Estoy ejecutando la última versión de grafana en dos instancias, pero me enfrento a muchos errores no autorizados al intentar acceder a ambas instancias. Para la autenticación, actualmente estoy usando la base de datos incorporada, sin LDAP. La fuente de datos es influxdb.
¿Es esto un error conocido o una mala conducta?
 darox
darox
Todos 105 comentarios
¿Podría darnos más detalles?
- ¿Son estos dos casos separados?
- ¿Qué acción desencadena el error no autorizado?
- ¿Se está desconectando o son solo ciertas acciones que no funcionan?
 daniellee
en 2 feb. 2018
daniellee
en 2 feb. 2018
¿Están configurados en diferentes ips / nombres de dominio? si el nombre de dominio es el mismo y solo diferente por puerto, necesita tener cookies de sesión únicas y recordarme cookies
 torkelo
en 2 feb. 2018
torkelo
en 2 feb. 2018
-Estas son instancias separadas
-No sé qué acción desencadena la no autorizada, solo sucede cuando miro gráficos o cuando accedo a grafana
-A veces me desconecto
-Dominios separados
darox
en 2 feb. 2018
Me encuentro con esto en Grafana 4.6.x con oauth a través de Github. Es aparentemente aleatorio cuando cambio de pestaña y vuelvo a Grafana. Una actualización "corregirá" el problema, pero a veces vuelve más tarde.
 pgporada
en 7 mar. 2018
pgporada
en 7 mar. 2018

Veo el mismo problema en Grafana v4.6.2 (commit: 8db5f08), todo funciona como se esperaba y, de repente, recibo una advertencia no autorizada (y algunos gráficos están vacíos, pero algunos aparecen normalmente).
Utilizo Prometheus como fuente de datos.
También creo que esto sucede principalmente cuando el tablero se actualiza automáticamente, pero se corrige solo cuando lo actualizo manualmente.
 ajardan
en 8 mar. 2018
ajardan
en 8 mar. 2018
Aquí también hay un problema similar, pero con una única instancia de Grafana con HTTPS y fuente de datos Postgres.
Cuando se abre el tablero, todos los gráficos son buenos. Pero a veces después, algunos de los gráficos comienzan a mostrar errores "no autorizados" en la actualización automática, pero en la siguiente (o en las siguientes) actualización automática se recuperan al estado normal, pero luego se vuelven "no autorizados" a veces más tarde, repitiendo este comportamiento aleatorio en cada actualización automática.
No estoy seguro de si está relacionado, pero encontré los siguientes mensajes de registro.
lvl = eror msg = "No se pudo obtener el usuario con id" logger = context userId = 1 error = "Usuario no encontrado"
La versión de Grafana es la siguiente:
lvl = info msg = "Iniciando Grafana" logger = versión del servidor = 5.0.4 commit = 7dc36ae compilado = 2018-03-28T20: 52: 41 + 0900
Estoy usando Firefox, y por lo general dejo el panel de control abierto y sin tocar durante varios días, con la máquina cliente (no la máquina servidor que aloja Grafana) entrando en modo de suspensión de vez en cuando.
 after-the-sunrise
en 12 abr. 2018
after-the-sunrise
en 12 abr. 2018
Esto ya no me está pasando con grafana 5.x
darox
en 12 abr. 2018
Todavía tengo exactamente el mismo problema con Grafana 5.0.4, los mismos mensajes de usuario que no se encuentran en el registro (esto es con un simple usuario local de Grafana).
 SoulSeekkor
en 13 abr. 2018
SoulSeekkor
en 13 abr. 2018
Yo también tengo este problema. Y el tema es muy interesante. Puede suceder cuando abro dos páginas de grafana de diferente versión en el mismo navegador e intento realizar algunas operaciones.
Tengo una versión anterior de grafana (v4.3.2 (commit: ed4d170)) y ha funcionado bien en grafana.mydomain.com durante mucho tiempo. Hoy quiero actualizar mi grafana a v5.0.4. En lugar de actualizar en su lugar. Quería configurar el nuevo Grafana en la misma máquina, copiar el tablero que quiero y luego derribar el anterior.
Entonces, lo que hice:
- Docker ejecuta grafana5 en la misma máquina que la anterior con el mapa de puertos a 3005
- abrió el antiguo grafana4 en
grafana.mydomain.comen Safari
Y funciona bien - visita Grafana5 en
grafana.mydomain.com:3005en Safari
Así que ahora tengo dos pestañas abiertas de Grafana4 y Grafana5 en mi pantalla - iniciar sesión en Grafana5, intentando realizar algunas operaciones ... como [crear panel]
Ahora ambas páginas de Grafana se bloquearon
Ambos Grafana obtendrán errores de Unauthorized y no obtendrán puntos de datos
Actualización : cambié mi paso 3 visitando Grafana5 con [ip]: 3005. Funciona bien por ahora.
Parece que puede haber algunos conflictos al abrir dos páginas de Grafana dentro del mismo dominio.
 kehao95
en 18 abr. 2018
kehao95
en 18 abr. 2018
@ kehao95 su caso de uso de en el mismo navegador abriendo dos instancias de Grafana en el mismo dominio pero con puertos diferentes no es compatible. (Torkel mencionó eso arriba).
@ajardan, ¿ están tus instancias en el mismo dominio o en diferentes?
daniellee
en 30 abr. 2018
@daniellee En realidad, solo uso una instancia todo el tiempo. Y los gráficos en el tablero que miro se obtienen de 2 fuentes de datos diferentes (Prometheus y Cloudera)
ajardan
en 7 may. 2018
También recibo este extraño problema "No autorizado" de vez en cuando. La actualización de la página "soluciona" el problema. Ejecuto Grafana v5.1.0 (844bdc53a) desde la imagen oficial de Docker. La fuente de datos es InfluxDb. Creé 2 organizaciones en Grafana, pero en realidad solo uso una. Usuario único "administrador".
 dogada
en 8 may. 2018
dogada
en 8 may. 2018
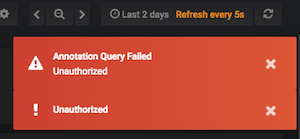
Recién recibí este error una vez más con un nuevo mensaje de error "Error en la consulta de anotación. No autorizado"
dogada
en 8 may. 2018
Mi grafana en win10 x64 funcionó perfectamente bien durante un par de días hasta que recibí una advertencia "No autorizado". El comportamiento es el mismo que el descrito por @dogada y también estoy ejecutando v5.1.0 con influxdb. Tanto grafana como influxdb están en la misma computadora.
 schwarzlowe
en 9 may. 2018
schwarzlowe
en 9 may. 2018
Mismo problema. Una instancia de grafana 5.1 en Docker. Google oauth para autorización.
