Tensorflow: MultiWorkerMirroredStrategy Performance is low (2gpu, 2node) X1.3 speed-up
Informação do sistema
Have I written custom code (as opposed to using a stock example script provided in TensorFlow):
OS Platform and Distribution: Ubuntu 18.04
TensorFlow installed from (source or binary): pip install tensorflow-gpu
TensorFlow version (use command below): 2.0
Python version: 3.6.9
CUDA/cuDNN version: 10/7.6.4.38
GPU model and memory: Tesla P4 8G
Descreva o comportamento atual
Eu executo o código descrito abaixo:
TESTE 1: (duas máquinas)
os.environ ['TF_CONFIG'] = json.dumps ({
'grupo': {
'trabalhador': ["servidor1: 12345", "servidor2: 12345"]
},
'tarefa': {'tipo': 'trabalhador', 'índice': 0}
})
Na outra maquina
os.environ ['TF_CONFIG'] = json.dumps ({
'grupo': {
'trabalhador': ["servidor1: 12345", "servidor2: 12345"]
},
'tarefa': {'tipo': 'trabalhador', 'índice': 1}
})
Quando o script começa a processar a primeira época, ele trava,
Descreva o comportamento esperado
15s / época é tão lento
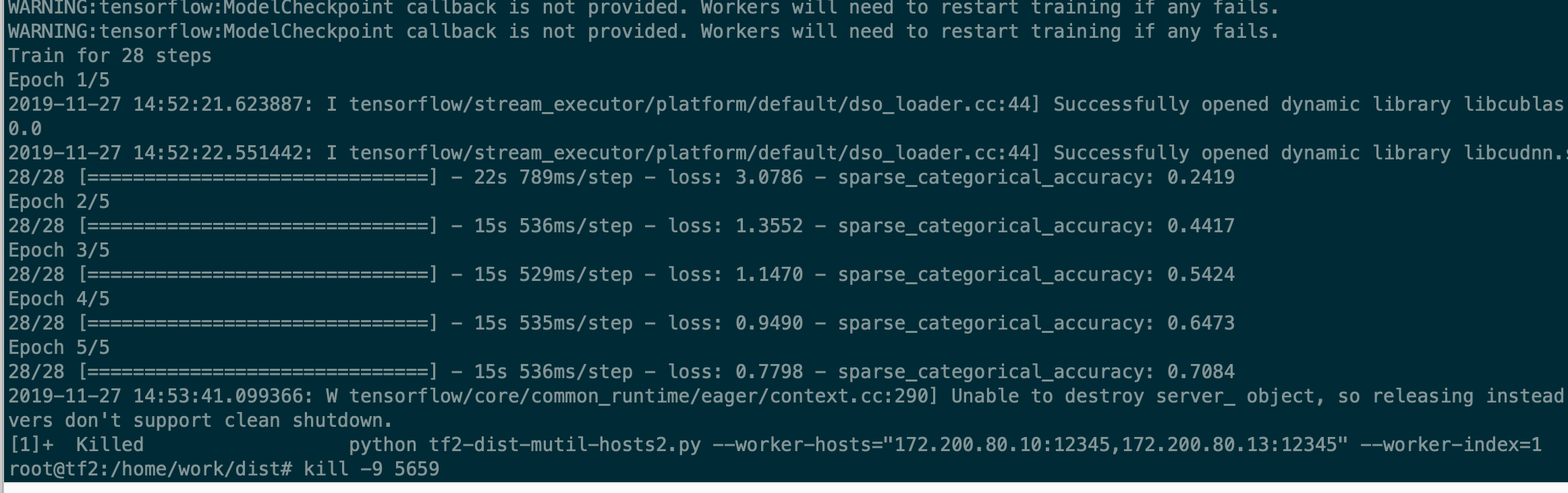
TESTE 2: (uma máquina)
os.environ ['TF_CONFIG'] = json.dumps ({
'grupo': {
'trabalhador': ["servidor1: 12345"]
},
'tarefa': {'tipo': 'trabalhador', 'índice': 0}
})
Descreva o comportamento esperado
5s / época igual a usar estratégia = tf.distribute.MirroredStrategy () uma placa GPU
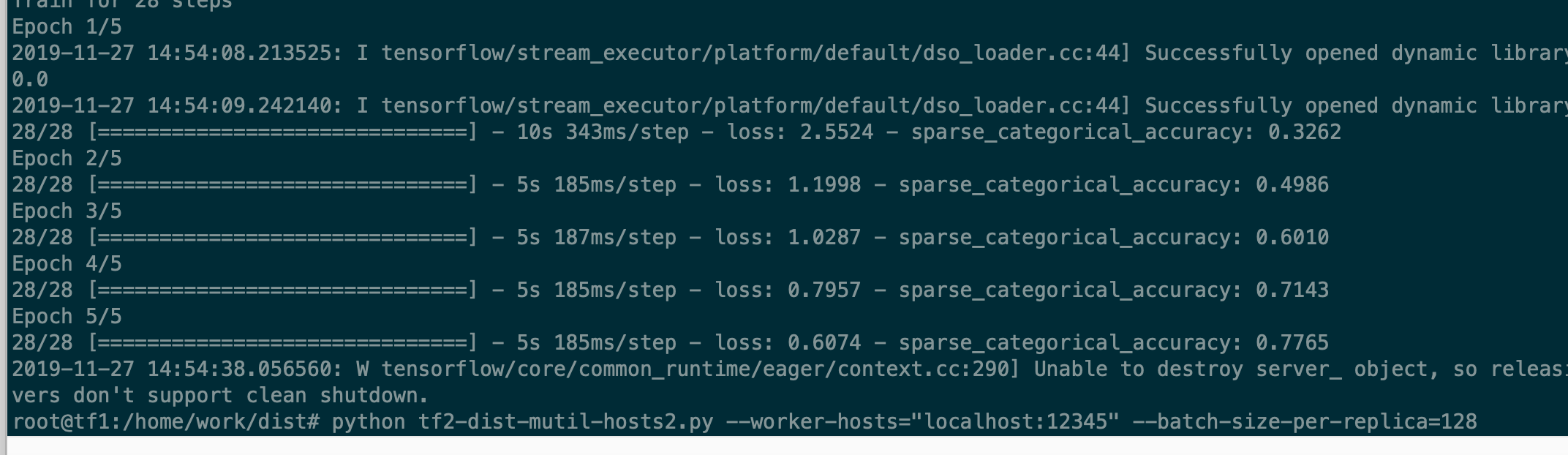
CÓDIGO
import ssl
import os
import json
import argparse
import time
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
ssl._create_default_https_context = ssl._create_unverified_context
def configure_cluster(worker_hosts=None, task_index=-1):
"""Set multi-worker cluster spec in TF_CONFIG environment variable.
Args:
worker_hosts: comma-separated list of worker ip:port pairs.
Returns:
Number of workers in the cluster.
"""
tf_config = json.loads(os.environ.get('TF_CONFIG', '{}'))
if tf_config:
num_workers = len(tf_config['cluster'].get('worker', []))
elif worker_hosts:
workers = worker_hosts.split(',')
num_workers = len(workers)
if num_workers > 1 and task_index < 0:
raise ValueError('Must specify task_index when number of workers > 1')
task_index = 0 if num_workers == 1 else task_index
os.environ['TF_CONFIG'] = json.dumps({
'cluster': {
'worker': workers
},
'task': {'type': 'worker', 'index': task_index}
})
else:
num_workers = 1
return num_workers
parser = argparse.ArgumentParser(description='TensorFlow Benchmark',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--num-epochs', type=int, default=5, help='input batch size')
parser.add_argument('--batch-size-per-replica', type=int, default=32, help='input batch size')
parser.add_argument('--worker-method', type=str, default="NCCL")
parser.add_argument('--worker-hosts', type=str, default="localhost:23456")
parser.add_argument('--worker-index', type=int, default=0)
args = parser.parse_args()
worker_num = configure_cluster(args.worker_hosts, args.worker_index)
batch_size = args.batch_size_per_replica * worker_num
print('Batch Size: %d' % batch_size)
gpus = tf.config.experimental.list_physical_devices('GPU')
print("Physical GPU Devices Num:", len(gpus))
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
if args.worker_method == "AUTO":
communication = tf.distribute.experimental.CollectiveCommunication.AUTO
elif args.worker_method == "RING":
communication = tf.distribute.experimental.CollectiveCommunication.RING
else:
communication = tf.distribute.experimental.CollectiveCommunication.NCCL
strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy(
communication=communication)
# logical_gpus = tf.config.experimental.list_logical_devices('GPU')
# print("Logical GPU Devices Num:", len(gpus))
def resize(image, label):
image = tf.image.resize(image, [128, 128]) / 255.0
return image, label
# if as_supervised is True,return image abd label
dataset, info = tfds.load("tf_flowers", split=tfds.Split.TRAIN, with_info=True, as_supervised=True)
dataset = dataset.map(resize).repeat().shuffle(1024).batch(batch_size)
# options = tf.data.Options()
# options.experimental_distribute.auto_shard = False
# dataset = dataset.with_options(options)
def build_and_compile_cnn_model():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, [3, 3], activation='relu'),
tf.keras.layers.Conv2D(64, [3, 3], activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(info.features['label'].num_classes, activation='softmax')
])
model.compile(
opt=tf.keras.optimizers.Adam(learning_rate=0.0001),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
return model
with strategy.scope():
multi_worker_model = build_and_compile_cnn_model()
print("Now training the distributed model")
class TimeHistory(tf.keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.times = []
self.totaltime = time.time()
def on_train_end(self, logs={}):
self.totaltime = time.time() - self.totaltime
def on_epoch_begin(self, batch, logs={}):
self.epoch_time_start = time.time()
def on_epoch_end(self, batch, logs={}):
self.times.append(time.time() - self.epoch_time_start)
time_callback = TimeHistory()
steps_per_epoch = 100
print('Running benchmark...')
multi_worker_model.fit(dataset, steps_per_epoch=steps_per_epoch, epochs=args.num_epochs, callbacks=[time_callback])
per_epoch_time = np.mean(time_callback.times[1:])
print("per_epoch_time:", per_epoch_time)
img_sec = batch_size * steps_per_epoch / per_epoch_time
print("Result: {:.1f} pic/sec".format(img_sec))
No TESTE 2: apenas 1 trabalhador, 440pic / s (batch_szie = 128)
No TESTE 1: 2 trabalhadores, 610 pic / s (batch_szie = 128 * 2) [Expect 440 * 2 = 800+]
Questão 1:
com dist MultiWorkerMirroredStrategy worker nums> 1, por que o treinamento é tão lento
Espero
 zwqjoy
zwqjoy
Todos 3 comentários
Existem muitos motivos pelos quais seus modelos podem ser lentos: rede, leitura de dados, contenção de threads etc. Você pode criar o perfil de seu programa para ver qual parte é o gargalo: https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras
 yuefengz
em 6 fev. 2020
yuefengz
em 6 fev. 2020
![tensorflow-bot[bot] picture](https://avatars0.githubusercontent.com/u/1913207?v=4&s=40) tensorflow-bot[bot]
tensorflow-bot[bot]
Fechando agora. Sinta-se à vontade para reabrir ou registrar um novo problema se encontrar problemas óbvios em seu perfil.
yuefengz
em 13 fev. 2020
Questões relacionadas
 indiejoseph
·
3Comentários
indiejoseph
·
3Comentários
 wfs
·
3Comentários
wfs
·
3Comentários
 aerointern16
·
3Comentários
aerointern16
·
3Comentários
 nicholaslocascio
·
3Comentários
nicholaslocascio
·
3Comentários
 jacobma-create
·
3Comentários
jacobma-create
·
3Comentários