dans 1.7.
PS. Vu cette situation avec l'origine 3.6 (kubernetes 1.6).
 livelace
le 2 oct. 2017
livelace
le 2 oct. 2017
Salut,
J'ai moi-même un problème PLEG (Azure, k8s 1.7.7):
Oct 5 08:13:27 k8s-agent-27569017-1 docker[1978]: E1005 08:13:27.386295 2209 remote_runtime.go:168] ListPodSandbox with filter "nil" from runtime service failed: rpc error: code = 4 desc = context deadline exceeded
Oct 5 08:13:27 k8s-agent-27569017-1 docker[1978]: E1005 08:13:27.386351 2209 kuberuntime_sandbox.go:197] ListPodSandbox failed: rpc error: code = 4 desc = context deadline exceeded
Oct 5 08:13:27 k8s-agent-27569017-1 docker[1978]: E1005 08:13:27.386360 2209 generic.go:196] GenericPLEG: Unable to retrieve pods: rpc error: code = 4 desc = context deadline exceeded
Oct 5 08:13:30 k8s-agent-27569017-1 docker[1978]: I1005 08:13:30.953599 2209 helpers.go:102] Unable to get network stats from pid 60677: couldn't read network stats: failure opening /proc/60677/net/dev: open /proc/60677/net/dev: no such file or directory
Oct 5 08:13:30 k8s-agent-27569017-1 docker[1978]: I1005 08:13:30.953634 2209 helpers.go:125] Unable to get udp stats from pid 60677: failure opening /proc/60677/net/udp: open /proc/60677/net/udp: no such file or directory
Oct 5 08:13:30 k8s-agent-27569017-1 docker[1978]: I1005 08:13:30.953642 2209 helpers.go:132] Unable to get udp6 stats from pid 60677: failure opening /proc/60677/net/udp6: open /proc/60677/net/udp6: no such file or directory
Oct 5 08:13:31 k8s-agent-27569017-1 docker[1978]: I1005 08:13:31.763914 2209 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 13h42m52.628402637s ago; threshold is 3m0s]
Oct 5 08:13:35 k8s-agent-27569017-1 docker[1978]: I1005 08:13:35.977487 2209 kubelet_node_status.go:467] Using Node Hostname from cloudprovider: "k8s-agent-27569017-1"
Oct 5 08:13:36 k8s-agent-27569017-1 docker[1978]: I1005 08:13:36.764105 2209 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 13h42m57.628610126s ago; threshold is 3m0s]
Oct 5 08:13:39 k8s-agent-27569017-1 docker[1275]: time="2017-10-05T08:13:39.185111999Z" level=warning msg="Health check error: rpc error: code = 4 desc = context deadline exceeded"
Oct 5 08:13:41 k8s-agent-27569017-1 docker[1978]: I1005 08:13:41.764235 2209 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 13h43m2.628732806s ago; threshold is 3m0s]
Oct 5 08:13:41 k8s-agent-27569017-1 docker[1978]: I1005 08:13:41.875074 2209 helpers.go:102] Unable to get network stats from pid 60677: couldn't read network stats: failure opening /proc/60677/net/dev: open /proc/60677/net/dev: no such file or directory
Oct 5 08:13:41 k8s-agent-27569017-1 docker[1978]: I1005 08:13:41.875102 2209 helpers.go:125] Unable to get udp stats from pid 60677: failure opening /proc/60677/net/udp: open /proc/60677/net/udp: no such file or directory
Oct 5 08:13:41 k8s-agent-27569017-1 docker[1978]: I1005 08:13:41.875113 2209 helpers.go:132] Unable to get udp6 stats from pid 60677: failure opening /proc/60677/net/udp6: open /proc/60677/net/udp6: no such file or directory
 sylr
le 5 oct. 2017
sylr
le 5 oct. 2017
Nous exécutons v1.7.4+coreos.0 sur CoreOS stable. Nous constatons que nos nœuds k8s tombent en panne (et ne remontent pas tant que nous n'avons pas redémarré le service docker et / ou kubelet) aussi fréquemment que toutes les 8 heures à cause de PLEG. Les conteneurs continuent de fonctionner mais dans k8s sont signalés comme inconnus. Je devrais mentionner que nous déployons en utilisant Kubespray.
Nous avons retracé le problème jusqu'à ce que nous croyons être l'algorithme d'interruption dans GRPC lors de la communication avec docker afin de répertorier les conteneurs. Ce PR https://github.com/moby/moby/pull/33483 modifie le délai d'attente à un maximum de 2 secondes et est disponible en 17.06, mais kubernetes ne prend pas en charge le 17.06 jusqu'au 1.8, n'est-ce pas?
La ligne dans PLEG qui pose problème est la suivante .
Nous avons utilisé prometheus pour inspecter les métriques PLEGRelistInterval et PLEGRelistLatency et avons obtenu le résultat suivant qui est assez cohérent avec la théorie de l'algorithme de backoff.


 ssboisen
le 11 oct. 2017
ssboisen
le 11 oct. 2017
@ssboisen merci pour les rapports avec les graphiques (ils semblent intéressants)!
Nous constatons que nos nœuds k8s tombent en panne (et ne remontent pas tant que nous n'avons pas redémarré le service docker et / ou kubelet) aussi fréquemment que toutes les 8 heures à cause de PLEG. Les conteneurs continuent de fonctionner mais dans k8s sont signalés comme inconnus. Je devrais mentionner que nous déployons en utilisant Kubespray.
Quelques questions que j'ai:
- Le redémarrage de l'un des docker et kubelet résout-il le problème?
- Lorsque le problème survient, est-ce que
docker psrépond normalement?
Nous avons retracé le problème jusqu'à ce que nous croyons être l'algorithme d'interruption dans GRPC lors de la communication avec docker afin de répertorier les conteneurs. Ce PR moby / moby # 33483 modifie le délai d'attente à un maximum de 2 secondes et est disponible en 17.06, mais kubernetes ne prend pas en charge 17.06 jusqu'à 1.8, n'est-ce pas?
J'ai regardé les problèmes moby que vous avez mentionnés, mais dans cette discussion, tous les appels docker ps fonctionnaient toujours correctement (même si la connexion dockerd <-> containerd était interrompue). Cela semble différent du problème PLEG que vous avez mentionné. De plus, kubelet ne parle pas à dockerd en utilisant grpc. Il utilise grpc pour communiquer avec le dockershim, mais il s'agit essentiellement du même processus et ne devrait pas rencontrer le problème de l'un est tué alors que l'autre est encore en vie (conduisant à une connexion interrompue).
grpc http grpc
kubelet <----> dockershim <----> dockerd <----> containerd
Quel est le message d'erreur que vous avez vu dans le journal kubelet? La plupart des commentaires ci-dessus contenaient des messages d'erreur "Délai de contexte dépassé",
yujuhong
le 11 oct. 2017
- Le redémarrage de l'un des docker et kubelet résout-il le problème?
Cela change, le plus souvent il suffit de redémarrer kubelet mais nous avons eu des situations où un redémarrage du docker était nécessaire.
- Lorsque le problème survient, est-ce que
docker psrépond normalement?
Nous n'avons aucun problème à exécuter docker ps sur le nœud lorsque le PLEG agit. Je ne connaissais pas le dockershim, je me demande si c'est la connexion entre kubelet et dockershim qui est le problème, la cale ne pourrait-elle pas répondre à temps conduisant à des retours de force?
Le message d'erreur dans le journal est une combinaison des deux lignes suivantes:
generic.go:196] GenericPLEG: Unable to retrieve pods: rpc error: code = 14 desc = grpc: the connection is unavailable
kubelet.go:1820] skipping pod synchronization - [container runtime is down PLEG is not healthy: pleg was last seen active 11h5m56.959313178s ago; threshold is 3m0s]
Avez-vous des suggestions sur la façon dont nous pourrions obtenir plus d'informations afin que nous puissions mieux déboguer ce problème?
ssboisen
le 12 oct. 2017
- Le redémarrage de l'un des docker et kubelet résout-il le problème?
Oui, redémarrez simplement le docker pour le réparer, ce n'est donc pas un problème de k8 - Lorsque le problème survient, docker ps répond-il normalement?
Nan. il se bloque. Docker exécute tout conteneur sur ce nœud se bloque.
Très probablement un problème de docker pour moi, pas k8s, qui fait la bonne chose. Cependant, impossible de trouver pourquoi docker se comporte mal ici. Toutes les ressources CPU / mémoire / disque sont excellentes.
redémarrer le service docker reprend son bon état.
chenww
le 23 oct. 2017
Avez-vous des suggestions sur la façon dont nous pourrions obtenir plus d'informations afin que nous puissions mieux déboguer ce problème?
Je pense que la première étape consiste à confirmer quel composant (dockershim ou docker / containerd) a renvoyé le message d'erreur.
Vous pourriez probablement le comprendre en faisant des références croisées aux journaux kubelet et docker.
yujuhong
le 23 oct. 2017
Très probablement un problème de docker pour moi, pas k8s, qui fait la bonne chose. Cependant, impossible de trouver pourquoi docker se comporte mal ici. Toutes les ressources CPU / mémoire / disque sont excellentes.
Oui. Dans votre cas, il semble que le démon docker se bloque réellement. Vous pouvez démarrer le démon docker en mode débogage et obtenir une trace de pile lorsque cela se produit.
https://docs.docker.com/engine/admin/#force -a-stack-trace-to-be-log
yujuhong
le 23 oct. 2017
@yujuhong J'ai à nouveau rencontré ce problème après un test de charge de k8s, presque tous les nœuds deviennent not ready et n'ont pas récupéré après avoir nettoyé les pods pendant plusieurs jours, j'ai ouvert le mode verbeux dans chaque kubelet et j'ai obtenu les journaux ci-dessous, espérons que ces journaux aideront à résoudre le problème:
Oct 24 21:16:39 docker34-91 kubelet[24165]: I1024 21:16:39.539054 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:39 docker34-91 kubelet[24165]: I1024 21:16:39.639305 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:39 docker34-91 kubelet[24165]: I1024 21:16:39.739585 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:39 docker34-91 kubelet[24165]: I1024 21:16:39.839829 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:39 docker34-91 kubelet[24165]: I1024 21:16:39.940111 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.040374 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.128789 24165 kubelet.go:2064] Container runtime status: Runtime Conditions: RuntimeReady=true reason: message:, NetworkReady=true reason: message:
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.140634 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.240851 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.341125 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.441471 24165 config.go:101] Looking for [api file], have seen map[api:{} file:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.541781 24165 config.go:101] Looking for [api file], have seen map[api:{} file:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.642070 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.742347 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.842562 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.942867 24165 config.go:101] Looking for [api file], have seen map[api:{} file:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.006656 24165 kubelet.go:1752] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 6m20.171705404s ago; threshold is 3m0s]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.043126 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.143372 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.243620 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.343911 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.444156 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.544420 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.644732 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.745002 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.845268 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.945524 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:42 docker34-91 kubelet[24165]: I1024 21:16:42.045814 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
^C
[root@docker34-91 ~]# journalctl -u kubelet -f
-- Logs begin at Wed 2017-10-25 17:19:29 CST. --
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0b 0a 02 76 31 12 05 45 76 65 6e |k8s.....v1..Even|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000010 74 12 d3 03 0a 4f 0a 33 6c 64 74 65 73 74 2d 37 |t....O.3ldtest-7|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000020 33 34 33 39 39 64 67 35 39 2d 33 33 38 32 38 37 |34399dg59-338287|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000030 31 36 38 35 2d 78 32 36 70 30 2e 31 34 66 31 34 |1685-x26p0.14f14|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000040 63 30 39 65 62 64 32 64 66 66 34 12 00 1a 0a 6c |c09ebd2dff4....l|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000050 64 74 65 73 74 2d 30 30 35 22 00 2a 00 32 00 38 |dtest-005".*.2.8|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000060 00 42 00 7a 00 12 6b 0a 03 50 6f 64 12 0a 6c 64 |.B.z..k..Pod..ld|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000070 74 65 73 74 2d 30 30 35 1a 22 6c 64 74 65 73 74 |test-005."ldtest|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000080 2d 37 33 34 33 39 39 64 67 35 39 2d 33 33 38 32 |-734399dg59-3382|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000090 38 37 31 36 38 35 2d 78 32 36 70 30 22 24 61 35 |871685-x26p0"$a5|
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.098922 24165 kubelet.go:2064] Container runtime status: Runtime Conditions: RuntimeReady=true reason: message:, NetworkReady=true reason: message:
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.175027 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.275290 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.375594 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.475872 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.576140 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.676412 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.776613 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.876855 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.977126 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.000354 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "a052cabc-bab9-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.000509 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-276aa6023f-1106740979-hbtcv
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001753 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-276aa6023f-1106740979-hbtcv 404 Not Found in 1 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001768 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001773 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001776 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001780 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001838 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 32 37 36 61 61 36 30 32 33 66 2d 31 31 |st-276aa6023f-11|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 30 36 37 34 30 39 37 39 2d 68 62 74 63 76 22 20 |06740979-hbtcv" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 32 37 |und*.."ldtest-27|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 36 61 61 36 30 32 33 66 2d 31 31 30 36 37 34 30 |6aa6023f-1106740|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 39 37 39 2d 68 62 74 63 76 12 00 1a 04 70 6f 64 |979-hbtcv....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001885 24165 status_manager.go:425] Pod "ldtest-276aa6023f-1106740979-hbtcv" (a052cabc-bab9-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001900 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "a584c63e-bab7-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001946 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-734399dg59-3382871685-x26p0
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002559 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-734399dg59-3382871685-x26p0 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002569 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002573 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002577 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002580 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002627 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 37 33 34 33 39 39 64 67 35 39 2d 33 33 |st-734399dg59-33|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 38 32 38 37 31 36 38 35 2d 78 32 36 70 30 22 20 |82871685-x26p0" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 37 33 |und*.."ldtest-73|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 34 33 39 39 64 67 35 39 2d 33 33 38 32 38 37 31 |4399dg59-3382871|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 36 38 35 2d 78 32 36 70 30 12 00 1a 04 70 6f 64 |685-x26p0....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002659 24165 status_manager.go:425] Pod "ldtest-734399dg59-3382871685-x26p0" (a584c63e-bab7-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002668 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "2727277f-bab3-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002711 24165 round_trippers.go:398] curl -k -v -XGET -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" -H "Accept: application/vnd.kubernetes.protobuf, */*" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-4bc7922c25-2238154508-xt94x
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003318 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-4bc7922c25-2238154508-xt94x 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003328 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003332 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003336 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003339 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003379 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 34 62 63 37 39 32 32 63 32 35 2d 32 32 |st-4bc7922c25-22|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 33 38 31 35 34 35 30 38 2d 78 74 39 34 78 22 20 |38154508-xt94x" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 34 62 |und*.."ldtest-4b|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 63 37 39 32 32 63 32 35 2d 32 32 33 38 31 35 34 |c7922c25-2238154|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 35 30 38 2d 78 74 39 34 78 12 00 1a 04 70 6f 64 |508-xt94x....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003411 24165 status_manager.go:425] Pod "ldtest-4bc7922c25-2238154508-xt94x" (2727277f-bab3-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003423 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "43dd5201-bab4-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003482 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-g02c441308-3753936377-d6q69
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004051 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-g02c441308-3753936377-d6q69 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004059 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004062 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004066 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004069 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004115 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 67 30 32 63 34 34 31 33 30 38 2d 33 37 |st-g02c441308-37|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 35 33 39 33 36 33 37 37 2d 64 36 71 36 39 22 20 |53936377-d6q69" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 67 30 |und*.."ldtest-g0|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 32 63 34 34 31 33 30 38 2d 33 37 35 33 39 33 36 |2c441308-3753936|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 33 37 37 2d 64 36 71 36 39 12 00 1a 04 70 6f 64 |377-d6q69....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004142 24165 status_manager.go:425] Pod "ldtest-g02c441308-3753936377-d6q69" (43dd5201-bab4-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004148 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "8fd9d66f-bab7-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004195 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-cf2eg79b08-3660220702-x0j2j
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004752 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-cf2eg79b08-3660220702-x0j2j 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004761 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004765 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004769 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004773 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004812 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 63 66 32 65 67 37 39 62 30 38 2d 33 36 |st-cf2eg79b08-36|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 36 30 32 32 30 37 30 32 2d 78 30 6a 32 6a 22 20 |60220702-x0j2j" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 63 66 |und*.."ldtest-cf|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 32 65 67 37 39 62 30 38 2d 33 36 36 30 32 32 30 |2eg79b08-3660220|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 37 30 32 2d 78 30 6a 32 6a 12 00 1a 04 70 6f 64 |702-x0j2j....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004841 24165 status_manager.go:425] Pod "ldtest-cf2eg79b08-3660220702-x0j2j" (8fd9d66f-bab7-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004853 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "eb5a5f4a-baba-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004921 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-9b47680d12-2536408624-jhp18
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005436 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-9b47680d12-2536408624-jhp18 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005446 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005450 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005454 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005457 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005499 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 39 62 34 37 36 38 30 64 31 32 2d 32 35 |st-9b47680d12-25|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 33 36 34 30 38 36 32 34 2d 6a 68 70 31 38 22 20 |36408624-jhp18" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 39 62 |und*.."ldtest-9b|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 34 37 36 38 30 64 31 32 2d 32 35 33 36 34 30 38 |47680d12-2536408|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 36 32 34 2d 6a 68 70 31 38 12 00 1a 04 70 6f 64 |624-jhp18....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005526 24165 status_manager.go:425] Pod "ldtest-9b47680d12-2536408624-jhp18" (eb5a5f4a-baba-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005533 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "2db95639-bab5-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005588 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-5f8ba1eag0-2191624653-dm374
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006150 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-5f8ba1eag0-2191624653-dm374 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006176 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006182 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006189 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006195 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006251 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 35 66 38 62 61 31 65 61 67 30 2d 32 31 |st-5f8ba1eag0-21|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 39 31 36 32 34 36 35 33 2d 64 6d 33 37 34 22 20 |91624653-dm374" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 35 66 |und*.."ldtest-5f|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 38 62 61 31 65 61 67 30 2d 32 31 39 31 36 32 34 |8ba1eag0-2191624|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 36 35 33 2d 64 6d 33 37 34 12 00 1a 04 70 6f 64 |653-dm374....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006297 24165 status_manager.go:425] Pod "ldtest-5f8ba1eag0-2191624653-dm374" (2db95639-bab5-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006330 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "ecf58d7f-bab2-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006421 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-0fe4761ce1-763135991-2gv5x
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006983 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-0fe4761ce1-763135991-2gv5x 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006995 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.007001 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.007007 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.007014 24165 round_trippers.go:426] Content-Length: 151
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.007064 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 7f 0a 04 0a 00 12 00 12 07 46 61 69 6c |us..........Fail|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 75 72 65 1a 32 70 6f 64 73 20 22 6c 64 74 65 73 |ure.2pods "ldtes|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 74 2d 30 66 65 34 37 36 31 63 65 31 2d 37 36 33 |t-0fe4761ce1-763|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 31 33 35 39 39 31 2d 32 67 76 35 78 22 20 6e 6f |135991-2gv5x" no|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f 75 6e |t found".NotFoun|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 64 2a 2d 0a 21 6c 64 74 65 73 74 2d 30 66 65 34 |d*-.!ldtest-0fe4|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 37 36 31 63 65 31 2d 37 36 33 31 33 35 39 39 31 |761ce1-763135991|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 2d 32 67 76 35 78 12 00 1a 04 70 6f 64 73 28 00 |-2gv5x....pods(.|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 30 94 03 1a 00 22 00 |0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.007106 24165 status_manager.go:425] Pod "ldtest-0fe4761ce1-763135991-2gv5x" (ecf58d7f-bab2-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.077334 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.177546 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.277737 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.377939 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.478169 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.578369 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.603649 24165 eviction_manager.go:197] eviction manager: synchronize housekeeping
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.678573 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682080 24165 summary.go:389] Missing default interface "eth0" for node:172.23.34.91
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682132 24165 summary.go:389] Missing default interface "eth0" for pod:kube-system_kube-proxy-qcft5
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682176 24165 helpers.go:744] eviction manager: observations: signal=imagefs.available, available: 515801344Ki, capacity: 511750Mi, time: 2017-10-27 10:22:56.499173632 +0800 CST
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682197 24165 helpers.go:744] eviction manager: observations: signal=imagefs.inodesFree, available: 523222251, capacity: 500Mi, time: 2017-10-27 10:22:56.499173632 +0800 CST
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682203 24165 helpers.go:746] eviction manager: observations: signal=allocatableMemory.available, available: 65544340Ki, capacity: 65581868Ki
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682207 24165 helpers.go:744] eviction manager: observations: signal=memory.available, available: 57973412Ki, capacity: 65684268Ki, time: 2017-10-27 10:22:56.499173632 +0800 CST
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682213 24165 helpers.go:744] eviction manager: observations: signal=nodefs.available, available: 99175128Ki, capacity: 102350Mi, time: 2017-10-27 10:22:56.499173632 +0800 CST
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682218 24165 helpers.go:744] eviction manager: observations: signal=nodefs.inodesFree, available: 104818019, capacity: 100Mi, time: 2017-10-27 10:22:56.499173632 +0800 CST
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682233 24165 eviction_manager.go:292] eviction manager: no resources are starved
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.778792 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.879040 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.979304 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.079534 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.179753 24165 config.go:101] Looking for [api file], have seen map[api:{} file:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.280026 24165 config.go:101] Looking for [api file], have seen map[api:{} file:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.380246 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.480450 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.580695 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.680957 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.781224 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.881418 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.981643 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.081882 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.182810 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.283410 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.383626 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.483942 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.584211 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.684460 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.784699 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.884949 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960855 24165 factory.go:115] Factory "docker" was unable to handle container "/system.slice/data-docker-overlay-c0d3c4b3834cfe9f12cd5c35345cab9c8e71bb64c689c8aea7a458c119a5a54e-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960885 24165 factory.go:108] Factory "systemd" can handle container "/system.slice/data-docker-overlay-c0d3c4b3834cfe9f12cd5c35345cab9c8e71bb64c689c8aea7a458c119a5a54e-merged.mount", but ignoring.
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960906 24165 manager.go:867] ignoring container "/system.slice/data-docker-overlay-c0d3c4b3834cfe9f12cd5c35345cab9c8e71bb64c689c8aea7a458c119a5a54e-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960912 24165 factory.go:115] Factory "docker" was unable to handle container "/system.slice/data-docker-overlay-ce9656ff9d3cd03baaf93e42d0874377fa37bfde6c9353b3ba954c90bf4332f3-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960919 24165 factory.go:108] Factory "systemd" can handle container "/system.slice/data-docker-overlay-ce9656ff9d3cd03baaf93e42d0874377fa37bfde6c9353b3ba954c90bf4332f3-merged.mount", but ignoring.
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960926 24165 manager.go:867] ignoring container "/system.slice/data-docker-overlay-ce9656ff9d3cd03baaf93e42d0874377fa37bfde6c9353b3ba954c90bf4332f3-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960931 24165 factory.go:115] Factory "docker" was unable to handle container "/system.slice/data-docker-overlay-b3600c0fe81445773b9241c5d1da8b1f97612d0a235f8b32139478a5717f79e1-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960937 24165 factory.go:108] Factory "systemd" can handle container "/system.slice/data-docker-overlay-b3600c0fe81445773b9241c5d1da8b1f97612d0a235f8b32139478a5717f79e1-merged.mount", but ignoring.
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960944 24165 manager.go:867] ignoring container "/system.slice/data-docker-overlay-b3600c0fe81445773b9241c5d1da8b1f97612d0a235f8b32139478a5717f79e1-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960949 24165 factory.go:115] Factory "docker" was unable to handle container "/system.slice/data-docker-overlay-ed2fe0d57c56cf6b051e1bda1ca0185ceef4756b1a8f9af4c19f4e512bcc60f4-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960955 24165 factory.go:108] Factory "systemd" can handle container "/system.slice/data-docker-overlay-ed2fe0d57c56cf6b051e1bda1ca0185ceef4756b1a8f9af4c19f4e512bcc60f4-merged.mount", but ignoring.
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960979 24165 manager.go:867] ignoring container "/system.slice/data-docker-overlay-ed2fe0d57c56cf6b051e1bda1ca0185ceef4756b1a8f9af4c19f4e512bcc60f4-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960984 24165 factory.go:115] Factory "docker" was unable to handle container "/system.slice/data-docker-overlay-0ba6483a0117c539493cd269be9f87d31d1d61aa813e7e0381c5f5d8b0623275-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960990 24165 factory.go:108] Factory "systemd" can handle container "/system.slice/data-docker-overlay-0ba6483a0117c539493cd269be9f87d31d1d61aa813e7e0381c5f5d8b0623275-merged.mount", but ignoring.
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960997 24165 manager.go:867] ignoring container "/system.slice/data-docker-overlay-0ba6483a0117c539493cd269be9f87d31d1d61aa813e7e0381c5f5d8b0623275-merged.mount"
Hit problème similaire:
Oct 28 09:15:38 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:15:38.711430 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:15:51 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:15:51.439135 3299 kuberuntime_manager.go:843] PodSandboxStatus of sandbox "9c1c1f2d4a9d277a41a97593c330f41e00ca12f3ad858c19f61fd155d18d795e" for pod "pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)" error: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:15:51 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:15:51.439188 3299 generic.go:241] PLEG: Ignoring events for pod pickup-566929041-bn8t9/staging: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:15:51 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:15:51.711168 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:16:03 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:16:03.711164 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:16:18 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:16:18.715381 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:16:33 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:16:33.711198 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:16:46 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:16:46.712983 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:16:51 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:16:51.711142 3299 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.31269053s ago; threshold is 3m0s]
Oct 28 09:16:56 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:16:56.711341 3299 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m5.312886434s ago; threshold is 3m0s]
Oct 28 09:17:01 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:17:01.351771 3299 kubelet_node_status.go:734] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-10-28 09:17:01.35173325 +0000 UTC LastTransitionTime:2017-10-28 09:17:01.35173325 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m9.95330596s ago; threshold is 3m0s}
Oct 28 09:17:01 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:17:01.711552 3299 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m10.31309378s ago; threshold is 3m0s]
Oct 28 09:17:06 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:17:06.711871 3299 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m15.313406671s ago; threshold is 3m0s]
Oct 28 09:17:11 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:17:11.712162 3299 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m20.313691126s ago; threshold is 3m0s]
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 transport: http2Server.HandleStreams failed to read frame: read unix /var/run/dockershim.sock->@: use of closed network connection
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 transport: http2Client.notifyError got notified that the client transport was broken EOF.
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 grpc: addrConn.resetTransport failed to create client transport: connection error: desc = "transport: dial unix /var/run/dockershim.sock: connect: no such file or directory"; Reconnecting to {/var/run/dockershim.sock <nil>}
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:17:12.556535 3299 kuberuntime_manager.go:843] PodSandboxStatus of sandbox "9c1c1f2d4a9d277a41a97593c330f41e00ca12f3ad858c19f61fd155d18d795e" for pod "pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)" error: rpc error: code = 13 desc = transport is closing
Après ces messages, kubelet est entré en boucle de redémarrage.
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: Main process exited, code=exited, status=1/FAILURE
Oct 28 09:18:42 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: State 'stop-final-sigterm' timed out. Killing.
Oct 28 09:18:42 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: Killing process 1661 (calico) with signal SIGKILL.
Oct 28 09:20:12 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: Processes still around after final SIGKILL. Entering failed mode.
Oct 28 09:20:12 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: Stopped Kubernetes Kubelet.
Oct 28 09:20:12 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: Unit entered failed state.
Oct 28 09:20:12 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: Failed with result 'exit-code'.
Cela me semble un problème de docker, car je vois que les derniers messages sont:
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 transport: http2Server.HandleStreams failed to read frame: read unix /var/run/dockershim.sock->@: use of closed network connection
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 transport: http2Client.notifyError got notified that the client transport was broken EOF.
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 grpc: addrConn.resetTransport failed to create client transport: connection error: desc = "transport: dial unix /var/run/dockershim.sock: connect: no such file or directory"; Reconnecting to {/var/run/dockershim.sock <nil>}
 zihaoyu
le 28 oct. 2017
zihaoyu
le 28 oct. 2017
Les derniers messages proviennent du dockershim. Ces journaux seraient également très utiles.
 rphillips
le 15 nov. 2017
rphillips
le 15 nov. 2017
Bonjour, Kubernetes 1.7.10, basé sur Kops @ AWS, avec Calico et CoreOS.
Nous avons les mêmes problèmes PLEG
Ready False KubeletNotReady PLEG is not healthy: pleg was last seen active 3m29.396986143s ago; threshold is 3m0s
Le seul problème supplémentaire que nous avons et je pense qu'il est lié - est que dernièrement, en particulier sur 1.7.8+ - lorsque nous redéployons, par exemple, apportons une nouvelle version d'une application afin que l'ancien jeu de répliques tombe en panne, un nouveau est tourné avec le pods, les pods du précédent déploiement ver / do restent pour toujours dans l'état 'Terminating'.
Ensuite, je dois manuellement force kill them
 javapapo
le 18 nov. 2017
javapapo
le 18 nov. 2017
Nous avons les mêmes problèmes PLEG k8s 1.8.1
 tanhui2333
le 21 nov. 2017
tanhui2333
le 21 nov. 2017
+1
1.6.9
avec docker 1.12.6
 zhangxiaoyu-zidif
le 29 nov. 2017
zhangxiaoyu-zidif
le 29 nov. 2017
+1
1.8.2
 dElogics
le 29 nov. 2017
dElogics
le 29 nov. 2017
+1
1.6.0
 majid021
le 29 nov. 2017
majid021
le 29 nov. 2017
- 1.8.4
Et plus de question:
- C'est vrai, le processeur et la mémoire étaient proches de 100%. Mais ma question est de savoir pourquoi les pods ne sont pas affectés à l'autre nœud puisque le nœud n'est pas prêt depuis longtemps?
 gogeof
le 6 déc. 2017
gogeof
le 6 déc. 2017
+1 Les nœuds qui passaient à l'état NotReady se produisaient assez régulièrement les deux derniers jours après la mise à niveau vers Kubernets 1.8.5. Je pense que le problème pour moi était que je n'ai pas mis à niveau le cluster-autoscaler. Une fois que j'ai mis à niveau l'autoscaler vers 1.03 (helm 0.3.0), je n'ai vu aucun nœud dans l'état "NotReady". Il semble que j'ai à nouveau un cluster stable.
- kops: 1.8.0
- kubectl: 1.8.5
- barre: 2.7.2
- cluster-autoscaler: v0.6.0 ---> mis à niveau vers 1.03 (helm 0.3.0)
 iamrandys
le 11 déc. 2017
iamrandys
le 11 déc. 2017
même le docker est accroché, le pleg ne doit pas être inactif
 timchenxiaoyu
le 15 déc. 2017
timchenxiaoyu
le 15 déc. 2017
Idem ici, 1.8.5
pas de mise à jour à partir de la version basse, créer à partir de vide.
la ressource suffit
Mémoire
# free -mg
total used free shared buff/cache available
Mem: 15 2 8 0 5 12
Swap: 15 0 15
Haut
top - 04:34:39 up 24 days, 6:23, 2 users, load average: 31.56, 83.38, 66.29
Tasks: 432 total, 5 running, 427 sleeping, 0 stopped, 0 zombie
%Cpu(s): 9.2 us, 1.9 sy, 0.0 ni, 87.5 id, 1.3 wa, 0.0 hi, 0.1 si, 0.0 st
KiB Mem : 16323064 total, 8650144 free, 2417236 used, 5255684 buff/cache
KiB Swap: 16665596 total, 16646344 free, 19252 used. 12595460 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
31905 root 20 0 1622320 194096 51280 S 14.9 1.2 698:10.66 kubelet
19402 root 20 0 12560 9696 1424 R 10.3 0.1 442:05.00 memtester
2626 root 20 0 12560 9660 1392 R 9.6 0.1 446:41.38 memtester
8680 root 20 0 12560 9660 1396 R 9.6 0.1 444:34.38 memtester
15004 root 20 0 12560 9704 1432 R 9.6 0.1 443:04.98 memtester
1663 root 20 0 8424940 424912 20556 S 4.6 2.6 2809:24 dockerd
409 root 20 0 49940 37068 20648 S 2.3 0.2 144:03.37 calico-felix
551 root 20 0 631788 20952 11824 S 1.3 0.1 100:36.78 costor
9527 root 20 0 10.529g 24800 13612 S 1.0 0.2 3:43.55 etcd
2608 root 20 0 421936 6040 3288 S 0.7 0.0 31:29.78 containerd-shim
4136 root 20 0 780344 24580 12316 S 0.7 0.2 45:58.60 costor
4208 root 20 0 755756 22208 12176 S 0.7 0.1 41:49.58 costor
8665 root 20 0 210344 5960 3208 S 0.7 0.0 31:27.75 cont
J'ai trouvé la situation suivante en ce moment.
comme Docker Storage Setup a été configuré pour prendre 80% du thin pool, l'expulsion matérielle de kubelet était de 10%. Les deux ne machtaient pas.
Docker s'est écrasé d'une manière ou d'une autre en interne et kubelet est venu avec cette erreur PLEG.
L'augmentation de l'expulsion matérielle de kubelet (imagefs.available) à 20% atteint la configuration du docker et kubelet a commencé à supprimer les anciennes images.
Dans la version 1.8, nous sommes passés de image-gc-threshold à hard-eviction et avons choisi les mauvais paramètres correspondants.
J'observerai notre groupe pour cela dès maintenant.
Kube: 1,8,5
Docker: 1.12.6
Système d'exploitation: RHEL7
 sybnex
le 21 déc. 2017
sybnex
le 21 déc. 2017
en regardant la métrique interne kubelet_pleg_relist_latency_microseconds de prométhée, cela semble suspect.
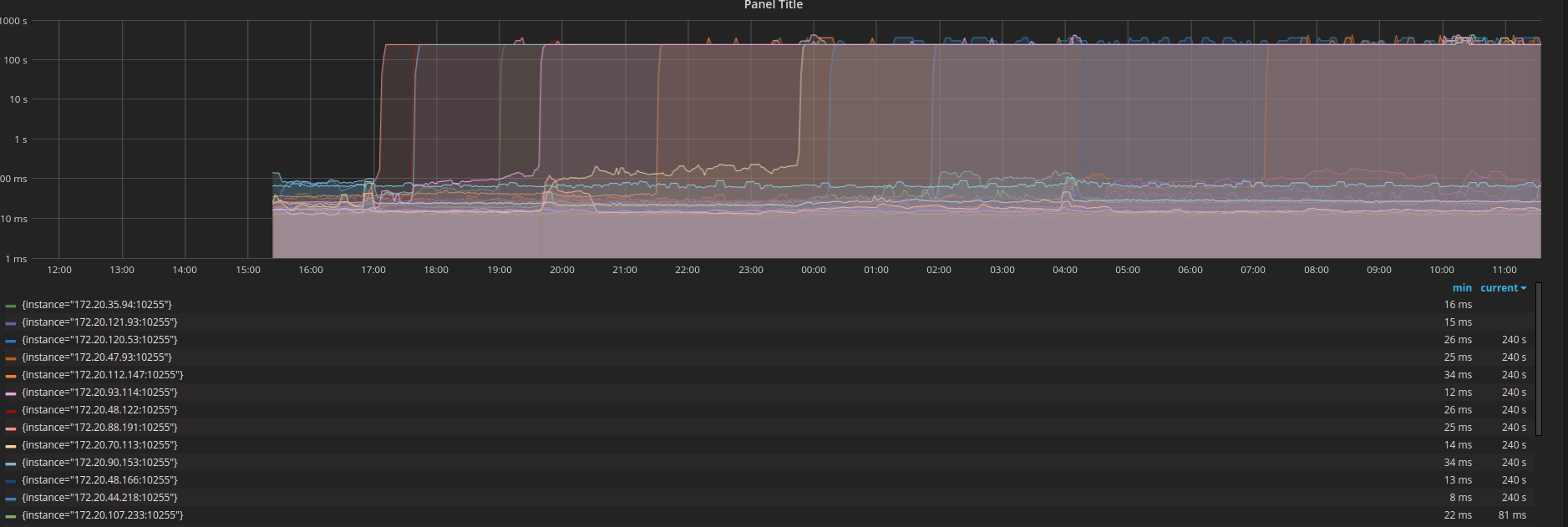
kops a installé kube 1.8.4 avec coreOS
docker info
Containers: 246
Running: 222
Paused: 0
Stopped: 24
Images: 30
Server Version: 17.09.0-ce
Storage Driver: overlay
Backing Filesystem: extfs
Supports d_type: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file logentries splunk syslog
Swarm: inactive
Runtimes: runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 06b9cb35161009dcb7123345749fef02f7cea8e0
runc version: 3f2f8b84a77f73d38244dd690525642a72156c64
init version: v0.13.2 (expected: 949e6facb77383876aeff8a6944dde66b3089574)
Security Options:
seccomp
Profile: default
selinux
Kernel Version: 4.13.16-coreos-r2
Operating System: Container Linux by CoreOS 1576.4.0 (Ladybug)
OSType: linux
Architecture: x86_64
CPUs: 8
Total Memory: 14.69GiB
Name: ip-172-20-120-53.eu-west-1.compute.internal
ID: SI53:ECLM:HXFE:LOVY:STTS:C4X2:WRFK:UGBN:7NYP:4N3E:MZGS:EAVM
Docker Root Dir: /var/lib/docker
Debug Mode (client): false
Debug Mode (server): false
Registry: https://index.docker.io/v1/
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
 Deshke
le 21 déc. 2017
Deshke
le 21 déc. 2017
+1
origine v3.7.0
kubernetes v1.7.6
docker v1.12.6
OS CentOS 7.4
Il semble que le conteneur d'exécution GC prend effet lors de la création et de la fin du pod
Laissez-moi essayer de rapporter ce qui s'est passé après la désactivation de GC.
 esevan
le 29 déc. 2017
esevan
le 29 déc. 2017
Dans mon cas, CNI ne gère pas la situation.
selon mon analyse, la séquence de code est tout aussi suivante
1. kuberuntime_gc.go: client.StopPodSandbox (Timeout Default: 2m)
-> docker_sandbox.go: StopPodSandbox
-> cni.go: TearDownPod
-> CNI deleteFromNetwork (Timeout Default: 3m) <- Nothing gonna happen if CNI doesn't handle this situation.
-> docker_service.go: StopContainer
2. kuberuntime_gc.go: client.RemovePodSandbox
StopPodSandbox déclenche une exception de délai d'expiration, puis retourne sans traitement Supprimer le bac à sable du pod
Cependant, le processus CNI est en cours après l'expiration de StopPodSandbox.
C'est comme si les threads kubelet sont affamés par le processus CNI, de sorte que kubelet ne peut pas surveiller correctement le PLEG en conséquence.
J'ai résolu ce problème en modifiant CNI pour qu'il retourne simplement lorsque CNI_NS est vide (car cela signifie un pod mort).
(BTW, j'utilise kuryr-kubernetes comme plugin CNI)
J'espère que cela vous aidera les gars!
esevan
le 3 janv. 2018
@esevan pourriez-vous proposer un patch?
rphillips
le 8 janv. 2018
@rphillips Ce bogue est en fait proche du bogue CNI, et je vais sûrement télécharger le correctif sur openstack / kuryr-kubernetes après avoir examiné le comportement davantage.
esevan
le 9 janv. 2018
Dans notre cas, il s'agit de https://github.com/moby/moby/issues/33820
Arrêter les délais d'expiration du conteneur Docker, puis le nœud commence à basculer entre prêt / non prêt avec le message PLEG.
Le rétablissement de la version de Docker résout le problème. (17.09-ce -> 12.06)
 ghost
le 11 janv. 2018
ghost
le 11 janv. 2018
Le même journal d'erreurs avec kubelet v1.9.1:
...
Jan 15 12:36:52 l23-27-101 kubelet[7335]: I0115 12:36:52.884617 7335 status_manager.go:136] Kubernetes client is nil, not starting status manager.
Jan 15 12:36:52 l23-27-101 kubelet[7335]: I0115 12:36:52.884636 7335 kubelet.go:1767] Starting kubelet main sync loop.
Jan 15 12:36:52 l23-27-101 kubelet[7335]: I0115 12:36:52.884692 7335 kubelet.go:1778] skipping pod synchronization - [container runtime is down PLEG is not healthy: pleg was last seen active 2562047h47m16.854775807s ago; threshold is 3m0s]
Jan 15 12:36:52 l23-27-101 kubelet[7335]: E0115 12:36:52.884788 7335 container_manager_linux.go:583] [ContainerManager]: Fail to get rootfs information unable to find data for container /
Jan 15 12:36:52 l23-27-101 kubelet[7335]: I0115 12:36:52.885001 7335 volume_manager.go:247] Starting Kubelet Volume Manager
...
 shenshouer
le 15 janv. 2018
shenshouer
le 15 janv. 2018
Quelqu'un at-il ce problème avec docker> 12.6 ??? (Sauf la version 17.09 non prise en charge)
Je me demande simplement si le passage à 13.1 ou 17.06 serait utile.
sybnex
le 15 janv. 2018
@sybnex 17.03 a également ce problème dans notre cluster, c'est plus comme un bogue CNI.
yangyuw
le 16 janv. 2018
Pour moi, cela s'est produit parce que kubelet prenait trop de CPU pour les tâches de maintenance, par conséquent, il ne restait plus de temps CPU pour docker. La réduction de l'intervalle d'entretien ménager a résolu le problème pour moi.
dElogics
le 17 janv. 2018
@esevan : J'apprécierais le patch kuryr-kubernetes :-)
 celebdor
le 17 janv. 2018
celebdor
le 17 janv. 2018
Pour info, nous utilisons Origin 1.5 / Kubernetes 1.5 et Kuryr (premières versions) sans aucun problème :)
livelace
le 17 janv. 2018
@livelace une raison pour ne pas utiliser les versions ultérieures?
celebdor
le 17 janv. 2018
@celebdor Il n'y a pas besoin, tout fonctionne :) Nous utilisons Origin + Openstack et ces versions couvrent tous nos besoins, nous n'avons pas besoin de nouvelles fonctionnalités de Kubernetes / Openstack, Kuryr fonctionne juste. Peut-être que nous aurons des problèmes lorsque deux équipes supplémentaires rejoindront notre infrastructure.
livelace
le 18 janv. 2018
Le seuil par défaut pleg-relist est de 3 minutes.
Pourquoi ne pouvons-nous pas rendre le seuil pleg-relist configurable, puis lui attribuer une valeur plus élevée.
J'ai fait un PR pour ce faire.
quelqu'un peut-il jeter un oeil?
https://github.com/kubernetes/kubernetes/pull/58279
 linyouchong
le 23 janv. 2018
linyouchong
le 23 janv. 2018
J'obtiens un peu de confusion à propos de PLEG et ProbeManager.
Le PLEG doit maintenir les pods et les conteneurs sains dans le nœud.
Le ProbeManager maintient également les conteneurs sains dans le nœud.
Pourquoi les deux modules font-ils la même chose?
Lorsque le ProbeManager trouve que le conteneur est arrêté, il redémarre le conteneur.
si PLEG a également trouvé que le conteneur est arrêté, le PLEG crée-t-il un événement pour dire au kubelet de faire de même
chose?
 liucimin
le 31 janv. 2018
liucimin
le 31 janv. 2018
+1
Gouverneurs v1.8.4
 erstaples
le 31 janv. 2018
erstaples
le 31 janv. 2018
@celebdor Après la mise à jour de cni vers un démonisé, il est maintenant stabilisé sans patch cni.
esevan
le 1 févr. 2018
+1
kubernetes v1.9.2
docker 17.03.2-ce
 huzhengchuan
le 27 févr. 2018
huzhengchuan
le 27 févr. 2018
+1
kubernetes v1.9.2
docker 17.03.2-ce
les journaux d'erreurs dans le journal kubelet:
Feb 27 16:19:12 node-2 kubelet: E0227 16:19:12.839866 47544 remote_runtime.go:169] ListPodSandbox with filter nil from runtime service failed: rpc error: code = Unknown desc = Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
Feb 27 16:19:12 node-2 kubelet: E0227 16:19:12.839919 47544 kuberuntime_sandbox.go:192] ListPodSandbox failed: rpc error: code = Unknown desc = Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
Feb 27 16:19:12 node-2 kubelet: E0227 16:19:12.839937 47544 generic.go:197] GenericPLEG: Unable to retrieve pods: rpc error: code = Unknown desc = Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
kubelet utilise dockerclient (httpClient) pour appeler ContainerList (tous les statuts && io.kubernetes.docker.type == "podsandbox") avec 2 minutes de délai.
docker ps -a --filter "label=io.kubernetes.docker.type=podsandbox"
Exécutez la commande directement lorsque le nœud est devenu NotReady peut-être utile pour le débogage
ce qui suit est Do request code dans dockerclient, cette erreur ressemble à un délai d'expiration:
if err, ok := err.(net.Error); ok {
if err.Timeout() {
return serverResp, ErrorConnectionFailed(cli.host)
}
if !err.Temporary() {
if strings.Contains(err.Error(), "connection refused") || strings.Contains(err.Error(), "dial unix") {
return serverResp, ErrorConnectionFailed(cli.host)
}
}
}
 chestack
le 27 févr. 2018
chestack
le 27 févr. 2018
+1
Gouverneurs 1.8.4
docker 17.09.1-ce
Éditer:
kube-aws 0.9.9
 Labbs
le 27 févr. 2018
Labbs
le 27 févr. 2018
+1
Kubernetes v1.9.3
docker 17.12.0-ce (je sais que ce n'est pas officiellement pris en charge)
tissage / tissage - kube: 2.2.0
Ubuntu 16.04.3 LTS || Noyau: 4.4.0-112
Installation via kubeadm avec master + worker (le master n'affiche pas ce comportement prêt / pas prêt, seulement le worker).
 MarcosCela
le 28 févr. 2018
MarcosCela
le 28 févr. 2018
+1
Kubernetes: 1.8.8
Docker: 1.12.6-cs13
Fournisseur de cloud: GCE
Système d'exploitation: Ubuntu 16.04.3 LTS
Noyau: 4.13.0-1011-gcp
Installer les outils: kubeadm
J'utilise calico pour le réseautage
 albertvaka
le 13 mars 2018
albertvaka
le 13 mars 2018
ce problème de correction de validation dans mon env
https://github.com/moby/moby/pull/31273/commits/8e425ebc422876ddf2ffb3beaa5a0443a6097e46
ceci est un lien utile sur "docker ps hang":
https://github.com/moby/moby/pull/31273
mise à jour : le retour à docker 1.13.1 a aidé, les commits ci-dessus ne sont pas dans docker 1.13.1
chestack
le 19 mars 2018
+1
Kubernetes: 1.8.9
Docker: 17.09.1-ce
Fournisseur cloud: AWS
Système d'exploitation: CoreOS 1632.3.0
Noyau: 4.14.19-coreos
Installer les outils: kops
Calico 2.6.6 pour la mise en réseau
 juris
le 19 mars 2018
juris
le 19 mars 2018
Pour résoudre ce problème, j'utilise une ancienne version coreos (1520.9.0). Cette version utilise docker 1.12.6.
Depuis ce changement, aucun problème de battement.