¿Alguna actualización?
 StupidScience
en 11 may. 2018
StupidScience
en 11 may. 2018
Mismo comportamiento. Actualmente se ejecuta v5.0.3 en la ventana acoplable, autenticación interna, usuario administrador único, proxy a través de nginx, la fuente de datos es influxdb. El tablero se corrige solo cuando se actualizan automáticamente los datos. Suele ocurrir cuando la pestaña está en segundo plano durante mucho tiempo
 radium88
en 15 may. 2018
radium88
en 15 may. 2018
Se observa el mismo problema al tener dos pestañas abiertas en la misma instancia.
 lamoni
en 15 may. 2018
lamoni
en 15 may. 2018
La actualización a la última imagen de la ventana acoplable v5.1.2 (confirmación: c3c690e21) no soluciona el problema
radium88
en 16 may. 2018
Tengo lo que creo que es el mismo problema con Grafana 5.0.0 en Docker usando GitHub OAuth. Lo he visto en paneles con InfluxDB, CloudWatch y una combinación de ambas fuentes de datos. (Una instancia, un puerto, HTTPS, detrás de un ELB).
Al igual que otros en este hilo, parece que lo veo desencadenado por una actualización automática y desaparece después de una recarga de página. A veces veo el mensaje de error básico "No autorizado" (con fallas en la carga de gráficos) y, a veces (más raramente) el mensaje "Error en la consulta de anotación. No autorizado" también.
~ ¿Mi sospecha apunta a algo con los complementos de OAuth? ~ Es casi seguro que se debe al backend de la sesión, ver más abajo.
 bjacobel
en 16 may. 2018
bjacobel
en 16 may. 2018
Para agregar más detalles que encontré después de profundizar un poco más, veo muchos errores como este en mis registros:
t=2018-05-16T16:55:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
El único lugar donde veo un error de este tipo es en esta línea de código, que parece estar relacionada con la administración de sesiones y cookies de sesión.
Estoy almacenando mis sesiones usando el backend file predeterminado, pero a través de un recurso compartido EFS montado, me pregunto si eso es una complicación potencial.
bjacobel
en 16 may. 2018
Enfrenté este problema cuando intenté abrir dos Grafana diferentes (que se ejecutan en un puerto diferente) en el mismo navegador.
Recibo errores no autorizados y, a veces, me desconecto
 harshitha-m
en 23 may. 2018
harshitha-m
en 23 may. 2018
Sería realmente interesante ver qué consultas SQL se ejecutan cuando recibe el mensaje No se pudo obtener el usuario con el registro de
[database]
# Set to true to log the sql calls and execution times.
log_queries = true
Gracias
 marefr
en 30 may. 2018
marefr
en 30 may. 2018
@marefr Parece que estos errores siempre ocurren rodeados de una de estas dos consultas:
SELECT\n\t\tu.id as user_id,\n\t\tu.is_admin as is_grafana_admin,\n\t\tu.email as email,\n\t\tu.login as login,\n\t\tu.name as name,\n\t\tu.help_flags1 as help_flags1,\n\t\tu.last_seen_at as last_seen_at,\n\t\t(SELECT COUNT(*) FROM org_user where org_user.user_id = u.id) as org_count,\n\t\torg.name as org_name,\n\t\torg_user.role as org_role,\n\t\torg.id as org_id\n\t\tFROM `user` as u\n\t\tLEFT OUTER JOIN org_user on org_user.org_id = 1 and org_user.user_id = u.id\n\t\tLEFT OUTER JOIN org on org.id = org_user.org_id WHERE u.id=? []interface
UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
Registros de ejemplo completos:
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] SELECT\n\t\tu.id as user_id,\n\t\tu.is_admin as is_grafana_admin,\n\t\tu.email as email,\n\t\tu.login as login,\n\t\tu.name as name,\n\t\tu.help_flags1 as help_flags1,\n\t\tu.last_seen_at as last_seen_at,\n\t\t(SELECT COUNT(*) FROM org_user where org_user.user_id = u.id) as org_count,\n\t\torg.name as org_name,\n\t\torg_user.role as org_role,\n\t\torg.id as org_id\n\t\tFROM `user` as u\n\t\tLEFT OUTER JOIN org_user on org_user.org_id = 1 and org_user.user_id = u.id\n\t\tLEFT OUTER JOIN org on org.id = org_user.org_id WHERE u.id=? []interface
{}
{2} - took: 54.517418ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 42.957209ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] SELECT\n\t\tu.id as user_id,\n\t\tu.is_admin as is_grafana_admin,\n\t\tu.email as email,\n\t\tu.login as login,\n\t\tu.name as name,\n\t\tu.help_flags1 as help_flags1,\n\t\tu.last_seen_at as last_seen_at,\n\t\t(SELECT COUNT(*) FROM org_user where org_user.user_id = u.id) as org_count,\n\t\torg.name as org_name,\n\t\torg_user.role as org_role,\n\t\torg.id as org_id\n\t\tFROM `user` as u\n\t\tLEFT OUTER JOIN org_user on org_user.org_id = 1 and org_user.user_id = u.id\n\t\tLEFT OUTER JOIN org on org.id = org_user.org_id WHERE u.id=? []interface
{}
{2} - took: 69.013955ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 5.593997ms" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 46.673µs" logger=sqlstore.xorm
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-05-30T15:59:39+0000 lvl=info msg="[SQL] UPDATE `user` SET `last_seen_at` = ? WHERE `id`=? []interface
{}
{\"2018-05-30 15:59:39\", 2} - took: 621.538µs" logger=sqlstore.xorm
Muchas gracias @bjacobel. Todo se ve bien aquí según yo. Se proporciona una identificación de usuario real hasta la consulta de la base de datos. Muy extraño. Empezando a pensar que hay un error con nuestra base de datos de terceros lib xorm.
¿Hizo algo específico para generar esos mensajes de registro?
¿Qué base de datos estás utilizando? ¿Qué almacenamiento de sesión?
Qué solicitud resulta no autorizada, puede habilitar el registro del enrutador para registrar todas las solicitudes:
[server]
router_logging = true
Tenemos el mismo error en 5.1.4 en Kubernetes.
 benkeil
en 21 jun. 2018
benkeil
en 21 jun. 2018
Hola @marefr , lo siento, olvidé responder con el detalle adicional solicitado.
¿Hizo algo específico para generar esos mensajes de registro?
Las consultas se generan cargando un panel y luego esperando una actualización automática. No ocurre en cada actualización automática y, a veces, puede activarse con un clic manual en el botón de actualización del panel (el que está integrado en Grafana, no el botón de actualización del navegador) pero, en general, parece suceder con más frecuencia cuando el usuario está inactivo (dejando grafana en una pestaña de fondo, por ejemplo).
¿Qué base de datos estás utilizando? ¿Qué almacenamiento de sesión?
La base de datos es SQLite en un recurso compartido NFS (EFS) montado, y el almacenamiento de la sesión es el (archivo) predeterminado, aunque también probé el almacenamiento basado en memoria y también tuve el mismo problema. Tenemos un host de Grafana detrás de un equilibrador de carga y habilité la permanencia de la sesión en ese equilibrador de carga.
¿Qué solicitud resulta no autorizada?
No habilité el registro del enrutador, porque puedo ver la solicitud que resulta no autorizada desde el navegador:
[Alguna información confidencial redactada]
Request URL: https://[my grafana hostname]/api/tsdb/query
Request Method: POST
Status Code: 401
Remote Address: [my load balancer IP]:443
Referrer Policy: no-referrer-when-downgrade
:authority: [my grafana hostname]
:method: POST
:path: /api/tsdb/query
:scheme: https
accept: application/json, text/plain, */*
accept-encoding: gzip, deflate, br
accept-language: en-US,en;q=0.9
cache-control: no-cache
content-length: 478
content-type: application/json;charset=UTF-8
cookie: _ga=GA1.2.1782868908.1520436196; __gads=ID=b1c7d78e4fd8b9fb:T=1520436200:S=ALNI_MYT2aRMJqYtHY-CkgaPWmuNtsGEtA; sailthru_hid=919b24e8c99698a8b1829b81eda7135a5956a753dd4c29265f8b45b3a11fb749fc11562ad2abbb1220b9ef37; grafana_sess=[16-char hexadecimal session string]; AWSALB=IUyH6LlTXI/TJlteL8pr838fC7nsvth7s63o5WzqOa6wsCPRpHg20vYurCrYpbIWci27fQtzQpoRxVlIc8Ud/rEPIJvqWvT21an4e9aQmZioTEAFHA3+iWv7bPHs
dnt: 1
origin: https://[my grafana hostname]
pragma: no-cache
referer: https://[my grafana hostname]/d/[dashboard path]?refresh=5m&orgId=1&from=now-1h&to=now
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36
x-grafana-org-id: 1
Hola @marefr , lo siento, olvidé responder con el detalle adicional solicitado. ...
@bjacobel, esto probablemente no esté relacionado con el problema específico, sin embargo, los desarrolladores de SQLite recomiendan no ejecutar SQLite sobre NFS. Específicamente, el proceso de Grafana no debe acceder a la base de datos a través de un montaje NFS, y no se recomienda ejecutar desde cualquier sistema de archivos en red sin un fuerte soporte de bloqueo de archivos.
En una nota al margen, usamos SQLite con el almacenamiento de sesiones como lo hace usted, pero en el sistema de archivos local. No hemos experimentado este mismo problema.
También hemos ajustado la configuración de SQLite en grafana para usar el modo WAL (del cual eventualmente haré un PR) para un mejor rendimiento.
Enviado con GitHawk
 davewat
en 24 jun. 2018
davewat
en 24 jun. 2018
Tengo el mismo problema en mi pila Docker Grafana e InfluxDB.
Grafana v5.1.3 (confirmación: 087143285)
InfluxDB 1.5.3
Grafana está utilizando almacenamiento local a través de volúmenes de docker con base de datos sqlite. Los volúmenes utilizan SSD local.
Recibo el error cada vez que salgo de la pestaña durante más de unos minutos. Si dejo las herramientas de desarrollo en Firefox, veo:
GET http://x.x.x.x:3000/api/datasources/proxy/1/query?db=(Redacted info)
{"message":"Unauthorized"}
Cualquier tipo de actualización borra los errores.
 isclever
en 25 jun. 2018
isclever
en 25 jun. 2018
Me encontré con el mismo problema. Para mí, estaba relacionado con la falta de "session_provider = memcahched"
Puede consultar http://docs.grafana.org/installation/configuration/#provider -config para obtener más opciones de configuración
 nikskiz
en 11 jul. 2018
nikskiz
en 11 jul. 2018
El mismo problema está aquí también. Mi configuración de Docker es:
FROM grafana/grafana:5.1.0
FROM influxdb:1.5.3
 BentCoder
en 13 jul. 2018
BentCoder
en 13 jul. 2018
Cerrando esto ya que parece estar relacionado con la configuración / configuración
torkelo
en 13 jul. 2018
@torkelo ¿Existe una solución obvia a este problema? ¿O una pista para ayudar a determinar cuál podría ser la posible solución?
BentCoder
en 13 jul. 2018
Asegúrese de que la configuración de la sesión funcione para la configuración de HA o de que las sesiones fijas en el equilibrador de carga estén funcionando
torkelo
en 13 jul. 2018
Sin embargo, no uso el equilibrador de carga.
BentCoder
en 17 jul. 2018
Mismo problema aquí sin múltiples réplicas
Acabo de recibir un error 401 en / api / login / ping a veces al azar
 WTFKr0
en 25 jul. 2018
WTFKr0
en 25 jul. 2018
El mismo problema aquí (durante años, antes de los 5.0 días), SQLite en ext4, réplica única en Kubernetes. Última imagen oficial de Docker.
Las solicitudes fallan aleatoriamente cuando Grafana se actualiza automáticamente y, finalmente, todos los widgets dejan de informar de algo. Registros relevantes:
t=2018-07-31T01:38:04+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-07-31T01:38:04+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-07-31T01:38:04+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="User not found"
t=2018-07-31T01:38:04+0000 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=GET path=/api/datasources/proxy/4/query status=401 remote_addr=192.168.1.72 time_ms=28 size=26 referer="REDACTED"
Intentaré depurar un poco, estoy 99% seguro de que se trata de un error de Grafana (o de una de sus bibliotecas).
/ cc @torkelo
 lorenz
en 31 jul. 2018
lorenz
en 31 jul. 2018
Estoy 95% seguro de que falta un reintento en caso de que la tabla SQLite esté bloqueada. Implementaré una solución localmente y PR si funciona.
EDITAR: Elimine eso, eso tomaría una ruta de código diferente.
lorenz
en 31 jul. 2018
Aquí hay un ejemplo de error mío.
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=eror msg="Failed to get user with id" logger=context userId=1 error="User not found"
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=GET path=/api/login/ping status=401 remote_addr=192.168.33.1 time_ms=35 size=26 referer="http://192.168.33.10:3000/d/ZJ65a0Dmz/yowyow?refresh=5s&orgId=1&from=now-30d&to=now"
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
grafana_1 | t=2018-07-31T09:23:06+0100 lvl=info msg="Request Completed" logger=context userId=1 orgId=1 uname=admin method=GET path=/api/login/ping status=401 remote_addr=192.168.33.1 time_ms=24 size=26 referer="http://192.168.33.10:3000/d/ZJ65a0Dmz/yowyow?refresh=5s&orgId=1&from=now-30d&to=now"
Lo dejo correr durante la noche para generar algunos fallos más y estoy seguro de que no es nada con las sesiones. Está en la capa ORM, específicamente en user.go GetSignedInUser() donde esa capa a veces no devuelve una respuesta correcta. Grabé todas las solicitudes en un panel de gráficos de 50 gruesos en 1 minuto durante una noche y vi un patrón muy aleatorio con errores agrupados, todo apunta hacia algún problema de concurrencia / carrera. Actualmente estoy ejecutando un parche que propaga correctamente los errores del lector de filas (el candidato principal para este problema), veré si recibo un mensaje de error diferente.
lorenz
en 31 jul. 2018
Eso fue rápido. Con mi parche de propagación de errores aplicado, encontré la causa raíz:
t=2018-07-31T17:26:46+0000 lvl=eror msg="Failed to get user with id" logger=context userId=2 error="database table is locked"
Los reintentos se implementan incorrectamente en algún lugar del controlador de ejecución de SQLite.
lorenz
en 31 jul. 2018
Lo investigué un poco más y hay varios problemas aquí:
- No se sabe que go-sqlite sea seguro para goroutine (lo que hace que todo esto con una conexión central administrada por xorm sea posiblemente una mala idea).
- SQLite no admite consultas simultáneas en una única "conexión". Necesitaríamos obtener xorm para abrir múltiples conexiones a SQLite. De lo contrario, podríamos encontrarnos con puntos muertos o estos errores de bloqueo, ya que SQLite no intentará resolver los bloqueos si son de la misma conexión.
He visto a personas hacer varias cosas para evitar estos problemas de SQLite, incluido envolver todo el acceso de SQLite en un solo mutex y abrir una nueva instancia de SQLite por solicitud. Lo más fácil de hacer es probablemente piratear go-sqlite3 para que contenga un mutex por "conexión" y simplemente serializar todo el acceso a él (EDITAR: Me acabo de dar cuenta de que esto probablemente no funcionará ya que los bloqueos aparecen cuando se lee desde un cursor, que no se puede bloquear sin correr el riesgo de interbloqueos). Esa es la forma en que lo haría un programa en C (para lo que se hizo SQLite). Puede que sea lento, pero las personas que necesitan el rendimiento deben ir a PostgreSQL de todos modos.
lorenz
en 31 jul. 2018
Muchas gracias, @lorenz , por investigar esto. Su indicación de que esto probablemente sea causado por algo en el nivel sqlite me impulsó a mover la base de datos de configuración de nuestra instancia de SQLite a Postgres (y también a poner nuestras sesiones en Postgres, que anteriormente habían sido respaldadas por archivos). No es una prueba concluyente, pero no he visto los problemas no autorizados desde entonces.
Para otros interesados en probar esta solución alternativa, utilicé pgloader con la configuración predeterminada y no eliminé datos de sesión ni de usuario durante la migración.
bjacobel
en 3 ago. 2018
El problema es definitivamente solo con el backend de SQLite ya que todas las bases de datos "más grandes" tienen MVCC que resuelve este problema. Personalmente, también moví mis instancias de producción a PostgreSQL. El problema sigue siendo si deberíamos resolver esto para el backend de SQLite y cómo hacerlo. No veo una manera fácil de hacerlo, ya que Grafana (debido a que está escrito en Go) hace un uso intensivo de la concurrencia, lo que requiere un cuidado especial en SQLite más allá de lo que Xorm proporciona actualmente.
Ya hay un montón de bloqueos y reintentos en el código que intentan solucionarlo, pero son inadecuados. Desde que solucioné el manejo de errores para el lector de filas (que actualmente se traga silenciosamente los errores de bloqueo y, por lo tanto, crea un comportamiento impredecible, pronto lo corregiré), he visto que los errores de bloqueo aparecen en muchos más lugares que solo los datos proxy de origen, es solo el punto final que se golpea con más frecuencia y, debido a la naturaleza probabilística del error, es el más visible para el usuario. Por lo que puedo ver, todas las soluciones a esto requieren piratear Xorm o go-sqlite3, lo que generalmente no es deseable.
lorenz
en 3 ago. 2018
¡Gracias por el gran análisis @lorenz! ¿Crees que devolver 500 en este caso sería una solución alternativa razonable a corto plazo? Como está ahora, 401 obliga al navegador (al menos Chrome) a olvidar la contraseña y requiere que mis usuarios la vuelvan a escribir. A veces, se debe escribir varias veces hasta que finalmente se acepta la contraseña.
