Estou executando a versão mais recente do grafana em duas instâncias, mas estou enfrentando muitos erros não autorizados ao tentar acessar as duas instâncias. Para autenticação, estou usando o banco de dados integrado, sem LDAP. A fonte de dados é um influxdb.
Este é um bug conhecido ou mau comportamento?
 darox
darox
Todos 105 comentários
Você poderia dar mais alguns detalhes:
- Essas duas instâncias são separadas?
- Qual ação aciona o erro não autorizado?
- Você está sendo desconectado ou apenas algumas ações não funcionam?
 daniellee
em 2 fev. 2018
daniellee
em 2 fev. 2018
Eles estão configurados em diferentes ips / nomes de domínio? se o nome de domínio for o mesmo e apenas diferente por porta, você precisa ter cookies de sessão exclusivos e cookies de lembrar-me
 torkelo
em 2 fev. 2018
torkelo
em 2 fev. 2018
- Essas são instâncias separadas
-Não sei qual ação aciona o não autorizado, só acontece quando eu assisto os gráficos ou ao acessar a grafana
-Às vezes eu sou desconectado
- Domínios separados
darox
em 2 fev. 2018
Estou encontrando isso no Grafana 4.6.x com oauth por meio do Github. Parece aleatório quando eu mudo as guias e volto para o Grafana. Uma atualização "corrigirá" o problema, mas às vezes volta mais tarde.
 pgporada
em 7 mar. 2018
pgporada
em 7 mar. 2018

Vejo o mesmo problema no Grafana v4.6.2 (commit: 8db5f08), tudo funciona como esperado e, de repente, recebo um aviso de não autorizado (e alguns gráficos estão vazios, mas alguns aparecem normalmente).
Eu uso o Prometheus como a fonte de dados.
Também acho que isso acontece principalmente quando o painel é atualizado automaticamente, mas se corrige quando eu o atualizo manualmente.
 ajardan
em 8 mar. 2018
ajardan
em 8 mar. 2018
Problema semelhante aqui também, mas com uma única instância Grafana com HTTPS e fonte de dados Postgres.
Quando o painel é aberto, todos os gráficos são bons. Mas, às vezes, depois, alguns dos gráficos começam a mostrar erros "Não autorizado" na atualização automática, mas na próxima (ou nas próximas) atualização automática, eles se recuperam para o estado normal, mas passam para o estado "Não autorizado" às vezes mais tarde, repetindo este comportamento aleatório em cada atualização automática.
Não tenho certeza se está relacionado, mas encontrou as seguintes mensagens de log.
lvl = eror msg = "Falha ao obter o usuário com id" logger = contexto userId = 1 erro = "Usuário não encontrado"
A versão do Grafana é a seguinte:
lvl = info msg = "Iniciando Grafana" logger = versão do servidor = 5.0.4 commit = 7dc36ae compilado = 2018-03-28T20: 52: 41 + 0900
Estou usando o Firefox e geralmente deixo o painel aberto e intocado por vários dias, com a máquina do cliente (não a máquina do servidor que hospeda o Grafana) entrando no modo de hibernação de vez em quando.
 after-the-sunrise
em 12 abr. 2018
after-the-sunrise
em 12 abr. 2018
Isso não está mais acontecendo comigo com grafana 5.x
darox
em 12 abr. 2018
Ainda estou tendo exatamente o mesmo problema com o Grafana 5.0.4, mesmas mensagens do usuário não encontradas no log (isso é com um simples usuário local do Grafana).
 SoulSeekkor
em 13 abr. 2018
SoulSeekkor
em 13 abr. 2018
Também estou tendo esse problema. E a questão é muito interessante. Pode acontecer quando abro duas páginas grafana de versão diferente no mesmo navegador e tento fazer algumas operações.
Eu tenho uma versão mais antiga do grafana (v4.3.2 (commit: ed4d170)) e funcionou bem em grafana.mydomain.com por um longo tempo. Hoje eu quero atualizar meu grafana para v5.0.4. Em vez de atualização no local. Eu queria configurar o novo Grafana na mesma máquina, copiar o painel que desejo e, em seguida, derrubar o antigo.
Então o que eu fiz:
- docker executa grafana5 na mesma máquina da antiga com mapa de porta para 3005
- abriu o antigo grafana4 em
grafana.mydomain.comno Safari
E funciona bem - visite Grafana5 em
grafana.mydomain.com:3005no Safari
Agora eu tenho duas guias abertas de Grafana4 e Grafana5 na minha tela - faça login no Grafana5, tentando fazer algumas operações .... como [criar painel]
Agora, ambas as páginas do Grafana travaram
Ambos os Grafana receberão Unauthorized erros e não obterão pontos de dados
Atualização : mudei minha etapa 3 visitando Grafana5 com [ip]: 3005. Funciona bem por enquanto.
Parece que pode haver alguns conflitos ao abrir duas páginas do Grafana no mesmo domínio.
 kehao95
em 18 abr. 2018
kehao95
em 18 abr. 2018
@ kehao95 seu caso de uso de no mesmo navegador abrir duas instâncias Grafana no mesmo domínio, mas com portas diferentes, não é suportado. (Torkel mencionou isso acima).
@ajardan suas instâncias estão no mesmo domínio ou em diferentes?
daniellee
em 30 abr. 2018
@daniellee Na verdade, só uso uma instância o tempo todo. E os gráficos no painel que examino são extraídos de 2 fontes de dados diferentes (Prometheus e Cloudera)
ajardan
em 7 mai. 2018
Eu também recebo esse estranho problema de "Não autorizado" de vez em quando. A atualização da página "corrige" o problema. Eu executo o Grafana v5.1.0 (844bdc53a) a partir da imagem oficial do Docker. A fonte de dados é InfluxDb. Criei 2 organizações no Grafana, mas uso apenas uma na verdade. Único usuário 'admin'.
 dogada
em 8 mai. 2018
dogada
em 8 mai. 2018
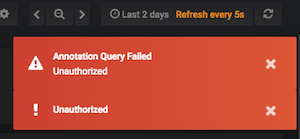
Acabei de receber este erro mais uma vez com uma nova mensagem de erro "Falha na consulta de anotação. Não autorizado"
dogada
em 8 mai. 2018
Minha grafana no win10 x64 funcionou perfeitamente bem por alguns dias, até que recebo um aviso "Não autorizado". O comportamento é o mesmo descrito por @dogada e também estou executando a v5.1.0 com influxdb. Grafana e influxdb estão no mesmo computador.
 schwarzlowe
em 9 mai. 2018
schwarzlowe
em 9 mai. 2018
O mesmo problema. Uma instância grafana 5.1 no docker. Oauth do Google para autorização.