Labbs
le 19 mars 2018
+1
Kubernetes: 1.9.3
Docker: 17.09.1-ce
Fournisseur cloud: AWS
Système d'exploitation: CoreOS 1632.3.0
Noyau: 4.14.19-coreos
Installer les outils: kops
Tisser
 leeeboo
le 22 mars 2018
leeeboo
le 22 mars 2018
+1
Kubernetes: 1.9.6
Docker: 17.12.0-ce
Système d'exploitation: Redhat 7.4
Noyau: 3.10.0-693.el7.x86_64
CNI: flanelle
 dragon9783
le 29 mars 2018
dragon9783
le 29 mars 2018
FYI. Même pour le dernier Kubernetes 1.10
Les versions de docker validées sont les mêmes que pour v1.9: 1.11.2 à 1.13.1 et 17.03.x
Dans mon cas, revenir à 1.12.6 a aidé.
juris
le 29 mars 2018
Observé les mêmes problèmes:
Kubernetes : 1.9.6
Docker : 17.12.0-ce
Système d'exploitation : Ubuntu 16.04
CNI : tissage
Ce qui a résolu le problème était de passer à Docker 17.03
 briandeheus
le 30 mars 2018
briandeheus
le 30 mars 2018
J'ai eu le même problème et il semble résolu par la mise à jour vers Debian Strech. Le cluster s'exécute sur AWS déployé avec kops.
Kubernetes: 1.8.7
Docker: 1.13.1
Système d'exploitation: Debian Stretch
CNI: Calico
Noyau: 4.9.0-5-amd64
Par défaut, Debian Jessie était utilisée avec la version 4.4 du noyau, je pense et cela ne fonctionnait pas bien.
 komljen
le 30 mars 2018
komljen
le 30 mars 2018
Le problème se produit dans notre ENV et nous faisons une analyse de ce problème:
k8s version 1.7/1.8
Les informations sur la pile proviennent de k8s 1.7
Notre env a beaucoup de conteneurs sortis (plus de 1k) à cause de notre bug de plugin réseau.
Lorsque nous redémarrons le kubelet . Après un certain temps, kubelet devient unhealthy .
Nous suivons le journal et la pile.
Lorsque PLEG effectue l'opération de remise en vente .
La première fois, il obtiendra de nombreux événements (chaque conteneur aura un événement) à gérer à https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L228
La mise à jour du cache prend plusieurs fois (https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L240)
Lorsque nous imprimons la pile, la plupart du temps, la pile est comme:
k8s.io/kubernetes/vendor/google.golang.org/grpc/transport.(*Stream).Header(0xc42537aff0, 0x3b53b68, 0xc42204f060, 0x59ceee0)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/transport/transport.go:239 +0x146
k8s.io/kubernetes/vendor/google.golang.org/grpc.recvResponse(0x0, 0x0, 0x59c4c60, 0x5b0c6b0, 0x0, 0x0, 0x0, 0x0, 0x59a8620, 0xc4217f2460, ...)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/call.go:61 +0x9e
k8s.io/kubernetes/vendor/google.golang.org/grpc.invoke(0x7ff04e8b9800, 0xc424be3380, 0x3aa3c5e, 0x28, 0x374bb00, 0xc424ca0590, 0x374bbe0, 0xc421f428b0, 0xc421800240, 0x0, ...)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/call.go:208 +0x862
k8s.io/kubernetes/vendor/google.golang.org/grpc.Invoke(0x7ff04e8b9800, 0xc424be3380, 0x3aa3c5e, 0x28, 0x374bb00, 0xc424ca0590, 0x374bbe0, 0xc421f428b0, 0xc421800240, 0x0, ...)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/call.go:118 +0x19c
k8s.io/kubernetes/pkg/kubelet/apis/cri/v1alpha1/runtime.(*runtimeServiceClient).PodSandboxStatus(0xc4217f6038, 0x7ff04e8b9800, 0xc424be3380, 0xc424ca0590, 0x0, 0x0, 0x0, 0xc424d92870, 0xc42204f3e8, 0x28)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/apis/cri/v1alpha1/runtime/api.pb.go:3409 +0xd2
k8s.io/kubernetes/pkg/kubelet/remote.(*RemoteRuntimeService).PodSandboxStatus(0xc4217ec440, 0xc424c7a740, 0x40, 0x0, 0x0, 0x0)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/remote/remote_runtime.go:143 +0x113
k8s.io/kubernetes/pkg/kubelet/kuberuntime.instrumentedRuntimeService.PodSandboxStatus(0x59d86a0, 0xc4217ec440, 0xc424c7a740, 0x40, 0x0, 0x0, 0x0)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/kuberuntime/instrumented_services.go:192 +0xc4
k8s.io/kubernetes/pkg/kubelet/kuberuntime.(*instrumentedRuntimeService).PodSandboxStatus(0xc4217f41f0, 0xc424c7a740, 0x40, 0xc421f428a8, 0x1, 0x1)
<autogenerated>:1 +0x59
k8s.io/kubernetes/pkg/kubelet/kuberuntime.(*kubeGenericRuntimeManager).GetPodStatus(0xc421802340, 0xc421dfad80, 0x24, 0xc422358e00, 0x1c, 0xc42172aa17, 0x5, 0x50a3ac, 0x5ae88e0, 0xc400000000)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/kuberuntime/kuberuntime_manager.go:841 +0x373
k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).updateCache(0xc421027260, 0xc421f0e840, 0xc421dfad80, 0x24, 0xc423e86ea8, 0x1)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:346 +0xcf
k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).relist(0xc421027260)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:242 +0xbe1
k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).(k8s.io/kubernetes/pkg/kubelet/pleg.relist)-fm()
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:129 +0x2a
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.JitterUntil.func1(0xc4217c81c0)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:97 +0x5e
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.JitterUntil(0xc4217c81c0, 0x3b9aca00, 0x0, 0x1, 0xc420084120)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:98 +0xbd
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.Until(0xc4217c81c0, 0x3b9aca00, 0xc420084120)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:52 +0x4d
created by k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).Start
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:129 +0x8a
Nous imprimons l'horodatage de chaque événement, il faut environ 1 seconde à kubelet pour gérer chaque événement.
Donc, cela a causé PLEG ne peut pas faire la remise en
Ensuite, le syncLoop cesse de fonctionner en raison d'un PLEG défectueux (https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/kubelet.go#L1758).
Ainsi, le canal d'événements PLEG ne sera pas utilisé par
Mais PLEG continue de gérer les événements et d'envoyer l'événement à plegChannel (https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L261)
Une fois le canal plein (la capacité du canal est de 1000 https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/kubelet.go#L144)
Le PLEG sera bloqué. L'horodatage de la relist pleg ne sera jamais mis à jour (https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L201)
infos sur la pile:
goroutine 422 [chan send, 3 minutes]:
k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).relist(0xc421027260)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:263 +0x95a
k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).(k8s.io/kubernetes/pkg/kubelet/pleg.relist)-fm()
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:129 +0x2a
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.JitterUntil.func1(0xc4217c81c0)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:97 +0x5e
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.JitterUntil(0xc4217c81c0, 0x3b9aca00, 0x0, 0x1, 0xc420084120)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:98 +0xbd
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.Until(0xc4217c81c0, 0x3b9aca00, 0xc420084120)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:52 +0x4d
created by k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).Start
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:129 +0x8a
Après avoir supprimé les conteneurs sortis, puis redémarré le kubelet, il revient.
Il y a donc un risque de blocage de
La solution est que nous pouvons faire la mise à jour du cache de pod en parallèle (https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L236)
Ou il devrait y avoir un délai d'expiration défini lors de la gestion des événements.
@ yingnanzhang666
 wenlxie
le 3 avr. 2018
wenlxie
le 3 avr. 2018
Lorsque mon nœud commence à basculer entre Ready / NotReady en raison de problèmes PLEG, il est invariablement l'un des conteneurs gcr.io/google_containers/pause sur lesquels docker inspect bloque. Le redémarrage du démon docker résout le problème.
erstaples
le 13 avr. 2018
Bonjour à tous, je peux voir que le problème est signalé via différentes combinaisons de binaires CoreOS / Docker / Kubernetes. Dans notre cas, nous sommes toujours sur la même pile kubernetes - (1.7.10 / CoreOS / kops / AWS), je ne pense pas que le problème soit résolu BUt nous avons réussi à réduire l'effet à presque zéro, quand nous avons finalement introduit 'tini '(https://github.com/krallin/tini) dans le cadre de nos images docker déployées sur kubernetes. Nous avons environ 20 conteneurs (applications) différents déployés et nous déployons très souvent. donc cela signifie - beaucoup d'arrêts et de lancement de nouvelles répliques, etc. Donc, plus nous déployions souvent, plus nous avons été touchés par des «nœuds» non prêts et PLEG. Lorsque nous avons déployé tini sur la majorité des images - en veillant à ce que les PId soient récoltés et tués en conséquence - nous avons arrêté de voir cet effet secondaire. Je vous suggère fortement de jeter un œil à tini, ou à toute autre image de base de docker qui peut gérer correctement la récolte de sous-processus, car je pense que cela est étroitement lié au problème. J'espère que ça t'as aidé. Bien sûr, le problème central demeure, donc le problème est toujours d'actualité.
javapapo
le 14 avr. 2018
Étant donné que ce problème n'est toujours pas résolu et affecte mes clusters de manière semi-régulière, j'aimerais faire partie de la solution et me mettre au travail en développant un opérateur personnalisé capable de réparer automatiquement les nœuds affectés par le battement de nœud, PLEG is not healthy via une sorte d'opérateur de réparation automatique générique. Mon inspiration pour cela vient de ce problème ouvert dans le repo Node Problem Detector . J'ai configuré un moniteur personnalisé à l'aide du détecteur de problème de nœud qui définit une condition de nœud PLEGNotHealthy sur true chaque fois que le PLEG is not healthy commence à apparaître dans les journaux kubelet. L'étape suivante est un système de recours automatisé qui vérifie les conditions de nœud, telles que PLEGNotHealthy , qui indiquent un nœud défectueux, puis bouclent, expulsent et redémarrent le démon docker sur le nœud (ou toute autre correction appropriée pour le condition donnée). Je regarde l' opérateur de mise à jour CoreOS comme une référence pour l'opérateur que je souhaite développer. Je suis curieux de savoir si quelqu'un d'autre a des idées à ce sujet ou a déjà mis au point une solution de correction automatique qui pourrait s'appliquer à ce problème. Désolé, ce n'est pas le bon forum pour cette discussion.
erstaples
le 16 avr. 2018
Dans notre cas, il se bloque parfois dans PodSandboxStatus() pour les sorties 2min et kubelet:
rpc error: code = 4 desc = context deadline exceeded
sorties du noyau:
unregister_netdevice: waiting for eth0 to become free. Usage count = 1
Mais cela s'est produit uniquement lors de la suppression d'un pod spécifique (avec un trafic réseau important).
Premièrement, les sandbox PodSpec arrêtent le succès, mais l'arrêt du sandbox de pause a échoué (fonctionnera pour toujours). Ensuite, il restera toujours bloqué ici lors de la récupération de l'état avec le même identifiant de sandbox.
En conséquence, -> latence PLEG élevée -> PLEG défectueux (invoquer deux fois, 2 min * 2 = 4 min> 3 min) -> NodeNotReady
codes associés dans docker_sandbox.go :
func (ds *dockerService) PodSandboxStatus(podSandboxID string) (*runtimeapi.PodSandboxStatus, error) {
// Inspect the container.
// !!! maybe stuck here for 2 min !!!
r, err := ds.client.InspectContainer(podSandboxID)
if err != nil {
return nil, err
}
...
}
func (ds *dockerService) StopPodSandbox(podSandboxID string) error {
var namespace, name string
var checkpointErr, statusErr error
needNetworkTearDown := false
// Try to retrieve sandbox information from docker daemon or sandbox checkpoint
// !!! maybe stuck here !!!
status, statusErr := ds.PodSandboxStatus(podSandboxID)
...
Selon la surveillance de prometheus, la latence d'inspection de docker est normale, mais l'opération d'inspection / d'arrêt de kubelet prend trop de temps.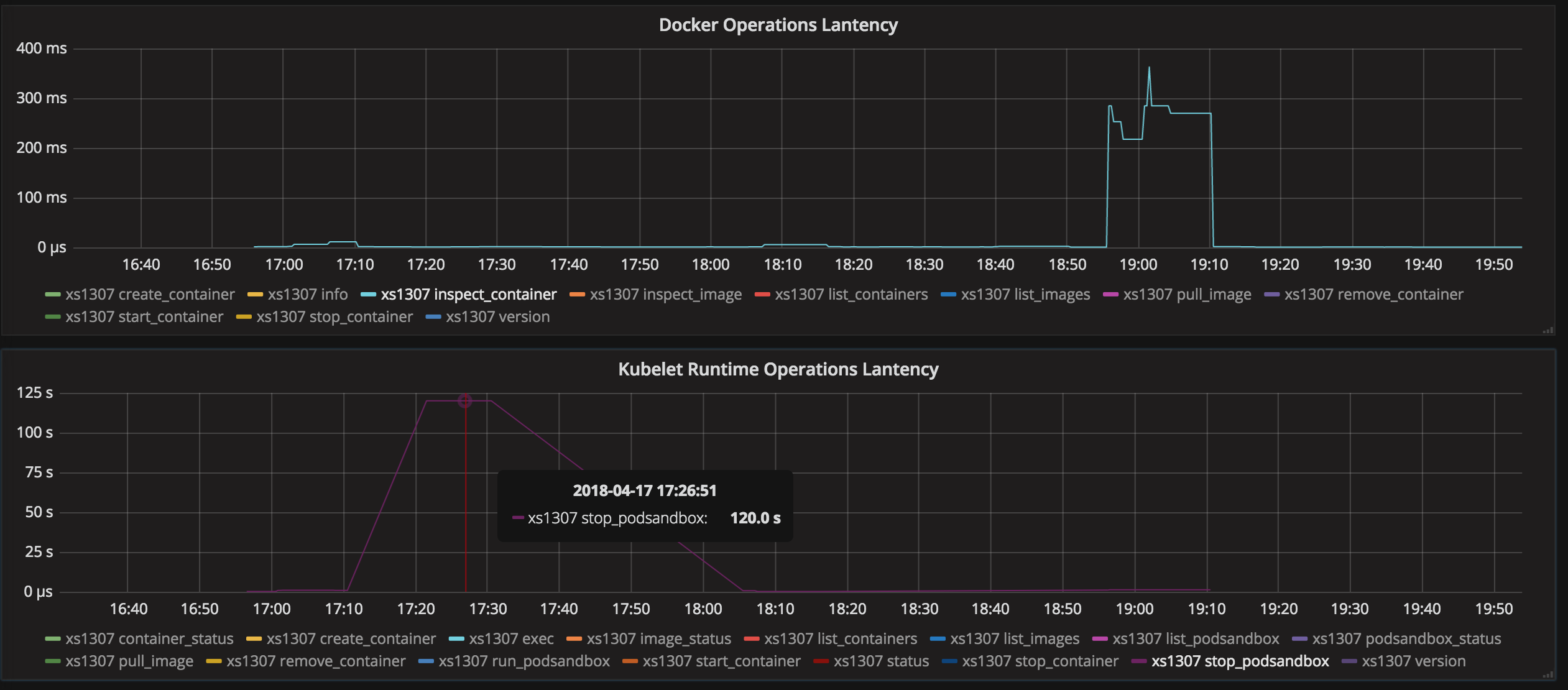
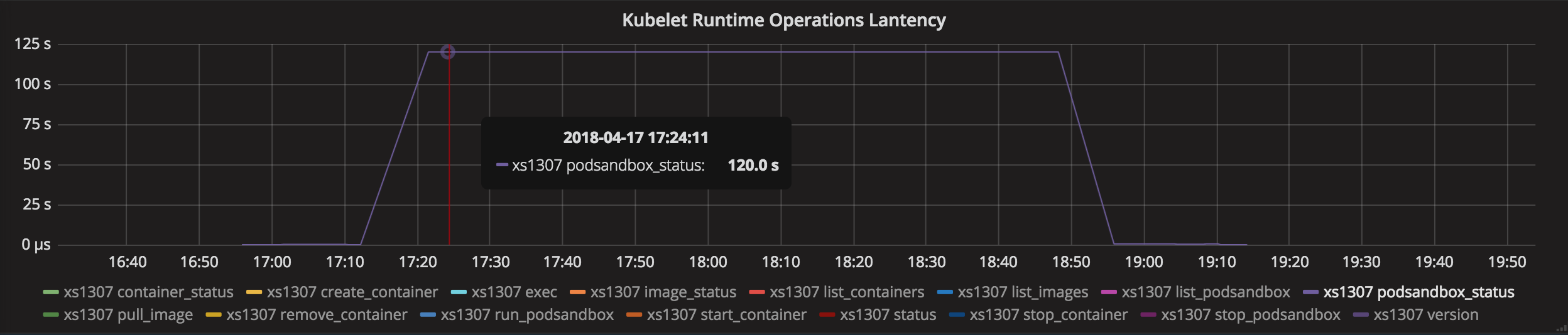
version docker: 1.12.6
version kubelet: 1.7.12
version du noyau Linux: 4.4.0-72-générique
CNI: calicot
comme le mentionne @yujuhong :
grpc http grpc
kubelet <----> dockershim <----> dockerd <----> containerd
Lorsque la situation se produit, j'essaye d'exécuter docker ps . Ça marche. Utilisation de curl à /var/run/docker.sock
pour obtenir le json de conteneur de pause, cela fonctionne également. Je me demande s'il s'agit d'un problème de réponse grpc entre kubelet et dockershim?
curl --unix-socket /var/run/docker.sock http:/v1.24/containers/66755504b8dc3a5c17454e04e0b74676a8d45089a7e522230aad8041ab6f3a5a/json
Lorsque mon nœud commence à basculer entre Ready / NotReady en raison de problèmes PLEG, il est invariablement l'un des conteneurs gcr.io/google_containers/pause sur lesquels le docker inspecte se bloque. Le redémarrage du démon docker résout le problème.
Il semble que notre cas soit similaire à la description de docker stop & docker rm le conteneur de pause qui se bloque, au lieu de redémarrer dockerd.
 whypro
le 18 avr. 2018
whypro
le 18 avr. 2018
Je peux également voir l'erreur unregister_netdevice: waiting for eth0 to become free. Usage count = 1 si j'exécute dmesg sur le nœud. Le pod ne s'arrête jamais car le système ne peut pas libérer le périphérique réseau. Cela provoque PodSandboxStatus of sandbox "XXX" for pod "YYY" error: rpc error: code = DeadlineExceeded desc = context deadline exceeded erreur journalctl -u kubelet .
Peut-être lié au plugin réseau Kubernetes? Quelques personnes dans ce fil semblent utiliser Calico. Peut-être que c'est quelque chose là-bas?
albertvaka
le 24 avr. 2018
@deitch vous dites quelque chose sur les problèmes de CoreOS ici . Pouvez-vous fournir des informations supplémentaires sur la manière de résoudre ces problèmes de réseau?
Je suis confronté aux mêmes problèmes ici, mais je teste avec un nœud baremetal de 768 Go de RAM. C'est avec plus de 2k images chargées (j'en élague certaines).
Nous utilisons k8s 1.7.15 et Docker 17.09. Je pense revenir à Docker 1.13 comme mentionné dans certains commentaires ici, mais je ne suis pas sûr que cela résoudra mon problème.
Nous avons également des problèmes plus spécifiques, comme la perte de connexion de Bonding avec l'un des commutateurs, mais je ne sais pas comment cela est lié au problème de réseau CoreOS.
De plus, kubelet et docker passent beaucoup de temps CPU (presque plus que toute autre chose dans le système)
Merci!
 rikatz
le 10 mai 2018
rikatz
le 10 mai 2018
Voir cela sur Kubernetes v1.8.7 et calico v2.8.6. Dans notre cas, certains pods sont bloqués dans l'état Terminating , et Kubelet renvoie des erreurs PLEG :
E0515 16:15:34.039735 1904 generic.go:241] PLEG: Ignoring events for pod myapp-5c7f7dbcf7-xvblm/production: rpc error: code = DeadlineExceeded desc = context deadline exceeded
I0515 16:16:34.560821 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.529418824s ago; threshold is 3m0s]
I0515 16:16:39.561010 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m5.529605547s ago; threshold is 3m0s]
I0515 16:16:41.857069 1904 kubelet_node_status.go:791] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2018-05-15 16:16:41.857046605 +0000 UTC LastTransitionTime:2018-05-15 16:16:41.857046605 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.825663114s ago; threshold is 3m0s}
I0515 16:16:44.561281 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m10.52986717s ago; threshold is 3m0s]
I0515 16:16:49.561499 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m15.530093202s ago; threshold is 3m0s]
I0515 16:16:54.561740 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m20.530326452s ago; threshold is 3m0s]
I0515 16:16:59.561943 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m25.530538095s ago; threshold is 3m0s]
I0515 16:17:04.562205 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m30.530802216s ago; threshold is 3m0s]
I0515 16:17:09.562432 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m35.531029395s ago; threshold is 3m0s]
I0515 16:17:14.562644 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m40.531229806s ago; threshold is 3m0s]
I0515 16:17:19.562899 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m45.531492495s ago; threshold is 3m0s]
I0515 16:17:24.563168 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m50.531746392s ago; threshold is 3m0s]
I0515 16:17:29.563422 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m55.532013675s ago; threshold is 3m0s]
I0515 16:17:34.563740 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 4m0.532327398s ago; threshold is 3m0s]
E0515 16:17:34.041174 1904 generic.go:271] PLEG: pod myapp-5c7f7dbcf7-xvblm/production failed reinspection: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Quand j'exécute docker ps , je ne vois que le conteneur pause pour le pod myapp-5c7f7dbcf7-xvblm .
ip-10-72-160-222 core # docker ps | grep myapp-5c7f7dbcf7-xvblm
c6c34d9b1e86 gcr.io/google_containers/pause-amd64:3.0 "/pause" 9 hours ago Up 9 hours k8s_POD_myapp-5c7f7dbcf7-xvblm_production_baa0e029-5810-11e8-a9e8-0e88e0071844_0
Après avoir redémarré kubelet , le conteneur zombie pause (id c6c34d9b1e86 ) a été supprimé. kubelet journaux:
W0515 16:56:26.439306 79462 docker_sandbox.go:343] failed to read pod IP from plugin/docker: NetworkPlugin cni failed on the status hook for pod "myapp-5c7f7dbcf7-xvblm_production": CNI failed to retrieve network namespace path: Cannot find network namespace for the terminated container "c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b"
W0515 16:56:26.439962 79462 cni.go:265] CNI failed to retrieve network namespace path: Cannot find network namespace for the terminated container "c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b"
2018-05-15 16:56:26.428 [INFO][79799] calico-ipam.go 249: Releasing address using handleID handleID="k8s-pod-network.c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b" workloadID="production.myapp-5c7f7dbcf7-xvblm"
2018-05-15 16:56:26.428 [INFO][79799] ipam.go 738: Releasing all IPs with handle 'k8s-pod-network.c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b'
2018-05-15 16:56:26.739 [INFO][81206] ipam.go 738: Releasing all IPs with handle 'k8s-pod-network.c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b'
2018-05-15 16:56:26.742 [INFO][81206] ipam.go 738: Releasing all IPs with handle 'production.myapp-5c7f7dbcf7-xvblm'
2018-05-15 16:56:26.742 [INFO][81206] calico-ipam.go 261: Releasing address using workloadID handleID="k8s-pod-network.c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b" workloadID="production.myapp-5c7f7dbcf7-xvblm"
2018-05-15 16:56:26.742 [WARNING][81206] calico-ipam.go 255: Asked to release address but it doesn't exist. Ignoring handleID="k8s-pod-network.c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b" workloadID="production.myapp-5c7f7dbcf7-xvblm"
Calico CNI releasing IP address
2018-05-15 16:56:26.745 [INFO][80545] k8s.go 379: Teardown processing complete. Workload="production.myapp-5c7f7dbcf7-xvblm"
À partir des journaux du noyau:
[40473.123736] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[40483.187768] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[40493.235781] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
Je pense qu'il existe un ticket similaire ouvert https://github.com/moby/moby/issues/5618
zihaoyu
le 15 mai 2018
C'est un cas complètement différent. Ici, vous connaissez la raison pour laquelle le nœud bat.
dElogics
le 18 mai 2018
Nous rencontrons ce problème pour faire tomber des nœuds sur nos clusters de production. Les pods ne peuvent pas se terminer ou créer. Kubernetes 1.9.7 avec CoreOS 1688.5.3 (Rhyolite) sur Linux Kernel 4.14.32 et Docker 17.12.1-ce. Notre CNI est Calico.
