用户因资源不足而无法安排 Pod 而陷入困境。 可能很难知道 Pod 何时处于挂起状态,因为它还没有启动,或者因为集群没有空间来调度它。 http://kubernetes.io/v1.1/docs/user-guide/compute-resources.html#monitoring -compute-resource-usage 有帮助,但不是很容易发现(我倾向于在pod 首先处于待处理状态,只有在等待一段时间并看到它“卡在”待处理状态后,我才使用“描述”来意识到这是一个调度问题)。
由于系统 pod 位于隐藏的命名空间中,这也变得复杂。 用户忘记了这些 Pod 的存在,并“计入”集群资源。
有几种可能的修复方法,我不知道什么是理想的:
1) 开发一个新的 Pod 状态而不是 Pending 来表示“试图调度但由于缺乏资源而失败”。
2) 让 kubectl get po 或 kubectl get po -o=wide 显示一列以详细说明某些事情挂起的原因(在这种情况下可能是正在等待的 container.state,或最近的 event.message)。
3)新建一个kubectl命令,更方便的描述资源。 我正在想象一个“kubectl 使用情况”,它概述了整个集群 CPU 和 Mem、每个节点的 CPU 和 Mem 以及每个 pod/容器的使用情况。 在这里,我们将包括所有 pod,包括系统 pod。 从长远来看,这可能与更复杂的调度程序一起使用,或者当您的集群有足够的资源但没有单个节点时(诊断“没有足够大的孔”问题)。
 goltermann
goltermann
所有88条评论
类似于 (2) 的内容似乎是合理的,尽管 UX 人员会比我更了解。
(3) 似乎与 #15743 隐约相关,但我不确定它们是否足够接近以合并。
 davidopp
于 2015-11-20
davidopp
于 2015-11-20
除了上述情况外,很高兴看到我们获得的资源利用率。
kubectl utilization requests可能会显示(也许kubectl util或kubectl usage更好/更短):
cores: 4.455/5 cores (89%)
memory: 20.1/30 GiB (67%)
...
在此示例中,聚合容器请求为 4.455 个核心和 20.1 GiB,集群中有 5 个核心和 30GiB。
 chrishiestand
于 2016-09-16
chrishiestand
于 2016-09-16
有:
$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
cluster1-k8s-master-1 312m 15% 1362Mi 68%
cluster1-k8s-node-1 124m 12% 233Mi 11%
 xmik
于 2016-12-19
xmik
于 2016-12-19
我使用下面的命令来快速查看资源使用情况。 这是我找到的最简单的方法。
kubectl describe nodes
 ozbillwang
于 2017-01-11
ozbillwang
于 2017-01-11
如果有一种方法可以“格式化” kubectl describe nodes的输出,我不介意编写脚本来总结所有节点的资源请求/限制。
 tonglil
于 2017-01-20
tonglil
于 2017-01-20
这是我的黑客kubectl describe nodes | grep -A 2 -e "^\\s*CPU Requests"
 from-nibly
于 2017-02-02
from-nibly
于 2017-02-02
@from-nably 谢谢,正是我想要的
 jredl-va
于 2017-05-25
jredl-va
于 2017-05-25
是的,这是我的:
$ cat bin/node-resources.sh
#!/bin/bash
set -euo pipefail
echo -e "Iterating...\n"
nodes=$(kubectl get node --no-headers -o custom-columns=NAME:.metadata.name)
for node in $nodes; do
echo "Node: $node"
kubectl describe node "$node" | sed '1,/Non-terminated Pods/d'
echo
done
@goltermann在这个问题上没有 sig 标签。 请通过以下方式添加 sig 标签:
(1) 提及一个签名: @kubernetes/sig-<team-name>-misc
(2) 手动指定标签: /sig <label>
_注意:方法(1)将触发通知团队。 您可以在此处找到团队列表。_
 k8s-github-robot
于 2017-06-01
k8s-github-robot
于 2017-06-01
@ kubernetes / sig-cli-misc
 kargakis
于 2017-06-10
kargakis
于 2017-06-10
您可以使用以下命令来查找节点的 CPU 利用率百分比
alias util='kubectl get nodes | grep node | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
Note: 4000m cores is the total cores in one node
alias cpualloc="util | grep % | awk '{print \$1}' | awk '{ sum += \$1 } END { if (NR > 0) { result=(sum**4000); printf result/NR \"%\n\" } }'"
$ cpualloc
3.89358%
Note: 1600MB is the total cores in one node
alias memalloc='util | grep % | awk '\''{print $3}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { result=(sum*100)/(NR*1600); printf result/NR "%\n" } }'\'''
$ memalloc
24.6832%
 alok87
于 2017-07-05
alok87
于 2017-07-05
@tomfotherby alias util='kubectl get nodes | grep node | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
alok87
于 2017-07-21
@alok87 - 感谢您的别名。 就我而言,鉴于我们使用bash和m3.large实例类型(2 cpu,7.5G 内存),这对我有用。
alias util='kubectl get nodes --no-headers | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
# Get CPU request total (we x20 because because each m3.large has 2 vcpus (2000m) )
alias cpualloc='util | grep % | awk '\''{print $1}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { print sum/(NR*20), "%\n" } }'\'''
# Get mem request total (we x75 because because each m3.large has 7.5G ram )
alias memalloc='util | grep % | awk '\''{print $5}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { print sum/(NR*75), "%\n" } }'\'''
$util
ip-10-56-0-178.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
960m (48%) 2700m (135%) 630Mi (8%) 2034Mi (27%)
ip-10-56-0-22.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
920m (46%) 1400m (70%) 560Mi (7%) 550Mi (7%)
ip-10-56-0-56.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
1160m (57%) 2800m (140%) 972Mi (13%) 3976Mi (53%)
ip-10-56-0-99.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
804m (40%) 794m (39%) 824Mi (11%) 1300Mi (17%)
cpualloc
48.05 %
$ memalloc
9.95333 %
 tomfotherby
于 2017-07-25
tomfotherby
于 2017-07-25
https://github.com/kubernetes/kubernetes/issues/17512#issuecomment -267992922 kubectl top显示用法,而不是分配。 分配是导致insufficient CPU问题的原因。 在这个问题上有很多关于差异的困惑。
AFAICT,没有简单的方法可以通过 pod 获取节点 CPU 分配的报告,因为请求是在规范中针对每个容器的。 即便如此,这也很困难,因为.spec.containers[*].requests可能有也可能没有limits / requests字段(以我的经验)
 nfirvine
于 2017-08-30
nfirvine
于 2017-08-30
/cc @mysterikkit
 misterikkit
于 2018-01-02
misterikkit
于 2018-01-02
加入这个 shell 脚本派对。 我有一个运行 CA 的旧集群,禁用了缩减。 我编写了这个脚本来大致确定当集群开始超过其 AWS 路由限制时我可以缩小多少:
#!/bin/bash
set -e
KUBECTL="kubectl"
NODES=$($KUBECTL get nodes --no-headers -o custom-columns=NAME:.metadata.name)
function usage() {
local node_count=0
local total_percent_cpu=0
local total_percent_mem=0
local readonly nodes=$@
for n in $nodes; do
local requests=$($KUBECTL describe node $n | grep -A2 -E "^\\s*CPU Requests" | tail -n1)
local percent_cpu=$(echo $requests | awk -F "[()%]" '{print $2}')
local percent_mem=$(echo $requests | awk -F "[()%]" '{print $8}')
echo "$n: ${percent_cpu}% CPU, ${percent_mem}% memory"
node_count=$((node_count + 1))
total_percent_cpu=$((total_percent_cpu + percent_cpu))
total_percent_mem=$((total_percent_mem + percent_mem))
done
local readonly avg_percent_cpu=$((total_percent_cpu / node_count))
local readonly avg_percent_mem=$((total_percent_mem / node_count))
echo "Average usage: ${avg_percent_cpu}% CPU, ${avg_percent_mem}% memory."
