Kubernetes: Нужна простая команда kubectl, чтобы увидеть использование ресурсов кластера
Пользователи оказываются сбитыми с толку из-за того, что модули не могут выполнить расписание из-за нехватки ресурсов. Может быть трудно узнать, когда модуль ожидает, потому что он еще не запущен или потому что в кластере нет места для его планирования. http://kubernetes.io/v1.1/docs/user-guide/compute-resources.html#monitoring -compute-resource-usage помогает, но не так легко обнаружить (я стараюсь pod в ожидании, и только после некоторого ожидания и того, что он «застрял» в ожидании, я использую «описать», чтобы понять, что это проблема планирования).
Это также усложняется тем, что системные модули находятся в скрытом пространстве имен. Пользователи забывают, что эти модули существуют, и «засчитывают» ресурсы кластера.
Есть несколько возможных исправлений, я не знаю, что было бы идеально:
1) Разработайте новое состояние модуля, отличное от «Ожидание», чтобы представить «пытался запланировать, но потерпел неудачу из-за нехватки ресурсов».
2) Попросите kubectl get po или kubectl get po -o = wide отобразить столбец, чтобы подробно описать, почему что-то ожидает обработки (возможно, container.state, который ожидает в данном случае, или самое последнее сообщение event.message).
3) Создайте новую команду kubectl, чтобы упростить описание ресурсов. Я представляю себе «использование kubectl», которое дает обзор общего объема ЦП и памяти кластера, ЦП узла и памяти, а также использования каждого модуля / контейнера. Сюда мы бы включили все поды, в том числе системные. Это может быть полезно в долгосрочной перспективе вместе с более сложными планировщиками или когда в вашем кластере достаточно ресурсов, но нет ни одного узла (диагностика проблемы «нет достаточно больших дыр»).
 goltermann
goltermann
Все 88 Комментарий
Что-то вроде (2) кажется разумным, хотя специалисты по UX знают лучше меня.
(3) кажется отдаленно связанным с # 15743, но я не уверен, что они достаточно близки, чтобы их можно было объединить.
 davidopp
20 нояб. 2015
davidopp
20 нояб. 2015
В дополнение к описанному выше случаю было бы неплохо увидеть, какое использование ресурсов мы получаем.
kubectl utilization requests может отображаться (возможно, kubectl util или kubectl usage лучше / короче):
cores: 4.455/5 cores (89%)
memory: 20.1/30 GiB (67%)
...
В этом примере совокупные запросы контейнера составляют 4,455 ядер и 20,1 ГиБ, а всего в кластере 5 ядер и 30 ГБ.
 chrishiestand
16 сент. 2016
chrishiestand
16 сент. 2016
Там есть:
$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
cluster1-k8s-master-1 312m 15% 1362Mi 68%
cluster1-k8s-node-1 124m 12% 233Mi 11%
 xmik
19 дек. 2016
xmik
19 дек. 2016
Я использую команду ниже, чтобы быстро просмотреть использование ресурсов. Это самый простой способ, который я нашел.
kubectl describe nodes
 ozbillwang
11 янв. 2017
ozbillwang
11 янв. 2017
Если бы существовал способ «отформатировать» вывод kubectl describe nodes , я бы не возражал против написания сценария для суммирования всех запросов / ограничений ресурсов узла.
 tonglil
20 янв. 2017
tonglil
20 янв. 2017
вот мой хак kubectl describe nodes | grep -A 2 -e "^\\s*CPU Requests"
 from-nibly
2 февр. 2017
from-nibly
2 февр. 2017
@ конечно спасибо, именно то, что я искал
 jredl-va
25 мая 2017
jredl-va
25 мая 2017
Ага, это мое:
$ cat bin/node-resources.sh
#!/bin/bash
set -euo pipefail
echo -e "Iterating...\n"
nodes=$(kubectl get node --no-headers -o custom-columns=NAME:.metadata.name)
for node in $nodes; do
echo "Node: $node"
kubectl describe node "$node" | sed '1,/Non-terminated Pods/d'
echo
done
@goltermann В этом вопросе нет добавьте подпись :
(1) упоминание сигнатуры: @kubernetes/sig-<team-name>-misc
(2) указание метки вручную: /sig <label>
_Примечание: метод (1) вызовет уведомление для команды. Вы можете найти список команд здесь ._
 k8s-github-robot
1 июн. 2017
k8s-github-robot
1 июн. 2017
@ kubernetes / sig-cli-разное
 kargakis
10 июн. 2017
kargakis
10 июн. 2017
Вы можете использовать приведенную ниже команду, чтобы найти процент использования ЦП ваших узлов.
alias util='kubectl get nodes | grep node | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
Note: 4000m cores is the total cores in one node
alias cpualloc="util | grep % | awk '{print \$1}' | awk '{ sum += \$1 } END { if (NR > 0) { result=(sum**4000); printf result/NR \"%\n\" } }'"
$ cpualloc
3.89358%
Note: 1600MB is the total cores in one node
alias memalloc='util | grep % | awk '\''{print $3}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { result=(sum*100)/(NR*1600); printf result/NR "%\n" } }'\'''
$ memalloc
24.6832%
 alok87
5 июл. 2017
alok87
5 июл. 2017
@tomfotherby alias util='kubectl get nodes | grep node | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
alok87
21 июл. 2017
@ alok87 - Спасибо за псевдонимы. В моем случае это сработало для меня, учитывая, что мы используем типы экземпляров bash и m3.large (2 процессора, 7,5 ГБ памяти).
alias util='kubectl get nodes --no-headers | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
# Get CPU request total (we x20 because because each m3.large has 2 vcpus (2000m) )
alias cpualloc='util | grep % | awk '\''{print $1}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { print sum/(NR*20), "%\n" } }'\'''
# Get mem request total (we x75 because because each m3.large has 7.5G ram )
alias memalloc='util | grep % | awk '\''{print $5}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { print sum/(NR*75), "%\n" } }'\'''
$util
ip-10-56-0-178.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
960m (48%) 2700m (135%) 630Mi (8%) 2034Mi (27%)
ip-10-56-0-22.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
920m (46%) 1400m (70%) 560Mi (7%) 550Mi (7%)
ip-10-56-0-56.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
1160m (57%) 2800m (140%) 972Mi (13%) 3976Mi (53%)
ip-10-56-0-99.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
804m (40%) 794m (39%) 824Mi (11%) 1300Mi (17%)
cpualloc
48.05 %
$ memalloc
9.95333 %
 tomfotherby
25 июл. 2017
tomfotherby
25 июл. 2017
https://github.com/kubernetes/kubernetes/issues/17512#issuecomment -267992922 kubectl top показывает использование , а не распределение. Распределение - вот что вызывает проблему insufficient CPU . В этом вопросе много путаницы по поводу разницы.