Le journal de containerd montre des erreurs concernant un groupe de contrôle dont la suppression a été demandée, mais pas directement au moment de l'erreur.
May 21 17:35:00 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T17:35:00Z" level=error msg="stat cgroup bf717dbbf392b0ba7ef0452f7b90c4cfb4eca81e7329bfcd07fe020959b737df" error="cgroups: cgroup deleted"
May 21 17:44:32 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T17:44:32Z" level=error msg="stat cgroup a0887b496319a09b1f3870f1c523f65bf9dbfca19b45da73711a823917fdfa18" error="cgroups: cgroup deleted"
May 21 17:50:32 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T17:50:32Z" level=error msg="stat cgroup 2fbb4ba674050e67b2bf402c76137347c3b5f510b8934d6a97bc3b96069db8f8" error="cgroups: cgroup deleted"
May 21 17:56:22 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T17:56:22Z" level=error msg="stat cgroup f9501a4284257522917b6fae7e9f4766e5b8cf7e46989f48379b68876d953ef2" error="cgroups: cgroup deleted"
May 21 18:43:28 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T18:43:28Z" level=error msg="stat cgroup c37e7505019ae279941a7a78db1b7a6e7aab4006dfcdd83d479f1f973d4373d2" error="cgroups: cgroup deleted"
May 21 19:38:28 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T19:38:28Z" level=error msg="stat cgroup a327a775955d2b69cb01921beb747b4bba0df5ea79f637e0c9e59aeb7e670b43" error="cgroups: cgroup deleted"
May 21 19:50:26 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T19:50:26Z" level=error msg="stat cgroup 5d11f13d13b461fe2aa1396d947f1307a6c3a78e87fa23d4a1926a6d46794d58" error="cgroups: cgroup deleted"
May 21 19:52:26 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T19:52:26Z" level=error msg="stat cgroup fb7551cde0f9a640fbbb928d989ca84200909bce2821e03a550d5bfd293e786b" error="cgroups: cgroup deleted"
May 21 20:54:32 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T20:54:32Z" level=error msg="stat cgroup bcd1432a64b35fd644295e2ae75abd0a91cb38a9fa0d03f251c517c438318c53" error="cgroups: cgroup deleted"
May 21 21:56:28 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T21:56:28Z" level=error msg="stat cgroup 2a68f073a7152b4ceaf14d128f9d31fbb2d5c4b150806c87a640354673f11792" error="cgroups: cgroup deleted"
May 21 22:02:30 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T22:02:30Z" level=error msg="stat cgroup aa2224e7cfd0a6f44b52ff058a50a331056b0939d670de461b7ffc7d01bc4d59" error="cgroups: cgroup deleted"
May 21 22:18:32 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T22:18:32Z" level=error msg="stat cgroup 95e0c4f7607234ada85a1ab76b7ec2aa446a35e868ad8459a1cae6344bc85f4f" error="cgroups: cgroup deleted"
May 21 22:21:32 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T22:21:32Z" level=error msg="stat cgroup 76578ede18ba3bc1307d83c4b2ccd7e35659f6ff8c93bcd54860c9413f2f33d6" error="cgroups: cgroup deleted"
Kubelet montre quelques lignes intéressantes sur l'échec des opérations de bac à sable de pod.
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.578306 1513 remote_runtime.go:115] StopPodSandbox "922f625ced6d6f6adf33fe67e5dd8378040cd2e5c8cacdde20779fc692574ca5" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.578354 1513 kuberuntime_manager.go:800] Failed to stop sandbox {"docker" "922f625ced6d6f6adf33fe67e5dd8378040cd2e5c8cacdde20779fc692574ca5"}
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: W0523 18:17:25.579095 1513 docker_sandbox.go:196] Both sandbox container and checkpoint for id "a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" could not be found. Proceed without further sandbox information.
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: W0523 18:17:25.579426 1513 cni.go:242] CNI failed to retrieve network namespace path: Error: No such container: a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.723 [INFO][33881] calico.go 338: Extracted identifiers ContainerID="a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" Node="ip-10-5-76-113.ap-southeast-1.compute.internal" Orchestrator="cni" Workload="a89
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.723 [INFO][33881] utils.go 263: Configured environment: [CNI_COMMAND=DEL CNI_CONTAINERID=a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642 CNI_NETNS= CNI_ARGS=IgnoreUnknown=1;IgnoreUnknown=1;K8S_POD_NAMESP
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.723 [INFO][33881] client.go 202: Loading config from environment
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: Calico CNI releasing IP address
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.796 [INFO][33905] utils.go 263: Configured environment: [CNI_COMMAND=DEL CNI_CONTAINERID=a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642 CNI_NETNS= CNI_ARGS=IgnoreUnknown=1;IgnoreUnknown=1;K8S_POD_NAMESP
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.796 [INFO][33905] client.go 202: Loading config from environment
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.796 [INFO][33905] calico-ipam.go 249: Releasing address using handleID handleID="k8s-pod-network.a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" workloadID="a893f57acec1f3779c35aed743f128408e491ff2f53a3
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.796 [INFO][33905] ipam.go 738: Releasing all IPs with handle 'k8s-pod-network.a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642'
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.805 [WARNING][33905] calico-ipam.go 255: Asked to release address but it doesn't exist. Ignoring handleID="k8s-pod-network.a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" workloadID="a893f57acec1f3779c3
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.805 [INFO][33905] calico-ipam.go 261: Releasing address using workloadID handleID="k8s-pod-network.a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" workloadID="a893f57acec1f3779c35aed743f128408e491ff2f53
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.805 [INFO][33905] ipam.go 738: Releasing all IPs with handle 'a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642'
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.822 [INFO][33881] calico.go 373: Endpoint object does not exist, no need to clean up. Workload="a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" endpoint=api.WorkloadEndpointMetadata{ObjectMetadata:unver
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.824925 1513 kubelet.go:1527] error killing pod: failed to "KillPodSandbox" for "9c246b32-4f10-11e8-964a-0a7e4ae265be" with KillPodSandboxError: "rpc error: code = DeadlineExceeded desc = context deadline exceeded"
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.825025 1513 pod_workers.go:186] Error syncing pod 9c246b32-4f10-11e8-964a-0a7e4ae265be ("flntk8-fl01-j7lf4_splunk(9c246b32-4f10-11e8-964a-0a7e4ae265be)"), skipping: error killing pod: failed to "KillPodSandbo
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.969591 1513 kuberuntime_manager.go:860] PodSandboxStatus of sandbox "922f625ced6d6f6adf33fe67e5dd8378040cd2e5c8cacdde20779fc692574ca5" for pod "flntk8-fl01-j7lf4_splunk(9c246b32-4f10-11e8-964a-0a7e4ae265be)"
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.969640 1513 generic.go:241] PLEG: Ignoring events for pod flntk8-fl01-j7lf4/splunk: rpc error: code = DeadlineExceeded desc = context deadline exceeded
May 23 18:20:27 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: I0523 18:20:27.753523 1513 kubelet.go:1790] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.783603773s ago; threshold is 3m0s]
May 23 18:19:27 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:19:27.019252 1513 kuberuntime_manager.go:860] PodSandboxStatus of sandbox "922f625ced6d6f6adf33fe67e5dd8378040cd2e5c8cacdde20779fc692574ca5" for pod "flntk8-fl01-j7lf4_splunk(9c246b32-4f10-11e8-964a-0a7e4ae265be)"
May 23 18:19:27 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:19:27.019295 1513 generic.go:241] PLEG: Ignoring events for pod flntk8-fl01-j7lf4/splunk: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Le noyau montre les eth0 en attente de devenir des lignes libres qui semblent liées à: https://github.com/moby/moby/issues/5618
[1727395.220036] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[1727405.308152] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[1727415.404335] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[1727425.484491] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[1727435.524626] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[1727445.588785] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
Cependant, notre cas n'a pas montré l'adaptateur lo et n'a pas fait planter le noyau. Une enquête plus approfondie pointe vers https://github.com/projectcalico/calico/issues/1109 , qui conclut toujours qu'il s'agit d'un bogue de condition de concurrence du noyau qui n'est pas encore corrigé.
Le redémarrage de kubelet a suffisamment résolu le problème pour permettre aux pods de se terminer et de se créer, mais le spam waiting for eth0 to become free continué dans dmesg.
Voici une lecture intéressante sur la question: https://medium.com/@bcdonadio/when -the-blue-whale-sinks-55c40807c2fc
 integrii
le 23 mai 2018
integrii
le 23 mai 2018
@integrii
Non, cela arrive aussi sur le dernier centOS. Je l'ai reproduit une fois.
dElogics
le 3 juin 2018
Ok, je voudrais changer ce que j'ai dit plus tôt - le temps d'exécution du conteneur va soudainement tomber en se plaignant
ignorer la synchronisation des pods - [PLEG n'est pas sain: ...
Pendant que le docker exécute le fichier. Pendant ce temps, le redémarrage de kubelet rend PLEG sain et le nœud est à nouveau actif.
docker, kubelet kube-proxy sont tous définis sur la priorité RT.
dElogics
le 3 juin 2018
Une dernière chose - au redémarrage de kubelet, la même chose se produit à moins que je ne redémarre docker.
J'ai essayé d'utiliser curl sur la prise du docker, et cela fonctionne bien.
dElogics
le 3 juin 2018
+1
Kubernetes: 1.10.2
Docker: 1.12.6
Système d'exploitation: centos 7.4
Noyau: 3.10.0-693.el7.x86_64
CNI: calicot
 lanxenet
le 5 juin 2018
lanxenet
le 5 juin 2018
+1
Gouverneurs: 1.7.16
Docker: 17.12.1-ce
Système d'exploitation: CoreOS 1688.5.3
Noyau: 4.14.32-coreos
CNI: Calico (v2.6.7)
Depuis la v1.9.1
 phspagiari
le 14 juin 2018
phspagiari
le 14 juin 2018
Pensez-vous que l'augmentation de --runtime-request-timeout aidera?
dElogics
le 17 juin 2018
Je vois ce problème avec CRI-O sur l'un de mes nœuds. Kubernetes 1.10.1, CRI-O 1.10.1, Fedora 27, noyau 4.16.7-200.fc27, utilisant Flannel.
runc list et crictl pods sont tous les deux rapides, mais l'exécution de crictl ps prend quelques minutes.
 mcronce
le 26 juin 2018
mcronce
le 26 juin 2018
+1
Kubernetes: v1.8.7 + coreos.0
Docker: 17.05.0-ce
Système d'exploitation: Redhat 7x
CNI: Calico
Kubespary 2.4
Nous voyons ce problème fréquemment. Nous redémarrons docker et kubelet et cela disparaît.
 sivarajp
le 13 juil. 2018
sivarajp
le 13 juil. 2018
Avec le dernier CoreOS stable 1745.7.0 je ne vois plus ce problème.
komljen
le 13 juil. 2018
Depuis combien de temps regardez-vous après avoir mis à jour @komljen? Pour nous, cela prend un certain temps.
integrii
le 13 juil. 2018
J'ai eu ces problèmes tous les quelques jours sur un grand environnement CI, et je pense que j'ai tout essayé sans succès. Changer le système d'exploitation pour une version supérieure à CoreOS était la clé, et je ne vois aucun problème depuis un mois déjà.
komljen
le 13 juil. 2018
Je n'ai pas non plus vu le problème depuis plus d'un mois; sans aucun changement, donc je ne serais pas si rapide à déclarer le patient en bonne santé :-)
 oivindoh
le 13 juil. 2018
oivindoh
le 13 juil. 2018
@komljen Nous exécutons centos 7. Même aujourd'hui, l'un de nos nœuds est tombé en panne.
sivarajp
le 13 juil. 2018
Je n'ai pas non plus vu le problème depuis plus d'un mois; sans aucun changement, donc je ne serais pas si rapide à déclarer le patient en bonne santé :-)
@oivindoh Je n'ai pas eu le temps de vérifier ce qui avait été changé dans cette version particulière du noyau, mais dans mon cas, cela a résolu le problème.
komljen
le 14 juil. 2018
J'ai trouvé la cause de ce problème dans notre cluster. En résumé, le bogue est causé par une commande CNI (calico) qui ne se termine jamais, ce qui bloque à jamais un gestionnaire de serveur dockershim. Par conséquent, le RPC appelle PodSandboxStatus() pour un pod défectueux toujours expiré, ce qui rend le PLEG défectueux.
Effets du bug:
- Le mauvais pod coincé dans l'état
Terminatingpour toujours - D'autres états de pod pourraient perdre la synchronisation avec les serveurs kubeapi pendant quelques minutes (provoquant des erreurs kube2iam dans notre cluster)
- La mémoire fuit, car la fonction est appelée plusieurs fois et ne retourne jamais
Voici ce que vous pouvez voir sur un nœud lorsque cela se produit:
- les messages d'erreur suivants dans le journal kubelet:
Jul 13 23:52:15 E0713 23:52:15.461144 1740 kuberuntime_manager.go:860] PodSandboxStatus of sandbox "01d8b790bc9ede72959ddf0669e540dfb1f84bfd252fb364770a31702d9e7eeb" for pod "pod-name" error: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 13 23:52:15 E0713 23:52:15.461215 1740 generic.go:241] PLEG: Ignoring events for pod pod-name: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 13 23:52:16 E0713 23:52:16.682555 1740 pod_workers.go:186] Error syncing pod 7f3fd634-7e57-11e8-9ddb-0acecd2e6e42 ("pod-name"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 13 23:53:15 I0713 23:53:15.682254 1740 kubelet.go:1790] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.267402933s ago; threshold is 3m0s]
- les métriques d'expiration suivantes:
$ curl -s http://localhost:10255/metrics | grep 'quantile="0.5"' | grep "e+08"
kubelet_pleg_relist_interval_microseconds{quantile="0.5"} 2.41047643e+08
kubelet_pleg_relist_latency_microseconds{quantile="0.5"} 2.40047461e+08
kubelet_runtime_operations_latency_microseconds{operation_type="podsandbox_status",quantile="0.5"} 1.2000027e+08
- un processus fils (calico) de kubelet est bloqué:
$ ps -A -o pid,ppid,start_time,comm | grep 1740
1740 1 Jun15 kubelet
5428 1740 Jul04 calico
Voici la trace de la pile dans le serveur dockershim:
PodSandboxStatus() :: pkg/kubelet/dockershim/docker_sandbox.go
... -> GetPodNetworkStatus() :: pkg/kubelet/network/plugins.go
^^^^^ this function stuck on pm.podLock(fullPodName).Lock()
Pour résoudre le problème, kubelet doit utiliser le délai d'expiration sur les appels de fonction de bibliothèque CNI ( DelNetwork() etc) et d'autres appels de bibliothèque externes qui peuvent prendre une éternité à revenir.
 mechpen
le 16 juil. 2018
mechpen
le 16 juil. 2018
@mechpen Je suis content que quelqu'un ait trouvé une réponse quelque part. Je ne pense pas que cela s'applique ici (nous utilisons le tissage, pas le calicot, du moins dans ce cluster; j'utilise le calicot ailleurs et j'en ai piloté plusieurs), et nous n'avons pas vu de messages d'erreur similaires.
Si cela apparaît, cependant, vous avez dit:
Pour résoudre le problème, kubelet doit utiliser le délai d'expiration sur les appels de fonction de bibliothèque CNI (DelNetwork () et etc.) ou sur tout appel de bibliothèque externe qui peut prendre une éternité à revenir
Configurable? Ou nécessite kubelet modification de
deitch
le 16 juil. 2018
@deitch, cette erreur peut également arriver à tisser si une commande CNI de tissage ne se termine pas (peut être causée par des bogues de bas niveau partagés par tous les systèmes).
Le correctif nécessite des modifications du code de kubelet.
mechpen
le 16 juil. 2018
@mechpen Nous voyons également ce problème dans le cluster fonctionnant en flanelle? Le correctif est-il le même?
sivarajp
le 17 juil. 2018
@komljen Je viens de voir ce problème avec 1745.7.0
Je vois ce problème sur calico actuellement avec k8s 1.9
J'ai un pod sur ce nœud exact qui est bloqué dans Terminating. Laissez-moi le tuer et voir si le problème s'arrête.
 sstarcher
le 17 juil. 2018
sstarcher
le 17 juil. 2018
@mechpen avez-vous ouvert un problème pour k8s pour votre suggestion?
sstarcher
le 17 juil. 2018
@mechpen devrait-on aussi ouvrir un ticket contre calico?
sstarcher
le 17 juil. 2018
@sstarcher Je n'ai pas encore déposé de ticket. J'essaie toujours de savoir pourquoi le calicot est suspendu pour toujours.
Je vois beaucoup de messages du noyau:
[2797545.570844] unregister_netdevice: waiting for eth0 to become free. Usage count = 2
Cette erreur hante linux / conteneur depuis de nombreuses années.
mechpen
le 18 juil. 2018
@mechpen
@sstarcher
@deitch
Oui, ce problème, je l'ai attrapé il y a un mois.
Et j'ai ouvert un problème.
J'essaie de résoudre ce problème dans kubelet, mais il devrait d'abord le résoudre dans cni.
Donc, je le répare d'abord dans cni puis je le répare dans kubelet.
THX
# 65743
https://github.com/containernetworking/cni/issues/567
https://github.com/containernetworking/cni/pull/568
liucimin
le 19 juil. 2018
@sstarcher @mechpen calico ticket lié à ce problème:
https://github.com/projectcalico/calico/issues/1109
 r0bj
le 25 juil. 2018
r0bj
le 25 juil. 2018
@mechpen voir https://github.com/moby/moby/issues/5618 pour le problème.
dElogics
le 30 juil. 2018
Juste arrivé à nouveau sur notre cluster de production
Kubernetes: 1.11.0
coreos: 1520.9.0
docker: 1.12.6
cni: calicot
J'ai redémarré le kubelet et dockerd sur le nœud notready et cela semble bien maintenant.
la seule différence entre le nœud non prêt et le nœud prêt est qu'il y a beaucoup de démarrage et d'arrêt de pod cronjob et tué sur un nœud non prêt.
leeeboo
le 31 juil. 2018
@mechpen
Je ne sais pas si je rencontre le même problème ou non.
Jul 30 17:52:15 cloud-blade-31 kubelet[24734]: I0730 17:52:15.585102 24734 kubelet_node_status.go:431] Recording NodeNotReady event message for node cloud-blade-31
Jul 30 17:52:15 cloud-blade-31 kubelet[24734]: I0730 17:52:15.585137 24734 kubelet_node_status.go:792] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2018-07-30 17:52:15.585076295 -0700 PDT m=+13352844.638760537 LastTransitionTime:2018-07-30 17:52:15.585076295 -0700 PDT m=+13352844.638760537 Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m0.948768335s ago; threshold is 3m0s}
Jul 30 17:52:25 cloud-blade-31 kubelet[24734]: I0730 17:52:25.608101 24734 kubelet_node_status.go:443] Using node IP: "10.11.3.31"
Jul 30 17:52:35 cloud-blade-31 kubelet[24734]: I0730 17:52:35.640422 24734 kubelet_node_status.go:443] Using node IP: "10.11.3.31"
Jul 30 17:52:36 cloud-blade-31 kubelet[24734]: E0730 17:52:36.556409 24734 remote_runtime.go:169] ListPodSandbox with filter nil from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 30 17:52:36 cloud-blade-31 kubelet[24734]: E0730 17:52:36.556474 24734 kuberuntime_sandbox.go:192] ListPodSandbox failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 30 17:52:36 cloud-blade-31 kubelet[24734]: W0730 17:52:36.556492 24734 image_gc_manager.go:173] [imageGCManager] Failed to monitor images: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 30 17:52:45 cloud-blade-31 kubelet[24734]: I0730 17:52:45.667169 24734 kubelet_node_status.go:443] Using node IP: "10.11.3.31"
Jul 30 17:52:55 cloud-blade-31 kubelet[24734]: I0730 17:52:55.692889 24734 kubelet_node_status.go:443] Using node IP: "10.11.3.31"
Jul 30 17:53:05 cloud-blade-31 kubelet[24734]: I0730 17:53:05.729182 24734 kubelet_node_status.go:443] Using node IP: "10.11.3.31"
Jul 30 17:53:15 cloud-blade-31 kubelet[24734]: E0730 17:53:15.265668 24734 remote_runtime.go:169] ListPodSandbox with filter &PodSandboxFilter{Id:,State:&PodSandboxStateValue{State:SANDBOX_READY,},LabelSelector:map[string]string{},} from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Mes nœuds vont NotReady quand (apparemment) le démon Docker cesse de répondre aux vérifications de l'état. Sur la machine elle-même docker ps bloque mais un docker version retourne. Je dois redémarrer le démon docker pour que le nœud redevienne Ready . Je ne sais pas si je peux dire si j'ai des pods bloqués ou non, car je ne peux apparemment pas lister de conteneurs.
Kubernetes: 1.9.2
Commit Docker 17.03.1-ce c6d412e
Système d'exploitation: Ubuntu 16.04
Noyau: Linux 4.13.0-31-generic # 34 ~ 16.04.1-Ubuntu SMP Ven 19 janvier 17:11:01 UTC 2018 x86_64 x86_64 x86_64 GNU / Linux
 saurfangg
le 31 juil. 2018
saurfangg
le 31 juil. 2018
J'ai le même problème. Cela arrive si fréquemment qu'un nœud ne survit pas à une période de 5 minutes de programmation de pods.
L'erreur se produit à la fois sur mon cluster principal (flanelle) ainsi que sur mes clusters de test (calico).
J'ai essayé de faire varier la version de kubernetes (1.9.? / 1.11.1), la distribution (debian, ubuntu), le fournisseur de cloud (ec2, hetzner cloud), la version docker (17.3.2, 17.06.2). Je n'ai pas testé la matrice complète uniquement les variations d'une variable.
Ma charge de travail est très simple (Pod avec un conteneur, pas de volumes, mise en réseau par défaut, planifié en vrac de 30 pods)
Le cluster est fraîchement configuré avec kubeadm sans personnalisation (sauf mon test initial avec flanelle)
L'erreur se produit en quelques minutes. docker ps ne revient pas / est bloqué, les pods bloqués en fin de compte, etc.
Maintenant, je me demande s'il existe actuellement une configuration connue (utilisant debian ou ubuntu) qui ne conduit pas à cette erreur?
Y a-t-il quelqu'un qui n'est pas affecté par ce bogue qui pourrait partager ses combinaisons de travail de réseaux de superposition et d'autres versions qui produisent des nœuds stables?
 nielsole
le 4 août 2018
nielsole
le 4 août 2018
Cela se produit dans OpenShift sur les nœuds Baremetal.
Pour cette occurrence particulière de PLEG, le problème a été constaté lorsqu'un grand nombre de conteneurs ont été démarrés en même temps (via un cronjob emballé) sur des nœuds OpenShift qui avaient un grand nombre de processeurs virtuels configurés. Les nœuds atteignaient au maximum les 250 pods par nœud et devenaient surchargés.
Une solution peut être de réduire le nombre de processeurs virtuels attribués aux machines virtuelles de nœud OpenShift en réduisant le nombre de processeurs virtuels à 8 (par exemple), ce qui signifierait que le nombre maximum de pods pouvant être planifiés serait de 80 pods (limite par défaut de 10 pods par CPU ) au lieu de 250. Il est généralement recommandé d'avoir des nœuds de taille plus raisonnable au lieu de nœuds plus grands.
J'ai des nœuds avec 224 cpus. Kubernetes version 1.7.1 - Redhat 7.4
 jcperezamin
le 13 août 2018
jcperezamin
le 13 août 2018
Je crois que j'ai un problème similaire. mes pods se bloquent en attendant la résiliation et il y a des rapports d'un PLEG malsain dans les journaux. dans ma situation cependant, il ne revient jamais sain jusqu'à ce que je tue manuellement le processus kubelet. un simple sudo systemctl restart kubelet a résolu le problème, mais je dois le faire pour environ 1/4 de nos machines à chaque fois que nous faisons un déploiement. ce n'est pas génial.
Je ne peux pas dire exactement ce qui se passe ici, mais étant donné que je vois une commande bridge s'exécuter sous le processus kubelet, peut-être est-ce lié à CNI comme mentionné précédemment dans ce fil? J'ai joint une tonne de journaux à partir de 2 instances distinctes de ceci aujourd'hui et je suis plus qu'heureux de travailler avec quelqu'un pour déboguer ce problème.
bien sûr, chaque machine avec ce problème crache le classique unregister_netdevice: waiting for eth0 to become free. Usage count = 2 - J'ai attaché 2 journaux kubelet différents dans logs.tar.gz avec un SIGABRT envoyé pour obtenir les routines go en cours d'exécution. j'espère que cela aide. J'ai vu quelques appels qui semblent liés alors je vais les appeler ici
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: goroutine 2895825 [semacquire, 17 minutes]:
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: sync.runtime_SemacquireMutex(0xc422082d4c)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/runtime/sema.go:62 +0x34
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: sync.(*Mutex).Lock(0xc422082d48)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/sync/mutex.go:87 +0x9d
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: k8s.io/kubernetes/pkg/kubelet/network.(*PluginManager).GetPodNetworkStatus(0xc420ddbbc0, 0xc421e36f76, 0x17, 0xc421e36f69, 0xc, 0x36791df, 0x6, 0xc4223f6180, 0x40, 0x0, ...)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /workspace/anago-v1.8.7-beta.0.34+b30876a5539f09/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/network/plugins.go:376 +0xe6
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: goroutine 2895819 [syscall, 17 minutes]:
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: syscall.Syscall6(0xf7, 0x1, 0x25d7, 0xc422c96d70, 0x1000004, 0x0, 0x0, 0x7f7dc6909e10, 0x0, 0xc4217e9980)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/syscall/asm_linux_amd64.s:44 +0x5
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: os.(*Process).blockUntilWaitable(0xc42216af90, 0xc421328c60, 0xc4217e99e0, 0x1)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/os/wait_waitid.go:28 +0xa5
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: os.(*Process).wait(0xc42216af90, 0x411952, 0xc4222554c0, 0xc422255480)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/os/exec_unix.go:22 +0x4d
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: os.(*Process).Wait(0xc42216af90, 0x0, 0x0, 0x379bbc8)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/os/exec.go:115 +0x2b
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: os/exec.(*Cmd).Wait(0xc421328c60, 0x0, 0x0)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/os/exec/exec.go:435 +0x62
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: os/exec.(*Cmd).Run(0xc421328c60, 0xc422255480, 0x0)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/os/exec/exec.go:280 +0x5c
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: k8s.io/kubernetes/vendor/github.com/containernetworking/cni/pkg/invoke.(*RawExec).ExecPlugin(0x5208390, 0xc4217e98a0, 0x1b, 0xc4212e66e0, 0x156, 0x160, 0xc422b7fd40, 0xf, 0x12, 0x4121a8, ...)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /workspace/anago-v1.8.7-beta.0.34+b30876a5539f09/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/github.com/containernetworking/cni/pkg/invoke/raw_exec.go:42 +0x215
Kubernetes 1.8.7 sur GCE utilisant Container-Optimized OS sur Kernel 4.14.33+ avec kubenet.
 theRealWardo
le 14 août 2018
theRealWardo
le 14 août 2018
@jcperezamin , Dans les versions 3.10 et ultérieures d'OpenShift, il n'y a pas de valeur par défaut (Nombre de pods par cœur). La valeur maximale prise en charge est le nombre de pods par nœud.
warmchang
le 14 août 2018
Je reçois ça sur du métal nu. Utilisation d'une nouvelle installation d'Ubuntu 18.04, configurée avec kubeadm (maître à nœud unique).
Je suis tombé sur Warning ContainerGCFailed 8m (x438 over 8h) ... rpc error: code = ResourceExhausted desc = grpc: trying to send message larger than max (8400302 vs. 8388608)
. Le nœud avait accumulé environ 11 500 conteneurs arrêtés. J'ai effacé manuellement certains conteneurs, ce qui a corrigé GC, mais le nœud est entré dans NotReady à cause de PLEG immédiatement après.
J'utilise une configuration k8s assez simple, avec une flanelle pour le réseautage. Le nœud affecté est une ancienne machine basée sur Xeon E5-2670 avec 6 disques SAS 10k en RAID6 matériel.
Le problème PLEG ne s'était pas résolu en une heure, le redémarrage de kubelet a immédiatement résolu le problème.
 pnovotnak
le 24 août 2018
pnovotnak
le 24 août 2018
Semble se produire chaque fois que je charge lourdement la machine, et le nœud ne récupère jamais tout seul. En vous connectant via SSH, le processeur du nœud et les autres ressources sont vides. Peu de conteneurs de docker, d'images, de volumes, etc. La liste de ces ressources est rapide. Et simplement reformuler le kubelet résout toujours le problème instantanément.
J'utilise les versions suivantes:
- Ubuntu: 18.04.1
- Linux: 4.15.0-33-générique
- Serveur Kubernetes: v1.11.0
- Kubeadm: v1.11.2
- Docker: 18.06.1-ce
pnovotnak
le 27 août 2018
Je viens de rencontrer ce problème sur un nœud bare-metal avec Kubernetes 1.11.1 :(
 adampl
le 28 août 2018
adampl
le 28 août 2018
Vivre cela aussi, trop souvent, et les nœuds sont vraiment puissants et sous-utilisés.
- Kubernetes: 1.10.2
- Noyau: 3.10.0
- Docker: 1.12.6
 devlounge
le 29 août 2018
devlounge
le 29 août 2018
Même problème...
Environnement:
Fournisseur de cloud ou configuration matérielle: bare metal
OS (par exemple à partir de / etc / os-release): Ubuntu 16.04
Noyau (par exemple uname -a): 4.4.0-109-generic
Kubernetes: 1.10.5
Docker: 1.12.3-0 ~ xenial
 x8k
le 3 sept. 2018
x8k
le 3 sept. 2018
Avoir le même problème après la migration vers kubernetes 1.10.3.
Version du client: version.Info {Majeur: "1", Mineur: "10", GitVersion: "v1.10.5"
Version du serveur: version.Info {Majeur: "1", Mineur: "10", GitVersion: "v1.10.3"
 angegar
le 4 sept. 2018
angegar
le 4 sept. 2018
Même problème sur un environnement bare-metal:
Environnement:
Fournisseur de cloud ou configuration matérielle: bare metal
OS (par exemple à partir de / etc / os-release): CoreOS 1688.5.3
Noyau (par exemple uname -a): 4.14.32
Kubernetes: 1.10.4
Docker: 17.12.1
 corest
le 12 sept. 2018
corest
le 12 sept. 2018
Il est intéressant de connaître la valeur IOWAIT sur les nœuds lors de l'arrivée du problème.
livelace
le 12 sept. 2018
Même problème vu à plusieurs reprises dans un autre environnement nu. Versions du hit le plus récent:
- Système d' exploitation: Ubuntu 16.04.5 LTS
- Noyau: Linux 4.4.0-134-generic
- Kubernetes:
- Hôte flottant
- Maîtres: v1.10.5 et v1.10.2
- Docker sur l'hôte flottant
 calder
le 14 sept. 2018
calder
le 14 sept. 2018
La cause est connue.
Le correctif en amont se produit ici:
https://github.com/containernetworking/cni/pull/568
L'étape suivante consiste à mettre à jour le cni utilisé par kubernetes si quelqu'un veut intervenir
et préparez ce pr. Vous voudrez probablement vous coordonner avec @liucimin ou moi
pour éviter de marcher sur les orteils.
Le ven 14 sept. 2018, 11:38 Calder Coalson [email protected]
a écrit:
Même problème vu à plusieurs reprises dans un autre environnement nu. Versions pour
le hit le plus récent:
- Système d' exploitation: Ubuntu 16.040.5 LTS
- Noyau: Linux 4.4.0-134-generic
- Kubernetes:
- Hôte flottant
- Maîtres: v1.10.5 et v1.10.2
- Docker sur l'hôte flottant
-
Vous recevez ceci parce que vous avez commenté.
Répondez directement à cet e-mail, affichez-le sur GitHub
https://github.com/kubernetes/kubernetes/issues/45419#issuecomment-421447751 ,
ou couper le fil
https://github.com/notifications/unsubscribe-auth/AFctXYnTJjNwtWquPmi5nozVMUYDetRlks5ua_eIgaJpZM4NSBta
.
pnovotnak
le 14 sept. 2018
@deitch
Salut, j'ai rencontré la même erreur comme celle-ci
Error syncing pod *********** ("pod-name"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
et je demande les informations sur le conteneur par dockerd et j'ai trouvé que cette demande était bloquée et aucun résultat ne retournait
curl -XGET --unix-socket /var/run/docker.sock http://localhost/containers/******("yourcontainerid")/json
Donc je pense que c'est peut-être une erreur de docker
 Nebulazhang
le 19 sept. 2018
Nebulazhang
le 19 sept. 2018
il s'agit du blocage du démon docker lors de la persistance des journaux sur le disque.
Il y a du travail dans l'adresse du docker mais il n'atterrit que le 18.06 (pas encore un docker vérifié pour l'utilisation de k8s)
https://docs.docker.com/config/containers/logging/configure/#configure -the-delivery-mode-of-log-messages-from-container-to-log-driver
Étant donné que le démon docker bloque la journalisation par défaut, nous ne pouvons pas le résoudre tant que nous ne pouvons pas contourner ce problème.
Cela est également en corrélation avec le fait que iowait est plus élevé lorsque le problème se produit.
Les conteneurs qui utilisent une vérification de l'état de l'exécutif produisent de nombreux journaux. Il existe d'autres modèles qui accentuent également le mécanisme de journalisation.
Juste mon 2c
 mauilion
le 19 sept. 2018
mauilion
le 19 sept. 2018
Nous ne voyons pas de haut iowait sur nos machines faisant cela. (CoreOS, Kube 1.10, Docker 17.03)
@mauilion Pouvez-vous nous signaler un problème ou un MR qui explique le problème de journalisation?
 mariusgrigoriu
le 12 oct. 2018
mariusgrigoriu
le 12 oct. 2018
J'ai eu le même problème que deux nœuds Kubernetes oscillaient entre Ready et Not Ready. Croyez-le ou non, la solution était de retirer un conteneur docker sorti et les pods associés.
d4e5d7ef1b5c gcr.io/google_containers/pause-amd64:3.0 Exited (137) 3 days ago
Ensuite, le cluster est redevenu stable, sans autre intervention.
De plus, c'était le message du journal trouvé dans syslog:
E1015 07:48:49.386113 1323 remote_runtime.go:115] StopPodSandbox "d4e5d7ef1b5c3d13a4e537abbc7c4324e735d455969f7563287bcfc3f97b
085f" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
 rchicoli
le 16 oct. 2018
rchicoli
le 16 oct. 2018
Juste face à ce problème en ce moment:
OS: Oracle Linux 7.5
Kernel: 4.17.5-1.el7.elrepo.x86_64
Kubernetes: 1.11.3
Flapping host: v1.11.3
Docker on flapping host: 18.03.1-ce (compiled with go1.9.5)
 emedina
le 24 oct. 2018
emedina
le 24 oct. 2018
https://github.com/containernetworking/cni/pull/568 a été fusionné dans CNI.
IIUC, une nouvelle version de CNI contenant le correctif ci-dessus devrait être en mesure de résoudre ce problème dans k8s.
Une coordination est nécessaire - @bboreham @liucimin . Publier également sur sig-network
 nikopen
le 24 oct. 2018
nikopen
le 24 oct. 2018
Quelle version de kubernetes-cni inclura le correctif? Merci!
 roywangtj
le 16 nov. 2018
roywangtj
le 16 nov. 2018
Un problème plus ciblé à propos des délais d'expiration est # 65743
Comme je l'ai dit là-bas, l'étape suivante est du côté de Kubernetes, pour vérifier que le changement résout bien le problème, par exemple en écrivant un test. Aucune version n'est nécessaire pour vérifier cela: il suffit de saisir le dernier code libCNI.
 bboreham
le 16 nov. 2018
bboreham
le 16 nov. 2018
/ sig network
 tossmilestone
le 26 nov. 2018
tossmilestone
le 26 nov. 2018
Si cela et bloqué docker ps se produisent en conjonction avec MOO déclenché par des pods garantis, jetez un œil à # 72294. comme le conteneur infra pod est tué et redémarré, il peut s'agir d'un cas qui déclenche la réinitialisation cni qui déclenche alors les problèmes de délai d'expiration / de verrouillage mentionnés ci-dessus.
 clkao
le 22 déc. 2018
clkao
le 22 déc. 2018
Nous voyons quelque chose qui semble similaire à ceci - le battement constant de PLEG entre Ready / NotReady - redémarrer kubelet semble résoudre le problème. J'ai remarqué que dans les décharges de goroutines de kubelet, nous en avons un grand nombre (actuellement plus de 15000 goroutines coincées dans la pile suivante:
goroutine 29624527 [semacquire, 2766 minutes]:
sync.runtime_SemacquireMutex(0xc428facb3c, 0xc4216cca00)
/usr/local/go/src/runtime/sema.go:71 +0x3d
sync.(*Mutex).Lock(0xc428facb38)
/usr/local/go/src/sync/mutex.go:134 +0xee
k8s.io/kubernetes/pkg/kubelet/network.(*PluginManager).GetPodNetworkStatus(0xc420820980, 0xc429076242, 0xc, 0xc429076209, 0x38, 0x4dcdd86, 0x6, 0xc4297fa040, 0x40, 0x0, ...)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/network/plugins.go:395 +0x13d
k8s.io/kubernetes/pkg/kubelet/dockershim.(*dockerService).getIPFromPlugin(0xc4217c4500, 0xc429e21050, 0x40, 0xed3bf0000, 0x1af5b22d, 0xed3bf0bc6)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/dockershim/docker_sandbox.go:304 +0x1c6
k8s.io/kubernetes/pkg/kubelet/dockershim.(*dockerService).getIP(0xc4217c4500, 0xc4240d9dc0, 0x40, 0xc429e21050, 0xe55ef53, 0xed3bf0bc7)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/dockershim/docker_sandbox.go:333 +0xc4
k8s.io/kubernetes/pkg/kubelet/dockershim.(*dockerService).PodSandboxStatus(0xc4217c4500, 0xb38ad20, 0xc429e20ed0, 0xc4216214c0, 0xc4217c4500, 0x1, 0x0)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/dockershim/docker_sandbox.go:398 +0x291
k8s.io/kubernetes/pkg/kubelet/apis/cri/runtime/v1alpha2._RuntimeService_PodSandboxStatus_Handler(0x4d789e0, 0xc4217c4500, 0xb38ad20, 0xc429e20ed0, 0xc425afaf00, 0x0, 0x0, 0x0, 0x0, 0x2)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/apis/cri/runtime/v1alpha2/api.pb.go:4146 +0x276
k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).processUnaryRPC(0xc420294640, 0xb399760, 0xc421940000, 0xc4264d8900, 0xc420d894d0, 0xb335000, 0x0, 0x0, 0x0)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/server.go:843 +0xab4
k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).handleStream(0xc420294640, 0xb399760, 0xc421940000, 0xc4264d8900, 0x0)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/server.go:1040 +0x1528
k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).serveStreams.func1.1(0xc42191c020, 0xc420294640, 0xb399760, 0xc421940000, 0xc4264d8900)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/server.go:589 +0x9f
created by k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).serveStreams.func1
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/server.go:587 +0xa1
Je remarque que le nombre de goroutines coincées dans cette pile augmente régulièrement avec le temps (environ 1 supplémentaire toutes les 2 minutes)
Les nœuds qui en font l'expérience ont généralement un pod bloqué dans Terminating - lorsque je redémarre kubelet, le pod Terminating disparaît et je ne vois plus les problèmes PLEG.
@pnovotnak des idées si cela ressemble au même problème qui devrait être résolu par le changement pour ajouter Timeout à CNI, ou autre chose? Semble être des symptômes similaires dans la zone de réseautage.
 mcginne
le 21 janv. 2019
mcginne
le 21 janv. 2019
J'ai la même question: https://github.com/kubernetes/kubernetes/issues/45419#issuecomment -439267946
Quelle version de kubernetes-cni inclura le correctif? Merci!
warmchang
le 1 mars 2019
@warmchang le paquet de plugins kubernetes-cni n'est pas pertinent. La modification requise se trouve dans libcni, qui est vendue (copiée dans ce dépôt) à partir de https://github.com/containernetworking/cni.
Le changement est fusionné; aucune libération n'est nécessaire (bien que cela puisse aider les gens à se sentir mieux).
bboreham
le 1 mars 2019
@bboreham Merci pour la réponse.
Je veux dire le code CNI (libcni) dans le répertoire du fournisseur, pas le plugin CNI (comme flannel / calico, etc.).
Et j'ai trouvé ce PR https://github.com/kubernetes/kubernetes/pull/71653 qui attend l'approbation.
warmchang
le 1 mars 2019
/ jalon v1.14
nikopen
le 1 mars 2019
Je rencontre ce problème, mon env:
docker 18.06
os: centos7.4
noyau: 4.19
kubelet: 1.12.3
mes nœuds battaient entre Ready et Not Ready.
Ceci avant, j'ai supprimé certains pods avec --- force --grace-period = 0. car le pod que je supprime toujours en état de fin.
puis, j'ai trouvé quelques logs dans kubelet:
kubelet [10937]: I0306 19: 23: 32.474487 10937 handlers.go: 62] Crochet de cycle de vie Exec ([/home/work/webserver/loadnginx.sh stop]) pour le conteneur "odp-saas" dans le pod "saas-56bd6d8588- xlknh (15ebc67d-3bed-11e9-ba81-246e96352590) "a échoué - erreur: la commande '/home/work/webserver/loadnginx.sh stop' s'est terminée avec 126:, message:" impossible de trouver le travail de l'utilisateur: aucune entrée correspondante dans passwd fichier \ r \ n "_
car j'utilise la commande prestop de section de cycle de vie dans le déploiement.
#cycle de la vie:
# preStop:
# exec:
# #SIGTERM déclenche une sortie rapide; terminer gracieusement à la place
# commande: ["/home/work/webserver/loadnginx.sh","stop"]
et d'autres journaux montrent que:
kubelet [17119]: E0306 19: 35: 11.223925 17119 remote_runtime.go: 282] ContainerStatus "cbc957993825885269935a343e899b807ea9a49cb9c7f94e68240846af3e701d" de runti
kubelet [17119]: E0306 19: 35: 11.223970 17119 kuberuntime_container.go: 393] ContainerStatus pour cbc957993825885269935a343e899b807ea9a49cb9c7f94e68240846af3e701d e
kubelet [17119]: E0306 19: 35: 11.223978 17119 kuberuntime_manager.go: 866] getPodContainerStatuses pour le pod "gz-saas-56bd6d8588-sk88t_storeic (1303430e-3ffa-11e9-ba8
kubelet [17119]: E0306 19: 35: 11.223994 17119 generic.go: 241] PLEG: Ignorer les événements pour le pod saas-56bd6d8588-sk88t / storeic: rpc error: code = DeadlineExceeded d
kubelet [17119]: E0306 19: 35: 11.224123 17119 pod_workers.go: 186] Erreur de synchronisation du pod 1303430e-3ffa-11e9-ba81-246e96352590 ("gz-saas-56bd6d8588-sk88t_storeic (130343
Mkubelet [17119]: E0306 19: 35: 12.509163 17119 remote_runtime.go: 282] ContainerStatus "4ff7ff8e1eb18ede5eecbb03b60bdb0fd7f7831d8d7e81f59bc69d166d422fb6" de runti
kubelet [17119]: E0306 19: 35: 12.509163 17119 remote_runtime.go: 282] ContainerStatus "cbc957993825885269935a343e899b807ea9a49cb9c7f94e68240846af3e701d" de runti
kubelet [17119]: E0306 19: 35: 12.509220 17119 kubelet_pods.go: 1086] Impossible de tuer le pod "saas-56bd6d8588-rsfh5": échec de "KillContainer" pour "saas" wi
kubelet [17119]: E0306 19: 35: 12.509230 17119 kubelet_pods.go: 1086] Impossible de tuer le pod "saas-56bd6d8588-sk88t": échec de "KillContainer" pour "saas" wi
kubelet [17119]: I0306 19: 35: 12.788887 17119 kubelet.go: 1821] saut de synchronisation de pod - [PLEG n'est pas sain: pleg a été vu pour la dernière fois actif il y a 4m1.597223765s;
k8s ne peut pas arrêter le conteneur, ces conteneurs sont bloqués. cela cause le PLEG pas sain.
enfin, je redémarre le démon docker qui a le conteneur d'erreur, le nœud récupère pour être prêt.
Je ne sais pas pourquoi le conteneur ne peut pas s'arrêter !!! peut être le prestop?
 Damien9527
le 6 mars 2019
Damien9527
le 6 mars 2019
/ jalon v1.15
nikopen
le 11 mars 2019
+1
k8s v1.10.5
docker 17.09.0-ce
 hello2mao
le 22 mars 2019
hello2mao
le 22 mars 2019
+1
k8s v1.12.3
docker 18.06.2-ce
 zhan849
le 11 avr. 2019
zhan849
le 11 avr. 2019
+1
k8s v1.13.4
docker-1.13.1-94.gitb2f74b2.el7.x86_64
 Wade201801
le 16 avr. 2019
Wade201801
le 16 avr. 2019
@ kubernetes / sig-network-bugs @thockin @spiffxp : ping convivial. Cela semble s'être à nouveau arrêté.
calder
le 19 avr. 2019
@calder :
@ kubernetes / sig-network-bugs
En réponse à cela :
@ kubernetes / sig-network-bugs @thockin @spiffxp : ping convivial. Cela semble s'être à nouveau arrêté.
Les instructions pour interagir avec moi en utilisant les commentaires PR sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème sur le
 k8s-ci-robot
le 19 avr. 2019
k8s-ci-robot
le 19 avr. 2019
Bonjour,
Nous avons également trouvé ce problème sur l'une de nos plateformes. La seule différence que nous avions avec les autres clusters est qu'il n'avait qu'un seul nœud maître. Et en effet, nous avons recréé le cluster avec 3 maîtres et nous n'avons pas remarqué le problème jusqu'à présent (quelques jours maintenant).
Donc, je suppose que ma question est: est-ce que quelqu'un a remarqué ce problème sur un cluster multi-maître (> = 3)?
 Kanshiroron
le 29 avr. 2019
Kanshiroron
le 29 avr. 2019
@Kanshiroron oui, nous avons un cluster à 3 maîtres et avons rencontré ce problème sur un nœud de travail hier. Nous avons vidé le nœud et l'avons redémarré et il est revenu proprement. La plate-forme est Docker EE avec k8s v1.11.8 et Docker Enterprise 18.09.2-ee
 mshade
le 1 mai 2019
mshade
le 1 mai 2019
Nous avons un cluster à 3 maîtres (avec un cluster etcd à 3 nœuds). Il existe 18 nœuds de travail et chacun des nœuds exécute entre 50 et 100 conteneurs docker en moyenne (pas de pods, mais un total de conteneurs).
Je constate une corrélation positive nette entre des événements de spinup de pod importants et le besoin de redémarrer un nœud en raison d'erreurs PLEG. À l'occasion, certaines de nos spin-ups provoquent la création de plus de 100 conteneurs dans l'infrastructure, et lorsque cela se produit, nous voyons presque toujours des erreurs PLEG qui en résultent.
Avons-nous une compréhension de ce qui cause cela, au niveau d'un nœud ou d'un cluster?
 standaloneSA
le 8 mai 2019
standaloneSA
le 8 mai 2019
Je suis un peu déconnecté de cela - savons-nous ce qui se passe? Y a-t-il un correctif @bboreham (puisque vous
 thockin
le 9 mai 2019
thockin
le 9 mai 2019
Je soupçonne que ce symptôme peut être causé de plusieurs façons, et nous n'avons pas grand-chose à faire pour la plupart des commentaires «J'ai le même problème» ici.
L'un de ces moyens a été détaillé sur https://github.com/kubernetes/kubernetes/issues/45419#issuecomment -405168344 et similaire sur https://github.com/kubernetes/kubernetes/issues/45419#issuecomment -456081337 - appels dans CNI pourrait pendre pour toujours, brisant Kubelet. Le problème # 65743 indique que nous devrions ajouter un délai.
Pour résoudre ce problème, nous avons décidé d'insérer un Context dans libcni afin que l'annulation puisse être implémentée par exec.CommandContext() . Le PR # 71653 ajoute un délai d'expiration du côté CRI de cette API.
(pour plus de clarté: aucune modification des plugins CNI n'est impliquée; il s'agit d'une modification du code qui exécute le plugin)
bboreham
le 9 mai 2019
D'accord, j'ai eu l'occasion de faire du débogage sur un essaim PLEG (ce que nous appelons cela récemment), et j'ai trouvé des corrélations entre les erreurs PLEG signalées par K8 et les entrées du journal Docker.service:
Sur deux serveurs, j'ai trouvé ceci:
À partir du script qui surveillait les erreurs:
Sat May 11 03:27:19 PDT 2019 - SERVER-A
Found: Ready False Sat, 11 May 2019 03:27:10 -0700 Sat, 11 May 2019 03:13:16 -0700 KubeletNotReady PLEG is not healthy: pleg was last seen active 16m53.660513472s ago; threshold is 3m0s
Les entrées correspondantes dans la sortie de SERVER-A de 'journalctl -u docker.service':
May 11 03:10:20 SERVER-A dockerd[1133]: time="2019-05-11T03:10:20.641064617-07:00" level=error msg="stream copy error: reading from a closed fifo"
May 11 03:10:20 SERVER-A dockerd[1133]: time="2019-05-11T03:10:20.641083454-07:00" level=error msg="stream copy error: reading from a closed fifo"
May 11 03:10:20 SERVER-A dockerd[1133]: time="2019-05-11T03:10:20.740845910-07:00" level=error msg="Error running exec a9fe257c0fca6ff3bb05a7582015406e2f7f6a7db534b76ef1b87d297fb3dcb9 in container: OCI runtime exec failed: exec failed: container_linux.go:344: starting container process caused \"process_linux.go:113: writing config to pipe caused \\\"write init-p: broken pipe\\\"\": unknown"
May 11 03:10:20 SERVER-A dockerd[1133]: time="2019-05-11T03:10:20.767528843-07:00" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
27 lines of this^^ repeated
Ensuite, sur un serveur différent, à partir de mon script:
Sat May 11 03:38:25 PDT 2019 - SERVER-B
Found: Ready False Sat, 11 May 2019 03:38:16 -0700 Sat, 11 May 2019 03:38:16 -0700 KubeletNotReady PLEG is not healthy: pleg was last seen active 3m6.168050703s ago; threshold is 3m0s
et du journal des dockers:
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.745124988-07:00" level=error msg="stream copy error: reading from a closed fifo"
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.745139806-07:00" level=error msg="stream copy error: reading from a closed fifo"
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.803182460-07:00" level=error msg="1a5dbb24b27cd516373473d34717edccc095e712238717ef051ce65022e10258 cleanup: failed to delete container from containerd: no such container"
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.803267414-07:00" level=error msg="Handler for POST /v1.38/containers/1a5dbb24b27cd516373473d34717edccc095e712238717ef051ce65022e10258/start returned error: OCI runtime create failed: container_linux.go:344: starting container process caused \"process_linux.go:297: getting the final child's pid from pipe caused \\\"EOF\\\"\": unknown"
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.876522066-07:00" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.964447832-07:00" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
Malheureusement, lors de la validation de cela sur mes nœuds «sains», je peux également trouver des exemples de ceux-ci se produisant ensemble.
Je vais travailler pour corréler cela avec d'autres variables, mais la recherche de ces messages d'erreur conduit à des discussions intéressantes:
Kubernetes: augmenter le nombre maximal de pods par nœud # 23349
Ce dernier lien a un commentaire particulièrement intéressant de @dElogics (faisant référence à ce ticket):
Juste pour ajouter des informations précieuses, l'exécution de nombreux pods par nœud aboutit à # 45419. Comme correctif, supprimez le répertoire docker et redémarrez docker et kubelet ensemble.
standaloneSA
le 11 mai 2019
Dans mon cas, j'utilise K8s v1.10.2 et docker-ce v18.03.1. Je trouve quelques journaux de kubelet qui fonctionnent sur le nœud battant Ready / NotReady comme:
E0512 09:17:56.721343 4065 pod_workers.go:186] Error syncing pod e5b8f48a-72c2-11e9-b8bf-005056871a33 ("uac-ddfb6d878-f6ph2_default(e5b8f48a-72c2-11e9-b8bf-005056871a33)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
E0512 09:17:17.154676 4065 kuberuntime_manager.go:859] PodSandboxStatus of sandbox "a34943dabe556924a2793f1be2f7181aede3621e2c61daef0838cf3fc61b7d1b" for pod "uac-ddfb6d878-f6ph2_default(e5b8f48a-72c2-11e9-b8bf-005056871a33)" error: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Et j'ai trouvé que ce pod uac-ddfb6d878-f6ph2_default se terminait, donc ma solution de contournement est de forcer la suppression du pod et de supprimer tous les conteneurs de ce pod sur ce nœud et ce nœud fonctionne bien après cela:
$ kubectl delete pod uac-ddfb6d878-f6ph2 --force --grace-period=0
$ docker ps -a | grep uac-ddfb6d878-f6ph2_default
 thaonguyenct
le 12 mai 2019
thaonguyenct
le 12 mai 2019
salut! Nous avons lancé Bug Freeze pour la version 1.15. Cette question est-elle toujours prévue pour être intégrée dans 1.15?
 soggiest
le 29 mai 2019
soggiest
le 29 mai 2019
salut
Nous rencontrions ce même problème sur notre cluster OKD.
Nous avons enquêté sur les nœuds qui battaient et, après quelques fouilles, nous avons trouvé ce que nous pensions être notre problème.
Lorsque nous avons étudié le battement des nœuds, nous avons constaté que les nœuds qui battaient avaient des valeurs de charge moyenne absurdement élevées, l'un des nœuds (16 cœurs, 32 threads, 96 Go de mémoire) avait une valeur de charge moyenne de, à son apogée, 850.
Trois de nos nœuds sont équipés de Rook Ceph.
Nous avons découvert que Prometheus utilisait le stockage par blocs de Rook Ceph et inondait les périphériques de blocs de lecture / écriture.
Dans le même temps, ElasticSearch utilisait également le stockage en bloc de Rook Ceph. Nous avons constaté que les processus ElasticSearch tentaient d'effectuer une opération d'E / S de disque, pendant que Prometheus inondait les périphériques de bloc, et entreraient dans un état ininterrompu en attendant la fin de l'opération d'E / S.
Ensuite, un autre processus ES tenterait la même chose.
Ensuite un autre.
Et un autre.
Nous entrerions dans un état où tout le processeur de notre nœud avait des threads réservés pour les processus ES qui étaient dans des états ininterrompus en attendant que le périphérique de bloc Ceph se libère de l'inondation Prometheus.
Même si le processeur n'était pas à 100% de charge, les threads étaient réservés.
Cela a obligé tous les autres processus à attendre le temps processeur, ce qui a provoqué l'échec des opérations Docker, ce qui a entraîné l'expiration de PLEG et le nœud commence à clignoter.
Notre solution était de redémarrer le pod Prometheus incriminé.
Version OKD / K8s:
$ oc version
oc v3.11.0+0cbc58b
kubernetes v1.11.0+d4cacc0
features: Basic-Auth GSSAPI Kerberos SPNEGO
Server https://okd.example.net:8443
openshift v3.11.0+d0f1080-153
kubernetes v1.11.0+d4cacc0
Version de Docker sur le nœud:
$ docker version
Client:
Version: 1.13.1
API version: 1.26
Package version: docker-1.13.1-88.git07f3374.el7.centos.x86_64
Go version: go1.9.4
Git commit: 07f3374/1.13.1
Built: Fri Dec 7 16:13:51 2018
OS/Arch: linux/amd64
Server:
Version: 1.13.1
API version: 1.26 (minimum version 1.12)
Package version: docker-1.13.1-88.git07f3374.el7.centos.x86_64
Go version: go1.9.4
Git commit: 07f3374/1.13.1
Built: Fri Dec 7 16:13:51 2018
OS/Arch: linux/amd64
Experimental: false
Éditer:
Pour résumer: je ne pense pas que ce soit un problème K8s / OKD, je pense que c'est un problème "une ressource sur votre nœud est verrouillée par quelque chose qui provoque une accumulation de processus en attendant le temps CPU et qui casse tout".
 rblaine95
le 29 mai 2019
rblaine95
le 29 mai 2019
/ jalon v1.16
soggiest
le 7 juin 2019
@bboreham @soggiest Bonjour! Je suis une ombre de triage des bogues pour le cycle de publication de la version 1.16 et étant donné que ce problème est marqué pour la version 1.16, mais pas mis à jour depuis longtemps, j'aimerais vérifier son statut. Le gel du code commence le 29 août (dans environ 1,5 semaine à partir de maintenant), ce qui signifie qu'il devrait y avoir un PR prêt (et fusionné) d'ici là.
Est-ce que nous ciblons toujours ce problème à résoudre pour la version 1.16?
 makoscafee
le 23 août 2019
makoscafee
le 23 août 2019
@makoscafee Peut confirmer que cela ne se produit plus dans la version 1.13.6 (et les versions ultérieures) et dans le docker 18.06.3-ce
Pour nous, cela semble être en quelque sorte lié à un Timeout lors de l'appel de CNI ou à une intégration externe.
Nous avons été confrontés à cela récemment, mais avec un autre scénario, alors que certains des serveurs NFS utilisés dans notre cluster se sont fissurés (et que toutes les E / S de nos nœuds ont gelé), kubelet a commencé à imprimer des problèmes PLEG liés à l'incapacité de démarrer de nouveaux conteneurs car du délai d’expiration des E / S.
Cela pourrait donc être un signe qu'avec CNI et CRI, cela est PROBABLEMENT résolu, car nous ne l'avons pas revu dans notre cluster lié aux problèmes de réseau.
rikatz
le 26 août 2019
@makoscafee comme je l'ai déjà dit , il y a beaucoup de gens qui rapportent beaucoup de choses dans ce numéro; Je répondrai ici sur le point spécifique du délai d'expiration d'une demande CNI.
En regardant le code, je ne pense pas que kubelet a été mis à jour pour utiliser le nouveau comportement dans CNI où le contexte peut être annulé.
Par exemple, appeler CNI ici: https://github.com/kubernetes/kubernetes/blob/038e5fad7596d50f449f1c6f8625171a8acfc586/pkg/kubelet/dockershim/network/cni/cni.go#L348
Ce PR ajouterait un timeout: # 71653, mais est toujours en suspens.
Je ne peux pas parler de ce qui aurait changé dans la version 1.13.6 pour provoquer l'expérience @rikatz .
bboreham
le 26 août 2019
En effet, j'ai eu beaucoup de mises à jour dans Calico depuis, peut-être que quelque chose là-bas (et pas dans Kubernetes Code) a changé. Docker (qui pourrait également être un problème à cette époque) a également été mis à niveau à plusieurs reprises, donc pas de bon chemin à suivre ici
Je ressens une certaine honte ici de ne pas prendre de notes à l'époque où le problème est survenu (désolé) pour au moins vous dire ce qui a changé à partir de là pour devenir nos problèmes d'aujourd'hui.
rikatz
le 26 août 2019
Salut à tous,
Je voulais juste partager notre expérience avec cette erreur.
Nous avons rencontré cette erreur sur un cluster fraîchement déployé exécutant docker EE 19.03.1 et k8s v1.14.3.
Pour nous, il semble que le problème ait été déclenché par le pilote de journalisation. Notre moteur docker est configuré pour utiliser le pilote de journalisation fluentd. Après le nouveau déploiement du cluster, fluentd n'était pas encore déployé. Si, à ce stade, nous avons essayé de planifier des pods sur les nœuds de calcul, nous avons rencontré le même comportement que vous avez décrit ci-dessus (erreur PLEG sur les conteneurs kubelet sur les nœuds de travail et les nœuds de travail étant signalée au hasard comme défectueuse)
Cependant, une fois que nous avons déployé fluentd et que docker a pu s'y connecter, tous les problèmes ont disparu. Il semble donc que le fait de ne pas pouvoir communiquer avec fluentd en était la cause profonde.
J'espère que cela t'aides. À votre santé
 dariuscernea
le 27 août 2019
dariuscernea
le 27 août 2019
Cela a été un problème de longue date (k8s 1.6!) Et a dérangé pas mal de personnes travaillant avec k8s.
Outre les nœuds surchargés (max cpu%, io, interruptions), les problèmes PLEG sont parfois causés par des problèmes nuancés entre kubelet, docker, journalisation, mise en réseau, etc., la résolution du problème étant parfois brutale (redémarrage de tous les nœuds, etc. l'affaire).
En ce qui concerne le message d'origine, avec la fusion de https://github.com/kubernetes/kubernetes/pull/71653 , kubelet est mis à jour et est maintenant en mesure d'expirer une requête CNI, annulant le contexte avant que la date limite ne soit dépassée.
Kubernetes 1.16 contiendra le correctif.
Je vais également ouvrir les PR pour ramener cela à 1.14 et 1.15 car ils ont une version CNI qui contient la nouvelle fonctionnalité de délai d'expiration (> = 0.7.0). 1.13 a un CNI v plus ancien sans la fonctionnalité.
Ainsi, cela peut être finalement fermé.
/Fermer
nikopen
le 28 août 2019
@nikopen : Clôture de ce numéro.
En réponse à cela :
Cela a été un problème de longue date (k8s 1.6!) Et a dérangé pas mal de personnes travaillant avec k8s.
Il y a diverses choses qui causent des problèmes PLEG et qui ont généralement été compliquées entre kubelet, docker, journalisation, mise en réseau, etc., la résolution du problème étant parfois brutale (redémarrage de tous les nœuds, etc., selon le cas).
En ce qui concerne le message d'origine, avec la fusion de https://github.com/kubernetes/kubernetes/pull/71653 , kubelet est mis à jour et est maintenant en mesure d'expirer une requête CNI, annulant le contexte avant que la date limite ne soit dépassée.
Kubernetes 1.16 contiendra le correctif.
Je vais également ouvrir les PR pour ramener cela à 1.14 et 1.15 car ils ont une version CNI qui contient la nouvelle fonctionnalité de délai d'expiration (> = 0.7.0). 1.13 a un CNI v plus ancien sans la fonctionnalité.Ainsi, cela peut être finalement fermé.
/Fermer
Les instructions pour interagir avec moi en utilisant les commentaires PR sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème sur le
k8s-ci-robot
le 28 août 2019
D'après l'expérience personnelle depuis 1.6 en production, les problèmes PLEG apparaissent généralement lorsqu'un nœud se noie.
- La charge du processeur est très élevée
- Les E / S disque sont maximisées (journalisation?)
- Surcharge globale (CPU + disque + réseau) => CPU est interrompu tout le temps
Résultat => Le démon Docker ne répond pas
 Misteur-Z
le 28 août 2019
Misteur-Z
le 28 août 2019
D'après l'expérience personnelle depuis
1.6en production, les problèmes PLEG apparaissent généralement lorsqu'un nœud se noie.
- La charge du processeur est très élevée
- Les E / S disque sont maximisées (journalisation?)
- Surcharge globale (CPU + disque + réseau) => CPU est interrompu tout le temps
Résultat => Le démon Docker ne répond pas
Je suis d'accord avec cela, j'utilise la version 1.14.5 Kubernetes, a le même problème.
 Aisuko
le 6 sept. 2019
Aisuko
le 6 sept. 2019
même problème avec v1.13.10 exécuté dans le réseau calico.
 zx1986
le 19 sept. 2019
zx1986
le 19 sept. 2019
/ouvert
@nikopen : il semble que le PR soit pour 1.17? Je n'ai pas trouvé le numéro PR dans le journal des modifications pour 1.16.1.
 pdhung
le 7 oct. 2019
pdhung
le 7 oct. 2019
Je n'ai pas vu ce problème mentionné dans le journal des modifications de la version 1.14. Cela signifie-t-il qu'il n'a pas (encore) été cueilli à la cerise? Qu'il sera?
 kwaazaar
le 24 oct. 2019
kwaazaar
le 24 oct. 2019
Récupérer de PLEG n'est pas un problème sain
Désactivez le démarrage automatique de docker et kubelet, redémarrez puis nettoyez les pods kubelet et les fichiers docker:
systemctl désactiver docker && systemctl désactiver kubelet
redémarrer
rm -rf / var / lib / kubelet / pods /
rm -rf / var / lib / docker
démarrer et activer le docker
systemctl démarrer le docker && systemctl activer le docker
menu fixe d'état systemctl
Étant donné que / var / lib / docker a été nettoyé, veuillez importer les images nécessaires manuellement si le nœud ne peut pas se connecter à la bibliothèque d'images k8s.
chargement docker -i xxx.tar
démarrer Kubelet
systemctl démarrer kubelet && systemctl activer kubelet
kubelet d'état de systemctl
 jackie-qiu
le 14 nov. 2019
jackie-qiu
le 14 nov. 2019
@ jackie-qiu Mieux vaut faire sauter votre serveur avec une grenade ou le laisser tomber du 10ème étage, juste pour être sûr que le problème ne se reproduira plus ...
adampl
le 14 nov. 2019
même problème avec v1.15.6 exécuté dans le réseau de flanelle.
 leowucn
le 27 nov. 2019
leowucn
le 27 nov. 2019
Je n'ai pas grand-chose à ajouter sur les causes du problème car il semble que tout avait déjà été écrit ici. Nous utilisons une ancienne version du serveur 1.10.13. Nous avons essayé de mettre à niveau mais ce n'est pas si simple à faire.
Pour nous, cela se produit principalement dans l'un des environnements de production et très en arrière de notre environnement de développement. Dans cet environnement de production, où il est constamment reproduit, cela se produit uniquement pendant la mise à jour progressive et uniquement pour deux certains pods (jamais lorsque d'autres pods sont supprimés lors de la mise à jour progressive). Dans notre environnement de développement, cela est arrivé à d'autres pods.
La seule chose que je vois dans les journaux est:
Quand il réussit:
27 novembre 11:34:45 ip-172-31-174-8 kubelet [8024]: 2019-11-27 11: 34: 45.453 [INFO] [1946] client.go 202: Chargement de la configuration depuis l'environnement
27 novembre 11:34:45 ip-172-31-174-8 kubelet [8024]: 2019-11-27 11: 34: 45.454 [INFO] [1946] calico-ipam.go 249: Libération de l'adresse à l'aide de handleID handleID = "k8s-pod-network.e923743c5dc4833e606bf16f388c564c20c4c1373b18881d8ea1c8eb617f6e62" workloadID = "default.good-pod-name-557644b486-7rxw5"
27 novembre 11:34:45 ip-172-31-174-8 kubelet [8024]: 2019-11-27 11: 34: 45.454 [INFO] [1946] ipam.go 738: Libération de toutes les adresses IP avec le handle 'k8s- pod-network.e923743c5dc4833e606bf16f388c564c20c4c1373b18881d8ea1c8eb617f6e62 '
27 novembre 11:34:45 ip-172-31-174-8 kubelet [8024]: 2019-11-27 11: 34: 45.498 [INFO] [1946] ipam.go 877: descripteur décrémenté 'k8s-pod-network .e923743c5dc4833e606bf16f388c564c20c4c1373b18881d8ea1c8eb617f6e62 'par 1
27 novembre 11:34:45 ip-172-31-174-8 kubelet [8024]: 2019-11-27 11: 34: 45.498 [INFO] [1946] calico-ipam.go 257: Adresse libérée à l'aide de handleID handleID = "k8s-pod-network.e923743c5dc4833e606bf16f388c564c20c4c1373b18881d8ea1c8eb617f6e62" workloadID = "default.good-pod-name-557644b486-7rxw5"
27 novembre 11:34:45 ip-172-31-174-8 kubelet [8024]: 2019-11-27 11: 34: 45.498 [INFO] [1946] calico-ipam.go 261: Libération de l'adresse à l'aide de workloadID handleID = "k8s-pod-network.e923743c5dc4833e606bf16f388c564c20c4c1373b18881d8ea1c8eb617f6e62" workloadID = "default.good-pod-name-557644b486-7rxw5"
27 novembre 11:34:45 ip-172-31-174-8 kubelet [8024]: 2019-11-27 11: 34: 45.498 [INFO] [1946] ipam.go 738: Libération de toutes les adresses IP avec le handle par défaut. bon-nom-du-pod-557644b486-7rxw5 '
27 novembre 11:34:45 ip-172-31-174-8 kubelet [8024]: Calico CNI supprimant le périphérique dans netns / proc / 6337 / ns / net
27 novembre 11:34:45 ip-172-31-174-8 kubelet [8024]: 2019-11-27 11: 34: 45.590 [INFO] [1929] k8s.go 379: Traitement de démontage terminé. Workload = "default.good-pod-name-557644b486-7rxw5" "
En cas d'échec:
27 novembre 11:46:49 ip-172-31-174-8 kubelet [8024]: 2019-11-27 11: 46: 49.681 [INFO] [5496] client.go 202: Chargement de la configuration depuis l'environnement
27 novembre 11:46:49 ip-172-31-174-8 kubelet [8024]: 2019-11-27 11: 46: 49.681 [INFO] [5496] calico-ipam.go 249: Libération de l'adresse à l'aide de handleID handleID = "k8s-pod-network.3afc7f2064dc056cca5bb8c8ff20c81aaf6ee8b45a1346386c239b92527b945b" workloadID = "default.bad-pod-name-5fc88df4b-rkw7m"
27 novembre 11:46:49 ip-172-31-174-8 kubelet [8024]: 2019-11-27 11: 46: 49.681 [INFO] [5496] ipam.go 738: Libération de toutes les adresses IP avec le handle 'k8s- pod-network.3afc7f2064dc056cca5bb8c8ff20c81aaf6ee8b45a1346386c239b92527b945b '
27 novembre 11:46:49 ip-172-31-174-8 kubelet [8024]: 2019-11-27 11: 46: 49.716 [INFO] [5496] ipam.go 877: descripteur décrémenté 'k8s-pod-network .3afc7f2064dc056cca5bb8c8ff20c81aaf6ee8b45a1346386c239b92527b945b 'par 1
27 novembre 11:46:49 ip-172-31-174-8 kubelet [8024]: 2019-11-27 11: 46: 49.716 [INFO] [5496] calico-ipam.go 257: Adresse libérée à l'aide de handleID handleID = "k8s-pod-network.3afc7f2064dc056cca5bb8c8ff20c81aaf6ee8b45a1346386c239b92527b945b" workloadID = "default.bad-pod-name-5fc88df4b-rkw7m"
27 novembre 11:46:49 ip-172-31-174-8 kubelet [8024]: 2019-11-27 11: 46: 49.716 [INFO] [5496] calico-ipam.go 261: Libération de l'adresse à l'aide de workloadID handleID = "k8s-pod-network.3afc7f2064dc056cca5bb8c8ff20c81aaf6ee8b45a1346386c239b92527b945b" workloadID = "default.bad-pod-name-5fc88df4b-rkw7m"
27 novembre 11:46:49 ip-172-31-174-8 kubelet [8024]: 2019-11-27 11: 46: 49.716 [INFO] [5496] ipam.go 738: Libération de toutes les adresses IP avec le handle par défaut. mauvais-nom-pod-5fc88df4b-rkw7m '
27 novembre 11:46:49 ip-172-31-174-8 kubelet [8024]: Calico CNI supprimant le périphérique dans netns / proc / 7376 / ns / net
27 novembre 11:46:51 ip-172-31-174-8 ntpd [8188]: Suppression de l'interface # 1232 cali8e016aaff48, fe80 :: ecee: eeff : feee: eeee% 816 # 123 , statistiques de l'interface: reçu = 0, envoyé = 0, abandonné = 0, active_time = 242773 s
27 novembre 11:46:59 ip-172-31-174-8 noyau: [11155281.312094] unregister_netdevice: en attente de la libération d'eth0. Nombre d'utilisation = 1
 gilShin
le 2 déc. 2019
gilShin
le 2 déc. 2019
Quelqu'un a-t-il mis à niveau vers la v1.16? Quelqu'un peut-il confirmer si cela est résolu et que vous ne voyez plus de problème PLEG. Nous voyons fréquemment ce problème en production et la seule option est de redémarrer le nœud.
 ganeshv02
le 5 déc. 2019
ganeshv02
le 5 déc. 2019
J'ai une question concernant le correctif.
