Kubernetes: PLEGの問題でReady / NotReady間のノードフラッピング
問題を提出していただきありがとうございます! ボタンを押す前に、これらの質問に答えてください。
これは助けを求めるものですか? 番号
これを提出する前に、Kubernetesの問題でどのキーワードを検索しましたか? (重複を見つけた場合は、代わりにそこに返信する必要があります。):PLEG NotReady kubelet
これはバグレポートですか、それとも機能リクエストですか? バグ
これがバグレポートの場合は、次のことを行ってください。-以下のテンプレートをできるだけ多く記入してください。 あなたが情報を省略した場合、私たちもあなたを助けることはできません。 これが機能要求である場合は、次のことを行ってください。-表示したい機能/動作/変更を*詳細*に説明してください。 どちらの場合も、フォローアップの質問に備えて、タイムリーに回答してください。 バグを再現できない場合、または機能がすでに存在すると思われる場合は、問題を解決する可能性があります。 間違っている場合は、お気軽に再度開いて理由を説明してください。Kubernetesバージョン( kubectl version ):1.6.2
環境:
- クラウドプロバイダーまたはハードウェア構成:AWS上のCoreOS
- OS (例:/ etc / os-releaseから):CoreOS1353.7.0
- カーネル(例:
uname -a):4.9.24-coreos - ツールのインストール:
- その他:
何が起こったのか:
私は3人の労働者のクラスターを持っています。 2つ、場合によっては3つすべてのノードがNotReadyドロップし続け、 journalctl -u kubelet次のメッセージが表示されます。
May 05 13:59:56 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 13:59:56.872880 2858 kubelet_node_status.go:379] Recording NodeNotReady event message for node ip-10-50-20-208.ec2.internal
May 05 13:59:56 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 13:59:56.872908 2858 kubelet_node_status.go:682] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-05-05 13:59:56.872865742 +0000 UTC LastTransitionTime:2017-05-05 13:59:56.872865742 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.629592089s ago; threshold is 3m0s}
May 05 14:07:57 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:07:57.598132 2858 kubelet_node_status.go:379] Recording NodeNotReady event message for node ip-10-50-20-208.ec2.internal
May 05 14:07:57 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:07:57.598162 2858 kubelet_node_status.go:682] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-05-05 14:07:57.598117026 +0000 UTC LastTransitionTime:2017-05-05 14:07:57.598117026 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.346983738s ago; threshold is 3m0s}
May 05 14:17:58 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:17:58.536101 2858 kubelet_node_status.go:379] Recording NodeNotReady event message for node ip-10-50-20-208.ec2.internal
May 05 14:17:58 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:17:58.536134 2858 kubelet_node_status.go:682] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-05-05 14:17:58.536086605 +0000 UTC LastTransitionTime:2017-05-05 14:17:58.536086605 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.275467289s ago; threshold is 3m0s}
May 05 14:29:59 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:29:59.648922 2858 kubelet_node_status.go:379] Recording NodeNotReady event message for node ip-10-50-20-208.ec2.internal
May 05 14:29:59 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:29:59.648952 2858 kubelet_node_status.go:682] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-05-05 14:29:59.648910669 +0000 UTC LastTransitionTime:2017-05-05 14:29:59.648910669 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.377520804s ago; threshold is 3m0s}
May 05 14:44:00 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:44:00.938266 2858 kubelet_node_status.go:379] Recording NodeNotReady event message for node ip-10-50-20-208.ec2.internal
May 05 14:44:00 ip-10-50-20-208.ec2.internal kubelet[2858]: I0505 14:44:00.938297 2858 kubelet_node_status.go:682] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-05-05 14:44:00.938251338 +0000 UTC LastTransitionTime:2017-05-05 14:44:00.938251338 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.654775919s ago; threshold is 3m0s}
dockerデーモンは問題ありdocker ps (ローカルdocker imagesなどはすべて機能し、すぐに応答します)。
kubectl apply -f https://git.io/weave-kube-1.6介してインストールされたウィーブネットワークを使用する
あなたが起こると期待したこと:
準備ができているノード。
それを再現する方法(可能な限り最小限かつ正確に):
方法を知っていたらいいのに!
私たちが知る必要がある他のこと:
インターネットへのNATゲートウェイを備えた同じプライベートサブネット上のすべてのノード(ワーカーとマスター)。 マスターセキュリティグループからの無制限のアクセス(すべてのポート)を許可するセキュリティグループのワーカー。 マスターは、同じサブネットからのすべてのポートを許可します。 プロキシはワーカーで実行されています。 apiserver、コントローラーマネージャー、マスターのスケジューラー。
kubectl logsとkubectl execは、マスター自体から(または外部から)実行した場合でも、常にハングします。
 deitch
deitch
全てのコメント225件
@deitch 、ノードで実行されていたコンテナの数は? ノードの全体的なCPU使用率はどれくらいですか?
 yujuhong
2017年05月05日
yujuhong
2017年05月05日
基本的になし。 kube-dns、weave-net、weave-npc、および3つのテンプレートサンプルサービス。 2つには画像がなく、クリーンアップされる予定だったため、実際には1つだけです。 AWSm4.2xlarge。 リソースの問題ではありません。
最終的にノードを破棄して再作成する必要がありました。 破棄/再作成してからPLEGメッセージはなく、50%問題ないようです。 彼らはReadyですが、それでもkubectl execまたはkubectl logsを許可することを拒否します。
PLEGが実際に何であるかについてのドキュメントを見つけるのに本当に苦労しましたが、もっと重要なのは、それ自体のログと状態をチェックしてデバッグする方法です。
deitch
2017年05月05日
うーん...謎に追加するために、どのコンテナもホスト名を解決できません、そしてkubednsは以下を与えます:
E0505 17:30:49.412272 1 reflector.go:199] pkg/dns/config/sync.go:114: Failed to list *api.ConfigMap: Get https://10.200.0.1:443/api/v1/namespaces/kube-system/configmaps?fieldSelector=metadata.name%3Dkube-dns&resourceVersion=0: dial tcp 10.200.0.1:443: getsockopt: no route to host
E0505 17:30:49.412285 1 reflector.go:199] pkg/dns/dns.go:148: Failed to list *api.Service: Get https://10.200.0.1:443/api/v1/services?resourceVersion=0: dial tcp 10.200.0.1:443: getsockopt: no route to host
E0505 17:30:49.412272 1 reflector.go:199] pkg/dns/dns.go:145: Failed to list *api.Endpoints: Get https://10.200.0.1:443/api/v1/endpoints?resourceVersion=0: dial tcp 10.200.0.1:443: getsockopt: no route to host
I0505 17:30:51.855370 1 logs.go:41] skydns: failure to forward request "read udp 10.100.0.3:60364->10.50.0.2:53: i/o timeout"
FWIW、 10.200.0.1は内部のkube apiサービス、 10.200.0.5はDNS、 10.50.20.0/24と10.50.21.0/24はマスターとワーカーが存在するサブネット(2つの別々のAZ)です実行します。
ネットワーキングで本当にfubarなものはありますか?
deitch
2017年05月05日
ネットワーキングで本当にfubarなものはありますか?
@bborehamは、 https://github.com/weaveworks/weave/issues/2736で説明されているように、 IPALLOC_RANGE=10.100.0.0/16追加された標準の織り方
deitch
2017年05月05日
@deitch plegは、kubeletがノード内のポッドを定期的に一覧表示して、正常性を確認し、キャッシュを更新するためのものです。 plegタイムアウトログが表示される場合は、DNSに関連していない可能性がありますが、kubeletのdockerへの呼び出しがタイムアウトであるためです。
 qiujian16
2017年05月11日
qiujian16
2017年05月11日
ありがとう@ qiujian16 。 問題は解消されたようですが、確認方法がわかりません。 Docker自体は正常に見えました。 それがネットワーキングプラグインである可能性があるかどうか疑問に思いましたが、それはkubelet自体に影響を与えるべきではありません。
ここで、ペストの健康状態と状態を確認するためのヒントを教えてください。 その後、問題が再発するまでこれを閉じることができます。
deitch
2017年05月11日
@deitch plegは「ポッドライフサイクルイベントジェネレータ」の略で、kubeletの内部コンポーネントであり、そのステータスを直接確認できるとは思いません。(https://github.com/kubernetes/community/blob/master /contributors/design-proposals/pod-lifecycle-event-generator.md)
qiujian16
2017年05月11日
kubeletバイナリの内部モジュールですか? それは別のスタンドアロンコンテナ(docker、runc、cotnainerd)ですか? スタンドアロンのバイナリですか?
基本的に、kubeletがPLEGエラーを報告した場合、それらのエラーが何であるかを調べて、そのステータスを確認し、試行して複製することは非常に役立ちます。
deitch
2017年05月11日
それは内部モジュールです
qiujian16
2017年05月11日
@deitchは、Dockerの応答性が低い場合があり、PLEGがしきい値を逃した可能性があります。
yujuhong
2017年05月11日
すべてのノードで同様の問題が発生していますが、作成したばかりのクラスターが1つあります。
ログ:
kube-worker03.foo.bar.com kubelet[3213]: E0511 19:00:59.139374 3213 remote_runtime.go:109] StopPodSandbox "12c6a5c6833a190f531797ee26abe06297678820385b402371e196c69b67a136" from runtime service failed: rpc error: code = 4 desc = context deadline exceeded
May 11 19:00:59 kube-worker03.foo.bar.com kubelet[3213]: E0511 19:00:59.139401 3213 kuberuntime_gc.go:138] Failed to stop sandbox "12c6a5c6833a190f531797ee26abe06297678820385b402371e196c69b67a136" before removing: rpc error: code = 4 desc = context deadline exceeded
May 11 19:01:04 kube-worker03.foo.bar.com kubelet[3213]: E0511 19:01:04.627954 3213 pod_workers.go:182] Error syncing pod 1c43d9b6-3672-11e7-a6da-00163e041106
("kube-dns-4240821577-1wswn_kube-system(1c43d9b6-3672-11e7-a6da-00163e041106)"), skipping: rpc error: code = 4 desc = context deadline exceeded
May 11 19:01:18 kube-worker03.foo.bar.com kubelet[3213]: E0511 19:01:18.627819 3213 pod_workers.go:182] Error syncing pod 1c43d9b6-3672-11e7-a6da-00163e041106
("kube-dns-4240821577-1wswn_kube-system(1c43d9b6-3672-11e7-a6da-00163e041106)"),
skipping: rpc error: code = 4 desc = context deadline exceeded
May 11 19:01:21 kube-worker03.foo.bar.com kubelet[3213]: I0511 19:01:21.627670 3213 kubelet.go:1752] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.339074625s ago; threshold is 3m0s]
Dockerをダウングレードし、事実上すべてを再起動しても無駄になりました。ノードはすべてpuppetを介して管理されているため、完全に同一であると期待しています。何が問題なのかわかりません。 デバッグモードのDockerログは、これらのリクエストを取得していることを示しています
 bjhaid
2017年05月11日
bjhaid
2017年05月11日
@bjhaidネットワーキングに何を使用していますか? 当時、私はいくつかの興味深いネットワークの問題を見ていました。
deitch
2017年05月11日
@deitch weaveですが、kubeletとdockerの間の通信の問題のようであるため、これはネットワーク関連の問題ではないと思います。 dockerのデバッグログを介して、dockerがkubeletからこれらのリクエストを取得していることを確認できます
bjhaid
2017年05月11日
私のPlegの問題はなくなったように見えますが、次にこれらのクラスターを新たにセットアップするまで(すべて私が構築したテラフォームモジュールを介して)自信が持てません。
織りの問題が存在するか、k8s / dockerの可能性があります。
deitch
2017年05月11日
@deitch Plegの問題を解決するために何かしましたか、それとも魔法が起こりましたか?
bjhaid
2017年05月11日
実際にはホスト名の解決です。コントローラーは新しく作成されたノードのホスト名を解決できませんでした。ノイズが発生して申し訳ありません。
bjhaid
2017年05月11日
私は問題がないことをすぐに報告しました、問題はまだ存在します、私は何かを見つけたら探し続けて報告します
bjhaid
2017年05月11日
この問題はweave-kubeに関連していると思います。同じ問題が発生しました。今回は、クラスターを再作成せずに問題を解決するために、織りを削除して再適用する必要がありました(伝播するためにノードを再起動します)。削除順序)...そして戻ってきました
だから私はそれがweave-kube-1.6によるものであると確信している理由や方法がわかりません
 gbergere
2017年05月19日
gbergere
2017年05月19日
ここに戻るのを忘れました。問題は、ウィーブインターフェイスが起動しないため、コンテナーにネットワークがないことが原因でした。ただし、これは、ファイアウォールがウィーブデータとvxlanポートをブロックしているためで、このポートを開くと問題はありませんでした。
bjhaid
2017年05月19日
私が抱えていた問題は2つあり、おそらく関連していました。
- ペスト。 それらはなくなったと思いますが、完全に自信を持って十分なクラスターを再作成していません。 私はそれを実現するために_直接_変更したとは思いません。
- コンテナが何にも接続できないという織り方の問題。
不審なことに、plegのすべての問題は、ウィーブネットワークの問題と同時に発生しました。
Bryan @ weaveworksは、coreosの問題を指摘してくれました。 CoreOSは、ブリッジ、ベス、基本的にすべてを管理しようとするかなり積極的な傾向があります。 loと実際にはホスト上の物理インターフェイスを除いて、CoreOSがそれを実行できないようにすると、すべての問題が残りました。
人々はまだcoreosの実行に問題を抱えていますか?
deitch
2017年05月19日
私たちは先月かそこらでこれらの問題に悩まされてきました(クラスターを1.5.xから1.6.xにアップグレードした後に言いたいです)そしてそれは同じように不思議です。
私たちはawsでweave、debian jessie AMIを実行しており、クラスターはPLEGが正常ではないと判断することがあります。
この場合、ポッドはポイントを使用して正常に起動しているため、織りは問題ないようです。
私たちが指摘したことの1つは、すべてのレプリカを縮小すると問題は解決するように見えることですが、展開とステートフルセットの拡大を開始すると、特定の数のコンテナーの周りでこれが発生します。 (少なくとも今回は)。
docker ps; Docker情報はノード上で問題ないようです。
リソース使用率はわずかです:5%cpu util、1.5 / 8gbのRAMが使用され(root htopによる)、ノードリソースプロビジョニングの合計は約30%であり、スケジュールされているはずのすべてのものがスケジュールされています。
これについてはまったく頭を悩ませることはできません。
PLEGチェックがもう少し冗長になっていることを心から願っています。ビープ音が何をしているのかについて、実際に詳細なドキュメントがありました。これについては、膨大な数の問題が未解決であるように思われ、誰もそれが何であるかを実際には知らないためです。重要なモジュールです。失敗したと見なされるチェックを再現できるようにしたいと思います。
 hollowimage
2017年05月26日
hollowimage
2017年05月26日
私はペストの神秘性についての考えを2番目にしています。 しかし、私の側では、クライアントのために多くの作業を行った後、coreosとそのネットワークでの誤動作を安定させることが大いに役立ちました。
deitch
2017年05月26日
PLEGヘルスチェックはほとんど行いません。 すべての反復で、 docker psを呼び出してコンテナーの状態の変化を検出し、 docker psとinspectを呼び出してそれらのコンテナーの詳細を取得します。
各反復が終了すると、タイムスタンプが更新されます。 タイムスタンプがしばらく(つまり3分間)更新されていない場合、ヘルスチェックは失敗します。
PLEGが3分でこれらすべてを完了できない膨大な数のポッドがノードにロードされていない限り(これは発生しないはずです)、最も可能性の高い原因はDockerが遅いことです。 たまにdocker ps小切手でそれを観察できないかもしれませんが、それはそれがないという意味ではありません。
「不健康」ステータスを公開しないと、ユーザーから多くの問題が隠され、さらに多くの問題が発生する可能性があります。 たとえば、kubeletは変更にタイムリーに反応せず、さらに混乱を招きます。
これをよりデバッグ可能にする方法に関する提案を歓迎します...
yujuhong
2017年05月27日
PLEGの不健康な警告が発生し、ノードのヘルスステータスがフラッピングします:k8s 1.6.4 withweave。 (それ以外は同一の)ノードのサブセットにのみ表示されます。
 anurag
2017年05月27日
anurag
2017年05月27日
私たちの場合、ContainerCreatingでスタックしているフラッピングワーカーとポッドは、マスターとワーカー間、およびワーカー間のウィーブトラフィックを許可しないEC2インスタンスのセキュリティグループの問題でした。 そのため、ノードが正しく起動できず、NotReadyでスタックしました。
kuberrnetes 1.6.4
適切なセキュリティグループがあれば、今は機能します。
 agabert
2017年06月01日
agabert
2017年06月01日
私はこの設定でこの問題のようなものを経験しています...
Kubernetesバージョン(kubectlバージョンを使用):1.6.4
環境:
クラウドプロバイダーまたはハードウェア構成:単一のSystem76サーバー
OS(例:/ etc / os-releaseから):Ubuntu 16.04.2 LTS
カーネル(例:uname -a):Linux system76-server 4.4.0-78-generic#99-Ubuntu SMP Thu Apr 27 15:29:09 UTC 2017 x86_64 x86_64 x86_64 GNU / Linux
ツールのインストール:kubeadm + weave.works
これは単一ノードのクラスターであるため、この問題の私のバージョンはセキュリティグループやファイアウォールに関連しているとは思いません。
 wirehead
2017年06月01日
wirehead
2017年06月01日
クラスタを起動したばかりの場合は、セキュリティグループの問題は理にかなっています。 しかし、私たちが目にしているこれらの問題は、セキュリティグループが配置された状態で数か月間実行されているクラスターにあります。
hollowimage
2017年06月02日
GKEでkubeletバージョン1.6.2を実行しているときに、似たようなことが起こりました。
ノードの1つが準備完了状態に移行し、そのノードのkubeletログに2つの苦情がありました。1つはPLEGステータスチェックが失敗したこと、もう2つは興味深いことに画像リスト操作が失敗したことです。
画像関数の呼び出しが失敗したいくつかの例。
image_gc_manager.go:176
kuberuntime_image.go:106
remote_image.go:61
私が想定しているのは、dockerデーモンの呼び出しです。
これが起こっているとき、私はディスクIOスパイク、特に読み取り操作をたくさん見ました。 〜50kb / sマークから8mb / sマークまで。
約30〜45分後に自動的に修正されましたが、IOの増加を引き起こしたのは画像GCスイープだったのでしょうか。
すでに述べたように、PLEGはdockerデーモンを介してポッドを監視します。これが多くの操作を実行している場合、PLEGチェックをキューに入れることができますか?
 zoltrain
2017年06月02日
zoltrain
2017年06月02日
1.6.4および1.6.6(GKE上)でこの問題が発生し、結果としてNotReadyがフラッピングします。 これはGKEで利用可能な最新バージョンであるため、修正を次の1.6リリースにバックポートしてもらいたいと思います。
興味深い点の1つは、PLEGが最後にアクティブであると見なされた時刻は変更されず、常に_巨大な数値であるということです(おそらく、格納されているタイプの制限にあります)。
[container runtime is down PLEG is not healthy: pleg was last seen active 2562047h47m16.854775807s ago; threshold is 3m0s]
 bergman
2017年06月26日
bergman
2017年06月26日
[コンテナのランタイムがダウンしていますPLEGは正常ではありません:plegは2562047h47m16.854775807s前にアクティブであることが最後に確認されました。 しきい値は3m0sです]
@bergman私はこれを見たことがありませんが、もしそうなら、あなたのノードは決して準備ができていなかっただろう。 GKEチームがさらに調査できるように、GKEチャネルを通じてこれを報告してください。
約30〜45分後に自動的に修正されましたが、IOの増加を引き起こしたのは画像GCスイープだったのでしょうか。
これは確かに可能です。 Image GCにより、dockerデーモンの応答が非常に遅くなることがありました。 30〜45分はかなり長く聞こえます。 @zoltrainは、全期間を通じて画像が削除されていました。
前のステートメントを繰り返しますが、PLEGはほとんど何もせず、dockerデーモンが応答しないため、ヘルスチェックに失敗するだけです。 PLEGヘルスチェックを通じてこの情報を表示し、ノードがコンテナ統計を取得していない(およびそれらに反応していない)ことをコントロールプレーンに通知します。 このチェックを盲目的に削除すると、より深刻な問題が隠される可能性があります。
yujuhong
2017年06月26日
更新するには:ウィーブとIPスライスのプロビジョニングに関連する問題が私たちの側で見つかりました。 AWSでノードを頻繁に終了するため、weaveは元々、クラスター内のノードの永続的な破壊を考慮していませんでした。その後、新しいIPが続きます。 その結果、ネットワークが正しくセットアップされないため、内部範囲に関係するものはすべて正しく起動しませんでした。
https://github.com/weaveworks/weave/issues/2970
織りを使用する人のために。
hollowimage
2017年06月26日
[コンテナのランタイムがダウンしていますPLEGは正常ではありません:plegは2562047h47m16.854775807s前にアクティブであることが最後に確認されました。 しきい値は3m0sです]
@bergman私はこれを見たことがありませんが、もしそうなら、あなたのノードは決して準備ができていなかっただろう。 GKEチームがさらに調査できるように、GKEチャネルを通じてこれを報告してください。
ほとんどの場合、ノードは準備完了です。 このチェックが原因でkubeletが再起動されたか、他のチェックがReadyイベントを通知していると思います。 60秒ごとに約10秒のNotReadyが表示されます。 残りの時間、ノードは準備完了です。
bergman
2017年06月27日
@yujuhong PLEG is not healthyはエンドユーザーにとって非常に混乱し、コンテナランタイムが失敗した理由や、コンテナランタイムに関する詳細など、問題の診断には役立たないと言って、PLEGログを改善できると思います。応答する方が便利です
bjhaid
2017年06月27日
羽ばたきは見られませんが、1.6.4と三毛猫ねこネコが織り込まれていないノードの状態は常に準備ができていません。
 chenww
2017年07月21日
chenww
2017年07月21日
@yujuhong PLEGのログは改善できると思います。PLEGが正常でないことはエンドユーザーにとって非常に混乱し、コンテナランタイムが失敗した理由や、コンテナランタイムが応答しないことなどの問題の診断には役立ちません。より便利になる
承知しました。 気軽にPRを送ってください。
yujuhong
2017年07月21日
Dockerイメージのクリーンアップ中にこの問題が発生していました。 Dockerは忙しすぎたと思います。 画像が削除されると、通常の状態に戻ります。
 xcompass
2017年08月19日
xcompass
2017年08月19日
同じ問題が発生しました。 その理由は、ntpdが現在の時刻を修正しているためだと思います。
v1.6.9でntpdの正しい時刻を見てきました
Sep 12 19:05:08 node-6 systemd: Started logagt.
Sep 12 19:05:08 node-6 systemd: Starting logagt...
Sep 12 19:05:09 node-6 cnrm: "Log":"2017-09-12 19:05:09.197083#011ERROR#011node-6#011knitter.cnrm.mod-init#011TransactionID=1#011InstanceID=1174#011[ObjectType=null,ObjectID=null]#011registerOir: k8s.GetK8sClientSingleton().RegisterOir(oirName: hugepage, qty: 2048) FAIL, error: dial tcp 120.0.0.250:8080: getsockopt: no route to host, retry#011[init.go]#011[68]"
Sep 12 11:04:53 node-6 ntpd[902]: 0.0.0.0 c61c 0c clock_step -28818.771869 s
Sep 12 11:04:53 node-6 ntpd[902]: 0.0.0.0 c614 04 freq_mode
Sep 12 11:04:53 node-6 systemd: Time has been changed
Sep 12 11:04:54 node-6 ntpd[902]: 0.0.0.0 c618 08 no_sys_peer
Sep 12 11:05:04 node-6 systemd: Reloading.
Sep 12 11:05:04 node-6 systemd: Configuration file /usr/lib/systemd/system/auditd.service is marked world-inaccessible. This has no effect as configuration data is accessible via APIs without restrictions. Proceeding anyway.
Sep 12 11:05:04 node-6 systemd: Started opslet.
Sep 12 11:05:04 node-6 systemd: Starting opslet...
Sep 12 11:05:13 node-6 systemd: Reloading.
Sep 12 11:05:22 node-6 kubelet: E0912 11:05:22.425676 2429 event.go:259] Could not construct reference to: '&v1.Node{TypeMeta:v1.TypeMeta{Kind:"", APIVersion:""}, ObjectMeta:v1.ObjectMeta{Name:"120.0.0.251", GenerateName:"", Namespace:"", SelfLink:"", UID:"", ResourceVersion:"", Generation:0, CreationTimestamp:v1.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*v1.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string{"beta.kubernetes.io/os":"linux", "beta.kubernetes.io/arch":"amd64", "kubernetes.io/hostname":"120.0.0.251"}, Annotations:map[string]string{"volumes.kubernetes.io/controller-managed-attach-detach":"true"}, OwnerReferences:[]v1.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:""}, Spec:v1.NodeSpec{PodCIDR:"", ExternalID:"120.0.0.251", ProviderID:"", Unschedulable:false, Taints:[]v1.Taint(nil)}, Status:v1.NodeStatus{Capacity:v1.ResourceList{"cpu":resource.Quantity{i:resource.int64Amount{value:4000, scale:-3}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"DecimalSI"}, "memory":resource.Quantity{i:resource.int64Amount{value:3974811648, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"BinarySI"}, "hugePages":resource.Quantity{i:resource.int64Amount{value:1024, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"DecimalSI"}, "pods":resource.Quantity{i:resource.int64Amount{value:110, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"DecimalSI"}}, Allocatable:v1.ResourceList{"cpu":resource.Quantity{i:resource.int64Amount{value:3500, scale:-3}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"DecimalSI"}, "memory":resource.Quantity{i:resource.int64Amount{value:1345666048, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"BinarySI"}, "hugePages":resource.Quantity{i:resource.int64Amount{value:1024, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"",
Sep 12 11:05:22 node-6 kubelet: Format:"DecimalSI"}, "pods":resource.Quantity{i:resource.int64Amount{value:110, scale:0}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, l:[]int64(nil), s:"", Format:"DecimalSI"}}, Phase:"", Conditions:[]v1.NodeCondition{v1.NodeCondition{Type:"OutOfDisk", Status:"False", LastHeartbeatTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196025689, loc:(*time.Location)(0x4e8e3a0)}}, LastTransitionTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196025689, loc:(*time.Location)(0x4e8e3a0)}}, Reason:"KubeletHasSufficientDisk", Message:"kubelet has sufficient disk space available"}, v1.NodeCondition{Type:"MemoryPressure", Status:"False", LastHeartbeatTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196099492, loc:(*time.Location)(0x4e8e3a0)}}, LastTransitionTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196099492, loc:(*time.Location)(0x4e8e3a0)}}, Reason:"KubeletHasSufficientMemory", Message:"kubelet has sufficient memory available"}, v1.NodeCondition{Type:"DiskPressure", Status:"False", LastHeartbeatTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196107935, loc:(*time.Location)(0x4e8e3a0)}}, LastTransitionTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196107935, loc:(*time.Location)(0x4e8e3a0)}}, Reason:"KubeletHasNoDiskPressure", Message:"kubelet has no disk pressure"}, v1.NodeCondition{Type:"Ready", Status:"False", LastHeartbeatTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196114314, loc:(*time.Location)(0x4e8e3a0)}}, LastTransitionTime:v1.Time{Time:time.Time{sec:63640811081, nsec:196114314, loc:(*time.Location)(0x4e8e3a0)}}, Reason:"KubeletNotReady", Message:"container runtime is down,PLEG is not healthy: pleg was last seen active 2562047h47m16.854775807s ago; threshold is 3m0s,network state unknown"}}, Addresses:[]v1.NodeAddress{v1.NodeAddress{Type:"LegacyHostIP", Address:"120.0.0.251"}, v1.NodeAddress{Type:"InternalIP", Address:"120.0.0.251"}, v1.NodeAddress{Type:"Hostname", Address:"120.0.0.251"}}, DaemonEndpoints:v1.NodeDaemonEndpoints{KubeletEndpoint:v1.DaemonEndpoint{Port:10250}}, NodeInfo:v1.NodeS
 yanxuean
2017年09月14日
yanxuean
2017年09月14日
マーク。
 warmchang
2017年09月14日
warmchang
2017年09月14日
ここで同じ問題。
ポッドを強制終了したが、強制終了状態でスタックした場合に表示されますNormal Killing Killing container with docker id 472802bf1dba: Need to kill pod.
およびkubeletログは次のようになります。
skipping pod synchronization - [PLEG is not healthy: pleg was last seen active
k8s clusteバージョン:1.6.4
@xcompass kubelet構成に--image-gc-high-thresholdおよび--image-gc-low-thresholdフラグを使用していますか? kubelet gc dockerdeamonを忙しくしているのではないかと思います。
 alirezaDavid
2017年09月19日
alirezaDavid
2017年09月19日
@alirezaDavid私はあなたと同じ問題に遭遇しました、ポッドの開始と終了が非常に遅く、ノードが時々notReadyになり、ノードでkubeletを再起動するか、dockerを再起動すると問題が解決するように見えますが、これは正しい方法ではありません。
 yangyuw
2017年09月19日
yangyuw
2017年09月19日
@ yu-yang2うん、正確に、kubeletを再起動します
しかし、kubeletを再起動する前に、 docker psとsystemctl -u dockerをチェックアウトしましたが、すべてが機能しているようです。
alirezaDavid
2017年09月19日
この問題は、織りとオートスケーラーを備えたkubernetesで発生しました。 weaveには割り当てるIPアドレスがもうないことが判明しました。 これは、を実行することで検出されました。 この問題からステータスipamを織ります: https :
根本的な原因はここにあります: https :
ドキュメントはオートスケーラーとウィーブについて警告しています: //www.weave.works/docs/net/latest/operational-guide/tasks/
weave --local status ipamを実行すると、多数のIPアドレスが割り当てられた数百の使用できないノードがありました。 これは、オートスケーラーがweaveに通知せずにインスタンスを終了するために発生します。 これにより、実際に接続されたノードはほんの一握りになりました。 weave rmpeerを使用して、使用できないピアの一部をクリアしました。 これにより、iが実行していたノードがIPアドレスのグループになりました。 次に、実行中の他のウィーブノードに移動し、それらからいくつかのrmpeerコマンドも実行しました(それが必要かどうかはわかりません)。
一部のec2インスタンスを終了すると、新しいインスタンスがオートスケーラーによって起動され、すぐにIPアドレスが割り当てられました。
 mattthelee
2017年09月29日
mattthelee
2017年09月29日
こんにちは皆さん。 私の場合、サンドボックスにはネットワーク名前空間がなかったため、サンドボックスの削除に関するPLEGの問題が発生しました。 https://github.com/kubernetes/kubernetes/issues/44307で説明されているその状況
私の問題は:
- ポッドが展開されました。
- ポッドが削除されました。 アプリケーションのコンテナが問題なく削除されました。 アプリケーションのサンドボックスは削除されませんでした。
- PLEGはサンドボックスをコミット/削除/終了しようとしますが、PLEGはこれを実行できず、ノードを異常としてマークします。
ご覧のとおり、このバグのすべての人が1.6。*のKubernetesを使用しています。1.7で修正する必要があります。
PS。 オリジン3.6(kubernetes 1.6)でこの状況を見ました。
 livelace
2017年10月02日
livelace
2017年10月02日
こんにちは、
私は自分でPLEGの問題を抱えています(Azure、k8s 1.7.7):
Oct 5 08:13:27 k8s-agent-27569017-1 docker[1978]: E1005 08:13:27.386295 2209 remote_runtime.go:168] ListPodSandbox with filter "nil" from runtime service failed: rpc error: code = 4 desc = context deadline exceeded
Oct 5 08:13:27 k8s-agent-27569017-1 docker[1978]: E1005 08:13:27.386351 2209 kuberuntime_sandbox.go:197] ListPodSandbox failed: rpc error: code = 4 desc = context deadline exceeded
Oct 5 08:13:27 k8s-agent-27569017-1 docker[1978]: E1005 08:13:27.386360 2209 generic.go:196] GenericPLEG: Unable to retrieve pods: rpc error: code = 4 desc = context deadline exceeded
Oct 5 08:13:30 k8s-agent-27569017-1 docker[1978]: I1005 08:13:30.953599 2209 helpers.go:102] Unable to get network stats from pid 60677: couldn't read network stats: failure opening /proc/60677/net/dev: open /proc/60677/net/dev: no such file or directory
Oct 5 08:13:30 k8s-agent-27569017-1 docker[1978]: I1005 08:13:30.953634 2209 helpers.go:125] Unable to get udp stats from pid 60677: failure opening /proc/60677/net/udp: open /proc/60677/net/udp: no such file or directory
Oct 5 08:13:30 k8s-agent-27569017-1 docker[1978]: I1005 08:13:30.953642 2209 helpers.go:132] Unable to get udp6 stats from pid 60677: failure opening /proc/60677/net/udp6: open /proc/60677/net/udp6: no such file or directory
Oct 5 08:13:31 k8s-agent-27569017-1 docker[1978]: I1005 08:13:31.763914 2209 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 13h42m52.628402637s ago; threshold is 3m0s]
Oct 5 08:13:35 k8s-agent-27569017-1 docker[1978]: I1005 08:13:35.977487 2209 kubelet_node_status.go:467] Using Node Hostname from cloudprovider: "k8s-agent-27569017-1"
Oct 5 08:13:36 k8s-agent-27569017-1 docker[1978]: I1005 08:13:36.764105 2209 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 13h42m57.628610126s ago; threshold is 3m0s]
Oct 5 08:13:39 k8s-agent-27569017-1 docker[1275]: time="2017-10-05T08:13:39.185111999Z" level=warning msg="Health check error: rpc error: code = 4 desc = context deadline exceeded"
Oct 5 08:13:41 k8s-agent-27569017-1 docker[1978]: I1005 08:13:41.764235 2209 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 13h43m2.628732806s ago; threshold is 3m0s]
Oct 5 08:13:41 k8s-agent-27569017-1 docker[1978]: I1005 08:13:41.875074 2209 helpers.go:102] Unable to get network stats from pid 60677: couldn't read network stats: failure opening /proc/60677/net/dev: open /proc/60677/net/dev: no such file or directory
Oct 5 08:13:41 k8s-agent-27569017-1 docker[1978]: I1005 08:13:41.875102 2209 helpers.go:125] Unable to get udp stats from pid 60677: failure opening /proc/60677/net/udp: open /proc/60677/net/udp: no such file or directory
Oct 5 08:13:41 k8s-agent-27569017-1 docker[1978]: I1005 08:13:41.875113 2209 helpers.go:132] Unable to get udp6 stats from pid 60677: failure opening /proc/60677/net/udp6: open /proc/60677/net/udp6: no such file or directory
 sylr
2017年10月05日
sylr
2017年10月05日
安定したCoreOSでv1.7.4+coreos.0を実行しています。 PLEGが原因で、k8sノードが8時間ごとに頻繁にダウンする(そして、dockerやkubeletサービスを再起動するまで起動しない)ことがあります。 コンテナは実行を続けますが、k8sでは不明として報告されます。 Kubesprayを使用してデプロイすることを言及する必要があります。
コンテナを一覧表示するためにdockerと通信するときのGRPCのバックオフアルゴリズムであると思われる問題を追跡しました。 このPRhttps ://github.com/moby/moby/pull/33483は、バックオフを最大2秒に変更し、17.06で利用できますが、kubernetesは1.8まで17.06をサポートしていません。
問題を引き起こしているPLEGの行はこれです。
プロメテウスを使用してPLEGRelistIntervalメトリックとPLEGRelistLatencyメトリックを検査したところ、バックオフアルゴリズム理論とかなり一致する次の結果が得られました。


 ssboisen
2017年10月11日
ssboisen
2017年10月11日
@ssboisenグラフで報告してくれてありがとう(彼らは面白そうに見えます)!
PLEGが原因で、k8sノードが8時間ごとに頻繁にダウンする(そして、dockerやkubeletサービスを再起動するまで起動しない)ことがあります。 コンテナは実行を続けますが、k8sでは不明として報告されます。 Kubesprayを使用してデプロイすることを言及する必要があります。
私が持っているいくつかの質問:
- dockerとkubeletのいずれかを再起動すると問題は解決しますか?
- 問題が発生した場合、
docker psは正常に応答しますか?
コンテナを一覧表示するためにdockerと通信するときのGRPCのバックオフアルゴリズムであると思われる問題を追跡しました。 このPRmoby / moby#33483は、バックオフを最大2秒に変更し、17.06で利用できますが、kubernetesは1.8まで17.06をサポートしていません。
あなたが言及したmobyの問題を調べましたが、その議論では、すべてのdocker ps呼び出しはまだ正しく機能していました(dockerd <->コンテナー接続が切断された場合でも)。 これはあなたが言及したPLEGの問題とは異なるようです。 また、kubeletはgrpcを使用してdockerdと通信しません。 それはdockershimと通信するためにgrpcを使用しますが、それらは本質的に同じプロセスであり、もう一方がまだ生きている間に一方が殺される(接続の切断につながる)という問題に遭遇するべきではありません。
grpc http grpc
kubelet <----> dockershim <----> dockerd <----> containerd
kubeletログに表示されたエラーメッセージは何ですか? 上記のコメントのほとんどには、「コンテキスト期限を超えました」というエラーメッセージがありました。
yujuhong
2017年10月11日
- dockerとkubeletのいずれかを再起動すると問題は解決しますか?
変更されます。ほとんどの場合、kubeletを再起動するだけで十分ですが、Dockerの再起動が必要な状況がありました。
- 問題が発生した場合、
docker psは正常に応答しますか?
PLEGが動作しているときに、ノードでdocker psを実行しても問題はありません。 私はドッカーシムについて知りませんでした、それが問題であるのはクベレットとドッカーシムの間の接続であるかどうか疑問に思います、シムは登山のバックオフにつながる時間内に答えることができませんでしたか?
ログのエラーメッセージは、次の2行の組み合わせです。
generic.go:196] GenericPLEG: Unable to retrieve pods: rpc error: code = 14 desc = grpc: the connection is unavailable
kubelet.go:1820] skipping pod synchronization - [container runtime is down PLEG is not healthy: pleg was last seen active 11h5m56.959313178s ago; threshold is 3m0s]
この問題をより適切にデバッグできるように、より多くの情報を取得する方法について何か提案はありますか?
ssboisen
2017年10月12日
- dockerとkubeletのいずれかを再起動すると問題は解決しますか?
はい、dockerを再起動するだけで修正されるため、k8sの問題ではありません - 問題が発生した場合、docker psは正常に応答しますか?
いいえ。 ハングします。 Dockerは、そのノードでコンテナーを実行するとハングします。
おそらく、正しいことをしているk8sではなく、Dockerの問題です。 ただし、dockerがここで誤動作している理由を見つけることができませんでした。 すべてのCPU /メモリ/ディスクリソースは素晴らしいです。
dockerserviceを再起動すると良好な状態に戻ります。
chenww
2017年10月23日
この問題をより適切にデバッグできるように、より多くの情報を取得する方法について何か提案はありますか?
最初のステップは、どのコンポーネント(dockershimまたはdocker / containerd)がエラーメッセージを返したかを確認することだと思います。
おそらく、kubeletとdockerのログを相互参照することでこれを理解できます。
yujuhong
2017年10月23日
おそらく、正しいことをしているk8sではなく、Dockerの問題です。 ただし、dockerがここで誤動作している理由を見つけることができませんでした。 すべてのCPU /メモリ/ディスクリソースは素晴らしいです。
うん。 あなたの場合、dockerデーモンが実際にハングしているように見えます。 Dockerデーモンをデバッグモードで起動し、発生したときにスタックトレースを取得できます。
https://docs.docker.com/engine/admin/#force -a-stack-trace-to-be-logged
yujuhong
2017年10月23日
@yujuhong k8sの負荷テスト後にこの問題が再び発生し、ほとんどすべてのノードがnot readyなり、ポッドを数日間クリーンアップしても回復しませんでした。すべてのkubeletで冗長モードを開き、ログを取得しました。以下では、これらのログが問題の解決に役立つことを願っています。
Oct 24 21:16:39 docker34-91 kubelet[24165]: I1024 21:16:39.539054 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:39 docker34-91 kubelet[24165]: I1024 21:16:39.639305 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:39 docker34-91 kubelet[24165]: I1024 21:16:39.739585 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:39 docker34-91 kubelet[24165]: I1024 21:16:39.839829 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:39 docker34-91 kubelet[24165]: I1024 21:16:39.940111 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.040374 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.128789 24165 kubelet.go:2064] Container runtime status: Runtime Conditions: RuntimeReady=true reason: message:, NetworkReady=true reason: message:
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.140634 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.240851 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.341125 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.441471 24165 config.go:101] Looking for [api file], have seen map[api:{} file:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.541781 24165 config.go:101] Looking for [api file], have seen map[api:{} file:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.642070 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.742347 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.842562 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:40 docker34-91 kubelet[24165]: I1024 21:16:40.942867 24165 config.go:101] Looking for [api file], have seen map[api:{} file:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.006656 24165 kubelet.go:1752] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 6m20.171705404s ago; threshold is 3m0s]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.043126 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.143372 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.243620 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.343911 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.444156 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.544420 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.644732 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.745002 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.845268 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:41 docker34-91 kubelet[24165]: I1024 21:16:41.945524 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 24 21:16:42 docker34-91 kubelet[24165]: I1024 21:16:42.045814 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
^C
[root@docker34-91 ~]# journalctl -u kubelet -f
-- Logs begin at Wed 2017-10-25 17:19:29 CST. --
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0b 0a 02 76 31 12 05 45 76 65 6e |k8s.....v1..Even|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000010 74 12 d3 03 0a 4f 0a 33 6c 64 74 65 73 74 2d 37 |t....O.3ldtest-7|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000020 33 34 33 39 39 64 67 35 39 2d 33 33 38 32 38 37 |34399dg59-338287|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000030 31 36 38 35 2d 78 32 36 70 30 2e 31 34 66 31 34 |1685-x26p0.14f14|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000040 63 30 39 65 62 64 32 64 66 66 34 12 00 1a 0a 6c |c09ebd2dff4....l|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000050 64 74 65 73 74 2d 30 30 35 22 00 2a 00 32 00 38 |dtest-005".*.2.8|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000060 00 42 00 7a 00 12 6b 0a 03 50 6f 64 12 0a 6c 64 |.B.z..k..Pod..ld|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000070 74 65 73 74 2d 30 30 35 1a 22 6c 64 74 65 73 74 |test-005."ldtest|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000080 2d 37 33 34 33 39 39 64 67 35 39 2d 33 33 38 32 |-734399dg59-3382|
Oct 27 10:22:35 docker34-91 kubelet[24165]: 00000090 38 37 31 36 38 35 2d 78 32 36 70 30 22 24 61 35 |871685-x26p0"$a5|
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.098922 24165 kubelet.go:2064] Container runtime status: Runtime Conditions: RuntimeReady=true reason: message:, NetworkReady=true reason: message:
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.175027 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.275290 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.375594 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.475872 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.576140 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.676412 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.776613 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.876855 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:02 docker34-91 kubelet[24165]: I1027 10:23:02.977126 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.000354 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "a052cabc-bab9-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.000509 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-276aa6023f-1106740979-hbtcv
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001753 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-276aa6023f-1106740979-hbtcv 404 Not Found in 1 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001768 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001773 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001776 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001780 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001838 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 32 37 36 61 61 36 30 32 33 66 2d 31 31 |st-276aa6023f-11|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 30 36 37 34 30 39 37 39 2d 68 62 74 63 76 22 20 |06740979-hbtcv" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 32 37 |und*.."ldtest-27|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 36 61 61 36 30 32 33 66 2d 31 31 30 36 37 34 30 |6aa6023f-1106740|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 39 37 39 2d 68 62 74 63 76 12 00 1a 04 70 6f 64 |979-hbtcv....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001885 24165 status_manager.go:425] Pod "ldtest-276aa6023f-1106740979-hbtcv" (a052cabc-bab9-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001900 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "a584c63e-bab7-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.001946 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-734399dg59-3382871685-x26p0
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002559 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-734399dg59-3382871685-x26p0 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002569 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002573 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002577 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002580 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002627 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 37 33 34 33 39 39 64 67 35 39 2d 33 33 |st-734399dg59-33|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 38 32 38 37 31 36 38 35 2d 78 32 36 70 30 22 20 |82871685-x26p0" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 37 33 |und*.."ldtest-73|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 34 33 39 39 64 67 35 39 2d 33 33 38 32 38 37 31 |4399dg59-3382871|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 36 38 35 2d 78 32 36 70 30 12 00 1a 04 70 6f 64 |685-x26p0....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002659 24165 status_manager.go:425] Pod "ldtest-734399dg59-3382871685-x26p0" (a584c63e-bab7-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002668 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "2727277f-bab3-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.002711 24165 round_trippers.go:398] curl -k -v -XGET -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" -H "Accept: application/vnd.kubernetes.protobuf, */*" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-4bc7922c25-2238154508-xt94x
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003318 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-4bc7922c25-2238154508-xt94x 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003328 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003332 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003336 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003339 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003379 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 34 62 63 37 39 32 32 63 32 35 2d 32 32 |st-4bc7922c25-22|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 33 38 31 35 34 35 30 38 2d 78 74 39 34 78 22 20 |38154508-xt94x" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 34 62 |und*.."ldtest-4b|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 63 37 39 32 32 63 32 35 2d 32 32 33 38 31 35 34 |c7922c25-2238154|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 35 30 38 2d 78 74 39 34 78 12 00 1a 04 70 6f 64 |508-xt94x....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003411 24165 status_manager.go:425] Pod "ldtest-4bc7922c25-2238154508-xt94x" (2727277f-bab3-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003423 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "43dd5201-bab4-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.003482 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-g02c441308-3753936377-d6q69
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004051 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-g02c441308-3753936377-d6q69 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004059 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004062 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004066 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004069 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004115 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 67 30 32 63 34 34 31 33 30 38 2d 33 37 |st-g02c441308-37|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 35 33 39 33 36 33 37 37 2d 64 36 71 36 39 22 20 |53936377-d6q69" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 67 30 |und*.."ldtest-g0|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 32 63 34 34 31 33 30 38 2d 33 37 35 33 39 33 36 |2c441308-3753936|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 33 37 37 2d 64 36 71 36 39 12 00 1a 04 70 6f 64 |377-d6q69....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004142 24165 status_manager.go:425] Pod "ldtest-g02c441308-3753936377-d6q69" (43dd5201-bab4-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004148 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "8fd9d66f-bab7-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004195 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-cf2eg79b08-3660220702-x0j2j
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004752 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-cf2eg79b08-3660220702-x0j2j 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004761 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004765 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004769 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004773 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004812 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 63 66 32 65 67 37 39 62 30 38 2d 33 36 |st-cf2eg79b08-36|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 36 30 32 32 30 37 30 32 2d 78 30 6a 32 6a 22 20 |60220702-x0j2j" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 63 66 |und*.."ldtest-cf|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 32 65 67 37 39 62 30 38 2d 33 36 36 30 32 32 30 |2eg79b08-3660220|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 37 30 32 2d 78 30 6a 32 6a 12 00 1a 04 70 6f 64 |702-x0j2j....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004841 24165 status_manager.go:425] Pod "ldtest-cf2eg79b08-3660220702-x0j2j" (8fd9d66f-bab7-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004853 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "eb5a5f4a-baba-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.004921 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-9b47680d12-2536408624-jhp18
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005436 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-9b47680d12-2536408624-jhp18 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005446 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005450 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005454 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005457 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005499 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 39 62 34 37 36 38 30 64 31 32 2d 32 35 |st-9b47680d12-25|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 33 36 34 30 38 36 32 34 2d 6a 68 70 31 38 22 20 |36408624-jhp18" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 39 62 |und*.."ldtest-9b|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 34 37 36 38 30 64 31 32 2d 32 35 33 36 34 30 38 |47680d12-2536408|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 36 32 34 2d 6a 68 70 31 38 12 00 1a 04 70 6f 64 |624-jhp18....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005526 24165 status_manager.go:425] Pod "ldtest-9b47680d12-2536408624-jhp18" (eb5a5f4a-baba-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005533 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "2db95639-bab5-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.005588 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-5f8ba1eag0-2191624653-dm374
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006150 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-5f8ba1eag0-2191624653-dm374 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006176 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006182 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006189 24165 round_trippers.go:426] Content-Length: 154
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006195 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006251 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 81 01 0a 04 0a 00 12 00 12 07 46 61 69 |us...........Fai|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 6c 75 72 65 1a 33 70 6f 64 73 20 22 6c 64 74 65 |lure.3pods "ldte|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 73 74 2d 35 66 38 62 61 31 65 61 67 30 2d 32 31 |st-5f8ba1eag0-21|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 39 31 36 32 34 36 35 33 2d 64 6d 33 37 34 22 20 |91624653-dm374" |
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 6e 6f 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f |not found".NotFo|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 75 6e 64 2a 2e 0a 22 6c 64 74 65 73 74 2d 35 66 |und*.."ldtest-5f|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 38 62 61 31 65 61 67 30 2d 32 31 39 31 36 32 34 |8ba1eag0-2191624|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 36 35 33 2d 64 6d 33 37 34 12 00 1a 04 70 6f 64 |653-dm374....pod|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 73 28 00 30 94 03 1a 00 22 00 |s(.0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006297 24165 status_manager.go:425] Pod "ldtest-5f8ba1eag0-2191624653-dm374" (2db95639-bab5-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006330 24165 status_manager.go:410] Status Manager: syncPod in syncbatch. pod UID: "ecf58d7f-bab2-11e7-92f6-3497f60062c3"
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006421 24165 round_trippers.go:398] curl -k -v -XGET -H "Accept: application/vnd.kubernetes.protobuf, */*" -H "User-Agent: kubelet/v1.6.4 (linux/amd64) kubernetes/d6f4332" http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-0fe4761ce1-763135991-2gv5x
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006983 24165 round_trippers.go:417] GET http://172.23.48.211:8080/api/v1/namespaces/ldtest-005/pods/ldtest-0fe4761ce1-763135991-2gv5x 404 Not Found in 0 milliseconds
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.006995 24165 round_trippers.go:423] Response Headers:
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.007001 24165 round_trippers.go:426] Content-Type: application/vnd.kubernetes.protobuf
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.007007 24165 round_trippers.go:426] Date: Fri, 27 Oct 2017 02:23:03 GMT
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.007014 24165 round_trippers.go:426] Content-Length: 151
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.007064 24165 request.go:989] Response Body:
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000000 6b 38 73 00 0a 0c 0a 02 76 31 12 06 53 74 61 74 |k8s.....v1..Stat|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000010 75 73 12 7f 0a 04 0a 00 12 00 12 07 46 61 69 6c |us..........Fail|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000020 75 72 65 1a 32 70 6f 64 73 20 22 6c 64 74 65 73 |ure.2pods "ldtes|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000030 74 2d 30 66 65 34 37 36 31 63 65 31 2d 37 36 33 |t-0fe4761ce1-763|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000040 31 33 35 39 39 31 2d 32 67 76 35 78 22 20 6e 6f |135991-2gv5x" no|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000050 74 20 66 6f 75 6e 64 22 08 4e 6f 74 46 6f 75 6e |t found".NotFoun|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000060 64 2a 2d 0a 21 6c 64 74 65 73 74 2d 30 66 65 34 |d*-.!ldtest-0fe4|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000070 37 36 31 63 65 31 2d 37 36 33 31 33 35 39 39 31 |761ce1-763135991|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000080 2d 32 67 76 35 78 12 00 1a 04 70 6f 64 73 28 00 |-2gv5x....pods(.|
Oct 27 10:23:03 docker34-91 kubelet[24165]: 00000090 30 94 03 1a 00 22 00 |0....".|
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.007106 24165 status_manager.go:425] Pod "ldtest-0fe4761ce1-763135991-2gv5x" (ecf58d7f-bab2-11e7-92f6-3497f60062c3) does not exist on the server
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.077334 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.177546 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.277737 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.377939 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.478169 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.578369 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.603649 24165 eviction_manager.go:197] eviction manager: synchronize housekeeping
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.678573 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682080 24165 summary.go:389] Missing default interface "eth0" for node:172.23.34.91
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682132 24165 summary.go:389] Missing default interface "eth0" for pod:kube-system_kube-proxy-qcft5
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682176 24165 helpers.go:744] eviction manager: observations: signal=imagefs.available, available: 515801344Ki, capacity: 511750Mi, time: 2017-10-27 10:22:56.499173632 +0800 CST
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682197 24165 helpers.go:744] eviction manager: observations: signal=imagefs.inodesFree, available: 523222251, capacity: 500Mi, time: 2017-10-27 10:22:56.499173632 +0800 CST
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682203 24165 helpers.go:746] eviction manager: observations: signal=allocatableMemory.available, available: 65544340Ki, capacity: 65581868Ki
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682207 24165 helpers.go:744] eviction manager: observations: signal=memory.available, available: 57973412Ki, capacity: 65684268Ki, time: 2017-10-27 10:22:56.499173632 +0800 CST
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682213 24165 helpers.go:744] eviction manager: observations: signal=nodefs.available, available: 99175128Ki, capacity: 102350Mi, time: 2017-10-27 10:22:56.499173632 +0800 CST
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682218 24165 helpers.go:744] eviction manager: observations: signal=nodefs.inodesFree, available: 104818019, capacity: 100Mi, time: 2017-10-27 10:22:56.499173632 +0800 CST
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.682233 24165 eviction_manager.go:292] eviction manager: no resources are starved
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.778792 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.879040 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:03 docker34-91 kubelet[24165]: I1027 10:23:03.979304 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.079534 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.179753 24165 config.go:101] Looking for [api file], have seen map[api:{} file:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.280026 24165 config.go:101] Looking for [api file], have seen map[api:{} file:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.380246 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.480450 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.580695 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.680957 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.781224 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.881418 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:04 docker34-91 kubelet[24165]: I1027 10:23:04.981643 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.081882 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.182810 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.283410 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.383626 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.483942 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.584211 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.684460 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.784699 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.884949 24165 config.go:101] Looking for [api file], have seen map[file:{} api:{}]
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960855 24165 factory.go:115] Factory "docker" was unable to handle container "/system.slice/data-docker-overlay-c0d3c4b3834cfe9f12cd5c35345cab9c8e71bb64c689c8aea7a458c119a5a54e-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960885 24165 factory.go:108] Factory "systemd" can handle container "/system.slice/data-docker-overlay-c0d3c4b3834cfe9f12cd5c35345cab9c8e71bb64c689c8aea7a458c119a5a54e-merged.mount", but ignoring.
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960906 24165 manager.go:867] ignoring container "/system.slice/data-docker-overlay-c0d3c4b3834cfe9f12cd5c35345cab9c8e71bb64c689c8aea7a458c119a5a54e-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960912 24165 factory.go:115] Factory "docker" was unable to handle container "/system.slice/data-docker-overlay-ce9656ff9d3cd03baaf93e42d0874377fa37bfde6c9353b3ba954c90bf4332f3-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960919 24165 factory.go:108] Factory "systemd" can handle container "/system.slice/data-docker-overlay-ce9656ff9d3cd03baaf93e42d0874377fa37bfde6c9353b3ba954c90bf4332f3-merged.mount", but ignoring.
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960926 24165 manager.go:867] ignoring container "/system.slice/data-docker-overlay-ce9656ff9d3cd03baaf93e42d0874377fa37bfde6c9353b3ba954c90bf4332f3-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960931 24165 factory.go:115] Factory "docker" was unable to handle container "/system.slice/data-docker-overlay-b3600c0fe81445773b9241c5d1da8b1f97612d0a235f8b32139478a5717f79e1-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960937 24165 factory.go:108] Factory "systemd" can handle container "/system.slice/data-docker-overlay-b3600c0fe81445773b9241c5d1da8b1f97612d0a235f8b32139478a5717f79e1-merged.mount", but ignoring.
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960944 24165 manager.go:867] ignoring container "/system.slice/data-docker-overlay-b3600c0fe81445773b9241c5d1da8b1f97612d0a235f8b32139478a5717f79e1-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960949 24165 factory.go:115] Factory "docker" was unable to handle container "/system.slice/data-docker-overlay-ed2fe0d57c56cf6b051e1bda1ca0185ceef4756b1a8f9af4c19f4e512bcc60f4-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960955 24165 factory.go:108] Factory "systemd" can handle container "/system.slice/data-docker-overlay-ed2fe0d57c56cf6b051e1bda1ca0185ceef4756b1a8f9af4c19f4e512bcc60f4-merged.mount", but ignoring.
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960979 24165 manager.go:867] ignoring container "/system.slice/data-docker-overlay-ed2fe0d57c56cf6b051e1bda1ca0185ceef4756b1a8f9af4c19f4e512bcc60f4-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960984 24165 factory.go:115] Factory "docker" was unable to handle container "/system.slice/data-docker-overlay-0ba6483a0117c539493cd269be9f87d31d1d61aa813e7e0381c5f5d8b0623275-merged.mount"
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960990 24165 factory.go:108] Factory "systemd" can handle container "/system.slice/data-docker-overlay-0ba6483a0117c539493cd269be9f87d31d1d61aa813e7e0381c5f5d8b0623275-merged.mount", but ignoring.
Oct 27 10:23:05 docker34-91 kubelet[24165]: I1027 10:23:05.960997 24165 manager.go:867] ignoring container "/system.slice/data-docker-overlay-0ba6483a0117c539493cd269be9f87d31d1d61aa813e7e0381c5f5d8b0623275-merged.mount"
同様の問題をヒット:
Oct 28 09:15:38 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:15:38.711430 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:15:51 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:15:51.439135 3299 kuberuntime_manager.go:843] PodSandboxStatus of sandbox "9c1c1f2d4a9d277a41a97593c330f41e00ca12f3ad858c19f61fd155d18d795e" for pod "pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)" error: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:15:51 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:15:51.439188 3299 generic.go:241] PLEG: Ignoring events for pod pickup-566929041-bn8t9/staging: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:15:51 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:15:51.711168 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:16:03 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:16:03.711164 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:16:18 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:16:18.715381 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:16:33 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:16:33.711198 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:16:46 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:16:46.712983 3299 pod_workers.go:182] Error syncing pod 7d3b94f3-afa7-11e7-aaec-06936c368d26 ("pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)"), skipping: rpc error: code = 4 desc = context deadline exceeded
Oct 28 09:16:51 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:16:51.711142 3299 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.31269053s ago; threshold is 3m0s]
Oct 28 09:16:56 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:16:56.711341 3299 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m5.312886434s ago; threshold is 3m0s]
Oct 28 09:17:01 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:17:01.351771 3299 kubelet_node_status.go:734] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2017-10-28 09:17:01.35173325 +0000 UTC LastTransitionTime:2017-10-28 09:17:01.35173325 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m9.95330596s ago; threshold is 3m0s}
Oct 28 09:17:01 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:17:01.711552 3299 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m10.31309378s ago; threshold is 3m0s]
Oct 28 09:17:06 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:17:06.711871 3299 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m15.313406671s ago; threshold is 3m0s]
Oct 28 09:17:11 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: I1028 09:17:11.712162 3299 kubelet.go:1820] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m20.313691126s ago; threshold is 3m0s]
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 transport: http2Server.HandleStreams failed to read frame: read unix /var/run/dockershim.sock->@: use of closed network connection
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 transport: http2Client.notifyError got notified that the client transport was broken EOF.
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 grpc: addrConn.resetTransport failed to create client transport: connection error: desc = "transport: dial unix /var/run/dockershim.sock: connect: no such file or directory"; Reconnecting to {/var/run/dockershim.sock <nil>}
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: E1028 09:17:12.556535 3299 kuberuntime_manager.go:843] PodSandboxStatus of sandbox "9c1c1f2d4a9d277a41a97593c330f41e00ca12f3ad858c19f61fd155d18d795e" for pod "pickup-566929041-bn8t9_staging(7d3b94f3-afa7-11e7-aaec-06936c368d26)" error: rpc error: code = 13 desc = transport is closing
これらのメッセージの後、 kubeletは再起動ループに入りました。
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: Main process exited, code=exited, status=1/FAILURE
Oct 28 09:18:42 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: State 'stop-final-sigterm' timed out. Killing.
Oct 28 09:18:42 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: Killing process 1661 (calico) with signal SIGKILL.
Oct 28 09:20:12 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: Processes still around after final SIGKILL. Entering failed mode.
Oct 28 09:20:12 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: Stopped Kubernetes Kubelet.
Oct 28 09:20:12 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: Unit entered failed state.
Oct 28 09:20:12 ip-10-72-17-119.us-west-2.compute.internal systemd[1]: kube-kubelet.service: Failed with result 'exit-code'.
最後のメッセージは次のとおりです。Dockerの問題のようです。
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 transport: http2Server.HandleStreams failed to read frame: read unix /var/run/dockershim.sock->@: use of closed network connection
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 transport: http2Client.notifyError got notified that the client transport was broken EOF.
Oct 28 09:17:12 ip-10-72-17-119.us-west-2.compute.internal kubelet[3299]: 2017/10/28 09:17:12 grpc: addrConn.resetTransport failed to create client transport: connection error: desc = "transport: dial unix /var/run/dockershim.sock: connect: no such file or directory"; Reconnecting to {/var/run/dockershim.sock <nil>}
 zihaoyu
2017年10月28日
zihaoyu
2017年10月28日
最後のメッセージはdockershimからです。 これらのログも非常に役立ちます。
 rphillips
2017年11月15日
rphillips
2017年11月15日
こんにちは、Kubernetes 1.7.10、Kops @ AWSに基づいており、CalicoとCoreOSを使用しています。
同じPLEGの問題があります
Ready False KubeletNotReady PLEG is not healthy: pleg was last seen active 3m29.396986143s ago; threshold is 3m0s
私たちが抱えている唯一の追加の問題は、最近特に1.7.8以降で再デプロイするときに発生すると思います。たとえば、新しいバージョンのアプリを持ってきて、古いレプリカセットがダウンするようにすると、新しいレプリカセットが一緒にスピンされます。ポッド、以前のデプロイメントバージョンのポッドは、「終了」状態のままになります。
次に、手動でforce kill them
 javapapo
2017年11月18日
javapapo
2017年11月18日
同じPLEGの問題がありますk8s1.8.1
 tanhui2333
2017年11月21日
tanhui2333
2017年11月21日
+1
1.6.9
Docker1.12.6を使用
 zhangxiaoyu-zidif
2017年11月29日
zhangxiaoyu-zidif
2017年11月29日
+1
1.8.2
 dElogics
2017年11月29日
dElogics
2017年11月29日
+1
1.6.0
 majid021
2017年11月29日
majid021
2017年11月29日
- 1.8.4
そしてより多くの質問:
- そうです、CPUとメモリはほぼ100%でした。 しかし、私の質問は、ノードの準備が長いためにポッドが他のノードに割り当てられないのはなぜですか?
 gogeof
2017年12月06日
gogeof
2017年12月06日
+1ノードがNotReady状態になることは、Kubernets 1.8.5にアップグレードした後、過去2日間でほぼ一貫して発生していました。 私にとっての問題は、クラスターオートスケーラーをアップグレードしなかったことだと思います。 オートスケーラーを1.03(ヘルム0.3.0)にアップグレードした後、「NotReady」状態のノードは表示されません。 再び安定したクラスターがあるようです。
- kops:1.8.0
- kubectl:1.8.5
- ヘルム:2.7.2
- cluster-autoscaler:v0.6.0 ---> 1.03にアップグレード(ヘルム0.3.0)
 iamrandys
2017年12月11日
iamrandys
2017年12月11日
港湾労働者がぶら下がっていても、ペストは非アクティブであってはなりません
 timchenxiaoyu
2017年12月15日
timchenxiaoyu
2017年12月15日
ここでも同じ、1.8.5
低バージョンから更新せず、空から作成します。
リソースは十分です
記憶
# free -mg
total used free shared buff/cache available
Mem: 15 2 8 0 5 12
Swap: 15 0 15
上
top - 04:34:39 up 24 days, 6:23, 2 users, load average: 31.56, 83.38, 66.29
Tasks: 432 total, 5 running, 427 sleeping, 0 stopped, 0 zombie
%Cpu(s): 9.2 us, 1.9 sy, 0.0 ni, 87.5 id, 1.3 wa, 0.0 hi, 0.1 si, 0.0 st
KiB Mem : 16323064 total, 8650144 free, 2417236 used, 5255684 buff/cache
KiB Swap: 16665596 total, 16646344 free, 19252 used. 12595460 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
31905 root 20 0 1622320 194096 51280 S 14.9 1.2 698:10.66 kubelet
19402 root 20 0 12560 9696 1424 R 10.3 0.1 442:05.00 memtester
2626 root 20 0 12560 9660 1392 R 9.6 0.1 446:41.38 memtester
8680 root 20 0 12560 9660 1396 R 9.6 0.1 444:34.38 memtester
15004 root 20 0 12560 9704 1432 R 9.6 0.1 443:04.98 memtester
1663 root 20 0 8424940 424912 20556 S 4.6 2.6 2809:24 dockerd
409 root 20 0 49940 37068 20648 S 2.3 0.2 144:03.37 calico-felix
551 root 20 0 631788 20952 11824 S 1.3 0.1 100:36.78 costor
9527 root 20 0 10.529g 24800 13612 S 1.0 0.2 3:43.55 etcd
2608 root 20 0 421936 6040 3288 S 0.7 0.0 31:29.78 containerd-shim
4136 root 20 0 780344 24580 12316 S 0.7 0.2 45:58.60 costor
4208 root 20 0 755756 22208 12176 S 0.7 0.1 41:49.58 costor
8665 root 20 0 210344 5960 3208 S 0.7 0.0 31:27.75 cont
現在、以下の状況が見つかりました。
Docker Storage Setupがシンプールの80%を使用するように構成されているため、kubeletのハードエビクションは10%でした。 どちらも機械加工ではありませんでした。
Dockerが何らかの形で内部的にクラッシュし、kubeletにこのPLEGエラーが発生しました。
kubeletのハードエビクション(imagefs.available)を20%に増やすと、Dockerのセットアップがヒットし、kubeletは古いイメージの削除を開始しました。
1.8では、image-gc-thresholdからhard-evictionに変更し、間違った一致するパラメーターを選択しました。
これについては、今すぐクラスターを観察します。
久部:1.8.5
Docker:1.12.6
OS:RHEL7
 sybnex
2017年12月21日
sybnex
2017年12月21日
prometheusからの内部kubelet_pleg_relist_latency_microsecondsメトリックを見ると、これは疑わしいように見えます。
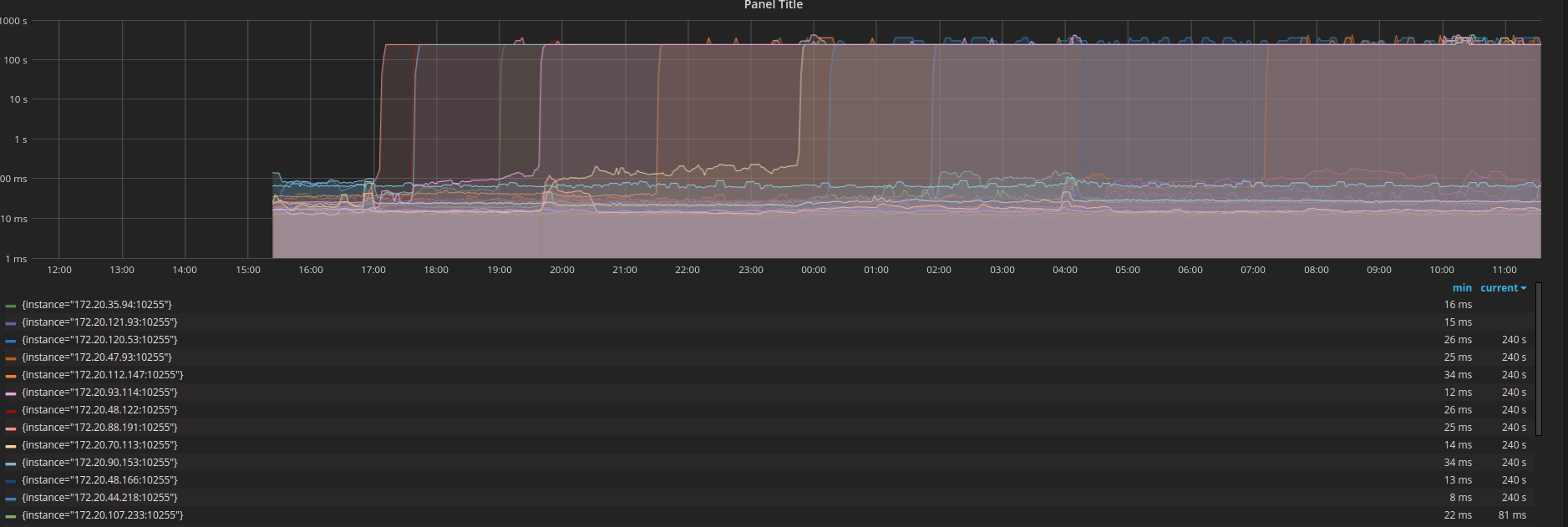
kopsはcoreOSでkube1.8.4をインストールしました
docker info
Containers: 246
Running: 222
Paused: 0
Stopped: 24
Images: 30
Server Version: 17.09.0-ce
Storage Driver: overlay
Backing Filesystem: extfs
Supports d_type: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file logentries splunk syslog
Swarm: inactive
Runtimes: runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 06b9cb35161009dcb7123345749fef02f7cea8e0
runc version: 3f2f8b84a77f73d38244dd690525642a72156c64
init version: v0.13.2 (expected: 949e6facb77383876aeff8a6944dde66b3089574)
Security Options:
seccomp
Profile: default
selinux
Kernel Version: 4.13.16-coreos-r2
Operating System: Container Linux by CoreOS 1576.4.0 (Ladybug)
OSType: linux
Architecture: x86_64
CPUs: 8
Total Memory: 14.69GiB
Name: ip-172-20-120-53.eu-west-1.compute.internal
ID: SI53:ECLM:HXFE:LOVY:STTS:C4X2:WRFK:UGBN:7NYP:4N3E:MZGS:EAVM
Docker Root Dir: /var/lib/docker
Debug Mode (client): false
Debug Mode (server): false
Registry: https://index.docker.io/v1/
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
 Deshke
2017年12月21日
Deshke
2017年12月21日
+1
オリジンv3.7.0
kubernetes v1.7.6
docker v1.12.6
OS CentOS 7.4
ランタイムコンテナGCがポッドの作成と終了に影響を与えるようです
GCを無効にした後に何が起こったのかを報告してみましょう。
 esevan
2017年12月29日
esevan
2017年12月29日
私の場合、CNIは状況を処理しません。
私の分析によると、コードシーケンスは次のとおりです
1. kuberuntime_gc.go: client.StopPodSandbox (Timeout Default: 2m)
-> docker_sandbox.go: StopPodSandbox
-> cni.go: TearDownPod
-> CNI deleteFromNetwork (Timeout Default: 3m) <- Nothing gonna happen if CNI doesn't handle this situation.
-> docker_service.go: StopContainer
2. kuberuntime_gc.go: client.RemovePodSandbox
StopPodSandboxはタイムアウト例外を発生させ、処理せずに戻ってポッドサンドボックスを削除します
ただし、StopPodSandboxがタイムアウトした後、CNIプロセスは進行中です。
これは、kubeletスレッドがCNIプロセスによって不足しているため、結果としてkubeletがPLEGを適切に監視できないようです。
この問題は、CNI_NSが空のときに戻るようにCNIを変更することで解決しました(ポッドがデッドであることを意味するため)。
(ところで、CNIプラグインとしてkuryr-kubernetesを使用しています)
これが皆さんのお役に立てば幸いです。
esevan
2018年01月03日
@esevanパッチを提案してもらえますか?
rphillips
2018年01月08日
@rphillipsこのバグは実際にはCNIバグに近いものであり、動作を詳しく調べた後、確実にパッチをopenstack / kuryr-kubernetesにアップロードします。
esevan
2018年01月09日
私たちの場合、それはhttps://github.com/moby/moby/issues/33820に関連しています
Dockerコンテナのタイムアウトを停止すると、ノードはPLEGメッセージでready / notReadyの間でフラッピングを開始します。
Dockerのバージョンを元に戻すと、問題が修正されます。 (17.09-ce-> 12.06)
 ghost
2018年01月11日
ghost
2018年01月11日
kubelet v1.9.1と同じエラーログ。
...
Jan 15 12:36:52 l23-27-101 kubelet[7335]: I0115 12:36:52.884617 7335 status_manager.go:136] Kubernetes client is nil, not starting status manager.
Jan 15 12:36:52 l23-27-101 kubelet[7335]: I0115 12:36:52.884636 7335 kubelet.go:1767] Starting kubelet main sync loop.
Jan 15 12:36:52 l23-27-101 kubelet[7335]: I0115 12:36:52.884692 7335 kubelet.go:1778] skipping pod synchronization - [container runtime is down PLEG is not healthy: pleg was last seen active 2562047h47m16.854775807s ago; threshold is 3m0s]
Jan 15 12:36:52 l23-27-101 kubelet[7335]: E0115 12:36:52.884788 7335 container_manager_linux.go:583] [ContainerManager]: Fail to get rootfs information unable to find data for container /
Jan 15 12:36:52 l23-27-101 kubelet[7335]: I0115 12:36:52.885001 7335 volume_manager.go:247] Starting Kubelet Volume Manager
...
 shenshouer
2018年01月15日
shenshouer
2018年01月15日
誰かがdocker> 12.6でこの問題を抱えていますか? (サポートされていないバージョン17.09を除く)
13.1または17.06に切り替えることが役立つかどうか疑問に思っています。
sybnex
2018年01月15日
@sybnex 17.03もクラスターでこの問題を抱えています。これは、CNIのバグに最もよく似ています。
yangyuw
2018年01月16日
私にとって、これは、kubeletがハウスキーピングタスクを実行するためにCPUを大量に使用していたために発生しました。その結果、DockerにCPU時間が残っていませんでした。 ハウスキーピングの間隔を短くすることで、問題は解決しました。
dElogics
2018年01月17日
@esevan :kuryr-kubernetesパッチをいただければ幸いです:-)
 celebdor
2018年01月17日
celebdor
2018年01月17日
参考までに、Origin 1.5 / Kubernetes 1.5とKuryr(最初のバージョン)を問題なく使用しています:)
livelace
2018年01月17日
@livelace以降のバージョンを使用しない理由はありますか?
celebdor
2018年01月17日
@celebdor必要はありません、すべてが機能します:) Origin + Openstackを使用し、これらのバージョンはすべてのニーズをカバーします。Kubernetes/ Openstackの新機能は必要ありません。Kuryrは機能します。 2つの追加チームがインフラストラクチャに参加すると、問題が発生する可能性があります。
livelace
2018年01月18日
デフォルトのpleg-relist-thresholdは3分です。
pleg-relist-thresholdを構成可能にしてから、より大きな値を設定できないのはなぜですか。
私はこれを行うためのPRを行いました。
誰かが見ることができますか?
https://github.com/kubernetes/kubernetes/pull/58279
 linyouchong
2018年01月23日
linyouchong
2018年01月23日
PLEGとProbeManagerについて混乱が生じます。
PLEGは、ノード内でポッドとコンテナを正常に保持する必要があります。
ProbeManagerは、ノード内のコンテナの正常性も保持します。
2つのモジュールに同じことをさせるのはなぜですか?
ProbeManagerは、コンテナが停止していることを検出すると、コンテナを再起動します。同時に
PLEGがコンテナが停止していることも検出した場合、PLEGはkubeletに同じことを行うように指示するイベントを作成しますか
事?
 liucimin
2018年01月31日
liucimin
2018年01月31日
+1
Kubernetes v1.8.4
 erstaples
2018年01月31日
erstaples
2018年01月31日
@celebdor cniをデーモン化されたものに更新した後、cniパッチなしで安定化されました。
esevan
2018年02月01日
+1
kubernetes v1.9.2
docker 17.03.2-ce
 huzhengchuan
2018年02月27日
huzhengchuan
2018年02月27日
+1
kubernetes v1.9.2
docker 17.03.2-ce
kubeletログのエラーログ:
Feb 27 16:19:12 node-2 kubelet: E0227 16:19:12.839866 47544 remote_runtime.go:169] ListPodSandbox with filter nil from runtime service failed: rpc error: code = Unknown desc = Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
Feb 27 16:19:12 node-2 kubelet: E0227 16:19:12.839919 47544 kuberuntime_sandbox.go:192] ListPodSandbox failed: rpc error: code = Unknown desc = Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
Feb 27 16:19:12 node-2 kubelet: E0227 16:19:12.839937 47544 generic.go:197] GenericPLEG: Unable to retrieve pods: rpc error: code = Unknown desc = Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
kubeletはdockerclient(httpClient)を使用して、2分のタイムアウトでContainerList(all status && io.kubernetes.docker.type == "podsandbox")を呼び出します。
docker ps -a --filter "label=io.kubernetes.docker.type=podsandbox"
ノードがNotReadyになったときにコマンドを直接実行すると、デバッグに役立つ可能性があります
以下はdockerclientのDoリクエストコードです。このエラーはタイムアウトになっているようです。
if err, ok := err.(net.Error); ok {
if err.Timeout() {
return serverResp, ErrorConnectionFailed(cli.host)
}
if !err.Temporary() {
if strings.Contains(err.Error(), "connection refused") || strings.Contains(err.Error(), "dial unix") {
return serverResp, ErrorConnectionFailed(cli.host)
}
}
}
 chestack
2018年02月27日
chestack
2018年02月27日
+1
知事1.8.4
docker 17.09.1-ce
編集:
kube-aws 0.9.9
 Labbs
2018年02月27日
Labbs
2018年02月27日
+1
Kubernetes v1.9.3
docker 17.12.0-ce(正式にサポートされていないことはわかっています)
weaveworks / weave- kube :2.2.0
Ubuntu 16.04.3 LTS || カーネル:4.4.0-112
マスター+ワーカーを使用したkubeadmを介したインストール(マスターはこの準備完了/準備完了でない動作を表示せず、ワーカーのみを表示します)。
 MarcosCela
2018年02月28日
MarcosCela
2018年02月28日
+1
Kubernetes:1.8.8
Docker:1.12.6-cs13
クラウドプロバイダー:GCE
OS:Ubuntu 16.04.3 LTS
カーネル:4.13.0-1011-gcp
ツールのインストール:kubeadm
ネットワーキングにキャラコを使用しています
 albertvaka
2018年03月13日
albertvaka
2018年03月13日
私の環境でのこのコミット修正の問題
https://github.com/moby/moby/pull/31273/commits/8e425ebc422876ddf2ffb3beaa5a0443a6097e46
これは「dockerpshang」に関する役立つリンクです。
https://github.com/moby/moby/pull/31273
更新:実際にdocker 1.13.1にロールバックすると、上記のコミットはdocker1.13.1にはありません。
chestack
2018年03月19日
+1
Kubernetes:1.8.9
Docker:17.09.1-ce
クラウドプロバイダー:AWS
OS:CoreOS 1632.3.0
カーネル:4.14.19-coreos
ツールのインストール:kops
ネットワーキング用のCalico2.6.6
 juris
2018年03月19日
juris
2018年03月19日
この問題を解決するために、私は古いcoreosバージョン(1520.9.0)を使用します。 このバージョンはdocker1.12.6を使用します。
この変更以降、羽ばたきの問題はありません。
Labbs
2018年03月19日
+1
Kubernetes:1.9.3
Docker:17.09.1-ce
クラウドプロバイダー:AWS
OS:CoreOS 1632.3.0
カーネル:4.14.19-coreos
ツールのインストール:kops
織り
 leeeboo
2018年03月22日
leeeboo
2018年03月22日
+1
Kubernetes:1.9.6
Docker:17.12.0-ce
OS:Redhat 7.4
カーネル:3.10.0-693.el7.x86_64
CNI:フランネル
 dragon9783
2018年03月29日
dragon9783
2018年03月29日
ご参考までに。 最新のKubernetes1.10でも
検証済みのDockerバージョンはv1.9と同じです:1.11.2から1.13.1および17.03.x
私の場合、1.12.6にロールバックすることが役に立ちました。
juris
2018年03月29日
同じ問題が観察されました:
Kubernetes :1.9.6
Docker :17.12.0-ce
OS :Ubuntu 16.04
CNI :織り
それを修正したのはDocker17.03へのダウングレードでした
 briandeheus
2018年03月30日
briandeheus
2018年03月30日
同じ問題が発生しましたが、DebianStrechにアップグレードすることで修正されたようです。 クラスターは、kopsでデプロイされたAWSで実行されています。
Kubernetes:1.8.7
Docker:1.13.1
OS:Debian Stretch
CNI:Calico
カーネル:4.9.0-5-amd64
デフォルトでは、Debian Jessieはカーネルバージョン4.4で使用されていたと思いますが、正常に機能していませんでした。
 komljen
2018年03月30日
komljen
2018年03月30日
この問題はENVで発生し、この問題の分析を行います。
k8s version 1.7/1.8
スタック情報はk8s1.7からのものです
ネットワークプラグインのバグのため、環境には多数の既存のコンテナ(1k以上)があります。
kubeletを再起動するkubeletはunhealthyます。
ログとスタックをトレースします。
PLEGが再リスト操作を行うとき。
初めて、 https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L228処理する必要のある多くのイベント(各コンテナにイベントがあります)を取得します
キャッシュの更新には何回もかかります(https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L240)
スタックを印刷すると、ほとんどの場合、スタックは次のようになります。
k8s.io/kubernetes/vendor/google.golang.org/grpc/transport.(*Stream).Header(0xc42537aff0, 0x3b53b68, 0xc42204f060, 0x59ceee0)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/transport/transport.go:239 +0x146
k8s.io/kubernetes/vendor/google.golang.org/grpc.recvResponse(0x0, 0x0, 0x59c4c60, 0x5b0c6b0, 0x0, 0x0, 0x0, 0x0, 0x59a8620, 0xc4217f2460, ...)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/call.go:61 +0x9e
k8s.io/kubernetes/vendor/google.golang.org/grpc.invoke(0x7ff04e8b9800, 0xc424be3380, 0x3aa3c5e, 0x28, 0x374bb00, 0xc424ca0590, 0x374bbe0, 0xc421f428b0, 0xc421800240, 0x0, ...)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/call.go:208 +0x862
k8s.io/kubernetes/vendor/google.golang.org/grpc.Invoke(0x7ff04e8b9800, 0xc424be3380, 0x3aa3c5e, 0x28, 0x374bb00, 0xc424ca0590, 0x374bbe0, 0xc421f428b0, 0xc421800240, 0x0, ...)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/call.go:118 +0x19c
k8s.io/kubernetes/pkg/kubelet/apis/cri/v1alpha1/runtime.(*runtimeServiceClient).PodSandboxStatus(0xc4217f6038, 0x7ff04e8b9800, 0xc424be3380, 0xc424ca0590, 0x0, 0x0, 0x0, 0xc424d92870, 0xc42204f3e8, 0x28)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/apis/cri/v1alpha1/runtime/api.pb.go:3409 +0xd2
k8s.io/kubernetes/pkg/kubelet/remote.(*RemoteRuntimeService).PodSandboxStatus(0xc4217ec440, 0xc424c7a740, 0x40, 0x0, 0x0, 0x0)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/remote/remote_runtime.go:143 +0x113
k8s.io/kubernetes/pkg/kubelet/kuberuntime.instrumentedRuntimeService.PodSandboxStatus(0x59d86a0, 0xc4217ec440, 0xc424c7a740, 0x40, 0x0, 0x0, 0x0)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/kuberuntime/instrumented_services.go:192 +0xc4
k8s.io/kubernetes/pkg/kubelet/kuberuntime.(*instrumentedRuntimeService).PodSandboxStatus(0xc4217f41f0, 0xc424c7a740, 0x40, 0xc421f428a8, 0x1, 0x1)
<autogenerated>:1 +0x59
k8s.io/kubernetes/pkg/kubelet/kuberuntime.(*kubeGenericRuntimeManager).GetPodStatus(0xc421802340, 0xc421dfad80, 0x24, 0xc422358e00, 0x1c, 0xc42172aa17, 0x5, 0x50a3ac, 0x5ae88e0, 0xc400000000)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/kuberuntime/kuberuntime_manager.go:841 +0x373
k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).updateCache(0xc421027260, 0xc421f0e840, 0xc421dfad80, 0x24, 0xc423e86ea8, 0x1)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:346 +0xcf
k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).relist(0xc421027260)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:242 +0xbe1
k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).(k8s.io/kubernetes/pkg/kubelet/pleg.relist)-fm()
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:129 +0x2a
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.JitterUntil.func1(0xc4217c81c0)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:97 +0x5e
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.JitterUntil(0xc4217c81c0, 0x3b9aca00, 0x0, 0x1, 0xc420084120)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:98 +0xbd
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.Until(0xc4217c81c0, 0x3b9aca00, 0xc420084120)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:52 +0x4d
created by k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).Start
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:129 +0x8a
各イベントのタイムスタンプを出力します。kubeletが各イベントを処理するのに約1秒かかります。
そのため、 PLEGは3分以内に
次に、 PLEGが正常でないため、
そのため、PLEGイベントチャネルはsyncLoop (https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/kubelet.go#L1862)によって消費されません。
ただし、PLEGは引き続きイベントを処理し、イベントをplegChannel(https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L261)に送信します。
チャネルがいっぱいになった後(チャネル容量は1000 https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/kubelet.go#L144)
PLEGはスタックします。 pleg relistのタイムスタンプは更新されません(https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L201)
スタック情報:
goroutine 422 [chan send, 3 minutes]:
k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).relist(0xc421027260)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:263 +0x95a
k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).(k8s.io/kubernetes/pkg/kubelet/pleg.relist)-fm()
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:129 +0x2a
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.JitterUntil.func1(0xc4217c81c0)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:97 +0x5e
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.JitterUntil(0xc4217c81c0, 0x3b9aca00, 0x0, 0x1, 0xc420084120)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:98 +0xbd
k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.Until(0xc4217c81c0, 0x3b9aca00, 0xc420084120)
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:52 +0x4d
created by k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).Start
/mnt/tess/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/pkg/kubelet/pleg/generic.go:129 +0x8a
終了したコンテナを削除し、kubeletを再起動すると、元に戻ります。
そのため、ノードに1,000を超えるコンテナがあると、
解決策は、ポッドキャッシュの更新を並行して行うことができることです(https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L236)
または、イベントを処理するときにタイムアウトを設定する必要があります。
@ yingnanzhang666
 wenlxie
2018年04月03日
wenlxie
2018年04月03日
PLEGの問題が原因でノードがReady / NotReady間でフラッピングを開始すると、常にdocker inspectがハングアップする終了したgcr.io/google_containers/pauseコンテナの1つになります。 dockerデーモンを再起動すると、問題が修正されます。
erstaples
2018年04月13日
みなさん、こんにちは。CoreOS/ Docker / Kubernetesバイナリのさまざまな組み合わせで問題が報告されていることがわかります。 私たちの場合、私たちはまだ同じkubernetesスタックにいます-(1.7.10 / CoreOS / kops / AWS)、問題が解決したとは思いませんが、最終的に 'tiniを導入したときに、効果をほぼゼロに減らすことができました'(https://github.com/krallin/tini)kubernetesにデプロイされたDockerイメージの一部として。 約20の異なるコンテナー(アプリ)がデプロイされており、非常に頻繁にデプロイされます。 つまり、これは、多くのシャットダウンと新しいレプリカのスピンアップなどを意味します。したがって、展開する頻度が高いほど、「ノード」の準備ができておらず、PLEGに見舞われることが多くなります。 大部分の画像にtiniをロールアウトしたとき、PIdが刈り取られ、それに応じて殺されたことを確認したとき、この副作用の発生を停止しました。 問題との関連性が高いと思うので、tini、またはサブプロセスの刈り取りを正しく処理できるその他のDockerベースイメージを確認することを強くお勧めします。 お役に立てば幸いです。 もちろん、コアの問題は残っているので、問題はまだ有効です。
javapapo
2018年04月14日
この問題はまだ解決されておらず、半定期的にクラスターに影響を与えているので、ソリューションの一部になり、ノードフラッピングの影響を受けたノードを自動的に修復できるカスタムオペレーターの開発に取り掛かりたいと思います。 PLEG is not healthyある種の一般的な自動修復演算子を介したは、Node ProblemDetectorリポジトリのこの未解決の問題から来てPLEG is not healthyがkubeletログに表示され始めるたびに、 PLEGNotHealthyノード条件をtrueに設定するNode ProblemDetectorを使用してカスタムモニターを構成しました。 次のステップは、 PLEGNotHealthyなど、異常なノードを示すノードの状態をチェックし、ノード上のdockerデーモンをコードン、エビクト、および再起動する自動化された修復システムです(または、与えられた条件)。 開発したいオペレーターのリファレンスとしてCoreOSUpdateOperatorを見ています。 他の誰かがこれについて考えているかどうか、またはこの問題に適用できる自動修復ソリューションをすでにまとめているかどうかを知りたいです。 申し訳ありませんが、これはこのディスカッションに適したフォーラムではありません。
erstaples
2018年04月16日
私たちの場合、2分間PodSandboxStatus()でスタックし、kubelet出力が発生することがあります。
rpc error: code = 4 desc = context deadline exceeded
カーネル出力:
unregister_netdevice: waiting for eth0 to become free. Usage count = 1
ただし、特定のポッドの削除(ネットワークトラフィックが多い場合)で発生しただけです。
まず、PodSpecサンドボックスは成功を停止しますが、一時停止サンドボックスの停止は失敗しました(永久に実行されます)。 次に、同じサンドボックスIDでステータスをフェッチすると、常にここでスタックします。
その結果、-> PLEGレイテンシーが高い-> PLEGが不健全(2回呼び出す、2分* 2 = 4分> 3分)-> NodeNotReady
docker_sandbox.go関連コード:
func (ds *dockerService) PodSandboxStatus(podSandboxID string) (*runtimeapi.PodSandboxStatus, error) {
// Inspect the container.
// !!! maybe stuck here for 2 min !!!
r, err := ds.client.InspectContainer(podSandboxID)
if err != nil {
return nil, err
}
...
}
func (ds *dockerService) StopPodSandbox(podSandboxID string) error {
var namespace, name string
var checkpointErr, statusErr error
needNetworkTearDown := false
// Try to retrieve sandbox information from docker daemon or sandbox checkpoint
// !!! maybe stuck here !!!
status, statusErr := ds.PodSandboxStatus(podSandboxID)
...
プロメテウスの監視によると、Dockerの検査の待ち時間は正常ですが、kubeletの実行時の検査/停止操作に時間がかかりすぎます。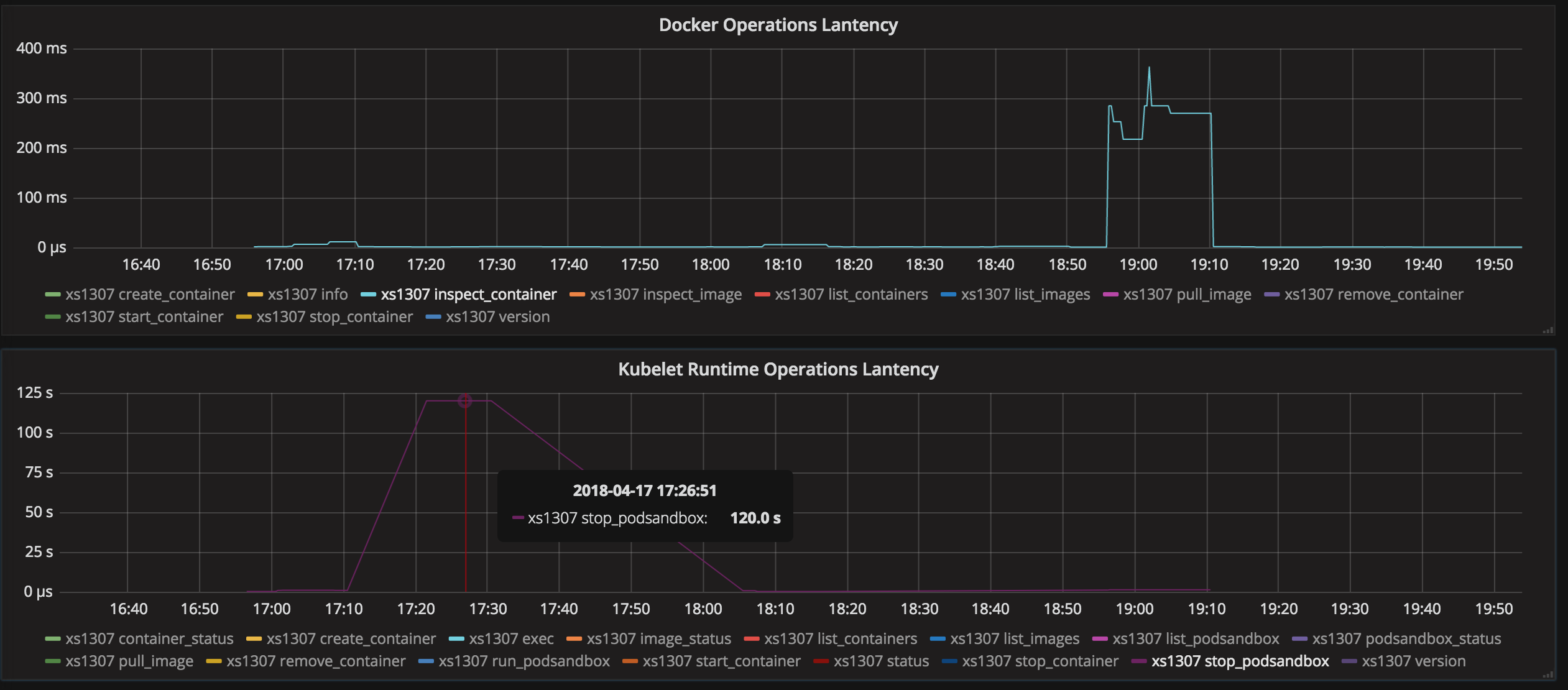
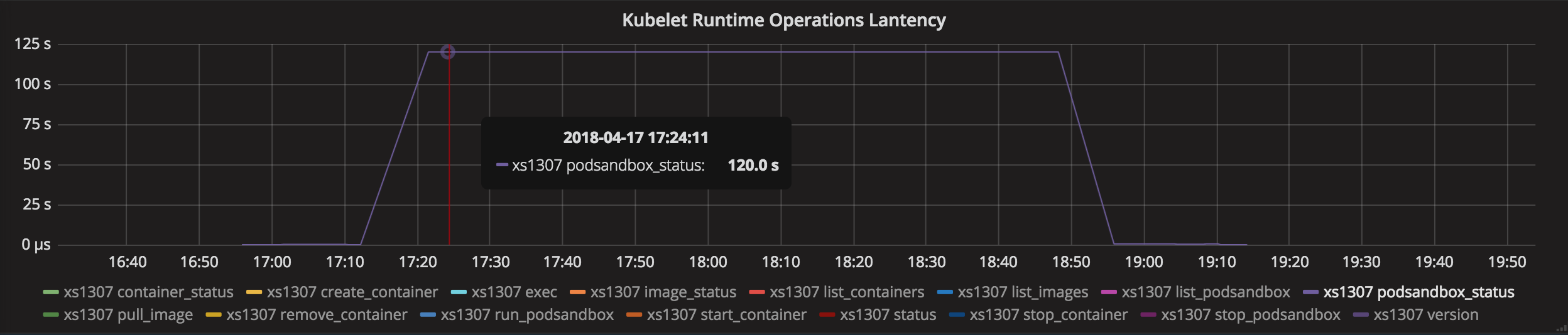
Dockerバージョン:1.12.6
kubeletバージョン:1.7.12
Linuxカーネルバージョン:4.4.0-72-generic
CNI:キャラコ
@yujuhongが言及するように:
grpc http grpc
kubelet <----> dockershim <----> dockerd <----> containerd
状況が発生したとき、私はdocker psを実行しようとします。 できます。 curlから/var/run/docker.sock
一時停止コンテナのjsonを取得することもできます。 kubeletとdockershimの間のgrpc応答の問題なのだろうか?
curl --unix-socket /var/run/docker.sock http:/v1.24/containers/66755504b8dc3a5c17454e04e0b74676a8d45089a7e522230aad8041ab6f3a5a/json
PLEGの問題が原因でノードがReady / NotReady間でフラッピングを開始すると、常に、dockerinspectがハングアップする終了したgcr.io/google_containers/pauseコンテナーの1つになります。 dockerデーモンを再起動すると、問題が修正されます。
私たちのケースは@erstaplesの説明に似ているようです。 dockerdを再起動する代わりに、ハングしている一時停止コンテナをdocker stop & docker rmだけで解決できると思います。
 whypro
2018年04月18日
whypro
2018年04月18日
ノードでdmesgを実行すると、 unregister_netdevice: waiting for eth0 to become free. Usage count = 1エラーも表示されます。 システムがネットワークデバイスを解放できないため、ポッドが終了することはありません。 これにより、 journalctl -u kubelet PodSandboxStatus of sandbox "XXX" for pod "YYY" error: rpc error: code = DeadlineExceeded desc = context deadline exceededエラーが発生します。
Kubernetesネットワークプラグインに関連している可能性がありますか? このスレッドの何人かの人々はCalicoを使用しているようです。 多分それはそこにあるものですか?
albertvaka
2018年04月24日
@deitchここでCoreOSの問題について何か言い
ここでも同じ問題に直面していますが、768GbのRAMのベアメタルノードでテストしています。 2kを超える画像が読み込まれています(そのうちのいくつかを削除しています)。
k8s1.7.15とDocker17.09を使用しています。 ここでいくつかのコメントに記載されているように、これをDocker 1.13に戻すことを考えていますが、これで問題が解決するかどうかはわかりません。
ボンディングがスイッチの1つとの接続を失うなど、より具体的な問題もいくつかありますが、これがCoreOSネットワークの問題とどのように関連しているかはわかりません。
また、kubeletとdockerは多くのCPU時間を費やしています(システム内の他の何よりも)
ありがとう!
 rikatz
2018年05月10日
rikatz
2018年05月10日
これはKubernetesv1.8.7とcalicov2.8.6で確認できます。 この場合、一部のポッドはTerminating状態でスタックし、KubeletはPLEGエラーをスローします。
E0515 16:15:34.039735 1904 generic.go:241] PLEG: Ignoring events for pod myapp-5c7f7dbcf7-xvblm/production: rpc error: code = DeadlineExceeded desc = context deadline exceeded
I0515 16:16:34.560821 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.529418824s ago; threshold is 3m0s]
I0515 16:16:39.561010 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m5.529605547s ago; threshold is 3m0s]
I0515 16:16:41.857069 1904 kubelet_node_status.go:791] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2018-05-15 16:16:41.857046605 +0000 UTC LastTransitionTime:2018-05-15 16:16:41.857046605 +0000 UTC Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m7.825663114s ago; threshold is 3m0s}
I0515 16:16:44.561281 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m10.52986717s ago; threshold is 3m0s]
I0515 16:16:49.561499 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m15.530093202s ago; threshold is 3m0s]
I0515 16:16:54.561740 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m20.530326452s ago; threshold is 3m0s]
I0515 16:16:59.561943 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m25.530538095s ago; threshold is 3m0s]
I0515 16:17:04.562205 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m30.530802216s ago; threshold is 3m0s]
I0515 16:17:09.562432 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m35.531029395s ago; threshold is 3m0s]
I0515 16:17:14.562644 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m40.531229806s ago; threshold is 3m0s]
I0515 16:17:19.562899 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m45.531492495s ago; threshold is 3m0s]
I0515 16:17:24.563168 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m50.531746392s ago; threshold is 3m0s]
I0515 16:17:29.563422 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m55.532013675s ago; threshold is 3m0s]
I0515 16:17:34.563740 1904 kubelet.go:1779] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 4m0.532327398s ago; threshold is 3m0s]
E0515 16:17:34.041174 1904 generic.go:271] PLEG: pod myapp-5c7f7dbcf7-xvblm/production failed reinspection: rpc error: code = DeadlineExceeded desc = context deadline exceeded
docker psを実行すると、ポッドmyapp-5c7f7dbcf7-xvblmのpauseコンテナのみが表示されます。
ip-10-72-160-222 core # docker ps | grep myapp-5c7f7dbcf7-xvblm
c6c34d9b1e86 gcr.io/google_containers/pause-amd64:3.0 "/pause" 9 hours ago Up 9 hours k8s_POD_myapp-5c7f7dbcf7-xvblm_production_baa0e029-5810-11e8-a9e8-0e88e0071844_0
kubelet再起動した後、ゾンビpauseコンテナ(id c6c34d9b1e86 )が削除されました。 kubeletログ:
W0515 16:56:26.439306 79462 docker_sandbox.go:343] failed to read pod IP from plugin/docker: NetworkPlugin cni failed on the status hook for pod "myapp-5c7f7dbcf7-xvblm_production": CNI failed to retrieve network namespace path: Cannot find network namespace for the terminated container "c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b"
W0515 16:56:26.439962 79462 cni.go:265] CNI failed to retrieve network namespace path: Cannot find network namespace for the terminated container "c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b"
2018-05-15 16:56:26.428 [INFO][79799] calico-ipam.go 249: Releasing address using handleID handleID="k8s-pod-network.c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b" workloadID="production.myapp-5c7f7dbcf7-xvblm"
2018-05-15 16:56:26.428 [INFO][79799] ipam.go 738: Releasing all IPs with handle 'k8s-pod-network.c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b'
2018-05-15 16:56:26.739 [INFO][81206] ipam.go 738: Releasing all IPs with handle 'k8s-pod-network.c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b'
2018-05-15 16:56:26.742 [INFO][81206] ipam.go 738: Releasing all IPs with handle 'production.myapp-5c7f7dbcf7-xvblm'
2018-05-15 16:56:26.742 [INFO][81206] calico-ipam.go 261: Releasing address using workloadID handleID="k8s-pod-network.c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b" workloadID="production.myapp-5c7f7dbcf7-xvblm"
2018-05-15 16:56:26.742 [WARNING][81206] calico-ipam.go 255: Asked to release address but it doesn't exist. Ignoring handleID="k8s-pod-network.c6c34d9b1e86be38b41bba5ba60e1b2765584f3d3877cd6184562707d0c2177b" workloadID="production.myapp-5c7f7dbcf7-xvblm"
Calico CNI releasing IP address
2018-05-15 16:56:26.745 [INFO][80545] k8s.go 379: Teardown processing complete. Workload="production.myapp-5c7f7dbcf7-xvblm"
カーネルログから:
[40473.123736] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[40483.187768] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[40493.235781] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
同様のチケットが開いていると思いますhttps://github.com/moby/moby/issues/5618
zihaoyu
2018年05月15日
これはまったく別のケースです。 ここで、ノードがフラッピングしている理由がわかります。
dElogics
2018年05月18日
この問題により、本番クラスターのノードがダウンします。 ポッドを終了または作成することはできません。 Linuxカーネル4.14.32およびDocker17.12.1-ce上のCoreOS1688.5.3(Rhyolite)を使用したKubernetes1.9.7。 私たちのCNIはCalicoです。
containerdのログには、削除が要求されたcgroupに関するいくつかのエラーが表示されますが、エラーの前後には直接表示されません。
May 21 17:35:00 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T17:35:00Z" level=error msg="stat cgroup bf717dbbf392b0ba7ef0452f7b90c4cfb4eca81e7329bfcd07fe020959b737df" error="cgroups: cgroup deleted"
May 21 17:44:32 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T17:44:32Z" level=error msg="stat cgroup a0887b496319a09b1f3870f1c523f65bf9dbfca19b45da73711a823917fdfa18" error="cgroups: cgroup deleted"
May 21 17:50:32 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T17:50:32Z" level=error msg="stat cgroup 2fbb4ba674050e67b2bf402c76137347c3b5f510b8934d6a97bc3b96069db8f8" error="cgroups: cgroup deleted"
May 21 17:56:22 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T17:56:22Z" level=error msg="stat cgroup f9501a4284257522917b6fae7e9f4766e5b8cf7e46989f48379b68876d953ef2" error="cgroups: cgroup deleted"
May 21 18:43:28 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T18:43:28Z" level=error msg="stat cgroup c37e7505019ae279941a7a78db1b7a6e7aab4006dfcdd83d479f1f973d4373d2" error="cgroups: cgroup deleted"
May 21 19:38:28 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T19:38:28Z" level=error msg="stat cgroup a327a775955d2b69cb01921beb747b4bba0df5ea79f637e0c9e59aeb7e670b43" error="cgroups: cgroup deleted"
May 21 19:50:26 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T19:50:26Z" level=error msg="stat cgroup 5d11f13d13b461fe2aa1396d947f1307a6c3a78e87fa23d4a1926a6d46794d58" error="cgroups: cgroup deleted"
May 21 19:52:26 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T19:52:26Z" level=error msg="stat cgroup fb7551cde0f9a640fbbb928d989ca84200909bce2821e03a550d5bfd293e786b" error="cgroups: cgroup deleted"
May 21 20:54:32 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T20:54:32Z" level=error msg="stat cgroup bcd1432a64b35fd644295e2ae75abd0a91cb38a9fa0d03f251c517c438318c53" error="cgroups: cgroup deleted"
May 21 21:56:28 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T21:56:28Z" level=error msg="stat cgroup 2a68f073a7152b4ceaf14d128f9d31fbb2d5c4b150806c87a640354673f11792" error="cgroups: cgroup deleted"
May 21 22:02:30 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T22:02:30Z" level=error msg="stat cgroup aa2224e7cfd0a6f44b52ff058a50a331056b0939d670de461b7ffc7d01bc4d59" error="cgroups: cgroup deleted"
May 21 22:18:32 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T22:18:32Z" level=error msg="stat cgroup 95e0c4f7607234ada85a1ab76b7ec2aa446a35e868ad8459a1cae6344bc85f4f" error="cgroups: cgroup deleted"
May 21 22:21:32 ip-10-5-76-113.ap-southeast-1.compute.internal env[1282]: time="2018-05-21T22:21:32Z" level=error msg="stat cgroup 76578ede18ba3bc1307d83c4b2ccd7e35659f6ff8c93bcd54860c9413f2f33d6" error="cgroups: cgroup deleted"
Kubeletは、ポッドサンドボックス操作の失敗に関するいくつかの興味深い行を示しています。
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.578306 1513 remote_runtime.go:115] StopPodSandbox "922f625ced6d6f6adf33fe67e5dd8378040cd2e5c8cacdde20779fc692574ca5" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.578354 1513 kuberuntime_manager.go:800] Failed to stop sandbox {"docker" "922f625ced6d6f6adf33fe67e5dd8378040cd2e5c8cacdde20779fc692574ca5"}
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: W0523 18:17:25.579095 1513 docker_sandbox.go:196] Both sandbox container and checkpoint for id "a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" could not be found. Proceed without further sandbox information.
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: W0523 18:17:25.579426 1513 cni.go:242] CNI failed to retrieve network namespace path: Error: No such container: a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.723 [INFO][33881] calico.go 338: Extracted identifiers ContainerID="a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" Node="ip-10-5-76-113.ap-southeast-1.compute.internal" Orchestrator="cni" Workload="a89
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.723 [INFO][33881] utils.go 263: Configured environment: [CNI_COMMAND=DEL CNI_CONTAINERID=a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642 CNI_NETNS= CNI_ARGS=IgnoreUnknown=1;IgnoreUnknown=1;K8S_POD_NAMESP
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.723 [INFO][33881] client.go 202: Loading config from environment
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: Calico CNI releasing IP address
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.796 [INFO][33905] utils.go 263: Configured environment: [CNI_COMMAND=DEL CNI_CONTAINERID=a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642 CNI_NETNS= CNI_ARGS=IgnoreUnknown=1;IgnoreUnknown=1;K8S_POD_NAMESP
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.796 [INFO][33905] client.go 202: Loading config from environment
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.796 [INFO][33905] calico-ipam.go 249: Releasing address using handleID handleID="k8s-pod-network.a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" workloadID="a893f57acec1f3779c35aed743f128408e491ff2f53a3
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.796 [INFO][33905] ipam.go 738: Releasing all IPs with handle 'k8s-pod-network.a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642'
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.805 [WARNING][33905] calico-ipam.go 255: Asked to release address but it doesn't exist. Ignoring handleID="k8s-pod-network.a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" workloadID="a893f57acec1f3779c3
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.805 [INFO][33905] calico-ipam.go 261: Releasing address using workloadID handleID="k8s-pod-network.a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" workloadID="a893f57acec1f3779c35aed743f128408e491ff2f53
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.805 [INFO][33905] ipam.go 738: Releasing all IPs with handle 'a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642'
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: 2018-05-23 18:17:25.822 [INFO][33881] calico.go 373: Endpoint object does not exist, no need to clean up. Workload="a893f57acec1f3779c35aed743f128408e491ff2f53a312895fe883e2c68d642" endpoint=api.WorkloadEndpointMetadata{ObjectMetadata:unver
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.824925 1513 kubelet.go:1527] error killing pod: failed to "KillPodSandbox" for "9c246b32-4f10-11e8-964a-0a7e4ae265be" with KillPodSandboxError: "rpc error: code = DeadlineExceeded desc = context deadline exceeded"
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.825025 1513 pod_workers.go:186] Error syncing pod 9c246b32-4f10-11e8-964a-0a7e4ae265be ("flntk8-fl01-j7lf4_splunk(9c246b32-4f10-11e8-964a-0a7e4ae265be)"), skipping: error killing pod: failed to "KillPodSandbo
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.969591 1513 kuberuntime_manager.go:860] PodSandboxStatus of sandbox "922f625ced6d6f6adf33fe67e5dd8378040cd2e5c8cacdde20779fc692574ca5" for pod "flntk8-fl01-j7lf4_splunk(9c246b32-4f10-11e8-964a-0a7e4ae265be)"
May 23 18:17:25 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:17:25.969640 1513 generic.go:241] PLEG: Ignoring events for pod flntk8-fl01-j7lf4/splunk: rpc error: code = DeadlineExceeded desc = context deadline exceeded
May 23 18:20:27 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: I0523 18:20:27.753523 1513 kubelet.go:1790] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.783603773s ago; threshold is 3m0s]
May 23 18:19:27 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:19:27.019252 1513 kuberuntime_manager.go:860] PodSandboxStatus of sandbox "922f625ced6d6f6adf33fe67e5dd8378040cd2e5c8cacdde20779fc692574ca5" for pod "flntk8-fl01-j7lf4_splunk(9c246b32-4f10-11e8-964a-0a7e4ae265be)"
May 23 18:19:27 ip-10-5-76-113.ap-southeast-1.compute.internal kubelet[1513]: E0523 18:19:27.019295 1513 generic.go:241] PLEG: Ignoring events for pod flntk8-fl01-j7lf4/splunk: rpc error: code = DeadlineExceeded desc = context deadline exceeded
カーネルは、以下に関連しているように見えるフリーラインになるのを待っているeth0を示しています: //github.com/moby/moby/issues/5618
[1727395.220036] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[1727405.308152] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[1727415.404335] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[1727425.484491] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[1727435.524626] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
[1727445.588785] unregister_netdevice: waiting for eth0 to become free. Usage count = 1
ただし、このケースでは、アダプターloは表示されず、カーネルはクラッシュしませんでした。 さらなる調査はhttps://github.com/projectcalico/calico/issues/1109を指摘しており、これはまだ修正されていないカーネルの競合状態のバグであると結論付けています。
kubeletを再起動すると、ポッドが終了して作成されるのに十分な問題が修正されましたが、 waiting for eth0 to become freeスパムがdmesgで継続しました。
この問題に関する興味深い読み物は次のとおりです: https ://medium.com/@bcdonadio/when -the-blue-whale-sinks-55c40807c2fc
 integrii
2018年05月23日
integrii
2018年05月23日
@integrii
いいえ、最新のcentOSでも発生します。 一度再現してもらいました。
dElogics
2018年06月03日
さて、私は以前に言ったことを変更したいと思います-コンテナランタイムは突然ダウンして文句を言います
ポッドの同期をスキップする-[PLEGは正常ではありません:..。
dockerがファイルを実行している間。 その間に、kubeletを再起動すると、PLEGが正常になり、ノードが再び稼働します。
docker、kubeletkube-proxyはすべてRT優先度に設定されています。
dElogics
2018年06月03日
もう1つ、kubeletを再起動すると、dockerを再起動しない限り同じことが起こります。
Dockerのソケットでcurlを使用してみましたが、正常に機能しています。
dElogics
2018年06月03日
+1
Kubernetes:1.10.2
Docker:1.12.6
OS:centos 7.4
カーネル:3.10.0-693.el7.x86_64
CNI:カリコ
 lanxenet
2018年06月05日
lanxenet
2018年06月05日
+1
知事:1.7.16
Docker:17.12.1-ce
OS:CoreOS 1688.5.3
カーネル:4.14.32-coreos
CNI:Calico(v2.6.7)
v1.9.1以降
 phspagiari
2018年06月14日
phspagiari
2018年06月14日
--runtime-request-timeoutを増やすと役立つと思いますか?
dElogics
2018年06月17日
ノードの1つでCRI-Oでこの問題が発生しています。 Kubernetes 1.10.1、CRI-O 1.10.1、Fedora 27、カーネル4.16.7-200.fc27、Flannelを使用。
runc listとcrictl podsはどちらも高速ですが、 crictl ps実行には数分かかります。
 mcronce
2018年06月26日
mcronce
2018年06月26日
+1
Kubernetes:v1.8.7 + coreos.0
Docker:17.05.0-ce
OS:Redhat 7x
CNI:Calico
Kubespary 2.4
この問題は頻繁に発生します。 dockerとkubeletを再起動すると、消えます。
 sivarajp
2018年07月13日
sivarajp
2018年07月13日
最新の安定したCoreOS 1745.7.0では、この問題は発生しなくなりました。
komljen
2018年07月13日
@komljenを更新してからどれくらい見ていますか? 私たちにとって、これは発生するのにしばらく時間がかかります。
integrii
2018年07月13日
1つの大規模なCI環境で数日おきにこれらの問題が発生しましたが、すべてを試しても成功しなかったと思います。 OSをCoreOS以上のバージョンに変更することが重要であり、1か月間問題は発生していません。
komljen
2018年07月13日
私も1か月以上この問題を見ていません。 何も変更しないので、私は患者が健康であると宣言するのはそれほど速くありません:-)
 oivindoh
2018年07月13日
oivindoh
2018年07月13日
@komljen centos7を実行します。今日でもノードの1つがダウンしました。
sivarajp
2018年07月13日
私も1か月以上この問題を見ていません。 何も変更しないので、私は患者が健康であると宣言するのはそれほど速くありません:-)
@oivindohその特定のカーネルバージョンで何が変更されたかを確認する時間がありませんでしたが、私の場合は問題が解決しました。
komljen
2018年07月14日
この問題の原因はクラスターで見つかりました。 要約すると、このバグは、終了しないCNIコマンド(calico)が原因で発生します。これにより、dockershimサーバーハンドラーが永久にスタックします。 その結果、RPCは不良ポッドに対してPodSandboxStatus()を呼び出すと、常にタイムアウトになり、PLEGが異常になります。
バグの影響:
- 悪いポッドは
Terminating状態で永遠に立ち往生 - 他のポッド状態は、kubeapiサーバーとの同期を数分間失う可能性があります(クラスターでkube2iamエラーが発生します)
- 関数が何度も呼び出されて戻らないため、メモリリークが発生します
これが発生したときにノードに表示されるものは次のとおりです。
- kubeletログの次のエラーメッセージ:
Jul 13 23:52:15 E0713 23:52:15.461144 1740 kuberuntime_manager.go:860] PodSandboxStatus of sandbox "01d8b790bc9ede72959ddf0669e540dfb1f84bfd252fb364770a31702d9e7eeb" for pod "pod-name" error: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 13 23:52:15 E0713 23:52:15.461215 1740 generic.go:241] PLEG: Ignoring events for pod pod-name: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 13 23:52:16 E0713 23:52:16.682555 1740 pod_workers.go:186] Error syncing pod 7f3fd634-7e57-11e8-9ddb-0acecd2e6e42 ("pod-name"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 13 23:53:15 I0713 23:53:15.682254 1740 kubelet.go:1790] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.267402933s ago; threshold is 3m0s]
- 次のタイムアウトメトリック:
$ curl -s http://localhost:10255/metrics | grep 'quantile="0.5"' | grep "e+08"
kubelet_pleg_relist_interval_microseconds{quantile="0.5"} 2.41047643e+08
kubelet_pleg_relist_latency_microseconds{quantile="0.5"} 2.40047461e+08
kubelet_runtime_operations_latency_microseconds{operation_type="podsandbox_status",quantile="0.5"} 1.2000027e+08
- kubeletの子プロセス(calico)がスタックしています:
$ ps -A -o pid,ppid,start_time,comm | grep 1740
1740 1 Jun15 kubelet
5428 1740 Jul04 calico
dockershimサーバーのスタックトレースは次のとおりです。
PodSandboxStatus() :: pkg/kubelet/dockershim/docker_sandbox.go
... -> GetPodNetworkStatus() :: pkg/kubelet/network/plugins.go
^^^^^ this function stuck on pm.podLock(fullPodName).Lock()
この問題を修正するには、kubeletは、CNIライブラリ関数呼び出し( DelNetwork()など)および戻るのに永遠にかかる可能性のあるその他の外部ライブラリ呼び出しでタイムアウトを使用する必要があります。
 mechpen
2018年07月16日
mechpen
2018年07月16日
@mechpen誰かがどこかで答えを見つけてくれてうれしいです。 ここでは当てはまらないと思います(少なくともこのクラスターでは、calicoではなくweaveを使用しています。他の場所でcalicoを使用しており、そのマルチアーチを駆動しています)。同様のエラーメッセージは表示されていません。
ただし、表示される場合は、次のように述べています。
この問題を修正するには、kubeletはCNIライブラリ関数呼び出し(DelNetwork()など)または戻るのに永遠にかかる可能性のある外部ライブラリ呼び出しでタイムアウトを使用する必要があります
構成可能ですか? またはkubelet変更が必要ですか?
deitch
2018年07月16日
@deitchこのエラーは、weave CNIコマンドが終了しない場合にも発生する可能性があります(すべてのシステムで共有される低レベルのバグが原因である可能性があります)。
修正には、kubeletコードの変更が必要です。
mechpen
2018年07月16日
@mechpenこの問題は、フランネルで実行されているクラスターでも発生しますか? 修正は同じですか?
sivarajp
2018年07月17日
@komljen 1745.7.0この問題を見たばかりです
現在k8s1.9でcalicoこの問題が発生しています
その正確なノードに、終了でスタックしているポッドがあります。 それを強制的に殺して、問題が止まるかどうか見てみましょう。
 sstarcher
2018年07月17日
sstarcher
2018年07月17日
@mechpen提案のためにk8sの問題を開きましたか?
sstarcher
2018年07月17日
@mechpenまた、
sstarcher
2018年07月17日
@sstarcherまだチケットを提出していません。 まだカリコが永遠にハングする理由を見つけようとしています。
カーネルメッセージがたくさん表示されます。
[2797545.570844] unregister_netdevice: waiting for eth0 to become free. Usage count = 2
このエラーは何年もの間linux / containerを悩ませてきました。
mechpen
2018年07月18日
@mechpen
@sstarcher
@deitch
はい、この問題は1か月前に発生しました。
そして、私はそれを発行しました。
kubeletでこの問題を修正しようとしていますが、最初にcniで修正する必要があります。
だから私は最初にcniで修正し、次にkubeletで修正します。
THX
#65743
https://github.com/containernetworking/cni/issues/567
https://github.com/containernetworking/cni/pull/568
liucimin
2018年07月19日
この問題に関連する@ sstarcher @ mechpen calicoチケット:
https://github.com/projectcalico/calico/issues/1109
 r0bj
2018年07月25日
r0bj
2018年07月25日
本番クラスターで再び発生しました
Kubernetes:1.11.0
coreos:1520.9.0
docker:1.12.6
cni:キャラコ
まだノードでkubeletとdockerdを再起動しましたが、今は問題ないようです。
notreadyノードとreadyノードの唯一の違いは、cronjobポッドの開始と停止がたくさんあり、notreadyノードで強制終了されることです。
leeeboo
2018年07月31日
@mechpen
同じ問題が発生しているかどうかはわかりません。
Jul 30 17:52:15 cloud-blade-31 kubelet[24734]: I0730 17:52:15.585102 24734 kubelet_node_status.go:431] Recording NodeNotReady event message for node cloud-blade-31
Jul 30 17:52:15 cloud-blade-31 kubelet[24734]: I0730 17:52:15.585137 24734 kubelet_node_status.go:792] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2018-07-30 17:52:15.585076295 -0700 PDT m=+13352844.638760537 LastTransitionTime:2018-07-30 17:52:15.585076295 -0700 PDT m=+13352844.638760537 Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m0.948768335s ago; threshold is 3m0s}
Jul 30 17:52:25 cloud-blade-31 kubelet[24734]: I0730 17:52:25.608101 24734 kubelet_node_status.go:443] Using node IP: "10.11.3.31"
Jul 30 17:52:35 cloud-blade-31 kubelet[24734]: I0730 17:52:35.640422 24734 kubelet_node_status.go:443] Using node IP: "10.11.3.31"
Jul 30 17:52:36 cloud-blade-31 kubelet[24734]: E0730 17:52:36.556409 24734 remote_runtime.go:169] ListPodSandbox with filter nil from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 30 17:52:36 cloud-blade-31 kubelet[24734]: E0730 17:52:36.556474 24734 kuberuntime_sandbox.go:192] ListPodSandbox failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 30 17:52:36 cloud-blade-31 kubelet[24734]: W0730 17:52:36.556492 24734 image_gc_manager.go:173] [imageGCManager] Failed to monitor images: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 30 17:52:45 cloud-blade-31 kubelet[24734]: I0730 17:52:45.667169 24734 kubelet_node_status.go:443] Using node IP: "10.11.3.31"
Jul 30 17:52:55 cloud-blade-31 kubelet[24734]: I0730 17:52:55.692889 24734 kubelet_node_status.go:443] Using node IP: "10.11.3.31"
Jul 30 17:53:05 cloud-blade-31 kubelet[24734]: I0730 17:53:05.729182 24734 kubelet_node_status.go:443] Using node IP: "10.11.3.31"
Jul 30 17:53:15 cloud-blade-31 kubelet[24734]: E0730 17:53:15.265668 24734 remote_runtime.go:169] ListPodSandbox with filter &PodSandboxFilter{Id:,State:&PodSandboxStateValue{State:SANDBOX_READY,},LabelSelector:map[string]string{},} from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Dockerデーモンがヘルスチェックへの応答を停止すると、ノードはNotReadyなります。 マシン自体ではdocker psがハングしますが、 docker versionが戻ります。 ノードをReady戻すには、dockerデーモンを再起動する必要があります。 ポッドがスタックしているかどうかはわかりません。コンテナを一覧表示できないようです。
Kubernetes:1.9.2
Docker 17.03.1-ce commit c6d412e
OS:Ubuntu 16.04
カーネル:Linux 4.13.0-31-generic#34〜16.04.1-Ubuntu SMP Fri Jan 19 17:11:01 UTC 2018 x86_64 x86_64 x86_64 GNU / Linux
 saurfangg
2018年07月31日
saurfangg
2018年07月31日
同じ問題があります。 これは非常に頻繁に発生するため、ノードは5分間のポッドのスケジューリングに耐えられません。
エラーは、メインクラスター(フランネル)とテストクラスター(カリコ)の両方で発生します。
kubernetesバージョン(1.9。?/ 1.11.1)、ディストリビューション(debian、ubuntu)、クラウドプロバイダー(ec2、hetzner cloud)、dockerバージョン(17.3.2、17.06.2)を変えてみました。 完全な行列をテストしたのは、1つの変数のバリエーションだけではありませんでした。
私のワークロードは非常に単純です(1つのコンテナー、ボリュームなし、デフォルトのネットワーク、30個のポッドのバルクでスケジュールされたポッド)
クラスターは、カスタマイズせずにkubeadmを使用して新たにセットアップされます(フランネルを使用した最初のテストを除く)
エラーは数分以内に発生しています。 docker psが戻ってこない/スタックしている、ポッドが終了してスタックしているなど。
現在、このエラーを引き起こさない既知の構成(debianまたはubuntuを使用)があるかどうか疑問に思っていますか?
安定したノードを生成するオーバーレイネットワークと他のバージョンの作業の組み合わせを共有できる、このバグの影響を受けていない人はいますか?
 nielsole
2018年08月04日
nielsole
2018年08月04日
これは、BaremetalノードのOpenshiftで発生します。
このPLEGの特定の発生では、多数のvCPUが設定されているOpenShiftノードで多数のコンテナーが(暴走したcronジョブを介して)一度に開始されたときに問題が発生しました。 ノードはノードあたり最大250ポッドに達し、過負荷になりました。
解決策は、vCPUの数を8に減らすことでOpenShiftノード仮想マシンに割り当てられるvCPUを減らすことです(たとえば)。これは、スケジュールできるポッドの最大数が80ポッドになることを意味します(CPUあたりのデフォルトの制限は10ポッド) )250の代わりに。通常、より大きなノードではなく、より適切なサイズのノードを使用することをお勧めします。
224CPUのノードがあります。 Kubernetesバージョン1.7.1-Redhat7.4
 jcperezamin
2018年08月13日
jcperezamin
2018年08月13日
同様の問題があると思います。 私のポッドは終了するまでハングし、ログに不健康なPLEGの報告があります。 しかし、私の状況では、手動でkubeletプロセスを強制終了するまで、正常に戻ることはありません。 単純なsudo systemctl restart kubelet問題が解決しましたが、ロールアウトを行うたびに、マシンの約1/4で解決する必要があります。 それは素晴らしいことではありません。
ここで何が起こっているのか正確にはわかりませんが、kubeletプロセスでbridgeコマンドが実行されているのを見ると、このスレッドで前述したように、CNIに関連しているのでしょうか。 今日、この2つの別々のインスタンスから大量のログを添付しました。誰かと協力して、この問題をデバッグできることをうれしく思います。
もちろん、この問題のあるすべてのマシンは、従来のunregister_netdevice: waiting for eth0 to become free. Usage count = 2を吐き出します-実行中のgoルーチンを取得するために送信されたSIGABRTを使用してlogs.tar.gzに2つの異なるkubeletログを うまくいけば、これが役立つでしょう。 関連しているように見えるいくつかの電話を見たので、ここでそれらを呼び出します
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: goroutine 2895825 [semacquire, 17 minutes]:
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: sync.runtime_SemacquireMutex(0xc422082d4c)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/runtime/sema.go:62 +0x34
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: sync.(*Mutex).Lock(0xc422082d48)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/sync/mutex.go:87 +0x9d
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: k8s.io/kubernetes/pkg/kubelet/network.(*PluginManager).GetPodNetworkStatus(0xc420ddbbc0, 0xc421e36f76, 0x17, 0xc421e36f69, 0xc, 0x36791df, 0x6, 0xc4223f6180, 0x40, 0x0, ...)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /workspace/anago-v1.8.7-beta.0.34+b30876a5539f09/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/network/plugins.go:376 +0xe6
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: goroutine 2895819 [syscall, 17 minutes]:
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: syscall.Syscall6(0xf7, 0x1, 0x25d7, 0xc422c96d70, 0x1000004, 0x0, 0x0, 0x7f7dc6909e10, 0x0, 0xc4217e9980)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/syscall/asm_linux_amd64.s:44 +0x5
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: os.(*Process).blockUntilWaitable(0xc42216af90, 0xc421328c60, 0xc4217e99e0, 0x1)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/os/wait_waitid.go:28 +0xa5
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: os.(*Process).wait(0xc42216af90, 0x411952, 0xc4222554c0, 0xc422255480)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/os/exec_unix.go:22 +0x4d
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: os.(*Process).Wait(0xc42216af90, 0x0, 0x0, 0x379bbc8)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/os/exec.go:115 +0x2b
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: os/exec.(*Cmd).Wait(0xc421328c60, 0x0, 0x0)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/os/exec/exec.go:435 +0x62
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: os/exec.(*Cmd).Run(0xc421328c60, 0xc422255480, 0x0)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /usr/local/go/src/os/exec/exec.go:280 +0x5c
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: k8s.io/kubernetes/vendor/github.com/containernetworking/cni/pkg/invoke.(*RawExec).ExecPlugin(0x5208390, 0xc4217e98a0, 0x1b, 0xc4212e66e0, 0x156, 0x160, 0xc422b7fd40, 0xf, 0x12, 0x4121a8, ...)
Aug 13 22:57:30 worker-4bm5 kubelet[1563]: /workspace/anago-v1.8.7-beta.0.34+b30876a5539f09/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/github.com/containernetworking/cni/pkg/invoke/raw_exec.go:42 +0x215
カーネル4.14.33以降でコンテナ最適化OSをkubenetで使用するGCE上のKubernetes1.8.7。
 theRealWardo
2018年08月14日
theRealWardo
2018年08月14日
@ jcperezamin 、
warmchang
2018年08月14日
私はこれをベアメタルで取得しています。 kubeadm(シングルノードマスター)で構成されたUbuntu18.04の新規インストールを使用します。
Warning ContainerGCFailed 8m (x438 over 8h) ... rpc error: code = ResourceExhausted desc = grpc: trying to send message larger than max (8400302 vs. 8388608)
に遭遇しました。 ノードは最大11,500個の停止したコンテナーを蓄積していました。 一部のコンテナを手動でクリアしてGCを修正しましたが、直後にPLEGが原因でノードがNotReadyになりました。
ネットワーク用のフランネルを備えた、かなり必要最低限のk8s構成を使用しています。 影響を受けるノードは、ハードウェアRAID6に6x 10kSASドライブを搭載した古いXeonE5-2670ベースのマシンです。
PLEGの問題は1時間以内に解決せず、kubeletを再起動するとすぐに問題が修正されました。
 pnovotnak
2018年08月24日
pnovotnak
2018年08月24日
マシンに大きな負荷をかけるたびに発生しているようで、ノードが自動的に回復することはありません。 SSH経由でログインすると、ノードのCPUとその他のリソースは空になります。 Dockerコンテナー、イメージ、ボリュームなどはそれほど多くありません。これらのリソースの一覧表示は高速です。 そして、単にkubeletを再記述すると、常に問題が即座に修正されます。
私は次のバージョンを使用しています:
- Ubuntu:18.04.1
- Linux:4.15.0-33-generic
- Kubernetesサーバー:v1.11.0
- Kubeadm:v1.11.2
- Docker:18.06.1-ce
pnovotnak
2018年08月27日
Kubernetes1.11.1のベアメタルノードでこの問題が発生しました:(
 adampl
2018年08月28日
adampl
2018年08月28日
これも頻繁に経験し、ノードは非常に強力で十分に活用されていません。
- Kubernetes:1.10.2
- カーネル:3.10.0
- Docker:1.12.6
 devlounge
2018年08月29日
devlounge
2018年08月29日
同じ問題...
環境:
クラウドプロバイダーまたはハードウェア構成:ベアメタル
OS(例:/ etc / os-releaseから):Ubuntu 16.04
カーネル(例:uname -a):4.4.0-109-generic
Kubernetes:1.10.5
Docker:1.12.3-0〜xenial
 x8k
2018年09月03日
x8k
2018年09月03日
kubernetes 1.10.3に移行した後も、同じ問題が発生します。
クライアントバージョン:version.Info {メジャー: "1"、マイナー: "10"、GitVersion: "v1.10.5"
サーバーバージョン:version.Info {メジャー: "1"、マイナー: "10"、GitVersion: "v1.10.3"
 angegar
2018年09月04日
angegar
2018年09月04日
ベアメタル環境での同じ問題:
環境:
クラウドプロバイダーまたはハードウェア構成:ベアメタル
OS(例:/ etc / os-releaseから):CoreOS 1688.5.3
カーネル(例:uname -a):4.14.32
Kubernetes:1.10.4
Docker:17.12.1
 corest
2018年09月12日
corest
2018年09月12日
問題の到着時にノードのIOWAIT値を知ることは興味深いことです。
livelace
2018年09月12日
同じ問題が別のベアメタル環境で繰り返し見られます。 最新のヒットのバージョン:
- OS: Ubuntu 16.04.5 LTS
- カーネル: Linux4.4.0-134-generic
- Kubernetes:
- 羽ばたきホスト: v1.10.3
- マスター: v1.10.5およびv1.10.2
- フラッピングホスト上のDocker: 18.03.1-ce(go1.9.5でコンパイル)
 calder
2018年09月14日
calder
2018年09月14日
原因はわかっています。
ここでアップストリームの修正が行われています:
https://github.com/containernetworking/cni/pull/568
次のステップは、誰かがジャンプしたい場合にkubernetesが使用するcniを更新することです
そしてそのPRを準備します。 あなたはおそらく@liuciminまたは私と調整したいと思うでしょう
つま先を踏まないように。
金には、2018年9月14日、11:38 AMカルダーCoalson [email protected]
書きました:
同じ問題が別のベアメタル環境で繰り返し見られます。 のバージョン
最新のヒット:
- OS: Ubuntu 16.040.5 LTS
- カーネル: Linux4.4.0-134-generic
- Kubernetes:
- 羽ばたきホスト: v1.10.3
- マスター: v1.10.5およびv1.10.2
- フラッピングホスト上のDocker: 18.03.1-ce(go1.9.5でコンパイル)
—
あなたがコメントしたのであなたはこれを受け取っています。
このメールに直接返信し、GitHubで表示してください
https://github.com/kubernetes/kubernetes/issues/45419#issuecomment-421447751 、
またはスレッドをミュートします
https://github.com/notifications/unsubscribe-auth/AFctXYnTJjNwtWquPmi5nozVMUYDetRlks5ua_eIgaJpZM4NSBta
。
pnovotnak
2018年09月14日
@deitch
こんにちは、私はこのような同じエラーに遭遇しましたError syncing pod *********** ("pod-name"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
dockerdでコンテナ情報をリクエストしましたが、このリクエストがブロックされ、結果が返されませんでしたcurl -XGET --unix-socket /var/run/docker.sock http://localhost/containers/******("yourcontainerid")/json
だから多分これはDockerエラーだと思います
 Nebulazhang
2018年09月19日
Nebulazhang
2018年09月19日
これは、ログをディスクに永続化する際のDockerデーモンのブロックに関するものです。
dockerでこれに対処する作業がありますが、18.06まで着陸しません(k8sの使用についてはまだ検証済みのdockerではありません)
https://docs.docker.com/config/containers/logging/configure/#configure -the-delivery-mode-of-log-messages-from-container-to-log-driver
dockerデーモンはデフォルトでロギングをブロックするため、その問題を回避できるようになるまで対処できません。
これは、問題が発生しているときにiowaitが高くなることとも相関しています。
execヘルスチェックを使用するコンテナは、大量のログを生成します。 ロギングメカニズムを強調する他のパターンもあります。
ちょうど私の2c
 mauilion
2018年09月19日
mauilion
2018年09月19日
これを実行しているマシンで高いiowaitが発生することはありません。 (CoreOS、Kube 1.10、Docker 17.03)
@mauilionロギングの問題を説明する問題またはMRを教えてください。
 mariusgrigoriu
2018年10月12日
mariusgrigoriu
2018年10月12日
同じ問題が発生し、2つのKubernetesノードがReadyとNotReadyの間でフラップしていました。 信じられないかもしれませんが、解決策は、終了したDockerコンテナと関連するポッドを削除することでした。
d4e5d7ef1b5c gcr.io/google_containers/pause-amd64:3.0 Exited (137) 3 days ago
その後、他の介入なしに、クラスターは再び安定しました。
さらに、これはsyslogで見つかったログメッセージでした。
E1015 07:48:49.386113 1323 remote_runtime.go:115] StopPodSandbox "d4e5d7ef1b5c3d13a4e537abbc7c4324e735d455969f7563287bcfc3f97b
085f" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
 rchicoli
2018年10月16日
rchicoli
2018年10月16日
今この問題に直面している:
OS: Oracle Linux 7.5
Kernel: 4.17.5-1.el7.elrepo.x86_64
Kubernetes: 1.11.3
Flapping host: v1.11.3
Docker on flapping host: 18.03.1-ce (compiled with go1.9.5)
 emedina
2018年10月24日
emedina
2018年10月24日
https://github.com/containernetworking/cni/pull/568がCNIに統合されました。
上記の修正を含むCNIの新しいリリースであるIIUCは、k8sでこれを修正できるはずです。
調整が必要です- @ bboreham @ liucimin 。 sig-networkへの投稿も
 nikopen
2018年10月24日
nikopen
2018年10月24日
どのバージョンのkubernetes-cniに修正が含まれますか? ありがとう!
 roywangtj
2018年11月16日
roywangtj
2018年11月16日
タイムアウトに関するより焦点を絞った問題は#65743です
そこで述べたように、次のステップはKubernetes側で、テストを作成するなどして、変更によって問題が実際に修正されることを確認します。 これを確認するためにリリースは必要ありません。最新のlibCNIコードをプルするだけです。
 bboreham
2018年11月16日
bboreham
2018年11月16日
/ sigネットワーク
 tossmilestone
2018年11月26日
tossmilestone
2018年11月26日
これとスタックしたdocker psが、保証されたポッドによってトリガーされたOOMに関連して発生している場合は、#72294を参照してください。 ポッドインフラコンテナが強制終了されて再起動されると、cniの再初期化がトリガーされ、次に上記のタイムアウト/ロックの問題がトリガーされる場合があります。
 clkao
2018年12月22日
clkao
2018年12月22日
これに似たものが見られます-Ready / NotReady間で常にPLEGがバタバタしています-kubeletを再起動すると問題が解決するようです。 kubeletからのゴルーチンダンプで、多数あることに気づきました(現在、15000を超えるゴルーチンが次のスタックにスタックしています:
goroutine 29624527 [semacquire, 2766 minutes]:
sync.runtime_SemacquireMutex(0xc428facb3c, 0xc4216cca00)
/usr/local/go/src/runtime/sema.go:71 +0x3d
sync.(*Mutex).Lock(0xc428facb38)
/usr/local/go/src/sync/mutex.go:134 +0xee
k8s.io/kubernetes/pkg/kubelet/network.(*PluginManager).GetPodNetworkStatus(0xc420820980, 0xc429076242, 0xc, 0xc429076209, 0x38, 0x4dcdd86, 0x6, 0xc4297fa040, 0x40, 0x0, ...)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/network/plugins.go:395 +0x13d
k8s.io/kubernetes/pkg/kubelet/dockershim.(*dockerService).getIPFromPlugin(0xc4217c4500, 0xc429e21050, 0x40, 0xed3bf0000, 0x1af5b22d, 0xed3bf0bc6)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/dockershim/docker_sandbox.go:304 +0x1c6
k8s.io/kubernetes/pkg/kubelet/dockershim.(*dockerService).getIP(0xc4217c4500, 0xc4240d9dc0, 0x40, 0xc429e21050, 0xe55ef53, 0xed3bf0bc7)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/dockershim/docker_sandbox.go:333 +0xc4
k8s.io/kubernetes/pkg/kubelet/dockershim.(*dockerService).PodSandboxStatus(0xc4217c4500, 0xb38ad20, 0xc429e20ed0, 0xc4216214c0, 0xc4217c4500, 0x1, 0x0)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/dockershim/docker_sandbox.go:398 +0x291
k8s.io/kubernetes/pkg/kubelet/apis/cri/runtime/v1alpha2._RuntimeService_PodSandboxStatus_Handler(0x4d789e0, 0xc4217c4500, 0xb38ad20, 0xc429e20ed0, 0xc425afaf00, 0x0, 0x0, 0x0, 0x0, 0x2)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/pkg/kubelet/apis/cri/runtime/v1alpha2/api.pb.go:4146 +0x276
k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).processUnaryRPC(0xc420294640, 0xb399760, 0xc421940000, 0xc4264d8900, 0xc420d894d0, 0xb335000, 0x0, 0x0, 0x0)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/server.go:843 +0xab4
k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).handleStream(0xc420294640, 0xb399760, 0xc421940000, 0xc4264d8900, 0x0)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/server.go:1040 +0x1528
k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).serveStreams.func1.1(0xc42191c020, 0xc420294640, 0xb399760, 0xc421940000, 0xc4264d8900)
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/server.go:589 +0x9f
created by k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).serveStreams.func1
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/google.golang.org/grpc/server.go:587 +0xa1
このスタックにスタックしているゴルーチンの数が時間の経過とともに着実に増加していることに気付きました(2分ごとに約1つ余分に)
これが発生したノードでは、通常、ポッドがTerminatingスタックしています。kubeletを再起動すると、 Terminatingポッドが移動し、PLEGの問題が発生しなくなります。
@pnovotnakこれが、CNIにタイムアウトを追加するための変更、または他の何かによって修正されるべき同じ問題のように聞こえる場合、何かアイデアはありますか? ネットワーク分野でも同様の症状のようです。
 mcginne
2019年01月21日
mcginne
2019年01月21日
同じ質問があります: https :
どのバージョンのkubernetes-cniに修正が含まれますか? ありがとう!
warmchang
2019年03月01日
@ warmchangkubernetes-cniプラグインパッケージは関係ありません。 必要な変更はlibcniにあり、これはhttps://github.com/containernetworking/cniからベンダー化されています(このリポジトリにコピーされてい
変更はマージされます。 リリースは必要ありません(ただし、気分が良くなる可能性があります)。
bboreham
2019年03月01日
@bboreham返信ありがとうございます。
CNIプラグイン(flannel / calicoなど)ではなく、ベンダーディレクトリ内のCNIコード(libcni)を意味します。
そして、承認を待っているこのPRhttps ://github.com/kubernetes/kubernetes/pull/71653を見つけました。
warmchang
2019年03月01日
/ milestone v1.14
nikopen
2019年03月01日
私はこの問題に遭遇します、私の環境:
docker 18.06
os:centos7.4
カーネル:4.19
kubelet:1.12.3
私のノードはReadyとNotReadyの間でバタバタしていました。
これまでに、--- force --grace-period = 0のポッドをいくつか削除しました。 ポッドを削除しても、終了ステータスのままであるためです。
その後、kubeletでいくつかのログを見つけました:
kubelet [10937]:I0306 19:23:32.474487 10937 handlers.go:62]ポッド "saas-56bd6d8588-のコンテナー" odp-saas "の実行ライフサイクルフック([/home/work/webserver/loadnginx.sh stop]) xlknh(15ebc67d-3bed-11e9-ba81-246e96352590) "失敗-エラー:コマンド '/home/work/webserver/loadnginx.sh stop'が126で終了しました:、メッセージ:"ユーザーの作業が見つかりません:passwdに一致するエントリがありませんファイル\ r \ n "_
デプロイメントでlifecyclesectionprestopコマンドを使用しているためです。
#ライフサイクル:
#preStop:
#exec:
## SIGTERMはクイック終了をトリガーします。 代わりに正常に終了します
#コマンド:["/ home / work / webserver / loadnginx.sh"、 "stop"]
およびその他のログは次のことを示しています。
kubelet [17119]:E0306 19:35:11.223925 17119 remote_runtime.go:282] ContainerStatus "cbc957993825885269935a343e899b807ea9a49cb9c7f94e68240846af3e701d" from runti
kubelet [17119]:E0306 19:35:11.223970 17119 kuberuntime_container.go:393] cbc957993825885269935a343e899b807ea9a49cb9c7f94e68240846af3e701dのContainerStatus
kubelet [17119]:E0306 19:35:11.223978 17119 kuberuntime_manager.go:866]ポッド「gz-saas-56bd6d8588-sk88t_storeic(1303430e-3ffa-11e9-ba8」のgetPodContainerStatuses
kubelet [17119]:E0306 19:35:11.223994 17119 generic.go:241] PLEG:ポッドsaasのイベントを無視します-56bd6d8588-sk88t / storeic:rpcエラー:コード= DeadlineExceeded d
kubelet [17119]:E0306 19:35:11.224123 17119 pod_workers.go:186]ポッドの同期中にエラーが発生しました1303430e-3ffa-11e9-ba81-246e96352590( "gz-saas-56bd6d8588-sk88t_storeic(130343
Mkubelet [17119]:E0306 19:35:12.509163 17119 remote_runtime.go:282] ContainerStatus "4ff7ff8e1eb18ede5eecbb03b60bdb0fd7f7831d8d7e81f59bc69d166d422fb6" from runti
kubelet [17119]:E0306 19:35:12.509163 17119 remote_runtime.go:282] ContainerStatus "cbc957993825885269935a343e899b807ea9a49cb9c7f94e68240846af3e701d" from runti
kubelet [17119]:E0306 19:35:12.509220 17119 kubelet_pods.go:1086]ポッド「saas-56bd6d8588-rsfh5」の強制終了に失敗しました:「saas」wiの「KillContainer」に失敗しました
kubelet [17119]:E0306 19:35:12.509230 17119 kubelet_pods.go:1086]ポッド「saas-56bd6d8588-sk88t」の強制終了に失敗しました:「saas」wiの「KillContainer」に失敗しました
kubelet [17119]:I0306 19:35:12.788887 17119 kubelet.go:1821]ポッド同期のスキップ-[PLEGは正常ではありません:plegは4分1.597223765秒前にアクティブに最後に見られました。
k8sはコンテナを停止できません。これらのコンテナはスタック状態になりました。 これにより、PLEGが健康になりません。
最後に、エラーコンテナがあるdockerデーモンを再起動すると、ノードは準備完了に回復します。
なぜコンテナが止まらないのかわかりません!!! プレストップかもしれませんか?
 Damien9527
2019年03月06日
Damien9527
2019年03月06日
/ milestone v1.15
nikopen
2019年03月11日
+1
k8s v1.10.5
docker 17.09.0-ce
 hello2mao
2019年03月22日
hello2mao
2019年03月22日
+1
k8s v1.12.3
docker 06.18.2-ce
 zhan849
2019年04月11日
zhan849
2019年04月11日
+1
k8s v1.13.4
docker-1.13.1-94.gitb2f74b2.el7.x86_64
 Wade201801
2019年04月16日
Wade201801
2019年04月16日
@ kubernetes / sig-network-bugs @thockin @spiffxp :フレンドリーなping。 これは再び行き詰まったようです。
calder
2019年04月19日
@calder :通知をトリガーするために言及を繰り返します:
@ kubernetes / sig-network-bugs
対応して、この:
@ kubernetes / sig-network-bugs @thockin @spiffxp :フレンドリーなping。 これは再び行き詰まったようです。
PRコメントを使用して私とやり取りするための手順は、こちらから入手できkubernetes / test-infraリポジトリに対して問題を
 k8s-ci-robot
2019年04月19日
k8s-ci-robot
2019年04月19日
こんにちは、
この問題は、プラットフォームの1つでも見つかりました。 他のクラスターとの唯一の違いは、マスターノードが1つしかないことです。 実際、3つのマスターを使用してクラスターを再作成しましたが、これまでのところ(数日後)問題に気づいていません。
だから私の質問は:マルチマスター(> = 3)クラスターでこの問題に気づいた人はいますか?
 Kanshiroron
2019年04月29日
Kanshiroron
2019年04月29日
@Kanshiroronはい、3つのマスタークラスターがあり、昨日1つのワーカーノードでこの問題が発生しました。 ノードをドレインして再起動すると、正常に戻ってきました。 プラットフォームは、k8sv1.11.8およびDockerEnterprise18.09.2-eeを搭載したDockerEEです。
 mshade
2019年05月01日
mshade
2019年05月01日
3マスタークラスター(3ノードetcdクラスター)があります。 18個のワーカーノードがあり、各ノードは平均して50〜100個のDockerコンテナー(ポッドではなく、コンテナー全体)で実行されています。
かなりのポッドスピンアップイベントと、PLEGエラーのためにノードを再起動する必要があることとの間に明確な正の相関関係が見られます。 場合によっては、スピンアップによってインフラストラクチャ全体で100を超えるコンテナが作成されることがあります。これが発生すると、ほとんどの場合、結果としてPLEGエラーが発生します。
ノードまたはクラスターレベルで、これを引き起こしている原因を理解していますか?
 standaloneSA
2019年05月08日
standaloneSA
2019年05月08日
私はこれから少し離れています-何が起こっているのか知っていますか? @bborehamの修正はありますか(何が起きているか知っているようだったので)? PRはありますか?
 thockin
2019年05月09日
thockin
2019年05月09日
この症状はさまざまな原因で発生する可能性があると思われますが、ここでの「同じ問題があります」というコメントのほとんどについては、あまり続ける必要はありません。
これらの方法の一つはで詳細に説明されたhttps://github.com/kubernetes/kubernetes/issues/45419#issuecommentで-405168344と同様のhttps://github.com/kubernetes/kubernetes/issues/45419#issuecomment -456081337 -通話をCNIに入ると、Kubeletが壊れて、永遠にハングする可能性があります。 問題#65743は、タイムアウトを追加する必要があると述べています。
これに対処するために、 Contextをlibcniに挿入して、キャンセルをexec.CommandContext()で実装できるようにすることにしました。 PR#71653は、そのAPIのCRI側にタイムアウトを追加します。
(わかりやすくするために、CNIプラグインへの変更は含まれていません。これは、プラグインを実行するコードへの変更です)
bboreham
2019年05月09日
さて、PLEGスウォーム(最近これを呼んでいます)でデバッグを行う機会を得ました。K8sによって報告されたPLEGエラーとDocker.serviceログのエントリとの間にいくつかの相関関係が見つかりました。
2つのサーバーで、私はこれを見つけました:
エラーを監視していたスクリプトから:
Sat May 11 03:27:19 PDT 2019 - SERVER-A
Found: Ready False Sat, 11 May 2019 03:27:10 -0700 Sat, 11 May 2019 03:13:16 -0700 KubeletNotReady PLEG is not healthy: pleg was last seen active 16m53.660513472s ago; threshold is 3m0s
'journalctl -u docker.service'からのSERVER-Aの出力で一致するエントリ:
May 11 03:10:20 SERVER-A dockerd[1133]: time="2019-05-11T03:10:20.641064617-07:00" level=error msg="stream copy error: reading from a closed fifo"
May 11 03:10:20 SERVER-A dockerd[1133]: time="2019-05-11T03:10:20.641083454-07:00" level=error msg="stream copy error: reading from a closed fifo"
May 11 03:10:20 SERVER-A dockerd[1133]: time="2019-05-11T03:10:20.740845910-07:00" level=error msg="Error running exec a9fe257c0fca6ff3bb05a7582015406e2f7f6a7db534b76ef1b87d297fb3dcb9 in container: OCI runtime exec failed: exec failed: container_linux.go:344: starting container process caused \"process_linux.go:113: writing config to pipe caused \\\"write init-p: broken pipe\\\"\": unknown"
May 11 03:10:20 SERVER-A dockerd[1133]: time="2019-05-11T03:10:20.767528843-07:00" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
27 lines of this^^ repeated
次に、私のスクリプトとは別のサーバーで:
Sat May 11 03:38:25 PDT 2019 - SERVER-B
Found: Ready False Sat, 11 May 2019 03:38:16 -0700 Sat, 11 May 2019 03:38:16 -0700 KubeletNotReady PLEG is not healthy: pleg was last seen active 3m6.168050703s ago; threshold is 3m0s
およびDockerジャーナルから:
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.745124988-07:00" level=error msg="stream copy error: reading from a closed fifo"
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.745139806-07:00" level=error msg="stream copy error: reading from a closed fifo"
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.803182460-07:00" level=error msg="1a5dbb24b27cd516373473d34717edccc095e712238717ef051ce65022e10258 cleanup: failed to delete container from containerd: no such container"
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.803267414-07:00" level=error msg="Handler for POST /v1.38/containers/1a5dbb24b27cd516373473d34717edccc095e712238717ef051ce65022e10258/start returned error: OCI runtime create failed: container_linux.go:344: starting container process caused \"process_linux.go:297: getting the final child's pid from pipe caused \\\"EOF\\\"\": unknown"
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.876522066-07:00" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 11 03:35:25 SERVER-B dockerd[1102]: time="2019-05-11T03:35:25.964447832-07:00" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
残念ながら、これを「正常な」ノード全体で検証すると、これらのインスタンスが一緒に発生していることもわかります。
これを他の変数と相関させるように努めますが、これらのエラーメッセージを検索すると、いくつかの興味深い議論につながります。
Docker-ce 18.06.1-ce-rc2:コンテナーを実行できません、「ストリームコピーエラー:閉じたFIFOからの読み取り」
Moby:同じチェックポイントから多数のコンテナーを同時に開始すると、エラーが発生します:「コンテキストの期限を超えました」#29369
Kubernetes:ノードあたりの最大ポッド数を増やす#23349
その最後のリンクには、 @ dElogicsによる特に興味深いコメントがあり
いくつかの貴重な情報を追加するだけで、ノードごとに多数のポッドを実行すると、#45419になります。 修正として、dockerディレクトリを削除し、dockerとkubeletを一緒に再起動します。
standaloneSA
2019年05月11日
私の場合、K8sv1.10.2とdocker-cev18.03.1を使用しています。 次のようなノードフラッピングReady / NotReadyで実行されているkubeletのログをいくつか見つけました。
E0512 09:17:56.721343 4065 pod_workers.go:186] Error syncing pod e5b8f48a-72c2-11e9-b8bf-005056871a33 ("uac-ddfb6d878-f6ph2_default(e5b8f48a-72c2-11e9-b8bf-005056871a33)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
E0512 09:17:17.154676 4065 kuberuntime_manager.go:859] PodSandboxStatus of sandbox "a34943dabe556924a2793f1be2f7181aede3621e2c61daef0838cf3fc61b7d1b" for pod "uac-ddfb6d878-f6ph2_default(e5b8f48a-72c2-11e9-b8bf-005056871a33)" error: rpc error: code = DeadlineExceeded desc = context deadline exceeded
そして、このポッドuac-ddfb6d878-f6ph2_defaultが終了していることがわかったので、回避策は、ポッドを強制的に削除し、そのノード上のこのポッドのすべてのコンテナーを削除することです。その後、このノードは正常に機能します。
$ kubectl delete pod uac-ddfb6d878-f6ph2 --force --grace-period=0
$ docker ps -a | grep uac-ddfb6d878-f6ph2_default
 thaonguyenct
2019年05月12日
thaonguyenct
2019年05月12日
こんにちは! 1.15のBugFreezeを開始しました。 この問題はまだ1.15に組み込まれる予定ですか?
 soggiest
2019年05月29日
soggiest
2019年05月29日
こんにちは
OKDクラスターでも同じ問題が発生していました。
羽ばたきしているノードを調査し、少し掘り下げた後、問題であると思われるものを見つけました。
ノードのフラッピングを調査したところ、フラッピングしていたノードの平均負荷値が異常に高く、ノードの1つ(16コア、32スレッド、96GBメモリ)の平均負荷値は、ピーク時に850でした。
3つのノードでRookCephが実行されています。
PrometheusがRookCephのブロックストレージを使用していて、ブロックデバイスを読み取り/書き込みで溢れさせていることを発見しました。
同時に、ElasticSearchはRookCephのブロックストレージも使用していました。 Prometheusがブロックデバイスをフラッディングしている間、ElasticSearchプロセスはディスクI / O操作を実行しようとし、I / O操作が終了するのを待っている間は中断できない状態になることがわかりました。
次に、別のESプロセスが同じことを試みます。
その後、別の。
そしてもう一つ。
ノードのCPU全体がESプロセス用に予約されたスレッドを持ち、CephブロックデバイスがPrometheusフラッディングから解放されるのを待っている中断できない状態になります。
CPUの負荷が100%でなかったとしても、スレッドは予約されていました。
これにより、他のすべてのプロセスがCPU時間を待機し、Docker操作が失敗し、PLEGがタイムアウトし、ノードがフラッピングを開始しました。
私たちの解決策は、問題のあるPrometheusポッドを再起動することでした。
OKD / K8sバージョン:
$ oc version
oc v3.11.0+0cbc58b
kubernetes v1.11.0+d4cacc0
features: Basic-Auth GSSAPI Kerberos SPNEGO
Server https://okd.example.net:8443
openshift v3.11.0+d0f1080-153
kubernetes v1.11.0+d4cacc0
ノード上のDockerバージョン:
$ docker version
Client:
Version: 1.13.1
API version: 1.26
Package version: docker-1.13.1-88.git07f3374.el7.centos.x86_64
Go version: go1.9.4
Git commit: 07f3374/1.13.1
Built: Fri Dec 7 16:13:51 2018
OS/Arch: linux/amd64
Server:
Version: 1.13.1
API version: 1.26 (minimum version 1.12)
Package version: docker-1.13.1-88.git07f3374.el7.centos.x86_64
Go version: go1.9.4
Git commit: 07f3374/1.13.1
Built: Fri Dec 7 16:13:51 2018
OS/Arch: linux/amd64
Experimental: false
編集:
要約すると、これはK8s / OKDの問題ではないと思います。これは、「ノード上の一部のリソースが、CPU時間を待ってプロセスを積み上げ、すべてを壊している何かによってロックされている」問題だと思います。
 rblaine95
2019年05月29日
rblaine95
2019年05月29日
/ milestone v1.16
soggiest
2019年06月07日
@bboreham @soggiestこんにちは! 私は1.16リリースサイクルのバグトリアージシャドウであり、この問題は1.16のタグが付けられているが、長期間更新されていないことを考慮して、そのステータスを確認したいと思います。 コードのフリーズは8月29日(今から約1.5週間後)に始まります。つまり、それまではPRの準備ができている(そしてマージされている)はずです。
この問題は1.16で修正される予定ですか?
 makoscafee
2019年08月23日
makoscafee
2019年08月23日
@makoscafee 1.13.6(およびそれ以降のバージョン)およびdocker18.06.3-ceではこれが発生しなくなったことを確認できます
私たちにとって、これはCNIまたは外部統合を呼び出す際のタイムアウトに何らかの形で関連しているようです。
最近これに直面しましたが、他のシナリオでは、クラスターで使用されているNFSサーバーの一部がクラックされた(そしてノードからのI / O全体がフリーズした)一方で、kubeletは新しいコンテナーを起動できないことに関連するPLEGの問題を出力し始めました。 I / Oタイムアウトの。
したがって、これは、CNIとCRIを使用すると、ネットワークの問題に関連するクラスターでこれが再び見られなかったため、おそらく解決されたことを示している可能性があります。
rikatz
2019年08月26日
@makoscafee前に
コードを見ると、コンテキストをキャンセルできるCNIの新しい動作を使用するようにkubeletが更新されているとは思いません。
たとえば、ここでCNIを呼び出す: https :
このPRはタイムアウトを追加します:#71653、しかしそれでも未解決です。
@rikatzのエクスペリエンスを引き起こすために
bboreham
2019年08月26日
確かに、それ以来、私はCalicoで多くのアップグレードを行ってきましたが、おそらくそこで(Kubernetesコードではなく)何かが変更されました。 また、Docker(当時も問題になる可能性があります)は何度もアップグレードされたため、ここをたどる正しい道はありません
ここで、問題が発生したときにメモをとらないこと(それについては申し訳ありません)に、少なくともそこから今日の問題に何が変わったのかを伝えるのは恥ずかしいことです。
rikatz
2019年08月26日
こんにちは、みんな、
このエラーに関する私たちの経験を共有したかっただけです。
Docker EE19.03.1およびk8sv1.14.3を実行している新しくデプロイされたクラスターでこのエラーが発生しました。
私たちにとって、この問題はロギングドライバによって引き起こされたようです。 Dockerエンジンは、fluentdロギングドライバーを使用するようにセットアップされています。 クラスターの新規デプロイ後、fluentdはまだデプロイされていません。 この時点で、ワーカーでポッドをスケジュールしようとすると、上記と同じ動作が発生しました(ワーカーノードとワーカーノードのkubeletコンテナーでのPLEGエラーがランダムに報告されます)
ただし、fluentdをデプロイし、dockerがそれに接続できるようになると、すべての問題が解消されました。 したがって、fluentdと通信できないことが根本的な原因のようです。
お役に立てれば。 乾杯
 dariuscernea
2019年08月27日
dariuscernea
2019年08月27日
これは長年の問題(k8s 1.6!)であり、k8sを使用するかなりの数の人々を悩ませてきました。
過負荷のノード(最大CPU%、io、割り込み)とは別に、PLEGの問題は、kubelet、docker、logging、networkingなどの間の微妙な問題によって引き起こされることがあり、問題の修正は残酷な場合があります(すべてのノードの再起動など、ケース)。
元の投稿に関する限り、 https://github.com/kubernetes/kubernetes/pull/71653が最終的にマージされ、kubeletが更新され、CNIリクエストをタイムアウトして、期限を超える前にコンテキストをキャンセルできるようになりました。
Kubernetes1.16に修正が含まれます。
また、PRを開いて、これを1.14と1.15に戻します。これは、新しいタイムアウト機能(> = 0.7.0)を含むCNIバージョンがあるためです。 1.13には、この機能のない古いCNIvがあります。
したがって、これは最終的に閉じることができます。
/閉じる
nikopen
2019年08月28日
@nikopen :この問題を解決します。
対応して、この:
これは長年の問題(k8s 1.6!)であり、k8sを使用するかなりの数の人々を悩ませてきました。
PLEGの問題を引き起こすさまざまなものがあり、一般的にkubelet、docker、logging、networkingなどの間で複雑になり、問題の修正が残酷な場合があります(場合によっては、すべてのノードを再起動するなど)。
元の投稿に関する限り、 https://github.com/kubernetes/kubernetes/pull/71653が最終的にマージされ、kubeletが更新され、CNIリクエストをタイムアウトして、期限を超える前にコンテキストをキャンセルできるようになりました。
Kubernetes1.16に修正が含まれます。
また、PRを開いて、これを1.14と1.15に戻します。これは、新しいタイムアウト機能(> = 0.7.0)を含むCNIバージョンがあるためです。 1.13には、この機能のない古いCNIvがあります。したがって、これは最終的に閉じることができます。
/閉じる
PRコメントを使用して私とやり取りするための手順は、こちらから入手できkubernetes / test-infraリポジトリに対して問題を
k8s-ci-robot
2019年08月28日
実稼働環境での1.6以降の個人的な経験から、PLEGの問題は通常、ノードが溺れているときに発生します。
- CPU負荷が非常に高い
- ディスクI / Oが最大になっています(ロギング?)
- グローバル過負荷(CPU +ディスク+ネットワーク)=> CPUは常に中断されています
結果=> Dockerデーモンが応答しません
 Misteur-Z
2019年08月28日
Misteur-Z
2019年08月28日
実稼働環境での
1.6以降の個人的な経験から、PLEGの問題は通常、ノードが溺れているときに発生します。
- CPU負荷が非常に高い
- ディスクI / Oが最大になっています(ロギング?)
- グローバル過負荷(CPU +ディスク+ネットワーク)=> CPUは常に中断されています
結果=> Dockerデーモンが応答しません
これに同意します。 1.14.5バージョンのKubernetesを使用していますが、同じ問題があります。
 Aisuko
2019年09月06日
Aisuko
2019年09月06日
v1.13.10同じ問題がcalicoネットワークで実行されます。
 zx1986
2019年09月19日
zx1986
2019年09月19日
/開いた
@nikopen :PRは1.17用のようですか? 1.16.1の変更ログにPR番号が見つかりません。
 pdhung
2019年10月07日
pdhung
2019年10月07日
1.14の変更ログにこの問題が記載されていません。 それは(まだ)チェリーピックではなかったことを意味しますか? なりますか?
 kwaazaar
2019年10月24日
kwaazaar
2019年10月24日
PLEGからの回復は健康的な問題ではありません
dockerとkubeletの自動起動を無効にし、再起動してから、kubeletポッドとdockerファイルをクリーンアップします。
systemctl disable docker && systemctl disable kubelet
リブート
rm -rf / var / lib / kubelet / pods /
rm -rf / var / lib / docker
Dockerを起動して有効にする
systemctl start docker && systemctl enable docker
systemctl status docker
/ var / lib / dockerがクリーンアップされているため、ノードがk8sイメージライブラリに接続できない場合は、必要なイメージを手動でインポートしてください。
docker load -i xxx.tar
Kubeletを開始します
systemctl start kubelet && systemctl enable kubelet
systemctl status kubelet
 jackie-qiu
2019年11月14日
jackie-qiu
2019年11月14日
@ jackie-qiu問題が二度と起こらないようにするために、手榴弾でサーバーを爆破するか、10階からドロップすることをお勧めします...
adampl
2019年11月14日
フランネルネットワークで実行されるv1.15.6と同じ問題。
 leowucn
2019年11月27日
leowucn
2019年11月27日
すべてがすでにここに書かれているように見えるので、問題の原因について追加することはあまりありません。 古いバージョンのサーバー1.10.13を使用しています。 アップグレードを試みましたが、それほど簡単なことではありません。
私たちにとって、それは主に本番環境の1つで発生し、開発環境の非常に後方で発生します。 常に複製される本番環境では、ローリング更新中にのみ発生し、特定の2つのポッドに対してのみ発生します(ローリング更新中に他のポッドが削除されることはありません)。 私たちの開発環境では、他のポッドでも発生しました。
ログに表示されるのは次のとおりです。
成功した場合:
11月27日11:34:45ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.453 [INFO] [1946] client.go 202:環境から構成を読み込んでいます
11月27日11:34:45ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.454 [INFO] [1946] calico-ipam.go 249:handleIDを使用してアドレスを解放するhandleID = 「k8s-pod-network.e923743c5dc4833e606bf16f388c564c20c4c1373b18881d8ea1c8eb617f6e62」workloadID = "default.good-pod-name-557644b486-7rxw5"
11月27日11:34:45ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.454 [INFO] [1946] ipam.go 738:ハンドル 'k8s-ですべてのIPを解放するpod-network.e923743c5dc4833e606bf16f388c564c20c4c1373b18881d8ea1c8eb617f6e62 '
11月27日11:34:45ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.498 [INFO] [1946] ipam.go 877:デクリメントされたハンドル 'k8s-pod-network .e923743c5dc4833e606bf16f388c564c20c4c1373b18881d8ea1c8eb617f6e62'by 1
11月27日11:34:45ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.498 [INFO] [1946] calico-ipam.go 257:handleIDを使用してアドレスを解放handleID = 「k8s-pod-network.e923743c5dc4833e606bf16f388c564c20c4c1373b18881d8ea1c8eb617f6e62」workloadID = "default.good-pod-name-557644b486-7rxw5"
11月27日11:34:45ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.498 [INFO] [1946] calico-ipam.go 261:workloadIDを使用してアドレスを解放するhandleID = 「k8s-pod-network.e923743c5dc4833e606bf16f388c564c20c4c1373b18881d8ea1c8eb617f6e62」workloadID = "default.good-pod-name-557644b486-7rxw5"
11月27日11:34:45ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.498 [INFO] [1946] ipam.go 738:ハンドルがデフォルトのすべてのIPを解放します。 good-pod-name-557644b486-7rxw5 '
11月27日11:34:45ip-172-31-174-8 kubelet [8024]:netns / proc / 6337 / ns / netのCalicoCNI削除デバイス
11月27日11:34:45ip-172-31-174-8 kubelet [8024]:2019-11-27 11:34:45.590 [INFO] [1929] k8s.go 379:ティアダウン処理が完了しました。 Workload = "default.good-pod-name-557644b486-7rxw5" "
失敗した場合:
11月27日11:46:49ip-172-31-174-8 kubelet [8024]:2019-11-27 11:46:49.681 [INFO] [5496] client.go 202:環境から構成を読み込んでいます
11月27日11:46:49ip-172-31-174-8 kubelet [8024]:2019-11-27 11:46:49.681 [INFO] [5496] calico-ipam.go 249:handleIDを使用してアドレスを解放するhandleID = 「k8s-pod-network.3afc7f2064dc056cca5bb8c8ff20c81aaf6ee8b45a1346386c239b92527b945b」workloadID = "default.bad-pod-name-5fc88df4b-rkw7m"
11月27日11:46:49ip-172-31-174-8 kubelet [8024]:2019-11-27 11:46:49.681 [INFO] [5496] ipam.go 738:ハンドル 'k8s-ですべてのIPを解放するpod-network.3afc7f2064dc056cca5bb8c8ff20c81aaf6ee8b45a1346386c239b92527b945b '
11月27日11:46:49ip-172-31-174-8 kubelet [8024]:2019-11-27 11:46:49.716 [INFO] [5496] ipam.go 877:デクリメントされたハンドル 'k8s-pod-network .3afc7f2064dc056cca5bb8c8ff20c81aaf6ee8b45a1346386c239b92527b945b'by 1
11月27日11:46:49ip-172-31-174-8 kubelet [8024]:2019-11-27 11:46:49.716 [INFO] [5496] calico-ipam.go 257:handleIDを使用してアドレスを解放handleID = 「k8s-pod-network.3afc7f2064dc056cca5bb8c8ff20c81aaf6ee8b45a1346386c239b92527b945b」workloadID = "default.bad-pod-name-5fc88df4b-rkw7m"
11月27日11:46:49ip-172-31-174-8 kubelet [8024]:2019-11-27 11:46:49.716 [INFO] [5496] calico-ipam.go 261:workloadIDを使用してアドレスを解放するhandleID = 「k8s-pod-network.3afc7f2064dc056cca5bb8c8ff20c81aaf6ee8b45a1346386c239b92527b945b」workloadID = "default.bad-pod-name-5fc88df4b-rkw7m"
11月27日11:46:49ip-172-31-174-8 kubelet [8024]:2019-11-27 11:46:49.716 [INFO] [5496] ipam.go 738:ハンドルがデフォルトのすべてのIPを解放します。 bad-pod-name-5fc88df4b-rkw7m '
11月27日11:46:49ip-172-31-174-8 kubelet [8024]:netns / proc / 7376 / ns / netのCalicoCNI削除デバイス
11月27日11 :46 :51ip-172-31-174-8 ntpd [8188]:インターフェイス#1232の削除cali8e016aaff48、fe80 :: :eeff:feee:eeee%816#123 、インターフェイス統計:受信= 0、送信= 0、dropped = 0、active_time = 242773秒
11月27日11:46:59ip-172-31-174-8カーネル:[11155281.312094] unregister_netdevice:eth0が解放されるのを待っています。 使用回数= 1
 gilShin
2019年12月02日
gilShin
2019年12月02日
誰かがv1.16にアップグレードしましたか? これが修正され、PLEGの問題が発生していないかどうかを誰かが確認できますか? この問題は本番環境で頻繁に発生し、唯一のオプションはノードを再起動することです。
 ganeshv02
2019年12月05日
ganeshv02
2019年12月05日
修正について質問があります。
タイムアウト修正を含む新しいバージョンをインストールしているとしましょう。 クブレットが解放され、終了状態でスタックしているポッドがダウンすることを許可することを理解していますが、eth0も解放しますか? 新しいポッドはそのノードで実行できますか、それとも準備完了/準備完了状態のままになりますか?
gilShin
2019年12月05日
私の場合、Docker 19.03.4は、両方のポッドが終了状態でスタックし、ノードがPLEGの問題でReady / NotReady間でフラップする問題を修正しました。
Kubernetesのバージョンは1.15.6から変更されていません。 クラスターでの唯一の変更は、新しいDockerでした。
 hakman
2019年12月05日
hakman
2019年12月05日
Ubuntu16.04のカーネルを4.4から4.15にアップグレードしました。 エラーが再発するまでに3日かかりました。
ubuntu 16.04でhakmanが提案したように、Dockerのバージョンを17から19にアップグレードできるかどうかを確認します。
Ubuntuのバージョンをアップグレードしたくない。
gilShin
2019年12月15日
k8s1.10でdockerを19にアップグレードする方法はありません。 最初に1.15にアップグレードする必要がありますが、1.15海峡にアップグレードする方法がないため、しばらく時間がかかります。 1.10-> 1.11-> 1.12などを1つずつアップグレードする必要があります。
gilShin
2019年12月15日
PLEGヘルスチェックはほとんど行いません。 すべての反復で、
docker psを呼び出してコンテナーの状態の変化を検出し、docker psとinspectを呼び出してそれらのコンテナーの詳細を取得します。
各反復が終了すると、タイムスタンプが更新されます。 タイムスタンプがしばらく(つまり3分間)更新されていない場合、ヘルスチェックは失敗します。PLEGが3分でこれらすべてを完了できない膨大な数のポッドがノードにロードされていない限り(これは発生しないはずです)、最も可能性の高い原因はDockerが遅いことです。 たまに
docker ps小切手でそれを観察できないかもしれませんが、それはそれがないという意味ではありません。「不健康」ステータスを公開しないと、ユーザーから多くの問題が隠され、さらに多くの問題が発生する可能性があります。 たとえば、kubeletは変更にタイムリーに反応せず、さらに混乱を招きます。
これをよりデバッグ可能にする方法に関する提案を歓迎します...
これは長年の問題(k8s 1.6!)であり、k8sを使用するかなりの数の人々を悩ませてきました。
過負荷のノード(最大CPU%、io、割り込み)とは別に、PLEGの問題は、kubelet、docker、logging、networkingなどの間の微妙な問題によって引き起こされることがあり、問題の修正は残酷な場合があります(すべてのノードの再起動など、ケース)。
元の投稿に関する限り、#71653が最終的にマージされ、kubeletが更新され、CNIリクエストをタイムアウトして、期限を超える前にコンテキストをキャンセルできるようになりました。
Kubernetes1.16に修正が含まれます。
また、PRを開いて、これを1.14と1.15に戻します。これは、新しいタイムアウト機能(> = 0.7.0)を含むCNIバージョンがあるためです。 1.13には、この機能のない古いCNIvがあります。したがって、これは最終的に閉じることができます。
/閉じる
私は混乱しています...これが遅いdockerデーモンによって引き起こされる可能性がある場合、cni呼び出しにタイムアウトを追加するだけで修正できるのはなぜですか?
 jmf0526
2019年12月30日
jmf0526
2019年12月30日
containerd + kubernetes 1.16を使用していますが、ノードごとに191個のコンテナーがある場合でも、これは簡単に発生します。 しきい値を上げてみませんか? またはより良い解決策はありますか? @yujuhong
 haosdent
2020年01月31日
haosdent
2020年01月31日
@haosdent修正がご使用のバージョンのKubernetesにマージされているかどうかを確認します。 1.16になっている場合は、最新のリリースである必要があります。 または、1.17にアップグレードすると、100%になります。
adampl
2020年02月02日
@haosdentと同じ質問があった
- #71653はv1.16にバックポートされました(PR:#86825)。 v1.16.7( changelog )に含まれています。
- v1.15以前にバックポートされていないようです( PR検索、 v1.15変更ログ)。
したがって、v1.16.7またはv1.17.0は、その修正を取得するために必要な最小のk8sリリースのようです。
 david-in-perth
2020年03月17日
david-in-perth
2020年03月17日
cilium v1.6.5を使用して、kops debianイメージを4.19にアップグレードしたカーネルを使用して、kopsによってプロビジョニングされたAWSで最小限の負荷でv1.16.7を実行しています。
:man_shrugging:それでまだそこにあります:/
しかし、さらに調査する必要があります。
_sidenote_は、kubesprayによってv1.16.4プロビジョニングされたubuntuでも発生しました
今のところ、ノードを再起動すると、短時間で解決されます。
c5.large ec2ノードでのみ発生しました
Dockerはどちらの場合も18.04でした。 したがって、上記のようにdockerを19.03.4にアップグレードしようとします。
 fentas
2020年04月02日
fentas
2020年04月02日
この問題は、古いバージョンのsystemdが原因である可能性もあります。systemdをアップグレードしてみてください。
参照:
https://my.oschina.net/yunqi/blog/3041189 (中国語のみ)
https://github.com/lnykryn/systemd-rhel/pull/322
 hulucc
2020年04月08日
hulucc
2020年04月08日
この問題は1.16.8+ docker18.06.2でも見られます
# docker info
Containers: 186
Running: 155
Paused: 0
Stopped: 31
Images: 48
Server Version: 18.06.2-ce
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file logentries splunk syslog
Swarm: inactive
Runtimes: nvidia runc
Default Runtime: nvidia
Init Binary: docker-init
containerd version: 468a545b9edcd5932818eb9de8e72413e616e86e
runc version: 6635b4f0c6af3810594d2770f662f34ddc15b40d-dirty (expected: 69663f0bd4b60df09991c08812a60108003fa340)
init version: fec3683
Security Options:
apparmor
seccomp
Profile: default
Kernel Version: 5.0.0-1027-aws
Operating System: Ubuntu 18.04.4 LTS
OSType: linux
Architecture: x86_64
CPUs: 48
Total Memory: 373.8GiB
Name: node-cmp-test-kubecluster-2-0a03fdfa
ID: E74R:BMMI:XOFX:BK4X:53AT:JQLZ:CDF6:M6X7:J56G:2DTZ:OTRK:5OJB
Docker Root Dir: /mnt/docker
Debug Mode (client): false
Debug Mode (server): false
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: true
WARNING: No swap limit support
PLEGが正常でなく、ノードがフラップする前に、dockerがファイルソケットへの書き込みでタイムアウトに遭遇する可能性があることを参照してください。 この場合、カーネルはスタックしたプロセスを強制終了でき、ノードは回復できます。 しかし、他の多くの場合、ノードは回復できず、SSH接続さえできないため、さまざまな問題の組み合わせである可能性もあります。
最大の問題点の1つは、プラットフォームプロバイダーとして、PLEGが「異常」として報告される前に、Dockerが間違った方向に進む可能性があるため、問題を事前に検出してユーザーの混乱をクリーンアップするのではなく、常にユーザーがエラーを報告することです。 問題が発生すると、メトリックの2つの興味深い現象:
- 問題が発生する前に、CRIメトリックはQPSの急上昇を示しません
- 問題が発生した後、kubeletから生成されたメトリックはありません(監視バックエンドは何も受信しませんが、そのようなPLEGの正常でない問題は通常、ノードがsshできないため、ここにデバッグデータポイントがありません)
Dockerメトリックを調べて、アラートを設定できるかどうかを確認しています。
May 8 16:32:25 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:25Z" level=info msg="shim reaped" id=522fbf813ab6c63b17f517a070a5ebc82df7c8f303927653e466b2d12974cf45
--
May 8 16:32:25 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:25.557712045Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:32:26 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:26.204921094Z" level=warning msg="Your kernel does not support swap limit capabilities,or the cgroup is not mounted. Memory limited without swap."
May 8 16:32:26 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:26Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/679b08e796acdd04b40802f2feff8086d7ba7f96182dcf874bb652fa9d9a7aec/shim.sock" debug=false pid=6592
May 8 16:32:26 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:26Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/2ef0c4109b9cd128ae717d5c55bbd59810f88f3d8809424b620793729ab304c3/shim.sock" debug=false pid=6691
May 8 16:32:26 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:26.871411364Z" level=warning msg="Your kernel does not support swap limit capabilities,or the cgroup is not mounted. Memory limited without swap."
May 8 16:32:26 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:26Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/905b3c35be073388e3c037da65fe55bdb4f4b236b86dcf1e1698d6987dfce28c/shim.sock" debug=false pid=6790
May 8 16:32:27 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:27Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/b4e6991f9837bf82533569d83a942fd8f3ae9fa869d5a0e760a967126f567a05/shim.sock" debug=false pid=6884
May 8 16:32:42 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:32:42.409620423Z" level=warning msg="Your kernel does not support swap limit capabilities,or the cgroup is not mounted. Memory limited without swap."
May 8 16:37:28 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:27Z" level=info msg="shim reaped" id=2ef0c4109b9cd128ae717d5c55bbd59810f88f3d8809424b620793729ab304c3
May 8 16:37:28 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:28.400830650Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:37:30 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:29Z" level=info msg="shim reaped" id=905b3c35be073388e3c037da65fe55bdb4f4b236b86dcf1e1698d6987dfce28c
May 8 16:37:30 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:30.316345816Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:37:30 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:30Z" level=info msg="shim reaped" id=b4e6991f9837bf82533569d83a942fd8f3ae9fa869d5a0e760a967126f567a05
May 8 16:37:30 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:30.931134481Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:37:35 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:35Z" level=info msg="shim reaped" id=679b08e796acdd04b40802f2feff8086d7ba7f96182dcf874bb652fa9d9a7aec
May 8 16:37:36 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:37:36.747358875Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:39:31 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63281.723692] mybr0: port 2(veth3f150f6c) entered disabled state
May 8 16:39:31 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63281.752694] device veth3f150f6c left promiscuous mode
May 8 16:39:31 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63281.756449] mybr0: port 2(veth3f150f6c) entered disabled state
May 8 16:39:35 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:39:34Z" level=info msg="shim reaped" id=fa731d8d33f9d5a8aef457e5dab43170c1aedb529ce9221fd6d916a4dba07ff1
May 8 16:39:35 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:39:35.106265137Z" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.505842] INFO: task dockerd:7970 blocked for more than 120 seconds.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.510931] Not tainted 5.0.0-1019-aws #21~18.04.1-Ubuntu
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.515010] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.521419] dockerd D 0 7970 1 0x00000080
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.525333] Call Trace:
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.528060] __schedule+0x2c0/0x870
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.531107] schedule+0x2c/0x70
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.534027] rwsem_down_write_failed+0x157/0x350
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.537630] ? blk_finish_plug+0x2c/0x40
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.540890] ? generic_writepages+0x68/0x90
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.544296] call_rwsem_down_write_failed+0x17/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.547999] ? call_rwsem_down_write_failed+0x17/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.551674] down_write+0x2d/0x40
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.554612] sync_inodes_sb+0xb9/0x2c0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.557762] ? __filemap_fdatawrite_range+0xcd/0x100
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.561468] __sync_filesystem+0x1b/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.564697] sync_filesystem+0x3c/0x50
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.568544] ovl_sync_fs+0x3f/0x60 [overlay]
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.572831] __sync_filesystem+0x33/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.576767] sync_filesystem+0x3c/0x50
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.580565] generic_shutdown_super+0x27/0x120
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.584632] kill_anon_super+0x12/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.587958] deactivate_locked_super+0x48/0x80
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.591696] deactivate_super+0x40/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.594998] cleanup_mnt+0x3f/0x90
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.598081] __cleanup_mnt+0x12/0x20
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.601194] task_work_run+0x9d/0xc0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.604388] exit_to_usermode_loop+0xf2/0x100
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.607843] do_syscall_64+0x107/0x120
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.611173] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.615128] RIP: 0033:0x556561f280e0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.618303] Code: Bad RIP value.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.621256] RSP: 002b:000000c428ec51c0 EFLAGS: 00000206 ORIG_RAX: 00000000000000a6
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.627790] RAX: 0000000000000000 RBX: 0000000000000000 RCX: 0000556561f280e0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.632469] RDX: 0000000000000000 RSI: 0000000000000002 RDI: 000000c4268a0d20
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.637203] RBP: 000000c428ec5220 R08: 0000000000000000 R09: 0000000000000000
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.641900] R10: 0000000000000000 R11: 0000000000000206 R12: ffffffffffffffff
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.646535] R13: 0000000000000024 R14: 0000000000000023 R15: 0000000000000055
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.651404] INFO: task dockerd:33393 blocked for more than 120 seconds.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.655956] Not tainted 5.0.0-1019-aws #21~18.04.1-Ubuntu
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.660155] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.666562] dockerd D 0 33393 1 0x00000080
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.670561] Call Trace:
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.673299] __schedule+0x2c0/0x870
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.676435] schedule+0x2c/0x70
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.679556] rwsem_down_write_failed+0x157/0x350
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.683276] ? blk_finish_plug+0x2c/0x40
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.686744] ? generic_writepages+0x68/0x90
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.690442] call_rwsem_down_write_failed+0x17/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.694243] ? call_rwsem_down_write_failed+0x17/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.698019] down_write+0x2d/0x40
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.700996] sync_inodes_sb+0xb9/0x2c0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.704283] ? __filemap_fdatawrite_range+0xcd/0x100
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.708127] __sync_filesystem+0x1b/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.711511] sync_filesystem+0x3c/0x50
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.714806] ovl_sync_fs+0x3f/0x60 [overlay]
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.718349] __sync_filesystem+0x33/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.721665] sync_filesystem+0x3c/0x50
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.724860] generic_shutdown_super+0x27/0x120
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.728449] kill_anon_super+0x12/0x30
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.731817] deactivate_locked_super+0x48/0x80
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.735511] deactivate_super+0x40/0x60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.738899] cleanup_mnt+0x3f/0x90
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.742023] __cleanup_mnt+0x12/0x20
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.745142] task_work_run+0x9d/0xc0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.748337] exit_to_usermode_loop+0xf2/0x100
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.751830] do_syscall_64+0x107/0x120
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.755145] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.759111] RIP: 0033:0x556561f280e0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.762292] Code: Bad RIP value.
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.765237] RSP: 002b:000000c4289c51c0 EFLAGS: 00000206 ORIG_RAX: 00000000000000a6
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.771715] RAX: 0000000000000000 RBX: 0000000000000000 RCX: 0000556561f280e0
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.776351] RDX: 0000000000000000 RSI: 0000000000000002 RDI: 000000c4252e5e60
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.781025] RBP: 000000c4289c5220 R08: 0000000000000000 R09: 0000000000000000
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.785705] R10: 0000000000000000 R11: 0000000000000206 R12: ffffffffffffffff
May 8 16:42:12 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b kernel: [63442.790445] R13: 0000000000000052 R14: 0000000000000051 R15: 0000000000000055
May 8 16:43:40 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:43:40.153619029Z" level=error msg="Handler for GET /containers/679b08e796acdd04b40802f2feff8086d7ba7f96182dcf874bb652fa9d9a7aec/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
May 8 16:43:40 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: http: multiple response.WriteHeader calls
May 8 16:44:15 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:44:15.461023232Z" level=error msg="Handler for GET /containers/fa731d8d33f9d5a8aef457e5dab43170c1aedb529ce9221fd6d916a4dba07ff1/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
May 8 16:44:15 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:44:15.461331976Z" level=error msg="Handler for GET /containers/fa731d8d33f9d5a8aef457e5dab43170c1aedb529ce9221fd6d916a4dba07ff1/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
May 8 16:44:15 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: http: multiple response.WriteHeader calls
May 8 16:44:15 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: http: multiple response.WriteHeader calls
May 8 16:59:55 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:59:55.489826112Z" level=info msg="No non-localhost DNS nameservers are left in resolv.conf. Using default external servers: [nameserver 8.8.8.8 nameserver 8.8.4.4]"
May 8 16:59:55 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:59:55.489858794Z" level=info msg="IPv6 enabled; Adding default IPv6 external servers: [nameserver 2001:4860:4860::8888 nameserver 2001:4860:4860::8844]"
May 8 16:59:55 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:59:55Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/5b85357b1e7b41f230a05d65fc97e6bdcf10537045db2e97ecbe66a346e40644/shim.sock" debug=false pid=5285
May 8 16:59:57 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:59:57Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/89c6e4f2480992f94e3dbefb1cbe0084a8e5637588296a1bb40df0dcca662cf0/shim.sock" debug=false pid=6776
May 8 16:59:58 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c414b dockerd[1747]: time="2020-05-08T16:59:58Z" level=info msg="shim reaped" id=89c6e4f2480992f94e3dbefb1cbe0084a8e5637588296a1bb40df0dcca662cf0
私たちのためにそれを引き起こしたものを共有したいだけです。
コンテナを実行して、最大3日間で多くのプロセスを「生成」し、最大に達しました。 これにより、新しいプロセスを生成できなかったため、システムが完全にフリーズしました(その後、PLEG警告が発生しました)。
だから私たちにとっては無関係な問題です。 すべての助けをありがとう:+1:
fentas
2020年05月19日
私が抱えていた問題は2つあり、おそらく関連していました。
- ペスト。 それらはなくなったと思いますが、完全に自信を持って十分なクラスターを再作成していません。 私はそれを実現するために_直接_変更したとは思いません。
- コンテナが何にも接続できないという織り方の問題。
不審なことに、plegのすべての問題は、ウィーブネットワークの問題と同時に発生しました。
Bryan @ weaveworksは、coreosの問題を指摘してくれました。 CoreOSは、ブリッジ、ベス、基本的にすべてを管理しようとするかなり積極的な傾向があります。
loと実際にはホスト上の物理インターフェイスを除いて、CoreOSがそれを実行できないようにすると、すべての問題が残りました。人々はまだcoreosの実行に問題を抱えていますか?
@deitchで行った変更を覚えていますか?
 JefClaes
2020年05月26日
JefClaes
2020年05月26日
私はこれを見つけました: https :
これは@deitchが提案したことに関連している可能性があります。 しかし、veth *を使用してユニットを作成し、これを管理されていないものとして配置するなど、適切なソリューションまたはよりエレガントなソリューションがあるかどうかも知りたいです。
rikatz
2020年05月27日
ここで見た問題の根本的な原因はわかったと思います。
dockerは、dockerpsとdockerinspectの間で混乱することがあります。コンテナーの破棄中に、docker psは、シムが既に刈り取られているコンテナーを含む、コンテナーに関するキャッシュ情報を表示できます。
time="2020-06-01T23:39:03Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/shim.sock" debug=false pid=11377
Jun 02 03:23:06 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T03:23:06Z" level=info msg="shim reaped" id=b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121
Jun 02 03:23:36 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T03:23:36.433087181Z" level=info msg="Container b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121 failed to exit within 30 seconds of signal 15 - using the force"
psはコンテナIDのプロセスを見つけることができません
# ps auxww | grep b7ae92902520
root 21510 0.0 0.0 14852 1000 pts/0 S+ 03:44 0:00 grep --color=auto b7ae92902520
docker psは、プロセスがまだ稼働中であることを示しています
# docker ps -a | grep b7ae92902520
b7ae92902520 450280d6866c "/srv/envoy-discover…" 4 hours ago Up 4 hours k8s_xxxxxx
このような場合、docker inspectのためにdocker sockをダイヤルするとスタックし、クライアント側のタイムアウトが発生します。 これはおそらく、docker psがキャッシュされたデータを使用しているのに対し、dockerinspectが刈り取られたシムにダイヤルしてcontainerdからの最新情報を取得するという事実が原因です。
# strace docker inspect b7ae92902520
......
newfstatat(AT_FDCWD, "/etc/.docker/config.json", {st_mode=S_IFREG|0644, st_size=124, ...}, 0) = 0
openat(AT_FDCWD, "/etc/.docker/config.json", O_RDONLY|O_CLOEXEC) = 3
epoll_ctl(4, EPOLL_CTL_ADD, 3, {EPOLLIN|EPOLLOUT|EPOLLRDHUP|EPOLLET, {u32=2124234496, u64=139889209065216}}) = -1 EPERM (Operation not permitted)
epoll_ctl(4, EPOLL_CTL_DEL, 3, 0xc420689884) = -1 EPERM (Operation not permitted)
read(3, "{\n \"credsStore\": \"ecr-login\","..., 512) = 124
close(3) = 0
futex(0xc420650948, FUTEX_WAKE, 1) = 1
socket(AF_UNIX, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, 0) = 3
setsockopt(3, SOL_SOCKET, SO_BROADCAST, [1], 4) = 0
connect(3, {sa_family=AF_UNIX, sun_path="/var/run/docker.sock"}, 23) = 0
epoll_ctl(4, EPOLL_CTL_ADD, 3, {EPOLLIN|EPOLLOUT|EPOLLRDHUP|EPOLLET, {u32=2124234496, u64=139889209065216}}) = 0
getsockname(3, {sa_family=AF_UNIX}, [112->2]) = 0
getpeername(3, {sa_family=AF_UNIX, sun_path="/var/run/docker.sock"}, [112->23]) = 0
futex(0xc420644548, FUTEX_WAKE, 1) = 1
read(3, 0xc4202c2000, 4096) = -1 EAGAIN (Resource temporarily unavailable)
write(3, "GET /_ping HTTP/1.1\r\nHost: docke"..., 83) = 83
futex(0xc420128548, FUTEX_WAKE, 1) = 1
futex(0x25390a8, FUTEX_WAIT, 0, NULL) = 0
futex(0x25390a8, FUTEX_WAIT, 0, NULL) = 0
futex(0x25390a8, FUTEX_WAIT, 0, NULL) = -1 EAGAIN (Resource temporarily unavailable)
futex(0x25390a8, FUTEX_WAIT, 0, NULL^C) = ? ERESTARTSYS (To be restarted if SA_RESTART is set)
strace: Process 13301 detached
ポッドの再リストには、すべてのポッドのすべてのコンテナーのDocker検査が含まれるため、このようなタイムアウトにより、PLEGの再リスト全体が長期間続くことになります。
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.523247 28263 generic.go:189] GenericPLEG: Relisting
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541890 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/51f959aa0c4cbcbc318c3fad7f90e5e967537e0acc8c727b813df17c50493af3: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541905 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/6c221cd2fb602fdf4ae5288f2ce80d010cf252a9144d676c8ce11cc61170a4cf: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541909 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/47bb03e0b56d55841e0592f94635eb67d5432edb82424fc23894cdffd755e652: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541913 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/ee861fac313fad5e0c69455a807e13c67c3c211032bc499ca44898cde7368960: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541917 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121: non-existent -> running
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541922 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/dd3f5c03f7309d0a3feb2f9e9f682b4c30ac4105a245f7f40b44afd7096193a0: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541925 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/57960fe13240af78381785cc66c6946f78b8978985bc847a1f77f8af8aef0f54: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541929 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/8ebaeed71f6ce99191a2d839a07d3573119472da221aeb4c7f646f25e6e9dd1b: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541932 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/b04da653f52e0badc54cc839b485dcc7ec5e2f6a8df326d03bcf3e5c8a14a3e3: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541936 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/a23912e38613fd455b26061c4ab002da294f18437b21bc1874e65a82ee1fba05: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541939 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/7f928360f1ba8890194ed795cfa22c5930c0d3ce5f6f2bc6d0592f4a3c1b579f: non-existent -> exited
Jun 2 04:37:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:03.541943 28263 generic.go:153] GenericPLEG: f0118c7e-82cb-4825-a01b-3014fe500e1f/c3bdab1ed8896399263672ca45365e3d74c4ddc3958f82e3c7549fe12bc6c74b: non-existent -> exited
Jun 2 04:37:05 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:37:05.580912 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:05 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:05.580983 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:18 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:37:18.277091 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:18 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:18.277187 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:29 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:37:29.276942 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:29 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:29.276994 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:44 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:37:44.276919 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:44 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:44.276964 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:56 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:37:56.277039 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:37:56 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:37:56.277116 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:08 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:38:08.276838 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:08 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:38:08.276913 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:22 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:38:22.277107 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:22 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:38:22.277151 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:37 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:38:37.277123 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:37 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:38:37.277189 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:51 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:38:51.277059 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:38:51 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:38:51.277101 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:02 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:02.276836 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:02 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:02.276908 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:03.554207 28263 remote_runtime.go:295] ContainerStatus "b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:03.554252 28263 kuberuntime_container.go:403] ContainerStatus for b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121 error: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:03.554265 28263 kuberuntime_manager.go:1122] getPodContainerStatuses for pod "optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)" failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:03.554272 28263 generic.go:397] PLEG: Write status for optimus-pr-b-6bgc3/jenkins: (*container.PodStatus)(nil) (err: rpc error: code = DeadlineExceeded desc = context deadline exceeded)
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:03.554285 28263 generic.go:252] PLEG: Ignoring events for pod optimus-pr-b-6bgc3/jenkins: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:03.554294 28263 generic.go:284] GenericPLEG: Reinspecting pods that previously failed inspection
Jun 2 04:39:17 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:17.277086 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:17 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:17.277137 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:28 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:28.276905 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:28 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:28.276976 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:40 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:40.276815 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:40 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:40.276858 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:51 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:39:51.276950 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:39:51 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:39:51.277015 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:40:04 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:40:04.276869 28263 pod_workers.go:191] Error syncing pod f0118c7e-82cb-4825-a01b-3014fe500e1f ("optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)"), skipping: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:40:04 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:40:04.276939 28263 event.go:274] Event(v1.ObjectReference{Kind:"Pod", Namespace:"jenkins", Name:"optimus-pr-b-6bgc3", UID:"f0118c7e-82cb-4825-a01b-3014fe500e1f", APIVersion:"v1", ResourceVersion:"4311315533", FieldPath:""}): type: 'Warning' reason: 'FailedSync' error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:41:03.566494 28263 remote_runtime.go:295] ContainerStatus "b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:41:03.566543 28263 kuberuntime_container.go:403] ContainerStatus for b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121 error: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: E0602 04:41:03.566554 28263 kuberuntime_manager.go:1122] getPodContainerStatuses for pod "optimus-pr-b-6bgc3_jenkins(f0118c7e-82cb-4825-a01b-3014fe500e1f)" failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:41:03.566561 28263 generic.go:397] PLEG: Write status for optimus-pr-b-6bgc3/jenkins: (*container.PodStatus)(nil) (err: rpc error: code = DeadlineExceeded desc = context deadline exceeded)
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:41:03.566575 28263 generic.go:288] PLEG: pod optimus-pr-b-6bgc3/jenkins failed reinspection: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jun 2 04:41:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 kubelet[28263]: I0602 04:41:03.566604 28263 generic.go:189] GenericPLEG: Relisting
現在のPLEGの正常なしきい値は3分であるため、PLEGの再リストが3分を超える場合、これはこの場合はかなり簡単ですが、PLEGは異常として報告されます。
単にdocker rmがそのような状態を修正するかどうかを確認する機会がありません。たとえば、約40分間スタックした後、dockerはそれ自体のブロックを解除します。
[root@node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69:/home/hzhang]# journalctl -u docker | grep b7ae92902520
Jun 01 23:39:03 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-01T23:39:03Z" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/shim.sock" debug=false pid=11377
Jun 02 03:23:06 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T03:23:06Z" level=info msg="shim reaped" id=b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121
Jun 02 03:23:36 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T03:23:36.433087181Z" level=info msg="Container b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121 failed to exit within 30 seconds of signal 15 - using the force"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.435460391Z" level=warning msg="Container b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121 is not running"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.435684282Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.435955786Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.436078347Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.436341875Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.436570634Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.436770587Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
Jun 02 04:41:45 node-k8s-use1-prod-shared-001-kubecluster-3-0a0c5d69 dockerd[1731]: time="2020-06-02T04:41:45.436905470Z" level=error msg="Handler for GET /containers/b7ae929025205a7ea9eeaec24bc0526bf642052edff6c7849bc5cc7b9afb9121/json returned error: write unix /var/run/docker.sock->@: write: broken pipe"
......
同様の現象に関して、さまざまな問題が発生しています。
https://github.com/docker/for-linux/issues/397
https://github.com/docker/for-linux/issues/543
https://github.com/moby/moby/issues/41054
ただし、docker 19.03 、つまりhttps://github.com/docker/for-linux/issues/397#issuecomment-515425324で引き続き表示されると主張されています
おそらく修復は、ウォッチドッグを使用してdocker psとps axを比較し、シムプロセスのないコンテナーをスクラブし、ポッドを強制終了してそれらのポッドのブロックを解除するか、 docker rm使用することです。コンテナを削除するには
zhan849
2020年06月02日
上記の調査を続行するには、スレッドダンプにより、Dockerがハングしている間、Dockerがコンテナー化された状態で待機しているため、コンテナー化された問題が発生している可能性があります。 (以下のスレッドダンプを参照)この場合
- これらの影響を受けるコンテナでは、dockerpsのみが機能します
- docker rm / docker stop / dockerinspectがハングします
- kubeletポッド再出品そのような容器を検査しようとするとタイムアウトになり、全体の再出品待ち時間が3分又は越え
- これにより、ユーザーポッドの進行が滞り、PLEG全体の速度が低下するため、kubeletの応答が遅くなります。
つまり、本番環境で行ったことは次のとおりです。
psとdocker ps間の不整合を確認し、影響を受けるコンテナを選択します。この場合、操作がスタックしているすべてのコンテナは、すでにシムを刈り取っています。- dockerは自動的に解決する場合もありますが、解決しない場合もあるため、タイムアウト後、影響を受けるポッドを強制的に削除してユーザーのブロックを解除します
- このような不整合が一般的に一定期間後に存在する場合は、dockerを再起動します
/ cc @ jmf0526 @haosdent @liucimin @yujuhong @thockin
後のスレッドで調査のために積極的に話していたようです
goroutine 1707386 [select, 22 minutes]:
--
github.com/docker/docker/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc420609680, 0x10, 0xc420f60fd8)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/transport/transport.go:222 +0x101
github.com/docker/docker/vendor/google.golang.org/grpc/transport.(*Stream).RecvCompress(0xc420609680, 0x555ab63e0730, 0xc420f61098)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/transport/transport.go:233 +0x2d
github.com/docker/docker/vendor/google.golang.org/grpc.(*csAttempt).recvMsg(0xc4267ef1e0, 0x555ab624f000, 0xc4288fd410, 0x0, 0x0)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/stream.go:515 +0x63b
github.com/docker/docker/vendor/google.golang.org/grpc.(*clientStream).RecvMsg(0xc4204fa800, 0x555ab624f000, 0xc4288fd410, 0x0, 0x0)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/stream.go:395 +0x45
github.com/docker/docker/vendor/google.golang.org/grpc.invoke(0x555ab6415260, 0xc4288fd4a0, 0x555ab581d40c, 0x2a, 0x555ab6249c00, 0xc428c04450, 0x555ab624f000, 0xc4288fd410, 0xc4202d4600, 0xc4202cdc40, ...)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/call.go:83 +0x185
github.com/docker/docker/vendor/github.com/containerd/containerd.namespaceInterceptor.unary(0x555ab57c9d91, 0x4, 0x555ab64151e0, 0xc420128040, 0x555ab581d40c, 0x2a, 0x555ab6249c00, 0xc428c04450, 0x555ab624f000, 0xc4288fd410, ...)
/go/src/github.com/docker/docker/vendor/github.com/containerd/containerd/grpc.go:35 +0xf6
github.com/docker/docker/vendor/github.com/containerd/containerd.(namespaceInterceptor).(github.com/docker/docker/vendor/github.com/containerd/containerd.unary)-fm(0x555ab64151e0, 0xc420128040, 0x555ab581d40c, 0x2a, 0x555ab6249c00, 0xc428c04450, 0x555ab624f000, 0xc4288fd410, 0xc4202d4600, 0x555ab63e07a0, ...)
/go/src/github.com/docker/docker/vendor/github.com/containerd/containerd/grpc.go:51 +0xf6
github.com/docker/docker/vendor/google.golang.org/grpc.(*ClientConn).Invoke(0xc4202d4600, 0x555ab64151e0, 0xc420128040, 0x555ab581d40c, 0x2a, 0x555ab6249c00, 0xc428c04450, 0x555ab624f000, 0xc4288fd410, 0x0, ...)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/call.go:35 +0x10b
github.com/docker/docker/vendor/google.golang.org/grpc.Invoke(0x555ab64151e0, 0xc420128040, 0x555ab581d40c, 0x2a, 0x555ab6249c00, 0xc428c04450, 0x555ab624f000, 0xc4288fd410, 0xc4202d4600, 0x0, ...)
/go/src/github.com/docker/docker/vendor/google.golang.org/grpc/call.go:60 +0xc3
github.com/docker/docker/vendor/github.com/containerd/containerd/api/services/tasks/v1.(*tasksClient).Delete(0xc422c96128, 0x555ab64151e0, 0xc420128040, 0xc428c04450, 0x0, 0x0, 0x0, 0xed66bcd50, 0x0, 0x0)
/go/src/github.com/docker/docker/vendor/github.com/containerd/containerd/api/services/tasks/v1/tasks.pb.go:430 +0xd4
github.com/docker/docker/vendor/github.com/containerd/containerd.(*task).Delete(0xc42463e8d0, 0x555ab64151e0, 0xc420128040, 0x0, 0x0, 0x0, 0xc42463e8d0, 0x0, 0x0)
/go/src/github.com/docker/docker/vendor/github.com/containerd/containerd/task.go:292 +0x24a
github.com/docker/docker/libcontainerd.(*client).DeleteTask(0xc4203d4e00, 0x555ab64151e0, 0xc420128040, 0xc421763740, 0x40, 0x0, 0x20, 0x20, 0x555ab5fc6920, 0x555ab4269945, ...)
/go/src/github.com/docker/docker/libcontainerd/client_daemon.go:504 +0xe2
github.com/docker/docker/daemon.(*Daemon).ProcessEvent(0xc4202c61c0, 0xc4216469c0, 0x40, 0x555ab57c9b55, 0x4, 0xc4216469c0, 0x40, 0xc421646a80, 0x40, 0x8f0000069c, ...)
/go/src/github.com/docker/docker/daemon/monitor.go:54 +0x23c
github.com/docker/docker/libcontainerd.(*client).processEvent.func1()
/go/src/github.com/docker/docker/libcontainerd/client_daemon.go:694 +0x130
github.com/docker/docker/libcontainerd.(*queue).append.func1(0xc421646900, 0x0, 0xc42a24e380, 0xc420300420, 0xc4203d4e58, 0xc4216469c0, 0x40)
/go/src/github.com/docker/docker/libcontainerd/queue.go:26 +0x3a
created by github.com/docker/docker/libcontainerd.(*queue).append
/go/src/github.com/docker/docker/libcontainerd/queue.go:22 +0x196
非常によく似た問題が発生しています(たとえば、docker psは機能しますが、docker inspectがスタックします)。 FedoraCoreOSでdocker19.3.8を使用してkubernetesv1.17.6を実行しています。
 TeroPihlaja
2020年06月18日
TeroPihlaja
2020年06月18日
また、dockerpsによってリストされたコンテナーがdockerinspectにハングアップするというこの問題も発生しました。
docker ps -a | tr -s " " | cut -d " " -f1 | xargs -Iarg sh -c 'echo arg; docker inspect arg> /dev/null'
私たちの場合、影響を受けたコンテナがrunc initスタックしていることに気づきました。 runc initのメインスレッドをアタッチまたはトレースするのに問題がありました。 信号が配信されていないようでした。 私たちが知る限り、プロセスはカーネルでスタックしていて、ユーザースペースに戻る遷移を行っていません。 私は実際にはLinuxカーネルのデバッグの専門家ではありませんが、私が知る限り、これはマウントのクリーンアップに関連するカーネルの問題のようです。 これは、 runc initプロセスがカーネルランドで実行していることのスタックトレースの例です。
[<0>] kmem_cache_alloc+0x162/0x1c0
[<0>] kmem_zone_alloc+0x61/0xe0 [xfs]
[<0>] xfs_buf_item_init+0x31/0x160 [xfs]
[<0>] _xfs_trans_bjoin+0x1e/0x50 [xfs]
[<0>] xfs_trans_read_buf_map+0x104/0x340 [xfs]
[<0>] xfs_imap_to_bp+0x67/0xd0 [xfs]
[<0>] xfs_iunlink_remove+0x16b/0x430 [xfs]
[<0>] xfs_ifree+0x42/0x140 [xfs]
[<0>] xfs_inactive_ifree+0x9e/0x1c0 [xfs]
[<0>] xfs_inactive+0x9e/0x140 [xfs]
[<0>] xfs_fs_destroy_inode+0xa8/0x1c0 [xfs]
[<0>] __dentry_kill+0xd5/0x170
[<0>] dentry_kill+0x4d/0x190
[<0>] dput.part.31+0xcb/0x110
[<0>] ovl_destroy_inode+0x15/0x60 [overlay]
[<0>] __dentry_kill+0xd5/0x170
[<0>] shrink_dentry_list+0x94/0x1b0
[<0>] shrink_dcache_parent+0x88/0x90
[<0>] do_one_tree+0xe/0x40
[<0>] shrink_dcache_for_umount+0x28/0x80
[<0>] generic_shutdown_super+0x1a/0x100
[<0>] kill_anon_super+0x14/0x30
[<0>] deactivate_locked_super+0x34/0x70
[<0>] cleanup_mnt+0x3b/0x70
[<0>] task_work_run+0x8a/0xb0
[<0>] exit_to_usermode_loop+0xeb/0xf0
[<0>] do_syscall_64+0x182/0x1b0
[<0>] entry_SYSCALL_64_after_hwframe+0x65/0xca
[<0>] 0xffffffffffffffff
Dockerを再起動すると、コンテナがDockerから削除され、PLEGの異常な問題を解決するのに十分ですが、スタックしたrunc initは削除されないことにも注意してください。
編集:興味のある人のためのバージョン:
Docker 19.03.8
runc 1.0.0-rc10
Linux:4.18.0-147.el8.x86_64
CentOS:8.1.1911
 debugmiller
2020年06月25日
debugmiller
2020年06月25日
この問題は解決されましたか?
クラスターでPLEGの問題が発生し、この未解決の問題を確認しました。
これに対する回避策はありますか?
 cshivashankar
2020年06月26日
cshivashankar
2020年06月26日
数日間稼働しているクラスターでも、PLEGの問題が発生しました。
セットアップ
K8Sv1.15.11-eks-af3cafを使用したEKSクラスター
Dockerバージョン18.09.9-ce
インスタンスタイプはm5ad.4xlargeです
問題
Jul 08 04:12:36 ip-56-0-1-191.us-west-2.compute.internal kubelet [5354]:I0708 04:12:36.051162 5354 setters.go:533]ノードの準備ができていません:{タイプ:準備完了ステータス: FalseLastHear tbeatTime:2020-07-08 04:12:36.051127368 +0000 UTC m = + 4279967.056220983 LastTrans itionTime:2020-07-08 04:12:36.051127368 +0000 UTC m = + 4279967.056220983理由:KubeletNotReadyメッセージ:PLEGは健康的ではありません
回復
Kubeletの再起動によりノードが回復しました。
解決策はありますか? Dockerバージョンのアップグレードは機能しますか?
 mak-454
2020年07月10日
mak-454
2020年07月10日
多分それはdockerコンテナの問題です、例えば。 コンテナ内のゾンビプロセスが多いと、「docker ps / inspect」が非常に遅くなります
 jonesmith518
2020年07月27日
jonesmith518
2020年07月27日
すべてのワーカーのsystemctl restart dockerで問題が修正されました。
 jetersen
2020年08月04日
jetersen
2020年08月04日
@jetersen Dockerで「live-restore」を有効にしていますか?
デフォルトでは、Dockerを再起動すると、すべてのコンテナーが再起動されます。これは、問題を解決するのにかなり大きなハンマーです。
bboreham
2020年08月04日
@bborehamはクラスターを破壊して再作成するほど大きくはありません😅
jetersen
2020年08月04日
この問題は、Kubernetes 1.15.3、1.16.3、および1.17.9を使用して発生しています。 dockerバージョン18.6.3(Container Linux)および19.3.12(Flatcar Linux)の場合。
各ノードには約50個のポッドがあります。
 FrederikNS
2020年09月04日
FrederikNS
2020年09月04日
また、dockerpsによってリストされたコンテナーがdockerinspectにハングアップするというこの問題も発生しました。
docker ps -a | tr -s " " | cut -d " " -f1 | xargs -Iarg sh -c 'echo arg; docker inspect arg> /dev/null'私たちの場合、影響を受けたコンテナが
runc initスタックしていることに気づきました。runc initのメインスレッドをアタッチまたはトレースするのに問題がありました。 信号が配信されていないようでした。 私たちが知る限り、プロセスはカーネルでスタックしていて、ユーザースペースに戻る遷移を行っていません。 私は実際にはLinuxカーネルのデバッグの専門家ではありませんが、私が知る限り、これはマウントのクリーンアップに関連するカーネルの問題のようです。 これは、runc initプロセスがカーネルランドで実行していることのスタックトレースの例です。[<0>] kmem_cache_alloc+0x162/0x1c0 [<0>] kmem_zone_alloc+0x61/0xe0 [xfs] [<0>] xfs_buf_item_init+0x31/0x160 [xfs] [<0>] _xfs_trans_bjoin+0x1e/0x50 [xfs] [<0>] xfs_trans_read_buf_map+0x104/0x340 [xfs] [<0>] xfs_imap_to_bp+0x67/0xd0 [xfs] [<0>] xfs_iunlink_remove+0x16b/0x430 [xfs] [<0>] xfs_ifree+0x42/0x140 [xfs] [<0>] xfs_inactive_ifree+0x9e/0x1c0 [xfs] [<0>] xfs_inactive+0x9e/0x140 [xfs] [<0>] xfs_fs_destroy_inode+0xa8/0x1c0 [xfs] [<0>] __dentry_kill+0xd5/0x170 [<0>] dentry_kill+0x4d/0x190 [<0>] dput.part.31+0xcb/0x110 [<0>] ovl_destroy_inode+0x15/0x60 [overlay] [<0>] __dentry_kill+0xd5/0x170 [<0>] shrink_dentry_list+0x94/0x1b0 [<0>] shrink_dcache_parent+0x88/0x90 [<0>] do_one_tree+0xe/0x40 [<0>] shrink_dcache_for_umount+0x28/0x80 [<0>] generic_shutdown_super+0x1a/0x100 [<0>] kill_anon_super+0x14/0x30 [<0>] deactivate_locked_super+0x34/0x70 [<0>] cleanup_mnt+0x3b/0x70 [<0>] task_work_run+0x8a/0xb0 [<0>] exit_to_usermode_loop+0xeb/0xf0 [<0>] do_syscall_64+0x182/0x1b0 [<0>] entry_SYSCALL_64_after_hwframe+0x65/0xca [<0>] 0xffffffffffffffffDockerを再起動すると、コンテナがDockerから削除され、PLEGの異常な問題を解決するのに十分ですが、スタックした
runc initは削除されないことにも注意してください。編集:興味のある人のためのバージョン:
Docker 19.03.8
runc 1.0.0-rc10
Linux:4.18.0-147.el8.x86_64
CentOS:8.1.1911
この問題は解決されましたか? どのバージョンで?
 liruishan
2020年09月05日
liruishan
2020年09月05日
マーク
 neighbour-oldhuang
2020年10月12日
neighbour-oldhuang
2020年10月12日
kubernetes version = v1.16.8-eks-e16311および://19.3.6のeksで再び問題に直面し
dockerとkubeletを再起動すると、ノードが回復しました。
mak-454
2020年11月17日
@ mak-454今日もEKSでこの問題が発生しました。問題の期間とともに、ノードが実行されていたリージョン/ AZを共有していただけませんか。 根本的なインフラの問題があったのではないかと知りたいです。
 JacobHenner
2020年11月18日
JacobHenner
2020年11月18日
@JacobHenner私のノードはeu-central-1リージョンで実行されていました。
mak-454
2020年11月18日
Kubernetesバージョン「1.15.12」およびdockerバージョン「19.03.6-ce」を使用するEKS(ca-central-1)でこの問題が発生しました
docker / kubeletを再起動すると、ノードイベントに次の行が表示されます。
Warning SystemOOM 14s (x3 over 14s) kubelet, ip-10-1-2-3.ca-central-1.compute.internal System OOM encountered
 imriss
2020年11月18日
imriss
2020年11月18日
関連する問題
 alexferl
·
3コメント
alexferl
·
3コメント
 ttripp
·
3コメント
ttripp
·
3コメント
 errordeveloper
·
3コメント
errordeveloper
·
3コメント
 zetaab
·
3コメント
zetaab
·
3コメント
 theothermike
·
3コメント
theothermike
·
3コメント
最も参考になるコメント
PLEGヘルスチェックはほとんど行いません。 すべての反復で、
docker psを呼び出してコンテナーの状態の変化を検出し、docker psとinspectを呼び出してそれらのコンテナーの詳細を取得します。各反復が終了すると、タイムスタンプが更新されます。 タイムスタンプがしばらく(つまり3分間)更新されていない場合、ヘルスチェックは失敗します。
PLEGが3分でこれらすべてを完了できない膨大な数のポッドがノードにロードされていない限り(これは発生しないはずです)、最も可能性の高い原因はDockerが遅いことです。 たまに
docker ps小切手でそれを観察できないかもしれませんが、それはそれがないという意味ではありません。「不健康」ステータスを公開しないと、ユーザーから多くの問題が隠され、さらに多くの問題が発生する可能性があります。 たとえば、kubeletは変更にタイムリーに反応せず、さらに混乱を招きます。
これをよりデバッグ可能にする方法に関する提案を歓迎します...