问题
在 PR #1410 上调试间歇性测试失败时, @christopherbunn和我在 circleci 上测量了单元测试的内存使用情况,发现完整的端到端运行在峰值时最多可以使用 20GB。
这比我预期的要多得多……问题是,为什么?
观察
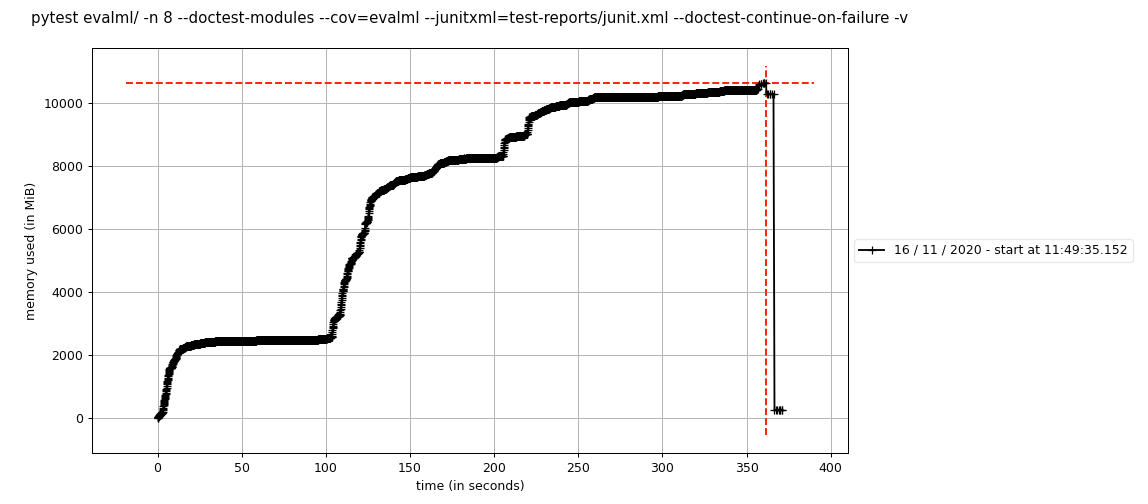
我们通过 ssh 进入一个在main上运行的 circleci 框,并使用memory-profiler运行以下内容:
mprof run --include-children pytest evalml/ -n 8 --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
它创建了以下图,用mprof plot可见:

我运行了两次并得到了一个类似的图,所以结果在运行中似乎是一致的。
这非常接近我们使用的 circleci worker 大小所允许的最大内存。 这就是我们开始研究这个问题的原因——在#1410 上,我们看到内存使用量由于某种原因增加了 5GB。
 dsherry
dsherry
所有11条评论
仅使用一名工作人员在本地运行此程序,看起来测试仅使用 2GB 内存,而当我使用 8 名工作人员时则为 10GB。 所以看起来这可能是 circle-ci 和 multiprocessing 的组合?
mprof run --include-children pytest evalml/ --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
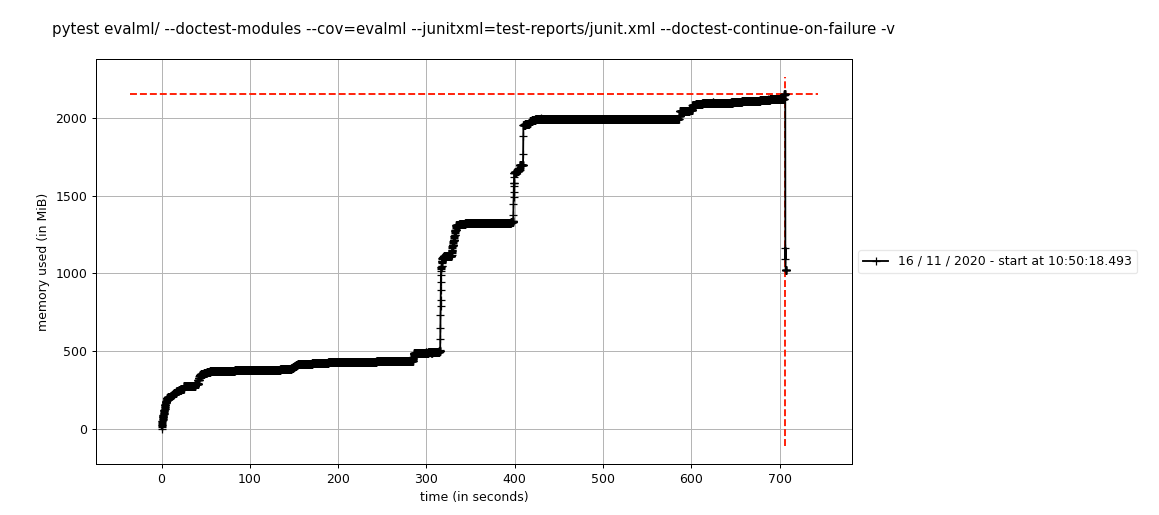
mprof run --include-children pytest evalml/ -n 8 --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
 freddyaboulton
于 2020-11-16
freddyaboulton
于 2020-11-16
与@rpeck @angela97lin @freddyaboulton @christopherbunn @ParthivNaresh 的站立讨论
假设
我们的测试夹具保留了不应该存在的东西,这导致了大部分问题。 但是,automl 本身也可能存在一些泄漏。
下一步
- 追踪哪些测试导致最大的内存增加
- 选择其中一个测试,使用堆跟踪运行它 20 倍(使用
tracemalloc?),看看泄漏在哪里 - 目标:是在 automl 中还是在 pytest/测试工具中泄漏?
dsherry