}
usage $NODES
产生如下输出:
ip-REDACTED.us-west-2.compute.internal: 38% CPU, 9% memory
...many redacted lines...
ip-REDACTED.us-west-2.compute.internal: 41% CPU, 8% memory
ip-REDACTED.us-west-2.compute.internal: 61% CPU, 7% memory
Average usage: 45% CPU, 15% memory.
 negz
于 2018-02-21
negz
于 2018-02-21
top 命令中还有 pod 选项:
kubectl top pod
 ylogx
于 2018-02-21
ylogx
于 2018-02-21
@ylogx https://github.com/kubernetes/kubernetes/issues/17512#issuecomment -326089708
nfirvine
于 2018-02-21
我在集群范围内获取分配的方法:
$ kubectl get po --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"
它产生类似的东西:
kube-system:heapster-v1.5.0-dc8df7cc9-7fqx6
heapster:88m
heapster-nanny:50m
kube-system:kube-dns-6cdf767cb8-cjjdr
kubedns:100m
dnsmasq:150m
sidecar:10m
prometheus-to-sd:
kube-system:kube-dns-6cdf767cb8-pnx2g
kubedns:100m
dnsmasq:150m
sidecar:10m
prometheus-to-sd:
kube-system:kube-dns-autoscaler-69c5cbdcdd-wwjtg
autoscaler:20m
kube-system:kube-proxy-gke-cluster1-default-pool-cd7058d6-3tt9
kube-proxy:100m
kube-system:kube-proxy-gke-cluster1-preempt-pool-57d7ff41-jplf
kube-proxy:100m
kube-system:kubernetes-dashboard-7b9c4bf75c-f7zrl
kubernetes-dashboard:50m
kube-system:l7-default-backend-57856c5f55-68s5g
default-http-backend:10m
kube-system:metrics-server-v0.2.0-86585d9749-kkrzl
metrics-server:48m
metrics-server-nanny:5m
kube-system:tiller-deploy-7794bfb756-8kxh5
tiller:10m
 shtouff
于 2018-03-04
shtouff
于 2018-03-04
这很奇怪。 我想知道我何时达到或接近分配容量。 这似乎是集群的一个非常基本的功能。 无论是显示高百分比的统计数据还是文本错误......其他人怎么知道这一点? 总是在云平台上使用自动缩放?
 kierenj
于 2018-03-13
kierenj
于 2018-03-13
我编写了https://github.com/dpetzold/kube-resource-explorer/来解决 #3。 这是一些示例输出:
$ ./resource-explorer -namespace kube-system -reverse -sort MemReq
Namespace Name CpuReq CpuReq% CpuLimit CpuLimit% MemReq MemReq% MemLimit MemLimit%
--------- ---- ------ ------- -------- --------- ------ ------- -------- ---------
kube-system event-exporter-v0.1.7-5c4d9556cf-kf4tf 0 0% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-mshh 100m 10% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-bv59 100m 10% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-ntfw 100m 10% 0 0% 0 0% 0 0%
kube-system kube-dns-autoscaler-244676396-xzgs4 20m 2% 0 0% 10Mi 0% 0 0%
kube-system l7-default-backend-1044750973-kqh98 10m 1% 10m 1% 20Mi 0% 20Mi 0%
kube-system kubernetes-dashboard-768854d6dc-jh292 100m 10% 100m 10% 100Mi 3% 300Mi 11%
kube-system kube-dns-323615064-8nxfl 260m 27% 0 0% 110Mi 4% 170Mi 6%
kube-system fluentd-gcp-v2.0.9-4qkwk 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system fluentd-gcp-v2.0.9-jmtpw 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system fluentd-gcp-v2.0.9-tw9vk 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system heapster-v1.4.3-74b5bd94bb-fz8hd 138m 14% 138m 14% 301856Ki 11% 301856Ki 11%
 dpetzold
于 2018-05-02
dpetzold
于 2018-05-02
@shtouff
root<strong i="7">@debian9</strong>:~# kubectl get po -n chenkunning-84 -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"
error: error parsing jsonpath {range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}, unrecognized character in action: U+0027 '''
root<strong i="8">@debian9</strong>:~# kubectl version
Client Version: version.Info{Major:"1", Minor:"6+", GitVersion:"v1.6.7-beta.0+$Format:%h$", GitCommit:"bb053ff0cb25a043e828d62394ed626fda2719a1", GitTreeState:"dirty", BuildDate:"2017-08-26T09:34:19Z", GoVersion:"go1.8", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"6+", GitVersion:"v1.6.7-beta.0+$Format:84c3ae0384658cd40c1d1e637f5faa98cf6a965c$", GitCommit:"3af2004eebf3cbd8d7f24b0ecd23fe4afb889163", GitTreeState:"clean", BuildDate:"2018-04-04T08:40:48Z", GoVersion:"go1.8.1", Compiler:"gc", Platform:"linux/amd64"}
 harryge00
于 2018-05-22
harryge00
于 2018-05-22
@harryge00 :U+0027 是一个卷曲引用,可能是复制粘贴问题
nfirvine
于 2018-05-22
@nfirvine谢谢! 我已经通过使用解决了问题:
kubectl get pods -n my-ns -o=jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.spec.containers[0].resources.limits.cpu} {"\n"}{end}' |awk '{sum+=$2 ; print $0} END{print "sum=",sum}'
它适用于每个 pod 仅包含 1 个容器的命名空间。
harryge00
于 2018-05-25
@xmik嘿,我正在使用 k8 1.7 并运行 hepaster。 当我运行 $ kubectl top nodes --heapster-namespace=kube-system 时,它显示“错误:指标尚不可用”。 任何解决错误的线索?
 abushoeb
于 2018-06-05
abushoeb
于 2018-06-05
@abushoeb :
我不认为编辑:支持此标志,您是对的: https :kubectl top支持 flag:--heapster-namespace。- 如果您看到“错误:指标尚不可用”,那么您应该检查 heapster 部署。 它的日志说什么? heapster 服务正常吗,端点不是
<none>吗? 使用如下命令检查后者:kubectl -n kube-system describe svc/heapster
xmik
于 2018-06-05
@xmik你是对的,heapster 没有正确配置。 非常感谢。 它现在正在工作。 不知道有没有办法实时获取GPU的使用信息? 此 top 命令仅提供 CPU 和内存使用情况。
abushoeb
于 2018-06-05
我不知道。 :(
xmik
于 2018-06-05
@abushoeb我收到同样的错误“错误:指标尚不可用”。 你怎么修好它的?
 avgKol
于 2018-06-21
avgKol
于 2018-06-21
@avgKol 首先检查您的 heapster 部署。 就我而言,它没有正确部署。 检查它的一种方法是通过 CURL 命令访问指标,如curl -L http://heapster-pod-ip:heapster-service-port/api/v1/model/metrics/ 。 如果它没有显示指标,则检查 heapster pod 和日志。 也可以像这样通过网络浏览器访问 hepster 指标。
abushoeb
于 2018-06-22
如果有人感兴趣,我创建了一个工具来为 Kubernetes 资源使用(和成本)生成静态 HTML: https :
 hjacobs
于 2018-07-18
hjacobs
于 2018-07-18
@hjacobs我想使用该工具,但不喜欢安装/使用 python 包。 介意将其打包为 docker 镜像吗?
tonglil
于 2018-07-18
@tonglil该项目还很早,但我的计划是拥有一个开箱即用的 Docker 映像,包括。 您可以使用kubectl apply -f ..执行的网络服务器。
hjacobs
于 2018-07-18
这是对我有用的:
kubectl get nodes -o=jsonpath="{range .items[*]}{.metadata.name}{'\t'}{.status.allocatable.memory}{'\t'}{.status.allocatable.cpu}{'\n'}{end}"
它显示输出为:
ip-192-168-101-177.us-west-2.compute.internal 251643680Ki 32
ip-192-168-196-254.us-west-2.compute.internal 251643680Ki 32
 arun-gupta
于 2018-09-12
arun-gupta
于 2018-09-12
@tonglil Docker 镜像现已可用: https :
hjacobs
于 2018-09-13
问题在 90 天不活动后变得陈旧。
使用/remove-lifecycle stale将问题标记为新问题。
陈旧的问题在额外 30 天不活动后腐烂并最终关闭。
如果现在可以安全关闭此问题,请使用/close关闭。
向 sig-testing、kubernetes/test-infra 和/或fejta发送反馈。
/生命周期陈旧
 fejta-bot
于 2018-12-17
fejta-bot
于 2018-12-17
/删除生命周期陈旧
每个月左右,我的谷歌搜索都会让我回到这个问题。 有很多方法可以使用长jq字符串获取我需要的统计信息,或者使用带有大量计算的 Grafana 仪表板……但是如果有这样的命令,那就太好了:
# kubectl utilization cluster
cores: 19.255/24 cores (80%)
memory: 16.4/24 GiB (68%)
# kubectl utilization [node name]
cores: 3.125/4 cores (78%)
memory: 2.1/4 GiB (52%)
(类似于@chrishiestand在线程前面提到的方式)。
我经常每周构建和销毁几十个测试集群,我宁愿不必构建自动化或添加一些 shell 别名,以便能够看到“如果我把这么多服务器放在那里,然后扔掉这些应用程序在他们身上,我的整体利用率/压力是多少”。
特别是对于更小/更深奥的集群,我不想设置自动缩放到月球(通常是出于金钱原因),但确实需要知道我是否有足够的开销来处理次要的 pod 自动缩放事件。
 geerlingguy
于 2018-12-30
geerlingguy
于 2018-12-30
一个额外的请求——我希望能够按命名空间查看总资源使用情况(至少;按部署/标签也很有用),因此我可以通过确定哪些命名空间值得来集中我的资源修剪工作专注于。
 evankanderson
于 2019-01-01
evankanderson
于 2019-01-01
我做了一个小插件kubectl-view-utilization ,它提供了@geerlingguy描述的功能。 可以通过 krew 插件管理器安装。 这是在 BASH 中实现的,它需要 awk 和 bc。
使用 kubectl 插件框架,这可以完全从核心工具中抽象出来。
 etopeter
于 2019-01-13
etopeter
于 2019-01-13
我很高兴其他人也面临着这个挑战。 我创建了 Kube Eagle(一个 prometheus 导出器),它帮助我更好地了解集群资源,并最终让我更好地利用可用的硬件资源:
https://github.com/google-cloud-tools/kube-eagle

 weeco
于 2019-03-03
weeco
于 2019-03-03
这是一个python脚本,用于以表格格式获取实际节点利用率
https://github.com/amelbakry/kube-node-utilization
Kubernetes 节点利用率......
+------------------------------------------------+ --------+--------+
| 节点名称 | 中央处理器 | 内存 |
+------------------------------------------------+ --------+--------+
| ip-176-35-32-139.eu-central-1.compute.internal | 13.49% | 60.87% |
| ip-176-35-26-21.eu-central-1.compute.internal | 5.89% | 15.10% |
| ip-176-35-9-122.eu-central-1.compute.internal | 8.08% | 65.51% |
| ip-176-35-22-243.eu-central-1.compute.internal | 6.29% | 19.28% |
+------------------------------------------------+ --------+--------+
 amelbakry
于 2019-04-24
amelbakry
于 2019-04-24
至少对我@amelbakry来说,重要的是集群级别的利用率:“我需要添加更多机器吗?” /“我应该移除一些机器吗?” /“我应该期待集群很快扩大规模吗?” ..
kierenj
于 2019-04-25
临时存储使用情况如何? 任何想法如何从所有豆荚中获取它?
为了有用,我的提示:
kubectl get pods -o json -n kube-system | jq -r '.items[] | .metadata.name + " \n Req. RAM: " + .spec.containers[].resources.requests.memory + " \n Lim. RAM: " + .spec.containers[].resources.limits.memory + " \n Req. CPU: " + .spec.containers[].resources.requests.cpu + " \n Lim. CPU: " + .spec.containers[].resources.limits.cpu + " \n Req. Eph. DISK: " + .spec.containers[].resources.requests["ephemeral-storage"] + " \n Lim. Eph. DISK: " + .spec.containers[].resources.limits["ephemeral-storage"] + "\n"'
...
kube-proxy-xlmjt
Req. RAM: 32Mi
Lim. RAM: 256Mi
Req. CPU: 100m
Lim. CPU:
Req. Eph. DISK: 100Mi
Lim. Eph. DISK: 512Mi
...
echo "\nRAM Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.memory' && echo "\nRAM Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests.memory + " | " + .metadata.name'
echo "\nRAM Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.memory' && echo "\nRAM Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits.memory + " | " + .metadata.name'
echo "\nCPU Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.cpu' && echo "\nCPU Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests.cpu + " | " + .metadata.name'
echo "\nCPU Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.cpu' && echo "\nCPU Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits.cpu + " | " + .metadata.name'
echo "\nEph. DISK Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.ephemeral-storage' && echo "\nEph. DISK Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests["ephemeral-storage"] + " | " + .metadata.name'
echo "\nEph. DISK Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.ephemeral-storage' && echo "\nEph. DISK Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits["ephemeral-storage"] + " | " + .metadata.name'
RAM Requests TOTAL:
requests.memory 3504Mi 16Gi
RAM Requests:
64Mi | aws-alb-ingress-controller-6b569b448c-jzj6f
...
 kivagant-ba
于 2019-04-25
kivagant-ba
于 2019-04-25
@kivagant-ba 你可以试试这个片段来获取每个节点的 pod 指标,你可以获得所有节点,比如
https://github.com/amelbakry/kube-node-utilization
def get_pod_metrics_per_node(node):
pod_metrics = "/api/v1/pods?fieldSelector=spec.nodeName%3D" + 节点
响应 = api_client.call_api(pod_metrics,
'GET', auth_settings=['BearerToken'],
response_type='json', _preload_content=False)
response = json.loads(response[0].data.decode('utf-8'))
返回响应
amelbakry
于 2019-04-25
@kierenj我认为基于云 kubernetes 运行的集群自动缩放器组件应该处理容量。 不确定这是否是您的问题。
amelbakry
于 2019-04-25
问题在 90 天不活动后变得陈旧。
使用/remove-lifecycle stale将问题标记为新问题。
陈旧的问题在额外 30 天不活动后腐烂并最终关闭。
如果现在可以安全关闭此问题,请使用/close关闭。
向 sig-testing、kubernetes/test-infra 和/或fejta发送反馈。
/生命周期陈旧
fejta-bot
于 2019-07-30
/删除生命周期陈旧
我和许多其他人一样,多年来一直回到这里来获得我们需要通过 CLI 管理集群的技巧(例如 AWS ASG)
 eduncan911
于 2019-08-28
eduncan911
于 2019-08-28
@etopeter感谢您提供如此酷的 CLI 插件。 喜欢它的简单。 关于如何更好地理解数字及其确切含义的任何建议?
 demisx
于 2019-08-28
demisx
于 2019-08-28
如果有人可以在这里找到它的用途,那么这里有一个脚本可以转储 pod 的当前限制。
kubectl get pods --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}\
{'.spec.nodeName -'} {.spec.nodeName}{'\n'}\
{range .spec.containers[*]}\
{'requests.cpu -'} {.resources.requests.cpu}{'\n'}\
{'limits.cpu -'} {.resources.limits.cpu}{'\n'}\
{'requests.memory -'} {.resources.requests.memory}{'\n'}\
{'limits.memory -'} {.resources.limits.memory}{'\n'}\
{'\n'}{end}\
{'\n'}{end}"
示例输出
...
kube -system:addon-http-application-routing-nginx-ingress-controller-6bq49l7
.spec.nodeName - aks-agentpool-84550961-0
请求.cpu -
限制.cpu -
requests.memory -
限制.内存 -
kube-系统:coredns-696c4d987c-pjht8
.spec.nodeName - aks-agentpool-84550961-0
requests.cpu - 100m
限制.cpu -
requests.memory - 70Mi
限制.内存 - 170Mi
kube-系统:coredns-696c4d987c-rtkl6
.spec.nodeName - aks-agentpool-84550961-2
requests.cpu - 100m
限制.cpu -
requests.memory - 70Mi
限制.内存 - 170Mi
kube-系统:coredns-696c4d987c-zgcbp
.spec.nodeName - aks-agentpool-84550961-1
requests.cpu - 100m
限制.cpu -
requests.memory - 70Mi
限制.内存 - 170Mi
kube-系统:coredns-autoscaler-657d77ffbf-7t72x
.spec.nodeName - aks-agentpool-84550961-2
requests.cpu - 20m
限制.cpu -
requests.memory - 10Mi
限制.内存 -
kube-系统:coredns-autoscaler-657d77ffbf-zrp6m
.spec.nodeName - aks-agentpool-84550961-0
requests.cpu - 20m
限制.cpu -
requests.memory - 10Mi
限制.内存 -
kube-系统:kube-proxy-57nw5
.spec.nodeName - aks-agentpool-84550961-1
requests.cpu - 100m
限制.cpu -
requests.memory -
限制.内存 -
...
 Spaceman1861
于 2019-09-02
Spaceman1861
于 2019-09-02
@Spaceman1861你能举个例子吗?
eduncan911
于 2019-09-02
@eduncan911完成
Spaceman1861
于 2019-09-02
我发现以表格格式读取输出更容易,如下所示(这显示的是请求而不是限制):
kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY(bytes)":.spec.containers[*].resources.requests.memory --all-namespaces
示例输出:
NAME CPU(cores) MEMORY(bytes)
pod1 100m 128Mi
pod2 100m 128Mi,128Mi
 lentzi90
于 2019-09-02
lentzi90
于 2019-09-02
@lentzi90仅供参考:您可以在Kubernetes Web View (“kubectl for the web”)中显示类似的自定义列,演示: https ://kube-web-view.demo.j-serv.de/clusters/local/namespaces/ ].resources.requests.cpu)%3BMemory+Requests=join(%27,%20% 27,%20spec.containers[ ].
关于自定义列的文档: https: //kube-web-view.readthedocs.io/en/latest/features.html#listing -resources
hjacobs
于 2019-09-02
哦,闪亮的
Spaceman1861
于 2019-09-02
这是一个脚本 (deployment-health.sh),用于根据使用情况和配置的限制获取部署中 pod 的利用率
https://github.com/amelbakry/kubernetes-scripts
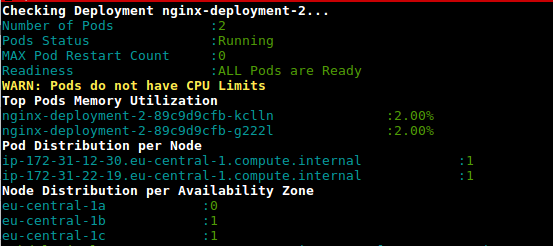
amelbakry
于 2019-09-02
受到@lentzi90和@ylogx答案的启发,我创建了自己的大脚本,显示实际资源使用情况( kubectl top pods )以及资源请求和限制:
join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '<none>' <(kubectl top pods) <(kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory) | column -t -s' '
输出示例:
NAME CPU(cores) MEMORY(bytes) CPU_REQ(cores) MEMORY_REQ(bytes) CPU_LIM(cores) MEMORY_LIM(bytes)
xxxxx-847dbbc4c-c6twt 20m 110Mi 50m 150Mi 150m 250Mi
xxx-service-7b6b9558fc-9cq5b 19m 1304Mi 1 <none> 1 <none>
xxxxxxxxxxxxxxx-hook-5d585b449b-zfxmh 0m 46Mi 200m 155M 200m 155M
这是您在终端中仅使用kstats的别名:
alias kstats='join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '"'"'<none>'"'"' <(kubectl top pods) <(kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory) | column -t -s'"'"' '"'"
PS 我只在我的 mac 上测试过脚本,对于 linux 和 windows 可能需要一些更改
 alikhil
于 2019-09-25
alikhil
于 2019-09-25
这是一个脚本 (deployment-health.sh),用于根据使用情况和配置的限制获取部署中 pod 的利用率
https://github.com/amelbakry/kubernetes-scripts
@amelbakry我尝试在 Mac 上执行它时遇到以下错误:
Failed to execute process './deployment-health.sh'. Reason:
exec: Exec format error
The file './deployment-health.sh' is marked as an executable but could not be run by the operating system.
哎呀,
“#!” 必须是第一行。 而是尝试“bash
./deployment-health.sh”来解决这个问题。
/查尔斯
附注。 PR已打开以解决问题
2019 年 9 月 25 日,星期三,上午 10:19,Dmitri Moore通知@github.com
写道:
这是一个脚本 (deployment-health.sh) 来获取 Pod 的利用率
在基于使用和配置限制的部署中
https://github.com/amelbakry/kubernetes-scripts@amelbakry https://github.com/amelbakry我得到以下信息
尝试在 Mac 上执行时出错:无法执行进程“./deployment-health.sh”。 原因:
exec: 执行格式错误
文件“./deployment-health.sh”被标记为可执行文件,但操作系统无法运行。—
您收到此消息是因为您订阅了此线程。
直接回复本邮件,在GitHub上查看
https://github.com/kubernetes/kubernetes/issues/17512?email_source=notifications&email_token=AACA3TODQEUPWK3V3UY3SF3QLOMSFA5CNFSM4BUXCUG2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD7SVHRQ#issuecomment-535122886 ,
或静音线程
https://github.com/notifications/unsubscribe-auth/AACA3TOPOBIWXFX2DAOT6JDQLOMSFANCNFSM4BUXCUGQ
.
 cgthayer
于 2019-09-25
cgthayer
于 2019-09-25
@cgthayer您可能希望在全球范围内应用该 PR 修复程序。 此外,当我在 MacOs Mojave 上运行脚本时,出现了一堆错误,包括我不使用的欧盟特定区域名称。 看起来这些脚本是为特定项目编写的。
demisx
于 2019-10-02
这是 join ex 的修改版本。 它也做列的总数。
oc_ns_pod_usage () {
# show pod usage for cpu/mem
ns="$1"
usage_chk3 "$ns" || return 1
printf "$ns\n"
separator=$(printf '=%.0s' {1..50})
printf "$separator\n"
output=$(join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '<none>' \
<(kubectl top pods -n $ns) \
<(kubectl get -n $ns pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory))
totals=$(printf "%s" "$output" | awk '{s+=$2; t+=$3; u+=$4; v+=$5; w+=$6; x+=$7} END {print s" "t" "u" "v" "w" "x}')
printf "%s\n%s\nTotals: %s\n" "$output" "$separator" "$totals" | column -t -s' '
printf "$separator\n"
}
例子
$ oc_ns_pod_usage ls-indexer
ls-indexer
==================================================
NAME CPU(cores) MEMORY(bytes) CPU_REQ(cores) MEMORY_REQ(bytes) CPU_LIM(cores) MEMORY_LIM(bytes)
ls-indexer-f5-7cd5859997-qsfrp 15m 741Mi 1 1000Mi 2 2000Mi
ls-indexer-f5-7cd5859997-sclvg 15m 735Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-4b7j2 92m 1103Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-5xj5l 88m 1124Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-6vvl2 92m 1132Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-85f66 85m 1151Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-924jz 96m 1124Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-g6gx8 119m 1119Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-hkhnt 52m 819Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-hrsrs 51m 1122Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-j4qxm 53m 885Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-lxlrb 83m 1215Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-mw6rt 86m 1131Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-pbdf8 95m 1115Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-qk9bm 91m 1141Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-sdv9r 54m 1194Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-t67v6 75m 1234Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-tkxs2 88m 1364Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-v6jl2 53m 747Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-wkqr7 53m 838Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-jp8qc 190m 1191Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-jv4bv 192m 1162Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-k4dcd 194m 1144Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-n46tz 192m 1155Mi 1 1000Mi 2 2000Mi
ls-indexer-packetbeat-db98f6fdf-8x446 35m 1198Mi 1 1000Mi 2 2000Mi
ls-indexer-packetbeat-db98f6fdf-gmxxd 22m 1203Mi 1 1000Mi 2 2000Mi
ls-indexer-syslog-5466bc4d4f-gzxw8 27m 1125Mi 1 1000Mi 2 2000Mi
ls-indexer-syslog-5466bc4d4f-zh7st 29m 1153Mi 1 1000Mi 2 2000Mi
==================================================
Totals: 2317 30365 28 28000 56 56000
==================================================
 slmingol
于 2019-10-21
slmingol
于 2019-10-21
什么是usage_chk3?
 cristifalcas
于 2019-10-25
cristifalcas
于 2019-10-25
我还想分享我的工具 ;-) kubectl-view-allocations:kubectl 插件来列出分配(cpu、内存、gpu、... X 请求、限制、可分配,...)。 ,欢迎提出要求。
我这样做是因为我想为我的(内部)用户提供一种查看“谁分配了什么”的方法。 默认情况下会显示每个资源,但在以下示例中,我只请求名称为“gpu”的资源。
> kubectl-view-allocations -r gpu
Resource Requested %Requested Limit %Limit Allocatable Free
nvidia.com/gpu 7 58% 7 58% 12 5
├─ node-gpu1 1 50% 1 50% 2 1
│ └─ xxxx-784dd998f4-zt9dh 1 1
├─ node-gpu2 0 0% 0 0% 2 2
├─ node-gpu3 0 0% 0 0% 2 2
├─ node-gpu4 1 50% 1 50% 2 1
│ └─ aaaa-1571819245-5ql82 1 1
├─ node-gpu5 2 100% 2 100% 2 0
│ ├─ bbbb-1571738839-dfkhn 1 1
│ └─ bbbb-1571738888-52c4w 1 1
└─ node-gpu6 2 100% 2 100% 2 0
├─ bbbb-1571738688-vlxng 1 1
└─ cccc-1571745684-7k6bn 1 1
即将推出的版本:
- 将允许隐藏(节点,pod)级别或选择如何分组,(例如仅提供资源概览)
- 通过 curl、krew、brew、...安装(目前二进制文件在 github 的发布部分下可用)
感谢kubectl-view-utilization的灵感,但是添加对其他资源的支持对于许多复制/粘贴或在 bash 中对我来说很难(对于通用方式)。
 davidB
于 2019-10-25
davidB
于 2019-10-25
这是我的黑客
kubectl describe nodes | grep -A 2 -e "^\\s*CPU Requests"
这不再起作用了:(
 libudas
于 2019-11-28
libudas
于 2019-11-28
试试kubectl describe node | grep -A5 "Allocated"
 MostafaGazar
于 2019-11-28
MostafaGazar
于 2019-11-28
这是目前通过竖起大拇指请求的第 4 高的问题,但仍然是priority/backlog 。
如果有人能指出我正确的方向,或者我们可以敲定提案,我很乐意尝试一下。 我认为@davidB工具的用户kubectl 。
 alexkreidler
于 2019-12-01
alexkreidler
于 2019-12-01
使用以下命令: kubectl top nodes & kubectl describe node我们不会得到一致的结果
例如,第一个 CPU(核心)为 1064m,但第二个(1480m)无法获取此结果:
kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
abcd-p174e23ea5qa4g279446c803f82-abc-node-0 1064m 53% 6783Mi 88%
kubectl describe node abcd-p174e23ea5qa4g279446c803f82-abc-node-0
...
Resource Requests Limits
-------- -------- ------
cpu 1480m (74%) 1300m (65%)
memory 2981486848 (37%) 1588314624 (19%)
关于在不使用kubectl top nodes情况下获取 CPU(核心)的任何想法?
 smpar
于 2019-12-18
smpar
于 2019-12-18
我还想分享我的工具 ;-) kubectl-view-allocations:kubectl 插件来列出分配(cpu、内存、gpu、... X 请求、限制、可分配,...)。 ,欢迎提出要求。
我这样做是因为我想为我的(内部)用户提供一种查看“谁分配了什么”的方法。 默认情况下会显示每个资源,但在以下示例中,我只请求名称为“gpu”的资源。
> kubectl-view-allocations -r gpu Resource Requested %Requested Limit %Limit Allocatable Free nvidia.com/gpu 7 58% 7 58% 12 5 ├─ node-gpu1 1 50% 1 50% 2 1 │ └─ xxxx-784dd998f4-zt9dh 1 1 ├─ node-gpu2 0 0% 0 0% 2 2 ├─ node-gpu3 0 0% 0 0% 2 2 ├─ node-gpu4 1 50% 1 50% 2 1 │ └─ aaaa-1571819245-5ql82 1 1 ├─ node-gpu5 2 100% 2 100% 2 0 │ ├─ bbbb-1571738839-dfkhn 1 1 │ └─ bbbb-1571738888-52c4w 1 1 └─ node-gpu6 2 100% 2 100% 2 0 ├─ bbbb-1571738688-vlxng 1 1 └─ cccc-1571745684-7k6bn 1 1即将推出的版本:
* will allow to hide (node, pod) level or to choose how to group, (eg to provide an overview with only resources) * installation via curl, krew, brew, ... (currently binary are available under the releases section of github)感谢kubectl-view-utilization的灵感,但是添加对其他资源的支持对于许多复制/粘贴或在 bash 中对我来说很难(对于通用方式)。
你好大卫,如果你为新发行版提供更多编译的二进制文件会很好。 在 Ubuntu 16.04 上,我们得到
kubectl-view-allocations:/lib/x86_64-linux-gnu/libc.so.6:未找到版本“GLIBC_2.25”(kubectl-view-allocations 需要)
dpkg -l |grep glib
ii libglib2.0-0:amd64 2.48.2-0ubuntu4.4
 omerfsen
于 2020-01-12
omerfsen
于 2020-01-12
@omerfsen您可以尝试新版本的 kubectl-view-allocations 并评论票证版本 `GLIBC_2.25' not found #14吗?
davidB
于 2020-01-15
我在集群范围内获取分配的方法:
$ kubectl get po --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"它产生类似的东西:
kube-system:heapster-v1.5.0-dc8df7cc9-7fqx6 heapster:88m heapster-nanny:50m kube-system:kube-dns-6cdf767cb8-cjjdr kubedns:100m dnsmasq:150m sidecar:10m prometheus-to-sd: kube-system:kube-dns-6cdf767cb8-pnx2g kubedns:100m dnsmasq:150m sidecar:10m prometheus-to-sd: kube-system:kube-dns-autoscaler-69c5cbdcdd-wwjtg autoscaler:20m kube-system:kube-proxy-gke-cluster1-default-pool-cd7058d6-3tt9 kube-proxy:100m kube-system:kube-proxy-gke-cluster1-preempt-pool-57d7ff41-jplf kube-proxy:100m kube-system:kubernetes-dashboard-7b9c4bf75c-f7zrl kubernetes-dashboard:50m kube-system:l7-default-backend-57856c5f55-68s5g default-http-backend:10m kube-system:metrics-server-v0.2.0-86585d9749-kkrzl metrics-server:48m metrics-server-nanny:5m kube-system:tiller-deploy-7794bfb756-8kxh5 tiller:10m
到目前为止最好的答案在这里。
 abelal83
于 2020-01-31
abelal83
于 2020-01-31
受上述脚本的启发,我创建了以下脚本来查看使用情况、请求和限制:
join -1 2 -2 2 -a 1 -a 2 -o "2.1 0 1.3 2.3 2.5 1.4 2.4 2.6" -e '<wait>' \
<( kubectl top pods --all-namespaces | sort --key 2 -b ) \
<( kubectl get pods --all-namespaces -o custom-columns=NAMESPACE:.metadata.namespace,NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory | sort --key 2 -b ) \
| column -t -s' '
因为join shell 脚本需要一个排序列表,所以上面给出的脚本对我来说失败了。
结果,您可以从顶部和部署中看到当前使用情况,以及(此处)所有命名空间的请求和限制:
NAMESPACE NAME CPU(cores) CPU_REQ(cores) CPU_LIM(cores) MEMORY(bytes) MEMORY_REQ(bytes) MEMORY_LIM(bytes)
kube-system aws-node-2jzxr 18m 10m <none> 41Mi <none> <none>
kube-system aws-node-5zn6w <wait> 10m <none> <wait> <none> <none>
kube-system aws-node-h8cc5 20m 10m <none> 42Mi <none> <none>
kube-system aws-node-h9n4f 0m 10m <none> 0Mi <none> <none>
kube-system aws-node-lz5fn 17m 10m <none> 41Mi <none> <none>
kube-system aws-node-tpmxr 20m 10m <none> 39Mi <none> <none>
kube-system aws-node-zbkkh 23m 10m <none> 47Mi <none> <none>
cluster-autoscaler cluster-autoscaler-aws-cluster-autoscaler-5db55fbcf8-mdzkd 1m 100m 500m 9Mi 300Mi 500Mi
cluster-autoscaler cluster-autoscaler-aws-cluster-autoscaler-5db55fbcf8-q9xs8 39m 100m 500m 75Mi 300Mi 500Mi
kube-system coredns-56b56b56cd-bb26t 6m 100m <none> 11Mi 70Mi 170Mi
kube-system coredns-56b56b56cd-nhp58 6m 100m <none> 11Mi 70Mi 170Mi
kube-system coredns-56b56b56cd-wrmxv 7m 100m <none> 12Mi 70Mi 170Mi
gitlab-runner-l gitlab-runner-l-gitlab-runner-6b8b85f87f-9knnx 3m 100m 200m 10Mi 128Mi 256Mi
gitlab-runner-m gitlab-runner-m-gitlab-runner-6bfd5d6c84-t5nrd 7m 100m 200m 13Mi 128Mi 256Mi
gitlab-runner-mda gitlab-runner-mda-gitlab-runner-59bb66c8dd-bd9xw 4m 100m 200m 17Mi 128Mi 256Mi
gitlab-runner-ops gitlab-runner-ops-gitlab-runner-7c5b85dc97-zkb4c 3m 100m 200m 12Mi 128Mi 256Mi
gitlab-runner-pst gitlab-runner-pst-gitlab-runner-6b8f9bf56b-sszlr 6m 100m 200m 20Mi 128Mi 256Mi
gitlab-runner-s gitlab-runner-s-gitlab-runner-6bbccb9b7b-dmwgl 50m 100m 200m 27Mi 128Mi 512Mi
gitlab-runner-shared gitlab-runner-shared-gitlab-runner-688d57477f-qgs2z 3m <none> <none> 15Mi <none> <none>
kube-system kube-proxy-5b65t 15m 100m <none> 19Mi <none> <none>
kube-system kube-proxy-7qsgh 12m 100m <none> 24Mi <none> <none>
kube-system kube-proxy-gn2qg 13m 100m <none> 23Mi <none> <none>
kube-system kube-proxy-pz7fp 15m 100m <none> 18Mi <none> <none>
kube-system kube-proxy-vdjqt 15m 100m <none> 23Mi <none> <none>
kube-system kube-proxy-x4xtp 19m 100m <none> 15Mi <none> <none>
kube-system kube-proxy-xlpn7 0m 100m <none> 0Mi <none> <none>
metrics-server metrics-server-5875c7d795-bj7cq 5m 200m 500m 29Mi 200Mi 500Mi
metrics-server metrics-server-5875c7d795-jpjjn 7m 200m 500m 29Mi 200Mi 500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-06t94f <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-10lpn9j 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-11jrxfh <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-129hpvl 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-13kswg8 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-15qhp5w <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
值得注意的是:您可以对 CPU 消耗进行排序,例如:
| awk 'NR<2{print $0;next}{print $0| "sort --key 3 --numeric -b --reverse"}
这适用于 Mac - 我不确定它是否也适用于 Linux(因为连接、排序等......)。
希望有人可以使用它,直到 kubectl 对此有了很好的了解。
 stefanjacobs
于 2020-02-11
stefanjacobs
于 2020-02-11
我对kube-capacity有很好的经验。
例子:
kube-capacity --util
NODE CPU REQUESTS CPU LIMITS CPU UTIL MEMORY REQUESTS MEMORY LIMITS MEMORY UTIL
* 560m (28%) 130m (7%) 40m (2%) 572Mi (9%) 770Mi (13%) 470Mi (8%)
example-node-1 220m (22%) 10m (1%) 10m (1%) 192Mi (6%) 360Mi (12%) 210Mi (7%)
example-node-2 340m (34%) 120m (12%) 30m (3%) 380Mi (13%) 410Mi (14%) 260Mi (9%)
 eyalev
于 2020-02-18
eyalev
于 2020-02-18
为了让这个工具真正有用,它应该检测部署在集群上的所有 kubernetes 设备插件并显示所有这些插件的使用情况。 CPU/Mem 显然是不够的。 还有 GPU、TPU(用于机器学习)、英特尔 QAT,可能还有更多我不知道的。 还有存储呢? 我应该能够轻松查看请求的内容和使用的内容(理想情况下也包括 iops)。
 boniek83
于 2020-04-09
boniek83
于 2020-04-09
@boniek83 ,这就是我创建kubectl-view-allocations 的原因,因为我需要列出 GPU,...欢迎任何反馈(在 github 项目上)。 我很想知道它是否检测到 TPU(如果它被列为节点的资源,它应该)
davidB
于 2020-04-09
@boniek83 ,这就是我创建kubectl-view-allocations 的原因,因为我需要列出 GPU,...欢迎任何反馈(在 github 项目上)。 我很想知道它是否检测到 TPU(如果它被列为节点的资源,它应该)
我知道你的工具,就我而言,它是目前可用的最好的。 谢谢你!
我会尝试在复活节后测试 TPU。 如果这些数据能够以带有漂亮图形的 Web 应用程序格式提供,那将会很有帮助,这样我就不必向数据科学家提供任何访问 kubernetes 的权限。 他们只想知道谁在消耗资源,仅此而已:)
boniek83
于 2020-04-09
由于上面的工具和脚本都不符合我的需要(而且这个问题仍然存在:(),我修改了我自己的变体:
https://github.com/eht16/kube-cargo-load
它提供集群中 POD 的快速概览,并显示其配置的内存请求和限制以及实际内存使用情况。 这个想法是要了解配置的内存限制和实际使用量之间的比率。
 eht16
于 2020-04-13
eht16
于 2020-04-13
我们如何获取 Pod 的内存转储日志?
豆荚经常被挂起,
 RahulRatan07
于 2020-04-26
RahulRatan07
于 2020-04-26
kubectl describe nodesORkubectl top nodes,计算集群资源利用率应该考虑哪一个?- 还有为什么这两个结果之间存在差异。
这有什么合乎逻辑的解释吗?
 hmsvigle
于 2020-04-27
hmsvigle
于 2020-04-27
/种类特征
 brianpursley
于 2020-04-29
brianpursley
于 2020-04-29
所有关于节点的评论和技巧对我来说都很有效。 我还需要一些更高的视图来跟踪……比如每个节点池的资源总和!
 prathameshd9
于 2020-04-30
prathameshd9
于 2020-04-30
你好,
我想在一段时间内每 5 分钟记录一次 pod 的 cpu 和内存使用情况。 然后我会使用这些数据在 excel 中创建一个图表。 有任何想法吗? 谢谢
 rajjar123456
于 2020-07-18
rajjar123456
于 2020-07-18
你好,
我很高兴看到 Google 向我们所有人指出了这个问题:-)(有点失望,它在将近 5 年后仍然开放。)感谢所有的 shell 剪辑和其他工具。
 yceoshda
于 2020-07-28
yceoshda
于 2020-07-28
简单快速的破解:
$ kubectl describe nodes | grep 'Name:\| cpu\| memory'
Name: XXX-2-wke2
cpu 1552m (77%) 2402m (120%)
memory 2185Mi (70%) 3854Mi (123%)
Name: XXX-2-wkep
cpu 1102m (55%) 1452m (72%)
memory 1601Mi (51%) 2148Mi (69%)
Name: XXX-2-wkwz
cpu 852m (42%) 1352m (67%)
memory 1125Mi (36%) 3624Mi (116%)
 SerheyDolgushev
于 2020-08-05
SerheyDolgushev
于 2020-08-05
简单快速的破解:
$ kubectl describe nodes | grep 'Name:\| cpu\| memory' Name: XXX-2-wke2 cpu 1552m (77%) 2402m (120%) memory 2185Mi (70%) 3854Mi (123%) Name: XXX-2-wkep cpu 1102m (55%) 1452m (72%) memory 1601Mi (51%) 2148Mi (69%) Name: XXX-2-wkwz cpu 852m (42%) 1352m (67%) memory 1125Mi (36%) 3624Mi (116%)设备插件不存在。 他们应该是。 这样的设备也是资源。
boniek83
于 2020-08-05
你好!
我创建了这个脚本并与您分享。
https://github.com/Sensedia/open-tools/blob/master/scripts/listK8sHardwareResources.sh
该脚本汇总了您在此处分享的一些想法。 脚本可以递增,并且可以帮助其他人更简单地获取指标。
感谢分享提示和命令!
 aeciopires
于 2020-08-07
aeciopires
于 2020-08-07
对于我的用例,我最终编写了一个简单的kubectl插件,该插件列出了表中节点的 CPU/RAM 限制/保留。 它还检查当前的 pod CPU/RAM 消耗(如kubectl top pods ),但按 CPU 降序排列输出。
它比其他任何东西都更方便,但也许其他人也会发现它也很有用。
 laurybueno
于 2020-08-09
laurybueno
于 2020-08-09
哇,这是一个多么庞大的线程,但 kubernetes 团队仍然没有合适的解决方案来正确计算整个集群的当前总体 CPU 使用率?
 denissabramovs
于 2020-09-20
denissabramovs
于 2020-09-20
对于那些希望在 minikube 上运行它的人,首先启用度量服务器附加组件minikube addons enable metrics-server
然后运行命令kubectl top nodes
 raul1991
于 2020-10-16
raul1991
于 2020-10-16
如果您使用Krew :
kubectl krew install resource-capacity
kubectl resource-capacity
NODE CPU REQUESTS CPU LIMITS MEMORY REQUESTS MEMORY LIMITS
* 16960m (35%) 18600m (39%) 26366Mi (14%) 3100Mi (1%)
ip-10-0-138-176.eu-north-1.compute.internal 2460m (31%) 4200m (53%) 567Mi (1%) 784Mi (2%)
ip-10-0-155-49.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-162-84.eu-north-1.compute.internal 3860m (48%) 3900m (49%) 8399Mi (27%) 414Mi (1%)
ip-10-0-200-101.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-231-146.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-251-167.eu-north-1.compute.internal 4160m (52%) 3900m (49%) 4491Mi (14%) 660Mi (2%)
 benjick
于 2020-11-14
benjick
于 2020-11-14
相关问题
 mml
·
3评论
mml
·
3评论
 Seb-Solon
·
3评论
Seb-Solon
·
3评论
 zetaab
·
3评论
zetaab
·
3评论
 errordeveloper
·
3评论
errordeveloper
·
3评论
 ddysher
·
3评论
ddysher
·
3评论
最有用的评论
有: