Kubernetes: Benötigen Sie einen einfachen kubectl-Befehl, um die Clusterressourcennutzung anzuzeigen
Benutzer werden durch Pods verunsichert, die aufgrund von Ressourcenmangel nicht planen können. Es kann schwer zu erkennen sein, wann ein Pod ausstehend ist, weil er einfach noch nicht gestartet wurde oder weil der Cluster keinen Platz zum Planen hat. http://kubernetes.io/v1.1/docs/user-guide/compute-resources.html#monitoring -compute-resource-usage hilft, aber ist das nicht auffindbar (ich neige dazu, ein 'get' auf a pod zuerst ausstehend, und erst nachdem ich eine Weile gewartet und gesehen habe, dass es in ausstehend "hängt", verwende ich "beschreiben", um zu erkennen, dass es sich um ein Planungsproblem handelt).
Dies wird auch dadurch erschwert, dass sich System-Pods in einem versteckten Namespace befinden. Benutzer vergessen, dass diese Pods vorhanden sind, und "zählen mit" Cluster-Ressourcen.
Es gibt mehrere mögliche Korrekturen, ich weiß nicht, was ideal wäre:
1) Entwickeln Sie einen anderen Pod-Status als Pending, um "versucht zu planen und scheiterten wegen Ressourcenmangels" darzustellen.
2) Lassen Sie kubectl get po oder kubectl get po -o=wide eine Spalte anzeigen, in der detailliert angegeben wird, warum etwas ansteht (in diesem Fall möglicherweise der container.state, der in diesem Fall Wartet, oder die neueste event.message).
3) Erstellen Sie einen neuen kubectl-Befehl, um Ressourcen einfacher zu beschreiben. Ich stelle mir eine "kubectl-Nutzung" vor, die einen Überblick über die gesamte Cluster-CPU und -Mem, pro Knoten-CPU und -Mem und die Nutzung jedes Pods/Containers gibt. Hier würden wir alle Pods einschließen, einschließlich der System-Pods. Dies kann langfristig neben komplexeren Schedulern nützlich sein oder wenn Ihr Cluster über genügend Ressourcen verfügt, aber kein einzelner Knoten dies tut (Diagnose des Problems „keine Löcher, die groß genug sind“).
 goltermann
goltermann
Alle 88 Kommentare
Etwas in der Art von (2) scheint vernünftig, obwohl die UX-Leute es besser wissen würden als ich.
(3) scheint vage mit #15743 verwandt zu sein, aber ich bin mir nicht sicher, ob sie nah genug sind, um sie zu kombinieren.
 davidopp
am 20. Nov. 2015
davidopp
am 20. Nov. 2015
Zusätzlich zum obigen Fall wäre es schön zu sehen, welche Ressourcenauslastung wir erhalten.
kubectl utilization requests könnte erscheinen (vielleicht sind kubectl util oder kubectl usage besser/kürzer):
cores: 4.455/5 cores (89%)
memory: 20.1/30 GiB (67%)
...
In diesem Beispiel sind die aggregierten Containeranforderungen 4,455 Kerne und 20,1 GiB und es gibt 5 Kerne und insgesamt 30 GiB im Cluster.
 chrishiestand
am 16. Sept. 2016
chrishiestand
am 16. Sept. 2016
Es gibt:
$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
cluster1-k8s-master-1 312m 15% 1362Mi 68%
cluster1-k8s-node-1 124m 12% 233Mi 11%
 xmik
am 19. Dez. 2016
xmik
am 19. Dez. 2016
Ich verwende den folgenden Befehl, um eine schnelle Ansicht der Ressourcennutzung zu erhalten. Es ist der einfachste Weg, den ich gefunden habe.
kubectl describe nodes
 ozbillwang
am 11. Jan. 2017
ozbillwang
am 11. Jan. 2017
Wenn es eine Möglichkeit gäbe, die Ausgabe von kubectl describe nodes zu "formatieren", würde ich gerne ein Skript erstellen, um alle Ressourcenanforderungen/-limits aller Knoten zusammenzufassen.
 tonglil
am 20. Jan. 2017
tonglil
am 20. Jan. 2017
hier ist mein Hack kubectl describe nodes | grep -A 2 -e "^\\s*CPU Requests"
 from-nibly
am 2. Feb. 2017
from-nibly
am 2. Feb. 2017
@from-nably danke, genau was ich gesucht habe
 jredl-va
am 25. Mai 2017
jredl-va
am 25. Mai 2017
Ja, das ist meins:
$ cat bin/node-resources.sh
#!/bin/bash
set -euo pipefail
echo -e "Iterating...\n"
nodes=$(kubectl get node --no-headers -o custom-columns=NAME:.metadata.name)
for node in $nodes; do
echo "Node: $node"
kubectl describe node "$node" | sed '1,/Non-terminated Pods/d'
echo
done
@goltermann Es gibt keine fügen Sie ein Sign-Label hinzu, indem Sie:
(1) ein Zeichen erwähnen: @kubernetes/sig-<team-name>-misc
(2) manuelles Angeben des Labels: /sig <label>
_Hinweis: Methode (1) löst eine Benachrichtigung an das Team aus. Die Teamliste finden Sie hier ._
 k8s-github-robot
am 1. Juni 2017
k8s-github-robot
am 1. Juni 2017
@ kubernetes / sig-cli-misc
 kargakis
am 10. Juni 2017
kargakis
am 10. Juni 2017
Sie können den folgenden Befehl verwenden, um die prozentuale CPU-Auslastung Ihrer Knoten zu ermitteln
alias util='kubectl get nodes | grep node | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
Note: 4000m cores is the total cores in one node
alias cpualloc="util | grep % | awk '{print \$1}' | awk '{ sum += \$1 } END { if (NR > 0) { result=(sum**4000); printf result/NR \"%\n\" } }'"
$ cpualloc
3.89358%
Note: 1600MB is the total cores in one node
alias memalloc='util | grep % | awk '\''{print $3}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { result=(sum*100)/(NR*1600); printf result/NR "%\n" } }'\'''
$ memalloc
24.6832%
 alok87
am 5. Juli 2017
alok87
am 5. Juli 2017
@tomfotherby alias util='kubectl get nodes | grep node | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
alok87
am 21. Juli 2017
@alok87 - Danke für deine Pseudonyme. In meinem Fall hat dies für mich funktioniert, da wir die Instanztypen bash und m3.large verwenden (2 CPU, 7,5 G Speicher).
alias util='kubectl get nodes --no-headers | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
# Get CPU request total (we x20 because because each m3.large has 2 vcpus (2000m) )
alias cpualloc='util | grep % | awk '\''{print $1}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { print sum/(NR*20), "%\n" } }'\'''
# Get mem request total (we x75 because because each m3.large has 7.5G ram )
alias memalloc='util | grep % | awk '\''{print $5}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { print sum/(NR*75), "%\n" } }'\'''
$util
ip-10-56-0-178.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
960m (48%) 2700m (135%) 630Mi (8%) 2034Mi (27%)
ip-10-56-0-22.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
920m (46%) 1400m (70%) 560Mi (7%) 550Mi (7%)
ip-10-56-0-56.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
1160m (57%) 2800m (140%) 972Mi (13%) 3976Mi (53%)
ip-10-56-0-99.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
804m (40%) 794m (39%) 824Mi (11%) 1300Mi (17%)
cpualloc
48.05 %
$ memalloc
9.95333 %
 tomfotherby
am 25. Juli 2017
tomfotherby
am 25. Juli 2017
https://github.com/kubernetes/kubernetes/issues/17512#issuecomment -267992922 kubectl top zeigt die Nutzung an , nicht die Zuordnung. Die Zuweisung verursacht das Problem insufficient CPU . In dieser Ausgabe herrscht eine Menge Verwirrung über den Unterschied.