AFAICT, нет простого способа получить отчет о распределении ЦП узла по модулям, поскольку в спецификации запросы относятся к каждому контейнеру. И даже тогда это сложно, поскольку .spec.containers[*].requests может иметь или не иметь полей limits / requests (по моему опыту)
 nfirvine
30 авг. 2017
nfirvine
30 авг. 2017
/ cc @mysterikkit
 misterikkit
2 янв. 2018
misterikkit
2 янв. 2018
Попадание в эту группу сценариев оболочки. У меня есть более старый кластер, на котором запущен ЦС с отключенным масштабированием. Я написал этот сценарий, чтобы примерно определить, насколько я могу уменьшить масштаб кластера, когда он начинает увеличивать свои ограничения маршрута AWS:
#!/bin/bash
set -e
KUBECTL="kubectl"
NODES=$($KUBECTL get nodes --no-headers -o custom-columns=NAME:.metadata.name)
function usage() {
local node_count=0
local total_percent_cpu=0
local total_percent_mem=0
local readonly nodes=$@
for n in $nodes; do
local requests=$($KUBECTL describe node $n | grep -A2 -E "^\\s*CPU Requests" | tail -n1)
local percent_cpu=$(echo $requests | awk -F "[()%]" '{print $2}')
local percent_mem=$(echo $requests | awk -F "[()%]" '{print $8}')
echo "$n: ${percent_cpu}% CPU, ${percent_mem}% memory"
node_count=$((node_count + 1))
total_percent_cpu=$((total_percent_cpu + percent_cpu))
total_percent_mem=$((total_percent_mem + percent_mem))
done
local readonly avg_percent_cpu=$((total_percent_cpu / node_count))
local readonly avg_percent_mem=$((total_percent_mem / node_count))
echo "Average usage: ${avg_percent_cpu}% CPU, ${avg_percent_mem}% memory."
}
usage $NODES
Производит такой вывод:
ip-REDACTED.us-west-2.compute.internal: 38% CPU, 9% memory
...many redacted lines...
ip-REDACTED.us-west-2.compute.internal: 41% CPU, 8% memory
ip-REDACTED.us-west-2.compute.internal: 61% CPU, 7% memory
Average usage: 45% CPU, 15% memory.
 negz
21 февр. 2018
negz
21 февр. 2018
В верхней команде также есть опция pod:
kubectl top pod
 ylogx
21 февр. 2018
ylogx
21 февр. 2018
@ylogx https://github.com/kubernetes/kubernetes/issues/17512#issuecomment -326089708
nfirvine
21 февр. 2018
Мой способ получить распределение для всего кластера:
$ kubectl get po --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"
Это производит что-то вроде:
kube-system:heapster-v1.5.0-dc8df7cc9-7fqx6
heapster:88m
heapster-nanny:50m
kube-system:kube-dns-6cdf767cb8-cjjdr
kubedns:100m
dnsmasq:150m
sidecar:10m
prometheus-to-sd:
kube-system:kube-dns-6cdf767cb8-pnx2g
kubedns:100m
dnsmasq:150m
sidecar:10m
prometheus-to-sd:
kube-system:kube-dns-autoscaler-69c5cbdcdd-wwjtg
autoscaler:20m
kube-system:kube-proxy-gke-cluster1-default-pool-cd7058d6-3tt9
kube-proxy:100m
kube-system:kube-proxy-gke-cluster1-preempt-pool-57d7ff41-jplf
kube-proxy:100m
kube-system:kubernetes-dashboard-7b9c4bf75c-f7zrl
kubernetes-dashboard:50m
kube-system:l7-default-backend-57856c5f55-68s5g
default-http-backend:10m
kube-system:metrics-server-v0.2.0-86585d9749-kkrzl
metrics-server:48m
metrics-server-nanny:5m
kube-system:tiller-deploy-7794bfb756-8kxh5
tiller:10m
 shtouff
4 мар. 2018
shtouff
4 мар. 2018
Это странно. Я хочу знать, когда я нахожусь или приближаюсь к выделенной емкости. Кажется, довольно простая функция кластера. Будь то статистика, показывающая высокий процент ошибок, или текстовая ошибка ... как другие люди узнают об этом? Просто всегда использовать автомасштабирование на облачной платформе?
 kierenj
13 мар. 2018
kierenj
13 мар. 2018
Я написал https://github.com/dpetzold/kube-resource-explorer/ для адреса №3. Вот пример вывода:
$ ./resource-explorer -namespace kube-system -reverse -sort MemReq
Namespace Name CpuReq CpuReq% CpuLimit CpuLimit% MemReq MemReq% MemLimit MemLimit%
--------- ---- ------ ------- -------- --------- ------ ------- -------- ---------
kube-system event-exporter-v0.1.7-5c4d9556cf-kf4tf 0 0% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-mshh 100m 10% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-bv59 100m 10% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-ntfw 100m 10% 0 0% 0 0% 0 0%
kube-system kube-dns-autoscaler-244676396-xzgs4 20m 2% 0 0% 10Mi 0% 0 0%
kube-system l7-default-backend-1044750973-kqh98 10m 1% 10m 1% 20Mi 0% 20Mi 0%
kube-system kubernetes-dashboard-768854d6dc-jh292 100m 10% 100m 10% 100Mi 3% 300Mi 11%
kube-system kube-dns-323615064-8nxfl 260m 27% 0 0% 110Mi 4% 170Mi 6%
kube-system fluentd-gcp-v2.0.9-4qkwk 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system fluentd-gcp-v2.0.9-jmtpw 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system fluentd-gcp-v2.0.9-tw9vk 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system heapster-v1.4.3-74b5bd94bb-fz8hd 138m 14% 138m 14% 301856Ki 11% 301856Ki 11%
 dpetzold
2 мая 2018
dpetzold
2 мая 2018
@shtouff
root<strong i="7">@debian9</strong>:~# kubectl get po -n chenkunning-84 -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"
error: error parsing jsonpath {range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}, unrecognized character in action: U+0027 '''
root<strong i="8">@debian9</strong>:~# kubectl version
Client Version: version.Info{Major:"1", Minor:"6+", GitVersion:"v1.6.7-beta.0+$Format:%h$", GitCommit:"bb053ff0cb25a043e828d62394ed626fda2719a1", GitTreeState:"dirty", BuildDate:"2017-08-26T09:34:19Z", GoVersion:"go1.8", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"6+", GitVersion:"v1.6.7-beta.0+$Format:84c3ae0384658cd40c1d1e637f5faa98cf6a965c$", GitCommit:"3af2004eebf3cbd8d7f24b0ecd23fe4afb889163", GitTreeState:"clean", BuildDate:"2018-04-04T08:40:48Z", GoVersion:"go1.8.1", Compiler:"gc", Platform:"linux/amd64"}
 harryge00
22 мая 2018
harryge00
22 мая 2018
@ harryge00 : U + 0027 - фигурная цитата, вероятно, проблема с копированием и
nfirvine
22 мая 2018
@nfirvine Спасибо! Я решил проблему, используя:
kubectl get pods -n my-ns -o=jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.spec.containers[0].resources.limits.cpu} {"\n"}{end}' |awk '{sum+=$2 ; print $0} END{print "sum=",sum}'
Он работает для пространств имен, модули которых содержат только по 1 контейнеру.
harryge00
25 мая 2018
@xmik Привет, я использую k8 1.7 и запускаю hepaster. Когда я запускаю верхние узлы $ kubectl --heapster-namespace = kube-system, он показывает мне «ошибка: показатели еще не доступны». Есть ключ к решению ошибки?
 abushoeb
5 июн. 2018
abushoeb
5 июн. 2018
@abushoeb :
Я не думаю, чтоИзменить: этот флаг поддерживается, вы были правы: https://github.com/kubernetes/kubernetes/issues/44540#issuecomment -362882035.kubectl topподдерживает флаг:--heapster-namespace.- Если вы видите «ошибка: показатели еще не доступны», то вам следует проверить развертывание кучи. Что говорят его журналы? Служба кучи в порядке, конечные точки - это не
<none>? Проверьте последнее с помощью такой команды:kubectl -n kube-system describe svc/heapster
xmik
5 июн. 2018
@xmik вы правы, куча не настроена должным образом. Большое спасибо. Теперь работает. Знаете ли вы, есть ли способ в реальном времени получать информацию об использовании графического процессора? Эта верхняя команда показывает только использование ЦП и памяти.
abushoeb
5 июн. 2018
Я этого не знаю. :(
xmik
5 июн. 2018
@abushoeb Я получаю ту же ошибку «ошибка: показатели еще не доступны». Как ты это починил?
 avgKol
21 июн. 2018
avgKol
21 июн. 2018
@avgKol сначала проверьте развертывание кучи. В моем случае он не был развернут должным образом. Один из способов проверить это - получить доступ к метрикам с помощью команды CURL, например curl -L http://heapster-pod-ip:heapster-service-port/api/v1/model/metrics/ . Если метрики не отображаются, проверьте модуль heapster и журналы. Доступ к метрикам hepster можно получить и через веб-браузер, как это .
abushoeb
22 июн. 2018
Если кому-то интересно, я создал инструмент для генерации статического HTML для использования ресурсов Kubernetes (и затрат): https://github.com/hjacobs/kube-resource-report
 hjacobs
18 июл. 2018
hjacobs
18 июл. 2018
@hjacobs Я бы хотел использовать этот инструмент, но не поклонник установки / использования пакетов Python. Не хотите упаковать его как образ докера?
tonglil
18 июл. 2018
@tonglil проект довольно ранний, но я планирую получить готовый образ Docker, включая готовый. веб-сервер, с которым вы можете просто сделать kubectl apply -f .. .
hjacobs
18 июл. 2018
Вот что у меня сработало:
kubectl get nodes -o=jsonpath="{range .items[*]}{.metadata.name}{'\t'}{.status.allocatable.memory}{'\t'}{.status.allocatable.cpu}{'\n'}{end}"
Он показывает вывод как:
ip-192-168-101-177.us-west-2.compute.internal 251643680Ki 32
ip-192-168-196-254.us-west-2.compute.internal 251643680Ki 32
 arun-gupta
12 сент. 2018
arun-gupta
12 сент. 2018
@tonglil теперь доступен образ Docker: https://github.com/hjacobs/kube-resource-report
hjacobs
13 сент. 2018
Проблемы устаревают после 90 дней бездействия.
Отметьте проблему как новую с помощью /remove-lifecycle stale .
Устаревшие выпуски гниют после дополнительных 30 дней бездействия и в конечном итоге закрываются.
Если сейчас проблему можно безопасно закрыть, сделайте это с помощью /close .
Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/ жизненный цикл устаревший
 fejta-bot
17 дек. 2018
fejta-bot
17 дек. 2018
/ remove-жизненный цикл устаревший
Каждый месяц или около того мой поиск в Google возвращает меня к этой проблеме. Есть способы получить нужную мне статистику с помощью длинных строк jq или с помощью панелей управления Grafana с кучей вычислений ... но было бы _так_ хорошо, если бы была такая команда, как:
# kubectl utilization cluster
cores: 19.255/24 cores (80%)
memory: 16.4/24 GiB (68%)
# kubectl utilization [node name]
cores: 3.125/4 cores (78%)
memory: 2.1/4 GiB (52%)
(аналогично тому, что @chrishiestand упоминал ранее в теме).
Я часто строю и разрушаю несколько десятков тестовых кластеров в неделю, и мне бы не пришлось создавать автоматизацию или добавлять какие-то псевдонимы оболочки, чтобы иметь возможность просто видеть, «поставлю ли я столько серверов и выброслю ли эти приложения на них, каково мое общее использование / давление ".
Специально для небольших / более эзотерических кластеров я не хочу настраивать автоматическое масштабирование до луны (обычно из соображений денег), но мне нужно знать, достаточно ли у меня накладных расходов для обработки незначительных событий автомасштабирования подов.
 geerlingguy
30 дек. 2018
geerlingguy
30 дек. 2018
Еще один запрос - я хотел бы видеть суммарное использование ресурсов по пространству имен (как минимум; по развертыванию / метке также было бы полезно), поэтому я могу сосредоточить свои усилия по обрезке ресурсов, выясняя, какие пространства имен стоят концентрируясь на.
 evankanderson
1 янв. 2019
evankanderson
1 янв. 2019
Я сделал небольшой плагин kubectl-view-utilization , который обеспечивает описанную @geerlingguy функциональность. Доступна установка через менеджер плагинов krew. Это реализовано в BASH и требует awk и bc.
С помощью инфраструктуры плагинов kubectl это можно полностью абстрагировать от основных инструментов.
 etopeter
13 янв. 2019
etopeter
13 янв. 2019
Я рад, что другие тоже столкнулись с этой проблемой. Я создал Kube Eagle (экспортера прометея), который помог мне получить лучший обзор ресурсов кластера и, в конечном итоге, позволил мне лучше использовать доступные аппаратные ресурсы:
https://github.com/google-cloud-tools/kube-eagle

 weeco
3 мар. 2019
weeco
3 мар. 2019
Это скрипт на Python для получения фактического использования узла в табличном формате.
https://github.com/amelbakry/kube-node-utilization
Использование узлов Kubernetes ..........
+ ------------------------------------------------ + -------- + -------- +
| NodeName | CPU | Память |
+ ------------------------------------------------ + -------- + -------- +
| ip-176-35-32-139.eu-central-1.compute.internal | 13,49% | 60,87% |
| ip-176-35-26-21.eu-central-1.compute.internal | 5,89% | 15,10% |
| ip-176-35-9-122.eu-central-1.compute.internal | 8,08% | 65,51% |
| ip-176-35-22-243.eu-central-1.compute.internal | 6,29% | 19,28% |
+ ------------------------------------------------ + -------- + -------- +
 amelbakry
24 апр. 2019
amelbakry
24 апр. 2019
Для меня, по крайней мере, @amelbakry важно использование уровня кластера: «нужно ли мне добавлять больше машин?» / "мне удалить некоторые машины?" / "следует ли мне ожидать, что кластер в ближайшее время расширится?" ..
kierenj
25 апр. 2019
А как насчет использования эфемерного хранилища? Есть идеи, как получить его из всех стручков?
И, чтобы быть полезными, мои подсказки:
kubectl get pods -o json -n kube-system | jq -r '.items[] | .metadata.name + " \n Req. RAM: " + .spec.containers[].resources.requests.memory + " \n Lim. RAM: " + .spec.containers[].resources.limits.memory + " \n Req. CPU: " + .spec.containers[].resources.requests.cpu + " \n Lim. CPU: " + .spec.containers[].resources.limits.cpu + " \n Req. Eph. DISK: " + .spec.containers[].resources.requests["ephemeral-storage"] + " \n Lim. Eph. DISK: " + .spec.containers[].resources.limits["ephemeral-storage"] + "\n"'
...
kube-proxy-xlmjt
Req. RAM: 32Mi
Lim. RAM: 256Mi
Req. CPU: 100m
Lim. CPU:
Req. Eph. DISK: 100Mi
Lim. Eph. DISK: 512Mi
...
echo "\nRAM Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.memory' && echo "\nRAM Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests.memory + " | " + .metadata.name'
echo "\nRAM Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.memory' && echo "\nRAM Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits.memory + " | " + .metadata.name'
echo "\nCPU Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.cpu' && echo "\nCPU Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests.cpu + " | " + .metadata.name'
echo "\nCPU Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.cpu' && echo "\nCPU Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits.cpu + " | " + .metadata.name'
echo "\nEph. DISK Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.ephemeral-storage' && echo "\nEph. DISK Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests["ephemeral-storage"] + " | " + .metadata.name'
echo "\nEph. DISK Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.ephemeral-storage' && echo "\nEph. DISK Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits["ephemeral-storage"] + " | " + .metadata.name'
RAM Requests TOTAL:
requests.memory 3504Mi 16Gi
RAM Requests:
64Mi | aws-alb-ingress-controller-6b569b448c-jzj6f
...
 kivagant-ba
25 апр. 2019
kivagant-ba
25 апр. 2019
@ kivagant-ba вы можете попробовать этот снипт, чтобы получить метрики pod для каждого узла, вы можете получить все узлы, например
https://github.com/amelbakry/kube-node-utilization
def get_pod_metrics_per_node (узел):
pod_metrics = "/api/v1/pods?fieldSelector=spec.nodeName%3D" + узел
response = api_client.call_api (pod_metrics,
'GET', auth_settings = ['BearerToken'],
response_type = 'json', _preload_content = False)
response = json.loads (response [0] .data.decode ('utf-8'))
ответ на ответ
amelbakry
25 апр. 2019
@kierenj Я думаю, что компонент кластера-автомасштабирования, основанный на том, какие облачные кубернеты работают, должен обрабатывать мощность. не уверен, что это ваш вопрос.
amelbakry
25 апр. 2019
Проблемы устаревают после 90 дней бездействия.
Отметьте проблему как новую с помощью /remove-lifecycle stale .
Устаревшие выпуски гниют после дополнительных 30 дней бездействия и в конечном итоге закрываются.
Если сейчас проблему можно безопасно закрыть, сделайте это с помощью /close .
Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/ жизненный цикл устаревший
fejta-bot
30 июл. 2019
/ remove-жизненный цикл устаревший
Я, как и многие другие, постоянно возвращаюсь сюда - в течение многих лет - чтобы получить хак, необходимый для управления кластерами через интерфейс командной строки (например, AWS ASG).
 eduncan911
28 авг. 2019
eduncan911
28 авг. 2019
@etopeter Спасибо за такой крутой плагин CLI. Мне нравится его простота. Есть какие-нибудь советы, как лучше понять числа и их точное значение?
 demisx
28 авг. 2019
demisx
28 авг. 2019
Если кому-то это пригодится, вот скрипт, который сбрасывает текущие ограничения для модулей.
kubectl get pods --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}\
{'.spec.nodeName -'} {.spec.nodeName}{'\n'}\
{range .spec.containers[*]}\
{'requests.cpu -'} {.resources.requests.cpu}{'\n'}\
{'limits.cpu -'} {.resources.limits.cpu}{'\n'}\
{'requests.memory -'} {.resources.requests.memory}{'\n'}\
{'limits.memory -'} {.resources.limits.memory}{'\n'}\
{'\n'}{end}\
{'\n'}{end}"
Пример вывода
...
система куба
.spec.nodeName - aks-agentpool-84550961-0
request.cpu -
limits.cpu -
request.memory -
limits.memory -
система кубе
.spec.nodeName - aks-agentpool-84550961-0
request.cpu - 100 млн
limits.cpu -
request.memory - 70Ми
limits.memory - 170Mi
система кубе
.spec.nodeName - aks-agentpool-84550961-2
request.cpu - 100 млн
limits.cpu -
request.memory - 70Ми
limits.memory - 170Mi
kube- система: coredns-696c4d987c-zgcbp
.spec.nodeName - aks-agentpool-84550961-1.
request.cpu - 100 млн
limits.cpu -
request.memory - 70Ми
limits.memory - 170Mi
kube- система: coredns-autoscaler-657d77ffbf-7t72x
.spec.nodeName - aks-agentpool-84550961-2
request.cpu - 20 млн
limits.cpu -
request.memory - 10Ми
limits.memory -
система куба
.spec.nodeName - aks-agentpool-84550961-0
request.cpu - 20 млн
limits.cpu -
request.memory - 10Ми
limits.memory -
kube- система: kube-proxy-57nw5
.spec.nodeName - aks-agentpool-84550961-1.
request.cpu - 100 млн
limits.cpu -
request.memory -
limits.memory -
...
 Spaceman1861
2 сент. 2019
Spaceman1861
2 сент. 2019
@ Spaceman1861 не могли бы вы показать пример?
eduncan911
2 сент. 2019
@ eduncan911 сделано
Spaceman1861
2 сент. 2019
Мне легче читать вывод в формате таблицы, например (здесь показаны запросы, а не ограничения):
kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY(bytes)":.spec.containers[*].resources.requests.memory --all-namespaces
Пример вывода:
NAME CPU(cores) MEMORY(bytes)
pod1 100m 128Mi
pod2 100m 128Mi,128Mi
 lentzi90
2 сент. 2019
lentzi90
2 сент. 2019
@ lentzi90 просто к сведению: вы можете показывать похожие настраиваемые столбцы в Kubernetes Web View («kubectl для Интернета»), демонстрация: https://kube-web-view.demo.j-serv.de/clusters/local/namespaces/ default / pods? join = metrics; customcols = CPU + Requests = join (% 27,% 20% 27,% 20spec.containers [ ] .resources.requests.cpu)% 3BMemory + Requests = join (% 27,% 20% 27,% 20spec.containers [ ] .resources.requests.memory)
Документы по настраиваемым столбцам: https://kube-web-view.readthedocs.io/en/latest/features.html#listing -resources
hjacobs
2 сент. 2019
Оооо, блестящий @hjacobs, мне это нравится.
Spaceman1861
2 сент. 2019
Это сценарий (deployment-health.sh) для получения возможности использования модулей при развертывании на основе использования и настроенных ограничений.
https://github.com/amelbakry/kubernetes-scripts
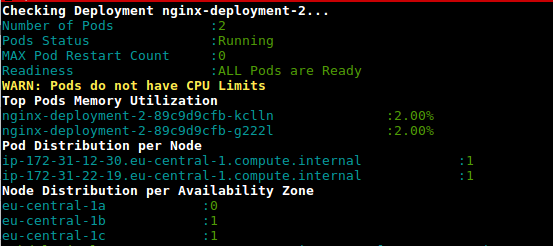
amelbakry
2 сент. 2019
Вдохновленный ответами @ lentzi90 и @ylogx , я создал собственный большой скрипт, который показывает фактическое использование ресурсов ( kubectl top pods ), а также запросы и ограничения ресурсов:
join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '<none>' <(kubectl top pods) <(kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory) | column -t -s' '
пример вывода:
NAME CPU(cores) MEMORY(bytes) CPU_REQ(cores) MEMORY_REQ(bytes) CPU_LIM(cores) MEMORY_LIM(bytes)
xxxxx-847dbbc4c-c6twt 20m 110Mi 50m 150Mi 150m 250Mi
xxx-service-7b6b9558fc-9cq5b 19m 1304Mi 1 <none> 1 <none>
xxxxxxxxxxxxxxx-hook-5d585b449b-zfxmh 0m 46Mi 200m 155M 200m 155M
Вот псевдоним, чтобы вы могли просто использовать kstats в своем терминале:
alias kstats='join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '"'"'<none>'"'"' <(kubectl top pods) <(kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory) | column -t -s'"'"' '"'"
PS Я тестировал скрипты только на своем Mac, для linux и windows могут потребоваться некоторые изменения
 alikhil
25 сент. 2019
alikhil
25 сент. 2019
Это сценарий (deployment-health.sh) для получения возможности использования модулей при развертывании на основе использования и настроенных ограничений.
https://github.com/amelbakry/kubernetes-scripts
@amelbakry Я получаю следующую ошибку при попытке выполнить ее на Mac:
Failed to execute process './deployment-health.sh'. Reason:
exec: Exec format error
The file './deployment-health.sh' is marked as an executable but could not be run by the operating system.
Вупс,
"#!" должна быть самой первой строкой. Вместо этого попробуйте "bash
./deployment-health.sh ", чтобы обойти проблему.
/ charles
PS. PR открыт, чтобы исправить проблему
В среду, 25 сентября 2019 г., в 10:19 Дмитрий Мур [email protected]
написал:
Это сценарий (deployment-health.sh) для использования модулей.
в развертывании на основе использования и настроенных ограничений
https://github.com/amelbakry/kubernetes-scripts@amelbakry https://github.com/amelbakry Я получаю следующее
ошибка при попытке выполнить его на Mac:Не удалось выполнить процесс './deployment-health.sh'. Причина:
exec: ошибка формата Exec
Файл ./deployment-health.sh отмечен как исполняемый, но не может быть запущен операционной системой.-
Вы получаете это, потому что подписаны на эту беседу.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/kubernetes/kubernetes/issues/17512?email_source=notifications&email_token=AACA3TODQEUPWK3V3UY3SF3QLOMSFA5CNFSM4BUXCUG2YY3PNVWWK3TUL52XG43LVMVPNVWWK3TUL52XG4DFV35VWWK3TREXWWM6DVMXVMXWM8CWMXWM8CWMW08
или отключить поток
https://github.com/notifications/unsubscribe-auth/AACA3TOPOBIWXFX2DAOT6JDQLOMSFANCNFSM4BUXCUGQ
.
 cgthayer
25 сент. 2019
cgthayer
25 сент. 2019
@cgthayer Возможно, вы захотите применить это исправление PR глобально. Кроме того, когда я запускал сценарии на MacOs Mojave, обнаружился ряд ошибок, включая имена зон, специфичные для ЕС, которые я не использую. Похоже, эти скрипты написаны для конкретного проекта.
demisx
2 окт. 2019
Вот модифицированная версия соединения ex. который также делает итоги по столбцам.
oc_ns_pod_usage () {
# show pod usage for cpu/mem
ns="$1"
usage_chk3 "$ns" || return 1
printf "$ns\n"
separator=$(printf '=%.0s' {1..50})
printf "$separator\n"
output=$(join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '<none>' \
<(kubectl top pods -n $ns) \
<(kubectl get -n $ns pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory))
totals=$(printf "%s" "$output" | awk '{s+=$2; t+=$3; u+=$4; v+=$5; w+=$6; x+=$7} END {print s" "t" "u" "v" "w" "x}')
printf "%s\n%s\nTotals: %s\n" "$output" "$separator" "$totals" | column -t -s' '
printf "$separator\n"
}
Пример
$ oc_ns_pod_usage ls-indexer
ls-indexer
==================================================
NAME CPU(cores) MEMORY(bytes) CPU_REQ(cores) MEMORY_REQ(bytes) CPU_LIM(cores) MEMORY_LIM(bytes)
ls-indexer-f5-7cd5859997-qsfrp 15m 741Mi 1 1000Mi 2 2000Mi
ls-indexer-f5-7cd5859997-sclvg 15m 735Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-4b7j2 92m 1103Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-5xj5l 88m 1124Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-6vvl2 92m 1132Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-85f66 85m 1151Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-924jz 96m 1124Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-g6gx8 119m 1119Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-hkhnt 52m 819Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-hrsrs 51m 1122Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-j4qxm 53m 885Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-lxlrb 83m 1215Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-mw6rt 86m 1131Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-pbdf8 95m 1115Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-qk9bm 91m 1141Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-sdv9r 54m 1194Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-t67v6 75m 1234Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-tkxs2 88m 1364Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-v6jl2 53m 747Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-wkqr7 53m 838Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-jp8qc 190m 1191Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-jv4bv 192m 1162Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-k4dcd 194m 1144Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-n46tz 192m 1155Mi 1 1000Mi 2 2000Mi
ls-indexer-packetbeat-db98f6fdf-8x446 35m 1198Mi 1 1000Mi 2 2000Mi
ls-indexer-packetbeat-db98f6fdf-gmxxd 22m 1203Mi 1 1000Mi 2 2000Mi
ls-indexer-syslog-5466bc4d4f-gzxw8 27m 1125Mi 1 1000Mi 2 2000Mi
ls-indexer-syslog-5466bc4d4f-zh7st 29m 1153Mi 1 1000Mi 2 2000Mi
==================================================
Totals: 2317 30365 28 28000 56 56000
==================================================
 slmingol
21 окт. 2019
slmingol
21 окт. 2019
А что такое usage_chk3?
 cristifalcas
25 окт. 2019
cristifalcas
25 окт. 2019
Я также хотел бы поделиться своими инструментами ;-) kubectl-view-allocations: плагин kubectl для перечисления распределений (cpu, memory, gpu, ... X запрошено, ограничено, выделяется, ...). Просьба приветствовать.
Я сделал это, потому что хотел предоставить моим (внутренним) пользователям способ увидеть, «кто что выделяет». По умолчанию отображаются все ресурсы, но в следующем примере я запрашиваю только ресурс с именем «gpu».
> kubectl-view-allocations -r gpu
Resource Requested %Requested Limit %Limit Allocatable Free
nvidia.com/gpu 7 58% 7 58% 12 5
├─ node-gpu1 1 50% 1 50% 2 1
│ └─ xxxx-784dd998f4-zt9dh 1 1
├─ node-gpu2 0 0% 0 0% 2 2
├─ node-gpu3 0 0% 0 0% 2 2
├─ node-gpu4 1 50% 1 50% 2 1
│ └─ aaaa-1571819245-5ql82 1 1
├─ node-gpu5 2 100% 2 100% 2 0
│ ├─ bbbb-1571738839-dfkhn 1 1
│ └─ bbbb-1571738888-52c4w 1 1
└─ node-gpu6 2 100% 2 100% 2 0
├─ bbbb-1571738688-vlxng 1 1
└─ cccc-1571745684-7k6bn 1 1
грядущая версия (и):
- позволит скрыть (узел, под) уровень или выбрать способ группировки (например, предоставить обзор только с ресурсами)
- установка через curl, krew, brew, ... (в настоящее время бинарные файлы доступны в разделе релизов на github)
Спасибо kubectl-view-utilization за вдохновение, но добавление поддержки к другим ресурсам для меня было трудным для копирования / вставки в bash (в общем случае).
 davidB
25 окт. 2019
davidB
25 окт. 2019
вот мой хак
kubectl describe nodes | grep -A 2 -e "^\\s*CPU Requests"
Это больше не работает :(
 libudas
28 нояб. 2019
libudas
28 нояб. 2019
Попробуй kubectl describe node | grep -A5 "Allocated"
 MostafaGazar
28 нояб. 2019
MostafaGazar
28 нояб. 2019
В настоящее время это 4-я проблема, наиболее часто запрашиваемая по оценкам "Нравится", но по-прежнему составляет priority/backlog .
Я был бы счастлив нанести удар по этому вопросу, если бы кто-нибудь мог указать мне правильное направление или если бы мы могли доработать предложение. Я думаю, что UX инструмента @davidB великолепен, но он действительно входит в основную kubectl .
 alexkreidler
1 дек. 2019
alexkreidler
1 дек. 2019
Используя следующие команды: kubectl top nodes & kubectl describe node мы не получаем согласованных результатов
Например, в первом случае процессор (количество ядер) составляет 1064 м, но этот результат не может быть получен со вторым (1480 м):
kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
abcd-p174e23ea5qa4g279446c803f82-abc-node-0 1064m 53% 6783Mi 88%
kubectl describe node abcd-p174e23ea5qa4g279446c803f82-abc-node-0
...
Resource Requests Limits
-------- -------- ------
cpu 1480m (74%) 1300m (65%)
memory 2981486848 (37%) 1588314624 (19%)
Есть идеи, как получить ЦП (ядра) без использования kubectl top nodes ?
 smpar
18 дек. 2019
smpar
18 дек. 2019
Я также хотел бы поделиться своими инструментами ;-) kubectl-view-allocations: плагин kubectl для перечисления распределений (cpu, memory, gpu, ... X запрошено, ограничено, выделяется, ...). Просьба приветствовать.
Я сделал это, потому что хотел предоставить моим (внутренним) пользователям способ увидеть, «кто что выделяет». По умолчанию отображаются все ресурсы, но в следующем примере я запрашиваю только ресурс с именем «gpu».
> kubectl-view-allocations -r gpu Resource Requested %Requested Limit %Limit Allocatable Free nvidia.com/gpu 7 58% 7 58% 12 5 ├─ node-gpu1 1 50% 1 50% 2 1 │ └─ xxxx-784dd998f4-zt9dh 1 1 ├─ node-gpu2 0 0% 0 0% 2 2 ├─ node-gpu3 0 0% 0 0% 2 2 ├─ node-gpu4 1 50% 1 50% 2 1 │ └─ aaaa-1571819245-5ql82 1 1 ├─ node-gpu5 2 100% 2 100% 2 0 │ ├─ bbbb-1571738839-dfkhn 1 1 │ └─ bbbb-1571738888-52c4w 1 1 └─ node-gpu6 2 100% 2 100% 2 0 ├─ bbbb-1571738688-vlxng 1 1 └─ cccc-1571745684-7k6bn 1 1грядущая версия (и):
* will allow to hide (node, pod) level or to choose how to group, (eg to provide an overview with only resources) * installation via curl, krew, brew, ... (currently binary are available under the releases section of github)Спасибо kubectl-view-utilization за вдохновение, но добавление поддержки к другим ресурсам для меня было трудным для копирования / вставки в bash (в общем случае).
Здравствуйте, Дэвид, было бы неплохо, если бы вы предоставили более скомпилированный двоичный файл для новых дистрибутивов. В Ubuntu 16.04 мы получаем
kubectl-view-allocations: /lib/x86_64-linux-gnu/libc.so.6: версия `GLIBC_2.25 'не найдена (требуется для kubectl-view-allocations)
dpkg -l |grep glib
ii libglib2.0-0: amd64 2.48.2-0ubuntu4.4
 omerfsen
12 янв. 2020
omerfsen
12 янв. 2020
@omerfsen, можете ли вы попробовать новую версию kubectl-view-allocations и прокомментировать версию тикета `GLIBC_2.25 'not found # 14 ?
davidB
15 янв. 2020
Мой способ получить распределение для всего кластера:
$ kubectl get po --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"Это производит что-то вроде:
kube-system:heapster-v1.5.0-dc8df7cc9-7fqx6 heapster:88m heapster-nanny:50m kube-system:kube-dns-6cdf767cb8-cjjdr kubedns:100m dnsmasq:150m sidecar:10m prometheus-to-sd: kube-system:kube-dns-6cdf767cb8-pnx2g kubedns:100m dnsmasq:150m sidecar:10m prometheus-to-sd: kube-system:kube-dns-autoscaler-69c5cbdcdd-wwjtg autoscaler:20m kube-system:kube-proxy-gke-cluster1-default-pool-cd7058d6-3tt9 kube-proxy:100m kube-system:kube-proxy-gke-cluster1-preempt-pool-57d7ff41-jplf kube-proxy:100m kube-system:kubernetes-dashboard-7b9c4bf75c-f7zrl kubernetes-dashboard:50m kube-system:l7-default-backend-57856c5f55-68s5g default-http-backend:10m kube-system:metrics-server-v0.2.0-86585d9749-kkrzl metrics-server:48m metrics-server-nanny:5m kube-system:tiller-deploy-7794bfb756-8kxh5 tiller:10m
безусловно, лучший ответ здесь.
 abelal83
31 янв. 2020
abelal83
31 янв. 2020
Вдохновленный приведенными выше сценариями, я создал следующий сценарий для просмотра использования, запросов и ограничений:
join -1 2 -2 2 -a 1 -a 2 -o "2.1 0 1.3 2.3 2.5 1.4 2.4 2.6" -e '<wait>' \
<( kubectl top pods --all-namespaces | sort --key 2 -b ) \
<( kubectl get pods --all-namespaces -o custom-columns=NAMESPACE:.metadata.namespace,NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory | sort --key 2 -b ) \
| column -t -s' '
Поскольку сценарий оболочки join ожидает отсортированный список, приведенные выше сценарии не помогли мне.
В результате вы видите текущее использование сверху и из развертывания, запросы и ограничения (здесь) всех пространств имен:
NAMESPACE NAME CPU(cores) CPU_REQ(cores) CPU_LIM(cores) MEMORY(bytes) MEMORY_REQ(bytes) MEMORY_LIM(bytes)
kube-system aws-node-2jzxr 18m 10m <none> 41Mi <none> <none>
kube-system aws-node-5zn6w <wait> 10m <none> <wait> <none> <none>
kube-system aws-node-h8cc5 20m 10m <none> 42Mi <none> <none>
kube-system aws-node-h9n4f 0m 10m <none> 0Mi <none> <none>
kube-system aws-node-lz5fn 17m 10m <none> 41Mi <none> <none>
kube-system aws-node-tpmxr 20m 10m <none> 39Mi <none> <none>
kube-system aws-node-zbkkh 23m 10m <none> 47Mi <none> <none>
cluster-autoscaler cluster-autoscaler-aws-cluster-autoscaler-5db55fbcf8-mdzkd 1m 100m 500m 9Mi 300Mi 500Mi
cluster-autoscaler cluster-autoscaler-aws-cluster-autoscaler-5db55fbcf8-q9xs8 39m 100m 500m 75Mi 300Mi 500Mi
kube-system coredns-56b56b56cd-bb26t 6m 100m <none> 11Mi 70Mi 170Mi
kube-system coredns-56b56b56cd-nhp58 6m 100m <none> 11Mi 70Mi 170Mi
kube-system coredns-56b56b56cd-wrmxv 7m 100m <none> 12Mi 70Mi 170Mi
gitlab-runner-l gitlab-runner-l-gitlab-runner-6b8b85f87f-9knnx 3m 100m 200m 10Mi 128Mi 256Mi
gitlab-runner-m gitlab-runner-m-gitlab-runner-6bfd5d6c84-t5nrd 7m 100m 200m 13Mi 128Mi 256Mi
gitlab-runner-mda gitlab-runner-mda-gitlab-runner-59bb66c8dd-bd9xw 4m 100m 200m 17Mi 128Mi 256Mi
gitlab-runner-ops gitlab-runner-ops-gitlab-runner-7c5b85dc97-zkb4c 3m 100m 200m 12Mi 128Mi 256Mi
gitlab-runner-pst gitlab-runner-pst-gitlab-runner-6b8f9bf56b-sszlr 6m 100m 200m 20Mi 128Mi 256Mi
gitlab-runner-s gitlab-runner-s-gitlab-runner-6bbccb9b7b-dmwgl 50m 100m 200m 27Mi 128Mi 512Mi
gitlab-runner-shared gitlab-runner-shared-gitlab-runner-688d57477f-qgs2z 3m <none> <none> 15Mi <none> <none>
kube-system kube-proxy-5b65t 15m 100m <none> 19Mi <none> <none>
kube-system kube-proxy-7qsgh 12m 100m <none> 24Mi <none> <none>
kube-system kube-proxy-gn2qg 13m 100m <none> 23Mi <none> <none>
kube-system kube-proxy-pz7fp 15m 100m <none> 18Mi <none> <none>
kube-system kube-proxy-vdjqt 15m 100m <none> 23Mi <none> <none>
kube-system kube-proxy-x4xtp 19m 100m <none> 15Mi <none> <none>
kube-system kube-proxy-xlpn7 0m 100m <none> 0Mi <none> <none>
metrics-server metrics-server-5875c7d795-bj7cq 5m 200m 500m 29Mi 200Mi 500Mi
metrics-server metrics-server-5875c7d795-jpjjn 7m 200m 500m 29Mi 200Mi 500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-06t94f <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-10lpn9j 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-11jrxfh <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-129hpvl 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-13kswg8 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-15qhp5w <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
Примечательно: вы можете отсортировать потребление ЦП, например:
| awk 'NR<2{print $0;next}{print $0| "sort --key 3 --numeric -b --reverse"}
Это работает на Mac - я не уверен, работает ли это и на Linux (из-за объединения, сортировки и т. Д.).
Надеюсь, кто-нибудь сможет использовать это, пока kubectl не получит для этого хорошее представление.
 stefanjacobs
11 февр. 2020
stefanjacobs
11 февр. 2020
Имею хороший опыт работы с кубе-емкостью .
Пример:
kube-capacity --util
NODE CPU REQUESTS CPU LIMITS CPU UTIL MEMORY REQUESTS MEMORY LIMITS MEMORY UTIL
* 560m (28%) 130m (7%) 40m (2%) 572Mi (9%) 770Mi (13%) 470Mi (8%)
example-node-1 220m (22%) 10m (1%) 10m (1%) 192Mi (6%) 360Mi (12%) 210Mi (7%)
example-node-2 340m (34%) 120m (12%) 30m (3%) 380Mi (13%) 410Mi (14%) 260Mi (9%)
 eyalev
18 февр. 2020
eyalev
18 февр. 2020
Чтобы этот инструмент был действительно полезным, он должен обнаруживать все плагины устройств Kubernetes, развернутые в кластере, и показывать использование для всех из них. CPU / Mem явно не хватает. Также есть графические процессоры, TPU (для машинного обучения), Intel QAT и, возможно, многое другое, о чем я не знаю. А как насчет хранения? Я должен легко видеть, что было запрошено и что используется (в идеале также с точки зрения iops).
 boniek83
9 апр. 2020
boniek83
9 апр. 2020
@ boniek83 , именно поэтому я создал kubectl-view-allocations , потому что мне нужно перечислить GPU, ... любые отзывы (по проекту github) приветствуются. Мне любопытно узнать, обнаруживает ли он TPU (должен, если он указан как ресурсы узла)
davidB
9 апр. 2020
@ boniek83 , именно поэтому я создал kubectl-view-allocations , потому что мне нужно перечислить GPU, ... любые отзывы (по проекту github) приветствуются. Мне любопытно узнать, обнаруживает ли он TPU (должен, если он указан как ресурсы узла)
Мне известно о вашем инструменте, и для моей цели это лучший инструмент из имеющихся на данный момент. Спасибо, что сделали это!
Постараюсь пройти тестирование TPU после Пасхи. Было бы полезно, если бы эти данные были доступны в формате веб-приложения с красивыми графиками, чтобы мне не пришлось предоставлять какой-либо доступ к кубернетам специалистам по данным. Они только хотят знать, кто пожирает ресурсы и ничего более :)
boniek83
9 апр. 2020
Поскольку ни один из вышеперечисленных инструментов и скриптов мне не подходит (и эта проблема все еще остается открытой :(), я взломал свой вариант:
https://github.com/eht16/kube-cargo-load
Он обеспечивает быстрый обзор POD в кластере и показывает их настроенные запросы и ограничения памяти, а также фактическое использование памяти. Идея состоит в том, чтобы получить картину соотношения между настроенными ограничениями памяти и фактическим использованием.
 eht16
13 апр. 2020
eht16
13 апр. 2020
Как мы можем получить журналы дампа памяти подов?
Стручки часто вешаются,
 RahulRatan07
26 апр. 2020
RahulRatan07
26 апр. 2020
kubectl describe nodesORkubectl top nodes, какой из них следует учитывать для расчета использования ресурсов кластера?- Также почему существует разница между этими двумя результатами.
Есть ли этому еще какое-нибудь логическое объяснение?
 hmsvigle
27 апр. 2020
hmsvigle
27 апр. 2020
/ kind feature
 brianpursley
29 апр. 2020
brianpursley
29 апр. 2020
Все комментарии и хаки с узлами мне понравились. Мне также нужно что-то для более высокого обзора, чтобы отслеживать ... например, сумму ресурсов на пул узлов!
 prathameshd9
30 апр. 2020
prathameshd9
30 апр. 2020
Привет,
Я хочу регистрировать использование процессора и памяти для модуля каждые 5 минут в течение определенного периода времени. Затем я бы использовал эти данные для создания графика в Excel. Любые идеи? Спасибо
 rajjar123456
18 июл. 2020
rajjar123456
18 июл. 2020
Привет,
Я рад видеть, что Google указал всем нам на эту проблему :-) (немного разочарован тем, что она все еще открыта спустя почти 5 лет.) Спасибо за все фрагменты оболочки и другие инструменты.
 yceoshda
28 июл. 2020
yceoshda
28 июл. 2020
Простой и быстрый взлом:
$ kubectl describe nodes | grep 'Name:\| cpu\| memory'
Name: XXX-2-wke2
cpu 1552m (77%) 2402m (120%)
memory 2185Mi (70%) 3854Mi (123%)
Name: XXX-2-wkep
cpu 1102m (55%) 1452m (72%)
memory 1601Mi (51%) 2148Mi (69%)
Name: XXX-2-wkwz
cpu 852m (42%) 1352m (67%)
memory 1125Mi (36%) 3624Mi (116%)
 SerheyDolgushev
5 авг. 2020
SerheyDolgushev
5 авг. 2020
Простой и быстрый взлом:
$ kubectl describe nodes | grep 'Name:\| cpu\| memory' Name: XXX-2-wke2 cpu 1552m (77%) 2402m (120%) memory 2185Mi (70%) 3854Mi (123%) Name: XXX-2-wkep cpu 1102m (55%) 1452m (72%) memory 1601Mi (51%) 2148Mi (69%) Name: XXX-2-wkwz cpu 852m (42%) 1352m (67%) memory 1125Mi (36%) 3624Mi (116%)Плагины устройства отсутствуют. Они должны быть. Такие устройства тоже являются ресурсами.
boniek83
5 авг. 2020
Привет!
Я создал этот сценарий и делюсь им с вами.
https://github.com/Sensedia/open-tools/blob/master/scripts/listK8sHardwareResources.sh
В этом сценарии собраны некоторые из идей, которыми вы здесь поделились. Сценарий может быть увеличен и может помочь другим людям получить метрики проще.
Спасибо, что поделились советами и командами!
 aeciopires
7 авг. 2020
aeciopires
7 авг. 2020
В моем случае я написал простой плагин kubectl который перечисляет ограничения / резервирование ЦП / ОЗУ для узлов в таблице. Он также проверяет текущее потребление ЦП / ОЗУ модуля (например, kubectl top pods ), но упорядочивает вывод по ЦП в порядке убывания.
Это больше удобство, чем что-либо еще, но, возможно, кому-то это тоже пригодится.
 laurybueno
9 авг. 2020
laurybueno
9 авг. 2020
Ого, какая огромная ветка и до сих пор нет подходящего решения от команды kubernetes для правильного расчета текущего общего использования ЦП для всего кластера?
 denissabramovs
20 сент. 2020
denissabramovs
20 сент. 2020
Для тех, кто хочет запустить это на minikube, сначала включите надстройку сервера метрик
minikube addons enable metrics-server
а затем запустите команду
kubectl top nodes
 raul1991
16 окт. 2020
raul1991
16 окт. 2020
Если вы используете Krew :
kubectl krew install resource-capacity
kubectl resource-capacity
NODE CPU REQUESTS CPU LIMITS MEMORY REQUESTS MEMORY LIMITS
* 16960m (35%) 18600m (39%) 26366Mi (14%) 3100Mi (1%)
ip-10-0-138-176.eu-north-1.compute.internal 2460m (31%) 4200m (53%) 567Mi (1%) 784Mi (2%)
ip-10-0-155-49.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-162-84.eu-north-1.compute.internal 3860m (48%) 3900m (49%) 8399Mi (27%) 414Mi (1%)
ip-10-0-200-101.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-231-146.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-251-167.eu-north-1.compute.internal 4160m (52%) 3900m (49%) 4491Mi (14%) 660Mi (2%)
 benjick
14 нояб. 2020
benjick
14 нояб. 2020
Смежные вопросы
 montanaflynn
·
3Комментарии
montanaflynn
·
3Комментарии
 sjenning
·
3Комментарии
sjenning
·
3Комментарии
 chowyu08
·
3Комментарии
chowyu08
·
3Комментарии
 Seb-Solon
·
3Комментарии
Seb-Solon
·
3Комментарии
 ttripp
·
3Комментарии
ttripp
·
3Комментарии
Самый полезный комментарий
Там есть: