問題
PR#1410で断続的なテストの失敗をデバッグしているときに、 @ christopherbunnと私は
それは私が予想していたよりもはるかに多いです...問題は、なぜですか?
観察
main実行されているcircleciボックスにSSHで接続し、 memory-profilerを使用して以下
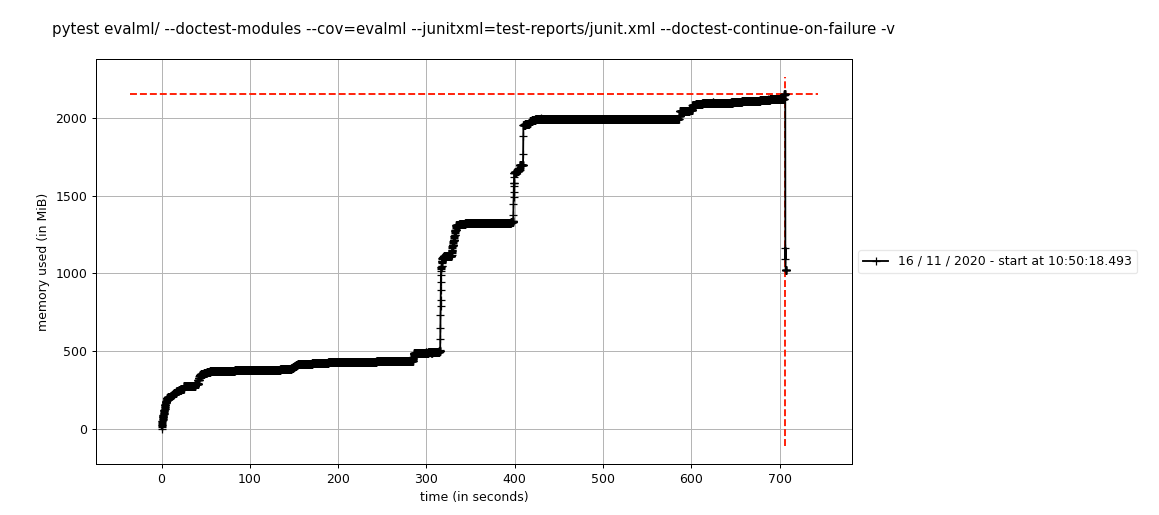
mprof run --include-children pytest evalml/ -n 8 --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
mprof plotで表示される次のプロットを作成しました:

これを2回実行して同様のプロットを取得したため、結果は実行間で一貫しているように見えます。
これは、使用しているcircleciワーカーサイズで許可されている最大メモリに危険なほど近づいています。 そのため、これを調査し始めました。#1410で、何らかの理由でメモリ使用量が5GB高くなっていることがわかりました。
 dsherry
dsherry
全てのコメント11件
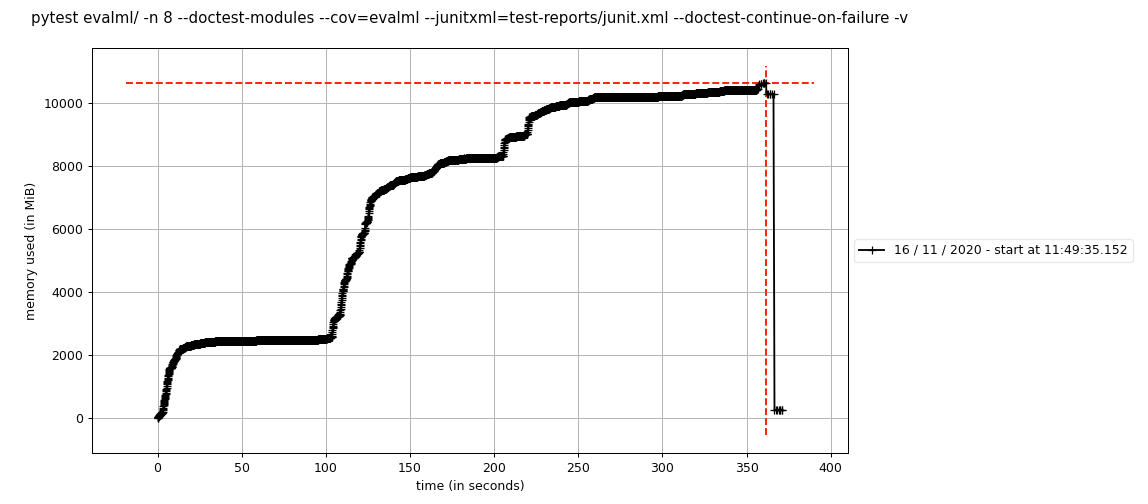
これを1人のワーカーだけでローカルに実行したところ、8人のワーカーを使用した場合の10 GBと比較して、テストでは2GBのメモリしか使用していないようです。 それで、これはcircle-ciとマルチプロセッシングの組み合わせである可能性があるように見えますか?
mprof run --include-children pytest evalml/ --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
mprof run --include-children pytest evalml/ -n 8 --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
 freddyaboulton
2020年11月16日
freddyaboulton
2020年11月16日
@rpeck @ angela97lin @freddyaboulton @christopherbunn @ParthivNareshと立ち上がりからディスカッション
仮説
私たちのテストフィクスチャは、あるべきではないものを保持しており、それが問題の大部分を引き起こしています。 しかしまた、automl自体にいくつかのリークがある可能性があります。
次のステップ
- どのテストが最大のメモリ増加を引き起こしているかを追跡します
- それらのテストの1つを選び、ヒープ追跡を使用して20回実行し(
- 目標:automl、またはpytest /テストハーネスにリークがありますか?
dsherry
2020年11月16日
@rpeck @dsherry @christopherbunnと私はこれを調べました、そしてここに私たちがこれまでに知っていることの要約があります:
memory-profileプロットに見られるスパイクの多くは、単体テストではなくインポートによるものです。 たとえば、AutoMLSearchインポートは約120MBです。 pytestコマンドで-n 8を設定すると、各サブプロセスですべてをインポートする必要があるため、インポートからのメモリフットプリントは8倍になります。そうは言っても、メモリフットプリントが大きい単体テストがいくつかあります。 たとえば、automlテスト
test_max_batches_worksは、アンサンブルを使用して20個のバッチを実行します。 フィットとスコアをモックしますが、メモリプロファイラーは、_automl_algorithm.add_result(....)へのすべての呼び出しが27mbのメモリに相当することを示しています。 テストを実行して、使用するメモリの量を確認し、テストの品質を損なうことなくメモリを削減する方法があるかどうかを確認する必要があります。メモリリークがあるかどうかはまだわかりません。 大きなリストを作成し、それをmemory-profilerを介して削除する単純なプログラムを実行すると、ステップ関数のように見えるメモリの単調な増加が示されます。 したがって、memory-profilerによって報告されているように、automl中のメモリの単調な増加がリークを示しているとは信じられません。 どちらかといえば、これは、同じプログラムの後続の実行でメモリがどのように割り当て/割り当て解除されるかを確認するために
tracemallocを使用する必要があることを意味していると思います。
当面は、pytestの並列処理をcircle-ciの8から4に減らすか、専用のワーカーを使用すると、#1410のブロックが解除されるかどうかを確認しています。
この問題は未解決のままにしておきます。 そのブランチの変更によってメモリの問題が非常に悪化する理由を理解し、テストでメモリをより意識できるかどうかを確認するには、まだやるべきことがたくさんあると思います。
見逃したものは何でも自由に追加してください!
freddyaboulton
2020年11月18日
うん! 私が付け加えたいことの1つは、分析でガベージコレクションを忘れたことです😆Pythonによって要求されたメモリが単調に増加しているという事実は、 mprofによって報告されたメモリの束のため、必ずしも問題ではありませんガベージコレクションによってまだ割り当てが解除されていない状態である可能性があります。
@rpeckは、各単体テストの前と後のメモリの変化を測定することを検討していました。 これにより、どのテストが最大の増加を示したかがわかります。つまり、これらのテストのプロファイリングと、最大の割り当てがどこから来ているかを確認することに集中できます。 その仕事を続けられることを願っています。
関連するアイデア:すべてのテストの後に実行され、 gc.collect()を呼び出してガベージコレクションを強制するpytestのポストフィクスチャを作成します。 テストの実行全体でメモリが着実に増加していることに気付いた場合、それはリークの証拠になります。 メモリが平均して実行全体で一定であることがわかった場合、それはリークがないことを示します。
dsherry
2020年11月19日
高いメモリ使用量がWoodworkを追加し、DataTablesを使用した結果であるかどうかを知りたいと思います。 おそらく、ユニットテストのバージョンごとのメモリ使用量を追跡する必要がありますか?
 gsheni
2020年11月19日
gsheni
2020年11月19日
@gsheniそれはいい考えです! 少なくともautomlテストについては、木工だけではないことがたくさんあると思います。 検索のプロファイルを作成したとき、木工品の変換は最大0.5MBしか使用しませんでしたが、一部の単体テストでは最大80MBが使用されていました。 一部のパイプライン/コンポーネントがwwとパンダの間で不要な変換を行っている可能性があるため、さらに掘り下げる必要があると思います。
私たちが気づいたことの1つは、 woodworkインポートには、主にsklearnとpandasのために最大60MBが必要であるということです。 これについて何ができるかわからないが、これをあなたの注意を引くことを望んだ。 wwリポジトリに何かを提出して幸せです!