Mi solución actual es ejecutar la base de datos desde tmpfs . Reduce la frecuencia de este problema, pero todavía ocurre de vez en cuando.
 kichik
en 11 ago. 2018
kichik
en 11 ago. 2018
@kichik Cuando haya publicado mi cambio en el manejo de errores, podríamos pensar en devolver HTTP 500 (o 503). Pero la única buena solución que puedo ver es usar una base de datos real compatible con MVCC como PostgreSQL o MySQL, que no presentan el problema en absoluto. Como expliqué en mi comentario anterior, este problema va más allá de las solicitudes de datos, por lo que devolver otro código de error que HTTP 401 solo para esos no solucionará el problema por completo.
lorenz
en 11 ago. 2018
Acabo de hacer un PR de mi informe de errores cambios en # 13007, esto debería ayudar a las personas a ver si están afectadas por el problema de bloqueo o si es algo que no está relacionado.
lorenz
en 22 ago. 2018
@torkelo ¿Podríamos reabrir esto ya que claramente es un problema con Grafana?
lorenz
en 22 ago. 2018
Definitivamente sucede en una sola pestaña (y un solo usuario) para mí.
También usando sqlite3. Curiosamente, no tuve este problema antes. Ahora que agregué algunos paneles pesados (en cuanto a consultas), con frecuencia obtengo este error, generalmente solo para uno de mis paneles pesados.
 Argon-
en 29 ago. 2018
Argon-
en 29 ago. 2018
Confirmar que cambiar a una base de datos que no sea sqlite3 me soluciona el problema. Estaba obteniendo con un solo usuario y una sola pestaña también, con paneles más pesados / ocupados que también se comportaban peor.
Actualización: las sesiones deben cambiarse para almacenarse en la base de datos separada para la corrección completa.
 astral303
en 29 ago. 2018
astral303
en 29 ago. 2018
Estoy usando mysqldb frente al mismo problema. Grafana versión 5.2.3, adherencia habilitada en el nivel Lb, pero el problema sigue ahí.
 vishksaj
en 5 sept. 2018
vishksaj
en 5 sept. 2018
También experimentando esto, usando sqlite como backend de datos pero redis como tienda de sesión en grafana 5.2.3
Aproximadamente 150 organizaciones configuradas. Aparece una advertencia no autorizada en la actualización interna, pero generalmente desaparece en la actualización manual.
Obtener esto en los registros de vez en cuando:
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=1
t=2018-09-22T18:10:17+0000 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=1
 reinhard-brandstaedter
en 12 sept. 2018
reinhard-brandstaedter
en 12 sept. 2018
Este problema puede deberse a la pérdida de la conexión mysql. Cuando bajo el valor max_idle_conn y conn_max_lifetime, esto no volverá a suceder. Espero que esto ayude
 xiaochai
en 11 oct. 2018
xiaochai
en 11 oct. 2018
@vishksaj @xiaochai Este es muy probablemente un problema diferente, ¿podrías abrir uno nuevo?
lorenz
en 11 oct. 2018
https://github.com/oleh-ozimok/grafana/commit/b19e416549553f582dccfbcaa3f4d3f1a742a462 - resuelto mi problema (imagen con revisión docker pull olegozimok/grafana:5.3.2 )
 oleh-ozimok
en 29 oct. 2018
oleh-ozimok
en 29 oct. 2018
Grafana 5.3.2. Configuración HA: 2 instancias de Grafana, base de datos principal MySQL, 2 instancias de memcached para sesiones, grafana dir y DB se almacenan en NFS. Los mismos errores "no autorizados" todo el tiempo, de manera impredecible. Lo mismo sucedió cuando DB era SQLite en NFS.
 dev-e
en 1 nov. 2018
dev-e
en 1 nov. 2018
El mismo problema que @ dev-e pero una configuración más sencilla. Grafana 5.3.2, instancia única, InfluxDB en el mismo host, organización única, usuario único. El mensaje aparece aleatoriamente y desaparece en la siguiente actualización de página.
 luizfzs
en 1 nov. 2018
luizfzs
en 1 nov. 2018
Tengo el mismo problema. Obteniendo errores no autorizados al azar.
La actualización a grafana 5.3.4 lo mejoró un poco, pero aún así hubo muchos errores.
En registros grafana:
t = 2018-11-19T09: 55: 07 + 0200 lvl = eror msg = "No se pudo obtener el usuario con id" logger = context userId = 1 error = "Usuario no encontrado"
t = 2018-11-19T09: 55: 07 + 0200 lvl = eror msg = "No se pudo obtener el usuario con id" logger = context userId = 1 error = "Usuario no encontrado"
t = 2018-11-19T09: 55: 07 + 0200 lvl = eror msg = "No se pudo obtener el usuario con id" logger = context userId = 1 error = "Usuario no encontrado"
Configuración lista para usar:
grafana / ahora 5.3.4 amd64
influxdb / ahora 1.6.0-1 amd64
 gigake
en 19 nov. 2018
gigake
en 19 nov. 2018
El mismo problema aqui:
t=2018-12-03T09:28:21+0000 lvl=eror msg="Failed to update last_seen_at" logger=context userId=12 orgId=1 uname=ht error="database table is locked"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:02:03+0000 lvl=eror msg="Failed to get user with id" logger=context userId=12 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:46:54+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
2018/12/03 10:51:54 http: proxy error: unexpected EOF
2018/12/03 10:51:54 http: proxy error: unexpected EOF
2018/12/03 10:51:54 http: proxy error: unexpected EOF
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:55+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:56+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:51:56+0000 lvl=eror msg="Failed to get user with id" logger=context userId=3 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
t=2018-12-03T10:52:25+0000 lvl=eror msg="Failed to get user with id" logger=context userId=17 error="User not found"
Single Grafana 5.3.4, el almacenamiento es el sistema de archivos Amazon EFS (montaje NFS)
La sesión está configurada en archivo, el almacenamiento de datos es sqlite (/var/lib/grafana/grafana.db)
Grafana se sienta detrás de un LB con terminación HTTPS
 roffe
en 3 dic. 2018
roffe
en 3 dic. 2018
Hizo un PR implementando la sugerencia de @ oleh-ozimok. No dudes en probarlo. Lo intentaré más una vez que vuelva a casa después de las vacaciones para poder tener una instancia de larga duración :)
@ oleh-ozimok Si quieres crear un PR, estoy más que feliz de fusionar eso en lugar del mío para darte el crédito.
¡Por cierto, gran trabajo
 bergquist
en 27 dic. 2018
bergquist
en 27 dic. 2018
Esto también afecta nuestra implementación. Constantemente obtenemos errores 401 no autorizados al usar dos bases de datos MySQL de Amazon Auora que se ejecutan en modo HA / Multi Master. He verificado que las sesiones están en ambas bases de datos. Pero aun así, apunté todas las instancias a la misma base de datos para ver si eso solucionaría el problema y no fue así. Definitivamente hay algún problema con la autenticación correcta de las sesiones. Esto incluso va más allá con nuestra configuración de Oauth. Hay ocasiones en las que el usuario inicia sesión con el proveedor de Oauth configurado y no puede iniciar sesión una vez que se le redirige. Si inician sesión unas 2-3 veces, funciona.
 buroa
en 26 ene. 2019
buroa
en 26 ene. 2019
Eso es muy extraño, ¿tal vez uno de los servidores está configurado de manera diferente?
¿Algún detalle de registro?
Estamos eliminando la necesidad de almacenamiento de sesiones y reescribiendo por completo cómo se administran las sesiones de inicio de sesión en v6, así que con suerte eso lo resolverá.
torkelo
en 27 ene. 2019
@buroa ¿Alguna posibilidad de que puedas probar 6.0-beta1? Hemos reescrito el token de autenticación y eliminado la mayor parte del uso del token de sesión (que todavía se usa cuando se usa auth_proxy) por completo y esperamos que la mayoría de estos problemas desaparezcan.
bergquist
en 5 feb. 2019
@bergquist actualizó mi configuración en 2019-02-01T09: 58: 20 + 0200, no sucedió este error por ahora.
 zcooler
en 5 feb. 2019
zcooler
en 5 feb. 2019
@buroa ¿Alguna posibilidad de que puedas probar 6.0-beta1? Hemos reescrito el token de autenticación y eliminado la mayor parte del uso del token de sesión (que todavía se usa cuando se usa auth_proxy) por completo y esperamos que la mayoría de estos problemas desaparezcan.
Estoy usando la última versión: https://github.com/buroa/grafana/tree/us-iso-regions
¿Tiene esto el cambio necesario?
buroa
en 5 feb. 2019
@buroa sí, pero aún así le sugiero que se fusione en el último master ya que hemos realizado algunos cambios desde 6.0-beta1.
marefr
en 5 feb. 2019
Hoy tengo un error
t = 2019-02-08T10: 05: 58 + 0200 lvl = info msg = "no se pudo buscar al usuario basado en la cookie" logger = error de contexto = "No se encontró el token de autenticación del usuario"
La pestaña del navegador no se cerraba, solo se actualizaba automáticamente cada hora, pero la PC estaba bloqueada.
 QuantumProjects
en 8 feb. 2019
QuantumProjects
en 8 feb. 2019
@QuantumProjects, ¿le importaría abrir un nuevo número ya que tiene un problema con Grafana v6.0-pre? Proporcione más detalles sobre la configuración de Grafana: ¿qué base de datos está en uso? ¿Versión de Grafana? ¿Varias instancias de Grafana? ¿Qué tipo de autenticación? ¿Proxy inverso? Gracias
marefr
en 8 feb. 2019
@marefr Ok
QuantumProjects
en 8 feb. 2019
@marefr estoy recibiendo los mismos pop-ups "no autorizados", tal vez mi configuración pueda ayudar a resolver el problema:
- Servidor de puerta de enlace con traefik como proxy inverso apuntando a un servidor local que aloja grafana
- servidor local con Grafana v5.4.3
- datasource es un influxdb v1.7.8 en el mismo servidor local
- ¿Cómo averiguar el tipo de autenticación cuestionado? Acabo de iniciar sesión como usuario administrador
Nota: cada servicio es un contenedor docker, traefik x64, grafana y influxdb arm32v7
 eiabea
en 19 feb. 2019
eiabea
en 19 feb. 2019
Esto también sucede en Grafana 6.0.0 (confirmación: 34a9a62, rama: HEAD). La base de datos SQLite no se usa, Grafana está trabajando detrás del proxy inverso nginx. La autenticación LDAP está configurada. Se está ejecutando una sola instancia de Grafana en esta VM.
Entrada de registro en el momento del error:
t=2019-03-06T13:39:24+0100 lvl=eror msg="failed to look up user based on cookie" logger=context error="database is locked"
 angryp
en 6 mar. 2019
angryp
en 6 mar. 2019
Solo agregando un punto de datos, una vez que moví mi base de datos de sqlite a postgres, dejé de ver estos errores. Anteriormente, habían sido lo suficientemente frecuentes como para hacer que el uso del sistema fuera bastante incómodo. Ejecución de un único servidor 5.4.3 con google oauth.
 qhartman
en 6 mar. 2019
qhartman
en 6 mar. 2019
Me sucedió en 5.4.3 conectado a postgres, de forma bastante aleatoria, pero solo cuando dejo que se actualice automáticamente. La instalación está en una red local donde la base de datos está en la misma caja que Grafana.
Recibo un montón de estos tipos de errores en syslog en el momento en que aparece el mensaje "No autorizado":
...
...
grafana-server[12619]: t=2019-03-06T22:42:02+0100 lvl=info msg="Database table locked, sleeping then retrying" logger=sqlstore retry=0
grafana-server[12619]: t=2019-03-06T22:42:03+0100 lvl=eror msg="Failed to get user with id" logger=context userId=1 error="User not found"
...
grafana-server[12619]: t=2019-03-06T22:42:03+0100 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=POST path=/api/tsdb/query status=401 remote_addr=192.168.0.2 time_ms=17 size=26 referer="http://192.168.0.1:3000/d/.....
...
Hay algunas variaciones en el registro en userId = 1 o 0 y en reintentar = 1 o 0
 ggggh
en 6 mar. 2019
ggggh
en 6 mar. 2019
Hola,
Hoy tuve el mismo problema. Tenemos Grafana 6.0.1 en un Debian Stretch simple actualizado unos días antes. Grafana se conecta a un balanceador de carga (proxysql) con MariaDB 10.2 (clúster de Galera) como backend (modo de sincronización con tres nodos).
Usamos LDAP (Windows AD) como autorización.
Mensaje de registro:
lvl=eror msg="failed to look up user based on cookie" logger=context error="invalid connection"
Lo único que funcionó fue usar la IP directa y no el balanceador de carga.
 linuxmail
en 14 mar. 2019
linuxmail
en 14 mar. 2019
Lo único que funcionó fue usar la IP directa y no el balanceador de carga.
Sin embargo, no suena como el mismo problema, ya que el nuestro es intermitente; tal vez uno de los paneles de cada docena de actualizaciones puede fallar con el error, pero generalmente funciona
ggggh
en 14 mar. 2019
Me pasa lo mismo en 6.0.2.
Del registro:
t=2019-03-23T12:04:22+0000 lvl=eror msg="failed to look up user based on cookie" logger=context error="database is locked"
y
t=2019-03-23T19:05:45+0000 lvl=eror msg="Failed to update last_seen_at" logger=context userId=1 orgId=1 uname=<username> error="database is locked"
Instalación de Docker regular con Traefik para proxy inverso.
 menteb
en 23 mar. 2019
menteb
en 23 mar. 2019
A mi me esta pasando lo mismo
versión 6.02
"no se pudo buscar al usuario según la cookie" logger = error de contexto = "la base de datos está bloqueada"
 tiagoalmeida10
en 28 mar. 2019
tiagoalmeida10
en 28 mar. 2019
Si su "base de datos está bloqueada" con Sqlite (predeterminado) probablemente sea un buen momento para migrar a mysql / postgres, ya que pueden manejar más transacciones / s
bergquist
en 3 abr. 2019
@bergquist Creo que esa es la solución. Acabo de migrar a MariaDB y ya no me echan de Grafana. ¡Virar!
menteb
en 4 abr. 2019
@bergquist Creo que esa es la solución. Acabo de migrar a MariaDB y ya no me echan de Grafana. ¡Virar!
Para aclarar, esa podría ser una solución para "La base de datos está bloqueada", no "Tabla de base de datos bloqueada". Estoy en PostgreSQL y estoy enfrentando el "bloqueo de la tabla".
ggggh
en 4 abr. 2019
Resuelto para mí después de una actualización de Raspbian que me llevó a Postgres 9.6 (desde 9.4). Grafana sigue en 5.4.3
ggggh
en 25 abr. 2019
Resuelto para mí después de una actualización de Raspbian que me llevó a Postgres 9.6 (desde 9.4). Grafana sigue en 5.4.3
Olvida lo que dije ... está de vuelta. Con menos frecuencia, diría yo ... pero sigue sucediendo.
ggggh
en 10 may. 2019
@ggggh ¿ alguna solución? ¡Simplemente comenzó a suceder de la nada para mí!
 devanshkv
en 22 may. 2019
devanshkv
en 22 may. 2019
@ggggh ¿ alguna solución? ¡Simplemente comenzó a suceder de la nada para mí!
Nada...! Se borró con la actualización de la versión de Postgres y parece que volverá, más a menudo cada día.
ggggh
en 22 may. 2019
@ggggh ¡Gracias!
Me cambié a Postgres, pero eso tampoco ayuda :(
devanshkv
en 22 may. 2019
tengo los mismos problemas al usar Grafana 6.2.1 y Postgress 11, pero esto sucede solo en dashbaords que cargo desde JSON y luego intento acceder a ellos.
¿Alguna actualización sobre esto?
 botzill
en 29 may. 2019
botzill
en 29 may. 2019
OK, encontré el problema en mi caso. Mi PG tenía un número limitado de conexiones y en grafana no se configuró max_open_conn . Después de configurar esta opción, funciona bien.
botzill
en 3 jun. 2019
Lo mismo me está sucediendo en Grafana 6.1.6 y SQLite DB empaquetado. Este problema rompe nuestros esfuerzos de desarrollo interno para personalizar Grafana. Cambiar max_open_conn no funciona (aunque no esperaba que lo hiciera ya que era una solución para Postgres).
 syardumian-chc
en 10 jun. 2019
syardumian-chc
en 10 jun. 2019
La causa principal de esto parece ser que Grafana intenta conectarse al
DB subyacente al autenticarse, pero no lo hace. Con SQLite, eso
sucederá a menudo y con un recuento bajo de uso concurrente ya que SQLite bloquea
tan agresivamente. En la mayoría de los casos, migrar a un RDBMS real (me gusta postgres)
resolverá el problema. Es posible que vuelva a aparecer si te encuentras con un
problema de límite de conexión (o similar), pero eso es una preocupación de DB más que una
Preocupación de Grafana. Si está utilizando Grafana para cualquier otra cosa que no sea una demostración,
deberías respaldarlo con una base de datos real. Si ese DB está configurado correctamente para
su uso, eso debería resolver este problema.
El lunes, 10 de junio de 2019 a las 11:20 a. M. Syardumian-chc [email protected]
escribió:
Lo mismo me está sucediendo en Grafana 6.1.6 y SQLite DB empaquetado. Esta
El problema interrumpe nuestros esfuerzos de desarrollo interno para personalizar Grafana. Cambiando
max_open_conn no funciona (aunque no esperaba que lo hiciera ya que era un
corrección para Postgres).-
Estás recibiendo esto porque estás suscrito a este hilo.
Responda a este correo electrónico directamente, véalo en GitHub
https://github.com/grafana/grafana/issues/10727?email_source=notifications&email_token=AAAK6YSUDLXPF2E4436CEOTPZ2EMFA5CNFSM4EO23EH2YY3PNVWWK3TUL52HS4DFVREXG43VMVODBXHWL2DFVREXG43VMVODBXHPWL2UZMXG43VMVODXHPWLNMX
o silenciar el hilo
https://github.com/notifications/unsubscribe-auth/AAAK6YQLR3FSCNEQR7SNEKLPZ2EMFANCNFSM4EO23EHQ
.
qhartman
en 10 jun. 2019
Aumenté el límite de conexión y el número máximo de conexiones inactivas, pero sigo abordando este problema de forma aleatoria. No solo eso, sino que los cuadros de mando que han estado abiertos durante un tiempo parecen volverse cada vez más lentos para actualizar, con el gif de carga evidente en cada panel y desapareciendo lentamente secuencialmente a medida que cada panel completa la carga. Está bien si cierro la ventana del navegador y abro una nueva. Supongo que mi panel de control se ha vuelto más complejo, pero eso no explica por qué una nueva carga de la página "lo arregla".
ggggh
en 12 jun. 2019
También recibo un error aleatorio. Realmente no sé cuál es el problema. El uso de la dirección IP parece estar bien, pero con el ingreso de kubeneters, muestra la "consulta de anotación fallida" al azar.
 naturalbeau
en 13 jun. 2019
naturalbeau
en 13 jun. 2019
FWIW, recientemente cambié mi balanceador de carga de entrada a Fabio (de Traefik) y actualicé Grafana (imagen de Docker, sin backends de base de datos adicionales) a v6.4.2, y los errores 401 no autorizados parecen haber desaparecido al realizar la actualización automática (intervalo establecido en 10 segundos, corriendo todo el día). Es poco probable que cambiar a Fabio solucionara el problema, supongo que fue la versión más nueva de Grafana la que ayudó, pero no estoy 100% seguro.
 kmott
en 9 oct. 2019
kmott
en 9 oct. 2019
Cerrando esto porque no hay nuevos informes recientemente. Si cree que todavía hay un problema, abra un nuevo problema.
torkelo
en 19 oct. 2019
Recientemente instalé grafana en mi clúster de kubernetes y encontré un problema similar.
Estoy usando la imagen de docker grafana / grafana: 6.4.3
Revisando mis registros de pod, encontré este pequeño dato interesante:
t=2019-11-01T15:18:33+0000 lvl=info msg="Successful Login" logger=http.server User=--snip--
t=2019-11-01T15:19:09+0000 lvl=eror msg="Failed to look up user based on cookie" logger=context error="dial tcp: lookup postgres.databases.svc.cluster.local: no such host"
t=2019-11-01T15:19:09+0000 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=GET path=/api/datasources/proxy/1/query status=401 remote_addr=--snip-- time_ms=11 size=26 referer="https://--snip--/d/TuobtjoZz/--snip--?orgId=1&refresh=5s&from=now-12h&to=now"
Los problemas de DNS no son algo que haya encontrado antes en mi clúster, pero busqué en Google y encontré este problema en particular: https://github.com/kubernetes/kubernetes/issues/30215
¿Sería posible que grafana envíe imágenes alpinas y no alpinas como lo hacen muchas imágenes de docker? Parece que eso resolvería el problema.
Si hay algo que pueda hacer para probar esto o ayudar a depurar, avíseme, proporcionaré la información solicitada.
 ikkerens
en 1 nov. 2019
ikkerens
en 1 nov. 2019
Después de degradar a 6.3.6 (que no está basado en alpine), el problema desapareció por completo de mi parte.
ikkerens
en 2 nov. 2019
Enfrenté el mismo problema, dos Grafana (contenedores) separados se abren en el mismo navegador
cuando inicie sesión en el segundo, el primero me pide que vuelva a iniciar sesión, inicie sesión en el primero, el segundo me pide que vuelva a iniciar sesión
no puedo mantener ambos inicios de sesión
la solución que encontré es cambiar en uno de los archivos Grafana default.ini
login_cookie_name = grafana_session
para
login_cookie_name = grafana_session_1
reinicia el contenedor y el navegador, ahora funciona bien
por ahora mantengo el archivo fuera del contenedor
Necesito establecer este parámetro al crear el contenedor.
 n0-bs
en 20 feb. 2020
n0-bs
en 20 feb. 2020
@ikkerens por favor intente la imagen basada en ubuntu luego, 6.6.2-ununtu
marefr
en 28 feb. 2020
@ n0-bs Lo siento, pero si está ejecutando varias instancias de Grafana, se sugiere usar MySQL o Postgres como base de datos.
marefr
en 28 feb. 2020
Lo siento, pero cómo, el uso de MySQL o Postgres como base de datos, resolverá el conflicto de cookies cuando abro estas dos instancias de Grafana diferentes en el mismo navegador, no estoy hablando del caso HA
Tengo dos instancias (contenedores) de Grafana diferentes en el mismo servidor
n0-bs
en 1 mar. 2020
Sigo viendo esto con 6.7.2. Actualicé de 6.5 a 6.6, luego 6.7. Usando Docker con PostgreSQL, probé la imagen 6.7.2 y luego 6.7.2-ubuntu.
Este es el error que recibo en los registros:
lvl=eror msg="Failed to look up user based on cookie" logger=context error="pq: remaining connection slots are reserved for non-replication superuser connections"
 helderco
en 16 abr. 2020
helderco
en 16 abr. 2020
Se corrigió (al menos por ahora) reiniciando postgres.
helderco
en 16 abr. 2020
Estoy usando la última versión de Grafana y sigo viendo el problema no autorizado cada vez que accedo a él. Estoy usando Grafana en kubernetes. Lo implementé en 3 pod diferentes en 3 nodos diferentes. Estoy usando la base de datos nativa. ¿Alguna sugerencia para solucionar el problema?
 emzfuu
en 1 jun. 2020
emzfuu
en 1 jun. 2020
@emzfuu Si ejecuta varias instancias, debe apuntar todas a la misma base de datos. mysql / postgres
bergquist
en 1 jun. 2020
@bergquist, ¿hay alguna otra forma de solucionar el problema?
emzfuu
en 2 jun. 2020
Solo para elaborar mi pregunta anterior, estoy usando 3 Grafana diferentes (independientes) a los que se accede a través de un solo equilibrador de carga. Los 3 Grafana tienen su propia base de datos (sqlite3). Cada vez que accedo a él, recibo el error de desautorización.
emzfuu
en 3 jun. 2020
Tengo el mismo problema, uso nfs.
 linux0x5c
en 8 jun. 2020
linux0x5c
en 8 jun. 2020
Temas relacionados
 Minims
·
3Comentarios
Minims
·
3Comentarios
 sslupsky
·
3Comentarios
sslupsky
·
3Comentarios
 victorhooi
·
3Comentarios
victorhooi
·
3Comentarios
 tuxinaut
·
3Comentarios
tuxinaut
·
3Comentarios
 ADeane6
·
3Comentarios
ADeane6
·
3Comentarios
Comentario más útil
Veo el mismo problema en Grafana v4.6.2 (commit: 8db5f08), todo funciona como se esperaba y, de repente, recibo una advertencia no autorizada (y algunos gráficos están vacíos, pero algunos aparecen normalmente).
Utilizo Prometheus como fuente de datos.
También creo que esto sucede principalmente cuando el tablero se actualiza automáticamente, pero se corrige solo cuando lo actualizo manualmente.