Evalml: Las pruebas unitarias utilizan hasta 20 GB de memoria en circleci
Problema
Al depurar fallas de prueba intermitentes en PR # 1410, @christopherbunn y yo medimos el uso de memoria de las pruebas unitarias en circleci y descubrimos que una ejecución completa de extremo a extremo puede usar hasta 20 GB en el pico.
Eso es mucho más de lo que hubiera esperado ... la pregunta es, ¿por qué?
Observaciones
Entramos en un cuadro circular que se ejecuta en main y ejecutamos lo siguiente usando memory-profiler :
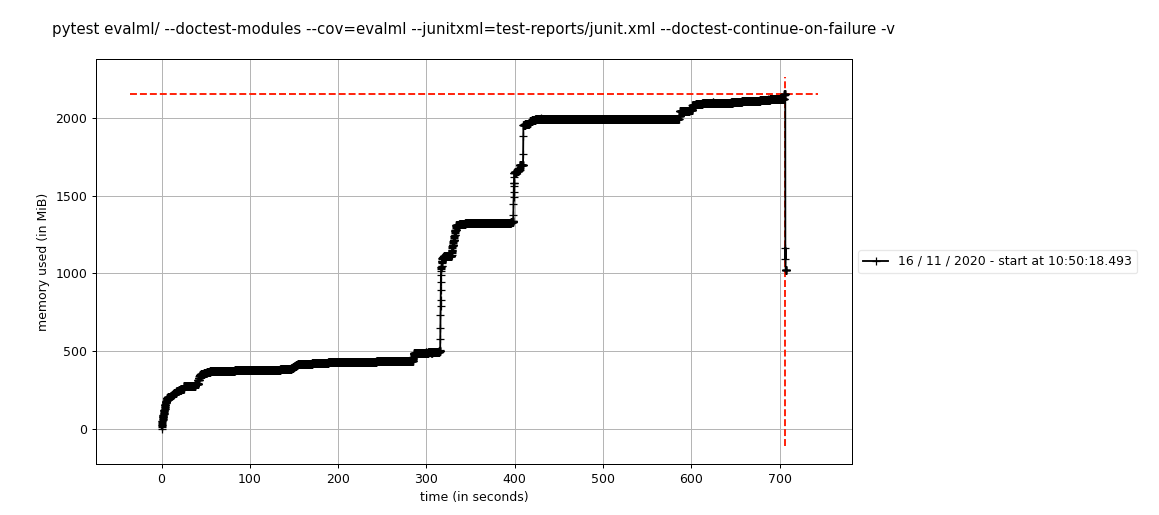
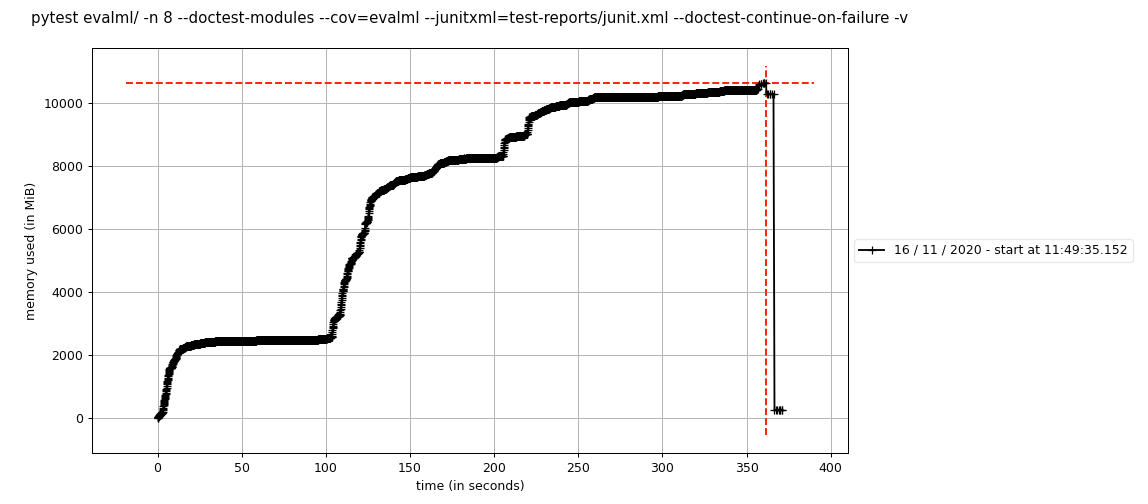
mprof run --include-children pytest evalml/ -n 8 --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
Que creó la siguiente gráfica, visible con mprof plot :

Ejecuté esto dos veces y obtuve un gráfico similar, por lo que los resultados parecen ser consistentes en todas las ejecuciones.
