Evalml: Les tests unitaires utilisent jusqu'à 20 Go de mémoire sur circleci
Problème
Lors du débogage des échecs de test intermittents sur PR #1410, @christopherbunn et moi avons mesuré l'utilisation de la mémoire des tests unitaires sur circleci et avons constaté qu'une exécution complète de bout en bout peut utiliser jusqu'à 20 Go au maximum.
C'est bien plus que ce à quoi je m'attendais... la question est, pourquoi ?
Observations
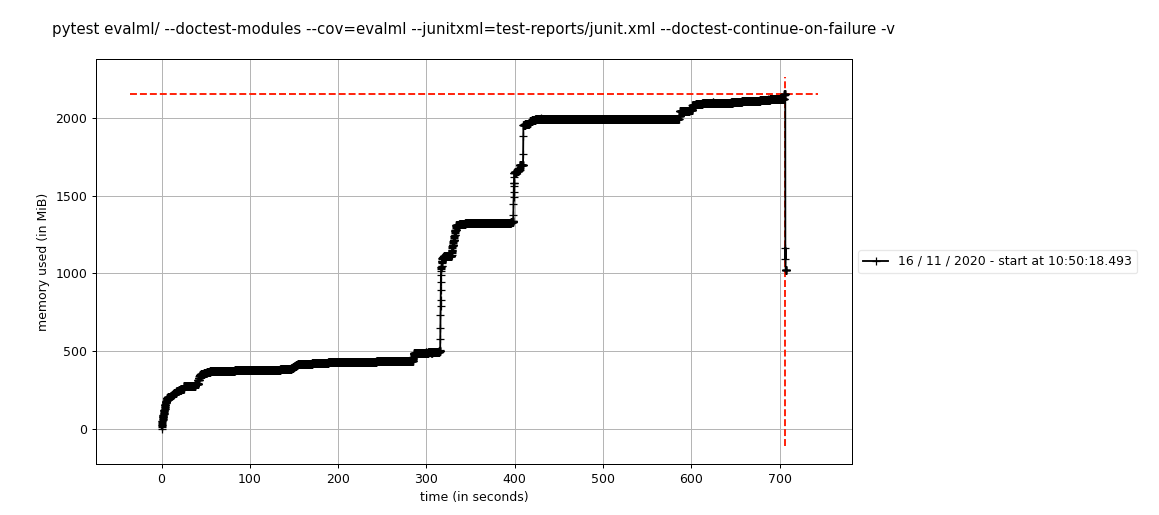
Nous sommes entrés dans une boîte circleci fonctionnant sur main et avons exécuté ce qui suit en utilisant memory-profiler :
mprof run --include-children pytest evalml/ -n 8 --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
Ce qui a créé le tracé suivant, visible avec mprof plot :

J'ai exécuté cela deux fois et j'ai obtenu un tracé similaire, de sorte que les résultats semblent être cohérents d'une exécution à l'autre.
C'est dangereusement proche de la mémoire maximale autorisée sur la taille du travailleur circleci que nous utilisons. C'est pourquoi nous avons commencé à nous pencher sur cette question : le n° 1410, nous avons constaté que l'utilisation de la mémoire avait augmenté de 5 Go pour une raison quelconque.
 dsherry
dsherry
Tous les 11 commentaires
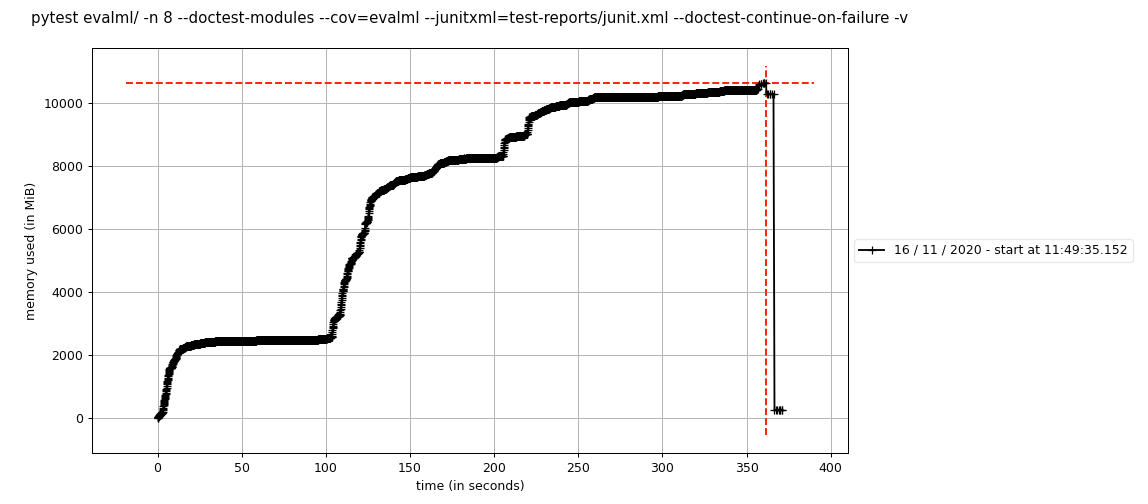
J'ai exécuté cela localement avec un seul travailleur et il semble que les tests n'utilisent que 2 Go de mémoire contre 10 Go lorsque j'utilise 8 travailleurs. On dirait donc que cela pourrait être une combinaison de circle-ci et de multitraitement ?
mprof run --include-children pytest evalml/ --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
mprof run --include-children pytest evalml/ -n 8 --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
 freddyaboulton
le 16 nov. 2020
freddyaboulton
le 16 nov. 2020
Discussion de stand-up avec @rpeck @angela97lin @freddyaboulton @christopherbunn @ParthivNaresh
Hypothèse
Notre appareil de test s'accroche à des choses qu'il ne devrait pas être, et c'est ce qui cause la majorité du problème. Mais aussi, il est possible qu'il y ait quelques fuites dans l'automl lui-même.
Prochaines étapes
- Identifiez les tests qui causent la plus grande augmentation de mémoire
- Choisissez l'un de ces tests, exécutez-le 20x avec suivi du tas ( utilisez
tracemalloc?), voyez où se trouve la fuite - Objectif : la fuite est-elle dans automl, ou dans pytest/test harnais ?
dsherry
le 16 nov. 2020
@rpeck @dsherry @christopherbunn et moi-même avons examiné cela et voici un résumé de ce que nous savons jusqu'à présent :
Une grande partie des pics que nous voyons dans les graphiques
memory-profileproviennent des importations par opposition aux tests unitaires. L'importation deAutoMLSearchreprésente environ 120 Mo, par exemple. Lorsque nous définissons-n 8dans la commande pytest, l'empreinte mémoire des importations est multipliée par 8, car chaque sous-processus doit avoir tout importé.Cela étant dit, certains tests unitaires ont une empreinte mémoire importante. Par exemple, le test automl
test_max_batches_works, exécute 20 lots avec assemblage. Même si nous nous moquons de l'ajustement et du score, le profileur de mémoire montre que tous les appels à_automl_algorithm.add_result(....)représentent 27 Mo de mémoire ! Nous devrions passer en revue nos tests pour voir combien de mémoire ils utilisent et voir s'il existe des moyens de la réduire sans compromettre la qualité des tests.Nous ne savons toujours pas s'il y a une fuite de mémoire ou non. L'exécution d'un programme simple qui crée une grande liste puis la supprime via le profileur de mémoire montre une augmentation monotone de la mémoire qui ressemble à une fonction pas à pas. Nous ne pouvons donc pas croire qu'une augmentation monotone de la mémoire pendant l'automl, telle que rapportée par memory-profiler, indique une fuite. Si quoi que ce soit, je pense que cela signifie simplement que nous devrions utiliser
tracemallocpour voir comment la mémoire est allouée/désallouée lors des exécutions suivantes du même programme.
Pour le moment, nous voyons si la diminution du parallélisme dans pytest de 8 à 4 dans circle-ci, ou en utilisant des travailleurs dédiés, débloquera #1410.
Nous garderons ce problème ouvert. Je pense qu'il reste encore beaucoup à faire pour comprendre pourquoi les changements dans cette branche aggravent nos problèmes de mémoire et voir si nous pouvons être plus soucieux de la mémoire dans nos tests.
N'hésitez pas à ajouter tout ce que j'ai manqué !
freddyaboulton
le 18 nov. 2020
Ouais! Une chose que j'ajouterais est que dans nos analyses, nous avons oublié le ramasse-miettes 😆 le fait que la mémoire réclamée par python augmente de façon monotone n'est pas nécessairement un problème, car un tas de la mémoire rapportée par mprof pourrait être un état qui n'a pas encore été désalloué par le ramasse-miettes.
@rpeck avait cherché à mesurer le changement de mémoire avant vs après chaque test unitaire. Cela nous indiquerait quels tests ont eu la plus forte augmentation, ce qui signifie que nous pouvons nous concentrer sur le profilage de ces tests et voir d'où viennent les plus grandes allocations. J'espère que nous pourrons continuer ce travail.
Une idée connexe : écrivez un post-fixage pour pytest qui s'exécute après chaque test et appelle gc.collect() pour forcer le ramasse-miettes. Si nous remarquons une augmentation constante de la mémoire au cours des tests, ce serait la preuve d'une fuite ; si nous voyions que la mémoire était constante d'une exécution à l'autre en moyenne, cela indiquerait qu'il n'y a pas de fuite.
dsherry
le 19 nov. 2020
Je serais curieux de savoir si l'utilisation élevée de la mémoire est le résultat de l'ajout de Woodwork et de l'utilisation de DataTables. Peut-être devrait-il suivre l'utilisation de la mémoire des tests unitaires de version en version ?
 gsheni
le 19 nov. 2020
gsheni
le 19 nov. 2020
@gsheni Ce serait une bonne idée ! Au moins pour les tests automatiques, je pense qu'il y a plus en jeu que de simples boiseries. Lorsque j'ai profilé la recherche, la conversion des boiseries n'a utilisé qu'environ 0,5 Mo alors que nous voyions certains tests unitaires utiliser environ 80 Mo. Il est possible que certains des pipelines/composants effectuent des conversions inutiles entre ww et pandas, donc je pense que nous devons absolument creuser plus loin.
Une chose que nous avons remarquée est que l'importation de woodwork nécessite environ 60 Mo principalement à cause de sklearn et des pandas. Je ne sais pas ce qui pourrait être fait à ce sujet, mais je voulais attirer votre attention sur ce point. Heureux de déposer quelque chose dans le repo ww !
Line # Mem usage Increment Occurences Line Contents
============================================================
3 37.8 MiB 37.8 MiB 1 <strong i="9">@profile</strong>
4 def ww_imports():
5 47.3 MiB 9.5 MiB 1 import numpy
6 65.8 MiB 18.5 MiB 1 import pandas
7 66.4 MiB 0.6 MiB 1 import click
8 93.2 MiB 26.8 MiB 1 import sklearn
9 96.3 MiB 3.2 MiB 1 import pyarrow
@freddyaboulton Peut-être que ww importe de plus grandes portions de ces bibliothèques que nécessaire ?
Ce serait génial d'avoir un outil qui optimise les importations en trouvant la fermeture transitive de tous les morceaux de la bibliothèque qui sont réellement utilisés...
 rpeck
le 20 nov. 2020
rpeck
le 20 nov. 2020
@freddyaboulton Peut-être que
wwimporte de plus grandes portions de ces bibliothèques que nécessaire ?Ce serait génial d'avoir un outil qui optimise les importations en trouvant la fermeture transitive de tous les morceaux de la bibliothèque qui sont réellement utilisés...
C'est la seule importation sklearn dans Woodwork : from sklearn.metrics.cluster import normalized_mutual_info_score . Je ne sais pas si nous pouvons faire quelque chose pour réduire cela.
En ce qui concerne les pandas, nous importons généralement toute la bibliothèque, mais c'est une si grosse partie du code Woodwork, je ne suis pas sûr que nous puissions facilement réduire cela non plus, mais nous pouvons l'examiner davantage si nécessaire.
 thehomebrewnerd
le 20 nov. 2020
thehomebrewnerd
le 20 nov. 2020
Merci pour l'explication @thehomebrewnerd ! Oui, il semble donc que l' importation d'un sous-module importera automatiquement le module parent . Nos importations importantes aggravent notre problème de mémoire, mais elles sont définitivement au bas du totem des éléments d'action que nous devons examiner du côté de l'evalml.
Je ne pense pas qu'une action de la part de ww soit encore nécessaire - je voulais juste attirer votre attention sur ce point ! Cela étant dit, apporter tout sklearn juste pour des informations mutuelles semble excessif. Peut-être que nous pouvons utiliser une impl alternative ou reporter l'importation à l'exécution, mais nous n'avons certainement pas besoin de le faire maintenant !
freddyaboulton
le 20 nov. 2020
@thehomebrewnerd @freddyaboulton Nous pourrions avoir une importation en ligne pour l'importation sklearn (elle ne s'exécute donc que lorsque vous appelez la fonction d'information mutuelle).
Je nous ai vus le faire explicitement dans quelques autres bibliothèques. Nous le faisons généralement pour éviter les importations circulaires. Ce serait bizarre de le faire juste pour économiser de la mémoire...
gsheni
le 20 nov. 2020
Nous avons remarqué que nous pouvons réduire de 1,5 Go uniquement les tests automl (presque la moitié !) En définissant manuellement n_jobs=1 pour tous les estimateurs utilisés par automl (tracés ci-dessous). Nous avons vérifié que la valeur de n_jobs n'est un facteur que dans les quelques tests automatiques qui ne se moquent pas de fit et de score . Sur cette base, nous avons élaboré le plan actuel :
- pour chaque composant qui accepte n_jobs comme paramètre (c'est-à-dire les estimateurs basés sur sklearn), assurez-vous que nous avons un test unitaire qui définit
n_jobs=-1, pour vérifier que cela fonctionne correctement pour ce composant. - pour tous les autres tests unitaires qui ne se moquent pas du
fitsous-jacent, définissezn_jobs=1pour tous les composants afin d'éviter les problèmes de mémoire et de threading - assurez-vous que dans le miroir, nous utilisons
n_jobs=-1, ce que je pense que nous sommes actuellement puisque la valeur par défaut den_jobspour les estimateurs pertinents est -1
Espérons qu'une fois cela fait, nous verrons de belles améliorations sur l'empreinte mémoire globale des tests unitaires !


freddyaboulton
le 24 nov. 2020
Questions connexes
dsherry
·
4Commentaires
dsherry
·
5Commentaires
 bchen1116
·
4Commentaires
bchen1116
·
4Commentaires
 angela97lin
·
4Commentaires
dsherry
·
3Commentaires
angela97lin
·
4Commentaires
dsherry
·
3Commentaires