Tensorflow: MultiWorkerMirroredStrategyのパフォーマンスが低い(2gpu、2ノード)X1.3の高速化
システムインフォメーション
Have I written custom code (as opposed to using a stock example script provided in TensorFlow):
OS Platform and Distribution: Ubuntu 18.04
TensorFlow installed from (source or binary): pip install tensorflow-gpu
TensorFlow version (use command below): 2.0
Python version: 3.6.9
CUDA/cuDNN version: 10/7.6.4.38
GPU model and memory: Tesla P4 8G
現在の行動を説明する
以下に説明するコードを実行します。
テスト1 :( 2台のマシン)
os.environ ['TF_CONFIG'] = json.dumps({
'集まる': {
'worker':["server1:12345"、 "server2:12345"]
}、
'タスク':{'タイプ': 'ワーカー'、 'インデックス':0}
})
他のマシンで
os.environ ['TF_CONFIG'] = json.dumps({
'集まる': {
'worker':["server1:12345"、 "server2:12345"]
}、
'タスク':{'タイプ': 'ワーカー'、 'インデックス':1}
})
スクリプトが最初のエポックの処理を開始すると、クラッシュします。
予想される動作を説明する
15秒/エポックはとても遅い
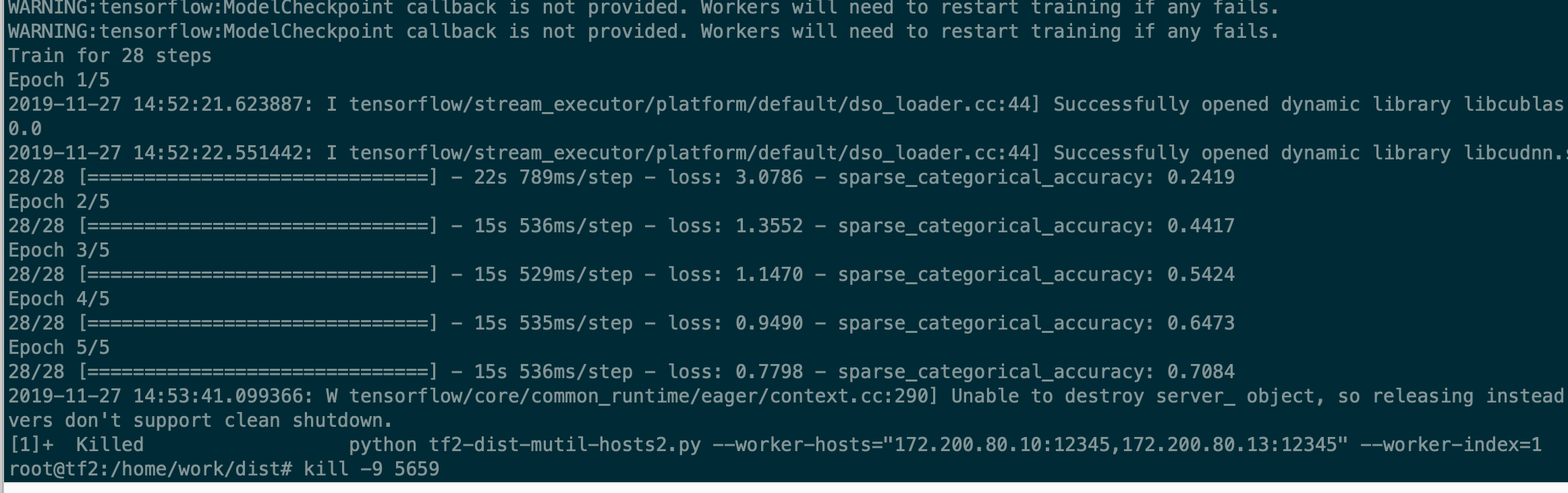
テスト2 :( 1台のマシン)
os.environ ['TF_CONFIG'] = json.dumps({
'集まる': {
'worker':["server1:12345"]
}、
'タスク':{'タイプ': 'ワーカー'、 'インデックス':0}
})
予想される動作を説明する
使用戦略と同じ5秒/エポック= tf.distribute.MirroredStrategy()1つのGPUカード
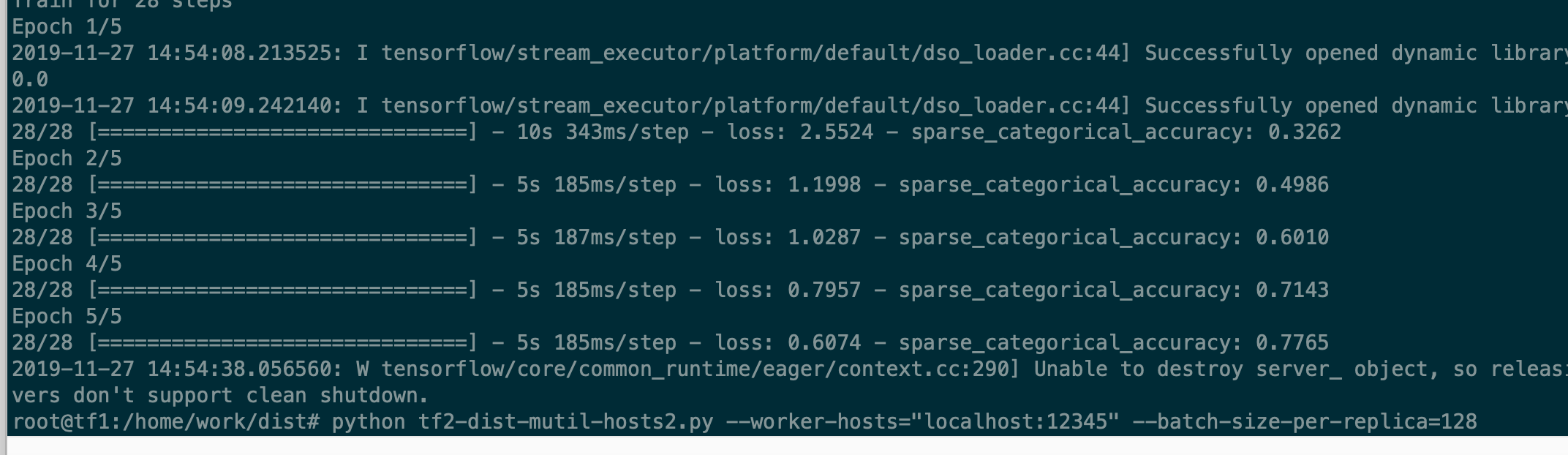
コード
import ssl
import os
import json
import argparse
import time
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
ssl._create_default_https_context = ssl._create_unverified_context
def configure_cluster(worker_hosts=None, task_index=-1):
"""Set multi-worker cluster spec in TF_CONFIG environment variable.
Args:
worker_hosts: comma-separated list of worker ip:port pairs.
Returns:
Number of workers in the cluster.
"""
tf_config = json.loads(os.environ.get('TF_CONFIG', '{}'))
if tf_config:
num_workers = len(tf_config['cluster'].get('worker', []))
elif worker_hosts:
workers = worker_hosts.split(',')
num_workers = len(workers)
if num_workers > 1 and task_index < 0:
raise ValueError('Must specify task_index when number of workers > 1')
task_index = 0 if num_workers == 1 else task_index
os.environ['TF_CONFIG'] = json.dumps({
'cluster': {
'worker': workers
},
'task': {'type': 'worker', 'index': task_index}
})
else:
num_workers = 1
return num_workers
parser = argparse.ArgumentParser(description='TensorFlow Benchmark',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--num-epochs', type=int, default=5, help='input batch size')
parser.add_argument('--batch-size-per-replica', type=int, default=32, help='input batch size')
parser.add_argument('--worker-method', type=str, default="NCCL")
parser.add_argument('--worker-hosts', type=str, default="localhost:23456")
parser.add_argument('--worker-index', type=int, default=0)
args = parser.parse_args()
worker_num = configure_cluster(args.worker_hosts, args.worker_index)
batch_size = args.batch_size_per_replica * worker_num
print('Batch Size: %d' % batch_size)
gpus = tf.config.experimental.list_physical_devices('GPU')
print("Physical GPU Devices Num:", len(gpus))
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
if args.worker_method == "AUTO":
communication = tf.distribute.experimental.CollectiveCommunication.AUTO
elif args.worker_method == "RING":
communication = tf.distribute.experimental.CollectiveCommunication.RING
else:
communication = tf.distribute.experimental.CollectiveCommunication.NCCL
strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy(
communication=communication)
# logical_gpus = tf.config.experimental.list_logical_devices('GPU')
# print("Logical GPU Devices Num:", len(gpus))
def resize(image, label):
image = tf.image.resize(image, [128, 128]) / 255.0
return image, label
# if as_supervised is True,return image abd label
dataset, info = tfds.load("tf_flowers", split=tfds.Split.TRAIN, with_info=True, as_supervised=True)
dataset = dataset.map(resize).repeat().shuffle(1024).batch(batch_size)
# options = tf.data.Options()
# options.experimental_distribute.auto_shard = False
# dataset = dataset.with_options(options)
def build_and_compile_cnn_model():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, [3, 3], activation='relu'),
tf.keras.layers.Conv2D(64, [3, 3], activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(info.features['label'].num_classes, activation='softmax')
])
model.compile(
opt=tf.keras.optimizers.Adam(learning_rate=0.0001),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
return model
with strategy.scope():
multi_worker_model = build_and_compile_cnn_model()
print("Now training the distributed model")
class TimeHistory(tf.keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.times = []
self.totaltime = time.time()
def on_train_end(self, logs={}):
self.totaltime = time.time() - self.totaltime
def on_epoch_begin(self, batch, logs={}):
self.epoch_time_start = time.time()
def on_epoch_end(self, batch, logs={}):
self.times.append(time.time() - self.epoch_time_start)
time_callback = TimeHistory()
steps_per_epoch = 100
print('Running benchmark...')
multi_worker_model.fit(dataset, steps_per_epoch=steps_per_epoch, epochs=args.num_epochs, callbacks=[time_callback])
per_epoch_time = np.mean(time_callback.times[1:])
print("per_epoch_time:", per_epoch_time)
img_sec = batch_size * steps_per_epoch / per_epoch_time
print("Result: {:.1f} pic/sec".format(img_sec))
テスト2:1人のワーカーのみ、440pic /秒(batch_szie = 128)
テスト1:2人のワーカー、610 pic / sec(batch_szie = 128 * 2)[440 * 2 = 800 +を期待]
質問1:
distMultiWorkerMirroredStrategyワーカー数> 1の場合、トレーニングが非常に遅い理由
期待する
 zwqjoy
zwqjoy
全てのコメント3件
モデルが遅くなる理由はたくさんあります。ネットワーク、データの読み取り、スレッドの競合などです。プログラムのプロファイルを作成して、どの部分がボトルネックであるかを確認できます: https :
 yuefengz
2020年02月06日
yuefengz
2020年02月06日
![tensorflow-bot[bot] picture](https://avatars0.githubusercontent.com/u/1913207?v=4&s=40) tensorflow-bot[bot]
tensorflow-bot[bot]
閉店しました。 プロファイルに明らかな問題が見つかった場合は、自由に再度開くか、新しい問題を提出してください。
yuefengz
2020年02月13日
関連する問題
 fobus42
·
3コメント
fobus42
·
3コメント
 nicholaslocascio
·
3コメント
nicholaslocascio
·
3コメント
 indiejoseph
·
3コメント
indiejoseph
·
3コメント
 aerointern16
·
3コメント
aerointern16
·
3コメント
 ppwwyyxx
·
3コメント
ppwwyyxx
·
3コメント