Kubernetes: "حذف القرون" ظهرت أوقات استجابة مكالمات واجهة برمجة التطبيقات في اختبارات الكتلة الكبيرة
وصف المشكلة المحدث مع أحدث النتائج:
قدم 50350 تغييرًا في حذف جراب kubelet أدى إلى تركيز مكالمات API من kubelets على delete pod فورًا بعد جمع القمامة في الحاوية.
عند إجراء حذف لأعداد كبيرة (الآلاف) من البودات عبر أعداد كبيرة (مئات) من العقد ، فإن استدعاءات الحذف المركزة الناتجة من kubelets تؤدي إلى زيادة زمن انتقال مكالمات API delete pods فوق الحد المستهدف:
Sep 27 14:34:14.484: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.551ms Perc90:10.216ms Perc99:1.403002s Perc100:0s} Count:122966}
تمت مشاهدته على https://k8s-gubernator.appspot.com/builds/kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/
غير مرئي على https://k8s-gubernator.appspot.com/builds/kubernetes-jenkins/logs/ci-kubernetes-kubemark-gce-scale/
تم رفع التفاصيل من https://github.com/kubernetes/kubernetes/issues/51899#issuecomment -332868313 في الوصف:
الرسوم البيانية على مدى ثلاث دقائق (زمن الوصول بالمللي ثانية وتوزيع مكالمات الحذف في الثانية):
تقوم مكالمات الحذف من وحدة تحكم gc فقط بتعيين الحذف الطابع الزمني على الحافظة (التي تلاحظها الكوبيليتات وتبدأ في إغلاق الكبسولات). يتم حذف مكالمات الحذف من kubelet بالفعل من etcd.


كانت هناك عدة ارتفاعات خلال التشغيل (تقابل عمليات حذف 3000 وحدة تحكم في النسخ المتماثل). فيما يلي رسم بياني لمكالمات الحذف التي استغرقت أكثر من ثانية واحدة خلال التشغيل بالكامل:
يبدو وكأنه قطيع رعدي ناتج عن kubelet ، عند حذف أعداد هائلة من القرون عبر أعداد هائلة من العقد. kubemark's gc ممزق نظرًا لعدم وجود حاويات حقيقية ، لذلك لم يتم ملاحظة ذلك هناك
فيما يلي وصف الإصدار الأصلي:
من اختبار كثافة 5k عقدة (رقم 26) يوم الجمعة الماضي:
I0901 10:11:29.395] Sep 1 10:11:29.395: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:66.805ms Perc90:375.804ms Perc99:8.111217s Perc100:0s} Count:11911}
I0901 10:11:29.396] Sep 1 10:11:29.395: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:417.103ms Perc90:1.090847s Perc99:2.336106s Perc100:0s} Count:1261}
I0901 10:11:29.396] Sep 1 10:11:29.395: INFO: WARNING Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:5.633ms Perc90:279.15ms Perc99:1.04109s Perc100:0s} Count:5543730}
I0901 10:11:29.396] Sep 1 10:11:29.395: INFO: Top latency metric: {Resource:pods Subresource:binding Verb:POST Latency:{Perc50:1.442ms Perc90:15.171ms Perc99:921.523ms Perc100:0s} Count:155096}
I0901 10:11:29.396] Sep 1 10:11:29.395: INFO: Top latency metric: {Resource:replicationcontrollers Subresource: Verb:POST Latency:{Perc50:3.13ms Perc90:218.472ms Perc99:886.065ms Perc100:0s} Count:5049}
ومن آخر تشغيل صحي (رقم 23) للاختبار:
I0826 03:49:44.301] Aug 26 03:49:44.301: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:830.411ms Perc90:1.468316s Perc99:2.627309s Perc100:0s} Count:10615}
I0826 03:49:44.302] Aug 26 03:49:44.301: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:337.423ms Perc90:427.443ms Perc99:998.426ms Perc100:0s} Count:1800}
I0826 03:49:44.302] Aug 26 03:49:44.301: INFO: Top latency metric: {Resource:apiservices Subresource: Verb:PUT Latency:{Perc50:954µs Perc90:5.726ms Perc99:138.528ms Perc100:0s} Count:840}
I0826 03:49:44.302] Aug 26 03:49:44.301: INFO: Top latency metric: {Resource:namespaces Subresource: Verb:GET Latency:{Perc50:445µs Perc90:2.641ms Perc99:83.57ms Perc100:0s} Count:1608}
I0826 03:49:44.302] Aug 26 03:49:44.301: INFO: Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.22ms Perc90:9.449ms Perc99:55.588ms Perc100:0s} Count:7033941}
هذه زيادة ضخمة نراها:
قرون القائمة: 2.6 ثانية -> 8.1 ثانية
عقد القائمة: 1 ثانية -> 2.3 ثانية
تصحيح حالة العقدة: 56 مللي ثانية -> 1 ثانية
...
cc @ kubernetes / sig-api-machinery-bugs @ kubernetes / sig- scalability - tgmarek
 shyamjvs
shyamjvs
ال 142 كومينتر
أحاول العثور على العلاقات العامة المخالفة. الفرق كبير جدًا عبر تلك المسارات.
لحسن الحظ ، يمكن رؤية هذا حتى في مجموعات أصغر نسبيًا مثل kubemark-500 - https://k8s-testgrid.appspot.com/sig-scalability#kubemark -500
shyamjvs
في ٤ سبتمبر ٢٠١٧
شعوري القوي أنه قد يكون مرتبطًا بالصفحات.
إذا كنت على حق ، فإن https://github.com/kubernetes/kubernetes/pull/51876 يجب أن يحل المشكلة.
تضمين التغريدة
 wojtek-t
في ٤ سبتمبر ٢٠١٧
wojtek-t
في ٤ سبتمبر ٢٠١٧
لكن هذا في الغالب تخمين وقد يكون شيئًا مختلفًا أيضًا.
wojtek-t
في ٤ سبتمبر ٢٠١٧
@ kubernetes / test-infra-callingers ليس لدينا أي سجلات (باستثناء سجل البناء من جينكينز) للتشغيل -26 من ci-kubernetes-e2e-gce-scale-performance لأن جينكينز تحطمت في منتصف الطريق في الاختبار:
ERROR: Connection was broken: java.io.IOException: Unexpected termination of the channel
at hudson.remoting.SynchronousCommandTransport$ReaderThread.run(SynchronousCommandTransport.java:50)
Caused by: java.io.EOFException
at java.io.ObjectInputStream$PeekInputStream.readFully(ObjectInputStream.java:2351)
at java.io.ObjectInputStream$BlockDataInputStream.readShort(ObjectInputStream.java:2820)
مثل هذه الإخفاقات (التي تحدث أيضًا في نهاية التشغيل) يمكن أن تؤثر علينا بشدة في تصحيح الأخطاء.
shyamjvs
في ٤ سبتمبر ٢٠١٧
@ wojtek-t نشهد أيضًا زيادة في زمن انتقال التصحيح. إذن من المحتمل أن يكون هناك تراجع آخر أيضًا؟
shyamjvs
في ٤ سبتمبر ٢٠١٧
حتى تشغيل 8132 ، بدا kubemark-500 جيدًا:
{
"data": {
"Perc50": 31.303,
"Perc90": 39.326,
"Perc99": 59.415
},
"unit": "ms",
"labels": {
"Count": "43",
"Resource": "nodes",
"Subresource": "",
"Verb": "LIST"
}
},
واجهتنا بعض حالات فشل بدء التشغيل في أبيض وأسود ويبدو أنه انطلق بدءًا من التشغيل 8141:
{
"data": {
"Perc50": 213.34,
"Perc90": 608.223,
"Perc99": 1014.937
},
"unit": "ms",
"labels": {
"Count": "53",
"Resource": "nodes",
"Subresource": "",
"Verb": "LIST"
}
},
أنظر إلى
shyamjvs
في ٤ سبتمبر ٢٠١٧
إمكانية أخرى (ذكرتها لي في وضع عدم الاتصال) هي:
https://github.com/kubernetes/kubernetes/pull/48287
لقد شككت في الأمر في البداية ، لكن الآن عندما أفكر في الأمر ، ربما يتعلق الأمر بتخصيص الذاكرة (لم أنظر بعناية ، لكن ربما يكون الأمر أعلى بكثير مع json-iter)؟
thockin - لمعلوماتك (ما زلت مجرد تخميني)
wojtek-t
في ٤ سبتمبر ٢٠١٧
على أي حال -shyamjvs نحتاج إلى مزيد من البيانات حول المقاييس الأخرى التي تغيرت (استخدام وحدة المعالجة المركزية ، التخصيصات ، عدد استدعاءات واجهة برمجة التطبيقات ، ...)
wojtek-t
في ٤ سبتمبر ٢٠١٧
بعد التخلص من العلاقات العامة التافهة وغير ذات الصلة ، يتبقى ما يلي:
- التراجع عن "توصيلات مدير وحدة المعالجة المركزية و
nonepolicy" # 51804 (أعتقد أن هذا الأمر يؤثر فقط على kubelet ، لذلك من غير المحتمل) - تقسيم APIVersion إلى APIGroup و APIVersion في أحداث التدقيق # 50007 (هذا يؤثر فقط على أحداث التدقيق)
- استخدم json-iterator بدلاً من ugorji لـ JSON. # 48287 (أنا متشكك في هذا الأمر)
- إضافة معلومات لتحديد نوع المصدر الفرعي # 49971 (هذا هو إضافة حقول المجموعة والإصدار إلى مصدر APIResource)
shyamjvs
في ٤ سبتمبر ٢٠١٧
على أي حال -shyamjvs نحتاج إلى مزيد من البيانات حول المقاييس الأخرى التي تغيرت (استخدام وحدة المعالجة المركزية ، التخصيصات ، عدد استدعاءات واجهة برمجة التطبيقات ، ...)
نعم .. أقوم ببعض التجارب المحلية للتحقق من ذلك. تم أيضًا دمج https://github.com/kubernetes/kubernetes/pull/51892 لبدء الحصول على سجلات kubemark الرئيسية.
shyamjvs
في ٤ سبتمبر ٢٠١٧
هل يمكنك الحصول على ملف تعريف وحدة المعالجة المركزية من السيد عند إجراء الاختبار؟ يجب أن يساعدك في معرفة السبب.
 gmarek
في ٤ سبتمبر ٢٠١٧
gmarek
في ٤ سبتمبر ٢٠١٧
مضيفا فريق صحفي:jdumarscalebamilesspiffxp
gmarek
في ٤ سبتمبر ٢٠١٧
لذلك أحضرت استخدام وحدة المعالجة المركزية والذاكرة لاختبار الحمل من آخر> 200 مرة من kubemark-500 ، ولا أرى أي زيادة ملحوظة. في الواقع يبدو أنه تحسن:


shyamjvs
في ٤ سبتمبر ٢٠١٧
هناك بعض عمليات التشغيل الفاشلة المتتالية (بسبب اختبار البق / الانحدار) مما يؤدي إلى فقدان النقاط أو الارتفاعات المؤقتة ... إهمال الضوضاء
shyamjvs
في ٤ سبتمبر ٢٠١٧
لقد أجريت الاختبارات محليًا على kubemark-500 مقابل الرأس (الالتزام ffed1d340843ed) وذهبت جيدًا مع قيم زمن الوصول المنخفضة كما كان من قبل. أعد التشغيل مرة أخرى لمعرفة ما إذا كان غير مستقر. سأستمر في البحث فيه غدًا.
shyamjvs
في ٤ سبتمبر ٢٠١٧
ما لم تقم بتشغيل جميع ميزات ألفا على kubemark ، لا ينبغي أن يكون لديك
لوحظ زيادة مع ترقيم الصفحات (وهو ما يبدو أكثر
القضاء على التحقيق). إذا قمت بتشغيل ميزات ألفا على kubemark
هذا هو بالضبط التحقق الذي كنت أبحث عنه مع التقسيم (هذا لا
حدث الانحدار) ، وهو أمر جيد. التقسيم سيزيد من المتوسط
زمن الوصول ولكن يجب أن يقلل زمن انتقال الذيل في معظم الحالات (التقسيم الساذج
من شأنه زيادة معدلات الخطأ).
في يوم الإثنين 4 سبتمبر 2017 الساعة 5:23 مساءً ، كتب Shyam JVS [email protected] :
أجريت الاختبارات محليًا على kubemark-500 ضد الرأس (الالتزام ffed1d3
https://github.com/kubernetes/kubernetes/commit/ffed1d340843ed5617a4bdfe5b16a9490476843a )
وقد مر بشكل جيد مع قيم وقت الاستجابة المنخفضة كما كان من قبل. إعادة التشغيل
مرة أخرى لمعرفة ما إذا كان غير مستقر. سأستمر في البحث فيه غدًا.-
أنت تتلقى هذا لأنه تم ذكرك.
قم بالرد على هذا البريد الإلكتروني مباشرة ، وقم بعرضه على GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-327029719 ،
أو كتم الخيط
https://github.com/notifications/unsubscribe-auth/ABG_p_ODR8S6ycmF1ppTOEZ8Bub3aVsaks5sfGpSgaJpZM4PL3gt
.
 smarterclayton
في ٥ سبتمبر ٢٠١٧
smarterclayton
في ٥ سبتمبر ٢٠١٧
حسنًا ... لذا فإن سبب فشل kubemark مختلف. كما أشار @ wojtek-t ، فإن حجم kubemark الرئيسي ليس صحيحًا.
لقد أجريت مؤخرًا بعض التغييرات في الاختبار أدناه حول الحساب التلقائي لحجم kubemark الرئيسي ويبدو أنه لم يتم تفعيله.
shyamjvs
في ٥ سبتمبر ٢٠١٧
راجع للشغل - وهذا يفسر أيضًا سبب عدم إعادة إنتاج الفشل محليًا بالنسبة لي. نظرًا لأنني تجاوزت كل منطق testinfra عن طريق بدء تشغيل المجموعات يدويًا ، فقد تم حسابها بشكل صحيح.
shyamjvs
في ٥ سبتمبر ٢٠١٧
smarterclayton شكرا على التوضيح. لقد تحققت من عدم استخدام أي من kubemark ولا اختبارات المجموعة الحقيقية الخاصة بنا ترقيم الصفحات (حيث لا يزال ?limit=1 جميع النتائج).
لذا يبدو أن الإخفاقات الحقيقية في اختبار 5k node لا علاقة لها بها.
shyamjvs
في ٥ سبتمبر ٢٠١٧
shyamjvs
في ٧ سبتمبر ٢٠١٧
@ wojtek- tshyamjvs : ما مدى سوء الوضع هنا؟ لا يزال مانع الإصدار؟
ما هي النظرية التالية التي يجب اختبارها؟ (json-iterator مقابل ugorji)
شكر،
يخفت
 dims
في ١٤ سبتمبر ٢٠١٧
dims
في ١٤ سبتمبر ٢٠١٧
إنه ليس سيئًا للغاية (نشهد بعض الطلبات ذات زمن انتقال عالٍ) ، ولكن يبدو أن هناك بالتأكيد تراجعًا. إنه مانع تحرير.
فيما يلي طلبات api التي فشلت في تلبية 1s SLO لدينا لوقت استجابة 99٪ ile (من آخر تشغيل ، أي تشغيل رقم 34 - https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/ci-kubernetes -E2e-gce-scale-performance / 34):
I0914 00:49:55.355] Sep 14 00:49:55.354: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.894ms Perc90:1.485486s Perc99:5.108352s Perc100:0s} Count:311825}
I0914 00:49:55.356] Sep 14 00:49:55.354: INFO: WARNING Top latency metric: {Resource:configmaps Subresource: Verb:POST Latency:{Perc50:4.018ms Perc90:757.506ms Perc99:1.924344s Perc100:0s} Count:342}
نظرت في سجلات apiserver وأرى التتبع التالي لرقم كبير. من مكالمات delete pod :
I0914 00:06:54.479459 8 trace.go:76] Trace[539192665]: "Delete /api/v1/namespaces/e2e-tests-density-30-32-wqj9b/pods/density150000-31-e5cb99f6-98b6-11e7-aeb5-0242ac110009-4mw6l" (started: 2017-09-14 00:06:48.217160315 +0000 UTC) (total time: 6.262275566s):
Trace[539192665]: [6.256412547s] [6.256412547s] About to delete object from database
يتوافق هذا التتبع مع الوقت المستغرق من بداية وظيفة معالج الموارد المحذوفة إلى النقطة التي سبقت استدعاء الحذف عند التخزين ، وبشكل أكثر تحديدًا هذا الجزء من الكود - https://github.com/kubernetes/kubernetes/blob/9aef242a4c1e423270488206670d3d1f23eaab52/ التدريج / src / k8s.io / apiserver / pkg / endpoints / handlers / rest.go # L931 -L994.
تبدو الأجزاء الأكثر إثارة للريبة بالنسبة لي مثل خطوة التدقيق وخطوة مراقبة الدخول. سأرسل علاقات عامة تضيف آثارًا لتلك الخطوات أيضًا.
shyamjvs
في ١٥ سبتمبر ٢٠١٧
shyamjvs حتى نتمكن من نقل هذا من 1.8 معلم؟
dims
في ١٨ سبتمبر ٢٠١٧
في حال كانت المشكلات التي تراها ناتجة عن دمج json-iterator في # 48287
لمعلوماتك: راجع ugorji / go @ 54210f4e076c57f351166f0ed60e67d3fca57a36
تحديثات الأداء الجوهرية التي تجعل الأداء بدون إنشاء رمز يتماشى مع ما تحصل عليه من مكرر json. لقد فعلنا ذلك أثناء استخدام "غير آمن" فقط في الأماكن المستهدفة للغاية ، مع علامة بناء للتبديل إلى الوضع "غير آمن". راجع helper_unsafe.go للاطلاع على الوظائف الوحيدة التي استخدمنا فيها الوظائف غير الآمنة ، مع الإصدارات "الآمنة" المكافئة ، لتوفر لك بعض راحة البال.
تم إرفاق النتائج ، لكنني سأعيد إنتاج نتائج مقاعد البدلاء لمقارنة النتائج بدون برنامج الترميز ثم باستخدام برنامج الترميز هنا للراحة. تم إجراء ذلك باستخدام مجموعة المعايير في https://github.com/ugorji/go-codec-bench ، والتي تستخدم التضمين المتكرر لبنية مفصلة كبيرة. الأرقام تتحدث عن ذاتها. قد يكون من المفيد العودة عاجلاً وليس آجلاً.
go test -bench "_(Json|Cbor)" -benchmem -bd 2 -tags "x" > no-codecgen.bench.out.txt
go test -bench "_(Json|Cbor)" -benchmem -bd 2 -tags "x codecgen" > with-codecgen.bench.out.txt
benchcmp no-codecgen.bench.out.txt with-codecgen.bench.out.txt > benchcmp.out.txt
النتائج:
benchmark old ns/op new ns/op delta
Benchmark__Cbor_______Encode-8 69672 37051 -46.82%
Benchmark__Json_______Encode-8 115274 87775 -23.86%
Benchmark__JsonIter___Encode-8 133558 133635 +0.06%
Benchmark__Std_Json___Encode-8 165240 157007 -4.98%
Benchmark__Cbor_______Decode-8 164396 131192 -20.20%
Benchmark__Json_______Decode-8 207014 156589 -24.36%
Benchmark__JsonIter___Decode-8 209418 208993 -0.20%
Benchmark__Std_Json___Decode-8 553650 557783 +0.75%
benchmark old allocs new allocs delta
Benchmark__Cbor_______Encode-8 32 7 -78.12%
Benchmark__Json_______Encode-8 45 20 -55.56%
Benchmark__JsonIter___Encode-8 1013 1013 +0.00%
Benchmark__Std_Json___Encode-8 560 560 +0.00%
Benchmark__Cbor_______Decode-8 713 697 -2.24%
Benchmark__Json_______Decode-8 756 736 -2.65%
Benchmark__JsonIter___Decode-8 2244 2244 +0.00%
Benchmark__Std_Json___Decode-8 1967 1967 +0.00%
benchmark old bytes new bytes delta
Benchmark__Cbor_______Encode-8 5529 2320 -58.04%
Benchmark__Json_______Encode-8 6290 3072 -51.16%
Benchmark__JsonIter___Encode-8 40496 40496 +0.00%
Benchmark__Std_Json___Encode-8 65248 65248 +0.00%
Benchmark__Cbor_______Decode-8 34384 34104 -0.81%
Benchmark__Json_______Decode-8 42976 42608 -0.86%
Benchmark__JsonIter___Decode-8 60128 60128 +0.00%
Benchmark__Std_Json___Decode-8 58320 58320 +0.00%
مقاعد البدلاءcmp.out.txt
no-codecgen.bench.out.txt
مع-codecgen.bench.out.txt
 ugorji
في ١٩ سبتمبر ٢٠١٧
ugorji
في ١٩ سبتمبر ٢٠١٧
لاحظ أنه يجب عدم استخدام JSON في هذه المجموعات ، وإذا كان كذلك
هذا في حد ذاته خطأ.
يجب أن نستخدم protobuf لجميع مكالمات intracluster باستثناء القمامة
جمع الموارد على CRD والإرشاد.
smarterclayton
في ١٩ سبتمبر ٢٠١٧
smarterclayton - أعتقد أننا نقوم بعمل تصحيحات على الرغم من JSON ، أليس كذلك؟
gmarek
في ١٩ سبتمبر ٢٠١٧
لم يتم فك رموز التصحيحات مطلقًا باستخدام ugorji ، لذلك لم يكن لمحول json-iterator أن يؤثر عليها ، ويتم تطبيق تصحيحات الدمج الإستراتيجية على كائنات واجهة [سلسلة] {} وسيطة للخريطة ، ولا يتم ذهابًا وإيابًا إلى JSON
 liggitt
في ١٩ سبتمبر ٢٠١٧
liggitt
في ١٩ سبتمبر ٢٠١٧
لا أعتقد أن تغيير ugorji هو الذي يتسبب في حدوث الانحدار (على الرغم من أنني كنت أشك في ذلك في الأصل) - على سبيل المثال ، ضع في اعتبارك patch node-status المكالمات (التي تُظهر الانحدار الرئيسي) ويتم إجراء هذه المكالمات بواسطة kubelet و npd ، كلاهما يستخدم protobufs للتحدث إلى apiserver. وعلاوة على ذلك كما أكدsmarterclayton وliggitt، وهذه هي دعوات intracluster العادية (لا CRD / تمديد المعنية) المستخدمة مع الترقيع دمج الاستراتيجي.
shyamjvs
في ١٩ سبتمبر ٢٠١٧
لقد بحثت في الأمر أكثر اليوم وهذا ما وجدته:
- لقد بدأنا نلاحظ زيادة في أوقات الاستجابة منذ التشغيل 27 لمهمة الأداء 5k (https://k8s-testgrid.appspot.com/google-gce-scale#gce-scale-performance). كان آخر تشغيل صحي هو run-23 (الذي كان له اختفاء طبيعي). إليك فرق الالتزامات عبر المسارات (ضخمة بعض الشيء) - https://github.com/kubernetes/kubernetes/compare/11299e363c538c...034c40be6f465d
- في كل عملية تشغيل منذ 27 ، كانت مكالمات api التي تنتهك SLO تتغير (بمجرد أن تصبح
POST configmaps، بمجرد أن تصبحPOST replicationcontrollers، إلخ). ومع ذلك ، يبدو أن زمن الانتقالPATCH node statusسيئ باستمرار عبر جميع عمليات التشغيل.
في الجولة 23 كانت النسبة 99٪ 55 ملي ثانية (في الجولة 18 كانت 200 ملي ثانية وهي لا تزال غير كافية):
INFO: Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.22ms Perc90:9.449ms Perc99:55.588ms Perc100:0s} Count:7033941}
وفي التشغيل 27 (التشغيل المفيد التالي) ، تم إطلاق 99٪ من الشق حتى أكثر من 1 ثانية (ترتيب زيادة الحجم):
INFO: WARNING Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:4.186ms Perc90:83.292ms Perc99:1.061816s Perc100:0s} Count:7063581}
وظلت مرتفعة منذ ذلك الحين. من سجلات apiserver ، أجد العديد من هذه الآثار لتلك المكالمات:
I0918 20:24:52.548401 7 trace.go:76] Trace[176777519]: "GuaranteedUpdate etcd3: *api.Node" (started: 2017-09-18 20:24:51.709667942 +0000 UTC) (total time: 838.710254ms):
Trace[176777519]: [838.643838ms] [837.934826ms] Transaction committed
ومن الكود الذي يبدو أنه الوقت المستغرق عند إعداد المعاملة ووقت الالتزام بها. بتعبير أدق هذا الجزء من الكود:
https://github.com/kubernetes/kubernetes/blob/a238fbd2539addc525bb740ae801a42524e5b706/staging/src/k8s.io/apiserver/pkg/storage/etcd3/store.go#L350 -L362
liggittsmarterclaytonsttts @ deads2k - لديه أي شيء حول التصحيح تغيير عقدة الوضع في الآونة الأخيرة؟ وبشكل أكثر تحديدًا ، هل بدأنا في استخدام تحديثات etcd3 مضمونة لهم أم تعتقد أنه شيء آخر؟ أي مؤشرات هنا ستكون موضع تقدير كبير :)
shyamjvs
في ١٩ سبتمبر ٢٠١٧
سم مكعب @dims kubernetes / kubernetes الإفراج مديريjdumars - وهذا هو تراجعا واضحا نراه هنا، وينبغي أن يكون بالتأكيد منع الإفراج عن هذا (كما هو مبين في اليوم الاجتماع burndown).
shyamjvs
في ١٩ سبتمبر ٢٠١٧
هل تم تغيير حالة عقدة التصحيح مؤخرًا؟ وبشكل أكثر تحديدًا ، هل بدأنا في استخدام تحديثات etcd3 مضمونة لهم أم تعتقد أنه شيء آخر؟
جميع التحديثات (التصحيح ، التحديث ، الحذف الجميل ، إلخ) تستخدم GuaranteedUpdate تحت الأغلفة. هذا لم يتغير. هل نحن غير قادرين على تضييق نطاق الالتزام أكثر؟ هل قمنا بتغيير إصدارات إلخ في هذا النطاق؟
liggitt
في ١٩ سبتمبر ٢٠١٧
أعتقد أن @ wojtek-t كان يقوم ببعض التحسين في مسار التصحيح.
gmarek
في ٢٠ سبتمبر ٢٠١٧
shyamjvs هل ذكرت أن هناك بعض البيانات التي أردت مشاركتها في الاجتماع أمس؟ هل اقتربنا من معرفة ما يتعين علينا القيام به من أجل ذلك؟
dims
في ٢٠ سبتمبر ٢٠١٧
483ee1853b هو رقم ثانوي يتم استدعاؤه أثناء عدد من التدفقات.
يوم الأربعاء 20 سبتمبر 2017 الساعة 10:45 صباحًا ، دافانوم سرينيفاس < [email protected]
كتب:
shyamjvs https://github.com/shyamjvs هل ذكرت أن هناك بعض
البيانات التي تريد مشاركتها في اجتماع أمس؟ هل نحن أقرب إلى
معرفة ما يتعين علينا القيام به من أجل هذا؟-
أنت تتلقى هذا لأنه تم ذكرك.
قم بالرد على هذا البريد الإلكتروني مباشرة ، وقم بعرضه على GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ،
أو كتم الخيط
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
في ٢١ سبتمبر ٢٠١٧
لم نقم بتمكين a4542ae528 افتراضيًا ، أليس كذلك؟
يوم الخميس 21 سبتمبر 2017 الساعة 12:24 صباحًا ، كلايتون كولمان [email protected]
كتب:
483ee1853b هو رقم ثانوي يتم استدعاؤه أثناء عدد من التدفقات.
يوم الأربعاء 20 سبتمبر 2017 الساعة 10:45 صباحًا ، دافانوم سرينيفاس <
[email protected]> كتب:shyamjvs https://github.com/shyamjvs هل ذكرت أن هناك بعض
البيانات التي تريد مشاركتها في اجتماع أمس؟ هل نحن أقرب إلى
معرفة ما يتعين علينا القيام به من أجل هذا؟-
أنت تتلقى هذا لأنه تم ذكرك.
قم بالرد على هذا البريد الإلكتروني مباشرة ، وقم بعرضه على GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ،
أو كتم الخيط
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
في ٢١ سبتمبر ٢٠١٧
9002dfcd0a أجد صعوبة في الاعتقاد بأن ذلك سيؤدي إلى زمن انتقال الذيل (أشبه
الكمون الأساسي)
يوم الخميس 21 سبتمبر 2017 الساعة 12:25 صباحًا ، كلايتون كولمان [email protected]
كتب:
لم نقم بتمكين a4542ae528 افتراضيًا ، أليس كذلك؟
يوم الخميس 21 سبتمبر 2017 الساعة 12:24 صباحًا ، كلايتون كولمان [email protected]
كتب:483ee1853b هو رقم ثانوي يتم استدعاؤه أثناء عدد من التدفقات.
يوم الأربعاء 20 سبتمبر 2017 الساعة 10:45 صباحًا ، دافانوم سرينيفاس <
[email protected]> كتب:shyamjvs https://github.com/shyamjvs هل ذكرت أن هناك بعض
البيانات التي تريد مشاركتها في اجتماع أمس؟ هل نحن أقرب إلى
معرفة ما يتعين علينا القيام به من أجل هذا؟-
أنت تتلقى هذا لأنه تم ذكرك.
قم بالرد على هذا البريد الإلكتروني مباشرة ، وقم بعرضه على GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ،
أو كتم الخيط
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
في ٢١ سبتمبر ٢٠١٧
طريقة سهلة للتحقق من عناصر json-iter هي إيقاف تشغيله تمامًا (الرجوع للخلف
إلى json.Unmarshal) ومعرفة ما إذا كانت أرقام وقت الاستجابة تزداد سوءًا.
يوم الخميس 21 سبتمبر 2017 الساعة 12:27 صباحًا ، كلايتون كولمان [email protected]
كتب:
9002dfcd0a أجد صعوبة في الاعتقاد بأن ذلك سيؤدي إلى زمن انتقال الذيل (أشبه
الكمون الأساسي)يوم الخميس 21 سبتمبر 2017 الساعة 12:25 صباحًا ، كلايتون كولمان [email protected]
كتب:لم نقم بتمكين a4542ae528 افتراضيًا ، أليس كذلك؟
يوم الخميس 21 سبتمبر 2017 الساعة 12:24 صباحًا ، كلايتون كولمان [email protected]
كتب:483ee1853b هو رقم ثانوي يتم استدعاؤه أثناء عدد من التدفقات.
يوم الأربعاء 20 سبتمبر 2017 الساعة 10:45 صباحًا ، دافانوم سرينيفاس <
[email protected]> كتب:shyamjvs https://github.com/shyamjvs هل ذكرت أن هناك بعض
البيانات التي تريد مشاركتها في اجتماع أمس؟ هل نحن أقرب إلى
معرفة ما يتعين علينا القيام به من أجل هذا؟-
أنت تتلقى هذا لأنه تم ذكرك.
قم بالرد على هذا البريد الإلكتروني مباشرة ، وقم بعرضه على GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ،
أو كتم الخيط
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
في ٢١ سبتمبر ٢٠١٧
هل نحصل على خلاف متعدد الأطراف في D3546434b7؟
يوم الخميس 21 سبتمبر 2017 الساعة 12:28 صباحًا ، كلايتون كولمان [email protected]
كتب:
طريقة سهلة للتحقق من عناصر json-iter هي إيقاف تشغيله تمامًا (الرجوع للخلف
إلى json.Unmarshal) ومعرفة ما إذا كانت أرقام وقت الاستجابة تزداد سوءًا.يوم الخميس 21 سبتمبر 2017 الساعة 12:27 صباحًا ، كلايتون كولمان [email protected]
كتب:9002dfcd0a أجد صعوبة في الاعتقاد بأن ذلك سيؤدي إلى زمن انتقال الذيل (أشبه
الكمون الأساسي)يوم الخميس 21 سبتمبر 2017 الساعة 12:25 صباحًا ، كلايتون كولمان [email protected]
كتب:لم نقم بتمكين a4542ae528 افتراضيًا ، أليس كذلك؟
يوم الخميس 21 سبتمبر 2017 الساعة 12:24 صباحًا ، كلايتون كولمان [email protected]
كتب:483ee1853b هو رقم ثانوي يتم استدعاؤه أثناء عدد من التدفقات.
يوم الأربعاء 20 سبتمبر 2017 الساعة 10:45 صباحًا ، دافانوم سرينيفاس <
[email protected]> كتب:shyamjvs https://github.com/shyamjvs هل ذكرت أنه كان هناك
بعض البيانات التي أردت مشاركتها في اجتماع أمس؟ هل نحن أقرب
لمعرفة ما يتعين علينا القيام به من أجل هذا؟-
أنت تتلقى هذا لأنه تم ذكرك.
قم بالرد على هذا البريد الإلكتروني مباشرة ، وقم بعرضه على GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ،
أو كتم الخيط
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
في ٢١ سبتمبر ٢٠١٧
هناك أيضًا تغييرات العميل a804d440c3 - لا أتذكر مدى جودة ذلك
تم تحديدها ولكن من المحتمل أنها تؤثر على المكالمات الأخرى.
يوم الخميس 21 سبتمبر 2017 الساعة 12:29 صباحًا ، كلايتون كولمان [email protected]
كتب:
هل نحصل على خلاف متعدد الأطراف في D3546434b7؟
يوم الخميس 21 سبتمبر 2017 الساعة 12:28 صباحًا ، كلايتون كولمان [email protected]
كتب:طريقة سهلة للتحقق من عناصر json-iter هي إيقاف تشغيله تمامًا (الرجوع للخلف
إلى json.Unmarshal) ومعرفة ما إذا كانت أرقام وقت الاستجابة تزداد سوءًا.يوم الخميس 21 سبتمبر 2017 الساعة 12:27 صباحًا ، كلايتون كولمان [email protected]
كتب:9002dfcd0a أجد صعوبة في الاعتقاد بأن ذلك سيؤدي إلى زمن انتقال الذيل (more
مثل الكمون الأساسي)يوم الخميس 21 سبتمبر 2017 الساعة 12:25 صباحًا ، كلايتون كولمان [email protected]
كتب:لم نقم بتمكين a4542ae528 افتراضيًا ، أليس كذلك؟
يوم الخميس 21 سبتمبر 2017 الساعة 12:24 صباحًا ، كلايتون كولمان [email protected]
كتب:483ee1853b هو رقم صغير يتم استدعاؤه خلال عدد من
يطفو.يوم الأربعاء 20 سبتمبر 2017 الساعة 10:45 صباحًا ، دافانوم سرينيفاس <
[email protected]> كتب:shyamjvs https://github.com/shyamjvs هل ذكرت أنه كان هناك
بعض البيانات التي أردت مشاركتها في اجتماع أمس؟ هل نحن أقرب
لمعرفة ما يتعين علينا القيام به من أجل هذا؟-
أنت تتلقى هذا لأنه تم ذكرك.
قم بالرد على هذا البريد الإلكتروني مباشرة ، وقم بعرضه على GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ،
أو كتم الخيط
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
في ٢١ سبتمبر ٢٠١٧
02281898f8 من غير المحتمل أن تضيف الكثير من العمل لخادم api ، لكنها ستكون كذلك
عدد قليل من الموارد المذكورة وإنشاء بقعة فقط.
يوم الخميس 21 سبتمبر 2017 الساعة 12:31 صباحًا ، كلايتون كولمان [email protected]
كتب:
هناك أيضًا تغييرات العميل a804d440c3 - لا أتذكر مدى جودة ذلك
تم تحديدها ولكن من المحتمل أنها تؤثر على المكالمات الأخرى.يوم الخميس 21 سبتمبر 2017 الساعة 12:29 صباحًا ، كلايتون كولمان [email protected]
كتب:هل نحصل على خلاف متعدد الأطراف في D3546434b7؟
يوم الخميس 21 سبتمبر 2017 الساعة 12:28 صباحًا ، كلايتون كولمان [email protected]
كتب:طريقة سهلة للتحقق من عناصر json-iter هي إيقاف تشغيله تمامًا (go
العودة إلى json.Unmarshal) ومعرفة ما إذا كانت أرقام وقت الاستجابة تزداد سوءًا.يوم الخميس 21 سبتمبر 2017 الساعة 12:27 صباحًا ، كلايتون كولمان [email protected]
كتب:9002dfcd0a أجد صعوبة في الاعتقاد بأن ذلك سيؤدي إلى زمن انتقال الذيل (more
مثل الكمون الأساسي)يوم الخميس 21 سبتمبر 2017 الساعة 12:25 صباحًا ، كلايتون كولمان [email protected]
كتب:لم نقم بتمكين a4542ae528 افتراضيًا ، أليس كذلك؟
يوم الخميس 21 سبتمبر 2017 الساعة 12:24 صباحًا ، كلايتون كولمان < [email protected]
كتب:
483ee1853b هو رقم صغير يتم استدعاؤه خلال عدد من
يطفو.يوم الأربعاء 20 سبتمبر 2017 الساعة 10:45 صباحًا ، دافانوم سرينيفاس <
[email protected]> كتب:shyamjvs https://github.com/shyamjvs هل ذكرت أنه كان هناك
بعض البيانات التي أردت مشاركتها في اجتماع أمس؟ هل نحن أقرب
لمعرفة ما يتعين علينا القيام به من أجل هذا؟-
أنت تتلقى هذا لأنه تم ذكرك.
قم بالرد على هذا البريد الإلكتروني مباشرة ، وقم بعرضه على GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ،
أو كتم الخيط
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
في ٢١ سبتمبر ٢٠١٧
shyamjvsgmareksmarterclayton لمعلوماتك، وهذا يبدو مثل معظم السبب المحتمل لتأخير 1.8.0. كيف يمكنني أنا أو فريق التحرير مساعدتك؟
 jdumars
في ٢١ سبتمبر ٢٠١٧
jdumars
في ٢١ سبتمبر ٢٠١٧
توافق على أنه من المحتمل أن يمنع هذا الإصدار. ما الذي يمكنني فعله للمساعدة؟
 thockin
في ٢١ سبتمبر ٢٠١٧
thockin
في ٢١ سبتمبر ٢٠١٧
حتى الشخص الذي يمكنه المساعدة في القيام ببعض التشريح الميكانيكي سيفعل ذلك على الأرجح
مساعدة. لا أعتقد أننا نمتلك الحد الأدنى من التكاثر رغم ذلك
يعقد هذا.
يوم الخميس 21 سبتمبر 2017 الساعة 11:24 صباحًا ، Tim Hockin [email protected]
كتب:
توافق على أنه من المحتمل أن يمنع هذا الإصدار. ما الذي يمكنني فعله للمساعدة؟
-
أنت تتلقى هذا لأنه تم ذكرك.
قم بالرد على هذا البريد الإلكتروني مباشرة ، وقم بعرضه على GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-331191088 ،
أو كتم الخيط
https://github.com/notifications/unsubscribe-auth/ABG_p2O2uX8YFJCns2lq0lKJcACCJG9hks5skn_IgaJpZM4PL3gt
.
smarterclayton
في ٢١ سبتمبر ٢٠١٧
smarterclayton شكرًا جزيلاً للتعرف على هؤلاء PRs - سأحاول إجراء الاختبارات مع تلك العلاقات العامة التي تم إرجاعها كملاذ أخير.
أظن أن السبب في ذلك هو أننا نختبر مع زيادة qps لـ apiserver (--max-Orders-inflight = 3000 --max-mutating-Orders-inflight = 1000) وهو ضعف ما نستخدمه لـ kubemark حيث يبدو وقت الاستجابة جيدًا ، على الرغم من أن الاختبار نفسه يفشل لسبب مختلف). أنا أقوم بتجربة انخفاض qps الآن.
shyamjvs
في ٢١ سبتمبر ٢٠١٧
smarterclayton / lavalamp هل يمكن لأحدكم lgtm https://github.com/kubernetes/kubernetes/pull/52732 إزالة الانتهاكات المزيفة على الأقل؟
shyamjvs
في ٢١ سبتمبر ٢٠١٧
هل نحصل على خلاف متعدد الأطراف في D354643؟
لا أعتقد ذلك ، ولكن إذا انتهى الأمر بقراءة الخلاف ، فقد صنعت نسخة خالية من القفل على https://github.com/kubernetes/kubernetes/pull/52860
liggitt
في ٢١ سبتمبر ٢٠١٧
حسنًا .. لقد راجعت مع Qps مخفضة وما زلت أرى مكالمات بزمن استجابة مرتفع في اختبار الكثافة:
I0921 21:43:02.755] Sep 21 21:43:02.754: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Scope:namespace Latency:{Perc50:5.572ms Perc90:1.529239s Perc99:7.868101s Perc100:0s} Count:338819}
I0921 21:43:02.755] Sep 21 21:43:02.754: INFO: WARNING Top latency metric: {Resource:configmaps Subresource: Verb:POST Scope:namespace Latency:{Perc50:3.852ms Perc90:1.152249s Perc99:3.848893s Perc100:0s} Count:340}
سأعود إلى qps الأصلي وسأبدأ في التقسيم والاختبار يدويًا. سيتم تشغيل اختبار الكثافة فقط لتوفير الوقت.
shyamjvs
في ٢٢ سبتمبر ٢٠١٧
@ kubernetes / test-infra -keepingers تظهر لي الخطأ التالي أثناء تشغيل go run hack/e2e.go -v -test :
Running Suite: Kubernetes e2e suite
===================================
Random Seed: 1506095473 - Will randomize all specs
Will run 1 of 678 specs
Sep 22 17:51:14.149: INFO: Fetching cloud provider for "gce"
I0922 17:51:14.201332 22354 gce.go:584] Using DefaultTokenSource <nil>
Sep 22 17:51:14.201: INFO: Failed to setup provider config: Error building GCE/GKE provider: google: could not find default credentials. See https://developers.google.com/accounts/docs/application-default-credentials for more information.
Failure [0.057 seconds]
[BeforeSuite] BeforeSuite
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/test/e2e/e2e.go:240
Sep 22 17:51:14.201: Failed to setup provider config: Error building GCE/GKE provider: google: could not find default credentials. See https://developers.google.com/accounts/docs/application-default-credentials for more information.
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/test/e2e/e2e.go:141
أي فكرة لماذا أرى هذا؟ تم بناء k8s الخاص بي مقابل الالتزام 11299e363.
shyamjvs
في ٢٢ سبتمبر ٢٠١٧
لمعلوماتك - go run hack/e2e.go -v -up يعمل بشكل جيد.
shyamjvs
في ٢٢ سبتمبر ٢٠١٧
هل شاهد أي شخص مكالمات PUT؟ الشيء الأكثر وضوحًا الذي يمكن أن يكون خاطئًا (على ما أعتقد) هو شيء جديد / تم تغييره على العقد والذي يعدل حالة العقدة عبر PUT ويفوز بالسباق باستمرار مع تصحيحات kubelet.
 lavalamp
في ٢٢ سبتمبر ٢٠١٧
lavalamp
في ٢٢ سبتمبر ٢٠١٧
لن يكون لمكالمات PUT الإضافية الافتراضية زمن انتقال عالٍ (حيث ستحصل فقط على تعارضات إذا خسروا السباق). كما أنها لن تحدث في kubemark ، بافتراض أنه كيان غير kubelet هو الجاني. يبدو هذا متسقًا مع كل ما هو مذكور في هذا الخطأ ، على الرغم من صعوبة متابعته.
lavalamp
في ٢٢ سبتمبر ٢٠١٧
هل يمكن لأي شخص الارتباط بتشغيل اختباري يحتوي على المشكلة ، حتى أتمكن من قراءة سجل الخادم؟
lavalamp
في ٢٢ سبتمبر ٢٠١٧
shyamjvs أعتقد أنك قد تحتاج إلى تشغيل gcloud auth application-default login .
 ixdy
في ٢٢ سبتمبر ٢٠١٧
ixdy
في ٢٢ سبتمبر ٢٠١٧
(عليك تشغيل كلاً من gcloud auth login و gcloud auth application-default login ، لأسباب.)
ixdy
في ٢٢ سبتمبر ٢٠١٧
فرضية أخرى مماثلة هي أن كاشف مشكلة العقدة و kubelet يحاولان الآن تعديل نفس المجال ، لذلك هناك خلاف جديد على الرغم من أنه نفس عدد مكالمات التصحيح.
lavalamp
في ٢٢ سبتمبر ٢٠١٧
من خلال التمعن في السجلات ، في الواقع ، أرى أن وحدة التحكم في العقدة تحصل على مجموعة من التعارضات على نقاط البيع:
I0922 09:02:23.479636 7 wrap.go:42] PUT /api/v1/nodes/gce-scale-cluster-minion-group-3-dpvj/status: (1.235319ms) 409 [[kube-controller-manager/v1.9.0 (linux/amd64) kubernetes/158f6b7/system:serviceaccount:kube-system:node-controller] [::1]:54918]
فيما يلي بعض العلاقات العامة التي لمست NodeController و / أو controller_utils.go ، من الأحدث إلى الأقل
https://github.com/kubernetes/kubernetes/pull/51603 (تم دمجه في 6 سبتمبر)
https://github.com/kubernetes/kubernetes/pull/49257 (تم دمجه في 31 أغسطس)
https://github.com/kubernetes/kubernetes/pull/50738 (تم دمجه في 29 أغسطس)
https://github.com/kubernetes/kubernetes/pull/49524 (تم دمجه في 7 أغسطس)
https://github.com/kubernetes/kubernetes/pull/49870 (تم دمجه في 1 أغسطس)
https://github.com/kubernetes/kubernetes/pull/47952 (تم دمجه في 12 يوليو)
من الناحية النظرية ، من المفترض أن يتم تعطيل كل هذه الأشياء افتراضيًا (باستثناء العنصر الأول ، وهو خطأ إصلاح) ، راجع
https://github.com/kubernetes/kubernetes/pull/49547
ومع ذلك ، لم أراجع أيًا من هذه العلاقات العامة.
/ سم مكعبgmarek @ k82cn
 davidopp
في ٢٢ سبتمبر ٢٠١٧
davidopp
في ٢٢ سبتمبر ٢٠١٧
ixdy شكرا جزيلا على الاقتراح ، الذي
هل شاهد أي شخص مكالمات PUT؟
lavalamp أفترض أنك تقصد مكالمات PUT لـ etcd (لأنه من سجلات apiserver أرى تصحيحات فقط). هل يمكن أن تخبرني كيف يمكنني التحقق من مكالمات PUT؟
شيء جديد / تم تغييره على العقد يقوم بتعديل حالة العقدة عبر PUT والفوز بالسباق باستمرار مع تصحيحات kubelet.
لا أرى أي PUTs لحالة العقدة من سجلات apiserver. إن npd و kubelet هما اللذان يقومان بتحديثهما (طوال الوقت تقريبًا) وكلاهما يستخدم PATCHs:
I0918 17:05:58.357710 7 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-554x/status: (2.195508ms) 200 [[node-problem-detector/v1.4.0 (linux/amd64) kubernetes/$Format] 35.190.133.106:55912]
I0918 17:06:01.312183 7 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-7sbx/status: (67.75199ms) 200 [[kubelet/v1.9.0 (linux/amd64) kubernetes/8ca1d9f] 35.196.121.123:51702]
I0918 17:05:58.359507 7 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-1-j446/status: (3.796612ms) 200 [[node-problem-detector/v1.4.0 (linux/amd64) kubernetes/$Format] 35.185.60.137:43894]
I0918 17:06:01.312296 7 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-1-b113/status: (67.888708ms) 200 [[kubelet/v1.9.0 (linux/amd64) kubernetes/8ca1d9f] 35.196.142.250:35162]
هل يمكن لأي شخص الارتباط بتشغيل اختباري يحتوي على المشكلة ، حتى أتمكن من قراءة سجل الخادم؟
إلى حد كبير كل العمليات القليلة الماضية التي أجريت الاختبار تحتوي على المشكلة. على سبيل المثال ، يمكنك إلقاء نظرة على https://storage.googleapis.com/kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/36/artifacts/gce-scale-cluster-master/kube -apiserver.log وهي عينة جيدة (من -36 )
فرضية أخرى مماثلة هي أن كاشف مشكلة العقدة و kubelet يحاولان الآن تعديل نفس المجال ، لذلك هناك خلاف جديد على الرغم من أنه نفس عدد مكالمات التصحيح.
أعتقد أن هذا كان الحال حتى من قبل. على سبيل المثال ، كنا نشهد هذا حتى بالنسبة للإصدار الأخير - https://github.com/kubernetes/node-problem-detector/issues/124. هل تقصد شيئًا آخر؟
.
shyamjvs
في ٢٢ سبتمبر ٢٠١٧
اقترح jpbetz (في موضوع آخر) تشغيل pprof من أجل etcd لمعرفة المزيد عن العمليات من الجانب etcd. هل يعرف أحد ما إذا كانت هناك طريقة سهلة لإضافة وسيطات اختبار إلى etcd (أجد KUBE_APISERVER_TEST_ARGS و KUBE_SCHEDULER_TEST_ARGS وما إلى ذلك .. ولكن لا شيء مثل ETCD_TEST_ARGS في config-test.sh ).
shyamjvs
في ٢٢ سبتمبر ٢٠١٧
shyamjvs @ فقط لمساعدتك على التخلص من بعض الاحتمالات. :)
لم نقم بتحديث إصدار NPD هذا الإصدار ، فهذا يعني أن NPD نفسه لا يتغير من 1.7 إلى 1.8. بالنسبة إلى البرنامج النصي لبدء التشغيل ، فإن التغيير الملحوظ الوحيد الذي أراه هو استخدام تارب NPD المحمّل مسبقًا بدلاً من التنزيل أثناء الطيران ، والذي لا أعتقد أنه قد يتسبب في حدوث هذه المشكلة.
 Random-Liu
في ٢٣ سبتمبر ٢٠١٧
Random-Liu
في ٢٣ سبتمبر ٢٠١٧
shyamjvs @ لقد اقتبست إدخال PUT في آخر تحديث لي. لم يتح لي الوقت للتحقق من أنه السبب.
إذا لم يغير NPD أي شيء ، فربما يتضمن تحديث حالة kubelet الآن حقلاً متعارضًا؟ يمكننا النظر في تضمين سطر تصحيح لطباعة محتويات طلب بطيء.
lavalamp
في ٢٣ سبتمبر ٢٠١٧
نعم .. رأيت ذلك. لكن هذه المكالمات من مدير التحكم نادرة جدًا مقارنةً بالتصحيحات من kubelet و npd. لقد تحققت من أحد عمليات التشغيل ، فقد كان شيئًا مثل 4000 PUTs مقارنة بـ 6 ملايين تصحيح وهذا يحدث أيضًا لبضع دقائق مرتين أثناء الاختبار والذي لا ينبغي أن يؤثر على 99 ٪ من اللف.
shyamjvs
في ٢٣ سبتمبر ٢٠١٧
تحديث: لقد أكدت أن الالتزام 11299e3 كان سليمًا مع فترات الاستجابة التالية (والتي تبدو جميعها طبيعية):
Sep 23 02:00:18.611: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:154.43ms Perc90:1.527089s Perc99:3.977228s Perc100:0s} Count:11429}
Sep 23 02:00:18.611: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:330.336ms Perc90:372.868ms Perc99:865.299ms Perc100:0s} Count:1642}
Sep 23 02:00:18.611: INFO: Top latency metric: {Resource:configmaps Subresource: Verb:PATCH Latency:{Perc50:1.541ms Perc90:6.507ms Perc99:180.346ms Perc100:0s} Count:184}
Sep 23 02:00:18.611: INFO: Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.344ms Perc90:9.737ms Perc99:78.242ms Perc100:0s} Count:6521257}
Sep 23 02:00:18.611: INFO: Top latency metric: {Resource:configmaps Subresource: Verb:POST Latency:{Perc50:3.861ms Perc90:5.871ms Perc99:28.857ms Perc100:0s} Count:184}
كان Run-27 (الالتزام 034c40be6f46) غير صحي. لذلك نحن الآن على يقين من المدى.
shyamjvs
في ٢٣ سبتمبر ٢٠١٧
51603 (تم دمجه في 6 سبتمبر) - لا يوجد تشغيل (إصلاحات ترتيب التهيئة)
49257 (تم الدمج في 31 أغسطس) - لا يوجد تشغيل على المجموعات العادية (تم وضع علامة عليها)
50738 (تم دمجه في 29 أغسطس) - لا يوجد مرجع (أعتقد - يستبدل DeepCopy القديم بـ deepCopy الجديد)
49524 (تم دمجه في 7 أغسطس) - لا يوجد عملية (تضيف إمكانية إضافة / إزالة ألوان متعددة في الوظائف المساعدة)
49870 (تم دمجه في 1 أغسطس) - لا يوجد عملية (إعادة تسمية متغيرة)
47952 (تم دمج 12 يوليو) - لا يوجد op (لا يغير أي استدعاءات API مباشرة ، بشكل غير مباشر يمكنه تغيير حذف Pod فقط)
باختصار ، لا أعتقد أن NC قد غيرت سلوكها غير المعتمد على بوابات في هذا الإصدار.
gmarek
في ٢٣ سبتمبر ٢٠١٧
OTOH كنا نشهد تعارضات التحديث التي نشأت عن NC عندما كانت Nodes تحتضر بسبب OOMs (التصادمات مع NPD / Kubelet).
gmarek
في ٢٣ سبتمبر ٢٠١٧
التزام 99a9ee5a3c غير صحي:
Sep 23 18:14:04.314: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:1.1407s Perc90:3.400196s Perc99:5.078185s Perc100:0s} Count:14832}
Sep 23 18:14:04.314: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:408.691ms Perc90:793.079ms Perc99:1.831115s Perc100:0s} Count:1703}
Sep 23 18:14:04.314: INFO: WARNING Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:4.134ms Perc90:103.428ms Perc99:1.139633s Perc100:0s} Count:7396342}
Sep 23 18:14:04.314: INFO: Top latency metric: {Resource:services Subresource: Verb:LIST Latency:{Perc50:1.057ms Perc90:5.84ms Perc99:474.047ms Perc100:0s} Count:511}
Sep 23 18:14:04.314: INFO: Top latency metric: {Resource:replicationcontrollers Subresource: Verb:LIST Latency:{Perc50:869µs Perc90:14.563ms Perc99:436.187ms Perc100:0s} Count:405}
نطاق جديد - https://github.com/kubernetes/kubernetes/compare/11299e363c538c...99a9ee5a3c52
shyamjvs
في ٢٤ سبتمبر ٢٠١٧
الالتزام cbe5f38ed2 غير صحي:
Sep 24 06:03:04.941: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:929.743ms Perc90:3.064274s Perc99:4.745392s Perc100:0s} Count:15353}
Sep 24 06:03:04.941: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:393.741ms Perc90:774.697ms Perc99:2.335875s Perc100:0s} Count:1859}
Sep 24 06:03:04.941: INFO: WARNING Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.742ms Perc90:93.829ms Perc99:1.108202s Perc100:0s} Count:8252670}
Sep 24 06:03:04.941: INFO: Top latency metric: {Resource:configmaps Subresource: Verb:POST Latency:{Perc50:3.778ms Perc90:123.878ms Perc99:650.641ms Perc100:0s} Count:210}
Sep 24 06:03:04.941: INFO: Top latency metric: {Resource:endpoints Subresource: Verb:GET Latency:{Perc50:476µs Perc90:37.661ms Perc99:365.414ms Perc100:0s} Count:13008}
مجموعة جديدة - https://github.com/kubernetes/kubernetes/compare/11299e363c538c...cbe5f38ed21
shyamjvs
في ٢٤ سبتمبر ٢٠١٧
الأشياء البارزة في هذا النطاق:
- تم تغيير إصدار GCI - https://github.com/kubernetes/kubernetes/commit/9fb015987b70ca84eff5694660f1dba701d10e92
- تم تغيير تنسيق التدقيق إلى JSON - https://github.com/kubernetes/kubernetes/commit/130f5d10adf13492f3435ab85a50d357a6831f6e
- أصبح فحص المكون الإضافي لحجم Flex ديناميكيًا - https://github.com/kubernetes/kubernetes/commit/396c3c7c6fd008663d2d30369c8e33a58cde5ee2
liggitt
في ٢٤ سبتمبر ٢٠١٧
ارتكاب a235ba4e49 غير صحي:
Sep 24 17:19:21.433: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:61.762ms Perc90:737.617ms Perc99:7.748733s Perc100:0s} Count:7430}
Sep 24 17:19:21.434: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:401.766ms Perc90:913.101ms Perc99:2.586065s Perc100:0s} Count:1151}
Sep 24 17:19:21.434: INFO: WARNING Top latency metric: {Resource:replicationcontrollers Subresource: Verb:POST Latency:{Perc50:3.072ms Perc90:378.118ms Perc99:1.277634s Perc100:0s} Count:5050}
Sep 24 17:19:21.434: INFO: WARNING Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.946ms Perc90:175.392ms Perc99:1.05636s Perc100:0s} Count:5239031}
Sep 24 17:19:21.434: INFO: Top latency metric: {Resource:resourcequotas Subresource: Verb:LIST Latency:{Perc50:924µs Perc90:287.15ms Perc99:960.978ms Perc100:0s} Count:3003}
نطاق جديد - https://github.com/kubernetes/kubernetes/compare/11299e363c538c...a235ba4e49451c779b8328378addf0d7bd7b84fd
shyamjvs
في ٢٤ سبتمبر ٢٠١٧
/ أنا أضع رهانًا على 130f5d1
dims
في ٢٤ سبتمبر ٢٠١٧
يجب أن تتخطى سياسة التدقيق تسجيل محتويات الاستجابة لأولئك:
يبدو أن التقاط السجل لم يكن يحفظ سجل التدقيق ، لذلك لست متأكدًا مما تم تسجيله بالفعل هناك ... فتح https://github.com/kubernetes/kubernetes/pull/52960 لحفظه
liggitt
في ٢٤ سبتمبر ٢٠١٧
نظرت في سجل التدقيق الذي تم الحصول عليه بواسطة kubemark على https://github.com/kubernetes/kubernetes/pull/52960
يبدو أن أسطر التدقيق الكبيرة غير المتوقعة الوحيدة التي يتم تسجيلها هي مكالمات deletecollection للكائنات ، والتي تقوم بتسجيل المجموعة الكاملة التي تم إرجاعها من الكائنات المحذوفة ... يمكنني رؤية حالة لتسجيل هذه العناصر ، نظرًا لأنها طفرة في هذه الكائنات ويتيح لك تتبع دورة حياة الكائن. ولكن تلك لم تكن حتى المكالمات التي تظهر مع وجود مشاكل في زمن الوصول
liggitt
في ٢٥ سبتمبر ٢٠١٧
الالتزام c04e516373 صحي:
Sep 25 03:47:20.967: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:178.225ms Perc90:1.455523s Perc99:3.071804s Perc100:0s} Count:11585}
Sep 25 03:47:20.967: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:351.796ms Perc90:393.656ms Perc99:778.841ms Perc100:0s} Count:1754}
Sep 25 03:47:20.967: INFO: Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.218ms Perc90:10.25ms Perc99:62.412ms Perc100:0s} Count:6976580}
Sep 25 03:47:20.967: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:896µs Perc90:6.393ms Perc99:26.436ms Perc100:0s} Count:764169}
Sep 25 03:47:20.967: INFO: Top latency metric: {Resource:pods Subresource: Verb:GET Latency:{Perc50:485µs Perc90:992µs Perc99:18.87ms Perc100:0s} Count:1255153}
نطاق جديد - https://github.com/kubernetes/kubernetes/compare/c04e516373...a235ba4e49451c779b8328378addf0d7bd7b84fd
shyamjvs
في ٢٥ سبتمبر ٢٠١٧
أعتقد أنه تغيير json التدقيق - سوف يؤكد.
أتذكر من أحد الآثار (حذف pods iirc) أن التدقيق كان جزءًا من كتلة التعليمات البرمجية التي استغرقت كل الوقت تقريبًا. ربما يفسر ذلك أيضًا سبب رؤيتنا زيادة في المكالمات المحولة.
shyamjvs
في ٢٥ سبتمبر ٢٠١٧
لم يكن تغيير التدقيق في النطاق https://github.com/kubernetes/kubernetes/compare/11299e363c538c...c04e516373 ؟
liggitt
في ٢٥ سبتمبر ٢٠١٧
إنه النصف الآخر الذي به الخطأ.
shyamjvs
في ٢٥ سبتمبر ٢٠١٧
كان لتعليقي الأصلي نطاقًا خاطئًا ، قمت بتصحيحه على الفور - آسف.
shyamjvs
في ٢٥ سبتمبر ٢٠١٧
تحديث:
- من النطاق أعلاه ، العلاقات العامة المشبوهة هي:
- اضبط --audit-log-format افتراضيًا على json # 50971
- قم بتحديث صورة cos إلى cos-stabil-60-9592-84-0 # 51207
- على الأرجح هو الأول لأن الطلبات المتغيرة هي التي تأثرت (وهي تمر عبر مسار رمز تسجيل التدقيق). أيضًا ، لا يبدو أن تسجيل التدقيق قيد التشغيل في kubemark (حيث لا نرى هذه المشكلة) مما يعززها بشكل أكبر.
- أنا حاليًا أتحقق محليًا من أن إعادة العلاقات العامة تؤدي إلى إصلاح الأشياء - يجب معرفة النتيجة خلال 2-3 ساعات
shyamjvs
في ٢٥ سبتمبر ٢٠١٧
shyamjvs ، قامت ترقية صورة COS أيضًا بترقية عامل الإرساء (من 1.11 إلى 1.13) ، والذي كان له بعض تأثيرات الأداء - يمكن لـ @ yguo0905 تقييم مدى صلة ذلك. إذا كان هذا يبدو مريبًا ، فيمكنك محاولة إجراء الاختبار مقابل صورة COS الأحدث ( cos-stable-61-9765-66-0 ) التي تحتوي على عامل الإرساء 17.03 ، والذي كان يتمتع بأداء أفضل.
 abgworrall
في ٢٥ سبتمبر ٢٠١٧
abgworrall
في ٢٥ سبتمبر ٢٠١٧
قامت ترقية صورة COS أيضًا بترقية عامل الإرساء (من 1.11 إلى 1.13) ، والذي كان له بعض التأثيرات على الأداء
ربما لن يؤثر أداء عامل الإرساء في وقت استجابة خادم واجهة برمجة التطبيقات
liggitt
في ٢٥ سبتمبر ٢٠١٧
نعم .. كما ذكرت على قناة Slack ، فإن القضية التي نراها هنا هي في جانب Apiserver. بالإضافة إلى أننا نستخدم صورة COS الجديدة في kubemark (التي تعمل بشكل جيد).
shyamjvs
في ٢٥ سبتمبر ٢٠١٧
shyamjvs يمكنك إيقاف تشغيل تسجيل التدقيق لاختبارات مقياس GCE الكبير حتى يتم إصلاح https://github.com/kubernetes/kubernetes/issues/53006 . يتم ذلك عن طريق تغيير ملف cluster/gce/config-test.sh : تبديل ENABLE_APISERVER_ADVANCED_AUDIT إلى false أو إلغاء تعيينه تمامًا.
 crassirostris
في ٢٥ سبتمبر ٢٠١٧
crassirostris
في ٢٥ سبتمبر ٢٠١٧
بعض الأفكار حول تراجع الأداء من التدقيق:
- لا يتم تمكين تسجيل التدقيق افتراضيًا ، ويجب تكوينه بشكل صريح (وهو ما نقوم به في بيئة الاختبار)
- AdavncedAuditing لا يزال في مرحلة تجريبية
- تنسيق الإخراج المحدد الذي يسبب الانحدار قابل للتكوين.
مع وضع ذلك في الاعتبار ، أميل إلى القول بأنه يجب علينا فقط توثيق هذه المشكلة باعتبارها مشكلة معروفة وإصلاحها في 1.9 (على سبيل المثال https://github.com/kubernetes/kubernetes/issues/53006)
 tallclair
في ٢٥ سبتمبر ٢٠١٧
tallclair
في ٢٥ سبتمبر ٢٠١٧
shyamjvs يمكنك إيقاف تشغيل تسجيل التدقيق لاختبارات مقياس GCE الكبير حتى يتم إصلاح # 53006
(كما تمت مناقشته في Slack معliggitt) لست متأكدًا مما إذا كان هذا هو أفضل نهج. الغرض من اختبار النطاق هو التحقق من صحة الإصدار وإيقاف تشغيله يعني أننا لا نتحقق منه حقًا. نحاول الحفاظ على التكوين الذي نقوم باختبار النطاق به في أقرب وقت ممكن من الإعدادات الافتراضية للإصدار.
ومع ذلك ، يمكنني التعايش مع الفكرة. ومع ذلك ، سيكون من الأفضل أن يتم تعطيله افتراضيًا في ملفات config - *. sh.
shyamjvs
في ٢٥ سبتمبر ٢٠١٧
نحاول الحفاظ على التكوين الذي نقوم باختبار النطاق به في أقرب وقت ممكن من الإعدادات الافتراضية للإصدار.
يتم إيقافه افتراضيًا في config-default.sh file لا يخضع للاختبار
يمكنك ضبط البيئة المحيطة في بيئة الاختبار أيضًا. لقد قمنا بهذا بالفعل لاختبارات الأداء لجعلها مطابقة للإنتاج ، أو لضبطها بالطريقة التي نضبط بها المجموعات الكبيرة.
فتحت https://github.com/kubernetes/kubernetes/pull/52998 (1.8 اختر في https://github.com/kubernetes/kubernetes/pull/53012) لتقليل كمية البيانات المرسلة إلى سجل التدقيق.
لقد فتحت أيضًا https://github.com/kubernetes/test-infra/pull/4720 لجعل اختبارات الأداء تطابق الإنتاج (من خلال تعطيل التدقيق تمامًا) ويمكننا إعادة النظر في هذا في 1.9
liggitt
في ٢٥ سبتمبر ٢٠١٧
تحديث:
- لا تحتوي تكوينات Prod على تسجيل تدقيق مُمكّن افتراضيًا لـ 1.8 ، لذلك سنقوم بتخطي اختبار النطاق للإصدار
- نحن لا نختار تغيير سياسة تدقيق نختبرها على أي حال
- سيتم حل مشكلة قابلية التوسع في 1.9 وهو الوقت الذي سنقوم فيه بتمكينها للاختبار ( tallclair / crassirostris - هل يمكن
shyamjvs
في ٢٥ سبتمبر ٢٠١٧
تم تقديم مشكلة: https://github.com/kubernetes/kubernetes/issues/53020
crassirostris
في ٢٥ سبتمبر ٢٠١٧
ركل مهمة أداء 5k على CI مع تعطيل التدقيق. نتوقع أن يكون لديك سباق أخضر (نأمل) بحلول الغد.
shyamjvs
في ٢٥ سبتمبر ٢٠١٧
لأولئك الذين يتابعونهم في المنزل ، يمكن إجراء الاختبارات التجريبية على https://k8s-gubernator.appspot.com/builds/kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/
liggitt
في ٢٦ سبتمبر ٢٠١٧
حسنًا .. لذا تم حل مشكلة حالة عقدة التصحيح بإيقاف تسجيل التدقيق ويبدو الوضع أفضل بكثير. ومع ذلك ، أظهرت أقراص الحذف مشكلة في التشغيل الأخير:
I0926 14:31:48.470] Sep 26 14:31:48.469: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Scope:namespace Latency:{Perc50:4.633ms Perc90:791.553ms Perc99:3.54603s Perc100:0s} Count:310018}
I0926 14:31:48.470] Sep 26 14:31:48.469: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Scope:namespace Latency:{Perc50:57.306ms Perc90:72.234ms Perc99:1.255s Perc100:0s} Count:10819}
I0926 14:31:48.470] Sep 26 14:31:48.469: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Scope:cluster Latency:{Perc50:409.094ms Perc90:544.723ms Perc99:1.016102s Perc100:0s} Count:2955}
I0926 14:31:48.471] Sep 26 14:31:48.469: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Scope:cluster Latency:{Perc50:211.299ms Perc90:385.941ms Perc99:726.57ms Perc100:0s} Count:1216}
I0926 14:31:48.471] Sep 26 14:31:48.469: INFO: Top latency metric: {Resource:pods Subresource:binding Verb:POST Scope:namespace Latency:{Perc50:1.151ms Perc90:6.838ms Perc99:404.557ms Perc100:0s} Count:155009}
يتم الآن تحميل السجلات إلى GCS .. تحتاج إلى الانتظار لبضع دقائق.
shyamjvs
في ٢٦ سبتمبر ٢٠١٧
ماذا كان حذف القرون في آخر تشغيل صحي (رقم 23)؟
liggitt
في ٢٦ سبتمبر ٢٠١٧
بالنسبة للتشغيل 23 ، كان 47.057 مللي ثانية من سجلات استجابة API . بالنسبة للتشغيل 27 ، كان 558 مللي ثانية (مأخوذ من سجل الإنشاء حيث كانت سجلات استجابة API مفقودة)
INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:5.11ms Perc90:33.011ms Perc99:558.028ms Perc100:0s} Count:314894}
كنا نعلم أن الالتزام c04e516 كان صحيًا من https://github.com/kubernetes/kubernetes/issues/51899#issuecomment -331759561. لذلك يجب أن يكون في https://github.com/kubernetes/kubernetes/compare/c04e516373...a235ba4e49451c779b8328378addf0d7bd7b84fd (ربما تغيرت صورة cos؟).
هل لا يزال ENABLE_ADVANCED_AUDIT_LOGGING=false يقوم ببعض عمليات تسجيل التدقيق الأساسية؟
shyamjvs
في ٢٦ سبتمبر ٢٠١٧
لذلك يجب أن يكون في c04e516 ... a235ba4 (ربما تتغير صورة cos؟).
لا يتم حظر استدعاء واجهة برمجة التطبيقات لحذف البود على عامل الإرساء. يمكنني أن أرى أن العقدة تستغرق وقتًا أطول لإغلاق البود ، ولكن لا تزيد من زمن الانتقال على مكالمات واجهة برمجة التطبيقات الفعلية.
هل ENABLE_ADVANCED_AUDIT_LOGGING = خطأ لا يزال يقوم ببعض عمليات تسجيل التدقيق الأساسية؟
لا ، هذا يتحكم فيه ENABLE_APISERVER_BASIC_AUDIT ، وهو افتراض كاذب.
liggitt
في ٢٦ سبتمبر ٢٠١٧
من المنطقي. لسوء الحظ ، فقدنا السجلات الرئيسية بسبب بعض مشكلات الاختبار بالأشعة تحت الحمراء (cc @ kubernetes / test-infra -keeperskrzyzacy) ، والتي من المفترض نسخها من عامل jenkins إلى GCS. لا أرى الاستدعاءات التالية لسجل الإنشاء (والتي تحدث عادةً):
I0922 10:02:12.439] Call: gsutil ls gs://kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/39/artifacts
I0922 10:02:14.951] process 31483 exited with code 0 after 0.0m
I0922 10:02:14.953] Call: gsutil -m -q -o GSUtil:use_magicfile=True cp -r -c -z log,txt,xml artifacts gs://kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/39
I0922 10:05:21.167] process 31618 exited with code 0 after 3.1m
liggitt أحد الأسباب التي
shyamjvs
في ٢٦ سبتمبر ٢٠١٧
liggitt أحد الأسباب التي
التدقيق معطل في هذه البيئة :)
liggitt
في ٢٦ سبتمبر ٢٠١٧
أوه نعم .. ليس هناك أي سجلات تدقيق على الإطلاق - آسف.
shyamjvs
في ٢٦ سبتمبر ٢٠١٧
سأغير وظيفة CI لتشغيل اختبار الكثافة فقط وإعادة تشغيله. يجب أن يكون لدينا شيء في 3-4 ساعات.
shyamjvs
في ٢٦ سبتمبر ٢٠١٧
يبدو أن التشغيل الحالي سيفشل أيضًا على الأرجح ، حيث أرى زمن الانتقال التالي لحذف مكالمات pod (في μs):
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="",verb="DELETE",quantile="0.99"} 4.462881e+06
من الآثار ، الخطوة الوحيدة المطبوعة (التي تستغرق معظم الوقت تقريبًا) هي:
I0926 21:32:57.199705 7 trace.go:76] Trace[1024874778]: "Delete /api/v1/namespaces/e2e-tests-density-30-21-8gvt2/pods/density150000-20-3b9db35a-a2dd-11e7-b671-0242ac110004-bzsjl" (started: 2017-09-26 21:32:56.246437691 +0000 UTC) (total time: 953.24642ms):
Trace[1024874778]: [949.787883ms] [949.73031ms] About to delete object from database
ويبدو أن هذا التتبع يتوافق مع هذا الجزء من الكود:
https://github.com/kubernetes/kubernetes/blob/a3ab97b7f395e1abd2d954cd9ada0386629d0411/staging/src/k8s.io/apiserver/pkg/endpoints/handlers/rest.go#L944 -L1009
shyamjvs
في ٢٧ سبتمبر ٢٠١٧
لقد أضفت بعض الآثار الإضافية في https://github.com/kubernetes/kubernetes/pull/52543 - لكن أعتقد أنه كان يجب علي إضافتها بعد الخطوة بدلاً من قبل الخطوة (لأننا لا نحصل على ما يكفي معلومات من التتبع الحالي للجزء الفرعي أعلاه استغرق أقصى وقت).
shyamjvs
في ٢٧ سبتمبر ٢٠١٧
بدء جولة ثانية من التقسيم (مع تعطيل تسجيل التدقيق) للقبض على الانحدار الثاني. نأمل أن يكون هذا أسرع.
shyamjvs
في ٢٧ سبتمبر ٢٠١٧
الالتزام 150a560eed غير صحي (أنا أختبر ضد مجموعة العقدة 2k):
Sep 27 14:34:14.484: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.551ms Perc90:10.216ms Perc99:1.403002s Perc100:0s} Count:122966}
من التنصيف السابق ، كان الالتزام c04e516 هو أحدث التزام صحي نعرفه.
shyamjvs
في ٢٧ سبتمبر ٢٠١٧
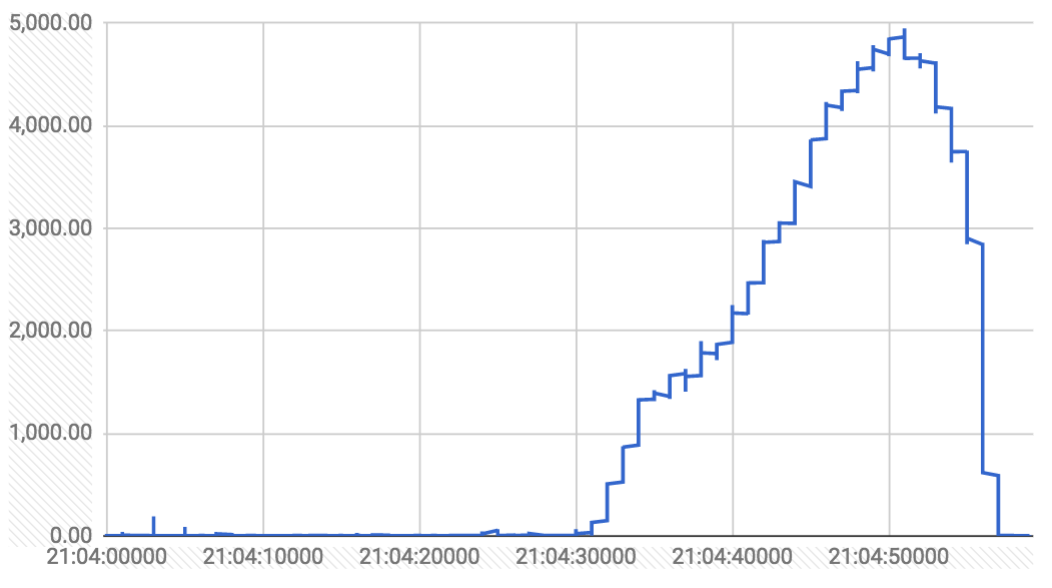
مقتطف من إحدى ارتفاعات الحذف من https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/41/ (y هي مللي ثانية ، x هو الوقت من استدعاء API)
أنا أتحقق من التغييرات لحذف المعالجة / التخزين / القبول / جمع القمامة في النطاق غير الصحي. لا شيء يقفز للخارج حتى الآن.
المثير للاهتمام هو توزيع استدعاءات حذف pod API خلال تلك الدقيقة:
- أول 30 ثانية:
- 63 كيلو بايت إجمالي مكالمات API
- 2146
delete podمكالمات API - 1166 بواسطة
kube-controller-manager/v1.8.0 (linux/amd64) kubernetes/a3ab97b/system:serviceaccount:kube-system:generic-garbage-collector - 980 بواسطة
kubelet/v1.8.0 (linux/amd64) kubernetes/a3ab97b
- 30 ثانية ثانية:
- 55 كيلو بايت إجمالي مكالمات API
- 1371
delete podمكالمات API - 1371 بواسطة
kubelet/v1.8.0 (linux/amd64) kubernetes/a3ab97b
تؤدي مكالمات جامع القمامة إلى الحذف الجميل ، في الواقع تحذف مكالمات kubelet القرون. أول 30 ثانية ، هناك زمن انتقال مهمل على مكالمات الحذف (1-100 مللي ثانية) ، والثاني 30 ثانية ، يزداد زمن الانتقال بشكل مطرد.
يكون العدد الإجمالي لمكالمات الحذف أعلى في أول 30 ثانية ، وكان الرقم الذي أدى بالفعل إلى عمليات الحذف وما إلى ذلك مقارنة بالثانية 30 ثانية (980 مقابل 1371).
liggitt
في ٢٧ سبتمبر ٢٠١٧
إكمال عملية المسح ، لا توجد مشكلات واضحة تتعلق بالقرون ، أو الحذف ، أو الإدخال ، أو غير ذلك ، أو التخزين في النطاق aa50c0f ... 150a560
هل يمتلك kubemark 5k نفس "إنشاء الكثير من البودات" / "يحذف الكثير من البودات المجدولة بالتوازي" بالنسبة للقرون؟ أتساءل لماذا لا نرى مشاكل وقت الاستجابة هناك
liggitt
في ٢٧ سبتمبر ٢٠١٧
لمعلوماتك جميعًا ، لدينا بالفعل موافقة شفهية من Google عبر abgworrall @ لجعل هذا الأمر معروفًا في 1.8.0 مع توفير التحذيرات. أحتاج إلى بعض المساعدة لإضافة هذا إلى # 53004 حتى يتم وصفه بشكل صحيح لتضمينه في ملاحظات الإصدار. في غضون ساعتين ، سأرفع ملصق حظر التحرير ما لم تظهر المزيد من المعلومات ونحتاج إلى إبقائها محظورة.
jdumars
في ٢٧ سبتمبر ٢٠١٧
liggitt نعم ، يقوم kubemark أيضًا بإجراء نفس الاختبار ، مما يؤدي إلى إنشاء نمط مماثل. لأولئك الفضوليين - باختصار نقوم بما يلي في اختبار الكثافة:
- تشبع الكتلة بـ 30 جرابًا / عقدة ، أي أننا ننشئ بعض وحدات التحكم عن بعد بإضافة ما يصل إلى إجمالي
30 * #nodespods - نقوم بعد ذلك بإنشاء قرون إضافية
#nodes(على الكتلة المشبعة) لقياس زمن انتقال بدء التشغيل - ثم نقوم بحذف تلك البودات الإضافية وأقراص التشبع والتقاط مقاييس وقت استجابة مكالمة api
أتساءل لماذا لا نرى مشاكل وقت الاستجابة هناك
يمكن أن يكون هناك شيء حول عدم تطابق التكوينات الرئيسية (https://github.com/kubernetes/kubernetes/issues/53021) أو تكوين qps مختلف (شيء مما يؤدي إلى إنشاء qps إضافي على مجموعات حقيقية) أو ..؟ تحتاج إلى التعمق فيها (https://github.com/kubernetes/kubernetes/issues/47544 و https://github.com/kubernetes/kubernetes/issues/47540 ذات صلة).
jdumars التحقق من
Sep 27 16:34:11.638: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:3.669ms Perc90:6.723ms Perc99:19.735ms Perc100:0s} Count:124000}
من الواضح أن هذا يعد تراجعًا ولست متأكدًا مما إذا كان يجب علينا إزالة حظر الإصدار. على الرغم من أنني أستطيع التعايش مع توثيقه وإصلاحه في إصدار تصحيح.
thockinsmarterclayton تعليقات؟
shyamjvs
في ٢٧ سبتمبر ٢٠١٧
ناقش abgworrall هذا داخليًا في Google ، واستنادًا إلى الظروف المحدودة للتأثير ، يمكن معالجته في 1.8.x.
jdumars
في ٢٧ سبتمبر ٢٠١٧
jdumars هل يمكننا نقل هذا من المرحلة الهامة بعد ذلك.
 grodrigues3
في ٢٧ سبتمبر ٢٠١٧
grodrigues3
في ٢٧ سبتمبر ٢٠١٧
يبدو جيدا. كما هو متفق عليه بشأن Slack - بمجرد معرفة الإصلاح ، سنعيده إلى 1.8.
shyamjvs
في ٢٧ سبتمبر ٢٠١٧
الاستمرار مع منصف ftw ... الالتزام 6b9ce5ba110 صحي:
Sep 27 20:11:35.950: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.404ms Perc90:6.688ms Perc99:20.853ms Perc100:0s} Count:131492}
الالتزام 57c3c2c0b صحي:
Sep 27 22:09:19.792: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:3.792ms Perc90:6.777ms Perc99:19.745ms Perc100:0s} Count:124000}
نطاق جديد: https://github.com/kubernetes/kubernetes/compare/57c3c2c0bc3b24905ecab52b7b8a50d4b0e6bae2...150a560eed43a1e1dac47ee9b73af89226827565
أشك في العلاقات العامة التالية (لم ألقي نظرة فاحصة):
- انتظر تنظيف الحاوية قبل حذف # 50350
shyamjvs
في ٢٧ سبتمبر ٢٠١٧
لكي أكون واضحًا: استند موافقتي اللفظية إلى: انحدار الأداء الذي ظهر فقط عندما تم تمكين تسجيل التدقيق ، وتم تكوينه بطريقة معينة.
ليس من الواضح بالنسبة لي ما هو نطاق انحدار الحذف ، الذي أصبح مرئيًا الآن ؛ هل تؤثر على كل التجمعات الكبيرة بشكل افتراضي؟ وما هو التأثير - زيادة بنسبة 25٪ في المتوسط ، أو زيادة بنسبة 2500٪ بنسبة 99٪ ، أم ماذا؟
(أعتذر إذا تم توضيح ذلك مسبقًا في هذا الموضوع ، لكنني سأقدر حقًا الملخص)
abgworrall
في ٢٧ سبتمبر ٢٠١٧
- لا يواجه kubemark هذه المشكلة ، على الرغم من تشغيله لأنماط إنشاء / حذف مماثلة
- يظهر التأثير بشكل أفضل في https://github.com/kubernetes/kubernetes/issues/51899#issuecomment -332515008
liggitt
في ٢٧ سبتمبر ٢٠١٧
abgworrall هناك
- زيادة زمن الوصول لمكالمات
patch node-status(وعدد قليل من المكالمات الأخرى بشكل غير مستقر) والتي نتجت عن تغيير سجل التدقيق إلى json. لقد قمنا بذلك عن طريق تعطيل تسجيل التدقيق في اختبار النطاق لدينا (انظر - https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-331973754) وتم حلها الآن - زمن انتقال متزايد لمكالمات
delete pods(20 مللي ثانية -> 1.4 ثانية) وأنا أقوم حاليًا بتقسيمها باستخدام مجموعة العقدة 2k. لقد قمت بتضييق نطاق الالتزام إلى ما يصل إلى https://github.com/kubernetes/kubernetes/compare/57c3c2c0bc3b24905ecab52b7b8a50d4b0e6bae2...150a560eed43a1e1dac47ee9b73af89226827565. تحتاج إلى تأكيد ما إذا كانت المشكلة غير مستقر.
shyamjvs
في ٢٧ سبتمبر ٢٠١٧
طيب .. لا يبدو وكأنه تقشر. فشل للمرة الثانية ضد 150a560:
Sep 28 01:54:50.933: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:5.031ms Perc90:2.082021s Perc99:6.116367s Perc100:0s} Count:124000}
dashpoleliggittsmarterclayton يمكن أن يكون https://github.com/kubernetes/kubernetes/pull/50350؟ (بناءً على آخر نطاق نشره shyam)
dims
في ٢٨ سبتمبر ٢٠١٧
لمعلوماتك - قمت بتشغيل جولتين أخريين من التنصيف بعد ذلك ووجدت:
الالتزام 78c82080 غير صحي:
Sep 28 06:25:03.471: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:3.995ms Perc90:209.142ms Perc99:3.174665s Perc100:0s} Count:124000}
والالتزام 6a314ce3a9cb صحي:
Sep 28 13:51:29.705: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:3.647ms Perc90:6.901ms Perc99:19.541ms Perc100:0s} Count:124000}
النطاق الجديد هو: https://github.com/kubernetes/kubernetes/compare/6a314ce3a9cb...78c82080
shyamjvs
في ٢٨ سبتمبر ٢٠١٧
/ me يزيد من حصصه على https://github.com/kubernetes/kubernetes/pull/50350/commits/9ac30e2c280f61a9629f3334f7e6e6424b7fb5f8
dims
في ٢٨ سبتمبر ٢٠١٧
/ لي يزيد من حصصه على 9ac30e2
من المؤكد أن عنوان الالتزام يبدو مرتبطًا ، لكنني تجاوزت ذلك الالتزام عشرات المرات ولا أرى أي شيء يتجاوز الحدود خارج kubelet الذي قد يؤثر على زمن انتقال خادم API. سنرى ، أفترض.
liggitt
في ٢٨ سبتمبر ٢٠١٧
في الواقع ، إحدى الفرضيات التي لدي هي أن هذا التغيير (iiuc) يجعل kubelet يرسل طلب حذف الحاوية فقط بعد حذف الحاوية ، وربما تغير معدل / توزيع تلك المكالمات. أثناء وجودك في kubemark ، لا تشغل kubelets أي حاويات حقيقية ، لذا يمكنهم حذف كائن pod على الفور (مما قد يؤدي إلى توزيع موحد لتلك المكالمات). Wdyt؟
shyamjvs
في ٢٨ سبتمبر ٢٠١٧
@ kubernetes / sig-node-bugs هل يحدث kubelet container GC بشكل دوري؟ كما في هذه الحالة ، قد تؤدي جميع الحاويات التي تم حذفها في دفعة واحدة إلى طلب مجموعة من delete pods دفعة واحدة. أو ربما شيء آخر أنا في عداد المفقودين؟
shyamjvs
في ٢٨ سبتمبر ٢٠١٧
راجع تحليل توزيع مكالمة الحذف في https://github.com/kubernetes/kubernetes/issues/51899#issuecomment -332515008
يحتوي النصف الأول من الرسم البياني والثاني على أرقام متطابقة تقريبًا من مكالمات الحذف ، ومع ذلك يظل النصف الأول مستجيبًا تمامًا بينما يتراكم الثاني زمن انتقال كبير. لا أعتقد أن الأمر بسيط مثل قطيع هائل.
liggitt
في ٢٨ سبتمبر ٢٠١٧
انتهيت للتو من التحقق .. الالتزام bcf22bcf6 صحي أيضًا:
Sep 28 16:09:14.084: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.114ms Perc90:6.221ms Perc99:17.737ms Perc100:0s} Count:124000}
وفي الالتزامات الثلاثة المتبقية (https://github.com/kubernetes/kubernetes/compare/bcf22bcf6...78c82080) ، هذا هو السبب على الأرجح. هناك حذف آخر للقرص الملامس (# 51186) ، ولكن هذا بعض التغيير في جانب kubectl ولا ينبغي استخدام kubectl في اختبارنا ولا في أي مكون رئيسي لمستوى التحكم iiuc.
shyamjvs
في ٢٨ سبتمبر ٢٠١٧
liggitt هل يمكنك الحصول على الرسم البياني لنطاق x أطول قليلاً من 60 ثانية (تستمر مرحلة الحذف للاختبار أكثر من 30 دقيقة)؟ هل كان مجرد ارتفاع واحد أم أن هناك العديد منهم؟ وهل هي دورية؟ ربما تحدث هذه المسامير عندما تتزامن طور gc الخاص بالعقد المتعددة؟
shyamjvs
في ٢٨ سبتمبر ٢٠١٧
سم مكعبdashpole @ dchen1107
shyamjvs
في ٢٨ سبتمبر ٢٠١٧
فيما يلي رسوم بيانية تزيد عن نافذة ثلاث دقائق (زمن الوصول بالمللي ثانية وتوزيع مكالمات الحذف في الثانية)
تقوم مكالمات الحذف من GC بتعيين الحذف فقط طابع زمني على الحجرة (التي تلاحظها الكوبيليتات وتبدأ في إغلاق البودات). يتم حذف مكالمات الحذف من kubelet بالفعل من etcd.
هل كان مجرد ارتفاع واحد أم أن هناك العديد منهم؟ وهل هي دورية؟ ربما تحدث هذه المسامير عندما تتزامن طور gc الخاص بالعقد المتعددة؟
كان هناك عدة ارتفاعات خلال السباق. فيما يلي رسم بياني لمكالمات الحذف التي استغرقت أكثر من ثانية واحدة خلال التشغيل بالكامل:
يبدو أن النتوءات تأتي في مجموعات من ثلاث ، بفاصل دقيقتين تقريبًا ، وتستمر من 20 إلى 30 ثانية
liggitt
في ٢٨ سبتمبر ٢٠١٧
جميلة! شكرا جزيلا على الرسوم البيانية.
لذلك يبدو الأمر حقًا دوريًا .. بالمناسبة - أعتقد أن نمط الدقيقتين مرتبط بكيفية حذفنا لبودات التشبع (التي شرحتها في https://github.com/kubernetes/kubernetes/issues/51899#issuecomment- 332577238) قرب نهاية اختبار الكثافة. نحن نحذف تلك RCs (لكل منها 3000 نسخة متماثلة) بفاصل دقيقتين تقريبًا:
I0928 03:52:02.643] [1mSTEP[0m: Cleaning up only the { ReplicationController}, garbage collector will clean up the pods
I0928 03:52:02.643] [1mSTEP[0m: deleting { ReplicationController} density150000-47-dc6c4af2-a3d1-11e7-9201-0242ac110008 in namespace e2e-tests-density-30-48-pbmpd, will wait for the garbage collector to delete the pods
I0928 03:52:03.048] Sep 28 03:52:03.047: INFO: Deleting { ReplicationController} density150000-47-dc6c4af2-a3d1-11e7-9201-0242ac110008 took: 39.093401ms
I0928 03:53:03.050] Sep 28 03:53:03.049: INFO: Terminating { ReplicationController} density150000-47-dc6c4af2-a3d1-11e7-9201-0242ac110008 pods took: 1m0.001823124s
I0928 03:54:13.051] [1mSTEP[0m: Cleaning up only the { ReplicationController}, garbage collector will clean up the pods
I0928 03:54:13.051] [1mSTEP[0m: deleting { ReplicationController} density150000-48-dc6c4af2-a3d1-11e7-9201-0242ac110008 in namespace e2e-tests-density-30-49-g5qvv, will wait for the garbage collector to delete the pods
I0928 03:54:13.438] Sep 28 03:54:13.437: INFO: Deleting { ReplicationController} density150000-48-dc6c4af2-a3d1-11e7-9201-0242ac110008 took: 40.001908ms
I0928 03:55:13.440] Sep 28 03:55:13.439: INFO: Terminating { ReplicationController} density150000-48-dc6c4af2-a3d1-11e7-9201-0242ac110008 pods took: 1m0.001894987s
I0928 03:56:23.440] [1mSTEP[0m: Cleaning up only the { ReplicationController}, garbage collector will clean up the pods
I0928 03:56:23.441] [1mSTEP[0m: deleting { ReplicationController} density150000-49-dc6c4af2-a3d1-11e7-9201-0242ac110008 in namespace e2e-tests-density-30-50-s62ds, will wait for the garbage collector to delete the pods
I0928 03:56:23.829] Sep 28 03:56:23.829: INFO: Deleting { ReplicationController} density150000-49-dc6c4af2-a3d1-11e7-9201-0242ac110008 took: 50.423057ms
I0928 03:57:23.831] Sep 28 03:57:23.830: INFO: Terminating { ReplicationController} density150000-49-dc6c4af2-a3d1-11e7-9201-0242ac110008 pods took: 1m0.0014941s
لا. من بين تلك المكالمات الواردة من تعليقك السابق كانت قريبة أيضًا من 3000 - على الرغم من أن ذلك كان في نطاق دقيقة واحدة (ولكن لدينا مكالمتان للحذف لكل pod iiuc - واحدة من gc وواحدة من kubelet).
shyamjvs
في ٢٨ سبتمبر ٢٠١٧
لمعلوماتك - لقد أكدت أن هذه العلاقات العامة هي التي تسبب المشكلة. الالتزام قبل أن يصبح صحيًا:
Sep 28 18:05:27.337: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.106ms Perc90:6.308ms Perc99:19.561ms Perc100:0s} Count:124000}
خيارات لدينا:
- التراجع عن الالتزام ثم إصلاح المشكلة في 1.9 (أفضل ذلك ، ما لم يكن الإصلاح تافهاً بما يكفي للانتقال إلى 1.8)
- إصلاحه - من المحتمل دفع الإصدار إلى الخلف (إذا أردنا أيضًا أن يكون لدينا ثقة كافية في جودة الإصدار)
- فليكن ووثق هذا كمشكلة معروفة في الإصدار (أنا لا أؤيد ذلك كثيرًا)
shyamjvs
في ٢٨ سبتمبر ٢٠١٧
أستطيع أن أرى كيف أن انتظار الحاوية gc على جانب kubelet قبل إصدار استدعاء حذف API سيؤدي إلى تجميع استدعاءات الحذف. يبدو وكأنه قطيع رعدي ناتج عن kubelet ، عند حذف أعداد هائلة من القرون عبر أعداد هائلة من العقد. kubemark's gc ممزق نظرًا لعدم وجود حاويات حقيقية ، لذلك لم يتم ملاحظة ذلك هناك
liggitt
في ٢٨ سبتمبر ٢٠١٧
نعم .. ما كنت أفكر فيه أيضًا - https://github.com/kubernetes/kubernetes/issues/51899#issuecomment -332847171
shyamjvs
في ٢٨ سبتمبر ٢٠١٧
MustafaHosny اللهم امين يارب
من تقديم العلاقات العامة (https://github.com/kubernetes/kubernetes/pull/50350)
liggitt
في ٢٨ سبتمبر ٢٠١٧
يمكنني نشر PR لعودة الجزء الرئيسي من # 50350.
 dashpole
في ٢٨ سبتمبر ٢٠١٧
dashpole
في ٢٨ سبتمبر ٢٠١٧
dashpole شكرا لك!
jdumars
في ٢٨ سبتمبر ٢٠١٧
أعتقد أننا يجب أن ننتظر أيضًا حتى يتم اختبار الإصلاح أيضًا (أضف حوالي ساعتين إضافيتين له).
shyamjvs
في ٢٨ سبتمبر ٢٠١٧
نشر العلاقات العامة: # 53210
dashpole
في ٢٨ سبتمبر ٢٠١٧
لقد أجريت مناقشة مع dashpole دون اتصال بالإنترنت ،
يجب علينا تحسين إدارة القرص بمزيد من الذكاء لاتخاذ إجراءات استباقية ، بدلاً من الاعتماد على gc الدورية.
 dchen1107
في ٢٨ سبتمبر ٢٠١٧
dchen1107
في ٢٨ سبتمبر ٢٠١٧
في حين أن هذا في 1.9 علامة فارقة ، هناك كل التوقعات بأن هذا سيتم حله في أقرب لحظة مسؤولة في إصدار التصحيح 1.8. يمكن الاطلاع على عملية اتخاذ القرار الكاملة حول هذا على https://youtu.be/r6D5DNel2l8
jdumars
في ٢٨ سبتمبر ٢٠١٧
أي تحديثات على هذا؟
 jpbetz
في ٢ أكتوبر ٢٠١٧
jpbetz
في ٢ أكتوبر ٢٠١٧
لدينا بالفعل ضحية العلاقات العامة - العلاقات العامة التي تصلح هو # 53233
wojtek-t
في ٢ أكتوبر ٢٠١٧
تم دمج 53233 للسيد. اختر 1.8.1 مفتوحًا على https://github.com/kubernetes/kubernetes/pull/53422
liggitt
في ٤ أكتوبر ٢٠١٧
[MILESTONENOTIFIER] تحتاج مشكلة الإنجاز إلى
dashpoleshyamjvs @ kubernetes / سيج-المعهد-آلات البق @ kubernetes / سيج عقدة-البق @ kubernetes / سيج-قابلية-البق
الإجراء المطلوب : يجب أن يكون لهذه المشكلة التصنيف status/approved-for-milestone المطبق من قبل مشرف SIG.تسميات العدد
sig/api-machinerysig/nodesig/scalability: سيتم تصعيد المشكلة إلى SIGs إذا لزم الأمر.priority/critical-urgent: لا تخرج تلقائيًا من مرحلة الإصدار ؛ التصعيد باستمرار للمساهم و SIG من خلال جميع القنوات المتاحة.kind/bug: إصلاح خطأ تم اكتشافه أثناء الإصدار الحالي.مساعدة
 k8s-github-robot
في ٦ أكتوبر ٢٠١٧
k8s-github-robot
في ٦ أكتوبر ٢٠١٧
/أغلق
مغلق عبر # 53422. الإصلاح يكون في 1.8.1.
dashpole
في ٦ أكتوبر ٢٠١٧
القضايا ذات الصلة
 errordeveloper
·
3تعليقات
errordeveloper
·
3تعليقات
 cooligc
·
3تعليقات
cooligc
·
3تعليقات
 sjenning
·
3تعليقات
sjenning
·
3تعليقات
 arun-gupta
·
3تعليقات
arun-gupta
·
3تعليقات
 rhohubbuild
·
3تعليقات
rhohubbuild
·
3تعليقات
التعليق الأكثر فائدة
ركل مهمة أداء 5k على CI مع تعطيل التدقيق. نتوقع أن يكون لديك سباق أخضر (نأمل) بحلول الغد.