Alguma atualização?
 StupidScience
em 11 mai. 2018
StupidScience
em 11 mai. 2018
Mesmo comportamento. Atualmente executando a v5.0.3 no docker, autenticação interna, usuário administrador único, proxy via nginx, fonte de dados é influxdb. O painel se corrige quando os dados são atualizados automaticamente. Acontece principalmente quando a guia fica muito tempo em segundo plano
 radium88
em 15 mai. 2018
radium88
em 15 mai. 2018
Mesmo problema visto ao ter duas guias abertas para a mesma instância.
 lamoni
em 15 mai. 2018
lamoni
em 15 mai. 2018
A atualização para a última imagem docker v5.1.2 (commit: c3c690e21) não corrigiu o problema
radium88
em 16 mai. 2018
Estou tendo o que acredito ser o mesmo problema com o Grafana 5.0.0 no Docker usando GitHub OAuth. Eu vi isso em painéis com InfluxDB, CloudWatch e uma mistura de ambas as fontes de dados. (Uma instância, uma porta, HTTPS, atrás de um ELB.)
Como outros neste tópico, parece que ele é acionado por uma atualização automática e desaparece após o recarregamento da página. Às vezes, vejo a mensagem de erro básica "Não autorizado" (com falhas no carregamento do gráfico) e às vezes (mais raramente) a mensagem "Falha na consulta de anotação. Não autorizado" também.
~ Minha suspeita está apontando para algo com os plug-ins OAuth? ~ É quase definitivamente devido ao back-end da sessão, veja abaixo.
 bjacobel
em 16 mai. 2018
bjacobel
em 16 mai. 2018
Para adicionar mais detalhes que encontrei depois de me aprofundar um pouco mais, vejo muitos erros como este em meus registros:
t=2018-05-16T16:55:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
O único lugar em que vejo esse erro lançado é nesta linha de código, que parece relacionada ao gerenciamento de sessões e cookies de sessão.
Estou armazenando minhas sessões usando o back-end padrão file , mas por meio de um compartilhamento EFS montado, me pergunto se isso é uma complicação potencial.
bjacobel
em 16 mai. 2018
Enfrentei esse problema quando tento abrir dois Grafana diferentes (que estão sendo executados em portas diferentes) no mesmo navegador.
Recebo erros não autorizados e às vezes sou desconectado
 harshitha-m
em 23 mai. 2018
harshitha-m
em 23 mai. 2018
Seria realmente interessante ver quais consultas SQL são executadas quando você recebe a mensagem de log Falha ao obter o usuário com id . Se você puder reproduzir isso facilmente, seria muito valioso se você pudesse habilitar o registro de consultas sql e relatar suas descobertas:
[database]
# Set to true to log the sql calls and execution times.
log_queries = true
Obrigado
 marefr
em 30 mai. 2018
marefr
em 30 mai. 2018
@marefr Parece que esses erros sempre ocorrem em uma dessas duas consultas:
SELECT\n\t\tu.id as user_id,\n\t\tu.is_admin as is_grafana_admin,\n\t\tu.email as email,\n\t\tu.login as login,\n\t\tu.name as name,\n\t\tu.help_flags1 as help_flags1,\n\t\tu.last_seen_at as last_seen_at,\n\t\t(SELECT COUNT(*) FROM org_user where org_user.user_id = u.id) as org_count,\n\t\torg.name as org_name,\n\t\torg_user.role as org_role,\n\t\torg.id as org_id\n\t\tFROM `user` as u\n\t\tLEFT OUTER JOIN org_user on org_user.org_id = 1 and org_user.user_id = u.id\n\t\tLEFT OUTER JOIN org on org.id = org_user.org_id WHERE u.id=? []interface
UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
Registros de exemplo completos:
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] SELECT\n\t\tu.id as user_id,\n\t\tu.is_admin as is_grafana_admin,\n\t\tu.email as email,\n\t\tu.login as login,\n\t\tu.name as name,\n\t\tu.help_flags1 as help_flags1,\n\t\tu.last_seen_at as last_seen_at,\n\t\t(SELECT COUNT(*) FROM org_user where org_user.user_id = u.id) as org_count,\n\t\torg.name as org_name,\n\t\torg_user.role as org_role,\n\t\torg.id as org_id\n\t\tFROM `user` as u\n\t\tLEFT OUTER JOIN org_user on org_user.org_id = 1 and org_user.user_id = u.id\n\t\tLEFT OUTER JOIN org on org.id = org_user.org_id WHERE u.id=? []interface
{}
{2} - took: 54.517418ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 42.957209ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] SELECT\n\t\tu.id as user_id,\n\t\tu.is_admin as is_grafana_admin,\n\t\tu.email as email,\n\t\tu.login as login,\n\t\tu.name as name,\n\t\tu.help_flags1 as help_flags1,\n\t\tu.last_seen_at as last_seen_at,\n\t\t(SELECT COUNT(*) FROM org_user where org_user.user_id = u.id) as org_count,\n\t\torg.name as org_name,\n\t\torg_user.role as org_role,\n\t\torg.id as org_id\n\t\tFROM `user` as u\n\t\tLEFT OUTER JOIN org_user on org_user.org_id = 1 and org_user.user_id = u.id\n\t\tLEFT OUTER JOIN org on org.id = org_user.org_id WHERE u.id=? []interface
{}
{2} - took: 69.013955ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 5.593997ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 46.673µs" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 621.538µs" logger=sqlstore.xorm
Muito obrigado @bjacobel. Tudo parece bem aqui de acordo com mim. Existe um ID de usuário real fornecido até a consulta do banco de dados. Realmente estranho. Começando a pensar que há um bug com nosso banco de dados lib xorm de terceiros.
Você fez algo específico para gerar essas mensagens de log?
Qual banco de dados você está usando? Qual armazenamento de sessão?
Qual solicitação está resultando em não autorizado, você pode ativar o registro do roteador para registrar todas as solicitações:
[server]
router_logging = true
Temos o mesmo erro em 5.1.4 no Kubernetes.
 benkeil
em 21 jun. 2018
benkeil
em 21 jun. 2018
Oi @marefr , desculpe, esqueci de responder com os detalhes adicionais solicitados.
Você fez algo específico para gerar essas mensagens de log?
As consultas são geradas carregando um painel e aguardando uma atualização automática. Isso não acontece a cada atualização automática e, às vezes, pode ser acionado com um clique manual no botão de atualização do painel (aquele embutido no Grafana, não o botão de atualização do navegador), mas geralmente parece acontecer com mais frequência quando o usuário está inativo (deixando grafana em uma guia de fundo, por exemplo.)
Qual banco de dados você está usando? Qual armazenamento de sessão?
O banco de dados é SQLite em um compartilhamento NFS (EFS) montado e o armazenamento da sessão é o padrão (arquivo), embora eu também tenha tentado o armazenamento baseado em memória e também tenha o mesmo problema. Temos um host grafana atrás de um balanceador de carga e habilitei a aderência da sessão nesse balanceador de carga.
Qual solicitação está resultando em não autorizado?
Não habilitei o registro do roteador, porque posso ver a solicitação que está resultando em não autorizado do navegador:
[Algumas informações confidenciais editadas]
Request URL: https://[my grafana hostname]/api/tsdb/query
Request Method: POST
Status Code: 401
Remote Address: [my load balancer IP]:443
Referrer Policy: no-referrer-when-downgrade
:authority: [my grafana hostname]
:method: POST
:path: /api/tsdb/query
:scheme: https
accept: application/json, text/plain, */*
accept-encoding: gzip, deflate, br
accept-language: en-US,en;q=0.9
cache-control: no-cache
content-length: 478
content-type: application/json;charset=UTF-8
cookie: _ga=GA1.2.1782868908.1520436196; __gads=ID=b1c7d78e4fd8b9fb:T=1520436200:S=ALNI_MYT2aRMJqYtHY-CkgaPWmuNtsGEtA; sailthru_hid=919b24e8c99698a8b1829b81eda7135a5956a753dd4c29265f8b45b3a11fb749fc11562ad2abbb1220b9ef37; grafana_sess=[16-char hexadecimal session string]; AWSALB=IUyH6LlTXI/TJlteL8pr838fC7nsvth7s63o5WzqOa6wsCPRpHg20vYurCrYpbIWci27fQtzQpoRxVlIc8Ud/rEPIJvqWvT21an4e9aQmZioTEAFHA3+iWv7bPHs
dnt: 1
origin: https://[my grafana hostname]
pragma: no-cache
referer: https://[my grafana hostname]/d/[dashboard path]?refresh=5m&orgId=1&from=now-1h&to=now
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36
x-grafana-org-id: 1
Oi @marefr , desculpe, esqueci de responder com os detalhes adicionais solicitados. ...
@bjacobel, isso provavelmente não está relacionado ao problema específico, no entanto, os desenvolvedores do SQLite recomendam não executar o SQLite sobre NFS. Especificamente, o processo Grafana não deve acessar o banco de dados por meio de uma montagem NFS e não é recomendado executar a partir de qualquer sistema de arquivos em rede sem suporte de bloqueio de arquivo forte.
Em uma nota lateral, usamos SQLite com armazenamento de sessão como você faz, mas no sistema de arquivos local. Não tivemos esse mesmo problema.
Também ajustamos a configuração do SQLite em grafana para usar o modo WAL (do qual irei eventualmente fazer um PR) para melhor desempenho.
Enviado com GitHawk
 davewat
em 24 jun. 2018
davewat
em 24 jun. 2018
Estou tendo o mesmo problema em minha pilha do docker Grafana e InfluxDB.
Grafana v5.1.3 (commit: 087143285)
InfluxDB 1.5.3
Grafana está usando armazenamento local por meio de volumes docker com banco de dados sqlite. Os volumes estão usando SSD local.
Recebo o erro sempre que deixo a guia por mais de alguns minutos. Se eu deixar as ferramentas de desenvolvimento ativadas no Firefox, vejo:
GET http://x.x.x.x:3000/api/datasources/proxy/1/query?db=(Redacted info)
{"message":"Unauthorized"}
Qualquer tipo de atualização limpa os erros.
 isclever
em 25 jun. 2018
isclever
em 25 jun. 2018
Eu me deparei com o mesmo problema. Para mim, estava relacionado à falta de "session_provider = memcahched"
Você pode consultar http://docs.grafana.org/installation/configuration/#provider -config para obter mais opções de configuração
 nikskiz
em 11 jul. 2018
nikskiz
em 11 jul. 2018
O mesmo problema está aqui também. Minha configuração do docker é:
FROM grafana/grafana:5.1.0
FROM influxdb:1.5.3
 BentCoder
em 13 jul. 2018
BentCoder
em 13 jul. 2018
Fechando isto porque parece estar relacionado a setup / config
torkelo
em 13 jul. 2018
@torkelo Existe uma solução óbvia para esse problema? Ou uma dica para ajudar a descobrir qual seria a solução possível?
BentCoder
em 13 jul. 2018
Certifique-se de que a configuração da sessão esteja funcionando para a configuração de HA ou que as sessões persistentes no balanceador de carga estejam funcionando
torkelo
em 13 jul. 2018
Eu não uso o balanceador de carga.
BentCoder
em 17 jul. 2018
O mesmo problema aqui sem múltiplas réplicas
Acabei de receber um erro 401 em / api / login / ping às vezes aleatoriamente
 WTFKr0
em 25 jul. 2018
WTFKr0
em 25 jul. 2018
O mesmo problema aqui (por anos, antes dos dias 5.0), SQLite no ext4, réplica única no Kubernetes. Imagem oficial mais recente do Docker.
As solicitações falham aleatoriamente quando o Grafana é atualizado automaticamente e, eventualmente, todos os widgets param de relatar qualquer coisa. Registros relevantes:
t=2018-07-31T01:38:04+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-07-31T01:38:04+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-07-31T01:38:04+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-07-31T01:38:04+0000 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=GET path=/api/datasources/proxy/4/query status=401 remote_addr=192.168.1.72 time_ms=28 size=26 referer="REDACTED"
Vou tentar fazer alguma depuração, tenho 99% de certeza que é um bug do Grafana (ou uma de suas bibliotecas).
/ cc @torkelo
 lorenz
em 31 jul. 2018
lorenz
em 31 jul. 2018
Tenho 95% de certeza de que está faltando uma nova tentativa, caso a tabela SQLite esteja bloqueada. Vou implantar uma correção localmente e PR se funcionar.
EDIT: risque isso, isso levaria um codepath diferente.
lorenz
em 31 jul. 2018
Aqui está um exemplo de erro meu.
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=eror msg="Failed to get user with id" logger=context userId=1 error="User not found"
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=GET path=/api/login/ping status=401 remote_addr=192.168.33.1 time_ms=35 size=26 referer="http://192.168.33.10:3000/d/ZJ65a0Dmz/yowyow?refresh=5s&orgId=1&from=now-30d&to=now"
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=info msg="Request Completed" logger=context userId=1 orgId=1 uname=admin method=GET path=/api/login/ping status=401 remote_addr=192.168.33.1 time_ms=24 size=26 referer="http://192.168.33.10:3000/d/ZJ65a0Dmz/yowyow?refresh=5s&orgId=1&from=now-30d&to=now"
Deixei rodar durante a noite para gerar mais algumas falhas e tenho certeza de que não é nada com as sessões. Está na camada ORM, especificamente em user.go GetSignedInUser() onde essa camada às vezes não retorna uma resposta correta. Eu gravei todas as solicitações em um painel gráfico de 50 em 1min durante uma noite e vi um padrão muito aleatório com erros agrupados, tudo aponta para algum problema de concorrência / corrida. No momento, estou executando um patch que propaga erros do leitor de linha corretamente (o principal candidato para esse problema). Vou ver se recebo uma mensagem de erro diferente.
lorenz
em 31 jul. 2018
Aquilo foi rápido. Com meu patch de propagação de erro aplicado, encontrei a causa raiz:
t=2018-07-31T17:26:46+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="database table is locked"
As novas tentativas são implementadas incorretamente em algum lugar do driver de execução SQLite.
lorenz
em 31 jul. 2018
Analisei mais um pouco e há vários problemas aqui:
- go-sqlite não é conhecido por ser seguro para goroutine (o que torna essa coisa toda com uma conexão gerenciada por xorm central possivelmente uma má ideia).
- O SQLite não oferece suporte a consultas simultâneas em uma única "conexão". Precisamos fazer com que o xorm abra várias conexões com o SQLite. Caso contrário, podemos encontrar deadlocks ou esses erros de bloqueio, pois o SQLite não tentará resolver os bloqueios se eles forem da mesma conexão.
Já vi pessoas fazerem várias coisas para evitar esses problemas de SQLite, incluindo agrupar todos os acessos SQLite em um único mutex e abrir uma nova instância SQLite por solicitação. A coisa mais fácil a fazer é provavelmente hackear go-sqlite3 para conter um mutex por "conexão" e apenas serializar todo o acesso a ele (EDITAR: Acabei de perceber que isso provavelmente não funcionará, pois os bloqueios aparecem ao ler de um cursor, o que você não pode travar sem arriscar bloqueios). É assim que um programa C faria (para o qual o SQLite foi feito). Pode ser lento, mas as pessoas que precisam do desempenho devem acessar o PostgreSQL de qualquer maneira.
lorenz
em 31 jul. 2018
Muito obrigado, @lorenz , por se aprofundar nisso. Sua indicação de que isso é provavelmente causado por algo no nível sqlite me levou a mover o banco de dados de configuração de nossa instância do SQLite para o Postgres (e a colocar nossas sessões no Postgres também, que anteriormente tinha backup de arquivo). Não é uma prova conclusiva, mas não vi as edições não autorizadas desde então.
Para outras pessoas interessadas em tentar essa solução alternativa, usei pgloader com as configurações padrão e não eliminei nenhuma sessão ou dados do usuário durante a migração.
bjacobel
em 3 ago. 2018
O problema é definitivamente apenas com o back-end SQLite, uma vez que todos os bancos de dados "maiores" têm MVCC que resolve este problema. Eu pessoalmente também movi minhas instâncias de produção para PostgreSQL. O problema ainda é se e como devemos resolver isso para o back-end SQLite. Não vejo uma maneira fácil de fazer isso, já que Grafana (devido a ter sido escrito em Go) faz uso intenso de simultaneidade, o que requer um cuidado especial no SQLite além do que o Xorm fornece atualmente.
Já existem vários bloqueios e novas tentativas no código que tentam contornar isso, mas são inadequados. Desde que eu corrigi o tratamento de erros para o leitor de linha (que atualmente engole silenciosamente os erros de bloqueio e, portanto, cria um comportamento imprevisível, vou corrigir a correção em breve), vi os erros de bloqueio aparecerem em muitos mais lugares do que apenas os dados proxy de origem, é apenas o endpoint que é atingido com mais frequência e, devido à natureza probabilística do bug, o torna o mais visível para o usuário. Pelo que posso ver, todas as correções para isso requerem hackear o Xorm ou go-sqlite3, o que geralmente não é desejável.
lorenz
em 3 ago. 2018
Obrigado pela ótima análise @lorenz! Você acha que devolver 500 neste caso seria uma solução alternativa razoável a curto prazo? Como está agora, 401 força o navegador (pelo menos o Chrome) a esquecer a senha e exige que meus usuários a digitem novamente. Às vezes, ele precisa ser digitado várias vezes até que a senha seja finalmente aceita.
Minha solução atual é executar o banco de dados de tmpfs . Isso reduz a frequência desse problema, mas ainda acontece de vez em quando.
 kichik
em 11 ago. 2018
kichik
em 11 ago. 2018
@kichik Quando eu tiver feito a RP da minha alteração no tratamento de erros, poderíamos pensar em retornar HTTP 500 (ou 503). Mas a única boa solução alternativa que posso ver é usar um banco de dados compatível com MVCC real, como PostgreSQL ou MySQL, que não apresenta o problema de forma alguma. Conforme expliquei em meu comentário anterior, esse problema vai além das solicitações de dados, portanto, retornar outro código de erro diferente de HTTP 401 apenas para aqueles não resolverá o problema por completo.
lorenz
em 11 ago. 2018
Acabei de fazer um PRed meu relatório de erro alterações no # 13007, isso deve ajudar as pessoas a ver se eles são afetados pelo problema de bloqueio ou se é algo não relacionado.
lorenz
em 22 ago. 2018
@torkelo Podemos reabrir isso, já que é claramente um problema com o Grafana?
lorenz
em 22 ago. 2018
Definitivamente acontece em uma única guia (e um único usuário) para mim.
Também usando sqlite3. Curiosamente, eu não tive esse problema antes. Agora que adicionei alguns painéis pesados (com base em consultas), frequentemente recebo esse erro, geralmente apenas para um dos meus painéis pesados.
 Argon-
em 29 ago. 2018
Argon-
em 29 ago. 2018
Confirmar que mudar para um banco de dados não sqlite3 corrige o problema para mim. Eu estava ficando com um único usuário e uma única guia também, com painéis mais pesados / ocupados se comportando pior também.
Atualização: as sessões devem ser alternadas para serem armazenadas em um banco de dados separado para a correção completa.
 astral303
em 29 ago. 2018
astral303
em 29 ago. 2018
Estou usando o mysqldb enfrentando o mesmo problema. Grafana versão 5.2.3, viscosidade habilitada no nível Lb, mas o problema ainda está lá.
 vishksaj
em 5 set. 2018
vishksaj
em 5 set. 2018
Também experimentando isso, usando sqlite como backend de dados, mas redis como armazenamento de sessão no grafana 5.2.3
Aproximadamente 150 organizações configuradas. Um aviso não autorizado aparece na atualização interna, mas geralmente desaparece na atualização manual.
Colocar isso nos registros de tempos em tempos:
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=1
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=1
 reinhard-brandstaedter
em 12 set. 2018
reinhard-brandstaedter
em 12 set. 2018
Este problema pode ser causado pela perda da conexão do mysql. Quando eu diminuo os valores max_idle_conn e conn_max_lifetime, isso não acontece novamente. Espero que esta ajuda
 xiaochai
em 11 out. 2018
xiaochai
em 11 out. 2018
@vishksaj @xiaochai Este é muito provavelmente um problema diferente. Você poderia abrir um novo?
lorenz
em 11 out. 2018
https://github.com/oleh-ozimok/grafana/commit/b19e416549553f582dccfbcaa3f4d3f1a742a462 - resolveu meu problema (imagem com hotfix docker pull olegozimok/grafana:5.3.2 )
 oleh-ozimok
em 29 out. 2018
oleh-ozimok
em 29 out. 2018
Grafana 5.3.2. Configuração HA: 2 instâncias Grafana, banco de dados principal MySQL, 2 instâncias de memcached para sessões, dir grafana e banco de dados são armazenados no NFS. Os mesmos erros "não autorizados" o tempo todo, de forma imprevisível. O mesmo acontecia quando DB era SQLite em NFS.
 dev-e
em 1 nov. 2018
dev-e
em 1 nov. 2018
Mesmo problema que @ dev-e, mas configuração mais simples. Grafana 5.3.2, instância única, InfluxDB no mesmo host, organização única, usuário único. A mensagem aparece aleatoriamente e desaparece na próxima atualização da página.
 luizfzs
em 1 nov. 2018
luizfzs
em 1 nov. 2018
Eu tenho o mesmo problema. Obtendo erros não autorizados aleatoriamente.
Atualizar para grafana 5.3.4 meio que o tornou melhor, mas ainda assim muitos erros.
Em toras de grafana:
t = 2018-11-19T09: 55: 07 + 0200 lvl = eror msg = "Falha ao obter o usuário com id" logger = contexto userId = 1 erro = "Usuário não encontrado"
t = 2018-11-19T09: 55: 07 + 0200 lvl = eror msg = "Falha ao obter o usuário com id" logger = contexto userId = 1 erro = "Usuário não encontrado"
t = 2018-11-19T09: 55: 07 + 0200 lvl = eror msg = "Falha ao obter o usuário com id" logger = contexto userId = 1 erro = "Usuário não encontrado"
Configuração imediata:
grafana / agora 5.3.4 amd64
influxdb / now 1.6.0-1 amd64
 gigake
em 19 nov. 2018
gigake
em 19 nov. 2018
Mesmo problema aqui:
t=2018-12-03T09:28:21+0000 lvl=eror msg="Failed to update last_seen_at" logger=context userId=12 orgId=1 uname=ht error="database table is locked"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
2018/12/03 10:51:54 http: proxy error: unexpected EOF
2018/12/03 10:51:54 http: proxy error: unexpected EOF
2018/12/03 10:51:54 http: proxy error: unexpected EOF
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:56+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:56+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
Grafana 5.3.4 único, o armazenamento é o sistema de arquivos Amazon EFS (montagem NFS)
A sessão está definida como arquivo, o armazenamento de dados é sqlite (/var/lib/grafana/grafana.db)
Grafana fica atrás de um LB de terminação HTTPS
 roffe
em 3 dez. 2018
roffe
em 3 dez. 2018
Fez um RP implementando a sugestão de @oleh-ozimok. Sinta-se à vontade para experimentar. Vou tentar mais uma vez quando estiver de volta em casa das férias para que eu possa ter uma instância de longa duração :)
@ oleh-ozimok Se você quiser criar um RP, ficarei mais do que feliz em mesclá-lo ao invés do meu para dar o crédito a você.
A propósito, ótimo trabalho
 bergquist
em 27 dez. 2018
bergquist
em 27 dez. 2018
Isso afeta nossa implantação também. Constantemente obtemos 401 erros não autorizados usando dois bancos de dados Amazon Auora MySQL em execução no modo HA / Multi Master. Verifiquei que as sessões estão em ambos os bancos de dados. Mas, mesmo assim, apontei todas as instâncias para o mesmo banco de dados para ver se isso resolveria o problema e não corrigiu. Definitivamente, há algo errado com as sessões sendo autenticadas corretamente. Isso vai ainda mais longe com nossa configuração Oauth. Há momentos em que o usuário faria o login usando o provedor Oauth configurado e não conseguiria fazer o login depois de redirecionado. Se eles entrarem 2 a 3 vezes, funciona.
 buroa
em 26 jan. 2019
buroa
em 26 jan. 2019
Isso é muito estranho, talvez um dos servidores esteja configurado de forma diferente?
Quaisquer detalhes de log?
Estamos eliminando a necessidade de armazenamento de sessão e reescrevendo completamente como as sessões de login são gerenciadas na v6, portanto, esperamos que isso resolva o problema.
torkelo
em 27 jan. 2019
@buroa alguma chance de você tentar 6.0-beta1? Reescrevemos o token de autenticação e removemos a maior parte do uso do token de sessão (ainda usado ao usar o auth_proxy) completamente e esperamos que a maioria desses problemas desapareça.
bergquist
em 5 fev. 2019
@bergquist atualizou minha configuração em 01/02/2019: 58: 20 + 0200, não aconteceu esse erro por enquanto.
 zcooler
em 5 fev. 2019
zcooler
em 5 fev. 2019
@buroa alguma chance de você tentar 6.0-beta1? Reescrevemos o token de autenticação e removemos a maior parte do uso do token de sessão (ainda usado ao usar o auth_proxy) completamente e esperamos que a maioria desses problemas desapareça.
Estou usando a compilação mais recente: https://github.com/buroa/grafana/tree/us-iso-regions
Isso tem a mudança necessária?
buroa
em 5 fev. 2019
@buroa sim, mas ainda assim sugiro que você mescle no último master, já que fizemos algumas alterações desde 6.0-beta1.
marefr
em 5 fev. 2019
Hoje deu um erro
t = 2019-02-08T10: 05: 58 + 0200 lvl = info msg = "falha ao procurar usuário com base no cookie" logger = erro de contexto = "Token de autenticação do usuário não encontrado"
A guia do navegador não fechava, apenas atualizava automaticamente a cada hora, mas o pc estava bloqueado.
 QuantumProjects
em 8 fev. 2019
QuantumProjects
em 8 fev. 2019
@QuantumProjects , você poderia abrir um novo problema, já que você tem um problema com o Grafana v6.0-pre. Forneça mais detalhes sobre a configuração do Grafana: qual banco de dados está em uso? Versão Grafana? Várias instâncias do Grafana? Qual tipo de autenticação? Proxy reverso? Obrigado
marefr
em 8 fev. 2019
@marefr Ok
QuantumProjects
em 8 fev. 2019
@marefr estou recebendo os mesmos pop-ups "Não autorizados", talvez minha configuração possa ajudar a descobrir o problema:
- Servidor de gateway com traefik como proxy reverso apontando para um servidor local que está hospedando grafana
- servidor local com Grafana v5.4.3
- fonte de dados é um influxdb v1.7.8 no mesmo servidor local
- como descobrir o tipo de autenticação questionada? Acabei de fazer login como um usuário administrador
Nota: cada serviço é um contêiner docker, traefik x64, grafana e influxdb arm32v7
 eiabea
em 19 fev. 2019
eiabea
em 19 fev. 2019
Isso também acontece no Grafana 6.0.0 (commit: 34a9a62, branch: HEAD). O banco de dados SQLite está fora de uso, Grafana está trabalhando por trás do proxy reverso nginx. A autenticação LDAP está configurada. Uma única instância do Grafana está em execução nesta VM.
Entrada de registro no momento do erro:
t=2019-03-06T13:39:24+0100 lvl=eror msg="failed to look up user based on cookie" logger=context error="database is locked"
 angryp
em 6 mar. 2019
angryp
em 6 mar. 2019
Apenas adicionando um ponto de dados, uma vez que movi meu banco de dados do sqlite para o postgres, parei de ver esses erros. Anteriormente, eles eram frequentes o suficiente para tornar o uso do sistema bastante desconfortável. Executando um único servidor 5.4.3 com google oauth.
 qhartman
em 6 mar. 2019
qhartman
em 6 mar. 2019
Acontecendo comigo no 5.4.3 conectado ao postgres, de forma bastante aleatória, mas apenas quando eu deixo a atualização automática. A instalação é em uma rede local onde o banco de dados está na mesma caixa que o Grafana.
Estou recebendo vários desses tipos de erros no syslog no momento em que "Não autorizado" aparece:
...
...
grafana-server[12619]: t=2019-03-06T22:42:02+0100 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
grafana-server[12619]: t=2019-03-06T22:42:03+0100 lvl=eror msg="Failed to get user with id" logger=context userId=1 error="User not found"
...
grafana-server[12619]: t=2019-03-06T22:42:03+0100 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=POST path=/api/tsdb/query status=401 remote_addr=192.168.0.2 time_ms=17 size=26 referer="http://192.168.0.1:3000/d/.....
...
Existem algumas variações no log em userId = 1 ou 0 e em nova tentativa = 1 ou 0
 ggggh
em 6 mar. 2019
ggggh
em 6 mar. 2019
Olá,
Tive hoje o mesmo problema. Temos o Grafana 6.0.1 em um Debian Stretch simples atualizado alguns dias antes. Grafana se conecta a um balanceador de carga (proxysql) com MariaDB 10.2 (cluster Galera) como back-end (modo de sincronização com três nós).
Usamos LDAP (Windows AD) como autorização.
Mensagem de registro:
lvl=eror msg="failed to look up user based on cookie" logger=context error="invalid connection"
A única coisa que funcionou, foi usar o IP direto e não o balanceador de carga.
 linuxmail
em 14 mar. 2019
linuxmail
em 14 mar. 2019
A única coisa que funcionou, foi usar o IP direto e não o balanceador de carga.
Não parece ser o mesmo problema, já que o nosso é intermitente - talvez um dos painéis a cada dez ou mais atualizações possa falhar com o erro, mas geralmente funciona
ggggh
em 14 mar. 2019
A mesma coisa está acontecendo comigo no 6.0.2.
Do registro:
t=2019-03-23T12:04:22+0000 lvl=eror msg="failed to look up user based on cookie" logger=context error="database is locked"
e
t=2019-03-23T19:05:45+0000 lvl=eror msg="Failed to update last_seen_at" logger=context userId=1 orgId=1 uname=<username> error="database is locked"
Docker regular instalado com Traefik para proxy reverso.
 menteb
em 23 mar. 2019
menteb
em 23 mar. 2019
Para mim está acontecendo a mesma coisa
versão 6.02
"falha ao procurar usuário com base no cookie" logger = erro de contexto = "banco de dados está bloqueado"
 tiagoalmeida10
em 28 mar. 2019
tiagoalmeida10
em 28 mar. 2019
Se a sua obtenção de "banco de dados está bloqueado" com Sqlite (padrão), é provavelmente um bom momento para migrar para mysql / postgres, pois eles podem lidar com mais transações / s
bergquist
em 3 abr. 2019
@bergquist Acho que essa é a solução. Acabei de migrar para o MariaDB e não sou mais expulso do Grafana. Tack!
menteb
em 4 abr. 2019
@bergquist Acho que essa é a solução. Acabei de migrar para o MariaDB e não sou mais expulso do Grafana. Tack!
Para esclarecer, isso pode ser uma solução para "Banco de dados bloqueado", não "Tabela de banco de dados bloqueada" - estou no PostgreSQL e enfrentando o "bloqueio de tabela".
ggggh
em 4 abr. 2019
Resolvido para mim após uma atualização do Raspbian que me levou ao Postgres 9.6 (de 9.4). Grafana ainda em 5.4.3
ggggh
em 25 abr. 2019
Resolvido para mim após uma atualização do Raspbian que me levou ao Postgres 9.6 (de 9.4). Grafana ainda em 5.4.3
Esqueça o que eu disse ... está de volta. Com menos frequência, eu diria ... mas ainda está acontecendo.
ggggh
em 10 mai. 2019
@ggggh alguma solução? Simplesmente começou a acontecer do nada para mim!
 devanshkv
em 22 mai. 2019
devanshkv
em 22 mai. 2019
@ggggh alguma solução? Simplesmente começou a acontecer do nada para mim!
Nada...! Foi resolvido com a atualização da versão do postgres e parece estar voltando novamente, com mais frequência a cada dia
ggggh
em 22 mai. 2019
@ggggh Obrigado!
Mudei para o Postgres, mas isso também não está ajudando :(
devanshkv
em 22 mai. 2019
tendo os mesmos problemas ao usar o Grafana 6.2.1 e o Postgress 11, mas isso está acontecendo apenas nos dashbaords que carrego do JSON e tento acessá-los.
Alguma atualização sobre isso?
 botzill
em 29 mai. 2019
botzill
em 29 mai. 2019
OK, encontrei o problema no meu caso. Meu PG tinha um número limitado de conexões e na grafana max_open_conn não estava definido. Depois de definir essa opção, ela funciona bem.
botzill
em 3 jun. 2019
O mesmo está acontecendo comigo no Grafana 6.1.6 e no banco de dados SQLite empacotado. Esse problema interrompe nossos esforços de desenvolvimento internos para personalizar o Grafana. Alterar max_open_conn não funciona (embora eu não esperava que funcionasse, pois era uma correção para o Postgres).
 syardumian-chc
em 10 jun. 2019
syardumian-chc
em 10 jun. 2019
A causa raiz disso parece ser grafana tentando se conectar ao
DB subjacente ao autenticar, mas não ao fazê-lo. Com SQLite, isso
acontecerá com frequência e com uma contagem baixa de uso simultâneo, uma vez que o SQLite bloqueia
tão agressivamente. Na maioria dos casos, migrar para um RDBMS real (gosto de postgres)
vai resolver o problema. É possível que volte a surgir se você encontrar um
problema de limite de conexão (ou semelhante), mas isso é uma preocupação do banco de dados mais do que um
Preocupação Grafana. Se você estiver usando o Grafana para outra coisa que não seja uma demonstração,
você deve apoiá-lo com um banco de dados real. Se esse banco de dados estiver configurado corretamente para
seu uso, isso deve resolver este problema.
Na segunda-feira, 10 de junho de 2019 às 11h20 syardumian-chc [email protected]
escreveu:
O mesmo está acontecendo comigo no Grafana 6.1.6 e no banco de dados SQLite empacotado. Esse
problema quebra nossos esforços de desenvolvimento interno para personalizar Grafana. Mudando
max_open_conn não funciona (embora eu não esperava que funcionasse, pois era um
correção para Postgres).-
Você está recebendo isto porque está inscrito neste tópico.
Responda a este e-mail diretamente, visualize-o no GitHub
https://github.com/grafana/grafana/issues/10727?email_source=notifications&email_token=AAAK6YSUDLXPF2E4436CEOTPZ2EMFA5CNFSM4EO23EH2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGODXKQ3UY#issuecomment-500501971 ,
ou silenciar o tópico
https://github.com/notifications/unsubscribe-auth/AAAK6YQLR3FSCNEQR7SNEKLPZ2EMFANCNFSM4EO23EHQ
.
qhartman
em 10 jun. 2019
Aumentei o limite de conexão e o número máximo de conexões ociosas, mas continuo encontrando esse problema aleatoriamente. Não apenas isso, mas os painéis que estiveram abertos por um tempo parecem ficar cada vez mais lentos para atualizar, com o gif de carregamento evidente em cada painel e desaparecendo sequencialmente conforme cada painel conclui o carregamento. Tudo bem se eu fechar a janela do navegador e abrir uma nova. Acho que meu painel ficou mais complexo, mas isso não explica por que um novo carregamento da página "corrige".
ggggh
em 12 jun. 2019
Estou recebendo erros aleatórios também. Realmente não sei qual é o problema. Usar o endereço IP parece bom, mas com o ingresso kubeneters, ele mostra a "consulta de anotação falhou" aleatoriamente.
 naturalbeau
em 13 jun. 2019
naturalbeau
em 13 jun. 2019
FWIW, recentemente mudei meu balanceador de carga de ingresso para Fabio (do Traefik) e atualizei Grafana (imagem Docker, sem back-ends de banco de dados adicionais) para v6.4.2, e os erros não autorizados 401 parecem ter desaparecido ao fazer a atualização automática (intervalo definido para 10 segundos, funcionando o dia todo). É improvável que mudar para o Fábio tenha resolvido o problema. Acho que foi a versão mais recente do Grafana que ajudou, mas não tenho 100% de certeza.
 kmott
em 9 out. 2019
kmott
em 9 out. 2019
Fechando isso porque não há novos relatórios recentemente. se você acha que ainda há um problema, abra um novo problema
torkelo
em 19 out. 2019
Recentemente, instalei o grafana em meu cluster Kubernetes e tive um problema semelhante.
Estou usando docker image grafana / grafana: 6.4.3
Verificando meus registros de pod, encontrei este petisco interessante:
t=2019-11-01T15:18:33+0000 lvl=info msg="Successful Login" logger=http.server User=--snip--
t=2019-11-01T15:19:09+0000 lvl=eror msg="Failed to look up user based on cookie" logger=context error="dial tcp: lookup postgres.databases.svc.cluster.local: no such host"
t=2019-11-01T15:19:09+0000 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=GET path=/api/datasources/proxy/1/query status=401 remote_addr=--snip-- time_ms=11 size=26 referer="https://--snip--/d/TuobtjoZz/--snip--?orgId=1&refresh=5s&from=now-12h&to=now"
Problemas de DNS não são algo que eu encontrei antes em meu cluster, mas fiz algumas pesquisas no Google e encontrei este problema específico: https://github.com/kubernetes/kubernetes/issues/30215
Seria possível para a grafana enviar imagens alpinas e não alpinas como muitas imagens docker fazem? Parece que isso resolveria o problema.
Se houver algo que eu possa fazer para testar isso ou ajudar na depuração, me avise, irei fornecer as informações conforme solicitado.
 ikkerens
em 1 nov. 2019
ikkerens
em 1 nov. 2019
Depois de fazer o downgrade para 6.3.6 (que não é baseado em alpino), o problema desapareceu totalmente do meu lado.
ikkerens
em 2 nov. 2019
Eu enfrentei o mesmo problema, dois Grafana (contêineres) separados abertos no mesmo navegador
ao fazer o login no segundo o primeiro me peça para fazer o login novamente, faça o login no primeiro o segundo me peça para fazer o login novamente
não posso manter os dois logins
a solução que encontrei é mudar em um dos arquivos Grafana default.ini
login_cookie_name = grafana_session
para
login_cookie_name = grafana_session_1
reinicie o contêiner e o navegador, agora está funcionando bem
por enquanto, mantenho o arquivo fora do contêiner
precisa definir este parâmetro ao criar o contêiner
 n0-bs
em 20 fev. 2020
n0-bs
em 20 fev. 2020
@ikkerens tente a imagem baseada no ubuntu então, 6.6.2-ununtu
marefr
em 28 fev. 2020
@ n0-bs Sinto muito, mas se você estiver executando várias instâncias do Grafana, sugerimos usar MySQL ou Postgres como banco de dados.
marefr
em 28 fev. 2020
Desculpe, mas como o uso de MySQL ou Postgres como banco de dados resolverá o conflito de cookies quando eu abrir essas duas instâncias diferentes do Grafana no mesmo navegador, não estou falando sobre o caso de HA
Eu tenho duas instâncias diferentes do Grafana (contêineres) no mesmo servidor
n0-bs
em 1 mar. 2020
Ainda estou vendo isso com 6.7.2. Eu atualizei de 6.5 para 6.6 e, em seguida, 6.7. Usando docker com PostgreSQL, tentei imagem 6.7.2 e 6.7.2-ubuntu.
Este é o erro que estou obtendo nos logs:
lvl=eror msg="Failed to look up user based on cookie" logger=context error="pq: remaining connection slots are reserved for non-replication superuser connections"
 helderco
em 16 abr. 2020
helderco
em 16 abr. 2020
Corrigido (pelo menos por agora) reiniciando o postgres.
helderco
em 16 abr. 2020
Estou usando a versão mais recente do Grafana e continuo vendo o problema não autorizado toda vez que o acesso. Estou usando Grafana no kubernetes. Eu o implantei em 3 pods diferentes em 3 nós diferentes. Estou usando o banco de dados nativo dele. Alguma sugestão para corrigir o problema?
 emzfuu
em 1 jun. 2020
emzfuu
em 1 jun. 2020
@emzfuu Se você executar várias instâncias, precisará apontar todas para o mesmo banco de dados. mysql / postgres
bergquist
em 1 jun. 2020
@bergquist existe alguma outra maneira de resolver o problema?
emzfuu
em 2 jun. 2020
Só para elaborar minha pergunta acima estou usando 3 Grafana diferentes (autônomos) que estão sendo acessados através de balanceador de carga único. O 3 Grafana tem seu próprio db (sqlite3). Cada vez que o acesso recebo o erro de não autorizar.
emzfuu
em 3 jun. 2020
Estou com o mesmo problema, uso nfs.
 linux0x5c
em 8 jun. 2020
linux0x5c
em 8 jun. 2020
Questões relacionadas
 SATHVIKRAJU
·
3Comentários
SATHVIKRAJU
·
3Comentários
 yuvaraj951
·
3Comentários
yuvaraj951
·
3Comentários
 tcolgate
·
3Comentários
tcolgate
·
3Comentários
 ericuldall
·
3Comentários
ericuldall
·
3Comentários
 sslupsky
·
3Comentários
sslupsky
·
3Comentários
Comentários muito úteis
Vejo o mesmo problema no Grafana v4.6.2 (commit: 8db5f08), tudo funciona como esperado e, de repente, recebo um aviso de não autorizado (e alguns gráficos estão vazios, mas alguns aparecem normalmente).
Eu uso o Prometheus como a fonte de dados.
Também acho que isso acontece principalmente quando o painel é atualizado automaticamente, mas se corrige quando eu o atualizo manualmente.