Esto está peligrosamente cerca de la memoria máxima permitida en el tamaño de trabajador de circleci que estamos usando. Es por eso que comenzamos a investigar esto: en el n. ° 1410, vimos que el uso de memoria aumentó 5 GB por alguna razón.
 dsherry
dsherry
Todos 11 comentarios
Ejecuté esto localmente con un solo trabajador y parece que las pruebas solo usan 2 GB de memoria en comparación con 10 GB cuando uso 8 trabajadores. Entonces, ¿parece que esto podría ser una combinación de circle-ci y multiprocesamiento?
mprof run --include-children pytest evalml/ --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
mprof run --include-children pytest evalml/ -n 8 --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
 freddyaboulton
en 16 nov. 2020
freddyaboulton
en 16 nov. 2020
Discusión desde standup con @ angela97lin @freddyaboulton @christopherbunn @ParthivNaresh
Hipótesis
Nuestro dispositivo de prueba se está aferrando a cosas que no debería ser, y eso está causando la mayor parte del problema. Pero también, es posible que haya algunas filtraciones en automl.
Próximos pasos
- Rastree qué pruebas están causando el mayor aumento de memoria
- Elija una de esas pruebas, ejecútela 20 veces con seguimiento de pila ( use
tracemalloc?), Vea dónde está la fuga - Objetivo: ¿la fuga está en automl o en pytest / test arnés?
dsherry
en 16 nov. 2020
@rpeck @dsherry @christopherbunn y he
Muchos de los picos que vemos en los gráficos
memory-profileprovienen de las importaciones en lugar de las pruebas unitarias. ImportarAutoMLSearches ~ 120 MB, por ejemplo. Cuando configuramos-n 8en el comando pytest, la huella de memoria de las importaciones se multiplica por 8, ya que cada subproceso debe tener todo importado.Dicho esto, hay algunas pruebas unitarias que tienen una gran huella de memoria. Por ejemplo, la prueba automática
test_max_batches_works, ejecuta 20 lotes con ensamblaje. Aunque simulamos el ajuste y la puntuación, el generador de perfiles de memoria muestra que todas las llamadas a_automl_algorithm.add_result(....)ascienden a 27 MB de memoria. Deberíamos pasar por nuestras pruebas para ver cuánta memoria usan y ver si hay formas de reducirla sin comprometer la calidad de la prueba.Todavía no estamos seguros de si hay una pérdida de memoria o no. Ejecutar un programa simple que crea una lista grande y luego la borra a través de memory-profiler muestra un aumento monótono en la memoria que parece una función escalonada. Por lo tanto, no podemos confiar en que un aumento monótono de la memoria durante el automl, según lo informado por el generador de perfiles de memoria, sea indicativo de una fuga. En todo caso, creo que esto solo significa que deberíamos usar
tracemallocpara ver cómo se asigna / desasigna la memoria en ejecuciones posteriores del mismo programa.
Por el momento, estamos viendo si disminuir el paralelismo en pytest de 8 a 4 en circle-ci, o usar trabajadores dedicados, desbloqueará # 1410.
Mantendremos este problema abierto. Creo que todavía queda mucho por hacer para entender por qué los cambios en esa rama empeoran nuestros problemas de memoria y ver si podemos ser más conscientes de la memoria en nuestras pruebas.
¡Siéntete libre de agregar cualquier cosa que me haya perdido!
freddyaboulton
en 18 nov. 2020
¡Sí! Una cosa que agregaría es que en nuestros análisis, nos olvidamos de la recolección de basura 😆 el hecho de que la memoria reclamada por python aumente de manera monótona no es necesariamente un problema, porque una gran parte de la memoria informada por mprof podría ser un estado que aún no ha sido desasignado por la recolección de basura.
@rpeck había estado buscando medir el cambio en la memoria antes y después de cada prueba unitaria. Esto nos diría qué pruebas tuvieron el mayor aumento, lo que significa que podemos centrarnos en perfilar esas pruebas y ver de dónde provienen las mayores asignaciones. Espero que podamos continuar con ese trabajo.
Una idea relacionada: escriba un accesorio de publicación para pytest que se ejecute después de cada prueba y llame a gc.collect() para forzar la recolección de basura. Si notamos un aumento constante en la memoria a lo largo de las ejecuciones de prueba, eso sería evidencia de una fuga; si viéramos que la memoria era constante en las ejecuciones en promedio, eso indicaría que no hay fugas.
dsherry
en 19 nov. 2020
Tendría curiosidad por saber si el alto uso de memoria es el resultado de agregar Woodwork y usar DataTables. ¿Quizás debería rastrear el uso de memoria de las pruebas unitarias de versión a versión?
 gsheni
en 19 nov. 2020
gsheni
en 19 nov. 2020
@gsheni ¡ Eso sería una buena idea! Al menos para las pruebas automáticas, creo que hay más en juego que solo carpintería. Cuando realicé el perfil de la búsqueda, la conversión de carpintería solo usó ~ 0.5 MB, mientras que veíamos que algunas pruebas unitarias usan ~ 80 MB. Es posible que algunos de los pipelines / componentes estén haciendo conversiones innecesarias entre ww y pandas, así que creo que definitivamente debemos investigar más.