Disons que j'installe la version la plus récente qui inclut le correctif du délai d'expiration. Je comprends qu'il publiera le kublet et que nous autoriserons le pod bloqué à l'état de terminaison à s'arrêter, mais est-ce qu'il publiera également eth0? Les nouveaux pods pourront-ils fonctionner sur ce nœud ou resteront-ils prêts / non prêts?
gilShin
le 5 déc. 2019
Pour moi, Docker 19.03.4 a corrigé les deux pods bloqués dans l'état de terminaison et les nœuds oscillant entre Ready / NotReady avec des problèmes PLEG.
La version de Kubernetes n'a pas changé depuis la 1.15.6. Le seul changement dans le cluster était le plus récent Docker.
 hakman
le 5 déc. 2019
hakman
le 5 déc. 2019
Mise à niveau du noyau d'Ubuntu 16.04 de 4.4 à 4.15. Il a fallu trois jours pour que l'erreur se reproduise.
Je vais voir si je peux mettre à niveau la version docker de 17 à 19 comme le suggérait hakman sur un Ubuntu 16.04.
Je préfère ne pas mettre à niveau la version Ubuntu.
gilShin
le 15 déc. 2019
Il n'y a aucun moyen de mettre à niveau le docker vers 19 avec k8s 1.10. Nous devrons d'abord passer à la version 1.15, ce qui prendra un certain temps car il n'y a aucun moyen de passer à la version 1.15 strait. Nous devrons mettre à jour un par un 1.10 -> 1.11 -> 1.12 etc '
gilShin
le 15 déc. 2019
Le bilan de santé PLEG fait très peu. À chaque itération, il appelle
docker pspour détecter les changements d'états des conteneurs, et appelledocker psetinspectpour obtenir les détails de ces conteneurs.
Après avoir terminé chaque itération, il met à jour un horodatage. Si l'horodatage n'a pas été mis à jour pendant un certain temps (c'est-à-dire 3 minutes), la vérification de l'état échoue.À moins que votre nœud ne soit chargé avec un grand nombre de pods que PLEG ne peut pas finir de faire tout cela en 3 minutes (ce qui ne devrait pas arriver), la cause la plus probable serait que le docker soit lent. Vous ne pouvez pas observer cela dans votre
docker psoccasionnelSi nous n'exposons pas le statut "malsain", cela cacherait de nombreux problèmes aux utilisateurs et causerait potentiellement plus de problèmes. Par exemple, kubelet ne réagissait pas silencieusement aux changements en temps opportun et causait encore plus de confusion.
Les suggestions sur la façon de rendre cela plus débuggable sont les bienvenues ...
Cela a été un problème de longue date (k8s 1.6!) Et a dérangé pas mal de personnes travaillant avec k8s.
Outre les nœuds surchargés (max cpu%, io, interruptions), les problèmes PLEG sont parfois causés par des problèmes nuancés entre kubelet, docker, journalisation, mise en réseau, etc., la résolution du problème étant parfois brutale (redémarrage de tous les nœuds, etc. l'affaire).
En ce qui concerne le message d'origine, avec # 71653 finalement fusionné, kubelet est mis à jour et est maintenant capable d'expirer une requête CNI, annulant le contexte avant que la date limite ne soit dépassée.
Kubernetes 1.16 contiendra le correctif.
Je vais également ouvrir les PR pour ramener cela à 1.14 et 1.15 car ils ont une version CNI qui contient la nouvelle fonctionnalité de délai d'expiration (> = 0.7.0). 1.13 a un CNI v plus ancien sans la fonctionnalité.Ainsi, cela peut être finalement fermé.
/Fermer
Je suis confus ... si ce problème peut être causé par un démon docker lent, comment se fait-il qu'il puisse être corrigé en ajoutant simplement un délai d'attente aux appels cni?
 jmf0526
le 30 déc. 2019
jmf0526
le 30 déc. 2019
J'utilise containerd + kubernetes 1.16, cela se produit toujours facilement lorsque j'ai 191 conteneurs par nœud. Que diriez-vous d'augmenter le seuil? Ou de meilleures solutions? @yujuhong
 haosdent
le 31 janv. 2020
haosdent
le 31 janv. 2020
@haosdent Vérifiez si le correctif a été fusionné dans votre version de Kubernetes. S'il s'agit de la version 1.16, il doit s'agir de la dernière version. Ou passez à la version 1.17 et vous l'aurez à 100%.
adampl
le 2 févr. 2020
Ayant eu la même question que @haosdent , je suis allé voir si # 71653 avait été rétroporté.
- # 71653 a été rétroporté vers la v1.16 (PR: # 86825). Il est inclus dans la v1.16.7 ( changelog ).
- Il ne semble pas avoir été rétroporté vers la v1.15 ou une version antérieure ( recherche PR , journal des modifications v1.15 ).
Il semble donc que v1.16.7 ou v1.17.0 soient les versions minimales de k8s requises pour obtenir ce correctif.
 david-in-perth
le 17 mars 2020
david-in-perth
le 17 mars 2020
Nous exécutons v1.16.7 avec une charge minimale sur AWS provisionné par kops avec le noyau de l'image debian de kops mis à niveau vers 4.19 en utilisant cilium v1.6.5.
: man_shrugging: Donc, il est toujours là: /
Mais doivent enquêter plus avant.
_sidenote_ s'est produit également avec ubuntu provisionné par kubespray avec v1.16.4
Pour l'instant, un redémarrage du nœud le résout pendant une courte période.
Seulement arrivé avec les nœuds c5.large ec2
Docker était dans les deux cas 18.04. Je vais donc essayer de mettre à niveau le docker vers 19.03.4 comme mentionné ci-dessus.
 fentas
le 2 avr. 2020
fentas
le 2 avr. 2020
Le problème peut également être causé par l'ancienne version de systemd, essayez de mettre à niveau systemd.
réf:
https://my.oschina.net/yunqi/blog/3041189 (chinois uniquement)
https://github.com/lnykryn/systemd-rhel/pull/322
 hulucc
le 8 avr. 2020
hulucc
le 8 avr. 2020
Nous voyons également ce problème dans 1.16.8 + docker 18.06.2
# docker info
Containers: 186
Running: 155
Paused: 0
Stopped: 31
Images: 48
Server Version: 18.06.2-ce
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file logentries splunk syslog
Swarm: inactive
Runtimes: nvidia runc
Default Runtime: nvidia
Init Binary: docker-init
containerd version: 468a545b9edcd5932818eb9de8e72413e616e86e
runc version: 6635b4f0c6af3810594d2770f662f34ddc15b40d-dirty (expected: 69663f0bd4b60df09991c08812a60108003fa340)
init version: fec3683
Security Options:
apparmor
seccomp
Profile: default
Kernel Version: 5.0.0-1027-aws
Operating System: Ubuntu 18.04.4 LTS
OSType: linux
Architecture: x86_64
CPUs: 48
Total Memory: 373.8GiB
Name: node-cmp-test-kubecluster-2-0a03fdfa
ID: E74R:BMMI:XOFX:BK4X:53AT:JQLZ:CDF6:M6X7:J56G:2DTZ:OTRK:5OJB
Docker Root Dir: /mnt/docker
Debug Mode (client): false
Debug Mode (server): false
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: true
WARNING: No swap limit support
See docker peut rencontrer un délai d'expiration lors de l'écriture dans le socket de fichier bien avant que PLEG ne soit pas sain et que le nœud soit flap. Dans ce cas, le noyau est capable de tuer le processus bloqué et le nœud peut récupérer. mais dans de nombreux autres cas, nous voyons que le nœud n'est pas capable de récupérer et ne peut même pas être ssh-ed, donc peut-être aussi une combinaison de différents problèmes.
L'un des plus gros problèmes est que, en tant que fournisseur de plate-forme, docker peut mal tourner avant que PLEG ne soit signalé comme "malsain", c'est donc toujours l'utilisateur qui nous signale l'erreur au lieu de détecter de manière proactive le problème et de nettoyer les dégâts pour l'utilisateur. Lorsque le problème survient, 2 phénomènes intéressants en métrique:
- Les métriques CRI n'indiquent pas de pic dans QPS avant que le problème ne se produise
- Une fois que le problème se produit, aucune métrique n'est générée à partir de kubelet (notre backend de surveillance ne reçoit rien, mais un tel problème PLEG non sain vient généralement avec un nœud non compatible avec ssh, donc manque de point de données de débogage ici)
Nous examinons les métriques de docker et voyons si une alerte peut être définie à ce sujet.
May 8 16:32:25 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:25Z" level=info msg="shim reaped" id=522fbf813ab6c63b17f517a070a5ebc82df7c8f303927653e466b2d12974cf45
--
May 8 16:32:25 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:25.557712045Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:32:26 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:26.204921094Z" level=warning msg="Your kernel does not support swap limit capabilities,or the cgroup is not mounted. Memory limited without swap."
May 8 16:32:26 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:26Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/679b08e796acdd04b40802f2feff8086d7ba7f96182dcf874bb652fa9d9a7aec/shim.sock" debug=false pid=6592
May 8 16:32:26 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:26Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/2ef0c4109b9cd128ae717d5c55bbd59810f88f3d8809424b620793729ab304c3/shim.sock" debug=false pid=6691
May 8 16:32:26 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:26.871411364Z" level=warning msg="Your kernel does not support swap limit capabilities,or the cgroup is not mounted. Memory limited without swap."
May 8 16:32:26 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:26Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/905b3c35be073388e3c037da65fe55bdb4f4b236b86dcf1e1698d6987dfce28c/shim.sock" debug=false pid=6790
May 8 16:32:27 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:27Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/b4e6991f9837bf82533569d83a942fd8f3ae9fa869d5a0e760a967126f567a05/shim.sock" debug=false pid=6884
May 8 16:32:42 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:42.409620423Z" level=warning msg="Your kernel does not support swap limit capabilities,or the cgroup is not mounted. Memory limited without swap."
May 8 16:37:28 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:27Z" level=info msg="shim reaped" id=2ef0c4109b9cd128ae717d5c55bbd59810f88f3d8809424b620793729ab304c3
May 8 16:37:28 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:28.400830650Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:37:30 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:29Z" level=info msg="shim reaped" id=905b3c35be073388e3c037da65fe55bdb4f4b236b86dcf1e1698d6987dfce28c
May 8 16:37:30 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:30.316345816Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:37:30 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:30Z" level=info msg="shim reaped" id=b4e6991f9837bf82533569d83a942fd8f3ae9fa869d5a0e760a967126f567a05
May 8 16:37:30 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:30.931134481Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:37:35 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:35Z" level=info msg="shim reaped" id=679b08e796acdd04b40802f2feff8086d7ba7f96182dcf874bb652fa9d9a7aec
May 8 16:37:36 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:36.747358875Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:39:31 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63281.723692] mybr0: port 2(veth3f150f6c) entered disabled state
May 8 16:39:31 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63281.752694] device veth3f150f6c left promiscuous mode
May 8 16:39:31 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63281.756449] mybr0: port 2(veth3f150f6c) entered disabled state
May 8 16:39:35 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:39:34Z" level=info msg="shim reaped" id=fa731d8d33f9d5a8aef457e5dab43170c1aedb529ce9221fd6d916a4dba07ff1
May 8 16:39:35 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:39:35.106265137Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.505842] INFO: task dockerd:7970 blocked for more than 120 seconds.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.510931] Not tainted 5.0.0-1019-aws #21~18.04.1-Ubuntu
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.515010] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.521419] dockerd D 0 7970 1 0x00000080
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.525333] Call Trace:
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.528060] __schedule+0x2c0/0x870
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.531107] schedule+0x2c/0x70
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.534027] rwsem_down_write_failed+0x157/0x350
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.537630] ? blk_finish_plug+0x2c/0x40
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.540890] ? generic_writepages+0x68/0x90
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.544296] call_rwsem_down_write_failed+0x17/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.547999] ? call_rwsem_down_write_failed+0x17/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.551674] down_write+0x2d/0x40
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.554612] sync_inodes_sb+0xb9/0x2c0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.557762] ? __filemap_fdatawrite_range+0xcd/0x100
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.561468] __sync_filesystem+0x1b/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.564697] sync_filesystem+0x3c/0x50
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.568544] ovl_sync_fs+0x3f/0x60 [overlay]
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.572831] __sync_filesystem+0x33/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.576767] sync_filesystem+0x3c/0x50
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.580565] generic_shutdown_super+0x27/0x120
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.584632] kill_anon_super+0x12/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.587958] deactivate_locked_super+0x48/0x80
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.591696] deactivate_super+0x40/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.594998] cleanup_mnt+0x3f/0x90
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.598081] __cleanup_mnt+0x12/0x20
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.601194] task_work_run+0x9d/0xc0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.604388] exit_to_usermode_loop+0xf2/0x100
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.607843] do_syscall_64+0x107/0x120
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.611173] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.615128] RIP: 0033:0x556561f280e0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.618303] Code: Bad RIP value.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.621256] RSP: 002b:000000c428ec51c0 EFLAGS: 00000206 ORIG_RAX: 00000000000000a6
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.627790] RAX: 0000000000000000 RBX: 0000000000000000 RCX: 0000556561f280e0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.632469] RDX: 0000000000000000 RSI: 0000000000000002 RDI: 000000c4268a0d20
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.637203] RBP: 000000c428ec5220 R08: 0000000000000000 R09: 0000000000000000
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.641900] R10: 0000000000000000 R11: 0000000000000206 R12: ffffffffffffffff
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.646535] R13: 0000000000000024 R14: 0000000000000023 R15: 0000000000000055
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.651404] INFO: task dockerd:33393 blocked for more than 120 seconds.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.655956] Not tainted 5.0.0-1019-aws #21~18.04.1-Ubuntu
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.660155] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.666562] dockerd D 0 33393 1 0x00000080
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.670561] Call Trace:
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.673299] __schedule+0x2c0/0x870
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.676435] schedule+0x2c/0x70
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.679556] rwsem_down_write_failed+0x157/0x350
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.683276] ? blk_finish_plug+0x2c/0x40
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.686744] ? generic_writepages+0x68/0x90
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.690442] call_rwsem_down_write_failed+0x17/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.694243] ? call_rwsem_down_write_failed+0x17/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.698019] down_write+0x2d/0x40
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.700996] sync_inodes_sb+0xb9/0x2c0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.704283] ? __filemap_fdatawrite_range+0xcd/0x100
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.708127] __sync_filesystem+0x1b/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.711511] sync_filesystem+0x3c/0x50
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.714806] ovl_sync_fs+0x3f/0x60 [overlay]
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.718349] __sync_filesystem+0x33/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.721665] sync_filesystem+0x3c/0x50
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.724860] generic_shutdown_super+0x27/0x120
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.728449] kill_anon_super+0x12/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.731817] deactivate_locked_super+0x48/0x80
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.735511] deactivate_super+0x40/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.738899] cleanup_mnt+0x3f/0x90
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.742023] __cleanup_mnt+0x12/0x20
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.745142] task_work_run+0x9d/0xc0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.748337] exit_to_usermode_loop+0xf2/0x100
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.751830] do_syscall_64+0x107/0x120
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.755145] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.759111] RIP: 0033:0x556561f280e0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.762292] Code: Bad RIP value.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.765237] RSP: 002b:000000c4289c51c0 EFLAGS: 00000206 ORIG_RAX: 00000000000000a6
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.771715] RAX: 0000000000000000 RBX: 0000000000000000 RCX: 0000556561f280e0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.776351] RDX: 0000000000000000 RSI: 0000000000000002 RDI: 000000c4252e5e60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.781025] RBP: 000000c4289c5220 R08: 0000000000000000 R09: 0000000000000000
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.785705] R10: 0000000000000000 R11: 0000000000000206 R12: ffffffffffffffff
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.790445] R13: 0000000000000052 R14: 0000000000000051 R15: 0000000000000055
May 8 16:43:40 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:43:40.153619029Z" level=error msg="Handler for GET /containers/679b08e796acdd04b40802f2feff8086d7ba7f96182dcf874bb652fa9d9a7aec/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
May 8 16:43:40 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: http: multiple response.WriteHeader calls
May 8 16:44:15 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:44:15.461023232Z" level=error msg="Handler for GET /containers/fa731d8d33f9d5a8aef457e5dab43170c1aedb529ce9221fd6d916a4dba07ff1/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
May 8 16:44:15 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:44:15.461331976Z" level=error msg="Handler for GET /containers/fa731d8d33f9d5a8aef457e5dab43170c1aedb529ce9221fd6d916a4dba07ff1/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
May 8 16:44:15 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: http: multiple response.WriteHeader calls
May 8 16:44:15 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: http: multiple response.WriteHeader calls
May 8 16:59:55 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:59:55.489826112Z" level=info msg="No non-localhost DNS nameservers are left in resolv.conf. Using default external servers: [nameserver 8.8.8.8 nameserver 8.8.4.4]"
May 8 16:59:55 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:59:55.489858794Z" level=info msg="IPv6 enabled; Adding default IPv6 external servers: [nameserver 2001:4860:4860::8888 nameserver 2001:4860:4860::8844]"
May 8 16:59:55 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:59:55Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/5b85357b1e7b41f230a05d65fc97e6bdcf10537045db2e97ecbe66a346e40644/shim.sock" debug=false pid=5285
May 8 16:59:57 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:59:57Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/89c6e4f2480992f94e3dbefb1cbe0084a8e5637588296a1bb40df0dcca662cf0/shim.sock" debug=false pid=6776
May 8 16:59:58 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:59:58Z" level=info msg="shim reaped" id=89c6e4f2480992f94e3dbefb1cbe0084a8e5637588296a1bb40df0dcca662cf0
Je veux juste partager ce qui l'a causé pour nous.
Nous avions un conteneur en cours d'exécution qui "produisait" un grand nombre de processus sur ~ 3 jours qui dans le et ont atteint un maximum. Cela a causé un gel complet du système car aucun nouveau processus ne pouvait être généré (il y avait alors l'avertissement PLEG).
Tellement gentil problème sans rapport pour nous. Merci pour toute l'aide: +1:
fentas
le 19 mai 2020
J'ai eu deux séries de problèmes, peut-être liés.
- PLEG. Je pense qu'ils sont partis, mais je n'ai pas recréé suffisamment de grappes pour être complètement confiant. Je ne crois pas avoir beaucoup changé (c'est-à-dire quoi que ce soit) _directement_ pour que cela se produise.
- Problèmes de tissage dans lesquels les conteneurs ne pouvaient pas se connecter à quoi que ce soit.
De manière suspecte, tous les problèmes avec pleg se sont produits exactement au même moment que les problèmes de réseau de tissage.
Bryan @ weaveworks, m'a indiqué les problèmes de coreos. CoreOS a une tendance plutôt agressive à essayer de gérer les ponts, les veths, en gros tout. Une fois que j'ai désactivé CoreOS de le faire, sauf sur
loet en fait les interfaces physiques sur l'hôte, tous mes problèmes sont restés.Les gens ont-ils encore des problèmes pour exécuter des coreos?
Vous souvenez-vous des modifications que vous avez apportées à @deitch?
 JefClaes
le 26 mai 2020
JefClaes
le 26 mai 2020
J'ai trouvé ceci: https://github.com/kontena/kontena/issues/1264#issuecomment -259381851
Ce qui pourrait être lié à ce que @deitch a suggéré. Mais j'aimerais aussi savoir s'il existe une solution correcte ou plus élégante, comme créer une unité avec veth * et la mettre comme non gérée
rikatz
le 27 mai 2020
Je pense avoir la cause première des problèmes que nous avons vus ici:
docker peut parfois être gâché entre docker ps et docker inspect: pendant le démontage du conteneur, docker ps peut afficher des informations mises en cache sur le conteneur, y compris ceux dont le shim est déjà récolté:
time="2020-06-01T23:39:03Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/shim.sock" debug=false pid=11377
Jun 02 03:23:06 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T03:23:06Z" level=info msg="shim reaped" id=b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121
Jun 02 03:23:36 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T03:23:36.433087181Z" level=info msg="Container b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121 failed to exit within 30 seconds of signal 15 - using the force"
ps ne trouve pas de processus avec l'ID de conteneur
# ps auxww | grep b7ae92902520
root 21510 0.0 0.0 14852 1000 pts/0 S+ 03:44 0:00 grep --color=auto b7ae92902520
docker ps montre que le processus est toujours en cours
# docker ps -a | grep b7ae92902520
b7ae92902520 450280d6866c "/srv/envoy-discover…" 4 hours ago Up 4 hours k8s_xxxxxx
Dans ce cas, la composition de la chaussette du docker pour l'inspection de docker serait bloquée et entraînerait un délai d'expiration côté client. Cela est peut-être dû au fait que docker inspect composerait le shim récolté pour obtenir des informations à jour de containerd, tandis que docker ps utilise des données mises en cache
# strace docker inspect b7ae92902520
......