AFAICT, es gibt keine einfache Möglichkeit, einen Bericht über die CPU-Zuweisung von Knoten nach Pod zu erhalten, da Anforderungen pro Container in der Spezifikation gelten. Und selbst dann ist es schwierig, da .spec.containers[*].requests die Felder limits / requests haben kann oder nicht (meiner Erfahrung nach)
 nfirvine
am 30. Aug. 2017
nfirvine
am 30. Aug. 2017
/cc @mysterikkit
 misterikkit
am 2. Jan. 2018
misterikkit
am 2. Jan. 2018
Teilnahme an dieser Shell-Scripting-Party. Ich habe einen älteren Cluster, auf dem die Zertifizierungsstelle mit deaktivierter Verkleinerung ausgeführt wird. Ich habe dieses Skript geschrieben, um ungefähr zu bestimmen, wie weit ich den Cluster herunterskalieren kann, wenn er beginnt, seine AWS-Routenlimits zu überschreiten:
#!/bin/bash
set -e
KUBECTL="kubectl"
NODES=$($KUBECTL get nodes --no-headers -o custom-columns=NAME:.metadata.name)
function usage() {
local node_count=0
local total_percent_cpu=0
local total_percent_mem=0
local readonly nodes=$@
for n in $nodes; do
local requests=$($KUBECTL describe node $n | grep -A2 -E "^\\s*CPU Requests" | tail -n1)
local percent_cpu=$(echo $requests | awk -F "[()%]" '{print $2}')
local percent_mem=$(echo $requests | awk -F "[()%]" '{print $8}')
echo "$n: ${percent_cpu}% CPU, ${percent_mem}% memory"
node_count=$((node_count + 1))
total_percent_cpu=$((total_percent_cpu + percent_cpu))
total_percent_mem=$((total_percent_mem + percent_mem))
done
local readonly avg_percent_cpu=$((total_percent_cpu / node_count))
local readonly avg_percent_mem=$((total_percent_mem / node_count))
echo "Average usage: ${avg_percent_cpu}% CPU, ${avg_percent_mem}% memory."
}
usage $NODES
Erzeugt Ausgaben wie:
ip-REDACTED.us-west-2.compute.internal: 38% CPU, 9% memory
...many redacted lines...
ip-REDACTED.us-west-2.compute.internal: 41% CPU, 8% memory
ip-REDACTED.us-west-2.compute.internal: 61% CPU, 7% memory
Average usage: 45% CPU, 15% memory.
 negz
am 21. Feb. 2018
negz
am 21. Feb. 2018
Es gibt auch eine Pod-Option im oberen Befehl:
kubectl top pod
 ylogx
am 21. Feb. 2018
ylogx
am 21. Feb. 2018
@ylogx https://github.com/kubernetes/kubernetes/issues/17512#issuecomment -326089708
nfirvine
am 21. Feb. 2018
Mein Weg, um die Zuteilung clusterweit zu erhalten:
$ kubectl get po --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"
Es produziert etwas wie:
kube-system:heapster-v1.5.0-dc8df7cc9-7fqx6
heapster:88m
heapster-nanny:50m
kube-system:kube-dns-6cdf767cb8-cjjdr
kubedns:100m
dnsmasq:150m
sidecar:10m
prometheus-to-sd:
kube-system:kube-dns-6cdf767cb8-pnx2g
kubedns:100m
dnsmasq:150m
sidecar:10m
prometheus-to-sd:
kube-system:kube-dns-autoscaler-69c5cbdcdd-wwjtg
autoscaler:20m
kube-system:kube-proxy-gke-cluster1-default-pool-cd7058d6-3tt9
kube-proxy:100m
kube-system:kube-proxy-gke-cluster1-preempt-pool-57d7ff41-jplf
kube-proxy:100m
kube-system:kubernetes-dashboard-7b9c4bf75c-f7zrl
kubernetes-dashboard:50m
kube-system:l7-default-backend-57856c5f55-68s5g
default-http-backend:10m
kube-system:metrics-server-v0.2.0-86585d9749-kkrzl
metrics-server:48m
metrics-server-nanny:5m
kube-system:tiller-deploy-7794bfb756-8kxh5
tiller:10m
 shtouff
am 4. März 2018
shtouff
am 4. März 2018
Das ist seltsam. Ich möchte wissen, wann ich die Zuweisungskapazität erreicht habe oder mir ihr nähere. Es scheint eine ziemlich grundlegende Funktion eines Clusters zu sein. Ob Statistik mit hohem Prozentsatz oder Textfehler... woher wissen das andere? Einfach immer Autoscaling auf einer Cloud-Plattform verwenden?
 kierenj
am 13. März 2018
kierenj
am 13. März 2018
Ich habe https://github.com/dpetzold/kube-resource-explorer/ an Adresse #3 verfasst. Hier ist eine Beispielausgabe:
$ ./resource-explorer -namespace kube-system -reverse -sort MemReq
Namespace Name CpuReq CpuReq% CpuLimit CpuLimit% MemReq MemReq% MemLimit MemLimit%
--------- ---- ------ ------- -------- --------- ------ ------- -------- ---------
kube-system event-exporter-v0.1.7-5c4d9556cf-kf4tf 0 0% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-mshh 100m 10% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-bv59 100m 10% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-ntfw 100m 10% 0 0% 0 0% 0 0%
kube-system kube-dns-autoscaler-244676396-xzgs4 20m 2% 0 0% 10Mi 0% 0 0%
kube-system l7-default-backend-1044750973-kqh98 10m 1% 10m 1% 20Mi 0% 20Mi 0%
kube-system kubernetes-dashboard-768854d6dc-jh292 100m 10% 100m 10% 100Mi 3% 300Mi 11%
kube-system kube-dns-323615064-8nxfl 260m 27% 0 0% 110Mi 4% 170Mi 6%
kube-system fluentd-gcp-v2.0.9-4qkwk 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system fluentd-gcp-v2.0.9-jmtpw 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system fluentd-gcp-v2.0.9-tw9vk 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system heapster-v1.4.3-74b5bd94bb-fz8hd 138m 14% 138m 14% 301856Ki 11% 301856Ki 11%
 dpetzold
am 2. Mai 2018
dpetzold
am 2. Mai 2018
@shtouff
root<strong i="7">@debian9</strong>:~# kubectl get po -n chenkunning-84 -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"
error: error parsing jsonpath {range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}, unrecognized character in action: U+0027 '''
root<strong i="8">@debian9</strong>:~# kubectl version
Client Version: version.Info{Major:"1", Minor:"6+", GitVersion:"v1.6.7-beta.0+$Format:%h$", GitCommit:"bb053ff0cb25a043e828d62394ed626fda2719a1", GitTreeState:"dirty", BuildDate:"2017-08-26T09:34:19Z", GoVersion:"go1.8", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"6+", GitVersion:"v1.6.7-beta.0+$Format:84c3ae0384658cd40c1d1e637f5faa98cf6a965c$", GitCommit:"3af2004eebf3cbd8d7f24b0ecd23fe4afb889163", GitTreeState:"clean", BuildDate:"2018-04-04T08:40:48Z", GoVersion:"go1.8.1", Compiler:"gc", Platform:"linux/amd64"}
 harryge00
am 22. Mai 2018
harryge00
am 22. Mai 2018
@harryge00 : U+0027 ist ein geschweiftes Zitat, wahrscheinlich ein Copy-Paste-Problem
nfirvine
am 22. Mai 2018
@nfirvine Danke! Ich habe das Problem gelöst, indem ich verwendet habe:
kubectl get pods -n my-ns -o=jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.spec.containers[0].resources.limits.cpu} {"\n"}{end}' |awk '{sum+=$2 ; print $0} END{print "sum=",sum}'
Es funktioniert für Namespaces, deren Pods nur jeweils 1 Container enthalten.