Line # Mem usage Increment Occurences Line Contents
============================================================
3 37.8 MiB 37.8 MiB 1 <strong i="9">@profile</strong>
4 def ww_imports():
5 47.3 MiB 9.5 MiB 1 import numpy
6 65.8 MiB 18.5 MiB 1 import pandas
7 66.4 MiB 0.6 MiB 1 import click
8 93.2 MiB 26.8 MiB 1 import sklearn
9 96.3 MiB 3.2 MiB 1 import pyarrow
@freddyaboultonおそらくwwは、これらのライブラリの大部分を必要以上にインポートしていますか?
実際に使用されているライブラリのすべての部分の推移閉包を見つけることによってインポートを最適化するツールがあると便利です...
 rpeck
2020年11月20日
rpeck
2020年11月20日
@freddyaboultonおそらく
wwは、これらのライブラリの大部分を必要以上にインポートしていますか?実際に使用されているライブラリのすべての部分の推移閉包を見つけることによってインポートを最適化するツールがあると便利です...
これはWoodworkでの唯一のsklearnインポートです: from sklearn.metrics.cluster import normalized_mutual_info_score 。 それを縮小するために私たちにできることがあるかどうかはわかりません。
パンダに関しては、通常、ライブラリ全体をインポートしますが、これはWoodworkコードの非常に大きな部分であり、簡単に縮小できるかどうかはわかりませんが、必要に応じてさらに調べることができます。
 thehomebrewnerd
2020年11月20日
thehomebrewnerd
2020年11月20日
説明ありがとうございます@thehomebrewnerd ! そうです、サブモジュールをインポートすると、親モジュールが自動的にインポートされるように見え
wwからはまだアクションは必要ないと思います-これをあなたの注意を引きたいと思いました! そうは言っても、相互情報のためだけにsklearnをすべて取り込むのは過剰に思えます。 おそらく、代替のimplを使用するか、インポートをランタイムに延期することができますが、今はそれを行う必要はありません。
freddyaboulton
2020年11月20日
@thehomebrewnerd @freddyaboulton sklearnインポートのインラインインポートを使用できます(したがって、相互情報関数を呼び出した場合にのみ実行されます)。
他のライブラリのいくつかでこれを明示的に行っているのを見てきました。 通常、循環インポートを回避するためにこれを行います。 メモリを節約するためだけにそれを行うのは奇妙に感じるでしょう...
gsheni
2020年11月20日
automlで使用されるすべての推定量にn_jobs=1を手動で設定することで、automlテストだけで1.5 GBを削減できることに気付きました(以下のプロット)。 n_jobsの値が、 fitとscoreモックしないいくつかのautomlテストでのみ要因であることを確認しました。 これに基づいて、現在の計画を考え出しました。
- n_jobsをパラメーターとして受け入れるコンポーネント(つまり、sklearnベースの推定量)ごとに、
n_jobs=-1を設定する単体テストが1つあることを確認して、そのコンポーネントで正しく機能することを確認します。 - 基盤となる
fitモックしない他のすべての単体テストでは、メモリとスレッドの問題を回避するために、すべてのコンポーネントにn_jobs=1を設定します。 - 見ているガラスで
n_jobs=-1で実行していることを確認してください。これは、関連する推定量のデフォルト値n_jobsが-1であるため、現在のところだと思います。
うまくいけば、これが完了すると、単体テストの全体的なメモリフットプリントにいくつかの素晴らしい改善が見られるでしょう!


freddyaboulton
2020年11月24日
関連する問題
 angela97lin
·
4コメント
angela97lin
·
4コメント
 bchen1116
·
4コメント
dsherry
·
3コメント
bchen1116
·
4コメント
bchen1116
·
4コメント
dsherry
·
3コメント
bchen1116
·
4コメント
 npapan69
·
4コメント
npapan69
·
4コメント