Evalml: Tes unit menggunakan memori hingga 20GB di circleci
Masalah
Saat men -debug kegagalan pengujian intermiten pada PR # @christopherbunn dan saya mengukur penggunaan memori dari pengujian unit pada circleci dan menemukan bahwa operasi ujung-ke-ujung yang lengkap dapat menggunakan hingga 20GB pada puncaknya.
Itu jauh lebih dari yang saya duga... pertanyaannya adalah, mengapa?
Pengamatan
Kami masuk ke kotak circleci yang berjalan di main dan menjalankan yang berikut menggunakan memory-profiler :
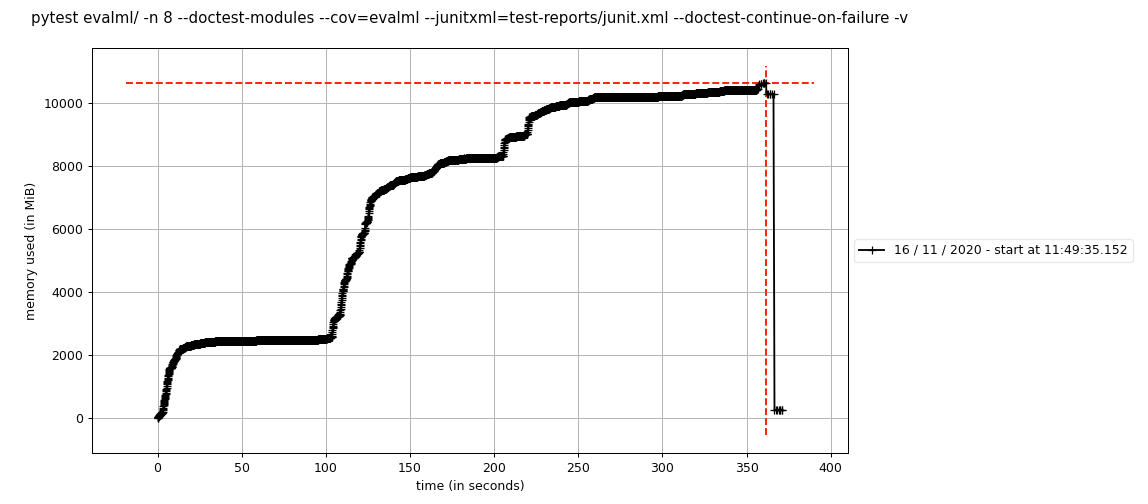
mprof run --include-children pytest evalml/ -n 8 --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
Yang membuat plot berikut, terlihat dengan mprof plot :

Saya menjalankan ini dua kali dan mendapatkan plot yang serupa, sehingga hasilnya tampak konsisten di seluruh proses.
Ini sangat dekat dengan memori maksimum yang diizinkan pada ukuran pekerja circleci yang kami gunakan. Itulah mengapa kami mulai menyelidiki hal ini -- pada #1410, kami melihat bahwa penggunaan memori menjadi 5GB lebih tinggi untuk beberapa alasan.
 dsherry
dsherry
Semua 11 komentar
Jalankan ini secara lokal dengan hanya satu pekerja dan sepertinya tes hanya menggunakan memori 2gb dibandingkan dengan 10gb ketika saya menggunakan 8 pekerja. Jadi sepertinya ini bisa menjadi kombinasi dari circle-ci dan multiprocessing?
mprof run --include-children pytest evalml/ --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
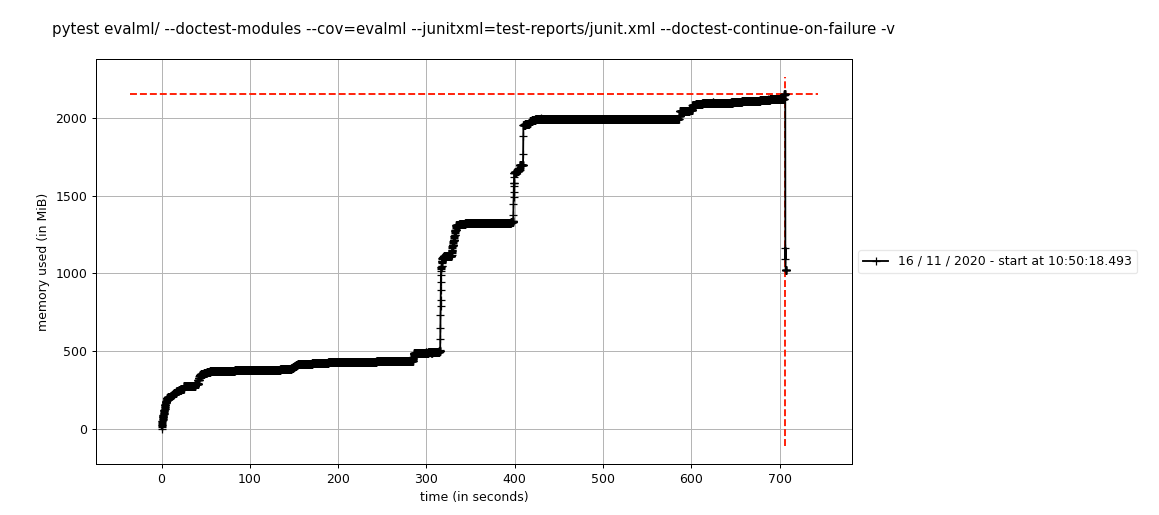
mprof run --include-children pytest evalml/ -n 8 --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
 freddyaboulton
pada 16 Nov 2020
freddyaboulton
pada 16 Nov 2020
Diskusi dari standup dengan @rpeck @angela97lin @freddyaboulton @christopherbunn @ParthivNaresh
Hipotesa
Perlengkapan pengujian kami memegang hal-hal yang tidak seharusnya, dan itulah yang menyebabkan sebagian besar masalah. Tetapi juga, mungkin ada beberapa kebocoran di automl itu sendiri.
Langkah selanjutnya
- Lacak tes mana yang menyebabkan peningkatan memori terbesar
- Pilih salah satu dari tes itu, jalankan 20x dengan pelacakan heap ( gunakan
tracemalloc?), lihat di mana kebocorannya - Sasaran: apakah kebocoran di automl, atau di pytest / test harness?
dsherry
pada 16 Nov 2020
@rpeck @dsherry @christopherbunn dan saya telah melihat ini dan inilah ringkasan dari apa yang kita ketahui sejauh ini:
Banyak lonjakan yang kita lihat di plot
memory-profileberasal dari impor sebagai lawan dari pengujian unit. MengimporAutoMLSearchadalah ~120 MB, misalnya. Ketika kita menetapkan-n 8dalam perintah pytest, jejak memori dari impor dikalikan dengan 8, karena setiap subproses harus memiliki semuanya yang diimpor.Meskipun demikian, ada beberapa pengujian unit yang memiliki jejak memori yang besar. Misalnya, tes automl
test_max_batches_works, menjalankan 20 batch dengan ensambling. Meskipun kami mengejek fit and score, profiler memori menunjukkan bahwa semua panggilan ke_automl_algorithm.add_result(....)berjumlah 27 mb memori! Kami harus melalui pengujian kami untuk melihat berapa banyak memori yang mereka gunakan dan melihat apakah ada cara untuk menguranginya tanpa mengurangi kualitas pengujian.Kami masih belum yakin apakah ada kebocoran memori atau tidak. Menjalankan program sederhana yang membuat daftar besar dan kemudian menghapusnya melalui profiler memori menunjukkan peningkatan monoton dalam memori yang terlihat seperti fungsi langkah. Jadi kami tidak percaya bahwa peningkatan monoton dalam memori selama automl, seperti yang dilaporkan oleh profiler memori, merupakan indikasi kebocoran. Jika ada, saya pikir ini hanya berarti kita harus menggunakan
tracemallocuntuk melihat bagaimana memori dialokasikan/dialokasikan pada menjalankan program yang sama berikutnya.
Untuk saat ini, kami melihat apakah penurunan paralelisme di pytest dari 8 menjadi 4 di lingkaran-ci, atau menggunakan pekerja khusus, akan membuka blokir #1410.
Kami akan tetap membuka masalah ini. Saya pikir masih banyak yang harus dilakukan untuk memahami mengapa perubahan di cabang itu membuat masalah memori kita jauh lebih buruk serta melihat apakah kita bisa lebih sadar memori dalam pengujian kita.
Jangan ragu untuk menambahkan apa pun yang saya lewatkan!
freddyaboulton
pada 18 Nov 2020
Ya! Satu hal yang saya tambahkan adalah bahwa dalam analisis kami, kami lupa tentang pengumpulan sampah fakta bahwa memori yang diklaim oleh python meningkat secara monoton tidak selalu menjadi masalah, karena banyak memori yang dilaporkan oleh mprof bisa menjadi negara yang belum dialokasikan oleh pengumpulan sampah.
@rpeck telah mencari cara untuk mengukur perubahan memori sebelum vs setelah setiap unit test. Ini akan memberi tahu kami pengujian mana yang memiliki peningkatan terbesar, yang berarti kami dapat fokus pada pembuatan profil pengujian tersebut dan melihat dari mana alokasi terbesar berasal. Saya berharap kami dapat melanjutkan pekerjaan itu.
Gagasan terkait: tulis perlengkapan pos untuk pytest yang berjalan setelah setiap pengujian dan panggil gc.collect() untuk memaksa pengumpulan sampah. Jika kami melihat peningkatan yang stabil dalam memori di seluruh pengujian, itu akan menjadi bukti kebocoran; jika kita melihat memori rata-rata konstan di seluruh proses, itu akan menunjukkan tidak ada kebocoran.
dsherry
pada 19 Nov 2020
Saya ingin tahu apakah penggunaan memori yang tinggi adalah hasil dari penambahan Woodwork, dan menggunakan DataTables. Mungkin harus melacak penggunaan memori dari versi pengujian unit ke versi?
 gsheni
pada 19 Nov 2020
gsheni
pada 19 Nov 2020
@gsheni Itu akan menjadi ide yang bagus! Setidaknya untuk tes automl, saya pikir ada lebih dari sekadar kayu. Ketika saya membuat profil pencarian, konversi kayu hanya menggunakan ~0,5MB sedangkan kami melihat beberapa pengujian unit menggunakan ~80MB. Mungkin beberapa pipa/komponen melakukan konversi yang tidak perlu antara ww dan panda jadi saya pikir kita pasti perlu menggali lebih jauh.
Satu hal yang kami perhatikan adalah bahwa mengimpor woodwork membutuhkan ~60MB terutama karena sklearn dan panda. Tidak yakin apa yang bisa dilakukan tentang ini tetapi ingin membawa ini menjadi perhatian Anda. Senang mengajukan sesuatu di repo ww!
Line # Mem usage Increment Occurences Line Contents
============================================================
3 37.8 MiB 37.8 MiB 1 <strong i="9">@profile</strong>
4 def ww_imports():
5 47.3 MiB 9.5 MiB 1 import numpy
6 65.8 MiB 18.5 MiB 1 import pandas
7 66.4 MiB 0.6 MiB 1 import click
8 93.2 MiB 26.8 MiB 1 import sklearn
9 96.3 MiB 3.2 MiB 1 import pyarrow
@freddyaboulton Mungkin ww mengimpor sebagian besar perpustakaan ini daripada yang diperlukan?
Akan sangat bagus untuk memiliki alat yang mengoptimalkan impor dengan menemukan penutupan transitif dari semua bagian perpustakaan yang benar-benar digunakan...
 rpeck
pada 20 Nov 2020
rpeck
pada 20 Nov 2020
@freddyaboulton Mungkin
wwmengimpor sebagian besar perpustakaan ini daripada yang diperlukan?Akan sangat bagus untuk memiliki alat yang mengoptimalkan impor dengan menemukan penutupan transitif dari semua bagian perpustakaan yang benar-benar digunakan...
Ini adalah satu-satunya impor sklearn di Woodwork: from sklearn.metrics.cluster import normalized_mutual_info_score . Tidak yakin apakah ada yang bisa kita lakukan untuk menguranginya.
Untuk panda, kami biasanya mengimpor seluruh perpustakaan, tetapi itu adalah bagian besar dari kode Woodwork, saya tidak yakin kami dapat dengan mudah menskalakannya kembali, tetapi dapat melihat lebih dalam jika diperlukan.
 thehomebrewnerd
pada 20 Nov 2020
thehomebrewnerd
pada 20 Nov 2020
Terima kasih atas penjelasannya @thehomebrewnerd ! Ya jadi sepertinya mengimpor submodul akan mengimpor modul induk secara otomatis . Impor besar kami membuat masalah memori kami lebih buruk tetapi mereka pasti berada di bagian bawah tiang totem item tindakan yang perlu kami perhatikan di sisi evalml.
Saya rasa belum ada tindakan yang diperlukan dari ww - saya hanya ingin menyampaikan ini kepada Anda! Bisa dikatakan, membawa semua sklearn hanya untuk saling info tampaknya berlebihan. Mungkin kita dapat menggunakan impl alternatif atau menunda impor ke runtime tetapi kita tentu tidak perlu melakukannya sekarang!
freddyaboulton
pada 20 Nov 2020
@thehomebrewnerd @freddyaboulton Kami dapat memiliki impor sebaris untuk impor sklearn (jadi ini hanya berjalan ketika Anda memanggil fungsi info bersama).
Saya telah melihat kami secara eksplisit melakukan ini di beberapa perpustakaan lain. Kami biasanya melakukannya untuk menghindari impor sirkular. Akan terasa aneh jika melakukannya hanya untuk menghemat memori...
gsheni
pada 20 Nov 2020
Kami melihat bahwa kami dapat mencukur 1,5 GB hanya dari pengujian automl (hampir setengah!) dengan menyetel n_jobs=1 secara manual untuk semua penaksir yang digunakan oleh automl (plot di bawah). Kami memverifikasi bahwa nilai n_jobs adalah faktor hanya dalam beberapa pengujian automl yang tidak mengejek fit dan score . Berdasarkan ini, kami telah membuat rencana saat ini:
- untuk setiap komponen yang menerima n_jobs sebagai parameter (yaitu estimator berbasis sklearn), pastikan kita memiliki satu unit test yang menetapkan
n_jobs=-1, untuk memverifikasi bahwa komponen tersebut berfungsi dengan baik. - untuk semua pengujian unit lain yang tidak mengejek
fitmendasarinya, seteln_jobs=1untuk semua komponen untuk menghindari masalah memori dan threading - pastikan bahwa dalam look glass kita menjalankan
n_jobs=-1, yang saya yakini saat ini karena nilai defaultn_jobsuntuk estimator yang relevan adalah -1
Semoga setelah ini selesai, kita akan melihat beberapa peningkatan yang bagus pada keseluruhan jejak memori dari unit test!


freddyaboulton
pada 24 Nov 2020
Masalah terkait
 dancuarini
·
11Komentar
dancuarini
·
11Komentar
 chukarsten
·
11Komentar
chukarsten
·
11Komentar
 angela97lin
·
8Komentar
dsherry
·
8Komentar
dsherry
·
10Komentar
angela97lin
·
8Komentar
dsherry
·
8Komentar
dsherry
·
10Komentar