harryge00
am 25. Mai 2018
@xmik Hey, ich verwende k8 1.7 und führe hepaster aus. Wenn ich $ kubectl top node --heapster-namespace=kube-system ausführe, wird mir "Fehler: Metriken noch nicht verfügbar" angezeigt. Irgendwelche Hinweise zur Behebung des Fehlers?
 abushoeb
am 5. Juni 2018
abushoeb
am 5. Juni 2018
@abushoeb :
Ich glaube nicht, dassBearbeiten: Dieses Flag wird unterstützt, Sie hatten Recht: https://github.com/kubernetes/kubernetes/issues/44540#issuecomment -362882035 .kubectl topdas Flag unterstützt:--heapster-namespace.- Wenn "Fehler: Metriken noch nicht verfügbar" angezeigt wird, sollten Sie die Heapster-Bereitstellung überprüfen. Was sagen seine Protokolle? Ist der Heapster-Dienst in Ordnung, die Endpunkte sind nicht
<none>? Überprüfen Sie letzteres mit einem Befehl wie:kubectl -n kube-system describe svc/heapster
xmik
am 5. Juni 2018
@xmik Sie haben Recht, der Heapster wurde nicht richtig konfiguriert. Danke vielmals. Es funktioniert jetzt. Wissen Sie, ob es eine Möglichkeit gibt, Informationen zur GPU-Nutzung in Echtzeit zu erhalten? Dieser oberste Befehl gibt nur die CPU- und Speichernutzung an.
abushoeb
am 5. Juni 2018
Das weiß ich nicht. :(
xmik
am 5. Juni 2018
@abushoeb Ich
 avgKol
am 21. Juni 2018
avgKol
am 21. Juni 2018
@avgKol überprüfen Sie zuerst curl -L http://heapster-pod-ip:heapster-service-port/api/v1/model/metrics/ auf Metriken zuzugreifen. Wenn keine Metriken angezeigt werden, überprüfen Sie den Heapster-Pod und die Protokolle. Die Hepster Metriken können auch über einen Webbrowser zugegriffen werden wie folgt aus .
abushoeb
am 22. Juni 2018
Wenn jemand interessiert ist, habe ich ein Tool erstellt, um statisches HTML für die Nutzung von Kubernetes-Ressourcen (und Kosten) zu generieren: https://github.com/hjacobs/kube-resource-report
 hjacobs
am 18. Juli 2018
hjacobs
am 18. Juli 2018
@hjacobs Ich würde dieses Tool gerne verwenden, bin aber kein Fan von der Installation/Verwendung von Python-Paketen. Kannst du es als Docker-Image verpacken?
tonglil
am 18. Juli 2018
@tonglil das Projekt ist ziemlich früh, aber mein Plan ist es, ein kubectl apply -f .. .
hjacobs
am 18. Juli 2018
Folgendes hat bei mir funktioniert:
kubectl get nodes -o=jsonpath="{range .items[*]}{.metadata.name}{'\t'}{.status.allocatable.memory}{'\t'}{.status.allocatable.cpu}{'\n'}{end}"
Es zeigt die Ausgabe als:
ip-192-168-101-177.us-west-2.compute.internal 251643680Ki 32
ip-192-168-196-254.us-west-2.compute.internal 251643680Ki 32
 arun-gupta
am 12. Sept. 2018
arun-gupta
am 12. Sept. 2018
@tonglil ein Docker-Image ist jetzt verfügbar: https://github.com/hjacobs/kube-resource-report
hjacobs
am 13. Sept. 2018
Die Probleme veralten nach 90 Tagen Inaktivität.
Markieren Sie das Problem mit /remove-lifecycle stale .
Veraltete Ausgaben verrotten nach weiteren 30 Tagen Inaktivität und werden schließlich geschlossen.
Wenn dieses Problem jetzt sicher geschlossen werden kann, tun Sie dies bitte mit /close .
Senden Sie Feedback an sig-testing, kubernetes/test-infra und/oder fejta .
/Lebenszyklus veraltet
 fejta-bot
am 17. Dez. 2018
fejta-bot
am 17. Dez. 2018
/Remove-Lifecycle-Stale
Jeden Monat oder so führt mich mein Googeln zu diesem Thema zurück. Es gibt Möglichkeiten, die Statistiken, die ich brauche, mit langen jq Strings oder mit Grafana-Dashboards mit einer Reihe von Berechnungen zu erhalten ... aber es wäre _so_ nett, wenn es einen Befehl wie diesen gäbe:
# kubectl utilization cluster
cores: 19.255/24 cores (80%)
memory: 16.4/24 GiB (68%)
# kubectl utilization [node name]
cores: 3.125/4 cores (78%)
memory: 2.1/4 GiB (52%)
(ähnlich dem, was @chrishiestand zuvor im Thread erwähnt hat).
Ich baue und zerstöre oft ein paar Dutzend Testcluster pro Woche, und ich möchte lieber keine Automatisierung aufbauen oder einige Shell-Aliasnamen hinzufügen, um nur zu sehen, "ob ich so viele Server da draußen stelle und diese Apps wegwerfe". auf sie, was ist meine Gesamtauslastung / mein Druck".
Insbesondere für kleinere / esoterischere Cluster möchte ich keine automatische Skalierung zum Mond einrichten (normalerweise aus Geldgründen), aber ich muss wissen, ob ich genug Overhead habe, um kleinere Pod-Autoscaling-Ereignisse zu verarbeiten.
 geerlingguy
am 30. Dez. 2018
geerlingguy
am 30. Dez. 2018
Eine zusätzliche Anfrage – ich möchte die summierte Ressourcennutzung nach Namespaces sehen (zumindest; nach Bereitstellung/Label wäre auch nützlich), damit ich meine Bemühungen zur Ressourcenreduzierung darauf konzentrieren kann, herauszufinden, welche Namespaces wert sind konzentrieren auf.
 evankanderson
am 1. Jan. 2019
evankanderson
am 1. Jan. 2019
Ich habe ein kleines Plugin kubectl-view-utilization erstellt , das die von @geerlingguy beschriebene Funktionalität
Mit dem kubectl-Plugin-Framework könnte dies vollständig von den Kernwerkzeugen abstrahiert werden.
 etopeter
am 13. Jan. 2019
etopeter
am 13. Jan. 2019
Ich bin froh, dass sich auch andere dieser Herausforderung gestellt haben. Ich habe Kube Eagle (einen prometheus-Exporteur) erstellt, der mir geholfen hat, einen besseren Überblick über die Cluster-Ressourcen zu gewinnen und letztendlich die verfügbaren Hardware-Ressourcen besser nutzen zu können:
https://github.com/google-cloud-tools/kube-eagle

 weeco
am 3. März 2019
weeco
am 3. März 2019
Dies ist ein Python-Skript, um die tatsächliche Knotenauslastung im Tabellenformat zu erhalten
https://github.com/amelbakry/kube-node-utilization
Kubernetes-Knotenauslastung............
+------------------------------------------------+ --------+--------+
| Knotenname | CPU | Speicher |
+------------------------------------------------+ --------+--------+
| ip-176-35-32-139.eu-central-1.compute.internal | 13,49% | 60,87 % |
| ip-176-35-26-21.eu-central-1.compute.internal | 5,89% | 15.10% |
| ip-176-35-9-122.eu-central-1.compute.internal | 8,08% | 65,51% |
| ip-176-35-22-243.eu-central-1.compute.internal | 6,29 % | 19.28% |
+------------------------------------------------+ --------+--------+
 amelbakry
am 24. Apr. 2019
amelbakry
am 24. Apr. 2019
Für mich zumindest @amelbakry ist die Auslastung auf Cluster-Ebene wichtig: "
kierenj
am 25. Apr. 2019
Wie sieht es mit der Nutzung von kurzlebigem Speicher aus? Irgendwelche Ideen, wie man es von allen Pods bekommt?
Und um nützlich zu sein, meine Hinweise:
kubectl get pods -o json -n kube-system | jq -r '.items[] | .metadata.name + " \n Req. RAM: " + .spec.containers[].resources.requests.memory + " \n Lim. RAM: " + .spec.containers[].resources.limits.memory + " \n Req. CPU: " + .spec.containers[].resources.requests.cpu + " \n Lim. CPU: " + .spec.containers[].resources.limits.cpu + " \n Req. Eph. DISK: " + .spec.containers[].resources.requests["ephemeral-storage"] + " \n Lim. Eph. DISK: " + .spec.containers[].resources.limits["ephemeral-storage"] + "\n"'
...
kube-proxy-xlmjt
Req. RAM: 32Mi
Lim. RAM: 256Mi
Req. CPU: 100m
Lim. CPU:
Req. Eph. DISK: 100Mi
Lim. Eph. DISK: 512Mi
...
echo "\nRAM Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.memory' && echo "\nRAM Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests.memory + " | " + .metadata.name'
echo "\nRAM Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.memory' && echo "\nRAM Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits.memory + " | " + .metadata.name'
echo "\nCPU Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.cpu' && echo "\nCPU Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests.cpu + " | " + .metadata.name'
echo "\nCPU Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.cpu' && echo "\nCPU Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits.cpu + " | " + .metadata.name'
echo "\nEph. DISK Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.ephemeral-storage' && echo "\nEph. DISK Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests["ephemeral-storage"] + " | " + .metadata.name'
echo "\nEph. DISK Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.ephemeral-storage' && echo "\nEph. DISK Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits["ephemeral-storage"] + " | " + .metadata.name'
RAM Requests TOTAL:
requests.memory 3504Mi 16Gi
RAM Requests:
64Mi | aws-alb-ingress-controller-6b569b448c-jzj6f
...
 kivagant-ba
am 25. Apr. 2019
kivagant-ba
am 25. Apr. 2019
@kivagant-ba Sie können diesen Ausschnitt ausprobieren, um Pod-Metriken pro Knoten zu erhalten. Sie können alle Knoten wie erhalten
https://github.com/amelbakry/kube-node-utilization
def get_pod_metrics_per_node(node):
pod_metrics = "/api/v1/pods?fieldSelector=spec.nodeName%3D" + Knoten
Antwort = api_client.call_api(pod_metrics,
'GET', auth_settings=['BearerToken'],
response_type='json', _preload_content=False)
antwort = json.loads(response[0].data.decode('utf-8'))
Antwort zurückgeben
amelbakry
am 25. Apr. 2019
@kierenj Ich denke, die Cluster-Autoscaler-Komponente, auf deren Grundlage Cloud Kubernetes ausgeführt wird, sollte die Kapazität bewältigen. nicht sicher, ob dies Ihre Frage ist.
amelbakry
am 25. Apr. 2019
Die Probleme veralten nach 90 Tagen Inaktivität.
Markieren Sie das Problem mit /remove-lifecycle stale .
Veraltete Ausgaben verrotten nach weiteren 30 Tagen Inaktivität und werden schließlich geschlossen.
Wenn dieses Problem jetzt sicher geschlossen werden kann, tun Sie dies bitte mit /close .
Senden Sie Feedback an sig-testing, kubernetes/test-infra und/oder fejta .
/Lebenszyklus veraltet
fejta-bot
am 30. Juli 2019
/Remove-Lifecycle-Stale
Ich komme, wie viele andere auch, immer wieder hierher - seit Jahren - um den Hack zu bekommen, den wir brauchen, um die Cluster über CLI zu verwalten (zB AWS ASGs)
 eduncan911
am 28. Aug. 2019
eduncan911
am 28. Aug. 2019
@etopeter Vielen Dank für so ein cooles CLI-Plugin. Liebe die Einfachheit. Haben Sie einen Tipp, wie Sie die Zahlen und ihre genaue Bedeutung besser verstehen können?
 demisx
am 28. Aug. 2019
demisx
am 28. Aug. 2019
Wenn jemand davon Gebrauch machen kann, ist hier ein Skript, das die aktuellen Grenzen von Pods ausgibt.
kubectl get pods --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}\
{'.spec.nodeName -'} {.spec.nodeName}{'\n'}\
{range .spec.containers[*]}\
{'requests.cpu -'} {.resources.requests.cpu}{'\n'}\
{'limits.cpu -'} {.resources.limits.cpu}{'\n'}\
{'requests.memory -'} {.resources.requests.memory}{'\n'}\
{'limits.memory -'} {.resources.limits.memory}{'\n'}\
{'\n'}{end}\
{'\n'}{end}"
Beispielausgabe
...
kube- system:addon-http-application-routing-nginx-ingress-controller-6bq49l7
.spec.nodeName - aks-agentpool-84550961-0
Anfragen.cpu -
limit.cpu -
Anfragen.Speicher -
Grenzen.Speicher -
kube- system:coredns-696c4d987c-pjht8
.spec.nodeName - aks-agentpool-84550961-0
Anfragen.cpu - 100m
limit.cpu -
Anfragen.Speicher - 70Mi
limit.memory - 170Mi
kube- system:coredns-696c4d987c-rtkl6
.spec.nodeName - aks-agentpool-84550961-2
Anfragen.cpu - 100m
limit.cpu -
Anfragen.Speicher - 70Mi
limit.memory - 170Mi
kube- system:coredns-696c4d987c-zgcbp
.spec.nodeName - aks-agentpool-84550961-1
Anfragen.cpu - 100m
limit.cpu -
Anfragen.Speicher - 70Mi
limit.memory - 170Mi
kube- system:coredns-autoscaler-657d77ffbf-7t72x
.spec.nodeName - aks-agentpool-84550961-2
Anfragen.cpu - 20m
limit.cpu -
Anfragen.Speicher - 10Mi
Grenzen.Speicher -
kube- system:coredns-autoscaler-657d77ffbf-zrp6m
.spec.nodeName - aks-agentpool-84550961-0
Anfragen.cpu - 20m
limit.cpu -
Anfragen.Speicher - 10Mi
Grenzen.Speicher -
kube- system:kube-proxy-57nw5
.spec.nodeName - aks-agentpool-84550961-1
Anfragen.cpu - 100m
limit.cpu -
Anfragen.Speicher -
Grenzen.Speicher -
...
 Spaceman1861
am 2. Sept. 2019
Spaceman1861
am 2. Sept. 2019
@Spaceman1861 könnten Sie ein Beispiel outout zeigen?
eduncan911
am 2. Sept. 2019
@eduncan911 fertig
Spaceman1861
am 2. Sept. 2019
Ich finde es einfacher, die Ausgabe im Tabellenformat wie folgt zu lesen (dies zeigt Anforderungen anstelle von Grenzen):
kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY(bytes)":.spec.containers[*].resources.requests.memory --all-namespaces
Beispielausgabe:
NAME CPU(cores) MEMORY(bytes)
pod1 100m 128Mi
pod2 100m 128Mi,128Mi
 lentzi90
am 2. Sept. 2019
lentzi90
am 2. Sept. 2019
@lentzi90 nur zur Kubernetes Web View ("kubectl for the web") anzeigen, Demo: https://kube-web-view.demo.j-serv.de/clusters/local/namespaces/ default/pods?join=metrics;customcols=CPU+Requests=join (%27,%20%27,%20spec.containers[ ].resources.requests.cpu)%3BMemory+Requests=join(%27,%20% 27,%20spec.containers[ ].resources.requests.memory)
Dokumente zu benutzerdefinierten Spalten: https://kube-web-view.readthedocs.io/en/latest/features.html#listing -resources
hjacobs
am 2. Sept. 2019
Oooo glänzend @hjacobs Das gefällt mir.
Spaceman1861
am 2. Sept. 2019
Dies ist ein Skript (deployment-health.sh), um die Auslastung der Pods in der Bereitstellung basierend auf der Nutzung und den konfigurierten Limits abzurufen
https://github.com/amelbakry/kubernetes-scripts
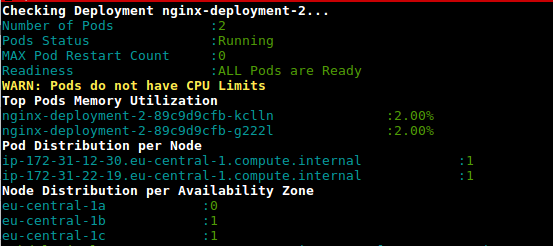
amelbakry
am 2. Sept. 2019
Inspiriert von den Antworten von @lentzi90 und @ylogx habe ich ein eigenes großes Skript erstellt, das die tatsächliche Ressourcennutzung ( kubectl top pods ) sowie Ressourcenanforderungen und -grenzen anzeigt:
join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '<none>' <(kubectl top pods) <(kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory) | column -t -s' '
Ausgabebeispiel:
NAME CPU(cores) MEMORY(bytes) CPU_REQ(cores) MEMORY_REQ(bytes) CPU_LIM(cores) MEMORY_LIM(bytes)
xxxxx-847dbbc4c-c6twt 20m 110Mi 50m 150Mi 150m 250Mi
xxx-service-7b6b9558fc-9cq5b 19m 1304Mi 1 <none> 1 <none>
xxxxxxxxxxxxxxx-hook-5d585b449b-zfxmh 0m 46Mi 200m 155M 200m 155M
Hier ist der Alias für Sie, um einfach kstats in Ihrem Terminal zu verwenden:
alias kstats='join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '"'"'<none>'"'"' <(kubectl top pods) <(kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory) | column -t -s'"'"' '"'"
PS Ich habe Skripte nur auf meinem Mac getestet, für Linux und Windows sind möglicherweise einige Änderungen erforderlich
 alikhil
am 25. Sept. 2019
alikhil
am 25. Sept. 2019
Dies ist ein Skript (deployment-health.sh), um die Auslastung der Pods in der Bereitstellung basierend auf der Nutzung und den konfigurierten Limits abzurufen
https://github.com/amelbakry/kubernetes-scripts
@amelbakry Ich wenn ich versuche, sie auf einem Mac auszuführen:
Failed to execute process './deployment-health.sh'. Reason:
exec: Exec format error
The file './deployment-health.sh' is marked as an executable but could not be run by the operating system.
Hoppla,
"#!" muss die allererste Zeile sein. Versuchen Sie stattdessen "bash
./deployment-health.sh", um das Problem zu umgehen.
/charles
PS. PR geöffnet, um das Problem zu beheben
Am Mi, 25.09.2019 um 10:19 Dmitri Moore [email protected]
schrieb:
Dies ist ein Skript (deployment-health.sh), um die Auslastung der Pods abzurufen
im Deployment basierend auf der Nutzung und den konfigurierten Limits
https://github.com/amelbakry/kubernetes-scripts@amelbakry https://github.com/amelbakry Ich bekomme folgendes
Fehler beim Versuch, es auf einem Mac auszuführen:Fehler beim Ausführen des Prozesses './deployment-health.sh'. Grund:
exec: Exec-Formatfehler
Die Datei './deployment-health.sh' ist als ausführbar markiert, konnte aber vom Betriebssystem nicht ausgeführt werden.—
Sie erhalten dies, weil Sie diesen Thread abonniert haben.
Antworten Sie direkt auf diese E-Mail und zeigen Sie sie auf GitHub an
https://github.com/kubernetes/kubernetes/issues/17512?email_source=notifications&email_token=AACA3TODQEUPWK3V3UY3SF3QLOMSFA5CNFSM4BUXCUG2YY3PNVWWK3TUL52HS4DFVREXG43VMVHBW63LNQWMD7
oder den Thread stumm schalten
https://github.com/notifications/unsubscribe-auth/AACA3TOPOBIWXFX2DAOT6JDQLOMSFANCNFSM4BUXCUGQ
.
 cgthayer
am 25. Sept. 2019
cgthayer
am 25. Sept. 2019
@cgthayer Vielleicht möchten Sie diesen PR-Fix global anwenden. Als ich die Skripte auf MacOs Mojave ausführte, tauchten außerdem eine Reihe von Fehlern auf, einschließlich EU-spezifischer Zonennamen, die ich nicht verwende. Anscheinend wurden diese Skripte für ein bestimmtes Projekt geschrieben.
demisx
am 2. Okt. 2019
Hier ist eine modifizierte Version des Join-Ex. die auch Summen von Spalten macht.
oc_ns_pod_usage () {
# show pod usage for cpu/mem
ns="$1"
usage_chk3 "$ns" || return 1
printf "$ns\n"
separator=$(printf '=%.0s' {1..50})
printf "$separator\n"
output=$(join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '<none>' \
<(kubectl top pods -n $ns) \
<(kubectl get -n $ns pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory))
totals=$(printf "%s" "$output" | awk '{s+=$2; t+=$3; u+=$4; v+=$5; w+=$6; x+=$7} END {print s" "t" "u" "v" "w" "x}')
printf "%s\n%s\nTotals: %s\n" "$output" "$separator" "$totals" | column -t -s' '
printf "$separator\n"
}
Beispiel
$ oc_ns_pod_usage ls-indexer
ls-indexer
==================================================
NAME CPU(cores) MEMORY(bytes) CPU_REQ(cores) MEMORY_REQ(bytes) CPU_LIM(cores) MEMORY_LIM(bytes)
ls-indexer-f5-7cd5859997-qsfrp 15m 741Mi 1 1000Mi 2 2000Mi
ls-indexer-f5-7cd5859997-sclvg 15m 735Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-4b7j2 92m 1103Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-5xj5l 88m 1124Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-6vvl2 92m 1132Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-85f66 85m 1151Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-924jz 96m 1124Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-g6gx8 119m 1119Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-hkhnt 52m 819Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-hrsrs 51m 1122Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-j4qxm 53m 885Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-lxlrb 83m 1215Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-mw6rt 86m 1131Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-pbdf8 95m 1115Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-qk9bm 91m 1141Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-sdv9r 54m 1194Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-t67v6 75m 1234Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-tkxs2 88m 1364Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-v6jl2 53m 747Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-wkqr7 53m 838Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-jp8qc 190m 1191Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-jv4bv 192m 1162Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-k4dcd 194m 1144Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-n46tz 192m 1155Mi 1 1000Mi 2 2000Mi
ls-indexer-packetbeat-db98f6fdf-8x446 35m 1198Mi 1 1000Mi 2 2000Mi
ls-indexer-packetbeat-db98f6fdf-gmxxd 22m 1203Mi 1 1000Mi 2 2000Mi
ls-indexer-syslog-5466bc4d4f-gzxw8 27m 1125Mi 1 1000Mi 2 2000Mi
ls-indexer-syslog-5466bc4d4f-zh7st 29m 1153Mi 1 1000Mi 2 2000Mi
==================================================
Totals: 2317 30365 28 28000 56 56000
==================================================
 slmingol
am 21. Okt. 2019
slmingol
am 21. Okt. 2019
Und was ist use_chk3?
 cristifalcas
am 25. Okt. 2019
cristifalcas
am 25. Okt. 2019
Ich möchte auch meine Tools teilen ;-) kubectl-view-allocations: kubectl-Plugin zum Auflisten von Zuweisungen (cpu, memory, gpu,... X angefordert, limit, allocable,...). , Anfrage sind willkommen.
Ich habe es gemacht, weil ich meinen (internen) Benutzern eine Möglichkeit bieten möchte, zu sehen, "wer was zuweist". Standardmäßig werden alle Ressourcen angezeigt, aber im folgenden Beispiel fordere ich nur Ressourcen mit dem Namen "gpu" an.
> kubectl-view-allocations -r gpu
Resource Requested %Requested Limit %Limit Allocatable Free
nvidia.com/gpu 7 58% 7 58% 12 5
├─ node-gpu1 1 50% 1 50% 2 1
│ └─ xxxx-784dd998f4-zt9dh 1 1
├─ node-gpu2 0 0% 0 0% 2 2
├─ node-gpu3 0 0% 0 0% 2 2
├─ node-gpu4 1 50% 1 50% 2 1
│ └─ aaaa-1571819245-5ql82 1 1
├─ node-gpu5 2 100% 2 100% 2 0
│ ├─ bbbb-1571738839-dfkhn 1 1
│ └─ bbbb-1571738888-52c4w 1 1
└─ node-gpu6 2 100% 2 100% 2 0
├─ bbbb-1571738688-vlxng 1 1
└─ cccc-1571745684-7k6bn 1 1
kommende Version(en):
- ermöglicht es, die Ebene (Knoten, Pod) auszublenden oder zu wählen, wie sie gruppiert werden sollen (z. B. um eine Übersicht nur mit Ressourcen bereitzustellen)
- Installation über curl, krew, brew, ... (derzeit sind Binärdateien im Abschnitt Releases von github verfügbar)
Danke an kubectl-view-utilization für die Inspiration, aber das Hinzufügen von Unterstützung für andere Ressourcen war für mich zu viel Kopieren/Einfügen oder für mich in der Bash (für eine allgemeine Art und Weise) schwierig.
 davidB
am 25. Okt. 2019
davidB
am 25. Okt. 2019
hier ist mein Hack
kubectl describe nodes | grep -A 2 -e "^\\s*CPU Requests"
Das geht nicht mehr :(
 libudas
am 28. Nov. 2019
libudas
am 28. Nov. 2019
Gib kubectl describe node | grep -A5 "Allocated" einen Versuch
 MostafaGazar
am 28. Nov. 2019
MostafaGazar
am 28. Nov. 2019
Dies ist derzeit das vierthäufigste angeforderte Problem mit Daumen hoch, kostet aber immer noch priority/backlog .
Ich würde mich freuen, wenn jemand mich in die richtige Richtung weisen könnte oder wenn wir einen Vorschlag abschließen könnten. Ich denke, die UX von @davidBs Tool ist großartig, aber das gehört wirklich zum Kern kubectl .
 alexkreidler
am 1. Dez. 2019
alexkreidler
am 1. Dez. 2019
Mit den folgenden Befehlen: kubectl top nodes & kubectl describe node wir keine konsistenten Ergebnisse
Zum Beispiel beträgt die CPU (Kerne) beim ersten 1064 m, aber dieses Ergebnis kann mit dem zweiten (1480 m) nicht abgerufen werden:
kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
abcd-p174e23ea5qa4g279446c803f82-abc-node-0 1064m 53% 6783Mi 88%
kubectl describe node abcd-p174e23ea5qa4g279446c803f82-abc-node-0
...
Resource Requests Limits
-------- -------- ------
cpu 1480m (74%) 1300m (65%)
memory 2981486848 (37%) 1588314624 (19%)
Irgendeine Idee, die CPU (Kerne) zu bekommen, ohne die kubectl top nodes ?
 smpar
am 18. Dez. 2019
smpar
am 18. Dez. 2019
Ich möchte auch meine Tools teilen ;-) kubectl-view-allocations: kubectl-Plugin zum Auflisten von Zuweisungen (cpu, memory, gpu,... X angefordert, limit, allocable,...). , Anfrage sind willkommen.
Ich habe es gemacht, weil ich meinen (internen) Benutzern eine Möglichkeit bieten möchte, zu sehen, "wer was zuweist". Standardmäßig werden alle Ressourcen angezeigt, aber im folgenden Beispiel fordere ich nur Ressourcen mit dem Namen "gpu" an.
> kubectl-view-allocations -r gpu Resource Requested %Requested Limit %Limit Allocatable Free nvidia.com/gpu 7 58% 7 58% 12 5 ├─ node-gpu1 1 50% 1 50% 2 1 │ └─ xxxx-784dd998f4-zt9dh 1 1 ├─ node-gpu2 0 0% 0 0% 2 2 ├─ node-gpu3 0 0% 0 0% 2 2 ├─ node-gpu4 1 50% 1 50% 2 1 │ └─ aaaa-1571819245-5ql82 1 1 ├─ node-gpu5 2 100% 2 100% 2 0 │ ├─ bbbb-1571738839-dfkhn 1 1 │ └─ bbbb-1571738888-52c4w 1 1 └─ node-gpu6 2 100% 2 100% 2 0 ├─ bbbb-1571738688-vlxng 1 1 └─ cccc-1571745684-7k6bn 1 1kommende Version(en):
* will allow to hide (node, pod) level or to choose how to group, (eg to provide an overview with only resources) * installation via curl, krew, brew, ... (currently binary are available under the releases section of github)Danke an kubectl-view-utilization für die Inspiration, aber das Hinzufügen von Unterstützung für andere Ressourcen war für mich zu viel Kopieren/Einfügen oder für mich in der Bash (für eine allgemeine Art und Weise) schwierig.
Hallo David, es wäre schön, wenn Sie mehr kompilierte Binärdateien für neue Distributionen bereitstellen. Unter Ubuntu 16.04 bekommen wir
kubectl-view-allocations: /lib/x86_64-linux-gnu/libc.so.6: Version `GLIBC_2.25' nicht gefunden (erforderlich für kubectl-view-allocations)
dpkg -l |grep glib
ii libglib2.0-0:amd64 2.48.2-0ubuntu4.4
 omerfsen
am 12. Jan. 2020
omerfsen
am 12. Jan. 2020
@omerfsen kannst du die neue Version kubectl-view-allocations ausprobieren und in die Ticketversion `GLIBC_2.25' not found #14 kommentieren?
