Kubernetes: Latensi panggilan API `delete pods` dijalankan pada pengujian cluster besar
Deskripsi masalah yang diperbarui dengan temuan terbaru:
50350 memperkenalkan perubahan pada penghapusan pod kubelet yang menyebabkan panggilan API delete pod dari kubelet dipusatkan segera setelah pengumpulan sampah kontainer.
Saat melakukan penghapusan sejumlah besar (ribuan) pod di sejumlah besar (ratusan) node, panggilan hapus terkonsentrasi yang dihasilkan dari kubelet menyebabkan peningkatan latensi panggilan API delete pods atas ambang target:
Sep 27 14:34:14.484: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.551ms Perc90:10.216ms Perc99:1.403002s Perc100:0s} Count:122966}
Tidak terlihat di https://k8s-gubernator.appspot.com/builds/kubernetes-jenkins/logs/ci-kubernetes-kubemark-gce-scale/
detail yang diangkat dari https://github.com/kubernetes/kubernetes/issues/51899#issuecomment -332868313 ke dalam deskripsi:
Grafik selama jendela tiga menit (latensi dalam md dan distribusi panggilan hapus per detik):
panggilan delete dari kontroler gc cukup setel deletionTimestamp pada pod (yang diamati kubelet dan mulai mematikan pod). panggilan delete dari kubelet sebenarnya delete dari etcd.


ada beberapa lonjakan sepanjang proses (terkait dengan penghapusan 3000 pengontrol replikasi pod). berikut adalah grafik panggilan hapus yang membutuhkan waktu lebih dari satu detik selama proses berjalan:
Tampak seperti kawanan gemuruh yang disebabkan oleh kubelet, ketika menghapus sejumlah besar pod di sejumlah besar node. gc kubemark dihentikan karena tidak ada container nyata, jadi ini tidak diamati di sana
Berikut deskripsi masalah asli:
Dari pengujian kepadatan 5k-node (no. 26) pada hari Jumat terakhir:
I0901 10:11:29.395] Sep 1 10:11:29.395: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:66.805ms Perc90:375.804ms Perc99:8.111217s Perc100:0s} Count:11911}
I0901 10:11:29.396] Sep 1 10:11:29.395: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:417.103ms Perc90:1.090847s Perc99:2.336106s Perc100:0s} Count:1261}
I0901 10:11:29.396] Sep 1 10:11:29.395: INFO: WARNING Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:5.633ms Perc90:279.15ms Perc99:1.04109s Perc100:0s} Count:5543730}
I0901 10:11:29.396] Sep 1 10:11:29.395: INFO: Top latency metric: {Resource:pods Subresource:binding Verb:POST Latency:{Perc50:1.442ms Perc90:15.171ms Perc99:921.523ms Perc100:0s} Count:155096}
I0901 10:11:29.396] Sep 1 10:11:29.395: INFO: Top latency metric: {Resource:replicationcontrollers Subresource: Verb:POST Latency:{Perc50:3.13ms Perc90:218.472ms Perc99:886.065ms Perc100:0s} Count:5049}
Dan dari tes sehat terakhir (no. 23):
I0826 03:49:44.301] Aug 26 03:49:44.301: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:830.411ms Perc90:1.468316s Perc99:2.627309s Perc100:0s} Count:10615}
I0826 03:49:44.302] Aug 26 03:49:44.301: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:337.423ms Perc90:427.443ms Perc99:998.426ms Perc100:0s} Count:1800}
I0826 03:49:44.302] Aug 26 03:49:44.301: INFO: Top latency metric: {Resource:apiservices Subresource: Verb:PUT Latency:{Perc50:954µs Perc90:5.726ms Perc99:138.528ms Perc100:0s} Count:840}
I0826 03:49:44.302] Aug 26 03:49:44.301: INFO: Top latency metric: {Resource:namespaces Subresource: Verb:GET Latency:{Perc50:445µs Perc90:2.641ms Perc99:83.57ms Perc100:0s} Count:1608}
I0826 03:49:44.302] Aug 26 03:49:44.301: INFO: Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.22ms Perc90:9.449ms Perc99:55.588ms Perc100:0s} Count:7033941}
Ini adalah peningkatan besar yang kami lihat:
Pod LIST: 2.6s -> 8.1s
Node LIST: 1s -> 2.3s
Status simpul PATCH: 56ms -> 1s
...
cc @ kubernetes / sig-api-mesin-bugs @ kubernetes / sig-scalability-misc @smarterclayton @ wojtek-t @gmarek
 shyamjvs
shyamjvs
Semua 142 komentar
Saya mencoba menemukan PR yang menyinggung. Perbedaannya terlalu besar di semua proses tersebut.
Untungnya ini bahkan terlihat pada cluster yang relatif lebih kecil untuk misalnya kubemark-500 - https://k8s-testgrid.appspot.com/sig-scalability#kubemark -500
shyamjvs
pada 4 Sep 2017
Perasaan kuat saya adalah bahwa ini mungkin terkait dengan penomoran halaman.
Jika saya benar, https://github.com/kubernetes/kubernetes/pull/51876 semoga dapat memperbaiki masalahnya.
@tokopedia
 wojtek-t
pada 4 Sep 2017
wojtek-t
pada 4 Sep 2017
Tetapi ini sebagian besar hanyalah tebakan dan mungkin juga sesuatu yang berbeda.
wojtek-t
pada 4 Sep 2017
@ kubernetes / test-infra-maintainers Kami tidak memiliki log (kecuali build-log dari jenkins) untuk run-26 dari ci-kubernetes-e2e-gce-scale-performance karena jenkins crash di tengah jalan dalam pengujian:
ERROR: Connection was broken: java.io.IOException: Unexpected termination of the channel
at hudson.remoting.SynchronousCommandTransport$ReaderThread.run(SynchronousCommandTransport.java:50)
Caused by: java.io.EOFException
at java.io.ObjectInputStream$PeekInputStream.readFully(ObjectInputStream.java:2351)
at java.io.ObjectInputStream$BlockDataInputStream.readShort(ObjectInputStream.java:2820)
Kegagalan seperti itu (yang terlalu tepat di akhir proses) dapat menghantam kita sangat sulit untuk melakukan debugging wrt.
shyamjvs
pada 4 Sep 2017
@ wojtek-t Kami juga melihat peningkatan dalam latensi tambalan. Jadi mungkin ada regresi lain juga?
shyamjvs
pada 4 Sep 2017
Hingga menjalankan 8132, kubemark-500 sepertinya baik-baik saja:
{
"data": {
"Perc50": 31.303,
"Perc90": 39.326,
"Perc99": 59.415
},
"unit": "ms",
"labels": {
"Count": "43",
"Resource": "nodes",
"Subresource": "",
"Verb": "LIST"
}
},
Kami mengalami beberapa kegagalan startup di b / w dan tampaknya melonjak mulai dari run 8141:
{
"data": {
"Perc50": 213.34,
"Perc90": 608.223,
"Perc99": 1014.937
},
"unit": "ms",
"labels": {
"Count": "53",
"Resource": "nodes",
"Subresource": "",
"Verb": "LIST"
}
},
Melihat perbedaannya sekarang.
shyamjvs
pada 4 Sep 2017
Kemungkinan lain (yang Anda sebutkan kepada saya secara offline) adalah:
https://github.com/kubernetes/kubernetes/pull/48287
Awalnya saya meragukannya, tetapi sekarang ketika saya memikirkannya, mungkin ini tentang alokasi memori (saya tidak melihat dengan cermat, tetapi mungkin jauh lebih tinggi dengan json-iter)?
@thockin - FYI (masih tebakan saya)
wojtek-t
pada 4 Sep 2017
Bagaimanapun - @shyamjvs kami membutuhkan lebih banyak data tentang apa yang telah diubah metrik lain (penggunaan cpu, alokasi, jumlah panggilan API, ...)
wojtek-t
pada 4 Sep 2017
Setelah menghilangkan PR yang sepele dan tidak terkait, berikut ini yang tersisa:
- Kembalikan "Pengkabelan pengelola CPU dan
nonepolicy" # 51804 (Saya pikir yang ini hanya memengaruhi kubelet, jadi tidak mungkin) - Pisahkan APIVersion menjadi APIGroup dan APIVersion dalam acara audit # 50007 (yang ini hanya memengaruhi acara audit)
- Gunakan json-iterator sebagai ganti ugorji untuk JSON. # 48287 (Saya paling curiga tentang ini)
- menambahkan informasi untuk penentuan jenis subresource # 49971 (Yang ini menambahkan bidang grup dan versi ke APIResource)
shyamjvs
pada 4 Sep 2017
Bagaimanapun - @shyamjvs kami membutuhkan lebih banyak data tentang apa yang telah diubah metrik lain (penggunaan cpu, alokasi, jumlah panggilan API, ...)
Yup .. Saya melakukan beberapa eksperimen lokal untuk memverifikasi ini. Juga telah menggabungkan https://github.com/kubernetes/kubernetes/pull/51892 untuk mulai mendapatkan log master kubemark.
shyamjvs
pada 4 Sep 2017
Bisakah Anda mengambil profil CPU dari master saat menjalankan pengujian? Ini akan membantu Anda mencari tahu penyebabnya.
 gmarek
pada 4 Sep 2017
gmarek
pada 4 Sep 2017
Menambahkan tim rilis: @jdumars @calebamiles @spiffxp
gmarek
pada 4 Sep 2017
Jadi saya mengambil penggunaan CPU & memori untuk uji beban dari> 200 operasi terakhir kubemark-500, dan saya tidak melihat peningkatan yang nyata. Sebenarnya sepertinya sudah membaik:


shyamjvs
pada 4 Sep 2017
Ada beberapa kegagalan berjalan berturut-turut (karena bug / regresi testinfra) yang menyebabkan poin hilang atau lonjakan sementara ... Abaikan kebisingan
shyamjvs
pada 4 Sep 2017
Saya menjalankan pengujian secara lokal di kubemark-500 terhadap head (commit ffed1d340843ed) dan berhasil dengan baik dengan nilai latensi rendah seperti sebelumnya. Jalankan kembali untuk melihat apakah sudah terkelupas. Saya akan terus menggalinya besok.
shyamjvs
pada 4 Sep 2017
Kecuali jika Anda telah mengaktifkan semua fitur alfa di kubemark, Anda seharusnya tidak melakukannya
melihat peningkatan dengan pagination (yang terdengar seperti lebih jauh
investigasi dihilangkan). Jika Anda memang mengaktifkan fitur alpha di kubemark
itulah validasi yang saya cari dengan chunking (tidak
regresi terjadi), yang bagus. Chunking akan meningkatkan rata-rata
latensi tetapi harus mengurangi latensi ekor dalam banyak kasus (pemotongan yang naif
akan meningkatkan tingkat kesalahan).
Pada hari Senin, 4 Sep 2017 pukul 17:23, Shyam JVS [email protected] menulis:
Saya menjalankan pengujian secara lokal di kubemark-500 terhadap head (commit ffed1d3
https://github.com/kubernetes/kubernetes/commit/ffed1d340843ed5617a4bdfe5b16a9490476843a )
dan berhasil dengan baik dengan nilai latensi rendah seperti sebelumnya. Berjalan kembali
sekali lagi untuk melihat apakah terkelupas. Saya akan terus menggalinya besok.-
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-327029719 ,
atau nonaktifkan utasnya
https://github.com/notifications/unsubscribe-auth/ABG_p_ODR8S6ycmF1ppTOEZ8Bub3aVsaks5sfGpSgaJpZM4PL3gt
.
 smarterclayton
pada 5 Sep 2017
smarterclayton
pada 5 Sep 2017
Oke ... Jadi alasan kubemark gagal berbeda. Seperti yang ditunjukkan @ wojtek-t, ukuran kubemark master tidak tepat.
Saya baru-baru ini membuat beberapa perubahan dalam test-infra seputar penghitungan otomatis ukuran master kubemark dan sepertinya itu tidak berpengaruh.
shyamjvs
pada 5 Sep 2017
Btw - itu juga menjelaskan mengapa kegagalan itu tidak mereproduksi secara lokal untuk saya. Karena saya melewati semua logika testinfra dengan memulai cluster secara manual, itu dihitung dengan benar.
shyamjvs
pada 5 Sep 2017
@smarterclayton Terima kasih atas penjelasannya. Saya memeriksa bahwa baik kubemark maupun pengujian cluster asli kami tidak menggunakan pagination (karena ?limit=1 masih mengembalikan semua hasil).
Jadi kegagalan pengujian node 5k yang sebenarnya tampaknya tidak ada hubungannya dengan itu.
shyamjvs
pada 5 Sep 2017
shyamjvs
pada 7 Sep 2017
@ wojtek-t @shyamjvs : seberapa buruk situasi di sini? Masih pemblokir rilis?
Apa teori selanjutnya untuk diuji? (json-iterator vs ugorji)
Terima kasih,
Redup
 dims
pada 14 Sep 2017
dims
pada 14 Sep 2017
Tidak terlalu buruk (kami melihat beberapa permintaan latensi tinggi), tetapi tampaknya ada kemunduran. Ini adalah pemblokir rilis.
Berikut ini adalah panggilan api yang gagal memenuhi SLO 1s kami untuk latensi ile ke-99 (dari operasi terakhir yaitu, jalankan no. 34 - https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/ci-kubernetes -e2e-gce-scale-performance / 34):
I0914 00:49:55.355] Sep 14 00:49:55.354: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.894ms Perc90:1.485486s Perc99:5.108352s Perc100:0s} Count:311825}
I0914 00:49:55.356] Sep 14 00:49:55.354: INFO: WARNING Top latency metric: {Resource:configmaps Subresource: Verb:POST Latency:{Perc50:4.018ms Perc90:757.506ms Perc99:1.924344s Perc100:0s} Count:342}
Saya melihat ke log apiserver dan saya melihat jejak berikut untuk tidak besar. dari delete pod panggilan:
I0914 00:06:54.479459 8 trace.go:76] Trace[539192665]: "Delete /api/v1/namespaces/e2e-tests-density-30-32-wqj9b/pods/density150000-31-e5cb99f6-98b6-11e7-aeb5-0242ac110009-4mw6l" (started: 2017-09-14 00:06:48.217160315 +0000 UTC) (total time: 6.262275566s):
Trace[539192665]: [6.256412547s] [6.256412547s] About to delete object from database
Pelacakan tersebut sesuai dengan waktu yang dibutuhkan sejak dimulainya fungsi delete resource handler ke titik sebelum memanggil delete pada penyimpanan, lebih khusus lagi bagian kode ini - https://github.com/kubernetes/kubernetes/blob/9aef242a4c1e423270488206670d3d1f23eaab52/ pementasan / src / k8s.io / apiserver / pkg / endpoints / handlers / rest.go # L931 -L994.
Bagian yang paling mencurigakan bagi saya terlihat seperti langkah audit dan langkah kontrol penerimaan. Saya akan mengirim PR menambahkan jejak untuk langkah-langkah itu juga.
shyamjvs
pada 15 Sep 2017
@shyamjvs Jadi kita bisa mengeluarkan ini dari 1,8 milestone?
dims
pada 18 Sep 2017
Jika masalah yang Anda lihat disebabkan oleh gabungan json-iterator di # 48287
FYI: Lihat ugorji / go @ 54210f4e076c57f351166f0ed60e67d3fca57a36
Pembaruan kinerja substansial yang membawa kinerja tanpa pembuatan kode sejalan dengan apa yang Anda dapatkan dari json-iterator. kami melakukan ini saat hanya menggunakan 'tidak aman' di tempat yang sangat ditargetkan, dengan tag build untuk beralih ke mode 'tidak tidak aman'. Lihat helper_unsafe.go untuk melihat satu-satunya fungsi di mana kami menggunakan unsafe, dengan versi 'aman' yang setara, untuk memberi Anda ketenangan pikiran.
Hasil terlampir, tetapi saya akan mereproduksi output benchcmp yang membandingkan hasil tanpa codecgen dan kemudian dengan codecgen, di sini untuk kenyamanan. Ini dilakukan menggunakan rangkaian benchmark di https://github.com/ugorji/go-codec-bench , yang menggunakan embedding rekursif dari struct mendetail besar. Angka-angka berbicara sendiri. Mungkin ada baiknya untuk kembali lebih cepat daripada nanti.
go test -bench "_(Json|Cbor)" -benchmem -bd 2 -tags "x" > no-codecgen.bench.out.txt
go test -bench "_(Json|Cbor)" -benchmem -bd 2 -tags "x codecgen" > with-codecgen.bench.out.txt
benchcmp no-codecgen.bench.out.txt with-codecgen.bench.out.txt > benchcmp.out.txt
Hasil:
benchmark old ns/op new ns/op delta
Benchmark__Cbor_______Encode-8 69672 37051 -46.82%
Benchmark__Json_______Encode-8 115274 87775 -23.86%
Benchmark__JsonIter___Encode-8 133558 133635 +0.06%
Benchmark__Std_Json___Encode-8 165240 157007 -4.98%
Benchmark__Cbor_______Decode-8 164396 131192 -20.20%
Benchmark__Json_______Decode-8 207014 156589 -24.36%
Benchmark__JsonIter___Decode-8 209418 208993 -0.20%
Benchmark__Std_Json___Decode-8 553650 557783 +0.75%
benchmark old allocs new allocs delta
Benchmark__Cbor_______Encode-8 32 7 -78.12%
Benchmark__Json_______Encode-8 45 20 -55.56%
Benchmark__JsonIter___Encode-8 1013 1013 +0.00%
Benchmark__Std_Json___Encode-8 560 560 +0.00%
Benchmark__Cbor_______Decode-8 713 697 -2.24%
Benchmark__Json_______Decode-8 756 736 -2.65%
Benchmark__JsonIter___Decode-8 2244 2244 +0.00%
Benchmark__Std_Json___Decode-8 1967 1967 +0.00%
benchmark old bytes new bytes delta
Benchmark__Cbor_______Encode-8 5529 2320 -58.04%
Benchmark__Json_______Encode-8 6290 3072 -51.16%
Benchmark__JsonIter___Encode-8 40496 40496 +0.00%
Benchmark__Std_Json___Encode-8 65248 65248 +0.00%
Benchmark__Cbor_______Decode-8 34384 34104 -0.81%
Benchmark__Json_______Decode-8 42976 42608 -0.86%
Benchmark__JsonIter___Decode-8 60128 60128 +0.00%
Benchmark__Std_Json___Decode-8 58320 58320 +0.00%
benchcmp.out.txt
no-codecgen.bench.out.txt
dengan-codecgen.bench.out.txt
 ugorji
pada 19 Sep 2017
ugorji
pada 19 Sep 2017
Perhatikan bahwa tidak boleh ada JSON yang digunakan di suite ini, dan jika memang demikian
itu sendiri adalah bug.
Kita harus menggunakan protobuf untuk semua panggilan intracluster kecuali sampah
koleksi CRD dan sumber daya ekstensi.
smarterclayton
pada 19 Sep 2017
@smarterclayton - Saya yakin kami melakukan tambalan melalui JSON, bukan?
gmarek
pada 19 Sep 2017
Tambalan tidak pernah didekode menggunakan ugorji, sehingga sakelar json-iterator tidak akan memengaruhinya, dan penerapan tambalan gabungan strategis dilakukan pada objek peta perantara [string] antarmuka {}, dan tidak berputar-putar ke JSON
 liggitt
pada 19 Sep 2017
liggitt
pada 19 Sep 2017
Saya tidak berpikir itu perubahan ugorji yang menyebabkan regresi (meskipun saya awalnya mencurigainya) - untuk misalnya pertimbangkan patch node-status panggilan (yang merupakan yang utama menunjukkan regresi) dan panggilan tersebut dibuat oleh kubelet dan npd, keduanya menggunakan protobuf untuk berbicara dengan apiserver. Selanjutnya setelah @smarterclayton dan @liggitt dikonfirmasi, ini adalah panggilan intracluster normal (tidak ada CRD / ekstensi yang terlibat) yang digunakan dengan patch penggabungan strategis.
shyamjvs
pada 19 Sep 2017
Saya memeriksanya lebih jauh hari ini dan inilah yang saya temukan:
- Kami mulai memperhatikan peningkatan latensi sejak menjalankan-27 tugas kinerja 5k kami (https://k8s-testgrid.appspot.com/google-gce-scale#gce-scale-performance). Langkah sehat terakhir adalah run-23 (yang memiliki latensi normal). Inilah perbedaan dari komit di seluruh proses (agak besar) - https://github.com/kubernetes/kubernetes/compare/11299e363c538c...034c40be6f465d
- Dalam setiap proses sejak 27, panggilan api yang melanggar SLO telah berubah (setelah
POST configmaps, setelahPOST replicationcontrollers, dll). Namun latensiPATCH node statustampaknya selalu buruk di semua proses.
Dalam run-23 itu 99% ile adalah 55ms (dalam run-18 itu ~ 200ms yang masih tidak banyak):
INFO: Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.22ms Perc90:9.449ms Perc99:55.588ms Perc100:0s} Count:7033941}
dan pada run-27 (run berguna berikutnya) ile ke 99% ditembakkan hingga lebih dari 1s (urutan peningkatan besaran):
INFO: WARNING Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:4.186ms Perc90:83.292ms Perc99:1.061816s Perc100:0s} Count:7063581}
dan tetap setinggi itu sejak saat itu. Dari log apiserver , saya menemukan banyak jejak untuk panggilan tersebut:
I0918 20:24:52.548401 7 trace.go:76] Trace[176777519]: "GuaranteedUpdate etcd3: *api.Node" (started: 2017-09-18 20:24:51.709667942 +0000 UTC) (total time: 838.710254ms):
Trace[176777519]: [838.643838ms] [837.934826ms] Transaction committed
Dan dari kode yang tampaknya waktu yang dibutuhkan b / w saat transaksi disiapkan dan saat dilakukan. Lebih tepatnya kode ini:
https://github.com/kubernetes/kubernetes/blob/a238fbd2539addc525bb740ae801a42524e5b706/staging/src/k8s.io/apiserver/pkg/storage/etcd3/store.go#L350 -L362
@liggitt @smarterclayton @sttts @ deads2k - Apakah ada perubahan status node patch baru-baru ini? Lebih khusus lagi, apakah kami sudah mulai menggunakan pembaruan etcd3 yang dijamin untuk mereka atau menurut Anda itu lagi? Setiap petunjuk di sini akan sangat dihargai :)
shyamjvs
pada 19 Sep 2017
cc @ kubernetes / kubernetes-release-manager @jdumars @dims - Ini adalah regresi yang jelas yang kita lihat di sini dan seharusnya memblokir rilis ini (seperti yang dibahas dalam pertemuan burndown hari ini).
shyamjvs
pada 19 Sep 2017
Apakah ada sesuatu di sekitar patch node-status berubah baru-baru ini? Lebih khusus lagi, apakah kami sudah mulai menggunakan pembaruan etcd3 yang dijamin untuk mereka atau menurut Anda itu lagi?
semua pembaruan (tambalan, pembaruan, penghapusan anggun, dll) menggunakan GuaranteedUpdate di bawah sampulnya. Itu tidak berubah. Apakah kita tidak dapat mempersempit rentang commit lebih jauh? Apakah kami mengubah versi etcd dalam kisaran itu?
liggitt
pada 19 Sep 2017
Saya pikir @ wojtek-t sedang melakukan beberapa optimasi di jalur Patch.
gmarek
pada 20 Sep 2017
@shyamjvs apakah kamu menyebutkan ada beberapa data yang ingin kamu bagikan dalam rapat kemarin? Apakah kita semakin dekat untuk mencari tahu apa yang perlu kita lakukan untuk ini?
dims
pada 20 Sep 2017
483ee1853b adalah salah satu minor yang akan dipanggil selama sejumlah aliran.
Pada Rabu, 20 Sep 2017 pukul 10.45, Davanum Srinivas < [email protected]
menulis:
@shyamjvs https://github.com/shyamjvs apakah Anda menyebutkan ada beberapa
data yang ingin Anda bagikan dalam rapat kemarin? Apakah kita lebih dekat
mencari tahu apa yang perlu kita lakukan untuk ini?-
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ,
atau nonaktifkan utasnya
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
pada 21 Sep 2017
Kami tidak mengaktifkan a4542ae528 secara default, bukan?
Pada Kamis, 21 Sep 2017 pukul 12.24, Clayton Coleman [email protected]
menulis:
483ee1853b adalah salah satu minor yang akan dipanggil selama sejumlah aliran.
Pada Rabu, 20 Sep 2017 jam 10.45, Davanum Srinivas <
[email protected]> menulis:@shyamjvs https://github.com/shyamjvs apakah Anda menyebutkan ada beberapa
data yang ingin Anda bagikan dalam rapat kemarin? Apakah kita lebih dekat
mencari tahu apa yang perlu kita lakukan untuk ini?-
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ,
atau nonaktifkan utasnya
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
pada 21 Sep 2017
9002dfcd0a Saya sulit percaya akan menyebabkan latensi ekor (lebih seperti
latensi dasar)
Pada Kamis, 21 Sep 2017 pukul 12.25, Clayton Coleman [email protected]
menulis:
Kami tidak mengaktifkan a4542ae528 secara default, bukan?
Pada Kamis, 21 Sep 2017 pukul 12.24, Clayton Coleman [email protected]
menulis:483ee1853b adalah salah satu minor yang akan dipanggil selama sejumlah aliran.
Pada Rabu, 20 Sep 2017 jam 10.45, Davanum Srinivas <
[email protected]> menulis:@shyamjvs https://github.com/shyamjvs apakah Anda menyebutkan ada beberapa
data yang ingin Anda bagikan dalam rapat kemarin? Apakah kita lebih dekat
mencari tahu apa yang perlu kita lakukan untuk ini?-
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ,
atau nonaktifkan utasnya
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
pada 21 Sep 2017
Cara mudah untuk memverifikasi barang json-iter adalah mematikannya sepenuhnya (kembali
ke json.Unmarshal) dan lihat apakah angka latensi menjadi lebih buruk.
Pada Kamis, 21 Sep 2017 pukul 12.27, Clayton Coleman [email protected]
menulis:
9002dfcd0a Saya sulit percaya akan menyebabkan latensi ekor (lebih seperti
latensi dasar)Pada Kamis, 21 Sep 2017 pukul 12.25, Clayton Coleman [email protected]
menulis:Kami tidak mengaktifkan a4542ae528 secara default, bukan?
Pada Kamis, 21 Sep 2017 pukul 12.24, Clayton Coleman [email protected]
menulis:483ee1853b adalah salah satu minor yang akan dipanggil selama sejumlah aliran.
Pada Rabu, 20 Sep 2017 jam 10.45, Davanum Srinivas <
[email protected]> menulis:@shyamjvs https://github.com/shyamjvs apakah Anda menyebutkan ada beberapa
data yang ingin Anda bagikan dalam rapat kemarin? Apakah kita lebih dekat
mencari tahu apa yang perlu kita lakukan untuk ini?-
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ,
atau nonaktifkan utasnya
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
pada 21 Sep 2017
Apakah kita mendapatkan pertentangan mutex di d3546434b7?
Pada Kamis, 21 Sep 2017 pukul 12.28, Clayton Coleman [email protected]
menulis:
Cara mudah untuk memverifikasi barang json-iter adalah mematikannya sepenuhnya (kembali
ke json.Unmarshal) dan lihat apakah angka latensi menjadi lebih buruk.Pada Kamis, 21 Sep 2017 pukul 12.27, Clayton Coleman [email protected]
menulis:9002dfcd0a Saya sulit percaya akan menyebabkan latensi ekor (lebih seperti
latensi dasar)Pada Kamis, 21 Sep 2017 pukul 12.25, Clayton Coleman [email protected]
menulis:Kami tidak mengaktifkan a4542ae528 secara default, bukan?
Pada Kamis, 21 Sep 2017 pukul 12.24, Clayton Coleman [email protected]
menulis:483ee1853b adalah salah satu minor yang akan dipanggil selama sejumlah aliran.
Pada Rabu, 20 Sep 2017 jam 10.45, Davanum Srinivas <
[email protected]> menulis:@shyamjvs https://github.com/shyamjvs apakah Anda menyebutkan ada
beberapa data yang ingin Anda bagikan dalam rapat kemarin? Apakah kita lebih dekat
untuk mencari tahu apa yang perlu kita lakukan untuk ini?-
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ,
atau nonaktifkan utasnya
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
pada 21 Sep 2017
Ada juga perubahan client-go a804d440c3 - Saya tidak ingat seberapa baik
itu terbatas tetapi mungkin memengaruhi panggilan lain.
Pada Kamis, 21 Sep 2017 pukul 12.29, Clayton Coleman [email protected]
menulis:
Apakah kita mendapatkan pertentangan mutex di d3546434b7?
Pada Kamis, 21 Sep 2017 pukul 12.28, Clayton Coleman [email protected]
menulis:Cara mudah untuk memverifikasi barang json-iter adalah mematikannya sepenuhnya (kembali
ke json.Unmarshal) dan lihat apakah angka latensi menjadi lebih buruk.Pada Kamis, 21 Sep 2017 pukul 12.27, Clayton Coleman [email protected]
menulis:9002dfcd0a Saya sulit percaya akan menyebabkan latensi ekor (lebih
seperti latensi dasar)Pada Kamis, 21 Sep 2017 pukul 12.25, Clayton Coleman [email protected]
menulis:Kami tidak mengaktifkan a4542ae528 secara default, bukan?
Pada Kamis, 21 Sep 2017 pukul 12.24, Clayton Coleman [email protected]
menulis:483ee1853b adalah salah satu minor yang akan dipanggil selama sejumlah
mengalir.Pada Rabu, 20 Sep 2017 jam 10.45, Davanum Srinivas <
[email protected]> menulis:@shyamjvs https://github.com/shyamjvs apakah Anda menyebutkan ada
beberapa data yang ingin Anda bagikan dalam rapat kemarin? Apakah kita lebih dekat
untuk mencari tahu apa yang perlu kita lakukan untuk ini?-
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ,
atau nonaktifkan utasnya
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
pada 21 Sep 2017
02281898f8 sepertinya tidak akan menambahkan banyak pekerjaan ke server api, tetapi mungkin saja
beberapa sumber daya yang disebutkan dan hanya membuat tempat.
Pada Kamis, 21 Sep 2017 pukul 12.31, Clayton Coleman [email protected]
menulis:
Ada juga perubahan client-go a804d440c3 - Saya tidak ingat seberapa baik
itu terbatas tetapi mungkin memengaruhi panggilan lain.Pada Kamis, 21 Sep 2017 pukul 12.29, Clayton Coleman [email protected]
menulis:Apakah kita mendapatkan pertentangan mutex di d3546434b7?
Pada Kamis, 21 Sep 2017 pukul 12.28, Clayton Coleman [email protected]
menulis:Cara mudah untuk memverifikasi barang json-iter adalah mematikannya sepenuhnya (buka
kembali ke json.Unmarshal) dan lihat apakah angka latensi menjadi lebih buruk.Pada Kamis, 21 Sep 2017 pukul 12.27, Clayton Coleman [email protected]
menulis:9002dfcd0a Saya sulit percaya akan menyebabkan latensi ekor (lebih
seperti latensi dasar)Pada Kamis, 21 Sep 2017 pukul 12.25, Clayton Coleman [email protected]
menulis:Kami tidak mengaktifkan a4542ae528 secara default, bukan?
Pada Kamis, 21 Sep 2017 jam 12.24, Clayton Coleman < [email protected]
menulis:
483ee1853b adalah salah satu minor yang akan dipanggil selama sejumlah
mengalir.Pada Rabu, 20 Sep 2017 jam 10.45, Davanum Srinivas <
[email protected]> menulis:@shyamjvs https://github.com/shyamjvs apakah Anda menyebutkan ada
beberapa data yang ingin Anda bagikan dalam rapat kemarin? Apakah kita lebih dekat
untuk mencari tahu apa yang perlu kita lakukan untuk ini?-
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ,
atau nonaktifkan utasnya
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
pada 21 Sep 2017
@shyamjvs @gmarek @smarterclayton FYI, sepertinya ini alasan yang paling mungkin untuk menunda 1.8.0. Bagaimana saya atau tim rilis membantu Anda?
 jdumars
pada 21 Sep 2017
jdumars
pada 21 Sep 2017
Setuju ini mungkin harus memblokir rilis. Apa yang saya bisa bantu?
 thockin
pada 21 Sep 2017
thockin
pada 21 Sep 2017
Bahkan seseorang yang dapat membantu melakukan pembelahan mekanis mungkin akan melakukannya
Tolong. Saya tidak berpikir kami memiliki reproduksi minimal
memperumit ini.
Pada Kamis, 21 Sep 2017 pukul 11.24, Tim Hockin [email protected]
menulis:
Setuju ini mungkin harus memblokir rilis. Apa yang saya bisa bantu?
-
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-331191088 ,
atau nonaktifkan utasnya
https://github.com/notifications/unsubscribe-auth/ABG_p2O2uX8YFJCns2lq0lKJcACCJG9hks5skn_IgaJpZM4PL3gt
.
smarterclayton
pada 21 Sep 2017
@smarterclayton Terima kasih banyak telah melihat PR itu - Saya akan mencoba menjalankan tes dengan PR tersebut dikembalikan sebagai pilihan terakhir.
Saya curiga itu karena kami menguji dengan peningkatan qps untuk apiserver (--max-request-inflight = 3000 --max-mutating-request-inflight = 1000) yang merupakan dua kali lipat dari yang kami gunakan untuk kubemark ( di mana latensi tampak baik-baik saja , meskipun pengujian itu sendiri gagal karena alasan yang berbeda). Saya sedang bereksperimen dengan qps yang lebih rendah sekarang.
shyamjvs
pada 21 Sep 2017
@smarterclayton / @lavalamp Bisakah salah satu dari Anda lgtm https://github.com/kubernetes/kubernetes/pull/52732 setidaknya menghapus pelanggaran palsu?
shyamjvs
pada 21 Sep 2017
Apakah kita mendapatkan pertentangan mutex di d354643?
Saya rasa tidak, tetapi jika pertengkaran membaca akhirnya menjadi masalah, saya membuat versi lock-free di https://github.com/kubernetes/kubernetes/pull/52860
liggitt
pada 21 Sep 2017
Oke .. Saya memeriksa dengan qps yang dikurangi dan saya masih melihat panggilan latensi tinggi dalam uji kepadatan:
I0921 21:43:02.755] Sep 21 21:43:02.754: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Scope:namespace Latency:{Perc50:5.572ms Perc90:1.529239s Perc99:7.868101s Perc100:0s} Count:338819}
I0921 21:43:02.755] Sep 21 21:43:02.754: INFO: WARNING Top latency metric: {Resource:configmaps Subresource: Verb:POST Scope:namespace Latency:{Perc50:3.852ms Perc90:1.152249s Perc99:3.848893s Perc100:0s} Count:340}
Saya akan beralih kembali ke qps asli dan akan mulai membagi dua dan menguji secara manual. Akan menjalankan hanya uji kepadatan untuk menghemat waktu.
shyamjvs
pada 22 Sep 2017
@ kubernetes / test-infra-maintainers Saya mendapatkan kesalahan berikut saat menjalankan go run hack/e2e.go -v -test :
Running Suite: Kubernetes e2e suite
===================================
Random Seed: 1506095473 - Will randomize all specs
Will run 1 of 678 specs
Sep 22 17:51:14.149: INFO: Fetching cloud provider for "gce"
I0922 17:51:14.201332 22354 gce.go:584] Using DefaultTokenSource <nil>
Sep 22 17:51:14.201: INFO: Failed to setup provider config: Error building GCE/GKE provider: google: could not find default credentials. See https://developers.google.com/accounts/docs/application-default-credentials for more information.
Failure [0.057 seconds]
[BeforeSuite] BeforeSuite
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/test/e2e/e2e.go:240
Sep 22 17:51:14.201: Failed to setup provider config: Error building GCE/GKE provider: google: could not find default credentials. See https://developers.google.com/accounts/docs/application-default-credentials for more information.
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/test/e2e/e2e.go:141
Tahu mengapa saya melihat ini? K8s saya telah dibuat untuk melawan commit 11299e363.
shyamjvs
pada 22 Sep 2017
fyi - go run hack/e2e.go -v -up berfungsi dengan baik.
shyamjvs
pada 22 Sep 2017
Apakah ada yang melihat panggilan PUT? Hal paling jelas yang mungkin salah (menurut saya) adalah sesuatu yang baru / berubah pada node yaitu memodifikasi status node melalui PUT dan secara konsisten memenangkan perlombaan dengan PATCH kubelet.
 lavalamp
pada 22 Sep 2017
lavalamp
pada 22 Sep 2017
Panggilan PUT tambahan hipotetis tidak akan memiliki latensi tinggi (karena mereka hanya akan mendapatkan konflik jika kalah dalam perlombaan). Mereka juga tidak akan terjadi di kubemark, dengan asumsi itu adalah entitas non-kubelet yang menjadi pelakunya. Tampaknya konsisten dengan semua yang dinyatakan dalam bug ini, meskipun agak sulit untuk diikuti.
lavalamp
pada 22 Sep 2017
Dapatkah seseorang menautkan ke uji coba yang berisi masalah tersebut, sehingga saya dapat membaca log apiserver?
lavalamp
pada 22 Sep 2017
@shyamjvs Saya rasa Anda mungkin perlu menjalankan gcloud auth application-default login .
 ixdy
pada 22 Sep 2017
ixdy
pada 22 Sep 2017
(Anda harus menjalankan gcloud auth login dan gcloud auth application-default login , karena alasannya.)
ixdy
pada 22 Sep 2017
Hipotesis lain yang serupa adalah sekarang node problem detector dan kubelet mencoba untuk memodifikasi field yang sama, jadi ada pertentangan baru meskipun jumlah panggilan patchnya sama.
lavalamp
pada 22 Sep 2017
Menggali log, memang, saya melihat pengontrol node mendapatkan banyak konflik di put:
I0922 09:02:23.479636 7 wrap.go:42] PUT /api/v1/nodes/gce-scale-cluster-minion-group-3-dpvj/status: (1.235319ms) 409 [[kube-controller-manager/v1.9.0 (linux/amd64) kubernetes/158f6b7/system:serviceaccount:kube-system:node-controller] [::1]:54918]
Berikut adalah beberapa PR yang menyentuh NodeController dan / atau controller_utils.go, dari yang terbaru hingga yang paling kecil
https://github.com/kubernetes/kubernetes/pull/51603 (digabungkan 6 Sep)
https://github.com/kubernetes/kubernetes/pull/49257 (digabungkan pada 31 Agustus)
https://github.com/kubernetes/kubernetes/pull/50738 (digabungkan pada 29 Agustus)
https://github.com/kubernetes/kubernetes/pull/49524 (digabungkan 7 Agustus)
https://github.com/kubernetes/kubernetes/pull/49870 (digabungkan 1 Agustus)
https://github.com/kubernetes/kubernetes/pull/47952 (digabungkan 12 Jul)
Secara teori semua hal ini seharusnya dinonaktifkan secara default (kecuali yang pertama, yang merupakan perbaikan bug), lihat
https://github.com/kubernetes/kubernetes/pull/49547
Namun, saya tidak meninjau satupun dari PR ini.
/ cc @gmarek @ k82cn
 davidopp
pada 22 Sep 2017
davidopp
pada 22 Sep 2017
@ixdy Terima kasih banyak atas sarannya, itu berhasil. Menjalankan tes terhadap komit terakhir yang tampaknya sehat untuk dikonfirmasi.
Apakah ada yang melihat panggilan PUT?
@ lavalamp Saya kira maksud Anda panggilan PUT untuk etcd (karena dari log apiserver saya hanya melihat tambalan). Bisakah Anda memberi tahu saya bagaimana cara memeriksa panggilan PUT?
sesuatu yang baru / berubah pada node yaitu memodifikasi status node melalui PUT dan secara konsisten memenangkan perlombaan dengan PATCH kubelet.
Saya tidak melihat PUT apa pun untuk status node dari log apiserver. Itu npd dan kubelet yang memperbarui mereka (hampir sepanjang waktu) dan keduanya menggunakan PATCH:
I0918 17:05:58.357710 7 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-554x/status: (2.195508ms) 200 [[node-problem-detector/v1.4.0 (linux/amd64) kubernetes/$Format] 35.190.133.106:55912]
I0918 17:06:01.312183 7 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-7sbx/status: (67.75199ms) 200 [[kubelet/v1.9.0 (linux/amd64) kubernetes/8ca1d9f] 35.196.121.123:51702]
I0918 17:05:58.359507 7 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-1-j446/status: (3.796612ms) 200 [[node-problem-detector/v1.4.0 (linux/amd64) kubernetes/$Format] 35.185.60.137:43894]
I0918 17:06:01.312296 7 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-1-b113/status: (67.888708ms) 200 [[kubelet/v1.9.0 (linux/amd64) kubernetes/8ca1d9f] 35.196.142.250:35162]
Dapatkah seseorang menautkan ke uji coba yang berisi masalah tersebut, sehingga saya dapat membaca log apiserver?
Hampir semua proses terakhir yang menjalankan pengujian mengandung masalah. Misalnya, Anda dapat melihat di https://storage.googleapis.com/kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/36/artifacts/gce-scale-cluster-master/kube -apiserver.log yang merupakan contoh yang bagus (dari run-36 )
Hipotesis lain yang serupa adalah sekarang node problem detector dan kubelet mencoba untuk memodifikasi field yang sama, jadi ada pertentangan baru meskipun jumlah panggilan patchnya sama.
Saya pikir ini adalah kasusnya bahkan sebelumnya. Misalnya, kami melihat ini bahkan untuk rilis terakhir - https://github.com/kubernetes/node-problem-detector/issues/124. Apakah maksud Anda sth lain?
.
shyamjvs
pada 22 Sep 2017
@jpbetz menyarankan (di utas lain) untuk mengaktifkan pprof untuk etcd untuk mengetahui lebih banyak tentang operasi dari sisi etcd. Apakah seseorang tahu jika ada cara mudah untuk menambahkan argumen pengujian ke etcd (Saya menemukan KUBE_APISERVER_TEST_ARGS, KUBE_SCHEDULER_TEST_ARGS, dll .. tetapi tidak ada yang seperti ETCD_TEST_ARGS di config-test.sh ).
shyamjvs
pada 22 Sep 2017
@shyamjvs Hanya untuk membantu Anda menghilangkan beberapa kemungkinan. :)
Kami tidak mengupdate NPD versi rilis ini, artinya NPD itu sendiri tidak berubah dari 1.7 menjadi 1.8. Sedangkan untuk skrip start-up, satu-satunya perubahan penting yang saya lihat adalah menggunakan tarbal NPD yang dimuat sebelumnya alih-alih mengunduh dalam penerbangan, yang menurut saya tidak dapat menyebabkan masalah ini.
 Random-Liu
pada 23 Sep 2017
Random-Liu
pada 23 Sep 2017
@shyamjvs Saya mengutip entri PUT di pembaruan terakhir saya. Saya belum punya waktu untuk memverifikasi itu penyebabnya.
Jika NPD tidak mengubah apa pun, mungkin pembaruan status kubelet sekarang menyertakan kolom yang bentrok? Kami dapat mempertimbangkan untuk menyertakan baris debug untuk mencetak konten permintaan yang lambat.
lavalamp
pada 23 Sep 2017
Yup .. Lihat itu. Tetapi panggilan dari controller-manager sangat jarang dibandingkan dengan PATCH dari kubelet dan npd. Saya memeriksa salah satu prosesnya, itu seperti 4000 PUT dibandingkan dengan 6 juta PATCH dan itu juga terjadi hanya untuk beberapa menit dua kali selama pengujian yang seharusnya hampir tidak mempengaruhi file 99%.
shyamjvs
pada 23 Sep 2017
Pembaruan: Saya mengonfirmasi bahwa komit 11299e3 sehat dengan latensi teratas berikut (yang semuanya tampak normal):
Sep 23 02:00:18.611: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:154.43ms Perc90:1.527089s Perc99:3.977228s Perc100:0s} Count:11429}
Sep 23 02:00:18.611: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:330.336ms Perc90:372.868ms Perc99:865.299ms Perc100:0s} Count:1642}
Sep 23 02:00:18.611: INFO: Top latency metric: {Resource:configmaps Subresource: Verb:PATCH Latency:{Perc50:1.541ms Perc90:6.507ms Perc99:180.346ms Perc100:0s} Count:184}
Sep 23 02:00:18.611: INFO: Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.344ms Perc90:9.737ms Perc99:78.242ms Perc100:0s} Count:6521257}
Sep 23 02:00:18.611: INFO: Top latency metric: {Resource:configmaps Subresource: Verb:POST Latency:{Perc50:3.861ms Perc90:5.871ms Perc99:28.857ms Perc100:0s} Count:184}
Run-27 (commit 034c40be6f46) tidak sehat. Jadi kami sekarang yakin tentang jangkauannya.
shyamjvs
pada 23 Sep 2017
51603 (digabungkan 6 Sep) - tidak ada operasi (memperbaiki urutan inisialisasi)
49257 (digabungkan pada 31 Agustus) - tidak ada operasi pada kluster normal (berpagar bendera)
50738 (digabungkan pada 29 Agustus) - tidak ada operasi (saya kira - menggantikan deepCopy lama dengan deepCopy baru)
49524 (digabungkan 7 Agustus) - tidak ada operasi (menambahkan kemampuan untuk menambah / menghapus banyak noda di fungsi pembantu)
49870 (digabungkan 1 Agustus) - tidak ada operasi (penggantian nama variabel)
47952 (digabungkan 12 Juli) - tidak ada operasi (tidak mengubah panggilan API apa pun secara langsung, secara tidak langsung hanya dapat mengubah penghapusan Pod)
Singkatnya, saya tidak percaya bahwa NC mengubah perilaku non-flag gated-nya dalam rilis ini.
gmarek
pada 23 Sep 2017
OTOH kami melihat konflik pembaruan yang berasal dari NC ketika Node sekarat karena OOM (tabrakan dengan NPD / Kubelet).
gmarek
pada 23 Sep 2017
Commit 99a9ee5a3c tidak sehat:
Sep 23 18:14:04.314: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:1.1407s Perc90:3.400196s Perc99:5.078185s Perc100:0s} Count:14832}
Sep 23 18:14:04.314: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:408.691ms Perc90:793.079ms Perc99:1.831115s Perc100:0s} Count:1703}
Sep 23 18:14:04.314: INFO: WARNING Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:4.134ms Perc90:103.428ms Perc99:1.139633s Perc100:0s} Count:7396342}
Sep 23 18:14:04.314: INFO: Top latency metric: {Resource:services Subresource: Verb:LIST Latency:{Perc50:1.057ms Perc90:5.84ms Perc99:474.047ms Perc100:0s} Count:511}
Sep 23 18:14:04.314: INFO: Top latency metric: {Resource:replicationcontrollers Subresource: Verb:LIST Latency:{Perc50:869µs Perc90:14.563ms Perc99:436.187ms Perc100:0s} Count:405}
Rentang baru - https://github.com/kubernetes/kubernetes/compare/11299e363c538c...99a9ee5a3c52
shyamjvs
pada 24 Sep 2017
Commit cbe5f38ed2 tidak sehat:
Sep 24 06:03:04.941: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:929.743ms Perc90:3.064274s Perc99:4.745392s Perc100:0s} Count:15353}
Sep 24 06:03:04.941: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:393.741ms Perc90:774.697ms Perc99:2.335875s Perc100:0s} Count:1859}
Sep 24 06:03:04.941: INFO: WARNING Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.742ms Perc90:93.829ms Perc99:1.108202s Perc100:0s} Count:8252670}
Sep 24 06:03:04.941: INFO: Top latency metric: {Resource:configmaps Subresource: Verb:POST Latency:{Perc50:3.778ms Perc90:123.878ms Perc99:650.641ms Perc100:0s} Count:210}
Sep 24 06:03:04.941: INFO: Top latency metric: {Resource:endpoints Subresource: Verb:GET Latency:{Perc50:476µs Perc90:37.661ms Perc99:365.414ms Perc100:0s} Count:13008}
Rentang baru - https://github.com/kubernetes/kubernetes/compare/11299e363c538c...cbe5f38ed21
shyamjvs
pada 24 Sep 2017
Hal-hal penting dalam kisaran itu:
- Versi GCI berubah - https://github.com/kubernetes/kubernetes/commit/9fb015987b70ca84eff5694660f1dba701d10e92
- format audit diubah menjadi JSON - https://github.com/kubernetes/kubernetes/commit/130f5d10adf13492f3435ab85a50d357a6831f6e
- pemeriksaan plugin volume fleksibel menjadi dinamis - https://github.com/kubernetes/kubernetes/commit/396c3c7c6fd008663d2d30369c8e33a58cde5ee2
liggitt
pada 24 Sep 2017
Commit a235ba4e49 tidak sehat:
Sep 24 17:19:21.433: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:61.762ms Perc90:737.617ms Perc99:7.748733s Perc100:0s} Count:7430}
Sep 24 17:19:21.434: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:401.766ms Perc90:913.101ms Perc99:2.586065s Perc100:0s} Count:1151}
Sep 24 17:19:21.434: INFO: WARNING Top latency metric: {Resource:replicationcontrollers Subresource: Verb:POST Latency:{Perc50:3.072ms Perc90:378.118ms Perc99:1.277634s Perc100:0s} Count:5050}
Sep 24 17:19:21.434: INFO: WARNING Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.946ms Perc90:175.392ms Perc99:1.05636s Perc100:0s} Count:5239031}
Sep 24 17:19:21.434: INFO: Top latency metric: {Resource:resourcequotas Subresource: Verb:LIST Latency:{Perc50:924µs Perc90:287.15ms Perc99:960.978ms Perc100:0s} Count:3003}
Rentang baru - https://github.com/kubernetes/kubernetes/compare/11299e363c538c...a235ba4e49451c779b8328378addf0d7bd7b84fd
shyamjvs
pada 24 Sep 2017
/ saya bertaruh pada 130f5d1
dims
pada 24 Sep 2017
Kebijakan audit harus melewatkan logging konten respon untuk mereka:
Sepertinya pengambilan log tidak menyimpan log audit, jadi saya tidak yakin apa yang sebenarnya sedang dicatat di sana ... buka https://github.com/kubernetes/kubernetes/pull/52960 untuk menyimpannya
liggitt
pada 24 Sep 2017
melihat log audit yang ditangkap oleh kubemark di https://github.com/kubernetes/kubernetes/pull/52960
Sepertinya satu-satunya baris audit besar yang tidak terduga yang dicatat adalah deletecollection panggilan untuk objek, yang mencatat seluruh kumpulan objek terhapus yang dikembalikan ... Saya bisa melihat kasus untuk mencatatnya, karena ini adalah mutasi objek tersebut dan memungkinkan Anda melacak siklus hidup objek. tetapi itu bahkan bukan panggilan yang muncul dengan masalah latensi
liggitt
pada 25 Sep 2017
Komit c04e516373 itu sehat:
Sep 25 03:47:20.967: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:178.225ms Perc90:1.455523s Perc99:3.071804s Perc100:0s} Count:11585}
Sep 25 03:47:20.967: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:351.796ms Perc90:393.656ms Perc99:778.841ms Perc100:0s} Count:1754}
Sep 25 03:47:20.967: INFO: Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.218ms Perc90:10.25ms Perc99:62.412ms Perc100:0s} Count:6976580}
Sep 25 03:47:20.967: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:896µs Perc90:6.393ms Perc99:26.436ms Perc100:0s} Count:764169}
Sep 25 03:47:20.967: INFO: Top latency metric: {Resource:pods Subresource: Verb:GET Latency:{Perc50:485µs Perc90:992µs Perc99:18.87ms Perc100:0s} Count:1255153}
Rentang baru - https://github.com/kubernetes/kubernetes/compare/c04e516373...a235ba4e49451c779b8328378addf0d7bd7b84fd
shyamjvs
pada 25 Sep 2017
Kira itu perubahan audit json - akan mengkonfirmasi.
Saya ingat dari salah satu jejak (hapus pods iirc) bahwa audit adalah bagian dari blok kode yang memakan waktu hampir sepanjang waktu. Mungkin itu juga menjelaskan mengapa kami melihat peningkatan untuk panggilan yang bermutasi.
shyamjvs
pada 25 Sep 2017
Perubahan audit tidak dalam rentang https://github.com/kubernetes/kubernetes/compare/11299e363c538c...c04e516373 ?
liggitt
pada 25 Sep 2017
Separuh lainnya yang memiliki bug.
shyamjvs
pada 25 Sep 2017
Komentar asli saya memiliki jangkauan yang salah, saya segera memperbaikinya - maaf.
shyamjvs
pada 25 Sep 2017
Memperbarui:
- Dari kisaran di atas, PR yang mencurigakan adalah:
- setel --audit-log-format default ke json # 50971
- Perbarui gambar cos ke cos-stable-60-9592-84-0 # 51207
- Kemungkinan besar itu yang pertama karena permintaan mutasi adalah yang telah terpengaruh (dan mereka melalui jalur kode pencatatan audit). Juga audit-logging tampaknya tidak diaktifkan di kubemark (di mana kami tidak melihat masalah ini) yang semakin memperkuatnya.
- Saat ini saya memverifikasi secara lokal bahwa mengembalikan barang perbaikan PR - akan mengetahui hasilnya dalam 2-3 jam
shyamjvs
pada 25 Sep 2017
@shyamjvs , peningkatan citra COS itu juga memutakhirkan buruh pelabuhan (dari 1,11 menjadi 1,13), yang memiliki beberapa dampak kinerja - @ yguo0905 dapat menilai seberapa relevan hal ini. Jika terlihat mencurigakan, maka Anda dapat mencoba menjalankan pengujian terhadap image COS yang lebih baru ( cos-stable-61-9765-66-0 ) yang memiliki buruh pelabuhan 17.03, yang memiliki kinerja yang lebih baik.
 abgworrall
pada 25 Sep 2017
abgworrall
pada 25 Sep 2017
bahwa peningkatan citra COS juga meningkatkan buruh pelabuhan (dari 1,11 menjadi 1,13), yang memiliki beberapa dampak kinerja
kinerja buruh pelabuhan mungkin tidak akan mempengaruhi latensi server API
liggitt
pada 25 Sep 2017
Ya .. Seperti yang saya sebutkan di saluran kendur, masalah yang kita lihat di sini ada di sisi apiserver. Selain itu kami menggunakan image COS baru di kubemark (yang berfungsi dengan baik).
shyamjvs
pada 25 Sep 2017
@shyamjvs Anda dapat menonaktifkan logging audit untuk pengujian skala GCE besar hingga https://github.com/kubernetes/kubernetes/issues/53006 diperbaiki. Ini dilakukan dengan mengubah file cluster/gce/config-test.sh : mengalihkan ENABLE_APISERVER_ADVANCED_AUDIT menjadi false atau membatalkan setelannya sama sekali.
 crassirostris
pada 25 Sep 2017
crassirostris
pada 25 Sep 2017
Beberapa pemikiran tentang regresi kinerja dari audit:
- Log audit tidak diaktifkan secara default, itu harus dikonfigurasi secara eksplisit (yang kami lakukan di lingkungan pengujian)
- AdavncedAuditing masih dalam versi beta
- Format keluaran spesifik yang menyebabkan regresi dapat dikonfigurasi.
Dengan pemikiran ini, saya cenderung mengatakan kita harus mendokumentasikan ini sebagai masalah yang diketahui dan memperbaikinya di 1.9 (misalnya https://github.com/kubernetes/kubernetes/issues/53006)
 tallclair
pada 25 Sep 2017
tallclair
pada 25 Sep 2017
@shyamjvs Anda dapat menonaktifkan logging audit untuk pengujian skala GCE besar hingga # 53006 diperbaiki
(Seperti yang dibahas di slack dengan @liggitt) Tidak yakin apakah itu pendekatan terbaik. Tujuan pengujian skala adalah untuk memvalidasi rilis dan mematikannya berarti kami tidak benar-benar memvalidasinya. Kami mencoba untuk menjaga konfigurasi yang kami uji skala sedekat mungkin dengan default rilis.
Yang mengatakan, saya bisa hidup dengan ide itu. Namun, akan lebih baik jika kemudian dinonaktifkan secara default di file config - * .sh.
shyamjvs
pada 25 Sep 2017
Kami mencoba untuk menjaga konfigurasi yang kami uji skala sedekat mungkin dengan default rilis.
itu defaultnya di non-tes config-default.sh file
Anda juga dapat menyetel env di pekerjaan uji env. kami sudah melakukan ini untuk pengujian performa agar sesuai dengan produksi, atau menyesuaikannya dengan cara kami menyesuaikan cluster besar.
Saya membuka https://github.com/kubernetes/kubernetes/pull/52998 (1,8 pick di https://github.com/kubernetes/kubernetes/pull/53012) untuk mengurangi jumlah data yang dikirim ke log audit.
Saya juga membuka https://github.com/kubernetes/test-infra/pull/4720 untuk membuat uji kinerja cocok dengan produksi (dengan menonaktifkan audit sepenuhnya) dan kami dapat mengunjungi kembali ini di 1.9
liggitt
pada 25 Sep 2017
Memperbarui:
- Konfigurasi prod tidak mengaktifkan pencatatan audit secara default untuk 1.8, jadi kami akan melewati pengujian skala untuk rilisnya
- Kami tidak memilih perubahan kebijakan audit
- Masalah skalabilitas akan diselesaikan di 1.9 yaitu saat kami akan mengaktifkannya untuk pengujian kami ( @tallclair / @crassirostris - Bisakah salah satu dari Anda mengajukan masalah atau menambahkan TODO untuk mengaktifkannya nanti?)
shyamjvs
pada 25 Sep 2017
Mengajukan masalah: https://github.com/kubernetes/kubernetes/issues/53020
crassirostris
pada 25 Sep 2017
Menendang pekerjaan berkinerja 5k di CI dengan audit dinonaktifkan. Berharap untuk memiliki lari hijau (semoga) besok.
shyamjvs
pada 25 Sep 2017
bagi mereka yang mengikuti di rumah, pengujian yang dijalankan ada di https://k8s-gubernator.appspot.com/builds/kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/
liggitt
pada 26 Sep 2017
Ok .. jadi masalah status node patch telah diatasi dengan menonaktifkan audit-logging dan situasinya terlihat jauh lebih baik. Namun pod hapus menunjukkan masalah dalam proses terakhir:
I0926 14:31:48.470] Sep 26 14:31:48.469: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Scope:namespace Latency:{Perc50:4.633ms Perc90:791.553ms Perc99:3.54603s Perc100:0s} Count:310018}
I0926 14:31:48.470] Sep 26 14:31:48.469: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Scope:namespace Latency:{Perc50:57.306ms Perc90:72.234ms Perc99:1.255s Perc100:0s} Count:10819}
I0926 14:31:48.470] Sep 26 14:31:48.469: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Scope:cluster Latency:{Perc50:409.094ms Perc90:544.723ms Perc99:1.016102s Perc100:0s} Count:2955}
I0926 14:31:48.471] Sep 26 14:31:48.469: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Scope:cluster Latency:{Perc50:211.299ms Perc90:385.941ms Perc99:726.57ms Perc100:0s} Count:1216}
I0926 14:31:48.471] Sep 26 14:31:48.469: INFO: Top latency metric: {Resource:pods Subresource:binding Verb:POST Scope:namespace Latency:{Perc50:1.151ms Perc90:6.838ms Perc99:404.557ms Perc100:0s} Count:155009}
Log sekarang sedang diunggah ke GCS .. perlu menunggu beberapa menit.
shyamjvs
pada 26 Sep 2017
apa yang menghapus pod pada proses sehat terakhir (no. 23)?
liggitt
pada 26 Sep 2017
Untuk run-23 itu 47.057ms dari log api-responsiveness . Untuk run-27, itu adalah 558ms (diambil dari build-log karena log respons-api tidak ada):
INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:5.11ms Perc90:33.011ms Perc99:558.028ms Perc100:0s} Count:314894}
Kami tahu bahwa commit c04e516 sehat dari https://github.com/kubernetes/kubernetes/issues/51899#issuecomment -331759561. Jadi harus di https://github.com/kubernetes/kubernetes/compare/c04e516373...a235ba4e49451c779b8328378addf0d7bd7b84fd (mungkin gambar cos berubah?).
Juga apakah ENABLE_ADVANCED_AUDIT_LOGGING=false masih melakukan beberapa pencatatan audit dasar?
shyamjvs
pada 26 Sep 2017
Jadi harus di c04e516 ... a235ba4 (mungkin gambar cos berubah?).
Panggilan API untuk menghapus sebuah pod tidak diblokir di buruh pelabuhan. Saya bisa melihat butuh waktu lebih lama bagi node untuk mematikan pod, tetapi tidak meningkatkan latensi pada panggilan API yang sebenarnya.
Juga apakah ENABLE_ADVANCED_AUDIT_LOGGING = false masih melakukan beberapa pencatatan audit dasar?
Tidak. Itu dikontrol oleh ENABLE_APISERVER_BASIC_AUDIT , yang defaultnya false.
liggitt
pada 26 Sep 2017
Masuk akal. Sayangnya kami melewatkan log master karena beberapa masalah test-infra (cc @ kubernetes / test-infra-maintainers @krzyzacy), yang seharusnya disalin dari pekerja jenkins ke GCS. Saya tidak melihat panggilan berikut untuk build-log (yang biasanya terjadi):
I0922 10:02:12.439] Call: gsutil ls gs://kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/39/artifacts
I0922 10:02:14.951] process 31483 exited with code 0 after 0.0m
I0922 10:02:14.953] Call: gsutil -m -q -o GSUtil:use_magicfile=True cp -r -c -z log,txt,xml artifacts gs://kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/39
I0922 10:05:21.167] process 31618 exited with code 0 after 3.1m
@liggitt Salah satu alasan mengapa saya curiga hal ini terjadi adalah karena Anda mengaktifkan log audit untuk juga disalin (yang cukup besar).
shyamjvs
pada 26 Sep 2017
@liggitt Salah satu alasan mengapa saya curiga hal ini terjadi adalah karena Anda mengaktifkan log audit untuk juga disalin (yang cukup besar).
audit dinonaktifkan di env ini :)
liggitt
pada 26 Sep 2017
Oh ya .. sama sekali tidak ada log audit - maaf.
shyamjvs
pada 26 Sep 2017
Saya akan mengubah pekerjaan CI untuk menjalankan hanya uji kepadatan dan memilihnya kembali. Kita harus memiliki sth dalam 3-4 jam.
shyamjvs
pada 26 Sep 2017
Sepertinya proses saat ini juga akan gagal, karena saya melihat latensi berikut untuk menghapus panggilan pod (dalam μs):
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="",verb="DELETE",quantile="0.99"} 4.462881e+06
Dari jejak, satu-satunya langkah yang dicetak (memakan waktu hampir setiap saat) adalah:
I0926 21:32:57.199705 7 trace.go:76] Trace[1024874778]: "Delete /api/v1/namespaces/e2e-tests-density-30-21-8gvt2/pods/density150000-20-3b9db35a-a2dd-11e7-b671-0242ac110004-bzsjl" (started: 2017-09-26 21:32:56.246437691 +0000 UTC) (total time: 953.24642ms):
Trace[1024874778]: [949.787883ms] [949.73031ms] About to delete object from database
Dan jejak itu sepertinya sesuai dengan bagian kode ini:
https://github.com/kubernetes/kubernetes/blob/a3ab97b7f395e1abd2d954cd9ada0386629d0411/staging/src/k8s.io/apiserver/pkg/endpoints/handlers/rest.go#L944 -L1009
shyamjvs
pada 27 Sep 2017
Saya telah menambahkan beberapa jejak tambahan di https://github.com/kubernetes/kubernetes/pull/52543 - tapi saya rasa saya harus menambahkannya setelah langkah alih-alih sebelum langkah (karena kami tidak mendapatkan cukup info dari jejak saat ini yang sub-bagian di atasnya membutuhkan waktu maksimum).
shyamjvs
pada 27 Sep 2017
Memulai putaran kedua dari pembagian dua (dengan pencatatan audit dinonaktifkan) untuk menangkap regresi kedua. Semoga yang ini lebih cepat.
shyamjvs
pada 27 Sep 2017
Commit 150a560eed tidak sehat (saya sedang menguji cluster 2k-node):
Sep 27 14:34:14.484: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.551ms Perc90:10.216ms Perc99:1.403002s Perc100:0s} Count:122966}
Dari pembagian dua saya sebelumnya, commit c04e516 adalah yang terbaru sehat yang kami ketahui.
shyamjvs
pada 27 Sep 2017
Cuplikan dari salah satu lonjakan penghapusan dari https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/41/ (y adalah milidetik, x adalah waktu dari panggilan API)
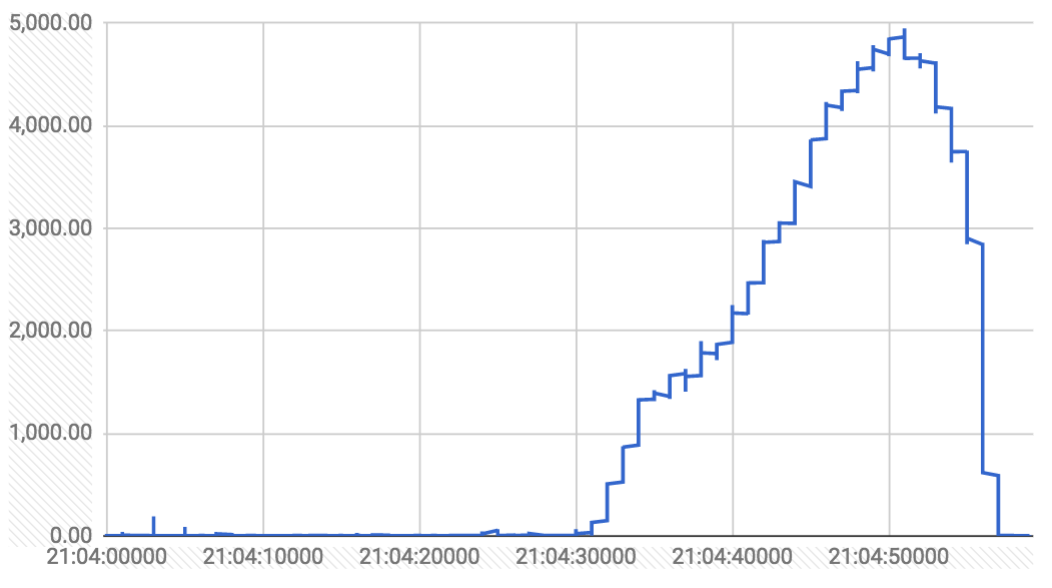
Saya memeriksa perubahan untuk menghapus penanganan / penyimpanan / masuk / pengumpulan sampah dalam kisaran yang tidak sehat. Tidak ada yang melompat sejauh ini.
Yang menarik adalah distribusi panggilan delete pod API selama menit itu:
- 30 detik pertama:
- 63k total panggilan API
- 2146
delete podpanggilan API - 1166 oleh
kube-controller-manager/v1.8.0 (linux/amd64) kubernetes/a3ab97b/system:serviceaccount:kube-system:generic-garbage-collector - 980 kali
kubelet/v1.8.0 (linux/amd64) kubernetes/a3ab97b
- 30 detik kedua:
- Total 55 ribu panggilan API
- 1371
delete podpanggilan API - 1371 oleh
kubelet/v1.8.0 (linux/amd64) kubernetes/a3ab97b
panggilan kolektor sampah memicu penghapusan anggun, panggilan kubelet sebenarnya menghapus pod. 30 detik pertama, ada latensi yang dapat diabaikan pada panggilan hapus (1-100 md), 30 detik kedua, latensi tumbuh dengan mantap.
Jumlah keseluruhan panggilan hapus lebih tinggi dalam 30 detik pertama, dan jumlah yang benar-benar menghasilkan penghapusan etcd sebanding dengan 30 detik kedua (980 vs 1371).
liggitt
pada 27 Sep 2017
menyelesaikan penyapuan, tidak ada masalah yang jelas terkait dengan pod, penghapusan, penerimaan, etcd, atau penyimpanan dalam kisaran aa50c0f ... 150a560
apakah kubemark 5k memiliki pola "buat banyak pod" / "hapus banyak pod terjadwal secara paralel" yang serupa? bertanya-tanya mengapa kami tidak melihat masalah latensi di sana
liggitt
pada 27 Sep 2017
Untuk diketahui semua, kami sudah memiliki persetujuan lisan dari Google melalui @abgworrall untuk
jdumars
pada 27 Sep 2017
@liggitt Ya, kubemark juga menjalankan pengujian yang sama, membuat pola yang serupa. Bagi mereka yang penasaran- singkatnya kami melakukan hal berikut dalam uji kepadatan:
- Menjenuhkan cluster dengan 30 pod / node, yaitu kita membuat beberapa RC yang menambahkan hingga total
30 * #nodespods - Kami kemudian membuat pod tambahan
#nodes(pada cluster jenuh) untuk mengukur latensi startup mereka - Kami kemudian menghapus pod tambahan dan pod saturasi tersebut dan merekam metrik latensi panggilan api
bertanya-tanya mengapa kami tidak melihat masalah latensi di sana
Bisa jadi tentang konfigurasi master yang tidak cocok (https://github.com/kubernetes/kubernetes/issues/53021) atau komposisi qps yang berbeda (sth membuat qps tambahan pada cluster nyata) atau ..? Perlu menggali lebih dalam (https://github.com/kubernetes/kubernetes/issues/47544 dan https://github.com/kubernetes/kubernetes/issues/47540 relevan).
@jdum Diverifikasi bahwa commit aa500f54c3 sehat:
Sep 27 16:34:11.638: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:3.669ms Perc90:6.723ms Perc99:19.735ms Perc100:0s} Count:124000}
Ini jelas merupakan regresi dan saya tidak yakin apakah kita harus menghapus pemblokiran rilis. Meskipun saya bisa hidup dengan mendokumentasikannya dan memperbaikinya dalam rilis patch.
@thockin @smarterclayton Komentar?
shyamjvs
pada 27 Sep 2017
@abgworrall membahas hal ini secara internal di Google, dan berdasarkan situasi dampak yang terbatas, hal ini dapat ditangani di 1.8.x.
jdumars
pada 27 Sep 2017
@jdumars bisa kita keluarkan ini dari milestone.
 grodrigues3
pada 27 Sep 2017
grodrigues3
pada 27 Sep 2017
Kedengarannya bagus. Seperti yang telah disepakati tentang kendur - setelah mengetahui perbaikannya, kami akan mendukungnya menjadi 1,8.
shyamjvs
pada 27 Sep 2017
Melanjutkan dengan bisect ftw ... commit 6b9ce5ba110 sehat:
Sep 27 20:11:35.950: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.404ms Perc90:6.688ms Perc99:20.853ms Perc100:0s} Count:131492}
Commit 57c3c2c0b itu sehat:
Sep 27 22:09:19.792: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:3.792ms Perc90:6.777ms Perc99:19.745ms Perc100:0s} Count:124000}
Rentang baru: https://github.com/kubernetes/kubernetes/compare/57c3c2c0bc3b24905ecab52b7b8a50d4b0e6bae2...150a560eed43a1e1dac47ee9b73af89226827565
Saya mencurigai PR berikut (belum melihat lebih dekat):
- Tunggu pembersihan kontainer sebelum menghapus # 50350
shyamjvs
pada 27 Sep 2017
Untuk memperjelas: OK lisan saya didasarkan pada: regresi kinerja yang hanya terwujud ketika pencatatan audit diaktifkan, dan dikonfigurasi dengan cara tertentu.
Tidak jelas bagi saya apa cakupan dari regresi delete-pods, yang sekarang menjadi terlihat, adalah; apakah ini memengaruhi semua cluster besar secara default? Dan apa dampaknya - peningkatan rata-rata 25%, atau peningkatan 2500% pada 99% ile, atau apa?
(Maaf jika ini dijelaskan sebelumnya di utas ini; tetapi saya sangat menghargai ringkasannya)
abgworrall
pada 27 Sep 2017
- kubemark tidak mengalami masalah ini, meskipun menjalankan pola buat / hapus yang serupa
- dampaknya paling baik dilihat di https://github.com/kubernetes/kubernetes/issues/51899#issuecomment -332515008
liggitt
pada 27 Sep 2017
@abgworrall Ada 2 masalah:
- Peningkatan latensi untuk
patch node-statuspanggilan (dan beberapa panggilan lainnya tidak stabil) yang disebabkan oleh perubahan log audit ke json. Kami melakukannya dengan menonaktifkan log-audit dalam pengujian skala kami (lihat - https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-331973754) dan itu diselesaikan sekarang - Peningkatan latensi untuk panggilan
delete pods(20ms -> 1.4s) dan saat ini saya membagi dua menggunakan cluster 2k-node. Saya mempersempit rentang komit sebanyak https://github.com/kubernetes/kubernetes/compare/57c3c2c0bc3b24905ecab52b7b8a50d4b0e6bae2...150a560eed43a1e1dac47ee9b73af89226827565. Perlu mengonfirmasi jika masalahnya tidak stabil.
shyamjvs
pada 27 Sep 2017
Oke .. Sepertinya bukan serpihan. Gagal untuk kedua kalinya melawan 150a560:
Sep 28 01:54:50.933: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:5.031ms Perc90:2.082021s Perc99:6.116367s Perc100:0s} Count:124000}
@dashpole @liggitt @smarterclayton mungkinkah https://github.com/kubernetes/kubernetes/pull/50350? (berdasarkan rentang terakhir yang diposting oleh shyam)
dims
pada 28 Sep 2017
Fyi - Saya menjalankan dua putaran lagi setelah itu dan menemukan:
Commit 78c82080 tidak sehat:
Sep 28 06:25:03.471: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:3.995ms Perc90:209.142ms Perc99:3.174665s Perc100:0s} Count:124000}
dan komit 6a314ce3a9cb sehat:
Sep 28 13:51:29.705: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:3.647ms Perc90:6.901ms Perc99:19.541ms Perc100:0s} Count:124000}
Rentang baru tersebut adalah: https://github.com/kubernetes/kubernetes/compare/6a314ce3a9cb...78c82080
shyamjvs
pada 28 Sep 2017
/ me meningkatkan taruhannya di https://github.com/kubernetes/kubernetes/pull/50350/commits/9ac30e2c280f61a9629f3334f7e6e6424b7fb5f8
dims
pada 28 Sep 2017
/ me meningkatkan taruhannya pada 9ac30e2
judul komit pasti tampak terkait, tetapi saya telah membahas komit itu belasan kali dan tidak melihat apa pun yang melewati batas di luar kubelet yang akan memengaruhi latensi server API. Kita akan lihat, kurasa.
liggitt
pada 28 Sep 2017
Sebenarnya salah satu hipotesis yang saya miliki adalah karena perubahan itu (iiuc) membuat kubelet mengirim permintaan delete pod hanya setelah container dihapus, mungkin rate / distribusi dari panggilan tersebut telah berubah. Saat berada di kubemark, kubelet tidak menjalankan container nyata, jadi mereka dapat langsung menghapus objek pod (yang mungkin mengarah ke distribusi yang seragam dari panggilan tersebut). Wdyt?
shyamjvs
pada 28 Sep 2017
@ kubernetes / sig-node-bugs Apakah kubelet container GC terjadi secara berkala? Seperti dalam kasus ini, semua penampung yang dihapus dalam satu kelompok dapat menghasilkan permintaan delete pods sekaligus. Atau mungkin sth lagi aku hilang?
shyamjvs
pada 28 Sep 2017
lihat analisis distribusi panggilan hapus di https://github.com/kubernetes/kubernetes/issues/51899#issuecomment -332515008
paruh pertama grafik dan paruh kedua memiliki jumlah panggilan hapus yang hampir sama, namun paruh pertama tetap responsif dan paruh kedua mengakumulasi latensi dramatis. Saya tidak berpikir itu sesederhana kawanan yang bergemuruh.
liggitt
pada 28 Sep 2017
Baru saja selesai memeriksa .. komit bcf22bcf6 juga sehat:
Sep 28 16:09:14.084: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.114ms Perc90:6.221ms Perc99:17.737ms Perc100:0s} Count:124000}
Dan di sisa 3 komitmen (https://github.com/kubernetes/kubernetes/compare/bcf22bcf6...78c82080), kemungkinan besar ini adalah penyebabnya. Ada satu lagi penghapusan pod yang menyentuh (# 51186), tetapi itu adalah beberapa perubahan di sisi kubectl dan kubectl tidak boleh digunakan dalam pengujian kami atau dalam komponen bidang kontrol utama iiuc.
shyamjvs
pada 28 Sep 2017
@liggitt Bisakah Anda mendapatkan grafik untuk rentang-x sedikit lebih lama dari 60
shyamjvs
pada 28 Sep 2017
cc @dashpole @ dchen1
shyamjvs
pada 28 Sep 2017
berikut adalah grafik selama jendela tiga menit (baik latensi dalam md dan distribusi panggilan hapus per detik)
panggilan delete dari GC hanya mengatur deletionTimestamp pada pod (yang diamati oleh kubelet dan mulai mematikan pod). panggilan delete dari kubelet sebenarnya delete dari etcd.
Apakah itu hanya satu lonjakan atau ada beberapa di antaranya? Dan apakah mereka berkala? Mungkin lonjakan tersebut terjadi ketika beberapa node memiliki fase gc yang bertepatan?
ada banyak lonjakan selama lari. berikut adalah grafik panggilan hapus yang membutuhkan waktu lebih dari satu detik selama proses berjalan:
paku tampaknya datang dalam set tiga, dengan interval ~ 2 menit, berlangsung 20-30 detik
liggitt
pada 28 Sep 2017
Cantik! Terima kasih banyak untuk grafiknya.
Jadi memang tampaknya cukup berkala .. Btw - Saya pikir pola 2 menit terkait dengan cara kami menghapus pod saturasi (yang saya jelaskan di https://github.com/kubernetes/kubernetes/issues/51899#issuecomment- 332577238) menjelang akhir uji kepadatan. Kami menghapus RC tersebut (masing-masing memiliki 3000 replika) dengan interval kira-kira 2 menit:
I0928 03:52:02.643] [1mSTEP[0m: Cleaning up only the { ReplicationController}, garbage collector will clean up the pods
I0928 03:52:02.643] [1mSTEP[0m: deleting { ReplicationController} density150000-47-dc6c4af2-a3d1-11e7-9201-0242ac110008 in namespace e2e-tests-density-30-48-pbmpd, will wait for the garbage collector to delete the pods
I0928 03:52:03.048] Sep 28 03:52:03.047: INFO: Deleting { ReplicationController} density150000-47-dc6c4af2-a3d1-11e7-9201-0242ac110008 took: 39.093401ms
I0928 03:53:03.050] Sep 28 03:53:03.049: INFO: Terminating { ReplicationController} density150000-47-dc6c4af2-a3d1-11e7-9201-0242ac110008 pods took: 1m0.001823124s
I0928 03:54:13.051] [1mSTEP[0m: Cleaning up only the { ReplicationController}, garbage collector will clean up the pods
I0928 03:54:13.051] [1mSTEP[0m: deleting { ReplicationController} density150000-48-dc6c4af2-a3d1-11e7-9201-0242ac110008 in namespace e2e-tests-density-30-49-g5qvv, will wait for the garbage collector to delete the pods
I0928 03:54:13.438] Sep 28 03:54:13.437: INFO: Deleting { ReplicationController} density150000-48-dc6c4af2-a3d1-11e7-9201-0242ac110008 took: 40.001908ms
I0928 03:55:13.440] Sep 28 03:55:13.439: INFO: Terminating { ReplicationController} density150000-48-dc6c4af2-a3d1-11e7-9201-0242ac110008 pods took: 1m0.001894987s
I0928 03:56:23.440] [1mSTEP[0m: Cleaning up only the { ReplicationController}, garbage collector will clean up the pods
I0928 03:56:23.441] [1mSTEP[0m: deleting { ReplicationController} density150000-49-dc6c4af2-a3d1-11e7-9201-0242ac110008 in namespace e2e-tests-density-30-50-s62ds, will wait for the garbage collector to delete the pods
I0928 03:56:23.829] Sep 28 03:56:23.829: INFO: Deleting { ReplicationController} density150000-49-dc6c4af2-a3d1-11e7-9201-0242ac110008 took: 50.423057ms
I0928 03:57:23.831] Sep 28 03:57:23.830: INFO: Terminating { ReplicationController} density150000-49-dc6c4af2-a3d1-11e7-9201-0242ac110008 pods took: 1m0.0014941s
Tidak. dari panggilan-panggilan tersebut dari komentar Anda sebelumnya juga mendekati 3000 - meskipun itu dalam rentang 1 menit (tetapi kami memiliki dua panggilan hapus per pod iiuc - satu dari gc dan satu dari kubelet).
shyamjvs
pada 28 Sep 2017
fyi - Saya mengonfirmasi bahwa PR inilah yang menyebabkan masalah. Komit sebelum sehat:
Sep 28 18:05:27.337: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.106ms Perc90:6.308ms Perc99:19.561ms Perc100:0s} Count:124000}
Opsi yang kami miliki:
- kembalikan komit dan kemudian perbaiki masalah di 1.9 (Saya lebih suka ini, kecuali jika perbaikannya cukup sepele untuk masuk ke 1.8)
- perbaiki - berpotensi mendorong rilis lebih jauh (jika kami juga ingin memiliki kepercayaan yang cukup pada kualitas rilis)
- biarlah dan dokumentasikan ini sebagai masalah yang diketahui dalam rilis (saya tidak terlalu mendukung ini)
shyamjvs
pada 28 Sep 2017
Saya bisa melihat bagaimana menunggu container gc di sisi kubelet sebelum mengeluarkan panggilan API delete akan membuat panggilan delete menjadi batch. Tampak seperti kawanan gemuruh yang disebabkan oleh kubelet, ketika menghapus sejumlah besar pod di sejumlah besar node. gc kubemark dihentikan karena tidak ada container nyata, jadi ini tidak diamati di sana
liggitt
pada 28 Sep 2017
Yup .. apa yang saya pikirkan juga - https://github.com/kubernetes/kubernetes/issues/51899#issuecomment -332847171
shyamjvs
pada 28 Sep 2017
cc @dashpole @vishh @ dchen1107
dari memperkenalkan PR (https://github.com/kubernetes/kubernetes/pull/50350)
liggitt
pada 28 Sep 2017
Saya dapat memposting PR untuk mengembalikan bagian penting dari # 50350.
 dashpole
pada 28 Sep 2017
dashpole
pada 28 Sep 2017
@dashpole terima kasih!
jdumars
pada 28 Sep 2017
Saya kira kita juga harus menunggu sampai perbaikannya diuji juga (tambahkan ~ 2 jam lagi untuk itu).
shyamjvs
pada 28 Sep 2017
PR memposting: # 53210
dashpole
pada 28 Sep 2017
@dashpole dan saya melakukan diskusi offline, dan berencana mengembalikan bagian # 50350. Pr asli diperkenalkan karena tanpa perubahan itu, pengelola penggusuran disk Kubelet mungkin menghapus lebih banyak kontainer jika tidak perlu.
Kami harus meningkatkan manajemen disk dengan lebih cerdas untuk mengambil tindakan proaktif, daripada mengandalkan gc berkala.
 dchen1107
pada 28 Sep 2017
dchen1107
pada 28 Sep 2017
Meskipun ini berada dalam tonggak 1.9, ada harapan bahwa ini akan diselesaikan pada saat yang bertanggung jawab paling awal dalam rilis 1.8 patch. Proses pengambilan keputusan lengkap terkait hal ini dapat dilihat di https://youtu.be/r6D5DNel2l8
jdumars
pada 28 Sep 2017
Ada pembaruan tentang ini?
 jpbetz
pada 2 Okt 2017
jpbetz
pada 2 Okt 2017
Kami sudah memiliki korban PR - PR yang memperbaiki # 53233
wojtek-t
pada 2 Okt 2017
53233 digabung menjadi master. pilih untuk 1.8.1 buka di https://github.com/kubernetes/kubernetes/pull/53422
liggitt
pada 4 Okt 2017
[MILESTONENOTIFIER] Masalah Tonggak Perlu Persetujuan
@dashpole @shyamjvs @ kubernetes / sig-api-machinery-bugs @ kubernetes / sig-node-bugs @ kubernetes / sig-scalability-bugs
Tindakan yang diperlukan : Masalah ini harus memiliki label status/approved-for-milestone diterapkan oleh pengelola SIG.Label Masalah
sig/api-machinerysig/nodesig/scalability: Masalah akan diteruskan ke SIG ini jika diperlukan.priority/critical-urgent: Tidak pernah secara otomatis keluar dari tonggak rilis; terus meningkat menjadi kontributor dan SIG melalui semua saluran yang tersedia.kind/bug: Memperbaiki bug yang ditemukan selama rilis saat ini.Tolong
 k8s-github-robot
pada 6 Okt 2017
k8s-github-robot
pada 6 Okt 2017
/Menutup
Ditutup melalui # 53422. Perbaikannya ada di 1.8.1.
dashpole
pada 6 Okt 2017
Masalah terkait
 ddysher
·
3Komentar
ddysher
·
3Komentar
 pwittrock
·
3Komentar
pwittrock
·
3Komentar
 tbchj
·
3Komentar
tbchj
·
3Komentar
 cooligc
·
3Komentar
cooligc
·
3Komentar
 sanjana-bhat
·
3Komentar
sanjana-bhat
·
3Komentar
Komentar yang paling membantu
Menendang pekerjaan berkinerja 5k di CI dengan audit dinonaktifkan. Berharap untuk memiliki lari hijau (semoga) besok.