أقوم بتشغيل أحدث إصدار من grafana في حالتين ، لكنني أواجه الكثير من الأخطاء غير المصرح بها عند محاولة الوصول إلى كلتا الحالتين. للمصادقة ، أستخدم حاليًا db المدمج ، ولا LDAP. مصدر البيانات هو تدفق.
هل هذا خطأ أو سوء سلوك معروف؟
 darox
darox
ال 105 كومينتر
هل يمكنك إعطاء المزيد من التفاصيل:
- هل هاتان حالتان منفصلتان؟
- ما الإجراء الذي يتسبب في حدوث الخطأ غير المصرح به؟
- هل يتم تسجيل خروجك أم أنها مجرد إجراءات معينة لا تفي بالغرض؟
 daniellee
في ٢ فبراير ٢٠١٨
daniellee
في ٢ فبراير ٢٠١٨
هل تم إعدادهم على أسماء نطاقات / IPS مختلفة؟ إذا كان اسم المجال هو نفسه ومختلف فقط حسب المنفذ ، فستحتاج إلى الحصول على ملفات تعريف ارتباط فريدة للجلسة وتذكر ملفات تعريف الارتباط الخاصة بي
 torkelo
في ٢ فبراير ٢٠١٨
torkelo
في ٢ فبراير ٢٠١٨
-هذه أمثلة منفصلة
- لا أعرف الإجراء الذي يؤدي إلى تشغيل غير المصرح به ، فهذا يحدث فقط عندما أشاهد الرسوم البيانية أو عند الوصول إلى grafana
-أحيانًا يتم تسجيل خروجي
- مجالات منفصلة
darox
في ٢ فبراير ٢٠١٨
أواجه هذا على Grafana 4.6.x مع oauth من خلال Github. يبدو الأمر عشوائيًا عندما أقوم بتبديل علامات التبويب والعودة إلى Grafana. التحديث سوف "يصحح" المشكلة ، ولكن في بعض الأحيان يعود في وقت لاحق.
 pgporada
في ٧ مارس ٢٠١٨
pgporada
في ٧ مارس ٢٠١٨

أرى نفس المشكلة في Grafana v4.6.2 (الالتزام: 8db5f08) ، كل شيء يعمل كما هو متوقع ، وفجأة تلقيت تحذيرًا غير مصرح به (وبعض الرسوم البيانية تكون emtpy ، لكن بعضها يظهر بشكل طبيعي).
أستخدم بروميثيوس كمصدر بيانات.
أعتقد أيضًا أن هذا يحدث بشكل أساسي عندما يتم تحديث لوحة القيادة تلقائيًا ، ولكنها تصلح نفسها عندما أقوم بتحديثها يدويًا.
 ajardan
في ٨ مارس ٢٠١٨
ajardan
في ٨ مارس ٢٠١٨
مشكلة مماثلة هنا أيضًا ، ولكن مع مثيل Grafana واحد مع مصدر بيانات HTTPS و Postgres.
عندما يتم فتح لوحة القيادة ، تكون جميع الرسوم البيانية جيدة. ولكن في بعض الأحيان بعد ذلك ، تبدأ بعض الرسوم البيانية في عرض أخطاء "غير مصرح بها" عند التحديث التلقائي ، ولكن خلال التحديث التلقائي التالي (أو التالي) ، فإنها تستعيد الحالة الطبيعية ، ولكنها تتحول بعد ذلك إلى حالة "غير مصرح به" في بعض الأحيان مرة أخرى في وقت لاحق هذا السلوك العشوائي في كل تحديث تلقائي.
لست متأكدًا مما إذا كان مرتبطًا ، ولكن تم العثور على رسائل السجل التالية.
lvl = eror msg = "فشل الحصول على مستخدم بالمعرف" المسجل = سياق userId = خطأ واحد = "المستخدم غير موجود"
إصدار Grafana كما يلي:
lvl = info msg = "بدء تشغيل Grafana" المسجل = إصدار الخادم = 5.0.4 الالتزام = 7dc36ae المترجمة = 2018-03-28T20: 52: 41 + 0900
أنا أستخدم Firefox ، وعادة ما أترك لوحة القيادة مفتوحة وغير متأثرة لعدة أيام ، مع دخول جهاز العميل (وليس جهاز الخادم الذي يستضيف Grafana) إلى وضع السكون من وقت لآخر.
 after-the-sunrise
في ١٢ أبريل ٢٠١٨
after-the-sunrise
في ١٢ أبريل ٢٠١٨
لم يعد هذا يحدث لي مع grafana 5.x
darox
في ١٢ أبريل ٢٠١٨
ما زلت أواجه نفس المشكلة بالضبط مع Grafana 5.0.4 ، نفس رسائل المستخدم غير الموجودة في السجل (هذا مع مستخدم Grafana محلي بسيط).
 SoulSeekkor
في ١٣ أبريل ٢٠١٨
SoulSeekkor
في ١٣ أبريل ٢٠١٨
أواجه هذه المشكلة أيضًا. والمسألة مثيرة جدا للاهتمام. قد يحدث ذلك عندما أفتح صفحتين من صفحات grafana بإصدار مختلف في نفس المتصفح وأحاول القيام ببعض العمليات.
لدي إصدار أقدم من grafana (v4.3.2 (الالتزام: ed4d170)) وقد عملت بشكل جيد على grafana.mydomain.com لفترة طويلة. أريد اليوم ترقية برنامج grafana الخاص بي إلى الإصدار 5.0.4. بدلا من الترقية في المكان. كنت أرغب في إعداد Grafana الجديد على نفس الجهاز ، ونسخ لوحة القيادة التي أريدها ، ثم مزق اللوحة القديمة.
إذن ما فعلته:
- تشغيل docker grafana5 على نفس الجهاز القديم مع خريطة المنفذ إلى 3005
- فتح grafana4 القديم على
grafana.mydomain.comفي Safari
وهو يعمل بشكل جيد - قم بزيارة Grafana5 على
grafana.mydomain.com:3005في Safari
الآن لديّ علامتا تبويب مفتوحتان لـ Grafana4 و Grafana5 على شاشتي - تسجيل الدخول إلى Grafana5 ، في محاولة للقيام ببعض العمليات .... مثل [إنشاء لوحة القيادة]
الآن تحطمت كل من صفحة Grafana
سيحصل كل من Grafana على أخطاء Unauthorized ولن يحصل على أي نقاط بيانات
تحديث : لقد غيرت خطوتي 3 من خلال زيارة Grafana5 باستخدام [ip]: 3005. إنه يعمل بشكل جيد في الوقت الحالي.
يبدو أنه قد تكون هناك بعض التعارضات في فتح صفحتين من Grafana داخل نفس المجال.
 kehao95
في ١٨ أبريل ٢٠١٨
kehao95
في ١٨ أبريل ٢٠١٨
@ kehao95 لا يتم دعم حالة الاستخدام الخاصة بك في نفس المتصفح عند فتح مثيلين من Grafana على نفس المجال ولكن مع منافذ مختلفة. (ذكر توركل ذلك أعلاه).
ajardan هل
daniellee
في ٣٠ أبريل ٢٠١٨
daniellee أنا في الواقع أستخدم
ajardan
في ٧ مايو ٢٠١٨
أحصل أيضًا على هذه المشكلات "غير المصرح بها" الغريبة من وقت لآخر. تحديث الصفحة "يصلح" المشكلة. أقوم بتشغيل Grafana v5.1.0 (844bdc53a) من صورة Docker الرسمية. مصدر البيانات هو InfluxDb. لقد أنشأت مؤسستين في Grafana ، لكنني أستخدم واحدة فقط في الواقع. مستخدم "إداري" واحد.
 dogada
في ٨ مايو ٢٠١٨
dogada
في ٨ مايو ٢٠١٨
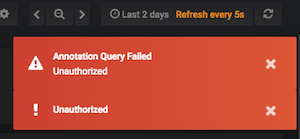
لقد حصلت للتو على هذا الخطأ مرة أخرى برسالة خطأ جديدة "فشل استعلام التعليقات التوضيحية. غير مصرح به"
dogada
في ٨ مايو ٢٠١٨
كان برنامج grafana الخاص بي على نظام التشغيل Win10 x64 يعمل بشكل جيد تمامًا لبضعة أيام حتى أتلقى تحذيرًا "غير مصرح به". السلوك هو نفسه الذي وصفه dogada وأنا أيضًا أقوم بتشغيل v5.1.0 مع influxdb. كل من grafana و influxdb موجودان على نفس الكمبيوتر.
 schwarzlowe
في ٩ مايو ٢٠١٨
schwarzlowe
في ٩ مايو ٢٠١٨
المشكلة نفسها. مثيل grafana 5.1 واحد في عامل الإرساء. جوجل oauth للحصول على إذن.
أي تحديثات؟
 StupidScience
في ١١ مايو ٢٠١٨
StupidScience
في ١١ مايو ٢٠١٨
نفس السلوك. قيد التشغيل حاليًا v5.0.3 في docker ، المصادقة الداخلية ، مستخدم مشرف واحد ، وكيل عبر nginx ، مصدر البيانات هو influxdb. لوحة القيادة تصلح نفسها عند التحديث التلقائي للبيانات. يحدث غالبًا عند علامة التبويب وقت طويل في الخلفية
 radium88
في ١٥ مايو ٢٠١٨
radium88
في ١٥ مايو ٢٠١٨
تظهر نفس المشكلة عند فتح علامتي تبويب على نفس المثيل.
 lamoni
في ١٥ مايو ٢٠١٨
lamoni
في ١٥ مايو ٢٠١٨
التحديث إلى أحدث إصدار من صورة عامل الإرساء v5.1.2 (الالتزام: c3c690e21) لا يصلح المشكلة
radium88
في ١٦ مايو ٢٠١٨
أواجه ما أعتقد أنه نفس المشكلة مع Grafana 5.0.0 في Docker باستخدام GitHub OAuth. لقد رأيته على لوحات المعلومات مع InfluxDB و CloudWatch ومزيج من كلا مصدري البيانات. (مثيل واحد ، منفذ واحد ، HTTPS ، خلف ELB.)
مثل الآخرين في هذا الموضوع ، يبدو أنني أرى أنه يتم تشغيله عن طريق التحديث التلقائي ، ويختفي بعد إعادة تحميل الصفحة. أحيانًا أرى رسالة الخطأ الأساسية "غير مصرح به" (مع فشل تحميل الرسم البياني) وأحيانًا (نادرًا) تظهر رسالة "فشل استعلام التعليقات التوضيحية. غير مصرح به" أيضًا.
~ شكوكي يشير إلى شيء ما مع مكونات OAuth الإضافية؟ ~ يكاد يكون من المؤكد أنه بسبب خلفية الجلسة ، انظر أدناه.
 bjacobel
في ١٦ مايو ٢٠١٨
bjacobel
في ١٦ مايو ٢٠١٨
لإضافة المزيد من التفاصيل التي وجدتها بعد البحث بشكل أعمق قليلاً ، أرى العديد من الأخطاء مثل هذا في سجلاتي:
t=2018-05-16T16:55:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
المكان الوحيد الذي أرى فيه مثل هذا الخطأ هو في هذا السطر من التعليمات البرمجية ، والذي يبدو مرتبطًا بإدارة الجلسات وملفات تعريف ارتباط الجلسة؟
أقوم بتخزين جلساتي باستخدام الواجهة الخلفية الافتراضية file ، ولكن عبر مشاركة EFS المركبة ، أتساءل عما إذا كان ذلك من المضاعفات المحتملة.
bjacobel
في ١٦ مايو ٢٠١٨
لقد واجهت هذه المشكلة عندما حاولت فتح جرافانا مختلفين (يعملان في منفذ مختلف) في نفس المتصفح.
أحصل على أخطاء غير مصرح بها وأحيانًا يتم تسجيل الخروج
 harshitha-m
في ٢٣ مايو ٢٠١٨
harshitha-m
في ٢٣ مايو ٢٠١٨
سيكون من المثير للاهتمام حقًا معرفة ما يتم تنفيذ استعلامات SQL عندما تتلقى رسالة فشل الحصول على المستخدم بسجل معرف . إذا كان بإمكانك إعادة إنتاج هذا بسهولة ، فسيكون من المفيد جدًا تمكين تسجيل استعلامات sql وتقديم تقرير بالنتائج التي توصلت إليها:
[database]
# Set to true to log the sql calls and execution times.
log_queries = true
شكرا لك
 marefr
في ٣٠ مايو ٢٠١٨
marefr
في ٣٠ مايو ٢٠١٨
marefr يبدو أن هذه الأخطاء تحدث دائمًا محاطة بأحد هذين الاستعلامين:
SELECT\n\t\tu.id as user_id,\n\t\tu.is_admin as is_grafana_admin,\n\t\tu.email as email,\n\t\tu.login as login,\n\t\tu.name as name,\n\t\tu.help_flags1 as help_flags1,\n\t\tu.last_seen_at as last_seen_at,\n\t\t(SELECT COUNT(*) FROM org_user where org_user.user_id = u.id) as org_count,\n\t\torg.name as org_name,\n\t\torg_user.role as org_role,\n\t\torg.id as org_id\n\t\tFROM `user` as u\n\t\tLEFT OUTER JOIN org_user on org_user.org_id = 1 and org_user.user_id = u.id\n\t\tLEFT OUTER JOIN org on org.id = org_user.org_id WHERE u.id=? []interface
UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
سجلات الأمثلة الكاملة:
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] SELECT\n\t\tu.id as user_id,\n\t\tu.is_admin as is_grafana_admin,\n\t\tu.email as email,\n\t\tu.login as login,\n\t\tu.name as name,\n\t\tu.help_flags1 as help_flags1,\n\t\tu.last_seen_at as last_seen_at,\n\t\t(SELECT COUNT(*) FROM org_user where org_user.user_id = u.id) as org_count,\n\t\torg.name as org_name,\n\t\torg_user.role as org_role,\n\t\torg.id as org_id\n\t\tFROM `user` as u\n\t\tLEFT OUTER JOIN org_user on org_user.org_id = 1 and org_user.user_id = u.id\n\t\tLEFT OUTER JOIN org on org.id = org_user.org_id WHERE u.id=? []interface
{}
{2} - took: 54.517418ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 42.957209ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] SELECT\n\t\tu.id as user_id,\n\t\tu.is_admin as is_grafana_admin,\n\t\tu.email as email,\n\t\tu.login as login,\n\t\tu.name as name,\n\t\tu.help_flags1 as help_flags1,\n\t\tu.last_seen_at as last_seen_at,\n\t\t(SELECT COUNT(*) FROM org_user where org_user.user_id = u.id) as org_count,\n\t\torg.name as org_name,\n\t\torg_user.role as org_role,\n\t\torg.id as org_id\n\t\tFROM `user` as u\n\t\tLEFT OUTER JOIN org_user on org_user.org_id = 1 and org_user.user_id = u.id\n\t\tLEFT OUTER JOIN org on org.id = org_user.org_id WHERE u.id=? []interface
{}
{2} - took: 69.013955ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 5.593997ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 46.673µs" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 621.538µs" logger=sqlstore.xorm
شكرا جزيلاbjacobel. كل شيء يبدو جيدا هنا بالنسبة لي. هناك معرف مستخدم فعلي مقدم وصولاً إلى استعلام قاعدة البيانات. غريب فعلا. بدأنا نعتقد أن هناك خطأ في قاعدة بيانات الطرف الثالث lib xorm.
هل فعلت أي شيء محدد لإنشاء رسائل السجل هذه؟
ما قاعدة البيانات التي تستخدمها؟ ما تخزين الجلسة؟
ما ينتج عن الطلب غير مصرح به ، يمكنك تمكين تسجيل جهاز التوجيه لتسجيل جميع الطلبات:
[server]
router_logging = true
لدينا نفس الخطأ في 5.1.4 في Kubernetes.
 benkeil
في ٢١ يونيو ٢٠١٨
benkeil
في ٢١ يونيو ٢٠١٨
مرحبًا marefr ، آسف ، لقد نسيت الرد بالتفاصيل الإضافية المطلوبة.
هل فعلت أي شيء محدد لإنشاء رسائل السجل هذه؟
يتم إنشاء الاستعلامات عن طريق تحميل لوحة القيادة ثم انتظار التحديث التلقائي. لا يحدث ذلك في كل تحديث تلقائي ، وفي بعض الأحيان يمكن تشغيله بنقرة يدوية على زر تحديث لوحة القيادة (الزر المدمج في Grafana ، وليس زر تحديث المتصفح) ولكن بشكل عام يبدو أنه يحدث في كثير من الأحيان عندما يكون المستخدم كذلك غير نشط (ترك grafana في علامة تبويب الخلفية ، على سبيل المثال.)
ما قاعدة البيانات التي تستخدمها؟ ما تخزين الجلسة؟
قاعدة البيانات عبارة عن SQLite على مشاركة NFS (EFS) ، وتخزين الجلسة هو (الملف) الافتراضي ، على الرغم من أنني جربت أيضًا التخزين المستند إلى الذاكرة وكان لديه نفس المشكلة أيضًا. لدينا مضيف grafana واحد خلف موازن التحميل ، وقمت بتمكين ثبات الجلسة على موازن التحميل هذا.
ما هو الطلب الذي أدى إلى غير مصرح به؟
لم أقم بتمكين تسجيل الموجه ، لأنني أستطيع رؤية الطلب الذي أدى إلى عدم التصريح من المتصفح:
[تم تنقيح بعض المعلومات الحساسة]
Request URL: https://[my grafana hostname]/api/tsdb/query
Request Method: POST
Status Code: 401
Remote Address: [my load balancer IP]:443
Referrer Policy: no-referrer-when-downgrade
:authority: [my grafana hostname]
:method: POST
:path: /api/tsdb/query
:scheme: https
accept: application/json, text/plain, */*
accept-encoding: gzip, deflate, br
accept-language: en-US,en;q=0.9
cache-control: no-cache
content-length: 478
content-type: application/json;charset=UTF-8
cookie: _ga=GA1.2.1782868908.1520436196; __gads=ID=b1c7d78e4fd8b9fb:T=1520436200:S=ALNI_MYT2aRMJqYtHY-CkgaPWmuNtsGEtA; sailthru_hid=919b24e8c99698a8b1829b81eda7135a5956a753dd4c29265f8b45b3a11fb749fc11562ad2abbb1220b9ef37; grafana_sess=[16-char hexadecimal session string]; AWSALB=IUyH6LlTXI/TJlteL8pr838fC7nsvth7s63o5WzqOa6wsCPRpHg20vYurCrYpbIWci27fQtzQpoRxVlIc8Ud/rEPIJvqWvT21an4e9aQmZioTEAFHA3+iWv7bPHs
dnt: 1
origin: https://[my grafana hostname]
pragma: no-cache
referer: https://[my grafana hostname]/d/[dashboard path]?refresh=5m&orgId=1&from=now-1h&to=now
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36
x-grafana-org-id: 1
مرحبًا marefr ، آسف ، لقد نسيت الرد بالتفاصيل الإضافية المطلوبة. ...
bjacobel من المحتمل أن هذا ليس له علاقة بالمشكلة المحددة ، لكن مطوري SQLite يوصون بعدم تشغيل SQLite عبر NFS. على وجه التحديد ، يجب ألا تصل عملية Grafana إلى قاعدة البيانات عبر تحميل NFS ، ولا يوصى بالتشغيل من أي نظام ملفات متصل بالشبكة بدون دعم قوي لقفل الملفات.
في ملاحظة جانبية ، نستخدم SQLite مع تخزين الجلسة كما تفعل ، ولكن على نظام الملفات المحلي. لم نواجه هذه المشكلة نفسها.
لقد قمنا أيضًا بتعديل تكوين SQLite في grafana لاستخدام وضع WAL (الذي سأقوم به في النهاية بالعلاقات العامة) للحصول على أداء أفضل.
مرسلة مع GitHawk
 davewat
في ٢٤ يونيو ٢٠١٨
davewat
في ٢٤ يونيو ٢٠١٨
أواجه نفس المشكلة في مكدس عامل الإرساء Grafana و InfluxDB.
Grafana v5.1.3 (الالتزام: 087143285)
InfluxDB 1.5.3
تستخدم Grafana التخزين المحلي عبر وحدات التخزين مع قاعدة بيانات sqlite. تستخدم وحدات التخزين SSD المحلي.
أتلقى الخطأ في كل مرة أغادر فيها علامة التبويب لأكثر من بضع دقائق. إذا تركت أدوات التطوير في Firefox ، أرى:
GET http://x.x.x.x:3000/api/datasources/proxy/1/query?db=(Redacted info)
{"message":"Unauthorized"}
أي نوع من التحديث يمسح الأخطاء.
 isclever
في ٢٥ يونيو ٢٠١٨
isclever
في ٢٥ يونيو ٢٠١٨
جئت عبر نفس المشكلة. بالنسبة لي كان متعلقًا بفقدان "session_provider = memcahched"
يمكنك الرجوع إلى http://docs.grafana.org/installation/configuration/#provider -config لمزيد من خيارات التكوين
 nikskiz
في ١١ يوليو ٢٠١٨
nikskiz
في ١١ يوليو ٢٠١٨
نفس المشكلة هنا أيضا. إعداد Docker الخاص بي هو:
FROM grafana/grafana:5.1.0
FROM influxdb:1.5.3
 BentCoder
في ١٣ يوليو ٢٠١٨
BentCoder
في ١٣ يوليو ٢٠١٨
إغلاق هذا حيث يبدو أنه مرتبط بالإعداد / التكوين
torkelo
في ١٣ يوليو ٢٠١٨
torkelo هل هناك حل واضح لهذه المشكلة؟ أو تلميح للمساعدة في إيجاد الحل الممكن؟
BentCoder
في ١٣ يوليو ٢٠١٨
تأكد من أن إعداد الجلسة يعمل لإعداد HA أو أن الجلسات الثابتة في موازن التحميل تعمل
torkelo
في ١٣ يوليو ٢٠١٨
أنا لا أستخدم موازن التحميل بالرغم من ذلك.
BentCoder
في ١٧ يوليو ٢٠١٨
نفس المشكلة هنا بدون نسخ متماثلة متعددة
حصلت للتو على خطأ 401 في / api / login / ping أحيانًا بشكل عشوائي
 WTFKr0
في ٢٥ يوليو ٢٠١٨
WTFKr0
في ٢٥ يوليو ٢٠١٨
نفس المشكلة هنا (لسنوات ، قبل 5.0 أيام) ، SQLite على ext4 ، نسخة متماثلة واحدة على Kubernetes. أحدث صورة Docker رسمية.
تفشل الطلبات بشكل عشوائي عند تحديث Grafana تلقائيًا ، وفي النهاية تتوقف جميع الأدوات عن الإبلاغ عن أي شيء. السجلات ذات الصلة:
t=2018-07-31T01:38:04+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-07-31T01:38:04+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-07-31T01:38:04+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-07-31T01:38:04+0000 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=GET path=/api/datasources/proxy/4/query status=401 remote_addr=192.168.1.72 time_ms=28 size=26 referer="REDACTED"
سأحاول إجراء بعض التصحيح ، فأنا متأكد بنسبة 99٪ أن هذا خطأ في Grafana (أو إحدى مكتباتها).
/ سم مكعبtorkelo
 lorenz
في ٣١ يوليو ٢٠١٨
lorenz
في ٣١ يوليو ٢٠١٨
أنا متأكد بنسبة 95٪ أن هذه إعادة المحاولة مفقودة في حالة قفل جدول SQLite. سأقوم بنشر الإصلاح محليًا والعلاقات العامة إذا كان يعمل.
تحرير: اخدش ذلك ، فقد يستغرق ذلك مسار كود مختلف.
lorenz
في ٣١ يوليو ٢٠١٨
هنا مثال خطأ مني.
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=eror msg="Failed to get user with id" logger=context userId=1 error="User not found"
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=GET path=/api/login/ping status=401 remote_addr=192.168.33.1 time_ms=35 size=26 referer="http://192.168.33.10:3000/d/ZJ65a0Dmz/yowyow?refresh=5s&orgId=1&from=now-30d&to=now"
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=info msg="Request Completed" logger=context userId=1 orgId=1 uname=admin method=GET path=/api/login/ping status=401 remote_addr=192.168.33.1 time_ms=24 size=26 referer="http://192.168.33.10:3000/d/ZJ65a0Dmz/yowyow?refresh=5s&orgId=1&from=now-30d&to=now"
لقد تركتها تعمل بين عشية وضحاها لتوليد المزيد من الإخفاقات وأنا متأكد من أنه لا شيء مع الجلسات. إنه موجود في طبقة ORM ، وتحديدًا في user.go GetSignedInUser() حيث لا تُرجع هذه الطبقة أحيانًا استجابة صحيحة. لقد سجلت جميع الطلبات على لوحة معلومات الرسم البياني 50 الدهون في دقيقة واحدة خلال ليلة واحدة ورأيت نمطًا عشوائيًا للغاية به أخطاء متفاوتة ، كل شيء يشير إلى مشكلة التزامن / السباق. أقوم حاليًا بتشغيل تصحيح ينشر الأخطاء من قارئ الصف بشكل صحيح (المرشح الأساسي لهذه المشكلة) ، وسأرى ما إذا تلقيت رسالة خطأ مختلفة.
lorenz
في ٣١ يوليو ٢٠١٨
ذلك كان سريعا. مع تطبيق تصحيح انتشار الخطأ الخاص بي ، وجدت السبب الجذري:
t=2018-07-31T17:26:46+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="database table is locked"
يتم تنفيذ عمليات إعادة المحاولة بشكل غير صحيح في مكان ما في برنامج تشغيل تنفيذ SQLite.
lorenz
في ٣١ يوليو ٢٠١٨
لقد بحثت في الأمر أكثر وهناك مشاكل متعددة هنا:
- لا يُعرف أن go-sqlite آمن على goroutine (مما يجعل هذا الأمر برمته مع اتصال مركزي مُدار بواسطة xorm فكرة سيئة).
- لا يدعم SQLite الاستعلامات المتزامنة على "اتصال" واحد. سنحتاج إلى الحصول على xorm لفتح اتصالات متعددة بـ SQLite. وإلا فقد نواجه حالات توقف تام أو أخطاء القفل هذه لأن SQLite لن تحاول حل الأقفال إذا كانت من نفس الاتصال.
لقد رأيت أشخاصًا يقومون بأشياء متعددة لتجنب مشكلات SQLite هذه ، بما في ذلك التفاف وصول SQLite بالكامل في كائن واحد وفتح مثيل SQLite جديد لكل طلب. أسهل ما يمكن فعله هو اختراق go-sqlite3 لاحتواء كائن المزامنة لكل "اتصال" وإجراء تسلسل لكل إمكانية الوصول إليه (تحرير: أدركت أن هذا لن يعمل على الأرجح نظرًا لأن الأقفال تظهر عند القراءة من مؤشر لا يمكنك قفله دون المخاطرة بالمآزق). هذه هي الطريقة التي يقوم بها برنامج C (والتي تم تصميم SQLite من أجلها). قد يكون الأمر بطيئًا ، ولكن يجب على الأشخاص الذين يحتاجون إلى الأداء الانتقال إلى PostgreSQL على أي حال.
lorenz
في ٣١ يوليو ٢٠١٨
شكرًا جزيلاً ، lorenz ، على
بالنسبة للآخرين المهتمين بتجربة هذا الحل البديل ، فقد استخدمت pgloader مع الإعدادات الافتراضية ولم أسقط أي جلسة أو بيانات مستخدم أثناء الترحيل.
bjacobel
في ٣ أغسطس ٢٠١٨
المشكلة هي بالتأكيد فقط مع الواجهة الخلفية لـ SQLite لأن قواعد البيانات "الأكبر" تحتوي على MVCC الذي يحل هذه المشكلة. أنا شخصياً قمت بنقل مثيلات الإنتاج الخاصة بي إلى PostgreSQL. لا تزال المشكلة قائمة هي ما إذا كان يجب علينا حل هذه المشكلة لخلفية SQLite وكيفية القيام بذلك. لا أرى طريقة سهلة للقيام بذلك لأن Grafana (بسبب كتابتها في Go) تستخدم بشكل مكثف للتزامن الذي يتطلب عناية خاصة في SQLite بما يتجاوز ما توفره Xorm حاليًا.
توجد بالفعل مجموعة من عمليات التأمين وإعادة المحاولة في الشفرة التي تحاول التغلب على ذلك ، لكنها غير كافية. نظرًا لأنني أصلحت معالجة الخطأ لقارئ الصف (الذي يبتلع حاليًا أخطاء القفل بصمت وبالتالي يخلق سلوكًا غير متوقع ، سأقوم بإصلاحه قريبًا) لقد رأيت أخطاء القفل تظهر في العديد من الأماكن أكثر من مجرد البيانات الخادم الوكيل المصدر ، إنه مجرد نقطة النهاية التي يتم الوصول إليها في أغلب الأحيان وبسبب الطبيعة الاحتمالية للخطأ يجعلها أكثر نقطة مرئية للمستخدم. بقدر ما أستطيع أن أرى جميع الإصلاحات لهذا تتطلب اختراق Xorm أو go-sqlite3 ، وهو أمر غير مرغوب فيه بشكل عام.
lorenz
في ٣ أغسطس ٢٠١٨
شكرا للتحليل الرائعlorenz! هل تعتقد أن إعادة 500 في هذه الحالة سيكون حلاً قصير المدى معقولاً؟ كما هو الحال الآن ، يجبر 401 المتصفح (على الأقل Chrome) على نسيان كلمة المرور ويطلب من المستخدمين كتابتها مرة أخرى. في بعض الأحيان يجب كتابتها عدة مرات حتى يتم قبول كلمة المرور أخيرًا.
الحل الحالي هو تشغيل قاعدة البيانات من tmpfs . إنه يقلل من تكرار هذه المشكلة ، لكنه لا يزال يحدث من وقت لآخر.
 kichik
في ١١ أغسطس ٢٠١٨
kichik
في ١١ أغسطس ٢٠١٨
kichik عندما أقوم بإجراء PR'ed التغيير الذي أجريته على معالجة الخطأ ، يمكننا التفكير في إعادة HTTP 500 (أو 503). لكن الحل الوحيد الجيد الذي يمكنني رؤيته هو استخدام قاعدة بيانات فعلية قادرة على MVCC مثل PostgreSQL أو MySQL والتي لا تعرض المشكلة على الإطلاق. كما أوضحت في تعليقي السابق ، فإن هذه المشكلة تتجاوز مجرد طلبات البيانات ، لذا فإن إعادة رمز خطأ آخر غير HTTP 401 فقط لهؤلاء لن يحل المشكلة تمامًا.
lorenz
في ١١ أغسطس ٢٠١٨
لقد قمت للتو بتغييرات الإبلاغ عن الأخطاء الخاصة بي في # 13007 ، وهذا من شأنه أن يساعد الأشخاص على معرفة ما إذا كانوا متأثرين بمشكلة القفل أو ما إذا كان هناك شيء غير ذي صلة.
lorenz
في ٢٢ أغسطس ٢٠١٨
torkelo هل يمكننا إعادة فتح هذا لأنه من الواضح أنه مشكلة مع Grafana؟
lorenz
في ٢٢ أغسطس ٢٠١٨
بالتأكيد يحدث في علامة تبويب واحدة (ومستخدم واحد) بالنسبة لي.
أيضًا باستخدام sqlite3. ومن المثير للاهتمام ، أنه لم يكن لدي هذه المشكلة من قبل. الآن بعد أن أضفت عددًا قليلاً من اللوحات الثقيلة (استعلام حكيم) ، أحصل على هذا الخطأ بشكل متكرر ، عادةً فقط لواحدة من اللوحات الثقيلة الخاصة بي.
 Argon-
في ٢٩ أغسطس ٢٠١٨
Argon-
في ٢٩ أغسطس ٢٠١٨
التأكيد على أن التبديل إلى قاعدة بيانات غير sqlite3 يعمل على إصلاح المشكلة بالنسبة لي. كنت أحصل على مستخدم واحد وعلامة تبويب واحدة أيضًا ، مع لوحات أثقل / أكثر انشغالًا تتصرف بشكل أسوأ أيضًا.
تحديث: يجب تبديل الجلسات ليتم تخزينها في ديسيبل منفصل للإصلاح الكامل.
 astral303
في ٢٩ أغسطس ٢٠١٨
astral303
في ٢٩ أغسطس ٢٠١٨
أنا أستخدم mysqldb في مواجهة نفس المشكلة. الإصدار 5.2.3 من Grafana ، تم تمكين الالتصاق في مستوى Lb ولكن المشكلة لا تزال قائمة.
 vishksaj
في ٥ سبتمبر ٢٠١٨
vishksaj
في ٥ سبتمبر ٢٠١٨
تواجه هذا أيضًا ، باستخدام sqlite كخلفية للبيانات ولكن redis كمخزن جلسة على grafana 5.2.3
تم تكوين ما يقرب من 150 مؤسسة. ينبثق تحذير غير مصرح به عند التحديث الداخلي ولكنه عادةً ما يختفي عند التحديث اليدوي.
إدخال هذا في السجلات من وقت لآخر:
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=1
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=1
 reinhard-brandstaedter
في ١٢ سبتمبر ٢٠١٨
reinhard-brandstaedter
في ١٢ سبتمبر ٢٠١٨
قد تتسبب هذه المشكلة في فقد اتصال mysql. عندما أقوم بتخفيض قيمة max_idle_conn و conn_max_lifetime ، فلن يحدث هذا مرة أخرى. نأمل أن تكون هذه المساعدة
 xiaochai
في ١١ أكتوبر ٢٠١٨
xiaochai
في ١١ أكتوبر ٢٠١٨
vishksajxiaochai هذا هو المرجح جدا مسألة مختلفة، هل يمكن فتح واحدة جديدة؟
lorenz
في ١١ أكتوبر ٢٠١٨
https://github.com/oleh-ozimok/grafana/commit/b19e416549553f582dccfbcaa3f4d3f1a742a462 - حل مشكلتي (الصورة مع الإصلاح العاجل docker pull olegozimok/grafana:5.3.2 )
 oleh-ozimok
في ٢٩ أكتوبر ٢٠١٨
oleh-ozimok
في ٢٩ أكتوبر ٢٠١٨
جرافانا 5.3.2. تكوين HA: يتم تخزين 2 مثيلات Grafana و قاعدة بيانات MySQL الرئيسية و 2 مثيلين من memcached للجلسات و grafana dir و DB على NFS. نفس الأخطاء "غير المصرح بها" طوال الوقت ، بشكل غير متوقع. كان الشيء نفسه عندما كان DB هو SQLite على NFS.
 dev-e
في ١ نوفمبر ٢٠١٨
dev-e
في ١ نوفمبر ٢٠١٨
نفس المشكلة مثل @ dev-e ولكن إعداد أبسط. Grafana 5.3.2 ، مثيل واحد ، InfluxDB على نفس المضيف ، مؤسسة واحدة ، مستخدم واحد. تظهر الرسالة بشكل عشوائي وتختفي عند تحديث الصفحة التالية.
 luizfzs
في ١ نوفمبر ٢٠١٨
luizfzs
في ١ نوفمبر ٢٠١٨
لدي نفس المشكلة. تلقي أخطاء غير مصرح بها بشكل عشوائي.
أدت الترقية إلى grafana 5.3.4 كيندا إلى تحسينه ، ولكن لا يزال هناك الكثير من الأخطاء.
في سجلات grafana:
t = 2018-11-19T09: 55: 07 + 0200 lvl = eror msg = "فشل الحصول على مستخدم بالمعرف" logger = Context userId = خطأ واحد = "المستخدم غير موجود"
t = 2018-11-19T09: 55: 07 + 0200 lvl = eror msg = "فشل الحصول على مستخدم بالمعرف" logger = Context userId = خطأ واحد = "المستخدم غير موجود"
t = 2018-11-19T09: 55: 07 + 0200 lvl = eror msg = "فشل الحصول على مستخدم بالمعرف" logger = Context userId = 1 خطأ = "المستخدم غير موجود"
الإعداد خارج الصندوق:
غرافانا / الآن 5.3.4 amd64
influxdb / الآن 1.6.0-1 amd64
 gigake
في ١٩ نوفمبر ٢٠١٨
gigake
في ١٩ نوفمبر ٢٠١٨
نفس المشكلة هنا:
t=2018-12-03T09:28:21+0000 lvl=eror msg="Failed to update last_seen_at" logger=context userId=12 orgId=1 uname=ht error="database table is locked"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
2018/12/03 10:51:54 http: proxy error: unexpected EOF
2018/12/03 10:51:54 http: proxy error: unexpected EOF
2018/12/03 10:51:54 http: proxy error: unexpected EOF
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:56+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:56+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
Single Grafana 5.3.4 ، التخزين هو نظام ملفات Amazon EFS (NFS mount)
تم تعيين الجلسة على ملف ، وتخزين البيانات هو sqlite (/var/lib/grafana/grafana.db)
يجلس Grafana خلف HTTPS إنهاء LB
 roffe
في ٣ ديسمبر ٢٠١٨
roffe
في ٣ ديسمبر ٢٠١٨
قدم علاقات عامة بتنفيذ اقتراح @ oleh-ozimok. لا تتردد في تجربته. سأجربها مرة أخرى عندما أعود إلى المنزل من العطلة حتى أتمكن من الحصول على نسخة طويلة الأمد :)
@ oleh-ozimok إذا كنت ترغب في إنشاء علاقات عامة ، يسعدني دمج ذلك بدلاً من الدمج الخاص بي لمنحك الفضل.
راجع للشغل عمل عظيم @ لورنز !
 bergquist
في ٢٧ ديسمبر ٢٠١٨
bergquist
في ٢٧ ديسمبر ٢٠١٨
هذا يؤثر على انتشارنا كذلك. نحصل باستمرار على 401 خطأ غير مصرح به باستخدام قاعدتي بيانات Amazon Auora MySQL تعملان في وضع HA / Multi Master. لقد تم التحقق من الجلسات على كلا قاعدتي البيانات. ولكن مع ذلك ، فقد أشرت جميع الحالات إلى نفس قاعدة البيانات لمعرفة ما إذا كان ذلك سيؤدي إلى حل المشكلة أم لا. هناك بالتأكيد خطأ ما في المصادقة على الجلسات بشكل صحيح. يذهب هذا إلى أبعد من ذلك مع إعداد Oauth الخاص بنا. هناك أوقات يقوم فيها المستخدم بتسجيل الدخول باستخدام موفر Oauth الذي تمت تهيئته وقد يفشل في تسجيل الدخول بمجرد إعادة توجيهه. إذا قاموا بتسجيل الدخول حوالي 2-3 مرات ، فهذا يعمل.
 buroa
في ٢٦ يناير ٢٠١٩
buroa
في ٢٦ يناير ٢٠١٩
هذا غريب جدًا ، ربما تم تكوين أحد الخوادم بشكل مختلف؟
أي تفاصيل سجل؟
نحن نزيل الحاجة إلى تخزين الجلسة ونعيد كتابة طريقة إدارة جلسات تسجيل الدخول بالكامل في الإصدار السادس ، لذلك نأمل أن يحل ذلك الأمر.
torkelo
في ٢٧ يناير ٢٠١٩
buroa أي فرصة يمكنك محاولة 6.0-beta1؟ لقد أعدنا كتابة رمز المصادقة وأزلنا معظم استخدام الرمز المميز للجلسة (لا يزال مستخدمًا عند استخدام auth_proxy) تمامًا ونأمل أن تختفي معظم هذه المشكلات.
bergquist
في ٥ فبراير ٢٠١٩
قامbergquist بتحديث الإعداد الخاص بي في 2019-02-01T09: 58: 20 + 0200 ، لم يحدث هذا الخطأ في الوقت الحالي.
 zcooler
في ٥ فبراير ٢٠١٩
zcooler
في ٥ فبراير ٢٠١٩
buroa أي فرصة يمكنك محاولة 6.0-beta1؟ لقد أعدنا كتابة رمز المصادقة وأزلنا معظم استخدام الرمز المميز للجلسة (لا يزال مستخدمًا عند استخدام auth_proxy) تمامًا ونأمل أن تختفي معظم هذه المشكلات.
أنا أستخدم أحدث إصدار: https://github.com/buroa/grafana/tree/us-iso-regions
هل هذا لديه التغيير المطلوب؟
buroa
في ٥ فبراير ٢٠١٩
buroa نعم ، ولكن لا يزال يقترح عليك الدمج في أحدث نسخة رئيسية نظرًا
marefr
في ٥ فبراير ٢٠١٩
حصلت اليوم على خطأ
t = 2019-02-08T10: 05: 58 + 0200 lvl = info msg = "فشل البحث عن المستخدم بناءً على ملف تعريف الارتباط" logger = خطأ في السياق = "لم يتم العثور على رمز مصادقة المستخدم"
لم تكن علامة تبويب المتصفح تغلق ، بل تم تحديثها تلقائيًا كل ساعة ، ولكن كان الكمبيوتر مقفلاً.
 QuantumProjects
في ٨ فبراير ٢٠١٩
QuantumProjects
في ٨ فبراير ٢٠١٩
QuantumProjects هل تمانع في فتح إصدار جديد لأن لديك مشكلة مع Grafana v6.0-pre. يرجى تقديم مزيد من التفاصيل حول إعداد Grafana الخاص بك: ما هي قاعدة البيانات المستخدمة؟ نسخة غرافانا؟ مثيلات Grafana متعددة؟ ما نوع المصادقة؟ وكيل عكسي؟ شكرا
marefr
في ٨ فبراير ٢٠١٩
تضمين التغريدة
QuantumProjects
في ٨ فبراير ٢٠١٩
marefr أحصل على نفس العناصر المنبثقة "غير المصرح بها" ، ربما يمكن أن يساعد الإعداد الخاص بي في اكتشاف المشكلة:
- خادم البوابة مع traefik كوكيل عكسي يشير إلى خادم محلي يستضيف grafana
- الخادم المحلي مع Grafana v5.4.3
- مصدر البيانات هو influxdb v1.7.8 على نفس الخادم المحلي
- كيف يمكنني معرفة نوع المصادقة المشكوك فيه؟ أنا فقط سجل الدخول كمستخدم مسؤول
ملاحظة: كل خدمة عبارة عن حاوية عامل ميناء ، traefik x64 ، grafana و influxdb arm32v7
 eiabea
في ١٩ فبراير ٢٠١٩
eiabea
في ١٩ فبراير ٢٠١٩
يحدث هذا في Grafana 6.0.0 (الالتزام: 34a9a62 ، الفرع: HEAD) أيضًا. قاعدة بيانات SQLite غير مستخدمة ، يعمل Grafana خلف الوكيل العكسي لـ nginx. تم تكوين مصادقة LDAP. يتم تشغيل مثيل Grafana الفردي على هذا الجهاز الظاهري.
إدخال السجل في وقت الخطأ:
t=2019-03-06T13:39:24+0100 lvl=eror msg="failed to look up user based on cookie" logger=context error="database is locked"
 angryp
في ٦ مارس ٢٠١٩
angryp
في ٦ مارس ٢٠١٩
مجرد إضافة نقطة بيانات ، بمجرد أن نقلت ديسيبل من sqlite إلى postgres ، توقفت عن رؤية هذه الأخطاء. في السابق كانوا متكررين بدرجة كافية لجعل استخدام النظام غير مريح تمامًا. تشغيل خادم 5.4.3 واحد مع google oauth.
 qhartman
في ٦ مارس ٢٠١٩
qhartman
في ٦ مارس ٢٠١٩
يحدث لي في 5.4.3 متصل بـ postgres ، بشكل عشوائي إلى حد ما ولكن فقط عندما أتركه التحديث التلقائي. الإعداد موجود على شبكة محلية حيث تكون قاعدة البيانات في نفس المربع مثل Grafana.
تظهر لي مجموعة من هذه الأنواع من الأخطاء في سجل النظام في الوقت الذي تظهر فيه الرسالة "غير المصرح به":
...
...
grafana-server[12619]: t=2019-03-06T22:42:02+0100 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
grafana-server[12619]: t=2019-03-06T22:42:03+0100 lvl=eror msg="Failed to get user with id" logger=context userId=1 error="User not found"
...
grafana-server[12619]: t=2019-03-06T22:42:03+0100 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=POST path=/api/tsdb/query status=401 remote_addr=192.168.0.2 time_ms=17 size=26 referer="http://192.168.0.1:3000/d/.....
...
توجد بعض الاختلافات في سجل الدخول معرّف المستخدم = 1 أو 0 وعند إعادة المحاولة = 1 أو 0
 ggggh
في ٦ مارس ٢٠١٩
ggggh
في ٦ مارس ٢٠١٩
أهلا،
كان لدي اليوم نفس المشكلة. لدينا Grafana 6.0.1 على نظام Debian Stretch العادي الذي تمت ترقيته قبل أيام قليلة. يتصل Grafana بموازن التحميل (proxysql) مع MariaDB 10.2 (مجموعة Galera) كخلفية (وضع المزامنة مع ثلاث عقد).
نحن نستخدم LDAP (Windows AD) كتخويل.
رسالة السجل:
lvl=eror msg="failed to look up user based on cookie" logger=context error="invalid connection"
الشيء الوحيد الذي نجح هو استخدام IP المباشر وليس موازن التحميل.
 linuxmail
في ١٤ مارس ٢٠١٩
linuxmail
في ١٤ مارس ٢٠١٩
الشيء الوحيد الذي نجح هو استخدام IP المباشر وليس موازن التحميل.
لا تبدو نفس المشكلة على الرغم من ذلك ، نظرًا لأن مشكلتنا متقطعة - ربما تفشل إحدى اللوحات في كل عشرات التحديثات أو نحو ذلك بسبب الخطأ ، ولكنها تعمل بشكل عام
ggggh
في ١٤ مارس ٢٠١٩
حدث نفس الشيء لي في 6.0.2.
من السجل:
t=2019-03-23T12:04:22+0000 lvl=eror msg="failed to look up user based on cookie" logger=context error="database is locked"
و
t=2019-03-23T19:05:45+0000 lvl=eror msg="Failed to update last_seen_at" logger=context userId=1 orgId=1 uname=<username> error="database is locked"
تثبيت عامل إرساء منتظم مع Traefik من أجل إنشاء وكيل عكسي.
 menteb
في ٢٣ مارس ٢٠١٩
menteb
في ٢٣ مارس ٢٠١٩
بالنسبة لي نفس الشيء يحدث
الإصدار 6.02.1
"فشل في البحث عن المستخدم بناءً على ملف تعريف الارتباط" المسجل = خطأ في السياق = "تم قفل قاعدة البيانات"
 tiagoalmeida10
في ٢٨ مارس ٢٠١٩
tiagoalmeida10
في ٢٨ مارس ٢٠١٩
إذا كان الحصول على "قاعدة البيانات مقفلة" باستخدام Sqlite (افتراضي) ، فمن المحتمل أن يكون هذا هو الوقت المناسب للترحيل إلى mysql / postgres حيث يمكنهم التعامل مع المزيد من المعاملات / المعاملات
bergquist
في ٣ أبريل ٢٠١٩
bergquist أعتقد أن هذا هو الحل بالفعل. هاجر للتو إلى MariaDB ولم أعد أطرد من غرافانا. تاك!
menteb
في ٤ أبريل ٢٠١٩
bergquist أعتقد أن هذا هو الحل بالفعل. هاجر للتو إلى MariaDB ولم أعد أطرد من غرافانا. تاك!
للتوضيح ، قد يكون هذا حلاً لـ "قاعدة البيانات مقفلة" ، وليس "جدول قاعدة البيانات مغلق" - أنا على PostgreSQL وأواجه "قفل الجدول".
ggggh
في ٤ أبريل ٢٠١٩
تم حلها بالنسبة لي بعد ترقية Raspbian التي نقلتني إلى Postgres 9.6 (من 9.4). لا يزال غرافانا في 5.4.3
ggggh
في ٢٥ أبريل ٢٠١٩
تم حلها بالنسبة لي بعد ترقية Raspbian التي نقلتني إلى Postgres 9.6 (من 9.4). لا يزال غرافانا في 5.4.3
انسى ما قلته ... لقد عاد. في كثير من الأحيان ، كنت أقول ... لكن ما زال يحدث.
ggggh
في ١٠ مايو ٢٠١٩
ggggh أي حلول؟ لقد بدأ للتو يحدث فجأة بالنسبة لي!
 devanshkv
في ٢٢ مايو ٢٠١٩
devanshkv
في ٢٢ مايو ٢٠١٩
ggggh أي حلول؟ لقد بدأ للتو يحدث فجأة بالنسبة لي!
لا شيئ...! تم مسحه مع ترقية إصدار postgres ، ويبدو أنه يعود مرة أخرى ، في كثير من الأحيان كل يوم
ggggh
في ٢٢ مايو ٢٠١٩
ggggh شكرا!
لقد قمت بالتبديل إلى Postgres ، لكن هذا لا يساعد أيضًا :(
devanshkv
في ٢٢ مايو ٢٠١٩
تواجه نفس المشكلات باستخدام Grafana 6.2.1 و Postgress 11 ، ولكن هذا يحدث فقط على dashbaords التي أحملها من JSON ثم أحاول الوصول إليها.
أي تحديثات على هذا؟
 botzill
في ٢٩ مايو ٢٠١٩
botzill
في ٢٩ مايو ٢٠١٩
حسنًا ، وجدت المشكلة في حالتي. كان PG الخاص بي يحتوي على عدد محدود من الاتصالات وفي grafana max_open_conn لم يتم تعيينه. بعد أن قمت بتعيين هذا الخيار ، يعمل بشكل جيد.
botzill
في ٣ يونيو ٢٠١٩
يحدث نفس الشيء بالنسبة لي على Grafana 6.1.6 و SQLite DB. تكسر هذه المشكلة جهود التطوير الداخلي لدينا لتخصيص Grafana. تغيير max_open_conn لا يعمل (على الرغم من أنني لم أتوقع ذلك لأنه كان إصلاحًا لـ Postgres).
 syardumian-chc
في ١٠ يونيو ٢٠١٩
syardumian-chc
في ١٠ يونيو ٢٠١٩
يبدو أن السبب الجذري لهذا هو محاولة grafana الاتصال بـ
قاعدة البيانات الأساسية عند المصادقة ، ولكن تفشل في القيام بذلك. مع سكليتي ، أن
سيحدث كثيرًا وبكميات قليلة من الاستخدام المتزامن منذ أقفال SQLite
بقوة. في معظم الحالات ، الترحيل إلى RDBMS حقيقي (أحب postgres)
سوف يحل المشكلة. من الممكن أن يظهر مرة أخرى إذا واجهت a
مشكلة حد الاتصال (أو ما شابه) ، ولكن هذا مصدر قلق في قاعدة البيانات أكثر من ملف
قلق جرافانا. إذا كنت تستخدم Grafana لأي شيء بخلاف العرض التوضيحي ،
يجب أن تدعمها بقاعدة بيانات حقيقية. إذا تم تكوين قاعدة البيانات هذه بشكل صحيح من أجل
استخدامك ، يجب أن يحل هذه المشكلة.
يوم الاثنين 10 يونيو 2019 الساعة 11:20 صباحًا syardumian-chc [email protected]
كتب:
يحدث نفس الشيء بالنسبة لي على Grafana 6.1.6 و SQLite DB. هذه
المشكلة تعطل جهود التطوير الداخلية لدينا لتخصيص Grafana. التغيير
لا يعمل max_open_conn (على الرغم من أنني لم أتوقع ذلك لأنه كان ملف
الإصلاح لـ Postgres).-
أنت تتلقى هذا لأنك مشترك في هذا الموضوع.
قم بالرد على هذا البريد الإلكتروني مباشرة ، وقم بعرضه على GitHub
https://github.com/grafana/grafana/issues/10727؟email_source=notifications&email_token=AAAK6YSUDLXPF2E4436CEOTPZ2EMFA5CNFSM4EO23EH2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63L
أو كتم الخيط
https://github.com/notifications/unsubscribe-auth/AAAK6YQLR3FSCNEQR7SNEKLPZ2EMFANCNFSM4EO23EHQ
.
qhartman
في ١٠ يونيو ٢٠١٩
لقد قمت بزيادة حد الاتصال والحد الأقصى للاتصالات الخاملة ، لكنني ما زلت أعاني من هذه المشكلة بشكل عشوائي. ليس ذلك فحسب ، ولكن يبدو أن لوحات المعلومات التي كانت مفتوحة لفترة من الوقت أصبحت أبطأ وأبطأ في التحديث ، مع ظهور صورة gif على كل لوحة وتختفي ببطء بالتتابع مع اكتمال تحميل كل لوحة. لا بأس إذا أغلقت نافذة المتصفح وفتحت نافذة جديدة. أعتقد أن لوحة التحكم الخاصة بي أصبحت أكثر تعقيدًا ، لكن هذا لا يفسر سبب "إصلاحها" عند تحميل الصفحة حديثًا.
ggggh
في ١٢ يونيو ٢٠١٩
أنا أتلقى خطأ عشوائي أيضًا. حقا لا أعرف ما هي المشكلة. يبدو استخدام عنوان IP جيدًا ، ولكن مع إدخال kubeneters ، فإنه يُظهر "فشل استعلام التعليق التوضيحي" بشكل عشوائي.
 naturalbeau
في ١٣ يونيو ٢٠١٩
naturalbeau
في ١٣ يونيو ٢٠١٩
FWIW ، لقد قمت مؤخرًا بتحويل أداة موازنة الدخول إلى Fabio (من Traefik) وقمت بتحديث Grafana (صورة Docker ، لا توجد خلفيات خلفية إضافية لقاعدة البيانات) إلى الإصدار 6.4.2 ، ويبدو أن الأخطاء غير المصرح بها 401 قد اختفت عند إجراء التحديث التلقائي (تم ضبط الفاصل الزمني على 10 ثواني ، تعمل طوال اليوم). من غير المحتمل أن يؤدي التبديل إلى Fabio إلى حل المشكلة ، أعتقد أن الإصدار الأحدث من Grafana هو الذي ساعدني ، لكنني لست متأكدًا بنسبة 100٪.
 kmott
في ٩ أكتوبر ٢٠١٩
kmott
في ٩ أكتوبر ٢٠١٩
سيتم إغلاق هذا لعدم وجود تقارير جديدة مؤخرًا. إذا كنت تعتقد أنه لا تزال هناك مشكلة ، يرجى فتح عدد جديد
torkelo
في ١٩ أكتوبر ٢٠١٩
لقد قمت مؤخرًا بتثبيت برنامج grafana على مجموعة kubernetes الخاصة بي وواجهت مشكلة مماثلة.
أنا أستخدم docker image grafana / grafana: 6.4.3
عند التحقق من سجلات البود الخاصة بي ، وجدت هذا الشهي الصغير المثير للاهتمام:
t=2019-11-01T15:18:33+0000 lvl=info msg="Successful Login" logger=http.server User=--snip--
t=2019-11-01T15:19:09+0000 lvl=eror msg="Failed to look up user based on cookie" logger=context error="dial tcp: lookup postgres.databases.svc.cluster.local: no such host"
t=2019-11-01T15:19:09+0000 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=GET path=/api/datasources/proxy/1/query status=401 remote_addr=--snip-- time_ms=11 size=26 referer="https://--snip--/d/TuobtjoZz/--snip--?orgId=1&refresh=5s&from=now-12h&to=now"
مشكلات DNS ليست شيئًا واجهته من قبل داخل المجموعة الخاصة بي ، لكنني قمت ببعض البحث على googling ووجدت هذه المشكلة بالذات: https://github.com/kubernetes/kubernetes/issues/30215
هل سيكون من الممكن أن تقوم grafana بشحن صور جبال الألب وغير الألبية كما تفعل الكثير من صور عامل الإرساء؟ يبدو أن هذا من شأنه أن يحل المشكلة.
إذا كان هناك أي شيء يمكنني القيام به في اختبار هذا أو المساعدة في تصحيح الأخطاء ، فأعلمني بذلك ، فسأقدم المعلومات على النحو المطلوب.
 ikkerens
في ١ نوفمبر ٢٠١٩
ikkerens
في ١ نوفمبر ٢٠١٩
بعد الرجوع إلى الإصدار 6.3.6 (الذي لا يعتمد على جبال الألب) ، اختفت المشكلة تمامًا من ناحيتي.
ikkerens
في ٢ نوفمبر ٢٠١٩
لقد واجهت نفس المشكلة ، حيث تم فتح حاويتين منفصلتين من Grafana في نفس المتصفح
عند تسجيل الدخول إلى الثانية ، يطلب مني تسجيل الدخول مرة أخرى ، قم بتسجيل الدخول إلى الأول ، ثم اطلب مني تسجيل الدخول مرة أخرى
لا يمكن الاحتفاظ بتسجيل الدخول على حد سواء
الحل الذي وجدته هو التغيير في أحد ملفات Grafana default.ini
login_cookie_name = grafana_session
إلى
login_cookie_name = grafana_session_1
أعد تشغيل الحاوية والمتصفح ، والآن يعمل بشكل جيد
في الوقت الحالي ، أبقي الملف خارج الحاوية
تحتاج إلى تعيين هذه المعلمة عند إنشاء الحاوية
 n0-bs
في ٢٠ فبراير ٢٠٢٠
n0-bs
في ٢٠ فبراير ٢٠٢٠
ikkerens يرجى تجربة الصورة المستندة إلى ubuntu إذن ، 6.6.2-ununtu
marefr
في ٢٨ فبراير ٢٠٢٠
@ n0-bs أنا آسف ولكن إذا كنت تقوم بتشغيل مثيلات متعددة من Grafana ، فمن المقترح استخدام MySQL أو Postgres كقاعدة بيانات.
marefr
في ٢٨ فبراير ٢٠٢٠
عذرًا ، ولكن كيف ، استخدام MySQL أو Postgres كقاعدة بيانات. ، سيحل تعارض ملفات تعريف الارتباط عندما أفتح هاتين المثيلين المختلفين من Grafana في نفس المتصفح ، ولا أتحدث عن حالة HA
لدي مثيلين مختلفين من Grafana (حاويات) على نفس الخادم
n0-bs
في ١ مارس ٢٠٢٠
ما زلت أرى هذا مع 6.7.2. قمت بالترقية من 6.5 إلى 6.6 ، ثم 6.7. باستخدام docker مع PostgreSQL ، جربت صورة 6.7.2 ثم 6.7.2-ubuntu.
هذا هو الخطأ الذي أحصل عليه في السجلات:
lvl=eror msg="Failed to look up user based on cookie" logger=context error="pq: remaining connection slots are reserved for non-replication superuser connections"
 helderco
في ١٦ أبريل ٢٠٢٠
helderco
في ١٦ أبريل ٢٠٢٠
تم إصلاحه (على الأقل في الوقت الحالي) عن طريق إعادة تشغيل postgres.
helderco
في ١٦ أبريل ٢٠٢٠
أنا أستخدم أحدث إصدار من Grafana وما زلت أرى المشكلة غير المصرح بها حتى وقت الوصول إليها. أنا أستخدم Grafana في kubernetes. لقد قمت بنشره في 3 حواجز مختلفة في 3 عقد مختلفة. أنا أستخدم قاعدة البيانات الأصلية لها. أي اقتراح لإصلاح المشكلة؟
 emzfuu
في ١ يونيو ٢٠٢٠
emzfuu
في ١ يونيو ٢٠٢٠
emzfuu إذا قمت بتشغيل مثيلات متعددة ، فأنت بحاجة إلى توجيههم جميعًا إلى نفس قاعدة البيانات. mysql / postgres
bergquist
في ١ يونيو ٢٠٢٠
bergquist هل هناك أي طريقة أخرى لإصلاح المشكلة؟
emzfuu
في ٢ يونيو ٢٠٢٠
فقط لتوضيح سؤالي أعلاه ، استخدم 3 Grafana مختلفة (قائمة بذاتها) والتي يتم الوصول إليها من خلال موازن التحميل الفردي. يحتوي 3 Grafana على ديسيبل خاص بهم (sqlite3). في كل مرة أصل إليه ، أتلقى خطأ غير مصرح به.
emzfuu
في ٣ يونيو ٢٠٢٠
لدي نفس المشكلة ، استخدم nFS.
 linux0x5c
في ٨ يونيو ٢٠٢٠
linux0x5c
في ٨ يونيو ٢٠٢٠
القضايا ذات الصلة
 ADeane6
·
3تعليقات
ADeane6
·
3تعليقات
 Minims
·
3تعليقات
Minims
·
3تعليقات
 royemmerich
·
3تعليقات
royemmerich
·
3تعليقات
 jackmeagher
·
3تعليقات
jackmeagher
·
3تعليقات
 tcolgate
·
3تعليقات
tcolgate
·
3تعليقات
التعليق الأكثر فائدة
أرى نفس المشكلة في Grafana v4.6.2 (الالتزام: 8db5f08) ، كل شيء يعمل كما هو متوقع ، وفجأة تلقيت تحذيرًا غير مصرح به (وبعض الرسوم البيانية تكون emtpy ، لكن بعضها يظهر بشكل طبيعي).
أستخدم بروميثيوس كمصدر بيانات.
أعتقد أيضًا أن هذا يحدث بشكل أساسي عندما يتم تحديث لوحة القيادة تلقائيًا ، ولكنها تصلح نفسها عندما أقوم بتحديثها يدويًا.