davidB
am 15. Jan. 2020
Mein Weg, um die Zuteilung clusterweit zu erhalten:
$ kubectl get po --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"Es produziert etwas wie:
kube-system:heapster-v1.5.0-dc8df7cc9-7fqx6 heapster:88m heapster-nanny:50m kube-system:kube-dns-6cdf767cb8-cjjdr kubedns:100m dnsmasq:150m sidecar:10m prometheus-to-sd: kube-system:kube-dns-6cdf767cb8-pnx2g kubedns:100m dnsmasq:150m sidecar:10m prometheus-to-sd: kube-system:kube-dns-autoscaler-69c5cbdcdd-wwjtg autoscaler:20m kube-system:kube-proxy-gke-cluster1-default-pool-cd7058d6-3tt9 kube-proxy:100m kube-system:kube-proxy-gke-cluster1-preempt-pool-57d7ff41-jplf kube-proxy:100m kube-system:kubernetes-dashboard-7b9c4bf75c-f7zrl kubernetes-dashboard:50m kube-system:l7-default-backend-57856c5f55-68s5g default-http-backend:10m kube-system:metrics-server-v0.2.0-86585d9749-kkrzl metrics-server:48m metrics-server-nanny:5m kube-system:tiller-deploy-7794bfb756-8kxh5 tiller:10m
mit Abstand die beste Antwort hier.
 abelal83
am 31. Jan. 2020
abelal83
am 31. Jan. 2020
Inspiriert von den obigen Skripten habe ich das folgende Skript erstellt, um die Nutzung, Anforderungen und Grenzen anzuzeigen:
join -1 2 -2 2 -a 1 -a 2 -o "2.1 0 1.3 2.3 2.5 1.4 2.4 2.6" -e '<wait>' \
<( kubectl top pods --all-namespaces | sort --key 2 -b ) \
<( kubectl get pods --all-namespaces -o custom-columns=NAMESPACE:.metadata.namespace,NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory | sort --key 2 -b ) \
| column -t -s' '
Da das Shell-Skript join eine sortierte Liste erwartet, sind die oben angegebenen Skripte für mich fehlgeschlagen.
Als Ergebnis sehen Sie die aktuelle Nutzung von oben und aus dem Deployment die Anfragen und die Grenzen (hier) aller Namespaces:
NAMESPACE NAME CPU(cores) CPU_REQ(cores) CPU_LIM(cores) MEMORY(bytes) MEMORY_REQ(bytes) MEMORY_LIM(bytes)
kube-system aws-node-2jzxr 18m 10m <none> 41Mi <none> <none>
kube-system aws-node-5zn6w <wait> 10m <none> <wait> <none> <none>
kube-system aws-node-h8cc5 20m 10m <none> 42Mi <none> <none>
kube-system aws-node-h9n4f 0m 10m <none> 0Mi <none> <none>
kube-system aws-node-lz5fn 17m 10m <none> 41Mi <none> <none>
kube-system aws-node-tpmxr 20m 10m <none> 39Mi <none> <none>
kube-system aws-node-zbkkh 23m 10m <none> 47Mi <none> <none>
cluster-autoscaler cluster-autoscaler-aws-cluster-autoscaler-5db55fbcf8-mdzkd 1m 100m 500m 9Mi 300Mi 500Mi
cluster-autoscaler cluster-autoscaler-aws-cluster-autoscaler-5db55fbcf8-q9xs8 39m 100m 500m 75Mi 300Mi 500Mi
kube-system coredns-56b56b56cd-bb26t 6m 100m <none> 11Mi 70Mi 170Mi
kube-system coredns-56b56b56cd-nhp58 6m 100m <none> 11Mi 70Mi 170Mi
kube-system coredns-56b56b56cd-wrmxv 7m 100m <none> 12Mi 70Mi 170Mi
gitlab-runner-l gitlab-runner-l-gitlab-runner-6b8b85f87f-9knnx 3m 100m 200m 10Mi 128Mi 256Mi
gitlab-runner-m gitlab-runner-m-gitlab-runner-6bfd5d6c84-t5nrd 7m 100m 200m 13Mi 128Mi 256Mi
gitlab-runner-mda gitlab-runner-mda-gitlab-runner-59bb66c8dd-bd9xw 4m 100m 200m 17Mi 128Mi 256Mi
gitlab-runner-ops gitlab-runner-ops-gitlab-runner-7c5b85dc97-zkb4c 3m 100m 200m 12Mi 128Mi 256Mi
gitlab-runner-pst gitlab-runner-pst-gitlab-runner-6b8f9bf56b-sszlr 6m 100m 200m 20Mi 128Mi 256Mi
gitlab-runner-s gitlab-runner-s-gitlab-runner-6bbccb9b7b-dmwgl 50m 100m 200m 27Mi 128Mi 512Mi
gitlab-runner-shared gitlab-runner-shared-gitlab-runner-688d57477f-qgs2z 3m <none> <none> 15Mi <none> <none>
kube-system kube-proxy-5b65t 15m 100m <none> 19Mi <none> <none>
kube-system kube-proxy-7qsgh 12m 100m <none> 24Mi <none> <none>
kube-system kube-proxy-gn2qg 13m 100m <none> 23Mi <none> <none>
kube-system kube-proxy-pz7fp 15m 100m <none> 18Mi <none> <none>
kube-system kube-proxy-vdjqt 15m 100m <none> 23Mi <none> <none>
kube-system kube-proxy-x4xtp 19m 100m <none> 15Mi <none> <none>
kube-system kube-proxy-xlpn7 0m 100m <none> 0Mi <none> <none>
metrics-server metrics-server-5875c7d795-bj7cq 5m 200m 500m 29Mi 200Mi 500Mi
metrics-server metrics-server-5875c7d795-jpjjn 7m 200m 500m 29Mi 200Mi 500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-06t94f <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-10lpn9j 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-11jrxfh <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-129hpvl 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-13kswg8 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-15qhp5w <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
Bemerkenswert: Sie können den CPU-Verbrauch sortieren mit zB:
| awk 'NR<2{print $0;next}{print $0| "sort --key 3 --numeric -b --reverse"}
Das funktioniert auf Mac - ich bin mir nicht sicher, ob es auch unter Linux funktioniert (wegen Join, Sort, etc...).
Hoffentlich kann das jemand verwenden, bis kubectl eine gute Ansicht dafür hat.
 stefanjacobs
am 11. Feb. 2020
stefanjacobs
am 11. Feb. 2020
Ich habe gute Erfahrungen mit kube-capacity gemacht .
Beispiel:
kube-capacity --util
NODE CPU REQUESTS CPU LIMITS CPU UTIL MEMORY REQUESTS MEMORY LIMITS MEMORY UTIL
* 560m (28%) 130m (7%) 40m (2%) 572Mi (9%) 770Mi (13%) 470Mi (8%)
example-node-1 220m (22%) 10m (1%) 10m (1%) 192Mi (6%) 360Mi (12%) 210Mi (7%)
example-node-2 340m (34%) 120m (12%) 30m (3%) 380Mi (13%) 410Mi (14%) 260Mi (9%)
 eyalev
am 18. Feb. 2020
eyalev
am 18. Feb. 2020
Damit dieses Tool wirklich nützlich ist, sollte es alle im Cluster bereitgestellten Kubernetes-Geräte-Plugins erkennen und die Verwendung für alle anzeigen. CPU/Mem ist definitiv nicht genug. Es gibt auch GPUs, TPUs (für maschinelles Lernen), Intel QAT und wahrscheinlich mehr, von dem ich nichts weiß. Und wie sieht es mit der Lagerung aus? Ich sollte in der Lage sein, leicht zu sehen, was angefordert wurde und was verwendet wird (idealerweise auch in Bezug auf iops).
 boniek83
am 9. Apr. 2020
boniek83
am 9. Apr. 2020
@boniek83 , Deshalb habe ich kubectl-view-allocations erstellt , weil ich die GPU auflisten muss,... jedes Feedback (zum Github-Projekt) ist willkommen. Ich bin gespannt, ob es TPU erkennt (sollte es sein, wenn es als Ressourcen eines Knotens aufgeführt ist).
davidB
am 9. Apr. 2020
@boniek83 , Deshalb habe ich kubectl-view-allocations erstellt , weil ich die GPU auflisten muss,... jedes Feedback (zum Github-Projekt) ist willkommen. Ich bin gespannt, ob es TPU erkennt (sollte es sein, wenn es als Ressourcen eines Knotens aufgeführt ist).
Ich kenne Ihr Tool und für meinen Zweck ist es das beste, das derzeit verfügbar ist. Danke, dass du es geschafft hast!
Ich werde versuchen, TPUs nach Ostern testen zu lassen. Es wäre hilfreich, wenn diese Daten im Web-App-Format mit hübschen Grafiken verfügbar wären, damit ich Data Scientists keinen Zugriff auf Kubernetes gewähren müsste. Sie wollen nur wissen, wer Ressourcen auffrisst und nicht mehr :)
boniek83
am 9. Apr. 2020
Da keines der oben genannten Tools und Skripte meinen Anforderungen entspricht (und dieses Problem noch offen ist :( ), habe ich meine eigene Variante gehackt:
https://github.com/eht16/kube-cargo-load
Es bietet einen schnellen Überblick über PODs in einem Cluster und zeigt deren konfigurierte Speicheranforderungen und -grenzen sowie die tatsächliche Speichernutzung an. Die Idee ist, sich ein Bild vom Verhältnis zwischen konfigurierten Speicherlimits und tatsächlicher Nutzung zu machen.
 eht16
am 13. Apr. 2020
eht16
am 13. Apr. 2020
Wie können wir Speicherabbildprotokolle der Pods abrufen?
Pods werden oft aufgehängt,
 RahulRatan07
am 26. Apr. 2020
RahulRatan07
am 26. Apr. 2020
kubectl describe nodesODERkubectl top nodes, was sollte bei der Berechnung der Clusterressourcenauslastung berücksichtigt werden?- Auch warum es einen Unterschied zwischen diesen 2 Ergebnissen gibt.
Gibt es dafür schon eine logische Erklärung?
 hmsvigle
am 27. Apr. 2020
hmsvigle
am 27. Apr. 2020
/freundliches Feature
 brianpursley
am 29. Apr. 2020
brianpursley
am 29. Apr. 2020
Alle Kommentare und Hacks mit Nodes haben bei mir gut funktioniert. Ich brauche auch etwas für eine höhere Ansicht, um den Überblick zu behalten ... wie die Summe der Ressourcen pro Knotenpool!
 prathameshd9
am 30. Apr. 2020
prathameshd9
am 30. Apr. 2020
Hi,
Ich möchte die CPU- und Speichernutzung für einen Pod alle 5 Minuten über einen bestimmten Zeitraum protokollieren. Ich würde dann diese Daten verwenden, um ein Diagramm in Excel zu erstellen. Irgendwelche Ideen? Vielen Dank
 rajjar123456
am 18. Juli 2020
rajjar123456
am 18. Juli 2020
Hi,
Ich freue mich zu sehen, dass Google uns alle auf dieses Problem aufmerksam gemacht hat :-) (ein bisschen enttäuscht, dass es nach fast 5 Jahren immer noch geöffnet ist.) Danke für all die Shell-Snips und anderen Tools.
 yceoshda
am 28. Juli 2020
yceoshda
am 28. Juli 2020
Einfacher und schneller Hack:
$ kubectl describe nodes | grep 'Name:\| cpu\| memory'
Name: XXX-2-wke2
cpu 1552m (77%) 2402m (120%)
memory 2185Mi (70%) 3854Mi (123%)
Name: XXX-2-wkep
cpu 1102m (55%) 1452m (72%)
memory 1601Mi (51%) 2148Mi (69%)
Name: XXX-2-wkwz
cpu 852m (42%) 1352m (67%)
memory 1125Mi (36%) 3624Mi (116%)
 SerheyDolgushev
am 5. Aug. 2020
SerheyDolgushev
am 5. Aug. 2020
Einfacher und schneller Hack:
$ kubectl describe nodes | grep 'Name:\| cpu\| memory' Name: XXX-2-wke2 cpu 1552m (77%) 2402m (120%) memory 2185Mi (70%) 3854Mi (123%) Name: XXX-2-wkep cpu 1102m (55%) 1452m (72%) memory 1601Mi (51%) 2148Mi (69%) Name: XXX-2-wkwz cpu 852m (42%) 1352m (67%) memory 1125Mi (36%) 3624Mi (116%)Geräte-Plugins gibt es nicht. Sie sollten sein. Solche Geräte sind auch Ressourcen.
boniek83
am 5. Aug. 2020
Hallo!
Ich habe dieses Skript erstellt und teile es mit Ihnen.
https://github.com/Sensedia/open-tools/blob/master/scripts/listK8sHardwareResources.sh
Dieses Skript enthält eine Zusammenstellung einiger der Ideen, die Sie hier geteilt haben. Das Skript kann inkrementiert werden und kann anderen Personen helfen, die Metriken einfacher zu erhalten.
Danke für das Teilen der Tipps und Befehle!
 aeciopires
am 7. Aug. 2020
aeciopires
am 7. Aug. 2020
Für meinen Anwendungsfall habe ich schließlich ein einfaches kubectl Plugin geschrieben, das CPU/RAM-Limits/Reservierungen für Knoten in einer Tabelle auflistet. Es überprüft auch den aktuellen CPU-/RAM-Verbrauch des Pods (wie kubectl top pods ), wobei die Ausgabe jedoch in absteigender Reihenfolge nach CPU sortiert wird.
Es ist eher eine Bequemlichkeitssache als alles andere, aber vielleicht findet es auch jemand anderes nützlich.
 laurybueno
am 9. Aug. 2020
laurybueno
am 9. Aug. 2020
Whoa, was für ein riesiger Thread und immer noch keine richtige Lösung vom Kubernetes-Team, um die aktuelle Gesamt-CPU-Auslastung eines ganzen Clusters richtig zu berechnen?
 denissabramovs
am 20. Sept. 2020
denissabramovs
am 20. Sept. 2020
Für diejenigen, die dies auf minikube ausführen möchten, aktivieren Sie zuerst das metrische Server-Add-on
minikube addons enable metrics-server
und dann den Befehl ausführen
kubectl top nodes
 raul1991
am 16. Okt. 2020
raul1991
am 16. Okt. 2020
Wenn Sie Krew verwenden :
kubectl krew install resource-capacity
kubectl resource-capacity
NODE CPU REQUESTS CPU LIMITS MEMORY REQUESTS MEMORY LIMITS
* 16960m (35%) 18600m (39%) 26366Mi (14%) 3100Mi (1%)
ip-10-0-138-176.eu-north-1.compute.internal 2460m (31%) 4200m (53%) 567Mi (1%) 784Mi (2%)
ip-10-0-155-49.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-162-84.eu-north-1.compute.internal 3860m (48%) 3900m (49%) 8399Mi (27%) 414Mi (1%)
ip-10-0-200-101.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-231-146.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-251-167.eu-north-1.compute.internal 4160m (52%) 3900m (49%) 4491Mi (14%) 660Mi (2%)
 benjick
am 14. Nov. 2020
benjick
am 14. Nov. 2020
Verwandte Themen
 alexferl
·
3Kommentare
alexferl
·
3Kommentare
 tbchj
·
3Kommentare
tbchj
·
3Kommentare
 sjenning
·
3Kommentare
sjenning
·
3Kommentare
 montanaflynn
·
3Kommentare
montanaflynn
·
3Kommentare
 broady
·
3Kommentare
broady
·
3Kommentare
Hilfreichster Kommentar
Es gibt: