Kubernetes: Задержки вызовов API `delete pods` резко увеличились при тестировании больших кластеров
Обновлено описание проблемы с учетом последних результатов:
В 50350 внесено изменение в удаление пода кубелетов, которое приводит к тому, что вызовы delete pod API из кубелетов концентрируются сразу после сборки мусора контейнера.
При удалении большого количества (тысяч) подов на большом количестве (сотнях) узлов результирующие вызовы концентрированного удаления из кубелетов вызывают увеличение задержки вызовов API delete pods выше целевого порога:
Sep 27 14:34:14.484: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.551ms Perc90:10.216ms Perc99:1.403002s Perc100:0s} Count:122966}
Не видно на https://k8s-gubernator.appspot.com/builds/kubernetes-jenkins/logs/ci-kubernetes-kubemark-gce-scale/
добавили детали из https://github.com/kubernetes/kubernetes/issues/51899#issuecomment -332868313 в описание:
Графики за трехминутное окно (как задержка в мс, так и распределение вызовов удаления в секунду):
вызовы delete от контроллера gc просто устанавливают deletionTimestamp на поде (который наблюдают кублеты и начинают отключать поды). вызовы delete из kubelet фактически удаляют из etcd.


на протяжении всего прогона было несколько всплесков (соответствующих удалению контроллеров репликации на 3000 контейнеров). вот график вызовов удаления, которые заняли более одной секунды на протяжении всего прогона:
Похоже на грохочущее стадо, вызванное кубелетами, при удалении большого количества стручков через огромное количество узлов. gc kubemark заглушен, так как реальных контейнеров нет, поэтому там этого не наблюдается
Исходное описание проблемы следующее:
Из прогона теста плотности 5 тыс. Узлов (№ 26) в последнюю пятницу:
I0901 10:11:29.395] Sep 1 10:11:29.395: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:66.805ms Perc90:375.804ms Perc99:8.111217s Perc100:0s} Count:11911}
I0901 10:11:29.396] Sep 1 10:11:29.395: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:417.103ms Perc90:1.090847s Perc99:2.336106s Perc100:0s} Count:1261}
I0901 10:11:29.396] Sep 1 10:11:29.395: INFO: WARNING Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:5.633ms Perc90:279.15ms Perc99:1.04109s Perc100:0s} Count:5543730}
I0901 10:11:29.396] Sep 1 10:11:29.395: INFO: Top latency metric: {Resource:pods Subresource:binding Verb:POST Latency:{Perc50:1.442ms Perc90:15.171ms Perc99:921.523ms Perc100:0s} Count:155096}
I0901 10:11:29.396] Sep 1 10:11:29.395: INFO: Top latency metric: {Resource:replicationcontrollers Subresource: Verb:POST Latency:{Perc50:3.13ms Perc90:218.472ms Perc99:886.065ms Perc100:0s} Count:5049}
И из последнего исправного запуска (№ 23) теста:
I0826 03:49:44.301] Aug 26 03:49:44.301: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:830.411ms Perc90:1.468316s Perc99:2.627309s Perc100:0s} Count:10615}
I0826 03:49:44.302] Aug 26 03:49:44.301: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:337.423ms Perc90:427.443ms Perc99:998.426ms Perc100:0s} Count:1800}
I0826 03:49:44.302] Aug 26 03:49:44.301: INFO: Top latency metric: {Resource:apiservices Subresource: Verb:PUT Latency:{Perc50:954µs Perc90:5.726ms Perc99:138.528ms Perc100:0s} Count:840}
I0826 03:49:44.302] Aug 26 03:49:44.301: INFO: Top latency metric: {Resource:namespaces Subresource: Verb:GET Latency:{Perc50:445µs Perc90:2.641ms Perc99:83.57ms Perc100:0s} Count:1608}
I0826 03:49:44.302] Aug 26 03:49:44.301: INFO: Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.22ms Perc90:9.449ms Perc99:55.588ms Perc100:0s} Count:7033941}
Мы наблюдаем огромный рост:
СПИСОК модулей: 2,6 с -> 8,1 с
СПИСОК узлов: 1 с -> 2,3 с
Статус узла PATCH: 56 мс -> 1 с
...
cc @ kubernetes / sig-api-machinery-bugs @ kubernetes / sig- scaleability -разное @gmarek
 shyamjvs
shyamjvs
Все 142 Комментарий
Я пытаюсь найти оскорбительные PR. Разница между этими прогонами слишком велика.
К счастью, это наблюдается даже на относительно небольших кластерах, например, для kubemark-500 - https://k8s-testgrid.appspot.com/sig-scalability#kubemark -500
shyamjvs
4 сент. 2017
Мне кажется, что это может быть связано с разбиением на страницы.
Если я прав, https://github.com/kubernetes/kubernetes/pull/51876, надеюсь, решит проблему.
@smarterclayton
 wojtek-t
4 сент. 2017
wojtek-t
4 сент. 2017
Но это в основном предположение, а может быть и другое.
wojtek-t
4 сент. 2017
@ kubernetes / test-infra-Maintainers У нас нет никаких журналов (кроме журнала сборки от jenkins) для выполнения 26 из ci-kubernetes-e2e-gce-scale-performance потому что jenkins разбился на полпути в тесте:
ERROR: Connection was broken: java.io.IOException: Unexpected termination of the channel
at hudson.remoting.SynchronousCommandTransport$ReaderThread.run(SynchronousCommandTransport.java:50)
Caused by: java.io.EOFException
at java.io.ObjectInputStream$PeekInputStream.readFully(ObjectInputStream.java:2351)
at java.io.ObjectInputStream$BlockDataInputStream.readShort(ObjectInputStream.java:2820)
Такие сбои (которые тоже происходят в самом конце прогона) могут сильно ударить по отладке.
shyamjvs
4 сент. 2017
@ wojtek-t Мы также наблюдаем увеличение задержки исправлений. Так что, вероятно, есть еще один регресс?
shyamjvs
4 сент. 2017
До запуска 8132 кубемарк-500 выглядел нормально:
{
"data": {
"Perc50": 31.303,
"Perc90": 39.326,
"Perc99": 59.415
},
"unit": "ms",
"labels": {
"Count": "43",
"Resource": "nodes",
"Subresource": "",
"Verb": "LIST"
}
},
У нас были некоторые сбои при запуске в ч / б, и, похоже, они резко выросли, начиная с запуска 8141:
{
"data": {
"Perc50": 213.34,
"Perc90": 608.223,
"Perc99": 1014.937
},
"unit": "ms",
"labels": {
"Count": "53",
"Resource": "nodes",
"Subresource": "",
"Verb": "LIST"
}
},
Смотрим на разницу прямо сейчас.
shyamjvs
4 сент. 2017
Другая возможность (о которой вы упомянули мне в автономном режиме):
https://github.com/kubernetes/kubernetes/pull/48287
Сначала я сомневался в этом, но теперь, когда я думаю об этом, может быть, дело в распределении памяти (я не смотрел внимательно, но, может быть, с json-iter намного выше)?
@thockin - FYI (все еще только мое предположение)
wojtek-t
4 сент. 2017
В любом случае - @shyamjvs нам нужно больше данных о том, какие другие метрики изменились (использование ЦП, выделения, количество вызовов API, ...)
wojtek-t
4 сент. 2017
После устранения тривиальных и не связанных между собой PR остается следующее:
- Отмените "Проводку диспетчера ЦП и
nonepolicy" # 51804 (я думаю, что это влияет только на kubelet, поэтому маловероятно) - Разделите APIVersion на APIGroup и APIVersion в событиях аудита # 50007 (это только влияет на события аудита)
- Используйте json-iterator вместо ugorji для JSON. # 48287 (я очень подозреваю это)
- добавить информацию для определения типа подресурса # 49971 (это добавляет поля группы и версии в APIResource)
shyamjvs
4 сент. 2017
В любом случае - @shyamjvs нам нужно больше данных о том, какие другие метрики изменились (использование ЦП, выделения, количество вызовов API, ...)
Ага .. Я провожу несколько локальных экспериментов, чтобы проверить это. Также объединен https://github.com/kubernetes/kubernetes/pull/51892, чтобы начать получать основные журналы kubemark.
shyamjvs
4 сент. 2017
Можете ли вы получить профиль ЦП от мастера при запуске теста? Это должно помочь вам выяснить причину.
 gmarek
4 сент. 2017
gmarek
4 сент. 2017
Добавление команды выпуска: @jdumars @calebamiles @spiffxp
gmarek
4 сент. 2017
Итак, я получил данные об использовании ЦП и памяти для нагрузочного теста из последних> 200 запусков kubemark-500, и я не вижу заметного увеличения. На самом деле это похоже на улучшение:


shyamjvs
4 сент. 2017
Есть несколько последовательных неудачных прогонов (из-за ошибок / регрессий testinfra), приводящих к пропущенным точкам или временным всплескам ... Не обращайте внимания на шум
shyamjvs
4 сент. 2017
Я запускал тесты локально на kubemark-500 против головы (commit ffed1d340843ed), и все прошло нормально с низкими значениями задержки, как и раньше. Повторный запуск снова, чтобы проверить, не шелушится ли он. Я продолжу копаться завтра.
shyamjvs
4 сент. 2017
Если вы не включили все альфа-функции на kubemark, у вас не должно быть
наблюдается увеличение с разбивкой на страницы (что звучит как дальнейшее
расследование исключено). Если вы включили альфа-функции на kubemark
это именно та проверка, которую я искал с разбивкой на части (что нет
произошла регрессия), что хорошо. Разделение на части увеличит среднее
задержка, но в большинстве случаев она должна уменьшить задержку хвоста (наивное разбиение
увеличит количество ошибок).
В понедельник, 4 сентября 2017 г., в 17:23 Shyam JVS [email protected] написал:
Я запускал тесты локально на kubemark-500 против головы (коммит ffed1d3
https://github.com/kubernetes/kubernetes/commit/ffed1d340843ed5617a4bdfe5b16a9490476843a )
и все прошло нормально с низкими значениями задержки, как и раньше. Повторный запуск
еще раз, чтобы увидеть, не шелушится. Я продолжу копаться завтра.-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-327029719 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/ABG_p_ODR8S6ycmF1ppTOEZ8Bub3aVsaks5sfGpSgaJpZM4PL3gt
.
 smarterclayton
5 сент. 2017
smarterclayton
5 сент. 2017
Хорошо ... Итак, причина сбоя kubemark в другом. Как отметил @ wojtek-t, размер мастера kubemark не подходит.
Недавно я внес некоторые изменения в test-infra, касающиеся автоматического расчета мастер-размера kubemark, и, похоже, это не сработало.
shyamjvs
5 сент. 2017
Кстати, это также объясняет, почему сбой не воспроизводился для меня локально. Поскольку я обошел всю логику testinfra, запустив кластеры вручную, он был рассчитан правильно.
shyamjvs
5 сент. 2017
@smarterclayton Спасибо за объяснение. Я проверил, что ни в kubemark, ни в наших реальных кластерных тестах не используется разбивка на страницы (поскольку ?limit=1 по-прежнему возвращает все результаты).
Так что настоящие сбои при тестировании 5 тыс. Узлов кажутся не связанными с этим.
shyamjvs
5 сент. 2017
shyamjvs
7 сент. 2017
@ wojtek-t @shyamjvs : насколько здесь плохая ситуация? Все еще блокировщик выпуска?
Какую следующую теорию нужно проверить? (json-итератор против угоржи)
Благодаря,
Затемняет
 dims
14 сент. 2017
dims
14 сент. 2017
Это не так уж и плохо (мы видим пару запросов с высокой задержкой), но определенно наблюдается регресс. Это релиз-блокатор.
Ниже приведены вызовы API, не удовлетворяющие нашему SLO 1 с для 99-процентной задержки файла (из последнего запуска, то есть запуска № 34 - https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/ci-kubernetes -e2e-gce-scale-performance / 34):
I0914 00:49:55.355] Sep 14 00:49:55.354: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.894ms Perc90:1.485486s Perc99:5.108352s Perc100:0s} Count:311825}
I0914 00:49:55.356] Sep 14 00:49:55.354: INFO: WARNING Top latency metric: {Resource:configmaps Subresource: Verb:POST Latency:{Perc50:4.018ms Perc90:757.506ms Perc99:1.924344s Perc100:0s} Count:342}
Я заглянул в журналы apiserver и вижу следующую трассировку большого нет. звонков delete pod :
I0914 00:06:54.479459 8 trace.go:76] Trace[539192665]: "Delete /api/v1/namespaces/e2e-tests-density-30-32-wqj9b/pods/density150000-31-e5cb99f6-98b6-11e7-aeb5-0242ac110009-4mw6l" (started: 2017-09-14 00:06:48.217160315 +0000 UTC) (total time: 6.262275566s):
Trace[539192665]: [6.256412547s] [6.256412547s] About to delete object from database
Эта трассировка соответствует времени, прошедшему от начала функции обработчика ресурсов удаления до точки непосредственно перед вызовом удаления в хранилище, а точнее этого фрагмента кода - https://github.com/kubernetes/kubernetes/blob/9aef242a4c1e423270488206670d3d1f23eaab52/ staging / src / k8s.io / apiserver / pkg / endpoints / handlers / rest.go # L931 -L994.
Наиболее подозрительными для меня являются этап аудита и этап контроля допуска. Я пришлю PR, добавив следы и для этих шагов.
shyamjvs
15 сент. 2017
@shyamjvs Значит, мы можем переместить это за рубеж 1,8?
dims
18 сент. 2017
Если проблемы, которые вы видите, вызваны слиянием json-iterator по адресу # 48287
К вашему сведению: см. Ugorji / go @ 54210f4e076c57f351166f0ed60e67d3fca57a36
Существенные обновления производительности, которые приводят производительность без генерации кода в соответствие с тем, что вы получаете от json-iterator. мы сделали это, используя «небезопасный» только в очень намеченных местах, с тегом сборки для переключения в «небезопасный» режим. См. Helper_unsafe.go, чтобы увидеть единственные функции, в которых мы использовали unsafe, с эквивалентными «безопасными» версиями, чтобы вы успокоились.
Результаты прилагаются, но я воспроизведу вывод benchcmp, сравнивая результаты без codecgen, а затем с codecgen, здесь для удобства. Это было сделано с использованием набора тестов в https://github.com/ugorji/go-codec-bench , который использует рекурсивное встраивание большой подробной структуры. Цифры говорят сами за себя. Возможно, стоит вернуться раньше, чем позже.
go test -bench "_(Json|Cbor)" -benchmem -bd 2 -tags "x" > no-codecgen.bench.out.txt
go test -bench "_(Json|Cbor)" -benchmem -bd 2 -tags "x codecgen" > with-codecgen.bench.out.txt
benchcmp no-codecgen.bench.out.txt with-codecgen.bench.out.txt > benchcmp.out.txt
Полученные результаты:
benchmark old ns/op new ns/op delta
Benchmark__Cbor_______Encode-8 69672 37051 -46.82%
Benchmark__Json_______Encode-8 115274 87775 -23.86%
Benchmark__JsonIter___Encode-8 133558 133635 +0.06%
Benchmark__Std_Json___Encode-8 165240 157007 -4.98%
Benchmark__Cbor_______Decode-8 164396 131192 -20.20%
Benchmark__Json_______Decode-8 207014 156589 -24.36%
Benchmark__JsonIter___Decode-8 209418 208993 -0.20%
Benchmark__Std_Json___Decode-8 553650 557783 +0.75%
benchmark old allocs new allocs delta
Benchmark__Cbor_______Encode-8 32 7 -78.12%
Benchmark__Json_______Encode-8 45 20 -55.56%
Benchmark__JsonIter___Encode-8 1013 1013 +0.00%
Benchmark__Std_Json___Encode-8 560 560 +0.00%
Benchmark__Cbor_______Decode-8 713 697 -2.24%
Benchmark__Json_______Decode-8 756 736 -2.65%
Benchmark__JsonIter___Decode-8 2244 2244 +0.00%
Benchmark__Std_Json___Decode-8 1967 1967 +0.00%
benchmark old bytes new bytes delta
Benchmark__Cbor_______Encode-8 5529 2320 -58.04%
Benchmark__Json_______Encode-8 6290 3072 -51.16%
Benchmark__JsonIter___Encode-8 40496 40496 +0.00%
Benchmark__Std_Json___Encode-8 65248 65248 +0.00%
Benchmark__Cbor_______Decode-8 34384 34104 -0.81%
Benchmark__Json_______Decode-8 42976 42608 -0.86%
Benchmark__JsonIter___Decode-8 60128 60128 +0.00%
Benchmark__Std_Json___Decode-8 58320 58320 +0.00%
benchcmp.out.txt
no-codecgen.bench.out.txt
с-codecgen.bench.out.txt
 ugorji
19 сент. 2017
ugorji
19 сент. 2017
Обратите внимание, что в этих пакетах не должно использоваться JSON, и если он
это само по себе ошибка.
Мы должны использовать protobuf для всех внутрикластерных вызовов, кроме мусора.
сборник на CRD и дополнительных ресурсах.
smarterclayton
19 сент. 2017
@smarterclayton - Я считаю, что мы делаем патчи через JSON, не так ли?
gmarek
19 сент. 2017
Патчи никогда не декодировались с помощью ugorji, поэтому переключатель json-iterator не повлиял бы на него, а применение стратегических патчей слияния выполняется на промежуточных объектах map [string] interface {}, а не на JSON.
 liggitt
19 сент. 2017
liggitt
19 сент. 2017
Я не думаю, что изменение ugorji вызывает регресс (хотя я изначально подозревал это) - например, рассмотрим вызовы patch node-status (который является основным показателем регрессии), и эти вызовы сделаны kubelet и npd, оба используют protobufs для общения с apiserver. Кроме того, как подтвердили @smarterclayton и @liggitt , это обычные внутрикластерные вызовы (без CRD / расширения), используемые со стратегическим исправлением слияния.
shyamjvs
19 сент. 2017
Я изучил это сегодня и вот что нашел:
- Мы начали замечать увеличение задержек после запуска 27 нашего задания производительности 5k (https://k8s-testgrid.appspot.com/google-gce-scale#gce-scale-performance). Последним работоспособным запуском был запуск-23 (у которого были нормальные задержки). Вот разница коммитов между прогонами (немного огромная) - https://github.com/kubernetes/kubernetes/compare/11299e363c538c...034c40be6f465d
- При каждом запуске, начиная с 27 года, вызовы api, нарушающие SLO, менялись (если это
POST configmaps, тоPOST replicationcontrollersи т. Д.). Однако задержкаPATCH node statusкажется постоянно плохой во всех прогонах.
В прогоне 23 это 99% ile было 55 мс (в прогоне 18 было ~ 200 мс, что все еще немного):
INFO: Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.22ms Perc90:9.449ms Perc99:55.588ms Perc100:0s} Count:7033941}
а в прогоне-27 (следующий полезный прогон) это 99-й% выстрел до более чем 1 с (увеличение на порядок):
INFO: WARNING Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:4.186ms Perc90:83.292ms Perc99:1.061816s Perc100:0s} Count:7063581}
и с тех пор он оставался таким высоким. В журналах apiserver я нашел много таких следов для этих вызовов:
I0918 20:24:52.548401 7 trace.go:76] Trace[176777519]: "GuaranteedUpdate etcd3: *api.Node" (started: 2017-09-18 20:24:51.709667942 +0000 UTC) (total time: 838.710254ms):
Trace[176777519]: [838.643838ms] [837.934826ms] Transaction committed
И из кода, который кажется временем, потраченным ч / б, когда транзакция была подготовлена и когда она была зафиксирована. Точнее этот фрагмент кода:
https://github.com/kubernetes/kubernetes/blob/a238fbd2539addc525bb740ae801a42524e5b706/staging/src/k8s.io/apiserver/pkg/storage/etcd3/store.go#L350 -L362
@liggitt @smarterclayton @sttts @ deads2k - Есть ли что-нибудь,
shyamjvs
19 сент. 2017
cc @ kubernetes / kubernetes-release- manager @jdumars @dims - это явный регресс, который мы наблюдаем здесь, и определенно должны заблокировать его выпуск (как обсуждалось на сегодняшнем совещании по Burndown).
shyamjvs
19 сент. 2017
Есть ли что-нибудь, связанное с изменением статуса патч-узла в последнее время? В частности, мы начали использовать для них гарантированные обновления etcd3 или вы думаете, что это что-то еще?
все обновления (патч, обновление, постепенное удаление и т. д.) скрыто используют GuaranteedUpdate. Это не изменилось. Разве мы не можем еще больше сузить диапазон фиксации? Изменили ли мы версии etcd в этом диапазоне?
liggitt
19 сент. 2017
Я думаю, что @ wojtek-t оптимизировал путь к патчу.
gmarek
20 сент. 2017
@shyamjvs вы упомянули, что вчера на собрании вы хотели поделиться некоторыми данными? Ближе ли мы к пониманию того, что нам для этого нужно делать?
dims
20 сент. 2017
483ee1853b - второстепенный, который будет вызываться во время ряда потоков.
В среду, 20 сентября 2017 г., в 10:45, Даванум Шринивас < [email protected]
написал:
@shyamjvs https://github.com/shyamjvs вы упоминали, что были некоторые
данные, которыми вы хотели поделиться вчера на встрече? Мы ближе к
выяснить, что нам для этого нужно сделать?-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
21 сент. 2017
Мы не включали a4542ae528 по умолчанию, верно?
В четверг, 21 сентября 2017 г., в 00:24 , Клейтон Коулман
написал:
483ee1853b - второстепенный, который будет вызываться во время ряда потоков.
В среду, 20 сентября 2017 г., в 10:45, Даванум Шринивас <
[email protected]> написал:@shyamjvs https://github.com/shyamjvs вы упоминали, что были некоторые
данные, которыми вы хотели поделиться вчера на встрече? Мы ближе к
выяснить, что нам для этого нужно сделать?-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
21 сент. 2017
9002dfcd0a Я не могу поверить, что это приведет к задержке хвоста (больше похоже на
базовая задержка)
В четверг, 21 сентября 2017 г., в 00:25, Клейтон Коулман [email protected]
написал:
Мы не включали a4542ae528 по умолчанию, верно?
В четверг, 21 сентября 2017 г., в 00:24 , Клейтон Коулман
написал:483ee1853b - второстепенный, который будет вызываться во время ряда потоков.
В среду, 20 сентября 2017 г., в 10:45, Даванум Шринивас <
[email protected]> написал:@shyamjvs https://github.com/shyamjvs вы упоминали, что были некоторые
данные, которыми вы хотели поделиться вчера на встрече? Мы ближе к
выяснить, что нам для этого нужно сделать?-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
21 сент. 2017
Простой способ проверить содержимое json-iter - полностью отключить его (вернуться
to json.Unmarshal) и посмотрите, не ухудшаются ли значения задержки.
В четверг, 21 сентября 2017 г., в 00:27, Клейтон Коулман [email protected]
написал:
9002dfcd0a Я не могу поверить, что это приведет к задержке хвоста (больше похоже на
базовая задержка)В четверг, 21 сентября 2017 г., в 00:25, Клейтон Коулман [email protected]
написал:Мы не включали a4542ae528 по умолчанию, верно?
В четверг, 21 сентября 2017 г., в 00:24 , Клейтон Коулман
написал:483ee1853b - второстепенный, который будет вызываться во время ряда потоков.
В среду, 20 сентября 2017 г., в 10:45, Даванум Шринивас <
[email protected]> написал:@shyamjvs https://github.com/shyamjvs вы упоминали, что были некоторые
данные, которыми вы хотели поделиться вчера на встрече? Мы ближе к
выяснить, что нам для этого нужно сделать?-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
21 сент. 2017
Мы получаем конкуренцию за мьютекс на d3546434b7?
В четверг, 21 сентября 2017 г., в 00:28, Клейтон Коулман [email protected]
написал:
Простой способ проверить содержимое json-iter - полностью отключить его (вернуться
to json.Unmarshal) и посмотрите, не ухудшаются ли значения задержки.В четверг, 21 сентября 2017 г., в 00:27, Клейтон Коулман [email protected]
написал:9002dfcd0a Я не могу поверить, что это приведет к задержке хвоста (больше похоже на
базовая задержка)В четверг, 21 сентября 2017 г., в 00:25, Клейтон Коулман [email protected]
написал:Мы не включали a4542ae528 по умолчанию, верно?
В четверг, 21 сентября 2017 г., в 00:24 , Клейтон Коулман
написал:483ee1853b - второстепенный, который будет вызываться во время ряда потоков.
В среду, 20 сентября 2017 г., в 10:45, Даванум Шринивас <
[email protected]> написал:@shyamjvs https://github.com/shyamjvs вы упоминали, что
какие данные вы хотели поделиться вчера на встрече? Мы ближе
чтобы выяснить, что нам для этого нужно сделать?-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
21 сент. 2017
Еще есть изменения client-go a804d440c3 - не помню насколько хорошо
они ограничены, но, возможно, это влияет на другие вызовы.
В четверг, 21 сентября 2017 г., в 00:29, Клейтон Коулман [email protected]
написал:
Мы получаем конкуренцию за мьютекс на d3546434b7?
В четверг, 21 сентября 2017 г., в 00:28, Клейтон Коулман [email protected]
написал:Простой способ проверить содержимое json-iter - полностью отключить его (вернуться
to json.Unmarshal) и посмотрите, не ухудшаются ли значения задержки.В четверг, 21 сентября 2017 г., в 00:27, Клейтон Коулман [email protected]
написал:9002dfcd0a Я не могу поверить, что это приведет к задержке хвоста (подробнее
как базовая задержка)В четверг, 21 сентября 2017 г., в 00:25, Клейтон Коулман [email protected]
написал:Мы не включали a4542ae528 по умолчанию, верно?
В четверг, 21 сентября 2017 г., в 00:24 , Клейтон Коулман
написал:483ee1853b - второстепенный, который будет вызываться во время ряда
потоки.В среду, 20 сентября 2017 г., в 10:45, Даванум Шринивас <
[email protected]> написал:@shyamjvs https://github.com/shyamjvs вы упоминали, что
какие данные вы хотели поделиться вчера на встрече? Мы ближе
чтобы выяснить, что нам для этого нужно сделать?-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
21 сент. 2017
02281898f8 вряд ли добавит много работы серверу api, но будет
некоторые из упомянутых ресурсов и только создают место.
В четверг, 21 сентября 2017 г., в 00:31 , Клейтон Коулман
написал:
Еще есть изменения client-go a804d440c3 - не помню насколько хорошо
они ограничены, но, возможно, это влияет на другие вызовы.В четверг, 21 сентября 2017 г., в 00:29, Клейтон Коулман [email protected]
написал:Мы получаем конкуренцию за мьютекс на d3546434b7?
В четверг, 21 сентября 2017 г., в 00:28, Клейтон Коулман [email protected]
написал:Простой способ проверить материал json-iter - полностью отключить его (перейти
вернемся к json.Unmarshal) и посмотрите, не ухудшаются ли показатели задержки.В четверг, 21 сентября 2017 г., в 00:27, Клейтон Коулман [email protected]
написал:9002dfcd0a Я не могу поверить, что это приведет к задержке хвоста (подробнее
как базовая задержка)В четверг, 21 сентября 2017 г., в 00:25, Клейтон Коулман [email protected]
написал:Мы не включали a4542ae528 по умолчанию, верно?
В четверг, 21 сентября 2017 г., в 00:24, Клейтон Коулман < [email protected]
написал:
483ee1853b - второстепенный, который будет вызываться во время ряда
потоки.В среду, 20 сентября 2017 г., в 10:45, Даванум Шринивас <
[email protected]> написал:@shyamjvs https://github.com/shyamjvs вы упоминали, что
какие данные вы хотели поделиться вчера на встрече? Мы ближе
чтобы выяснить, что нам для этого нужно сделать?-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-330874607 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/ABG_p-zsFvKci3NlSZ2tAn92JgN5xrg-ks5skSUHgaJpZM4PL3gt
.
smarterclayton
21 сент. 2017
@shyamjvs @gmarek @smarterclayton К вашему сведению, это выглядит как наиболее вероятная причина задержки 1.8.0. Как я или команда разработчиков могу вам помочь?
 jdumars
21 сент. 2017
jdumars
21 сент. 2017
Согласитесь, это, вероятно, должно заблокировать выпуск. Чем я могу помочь?
 thockin
21 сент. 2017
thockin
21 сент. 2017
Даже тот, кто может помочь сделать механическое деление пополам, вероятно,
Помогите. Я не думаю, что у нас есть минимальный репродуктор, который
усложняя это.
В четверг, 21 сентября 2017 г., в 11:24, Тим Хокин [email protected]
написал:
Согласитесь, это, вероятно, должно заблокировать выпуск. Чем я могу помочь?
-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-331191088 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/ABG_p2O2uX8YFJCns2lq0lKJcACCJG9hks5skn_IgaJpZM4PL3gt
.
smarterclayton
21 сент. 2017
@smarterclayton Большое спасибо за обнаружение этих крайнем случае я попробую запустить тесты с
Я подозреваю, что это потому, что мы тестируем с увеличенным qps для apiserver (--max-requests-inflight = 3000 --max-mutating-requests-inflight = 1000), что вдвое превышает то, что мы используем для kubemark ( где задержка кажется нормальной , хотя сам тест не проходит по другой причине). Сейчас экспериментирую с более низким значением qps.
shyamjvs
21 сент. 2017
@smarterclayton / @lavalamp Может ли кто-нибудь из вас lgtm https://github.com/kubernetes/kubernetes/pull/52732 хотя бы удалить фальшивые нарушения?
shyamjvs
21 сент. 2017
Мы получаем конкуренцию за мьютекс на d354643?
Я так не думаю, но если конкуренция за чтение становится проблемой, я сделал версию без блокировки по адресу https://github.com/kubernetes/kubernetes/pull/52860.
liggitt
21 сент. 2017
Хорошо .. Я проверил с уменьшенным qps, но все еще вижу вызовы с высокой задержкой в тесте плотности:
I0921 21:43:02.755] Sep 21 21:43:02.754: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Scope:namespace Latency:{Perc50:5.572ms Perc90:1.529239s Perc99:7.868101s Perc100:0s} Count:338819}
I0921 21:43:02.755] Sep 21 21:43:02.754: INFO: WARNING Top latency metric: {Resource:configmaps Subresource: Verb:POST Scope:namespace Latency:{Perc50:3.852ms Perc90:1.152249s Perc99:3.848893s Perc100:0s} Count:340}
Я вернусь к исходному qps и начну вручную делить пополам и тестировать. Провел бы только тест плотности, чтобы сэкономить время.
shyamjvs
22 сент. 2017
@ kubernetes / test-infra-Maintainers Я получаю следующую ошибку при запуске go run hack/e2e.go -v -test :
Running Suite: Kubernetes e2e suite
===================================
Random Seed: 1506095473 - Will randomize all specs
Will run 1 of 678 specs
Sep 22 17:51:14.149: INFO: Fetching cloud provider for "gce"
I0922 17:51:14.201332 22354 gce.go:584] Using DefaultTokenSource <nil>
Sep 22 17:51:14.201: INFO: Failed to setup provider config: Error building GCE/GKE provider: google: could not find default credentials. See https://developers.google.com/accounts/docs/application-default-credentials for more information.
Failure [0.057 seconds]
[BeforeSuite] BeforeSuite
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/test/e2e/e2e.go:240
Sep 22 17:51:14.201: Failed to setup provider config: Error building GCE/GKE provider: google: could not find default credentials. See https://developers.google.com/accounts/docs/application-default-credentials for more information.
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/test/e2e/e2e.go:141
Есть идеи, почему я это вижу? Мой k8s был построен против фиксации 11299e363.
shyamjvs
22 сент. 2017
fyi - go run hack/e2e.go -v -up отлично работает.
shyamjvs
22 сент. 2017
Кто-нибудь смотрел вызовы PUT? Самая очевидная вещь, которая может быть неправильной (я думаю), - это что-то новое / измененное на узлах, которое изменяет статус узла через PUT и последовательно выигрывает гонку с помощью патчей kubelet.
 lavalamp
22 сент. 2017
lavalamp
22 сент. 2017
Гипотетические дополнительные вызовы PUT не будут иметь большой задержки (поскольку они просто получат конфликты, если проиграют гонку). Этого также не произойдет в kubemark, если предположить, что преступником является не-kubelet сущность. Кажется, это согласуется со всем, что указано в этой ошибке, хотя уследить за ней довольно сложно.
lavalamp
22 сент. 2017
Может ли кто-нибудь дать ссылку на тестовый запуск, содержащий проблему, чтобы я мог прочитать журнал apiserver?
lavalamp
22 сент. 2017
@shyamjvs Думаю, вам может понадобиться запустить gcloud auth application-default login .
 ixdy
22 сент. 2017
ixdy
22 сент. 2017
(вам нужно запустить как gcloud auth login и gcloud auth application-default login причинам.)
ixdy
22 сент. 2017
Другая похожая гипотеза заключается в том, что теперь детектор проблем узла и kubelet пытаются изменить одно и то же поле, поэтому возникла новая конкуренция, даже если это одинаковое количество вызовов исправлений.
lavalamp
22 сент. 2017
Просматривая журналы, я действительно вижу, что контроллер узла получает кучу конфликтов при путях:
I0922 09:02:23.479636 7 wrap.go:42] PUT /api/v1/nodes/gce-scale-cluster-minion-group-3-dpvj/status: (1.235319ms) 409 [[kube-controller-manager/v1.9.0 (linux/amd64) kubernetes/158f6b7/system:serviceaccount:kube-system:node-controller] [::1]:54918]
Вот несколько PR, которые касались NodeController и / или controller_utils.go, от самых последних до наименее
https://github.com/kubernetes/kubernetes/pull/51603 (объединено 6 сентября)
https://github.com/kubernetes/kubernetes/pull/49257 (объединено 31 августа)
https://github.com/kubernetes/kubernetes/pull/50738 (объединено 29 августа)
https://github.com/kubernetes/kubernetes/pull/49524 (объединено 7 августа)
https://github.com/kubernetes/kubernetes/pull/49870 (объединено 1 августа)
https://github.com/kubernetes/kubernetes/pull/47952 (объединено 12 июля)
Теоретически все это должно быть отключено по умолчанию (кроме первого, которое является исправлением ошибки), см.
https://github.com/kubernetes/kubernetes/pull/49547
Однако я не проверял ни одного из этих PR.
/ cc @gmarek @ k82cn
 davidopp
22 сент. 2017
davidopp
22 сент. 2017
@ixdy Большое спасибо за предложение, которое сработало. Запуск теста с последней фиксацией, которая казалась здоровой для подтверждения.
Кто-нибудь смотрел вызовы PUT?
@lavalamp Я полагаю, вы имеете в виду вызовы PUT для etcd (потому что из журналов apiserver я вижу только патчи). Не могли бы вы сказать мне, как я могу проверить звонки PUT?
что-то новое / измененное на узлах, которое изменяет статус узла через PUT и постоянно выигрывает гонку с помощью патчей kubelet.
Я не вижу никаких PUT для статуса узла из журналов apiserver. Это npd и kubelet, которые обновляют их (почти все время), и они оба используют PATCH:
I0918 17:05:58.357710 7 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-554x/status: (2.195508ms) 200 [[node-problem-detector/v1.4.0 (linux/amd64) kubernetes/$Format] 35.190.133.106:55912]
I0918 17:06:01.312183 7 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-7sbx/status: (67.75199ms) 200 [[kubelet/v1.9.0 (linux/amd64) kubernetes/8ca1d9f] 35.196.121.123:51702]
I0918 17:05:58.359507 7 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-1-j446/status: (3.796612ms) 200 [[node-problem-detector/v1.4.0 (linux/amd64) kubernetes/$Format] 35.185.60.137:43894]
I0918 17:06:01.312296 7 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-1-b113/status: (67.888708ms) 200 [[kubelet/v1.9.0 (linux/amd64) kubernetes/8ca1d9f] 35.196.142.250:35162]
Может ли кто-нибудь дать ссылку на тестовый запуск, содержащий проблему, чтобы я мог прочитать журнал apiserver?
Практически все последние несколько запусков теста содержат проблему. Например, вы можете взглянуть на https://storage.googleapis.com/kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/36/artifacts/gce-scale-cluster-master/kube -apiserver.log, который является хорошим примером (из run-36 )
Другая похожая гипотеза заключается в том, что теперь детектор проблем узла и kubelet пытаются изменить одно и то же поле, поэтому возникла новая конкуренция, даже если это одинаковое количество вызовов исправлений.
Думаю, так было и раньше. Например, мы наблюдали это даже в последней версии - https://github.com/kubernetes/node-problem-detector/issues/124. Вы имели в виду что-то еще?
.
shyamjvs
22 сент. 2017
@jpbetz предложил (в другом потоке) включить pprof для etcd, чтобы узнать больше об операциях со стороны etcd. Кто-нибудь знает, есть ли простой способ добавить тестовые аргументы в etcd (я нахожу KUBE_APISERVER_TEST_ARGS, KUBE_SCHEDULER_TEST_ARGS и т. Д., Но ничего подобного ETCD_TEST_ARGS в config-test.sh ).
shyamjvs
22 сент. 2017
@shyamjvs Просто чтобы помочь вам устранить некоторые возможности. :)
Мы не обновляли версию NPD в этом выпуске, это означает, что сам NPD не меняется с 1.7 на 1.8. Что касается сценария запуска, единственное заметное изменение, которое я вижу, - это использование предварительно загруженного архива NPD вместо загрузки в полете, что, я не думаю, может вызвать эту проблему.
 Random-Liu
23 сент. 2017
Random-Liu
23 сент. 2017
@shyamjvs Я цитировал запись PUT в моем последнем обновлении. Однако у меня не было времени убедиться, что это причина.
Если NPD ничего не изменил, возможно, обновление статуса kubelet теперь включает конфликтующее поле? Мы могли бы рассмотреть возможность включения строки отладки для печати содержимого медленного запроса.
lavalamp
23 сент. 2017
Ага .. Видел это. Но эти вызовы от диспетчера-контроллера очень редки по сравнению с патчами от kubelet и npd. Я проверил, что в одном из прогонов было что-то вроде 4000 PUT по сравнению с 6 миллионами PATCH, и это тоже происходило всего на пару минут дважды во время теста, что вряд ли должно повлиять на 99% файла.
shyamjvs
23 сент. 2017
Обновление: я подтвердил, что фиксация 11299e3 работоспособна со следующими максимальными задержками (которые все кажутся нормальными):
Sep 23 02:00:18.611: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:154.43ms Perc90:1.527089s Perc99:3.977228s Perc100:0s} Count:11429}
Sep 23 02:00:18.611: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:330.336ms Perc90:372.868ms Perc99:865.299ms Perc100:0s} Count:1642}
Sep 23 02:00:18.611: INFO: Top latency metric: {Resource:configmaps Subresource: Verb:PATCH Latency:{Perc50:1.541ms Perc90:6.507ms Perc99:180.346ms Perc100:0s} Count:184}
Sep 23 02:00:18.611: INFO: Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.344ms Perc90:9.737ms Perc99:78.242ms Perc100:0s} Count:6521257}
Sep 23 02:00:18.611: INFO: Top latency metric: {Resource:configmaps Subresource: Verb:POST Latency:{Perc50:3.861ms Perc90:5.871ms Perc99:28.857ms Perc100:0s} Count:184}
Run-27 (commit 034c40be6f46) был нездоровым. Так что теперь мы уверены в ассортименте.
shyamjvs
23 сент. 2017
51603 (объединено 6 сентября) - нет операции (исправляет порядок инициализации)
49257 (объединено 31 августа) - нет операции на нормальных кластерах (флаг заблокирован)
50738 (объединено 29 августа) - нет операции (я думаю - заменяет старый deepCopy новым deepCopy)
49524 (объединено 7 августа) - нет операции (добавляет возможность добавлять / удалять несколько заражений в вспомогательных функциях)
49870 (объединено 1 августа) - нет операции (переименование переменной)
47952 (объединено 12 июля) - нет операции (напрямую не изменяет вызовы API, косвенно может изменять только удаление Pod)
Короче говоря, я не верю, что NC изменил свое поведение без флагов в этом выпуске.
gmarek
23 сент. 2017
OTOH мы наблюдали конфликты обновлений из-за NC, когда узлы умирали из-за OOM (коллизии с NPD / Kubelet).
gmarek
23 сент. 2017
Коммит 99a9ee5a3c неработоспособен:
Sep 23 18:14:04.314: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:1.1407s Perc90:3.400196s Perc99:5.078185s Perc100:0s} Count:14832}
Sep 23 18:14:04.314: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:408.691ms Perc90:793.079ms Perc99:1.831115s Perc100:0s} Count:1703}
Sep 23 18:14:04.314: INFO: WARNING Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:4.134ms Perc90:103.428ms Perc99:1.139633s Perc100:0s} Count:7396342}
Sep 23 18:14:04.314: INFO: Top latency metric: {Resource:services Subresource: Verb:LIST Latency:{Perc50:1.057ms Perc90:5.84ms Perc99:474.047ms Perc100:0s} Count:511}
Sep 23 18:14:04.314: INFO: Top latency metric: {Resource:replicationcontrollers Subresource: Verb:LIST Latency:{Perc50:869µs Perc90:14.563ms Perc99:436.187ms Perc100:0s} Count:405}
Новый ассортимент - https://github.com/kubernetes/kubernetes/compare/11299e363c538c...99a9ee5a3c52
shyamjvs
24 сент. 2017
Коммит cbe5f38ed2 нездоров:
Sep 24 06:03:04.941: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:929.743ms Perc90:3.064274s Perc99:4.745392s Perc100:0s} Count:15353}
Sep 24 06:03:04.941: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:393.741ms Perc90:774.697ms Perc99:2.335875s Perc100:0s} Count:1859}
Sep 24 06:03:04.941: INFO: WARNING Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.742ms Perc90:93.829ms Perc99:1.108202s Perc100:0s} Count:8252670}
Sep 24 06:03:04.941: INFO: Top latency metric: {Resource:configmaps Subresource: Verb:POST Latency:{Perc50:3.778ms Perc90:123.878ms Perc99:650.641ms Perc100:0s} Count:210}
Sep 24 06:03:04.941: INFO: Top latency metric: {Resource:endpoints Subresource: Verb:GET Latency:{Perc50:476µs Perc90:37.661ms Perc99:365.414ms Perc100:0s} Count:13008}
Новый ассортимент - https://github.com/kubernetes/kubernetes/compare/11299e363c538c...cbe5f38ed21
shyamjvs
24 сент. 2017
Примечательные вещи в этом диапазоне:
- Версия GCI изменена - https://github.com/kubernetes/kubernetes/commit/9fb015987b70ca84eff5694660f1dba701d10e92
- формат аудита изменен на JSON - https://github.com/kubernetes/kubernetes/commit/130f5d10adf13492f3435ab85a50d357a6831f6e
- проверка плагина гибкого тома стала динамической - https://github.com/kubernetes/kubernetes/commit/396c3c7c6fd008663d2d30369c8e33a58cde5ee2
liggitt
24 сент. 2017
Коммит a235ba4e49 является нездоровым:
Sep 24 17:19:21.433: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:61.762ms Perc90:737.617ms Perc99:7.748733s Perc100:0s} Count:7430}
Sep 24 17:19:21.434: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:401.766ms Perc90:913.101ms Perc99:2.586065s Perc100:0s} Count:1151}
Sep 24 17:19:21.434: INFO: WARNING Top latency metric: {Resource:replicationcontrollers Subresource: Verb:POST Latency:{Perc50:3.072ms Perc90:378.118ms Perc99:1.277634s Perc100:0s} Count:5050}
Sep 24 17:19:21.434: INFO: WARNING Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.946ms Perc90:175.392ms Perc99:1.05636s Perc100:0s} Count:5239031}
Sep 24 17:19:21.434: INFO: Top latency metric: {Resource:resourcequotas Subresource: Verb:LIST Latency:{Perc50:924µs Perc90:287.15ms Perc99:960.978ms Perc100:0s} Count:3003}
Новый ассортимент - https://github.com/kubernetes/kubernetes/compare/11299e363c538c...a235ba4e49451c779b8328378addf0d7bd7b84fd
shyamjvs
24 сент. 2017
/ me делает ставку на 130f5d1
dims
24 сент. 2017
Политика аудита должна пропускать запись содержимого ответа для тех, кто:
похоже, что захват журнала не сохранял журнал аудита, поэтому я не уверен, что на самом деле там записывалось ... открыл https://github.com/kubernetes/kubernetes/pull/52960, чтобы сохранить его
liggitt
24 сент. 2017
просмотрел журнал аудита, записанный kubemark на https://github.com/kubernetes/kubernetes/pull/52960
похоже, что единственные неожиданно большие строки аудита, которые регистрируются, - это вызовы deletecollection для объектов, которые регистрируют весь возвращенный набор удаленных объектов ... Я мог бы увидеть случай для их регистрации, поскольку это мутация этих объектов и позволяет отслеживать жизненный цикл объекта. но это были даже не звонки с проблемами задержки
liggitt
25 сент. 2017
Коммит c04e516373 исправен:
Sep 25 03:47:20.967: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Latency:{Perc50:178.225ms Perc90:1.455523s Perc99:3.071804s Perc100:0s} Count:11585}
Sep 25 03:47:20.967: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Latency:{Perc50:351.796ms Perc90:393.656ms Perc99:778.841ms Perc100:0s} Count:1754}
Sep 25 03:47:20.967: INFO: Top latency metric: {Resource:nodes Subresource:status Verb:PATCH Latency:{Perc50:3.218ms Perc90:10.25ms Perc99:62.412ms Perc100:0s} Count:6976580}
Sep 25 03:47:20.967: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:896µs Perc90:6.393ms Perc99:26.436ms Perc100:0s} Count:764169}
Sep 25 03:47:20.967: INFO: Top latency metric: {Resource:pods Subresource: Verb:GET Latency:{Perc50:485µs Perc90:992µs Perc99:18.87ms Perc100:0s} Count:1255153}
Новый ассортимент - https://github.com/kubernetes/kubernetes/compare/c04e516373...a235ba4e49451c779b8328378addf0d7bd7b84fd
shyamjvs
25 сент. 2017
Думаю, это изменение аудита json - подтвердю.
Я помню из одной из трассировок (удаление pods iirc), что аудит был частью блока кода, который занимал почти все время. Возможно, это также объясняет, почему мы наблюдаем рост числа мутирующих вызовов.
shyamjvs
25 сент. 2017
Изменение аудита не входило в диапазон https://github.com/kubernetes/kubernetes/compare/11299e363c538c...c04e516373 ?
liggitt
25 сент. 2017
Это другая половина, в которой есть ошибка.
shyamjvs
25 сент. 2017
В моем исходном комментарии был неправильный диапазон, я сразу исправил - извините.
shyamjvs
25 сент. 2017
Обновить:
- Из указанного выше диапазона подозрительными PR являются:
- установите --audit-log-format по умолчанию на json # 50971
- Обновить образ cos до cos-stable-60-9592-84-0 # 51207
- Скорее всего, это первый, так как изменяющиеся запросы - это те, которые были затронуты (и они проходят путь кода журнала аудита). Кроме того, в kubemark не включается ведение журнала аудита (где мы не видим этой проблемы), что еще больше усиливает ее.
- В настоящее время я проверяю на месте, что отмену исправлений PR - результат должен быть известен через 2-3 часа
shyamjvs
25 сент. 2017
@shyamjvs , это обновление образа COS также обновило докер (с 1.11 до 1.13), что имело некоторое влияние на производительность - @ yguo0905 может оценить, насколько это актуально. Если это выглядит подозрительно, вы можете попробовать запустить тест на новом образе COS ( cos-stable-61-9765-66-0 ), в котором есть docker 17.03, который имел более благоприятную производительность.
 abgworrall
25 сент. 2017
abgworrall
25 сент. 2017
это обновление образа COS также обновило докер (с 1.11 до 1.13), что оказало некоторое влияние на производительность
docker perf, вероятно, не повлияет на задержку сервера API
liggitt
25 сент. 2017
Да ... Как я уже упоминал на канале Slack, проблема, которую мы здесь видим, связана с apiserver. Кроме того, мы используем новый образ COS в kubemark (который работает нормально).
shyamjvs
25 сент. 2017
@shyamjvs Вы можете отключить ведение журнала аудита для крупномасштабных тестов GCE, пока не будет исправлено https://github.com/kubernetes/kubernetes/issues/53006 . Для этого нужно изменить файл cluster/gce/config-test.sh : переключить ENABLE_APISERVER_ADVANCED_AUDIT на false или полностью отключить его.
 crassirostris
25 сент. 2017
crassirostris
25 сент. 2017
Пара мыслей о падении производительности в результате аудита:
- Ведение журнала аудита не включено по умолчанию, его необходимо явно настроить (что мы и делаем в среде тестирования)
- AdavncedAuditing все еще находится в стадии бета-тестирования
- Конкретный выходной формат, вызывающий регрессию, можно настроить.
Имея это в виду, я склонен сказать, что мы должны просто задокументировать это как известную проблему и исправить ее в версии 1.9 (например, https://github.com/kubernetes/kubernetes/issues/53006).
 tallclair
25 сент. 2017
tallclair
25 сент. 2017
@shyamjvs Вы можете отключить ведение журнала аудита для крупномасштабных тестов GCE, пока # 53006 не будет исправлен.
(Как обсуждалось в Slack с @liggitt) Не уверен, что это лучший подход. Целью масштабного тестирования является проверка версии, а ее отключение означает, что мы ее не проверяем. Мы стараемся сохранить конфигурацию, с которой мы проводим масштабное тестирование, как можно ближе к настройкам по умолчанию.
Тем не менее, я могу жить с этой идеей. Однако было бы предпочтительно, чтобы он также был отключен по умолчанию в файлах config - *. Sh.
shyamjvs
25 сент. 2017
Мы стараемся сохранить конфигурацию, с которой мы проводим масштабное тестирование, как можно ближе к настройкам по умолчанию.
по умолчанию он отключен в не тестовом config-default.sh file
вы также можете установить env в env тестового задания. мы уже делаем это для тестов производительности, чтобы они соответствовали производственным или настраивали их так, как мы настраивали бы большие кластеры.
Я открыл https://github.com/kubernetes/kubernetes/pull/52998 (выбор 1,8 в https://github.com/kubernetes/kubernetes/pull/53012), чтобы уменьшить объем данных, отправляемых в журнал аудита.
Я также открыл https://github.com/kubernetes/test-infra/pull/4720, чтобы тесты производительности соответствовали производству (путем полного отключения аудита), и мы можем вернуться к этому в 1.9
liggitt
25 сент. 2017
Обновить:
- В конфигурациях Prod не включено ведение журнала аудита по умолчанию для версии 1.8, поэтому мы собираемся пропустить масштабное тестирование для этой версии.
- Мы не выбираем изменение политики аудита @liggitt на 1.8, поскольку мы все равно не проводим масштабное тестирование.
- Проблема масштабируемости будет решена в версии 1.9, когда мы @tallclair / @crassirostris - Может ли кто-нибудь из вас
shyamjvs
25 сент. 2017
Подал сообщение о проблеме: https://github.com/kubernetes/kubernetes/issues/53020
crassirostris
25 сент. 2017
Завершено задание производительности 5k на CI с отключенным аудитом. Ожидаем, что завтра будет зеленый пробег (надеюсь).
shyamjvs
25 сент. 2017
для тех, кто идет домой, тестовые прогоны проходят по адресу https://k8s-gubernator.appspot.com/builds/kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/
liggitt
26 сент. 2017
Итак ... проблема статуса патч-узла была решена с отключением журнала аудита, и ситуация выглядит намного лучше. Однако при последнем запуске модули удаления показали проблемы:
I0926 14:31:48.470] Sep 26 14:31:48.469: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Scope:namespace Latency:{Perc50:4.633ms Perc90:791.553ms Perc99:3.54603s Perc100:0s} Count:310018}
I0926 14:31:48.470] Sep 26 14:31:48.469: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Scope:namespace Latency:{Perc50:57.306ms Perc90:72.234ms Perc99:1.255s Perc100:0s} Count:10819}
I0926 14:31:48.470] Sep 26 14:31:48.469: INFO: Top latency metric: {Resource:nodes Subresource: Verb:LIST Scope:cluster Latency:{Perc50:409.094ms Perc90:544.723ms Perc99:1.016102s Perc100:0s} Count:2955}
I0926 14:31:48.471] Sep 26 14:31:48.469: INFO: Top latency metric: {Resource:pods Subresource: Verb:LIST Scope:cluster Latency:{Perc50:211.299ms Perc90:385.941ms Perc99:726.57ms Perc100:0s} Count:1216}
I0926 14:31:48.471] Sep 26 14:31:48.469: INFO: Top latency metric: {Resource:pods Subresource:binding Verb:POST Scope:namespace Latency:{Perc50:1.151ms Perc90:6.838ms Perc99:404.557ms Perc100:0s} Count:155009}
Журналы сейчас загружаются в GCS .. нужно подождать несколько минут.
shyamjvs
26 сент. 2017
что было удалением модулей в последнем работоспособном запуске (№ 23)?
liggitt
26 сент. 2017
Для запуска 23 это было 47,057 мс из журналов отклика
INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:5.11ms Perc90:33.011ms Perc99:558.028ms Perc100:0s} Count:314894}
Мы знали, что фиксация c04e516 исправна, из https://github.com/kubernetes/kubernetes/issues/51899#issuecomment -331759561. Так что это должно быть в https://github.com/kubernetes/kubernetes/compare/c04e516373...a235ba4e49451c779b8328378addf0d7bd7b84fd (может быть, изменение изображения cos?).
Также ENABLE_ADVANCED_AUDIT_LOGGING=false прежнему выполняет базовое ведение журнала аудита?
shyamjvs
26 сент. 2017
Значит, это должно быть в c04e516 ... a235ba4 (может быть, изменилось изображение cos?).
Вызов API для удаления модуля не блокируется докером. Я мог видеть, что для завершения работы модуля требуется больше времени, но это не увеличивает задержку при фактических вызовах API.
Также, ENABLE_ADVANCED_AUDIT_LOGGING = false по-прежнему выполняет базовое ведение журнала аудита?
Нет. Это контролируется ENABLE_APISERVER_BASIC_AUDIT , по умолчанию false.
liggitt
26 сент. 2017
Имеет смысл. К сожалению, мы пропустили главные журналы из-за некоторых проблем с тестовой инфраструктурой (cc @ kubernetes / test-infra-Maintainers @krzyzacy), которые, как предполагается, должны быть скопированы из рабочего jenkins в GCS. Я не вижу следующих вызовов журнала сборки (что обычно бывает):
I0922 10:02:12.439] Call: gsutil ls gs://kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/39/artifacts
I0922 10:02:14.951] process 31483 exited with code 0 after 0.0m
I0922 10:02:14.953] Call: gsutil -m -q -o GSUtil:use_magicfile=True cp -r -c -z log,txt,xml artifacts gs://kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/39
I0922 10:05:21.167] process 31618 exited with code 0 after 3.1m
@liggitt Одна из причин, по которой я подозреваю, что это произошло, заключается в том, что вы разрешили копирование журналов аудита (которые довольно огромны).
shyamjvs
26 сент. 2017
@liggitt Одна из причин, по которой я подозреваю, что это произошло, заключается в том, что вы разрешили копирование журналов аудита (которые довольно огромны).
аудит отключен в этом env :)
liggitt
26 сент. 2017
Ах да ... журналов аудита совсем нет - извините.
shyamjvs
26 сент. 2017
Я изменю задание CI, чтобы запустить только тест плотности, и перезапущу его. У нас должно быть что-то через 3-4 часа.
shyamjvs
26 сент. 2017
Похоже, что текущий запуск также, скорее всего, завершится неудачей, поскольку я вижу следующую задержку для вызовов удаления модуля (в мкс):
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="",verb="DELETE",quantile="0.99"} 4.462881e+06
Судя по трассировкам, единственный напечатанный шаг (занимающий почти все время):
I0926 21:32:57.199705 7 trace.go:76] Trace[1024874778]: "Delete /api/v1/namespaces/e2e-tests-density-30-21-8gvt2/pods/density150000-20-3b9db35a-a2dd-11e7-b671-0242ac110004-bzsjl" (started: 2017-09-26 21:32:56.246437691 +0000 UTC) (total time: 953.24642ms):
Trace[1024874778]: [949.787883ms] [949.73031ms] About to delete object from database
И этот след, кажется, соответствует этой части кода:
https://github.com/kubernetes/kubernetes/blob/a3ab97b7f395e1abd2d954cd9ada0386629d0411/staging/src/k8s.io/apiserver/pkg/endpoints/handlers/rest.go#L944 -L1009
shyamjvs
27 сент. 2017
Я добавил несколько дополнительных трассировок в https://github.com/kubernetes/kubernetes/pull/52543 - но, думаю, мне следовало добавить их после шага, а не до шага (поскольку мы не получаем достаточно информация из текущей трассы, для какой части выше потребовалось максимальное время).
shyamjvs
27 сент. 2017
Запуск второго раунда деления пополам (с отключенной регистрацией аудита), чтобы поймать вторую регрессию. Надеюсь, это быстрее.
shyamjvs
27 сент. 2017
Коммит 150a560eed неработоспособен (я тестирую на кластере из 2k узлов):
Sep 27 14:34:14.484: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.551ms Perc90:10.216ms Perc99:1.403002s Perc100:0s} Count:122966}
Из моего предыдущего коммита пополам c04e516 был последним исправным, о котором мы знаем.
shyamjvs
27 сент. 2017
Фрагмент одного из всплесков удаления из https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/41/ (y - миллисекунды, x - время вызова API)
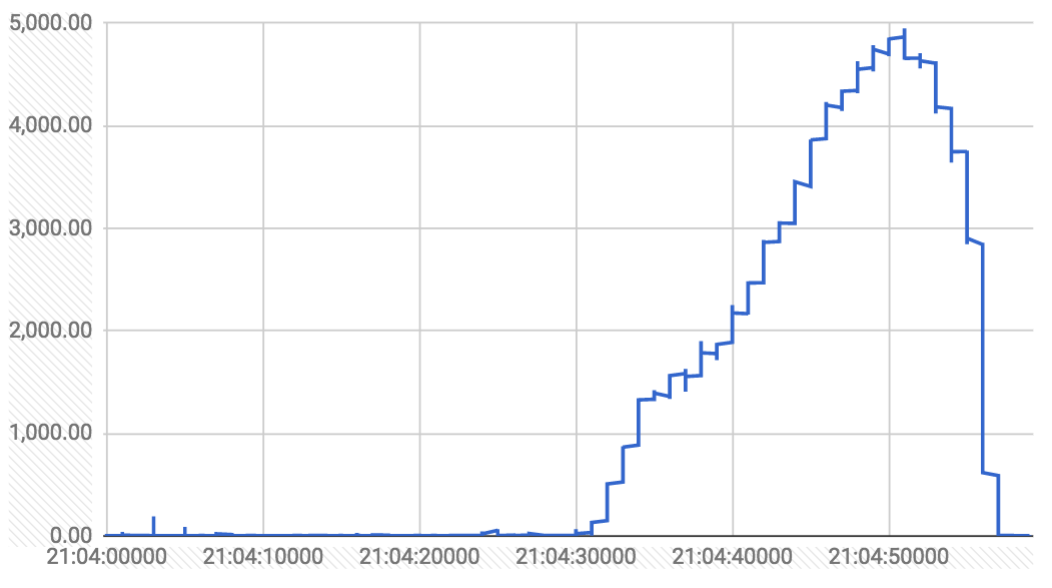
Я проверяю изменения для удаления обработки / хранения / допуска / сборки мусора в нездоровом диапазоне. Пока ничего не выскакивает.
Что интересно, так это распределение вызовов API удаления модуля в течение этой минуты:
- Первые 30 секунд:
- 63 тыс. Вызовов API
- 2146
delete podвызовов API - 1166, автор:
kube-controller-manager/v1.8.0 (linux/amd64) kubernetes/a3ab97b/system:serviceaccount:kube-system:generic-garbage-collector - 980 от
kubelet/v1.8.0 (linux/amd64) kubernetes/a3ab97b
- Вторые 30 секунд:
- Всего 55 тыс. Вызовов API
- 1371
delete podвызовов API - 1371, автор:
kubelet/v1.8.0 (linux/amd64) kubernetes/a3ab97b
сборщик мусора вызывает изящное удаление, вызовы kubelet фактически удаляют поды. первые 30 секунд задержка на вызовы удаления незначительна (1-100 мс), вторые 30 секунд задержка неуклонно растет.
Общее количество вызовов удаления выше в первые 30 секунд, а количество, которое фактически привело к удалению etcd, было сопоставимо со вторыми 30 секундами (980 против 1371).
liggitt
27 сент. 2017
сканирование завершено, нет очевидных проблем, связанных с модулями, удалением, допуском и т. д. или хранением в диапазоне aa50c0f ... 150a560
есть ли в kubemark 5k аналогичный шаблон «создать много модулей» / «удалить много запланированных модулей параллельно» для модулей? интересно, почему мы не видим там проблем с задержкой
liggitt
27 сент. 2017
К вашему сведению, у нас уже есть устное одобрение от Google через @abgworrall на то, чтобы эта проблема стала известной в версии 1.8.0 с оговорками. Мне нужна помощь в добавлении этого в # 53004, чтобы он был правильно описан для включения в примечания к выпуску. Через 2 часа я собираюсь снять ярлык блокировки выпуска, если не появится дополнительная информация, и нам нужно будет продолжать блокировку.
jdumars
27 сент. 2017
@liggitt Да, kubemark также запускает тот же тест, создавая аналогичный шаблон. Для любопытных - вкратце, в тесте плотности мы делаем следующее:
- Насыщение кластера 30 модулями на узел, т.е. мы создаем несколько RC, в сумме составляя
30 * #nodesмодулей - Затем мы создаем дополнительные
#nodes(в насыщенном кластере) для измерения задержек их запуска. - Затем мы удаляем эти дополнительные модули и модули насыщения и фиксируем показатели задержки вызова API.
интересно, почему мы не видим там проблем с задержкой
Может быть что-то из-за несоответствия основных конфигураций (https://github.com/kubernetes/kubernetes/issues/53021) или другого состава qps (sth создает дополнительные qps на реальных кластерах) или ..? Нужно вникнуть в него поглубже (актуальны https://github.com/kubernetes/kubernetes/issues/47544 и https://github.com/kubernetes/kubernetes/issues/47540).
@jdumars Подтверждено, что commit aa50c0f54c3 исправен:
Sep 27 16:34:11.638: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:3.669ms Perc90:6.723ms Perc99:19.735ms Perc100:0s} Count:124000}
Это явно регресс, и я не уверен, следует ли нам снимать блокировку выпуска. Хотя я могу жить, документируя это и исправляя в выпуске патча.
@thockin @smarterclayton Комментарии?
shyamjvs
27 сент. 2017
@abgworrall обсудил это внутри Google, и,
jdumars
27 сент. 2017
@jdumars, тогда можем ли мы переместить это за рубеж.
 grodrigues3
27 сент. 2017
grodrigues3
27 сент. 2017
Звучит неплохо. В соответствии с соглашением о слабине - как только исправление будет известно, мы перенесем его на версию 1.8.
shyamjvs
27 сент. 2017
Продолжая пополам ftw ... commit 6b9ce5ba110 здоров:
Sep 27 20:11:35.950: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.404ms Perc90:6.688ms Perc99:20.853ms Perc100:0s} Count:131492}
Новый диапазон: https://github.com/kubernetes/kubernetes/compare/6b9ce5ba1107f885998acfd0f5c2aad629e68fa1...150a560eed43a1e1dac47ee9b73af89226827565
shyamjvs
27 сент. 2017
Коммит 57c3c2c0b исправен:
Sep 27 22:09:19.792: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:3.792ms Perc90:6.777ms Perc99:19.745ms Perc100:0s} Count:124000}
Новый диапазон: https://github.com/kubernetes/kubernetes/compare/57c3c2c0bc3b24905ecab52b7b8a50d4b0e6bae2...150a560eed43a1e1dac47ee9b73af89226827565
Подозреваю следующий пиар (пока не присматриваюсь):
- Дождитесь очистки контейнера перед удалением # 50350
shyamjvs
27 сент. 2017
Чтобы быть ясным: мое словесное ОК было основано на: регрессии производительности, которая проявлялась только тогда, когда ведение журнала аудита было включено и настроено определенным образом.
Мне неясно, каковы масштабы регрессии удаления модулей, которая теперь стала видимой; влияет ли это на все большие кластеры по умолчанию? И каков эффект - в среднем увеличение на 25% или увеличение на 2500% при 99% ile, или как?
(Приносим извинения, если это поясняется ранее в этой ветке; но я бы очень признателен за резюме)
abgworrall
27 сент. 2017
- kubemark не сталкивается с этой проблемой, даже если он выполняет аналогичные шаблоны создания / удаления
- влияние лучше всего видно на https://github.com/kubernetes/kubernetes/issues/51899#issuecomment -332515008
liggitt
27 сент. 2017
@abgworrall Есть 2 проблемы:
- Увеличенные задержки для вызовов
patch node-status(и нескольких других вызовов), что было вызвано изменением журнала аудита на json. Мы решили это, отключив ведение журнала аудита в нашем масштабном тестировании (см. - https://github.com/kubernetes/kubernetes/issues/51899#issuecomment-331973754), и теперь проблема решена. - Увеличены задержки для вызовов
delete pods(20 мс -> 1,4 с), и в настоящее время я делю их пополам, используя кластер из 2k узлов. Я сузил диапазон фиксации до https://github.com/kubernetes/kubernetes/compare/57c3c2c0bc3b24905ecab52b7b8a50d4b0e6bae2...150a560eed43a1e1dac47ee9b73af89226827565. Необходимо подтвердить, является ли проблема нестабильной.
shyamjvs
27 сент. 2017
Хорошо .. Не похоже на хлопья. Второй раз провалился против 150a560:
Sep 28 01:54:50.933: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:5.031ms Perc90:2.082021s Perc99:6.116367s Perc100:0s} Count:124000}
@dashpole @liggitt @smarterclayton может быть https://github.com/kubernetes/kubernetes/pull/50350? (на основе последнего диапазона, опубликованного shyam)
dims
28 сент. 2017
К вашему сведению - после этого я провел еще два раунда деления пополам и обнаружил:
Коммит 78c82080 нездоров:
Sep 28 06:25:03.471: INFO: WARNING Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:3.995ms Perc90:209.142ms Perc99:3.174665s Perc100:0s} Count:124000}
и commit 6a314ce3a9cb здоров:
Sep 28 13:51:29.705: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:3.647ms Perc90:6.901ms Perc99:19.541ms Perc100:0s} Count:124000}
Новый диапазон: https://github.com/kubernetes/kubernetes/compare/6a314ce3a9cb...78c82080
shyamjvs
28 сент. 2017
/ me увеличивает свои ставки на https://github.com/kubernetes/kubernetes/pull/50350/commit/9ac30e2c280f61a9629f3334f7e6e6424b7fb5f8
dims
28 сент. 2017
/ me увеличивает свои ставки на 9ac30e2
заголовок фиксации, безусловно, кажется связанным, но я проходил эту фиксацию дюжину раз и не вижу ничего, что пересекает границу за пределами кублета, что могло бы повлиять на задержку сервера API. Думаю, посмотрим.
liggitt
28 сент. 2017
На самом деле у меня есть одна гипотеза, потому что это изменение (iiuc) заставляет kubelet отправлять запрос на удаление модуля только после удаления контейнера, возможно, изменилась скорость / распределение этих вызовов. Находясь в kubemark, кублеты не запускают никаких реальных контейнеров, поэтому они могут сразу удалить объект pod (что может привести к равномерному распределению этих вызовов). Wdyt?
shyamjvs
28 сент. 2017
@ kubernetes / sig-node-bugs Выполняется ли сборщик мусора контейнера kubelet периодически? Как и в этом случае, все контейнеры, которые удаляются одним пакетом, могут привести к одновременному отправлению большого количества запросов delete pods . Или, может быть, что-то еще мне не хватает?
shyamjvs
28 сент. 2017
см. анализ распределения вызовов удаления в https://github.com/kubernetes/kubernetes/issues/51899#issuecomment -332515008
первая половина графика и вторая имеют почти одинаковое количество вызовов удаления, но первая половина остается полностью отзывчивой, а вторая накапливает значительную задержку. Не думаю, что это так просто, как гремящее стадо.
liggitt
28 сент. 2017
Только что закончил проверку .. commit bcf22bcf6 тоже здоров:
Sep 28 16:09:14.084: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.114ms Perc90:6.221ms Perc99:17.737ms Perc100:0s} Count:124000}
И в 3 оставшихся коммитах (https://github.com/kubernetes/kubernetes/compare/bcf22bcf6...78c82080), скорее всего, причина. Есть еще одно касающееся удаления модуля (# 51186), но это некоторые изменения на стороне kubectl, и kubectl не следует использовать ни в нашем тесте, ни в каком-либо крупном компоненте уровня управления iiuc.
shyamjvs
28 сент. 2017
@liggitt Не могли бы вы получить график для диапазона x немного длиннее 60
shyamjvs
28 сент. 2017
cc @dashpole @ dchen1107
shyamjvs
28 сент. 2017
вот графики за трехминутное окно (как задержка в мс, так и распределение вызовов удаления в секунду)
вызовы удаления из GC просто устанавливают deletionTimestamp на поде (который наблюдают кублеты и начинают выключать поды). вызовы delete из kubelet фактически удаляют из etcd.
Был ли это всего лишь один спайк или их несколько? И они периодические? Может быть, эти всплески возникают, когда у нескольких узлов совпадают фазы gc?
на протяжении всего забега было несколько шипов. вот график вызовов удаления, которые заняли более одной секунды на протяжении всего прогона:
спайки появляются группами по три, с интервалом ~ 2 минуты, продолжительностью 20-30 секунд
liggitt
28 сент. 2017
Красивый! Большое спасибо за графики.
Так что это действительно кажется довольно периодическим ... Кстати - я думаю, что двухминутный шаблон связан с тем, как мы удаляем модули насыщения (это я объяснил в https://github.com/kubernetes/kubernetes/issues/51899#issuecomment- 332577238) ближе к концу теста плотности. Мы удаляем эти RC (каждый имеет 3000 реплик) примерно с интервалом в 2 минуты:
I0928 03:52:02.643] [1mSTEP[0m: Cleaning up only the { ReplicationController}, garbage collector will clean up the pods
I0928 03:52:02.643] [1mSTEP[0m: deleting { ReplicationController} density150000-47-dc6c4af2-a3d1-11e7-9201-0242ac110008 in namespace e2e-tests-density-30-48-pbmpd, will wait for the garbage collector to delete the pods
I0928 03:52:03.048] Sep 28 03:52:03.047: INFO: Deleting { ReplicationController} density150000-47-dc6c4af2-a3d1-11e7-9201-0242ac110008 took: 39.093401ms
I0928 03:53:03.050] Sep 28 03:53:03.049: INFO: Terminating { ReplicationController} density150000-47-dc6c4af2-a3d1-11e7-9201-0242ac110008 pods took: 1m0.001823124s
I0928 03:54:13.051] [1mSTEP[0m: Cleaning up only the { ReplicationController}, garbage collector will clean up the pods
I0928 03:54:13.051] [1mSTEP[0m: deleting { ReplicationController} density150000-48-dc6c4af2-a3d1-11e7-9201-0242ac110008 in namespace e2e-tests-density-30-49-g5qvv, will wait for the garbage collector to delete the pods
I0928 03:54:13.438] Sep 28 03:54:13.437: INFO: Deleting { ReplicationController} density150000-48-dc6c4af2-a3d1-11e7-9201-0242ac110008 took: 40.001908ms
I0928 03:55:13.440] Sep 28 03:55:13.439: INFO: Terminating { ReplicationController} density150000-48-dc6c4af2-a3d1-11e7-9201-0242ac110008 pods took: 1m0.001894987s
I0928 03:56:23.440] [1mSTEP[0m: Cleaning up only the { ReplicationController}, garbage collector will clean up the pods
I0928 03:56:23.441] [1mSTEP[0m: deleting { ReplicationController} density150000-49-dc6c4af2-a3d1-11e7-9201-0242ac110008 in namespace e2e-tests-density-30-50-s62ds, will wait for the garbage collector to delete the pods
I0928 03:56:23.829] Sep 28 03:56:23.829: INFO: Deleting { ReplicationController} density150000-49-dc6c4af2-a3d1-11e7-9201-0242ac110008 took: 50.423057ms
I0928 03:57:23.831] Sep 28 03:57:23.830: INFO: Terminating { ReplicationController} density150000-49-dc6c4af2-a3d1-11e7-9201-0242ac110008 pods took: 1m0.0014941s
Нет. из этих вызовов из вашего предыдущего комментария также было близко к 3000 - хотя это было в пределах 1 минуты (но у нас есть два вызова удаления для каждого pod iiuc - один от gc и один от kubelet).
shyamjvs
28 сент. 2017
fyi - я подтвердил, что именно этот пиар является причиной проблемы. Коммит перед тем, как он станет здоровым:
Sep 28 18:05:27.337: INFO: Top latency metric: {Resource:pods Subresource: Verb:DELETE Latency:{Perc50:4.106ms Perc90:6.308ms Perc99:19.561ms Perc100:0s} Count:124000}
Варианты у нас есть:
- отменить фиксацию, а затем исправить проблему в 1.9 (я предпочитаю это, если исправление не достаточно тривиально, чтобы перейти в 1.8)
- исправить - потенциально отодвигая выпуск еще дальше (если мы также хотим иметь достаточно уверенности в качестве выпуска)
- пусть будет и задокументируйте это как известную проблему в выпуске (я не очень поддерживаю это)
shyamjvs
28 сент. 2017
Я вижу, как ожидание контейнера gc на стороне kubelet перед вызовом API удаления приведет к пакетной обработке вызовов удаления. Похоже на грохочущее стадо, вызванное кубелетами, при удалении большого количества стручков через огромное количество узлов. gc kubemark заглушен, так как реальных контейнеров нет, поэтому там этого не наблюдается
liggitt
28 сент. 2017
Ага .. о чем я тоже думал - https://github.com/kubernetes/kubernetes/issues/51899#issuecomment -332847171
shyamjvs
28 сент. 2017
копи @dashpole @vishh @ dchen1107
от внедрения PR (https://github.com/kubernetes/kubernetes/pull/50350)
liggitt
28 сент. 2017
Я могу опубликовать PR, чтобы вернуть ключевую часть # 50350.
 dashpole
28 сент. 2017
dashpole
28 сент. 2017
@dashpole, спасибо!
jdumars
28 сент. 2017
Думаю, нам также следует подождать, пока исправление не будет протестировано (добавьте на это еще ~ 2 часа).
shyamjvs
28 сент. 2017
PR размещено: # 53210
dashpole
28 сент. 2017
У нас с @dashpole было офлайн-обсуждение, и мы планируем вернуть часть # 50350. Первоначальный pr был введен, потому что без этого изменения диспетчер удаления дисков Kubelet может без необходимости удалять больше контейнеров.
Мы должны улучшить управление дисками, добавив больше интеллекта для принятия упреждающих действий, вместо того, чтобы полагаться на периодическое издание gc.
 dchen1107
28 сент. 2017
dchen1107
28 сент. 2017
Хотя это находится на этапе 1.9, есть все основания полагать, что это будет решено в самый ранний ответственный момент в выпуске патча 1.8. Полный процесс принятия решения по этому поводу можно посмотреть на https://youtu.be/r6D5DNel2l8.
jdumars
28 сент. 2017
Есть обновления по этому поводу?
 jpbetz
2 окт. 2017
jpbetz
2 окт. 2017
У нас уже есть PR жертвы - PR, который фиксирует, # 53233
wojtek-t
2 окт. 2017
53233 объединен с мастером. выберите для 1.8.1 откройте https://github.com/kubernetes/kubernetes/pull/53422
liggitt
4 окт. 2017
[MILESTONENOTIFIER] Проблема с вехой требует одобрения
@dashpole @shyamjvs @ kubernetes / sig-api-machinery-bugs @ kubernetes / sig-node-bugs @ kubernetes / sig-scaleability-bugs
Требуется действие : к этой проблеме должен быть применен ярлык status/approved-for-milestone по сопровождению SIG.Ярлыки выпуска
sig/api-machinerysig/nodesig/scalability: При необходимости проблема будет передана этим SIG.priority/critical-urgent: никогда автоматически не выходить из этапа выпуска; постоянно сообщать участникам и SIG по всем доступным каналам.kind/bug: исправляет ошибку, обнаруженную в текущем выпуске.Помогите
 k8s-github-robot
6 окт. 2017
k8s-github-robot
6 окт. 2017
/Закрыть
Закрыт через # 53422. Исправление должно быть в 1.8.1.
dashpole
6 окт. 2017
Смежные вопросы
 zetaab
·
3Комментарии
zetaab
·
3Комментарии
 jadhavnitind
·
3Комментарии
jadhavnitind
·
3Комментарии
 sanjana-bhat
·
3Комментарии
sanjana-bhat
·
3Комментарии
 Seb-Solon
·
3Комментарии
Seb-Solon
·
3Комментарии
 pwittrock
·
3Комментарии
pwittrock
·
3Комментарии
Самый полезный комментарий
Завершено задание производительности 5k на CI с отключенным аудитом. Ожидаем, что завтра будет зеленый пробег (надеюсь).