Evalml: Unit-Tests verwenden bis zu 20 GB Speicher auf circleci
Problem
Beim Debuggen von zeitweiligen Testfehlern auf PR #1410 haben
Das ist viel mehr, als ich erwartet hätte... die Frage ist, warum?
Beobachtungen
Wir ssh'ed in eine Circleci-Box, die auf main lief, und führten Folgendes mit memory-profiler :
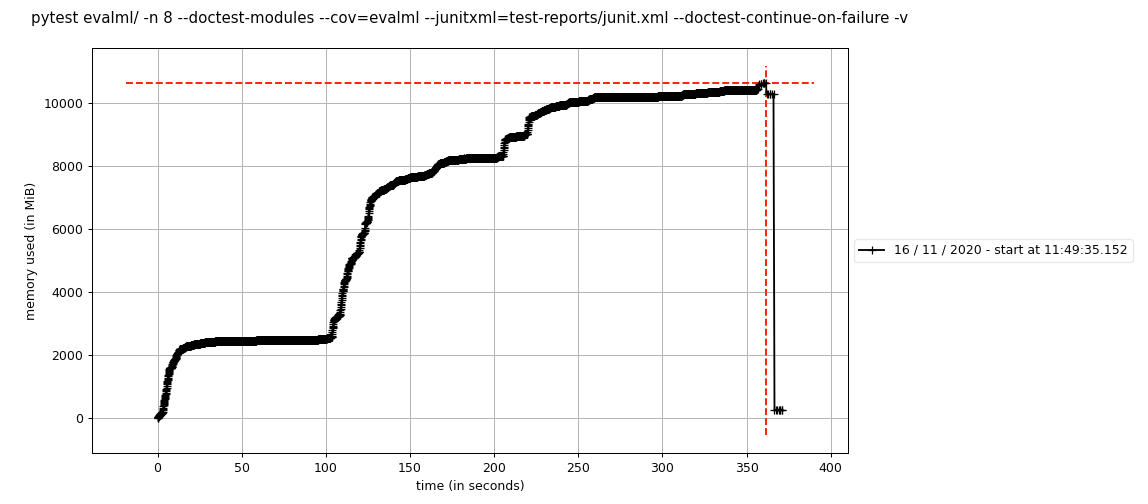
mprof run --include-children pytest evalml/ -n 8 --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
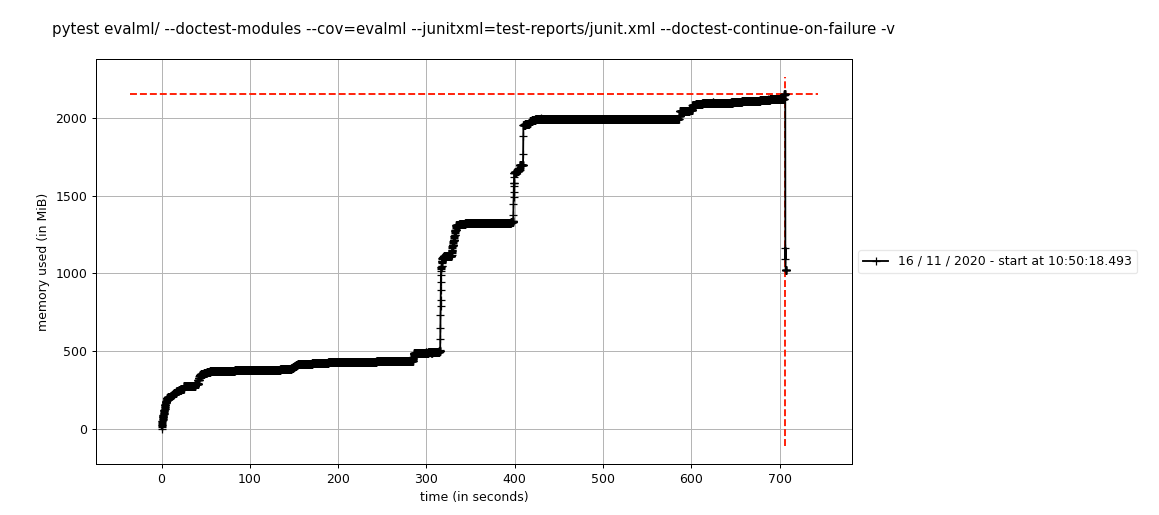
Dadurch wurde der folgende Plot erstellt, der mit mprof plot sichtbar ist:

Ich habe dies zweimal ausgeführt und ein ähnliches Diagramm erhalten, sodass die Ergebnisse bei allen Läufen konsistent zu sein scheinen.
Dies ist gefährlich nahe am maximalen Arbeitsspeicher, der für die von uns verwendete Circleci-Workergröße zulässig ist. Aus diesem Grund haben wir uns damit befasst – bei #1410 sahen wir, dass die Speichernutzung aus irgendeinem Grund um 5 GB gestiegen ist.
 dsherry
dsherry
Alle 11 Kommentare
Habe dies lokal mit nur einem Arbeiter ausgeführt und es sieht so aus, als würden die Tests nur 2 GB Speicher verwenden, verglichen mit 10 GB, wenn ich 8 Arbeiter verwende. Sieht also so aus, als könnte dies eine Kombination aus Circle-Ci und Multiprocessing sein?
mprof run --include-children pytest evalml/ --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
mprof run --include-children pytest evalml/ -n 8 --doctest-modules --cov=evalml --junitxml=test-reports/junit.xml --doctest-continue-on-failure -v
 freddyaboulton
am 16. Nov. 2020
freddyaboulton
am 16. Nov. 2020
Diskussion aus dem Standup mit @rpeck @angela97lin @freddyaboulton @christopherbunn @ParthivNaresh
Hypothese
Unser Testgerät hält an Sachen fest, die es nicht sein sollte, und das verursacht den Großteil des Problems. Aber es ist auch möglich, dass automl selbst ein paar Lecks hat.
Nächste Schritte
- Finden Sie heraus, welche Tests den größten Speicherzuwachs verursachen
- Wählen Sie einen dieser Tests aus, führen Sie ihn 20x mit Heap-Tracking aus ( verwenden Sie
tracemalloc?), sehen Sie, wo das Leck ist - Ziel: ist ein Leck in automl oder in pytest / test Harness?
dsherry
am 16. Nov. 2020
@rpeck @dsherry @christopherbunn und ich haben uns das angeschaut und hier ist eine Zusammenfassung dessen, was wir bisher wissen:
Viele der Spitzen, die wir in den
memory-profilePlots sehen, stammen von Importen und nicht von den Unit-Tests. Das Importieren vonAutoMLSearchist beispielsweise ~120 MB groß. Wenn wir im pytest-Befehl-n 8setzen, wird der Speicherbedarf der Importe mit 8 multipliziert, da jeder Unterprozess alles importiert haben muss.Davon abgesehen gibt es einige Unit-Tests, die einen großen Speicherbedarf haben. Beispielsweise führt der automl-Test
test_max_batches_works20 Batches mit Ensemble aus. Auch wenn wir Fit und Punkte nachahmen, zeigt der Speicherprofiler, dass alle Aufrufe von_automl_algorithm.add_result(....)27 MB Speicher betragen! Wir sollten unsere Tests durchgehen, um zu sehen, wie viel Speicher sie verwenden und ob es Möglichkeiten gibt, diesen zu reduzieren, ohne die Testqualität zu beeinträchtigen.Wir sind uns immer noch nicht sicher, ob es ein Speicherleck gibt oder nicht. Das Ausführen eines einfachen Programms, das eine große Liste erstellt und diese dann über den Speicherprofiler löscht, zeigt eine monotone Zunahme des Speichers, die wie eine Schrittfunktion aussieht. Wir können also nicht darauf vertrauen, dass ein monotoner Anstieg des Speichers während automl, wie von memory-profiler berichtet, auf ein Leck hinweist. Wenn überhaupt, bedeutet dies meiner Meinung nach nur, dass wir
tracemalloczu sehen, wie Speicher bei nachfolgenden Ausführungen desselben Programms zugewiesen/freigegeben wird.
Im Moment sehen wir, ob die Verringerung der Parallelität in pytest von 8 auf 4 in circle-ci oder die Verwendung dedizierter Arbeiter die Blockierung von #1410 aufheben wird.
Wir werden dieses Thema offen halten. Ich denke, es bleibt noch viel zu tun, um zu verstehen, warum die Änderungen in diesem Zweig unsere Gedächtnisprobleme so viel schlimmer machen, und um zu sehen, ob wir in unseren Tests gedächtnisbewusster sein können.
Fühlen Sie sich frei, alles hinzuzufügen, was ich vermisst habe!
freddyaboulton
am 18. Nov. 2020
Ja! Eine Sache, die ich hinzufügen möchte, ist, dass wir in unseren Analysen die Garbage Collection vergessen haben 😆 die Tatsache, dass der von Python beanspruchte Speicher monoton zunimmt, ist nicht unbedingt ein Problem, denn ein Haufen des Speichers, der von mprof gemeldet wird könnte ein Zustand sein, der noch nicht von der Garbage Collection freigegeben wurde.
@rpeck hatte sich mit der Messung der Speicheränderung vor vs. nach jedem Unit-Test beschäftigt. Dies würde uns sagen, welche Tests den größten Anstieg hatten, was bedeutet, dass wir uns darauf konzentrieren können, diese Tests zu profilieren und zu sehen, woher die größten Zuweisungen kommen. Ich hoffe, wir können diese Arbeit fortsetzen.
Eine verwandte Idee: Schreiben Sie ein Post-Fixture für pytest, das nach jedem Test ausgeführt wird und gc.collect() aufruft, um die Garbage Collection zu erzwingen. Wenn wir bei Testläufen eine stetige Zunahme des Speichers feststellen würden, wäre dies ein Hinweis auf ein Leck; Wenn wir sehen würden, dass der Speicher über die Durchläufe hinweg im Durchschnitt konstant war, würde dies darauf hindeuten, dass kein Leck vorliegt.
dsherry
am 19. Nov. 2020
Ich würde gerne wissen, ob der hohe Speicherverbrauch auf das Hinzufügen von Woodwork und die Verwendung von DataTables zurückzuführen ist. Vielleicht sollten Sie die Speichernutzung der Komponententests von Version zu Version verfolgen?
 gsheni
am 19. Nov. 2020
gsheni
am 19. Nov. 2020
@gsheni Das wäre eine gute Idee! Zumindest für die Automl-Tests denke ich, dass da mehr im Spiel ist als nur Holzarbeiten. Bei meiner Profilsuche verbrauchte die Holzkonvertierung nur ~ 0,5 MB, während einige Unit-Tests ~ 80 MB verbrauchten. Es ist möglich, dass einige der Pipelines / Komponenten unnötige Konvertierungen zwischen WW und Pandas vornehmen, also denke ich, dass wir definitiv weiter graben müssen.
Eine Sache, die uns aufgefallen ist, ist, dass das Importieren von woodwork ~60 MB benötigt, hauptsächlich wegen Sklearn und Pandas. Ich bin mir nicht sicher, was man dagegen tun könnte, wollte Sie aber darauf aufmerksam machen. Gerne etwas im ww-repo ablegen!
Line # Mem usage Increment Occurences Line Contents
============================================================
3 37.8 MiB 37.8 MiB 1 <strong i="9">@profile</strong>
4 def ww_imports():
5 47.3 MiB 9.5 MiB 1 import numpy
6 65.8 MiB 18.5 MiB 1 import pandas
7 66.4 MiB 0.6 MiB 1 import click
8 93.2 MiB 26.8 MiB 1 import sklearn
9 96.3 MiB 3.2 MiB 1 import pyarrow
@freddyaboulton Vielleicht ww größere Teile dieser Bibliotheken als nötig?
Es wäre großartig, ein Tool zu haben, das den Import optimiert, indem es den transitiven Abschluss aller tatsächlich verwendeten Teile der Bibliothek findet ...
 rpeck
am 20. Nov. 2020
rpeck
am 20. Nov. 2020
@freddyaboulton Vielleicht
wwgrößere Teile dieser Bibliotheken als nötig?Es wäre großartig, ein Tool zu haben, das den Import optimiert, indem es den transitiven Abschluss aller tatsächlich verwendeten Teile der Bibliothek findet ...
Dies ist der einzige Sklearn-Import in Woodwork: from sklearn.metrics.cluster import normalized_mutual_info_score . Ich bin mir nicht sicher, ob wir etwas tun können, um das zu reduzieren.
Was Pandas angeht, importieren wir normalerweise die gesamte Bibliothek, aber das ist ein so großer Teil des Woodwork-Codes, dass wir das auch nicht leicht zurückskalieren können, aber bei Bedarf genauer untersuchen können.
 thehomebrewnerd
am 20. Nov. 2020
thehomebrewnerd
am 20. Nov. 2020
Danke für die Erklärung @thehomebrewnerd ! Ja, es sieht so aus, als würde das Importieren eines Untermoduls das übergeordnete Modul automatisch importieren . Unsere großen Importe verschlimmern unser Speicherproblem, aber sie sind definitiv am unteren Ende des Totempfahls der Aktionsgegenstände, die wir auf der Bewertungsseite untersuchen müssen.
Ich glaube nicht, dass von ww noch etwas unternommen werden muss - ich wollte Sie nur darauf aufmerksam machen! Davon abgesehen scheint es übertrieben, alle Sklearn nur zur gegenseitigen Information einzubringen. Vielleicht können wir ein alternatives Impl verwenden oder den Import auf die Laufzeit verschieben, aber das müssen wir jetzt sicherlich nicht!
freddyaboulton
am 20. Nov. 2020
@thehomebrewnerd @freddyaboulton Wir könnten einen Inline-Import für den Sklearn-Import haben (also läuft er nur, wenn Sie die gegenseitige Info-Funktion aufrufen).
Ich habe gesehen, dass wir dies in einigen anderen Bibliotheken explizit getan haben. Wir tun dies im Allgemeinen, um zirkuläre Importe zu vermeiden. Es würde sich komisch anfühlen, es nur zu tun, um Speicher zu sparen...
gsheni
am 20. Nov. 2020
Wir haben festgestellt, dass wir allein bei den automl-Tests 1,5 GB (fast die Hälfte!) einsparen können, indem wir manuell n_jobs=1 für alle von automl verwendeten Schätzer festlegen (Plots unten). Wir haben überprüft, dass der Wert von n_jobs nur in den wenigen Automl-Tests ein Faktor ist, die fit und score nicht verspotten. Darauf aufbauend haben wir den aktuellen Plan erstellt:
- Stellen Sie für jede Komponente, die n_jobs als Parameter akzeptiert (dh die sklearn-basierten Schätzer), sicher, dass wir einen Unit-Test haben, der
n_jobs=-1festlegt, um zu überprüfen, ob diese Komponente richtig funktioniert. - für alle anderen Komponententests, die die zugrunde liegenden
fitnicht verspotten, setzen Sien_jobs=1für alle Komponenten, um Speicher- und Threading-Probleme zu vermeiden - Stellen Sie sicher, dass wir im Spiegel mit
n_jobs=-1, was meiner Meinung nach derzeit der Fall ist, da der Standardwert vonn_jobsfür relevante Schätzer -1 ist
Sobald dies erledigt ist, werden wir hoffentlich einige nette Verbesserungen beim Gesamtspeicherbedarf der Unit-Tests sehen!


freddyaboulton
am 24. Nov. 2020
Verwandte Themen
dsherry
·
3Kommentare
dsherry
·
3Kommentare
dsherry
·
3Kommentare
 angela97lin
·
4Kommentare
angela97lin
·
4Kommentare
angela97lin
·
4Kommentare
angela97lin
·
4Kommentare