Una cosa que notamos es que la importación de woodwork requiere ~ 60 MB principalmente debido a sklearn y pandas. No estoy seguro de qué se podría hacer al respecto, pero quería llamar su atención sobre esto. ¡Feliz de archivar algo en el repositorio de ww!
Line # Mem usage Increment Occurences Line Contents
============================================================
3 37.8 MiB 37.8 MiB 1 <strong i="9">@profile</strong>
4 def ww_imports():
5 47.3 MiB 9.5 MiB 1 import numpy
6 65.8 MiB 18.5 MiB 1 import pandas
7 66.4 MiB 0.6 MiB 1 import click
8 93.2 MiB 26.8 MiB 1 import sklearn
9 96.3 MiB 3.2 MiB 1 import pyarrow
@freddyaboulton ¿ Quizás ww está importando porciones más grandes de estas bibliotecas de lo necesario?
Sería genial tener una herramienta que optimizara las importaciones encontrando el cierre transitivo de todas las piezas de la biblioteca que realmente se utilizan ...
 rpeck
en 20 nov. 2020
rpeck
en 20 nov. 2020
@freddyaboulton ¿ Quizás
wwestá importando porciones más grandes de estas bibliotecas de lo necesario?Sería genial tener una herramienta que optimizara las importaciones encontrando el cierre transitivo de todas las piezas de la biblioteca que realmente se utilizan ...
Esta es la única importación de sklearn en Woodwork: from sklearn.metrics.cluster import normalized_mutual_info_score . No estoy seguro de si hay algo que podamos hacer para reducir eso.
En cuanto a los pandas, normalmente estamos importando toda la biblioteca, pero esa es una parte tan grande del código de Woodwork, no estoy seguro de que podamos escalarlo fácilmente, pero podemos investigarlo más si es necesario.
 thehomebrewnerd
en 20 nov. 2020
thehomebrewnerd
en 20 nov. 2020
¡Gracias por la explicación @thehomebrewnerd ! Sí, parece que la importación de un submódulo importará el módulo principal automáticamente . Nuestras grandes importaciones están empeorando nuestro problema de memoria, pero definitivamente están en la parte inferior del tótem de los elementos de acción que debemos analizar en el lado de la evaluación.
No creo que se necesite ninguna acción por parte de ww todavía, ¡solo quería llamar su atención sobre esto! Dicho esto, traer todo sklearn solo para información mutua parece excesivo. Tal vez podamos usar un impl alternativo o diferir la importación al tiempo de ejecución, ¡pero ciertamente no necesitamos hacerlo ahora!
freddyaboulton
en 20 nov. 2020
@thehomebrewnerd @freddyaboulton Podríamos tener una importación en línea para la importación de sklearn (por lo que solo se ejecuta cuando llama a la función de información mutua).
Nos he visto hacer esto explícitamente en algunas otras bibliotecas. Generalmente lo hacemos para evitar importaciones circulares. Sería extraño hacerlo solo para ahorrar memoria ...
gsheni
en 20 nov. 2020
Notamos que podemos recortar 1.5gb de solo las pruebas automl (¡casi la mitad!) Configurando manualmente n_jobs=1 para todos los estimadores utilizados por automl (gráficos a continuación). Verificamos que el valor de n_jobs es un factor solo en las pocas pruebas automáticas que no simulan fit y score . En base a esto, hemos elaborado el plan actual:
- para cada componente que acepta n_jobs como parámetro (es decir, los estimadores basados en sklearn), asegúrese de que tengamos una prueba unitaria que establezca
n_jobs=-1, para verificar que funcione correctamente para ese componente. - para todas las demás pruebas unitarias que no simulan el
fitsubyacente, configuren_jobs=1para todos los componentes para evitar problemas de memoria y subprocesos - asegúrese de que en el espejo estamos ejecutando con
n_jobs=-1, que creo que estamos actualmente, ya que el valor predeterminado den_jobspara los estimadores relevantes es -1
¡Con suerte, una vez hecho esto, veremos algunas mejoras agradables en la huella de memoria general de las pruebas unitarias!


freddyaboulton
en 24 nov. 2020
Temas relacionados
 bchen1116
·
4Comentarios
bchen1116
·
4Comentarios
freddyaboulton
·
3Comentarios
bchen1116
·
4Comentarios
bchen1116
·
4Comentarios
freddyaboulton
·
3Comentarios
 angela97lin
·
4Comentarios
angela97lin
·
4Comentarios
 SydneyAyx
·
3Comentarios
SydneyAyx
·
3Comentarios