于 2020-11-16
@rpeck @dsherry @christopherbunn和我对此进行了调查,以下是我们目前所知的摘要:
我们在
memory-profile图中看到的许多峰值来自进口,而不是单元测试。 例如,导入AutoMLSearch约为 120 MB。 当我们在 pytest 命令中设置-n 8时,导入的内存占用乘以 8,因为每个子进程都必须导入所有内容。话虽如此,有些单元测试的内存占用很大。 例如, automl 测试
test_max_batches_works,运行 20 个带集成的批次。 即使我们模拟了拟合和评分,内存分析器显示所有对_automl_algorithm.add_result(....)的调用都占用了 27 mb 的内存! 我们应该通过我们的测试,看看他们使用了多少内存,看看是否有办法在不影响测试质量的情况下减少它。我们仍然不确定是否存在内存泄漏。 运行一个简单的程序,该程序创建一个大列表,然后通过内存分析器将其删除,显示内存单调增加,看起来像一个步进函数。 因此,我们不能相信 automl 期间内存的单调增加,如 memory-profiler 报告的那样,表明存在泄漏。 如果有的话,我认为这只是意味着我们应该使用
tracemalloc来查看在同一程序的后续运行中如何分配/释放内存。
目前,我们正在查看是否将 pytest 中的并行度从 circle-ci 中的 8 降低到 4,或者使用专用的工作器,是否会解除阻塞 #1410。
我们将保持这个问题开放。 我认为还有很多工作要做,以了解为什么该分支中的更改使我们的记忆问题变得如此严重,以及看看我们是否可以在测试中更加注意记忆。
随意添加任何我错过的东西!
freddyaboulton
于 2020-11-18
是的! 有一点我想补充的是,在我们的分析中,我们忘记了垃圾收集😆一个事实,即蟒蛇声称内存是单调递增的不一定是问题,因为一堆记忆的报告mprof可能是尚未被垃圾收集释放的状态。
@rpeck一直在研究在每次单元测试之前和之后测量内存的变化。 这将告诉我们哪些测试的增幅最大,这意味着我们可以专注于分析这些测试并查看最大的分配来自哪里。 我希望我们可以继续这项工作。
一个相关的想法:为 pytest 编写一个 postfixture,它在每次测试后运行并调用gc.collect()来强制垃圾收集。 如果我们注意到测试运行期间内存稳步增加,这将是泄漏的证据; 如果我们看到内存在平均运行中保持不变,则表明没有泄漏。
dsherry
于 2020-11-19
我很想知道高内存使用率是否是添加 Woodwork 和使用 DataTables 的结果。 也许应该跟踪单元测试版本到版本的内存使用情况?
 gsheni
于 2020-11-19
gsheni
于 2020-11-19
@gsheni那是个好主意! 至少对于自动测试,我认为不仅仅是木制品。 当我分析搜索时,木工转换只用了大约 0.5MB,而我们看到一些单元测试使用了大约 80MB。 一些管道/组件可能会在 ww 和 pandas 之间进行不必要的转换,所以我认为我们肯定需要进一步挖掘。
我们注意到的一件事是导入woodwork需要~60MB,主要是因为 sklearn 和 pandas。 不知道可以对此做些什么,但想引起您的注意。 很高兴在 ww repo 中归档一些东西!
Line # Mem usage Increment Occurences Line Contents
============================================================
3 37.8 MiB 37.8 MiB 1 <strong i="9">@profile</strong>
4 def ww_imports():
5 47.3 MiB 9.5 MiB 1 import numpy
6 65.8 MiB 18.5 MiB 1 import pandas
7 66.4 MiB 0.6 MiB 1 import click
8 93.2 MiB 26.8 MiB 1 import sklearn
9 96.3 MiB 3.2 MiB 1 import pyarrow
@freddyaboulton也许ww正在导入这些库中不必要的更多部分?
如果有一个工具可以通过找到实际使用的库的所有部分的传递闭包来优化导入,那就太好了……
 rpeck
于 2020-11-20
rpeck
于 2020-11-20
@freddyaboulton也许
ww正在导入这些库中不必要的更多部分?如果有一个工具可以通过找到实际使用的库的所有部分的传递闭包来优化导入,那就太好了……
这是 Woodwork 中唯一的 sklearn 导入: from sklearn.metrics.cluster import normalized_mutual_info_score 。 不确定我们是否可以做任何事情来缩小规模。
至于pandas,我们通常会导入整个库,但这是Woodwork 代码的一大块,我不确定我们是否可以轻松地将其缩小,但如果需要,可以对其进行更多研究。
 thehomebrewnerd
于 2020-11-20
thehomebrewnerd
于 2020-11-20
感谢@thehomebrewnerd的解释! 是的,所以看起来导入子模块会自动导入父模块。 我们的大量导入使我们的记忆问题变得更糟,但它们绝对是我们需要在 evalml 方面研究的行动项目的图腾柱的底部。
我认为 ww 还不需要采取任何行动 - 我只是想引起您的注意! 话虽如此,仅仅为了相互信息而引入所有 sklearn 似乎过分了。 也许我们可以使用替代 impl 或将导入推迟到运行时,但我们现在当然不需要这样做!
freddyaboulton
于 2020-11-20
@thehomebrewnerd @freddyaboulton我们可以为 sklearn 导入进行内联导入(因此它仅在您调用互信息函数时运行)。
我已经在其他图书馆的一些图书馆中看到我们明确地这样做了。 我们通常这样做是为了避免循环导入。 这样做只是为了节省内存会感觉很奇怪......
gsheni
于 2020-11-20
我们注意到,通过为 automl 使用的所有估算器手动设置n_jobs=1 (下图),我们可以仅从 automl 测试中减少 1.5gb(几乎一半!)。 我们验证了n_jobs的值仅在少数不模拟fit和score automl 测试中是一个因素。 基于此,我们提出了目前的计划:
- 对于每个接受 n_jobs 作为参数的组件(即基于 sklearn 的估计器),确保我们有一个单元测试来设置
n_jobs=-1,以验证该组件是否正常工作。 - 对于不模拟底层
fit所有其他单元测试,为所有组件设置n_jobs=1以避免内存和线程问题 - 确保在镜子中我们使用
n_jobs=-1,我相信我们目前正在运行,因为相关估计器的n_jobs的默认值为 -1
希望一旦完成,我们将在单元测试的整体内存占用方面看到一些不错的改进!


freddyaboulton
于 2020-11-24
相关问题
freddyaboulton
·
3评论
 bchen1116
·
4评论
dsherry
·
4评论
bchen1116
·
4评论
dsherry
·
3评论
bchen1116
·
4评论
dsherry
·
4评论
bchen1116
·
4评论
dsherry
·
3评论