newfstatat(AT_FDCWD, "/etc/.docker/config.json", {st_mode=S_IFREG|0644, st_size=124, ...}, 0) = 0
openat(AT_FDCWD, "/etc/.docker/config.json", O_RDONLY|O_CLOEXEC) = 3
epoll_ctl(4, EPOLL_CTL_ADD, 3, {EPOLLIN|EPOLLOUT|EPOLLRDHUP|EPOLLET, {u32=2124234496, u64=139889209065216}}) = -1 EPERM (Operation not permitted)
epoll_ctl(4, EPOLL_CTL_DEL, 3, 0xc420689884) = -1 EPERM (Operation not permitted)
read(3, "{\n \"credsStore\": \"ecr-login\","..., 512) = 124
close(3) = 0
futex(0xc420650948, FUTEX_WAKE, 1) = 1
socket(AF_UNIX, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, 0) = 3
setsockopt(3, SOL_SOCKET, SO_BROADCAST, [1], 4) = 0
connect(3, {sa_family=AF_UNIX, sun_path="/var/run/docker.sock"}, 23) = 0
epoll_ctl(4, EPOLL_CTL_ADD, 3, {EPOLLIN|EPOLLOUT|EPOLLRDHUP|EPOLLET, {u32=2124234496, u64=139889209065216}}) = 0
getsockname(3, {sa_family=AF_UNIX}, [112->2]) = 0
getpeername(3, {sa_family=AF_UNIX, sun_path="/var/run/docker.sock"}, [112->23]) = 0
futex(0xc420644548, FUTEX_WAKE, 1) = 1
read(3, 0xc4202c2000, 4096) = -1 EAGAIN (Resource temporarily unavailable)
write(3, "GET /_ping HTTP/1.1\r\nHost: docke"..., 83) = 83
futex(0xc420128548, FUTEX_WAKE, 1) = 1
futex(0x25390a8, FUTEX_WAIT, 0, NULL) = 0
futex(0x25390a8, FUTEX_WAIT, 0, NULL) = 0
futex(0x25390a8, FUTEX_WAIT, 0, NULL) = -1 EAGAIN (Resource temporarily unavailable)
futex(0x25390a8, FUTEX_WAIT, 0, NULL^C) = ? ERESTARTSYS (To be restarted if SA_RESTART is set)
strace: Process 13301 detached
Étant donné que la remise en vente des pods inclura l'inspection par docker de chaque conteneur de chaque pod, un tel délai d'expiration entraînera la remise en vente complète de PLEG pendant une longue période
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.523247 28263 generic.go:189] GenericPLEG: Relisting
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541890 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/51f959aa0c4cbcbc318c3fad7f90e5e967537e0acc8c727b813df17c50493af3: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541905 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/6c221cd2fb602fdf4ae5288f2ce80d010cf252a9144d676c8ce11cc61170a4cf: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541909 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/47bb03e0b56d55841e0592f94635eb67d5432edb82424fc23894cdffd755e652: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541913 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/ee861fac313fad5e0c69455a807e13c67c3c211032bc499ca44898cde7368960: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541917 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121: non-existent -> running
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541922 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/dd3f5c03f7309d0a3feb2f9e9f682b4c30ac4105a245f7f40b44afd7096193a0: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541925 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/57960fe13240af78381785cc66c6946f78b8978985bc847a1f77f8af8aef0f54: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541929 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/8ebaeed71f6ce99191a2d839a07d3573119472da221aeb4c7f646f25e6e9dd1b: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541932 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/b04da653f52e0badc54cc839b485dcc7ec5e2f6a8df326d03bcf3e5c8a14a3e3: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541936 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/a23912e38613fd455b26061c4ab002da294f18437b21bc1874e65a82ee1fba05: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541939 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/7f928360f1ba8890194ed795cfa22c5930c0d3ce5f6f2bc6d0592f4a3c1b579f: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541943 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/c3bdab1ed8896399263672ca45365e3d74c4ddc3958f82e3c7549fe12bc6c74b: non-existent -> exited
Jun 2 04:37:05 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:37:05.580912 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:05 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:05.580983 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:18 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:37:18.277091 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:18 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:18.277187 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:29 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:37:29.276942 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:29 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:29.276994 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:44 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:37:44.276919 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:44 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:44.276964 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:56 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:37:56.277039 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:56 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:56.277116 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:08 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:38:08.276838 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:08 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:38:08.276913 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:22 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:38:22.277107 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:22 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:38:22.277151 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:37 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:38:37.277123 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:37 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:38:37.277189 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:51 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:38:51.277059 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:51 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:38:51.277101 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:02 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:02.276836 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:02 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:02.276908 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:03.554207 28263 remote_runtime.go:295] ContainerStatus "b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:03.554252 28263 kuberuntime_container.go:403] ContainerStatus for b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121 error: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:03.554265 28263 kuberuntime_manager.go:1122] getPodContainerStatuses for pod "optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)" failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:03.554272 28263 generic.go:397] PLEG: Write status for optimus-pr-b-6bgc3/jenkins: (*container.PodStatus)(nil) (err: rpc error: code = DeadlineExceeded desc = context deadline exceeded)
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:03.554285 28263 generic.go:252] PLEG: Ignoring events for pod optimus-pr-b-6bgc3/jenkins: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:03.554294 28263 generic.go:284] GenericPLEG: Reinspecting pods that previously failed inspection
Jun 2 04:39:17 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:17.277086 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:17 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:17.277137 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:28 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:28.276905 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:28 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:28.276976 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:40 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:40.276815 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:40 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:40.276858 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:51 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:51.276950 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:51 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:51.277015 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:40:04 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:40:04.276869 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:40:04 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:40:04.276939 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:41:03.566494 28263 remote_runtime.go:295] ContainerStatus "b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:41:03.566543 28263 kuberuntime_container.go:403] ContainerStatus for b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121 error: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:41:03.566554 28263 kuberuntime_manager.go:1122] getPodContainerStatuses for pod "optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)" failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:41:03.566561 28263 generic.go:397] PLEG: Write status for optimus-pr-b-6bgc3/jenkins: (*container.PodStatus)(nil) (err: rpc error: code = DeadlineExceeded desc = context deadline exceeded)
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:41:03.566575 28263 generic.go:288] PLEG: pod optimus-pr-b-6bgc3/jenkins failed reinspection: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:41:03.566604 28263 generic.go:189] GenericPLEG: Relisting
Le seuil actuel PLEG sain est de 3 min, donc si le PLEG remis en vente> 3 min, ce qui est assez facile dans ce cas, PLEG sera signalé comme malsain.
Je n'ai pas eu la chance de voir si simplement docker rm corrigerait un tel état, car après avoir été bloqué pendant ~ 40min, le docker se débloque
[root@node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69:/home/hzhang]# journalctl -u docker | grep b7ae92902520
Jun 01 23:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-01T23:39:03Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/shim.sock" debug=false pid=11377
Jun 02 03:23:06 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T03:23:06Z" level=info msg="shim reaped" id=b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121
Jun 02 03:23:36 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T03:23:36.433087181Z" level=info msg="Container b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121 failed to exit within 30 seconds of signal 15 - using the force"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.435460391Z" level=warning msg="Container b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121 is not running"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.435684282Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.435955786Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.436078347Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.436341875Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.436570634Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.436770587Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.436905470Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
......
Divers problèmes ont été ouverts concernant un phénomène similaire:
https://github.com/docker/for-linux/issues/397
https://github.com/docker/for-linux/issues/543
https://github.com/moby/moby/issues/41054
cependant, il prétend être toujours vu dans le docker 19.03 , c'est-à-dire https://github.com/docker/for-linux/issues/397#issuecomment -515425324
La correction consiste probablement à avoir un chien de garde pour comparer docker ps et ps ax et nettoyer les conteneurs qui n'ont pas de processus de shim et forcer la terminaison du pod à débloquer ces pods ou utiliser docker rm pour supprimer le conteneur
zhan849
le 2 juin 2020
pour continuer avec l'enquête ci-dessus - le vidage de thread a montré que pendant le blocage de docker, docker attend sur containerd donc c'est probablement un problème containerd là-bas. (voir thread dump ci-dessous) Dans ce cas
- seul docker ps fonctionnera pour ces conteneurs affectés
- docker rm / docker stop / docker inspect se bloque
- kubelet pod relist expirera quand il essaiera d'inspecter un tel conteneur, la latence de remise en vente entière peut ou ne
- cela entraînera le blocage du pod utilisateur dans la progression, ainsi que la réponse lente du kubelet lorsque l'ensemble du PLEG est ralenti
donc ce que nous avons fait en production est que:
- vérifier l'incohérence entre
psetdocker pset choisir le conteneur affecté, comme dans notre cas, tous les conteneurs avec des opérations bloquées ont déjà leur cale récoltée - docker se résout parfois lui-même mais parfois pas, donc après un délai d'attente, nous forçons la suppression des pods affectés pour débloquer l'utilisateur
- si une telle incohérence existe en général après un certain laps de temps, redémarrez docker
/ cc @ jmf0526 @haosdent @liucimin @yujuhong @thockin
il semble que vous en parliez également activement dans les fils d'enquêtes ultérieurs
goroutine 1707386 [select, 22 minutes]:
--
github.com/docker/docker/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc420609680, 0x10, 0xc420f60fd8)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/transport/transport.go:222 +0x101
github.com/docker/docker/vendor/google.golang.org/grpc/transport.(*Stream).RecvCompress(0xc420609680, 0x555ab63e0730, 0xc420f61098)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/transport/transport.go:233 +0x2d
github.com/docker/docker/vendor/google.golang.org/grpc.(*csAttempt).recvMsg(0xc4267ef1e0, 0x555ab624f000, 0xc4288fd410, 0x0, 0x0)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/stream.go:515 +0x63b
github.com/docker/docker/vendor/google.golang.org/grpc.(*clientStream).RecvMsg(0xc4204fa800, 0x555ab624f000, 0xc4288fd410, 0x0, 0x0)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/stream.go:395 +0x45
github.com/docker/docker/vendor/google.golang.org/grpc.invoke(0x555ab6415260, 0xc4288fd4a0, 0x555ab581d40c, 0x2a, 0x555ab6249c00, 0xc428c04450, 0x555ab624f000, 0xc4288fd410, 0xc4202d4600, 0xc4202cdc40, ...)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/call.go:83 +0x185
github.com/docker/docker/vendor/github.com/containerd/containerd.namespaceInterceptor.unary(0x555ab57c9d91, 0x4, 0x555ab64151e0, 0xc420128040, 0x555ab581d40c, 0x2a, 0x555ab6249c00, 0xc428c04450, 0x555ab624f000, 0xc4288fd410, ...)
/go/src/github.com/docker/docker/vendor/github.com/containerd/containerd/grpc.go:35 +0xf6
github.com/docker/docker/vendor/github.com/containerd/containerd.(namespaceInterceptor).(github.com/docker/docker/vendor/github.com/containerd/containerd.unary)-fm(0x555ab64151e0, 0xc420128040, 0x555ab581d40c, 0x2a, 0x555ab6249c00, 0xc428c04450, 0x555ab624f000, 0xc4288fd410, 0xc4202d4600, 0x555ab63e07a0, ...)
/go/src/github.com/docker/docker/vendor/github.com/containerd/containerd/grpc.go:51 +0xf6
github.com/docker/docker/vendor/google.golang.org/grpc.(*ClientConn).Invoke(0xc4202d4600, 0x555ab64151e0, 0xc420128040, 0x555ab581d40c, 0x2a, 0x555ab6249c00, 0xc428c04450, 0x555ab624f000, 0xc4288fd410, 0x0, ...)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/call.go:35 +0x10b
github.com/docker/docker/vendor/google.golang.org/grpc.Invoke(0x555ab64151e0, 0xc420128040, 0x555ab581d40c, 0x2a, 0x555ab6249c00, 0xc428c04450, 0x555ab624f000, 0xc4288fd410, 0xc4202d4600, 0x0, ...)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/call.go:60 +0xc3
github.com/docker/docker/vendor/github.com/containerd/containerd/api/services/tasks/v1.(*tasksClient).Delete(0xc422c96128, 0x555ab64151e0, 0xc420128040, 0xc428c04450, 0x0, 0x0, 0x0, 0xed66bcd50, 0x0, 0x0)
/go/src/github.com/docker/docker/vendor/github.com/containerd/containerd/api/services/tasks/v1/tasks.pb.go:430 +0xd4
github.com/docker/docker/vendor/github.com/containerd/containerd.(*task).Delete(0xc42463e8d0, 0x555ab64151e0, 0xc420128040, 0x0, 0x0, 0x0, 0xc42463e8d0, 0x0, 0x0)
/go/src/github.com/docker/docker/vendor/github.com/containerd/containerd/task.go:292 +0x24a
github.com/docker/docker/libcontainerd.(*client).DeleteTask(0xc4203d4e00, 0x555ab64151e0, 0xc420128040, 0xc421763740, 0x40, 0x0, 0x20, 0x20, 0x555ab5fc6920, 0x555ab4269945, ...)
/go/src/github.com/docker/docker/libcontainerd/client_daemon.go:504 +0xe2
github.com/docker/docker/daemon.(*Daemon).ProcessEvent(0xc4202c61c0, 0xc4216469c0, 0x40, 0x555ab57c9b55, 0x4, 0xc4216469c0, 0x40, 0xc421646a80, 0x40, 0x8f0000069c, ...)
/go/src/github.com/docker/docker/daemon/monitor.go:54 +0x23c
github.com/docker/docker/libcontainerd.(*client).processEvent.func1()
/go/src/github.com/docker/docker/libcontainerd/client_daemon.go:694 +0x130
github.com/docker/docker/libcontainerd.(*queue).append.func1(0xc421646900, 0x0, 0xc42a24e380, 0xc420300420, 0xc4203d4e58, 0xc4216469c0, 0x40)
/go/src/github.com/docker/docker/libcontainerd/queue.go:26 +0x3a
created by github.com/docker/docker/libcontainerd.(*queue).append
/go/src/github.com/docker/docker/libcontainerd/queue.go:22 +0x196
Nous constatons des problèmes très similaires (docker ps fonctionne mais docker inspect par exemple se bloque). Nous exécutons kubernetes v1.17.6 avec docker 19.3.8 sur Fedora CoreOS.
 TeroPihlaja
le 18 juin 2020
TeroPihlaja
le 18 juin 2020
Nous avons également rencontré ce problème où un conteneur répertorié par docker ps était suspendu à docker inspect
docker ps -a | tr -s " " | cut -d " " -f1 | xargs -Iarg sh -c 'echo arg; docker inspect arg> /dev/null'
Dans notre cas, nous avons remarqué que le conteneur concerné était bloqué sur runc init . Nous avions des problèmes pour attacher ou tracer le thread principal de runc init . Il semblait que les signaux n'étaient pas délivrés. Pour autant que nous puissions dire, le processus était bloqué dans le noyau et ne faisait pas de transitions vers l'espace utilisateur. Je ne suis pas vraiment un expert en débogage du noyau Linux, mais d'après ce que je peux dire, cela semble être un problème avec le noyau lié au nettoyage du montage. Voici un exemple de trace de pile pour ce que fait le processus runc init dans le noyau du noyau.
[<0>] kmem_cache_alloc+0x162/0x1c0
[<0>] kmem_zone_alloc+0x61/0xe0 [xfs]
[<0>] xfs_buf_item_init+0x31/0x160 [xfs]
[<0>] _xfs_trans_bjoin+0x1e/0x50 [xfs]
[<0>] xfs_trans_read_buf_map+0x104/0x340 [xfs]
[<0>] xfs_imap_to_bp+0x67/0xd0 [xfs]
[<0>] xfs_iunlink_remove+0x16b/0x430 [xfs]
[<0>] xfs_ifree+0x42/0x140 [xfs]
[<0>] xfs_inactive_ifree+0x9e/0x1c0 [xfs]
[<0>] xfs_inactive+0x9e/0x140 [xfs]
[<0>] xfs_fs_destroy_inode+0xa8/0x1c0 [xfs]
[<0>] __dentry_kill+0xd5/0x170
[<0>] dentry_kill+0x4d/0x190
[<0>] dput.part.31+0xcb/0x110
[<0>] ovl_destroy_inode+0x15/0x60 [overlay]
[<0>] __dentry_kill+0xd5/0x170
[<0>] shrink_dentry_list+0x94/0x1b0
[<0>] shrink_dcache_parent+0x88/0x90
[<0>] do_one_tree+0xe/0x40
[<0>] shrink_dcache_for_umount+0x28/0x80
[<0>] generic_shutdown_super+0x1a/0x100
[<0>] kill_anon_super+0x14/0x30
[<0>] deactivate_locked_super+0x34/0x70
[<0>] cleanup_mnt+0x3b/0x70
[<0>] task_work_run+0x8a/0xb0
[<0>] exit_to_usermode_loop+0xeb/0xf0
[<0>] do_syscall_64+0x182/0x1b0
[<0>] entry_SYSCALL_64_after_hwframe+0x65/0xca
[<0>] 0xffffffffffffffff
Notez également que le redémarrage de Docker a supprimé le conteneur de Docker, ce qui est suffisant pour résoudre le problème de PLEG malsain, mais n'a pas supprimé le runc init bloqué.
Edit: Versions pour les personnes intéressées:
Docker 19.03.8
runc 1.0.0-rc10
linux: 4.18.0-147.el8.x86_64
centos: 8.1.1911
 debugmiller
le 25 juin 2020
debugmiller
le 25 juin 2020
Ce problème est-il résolu?
Je reçois des problèmes PLEG dans mon cluster et j'ai observé ce problème ouvert.
Existe-t-il une solution de contournement pour cela?
 cshivashankar
le 26 juin 2020
cshivashankar
le 26 juin 2020
J'ai également rencontré le problème PLEG dans mon cluster qui est opérationnel depuis quelques jours.
Installer
Cluster EKS avec K8S v1.15.11-eks-af3caf
Version Docker 18.09.9-ce
Le type d'instance est m5ad.4xlarge
Problème
Jul 08 04:12:36 ip-56-0-1-191.us-west-2.compute.internal kubelet [5354]: I0708 04: 12: 36.051162 5354 setters.go: 533] Le nœud n'est pas prêt: { Type: Prêt Statut: Faux LastHear tbeatTime: 2020-07-08 04: 12: 36.051127368 +0000 UTC m = + 4279967.056220983 LastTrans itionTime: 2020-07-08 04: 12: 36.051127368 +0000 UTC m = + 4279967.056220983 Raison: Message KubeletNotReady : PLEG n'est pas sain: pleg a été vu pour la dernière fois actif il y a 3m9.146952991s; le seuil est de 3m0s}
Récupération
Le redémarrage de Kubelet a récupéré le nœud.
Y a-t-il une solution? La mise à niveau de la version Docker fonctionne?
 mak-454
le 10 juil. 2020
mak-454
le 10 juil. 2020
c'est peut-être le problème des conteneurs docker, par exemple. beaucoup de processus zombies dans le conteneur entraînent un "docker ps / inspect" extrêmement lent
 jonesmith518
le 27 juil. 2020
jonesmith518
le 27 juil. 2020
un systemctl restart docker sur tous mes travailleurs a résolu mon problème.
 jetersen
le 4 août 2020
jetersen
le 4 août 2020
@jetersen avez-vous activé la restauration en direct sur Docker?
La valeur par défaut est de redémarrer tous les conteneurs lorsque vous redémarrez Docker, ce qui est un gros marteau pour résoudre le problème.
bboreham
le 4 août 2020
@bboreham n'est pas aussi important que de détruire et de recréer le cluster 😅
jetersen
le 4 août 2020
Je rencontre ce problème en utilisant Kubernetes 1.15.3, 1.16.3 ainsi que 1.17.9. Sur les versions docker 18.6.3 (Container Linux) et 19.3.12 (Flatcar Linux).
Il y a environ 50 pods sur chaque nœud.
 FrederikNS
le 4 sept. 2020
FrederikNS
le 4 sept. 2020
Nous avons également rencontré ce problème où un conteneur répertorié par docker ps était suspendu à docker inspect
docker ps -a | tr -s " " | cut -d " " -f1 | xargs -Iarg sh -c 'echo arg; docker inspect arg> /dev/null'Dans notre cas, nous avons remarqué que le conteneur concerné était bloqué sur
runc init. Nous avions des problèmes pour attacher ou tracer le thread principal derunc init. Il semblait que les signaux n'étaient pas délivrés. Pour autant que nous puissions dire, le processus était bloqué dans le noyau et ne faisait pas de transitions vers l'espace utilisateur. Je ne suis pas vraiment un expert en débogage du noyau Linux, mais d'après ce que je peux dire, cela semble être un problème avec le noyau lié au nettoyage du montage. Voici un exemple de trace de pile pour ce que fait le processusrunc initdans le noyau du noyau.[<0>] kmem_cache_alloc+0x162/0x1c0 [<0>] kmem_zone_alloc+0x61/0xe0 [xfs] [<0>] xfs_buf_item_init+0x31/0x160 [xfs] [<0>] _xfs_trans_bjoin+0x1e/0x50 [xfs] [<0>] xfs_trans_read_buf_map+0x104/0x340 [xfs] [<0>] xfs_imap_to_bp+0x67/0xd0 [xfs] [<0>] xfs_iunlink_remove+0x16b/0x430 [xfs] [<0>] xfs_ifree+0x42/0x140 [xfs] [<0>] xfs_inactive_ifree+0x9e/0x1c0 [xfs] [<0>] xfs_inactive+0x9e/0x140 [xfs] [<0>] xfs_fs_destroy_inode+0xa8/0x1c0 [xfs] [<0>] __dentry_kill+0xd5/0x170 [<0>] dentry_kill+0x4d/0x190 [<0>] dput.part.31+0xcb/0x110 [<0>] ovl_destroy_inode+0x15/0x60 [overlay] [<0>] __dentry_kill+0xd5/0x170 [<0>] shrink_dentry_list+0x94/0x1b0 [<0>] shrink_dcache_parent+0x88/0x90 [<0>] do_one_tree+0xe/0x40 [<0>] shrink_dcache_for_umount+0x28/0x80 [<0>] generic_shutdown_super+0x1a/0x100 [<0>] kill_anon_super+0x14/0x30 [<0>] deactivate_locked_super+0x34/0x70 [<0>] cleanup_mnt+0x3b/0x70 [<0>] task_work_run+0x8a/0xb0 [<0>] exit_to_usermode_loop+0xeb/0xf0 [<0>] do_syscall_64+0x182/0x1b0 [<0>] entry_SYSCALL_64_after_hwframe+0x65/0xca [<0>] 0xffffffffffffffffNotez également que le redémarrage de Docker a supprimé le conteneur de Docker, ce qui est suffisant pour résoudre le problème de PLEG malsain, mais n'a pas supprimé le
runc initbloqué.Edit: Versions pour les personnes intéressées:
Docker 19.03.8
runc 1.0.0-rc10
linux: 4.18.0-147.el8.x86_64
centos: 8.1.1911
Ce problème a-t-il été résolu? Dans quelle version?
 liruishan
le 5 sept. 2020
liruishan
le 5 sept. 2020
marque
 neighbour-oldhuang
le 12 oct. 2020
neighbour-oldhuang
le 12 oct. 2020
Face au problème à nouveau sur eks avec kubernetes version = v1.16.8-eks-e16311 et docker version = docker: //19.3.6
Le redémarrage de docker et de kubelet a récupéré le nœud.
mak-454
le 17 nov. 2020
@ mak-454 J'ai également rencontré ce problème sur EKS aujourd'hui - cela vous dérangerait-il de partager la région / AZ où votre nœud s'exécutait, ainsi que la durée du problème? Je suis curieux de voir s'il y a eu un problème infra sous-jacent.
 JacobHenner
le 18 nov. 2020
JacobHenner
le 18 nov. 2020
@JacobHenner mes nœuds fonctionnaient dans la région eu-central-1.
mak-454
le 18 nov. 2020
rencontré ce problème sur EKS (ca-central-1) avec la version Kubernetes "1.15.12" et la version docker "19.03.6-ce"
Après avoir redémarré docker / kubelet, il y a cette ligne dans les événements de nœud:
Warning SystemOOM 14s (x3 over 14s) kubelet, ip-10-1-2-3.ca-central-1.compute.internal System OOM encountered
 imriss
le 18 nov. 2020
imriss
le 18 nov. 2020
Questions connexes
 tbchj
·
3Commentaires
tbchj
·
3Commentaires
 sanjana-bhat
·
3Commentaires
sanjana-bhat
·
3Commentaires
 sjenning
·
3Commentaires
sjenning
·
3Commentaires
 ddysher
·
3Commentaires
ddysher
·
3Commentaires
 jadhavnitind
·
3Commentaires
jadhavnitind
·
3Commentaires
Commentaire le plus utile
Le bilan de santé PLEG fait très peu. À chaque itération, il appelle
docker pspour détecter les changements d'états des conteneurs, et appelledocker psetinspectpour obtenir les détails de ces conteneurs.Après avoir terminé chaque itération, il met à jour un horodatage. Si l'horodatage n'a pas été mis à jour pendant un certain temps (c'est-à-dire 3 minutes), la vérification de l'état échoue.
À moins que votre nœud ne soit chargé avec un grand nombre de pods que PLEG ne peut pas finir de faire tout cela en 3 minutes (ce qui ne devrait pas arriver), la cause la plus probable serait que le docker soit lent. Vous ne pouvez pas observer cela dans votre
docker psoccasionnelSi nous n'exposons pas le statut "malsain", cela cacherait de nombreux problèmes aux utilisateurs et causerait potentiellement plus de problèmes. Par exemple, kubelet ne réagissait pas silencieusement aux changements en temps opportun et causait encore plus de confusion.
Les suggestions sur la façon de rendre cela plus débuggable sont les bienvenues ...