我在两个实例上运行最新版本的 grafana,但是在尝试访问两个实例时遇到了很多未经授权的错误。 对于身份验证,我目前使用的是内置数据库,没有 LDAP。 数据源是一个influxdb。
这是一个已知的错误还是不当行为?
 darox
darox
所有105条评论
您能否提供更多详细信息:
- 这是两个独立的实例吗?
- 什么操作会触发未经授权的错误?
- 您是否已注销或只是某些操作无效?
 daniellee
于 2018-02-02
daniellee
于 2018-02-02
它们是否设置在不同的 ips/域名上? 如果域名相同且仅因端口不同而不同,则您需要拥有唯一的会话 cookie 并记住我的 cookie
 torkelo
于 2018-02-02
torkelo
于 2018-02-02
- 那些是单独的实例
- 我不知道哪个动作触发了未经授权,它只是在我看图表或访问 grafana 时发生
- 有时我会退出
- 单独的域
darox
于 2018-02-02
我通过 Github 在带有 oauth 的 Grafana 4.6.x 上遇到了这个问题。 当我切换选项卡并返回 Grafana 时,这似乎是随机的。 刷新将“纠正”问题,但有时稍后会再次出现。
 pgporada
于 2018-03-07
pgporada
于 2018-03-07

我在 Grafana v4.6.2 (commit: 8db5f08) 上看到了同样的问题,一切都按预期工作,突然我收到一个未经授权的警告(有些图表是空的,但有些图表正常显示)。
我使用 Prometheus 作为数据源。
我还认为这主要发生在仪表板自动刷新时,但在我手动刷新时会自行修复。
 ajardan
于 2018-03-08
ajardan
于 2018-03-08
这里也有类似的问题,但只有一个带有 HTTPS 和 Postgres 数据源的 Grafana 实例。
当仪表板打开时,所有图形都很好。 但有时之后,一些图表在自动刷新时开始显示“未授权”错误,但在下一次(或接下来的几次)自动刷新中,它们恢复到正常状态,但有时稍后又会变成“未授权”状态,重复每次自动刷新时的这种随机行为。
不确定它是否相关,但发现以下日志消息。
lvl=eror msg="无法获取具有 id 的用户" logger=context userId=1 error="找不到用户"
Grafana版本如下:
lvl=info msg="启动 Grafana" logger=server version=5.0.4 commit=7dc36ae 编译=2018-03-28T20:52:41+0900
我正在使用 Firefox,并且我通常将仪表板打开并保持多天不变,客户端计算机(而不是托管 Grafana 的服务器计算机)不时进入睡眠模式。
 after-the-sunrise
于 2018-04-12
after-the-sunrise
于 2018-04-12
使用grafana 5.x,这不再发生在我身上
darox
于 2018-04-12
我仍然遇到与 Grafana 5.0.4 完全相同的问题,在日志中找不到用户的相同消息(这是一个简单的本地 Grafana 用户)。
 SoulSeekkor
于 2018-04-13
SoulSeekkor
于 2018-04-13
我也是这个问题而且这个问题非常有趣。 当我在同一浏览器中打开两个不同版本的grafana页面并尝试进行某些操作时可能会发生这种情况。
我有一个旧版本的 grafana(v4.3.2 (commit: ed4d170)) 并且在grafana.mydomain.com上运行良好很长时间。 今天我想把我的grafana升级到v5.0.4。 而不是就地升级。 我想在同一台机器上安装新的 Grafana,复制我想要的仪表板,然后拆掉旧的。
所以我做了什么:
- docker 在旧机器的同一台机器上运行 grafana5,端口映射到 3005
- 在 Safari 中的
grafana.mydomain.com上打开旧的 grafana4
它运作良好 - 在 Safari 中以
grafana.mydomain.com:3005访问 Grafana5
所以现在我的屏幕上有两个打开的 Grafana4 和 Grafana5 标签 - 登录Grafana5,尝试做一些操作....比如[创建仪表板]
现在两个 Grafana 页面都崩溃了
Grafana 都会得到Unauthorized错误并且没有数据点
更新:我通过使用 [ip]:3005 访问 Grafana5 更改了我的第 3 步。 它现在工作正常。
看起来在同一域中打开两个 Grafana 页面可能存在一些冲突。
 kehao95
于 2018-04-18
kehao95
于 2018-04-18
@kehao95不支持在同一浏览器中打开同一域上的两个 Grafana 实例但端口不同的用例。 (托克尔在上面提到过)。
@ajardan你的实例是在同一个域还是不同的域?
daniellee
于 2018-04-30
@daniellee我实际上一直只使用一个实例。 我查看的仪表板上的图表来自 2 个不同的数据源(Prometheus 和 Cloudera)
ajardan
于 2018-05-07
我也不时遇到这种奇怪的“未经授权”的问题。 页面刷新“修复”了问题。 我从官方 Docker 镜像运行 Grafana v5.1.0 (844bdc53a)。 数据源是 InfluxDb。 我在 Grafana 中创建了 2 个组织,但实际上只使用了一个。 单个“管理员”用户。
 dogada
于 2018-05-08
dogada
于 2018-05-08
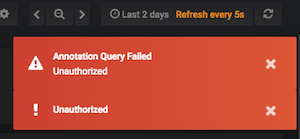
刚刚再次收到此错误,并显示一条新的错误消息“注释查询失败。未经授权”
dogada
于 2018-05-08
我在 win10 x64 上的 grafana 在几天内运行良好,直到我收到“未经授权”警告。 该行为与@dogada所描述的
 schwarzlowe
于 2018-05-09
schwarzlowe
于 2018-05-09
同样的问题。 docker 中的一个 grafana 5.1 实例。 谷歌 oauth 授权。
任何更新?
 StupidScience
于 2018-05-11
StupidScience
于 2018-05-11
同样的行为。 目前在 docker 中运行 v5.0.3,内部认证,单管理员用户,通过 nginx 代理,数据源是 influxdb。 仪表板在自动刷新数据时自行修复。 主要发生在标签长时间在后台时
 radium88
于 2018-05-15
radium88
于 2018-05-15
将两个选项卡打开到同一个实例时会出现相同的问题。
 lamoni
于 2018-05-15
lamoni
于 2018-05-15
更新到最新的 docker 镜像 v5.1.2(提交:c3c690e21)没有解决问题
radium88
于 2018-05-16
我在使用 GitHub OAuth 的 Docker 中遇到了我认为与 Grafana 5.0.0 相同的问题。 我已经在 InfluxDB、CloudWatch 和这两种数据源的混合仪表盘上看到过它。 (一个实例,一个端口,HTTPS,在 ELB 后面。)
与此线程中的其他人一样,我似乎看到它由自动刷新触发,并在页面重新加载后消失。 有时我会看到基本的“未授权”错误消息(图形加载失败),有时(更罕见)也会看到“注释查询失败。未授权”消息。
〜我的怀疑是指向 OAuth 插件的某些内容?〜这几乎肯定是由于会话后端,见下文。
 bjacobel
于 2018-05-16
bjacobel
于 2018-05-16
为了添加我在深入挖掘后发现的更多细节,我在日志中看到了许多这样的错误:
t=2018-05-16T16:55:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
我看到抛出这样一个错误的唯一地方是在这行代码中,这似乎与管理会话和会话 cookie 相关?
我正在使用默认的file后端存储我的会话,但是通过挂载的 EFS 共享,我想知道这是否是一个潜在的并发症。
bjacobel
于 2018-05-16
当我尝试在同一浏览器中打开两个不同的 Grafana(运行在不同的端口)时遇到了这个问题。
我收到未经授权的错误,有时会被注销
 harshitha-m
于 2018-05-23
harshitha-m
于 2018-05-23
当您收到Failed to get user with id日志消息时,看看执行哪些 SQL 查询会非常有趣。 如果您可以轻松地重现这一点,那么如果您可以启用 sql 查询的日志记录并报告您的发现,那将是非常有价值的:
[database]
# Set to true to log the sql calls and execution times.
log_queries = true
谢谢
 marefr
于 2018-05-30
marefr
于 2018-05-30
@marefr似乎这些错误总是被以下两个查询之一包围:
SELECT\n\t\tu.id as user_id,\n\t\tu.is_admin as is_grafana_admin,\n\t\tu.email as email,\n\t\tu.login as login,\n\t\tu.name as name,\n\t\tu.help_flags1 as help_flags1,\n\t\tu.last_seen_at as last_seen_at,\n\t\t(SELECT COUNT(*) FROM org_user where org_user.user_id = u.id) as org_count,\n\t\torg.name as org_name,\n\t\torg_user.role as org_role,\n\t\torg.id as org_id\n\t\tFROM `user` as u\n\t\tLEFT OUTER JOIN org_user on org_user.org_id = 1 and org_user.user_id = u.id\n\t\tLEFT OUTER JOIN org on org.id = org_user.org_id WHERE u.id=? []interface
UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
完整示例日志:
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] SELECT\n\t\tu.id as user_id,\n\t\tu.is_admin as is_grafana_admin,\n\t\tu.email as email,\n\t\tu.login as login,\n\t\tu.name as name,\n\t\tu.help_flags1 as help_flags1,\n\t\tu.last_seen_at as last_seen_at,\n\t\t(SELECT COUNT(*) FROM org_user where org_user.user_id = u.id) as org_count,\n\t\torg.name as org_name,\n\t\torg_user.role as org_role,\n\t\torg.id as org_id\n\t\tFROM `user` as u\n\t\tLEFT OUTER JOIN org_user on org_user.org_id = 1 and org_user.user_id = u.id\n\t\tLEFT OUTER JOIN org on org.id = org_user.org_id WHERE u.id=? []interface
{}
{2} - took: 54.517418ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 42.957209ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] SELECT\n\t\tu.id as user_id,\n\t\tu.is_admin as is_grafana_admin,\n\t\tu.email as email,\n\t\tu.login as login,\n\t\tu.name as name,\n\t\tu.help_flags1 as help_flags1,\n\t\tu.last_seen_at as last_seen_at,\n\t\t(SELECT COUNT(*) FROM org_user where org_user.user_id = u.id) as org_count,\n\t\torg.name as org_name,\n\t\torg_user.role as org_role,\n\t\torg.id as org_id\n\t\tFROM `user` as u\n\t\tLEFT OUTER JOIN org_user on org_user.org_id = 1 and org_user.user_id = u.id\n\t\tLEFT OUTER JOIN org on org.id = org_user.org_id WHERE u.id=? []interface
{}
{2} - took: 69.013955ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 5.593997ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 46.673µs" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 621.538µs" logger=sqlstore.xorm
非常感谢@bjacobel。 在我看来,这里一切都很好。 一直提供到数据库查询的实际用户 ID。 真的很奇怪。 开始认为我们的 3rd 方数据库 lib xorm 存在错误。
您是否执行了任何特定操作来生成这些日志消息?
你用的是什么数据库? 什么会话存储?
哪些请求导致未经授权,您可以启用路由器日志记录以记录所有请求:
[server]
router_logging = true
我们在 Kubernetes 的 5.1.4 上也有同样的错误。
 benkeil
于 2018-06-21
benkeil
于 2018-06-21
嗨@marefr ,抱歉,我忘了回复要求的其他详细信息。
您是否执行了任何特定操作来生成这些日志消息?
查询是通过加载仪表板然后等待自动刷新来生成的。 它不会在每次自动刷新时发生,有时它可以通过手动单击仪表板刷新按钮(Grafana 内置的按钮,而不是浏览器刷新按钮)触发,但通常在用户使用时它似乎更频繁地发生不活动(例如,将 grafana 留在后台选项卡中。)
你用的是什么数据库? 什么会话存储?
数据库是挂载的 NFS (EFS) 共享上的 SQLite,会话存储是默认的(文件),尽管我也尝试过基于内存的存储并且它也有同样的问题。 我们在负载均衡器后面有一个 grafana 主机,我在该负载均衡器上启用了会话粘性。
什么请求导致未经授权?
我没有启用路由器日志记录,因为我可以看到浏览器未经授权的请求:
【部分敏感信息已删减】
Request URL: https://[my grafana hostname]/api/tsdb/query
Request Method: POST
Status Code: 401
Remote Address: [my load balancer IP]:443
Referrer Policy: no-referrer-when-downgrade
:authority: [my grafana hostname]
:method: POST
:path: /api/tsdb/query
:scheme: https
accept: application/json, text/plain, */*
accept-encoding: gzip, deflate, br
accept-language: en-US,en;q=0.9
cache-control: no-cache
content-length: 478
content-type: application/json;charset=UTF-8
cookie: _ga=GA1.2.1782868908.1520436196; __gads=ID=b1c7d78e4fd8b9fb:T=1520436200:S=ALNI_MYT2aRMJqYtHY-CkgaPWmuNtsGEtA; sailthru_hid=919b24e8c99698a8b1829b81eda7135a5956a753dd4c29265f8b45b3a11fb749fc11562ad2abbb1220b9ef37; grafana_sess=[16-char hexadecimal session string]; AWSALB=IUyH6LlTXI/TJlteL8pr838fC7nsvth7s63o5WzqOa6wsCPRpHg20vYurCrYpbIWci27fQtzQpoRxVlIc8Ud/rEPIJvqWvT21an4e9aQmZioTEAFHA3+iWv7bPHs
dnt: 1
origin: https://[my grafana hostname]
pragma: no-cache
referer: https://[my grafana hostname]/d/[dashboard path]?refresh=5m&orgId=1&from=now-1h&to=now
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36
x-grafana-org-id: 1
嗨@marefr ,抱歉,我忘了回复要求的其他详细信息。 ...
@bjacobel这可能与特定问题无关,但是 SQLite 的开发人员建议不要通过 NFS 运行 SQLite。 具体来说,Grafana 进程不应通过 NFS 挂载访问数据库,并且不建议从任何没有强大文件锁支持的网络文件系统运行。
附带说明一下,我们像您一样使用 SQLite 和会话存储,但在本地文件系统上。 我们没有遇到过同样的问题。
我们还在 grafana 中调整了 SQLite 配置以使用 WAL 模式(我最终会做一个 PR)以获得更好的性能。
使用GitHawk发送
 davewat
于 2018-06-24
davewat
于 2018-06-24
我在我的 docker Grafana 和 InfluxDB 堆栈中遇到了同样的问题。
Grafana v5.1.3(提交:087143285)
流入数据库 1.5.3
Grafana 通过带有 sqlite 数据库的 docker 卷使用本地存储。 卷正在使用本地 SSD。
每次离开选项卡几分钟后,我都会收到错误消息。 如果我在 Firefox 中保留开发工具,我会看到:
GET http://x.x.x.x:3000/api/datasources/proxy/1/query?db=(Redacted info)
{"message":"Unauthorized"}
任何类型的刷新都会清除错误。
 isclever
于 2018-06-25
isclever
于 2018-06-25
我遇到了同样的问题。 对我来说,这与缺少“session_provider=memcahched”有关
您可以参考http://docs.grafana.org/installation/configuration/#provider -config 了解更多配置选项
 nikskiz
于 2018-07-11
nikskiz
于 2018-07-11
同样的问题也在这里。 我的码头设置是:
FROM grafana/grafana:5.1.0
FROM influxdb:1.5.3
 BentCoder
于 2018-07-13
BentCoder
于 2018-07-13
关闭它,因为它似乎与设置/配置相关
torkelo
于 2018-07-13
@torkelo这个问题有明显的解决方案吗? 或者帮助找出可能的解决方案的提示?
BentCoder
于 2018-07-13
确保会话设置适用于 HA 设置或负载均衡器中的粘性会话正在工作
torkelo
于 2018-07-13
不过我不使用负载均衡器。
BentCoder
于 2018-07-17
没有多个副本的相同问题
有时在 /api/login/ping 上随机出现 401 错误
 WTFKr0
于 2018-07-25
WTFKr0
于 2018-07-25
同样的问题(多年来,在 5.0 天之前),ext4 上的 SQLite,Kubernetes 上的单个副本。 最新的官方 Docker 镜像。
当 Grafana 自动刷新时,请求会随机失败,最终所有小部件都停止报告任何内容。 相关日志:
t=2018-07-31T01:38:04+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-07-31T01:38:04+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-07-31T01:38:04+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-07-31T01:38:04+0000 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=GET path=/api/datasources/proxy/4/query status=401 remote_addr=192.168.1.72 time_ms=28 size=26 referer="REDACTED"
我会尝试进行一些调试,我 99% 确定这是 Grafana(或其库之一)错误。
/cc @torkelo
 lorenz
于 2018-07-31
lorenz
于 2018-07-31
我 95% 确定这是在 SQLite 表被锁定的情况下丢失的重试。 如果可行,我将在本地部署修复程序和 PR。
编辑:从头开始,这将采用不同的代码路径。
lorenz
于 2018-07-31
这是我的示例错误。
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=eror msg="Failed to get user with id" logger=context userId=1 error="User not found"
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=GET path=/api/login/ping status=401 remote_addr=192.168.33.1 time_ms=35 size=26 referer="http://192.168.33.10:3000/d/ZJ65a0Dmz/yowyow?refresh=5s&orgId=1&from=now-30d&to=now"
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=info msg="Request Completed" logger=context userId=1 orgId=1 uname=admin method=GET path=/api/login/ping status=401 remote_addr=192.168.33.1 time_ms=24 size=26 referer="http://192.168.33.10:3000/d/ZJ65a0Dmz/yowyow?refresh=5s&orgId=1&from=now-30d&to=now"
我让它在一夜之间运行以产生更多失败,并且确信它与会话无关。 它在 ORM 层中,特别是在user.go GetSignedInUser() ,该层有时不会返回正确的响应。 我在一个晚上 1 分钟内将所有请求记录在一个宽大的 50 图表仪表板上,并看到了一个非常随机的模式和集群错误,一切都指向一些并发/竞争问题。 我目前正在运行一个补丁,它正确地传播来自行读取器的错误(这个问题的主要候选者),我会看看我是否收到不同的错误消息。
lorenz
于 2018-07-31
那很快。 应用我的错误传播补丁后,我找到了根本原因:
t=2018-07-31T17:26:46+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="database table is locked"
SQLite 执行驱动程序中的某处错误地实现了重试。
lorenz
于 2018-07-31
我进一步研究了它,这里有多个问题:
- 不知道 go-sqlite 是 goroutine 安全的(这使得使用中央 xorm 管理的连接的整个事情可能是一个坏主意)。
- SQLite 不支持对单个“连接”的并发查询。 我们需要使用 xorm 来打开到 SQLite 的多个连接。 否则我们可能会遇到死锁或这些锁定错误,因为如果来自同一连接,SQLite 将不会尝试解析锁定。
我看到人们做了很多事情来避免这些 SQLite 问题,包括将所有 SQLite 访问包装在一个互斥锁中,并为每个请求打开一个新的 SQLite 实例。 最简单的方法可能是破解 go-sqlite3 以包含每个“连接”的互斥锁,并序列化对它的所有访问(编辑:刚刚意识到这可能不起作用,因为从游标读取时会显示锁,其中你不能在不冒死锁风险的情况下锁定)。 这就是 C 程序会这样做的方式(SQLite 就是为此而设计的)。 它可能很慢,但是需要性能的人无论如何都应该去 PostgreSQL。
lorenz
于 2018-07-31
非常感谢@lorenz深入研究这个问题。 您表示这可能是由 sqlite 级别的某些原因引起的,这促使我将我们实例的配置数据库从 SQLite 移动到 Postgres(并将我们的会话也放在 Postgres 中,后者以前是文件支持的)。 这不是确凿的证据,但从那以后我还没有看到未经授权的问题。
对于有兴趣尝试此解决方法的其他人,我使用pgloader和默认设置,并且在迁移过程中没有删除会话或用户数据。
bjacobel
于 2018-08-03
问题肯定只与 SQLite 后端有关,因为“更大”的数据库都有解决这个问题的 MVCC。 我个人也将我的生产实例移到了 PostgreSQL。 问题仍然存在是我们是否以及如何为 SQLite 后端解决这个问题。 我认为没有简单的方法可以做到这一点,因为 Grafana(由于是用 Go 编写的)大量使用并发,这需要在 SQLite 中特别注意 Xorm 目前提供的内容。
代码中已经有很多锁和重试试图解决这个问题,但它们是不够的。 由于我已经修复了行读取器的错误处理(目前它会默默地吞下锁定错误并因此产生不可预测的行为,我很快就会发布修复程序)我已经看到锁定错误出现在更多的地方,而不仅仅是数据源代理,它只是最常被击中的端点,并且由于错误的概率性质使其成为用户最可见的端点。 据我所知,对此的所有修复都需要破解 Xorm 或 go-sqlite3,这通常是不可取的。
lorenz
于 2018-08-03
感谢@lorenz 的精彩分析! 您认为在这种情况下返回 500 是一个合理的短期解决方法吗? 就像现在一样,401 强制浏览器(至少是 Chrome)忘记密码并要求我的用户再次输入密码。 有时必须多次输入密码,直到最终接受密码。
我目前的解决方法是从tmpfs运行数据库。 它减少了这个问题的频率,但它仍然不时发生。
 kichik
于 2018-08-11
kichik
于 2018-08-11
@kichik当我对错误处理进行 PR 更改后,我们可以考虑返回 HTTP 500(或 503)。 但我能看到的唯一好的解决方法是使用实际的支持 MVCC 的数据库,如 PostgreSQL 或 MySQL,它们根本不会出现问题。 正如我在之前的评论中所解释的,这个问题不仅仅是数据请求,因此返回 HTTP 401 之外的另一个错误代码并不能完全解决问题。
lorenz
于 2018-08-11
我刚刚在 #13007 中发布了我的错误报告更改,这应该可以帮助人们了解他们是否受到锁定问题的影响,或者是否有无关的事情。
lorenz
于 2018-08-22
@torkelo我们能否重新打开它,因为这显然是 Grafana 的问题?
lorenz
于 2018-08-22
对我来说绝对发生在单个选项卡(和单个用户)上。
同样使用sqlite3。 有趣的是,我以前没有这个问题。 现在我已经添加了一些重型(查询明智)面板,我经常收到这个错误,通常只针对我的重型面板之一。
 Argon-
于 2018-08-29
Argon-
于 2018-08-29
确认切换到非 sqlite3 数据库为我解决了这个问题。 我也有一个用户和一个标签,更重/更繁忙的面板也表现得更糟。
更新:必须切换会话以存储在单独的数据库中才能进行完整修复。
 astral303
于 2018-08-29
astral303
于 2018-08-29
我正在使用 mysqldb 面临同样的问题。 Grafana 5.2.3 版,启用了 Lb 级别的粘性,但问题仍然存在。
 vishksaj
于 2018-09-05
vishksaj
于 2018-09-05
也遇到过这种情况,使用 sqlite 作为数据后端,但在 grafana 5.2.3 上使用 redis 作为会话存储
配置了大约 150 个组织。 未经授权的警告在内部刷新时弹出,但通常在手动刷新时消失。
不时在日志中获取此信息:
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=1
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=1
 reinhard-brandstaedter
于 2018-09-12
reinhard-brandstaedter
于 2018-09-12
此问题可能是由 mysql 连接丢失引起的。 当我降低 max_idle_conn 和 conn_max_lifetime 值时,这不会再发生。 希望这有帮助
 xiaochai
于 2018-10-11
xiaochai
于 2018-10-11
@vishksaj @xiaochai这很可能是一个不同的问题,你能开一个新的吗?
lorenz
于 2018-10-11
https://github.com/oleh-ozimok/grafana/commit/b19e416549553f582dccfbcaa3f4d3f1a742a462 - 解决了我的问题(带有修补程序的图像docker pull olegozimok/grafana:5.3.2 )
 oleh-ozimok
于 2018-10-29
oleh-ozimok
于 2018-10-29
格拉法纳 5.3.2。 HA配置:2个Grafana实例,MySQL主DB,2个用于会话的memcached实例,grafana dir和DB存储在NFS上。 总是出现相同的“未经授权”错误,不可预测。 当 DB 是 NFS 上的 SQLite 时也是如此。
 dev-e
于 2018-11-01
dev-e
于 2018-11-01
与@dev-e 相同的问题,但设置更简单。 Grafana 5.3.2,单实例,同一主机上的InfluxDB,单组织,单用户。 该消息随机出现并在下一页刷新时消失。
 luizfzs
于 2018-11-01
luizfzs
于 2018-11-01
我也有同样的问题。 随机得到未经授权的错误。
升级到 grafana 5.3.4 让它变得更好,但仍然有很多错误。
在 grafana 日志中:
t=2018-11-19T09:55:07+0200 lvl=eror msg="无法获取具有 id 的用户" logger=context userId=1 error="找不到用户"
t=2018-11-19T09:55:07+0200 lvl=eror msg="无法获取具有 id 的用户" logger=context userId=1 error="找不到用户"
t=2018-11-19T09:55:07+0200 lvl=eror msg="无法获取具有 id 的用户" logger=context userId=1 error="找不到用户"
开箱即用的设置:
grafana/现在 5.3.4 amd64
influxdb/现在 1.6.0-1 amd64
 gigake
于 2018-11-19
gigake
于 2018-11-19
同样的问题在这里:
t=2018-12-03T09:28:21+0000 lvl=eror msg="Failed to update last_seen_at" logger=context userId=12 orgId=1 uname=ht error="database table is locked"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
2018/12/03 10:51:54 http: proxy error: unexpected EOF
2018/12/03 10:51:54 http: proxy error: unexpected EOF
2018/12/03 10:51:54 http: proxy error: unexpected EOF
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:56+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:56+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
单个 Grafana 5.3.4,存储是 Amazon EFS 文件系统(NFS 挂载)
会话设置为文件,数据存储为 sqlite ( /var/lib/grafana/grafana.db )
Grafana 位于 HTTPS 终止 LB 的后面
 roffe
于 2018-12-03
roffe
于 2018-12-03
提出了实施@oleh-ozimok 建议的公关。 随意尝试一下。 我休假回家后会再试一次,这样我就可以有一个长期运行的实例:)
@oleh-ozimok 如果你想创建一个 PR,我更乐意合并它而不是我的来给你荣誉。
顺便说一句, @
 bergquist
于 2018-12-27
bergquist
于 2018-12-27
这也会影响我们的部署。 使用两个以 HA/多主模式运行的 Amazon Auora MySQL 数据库,我们不断收到 401 Unauthorized 错误。 我已经验证会话在两个数据库上。 但即便如此,我还是将所有实例都指向同一个数据库,看看这是否能解决问题,但事实并非如此。 会话被正确验证肯定有问题。 我们的 Oauth 设置更进一步。 有时用户会使用配置的 Oauth 提供程序登录,并且一旦重定向就无法登录。 如果他们登录大约 2-3 次,它就可以工作。
 buroa
于 2019-01-26
buroa
于 2019-01-26
这很奇怪,也许服务器上的配置不同?
有日志详细信息吗?
我们正在消除对会话存储的需求并完全重写 v6 中登录会话的管理方式,因此希望这能解决它。
torkelo
于 2019-01-27
@buroa你有机会尝试 6.0-beta1 吗? 我们已经重写了 auth 令牌并完全删除了大多数会话令牌的使用(在使用 auth_proxy 时仍然使用),并希望这些问题中的大多数都能消失。
bergquist
于 2019-02-05
@bergquist在 2019-02-01T09:58:20+0200 更新了我的设置,目前没有发生这个错误。
 zcooler
于 2019-02-05
zcooler
于 2019-02-05
@buroa你有机会尝试 6.0-beta1 吗? 我们已经重写了 auth 令牌并完全删除了大多数会话令牌的使用(在使用 auth_proxy 时仍然使用),并希望这些问题中的大多数都能消失。
我正在使用最新版本: https :
这有需要的改变吗?
buroa
于 2019-02-05
@buroa是的,但仍然建议您合并最新的 master,因为我们自 6.0-beta1 以来做了一些更改。
marefr
于 2019-02-05
今天出错了
t=2019-02-08T10:05:58+0200 lvl=info msg="无法根据 cookie 查找用户" logger=context error="未找到用户身份验证令牌"
浏览器选项卡没有关闭,只是每小时自动刷新一次,但电脑被锁定。
 QuantumProjects
于 2019-02-08
QuantumProjects
于 2019-02-08
@QuantumProjects你介意开一个新问题,因为你对 Grafana v6.0-pre 有问题。 请提供有关您的 Grafana 设置的更多详细信息:正在使用什么数据库? 格拉法纳版? 多个 Grafana 实例? 什么认证类型? 反向代理? 谢谢
marefr
于 2019-02-08
@marefr好的
QuantumProjects
于 2019-02-08
@marefr我得到相同的“未经授权”-弹出窗口,也许我的设置可以帮助解决问题:
- 使用traefik作为反向代理的网关服务器指向托管 grafana 的本地服务器
- 使用 Grafana v5.4.3 的本地服务器
- 数据源是同一本地服务器上的 influxdb v1.7.8
- 如何找出被质疑的认证类型? 我只是以管理员用户身份登录
注意:每个服务都是一个 docker 容器、traefik x64、grafana 和 influxdb arm32v7
 eiabea
于 2019-02-19
eiabea
于 2019-02-19
这也发生在 Grafana 6.0.0(提交:34a9a62,分支:HEAD)中。 SQLite 数据库未使用,Grafana 在 nginx 反向代理后面工作。 LDAP 身份验证已配置。 单个 Grafana 实例正在此 VM 上运行。
出错时的日志条目:
t=2019-03-06T13:39:24+0100 lvl=eror msg="failed to look up user based on cookie" logger=context error="database is locked"
 angryp
于 2019-03-06
angryp
于 2019-03-06
只需添加一个数据点,一旦我将数据库从 sqlite 移动到 postgres,我就不再看到这些错误了。 以前,它们的频率已经足够使使用该系统变得非常不舒服。 使用 google oauth 运行单个 5.4.3 服务器。
 qhartman
于 2019-03-06
qhartman
于 2019-03-06
在 5.4.3 上发生在我身上,连接到 postgres,相当随机,但只有当我让它自动刷新时。 安装程序位于本地网络上,其中数据库与 Grafana 位于同一台机器上。
当“未经授权”弹出时,我在系统日志上收到了一堆这些类型的错误:
...
...
grafana-server[12619]: t=2019-03-06T22:42:02+0100 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
grafana-server[12619]: t=2019-03-06T22:42:03+0100 lvl=eror msg="Failed to get user with id" logger=context userId=1 error="User not found"
...
grafana-server[12619]: t=2019-03-06T22:42:03+0100 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=POST path=/api/tsdb/query status=401 remote_addr=192.168.0.2 time_ms=17 size=26 referer="http://192.168.0.1:3000/d/.....
...
userId=1 或 0 和 retry=1 或 0 上的日志有一些变化
 ggggh
于 2019-03-06
ggggh
于 2019-03-06
你好,
我今天遇到了同样的问题。 几天前,我们在普通 Debian Stretch 上升级了 Grafana 6.0.1。 Grafana 使用 MariaDB 10.2(Galera 集群)作为后端(具有三个节点的同步模式)连接到负载均衡器(proxysql)。
我们使用 LDAP (Windows AD) 作为授权。
日志消息:
lvl=eror msg="failed to look up user based on cookie" logger=context error="invalid connection"
唯一有效的是使用直接 IP 而不是负载均衡器。
 linuxmail
于 2019-03-14
linuxmail
于 2019-03-14
唯一有效的是使用直接 IP 而不是负载均衡器。
听起来不像是同一个问题,因为我们的问题是间歇性的 - 也许每十次左右刷新中的一个面板可能会因错误而失败,但通常可以工作
ggggh
于 2019-03-14
同样的事情发生在 6.0.2 上。
从日志:
t=2019-03-23T12:04:22+0000 lvl=eror msg="failed to look up user based on cookie" logger=context error="database is locked"
和t=2019-03-23T19:05:45+0000 lvl=eror msg="Failed to update last_seen_at" logger=context userId=1 orgId=1 uname=<username> error="database is locked"
使用 Traefik 进行常规 docker 安装以进行反向代理。
 menteb
于 2019-03-23
menteb
于 2019-03-23
对我来说同样的事情正在发生
版本 6.02
“无法根据 cookie 查找用户” logger=context error="数据库被锁定"
 tiagoalmeida10
于 2019-03-28
tiagoalmeida10
于 2019-03-28
如果您使用 Sqlite(默认)获取“数据库已锁定”,则可能是迁移到 mysql/postgres 的好时机,因为它们可以处理更多事务/秒
bergquist
于 2019-04-03
@bergquist我认为这确实是解决方案。 刚刚迁移到 MariaDB,我不再被 Grafana 抛弃。 钉!
menteb
于 2019-04-04
@bergquist我认为这确实是解决方案。 刚刚迁移到 MariaDB,我不再被 Grafana 抛弃。 钉!
澄清一下,这可能是“数据库被锁定”而不是“数据库表被锁定”的解决方案——我在 PostgreSQL 上并面临“表锁定”。
ggggh
于 2019-04-04
在将我带到 Postgres 9.6(从 9.4)的 Raspbian 升级之后为我解决了。 Grafana 仍在 5.4.3 上
ggggh
于 2019-04-25
在将我带到 Postgres 9.6(从 9.4)的 Raspbian 升级之后为我解决了。 Grafana 仍在 5.4.3 上
忘记我说的话……它回来了。 不太经常,我会说......但仍然发生。
ggggh
于 2019-05-10
@ggggh 有什么解决办法吗? 对我来说,它刚刚开始突然发生!
 devanshkv
于 2019-05-22
devanshkv
于 2019-05-22
@ggggh 有什么解决办法吗? 对我来说,它刚刚开始突然发生!
没有...! 它随着 postgres 版本升级而清除,并且似乎每天都更频繁地再次回来
ggggh
于 2019-05-22
@ggggh谢谢!
我已经切换到 Postgres,但这也无济于事:(
devanshkv
于 2019-05-22
在使用 Grafana 6.2.1 和 Postgress 11 时遇到同样的问题,但这仅发生在我从 JSON 加载然后尝试访问它们的仪表盘上。
有任何更新吗?
 botzill
于 2019-05-29
botzill
于 2019-05-29
好的,我在我的案例中发现了这个问题。 我的 PG 的连接数量有限,并且在 grafana 中没有设置max_open_conn 。 在我设置了这个选项后,它工作正常。
botzill
于 2019-06-03
我在 Grafana 6.1.6 和打包的 SQLite DB 上也发生了同样的事情。 这个问题破坏了我们为定制 Grafana 所做的内部开发工作。 更改max_open_conn不起作用(尽管我没想到它会起作用,因为它是 Postgres 的修复程序)。
 syardumian-chc
于 2019-06-10
syardumian-chc
于 2019-06-10
其根本原因似乎是 grafana 试图连接到
身份验证时底层数据库,但未能这样做。 使用 SQLite,
由于 SQLite 锁定,将经常发生并且并发使用次数很少
如此积极。 在大多数情况下,迁移到真正的 RDBMS(我喜欢 postgres)
将解决问题。 如果您遇到一个问题,它可能会再次出现
连接限制(或类似)问题,但这不仅仅是一个数据库问题
Grafana 关注。 如果您将 Grafana 用于演示以外的任何用途,
你应该用一个真正的数据库来支持它。 如果该数据库配置正确
你的用法,应该可以解决这个问题。
2019 年 6 月 10 日星期一上午 11:20 syardumian-chc [email protected]
写道:
我在 Grafana 6.1.6 和打包的 SQLite DB 上也发生了同样的事情。 这个
问题破坏了我们为自定义 Grafana 所做的内部开发工作。 改变
max_open_conn 不起作用(虽然我没想到它会起作用,因为它是一个
修复 Postgres)。—
您收到此消息是因为您订阅了此线程。
直接回复本邮件,在GitHub上查看
https://github.com/grafana/grafana/issues/10727?email_source=notifications&email_token=AAAK6YSUDLXPF2E4436CEOTPZ2EMFA5CNFSM4EO23EH2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LODMX5KUYZGOZGODMX50000000000000000D
或静音线程
https://github.com/notifications/unsubscribe-auth/AAAK6YQLR3FSCNEQR7SNEKLPZ2EMFANCNFSM4EO23EHQ
.
qhartman
于 2019-06-10
我增加了连接限制和最大空闲连接数,但仍然随机遇到这个问题。 不仅如此,已打开一段时间的仪表板似乎刷新越来越慢,每个面板上的加载 gif 都很明显,并随着每个面板完成加载而依次缓慢消失。 如果我关闭浏览器窗口并打开一个新窗口就好了。 我想我的仪表板变得更复杂了,但这并不能解释为什么页面的新加载“修复它”。
ggggh
于 2019-06-12
我也收到随机错误。 真不知道是什么问题。 使用 IP 地址似乎没问题,但是使用 kubeneters 入口,它会随机显示“注释查询失败”。
 naturalbeau
于 2019-06-13
naturalbeau
于 2019-06-13
FWIW,我最近将我的入口负载均衡器切换到 Fabio(来自 Traefik)并将 Grafana(Docker 镜像,没有额外的数据库后端)更新到 v6.4.2,并且在执行自动刷新时 401 未授权错误似乎已经消失(间隔设置为 10秒,全天运行)。 切换到 Fabio 不太可能解决这个问题,我猜是新版本的 Grafana 有所帮助,但我不是 100% 确定。
 kmott
于 2019-10-09
kmott
于 2019-10-09
由于最近没有新报告,因此关闭此内容。 如果您认为仍然存在问题,请打开一个新问题
torkelo
于 2019-10-19
我最近在我的 kubernetes 集群上安装了 grafana 并遇到了类似的问题。
我正在使用 docker image grafana/ grafana:6.4.3
检查我的 pod 日志,我发现了这个有趣的小花絮:
t=2019-11-01T15:18:33+0000 lvl=info msg="Successful Login" logger=http.server User=--snip--
t=2019-11-01T15:19:09+0000 lvl=eror msg="Failed to look up user based on cookie" logger=context error="dial tcp: lookup postgres.databases.svc.cluster.local: no such host"
t=2019-11-01T15:19:09+0000 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=GET path=/api/datasources/proxy/1/query status=401 remote_addr=--snip-- time_ms=11 size=26 referer="https://--snip--/d/TuobtjoZz/--snip--?orgId=1&refresh=5s&from=now-12h&to=now"
DNS 问题不是我之前在集群中遇到的问题,但我做了一些谷歌搜索并发现了这个特殊问题: https :
grafana 是否可以像许多 docker 镜像那样同时发送 alpine 和非 alpine 镜像? 好像这样就能解决问题。
如果在测试或帮助调试方面我可以做任何事情,请告诉我,我会根据要求提供信息。
 ikkerens
于 2019-11-01
ikkerens
于 2019-11-01
降级到 6.3.6(不是基于 alpine 的)后,问题在我这边完全消失了。
ikkerens
于 2019-11-02
我遇到了同样的问题,在同一个浏览器中打开了两个单独的 Grafana(容器)
登录第二个时第一个要求我再次登录,登录第一个第二个要求我再次登录
不能同时登录
我找到的解决方案是更改 Grafana default.ini 文件之一
login_cookie_name = grafana_session
到
login_cookie_name = grafana_session_1
重新启动容器和浏览器,现在它工作正常
现在我把文件放在容器外面
创建容器时需要设置这个参数
 n0-bs
于 2020-02-20
n0-bs
于 2020-02-20
@ikkerens请尝试基于 ubuntu 的图像,然后 6.6.2-ununtu
marefr
于 2020-02-28
@n0-bs 抱歉,如果您运行多个 Grafana 实例,建议使用 MySQL 或 Postgres 作为数据库。
marefr
于 2020-02-28
抱歉,但是如何使用 MySQL 或 Postgres 作为数据库来解决我在同一浏览器中打开这两个不同的 Grafana 实例时的 cookie 冲突,我不是在谈论 HA 情况
我在同一台服务器上有两个不同的 Grafana 实例(容器)
n0-bs
于 2020-03-01
我仍然在 6.7.2 中看到这个。 我从 6.5 升级到 6.6,然后是 6.7。 将 docker 与 PostgreSQL 一起使用,尝试了 6.7.2 映像,然后是 6.7.2-ubuntu。
这是我在日志中遇到的错误:
lvl=eror msg="Failed to look up user based on cookie" logger=context error="pq: remaining connection slots are reserved for non-replication superuser connections"
 helderco
于 2020-04-16
helderco
于 2020-04-16
通过重新启动 postgres 修复(至少现在)。
helderco
于 2020-04-16
我使用的是最新版本的 Grafana,但每次访问它时仍然会看到未经授权的问题。 我在 kubernetes 中使用 Grafana。 我将它部署在 3 个不同节点的 3 个不同 pod 中。 我使用它的本机数据库。 有什么建议可以解决这个问题吗?
 emzfuu
于 2020-06-01
emzfuu
于 2020-06-01
@emzfuu如果您运行多个实例,则需要将所有实例都指向同一个数据库。 mysql/postgres
bergquist
于 2020-06-01
@bergquist还有其他方法可以解决这个问题吗?
emzfuu
于 2020-06-02
只是为了详细说明我上面的问题,我使用了 3 个不同的 Grafana(独立),它可以通过单个负载均衡器访问。 3 Grafana 有自己的数据库(sqlite3)。 每次访问它时,我都会收到未授权错误。
emzfuu
于 2020-06-03
我有同样的问题,使用 nfs。
 linux0x5c
于 2020-06-08
linux0x5c
于 2020-06-08
相关问题
 tuxinaut
·
3评论
tuxinaut
·
3评论
 calind
·
3评论
calind
·
3评论
 PaulKlumpp
·
3评论
PaulKlumpp
·
3评论
 kcajf
·
3评论
kcajf
·
3评论
 Azef1
·
3评论
Azef1
·
3评论
最有用的评论
我在 Grafana v4.6.2 (commit: 8db5f08) 上看到了同样的问题,一切都按预期工作,突然我收到一个未经授权的警告(有些图表是空的,但有些图表正常显示)。
我使用 Prometheus 作为数据源。
我还认为这主要发生在仪表板自动刷新时,但在我手动刷新时会自行修复。